Integrating Oracle and Kafka Robin Moffatt | #ACEsAtHome | @rmoff

A presentation at ACEs @ Home in June 2020 in by Robin Moffatt

Integrating Oracle and Kafka Robin Moffatt | #ACEsAtHome | @rmoff

$ whoami • Robin Moffatt (@rmoff) • Senior Developer Advocate at Confluent (Apache Kafka, not Wikis 😉) • Working in data & analytics since 2001 • Oracle ACE Director (Alumnus) http://rmoff.dev/talks · http://rmoff.dev/blog · http://rmoff.dev/youtube @rmoff | #ACEsAtHome | @confluentinc
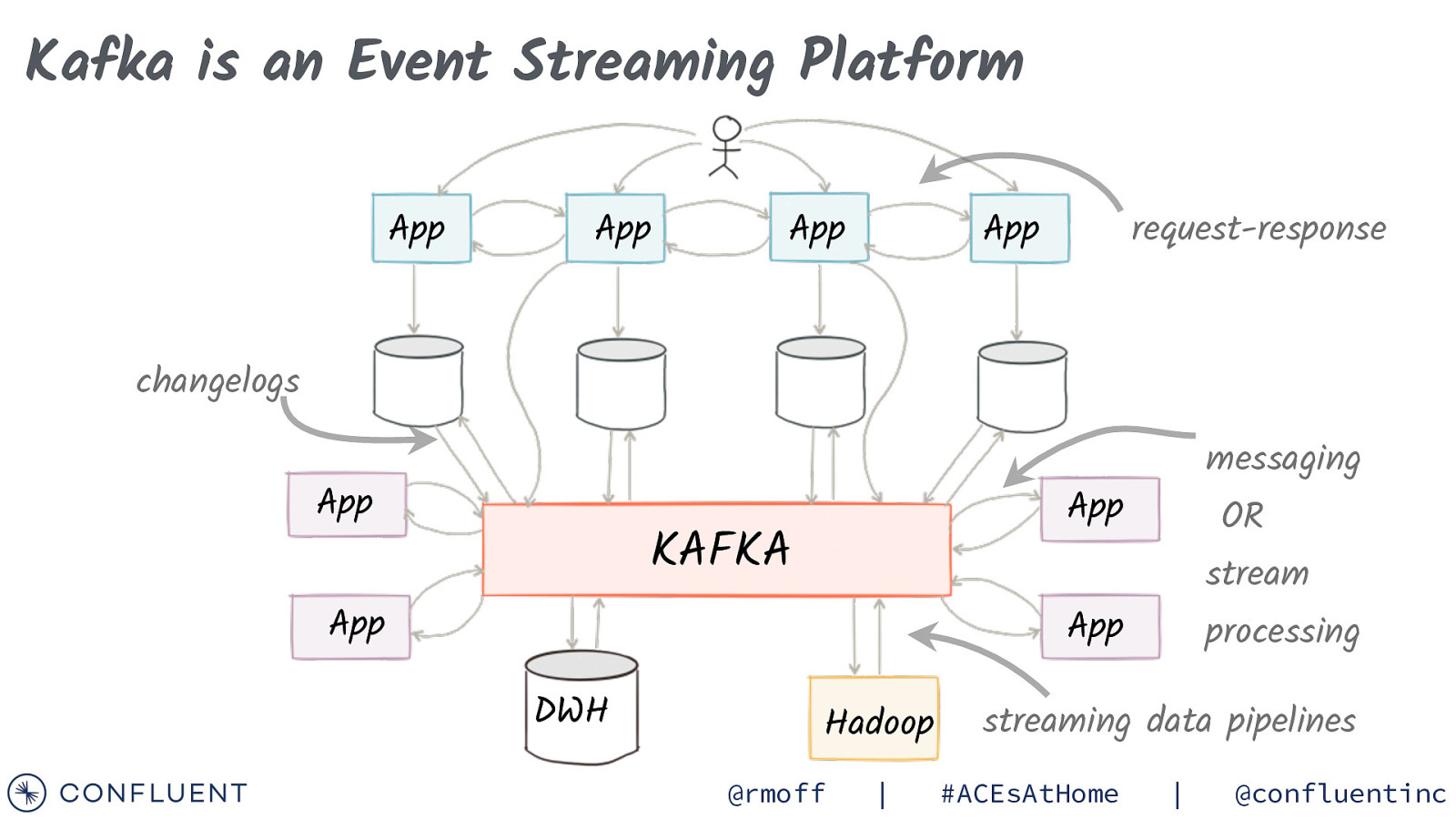
Kafka is an Event Streaming Platform App App App App request-response changelogs App messaging App KAFKA App OR stream App DWH Hadoop @rmoff | processing streaming data pipelines #ACEsAtHome | @confluentinc
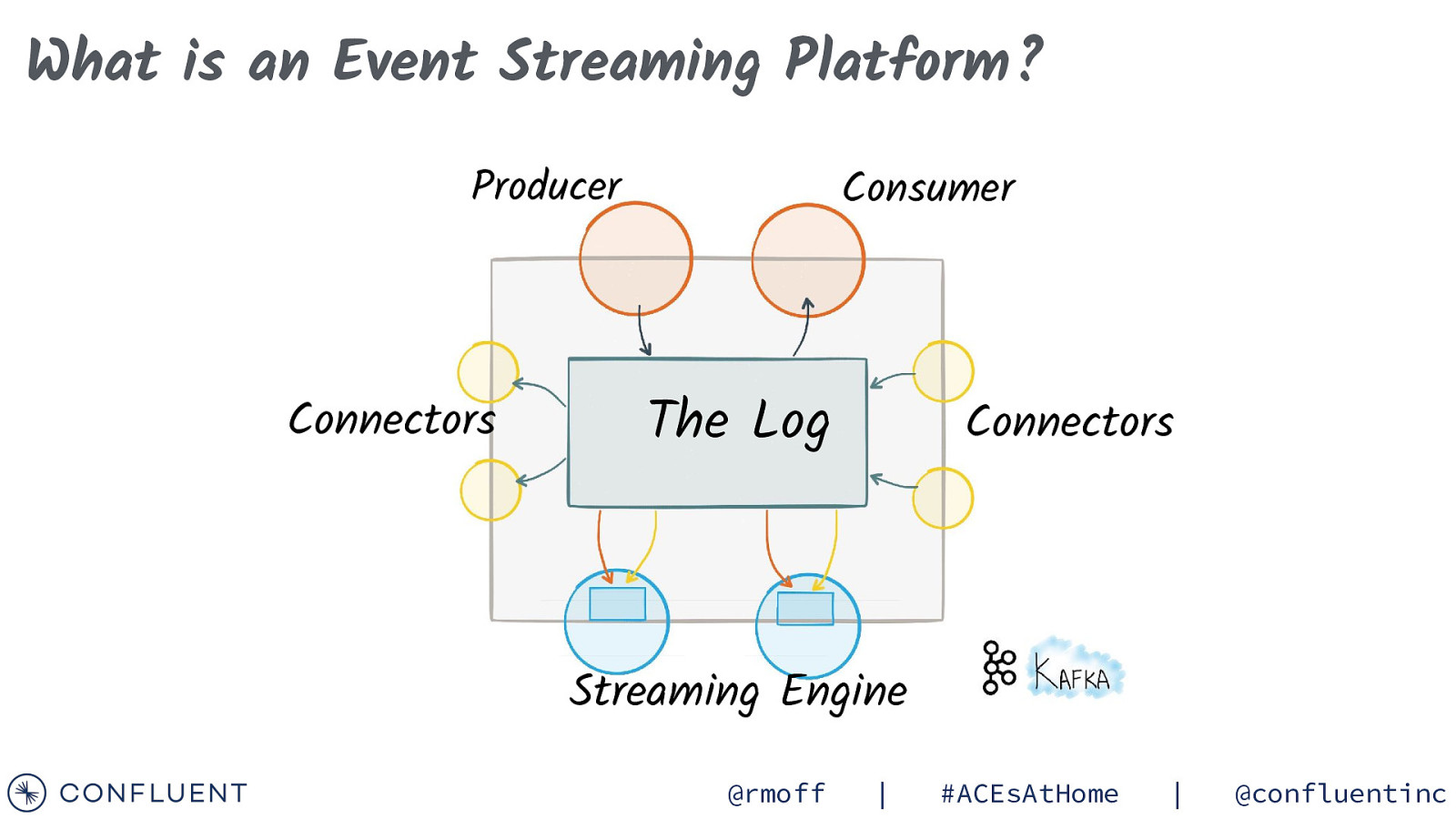
What is an Event Streaming Platform? Producer Connectors Consumer The Log Connectors Streaming Engine @rmoff | #ACEsAtHome | @confluentinc
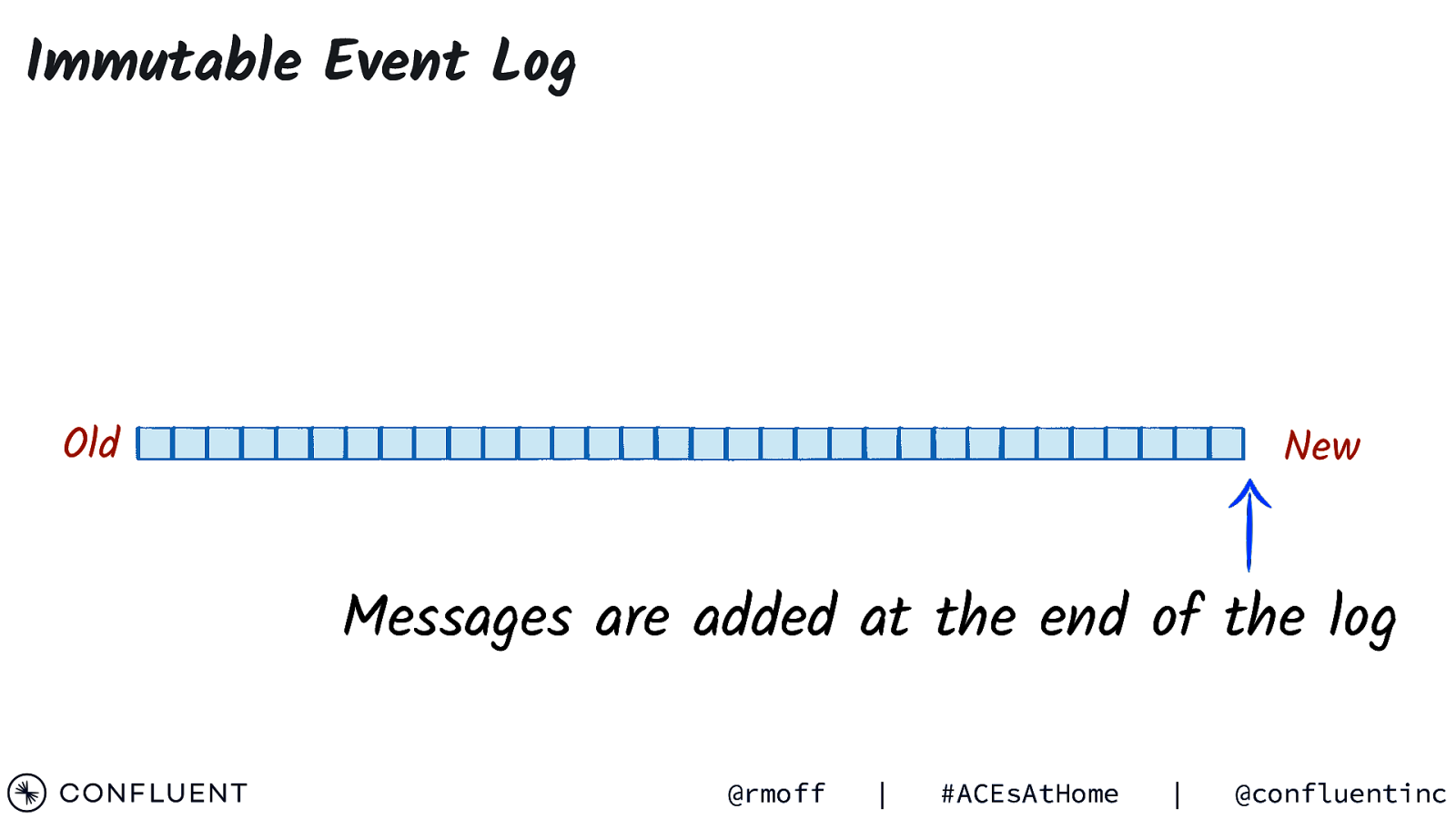
Immutable Event Log Old New Messages are added at the end of the log @rmoff | #ACEsAtHome | @confluentinc

Topics Clicks Orders Customers Topics are similar in concept to tables in a database @rmoff | #ACEsAtHome | @confluentinc
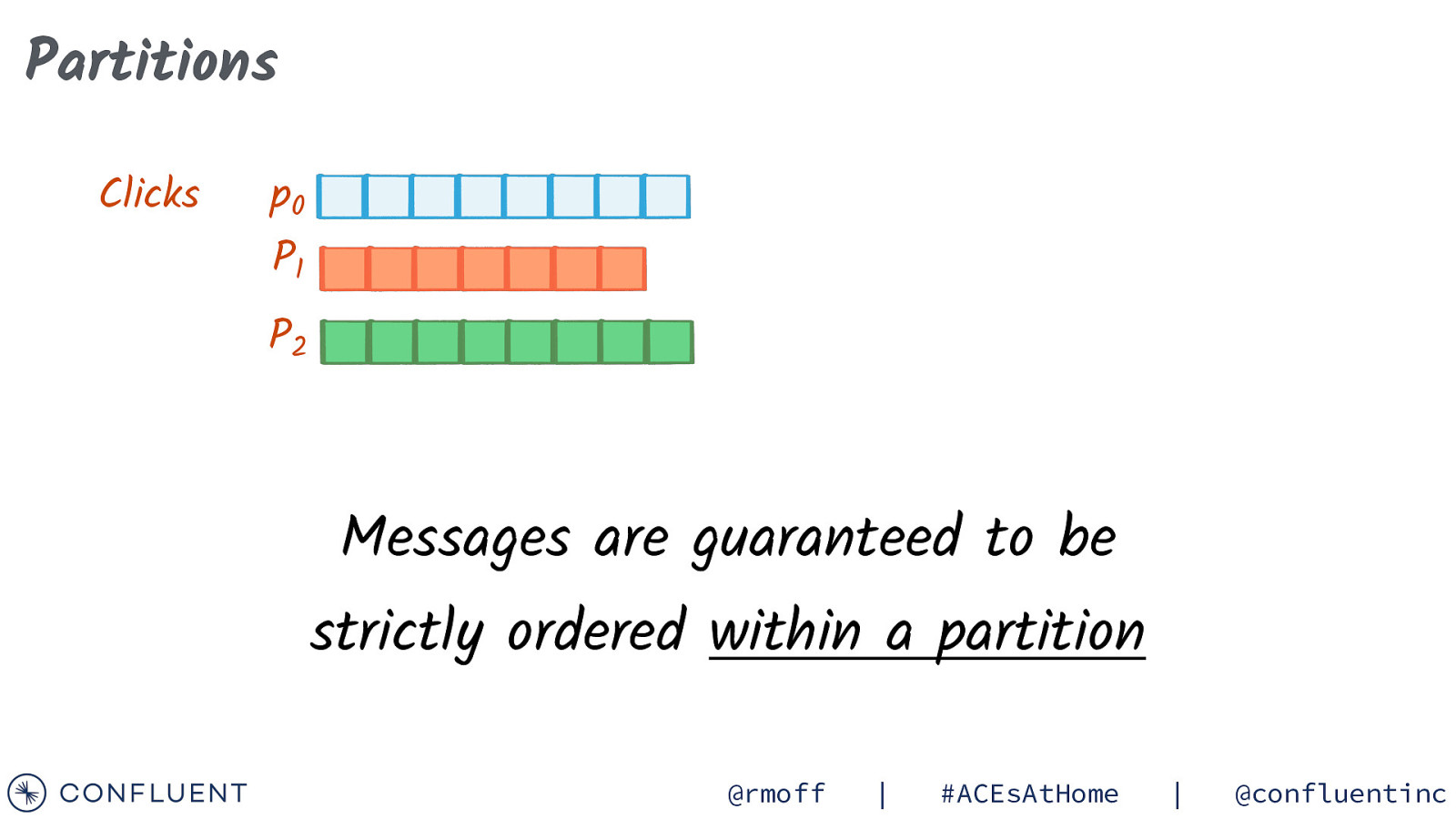
Partitions Clicks p0 P1 P2 Messages are guaranteed to be strictly ordered within a partition @rmoff | #ACEsAtHome | @confluentinc
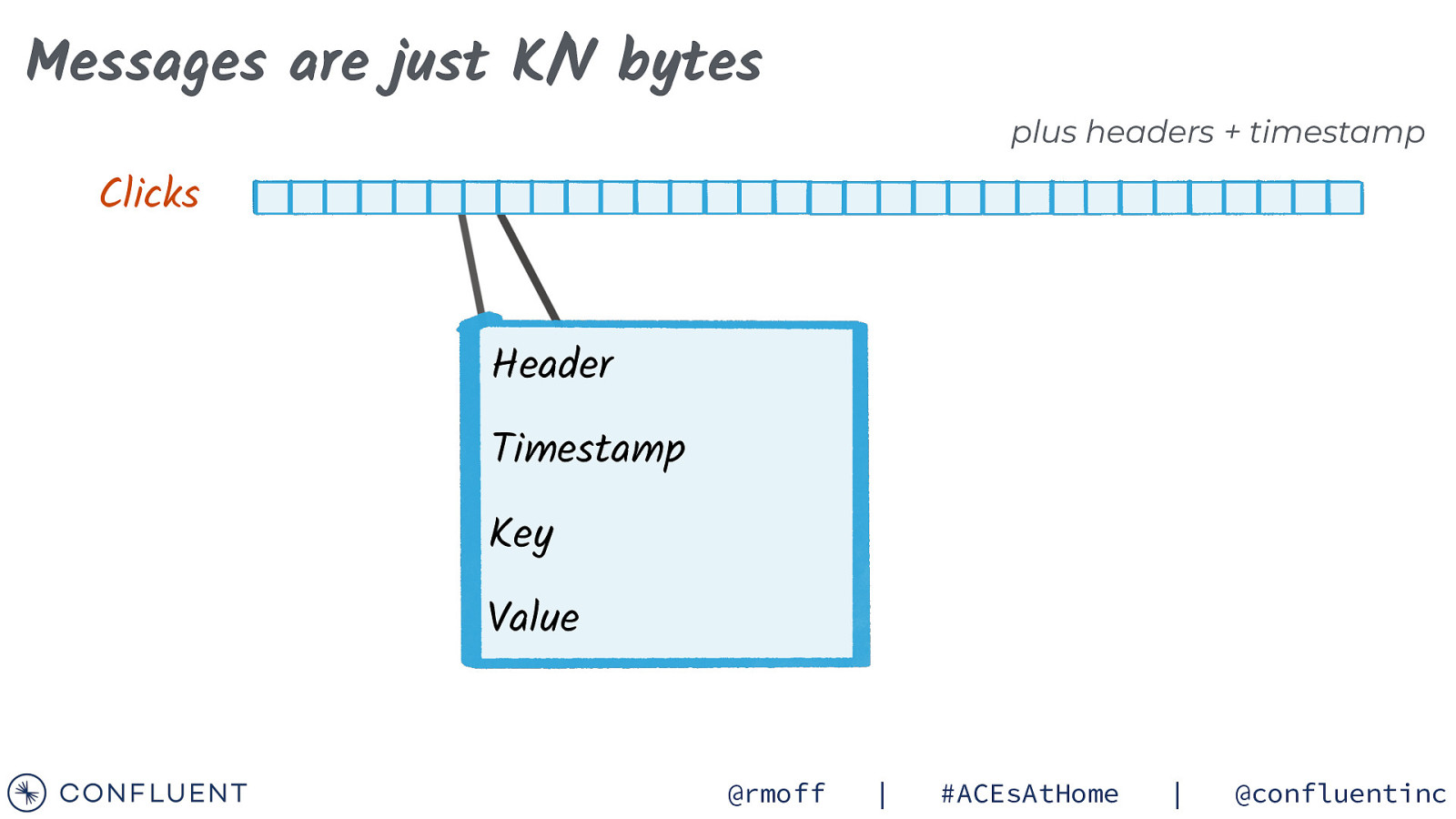
Messages are just K/V bytes plus headers + timestamp Clicks Header Timestamp Key Value @rmoff | #ACEsAtHome | @confluentinc

Serialisation & Schemas JSON Avro Protobuf Schema JSON CSV 👍 👍 👍 😬 https://qconnewyork.com/system/files/presentation-slides/qcon_17_-_schemas_and_apis.pdf @rmoff | #ACEsAtHome | @confluentinc
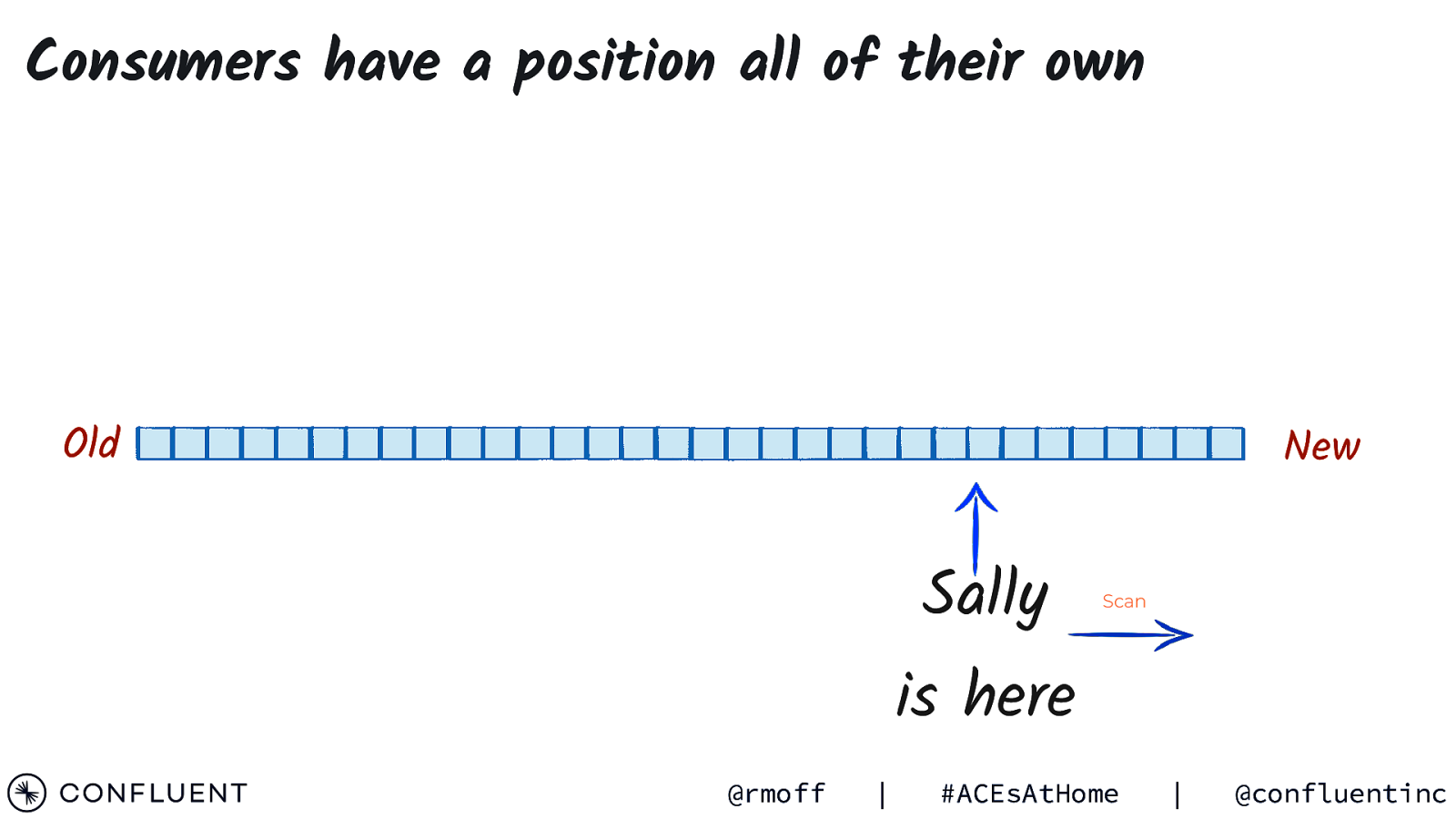
Consumers have a position all of their own Old New Sally Scan is here @rmoff | #ACEsAtHome | @confluentinc
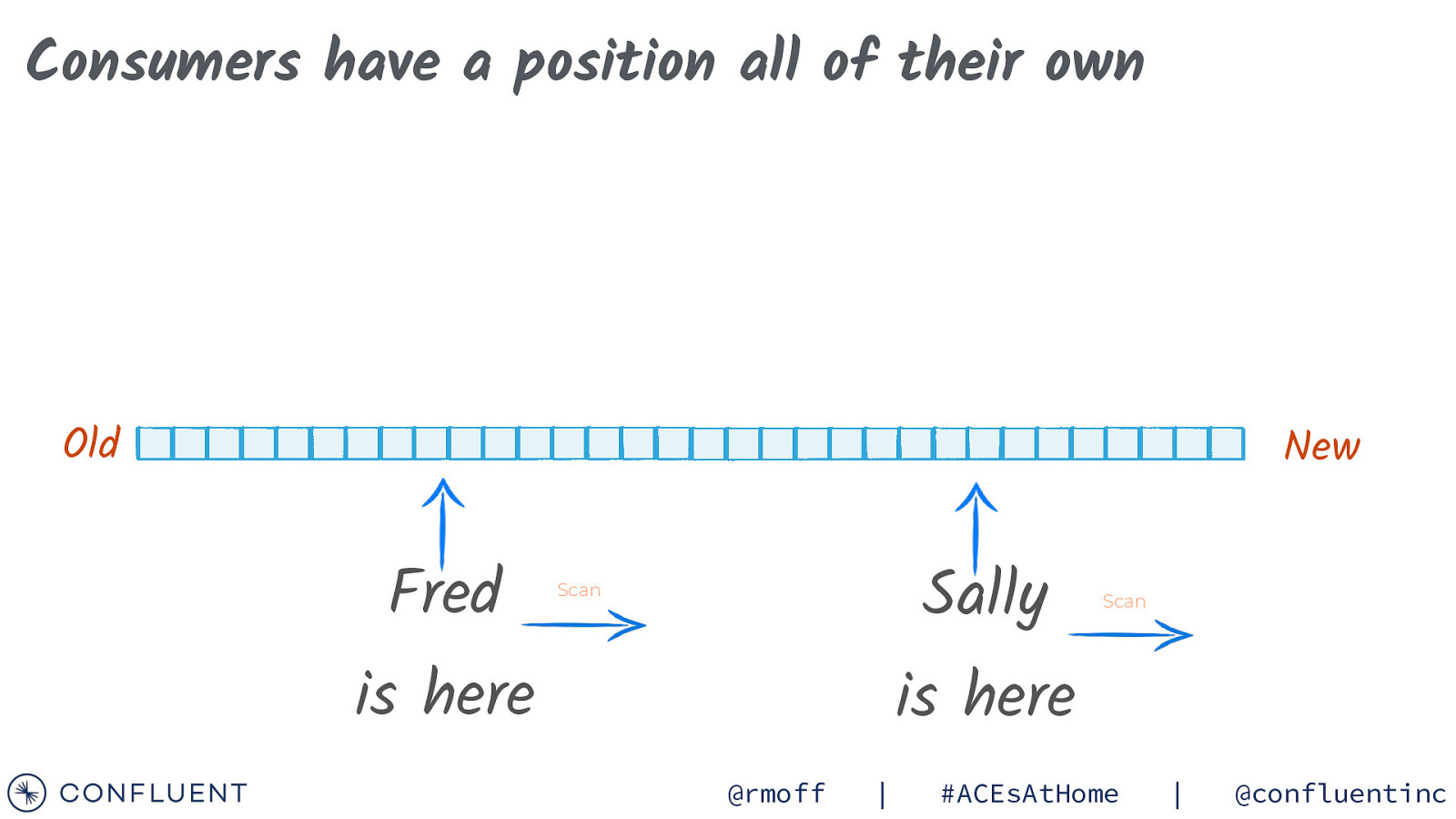
Consumers have a position all of their own Old New Fred Sally Scan is here Scan is here @rmoff | #ACEsAtHome | @confluentinc
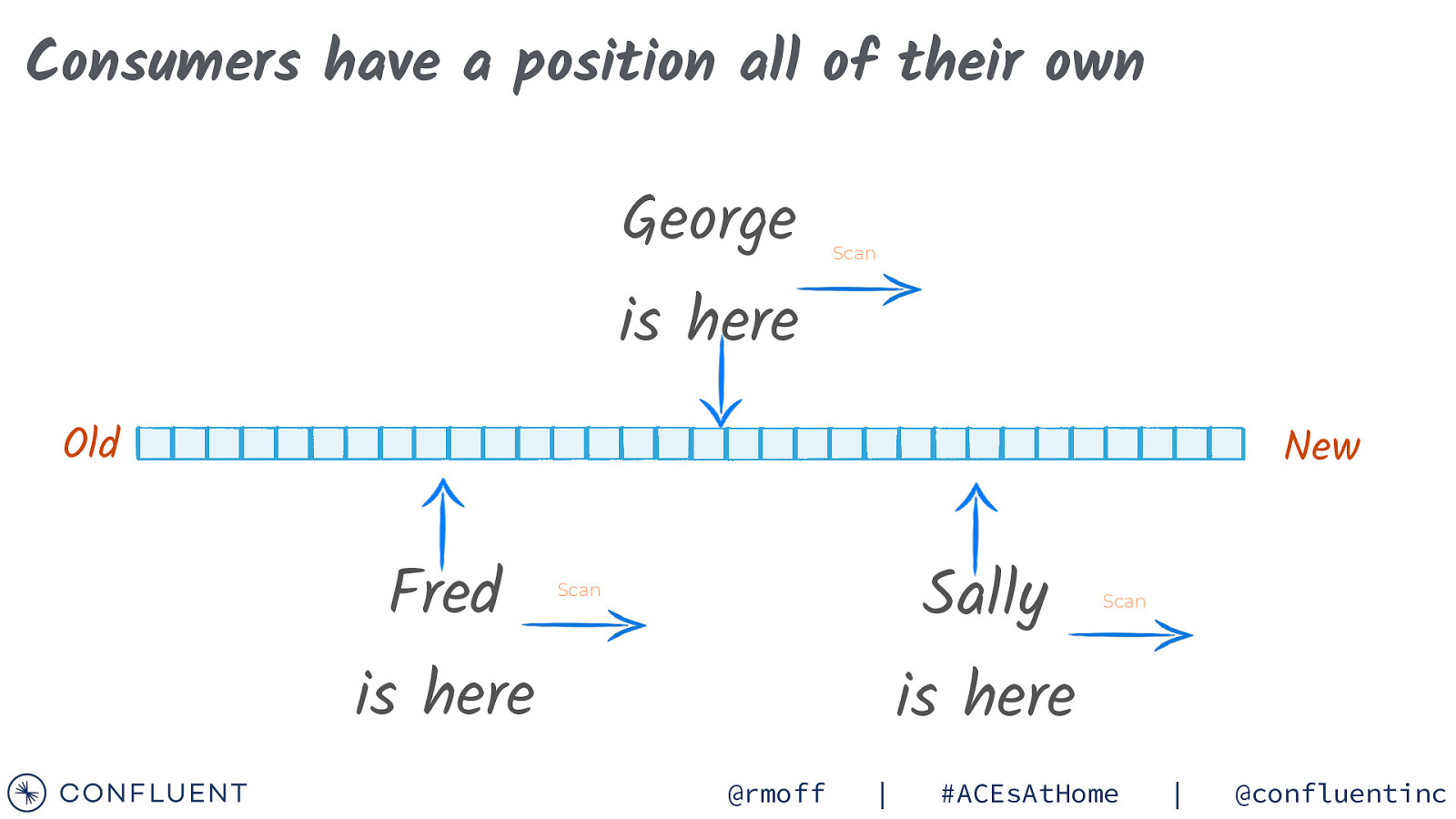
Consumers have a position all of their own George Scan is here Old New Fred Sally Scan is here Scan is here @rmoff | #ACEsAtHome | @confluentinc

