1
February 28th, 2017. We all remember where we were on this day.

A presentation at DevOpsDays Toronto in May 2019 in Toronto, ON, Canada by Jacquie Grindrod
February 28th, 2017. We all remember where we were on this day.

$150,000,000 The day 1 typo brought the internet to it’s knees and cost Amazon Web Service 4 hours of downtime & $150,000,000. All because of 1 typo, one easily avoidable mistake.

I am here to argue that our products are only as strong as their weakest link. Firefighting is inevitable until we view our products with a holistic lens, and as more than just a sum of their features. Regardless of where we are on our Journey today, there’s 1 thing we can all agree on. Downtime. Hurts.

On average it costs $5,600 per minute of downtime but that’s not the only cost we pay. We pay in time & sanity fighting Death By A Thousand Shouldertaps or when we play Ticket Hot Potato. We pay in reputation and productivity when we sell things we can’t build, design things we can’t code, code things we can’t deploy or maintain and in a secure manner.

How many of you have achieved 99.9% uptime?

99.9% works out to be 42 mins per month. Now, let’s try that again but be honest.

Assuming it takes 15 minutes to discover the outage, 15 to triage and 15 to develop and hot fix the problem, we’ve already taken 45 minutes and breached our SLA.

Planning for our products as a whole, including the critical internal services and processes they rely on will help us to treat other symptoms we experience such as outages and security vulnerabilities.

The Promised Land isn’t a place on a map we can reach or an aggregate of the perfect architecture and technology. It changes team to team, and time to time. For some, it’s containerizing our legacy applications as Andrew will tell you all about. For others, it’s empowering Developers so we can build tools to better support them. If you could do anything, at all, right now, without time or resource constraints, what would it be? Where do you want to go? What problems are jumping out at you? This is our happy path, our ideal place. This idea, is our Promised Land.

The Promised Land is built from the ground up. We take into consideration the different lenses our teammates have to paint the big picture. Your ideal state will be very different in a small start up just getting going vs a more larger, more mature company.

It’s important to approach this with an understanding that everyone is doing the best they can with what they know & what resources they have available. Every person will have a different opinion of what the Promised Land is, and this tapestry of opinions and experiences will help to define our destination & our guiding principles.

Does this seem familiar? I’m willing to be that every one of us has been here before, in one fashion or another. It’s scary. It’s scarier when you’re in Healthcare. Not only is downtime critical, it could be fatal. Hospitals, homes, doctors and patients rely on us for their day to day encounters.

Klotz story. Chatted Dreaded sticky note wall -> kanban board -> sprints & planning weeks and months in advance. celebrated our success at building out 3 new products on 2 new clouds in less than a year and how we made it from manually deploying to VMs in datacenters to successfully running Kubernetes in Production & managing it all with Terraform. We’d wrangled the wild west of organizational structure and services that had previously lived unchecked on a TODO list we hoped to one day reach.

