@skimbrel
BOWERBIRDS
OF
TECHNOLOGY
PYCON 2018
SAM KITAJIMA-KIMBREL @SKIMBREL

A presentation at PyCon 2018 in May 2018 in Cleveland, OH, USA by Sam Kitajima-Kimbrel

@skimbrel
BOWERBIRDS
OF
TECHNOLOGY
PYCON 2018
SAM KITAJIMA-KIMBREL @SKIMBREL

These are bowerbirds!
They build these structures called bowers out of sticks and colorful objects they find in their environment in an effort to attract mates.
More on them later; for now enjoy the nice photos of birds that I found on Flickr.

@skimbrel CAL HENDERSON, DJANGOCON US 2008 "Most websites aren't in the top 100 web sites." Speaking of Flickr, Cal Henderson used to work there.
"It turns out all but 100 of them are not in the top 100"
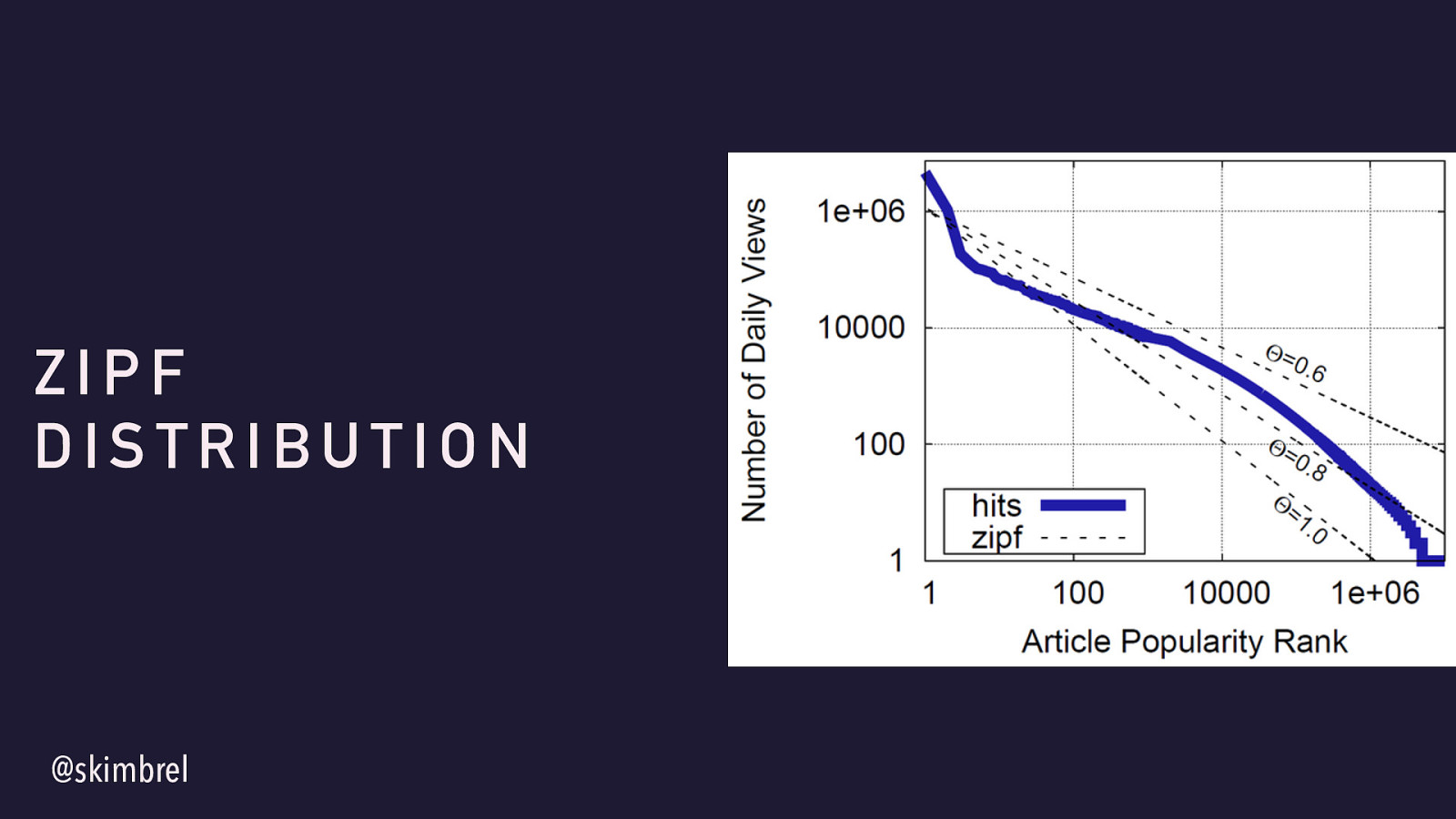
@skimbrel ZIPF DISTRIBUTION Zipfian distributions: # links / traffic / users / whatever metric you want is inversely proportional to rank among all sites (this graph happens to be Wikipedia articles and the axes are log/log)
Many empirical studies/measurements of the web have shown this holds true.