Free Books! https://rmoff.dev/aces @rmoff | #ACEsAtHome | @confluentinc
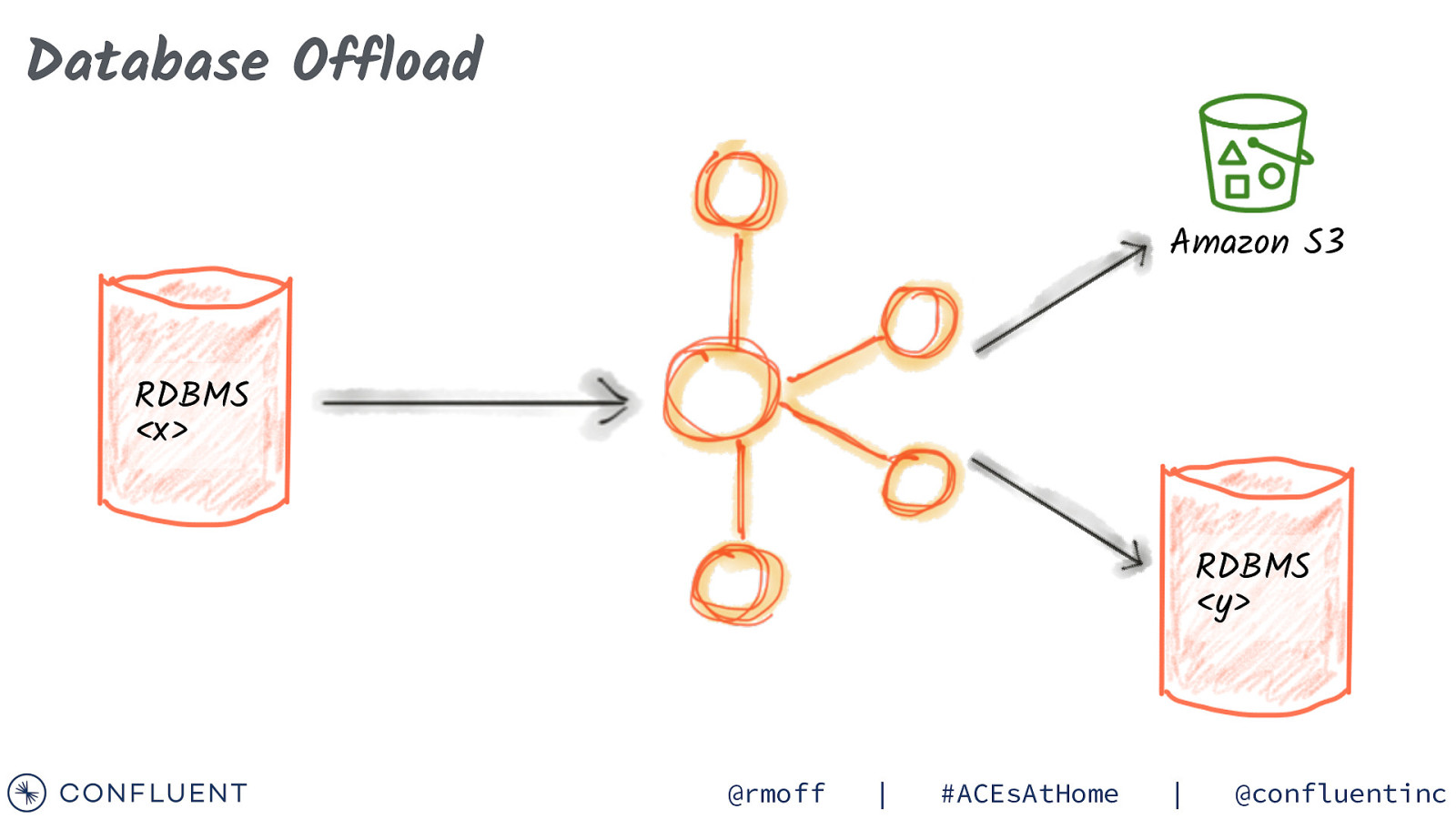
Database Offload Amazon S3 RDBMS <x> RDBMS <y> @rmoff | #ACEsAtHome | @confluentinc
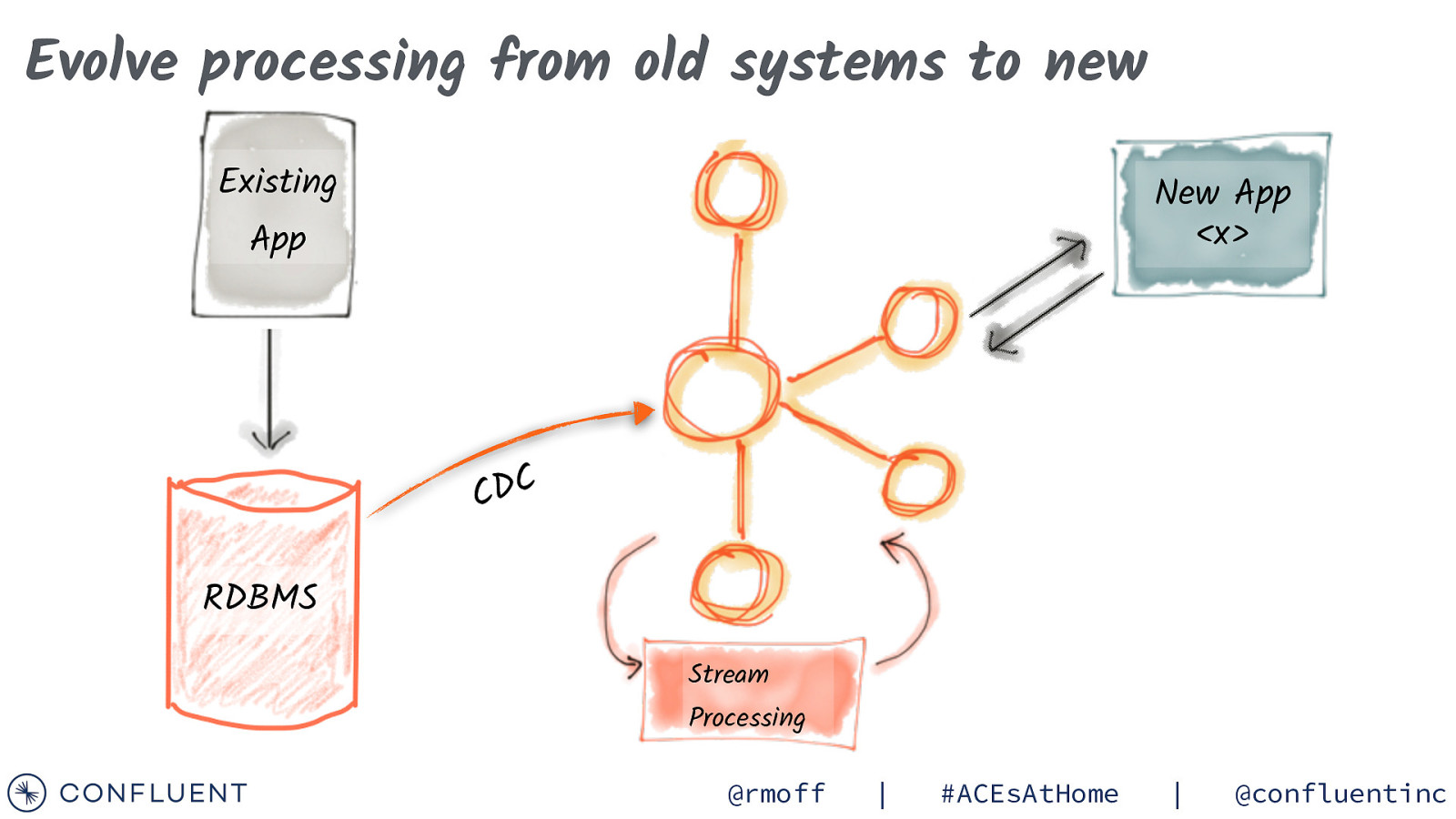
Evolve processing from old systems to new Existing New App <x> App C D C RDBMS Stream Processing @rmoff | #ACEsAtHome | @confluentinc
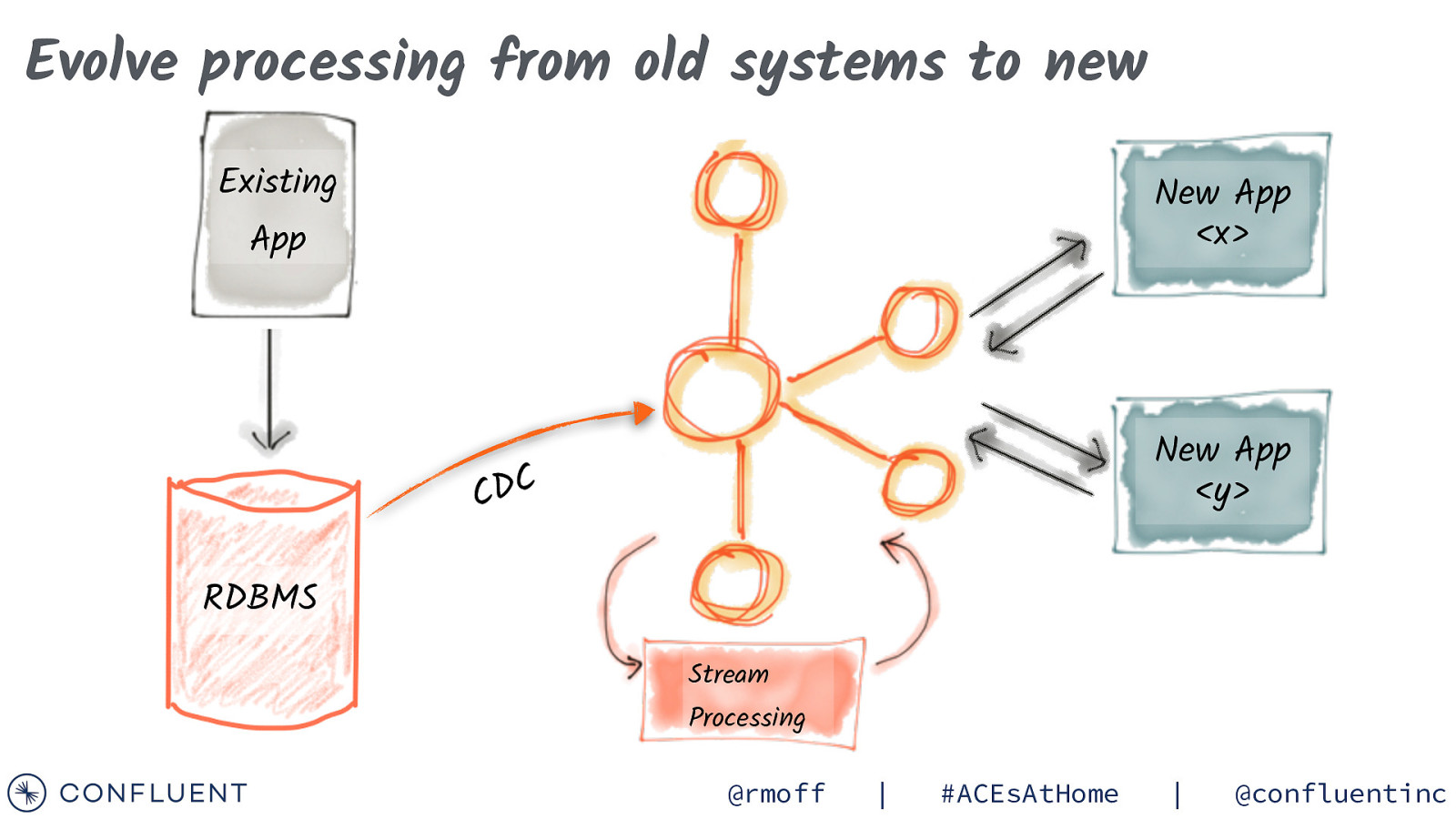
Evolve processing from old systems to new Existing New App <x> App New App <y> C D C RDBMS Stream Processing @rmoff | #ACEsAtHome | @confluentinc
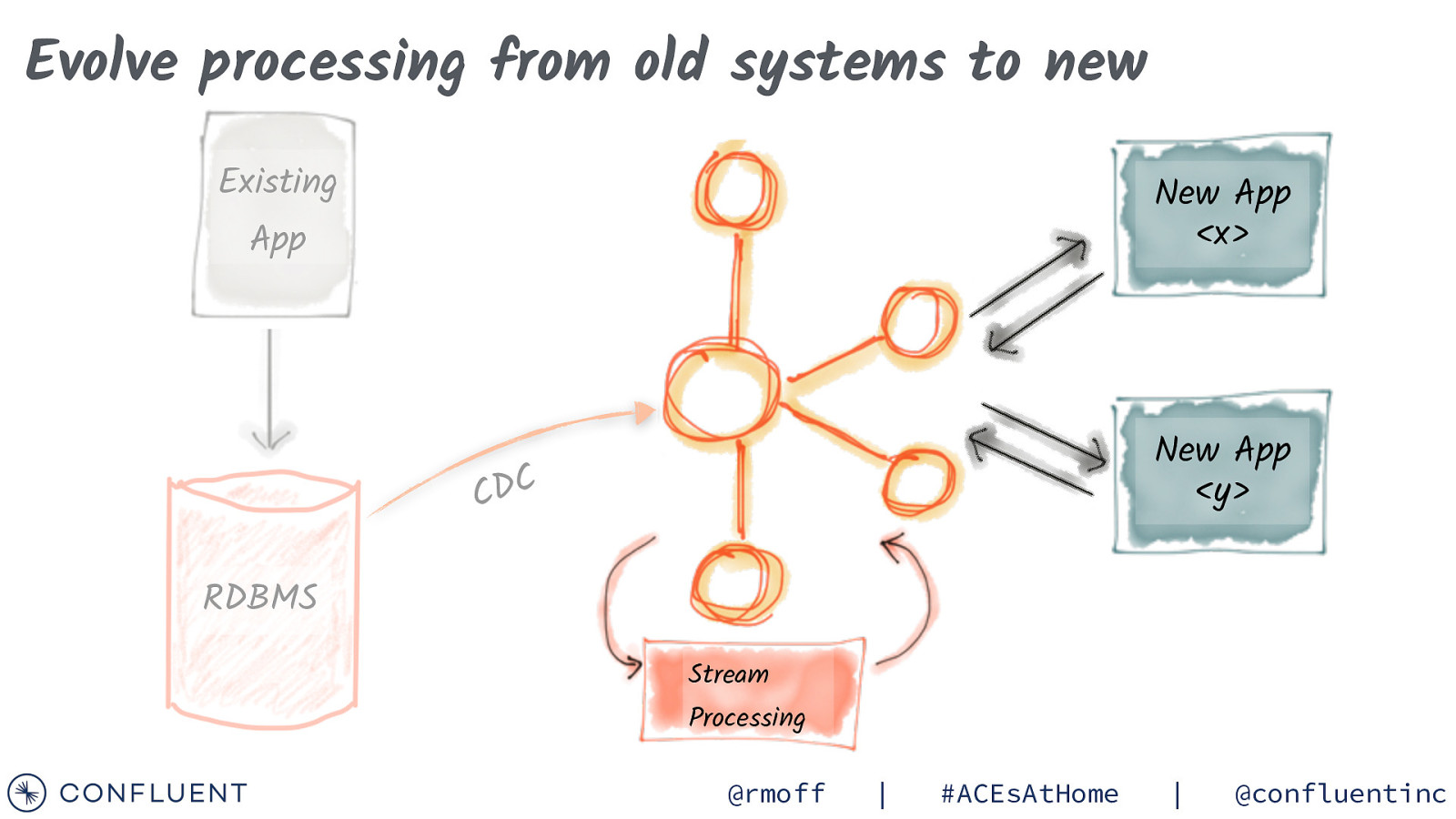
Evolve processing from old systems to new Existing New App <x> App New App <y> C D C RDBMS Stream Processing @rmoff | #ACEsAtHome | @confluentinc
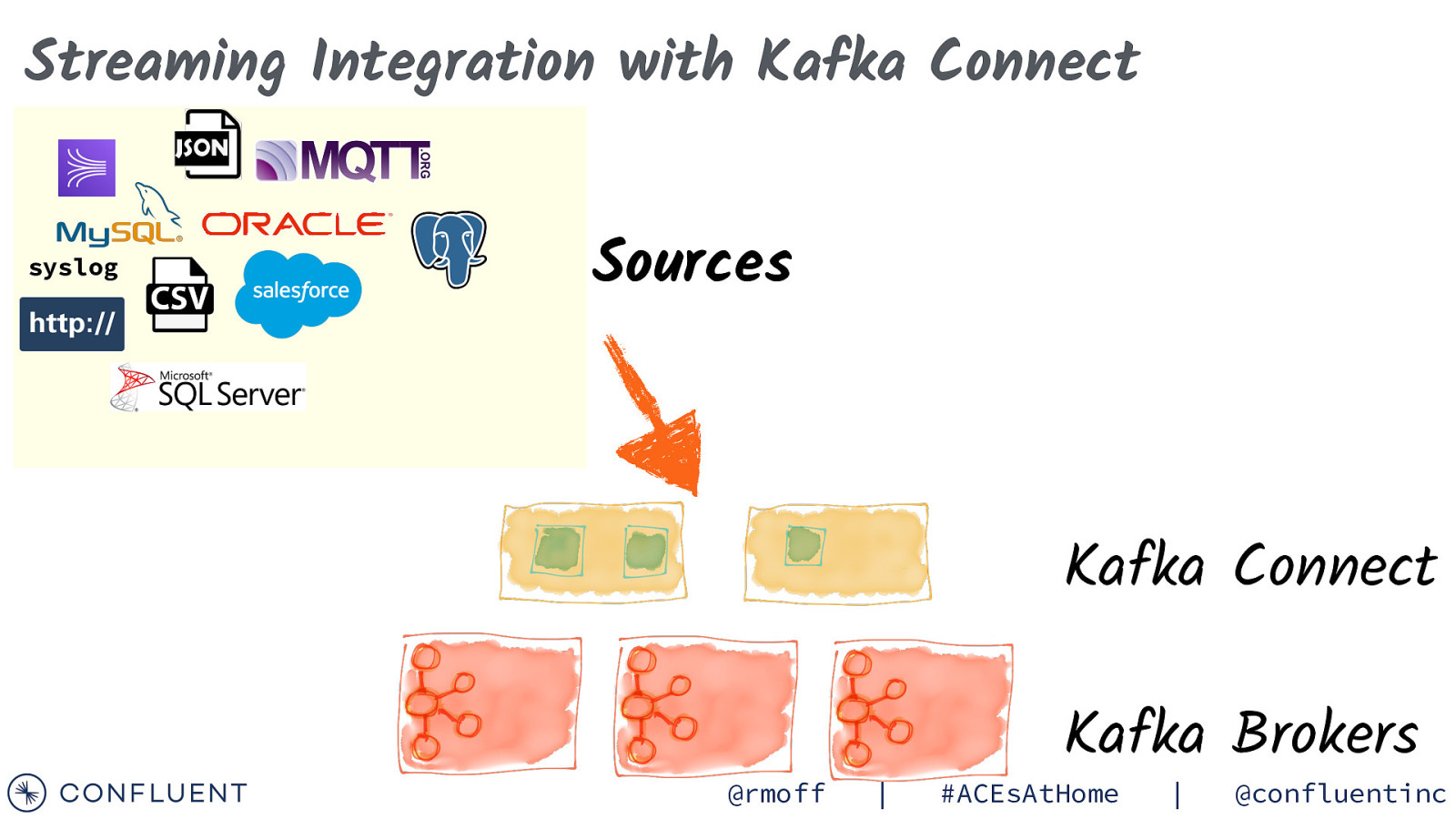
Streaming Integration with Kafka Connect syslog Sources Kafka Connect @rmoff | Kafka Brokers #ACEsAtHome | @confluentinc
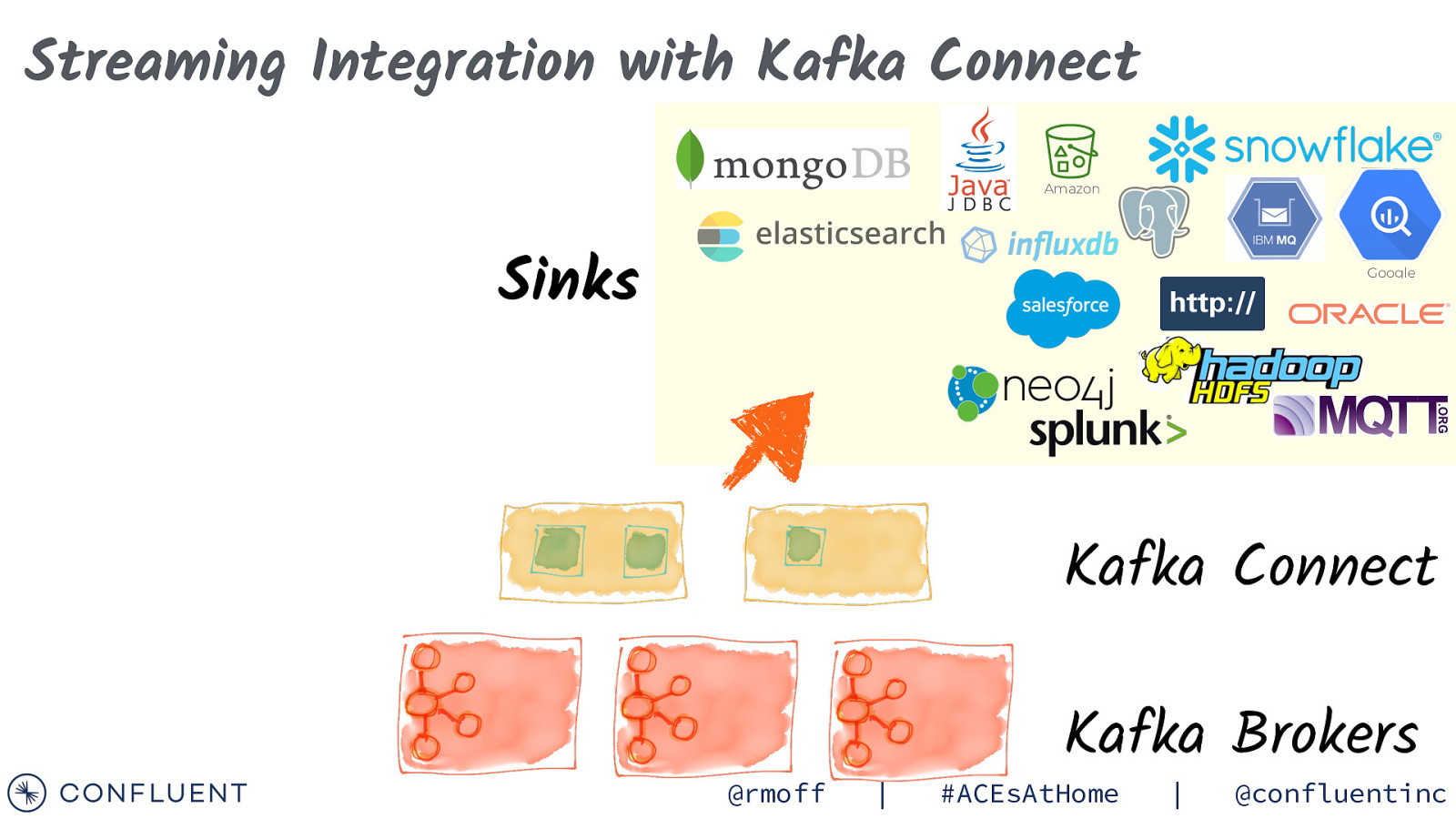
Streaming Integration with Kafka Connect Amazon Sinks Google Kafka Connect @rmoff | Kafka Brokers #ACEsAtHome | @confluentinc
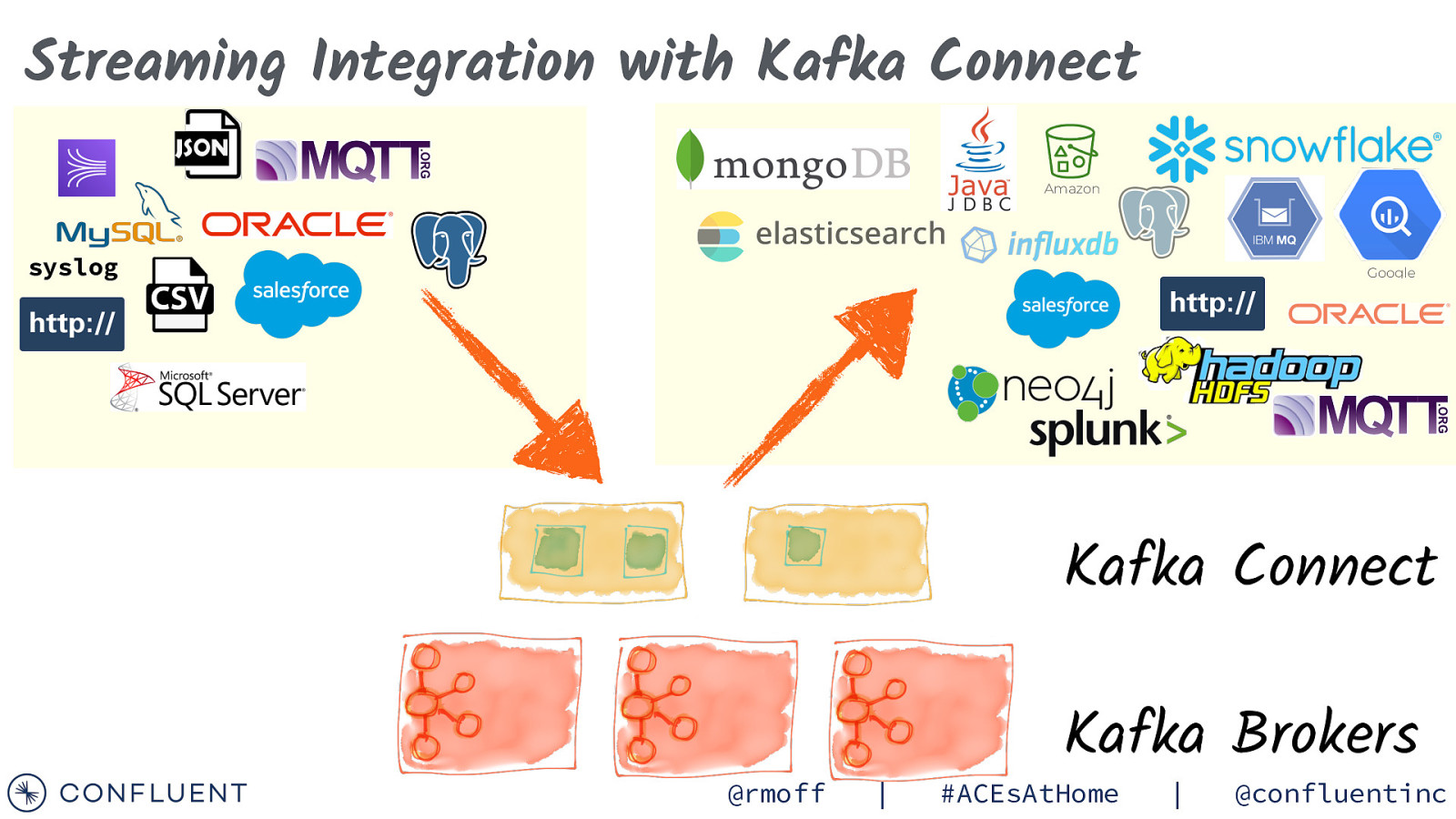
Streaming Integration with Kafka Connect Amazon syslog Google Kafka Connect @rmoff | Kafka Brokers #ACEsAtHome | @confluentinc