It was a rare moment of peace for me to sit back & truly appreciate how far we’d come. As my former colleague enthusiastically pointed out, Think Research had made it to what had once seemed so far out of reach, our Promised Land! If we want to break the cycle of fire fighting based on the loudest voice in the room, take charge of our Journey, and build really cool shit (bc ofc we do), we need to shift our perspectives and view products as more than just a sum of their features. Our Products are only as strong as their weakest link.
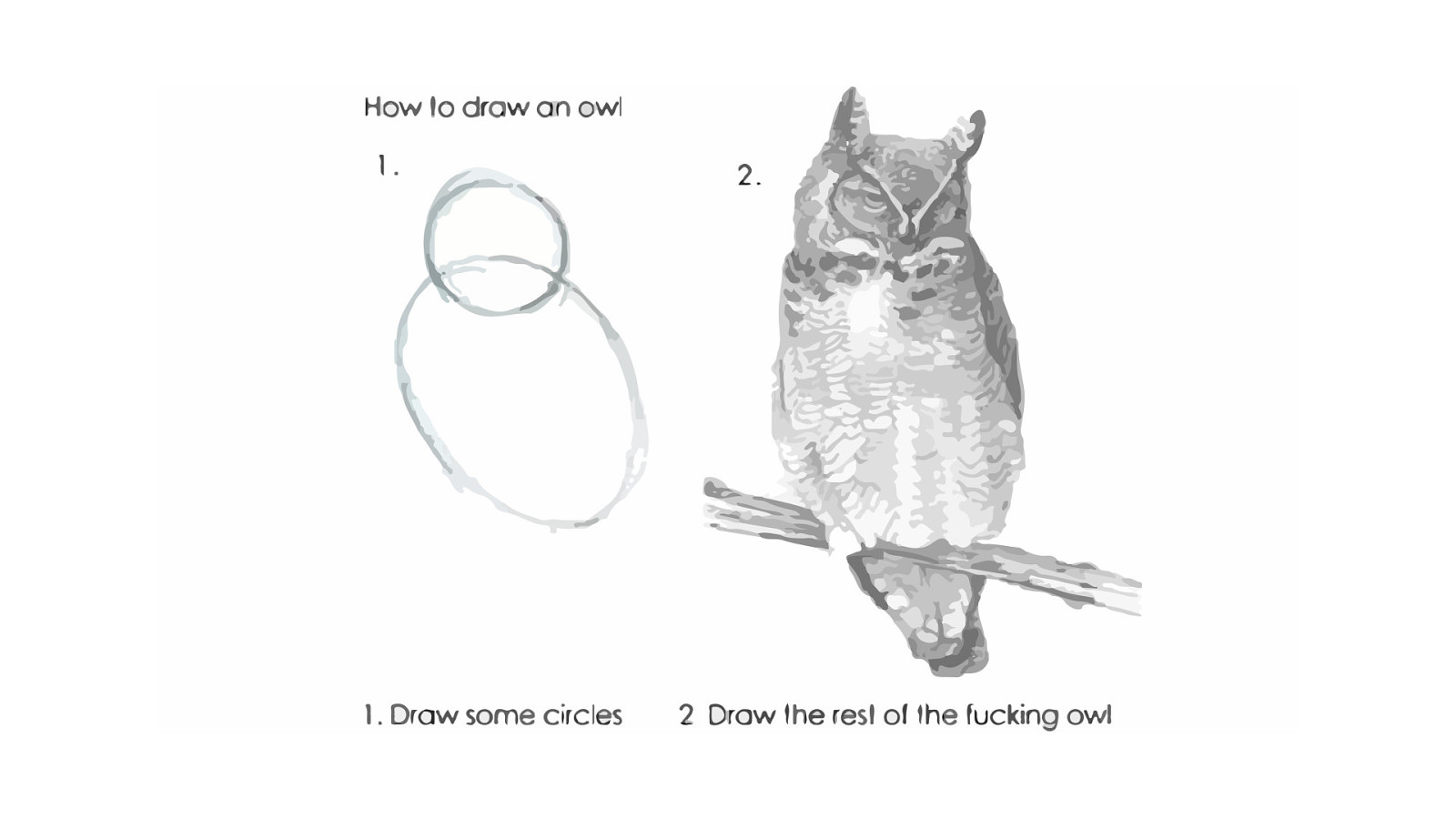
How many of us feel confident we can draw an owl now? As DevOps Enthusiasts we spend a lot of time discussing and dreaming about key principles such as Infrastructure as Code and Continuous Delivery but we often neglect the journey and all the questions asked and discussions held that helped us arrive at our solution. We leave out the why, which hamstrings our how. Why did we start with those 2 circles? How did we proceed to draw the rest of the owl? Without these details, it’s nearly impossible to teach others to do what we’ve done for themselves.

