Select Star: Flink SQL for Pulsar Folks Marta Paes (@morsapaes) Developer Advocate © 2020 Ververica

A presentation at Uber Apache Flink x Apache Pulsar Meetup 2021 in March 2021 in by Marta Paes

Select Star: Flink SQL for Pulsar Folks Marta Paes (@morsapaes) Developer Advocate © 2020 Ververica
Why Pulsar + Flink? J. Doe ● 1st 2 @morsapaes
Why Pulsar + Flink? 3 @morsapaes
Why Pulsar + Flink? “Batch as a special case of streaming” “Stream as a unified view on data” 4 @morsapaes
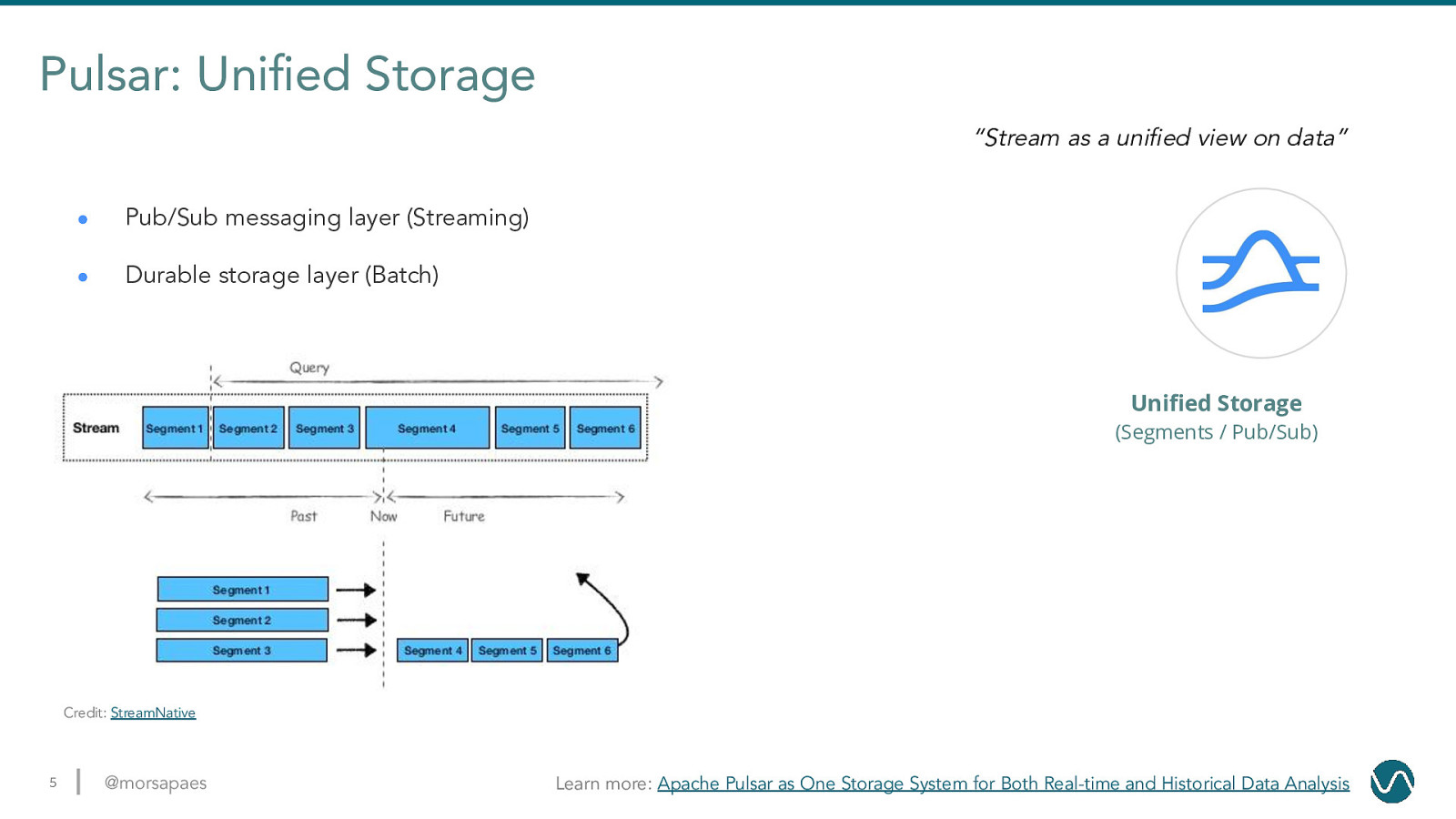
Pulsar: Unified Storage “Stream as a unified view on data” ● Pub/Sub messaging layer (Streaming) ● Durable storage layer (Batch) Unified Storage (Segments / Pub/Sub) Credit: StreamNative 5 @morsapaes Learn more: Apache Pulsar as One Storage System for Both Real-time and Historical Data Analysis
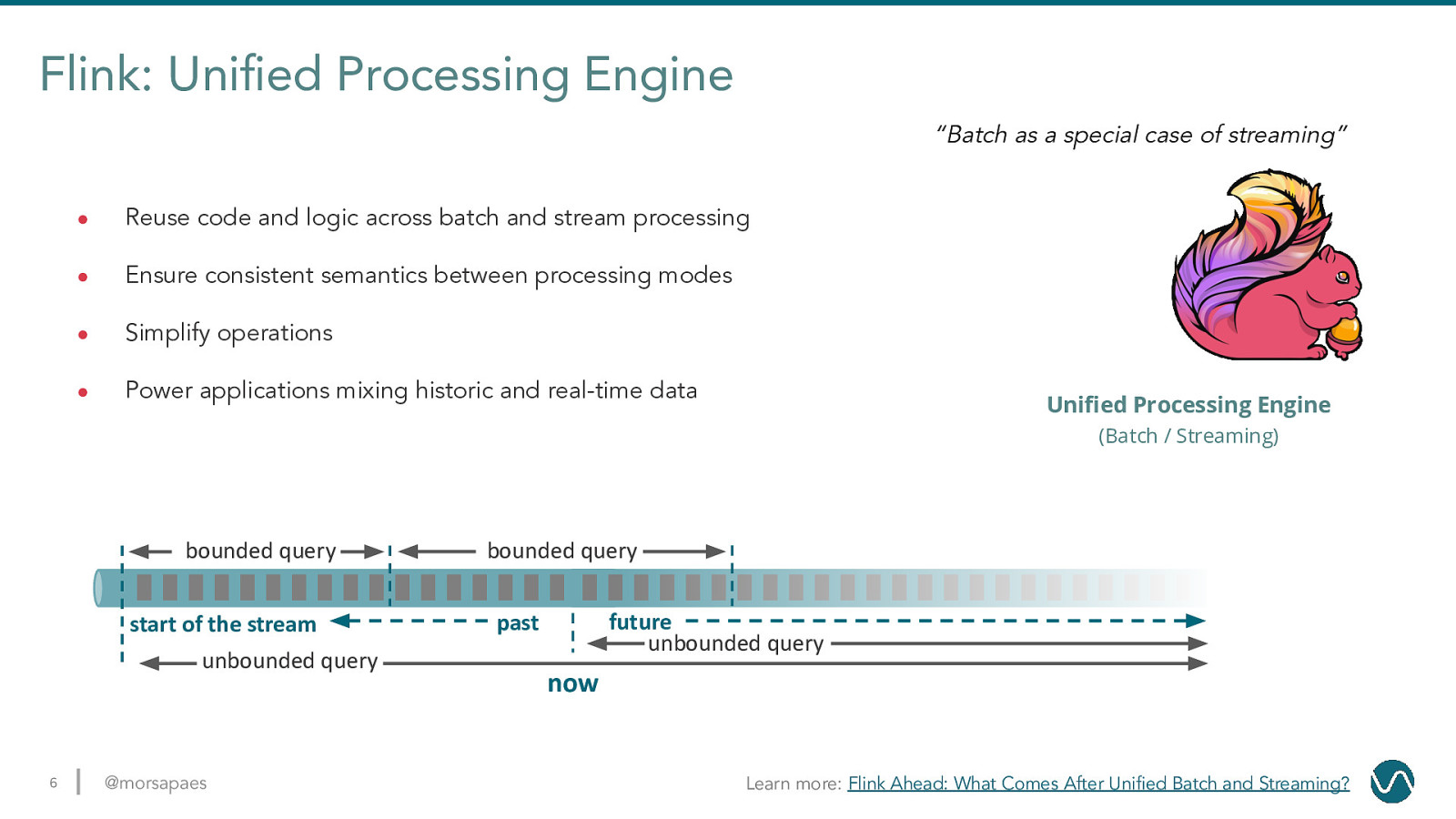
Flink: Unified Processing Engine “Batch as a special case of streaming” ● Reuse code and logic across batch and stream processing ● Ensure consistent semantics between processing modes ● Simplify operations ● Power applications mixing historic and real-time data Unified Processing Engine (Batch / Streaming) bounded query start of the stream unbounded query 6 @morsapaes bounded query future unbounded query past now Learn more: Flink Ahead: What Comes After Unified Batch and Streaming?
