Decoding Data Lakehouse: A Technical Breakdown Big Data Warsaw, Dipankar Mazumdar

A presentation at Big Data Technology Warsaw in March 2024 in Warsaw, Poland by Dipankar Mazumdar

Decoding Data Lakehouse: A Technical Breakdown Big Data Warsaw, Dipankar Mazumdar
Speaker Bio Dipankar Mazumdar - Staff Developer Advocate Open Source Contributor: Apache Hudi, Iceberg, XTable, Arrow Prev Work: BI, ML, Data Architecture in/dipankarmazumdar/ @dipankartnt

Agenda ● Evolution of Data Architecture ● Research - Hypothesis ● Data Warehouse ● Requirements of Data Warehousing ● Data Lakehouse & Open Table Formats
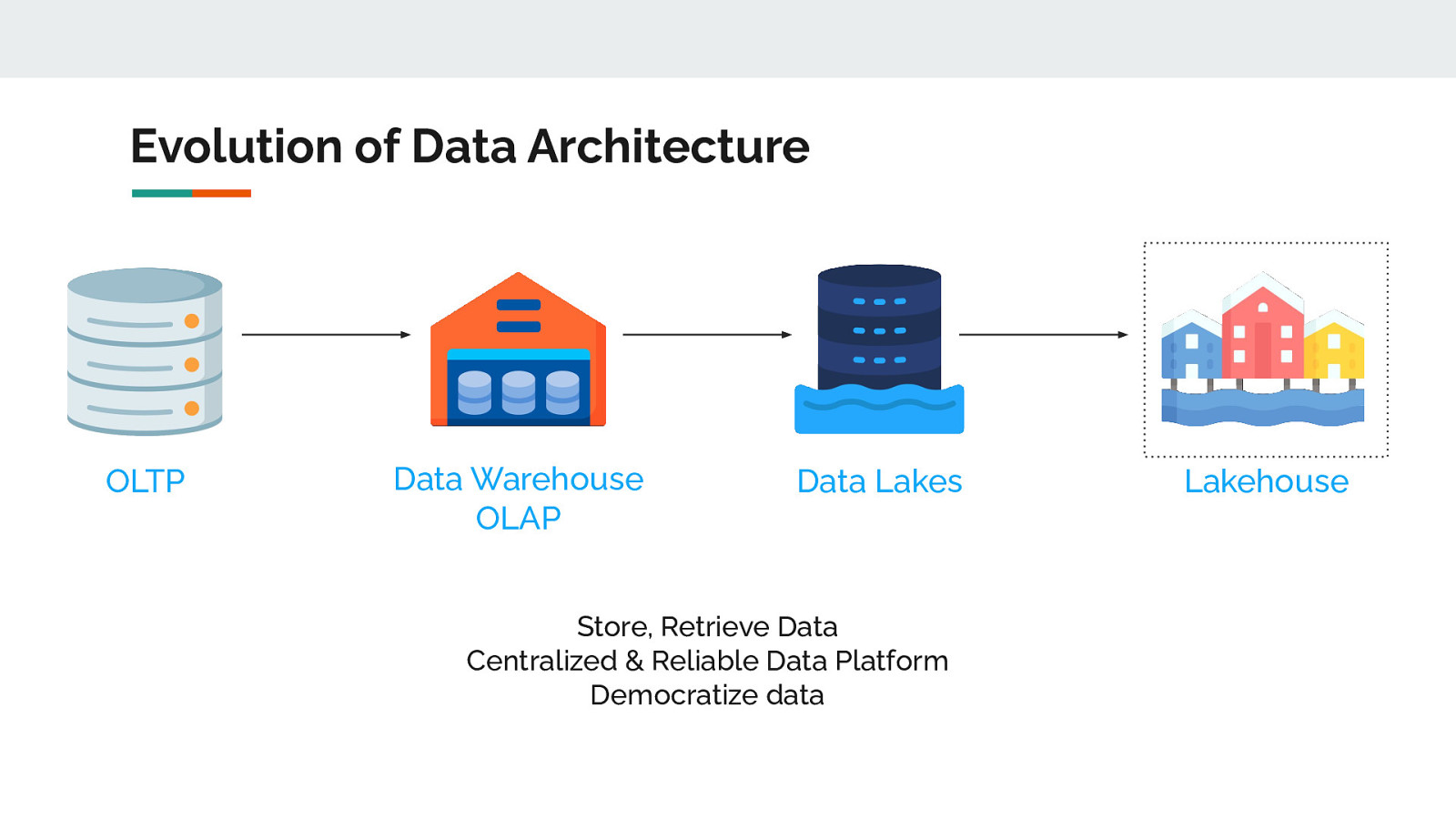
