Introduction into Elasticsearch & Spring Data Elasticsearch Alexander Reelsen Community Advocate alex@elastic.co | @spinscale

A presentation at Elastic User Group Morocco in September 2020 in by Alexander Reelsen

Introduction into Elasticsearch & Spring Data Elasticsearch Alexander Reelsen Community Advocate alex@elastic.co | @spinscale

TOC Why do you need a search engine in your app? Introduction into Elasticsearch Introduction into Spring Data Elasticsearch Demo Running Elasticsearch: Scaling your cluster Next steps

Why do you need a search engine? … or any data store

Speed, Scale & Relevance

Speed

Scale

Relevance

… and much more NRT: Searching & Indexing Read scalability & write scalability Resiliency Operational simplicity & monitoring capabilities Developer experience Infrastructure integration Team experience Use-Cases: Observability, Workplace Search, Security, Product Search, Wikipedia
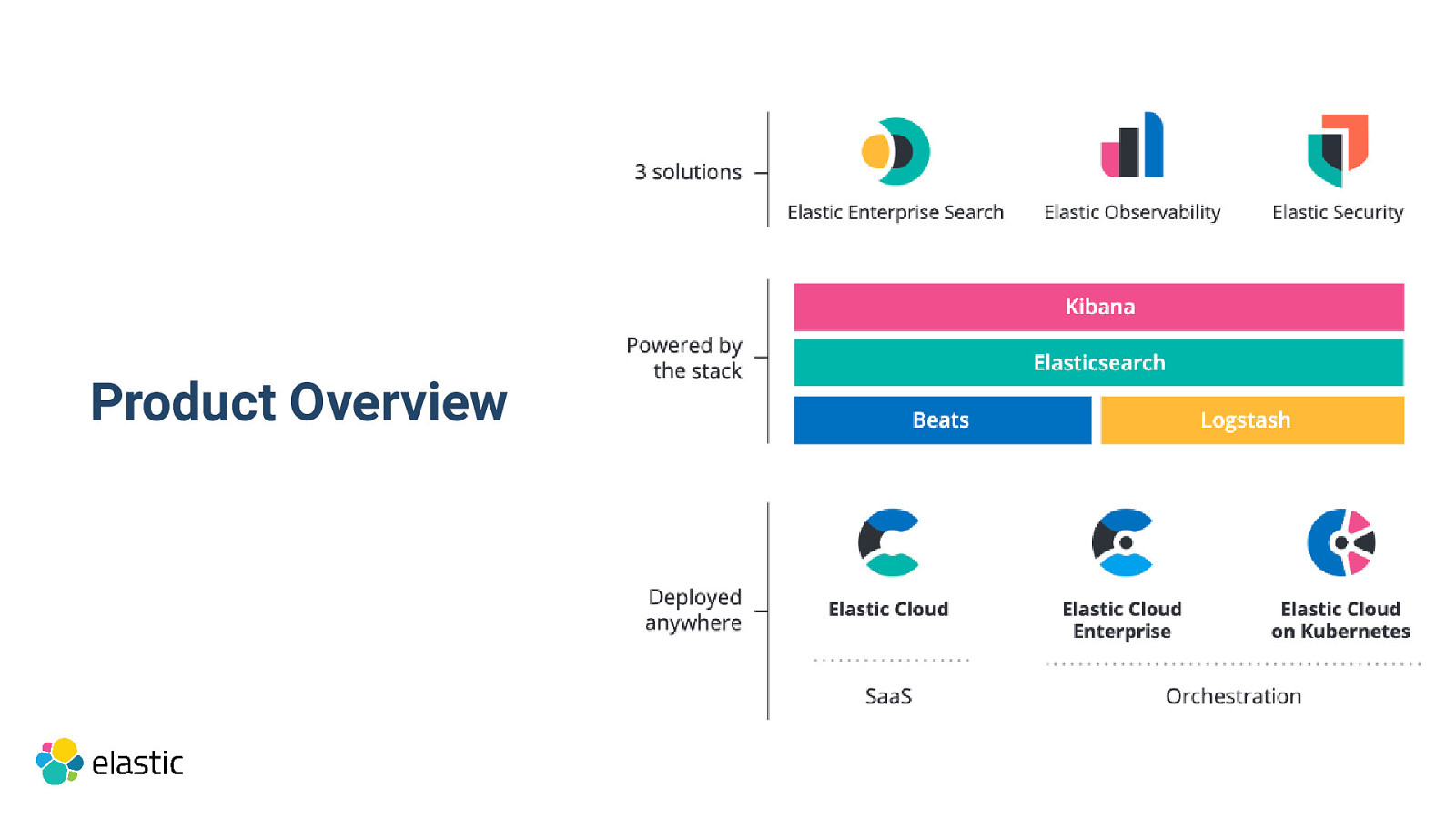
Product Overview

