I’m working on a big software program right now. It’s got at least seven engineering teams working on it in parallel.
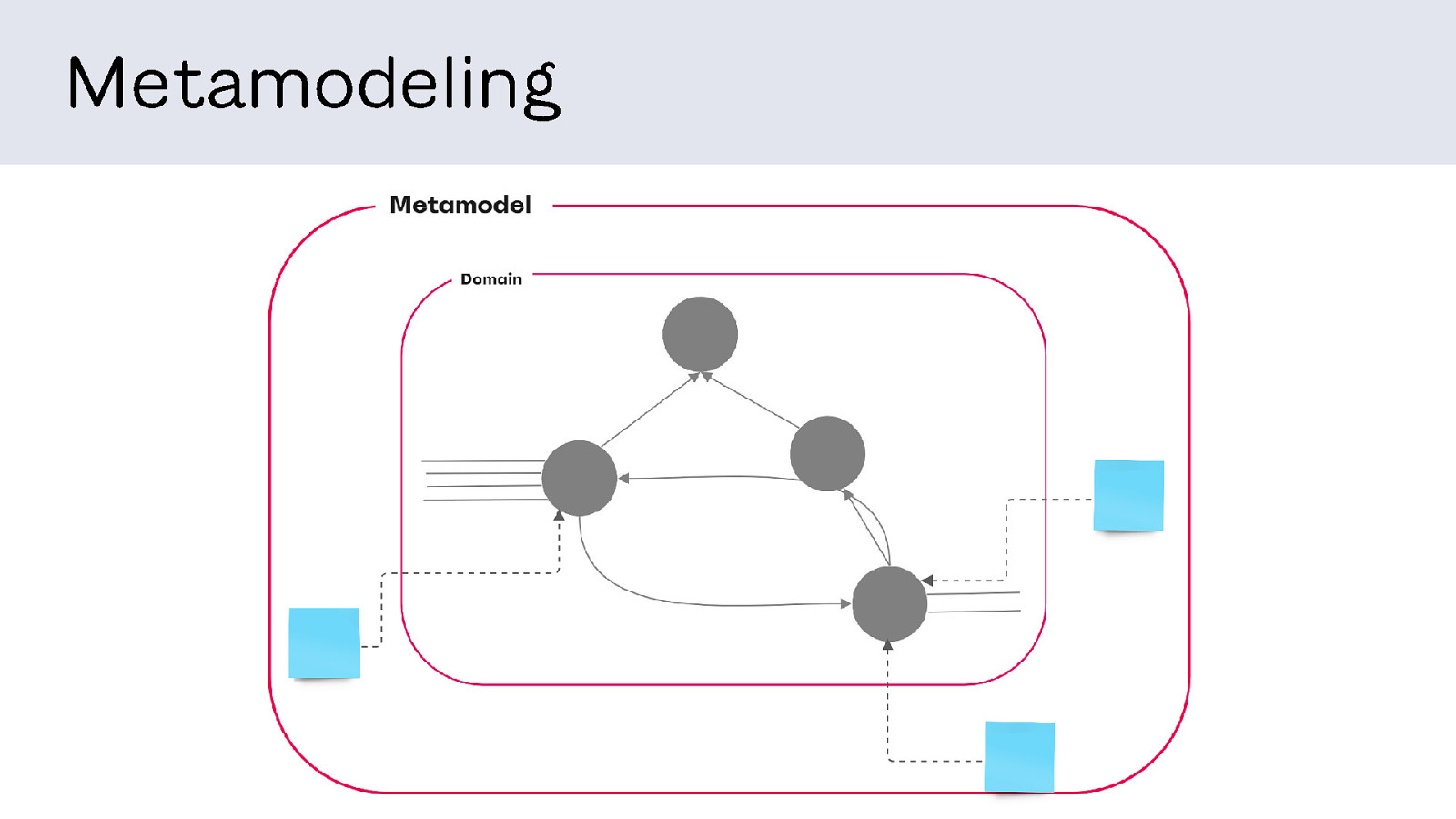
They try to coordinate, but inevitably teams develop hyperlocal understanding of what the product is and how it works based on their view into it. And this creates messes.