Evolution of Data Architecture OLTP Data Warehouse OLAP Data Lakes Store, Retrieve Data Centralized & Reliable Data Platform Democratize data Lakehouse

Hypothesis Research Paper 1. Lakehouse - more than a marketing term 2. Data Warehouse means different things 3. Data Lakehouse = Data Warehouse + Lake + (Additional Values) 4. Advantages with a Open Lakehouse

Data Warehouse
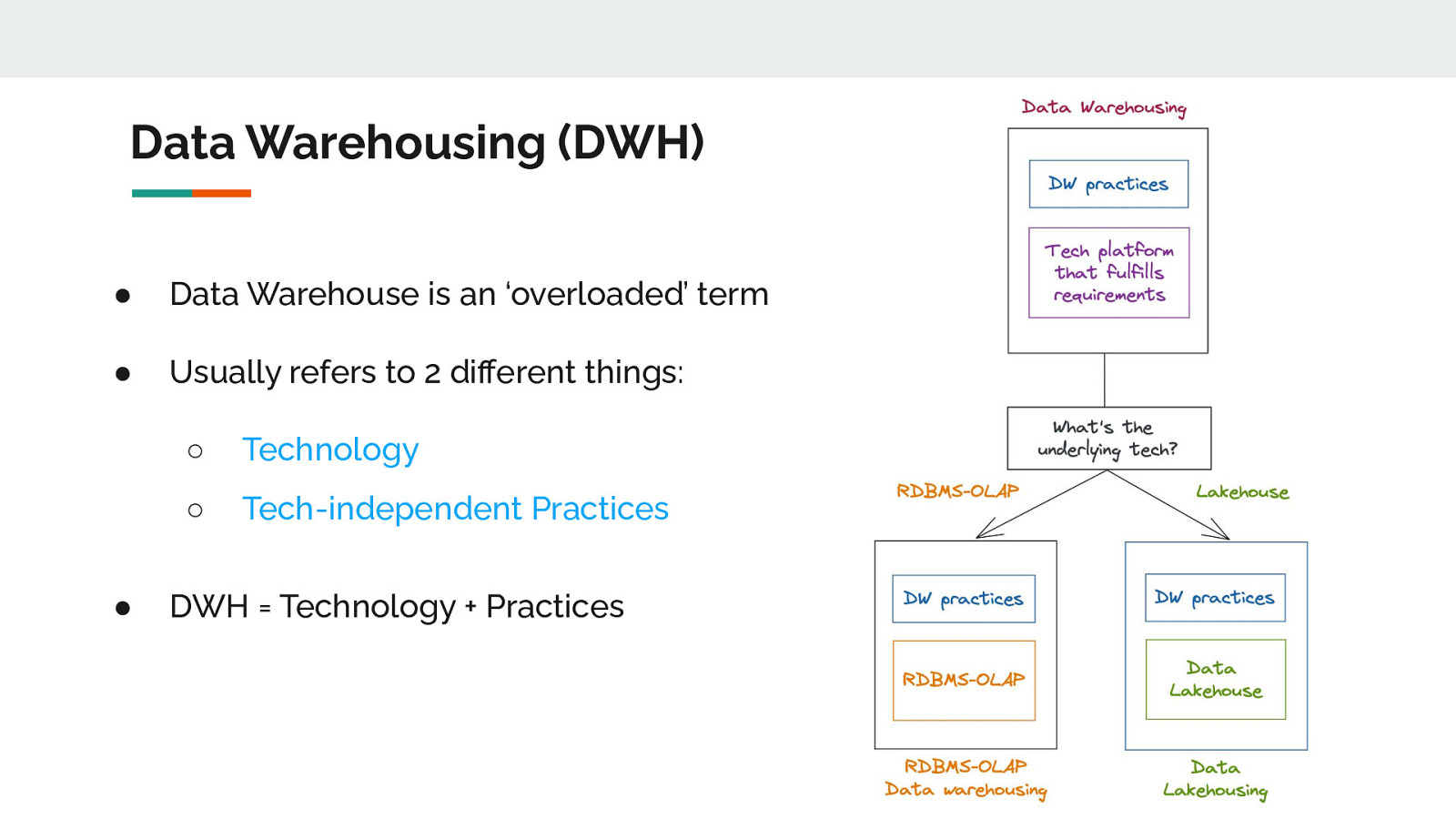
Data Warehousing (DWH) ● Data Warehouse is an ‘overloaded’ term ● Usually refers to 2 different things: ● ○ Technology ○ Tech-independent Practices DWH = Technology + Practices
Defining the Requirements ● How do we compare? ● Distilling down into 3 aspects: ○ Technical Components ○ Technical Capabilities ○ Technology-independent Practices
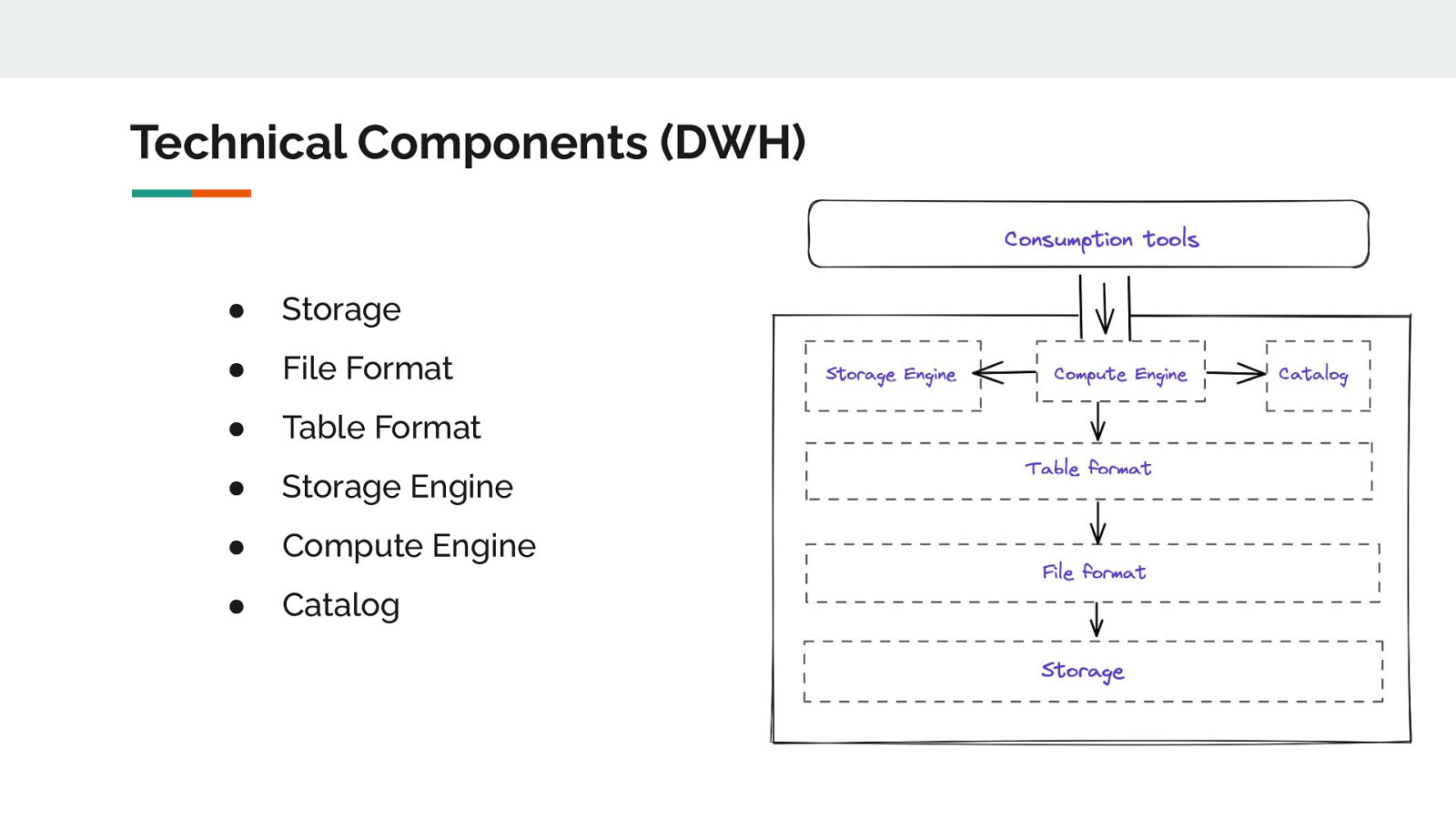
