Full-text search with distributed search engines Alexander Reelsen @spinscale alex@elastic.co

A presentation at unKonf in October 2019 in Mannheim, Germany by Alexander Reelsen

Full-text search with distributed search engines Alexander Reelsen @spinscale alex@elastic.co

Agenda • Overview • Indexing: Analysis, Tokenization, Filtering, on disk data structures • Searching: Scoring, Algorithms & Optimization • Aggregations • Distributed systems and search •Q&A

Overview Full text search introduction

SELECT * FROM products WHERE name LIKE = ‘%topf%’
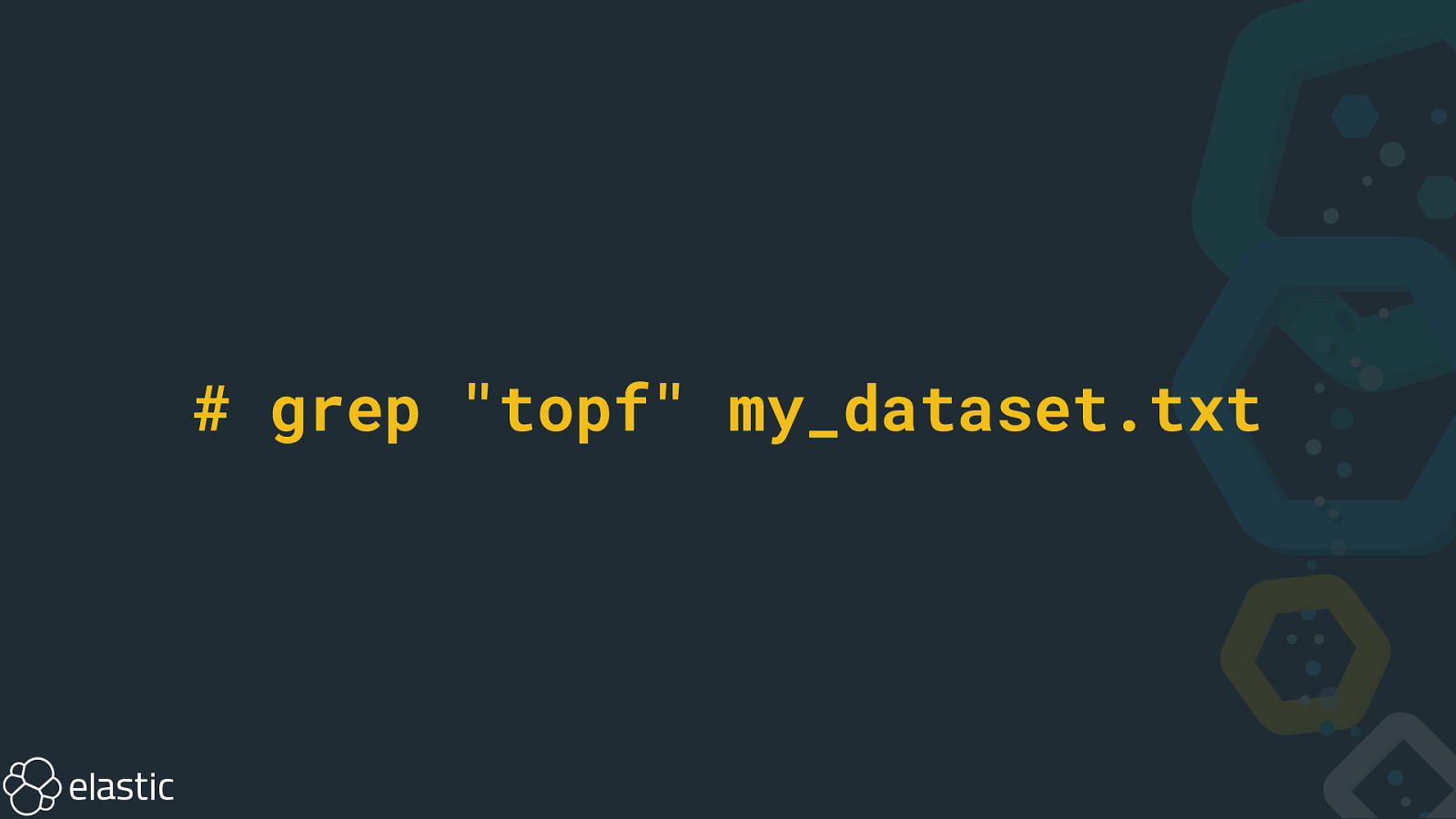

Problem • Scales linearly with the data set size • Relevancy • Spell correction • Synonyms • Phrases

Inverted Index

The quick brown fox jumped over the lazy dog
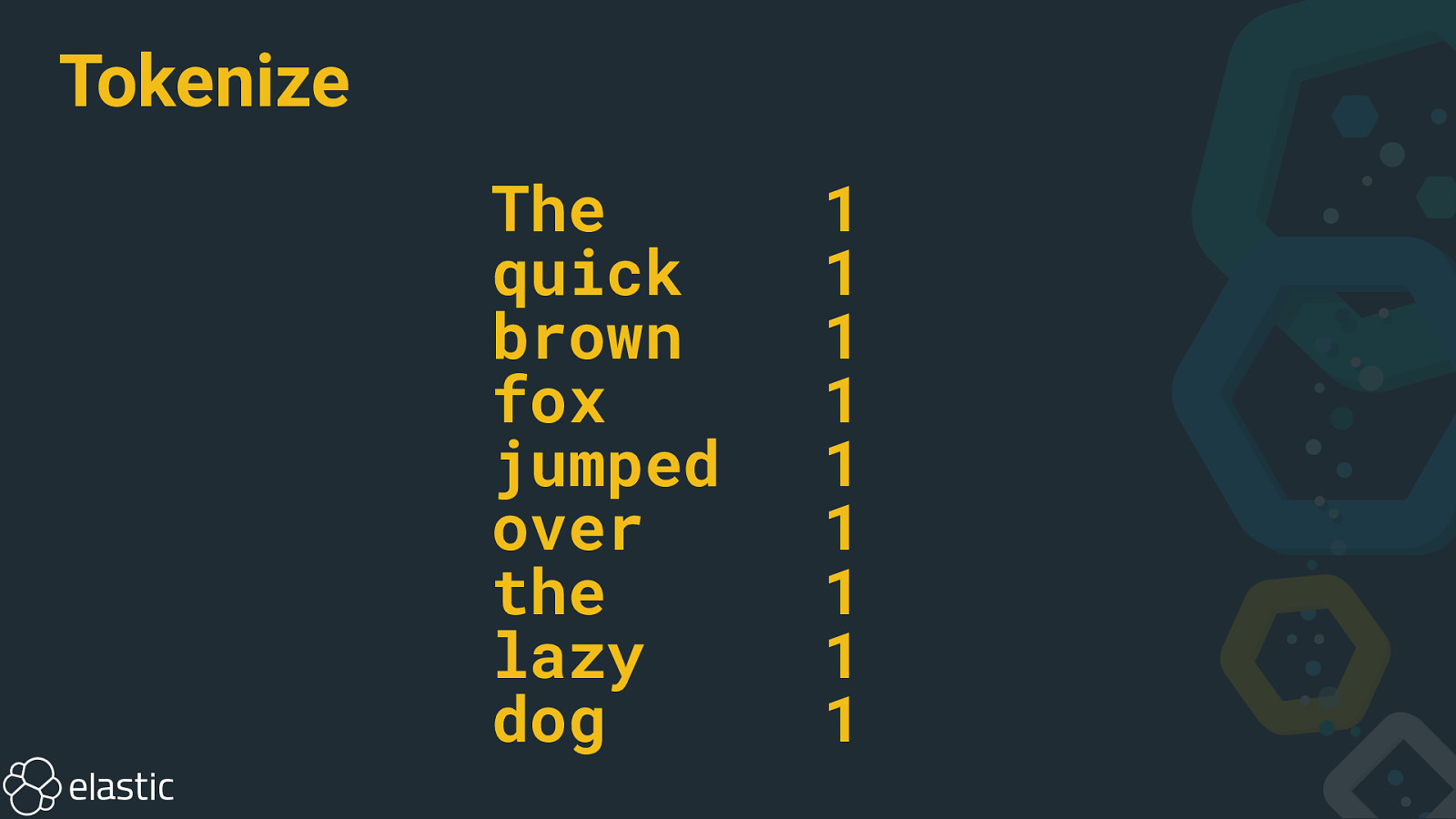
Tokenize The quick brown fox jumped over the lazy dog 1 1 1 1 1 1 1 1 1
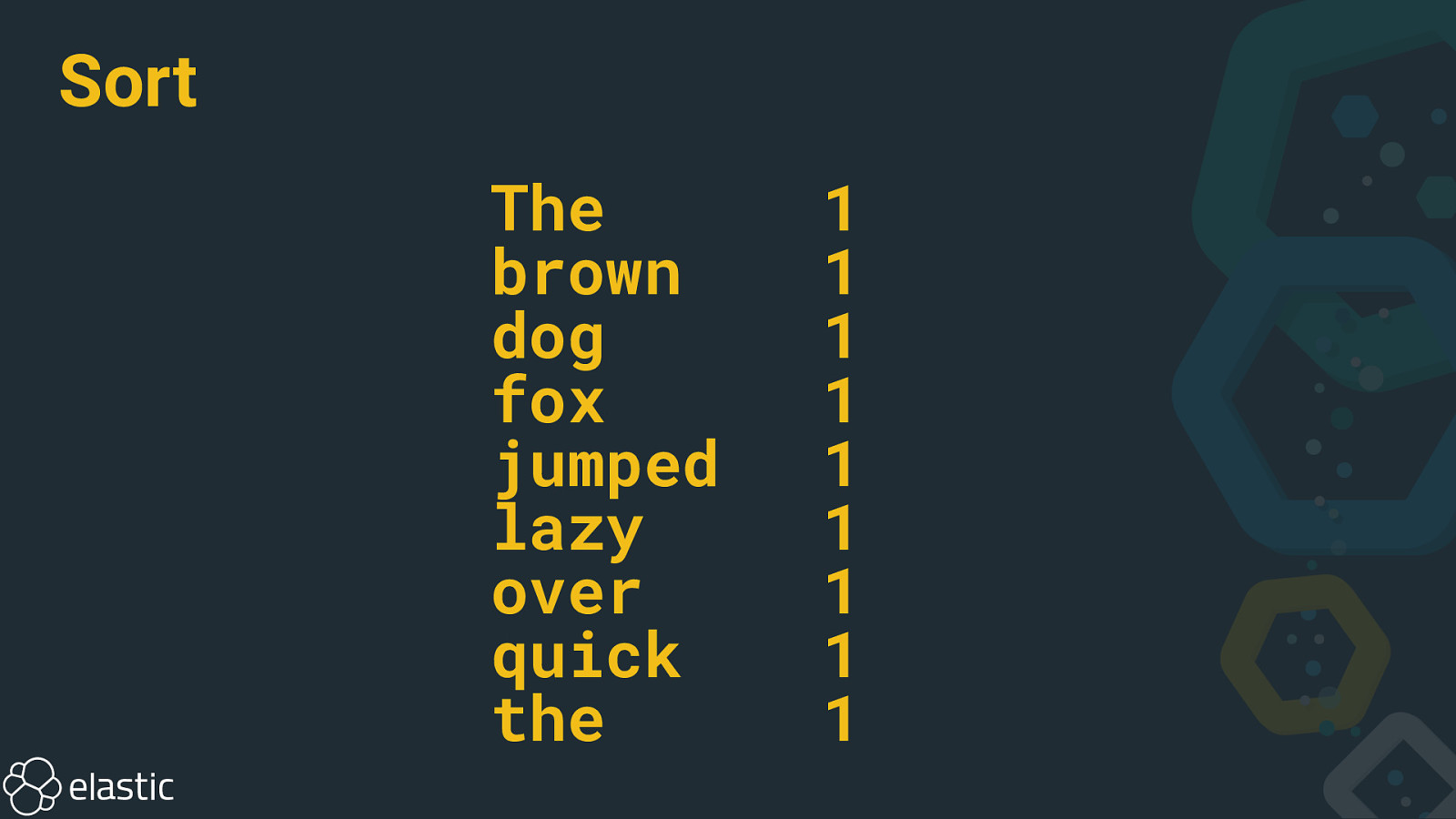
Sort The brown dog fox jumped lazy over quick the 1 1 1 1 1 1 1 1 1
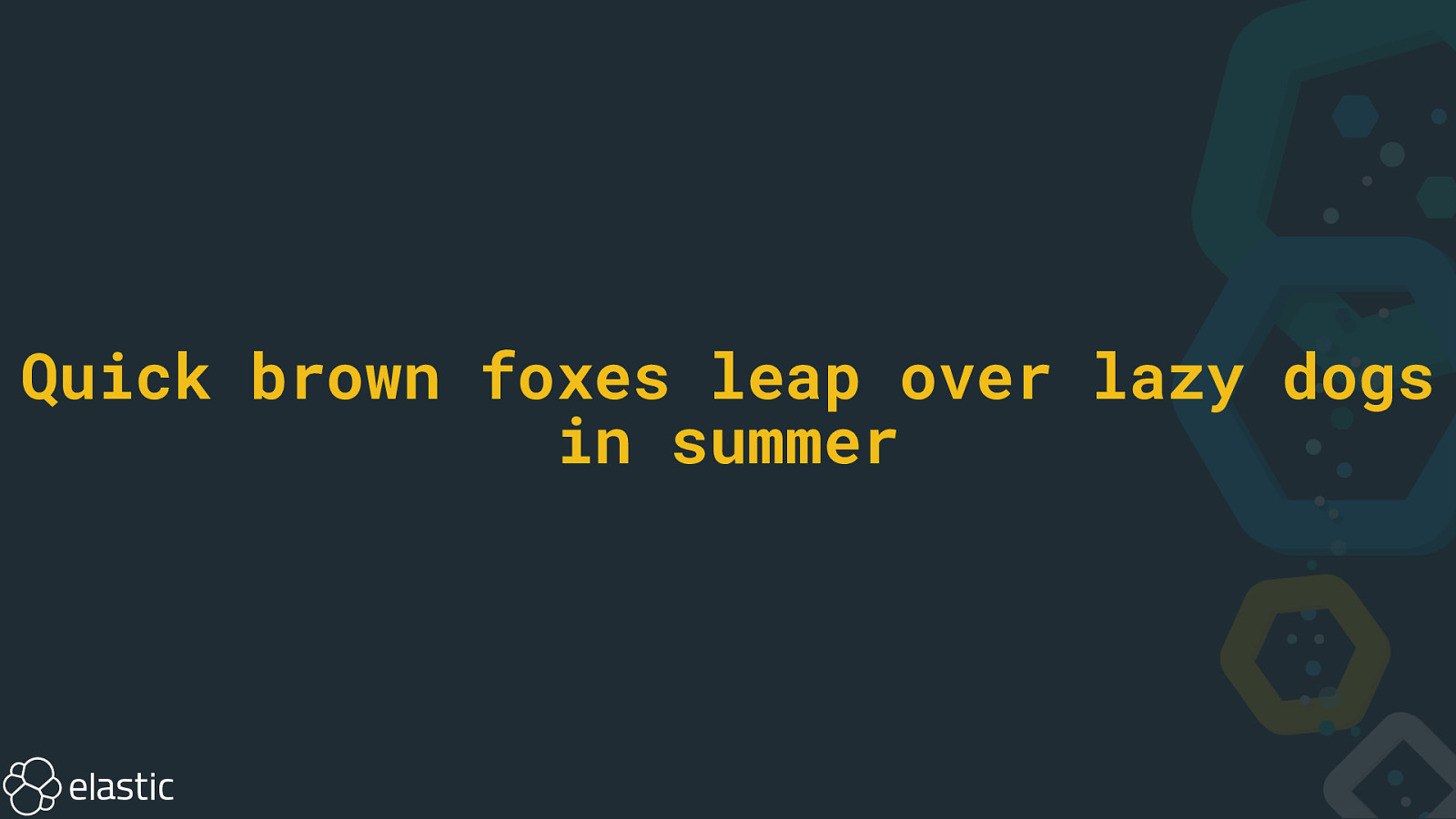
Quick brown foxes leap over lazy dogs in summer
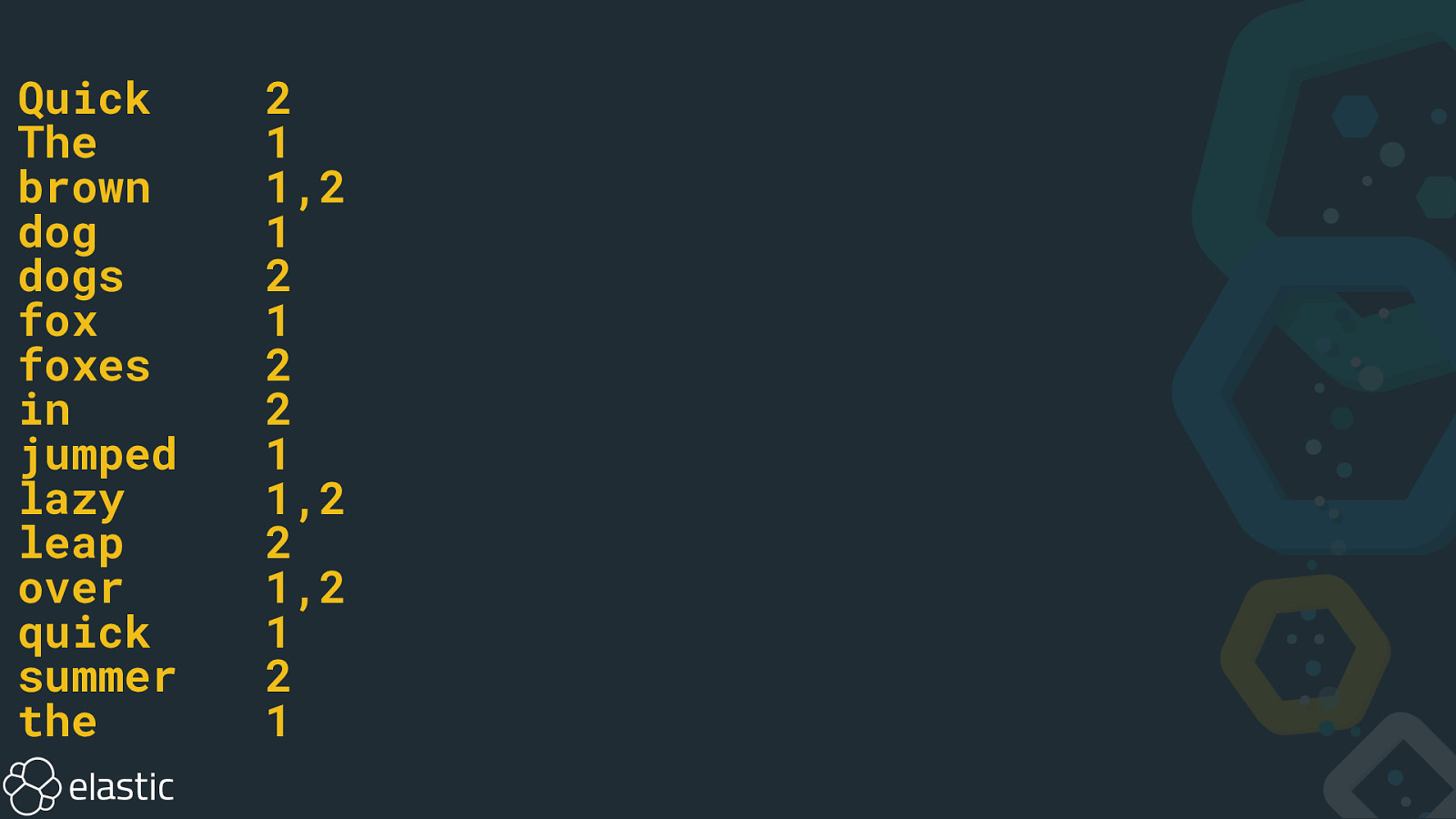
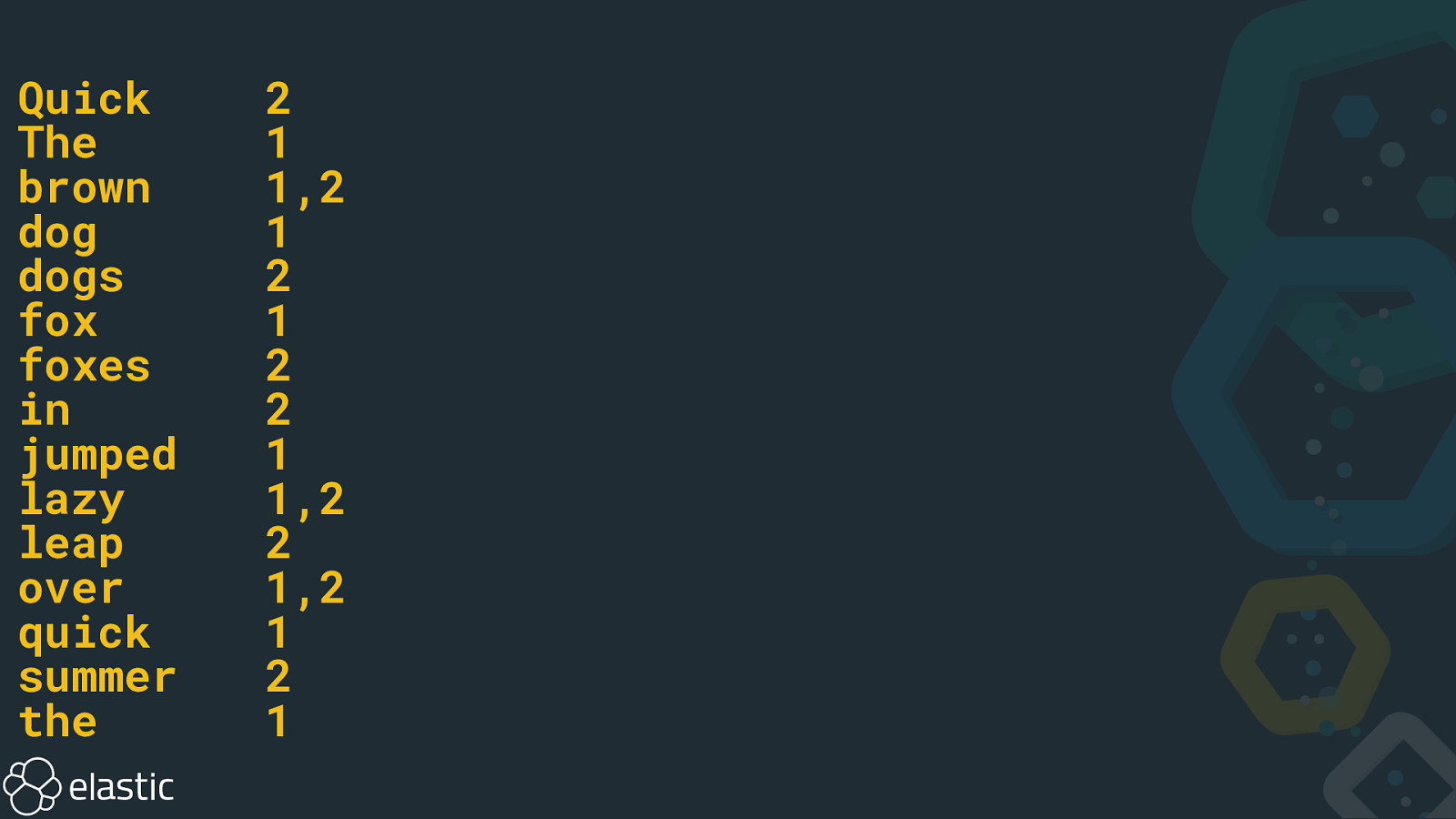
Quick The brown dog dogs fox foxes in jumped lazy leap over quick summer the 2 1 1,2 1 2 1 2 2 1 1,2 2 1,2 1 2 1
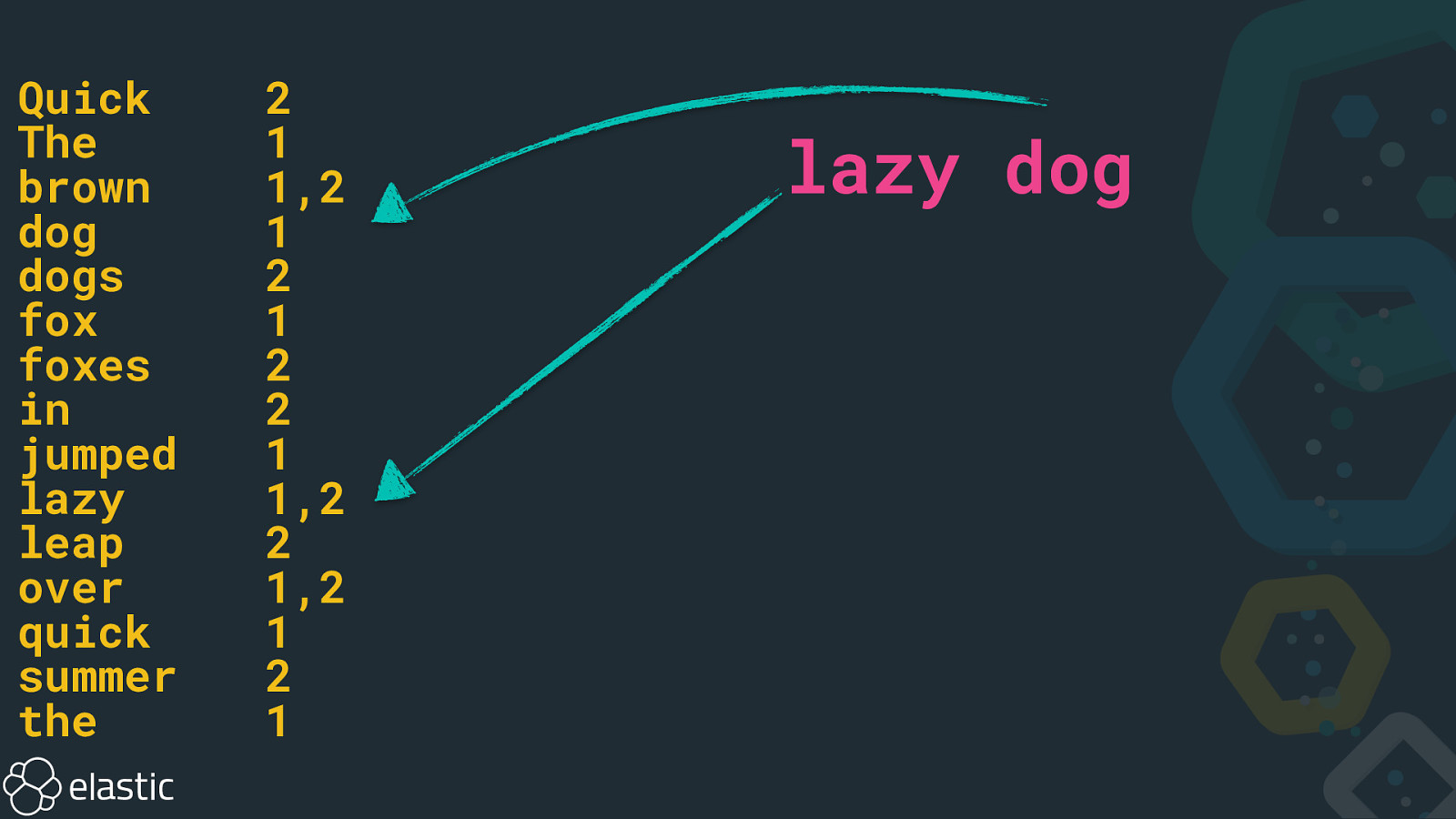
Quick The brown dog dogs fox foxes in jumped lazy leap over quick summer the 2 1 1,2 1 2 1 2 2 1 1,2 2 1,2 1 2 1 lazy dog
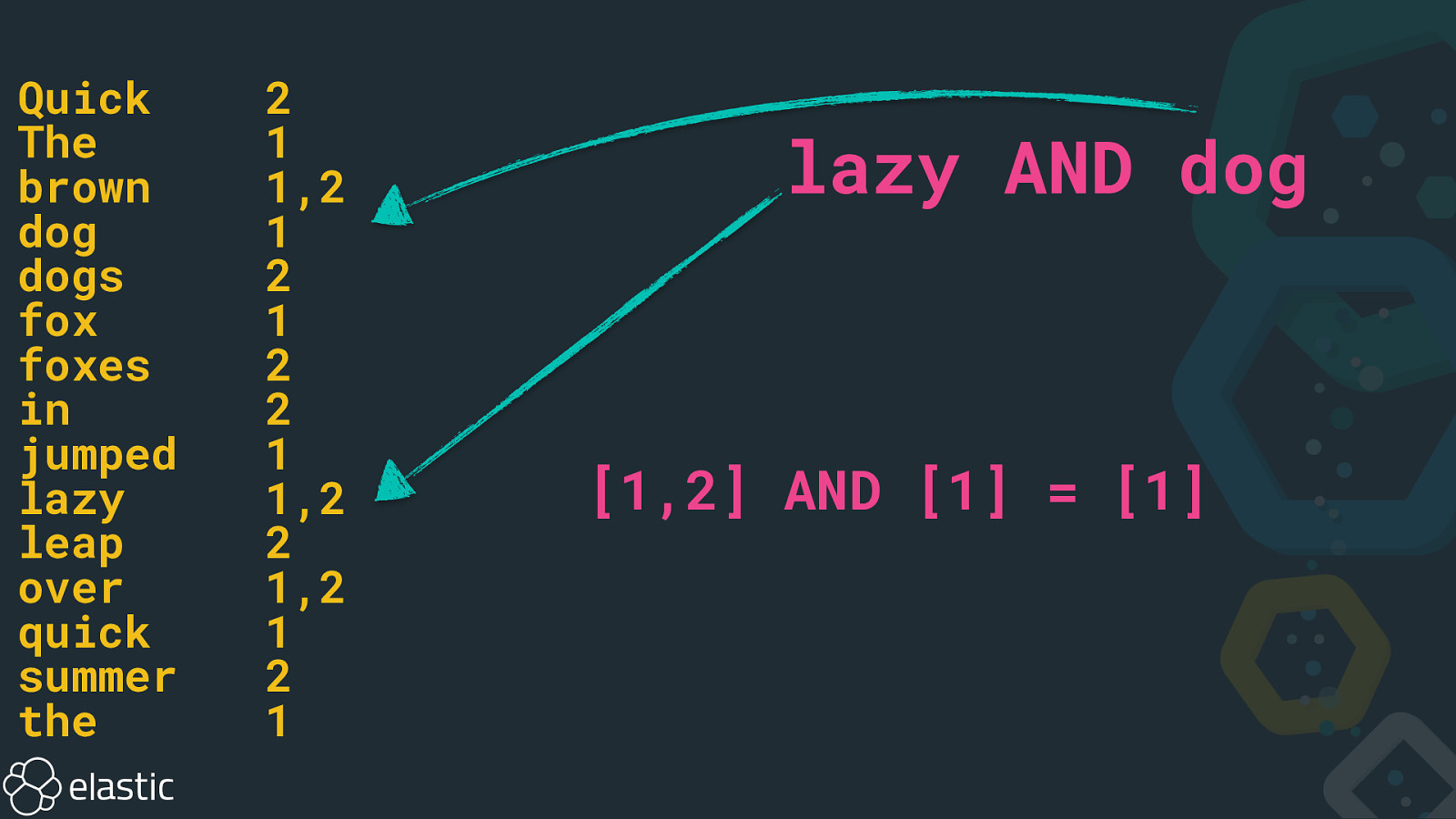
Quick The brown dog dogs fox foxes in jumped lazy leap over quick summer the 2 1 1,2 1 2 1 2 2 1 1,2 2 1,2 1 2 1 lazy AND dog [1,2] AND [1] = [1]
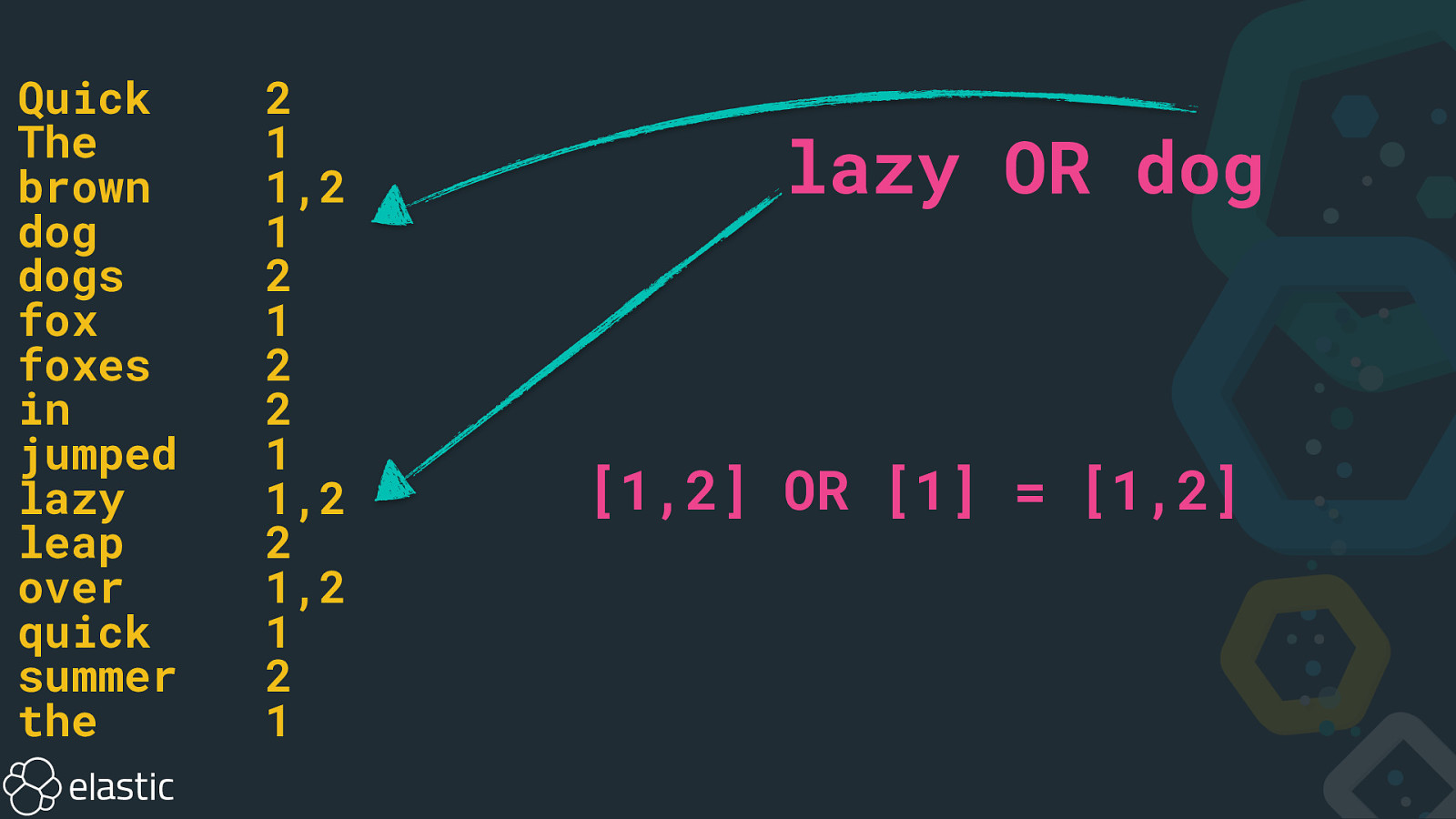
Quick The brown dog dogs fox foxes in jumped lazy leap over quick summer the 2 1 1,2 1 2 1 2 2 1 1,2 2 1,2 1 2 1 lazy OR dog [1,2] OR [1] = [1,2]

