🚂 On Track with Apache Kafka®: Building a Streaming ETL solution with Rail Data @rmoff @confluentinc

A presentation at Kafka Summit APAC in July 2021 in by Robin Moffatt

🚂 On Track with Apache Kafka®: Building a Streaming ETL solution with Rail Data @rmoff @confluentinc


h/t @kennybastani / @gamussa


@rmoff | @confluentinc
https://wiki.openraildata.com @rmoff | @confluentinc
@rmoff | @confluentinc
@rmoff | @confluentinc
ig nf Co Co nf ig SQL @rmoff | @confluentinc
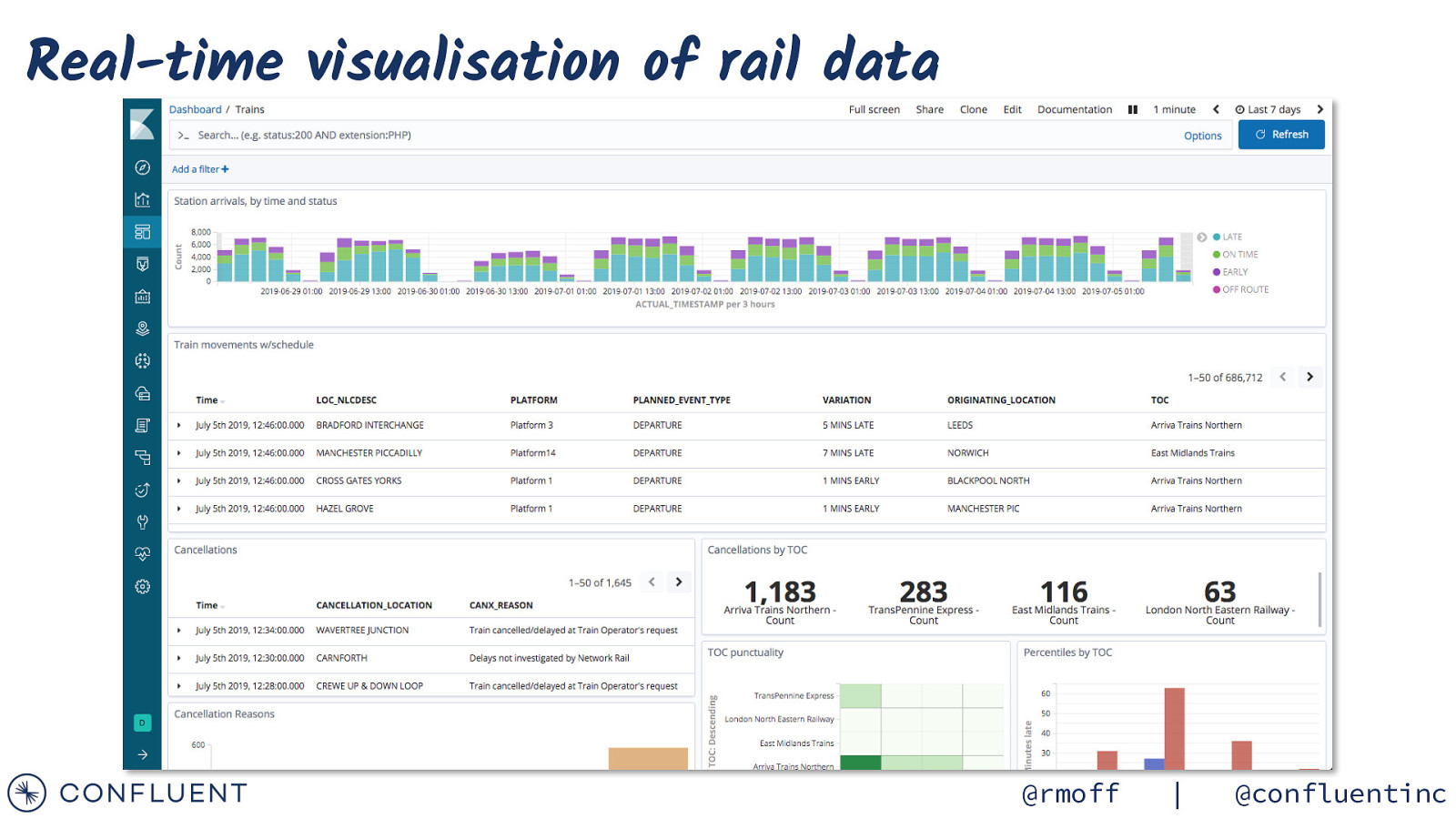
Real-time visualisation of rail data @rmoff | @confluentinc
Real-time visualisation of rail data O M E D @rmoff | @confluentinc
Code! http://rmoff.dev/kafka-trains-code-01 @rmoff | @confluentinc
Graph relationships @rmoff | @confluentinc
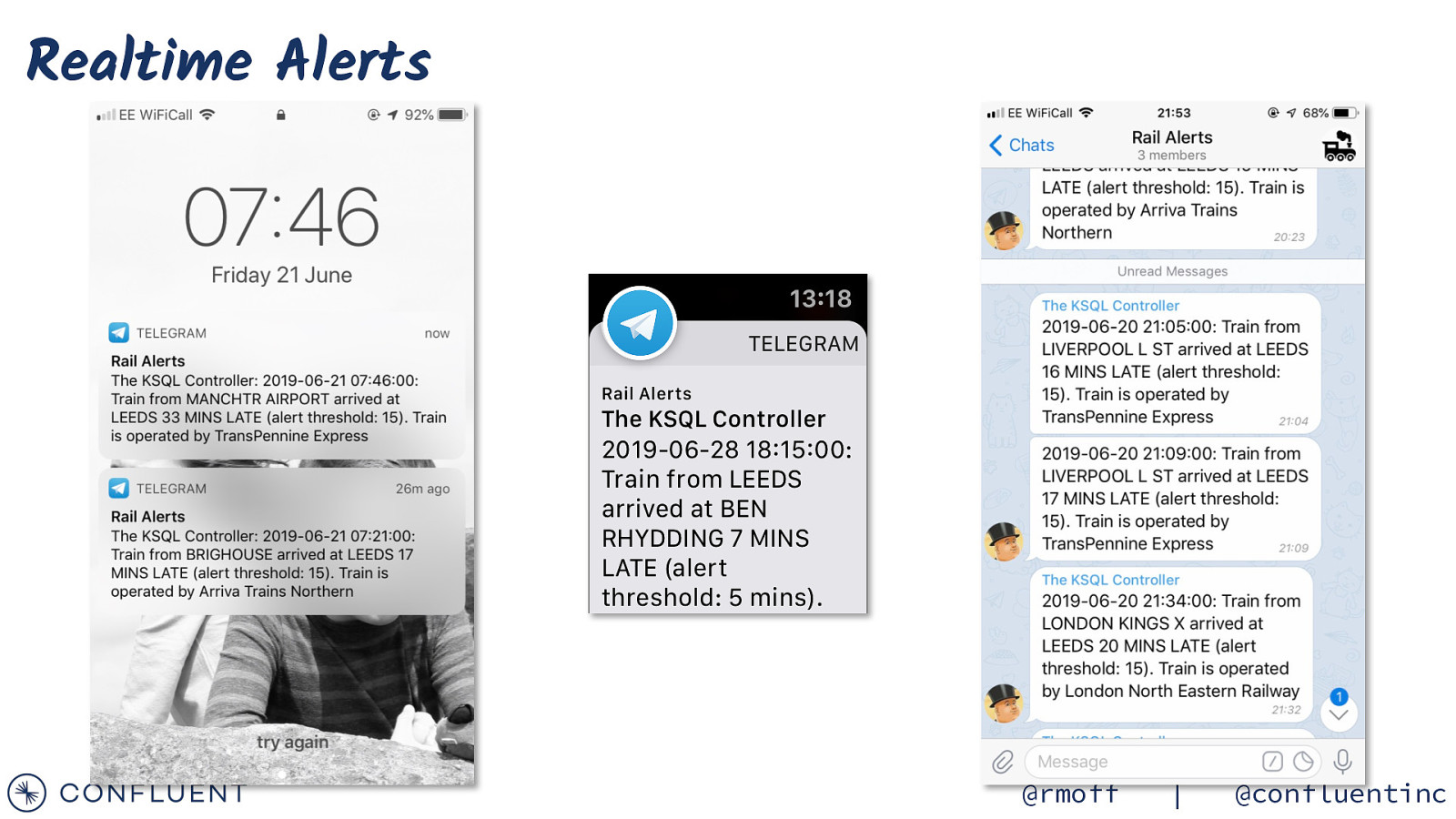
Realtime Alerts @rmoff | @confluentinc

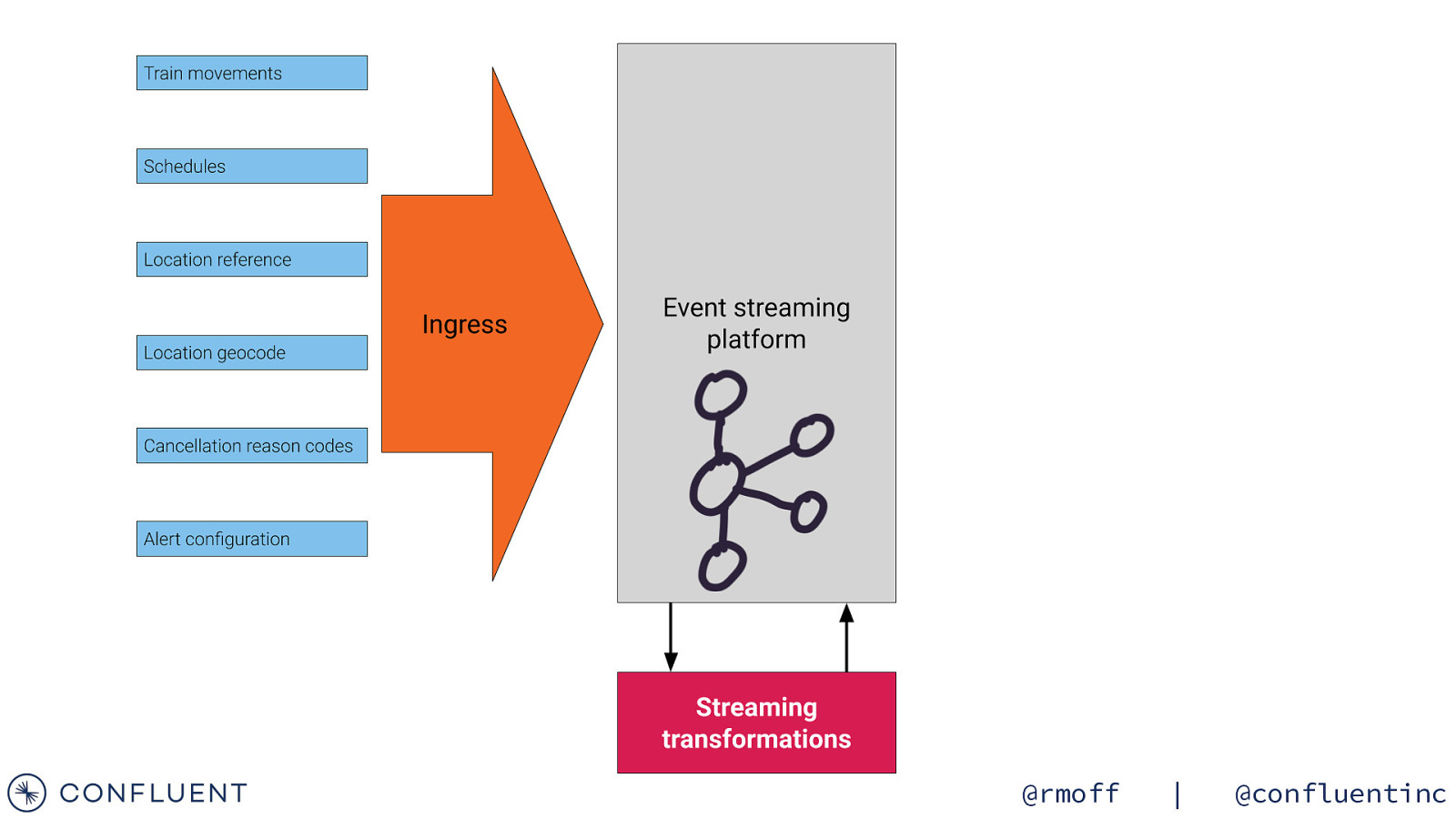
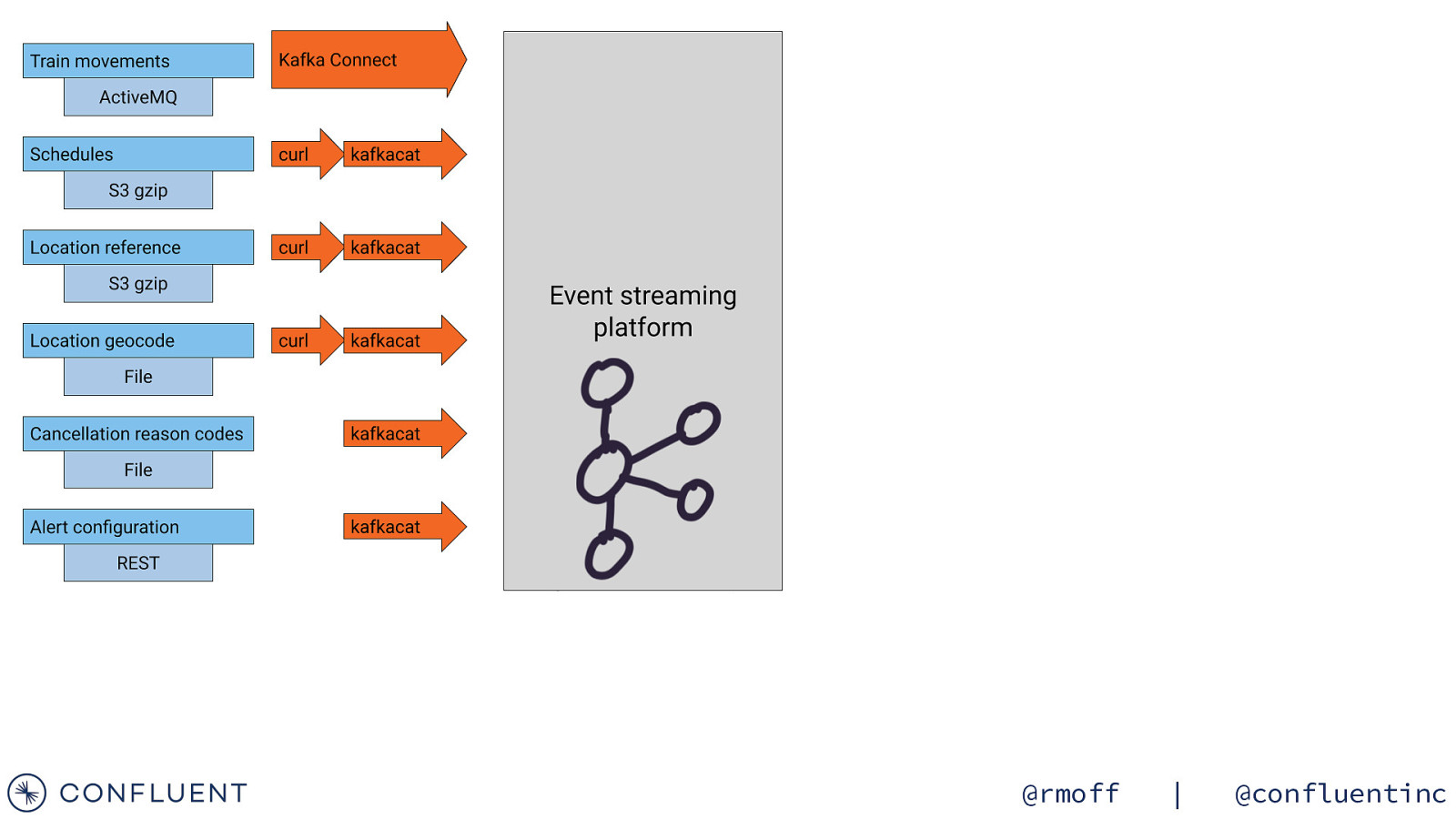
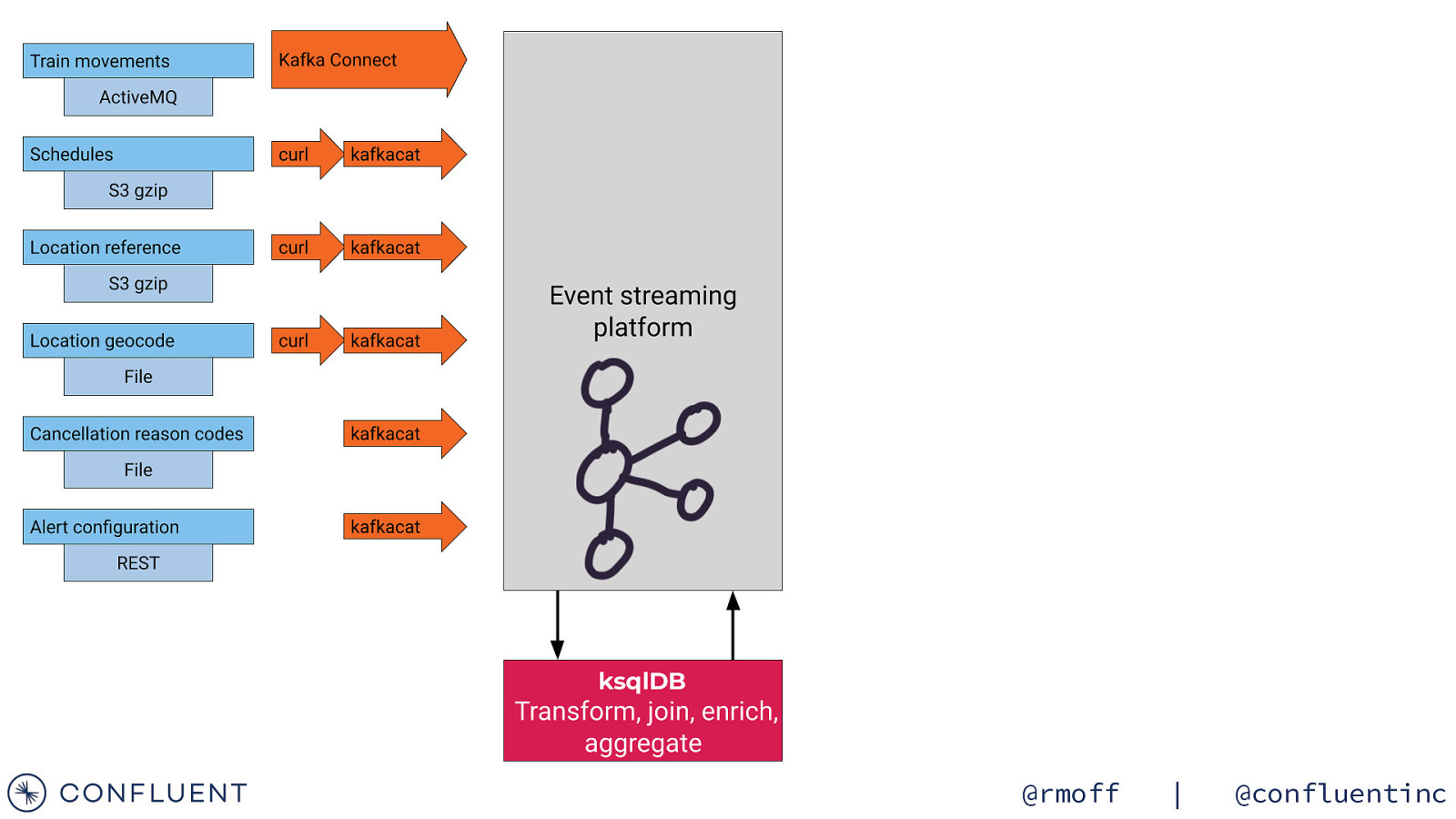
Getting the data in 📥 @rmoff | @confluentinc

Data Sources Train Movements Continuous feed Schedules Updated Daily Reference data Static @rmoff | @confluentinc
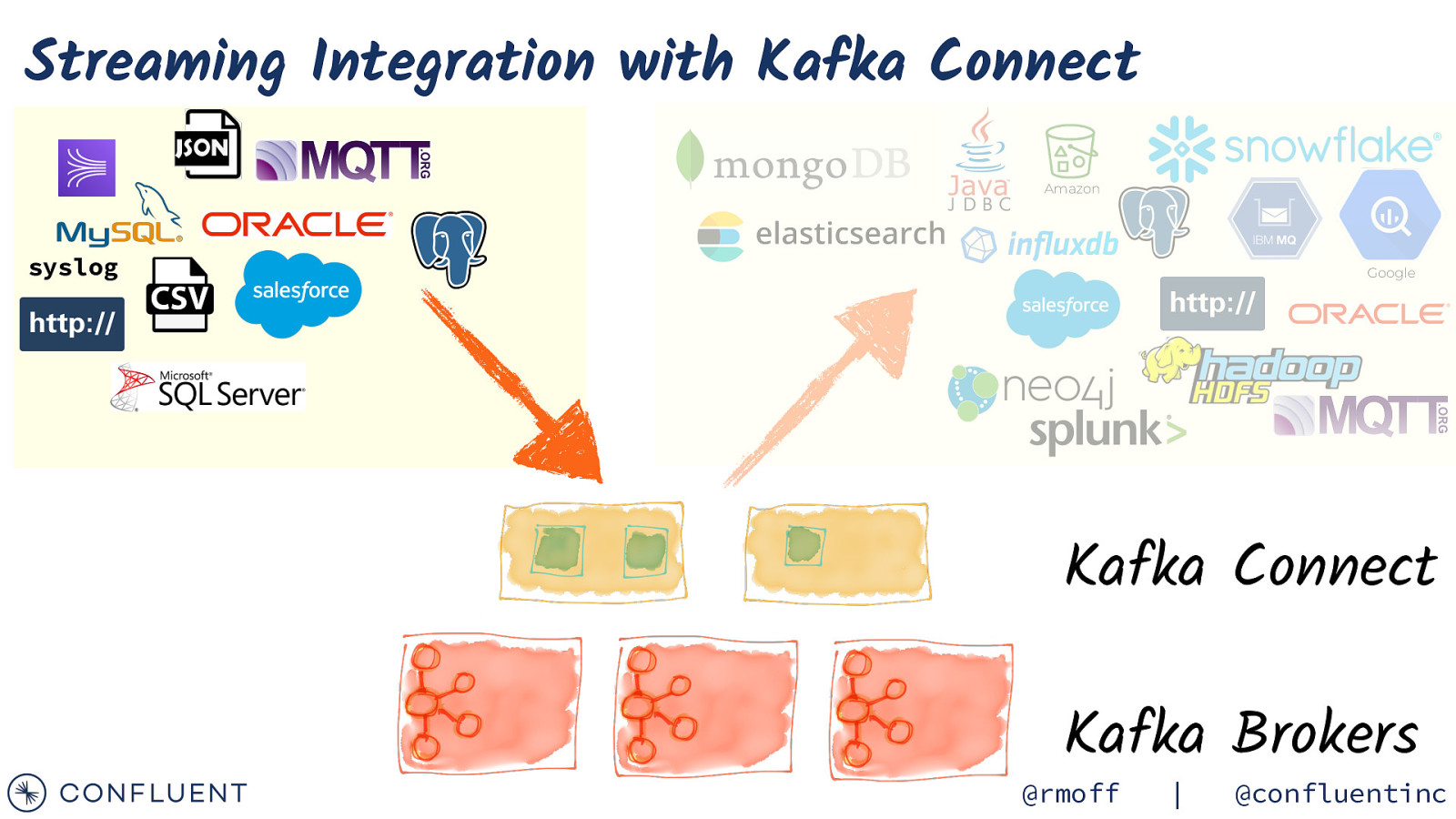
Streaming Integration with Kafka Connect Amazon syslog Google Kafka Connect Kafka Brokers @rmoff | @confluentinc

kafkacat • Kafka CLI producer & consumer • Also metadata inspection • Integrates beautifully with unix pipes! curl -s “https://my.api.endpoint” | \ kafkacat -b localhost:9092 -t topic -P • Get it! • https://github.com/edenhill/kafkacat/ • apt-get install kafkacat • brew install kafkacat • https://hub.docker.com/r/confluentinc/cp-kafkacat/ https://rmoff.net/2018/05/10/quick-n-easy-population-of-realistic-test-data-into-kafka/ @rmoff | @confluentinc

