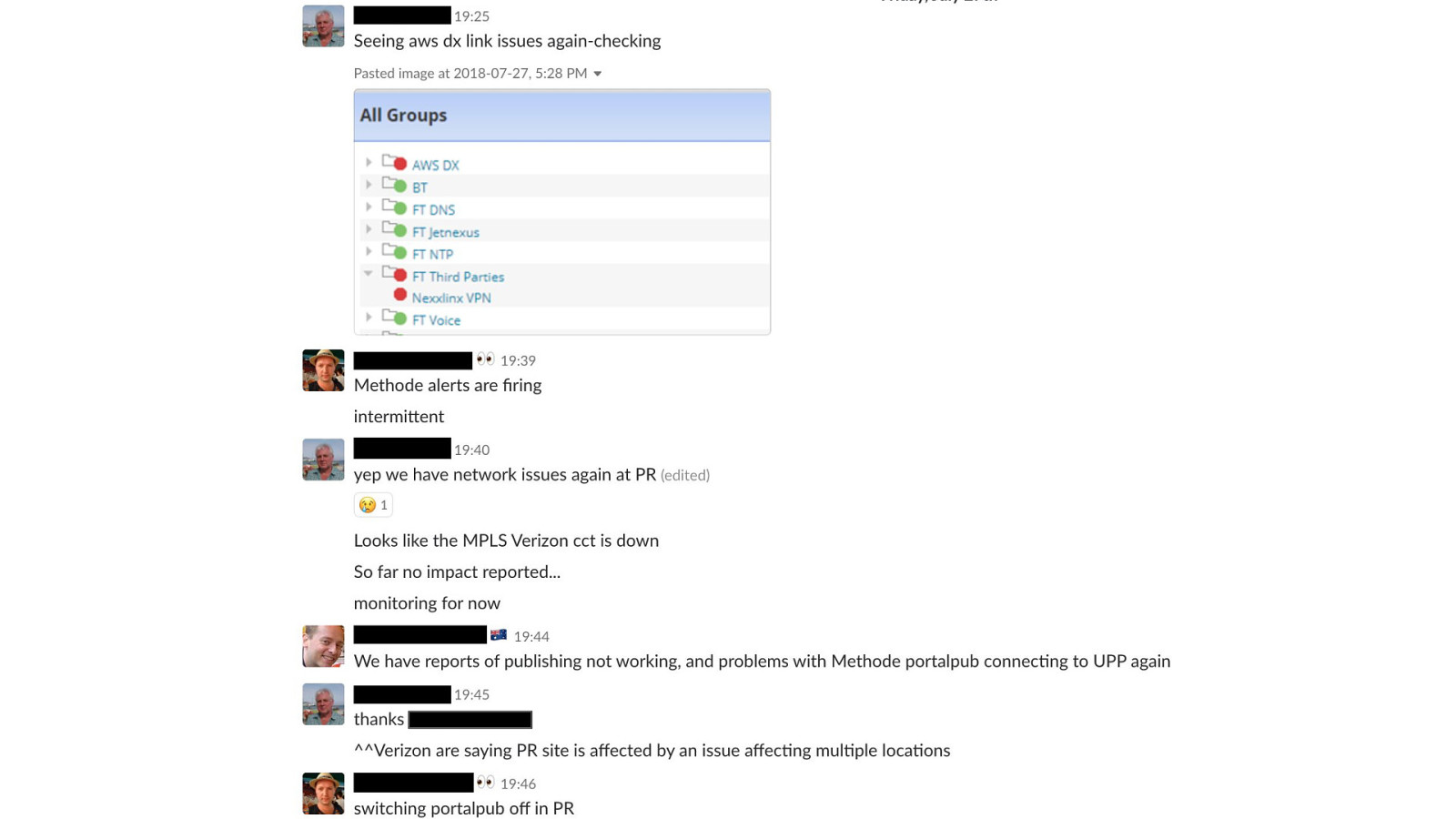
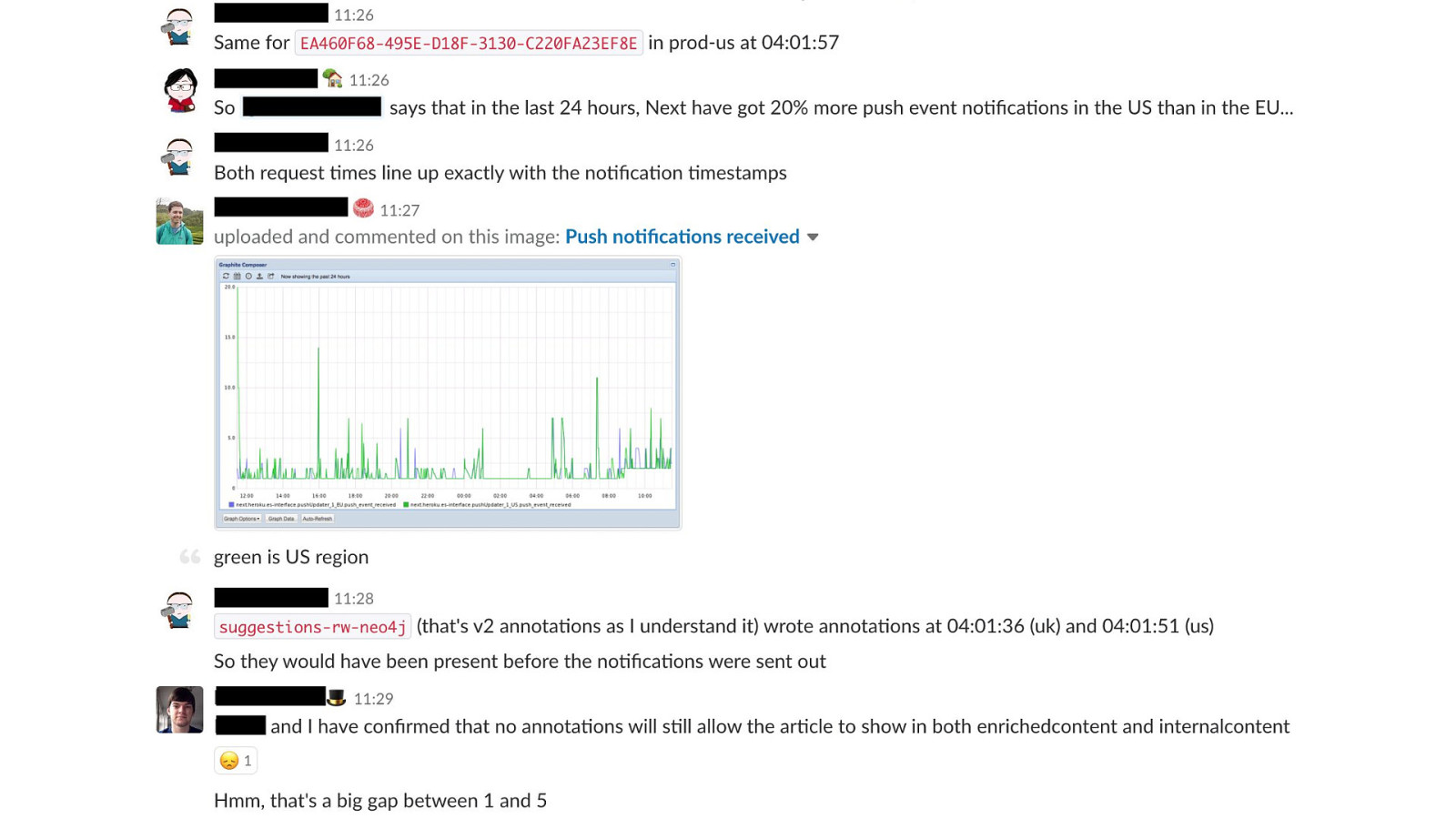
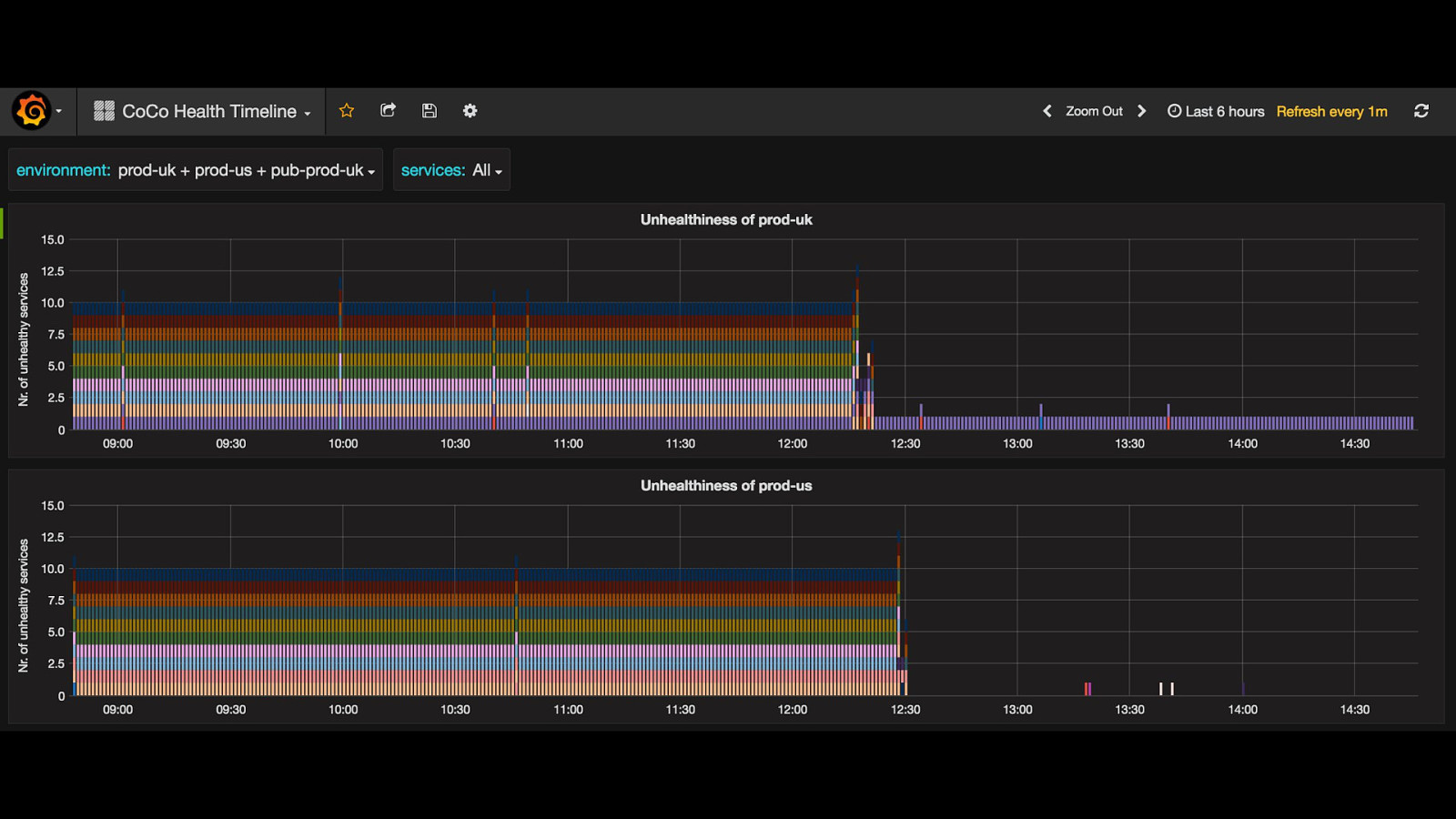
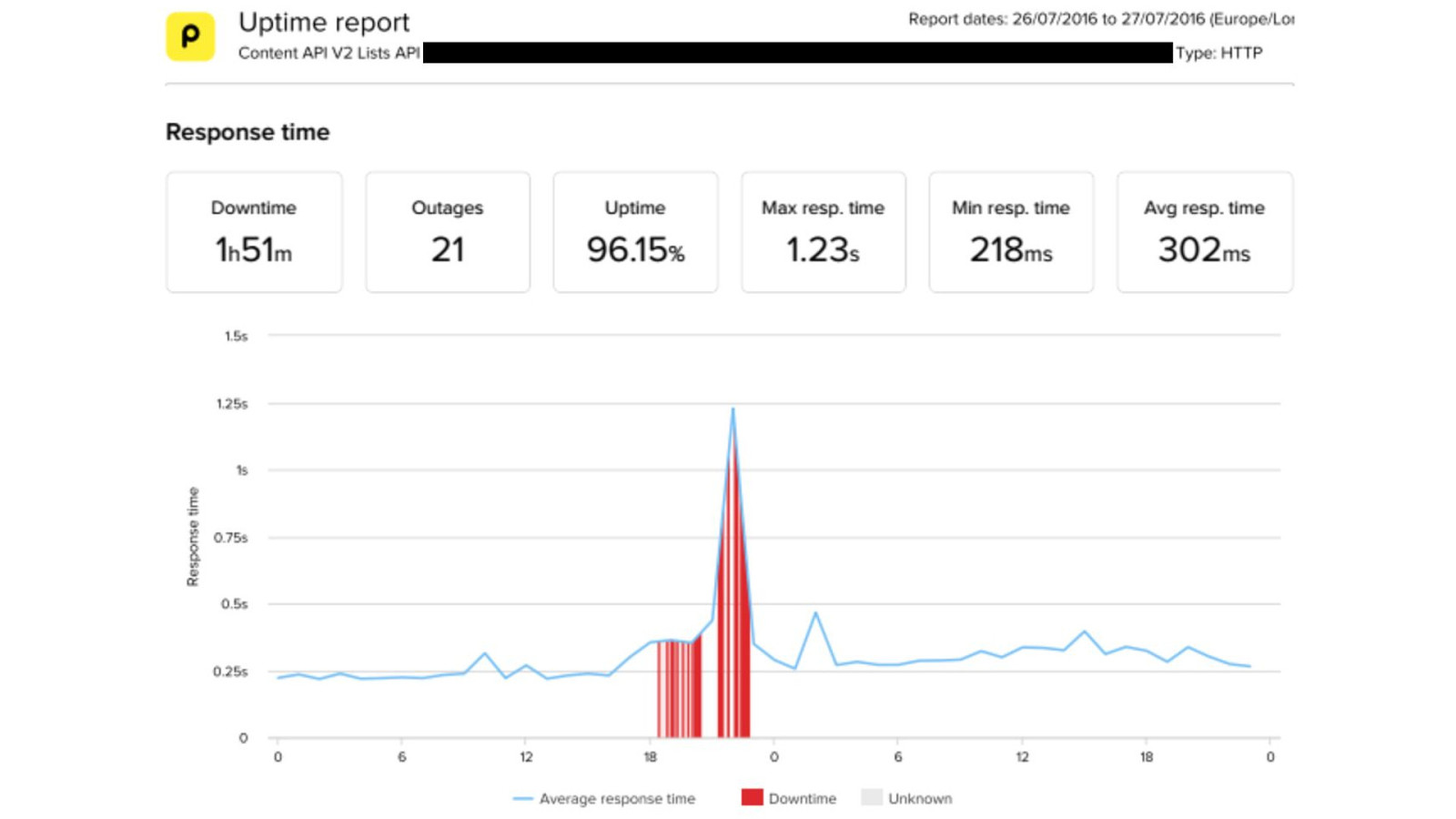