Technologies used today • Apache Lucene (search library) • Elasticsearch (distributed search engine built on top of Apache Lucene)

Indexing Analysis, Tokenization, Filtering Data structures
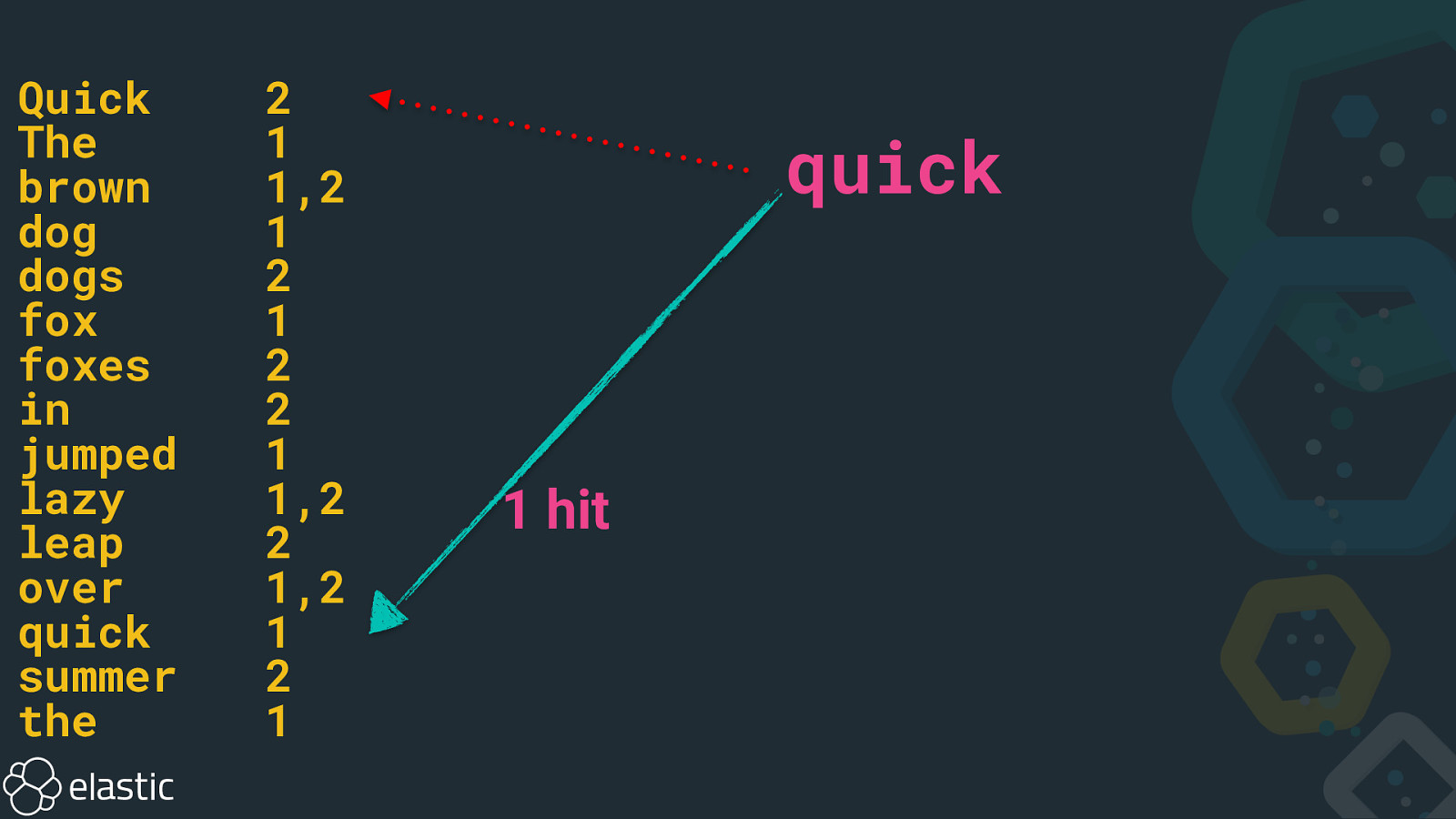
Quick The brown dog dogs fox foxes in jumped lazy leap over quick summer the 2 1 1,2 1 2 1 2 2 1 1,2 2 1,2 1 2 1 quick 1 hit
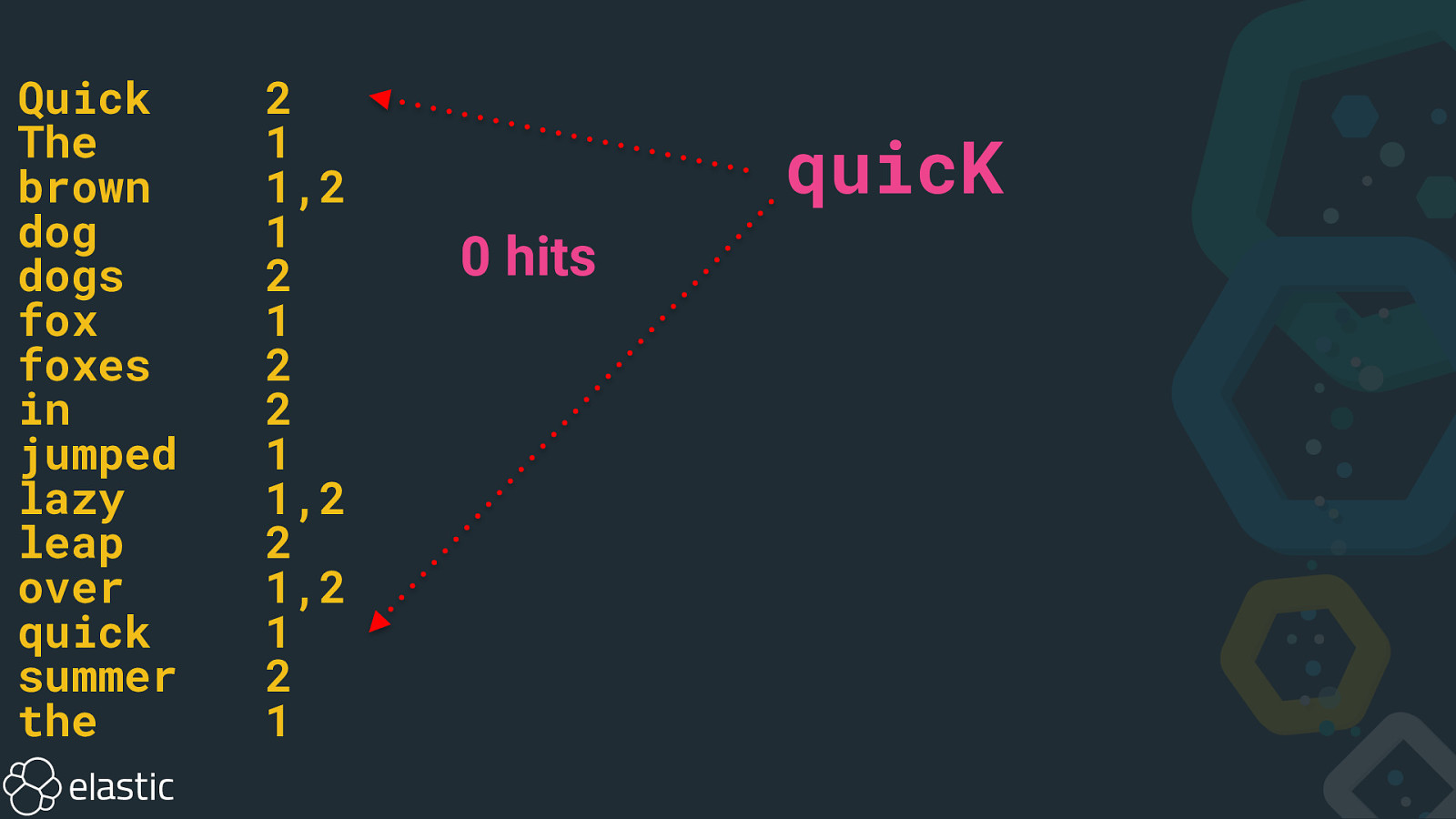
Quick The brown dog dogs fox foxes in jumped lazy leap over quick summer the 2 1 1,2 1 2 1 2 2 1 1,2 2 1,2 1 2 1 quicK 0 hits