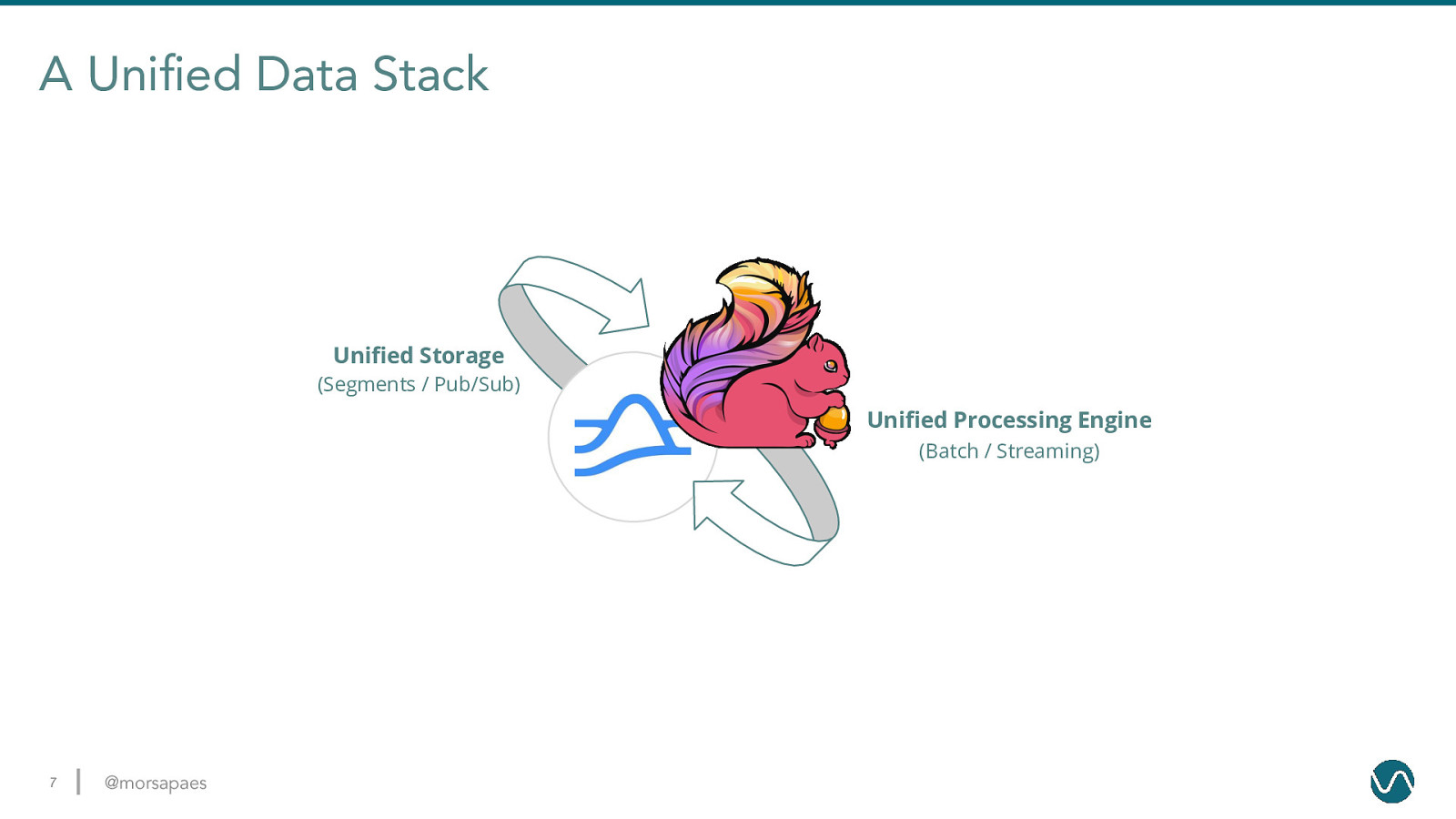
A Unified Data Stack Unified Storage (Segments / Pub/Sub) Unified Processing Engine (Batch / Streaming) 7 @morsapaes
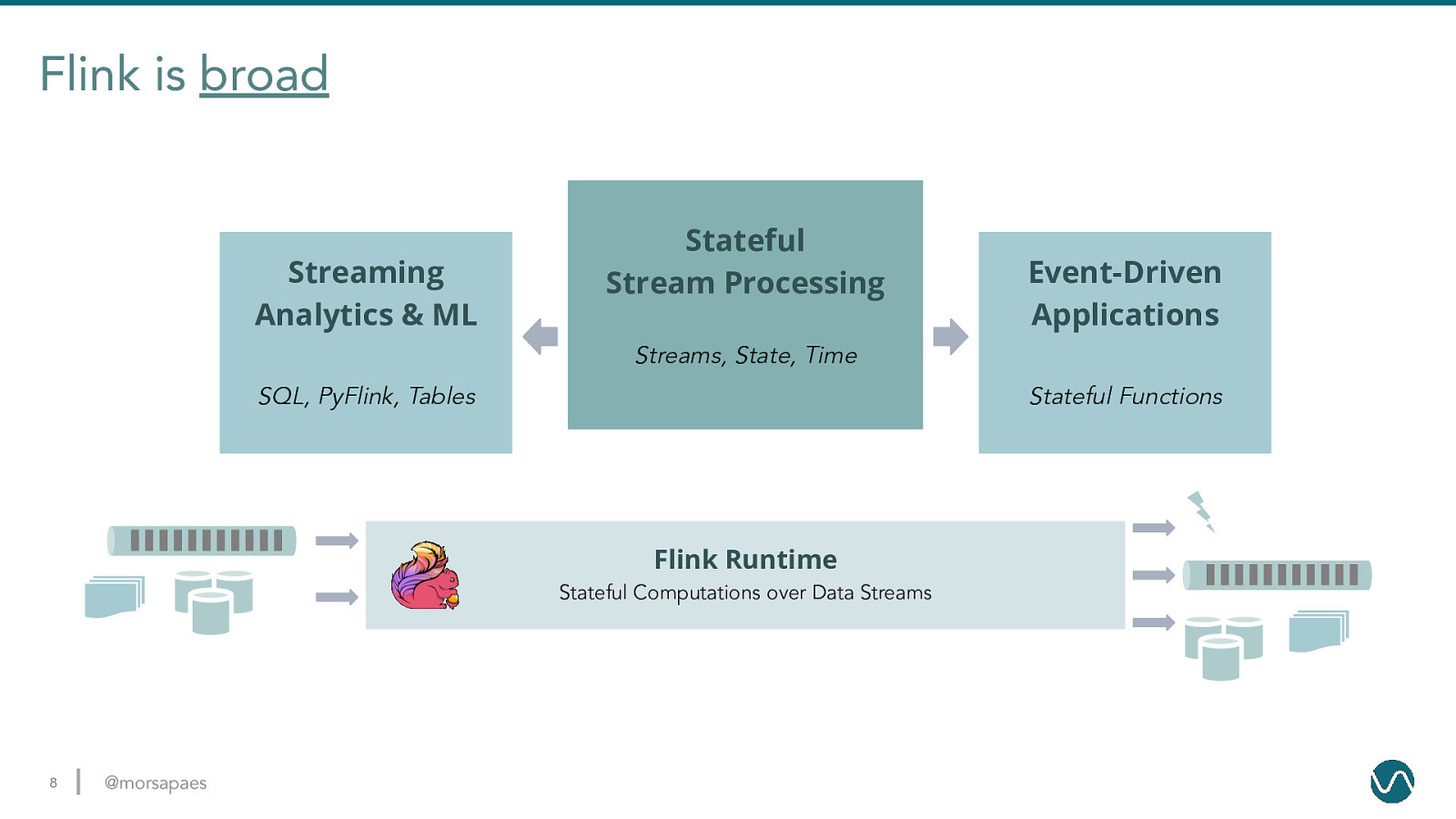
Flink is broad Streaming Analytics & ML Stateful Stream Processing Event-Driven Applications Streams, State, Time SQL, PyFlink, Tables Stateful Functions Flink Runtime Stateful Computations over Data Streams 8 @morsapaes

Flink is broad Streaming Analytics & ML Stateful Stream Processing Event-Driven Applications Streams, State, Time SQL, PyFlink, Tables Stateful Functions Flink Runtime Stateful Computations over Data Streams 9 @morsapaes
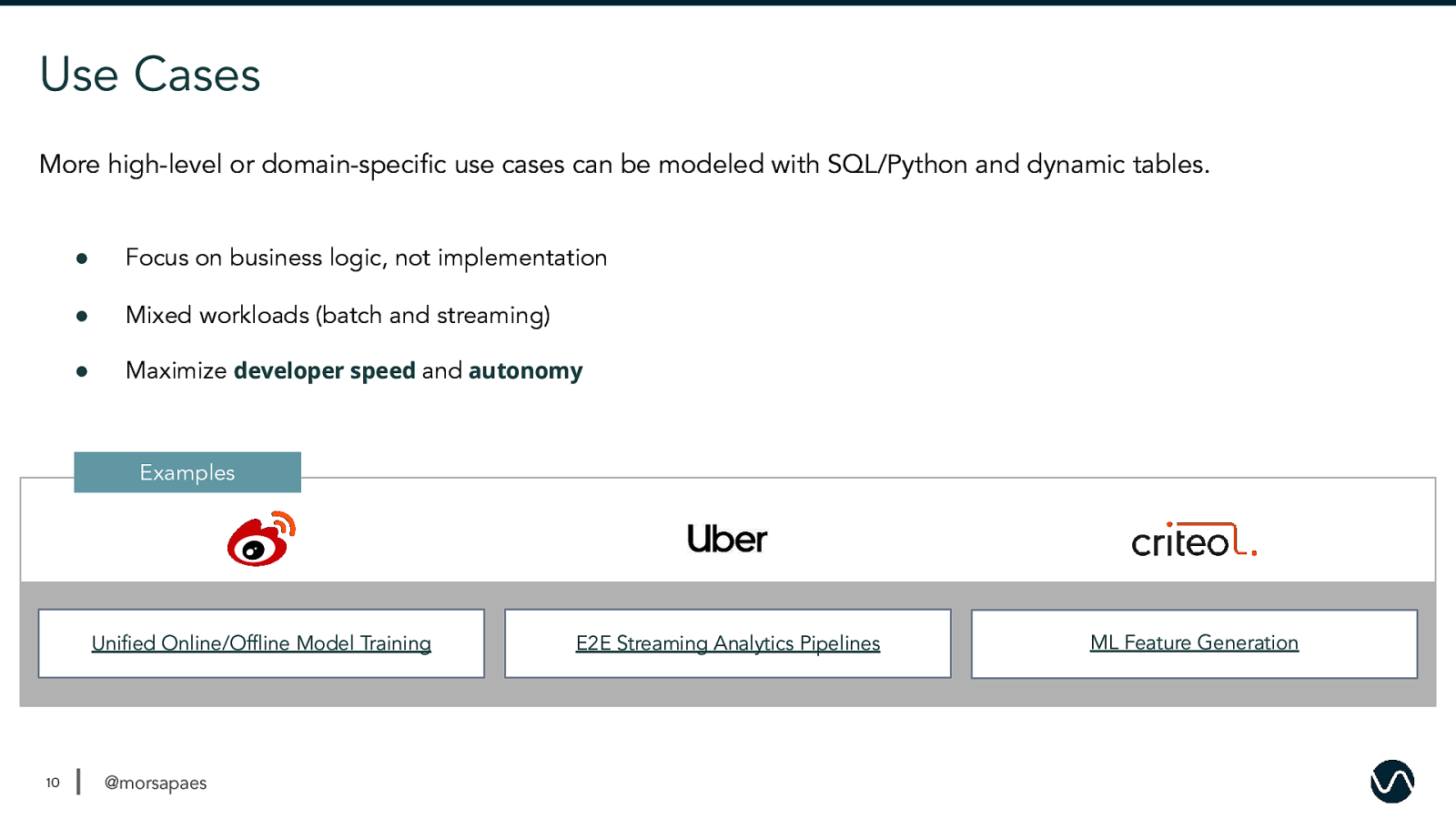
Use Cases More high-level or domain-specific use cases can be modeled with SQL/Python and dynamic tables. ● Focus on business logic, not implementation ● Mixed workloads (batch and streaming) ● Maximize developer speed and autonomy Examples Unified Online/Offline Model Training 10 @morsapaes E2E Streaming Analytics Pipelines ML Feature Generation

