Don't Panic! How to Cope Now You're Responsible for Production Euan Finlay @efinlay24 Hi! I'm Euan, and I'm here to talk about support and production incidents!

A presentation at HackConf in September 2018 in Sofia, Bulgaria by Euan Finlay

Don't Panic! How to Cope Now You're Responsible for Production Euan Finlay @efinlay24 Hi! I'm Euan, and I'm here to talk about support and production incidents!

/usr/bin/whoami @efinlay24 I'm a Senior Integration Engineer at the Financial Times. I originally started off in desktop support, did some time as a Linux sysadmin, and then fell into working in the DevOps space Currently I lead a team at the FT, who support and maintain our backend Content APIs, working with k8s, Docker and Go microservices.

/usr/bin/whodoiworkfor No such file or directory. @efinlay24 although we're most famous for the newspaper, we're primarily a digital content company last year was the first time revenue from our digital content overtook the physical paper and our advertising
https://www.ft.com our content and our website are absolutely critical to our survival - we invest heavily in technology, and we've got many teams working on different areas of the business we're currently in the process of transferring ownership of our key platforms, systems and APIs to our new office in Sofia at the FT, we're big believers in DevOps practices and empowered engineering teams, trusting them to make the best decisions around technology, architecture, and delivery as part of that, our teams fully own, run & support their services - from the beginning to the end of the product lifecycle

You've just been told you're on call. (and you're mildly terrified) @efinlay24 Maybe you're part of a team that's been running for a while: you're proud of the services that your team have built and deployed but it's still intimidating being told that you're now responsible for dealing with production issues Or maybe, you're a new developer or engineer that's started in technology recently: you've had time to settle in and started to get familiar with things but now you're being asked to go on the rota

Obligatory audience interaction. @efinlay24 hands up if you've been on call hands up if you've never had to support production hands up if you're don't like putting up your hand in the middle of conference talks I remember what it felt like the first time I was called out: - terrifying - was asked to fix a service I knew nothing about - couldn't find the documentation - thought it was the worst thing in the world - thought about quitting and becoming a farmer

Everyone feels the same way at the start. (I still do today) @efinlay24 It's something like imposter syndrome no matter how good you are, I suspect everyone feels something similar the first time they get called out or start handling production incidents even now, with experience - I still get a twinge of fear whenever my phone goes off in the middle of the night or if someone reports "the website is down!" - what if it's something I can't fix? - what if I'm not good enough?

How do you get to the point where you're more comfortable? @efinlay24 so how DO you get to the point where you're comfortable on call? the idea behind this talk, was thinking what tips, advice and suggestions I could give so that you're not dreading that phone call or that Slack message of "everything is broken!" --when writing this talk, I was told it helps to have a bit of a theme who else is quite grumpy (like lots of sysadmins) and gets woken up at 2am?

A tenuous link to A Christmas Carol. Scrooge from A Christmas Carol which actually leads nicely into a talk structure about dealing with production problems because, like A Christmas Carol, there are:

The Ghost of Incidents... > Future Present Past Things we can do right now, to help us the next time you get called out or have major problems Things we should do when something actually breaks And there are things we should do after an incident, to improve everything for next time

The Ghost of Incidents Future so knowing that things will go wrong at some point what can we do to plan ahead?

Handling incidents is the same as any other skill. @efinlay24 handling incidents IS the same as any other skill It can be learned, and taught, and practiced If the first time you try to do this is: without any training with no plan of action after a phone call at 2am, it's not going to go very well If you're familiar with dealing with your alerts, and what can go wrong - you'll be a lot more relaxed when you get called out

Get comfortable with your alerts. so get people on your teams to rotate through support regularly, in hours, when everyone else is available to help and support them It'll get everyone familiar with what can go wrong the alerts that go off the monitoring tools where to find things, like documentation or admin panel does everyone have access? you never want that moment of "hmm, I can't access the documentation" during an emergency...

Get comfortable with your alerts. (and bin the rubbish ones) and, alert noise is bad as well - every alert should be actionable otherwise, you may lose real issues in the noise or inversely, you may be called out for no reason my ex-boss Sarah Wells has done an excellent talk on alert overload, which I definitely recommend watching

Have a plan for when things break. @efinlay24 Depending on where you work, or what you work on, having an incident response plan might look very different Maybe your company is large enough to have a first-line team that escalates problems to you that they're unable to fix themselves your response plan may be very formal and defined across the whole business Alternatively if you're in a small start-up, it might just be a handful of you, getting called out by PagerDuty or an automated equivalent In that case you may just need a quick verbal discussion with your team, or some guidelines jotted down in a Google document somewhere Either way - you don't want to be wondering what you're meant to be doing when alerts start going off

Keep your documentation up to date. @efinlay24 and, keep your documentation up to date Nobody likes writing documentation, but you need to have information on what to do when services break what it does, where it lives, and how it works is a good start service panic guides or run books are important as well - these should contain solutions for common problems that might occur write them as though it's 2am and you've just been woken up you only want the essentials to get things fixed and up and running again it's awful trying to fix a system that has no documentation, when the only person who knows about it has left

