Lost production and don’t know why? Track your code releases! Nikita Lohia Senior Engineer, Financial Times @NikitaLohia HOLDING SCREEN - click once at start for timings!

A presentation at Continuous Lifecycle Online in May 2021 in by Nikita Lohia

Lost production and don’t know why? Track your code releases! Nikita Lohia Senior Engineer, Financial Times @NikitaLohia HOLDING SCREEN - click once at start for timings!

Lost production and don’t know why? Track your code releases! Nikita Lohia Senior Engineer, Financial Times @NikitaLohia HOLDING SCREEN - click once at start for timings! Thank you for joining me today. I would like to talk about why tracking code releases can be useful when you have microservices in your organisation.

Microservices are great ! But … We all appreciate the advantages of microservices. They are easily deployable, scalable and by definition they are small and many. However, with all that comes the challenge of understanding how they interact with each other. If you are a DevOps engineer working in a medium to large microservices ecosystem, you are expected to build, run and support your services. If one of your services suddenly starts throwing an error, knowing that some other dependent service could have changed, how quickly can you revert to a stable state?
https://medium.com/ft-product-technology/making-the-case-for-cloud-only-92f382ff8dd9 I am Nikita, and I am a senior Engineer at the FT. The Financial Times is one of the world’s leading business and financial news organisations. As of 2020, we are a fully cloud hosted company. Mark Barnes, my colleague at the FT has written an excellent blog on our journey to Cloud-only.
The Problem When something goes wrong, the first question you want answered is - what changed? @NikitaLohia At the FT, we have around 500 microservices being managed by multiple different teams, working in different timezones, releasing code at different times during the day. At any point in time, we want to be able to consistently and confidently answer the question - what changed recently and if that change causes a disruption how quickly can we fix it? This is not only important for the teams developing these services, but also important for our Operations team - watching over our entire estate 24/7. How can they associate an alert firing to a recent release? So we set ourselves a challenge - we need to track all code releases happening in our tech estate.
Our first attempt .. @NikitaLohia Our legacy Change Request API(CR API) Change and Release Management at the FT was not a new concept. Our legacy Change Request API, fondly called CRAPI (/ˈkræpɪ/) was tracking releases, both automated and manual, and storing them in a third party change management tool. There were a few reasons why it wasn’t a huge success and why it didn’t quite work anymore….
Our first attempt .. [redacted] @NikitaLohia Our legacy Change Request API(CR API) CR API was written in Java around 5 years ago, people who wrote it had long moved on. It moved around from team to team, without much of a handover. I was in the Reliability Engineering team at the time and we adopted it, albeit grudgingly. No-one in the team quite understood it anymore.
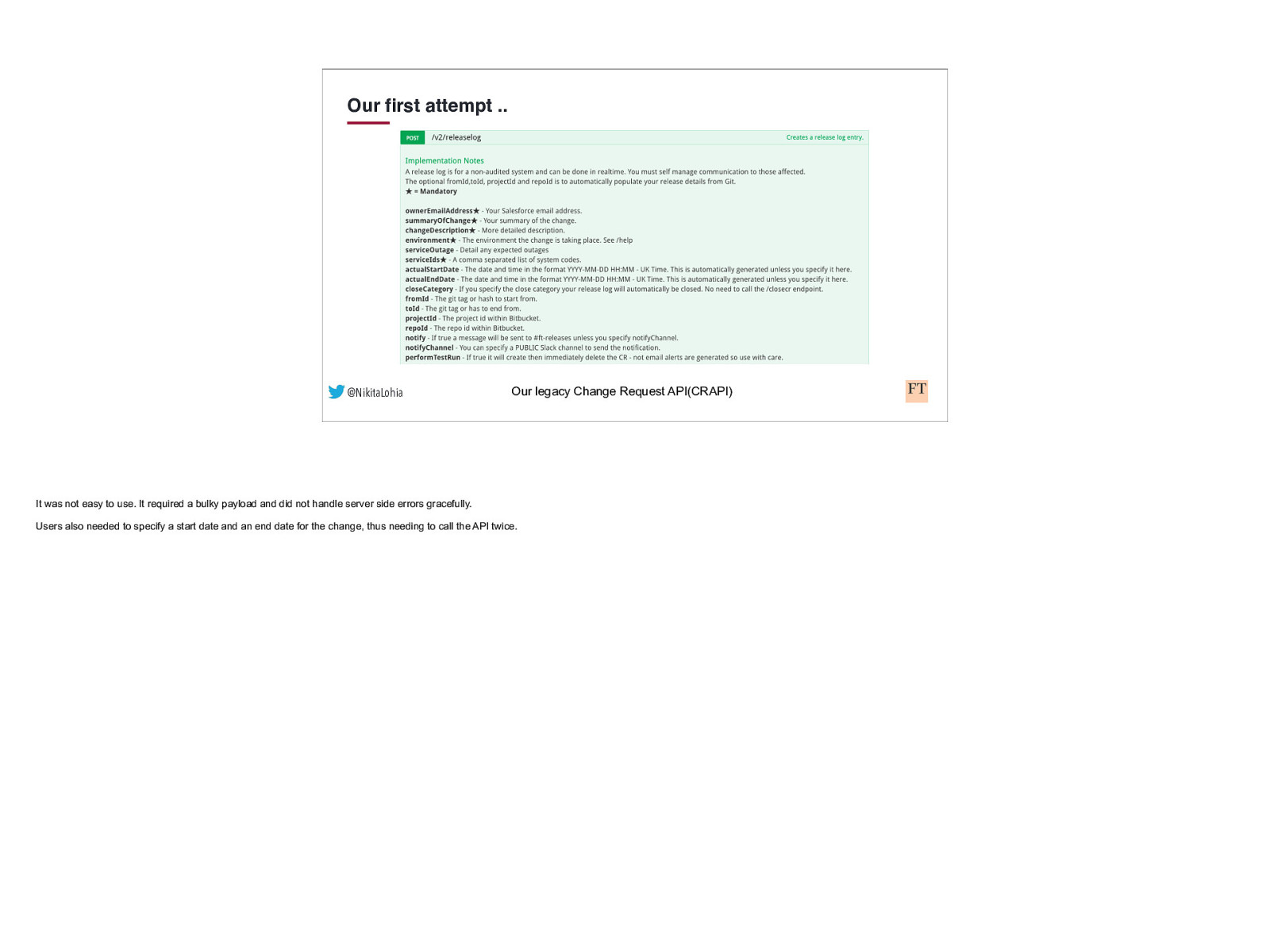
Our first attempt .. @NikitaLohia Our legacy Change Request API(CRAPI) It was not easy to use. It required a bulky payload and did not handle server side errors gracefully. Users also needed to specify a start date and an end date for the change, thus needing to call the API twice.
Our first attempt .. @NikitaLohia
Our first attempt .. @NikitaLohia

The journey… Lets go through our journey from migrating from this legacy , rarely used CR API to a fully integrated, automated release log process and the lessons we learnt along the way.

Learn from the past It would be really rare that you would have to start fixing a problem from scratch. Someone somewhere in your organisation would have thought about it, or at least written some documentation on it. Dig around a little, find out what research or mechanisms already exist. It not only saves you time in the long run, it also hints at what NOT to do. In our case, for example, we already had CRAPI. In the beginning, we spent some time talking to the handful of people who were using it. We asked them what about it works and what does not, what can we use and what can we throw away..

Learn from the past ● Make it simple ● Make it useful ● Make it reliable ● Make it fast Or… “SURF” :) @NikitaLohia We summarised all of that feedback and consolidated that into these 4 targets. Since we love us some acronyms, why not .. lets call it SURF :)
Learn from the past ● Make it simple @NikitaLohia So - how did we address these goals? How do we simplify sending Change logs?
Learn from the past - Make it simple For our end users, we reduced the amount of work they need to do @NikitaLohia CR API depended on its users for a lot of information. We decided to make the service, now rebranded and soon to be replaced by Change API, do the work. Instead of requiring 10 different fields, we asked Change API users to only provide 3 mandatory values :
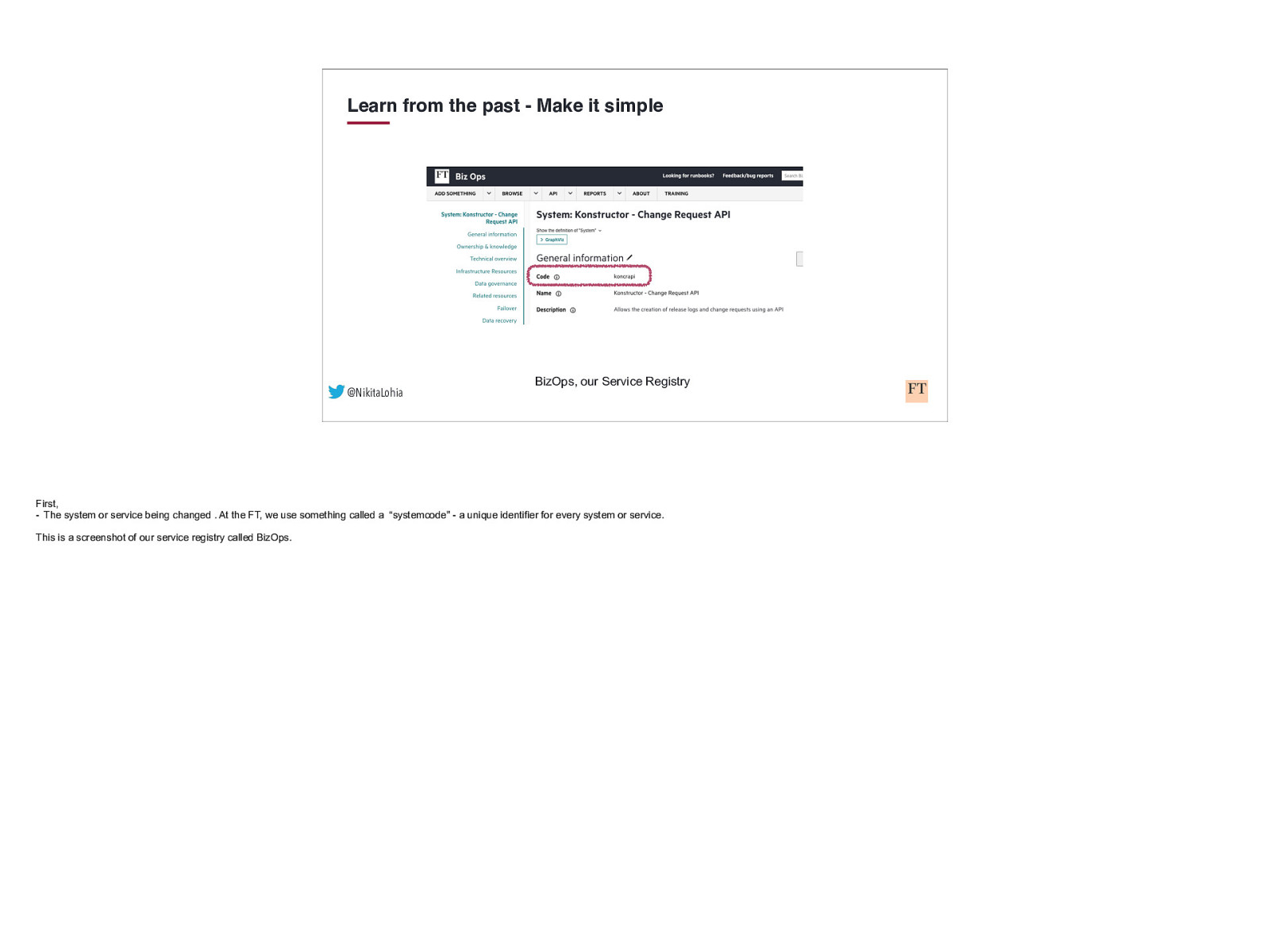
Learn from the past - Make it simple @NikitaLohia BizOps, our Service Registry First, - The system or service being changed . At the FT, we use something called a “systemcode” - a unique identifier for every system or service. This is a screenshot of our service registry called BizOps.
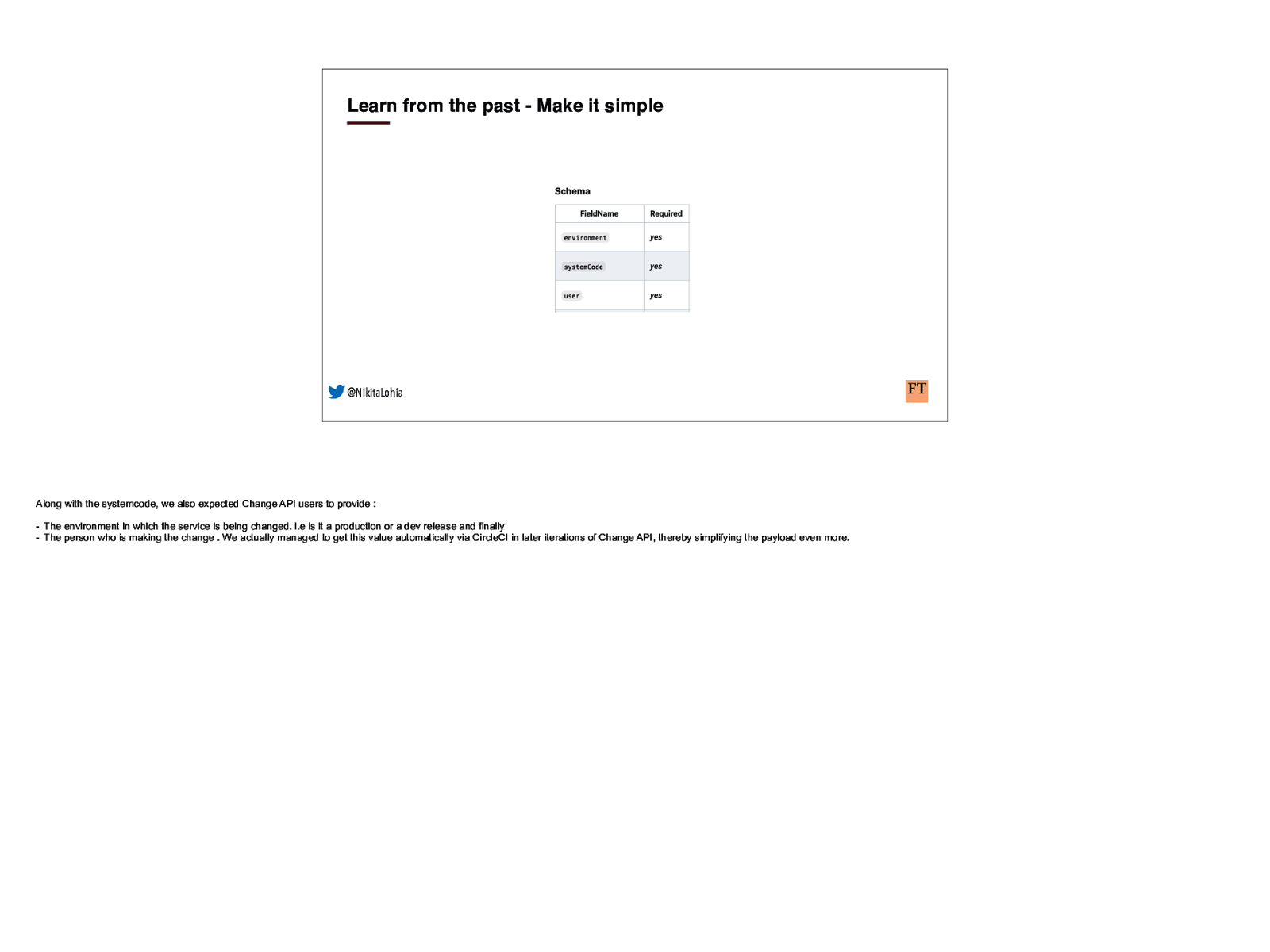
Learn from the past - Make it simple @NikitaLohia Along with the systemcode, we also expected Change API users to provide : - The environment in which the service is being changed. i.e is it a production or a dev release and finally - The person who is making the change . We actually managed to get this value automatically via CircleCI in later iterations of Change API, thereby simplifying the payload even more.

Learn from the past - Make it simple @NikitaLohia During our user research, not many users saw the benefit of logging the start and the end date for a release. Rightly so, since with microservices, most of the code releases only take a few minutes. When designing change API, we removed the need for the users to tell Change API the start date of the release. So instead of having to make two separate API calls…
Learn from the past - Make it simple @NikitaLohia they only need to call it once, after the change was done.
Learn from the past - Make it simple For ourselves, we decided to rewrite it in a language we understood @NikitaLohia Secondly, Since no-one in the team had a lot of experience with Java, we decided to rewrite it in JS to better support it.

Learn from the past ● Make it simple ● Make it fast @NikitaLohia How did we solve the problem of avoiding delays on team’s deployment pipelines?

Learn from the past - Make it fast We made API calls asynchronous @NikitaLohia We made Change API async. As long as the user was sending Change API the 3 mandatory fields and it was in a valid format, Change API would almost immediately send an “Accepted” response with a 202 status code. An invalid client request would return a 400 instead. Rest of the release log processing happened asynchronously. That dramatically reduced the response time of the API. As far as the user is concerned, the Change log request is completed within milliseconds, if that. By doing just these 2 things, we had already solved half of our problems.

Learn from the past ● Make it simple ● Make it fast ● Make it reliable @NikitaLohia How did we build trust in Change API ?
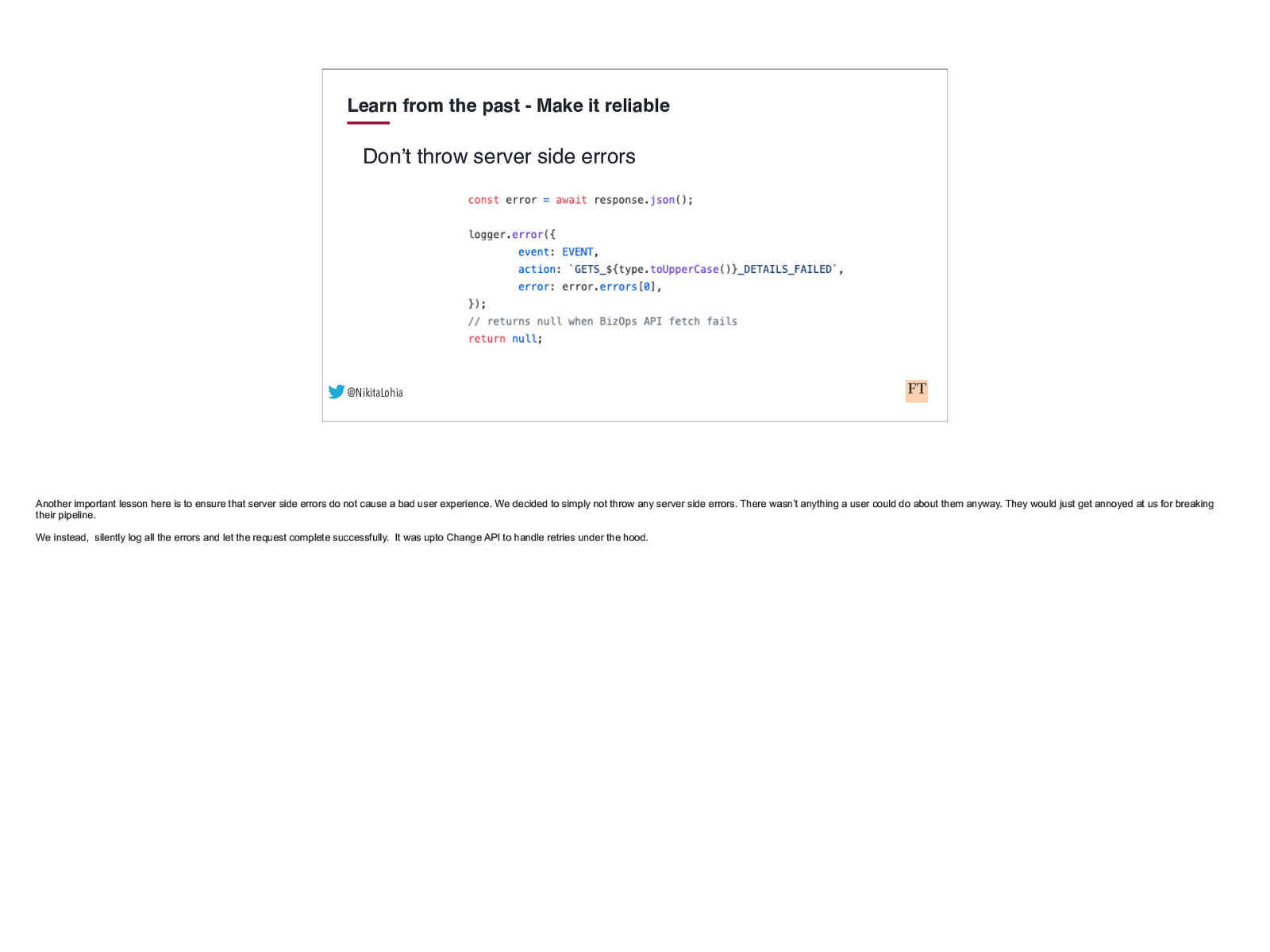
Learn from the past - Make it reliable Don’t throw server side errors @NikitaLohia Another important lesson here is to ensure that server side errors do not cause a bad user experience. We decided to simply not throw any server side errors. There wasn’t anything a user could do about them anyway. They would just get annoyed at us for breaking their pipeline. We instead, silently log all the errors and let the request complete successfully. It was upto Change API to handle retries under the hood.

Learn from the past - Make it reliable Don’t change how user interacts with it @NikitaLohia Over time, we made a LOT of improvements and modifications to Change API - ALL without changing user interaction with it. This provided our users some much needed assurance that adding Change API to their deploy pipelines will not stop their deployment, even in case of an error.

