Introduction to ksqlDB Robin Moffatt Running time: ~40 minutes including ~15 minute demo. #KafkaMeetup @rmoff

A presentation at Software Circus / Amsterdam Kafka Meetup in February 2020 in Amsterdam, Netherlands by Robin Moffatt

Introduction to ksqlDB Robin Moffatt Running time: ~40 minutes including ~15 minute demo. #KafkaMeetup @rmoff
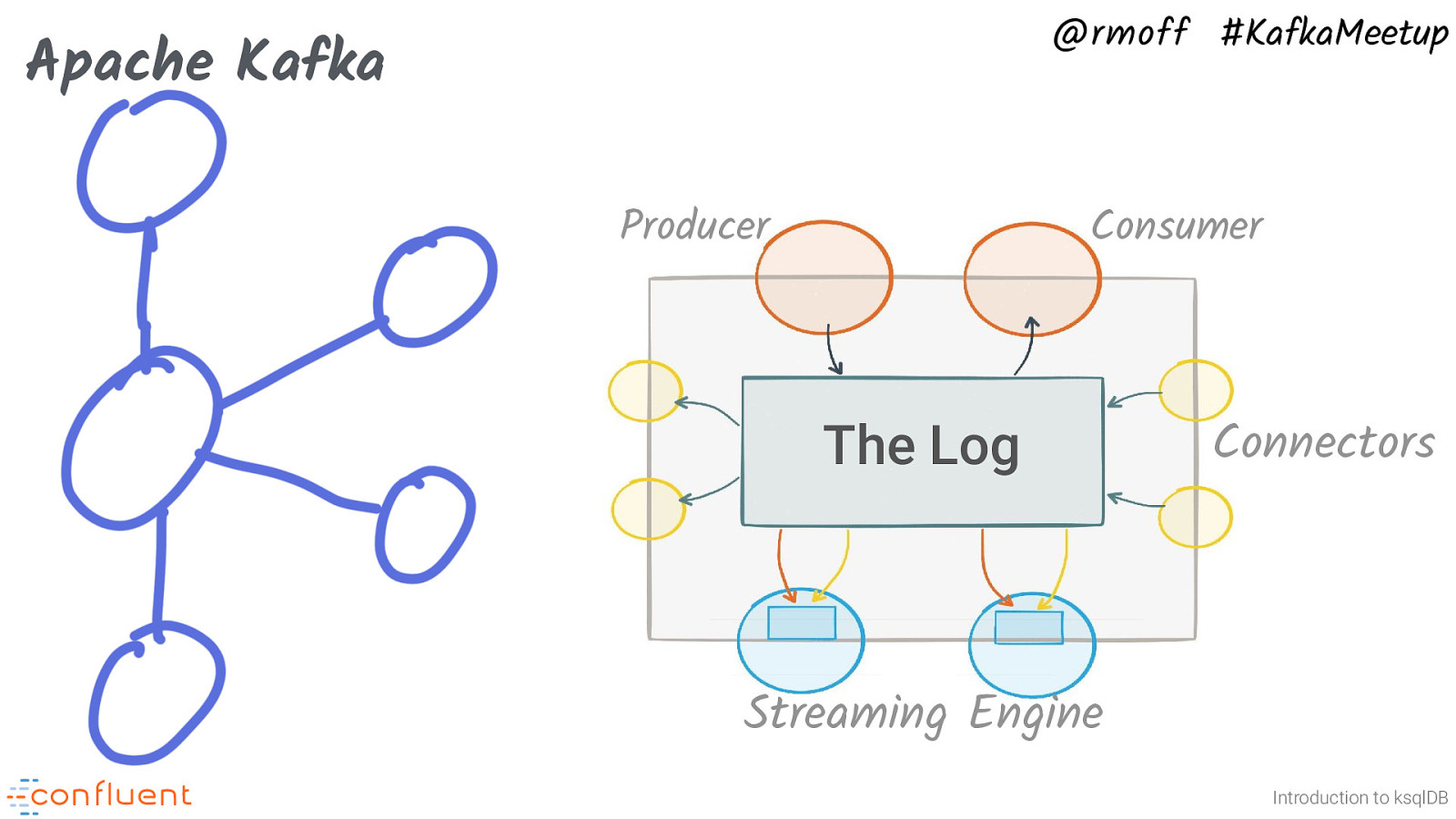
@rmoff #KafkaMeetup Apache Kafka Producer Consumer The Log Connectors Streaming Engine Introduction to ksqlDB Apache Kafka is an event streaming platform. It is: • Distributed (and thus scalable, elastic, fault-tolerant) • Append only, immutable • Stores data • Messages are not transient. Once consumed, they’re not deleted, so others can also read them. • Store data for ever, or based on a time or size limit
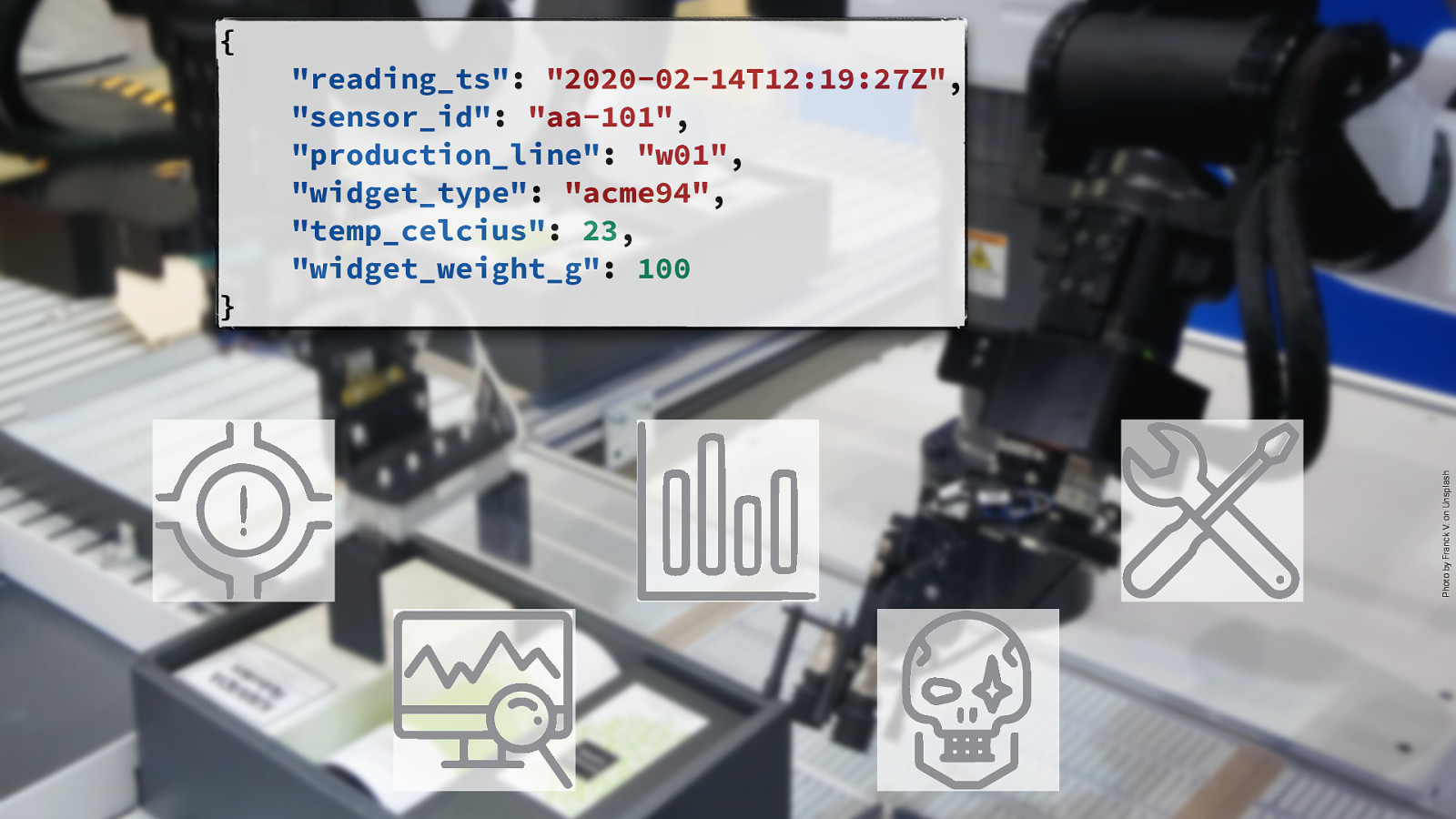
{ Photo by Franck V. on Unsplash } “reading_ts”: “2020-02-14T12:19:27Z”, “sensor_id”: “aa-101”, “production_line”: “w01”, “widget_type”: “acme94”, “temp_celcius”: 23, “widget_weight_g”: 100 @rmoff #KafkaMeetup But what about processing these events? Let’s take an example of a widget factory. It’s churning out widgets, and we’ve got sensors on the production line. Maybe we want to • Alert if weight is outside threshold • Count how many widgets we’ve made • Monitor behaviour across devices for aberrations But also • Capture the data for longer-term analytics • Capture the data for ML training
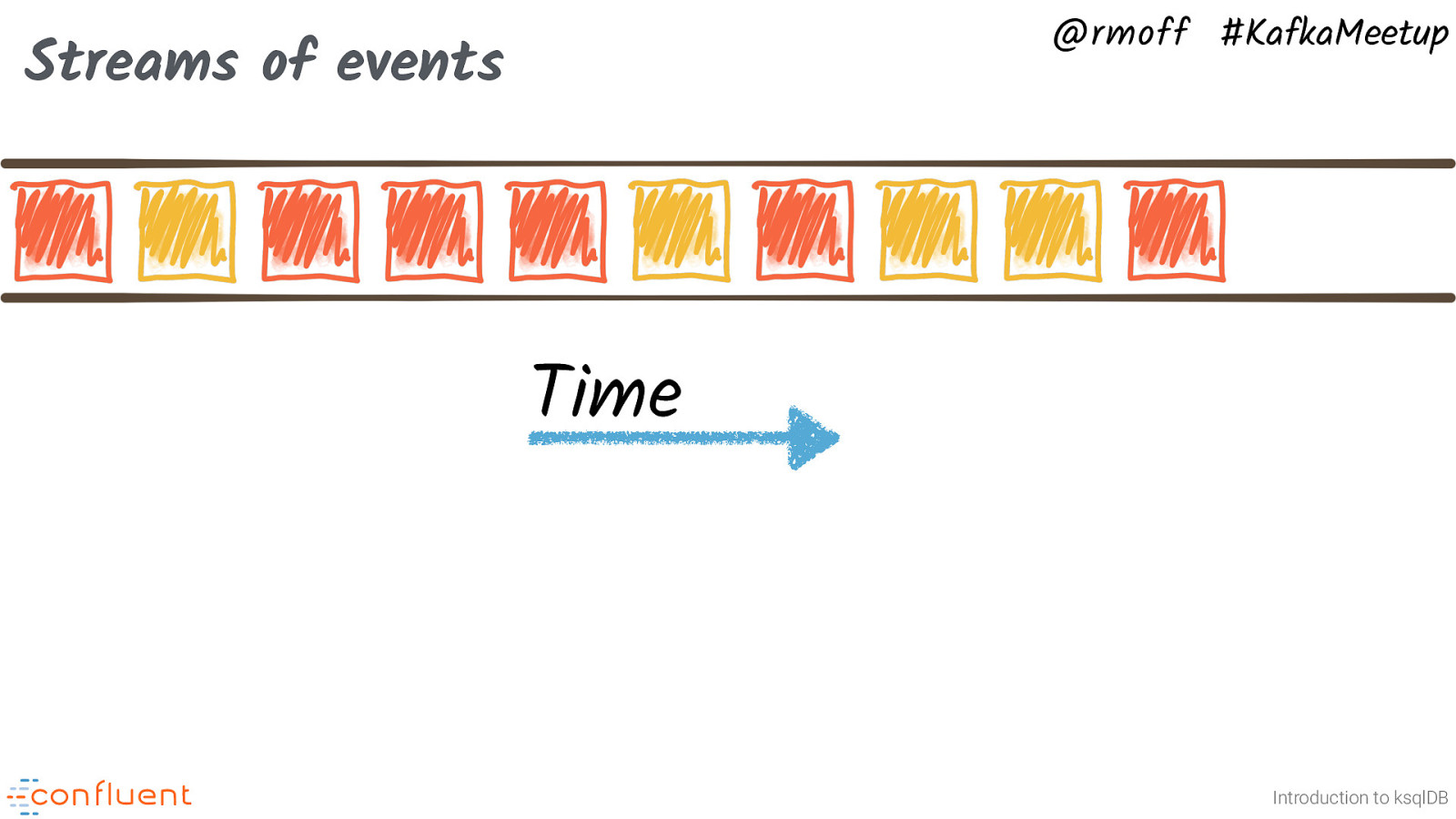
@rmoff #KafkaMeetup Streams of events Time Introduction to ksqlDB Let’s consider we mean by stream processing, and how it applies to our example of the factory data. Consider a stream of events about ‘widgets’ which have got a property of “colour”.
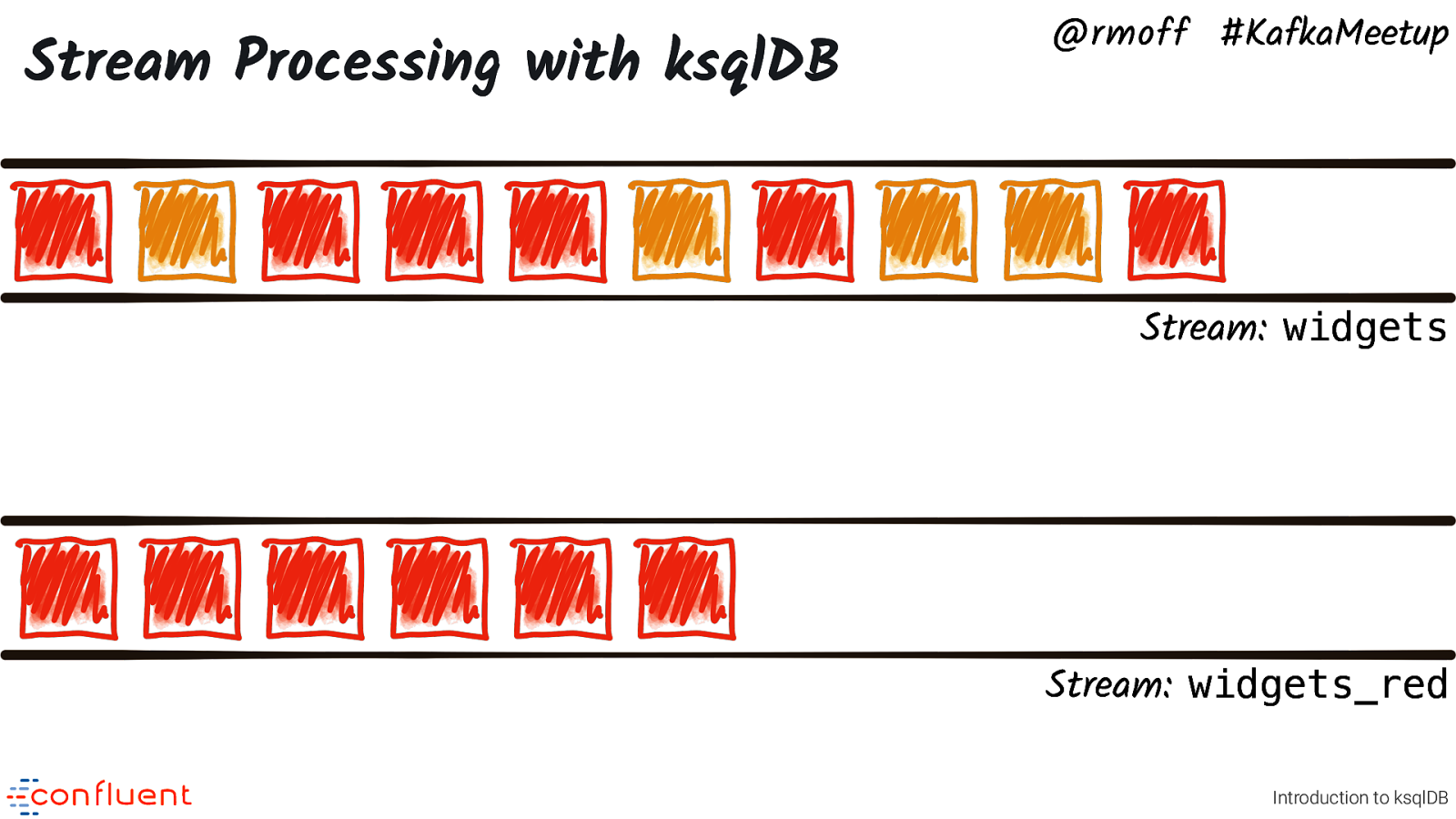
Stream Processing with ksqlDB @rmoff #KafkaMeetup Stream: widgets Stream: widgets_red Introduction to ksqlDB We’d like to create a new stream of events, which is just widgets that arrived which were red.
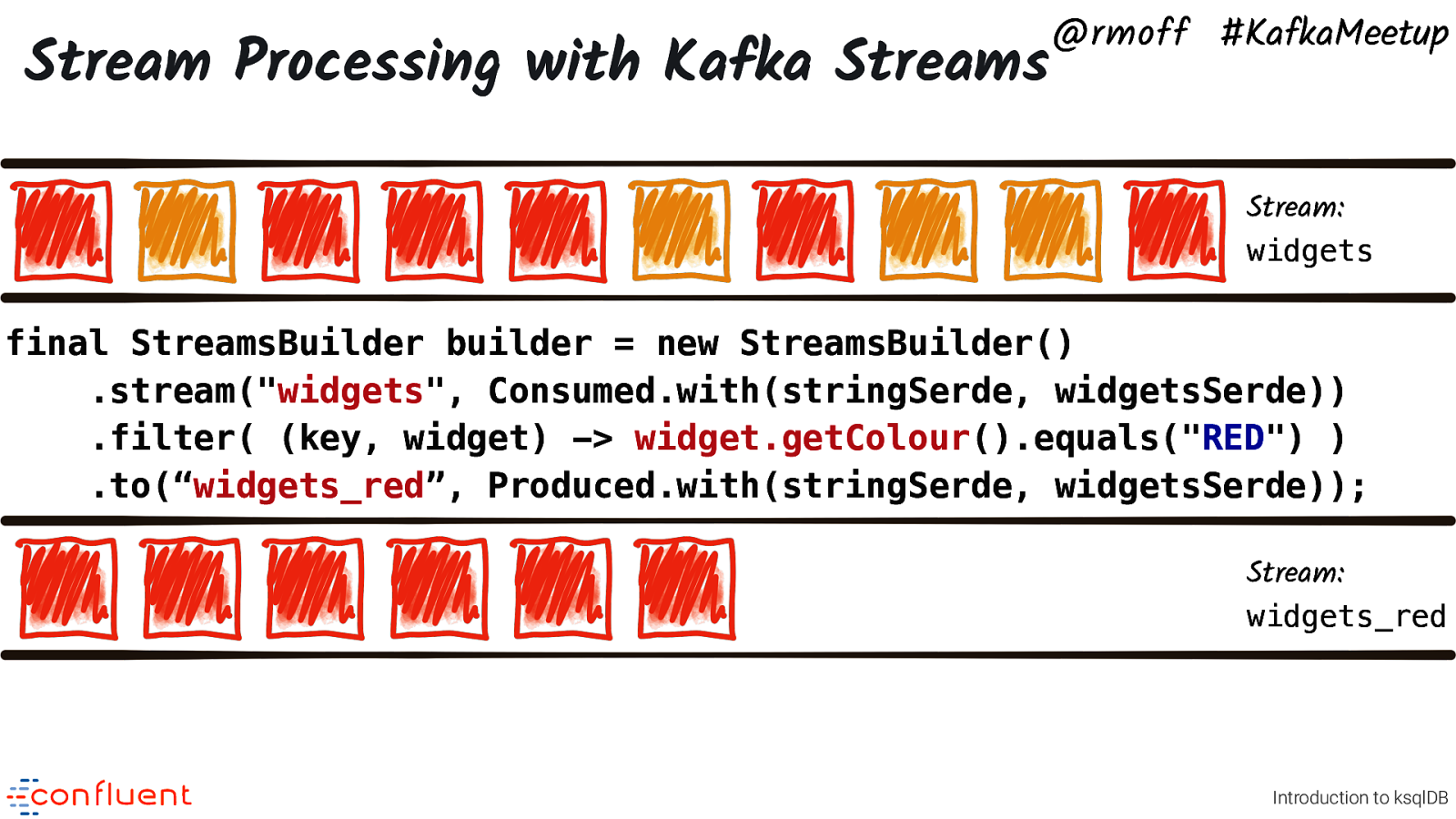
Stream Processing with Kafka Streams @rmoff #KafkaMeetup Stream: widgets final StreamsBuilder builder = new StreamsBuilder() .stream(“widgets”, Consumed.with(stringSerde, widgetsSerde)) .filter( (key, widget) -> widget.getColour().equals(“RED”) ) .to(“widgets_red”, Produced.with(stringSerde, widgetsSerde)); Stream: widgets_red Introduction to ksqlDB We can do this using Kafka Streams, which is a java library and part of Apache Kafka.
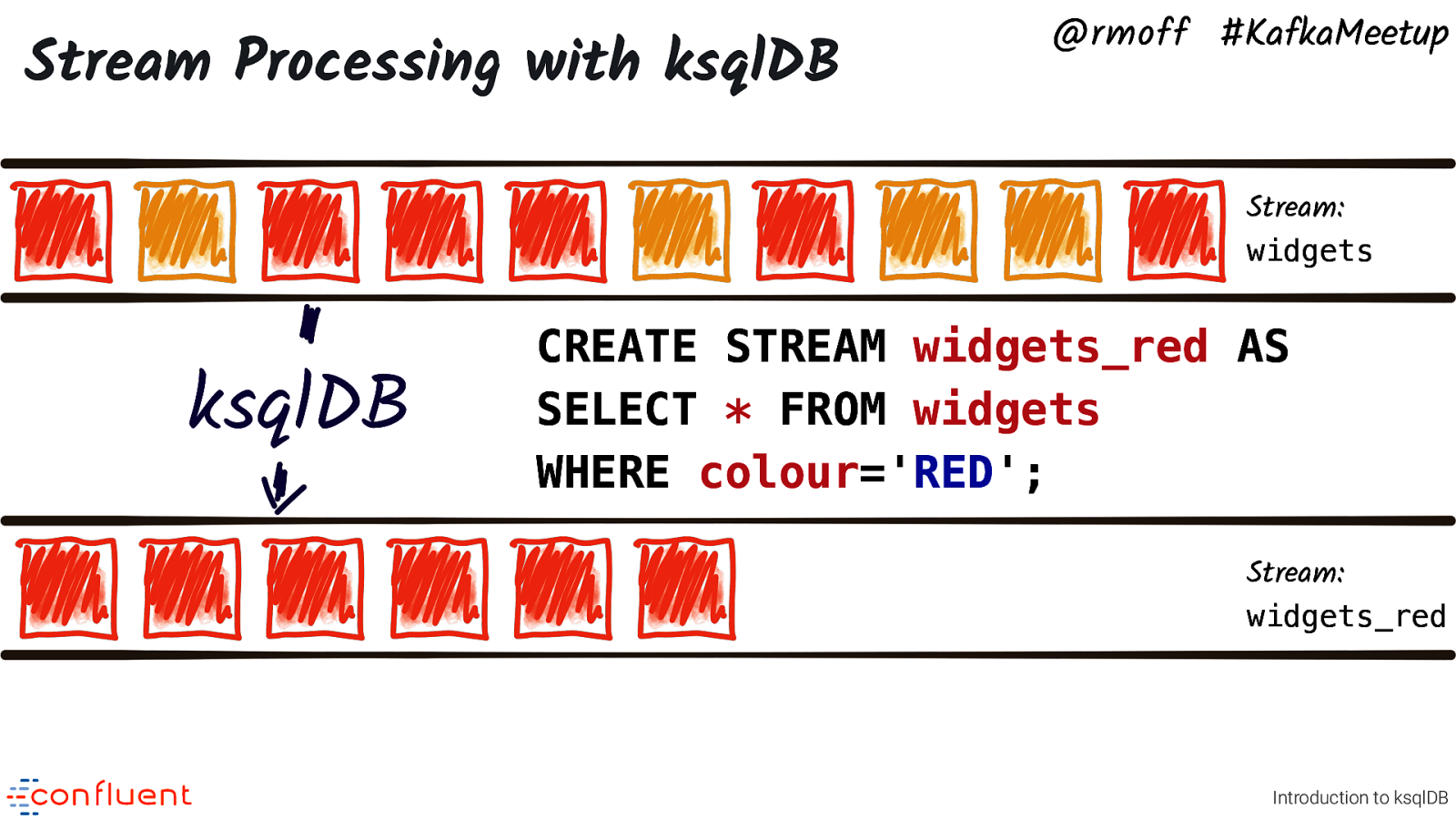
Stream Processing with ksqlDB @rmoff #KafkaMeetup Stream: widgets ksqlDB CREATE STREAM widgets_red AS SELECT * FROM widgets WHERE colour=’RED’; Stream: widgets_red Introduction to ksqlDB With ksqlDB we can apply this filter expressed in SQL. It’s just a SQL predicate. Write everything from here, to there, where the colour is RED.
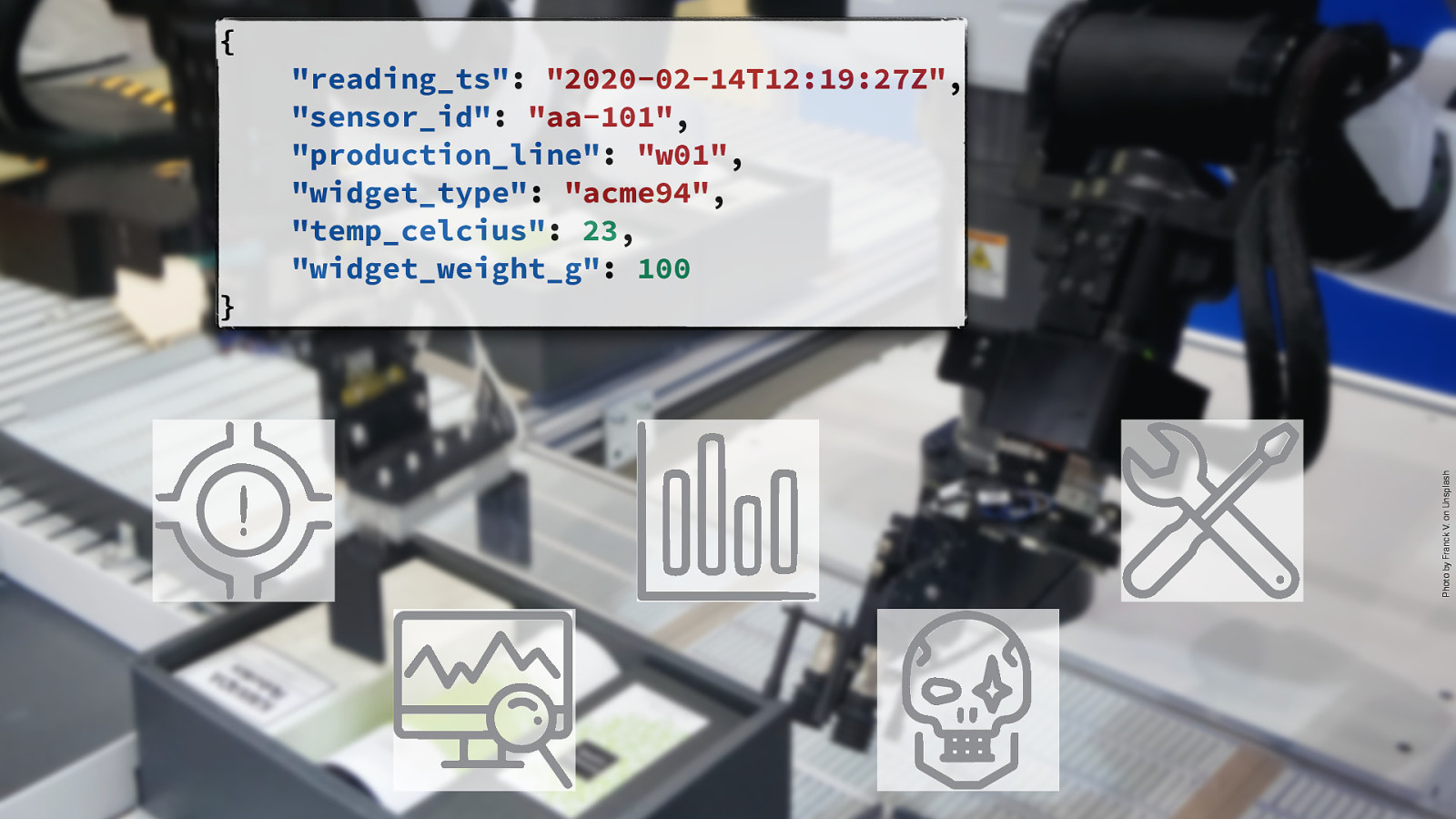
{ Photo by Franck V. on Unsplash } “reading_ts”: “2020-02-14T12:19:27Z”, “sensor_id”: “aa-101”, “production_line”: “w01”, “widget_type”: “acme94”, “temp_celcius”: 23, “widget_weight_g”: 100 @rmoff #KafkaMeetup But what about processing these events? Let’s take an example of a widget factory. It’s churning out widgets, and we’ve got sensors on the production line. Maybe we want to • Alert if weight is outside threshold • Count how many widgets we’ve made • Monitor behaviour across devices for aberrations But also • Capture the data for longer-term analytics • Capture the data for ML training
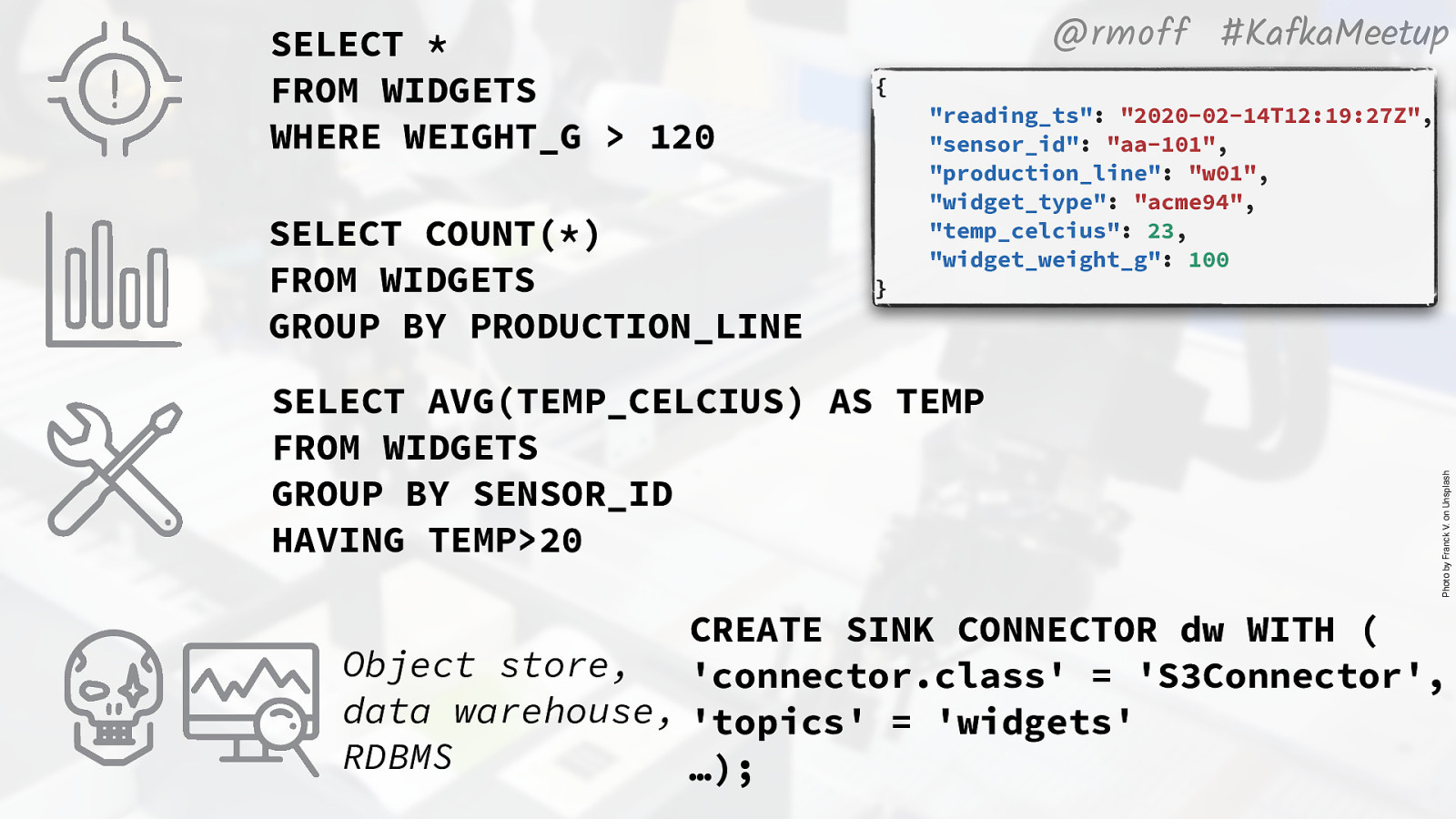
@rmoff #KafkaMeetup SELECT * FROM WIDGETS WHERE WEIGHT_G > 120 { SELECT COUNT() FROM WIDGETS GROUP BY PRODUCTION_LINE } SELECT AVG(TEMP_CELCIUS) AS TEMP FROM WIDGETS GROUP BY SENSOR_ID HAVING TEMP>20 Photo by Franck V. on Unsplash “reading_ts”: “2020-02-14T12:19:27Z”, “sensor_id”: “aa-101”, “production_line”: “w01”, “widget_type”: “acme94”, “temp_celcius”: 23, “widget_weight_g”: 100 CREATE SINK CONNECTOR dw WITH ( Object store, ‘connector.class’ = ‘S3Connector’, data warehouse, ‘topics’ = ‘widgets’ RDBMS …); Many of these things can be expressed as straight forward SQL. That’s the beauty of a DSL like SQL - it’s descriptive. <click> So we can define an alert using a predicate - a WHERE clause. “select events, where the weight in grams is over 120”. <click> We can describe other things we want to know. How many widgets have been produced on this line? “select count() … group by production_line”. So it’s maybe not quite as literal English as the predicate example, but the vast majority of people know enough SQL to understand exactly what you mean. <click> Same for monitoring equipment and things like the average temperature. It’s just SQL, except what we’re doing here is running it over a stream of events rather than polling a static lump of data in a database. <click> Sometimes though, it doesn’t make sense to use one tool for a job. It might be fun, but hitting a screw with a nail is rarely the best approach. So instead there are going to be some patterns in which we stream events to somewhere else. It could be an object store to feed into ML training, it could be a data warehouse for ad-hoc analytics.
