Introduction to Stream Processing With Apache Flink Marta Paes (@morsapaes) Developer Advocate © 2020 Ververica

A presentation at WeAreDevelopers Live in May 2020 in by Marta Paes

Introduction to Stream Processing With Apache Flink Marta Paes (@morsapaes) Developer Advocate © 2020 Ververica

Data Scientist Data Analyst Introduction to Stream Processing With Apache Flink Marta Paes (@morsapaes) Developer Advocate Data Engineer © 2020 Ververica
About Ververica Original Creators of Apache Flink® 3 @morsapaes Enterprise Stream Processing With Ververica Platform Part of Alibaba Group

Analytics…Not that Long Ago OLTP Database(s) Data Lake ETL … Data Warehouse (DWH) FTP Servers 4 @morsapaes

Analytics…Not that Long Ago The quest for data… Long, nightly jobs OLTP Databases x Data Lake Someone waking up Re-run long, nightly job ETL Someone complaining … Data Warehouse (DWH) FTP Servers 5 @morsapaes Results But in the end… • Most source data is continuously produced • Not everyone can wait for yesterday’s data • Most logic is not changing that frequently

Everything is a Stream @morsapaes
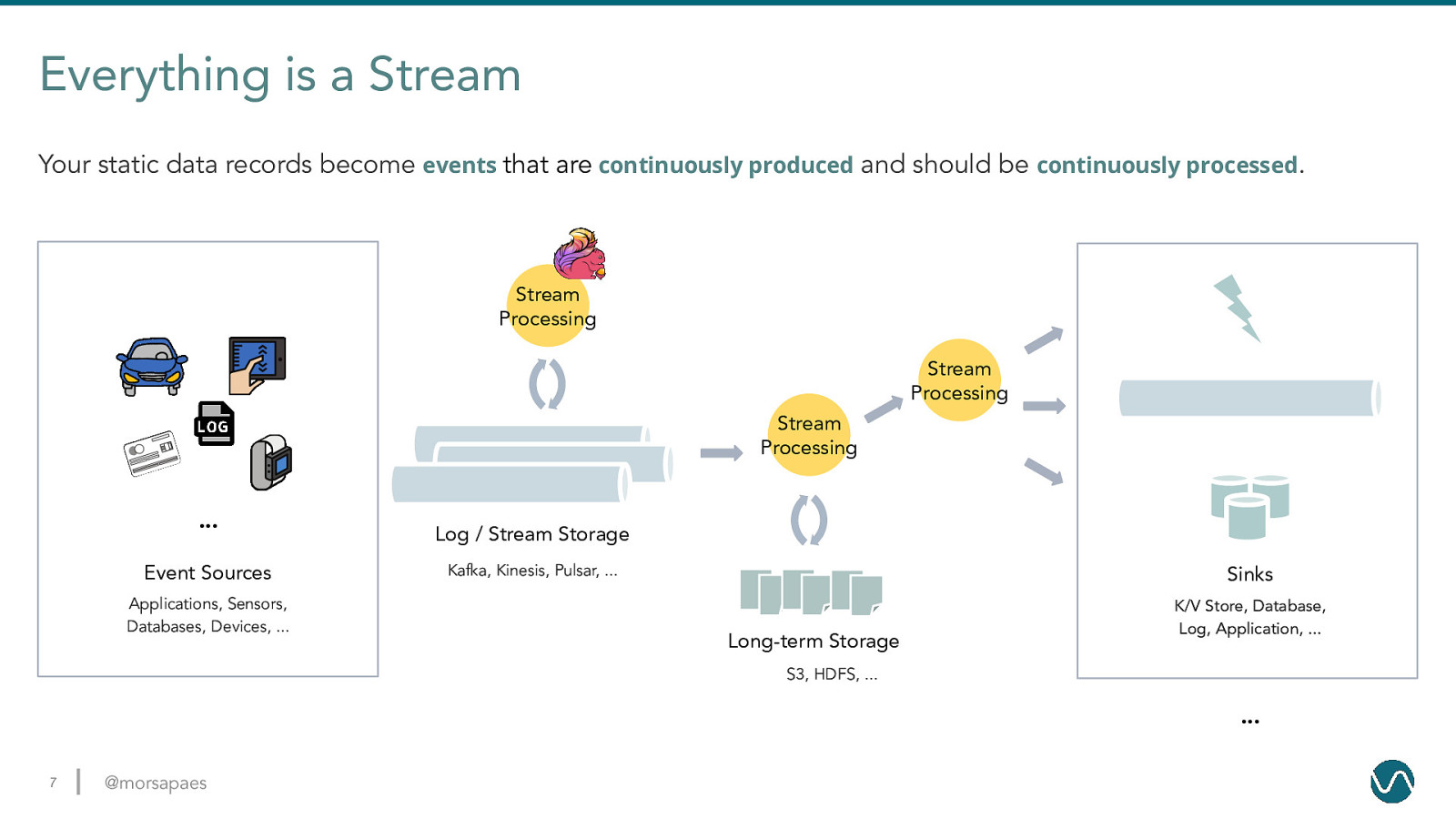
Everything is a Stream Your static data records become events that are continuously produced and should be continuously processed. Stream Processing Stream Processing Stream Processing … Event Sources Applications, Sensors, Databases, Devices, … Log / Stream Storage Kafka, Kinesis, Pulsar, … Sinks Long-term Storage K/V Store, Database, Log, Application, … S3, HDFS, … … 7 @morsapaes
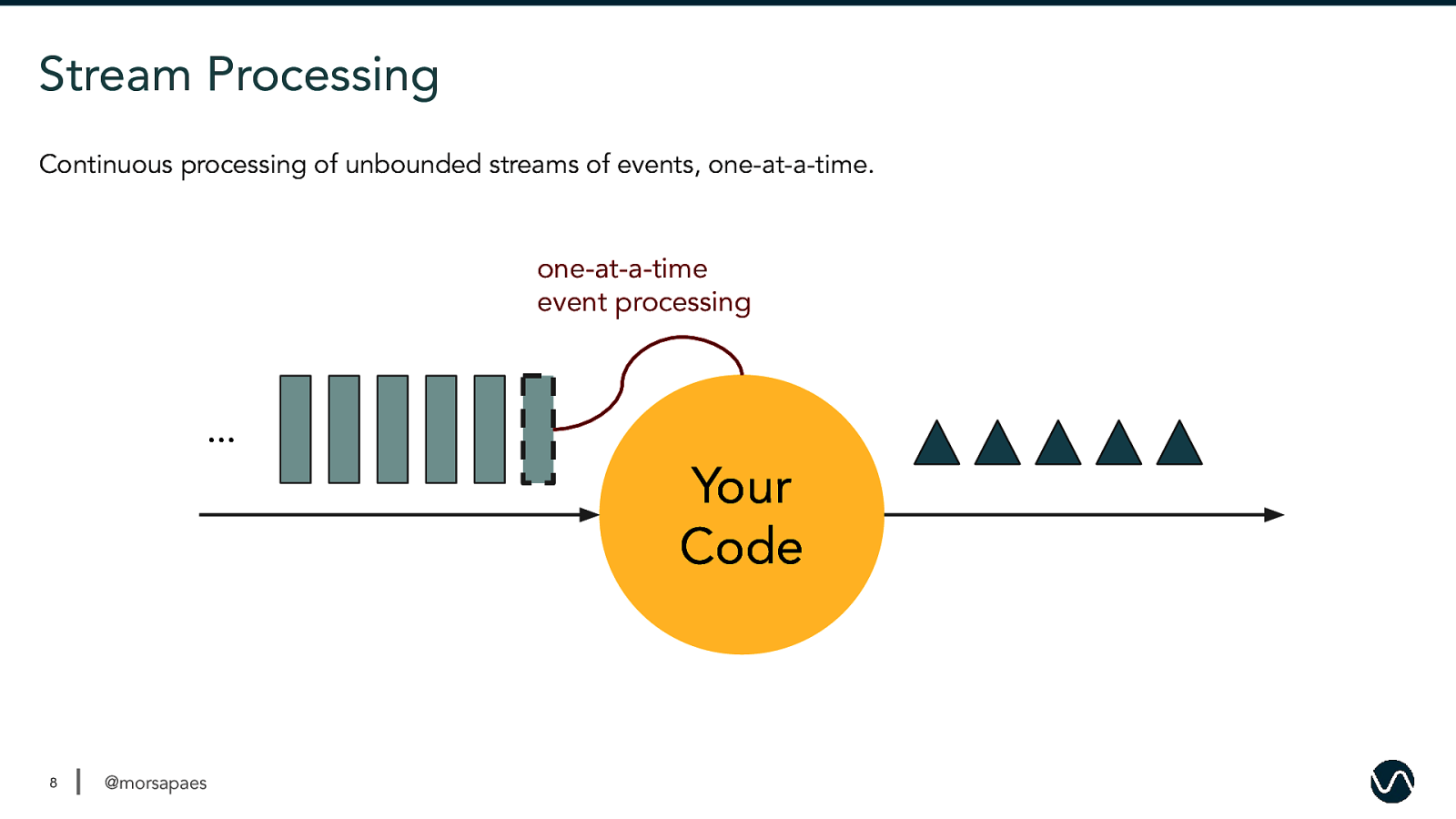
Stream Processing Continuous processing of unbounded streams of events, one-at-a-time. one-at-a-time event processing … Your Code 8 @morsapaes
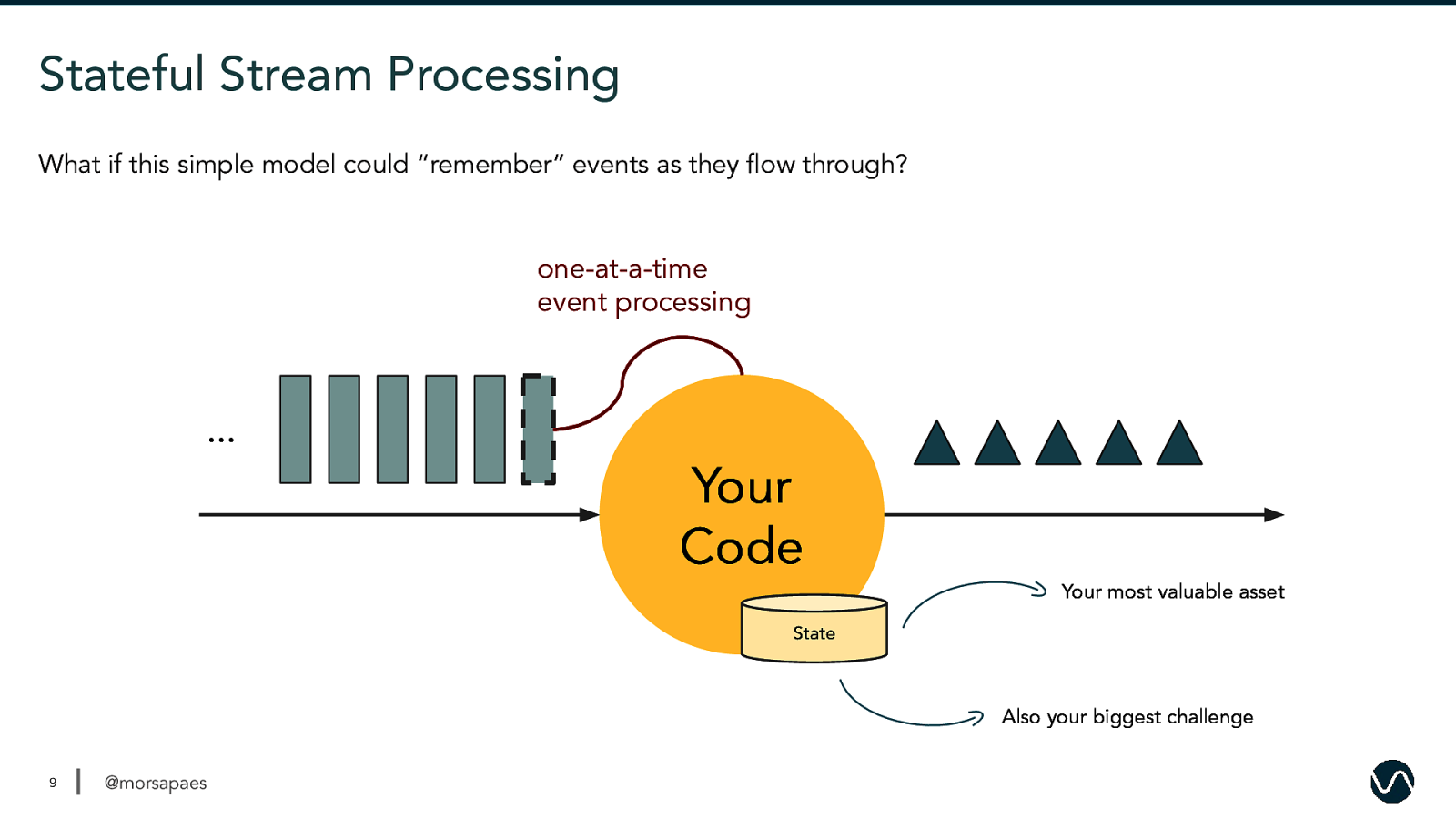
Stateful Stream Processing What if this simple model could “remember” events as they flow through? one-at-a-time event processing … Your Code Your most valuable asset State Also your biggest challenge 9 @morsapaes

