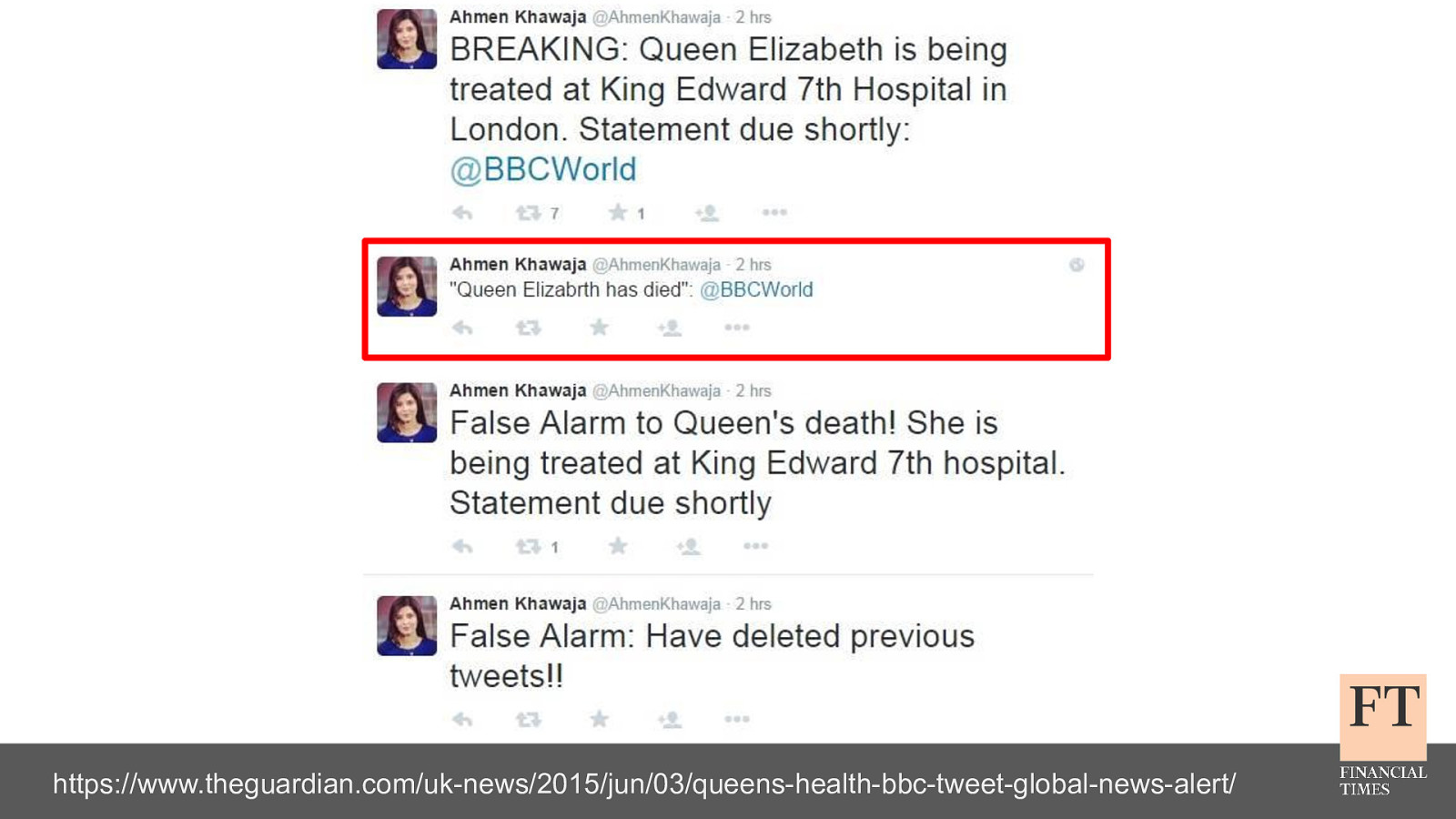
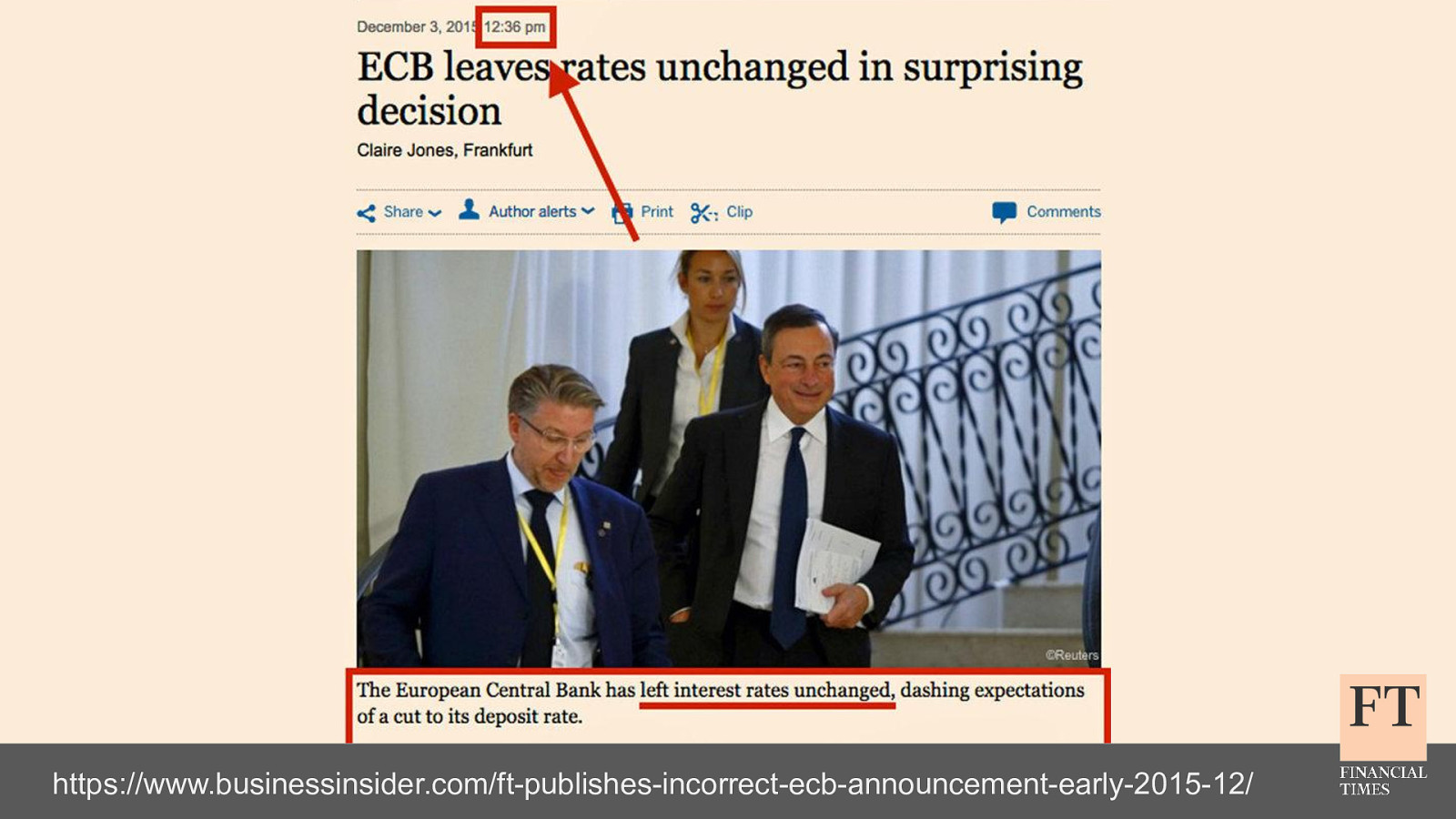
