Improving Machine Learning from Human Feedback Erin Mikail Staples + Nikolai Lubimov PyData DE 2023

A presentation at PyData Berlin in April 2023 in Berlin, Germany by Erin Mikail Staples

Improving Machine Learning from Human Feedback Erin Mikail Staples + Nikolai Lubimov PyData DE 2023

Erin Mikail Staples (she/her) Sr. Developer Community Advocate Empowers the open source community through education, collaboration, and content creation. Nikolai Liubimov (he/him) CTO Helps customers debug and adopt label studio usage best practices

Large Foundational Models have hit the cultural zeitgeist


We will not be creating Terminator here.

These large generative models are better with a human signal.

Why does this matter?

Bigger ≠ Better

Internet-trained models bring with them internet-scaled biases.

biases social problems poor data quality limited applications


Power of Reinforcement Learning

Reinforcement Learning with Human Feedback helps to adjust for problems that tend to come with large-scale foundational models.
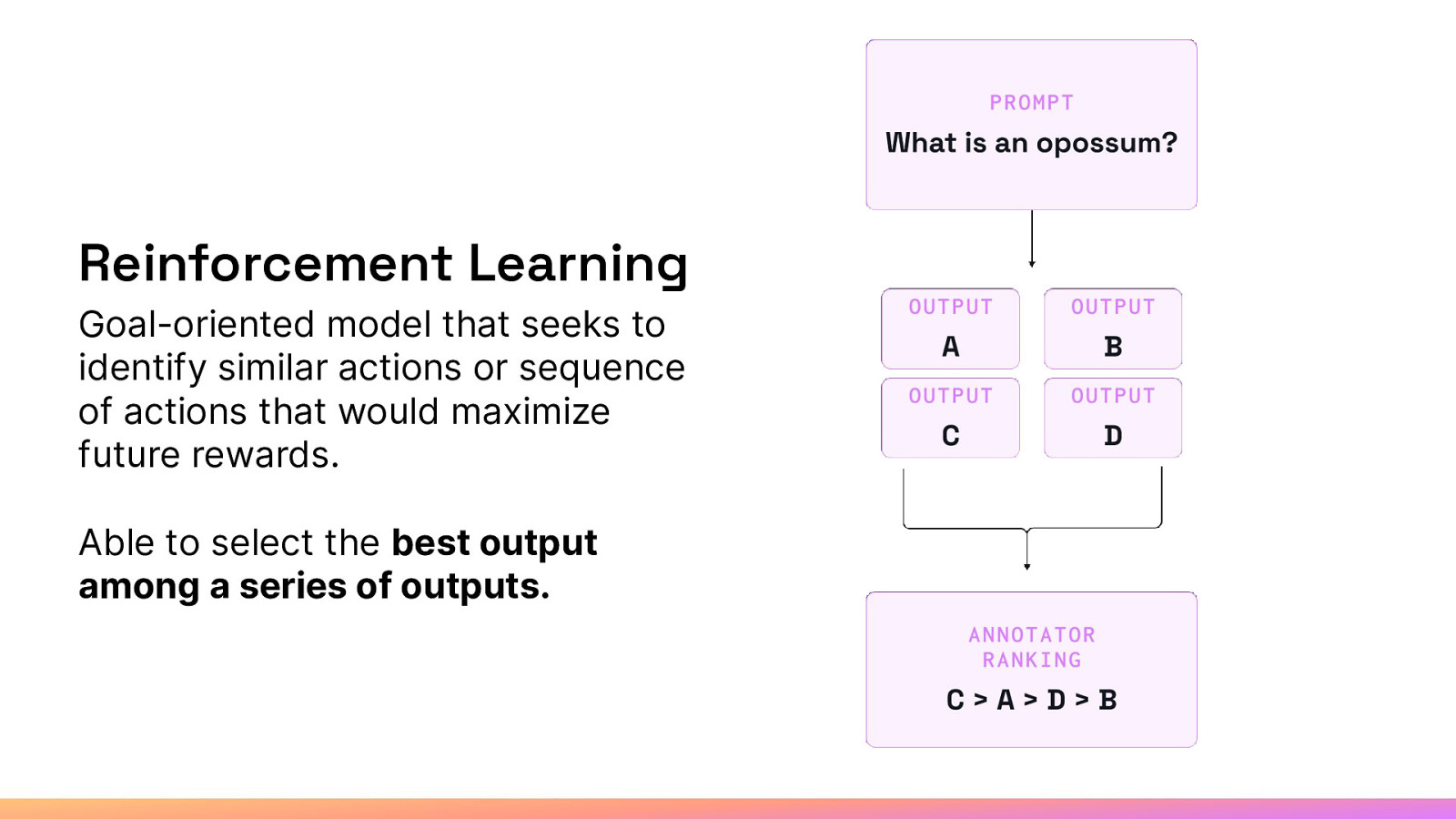
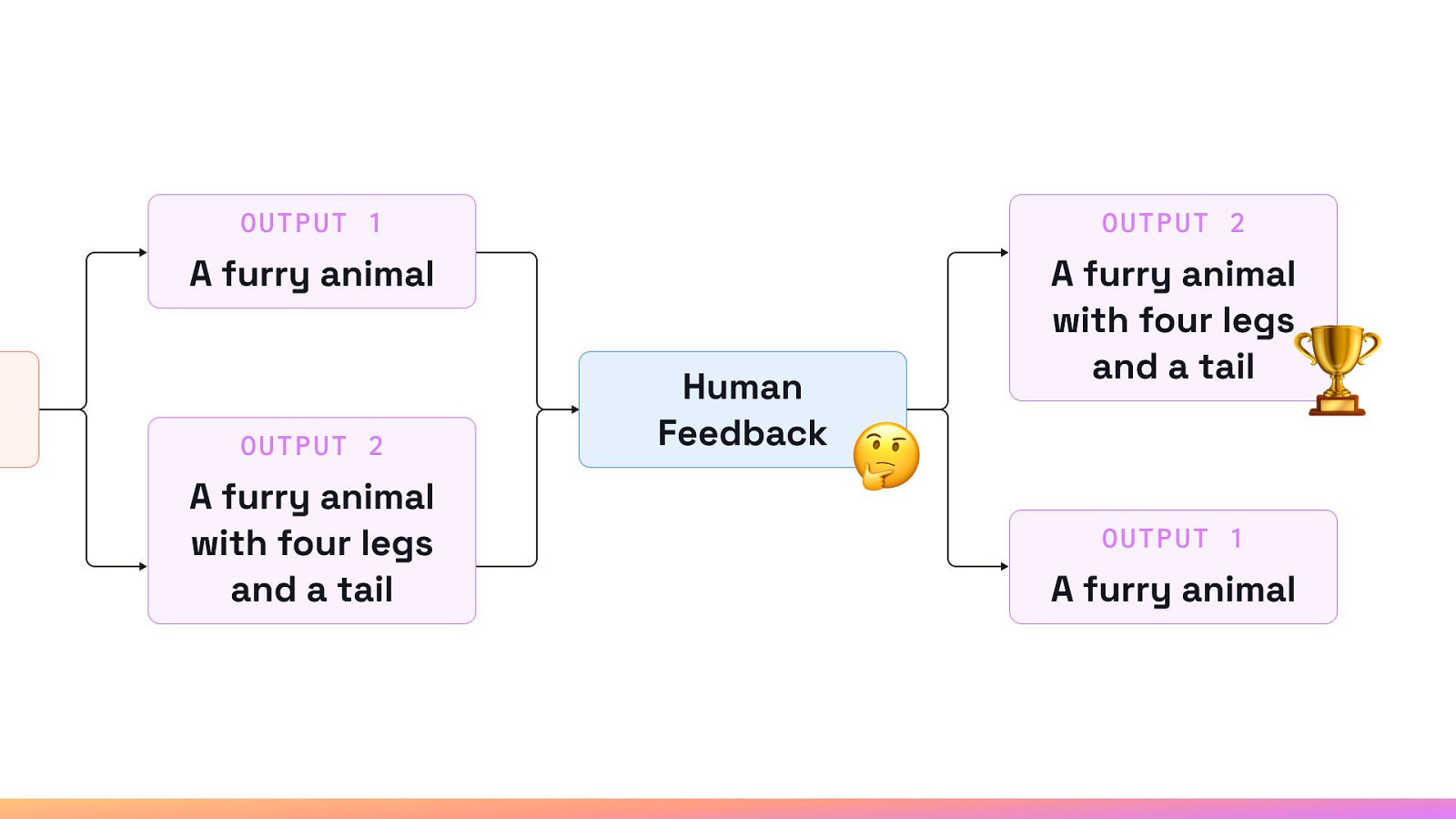
Reinforcement Learning Goal-oriented model that seeks to identify similar actions or sequence of actions that would maximize future rewards. Able to select the best output among a series of outputs.

