Building an E2E Analytics Pipeline with PyFlink Marta Paes (@morsapaes) Developer Advocate © 2020 Ververica

A presentation at Netflix Apache Flink Meetup 2021 in January 2021 in by Marta Paes

Building an E2E Analytics Pipeline with PyFlink Marta Paes (@morsapaes) Developer Advocate © 2020 Ververica
Why Flink + Python? Java Scala 2 @morsapaes
Why Flink + Python? Java Python Scala Expose the functionality of Flink beyond the JVM 3 @morsapaes

Why Flink + Python? Mature and intuitive analytics stack… 4 @morsapaes

Why Flink + Python? Mature and intuitive analytics stack… 2007 1995 2001 2008 …that doesn’t really scale. 5 @morsapaes
Why Flink + Python? 2007 1995 2001 Distribute and scale the functionality of Python through Flink 2008 6 @morsapaes
PyFlink Over Time PyFlink (Table API) Beta release Flink 1.9 Aug’19 7 @morsapaes
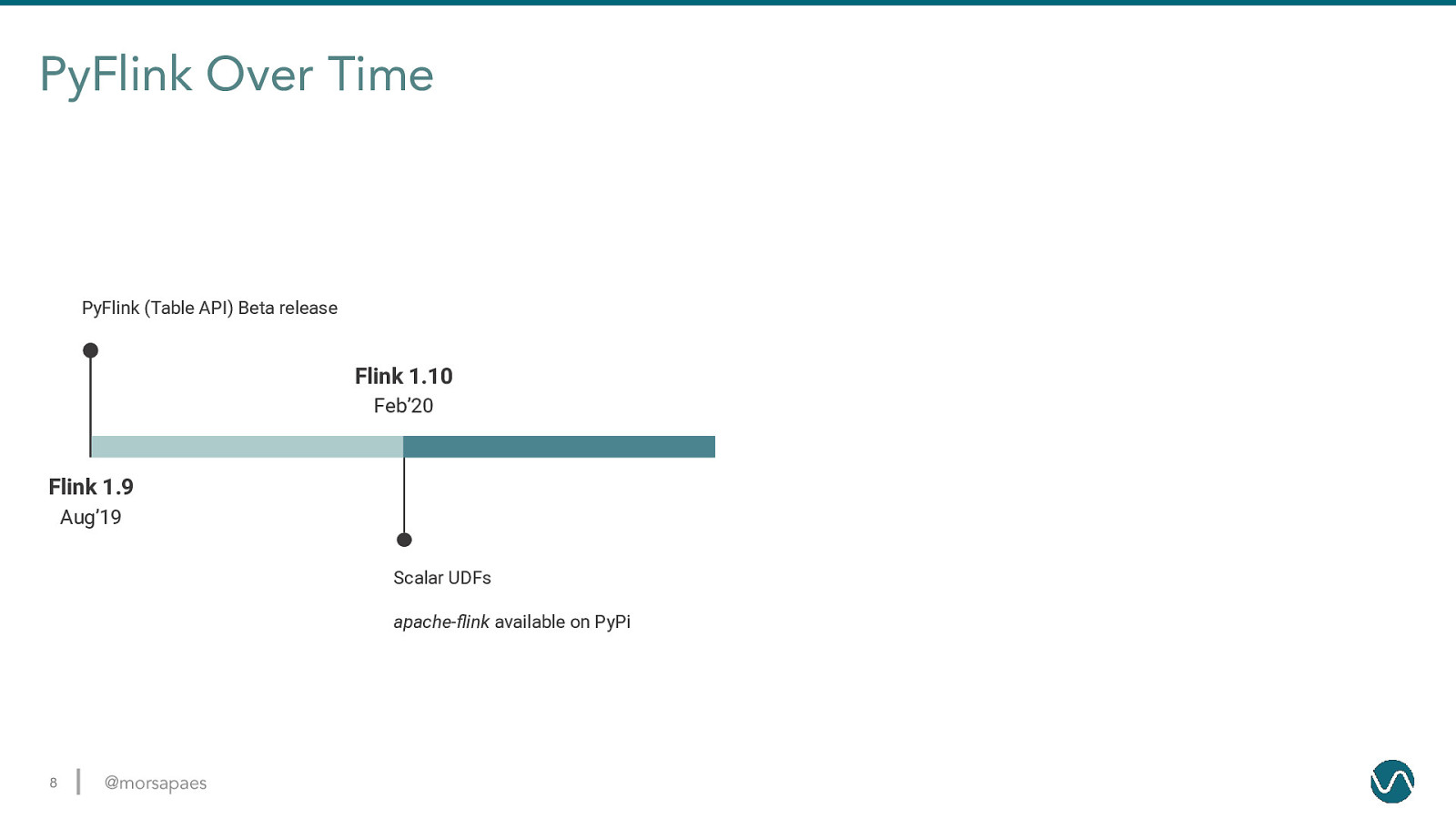