Look Ma, No Code! { “connector.class”: “io.confluent.connect.jdbc.JdbcSourceConnector”, “connection.url”: https://docs.confluent.io/current/ “jdbc:mysql://asgard:3306/demo”, “table.whitelist”: “sales,orders,customers” } @rmoff | #ACEsAtHome | @confluentinc
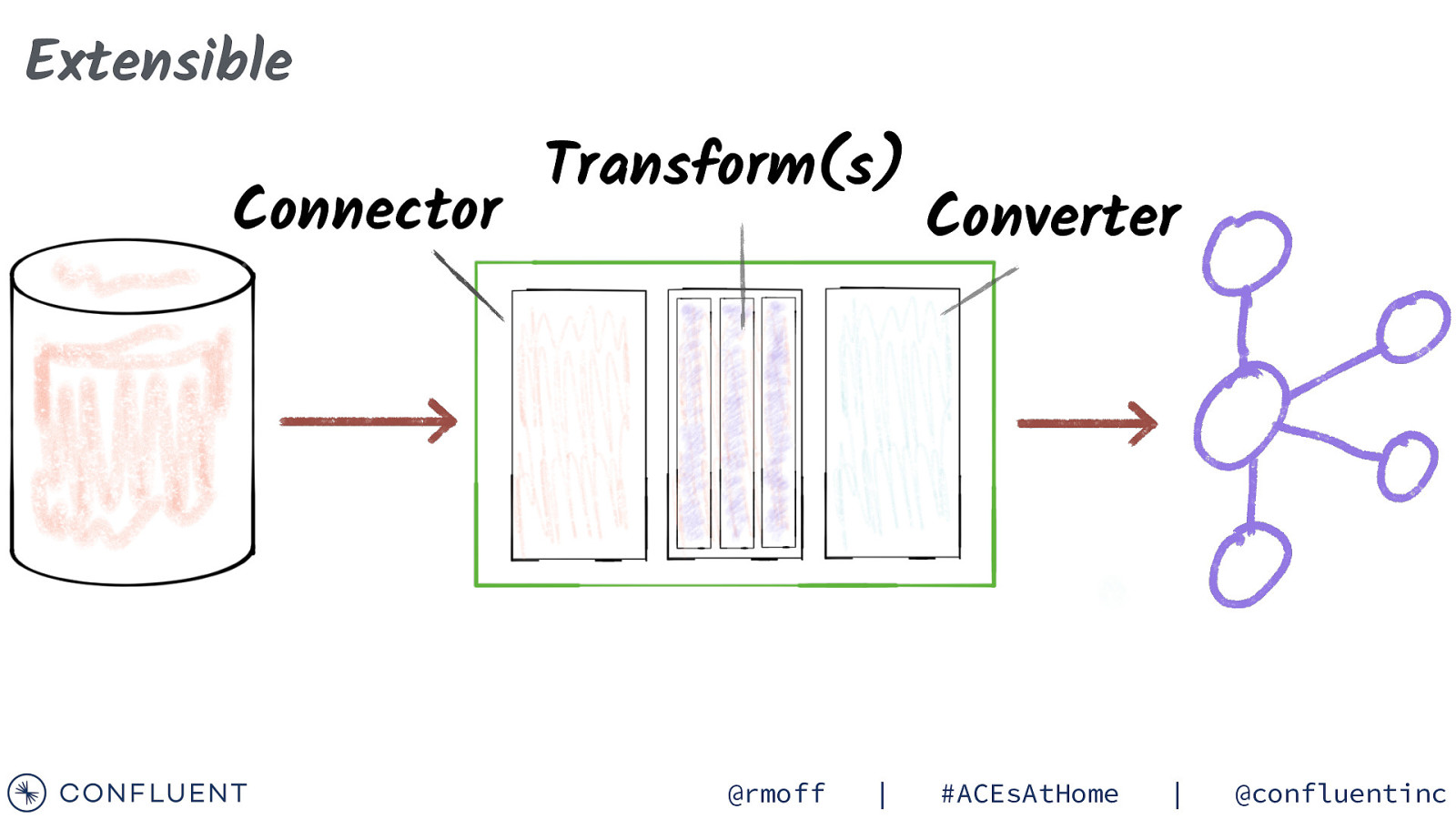
Extensible Connector Transform(s) @rmoff | Converter #ACEsAtHome | @confluentinc
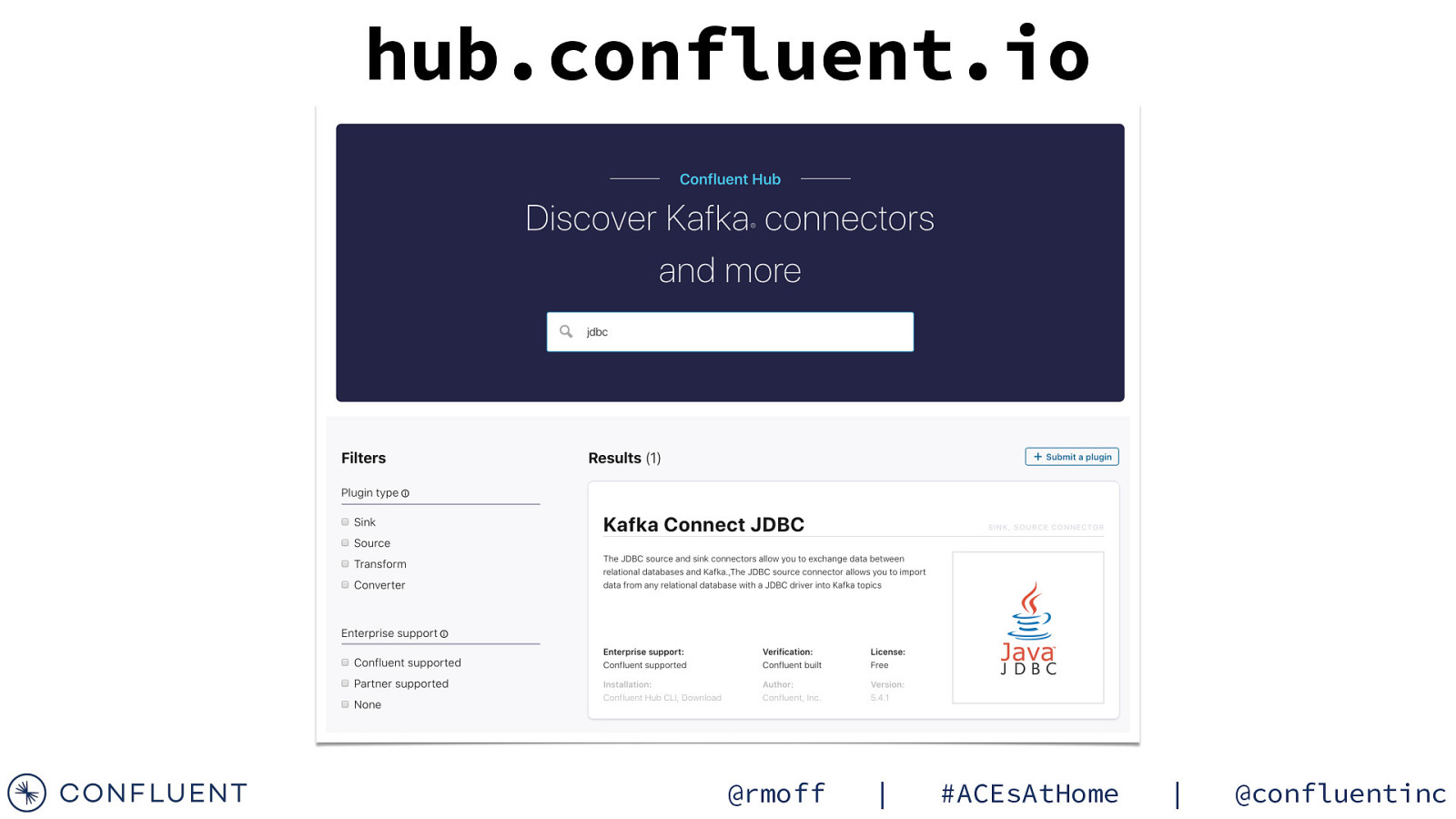
hub.confluent.io @rmoff | #ACEsAtHome | @confluentinc
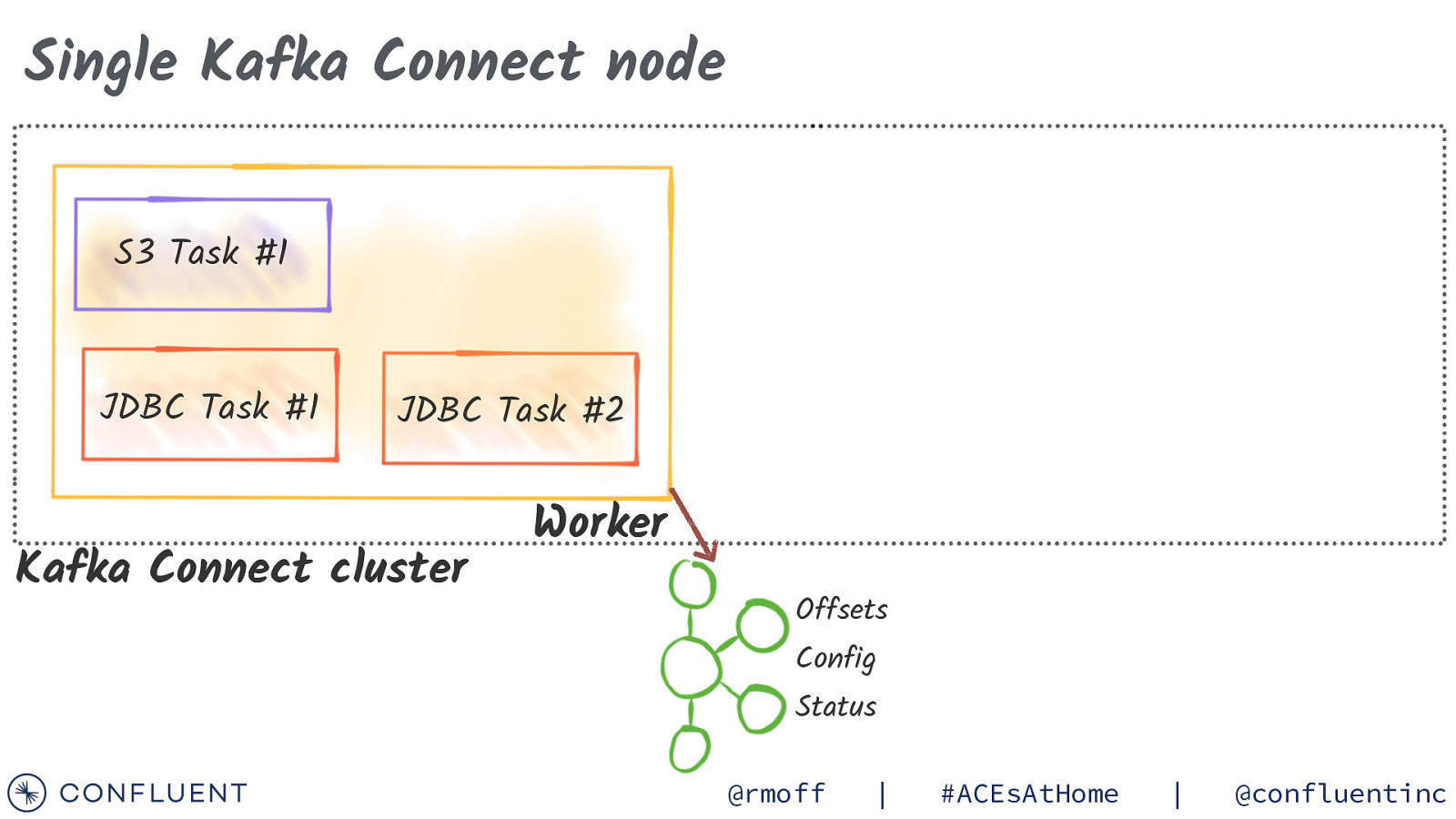
Single Kafka Connect node S3 Task #1 JDBC Task #1 JDBC Task #2 Kafka Connect cluster Worker Worker Offsets Config Status @rmoff | #ACEsAtHome | @confluentinc
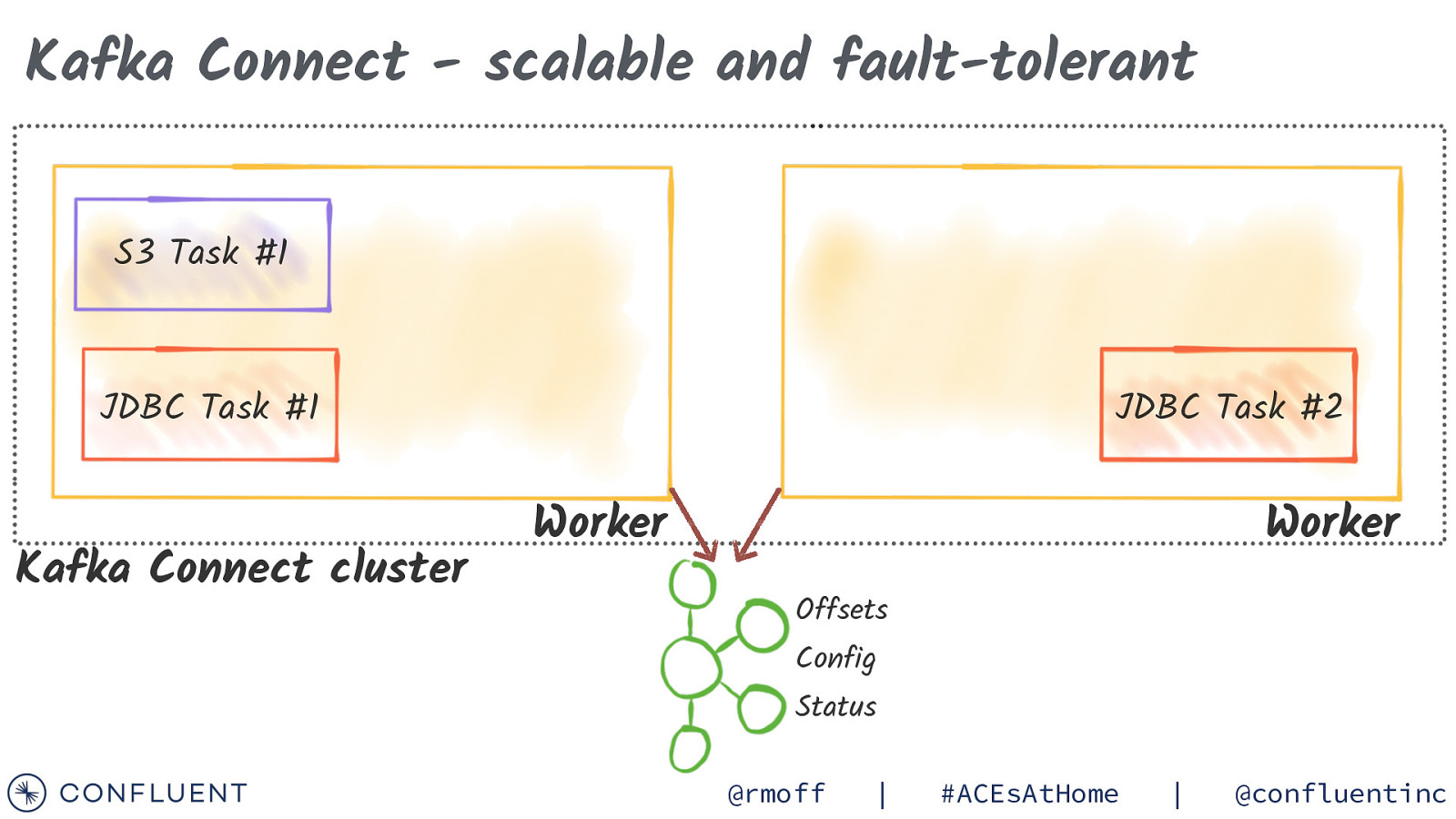
Kafka Connect - scalable and fault-tolerant S3 Task #1 JDBC Task #1 Kafka Connect cluster JDBC Task #2 Worker Worker Offsets Config Status @rmoff | #ACEsAtHome | @confluentinc
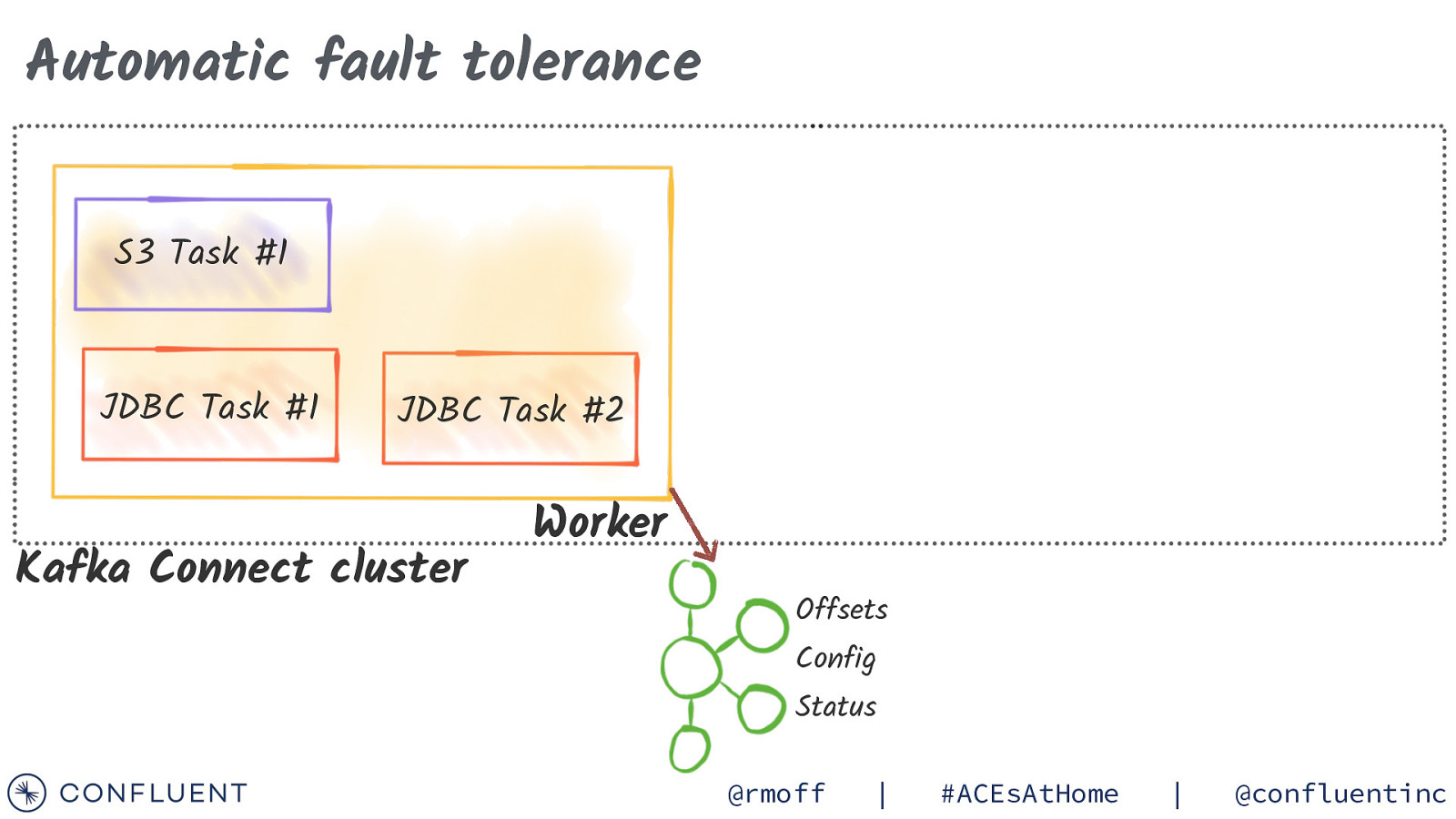
Automatic fault tolerance S3 Task #1 JDBC Task #1 JDBC Task #2 Kafka Connect cluster Worker Worker Offsets Config Status @rmoff | #ACEsAtHome | @confluentinc

Change-Data-Capture (CDC) Query-based Log-based @rmoff | #ACEsAtHome | @confluentinc
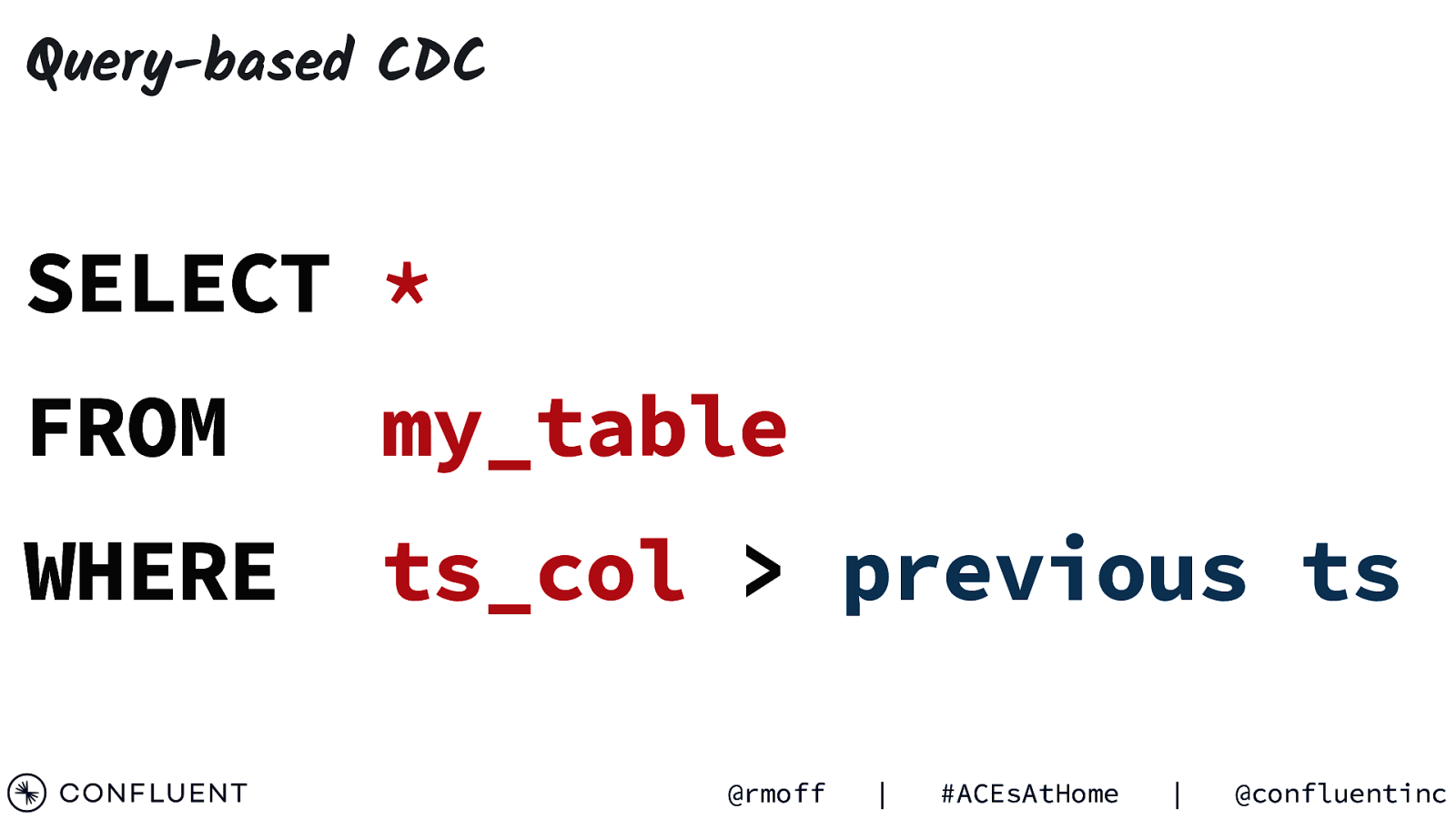
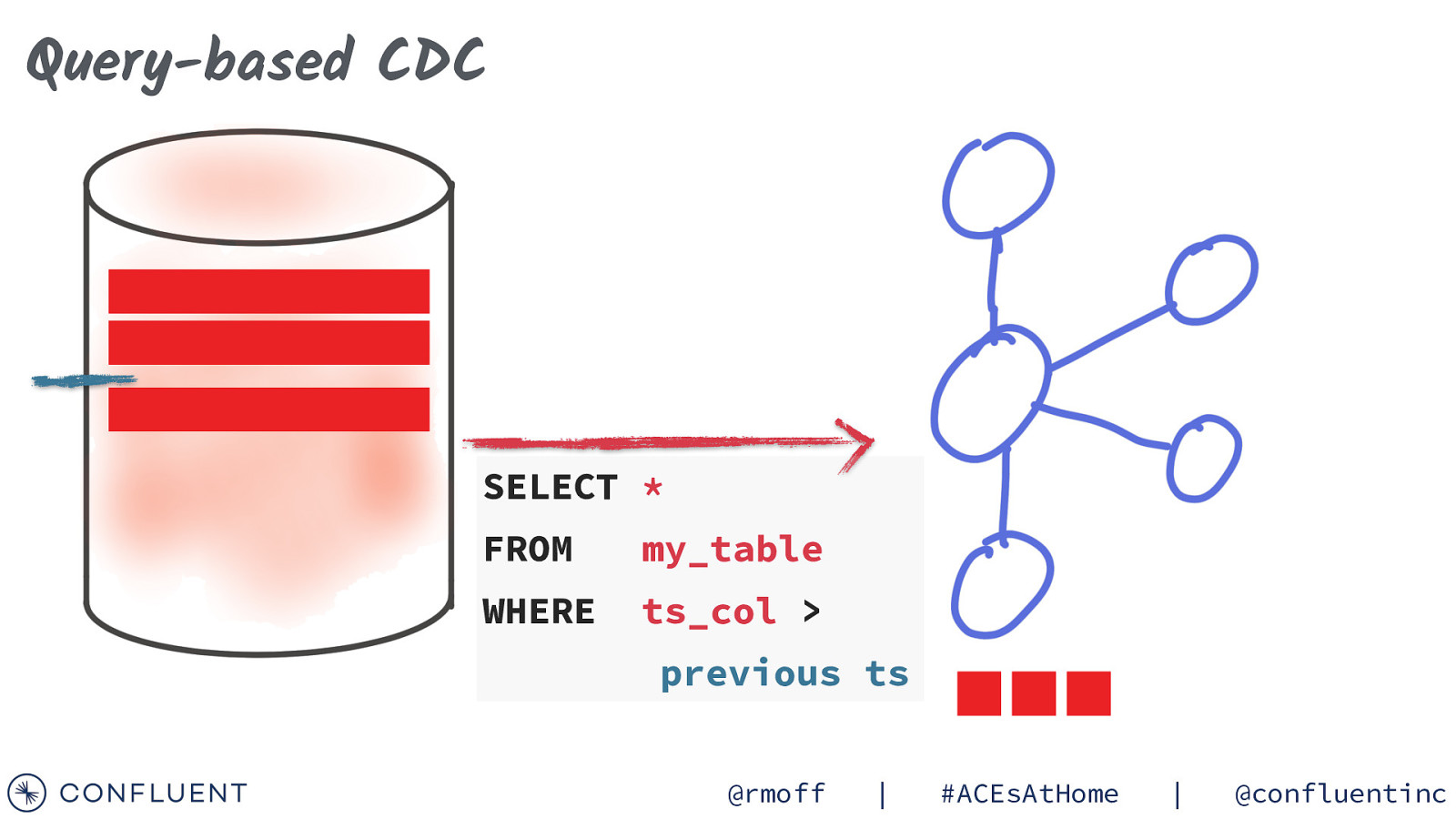
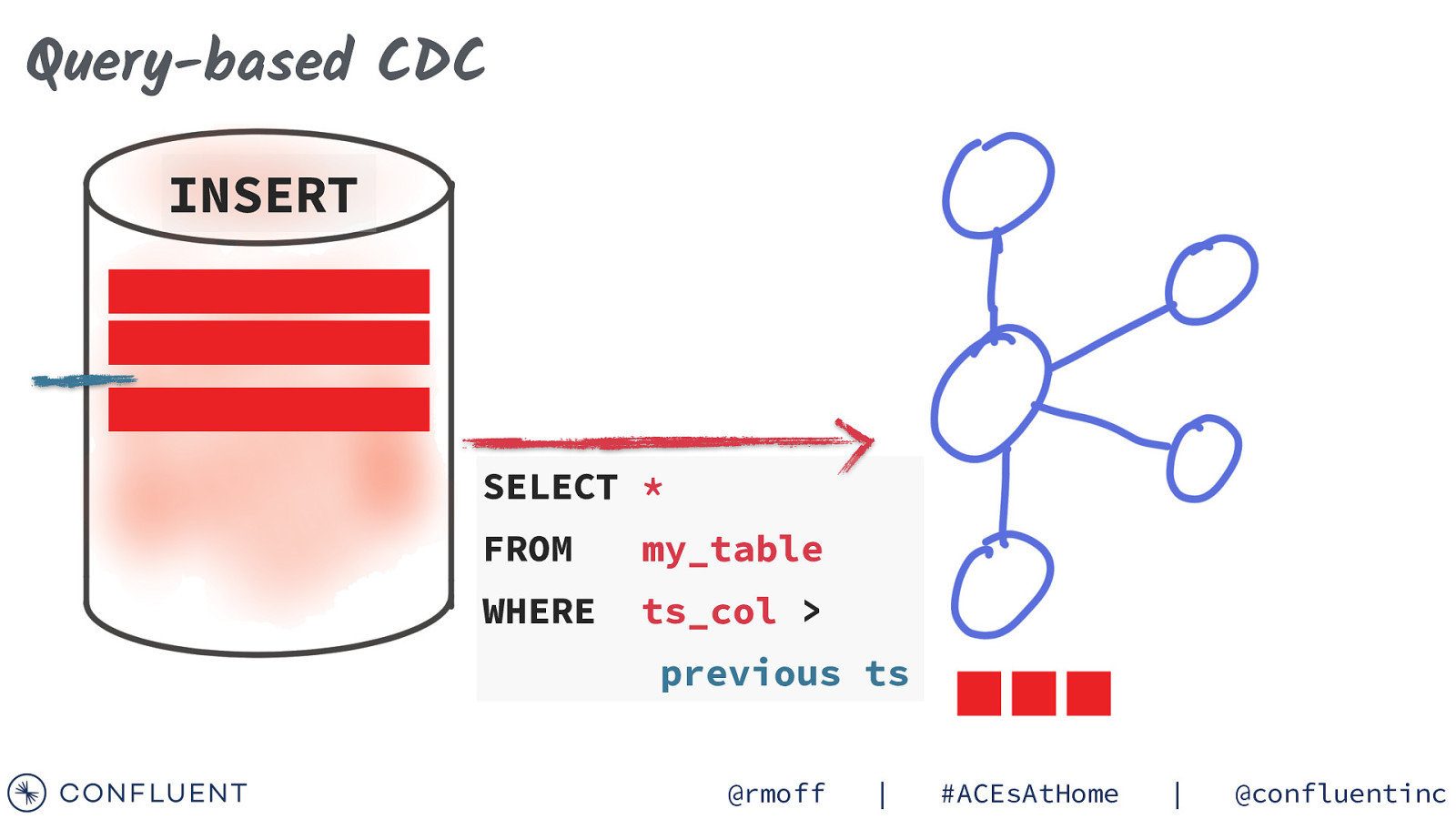
Query-based CDC SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #ACEsAtHome | @confluentinc
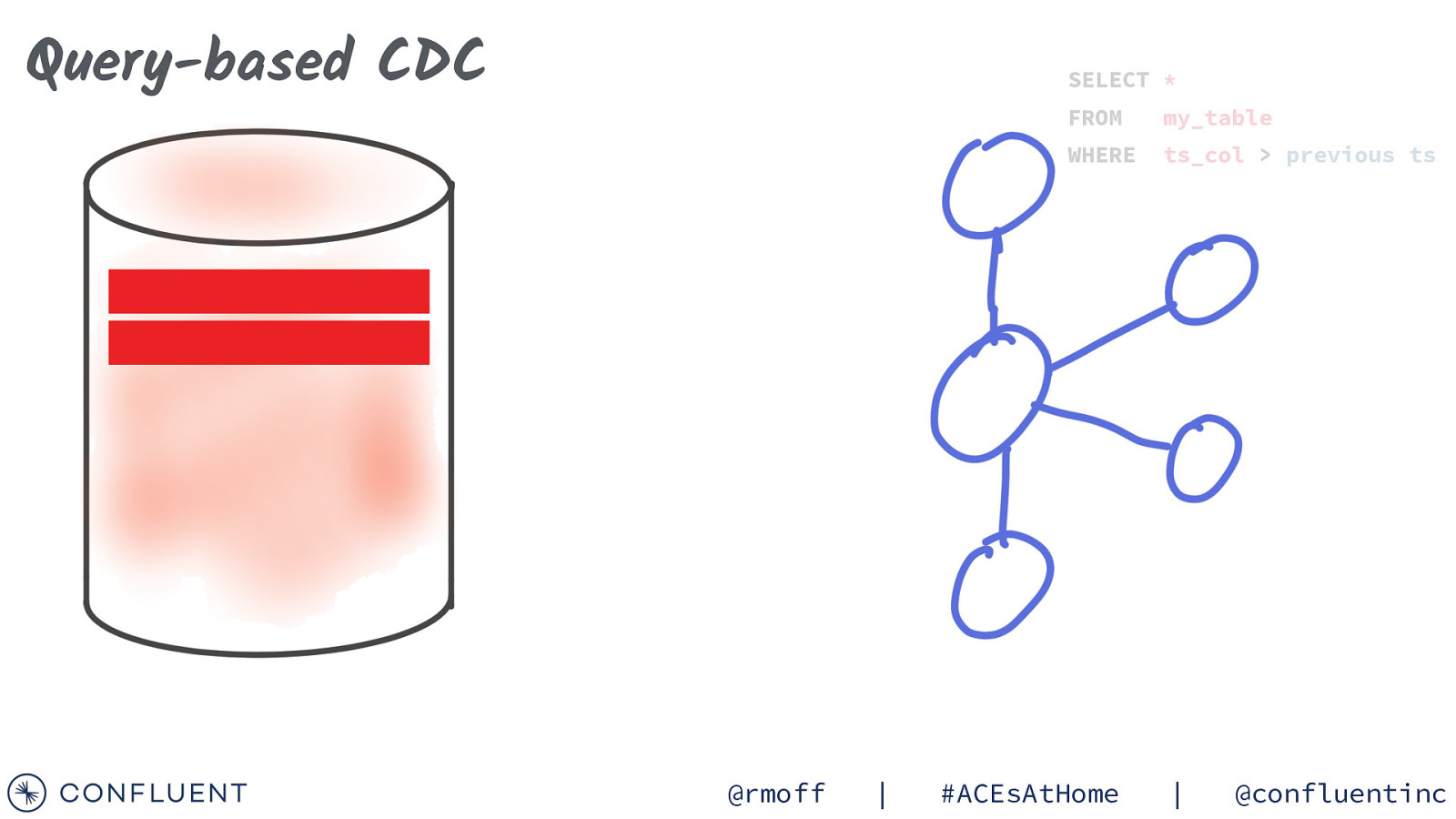
Query-based CDC SELECT * @rmoff | FROM my_table WHERE ts_col > previous ts #ACEsAtHome | @confluentinc
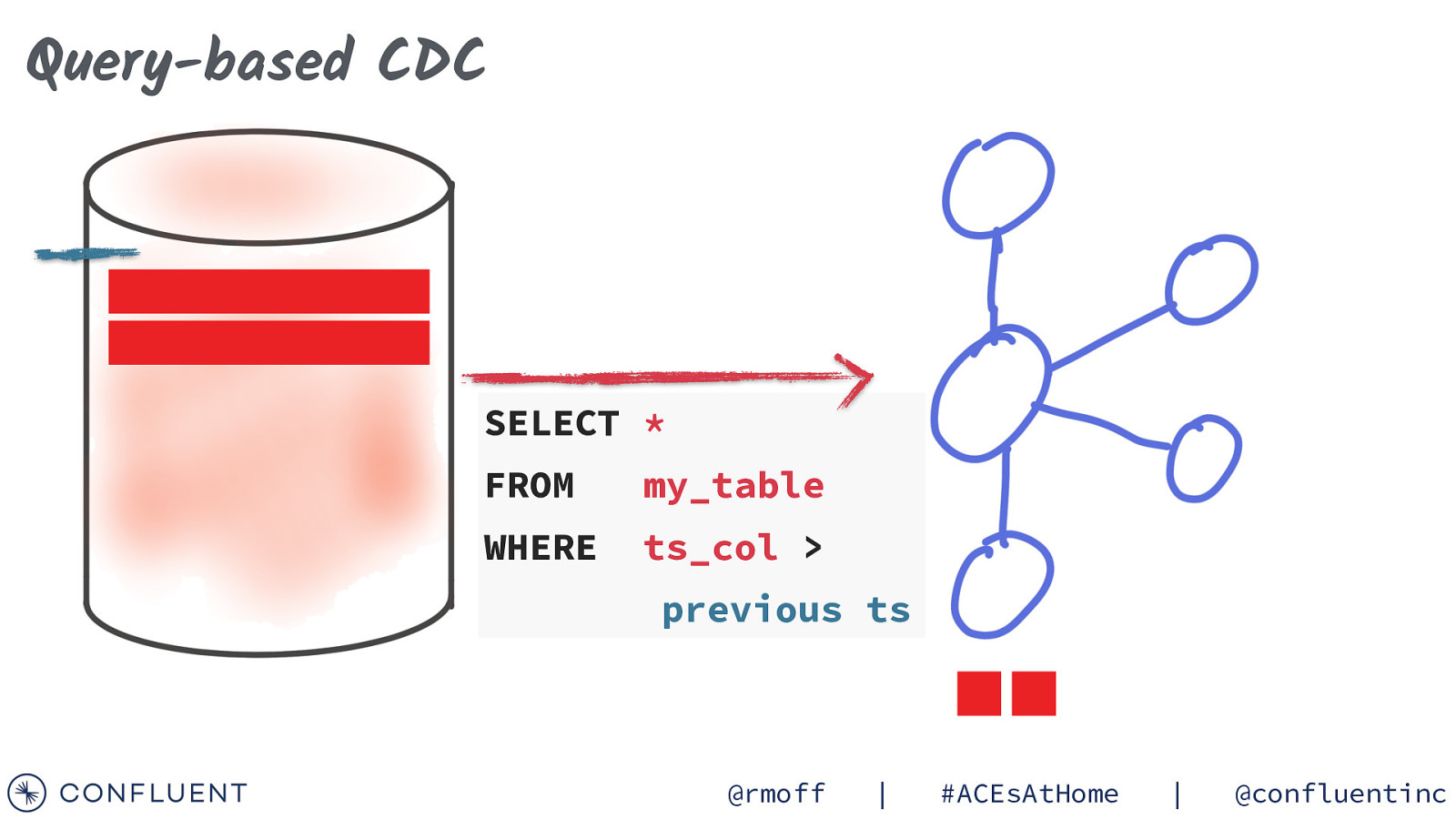
Query-based CDC SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #ACEsAtHome | @confluentinc
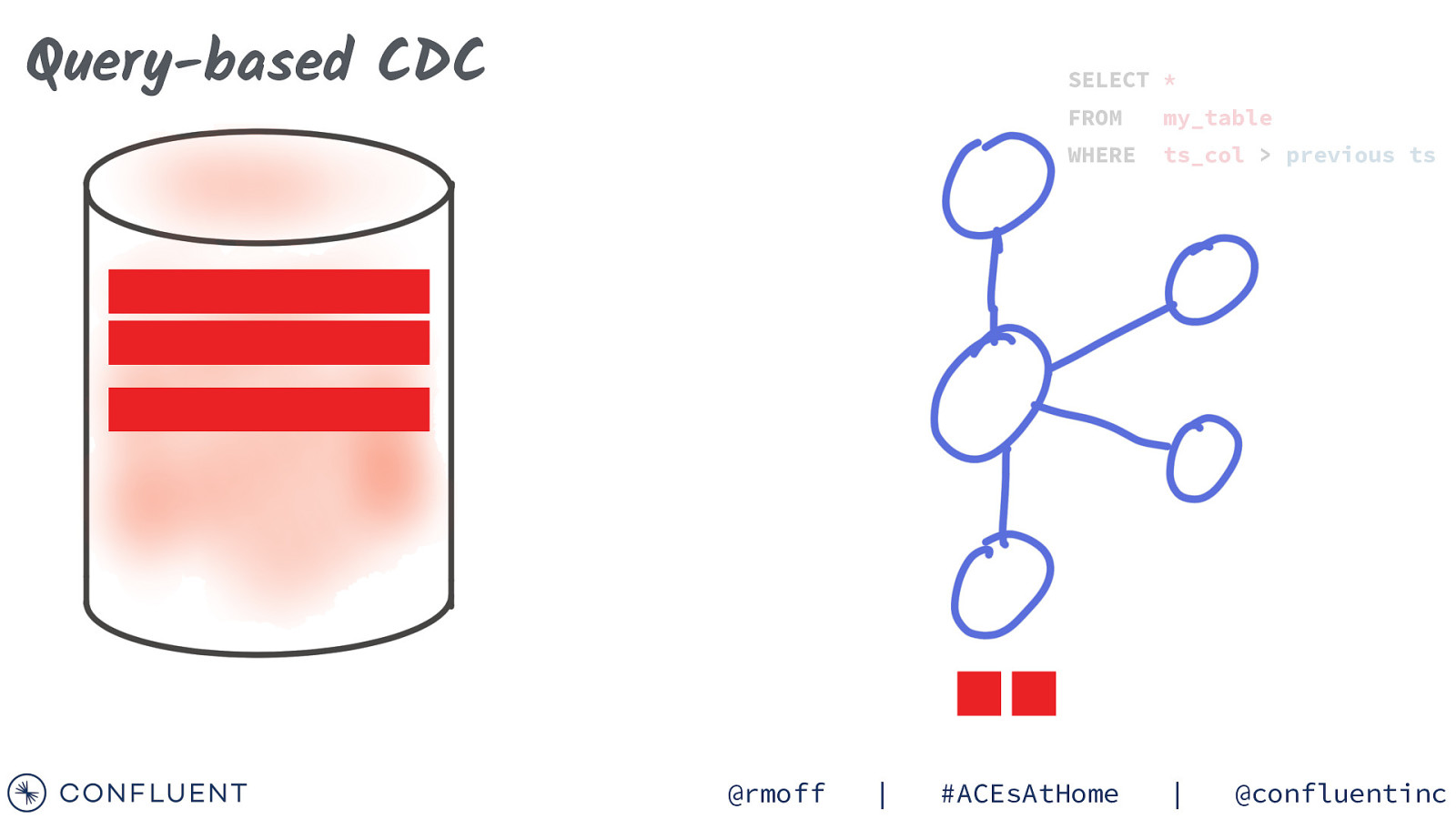
Query-based CDC SELECT * @rmoff | FROM my_table WHERE ts_col > previous ts #ACEsAtHome | @confluentinc
Query-based CDC SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #ACEsAtHome | @confluentinc

