Change Data Capture With Flink SQL and Debezium Marta Paes (@morsapaes) Developer Advocate © 2020 Ververica

A presentation at ApacheCon in September 2020 in by Marta Paes

Change Data Capture With Flink SQL and Debezium Marta Paes (@morsapaes) Developer Advocate © 2020 Ververica

About Ververica Original Creators of Apache Flink® 2 @morsapaes Enterprise Stream Processing With Ververica Platform Part of Alibaba Group Try out Ververica Platform Community Edition (free forever!): https://www.ververica.com/platform

What’s Wrong? 3 @morsapaes
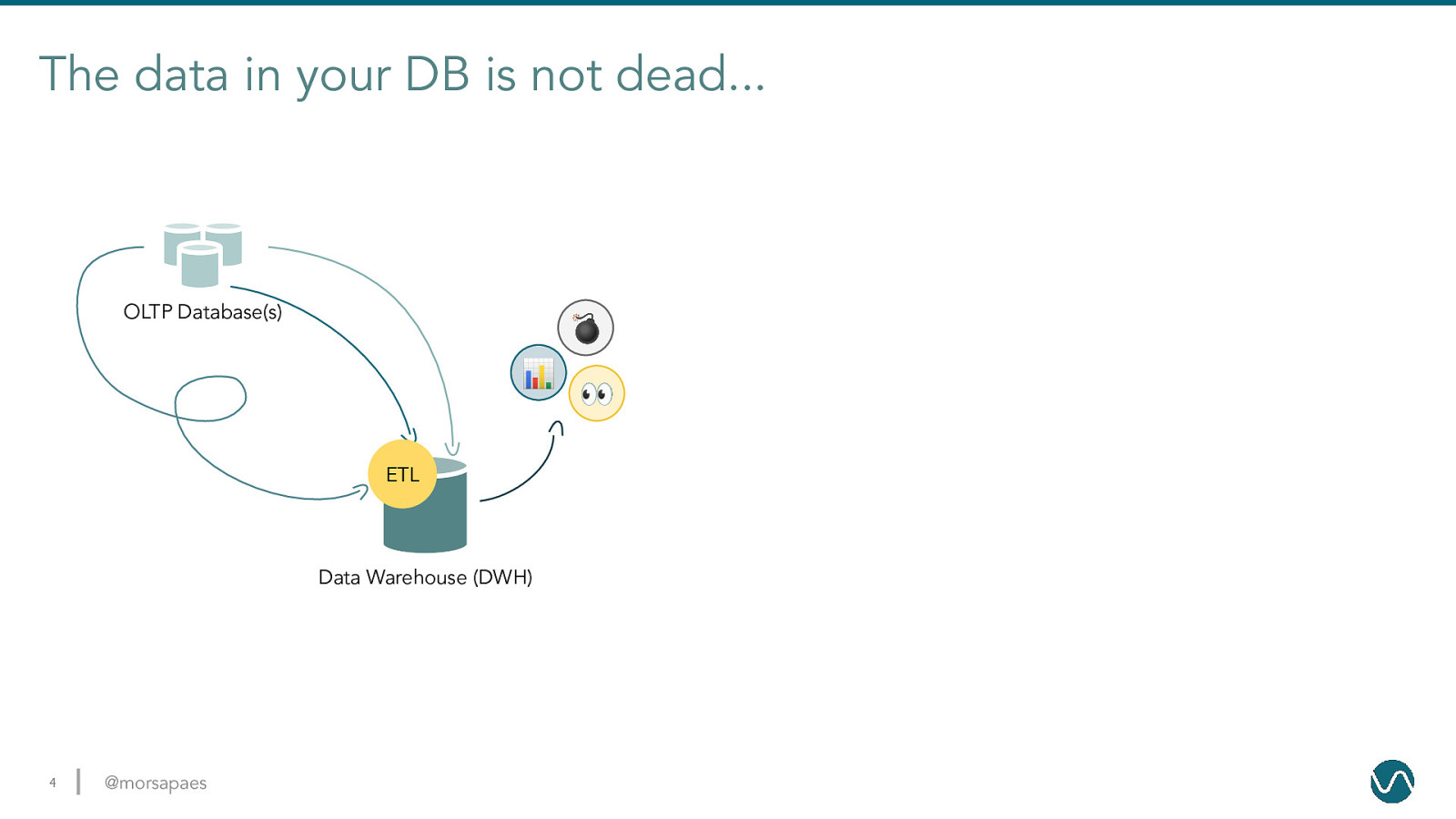
The data in your DB is not dead… OLTP Database(s) 💣 📊 ETL Data Warehouse (DWH) 4 @morsapaes 👀
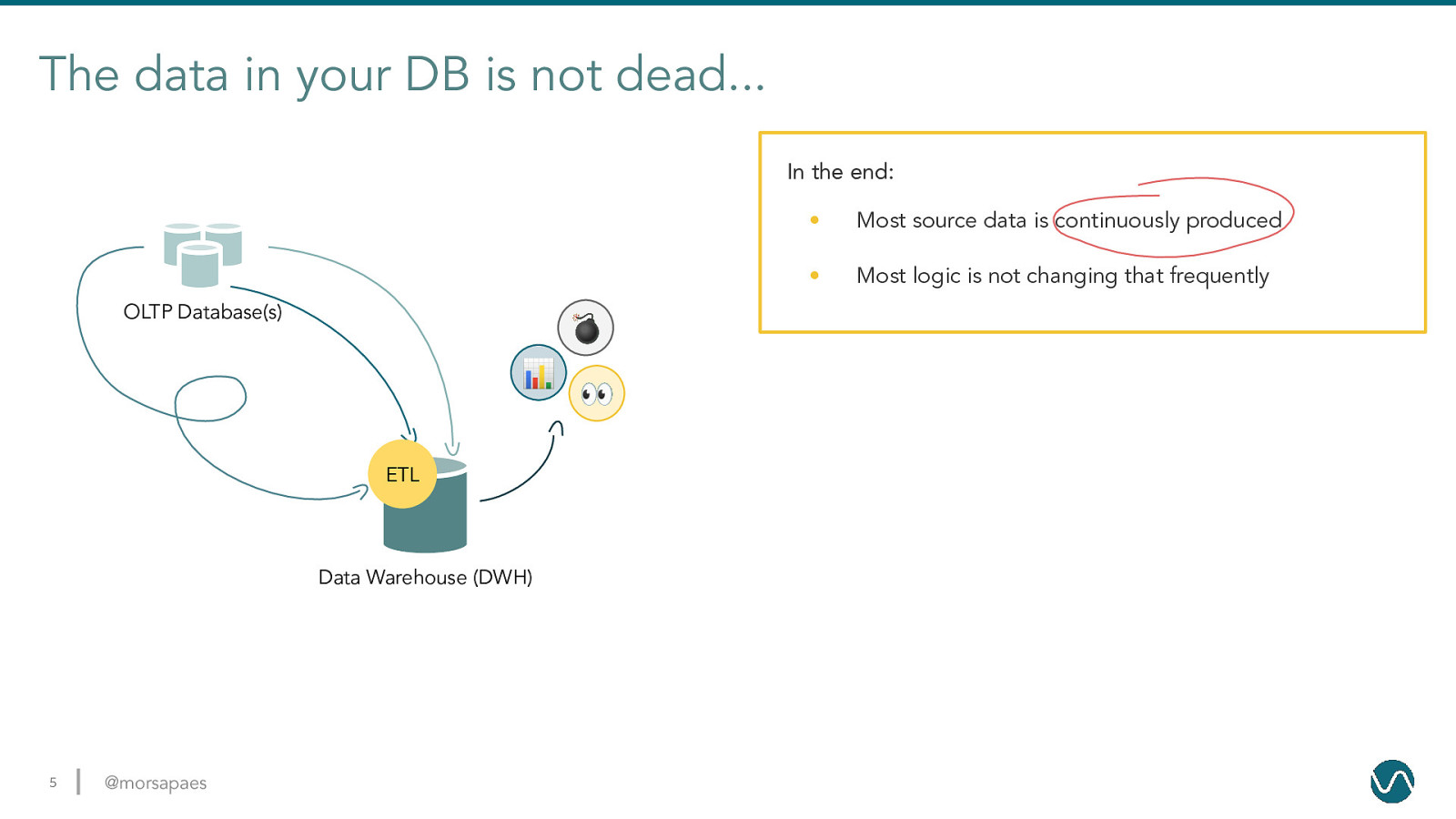
The data in your DB is not dead… In the end: OLTP Database(s) 💣 📊 ETL Data Warehouse (DWH) 5 @morsapaes 👀 • Most source data is continuously produced • Most logic is not changing that frequently

The data in your DB is not dead… In the end: OLTP Database(s) • Most source data is continuously produced • Most logic is not changing that frequently • Why are we looking at yesterday’s data? • Why are we not distributing the workload? • Why are we letting the data go “stale”? 💣 A source of events? 📊 ETL 👀 Data Warehouse (DWH) …but your integrations might be killing its value (and also some DBAs). 6 @morsapaes

