! 1 Aravind Putrevu Developer | Evangelist @aravindputrevu | aravindputrevu.in Getting Started with Elastic Stack

A presentation at Kochi Elastic Meetup in July 2018 in Kochi, Kerala, India by Aravind Putrevu

! 1 Aravind Putrevu Developer | Evangelist @aravindputrevu | aravindputrevu.in Getting Started with Elastic Stack

! 2 Elastic Stack 100% open source

Single install Extensions for the Elastic Stack Subscription pricing X-Pack ! 3 Security Alerting Monitoring Reporting Graph Machine Learning

Te c h Finance Te l c o Consumer ! 4 Enterprise Customers in Every Industry

! 5 Massive Startup Adoption

Search and analytics, it all started here ! 6 More than 60% of our customers have a search or analytics use case
! 7
! 8
! 9

Logs Logs Logs, many devices, many systems More than 40% of our customers use our products for operational log analysis ! 10

We collect more than 1.2 TB logs every day from our infrastructure, web servers, and applications. ! 11

75% of our customers use our products for multiple use cases SEARCH SECURITY CUSTOM APPS METRICS OPERATIONAL ANALYTICS LOG ANALYTICS ! 12

! 13 1,000+ developers use the Elastic Stack for use cases from trade tracking to creating new HR and compliance apps.

We send from Mars more than
30K messages 100K documents 4x a day for operational, telemetry, anomaly resolution, and log analysis. ! 14
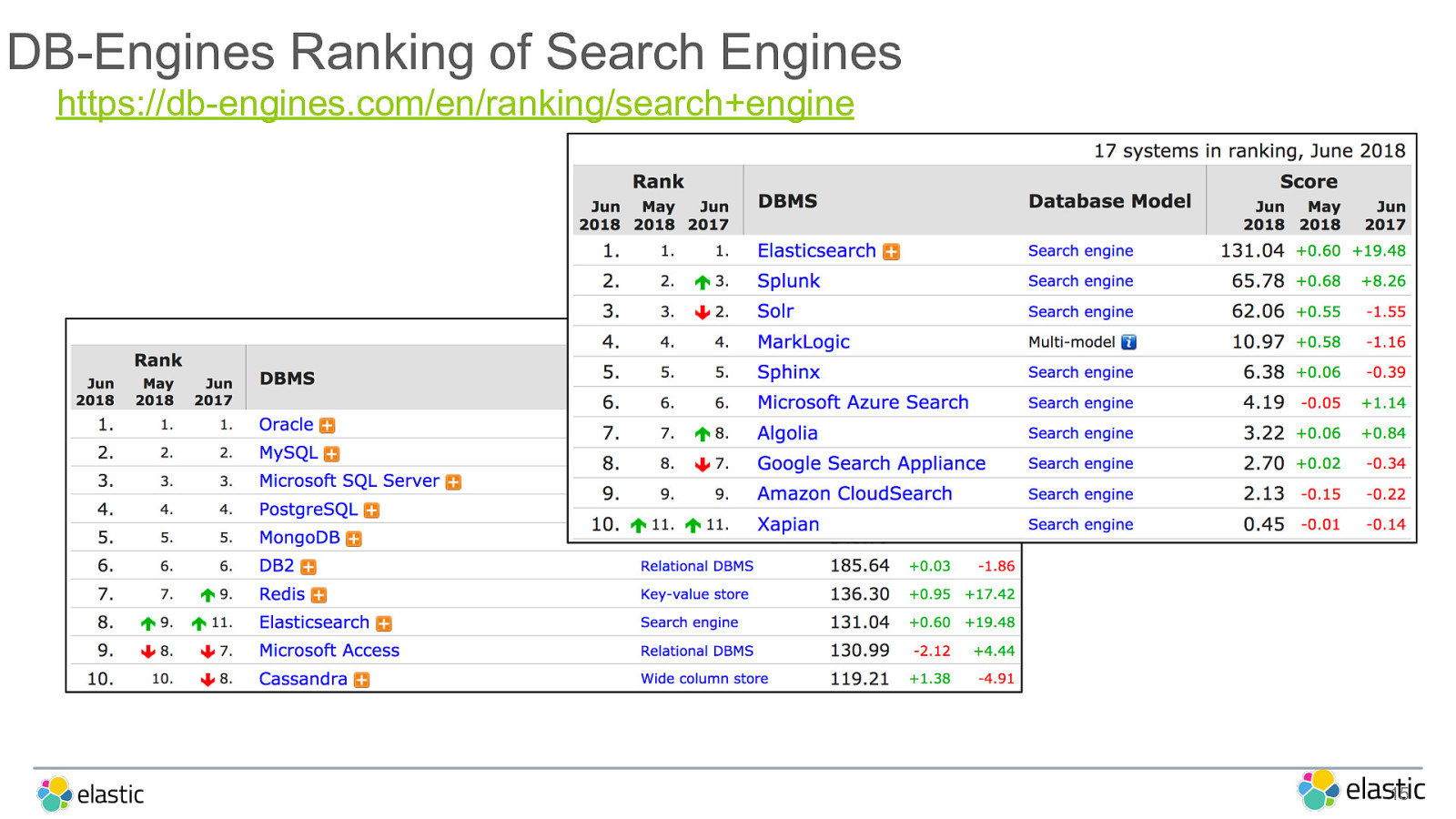
DB-Engines Ranking of Search Engines ! 15 https://db-engines.com/en/ranking/search+engine
! 16
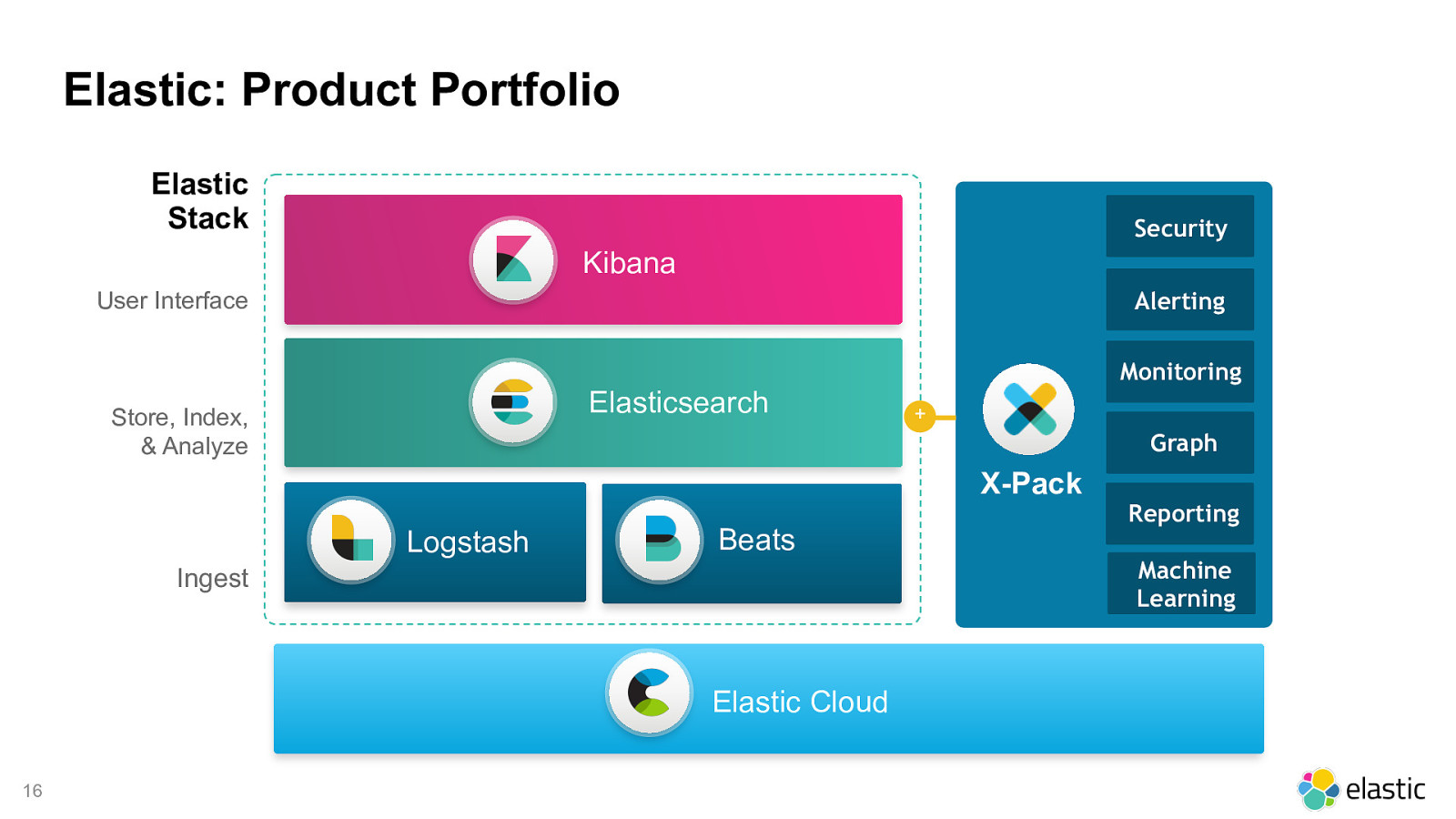
Elastic Cloud Kibana User Interface Elasticsearch Store, Index, & Analyze Ingest Logstash Beats Elastic Stack Elastic: Product Portfolio Security Monitoring Alerting Graph X-Pack + Reporting Machine Learning
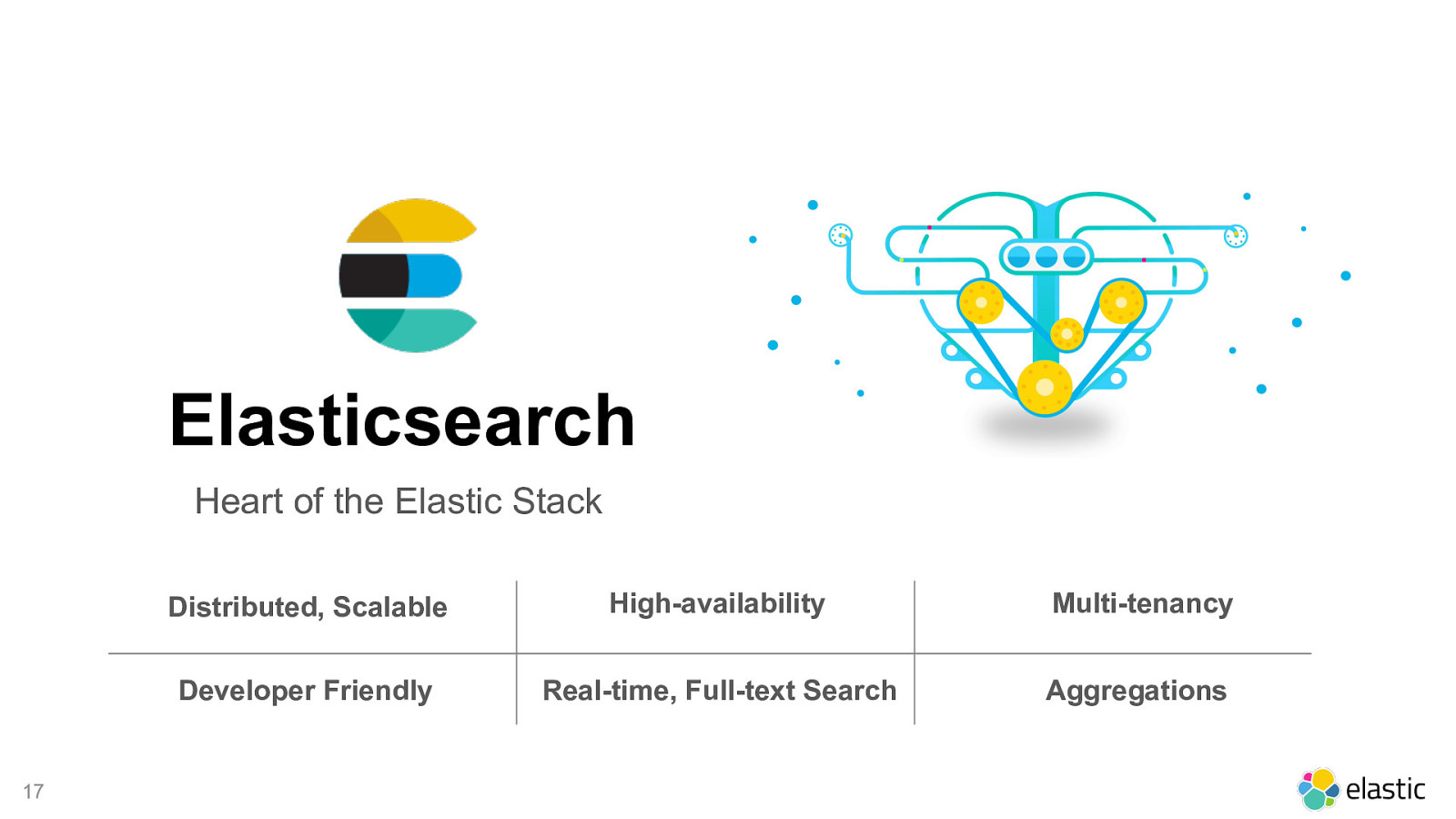
Elasticsearch Heart of the Elastic Stack ! 17 Distributed, Scalable High-availability Multi-tenancy Developer Friendly Real-time, Full-text Search Aggregations
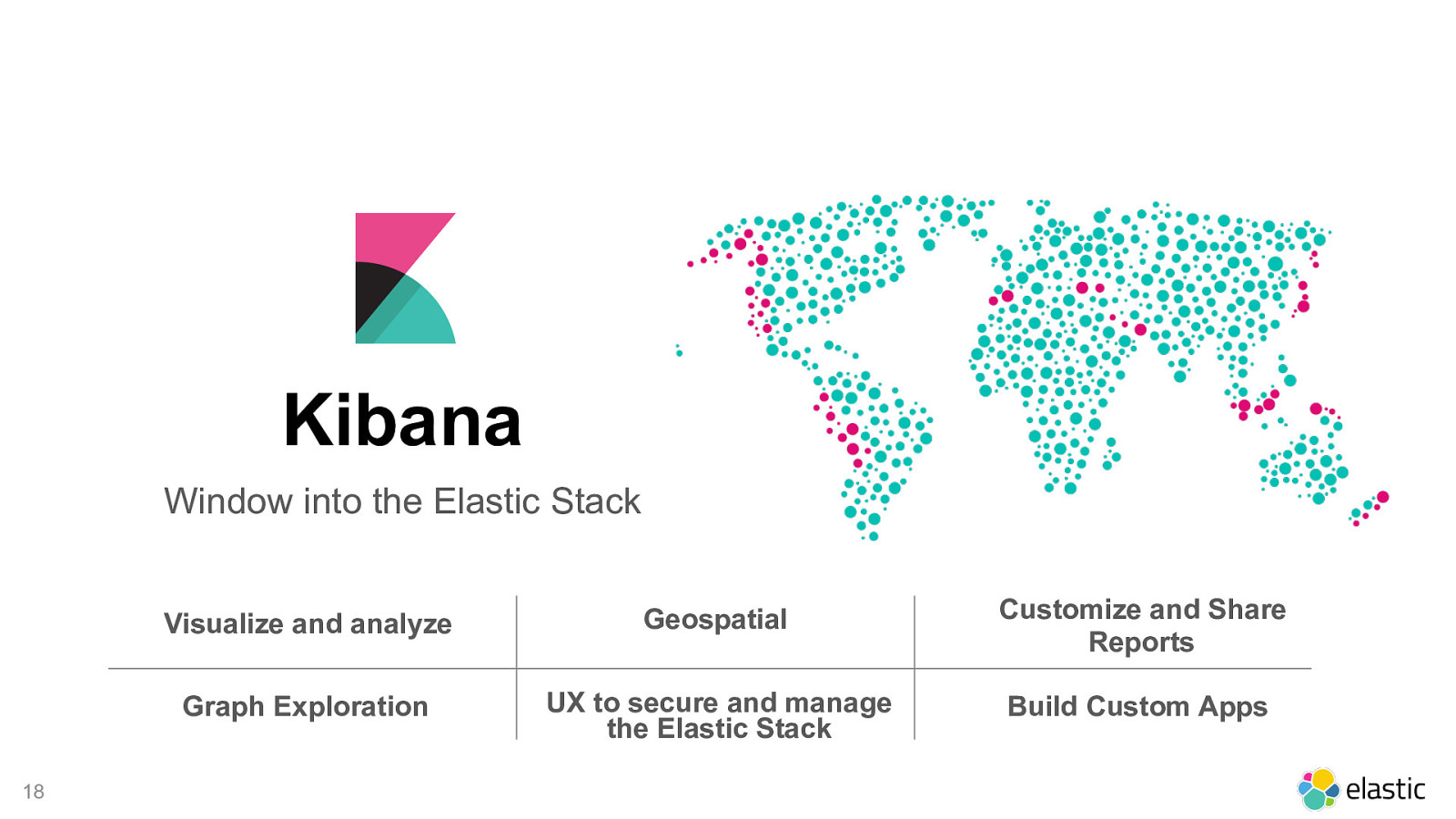
! 18 Kibana Window into the Elastic Stack Visualize and analyze Geospatial Customize and Share Reports Graph Exploration UX to secure and manage the Elastic Stack Build Custom Apps
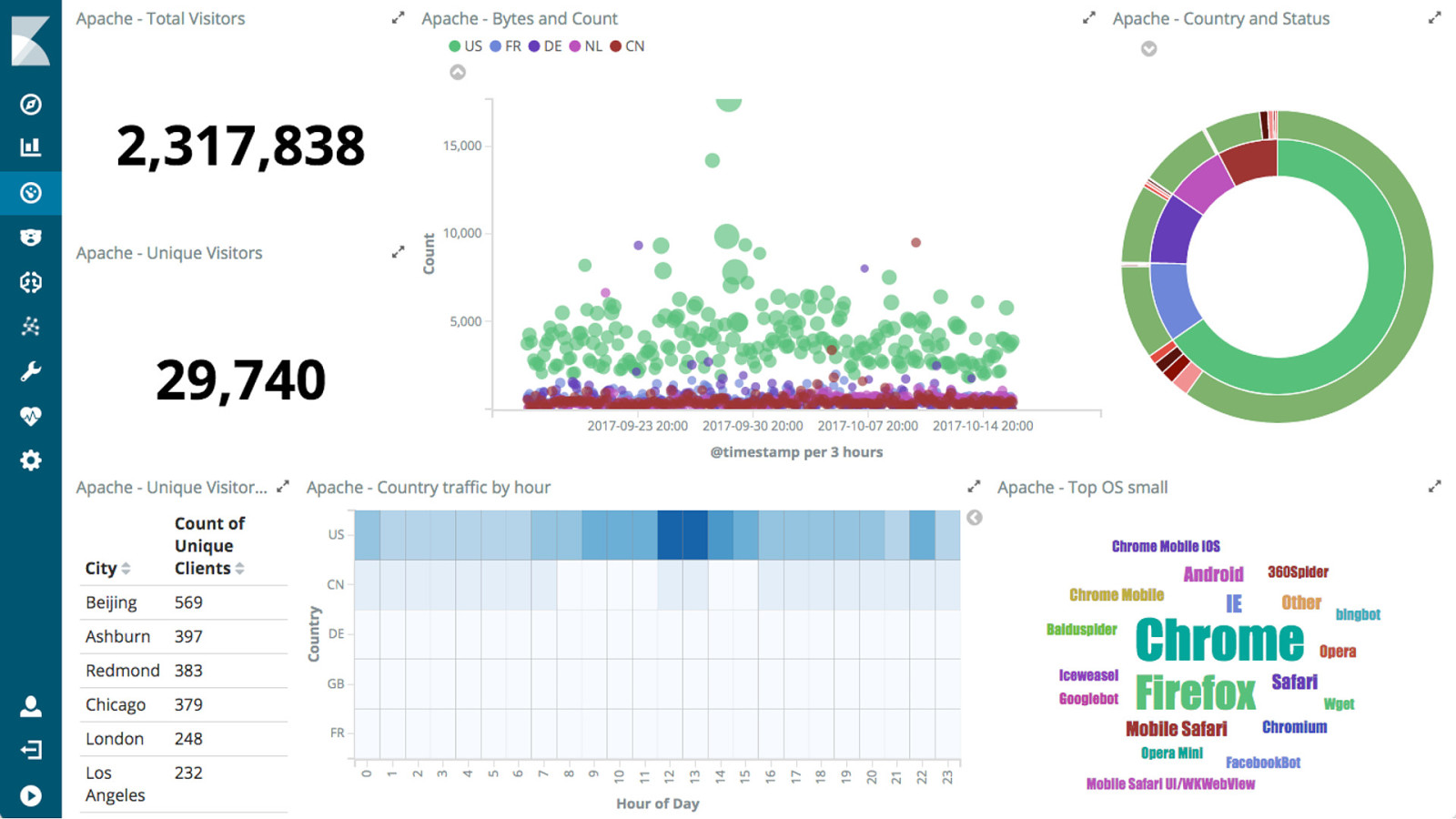
! 19
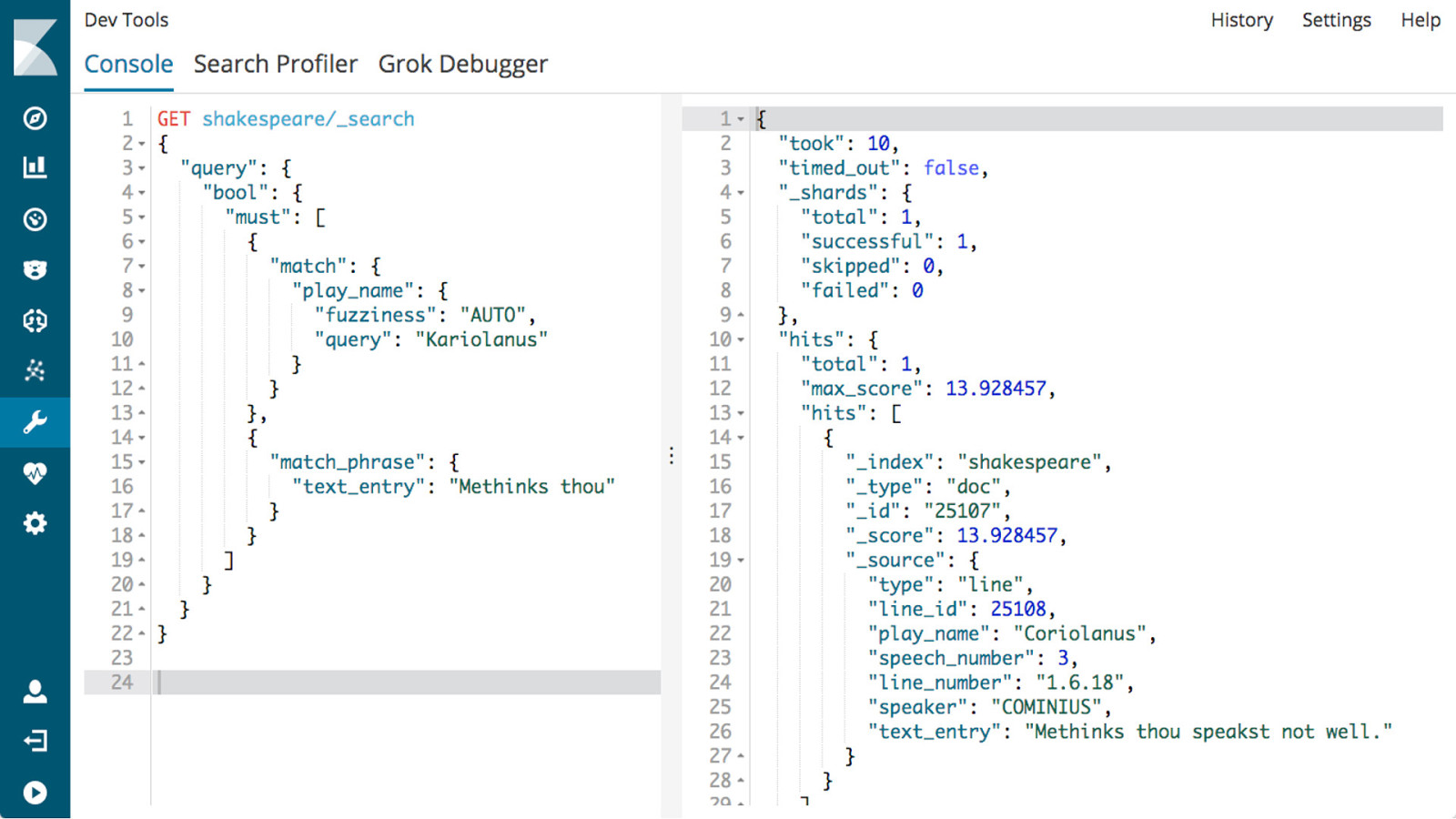
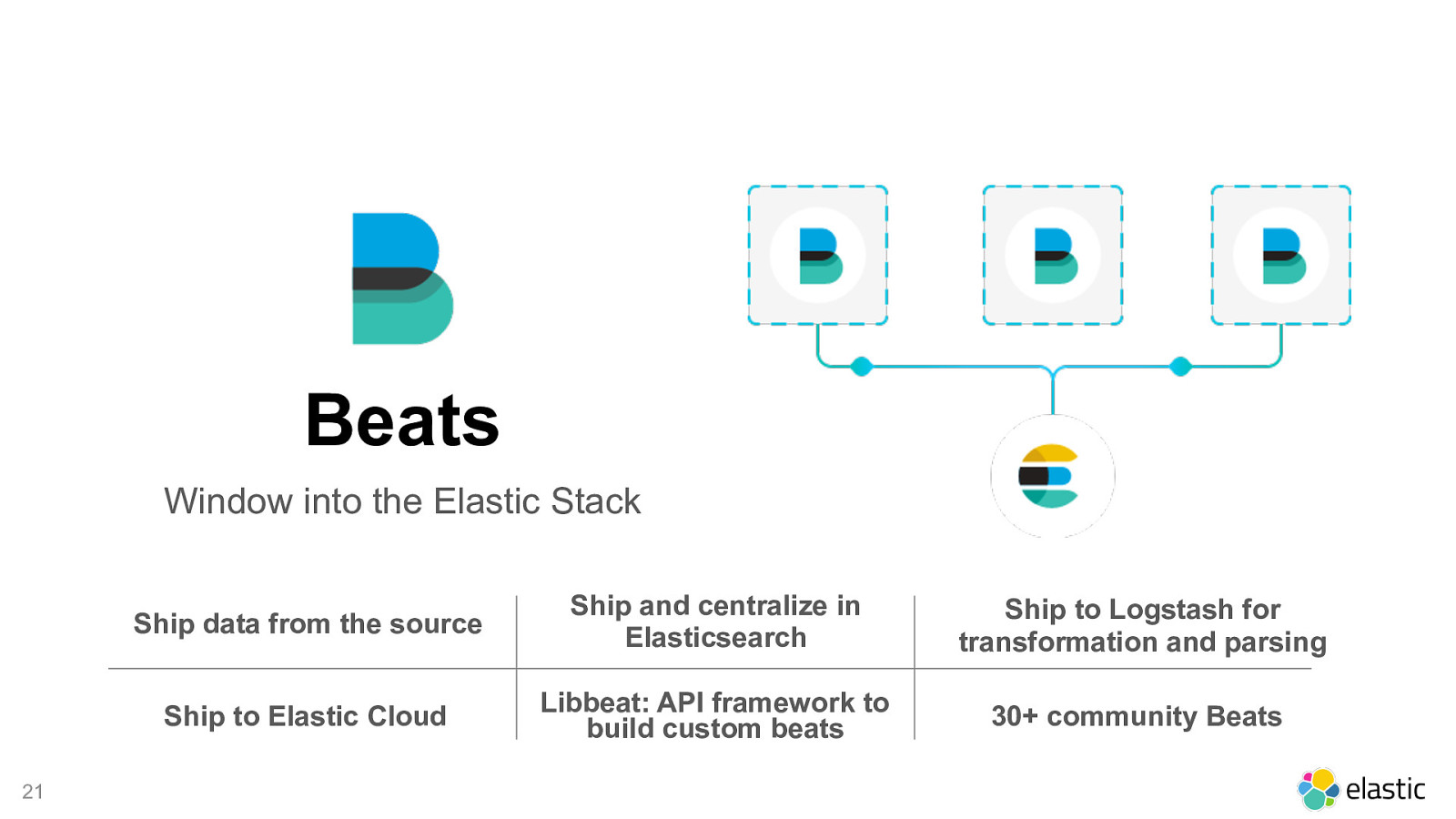
! 21 Beats Window into the Elastic Stack Ship data from the source Ship and centralize in Elasticsearch Ship to Logstash for transformation and parsing Ship to Elastic Cloud Libbeat: API framework to build custom beats 30+ community Beats