@skimbrel YOU ARE NOT GOOGLE, AND THAT'S OKAY! Or: most of us, excepting the ones who work at Google, are not Google. And that's okay!
Tons of products do just great at not-Google-scale.

@skimbrel I AM ALSO NOT GOOGLE I am also not Google. And that is me with a slightly different hair color if you're in the cheap seats.
Currently at Nuna where I build healthcare data analysis systems for Medicare, previously at Twilio, 8 years on large-and-fast-growing-but-not-Facebook-scale web services.

@skimbrel WHAT ARE GOOGLE'S PROBLEMS? What do Facebook, Amazon, and Google worry about?
Absurdly high throughput and data storage requirements
10s of 1000s of servers in dozens to hundreds of datacenters worldwide
Thousands of engineers and the ability to specialize them into very, very tiny niches
Virtually limitless resources and the patience to train people on their systems
How does this manifest? Let's look at examples.

@skimbrel ABSURDLY HIGH THROUGHPUT AND STORAGE DEMANDS

@skimbrel TENS OF THOUSANDS OF SERVERS HUNDREDS OF DATACENTERS

@skimbrel THOUSANDS OF DEVS

@skimbrel (NEAR-)UNLIMITED RESOURCES

@skimbrel CASE STUDIES Let's do a few brief case studies.
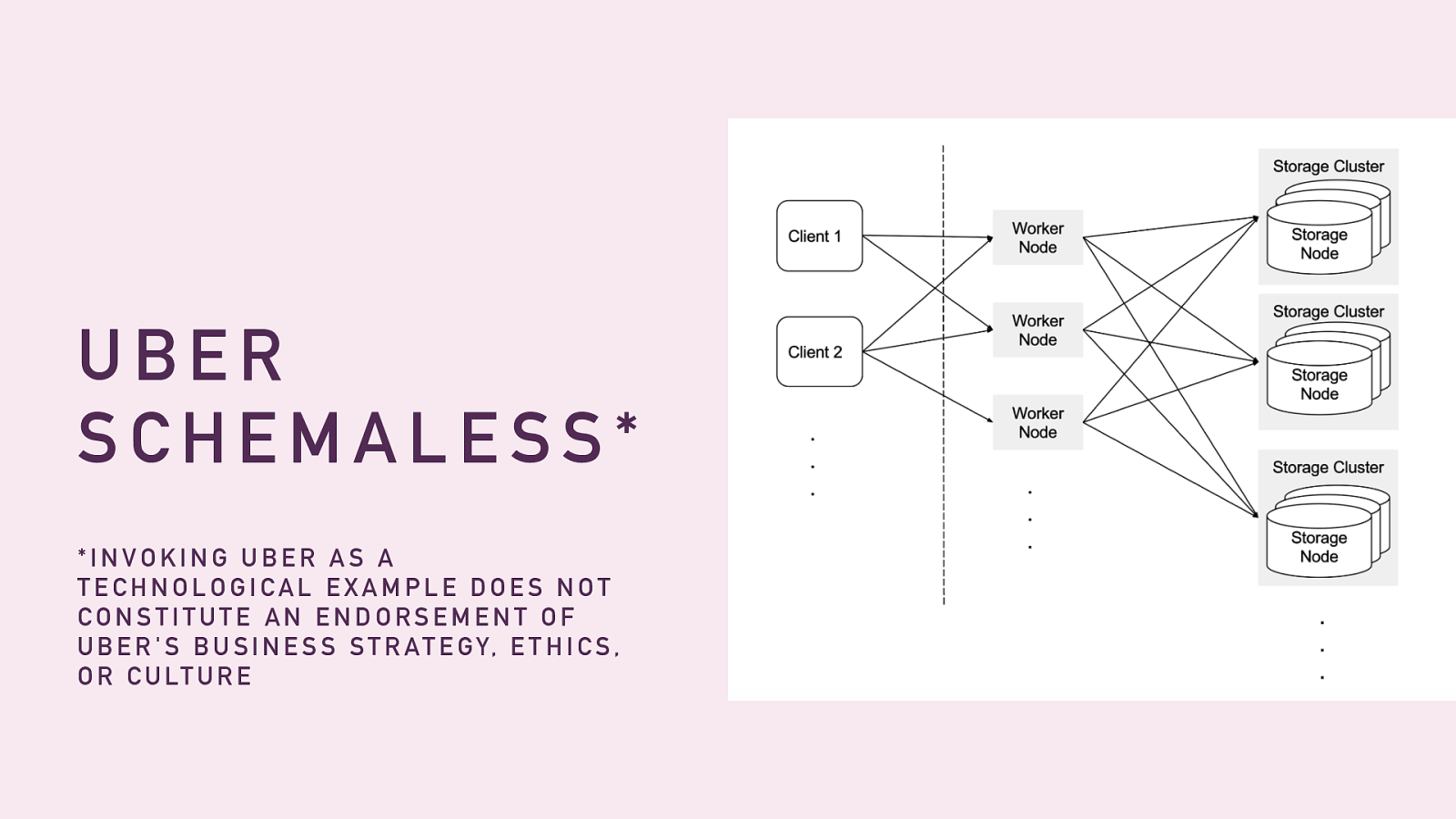
@skimbrel UBER SCHEMALESS* *INVOKING UBER AS A TECHNOLOGICAL EXAMPLE DOES NOT CONSTITUTE AN ENDORSEMENT OF UBER'S BUSINESS STRATEGY, ETHICS, OR CULTURE (Uber has given us plenty of bad examples in non-technological things and this is emphatically not an endorsement of any of their behavior towards human beings)