So…what is Apache Flink? @morsapaes

What is Apache Flink? Flink is an open source framework and distributed engine for stateful stream processing. Flink Runtime Stateful Computations over Data Streams Stateful Computations over Data Streams 11 ● State management is what makes Flink powerful. ● Consistent, one-at-a-time event processing is what makes Flink flexible. @morsapaes Learn more: flink.apache.org
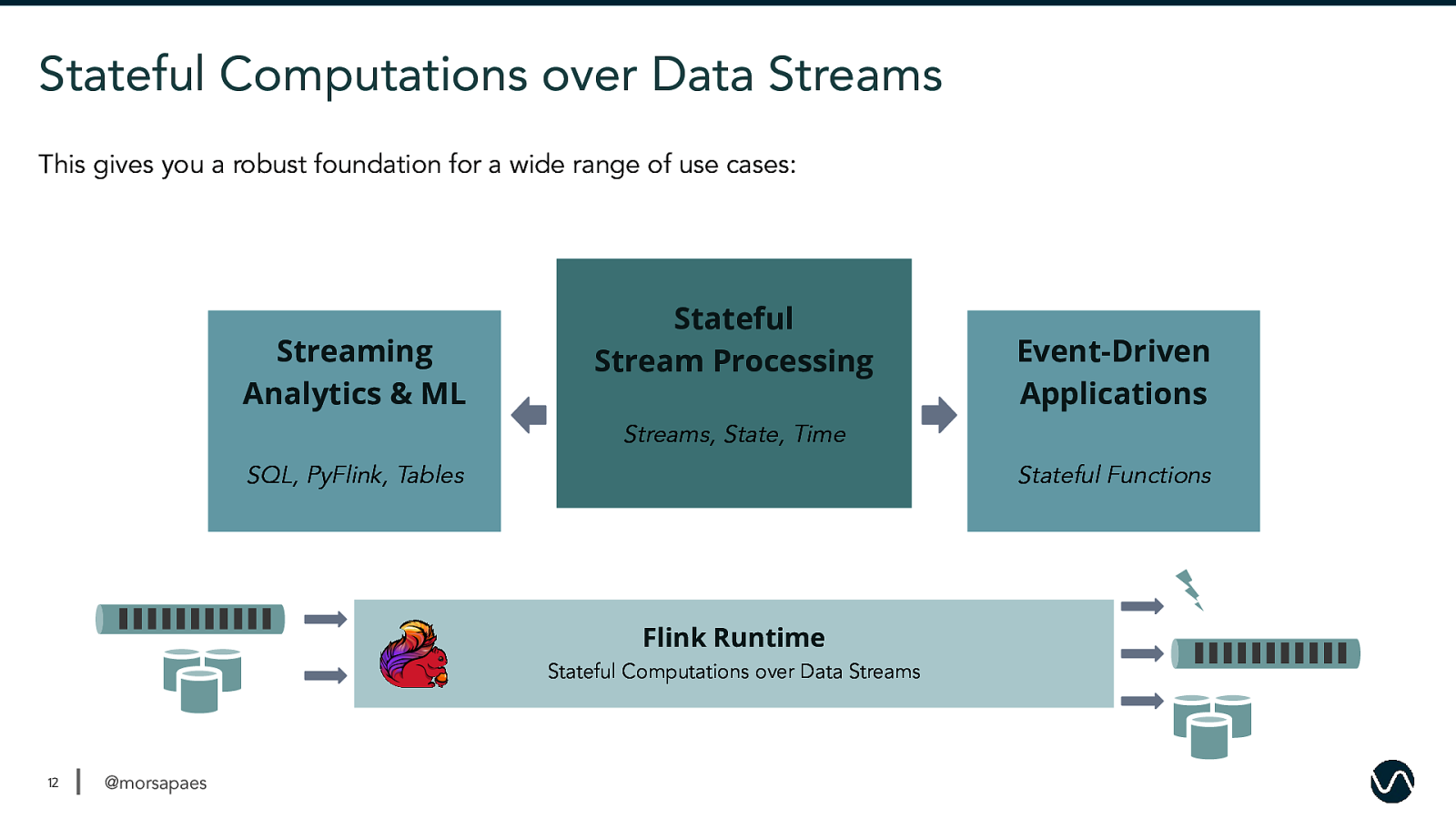
Stateful Computations over Data Streams This gives you a robust foundation for a wide range of use cases: Streaming Analytics & ML Stateful Stream Processing Event-Driven Applications Streams, State, Time SQL, PyFlink, Tables Stateful Functions Flink Runtime Stateful Computations over Data Streams 12 @morsapaes
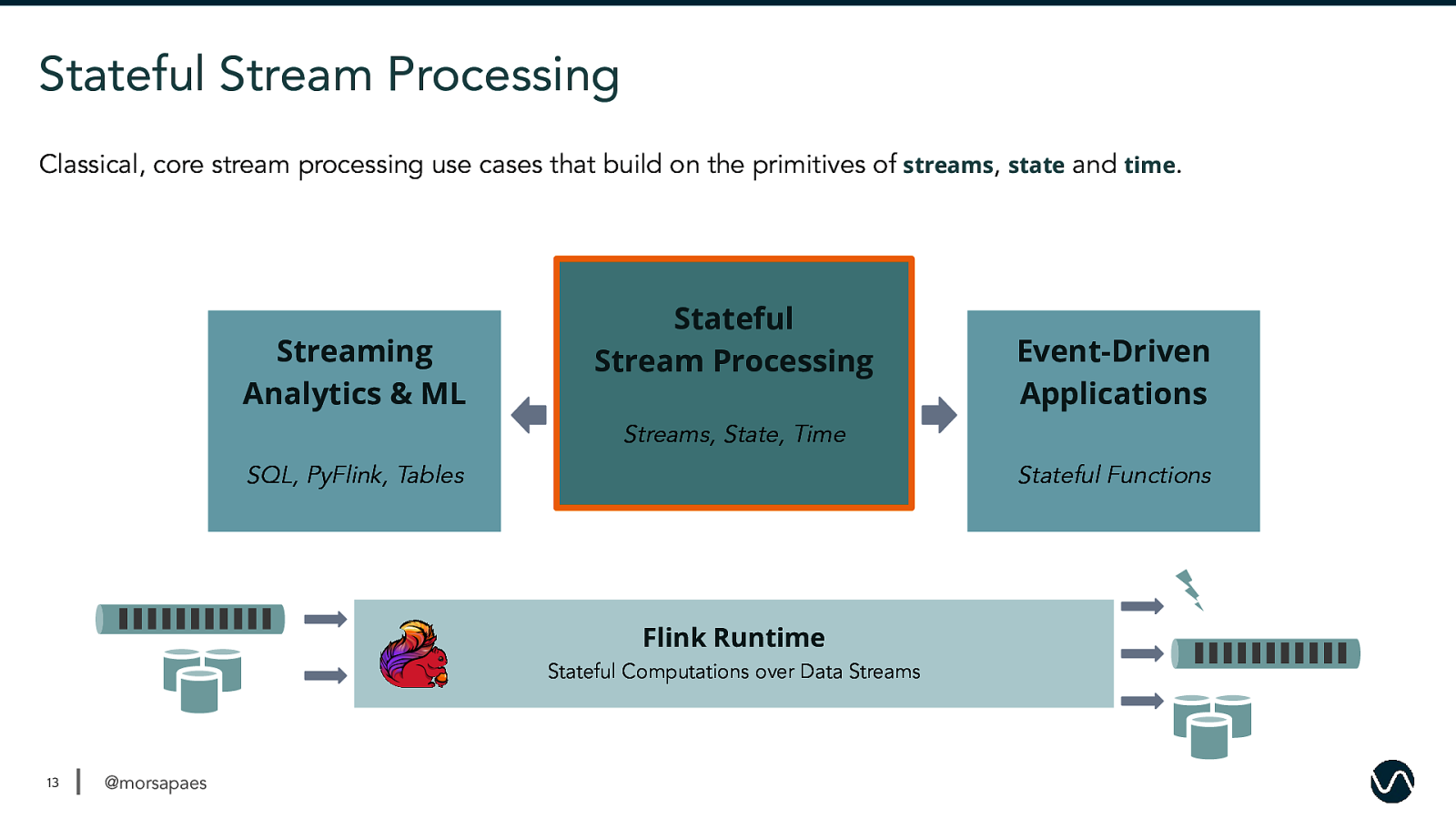
Stateful Stream Processing Classical, core stream processing use cases that build on the primitives of streams, state and time. Streaming Analytics & ML Stateful Stream Processing Event-Driven Applications Streams, State, Time SQL, PyFlink, Tables Stateful Functions Flink Runtime Stateful Computations over Data Streams 13 @morsapaes
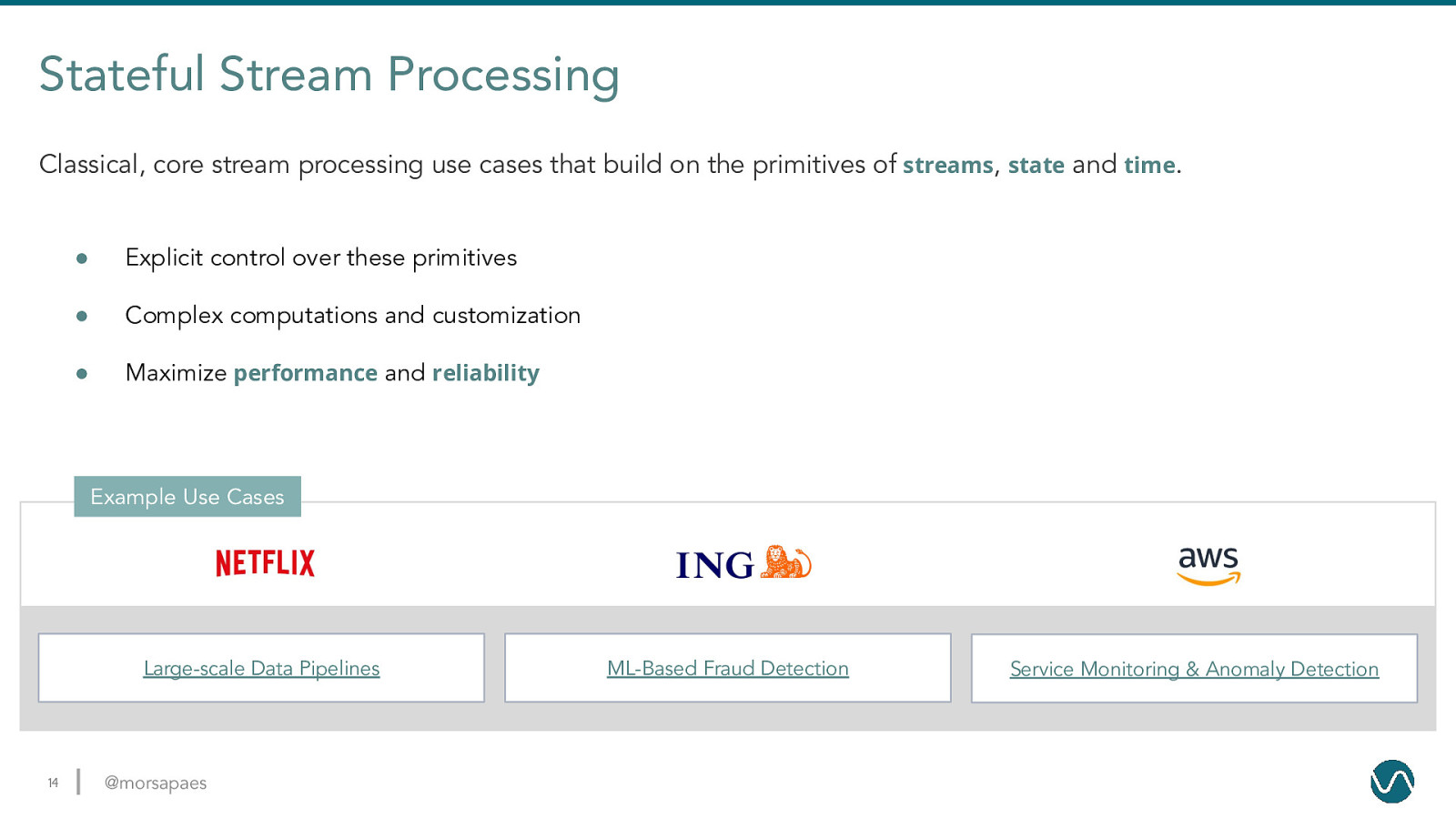
Stateful Stream Processing Classical, core stream processing use cases that build on the primitives of streams, state and time. ● Explicit control over these primitives ● Complex computations and customization ● Maximize performance and reliability Example Use Cases Large-scale Data Pipelines 14 @morsapaes ML-Based Fraud Detection Service Monitoring & Anomaly Detection
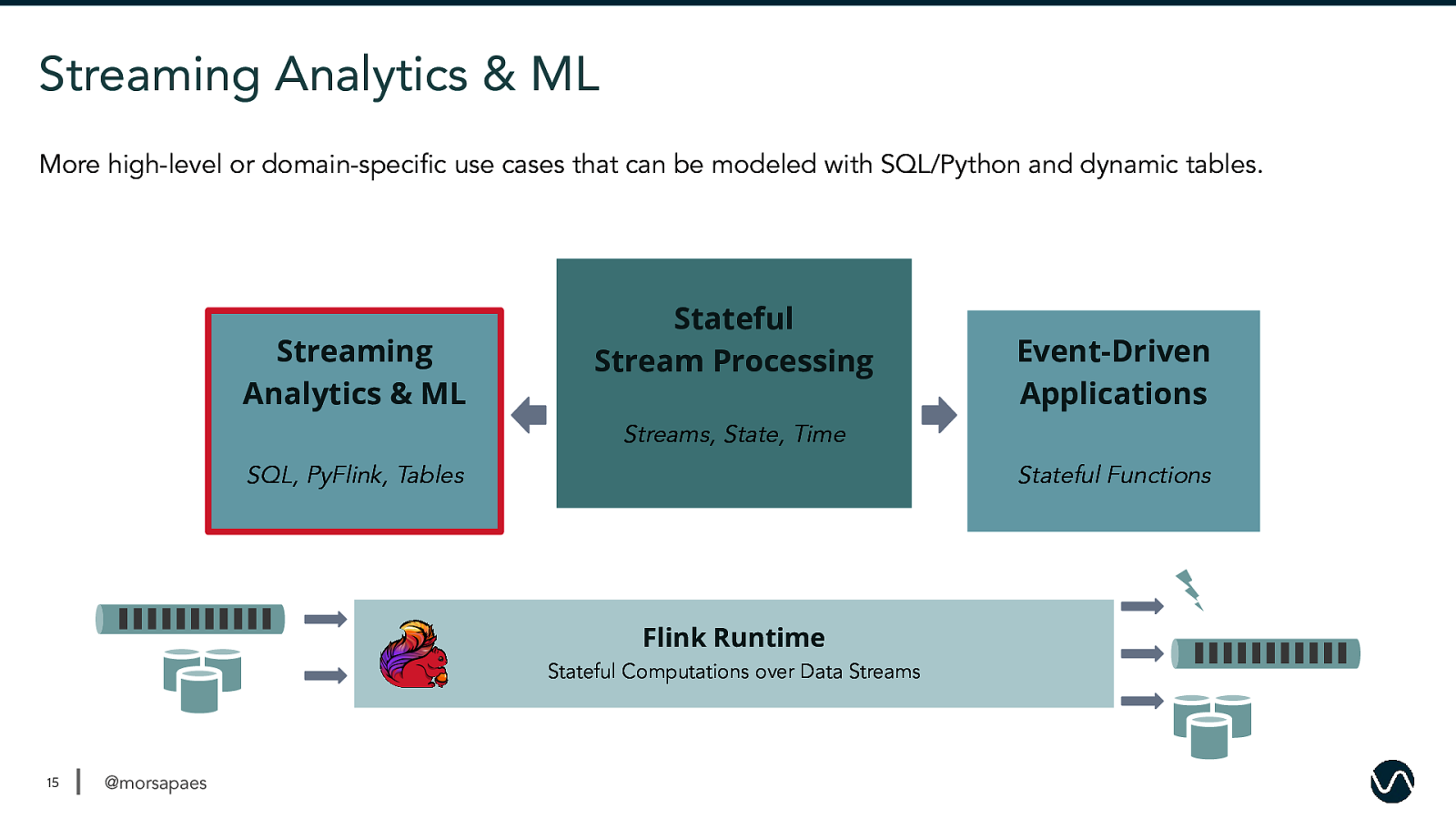
Streaming Analytics & ML More high-level or domain-specific use cases that can be modeled with SQL/Python and dynamic tables. Streaming Analytics & ML Stateful Stream Processing Event-Driven Applications Streams, State, Time SQL, PyFlink, Tables Stateful Functions Flink Runtime Stateful Computations over Data Streams 15 @morsapaes
Streaming Analytics & ML More high-level or domain-specific use cases that can be modeled with SQL/Python and dynamic tables. ● Focus on logic, not implementation ● Mixed workloads (batch and streaming) ● Maximize developer speed and autonomy Example Use Cases E2E Streaming Analytics Pipelines 16 @morsapaes Build and Maintain Materialized Views ML Feature Generation
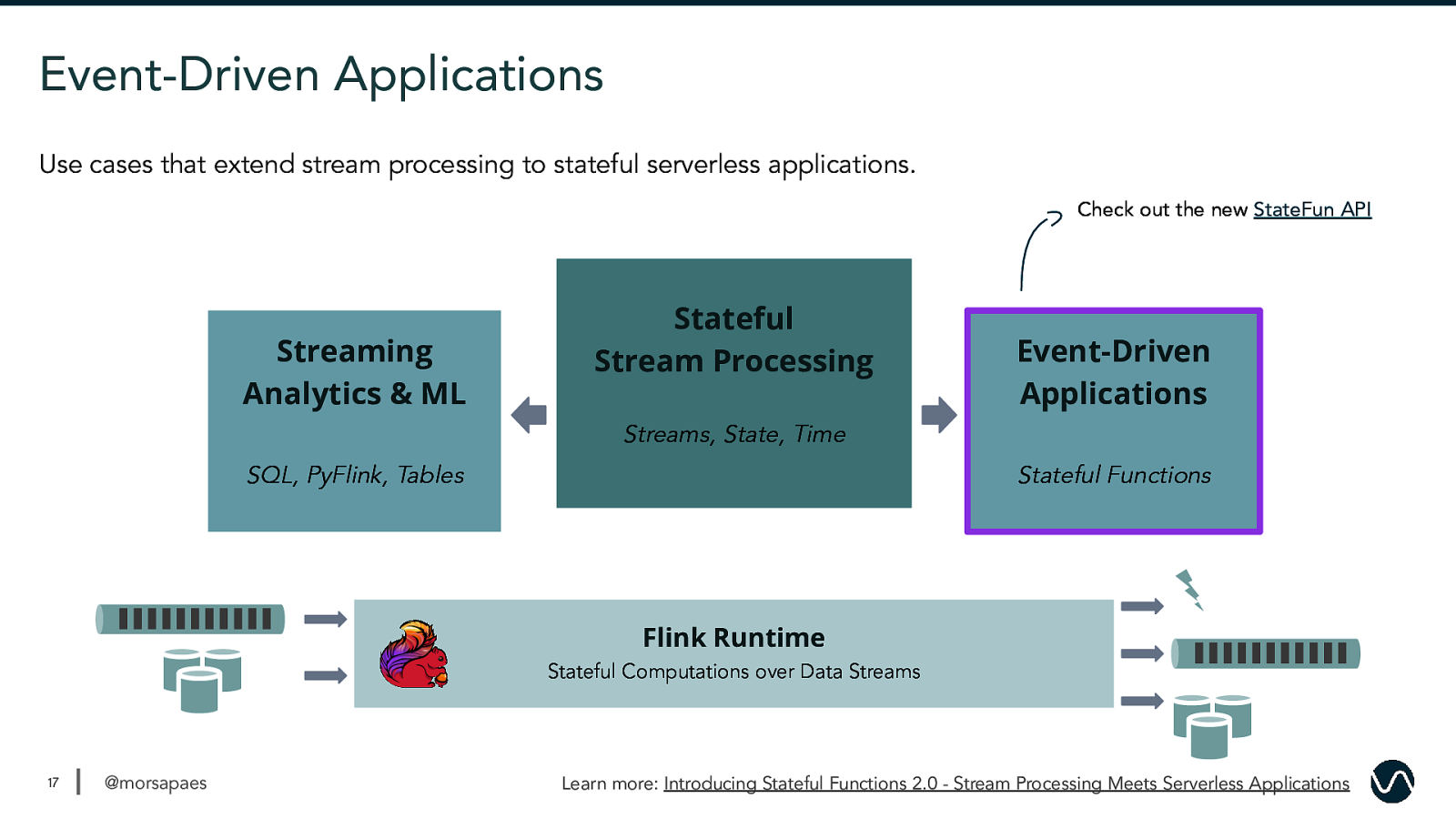
Event-Driven Applications Use cases that extend stream processing to stateful serverless applications. Check out the new StateFun API Streaming Analytics & ML Stateful Stream Processing Event-Driven Applications Streams, State, Time SQL, PyFlink, Tables Stateful Functions Flink Runtime Stateful Computations over Data Streams 17 @morsapaes Learn more: Introducing Stateful Functions 2.0 - Stream Processing Meets Serverless Applications