Solutions

Elastic Stack building blocks

Deployment options
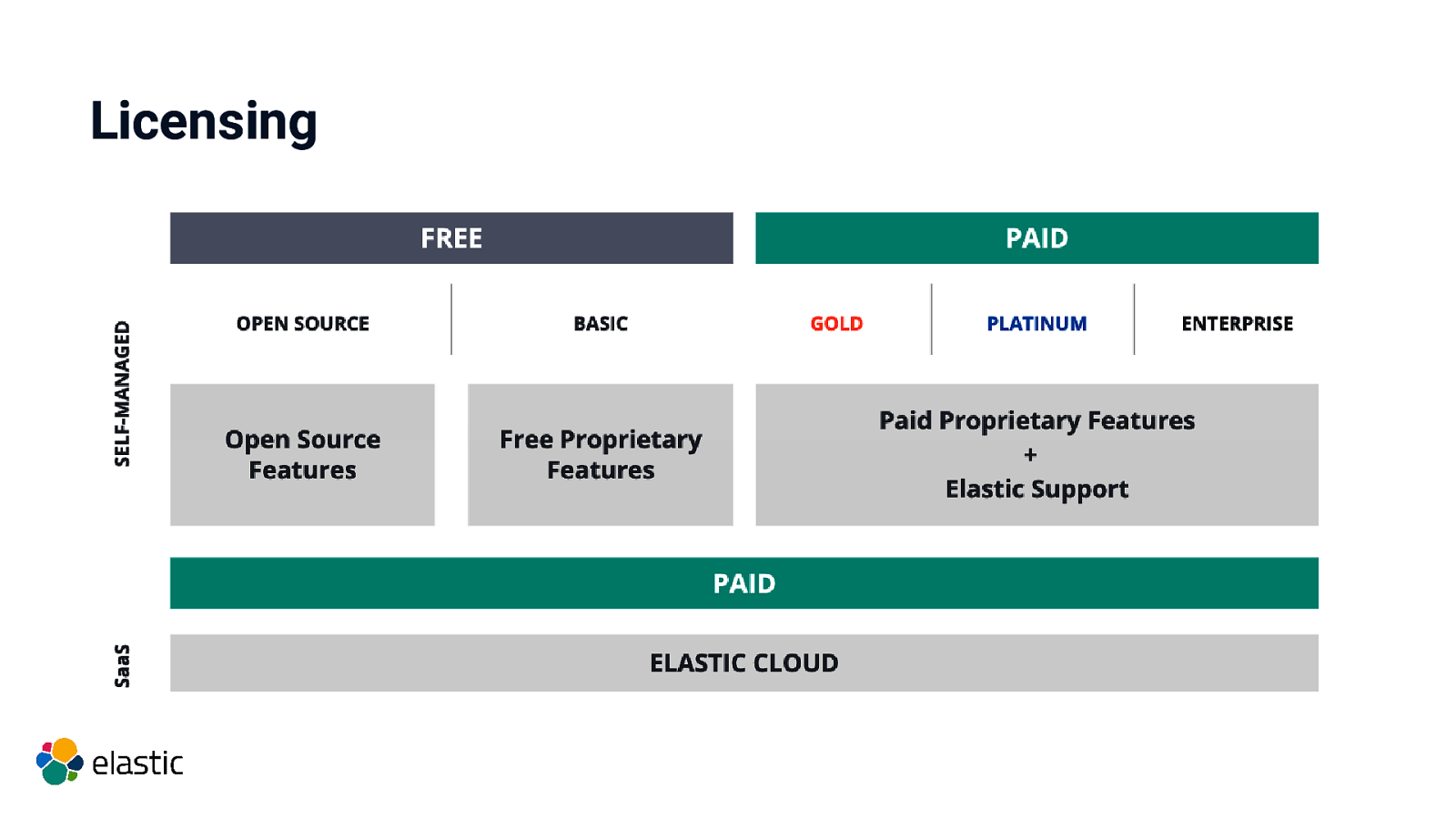
Licensing

Elastic Stack building blocks

Elasticsearch in 10 seconds Search Engine (FTS, Analytics, Geo), near real-time Distributed, scalable, highly available, resilient Interface: HTTP & JSON Heart of the Elastic Stack (Kibana, Logstash, Beats)
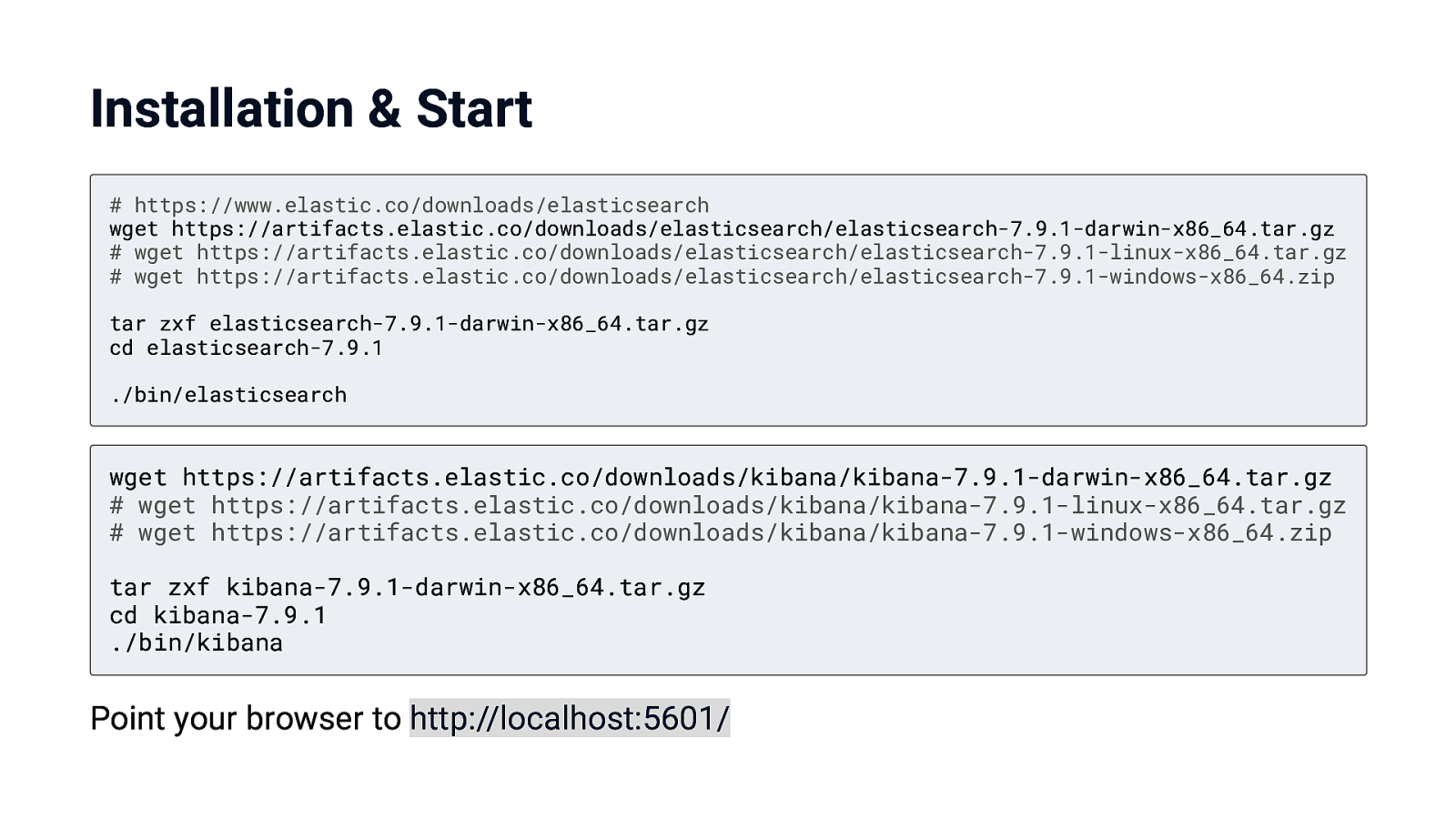