Log-based CDC #051024 17:24:13 server id 1 # Position Timestamp
end_log_pos 98 Type Master ID Size Master Pos Flags 0f 01 00 00 00 5e 00 00 00 62 00 00 00 00 00
2d 64 65 62 75 67 2d 6c |..5.0.15.debug.l|
00 00 00 00 00 00 00 00 |og…………..|
00 00 00 00 00 00 00 00 |…………….|
13 38 0d 00 08 00 12 00 |…….C.8……|
00 04 1a @rmoff |…….K…| | #ACEsAtHome | @confluentinc
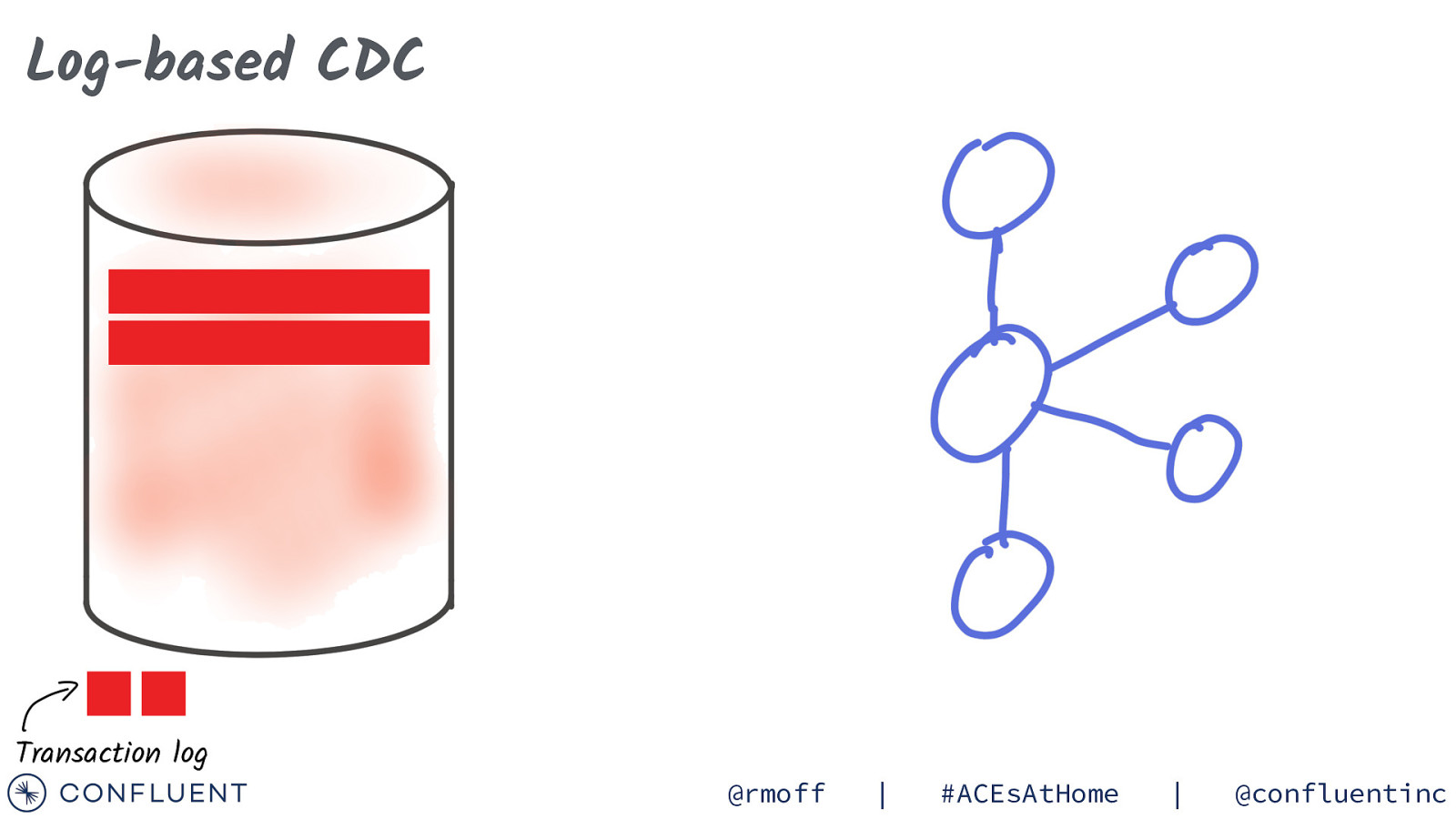
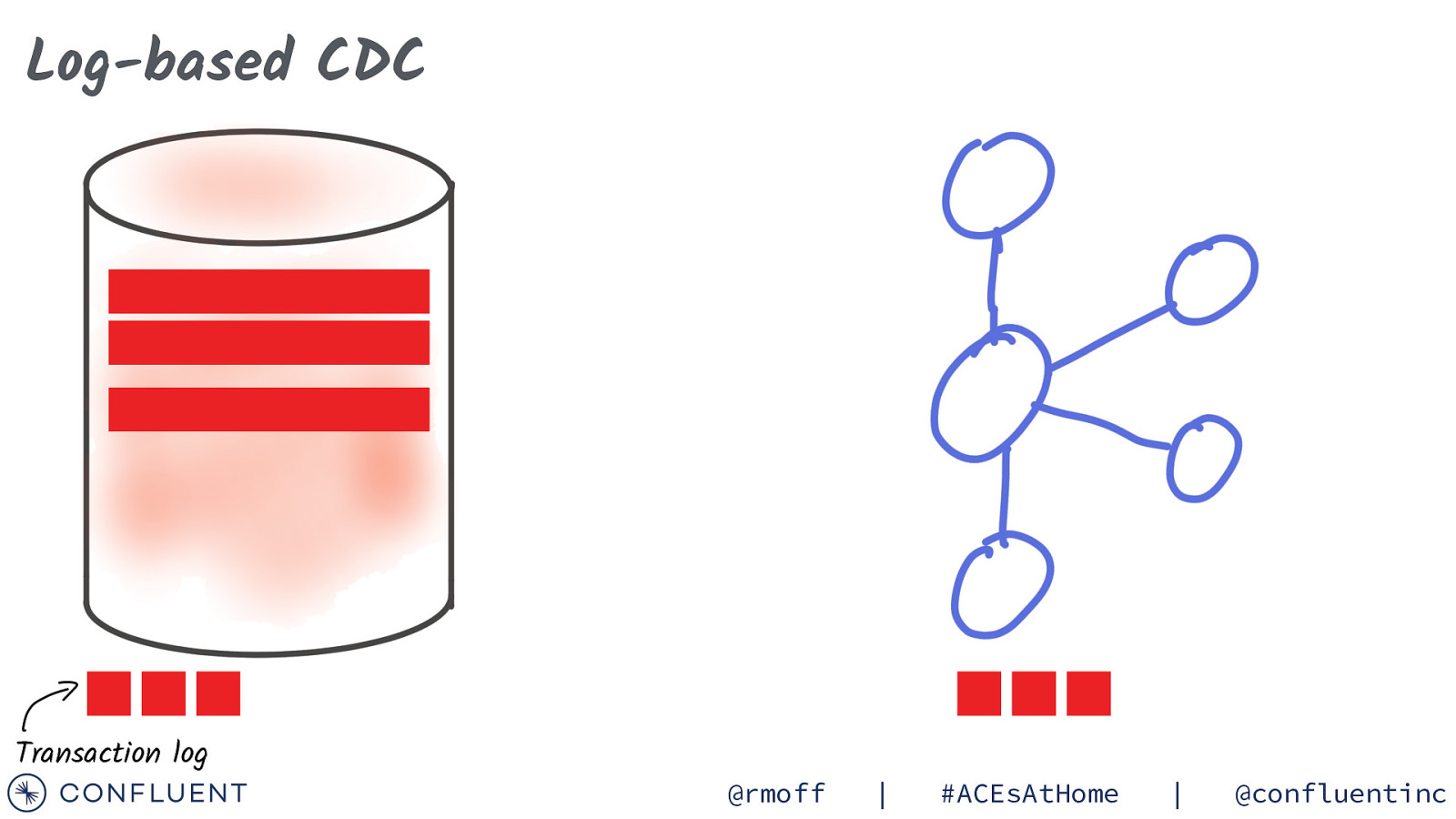
Log-based CDC Transaction log @rmoff | #ACEsAtHome | @confluentinc
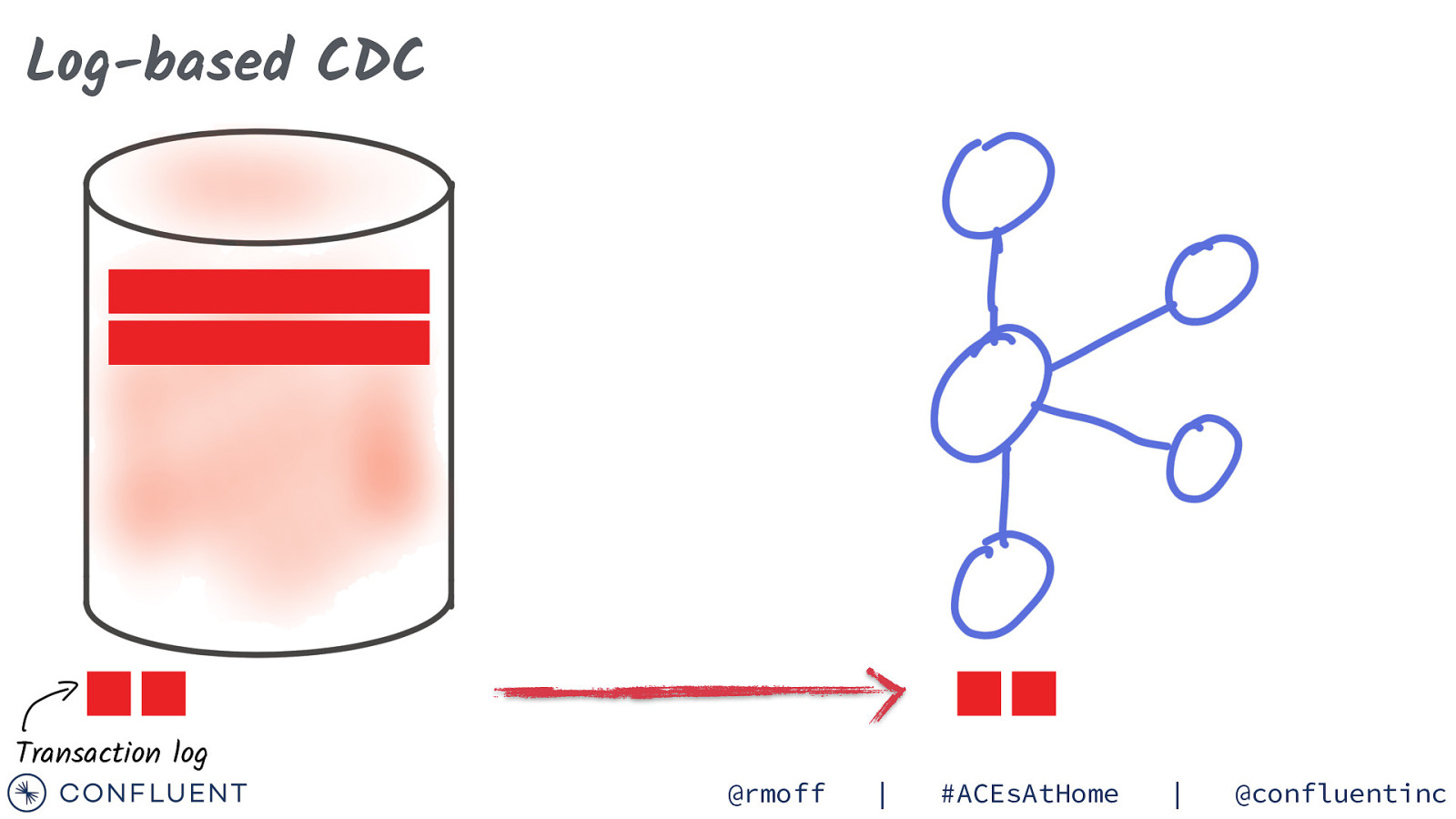
Log-based CDC Transaction log @rmoff | #ACEsAtHome | @confluentinc
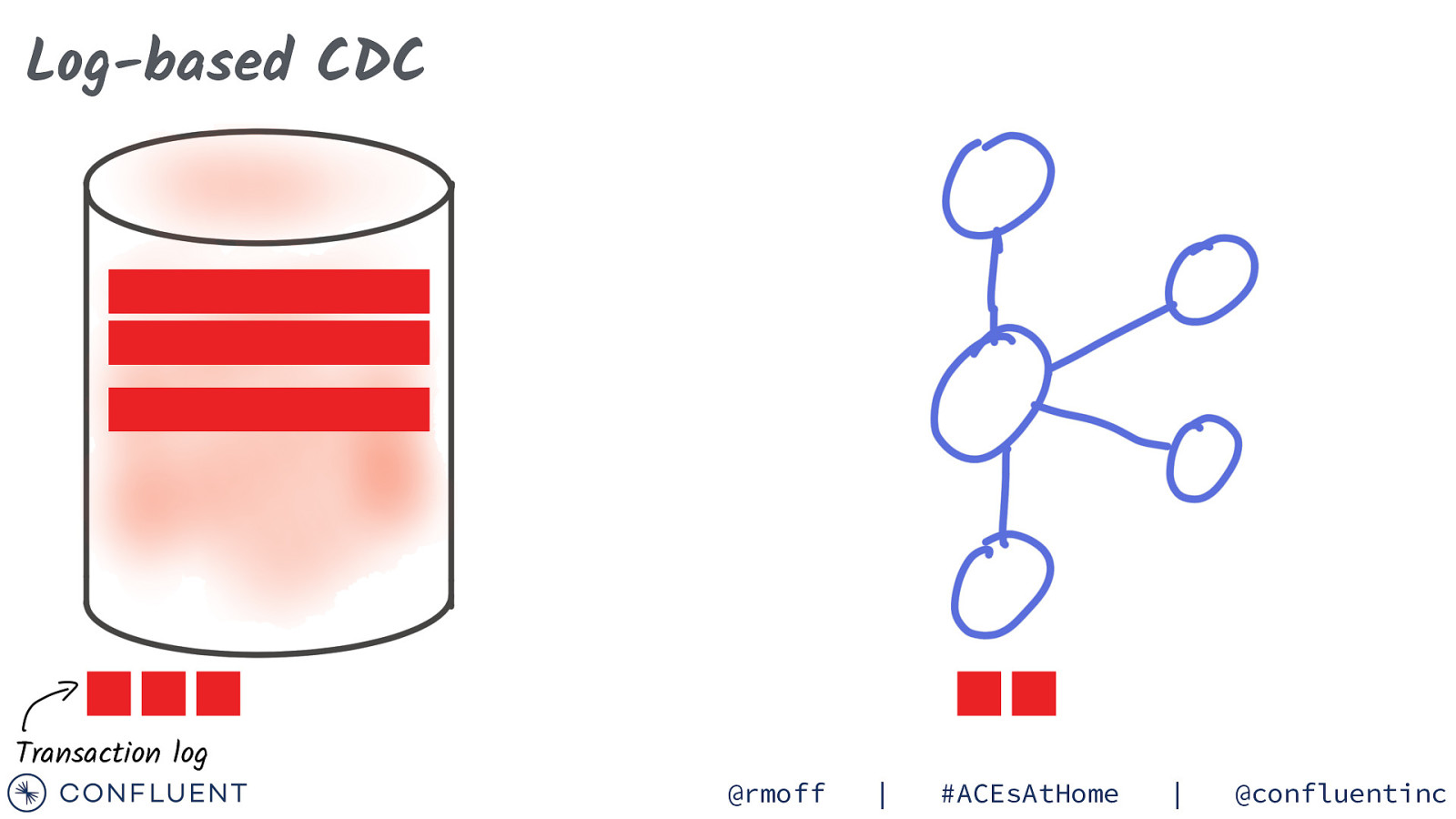
Log-based CDC Transaction log @rmoff | #ACEsAtHome | @confluentinc
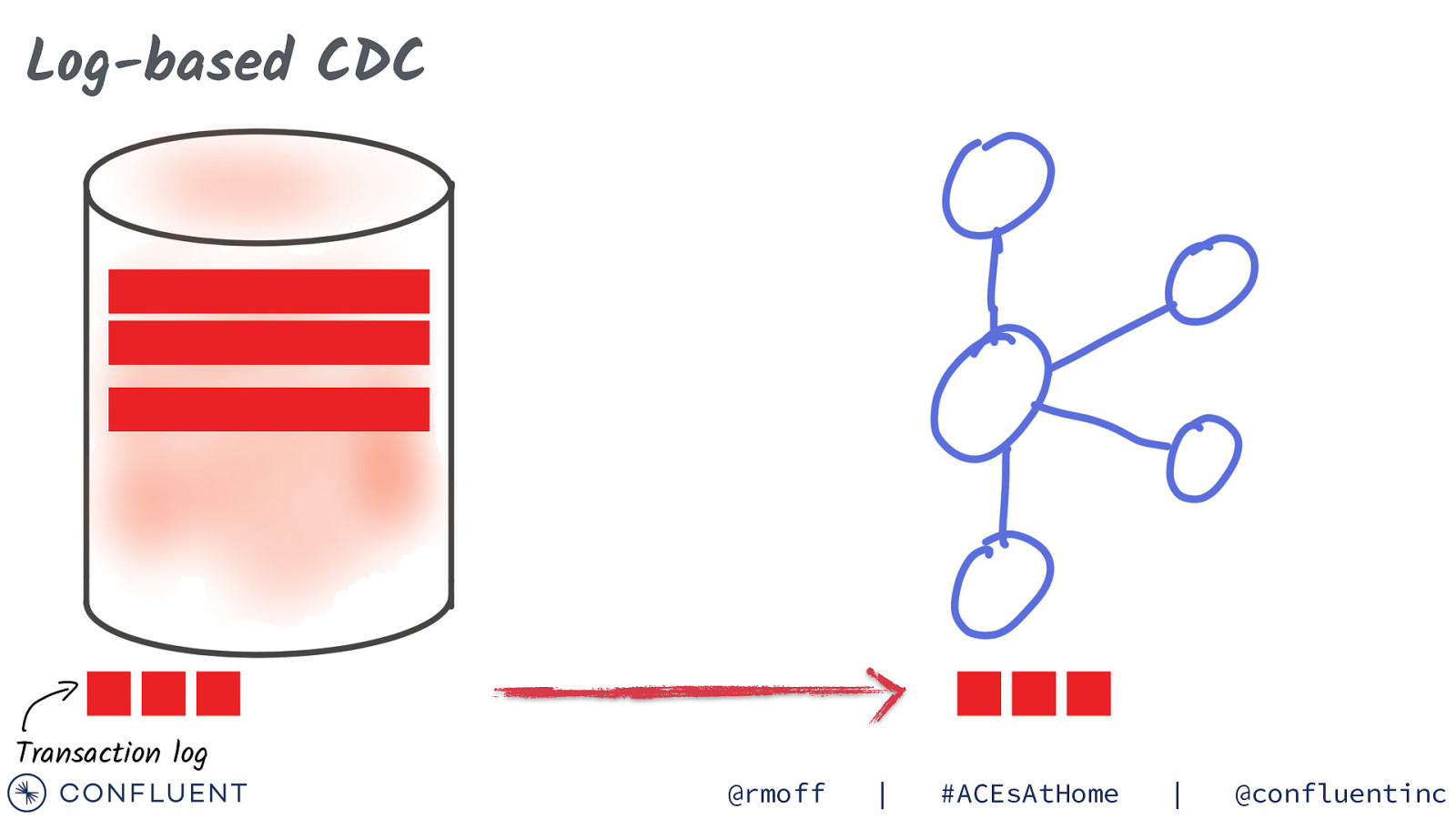
Log-based CDC Transaction log @rmoff | #ACEsAtHome | @confluentinc

DEMO Photo by Tom Moffatt @rmoff | #ACEsAtHome | @confluentinc

@rmoff | #ACEsAtHome | @confluentinc

Read more: http://cnfl.io/kafka-c Query-based CDC ✅ Usually easier to setup ✅ Requires fewer permissions 🛑 Needs specific columns in source schema to track changes Photo by Matese Fields on Unsplash 🛑 Impact of polling the DB (or higher latencies tradeoff) 🛑 Can’t track deletes 🛑 Can’t track multiple events between polling interval @rmoff | #ACEsAtHome | @confluentinc