! 22 FILEBEAT Log Files METRICBEAT Metrics PACKETBEAT Network Data WINGLOGBEAT Window Events More than 30 community Beats and growing … Apachebeat, dockbeat, httpbeat, mysqlbeat, nginxbeat, redis beats, twitterbeat, and more HEARTBEAT Uptime Monitoring
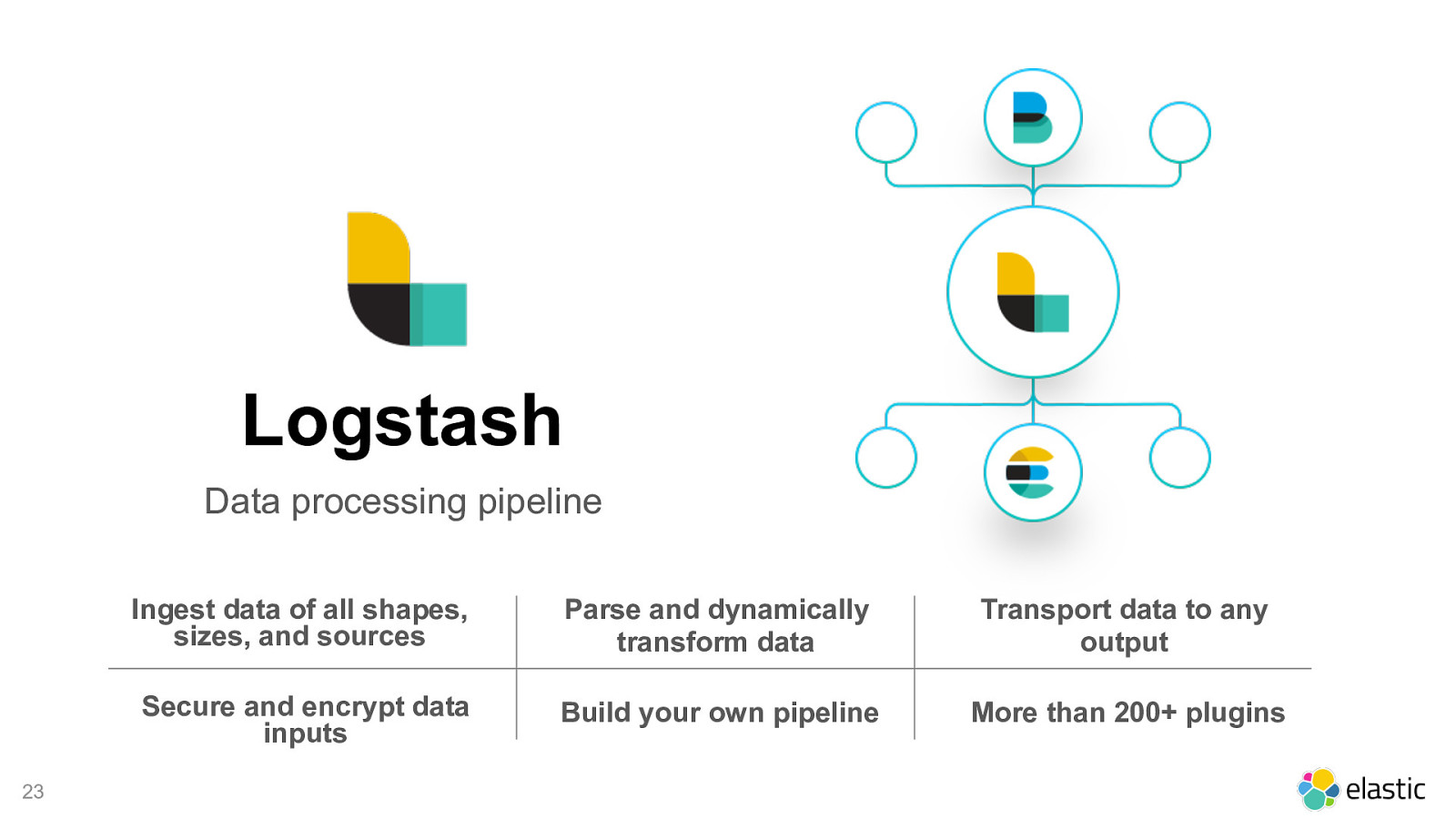
! 23 Logstash Data processing pipeline Ingest data of all shapes, sizes, and sources Parse and dynamically transform data Transport data to any output Secure and encrypt data inputs Build your own pipeline More than 200+ plugins
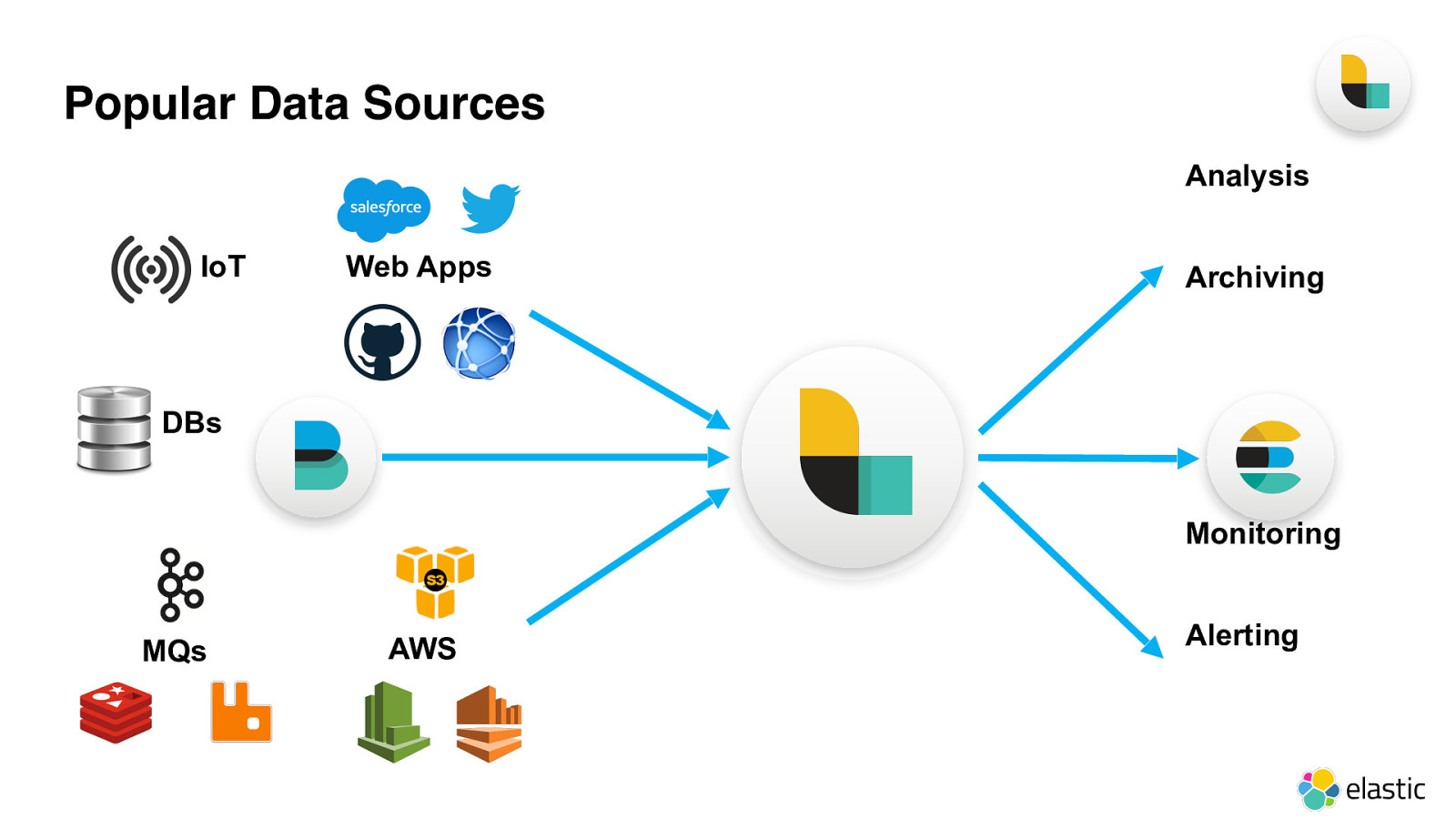
Popular Data Sources Analysis Archiving Monitoring Alerting MQs AW S Web Apps IoT DBs
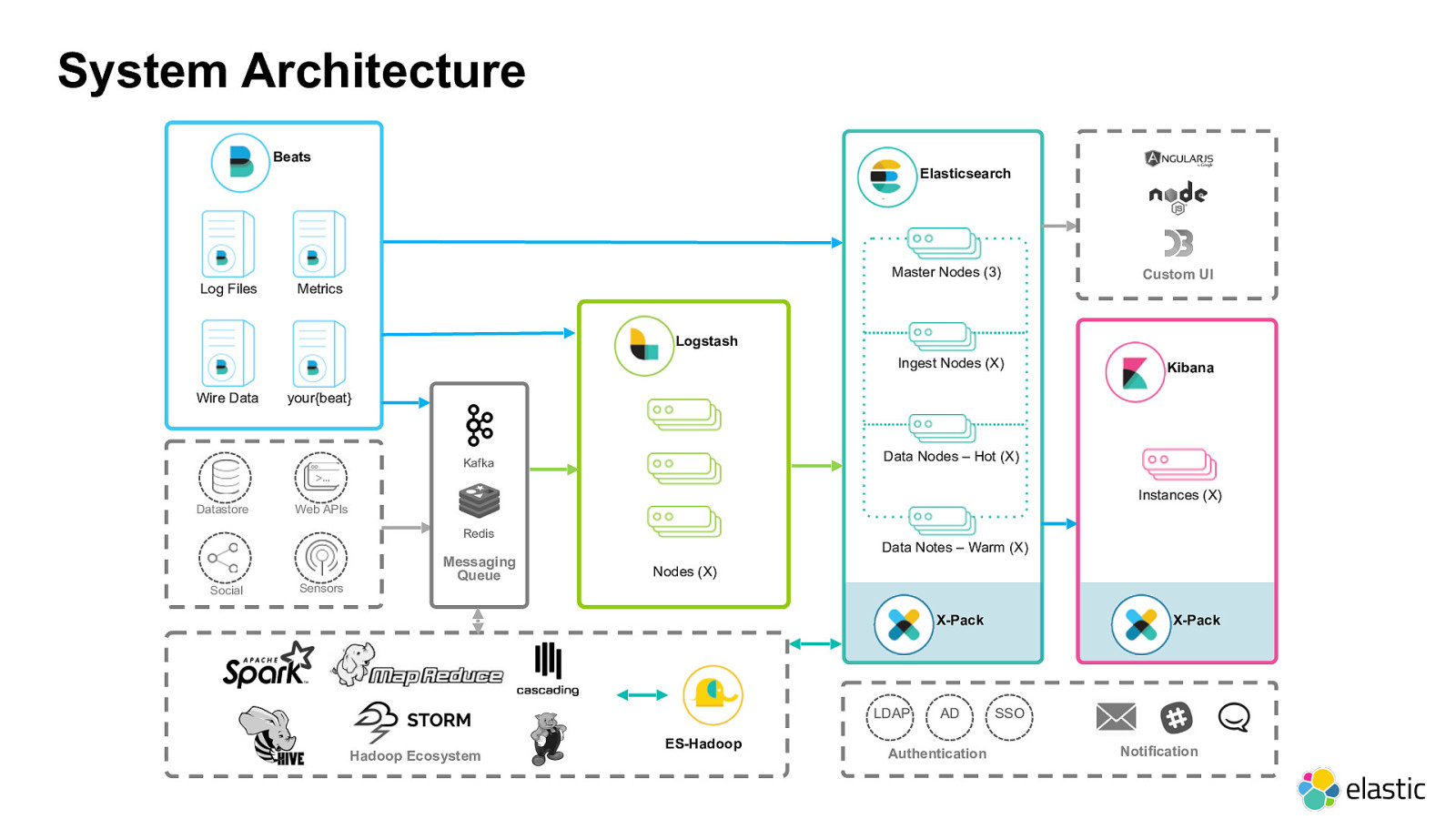
Beats Log Files Metrics Wire Data Datastore Web APIs Social Sensors Kafka Redis Messaging Queue Logstash ES-Hadoop Elasticsearch Kibana Nodes (X) Master Nodes (3) Ingest Nodes (X) Data Nodes – Hot (X) Data Notes – Warm (X) Instances (X) your{beat} X-Pack X-Pack Custom UI LDAP Authentication AD Notification SSO Hadoop Ecosystem System Architecture
! 26 X-Pack Extensions for the Elastic Stack Security Alerting Monitoring Graph Reporting Machine Learning

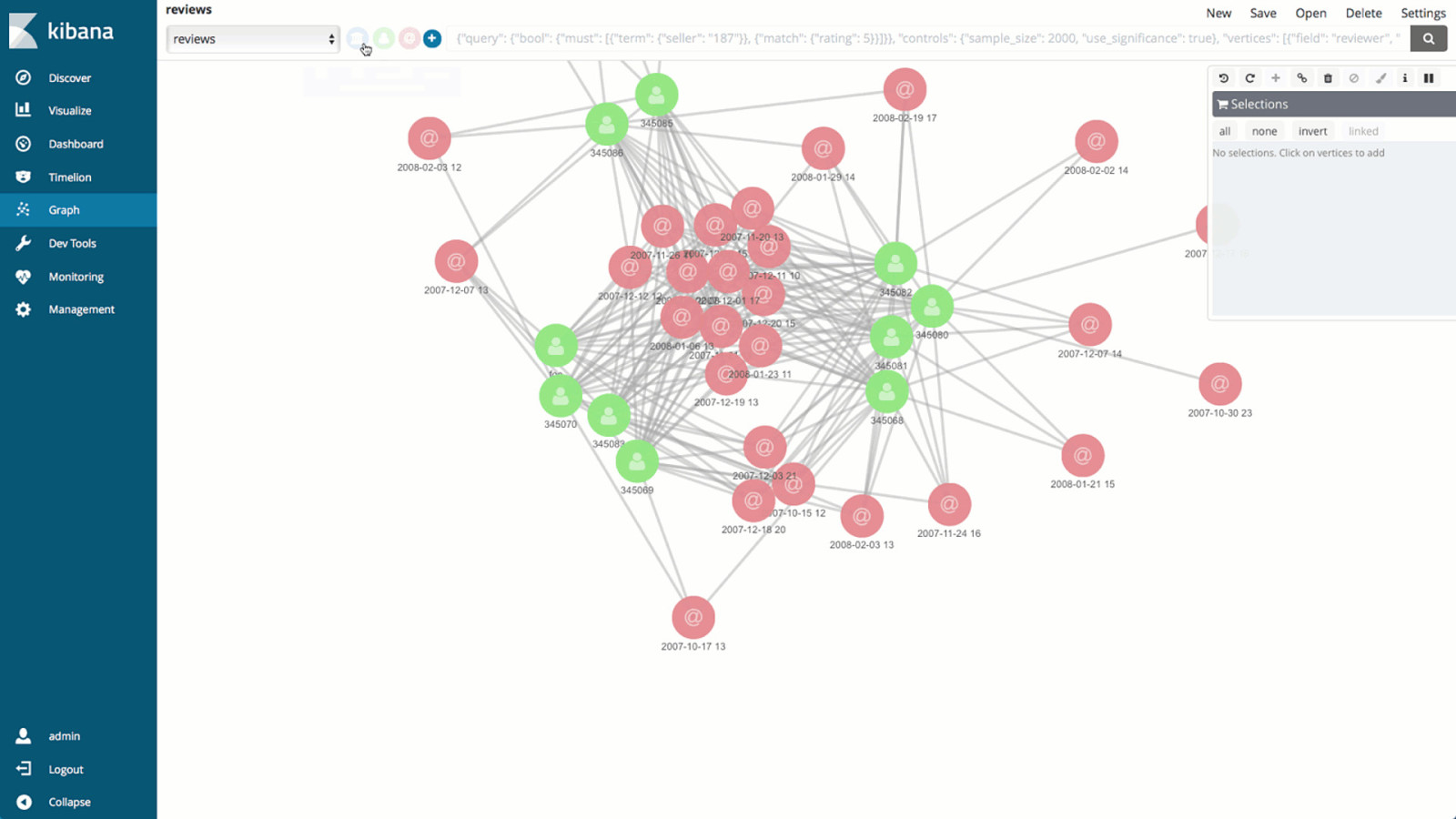
! 27 • Uses relevance capabilities of Elasticsearch
• Discover linkages and connections
• Leverage API and UI-drive tool
A NEW WAY TO EXPLORE DATA
EXTEND TO NEW USE CASES
•
Fraud discovery
•
Recommendations
•
Cyber security
•
Behavioral analyses
Graph
X-Pack
! 28

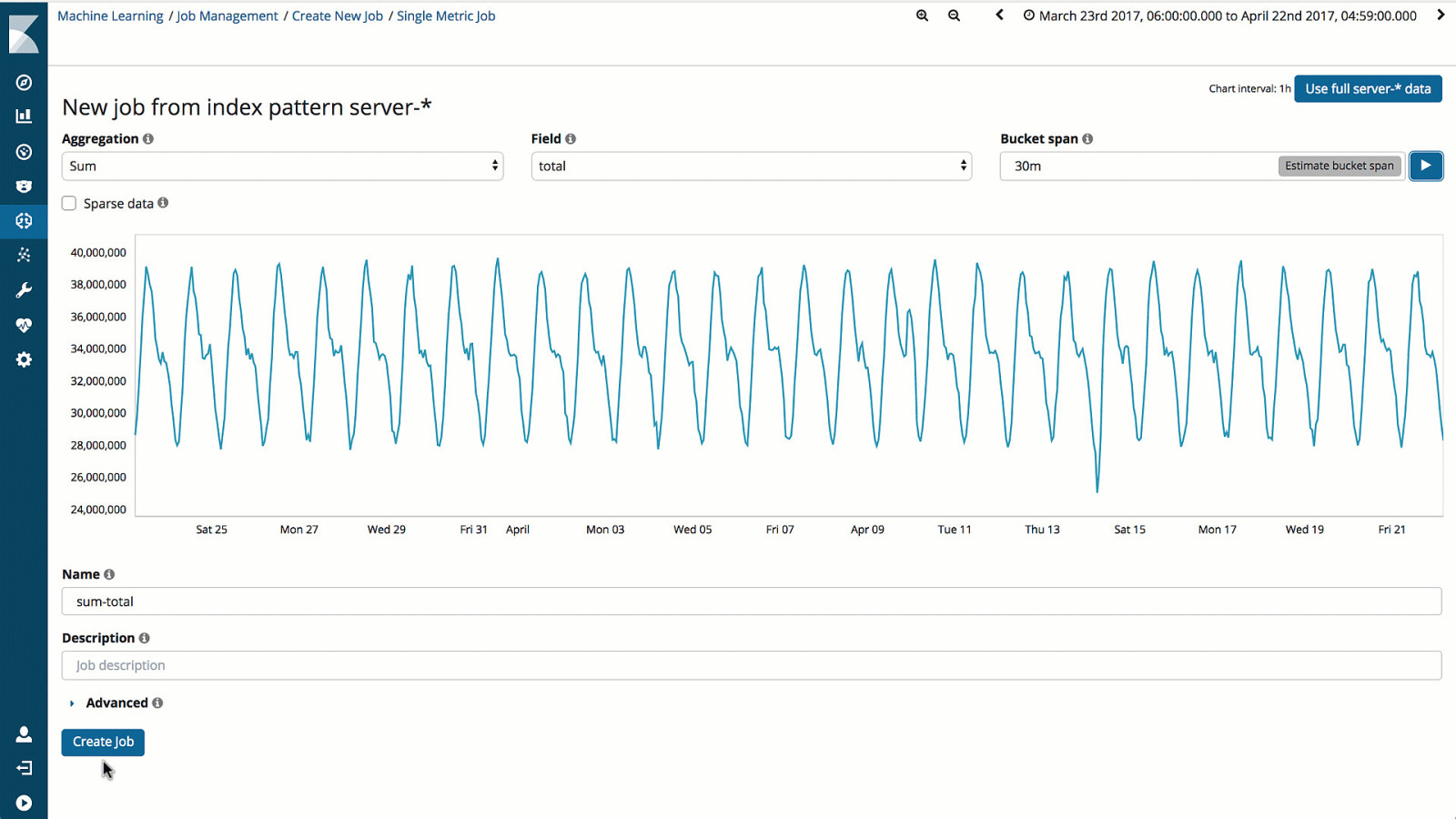
! 29 • Automatically detect anomalies
• Advanced correlation and categorization
• Identify root cause(s)
•
Expose early warning signs
UNSUPERVISED MACHINE LEARNING
ENABLE NEW USE CASES
•
Analyze time series data
•
Detect Anomalies
•
Expand security, IT Ops, fraud, finance, and
many more use cases
Machine
Learning
X-Pack
! 30