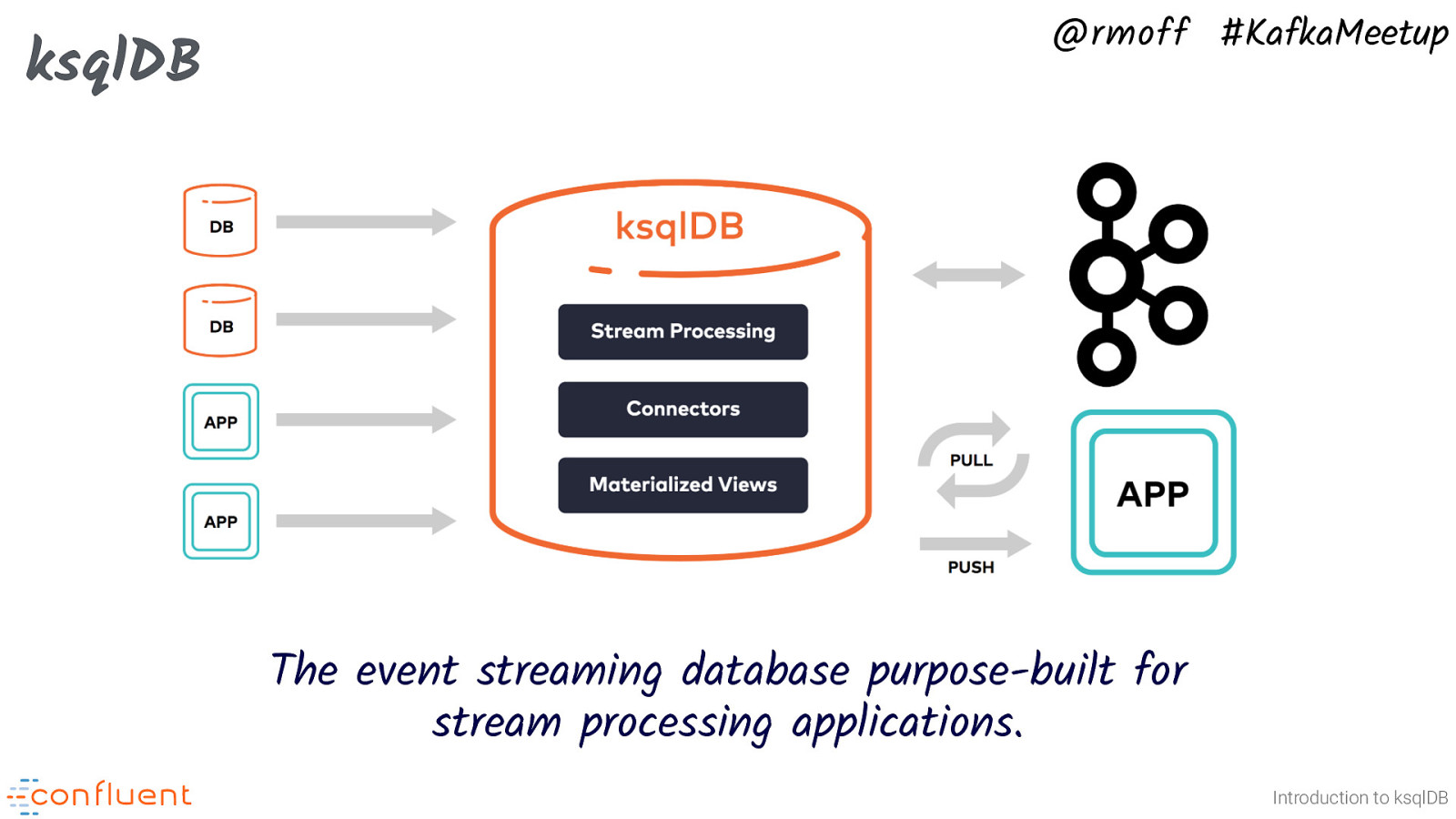
@rmoff #KafkaMeetup ksqlDB The event streaming database purpose-built for stream processing applications. Introduction to ksqlDB So this is where ksqlDB comes in. ksqlDB provides a SQL abstraction on top of data in Kafka. The data in Kafka is both existing data as well as new events as they arrive. In our widgets example the data from the sensors is being written into a Kafka topic, and then we can use ksqlDB with the exact SQL statements we saw a moment ago to do what we want with the data. ksqlDB supports much of standard SQL for manipulating data - JOIN, WHERE, GROUP BY, HAVING, CASE, etc etc ksqlDB also has built-in integration with many systems. • Pull data from sources into ksqlDB to process or enrich other data • Push data out to targets once processed Systems supported include databases, NoSQL stores, message queues, SaaS, syslog, and more
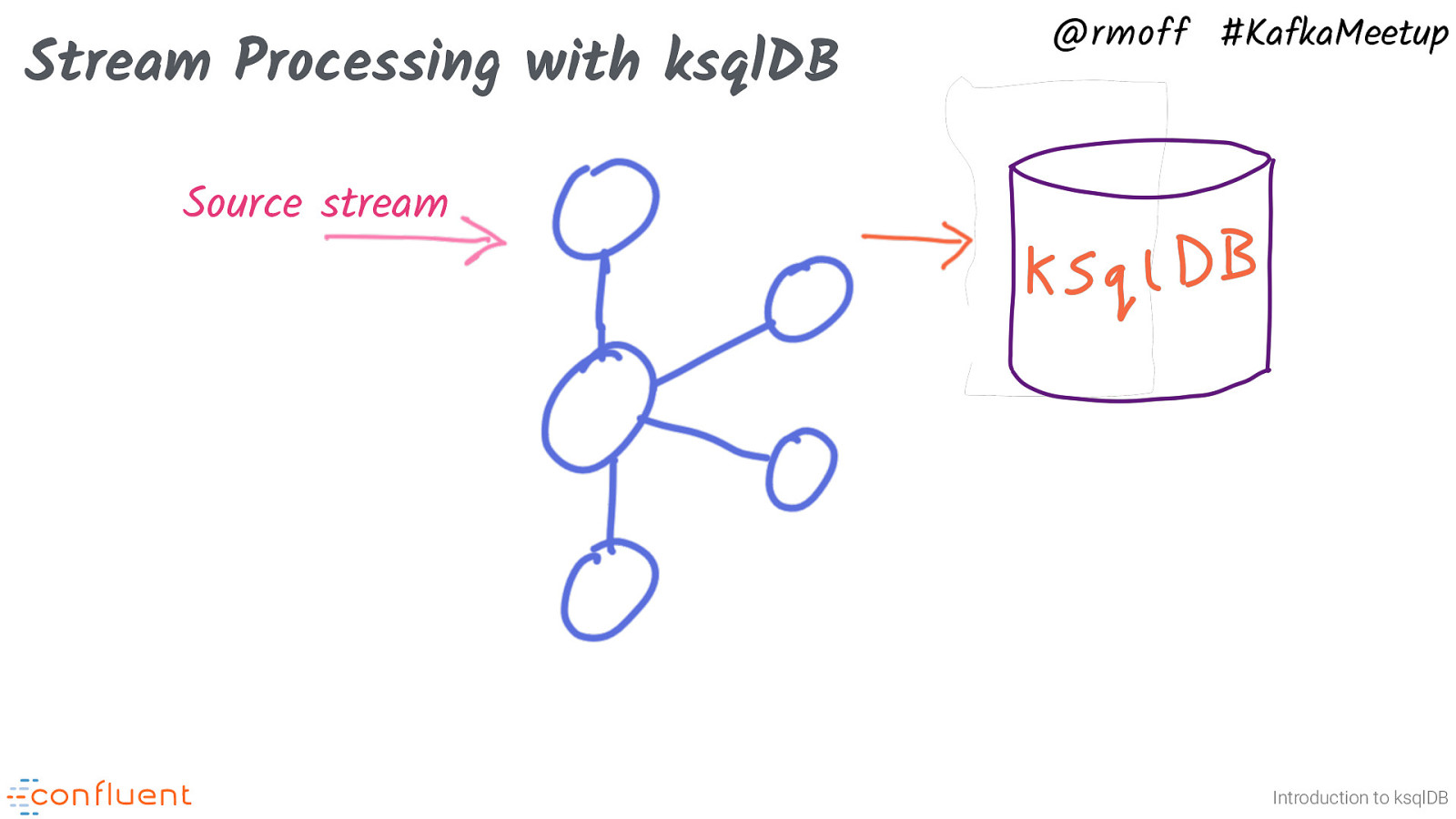
Stream Processing with ksqlDB @rmoff #KafkaMeetup Source stream Introduction to ksqlDB ksqlDB provides a SQL layer for working with data in Kafka It reads messages from Kafka topics, and can write to them too. ksqlDB lets you build stream processing applications. These are just SQL statements. The output of the SQL statement is written back into a Kafka topic. What kind of processing? Lots! * Filter * Enriching data with JOINs to other data in Kafka (or other systems such as databases, message queues). ksqlDB can create the connector to pull in data from these other systems. * Aggregate (SUM, COUNT, etc) * Transform (concatenate, explode arrays, CASE statements, etc)
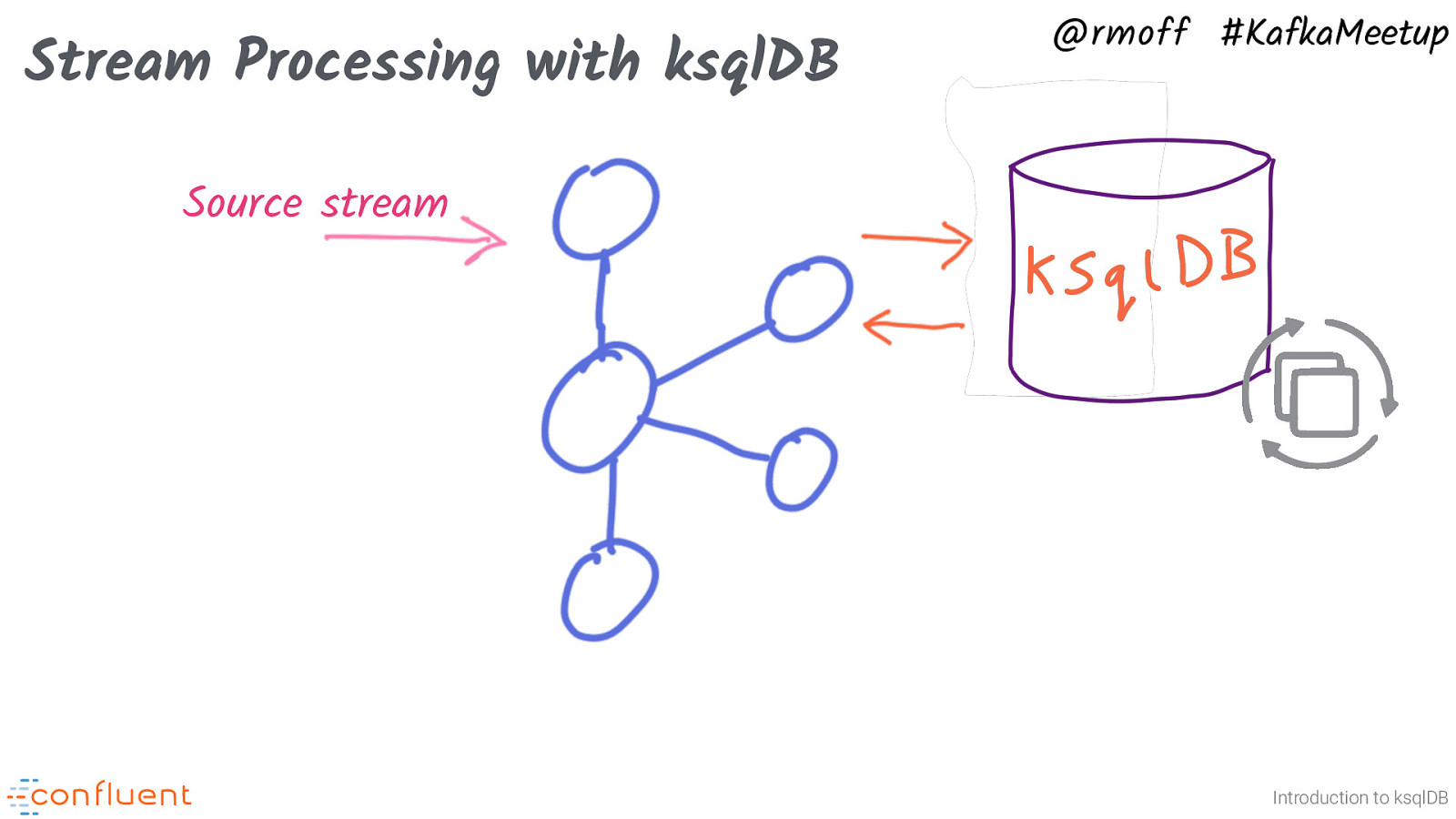
Stream Processing with ksqlDB @rmoff #KafkaMeetup Source stream Introduction to ksqlDB So ksqlDB queries write their data back into a Kafka topic. You can also just output the result to the screen which is useful when developing the SQL. Why write back to Kafka? Decoupling.
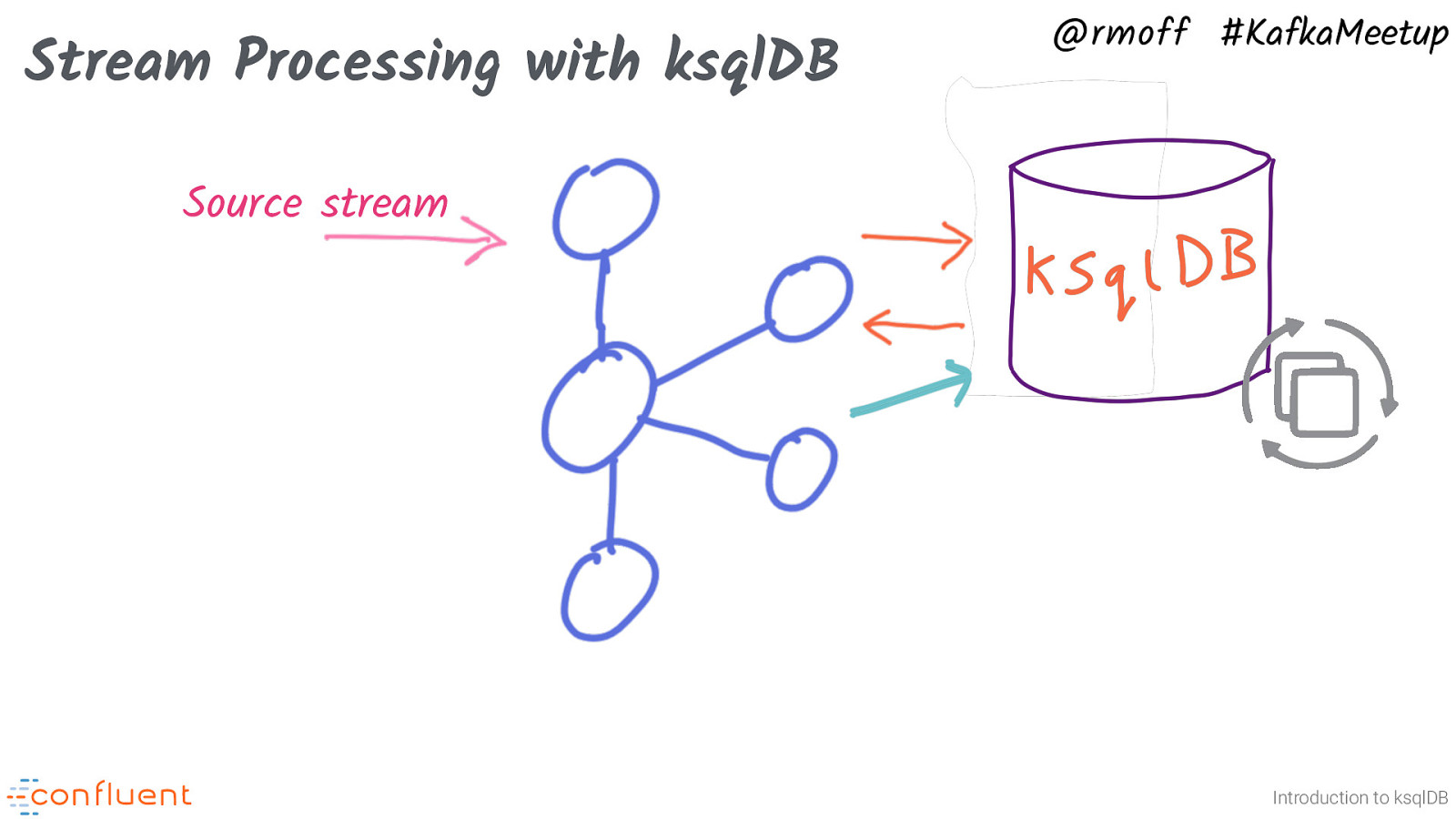
Stream Processing with ksqlDB @rmoff #KafkaMeetup Source stream Introduction to ksqlDB It could be that you want to transform the data further. You’d just read from the additional ksqlDB stream, and this way you can daisy-chain transformations.
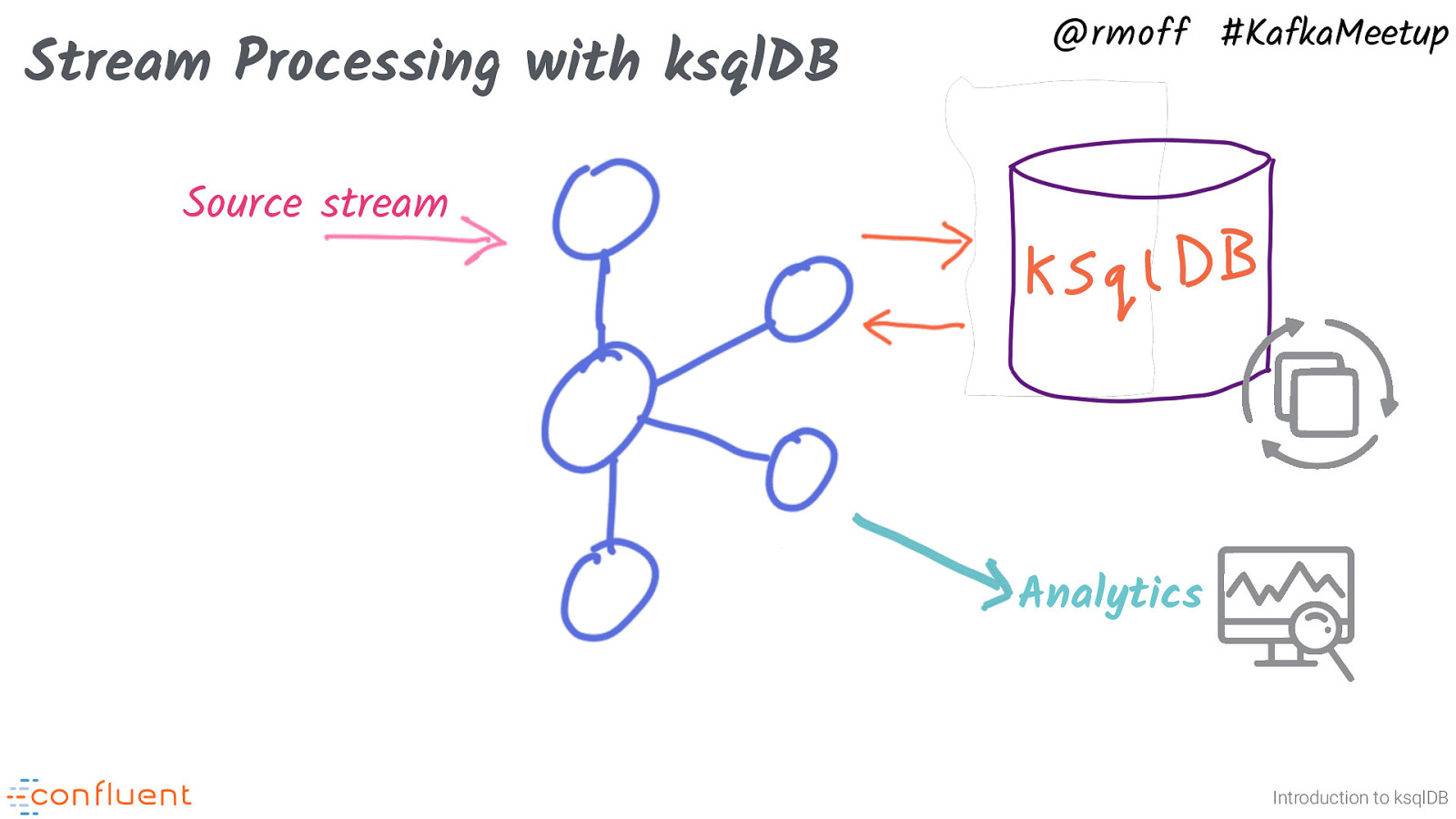
Stream Processing with ksqlDB @rmoff #KafkaMeetup Source stream Analytics Introduction to ksqlDB Often though, the purpose of a stream processing application is to prepare the stream in a way to make it suitable for use subsequently. There are two main patterns here • The data needs to be wrangled to get it into a form that can be loaded to a downstream datastore, such as Elasticsearch, HDFS, MySQL, etc. In this case ksqlDB can actually create the connector to send the data where it’s needed.
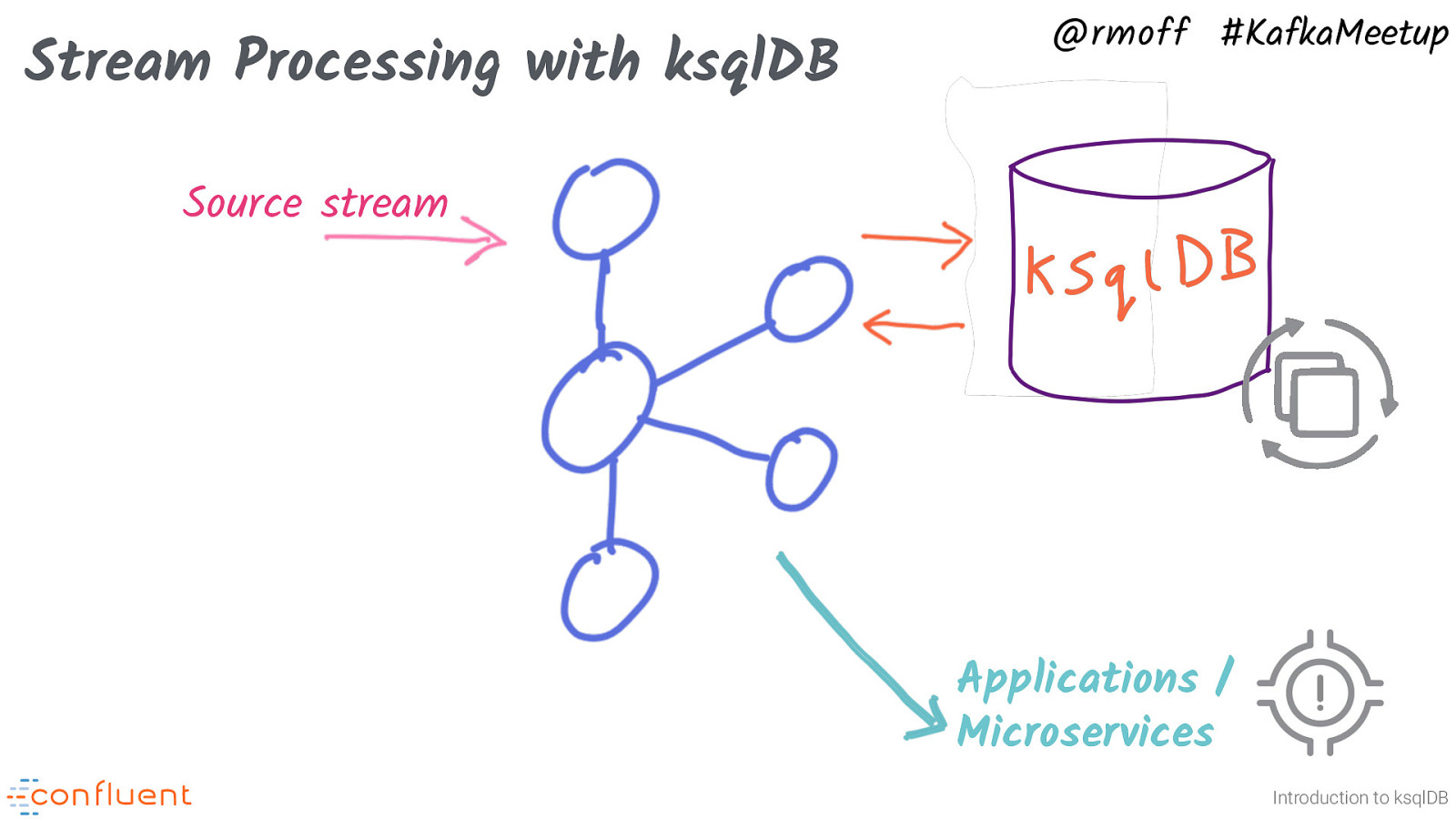
@rmoff #KafkaMeetup Stream Processing with ksqlDB Source stream Applications / Microservices Introduction to ksqlDB The second pattern is that ksqlDB provides the data required by an application. This could be in two ways: For an event-driven application, ksqlDB can prepare the event stream. For example, an order processing service. ksqlDB filters a stream of order events just for those which have been paid and passed fraud. The resulting stream is a topic to which the app can subscribe.
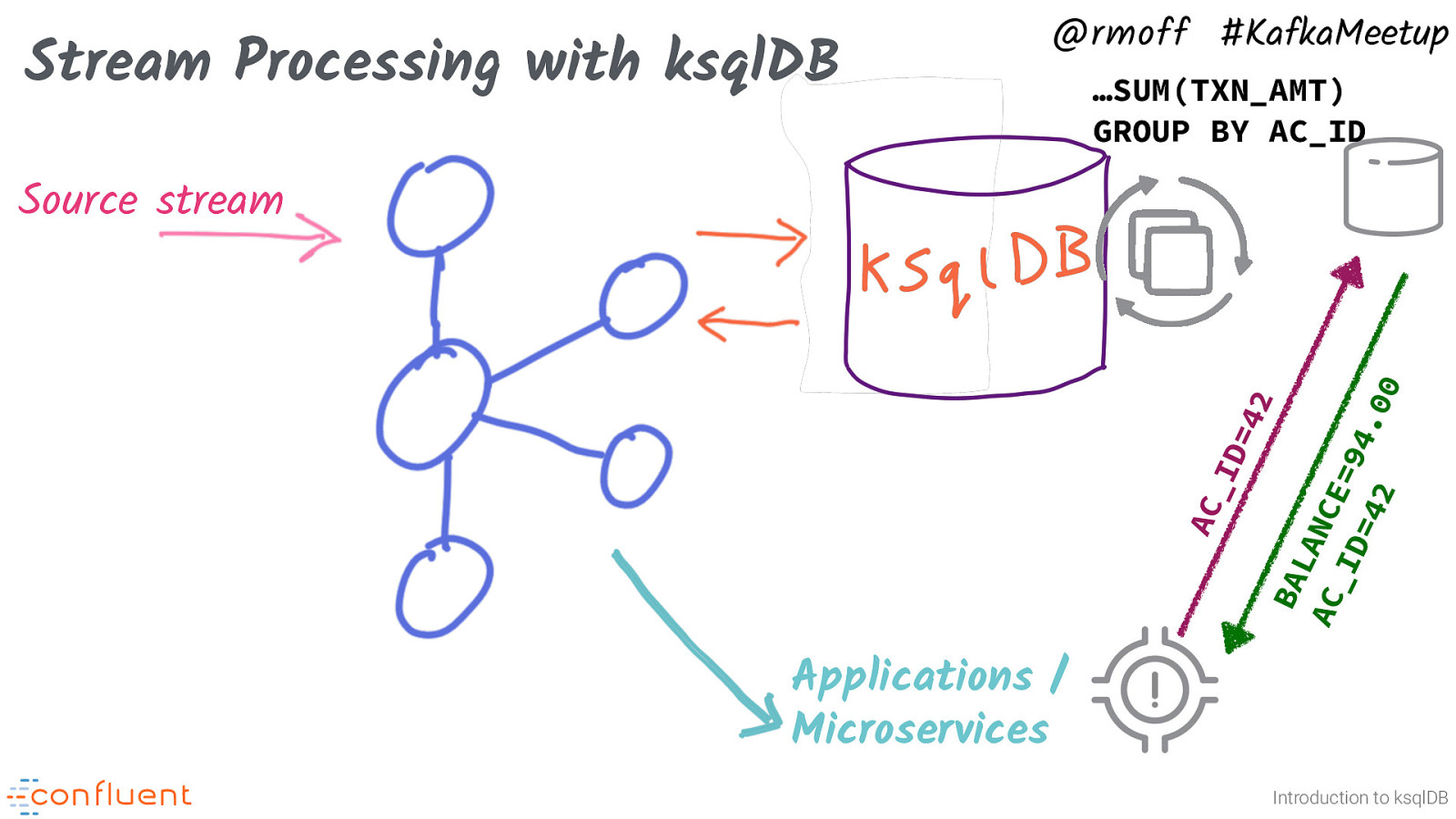
Stream Processing with ksqlDB @rmoff #KafkaMeetup …SUM(TXN_AMT) GROUP BY AC_ID AC _I D= 42 BA L AC ANCE _I D= =94. 42 00 Source stream Applications / Microservices Introduction to ksqlDB ksqlDB is not just about state-less transformation though. It can also calculate state from the events that it processes, and applications can do key/value lookups against this state directly. For example, given a stream of account transactions, what’s the balance for a given user?