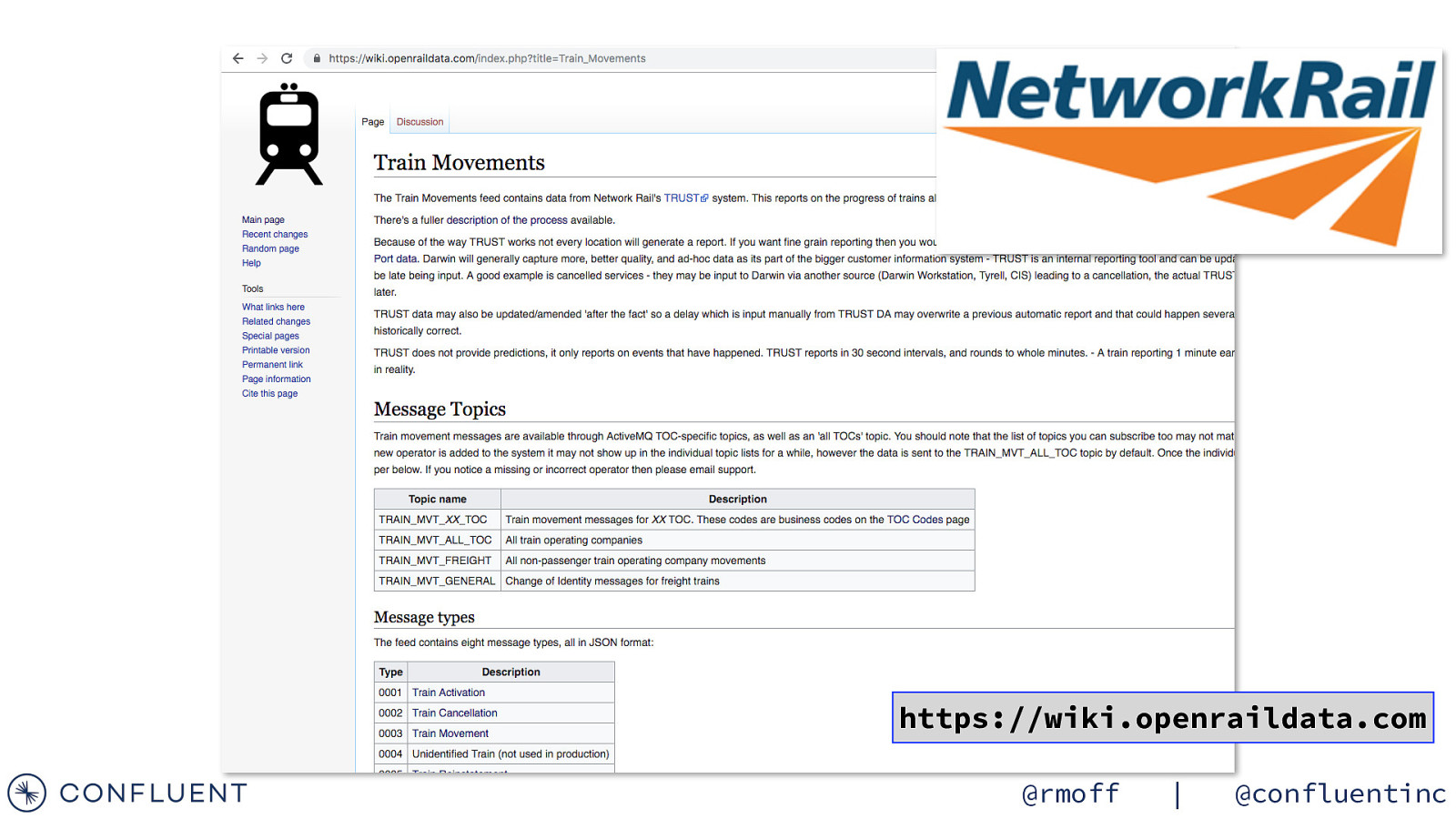
https://wiki.openraildata.com/index.php?title=Train_Movements Movement data A train’s movements Arrived / departed Where What time Variation from timetable A train was cancelled Where When Why A train was ‘activated’ Links a train to a schedule @rmoff | @confluentinc
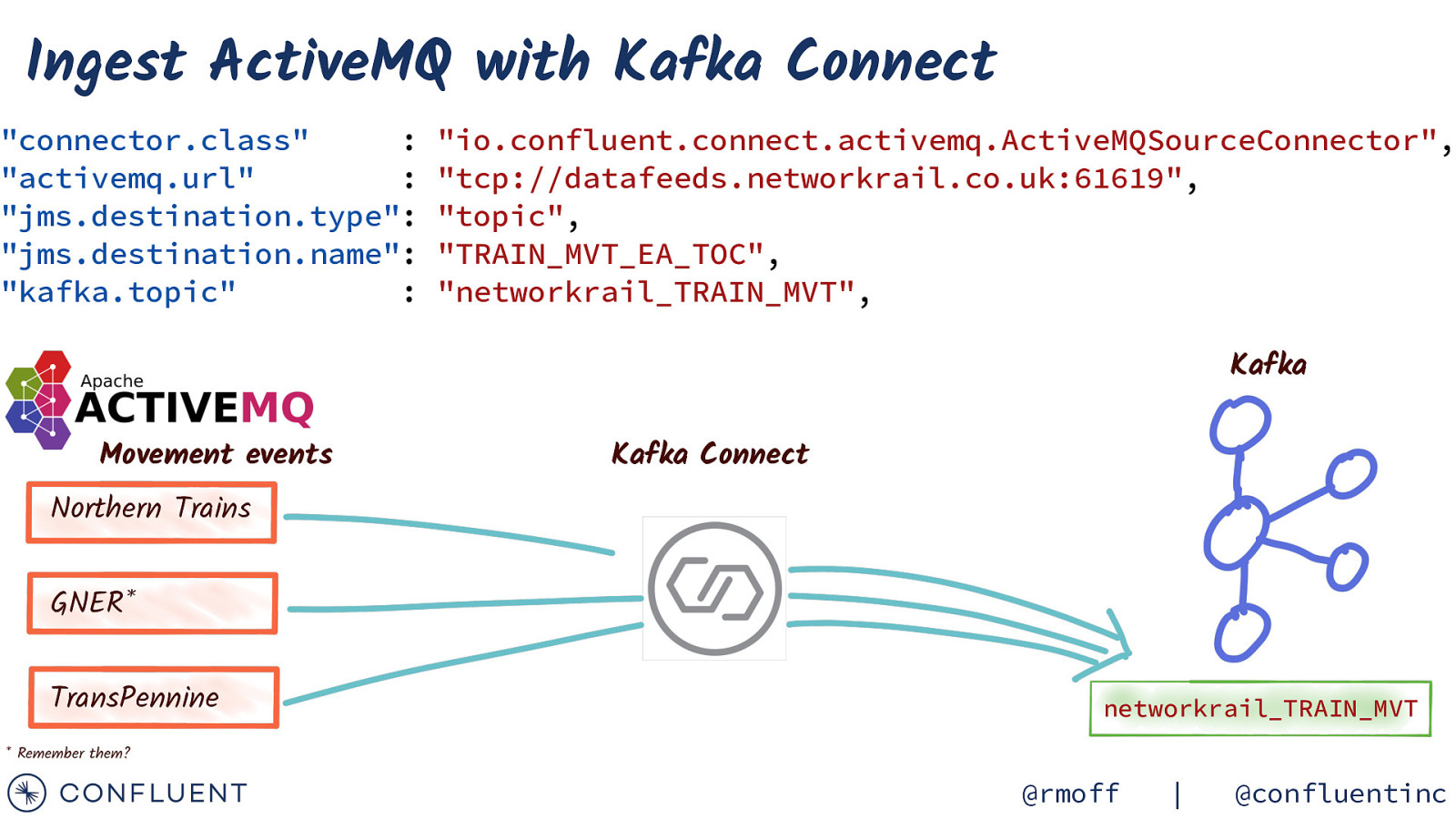
Ingest ActiveMQ with Kafka Connect “connector.class” : “activemq.url” : “jms.destination.type”: “jms.destination.name”: “kafka.topic” : “io.confluent.connect.activemq.ActiveMQSourceConnector”, “tcp://datafeeds.networkrail.co.uk:61619”, “topic”, “TRAIN_MVT_EA_TOC”, “networkrail_TRAIN_MVT”, Kafka Movement events Kafka Connect Northern Trains GNER* TransPennine networkrail_TRAIN_MVT

Envelope Payload @rmoff | @confluentinc

Message transformation Extract element Convert JSON Explode Array kafkacat -b localhost:9092 -G tm_explode networkrail_TRAIN_MVT -u | \ jq -c ‘.text|fromjson[]’ | \ kafkacat -b localhost:9092 -t networkrail_TRAIN_MVT_X -T -P @rmoff | @confluentinc

https://wiki.openraildata.com/index.php?title=SCHEDULE Schedule data Train routes Type of train (diesel/electric) Classes, sleeping accomodation, reservations, etc @rmoff | @confluentinc
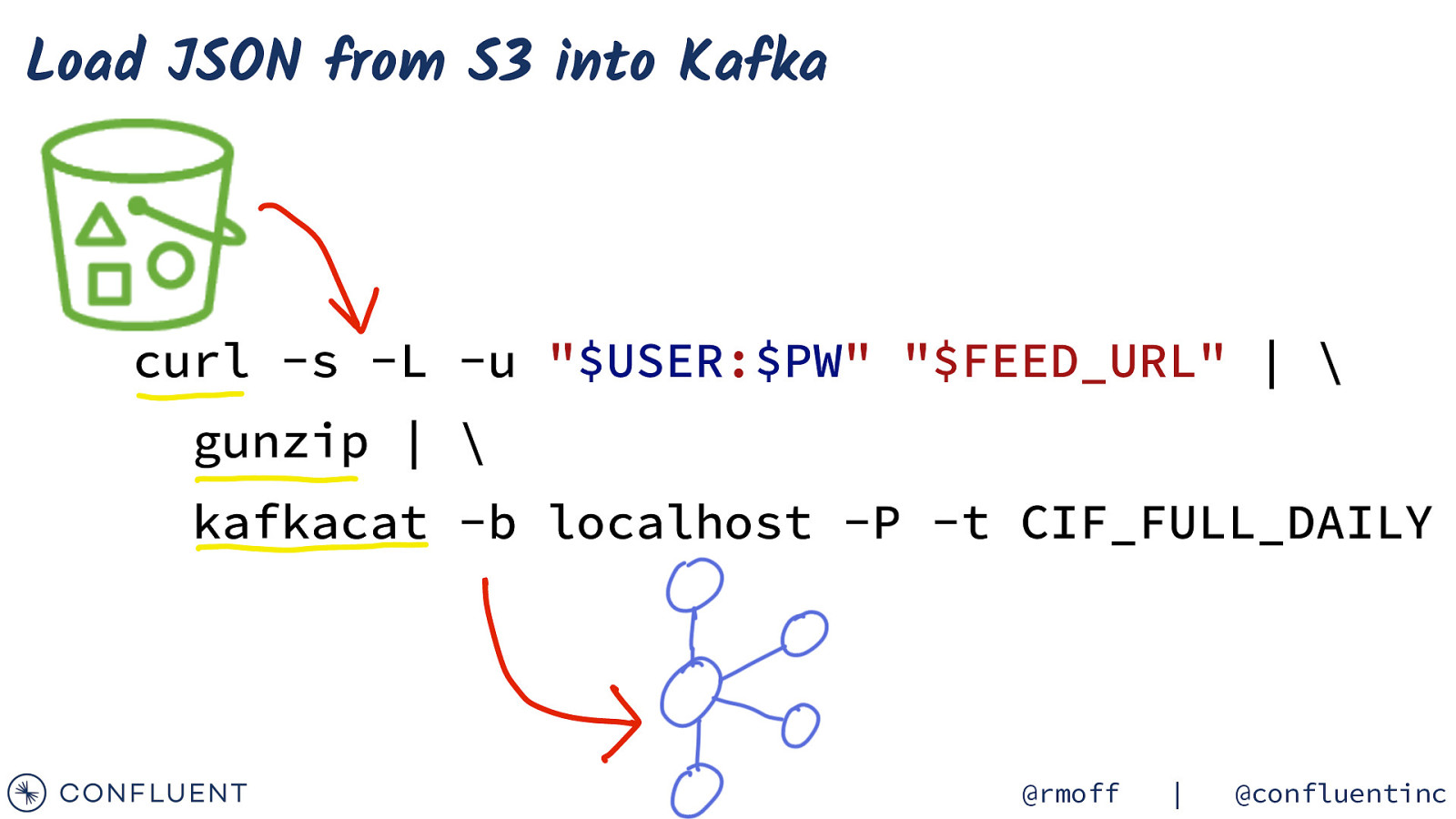
Load JSON from S3 into Kafka curl -s -L -u “$USER:$PW” “$FEED_URL” | \ gunzip | \ kafkacat -b localhost -P -t CIF_FULL_DAILY @rmoff | @confluentinc

https://wiki.openraildata.com/index.php?title=SCHEDULE Reference data Train company names Location codes Train type codes Location geocodes @rmoff | @confluentinc
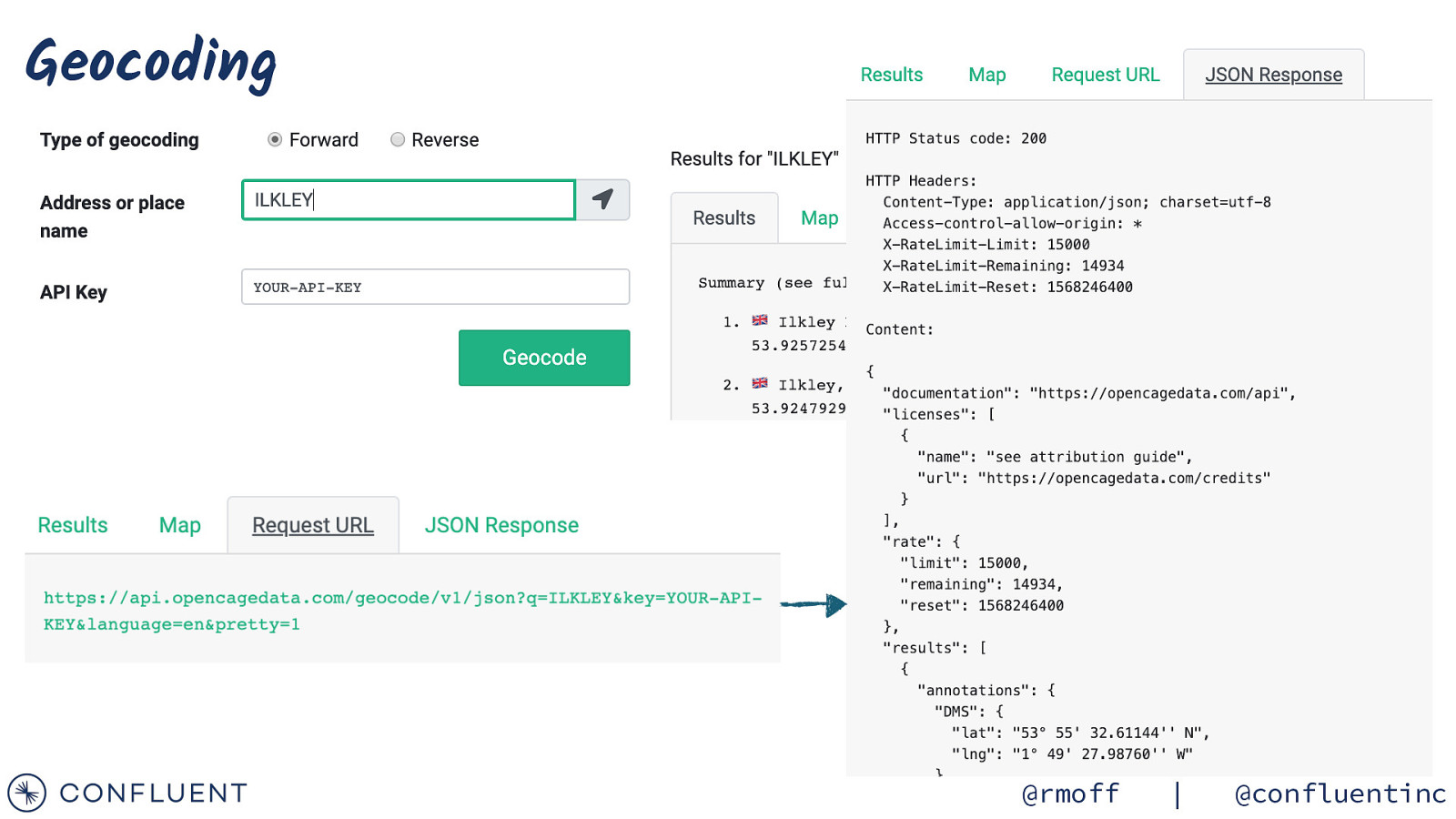
Geocoding @rmoff | @confluentinc
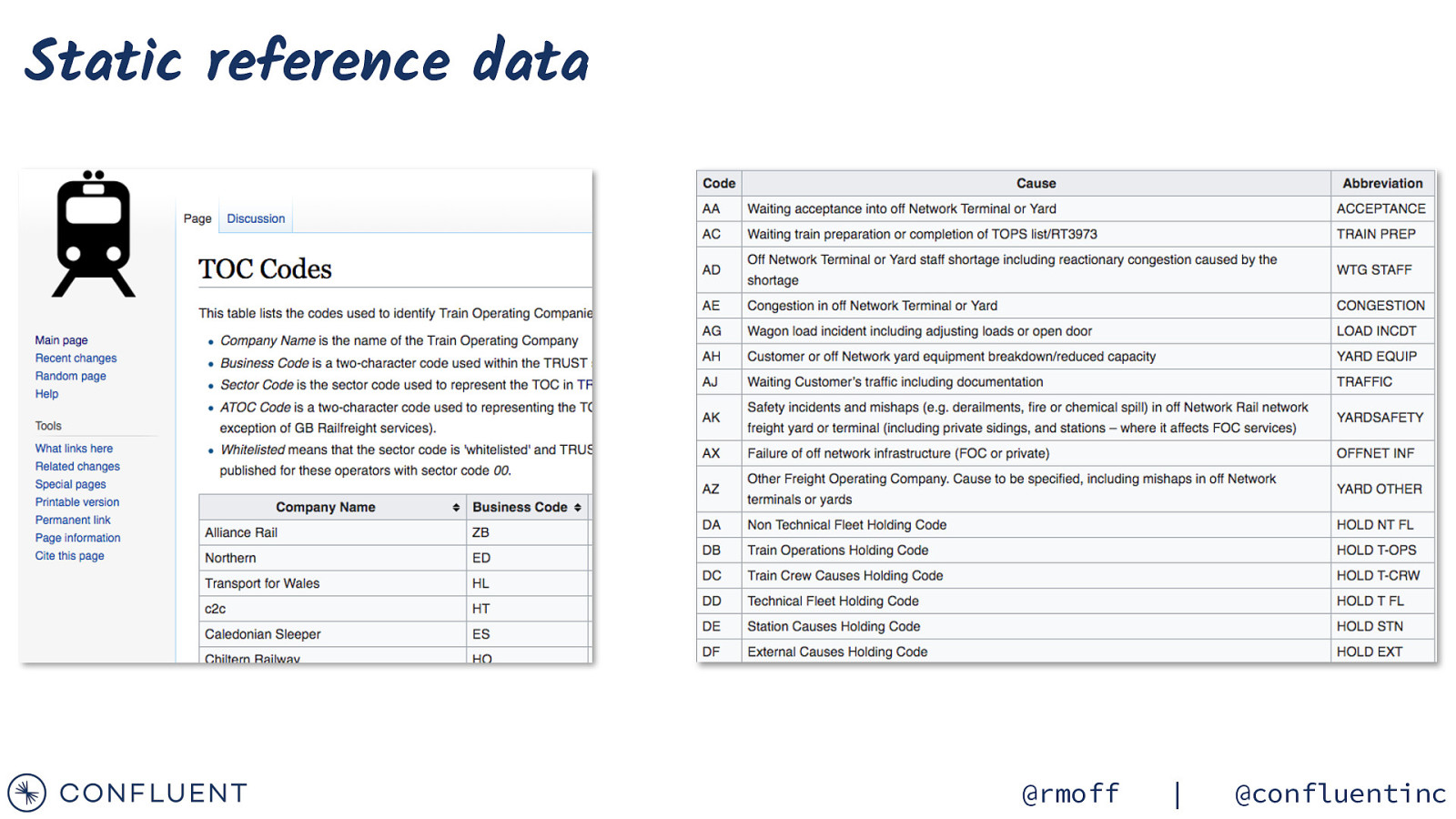
Static reference data @rmoff | @confluentinc

AA:{“canx_reason_code”:”AA”,”canx_reason”:”Waiting acceptance into off Network Terminal or Yard”} AC:{“canx_reason_code”:”AC”,”canx_reason”:”Waiting train preparation or completion of TOPS list/RT3973”} AE:{“canx_reason_code”:”AE”,”canx_reason”:”Congestion in off Network Terminal or Yard”} AG:{“canx_reason_code”:”AG”,”canx_reason”:”Wagon load incident including adjusting loads or open door”} AJ:{“canx_reason_code”:”AJ”,”canx_reason”:”Waiting Customer’s traffic including documentation”} DA:{“canx_reason_code”:”DA”,”canx_reason”:”Non Technical Fleet Holding Code”} DB:{“canx_reason_code”:”DB”,”canx_reason”:”Train Operations Holding Code”} DC:{“canx_reason_code”:”DC”,”canx_reason”:”Train Crew Causes Holding Code”} DD:{“canx_reason_code”:”DD”,”canx_reason”:”Technical Fleet Holding Code”} DE:{“canx_reason_code”:”DE”,”canx_reason”:”Station Causes Holding Code”} DF:{“canx_reason_code”:”DF”,”canx_reason”:”External Causes Holding Code”} DG:{“canx_reason_code”:”DG”,”canx_reason”:”Freight Terminal and or Yard Holding Code”} DH:{“canx_reason_code”:”DH”,”canx_reason”:”Adhesion and or Autumn Holding Code”} FA:{“canx_reason_code”:”FA”,”canx_reason”:”Dangerous goods incident”} FC:{“canx_reason_code”:”FC”,”canx_reason”:”Freight train driver”} kafkacat -l canx_reason_code.dat -b localhost:9092 -t canx_reason_code -P -K: @rmoff | @confluentinc
@rmoff | @confluentinc