More Apache Flink Users 18 @morsapaes Learn More: Powered by Flink, Speakers – Flink Forward San Francisco 2019, Speakers – Flink Forward Europe 2019

How big can you go? @morsapaes
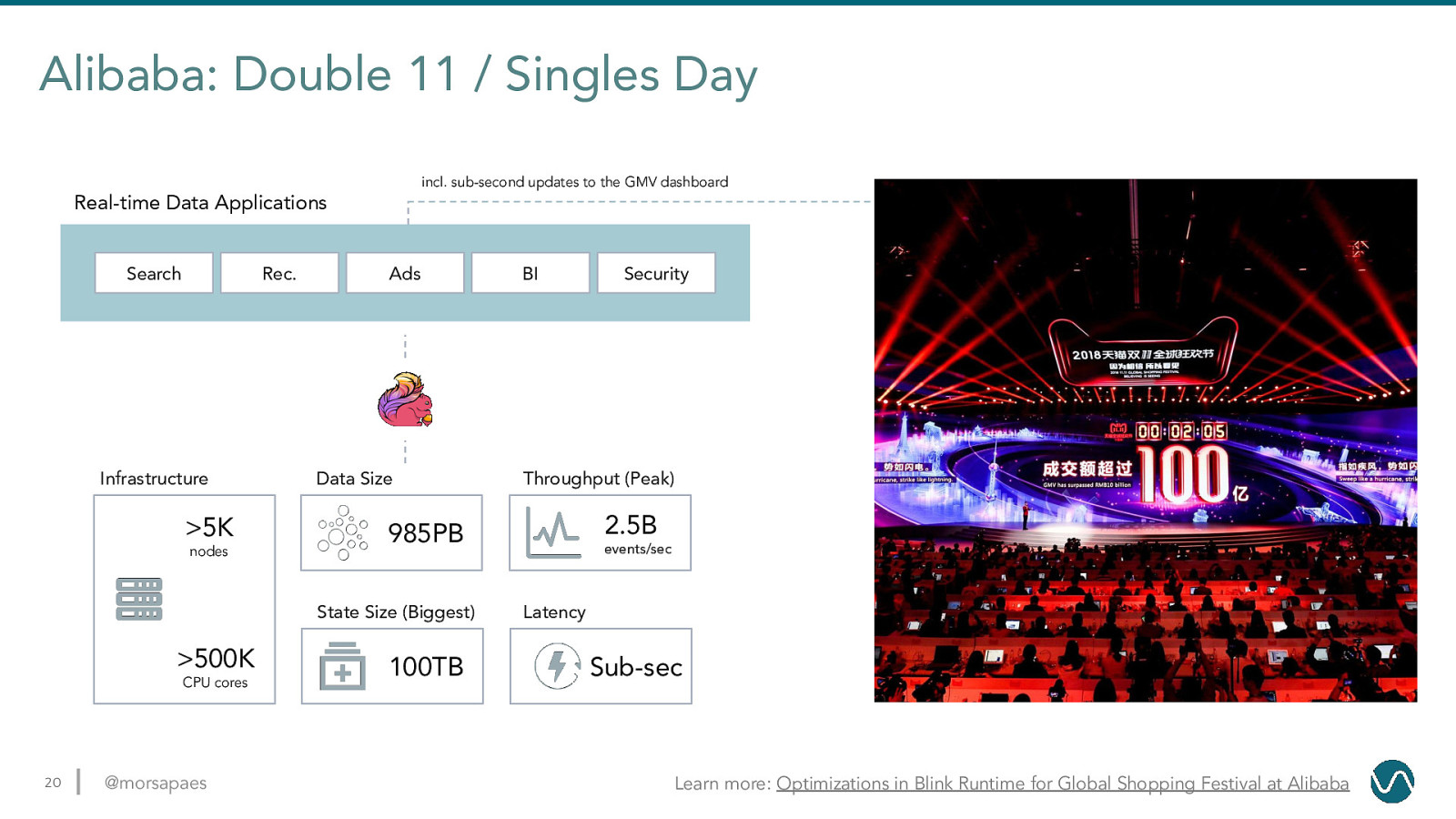
Alibaba: Double 11 / Singles Day incl. sub-second updates to the GMV dashboard Real-time Data Applications Search Rec. Infrastructure
5K nodes Ads Data Size CPU cores 20 @morsapaes 100TB Security Throughput (Peak) 2.5B 985PB State Size (Biggest) 500K BI events/sec Latency Sub-sec Learn more: Optimizations in Blink Runtime for Global Shopping Festival at Alibaba