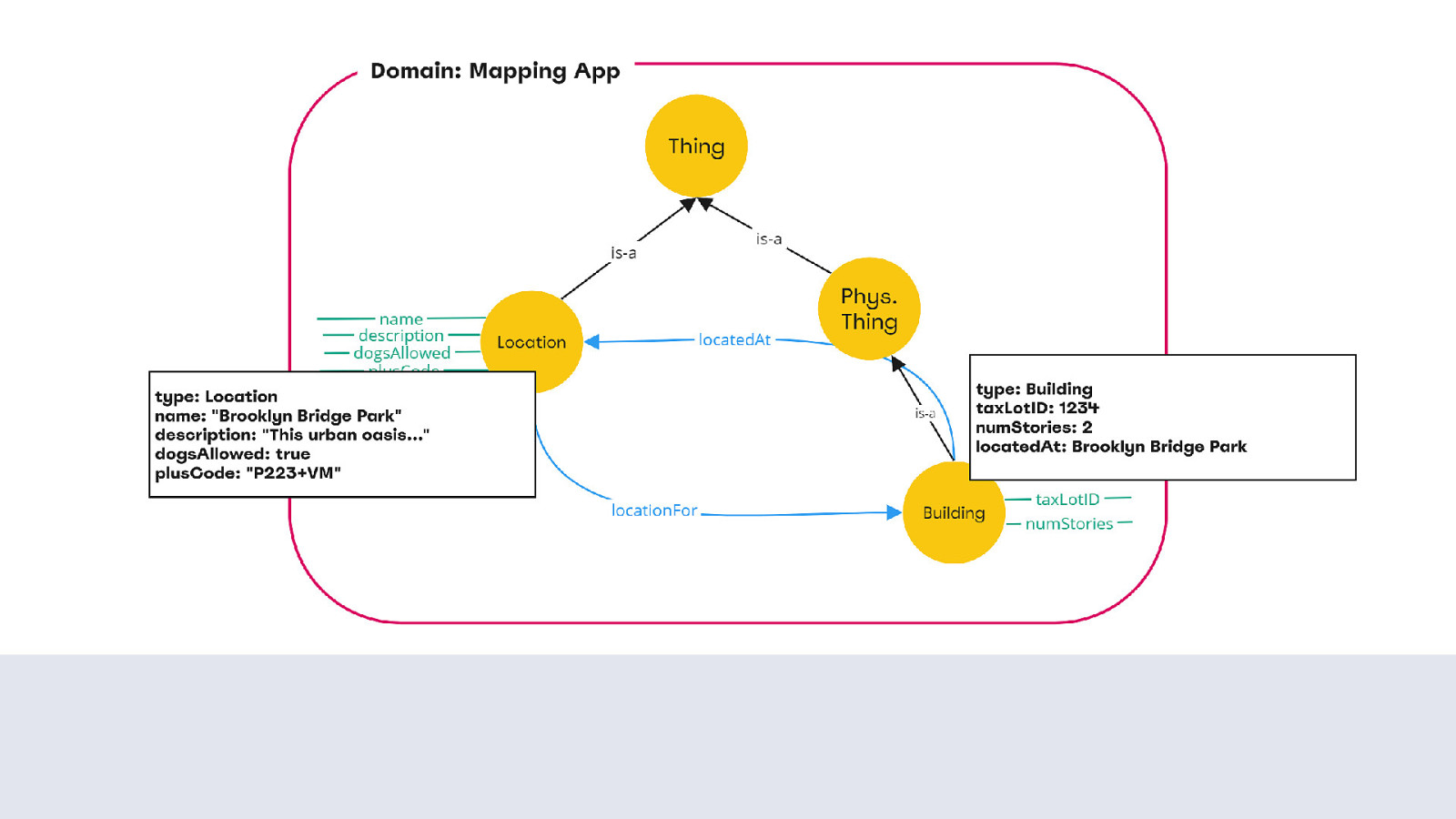
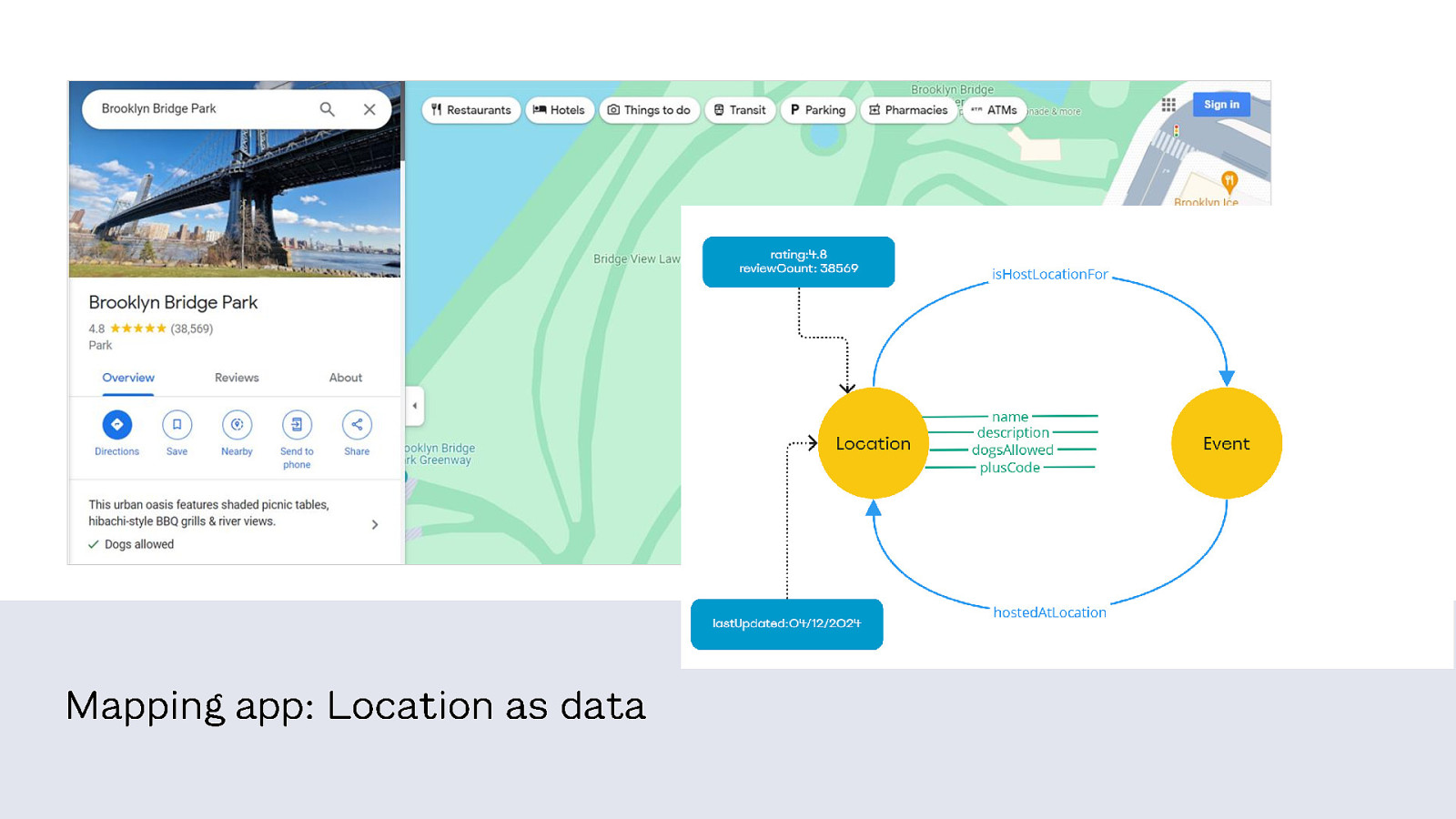
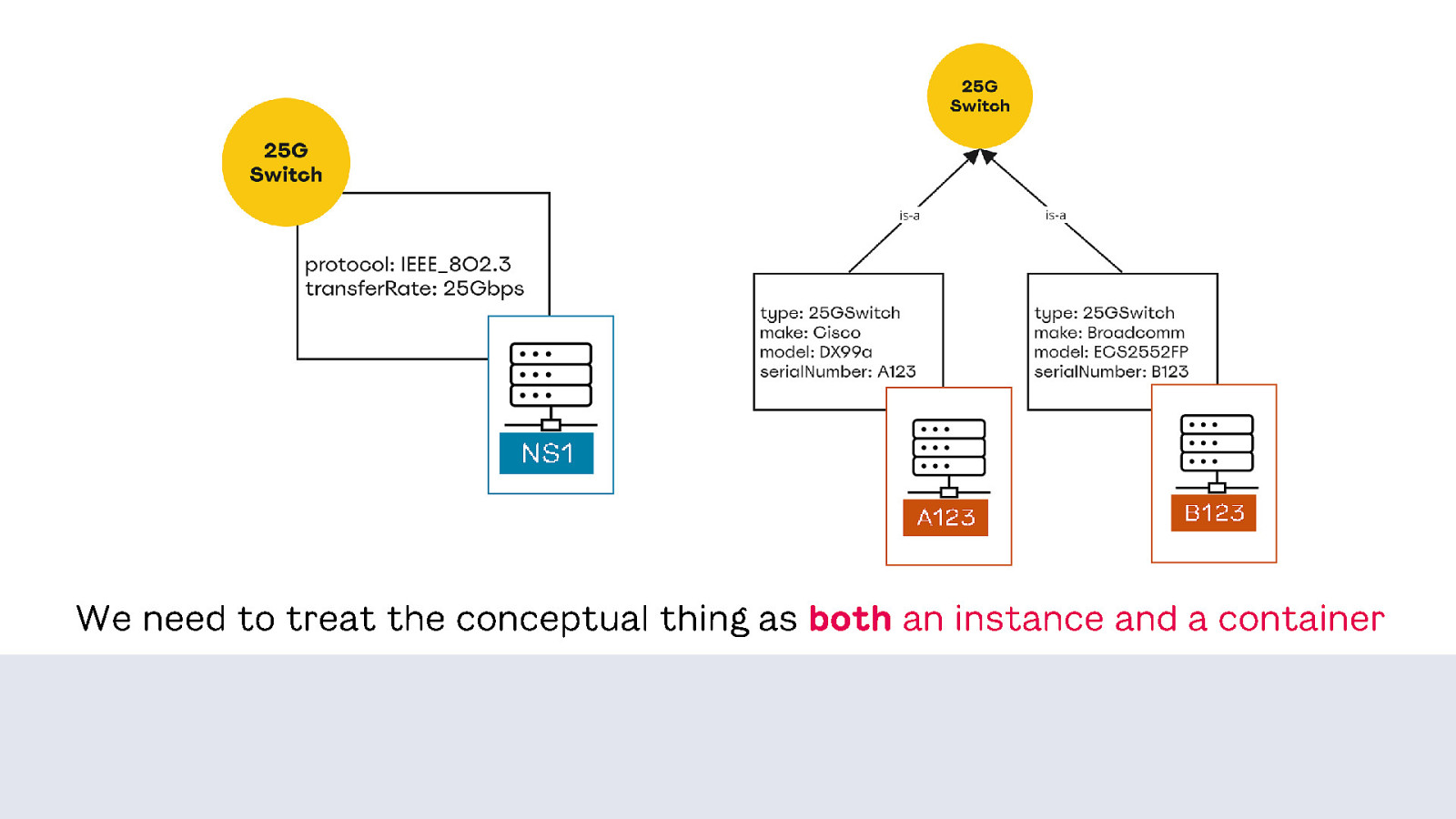
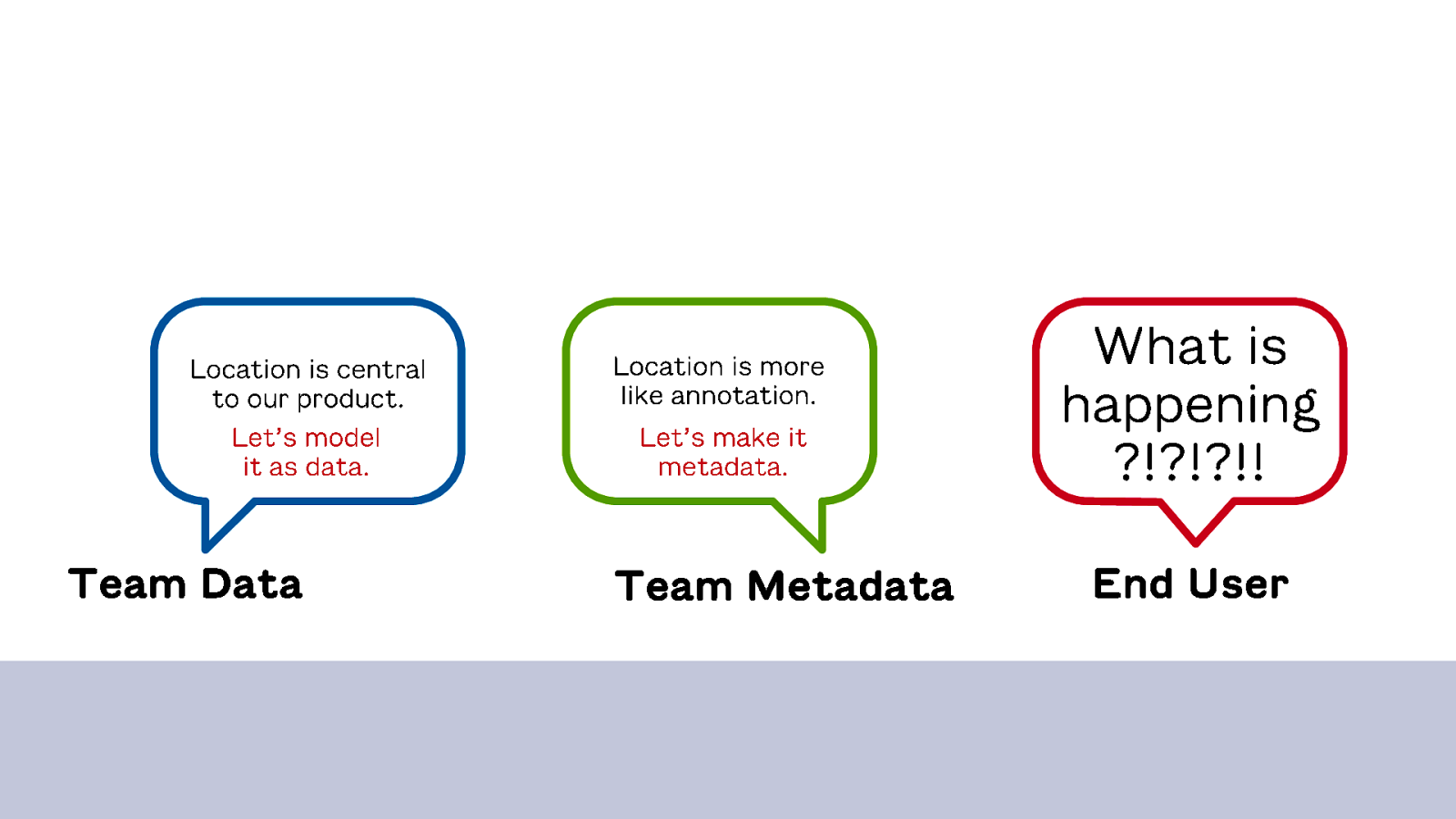
For example: location. It’s an important concept in the product, but there’s disagreement about how to model it. One team sees all the ways location connects to other things. They consider location primary to the product and treat it as data.
A second team working on another part of the product sees location almost as an annotation on another object that’s more important to them. They consider it secondary and treat it as metadata.
This means that in one part of the product, users encounter location as data – there’s a screen to manage it and you can assign attributes to it. And in other places they see it as tags in a corner of the interface. Which is confusing – are these the same things? Are they different?