Installation & Start # https://www.elastic.co/downloads/elasticsearch wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.1-darwin-x86_64.tar.gz # wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.1-linux-x86_64.tar.gz # wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.1-windows-x86_64.zip tar zxf elasticsearch-7.9.1-darwin-x86_64.tar.gz cd elasticsearch-7.9.1 ./bin/elasticsearch wget https://artifacts.elastic.co/downloads/kibana/kibana-7.9.1-darwin-x86_64.tar.gz # wget https://artifacts.elastic.co/downloads/kibana/kibana-7.9.1-linux-x86_64.tar.gz # wget https://artifacts.elastic.co/downloads/kibana/kibana-7.9.1-windows-x86_64.zip tar zxf kibana-7.9.1-darwin-x86_64.tar.gz cd kibana-7.9.1 ./bin/kibana Point your browser to http://localhost:5601/
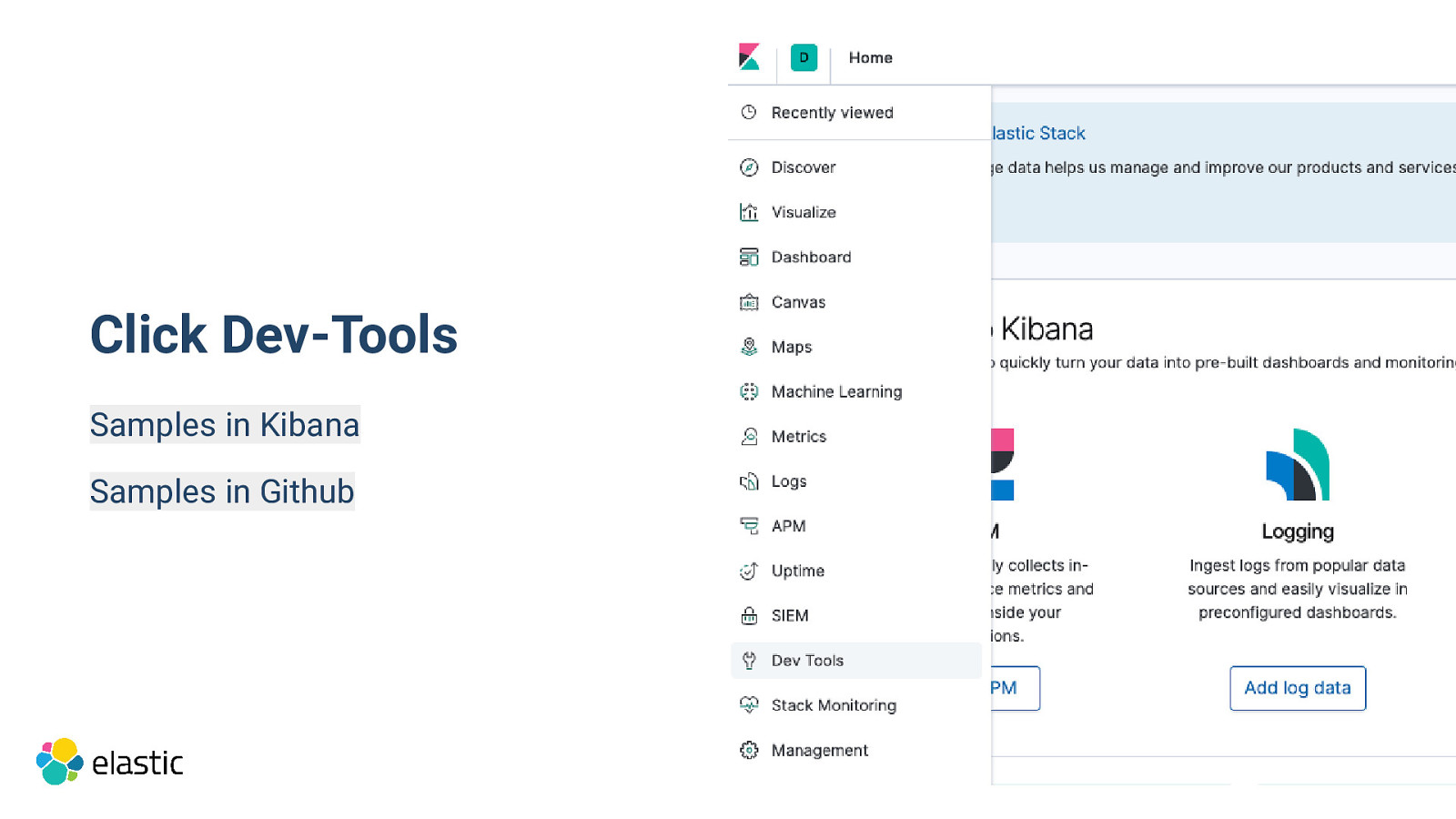
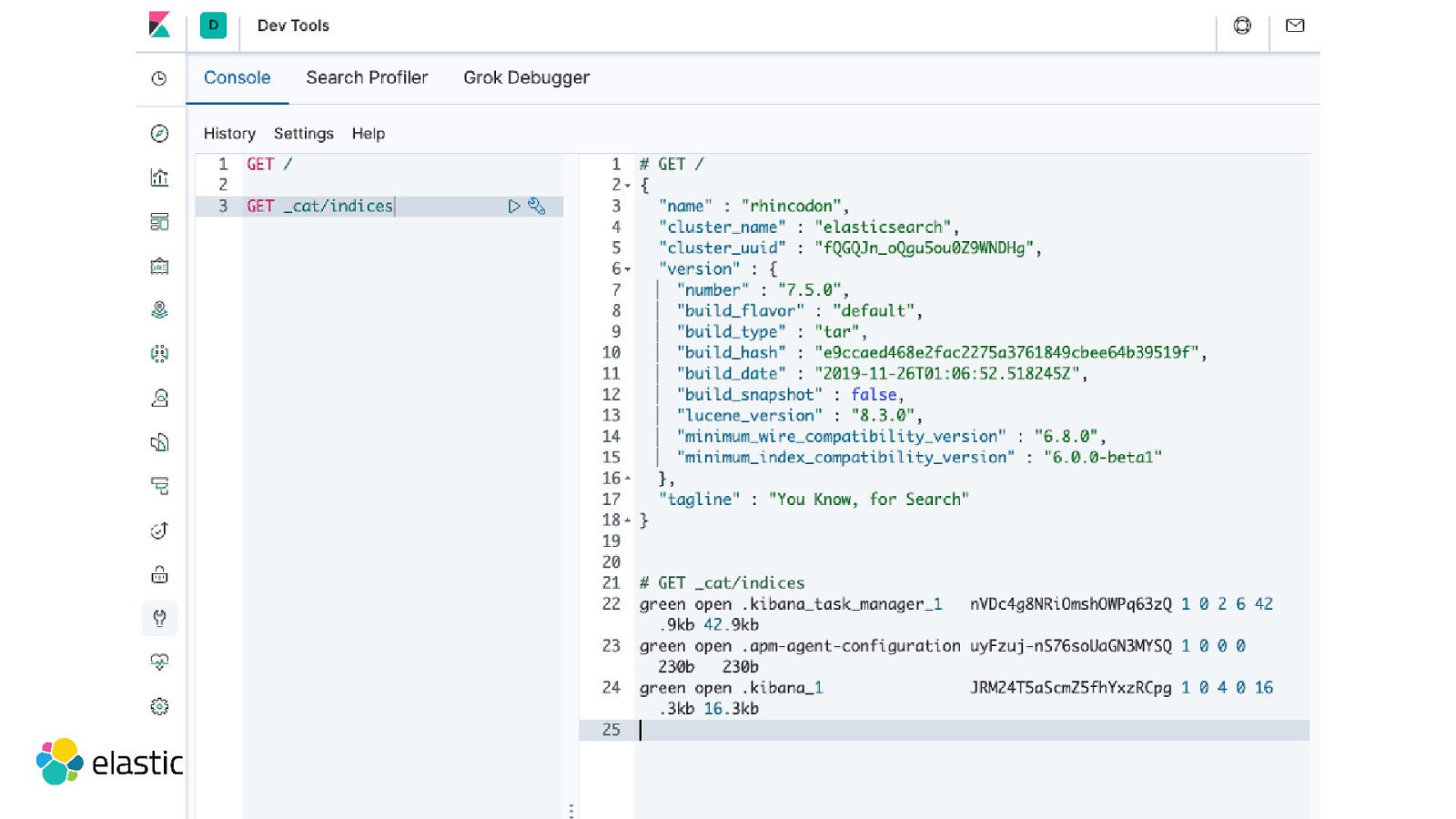
Click Dev-Tools Samples in Kibana Samples in Github

