Interactive Data Exploration With PyFlink and Zeppelin Notebooks Marta Paes (@morsapaes) Developer Advocate © 2020 Ververica

A presentation at ApacheCon in September 2020 in by Marta Paes

Interactive Data Exploration With PyFlink and Zeppelin Notebooks Marta Paes (@morsapaes) Developer Advocate © 2020 Ververica
About Ververica Original Creators of Apache Flink® 2 @morsapaes Enterprise Stream Processing With Ververica Platform Part of Alibaba Group
Apache Flink Flink is an open source framework and distributed engine for stateful stream processing. Flink Runtime Stateful Computations over Data Streams 3 @morsapaes Learn more: flink.apache.org
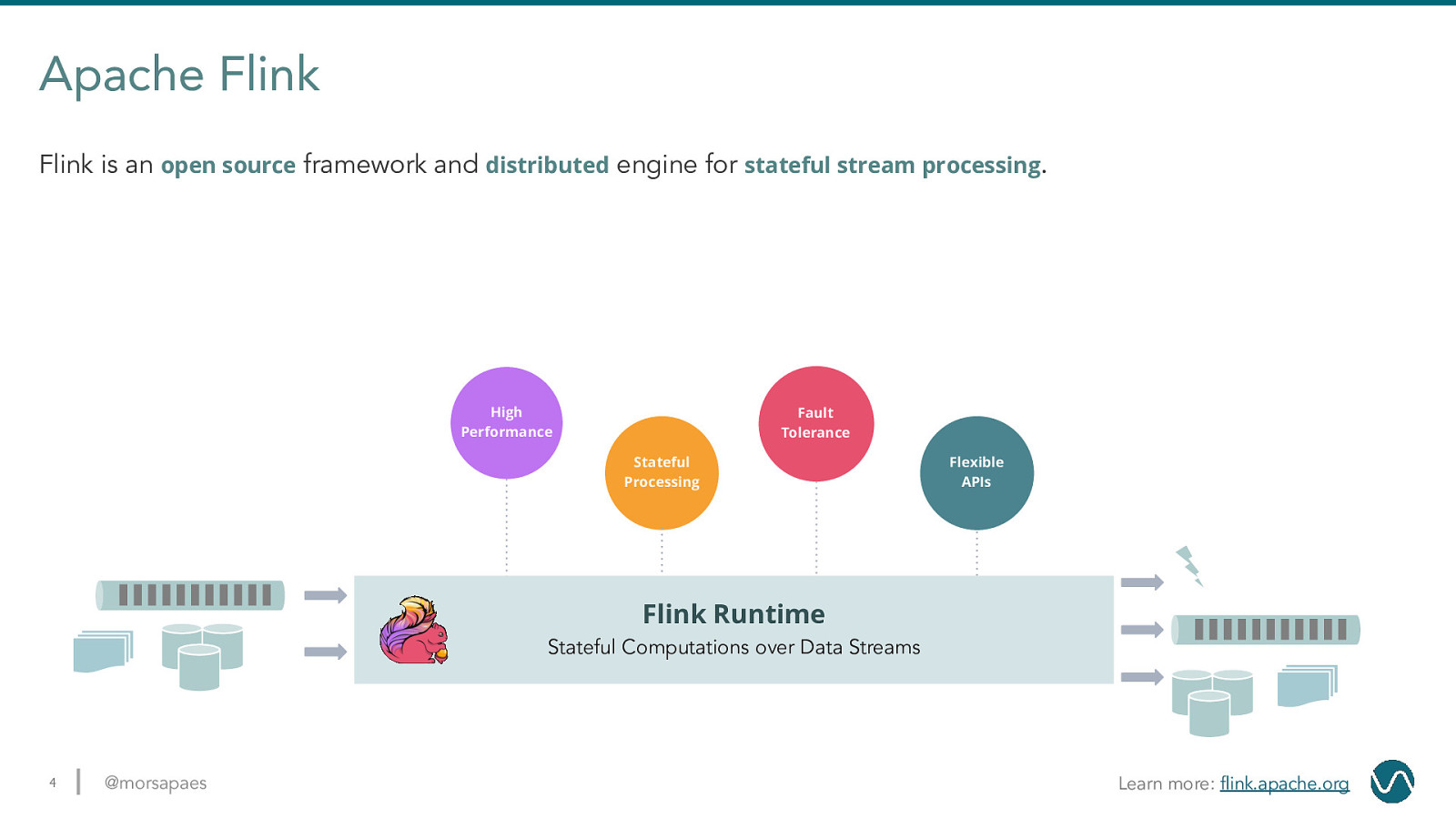
Apache Flink Flink is an open source framework and distributed engine for stateful stream processing. High Performance Fault Tolerance Stateful Processing Flexible APIs Flink Runtime Stateful Computations over Data Streams 4 @morsapaes Learn more: flink.apache.org
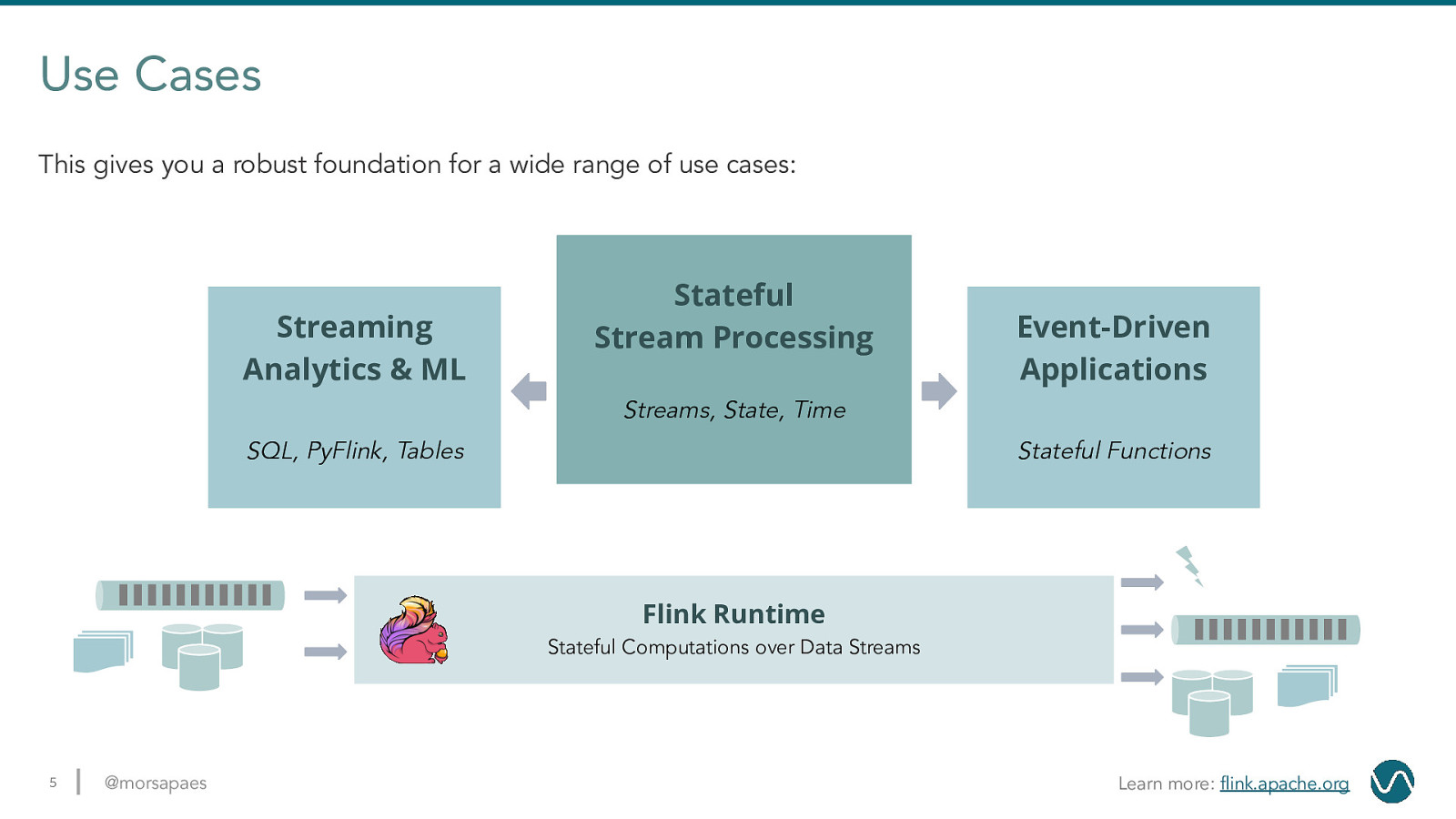