PyFlink Over Time PyFlink (Table API) Beta release Flink 1.10 Feb’20 Flink 1.9 Aug’19 Scalar UDFs apache-flink available on PyPi 8 @morsapaes

PyFlink Over Time Python UDFs in SQL DDL & SQL Client Tabular UDFs UDF metrics Pandas UDFs & Cython UDF Optimization PyFlink (Table API) Beta release Table conversion fromPandas/toPandas Flink 1.10 Feb’20 Flink 1.9 Flink 1.11 Aug’19 Jul’20 Scalar UDFs apache-flink available on PyPi 9 @morsapaes

PyFlink Over Time Python UDFs in SQL DDL & SQL Client Tabular UDFs UDF metrics Pandas UDFs & Cython UDF Optimization PyFlink (Table API) Beta release Table conversion fromPandas/toPandas Flink 1.10 Flink 1.12 Feb’20 Dec’20 Flink 1.9 Flink 1.11 Aug’19 Jul’20 Scalar UDFs Python DataStream API (Stateless) [FLIP-130] apache-flink available on PyPi PyFlink on (native) Kubernetes [FLINK-17480] UDAFs & Pandas UDAFs [FLIP-139, FLIP-137] Python Table API DSL [FLINK-19091] 10 @morsapaes

Can we use PyFlink to identify the most frequent topics in the User Mailing List? 11 @morsapaes
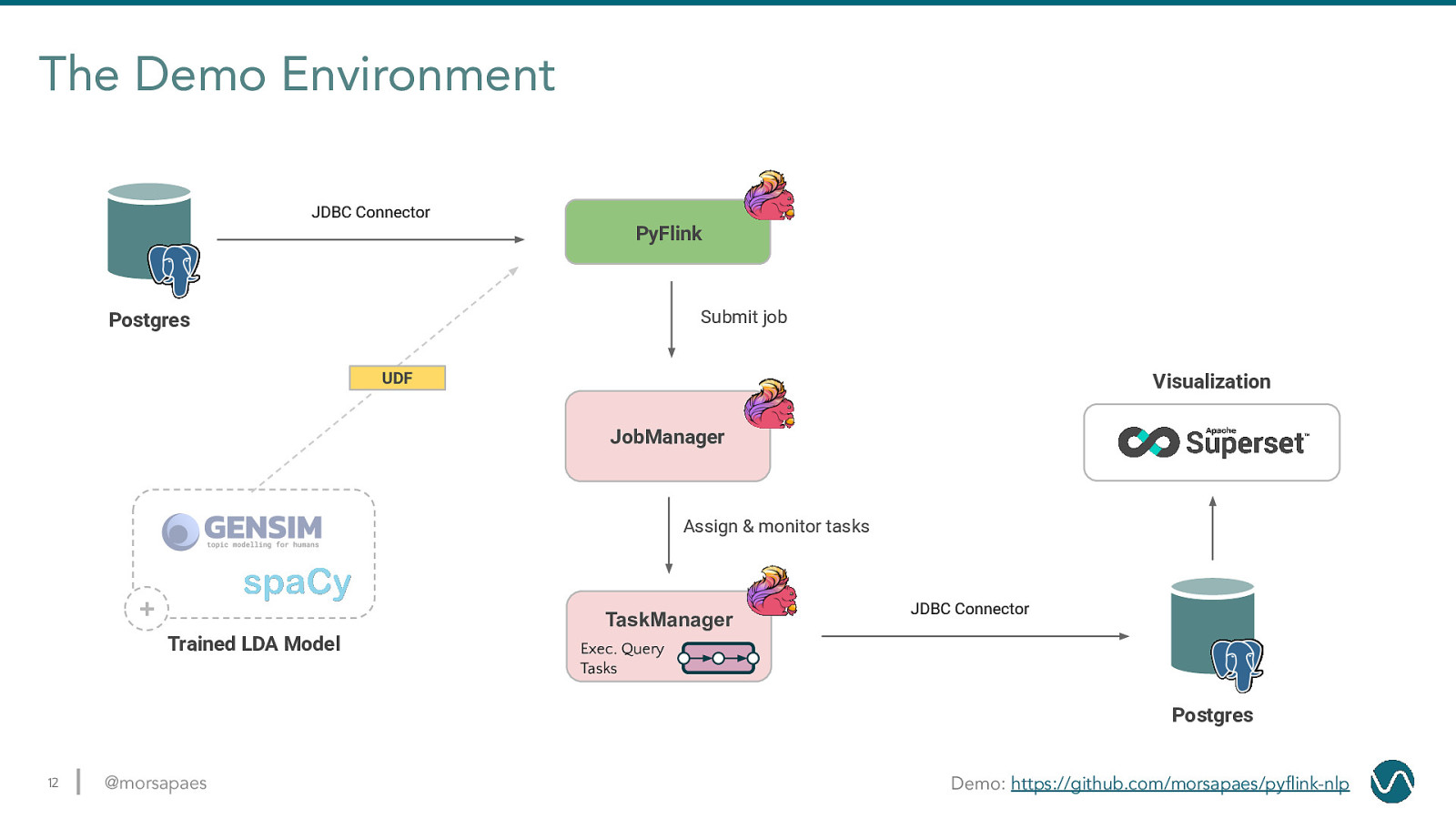
The Demo Environment JDBC Connector PyFlink Submit job Postgres UDF Visualization JobManager Assign & monitor tasks + TaskManager Trained LDA Model JDBC Connector Exec. Query Tasks Postgres 12 @morsapaes Demo: https://github.com/morsapaes/pyflink-nlp
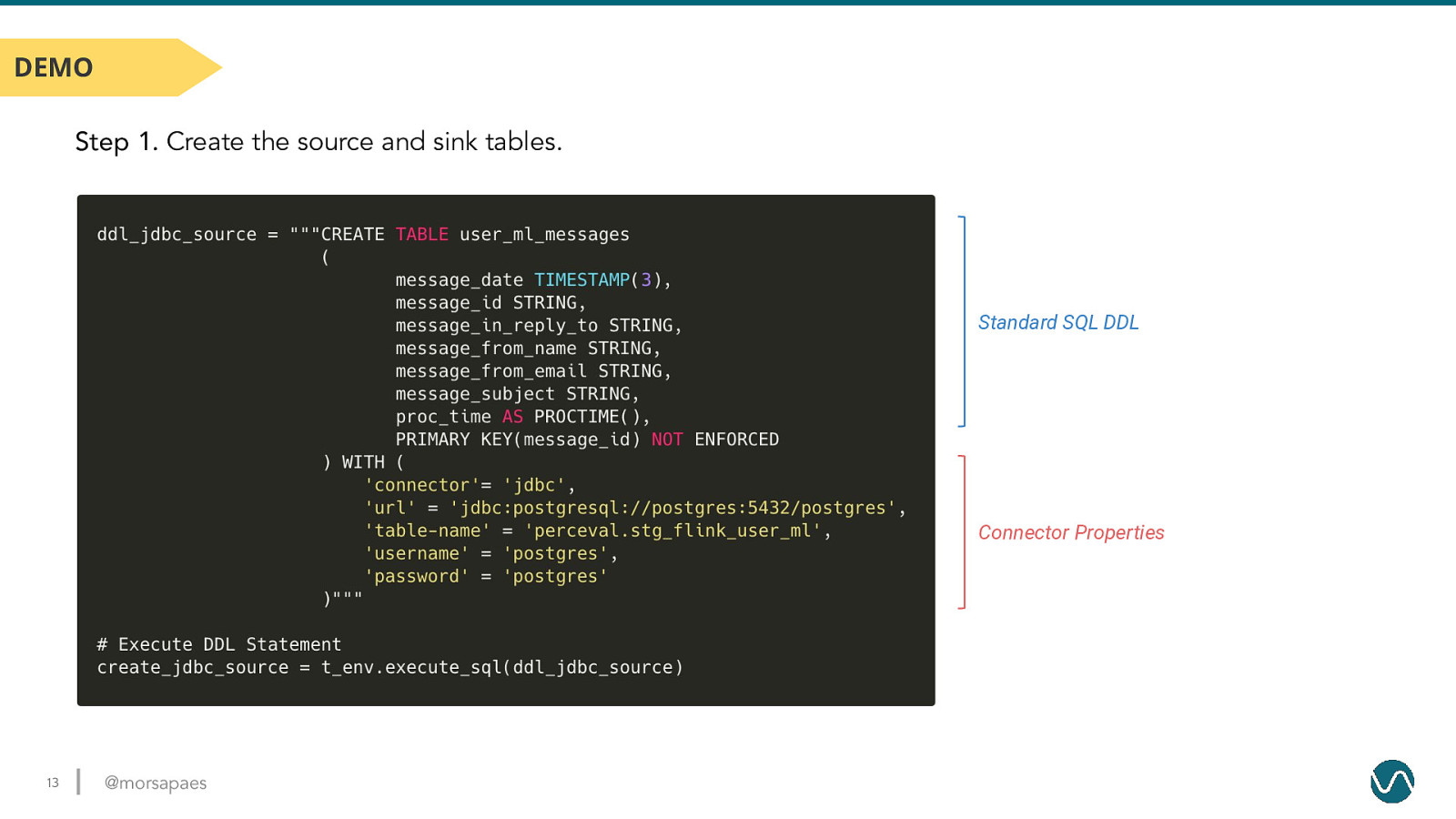