Elastic Cloud Hosted Elasticsearch & Kibana Includes X-Pack features Free 14-day trial ! 31
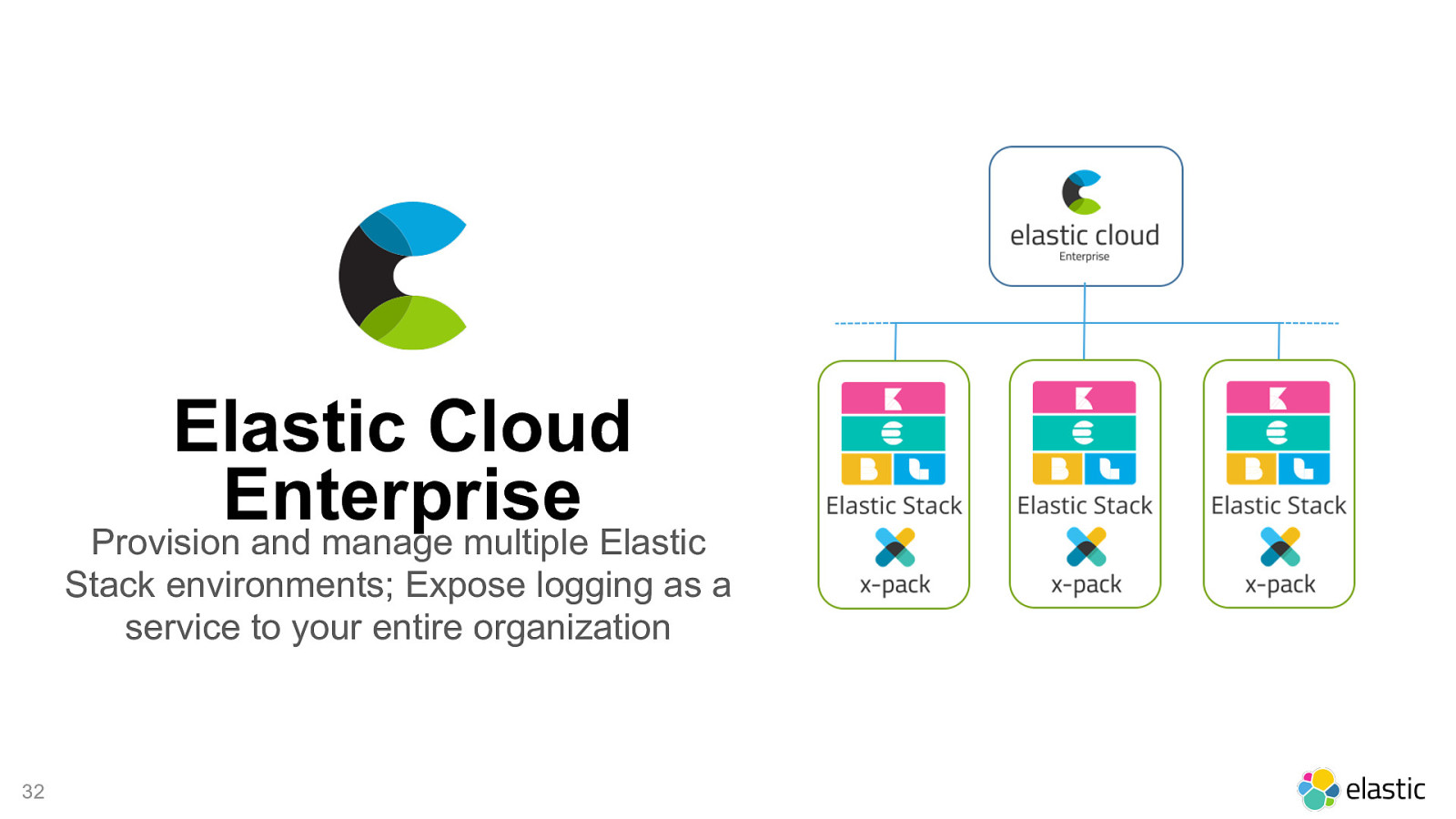
Elastic Cloud Enterprise Provision and manage multiple Elastic Stack environments; Expose logging as a service to your entire organization ! 32
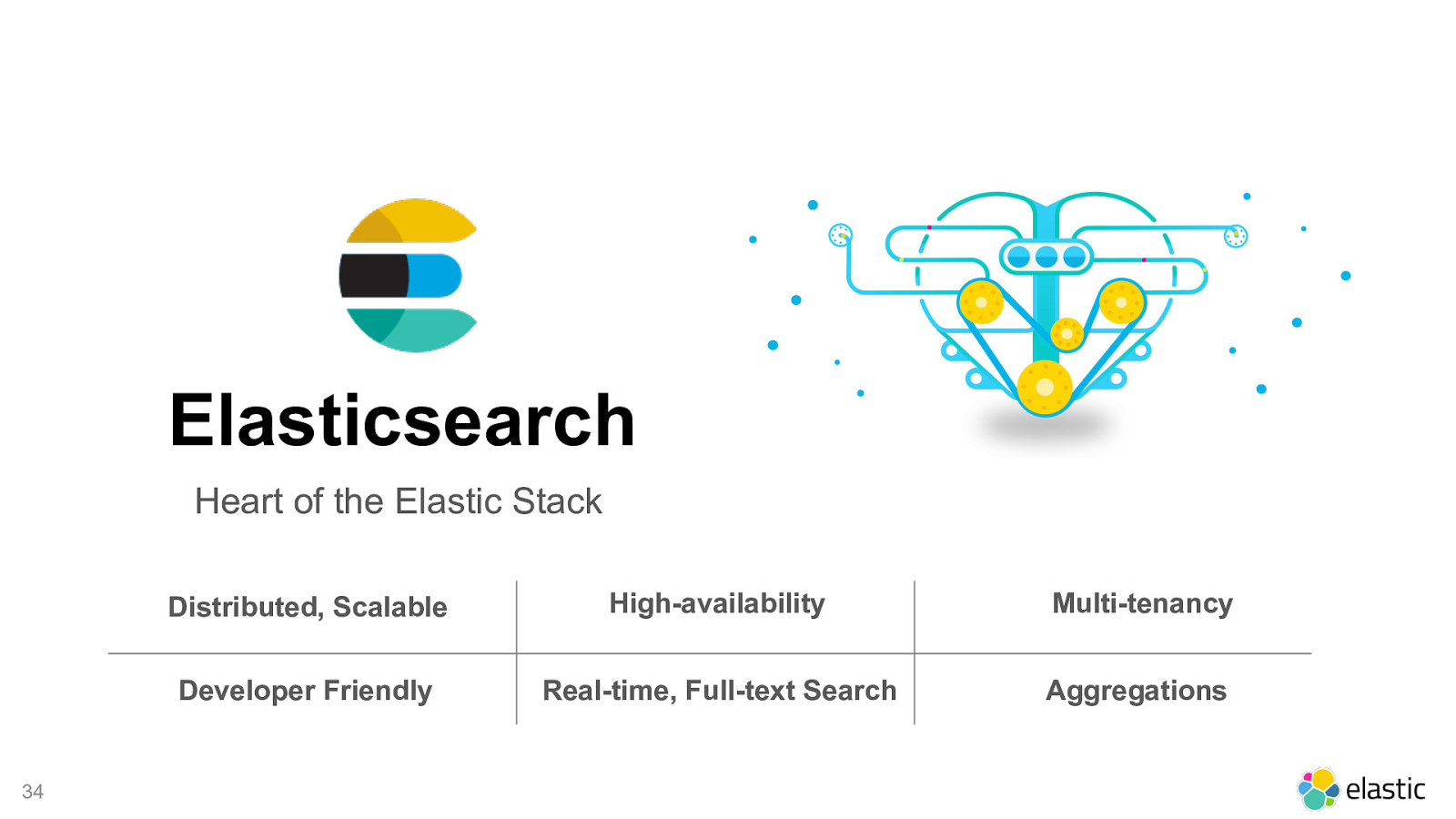
Elasticsearch Heart of the Elastic Stack ! 34 Distributed, Scalable High-availability Multi-tenancy Developer Friendly Real-time, Full-text Search Aggregations
! 35 Elasticsearch is… an open source , distributed, scalable, highly available, document-oriented, RESTful, full text search engine with real-time search and analytics capabilities Apache 2.0 License https://www.apache.org/licenses/LICENSE-2.0

! 36 Apache Lucene • Created by - Doug Cutting • Written in - Java • Apache Solr, Elasticsearch

! 37 Elasticsearch is… An open source, distributed, scalable, highly available , document-oriented, RESTful, full text search engine with real-time search and analytics capabilities
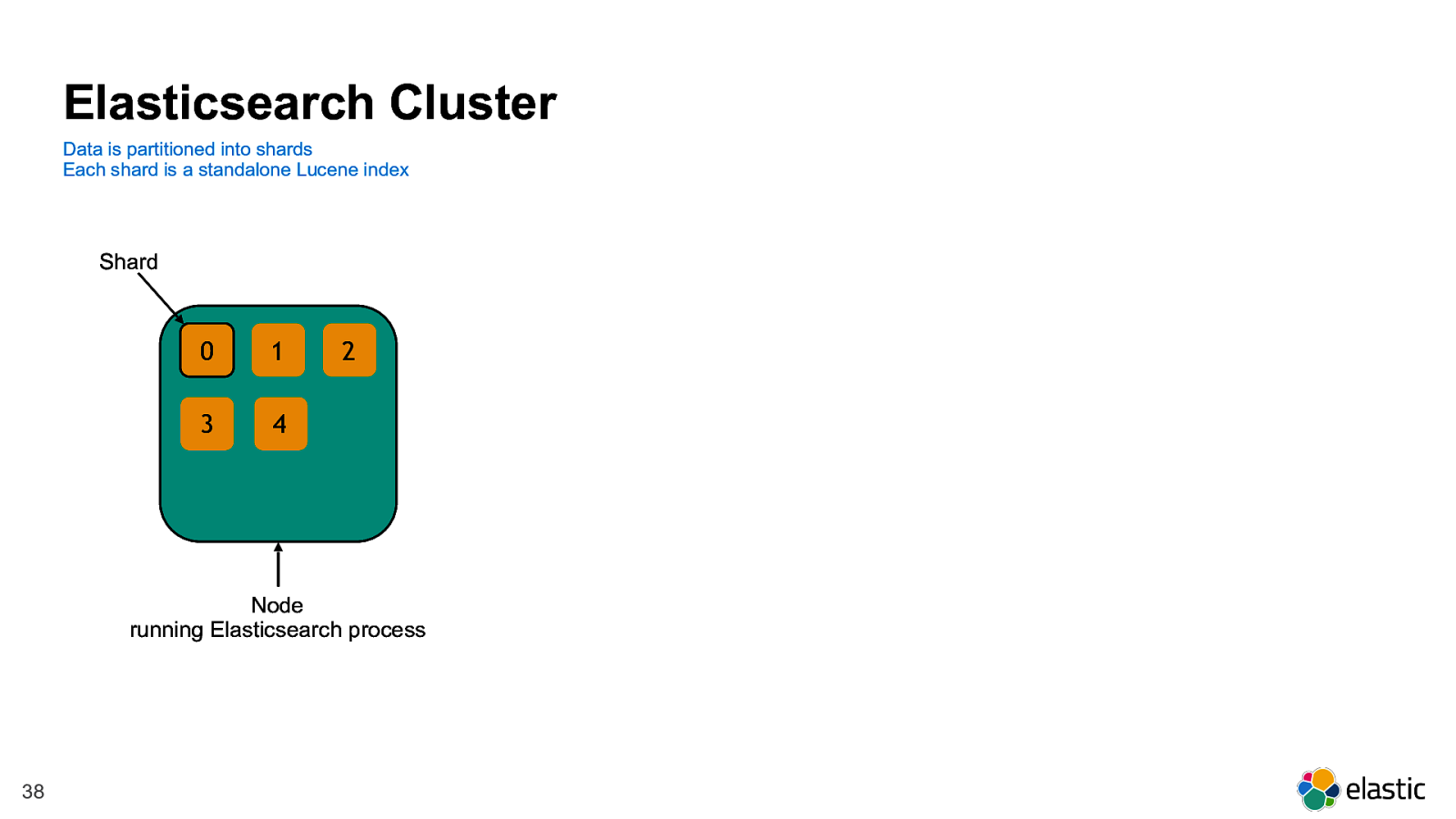
! 38 Elasticsearch Cluster Data is partitioned into shards Each shard is a standalone Lucene index 1 0 2 3 4 Node running Elasticsearch process Shard
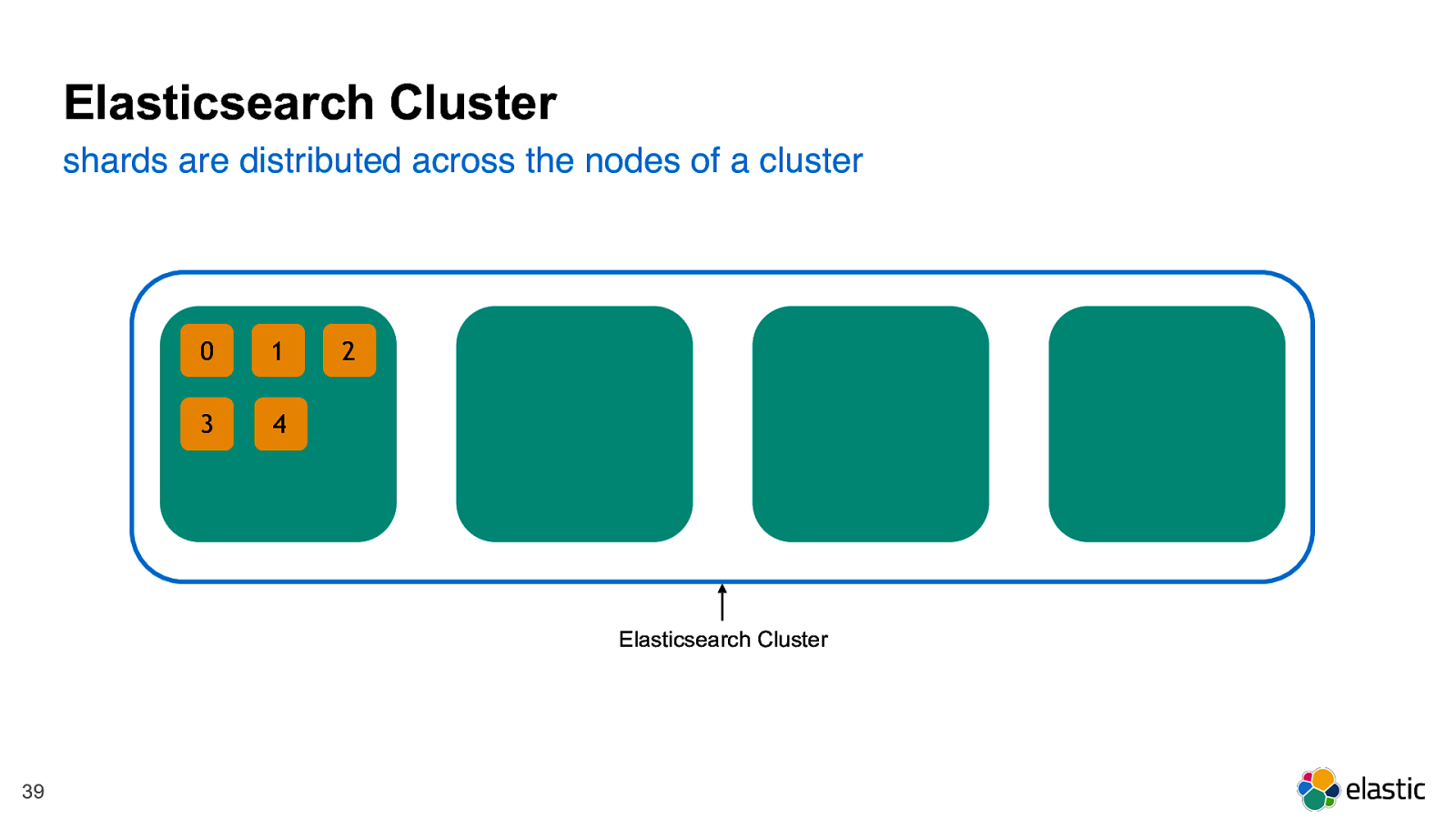
! 39 1 0 2 3 4 Elasticsearch Cluster shards are distributed across the nodes of a cluster Elasticsearch Cluster
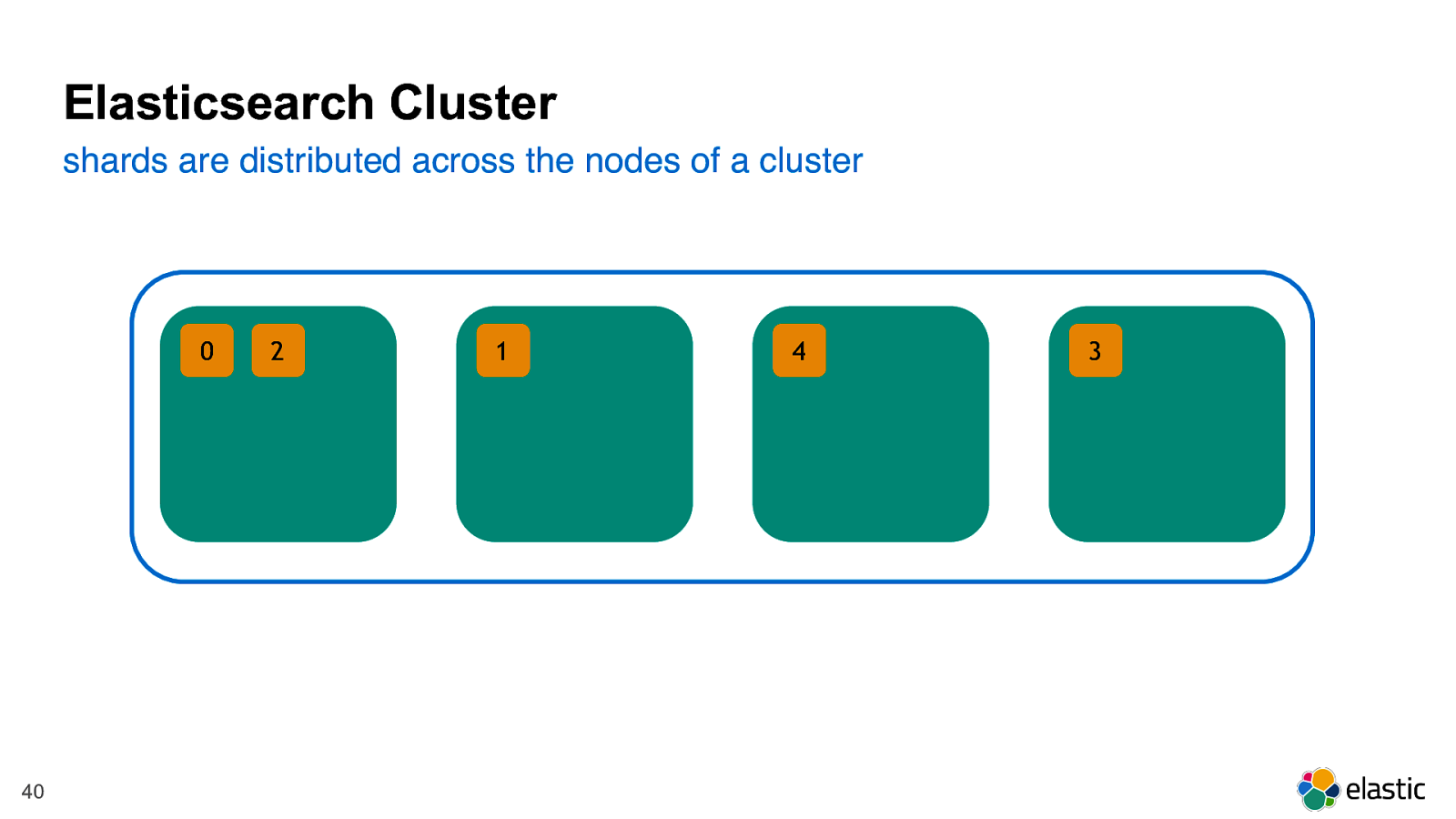
! 40 2 0 1 4 3 Elasticsearch Cluster shards are distributed across the nodes of a cluster
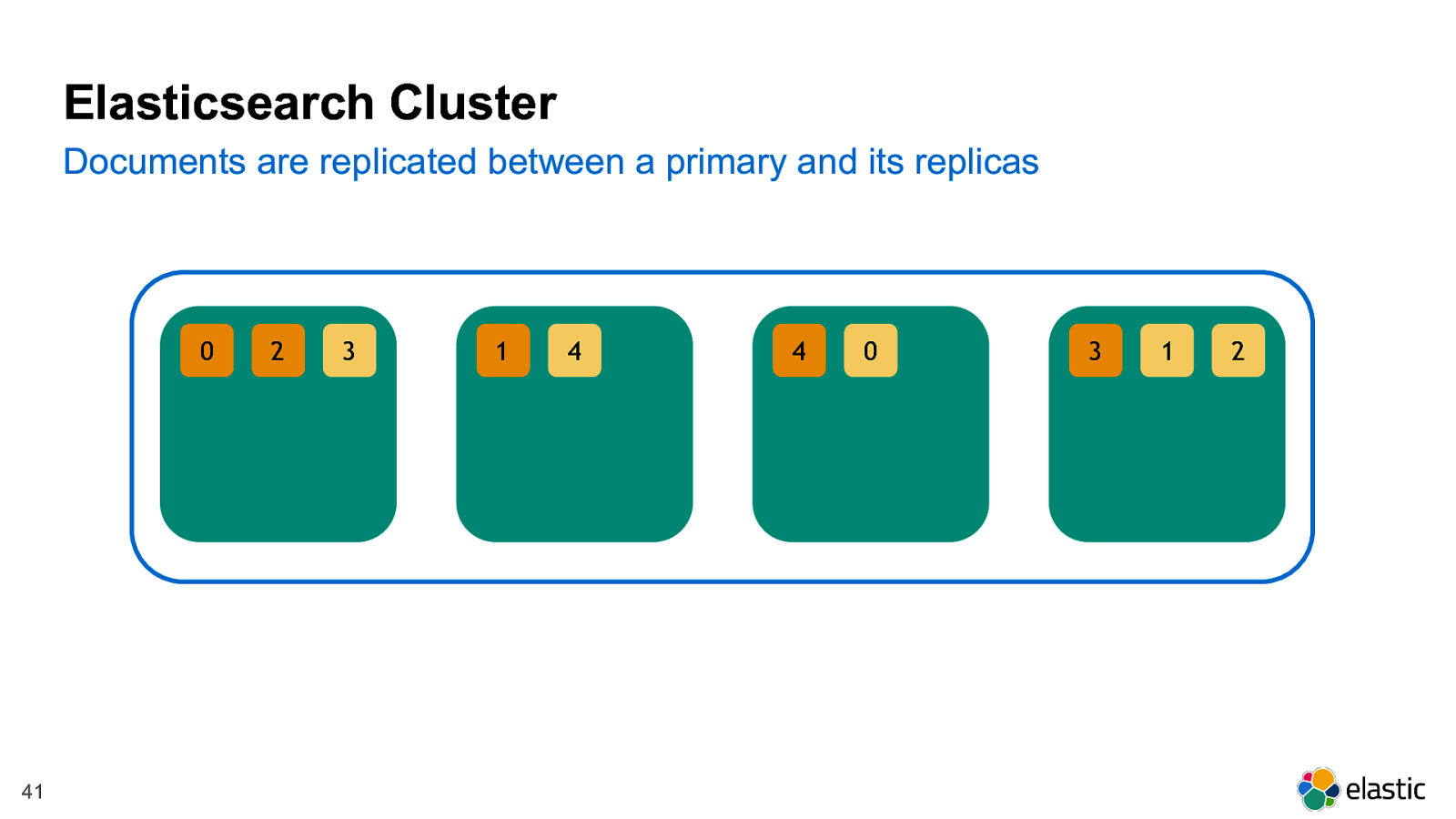
! 41 2 0 3 4 1 0 4 1 3 2 Documents are replicated between a primary and its replicas Elasticsearch Cluster
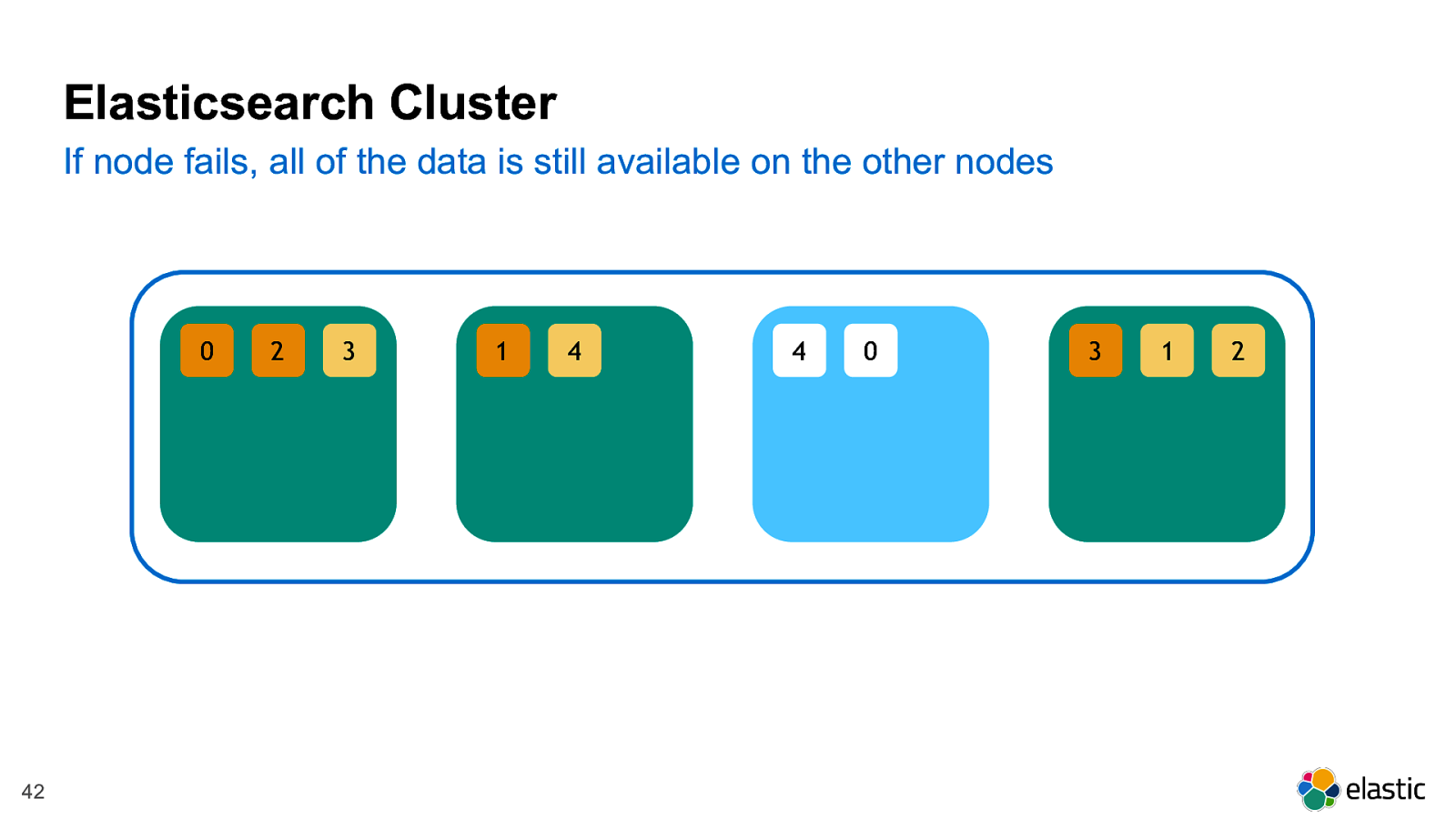
! 42 2 0 3 4 1 0 4 1 3 2 If node fails, all of the data is still available on the other nodes Elasticsearch Cluster
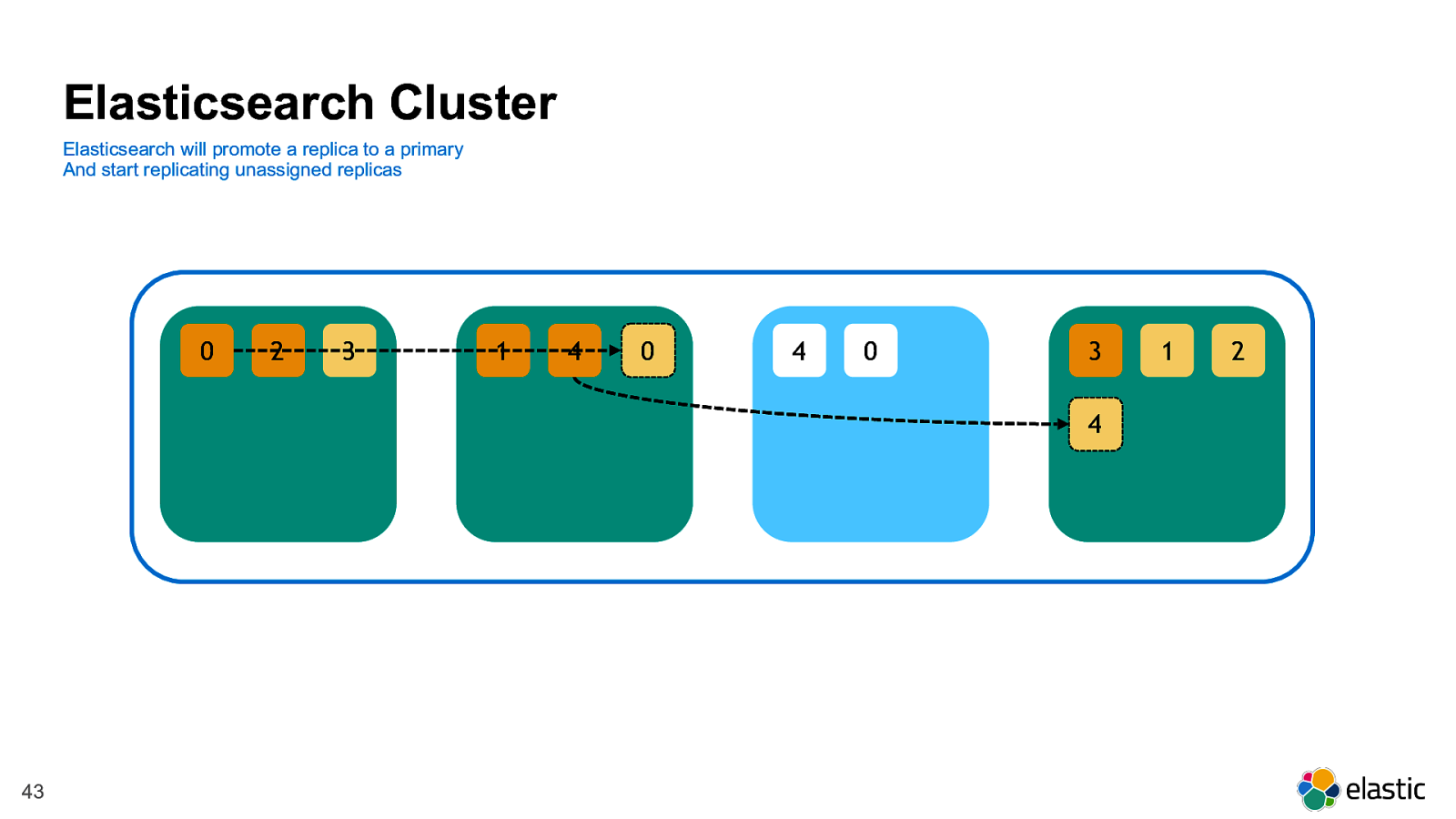
! 43 2 0 3 4 1 0 4 1 3 2 4 0 Elasticsearch will promote a replica to a primary And start replicating unassigned replicas Elasticsearch Cluster
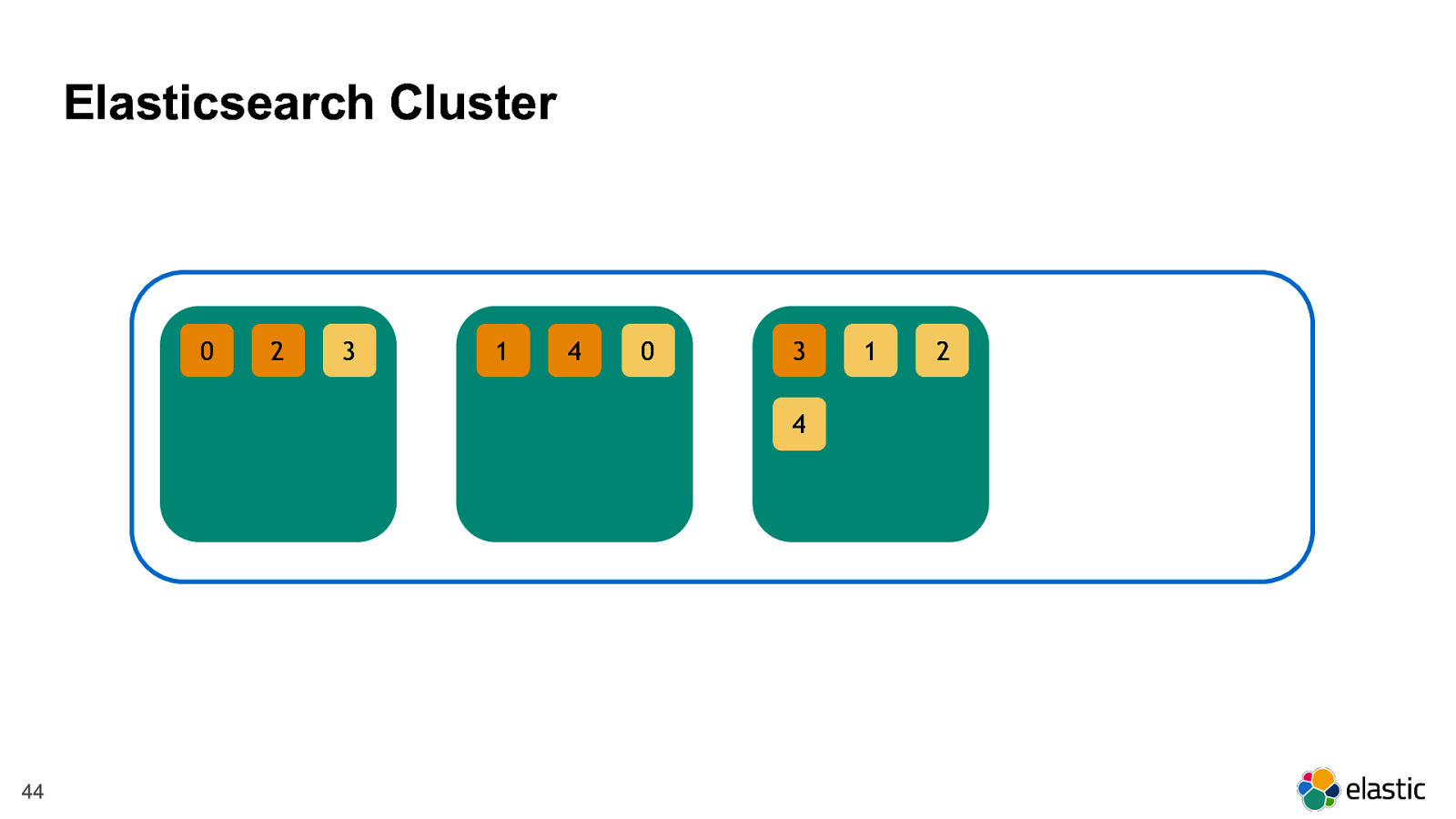
! 44 2 0 3 4 1 1 3 2 4 0 Elasticsearch Cluster