Practice regularly. @efinlay24 Once you have guides on how to: - fail over - rotate keys - rebuild from scratch Run through them on a regular basis to make sure they still work, and that people are familiar with them we did this in fairly spectacular fashion one day, when we performed an unscheduled test of our disaster recovery procedures we were provisioning a new production cluster using Ansible run our playbook, which should create us 5 new instances it turns out that If you're not careful with the way you write your playbooks, and say "give me 5 instances" Ansible ensures that you have 5 instances in total across your entire production account

The one where we decommissioned all our production servers the first we knew of this was when all the alerts went off, and I hear a very quiet "oh no" from my friend sat next to me Was it a problem? Sure we had an brief outage while we worked out what was going on

But we were back up and running fairly quickly - we failed over to our backup cluster and as we already had a guide on on how to spin everything back up from scratch it wasn't too long before we were back to normal we definitely wouldn't have wanted to find out that our DR guide didn't work at that point in time...

Break things, and see what happens. Did your systems do what you expected? @efinlay24 As an extension of that - actively break things, and check that your services behave the way you expect! Do your recovery guides still work? Do your alerts and monitoring work correctly? Chaos monkey is probably the most well known example, but you can do this manually in a controlled way, too Run DR tests to make sure you iron out any bugs with your processes

The Planned Datacenter Disconnect We ran a planned DR test - disconnecting the network to one of our datacenters, to make sure we could recover if it happened in real life Pulled the plug, and the Ops dashboard lit up with red lights - just as we expected we then moved to step 2 - failing over our systems to the healthy datacenter It was at that point we found that our failover service didn't work if a datacenter was missing… We fixed that up fairly quickly :)

We got complacent, and stopped running datacenter failure tests... @efinlay24 however, the last time that we ran one of those tests was about 3 years ago - maybe more for context, we've been moving away from our hosted DCs for the last few years, as part of a big cost-reduction push we've migrated a lot of our legacy services to the cloud, replaced them with externally hosted solutions, or decommissioned them altogether however, there's still a number of important legacy services that run out of our 2 DCs you can probably guess what the next slide is going to be...

The Unplanned Datacenter Disconnect because we had a live test of what exactly happens when one of our DCs drops off the network naturally, it happened on a weekend, in the middle of August, when lots of people were on holiday without access to their laptops as you can imagine, after two years since the last test, a lot of the the info we had was out of date it also turned out that there were a lot more important services depending on those datacenters than we expected

Have a central place for reporting changes and problems. @efinlay24 one of the useful things that we have at the FT is a chat channel that everyone can join we use this channel to: communicate changes that are in progress, and to report potential issues or problems that are happening as you can imagine, this channel got VERY busy during the outage, with lots of reports and issues from across the business
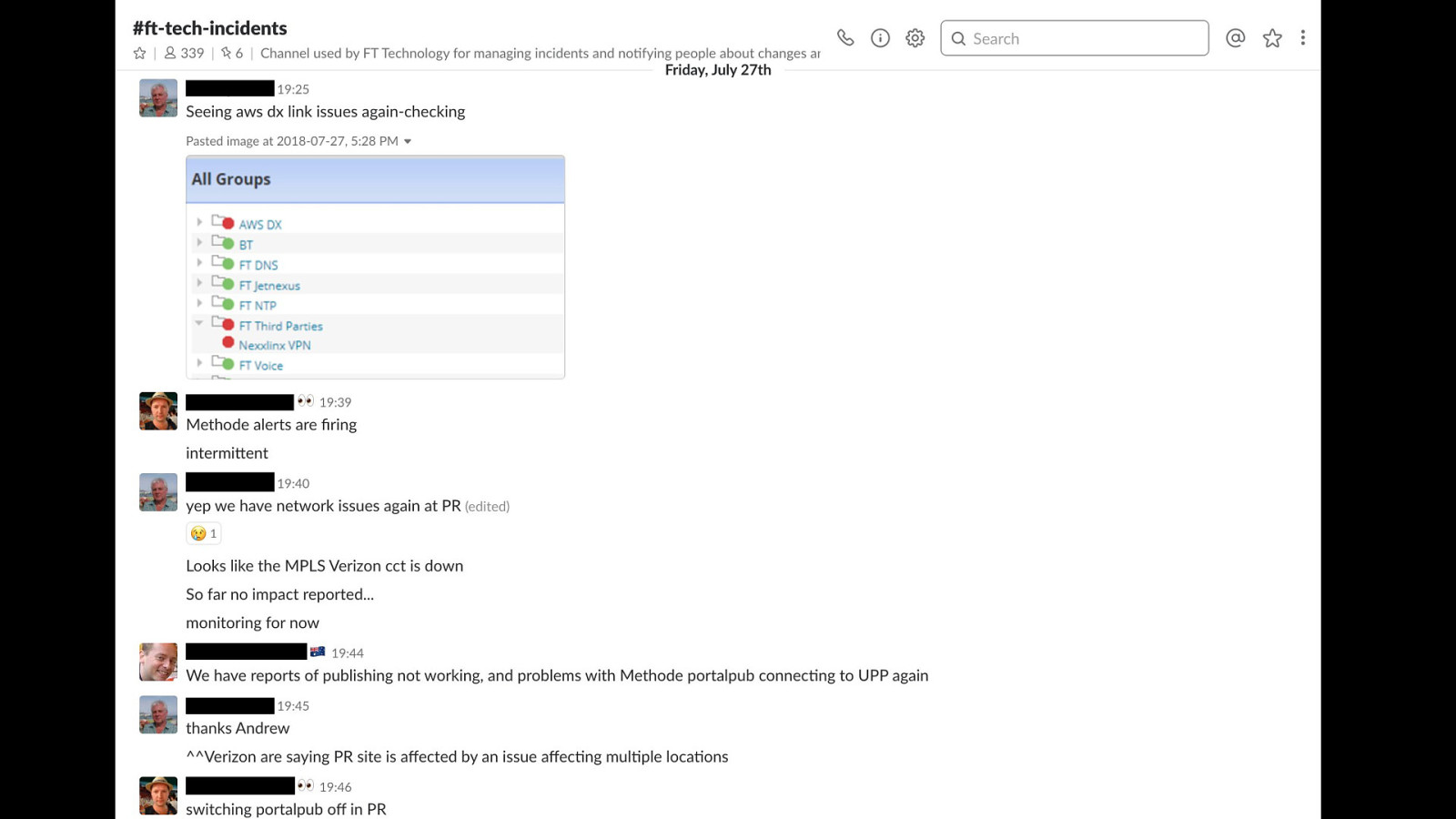
failover of these legacy services isn't simple or automated, either - it's a fiddly manual process involving DNS updates, configuration changes, and service restarts since it'd been so long since we'd last done it - we had to hope that the people with knowledge were available, and that they could remember what the failover steps were we did get everything stabilised though, without any major customer impact later, we found out that the cause of the problems was another customer decommissioning some of their network equipment in the process of doing that, they cut the fiber connection that provided internet access to all of our servers… there's no way we could have predicted that happening it took roughly 5 days for network connectivity to be fully restored, and for all of our services to be back to high availability and running out of both DCs