Learn from the past ● Make it simple ● Make it fast ● Make it reliable ● Make it useful @NikitaLohia How did we highlight the benefit of Change API?
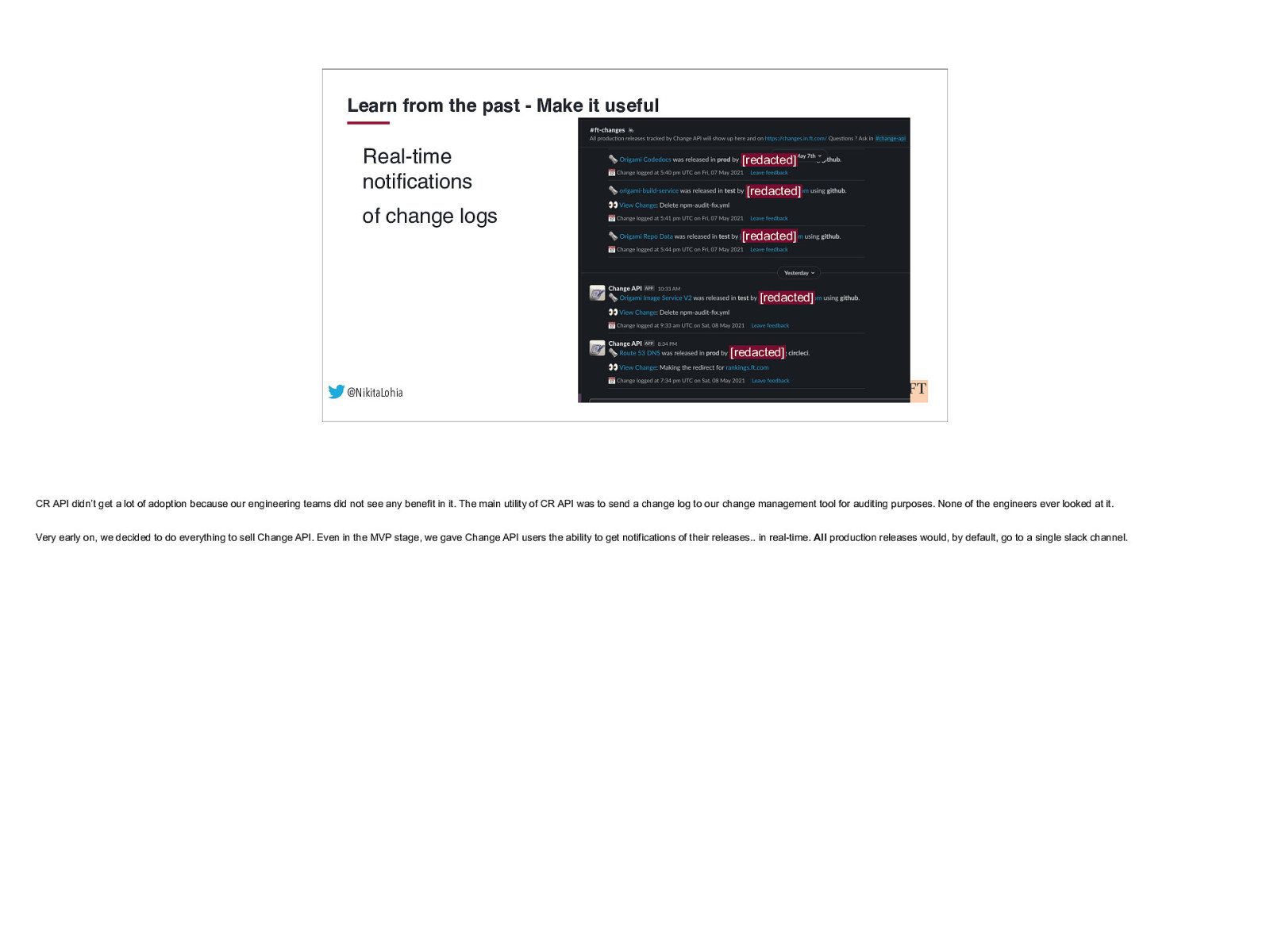
Learn from the past - Make it useful Real-time notifications [redacted] [redacted] of change logs [redacted] [redacted] [redacted] @NikitaLohia CR API didn’t get a lot of adoption because our engineering teams did not see any benefit in it. The main utility of CR API was to send a change log to our change management tool for auditing purposes. None of the engineers ever looked at it. Very early on, we decided to do everything to sell Change API. Even in the MVP stage, we gave Change API users the ability to get notifications of their releases.. in real-time. All production releases would, by default, go to a single slack channel.
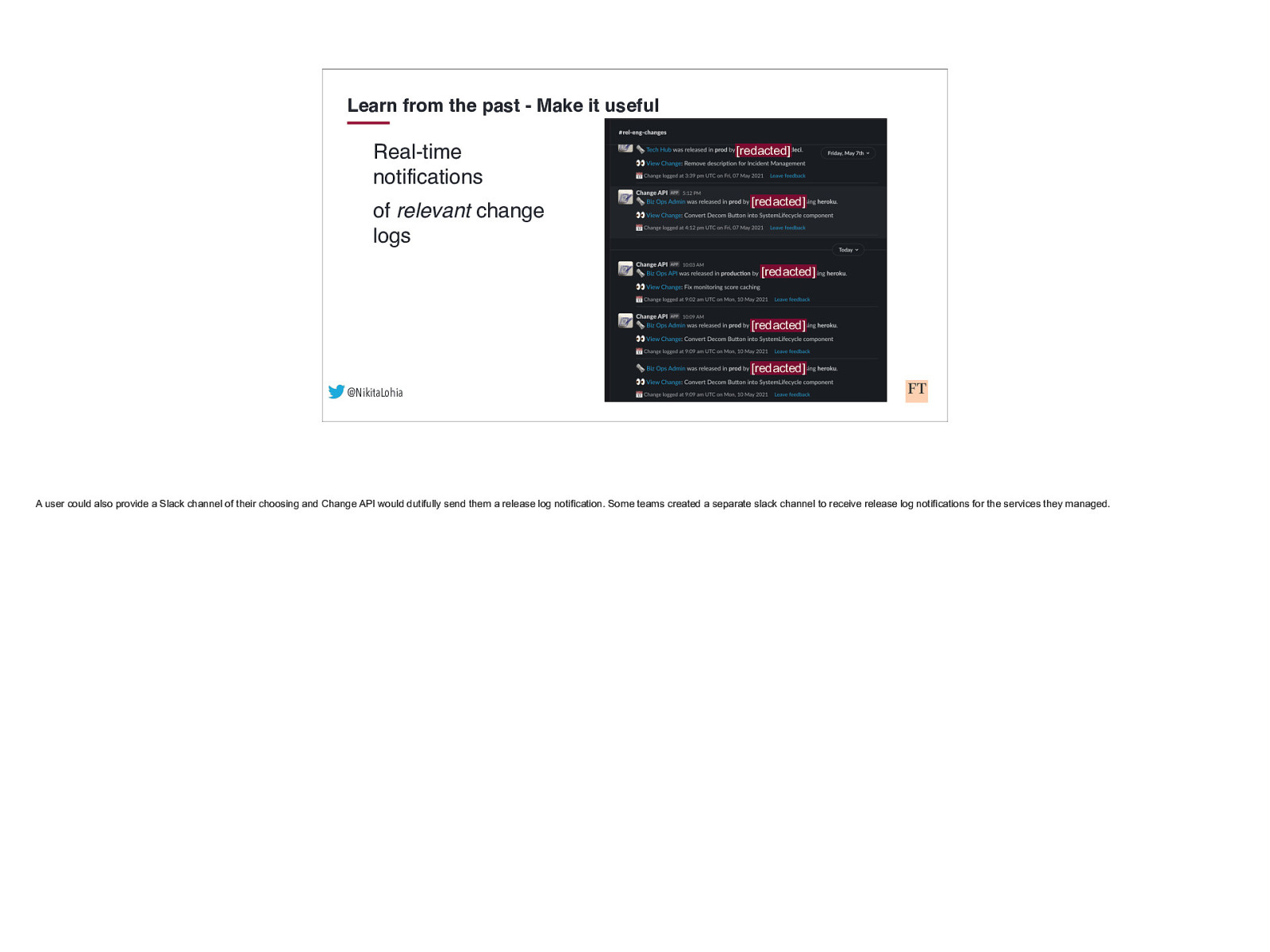
Learn from the past - Make it useful Real-time notifications of relevant change logs [redacted] [redacted] [redacted] [redacted] [redacted] @NikitaLohia A user could also provide a Slack channel of their choosing and Change API would dutifully send them a release log notification. Some teams created a separate slack channel to receive release log notifications for the services they managed.
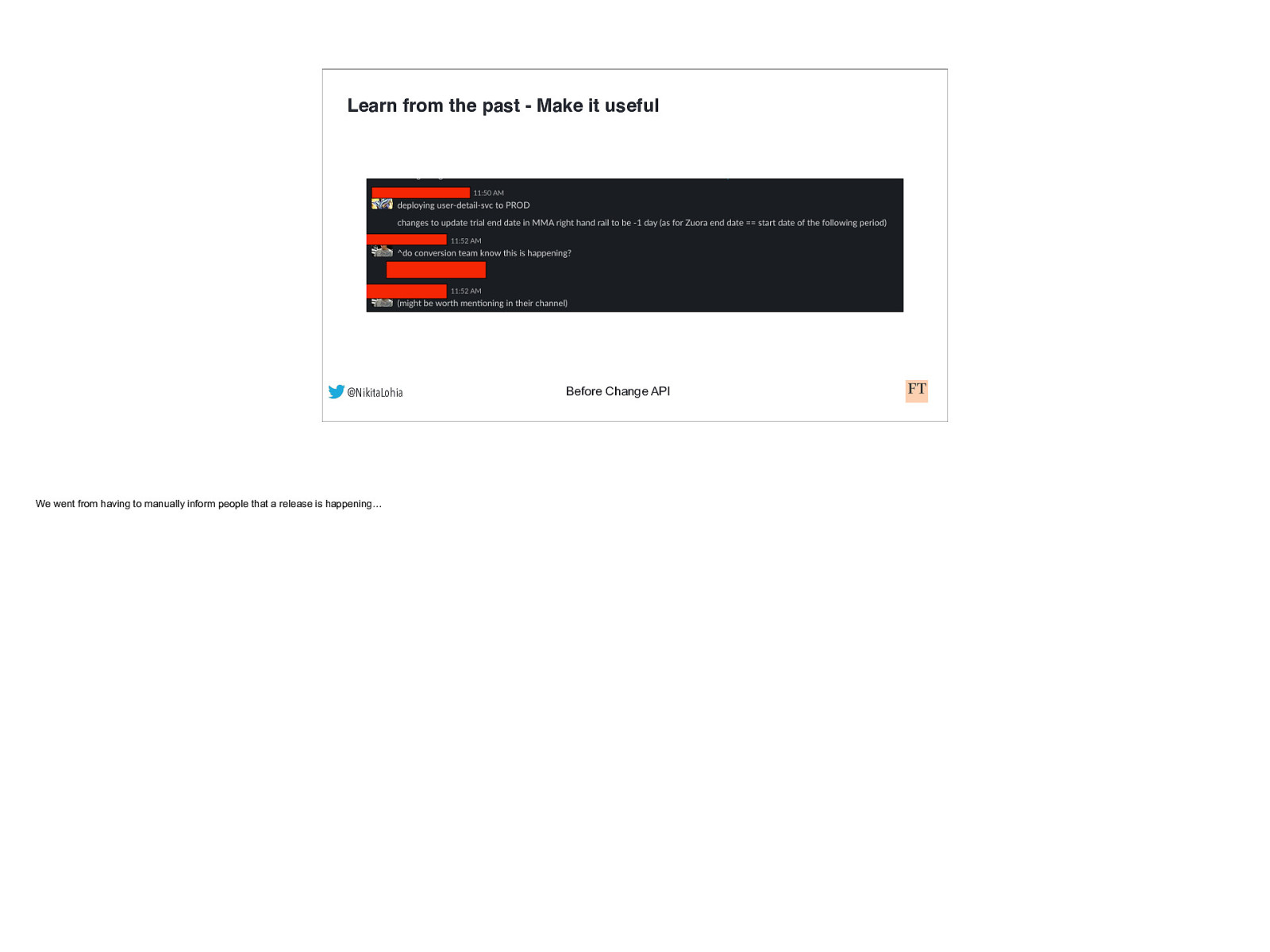
Learn from the past - Make it useful @NikitaLohia We went from having to manually inform people that a release is happening… Before Change API
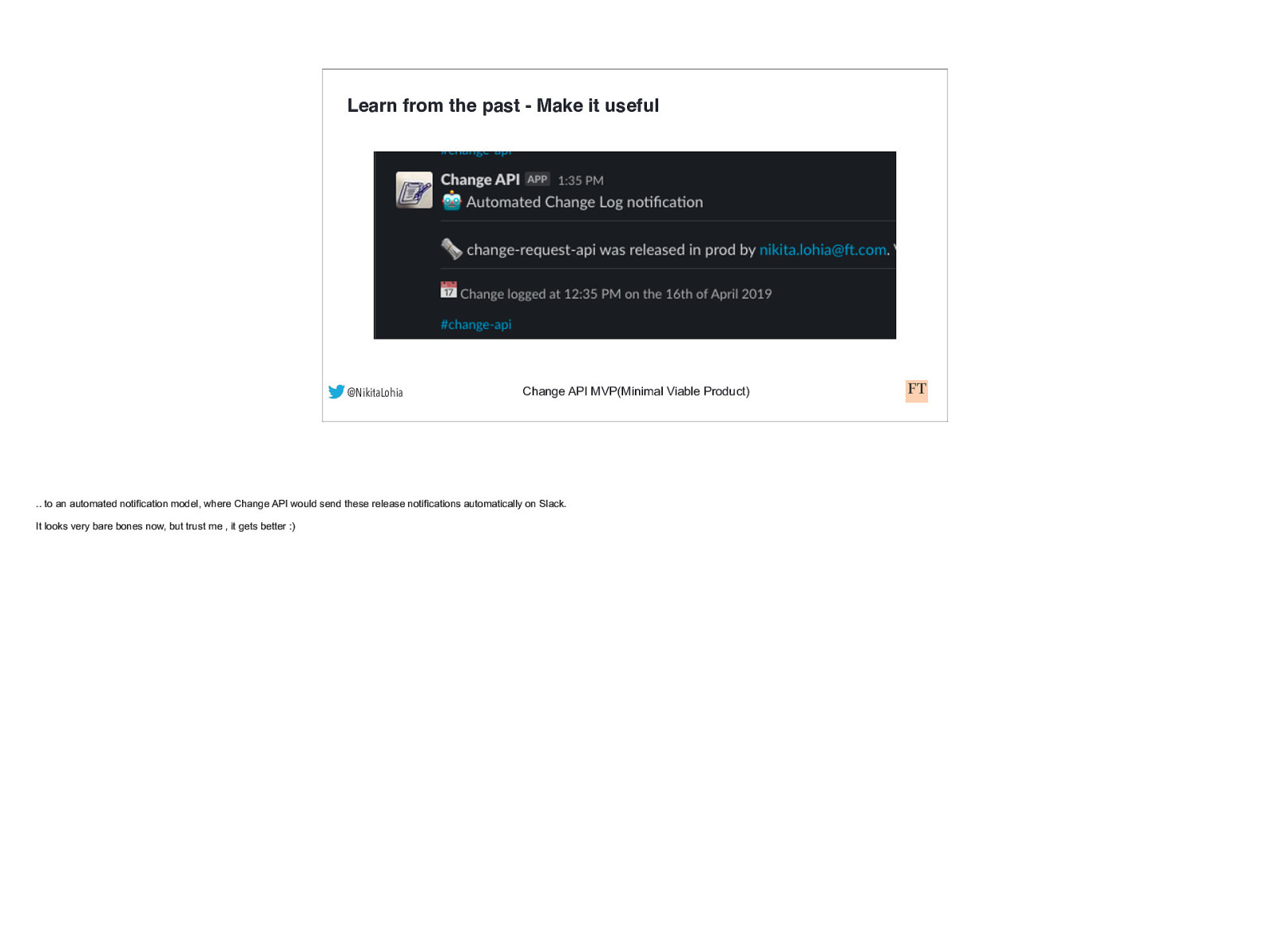
Learn from the past - Make it useful @NikitaLohia Change API MVP(Minimal Viable Product) .. to an automated notification model, where Change API would send these release notifications automatically on Slack. It looks very bare bones now, but trust me , it gets better :)

Walk before you run In other words, start small.
Walk before you run Choose your early adopters carefully @NikitaLohia Change and Release Management is big topic. If you think about it, external auditors, compliance team, dev teams, Project Managers, and Operations support team: they are all potential users of Change & Release Management Dont try to create a brand new Change Management system catering to all the users out there in the first pass. Think of a small, controlled user group which will drive maximum benefit and grant immediate feedback. For us, it were the developer teams. We knew that these teams already have automated deployment pipelines in place and it would be very easy to integrate Change API into this pipeline. Code releases amounts to about 80% of all changes happening in FT Tech. We picked a handful of engineering teams from different parts of the business using Github and CircleCI as our early adopters.
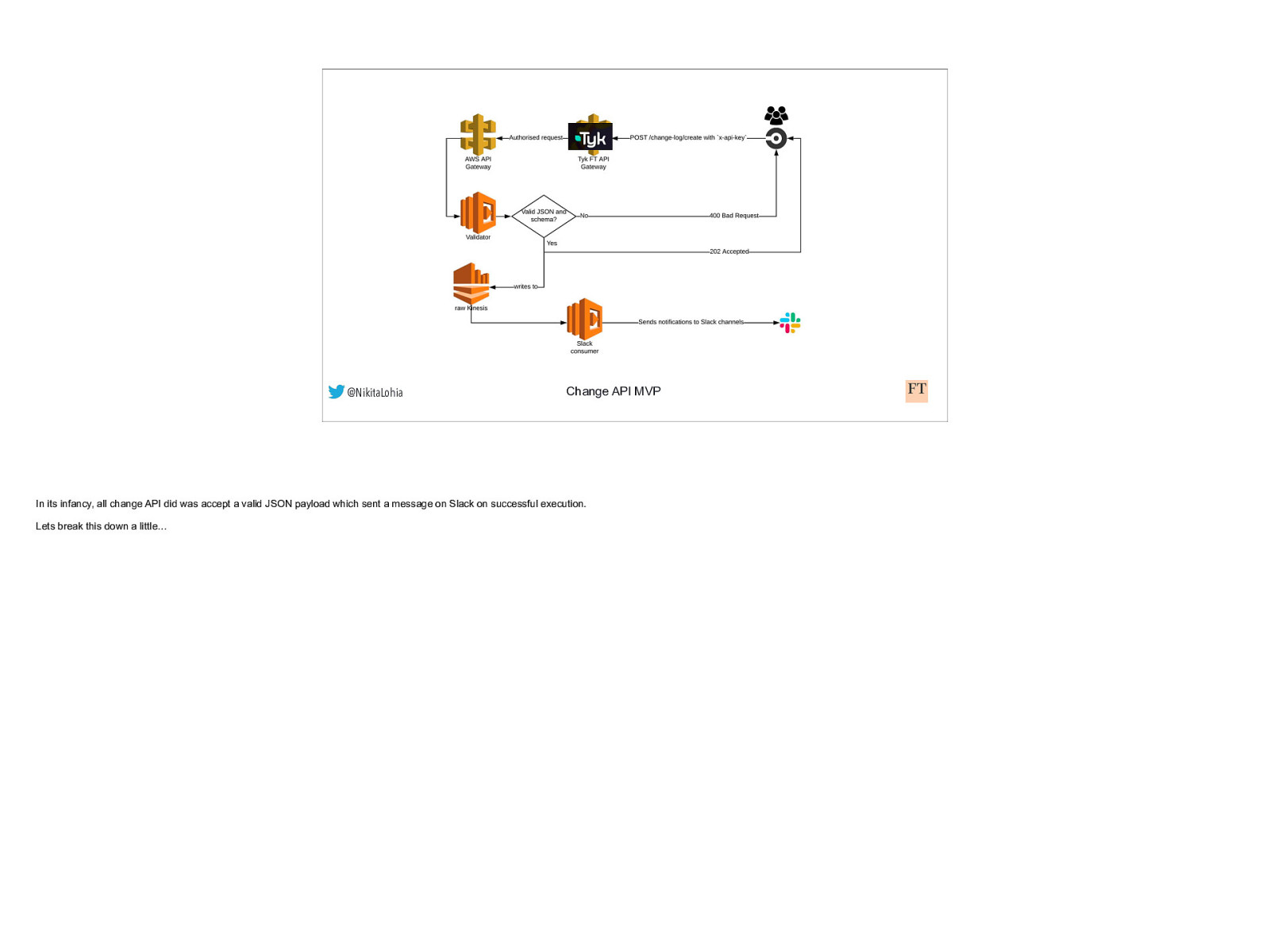
@NikitaLohia Change API MVP In its infancy, all change API did was accept a valid JSON payload which sent a message on Slack on successful execution. Lets break this down a little…