! 45 Cluster • Set using cluster.name:
• defaults to “elasticsearch” config/elasticsearch.yml cluster.name: elasticsearch bin/elasticsearch -E cluster.name=elasticsearch

! 46 Node • Every node should have a unique node.name • Nodes with the same cluster.name binds together. config/elasticsearch.yml node.name: "Node1" bin/elasticsearch -E node.name=Node1

!
47
Shard & Replica
curl -XPUT "http://localhost:9200/books" -H 'Content-Type: application/json' -d'
{
"settings": {
"number_of_shards": 5,
"number_of_replicas": 1
}
}'
curl -XPUT "http://localhost:9200/books/_settings" -H 'Content-Type: application/json' -d'
{
"number_of_replicas": 0
}'

! 48 Elasticsearch is… An open source, distributed, scalable, highly available, document-oriented , RESTful, full text search engine with real-time search and analytics capabilities Source: http://json.org

! 49 Elasticsearch is… An open source, distributed, scalable, highly available, document-oriented, RESTful , full text search engine with real-time search and analytics capabilities $ curl -XPUT http://localhost:9200/books/book/1 -d ' { "title" : "Elasticsearch Guide", "author" : "Kim", "date" : "2014-05-01", "pages" : 250 }’ -H 'Content-Type: application/json' {"_index":"books","_type":"book","_id":"1","_version":1,"created":true} host port index type document id method

! 50 curl -XPUT 'http://localhost:9200/books/book/1' -d ' { "title": "Romeo and Juliet", "author": "William Shakespeare", "category":"Tragedies", "written": "1562-12-01T20:40:00", "pages" : 125 }' -H 'Content-Type: application/json' curl -XPUT 'http://localhost:9200/books/book/2' -d ' { "title" : "Hamlet", "author": "William Shakespeare", "category":"Tragedies", "written": "1599-06-01T12:34:00", "pages" : 172 }' -H 'Content-Type: application/json' curl -XPUT 'http://localhost:9200/books/book/3' -d ' { "title": "The Prince and the Pauper", "author": "Mark Twain", "category":"Children book", "written": "1881-08-01T10:34:00", "pages" : 79}' -H 'Content-Type: application/json' Indexing a Document Use PUT command to index document.
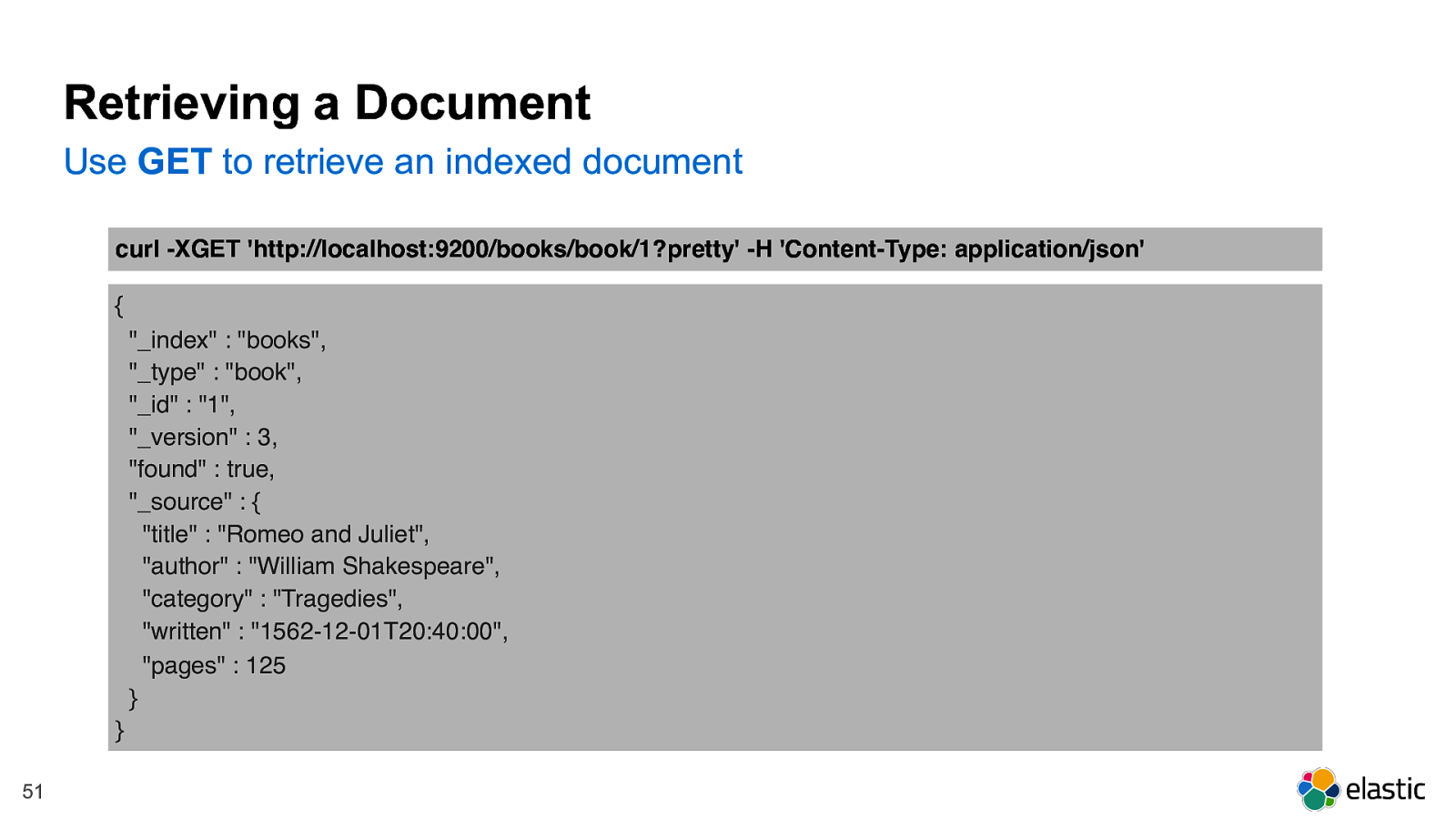
! 51 curl -XGET 'http://localhost:9200/books/book/1?pretty' -H 'Content-Type: application/json' Retrieving a Document Use GET to retrieve an indexed document { "_index" : "books", "_type" : "book", "_id" : "1", "_version" : 3, "found" : true, "_source" : { "title" : "Romeo and Juliet", "author" : "William Shakespeare", "category" : "Tragedies", "written" : "1562-12-01T20:40:00", "pages" : 125 } }
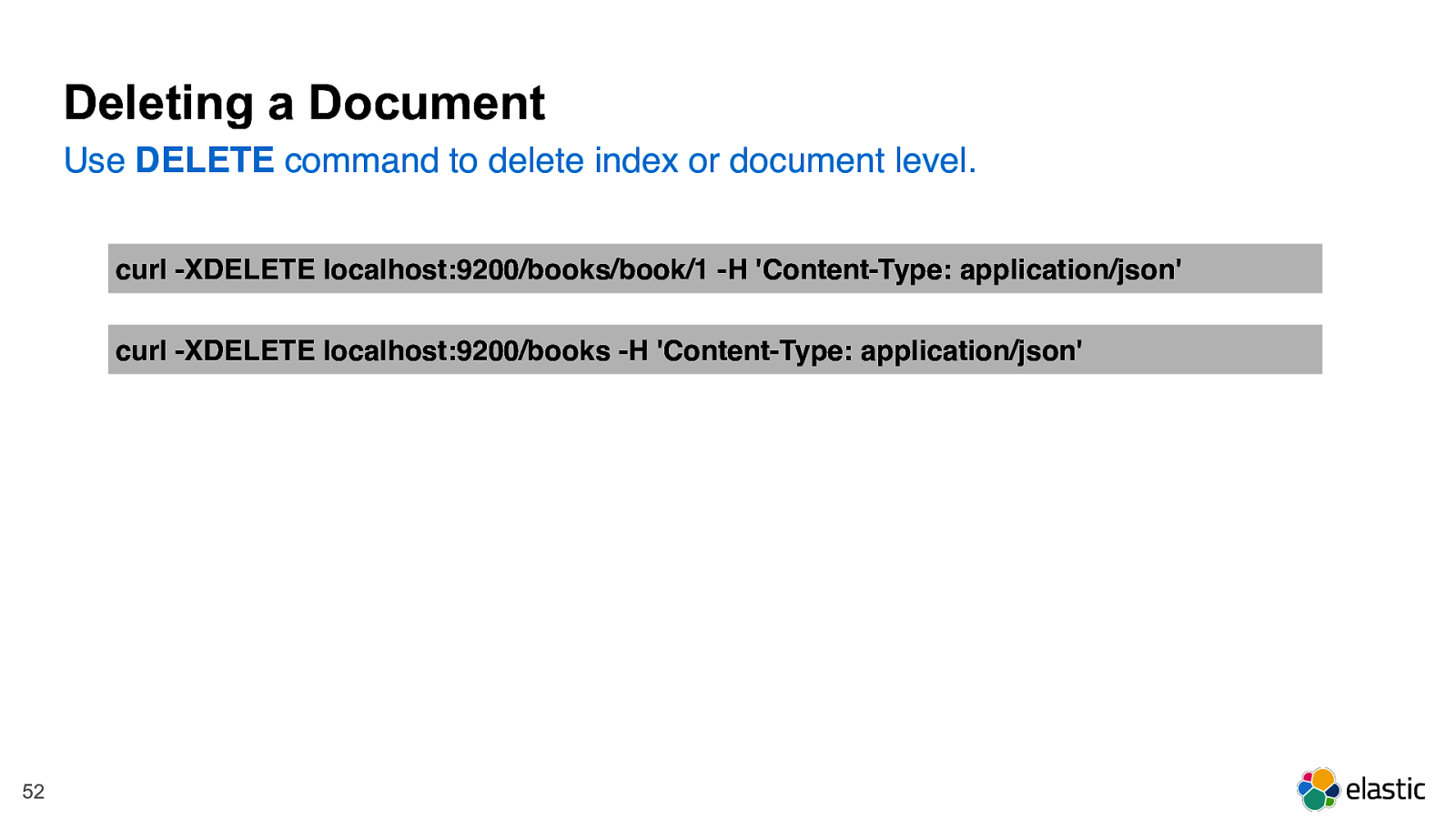
! 52 curl -XDELETE localhost:9200/books/book/1 -H 'Content-Type: application/json' curl -XDELETE localhost:9200/books -H 'Content-Type: application/json' Deleting a Document Use DELETE command to delete index or document level.

! 53 curl -XPOST "http://localhost:9200/books/book/_bulk" -d ' {"index":{"_id":"1"}} {"title":"Romeo and Juliet","author":"William Shakespeare","category":"Tragedies","written":"1562-12-01T20:40:00","pages":125} {"index":{"_id":"2"}} {"title":"Hamlet","author":"William Shakespeare","category":"Tragedies","written":"1599-06-01T12:34:00","pages":172} {"index":{"_id":"3"}} {"title":"The Prince and the Pauper","author":"Mark Twain","category":"Children book","written":"1881-08-01T10:34:00","pages":79} ' -H 'Content-Type: application/json' Use _bulk API to run multiple commands Bulk API

! 54 curl -XGET "http://localhost:9200/books/_search?pretty=true" Search documents Use _search API for search index. { … }, "hits" : { "total" : 3, "max_score" : 1.0, "hits" : [ { … "_source": { "title": "Romeo and Juliet", "author": "William Shakespeare", "category":"Tragedies", "written": "1562-12-01T20:40:00", "pages" : 125 } }, …

! 55 URI Search curl -XGET "http://localhost:9200/books/_search?pretty=true" curl -XGET "http://localhost:9200/books/_search?q=author:william&pretty=true" curl -XGET "http://localhost:9200/books/_search?q=william&df=author&pretty=true" curl -XGET "http://localhost:9200/books/_search? q=william%20AND%20romeo&pretty=true"

! 56 Request Body Search curl -XGET "http://localhost:9200/books/_search?pretty=true" -d' { "query": { "match": { "author": "william" } } }' -H 'Content-Type: application/json'
! 57 Elasticsearch is… An open source, distributed, scalable, highly available, document-oriented, RESTful, full text search engine with real-time search and analytics capabilities