Flink SQL “Everyone knows SQL, right?” SELECT user_id, COUNT(url) AS cnt FROM clicks GROUP BY user_id; This is standard SQL (ANSI SQL) 11 @morsapaes

Flink SQL “Everyone knows SQL, right?” SELECT user_id, COUNT(url) AS cnt FROM clicks GROUP BY user_id; This is standard SQL (ANSI SQL) also Flink SQL 12 @morsapaes
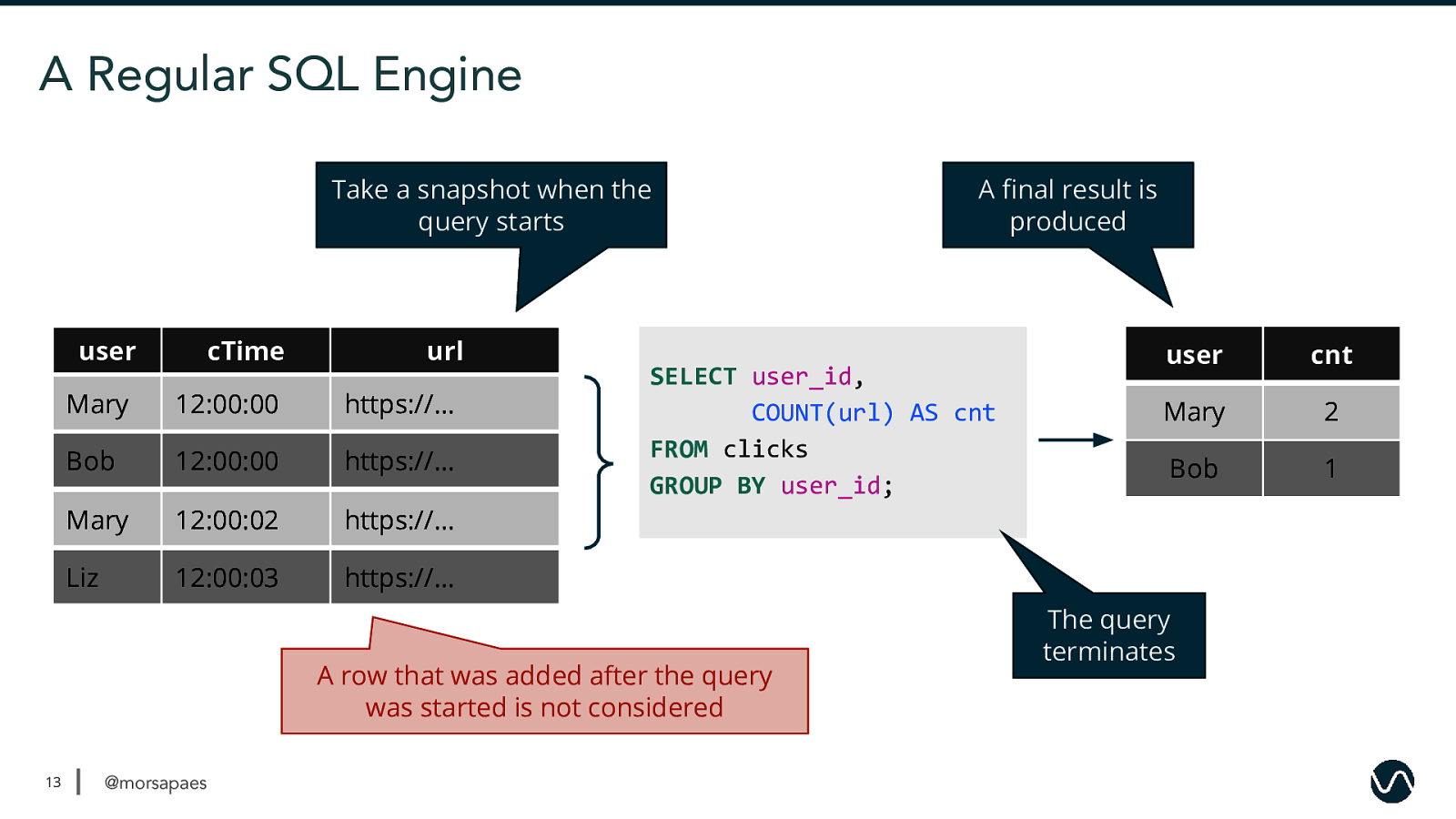
A Regular SQL Engine Take a snapshot when the query starts user cTime url Mary 12:00:00 https://… Bob 12:00:00 https://… Mary 12:00:02 https://… Liz 12:00:03 https://… SELECT user_id, COUNT(url) AS cnt FROM clicks GROUP BY user_id; A row that was added after the query was started is not considered 13 @morsapaes A final result is produced user cnt Mary 2 Bob 1 The query terminates
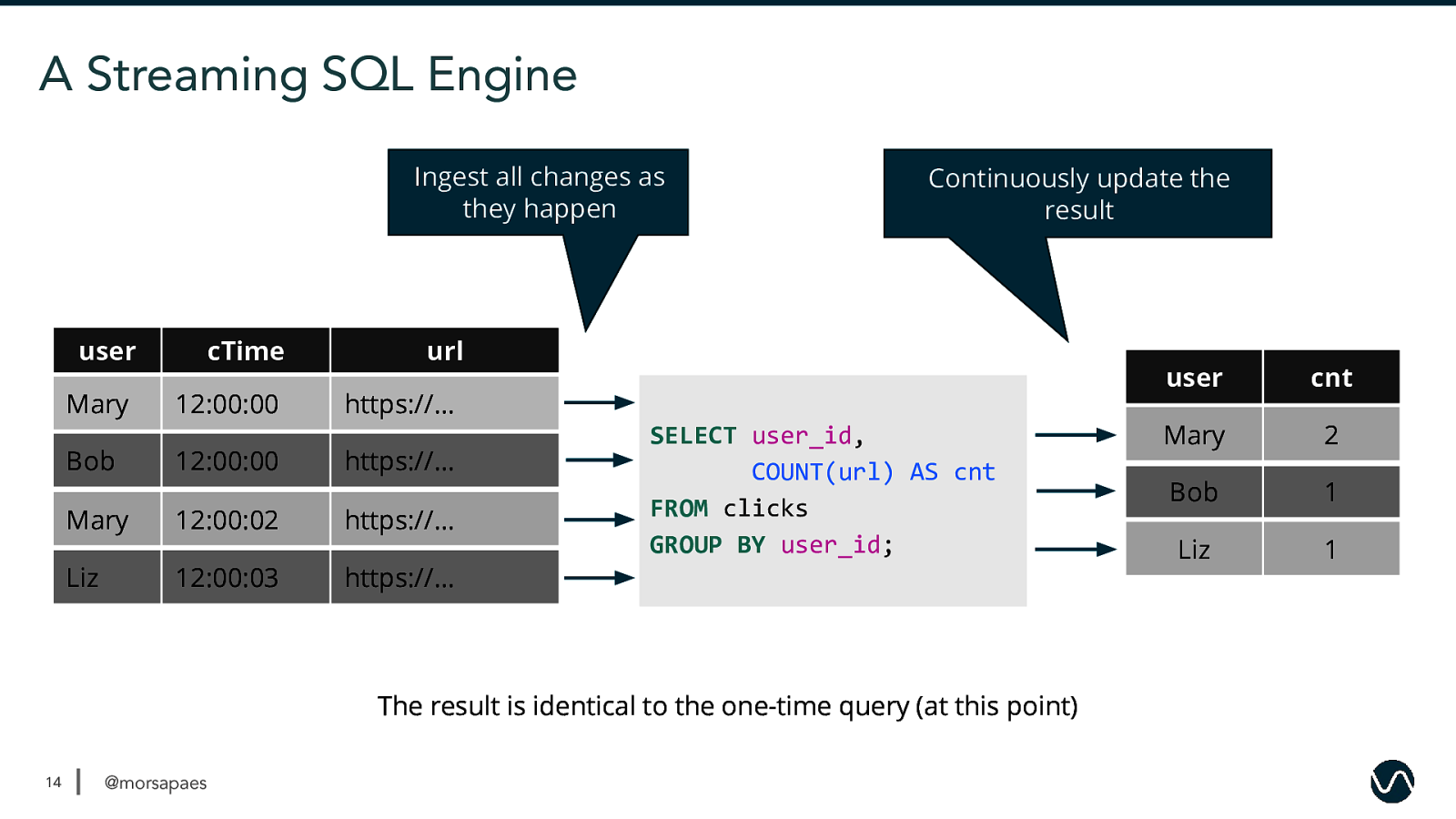