@NikitaLohia Change API MVP We asked teams using CircleCI to add a single POST request to their circleCI workflow. This request would contain a 3 key-value pair JSON and an API key header. This request would first get authenticated by Tyk, our API Gateway platform which would check the validity of the API key. If the authentication fails, the user gets an authentication error.
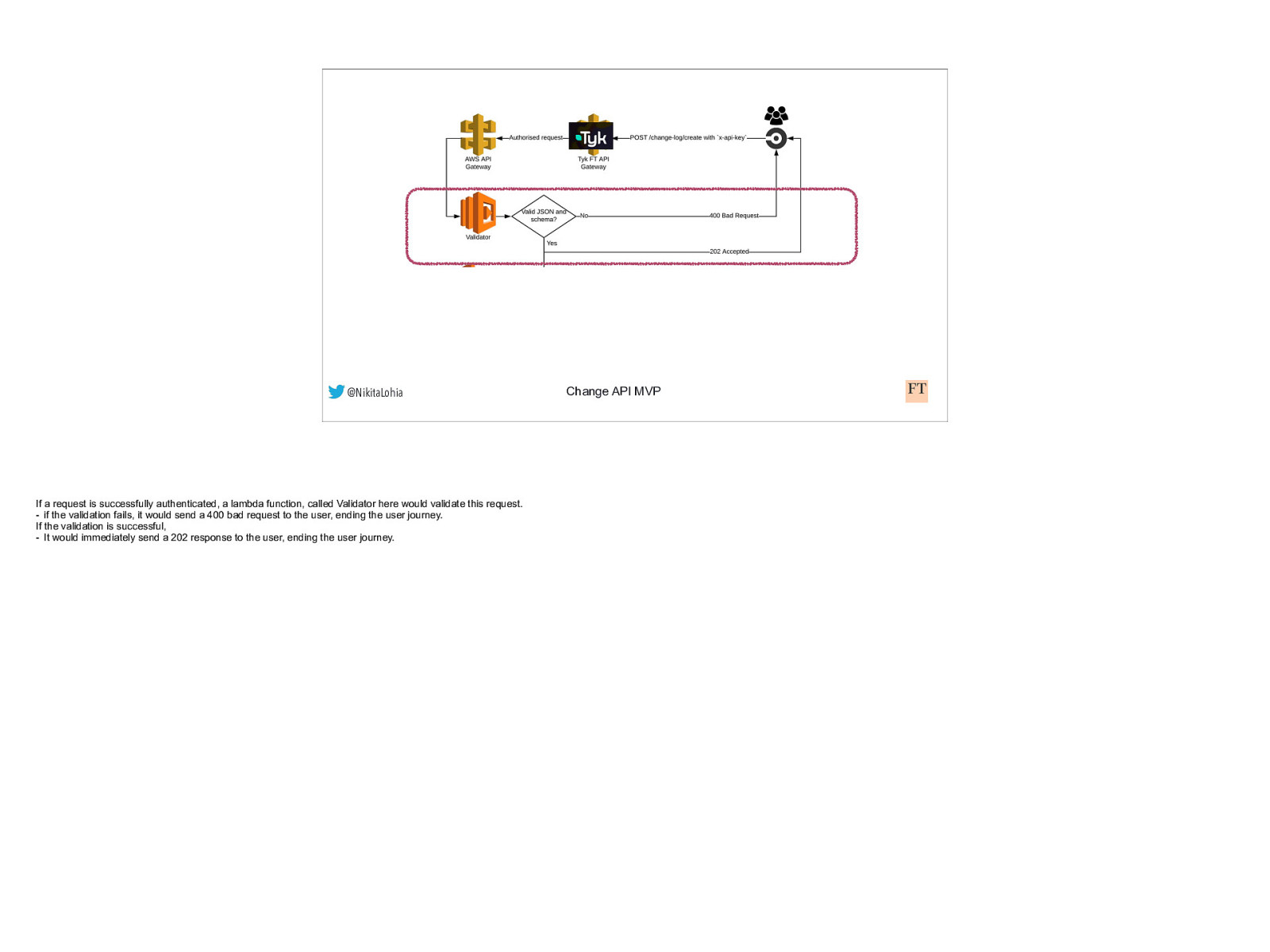
@NikitaLohia If a request is successfully authenticated, a lambda function, called Validator here would validate this request. - if the validation fails, it would send a 400 bad request to the user, ending the user journey. If the validation is successful, - It would immediately send a 202 response to the user, ending the user journey. Change API MVP
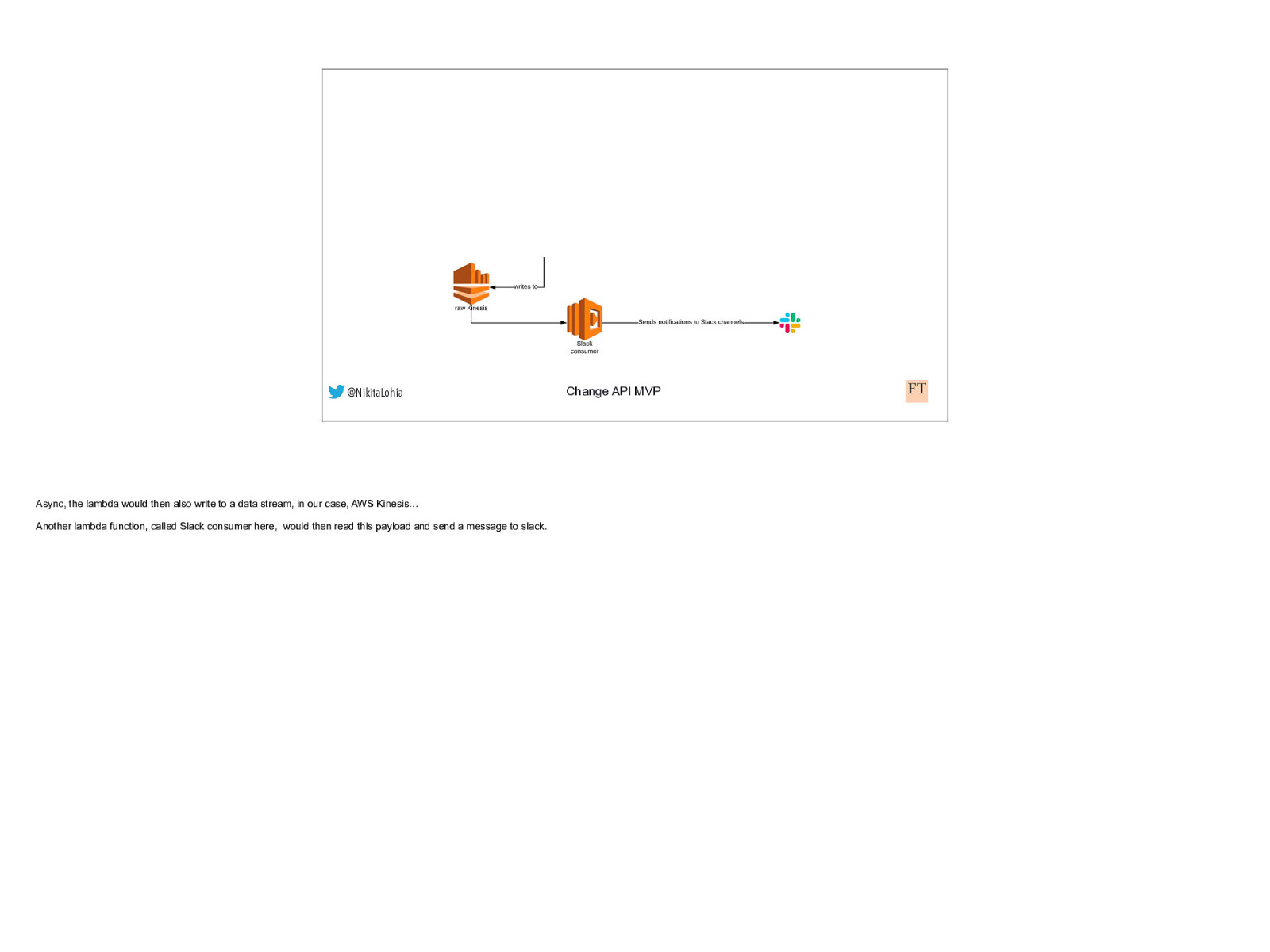
@NikitaLohia Async, the lambda would then also write to a data stream, in our case, AWS Kinesis… Another lambda function, called Slack consumer here, would then read this payload and send a message to slack. Change API MVP
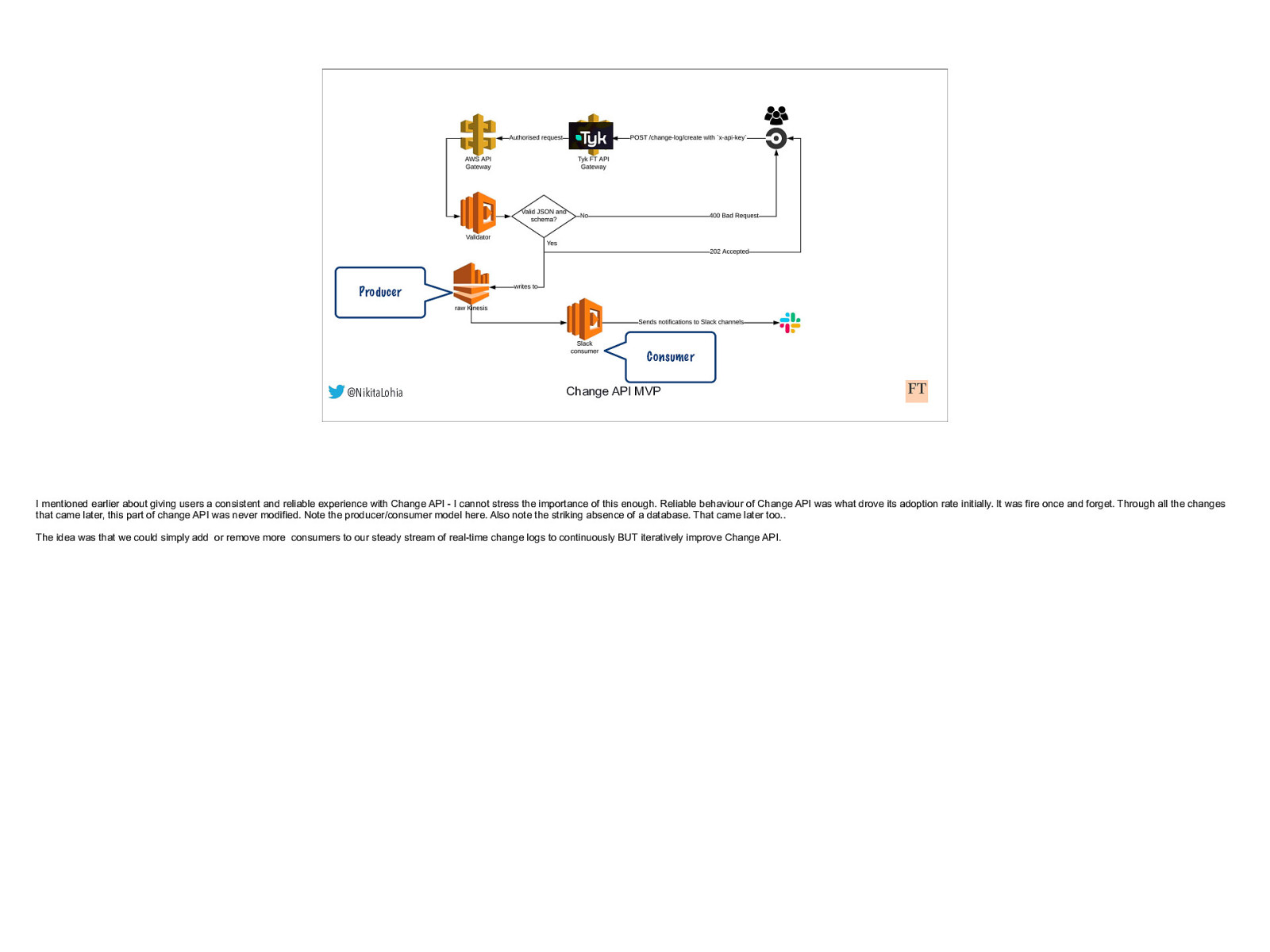
Producer Consumer @NikitaLohia Change API MVP I mentioned earlier about giving users a consistent and reliable experience with Change API - I cannot stress the importance of this enough. Reliable behaviour of Change API was what drove its adoption rate initially. It was fire once and forget. Through all the changes that came later, this part of change API was never modified. Note the producer/consumer model here. Also note the striking absence of a database. That came later too.. The idea was that we could simply add or remove more consumers to our steady stream of real-time change logs to continuously BUT iteratively improve Change API.