Introduction into Spring Data Elasticsearch Community maintained Spring Data Extension Reactive extension Make sure to use major version 4 (based on Elasticsearch 7.x), default in Spring Boot 2.3 Uses the Elasticsearch REST Client

Elasticsearch REST client Depends on the Elasticsearch core project Based on Apache HTTP Client (works on java 8), might want to consider shading Supports synchronous calls & cancellable async calls Threadsafe RestClient RestHighLevelClient
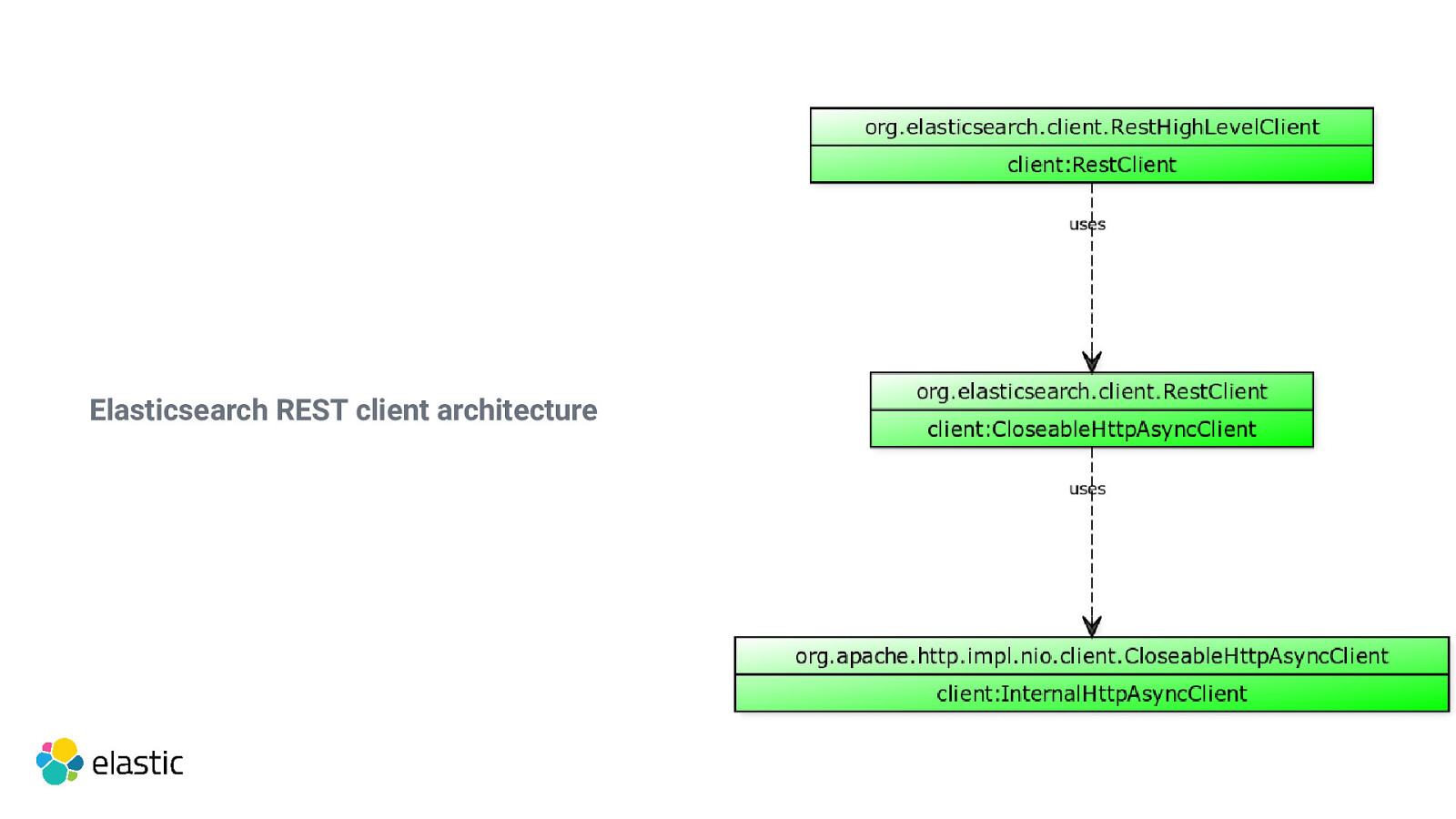
Elasticsearch REST client architecture