Transforming the data @rmoff | @confluentinc

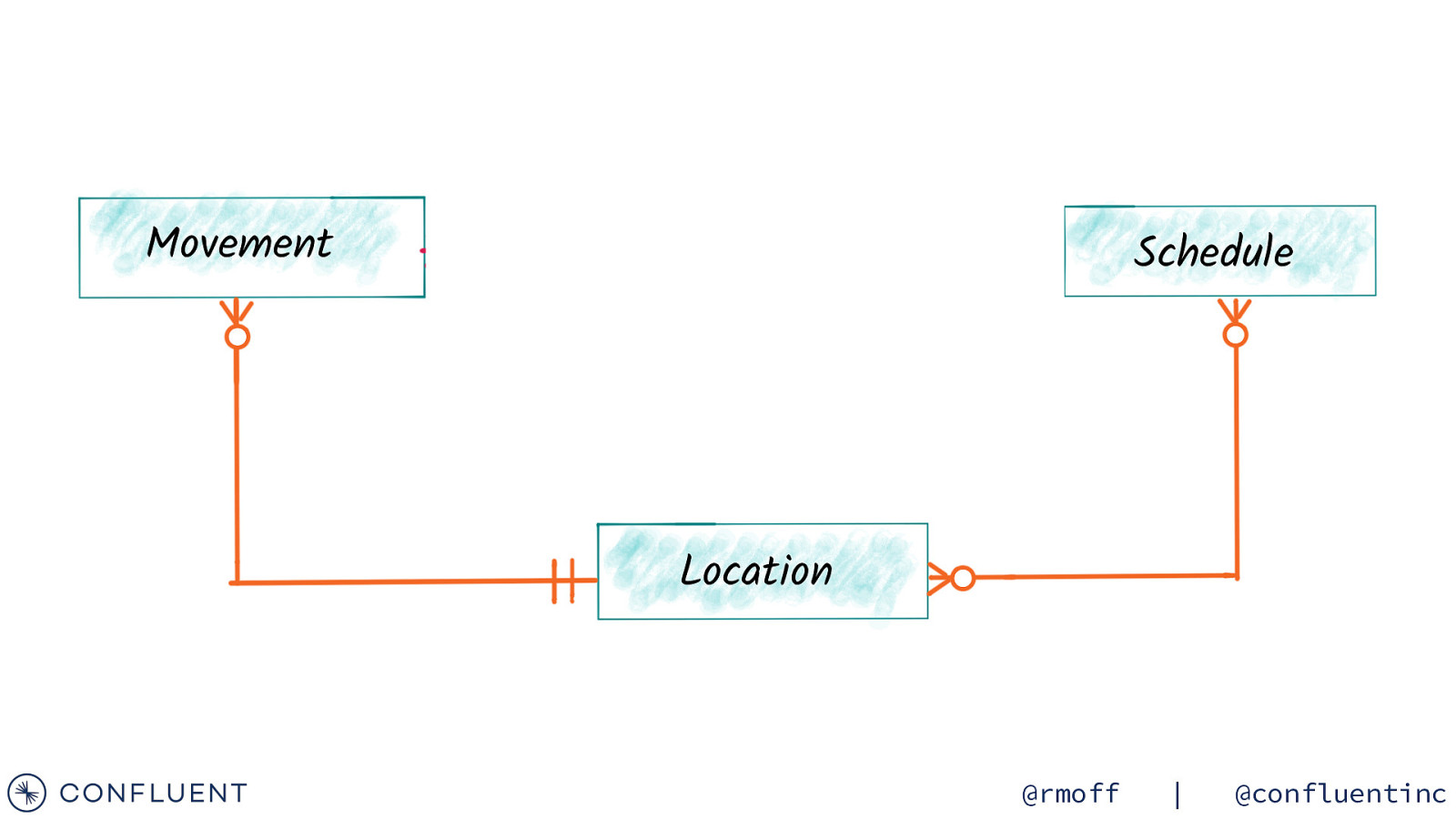
Movement Activation Schedule Location @rmoff | @confluentinc
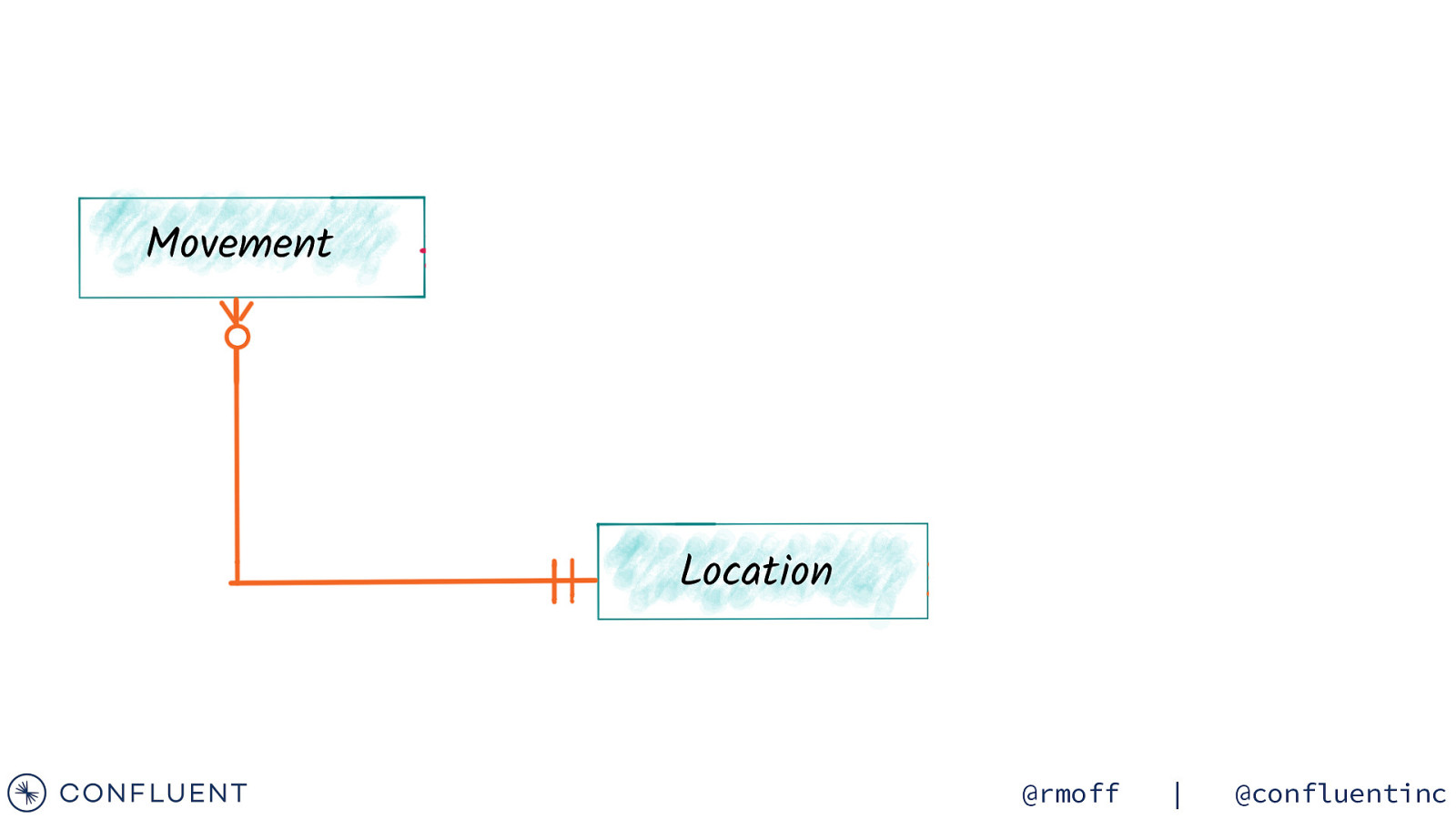
Movement Activation Schedule Location @rmoff | @confluentinc
Movement Activation Schedule Location @rmoff | @confluentinc
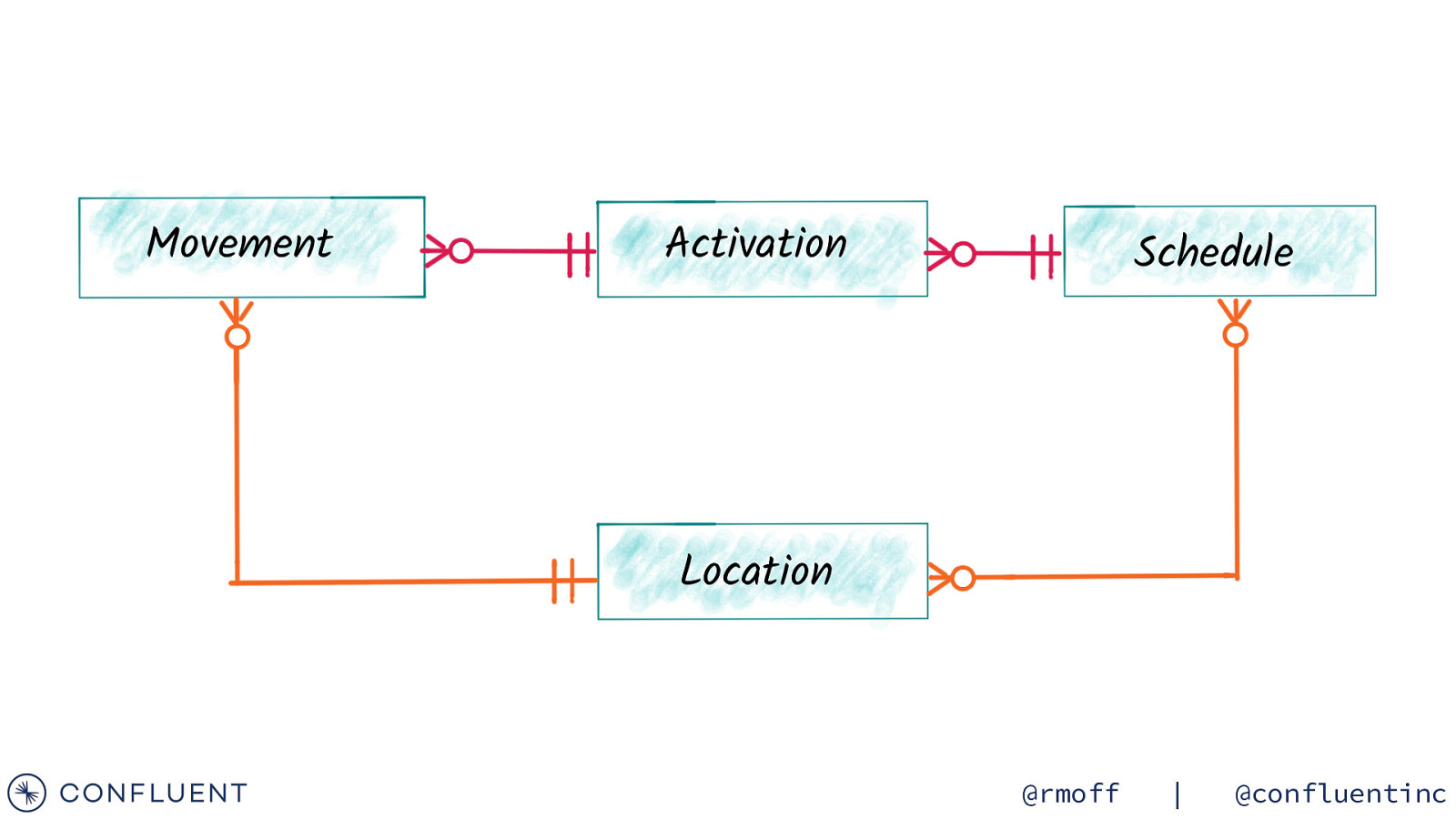
Movement Activation Schedule Location @rmoff | @confluentinc
Streams of events Time @rmoff | @confluentinc
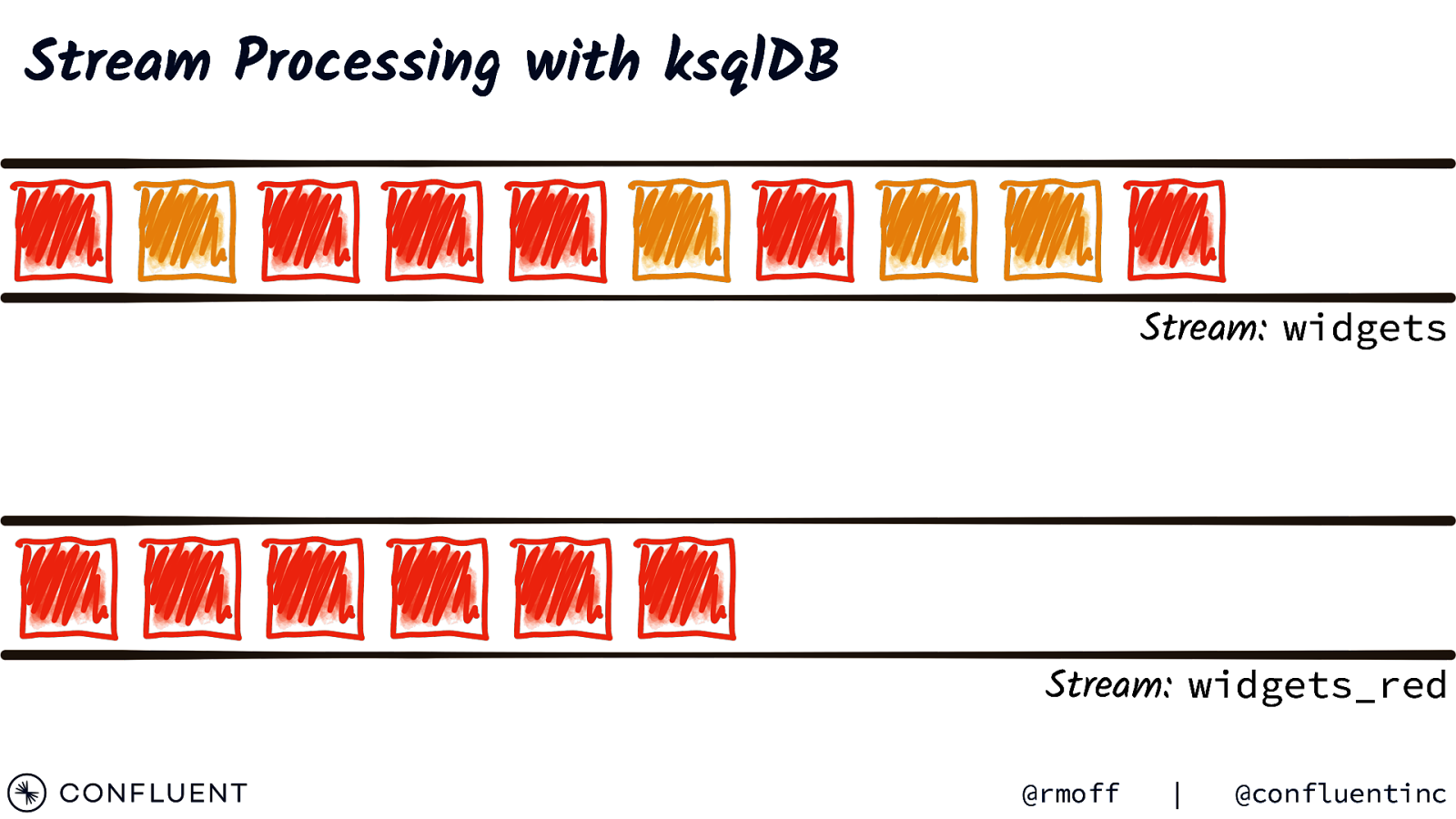
Stream Processing with ksqlDB Stream: widgets Stream: widgets_red @rmoff | @confluentinc
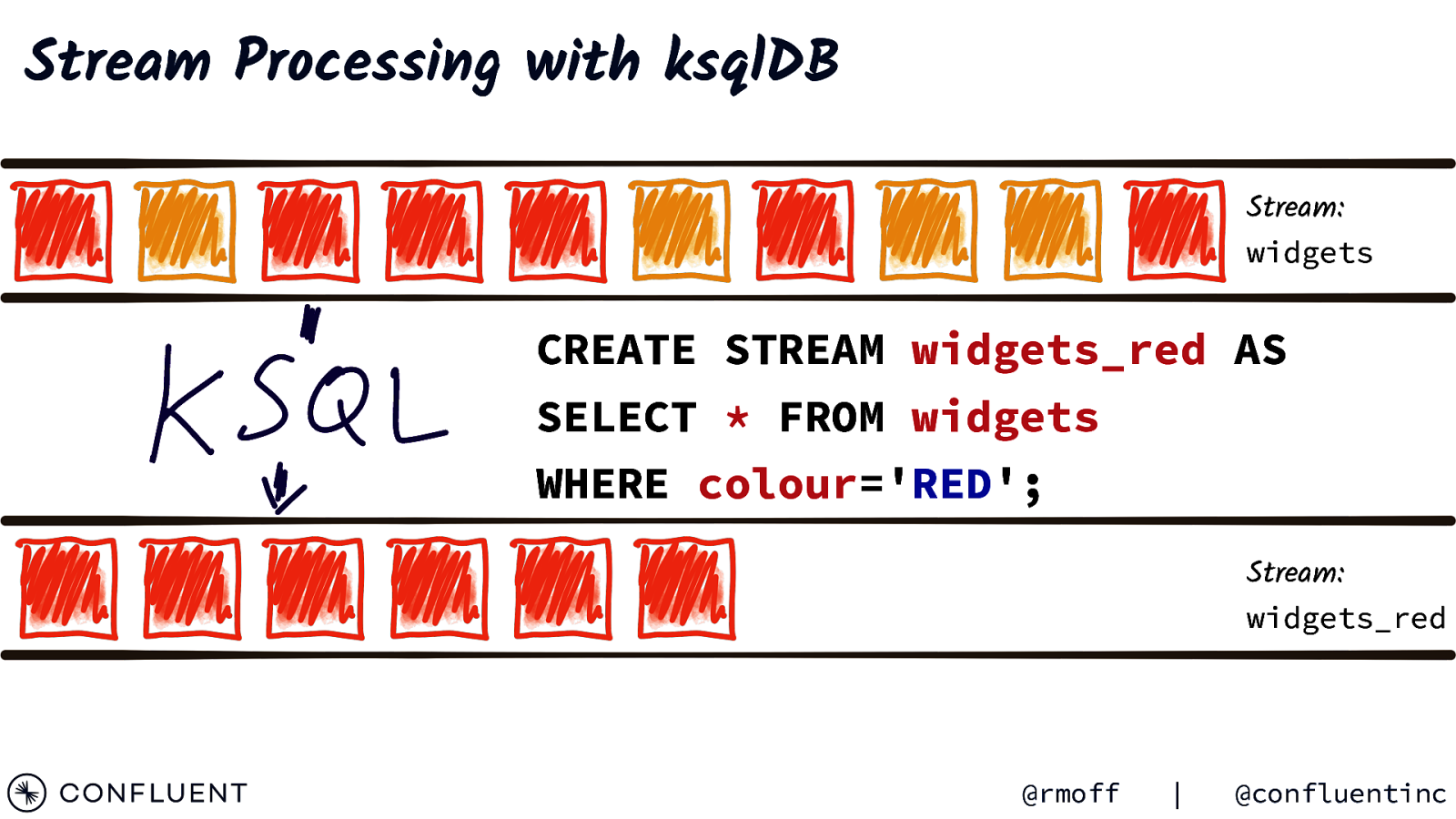
Stream Processing with ksqlDB Stream: widgets CREATE STREAM widgets_red AS SELECT * FROM widgets WHERE colour=’RED’; Stream: widgets_red @rmoff | @confluentinc
ksqlDB @rmoff | @confluentinc

Event data ActiveMQ Kafka Connect NETWORKRAIL_TRAIN_MVT_X @rmoff | @confluentinc
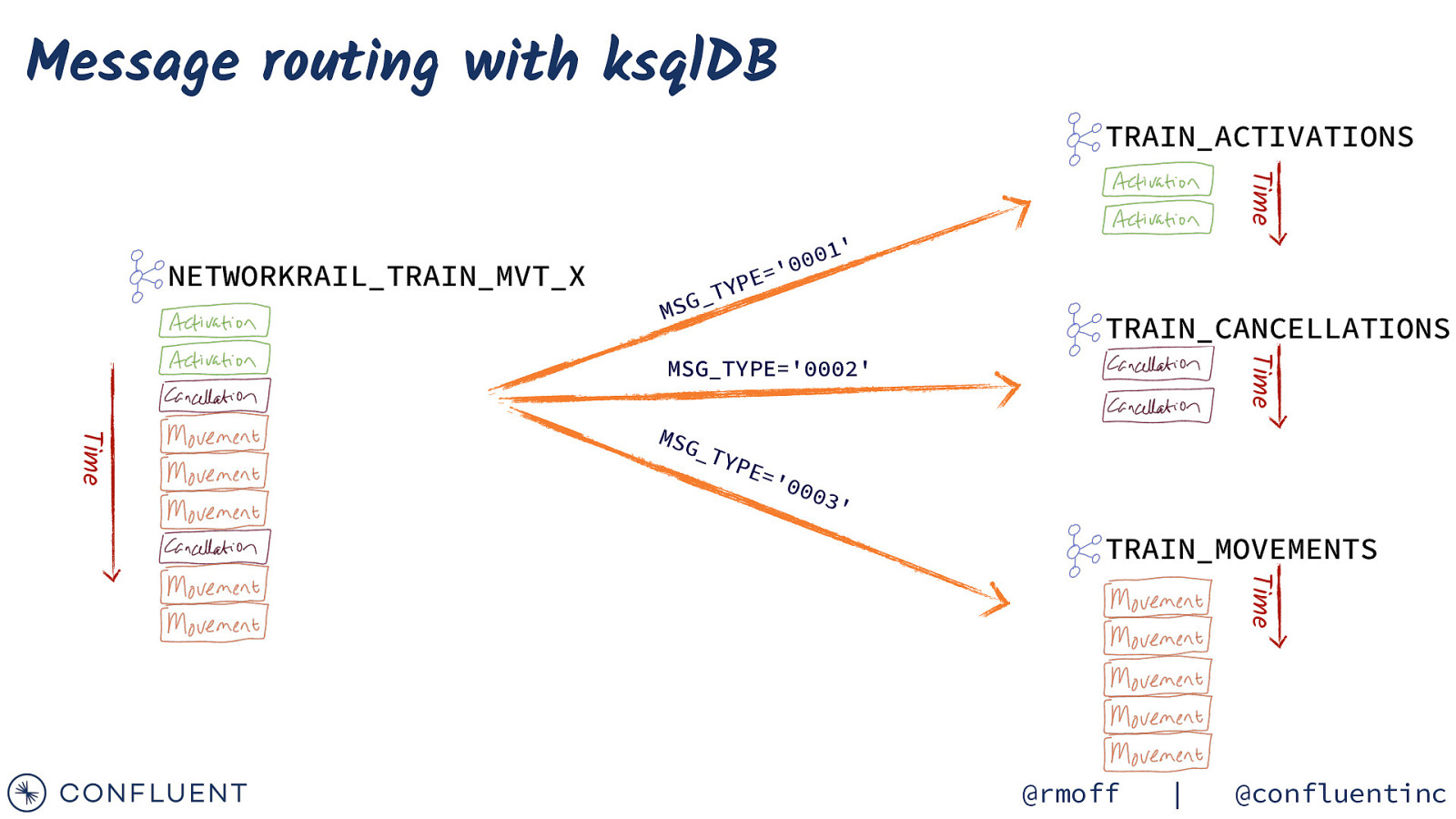
Message routing with ksqlDB TRAIN_ACTIVATIONS Time NETWORKRAIL_TRAIN_MVT_X ’ 1 0 00 ’ = E YP T _ G MS TRAIN_CANCELLATIONS Time MSG_TYPE=’0002’ Time MSG _TY PE= ‘00 03’ TRAIN_MOVEMENTS Time @rmoff | @confluentinc