Step changes Change API MVP passed with flying colours. We expanded our early adopters list and we kicked Change API development into high-gear.
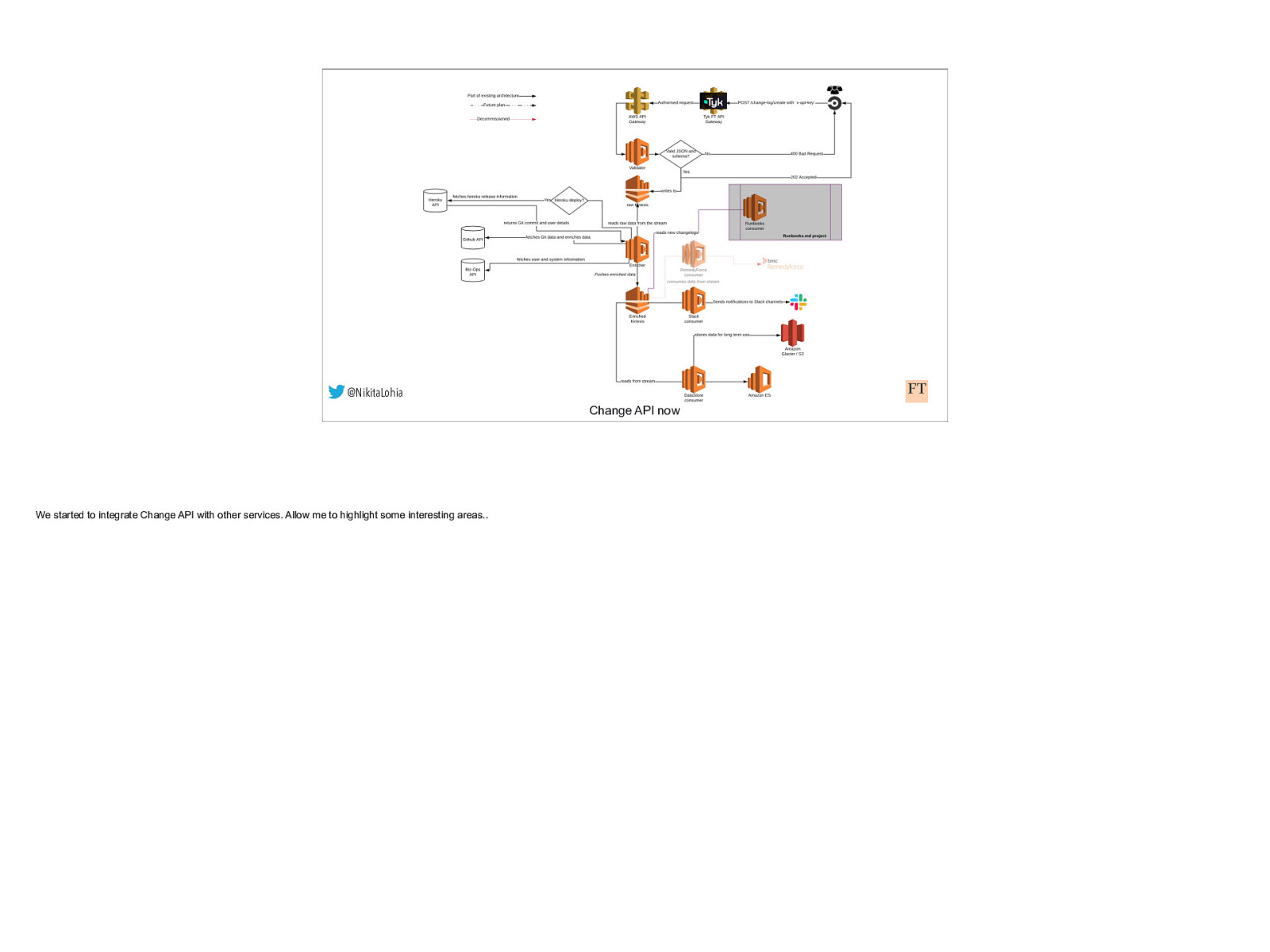
@NikitaLohia Change API now We started to integrate Change API with other services. Allow me to highlight some interesting areas..
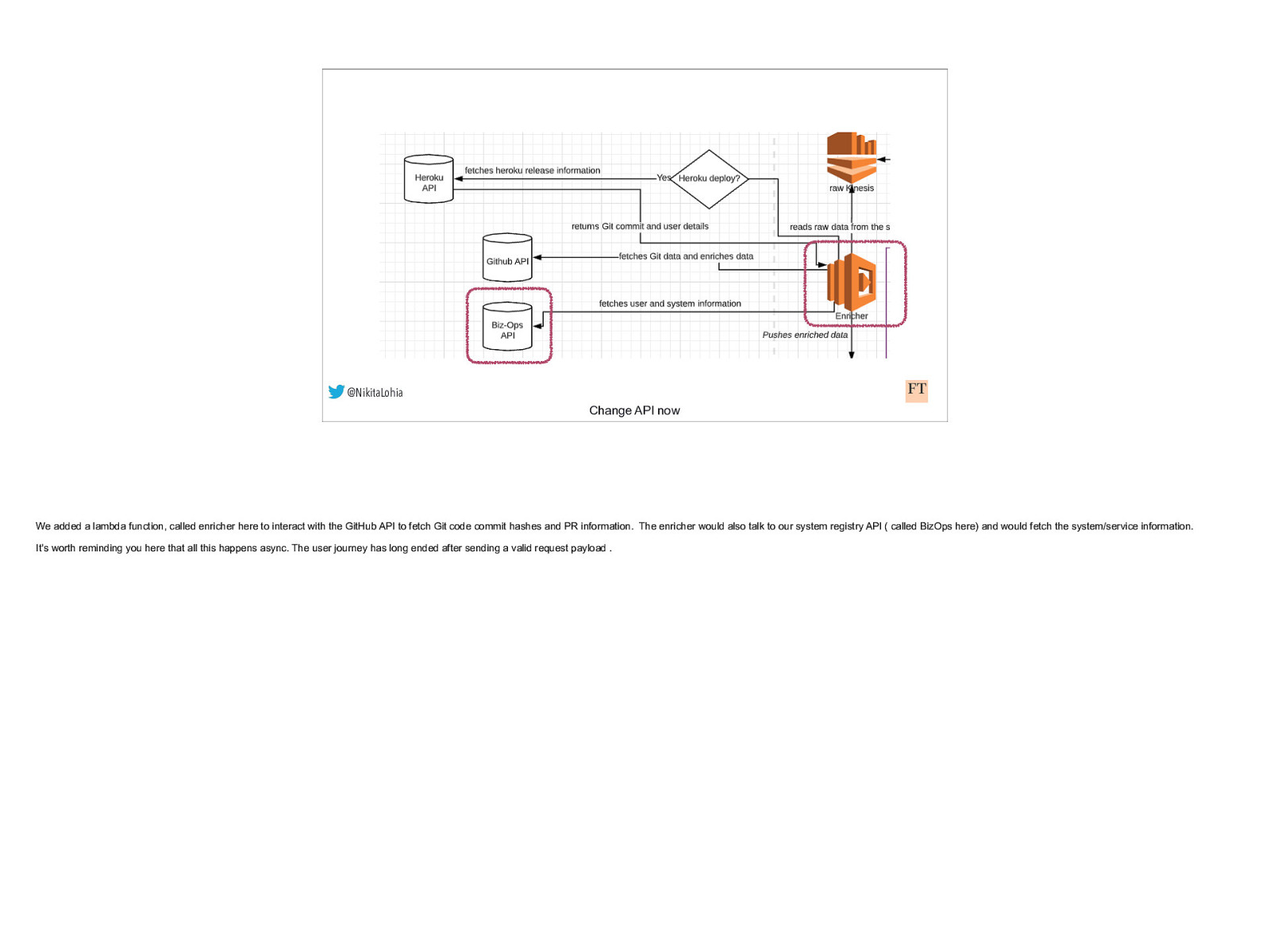
@NikitaLohia Change API now We added a lambda function, called enricher here to interact with the GitHub API to fetch Git code commit hashes and PR information. The enricher would also talk to our system registry API ( called BizOps here) and would fetch the system/service information. It’s worth reminding you here that all this happens async. The user journey has long ended after sending a valid request payload .
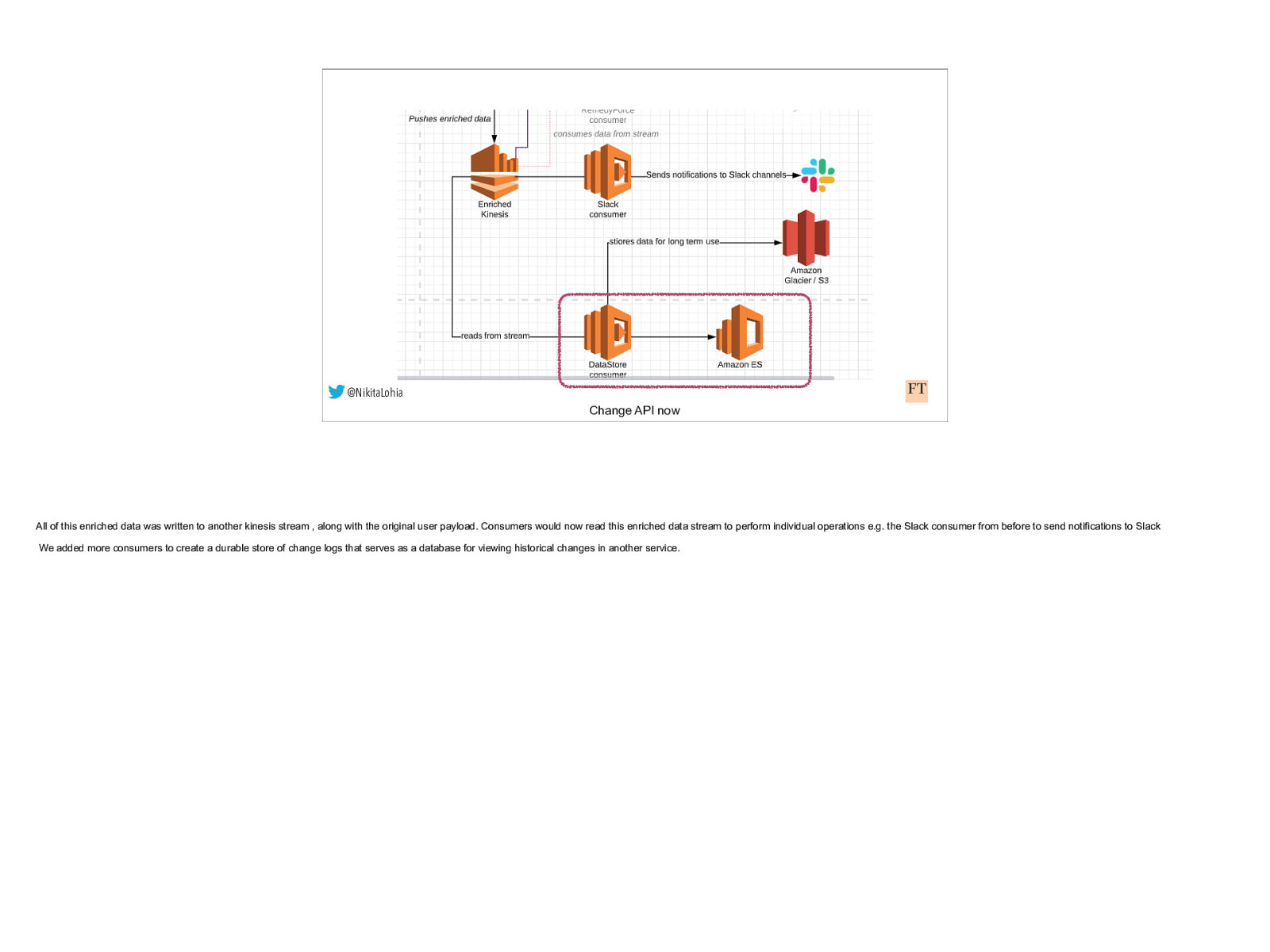
@NikitaLohia Change API now All of this enriched data was written to another kinesis stream , along with the original user payload. Consumers would now read this enriched data stream to perform individual operations e.g. the Slack consumer from before to send notifications to Slack We added more consumers to create a durable store of change logs that serves as a database for viewing historical changes in another service.
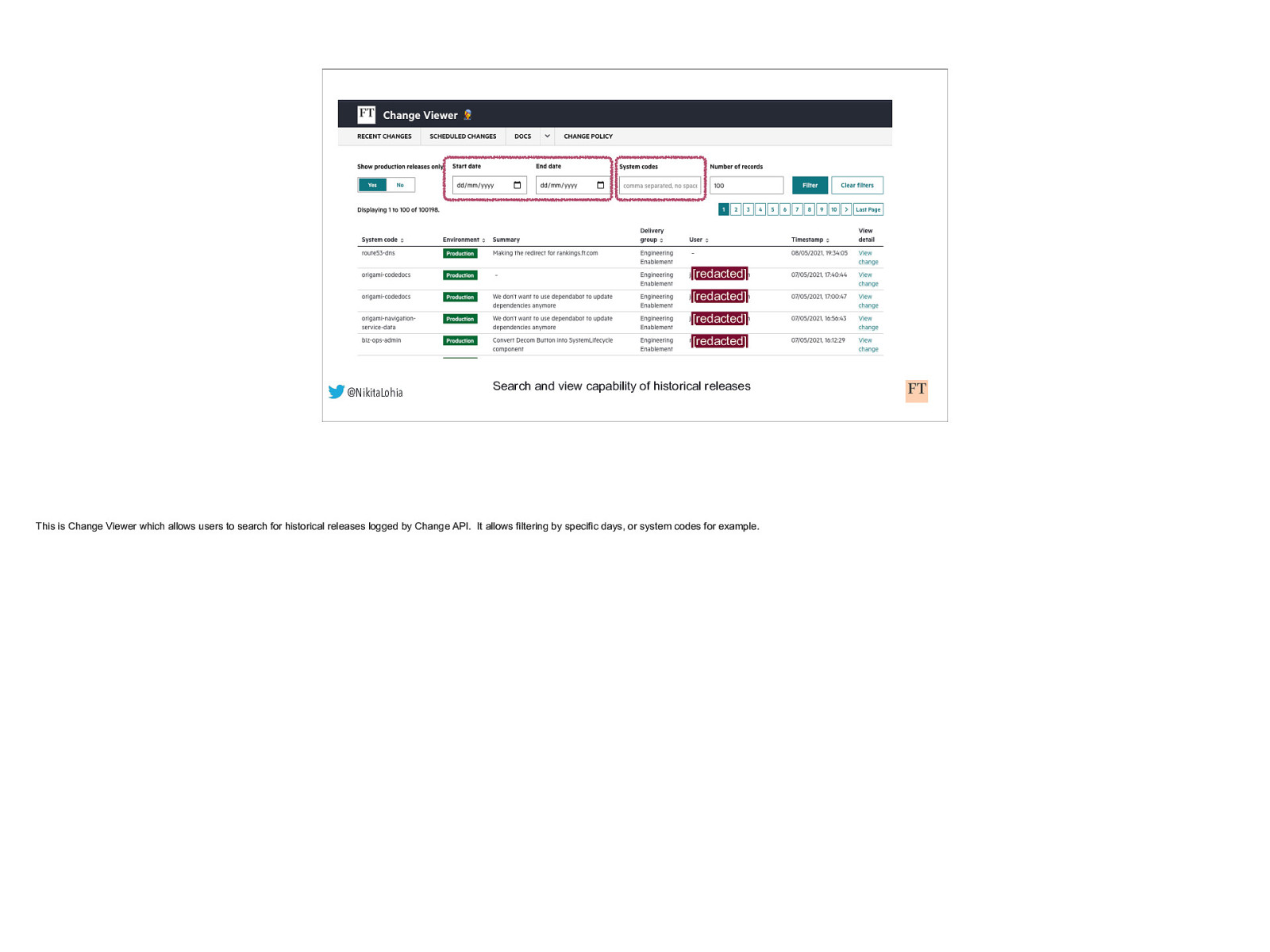
[redacted] [redacted] [redacted] [redacted] @NikitaLohia Search and view capability of historical releases This is Change Viewer which allows users to search for historical releases logged by Change API. It allows filtering by specific days, or system codes for example.
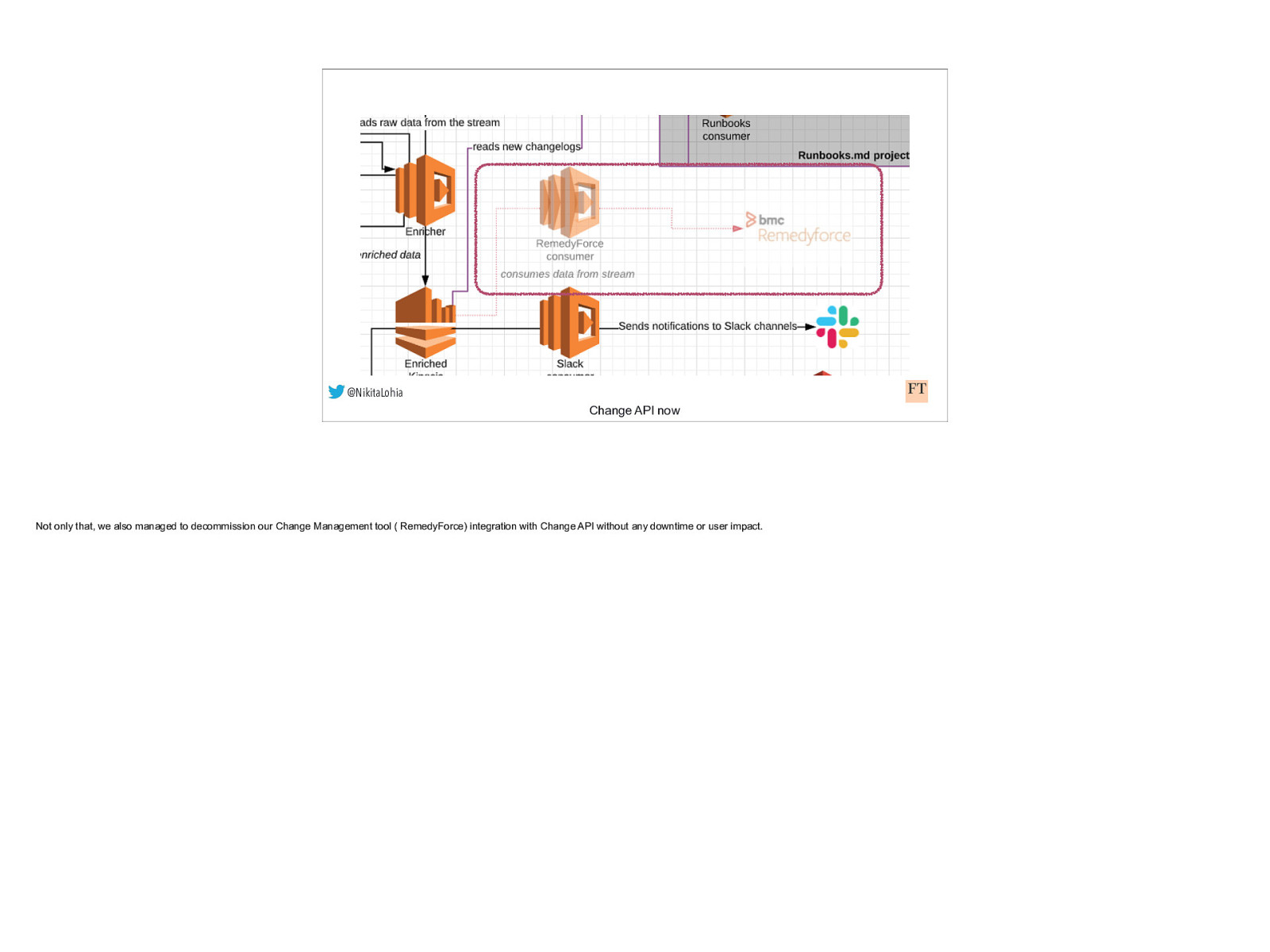
@NikitaLohia Change API now Not only that, we also managed to decommission our Change Management tool ( RemedyForce) integration with Change API without any downtime or user impact.
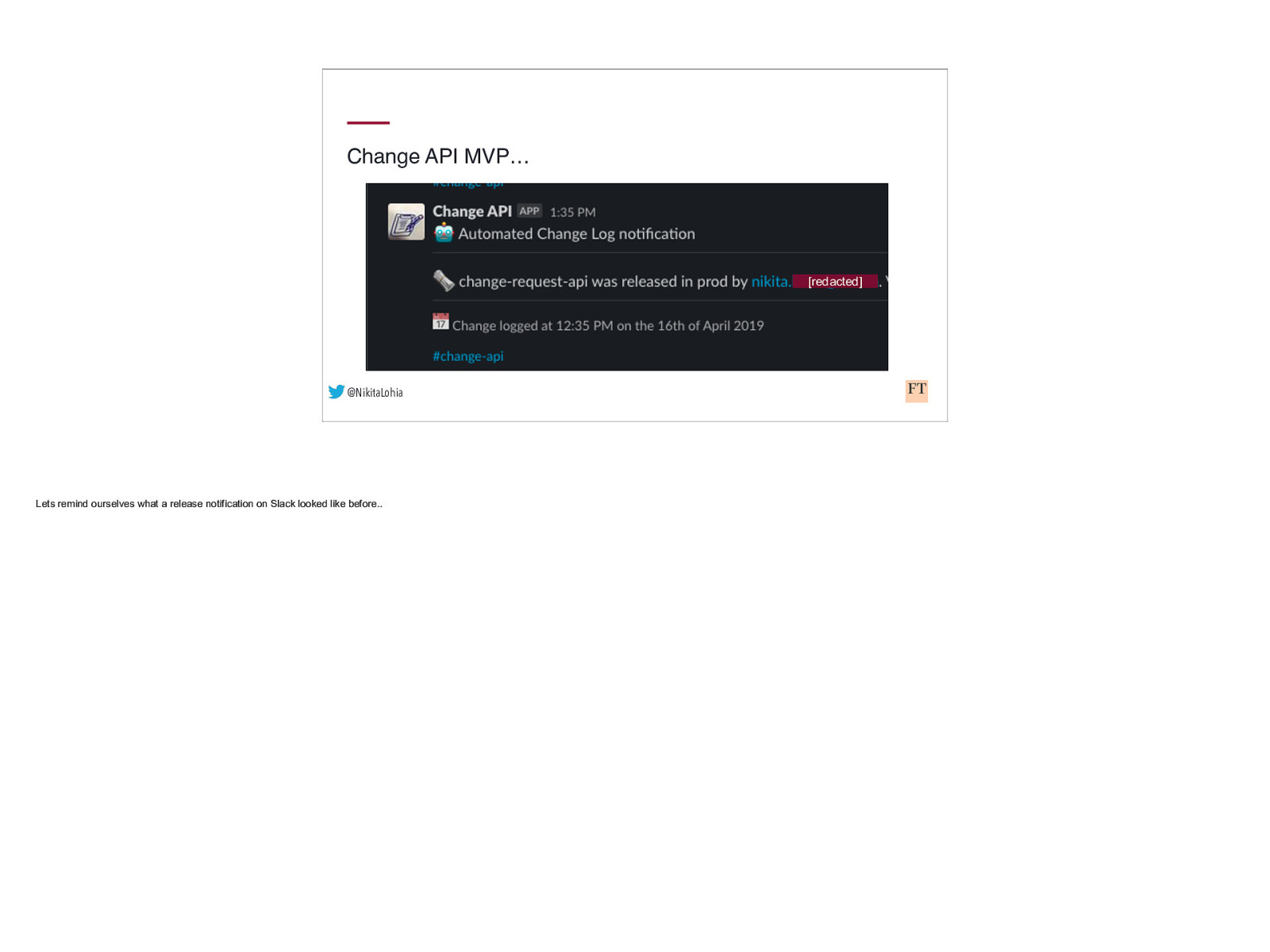
Change API MVP… [redacted] @NikitaLohia Lets remind ourselves what a release notification on Slack looked like before..
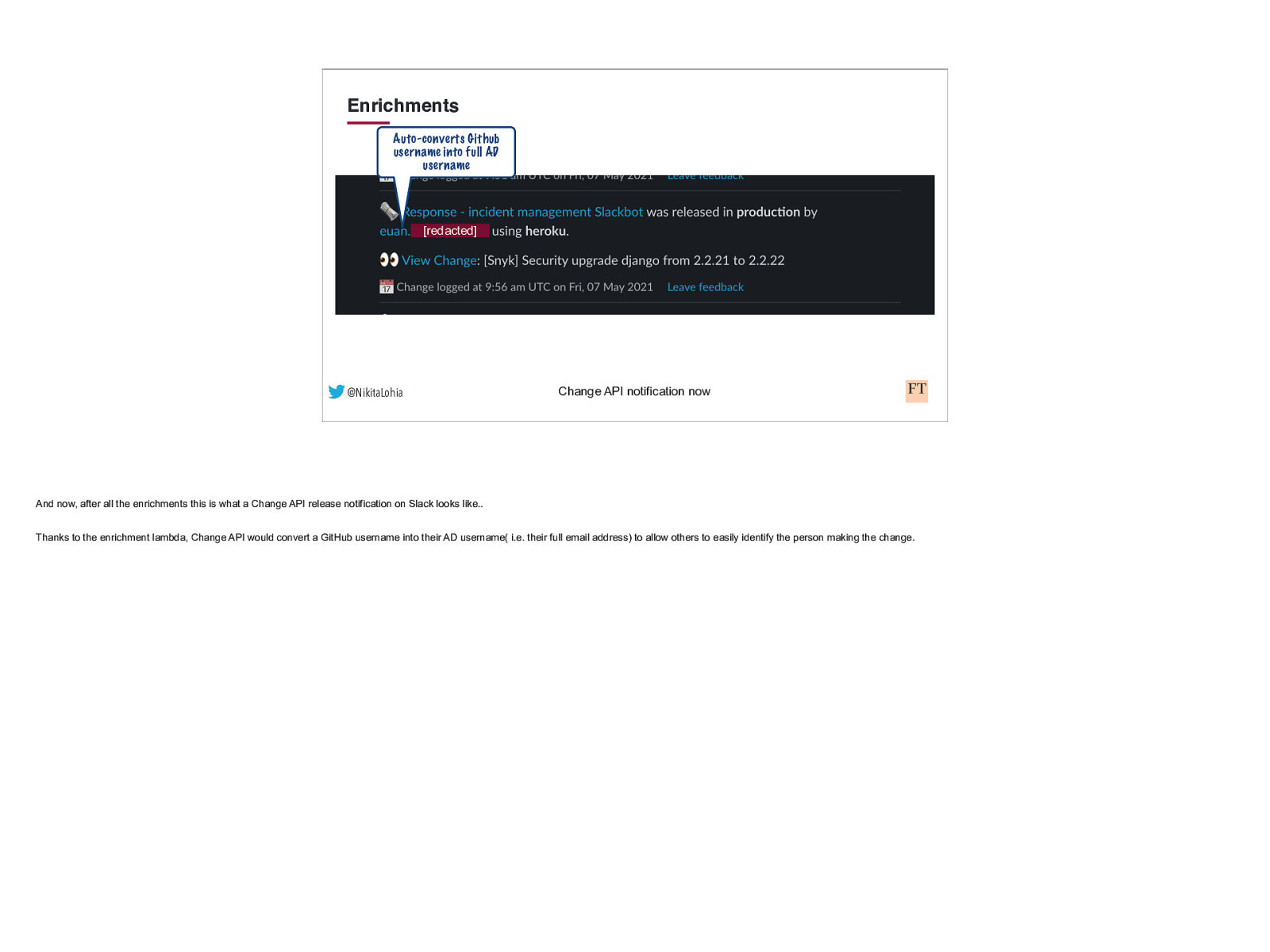
Enrichments Auto-converts Github username into full AD username [redacted] @NikitaLohia Change API notification now And now, after all the enrichments this is what a Change API release notification on Slack looks like.. Thanks to the enrichment lambda, Change API would convert a GitHub username into their AD username( i.e. their full email address) to allow others to easily identify the person making the change.
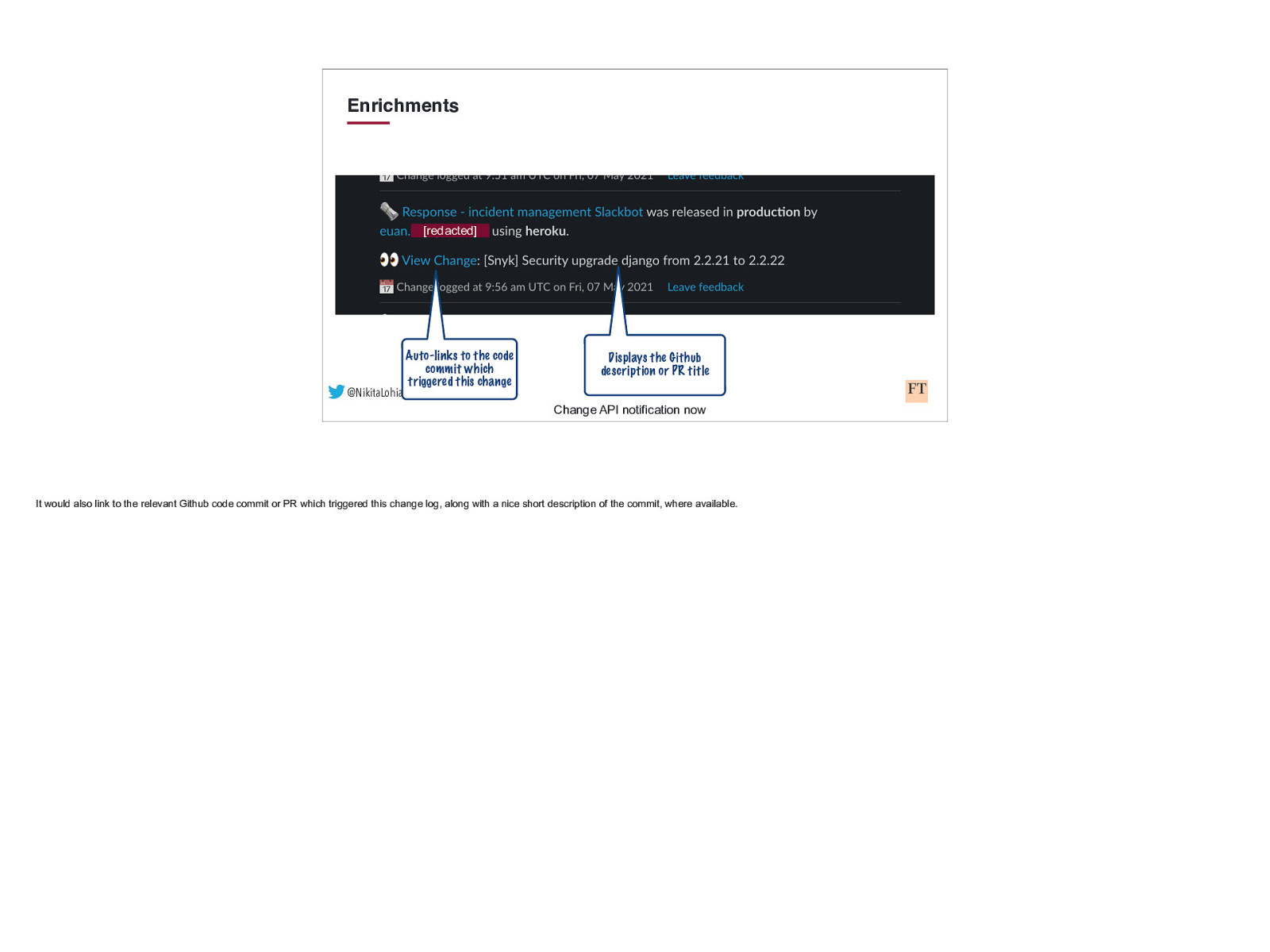