Case study: Uber hit scaling issues with Postgres and made themselves a new datastore.
What were they looking for?

@skimbrel "LINEARLY ADD CAPACITY BY ADDING MORE SERVERS"

@skimbrel "FAVOR WRITE AVAILABILITY OVER READ-YOUR-WRITE SEMANTICS"

@skimbrel EVENT NOTIFICATIONS (TRIGGERS) Side note: "we had an asynchronous event system built on Kafka 0.7 and we couldn't get it to run lossless". Have you tried upgrading?

@skimbrel WHAT IS IT, THEN? So what did they build?

@skimbrel "APPEND-ONLY SPARSE THREE-DIMENSIONAL PERSISTENT HASH MAP, VERY SIMILAR TO GOOGLE'S BIGTABLE" To which my only reply is this comic.

This comic is probably famous enough now but here it is again.

@skimbrel "So, how do I query the database?" "It's not a database. It's a key- value store!"
@skimbrel "Ok, it's not a database. How do I query it?" "You write a distributed map reduce function in Erlang!"

@skimbrel "Did you just tell me to go **** myself?" "I believe I did, Bob."

@skimbrel THIS HAS A COST Point is: this has a cost.

@skimbrel NEW ABSTRACTIONS Boundary between app and database changes — app has to know and enforce schemas and persistence strategies

@skimbrel
EVENTUAL
CONSISTENCY
You can't read things you just wrote, and neither can other processes.