The Unplanned Datacenter Disconnect (Part II) which was really fortunate, because a day later, we had a core network switch fail in our OTHER datacenter so we had to repeat the same exercise, but in the other direction… I have no idea what we would have done if we'd had BOTH of these problems at the same time...

We should have followed our own advice. @efinlay24 we should have followed our own advice if we'd practiced and tested the failover process, we'd have been a lot quicker, and we'd have had a much better understanding of the impact and what needed to happen but - we still did recover everything without any major business impact, and we learnt a lot about the remaining legacy services that are important to us we also uncovered a whole set of issues that we didn't know about, such as: a HA service that wasn't able to connect to one DC at all one of our monitoring tools really doesn't like it when it can't reliably connect to it's monitoring target and that some of our legacy services run out of memory when all traffic is routed to a single location

We're not perfect. (but we always try to improve) @efinlay24 all of those issues are now fixed, or in the process of being fixed most importantly - we've learnt from our experience, and used it to improve our legacy failover documentation and processes

The Ghosts of Incidents... Future > Present Past those are some ideas that you can go away, think about, and get started on before something goes wrong

The Ghost of Incidents Present but something's happened - alerts have gone off, and you've been called or been asked to investigate what's the first steps that you should take?

Calm down, take a deep breath: it's (probably) ok. @efinlay24 take a deep breath. Dealing with incidents is stressful - but do what you can to remind yourself that it's not the end of the world. for most of us, if our website goes down, or a service fails, it's not completely catastrophic in the grand scheme of things Unless you work at a nuclear power plant, in which case probably be a bit more worried

Don't dive straight in. Go back to first principles. @efinlay24 It's always tempting to immediately jump in and start trying to solve the problem Go back to basics first - treat it the same as anything else you do get as much information as possible before you start Generally speaking, no matter what the problem is, there's always a certain set of questions that I'll always ask myself, before digging into a problem further

What's the actual impact? @efinlay24 what's the actual impact? For example - for my team at the FT, we're a content company - our most critical considerations are: can the journalists publish content? can customers access the website? A problem preventing the news from going out is a huge issue, and we'll immediately get multiple people investigating ASAP. However, if our Jenkins box alerts that it's running low on disk space over a weekend? I'm unlikely to care, and I'll fix it on Monday

"All incidents are equal, but some incidents are more equal than others." George Orwell, probably @efinlay24 Things to consider: Is it affecting your customers? Is the issue blocking other teams right now? is there a brand impact - does it make your company look bad? If overnight and it doesn't need to be fixed immediately, perhaps it's safer to wait until morning, when you have a clearer head and more eyes on the fix. Let's assume it's an important system and it needs investigation

What's already been tried? @efinlay24 what's already been tried? Maybe nothing, if you're the first responder. Maybe first line have already run through the obvious solutions, restarting, failing over etc Or maybe your teammates have tried some fixes Get as much information as possible - getting vague details can sometimes hide the actual problem "I've restarted it" << what's it? the service? their laptop? CLICK

have they restarted the whole internet? I hope not...