Analysis: Tokenizer & Token Filters

Tokenization
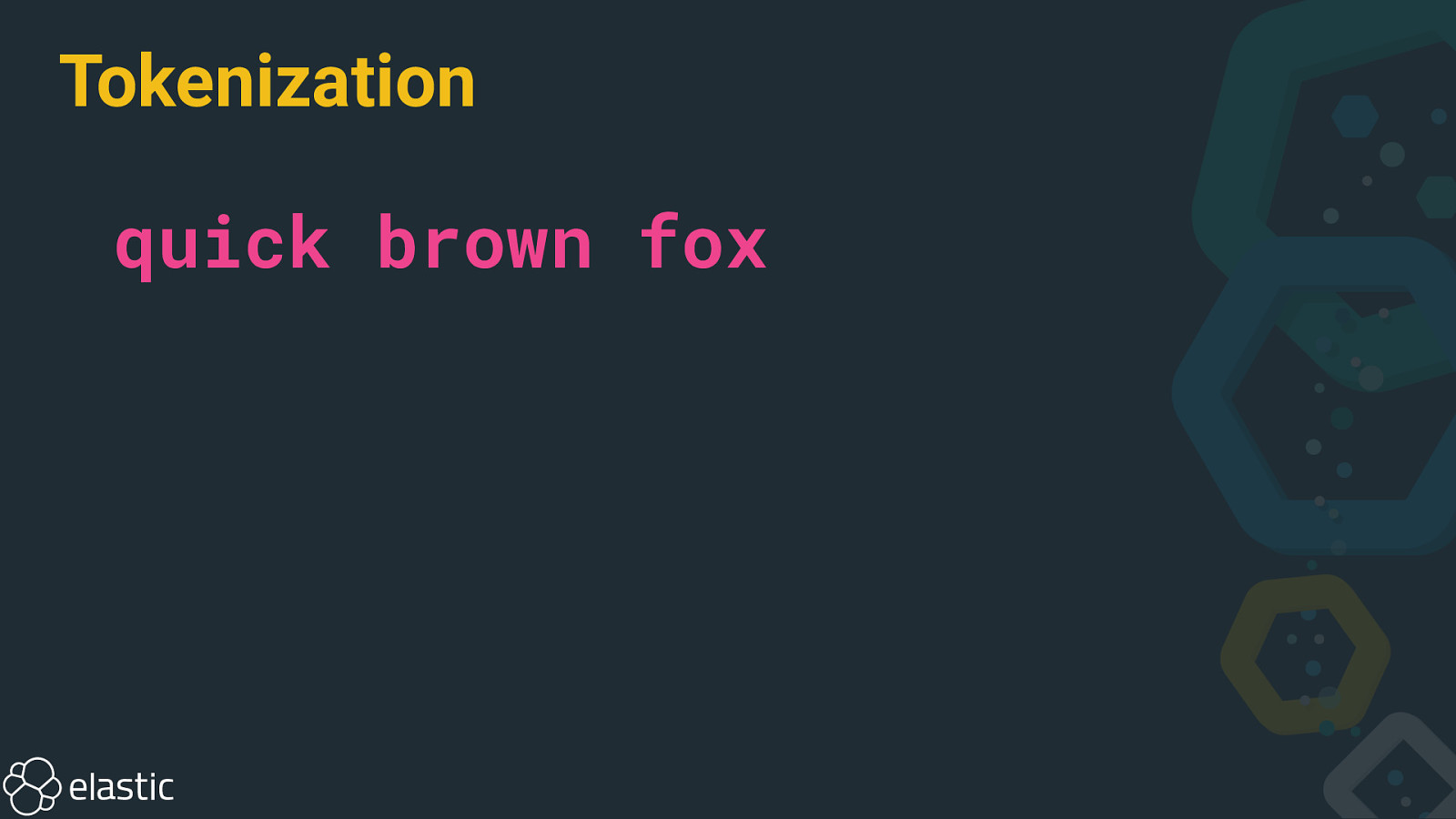
Tokenization quick brown fox
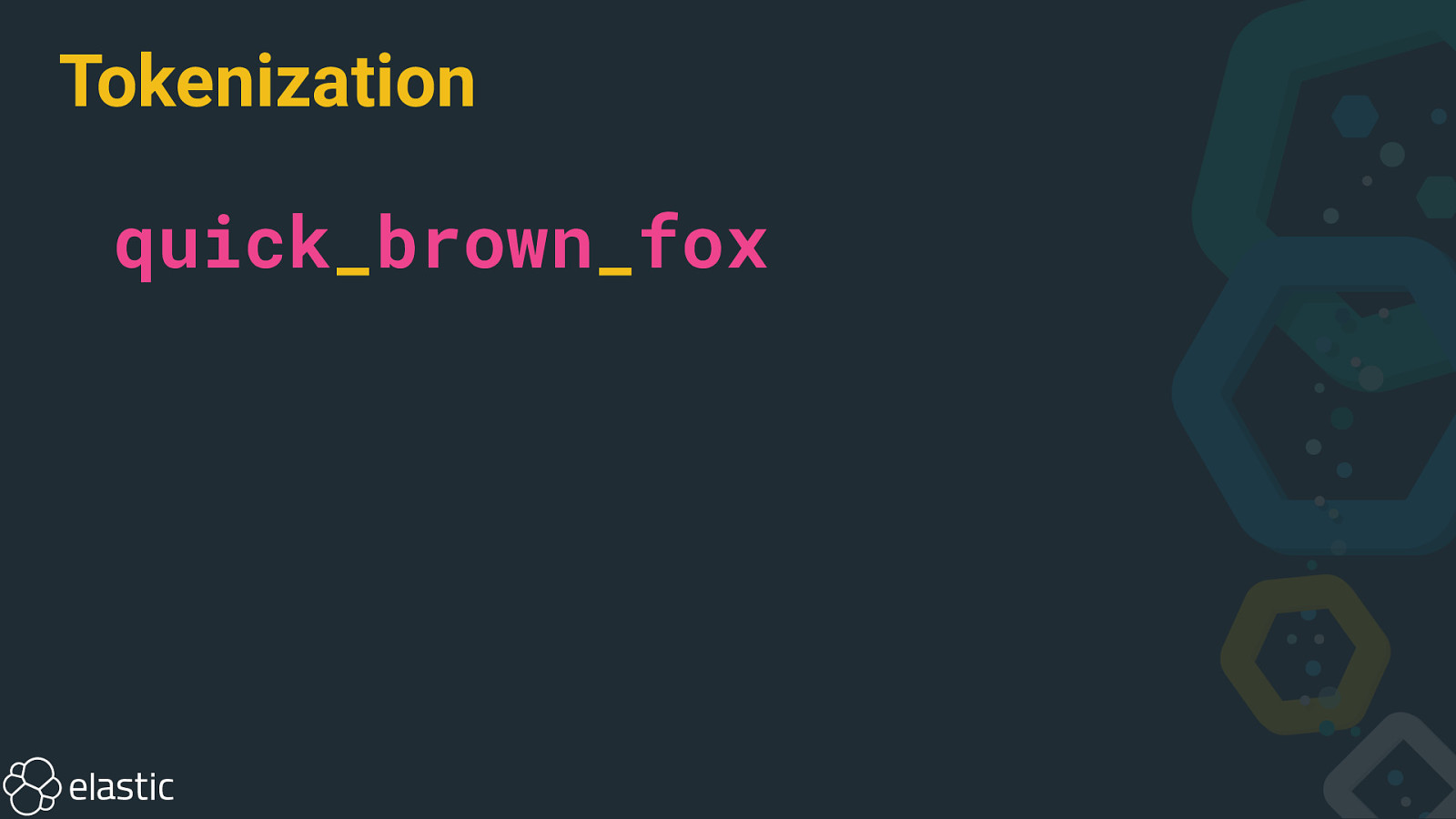
Tokenization quick_brown_fox
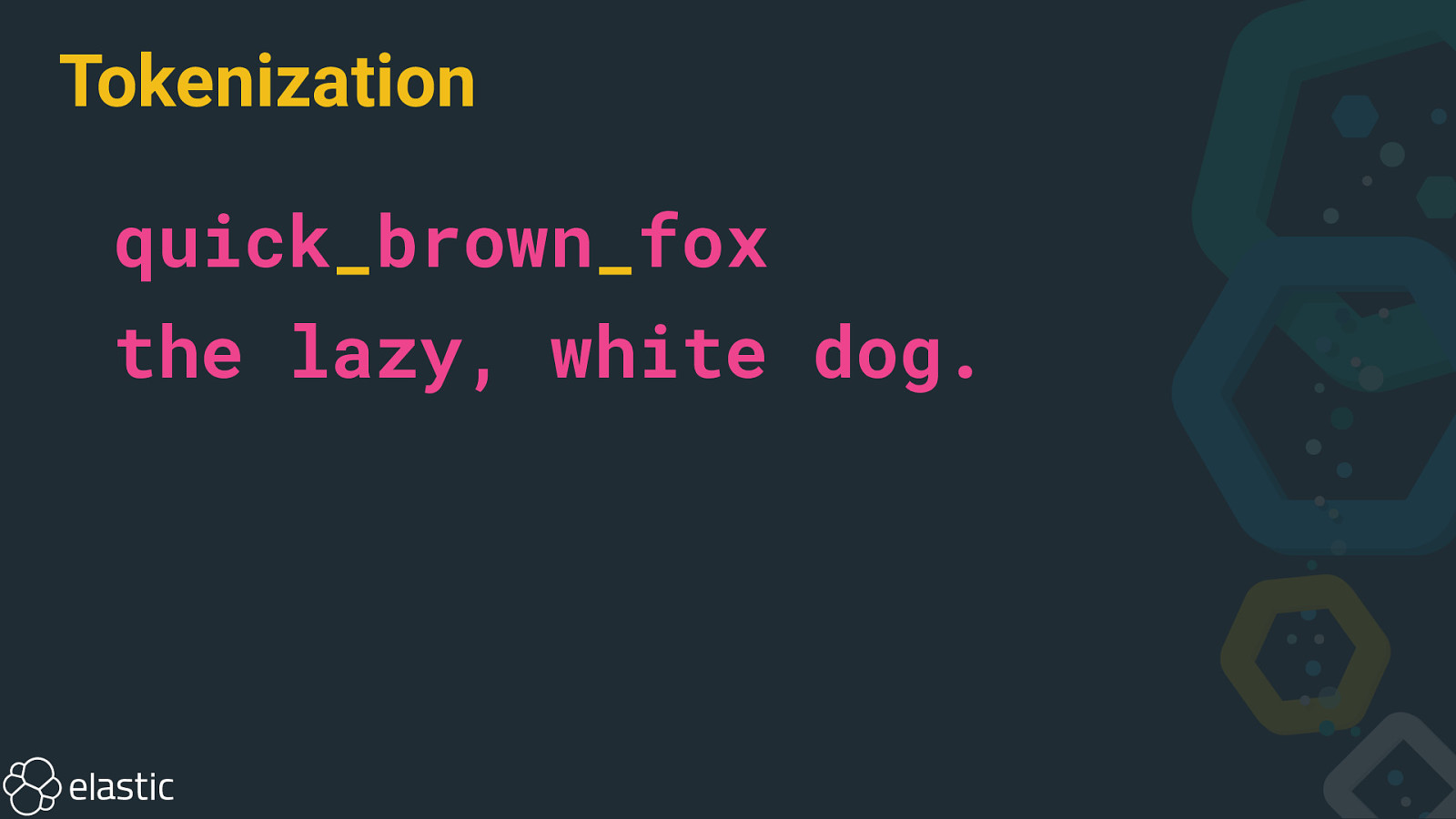
Tokenization quick_brown_fox the lazy, white dog.
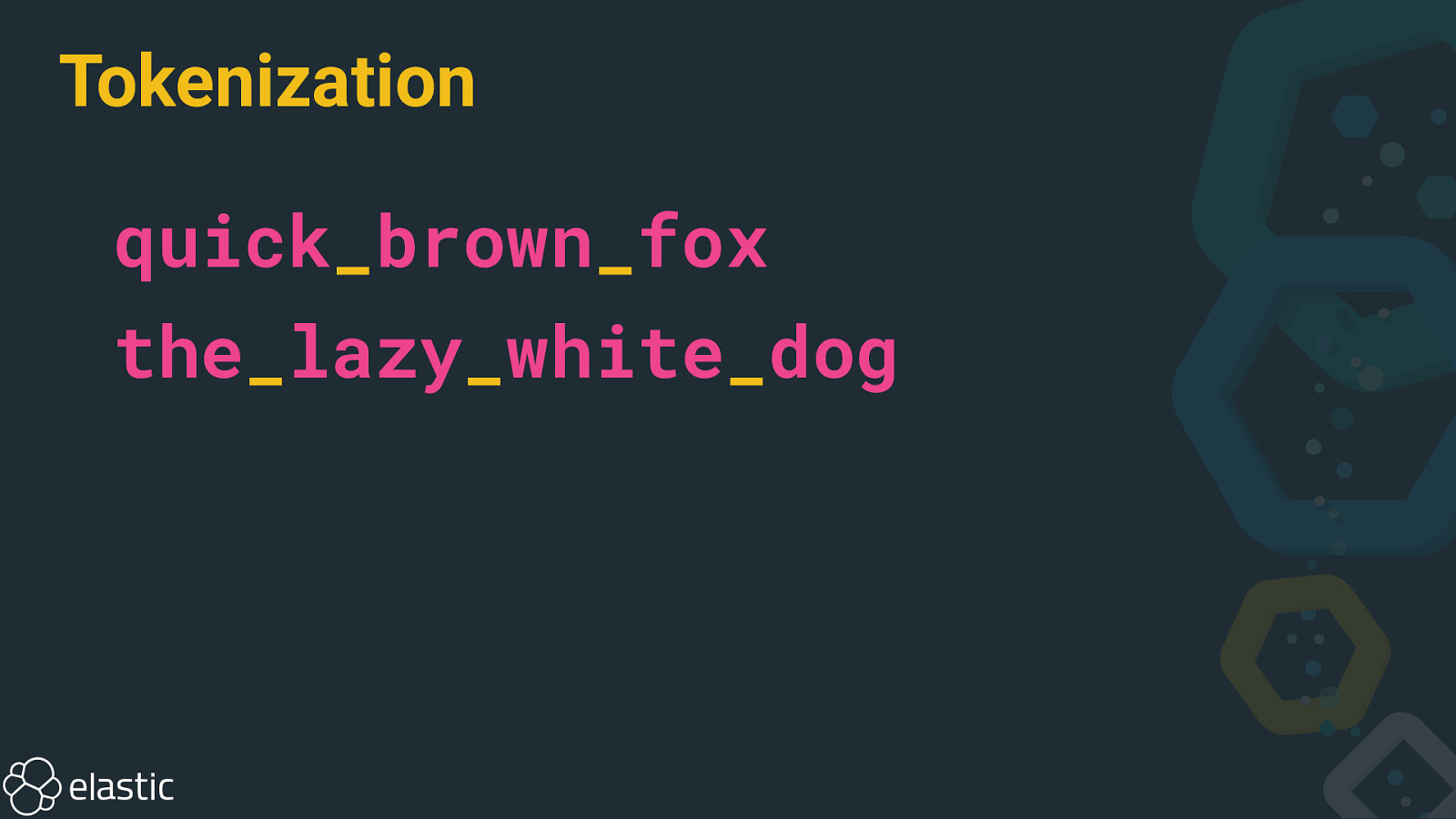
Tokenization quick_brown_fox the_lazy_white_dog

Tokenization quick_brown_fox the_lazy_white_dog https://unicode.org/reports/tr29/

Tokenization quick_brown_fox the_lazy_white_dog https://www.jade-hs.de

Tokenization quick_brown_fox the_lazy_white_dog https_www.jade_hs.de

Token Filter
Quick The brown dog dogs fox foxes in jumped lazy leap over quick summer the 2 1 1,2 1 2 1 2 2 1 1,2 2 1,2 1 2 1

Token filter The Quick brown fox
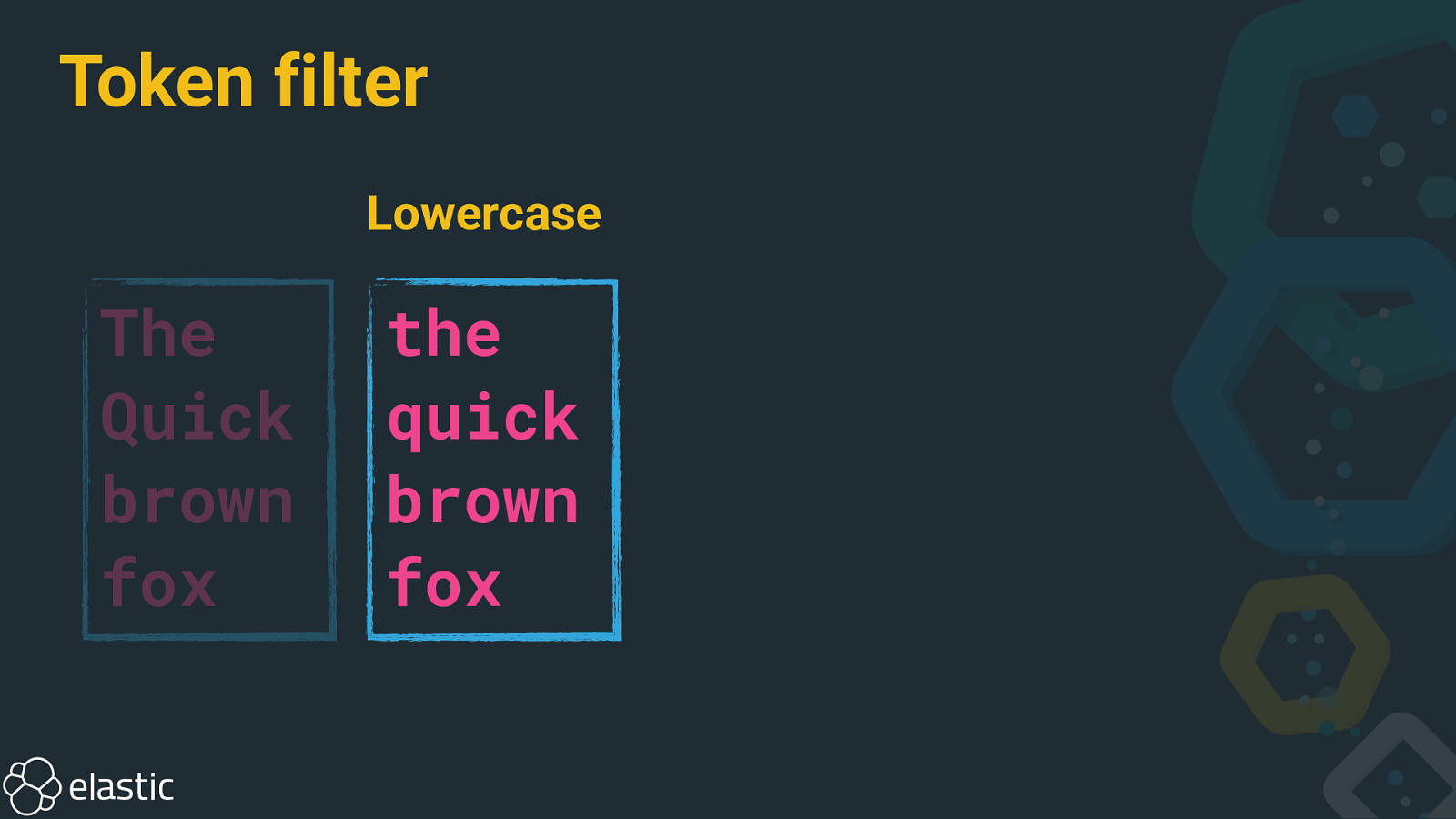
Token filter Lowercase The Quick brown fox the quick brown fox

Token filter The Quick brown fox Lowercase Stopwords the quick brown fox quick brown fox