DevOps Isn’t 1 size fits all which should come as no surprise given we can’t even nail down a consistent definition of it! Are we glorified SysAdmins? SREs? Automation developers? Evangelists and advocates? Do we have a specific space we work in or are we the catch all for the things the other teams don’t want to do? Just try reading a handful of job descriptions and you’ll quickly realize there’s no clear answer.

somewhere during my journey I made the conscious decision to make sense of my experiences, pain points, and own assumptions by developing a practical framework. I started retrospectively, by asking what steps did we take to reach the goals we had set?

How did we decide that these were the problems that we needed to solve?

“Why did we set these goals”? What pain or problem were we trying to solve?

Our Culture is our cornerstone, our foundation that we build everything else on top of, where we build our vision.

Process implementation and improvement is our next layer. This is our commitment to our vision.

Finally, we get to move on to the fun things and make technical and tooling decisions to empower ourselves to get to the future we want.

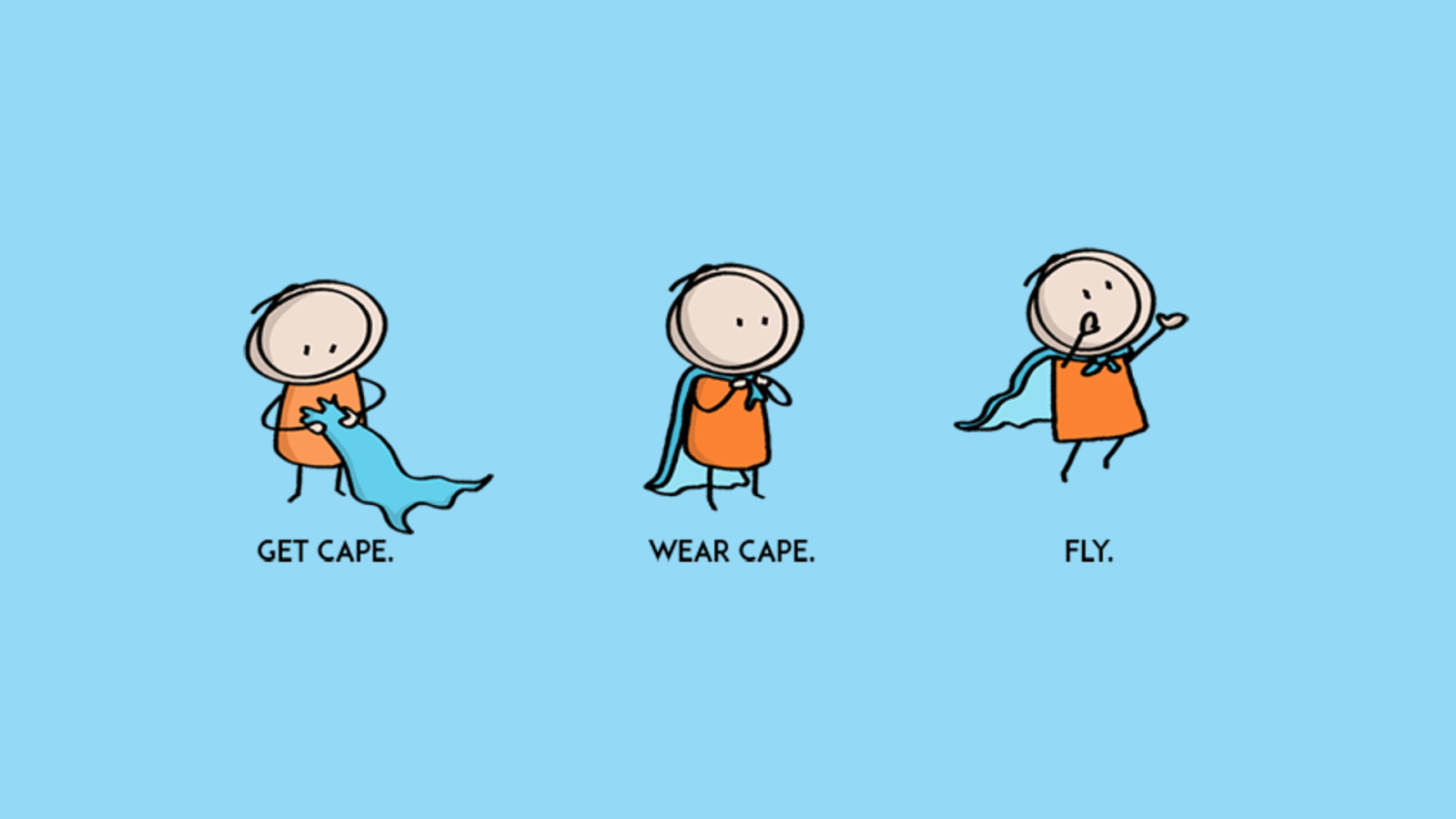
We’re getting our cape as we get ready to embark on our journey and discuss our vision We’re putting it on as we’re empowering ourselves to take that first jump. And finally, when we reach the fun stuff, we get to fly!