A Streaming SQL Engine Ingest all changes as they happen user Mary Bob cTime 12:00:00 12:00:00 Continuously update the result url https://… https://… Mary 12:00:02 https://… Liz 12:00:03 https://… SELECT user_id, COUNT(url) AS cnt FROM clicks GROUP BY user_id; The result is identical to the one-time query (at this point) 14 @morsapaes user cnt Mary Mary 1 2 Bob 1 Liz 1
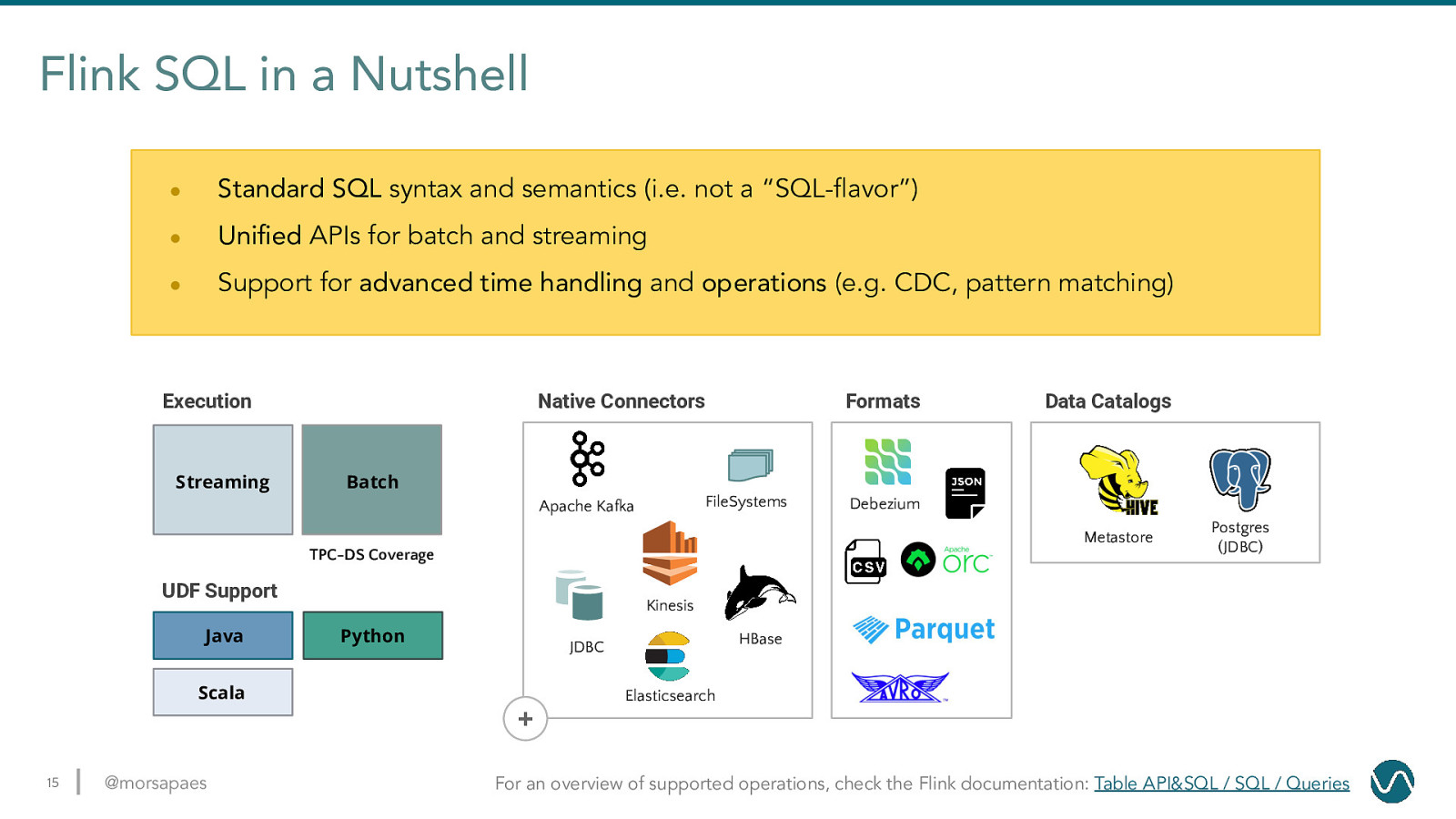
Flink SQL in a Nutshell ● Standard SQL syntax and semantics (i.e. not a “SQL-flavor”) ● Unified APIs for batch and streaming ● Support for advanced time handling and operations (e.g. CDC, pattern matching) Execution Streaming Native Connectors Formats Batch FileSystems Apache Kafka Debezium Metastore TPC-DS Coverage UDF Support Java Data Catalogs Postgres (JDBC) Kinesis Python HBase JDBC Scala Elasticsearch
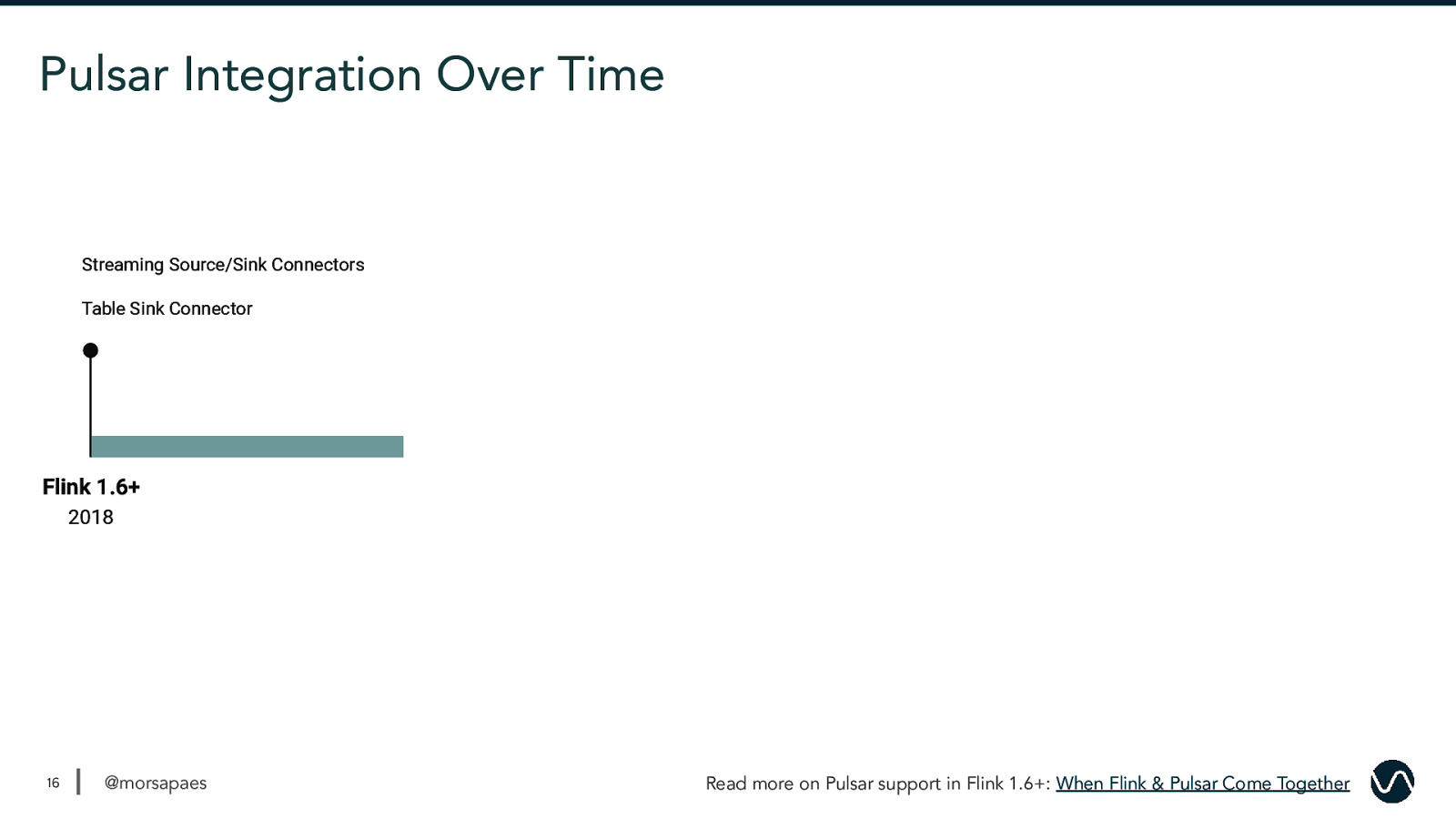
Pulsar Integration Over Time Streaming Source/Sink Connectors Table Sink Connector Flink 1.6+ 2018 16 @morsapaes Read more on Pulsar support in Flink 1.6+: When Flink & Pulsar Come Together

Pulsar Integration Over Time Streaming Source/Sink Connectors Table Sink Connector Flink 1.9+ Flink 1.6+ 2018 Pulsar Schema + Flink Catalog Integration Table API/SQL as first-class citizens Exactly-once Source At-least once Sink 17 @morsapaes Read more on Pulsar support in Flink 1.9+: How to Query Pulsar Streams using Apache Flink

Pulsar Integration Over Time Upserts (upsert-pulsar) DDL Computed Columns, Watermarks and Metadata Streaming Source/Sink Connectors End-to-end Exactly-once Table Sink Connector Key-shared Subscription Model Flink 1.9+ Flink 1.6+ Flink 1.12 2018 Pulsar Schema + Flink Catalog Integration Table API/SQL as first-class citizens Exactly-once Source At-least once Sink 18 @morsapaes Read more on Pulsar support in Flink 1.12+: What’s New in the Pulsar Flink Connector 2.7.0?