Token filter The Quick brown fox Lowercase Stopwords the quick brown fox quick brown fox Synonyms quick,fast brown fox
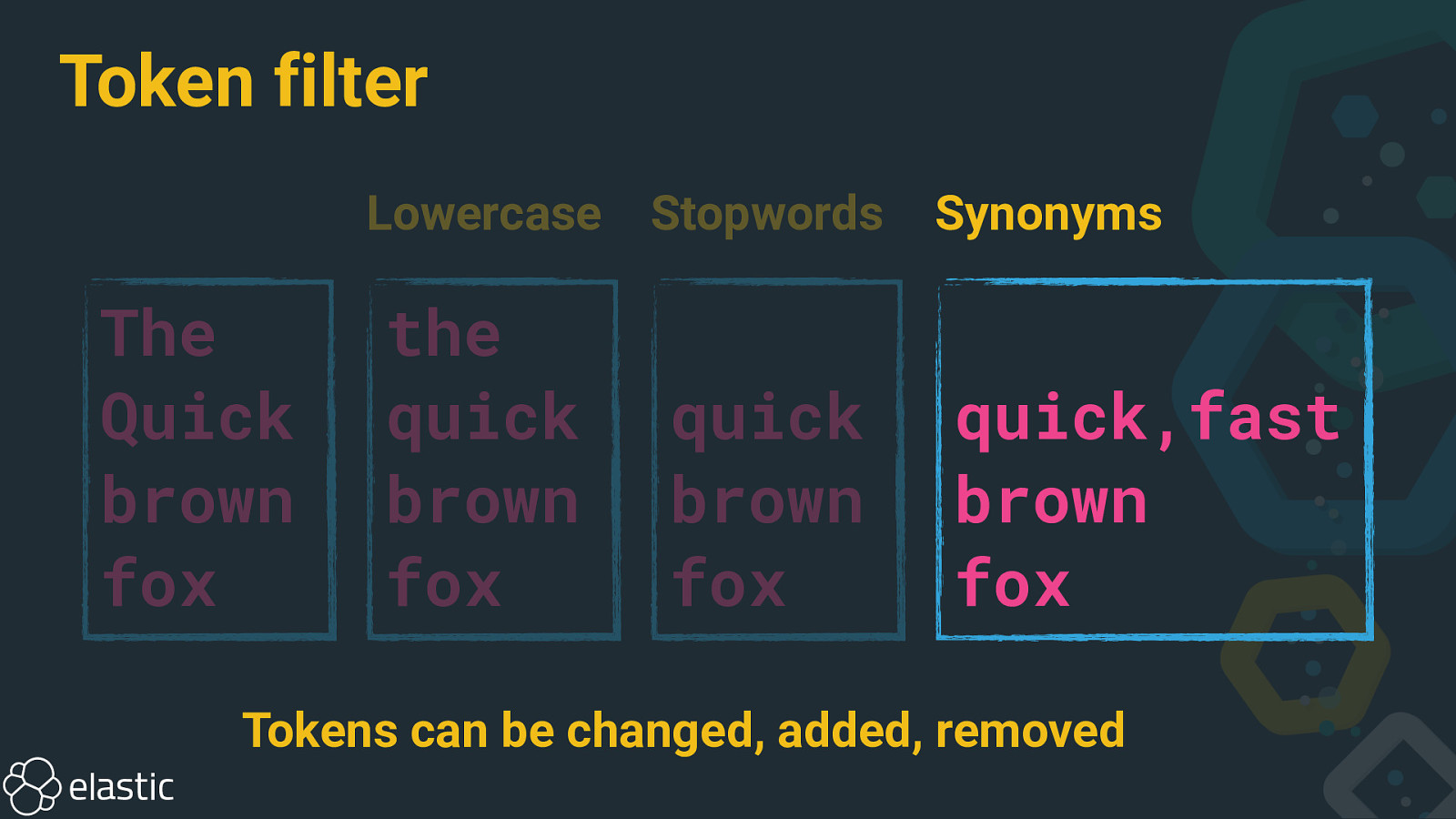
Token filter The Quick brown fox Lowercase Stopwords the quick brown fox quick brown fox Synonyms quick,fast brown fox Tokens can be changed, added, removed

Token filter The Quick brown fox Lowercase Stopwords the quick brown fox quick brown fox Synonyms quick,fast brown fox Queries need to be processed as well!

More analysis strategies • Phonetic analysis: Meyer vs. Meier • Stemming: foxes ⇾ fox • Compounding: Blumentopf ⇾ blumen topf • Folding: Spaß ⇾ Spass

(On-Disk) Data structures

What else is in an inverted index? • Documents: Find documents • Term frequencies: Relevancy • Positions: Positional Queries • Offsets: Highlighting • Stored fields: The original data

Segment: Unit of work • A fully self sufficient inverted index • An index consists of a number of segments • New segments are created for newly added documents • Segments are immutable!

Read-only data structures • Pro: Write-once, sequentially • Pro: Lock-free reading • Pro: File system cache • Contra: in-place updates & deletes • Contra: Housekeeping • Contra: Transactions
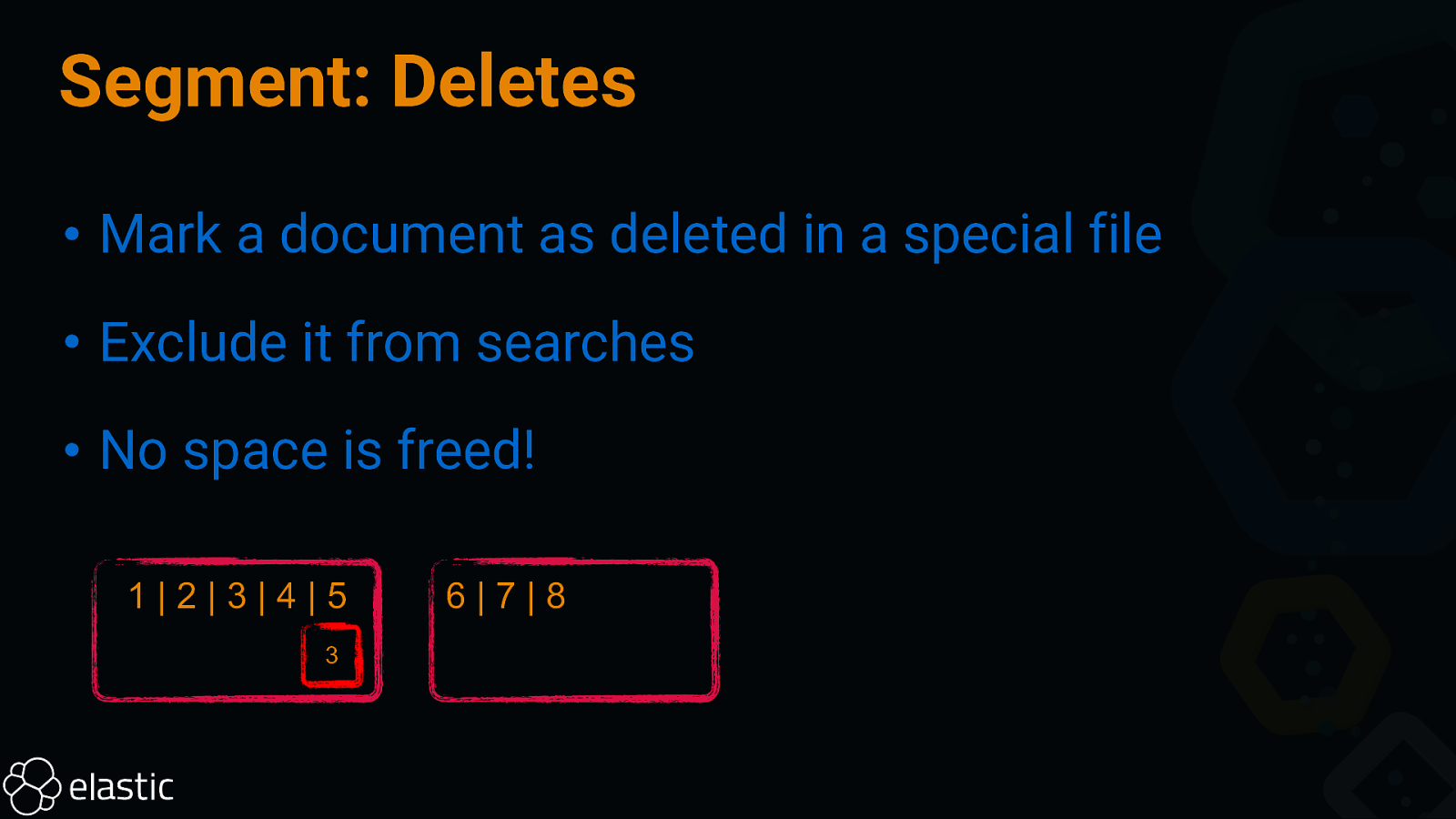
Segment: Deletes • Mark a document as deleted in a special file • Exclude it from searches • No space is freed! 1|2|3|4|5 3 6|7|8

Segment: Merging • Number of segments needs to be kept reasonable • Merge multiple segments into one (smaller index) • Delete expired documents 1|2|3|4|5 3 6|7|8

Segment: Merging • Number of segments needs to be kept reasonable • Merge multiple segments into one (smaller index) • Delete expired documents 1|2|3|4|5 3 6|7|8 1|2|4|5|6|7|8

Searching Precision vs. recall Scoring Algorithms and optimizations

Relevancy
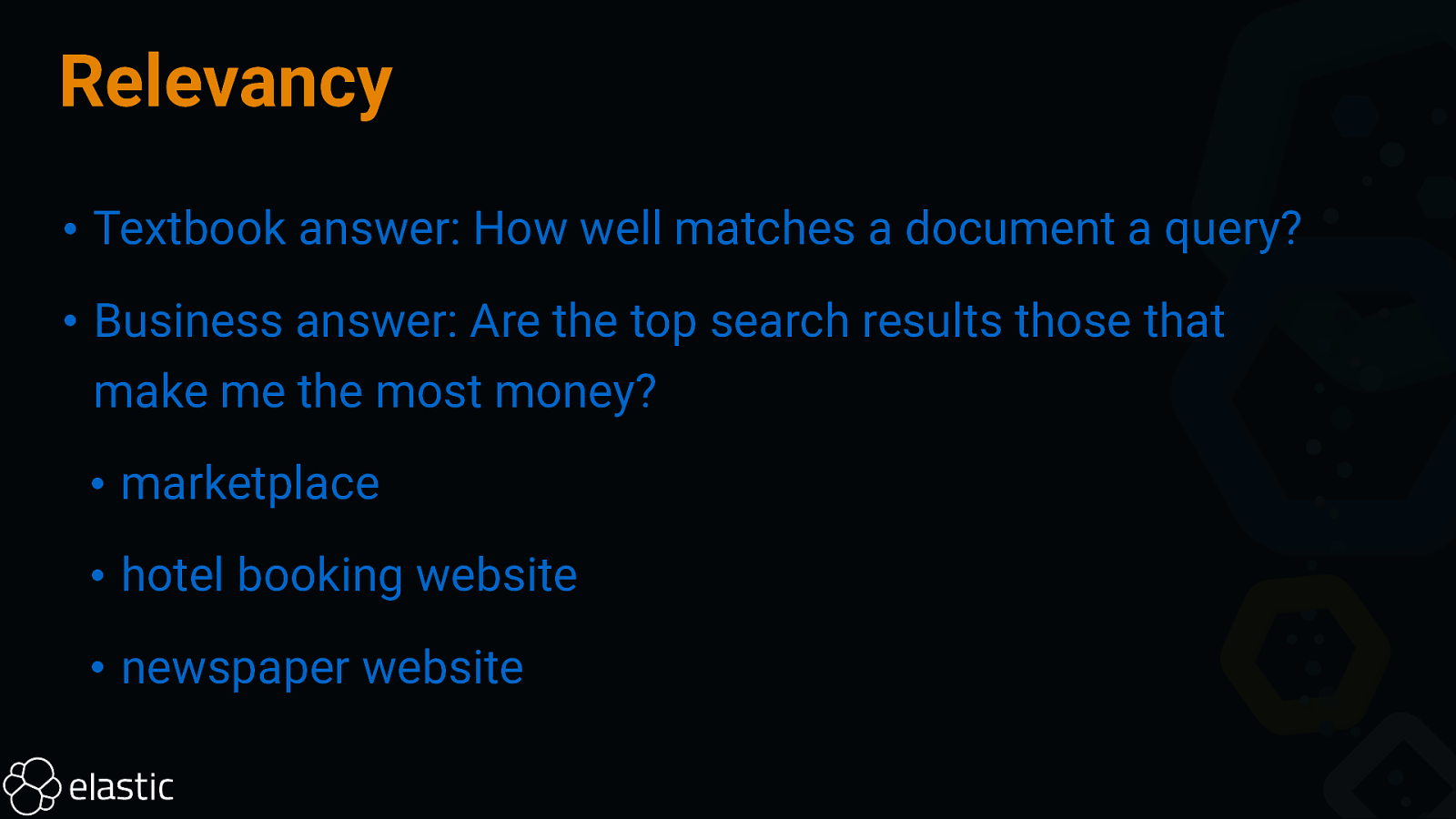
Relevancy • Textbook answer: How well matches a document a query? • Business answer: Are the top search results those that make me the most money? • marketplace • hotel booking website • newspaper website

Scoring
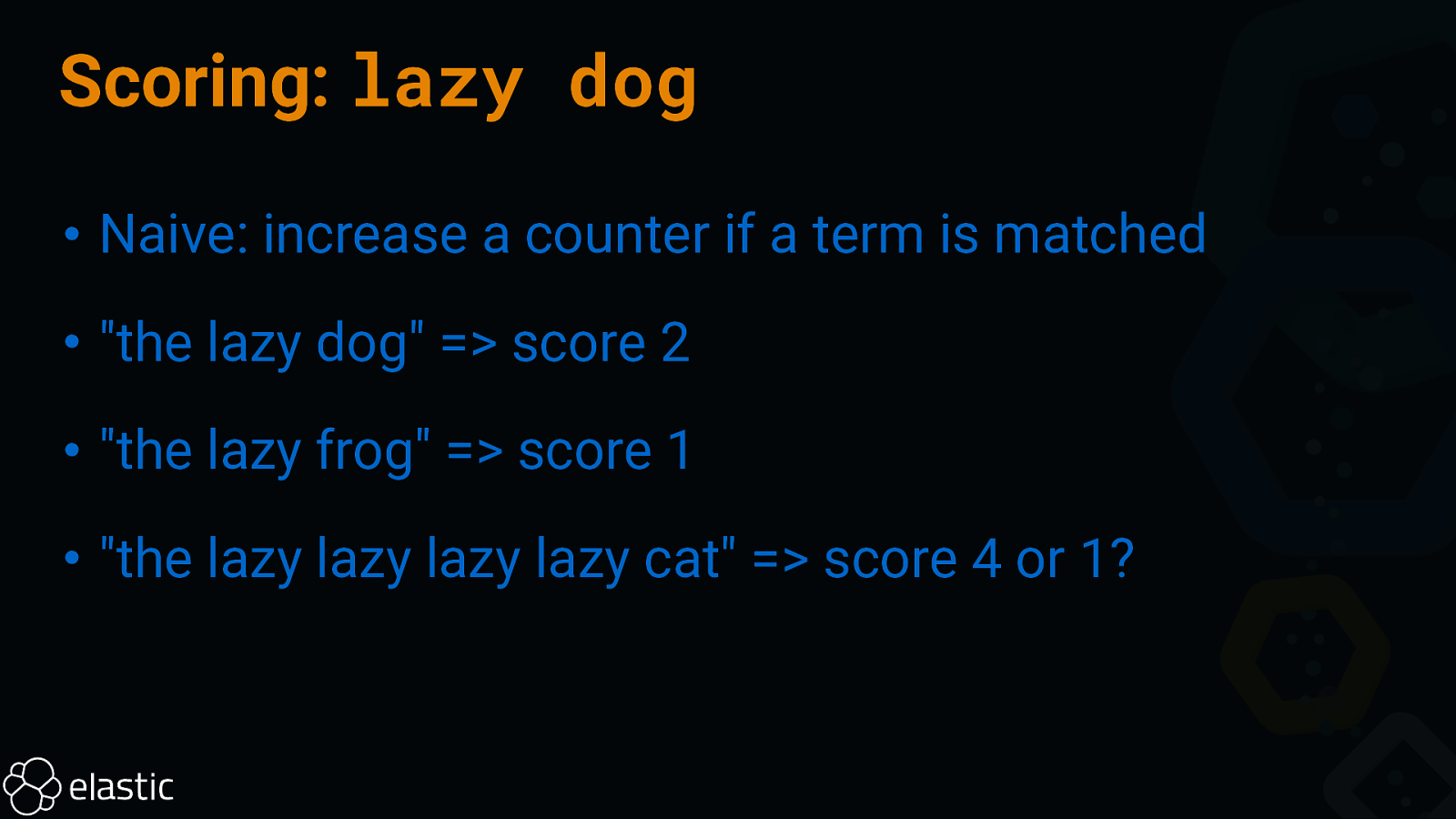
Scoring: lazy dog • Naive: increase a counter if a term is matched • “the lazy dog” => score 2 • “the lazy frog” => score 1 • “the lazy lazy lazy lazy cat” => score 4 or 1?

Scoring: More than term frequency • How about incorporating information about the whole document corpus in scoring? • Are lesser common terms more relevant? • news paper: “dieselgate news”

Scoring: TF-IDF • Term frequency: number of times a term occurs in a field • Inverse document frequency: inverse function of the number of documents in which it occurs

Scoring: Vector space model • Each term is a dimension • The length is based on tf-idf calculation • Similarity is the angle between vectors • Cosine similarity: best match == angle 0°

Scoring: TF-IDF in Lucene score(q,d) = ∑ ( tf(t in d) · 2 idf(t) · t.getBoost() · norm(t,d) )


BM25 • Default in Apache Lucene/Elasticsearch • Works better with stopwords (high TF) • Term frequency saturation • Improved field length normalization (per document)
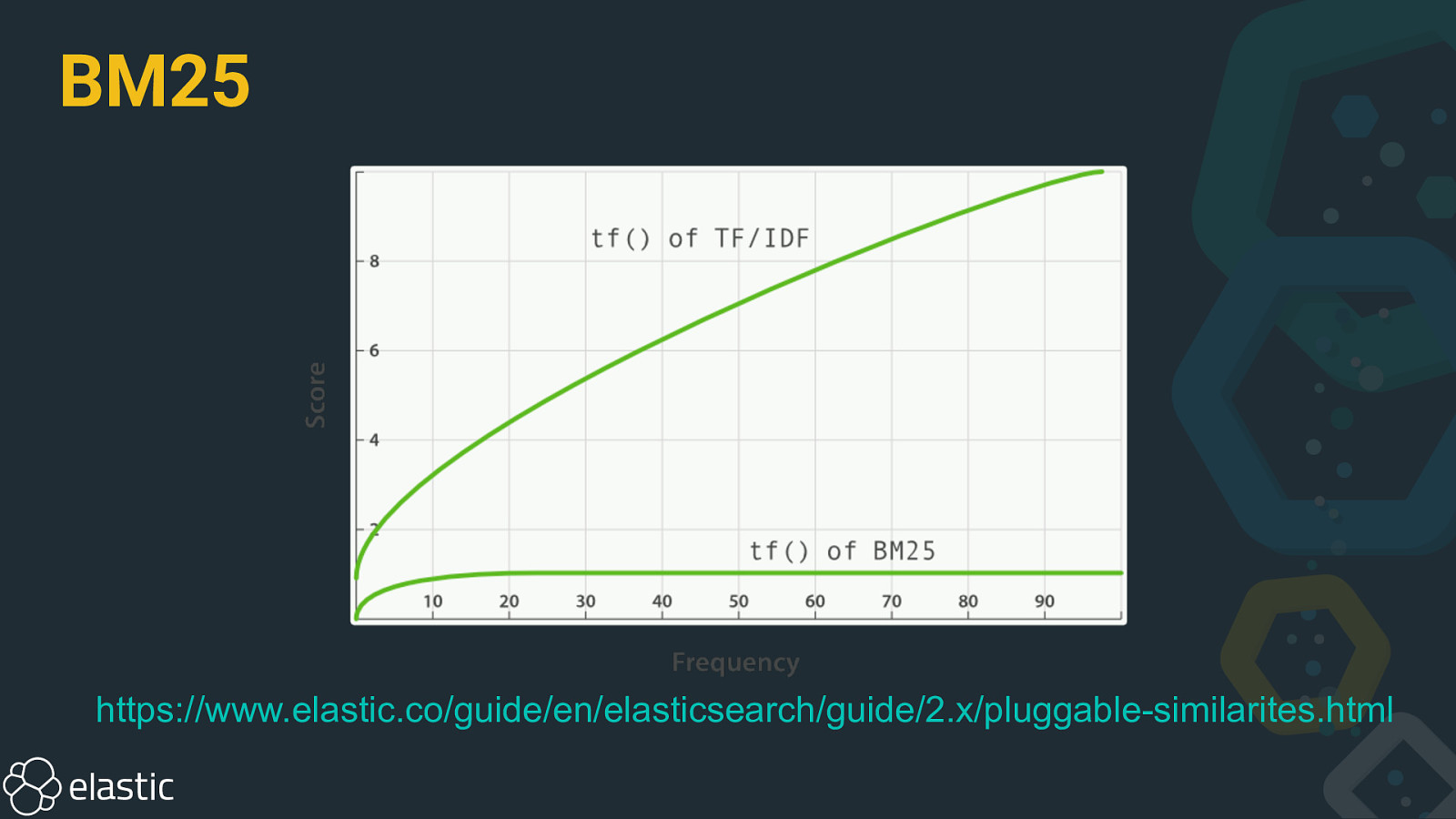
BM25 https://www.elastic.co/guide/en/elasticsearch/guide/2.x/pluggable-similarites.html