Have to know query patterns ahead of time
Mandatory sharding — can't read globally w/o extra work
No joins

Can't hire fast or can't ramp fast
People aren't gonna walk in knowing this
Good luck w/ contractors

@skimbrel
AMAZON AND
SERVICE ARCHITECTURE
Steve Yegge quit Amazon and went to Google. Accidentally made public a long rant about how AWS was going to eat Google's lunch. Major focus: how Amazon got its
service-oriented architecture. In 2002ish, Bezos gave the following orders.

@skimbrel "All teams will henceforth expose their data and functionality through service interfaces."

@skimbrel "Teams must communicate with each other through these interfaces."

@skimbrel "There will be no other form of interprocess communication allowed […]the only communication allowed is via service interface calls over the network."

@skimbrel "It doesn't matter what technology they use. HTTP, Corba, Pubsub, custom protocols — doesn't matter."

@skimbrel "All service interfaces, without exception, must be designed from the ground up to be externalizable." Externalizable here means "exposed to the outside world", i.e. to customers, and sold as a product.

@skimbrel "Anyone who doesn't do this will be fired." So yeah. Amazon's way of making systems and developer teams scale. They were and are serious about this.

@skimbrel AMAZON LEARNED SOME THINGS This also had a cost. Steve, on what Amazon learned:

@skimbrel "pager escalation gets way harder, because a ticket might bounce through 20 service calls before the real owner is identified"

@skimbrel "every single one of your peer teams suddenly becomes a potential DOS attacker"

@skimbrel "monitoring and QA are the same thing…"

@skimbrel "…the only thing still functioning in the server is the little component that knows how to say 'I'm fine, roger roger, over and out' in a cheery droid voice"

@skimbrel "you won't be able to find any of them without a service-discovery mechanism [...] which is itself another service" Which requires a service registry, which…

@skimbrel MASSIVELY SCALABLE INFRASTRUCTURE COSTS DEVELOPER TIME Again: the crux is that massively-scalable infra costs dev time because the mental model is so much more complicated.
And you don't have a lot of that.

@skimbrel BUT I WANT TO BE GOOGLE! "But I want to be Google!", you may cry.

@skimbrel GOOGLE WASN'T GOOGLE OVERNIGHT …

@skimbrel BEN GOMES ( HTTP://READWRITE.COM/2012/02/29/INTERVIEW_CHANGING_ENGINES_MID-FLIGHT_QA_WITH_GOOG/ ) “When I joined Google, it would take us about a month to crawl and build an index of about 50 million pages.” Google in 1999:
1 month to crawl and index 50MM pages.
10k queries per day
Google 2006: 10k queries per second
Google 2012: 1 minute to index 50MM pages

@skimbrel AND SOMETIMES STILL IS NOT GOOGLE. On good authority: many things internal to Google still run on vanilla MySQL. Really!
Even Google doesn't solve problems they don't have.
Which goes to show…

@skimbrel
"BORING" TECH
CAN GO REALLY FAR
PyCon US 2017: Instagram is still a Django monolith! And doesn't even seem to be using asyncio!
Horizontally-sharded RDBMSes — 15-year-old tech that goes 20k MPS at Twilio and still gives us full ACID.

@skimbrel EXPONENTIAL GROWTH FEELS SLOW AT FIRST If you and your product are lucky enough to experience the joys of irrational exuberance and exponential growth…
Low part of the curve is gentle enough to give you warning
There is no single point where your system will keel over and die instantly

@skimbrel
ITERATE
ITERATE
ITERATE
Find the Most On Fire thing
Evolve/replace it
Repeat

@skimbrel OK, I'M NOT GOOGLE (YET) … . SO WHAT? At this point in the talk I hope you're starting to think "OK, I'm not Google (yet)."
"So what? What does this mean I should worry about instead?"

@skimbrel USER TRUST ABOVE ALL ELSE Maintain your users' trust. Meet their needs.