Enrichments [redacted] @NikitaLohia Auto-links to the code commit which triggered this change Displays the Github description or PR title Change API notification now It would also link to the relevant Github code commit or PR which triggered this change log, along with a nice short description of the commit, where available.
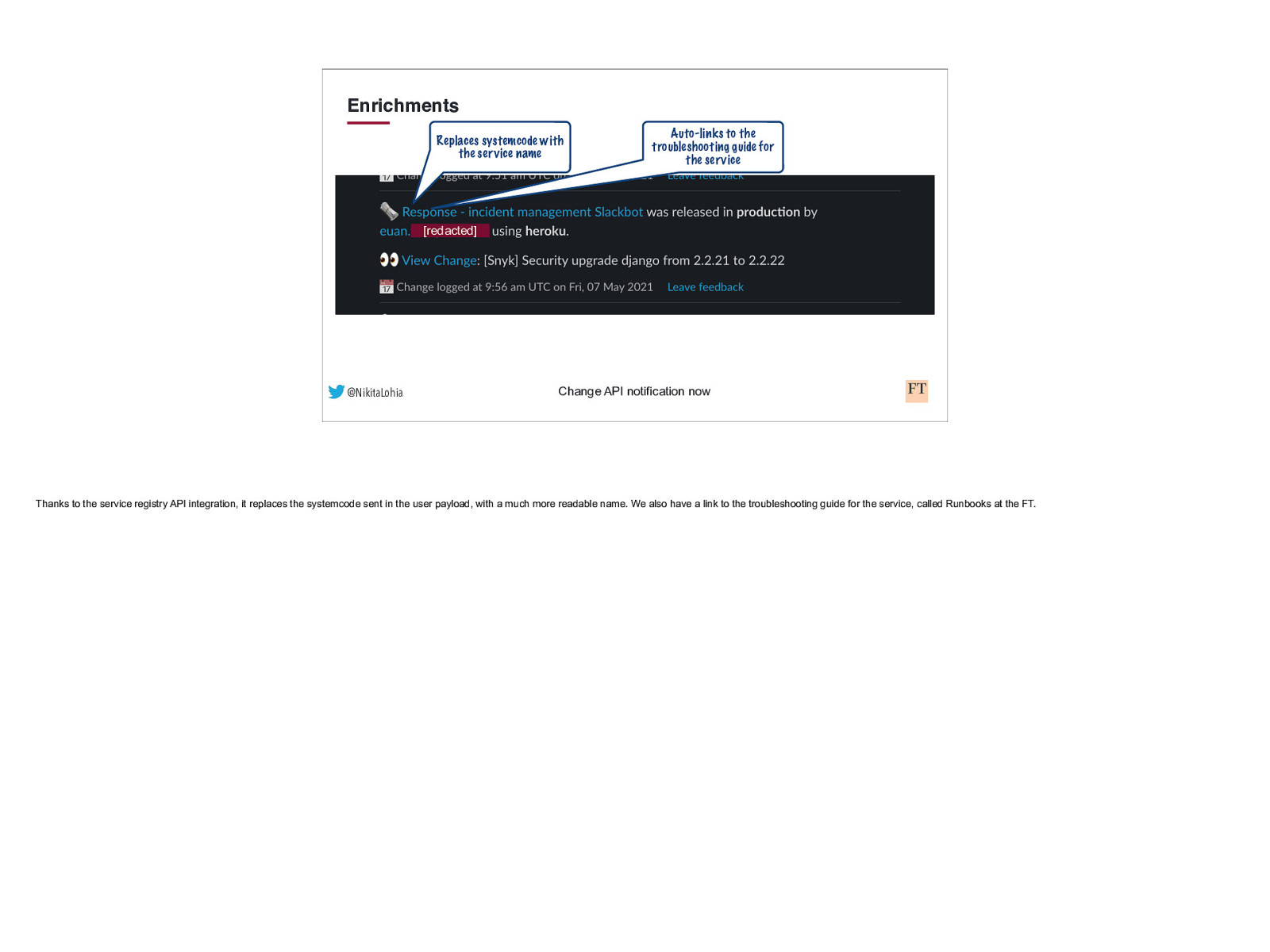
Enrichments Replaces systemcode with the service name Auto-links to the troubleshooting guide for the service [redacted] @NikitaLohia Change API notification now Thanks to the service registry API integration, it replaces the systemcode sent in the user payload, with a much more readable name. We also have a link to the troubleshooting guide for the service, called Runbooks at the FT.
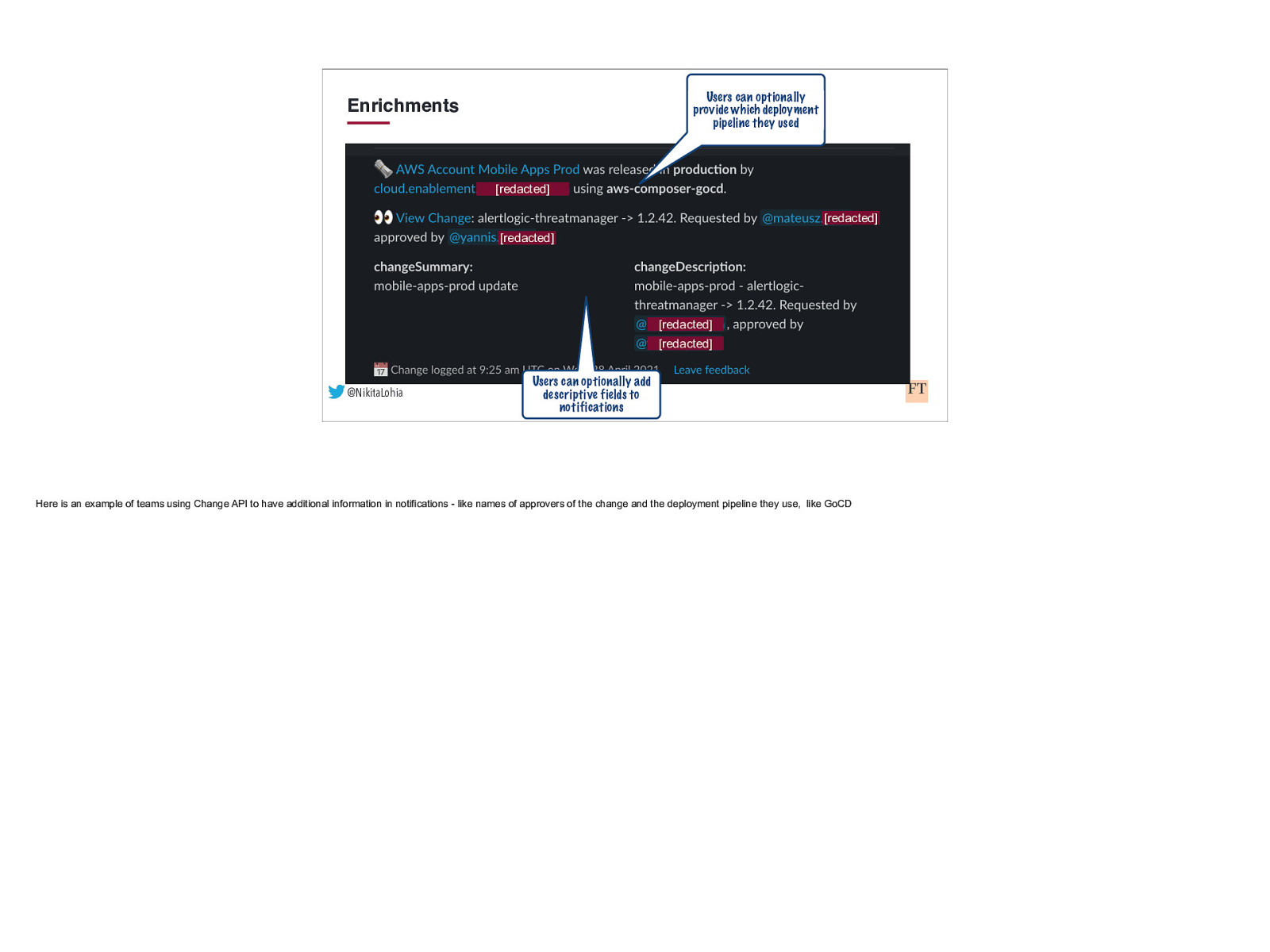
Users can optionally provide which deployment pipeline they used Enrichments [redacted] [redacted] [redacted] [redacted] [redacted] @NikitaLohia Users can optionally add descriptive fields to notifications Here is an example of teams using Change API to have additional information in notifications - like names of approvers of the change and the deployment pipeline they use, like GoCD
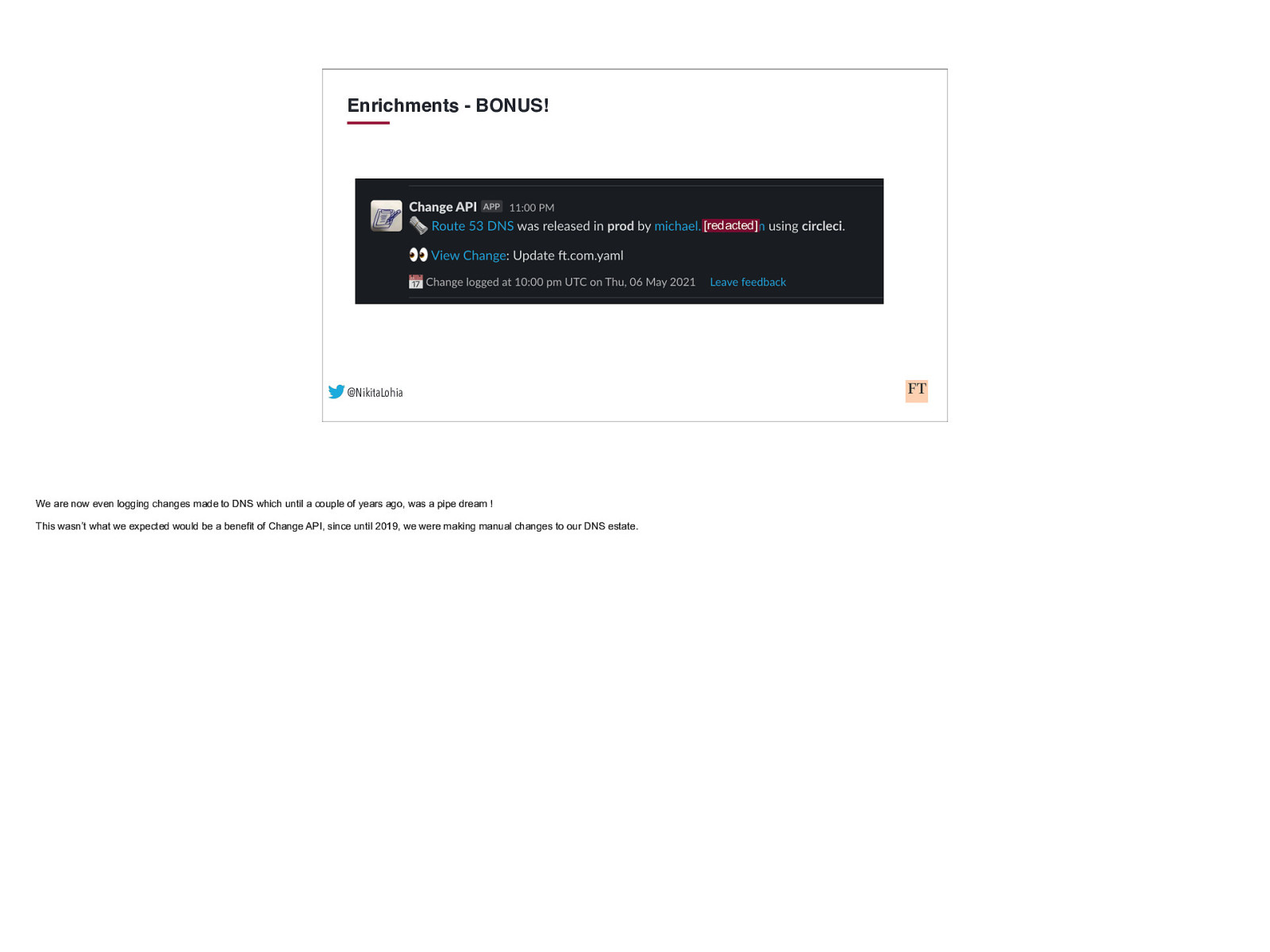
Enrichments - BONUS! [redacted] @NikitaLohia We are now even logging changes made to DNS which until a couple of years ago, was a pipe dream ! This wasn’t what we expected would be a benefit of Change API, since until 2019, we were making manual changes to our DNS estate.
Enrichments - BONUS! @NikitaLohia Any sys admins or devops engineers here? You probably have seen this Haiku before.. Would anyone care to guess how many DNS records does the FT have? Last I checked, we had upwards of 6500 DNS records From my experience, if what’s wrong is not obviously evident - it really is always DNS
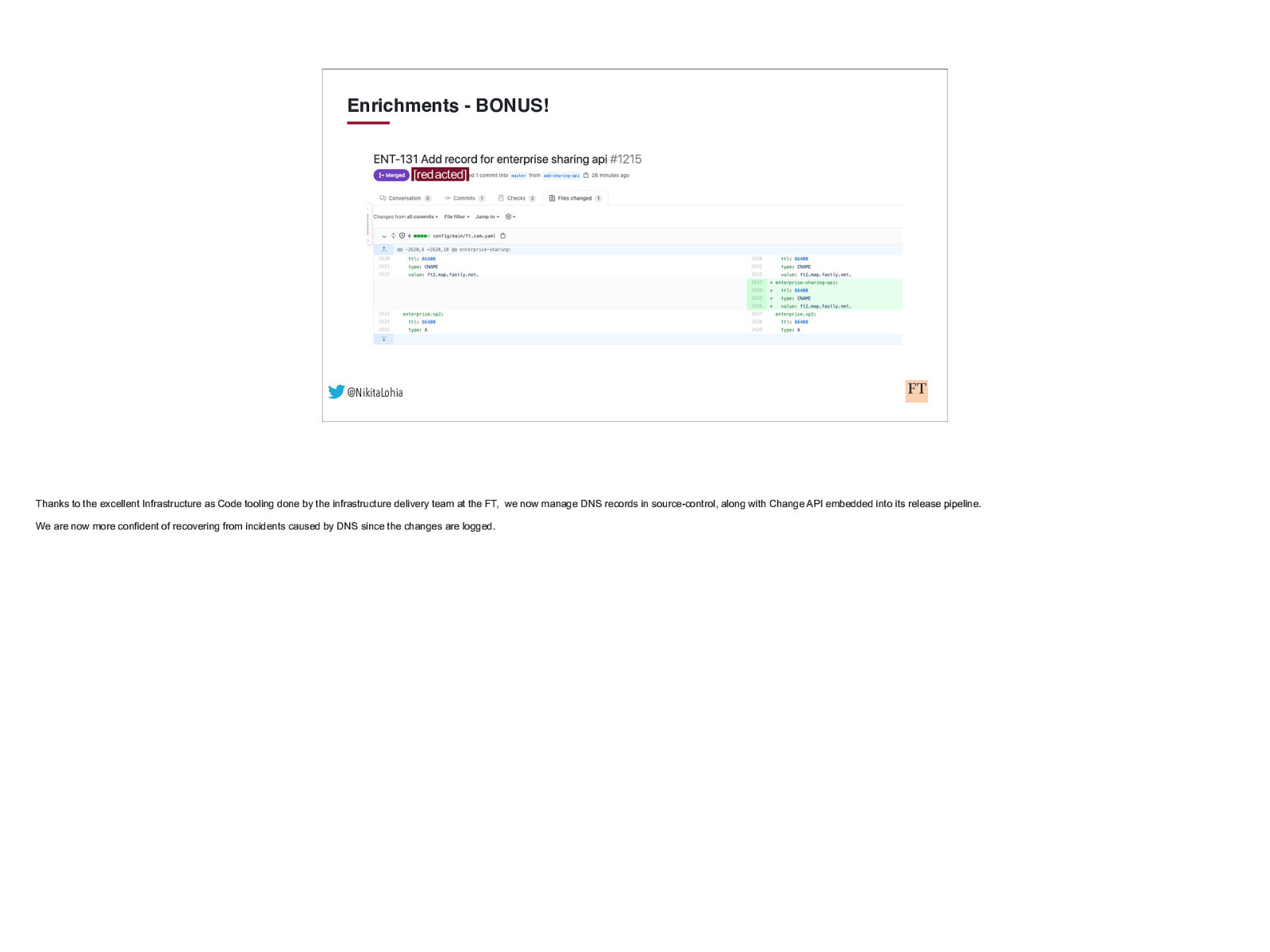
Enrichments - BONUS! [redacted] @NikitaLohia Thanks to the excellent Infrastructure as Code tooling done by the infrastructure delivery team at the FT, we now manage DNS records in source-control, along with Change API embedded into its release pipeline. We are now more confident of recovering from incidents caused by DNS since the changes are logged.
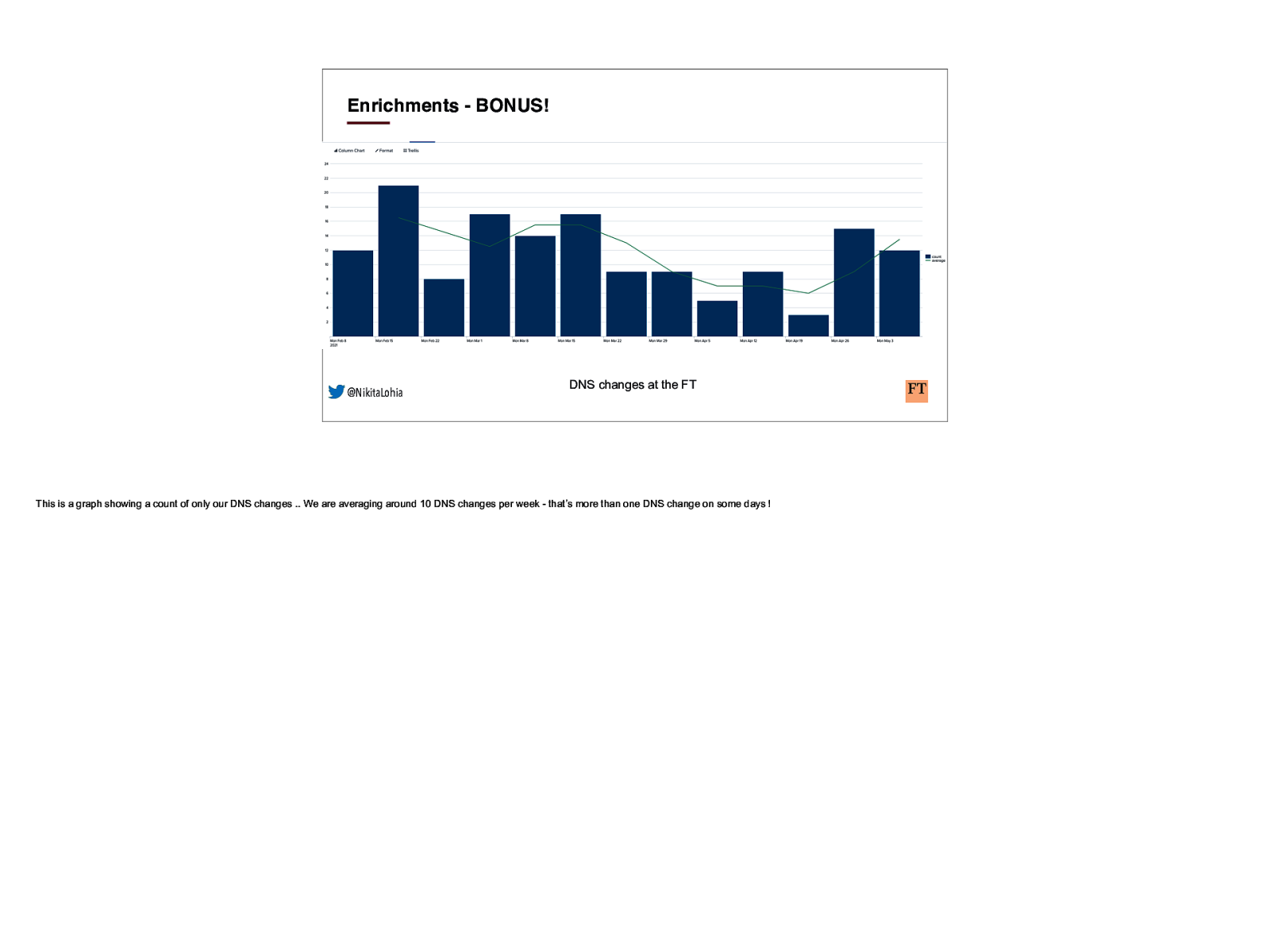
Enrichments - BONUS! @NikitaLohia DNS changes at the FT This is a graph showing a count of only our DNS changes .. We are averaging around 10 DNS changes per week - that’s more than one DNS change on some days !