Technical Components (DWH) ● Storage ● File Format ● Table Format ● Storage Engine ● Compute Engine ● Catalog
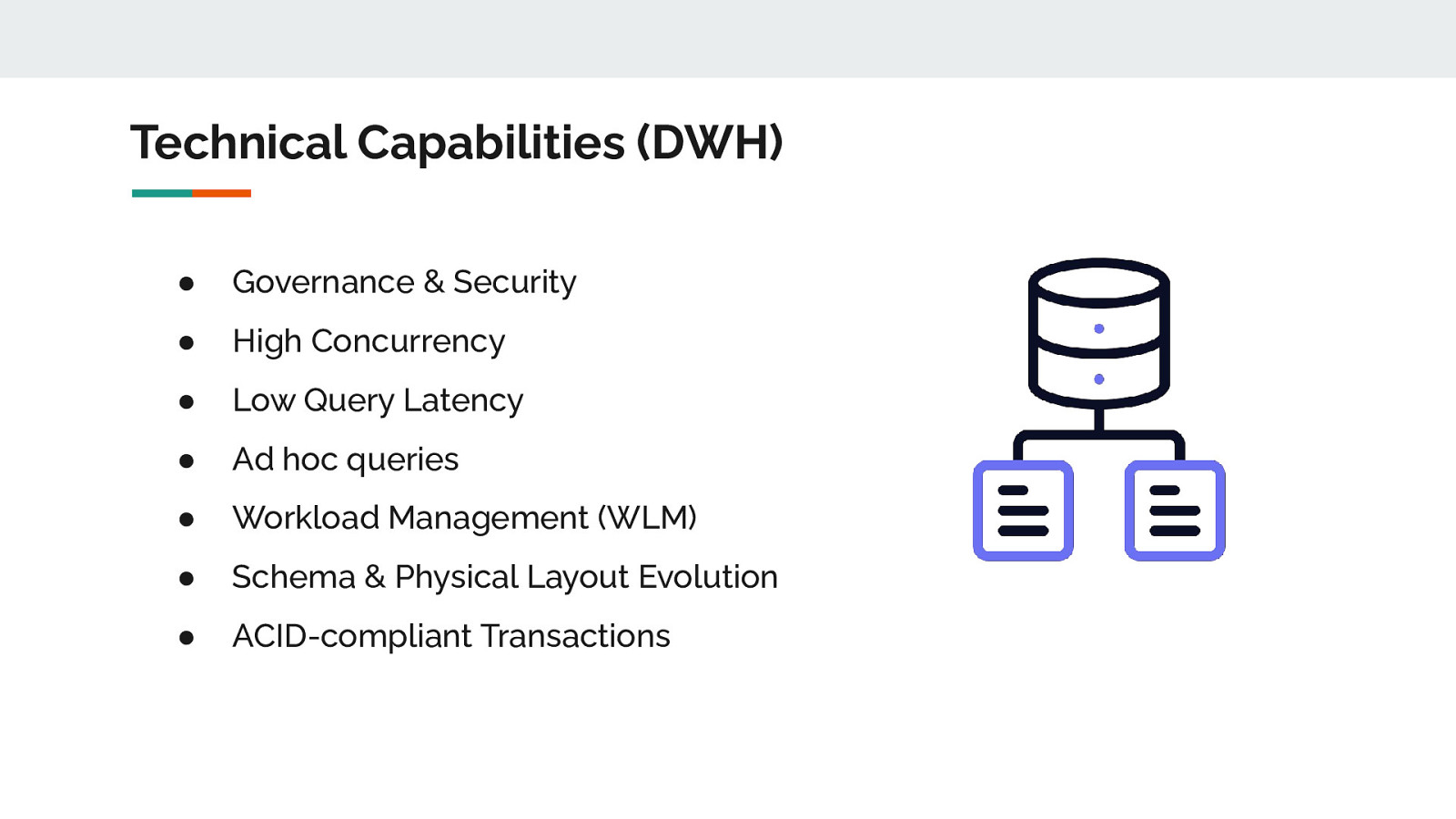
Technical Capabilities (DWH) ● Governance & Security ● High Concurrency ● Low Query Latency ● Ad hoc queries ● Workload Management (WLM) ● Schema & Physical Layout Evolution ● ACID-compliant Transactions

Tech-Independent Practices (DWH) ● Data Modeling ● ETL/ELT ● Data Quality ○ Master Data Management (MDM) ○ Referential Integrity ○ Slowly Changing Dimensions (SCD)

Challenges (DWH) Structured Workloads Vendor Lock-in High Costs

Data Lakehouse
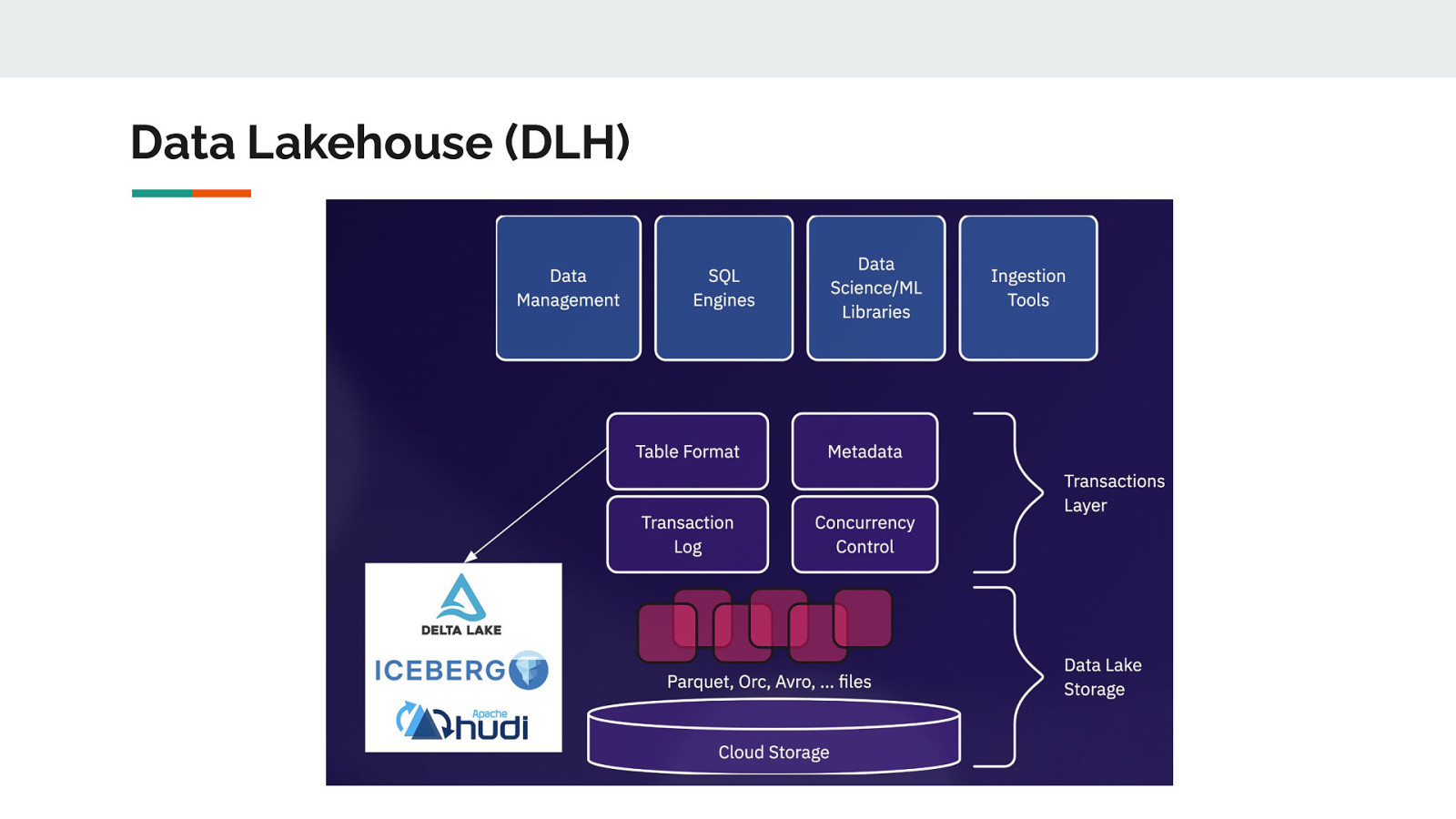
Data Lakehouse (DLH)
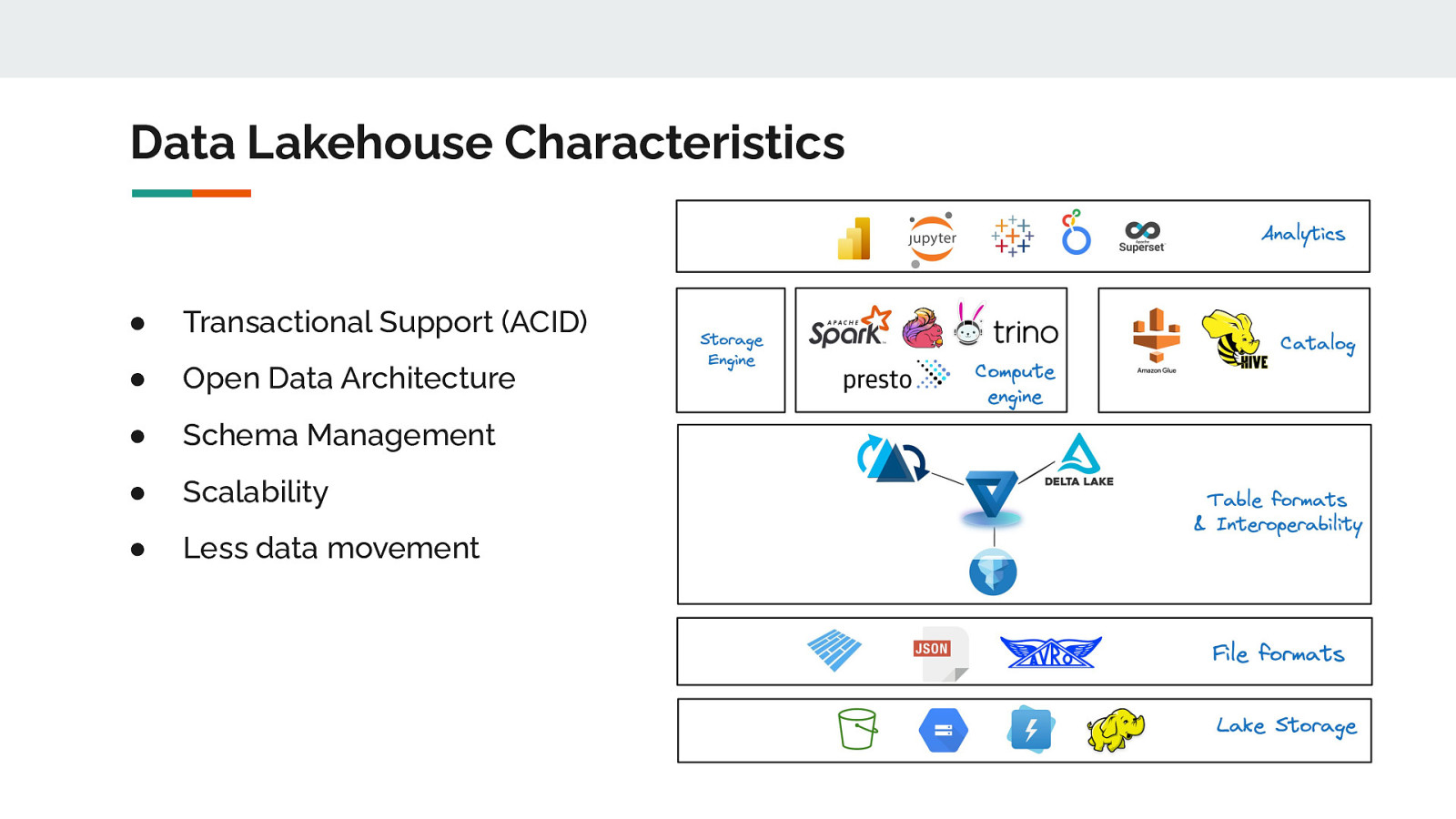