Use Cases This gives you a robust foundation for a wide range of use cases: Streaming Analytics & ML Stateful Stream Processing Event-Driven Applications Streams, State, Time SQL, PyFlink, Tables Stateful Functions Flink Runtime Stateful Computations over Data Streams 5 @morsapaes Learn more: flink.apache.org
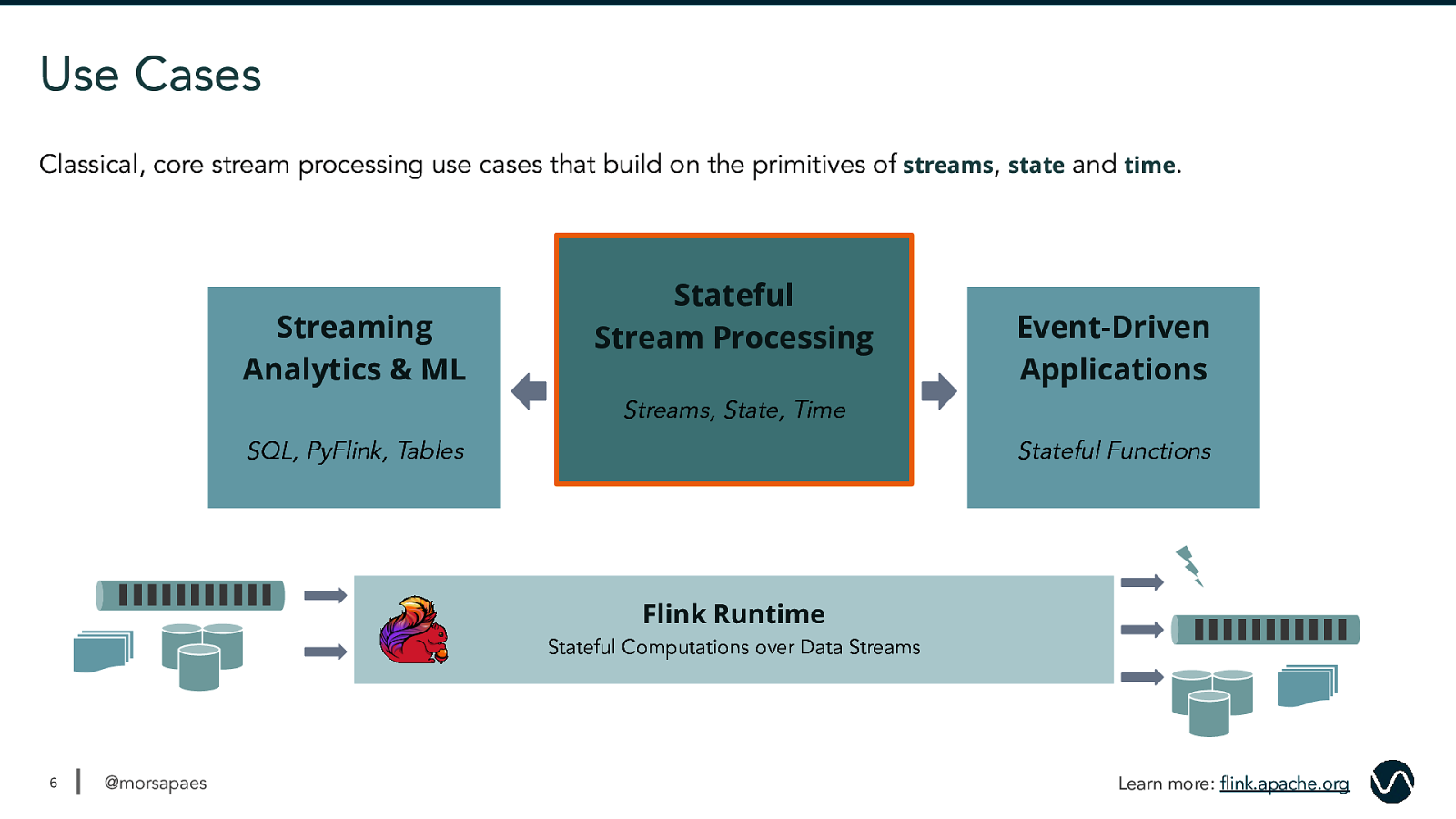
Use Cases Classical, core stream processing use cases that build on the primitives of streams, state and time. Streaming Analytics & ML Stateful Stream Processing Event-Driven Applications Streams, State, Time SQL, PyFlink, Tables Stateful Functions Flink Runtime Stateful Computations over Data Streams 6 @morsapaes Learn more: flink.apache.org
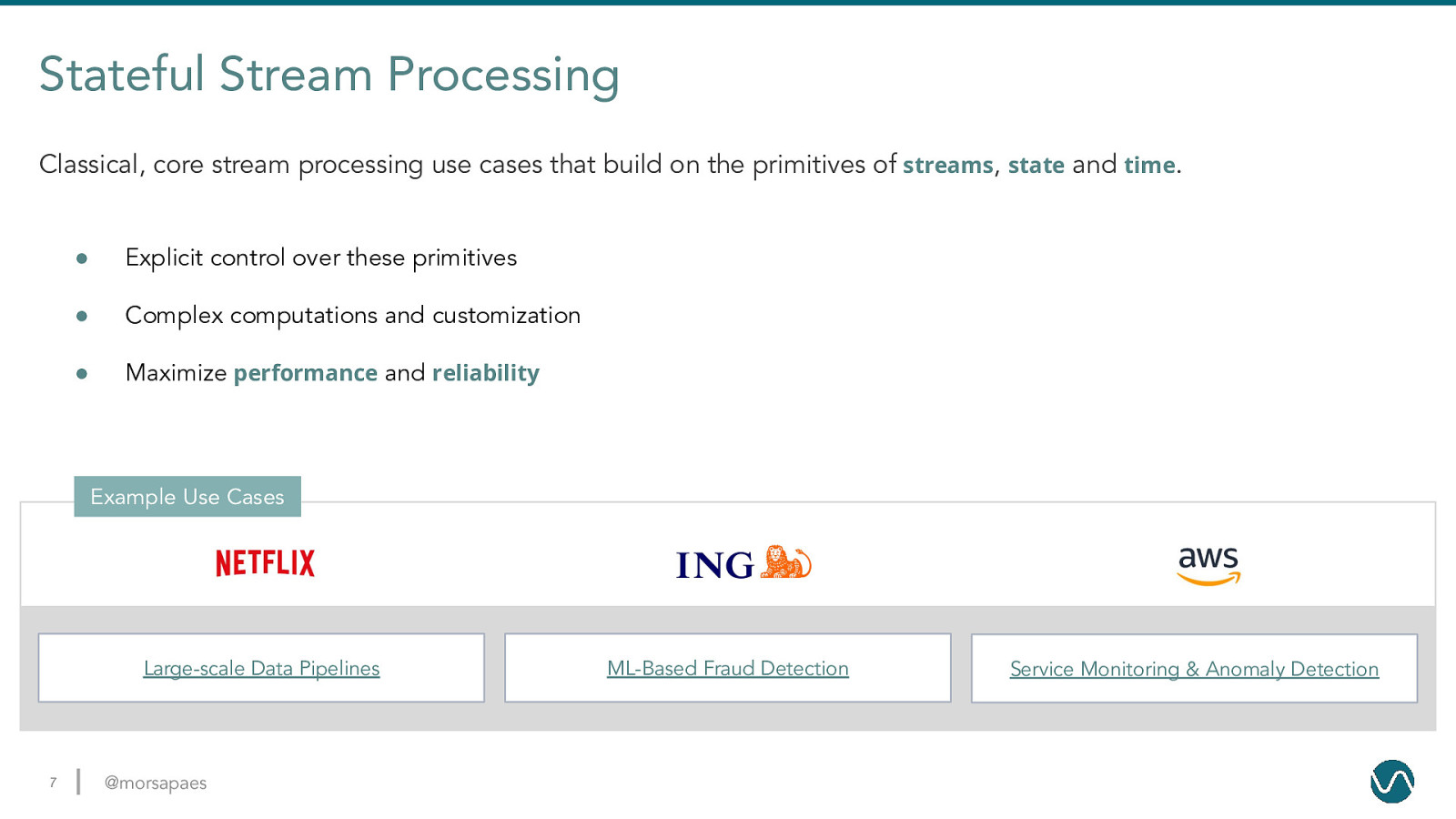
Stateful Stream Processing Classical, core stream processing use cases that build on the primitives of streams, state and time. ● Explicit control over these primitives ● Complex computations and customization ● Maximize performance and reliability Example Use Cases Large-scale Data Pipelines 7 @morsapaes ML-Based Fraud Detection Service Monitoring & Anomaly Detection