Spring Data Elasticsearch - Basics ElasticsearchTemplate & ElasticsearchRestTemplate MappingElasticsearchConverter CrudRepository Auditing, Entity Callbacks, efficient scroll searching
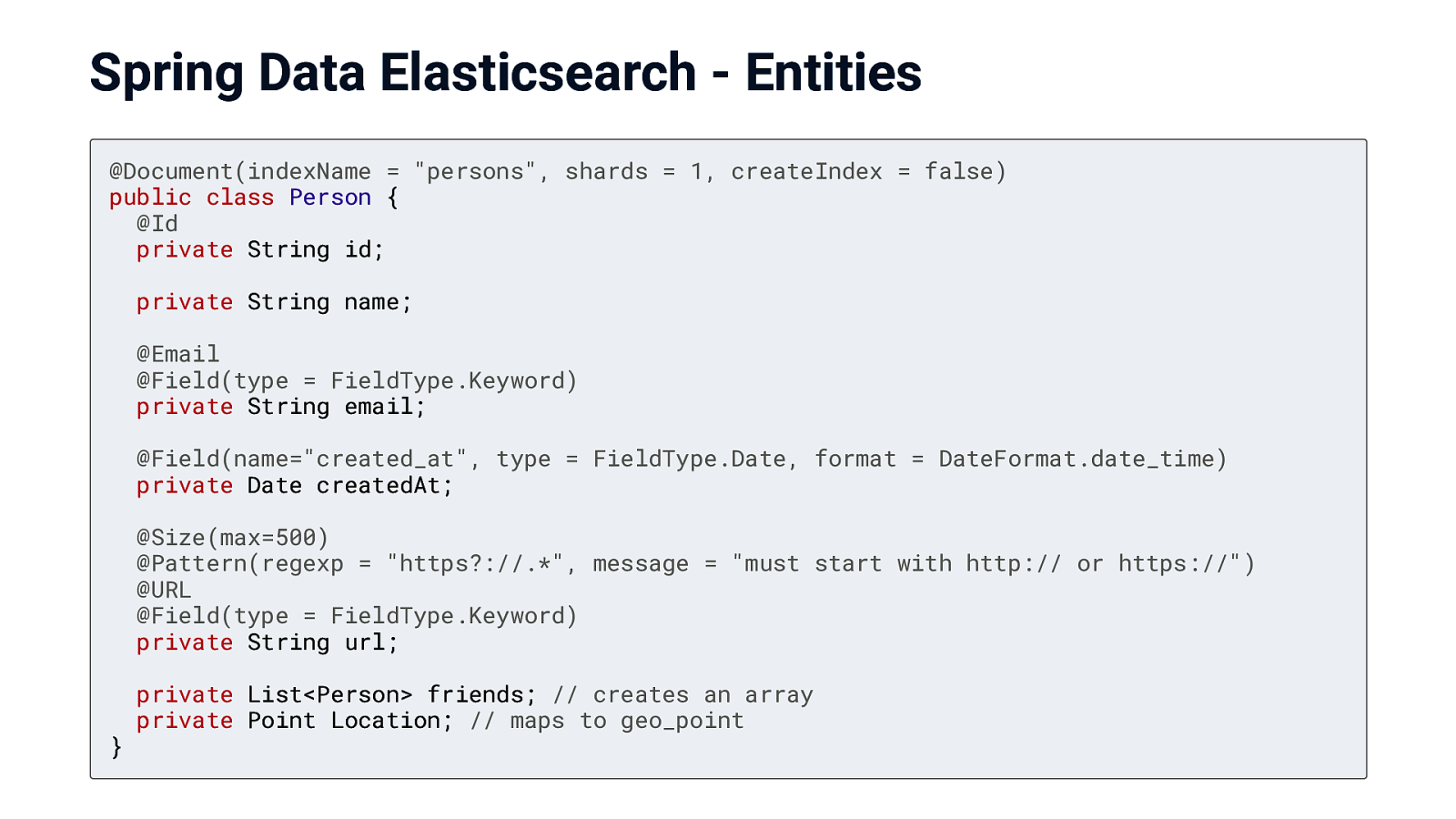
Spring Data Elasticsearch - Entities @Document(indexName = “persons”, shards = 1, createIndex = false) public class Person { @Id private String id; private String name; @Email @Field(type = FieldType.Keyword) private String email; @Field(name=”created_at”, type = FieldType.Date, format = DateFormat.date_time) private Date createdAt; @Size(max=500) @Pattern(regexp = “https?://.*”, message = “must start with http:// or https://”) @URL @Field(type = FieldType.Keyword) private String url; } private List<Person> friends; // creates an array private Point Location; // maps to geo_point

Spring Data Elasticsearch - Repositories import org.springframework.data.elasticsearch.repository.ElasticsearchRepository; public interface UserProfileRepository extends ElasticsearchRepository<UserProfile, String> { } Dynamic finders like findByEmail(String email) Attention: Inefficient queries like findByDescriptionEndingWith()

Spring Data Elasticsearch - Searching final BoolQueryBuilder qb = QueryBuilders.boolQuery() // somewhat stable randomization to make sure users get an arbitrary document .must(QueryBuilders.scriptScoreQuery(QueryBuilders.matchAllQuery(), new Script(“randomScore(1000, ‘created_at’)”))) // only consider contributions that are not yet approvaed .filter(QueryBuilders.termQuery(“state”, Contribution.State.CREATED.name())) // ensure only contributions from the same region are shown .filter(QueryBuilders.termQuery(“region”, profile.getRegion())) // only consider languages spoken by the user as well as english .filter(QueryBuilders.termsQuery(“language”, languages)) // exclude documents that were created by this user .mustNot(QueryBuilders.termQuery(“submitted_by.email”, profile.getEmail())) // exclude documents that were already voted on .mustNot(QueryBuilders.termQuery(“comments.submitted_by.email”, profile.getEmail())); Query query = new NativeSearchQuery(qb).setPageable(PageRequest.of(0, 1)); final SearchHit<Contribution> result = elasticsearchRestTemplate.searchOne(query, Contribution.class);