@skimbrel
FA S T, S A F E
ITERATION
Move fast without breaking things. Team’s time is one of the most precious resources; make the most of it.

@skimbrel HEALTHY TEAMS To do that, our team needs to be healthy — will focus on on-call in a bit but plenty of other things to consider

@skimbrel INCLUSIVE TEAMS Beyond on-call being manageable, having an inclusive team will help you. More here later too.

@skimbrel LET'S BE BOWERBIRDS! You don't have to reinvent the wheel. Build bowers instead.
Bowerbirds: build structures from found materials to attract mates.
Modern software ecosystem is our found environment
We want healthy relationships w/ our users and our team — find what we need & combine
First: technical decisions within this framework and then how to run a team and business

@skimbrel BE A PICKY BIRD First, let's talk about picking technologies.
OK, so we need a… bottle cap, it seems. Database? Browser framework? Web server? Who knows.
What do we want to think about?

@skimbrel PROJECT MATURITY Not brand-spanking new
Not in Apache Attic

@skimbrel MAINTAINERSHIP Not the originating company
Apache is the standard here if the project isn't big enough for, say, a DSF.
Release velocity?

@skimbrel SECURITY Search for CVEs.
How many?
Were they resolved? How quickly?
How hard is your deployment going to be?

@skimbrel STABILITY Two types!
API stability (is v2.0 gonna come out and break all the things?)
System stability (does the database, well, database)

@skimbrel PROJECT ECOSYSTEM Library support for your language(s)
Developer awareness/familiarity — can you hire people fast enough and how fast do they ramp up? Will consultants know it?
Picking tech that everyone knows means you won't have to wait three months for your new developers to be productive on your stack.

@skimbrel "OUT OF THE BOX" "Out of the box"-iness aka friction
What's the first 30 minutes like?
Are there Dockerfiles? Chef cookbooks?

@skimbrel DOCUMENTATION Existent?
Up-to-date?
Comprehensive?
Searchable?
Discoverable?

@skimbrel SUPPORT AND CONSULTANTS Can you get a support contract from someone?
When your main DB dies at 1 AM and your backup turns out to be corrupt… you will want help.

@skimbrel LICENSING LANDMINES GPL software can't go in Apple's App Store!
Or in the news recently: Apache declared Facebook's license + patent grant model no good. Panic ensued; Facebook ended up re-licensing with MIT.

@skimbrel BUY VS BUILD Open-source and DIY obviously aren't our only choices.
We can pay money for things!
How do we decide?

@skimbrel WHAT WOULD IT COST TO BUILD IT?

@skimbrel
HOW LONG
WOULD IT TAKE?
And what would you lose in the meantime to not having it tomorrow?
Not only do you not get The Shiny tomorrow, you have to choose something else not to build because you're using up some dev time for this.

@skimbrel
HOW HARD
IS IT TO REPLACE?
What happens if the vendor goes down? Goes out of business?

@skimbrel RELATIONSHIPS Last: how do we run services, projects, and businesses?
What should our relationships with our customers (whom we care about deeply because we want to acquire a billion of them) look like?
What does a healthy team look like?

@skimbrel TEAMS So, about healthy teams. I’m going to talk about a few things here: on-call, psychological safety, and inclusivity.

@skimbrel SUSTAINABLE ON-CALL First up, on-call.
We have a problem with on-call and pager rotations.
Who does on-call right? Hospitals, nuclear power plants, firefighters…

@skimbrel 168 HOURS ÷ 40 HOUR WORK WEEK = 4.2 PEOPLE Let's do some math.

@skimbrel 168 HOURS ÷ 40 HOUR WORK WEEK = 4.2 5 PEOPLE Oops, we can't have 0.2 of a person. Five.

@skimbrel 168 HOURS ÷ 40 HOUR WORK WEEK = 4.2
5 6 PEOPLE Are we okay with only 32 hours per week for PTO and sick time? Better make it six.
Show of hands please. Right.
So how do we make on-call be less awful?