Is there definitely a problem? @efinlay24 and, validate that the problem does exist there are times when, you'll have reports like "the website is slow" which could mean anything from "my home wifi router is broken" all the way to "there's been another denial of service attack on Dyn, and 90% of the internet has fallen over

or maybe the monitoring system is broken and has started spamming out alerts to everyone - that's happened to us before so, get as much information as you can it's worth spending a couple minutes just to validate that there is definitely a problem before you start jumping into trying to fix things let's assume there is indeed a problem

What's the minimum viable solution? @efinlay24 what's the least effort work you can do to bypass the problem and get back online depending on what your service is, this is often more important than fixing the root cause

Get it running before you get it fixed. For example: Can we just fail over? Can we just roll back a release? Can we just restore a snapshot?

Check the basics first. @efinlay24 but if you don't have a simple way to restore service, you'll need to investigate This will entirely depend on your system architecture, and your issue - but good starting points might be: check the logs check the disk, memory, cpu, network traffic have you checked the steps in your panic guide? has there been a new release / deployment? was there planned work around when the problems started

and are there other known issues or outages happening? for example, when the Dyn attack broke the internet back in 2016 or issues with AWS in the past, where S3 or EC2 have fallen over for a whole region

Let's assume that whatever's gone wrong isn't simple to solve… You've done your investigation You've tried the obvious solutions You're still stuck Everything is still on fire

Don't be afraid to call for help. @efinlay24 That's ok! Call for backup (if you can) it's often better to bring other people in, and get help quickly. You can't always fix everything on your own - and that's ok Do basic investigation first and and confirm it's not a simple problem But don't be afraid to get assistance if you need it. Nobody will think less of you.

The One Where a Manager Falls Through the Ceiling in my previous company, we had an aircon alert for office server room which went off at the weekend Tech Director got an alert from our monitoring system, and popped in to fix it - he lived near the office however, he couldn't remember the door code at this point, most people would have called us to get the new code instead, he decided to crawl through the false ceiling of the office to get into the server room in case you're not aware, office ceilings aren't designed to support the weight of a person

The One Where a Director Falls Through the Ceiling it gave way, he fell into the server room, which caused us even MORE problems than the aircon, which we then had to sort out on Monday… it turns out that wild servers are easily startled - they don't like having people fall on top of them unexpectedly and they definitely don't like breathing in many years of accumulated ceiling dust

(it didn't look like this) In his defence, his reasoning was that didn't want to disturb us on a weekend, which I can respect but it would have been MUCH better for everyone if he'd just called us up and we could have fixed the problem together without needing to replace the ceiling afterwards

Communication is key. Especially to your customers. @efinlay24 communication is really important it's really irritating if you're trying to use a service or product it's not working and you've no idea if it's being investigated, or if people are even aware of the issue

even though everything might be on fire, you still need to communicate with your customers and the business this is quite difficult when you're the person trying to actually fix the problem, so...

Put someone in charge. @efinlay24 make someone the incident manager they need to be in charge of handling communication It's extremely hard to multi-task in normal work, let alone during a stressful production incident give one person the task of updating the business and your customers make sure they provide regular updates and they prevent interruptions from senior management to the people trying to fix things
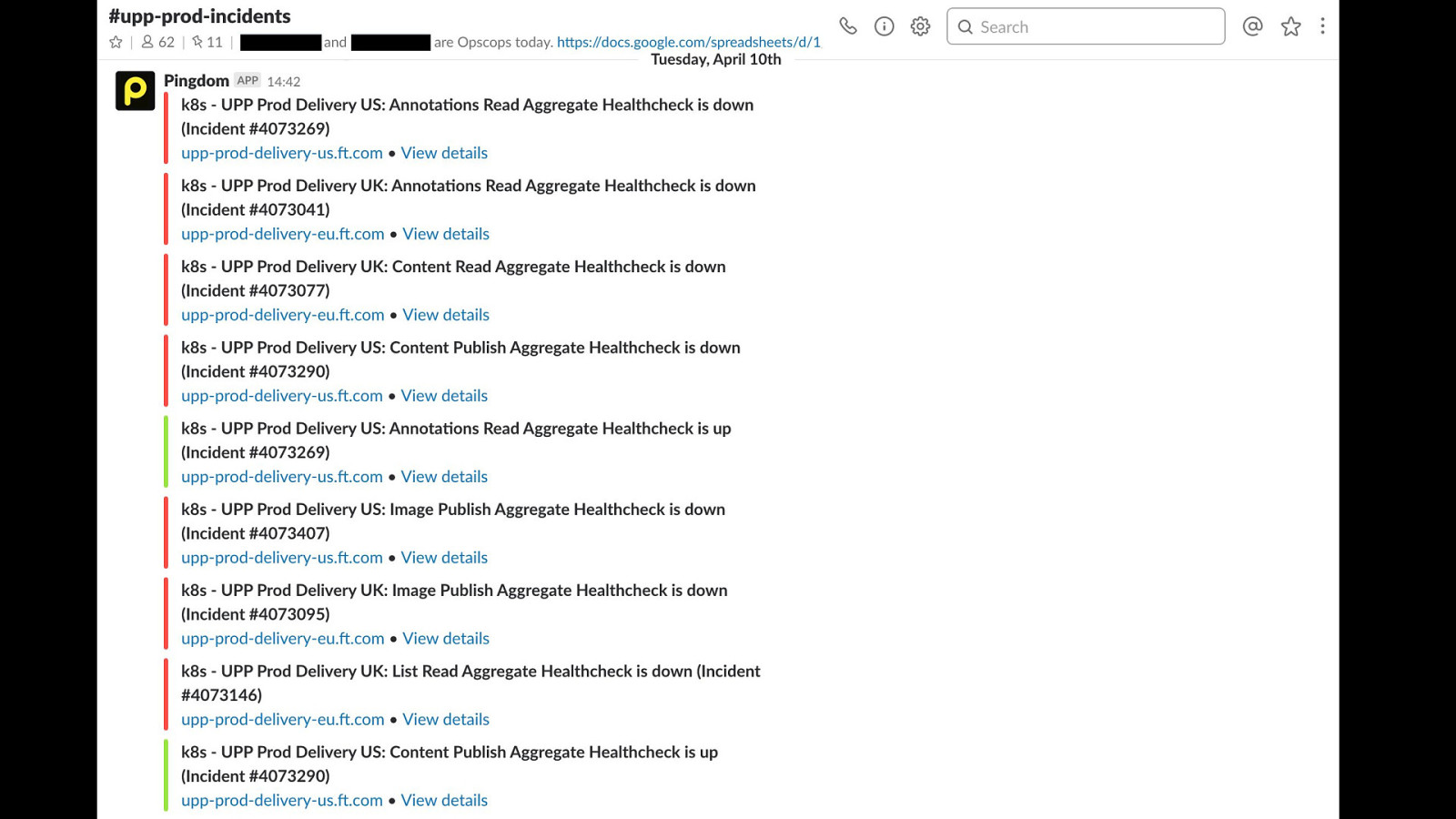
If you're like us and have alerts / notifications in your chat channels, then you've seen things like this before, alert spam makes the channel impossible to use for trying to discuss and solve the issue