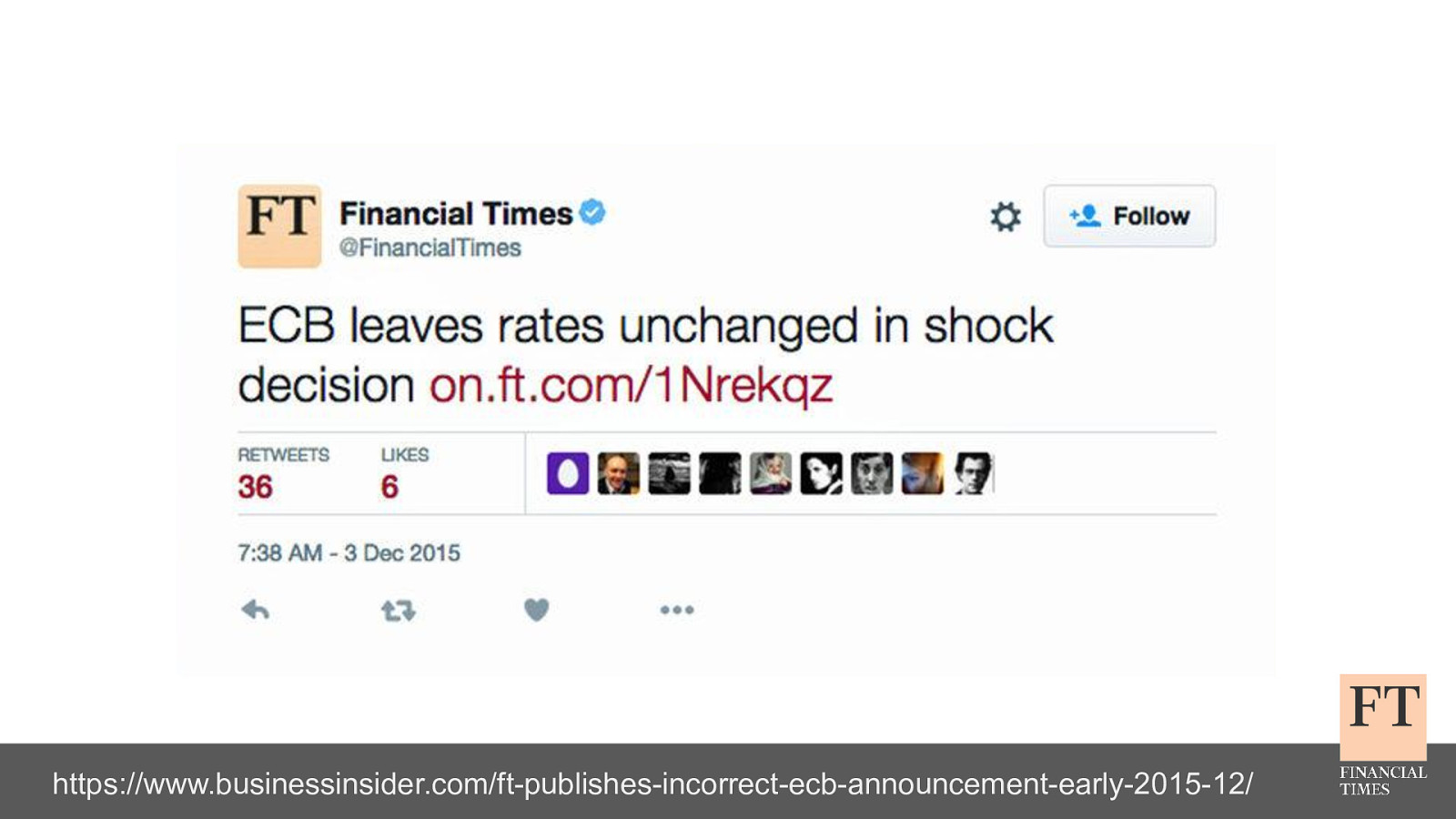
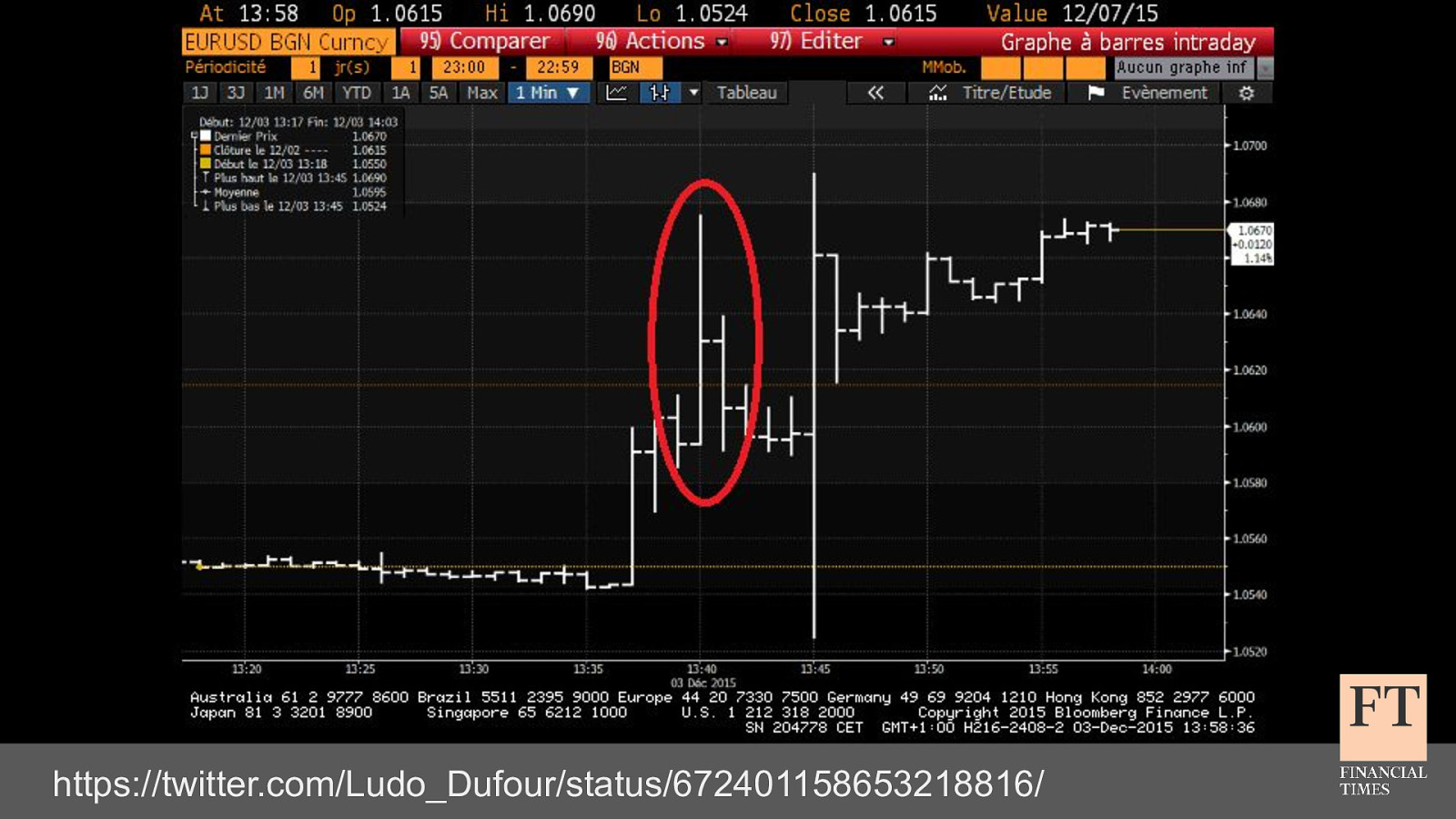
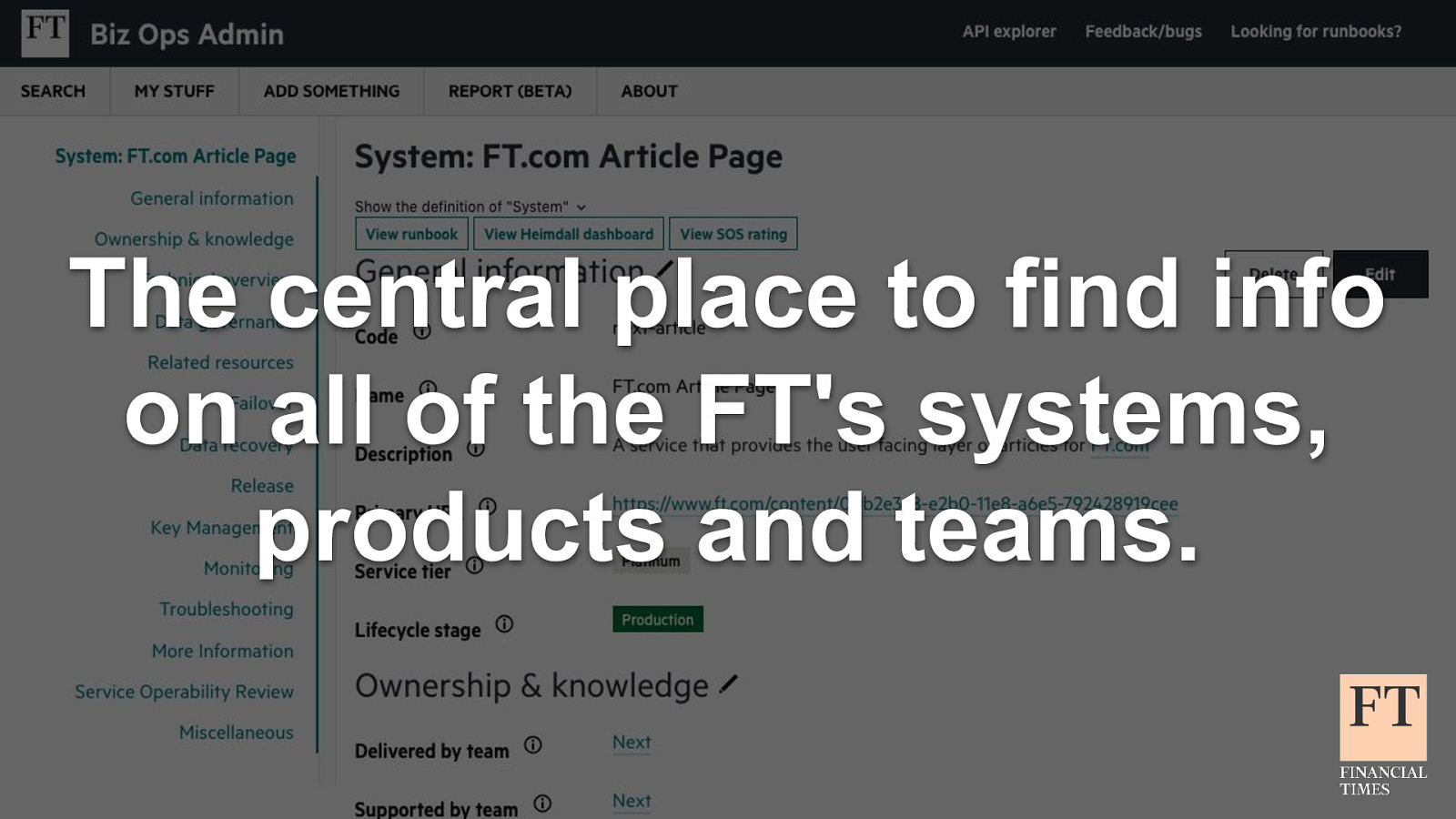