! 58 RDBMS creates table DOC TEXT 1 The quick brown fox jumps over the lazy dog 2 Fast jumping rabbits
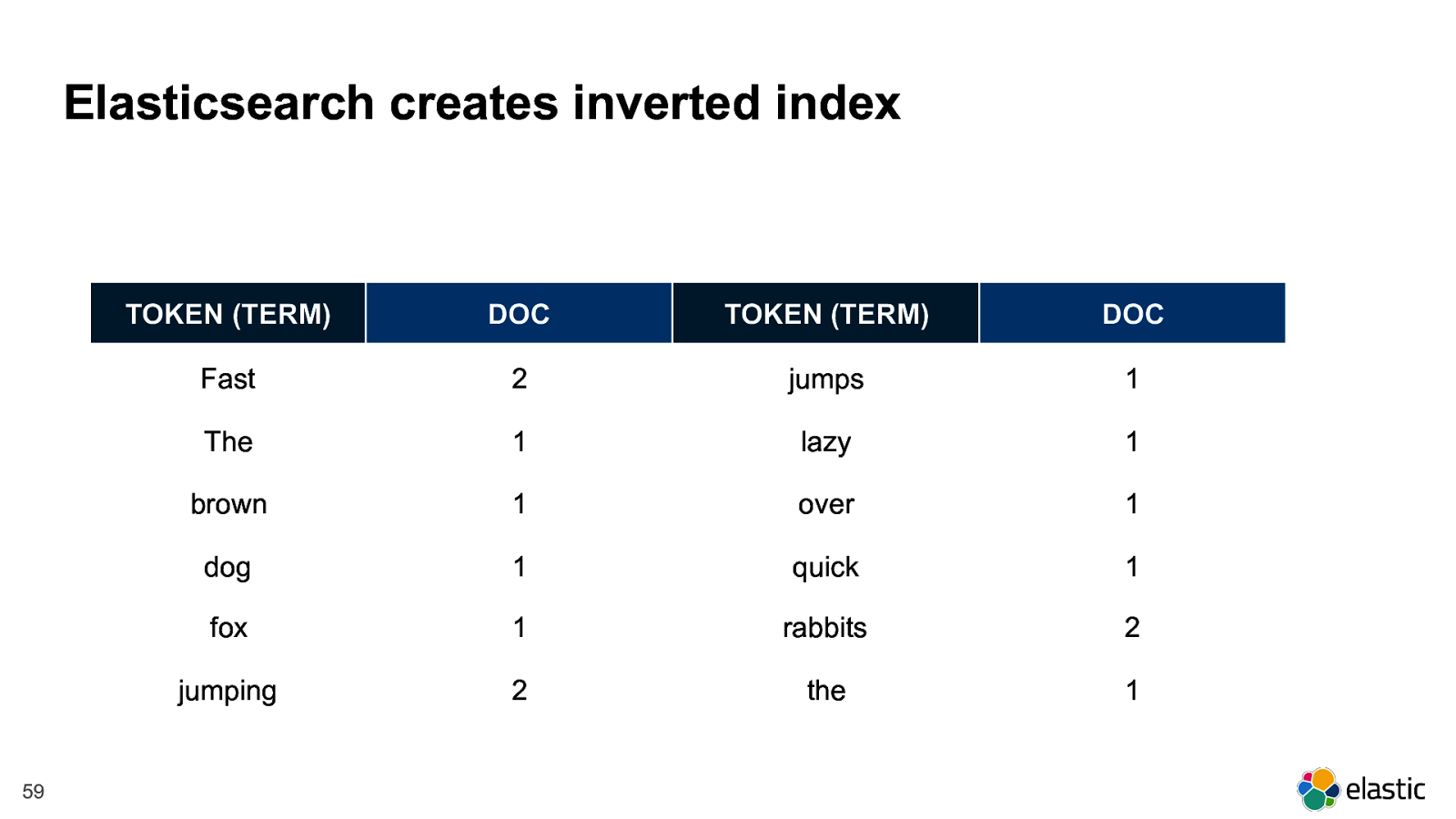
! 59 Elasticsearch creates inverted index TOKEN (TERM) DOC TOKEN (TERM) DOC Fast 2 jumps 1 The 1 lazy 1 brown 1 over 1 dog 1 quick 1 fox 1 rabbits 2 jumping 2 the 1
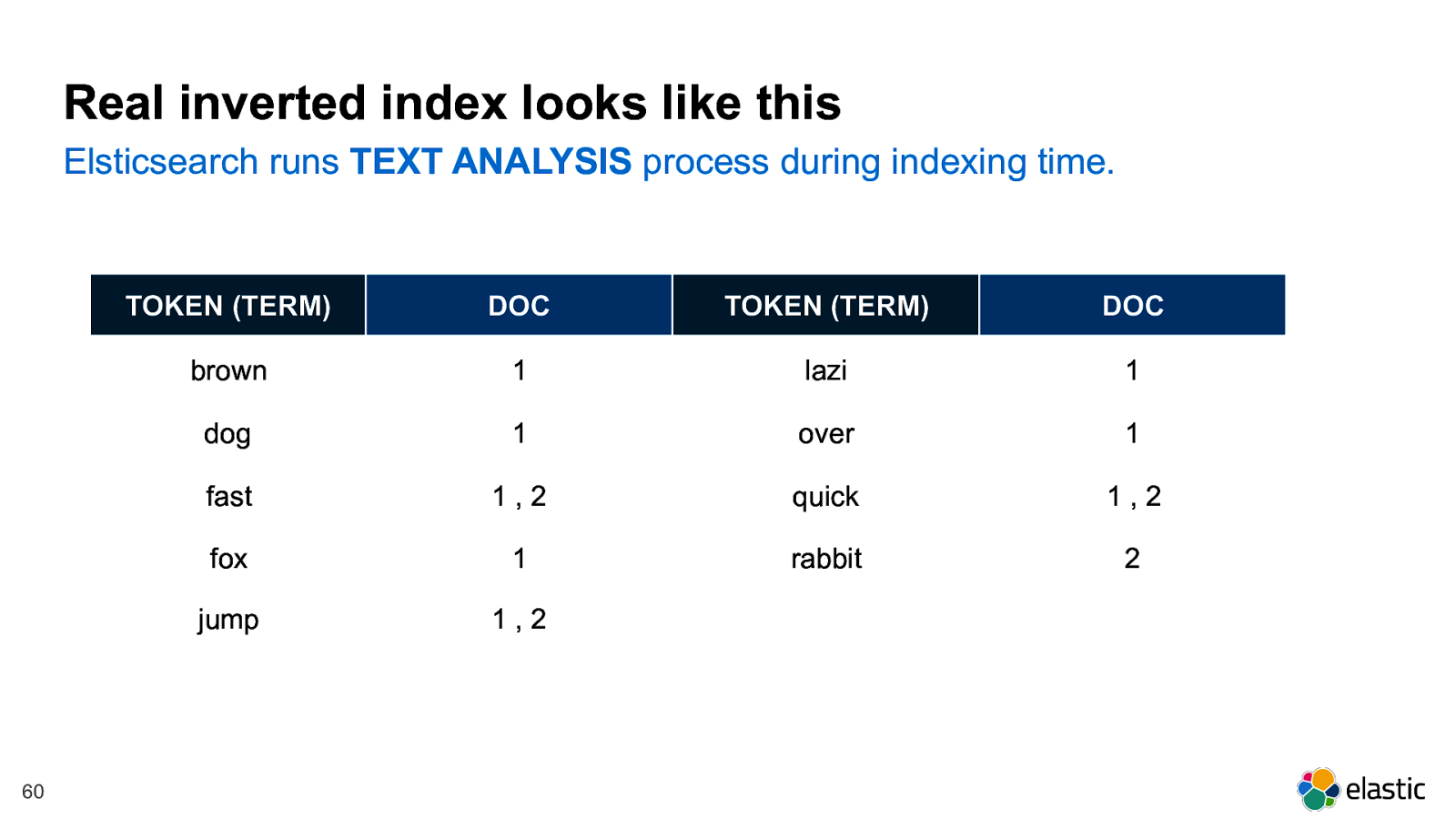
! 60 Real inverted index looks like this Elsticsearch runs TEXT ANALYSIS process during indexing time. TOKEN (TERM) DOC TOKEN (TERM) DOC brown 1 lazi 1 dog 1 over 1 fast 1 , 2 quick 1 , 2 fox 1 rabbit 2 jump 1 , 2
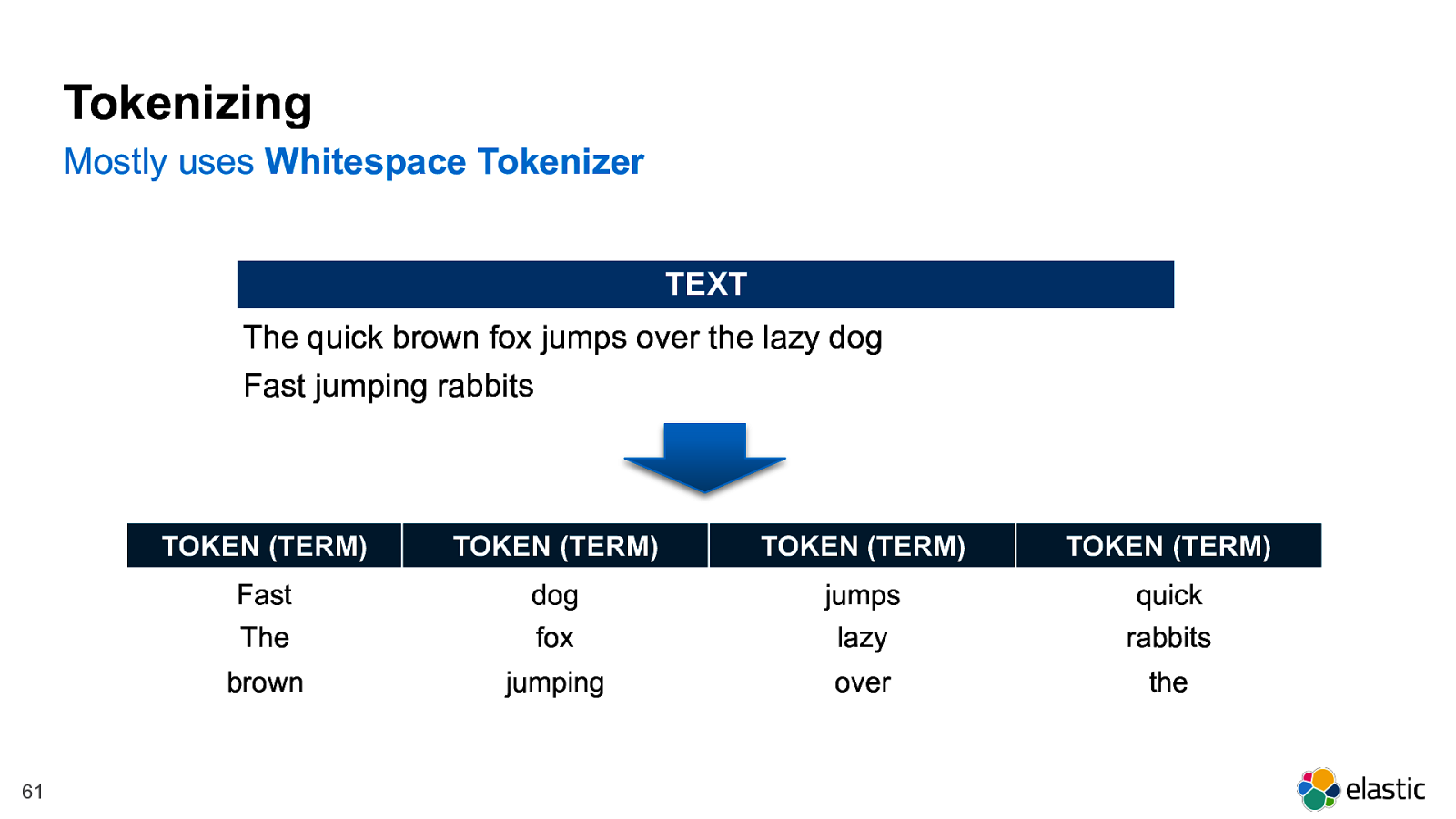
! 61 Tokenizing Mostly uses Whitespace Tokenizer TOKEN (TERM) TOKEN (TERM) TOKEN (TERM) TOKEN (TERM) Fast dog jumps quick The fox lazy rabbits brown jumping over the TEXT The quick brown fox jumps over the lazy dog Fast jumping rabbits
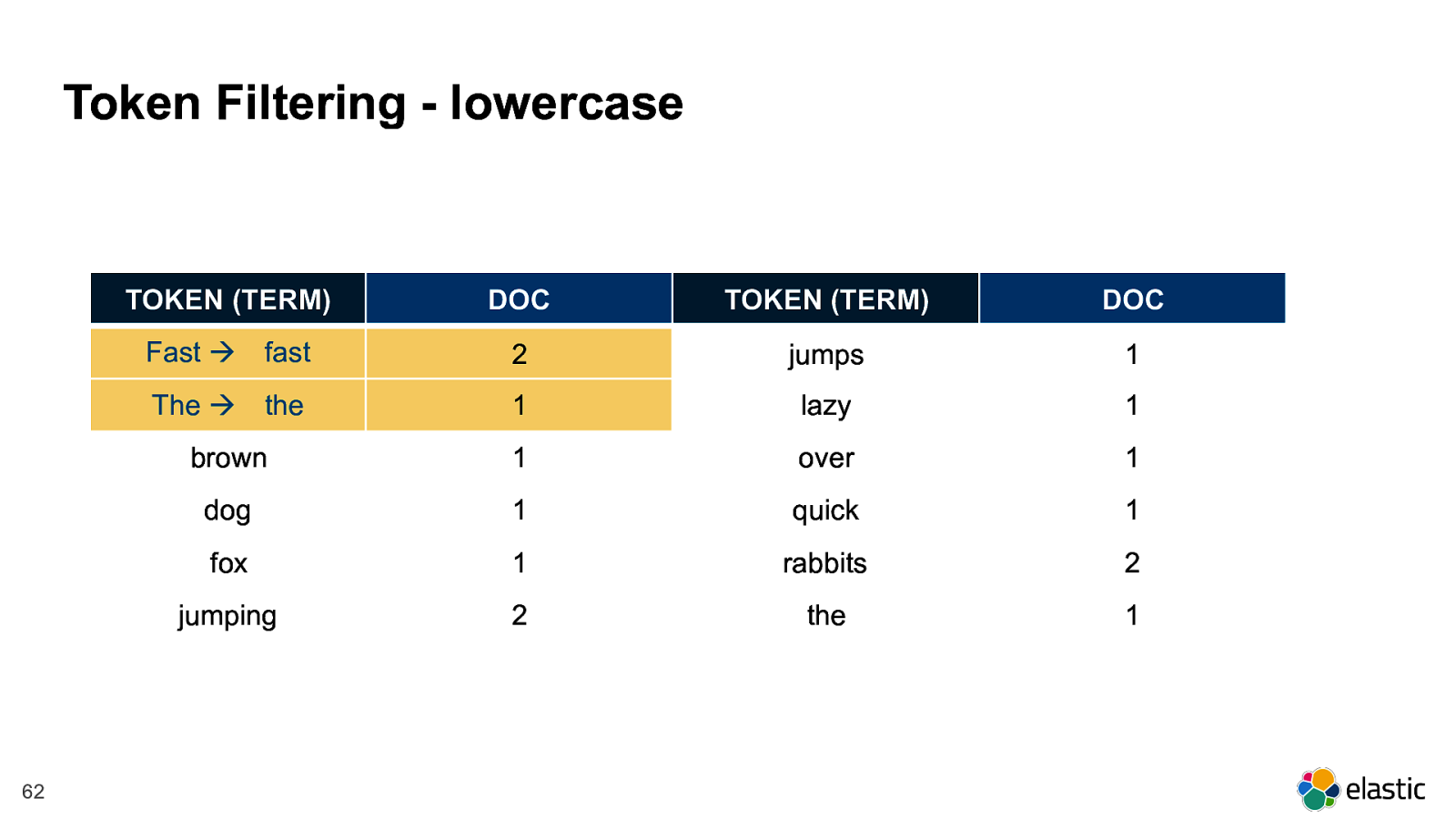
! 62 Token Filtering - lowercase TOKEN (TERM) DOC TOKEN (TERM) DOC Fast !
fast 2 jumps 1 The !
the 1 lazy 1 brown 1 over 1 dog 1 quick 1 fox 1 rabbits 2 jumping 2 the 1
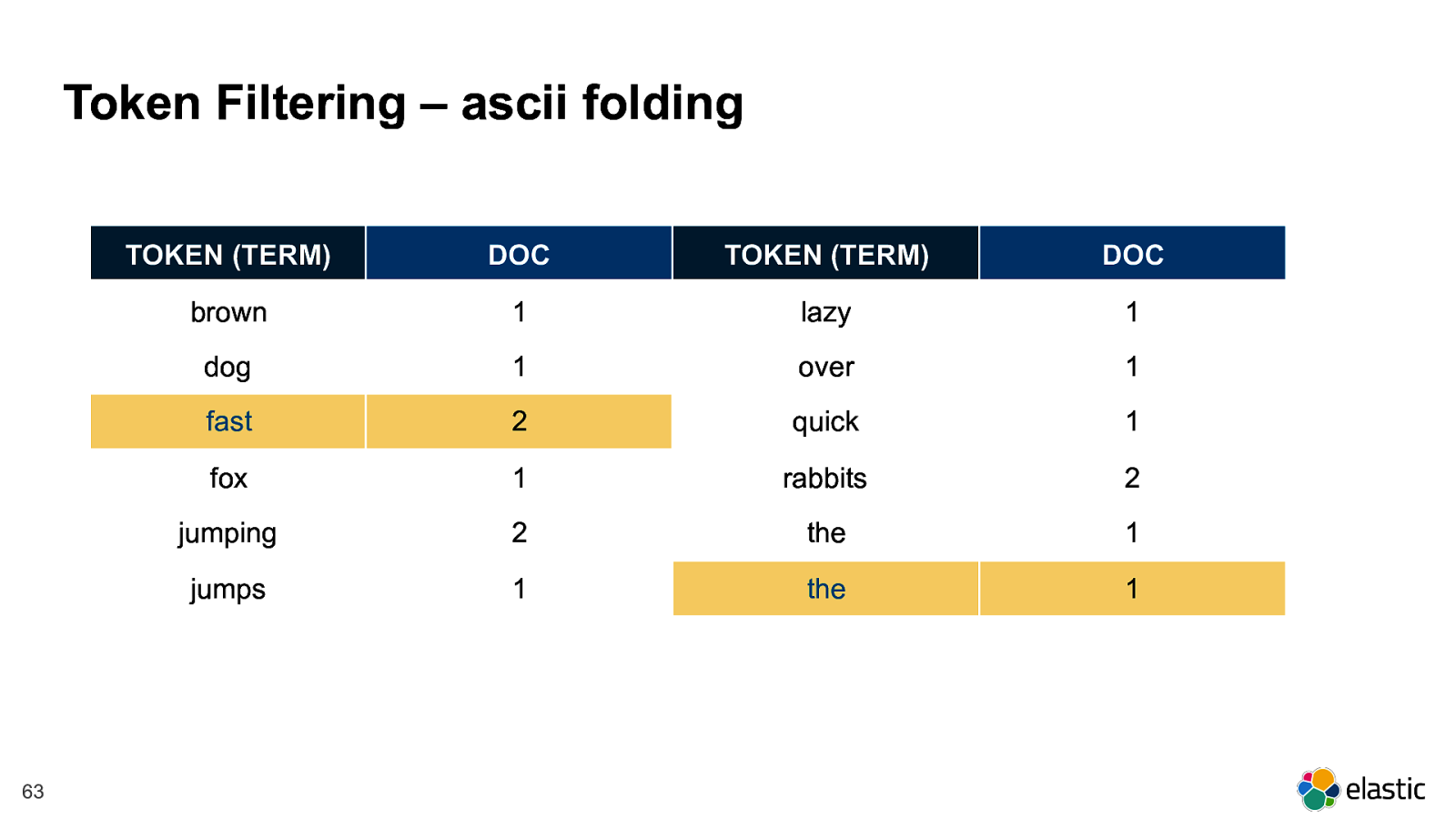
! 63 Token Filtering – ascii folding TOKEN (TERM) DOC TOKEN (TERM) DOC brown 1 lazy 1 dog 1 over 1 fast 2 quick 1 fox 1 rabbits 2 jumping 2 the 1 jumps 1 the 1
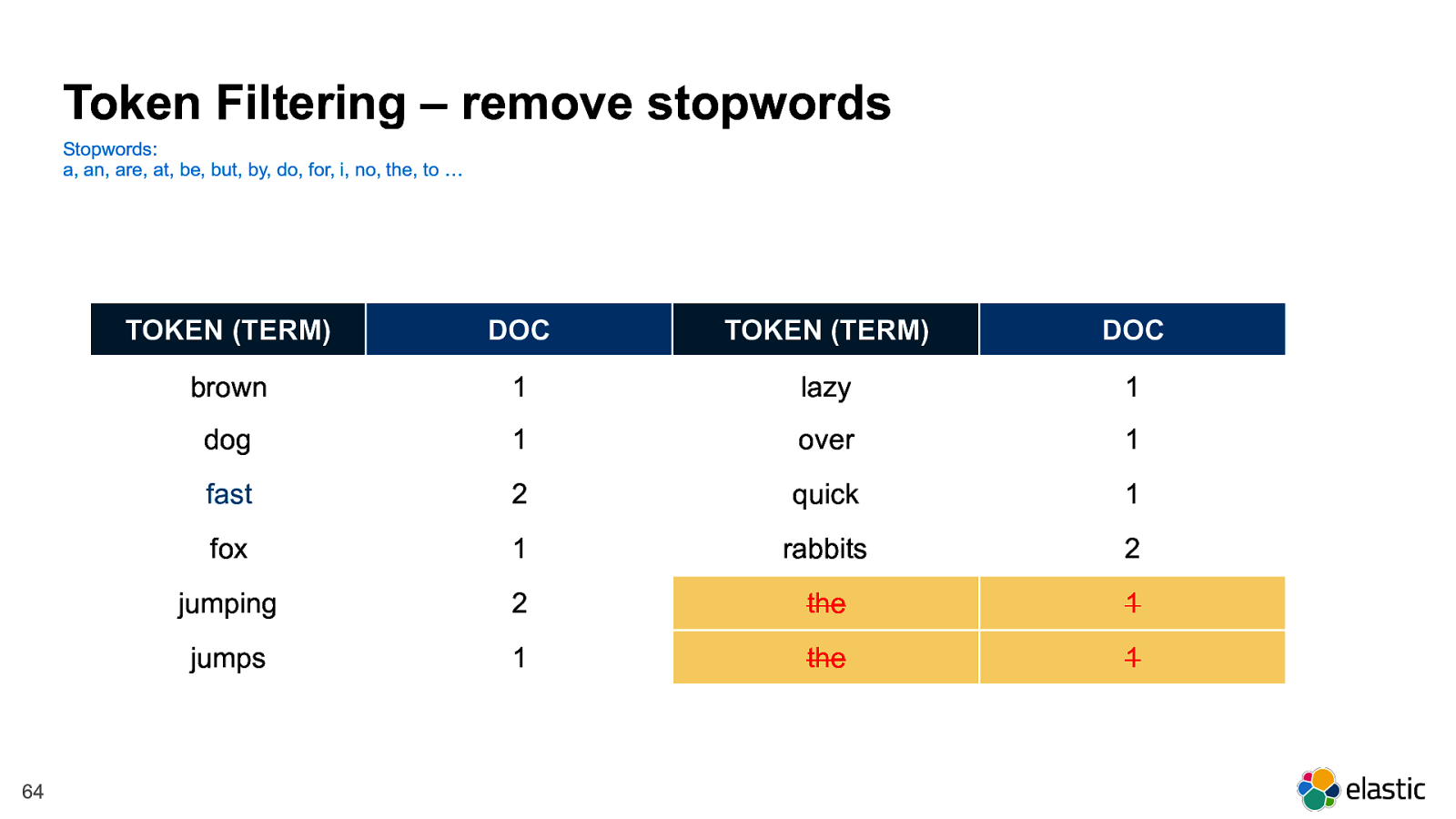
!
64
Token Filtering – remove stopwords
Stopwords:
a, an, are, at, be, but, by, do, for, i, no, the, to …
TOKEN (TERM)
DOC
TOKEN (TERM)
DOC
brown
1
lazy
1
dog
1
over
1
fast
2
quick
1
fox
1
rabbits
2
jumping
2
the
1
jumps
1
the
1
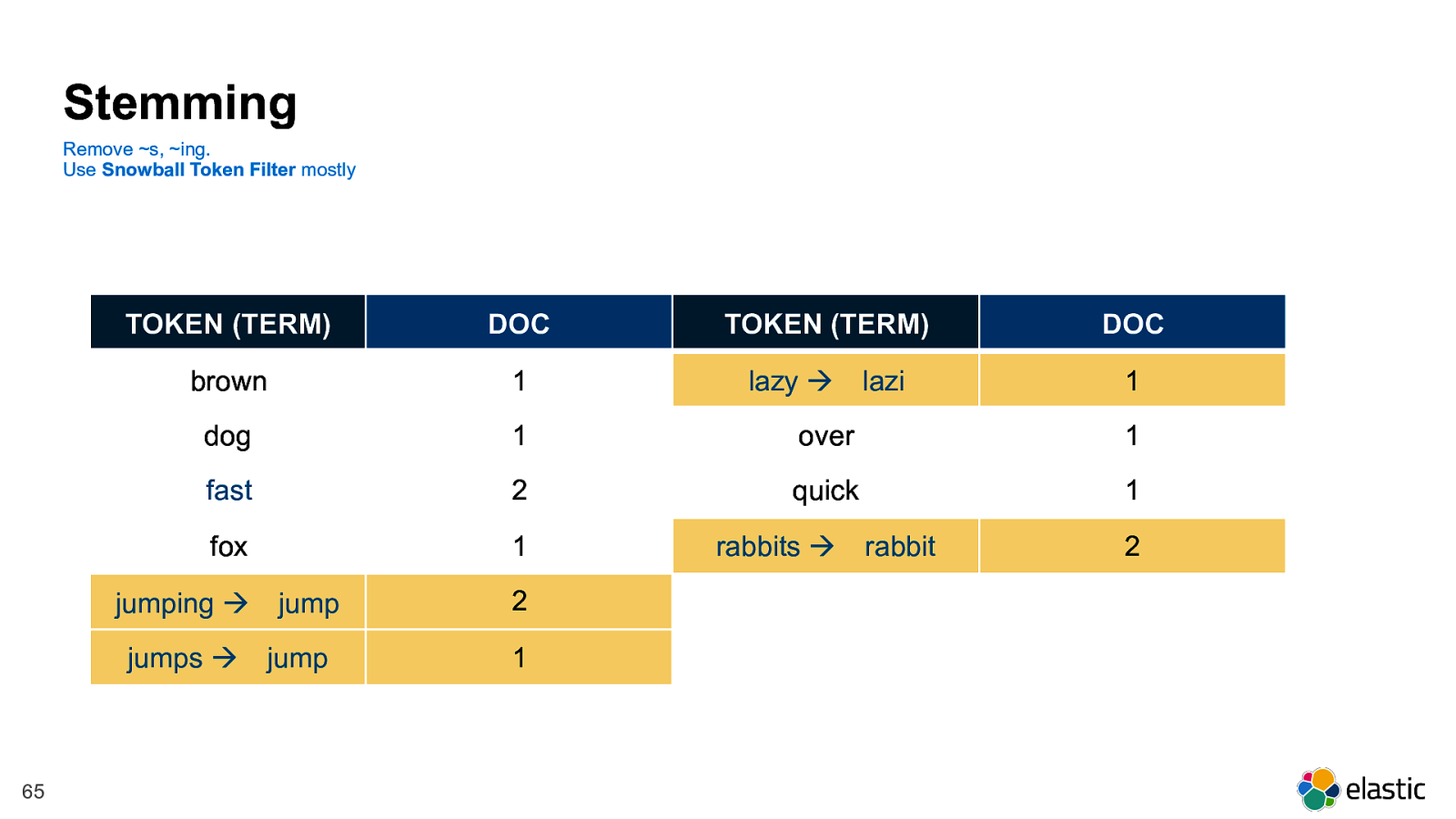
! 65 Stemming Remove ~s, ~ing. Use Snowball Token Filter mostly TOKEN (TERM) DOC TOKEN (TERM) DOC brown 1 lazy !
lazi 1 dog 1 over 1 fast 2 quick 1 fox 1 rabbits !
rabbit 2 jumping !
jump 2 jumps !
jump 1
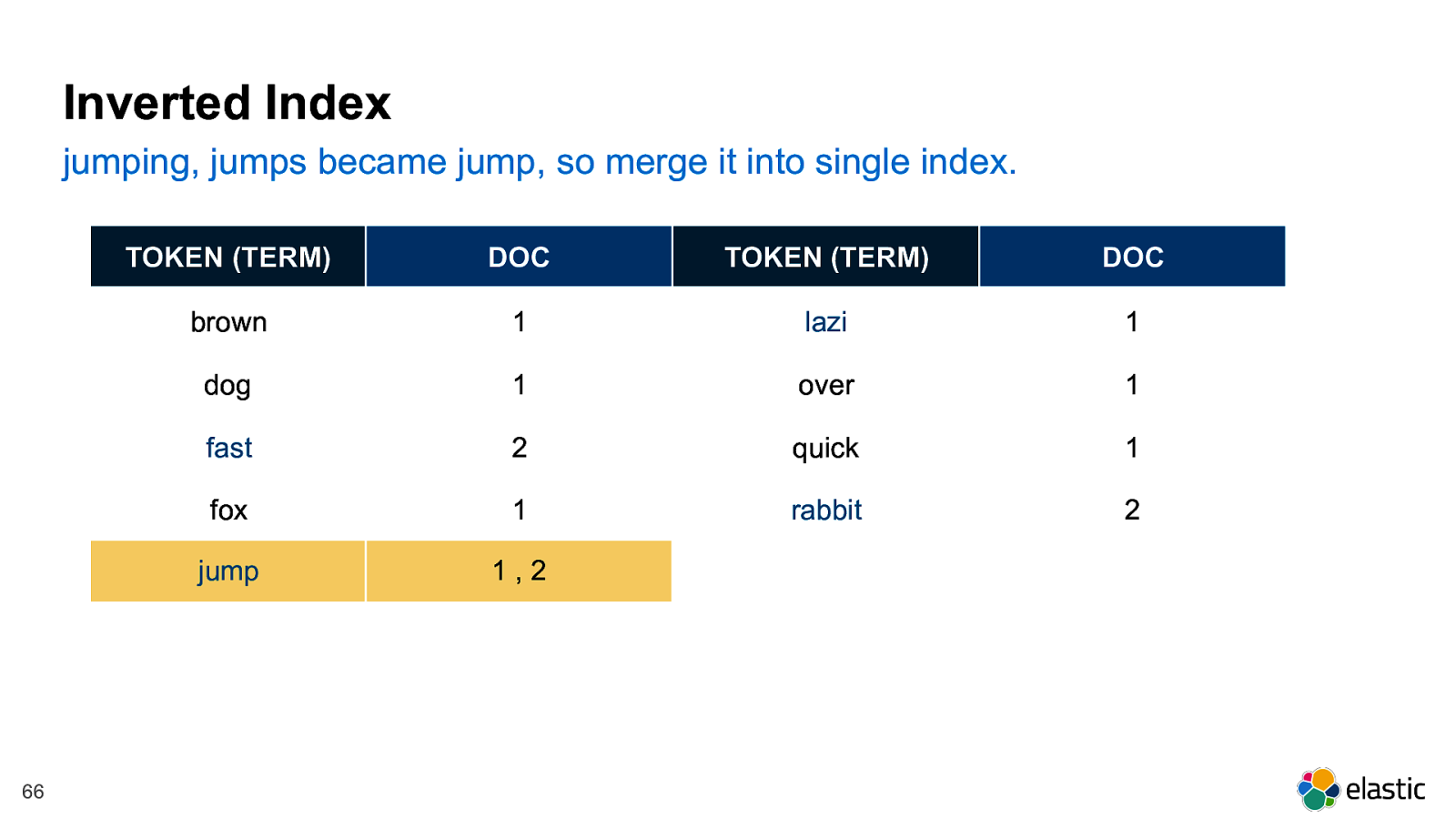
! 66 Inverted Index jumping, jumps became jump, so merge it into single index. TOKEN (TERM) DOC TOKEN (TERM) DOC brown 1 lazi 1 dog 1 over 1 fast 2 quick 1 fox 1 rabbit 2 jump 1 , 2
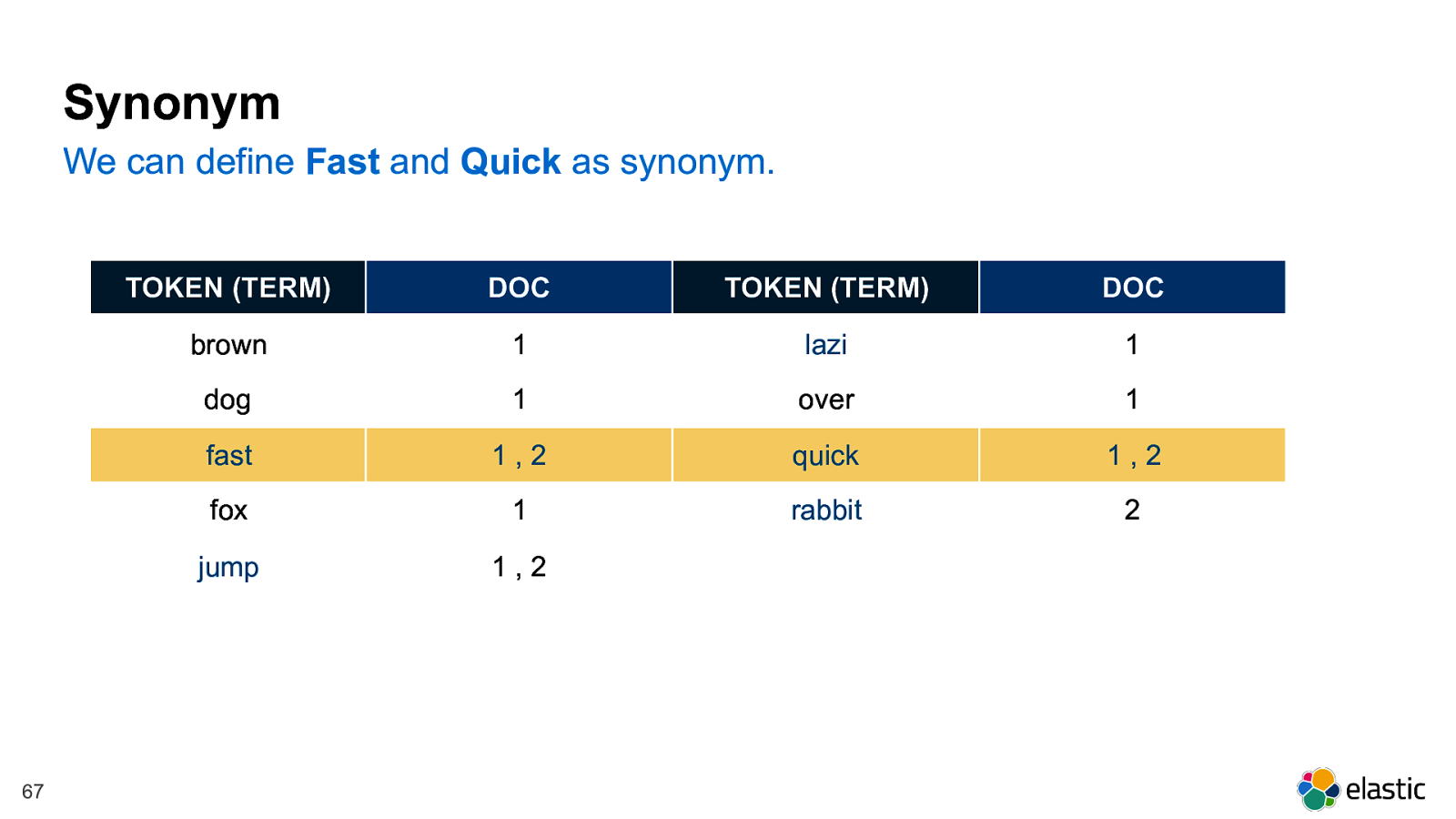
! 67 Synonym We can define Fast and Quick as synonym. TOKEN (TERM) DOC TOKEN (TERM) DOC brown 1 lazi 1 dog 1 over 1 fast 1 , 2 quick 1 , 2 fox 1 rabbit 2 jump 1 , 2