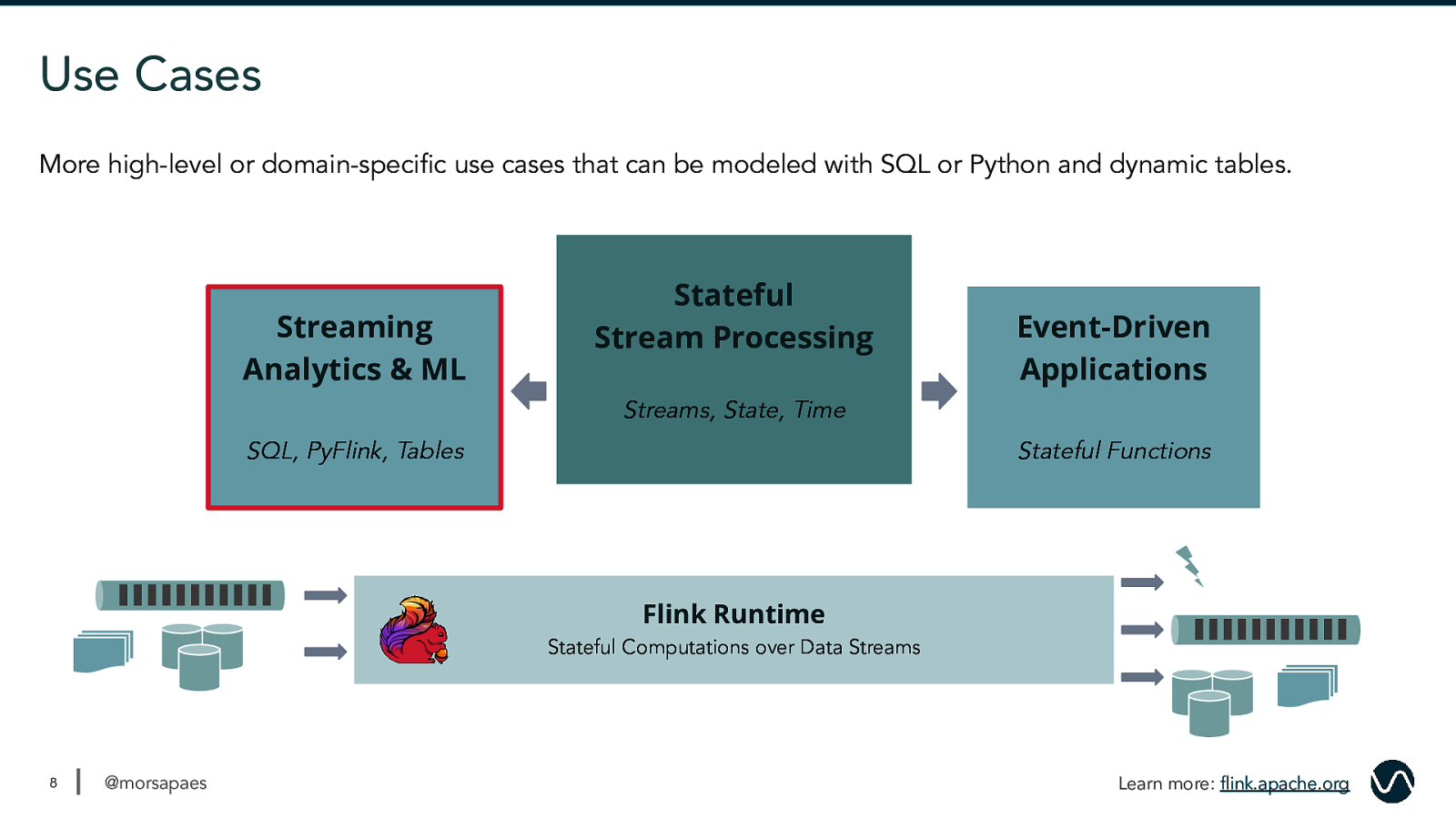
Use Cases More high-level or domain-specific use cases that can be modeled with SQL or Python and dynamic tables. Streaming Analytics & ML Stateful Stream Processing Event-Driven Applications Streams, State, Time SQL, PyFlink, Tables Stateful Functions Flink Runtime Stateful Computations over Data Streams 8 @morsapaes Learn more: flink.apache.org
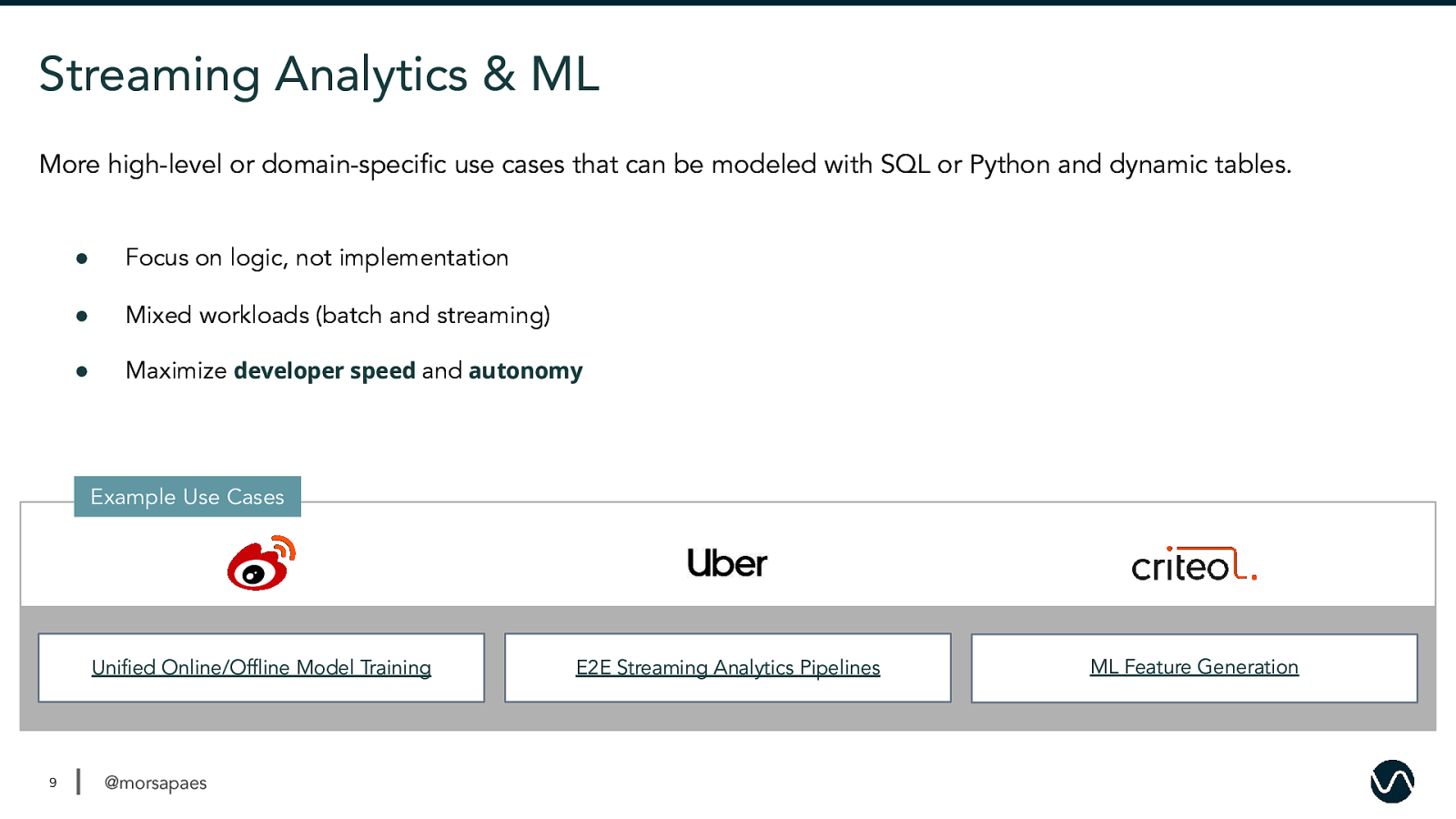
Streaming Analytics & ML More high-level or domain-specific use cases that can be modeled with SQL or Python and dynamic tables. ● Focus on logic, not implementation ● Mixed workloads (batch and streaming) ● Maximize developer speed and autonomy Example Use Cases Unified Online/Offline Model Training 9 @morsapaes E2E Streaming Analytics Pipelines ML Feature Generation

More Flink Users 10 @morsapaes Learn More: Powered by Flink, Speakers – Flink Forward San Francisco 2019, Speakers – Flink Forward Europe 2019

11 @morsapaes
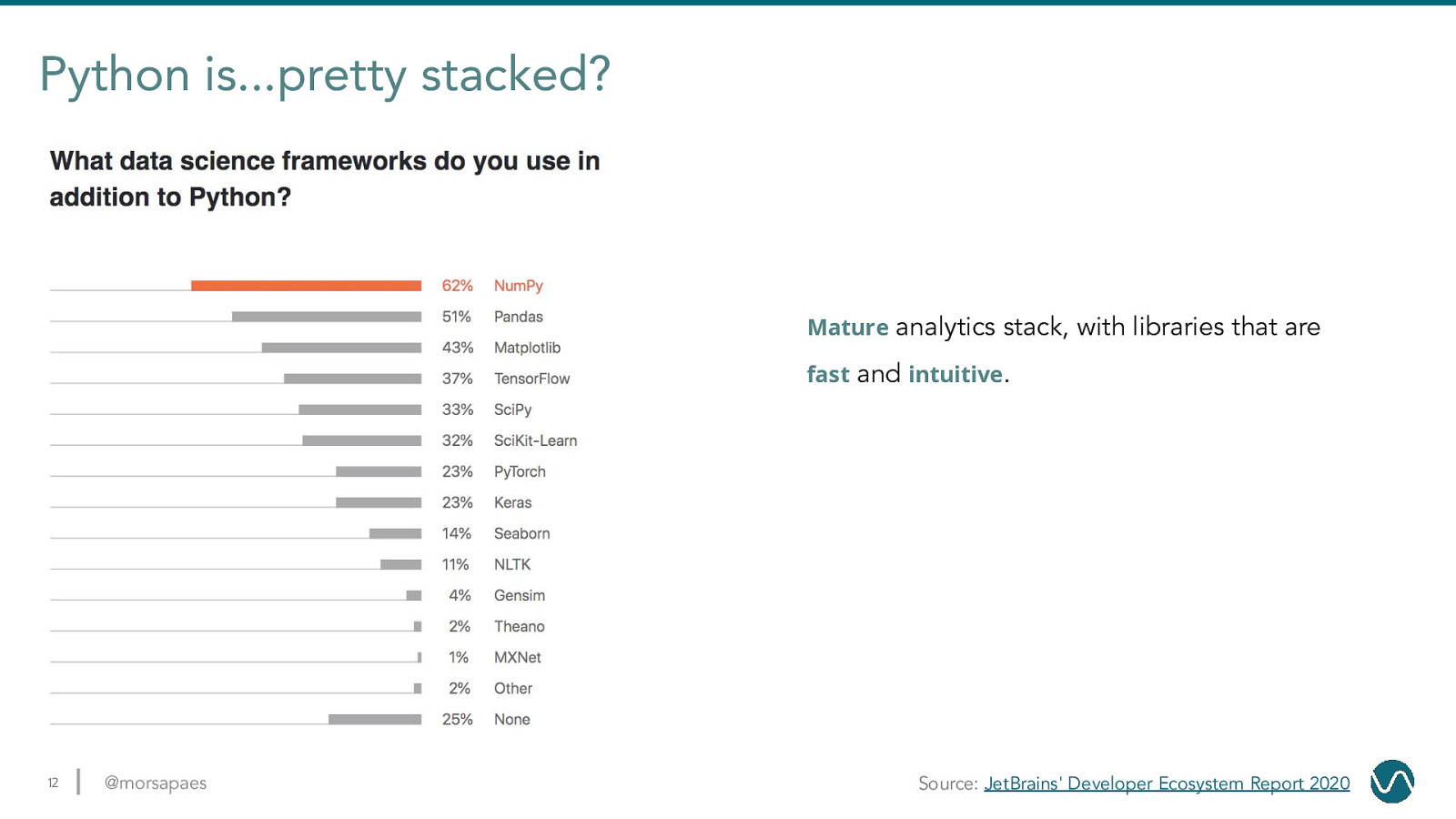