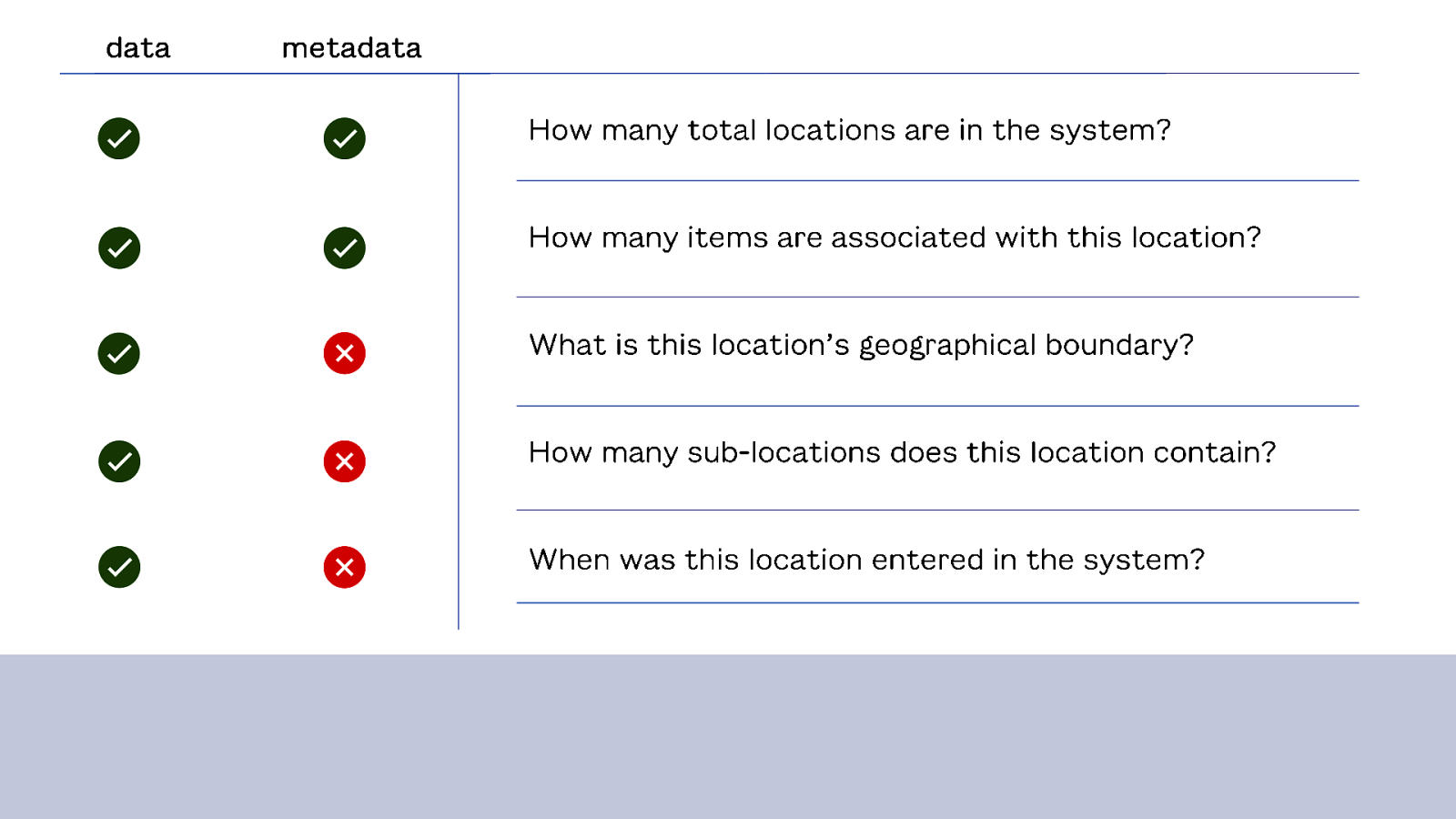
Conversations about this always come back to usage, which hasn’t gotten us to resolution. So, how can we shift that conversation and get to a clear answer of whether location should be considered data or metadata?