Create a temporary incident channel. @efinlay24 spin up a new channel or group, specifically for this incident this comes back to communication - if you have multiple people investigating / fixing a problem, you need somewhere they can coordinate. This is especially true if people from multiple teams or areas of the business are involved Also helps a lot with having a incident timeline later on You can go back and see who was doing what, when.

If you've ever tried to fix something with multiple people, it often ends up like this Having a central place to talk helps with coordination Make sure people share what they're doing, changing, investigating... The last thing you want is: "oh, wait - you were in the middle of rolling back the database? but I've just changed the network settings" and now your database is corrupt
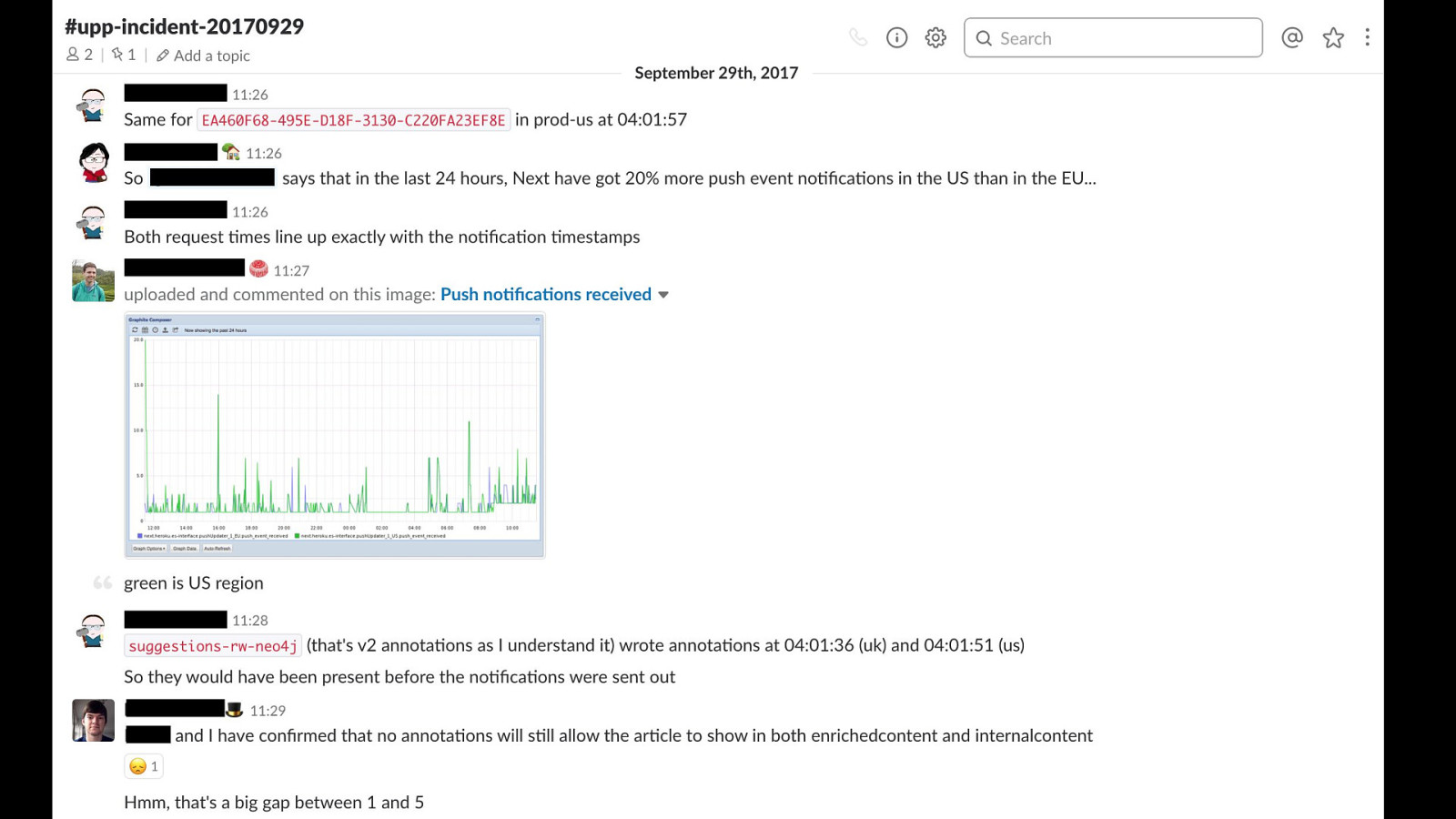
this is an example of one of our temporary incident channels as engineers trying to fix the problem, we we're going to be: - discussing the issue - sharing logs & graphs - announcing any changes, tests or fixes that we're running