Spring Data Elasticsearch - Count private boolean canSubmitMoreContributions(String email) { final BoolQueryBuilder qb = QueryBuilders.boolQuery() .filter(QueryBuilders.termQuery(“submitted_by.email”, email)) .filter(QueryBuilders.rangeQuery(“created_at”).gte(“now-1d”)); final long recentlySubmittedCount = elasticsearchRestTemplate.count(new NativeSearchQuery(qb), Contribution.class); return recentlySubmittedCount <= 10; }
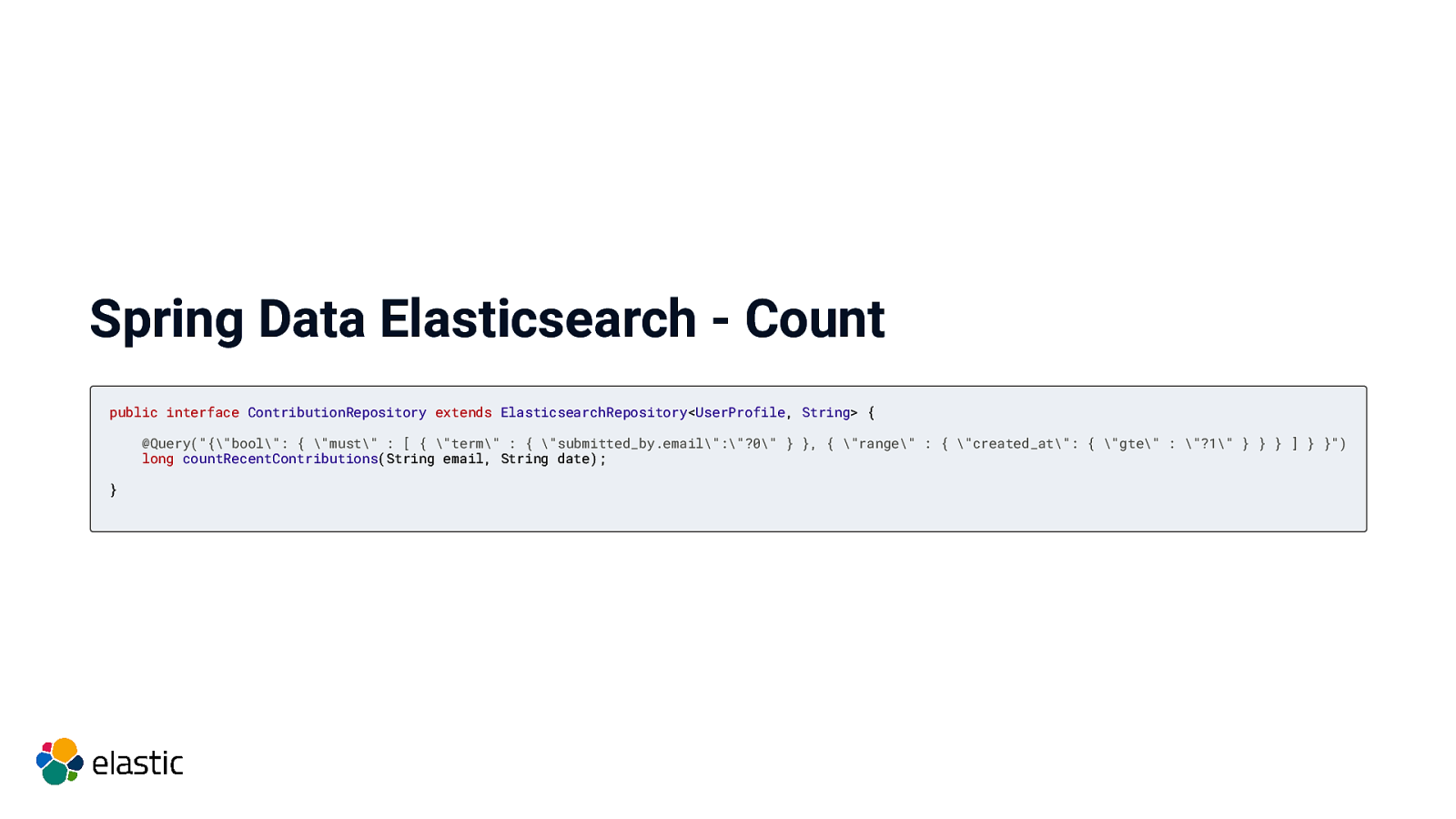
Spring Data Elasticsearch - Count public interface ContributionRepository extends ElasticsearchRepository<UserProfile, String> { @Query(“{“bool”: { “must” : [ { “term” : { “submitted_by.email”:”?0” } }, { “range” : { “created_at”: { “gte” : “?1” } } } ] } }”) long countRecentContributions(String email, String date); }

Spring Data Elasticsearch - Aggregations // filter by approved final BoolQueryBuilder qb = QueryBuilders.boolQuery() .filter(QueryBuilders.termQuery(“state”, Contribution.State.APPROVED.name())) .filter(QueryBuilders.termQuery(“region”, region.name())); final NativeSearchQuery query = new NativeSearchQuery(qb); // aggregate on username, get top 10, sum up score query.addAggregation(AggregationBuilders.terms(“by_user”).field(“submitted_by.email”).size(40) .subAggregation(AggregationBuilders.sum(“total_score”).field(“score”)) // make sure we get the full name of the last contribution .subAggregation(AggregationBuilders.topHits(“by_name”).size(1).sort(SortBuilders.fieldSort(“created_at”) .order(SortOrder.DESC)).fetchSource(“submitted_by.full_name”, “”))); query.setPageable(Pageable.unpaged()); final SearchHits<Contribution> hits = elasticsearchRestTemplate.search(query, Contribution.class); // returns an Elasticsearch class final Aggregations aggregations = hits.getAggregations();