! 68 _analyze API We can simulated analyzer with _analyze API analyzer consists of single tokenizer and multiple token filters curl -XPOST "http://localhost:9200/_analyze?pretty" -d ' { "tokenizer": "whitespace", "filter": ["lowercase", "stop", "snowball"], "text": [ "The quick brown fox jumps over the lazy dog", "Fast jumping rabbits" ] }' -H 'Content-Type: application/json'
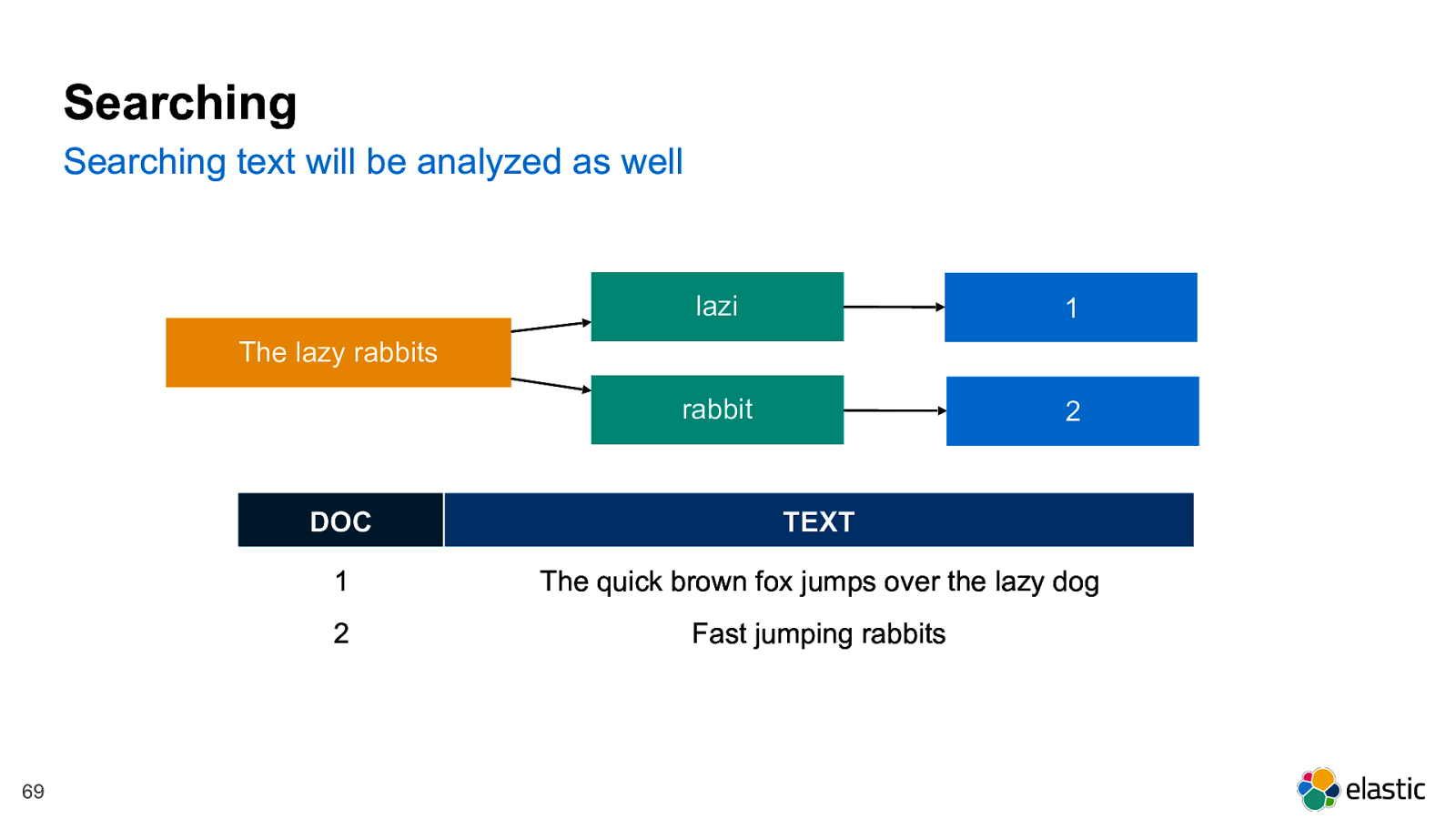
! 69 Searching Searching text will be analyzed as well The lazy rabbits lazi rabbit 1 DOC TEXT 1 The quick brown fox jumps over the lazy dog 2 Fast jumping rabbits 2

! 70 Termvectors API "terms": { " shakespeare ": { "term_freq": 1, "tokens": [ … ] }, " william ": { "term_freq": 1, "tokens": [ … ] } curl -XGET "http://localhost:9200/books/book/1/_termvectors?fields=author&pretty"
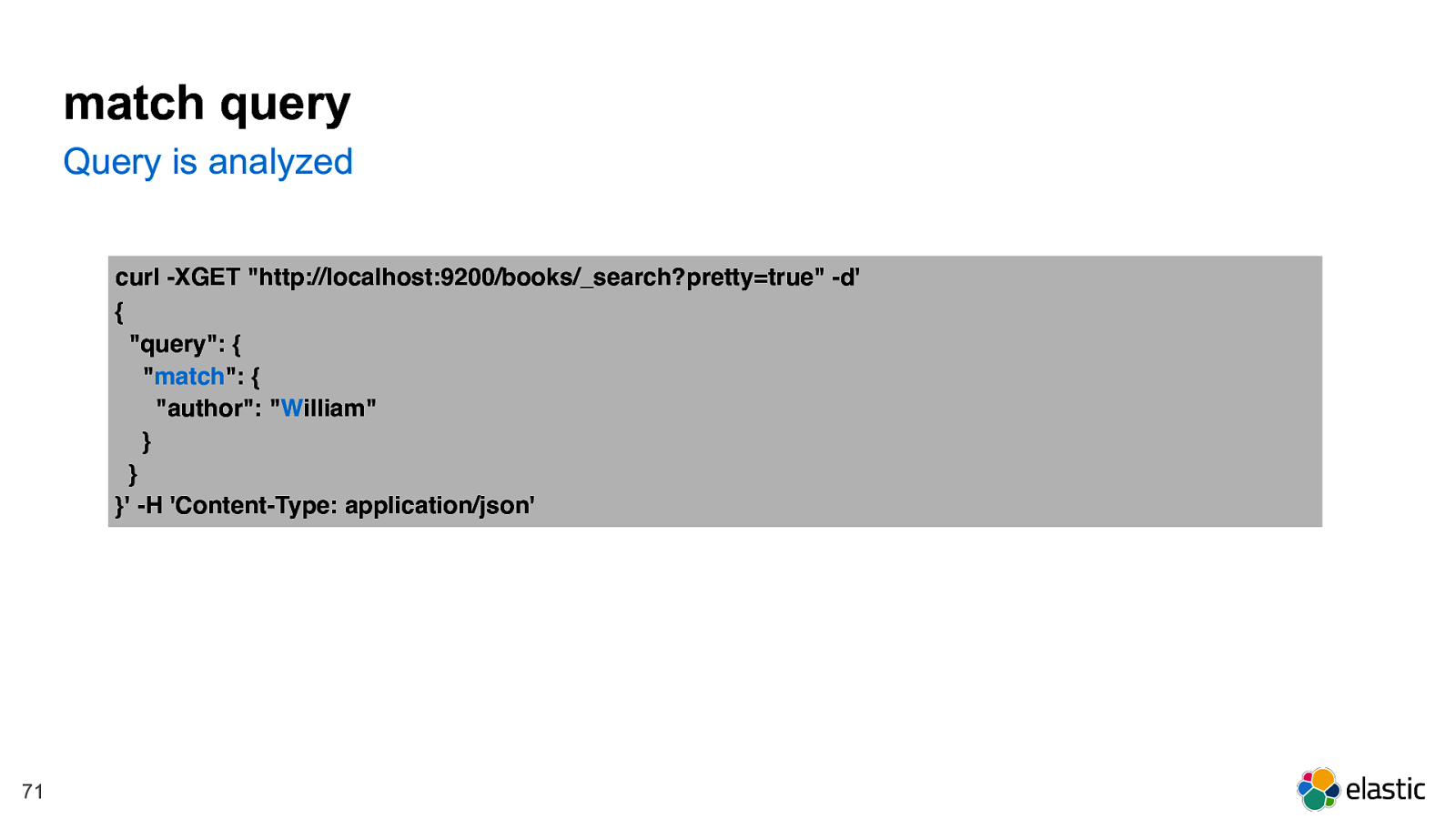
! 71 match query curl -XGET "http://localhost:9200/books/_search?pretty=true" -d' { "query": { " match ": { "author": " W illiam" } } }' -H 'Content-Type: application/json' Query is analyzed
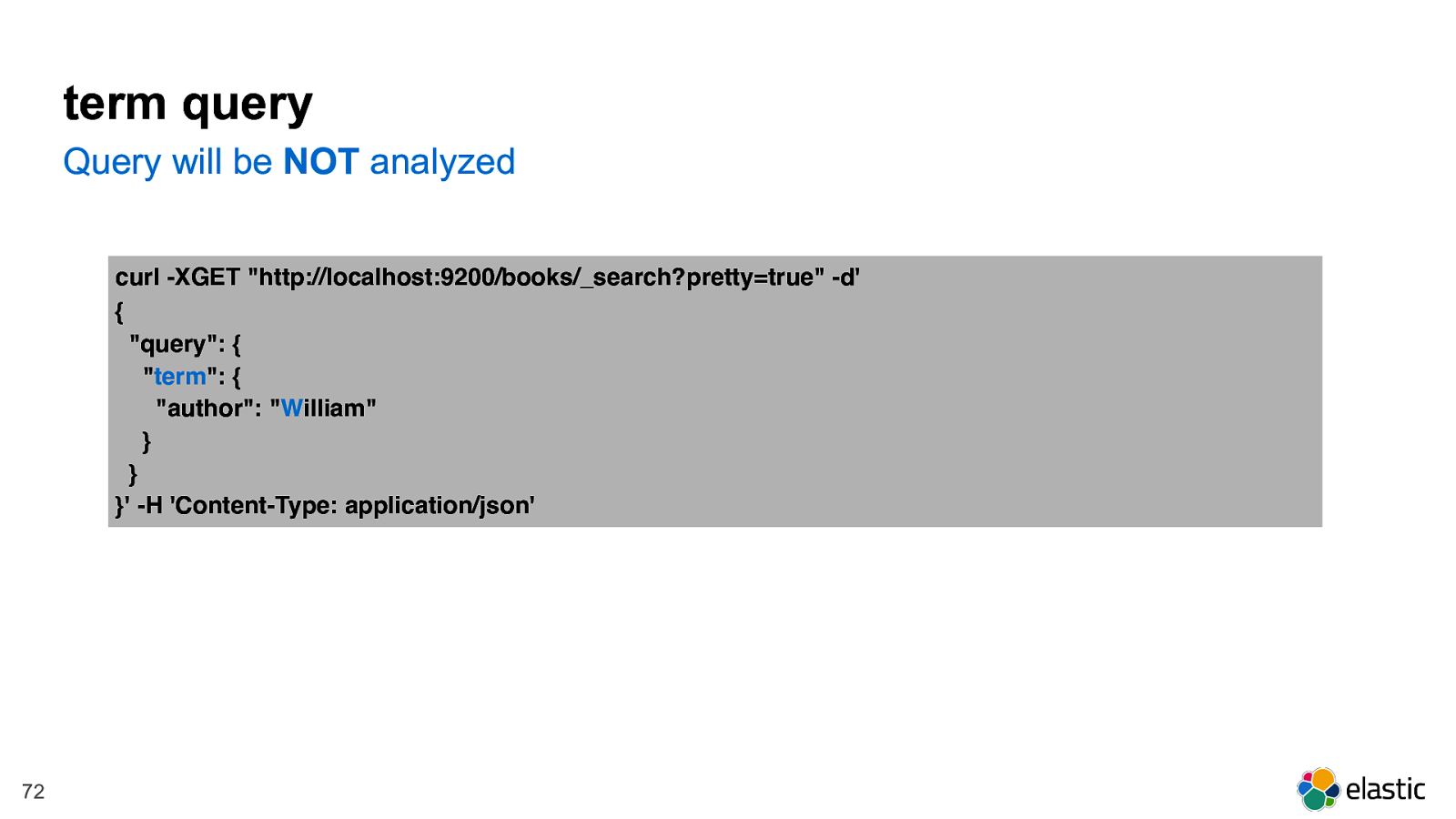
! 72 term query curl -XGET "http://localhost:9200/books/_search?pretty=true" -d' { "query": { " term ": { "author": " W illiam" } } }' -H 'Content-Type: application/json' Query will be NOT analyzed