Photo by Raoul Droog on Unsplash @rmoff #KafkaMeetup DEMO Introduction to ksqlDB See https://github.com/confluentinc/demo-scene/tree/ksqldb-introduction-feb20/introduction-to-ksqldb
Interacting with ksqlDB Photo by Tim Mossholder on Unsplash ksqlDB has several ways that you can interact with it, including a command line interface. If you’ve used CLIs from relational databases like Oracle’s sql*plus, or Postgres’ psql you’ll feel at home with this.
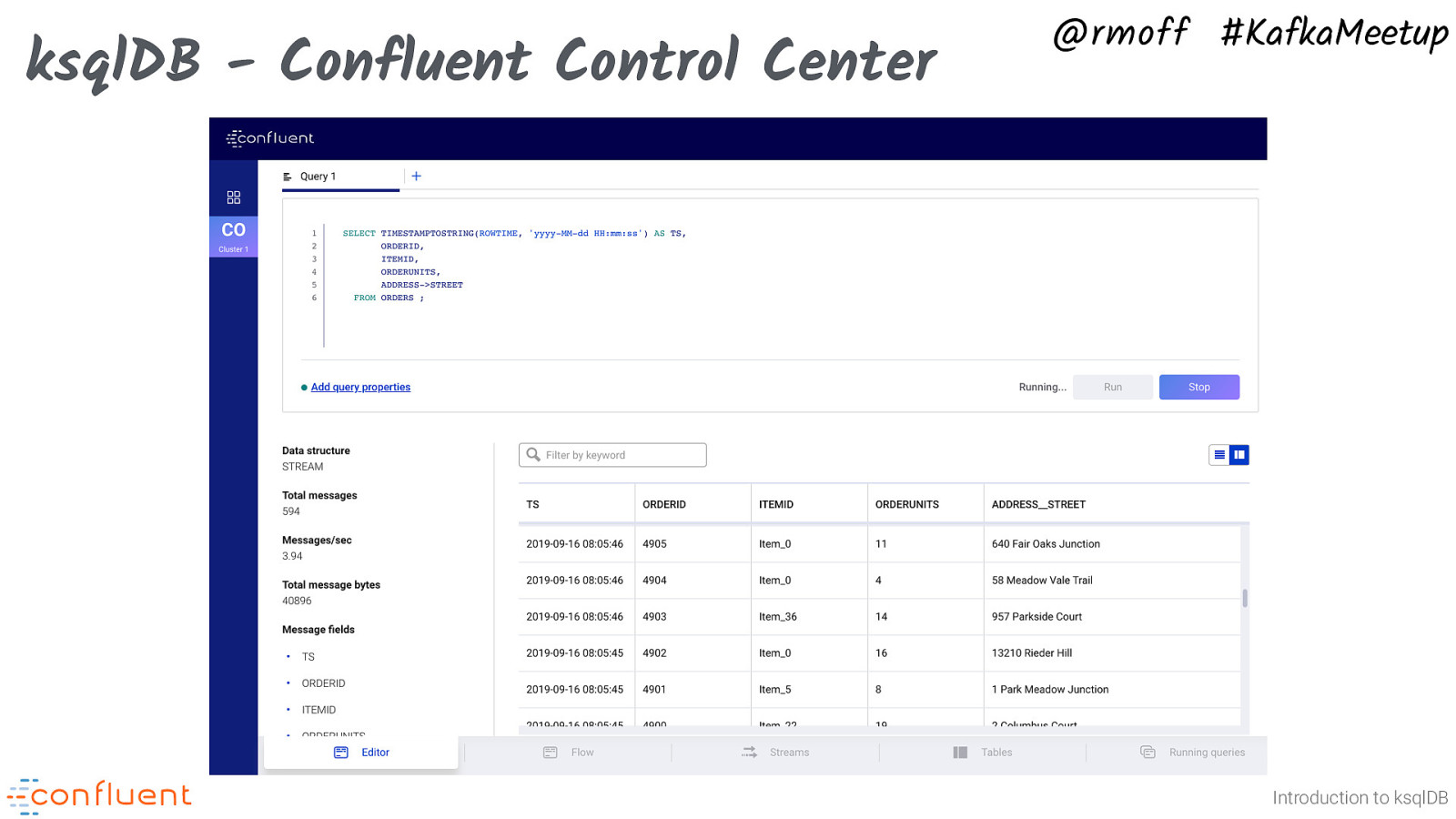
ksqlDB - Confluent Control Center @rmoff #KafkaMeetup Introduction to ksqlDB There’s also a web-based UI for ksqlDB that you’ll find in both Confluent Control Center (for self-managed deployments) and Confluent Cloud. You can use Confluent Control Center for free with a single Kafka broker (e.g. a developer laptop environment), or license it as part of Confluent Platform. Nit: ksqlDB is the new name for what we used to call KSQL. As of version 5.4 (February 2020) the official naming in the Confluent Platform distribution and on Confluent Cloud is KSQL.
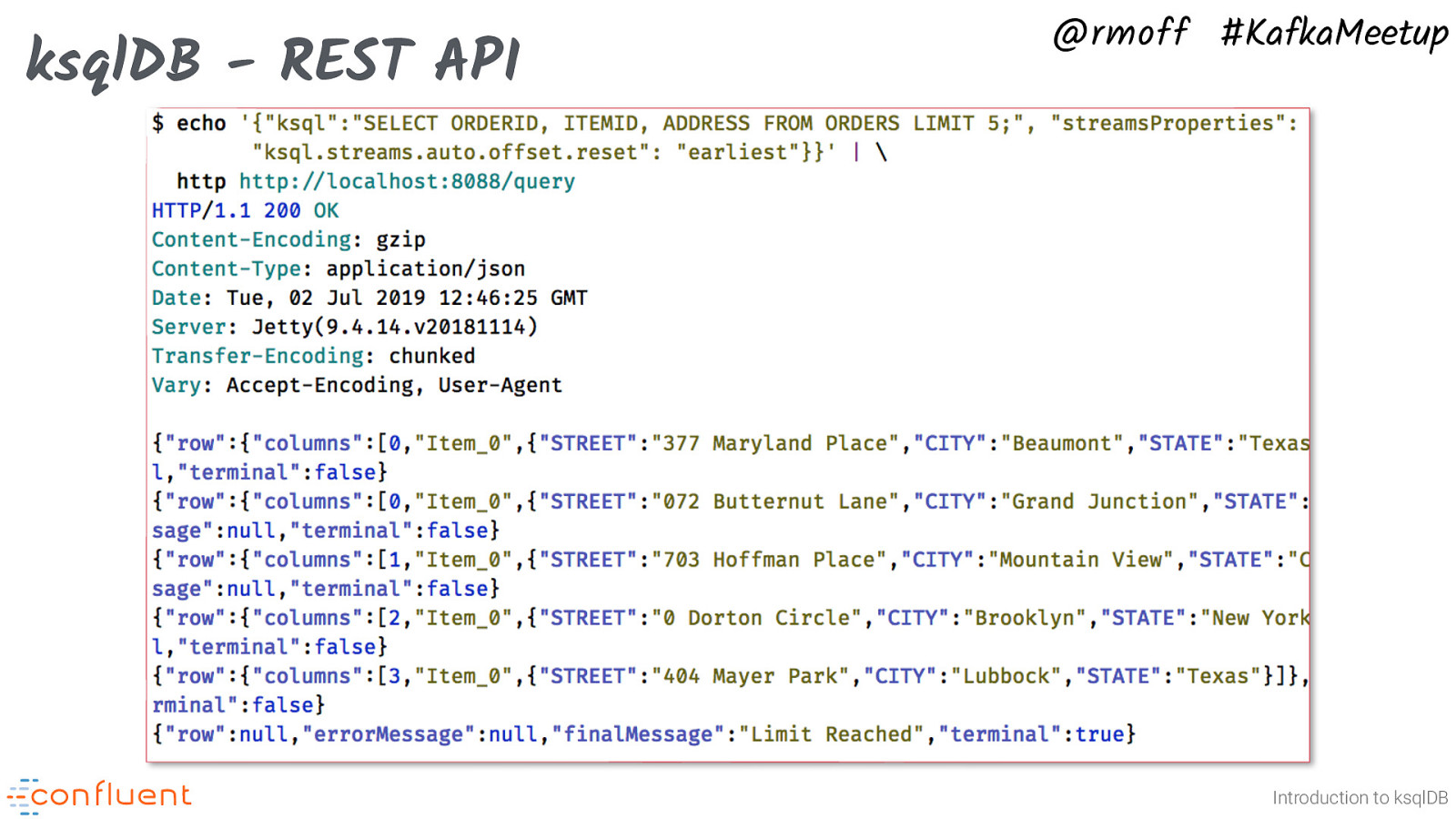
ksqlDB - REST API @rmoff #KafkaMeetup Introduction to ksqlDB The REST API is useful for programmatic access to ksqlDB and for scripted deployments of applications.
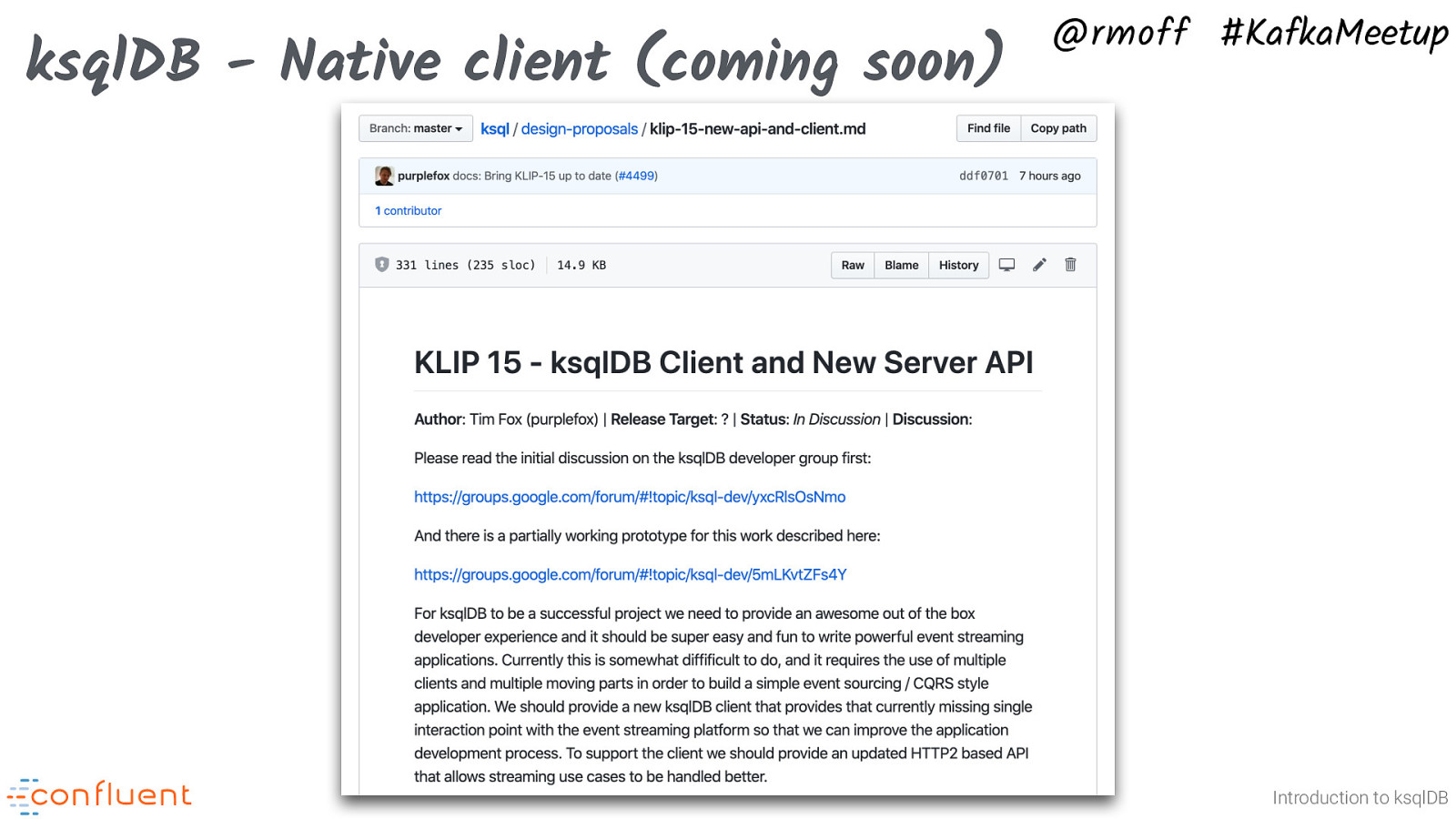
ksqlDB - Native client (coming soon) @rmoff #KafkaMeetup Introduction to ksqlDB Not available yet, but planned as part KLIP-15 (https://github.com/confluentinc/ksql/blob/master/design-proposals/klip-15-new-api-and-client.md) is a native client for Java, Javascript, Go, etc.

@rmoff #KafkaMeetup @rmoff #KafkaMeetup What else can ksqlDB do? Photo by Sereja Ris on Unsplash Introduction to ksqlDB It’s SQL—so what can you do with SQL? Lots.
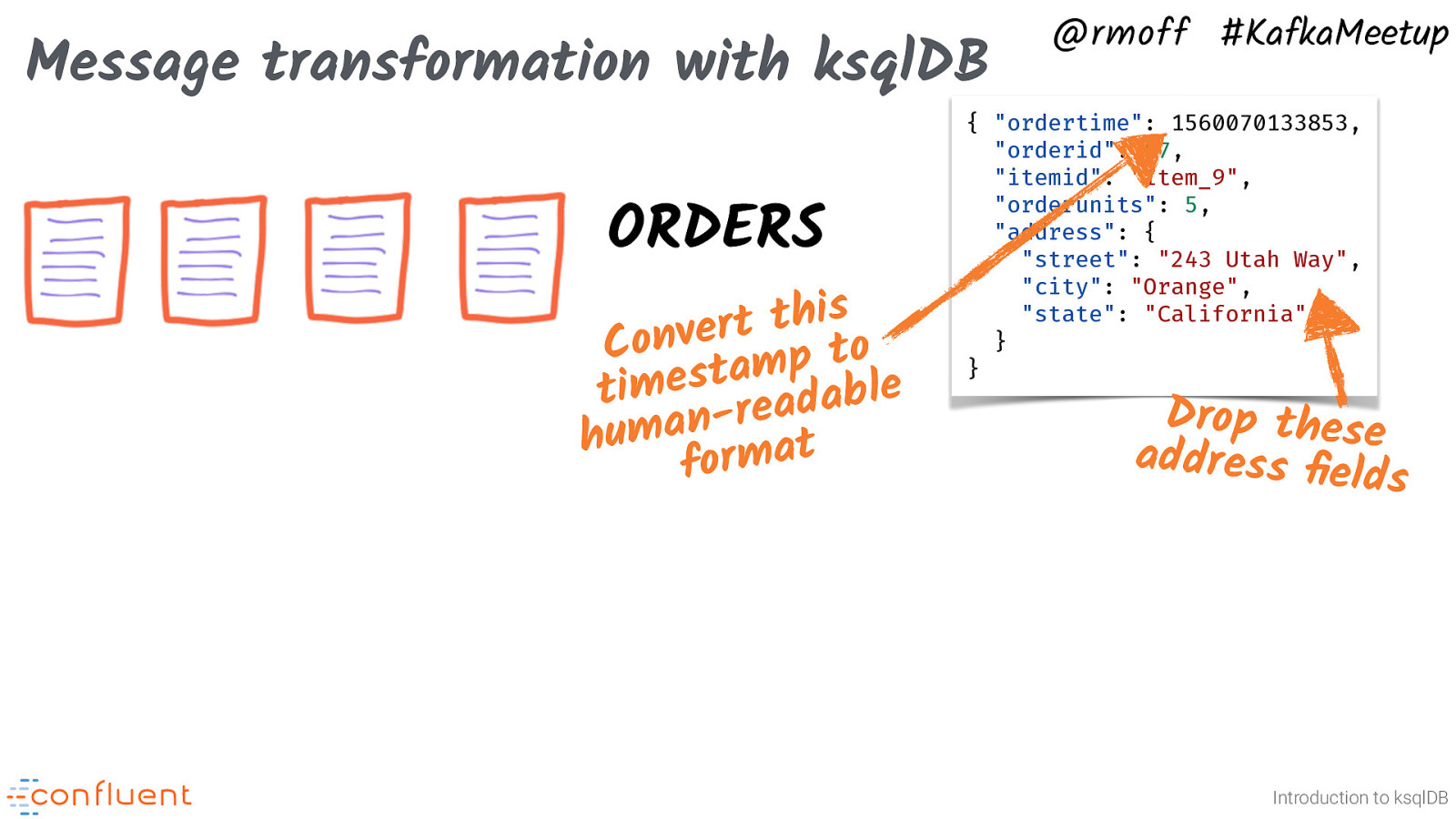
Message transformation with ksqlDB ORDERS this t r e v n o C mp to e a t s e m i t adabl e r n a hum rmat fo @rmoff #KafkaMeetup { “ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5, “address”: { “street”: “243 Utah Way”, “city”: “Orange”, “state”: “California” } } Drop these address field s Introduction to ksqlDB
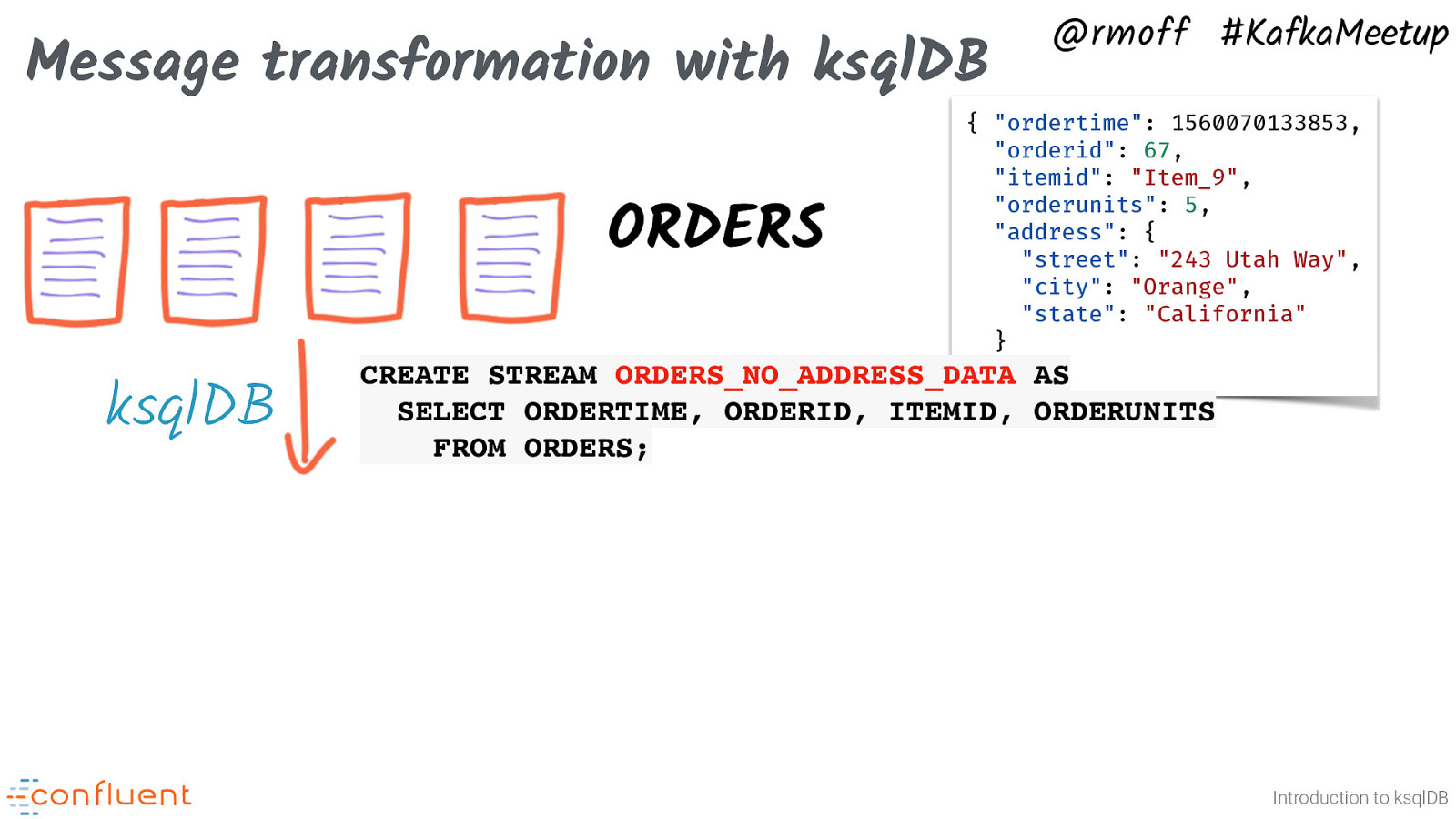
Message transformation with ksqlDB @rmoff #KafkaMeetup { “ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5, “address”: { “street”: “243 Utah Way”, “city”: “Orange”, “state”: “California” } } ORDERS_NO_ADDRESS_DATA AS ORDERS ksqlDB CREATE STREAM SELECT ORDERTIME, ORDERID, ITEMID, ORDERUNITS FROM ORDERS; Introduction to ksqlDB
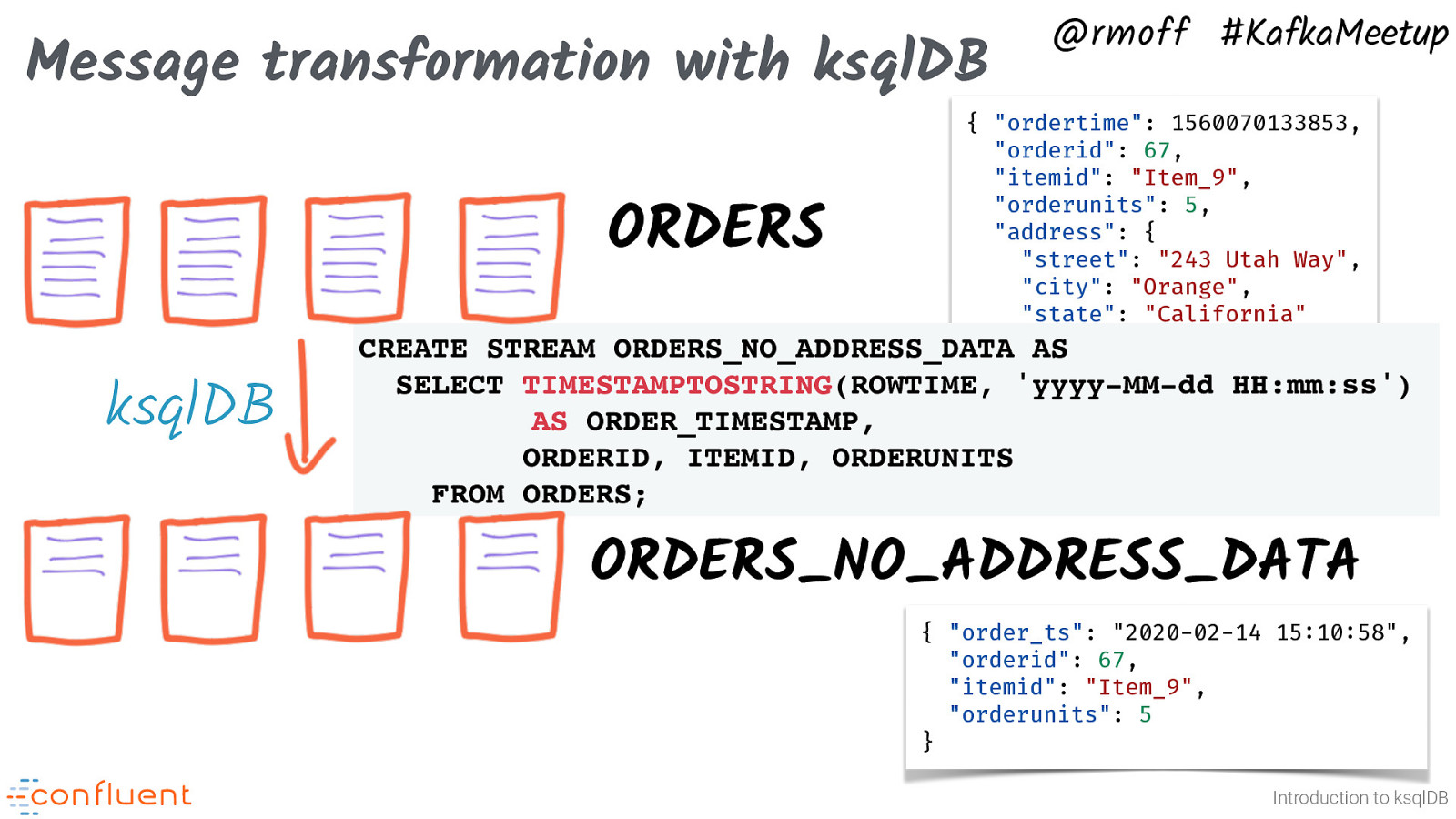
Message transformation with ksqlDB @rmoff #KafkaMeetup { “ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5, “address”: { “street”: “243 Utah Way”, “city”: “Orange”, “state”: “California” } ORDERS_NO_ADDRESS_DATA AS } ORDERS ksqlDB CREATE STREAM SELECT TIMESTAMPTOSTRING(ROWTIME, ‘yyyy-MM-dd HH:mm:ss’) AS ORDER_TIMESTAMP, ORDERID, ITEMID, ORDERUNITS FROM ORDERS; ORDERS_NO_ADDRESS_DATA { “order_ts”: “2020-02-14 15:10:58”, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5 } Introduction to ksqlDB
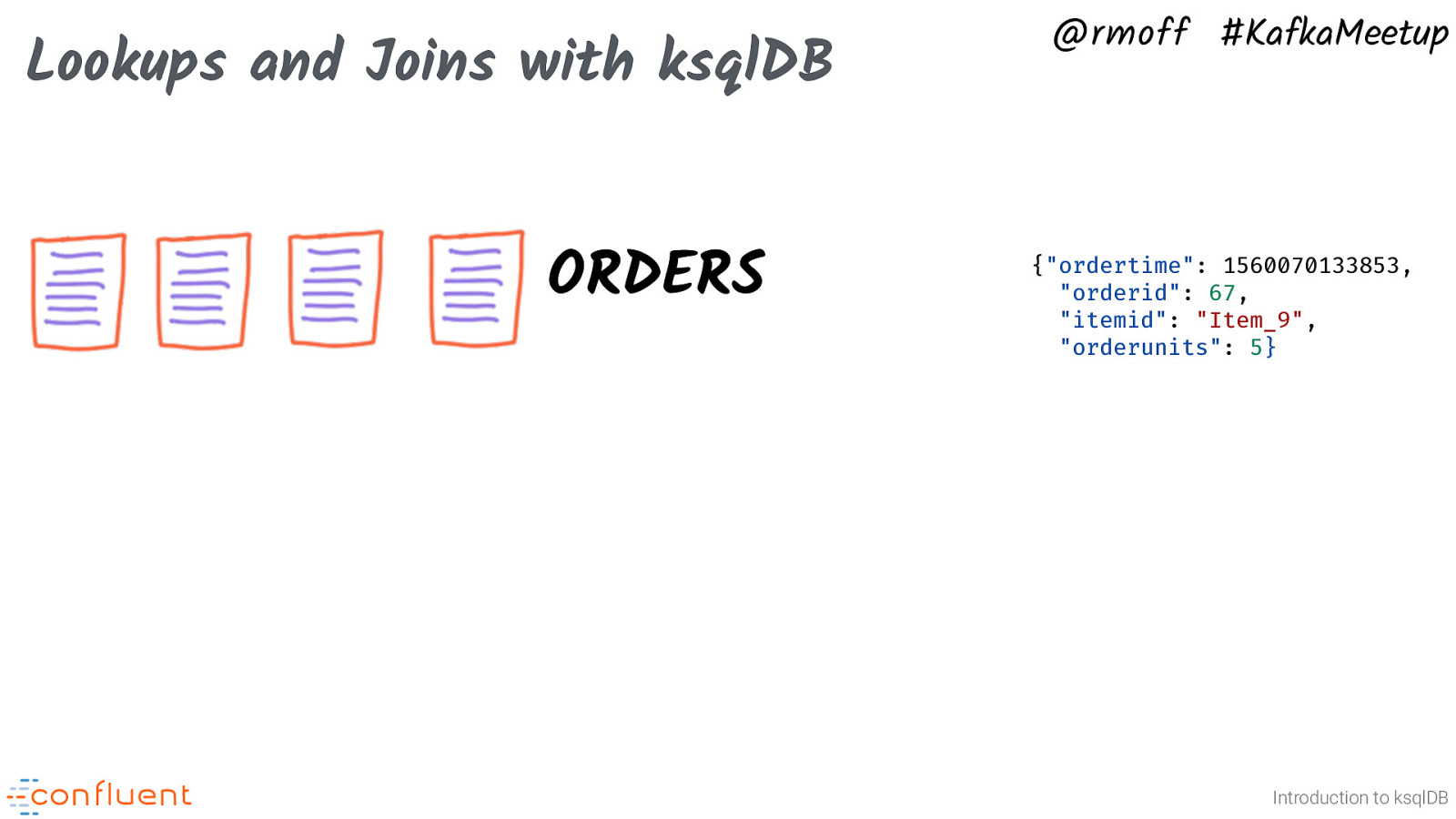
Lookups and Joins with ksqlDB ORDERS @rmoff #KafkaMeetup {“ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5} Introduction to ksqlDB
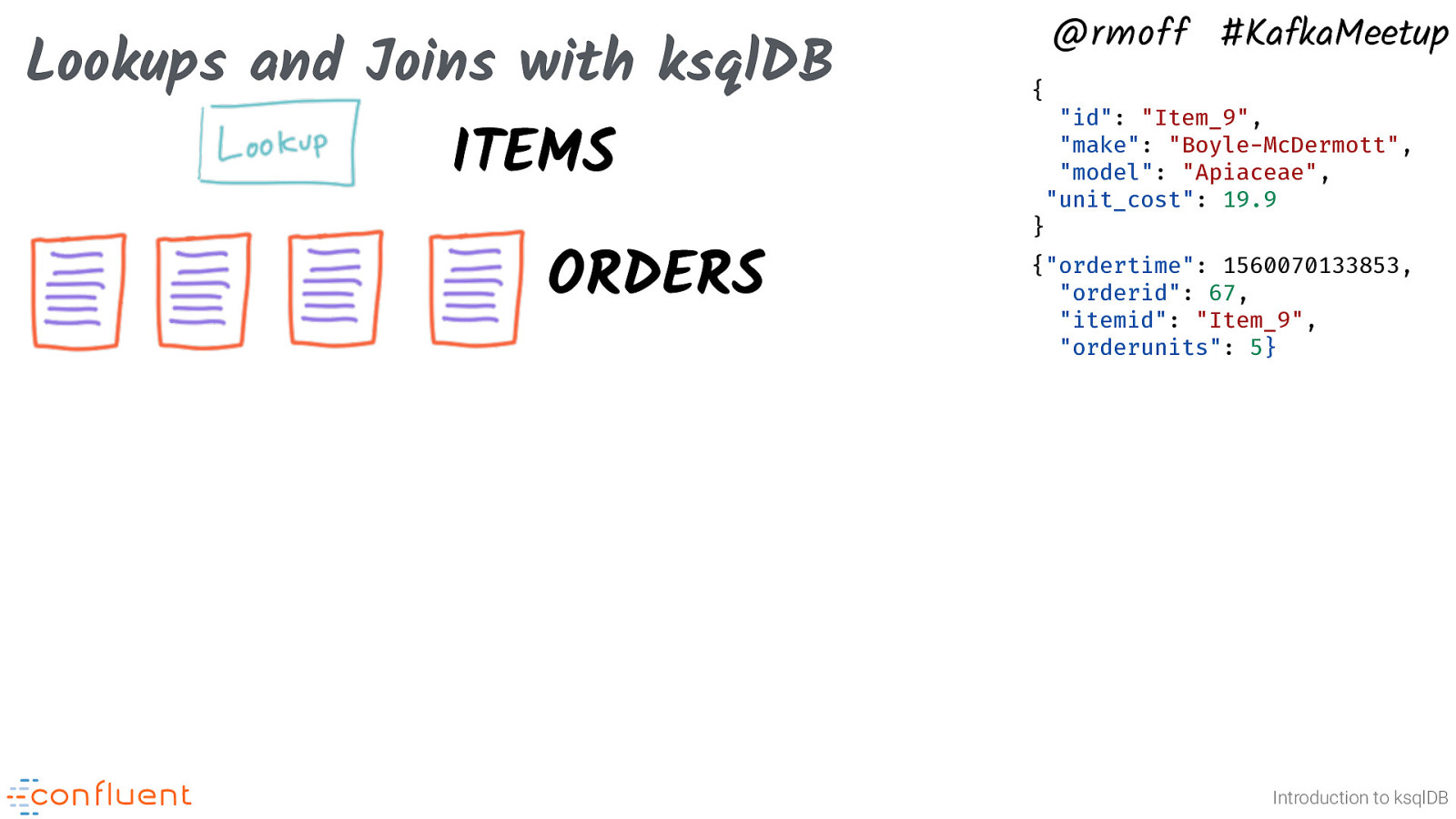
Lookups and Joins with ksqlDB @rmoff #KafkaMeetup { “id”: “Item_9”, “make”: “Boyle-McDermott”, “model”: “Apiaceae”, “unit_cost”: 19.9 ITEMS ORDERS } {“ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5} Introduction to ksqlDB