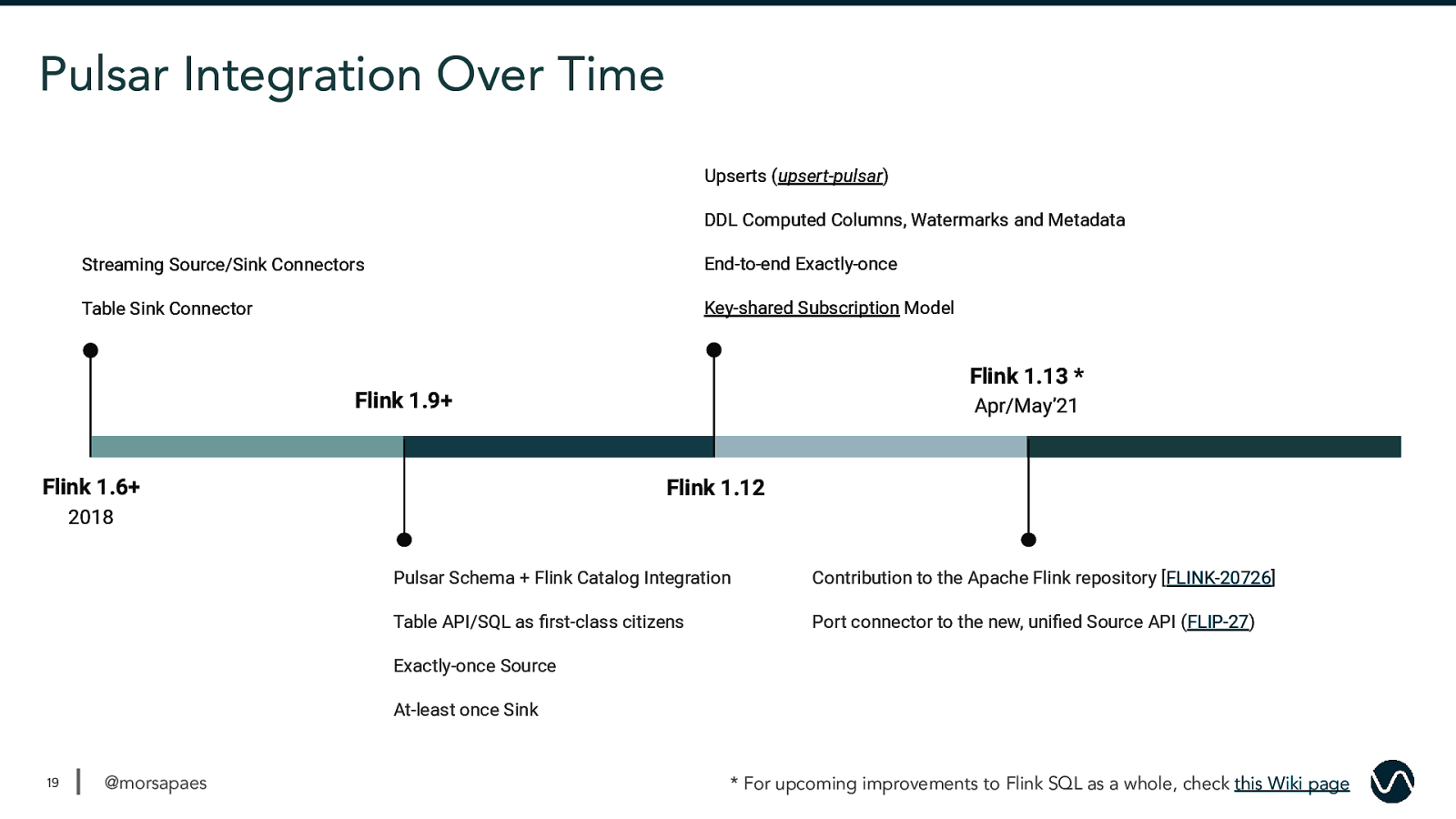
Pulsar Integration Over Time Upserts (upsert-pulsar) DDL Computed Columns, Watermarks and Metadata Streaming Source/Sink Connectors End-to-end Exactly-once Table Sink Connector Key-shared Subscription Model Flink 1.13 * Flink 1.9+ Flink 1.6+ Apr/May’21 Flink 1.12 2018 Pulsar Schema + Flink Catalog Integration Contribution to the Apache Flink repository [FLINK-20726] Table API/SQL as first-class citizens Port connector to the new, unified Source API (FLIP-27) Exactly-once Source At-least once Sink 19 @morsapaes
How does this look like, in practice? 20 @morsapaes
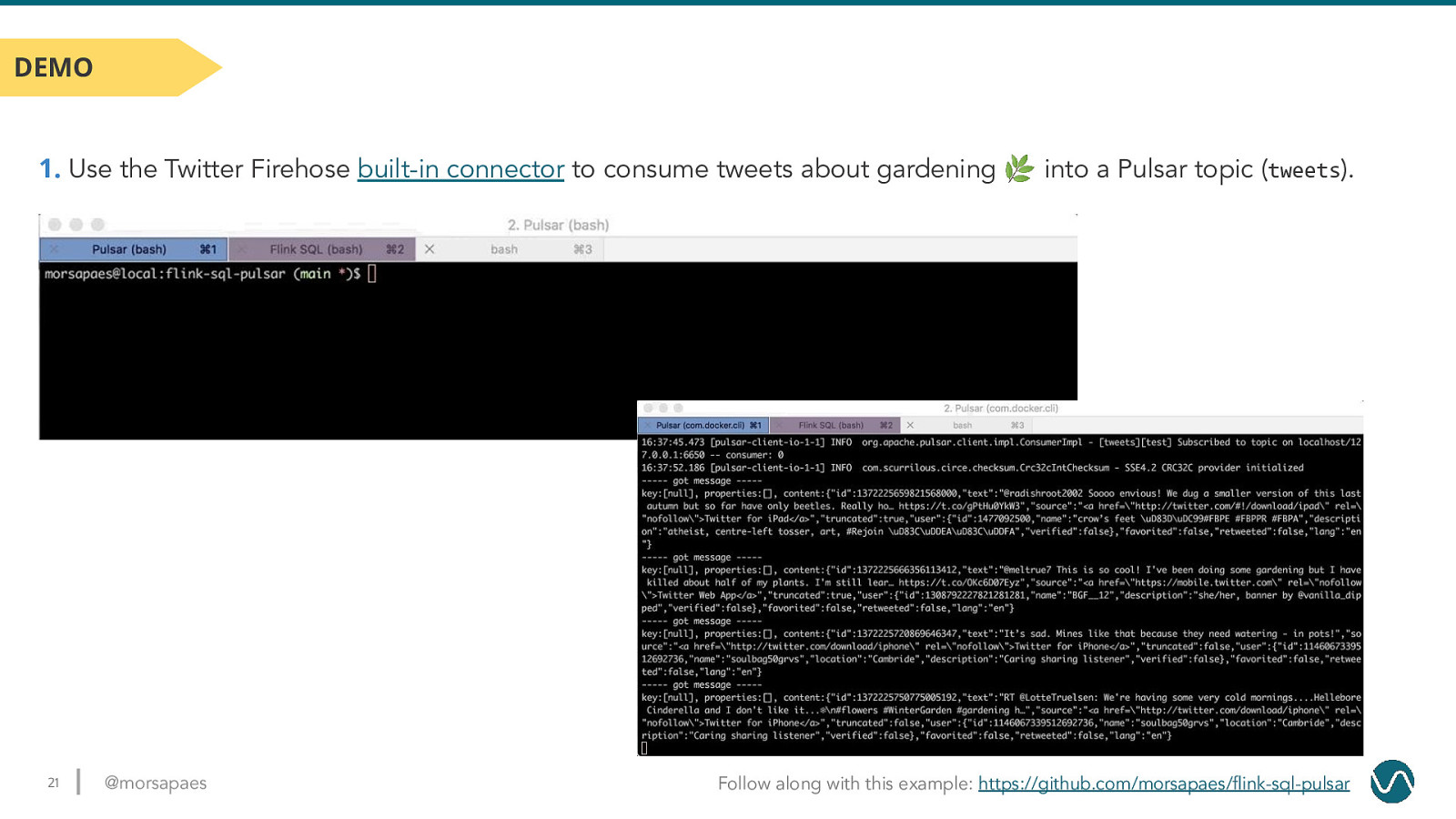
DEMO
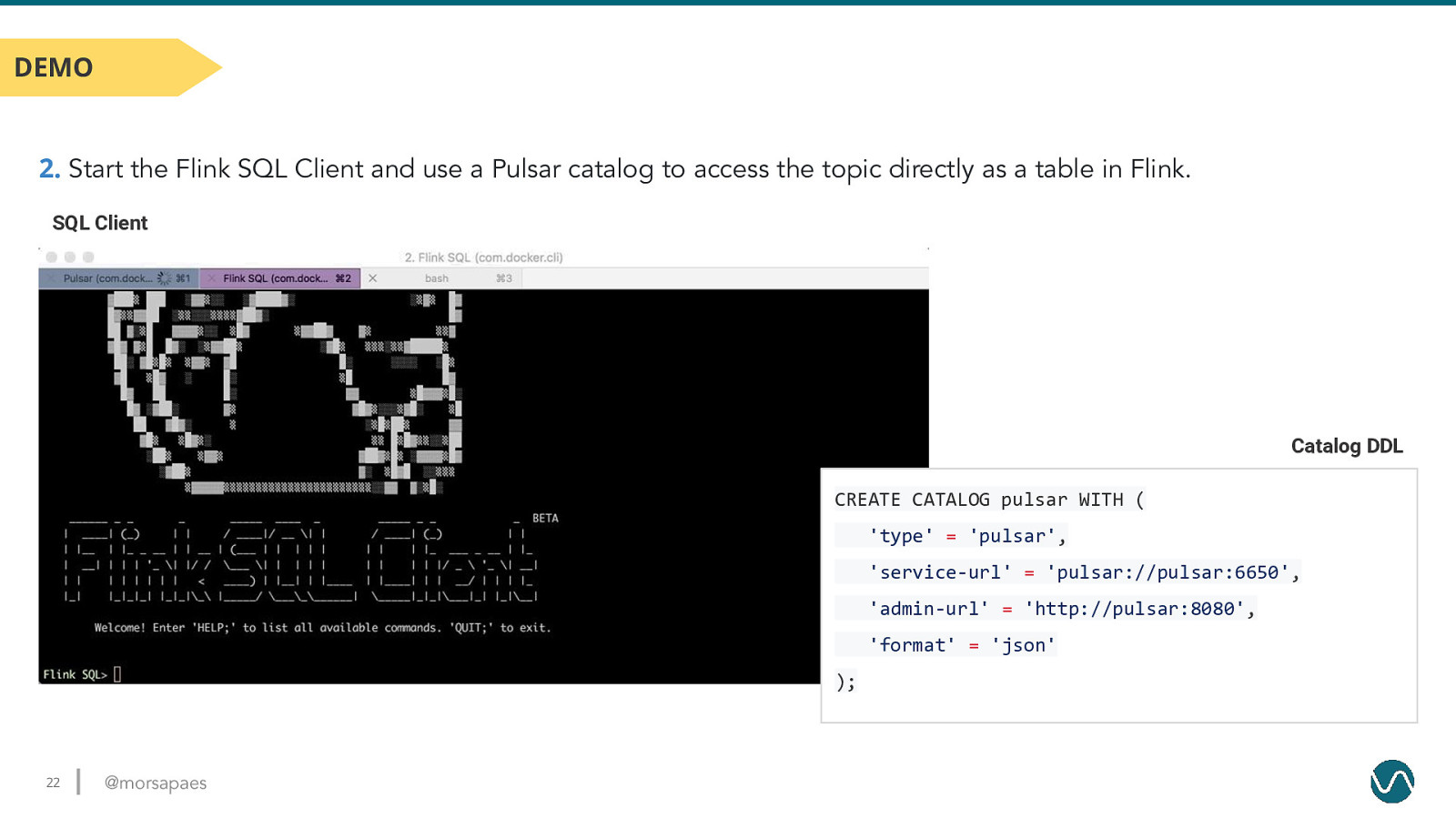
DEMO 2. Start the Flink SQL Client and use a Pulsar catalog to access the topic directly as a table in Flink. SQL Client Catalog DDL CREATE CATALOG pulsar WITH ( ‘type’ = ‘pulsar’, ‘service-url’ = ‘pulsar://pulsar:6650’, ‘admin-url’ = ‘http://pulsar:8080’, ‘format’ = ‘json’ ); 22 @morsapaes
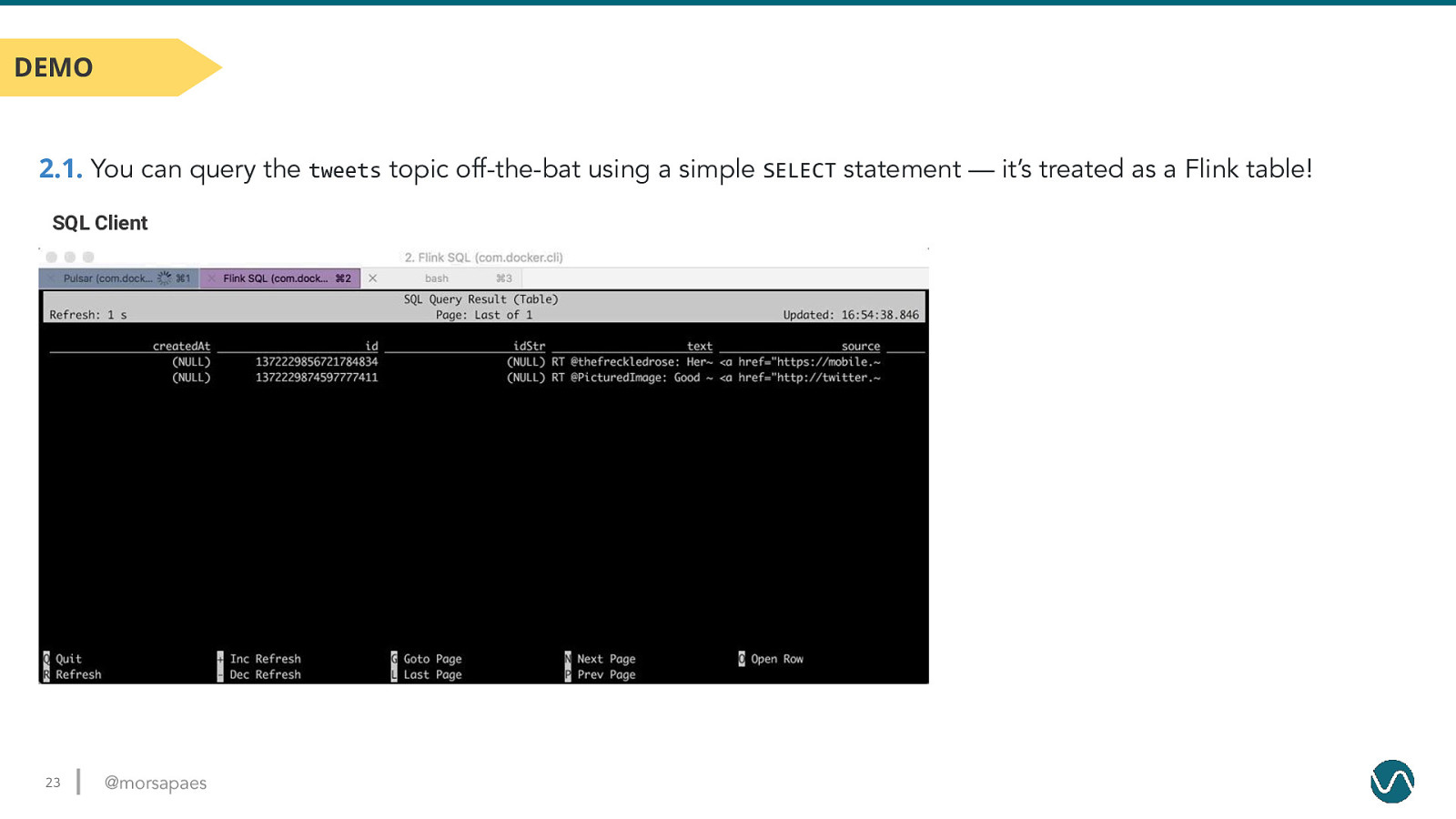