…but you can also go small… @morsapaes
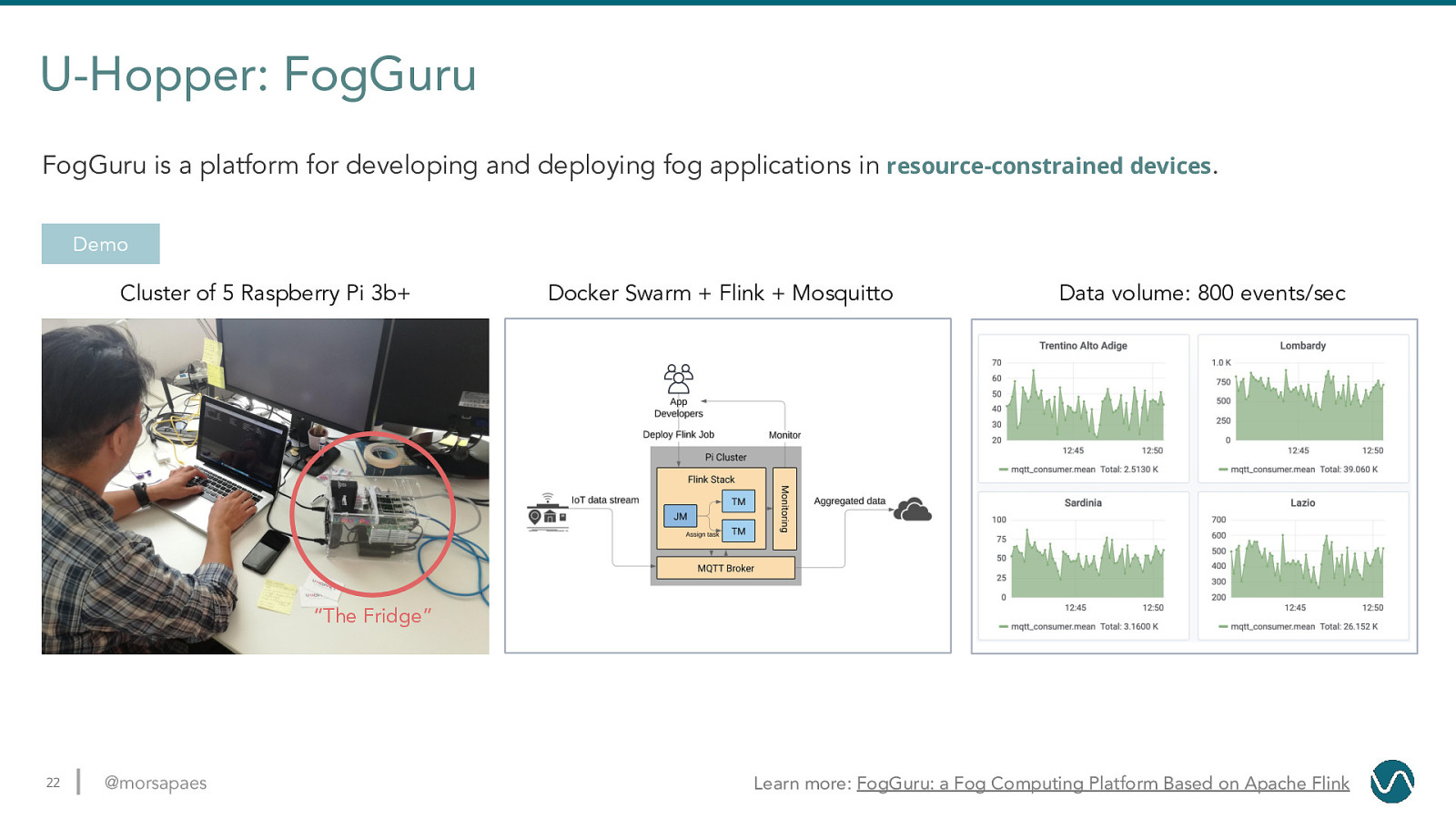
U-Hopper: FogGuru FogGuru is a platform for developing and deploying fog applications in resource-constrained devices. Demo Cluster of 5 Raspberry Pi 3b+ Docker Swarm + Flink + Mosquitto Data volume: 800 events/sec “The Fridge” 22 @morsapaes Learn more: FogGuru: a Fog Computing Platform Based on Apache Flink

…or just use your laptop + an IDE. @morsapaes
What Makes Flink…Flink? 24 @morsapaes Flexible APIs Stateful Processing High Performance Fault Tolerance
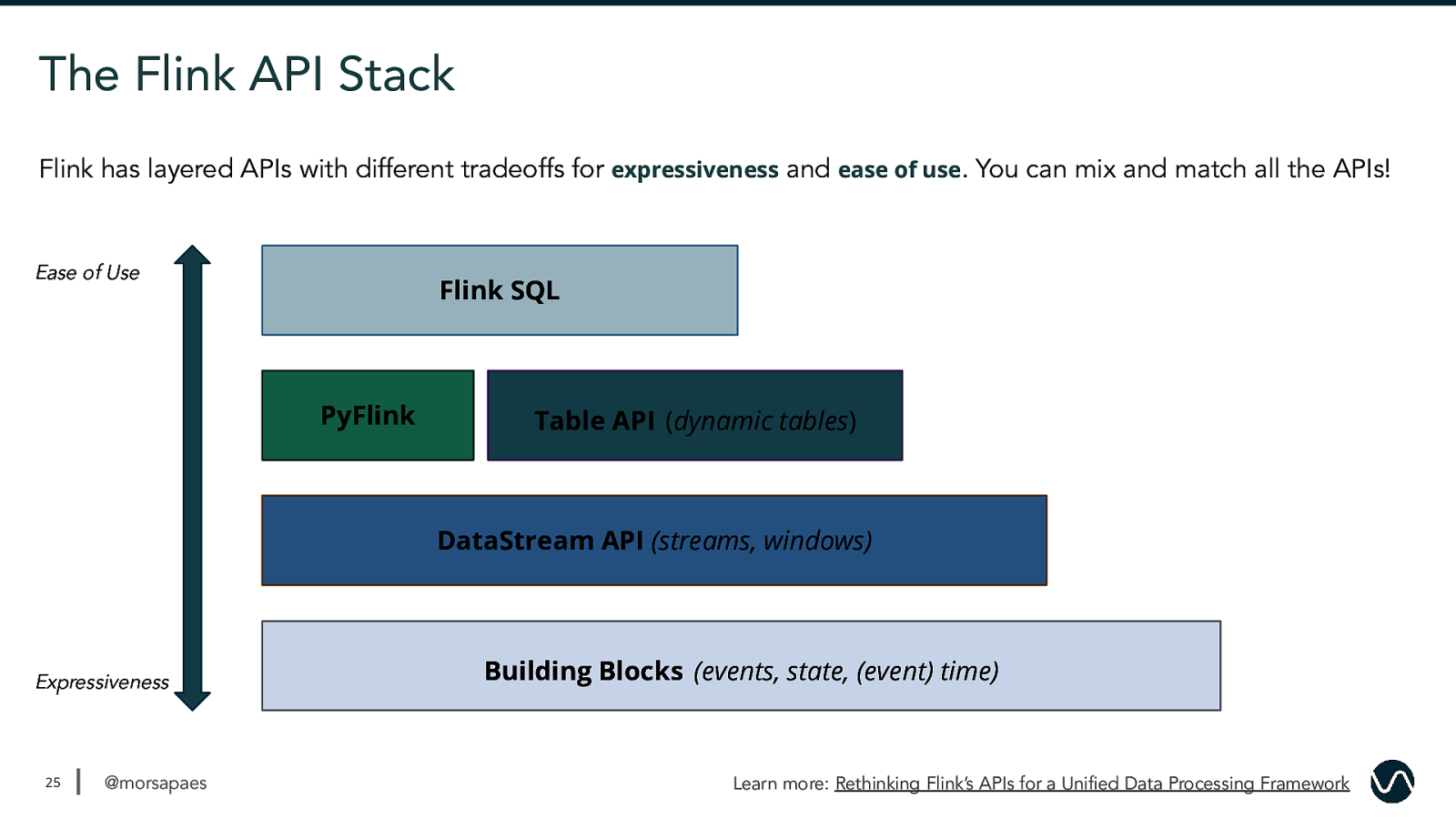
The Flink API Stack Flink has layered APIs with different tradeoffs for expressiveness and ease of use. You can mix and match all the APIs! Ease of Use Flink SQL PyFlink Table API (dynamic tables) 25 DataStream API (streams, windows) Expressiveness 25 @morsapaes Building Blocks (events, state, (event) time) Learn more: Rethinking Flink’s APIs for a Unified Data Processing Framework
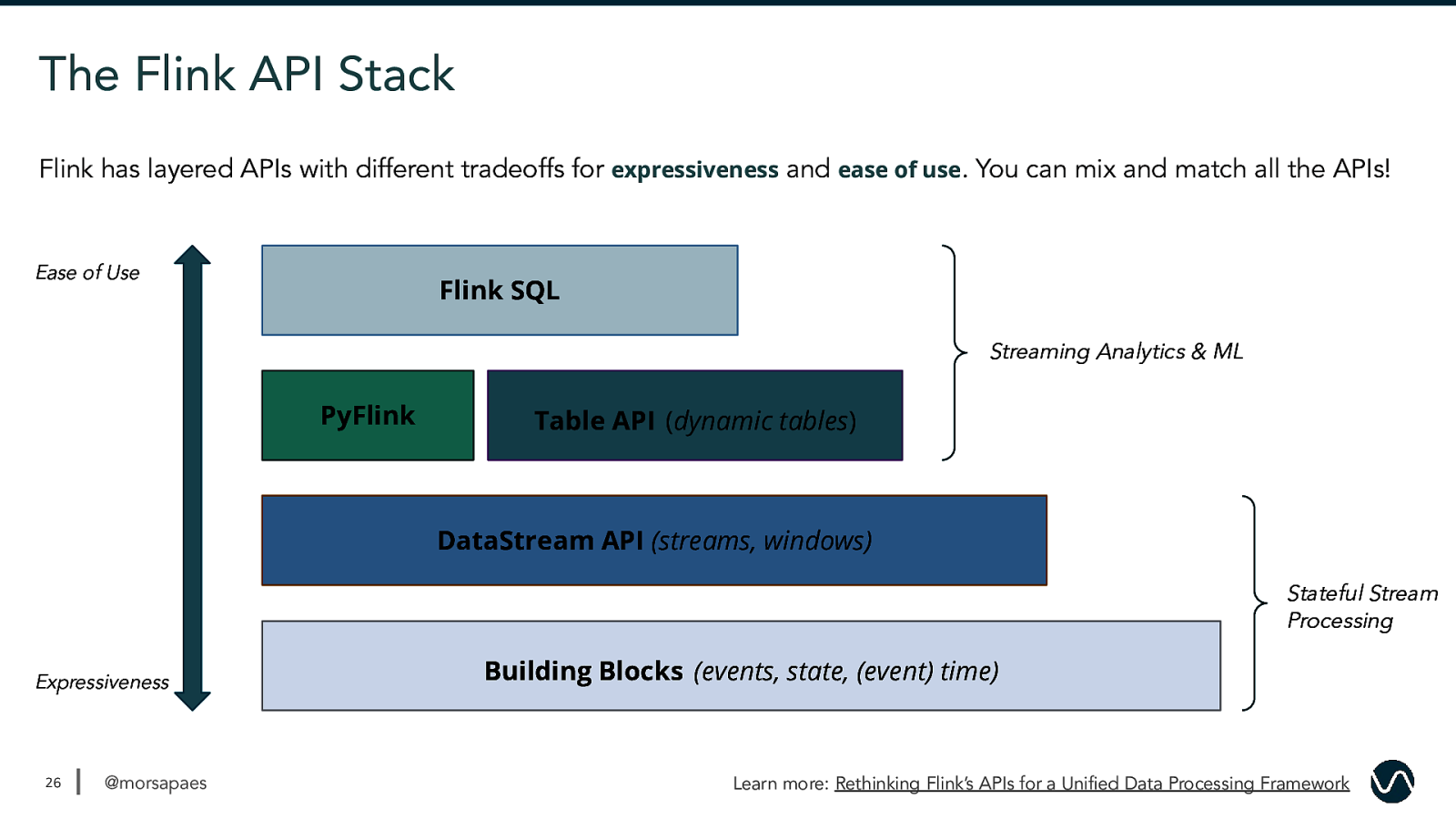
The Flink API Stack Flink has layered APIs with different tradeoffs for expressiveness and ease of use. You can mix and match all the APIs! Ease of Use Flink SQL Streaming Analytics & ML PyFlink Table API (dynamic tables) 26 DataStream API (streams, windows) Stateful Stream Processing Expressiveness 26 @morsapaes Building Blocks (events, state, (event) time) Learn more: Rethinking Flink’s APIs for a Unified Data Processing Framework