Lookups and Joins with ksqlDB @rmoff #KafkaMeetup { “id”: “Item_9”, “make”: “Boyle-McDermott”, “model”: “Apiaceae”, “unit_cost”: 19.9 ITEMS ORDERS ksqlDB CREATE STREAM ORDERS_ENRICHED AS SELECT O., I., O.ORDERUNITS * I.UNIT_COST AS TOTAL_ORDER_VALUE, FROM ORDERS O INNER JOIN ITEMS I ON O.ITEMID = I.ID ; } {“ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5} Introduction to ksqlDB
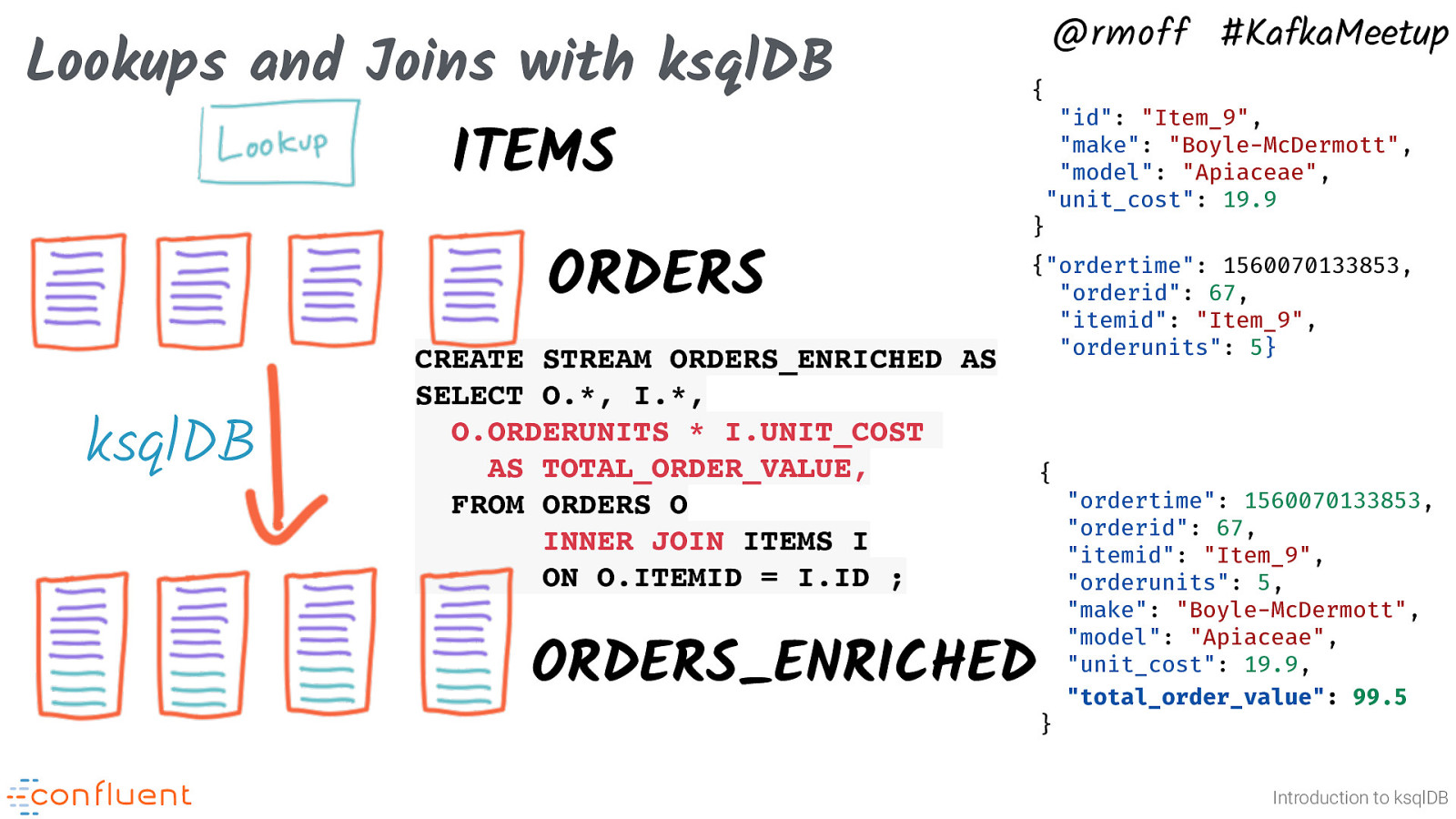
Lookups and Joins with ksqlDB @rmoff #KafkaMeetup { “id”: “Item_9”, “make”: “Boyle-McDermott”, “model”: “Apiaceae”, “unit_cost”: 19.9 ITEMS ORDERS ksqlDB CREATE STREAM ORDERS_ENRICHED AS SELECT O., I., O.ORDERUNITS * I.UNIT_COST AS TOTAL_ORDER_VALUE, FROM ORDERS O INNER JOIN ITEMS I ON O.ITEMID = I.ID ; } {“ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5} { ORDERS_ENRICHED “ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5, “make”: “Boyle-McDermott”, “model”: “Apiaceae”, “unit_cost”: 19.9, “total_order_value”: 99.5 } Introduction to ksqlDB

Connecting ksqlDB to other systems Photo by Mak on Unsplash @rmoff #KafkaMeetup Introduction to ksqlDB
Connecting ksqlDB to other systems @rmoff #KafkaMeetup syslog Google BigQuery Amazon S3 Introduction to ksqlDB
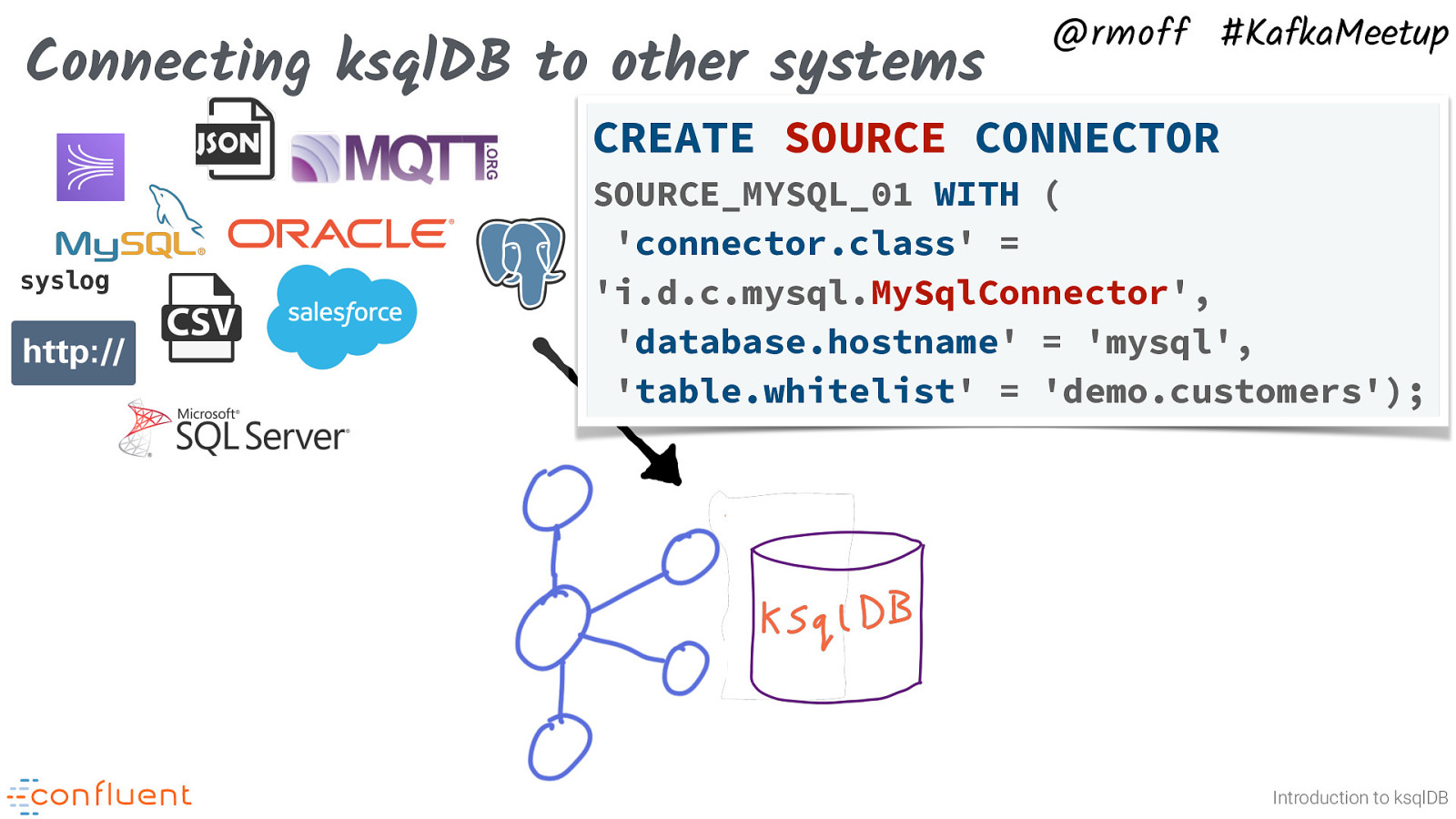
Connecting ksqlDB to other systems @rmoff #KafkaMeetup CREATE SOURCE CONNECTOR syslog SOURCE_MYSQL_01 WITH ( ‘connector.class’ = ‘i.d.c.mysql.MySqlConnector’, ‘database.hostname’ = ‘mysql’, ‘table.whitelist’ = ‘demo.customers’); Introduction to ksqlDB
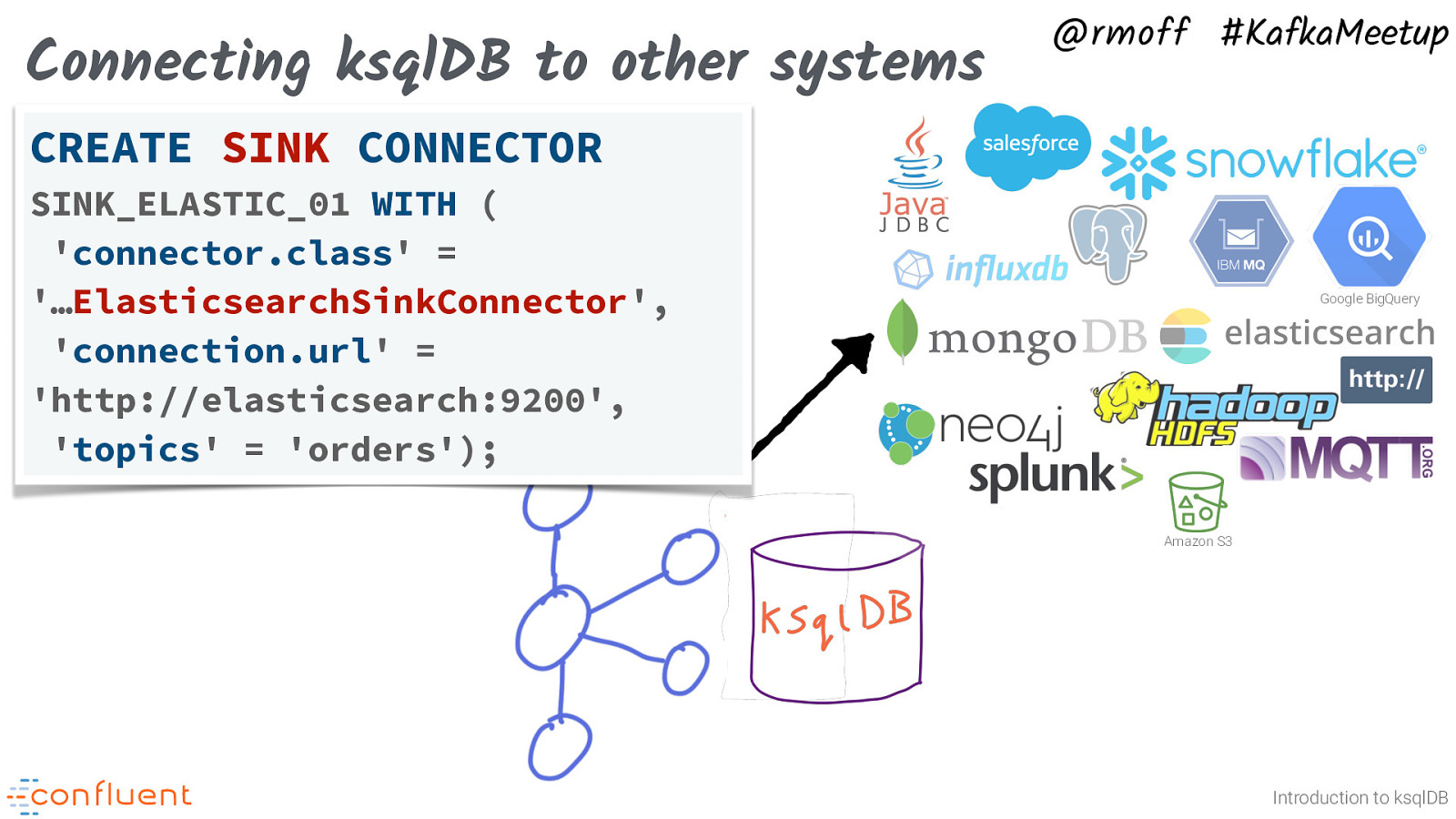
Connecting ksqlDB to other systems @rmoff #KafkaMeetup CREATE SINK CONNECTOR SINK_ELASTIC_01 WITH ( ‘connector.class’ = ‘…ElasticsearchSinkConnector’, ‘connection.url’ = ‘http://elasticsearch:9200’, ‘topics’ = ‘orders’); Google BigQuery Amazon S3 Introduction to ksqlDB

@rmoff #KafkaMeetup Streams & Tables Introduction to ksqlDB
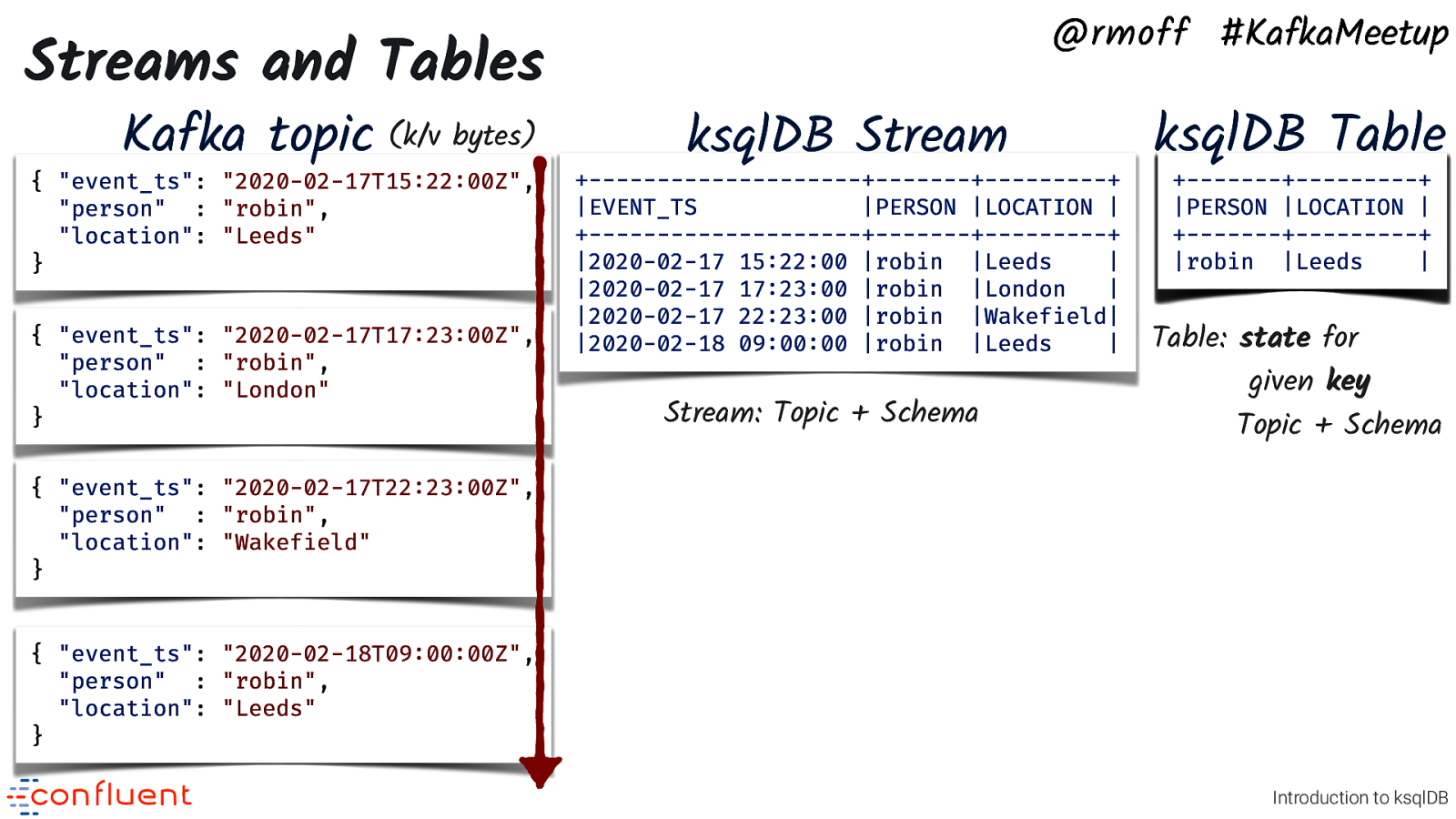
Streams and Tables Kafka topic (k/v bytes) { “event_ts”: “2020-02-17T15:22:00Z”, “person” : “robin”, “location”: “Leeds” } { “event_ts”: “2020-02-17T17:23:00Z”, “person” : “robin”, “location”: “London” } @rmoff #KafkaMeetup ksqlDB Stream +——————————+———-+————-+ |EVENT_TS |PERSON |LOCATION | +——————————+———-+————-+ |2020-02-17 15:22:00 |robin |Leeds | |2020-02-17 17:23:00 |robin |London | |2020-02-17 22:23:00 |robin |Wakefield| |2020-02-18 09:00:00 |robin |Leeds | Stream: Topic + Schema ksqlDB Table +———-+————-+ |PERSON |LOCATION | +———-+————-+ |robin |Leeds |London |Wakefield| | Table: state for given key Topic + Schema { “event_ts”: “2020-02-17T22:23:00Z”, “person” : “robin”, “location”: “Wakefield” } { “event_ts”: “2020-02-18T09:00:00Z”, “person” : “robin”, “location”: “Leeds” } Introduction to ksqlDB • • • It’s the same data (Kafka topic) underneath - but we use different semantics to model it • Kafka topics are k/v bytes • We use SerDe (JSON, Avro, CSV etc) with them Stream : append-only series of events Table : state for key
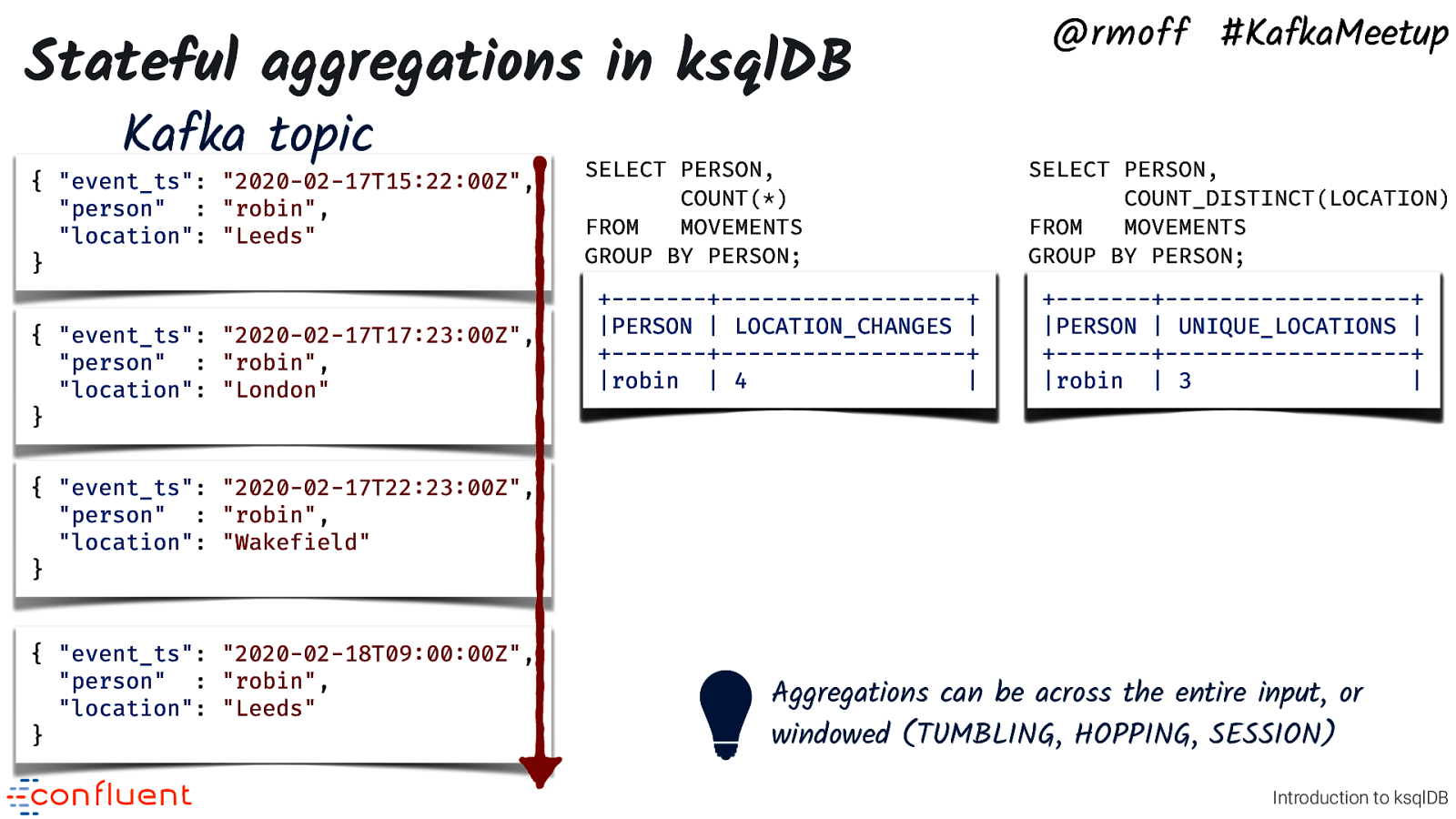
Stateful aggregations in ksqlDB Kafka topic { “event_ts”: “2020-02-17T15:22:00Z”, “person” : “robin”, “location”: “Leeds” } { “event_ts”: “2020-02-17T17:23:00Z”, “person” : “robin”, “location”: “London” } SELECT PERSON, COUNT(*) FROM MOVEMENTS GROUP BY PERSON; +———-+—————————+ |PERSON | LOCATION_CHANGES | +———-+—————————+ |robin | 4 1 2 3 | @rmoff #KafkaMeetup SELECT PERSON, COUNT_DISTINCT(LOCATION) FROM MOVEMENTS GROUP BY PERSON; +———-+—————————+ |PERSON | UNIQUE_LOCATIONS | +———-+—————————+ |robin | 3 1 2 | { “event_ts”: “2020-02-17T22:23:00Z”, “person” : “robin”, “location”: “Wakefield” } { “event_ts”: “2020-02-18T09:00:00Z”, “person” : “robin”, “location”: “Leeds” } Aggregations can be across the entire input, or windowed (TUMBLING, HOPPING, SESSION) Introduction to ksqlDB • ksqlDB can also do stateful aggregations, such as SUM, COUNT, COUNT_DISTINCT.