Split a stream of data (message routing) CREATE STREAM TRAIN_MOVEMENTS_00 AS SELECT * FROM NETWORKRAIL_TRAIN_MVT_X s t n e v e t n e m e ’ v 3 o 0 0 0 M ’ PE= Y T _ SG M WHERE header->msg_type = ‘0003’; NETWORKRAIL_TRAIN_MVT_X Source topic CREATE STREAM TRAIN_CANCELLATIONS_00 AS SELECT * Can cella t MSG _TY FROM NETWORKRAIL_TRAIN_MVT_X ion e v e PE= n t s ‘00 0 2’ WHERE header->msg_type = ‘0002’; @rmoff | @confluentinc
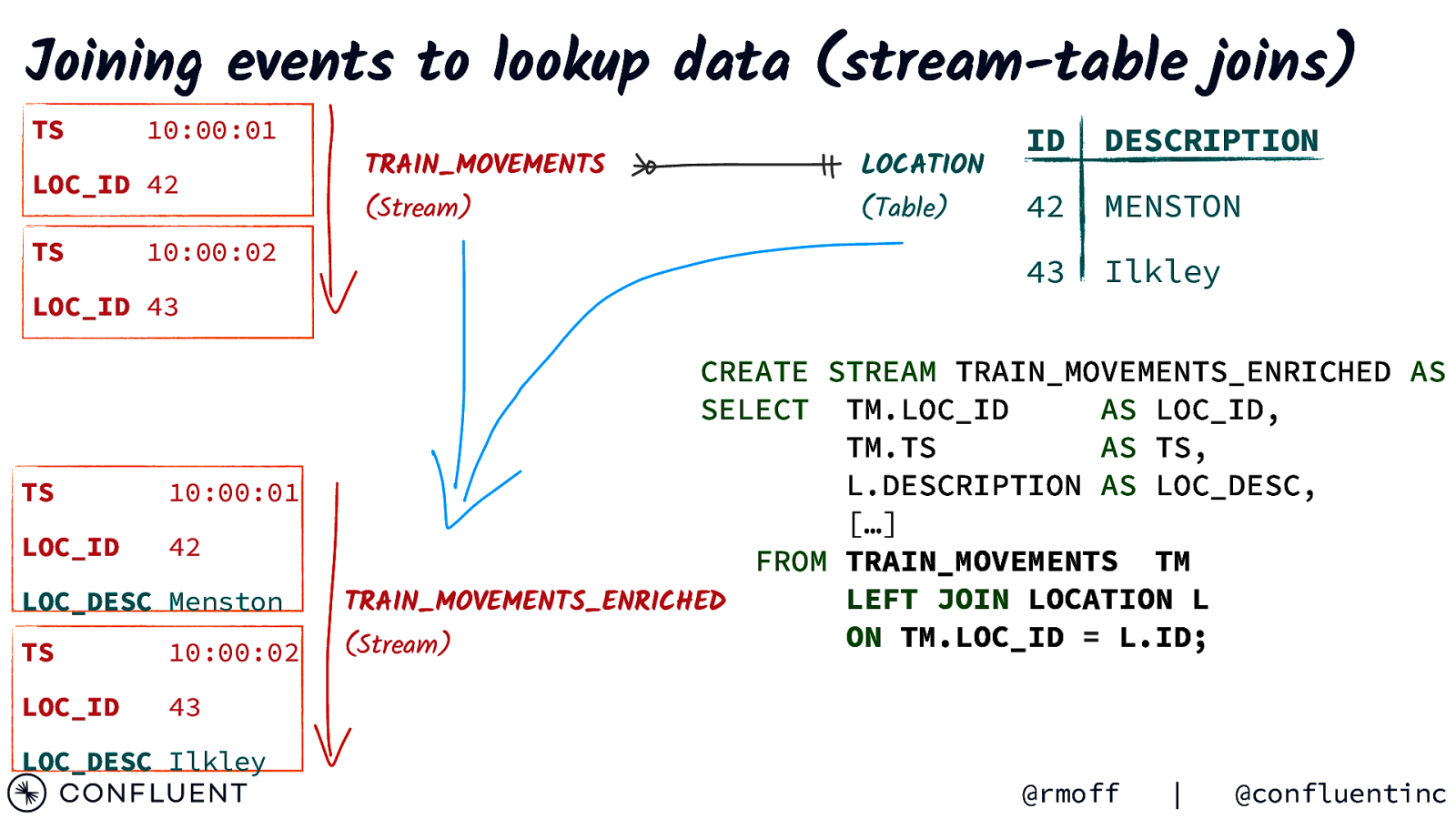
Joining events to lookup data (stream-table joins) TS 10:00:01 LOC_ID 42 TS 10:00:02 LOC_ID 43 TS 10:00:01 LOC_ID 42 LOC_DESC Menston TS 10:00:02 LOC_ID 43 LOC_DESC Ilkley TRAIN_MOVEMENTS (Stream) LOCATION (Table) ID DESCRIPTION 42 MENSTON 43 Ilkley CREATE STREAM TRAIN_MOVEMENTS_ENRICHED AS SELECT TM.LOC_ID AS LOC_ID, TM.TS AS TS, L.DESCRIPTION AS LOC_DESC, […] FROM TRAIN_MOVEMENTS TM LEFT JOIN LOCATION L TRAIN_MOVEMENTS_ENRICHED ON TM.LOC_ID = L.ID; (Stream) @rmoff | @confluentinc

Decode values, and generate composite key +———————-+————————+————-+——————————-+————————+————————————+ | CIF_train_uid | sched_start_dt | stp_ind | SCHEDULE_KEY | CIF_power_type | POWER_TYPE | +———————-+————————+————-+——————————-+————————+————————————+ | Y82535 | 2019-05-20 | P | Y82535/2019-05-20/P | E | Electric | | Y82537 | 2019-05-20 | P | Y82537/2019-05-20/P | DMU | Other | | Y82542 | 2019-05-20 | P | Y82542/2019-05-20/P | D | Diesel | | Y82535 | 2019-05-24 | P | Y82535/2019-05-24/P | EMU | Electric Multiple Unit | | Y82542 | 2019-05-24 | P | Y82542/2019-05-24/P | HST | High Speed Train | SELECT JsonScheduleV1->CIF_train_uid + ‘/’ + JsonScheduleV1->schedule_start_date + ‘/’ + JsonScheduleV1->CIF_stp_indicator AS SCHEDULE_KEY, CASE WHEN JsonScheduleV1->schedule_segment->CIF_power_type = ‘D’ THEN ‘Diesel’ WHEN JsonScheduleV1->schedule_segment->CIF_power_type = ‘E’ THEN ‘Electric’ WHEN JsonScheduleV1->schedule_segment->CIF_power_type = ‘ED’ THEN ‘Electro-Diesel’ END AS POWER_TYPE @rmoff | @confluentinc

Schemas CREATE STREAM SCHEDULE_RAW ( TiplocV1 STRUCT<transaction_type tiploc_code NALCO STANOX crs_code description tps_description WITH (KAFKA_TOPIC=’CIF_FULL_DAILY’, VALUE_FORMAT=’JSON’); @rmoff | VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR>) @confluentinc

Handling JSON data CREATE STREAM NETWORKRAIL_TRAIN_MVT_X ( header STRUCT< msg_type VARCHAR, […] >, body VARCHAR) WITH (KAFKA_TOPIC=’networkrail_TRAIN_MVT_X’, VALUE_FORMAT=’JSON’); CREATE STREAM TRAIN_CANCELLATIONS_00 AS SELECT HEADER, EXTRACTJSONFIELD(body,’$.canx_timestamp’) AS canx_timestamp, EXTRACTJSONFIELD(body,’$.canx_reason_code’) AS canx_reason_code, […] FROM networkrail_TRAIN_MVT_X WHERE header->msg_type = ‘0002’; @rmoff | @confluentinc
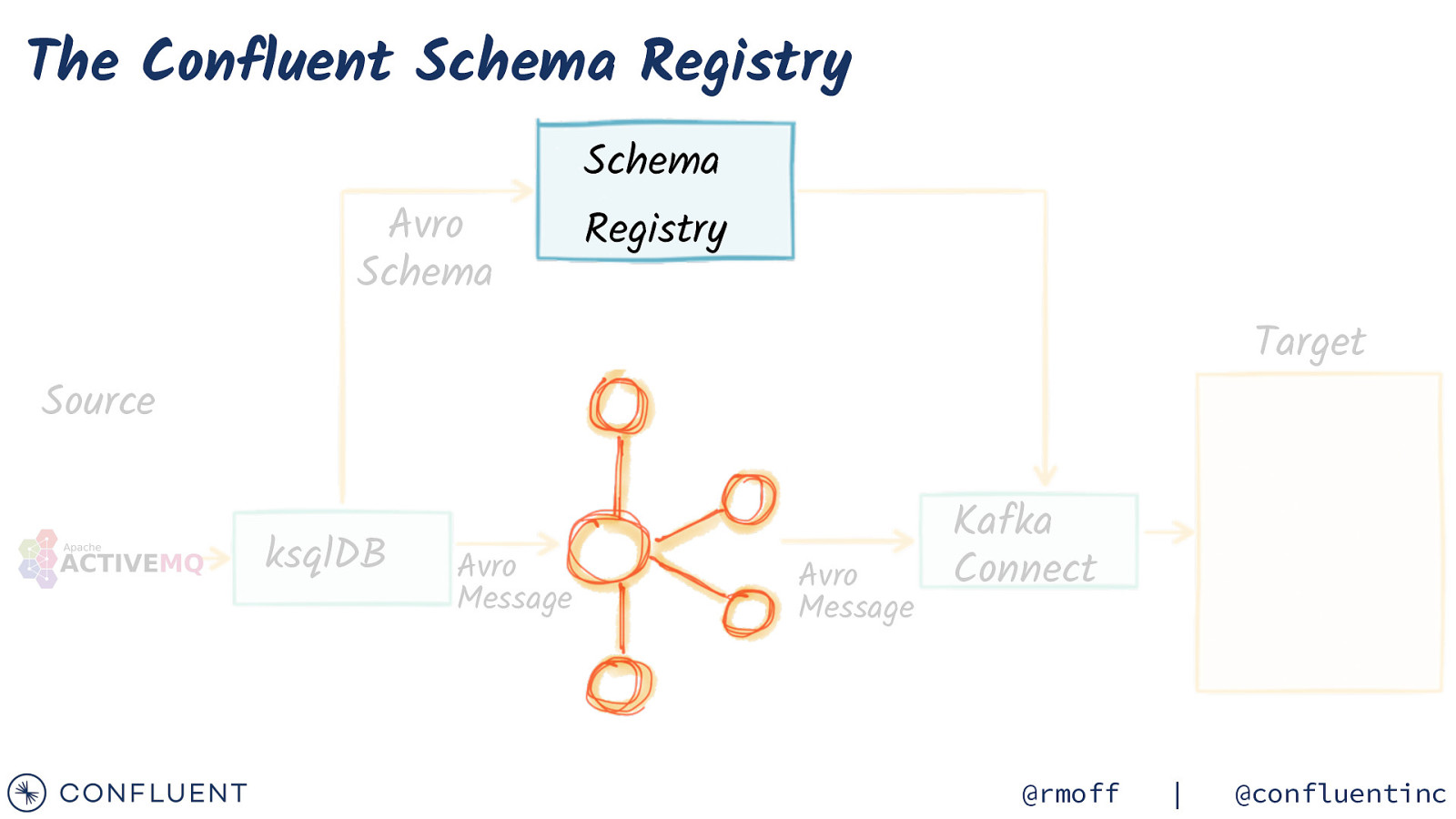
The Confluent Schema Registry Avro Schema Schema Registry Target Source ksqlDB Avro Message Avro Message Kafka Connect @rmoff | @confluentinc

Reserialise data CREATE STREAM TRAIN_CANCELLATIONS_00 WITH (VALUE_FORMAT=’AVRO’) AS SELECT * FROM networkrail_TRAIN_MVT_X WHERE header->msg_type = ‘0002’; @rmoff | @confluentinc
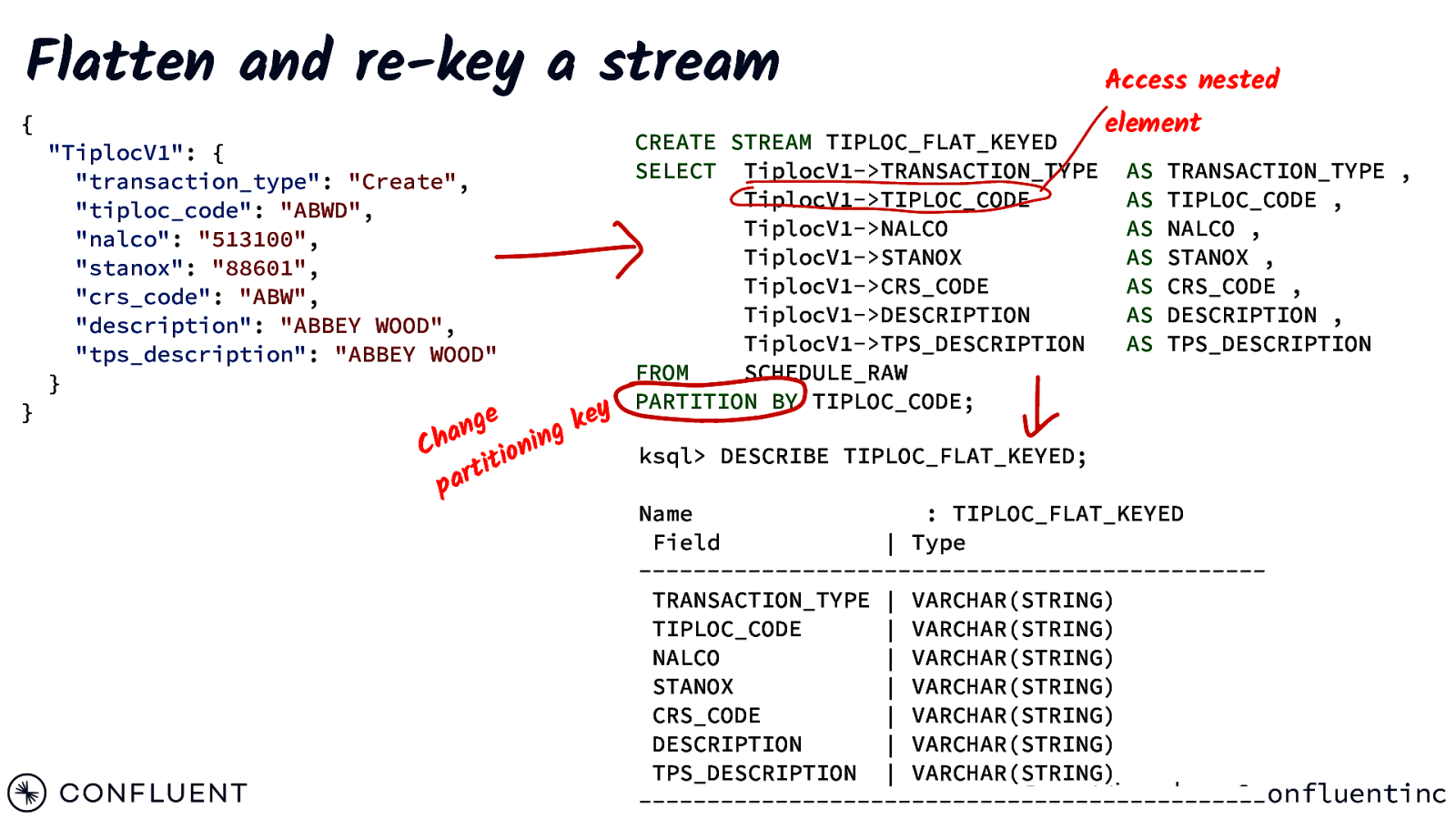
Flatten and re-key a stream { CREATE STREAM TIPLOC_FLAT_KEYED SELECT TiplocV1->TRANSACTION_TYPE TiplocV1->TIPLOC_CODE TiplocV1->NALCO TiplocV1->STANOX TiplocV1->CRS_CODE TiplocV1->DESCRIPTION TiplocV1->TPS_DESCRIPTION FROM SCHEDULE_RAW PARTITION BY TIPLOC_CODE; y e e g k n g a n h i C n ksql> DESCRIBE TIPLOC_FLAT_KEYED; io t i art “TiplocV1”: { “transaction_type”: “Create”, “tiploc_code”: “ABWD”, “nalco”: “513100”, “stanox”: “88601”, “crs_code”: “ABW”, “description”: “ABBEY WOOD”, “tps_description”: “ABBEY WOOD” } } p Access nested element AS AS AS AS AS AS AS TRANSACTION_TYPE , TIPLOC_CODE , NALCO , STANOX , CRS_CODE , DESCRIPTION , TPS_DESCRIPTION Name : TIPLOC_FLAT_KEYED Field | Type ——————————————————————-TRANSACTION_TYPE | VARCHAR(STRING) TIPLOC_CODE | VARCHAR(STRING) NALCO | VARCHAR(STRING) STANOX | VARCHAR(STRING) CRS_CODE | VARCHAR(STRING) DESCRIPTION | VARCHAR(STRING) TPS_DESCRIPTION | VARCHAR(STRING) @rmoff | @confluentinc ———————————————————————
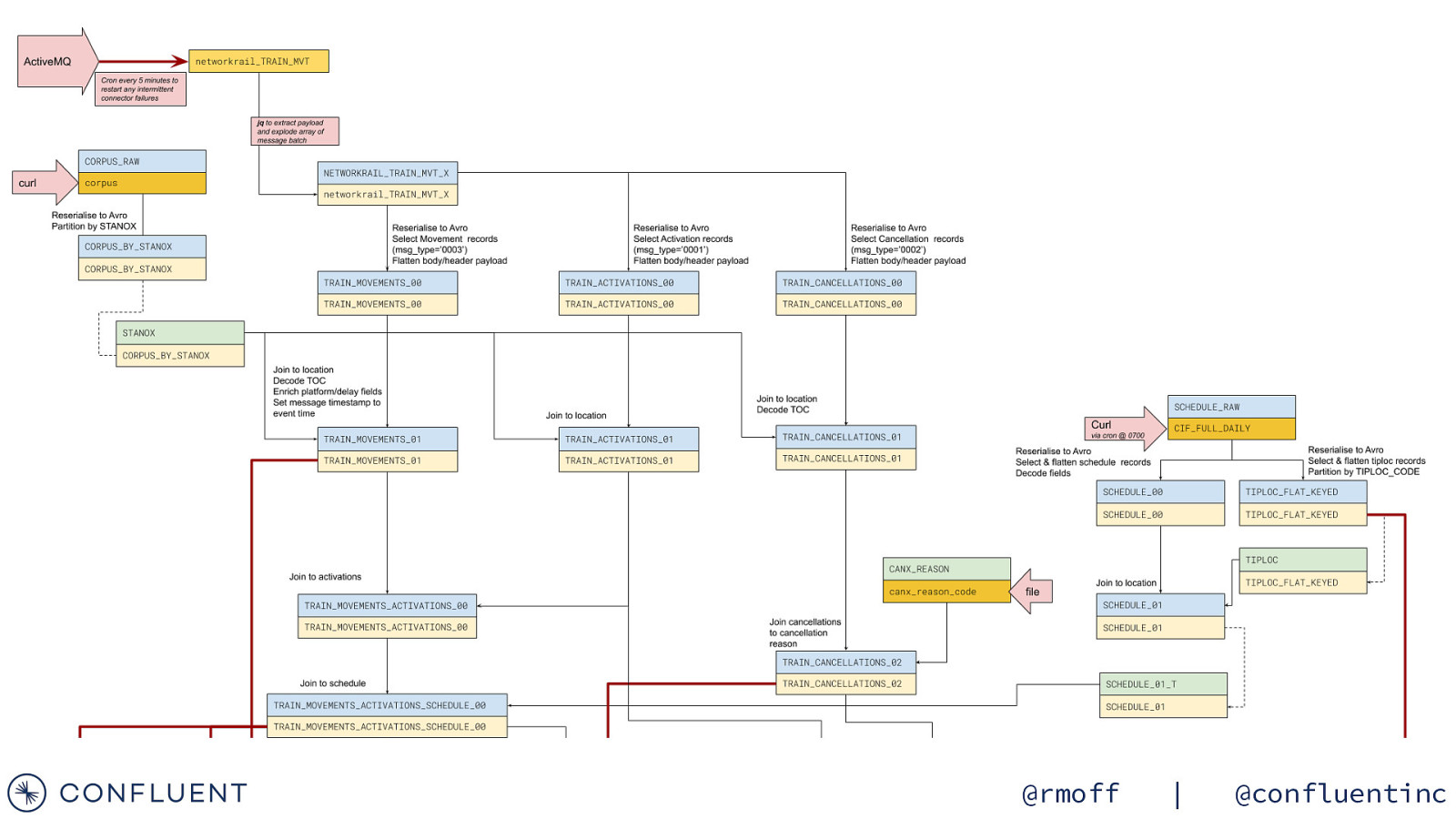
@rmoff | @confluentinc