Precision vs. recall
Precision and Recall
Precision and Recall relevant documents irerelevant documents
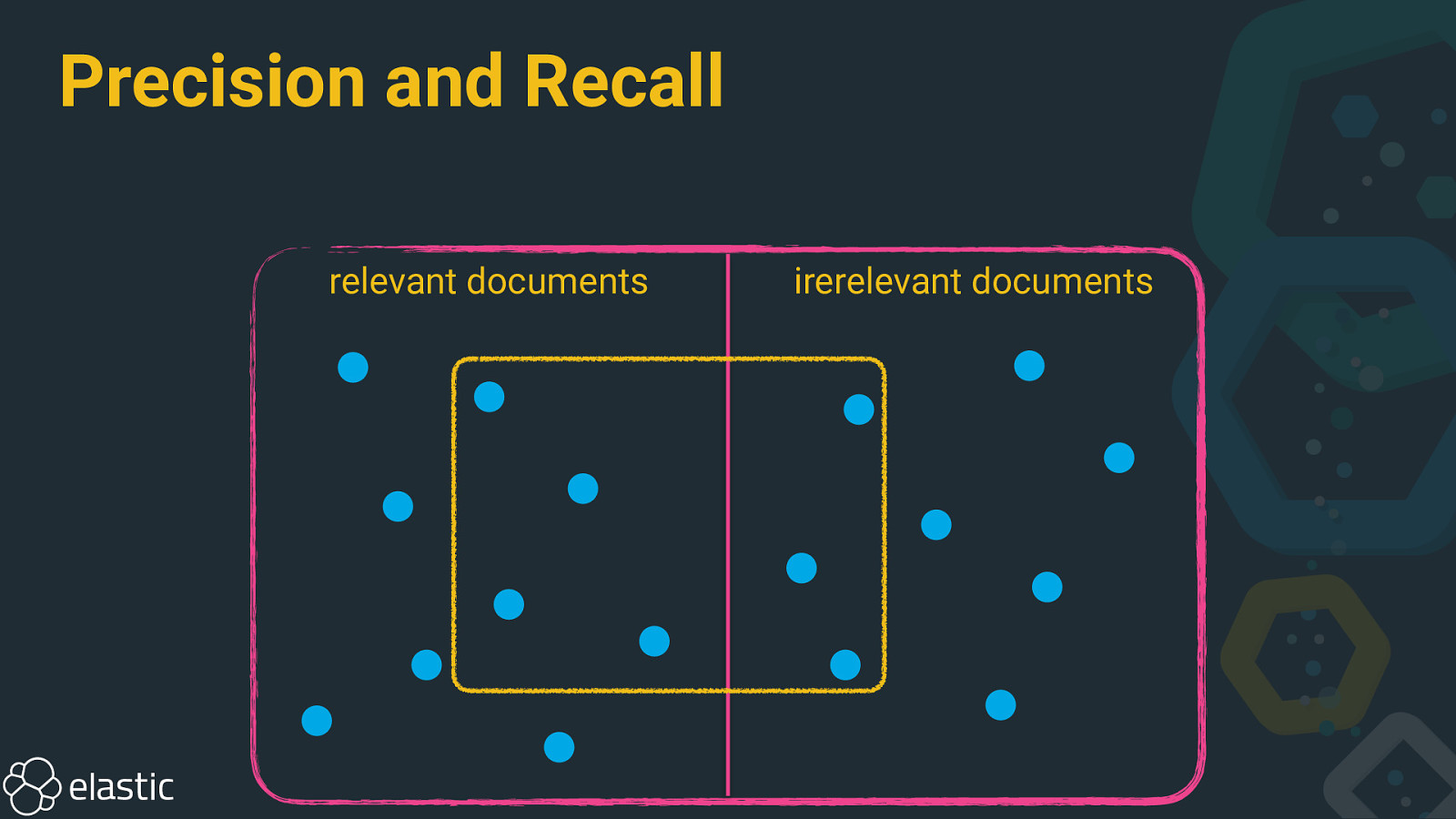
Precision and Recall relevant documents irerelevant documents
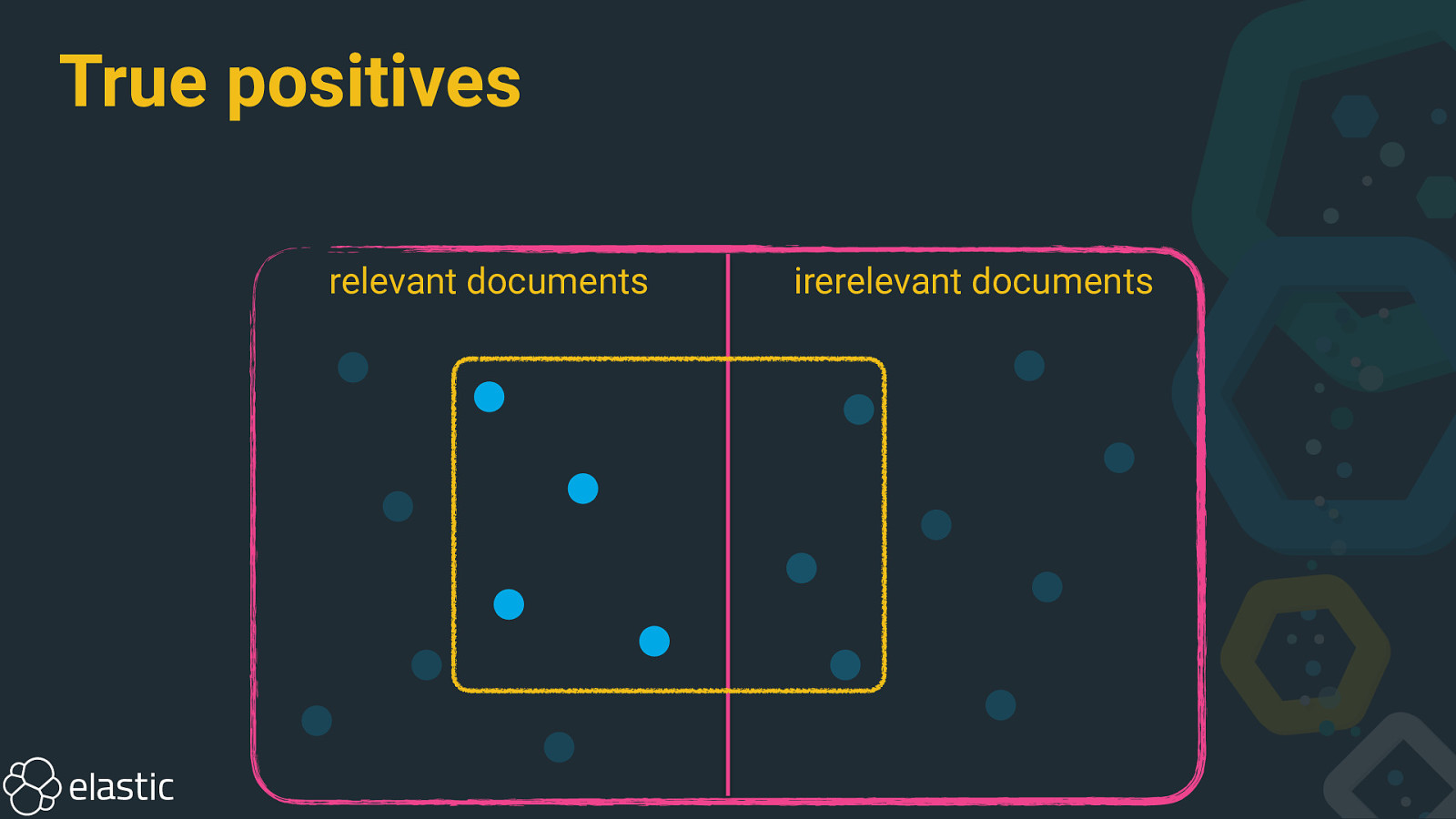
True positives relevant documents irerelevant documents
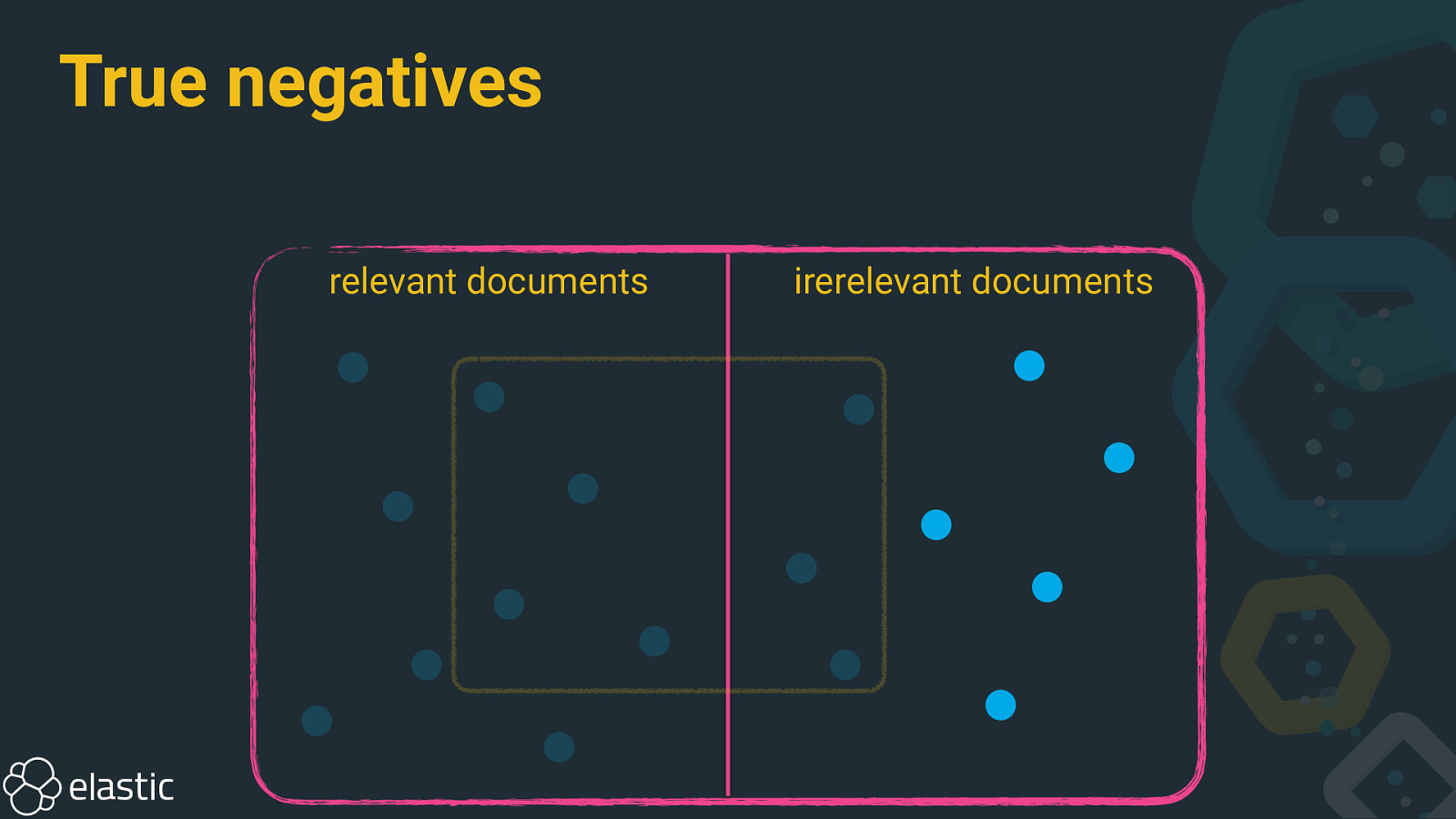
True negatives relevant documents irerelevant documents
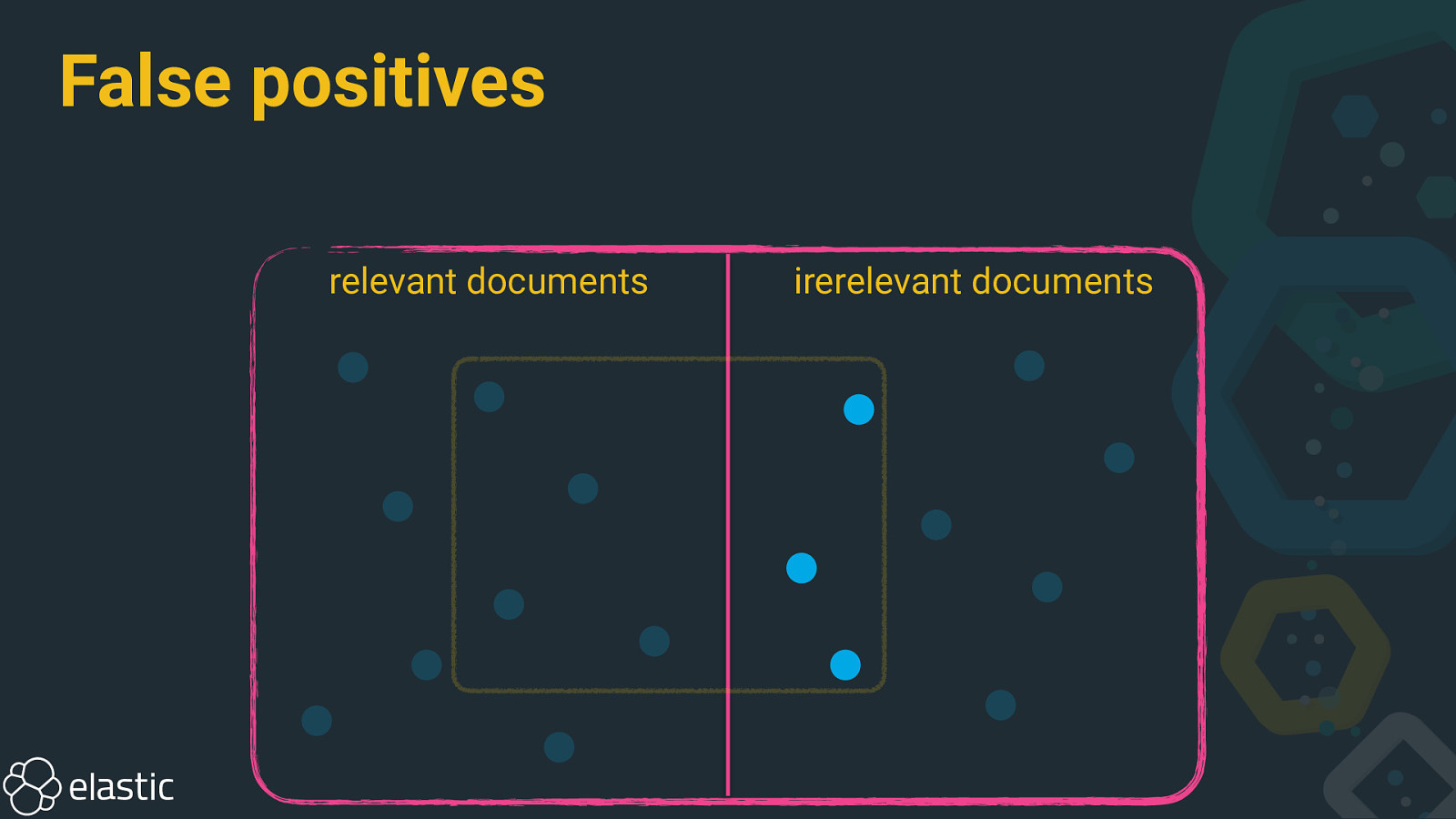
False positives relevant documents irerelevant documents
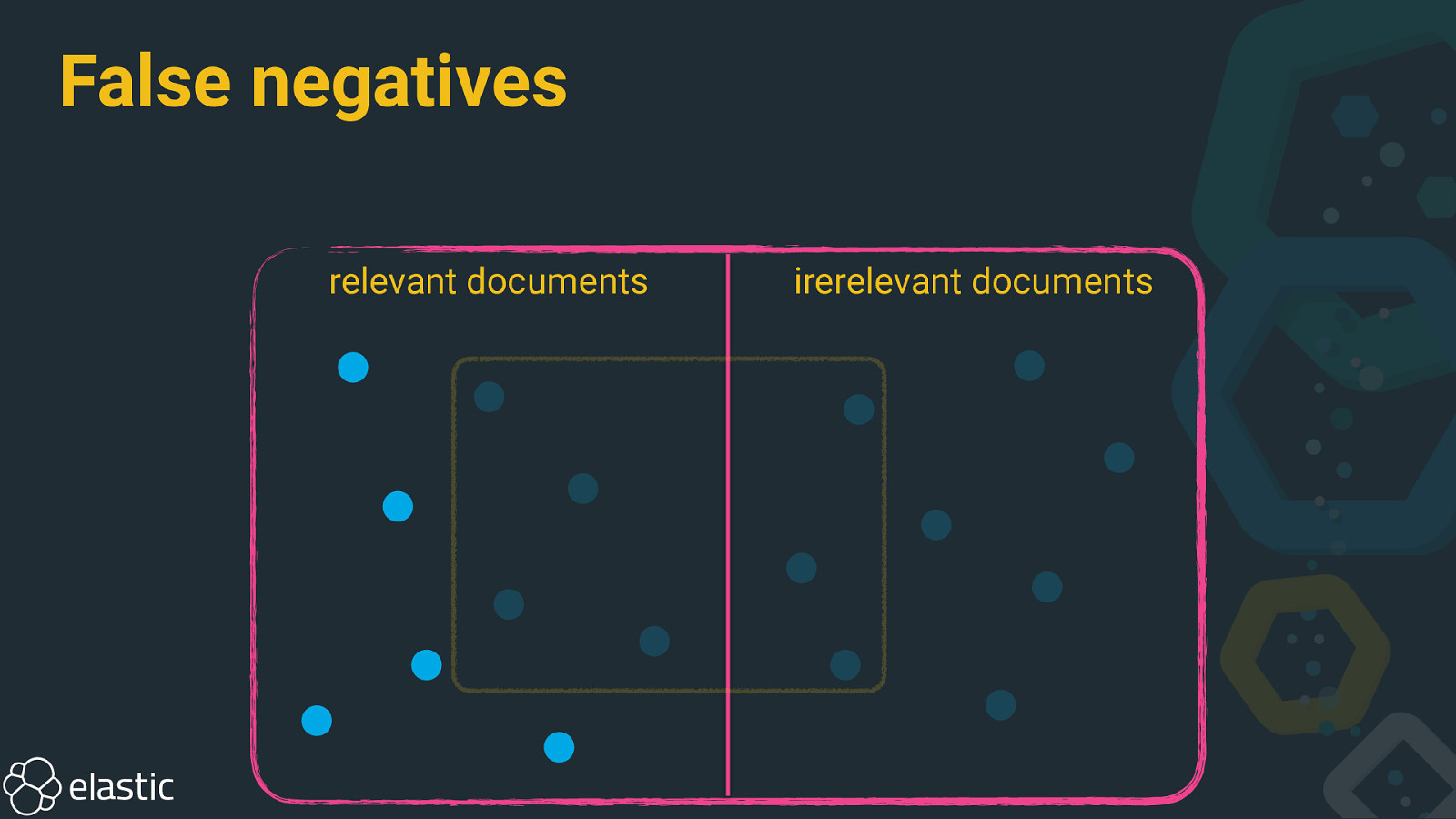
False negatives relevant documents irerelevant documents

Precision and recall • Precision: How many selected documents are relevant? • Recall: How many relevant documents are selected

Under the hood

Optimizations everywhere • leap frogging, skip lists • top-k • two phase iterations • integer compression

Query two phase iteration

Two phase iteration: Phrase query • Phrase query: “quick fox” • Approximation phase: document contains terms quick and fox • Verification phase: read positions of terms

Two phase iteration: Geo distance query • Geo distance query: Distance from reference point • Approximation phase: bbox around point • Verification phase: exact distance calculation

Two phase iteration: Geo distance query GET /my_locations/_search { “query”: { “bool” : { “filter” : { “geo_distance” : { “distance” : “200km”, “pin.location” : { “lat” : 40, “lon” : -70 } } } } } }

Two phase iteration: several queries • Powerful when several queries are used • “quick fox” AND brown • Approximation: quick AND fox AND brown • Verification: “quick fox” position check for hits

Skip lists & leap frogging

Skip lists • Term dictionary is a sorted skip list • Skip list is a linked list with ‘express lanes’ to leap forward https://en.wikipedia.org/wiki/Skip_list
Leap frogging elasticsearch AND kibana AND logstash
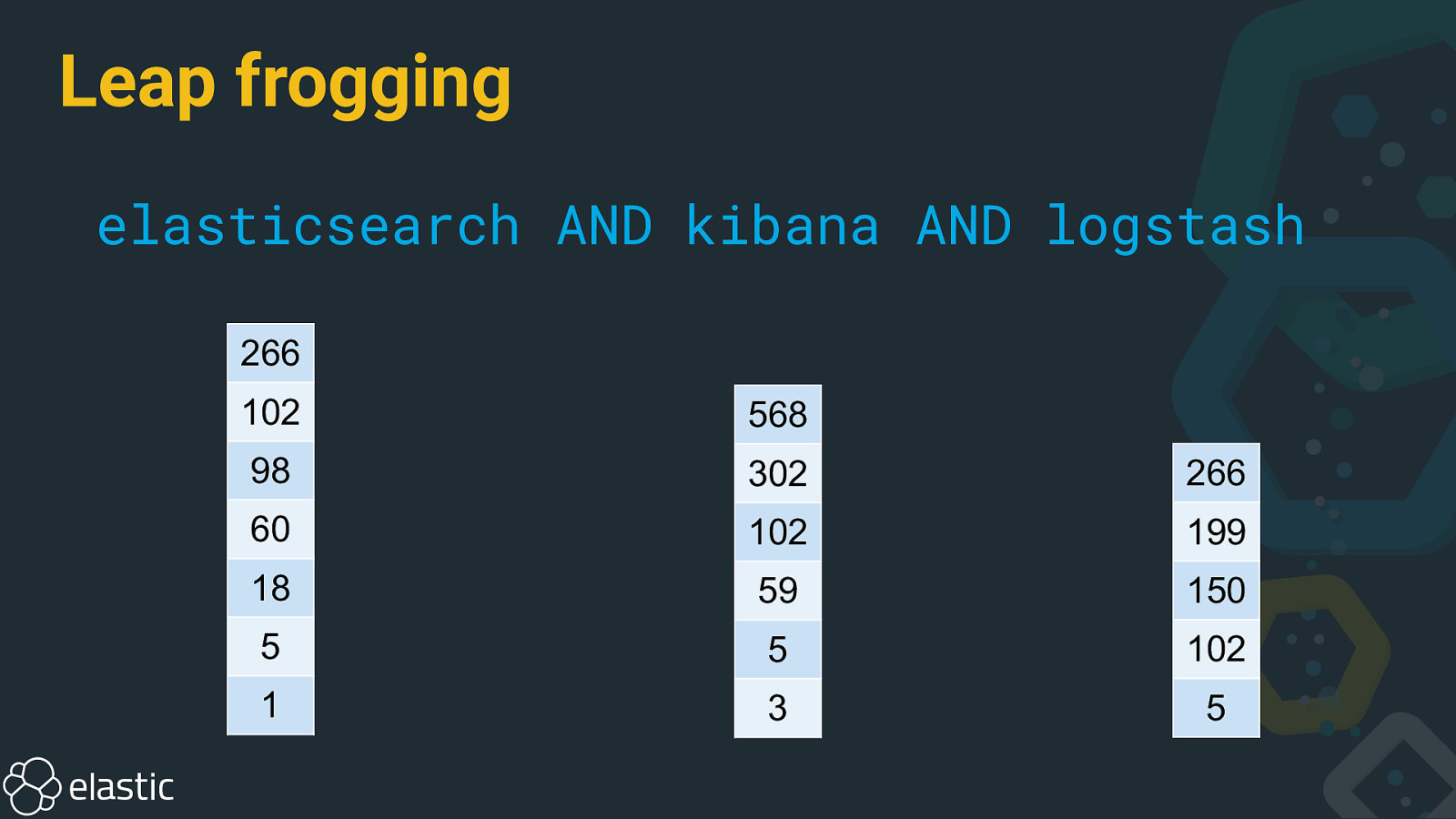
Leap frogging elasticsearch AND kibana AND logstash 266 102 568 98 302 266 60 102 199 18 59 150 5 5 102 1 3 5

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1 Hit!