Query-based CDC SELECT * @rmoff | FROM my_table WHERE ts_col > previous ts #ACEsAtHome | @confluentinc
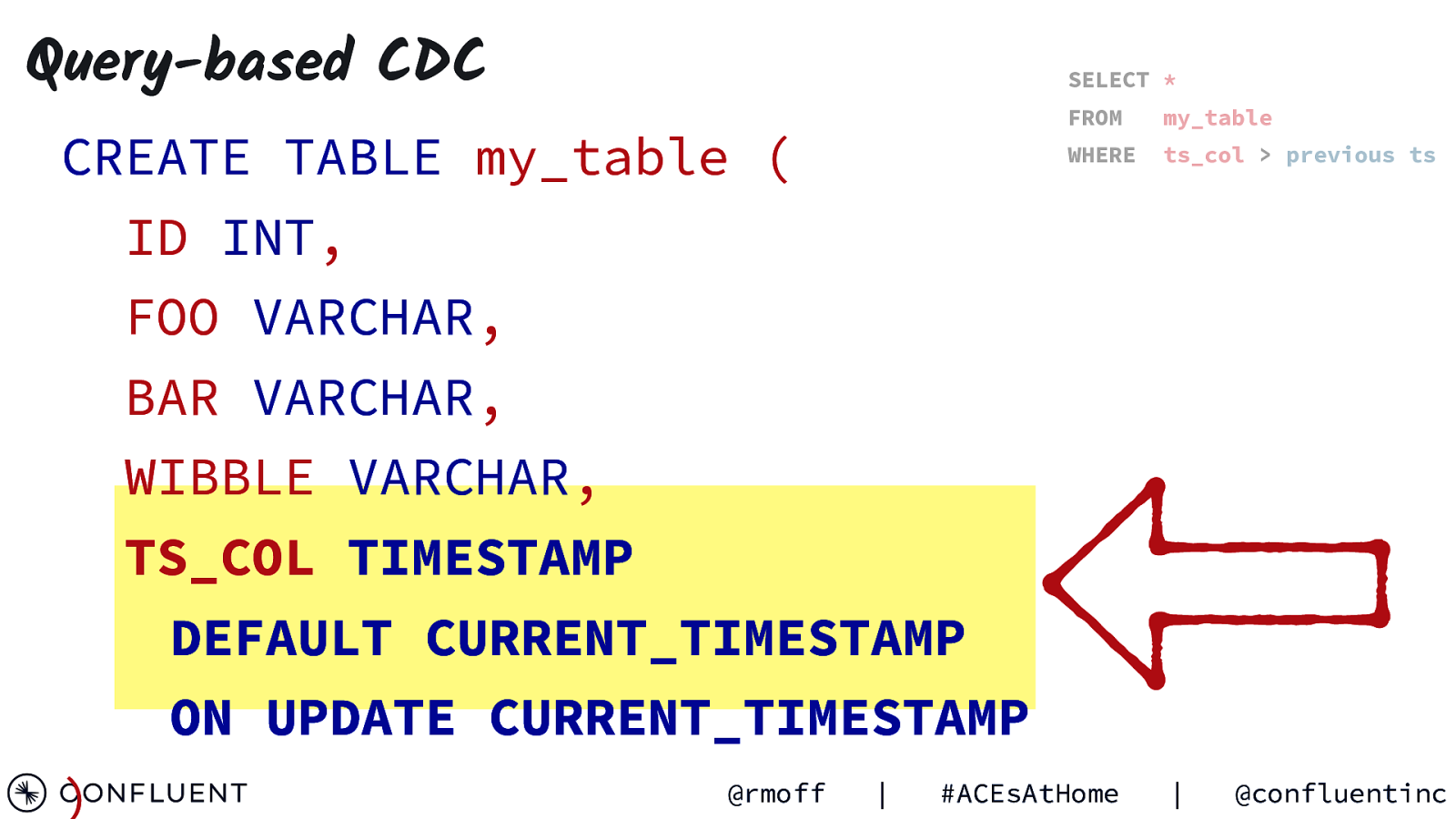
Query-based CDC SELECT * CREATE TABLE my_table ( FROM my_table WHERE ts_col > previous ts ID INT, FOO VARCHAR, BAR VARCHAR, WIBBLE VARCHAR, TS_COL TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP ) @rmoff | #ACEsAtHome | @confluentinc
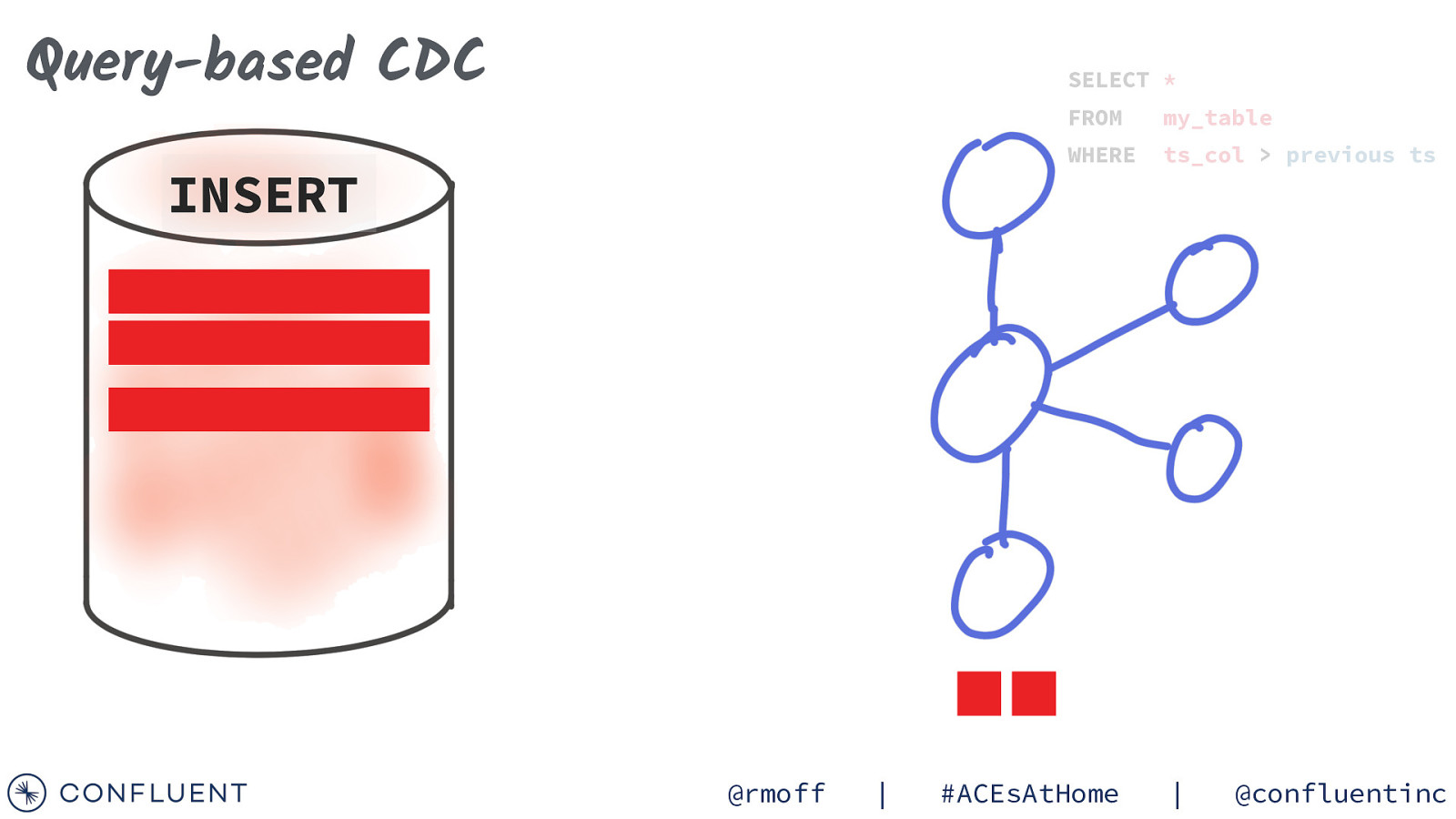
Query-based CDC SELECT * INSERT @rmoff | FROM my_table WHERE ts_col > previous ts #ACEsAtHome | @confluentinc
Query-based CDC INSERT SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #ACEsAtHome | @confluentinc
Query-based CDC UPDATE @rmoff | #ACEsAtHome | @confluentinc
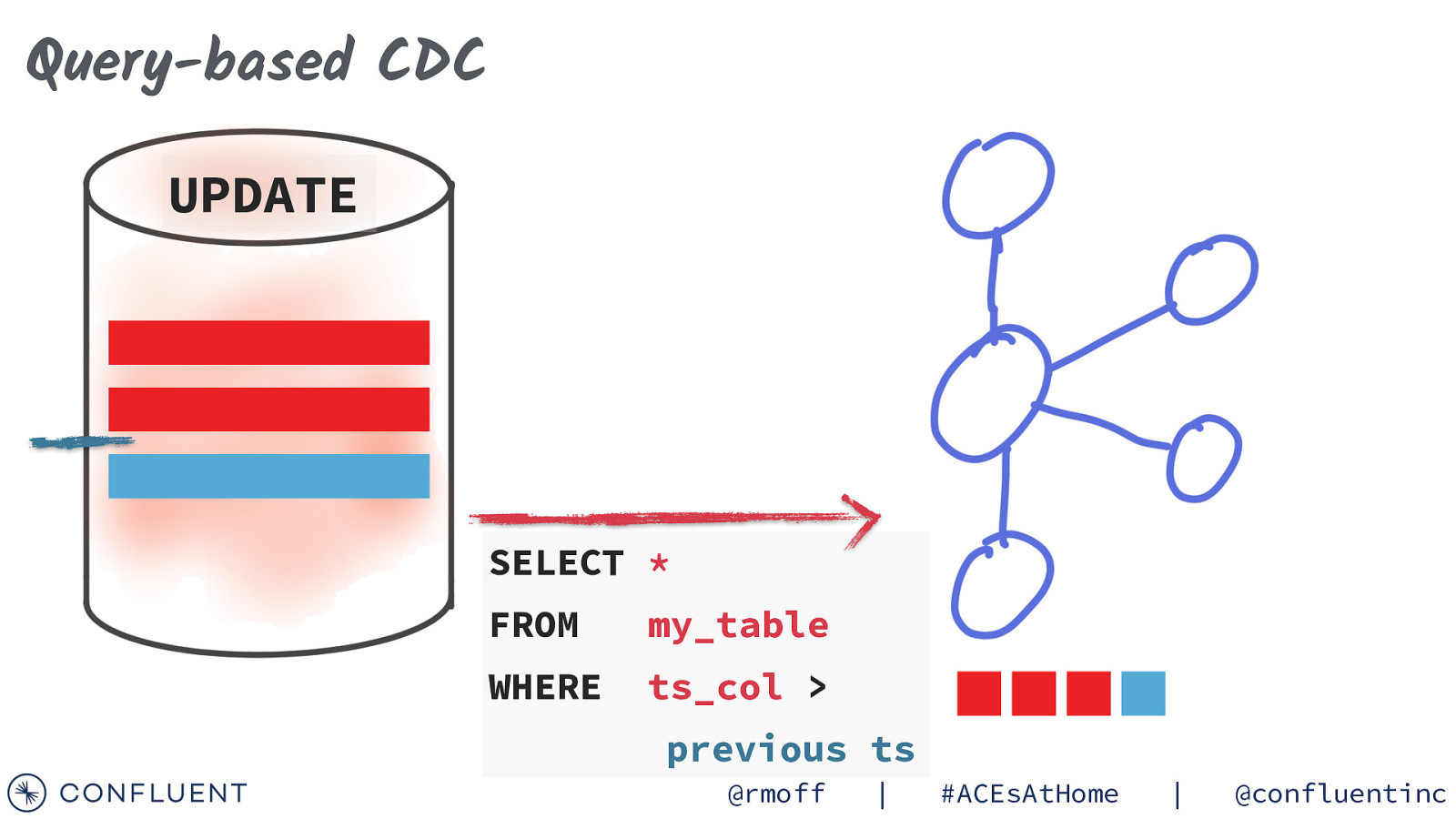
Query-based CDC UPDATE SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #ACEsAtHome | @confluentinc
Query-based CDC DELETE @rmoff | #ACEsAtHome | @confluentinc
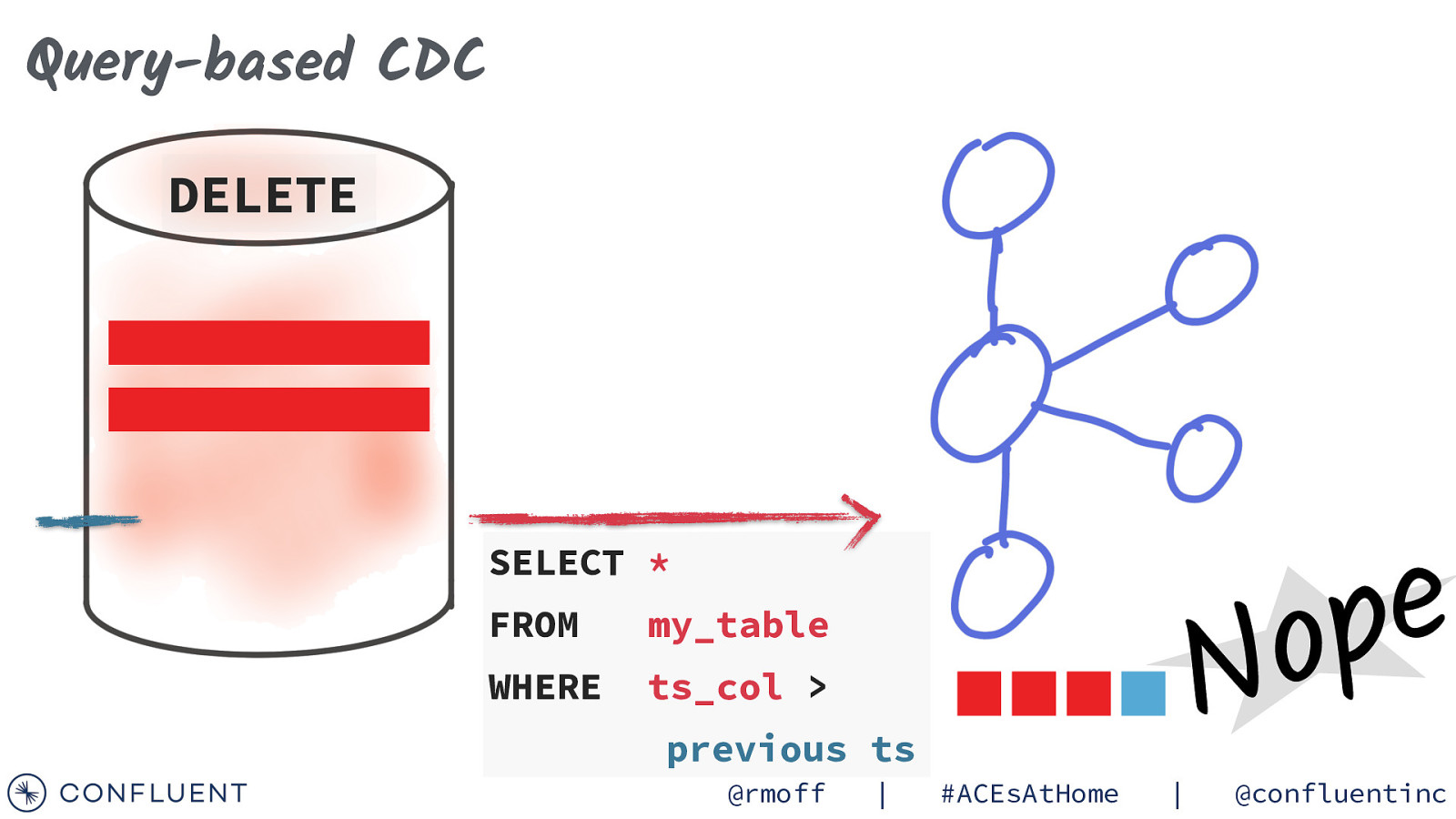
Query-based CDC DELETE e p o SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #ACEsAtHome | N @confluentinc

Query-based CDC orderID status address updateTS SELECT * FROM orders WHERE updateTS > previous ts @rmoff | #ACEsAtHome | @confluentinc

Query-based CDC orderID status address updateTS 42 29 Acacia Road 10:54:29 SHIPPED SELECT * FROM orders WHERE updateTS > { previous ts @rmoff | } “orderID”: 42, “status”: “SHIPPED”, “address”: “29 Acacia Road”, “updateTS”: “10:54:29” #ACEsAtHome | @confluentinc

10:54:00 PENDING INSERT INTO orders (orderID, status) VALUES (42, ‘PENDING’); @rmoff | #ACEsAtHome | @confluentinc

Query-based CDC orderID status address 42 1640 Riverside Drive 10:54:20 PENDING updateTS UPDATE orders SET address = ‘1640 Riverside Drive’ WHERE orderID = 42; @rmoff | #ACEsAtHome | @confluentinc

Query-based CDC orderID status address updateTS 42 29 Acacia Road 10:54:25 PENDING UPDATE orders SET address = ‘29 Acacia Road’ WHERE orderID = 42; @rmoff | #ACEsAtHome | @confluentinc

Query-based CDC orderID status address updateTS 42 29 Acacia Road 10:54:29 SHIPPED UPDATE orders SET status = ‘SHIPPED’ WHERE orderID = 42; @rmoff | #ACEsAtHome | @confluentinc
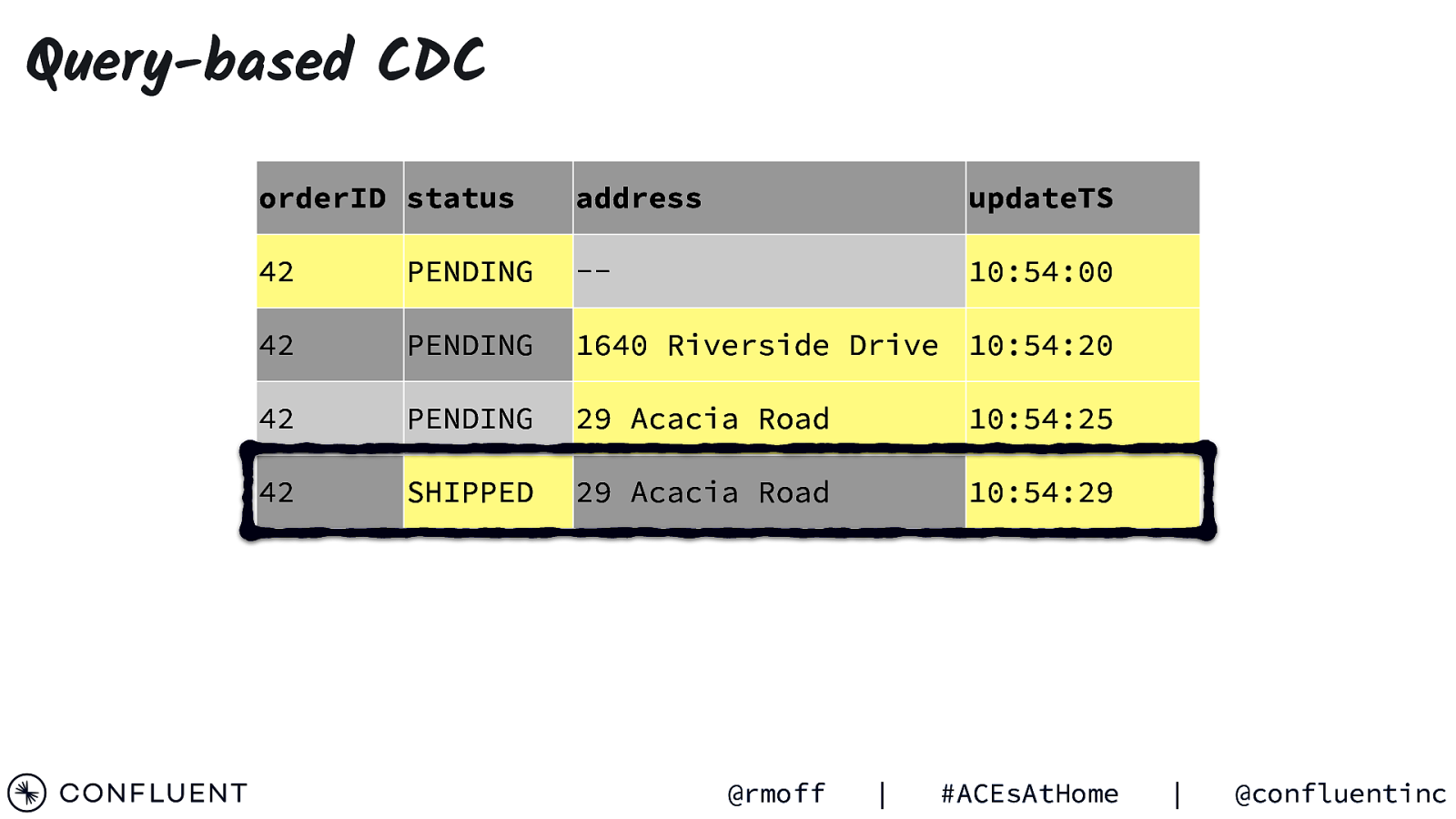
Query-based CDC orderID status orderID address status 42 SHIPPED 42 address 29 PENDING Acacia Road — updateTS updateTS 10:54:29 10:54:00 42 PENDING 1640 Riverside Drive 10:54:20 42 PENDING 29 Acacia Road 10:54:25 42 SHIPPED 29 Acacia Road 10:54:29 @rmoff | #ACEsAtHome | @confluentinc

Query-based CDC orderID status address updateTS 42 29 Acacia Road 10:54:29 SHIPPED SELECT * FROM orders WHERE updateTS > { previous ts @rmoff | } “orderID”: 42, “status”: “SHIPPED”, “address”: “29 Acacia Road”, “updateTS”: “10:54:29” #ACEsAtHome | @confluentinc

@rmoff Event-driven Query-based Log-based

Photo by Sebastian Pociecha on Unsp Log-based CDC ✅ Greater data fidelity ✅ Lower latency ✅ Lower impact on source 🛑 More setup steps 🛑 Higher system privileges required 🛑 For propriatory databases, usually $ $$ Read more: http://cnfl.io/kafka-cdc @rmoff | #ACEsAtHome | @confluentinc
Log-based CDC Transaction log @rmoff | #ACEsAtHome | @confluentinc
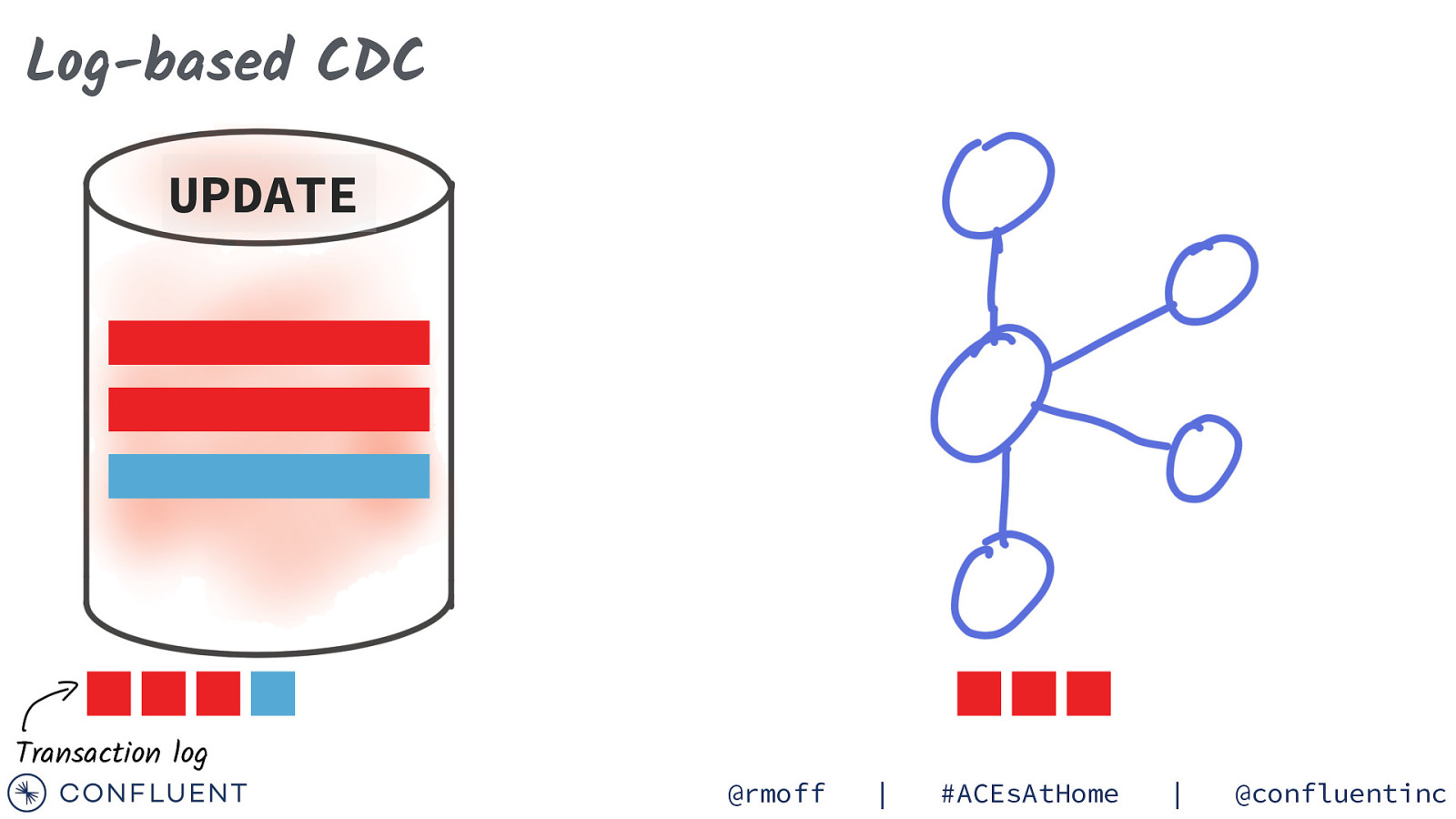
Log-based CDC UPDATE Transaction log @rmoff | #ACEsAtHome | @confluentinc
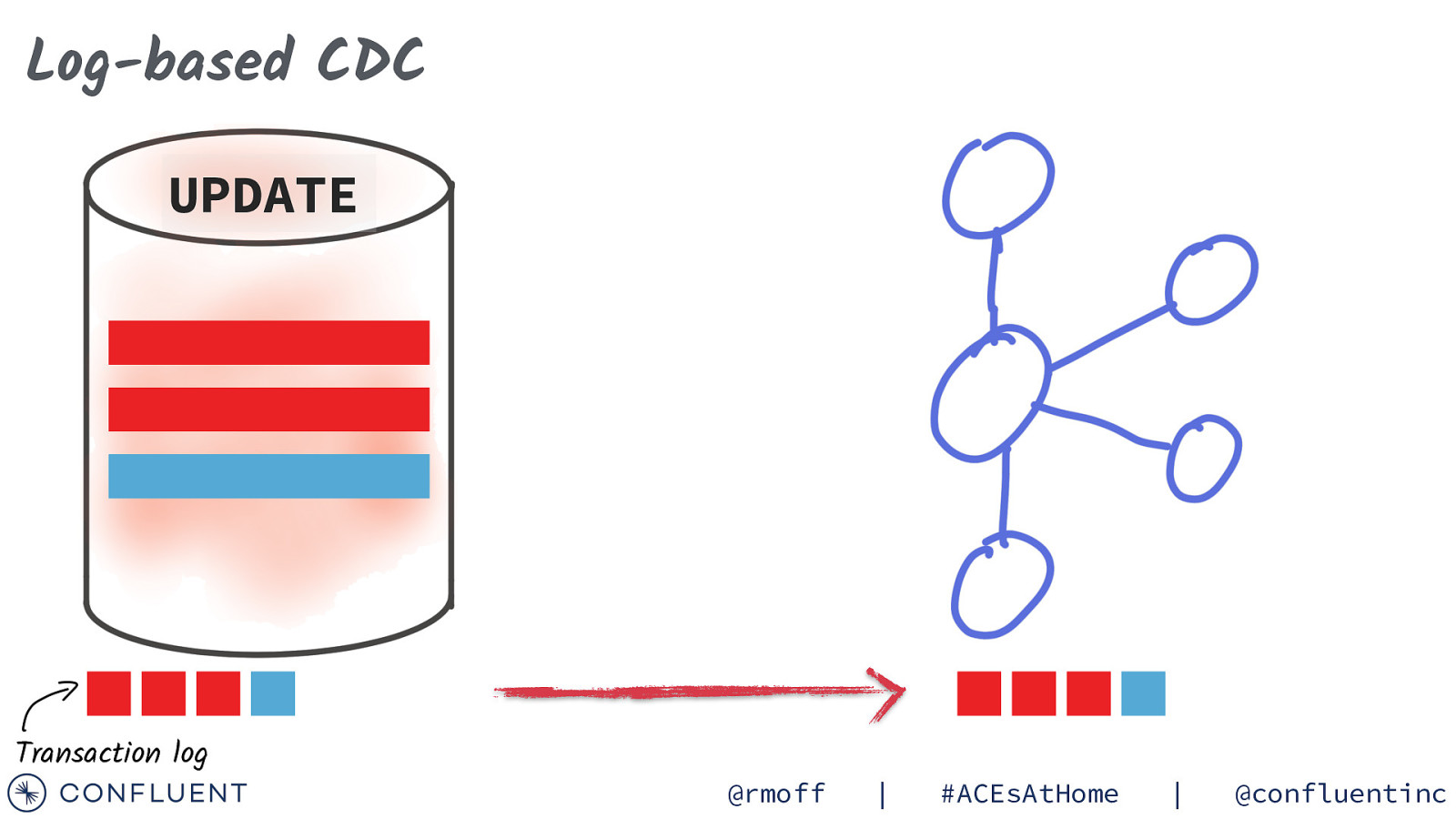
Log-based CDC UPDATE Transaction log @rmoff | #ACEsAtHome | @confluentinc
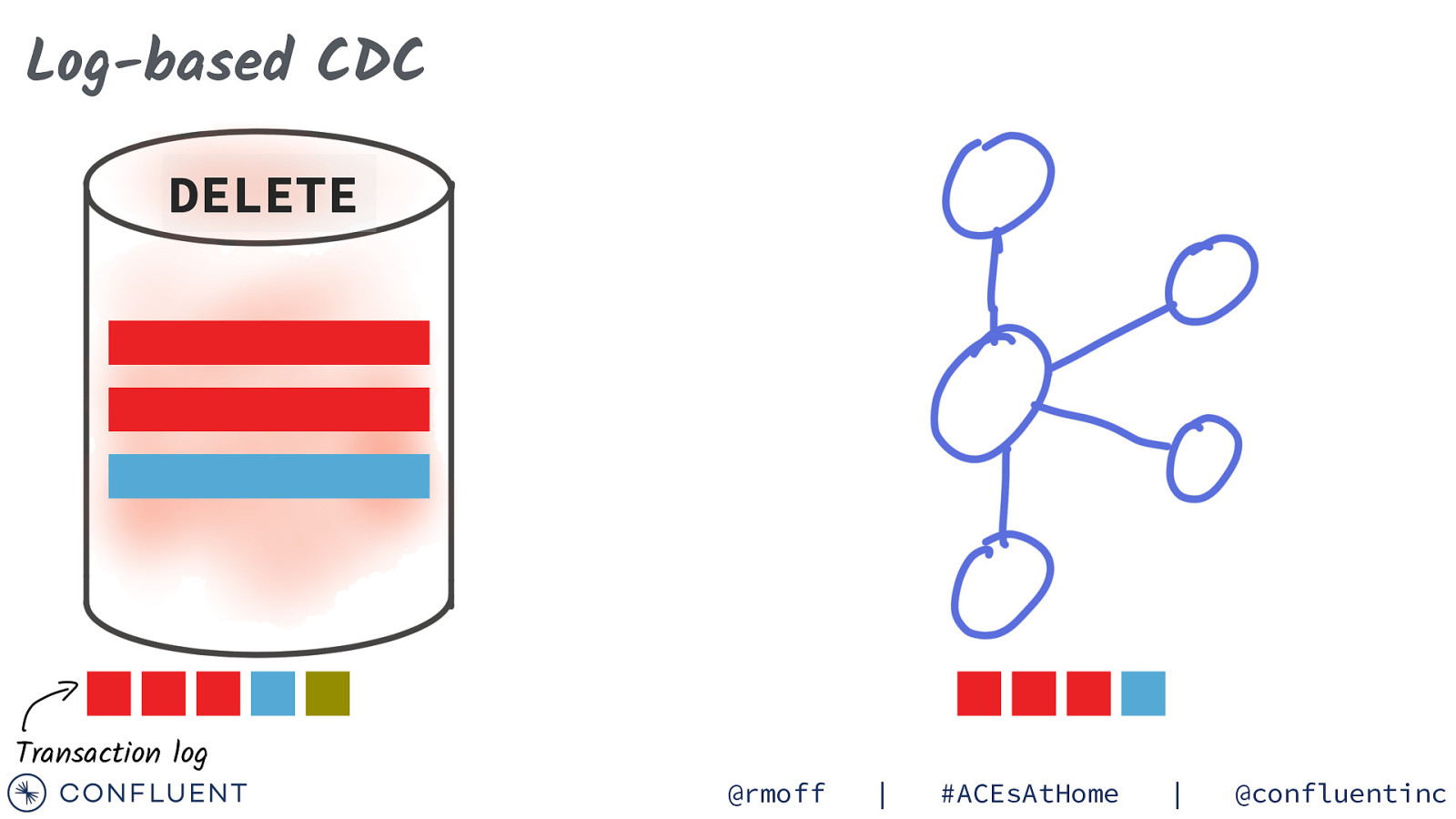
Log-based CDC DELETE Transaction log @rmoff | #ACEsAtHome | @confluentinc
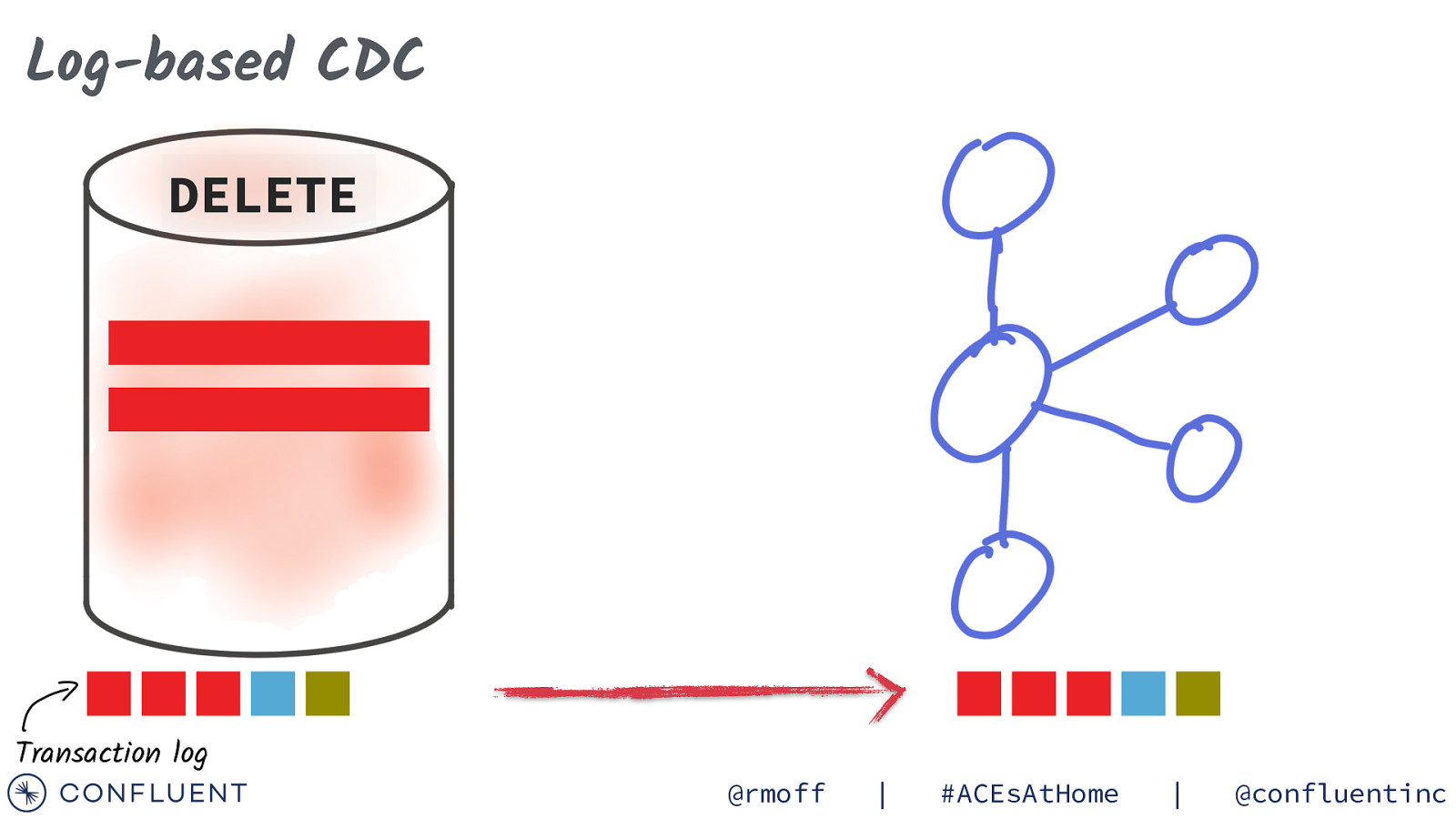
Log-based CDC DELETE Transaction log @rmoff | #ACEsAtHome | @confluentinc
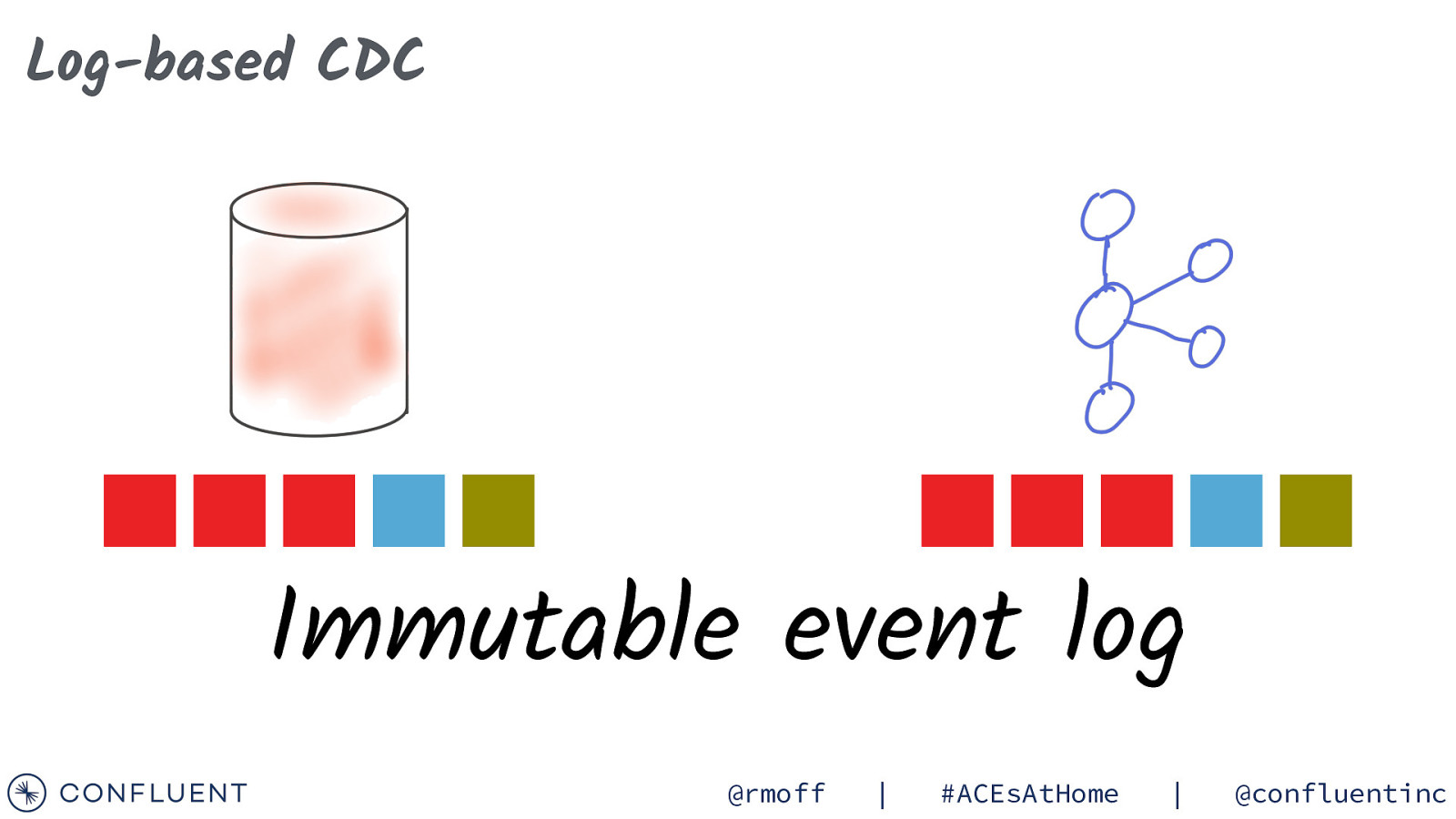
Log-based CDC Immutable event log @rmoff | #ACEsAtHome | @confluentinc
tl;dr : which tool do I use? • If you’re wanting to do query-based CDC, the choice is simple: confluent.io/hub @rmoff | #ACEsAtHome | @confluentinc