Python is…pretty stacked? Mature analytics stack, with libraries that are fast and intuitive. 12 @morsapaes Source: JetBrains’ Developer Ecosystem Report 2020
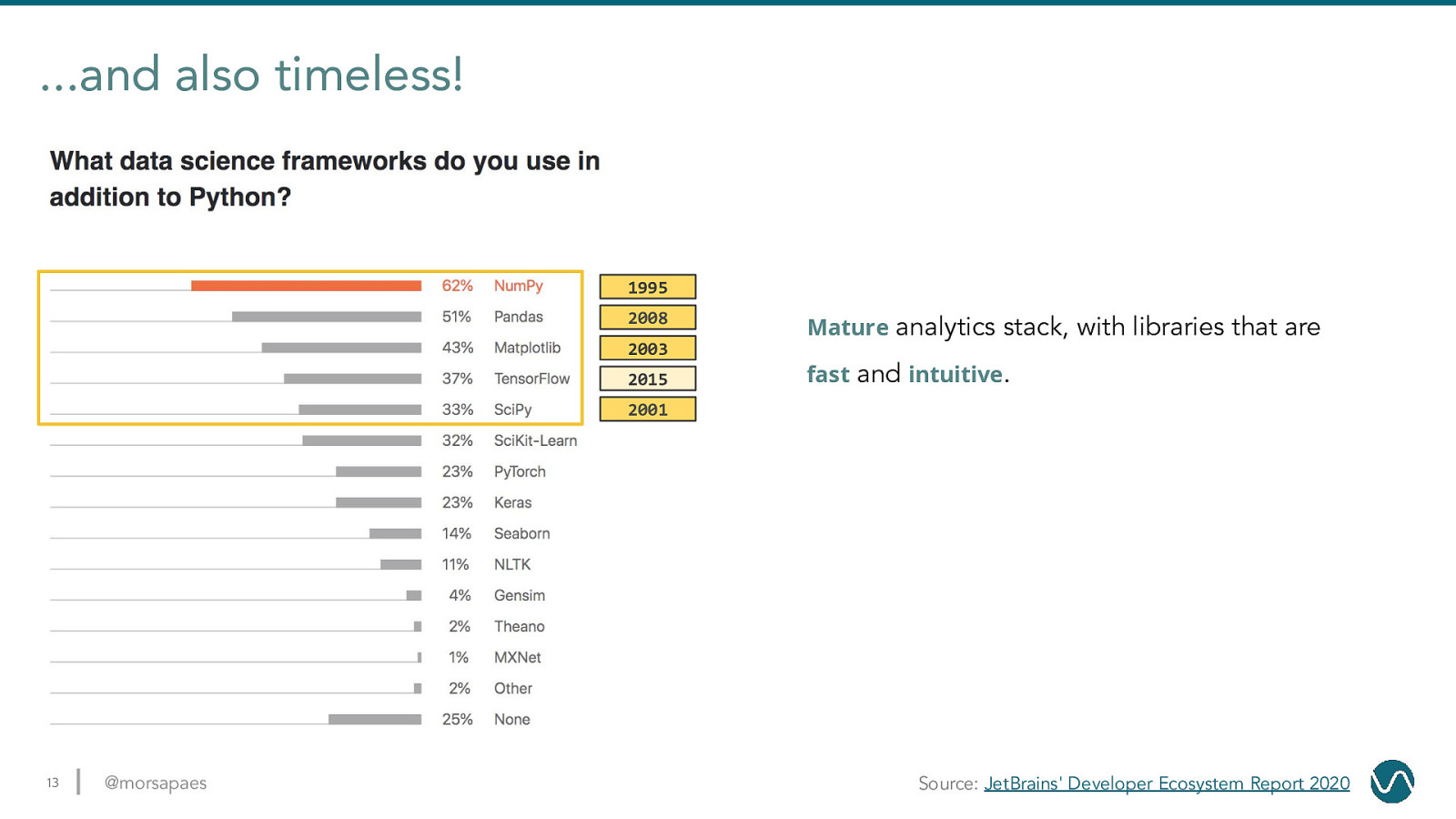
…and also timeless! 1995 2008 2003 2015 Mature analytics stack, with libraries that are fast and intuitive. 2001 13 @morsapaes Source: JetBrains’ Developer Ecosystem Report 2020
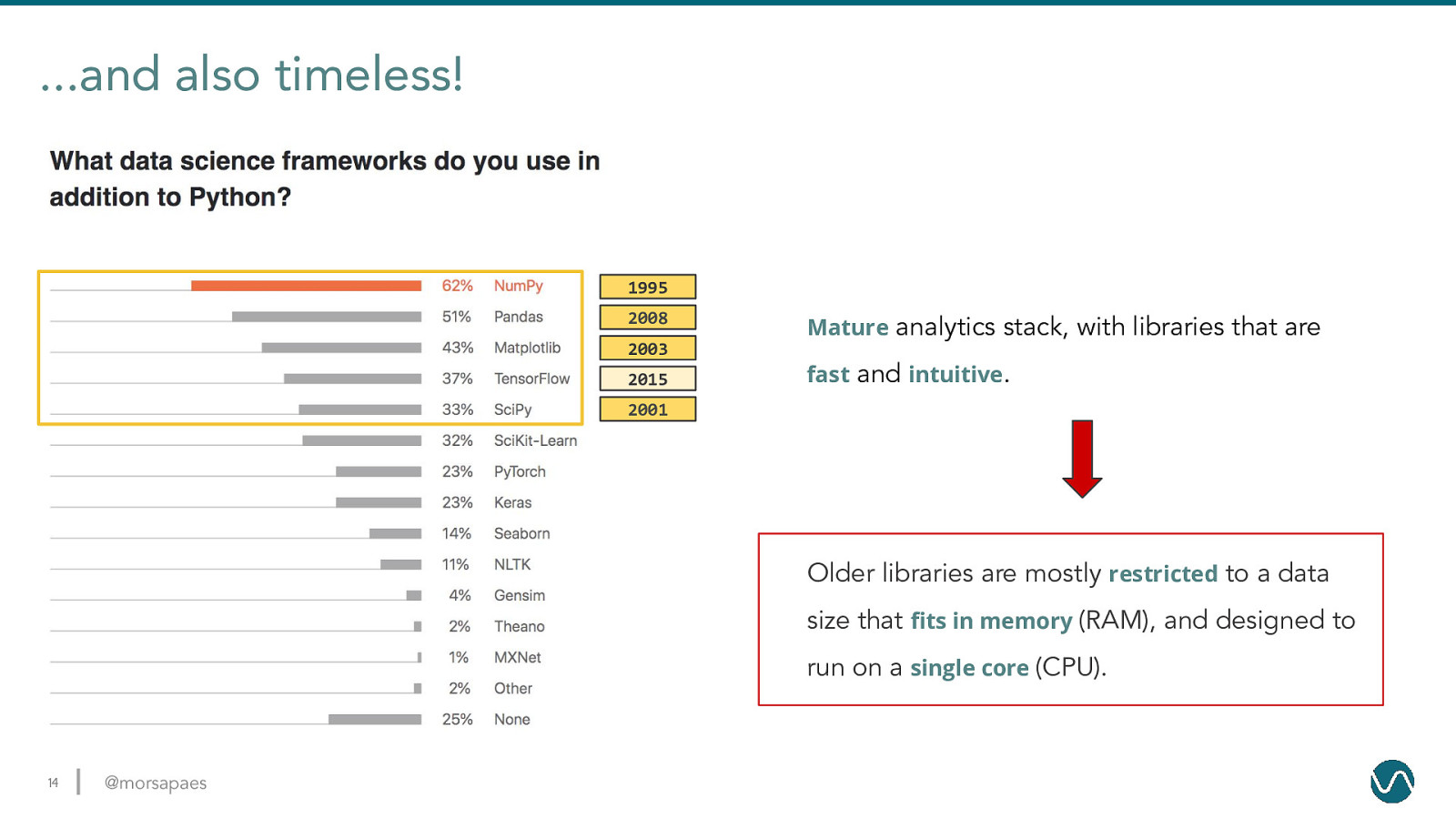
…and also timeless! 1995 2008 2003 2015 Mature analytics stack, with libraries that are fast and intuitive. 2001 Older libraries are mostly restricted to a data size that fits in memory (RAM), and designed to run on a single core (CPU). 14 @morsapaes
This is a problem. 15 @morsapaes

16 @morsapaes
But you still want to use these powerful libraries, right? 17 @morsapaes

Why PyFlink? 18 @morsapaes
Why PyFlink? Expose the functionality of Flink to Python users 19 @morsapaes
Why PyFlink? Distribute and scale the functionality of Python through Flink 20 @morsapaes Learn more: The Integration of Pandas into PyFlink.