! 73 Mappings • Mapping can be created automatticaly. • Since 5.x text type data will be create keyword multi filed. curl -XGET "http://localhost:9200/books/_mappings?pretty" "properties" : { "author" : { "type" : " text ", "fields" : { "keyword" : { "type" : " keyword ", "ignore_above" : 256 }
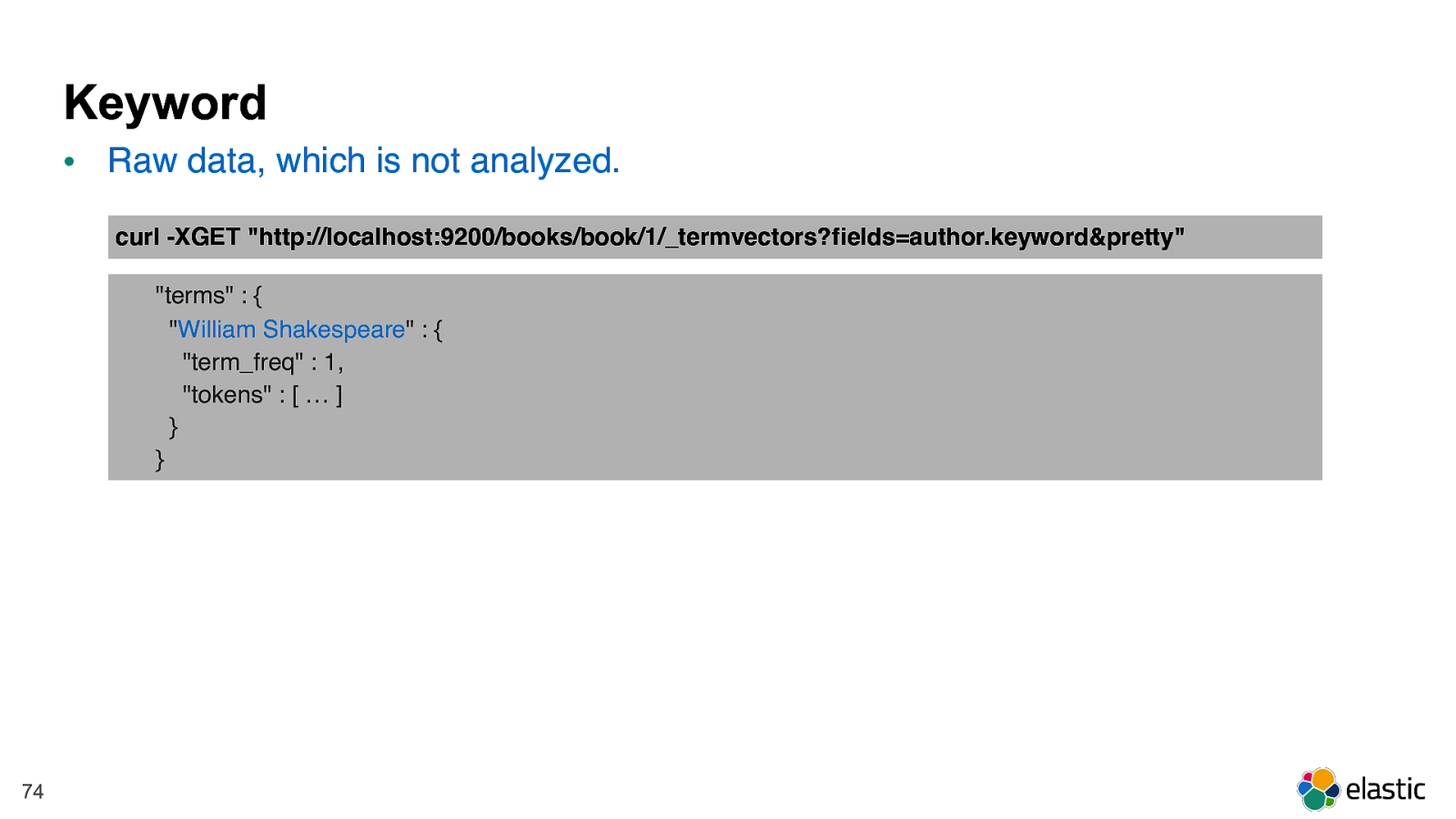
! 74 Keyword • Raw data, which is not analyzed. "terms" : { " William Shakespeare " : { "term_freq" : 1, "tokens" : [ … ] } } curl -XGET "http://localhost:9200/books/book/1/_termvectors?fields=author.keyword&pretty"
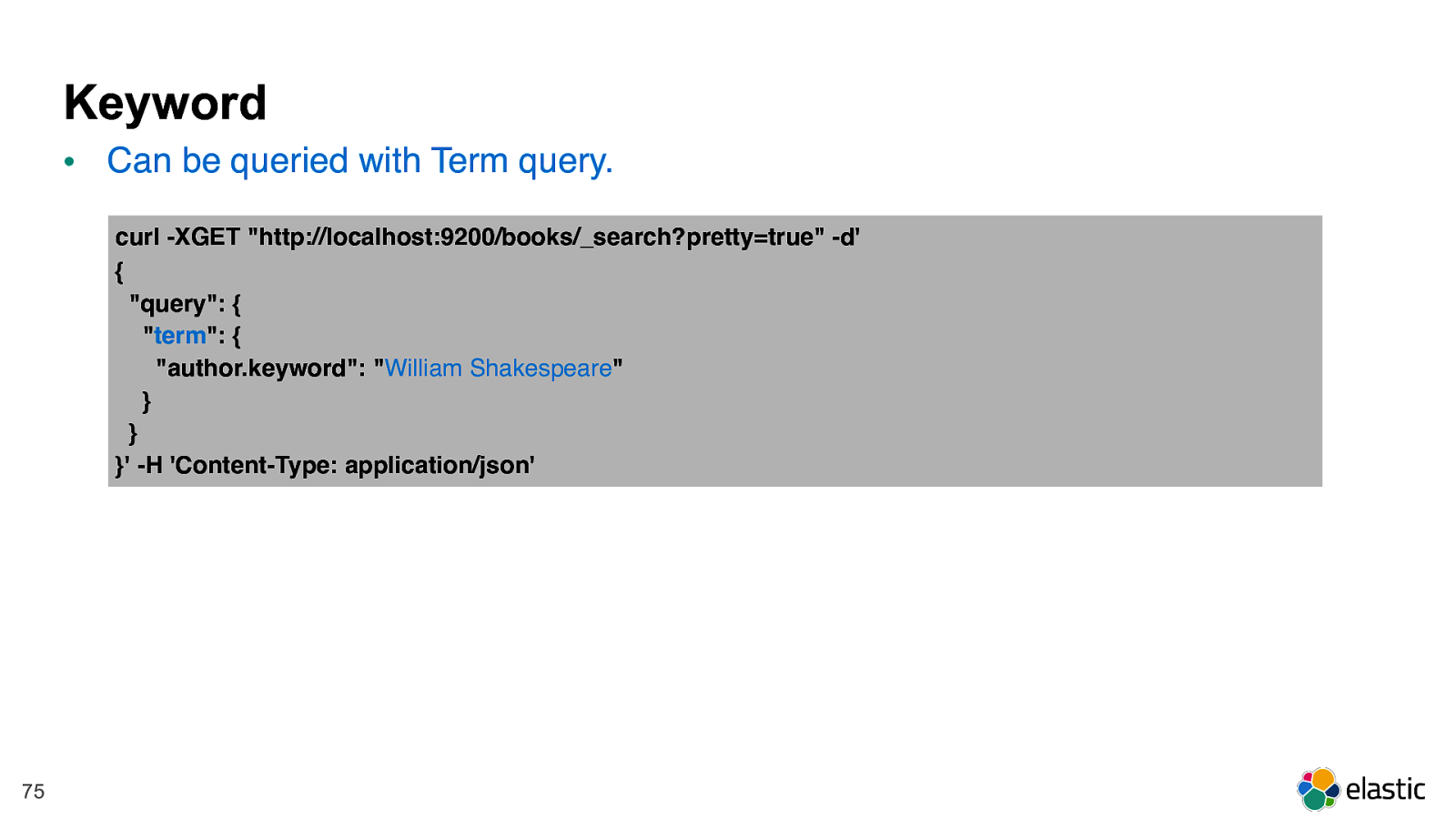
! 75 Keyword • Can be queried with Term query. curl -XGET "http://localhost:9200/books/_search?pretty=true" -d' { "query": { " term ": { "author.keyword": " William Shakespeare " } } }' -H 'Content-Type: application/json'
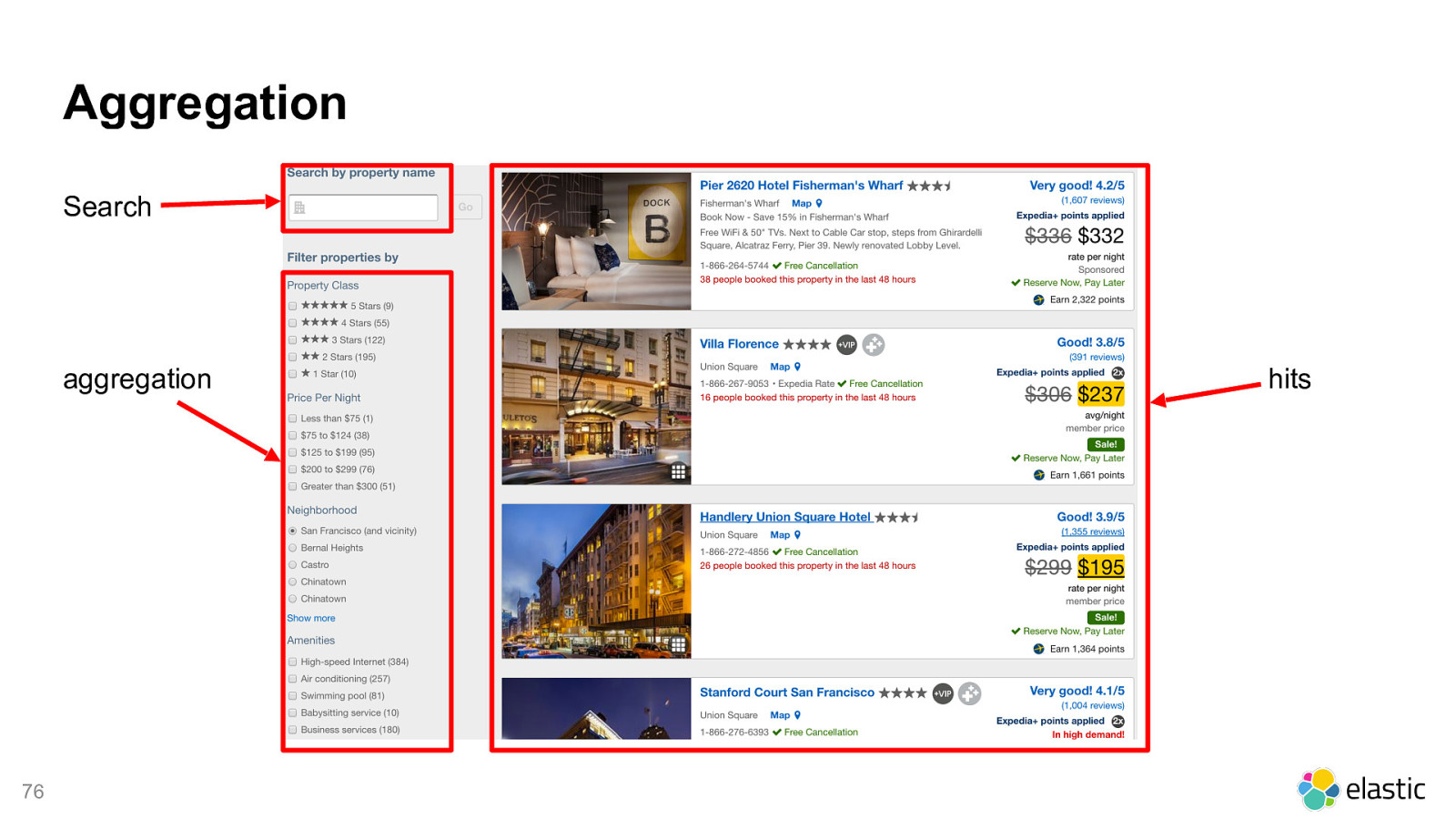
! 76 Aggregation Search aggregation hits
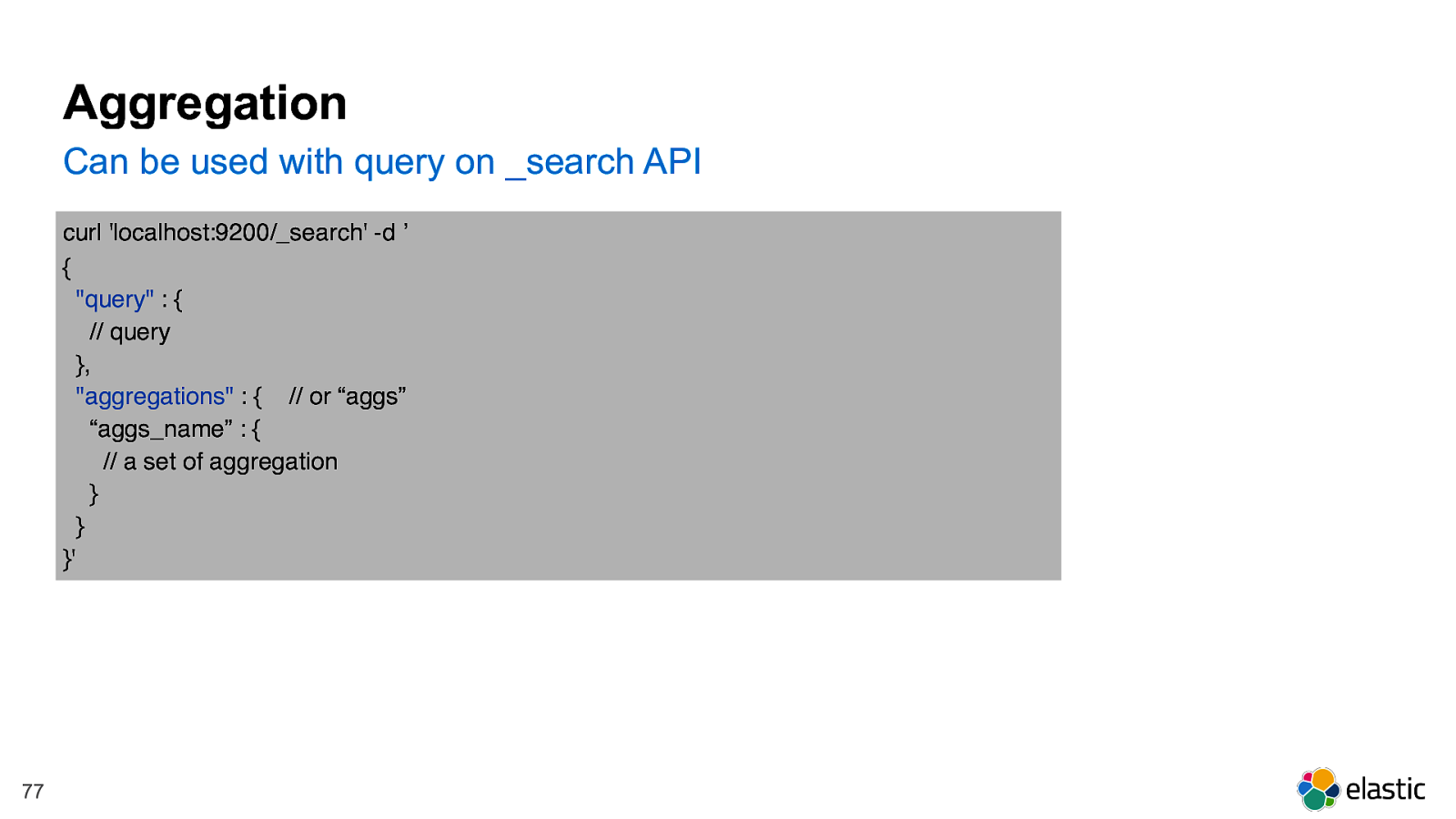
! 77 Aggregation Can be used with query on _search API curl 'localhost:9200/_search' -d ’ {
"query" : { // query },
"aggregations" : { // or “aggs” “aggs_name” : { // a set of aggregation } } }'

! 78 Aggregation Can be used with query on _search API curl -XGET "http://localhost:9200/books/_search?pretty" -d' { "query": { "match_all": {} }, "aggs": { "authors": { "terms": { "field": "author.keyword" } } } }' -H 'Content-Type: application/json' … "aggregations" : { "authors" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "William Shakespeare", "doc_count" : 2 }, { "key" : "Mark Twain", "doc_count" : 1 } ] }

! 79 Aggregation Bucket, Metric, Pipeline • Bucket ‒ Creats bucket, sub-group of documents. ‒ Bucket can conatin another aggregation. • Metric ‒ Calculates number field. • Pipeline ‒ Re-calculate Metric aggregation.

! 80 Aggregation • percentile • percentile_ranks • cardinality • significant_terms • top hits • scripted_metric • filters • range • geohash • terms • histogram • date_histogram • stats • extended stats • min / max • sum • pipeline aggregations

! 81 Agg. Combination curl -XGET "http://localhost:9200/books/_search?pretty" -d' { "query": { "match_all": {} }, "aggs": { "authors": { "terms": { "field": "author.keyword" }, "aggs": { "pages_per_author": { "sum": { "field": "pages" } } } } } }' -H 'Content-Type: application/json' … "aggregations" : { "authors" : { "doc_count_error_upper_bound" : 0, "sum_other_doc_count" : 0, "buckets" : [ { "key" : "William Shakespeare", "doc_count" : 2, "pages_per_author" : { "value" : 297.0 } }, { "key" : "Mark Twain", "doc_count" : 1, "pages_per_author" : { "value" : 79.0 } } ] }
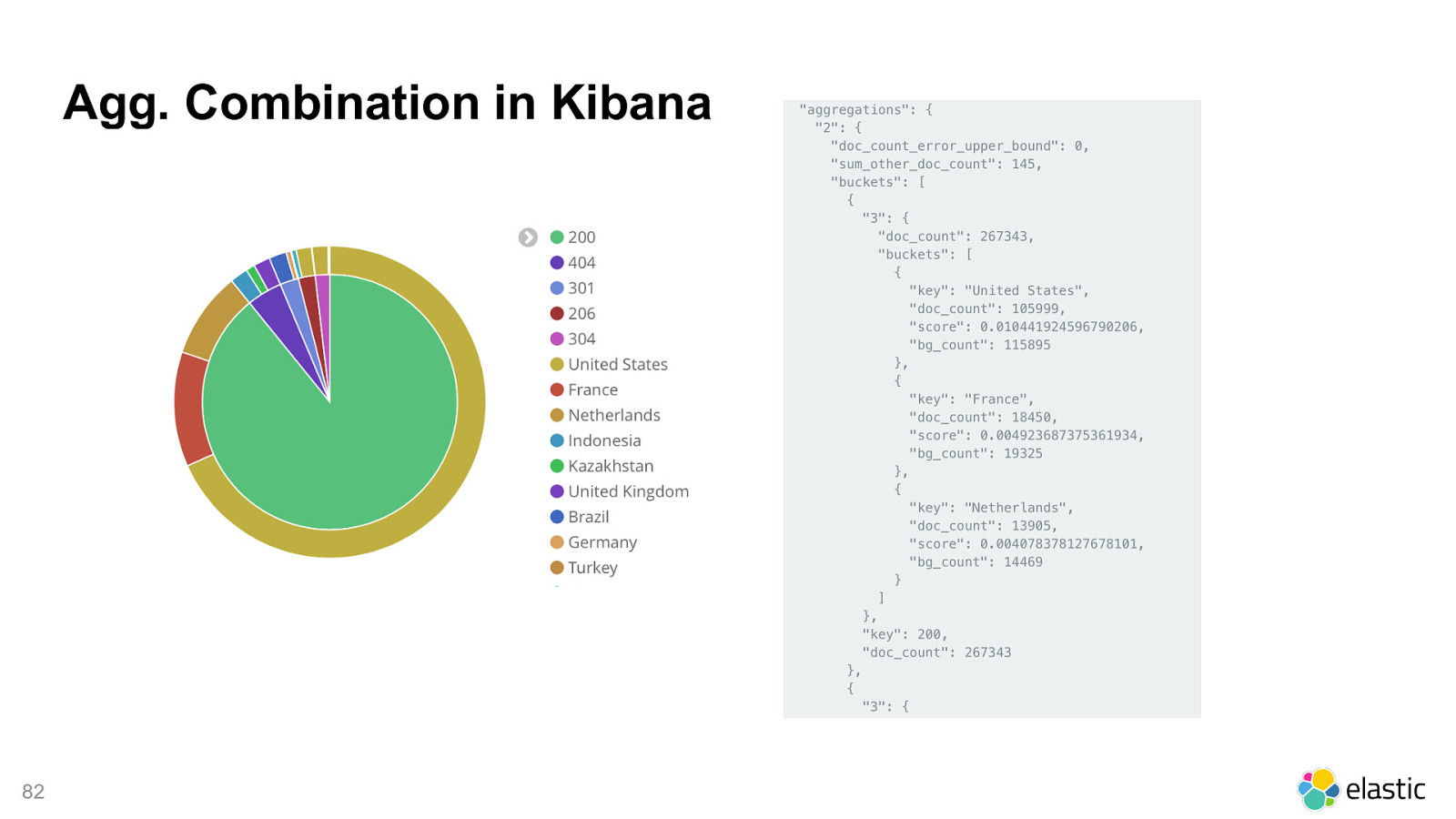
! 82 Agg. Combination in Kibana
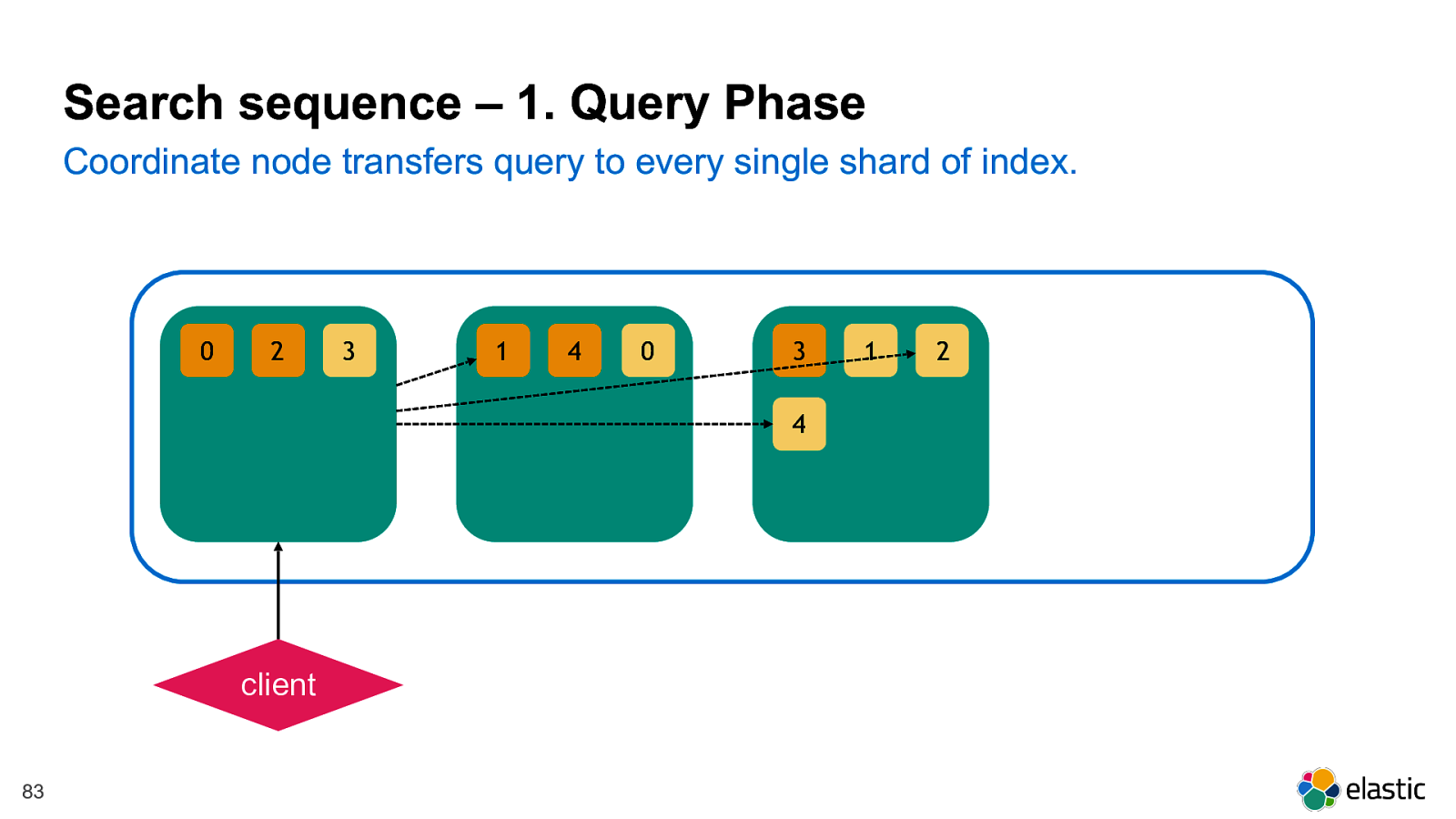
! 83 2 0 3 4 1 1 3 2 4 0 Coordinate node transfers query to every single shard of index. Search sequence – 1. Query Phase client
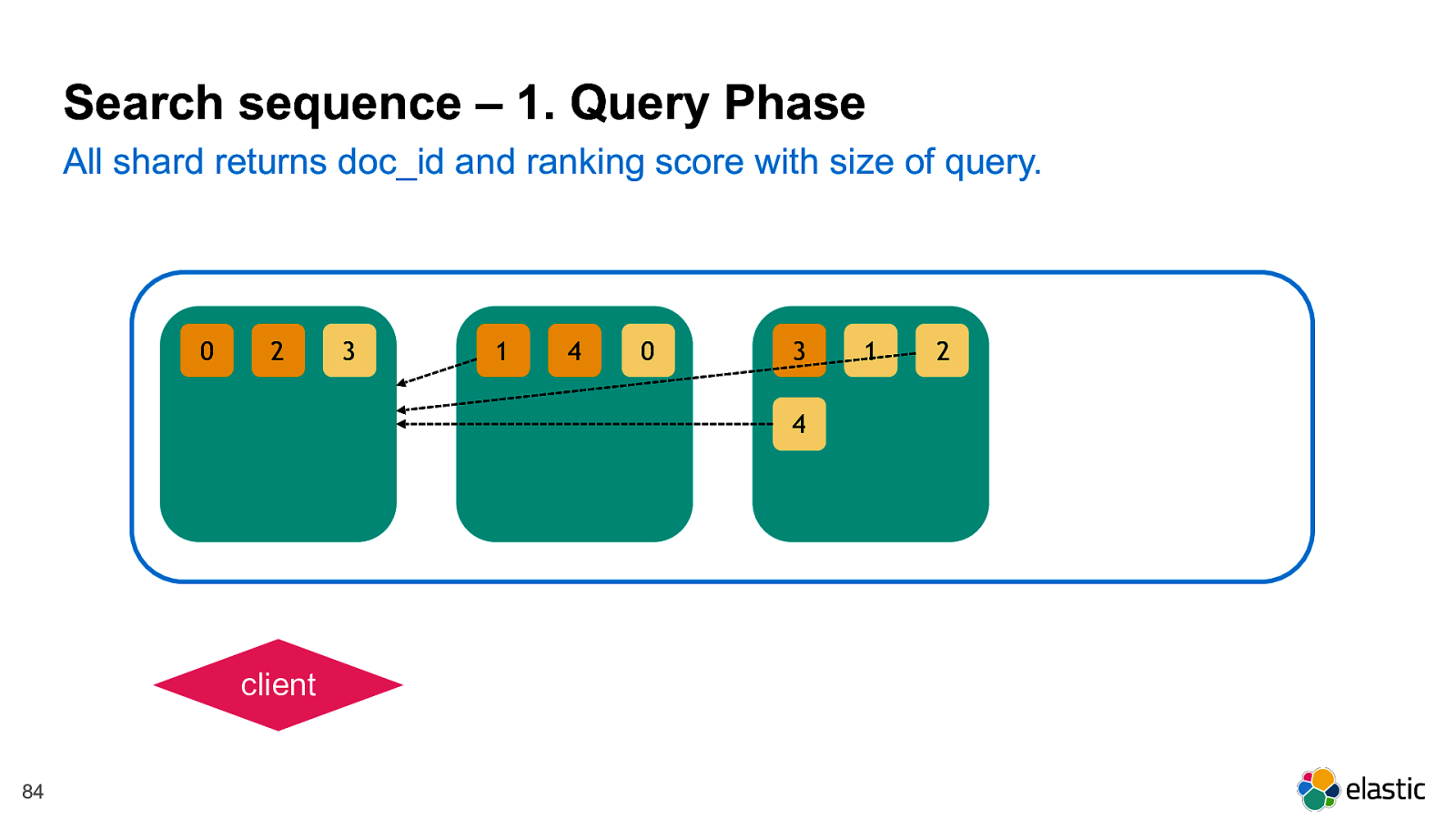
! 84 2 0 3 4 1 1 3 2 4 0 All shard returns doc_id and ranking score with size of query. Search sequence – 1. Query Phase client
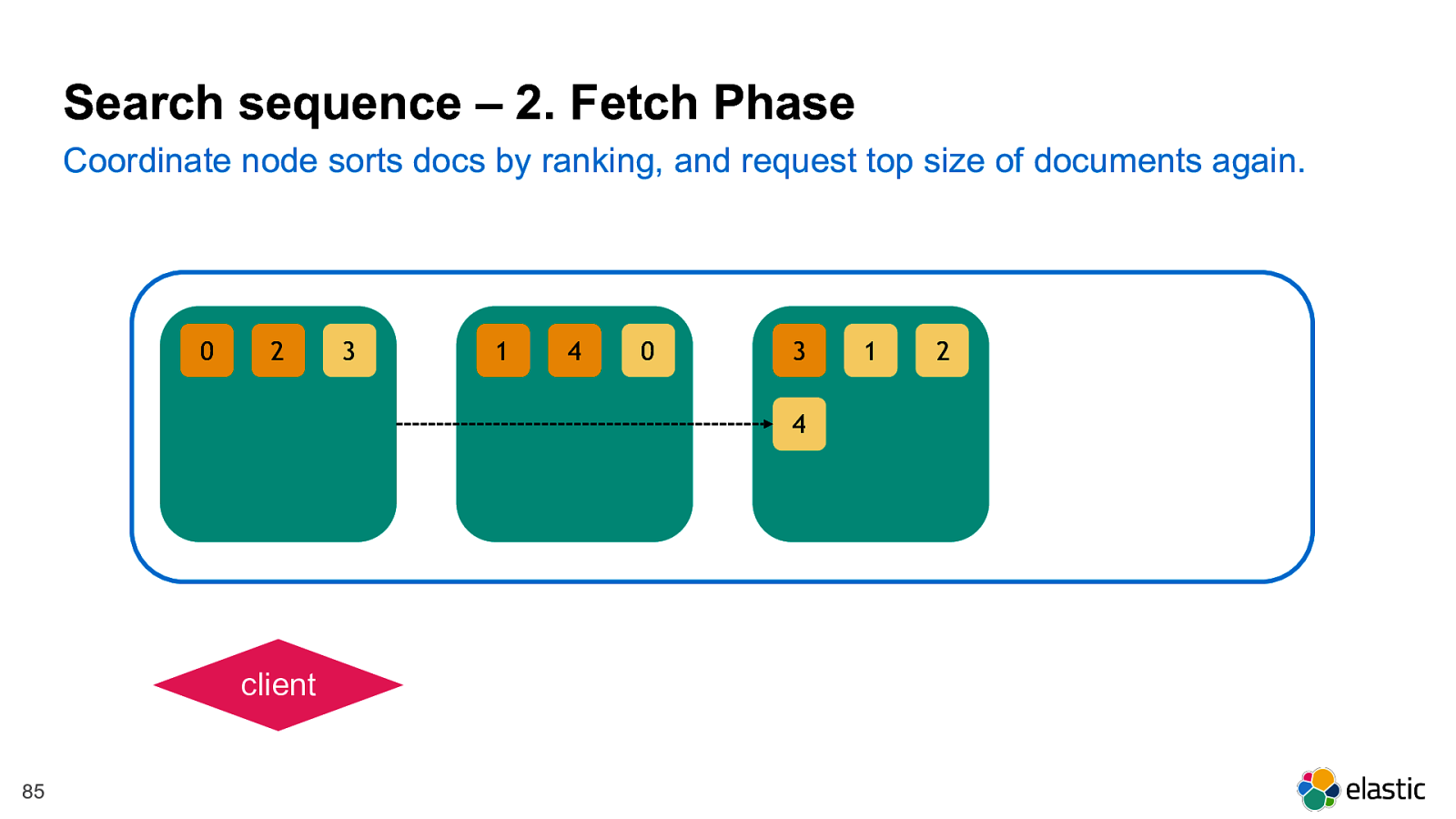
! 85 2 0 3 4 1 1 3 2 4 0 Coordinate node sorts docs by ranking, and request top size of documents again. Search sequence – 2. Fetch Phase client
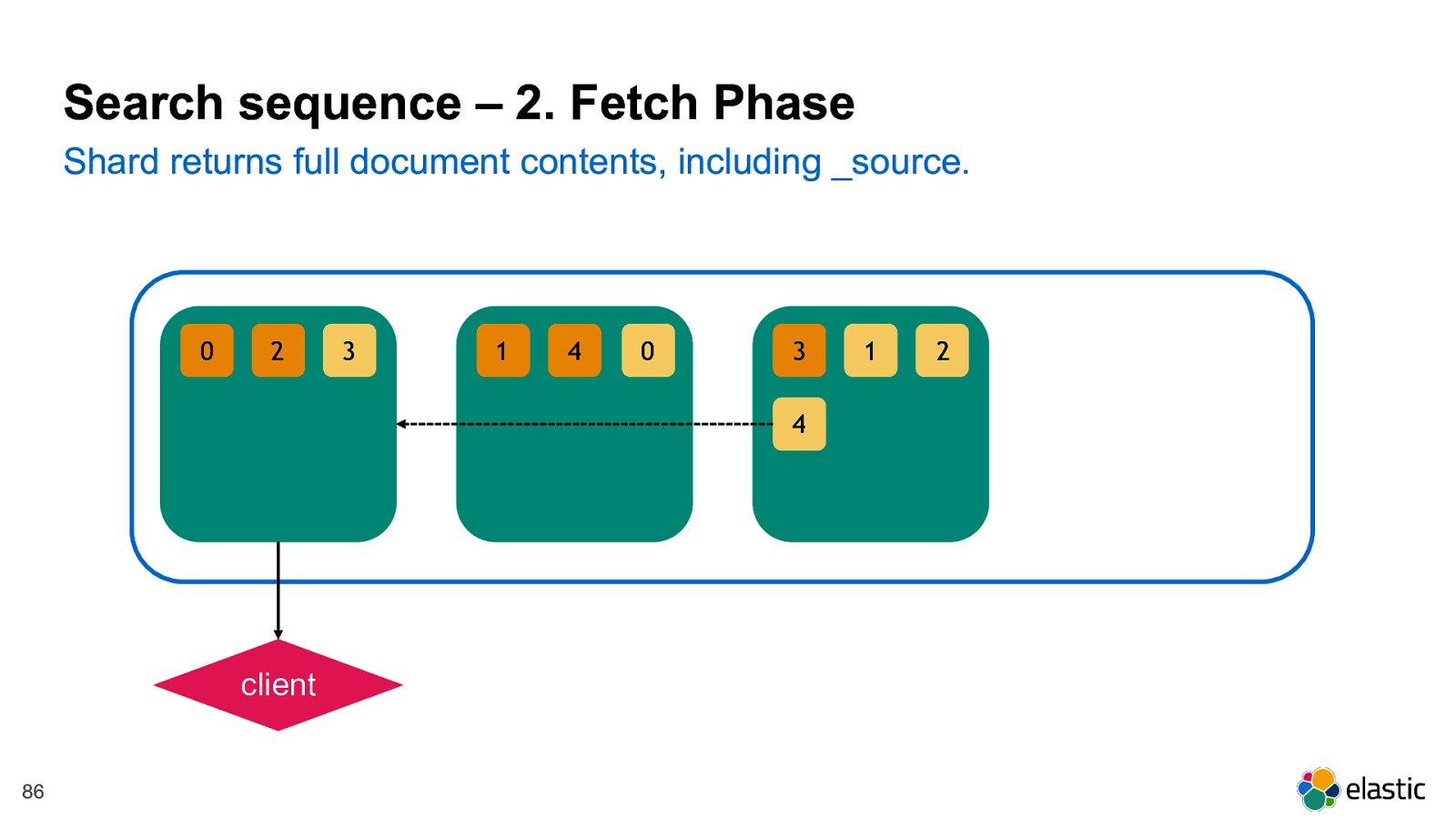
! 86 2 0 3 4 1 1 3 2 4 0 Shard returns full document contents, including _source. Search sequence – 2. Fetch Phase client