Which Log-Based CDC Tool? • Open Source RDBMS, e.g. MySQL, PostgreSQL • Debezium • (+ paid options) • Proprietory RDBMS, e.g. Oracle, MS SQL, DB2 • Oracle GoldenGate • Debezium + XStream • Attunity • Mainframe e.g. VSAM, IMS • IBM InfoSphere Data Replication • Attunity • SQData • SQData • HVR • tcVISION • tcVISION @rmoff | #ACEsAtHome | @confluentinc
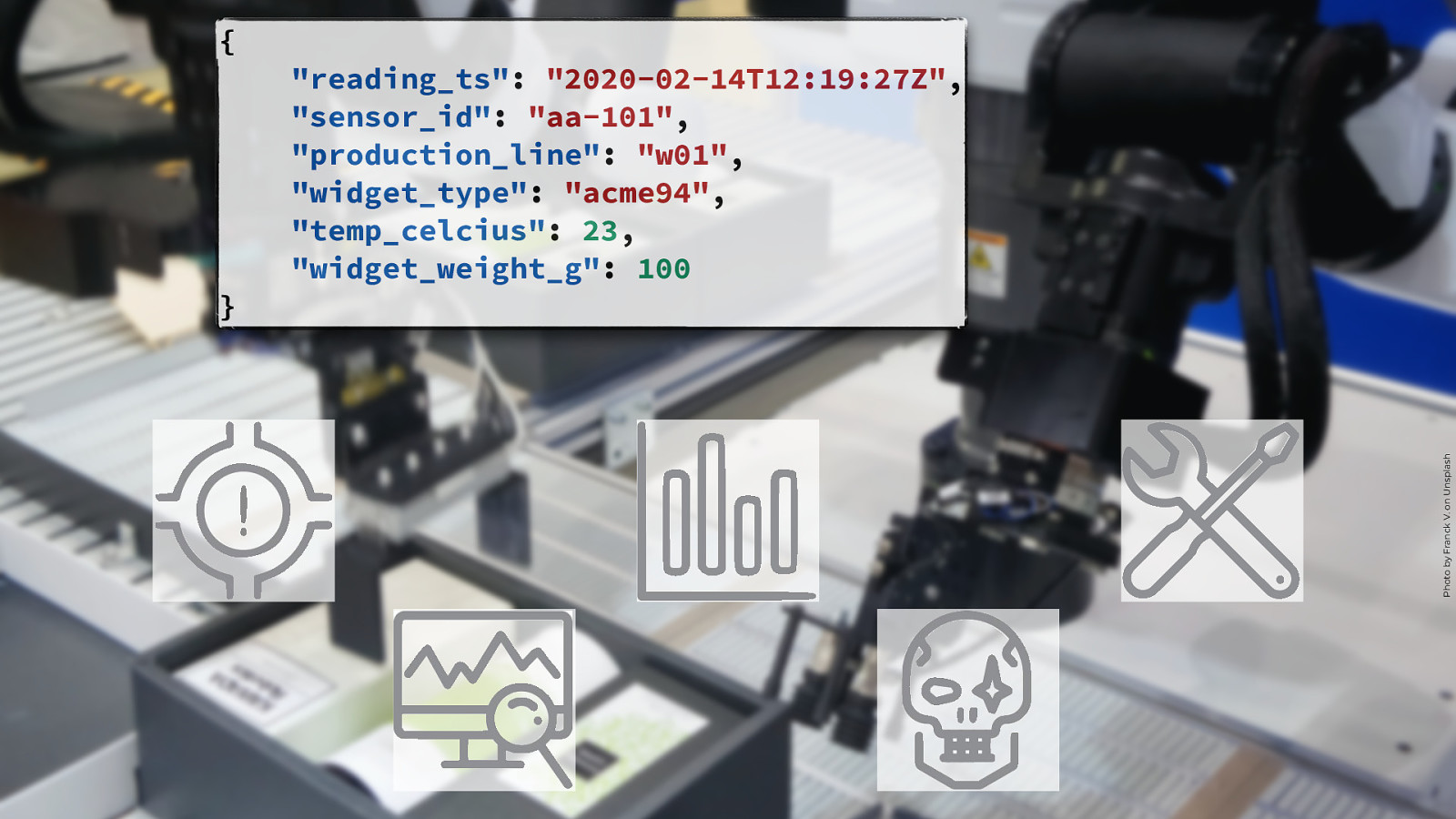
} “reading_ts”: “2020-02-14T12:19:27Z”, “sensor_id”: “aa-101”, “production_line”: “w01”, “widget_type”: “acme94”, “temp_celcius”: 23, “widget_weight_g”: 100 Photo by Franck V. on Unsplash { @rmoff | #ACEsAtHome | @confluentinc
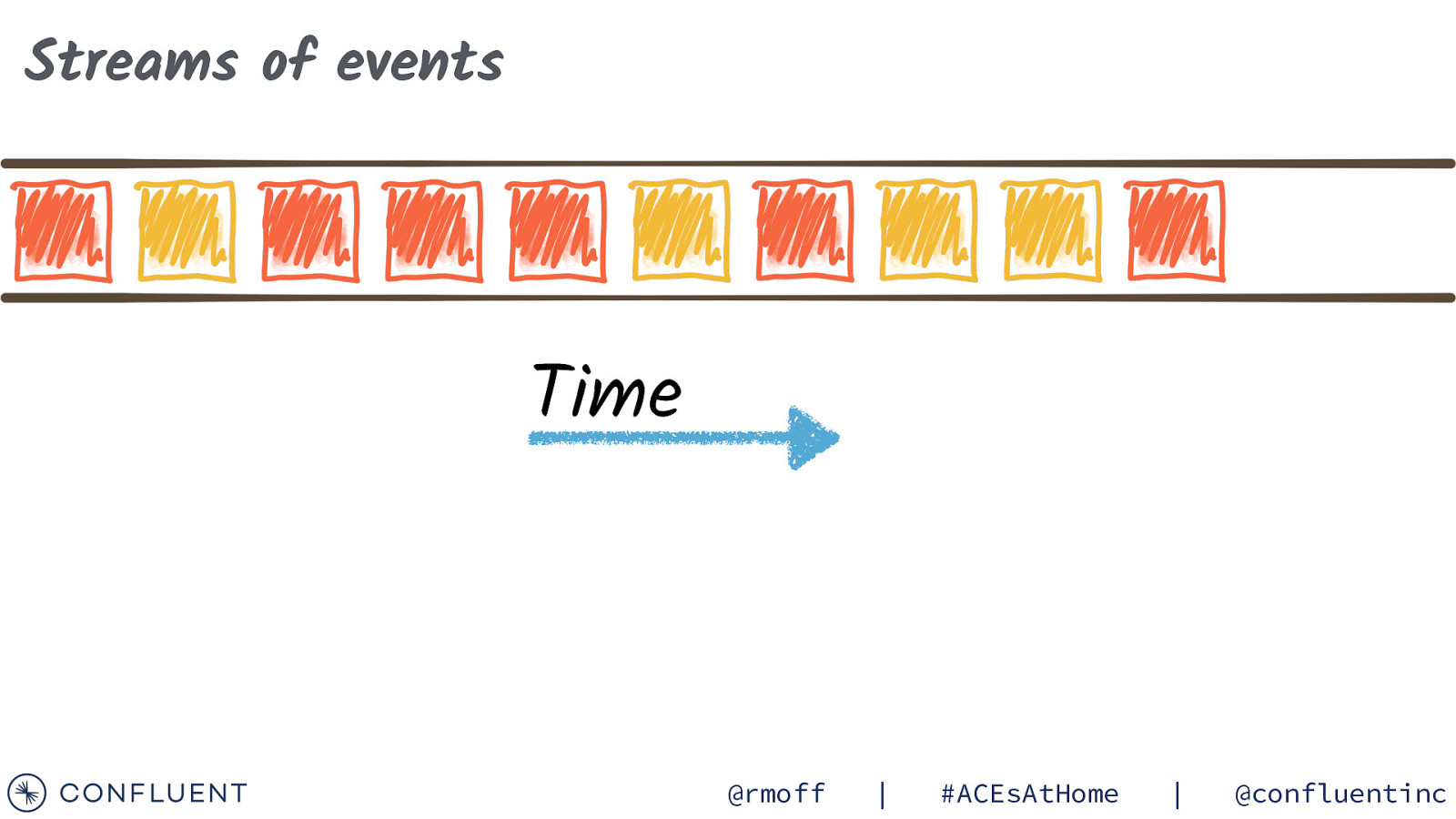
Streams of events Time @rmoff | #ACEsAtHome | @confluentinc
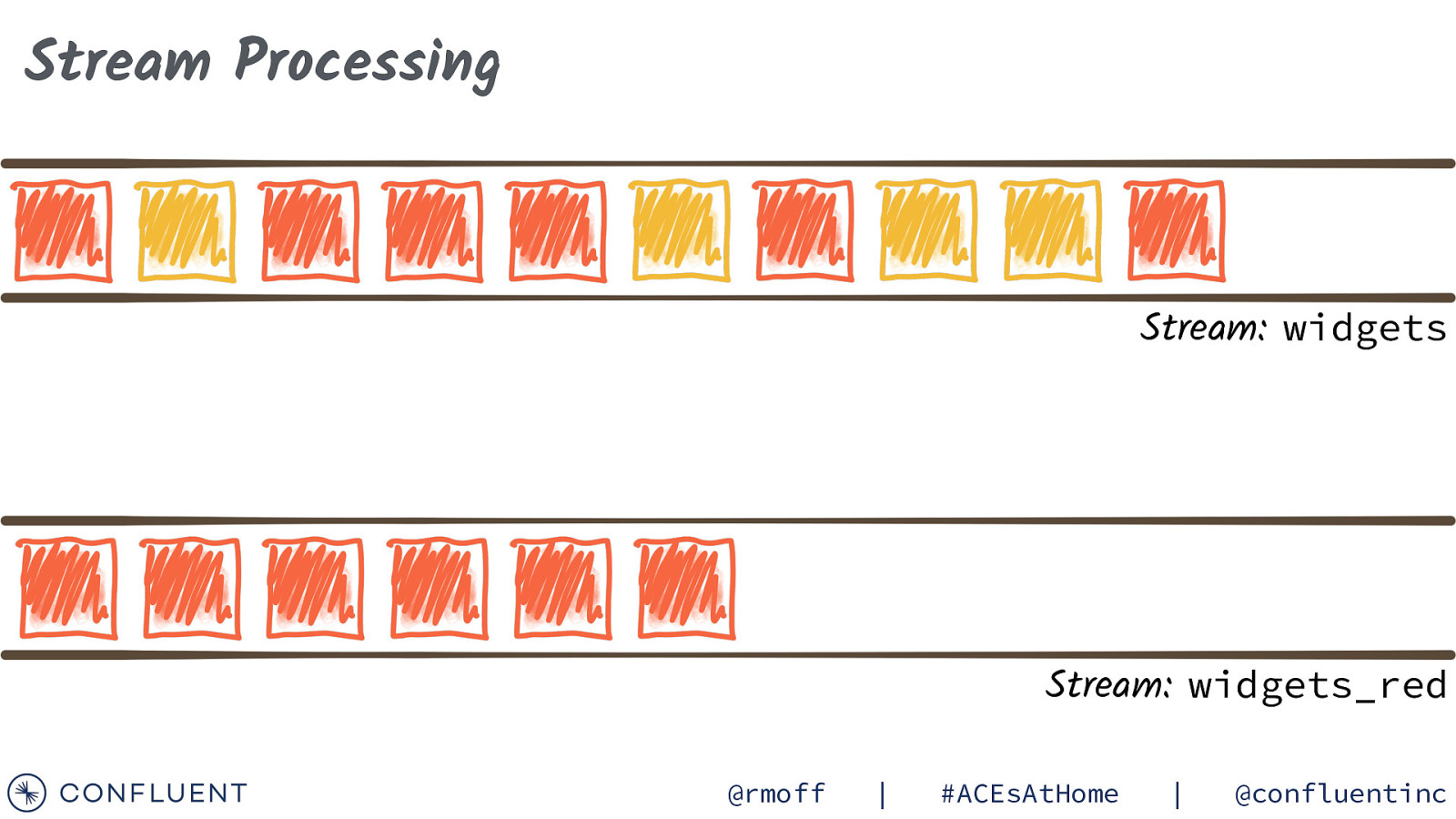
Stream Processing Stream: widgets Stream: widgets_red @rmoff | #ACEsAtHome | @confluentinc
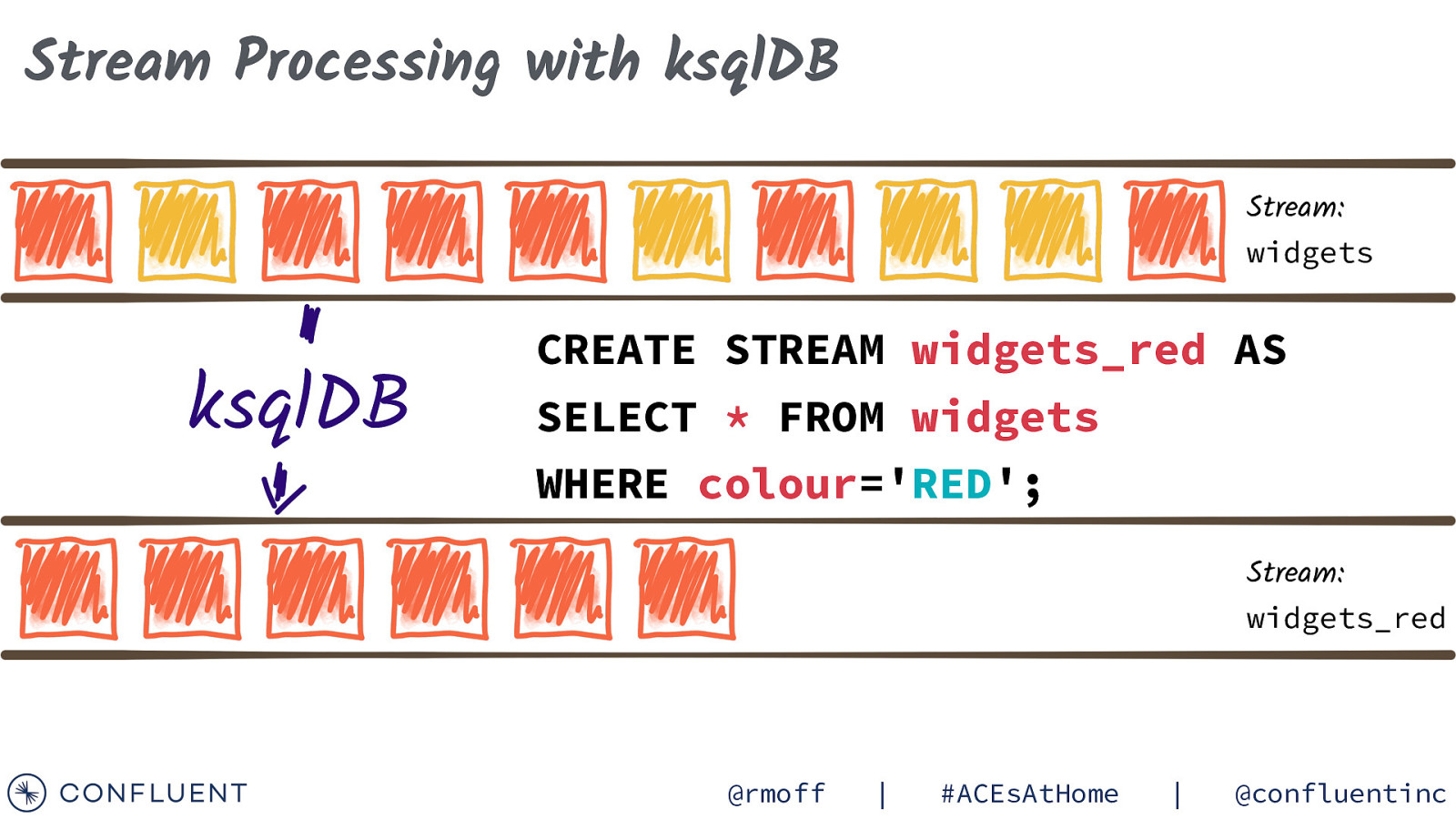
Stream Processing with ksqlDB Stream: widgets ksqlDB CREATE STREAM widgets_red AS SELECT * FROM widgets WHERE colour=’RED’; Stream: widgets_red @rmoff | #ACEsAtHome | @confluentinc
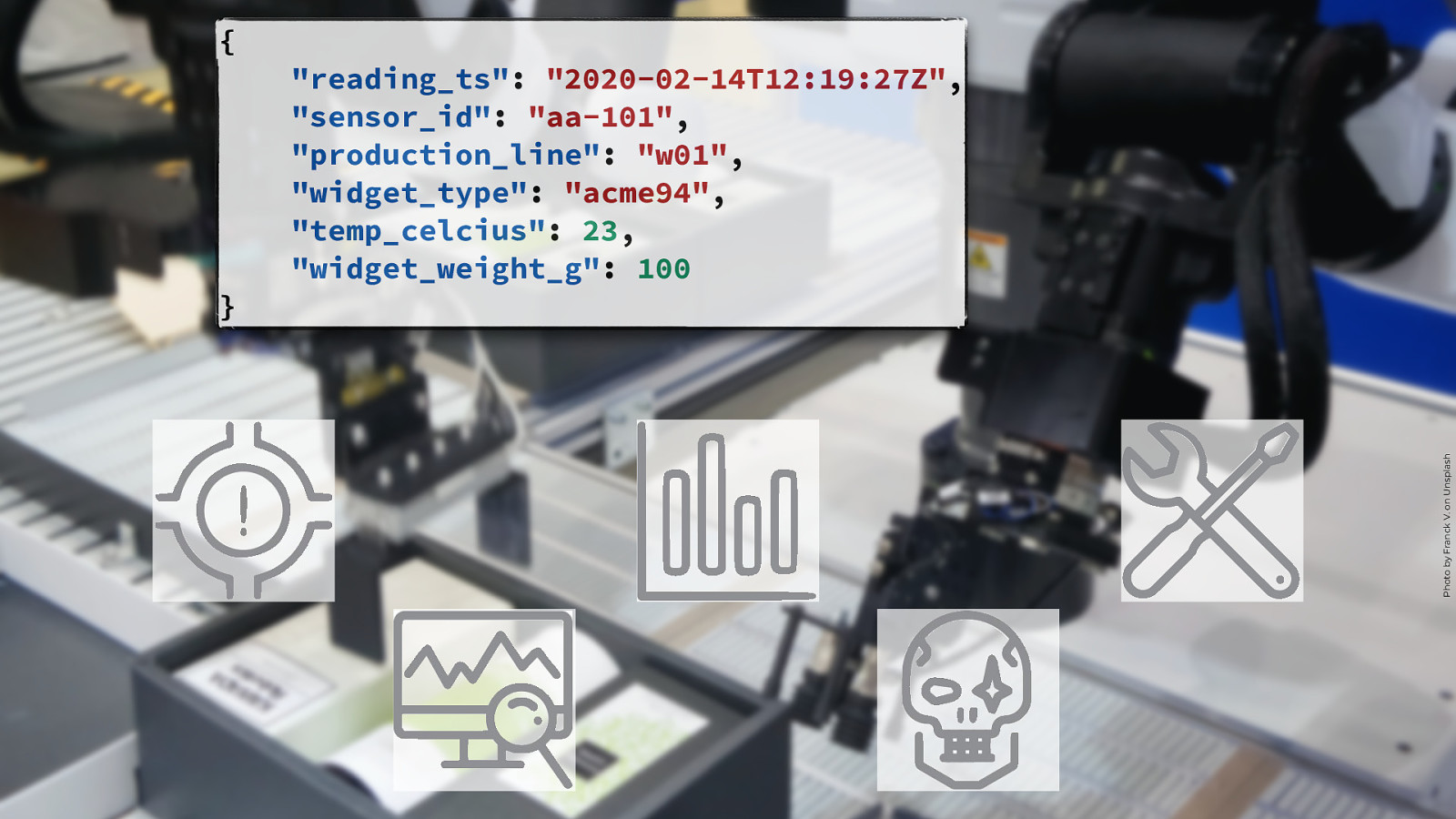
} “reading_ts”: “2020-02-14T12:19:27Z”, “sensor_id”: “aa-101”, “production_line”: “w01”, “widget_type”: “acme94”, “temp_celcius”: 23, “widget_weight_g”: 100 Photo by Franck V. on Unsplash { @rmoff | #ACEsAtHome | @confluentinc
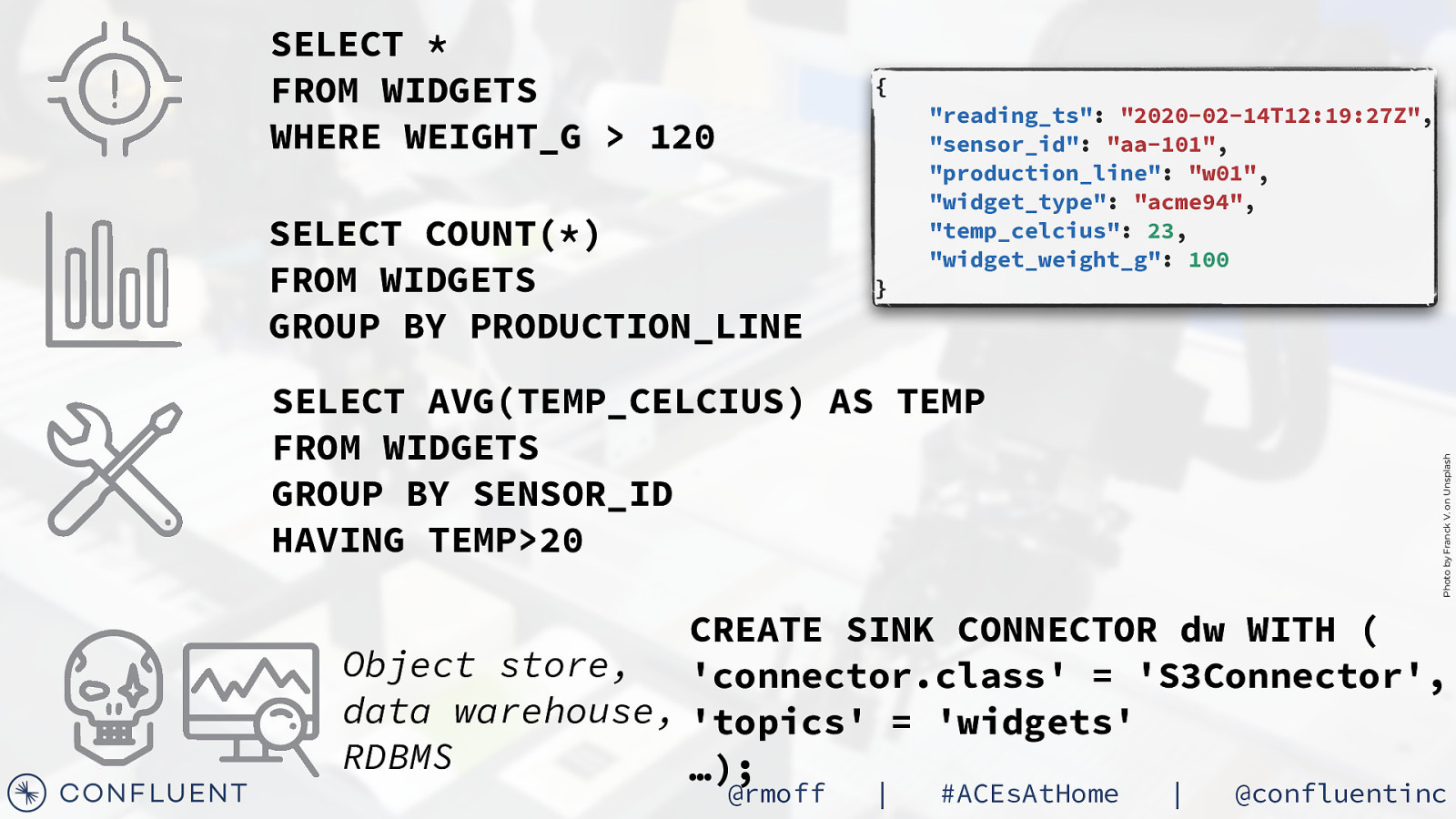
SELECT * FROM WIDGETS WHERE WEIGHT_G > 120 { SELECT COUNT(*) FROM WIDGETS GROUP BY PRODUCTION_LINE } “reading_ts”: “2020-02-14T12:19:27Z”, “sensor_id”: “aa-101”, “production_line”: “w01”, “widget_type”: “acme94”, “temp_celcius”: 23, “widget_weight_g”: 100 Photo by Franck V. on Unsplash SELECT AVG(TEMP_CELCIUS) AS TEMP FROM WIDGETS GROUP BY SENSOR_ID HAVING TEMP>20 CREATE SINK CONNECTOR dw WITH ( Object store, ‘connector.class’ = ‘S3Connector’, data warehouse, ‘topics’ = ‘widgets’ RDBMS …); @rmoff | #ACEsAtHome | @confluentinc
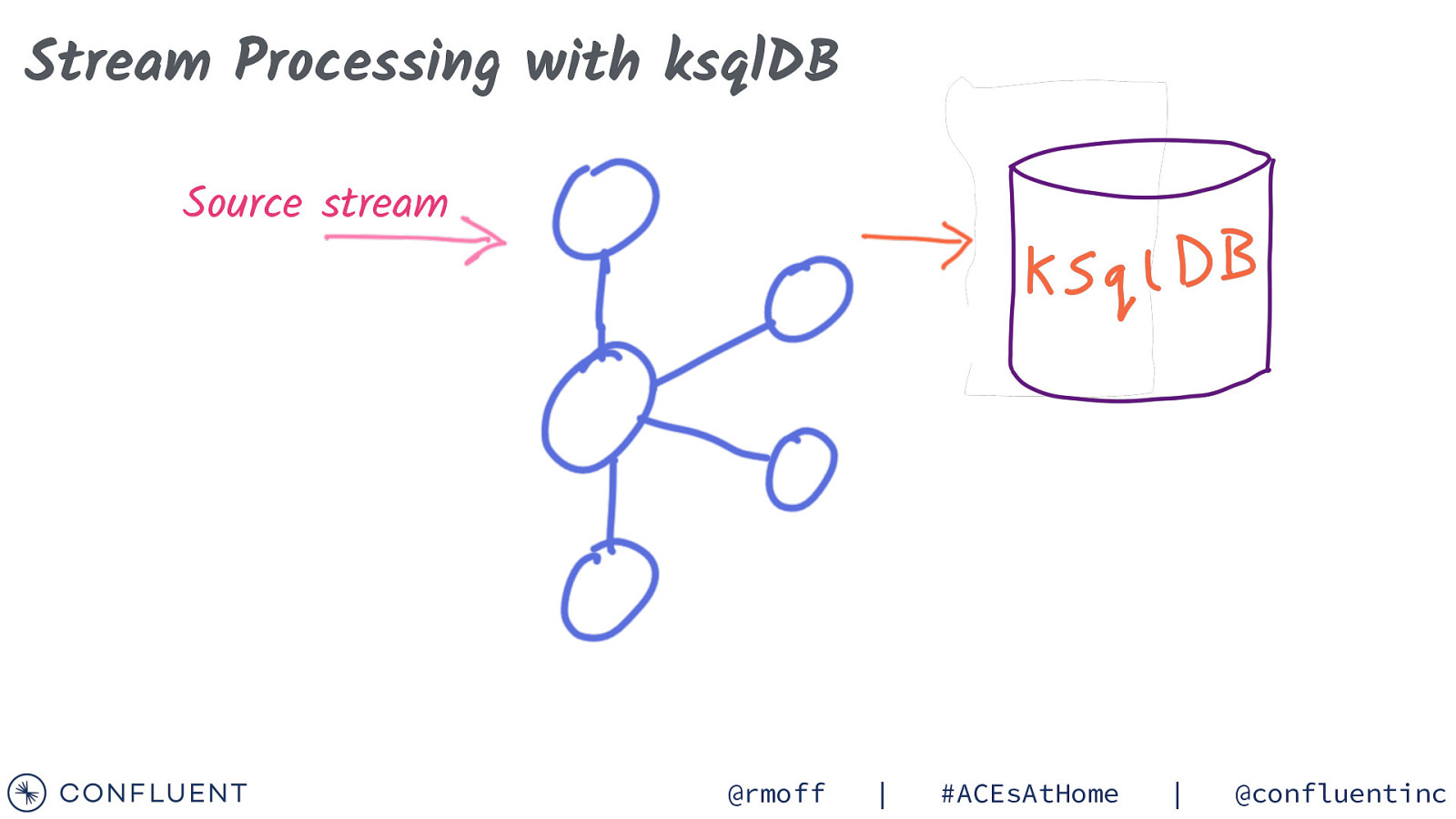
Stream Processing with ksqlDB Source stream @rmoff | #ACEsAtHome | @confluentinc
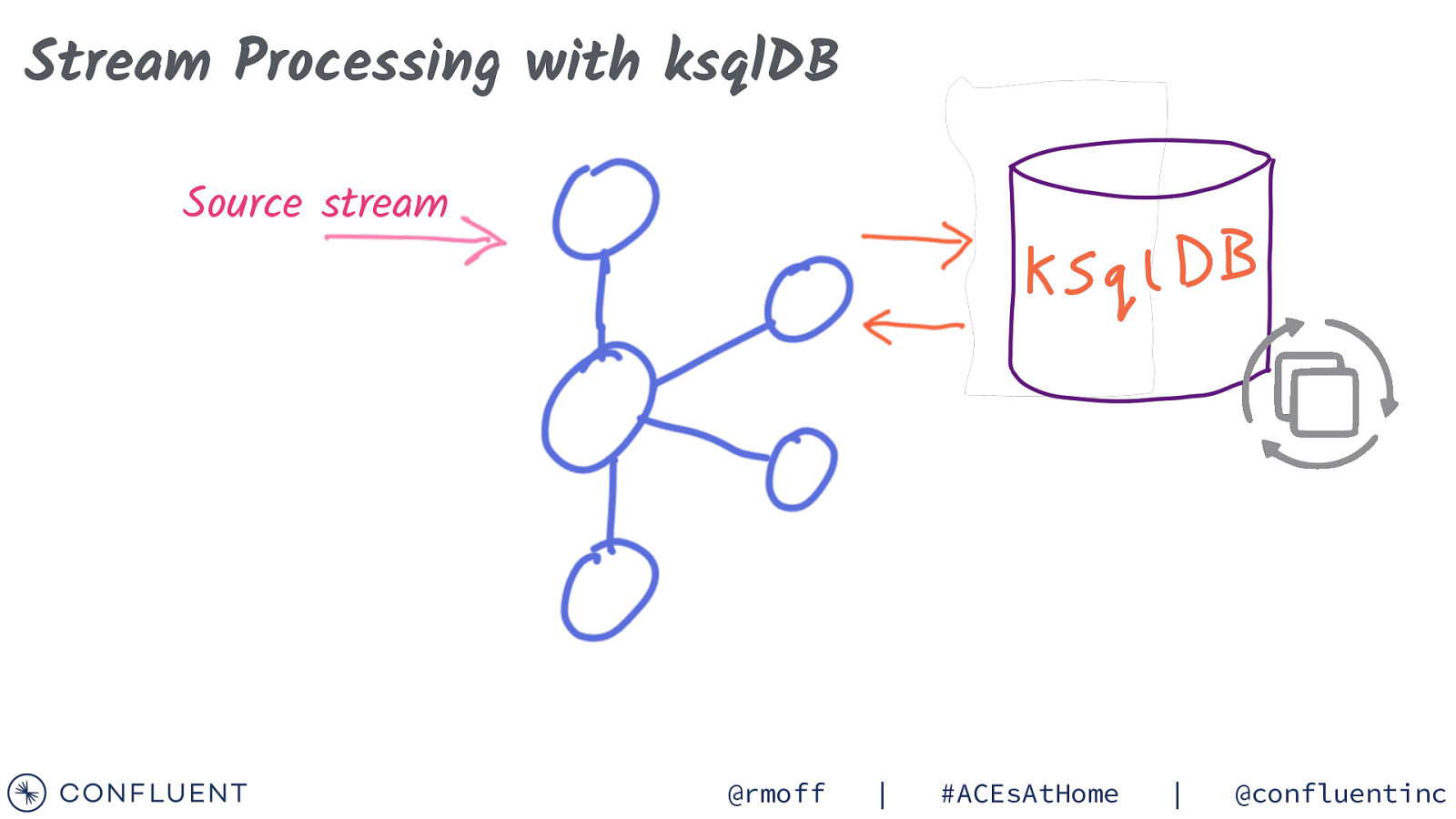
Stream Processing with ksqlDB Source stream @rmoff | #ACEsAtHome | @confluentinc
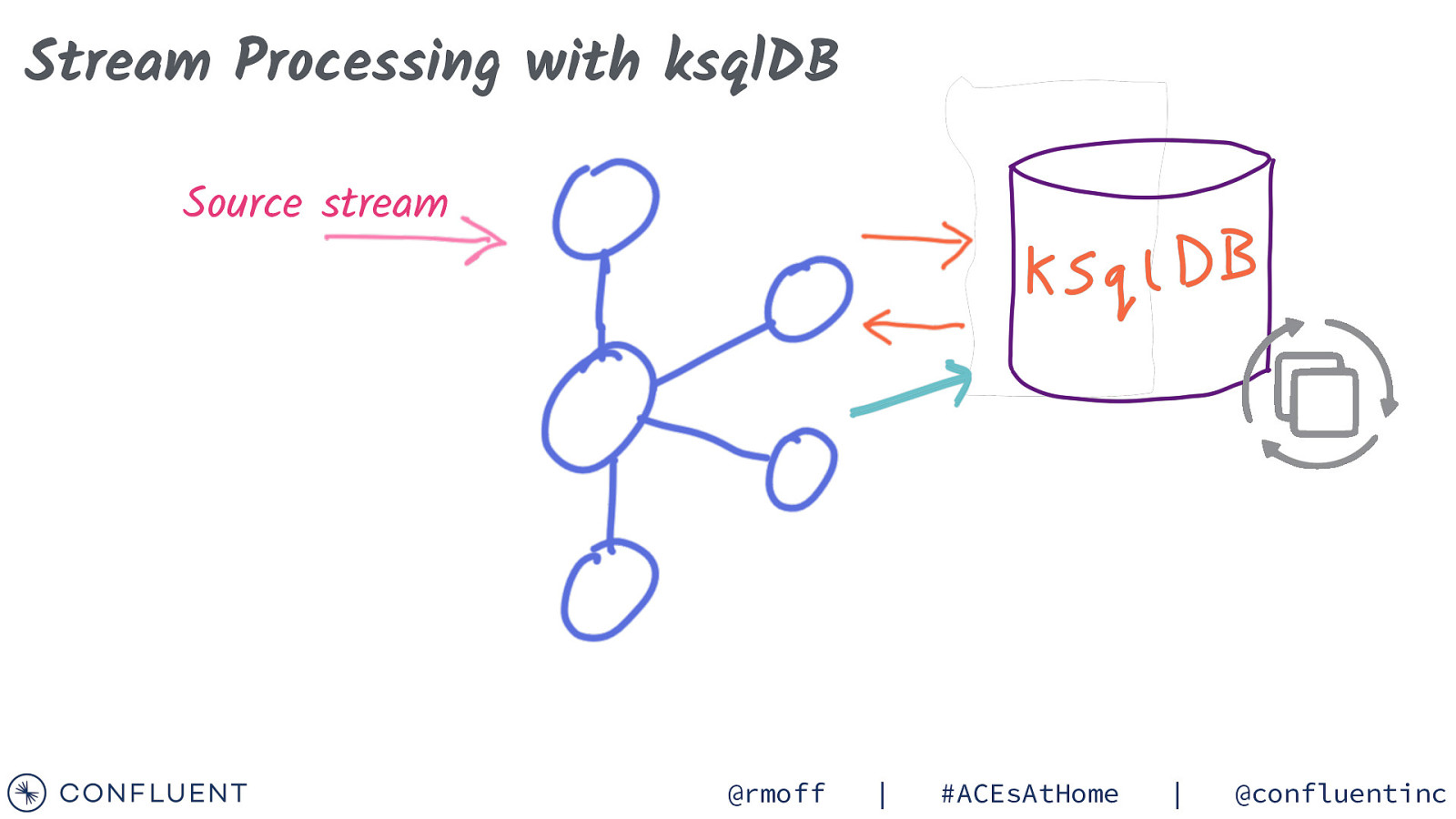
Stream Processing with ksqlDB Source stream @rmoff | #ACEsAtHome | @confluentinc
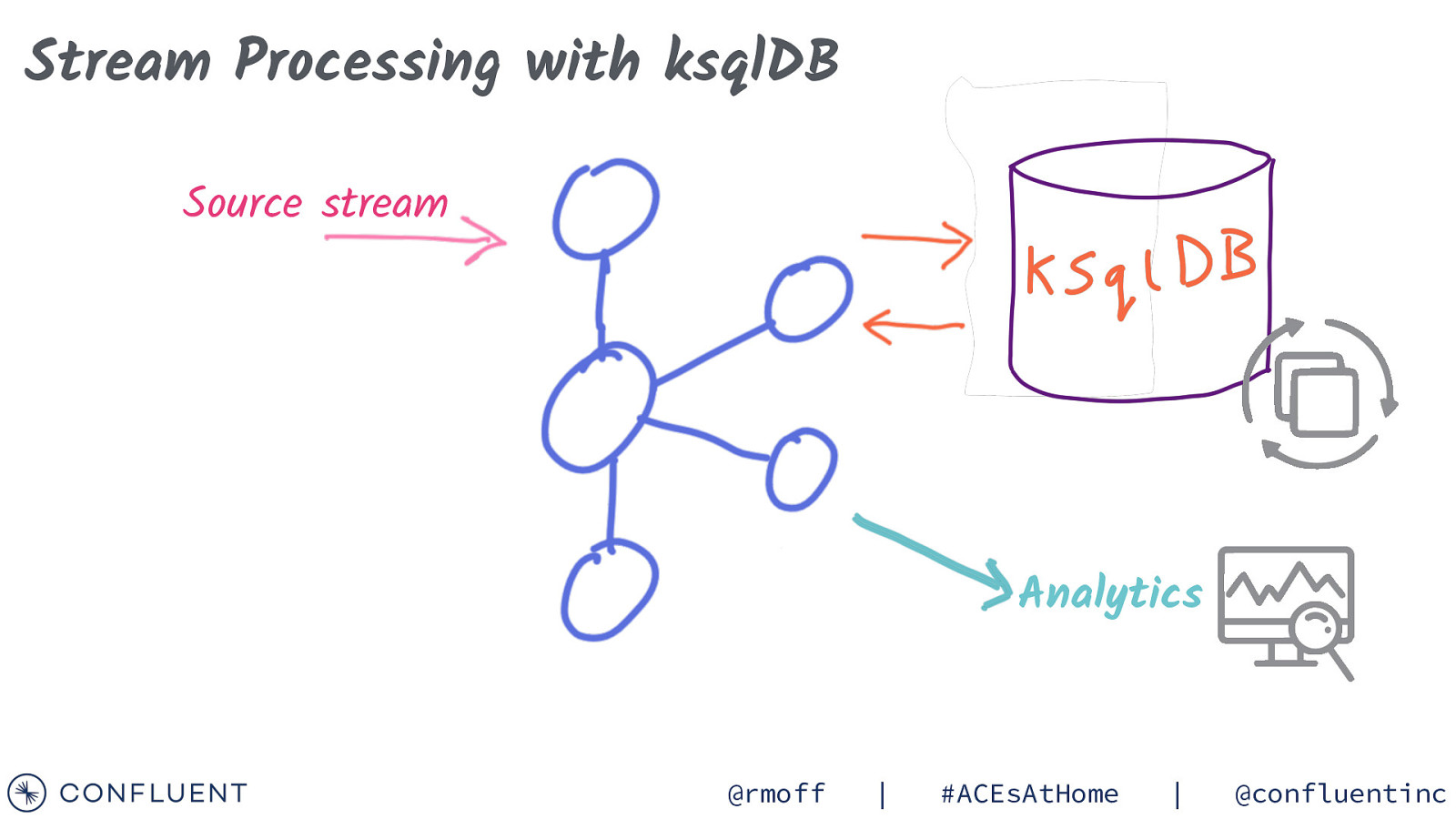
Stream Processing with ksqlDB Source stream Analytics @rmoff | #ACEsAtHome | @confluentinc
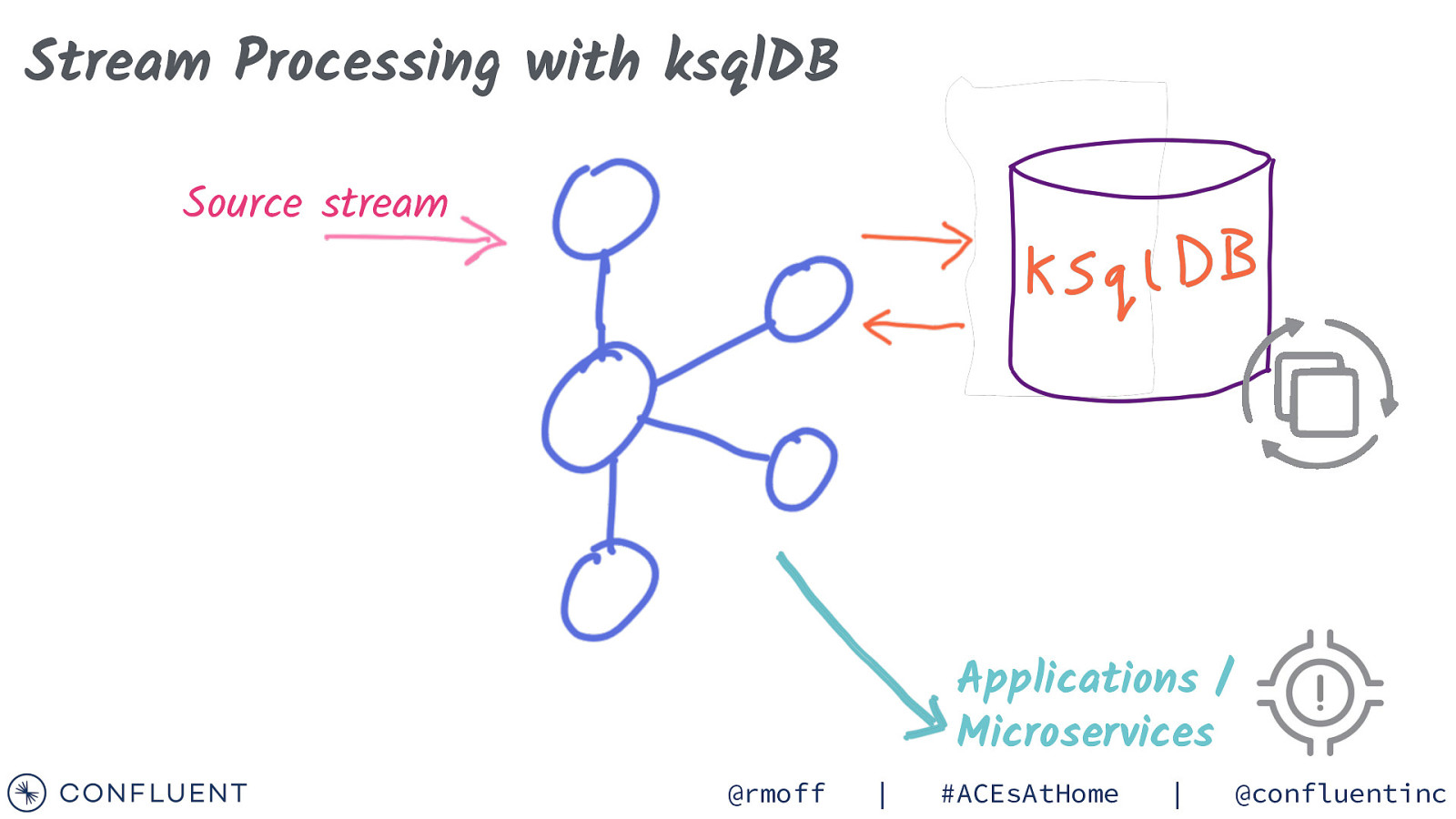
Stream Processing with ksqlDB Source stream Applications / Microservices @rmoff | #ACEsAtHome | @confluentinc
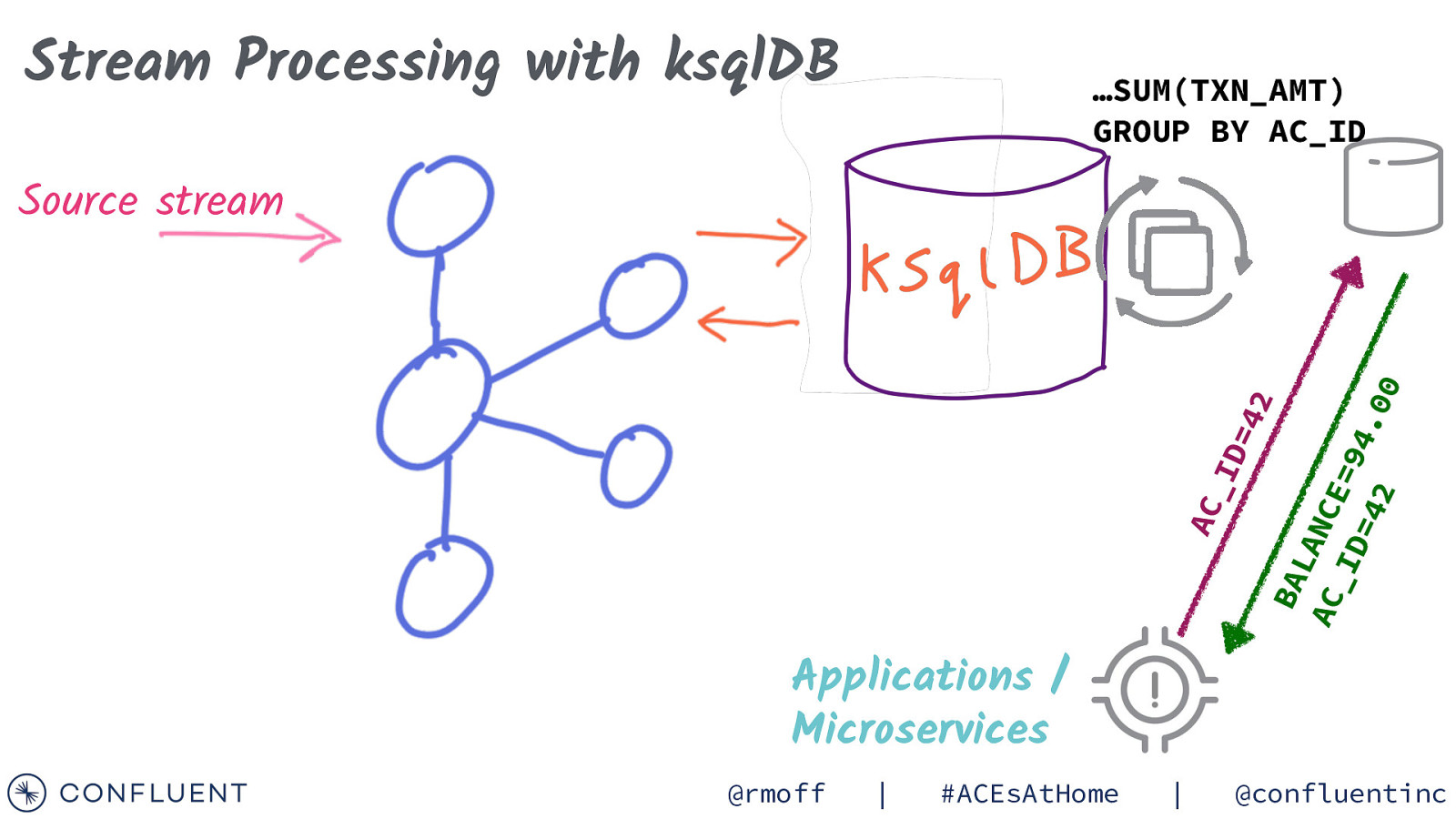
Stream Processing with ksqlDB …SUM(TXN_AMT) GROUP BY AC_ID AC _I D= 42 BA LA NC AC E= _I 94 D= .0 42 0 Source stream Applications / Microservices @rmoff | #ACEsAtHome | @confluentinc
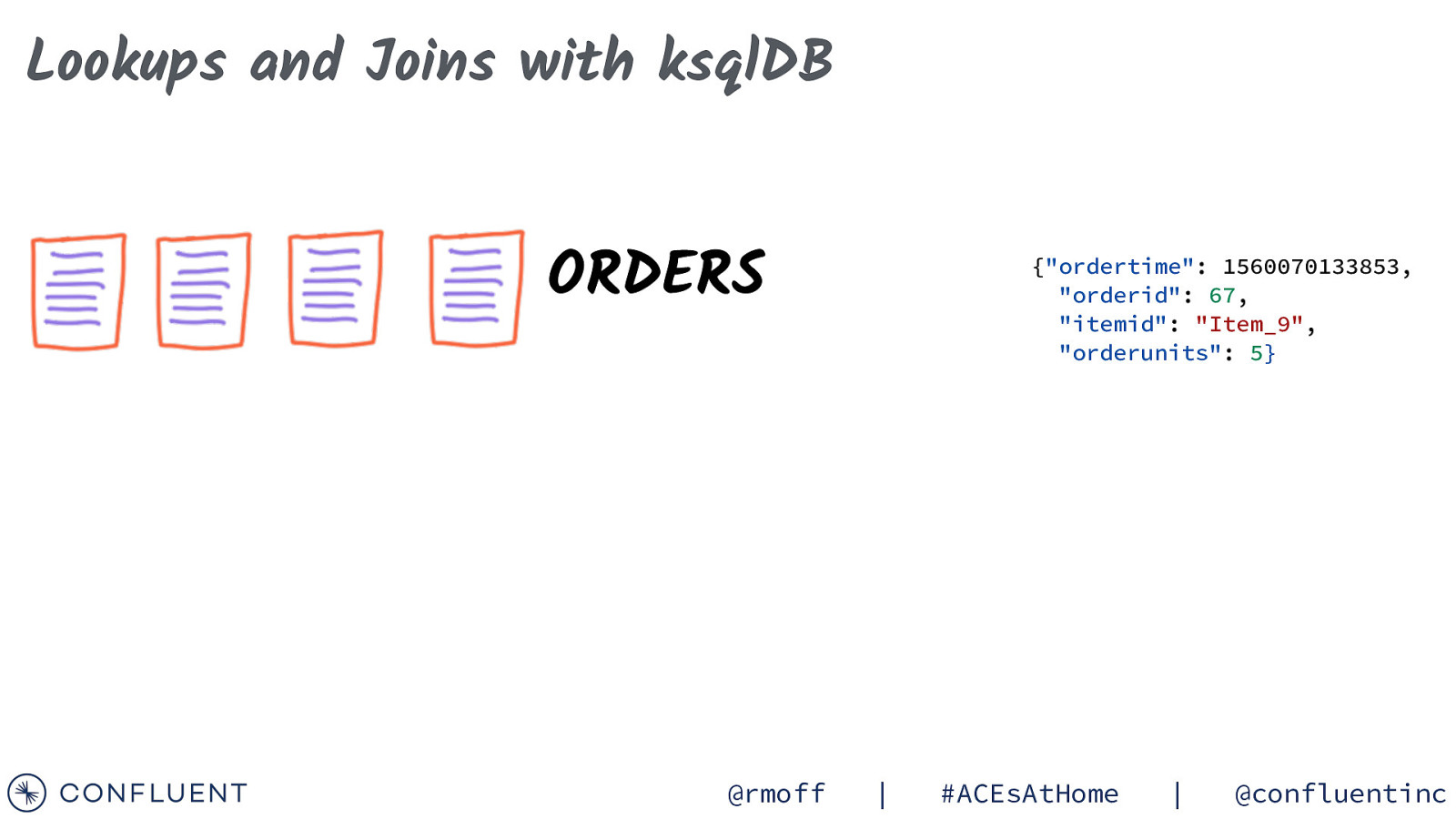
Lookups and Joins with ksqlDB ORDERS @rmoff {“ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5} | #ACEsAtHome | @confluentinc
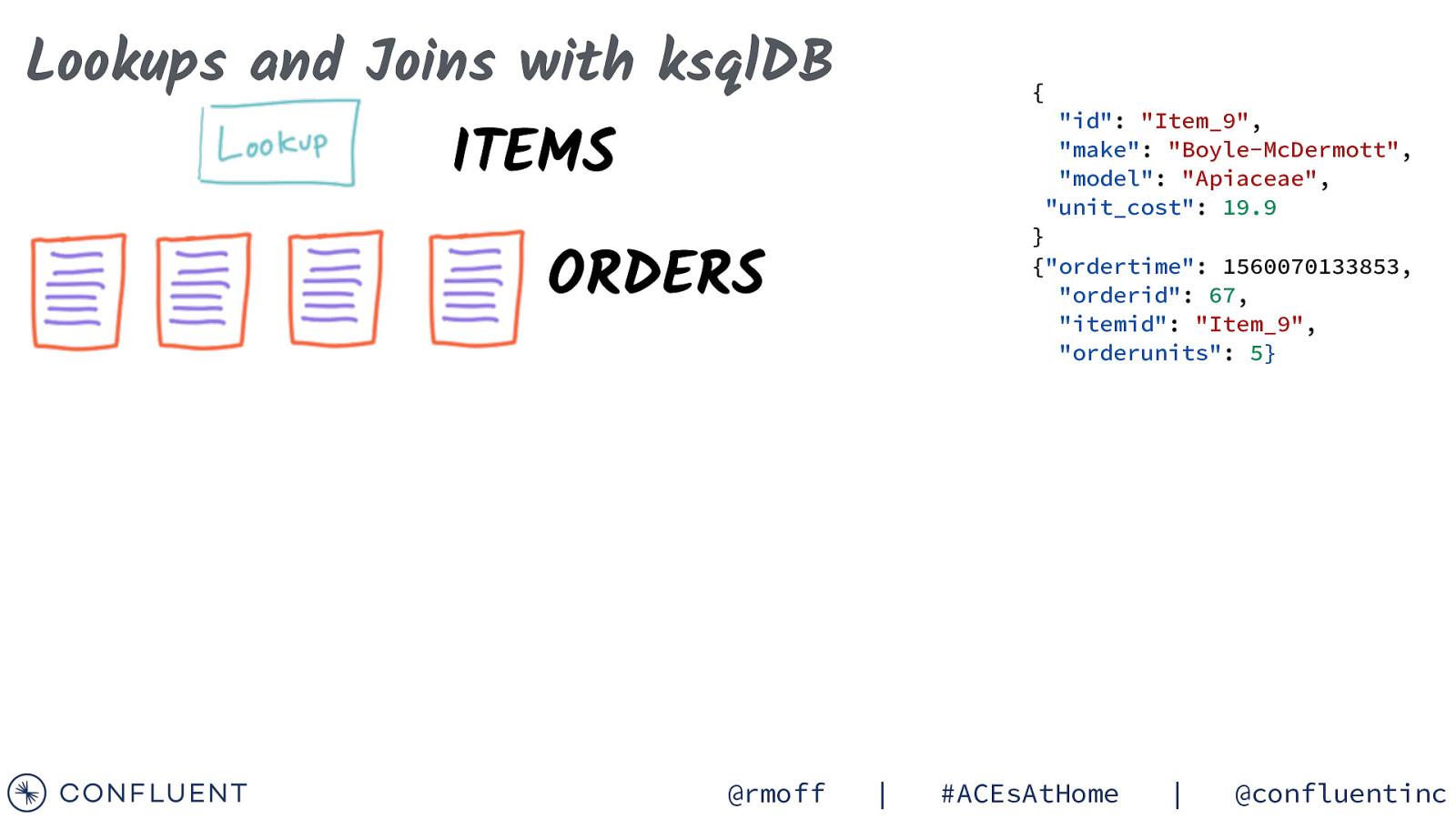
Lookups and Joins with ksqlDB { “id”: “Item_9”, “make”: “Boyle-McDermott”, “model”: “Apiaceae”, “unit_cost”: 19.9 ITEMS } {“ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5} ORDERS @rmoff | #ACEsAtHome | @confluentinc