@skimbrel EMPOWERMENT AND AUTOMATION One of the things that's come out of devops culture is that employing humans to be robots is bad. So don't do it.
On-call's job: get paged at 2 AM maybe once a week, ideally once a month, find the thing that broke and make it never do that again. Give them the time and space to do this.

@skimbrel
APPROPRIATE
AVA I L A B I L I T Y A N D
SCALABILITY
As shown earlier: you won't go 10k/day to 10k/sec overnight. Or even in a year.
Obvious path to 10x, and line of sight to 100x.
Also think about how available and reliable you need to be — telecom vs… say, doctor's o ffi ce appointment system.

@skimbrel 99% UPTIME? 3.65 days/year 7.2 hours/month 1.68 hours/week 14.4 minutes/day MATH TIME AGAIN!

@skimbrel THREE NINES 8.76 hours/year 43.8 minutes/month 10.1 minutes/week 1.44 minutes/day

@skimbrel FOUR NINES? 52.56 minutes/year 1.01 minutes/week 8.64 seconds/day

@skimbrel FIVE?! 5.26 minutes/year

@skimbrel DO YOU NEED THAT SLA? Don’t overcommit yourself. O ffi ce appointment app? Odds are your users won’t even notice an o ffl ine DB migration over the weekend.

@skimbrel HEALTHY TEAMS Humane on-call schedule + consciously-chosen SLAs + sensible alerting create a culture where people who might otherwise not have joined can show up — people with children, disabled people, etc. Which goes hand in hand w/ building a safe and inclusive work environment.

@skimbrel PSYCHOLOGICAL SAFETY Google study etc.

@skimbrel INCLUSIVITY, NOT JUST DIVERSITY This is a start towards building an inclusive team.
Diversity isn’t enough — people of differing backgrounds need to be comfortable being themselves.

@skimbrel SET GROUND RULES Set some ground rules with your teams — make a charter. Some things that might come up:
Code reviews
Meeting etiquette (no interruptions; 3 in 1 / 1 in 3 rule; give credit)
Space for learning (don’t feign surprise; no RTFM;
Handling conflict

@skimbrel ADDRESS BIAS Be aware of and take steps to address conscious and unconscious bias.

@skimbrel RETAIN AND PROMOTE Not enough just to hire women/POC/queer people/disabled people/… — ensure they have equal access to growth opportunities

@skimbrel GET PROFESSIONAL ASSISTANCE Final note: there are consulting firms helping with this.
Engage one and pay them — don’t just make the few URMs you do have do this work as an unpaid side gig!

@skimbrel SUMMARY: HUMANS FIRST So: make your on-call reasonable, and make your teams inclusive and safe for everyone working with you, because at the end of the day… you work with humans first.

@skimbrel HAPPY USERS Close with users — how do we keep them happy?

@skimbrel CUSTOMER EMPATHY Have empathy.

@skimbrel KNOW YOUR USER TECH BASE First, this means knowing who your users are.
Trade-offs, as always, but make sure you have the data and stories.

@skimbrel KNOW YOUR IMPACT Empathy also means knowing the impact on your users when you make changes, or when you go down. Especially when you go down.

@skimbrel SET EXPECTATIONS And using that empathy, manage your users' expectations ahead of time.
"Underpromise but overdeliver" is always a good strategy.

@skimbrel DEGRADE GRACEFULLY Netflix has default recommendations in case the personalization engine is down when you open the app.

@skimbrel (OVER)COMMUNICATE TALK TO YOUR USERS.
Update your status page when you even think there might be a problem.
Speaking of status pages…

@skimbrel AMAZON ( HTTPS://AWS.AMAZON.COM/MESSAGE/41926/ ) "we were unable to update the individual services’ status on the AWS Service Health Dashboard (SHD) because of a dependency the SHD administration console has on Amazon S3" Yes, this happened.
Put your status page somewhere that is completely independent of your infrastructure.
You're on AWS? Great, put it on Google Cloud Platform.