Can’t wait to scan a production database for changes using a 100-line query with 1000 business logic conditions. — No one 7 @morsapaes
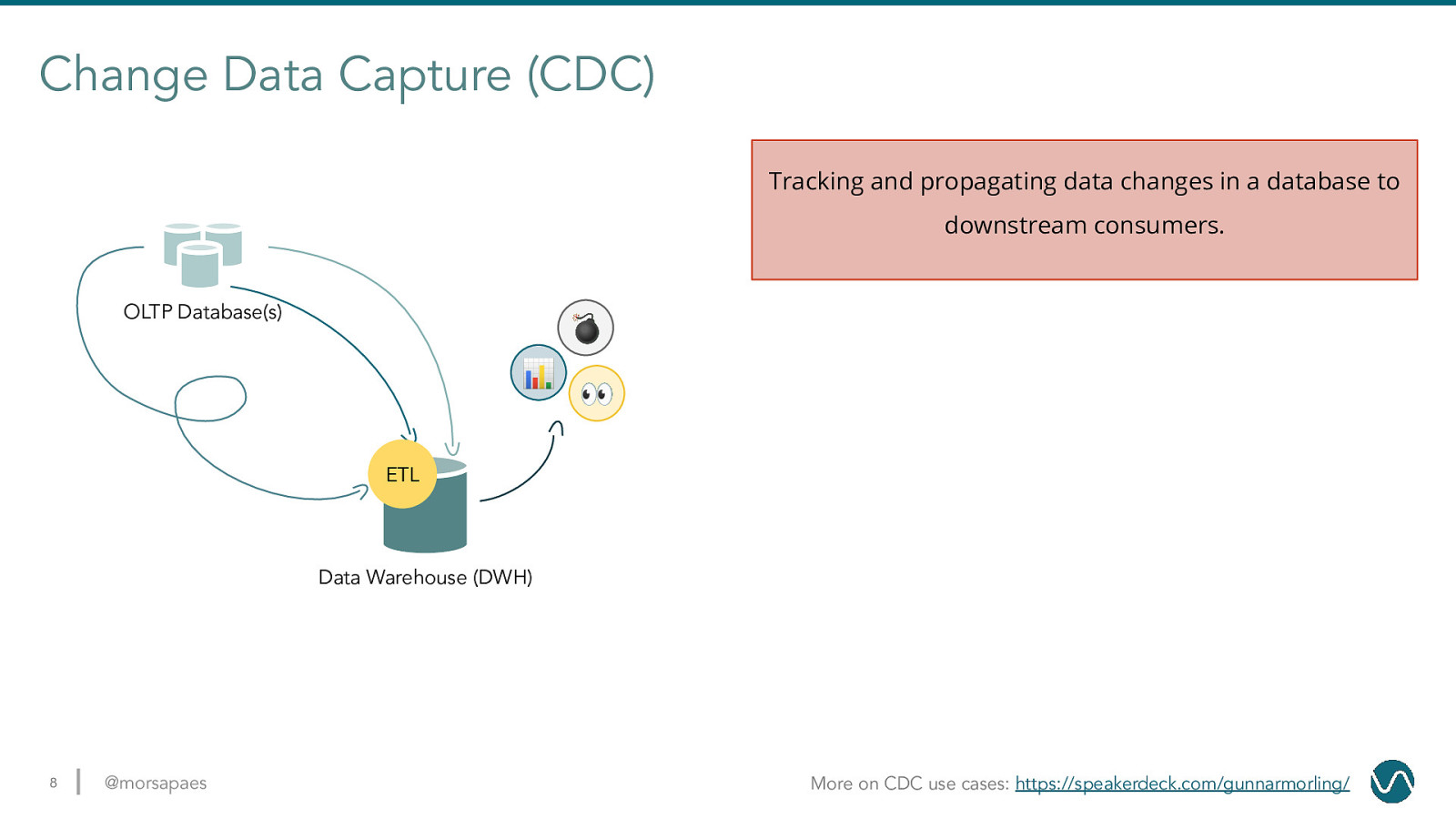
Change Data Capture (CDC) Tracking and propagating data changes in a database to downstream consumers. OLTP Database(s) 💣 📊 👀 ETL Data Warehouse (DWH) 8 @morsapaes More on CDC use cases: https://speakerdeck.com/gunnarmorling/
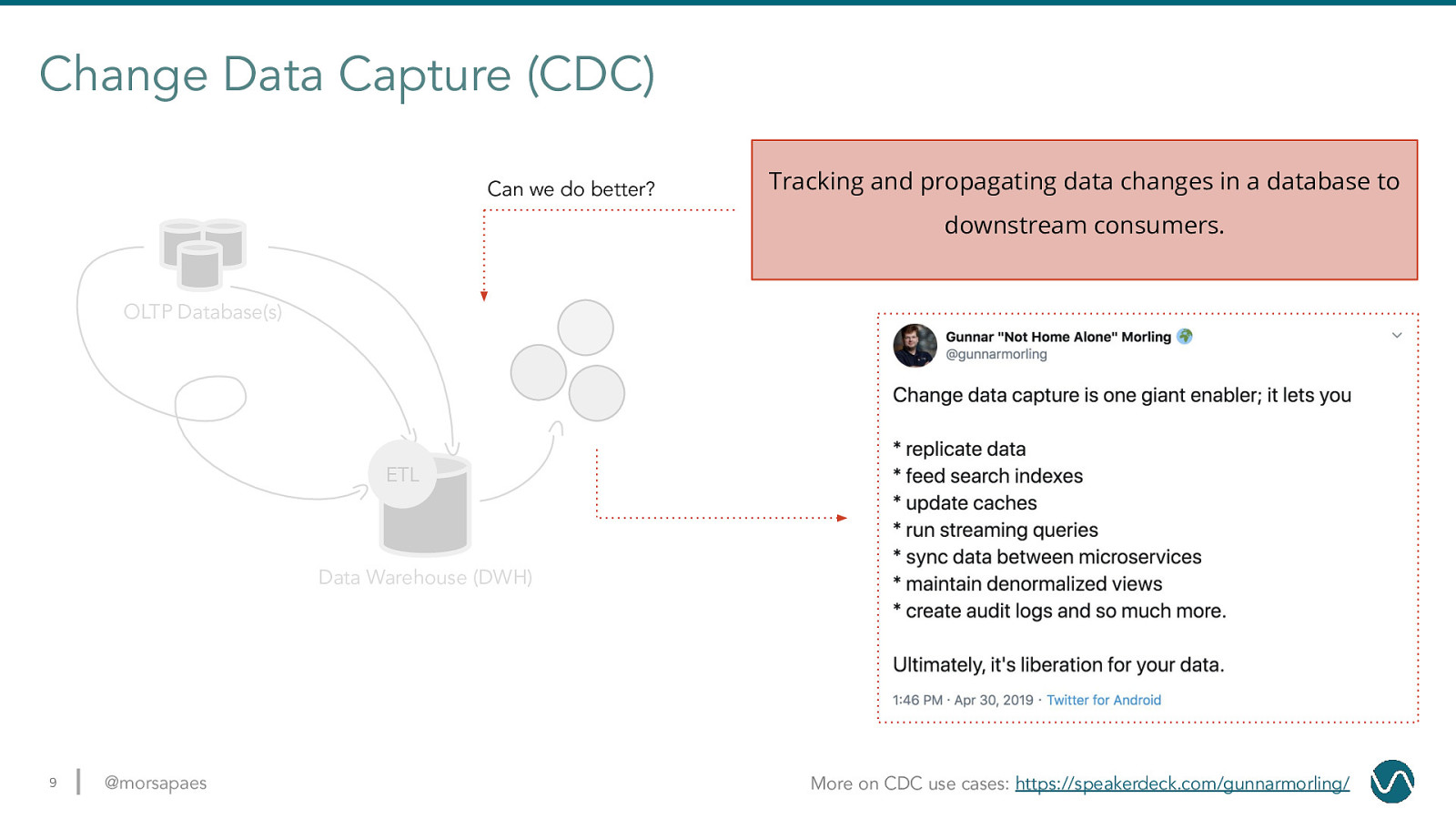
Change Data Capture (CDC) Can we do better? Tracking and propagating data changes in a database to downstream consumers. OLTP Database(s) ETL Data Warehouse (DWH) 9 @morsapaes More on CDC use cases: https://speakerdeck.com/gunnarmorling/