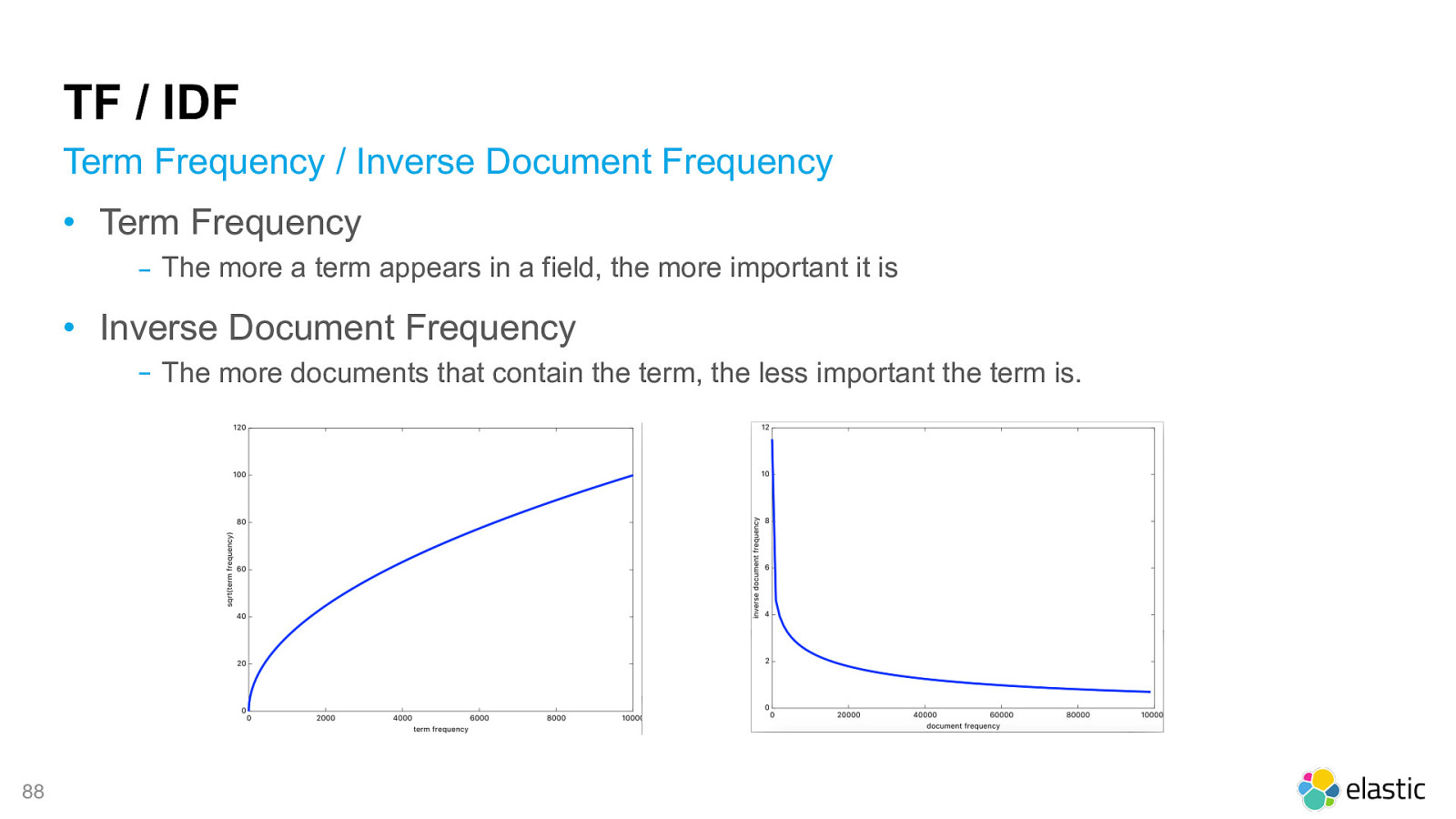
! 87 Ranking algorithm. TF/IDF Usually. Elasticsearch uses BM25
!
88
TF / IDF
•
Term Frequency
‒
The more a term appears in a field, the more important it is
•
Inverse Document Frequency
‒
The more documents that contain the term, the less important the term is.
Term Frequency / Inverse Document Frequency
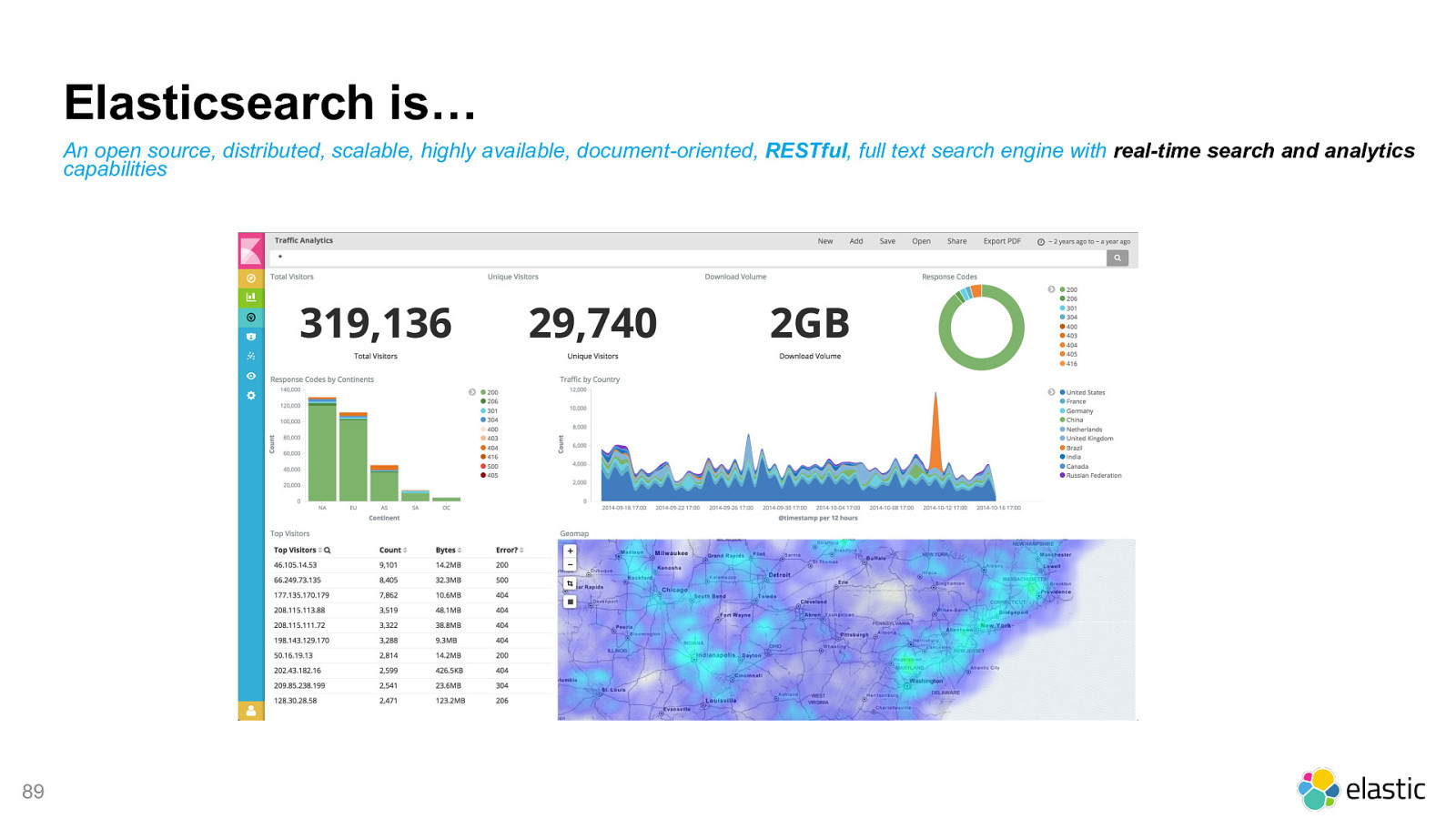
! 89 Elasticsearch is… An open source, distributed, scalable, highly available, document-oriented, RESTful , full text search engine with real-time search and analytics
capabilities
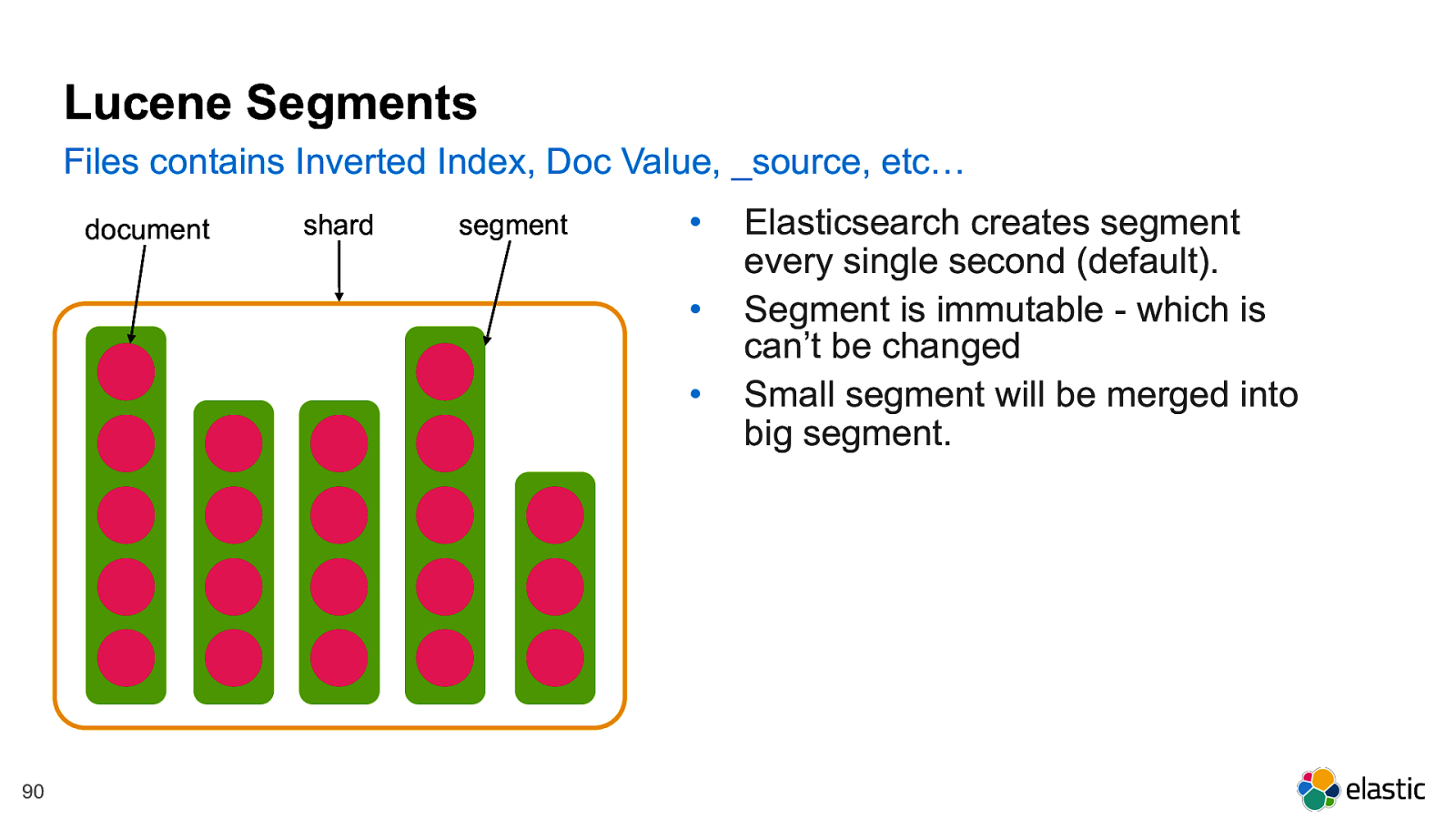
! 90 Lucene Segments Files contains Inverted Index, Doc Value, _source, etc… shard segment document • Elasticsearch creates segment every single second (default). • Segment is immutable - which is can’t be changed • Small segment will be merged into big segment.
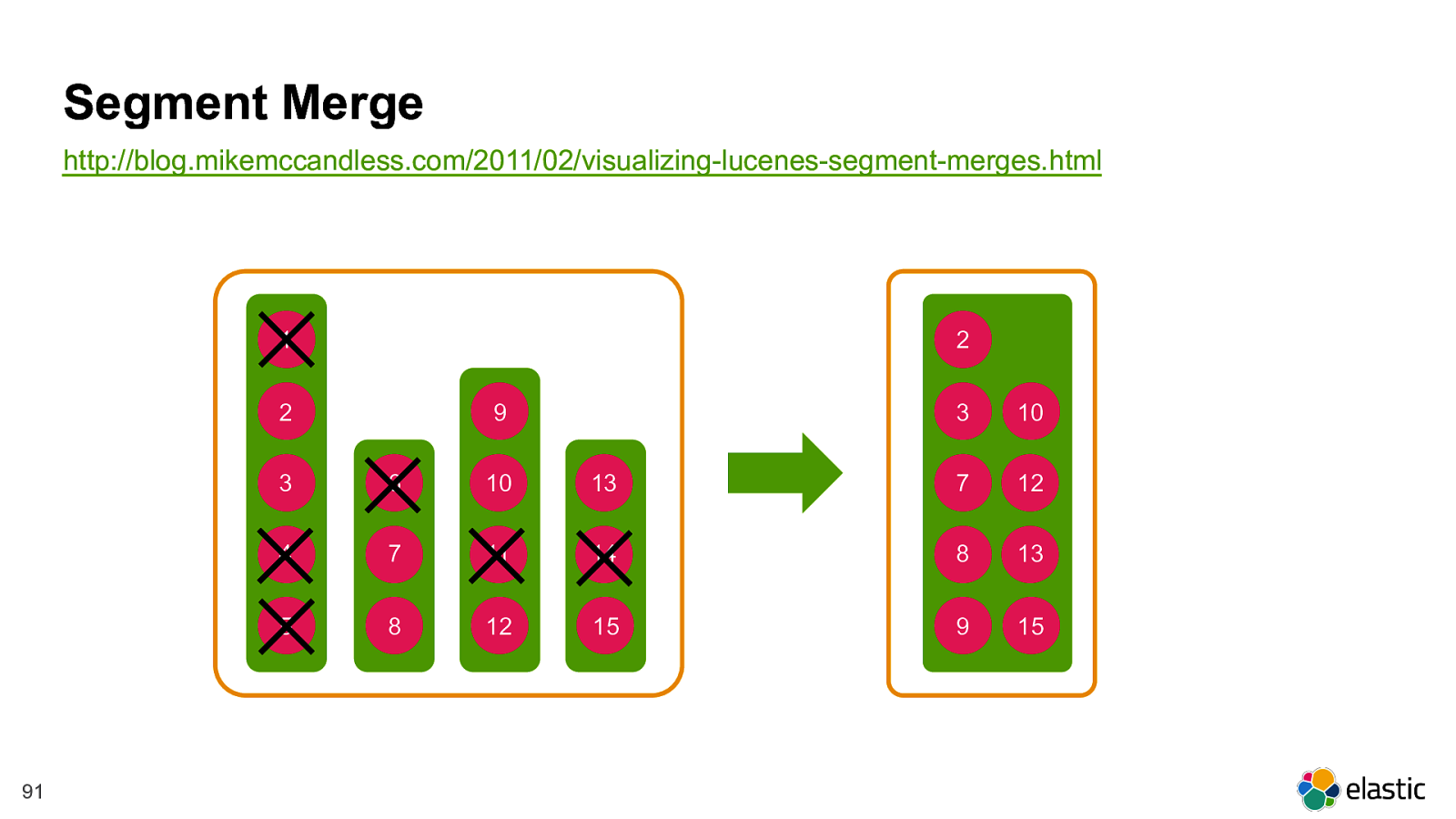
! 91 Segment Merge http://blog.mikemccandless.com/2011/02/visualizing-lucenes-segment-merges.html 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 2 3 7 8 9 10 12 13 15

! 92 https://www.elastic.co/community
https://www.facebook.com/groups/ElasticIndiaUserGroup/
community@elastic.co Thank you