Data Lakehouse Characteristics ● Transactional Support (ACID) ● Open Data Architecture ● Schema Management ● Scalability ● Less data movement
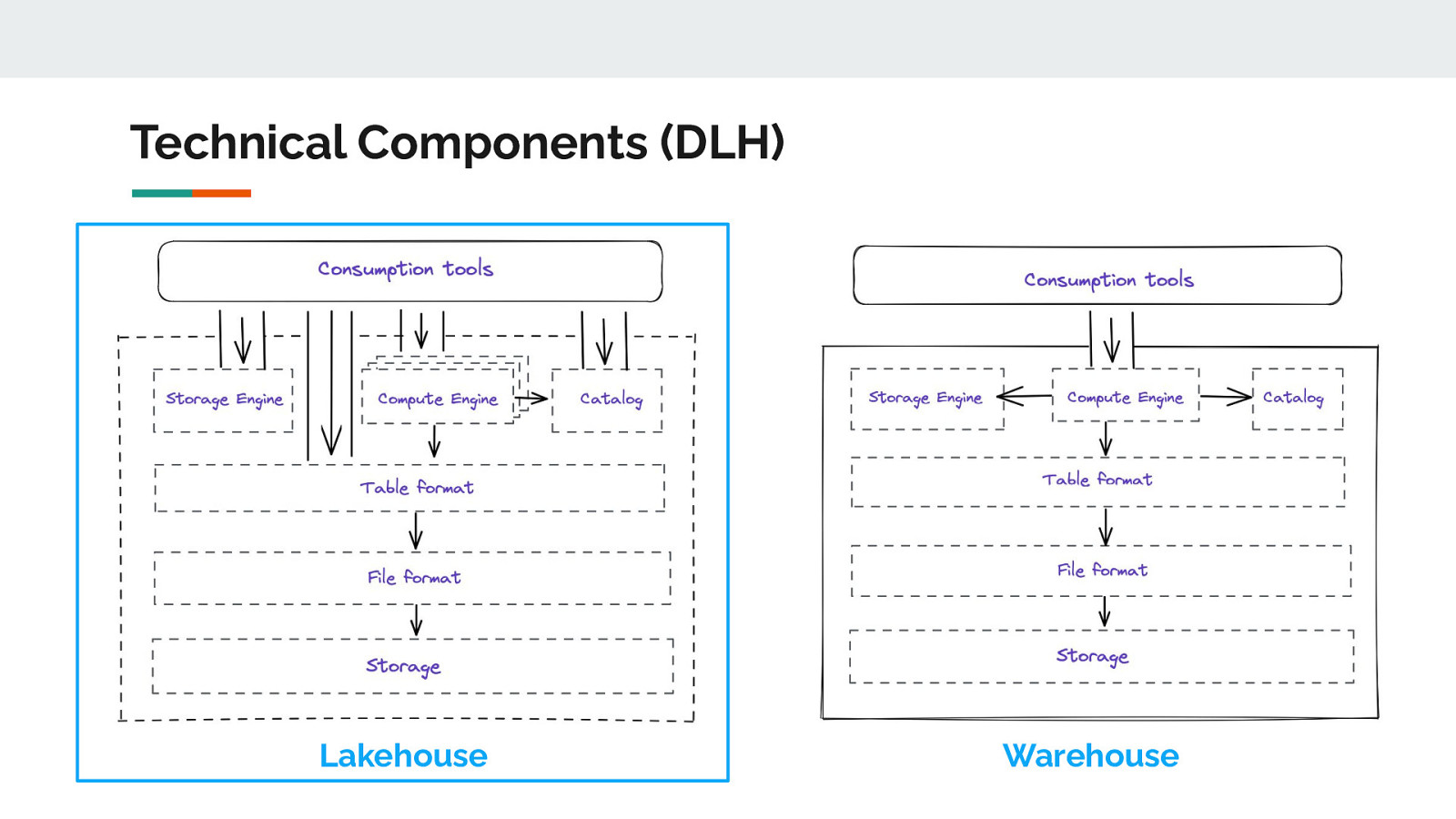
Technical Components (DLH) Lakehouse Warehouse
Storage ● Data lands after ingestion from operational systems ● Data files (such as Parquet) stored ● Supports storing data of any type (structured, unstructured) ● Cloud object stores: AWS S3, GCS, Azure; On-Prem: HDFS
File Format ● Holds raw data & are physically stored on Data Lakes ● Usually in columnar formats but can be row-based ● Open file formats allows access to different compute
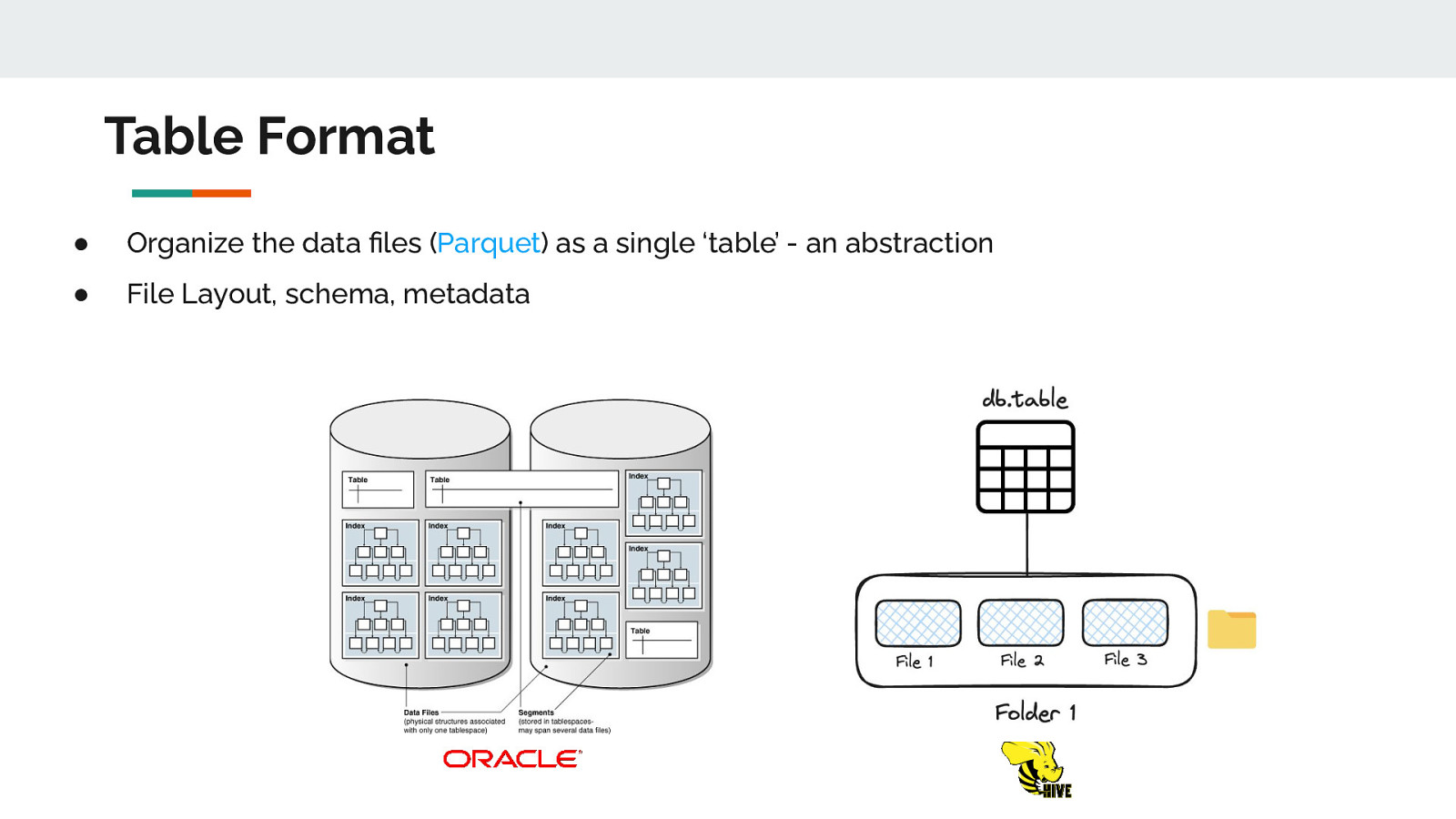
Table Format ● Organize the data files (Parquet) as a single ‘table’ - an abstraction ● File Layout, schema, metadata