Not all CDC is created equal Query-based CDC 10 ❌ Some data changes might get lost ❌ DELETE operations are not captured ❌ Trade-off: frequency vs. load on source DBs ❌ Can’t propagate schema changes @morsapaes
Not all CDC is created equal Query-based CDC What if we tapped into the transaction log? 11 @morsapaes
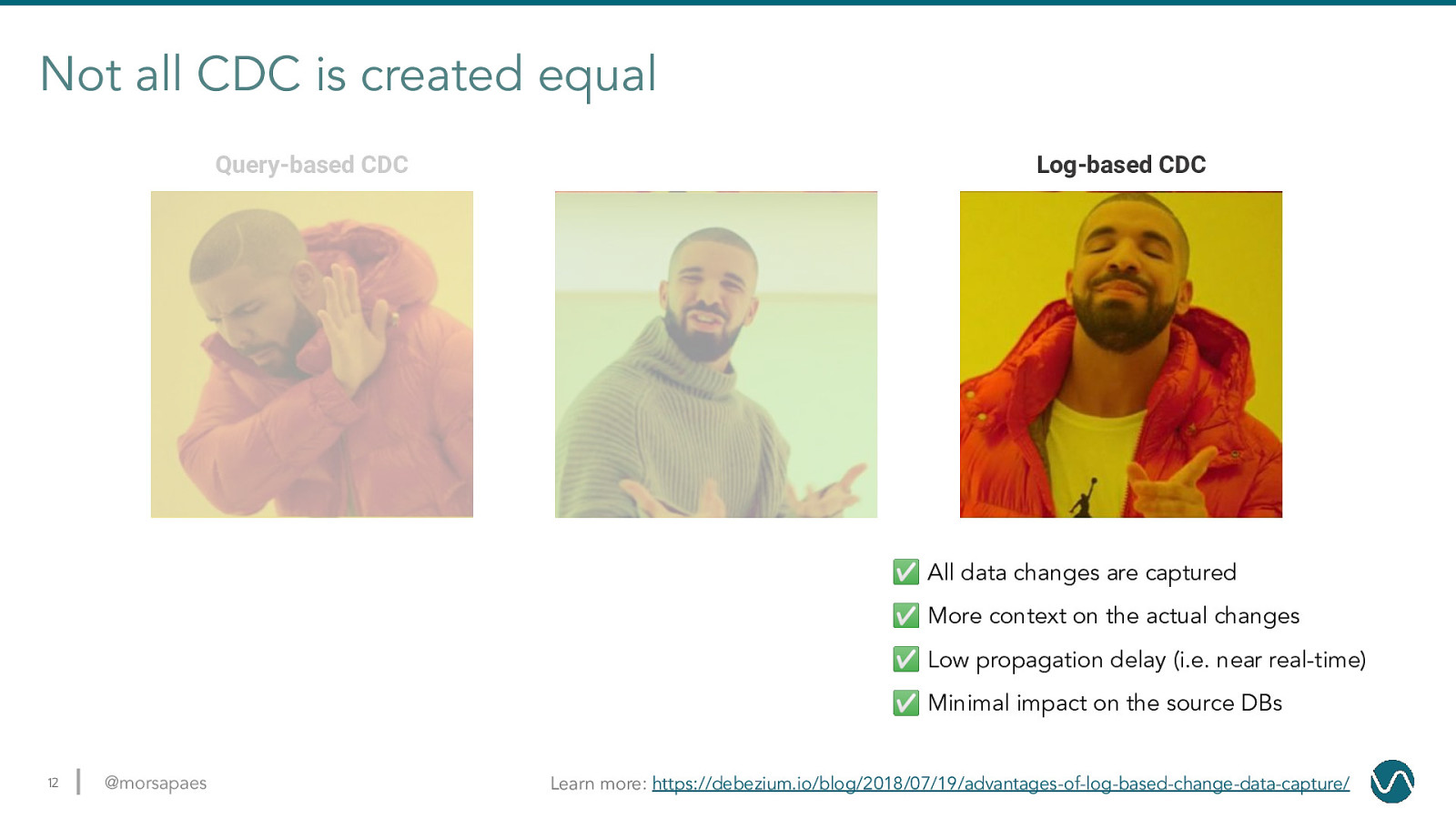
Not all CDC is created equal Query-based CDC Log-based CDC ✅ All data changes are captured ✅ More context on the actual changes ✅ Low propagation delay (i.e. near real-time) ✅ Minimal impact on the source DBs 12 @morsapaes Learn more: https://debezium.io/blog/2018/07/19/advantages-of-log-based-change-data-capture/
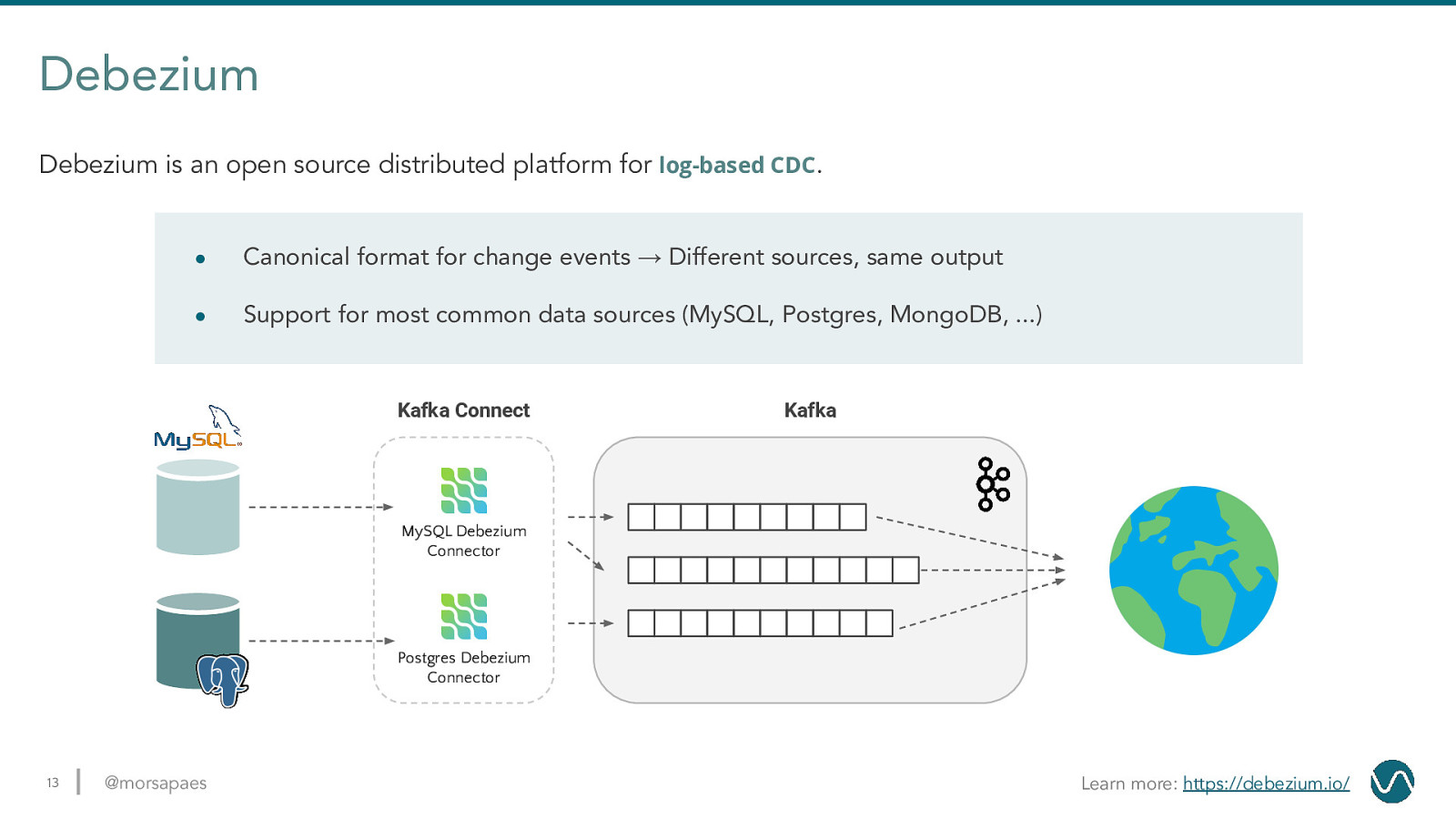
Debezium Debezium is an open source distributed platform for log-based CDC. ● Canonical format for change events → Different sources, same output ● Support for most common data sources (MySQL, Postgres, MongoDB, …) Kafka Connect Kafka MySQL Debezium Connector Postgres Debezium Connector 13 @morsapaes Learn more: https://debezium.io/
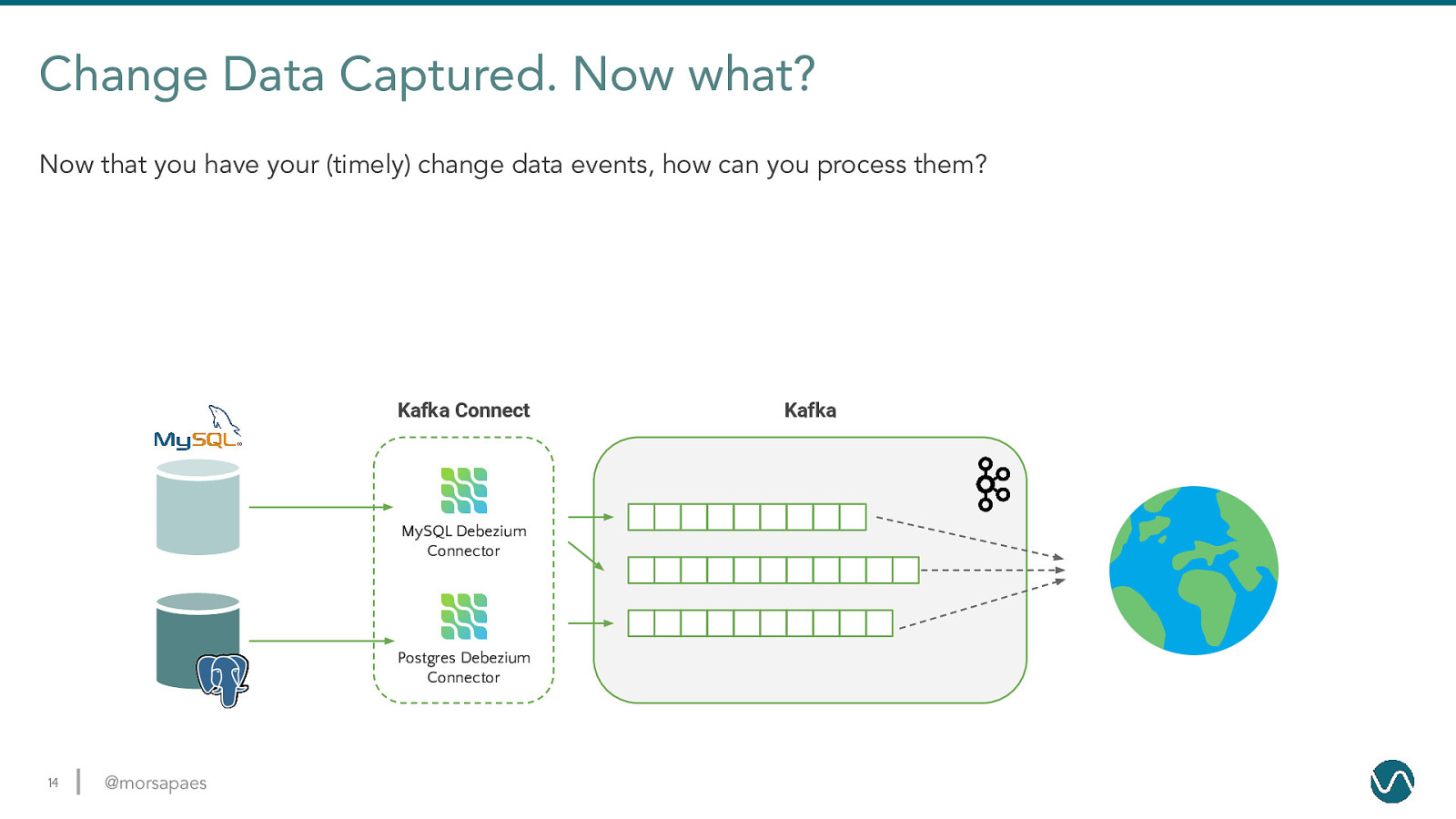
Change Data Captured. Now what? Now that you have your (timely) change data events, how can you process them? Kafka Connect MySQL Debezium Connector Postgres Debezium Connector 14 @morsapaes Kafka
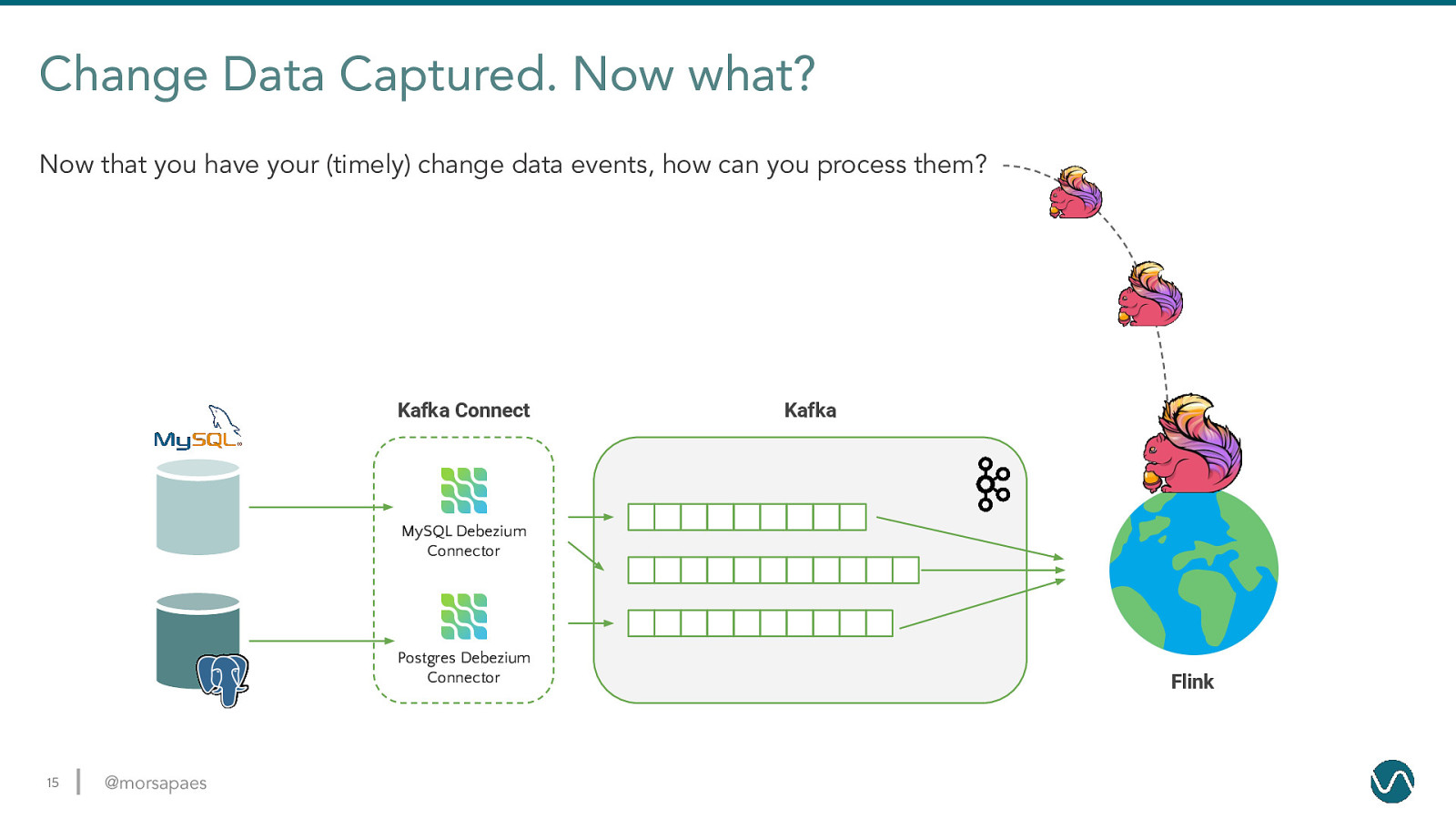
Change Data Captured. Now what? Now that you have your (timely) change data events, how can you process them? Kafka Connect Kafka MySQL Debezium Connector Postgres Debezium Connector 15 @morsapaes Flink
What is Apache Flink? Flink is an open source framework and distributed engine for stateful stream processing. Flink Runtime Stateful Computations over Data Streams 16 @morsapaes Learn more: flink.apache.org

What is Apache Flink? Flink is an open source framework and distributed engine for stateful stream processing. High Performance Fault Tolerance Stateful Processing Flexible APIs Flink Runtime Stateful Computations over Data Streams 17 @morsapaes Learn more: flink.apache.org

