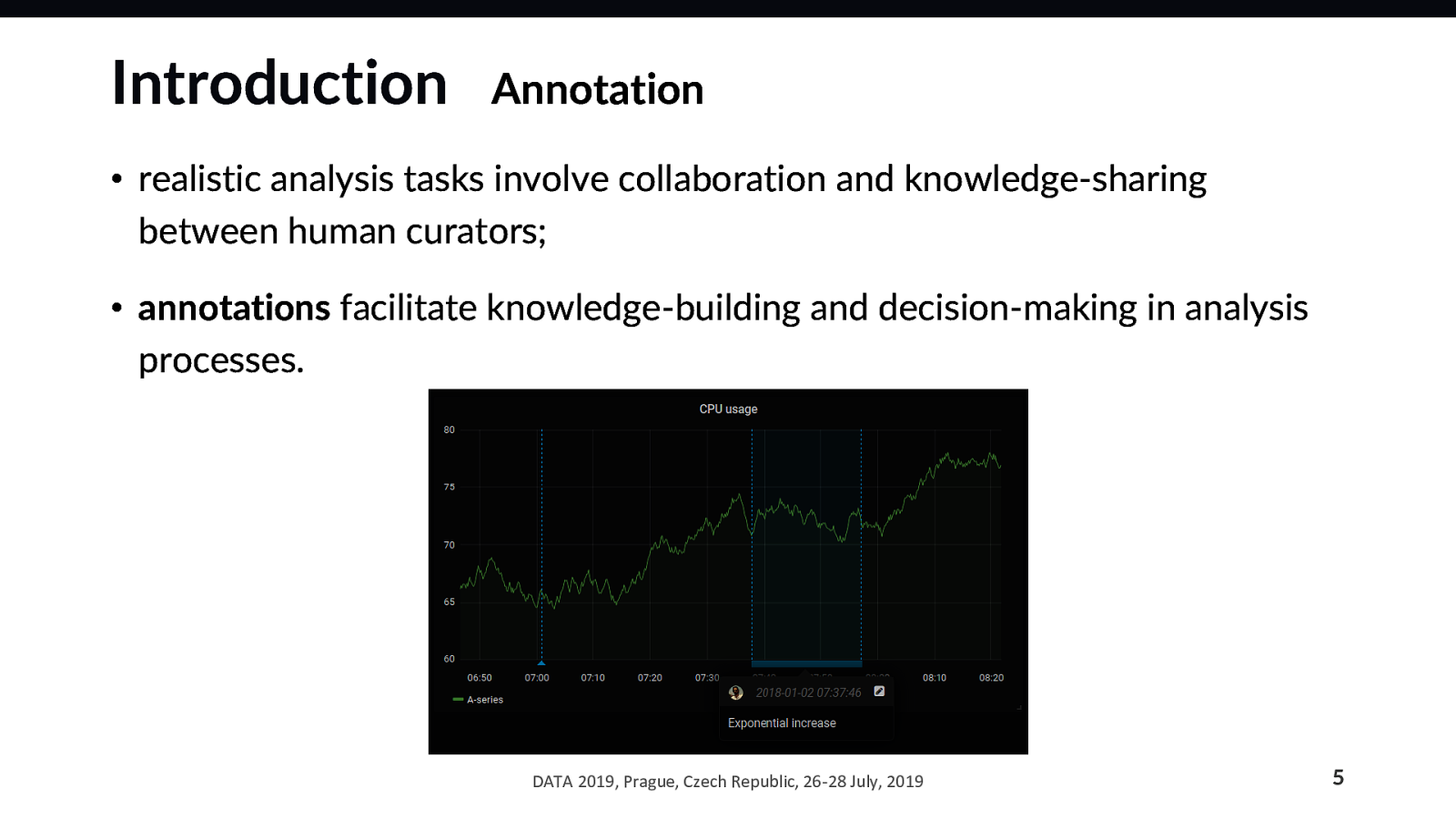

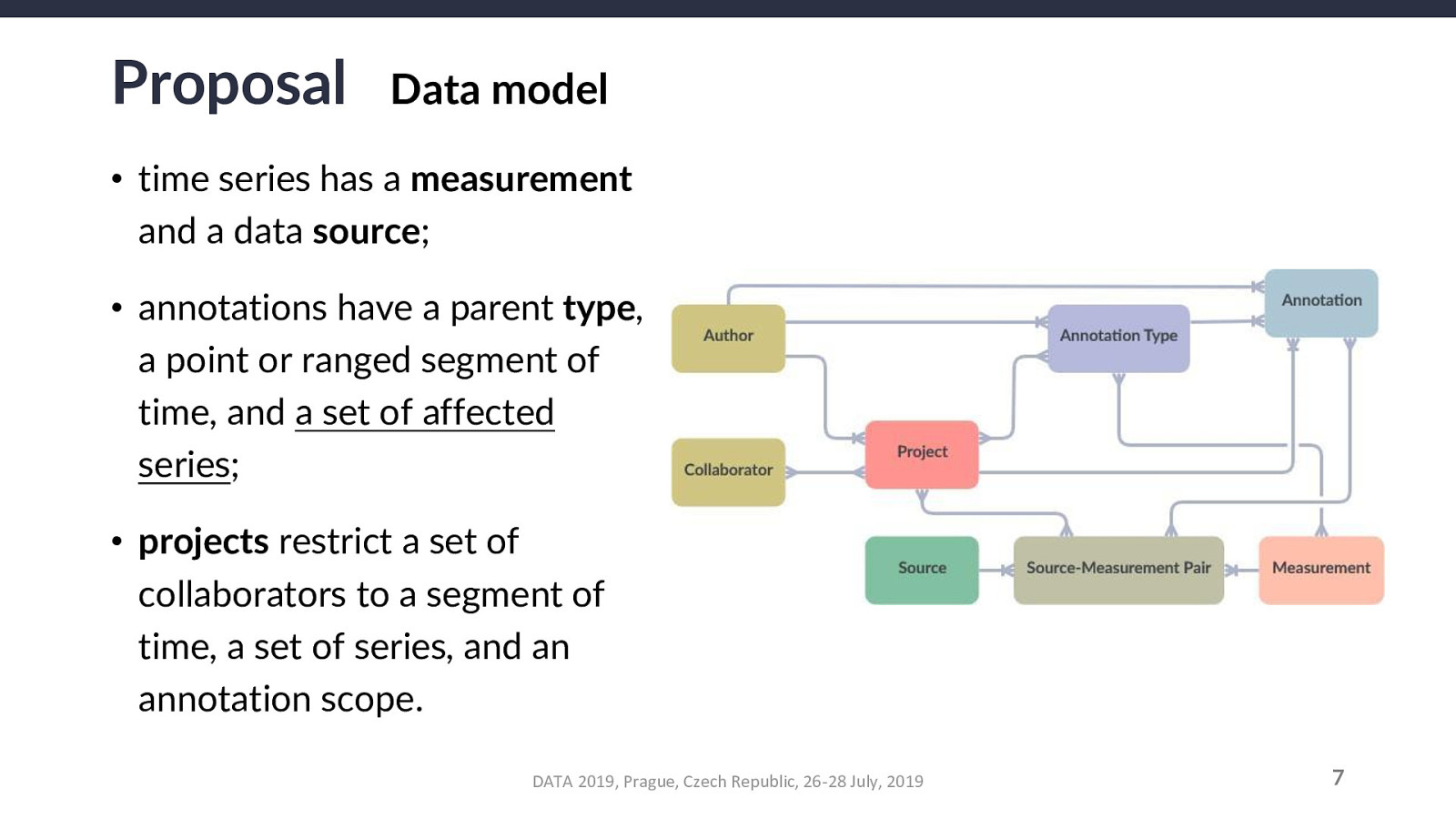
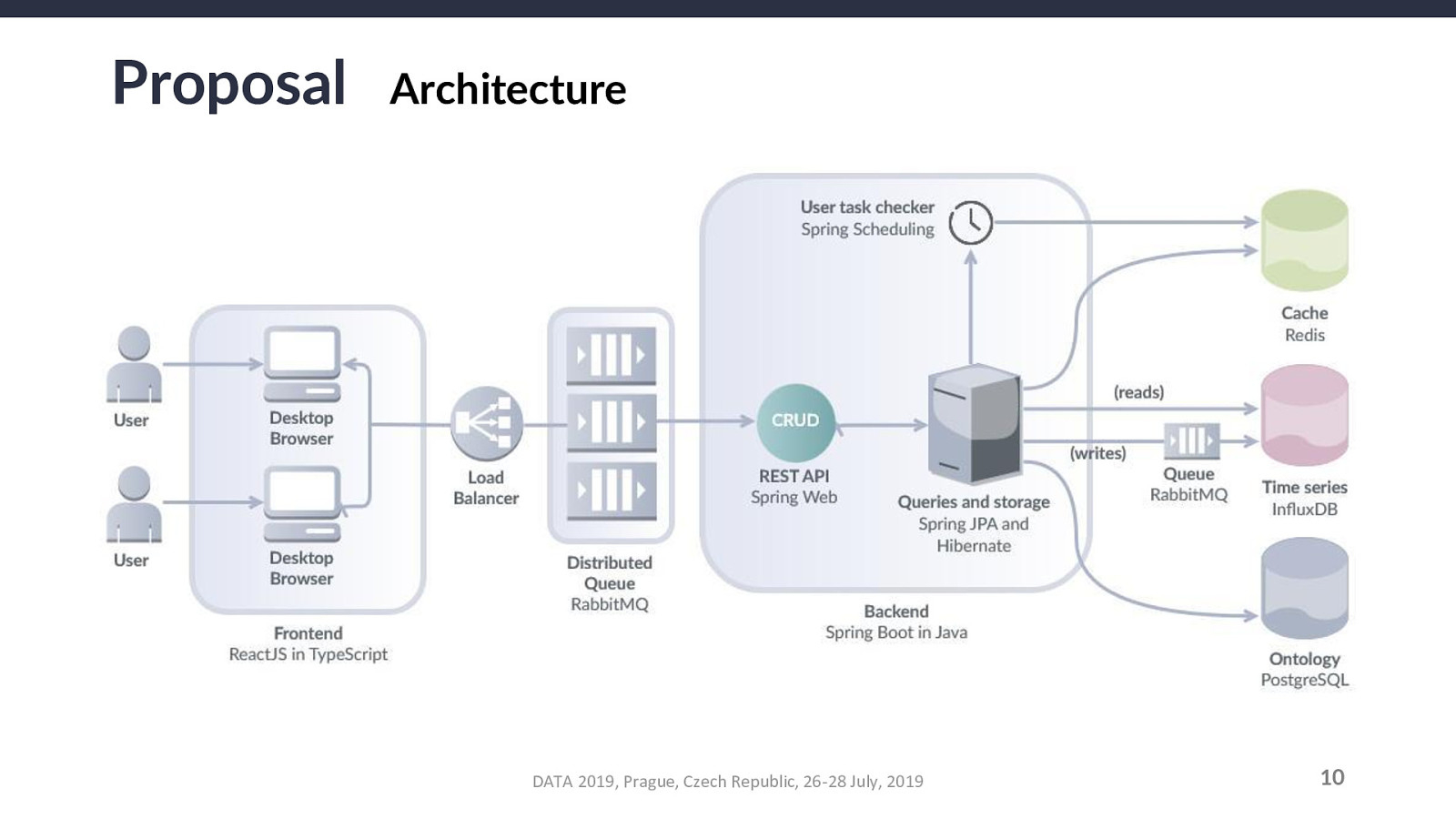
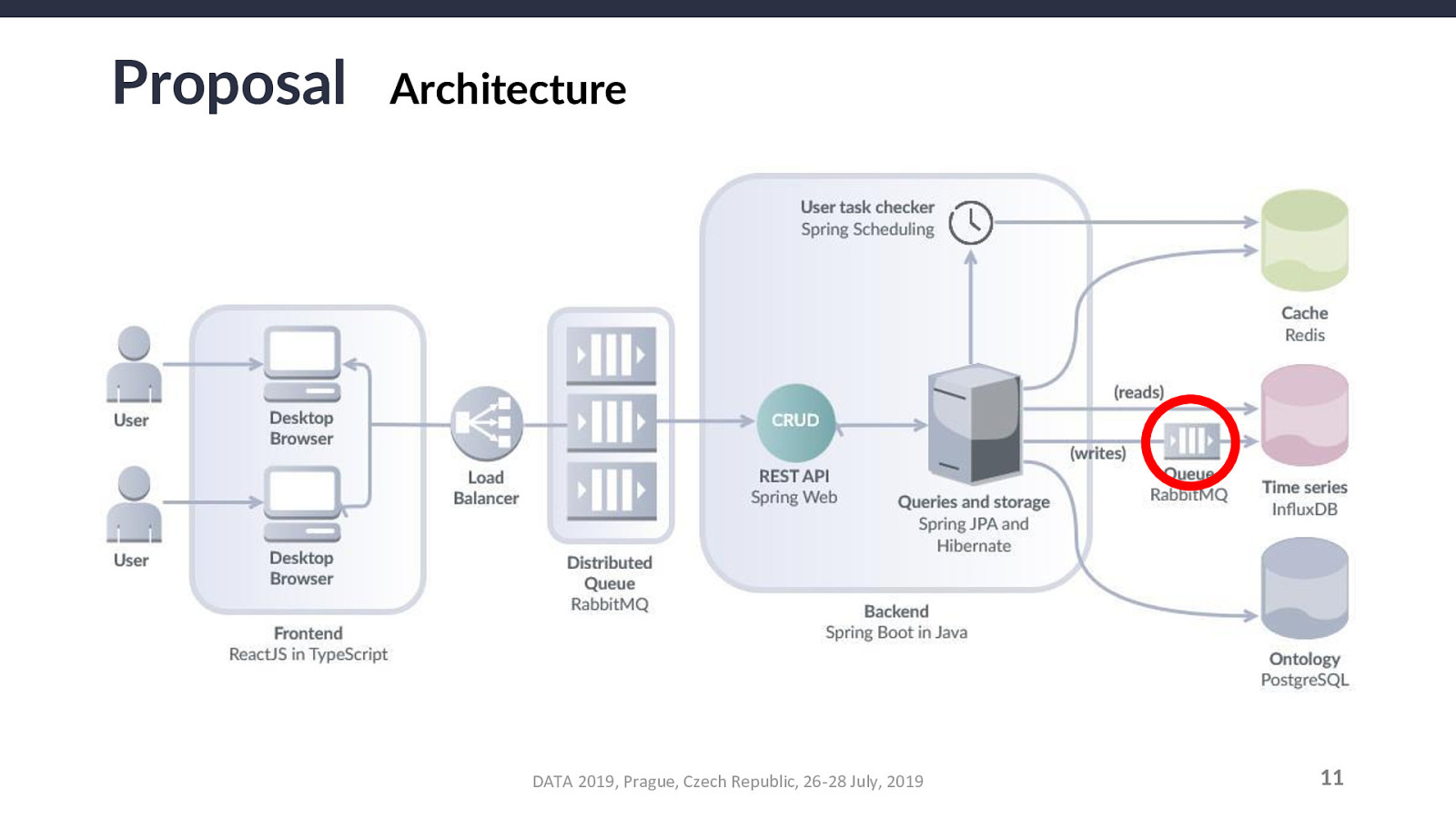