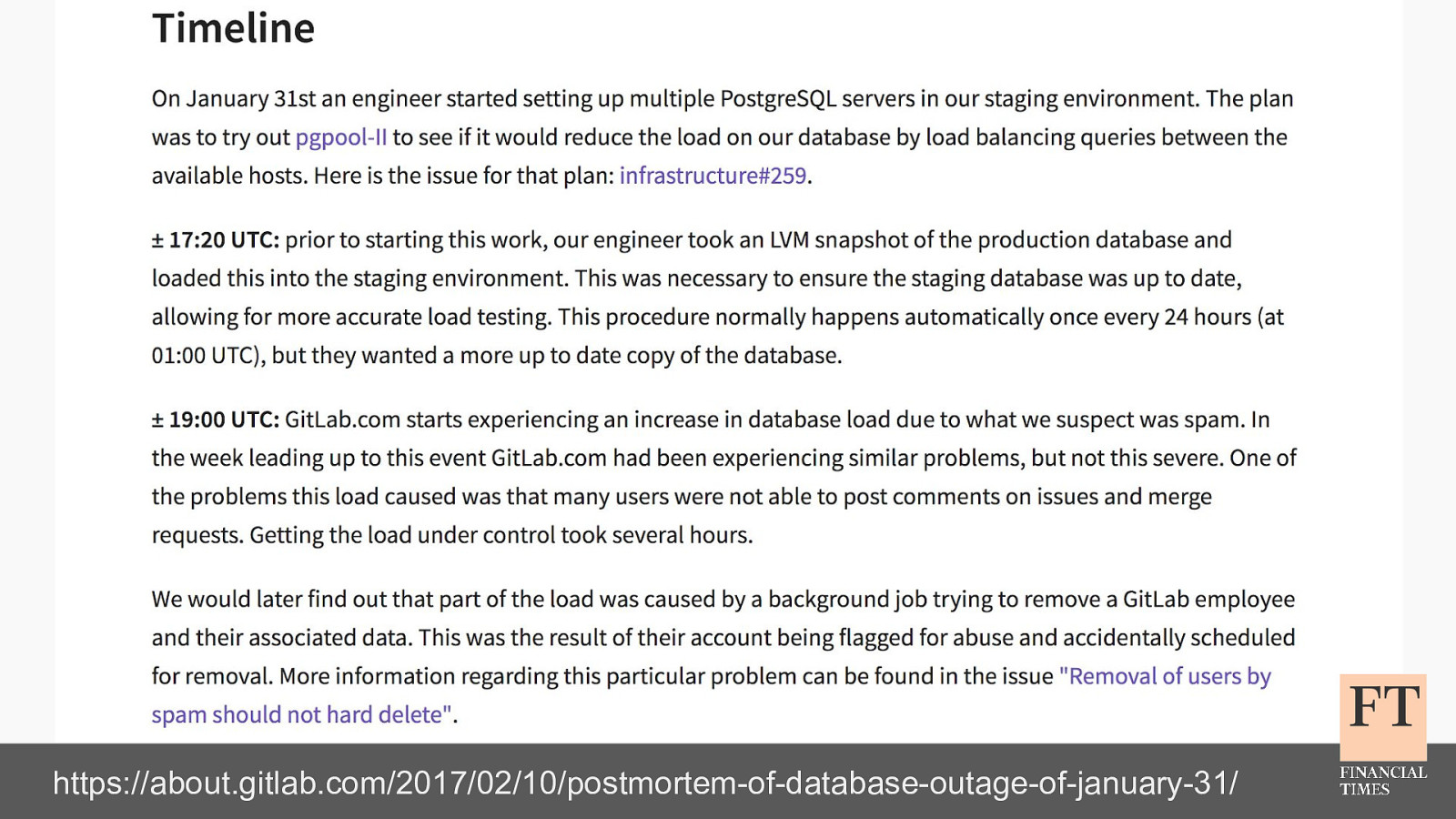
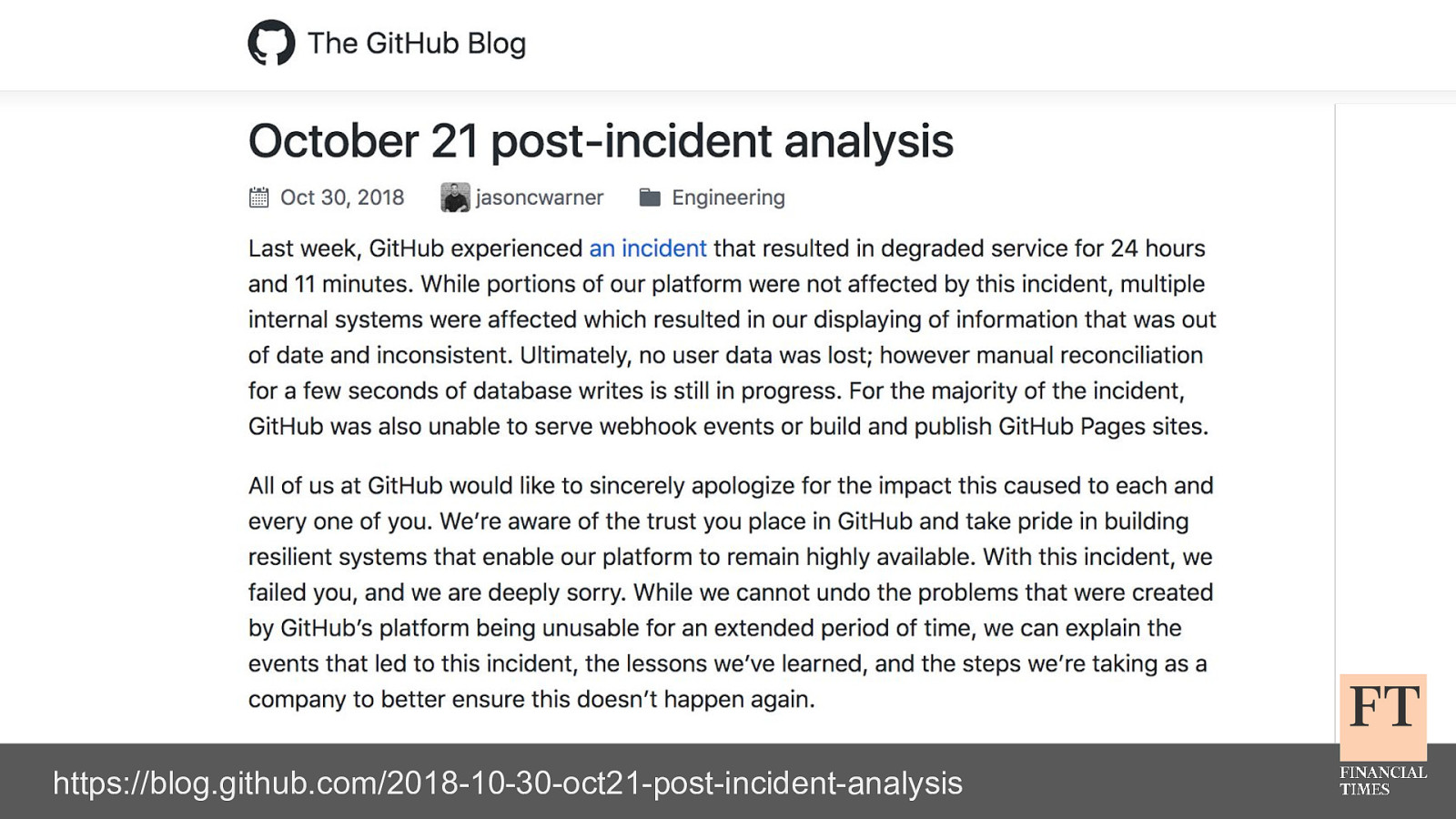
failover of these legacy services isn't simple or automated, either - it's a fiddly manual process involving DNS updates, configuration changes, and service restarts since it'd been so long since we'd last done it - we had to hope that the people with knowledge were available, and that they could remember what the failover steps were we did get everything stabilised though, without any major customer impact later, we found out that the cause of the problems was another customer decommissioning some of their network equipment in the process of doing that, they cut the fiber connection that provided internet access to all of our servers… there's no way we could have predicted that happening it took roughly 5 days for network connectivity to be fully restored, and for all of our services to be back to high availability and running out of both DCs