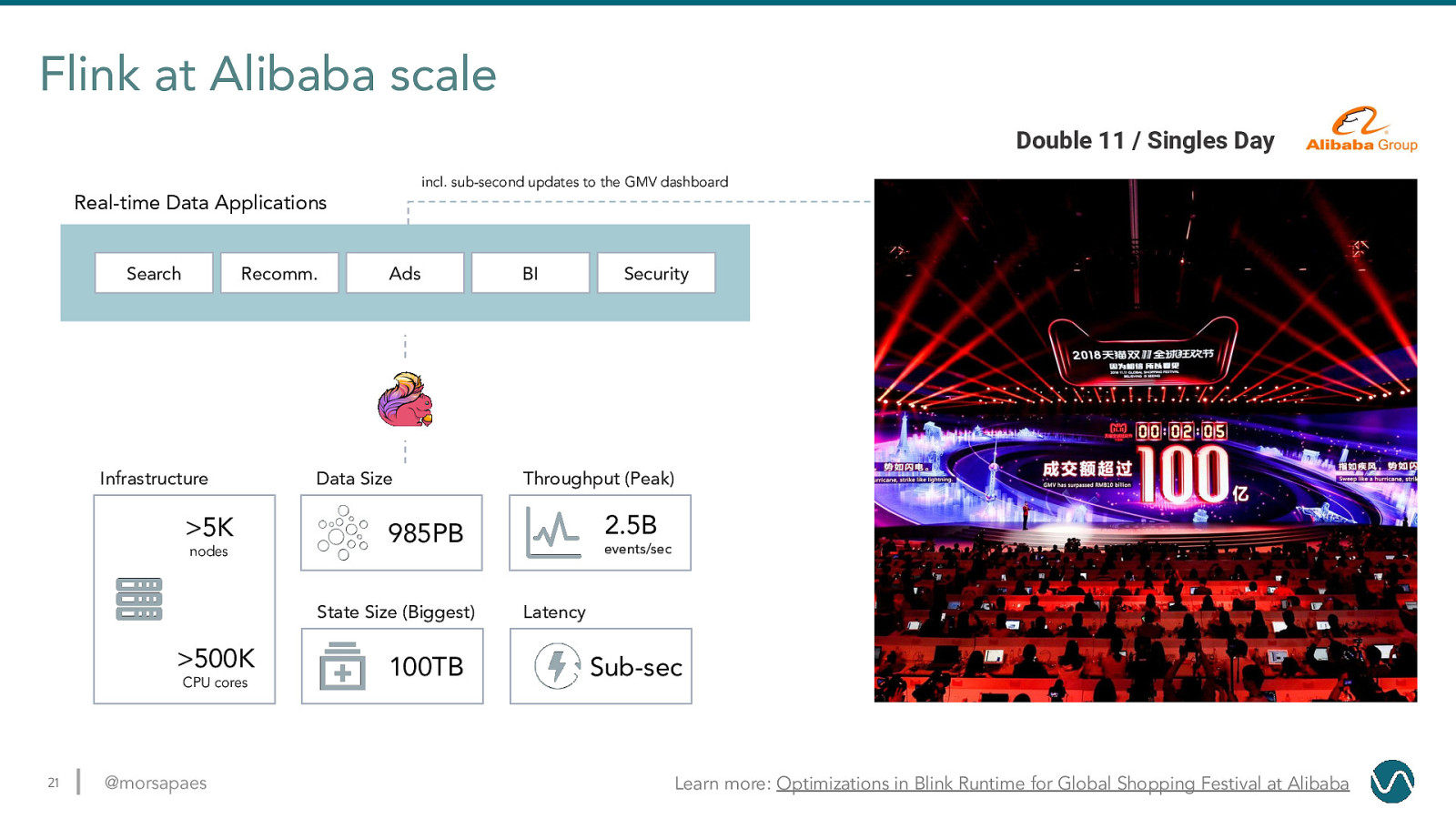
Flink at Alibaba scale Double 11 / Singles Day incl. sub-second updates to the GMV dashboard Real-time Data Applications Search Recomm. Infrastructure
5K nodes Ads Data Size CPU cores 21 @morsapaes 100TB Security Throughput (Peak) 2.5B 985PB State Size (Biggest) 500K BI events/sec Latency Sub-sec Learn more: Optimizations in Blink Runtime for Global Shopping Festival at Alibaba

PyFlink in a Nutshell* 22 ● Native SQL integration ● Unified APIs for batch and streaming ● Support for a large set of operations (incl. complex joins, windowing, pattern matching/CEP) @morsapaes