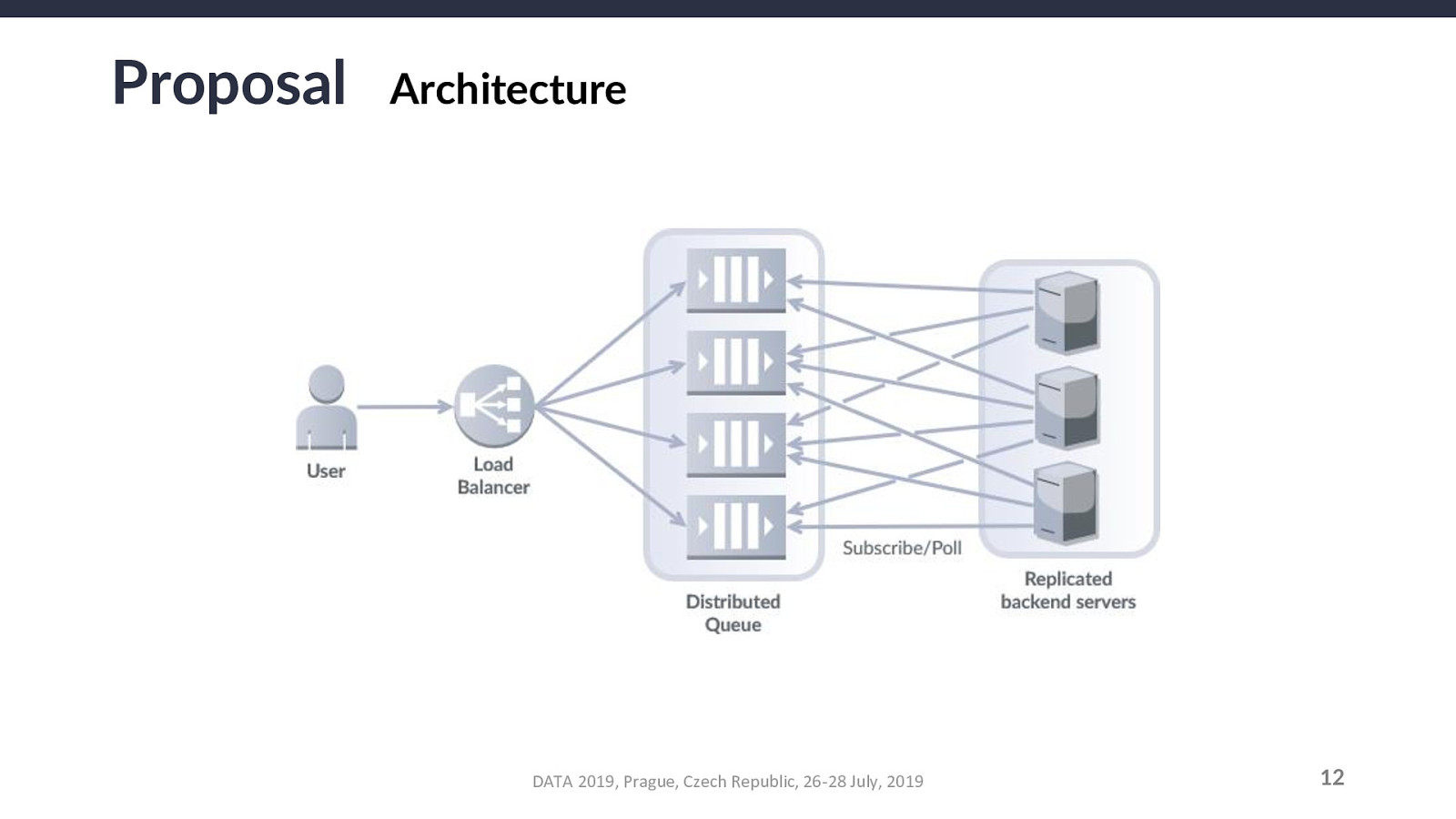

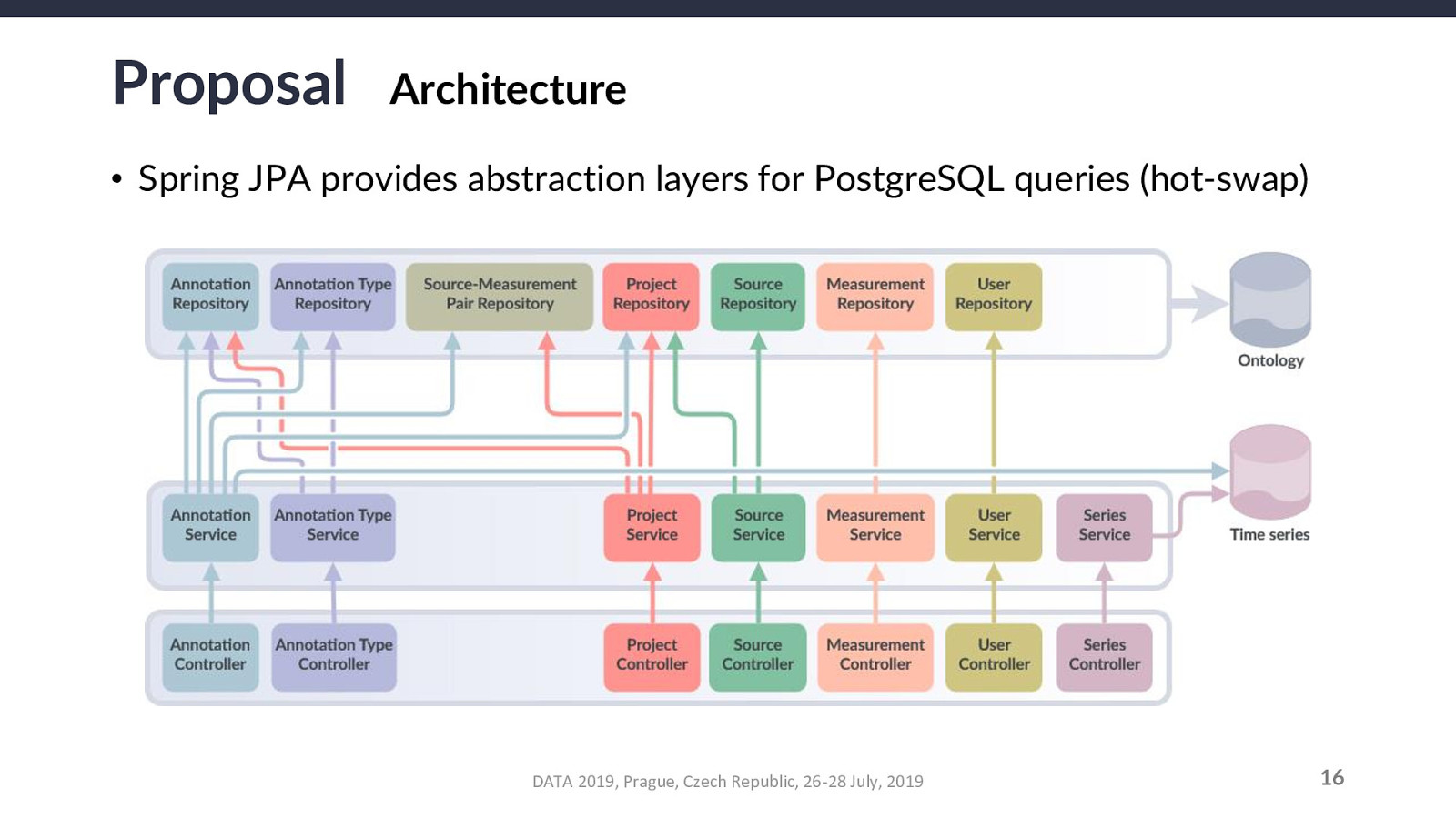
For an annotation A, a parent annotation-type T, a parent project P, a