Kafka topic { “event_ts”: “2020-02-17T15:22:00Z”, “person” : “robin”, “location”: “Leeds” } { “event_ts”: “2020-02-17T17:23:00Z”, “person” : “robin”, “location”: “London” } CREATE TABLE PERSON_MOVEMENTS AS SELECT PERSON, COUNT_DISTINCT(LOCATION) AS UNIQUE_LOCATIONS, COUNT(*) AS LOCATION_CHANGES FROM MOVEMENTS GROUP BY PERSON; PERSON_ MOVEMENTS Internal ksqlDB state store Stateful aggregations in ksqlDB @rmoff #KafkaMeetup { “event_ts”: “2020-02-17T22:23:00Z”, “person” : “robin”, “location”: “Wakefield” } { “event_ts”: “2020-02-18T09:00:00Z”, “person” : “robin”, “location”: “Leeds” } Introduction to ksqlDB • • • • We can take a stream of events in Apache Kafka and use ksqlDB to build a stateful aggregation of them Here’s the previous example we saw of COUNT and COUNT_DISTINCT being materialised into an actual TABLE Fun fact: the table is also backed by a Kafka topic! The topic here is a changelog of state changes in the table This materialised table we can query the state from
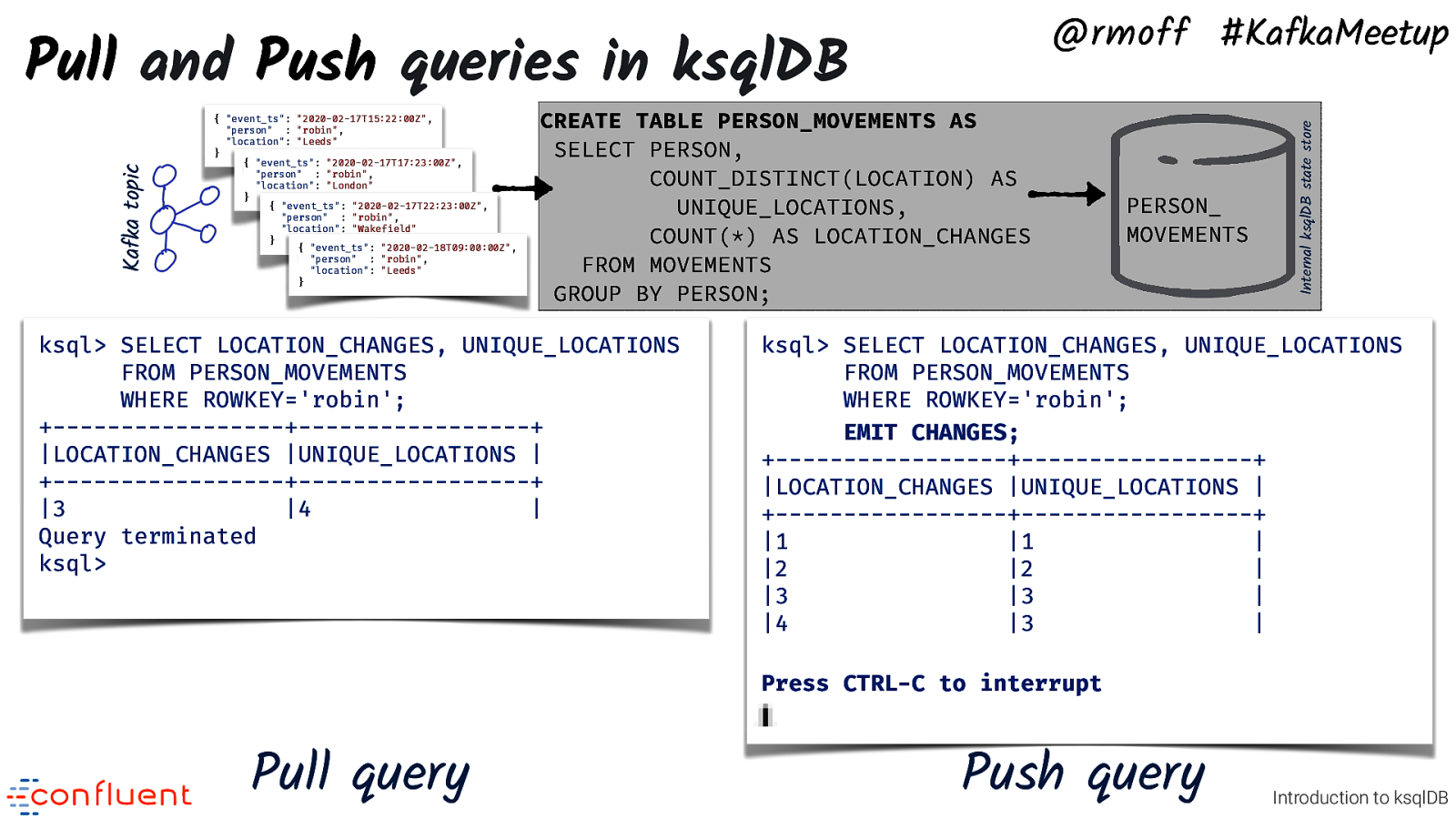
{ “event_ts”: “2020-02-17T15:22:00Z”, “person” : “robin”, “location”: “Leeds” } { “event_ts”: “2020-02-17T17:23:00Z”, “person” : “robin”, “location”: “London” } { “event_ts”: “2020-02-17T22:23:00Z”, “person” : “robin”, “location”: “Wakefield” } { “event_ts”: “2020-02-18T09:00:00Z”, “person” : “robin”, “location”: “Leeds” } CREATE TABLE PERSON_MOVEMENTS AS SELECT PERSON, COUNT_DISTINCT(LOCATION) AS UNIQUE_LOCATIONS, COUNT(*) AS LOCATION_CHANGES FROM MOVEMENTS GROUP BY PERSON; ksql> SELECT LOCATION_CHANGES, UNIQUE_LOCATIONS FROM PERSON_MOVEMENTS WHERE ROWKEY=’robin’; +————————-+————————-+ |LOCATION_CHANGES |UNIQUE_LOCATIONS | +————————-+————————-+ |3 |4 | Query terminated ksql> PERSON_ MOVEMENTS Internal ksqlDB state store Kafka topic Pull and Push queries in ksqlDB @rmoff #KafkaMeetup ksql> SELECT LOCATION_CHANGES, UNIQUE_LOCATIONS FROM PERSON_MOVEMENTS WHERE ROWKEY=’robin’; EMIT CHANGES; +————————-+————————-+ |LOCATION_CHANGES |UNIQUE_LOCATIONS | +————————-+————————-+ |1 |1 | |2 |2 | |3 |3 | |4 |3 | Press CTRL-C to interrupt Pull query • Push query Introduction to ksqlDB There are two types of query: • Pull: just like a key/value lookup in an RDBMS. Gives the current state and then ends. • Push: the client receives a stream of updates as the values change Here’s an example of a pull and push query. Note that the push query on the right has not terminated. Any new updates to the table for the key will be sent (‘pushed’) to the client.
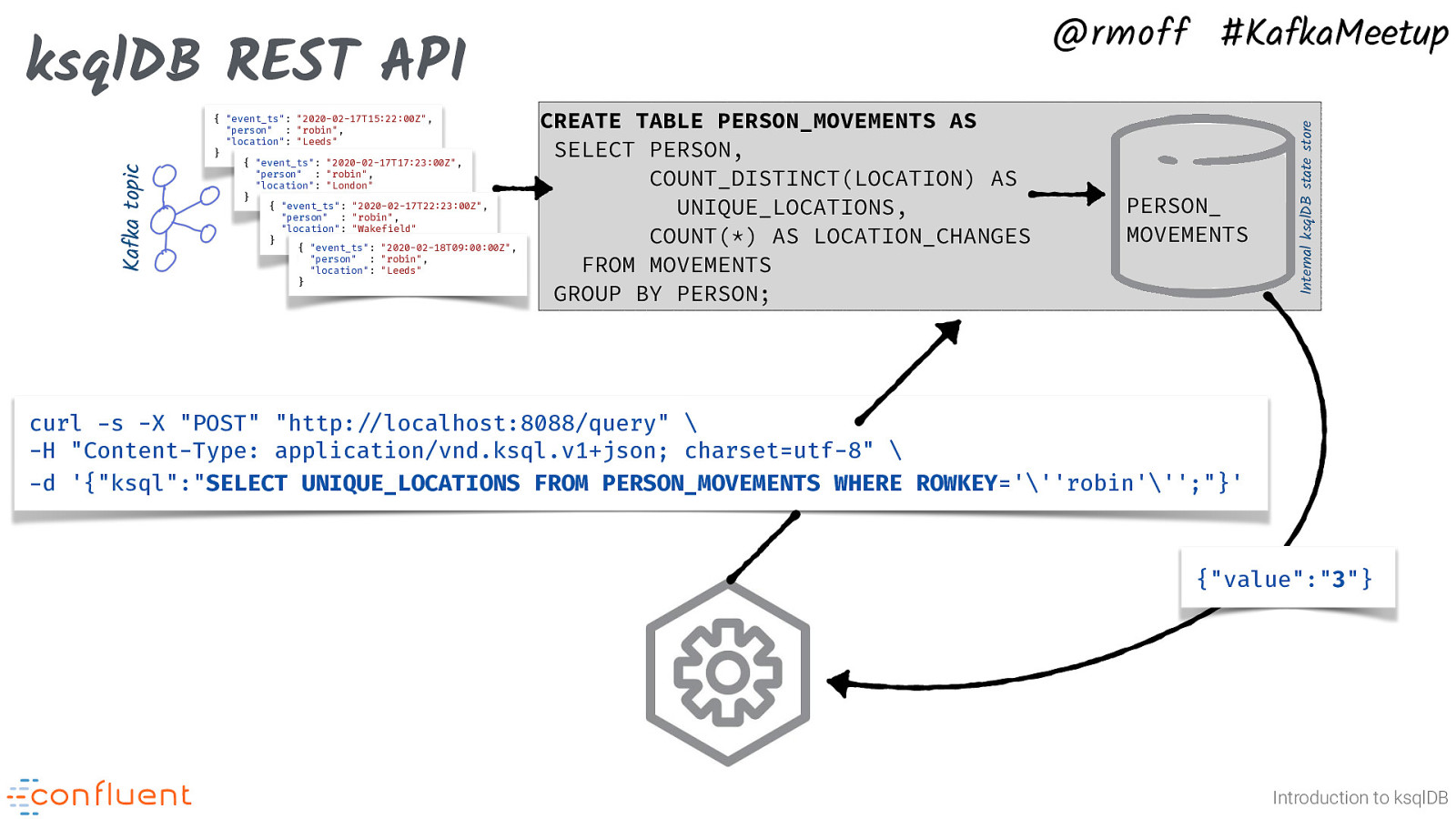
{ “event_ts”: “2020-02-17T15:22:00Z”, “person” : “robin”, “location”: “Leeds” } { “event_ts”: “2020-02-17T17:23:00Z”, “person” : “robin”, “location”: “London” } { “event_ts”: “2020-02-17T22:23:00Z”, “person” : “robin”, “location”: “Wakefield” } { “event_ts”: “2020-02-18T09:00:00Z”, “person” : “robin”, “location”: “Leeds” } CREATE TABLE PERSON_MOVEMENTS AS SELECT PERSON, COUNT_DISTINCT(LOCATION) AS UNIQUE_LOCATIONS, COUNT(*) AS LOCATION_CHANGES FROM MOVEMENTS GROUP BY PERSON; PERSON_ MOVEMENTS Internal ksqlDB state store Kafka topic ksqlDB REST API @rmoff #KafkaMeetup curl -s -X “POST” “http:#//localhost:8088/query” \ -H “Content-Type: application/vnd.ksql.v1+json; charset=utf-8” \ -d ‘{“ksql”:”SELECT UNIQUE_LOCATIONS FROM PERSON_MOVEMENTS WHERE ROWKEY=”’robin”’;”}’ {“value”:”3”} Introduction to ksqlDB Pull queries really come into their own when you consider that ksqlDB has a REST API. Now any application that can issue a REST call can do a point-in-time lookup on the materialised state of a Kafka topic.

Pull and Push queries in ksqlDB Pull query Tells you: Point in time value Exits: Immediately @rmoff #KafkaMeetup Push query All value changes Never Introduction to ksqlDB Push queries are applicable to all stream and table objects, and indicated with an EMIT CHANGES clause. Pull queries have some limitations currently: - are only available against tables - require the object to be materialised (i.e. a TABLE built using an aggregate) - Currently only available for single key lookup with optional window range - See more details at https://github.com/confluentinc/ksql/blob/master/design-proposals/klip-8-queryable-state-stores.md

@rmoff #KafkaMeetup Under the covers of ksqlDB Introduction to ksqlDB Photo by Vinicius de Moraes on Unsplash So far we’ve talked a lot about what ksqlDB does, but not really about how.
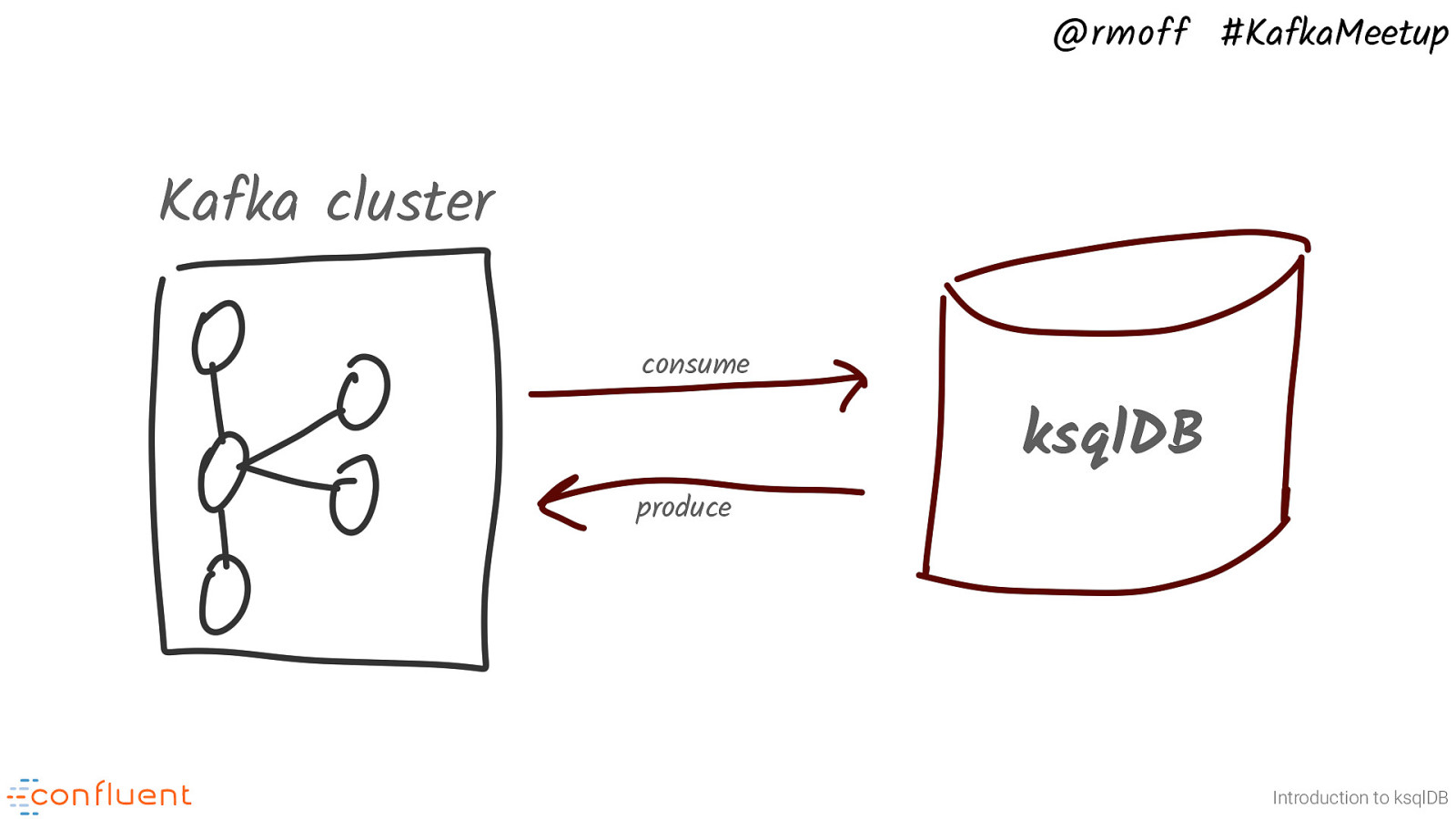
@rmoff #KafkaMeetup Kafka cluster consume produce ksqlDB Introduction to ksqlDB ksqlDB basically reads and writes from Kafka topics
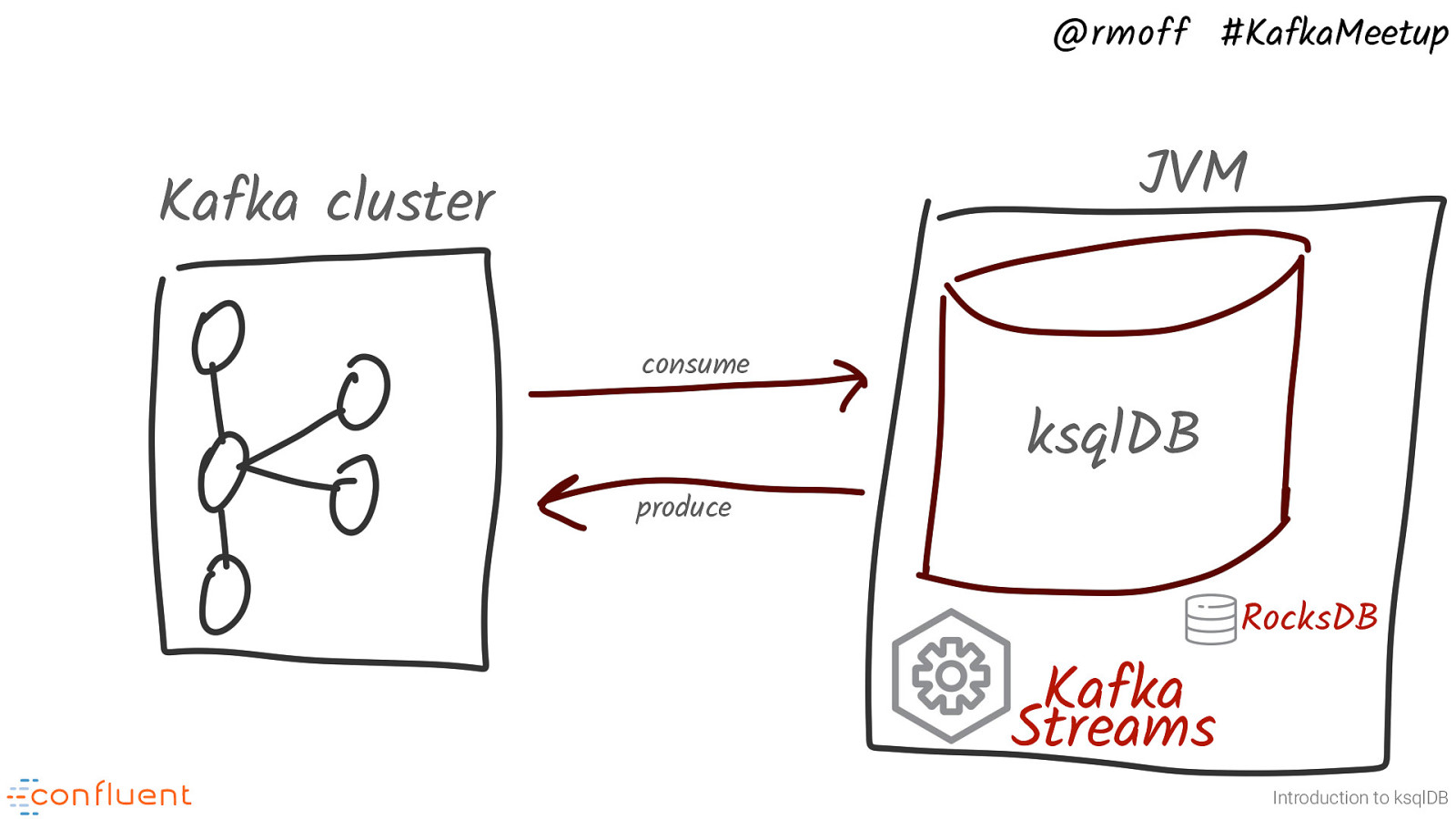
@rmoff #KafkaMeetup JVM Kafka cluster consume ksqlDB produce Kafka Streams RocksDB Introduction to ksqlDB It runs under the JVM, and executes the SQL statements that you give it as Kafka Streams applications. It uses RocksDB to store state

Because it’s just a JVM process, we can run it a bunch of places. It just needs a Kafka cluster.

& L Q S K Fully Managed Kafka ^ as a Service Quite obviously, Confluent Cloud is the best place to run KSQL :-D Here it’s a managed service and you just supply the SQL. (There are a couple of caveats - in Confluent Cloud we don’t yet offer pull queries or embedded connector integration)

Running ksqlDB - self-managed @rmoff #KafkaMeetup DEB, RPM, ZIP, TAR downloads http://confluent.io/download Docker images confluentinc/ksqldb-server ksqlDB Server (JVM process) …and many more… Introduction to ksqlDB If you want to run it yourself you can, on premises, in the cloud, bare metal or Docker - you choose.
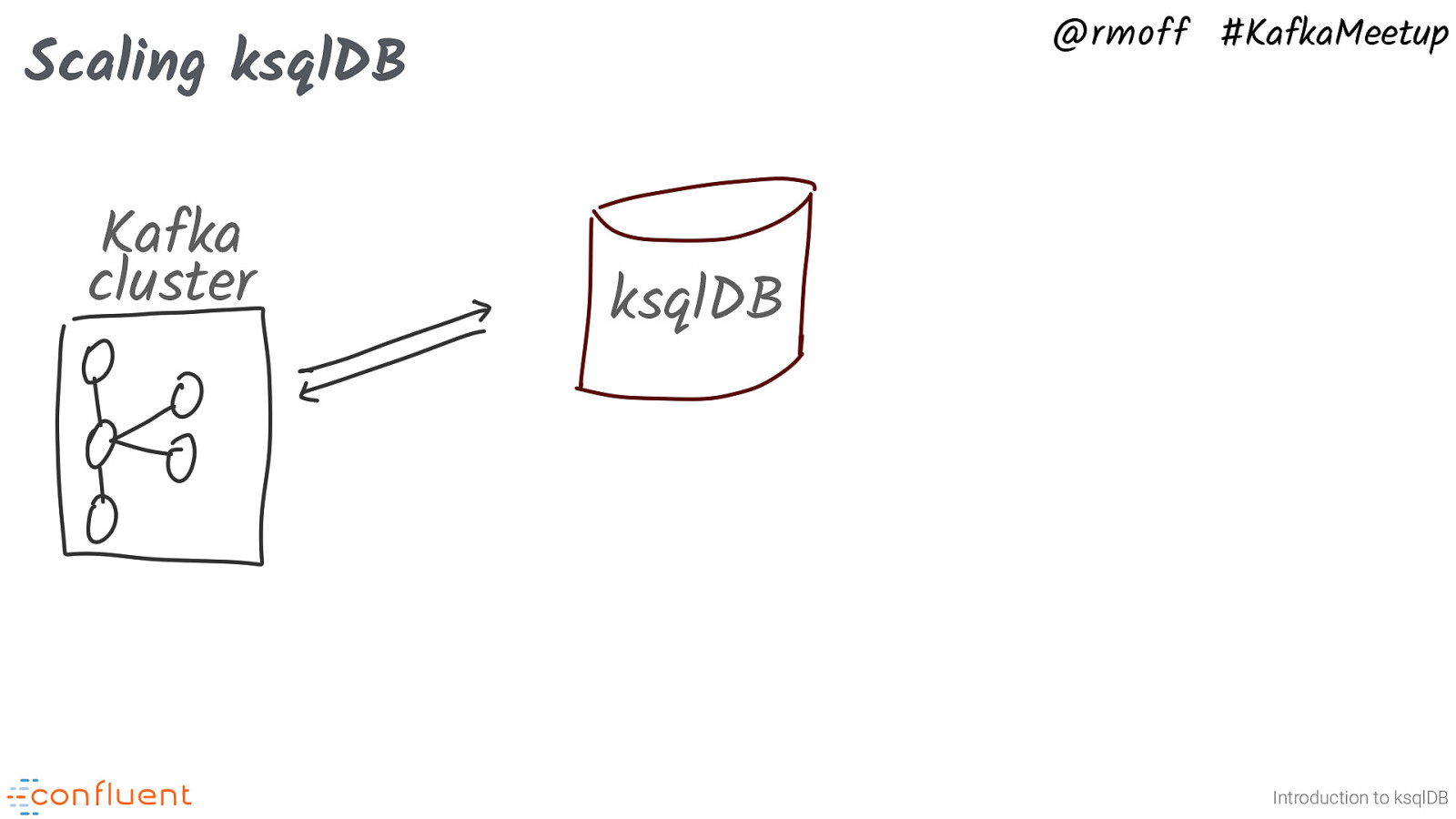
@rmoff #KafkaMeetup Scaling ksqlDB Kafka cluster ksqlDB Introduction to ksqlDB Just like Kafka, ksqlDB is a distributed system that uses partitions to scale its workload. You can have a single node…
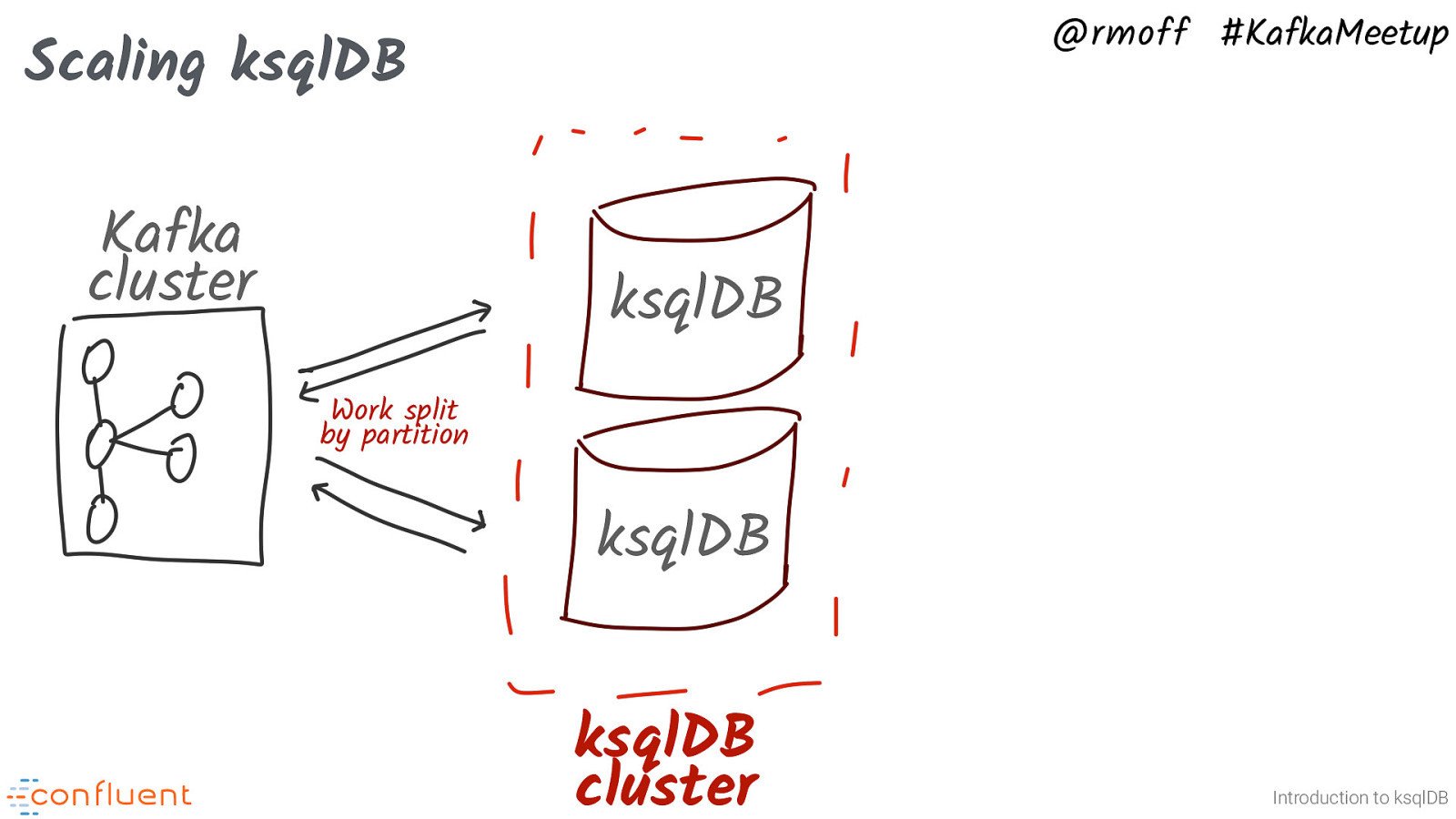
@rmoff #KafkaMeetup Scaling ksqlDB Kafka cluster ksqlDB Work split by partition ksqlDB ksqlDB cluster Introduction to ksqlDB …and you can scale out the nodes and they form a cluster. Just like Kafka consumer, and Kafka Streams, ksqlDB can parallelise throughput by allocating work on partitions to different nodes.