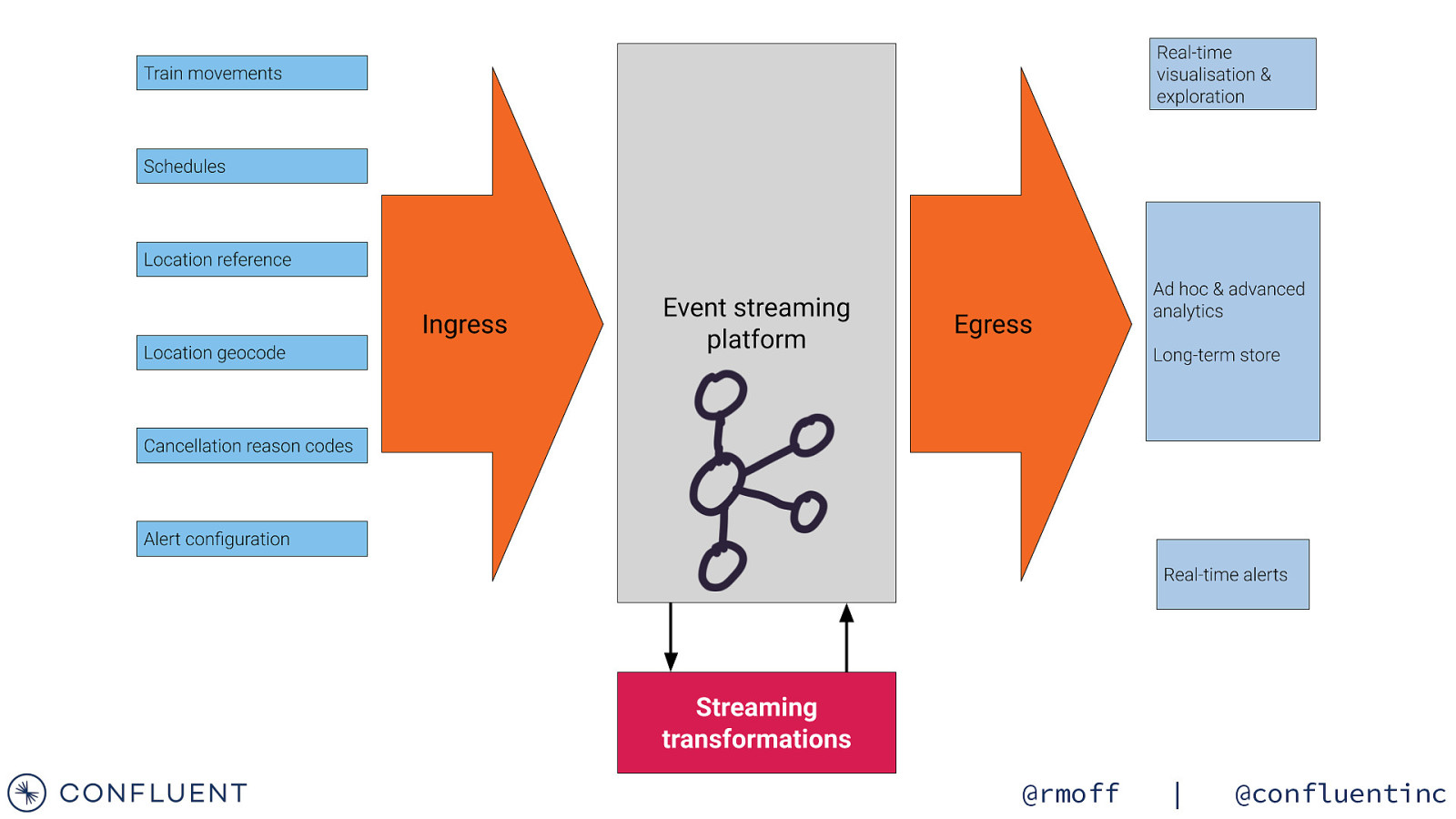
Using the data @rmoff | @confluentinc
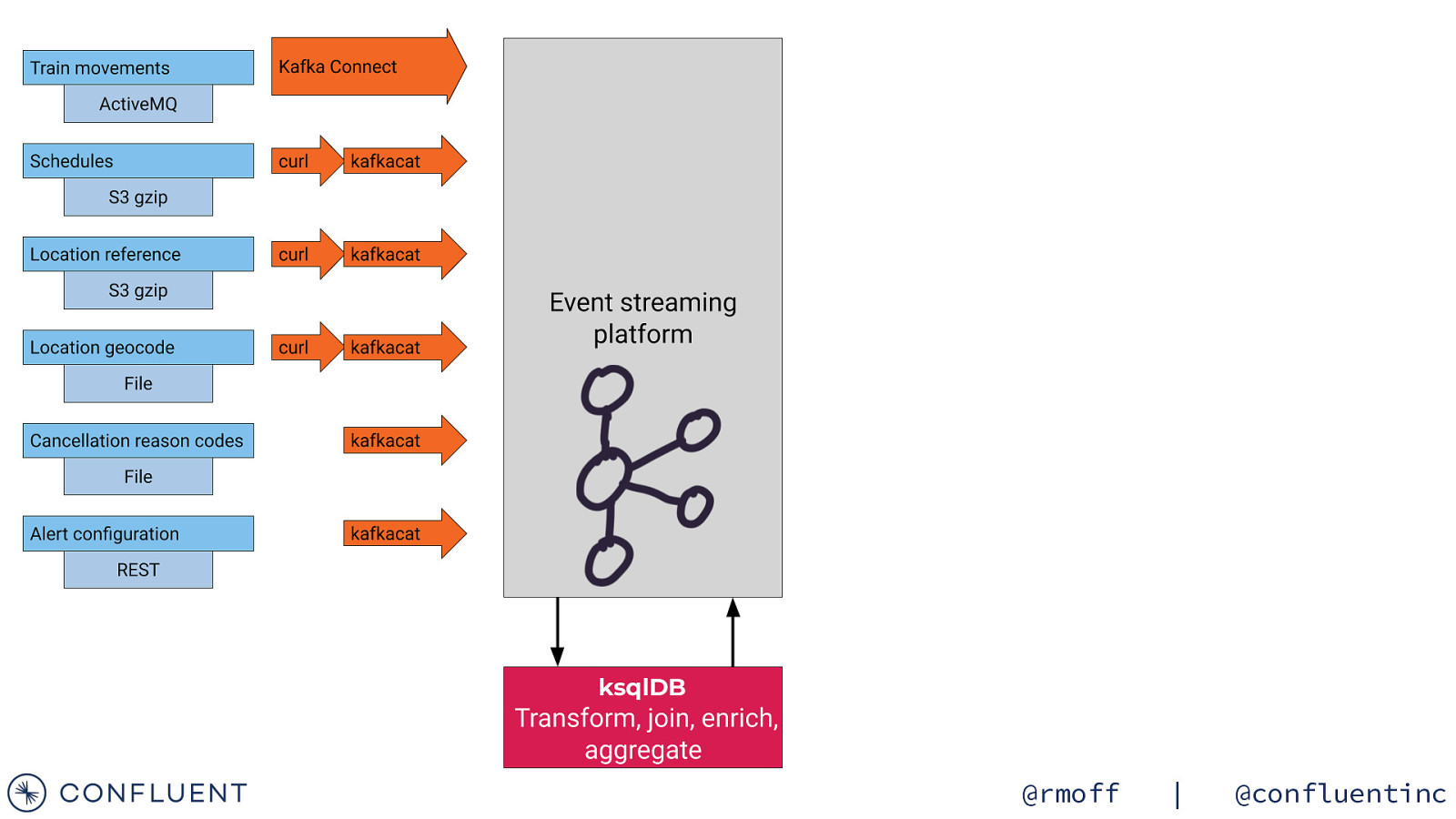
ksqlDB @rmoff | @confluentinc
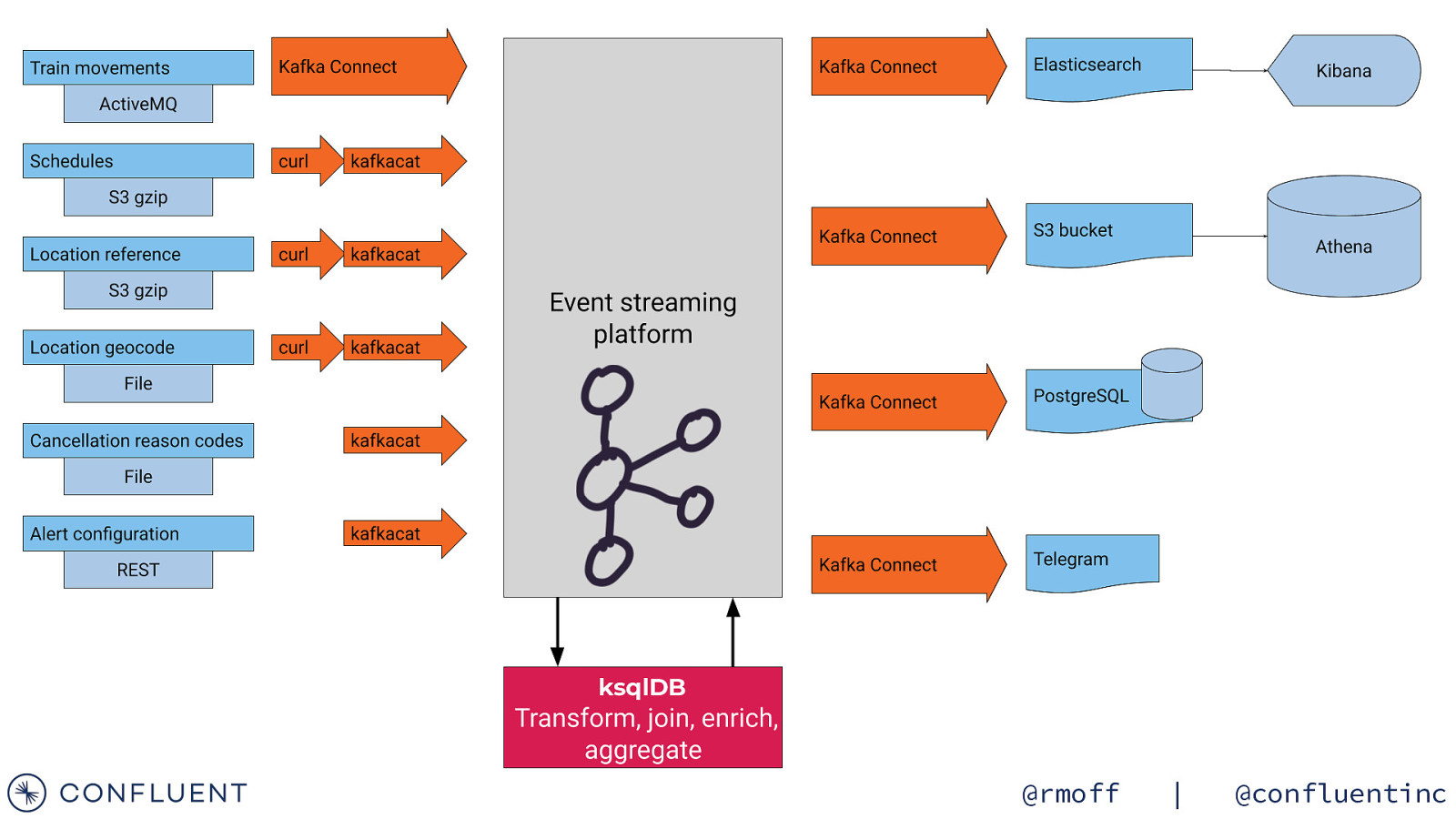
ksqlDB @rmoff | @confluentinc
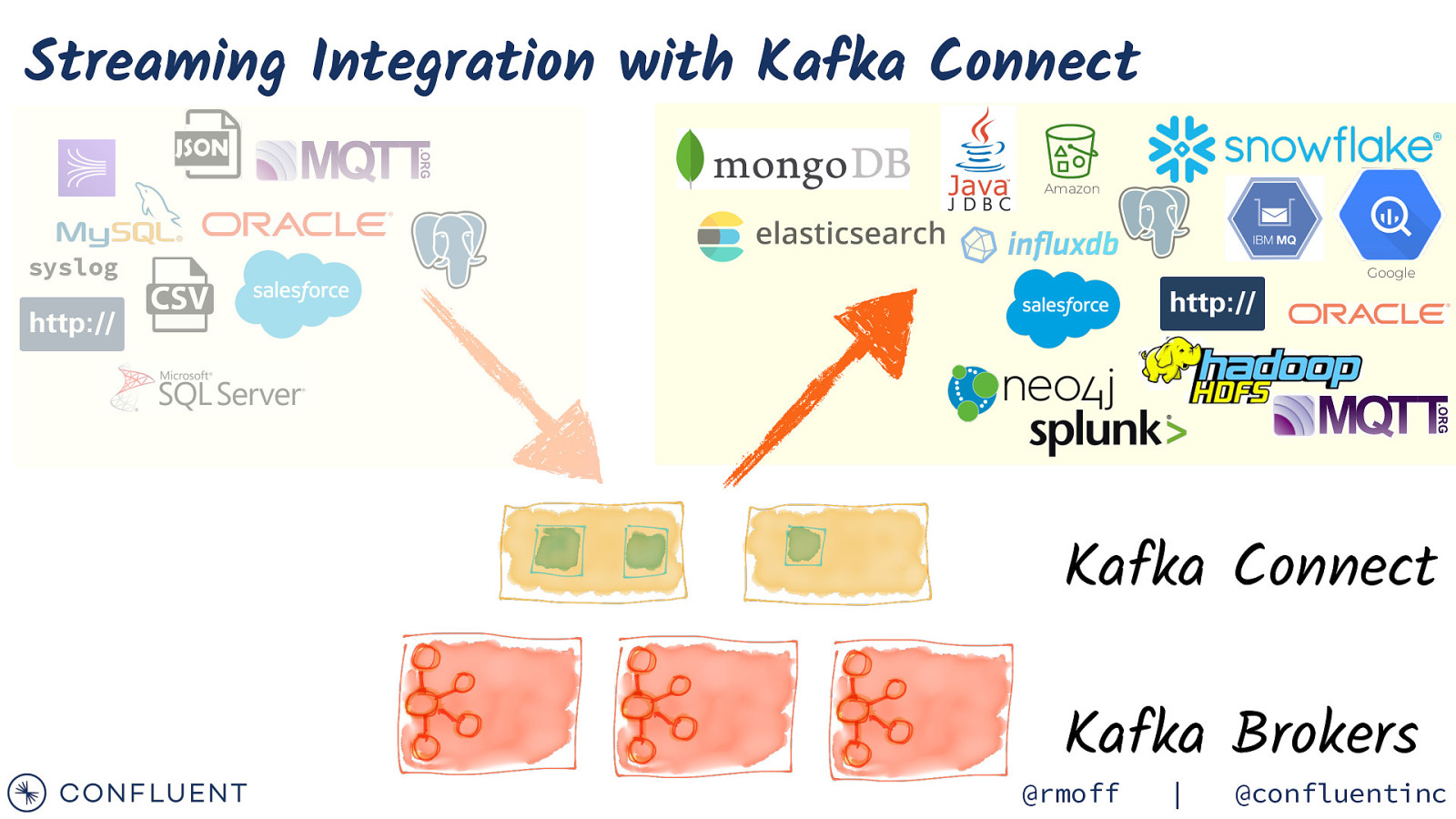
Streaming Integration with Kafka Connect Amazon syslog Google Kafka Connect Kafka Brokers @rmoff | @confluentinc

Kafka -> Elasticsearch { “connector.class”: “io.confluent.connect.elasticsearch.ElasticsearchSinkConnector”, “topics”: “TRAIN_MOVEMENTS_ACTIVATIONS_SCHEDULE_00”, “connection.url”: “http://elasticsearch:9200”, “type.name”: “type.name=kafkaconnect”, “key.ignore”: “false”, “schema.ignore”: “true”, “key.converter”: “org.apache.kafka.connect.storage.StringConverter” } @rmoff | @confluentinc
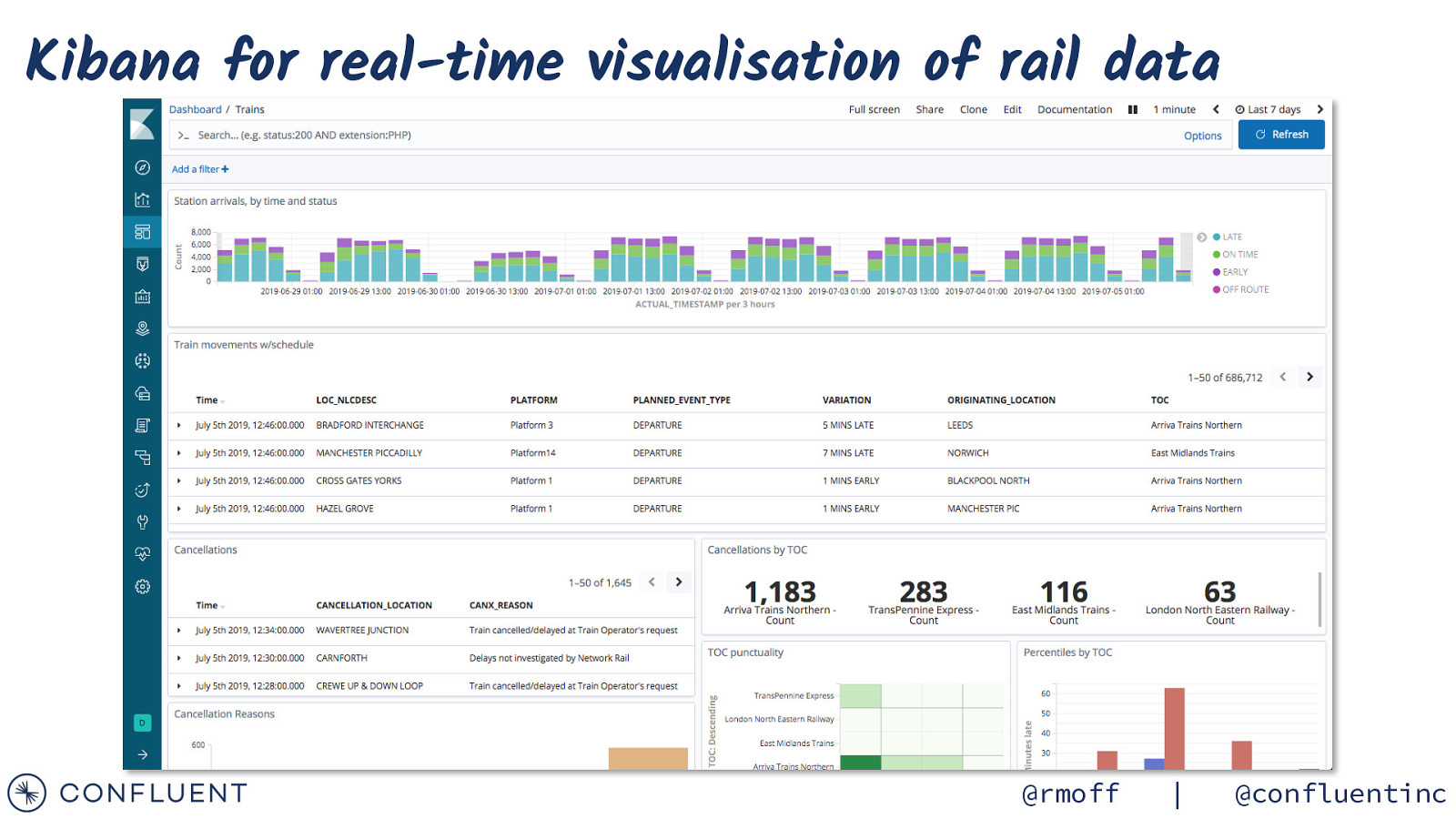
Kibana for real-time visualisation of rail data @rmoff | @confluentinc
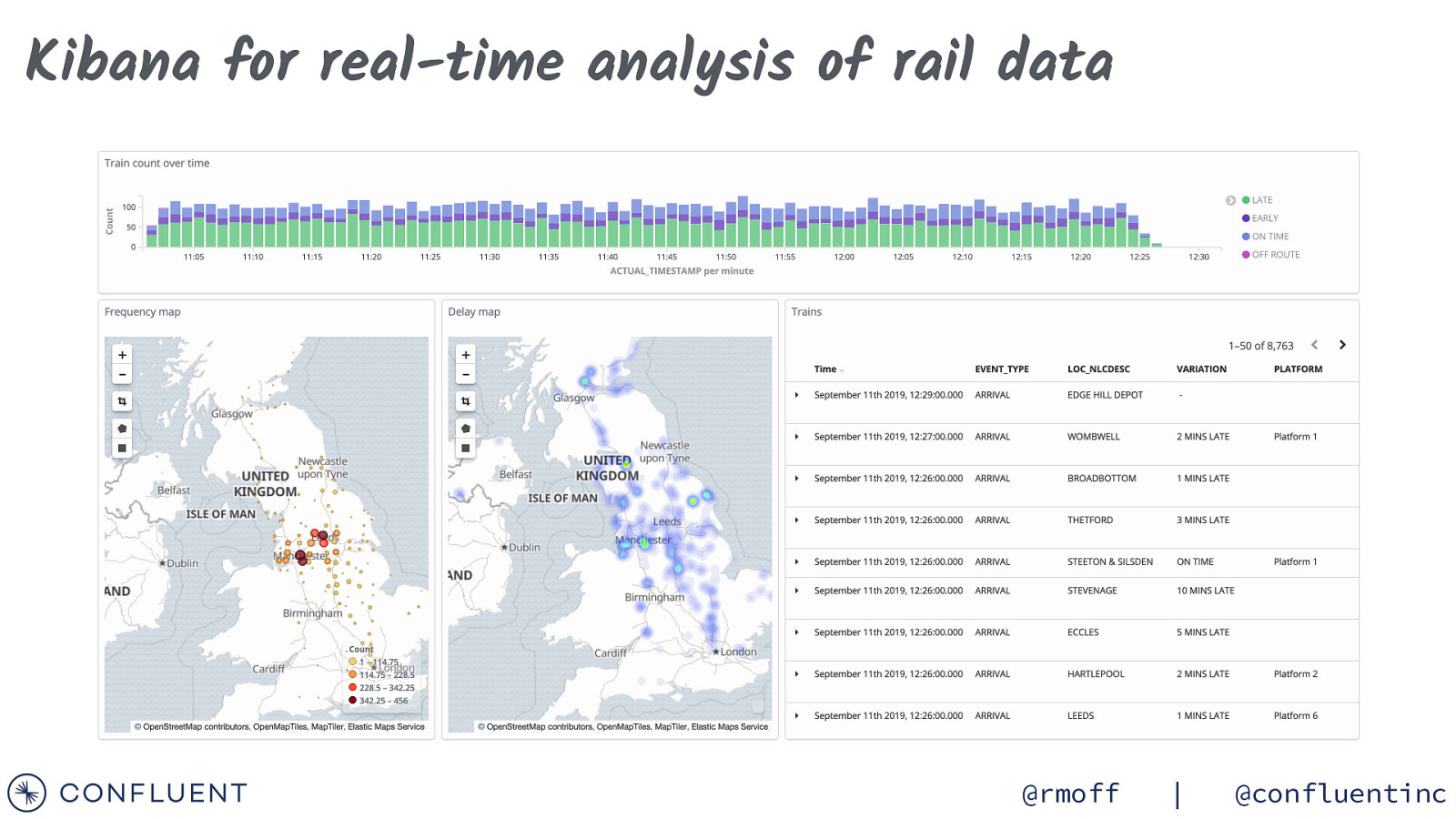
Kibana for real-time analysis of rail data @rmoff | @confluentinc