measurement M, and a source-measurement pair SM that combines any source with M, the relationship constraints that must be validated are as follows:
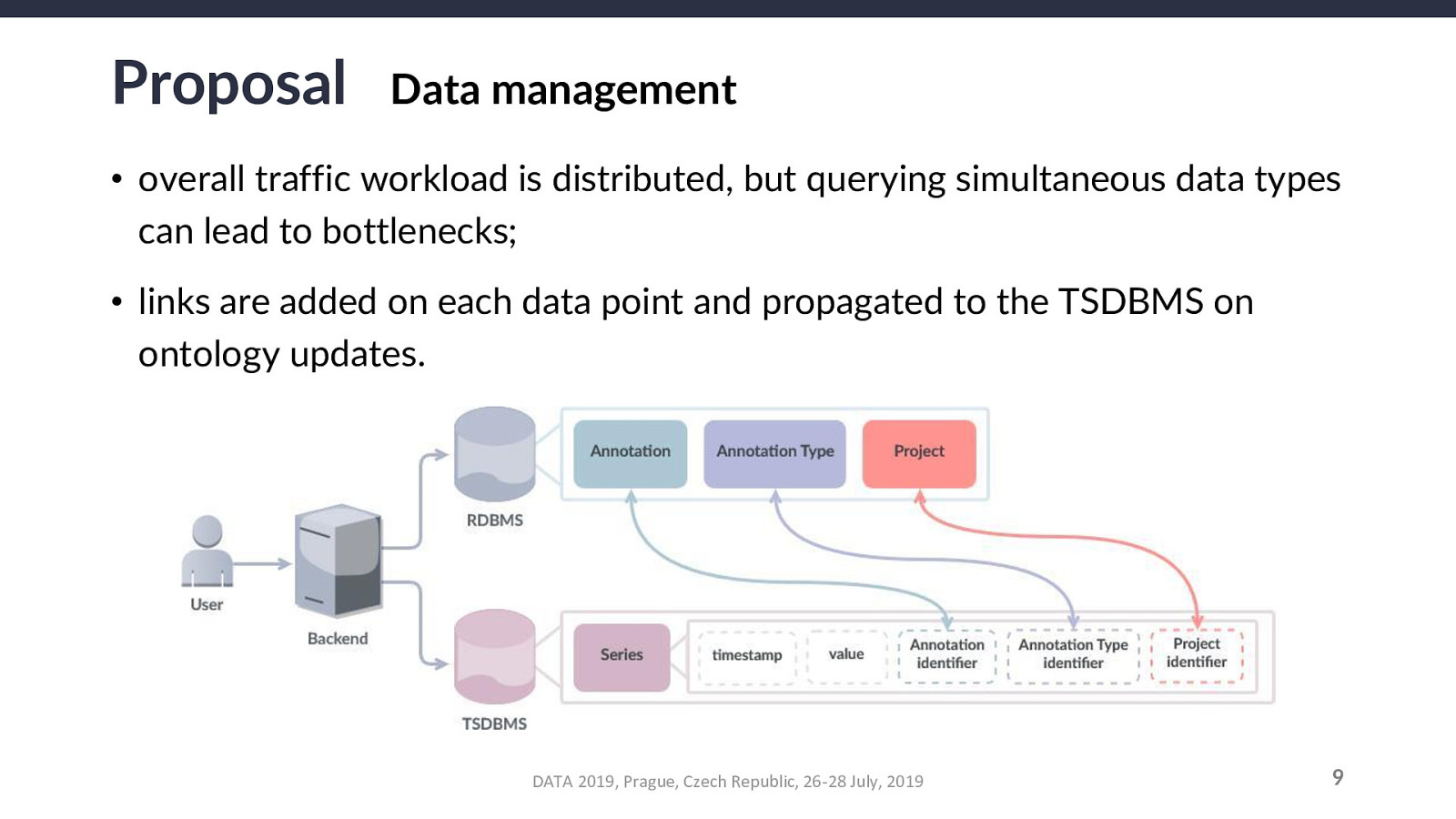
Their corollaries (in the case of removal operations) are:
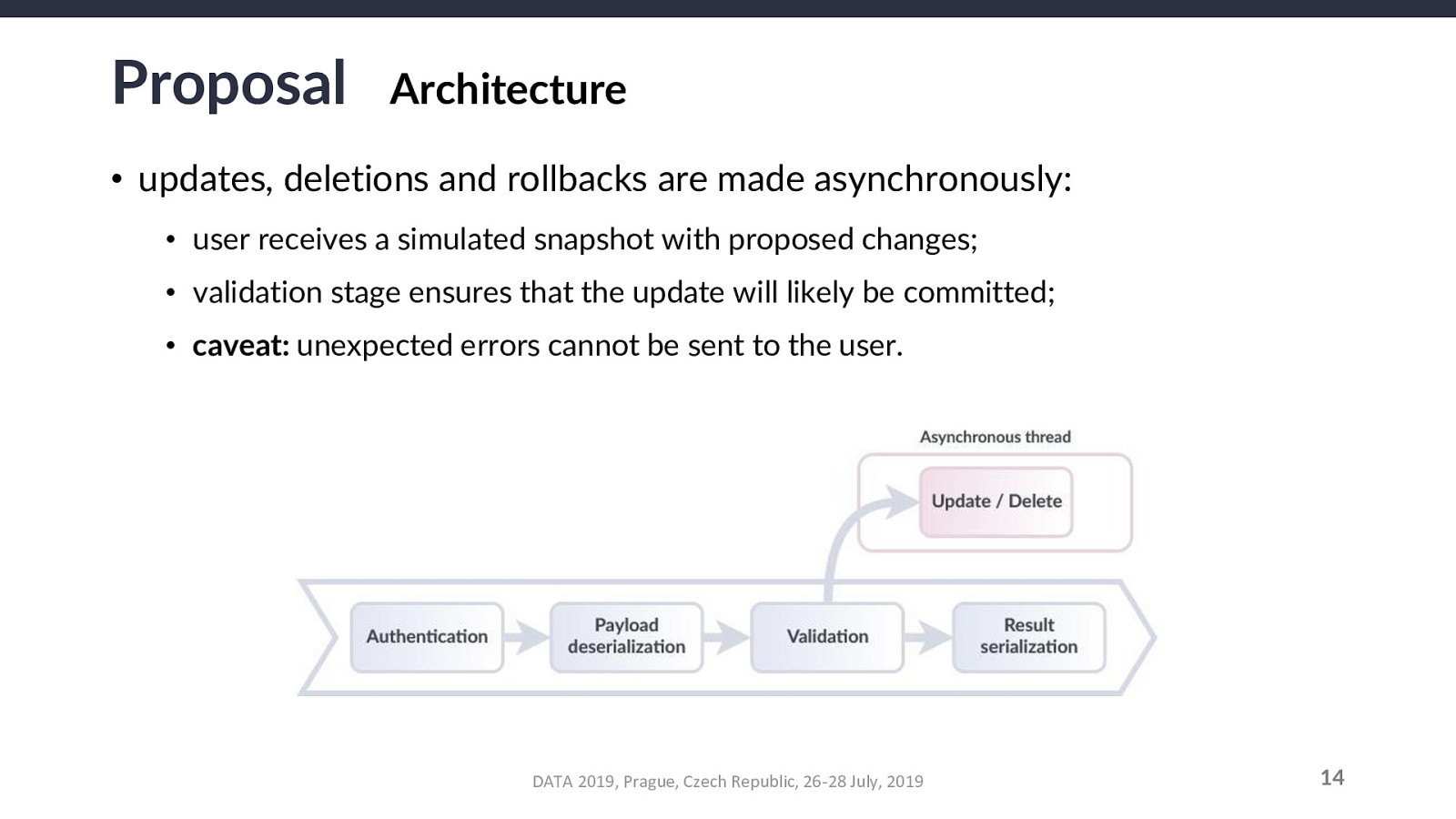
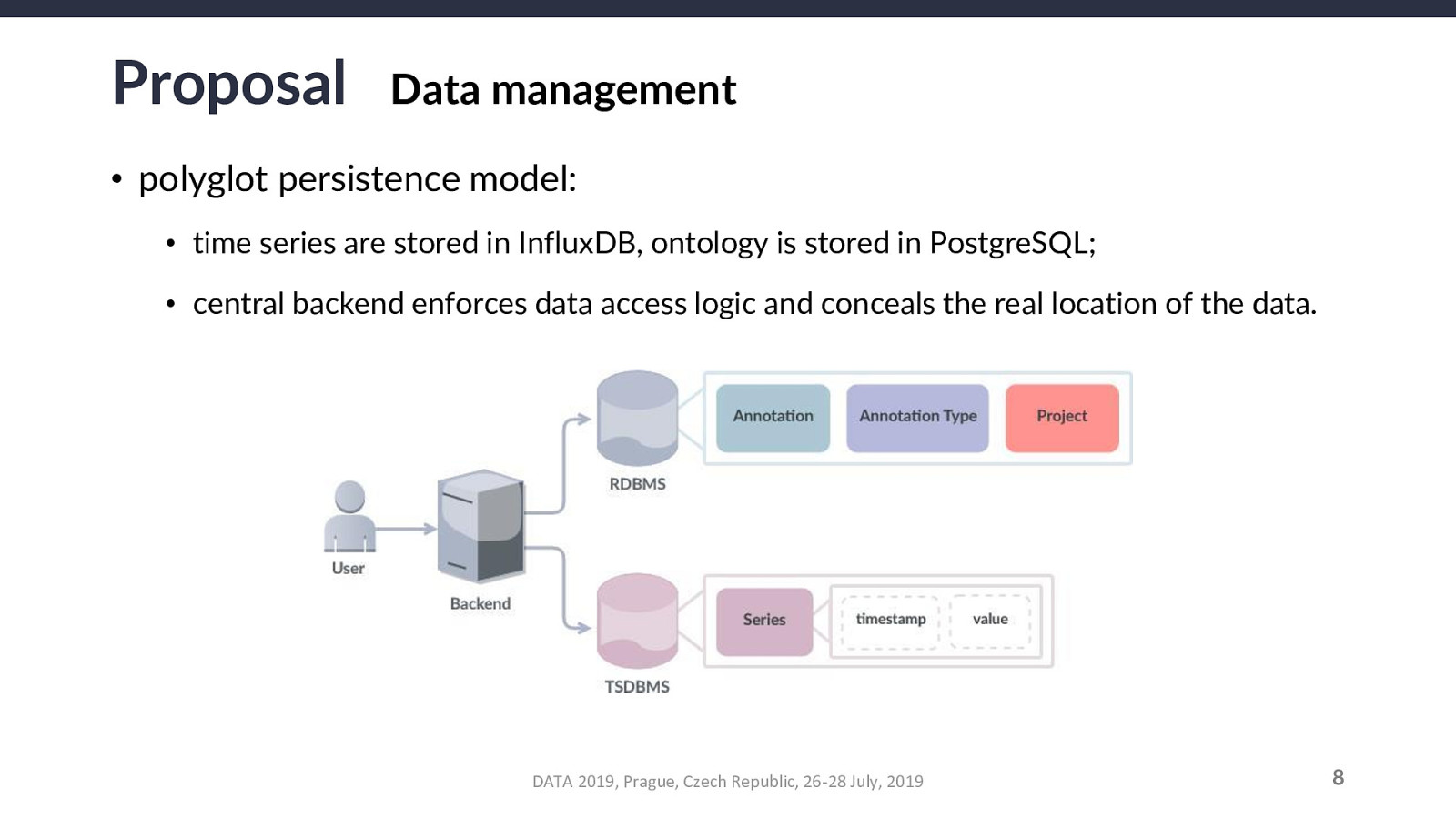