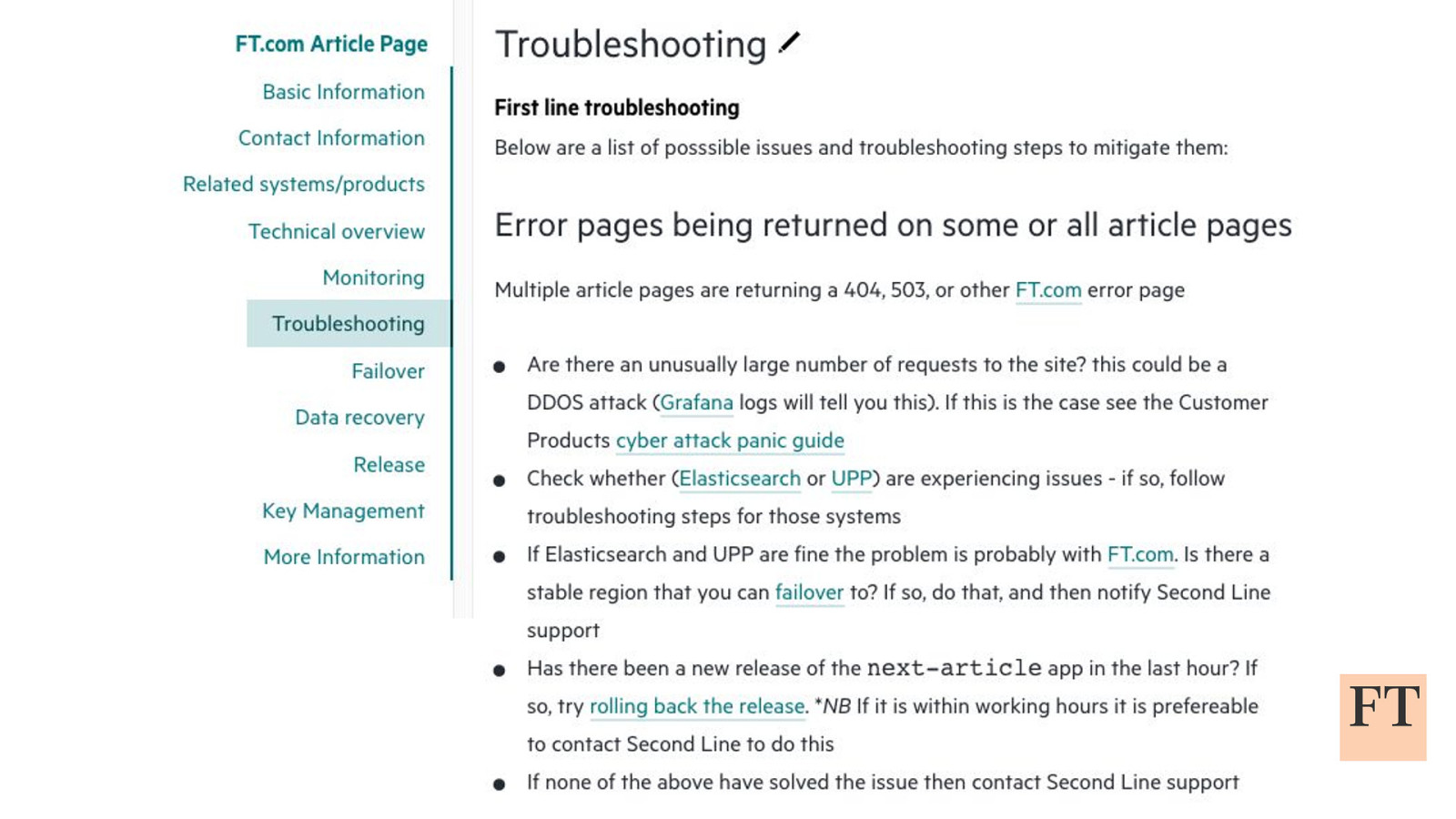
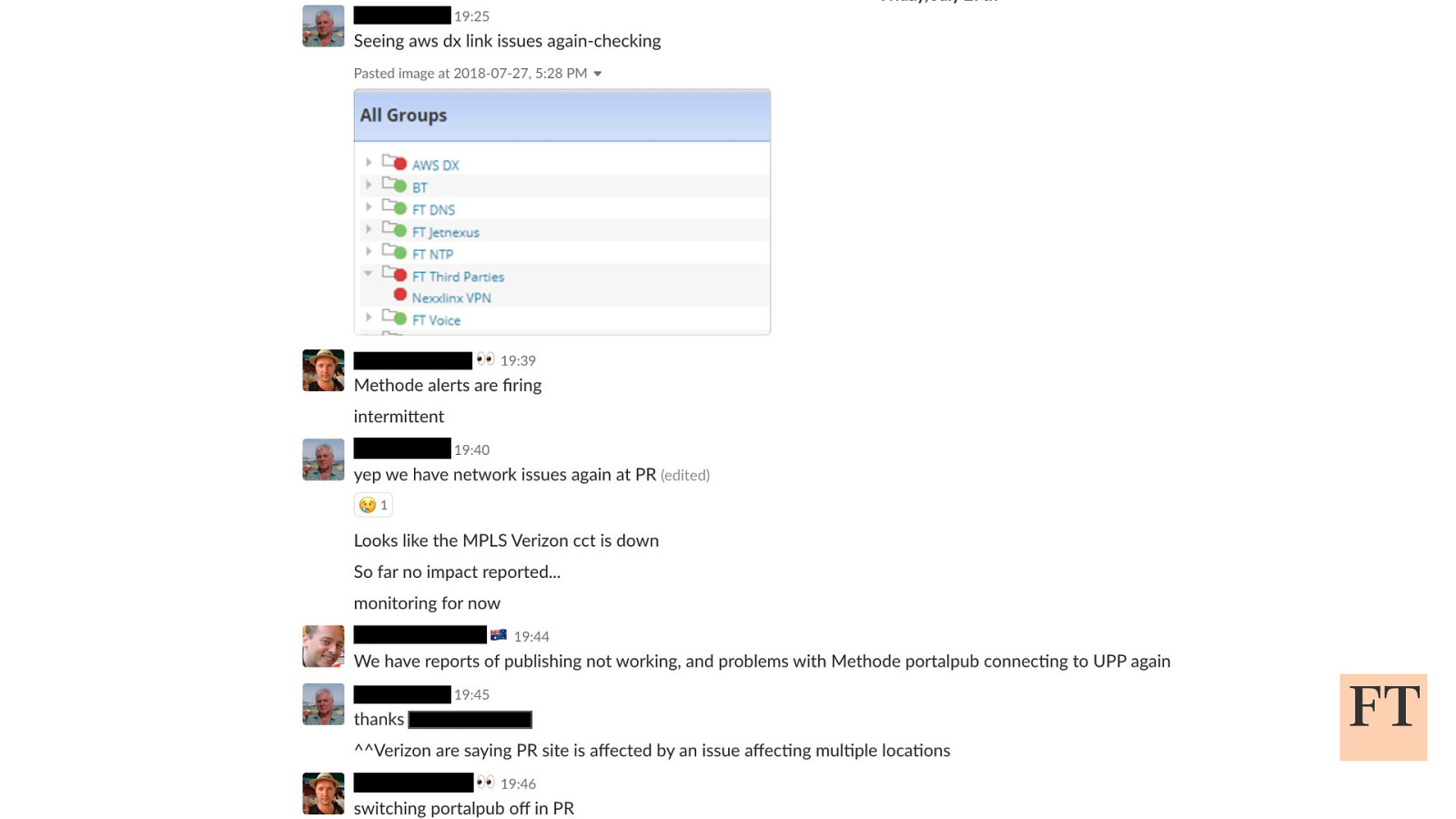