If you think you're over-communicating, it's probably just the right amount. @efinlay24 I've mentioned communication already, but it's so important Provide external updates elsewhere every 1/2hr give a high-level update just to let people know you're still working on it nothing worse than someone saying "I'm looking into it", and then nothing for an hour and you wonder - is it fixed? are they still investigating? have they gone for lunch

Tired people don't think good. @efinlay24 When you're tired and extremely stressed, you make mistakes Make sure people take breaks, especially if the problem is long-running! It's hard to make yourself take 15 mins to go get a coffee, go for a walk while things are still broken, because you feel obligated to stay until it's solved but if you don't ou'll be less effective, miss obvious things, maybe even make the problem worse For long running incidents, this may even involve rotating in shifts - or in large companies, handing over to other teams

Our longest running incident that I've been part of in the Content team was when our EU production cluster started failing due to CPU load at around 5pm on a Thursday, just as everyone's about to leave for the day no increase in traffic, so we spent some time trying to identify the cause of the issue, with no success given that our US cluster is healthy, we fail all of our traffic to the US the US then starts failing as well… we continue to spend several hours: - trying to work out what's causing the problem - attempting to get into a state where we can serve any content at all - swearing quite a lot by this point, it's around 10pm, the entire team is completely exhausted, and we're struggling for ideas

The one where we had to serve traffic from staging eventually, it takes our Director of Engineering to suggest routing our traffic through our staging environment manually editing our configuration files to pull data from our our old legacy platform, which we were migrating away from fortunately we hadn't decommissioned it yet and it was roughly around midnight before we managed to get to a point where we were serving stable traffic, in a very roundabout way
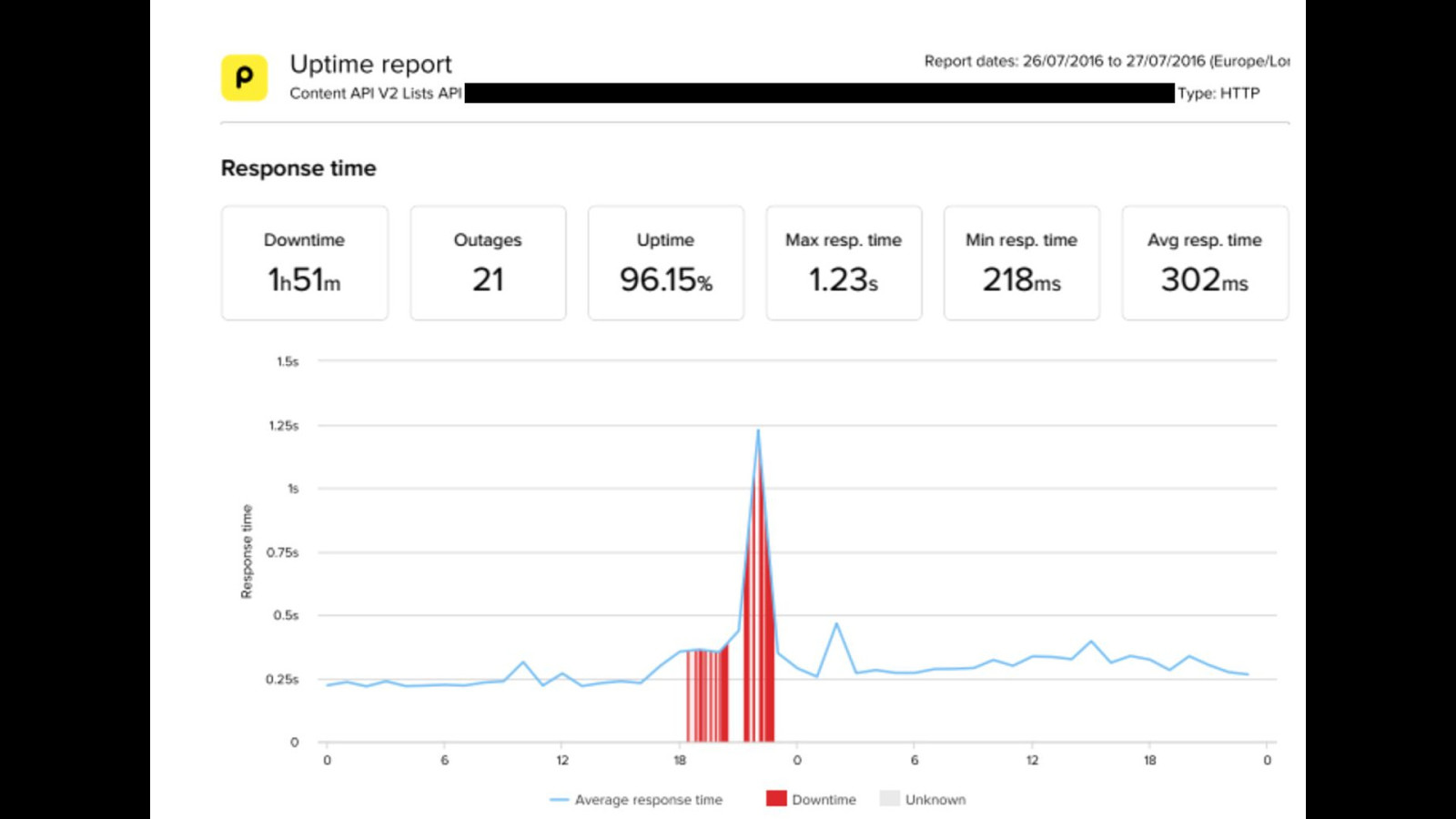
we all went home, then continued to investigate the next day eventually identified the root cause as an update to a database query making it extremely slow, which caused the overload on our databases, which eventually caused the cluster to collapse