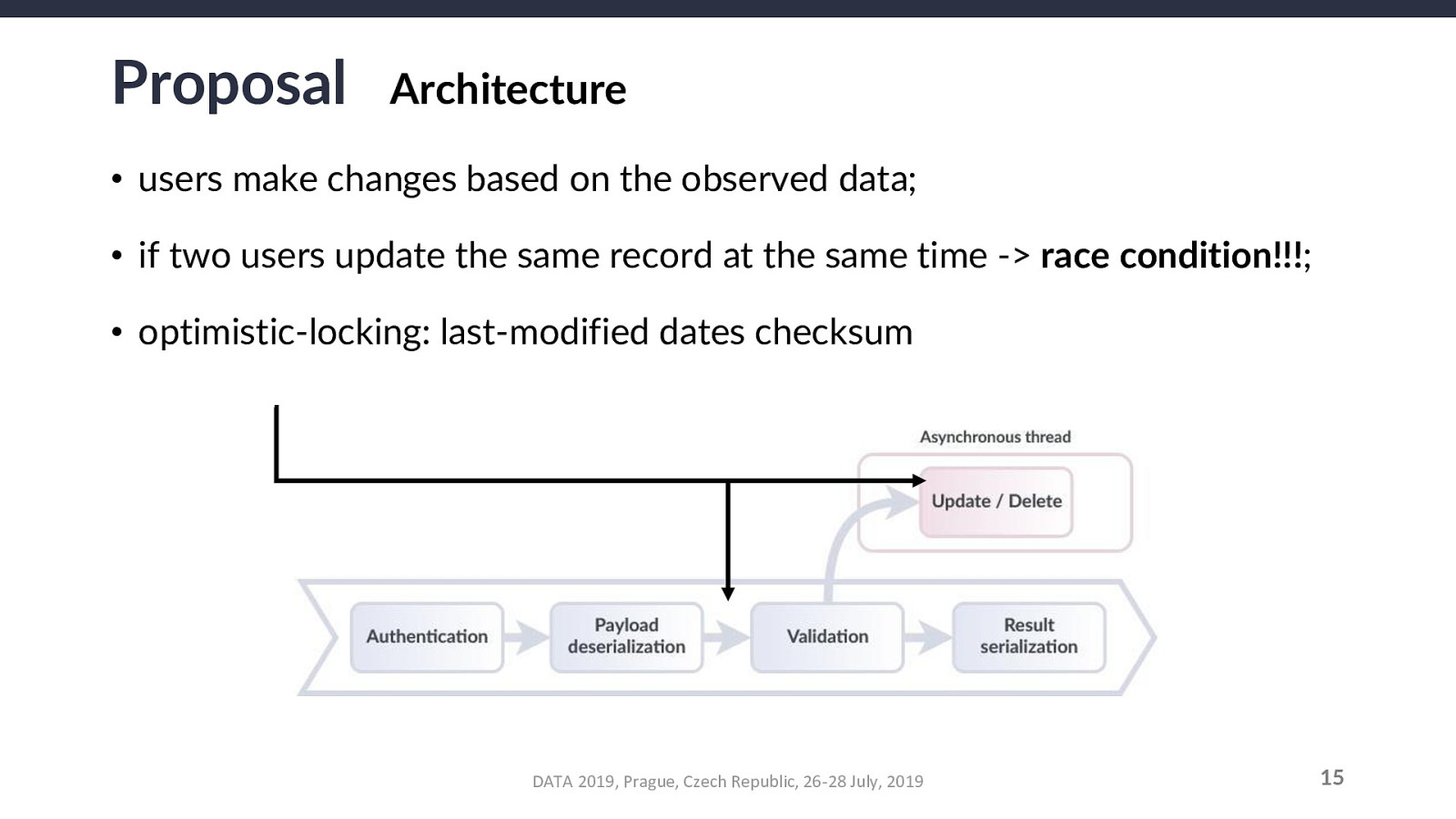
Another caveat: this opens an inconsistency window at the local level of the requesting user (between they receive the simulated snapshot and until the actual changes are committed to the database). This does NOT affect the actual system nor the other users.