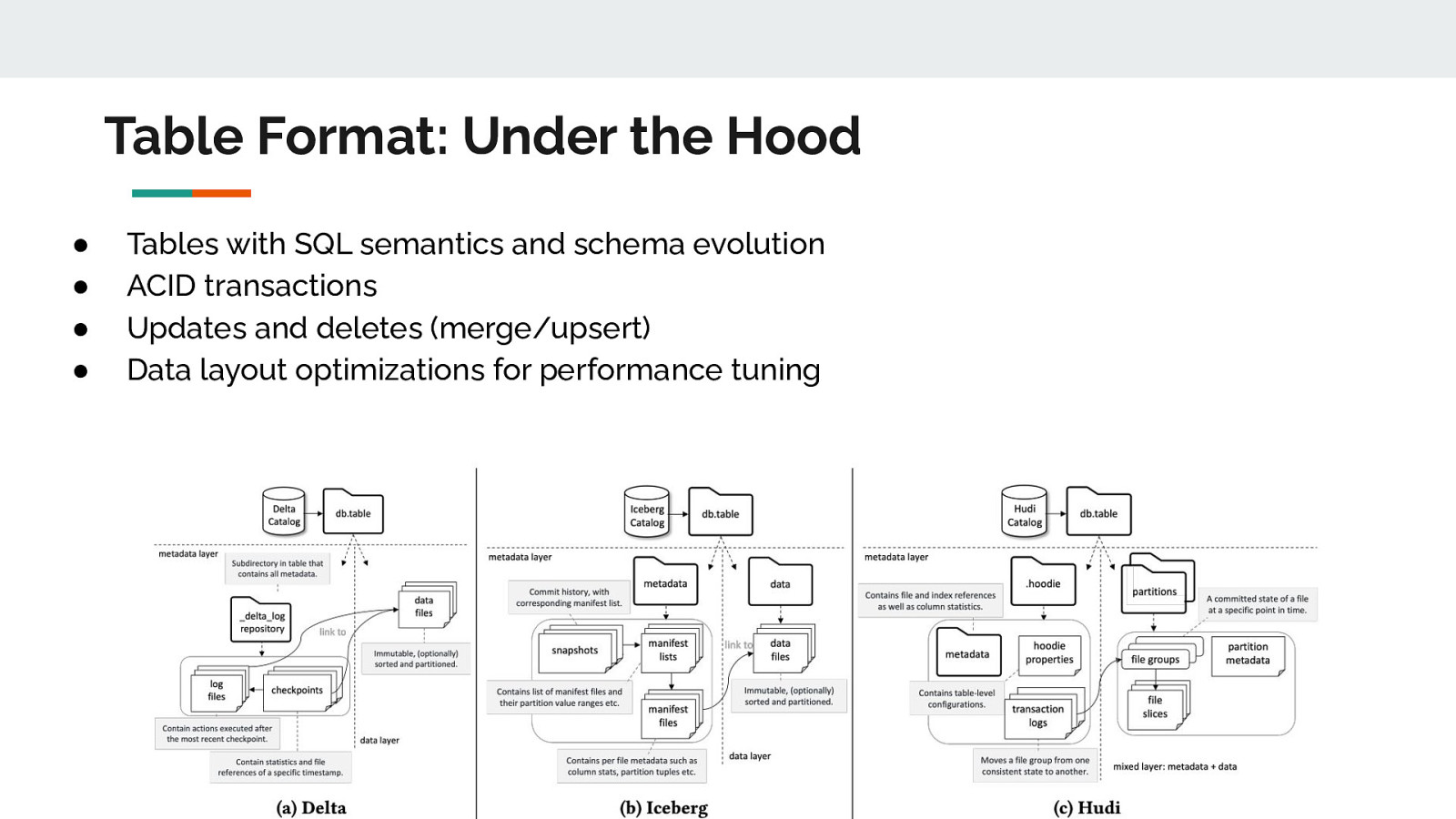
Table Format: Under the Hood ● ● ● ● Tables with SQL semantics and schema evolution ACID transactions Updates and deletes (merge/upsert) Data layout optimizations for performance tuning

Table Format: Under the Hood ● Fundamentals of table formats Hudi, Delta, Iceberg are not that different ● Each has a special metadata layer on top of Parquet
Storage Engine ● Keeps data layout optimized for performance ● Table Management tasks - Compaction, Clustering, Cleaning, Indexing ● Enabled by Table formats with Compute engine
Compute Engine ● Responsible for processing data ● Interacts with Open Table Formats’ APIs ● Cater to different types of workloads - Ad hoc SQL, Distributed ETL, Streaming engines