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1 Hit!

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1 Hit!

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1 Hit!

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1 Hit! Hit!

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1 Hit! Hit!

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1 Hit! Hit!

Leap frogging logstash AND kibana AND elasticsearch 266 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1 Hit! Hit!

Leap frogging logstash AND kibana AND elasticsearch 266 Done! 568 102 266 302 98 199 102 60 150 59 18 102 5 5 5 3 1 Hit! Hit!

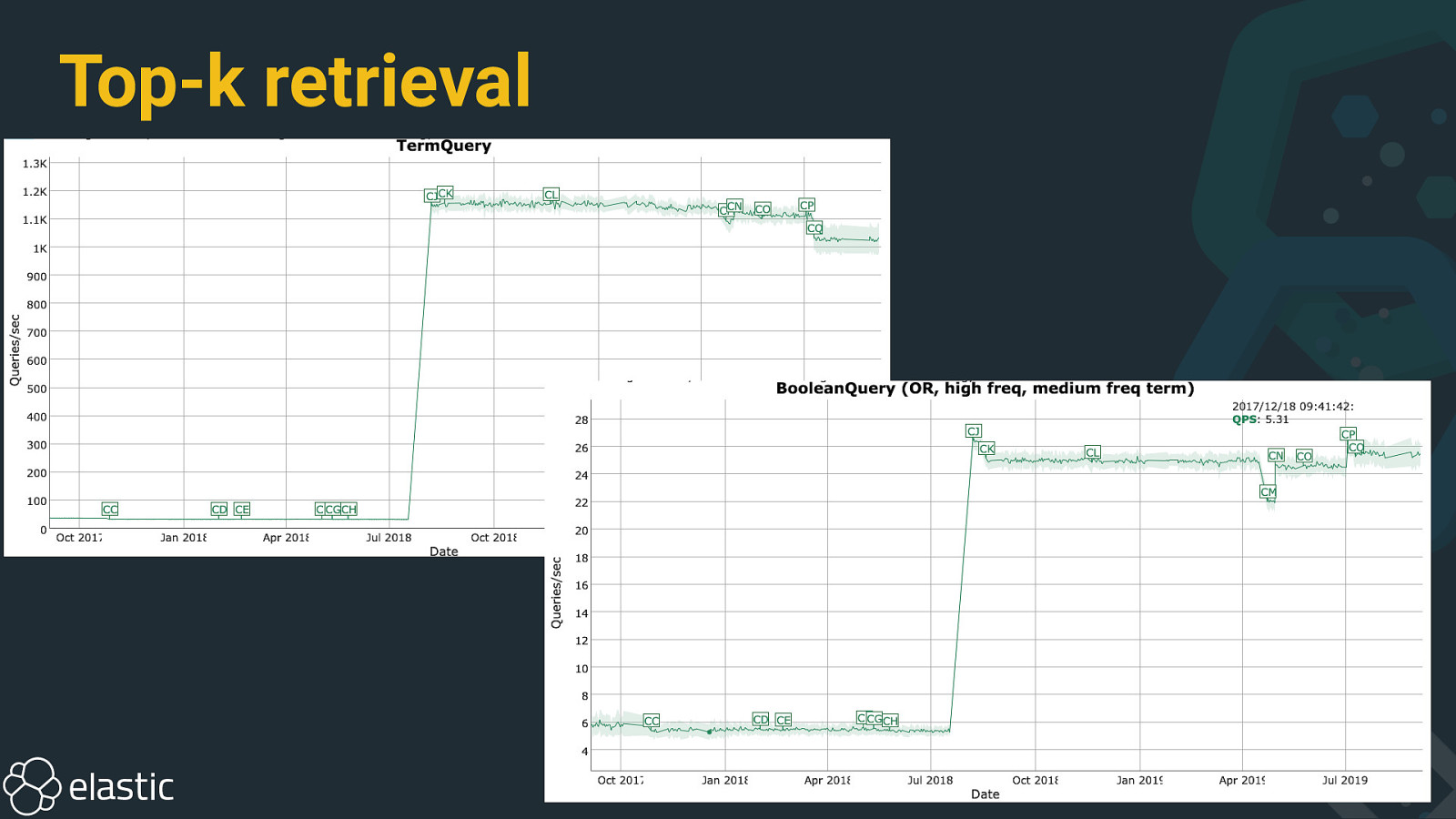
Top-k retrieval

Top-k retrieval • elasticsearch OR kibana • top 10 results wanted • maximum score for kibana is 3.0 • maximum score for elasticsearch is 5.0 • collecting documents: when 10th hit has score > 3, then only documents with elasticsearch need to be collected • total hit count is not accurate
Top-k retrieval

Index sorting

Order index by field values • each segment is sorted before write • criteria can be chosen by the user 5|2|3|1|4 retrieve sort top 2 5|2|3|1|4 5|4|3|2|1 5|4
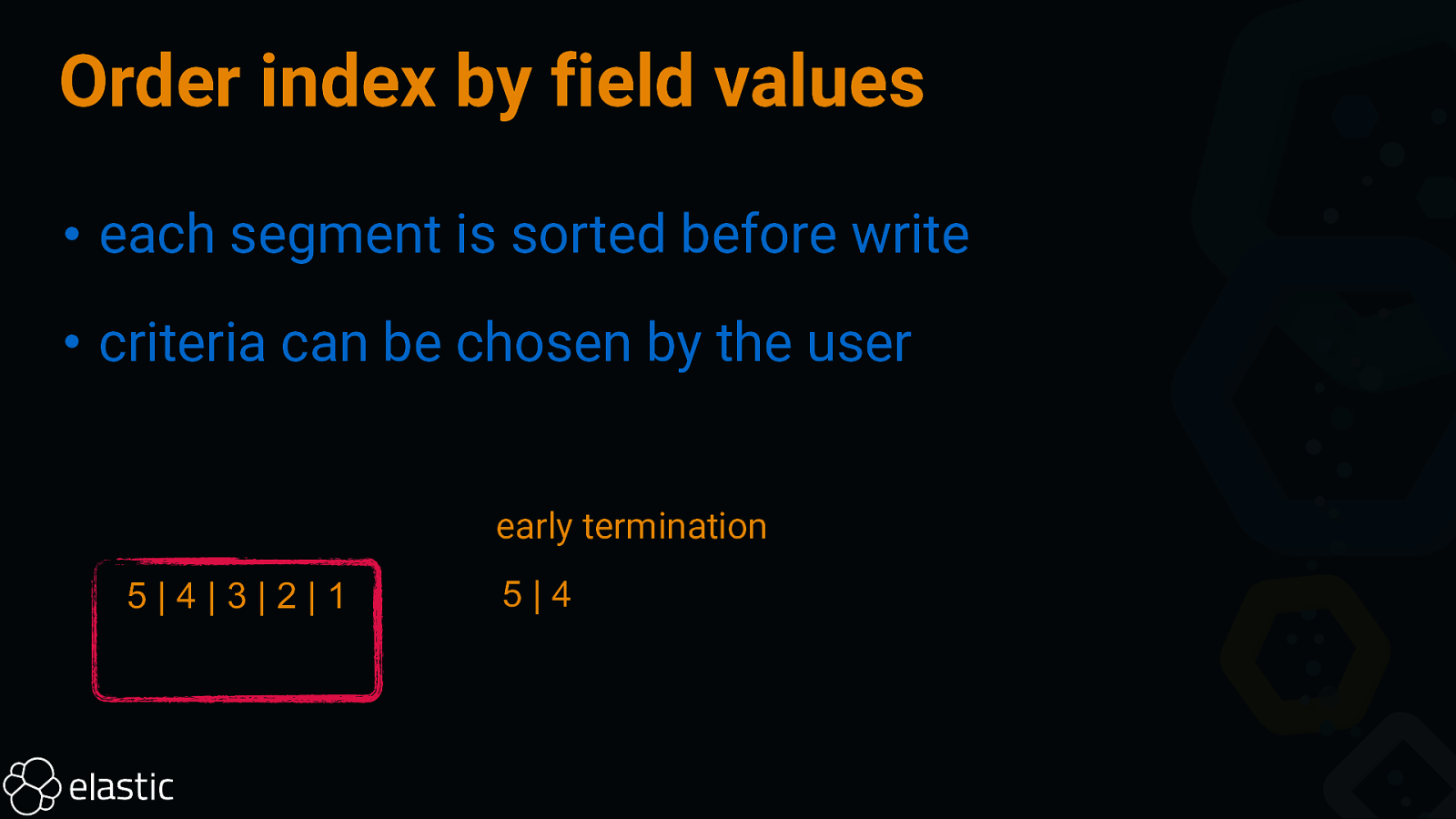
Order index by field values • each segment is sorted before write • criteria can be chosen by the user early termination 5|4|3|2|1 5|4

Aggregations Reducing data
Aggregations
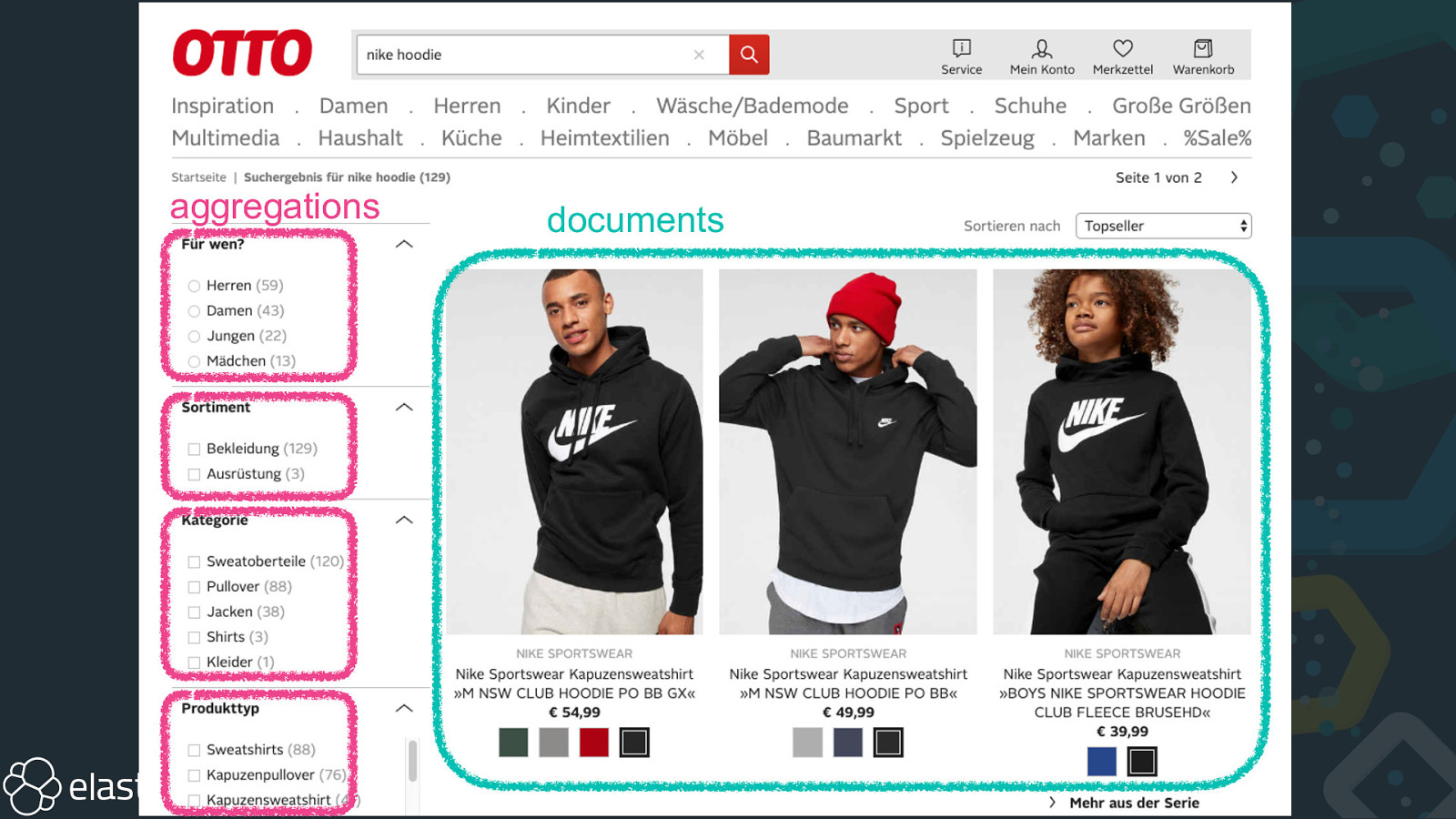
aggregations documents
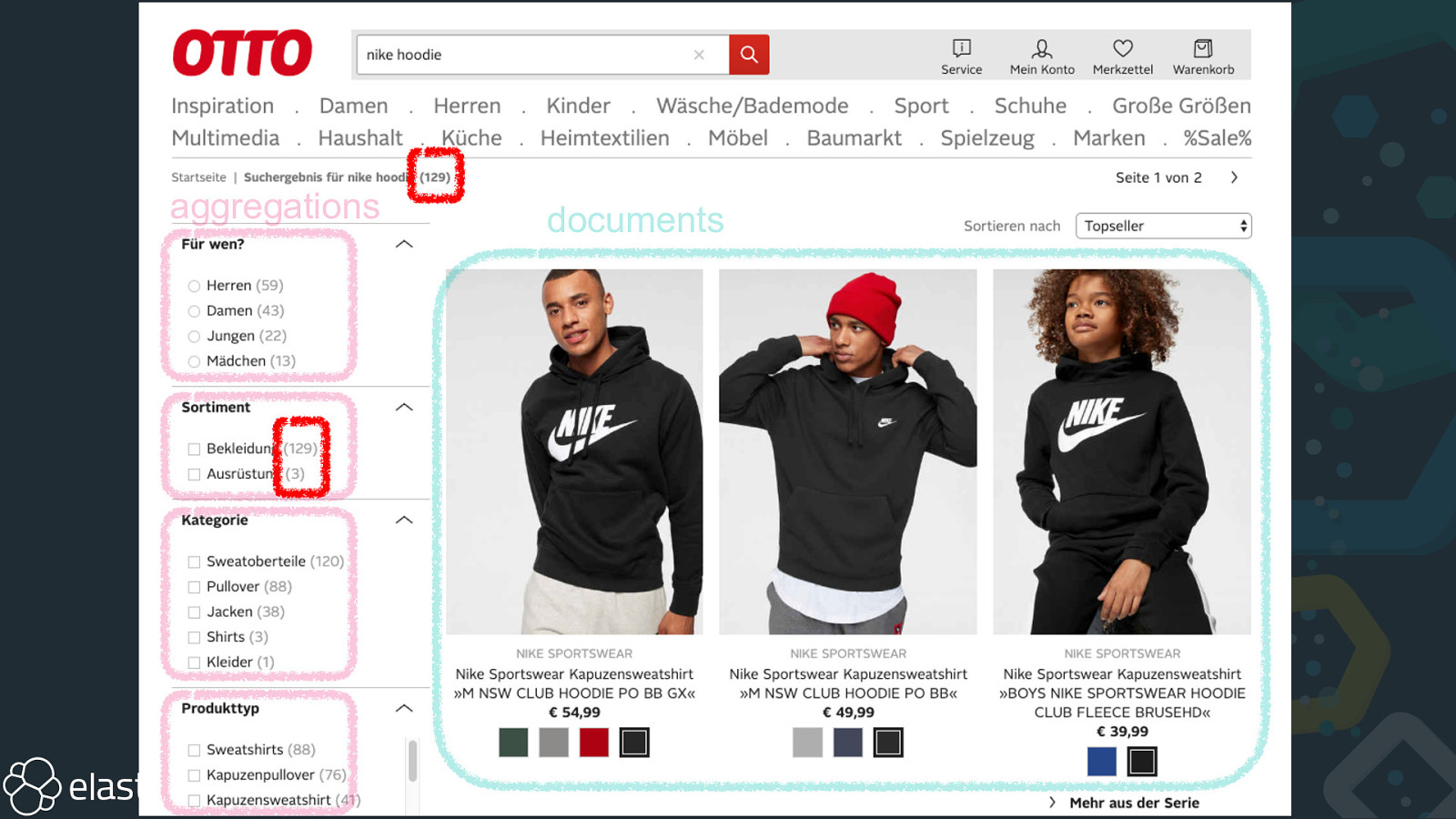
aggregations documents

Bucketing documents Pumps Sneakers Oxfords Sneakers Boots

Bucketing documents Sneakers Pumps Boots Oxfords

Bucketing documents Sneakers Pumps 2 bucket agg 1 metric agg doc_count Boots Oxfords 1 1

Bucketing documents Sneakers Pumps 50 bucket agg 95 metric agg avg price Boots Oxfords 90 23

Aggregations • bucket: terms, histogram, geo, range, sampler , significant text, nested • metric: value_count, avg, min, max, sum, stats, median deviation, geo, percentile, cardinality, • pipeline: min, max, sum, avg, derivative, stats, percentiles, cumulative sum, moving average, moving function, serial differencing