Enrichments Heimdall, our monitoring platform We also integrated Change API with our monitoring platform called Heimdall. Heimdall is built in-house, it aggregates checks from different monitoring sources and uses them to display dashboards for teams and services. This screenshot illustrates a banner on a service’s monitoring page if it was released within an hour. We made this happen by ensuring that Change API writes the timestamps of the latest releases to our service registry, BizOps. Heimdall then reads this information from BizOps and displays this on the appropriate service dashboard. This was a huge success since now we can immediately co-relate a service alerting with its recent release.

@NikitaLohia Here is how it plays out on Slack … An alert fires for a service…
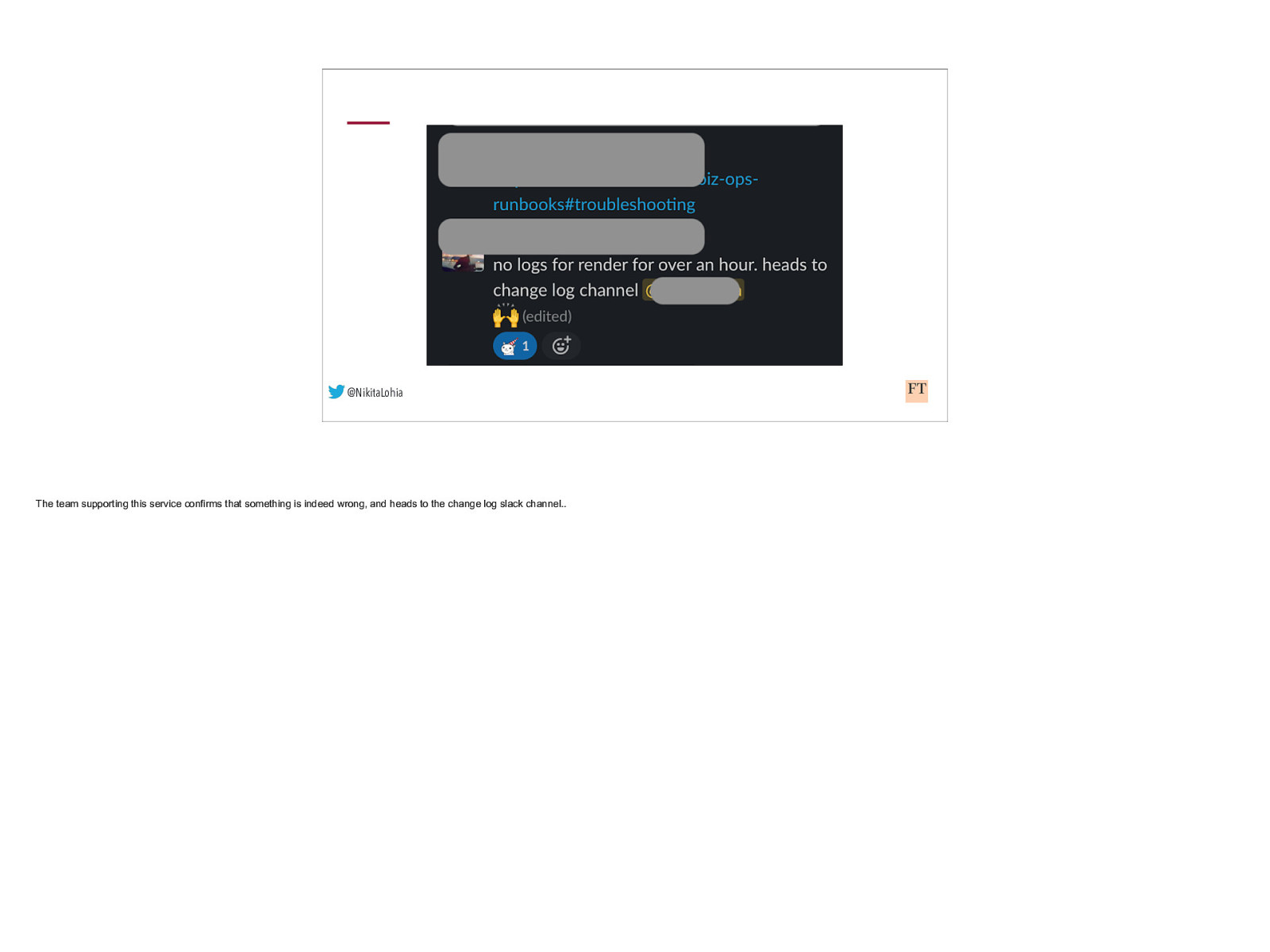
@NikitaLohia The team supporting this service confirms that something is indeed wrong, and heads to the change log slack channel..
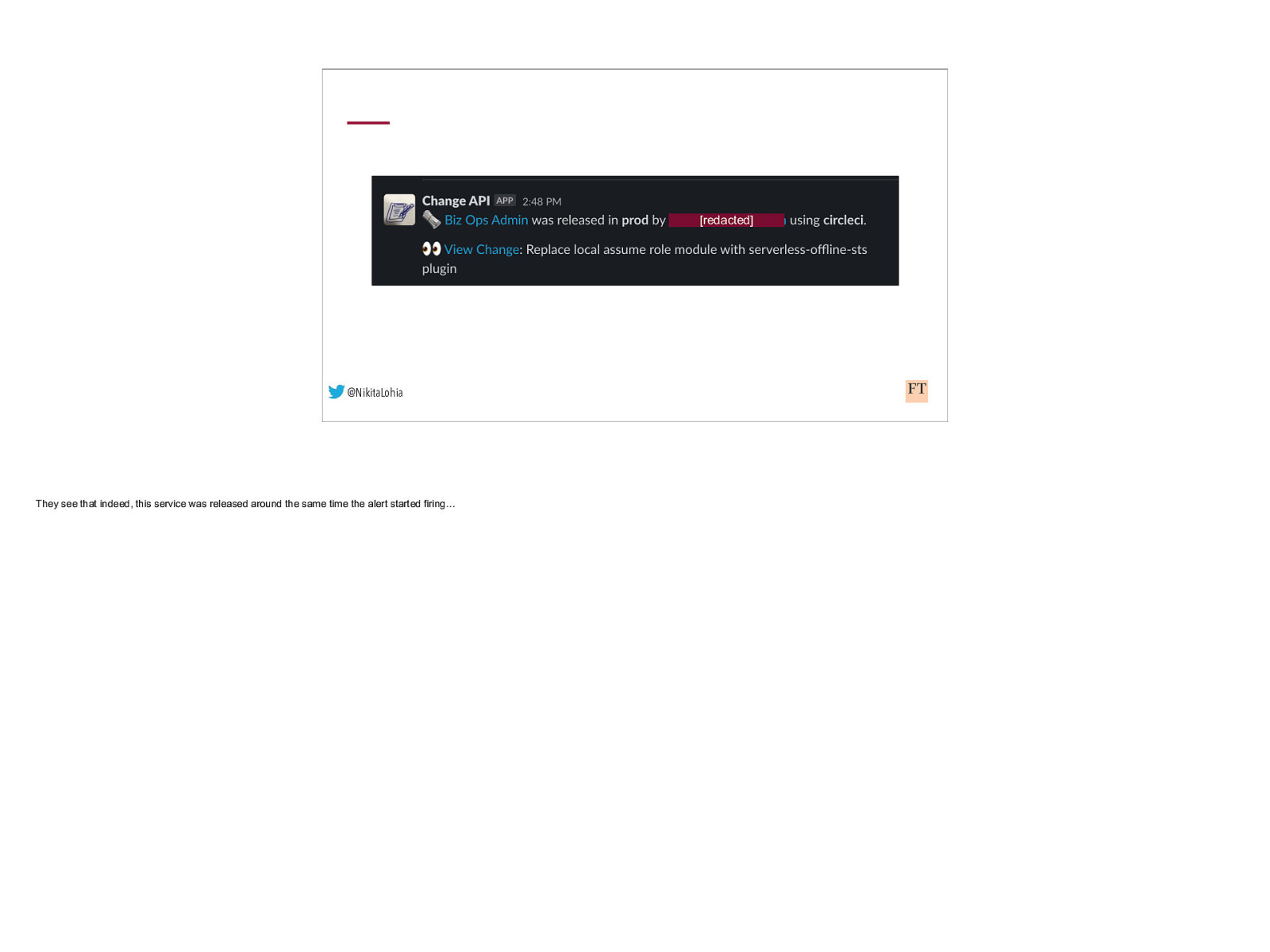
[redacted] @NikitaLohia They see that indeed, this service was released around the same time the alert started firing…
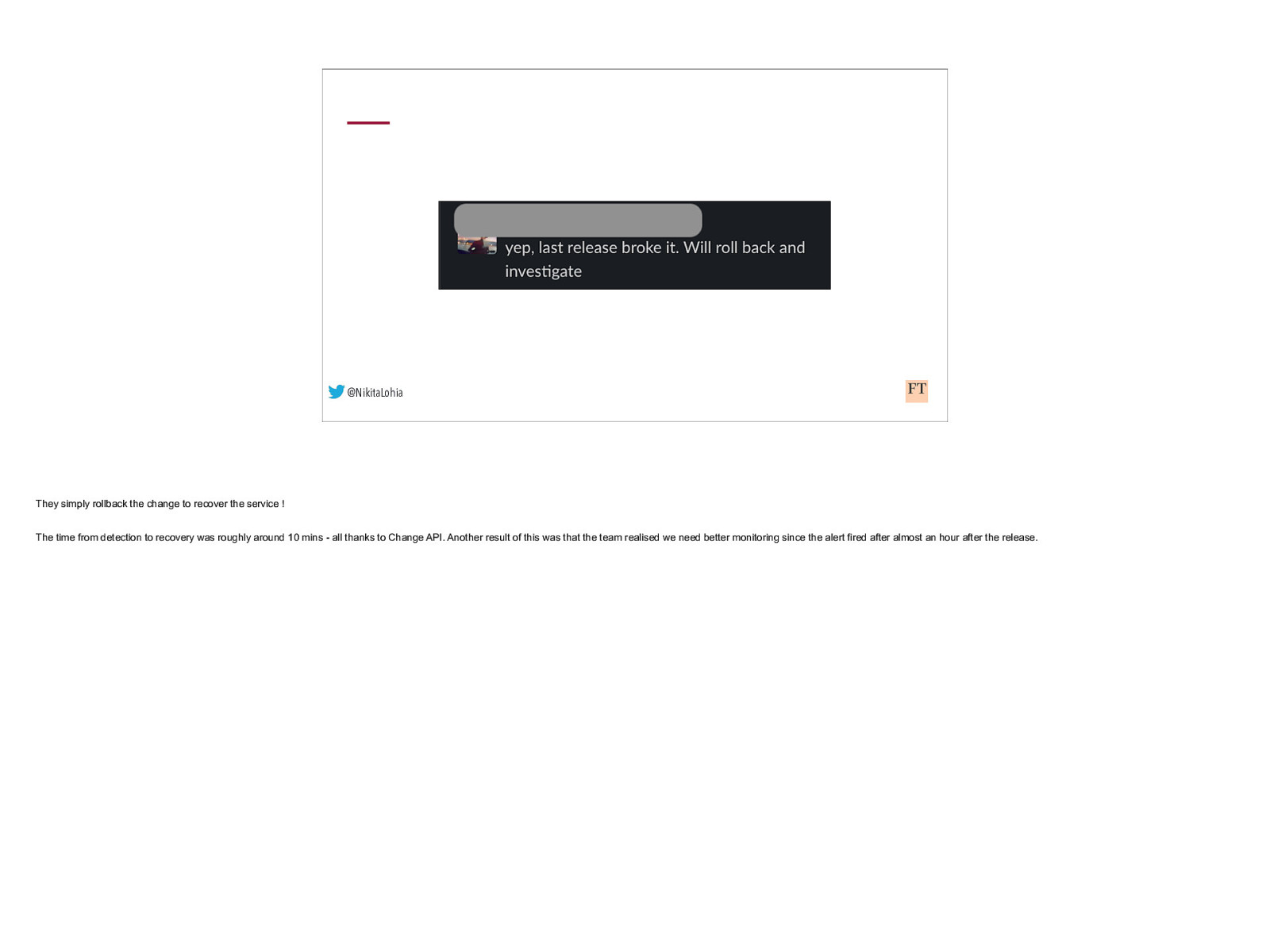
@NikitaLohia They simply rollback the change to recover the service ! The time from detection to recovery was roughly around 10 mins - all thanks to Change API. Another result of this was that the team realised we need better monitoring since the alert fired after almost an hour after the release.
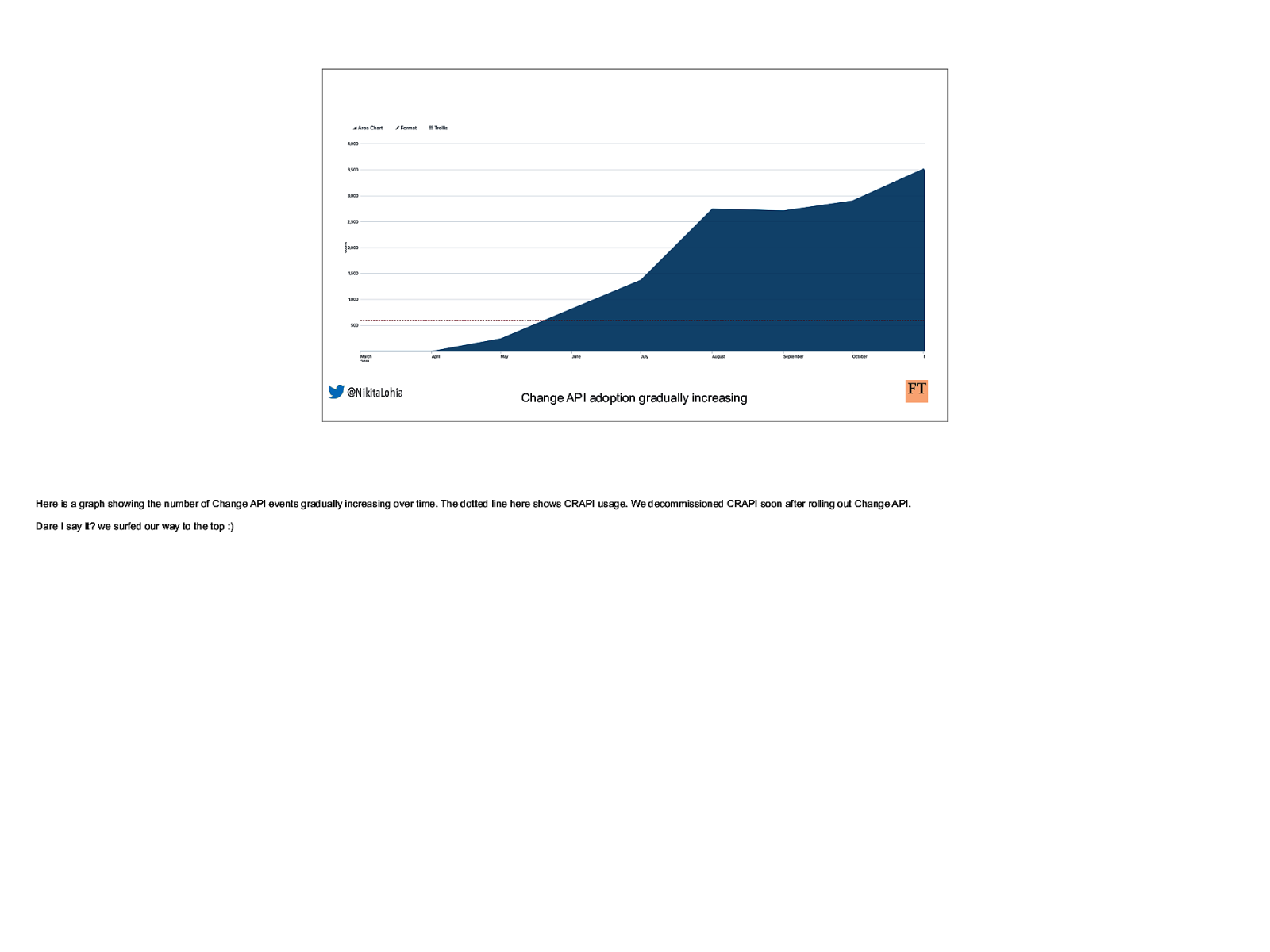
@NikitaLohia Change API adoption gradually increasing Here is a graph showing the number of Change API events gradually increasing over time. The dotted line here shows CRAPI usage. We decommissioned CRAPI soon after rolling out Change API. Dare I say it? we surfed our way to the top :)