Catalog ● Logical separation of metastore ● Efficient search & data discovery via metadata ● Governance, Security & Data Federation
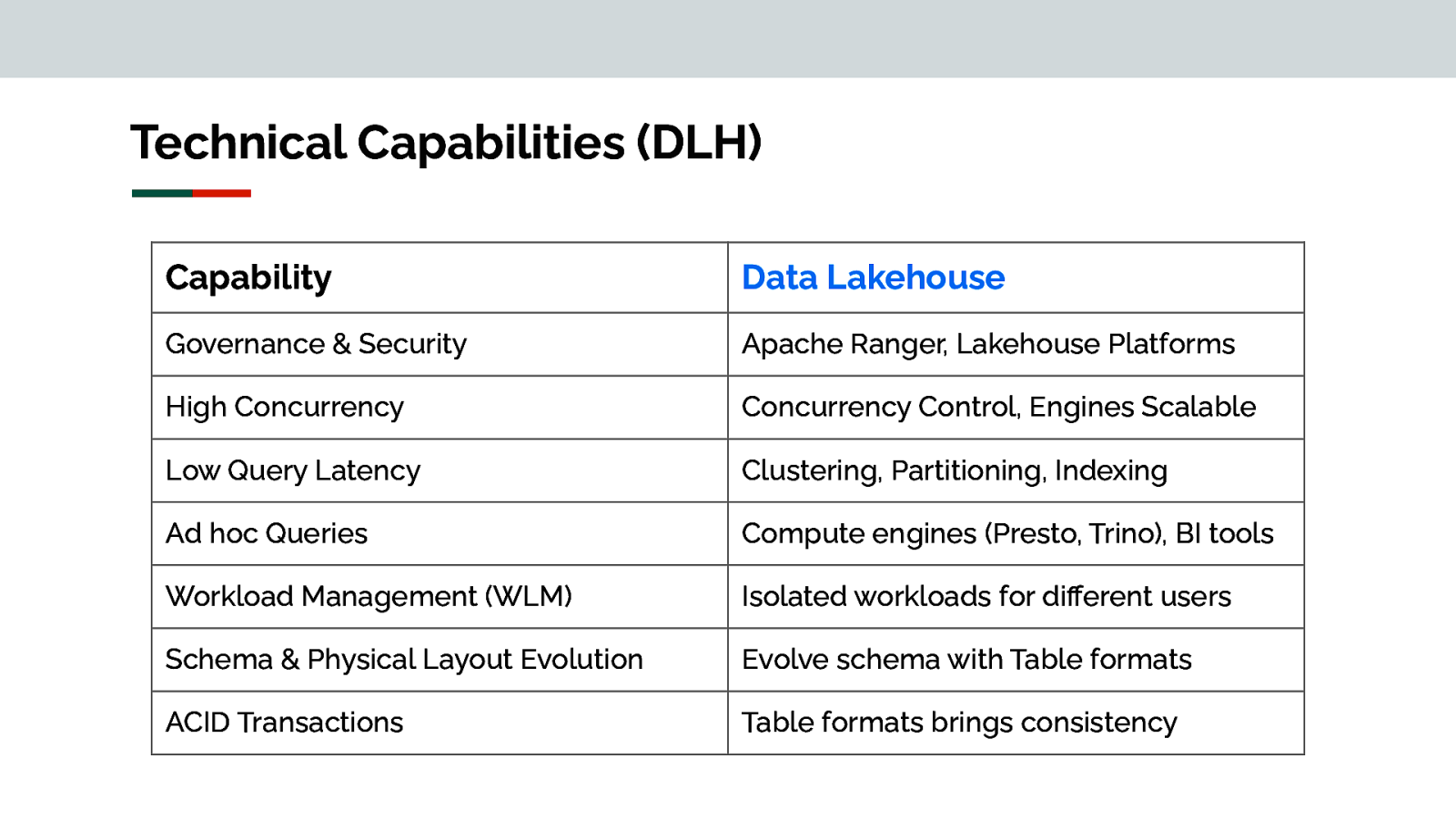
Technical Capabilities (DLH) Capability Data Lakehouse Governance & Security Apache Ranger, Lakehouse Platforms High Concurrency Concurrency Control, Engines Scalable Low Query Latency Clustering, Partitioning, Indexing Ad hoc Queries Compute engines (Presto, Trino), BI tools Workload Management (WLM) Isolated workloads for different users Schema & Physical Layout Evolution Evolve schema with Table formats ACID Transactions Table formats brings consistency
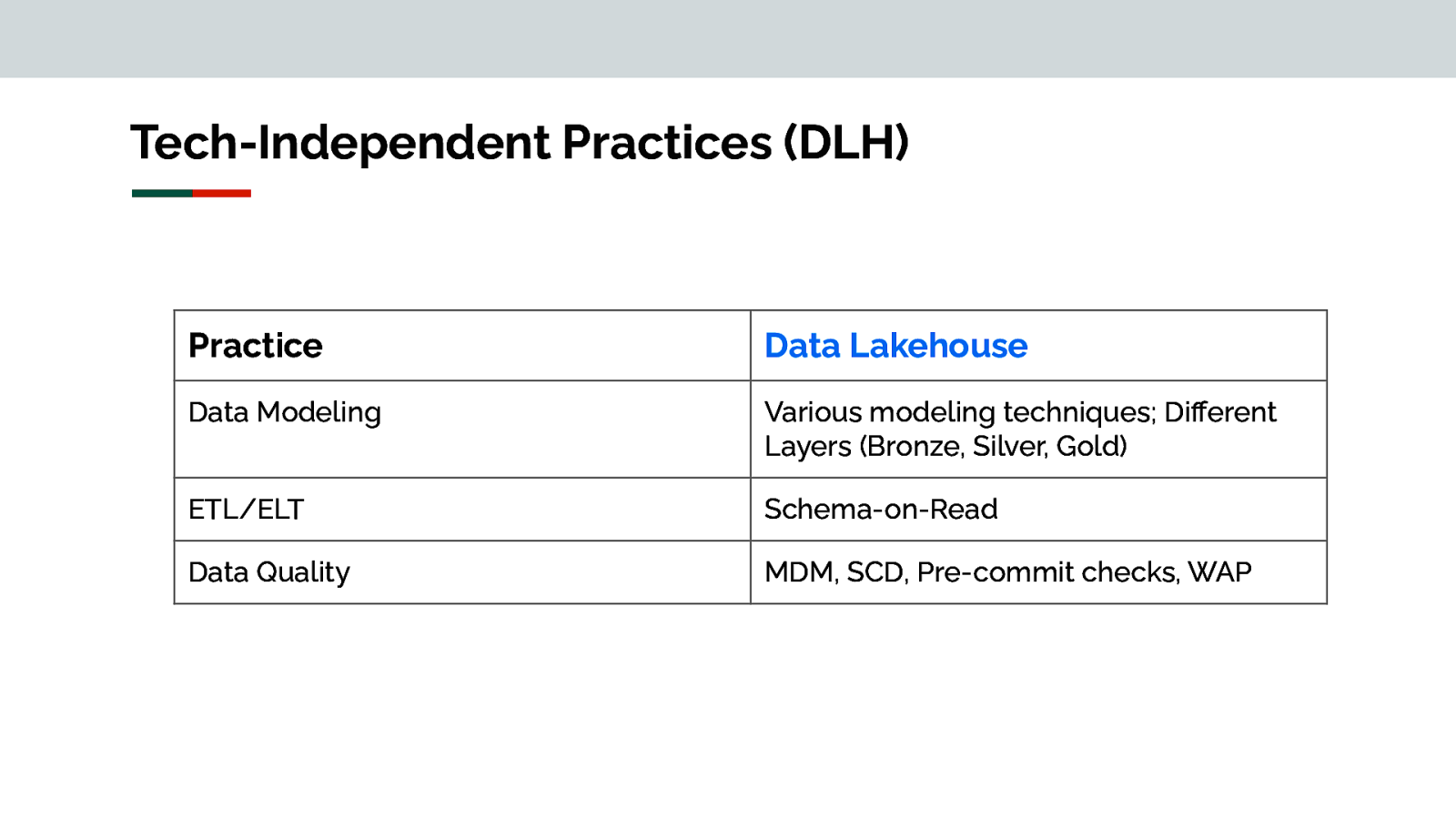