Kafka -> Postgres { “connector.class”: “io.confluent.connect.jdbc.JdbcSinkConnector”, “key.converter”: “org.apache.kafka.connect.storage.StringConverter”, “connection.url”: “jdbc:postgresql://postgres:5432/”, “connection.user”: “postgres”, “connection.password”: “postgres”, “auto.create”: true, “auto.evolve”: true, “insert.mode”: “upsert”, “pk.mode”: “record_key”, “pk.fields”: “MESSAGE_KEY”, “topics”: “TRAIN_MOVEMENTS_ACTIVATIONS_SCHEDULE_00”, “transforms”: “dropArrays”, “transforms.dropArrays.type”: “org.apache.kafka.connect.transforms.ReplaceField$Value”, “transforms.dropArrays.blacklist”: “SCHEDULE_SEGMENT_LOCATION, HEADER” } @rmoff | @confluentinc
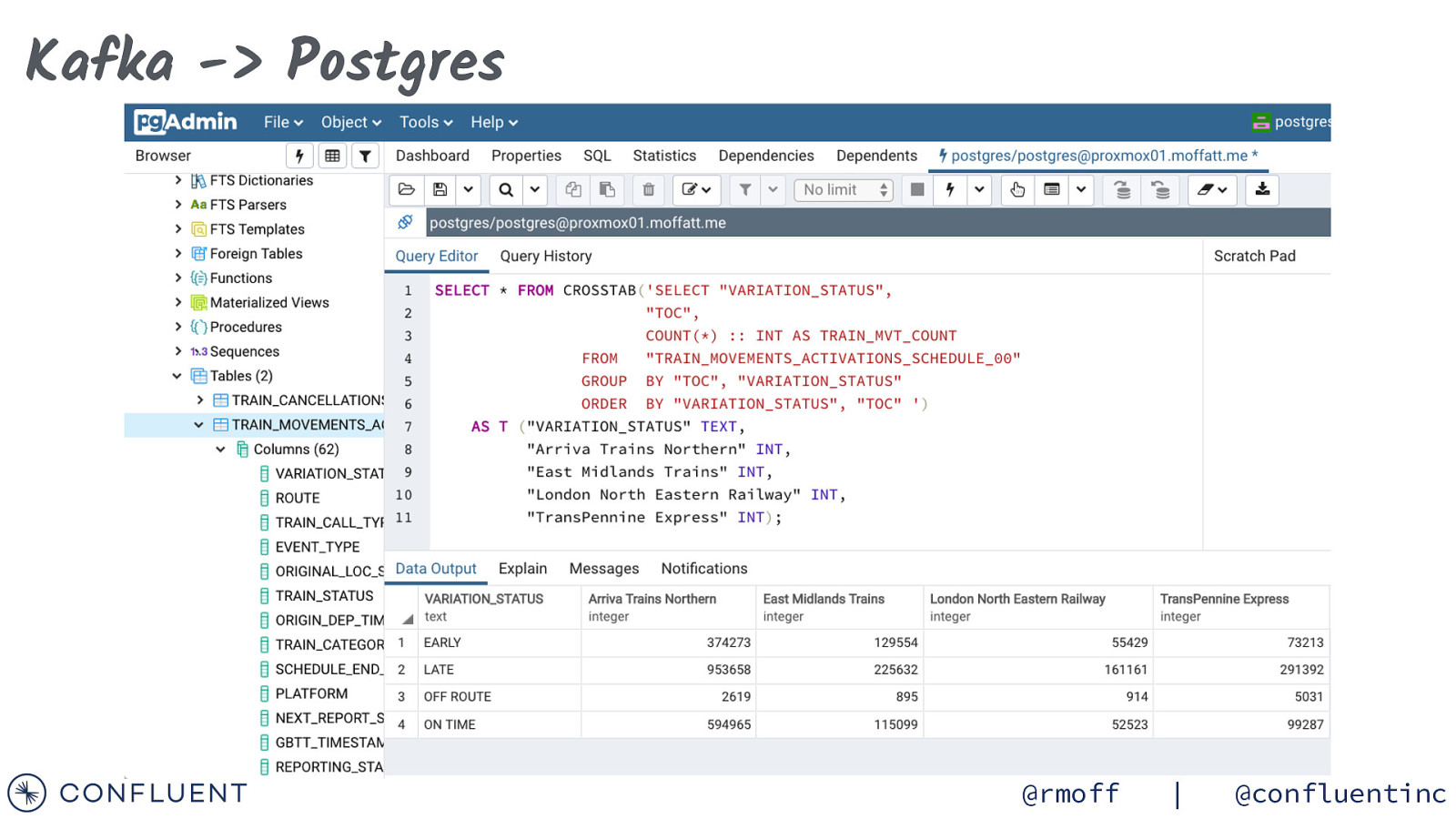
Kafka -> Postgres @rmoff | @confluentinc
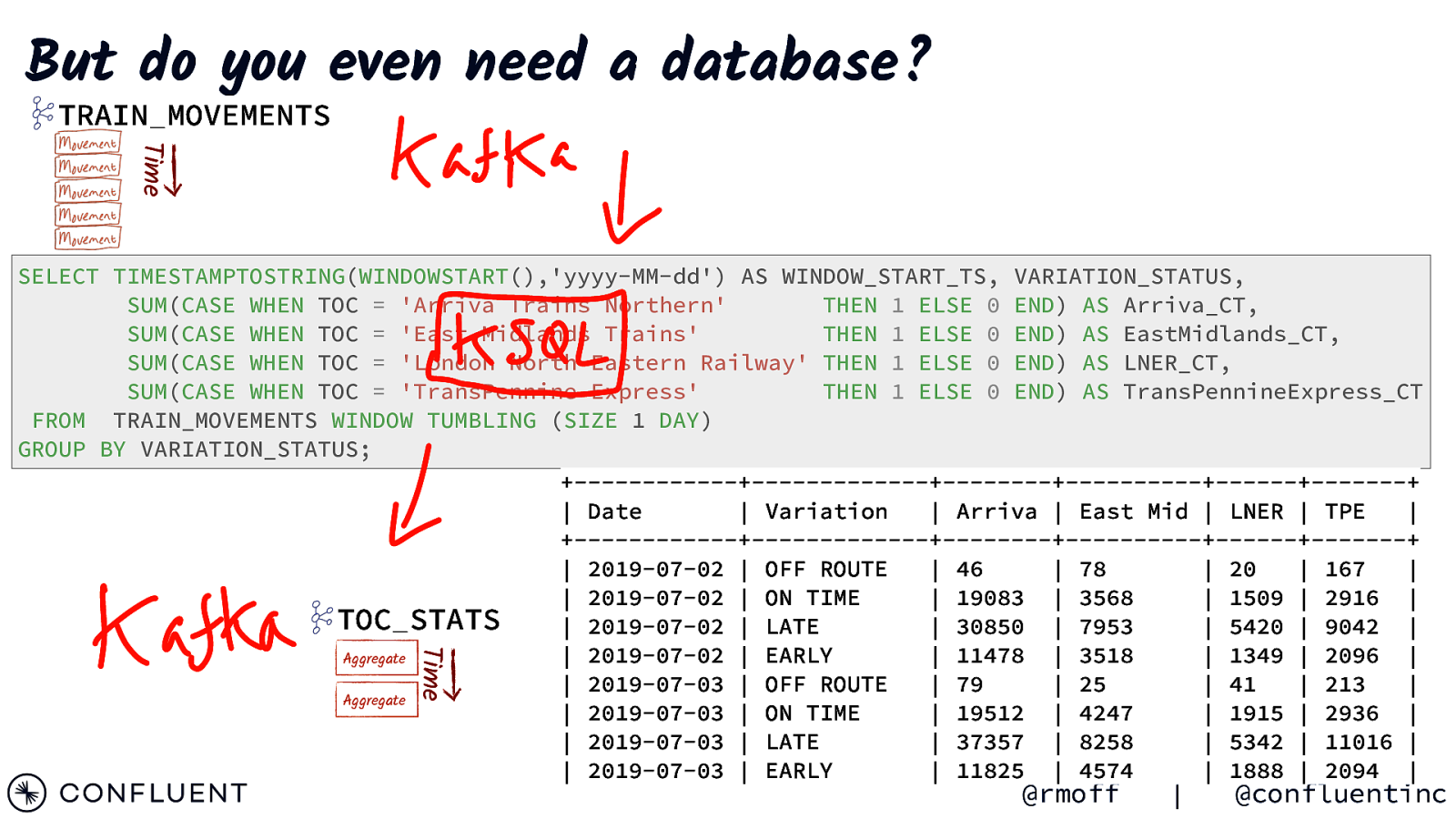
But do you even need a database? TRAIN_MOVEMENTS Time Time SELECT TIMESTAMPTOSTRING(WINDOWSTART(),’yyyy-MM-dd’) AS WINDOW_START_TS, VARIATION_STATUS, SUM(CASE WHEN TOC = ‘Arriva Trains Northern’ THEN 1 ELSE 0 END) AS Arriva_CT, SUM(CASE WHEN TOC = ‘East Midlands Trains’ THEN 1 ELSE 0 END) AS EastMidlands_CT, SUM(CASE WHEN TOC = ‘London North Eastern Railway’ THEN 1 ELSE 0 END) AS LNER_CT, SUM(CASE WHEN TOC = ‘TransPennine Express’ THEN 1 ELSE 0 END) AS TransPennineExpress_CT FROM TRAIN_MOVEMENTS WINDOW TUMBLING (SIZE 1 DAY) GROUP BY VARIATION_STATUS; +——————+——————-+————+—————+———+———-+ | Date | Variation | Arriva | East Mid | LNER | TPE | +——————+——————-+————+—————+———+———-+ | 2019-07-02 | OFF ROUTE | 46 | 78 | 20 | 167 | | 2019-07-02 | ON TIME | 19083 | 3568 | 1509 | 2916 | TOC_STATS | 2019-07-02 | LATE | 30850 | 7953 | 5420 | 9042 | | 2019-07-02 | EARLY | 11478 | 3518 | 1349 | 2096 | Aggregate | 2019-07-03 | OFF ROUTE | 79 | 25 | 41 | 213 | Aggregate | 2019-07-03 | ON TIME | 19512 | 4247 | 1915 | 2936 | | 2019-07-03 | LATE | 37357 | 8258 | 5342 | 11016 | | 2019-07-03 | EARLY | 11825 | 4574 | 1888 | 2094 | @rmoff | @confluentinc

{ Kafka -> S3 “connector.class”: “io.confluent.connect.s3.S3SinkConnector”, “key.converter”:”org.apache.kafka.connect.storage.StringConverter”, “tasks.max”: “1”, “topics”: “TRAIN_MOVEMENTS_ACTIVATIONS_SCHEDULE_00”, “s3.region”: “us-west-2”, “s3.bucket.name”: “rmoff-rail-streaming-demo”, “flush.size”: “65536”, “storage.class”: “io.confluent.connect.s3.storage.S3Storage”, “format.class”: “io.confluent.connect.s3.format.avro.AvroFormat”, “schema.generator.class”: “io.confluent.connect.storage.hive.schema.DefaultSchemaGenerator”, “schema.compatibility”: “NONE”, “partitioner.class”: “io.confluent.connect.storage.partitioner.TimeBasedPartitioner”, “path.format”:“‘year’=YYYY/’month’=MM/’day’=dd”, “timestamp.extractor”:”Record”, “partition.duration.ms”: 1800000, “locale”:”en”, “timezone”: “UTC” } @rmoff | @confluentinc
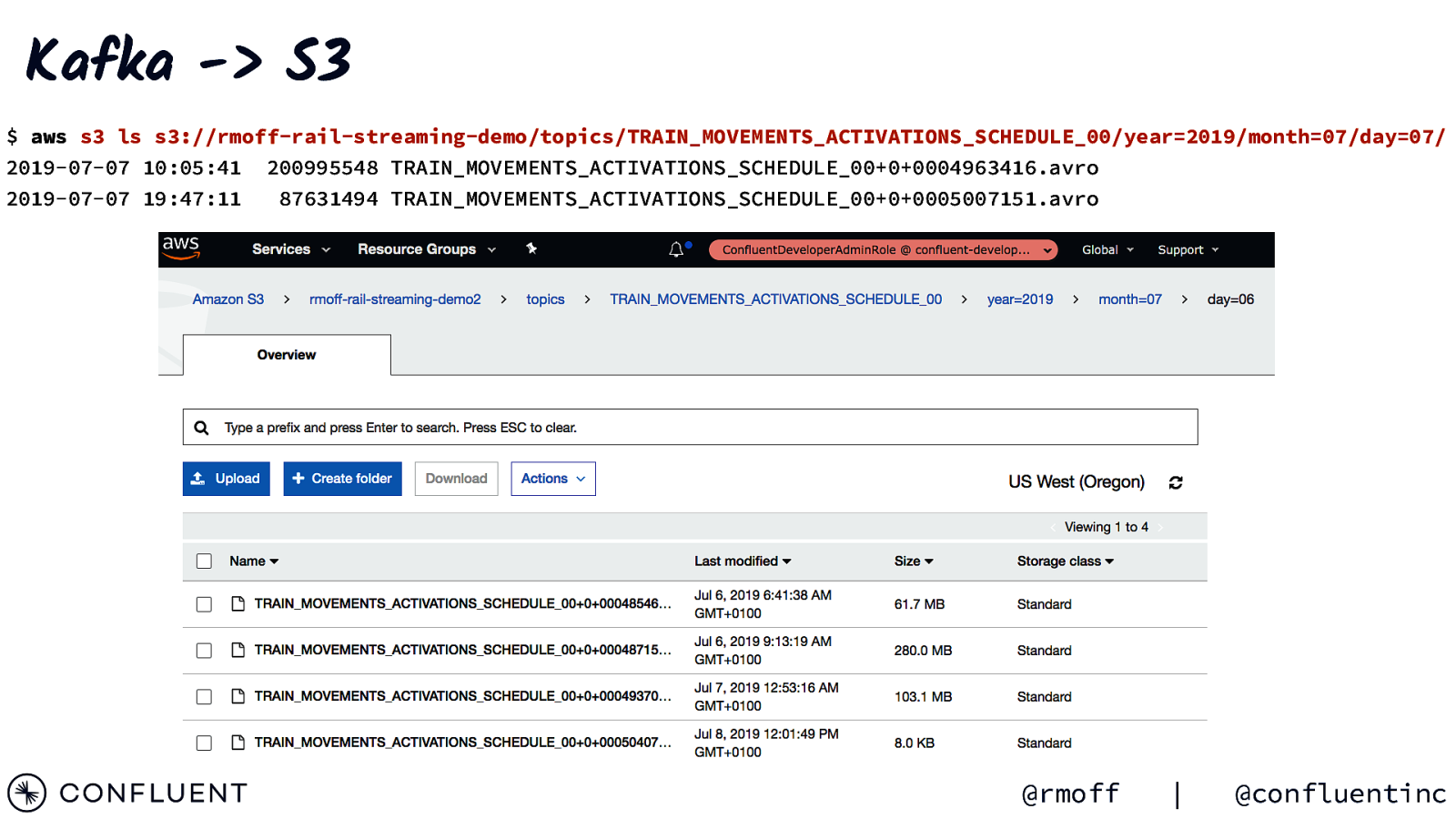
Kafka -> S3 $ aws s3 ls s3://rmoff-rail-streaming-demo/topics/TRAIN_MOVEMENTS_ACTIVATIONS_SCHEDULE_00/year=2019/month=07/day=07/ 2019-07-07 10:05:41 200995548 TRAIN_MOVEMENTS_ACTIVATIONS_SCHEDULE_00+0+0004963416.avro 2019-07-07 19:47:11 87631494 TRAIN_MOVEMENTS_ACTIVATIONS_SCHEDULE_00+0+0005007151.avro @rmoff | @confluentinc
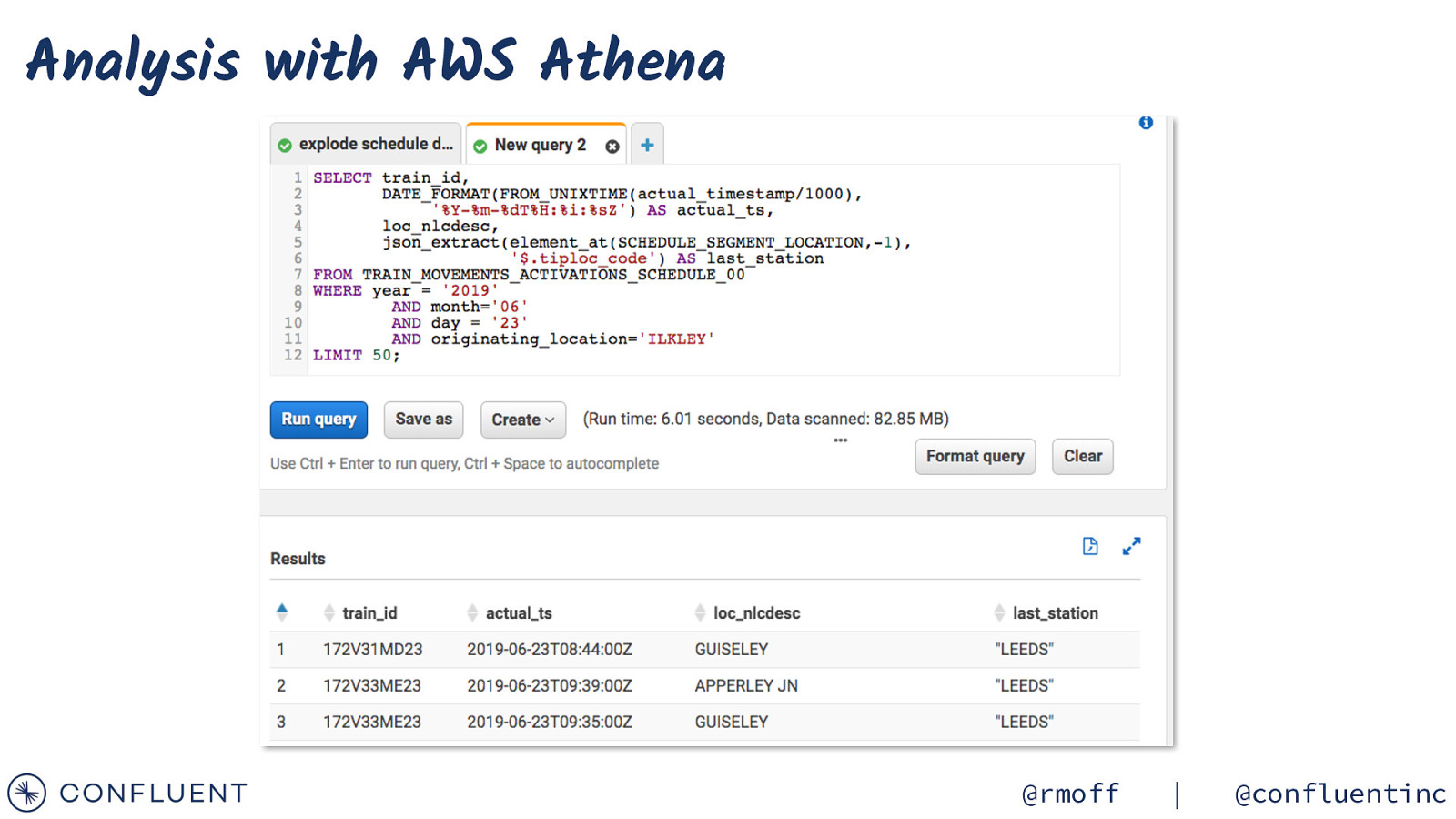
Analysis with AWS Athena @rmoff | @confluentinc