Distributed systems & search Fanning out a search, reducing the results

Elasticsearch
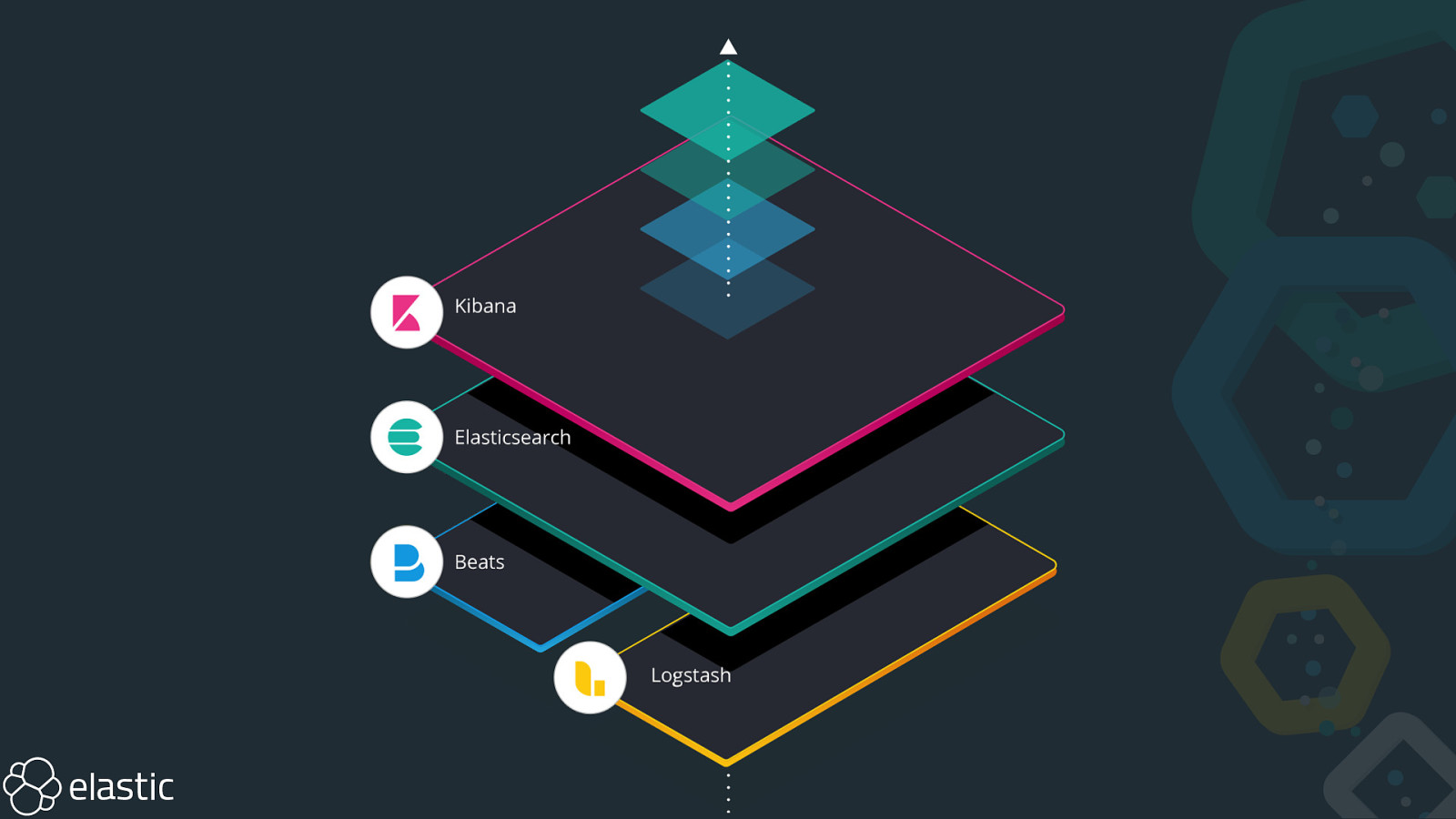

Elasticsearch in 10 seconds • Search Engine (FTS, Analytics, Geo), near real-time • Distributed, scalable, highly available, resilient • Interface: HTTP & JSON • Centrepiece of the Elastic Stack • Uneducated conservative guess: Tens of thousands of clusters worldwide, hundreds of thousands of instances

Distributed systems

Distributed systems • How do nodes communicate with each other? • Who is taking and executing decisions? • Failure detection? • Replication strategy? • Consistency? • Enter consensus algorithms…

A fundamental problem in distributed computing and multi-agent systems is to achieve overall system reliability in the presence of a number of faulty processes. This often requires processes to agree on some data value that is needed during computation https://en.wikipedia.org/wiki/Consensus_(computer_science) 113

Consensus algorithms • Leader based: Paxos, Raft • Non leader based: BTC, gossip

Consensus in Elasticsearch • Custom consensus algorithm, improving the existing one • Formally verified • Optimized for Elasticsearch use-case (rolling restarts, growing/shrinking clusters, log-ofoperations vs. cluster state)
Consensus in Elasticsearch node 1 node 2 node 3 node 4
Consensus in Elasticsearch node 1 node 2 node 3 node 4

Consensus in Elasticsearch node 1 node 2 node 3 node 4
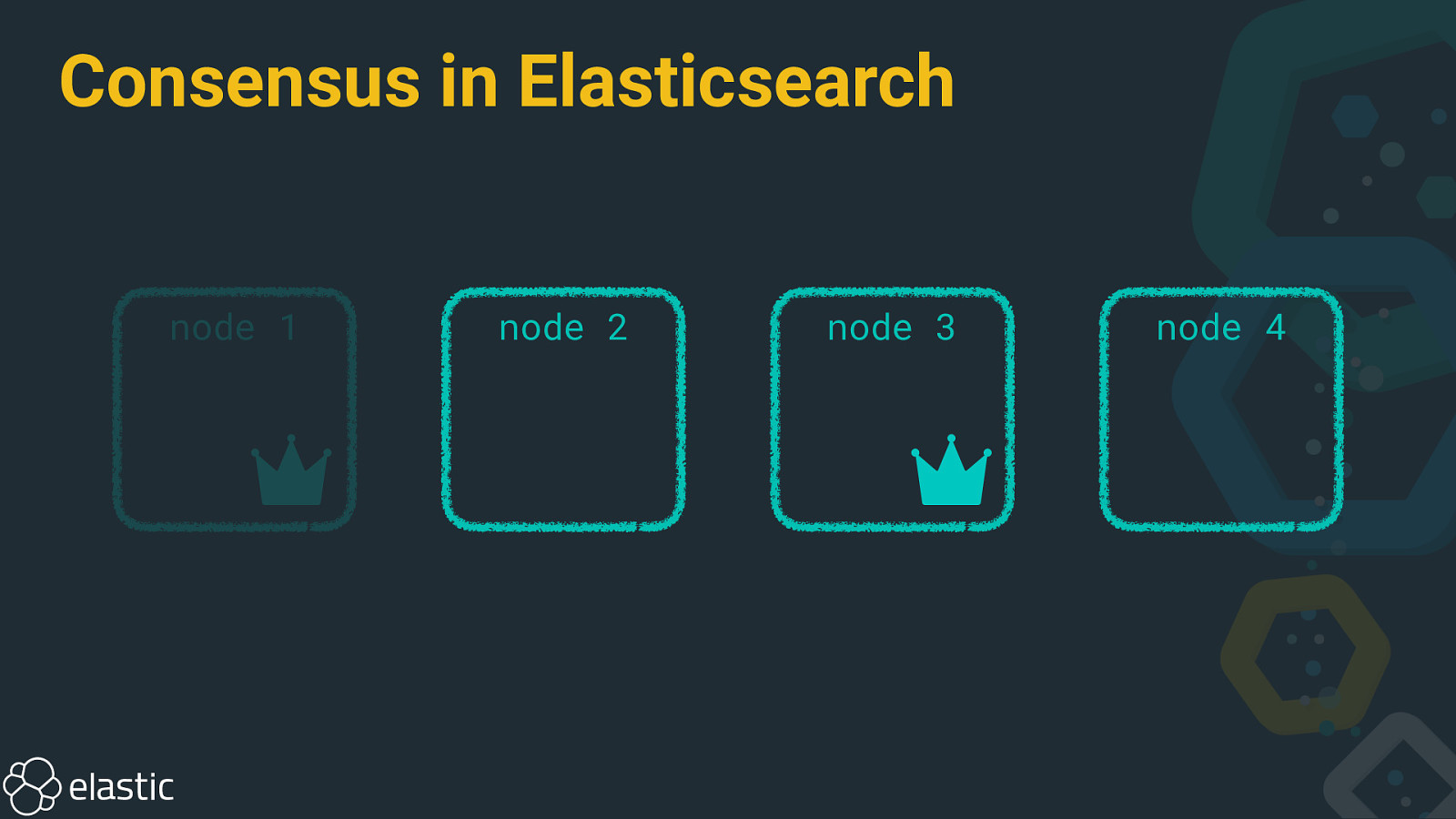
Consensus in Elasticsearch node 1 node 2 node 3 node 4

Master node tasks • Deciding where data should be stored • Pinging other nodes • Reacting on node leaves/joins • Updating cluster state • Distributing cluster state
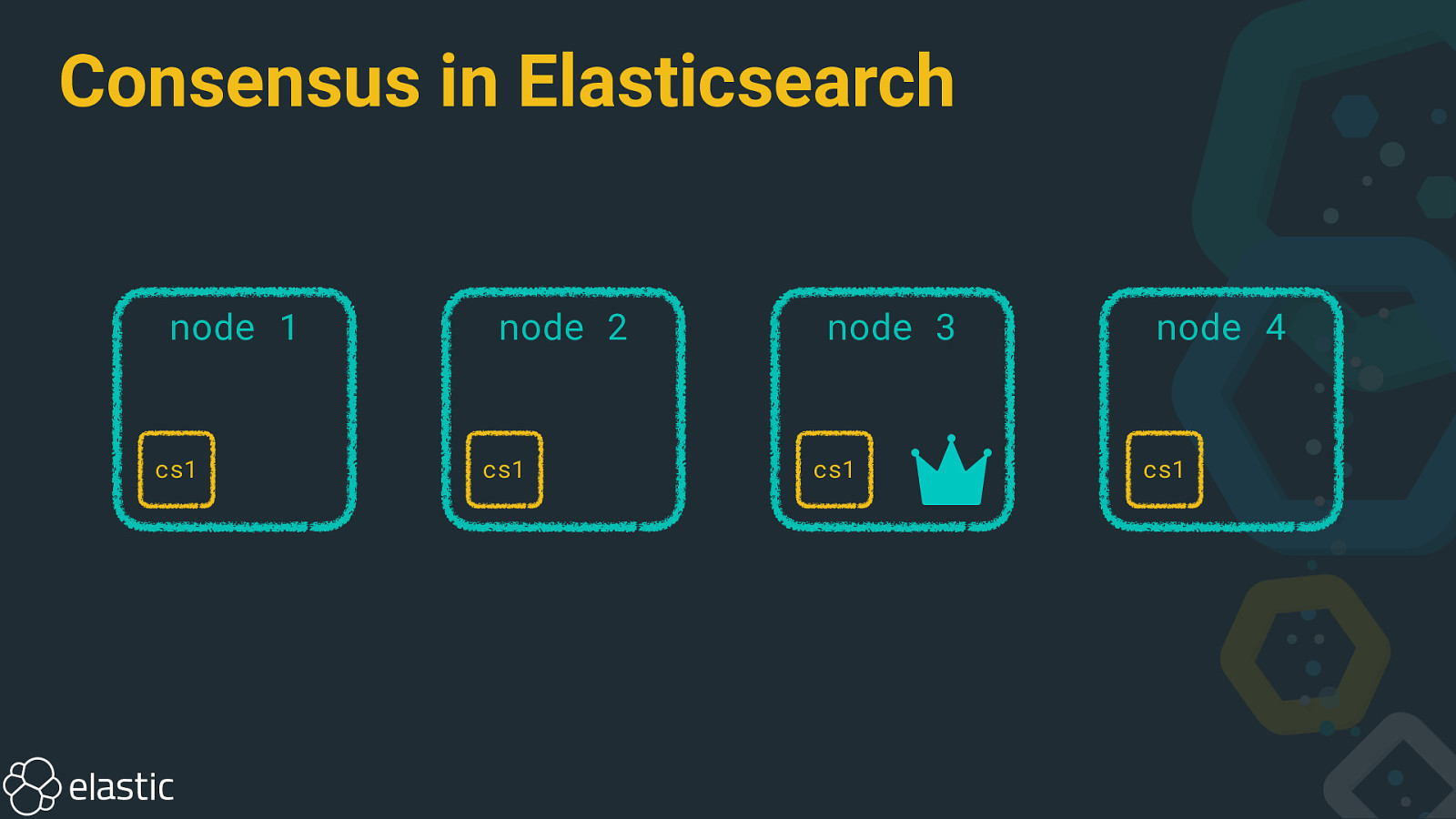
Consensus in Elasticsearch node 1 cs1 node 2 cs1 node 3 cs1 node 4 cs1
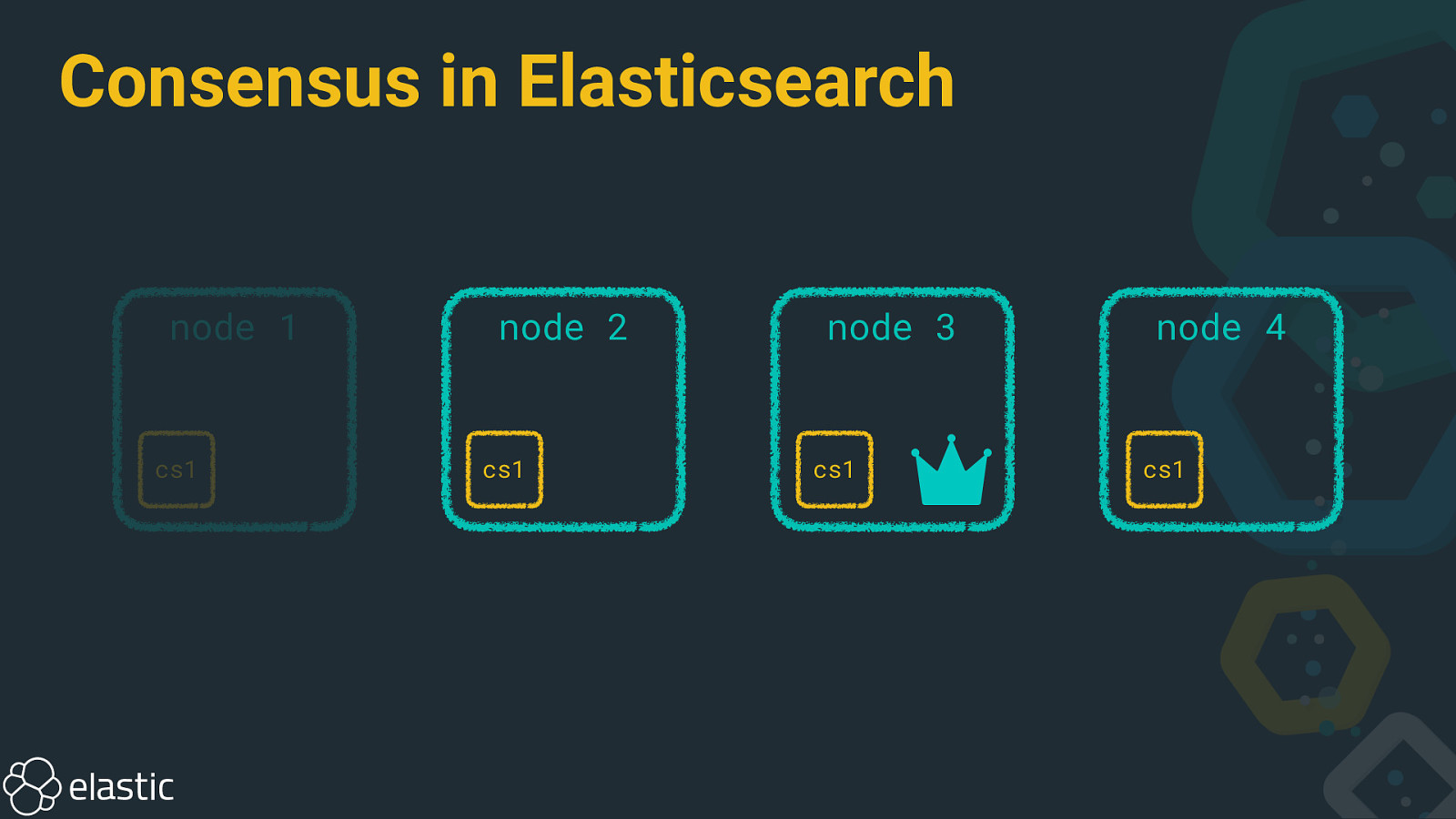
Consensus in Elasticsearch node 1 cs1 node 2 cs1 node 3 cs1 node 4 cs1
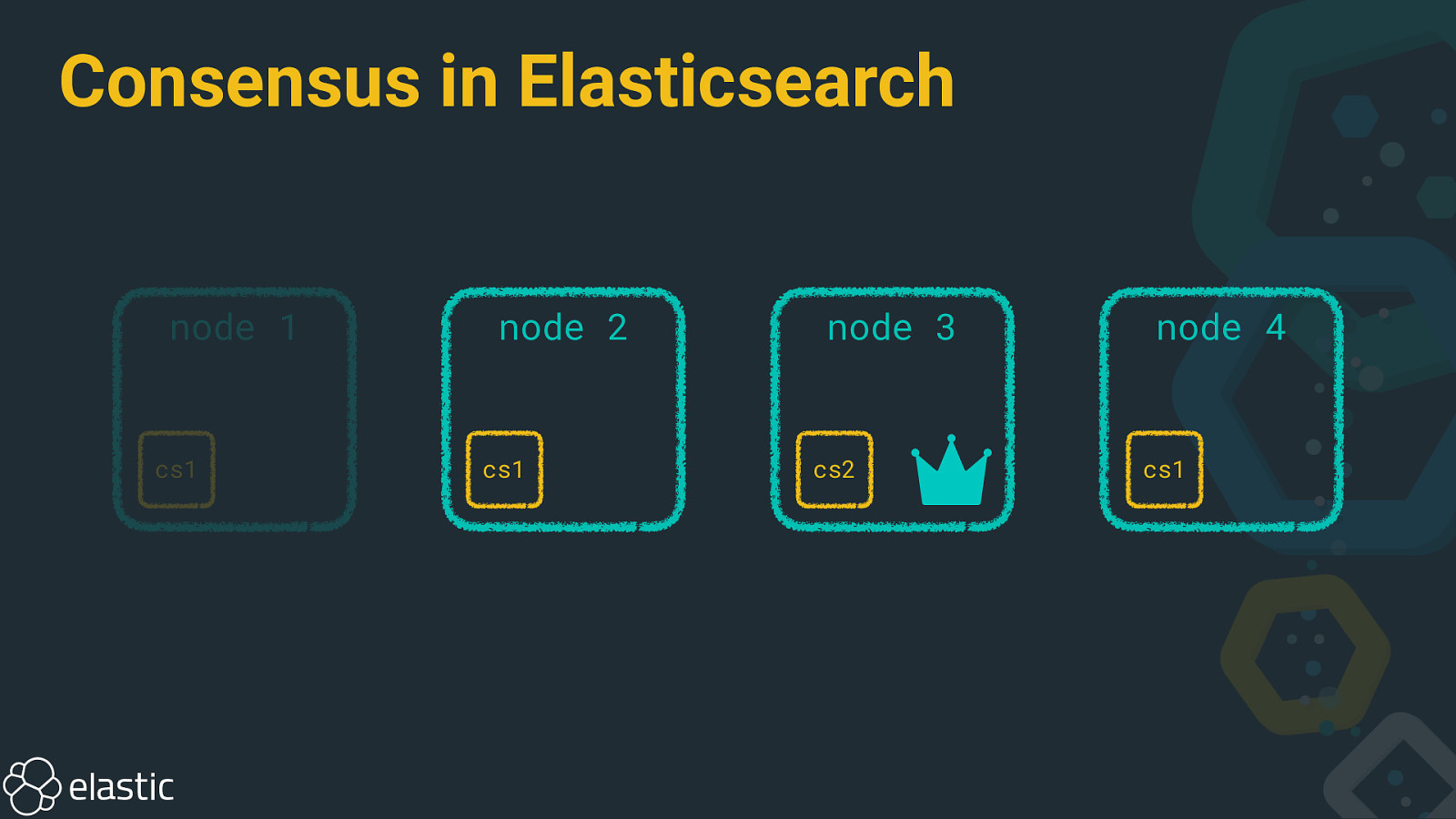
Consensus in Elasticsearch node 1 cs1 node 2 cs1 node 3 cs2 node 4 cs1
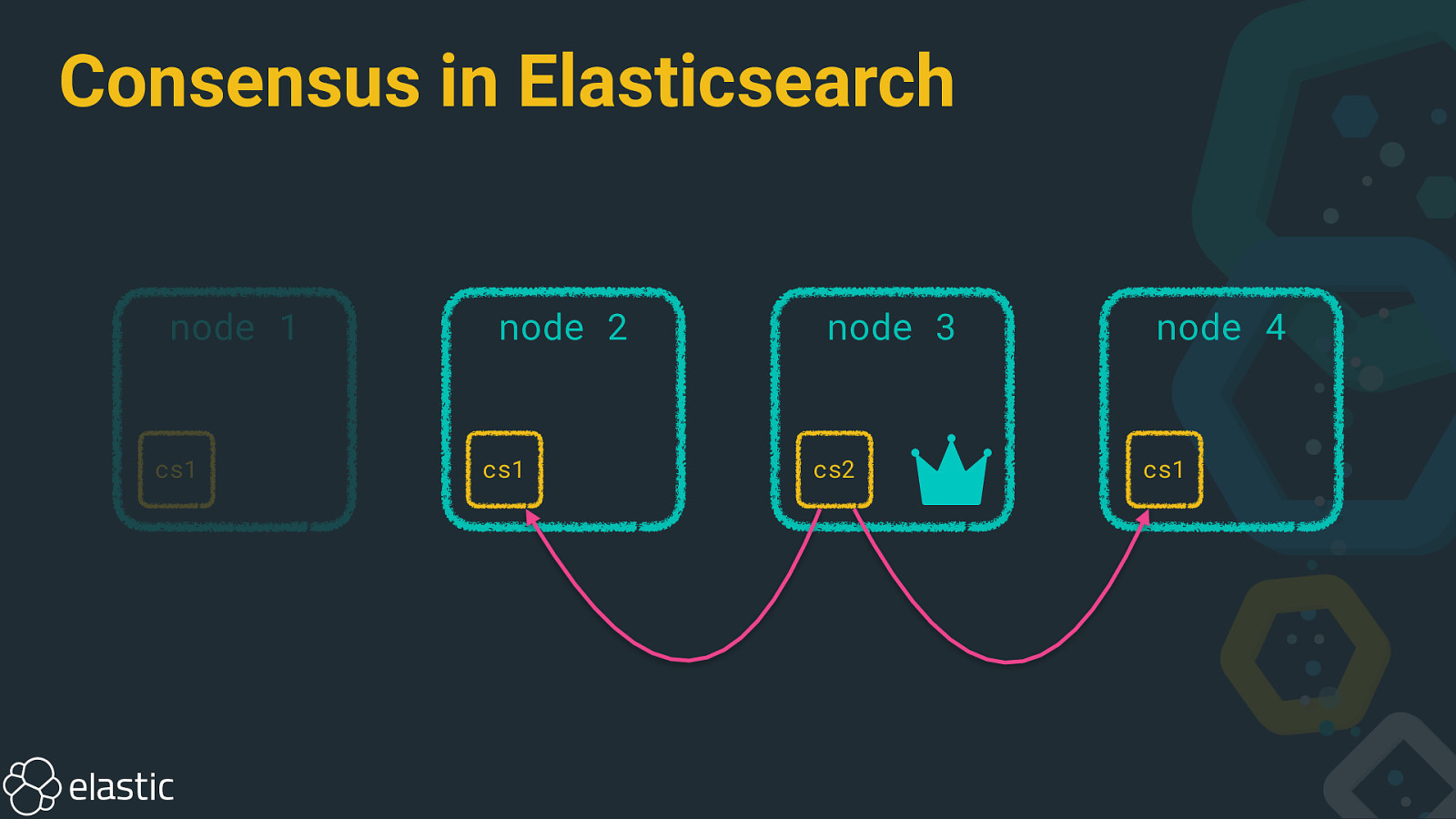
Consensus in Elasticsearch node 1 cs1 node 2 cs1 node 3 cs2 node 4 cs1
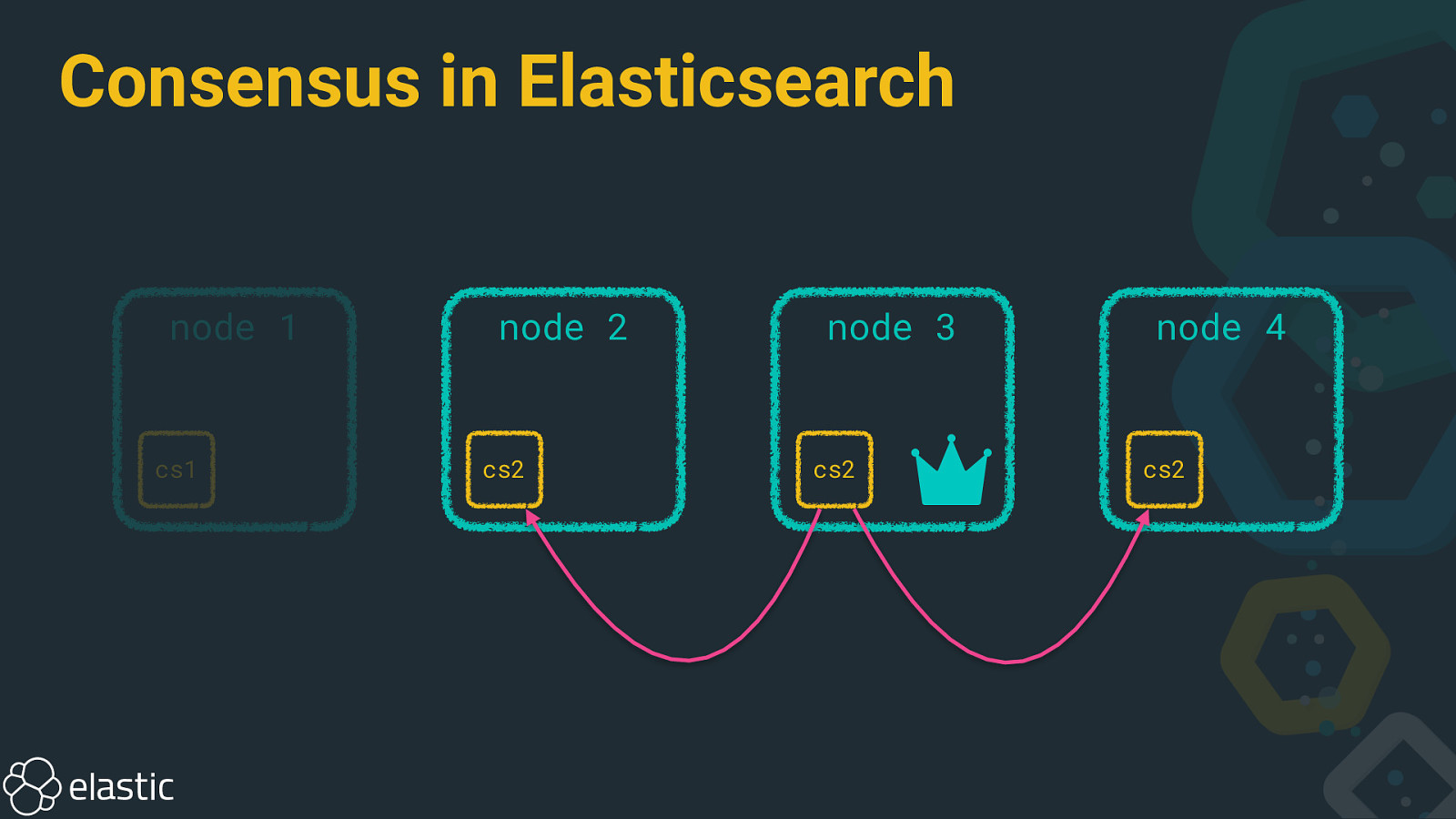
Consensus in Elasticsearch node 1 cs1 node 2 cs2 node 3 cs2 node 4 cs2