Lookups and Joins with ksqlDB { “id”: “Item_9”, “make”: “Boyle-McDermott”, “model”: “Apiaceae”, “unit_cost”: 19.9 ITEMS ORDERS ksqlDB CREATE STREAM ORDERS_ENRICHED AS SELECT O., I., O.ORDERUNITS * I.UNIT_COST AS TOTAL_ORDER_VALUE, FROM ORDERS O INNER JOIN ITEMS I ON O.ITEMID = I.ID ; @rmoff | } {“ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5} #ACEsAtHome | @confluentinc
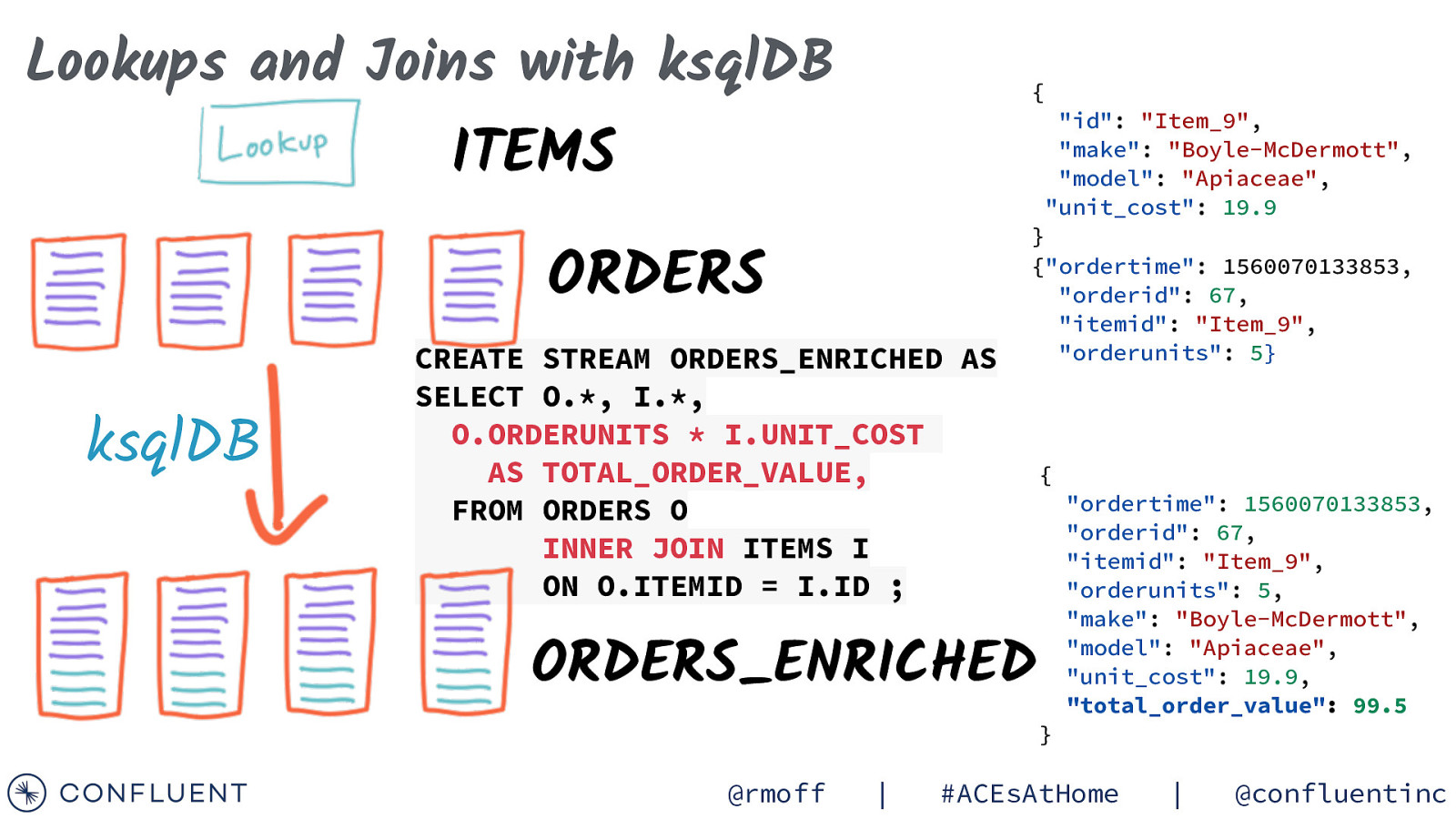
Lookups and Joins with ksqlDB { “id”: “Item_9”, “make”: “Boyle-McDermott”, “model”: “Apiaceae”, “unit_cost”: 19.9 ITEMS ORDERS ksqlDB CREATE STREAM ORDERS_ENRICHED AS SELECT O., I., O.ORDERUNITS * I.UNIT_COST AS TOTAL_ORDER_VALUE, FROM ORDERS O INNER JOIN ITEMS I ON O.ITEMID = I.ID ; } {“ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5} { “ordertime”: 1560070133853, “orderid”: 67, “itemid”: “Item_9”, “orderunits”: 5, “make”: “Boyle-McDermott”, “model”: “Apiaceae”, “unit_cost”: 19.9, “total_order_value”: 99.5 ORDERS_ENRICHED } @rmoff | #ACEsAtHome | @confluentinc