DEMO 2.1. You can query the tweets topic off-the-bat using a simple SELECT statement — it’s treated as a Flink table! SQL Client 23 @morsapaes
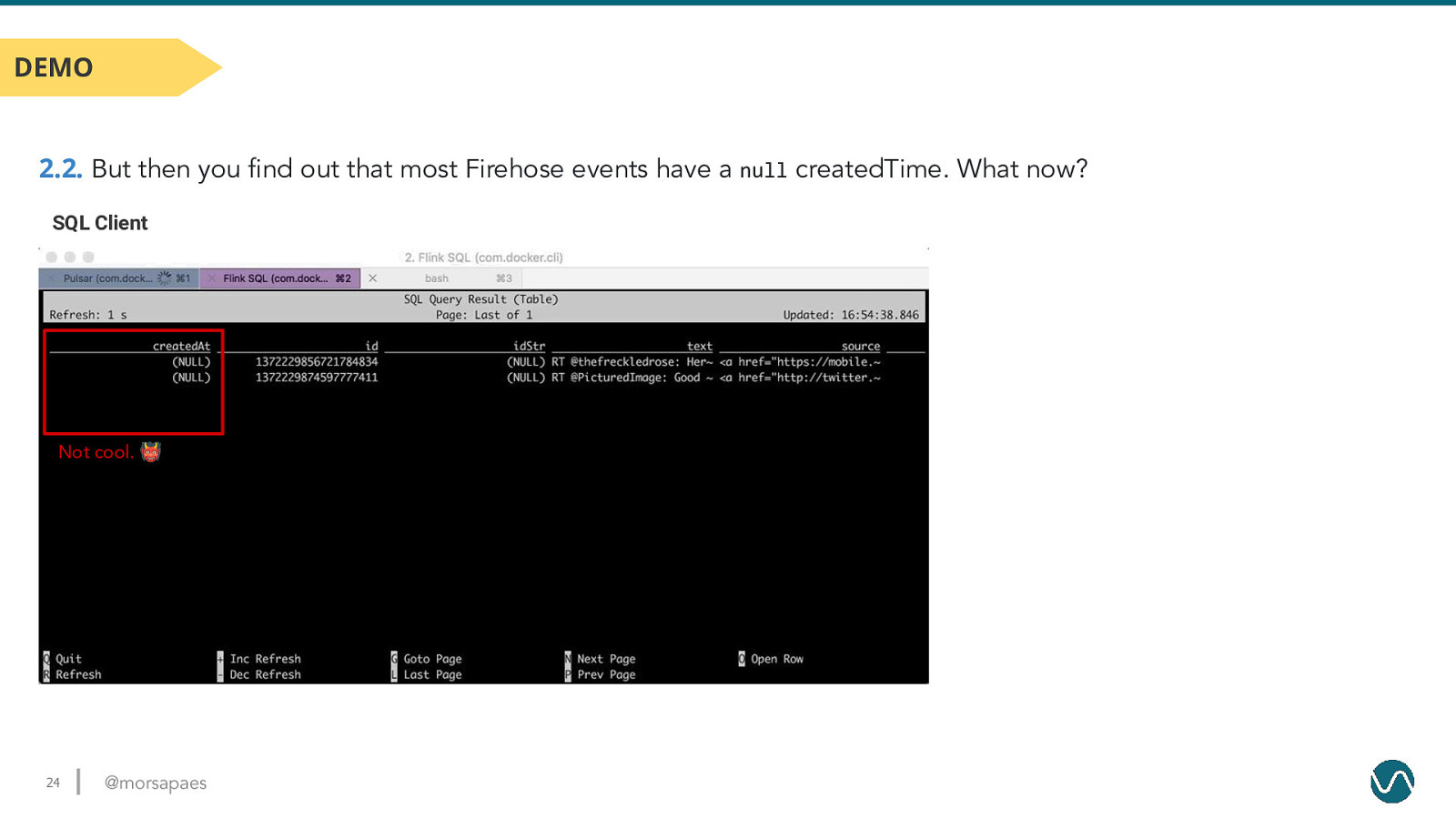
DEMO 2.2. But then you find out that most Firehose events have a null createdTime. What now? SQL Client Not cool. 👹 24 @morsapaes

DEMO 3. One way to get a relevant timestamp is to use Pulsar metadata to get the publishTime (i.e. ingestion time). Source Table DDL CREATE TABLE pulsar_tweets ( publishTime TIMESTAMP(3) METADATA, WATERMARK FOR publishTime AS publishTime - INTERVAL ‘5’ SECOND Read and use Pulsar message metadata ) WITH ( ‘connector’ = ‘pulsar’, ‘topic’ = ‘persistent://public/default/tweets’, ‘value.format’ = ‘json’, ‘service-url’ = ‘pulsar://pulsar:6650’, Define the source connector (Pulsar) ‘admin-url’ = ‘http://pulsar:8080’, ‘scan.startup.mode’ = ‘earliest-offset’ ) LIKE tweets; 25 @morsapaes Derive schema from the original topic Pulsar Flink connector repo: https://github.com/streamnative/pulsar-flink