At the Core: Streaming Dataflows DataStream<SensorReading> sensorData = env.addSource(new FlinkKafkaConsumer(…)); Source DataStream<SensorReading> avgTemp = sensorData .map(r -> new SensorReading(r.id, r.timestamp, (r.temperature-32) * (5.0/9.0))) .keyBy(r -> r.id) .timeWindow(Time.seconds(5)) .apply(new TemperatureAverager()); Transformations avgTemp.addSink(new ElasticSearchSink(…)); Sink 27 @morsapaes

At the Core: Streaming Dataflows DataStream<SensorReading> sensorData = env.addSource(new FlinkKafkaConsumer(…)); Source DataStream<SensorReading> avgTemp = sensorData .map(r -> new SensorReading(r.id, r.timestamp, (r.temperature-32) * (5.0/9.0))) .keyBy(r -> r.id) .timeWindow(Time.seconds(5)) .apply(new TemperatureAverager()); Transformations avgTemp.addSink(new ElasticSearchSink(…)); Sink Streaming Dataflow State Source 28 @morsapaes Transform Window (state read/write) Sink
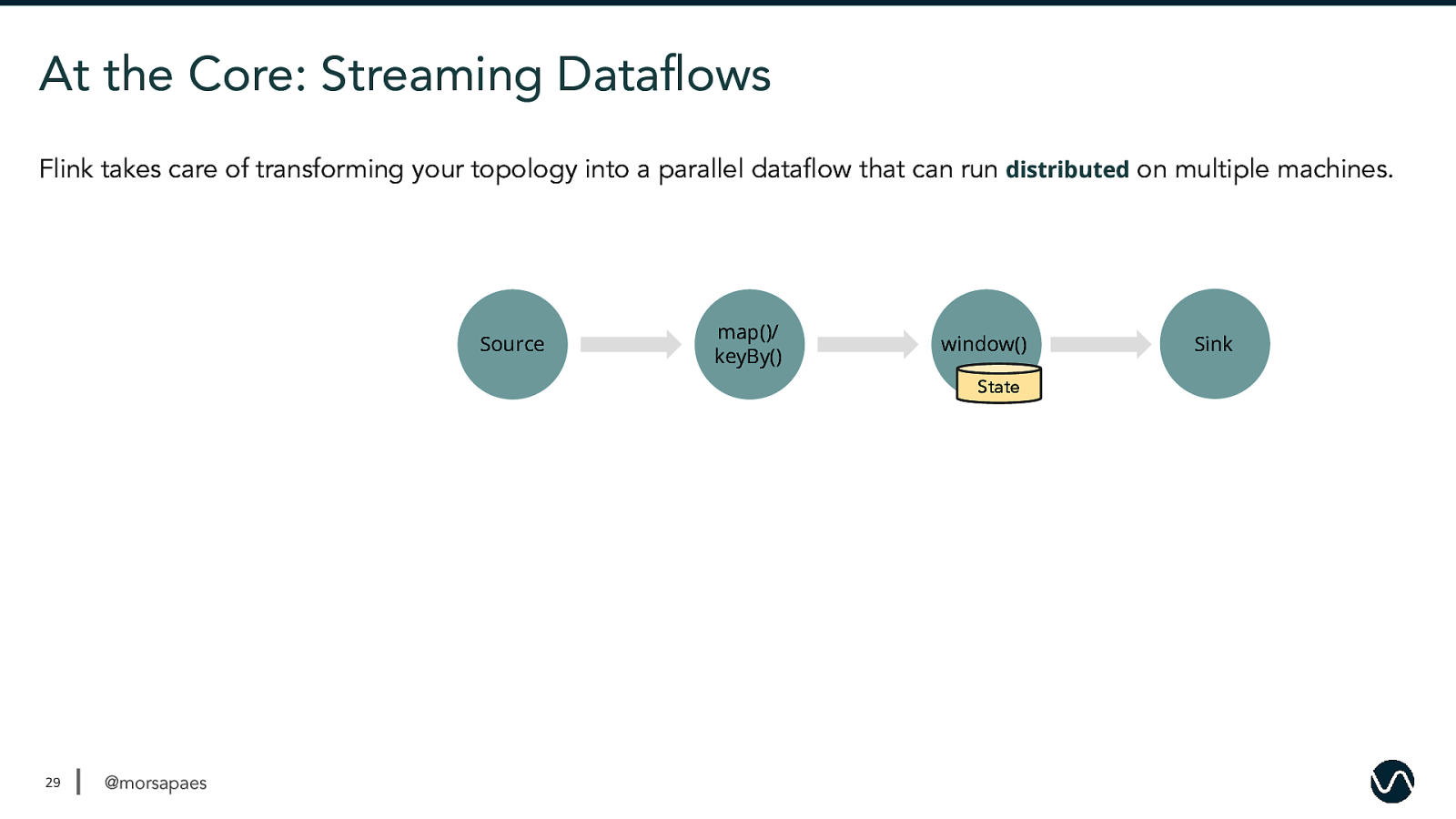
At the Core: Streaming Dataflows Flink takes care of transforming your topology into a parallel dataflow that can run distributed on multiple machines. Source map()/ keyBy() window() State 29 @morsapaes Sink
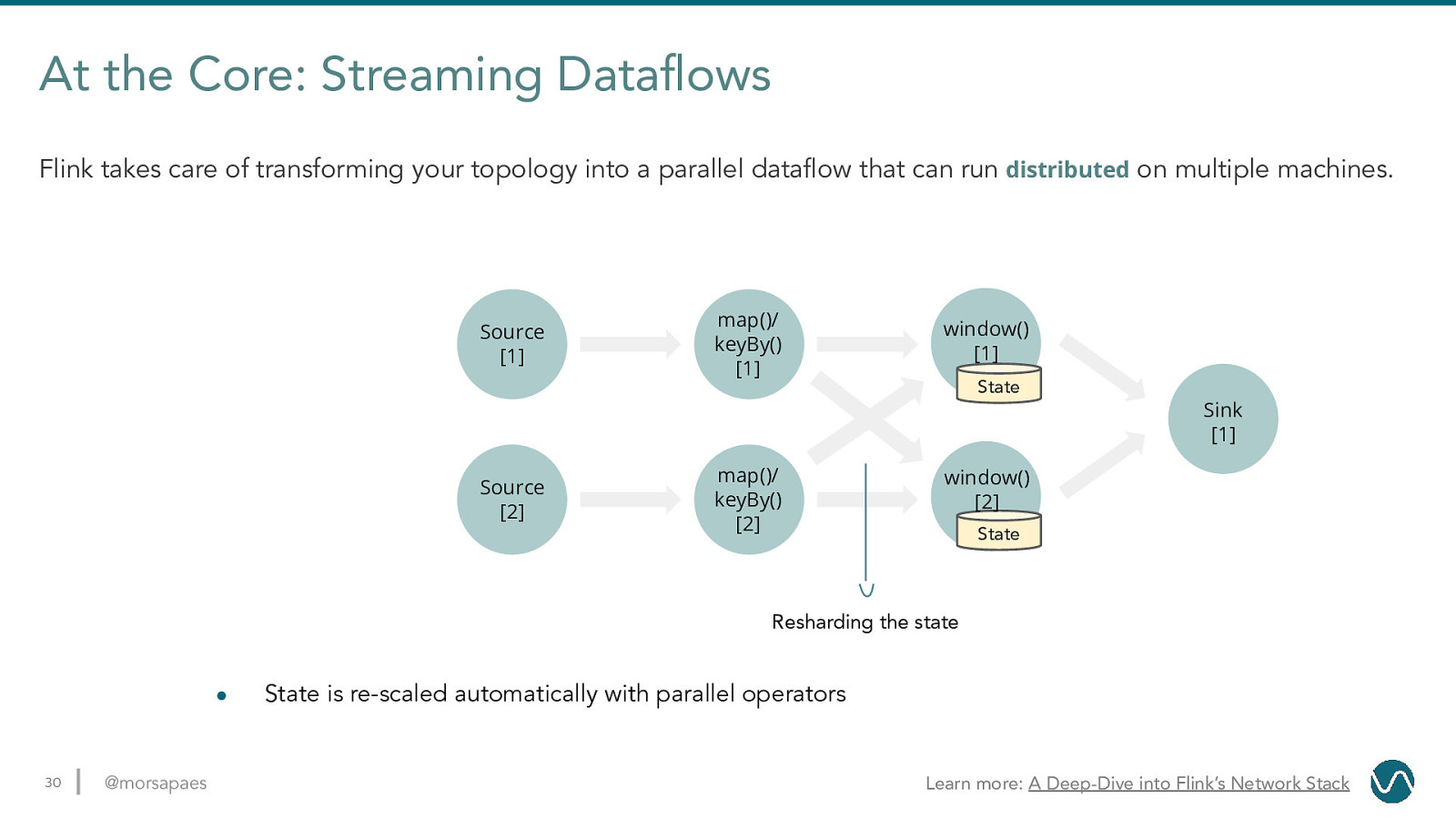
At the Core: Streaming Dataflows Flink takes care of transforming your topology into a parallel dataflow that can run distributed on multiple machines. Source [1] map()/ keyBy() [1] window() [1] State Sink [1] Source [2] map()/ keyBy() [2] window() [2] State Resharding the state ● 30 @morsapaes State is re-scaled automatically with parallel operators Learn more: A Deep-Dive into Flink’s Network Stack
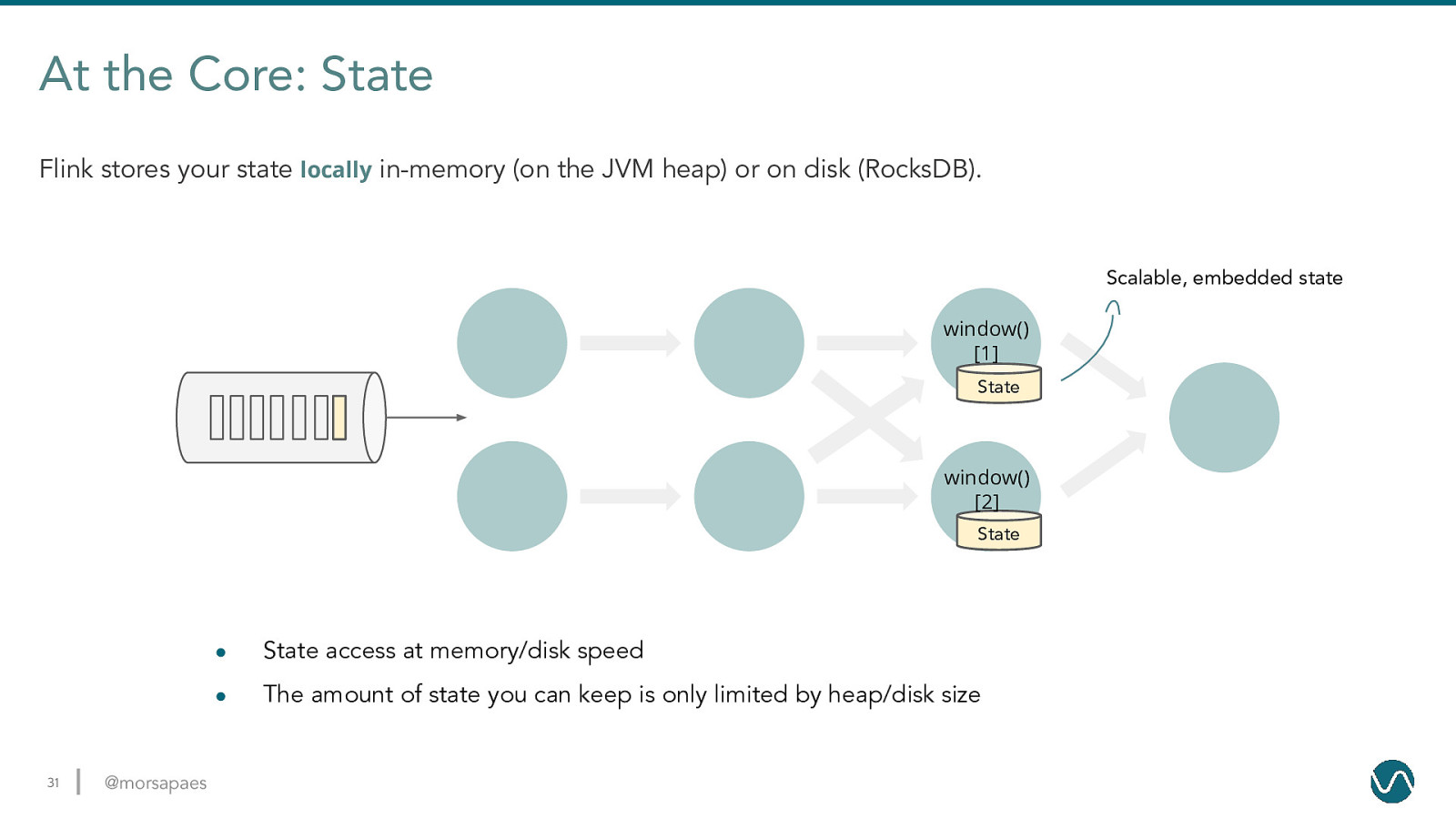
At the Core: State Flink stores your state locally in-memory (on the JVM heap) or on disk (RocksDB). Scalable, embedded state window() [1] State window() [2] State 31 @morsapaes ● State access at memory/disk speed ● The amount of state you can keep is only limited by heap/disk size
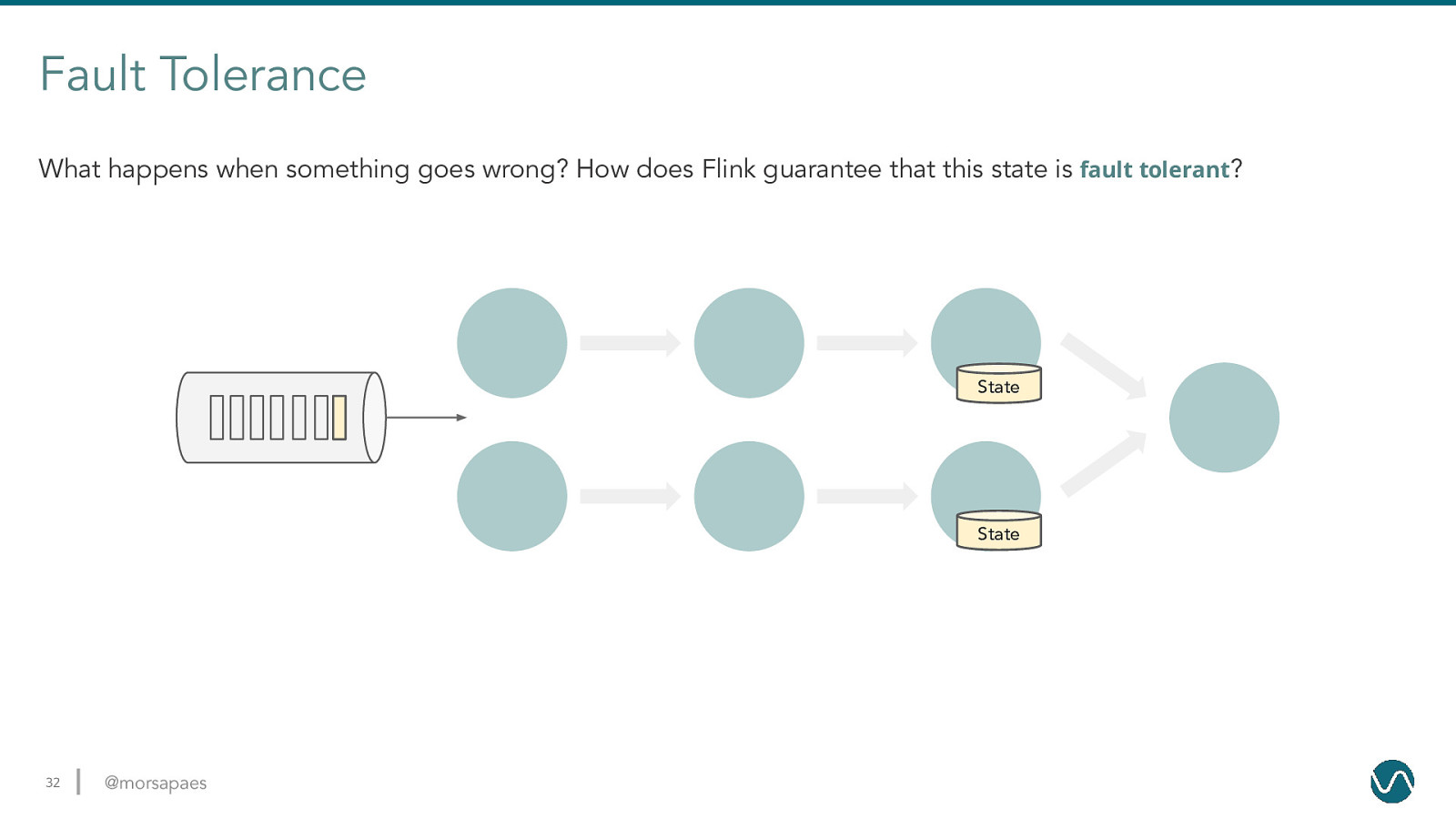
Fault Tolerance What happens when something goes wrong? How does Flink guarantee that this state is fault tolerant? State State 32 @morsapaes
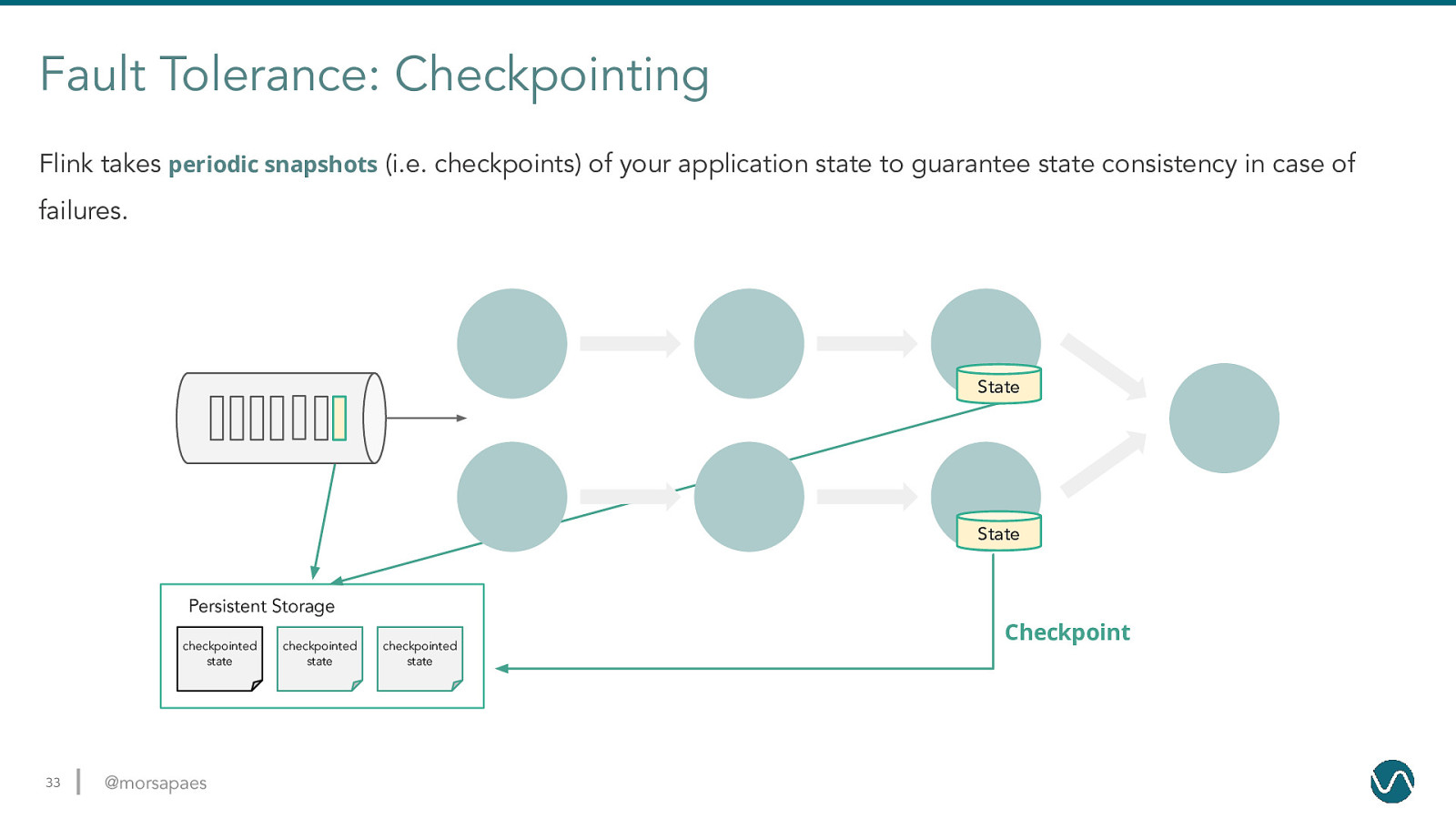
Fault Tolerance: Checkpointing Flink takes periodic snapshots (i.e. checkpoints) of your application state to guarantee state consistency in case of failures. State State Persistent Storage checkpointed state 33 @morsapaes checkpointed state checkpointed state Checkpoint