DEMO Step 1. Create the source and sink tables. Standard SQL DDL Connector Properties 13 @morsapaes
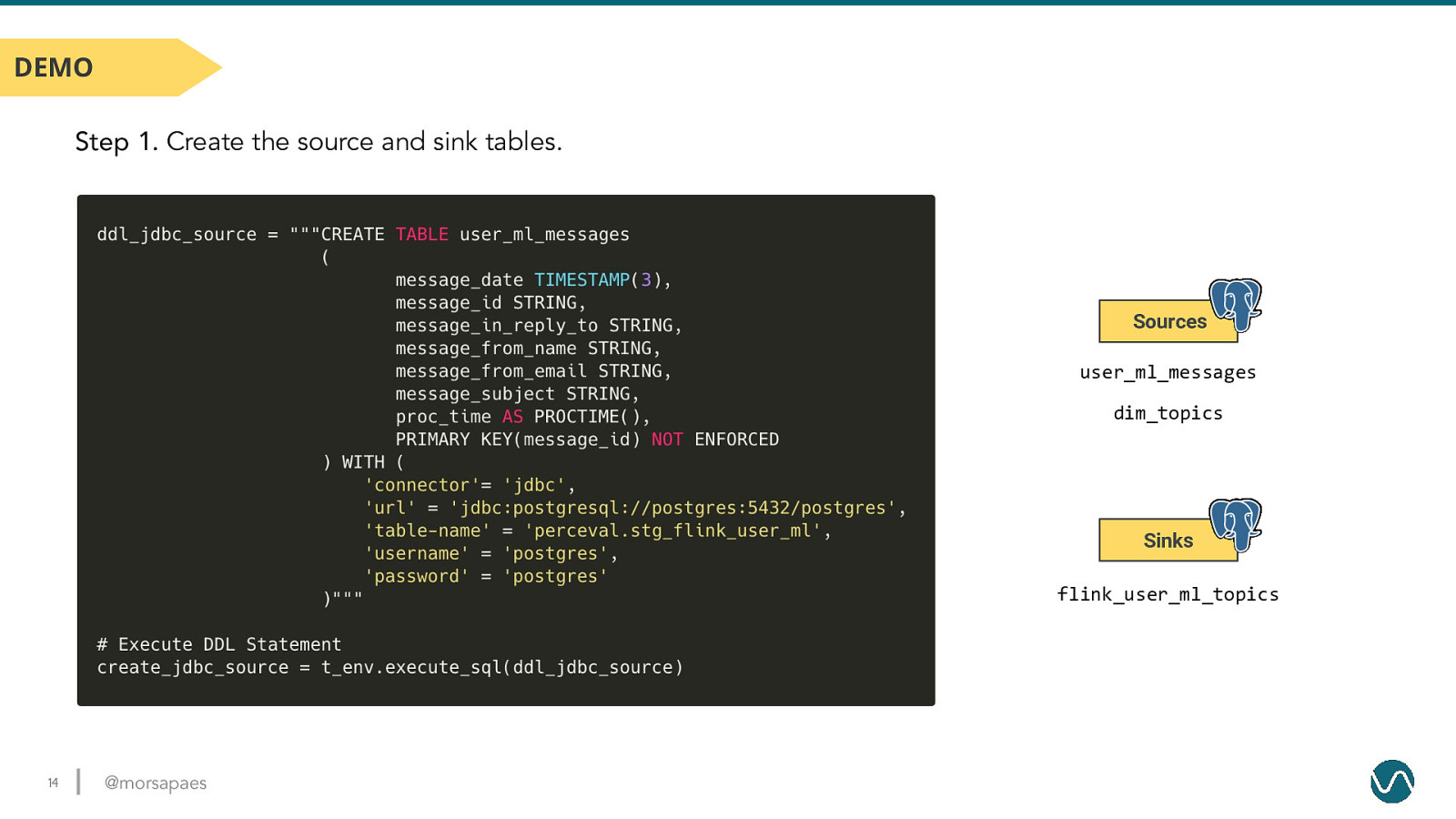
DEMO Step 1. Create the source and sink tables. Sources user_ml_messages dim_topics Sinks flink_user_ml_topics 14 @morsapaes
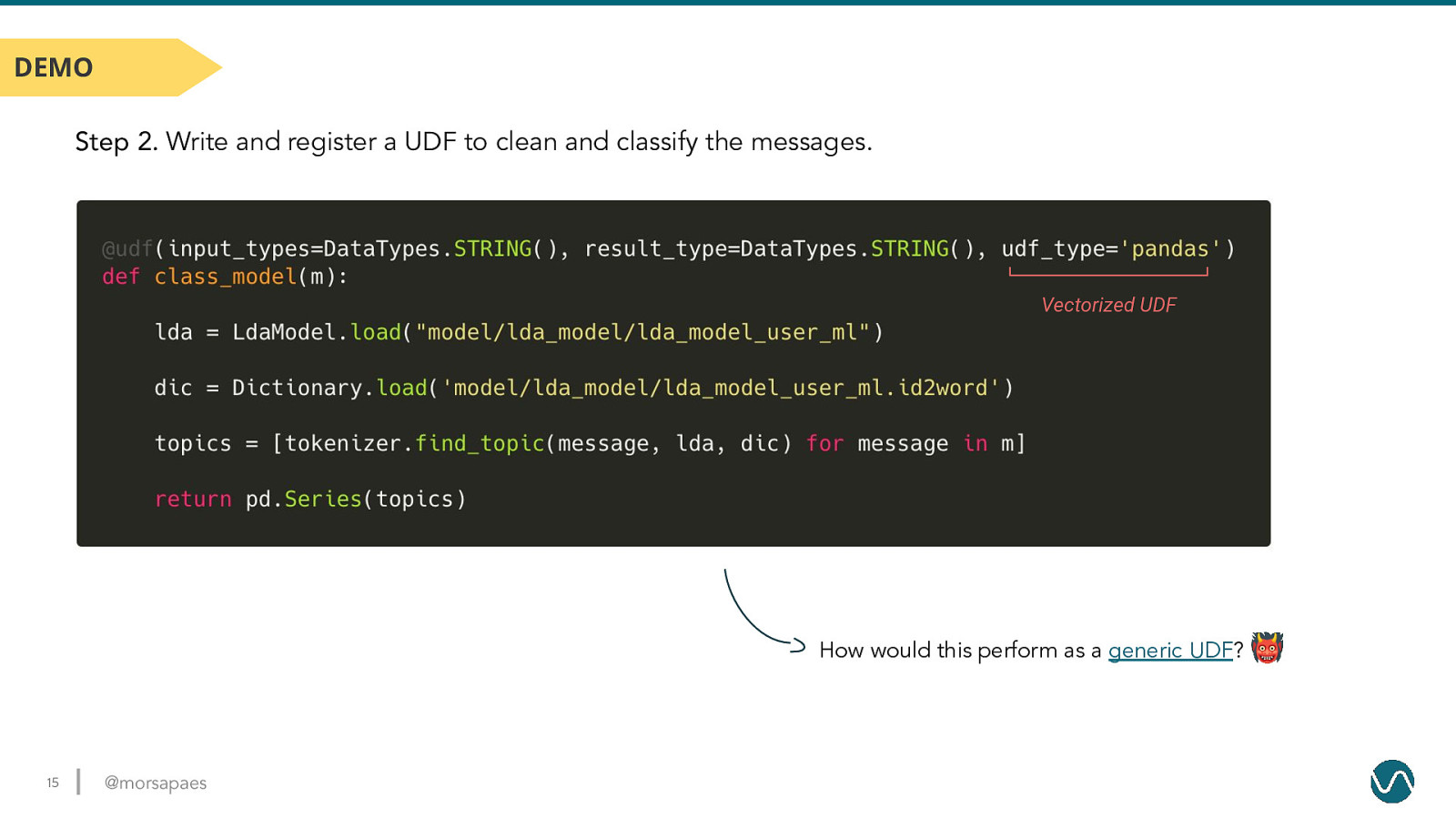
DEMO Step 2. Write and register a UDF to clean and classify the messages. Vectorized UDF How would this perform as a generic UDF? 👹 15 @morsapaes
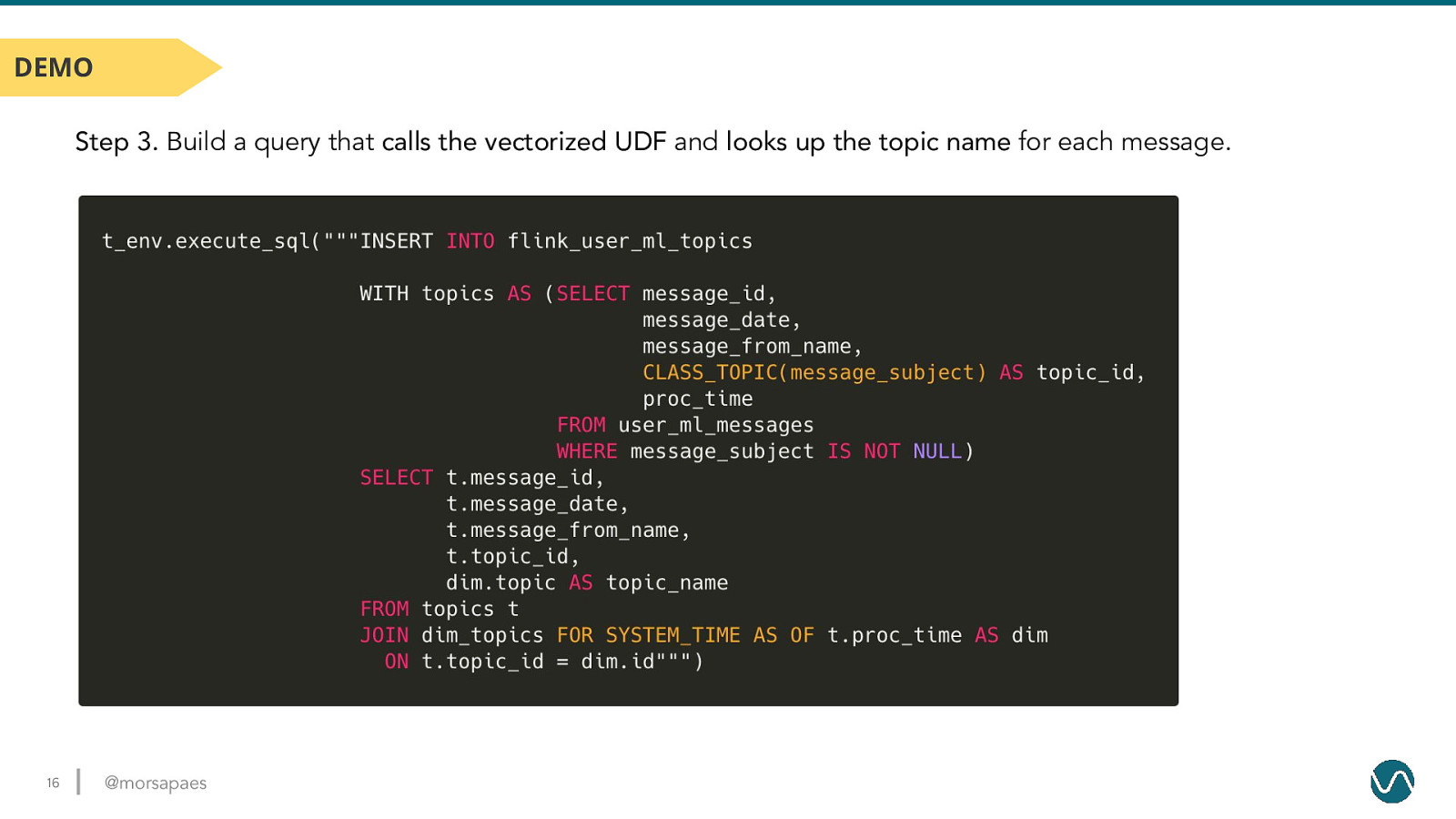