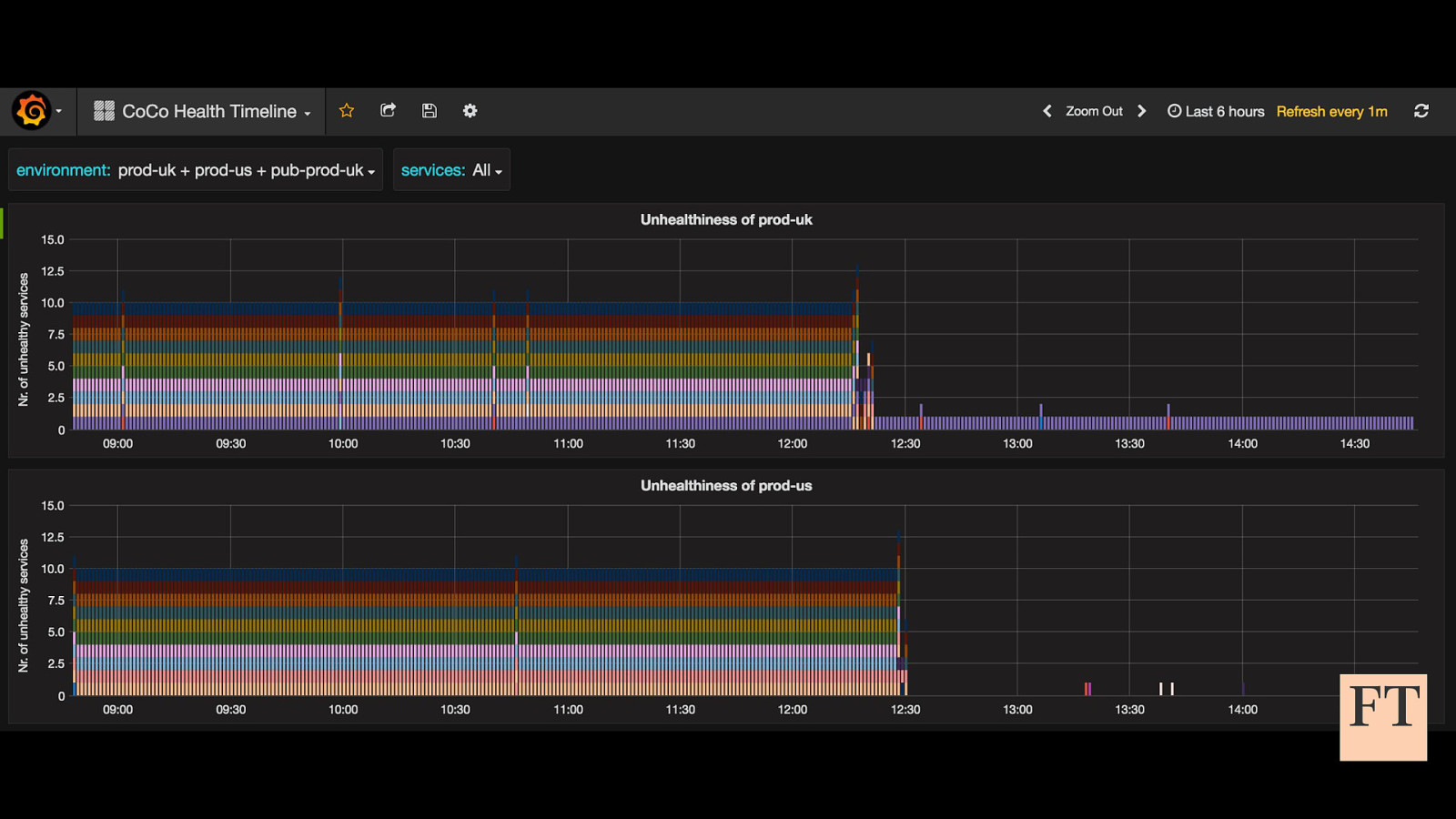
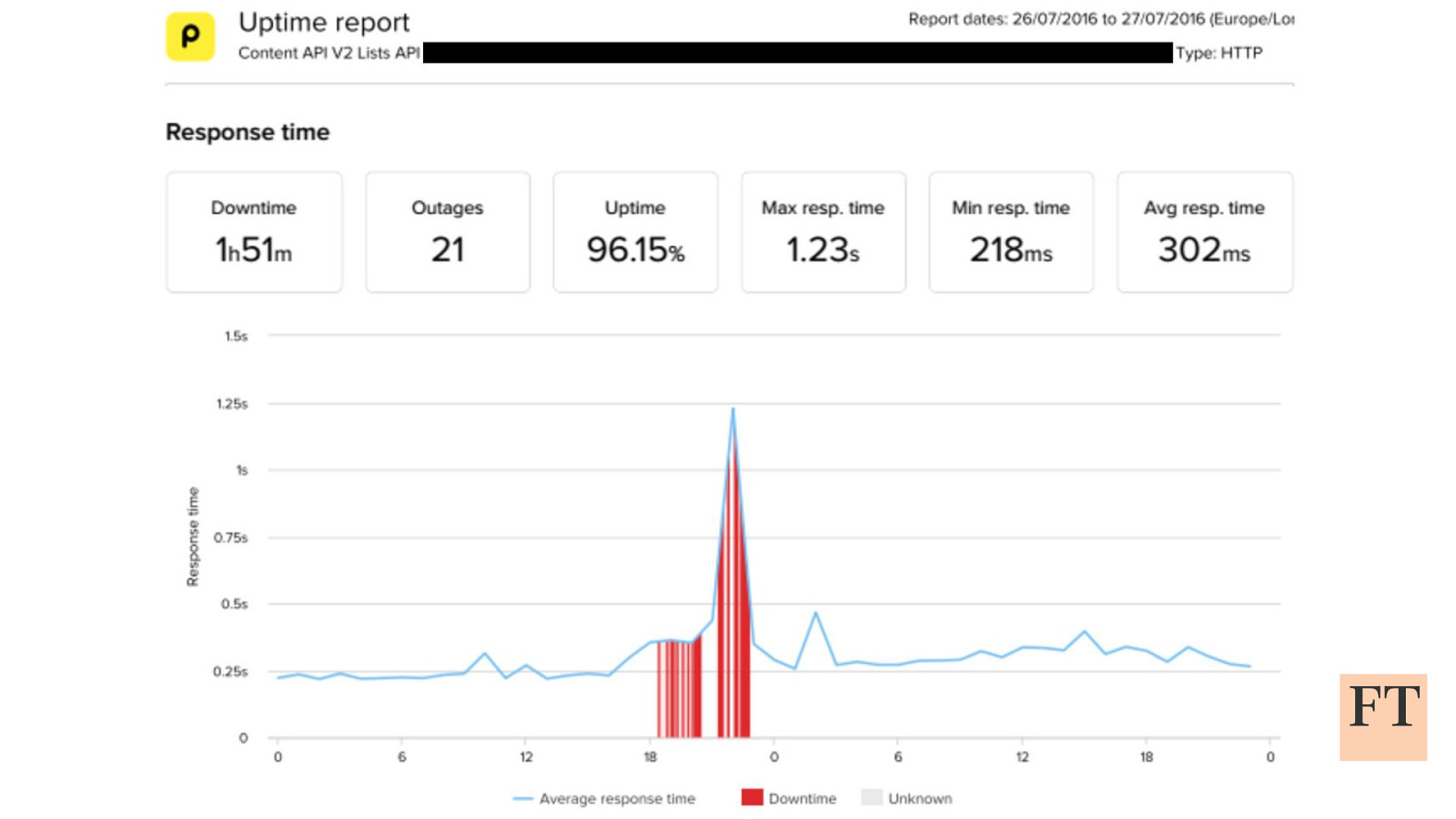