State State 34 @morsapaes
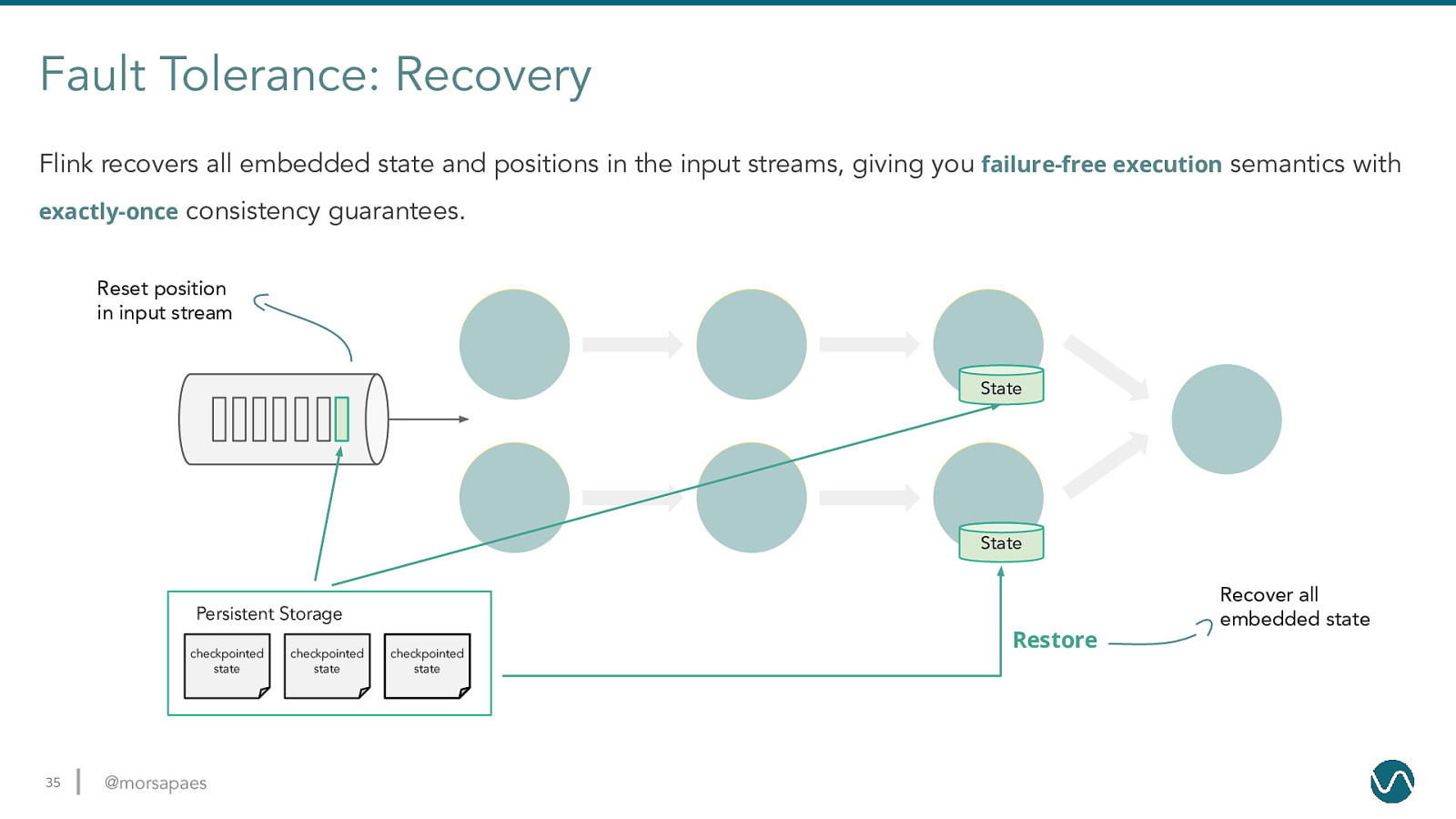
Fault Tolerance: Recovery Flink recovers all embedded state and positions in the input streams, giving you failure-free execution semantics with exactly-once consistency guarantees. Reset position in input stream State State Recover all embedded state Persistent Storage checkpointed state 35 @morsapaes checkpointed state checkpointed state Restore