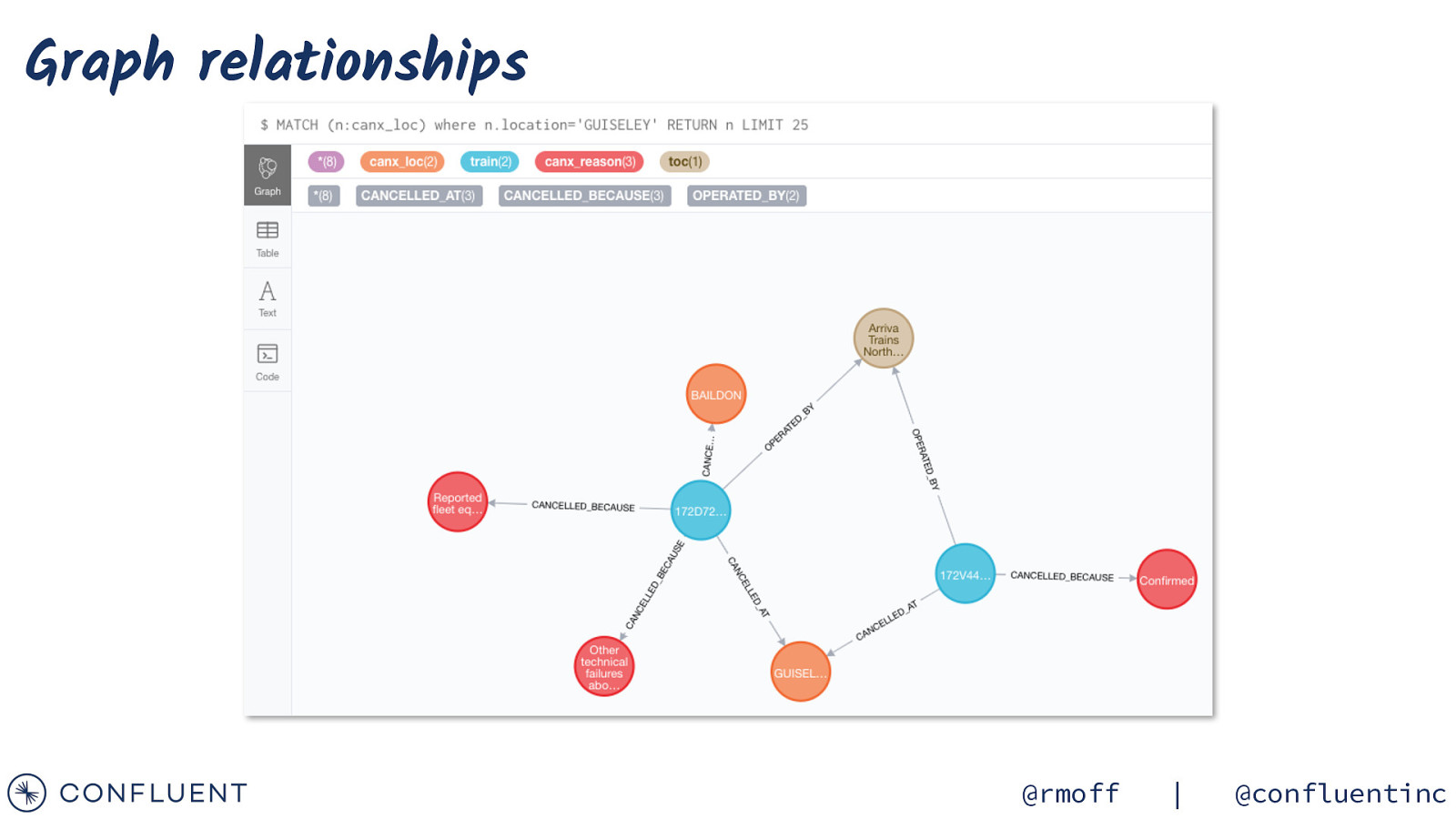
Graph analysis { “connector.class”: “streams.kafka.connect.sink.Neo4jSinkConnector”, “topics”: “TRAIN_CANCELLATIONS_02”, “key.converter”:”org.apache.kafka.connect.storage.StringConverter”, “errors.tolerance”: “all”, “errors.deadletterqueue.topic.name”: “sink-neo4j-train-00_dlq”, “errors.deadletterqueue.topic.replication.factor”: 1, “errors.deadletterqueue.context.headers.enable”:true, “neo4j.server.uri”: “bolt://neo4j:7687”, “neo4j.authentication.basic.username”: “neo4j”, “neo4j.authentication.basic.password”: “connect”, “neo4j.topic.cypher.TRAIN_CANCELLATIONS_02”: “MERGE (train:train{id: event.TRAIN_ID}) MERGE (toc:toc{toc: event.TOC}) MERGE (canx_reason:canx_reason{reason: event.CANX_REASON}) MERGE (canx_loc:canx_loc{location: coalesce(event.CANCELLATION_LOCATION,’<unknown>’)}) MERGE (train)[:OPERATED_BY]->(toc) MERGE (canx_loc)<-[:CANCELLED_AT{reason:event.CANX_REASON, time:event.CANX_TIMESTAMP}]-(train)-[:CANCELLED_BECAUSE]->(canx_reason)” } @rmoff | @confluentinc
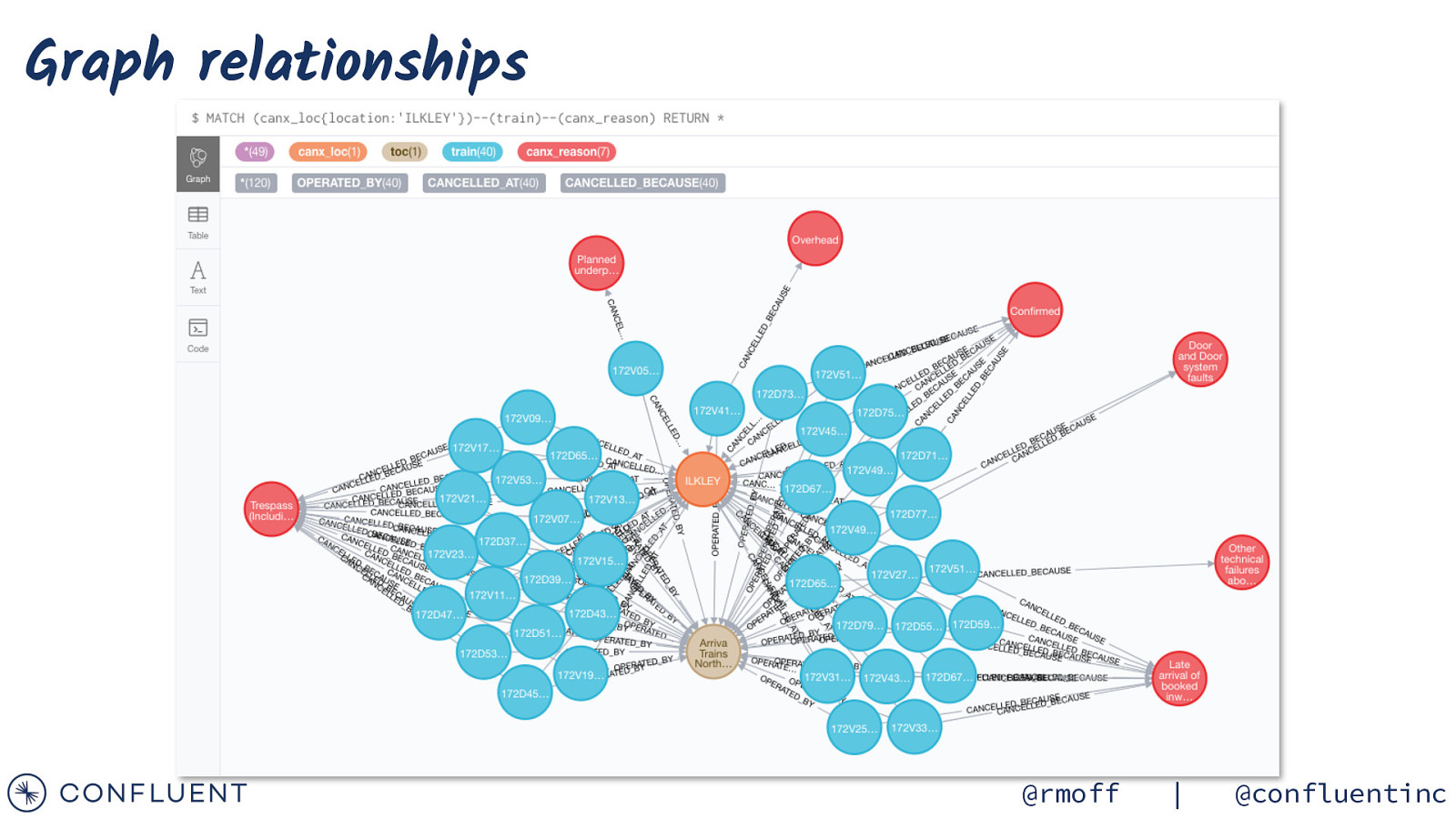
Graph relationships @rmoff | @confluentinc
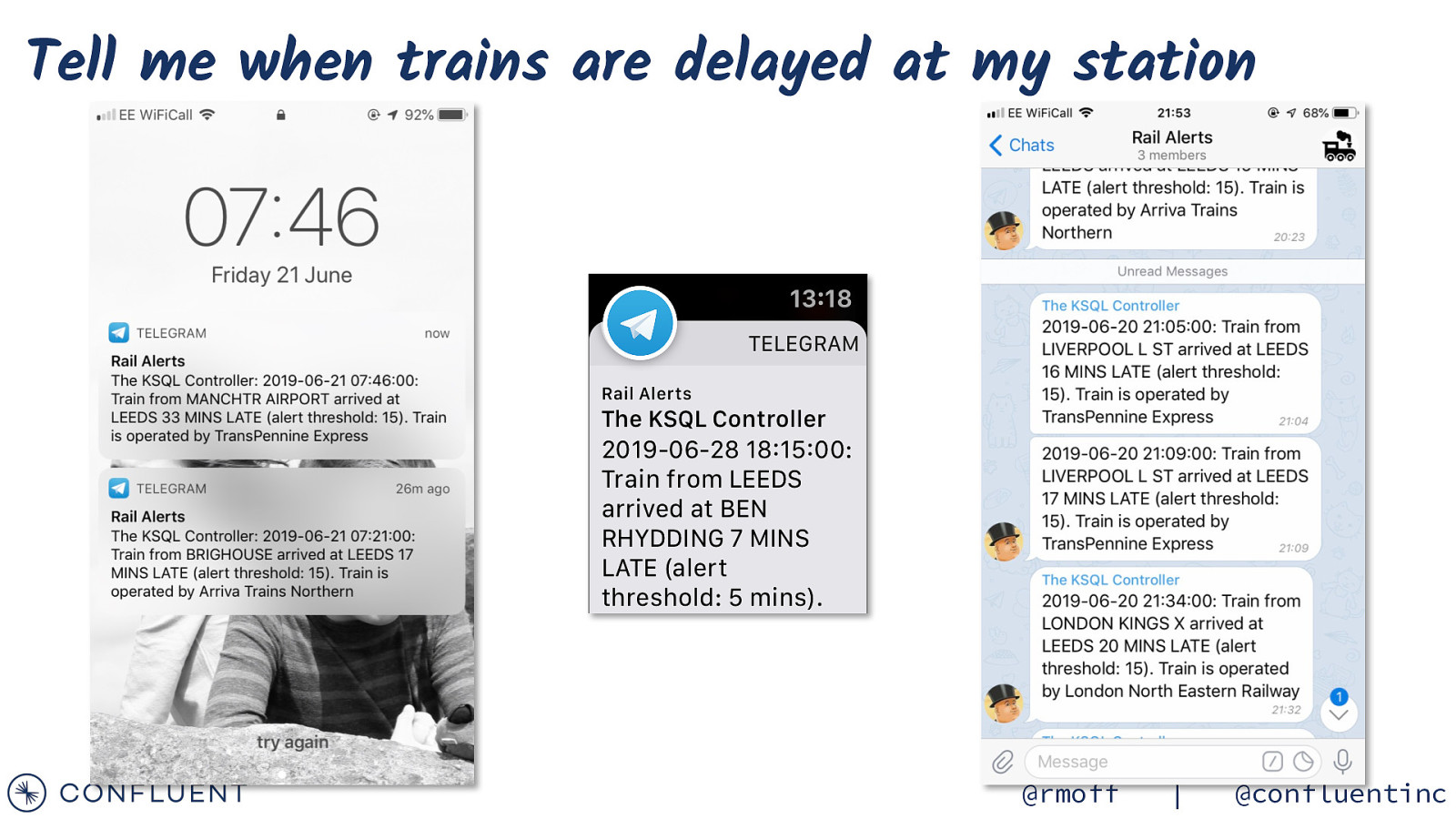
Tell me when trains are delayed at my station @rmoff | @confluentinc
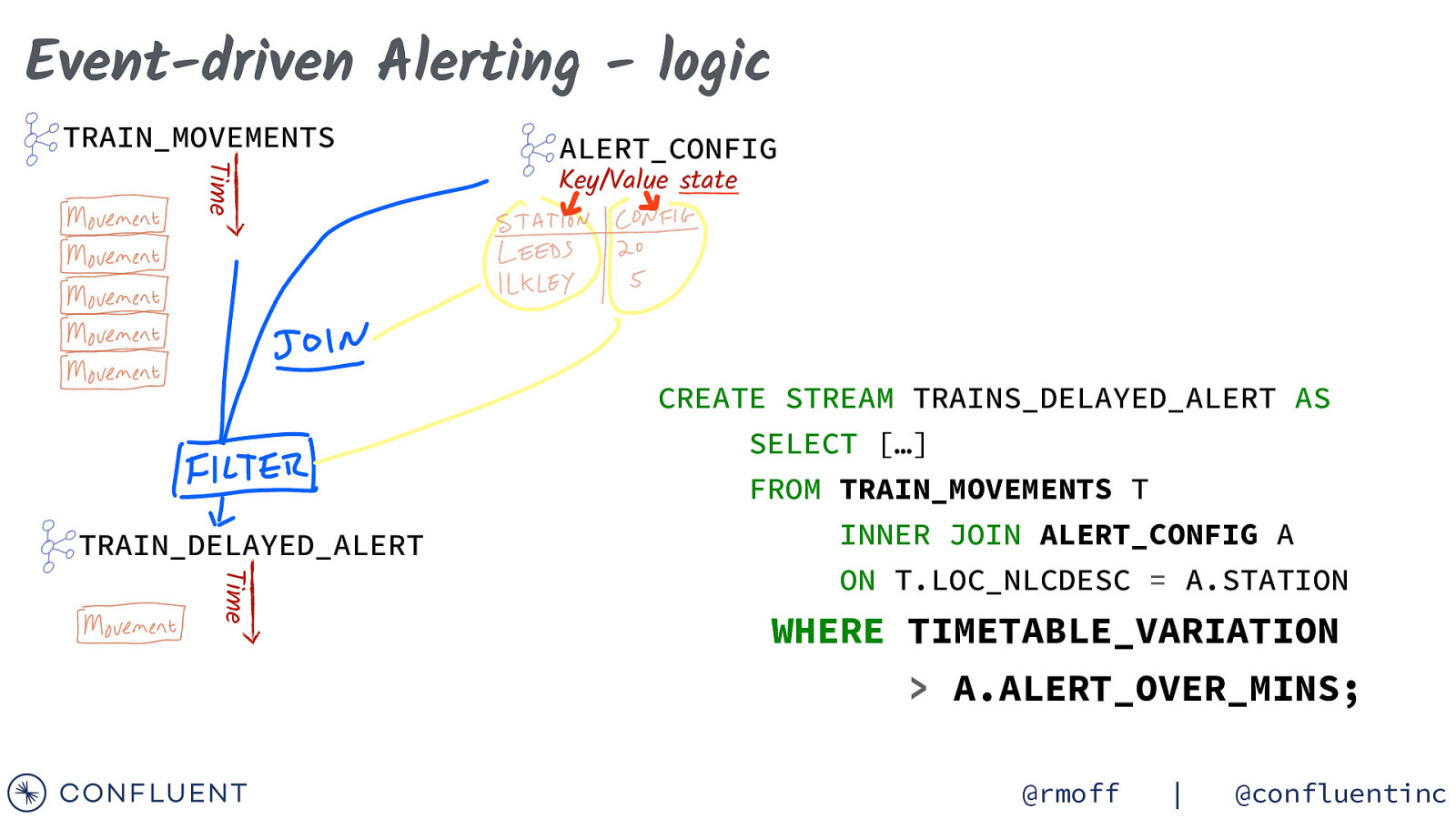
Event-driven Alerting - logic TRAIN_MOVEMENTS Time TRAIN_DELAYED_ALERT ALERT_CONFIG Key/Value state Time CREATE STREAM TRAINS_DELAYED_ALERT AS SELECT […] FROM TRAIN_MOVEMENTS T INNER JOIN ALERT_CONFIG A ON T.LOC_NLCDESC = A.STATION WHERE TIMETABLE_VARIATION > A.ALERT_OVER_MINS; @rmoff | @confluentinc
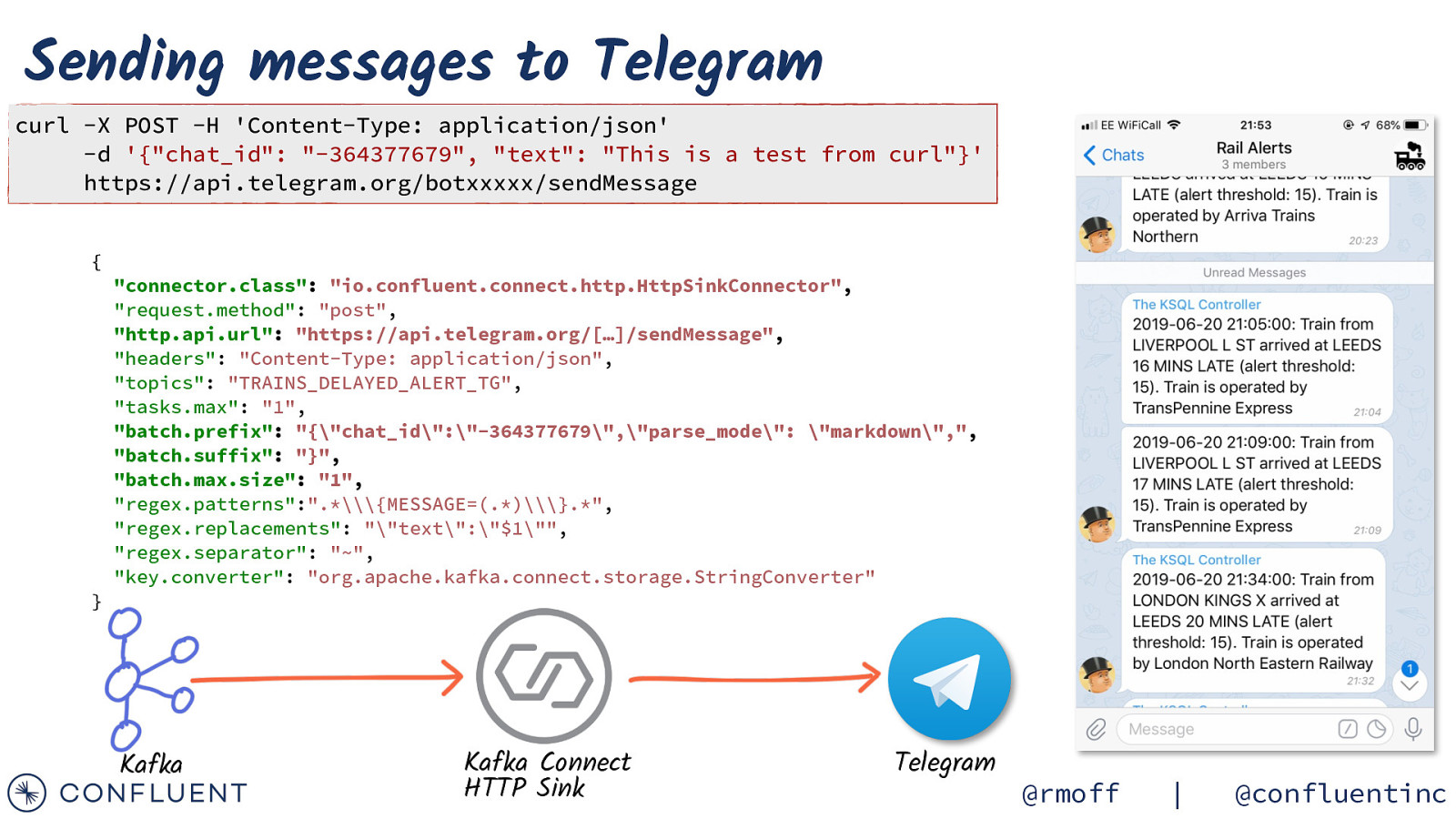
Sending messages to Telegram curl -X POST -H ‘Content-Type: application/json’ -d ‘{“chat_id”: “-364377679”, “text”: “This is a test from curl”}’ https://api.telegram.org/botxxxxx/sendMessage { “connector.class”: “io.confluent.connect.http.HttpSinkConnector”, “request.method”: “post”, “http.api.url”: “https://api.telegram.org/[…]/sendMessage”, “headers”: “Content-Type: application/json”, “topics”: “TRAINS_DELAYED_ALERT_TG”, “tasks.max”: “1”, “batch.prefix”: “{“chat_id”:”-364377679”,”parse_mode”: “markdown”,”, “batch.suffix”: “}”, “batch.max.size”: “1”, “regex.patterns”:”.\{MESSAGE=(.)\}.*”, “regex.replacements”: “”text”:”$1”“, “regex.separator”: “~”, “key.converter”: “org.apache.kafka.connect.storage.StringConverter” } Kafka Kafka Connect HTTP Sink Telegram @rmoff | @confluentinc

