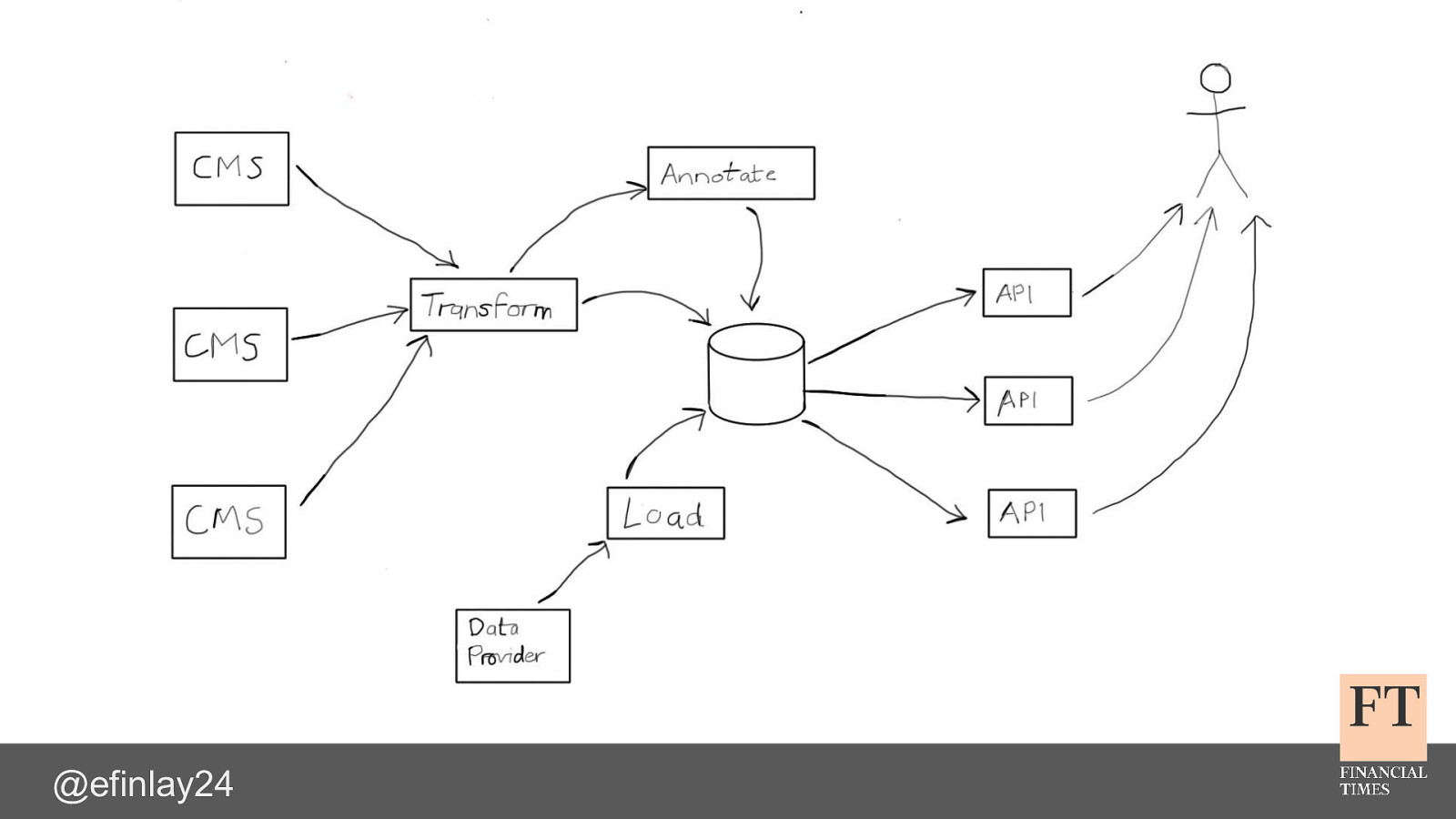
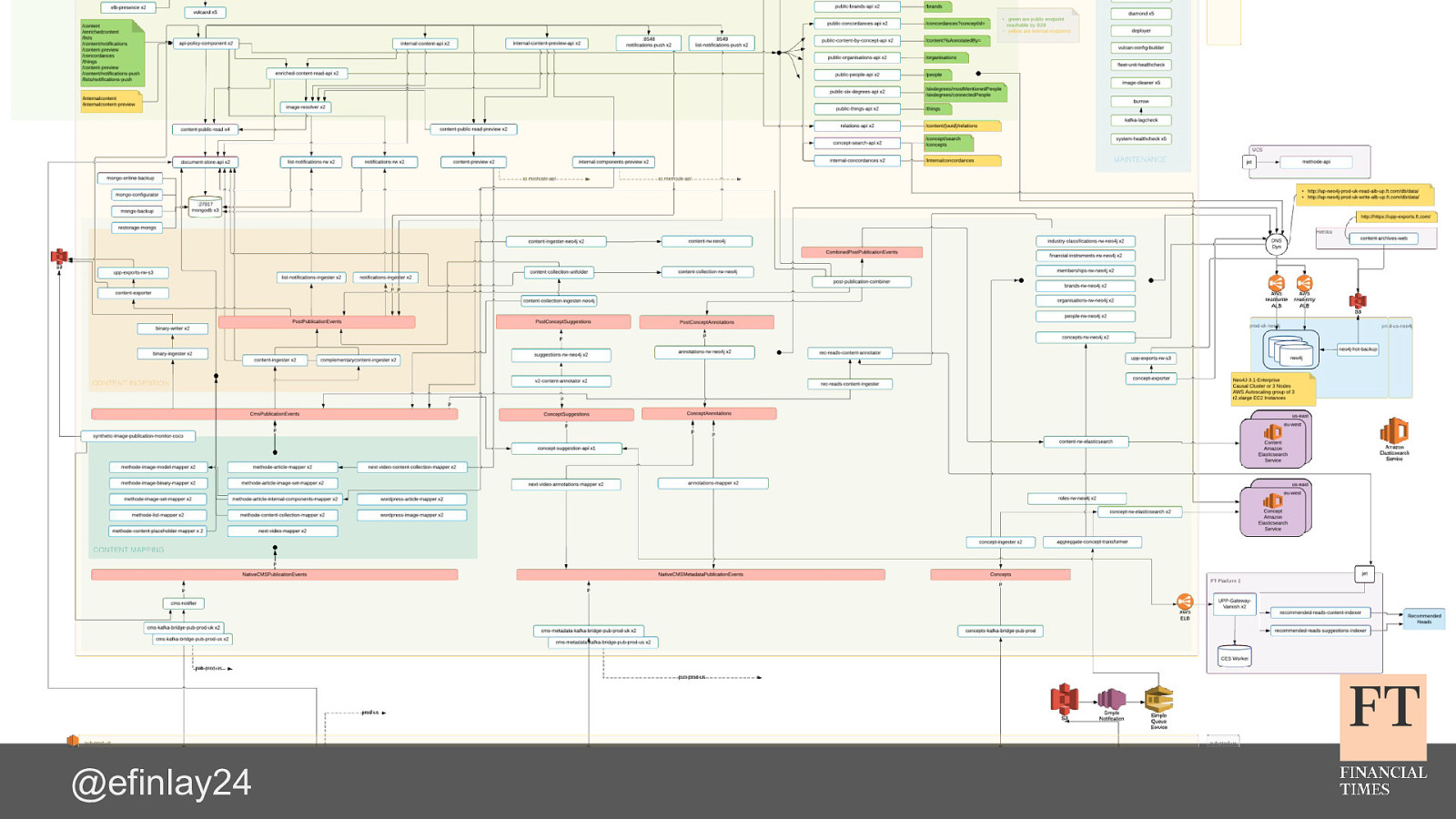
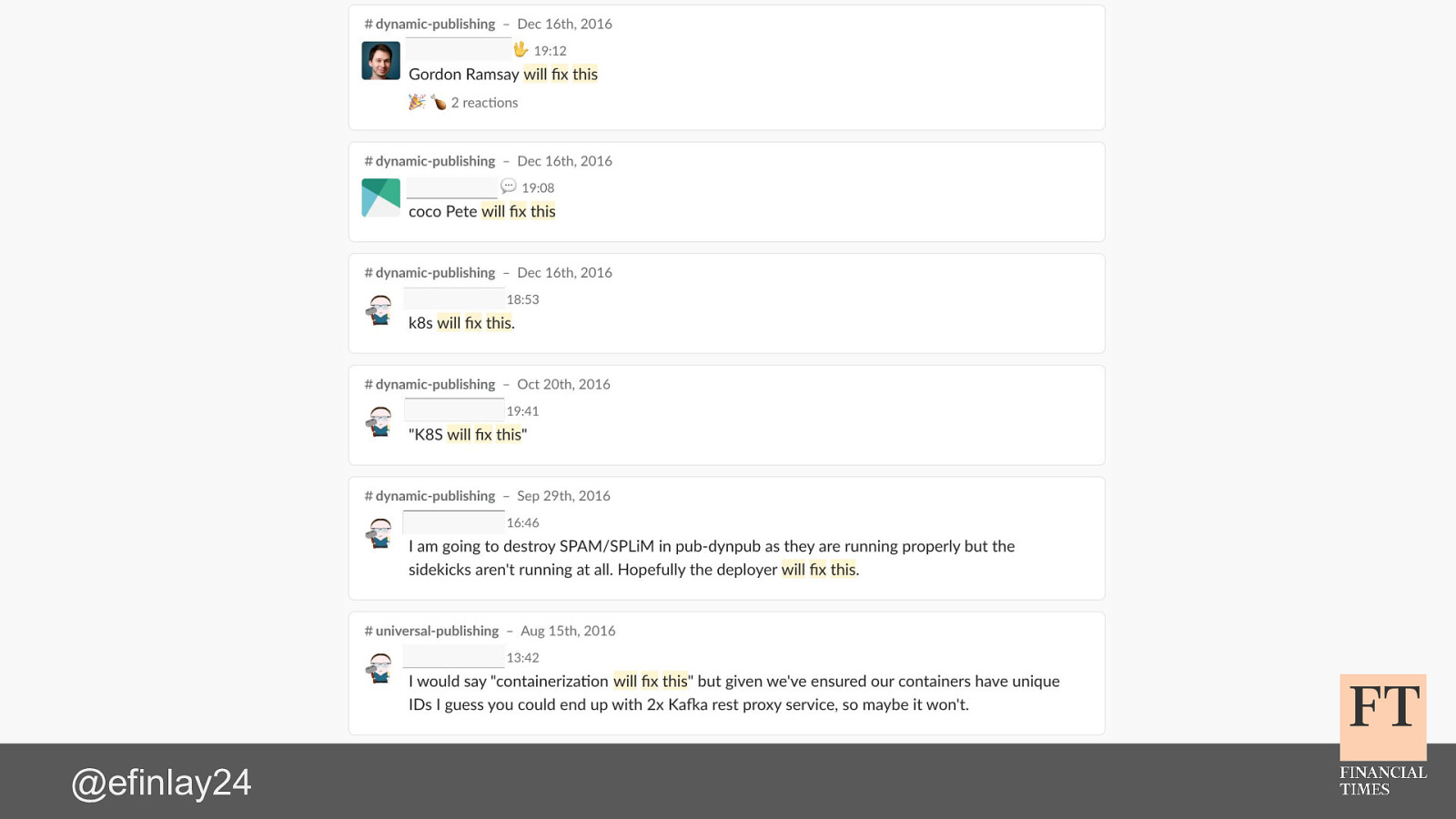
Switching Horses Midstream The challenge of migrating 150 microservices to Kubernetes Euan Finlay @efinlay24 hi! thank you for the introduction back in 2015, the Content team at the Financial Times were having problems we had been struggling with the stability of our containerised platform our developers were constantly firefighting which was increasing their stress levels, and dropping morale across the team how did we get into that situation? and how did we manage to turn things around, with the help of iQuest?