Beyond Fault Tolerance You can also explicitly trigger these snapshots (i.e. savepoints) for planned, manual backup. Upgrades and Rollbacks Cross Datacenter Failover State Archiving Blue / Green Deployments 36 @morsapaes Schema Evolution Learn more: “State Unlocked”, Flink Forward Virtual Conference
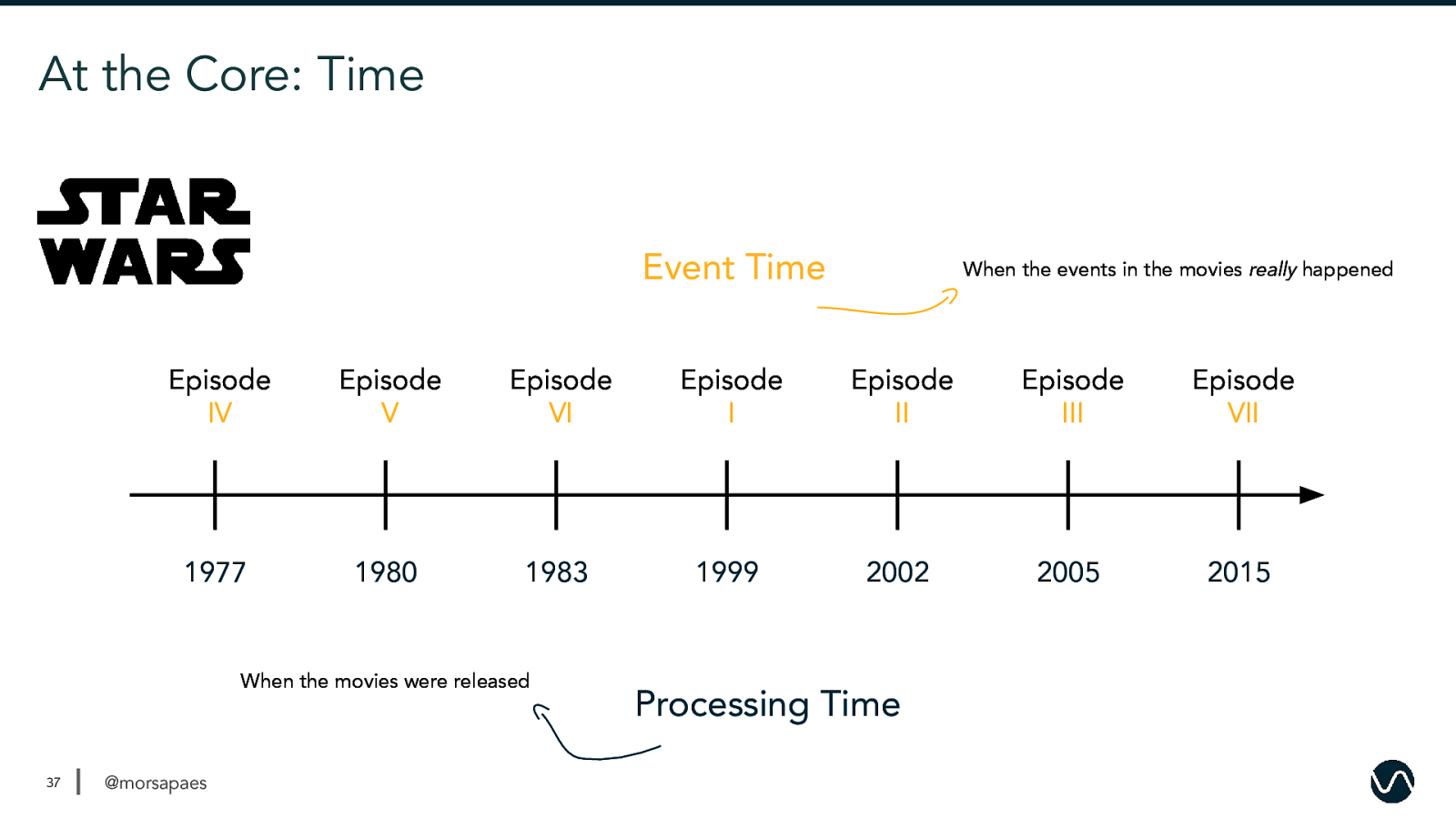
At the Core: Time Event Time Episode IV Episode V Episode VI Episode I Episode II Episode III Episode VII 1977 1980 1983 1999 2002 2005 2015 When the movies were released 37 When the events in the movies really happened @morsapaes Processing Time
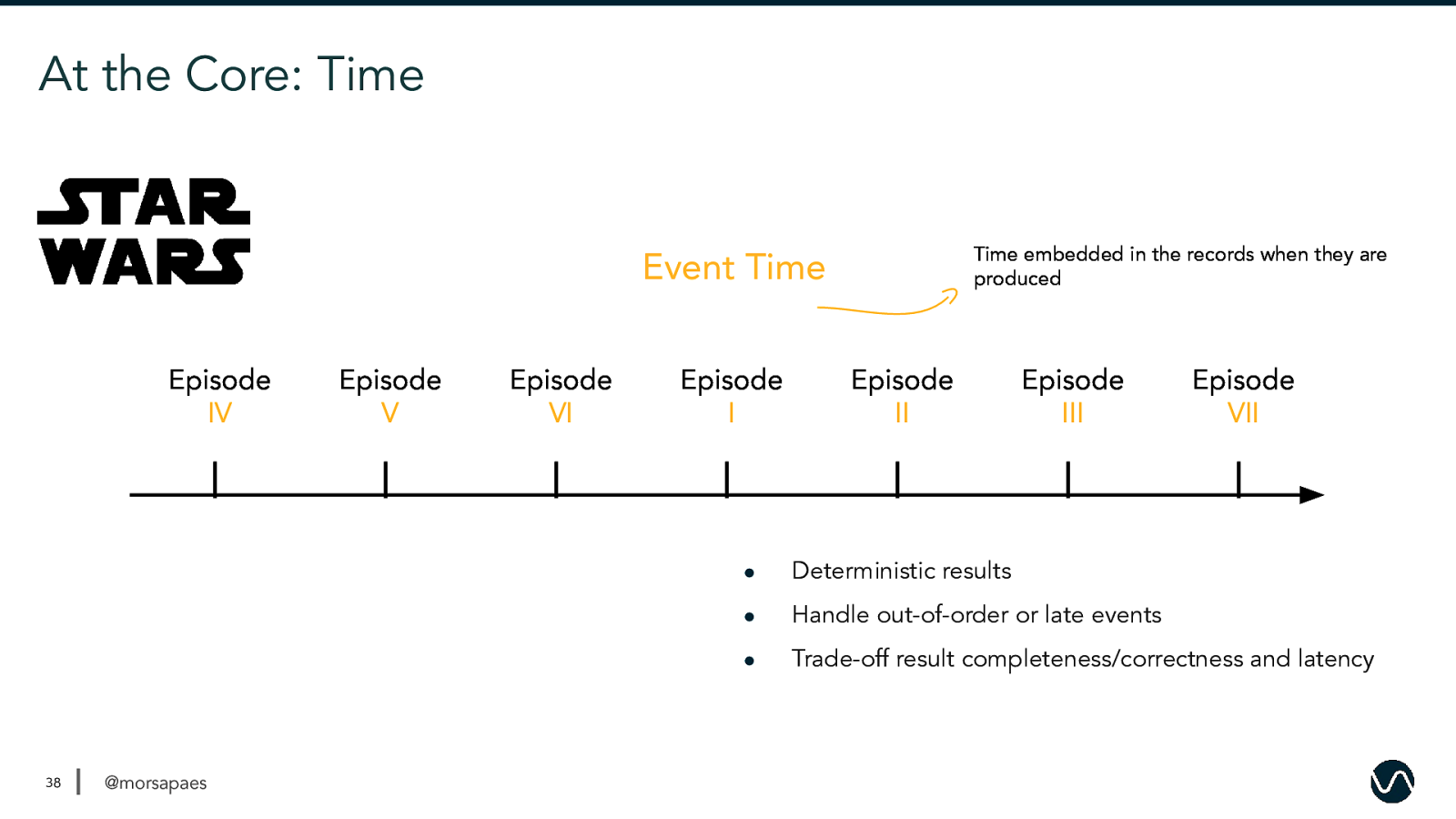
At the Core: Time Time embedded in the records when they are produced Event Time Episode IV 38 @morsapaes Episode V Episode VI Episode I Episode II Episode III Episode VII ● Deterministic results ● Handle out-of-order or late events ● Trade-off result completeness/correctness and latency
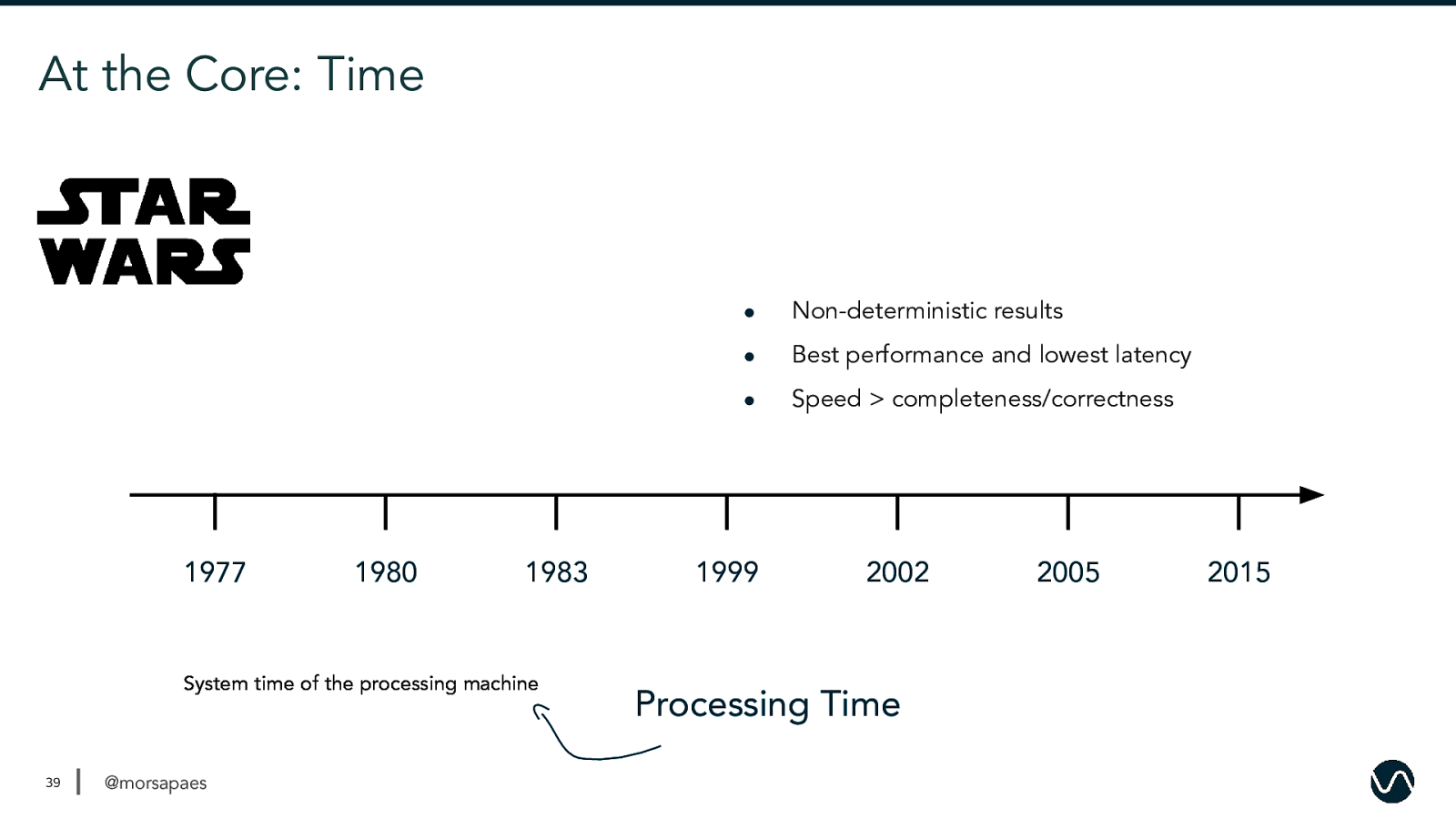
At the Core: Time 1977 1980 1983 System time of the processing machine 39 @morsapaes ● Non-deterministic results ● Best performance and lowest latency ● Speed > completeness/correctness 1999 2002 Processing Time 2005 2015