Where are you going? Why?

It’s all too easy to fall into a culture of Duct Tape & Bubblegum, blindly racing from one problem to the other. That hurts. It’s stressful, hard to track, and leaves us constantly living in the past/present and struggling to make proactive decisions. If we want to sell things we can build, design things we can code, code things we can deploy and maintain in a secure fashion, then we need to acknowledge that building a stable product starts long before any code is committed.

Our culture is the core foundation that everything else sits on and without it, we won’t be able to fly. Defining our destination helps us to be aligned on where we’re going. If we were to plan a group vacation, perhaps we’d start out by deciding what’s important. Do we want to be somewhere warm? Maybe somewhere with mountains? Near the ocean?

Creating a culture of curiosity gives our team the space to voice opinions and be validated. Being curious and starting with “why” builds empathy and gives us valuable insight.

Treating learning as a currency is a key part of our culture because it allows us to fall down and get back up again. Keep trying. Remember when I said it’s important to approach our problems with an understanding that everyone is doing the best they can w what they know & what resources they have available. For anyone who needs to hear this: Making mistakes is okay. Not getting it perfect, is okay. Taking time, is okay. As long as we learn from these mistakes and take that experience to keep building something better.

Tell me if some variation of this sounds familiar. Team A needs some work from Team B. They ask Team B who says “I don’t think that’s us, it’s actually Team C”. The ticket continues to get passed around for days, or maybe even sprints. It’s a problem. Getting these teams or some representatives from them into 1 room and defining the requirements and timelines from the beginning would help to avoid this.

Last year, we were working on building a brand new product, on a brand new cloud, using brand new technology. It was a huge learning curve for everyone involved, and due to the speed we were building at there were some walls to help keep us focused.
Our Dev team requested a pipeline as they were losing a lot of time doing manual deploys, and even more if the deploy went wrong. We had experience building pipelines for other teams and other companies, but still took some time to refresh on best practices and what other companies were doing. We spent a lot of time discussing, whiteboarding and building but we made 1 big mistake. We didn’t actually dig into what the Devs wanted from us. So we built what we thought was the best solution for their problem given our knowledge at the time and some opinionated decisions regarding best practices.
It worked, sometimes. In some scenarios. But in others, turned out to be a huge headache. They wanted to deploy in a way we hadn’t anticipated or built for. This led to a lot of tension and frustration, as well as productivity lost. It could have been avoided if we had just gotten together and discussed openly what each side wanted out of this tool.

Process is about finding your weaknesses and bottlenecks and proactively working to balance them out. Making Procedural Changes is buying in to your discussion. It’s saying “we want this & we’re ready to start setting up for success”. We are fastening on our cape and getting ready to take flight. Here, we should scrutinize how we communicate, how we share knowledge, how we track/plan/prioritize work.

Where are things getting stuck? What causes the slow down? Hands up if you’ve read the Phoenix Project? Find your Brent. Where are your knowledge silos?

Priorities are important. Setting a process around who decides priorities, or even what the priority actually is helps us to do the work that matters in a timeline that works. Knowing truly is half the battle.

