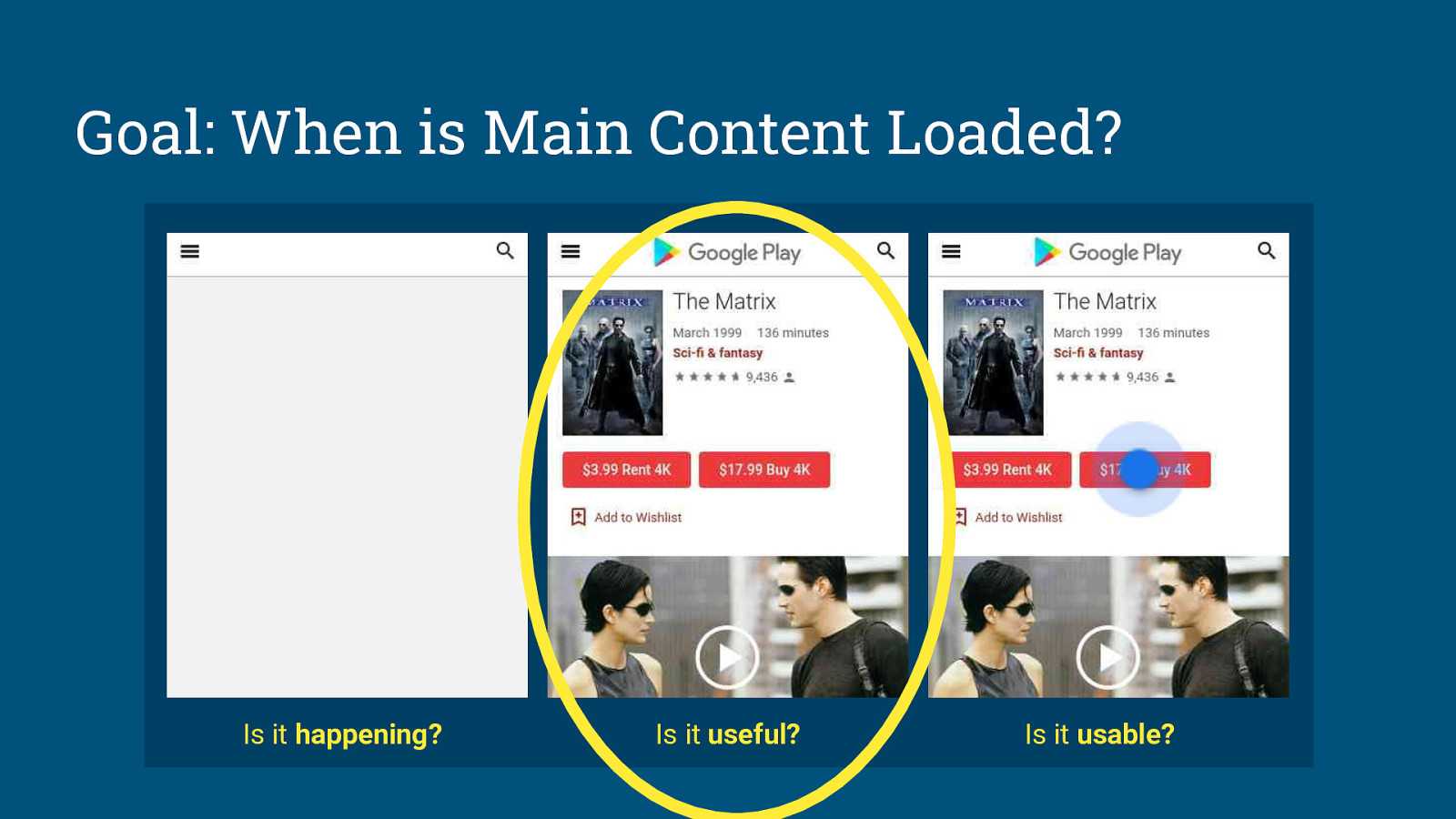
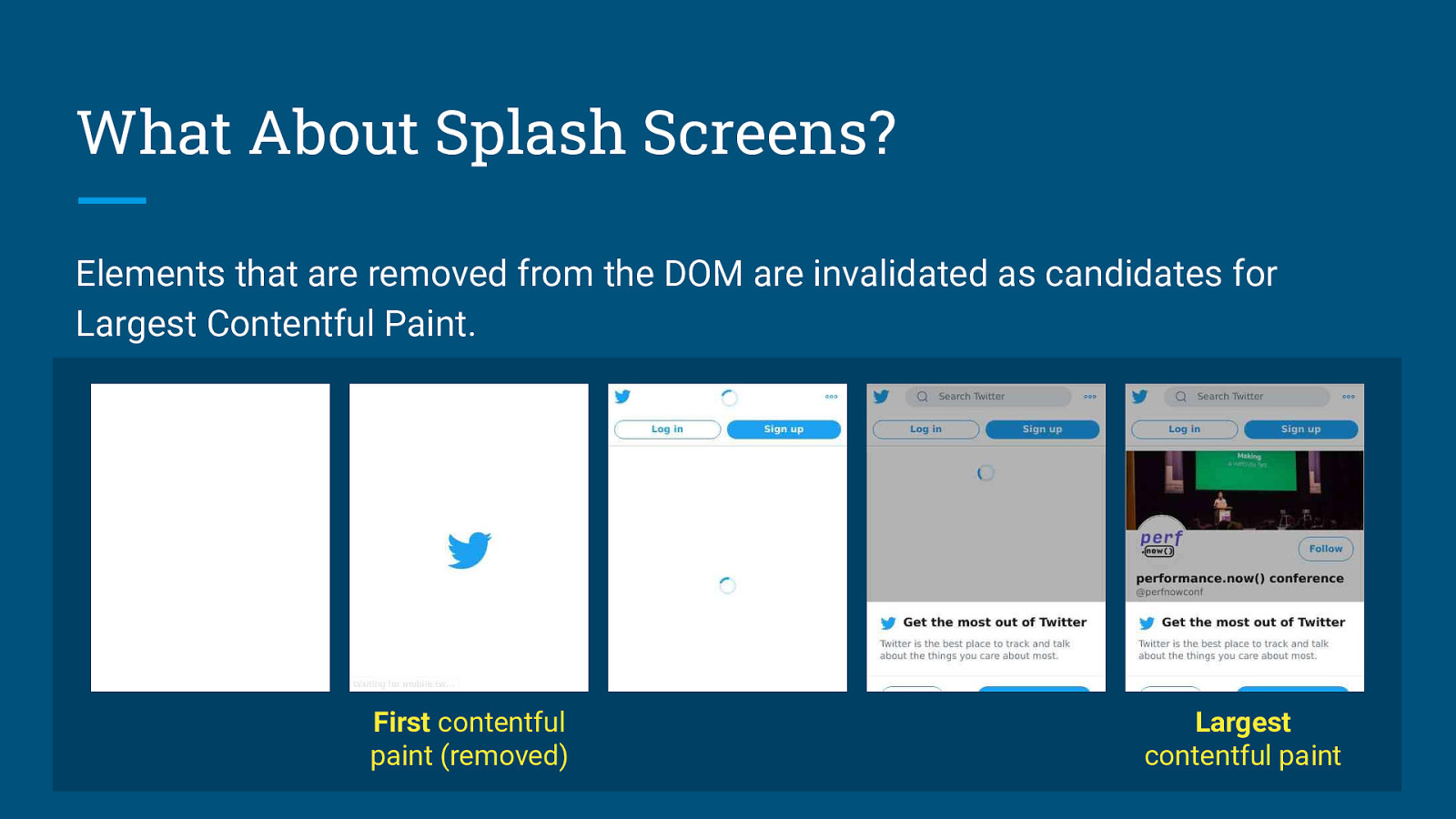
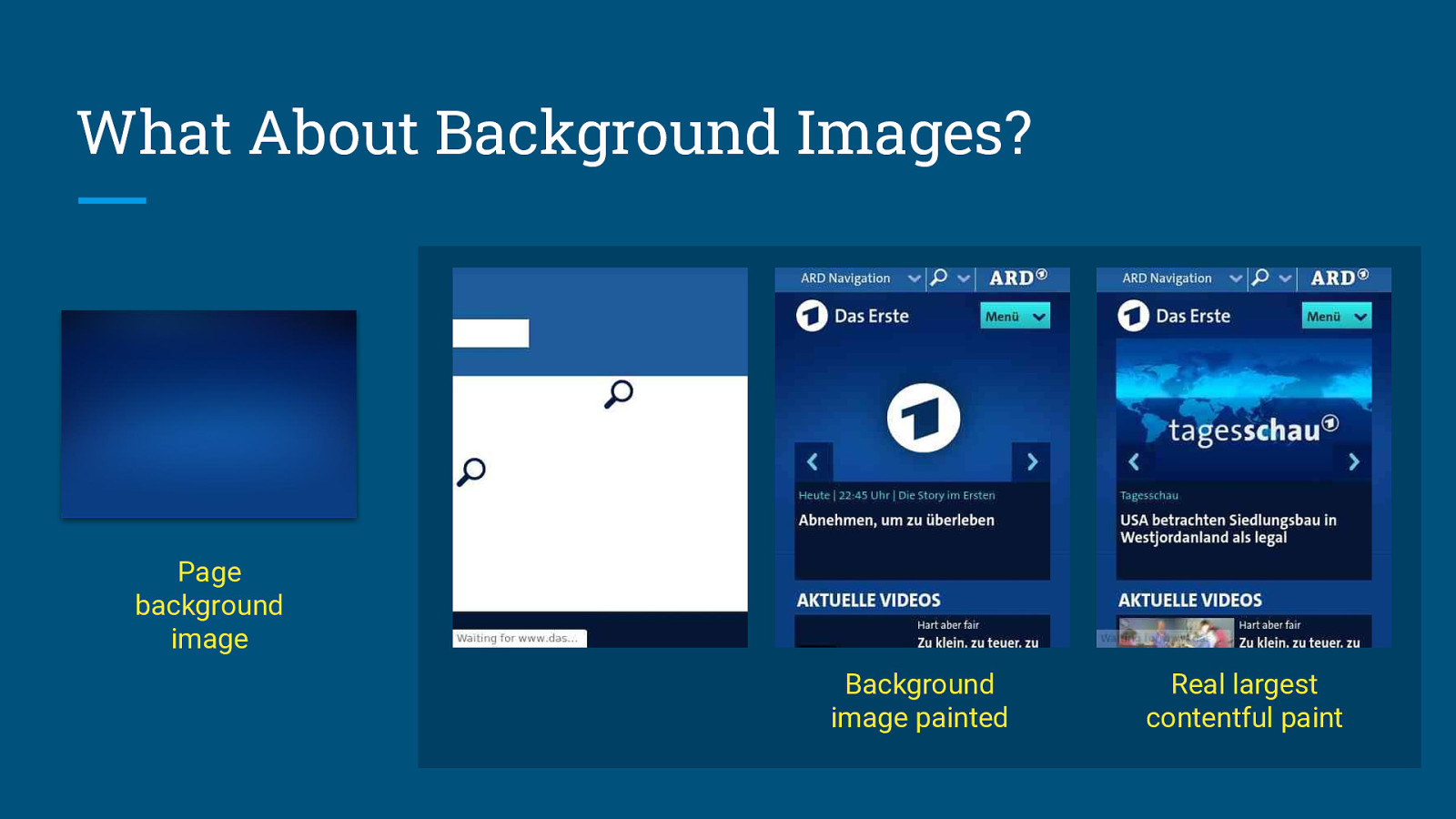
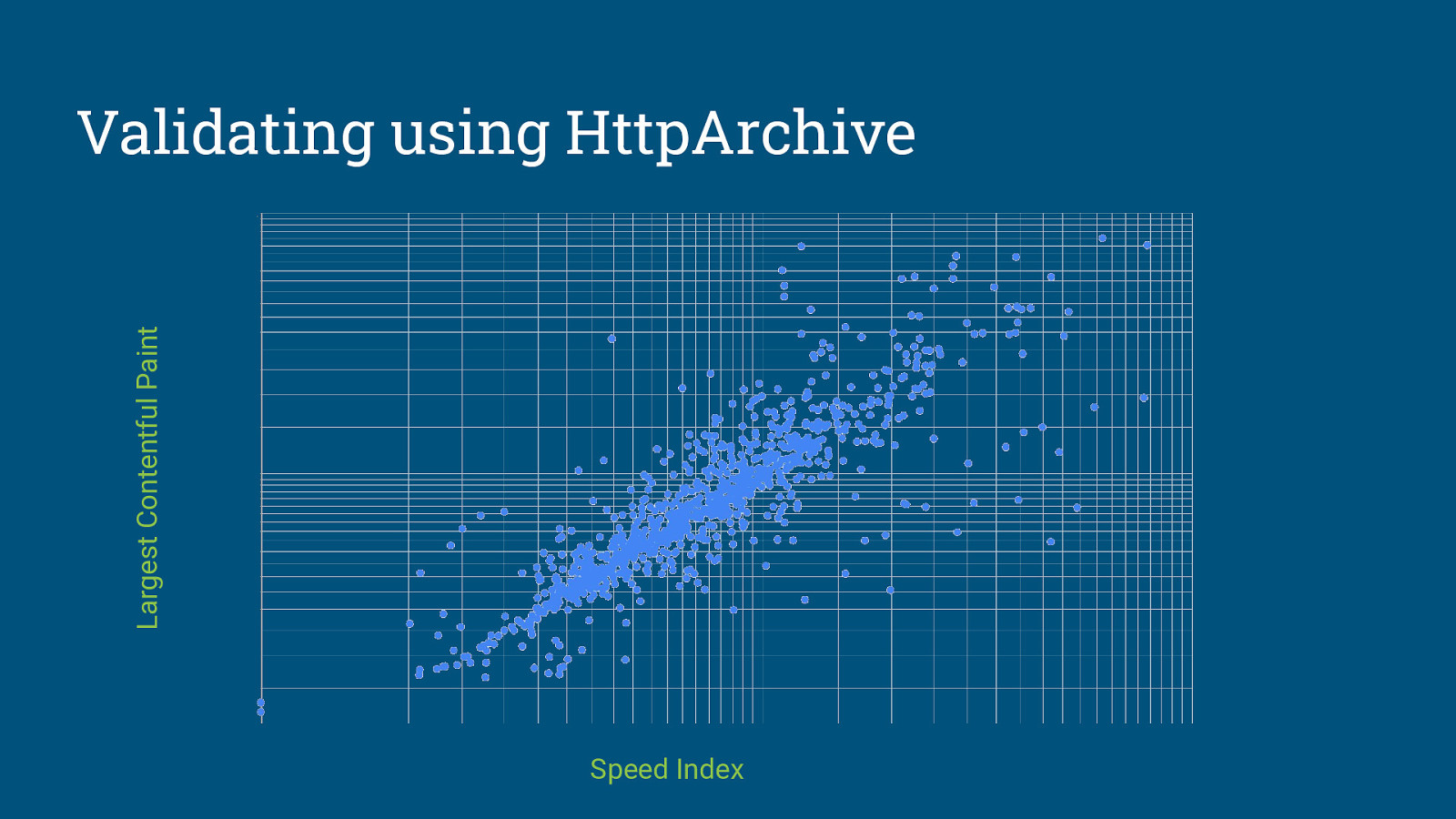
Lab metrics need to be Stable and Elastic.
Lab Fewer data points than RUM
This can put them at odds with being Simple and Interpretable. They don’t require Realtime. Care should be put into handling user input.
First, in the lab, where we do performance testing before shipping to customers. There’s far less data in the lab than in the real world, so it’s much more important that lab metrics be stable and elastic than field metrics. Let’s take the example of first contentful paint. It’s very simple (first text or image painted on the screen) but it’s not very elastic, since things like shifts in viewport can change the value a lot, and it’s not very stable, since race conditions in which element is painted first can randomize the value. In the field, the large volume of data makes up for this. But in the lab, we can consider alternatives. One alternative Chrome uses is to monitor CPU time to first contentful paint instead of wall time, since it’s more stable and elastic, but it’s clearly less representative of user experience. Another issue to be aware of in the lab is that timing for tests which require user input is quite difficult. Let’s say we wanted to write a performance test for first input delay. A simple approach would be to wait say, 3 seconds and click and element and measure the queueing time. But what happens in practice with a test like that is that work ends up being shifted after our arbitrary 3 second mark so that the benchmark does not regress, because developers assume we have a good reason for wanting an input in the first 3 seconds to be processed quickly. We could randomize the input time, but then the metric will be much less stable. So instead we wrote a metric that computes when the page will likely be interactable. This is Time to Interactive, and it’s what we use in the lab. But FID is much simpler and more accurate for RUM, which is why we have the two metrics.