What is Apache Flink? This gives you a robust foundation for a wide range of use cases: Streaming Analytics & ML Stateful Stream Processing Event-Driven Applications Streams, State, Time SQL, PyFlink, Tables Stateful Functions Flink Runtime Stateful Computations over Data Streams 18 @morsapaes Learn more: flink.apache.org
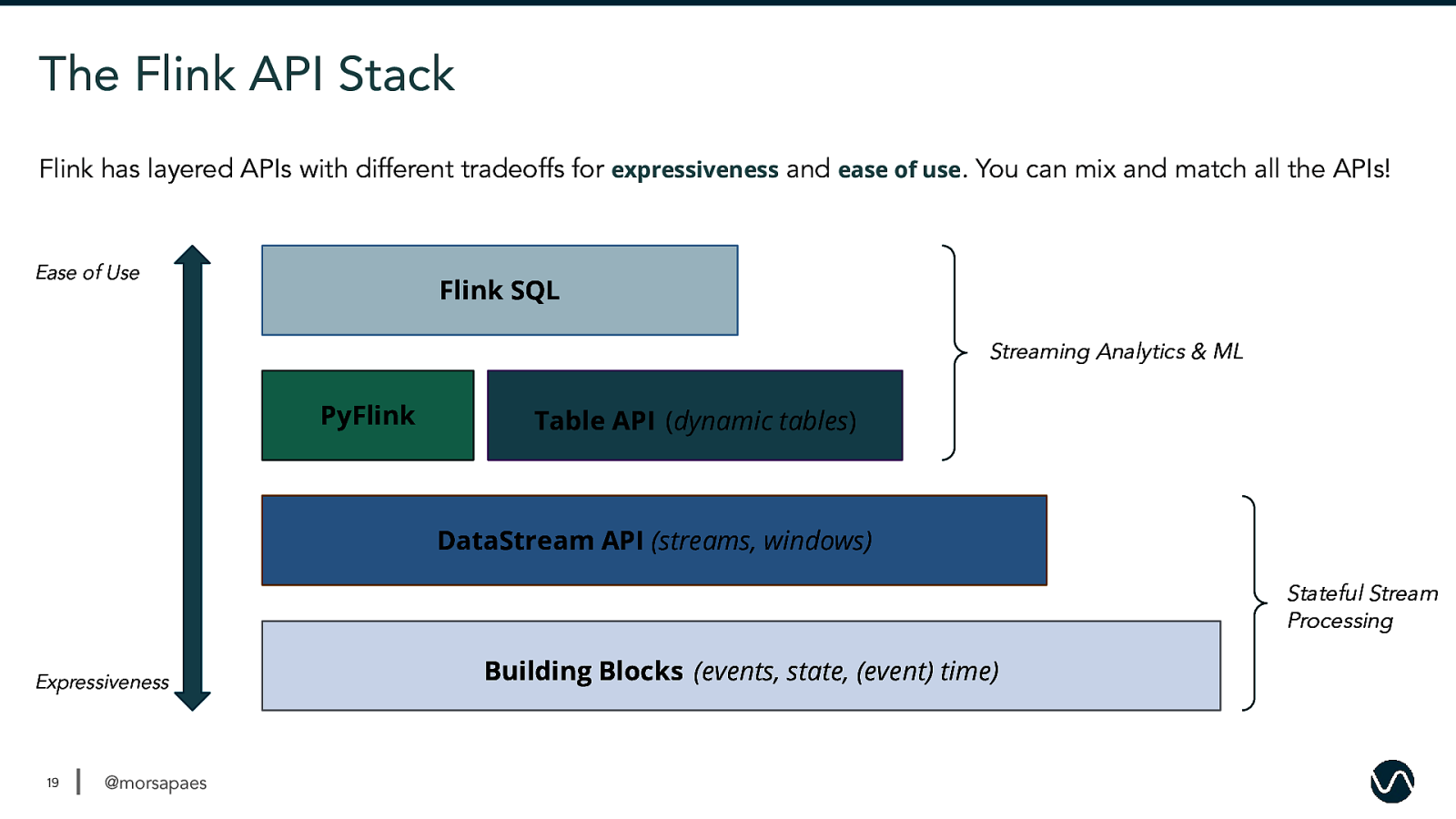
The Flink API Stack Flink has layered APIs with different tradeoffs for expressiveness and ease of use. You can mix and match all the APIs! Ease of Use Flink SQL Streaming Analytics & ML PyFlink Table API (dynamic tables) 19 DataStream API (streams, windows) Stateful Stream Processing Expressiveness 19 @morsapaes Building Blocks (events, state, (event) time)

The Flink API Stack For some use cases, you need Flink’s full workhorse power. Ease of Use Flink SQL PyFlink ● Explicit control over core primitives (events, state, time) ● Complex computations and customization ● Maximize performance and reliability Table API (dynamic tables) 20 DataStream API (streams, windows) Expressiveness 20 @morsapaes Building Blocks (events, state, (event) time)

The Flink API Stack But for a lot of others, you don’t. Ease of Use Flink SQL PyFlink ● Focus on logic, not implementation ● Mixed workloads (batch and streaming) ● Maximize developer speed and autonomy Table API (dynamic tables) 21 DataStream API (streams, windows) Expressiveness 21 @morsapaes Building Blocks (events, state, (event) time)

The Flink API Stack But for a lot of others, you don’t. Ease of Use Flink SQL PyFlink ● Focus on logic, not implementation ● Mixed workloads (batch and streaming) ● Maximize developer speed and autonomy Table API (dynamic tables) 22 DataStream API (streams, windows) Expressiveness 22 @morsapaes Building Blocks (events, state, (event) time)

Flink SQL “Everyone knows SQL, right?” SELECT user_id, COUNT(url) AS cnt FROM clicks GROUP BY user_id; This is standard SQL (ANSI SQL) 23 @morsapaes

Flink SQL “Everyone knows SQL, right?” SELECT user_id, COUNT(url) AS cnt FROM clicks GROUP BY user_id; This is standard SQL (ANSI SQL) also Flink SQL 24 @morsapaes
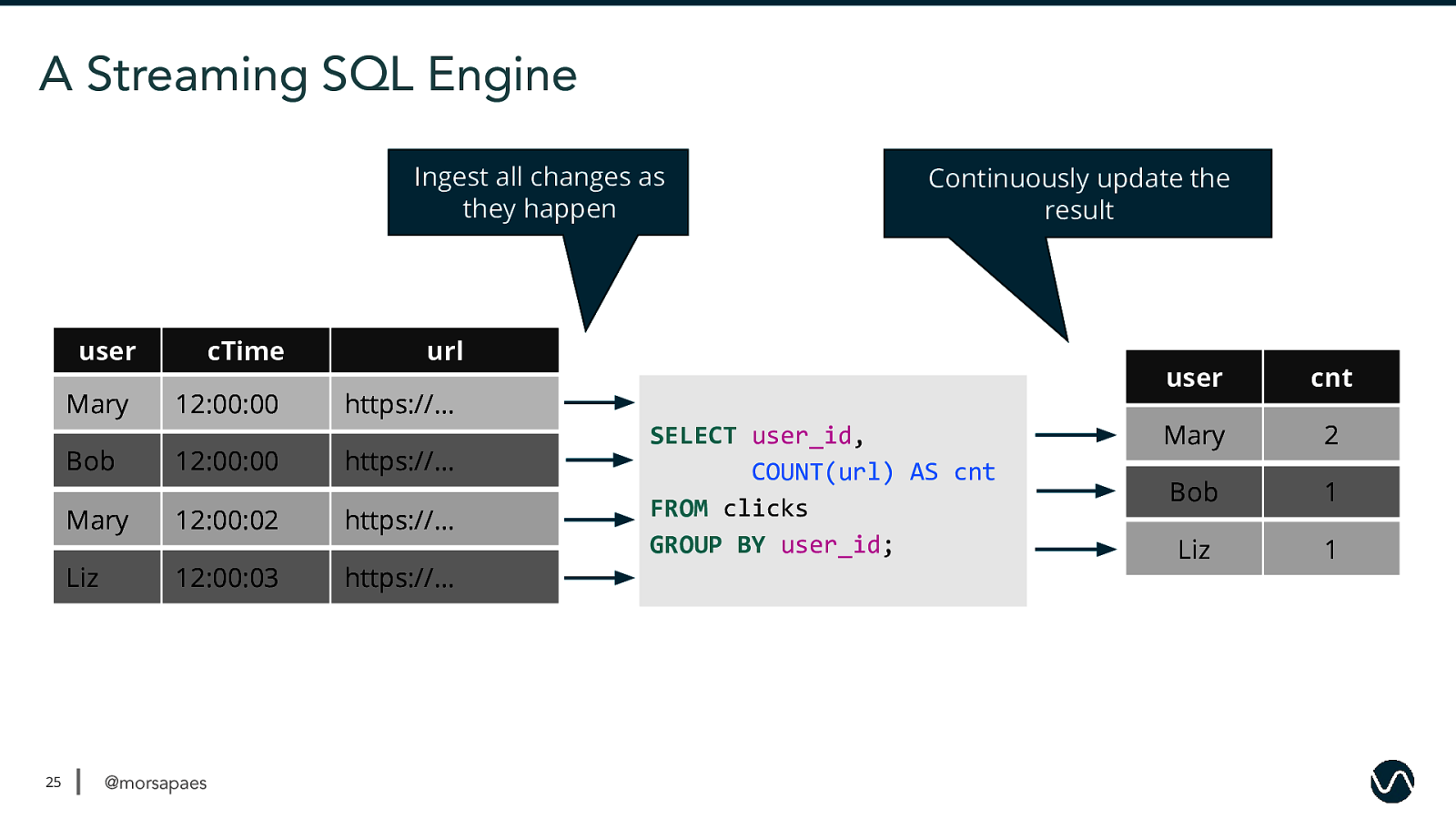
A Streaming SQL Engine Ingest all changes as they happen user Mary Bob 25 cTime 12:00:00 12:00:00 url https://… https://… Mary 12:00:02 https://… Liz 12:00:03 https://… @morsapaes Continuously update the result SELECT user_id, COUNT(url) AS cnt FROM clicks GROUP BY user_id; user cnt Mary Mary 1 2 Bob 1 Liz 1
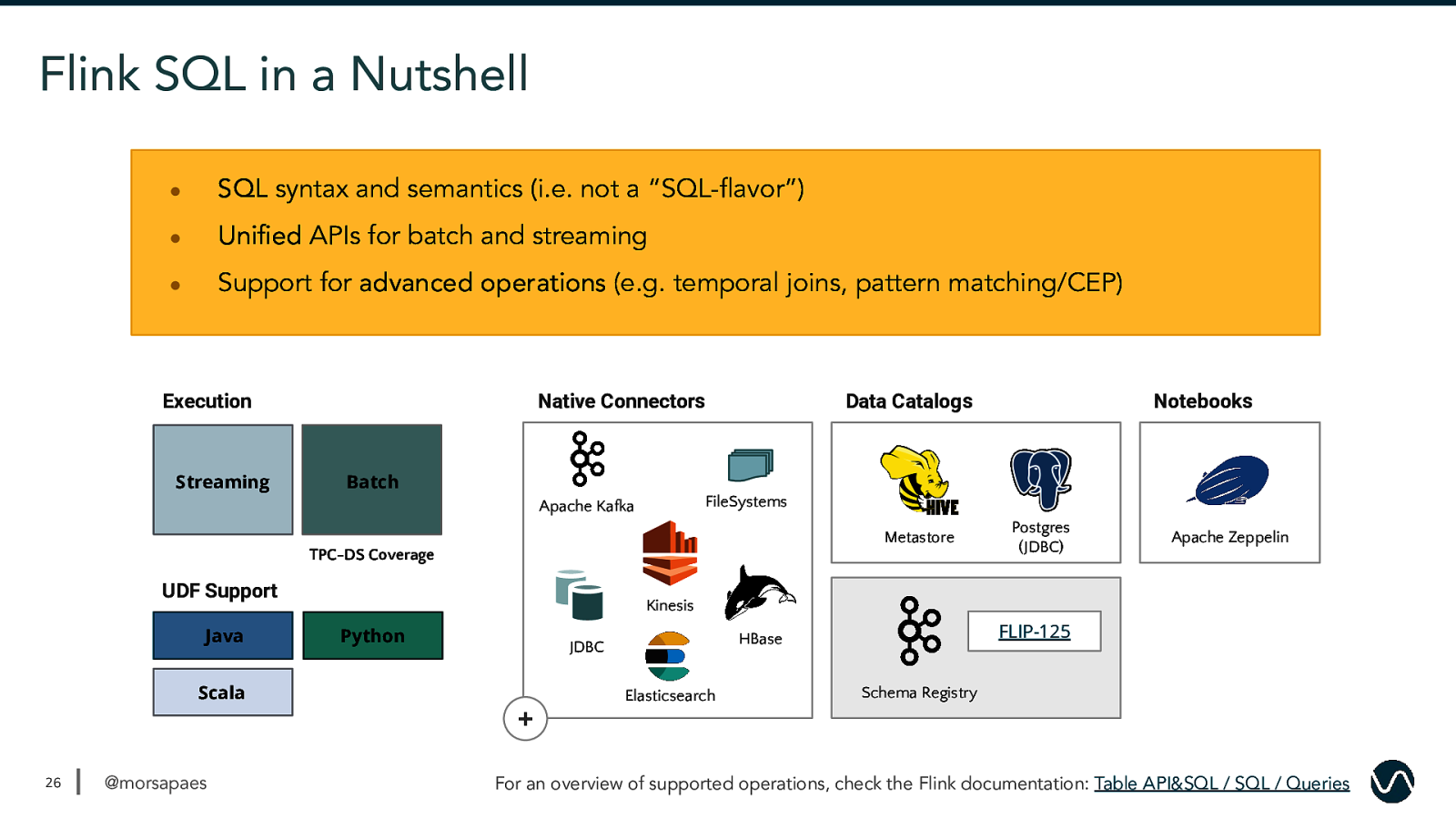
Flink SQL in a Nutshell ● SQL syntax and semantics (i.e. not a “SQL-flavor”) ● Unified APIs for batch and streaming ● Support for advanced operations (e.g. temporal joins, pattern matching/CEP) Execution Streaming Native Connectors Data Catalogs Batch FileSystems Apache Kafka Metastore TPC-DS Coverage UDF Support Java Notebooks Postgres (JDBC) Apache Zeppelin Kinesis Python Scala FLIP-125 HBase JDBC Elasticsearch Schema Registry
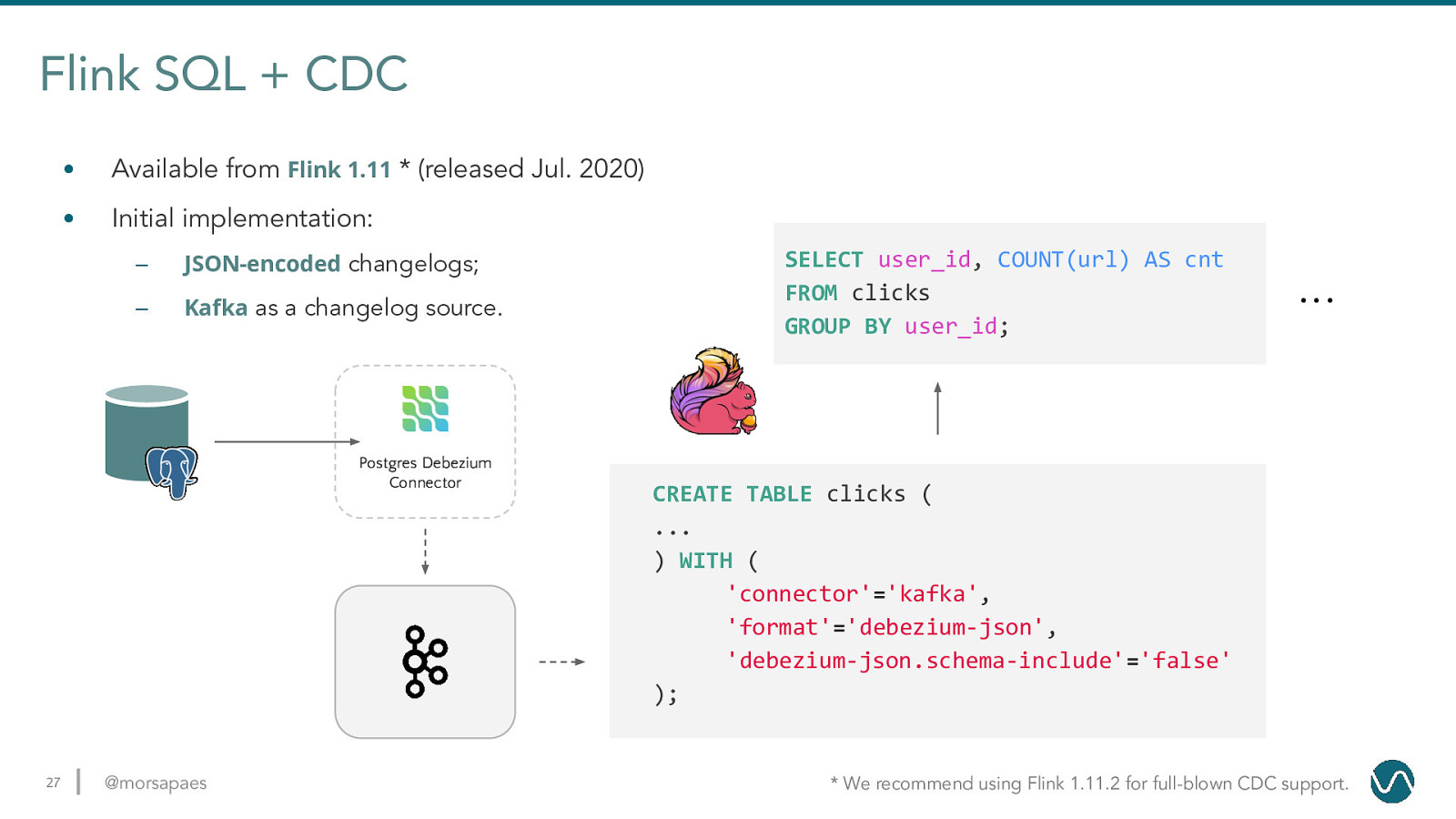
Flink SQL + CDC • Available from Flink 1.11 * (released Jul. 2020) • Initial implementation: – JSON-encoded changelogs; – Kafka as a changelog source. Postgres Debezium Connector 27 @morsapaes SELECT user_id, COUNT(url) AS cnt FROM clicks GROUP BY user_id; … CREATE TABLE clicks ( … ) WITH ( ‘connector’=’kafka’, ‘format’=’debezium-json’, ‘debezium-json.schema-include’=’false’ );
(Un)Demo 28 @morsapaes