Use behavioural science to drive change All through the development of Change API - we were using behavioural science to nudge people in the direction of using Change API. After all, the success or failure of this project largely depended on a majority, if not all, of the services at the FT using Change API
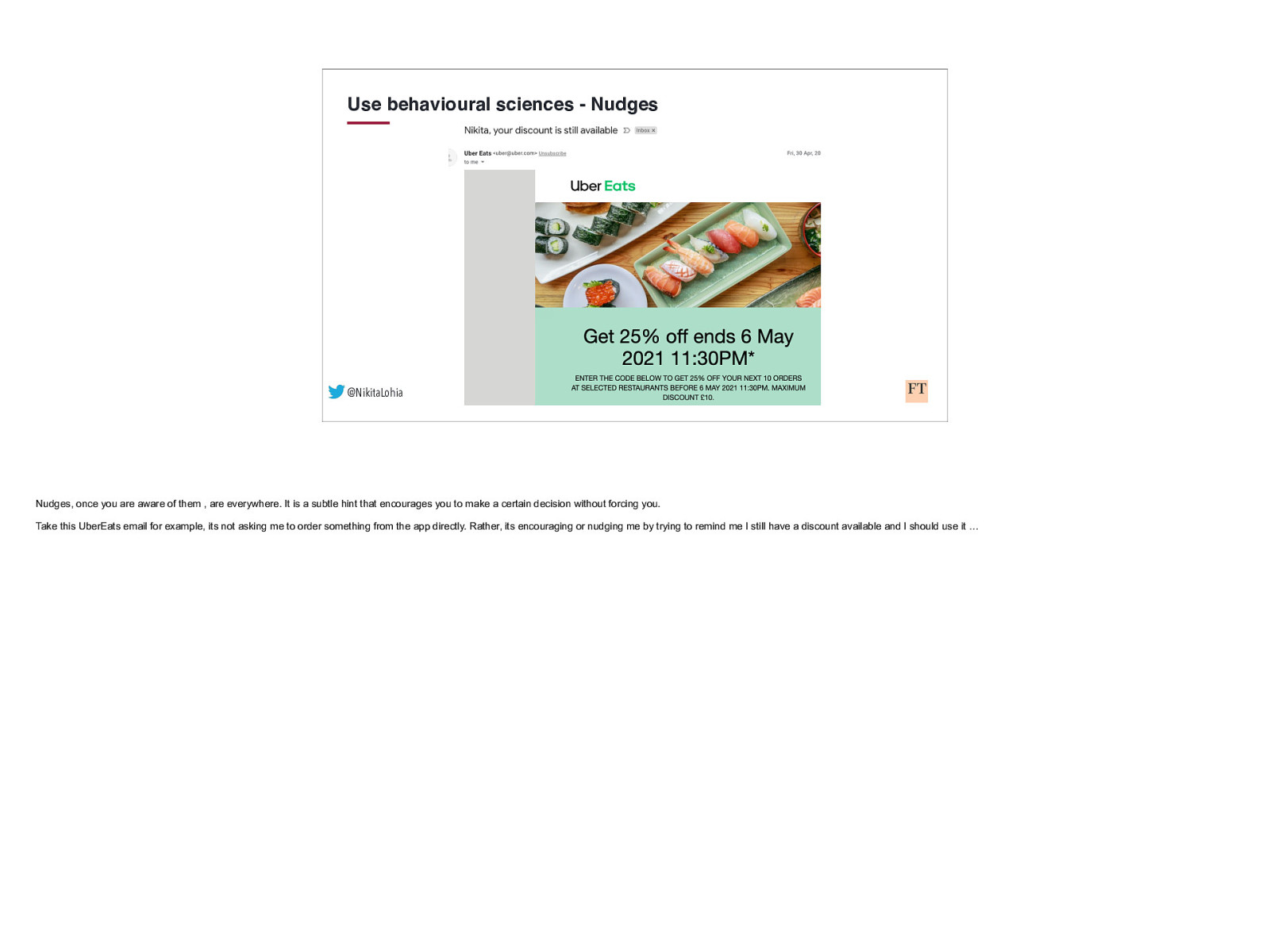
Use behavioural sciences - Nudges @NikitaLohia Nudges, once you are aware of them , are everywhere. It is a subtle hint that encourages you to make a certain decision without forcing you. Take this UberEats email for example, its not asking me to order something from the app directly. Rather, its encouraging or nudging me by trying to remind me I still have a discount available and I should use it …
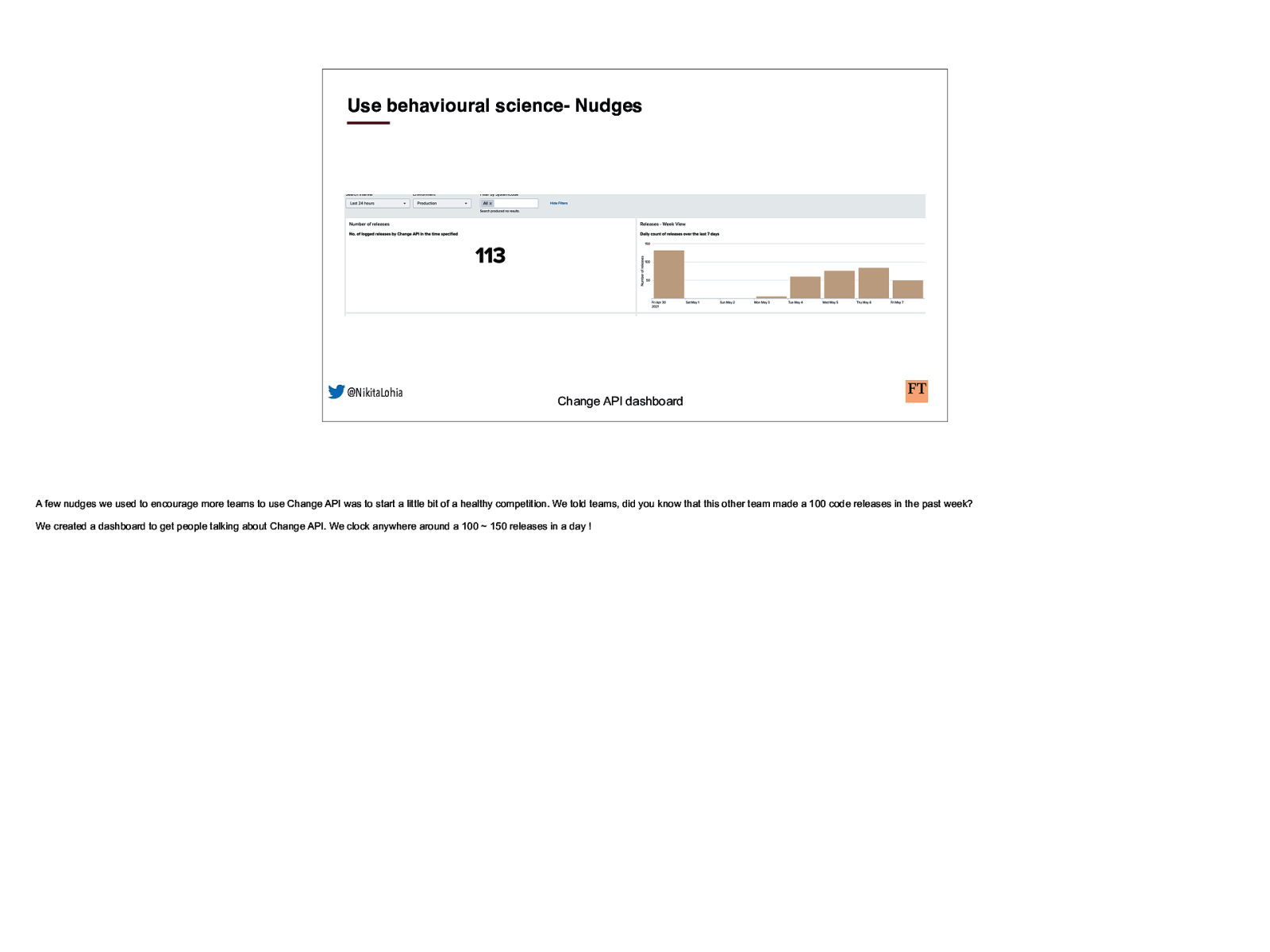
Use behavioural science- Nudges @NikitaLohia Change API dashboard A few nudges we used to encourage more teams to use Change API was to start a little bit of a healthy competition. We told teams, did you know that this other team made a 100 code releases in the past week? We created a dashboard to get people talking about Change API. We clock anywhere around a 100 ~ 150 releases in a day !
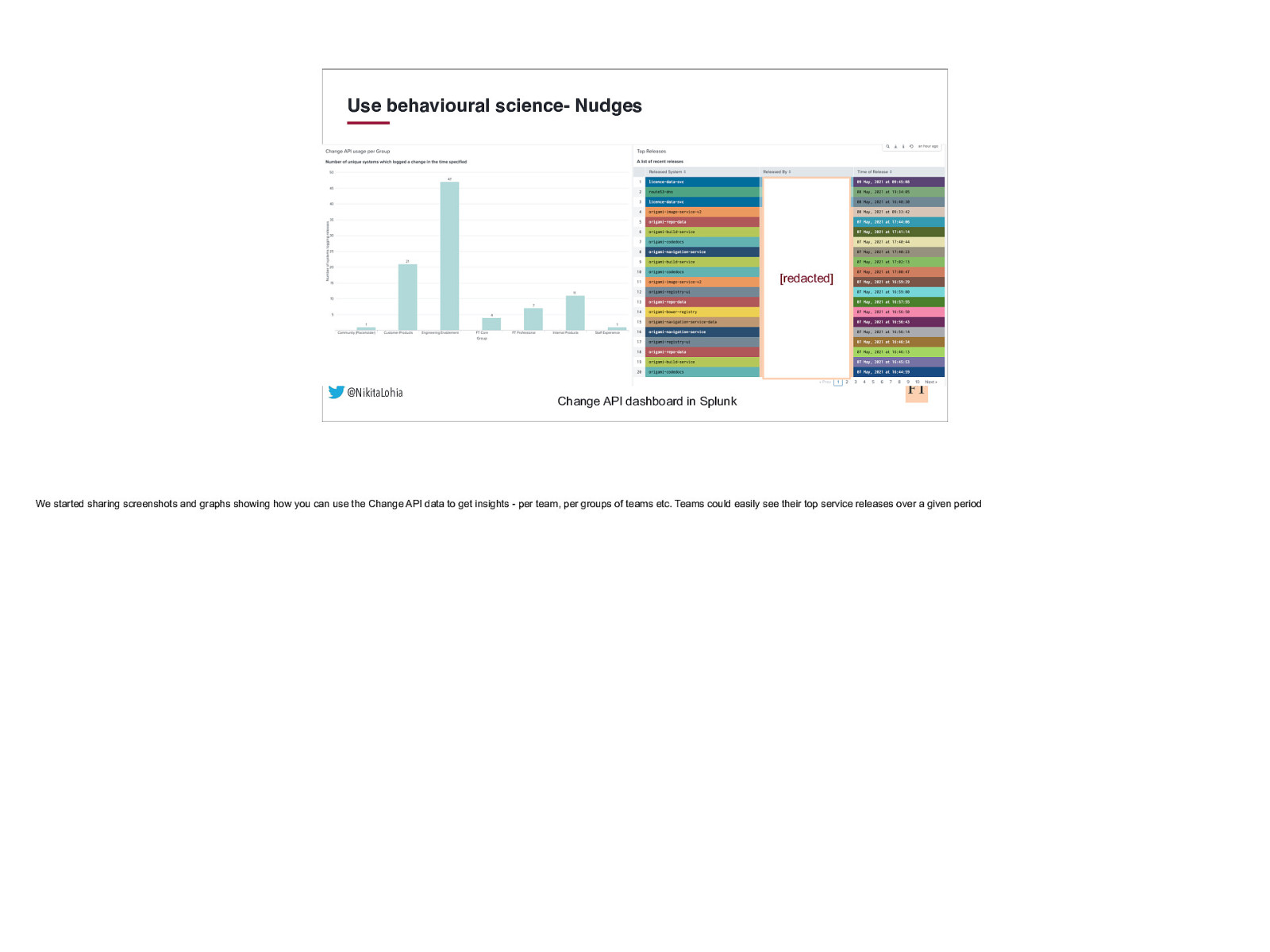
Use behavioural science- Nudges [redacted] @NikitaLohia Change API dashboard in Splunk We started sharing screenshots and graphs showing how you can use the Change API data to get insights - per team, per groups of teams etc. Teams could easily see their top service releases over a given period
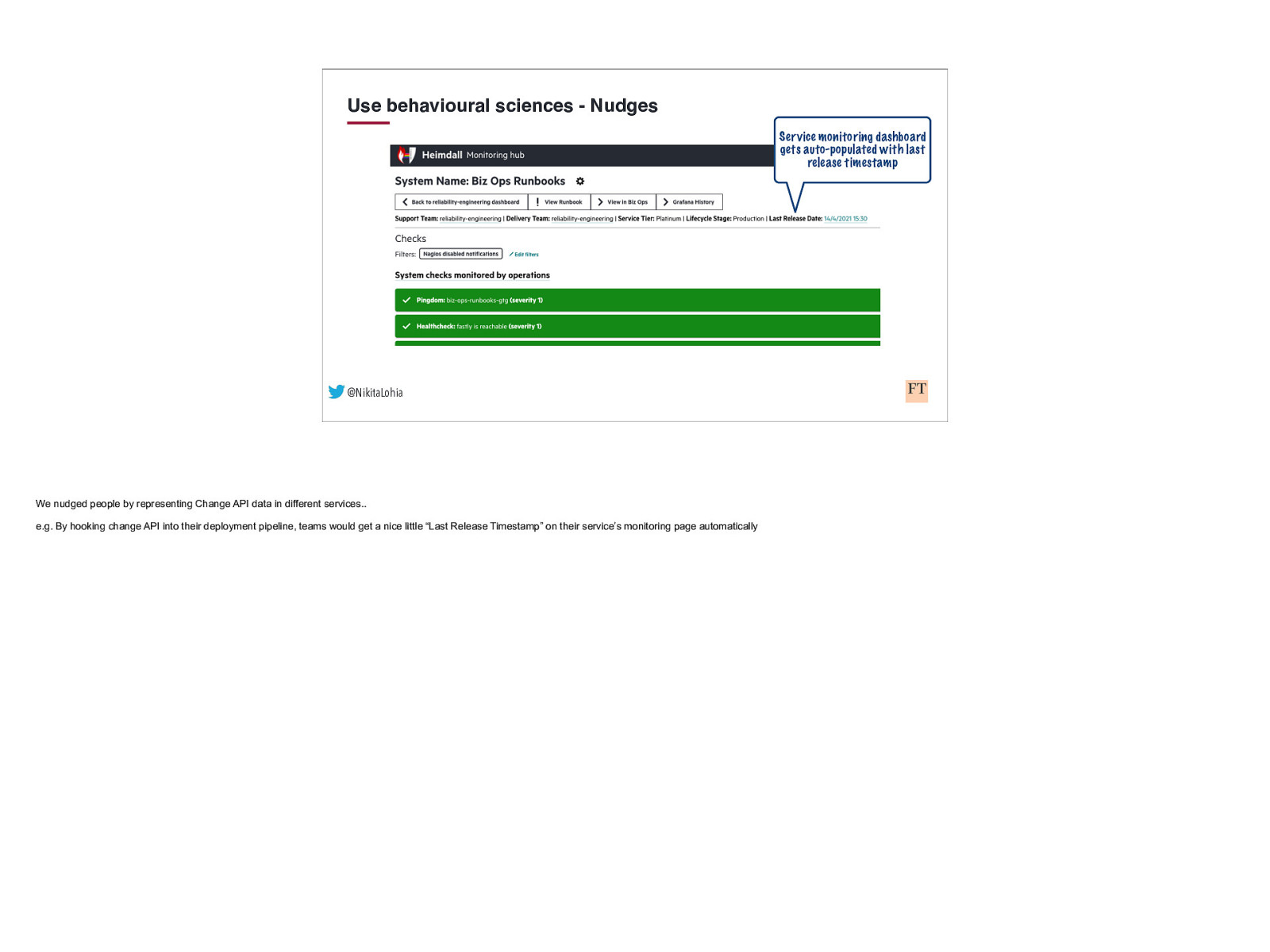
Use behavioural sciences - Nudges Service monitoring dashboard gets auto-populated with last release timestamp @NikitaLohia We nudged people by representing Change API data in different services.. e.g. By hooking change API into their deployment pipeline, teams would get a nice little “Last Release Timestamp” on their service’s monitoring page automatically
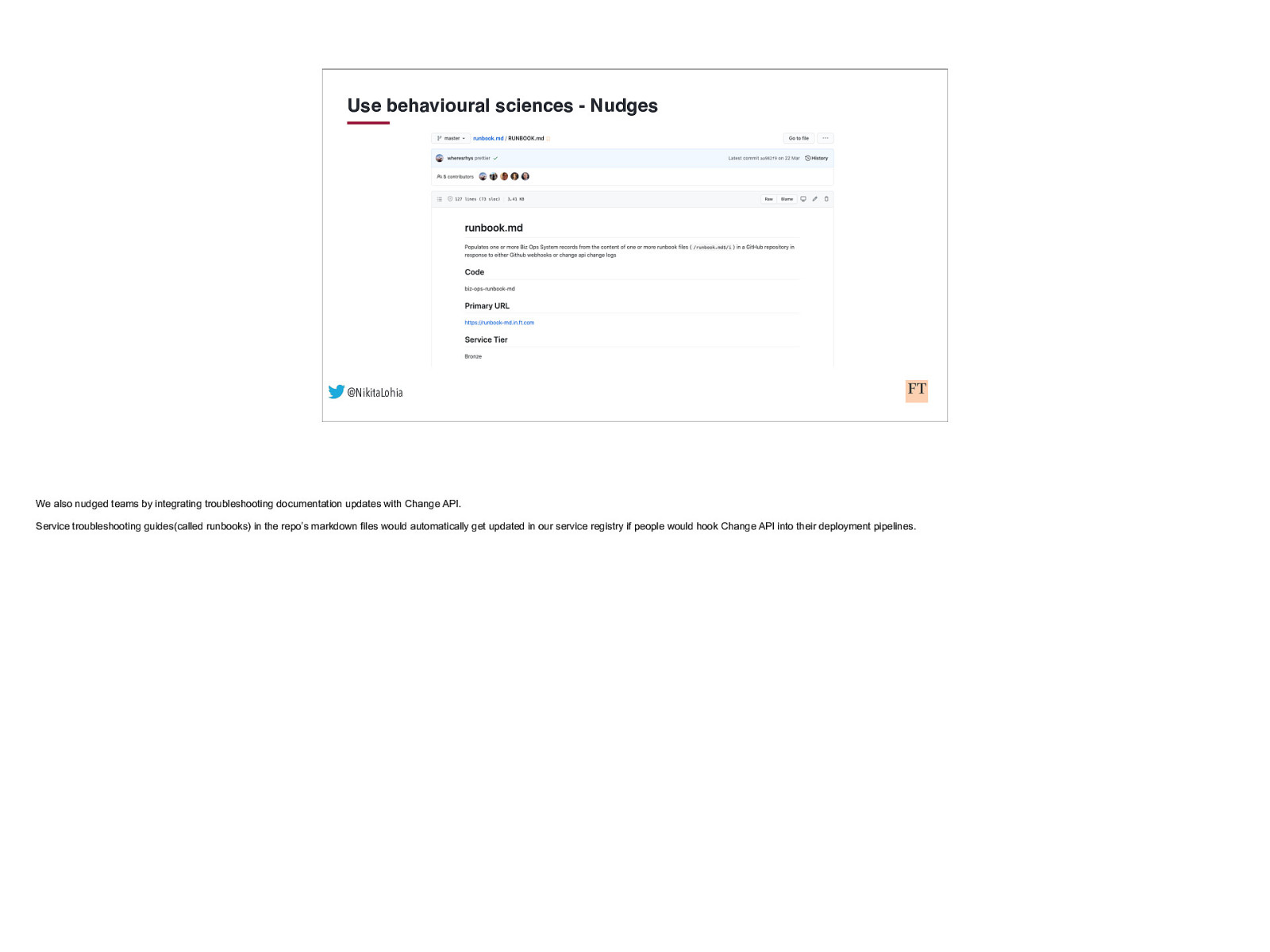
Use behavioural sciences - Nudges @NikitaLohia We also nudged teams by integrating troubleshooting documentation updates with Change API. Service troubleshooting guides(called runbooks) in the repo’s markdown files would automatically get updated in our service registry if people would hook Change API into their deployment pipelines.
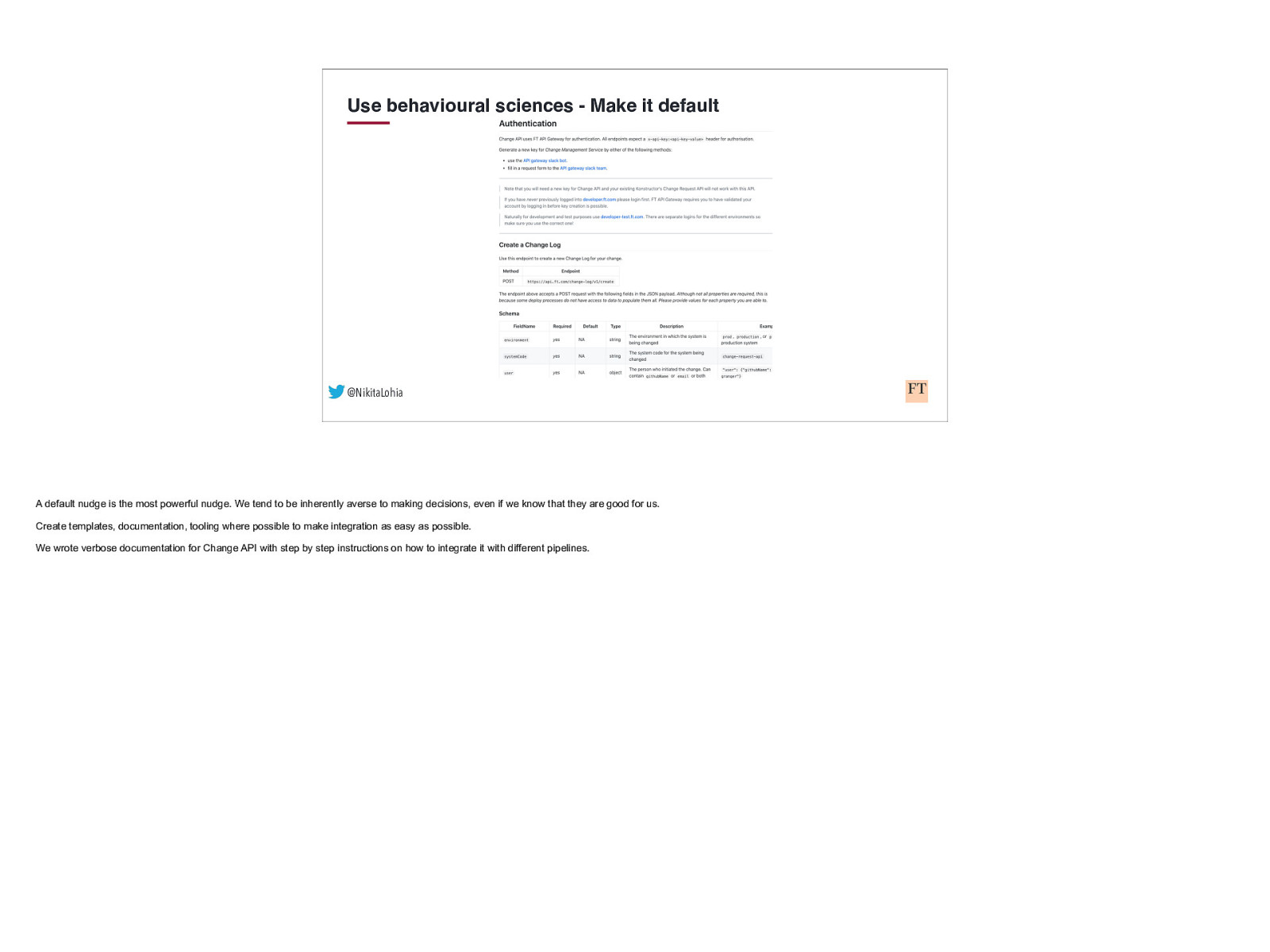
Use behavioural sciences - Make it default @NikitaLohia A default nudge is the most powerful nudge. We tend to be inherently averse to making decisions, even if we know that they are good for us. Create templates, documentation, tooling where possible to make integration as easy as possible. We wrote verbose documentation for Change API with step by step instructions on how to integrate it with different pipelines.
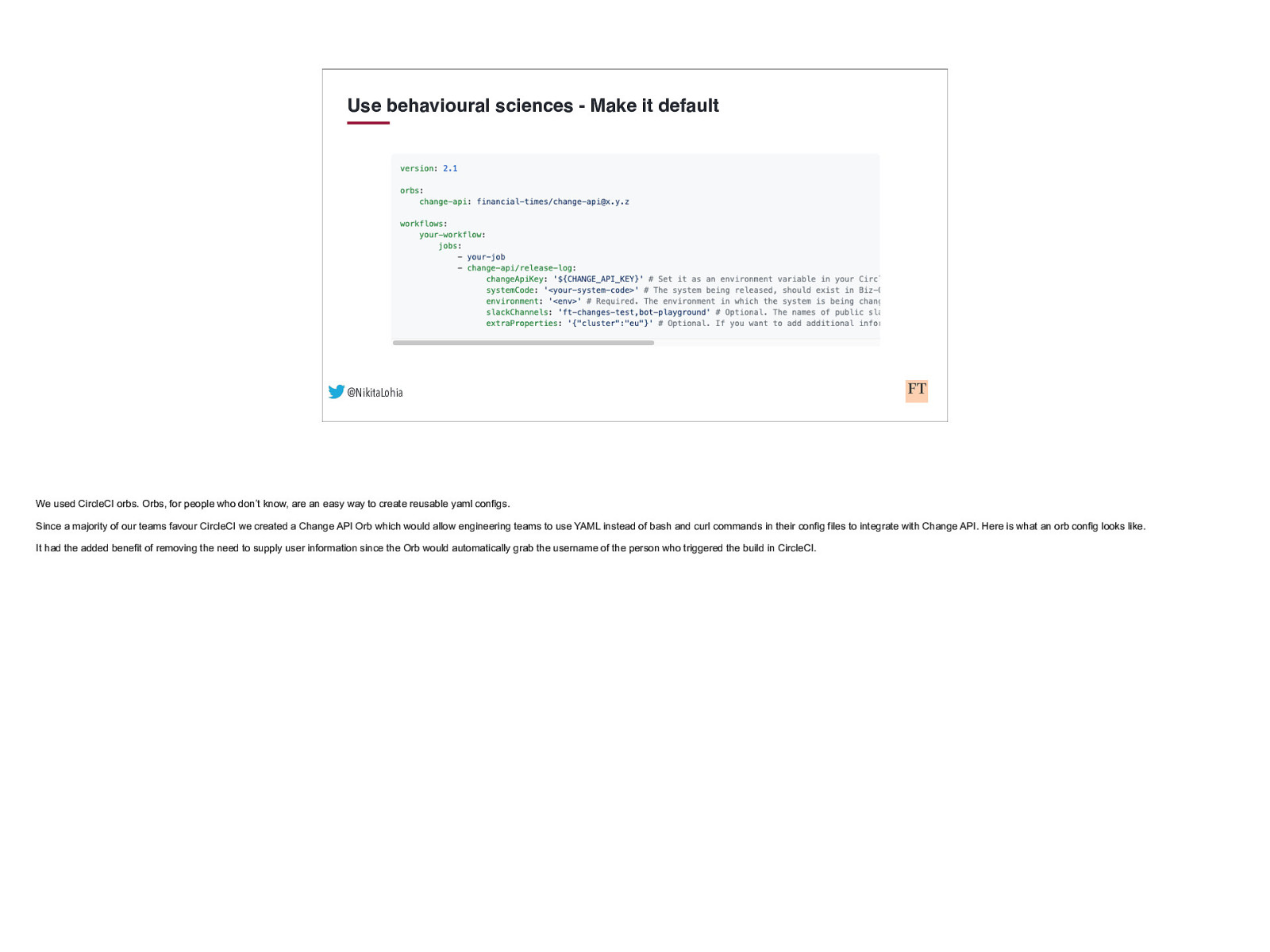
Use behavioural sciences - Make it default @NikitaLohia We used CircleCI orbs. Orbs, for people who don’t know, are an easy way to create reusable yaml configs. Since a majority of our teams favour CircleCI we created a Change API Orb which would allow engineering teams to use YAML instead of bash and curl commands in their config files to integrate with Change API. Here is what an orb config looks like. It had the added benefit of removing the need to supply user information since the Orb would automatically grab the username of the person who triggered the build in CircleCI.
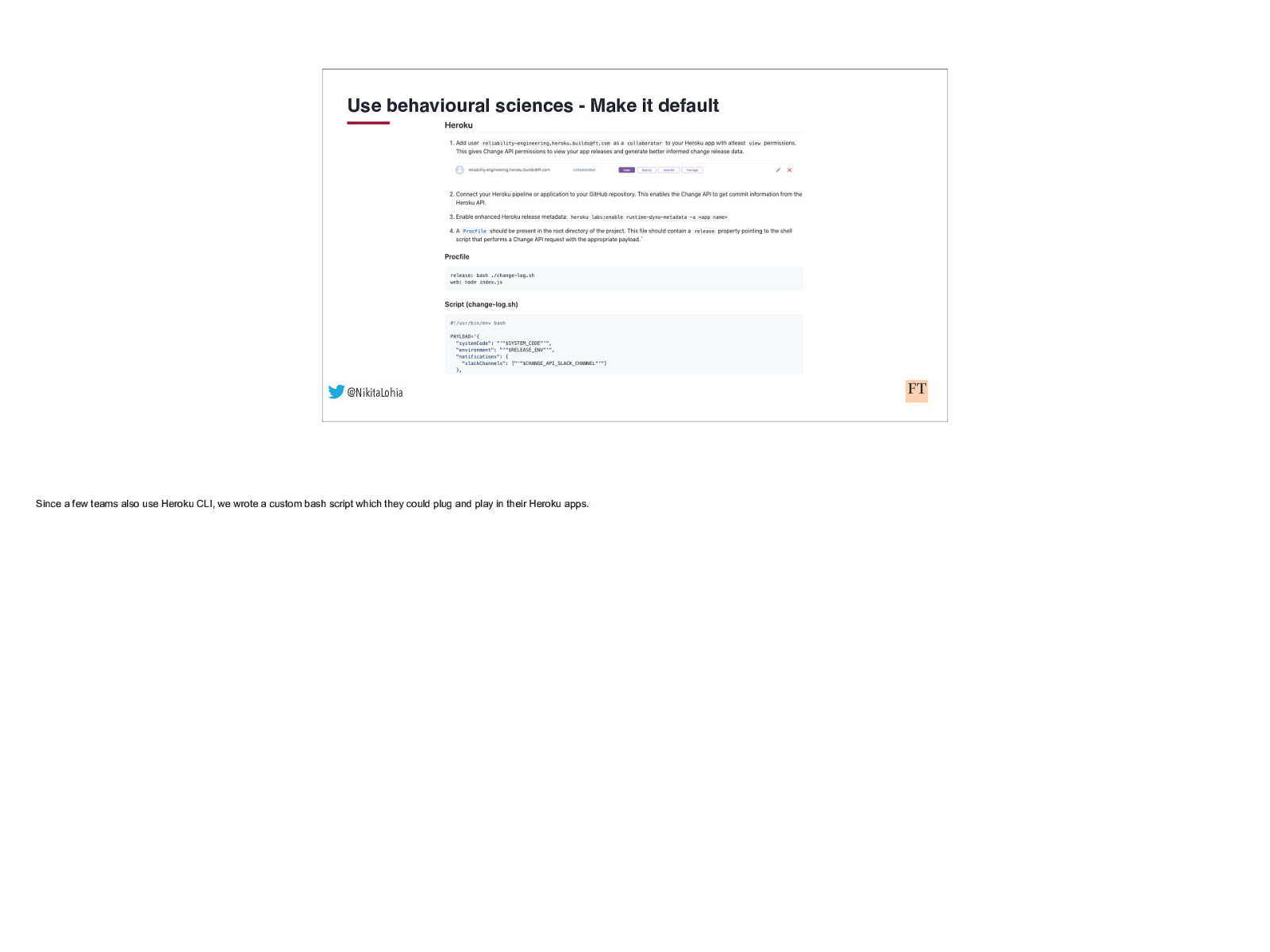
Use behavioural sciences - Make it default @NikitaLohia Since a few teams also use Heroku CLI, we wrote a custom bash script which they could plug and play in their Heroku apps.
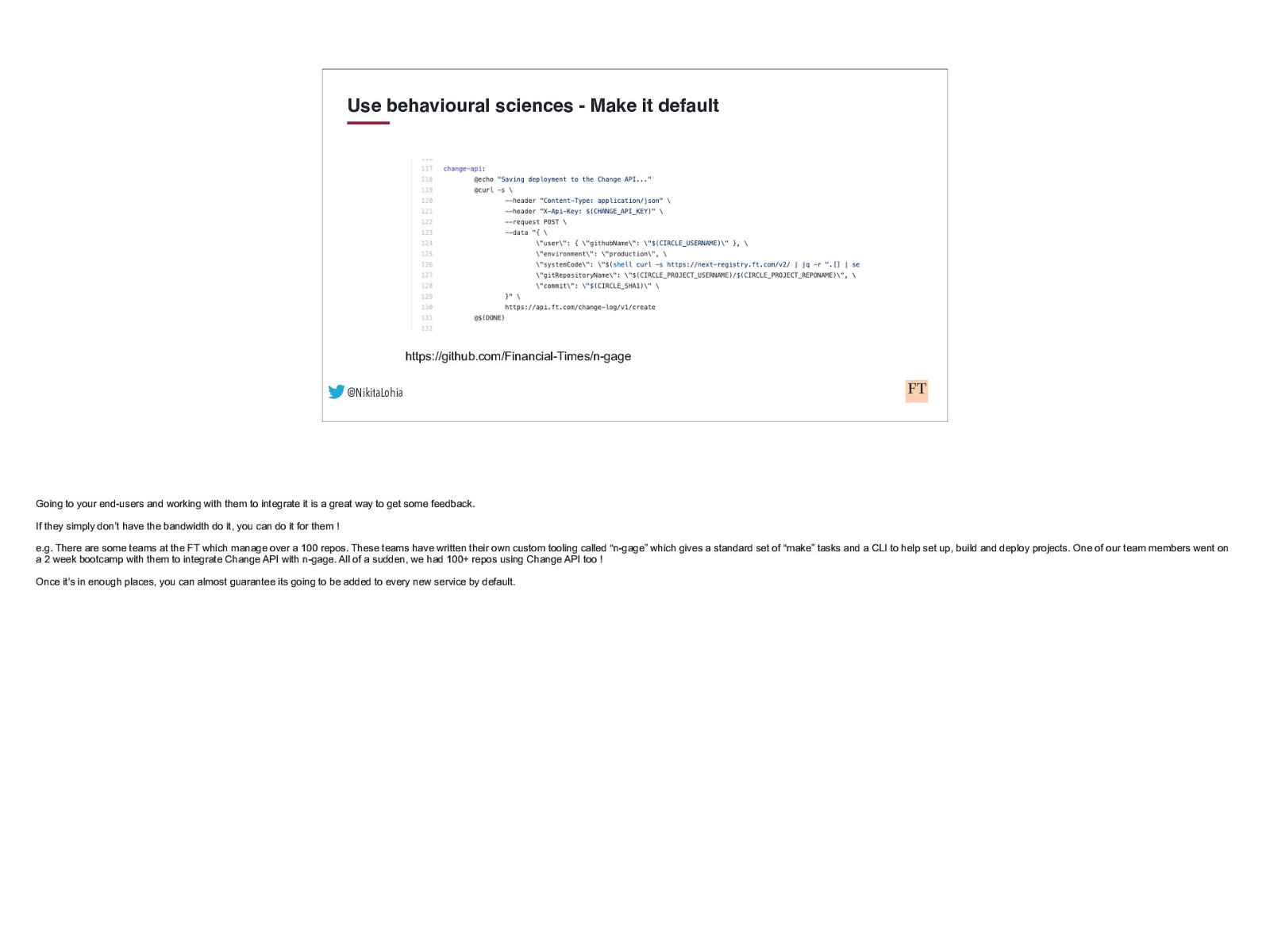
Use behavioural sciences - Make it default https://github.com/Financial-Times/n-gage @NikitaLohia Going to your end-users and working with them to integrate it is a great way to get some feedback. If they simply don’t have the bandwidth do it, you can do it for them ! e.g. There are some teams at the FT which manage over a 100 repos. These teams have written their own custom tooling called “n-gage” which gives a standard set of “make” tasks and a CLI to help set up, build and deploy projects. One of our team members went on a 2 week bootcamp with them to integrate Change API with n-gage. All of a sudden, we had 100+ repos using Change API too ! Once it’s in enough places, you can almost guarantee its going to be added to every new service by default.
Use behavioural sciences https://skillsmatter.com/skillscasts/9858-nudge-theory-influencing-empowered-teams-to-do-the-things-that-matterto-you-sarah-wells @NikitaLohia There is an excellent talk by my colleague Sarah Wells which talks about Nudge Theory in greater detail. She also talks about the EAST framework which can be a really good guide to influence behaviour.