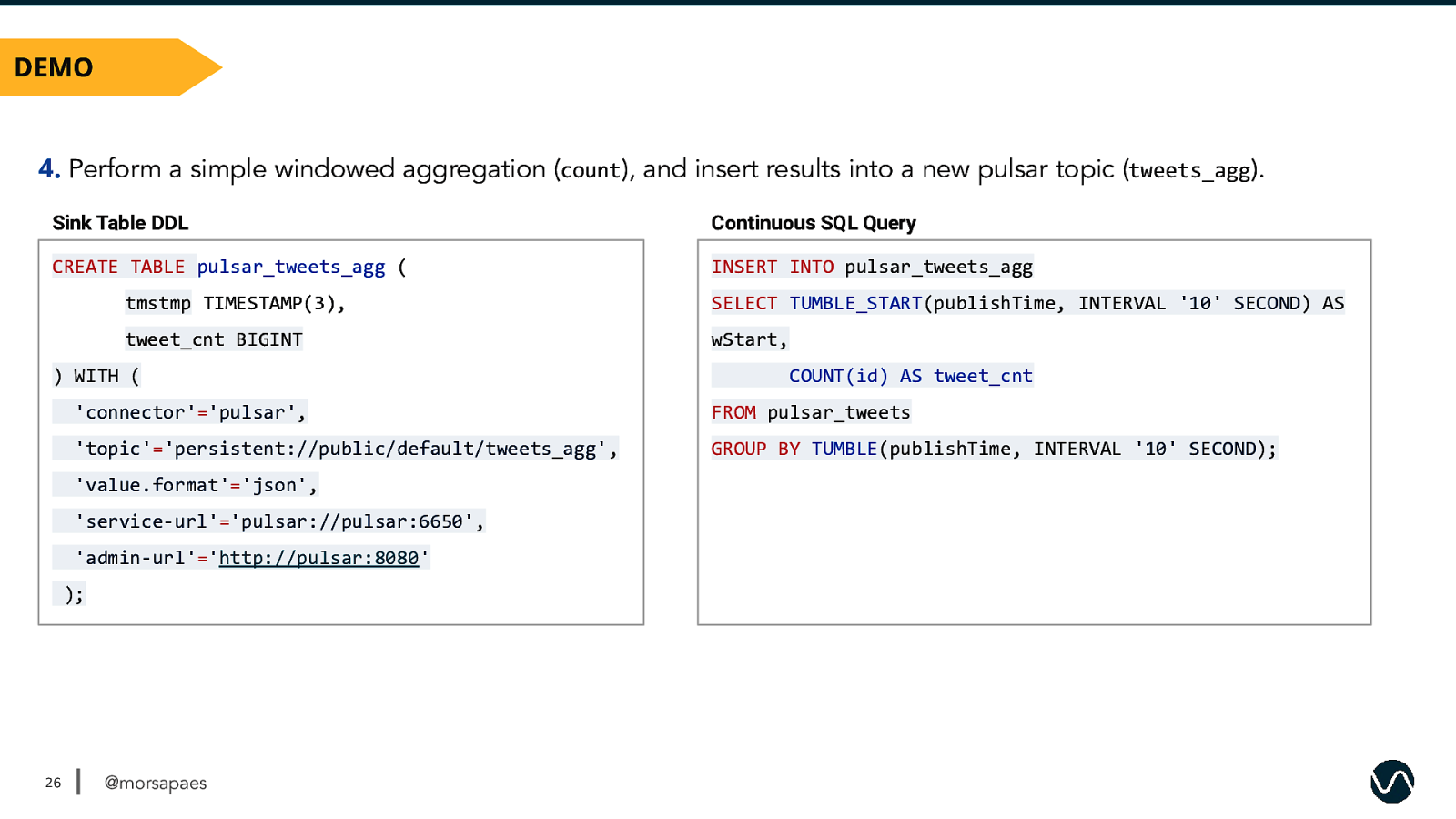
DEMO 4. Perform a simple windowed aggregation (count), and insert results into a new pulsar topic (tweets_agg). Sink Table DDL Continuous SQL Query CREATE TABLE pulsar_tweets_agg ( INSERT INTO pulsar_tweets_agg tmstmp TIMESTAMP(3), SELECT TUMBLE_START(publishTime, INTERVAL ‘10’ SECOND) AS tweet_cnt BIGINT wStart, ) WITH ( ‘connector’=’pulsar’, FROM pulsar_tweets ‘topic’=’persistent://public/default/tweets_agg’, GROUP BY TUMBLE(publishTime, INTERVAL ‘10’ SECOND); ‘value.format’=’json’, ‘service-url’=’pulsar://pulsar:6650’, ‘admin-url’=’http://pulsar:8080’ ); 26 COUNT(id) AS tweet_cnt @morsapaes
DEMO 5. We’ll get a count of the # of tweets in windows of 10 seconds (based on event time!). 27 @morsapaes
There’s a lot more to it! Check out the Flink SQL Cookbook, where we share hands-on examples, patterns, and use cases for Flink SQL. 28 @morsapaes

Thank you! Follow me on Twitter: @morsapaes Learn more about Flink: https://flink.apache.org/ © 2020 Ververica