BUT we are not just rebuilding a single huge “database” cluster
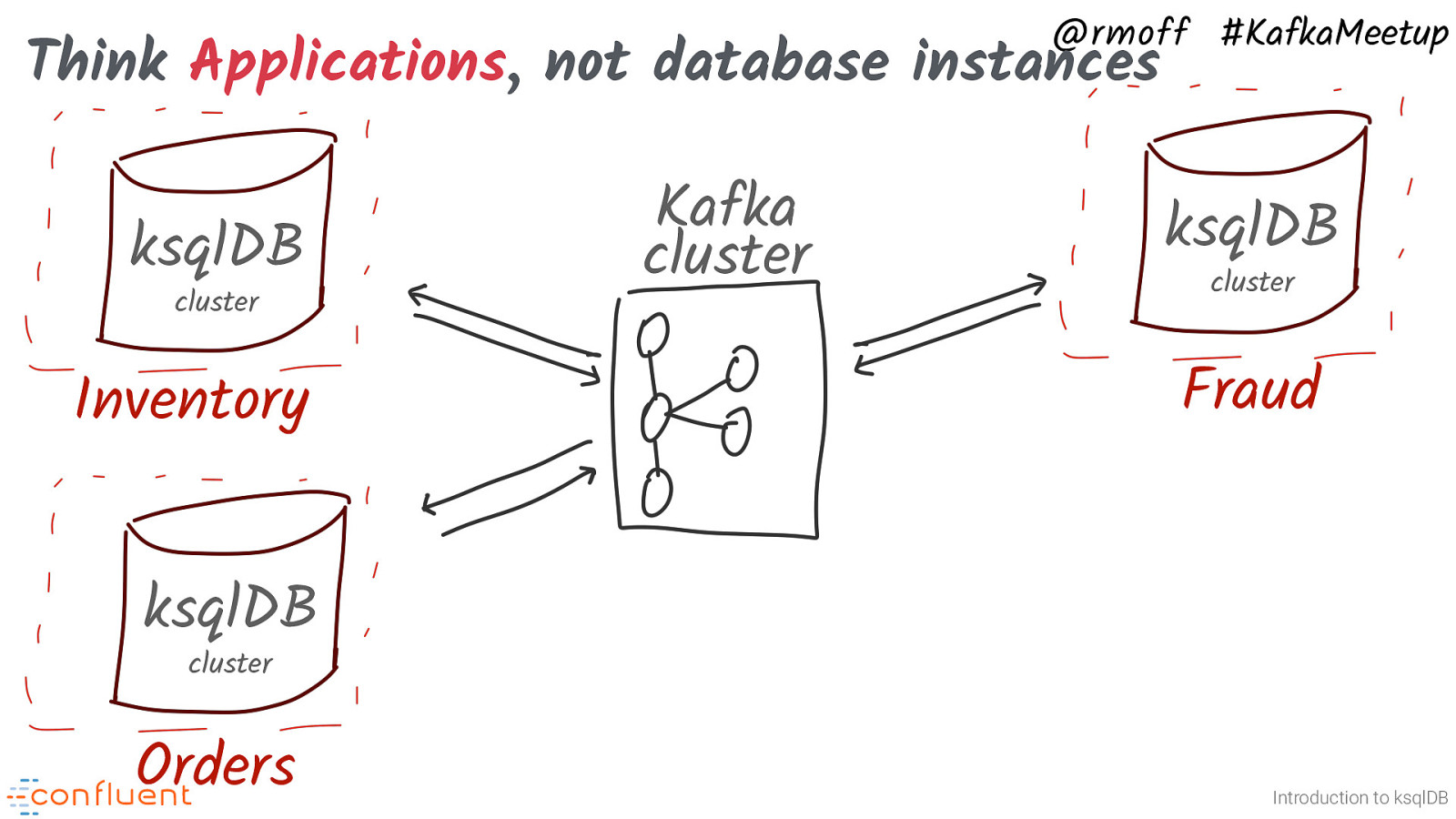
@rmoff #KafkaMeetup Think Applications, not database instances ksqlDB cluster Inventory Kafka cluster ksqlDB cluster Fraud ksqlDB cluster Orders Introduction to ksqlDB ksqlDB serves applications, and the general pattern is one cluster per function (or team, or domain - however you like to carve it up)
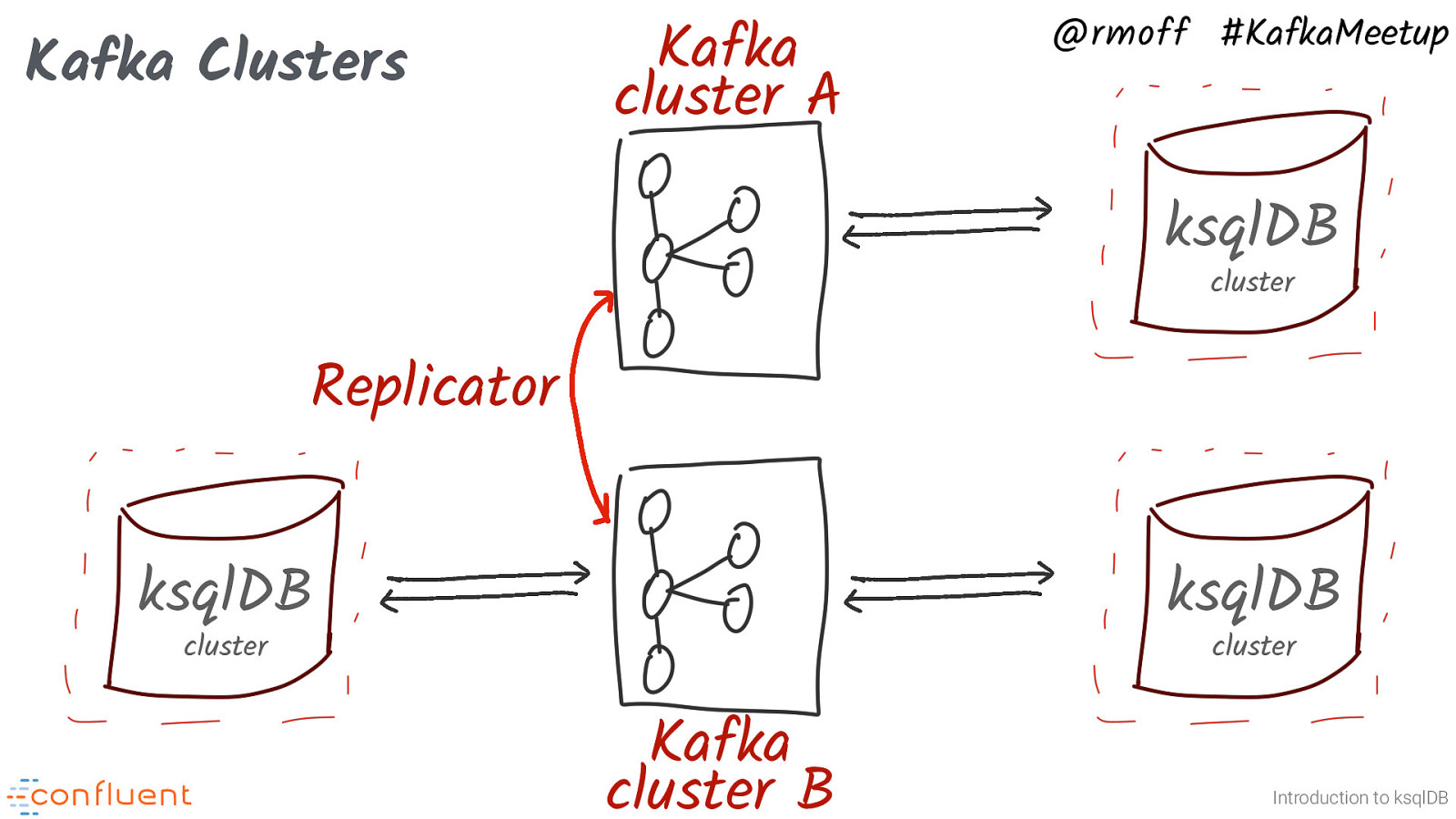
Kafka Clusters Kafka cluster A @rmoff #KafkaMeetup ksqlDB cluster Replicator ksqlDB ksqlDB cluster cluster Kafka cluster B Introduction to ksqlDB A last point on this - just as you can have multiple ksqlDB clusters, you might also have more than one Kafka cluster. Perhaps you want to isolate the work of one ksqlDB cluster from another, or have data residing on one cluster that you need in another. Replicator (or similar tools, such as MirrorMaker 2) let you stream topics between clusters so that they can be used by other consumers (such as ksqlDB).

@rmoff #KafkaMeetup ksqlDB or Kafka Streams? Photo by Ramiz Dedaković Unsplash Introduction to onksqlDB So we mentioned Kafka Streams in passing earlier, as the runtime into which ksqlDB statements are compiled. But if all we’re doing is generating Kafka Streams applications, why not just use Kafka Streams from the outset? There are several reasons, not least of which is that not everyone codes Java!
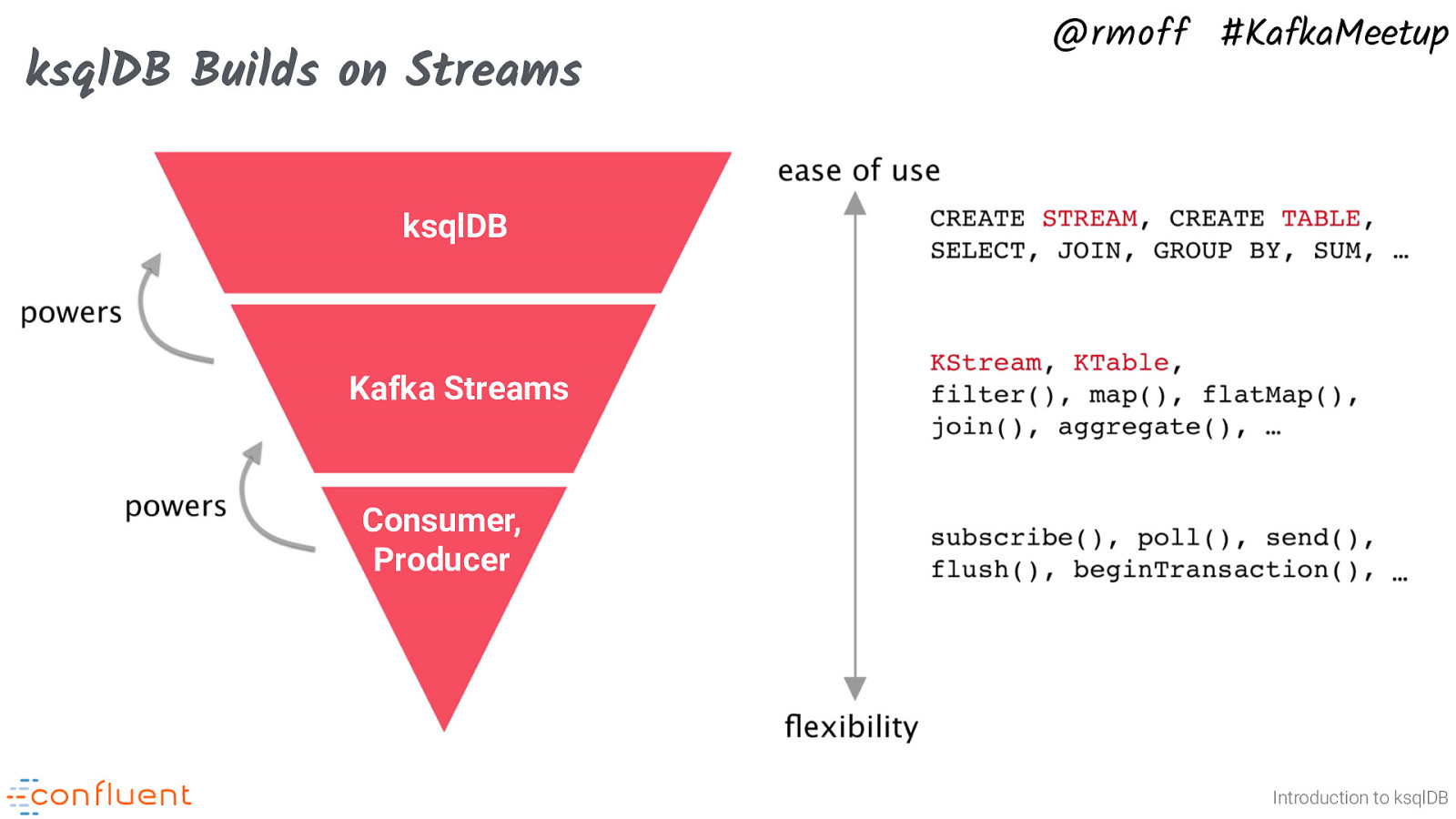
ksqlDB Builds on Streams @rmoff #KafkaMeetup ksqlDB Kafka Streams Consumer, Producer Introduction to ksqlDB ksqlDB is available to the widest audience - more people write SQL than Java. It’s also very simple to run, and expressive in its intent. ksqlDB can’t do everything, and as you hit up against certain requirements you might find yourself reaching for Kafka Streams DSL or Processor API. You may also decide if you’re a Java team through-and-through that you just want to use Kafka Streams, and that’s fine. There’s nothing that you can do in ksqlDB that you can’t in Kafka Streams. More details: https://docs.confluent.io/current/ksql/docs/concepts/ksql-and-kafka-streams.html

ksqlDB supports UDF, UDAF, UDTF @rmoff #KafkaMeetup Introduction to ksqlDB A useful bridge between having to write Kafka Streams applications, and functionality that you want to access in ksqlDB, can be UDFs. With these you can then continue to offer end-users a SQL interface to stream processing, but with UDFs developed by a Java resource to cover the additional functionality required.
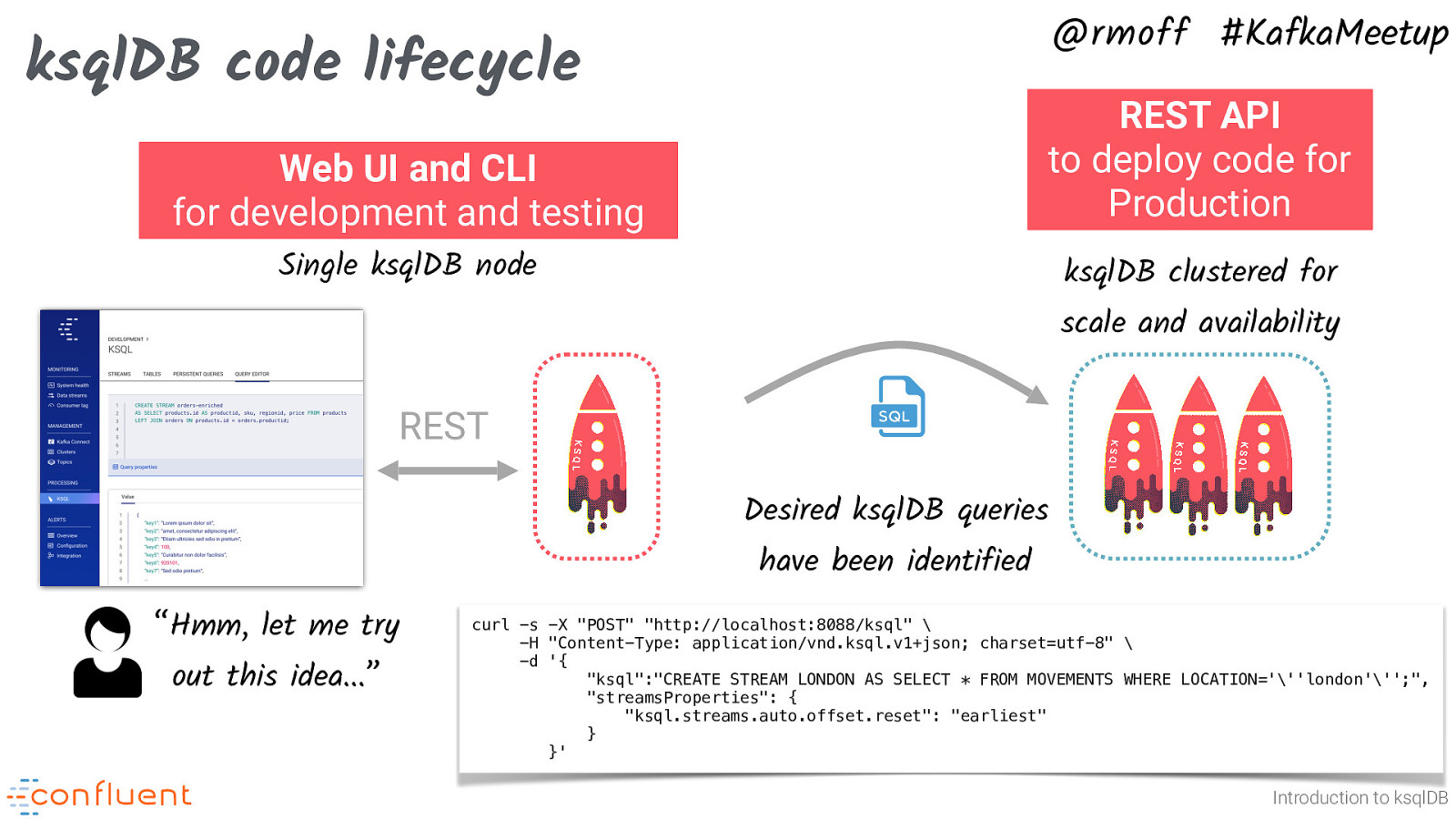
@rmoff #KafkaMeetup ksqlDB code lifecycle Web UI and CLI for development and testing REST API to deploy code for Production Single ksqlDB node ksqlDB clustered for scale and availability REST Desired ksqlDB queries have been identified “Hmm, let me try out this idea…” curl -s -X “POST” “http://localhost:8088/ksql” \ -H “Content-Type: application/vnd.ksql.v1+json; charset=utf-8” \ -d ‘{ “ksql”:”CREATE STREAM LONDON AS SELECT * FROM MOVEMENTS WHERE LOCATION=”’london”’;”, “streamsProperties”: { “ksql.streams.auto.offset.reset”: “earliest” } }’ Introduction to ksqlDB
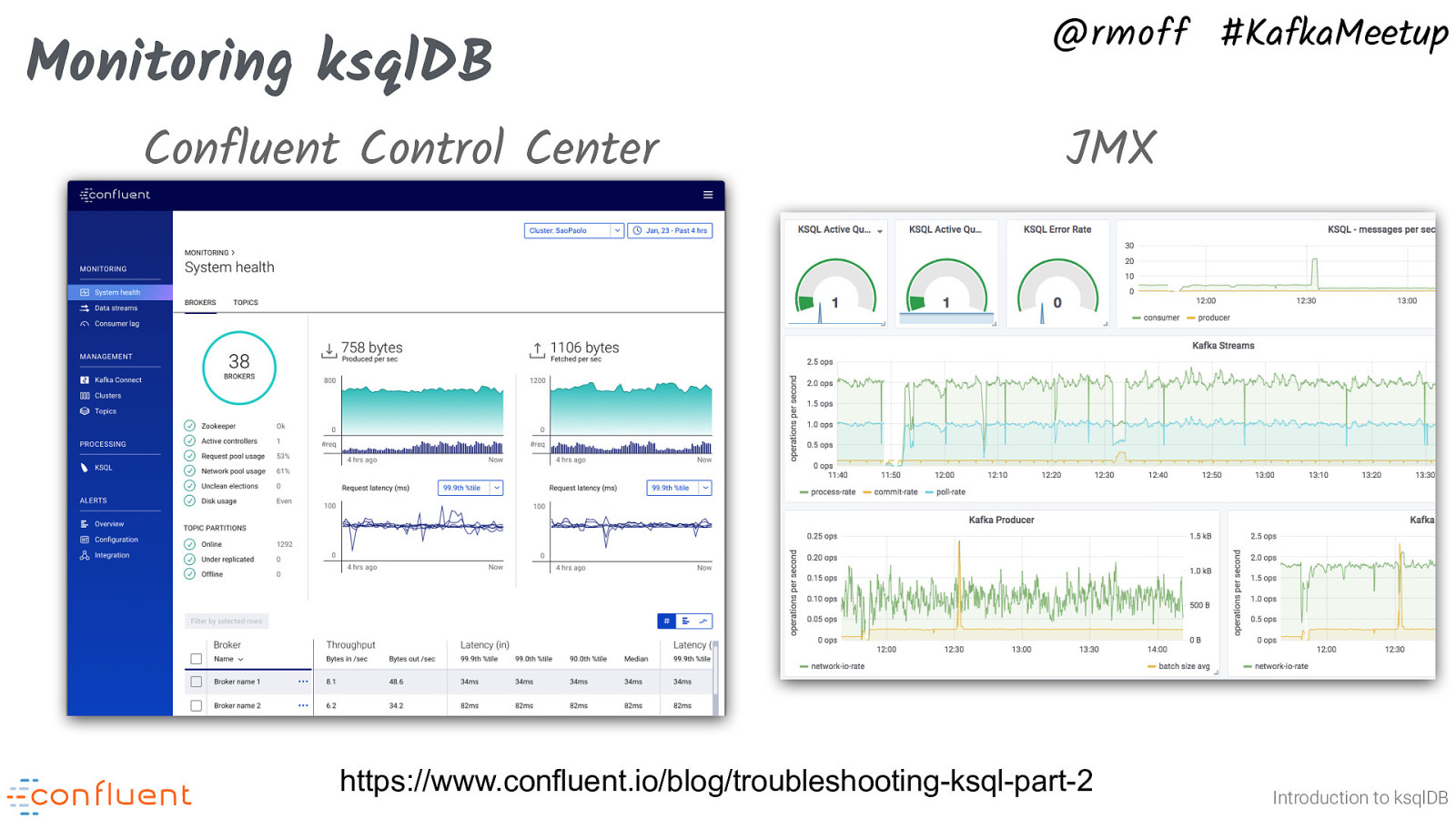
Monitoring ksqlDB Confluent Control Center @rmoff #KafkaMeetup JMX https://www.confluent.io/blog/troubleshooting-ksql-part-2 Introduction to ksqlDB

Photo by Tucker Good on Unsplash @rmoff #KafkaMeetup Want to learn more? CTAs, not CATs (sorry, not sorry) Docs: https://docs.ksqldb.io/ Community support: #ksqldb channel on http://cnfl.io/slack Introduction to ksqlDB

kafka-summit.org Moffatt30 30% OFF* *Standard Priced Conference pass
Kafka Tutorials @rmoff #KafkaMeetup https://kafka-tutorials.confluent.io/ Introduction to ksqlDB
Get Started with ksqlDB @rmoff #KafkaMeetup https://ksqldb.io Introduction to ksqlDB https://rmoff.dev/e0c95

Free Books! @rmoff #KafkaMeetup https://rmoff.dev/ams-feb-20 Introduction to ksqlDB