What are we doing? Processing (fake) insurance claim data related to animal attacks in Australia. ● Get Debezium up and running with Kafka ● Register a Postgres catalog to access external table metadata ● Create a changelog source to consume Debezium CDC data from Kafka ● See CDC in action! ● Maintain a Materialized View (MV) in Elasticsearch ● Visualize the results in Kibana A Cassowary aka the world’s most dangerous bird. 29 @morsapaes Try out the demo: https://github.com/morsapaes/flink-sql-CDC
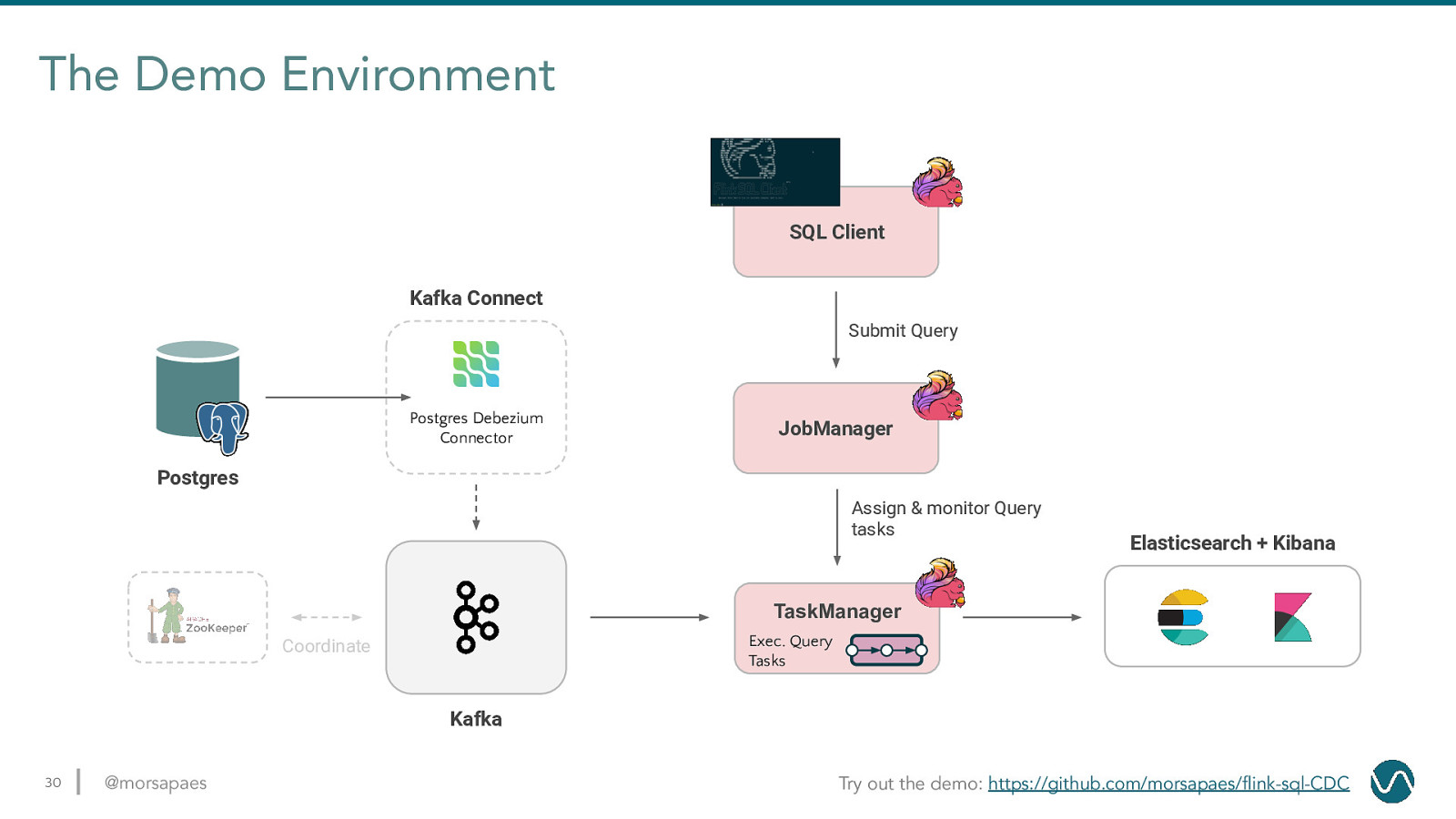
The Demo Environment SQL Client Kafka Connect Submit Query Postgres Debezium Connector JobManager Postgres Assign & monitor Query tasks Elasticsearch + Kibana TaskManager Exec. Query Tasks Coordinate Kafka 30 @morsapaes Try out the demo: https://github.com/morsapaes/flink-sql-CDC
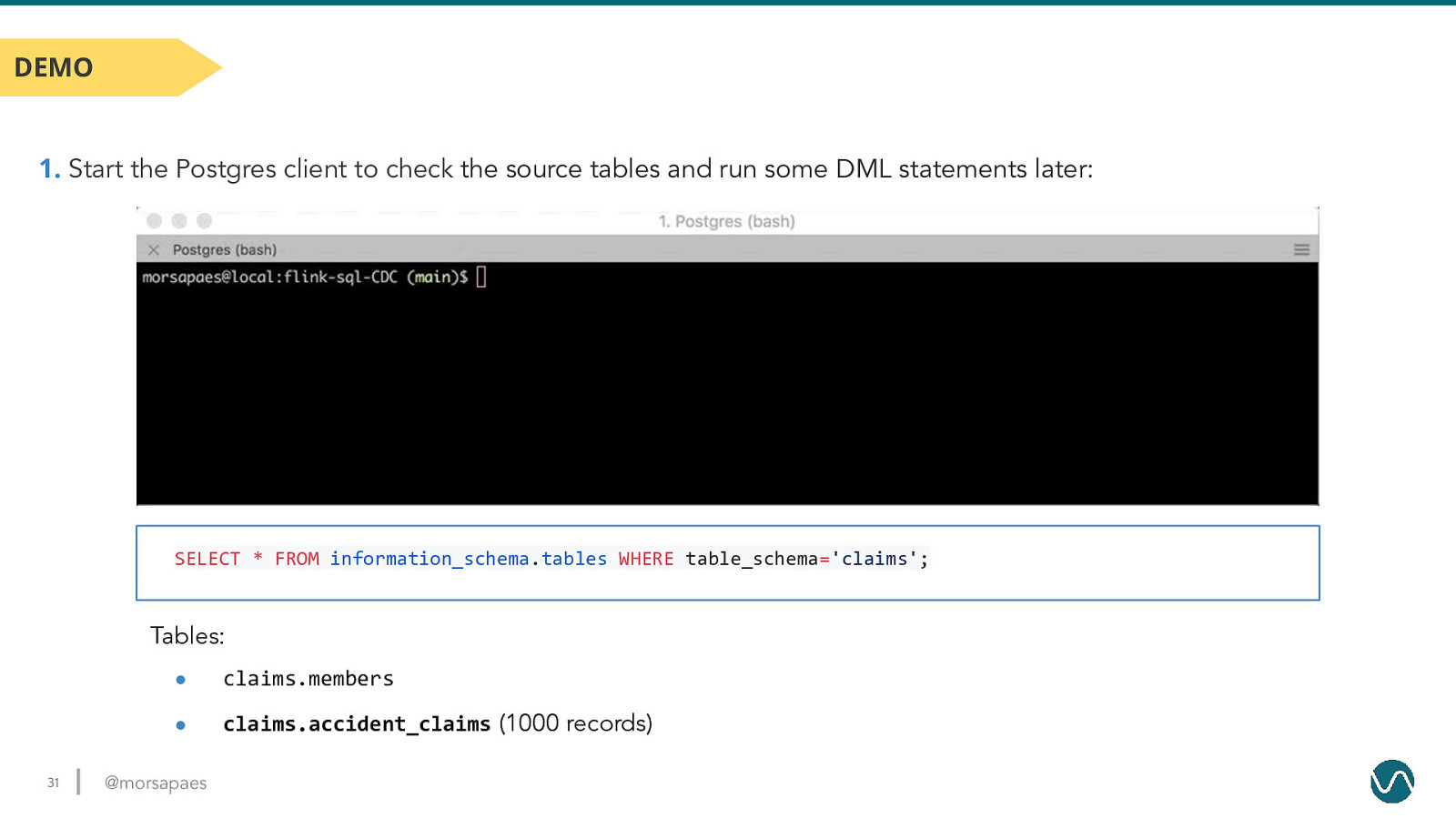
DEMO
DEMO 2. Register the Debezium Postgres connector in Kafka Connect. curl -i -X POST -H “Accept:application/json” -H “Content-Type:application/json” http://localhost:8083/connectors/ -d @register-postgres.json 32 @morsapaes
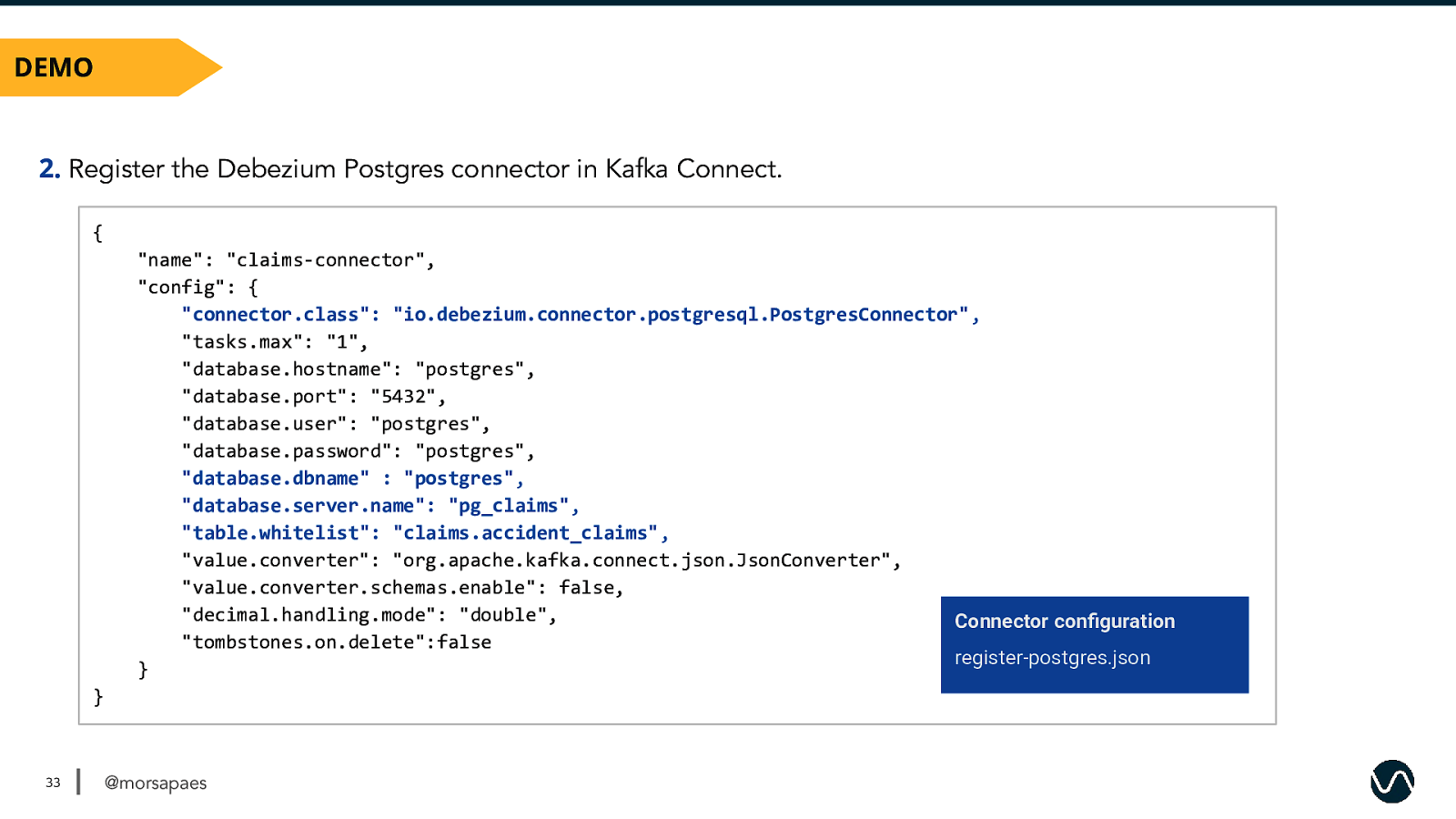