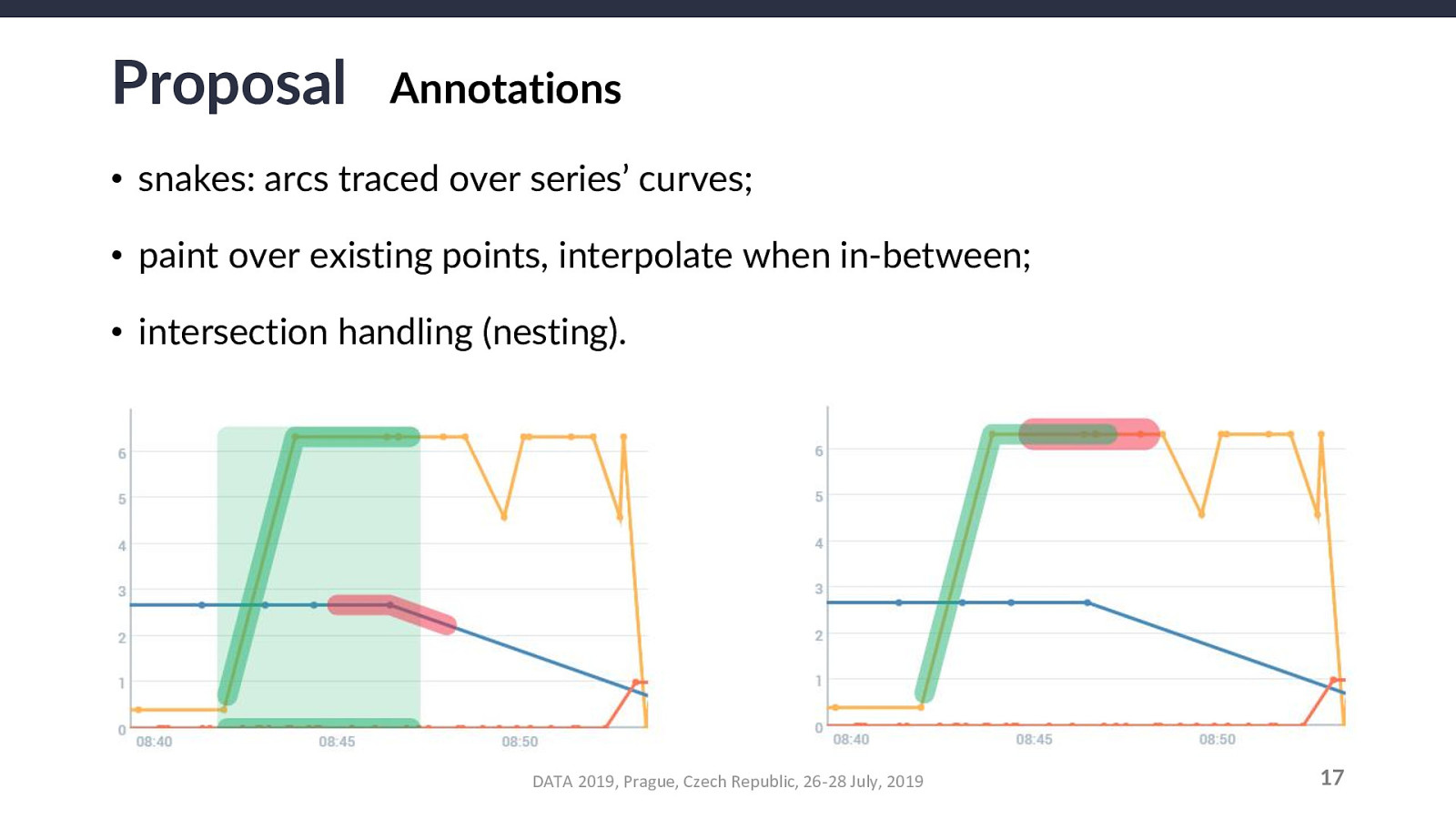

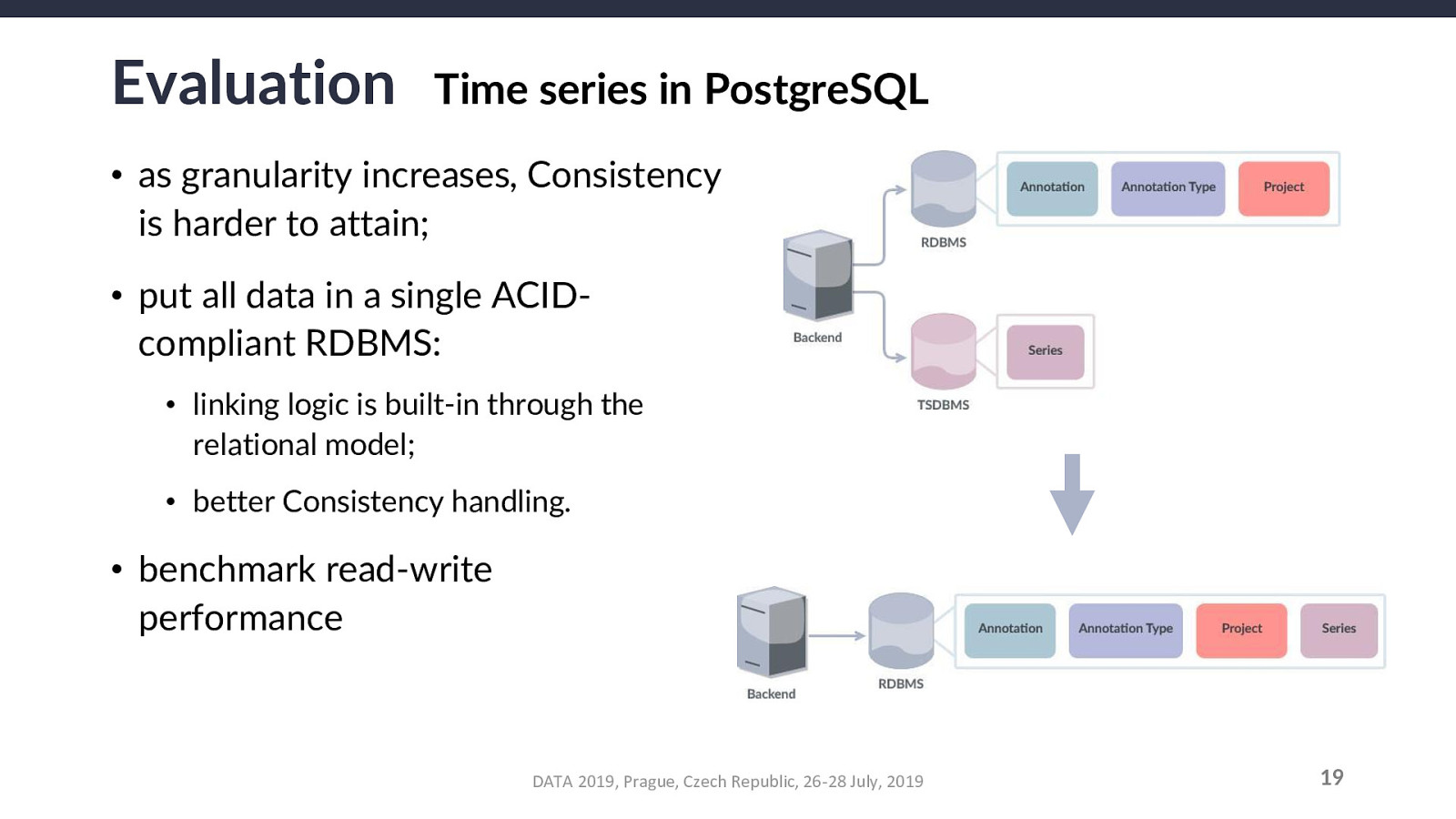
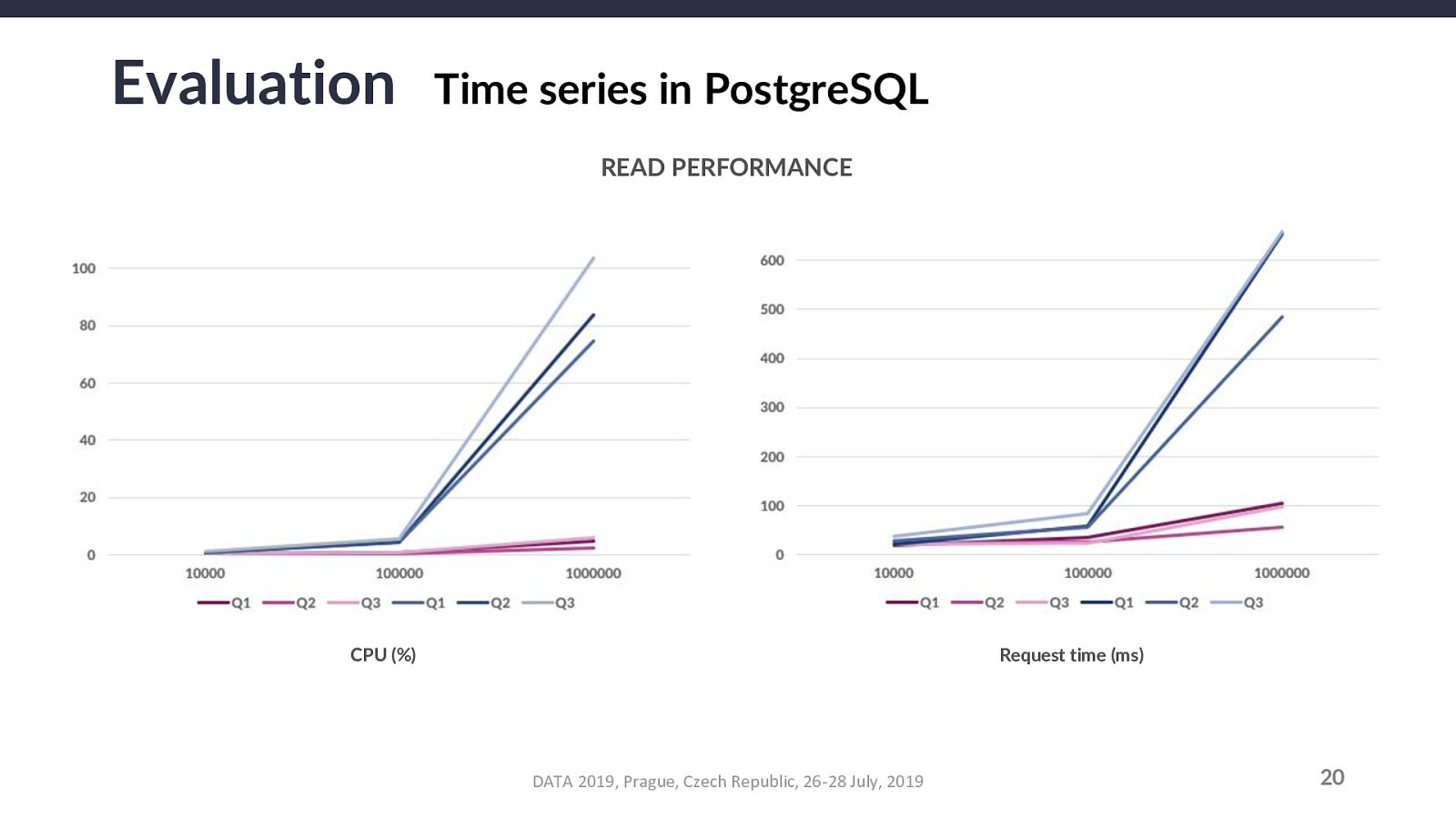
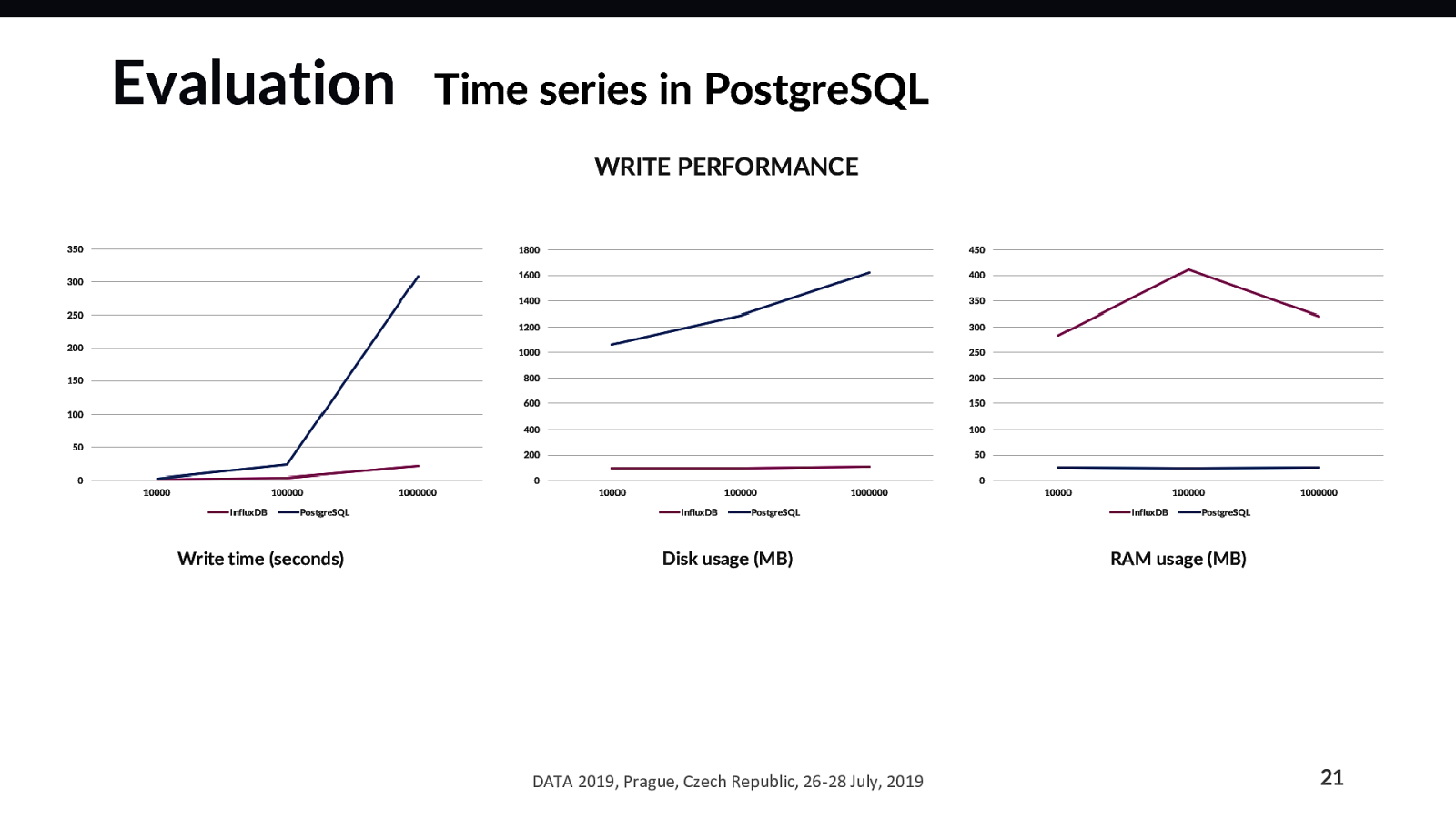
The end goal is to recognize either an improvement or a negligible drop: if PostgreSQL has an inconsequentially lower performance, it is still worth using it for series for the possible gains (higher system consistency).