In summary… So, in summary.

Tracking code changes centrally is easier than you might think and much more beneficial than you might imagine @NikitaLohia Hopefully , I have managed to convince you that tracking code changes centrally is not that hard and you have some pointers on getting started and making a business case for it in your organisation.

You can end up with some really interesting data.. @NikitaLohia https://medium.com/ft-product-technology/the-advent-of-change-api-8dae0f95245e Along with the capability to consistently and confidently be aware of what changed in our microservice estate , we were able to answer some really interesting questions like “How has the pandemic affected our code releases?”, “Do our developers prefer a specific time or day to push changes?”
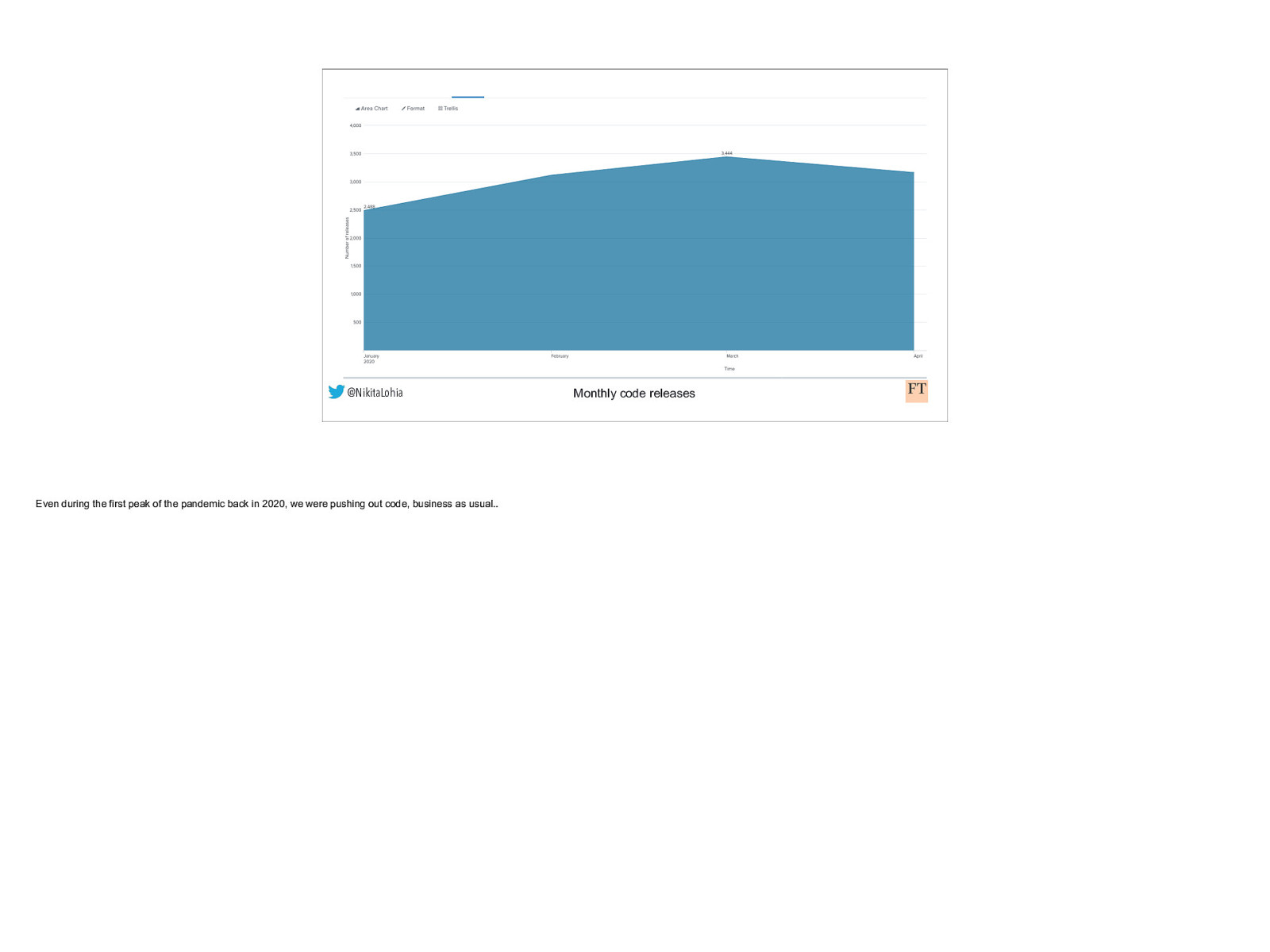
@NikitaLohia Even during the first peak of the pandemic back in 2020, we were pushing out code, business as usual.. Monthly code releases
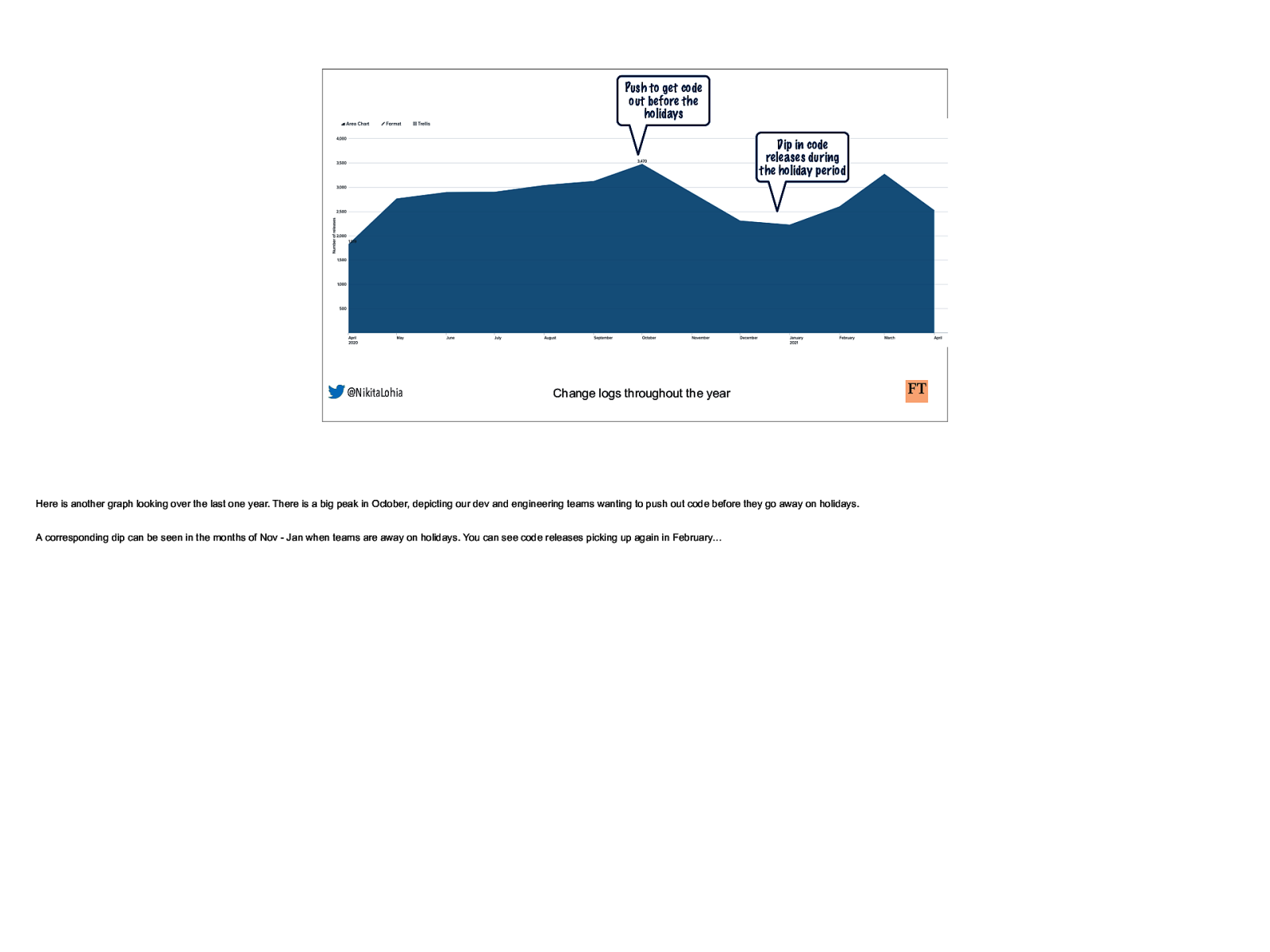
Push to get code out before the holidays Dip in code releases during the holiday period @NikitaLohia Change logs throughout the year Here is another graph looking over the last one year. There is a big peak in October, depicting our dev and engineering teams wanting to push out code before they go away on holidays. A corresponding dip can be seen in the months of Nov - Jan when teams are away on holidays. You can see code releases picking up again in February…
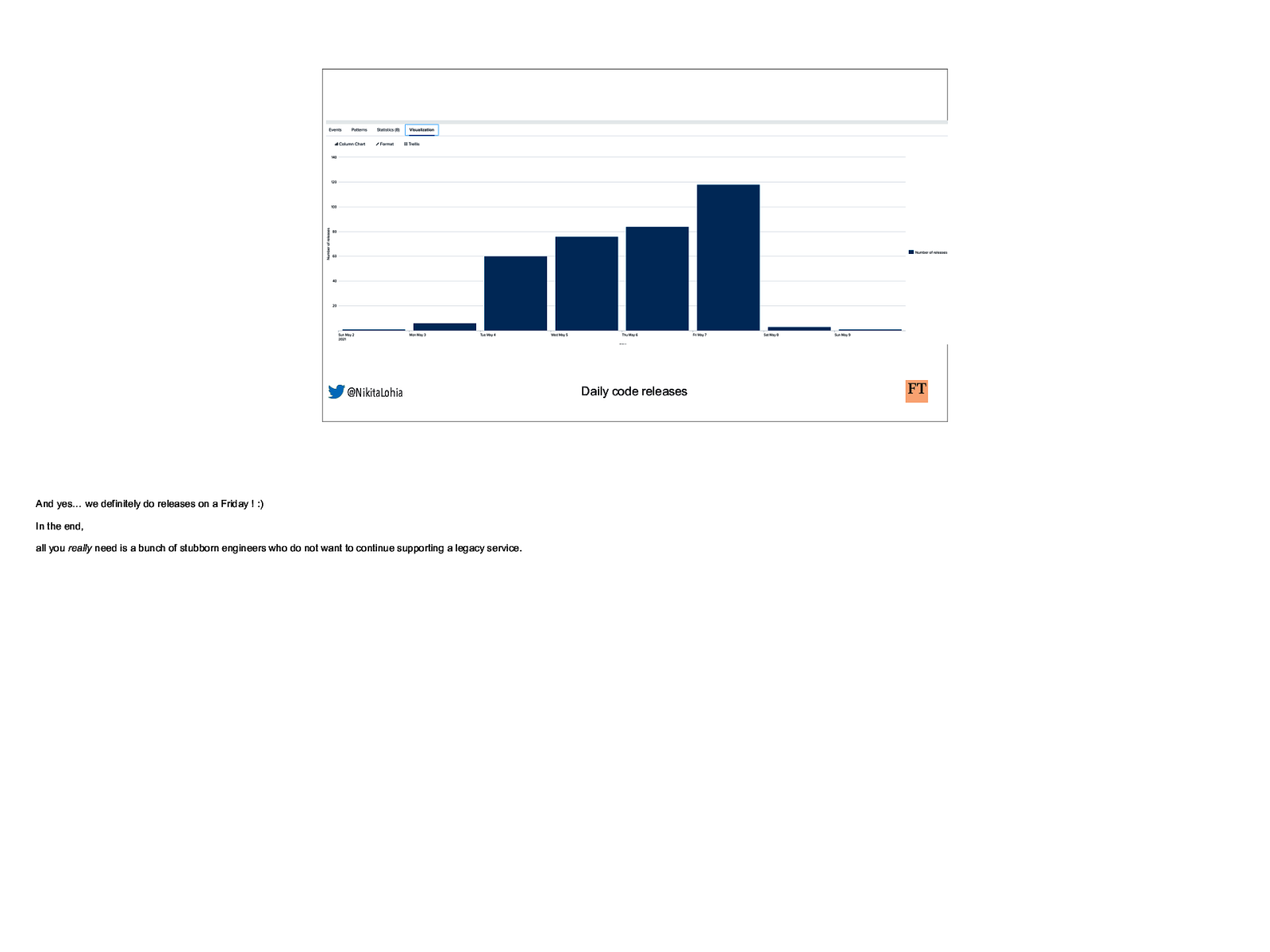
@NikitaLohia And yes… we definitely do releases on a Friday ! :) In the end, all you really need is a bunch of stubborn engineers who do not want to continue supporting a legacy service. Daily code releases
Thank you! ● https://medium.com/ft-product-technology @NikitaLohia