Unsupervised Learning and Prompt Engineering focuses on adapting to an existing model’s limitations.

Known limitations include: - Harmful Speech - Overgeneralized Data - Out-of-Date Data

Reinforcement Learning focuses on optimizing for the end goal by adapting the model itself to new and possibly uncertain information based on a human signal.

With RLHF one can align model output with one’s specific needs while reducing bias at a fraction of the original training cost.


We’re already seeing RLHF used in the wild

So how did they do it?
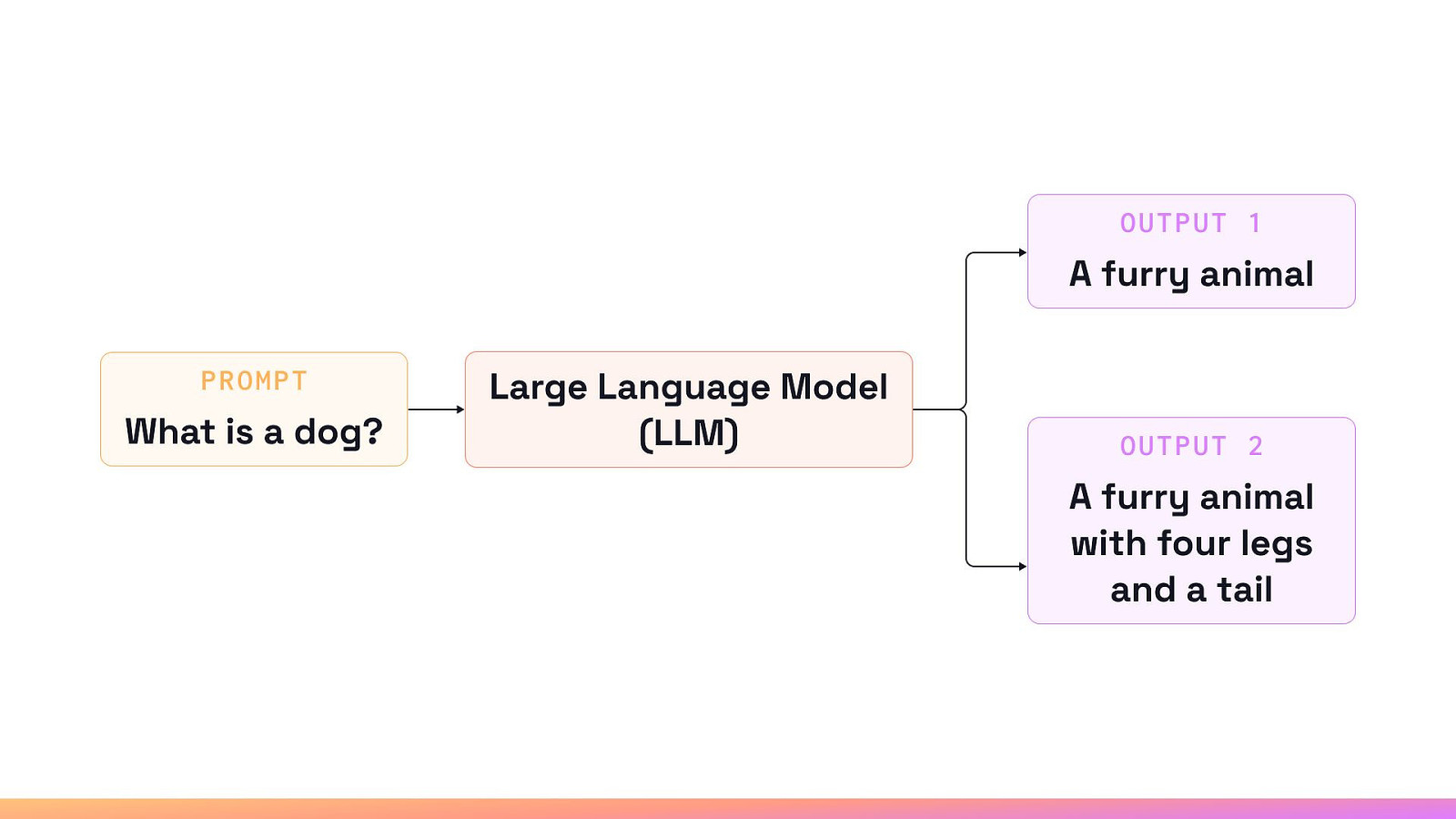
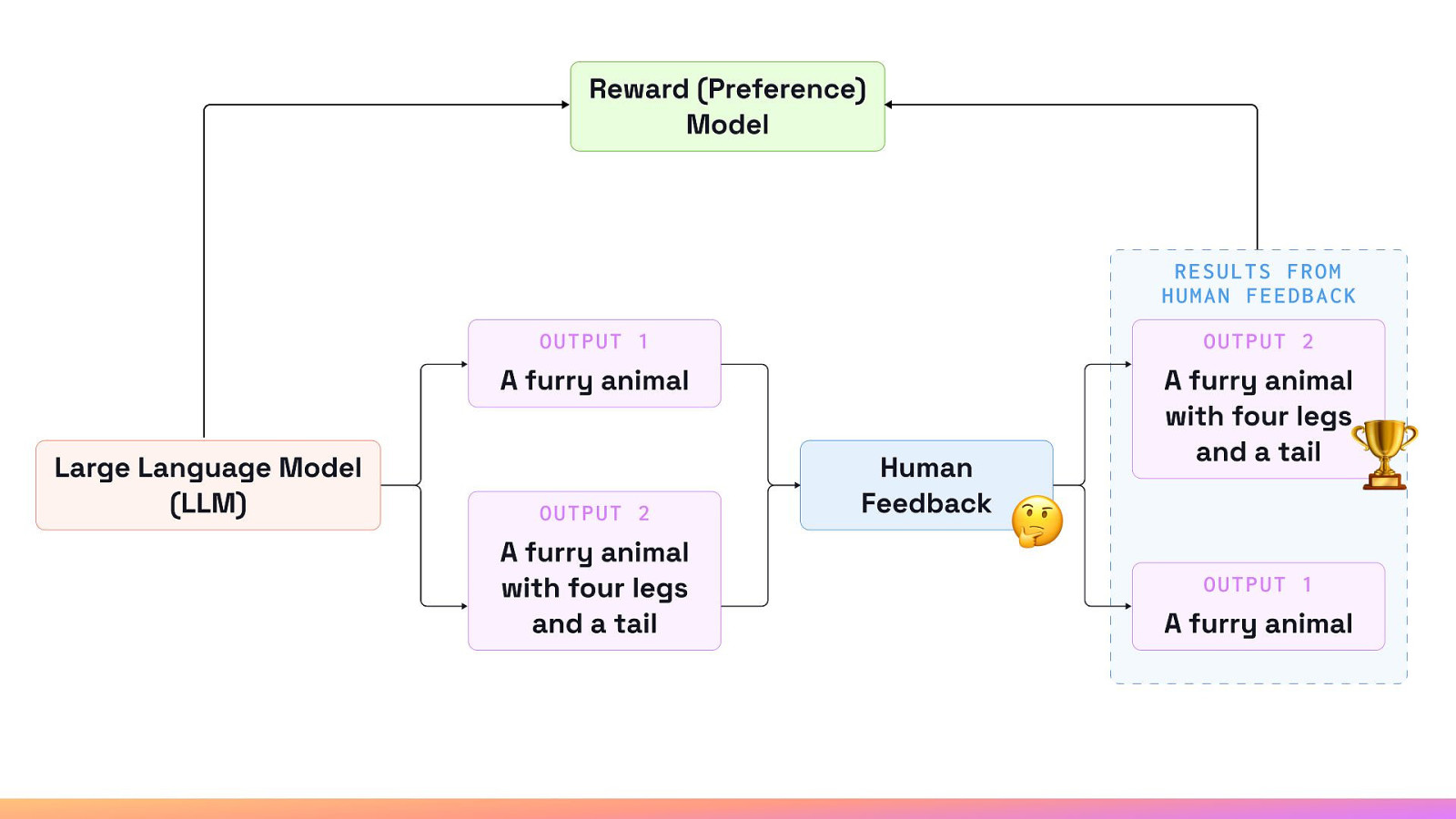
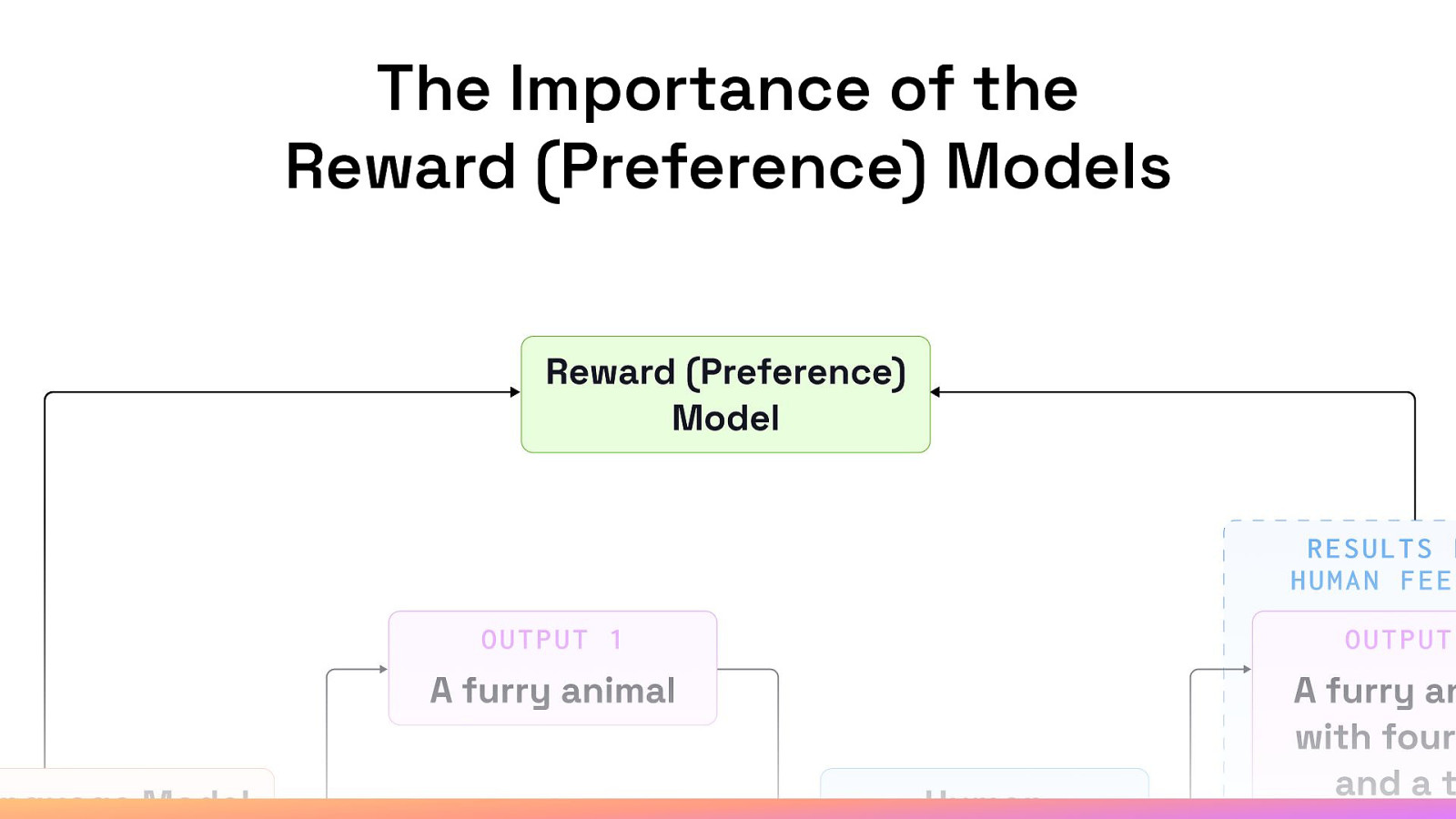