Tech-Independent Practices (DLH) Practice Data Lakehouse Data Modeling Various modeling techniques; Different Layers (Bronze, Silver, Gold) ETL/ELT Schema-on-Read Data Quality MDM, SCD, Pre-commit checks, WAP

Additional Values
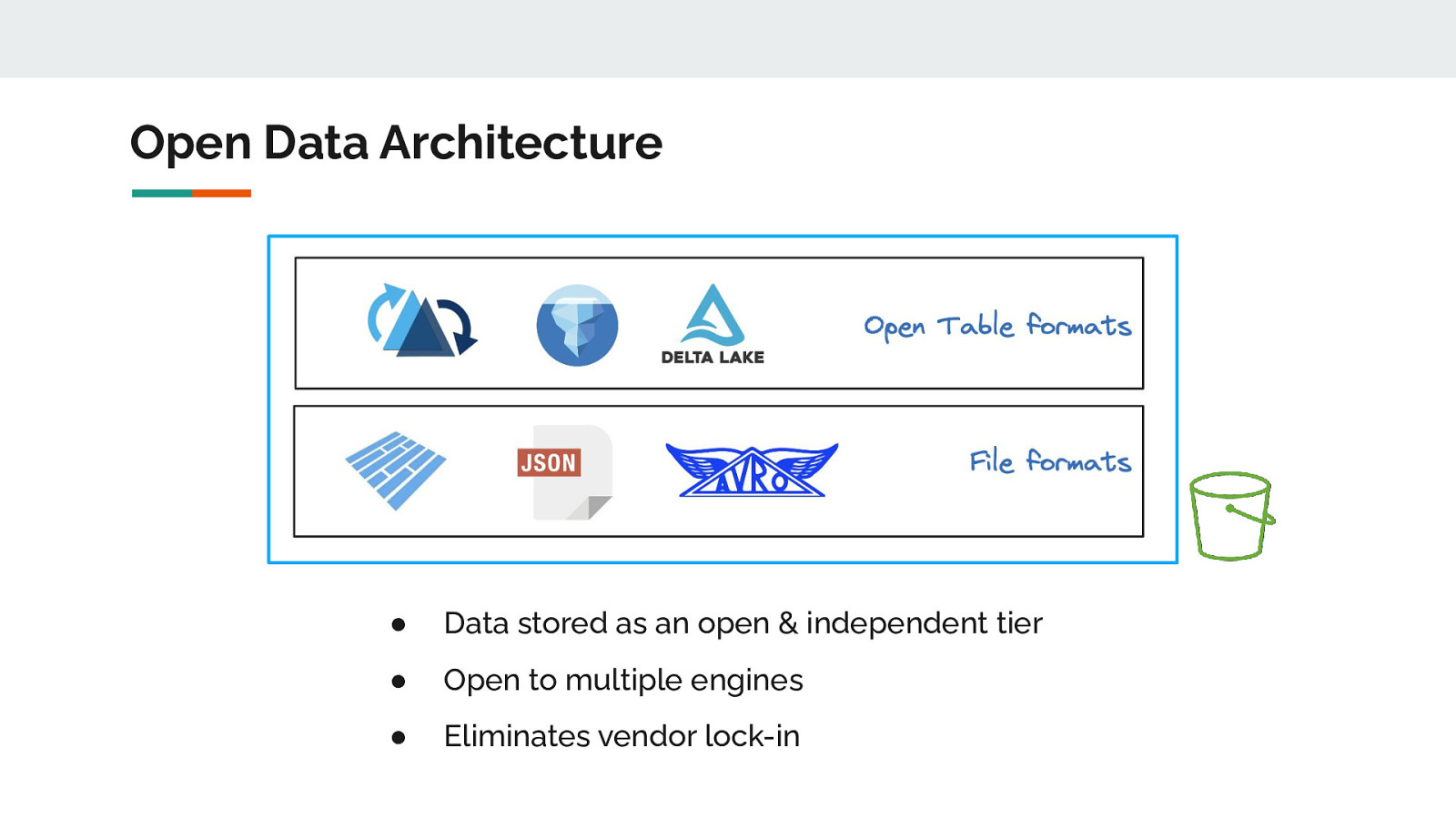
Open Data Architecture ● Data stored as an open & independent tier ● Open to multiple engines ● Eliminates vendor lock-in
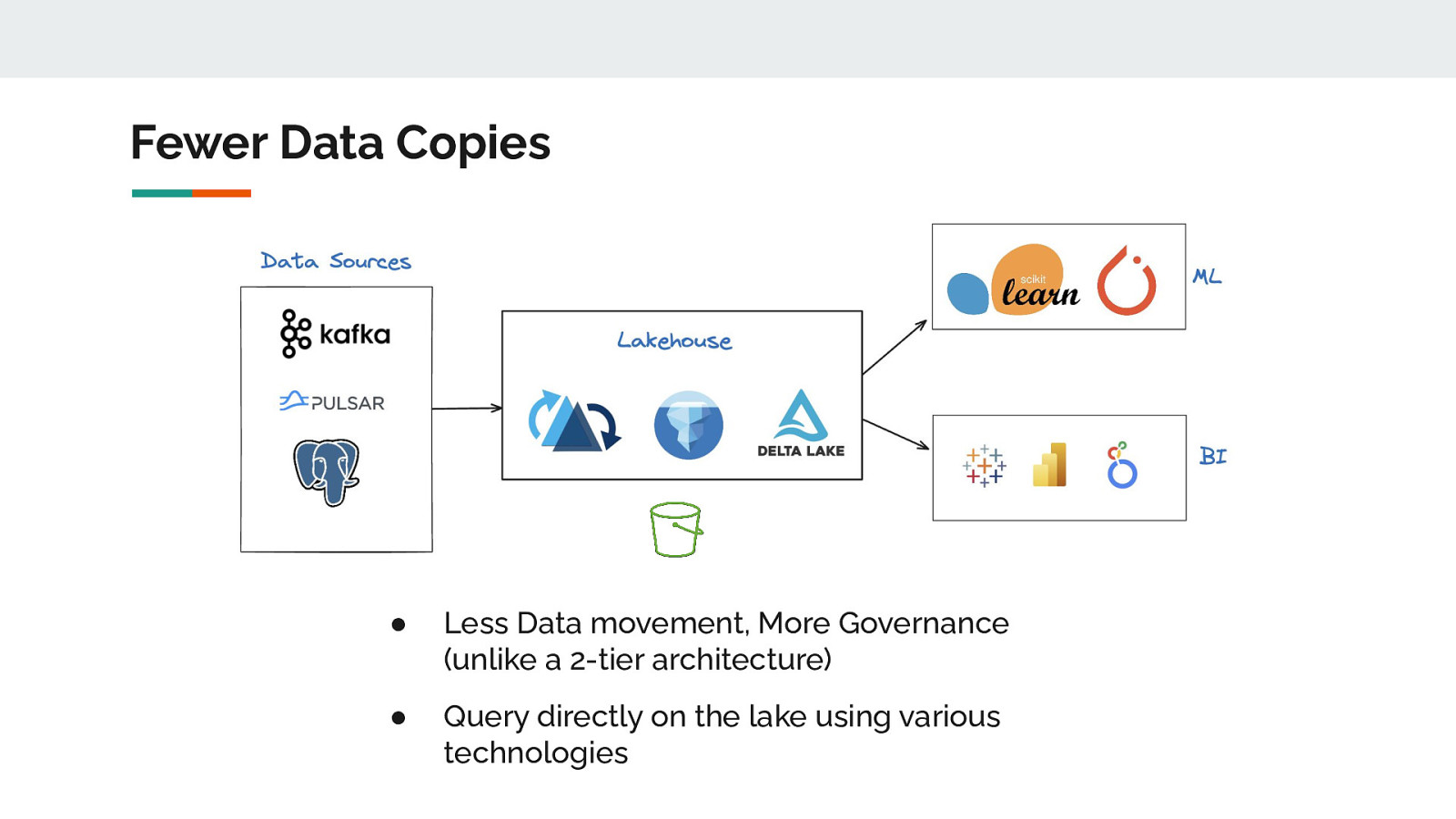
Fewer Data Copies ● Less Data movement, More Governance (unlike a 2-tier architecture) ● Query directly on the lake using various technologies
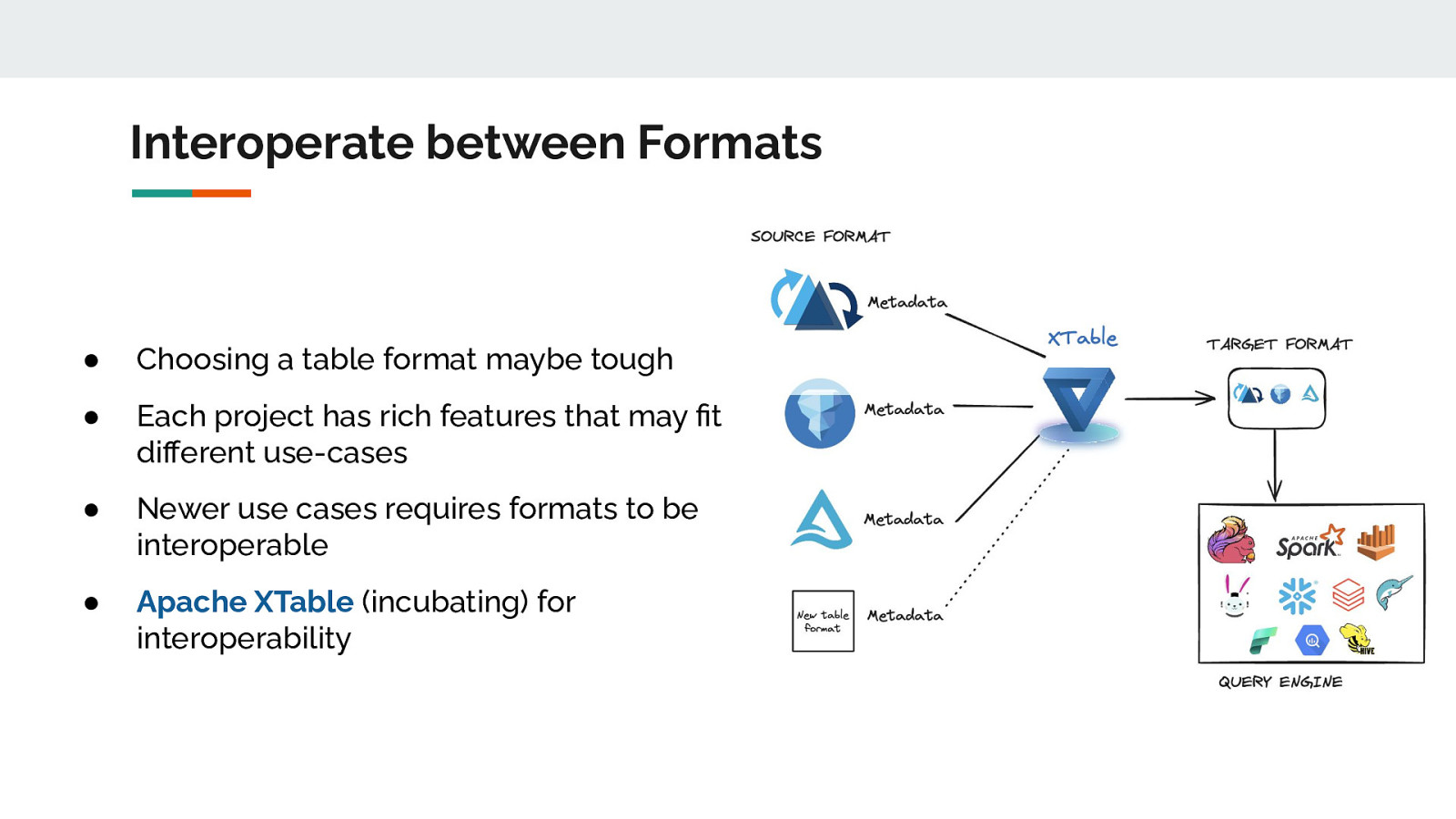