It wasn't great, but it wasn't the end of the world. @efinlay24 Fortunately, the ft.com team are rather good, and failed gracefully in this situation, even though our backend APIs were extremely unreliable zero end-user downtime, but we did serve stale content for several hours would've been a problem in a breaking news situation, but fortunately it all worked out

The Ghosts of Incidents... Future Present > Past so there's some (hopefully useful) tips for how to deal with incidents in progress

The Ghost of Incidents Past what do you need to do once the dust has settled, and you're back online?
Congratulations! You survived. It probably wasn't that bad, was it? @efinlay24 Take some time, for your own mental health. Incidents are stressful, and if you've been working all day yesterday and through the night, you need to take some time for yourself

Run a post-mortem with everyone involved. @efinlay24 run a meeting to discuss the incident with everyone Especially if the incident had a serious impact, or had multiple people involved. The objective isn't to point fingers and assign blame but it's to discuss what worked, what didn't, and what can be improved for next time Do it soon after the incident - if you leave it too long, everyone will forget things, and move on to other work

Incident reports are important. @efinlay24 again, I don't like writing documentation, but incident reports are extremely valuable This is where keeping a timeline comes in handy Depending on where you are, incident reports may be required and very formal You might need to make them public, if you have external customers Even if you don't, it's worth having them internally for your team, so that you have a record of previous incidents that you can refer back to later

DRINK there's nothing worse than running into a production problem, and your friend says: "oh yeah, it's exactly like that time when this happened last year!" and then NOBODY BEING ABLE TO REMEMBER HOW TO FIX IT so make sure you write up what happened and what the solution was reports are also very useful for writing talks like this...

Prioritise follow-up actions. @efinlay24 and, at the FT, find that most of the value comes from identifying follow-up actions Arguably, they're the most important parts of the whole process: what could have prevented the problem? what can be fixed, improved for next time? and that might be code or infrastructure, or process and procedure Make sure these actions they get done!

https://blog.travis-ci.com/2018-04-03-incident-post-mortem a good example of an incident report (I have nothing against and no experience with Travis CI, by the way - I just liked their incident writeup) environment variable on a developers machine pointing to the production database When they ran some tests, they ran against prod, and dropped the production database The outage then turned into a fairly serious security problem users had their user IDs reset, and then found they'd logged in as someone else… with access to personal info, and payment details fortunately for them, GDPR wasn't in play yet...

https://blog.travis-ci.com/2018-04-03-incident-post-mortem but as part of their report, they included their follow up actions it's a clear list of things that mean this problem shouldn't happen again, or at least reduces the chances of it happening in this case, they removed truncate permissions from their databases added a prompt warning when people are connected to production

Identify what can be done better next time. work out what can be improved for next time This can encompass multiple things - it might include improvements to your incident process Nobody's plans are perfect when they start out, and you can change them to make them better Maybe the call-out or escalation process didn't work very well, and needs to be improved. Maybe the documentation was incomplete and needs to be updated Perhaps there's some obvious bugs or changes to the system that can be fixed up to prevent issues in future

The One with the Badly Named Database We had an outage at a company I used to work at where a business analyst ran some scripts against the production database, thinking they were connected to pre-production similar to what happened with TravisCI the reason that I tell this story, was that the production database name was prod - as you'd expect but the pre-production database CLICK