DEMO 2. Register the Debezium Postgres connector in Kafka Connect. { “name”: “claims-connector”, “config”: { “connector.class”: “io.debezium.connector.postgresql.PostgresConnector”, “tasks.max”: “1”, “database.hostname”: “postgres”, “database.port”: “5432”, “database.user”: “postgres”, “database.password”: “postgres”, “database.dbname” : “postgres”, “database.server.name”: “pg_claims”, “table.whitelist”: “claims.accident_claims”, “value.converter”: “org.apache.kafka.connect.json.JsonConverter”, “value.converter.schemas.enable”: false, “decimal.handling.mode”: “double”, Connector configuration “tombstones.on.delete”:false register-postgres.json } } 33 @morsapaes
DEMO 3. Check that the snapshot events have been pushed to the pg_claims.claims.accident_claims Kafka topic. 34 @morsapaes
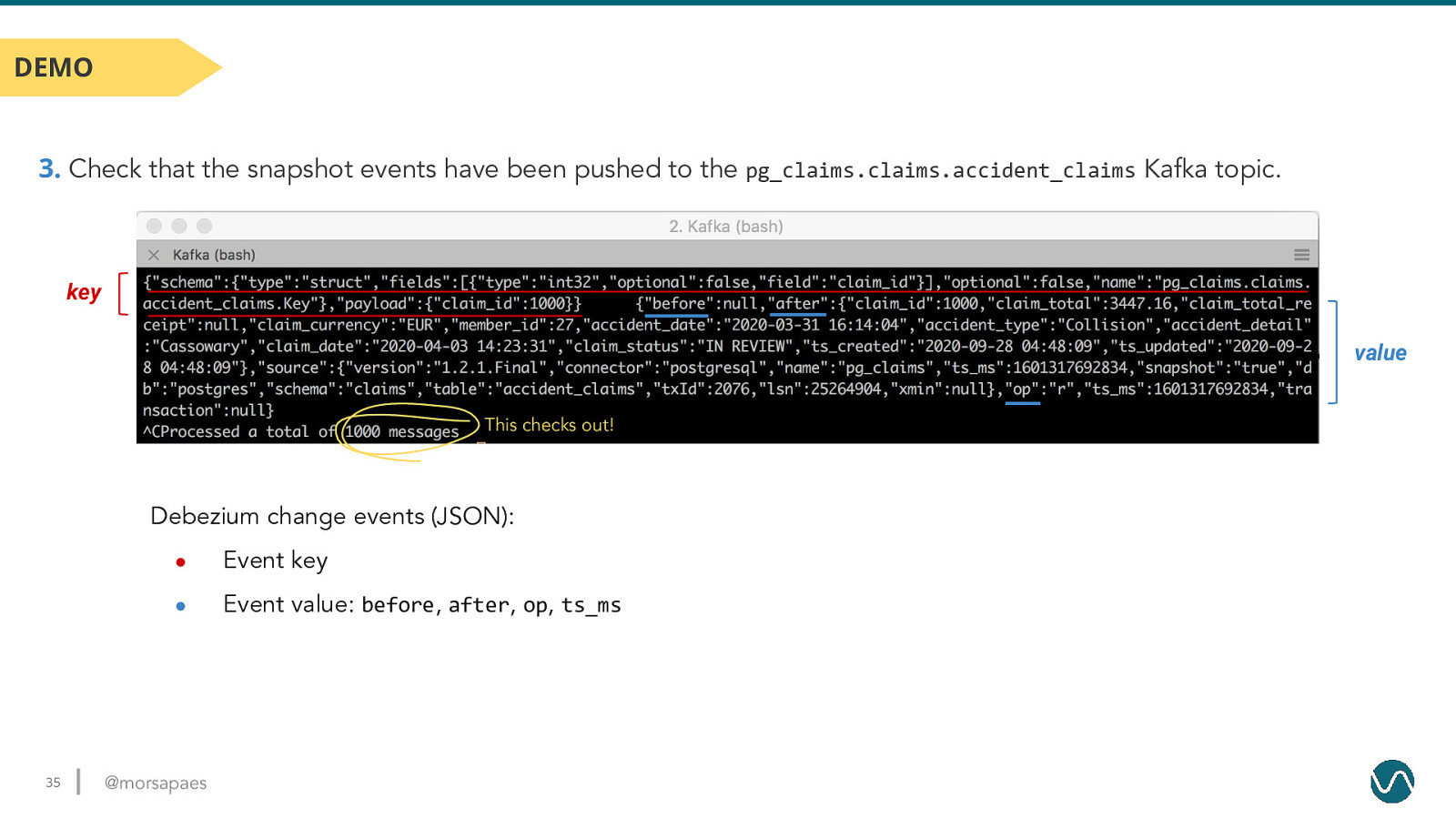
DEMO 3. Check that the snapshot events have been pushed to the pg_claims.claims.accident_claims Kafka topic. key value This checks out! Debezium change events (JSON): 35 ● Event key ● Event value: before, after, op, ts_ms @morsapaes
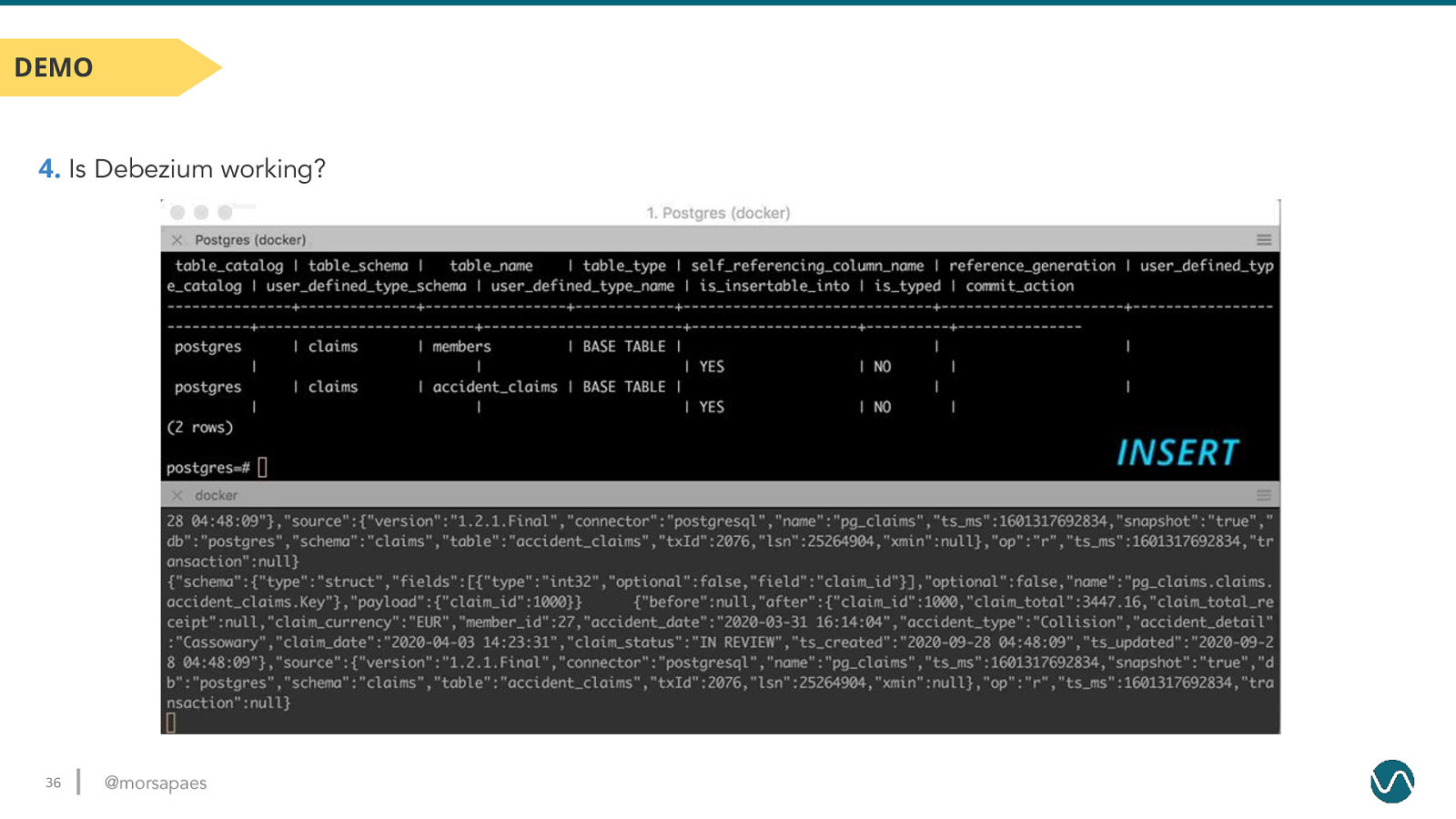