We need to make an effort to build team rapport, encourage curiosity and support transparent communication with eachother. While I understand how that last bit definitely feels like it could/should be in culture, I’ve chosen to include it here instead for a few reasons. Defining & following a process helps to create a safe space to introduce feedback as well as providing the time/method to do so. Following my earlier example of the pipeline we delivered to our developers that didn’t take in their needs, we tried to find ways to open communication to/from our team and others. We continued to adapt and try new ways of taking in planned and unplanned work, and got feedback on how the other teams and us felt about the new processes.

Which leads us to lessons learned on how to avoid Death By A Thousand Shouldertaps. How do you handle unplanned work & firefighting? How you you manage the chaos of people, communication and planning or prioritizing? First we tried a stopwatch timer to track the time we were spending on unplanned work. Spoiler, it was a bad idea. Our devs felt like they couldn’t ask us for help because they were wasting our time. So next we tried a help request form. Also bad. It built a barrier between us and the devs. Finally we tried a shark tank styled meeting.

What steps will you take to get there? Now that we’ve defined pain points and tried to set up processes to help with filtering shouldertaps, practicing time management, giving estimates and assinging priorities plus communication, we’re finally ready for the fun stuff! A mistake we commonly make in our industry is to jump straight to this step without clearly defining out root cause or the solution we need.

What are we trying to solve/accomplish? Will this tool truly do it? Do we need a new tool or can something we already have do it? If the second but the new one is better, can we move the existing work to the new tool as well? What are the risks?

Our products are more than just a sum of their features. Don’t be a bird & shove your code out of the nest hoping it’ll fly. We need to nurture and care for the code we don’t show to our users as well as the shiny cool things they use. No matter how clean or fast our application code is, if the critical internal services our product rely on aren’t as well maintained then WE WILL HAVE DOWNTIME.

Beware tool sprawl Multiple tools for the same general purpose create additional strain on developers and teams. They’re a risk for adding new knowledge silos.

We discovered Kubernetes, and it was great! It was fast! It even kept our Docker containers alive and running! And then, we found this thing called Helm. Fantastic! Even faster! You need a highly available database? Helm it up. Done! How about a ELK Stack? Helm it up! Done. Kafka? You got it! - Except, it wasn’t great. We didn’t understand the way it had been built which led to difficulty in troubleshooting, and often the Helm Chart builders weren’t the original company either. Nothing like finding out all your crash logs are silently disappearing into the void.


If we want to sell things we can build, design things we can code, code things we can deploy and maintain, and deploy things we have properly secured then we need to acknowledge that building a stable product starts long before any code is committed.



Where do we start? FIND WHAT HURTS. It’s easiest to build motivation & curiosity when there’s something we’re already suffering from. Get a variety of people and roles together to get perspectives and outline requirements. Anything that makes communication, teamwork or acts as a barrier to entry will likely not land as well as we’d like. Doing this will help us to see the big picture and to avoid we building we don’t need or isn’t what our users want. Fail fast is great, but failing smart is the fastest.

Whatever that pain point was, just get started. It’s always easier to fix a failure than it is to fix a non-attempt. We need to stop looking at ‘failures’ as wasted time and find the value in the learned & knowledge we gleaned we gained from the attempts. While we might not know what fill be the fix yet, we know now something that is not and we might be able to extrapolate to others that seem less likely to work now.

There’s a lot of things to tackle here & All of this at once sounds incredibly overwhelming. Take it one intentional, atomic change at a time. Continuous small improvements will make all the difference, as long as you keep putting one foot in front of the other. If something doesn’t work, find another way. While things still weren’t perfect and needed a ton of work, they were vastly improved compared to where they were, and that’s what matters.


I’d love to keep the discussion going. Please come up to me with questions you have and let’s discuss! Email me or message me on linkedin. This has been my second time speaking & I couldn’t have asked for team of speakers & organizers to take this on with, or a better audience! Thank you for attending my talk & I look forward to our upcoming discussions.