Interoperate between Formats ● Choosing a table format maybe tough ● Each project has rich features that may fit different use-cases ● Newer use cases requires formats to be interoperable ● Apache XTable (incubating) for interoperability

Apache XTable ● An omni-directional interop of lakehouse table formats ● NOT a new or separate format ● XTable provides abstractions and tools for the translation of metadata Read your table as any of the formats: 1: Choose your “source” format 2: Choose your “destination” format(s) 3: XTable will translate the metadata layers
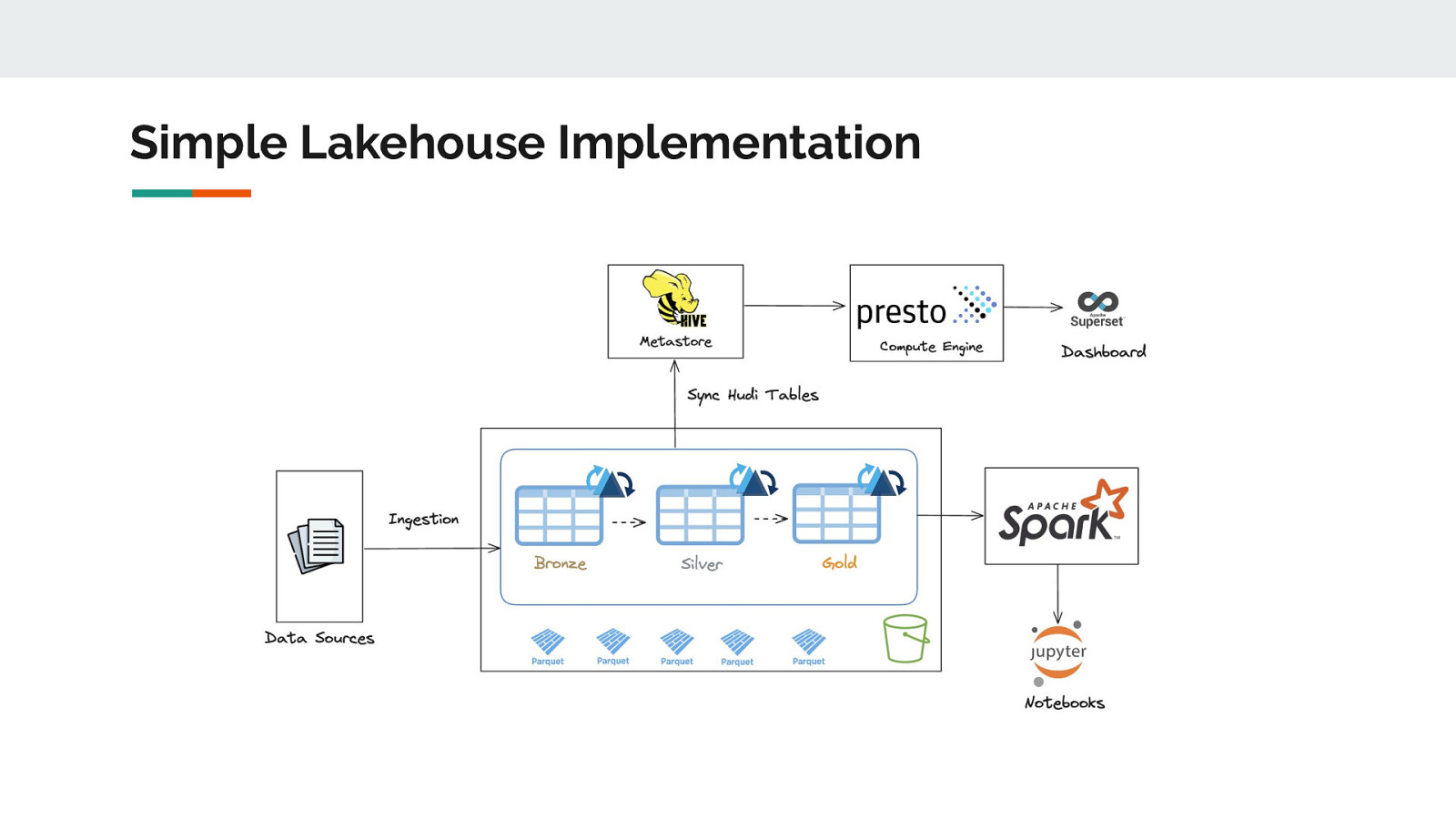
Simple Lakehouse Implementation

Revisiting Hypothesis Going beyond the jargons Data Warehousing = Tech + Practices Data Lakehouse = DWH + DL + Additional Stuff Advantages (Open architecture, Interoperability)

Q&A