DEMO 4. Is Debezium working? 36 @morsapaes
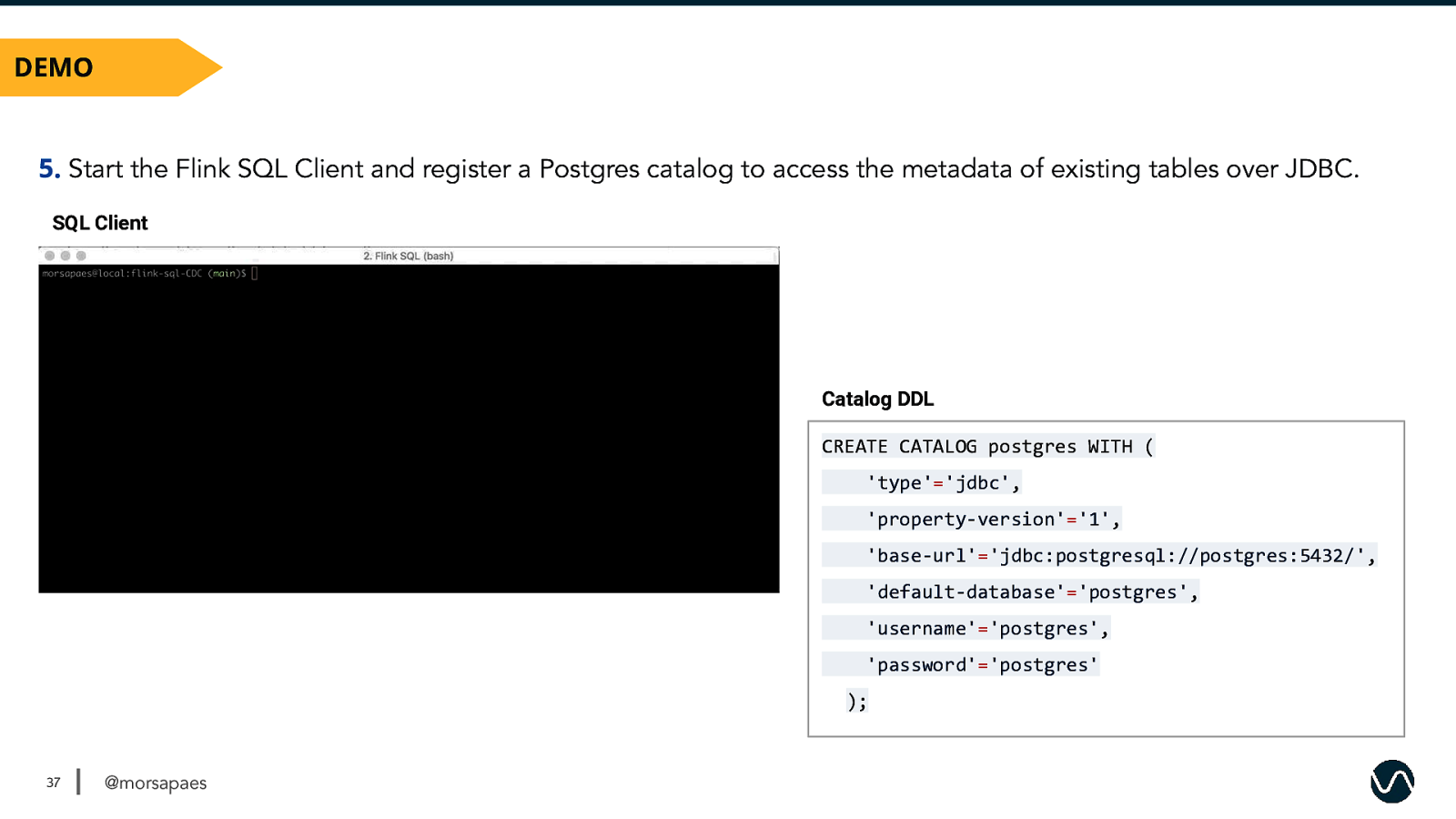
DEMO 5. Start the Flink SQL Client and register a Postgres catalog to access the metadata of existing tables over JDBC. SQL Client Catalog DDL CREATE CATALOG postgres WITH ( ‘type’=’jdbc’, ‘property-version’=’1’, ‘base-url’=’jdbc:postgresql://postgres:5432/’, ‘default-database’=’postgres’, ‘username’=’postgres’, ‘password’=’postgres’ ); 37 @morsapaes
DEMO
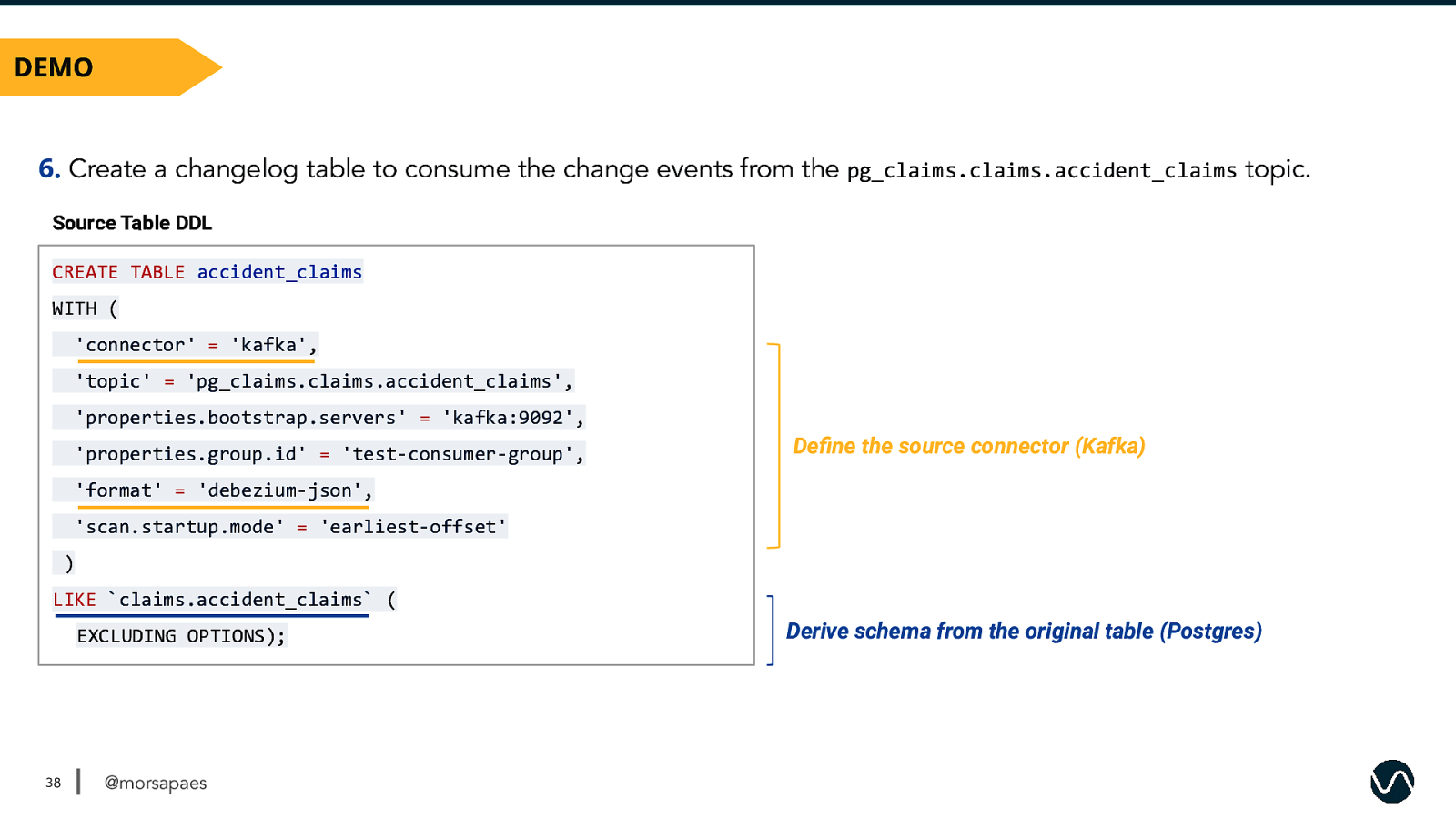
6. Create a changelog table to consume the change events from the pg_claims.claims.accident_claims topic. Source Table DDL CREATE TABLE accident_claims WITH ( ‘connector’ = ‘kafka’, ‘topic’ = ‘pg_claims.claims.accident_claims’, ‘properties.bootstrap.servers’ = ‘kafka:9092’, ‘properties.group.id’ = ‘test-consumer-group’,
Define the source connector (Kafka)
‘format’ = ‘debezium-json’, ‘scan.startup.mode’ = ‘earliest-offset’ ) LIKE claims.accident_claims ( EXCLUDING OPTIONS);
38
@morsapaes
Derive schema from the original table (Postgres)
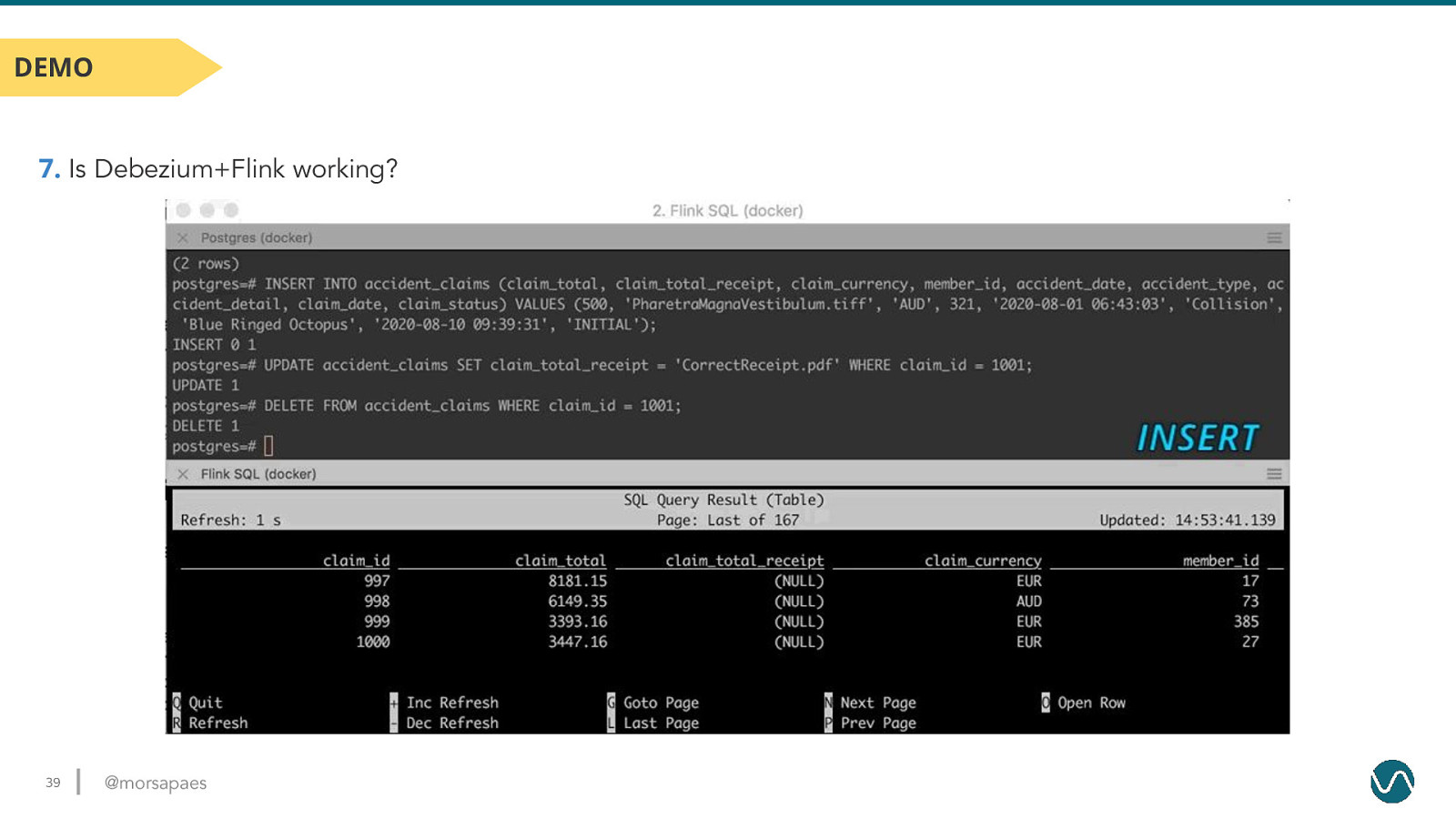
DEMO 7. Is Debezium+Flink working? 39 @morsapaes