Running it & monitoring & maintenance @rmoff | @confluentinc

System health & Throughput @rmoff | @confluentinc
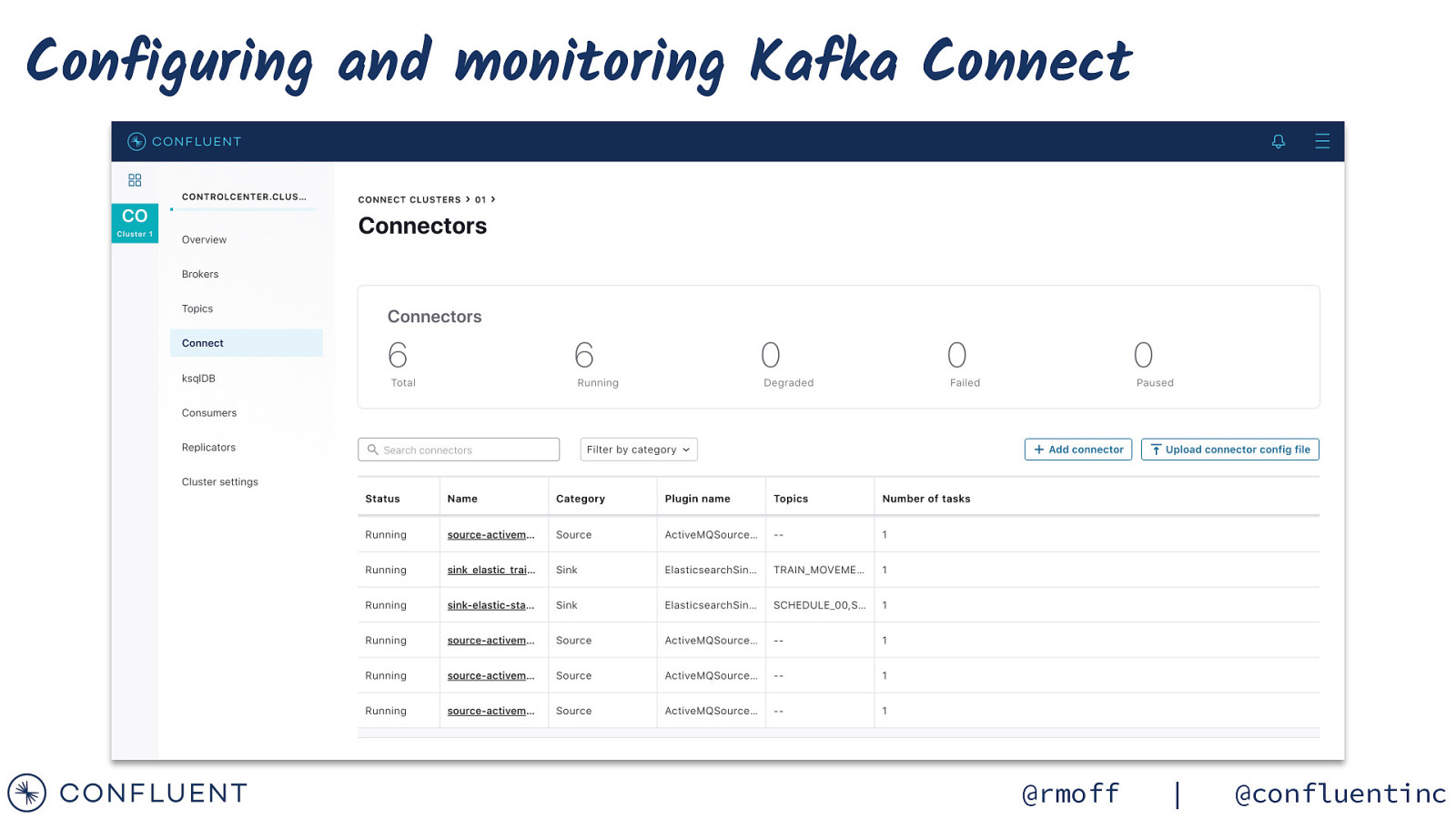
Configuring and monitoring Kafka Connect @rmoff | @confluentinc
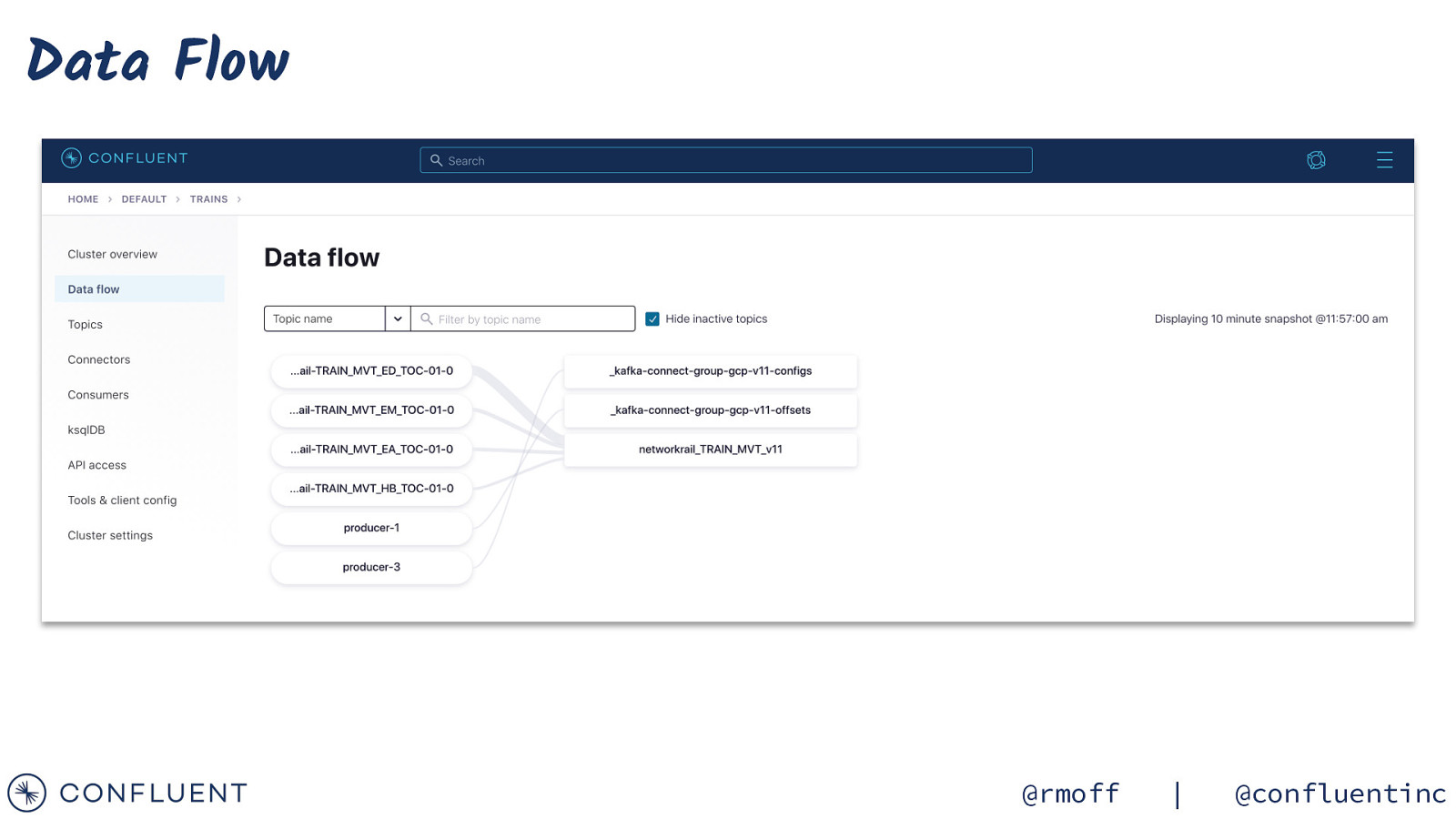
Data Flow @rmoff | @confluentinc
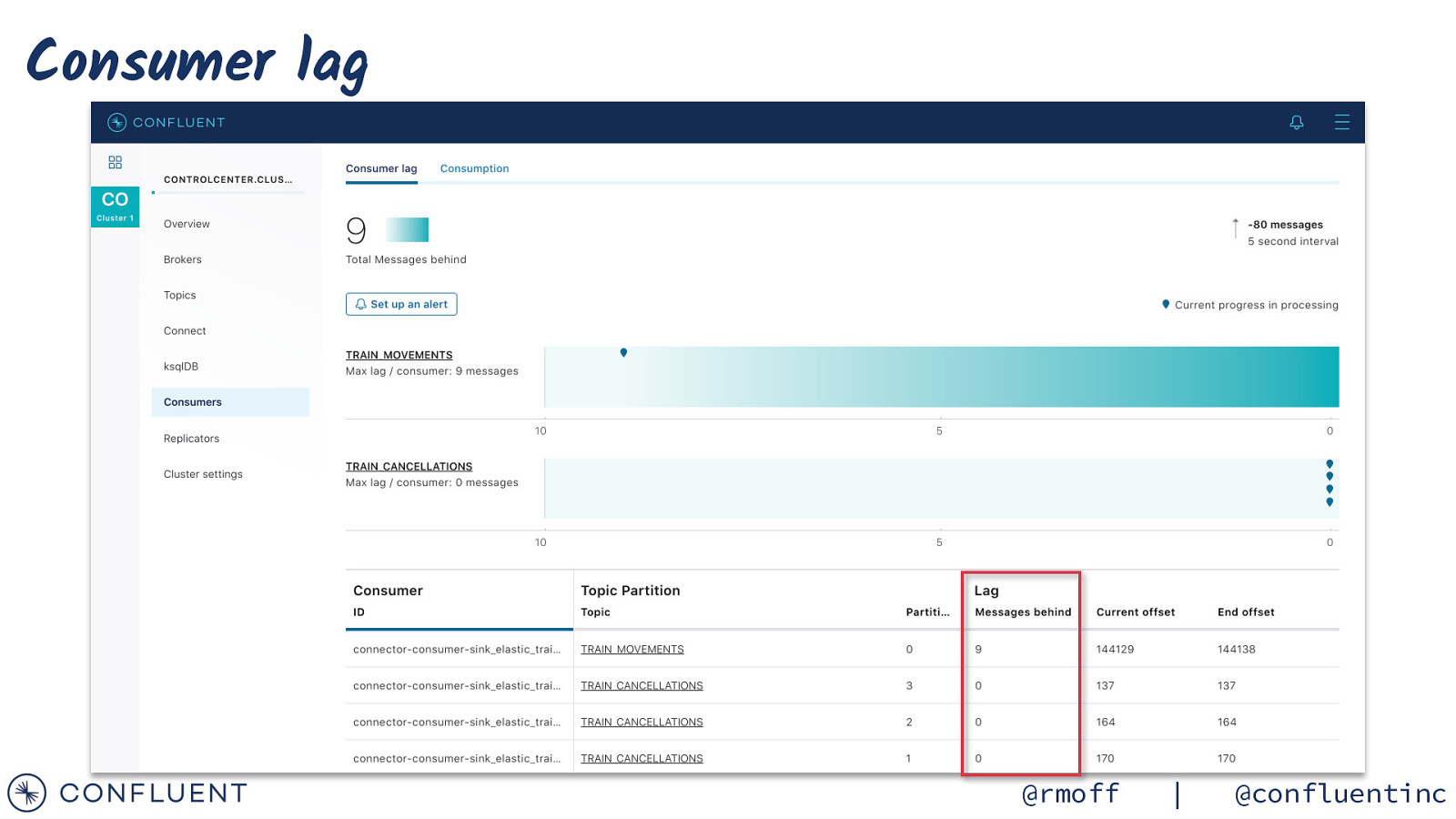
Consumer lag @rmoff | @confluentinc

@rmoff @confluentinc Restart failing connectors rmoff@proxmox01 > crontab -l “*/5 * * * * /home/rmoff/restart_failed_connector_tasks.sh rmoff@proxmox01 > cat /home/rmoff/restart_failed_connector_tasks.sh “#!/usr/bin/env bash # @rmoff / June 6, 2019
🚂 On Track with Apache Kafka: Building a Streaming ETL solution with Rail Data
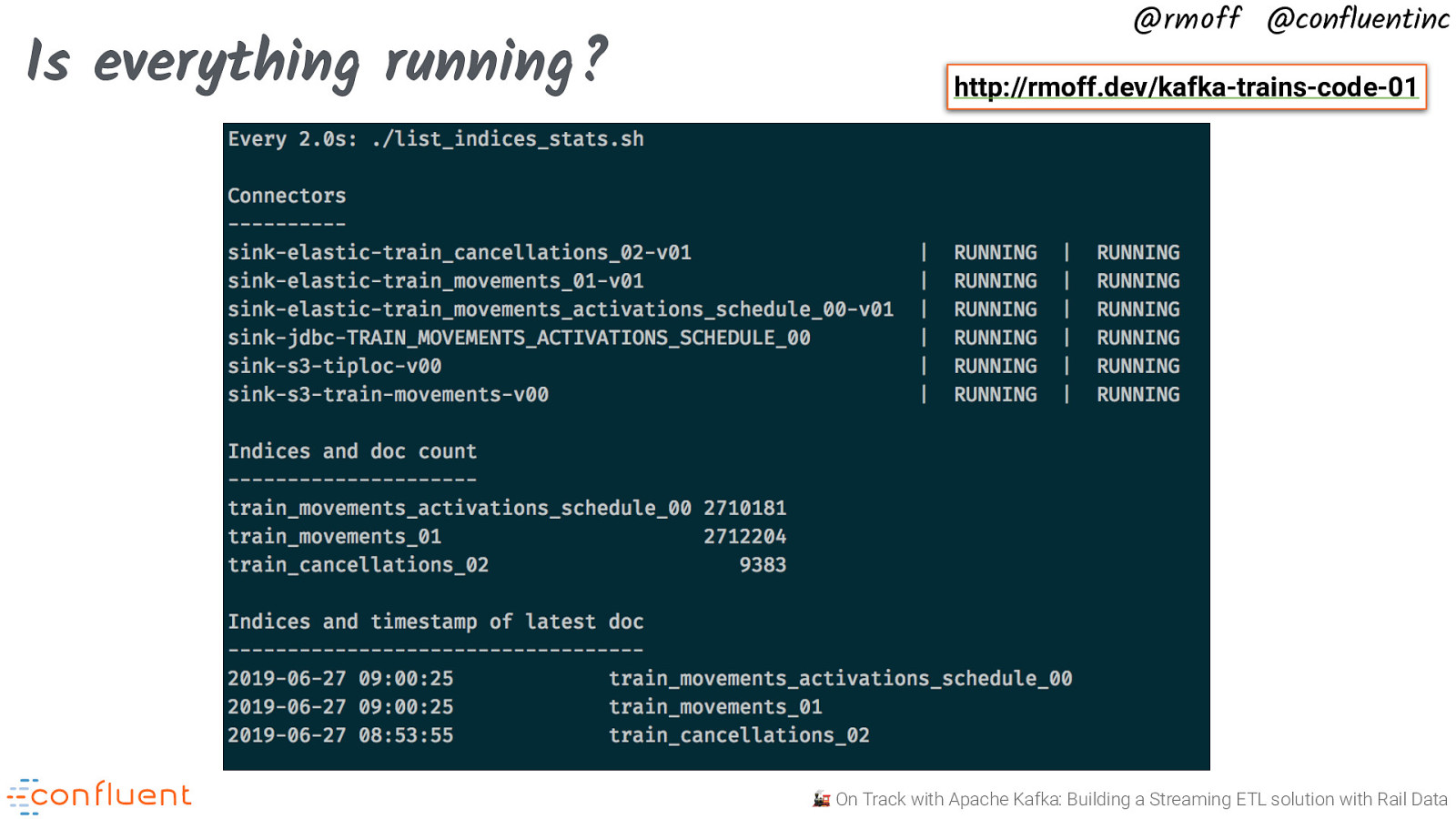
Is everything running? @rmoff @confluentinc http://rmoff.dev/kafka-trains-code-01 🚂 On Track with Apache Kafka: Building a Streaming ETL solution with Rail Data

@rmoff @confluentinc check_latest_timestamp.sh Start at latest Just read one message message kafkacat -b localhost:9092 -t networkrail_TRAIN_MVT_X -o-1 -c1 -C | \ jq ‘.header.msg_queue_timestamp’ | \ sed -e ‘s/”“//g’ | \ sed -e ‘s/000$”//g’ | \ Convert from epoch to humanxargs -Ifoo date “—date=@foo readable timestamp format $ ./check_latest_timestamp.sh Mon 25 Jan 2021 13:39:40 GMT 🚂 On Track with Apache Kafka: Building a Streaming ETL solution with Rail Data
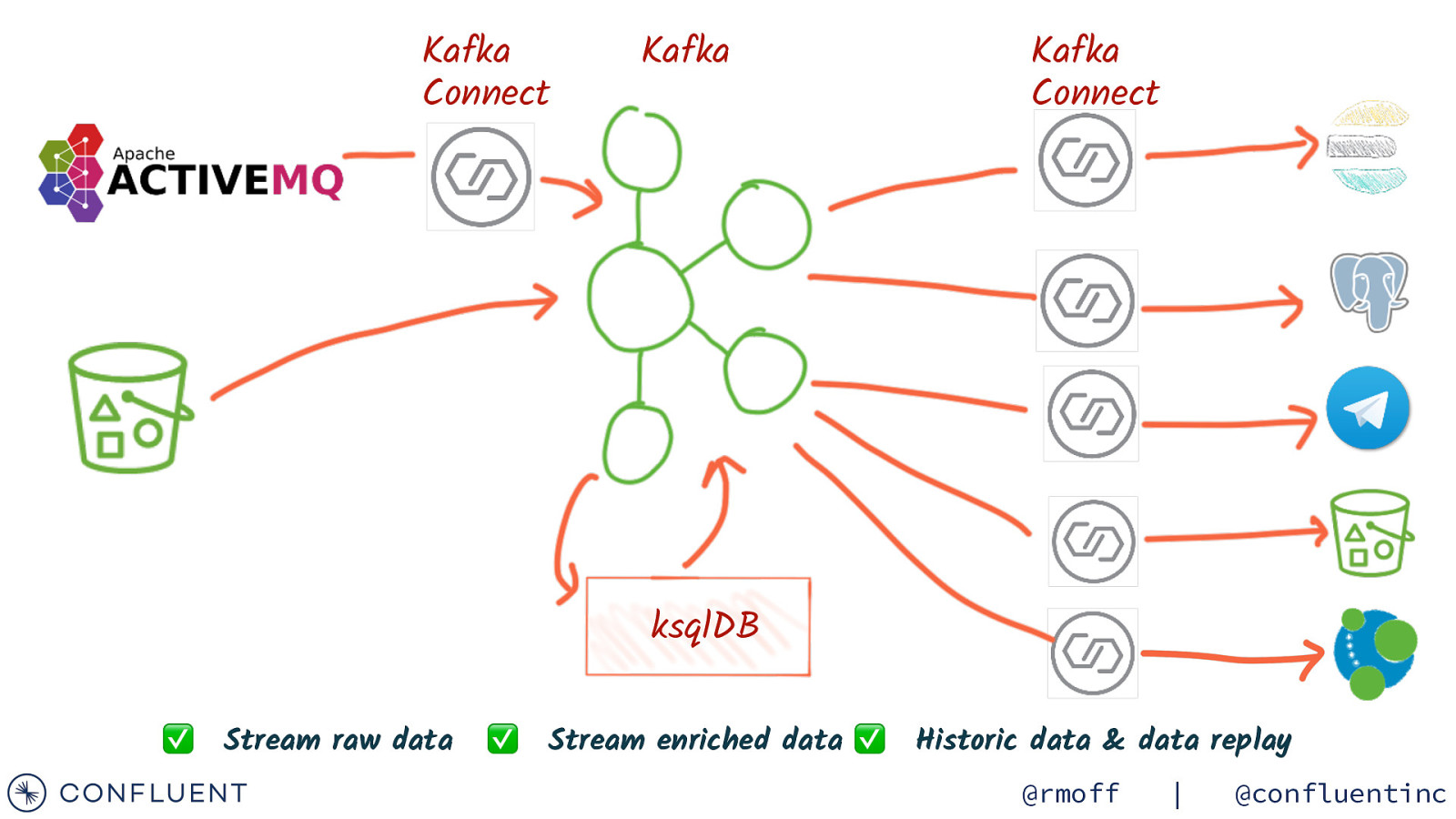
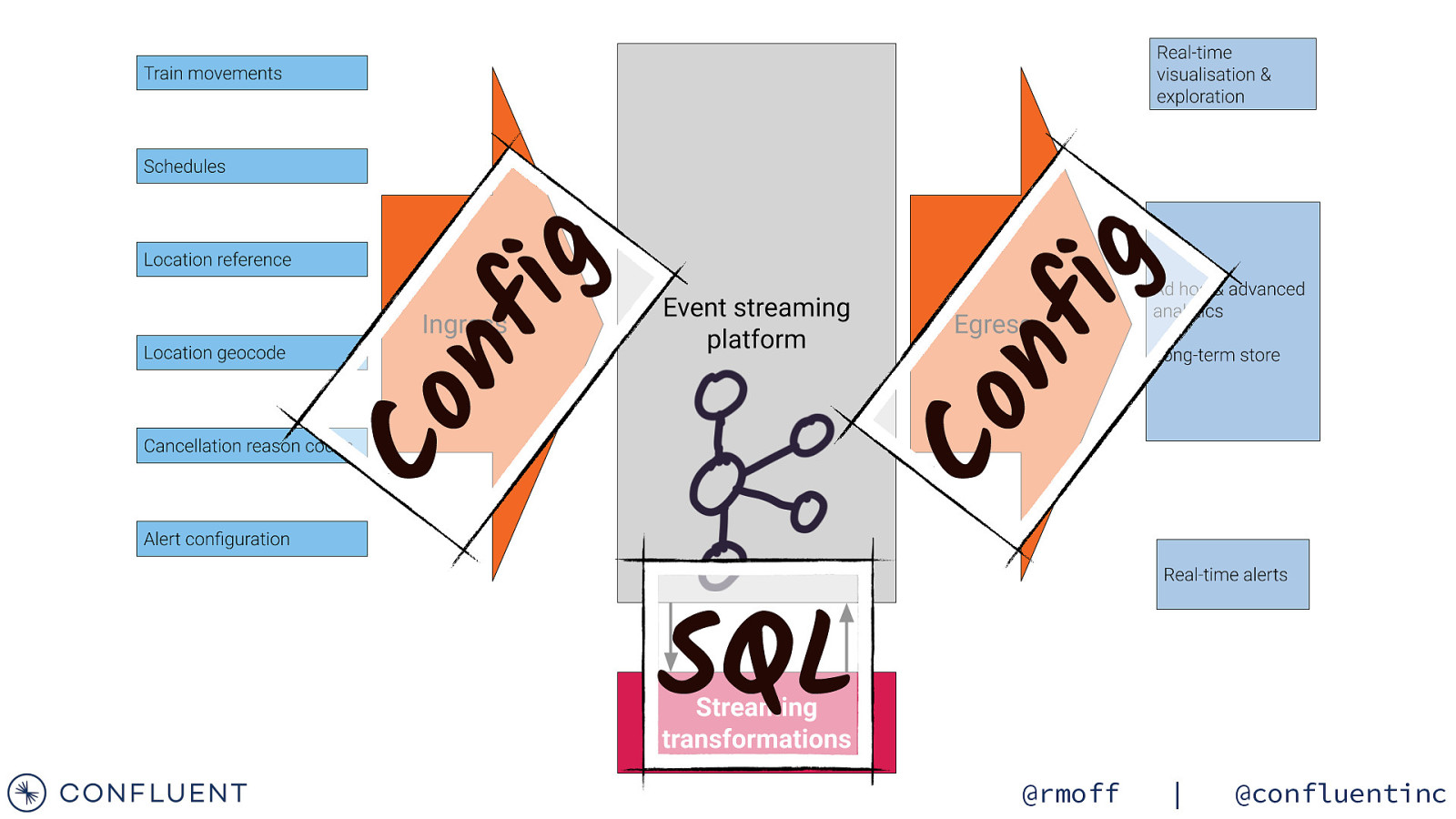
Kafka Connect Kafka Kafka Connect ksqlDB ✅ Stream raw data ✅ Stream enriched data ✅ Historic data & data replay @rmoff | @confluentinc
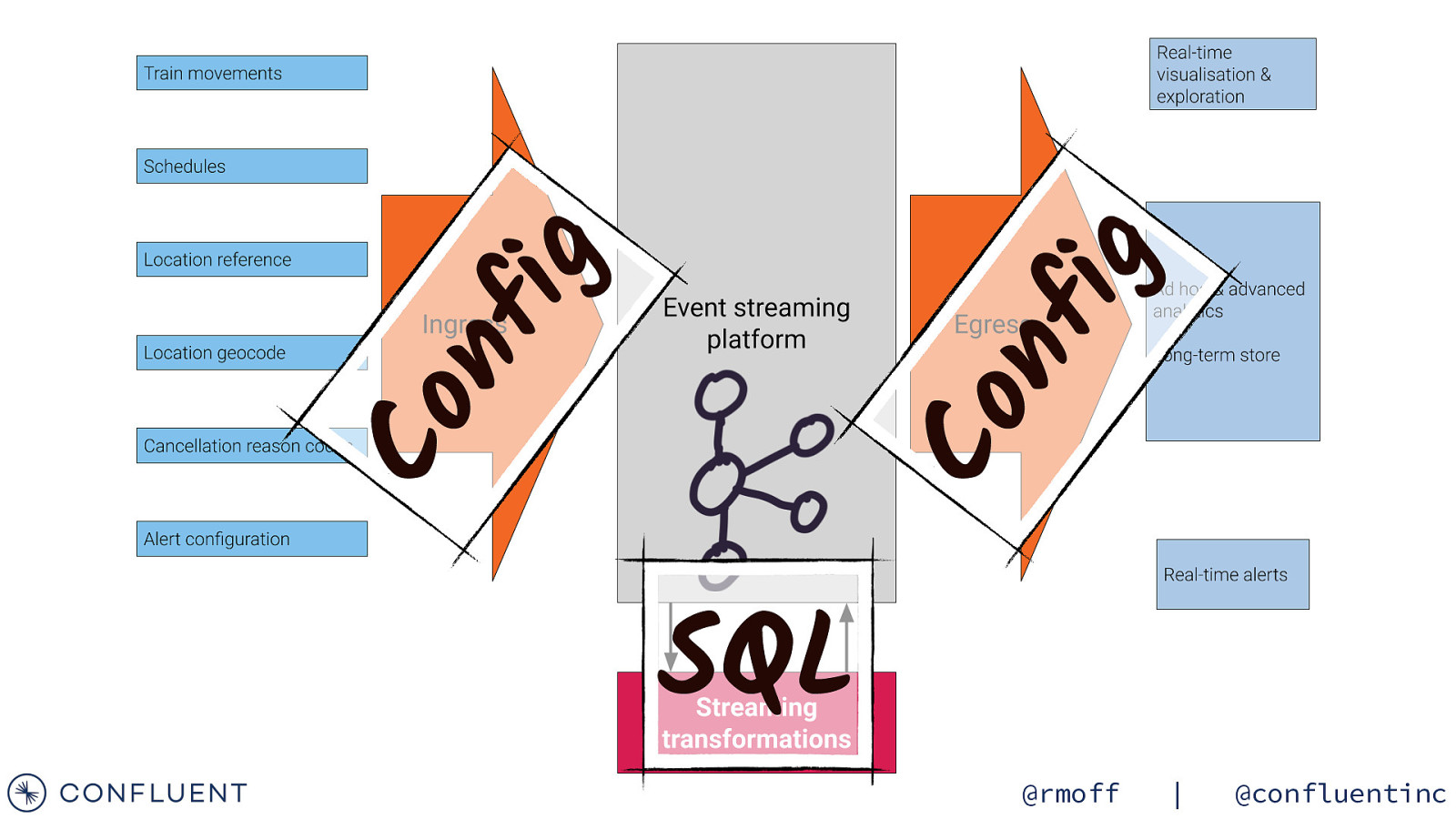
ig nf Co Co nf ig SQL @rmoff | @confluentinc

RM OF F2 00 $200 USD off your bill each calendar month for the first three months when you sign up https://rmoff.dev/ccloud Free money! (additional $200 towards your bill 😄 ) Fully Managed Kafka as a Service * T&C: https://www.confluent.io/confluent-cloud-promo-disclaimer

Learn Kafka. Start building with Apache Kafka at Confluent Developer. developer.confluent.io

#EOF