@skimbrel
GITLAB
DATABASE FAILURE
HTTPS://ABOUT.GITLAB.COM/2017/02/10/POSTMORTEM-OF-DATABASE-OUTAGE-OF-JANUARY-31/
Gitlab had a major incident with their primary database deployment.
Public Google doc w/ incident notes in realtime.

@skimbrel (OVER)COMMUNICATE Err towards overcommunication.
Staff up:
Social media
Zendesk or w/e
AND LISTEN TO THOSE PEOPLE.

@skimbrel MEASURE SUPPORT PERFORMANCE Uptime isn't the only SLA!
Time to first response
Time to resolution
Overall satisfaction score
etc

@skimbrel DISASTER RECOVERY Because it will happen.

@skimbrel IDENTIFY FAU LT D O M A I N S

@skimbrel
FAU LT TO L E R A N C E
HAS COSTS
How much does it cost to survive a failure of a:
Host
AWS AZ
AWS region
…?

@skimbrel PRACTICE Exercise your failover mechanisms and backup recovery ahead of time in controlled conditions. You will thank me later.

@skimbrel SECURITY Please do consider security.

@skimbrel OWASP Open Web Application Security Project
Immensely useful guides to just about everything.

Valuable assets
Vectors of attack
Mitigations

Yes, I really need to say this.

@skimbrel AND DON'T DO THIS

Treat security breaches like any other incident. The longer you keep it secret the worse the backlash will be.
What was compromised? For how many people? How? Can it happen again (no, it can't)?

So that was a lot! I hope this advice helps you get more content and comfortable no matter how big or small your system is. We may not all be Google or Facebook, but we can all learn from their paths to the dizzying heights of scale, and we can all adopt code and ideas from them and everyone else who came before us to build amazing new bowers of technology for our users.

And finally… before I thought to use bowerbirds as the metaphor, the best thing I had was dung beetles. Aren't you glad you got a talk with pretty bird pictures instead?

@skimbrel HAPPY BOWER-BUILDING!

@skimbrel FURTHER READING https://samkimbrel.com/posts/bowerbirds.html I was a bowerbird when I built this talk, so here are some of the pieces that inspired me. (Or there will be, shortly)

@skimbrel SOURCES CC BY-NC-ND 2.0 ccdoh1 https://www.flickr.com/photos/ccdoh1/5282484075/
CC BY 2.0 https://www.flickr.com/photos/rileyfive/25506971724
CC BY-SA 3.0 Andrew West https://commons.wikimedia.org/wiki/ File:Wikipedia_view_distribution_by_article_rank.png
CC BY-ND 2.0 Melanie Underwood https://www.flickr.com/photos/warblerlady/7664022750/
CC BY-NC 2.0 Nick Morieson https://www.flickr.com/photos/ngmorieson/8056110806/
CC BY-NC-ND 2.0 Julie Bergher https://www.flickr.com/photos/sunphlo/11578609646/
CC BY-NC-ND 2.0 Nathan Rupert https://www.flickr.com/photos/nathaninsandiego/20291539244/
CC BY-NC-ND 2.0 Nathan Rupert https://www.flickr.com/photos/nathaninsandiego/20726159958/
CC BY-NC-ND 2.0 Julie Burgher https://www.flickr.com/photos/sunphlo/11522540164/
CC BY-NC-ND 2.0 Neil Saunders https://www.flickr.com/photos/nsaunders/22748694318/
CC BY 2.0 thinboyfatter https://www.flickr.com/photos/1234abcd/4717190370/
CC BY-SA 2.0 Jim Bendon https://www.flickr.com/photos/jim_bendon_1957/11722386055
https://cispa.saarland/wp-content/uploads/2015/02/MongoDB_documentation.pdf
CC BY-NC-ND 2.0 Julie Bergher https://www.flickr.com/photos/sunphlo/11578609646/
CC BY-SA 3.0 Kay-africa https://commons.wikimedia.org/wiki/ File:Flightless_Dung_Beetle_Circellium_Bachuss,_Addo_Elephant_National_Park,_South_Africa.JPG
CC BY-SA 2.0 Robyn Jay https://www.flickr.com/photos/learnscope/14602494872