DEMO Step 3. Build a query that calls the vectorized UDF and looks up the topic name for each message. 16 @morsapaes
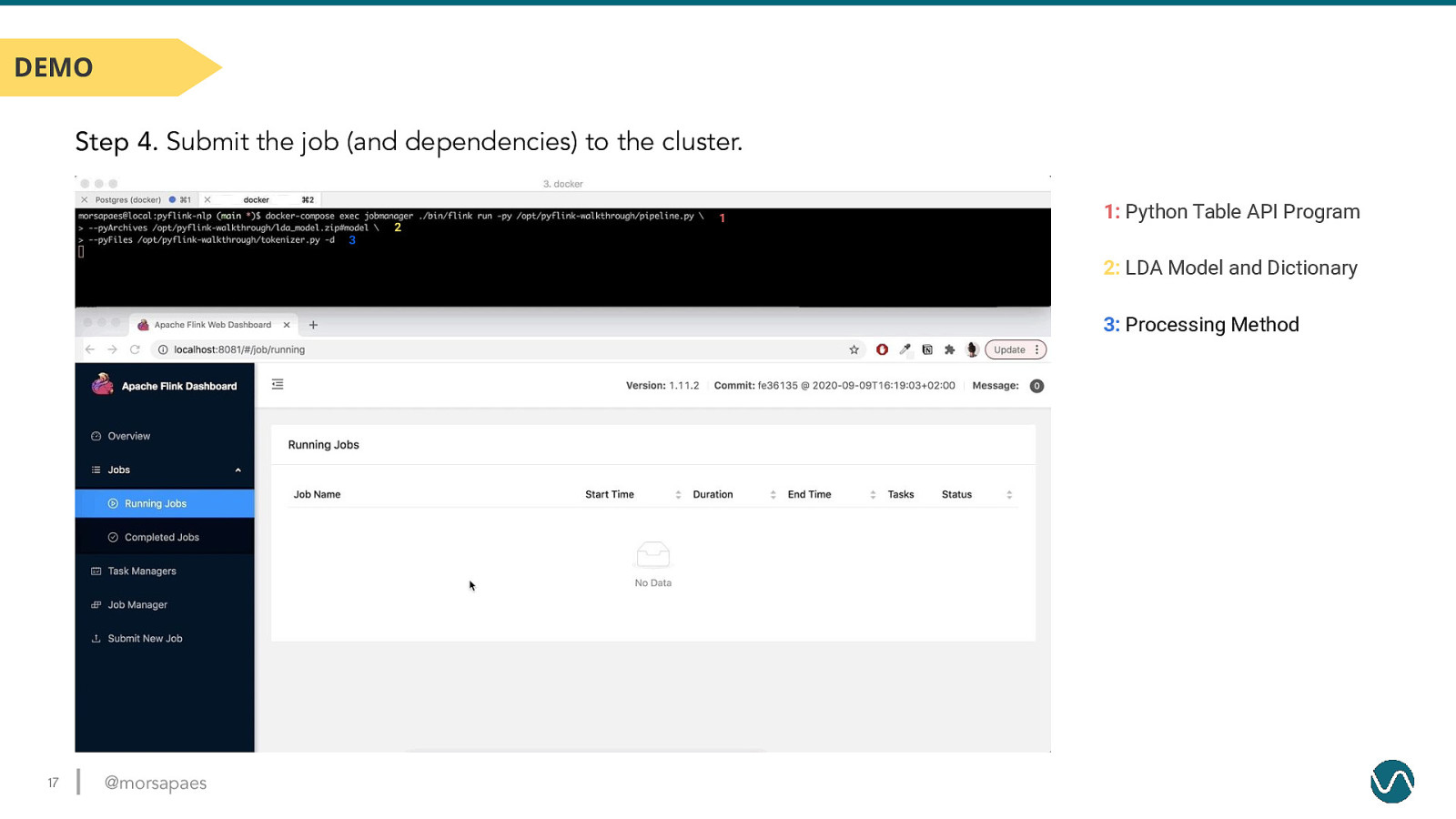
DEMO Step 4. Submit the job (and dependencies) to the cluster. 2 1 1: Python Table API Program 3 2: LDA Model and Dictionary 3: Processing Method 17 @morsapaes
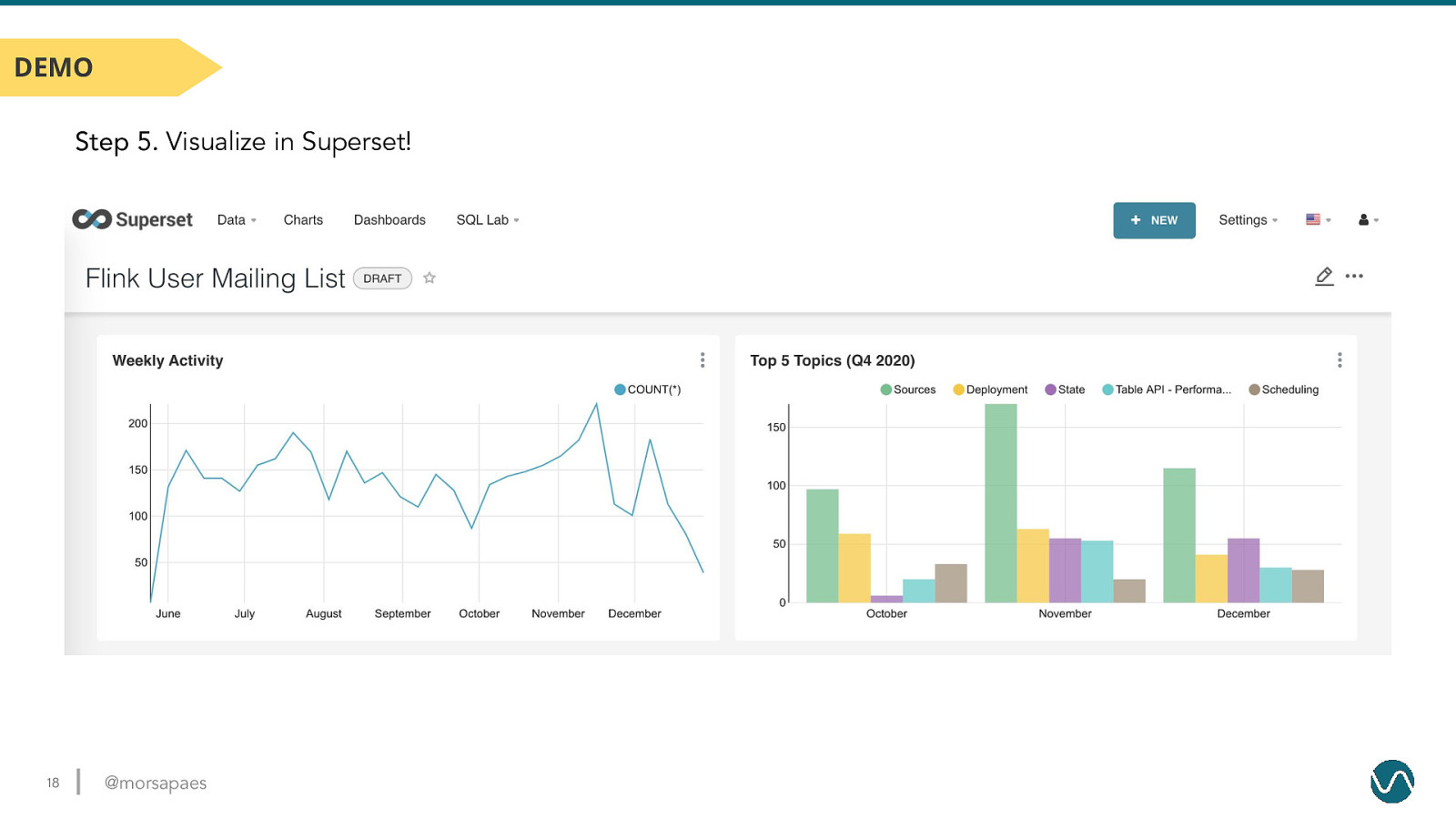
DEMO Step 5. Visualize in Superset! 18 @morsapaes
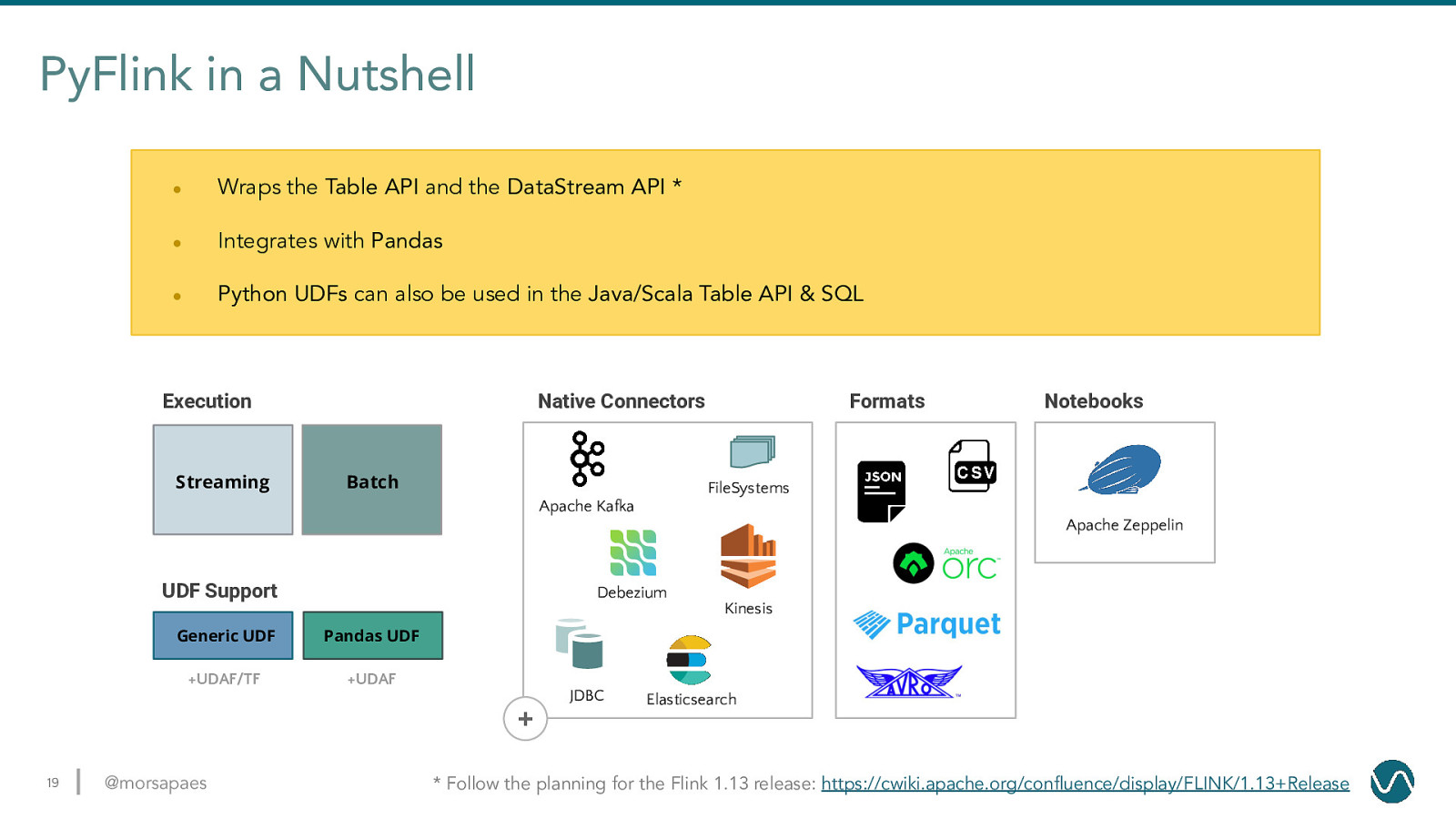
PyFlink in a Nutshell ● Wraps the Table API and the DataStream API * ● Integrates with Pandas ● Python UDFs can also be used in the Java/Scala Table API & SQL Execution Streaming Native Connectors Batch Formats Notebooks FileSystems Apache Kafka Apache Zeppelin UDF Support Debezium Generic UDF Pandas UDF +UDAF/TF +UDAF JDBC

Thank you! Follow me on Twitter: @morsapaes Learn more about Flink: https://flink.apache.org/ © 2020 Ververica