Streams & Tables @rmoff | #ACEsAtHome | @confluentinc
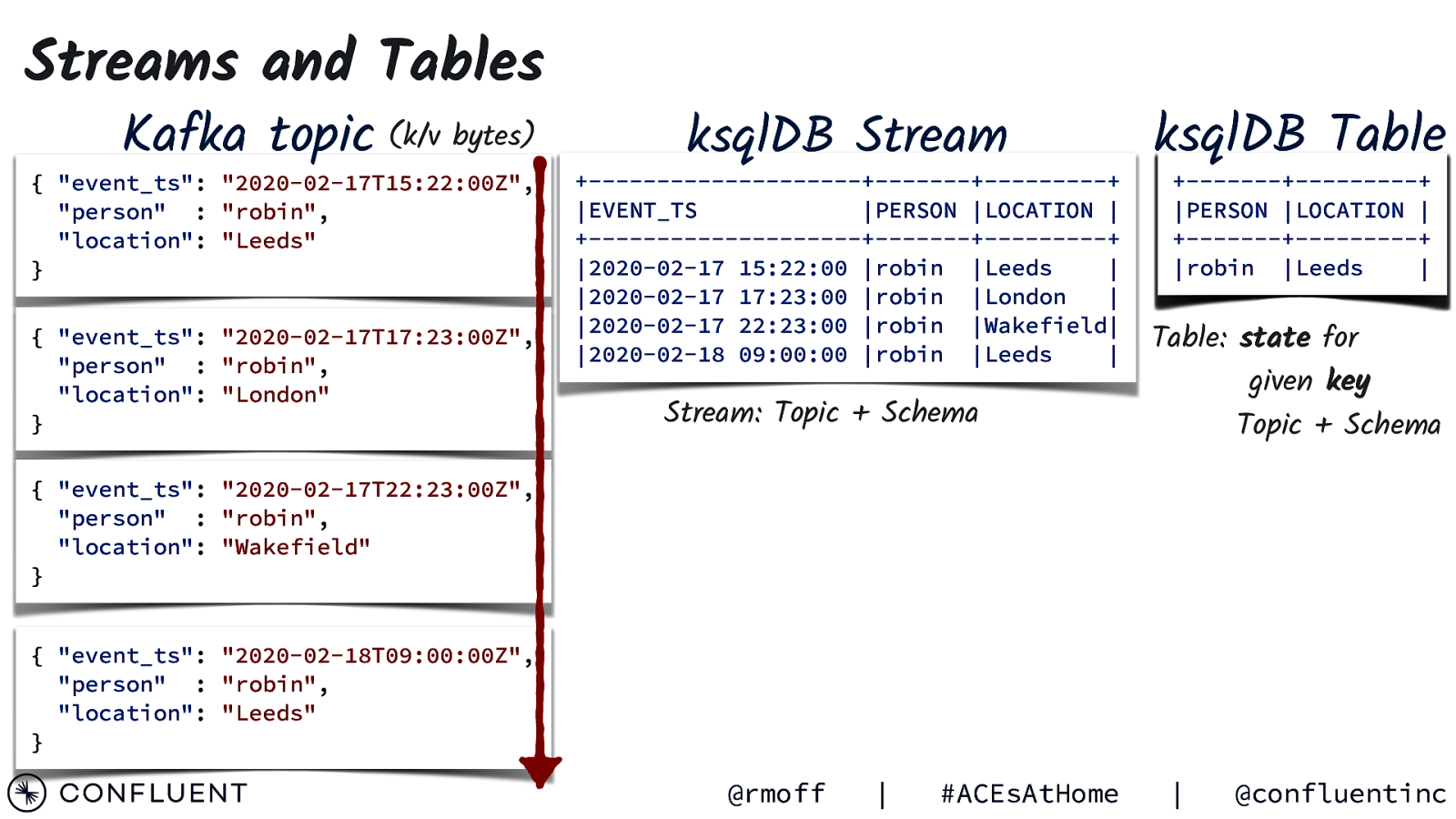
Streams and Tables Kafka topic (k/v bytes) { “event_ts”: “2020-02-17T15:22:00Z”, “person” : “robin”, “location”: “Leeds” } { “event_ts”: “2020-02-17T17:23:00Z”, “person” : “robin”, “location”: “London” } ksqlDB Stream +——————————+———-+————-+ |EVENT_TS |PERSON |LOCATION | +——————————+———-+————-+ |2020-02-17 15:22:00 |robin |Leeds | |2020-02-17 17:23:00 |robin |London | |2020-02-17 22:23:00 |robin |Wakefield| |2020-02-18 09:00:00 |robin |Leeds | Stream: Topic + Schema ksqlDB Table +———-+————-+ |PERSON |LOCATION | +———-+————-+ |robin |Leeds |London |Wakefield| | Table: state for given key Topic + Schema { “event_ts”: “2020-02-17T22:23:00Z”, “person” : “robin”, “location”: “Wakefield” } { “event_ts”: “2020-02-18T09:00:00Z”, “person” : “robin”, “location”: “Leeds” } @rmoff | #ACEsAtHome | @confluentinc
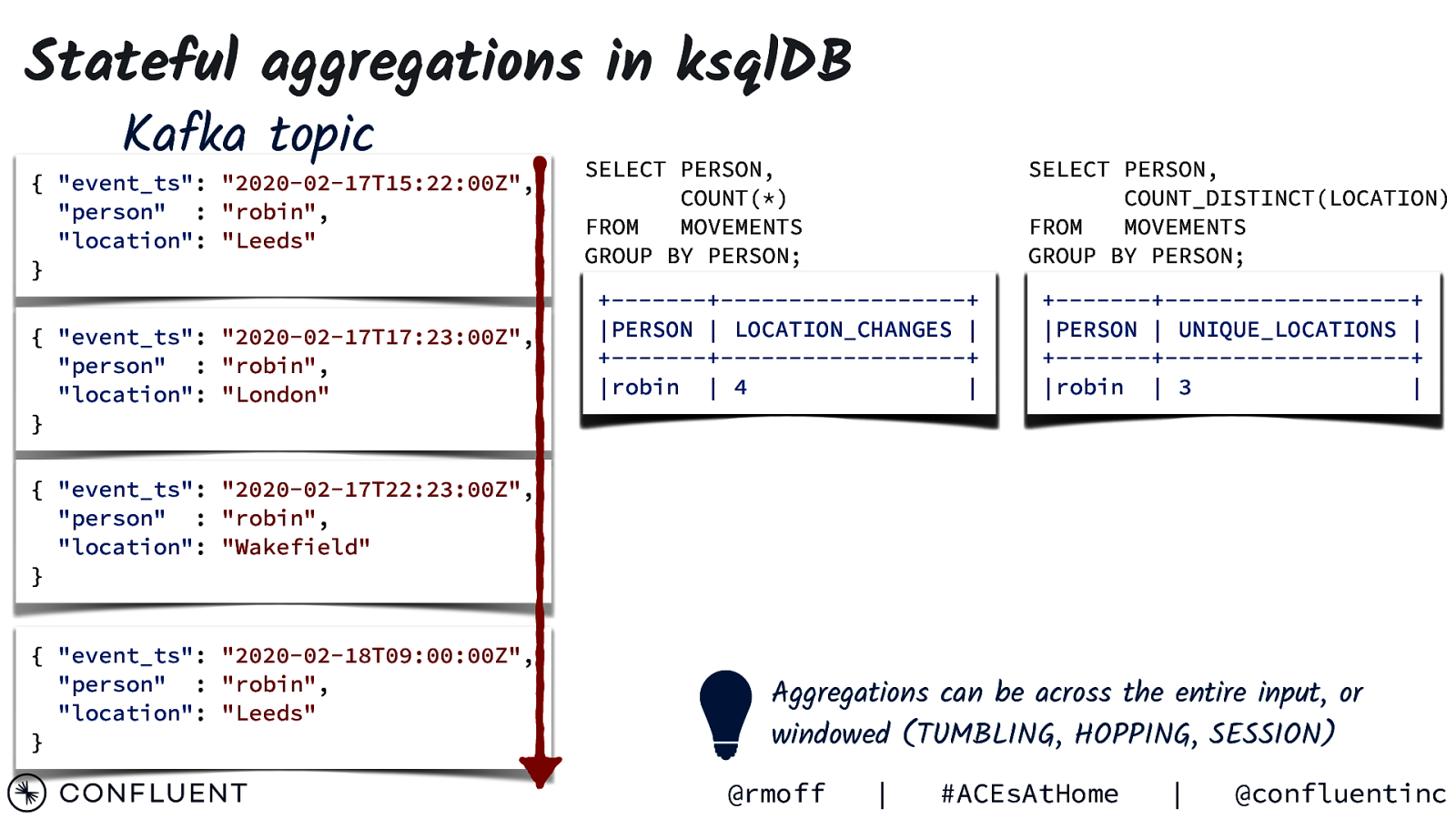
Stateful aggregations in ksqlDB Kafka topic { “event_ts”: “2020-02-17T15:22:00Z”, “person” : “robin”, “location”: “Leeds” } { “event_ts”: “2020-02-17T17:23:00Z”, “person” : “robin”, “location”: “London” } SELECT PERSON, COUNT(*) FROM MOVEMENTS GROUP BY PERSON; SELECT PERSON, COUNT_DISTINCT(LOCATION) FROM MOVEMENTS GROUP BY PERSON; +———-+—————————+ |PERSON | LOCATION_CHANGES | +———-+—————————+ |robin | 4 1 2 3 | +———-+—————————+ |PERSON | UNIQUE_LOCATIONS | +———-+—————————+ |robin | 3 1 2 | { “event_ts”: “2020-02-17T22:23:00Z”, “person” : “robin”, “location”: “Wakefield” } { “event_ts”: “2020-02-18T09:00:00Z”, “person” : “robin”, “location”: “Leeds” } Aggregations can be across the entire input, or windowed (TUMBLING, HOPPING, SESSION) @rmoff | #ACEsAtHome | @confluentinc

Kafka topic { “event_ts”: “2020-02-17T15:22:00Z”, “person” : “robin”, “location”: “Leeds” } { “event_ts”: “2020-02-17T17:23:00Z”, “person” : “robin”, “location”: “London” } CREATE TABLE PERSON_MOVEMENTS AS SELECT PERSON, COUNT_DISTINCT(LOCATION) AS UNIQUE_LOCATIONS, COUNT(*) AS LOCATION_CHANGES FROM MOVEMENTS GROUP BY PERSON; PERSON_ MOVEMENTS Internal ksqlDB state store Stateful aggregations in ksqlDB { “event_ts”: “2020-02-17T22:23:00Z”, “person” : “robin”, “location”: “Wakefield” } { “event_ts”: “2020-02-18T09:00:00Z”, “person” : “robin”, “location”: “Leeds” } @rmoff | #ACEsAtHome | @confluentinc
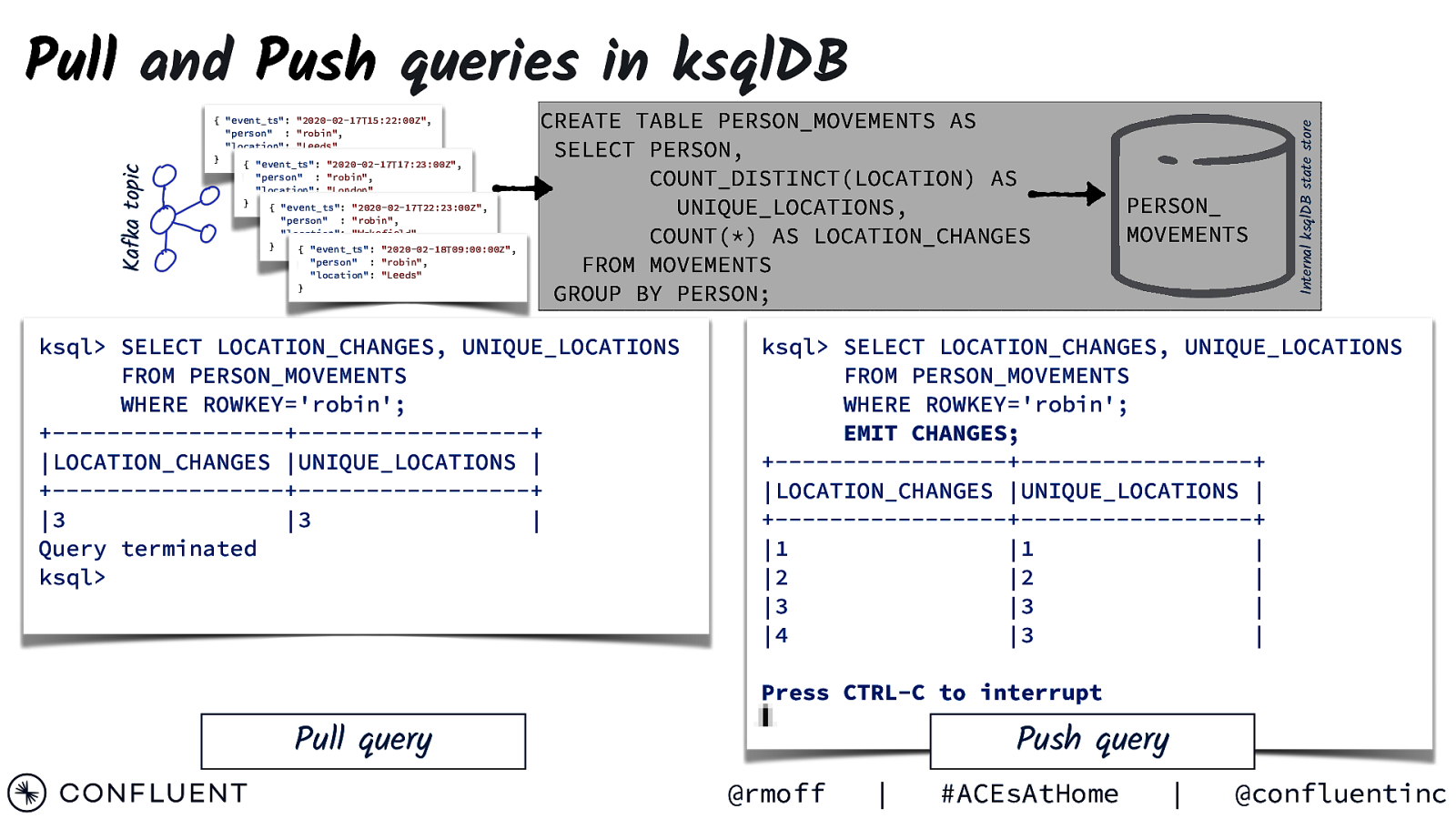
{ “event_ts”: “2020-02-17T15:22:00Z”, “person” : “robin”, “location”: “Leeds” } { “event_ts”: “2020-02-17T17:23:00Z”, “person” : “robin”, “location”: “London” } { “event_ts”: “2020-02-17T22:23:00Z”, “person” : “robin”, “location”: “Wakefield” } { “event_ts”: “2020-02-18T09:00:00Z”, “person” : “robin”, “location”: “Leeds” } CREATE TABLE PERSON_MOVEMENTS AS SELECT PERSON, COUNT_DISTINCT(LOCATION) AS UNIQUE_LOCATIONS, COUNT(*) AS LOCATION_CHANGES FROM MOVEMENTS GROUP BY PERSON; ksql> SELECT LOCATION_CHANGES, UNIQUE_LOCATIONS FROM PERSON_MOVEMENTS WHERE ROWKEY=’robin’; +————————-+————————-+ |LOCATION_CHANGES |UNIQUE_LOCATIONS | +————————-+————————-+ |3 |3 | Query terminated ksql> PERSON_ MOVEMENTS Internal ksqlDB state store Kafka topic Pull and Push queries in ksqlDB ksql> SELECT LOCATION_CHANGES, UNIQUE_LOCATIONS FROM PERSON_MOVEMENTS WHERE ROWKEY=’robin’; EMIT CHANGES; +————————-+————————-+ |LOCATION_CHANGES |UNIQUE_LOCATIONS | +————————-+————————-+ |1 |1 | |2 |2 | |3 |3 | |4 |3 | Press CTRL-C to interrupt Pull query Push query @rmoff | #ACEsAtHome | @confluentinc
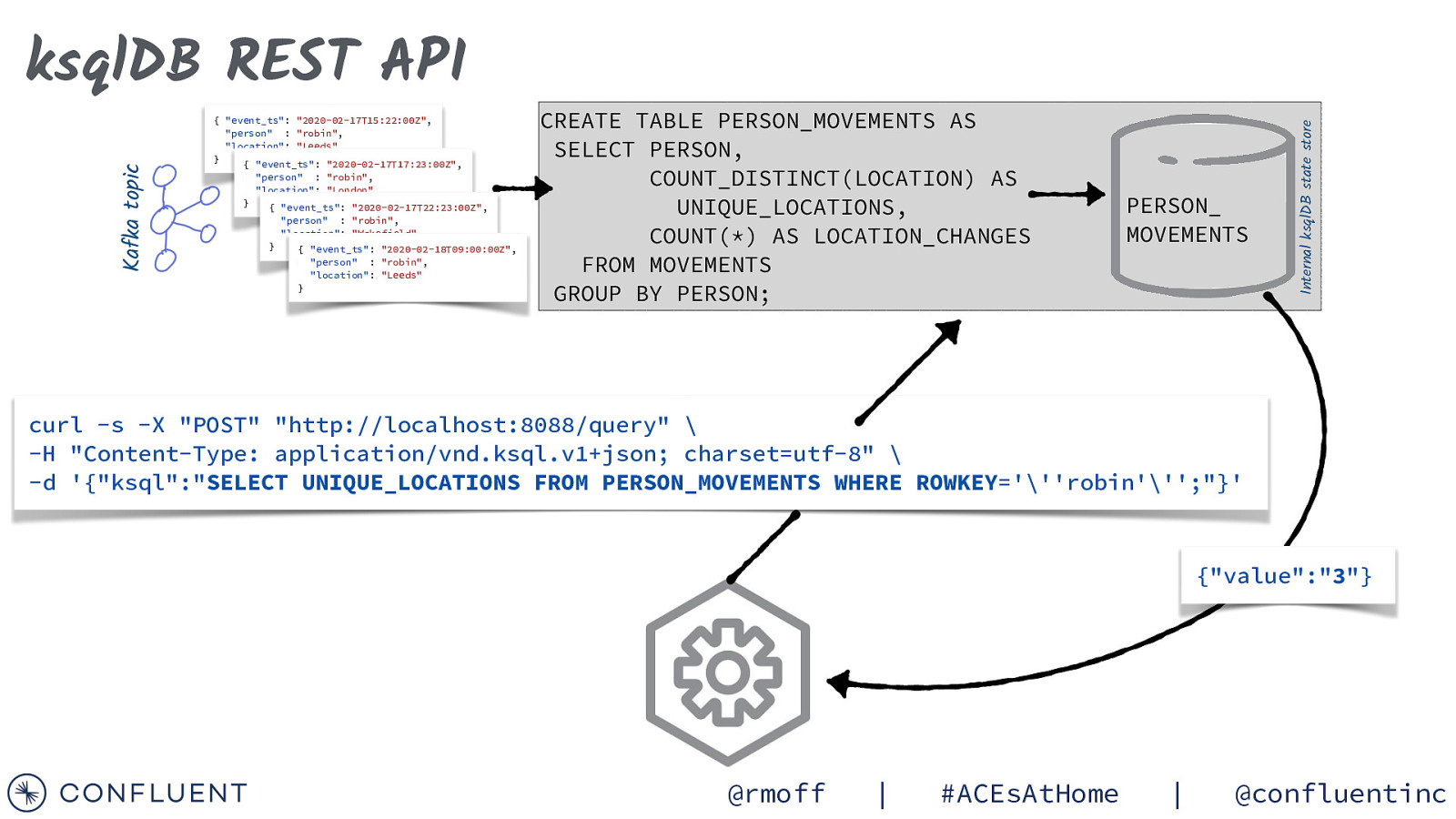
{ “event_ts”: “2020-02-17T15:22:00Z”, “person” : “robin”, “location”: “Leeds” } { “event_ts”: “2020-02-17T17:23:00Z”, “person” : “robin”, “location”: “London” } { “event_ts”: “2020-02-17T22:23:00Z”, “person” : “robin”, “location”: “Wakefield” } { “event_ts”: “2020-02-18T09:00:00Z”, “person” : “robin”, “location”: “Leeds” } CREATE TABLE PERSON_MOVEMENTS AS SELECT PERSON, COUNT_DISTINCT(LOCATION) AS UNIQUE_LOCATIONS, COUNT(*) AS LOCATION_CHANGES FROM MOVEMENTS GROUP BY PERSON; PERSON_ MOVEMENTS Internal ksqlDB state store Kafka topic ksqlDB REST API curl -s -X “POST” “http://localhost:8088/query” \ -H “Content-Type: application/vnd.ksql.v1+json; charset=utf-8” \ -d ‘{“ksql”:”SELECT UNIQUE_LOCATIONS FROM PERSON_MOVEMENTS WHERE ROWKEY=”’robin”’;”}’ {“value”:”3”} @rmoff | #ACEsAtHome | @confluentinc

Pull and Push queries in ksqlDB Pull query Tells you: Point in time value Push query All value changes Exits: Immediately Never @rmoff | #ACEsAtHome | @confluentinc

on Photo by Want to learn more? CTAs, not CATs (sorry, not sorry) @rmoff | #ACEsAtHome | @confluentinc

Free Books! https://rmoff.dev/aces @rmoff | #ACEsAtHome | @confluentinc

60 DE VA DV $50 USD off your bill each calendar month for the first three months when you sign up https://rmoff.dev/ccloud Free money! (additional $60 towards your bill 😄 ) Fully Managed Kafka as a Service * Limited availability. Activate by 11th September 2020. Expires after 90 days of activation. Any unused promo value on the expiration date will be forfeited.

Learn Kafka. Start building with Apache Kafka at Confluent Developer. developer.confluent.io

Confluent Community Slack group cnfl.io/slack @rmoff | #ACEsAtHome | @confluentinc

Further reading / watching • Kafka as a Platform: the Ecosystem from the Ground Up http://rmoff.dev/youtube • https://rmoff.dev/kafka101 • Apache Kafka and ksqlDB in Action: Let’s Build a Streaming Data Pipeline! • https://rmoff.dev/ljc-kafka-01 • From Zero to Hero with Kafka Connect • https://rmoff.dev/ljc-kafka-02 • Introduction to ksqlDB • https://rmoff.dev/ljc-kafka-03 • The Changing Face of ETL: Event-Driven Architectures for Data Engineers • https://rmoff.dev/oredev19-changing-face-of-etl • 🚂On Track with Apache Kafka: Building a Streaming Platform solution with Rail Data • https://rmoff.dev/oredev19-on-track-with-kafka @rmoff | #ACEsAtHome | @confluentinc

#EOF @rmoff #ACEsAtHome rmoff.dev/talks