The Importance of the Reward (Preference) Models
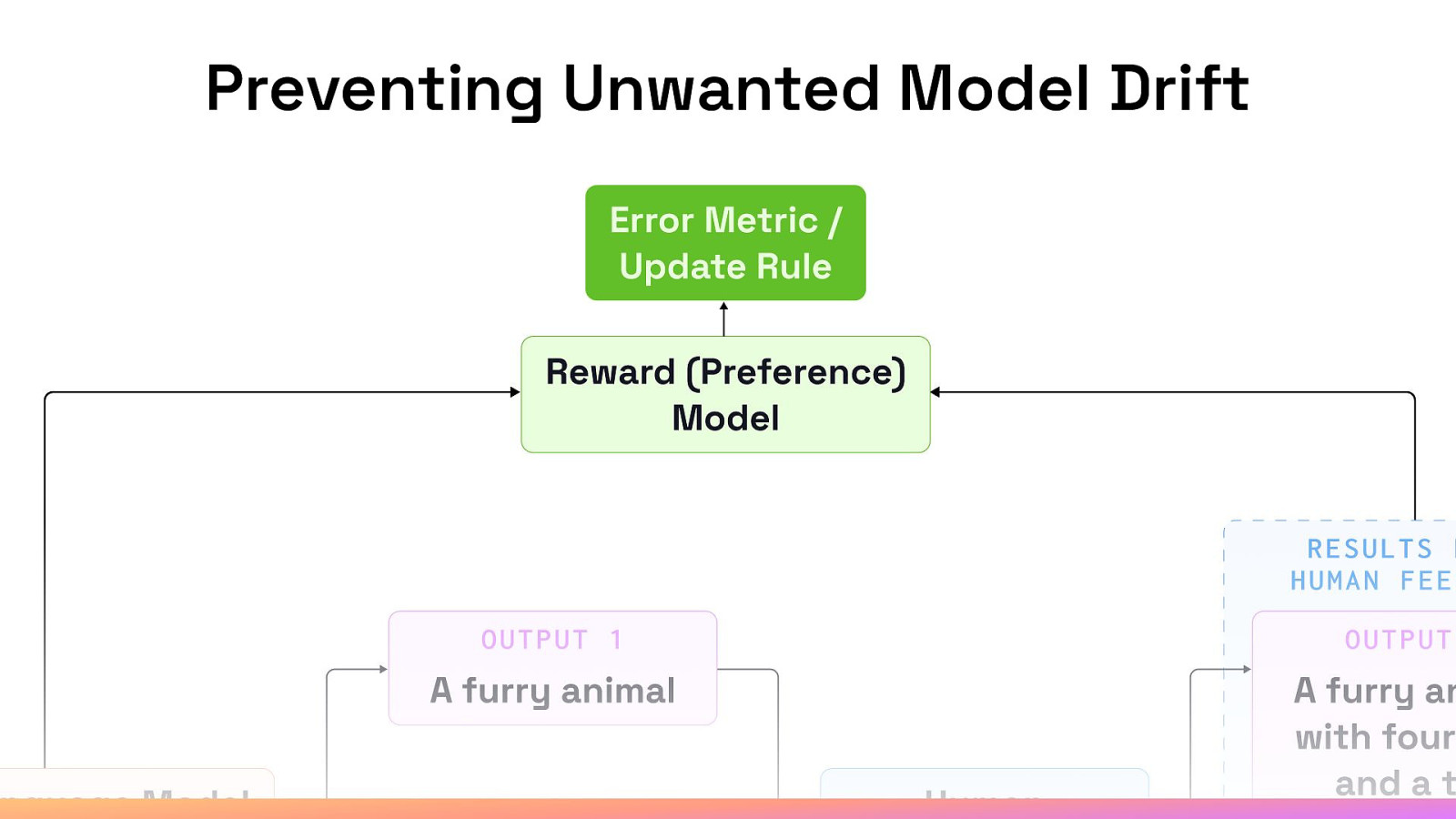
Preventing Unwanted Model Drift
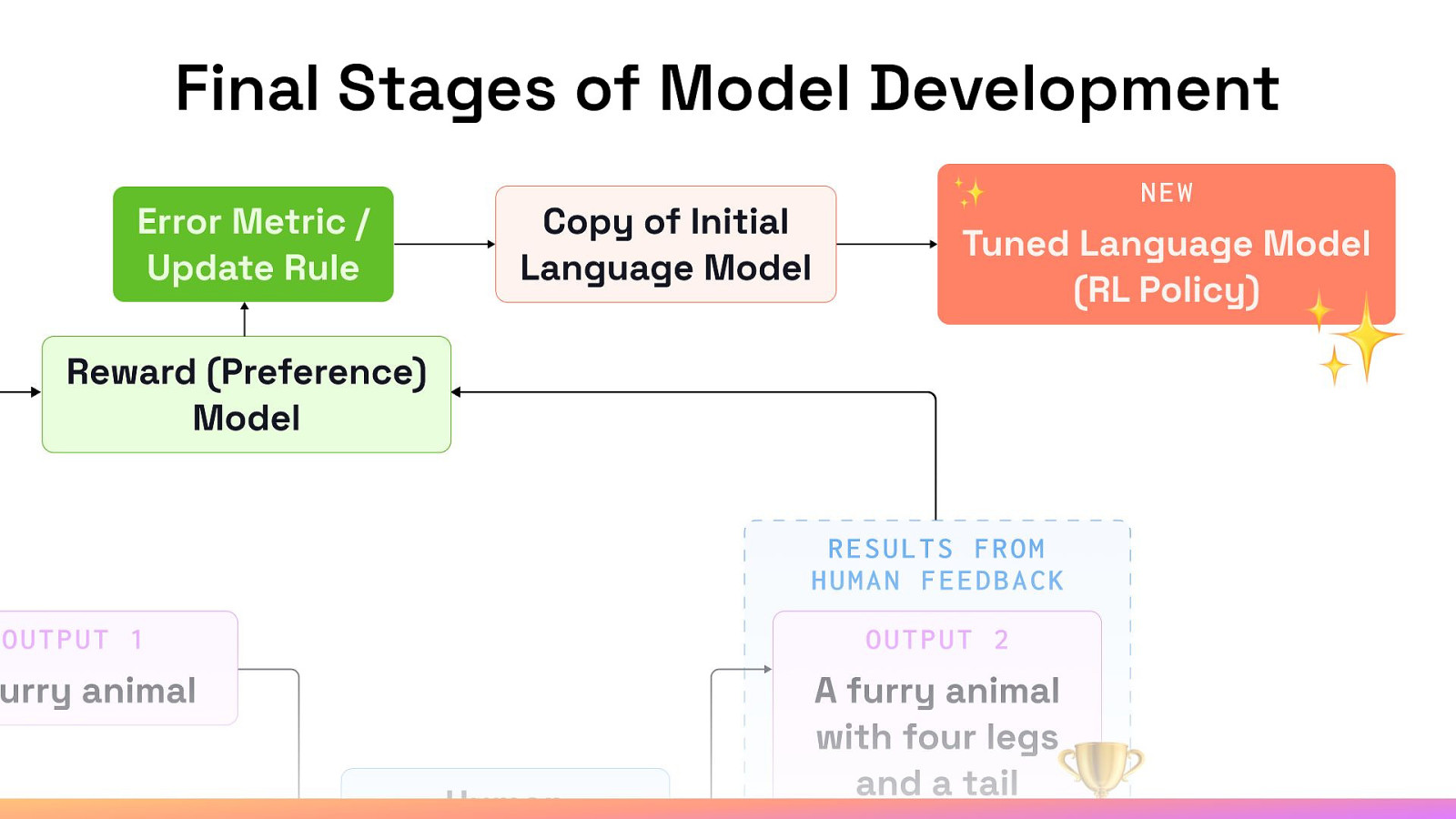
Final Stages of Model Development
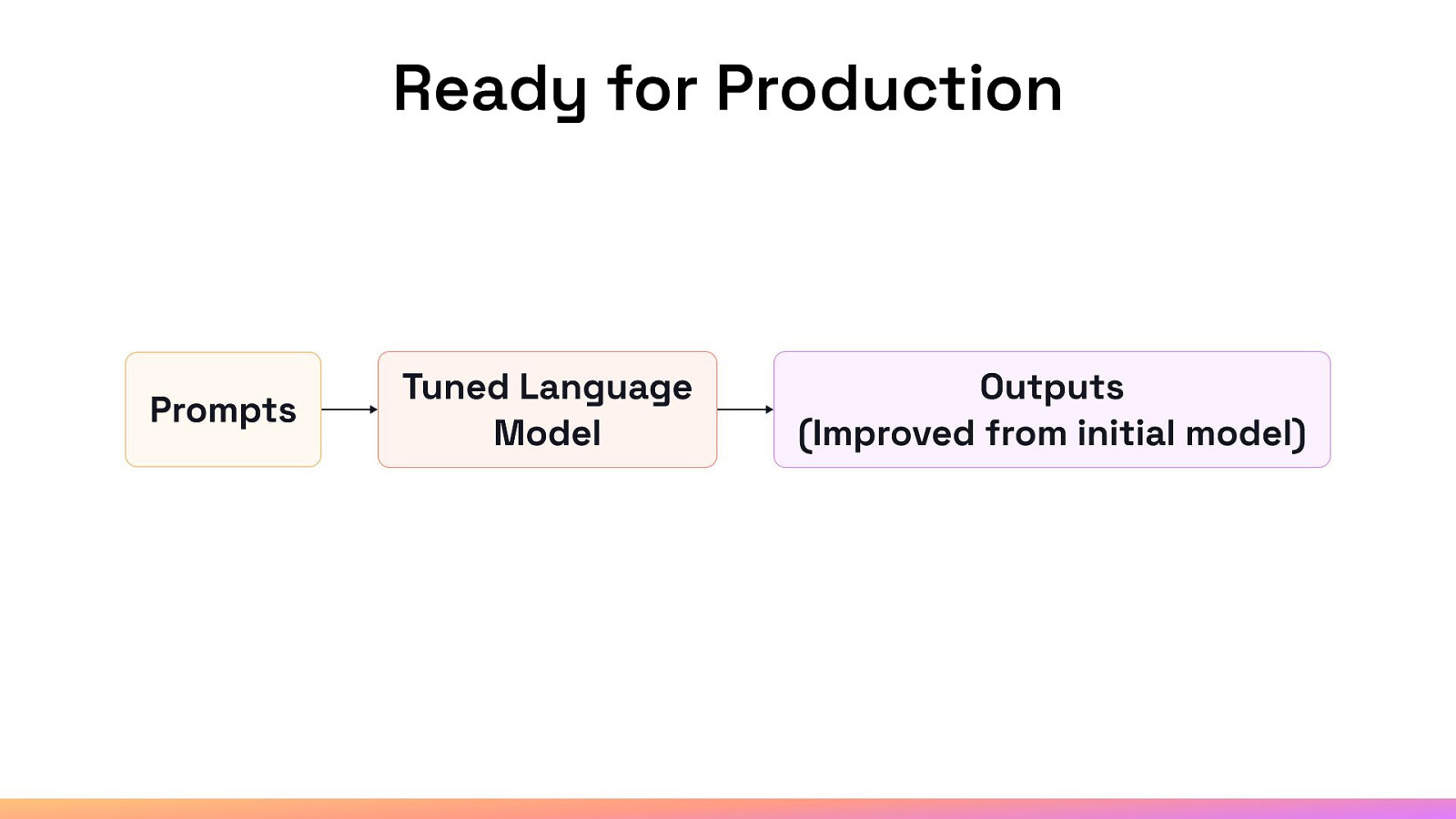
Ready for Production

We know what this looks like theoretically…

… now let’s demonstrate this in real time.

See it in action! https://github.com/heartexlabs/RLHF

Problems with RLHF

Humans ruin everything.

RLHF relies on social engineering and data integrity as much as it does technical skill.

Keeping annotators well-informed and motivated

Try out RLHF for yourself. ➡ @erinmikail @liubimovnik @labelstudioHQ community@labelstud.io https://labelstud.io/pydata-berlin