More ksqlDB examples Photo by Tengyart on Unsplash
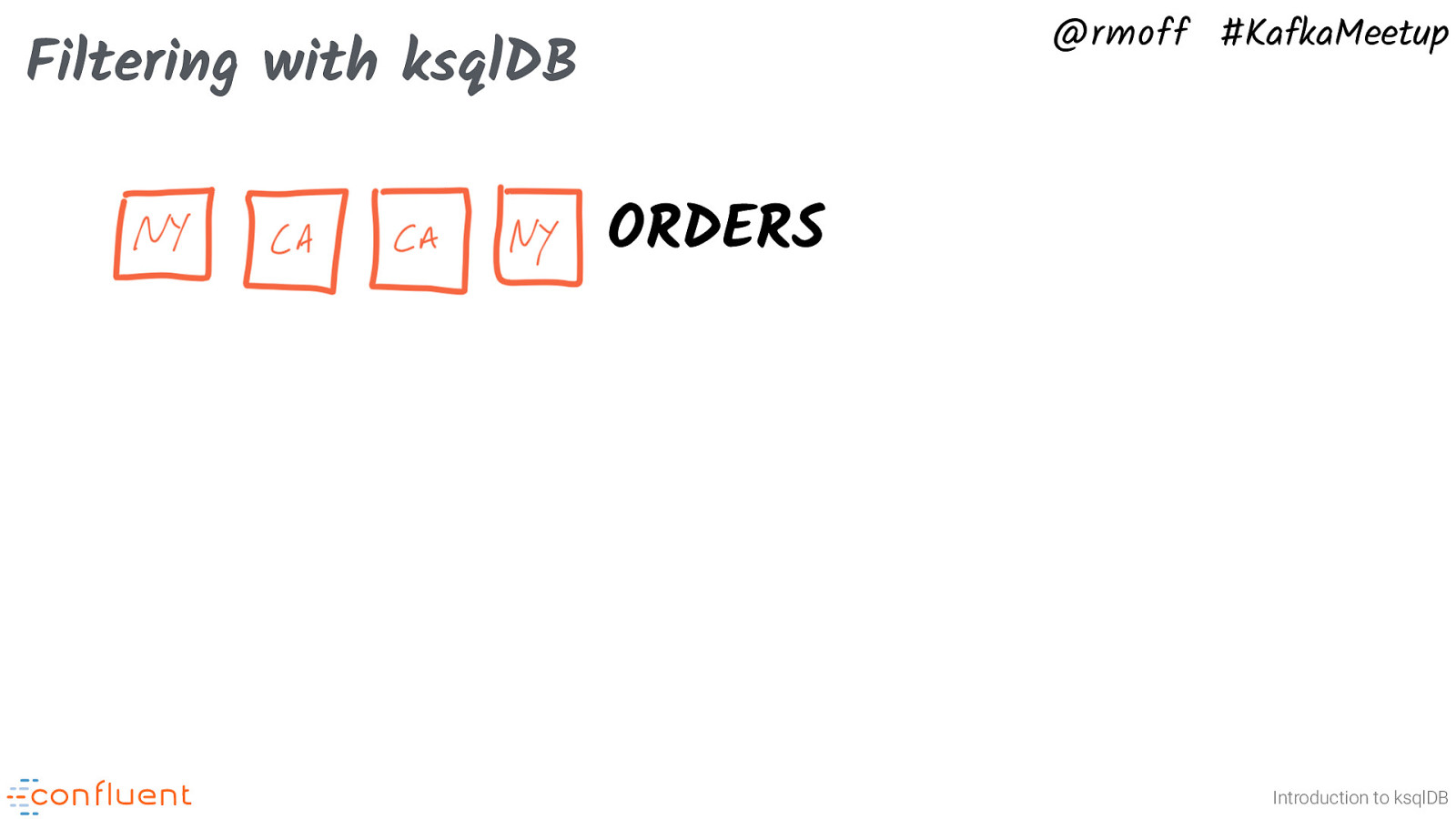
@rmoff #KafkaMeetup Filtering with ksqlDB ORDERS Introduction to ksqlDB
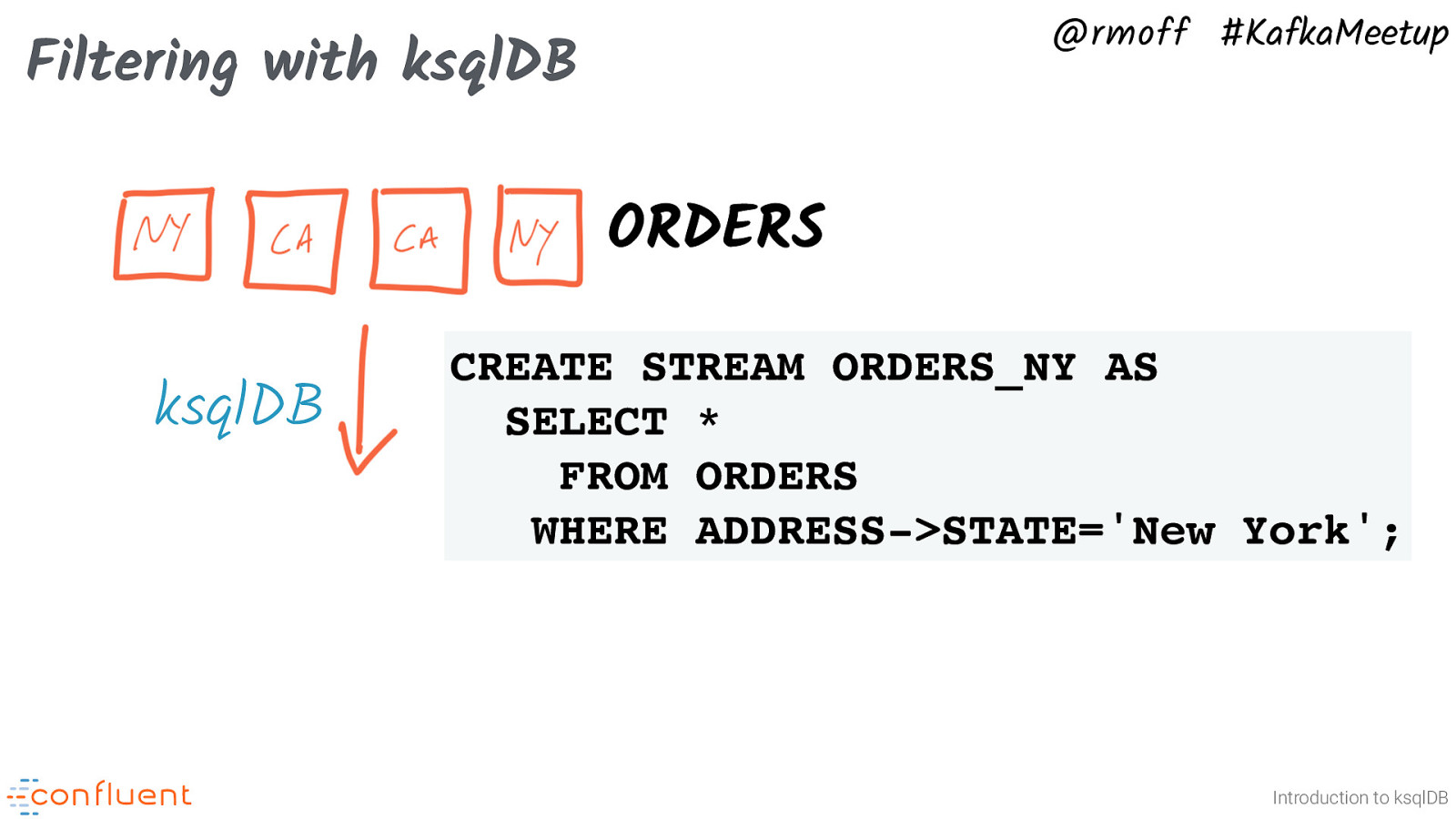
@rmoff #KafkaMeetup Filtering with ksqlDB ORDERS ksqlDB CREATE STREAM ORDERS_NY AS SELECT * FROM ORDERS WHERE ADDRESS->STATE=’New York’; Introduction to ksqlDB
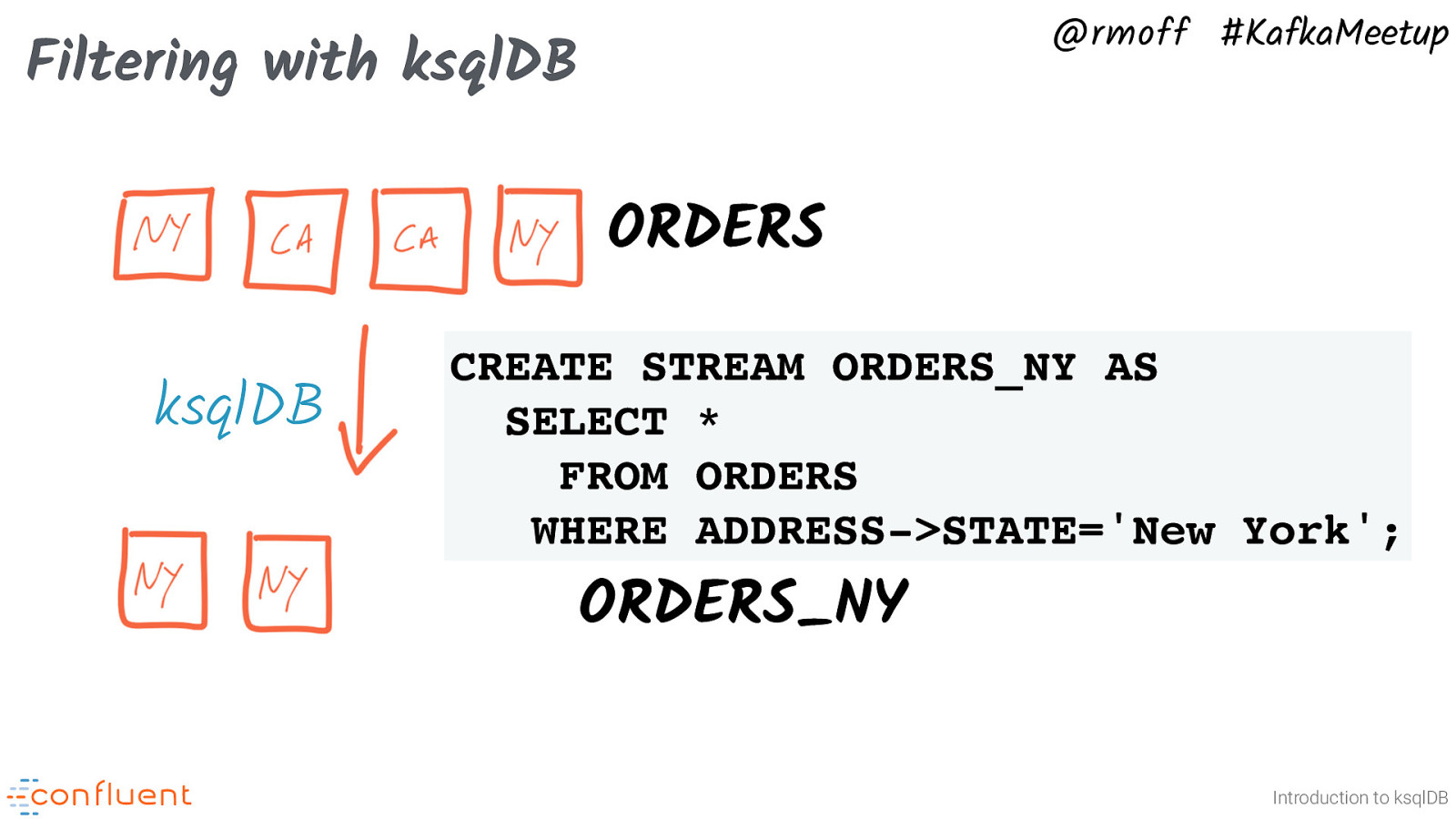
@rmoff #KafkaMeetup Filtering with ksqlDB ORDERS ksqlDB CREATE STREAM ORDERS_NY AS SELECT * FROM ORDERS WHERE ADDRESS->STATE=’New York’; ORDERS_NY Introduction to ksqlDB
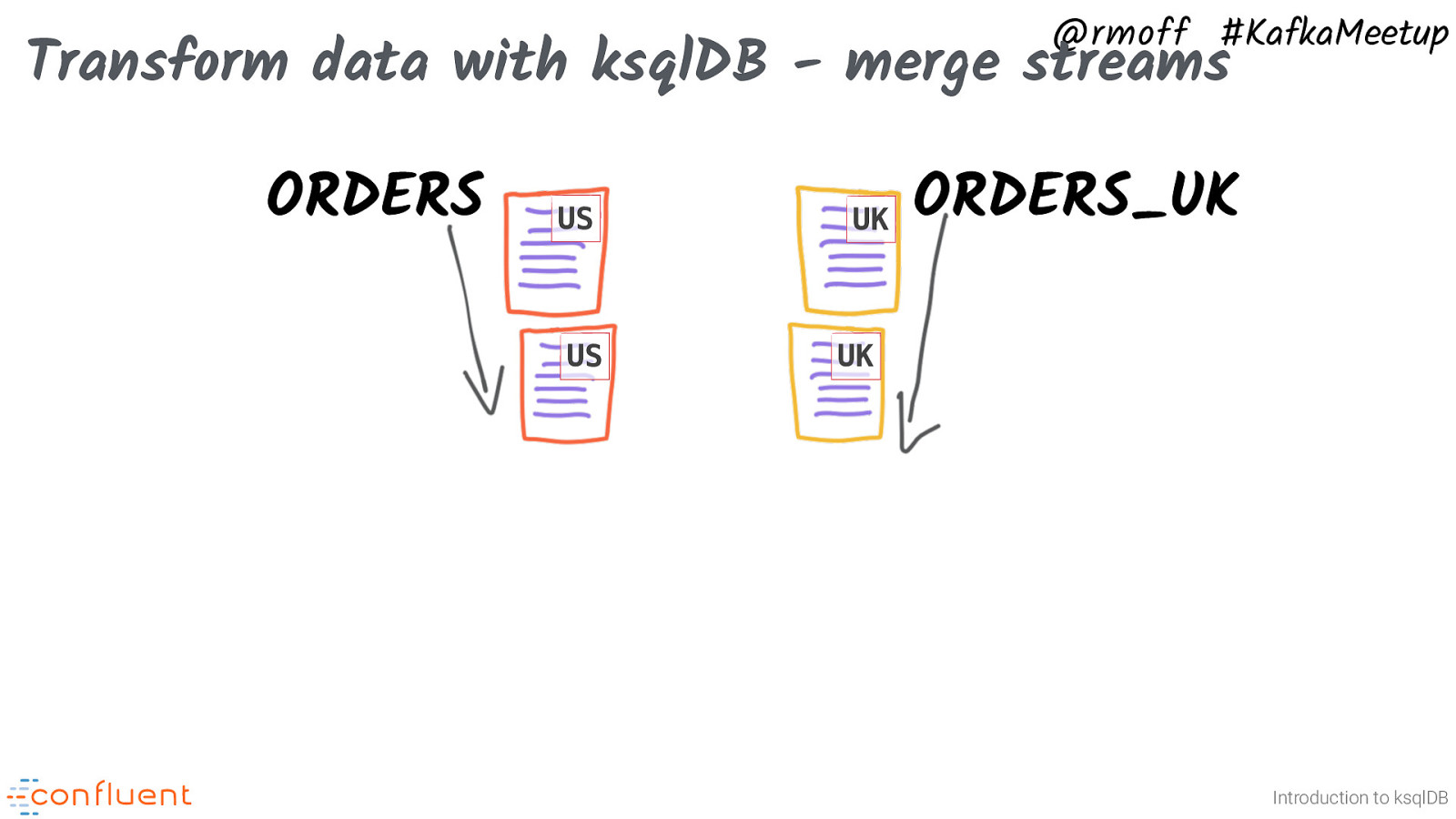
@rmoff #KafkaMeetup Transform data with ksqlDB - merge streams ORDERS US US UK ORDERS_UK UK Introduction to ksqlDB
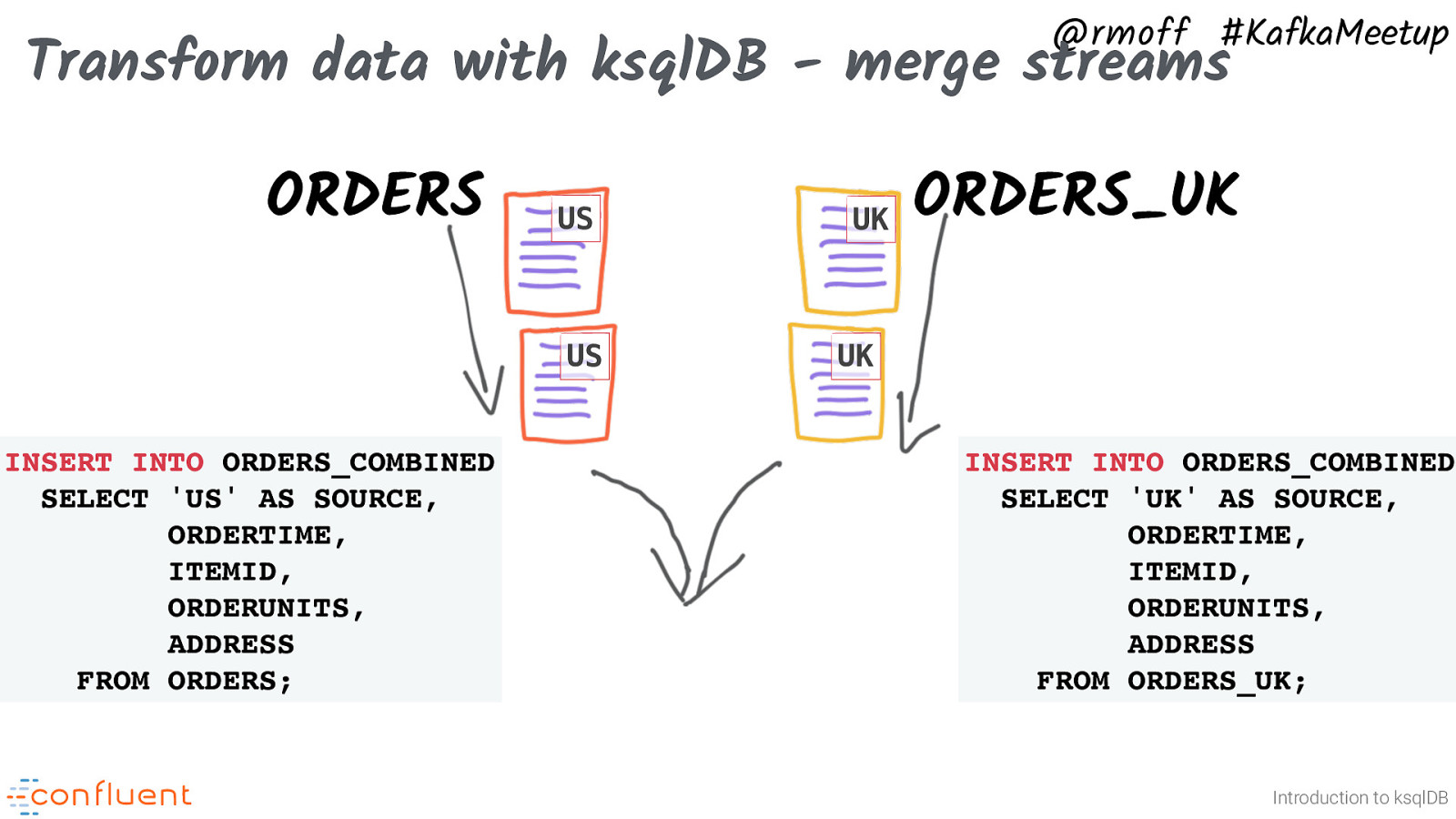
@rmoff #KafkaMeetup Transform data with ksqlDB - merge streams ORDERS US US INSERT INTO ORDERS_COMBINED SELECT ‘US’ AS SOURCE, ORDERTIME, ITEMID, ORDERUNITS, ADDRESS FROM ORDERS; UK ORDERS_UK UK INSERT INTO ORDERS_COMBINED SELECT ‘UK’ AS SOURCE, ORDERTIME, ITEMID, ORDERUNITS, ADDRESS FROM ORDERS_UK; Introduction to ksqlDB
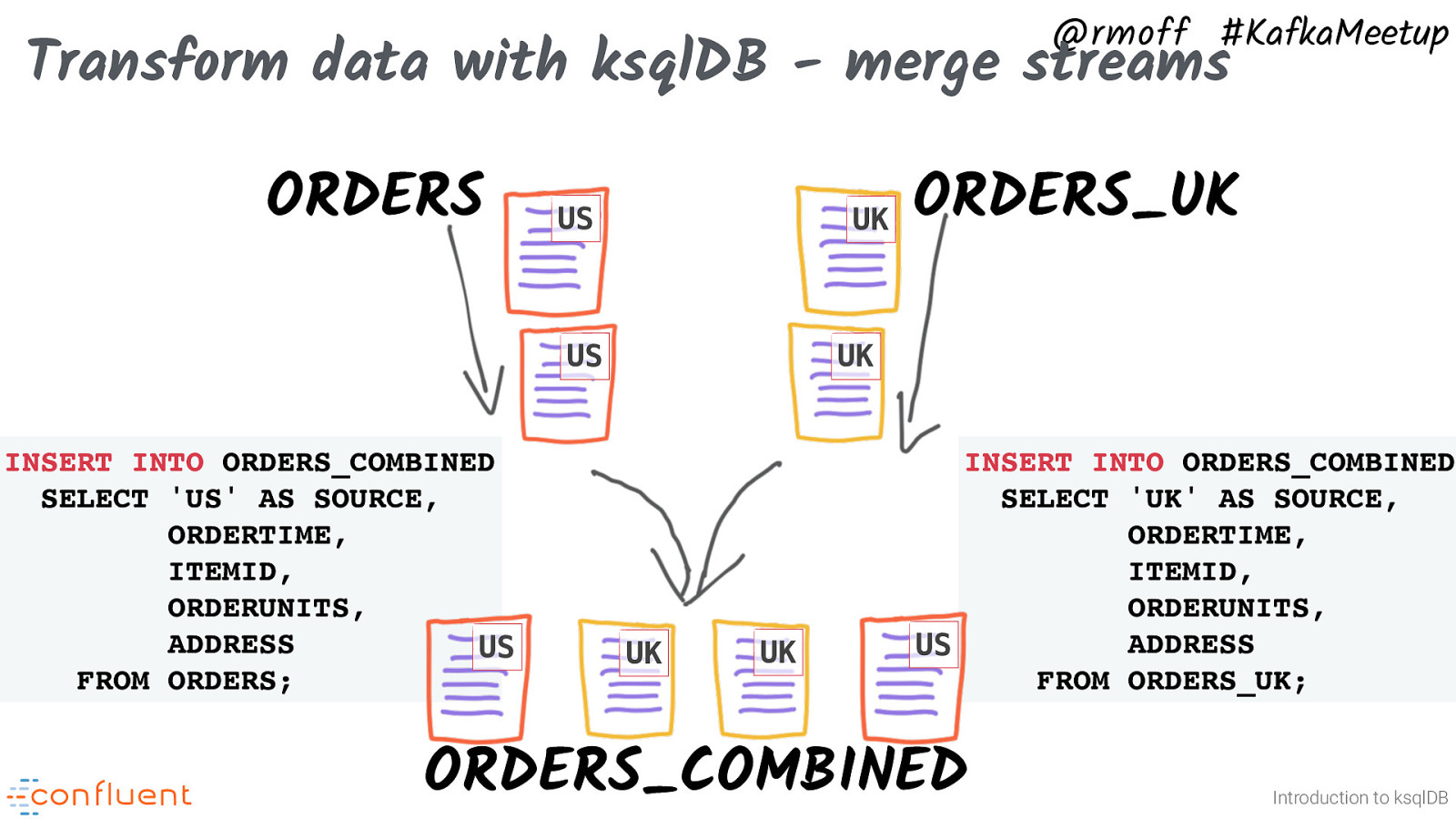
@rmoff #KafkaMeetup Transform data with ksqlDB - merge streams ORDERS US UK US INSERT INTO ORDERS_COMBINED SELECT ‘US’ AS SOURCE, ORDERTIME, ITEMID, ORDERUNITS, ADDRESS US FROM ORDERS; ORDERS_UK UK UK UK INSERT INTO ORDERS_COMBINED SELECT ‘UK’ AS SOURCE, ORDERTIME, ITEMID, ORDERUNITS, ADDRESS US FROM ORDERS_UK; ORDERS_COMBINED Introduction to ksqlDB
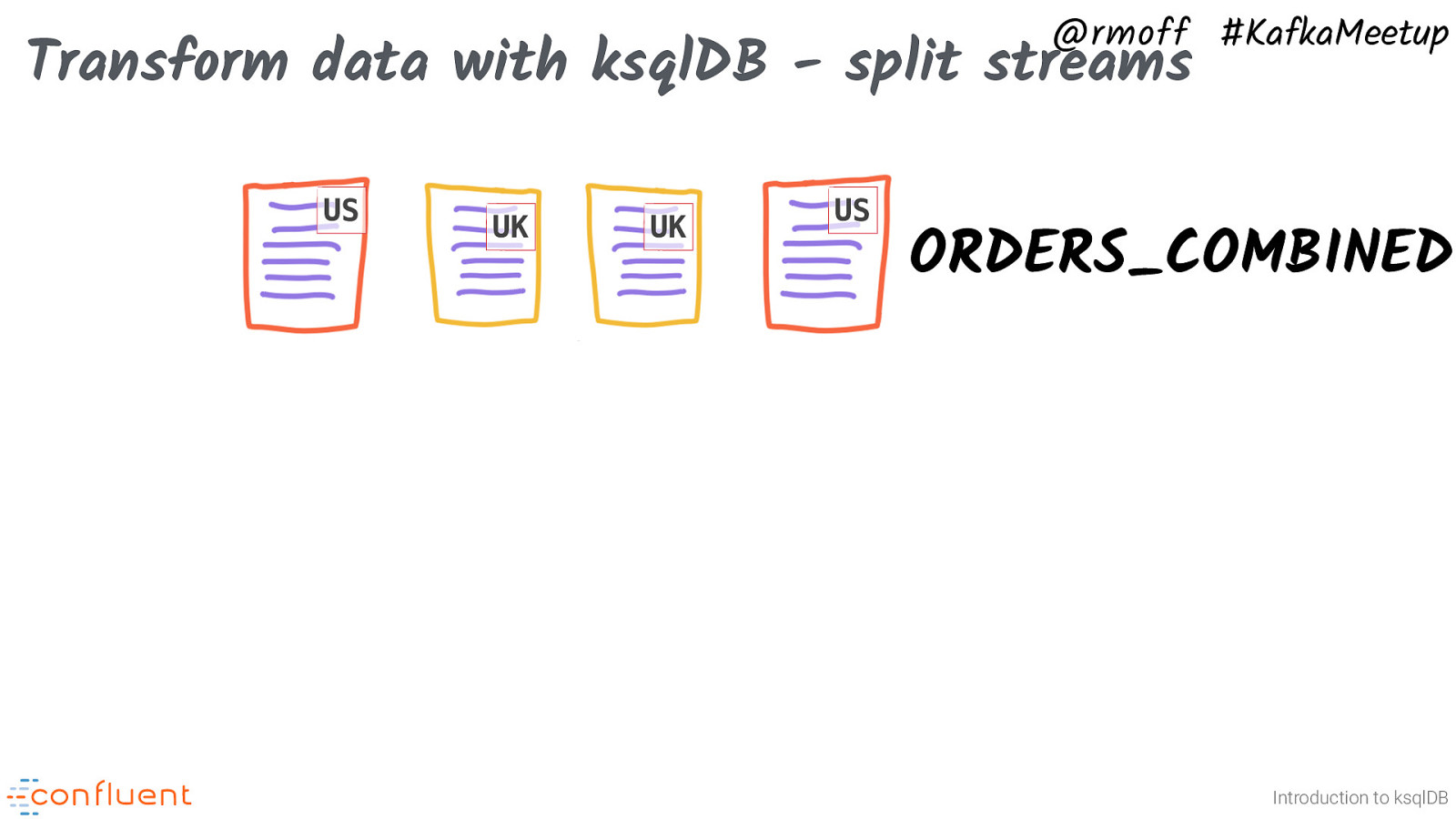
@rmoff #KafkaMeetup Transform data with ksqlDB - split streams US UK UK US ORDERS_COMBINED Introduction to ksqlDB
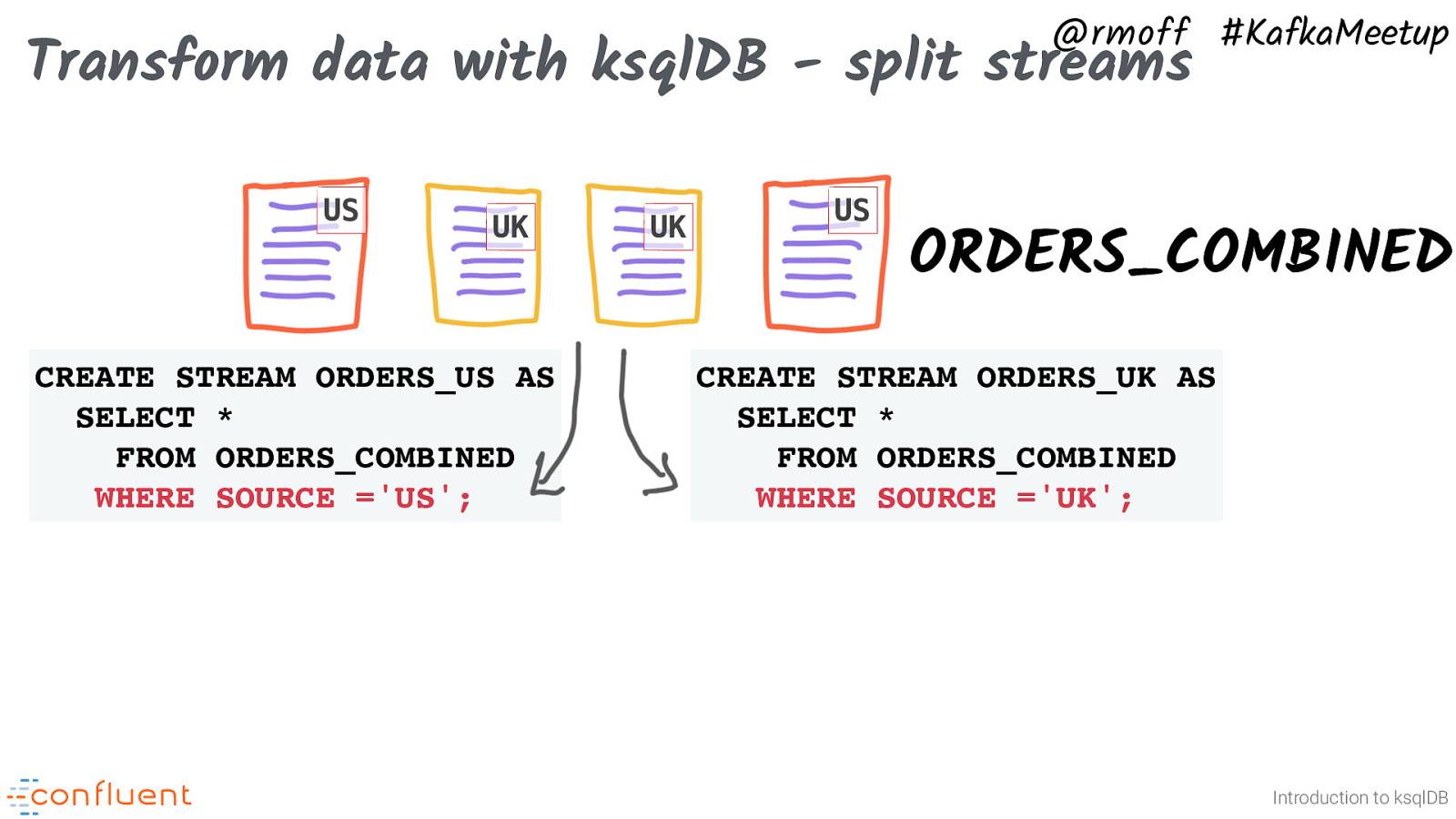
@rmoff #KafkaMeetup Transform data with ksqlDB - split streams US UK CREATE STREAM ORDERS_US AS SELECT * FROM ORDERS_COMBINED WHERE SOURCE =’US’; UK US ORDERS_COMBINED CREATE STREAM ORDERS_UK AS SELECT * FROM ORDERS_COMBINED WHERE SOURCE =’UK’; Introduction to ksqlDB
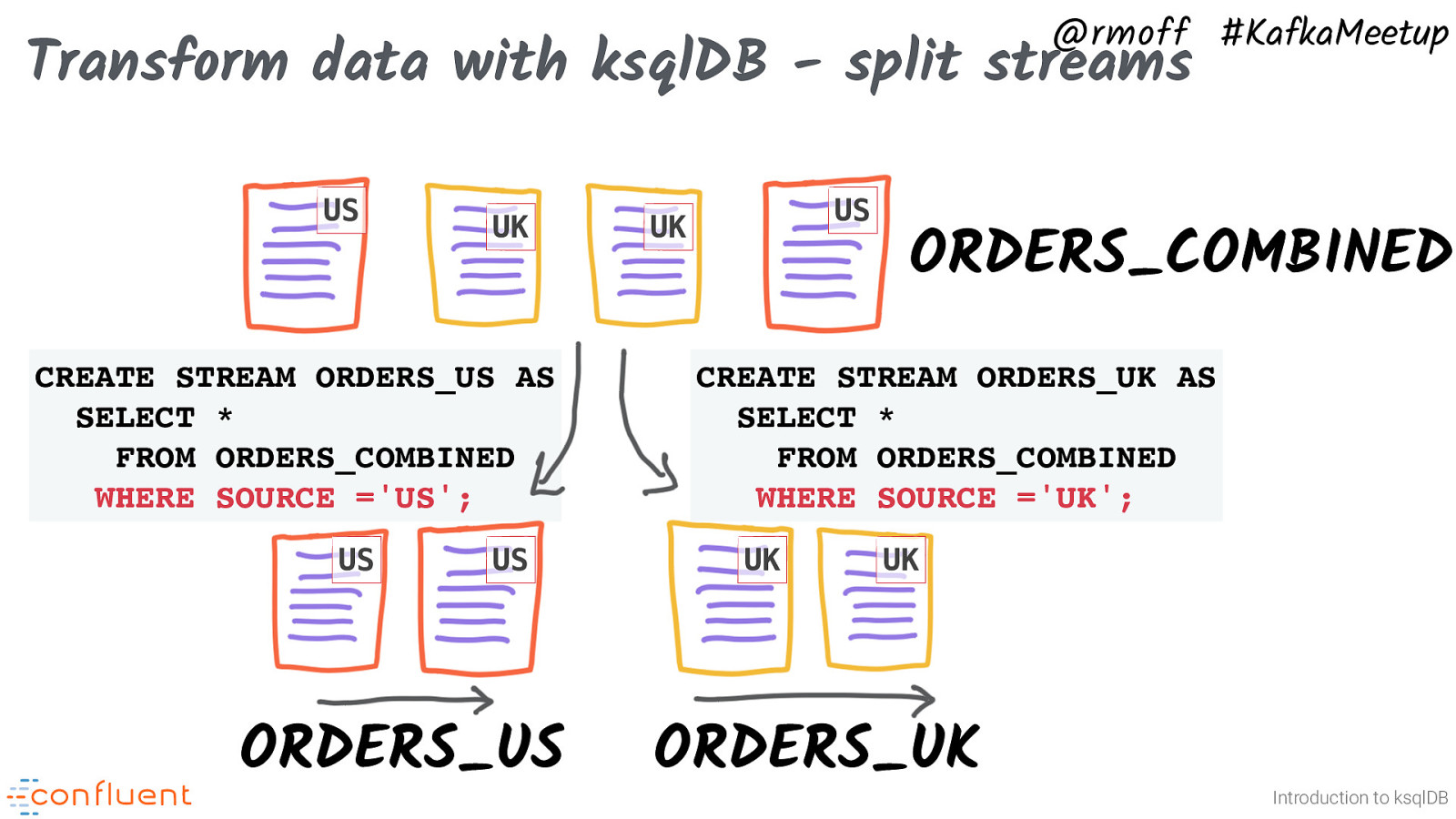
@rmoff #KafkaMeetup Transform data with ksqlDB - split streams US UK CREATE STREAM ORDERS_US AS SELECT * FROM ORDERS_COMBINED WHERE SOURCE =’US’; US US ORDERS_US US UK ORDERS_COMBINED CREATE STREAM ORDERS_UK AS SELECT * FROM ORDERS_COMBINED WHERE SOURCE =’UK’; UK UK ORDERS_UK Introduction to ksqlDB
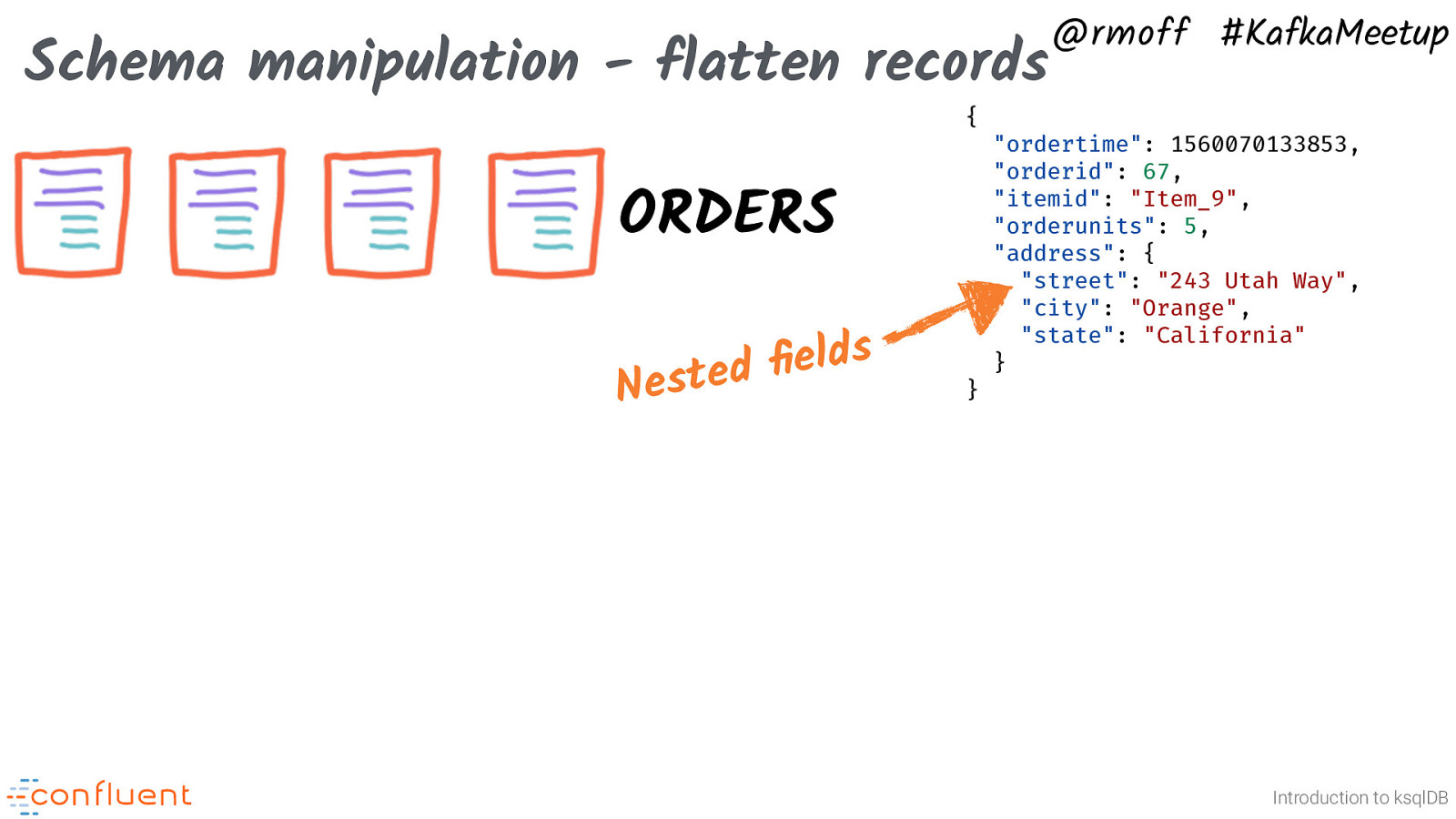
Schema manipulation - flatten records { ORDERS Nested fields @rmoff #KafkaMeetup “ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5, “address”: { “street”: “243 Utah Way”, “city”: “Orange”, “state”: “California” } } Introduction to ksqlDB