DEMO 8. Continuously write results to Elasticsearch and visualize the changes using Kibana. Sink Table DDL CREATE TABLE agg_insurance_costs ( Continuous SQL Query INSERT INTO agg_insurance_costs es_key STRING PRIMARY KEY NOT ENFORCED, SELECT UPPER(SUBSTRING(m.insurance_company,0,4) || ‘_’ || insurance_company STRING, SUBSTRING (ac.accident_detail,0,4)) es_key, accident_detail STRING, m.insurance_company, accident_agg_cost DOUBLE ac.accident_detail, ) WITH ( SUM(ac.claim_total) member_total ‘connector’ = ‘elasticsearch-7’, FROM accident_claims ac ‘hosts’ = ‘http://elasticsearch:9200’, JOIN members m ‘index’ = ‘agg_insurance_costs’ ON ac.member_id = m.id ); WHERE ac.claim_status <> ‘DENIED’ GROUP BY m.insurance_company, ac.accident_detail; 40 @morsapaes
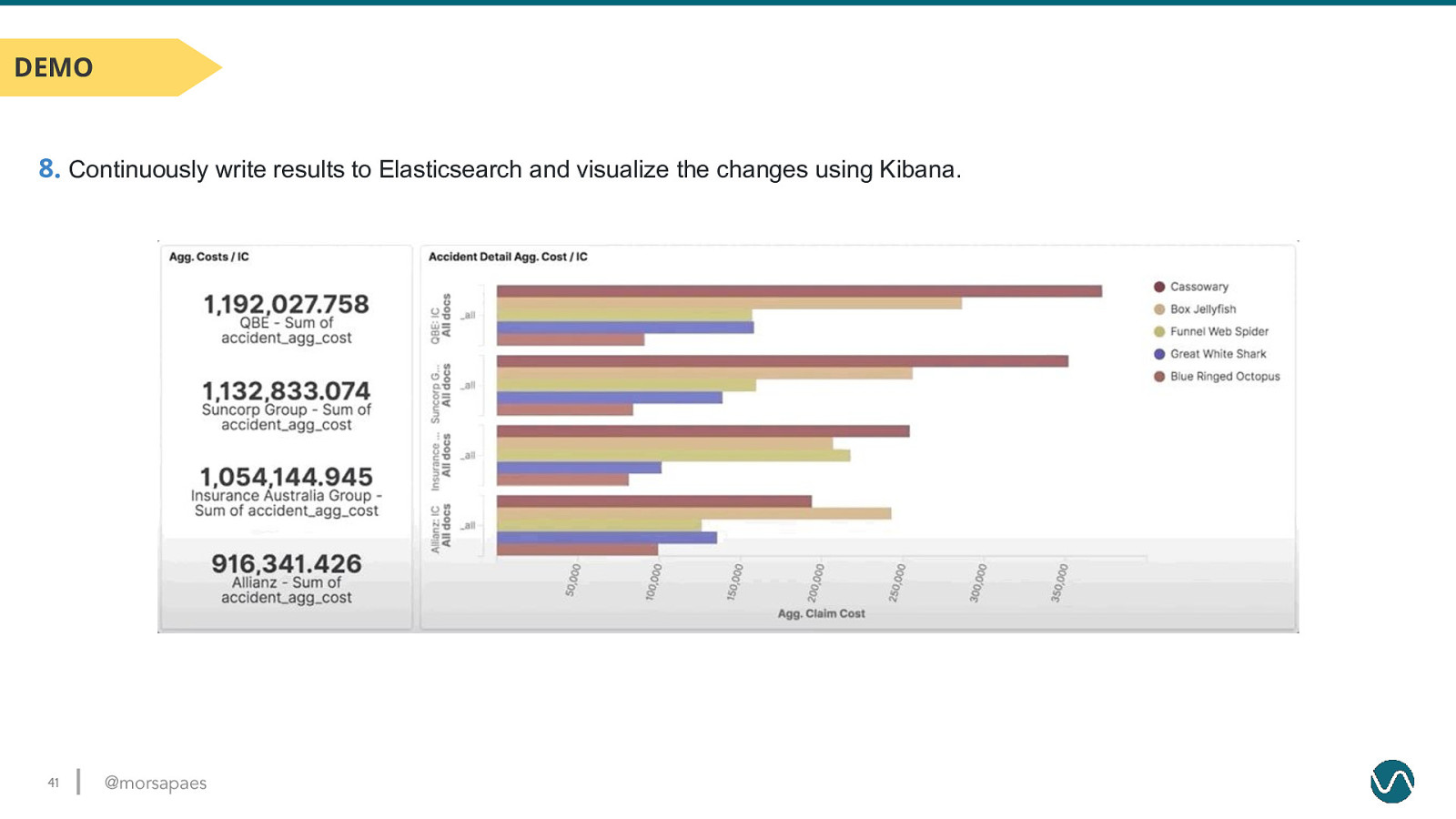
DEMO 8. Continuously write results to Elasticsearch and visualize the changes using Kibana. 41 @morsapaes
(Un)Demo 42 @morsapaes
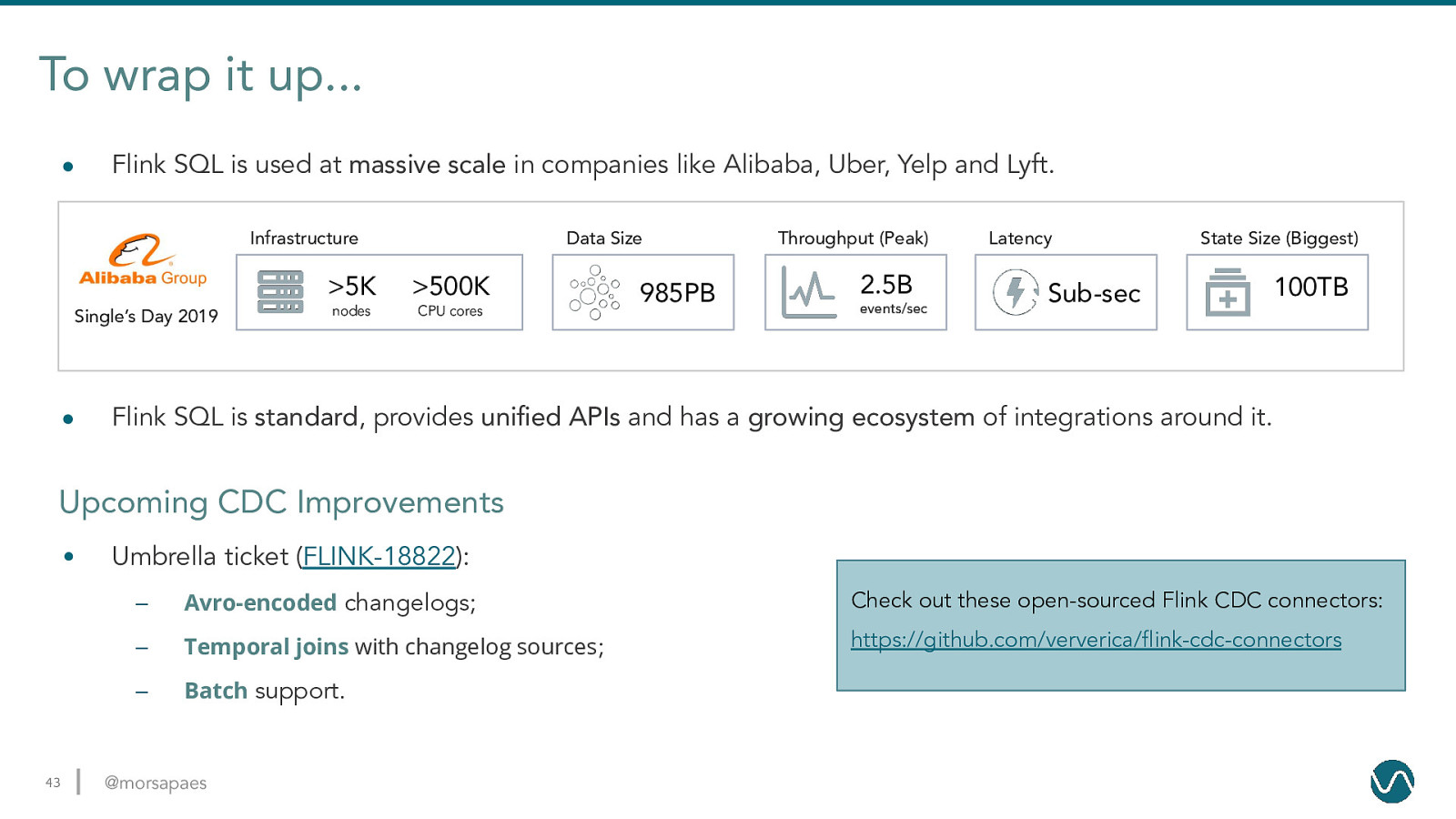
To wrap it up… ● Flink SQL is used at massive scale in companies like Alibaba, Uber, Yelp and Lyft. Infrastructure Single’s Day 2019 ● Data Size
5K 500K nodes CPU cores 985PB Throughput (Peak) 2.5B events/sec Latency State Size (Biggest) Sub-sec 100TB Flink SQL is standard, provides unified APIs and has a growing ecosystem of integrations around it. Upcoming CDC Improvements • 43 Umbrella ticket (FLINK-18822): – Avro-encoded changelogs; Check out these open-sourced Flink CDC connectors: – Temporal joins with changelog sources; https://github.com/ververica/flink-cdc-connectors – Batch support. @morsapaes

Want to learn more about Flink? 44 @morsapaes

Thank you, ApacheCon! Follow me on Twitter: @morsapaes Learn more about Flink: https://flink.apache.org/ © 2020 Ververica