PyFlink in a Nutshell* ● Native SQL integration ● Unified APIs for batch and streaming ● Support for a large set of operations (incl. complex joins, windowing, pattern matching/CEP) Execution Streaming Batch UDF Support 23 Python UDF Pandas UDF +UDAF (WIP) +UDAF (WIP) @morsapaes

PyFlink in a Nutshell* ● Native SQL integration ● Unified APIs for batch and streaming ● Support for a large set of operations (incl. complex joins, windowing, pattern matching/CEP) Execution Streaming Native Connectors Formats Batch FileSystems Apache Kafka ML Library (WIP) FLIP-39 Notebooks UDF Support Kinesis Python UDF Pandas UDF +UDAF (WIP) +UDAF (WIP) HBase JDBC Elasticsearch Apache Zeppelin
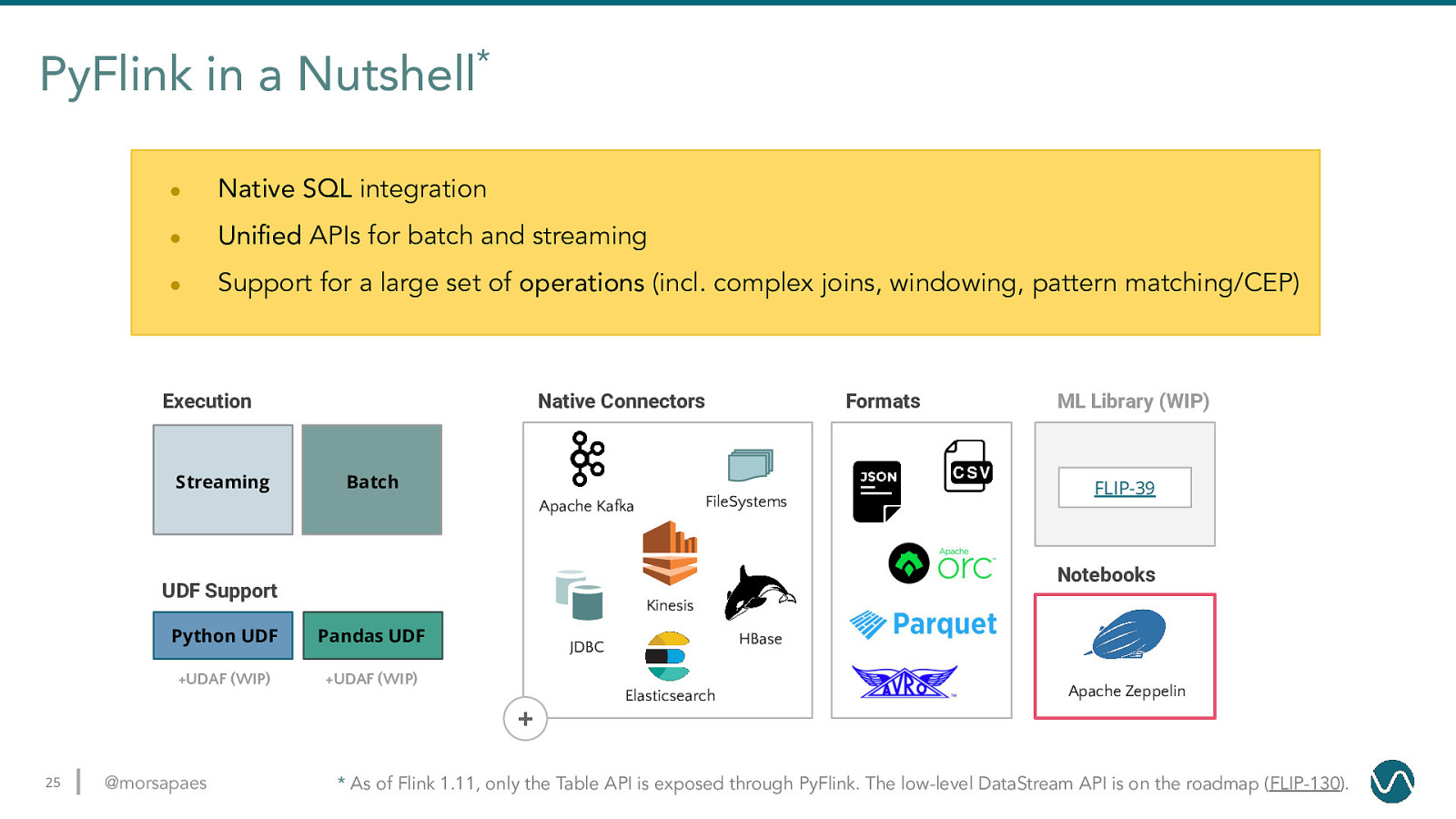
PyFlink in a Nutshell* ● Native SQL integration ● Unified APIs for batch and streaming ● Support for a large set of operations (incl. complex joins, windowing, pattern matching/CEP) Execution Streaming Native Connectors Formats Batch FileSystems Apache Kafka ML Library (WIP) FLIP-39 Notebooks UDF Support Kinesis Python UDF Pandas UDF +UDAF (WIP) +UDAF (WIP) HBase JDBC Elasticsearch Apache Zeppelin

26 @morsapaes

Apache Zeppelin Web-based notebook that provides an interactive and collaborative computing environment. … 27 @morsapaes Advantages ● Support for a lot of interpreters ● Polyglot notes ● Built-in interactive visualizations ● Multi-tenancy ● Pluggable notebook storage (e.g. git)
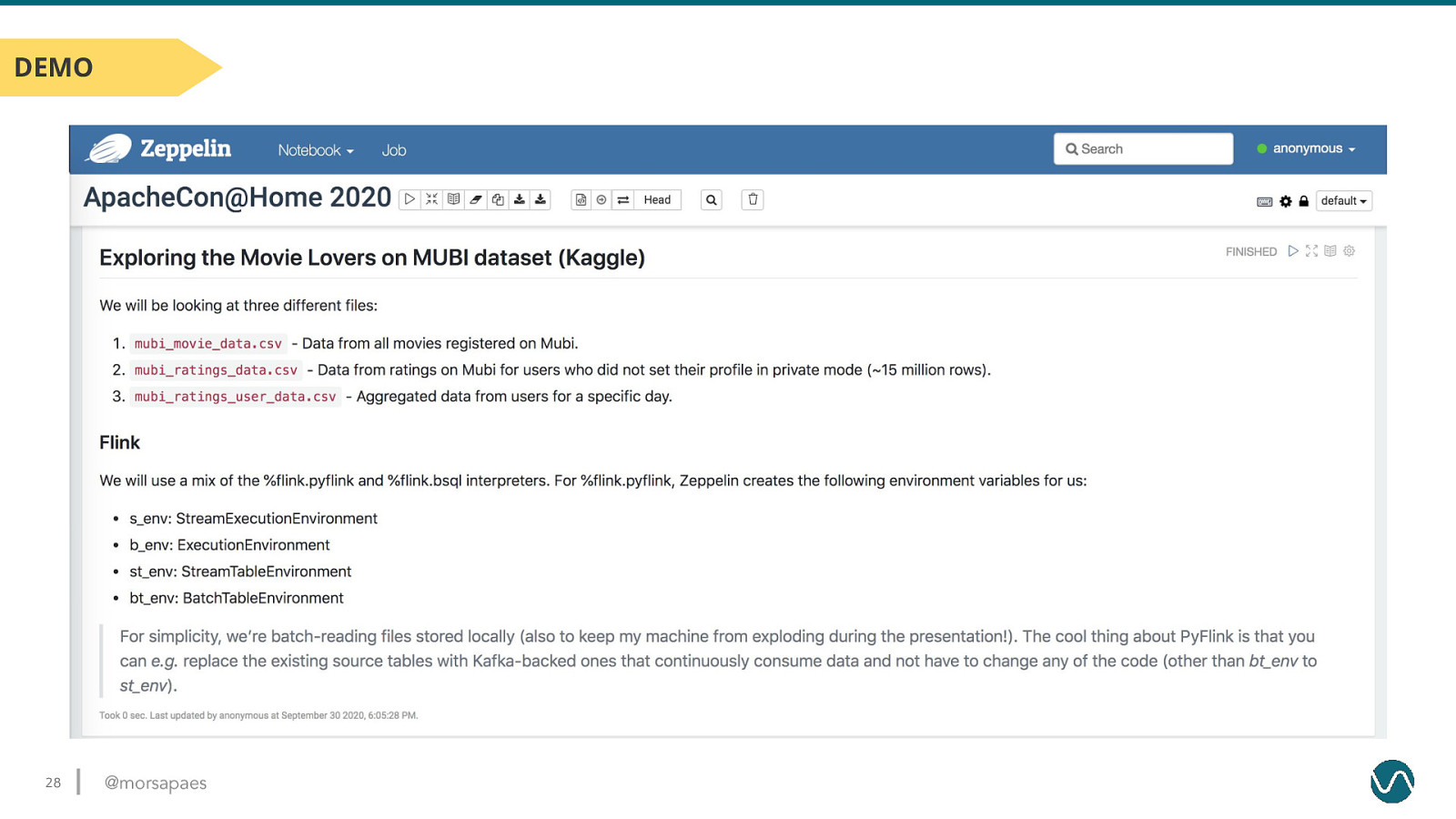
DEMO 28 @morsapaes
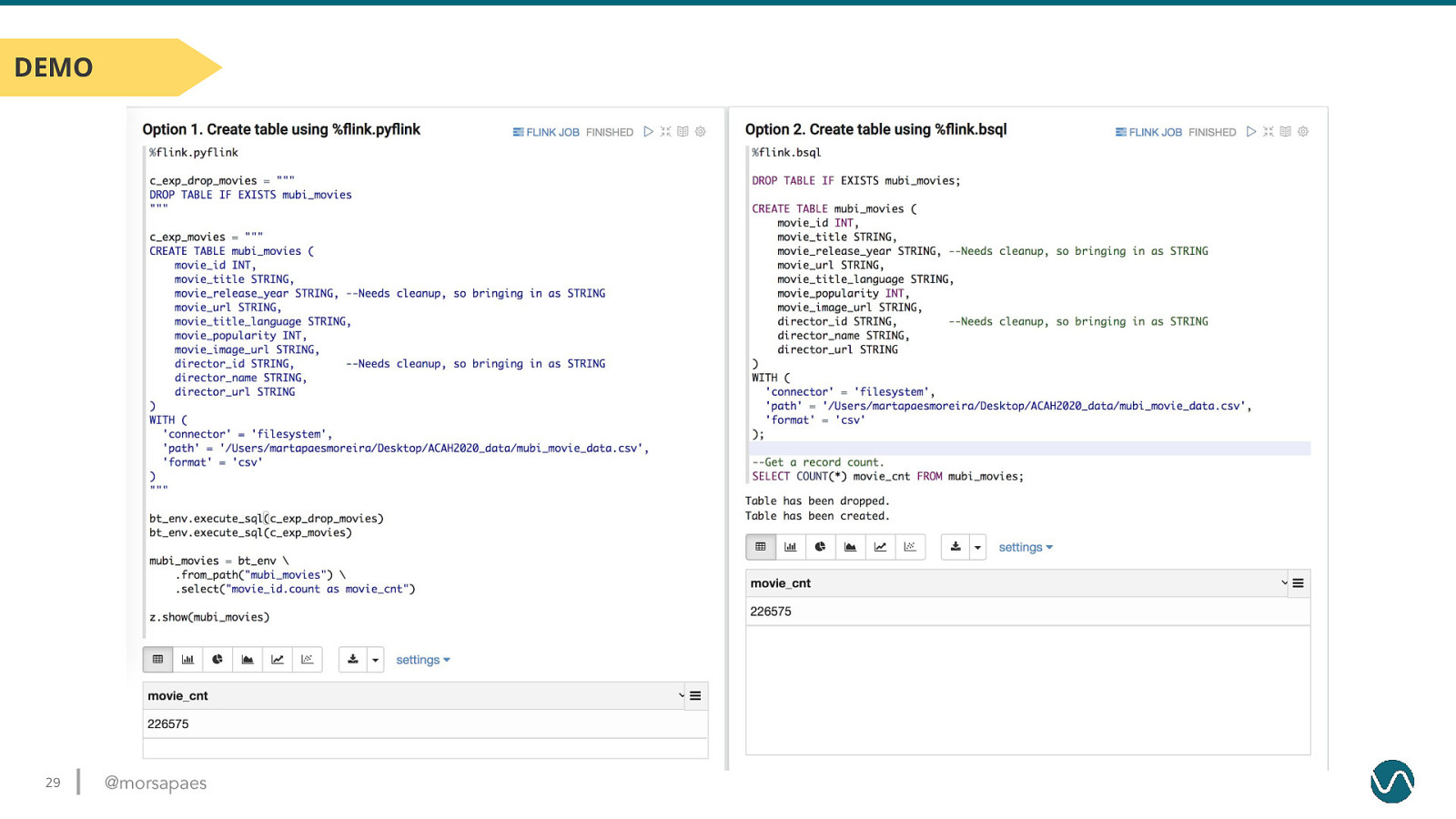
DEMO 29 @morsapaes
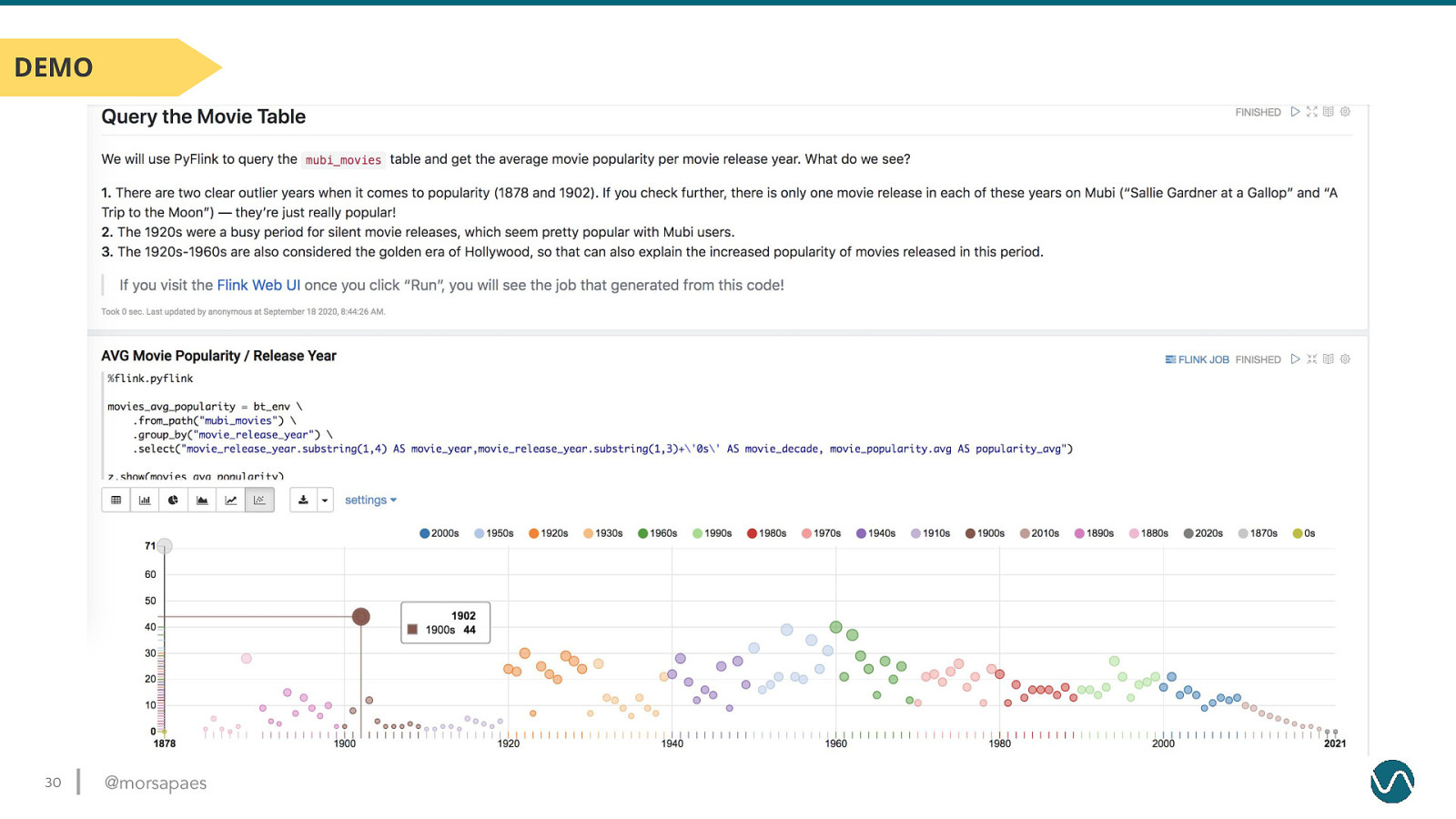
DEMO 30 @morsapaes
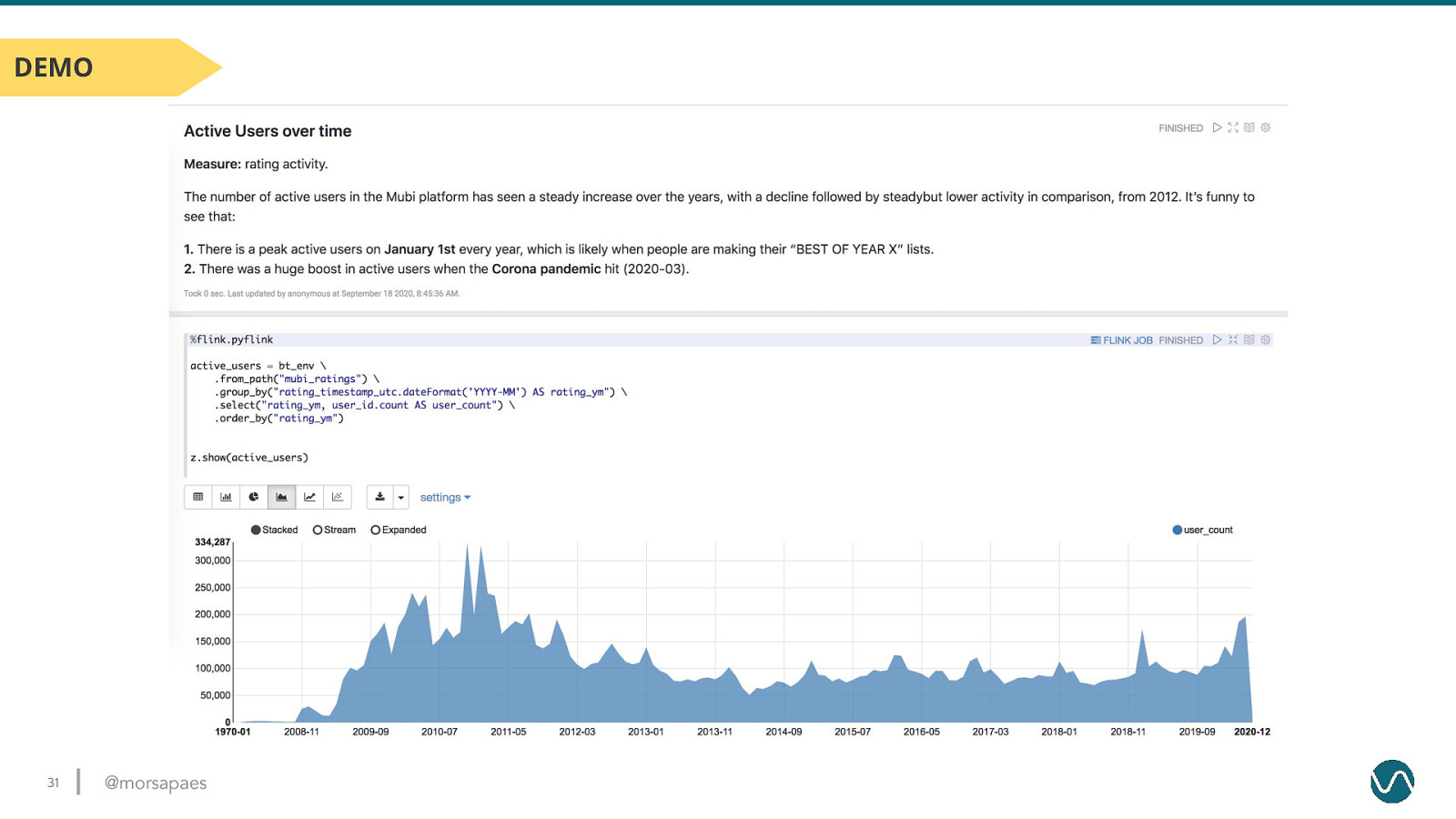
DEMO 31 @morsapaes
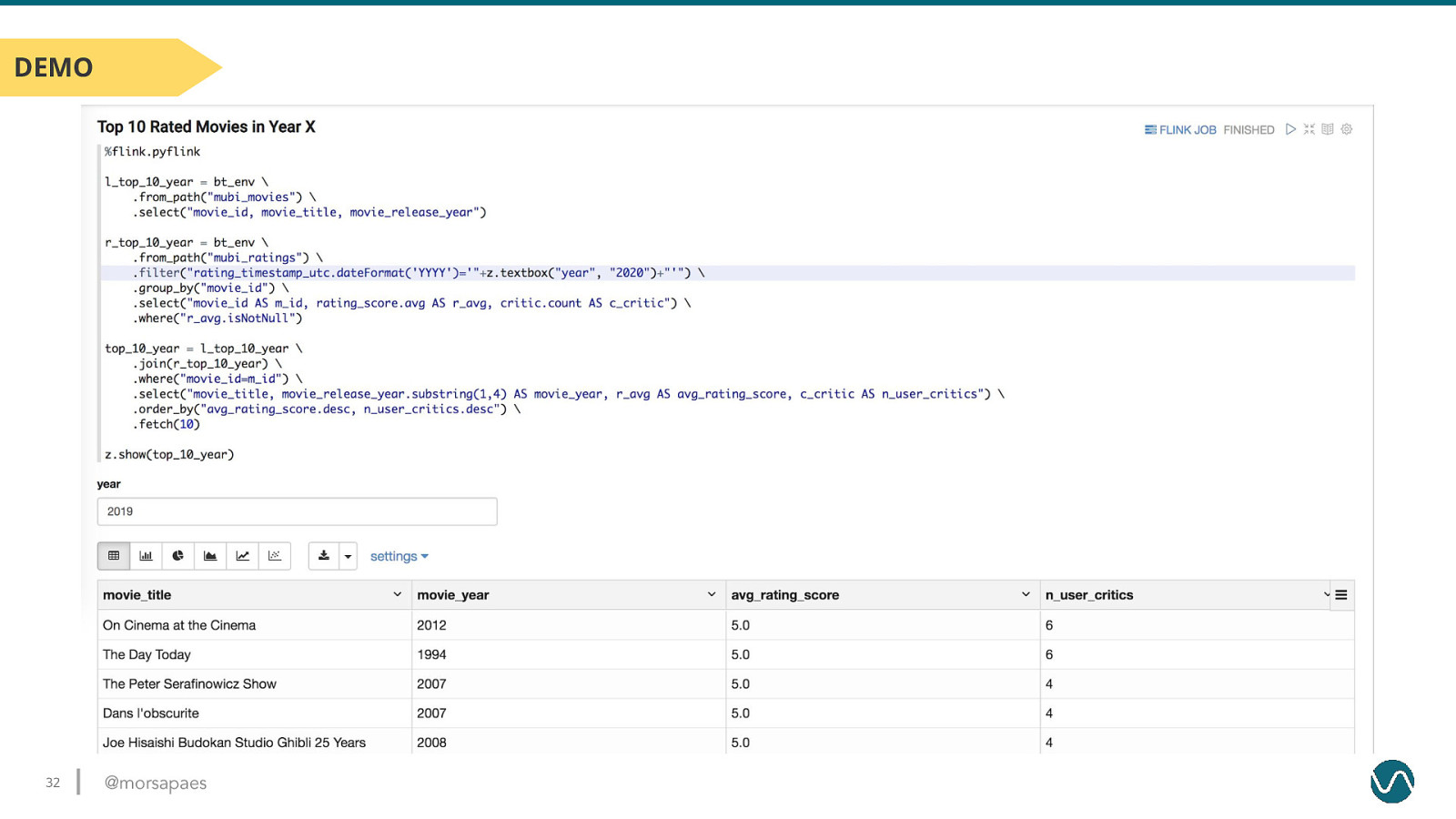
DEMO 32 @morsapaes
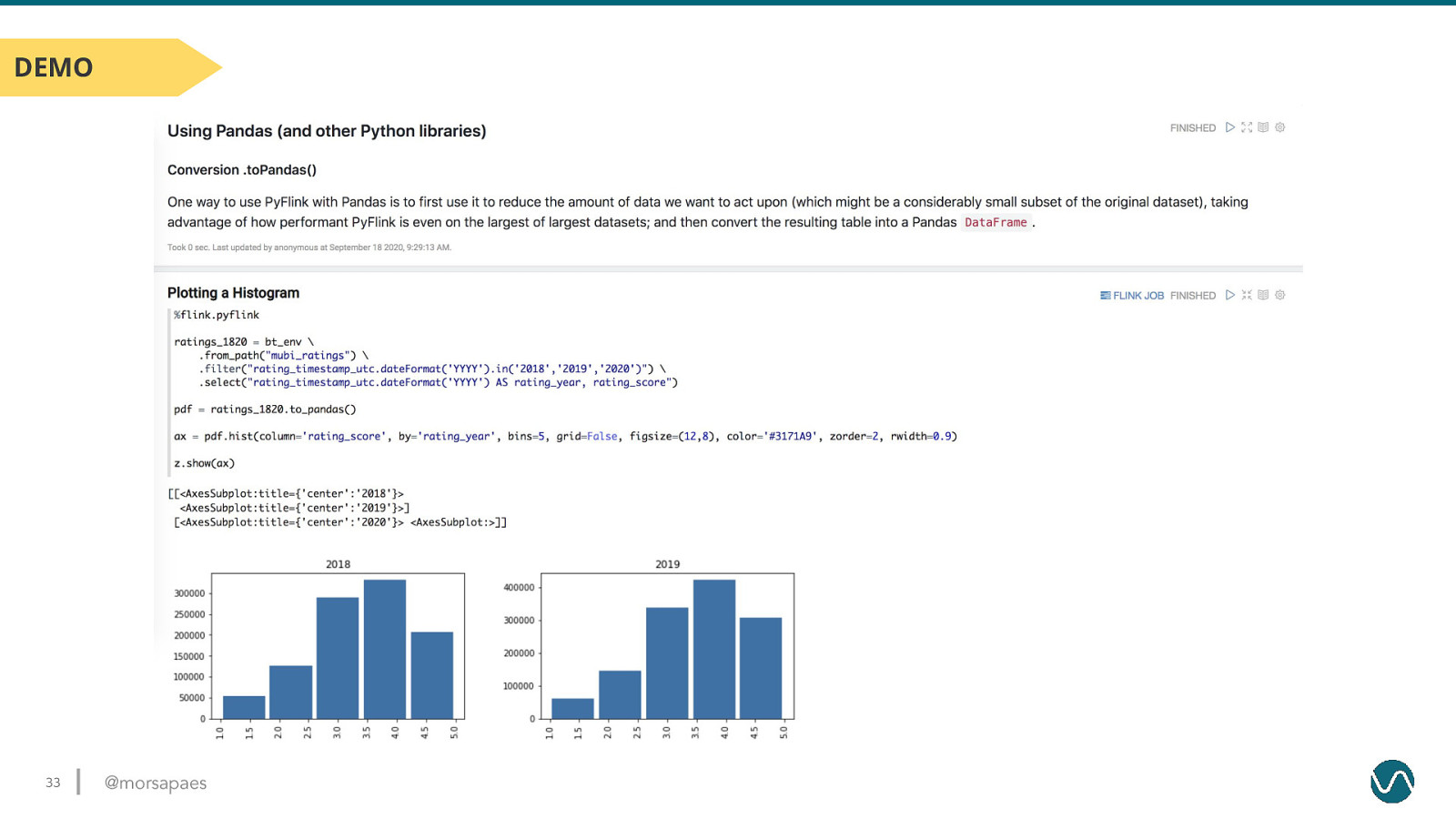
DEMO 33 @morsapaes

Want to learn more about Flink? 34 @morsapaes

Thank you, ApacheCon! Follow me on Twitter: @morsapaes Learn more about Flink: https://flink.apache.org/ © 2020 Ververica