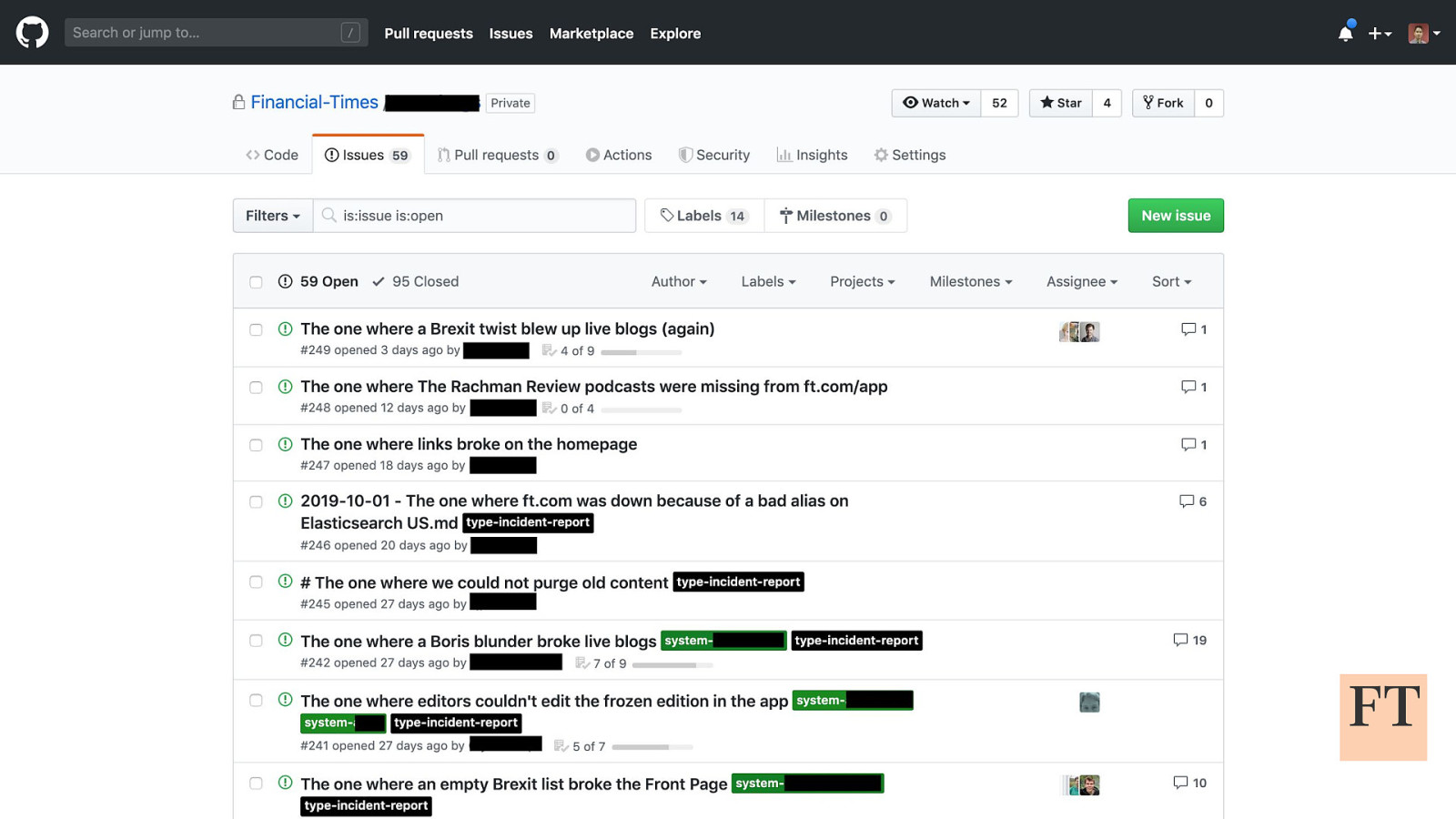
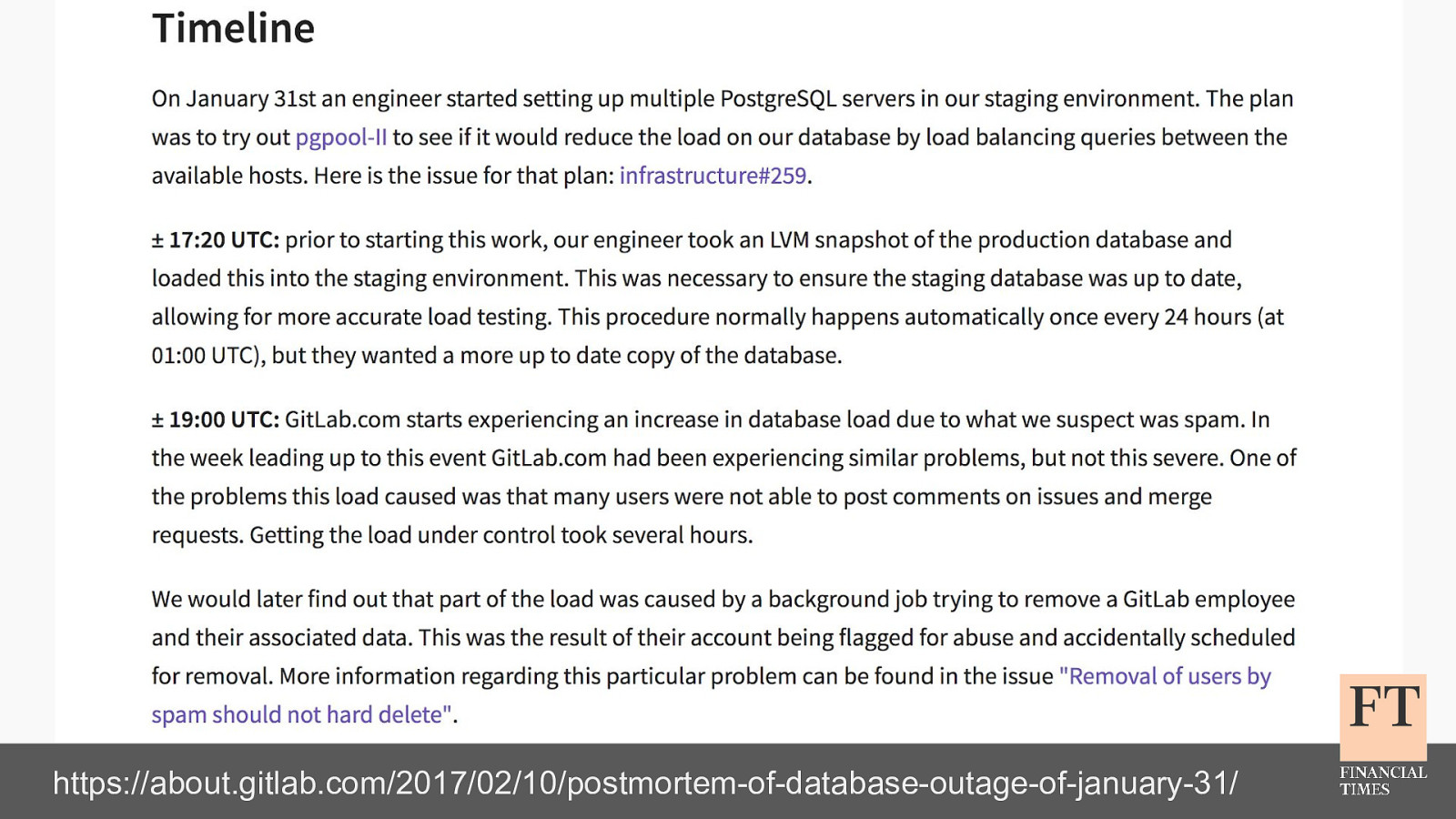
Don’t Panic! How to Cope Now You’re Responsible for Production Euan Finlay @efinlay24 | #DevReach2019 Hi! Thanks for coming despite this being a technical talk the scariest production incident that I’ve been part of in my five years at the Financial Times wasn’t actually caused by anything in our technology stack