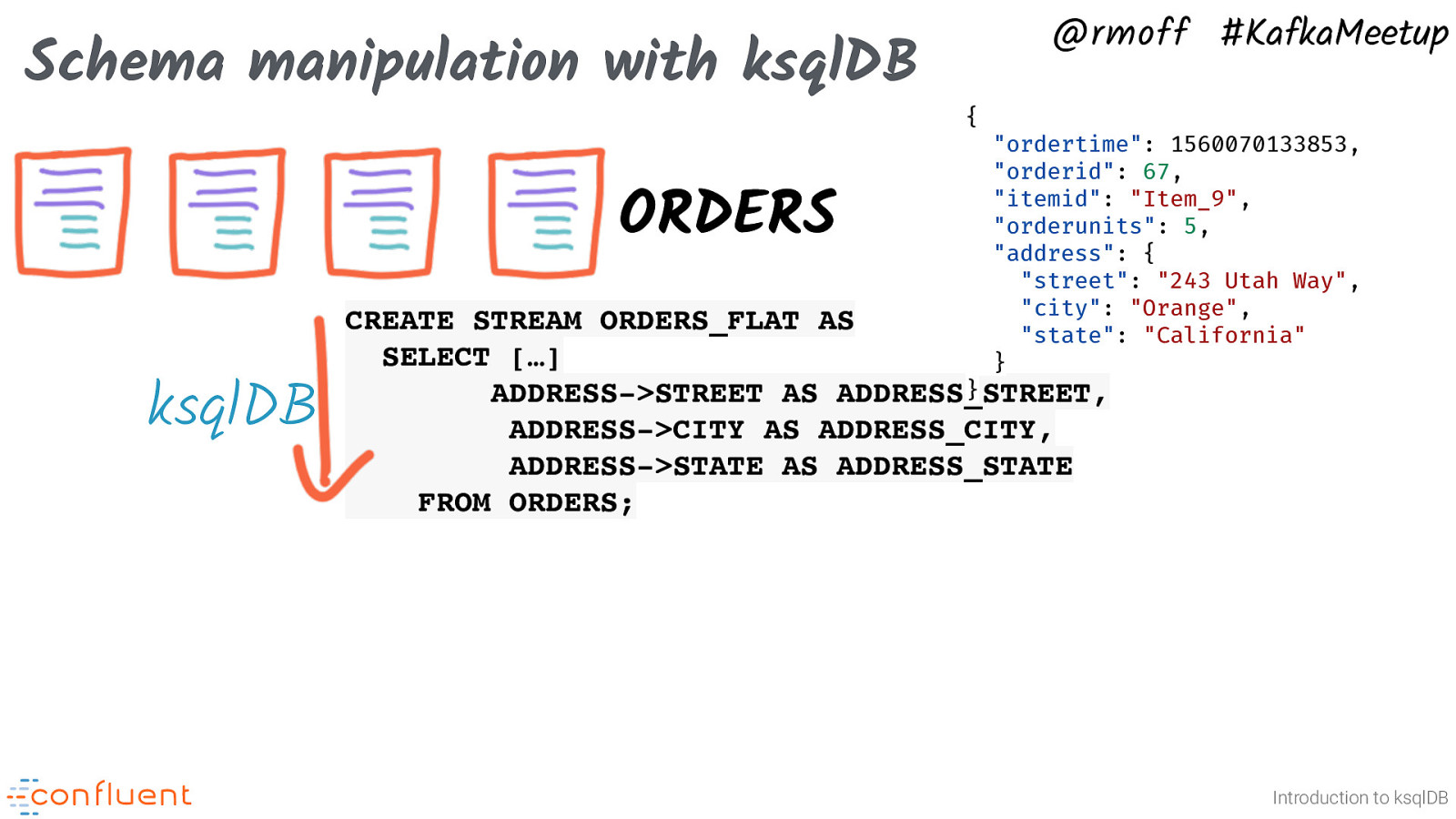
Schema manipulation with ksqlDB ORDERS ksqlDB @rmoff #KafkaMeetup { “ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5, “address”: { “street”: “243 Utah Way”, “city”: “Orange”, “state”: “California” } CREATE STREAM ORDERS_FLAT AS SELECT […] } ADDRESS->STREET AS ADDRESS_STREET, ADDRESS->CITY AS ADDRESS_CITY, ADDRESS->STATE AS ADDRESS_STATE FROM ORDERS; Introduction to ksqlDB
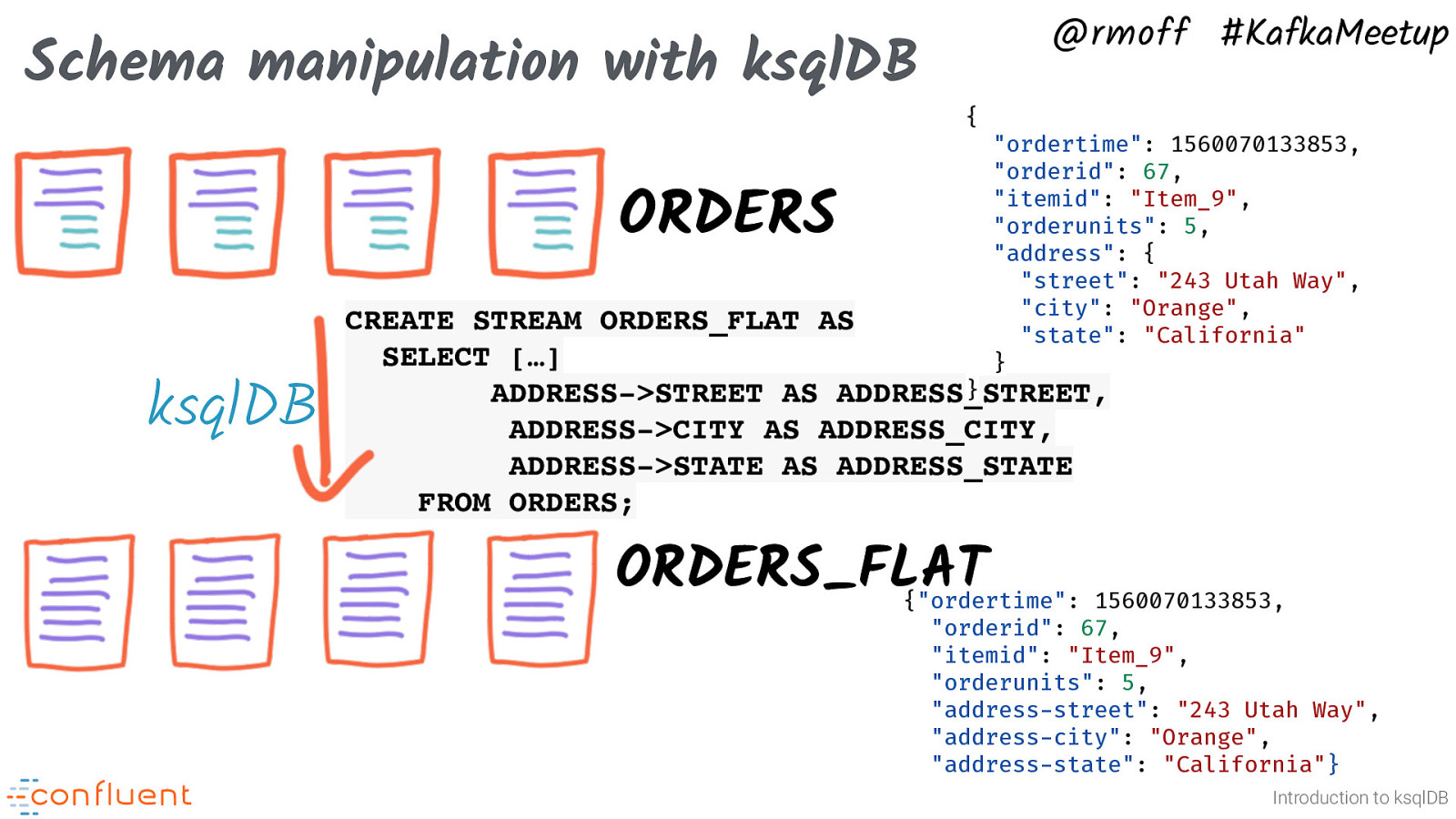
Schema manipulation with ksqlDB @rmoff #KafkaMeetup { ORDERS ksqlDB “ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5, “address”: { “street”: “243 Utah Way”, “city”: “Orange”, “state”: “California” } CREATE STREAM ORDERS_FLAT AS SELECT […] } ADDRESS->STREET AS ADDRESS_STREET, ADDRESS->CITY AS ADDRESS_CITY, ADDRESS->STATE AS ADDRESS_STATE FROM ORDERS; ORDERS_FLAT {“ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5, “address-street”: “243 Utah Way”, “address-city”: “Orange”, “address-state”: “California”} Introduction to ksqlDB
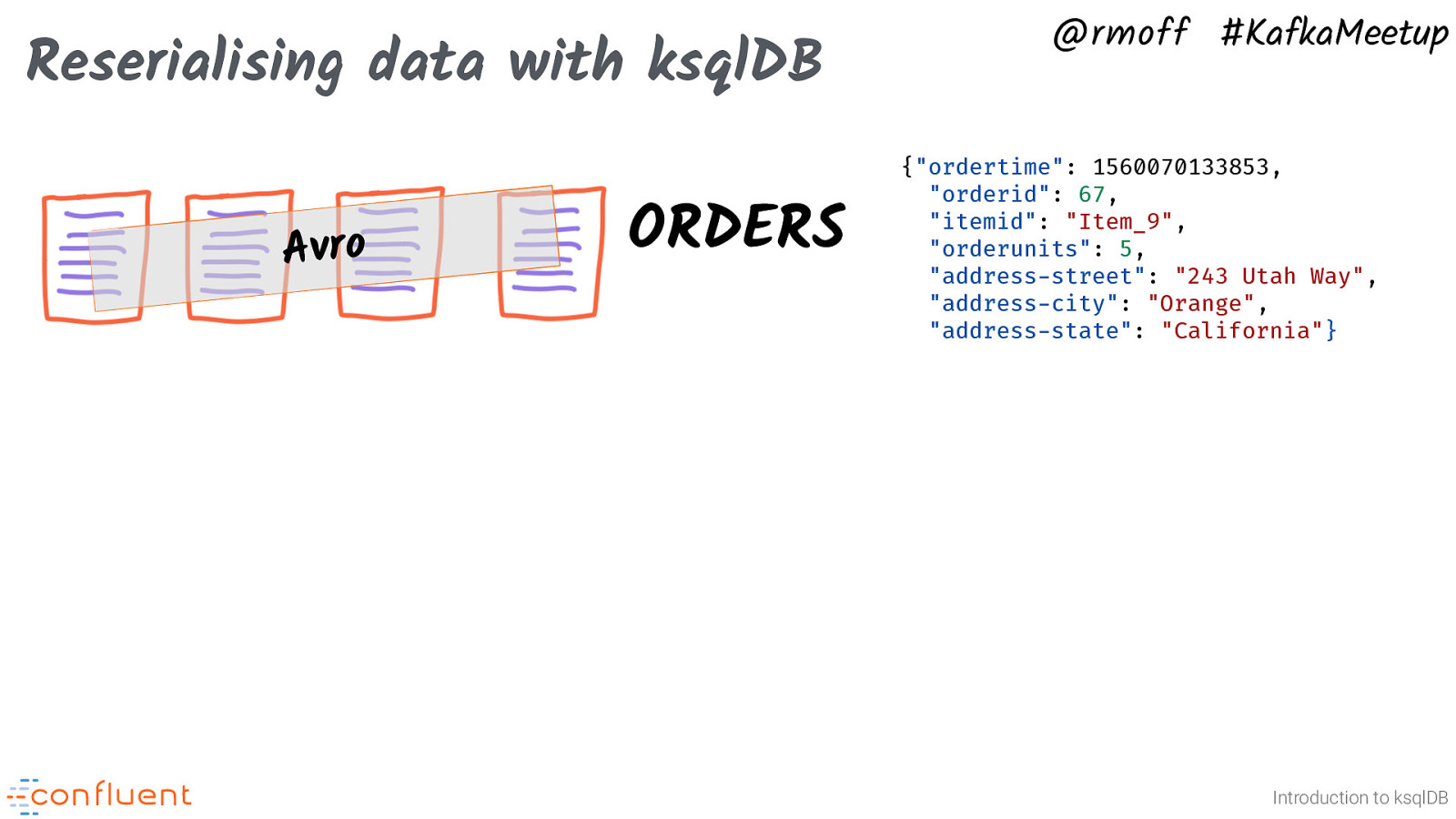
Reserialising data with ksqlDB Avro ORDERS @rmoff #KafkaMeetup {“ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5, “address-street”: “243 Utah Way”, “address-city”: “Orange”, “address-state”: “California”} Introduction to ksqlDB
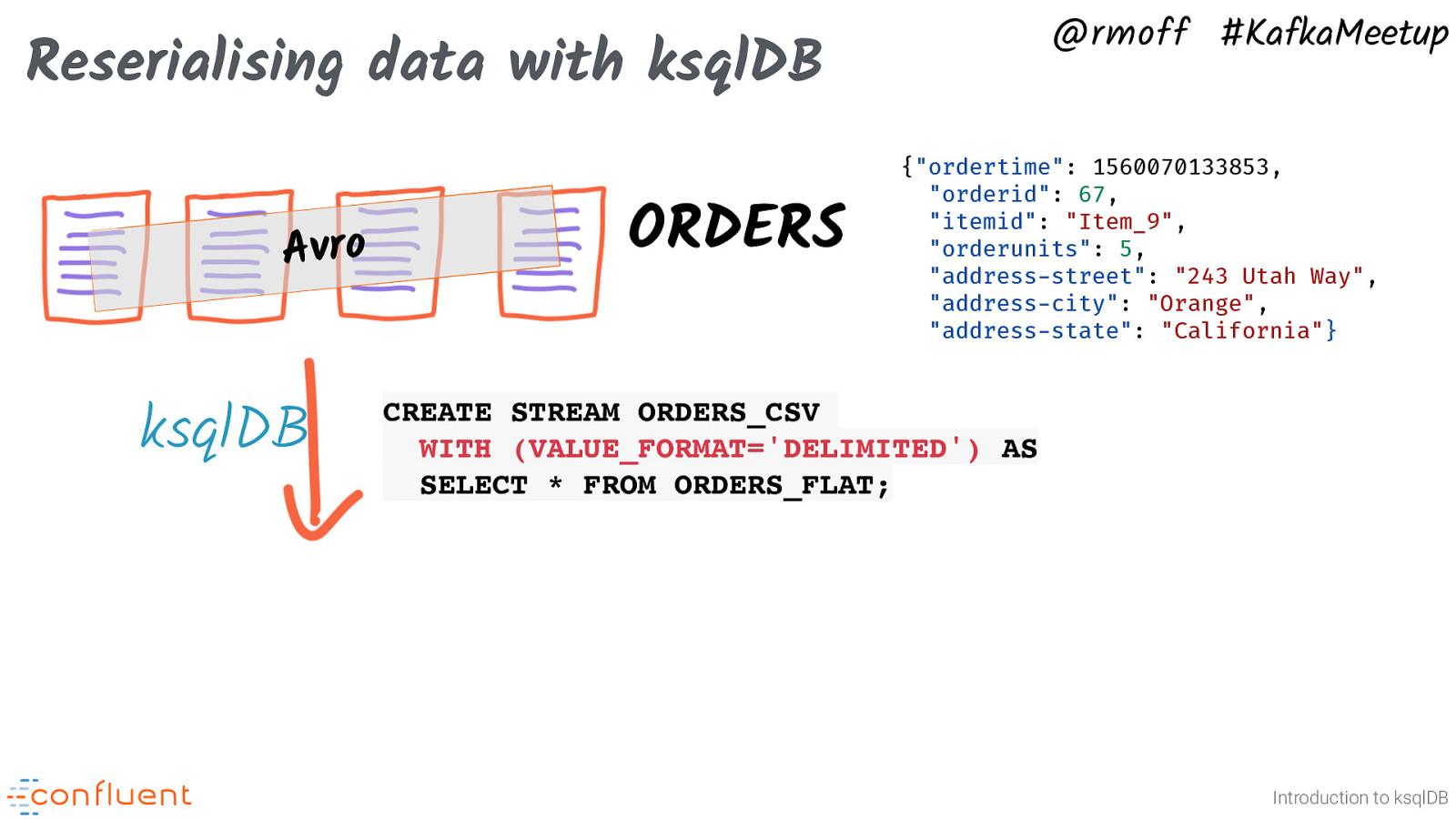
@rmoff #KafkaMeetup Reserialising data with ksqlDB Avro ksqlDB ORDERS {“ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5, “address-street”: “243 Utah Way”, “address-city”: “Orange”, “address-state”: “California”} CREATE STREAM ORDERS_CSV WITH (VALUE_FORMAT=’DELIMITED’) AS SELECT * FROM ORDERS_FLAT; Introduction to ksqlDB
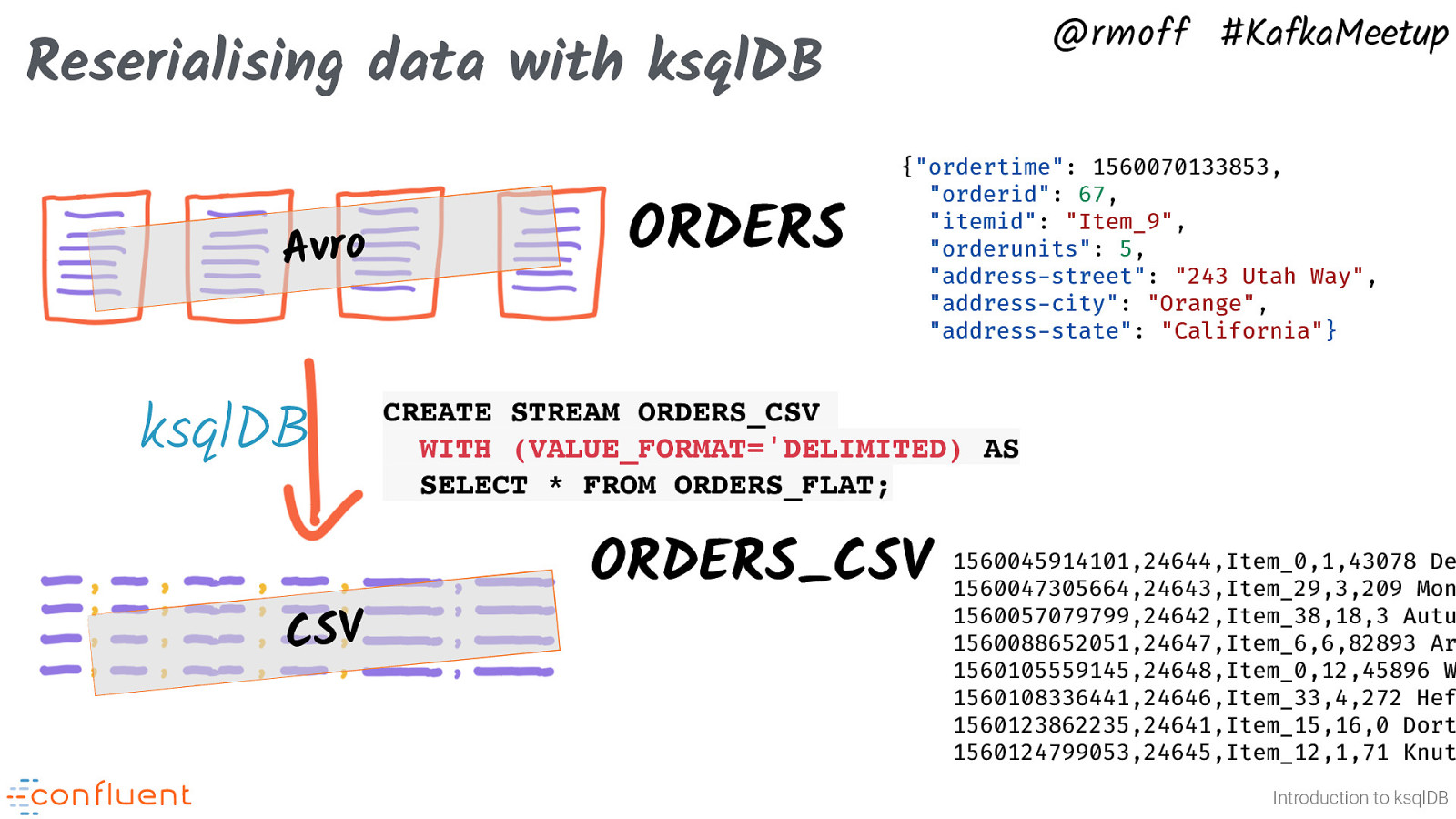
@rmoff #KafkaMeetup Reserialising data with ksqlDB Avro ksqlDB CSV ORDERS {“ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5, “address-street”: “243 Utah Way”, “address-city”: “Orange”, “address-state”: “California”} CREATE STREAM ORDERS_CSV WITH (VALUE_FORMAT=’DELIMITED) AS SELECT * FROM ORDERS_FLAT; ORDERS_CSV 1560045914101,24644,Item_0,1,43078 Dexter Pass,Port Washington,New York 1560047305664,24643,Item_29,3,209 Monterey Pass,Chula Vista,California 1560057079799,24642,Item_38,18,3 Autumn Leaf Plaza,San Diego,California 1560088652051,24647,Item_6,6,82893 Arkansas Center,El Paso,Texas 1560105559145,24648,Item_0,12,45896 Warner Parkway,South Lake Tahoe,California 1560108336441,24646,Item_33,4,272 Heffernan Way,El Paso,Texas 1560123862235,24641,Item_15,16,0 Dorton Circle,Brooklyn,New York 1560124799053,24645,Item_12,1,71 Knutson Parkway,Dallas,Texas Introduction to ksqlDB