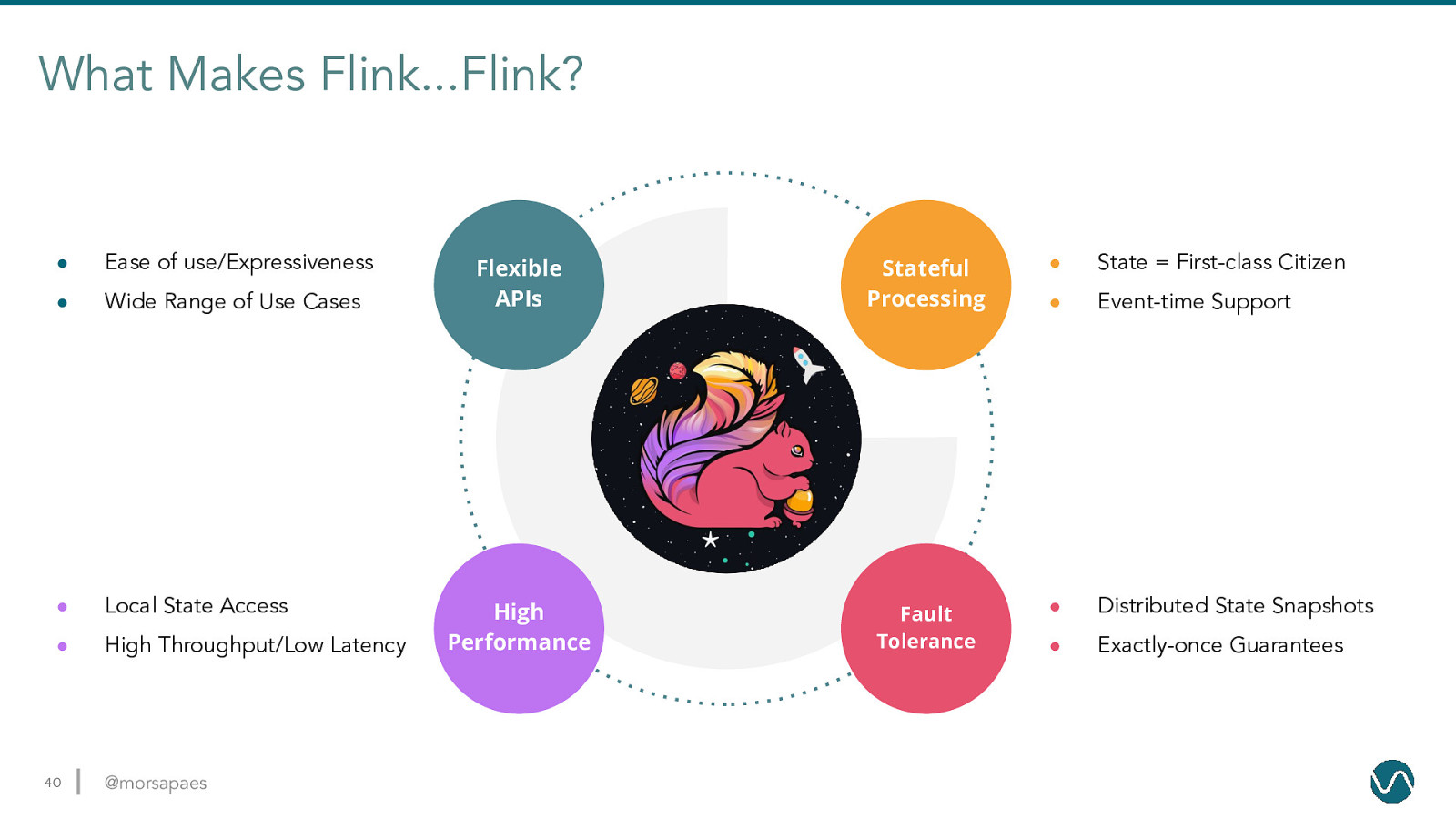
What Makes Flink…Flink? ● Ease of use/Expressiveness ● Wide Range of Use Cases ● Local State Access ● High Throughput/Low Latency 40 @morsapaes Flexible APIs Stateful Processing ● State = First-class Citizen ● Event-time Support High Performance Fault Tolerance ● Distributed State Snapshots ● Exactly-once Guarantees
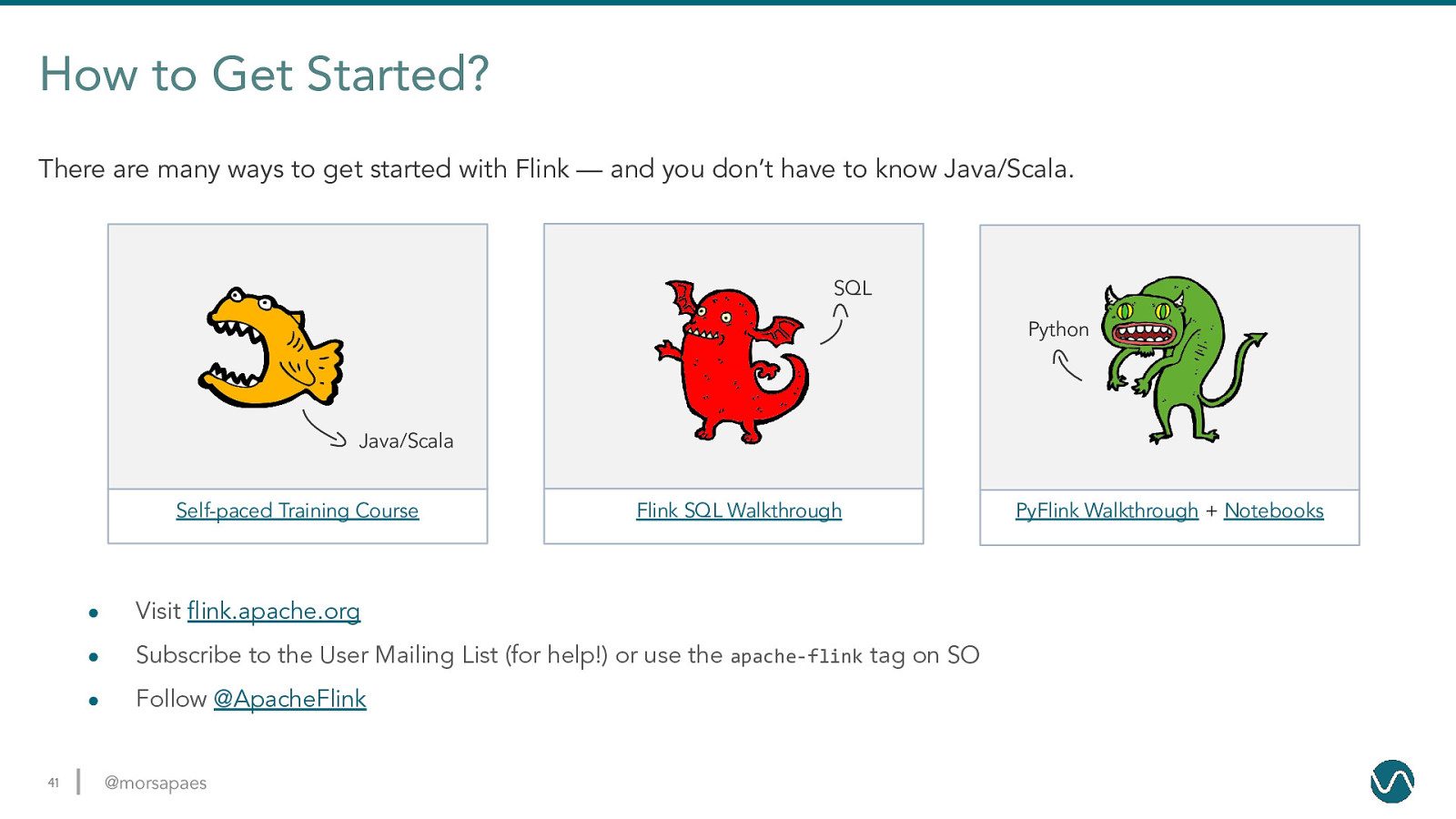
How to Get Started? There are many ways to get started with Flink — and you don’t have to know Java/Scala. SQL Python Java/Scala Self-paced Training Course 41 Flink SQL Walkthrough ● Visit flink.apache.org ● Subscribe to the User Mailing List (for help!) or use the apache-flink tag on SO ● Follow @ApacheFlink @morsapaes PyFlink Walkthrough + Notebooks
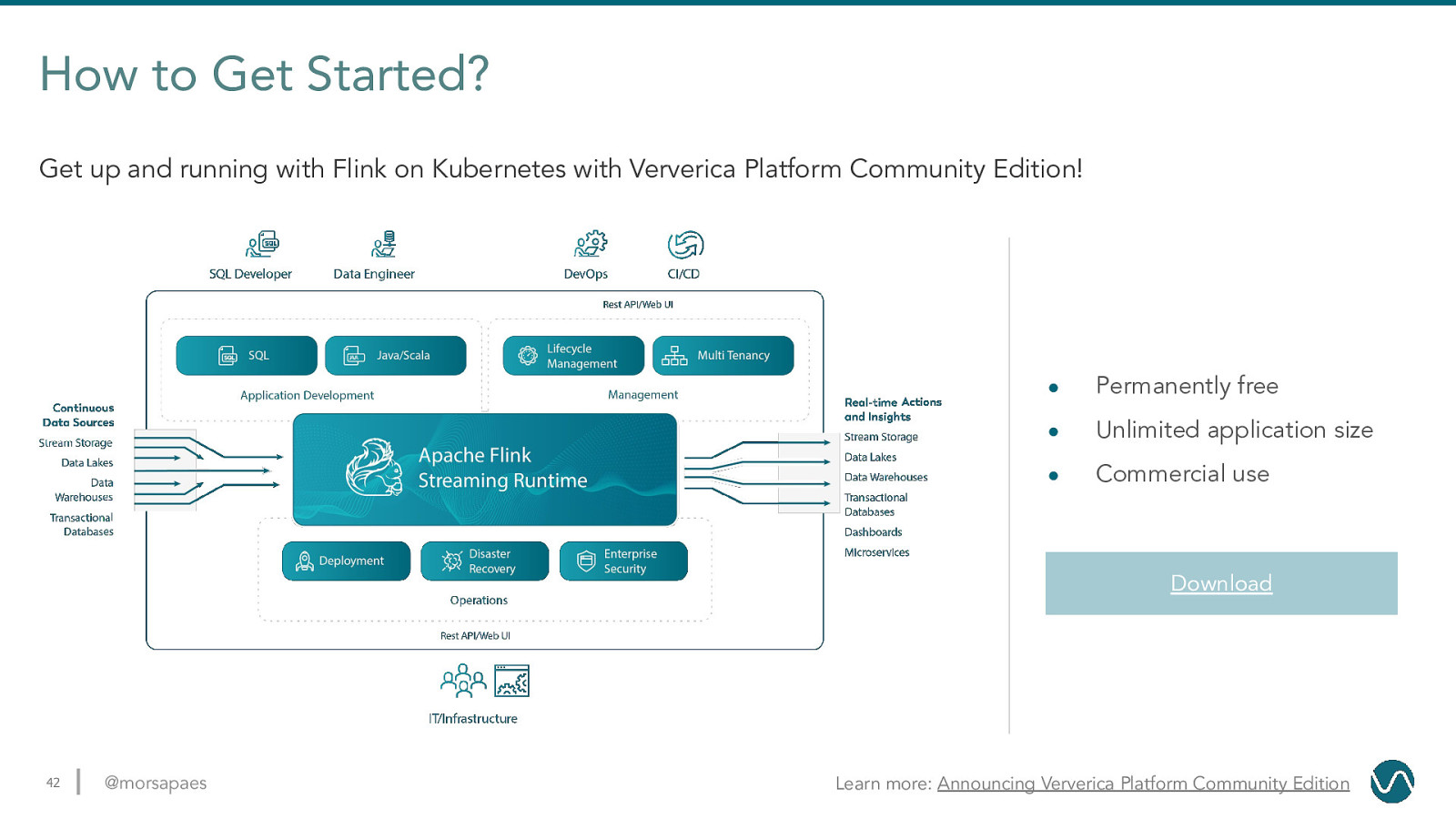
How to Get Started? Get up and running with Flink on Kubernetes with Ververica Platform Community Edition! ● Permanently free ● Unlimited application size ● Commercial use Download 42 @morsapaes Learn more: Announcing Ververica Platform Community Edition

Thank you! Marta Paes (@morsapaes) Developer Advocate © 2020 Ververica