Don't name your pre-production database: 'pprod' Seriously, who does that? @efinlay24 was named pprod I didn't name it, but top of our list of actions: - rename that database - don't give databases really similar names in future
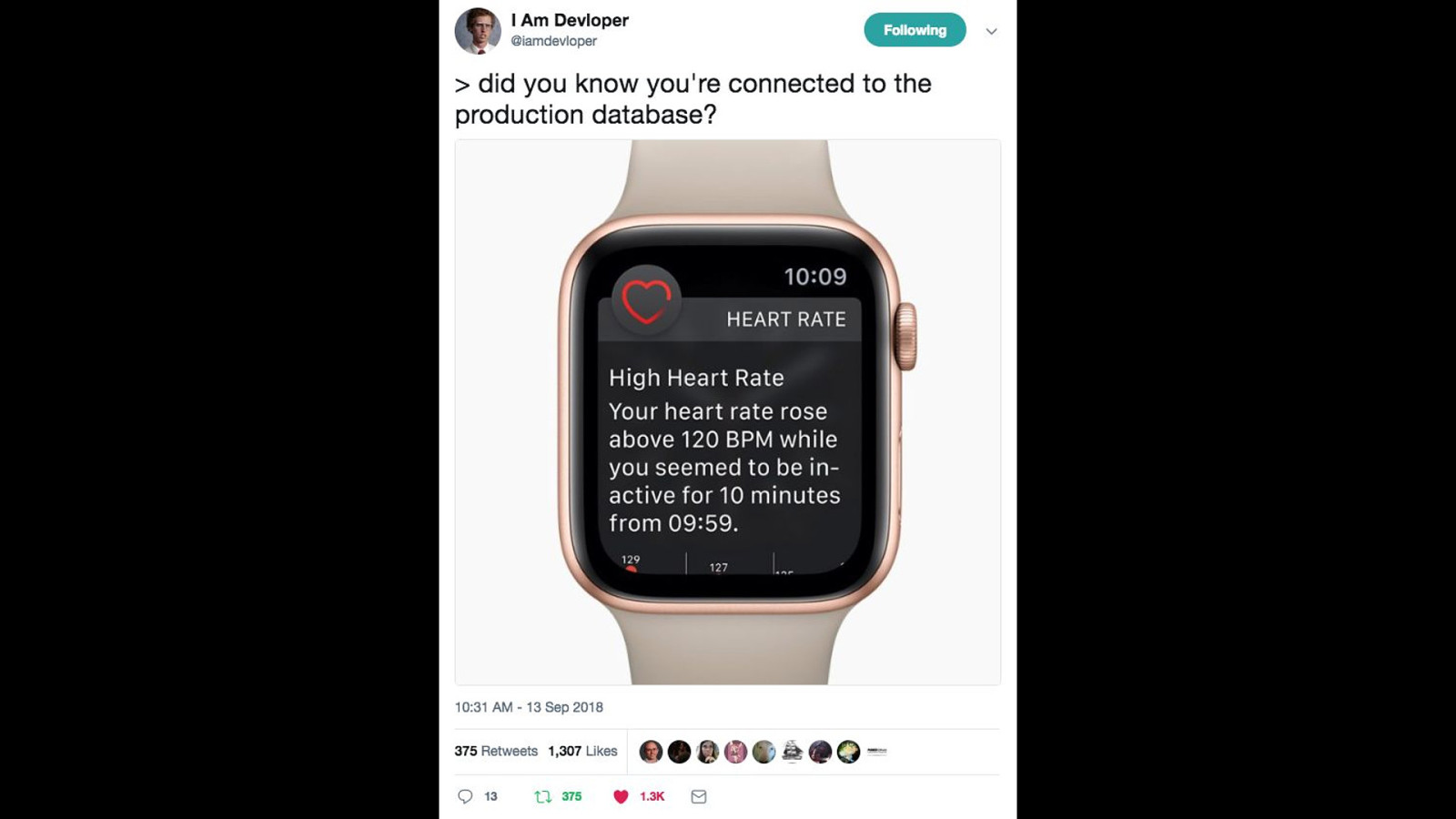
and restrict access to production so people can't accidentally connect

Nearly the end. (don't clap yet) @efinlay24 That's pretty much everything I wanted to cover - I hope you've found it interesting and useful

Problems will always happen. (and that's ok) @efinlay24 To sum up - incidents and issues are a just another part of what we deal with in technology It's how we plan for them, respond to them, and then improve things afterwards that makes the difference. For those of you that are new to support - I hope I've not completely scared you off! hopefully you've got some ideas of things you can go away and do after this, to make your lives easier when something does eventually go wrong And if you need to go on call, you'll have some plans in place to cope - so it won't be as terrifying as going in completely blind

The end. (please clap) clap clap clap

@efinlay24 euan.finlay@ft.com We're hiring! https://ft.com/dev/null https://aboutus.ft.com/en-gb/careers/ Image links: https://goo.gl/3DeojV I'm working here in Sofia for the next few months, so please feel free to get in touch and ask any questions. :) bye