Demo

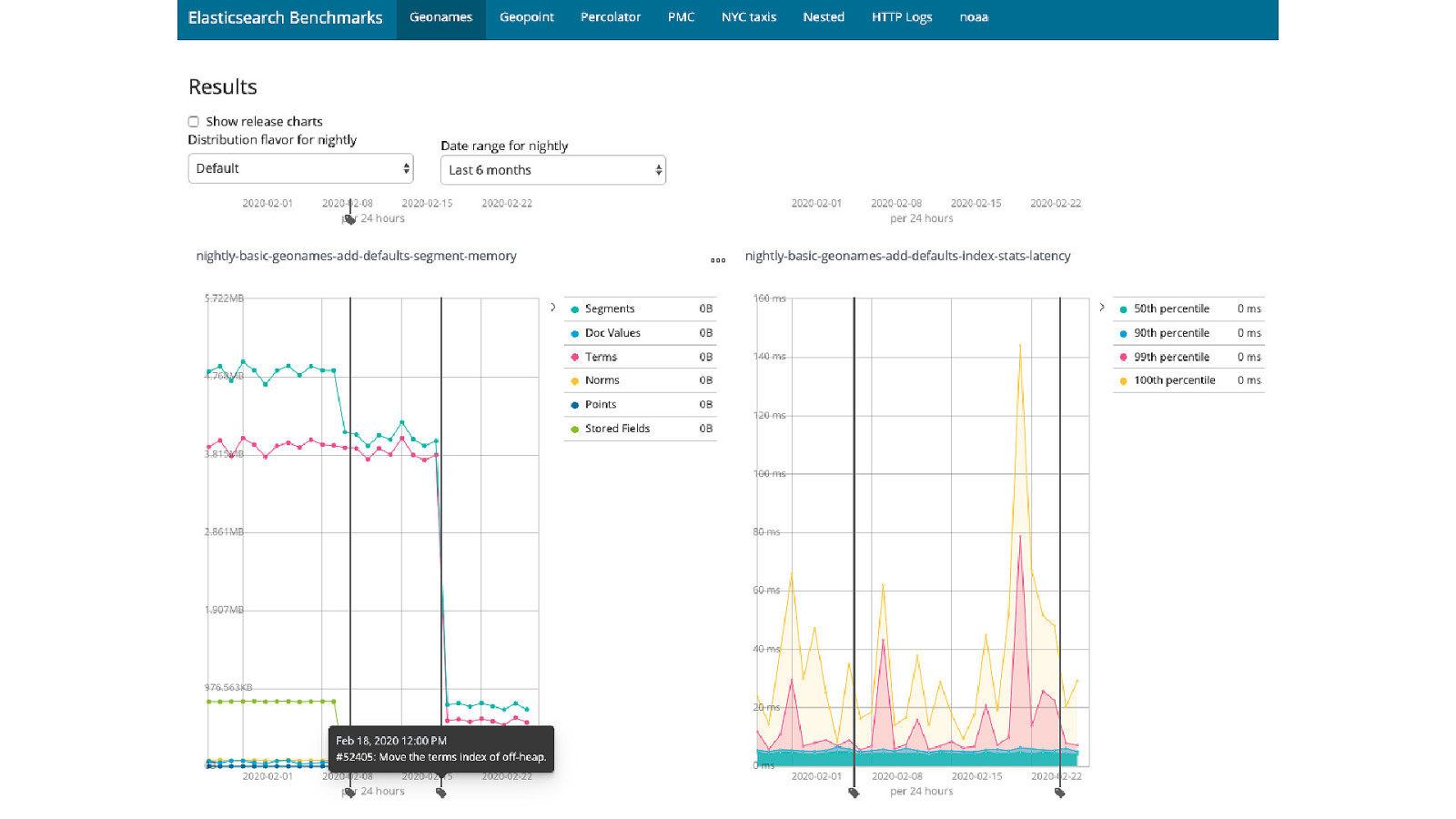
Running Elasticsearch: Scaling your cluster Do not overshard: Single shard can easily contain 20-50GB Let the filesystem cache get to work Performance test, on your data! Use rally Hint: Capacity Planning Webinar

Compute Resources Storage: SSDs for hot data, HDDs for warm/cold, avoid NAS Memory: JVM heap + OS cache Compute: Thread pool scaling based on CPU count Network: The faster the better (careful cloud providers with burst rates)

Next steps Improve your search: Learn about mappings and queries Improve your model Figure out expected throughput Use aliases, always!

Summary Search is never done! Use the reference documentation Ask your users about expectations, do not guess! Testing: TestContainers

Resources spinscale/link-rating Qovery Spring Data Elasticsearch Documentation Elasticsearch Java REST Client Documentation Elasticsearch Nightly Benchmarks

Thanks for listening Q&A Alexander Reelsen Community Advocate alex@elastic.co | @spinscale
Elastic Cloud
Elastic Support Subscriptions
Discuss Forum https://discuss.elastic.co

Community & Meetups https://community.elastic.co
Elastic YouTube Community https://ela.st/yt-community

Thanks for listening Q&A Alexander Reelsen Community Advocate alex@elastic.co | @spinscale