Distributed search

Distributed search in Elasticsearch node 1 node 2 node 3 p0 Primary Shard (Lucene Index) node 4

Distributed search in Elasticsearch node 1 p0 node 2 r0 Replica shard (copy) node 3 node 4
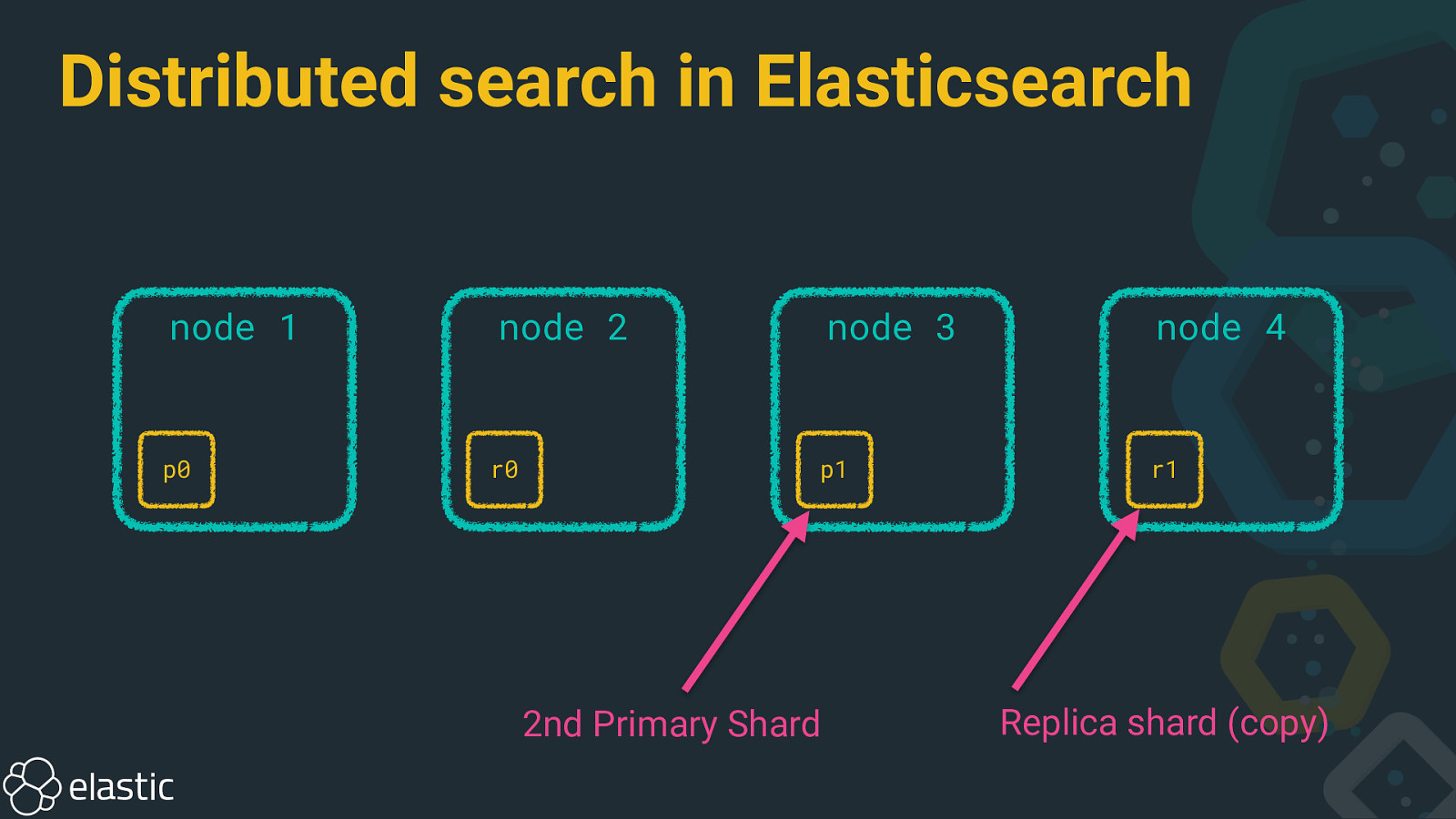
Distributed search in Elasticsearch node 1 p0 node 2 r0 node 3 node 4 p1 r1 2nd Primary Shard Replica shard (copy)

Distributed search in Elasticsearch • Shard: Lucene index, unit of scale • Primary shard: Write scalability • Replica shard: Read scalability, availability
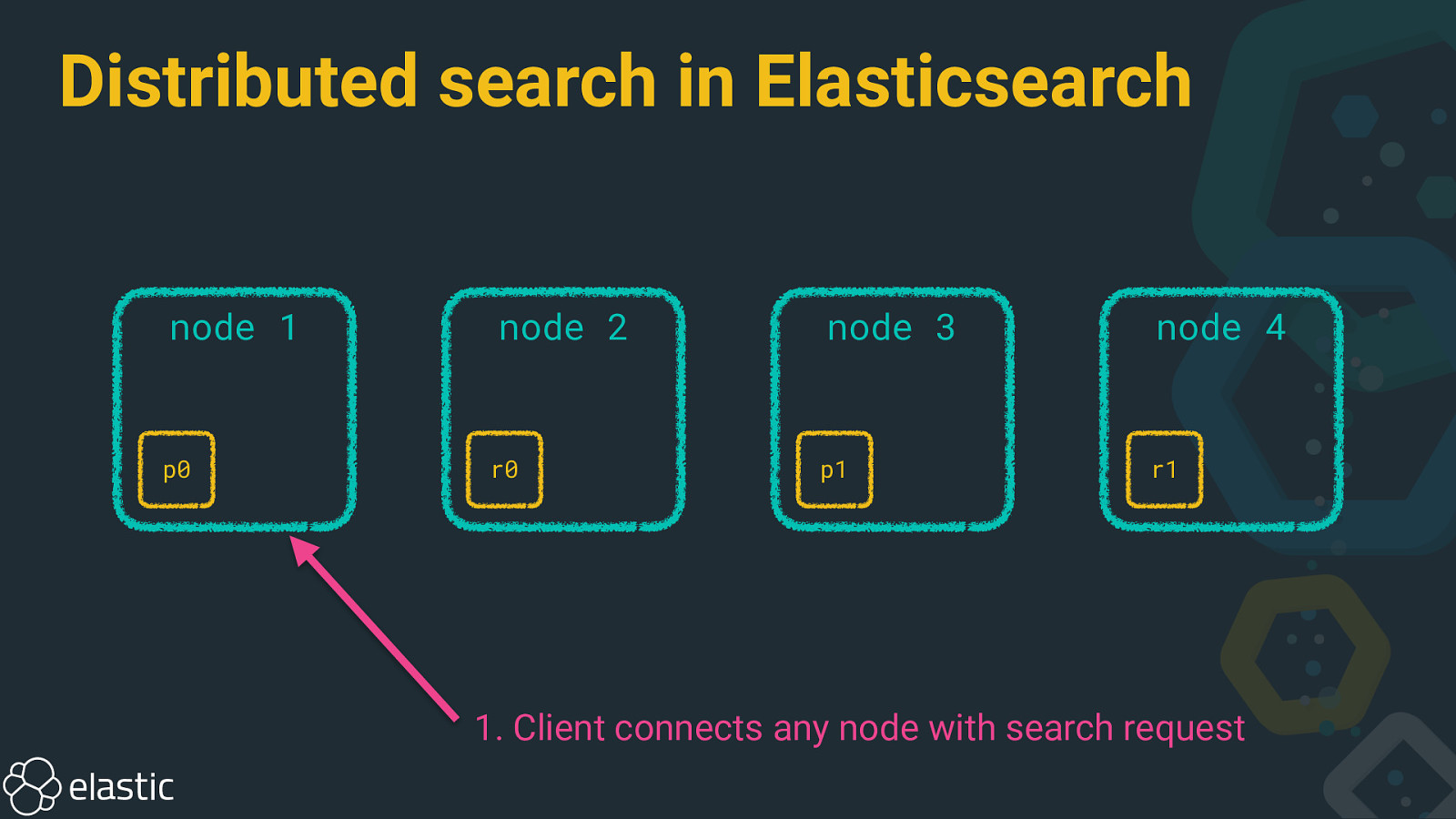
Distributed search in Elasticsearch node 1 p0 node 2 r0 node 3 node 4 p1 r1
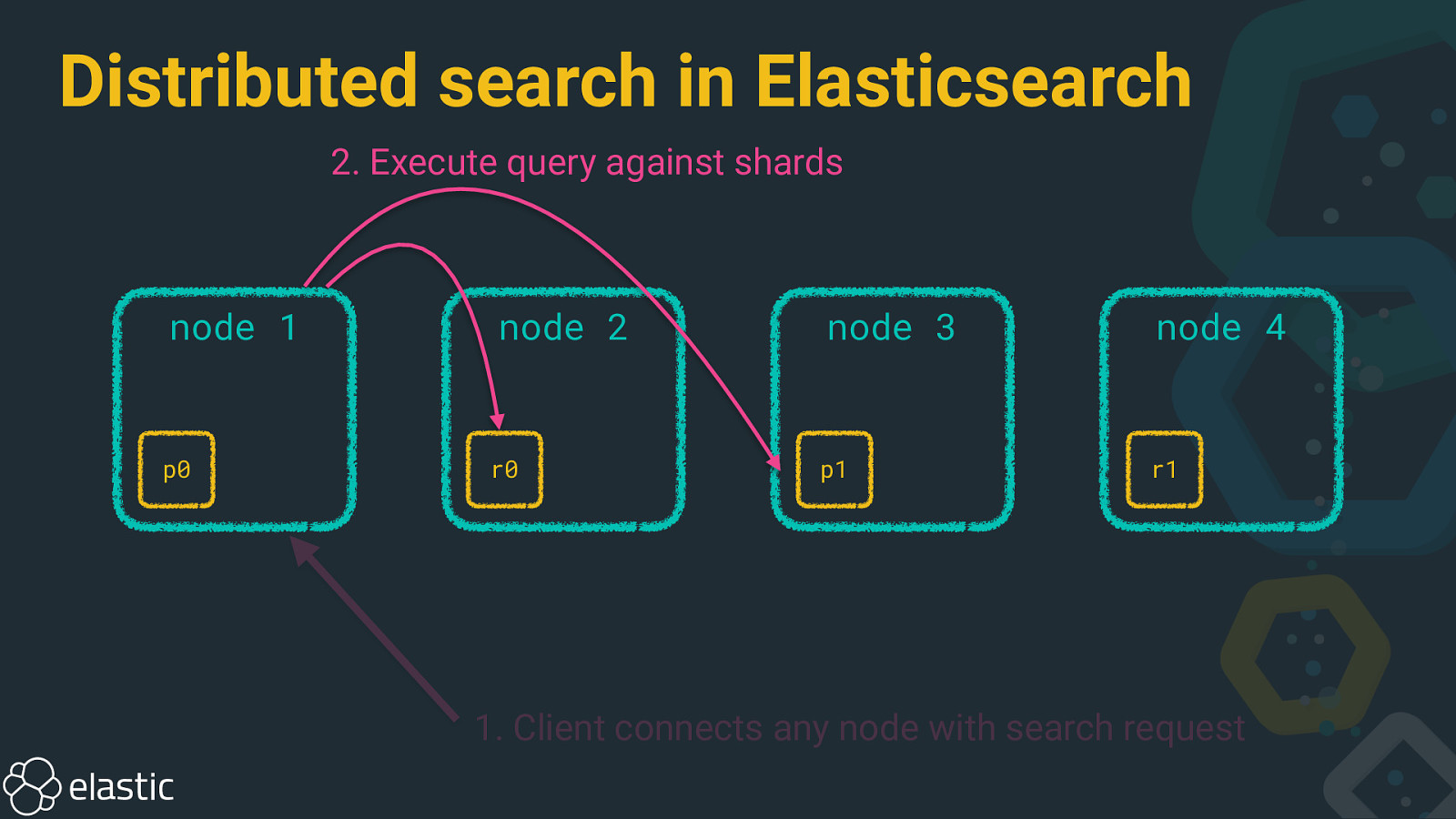
Distributed search in Elasticsearch 2. Execute query against shards node 1 p0 node 2 r0 node 3 node 4 p1 r1
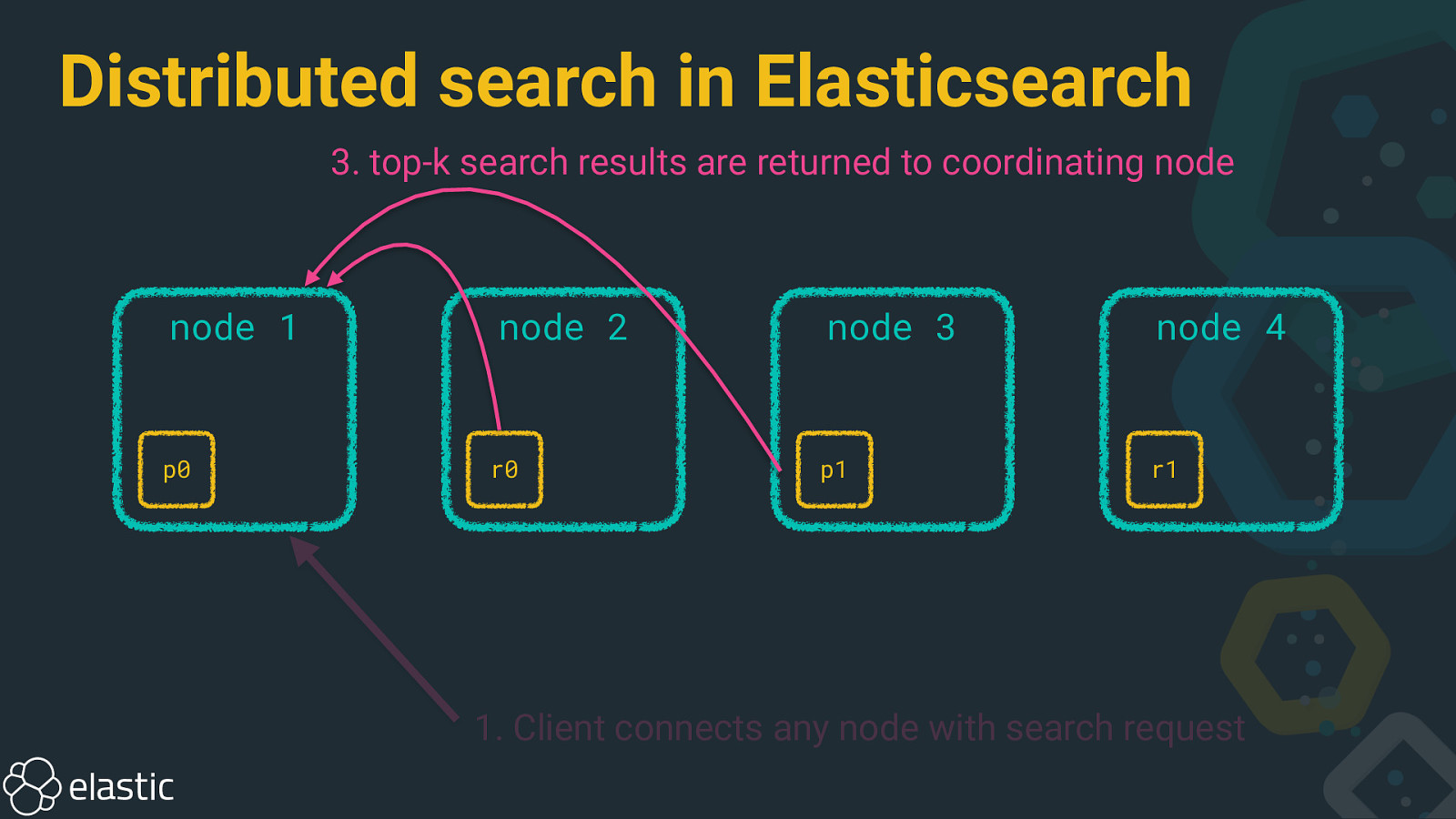
Distributed search in Elasticsearch 3. top-k search results are returned to coordinating node node 1 p0 node 2 r0 node 3 node 4 p1 r1
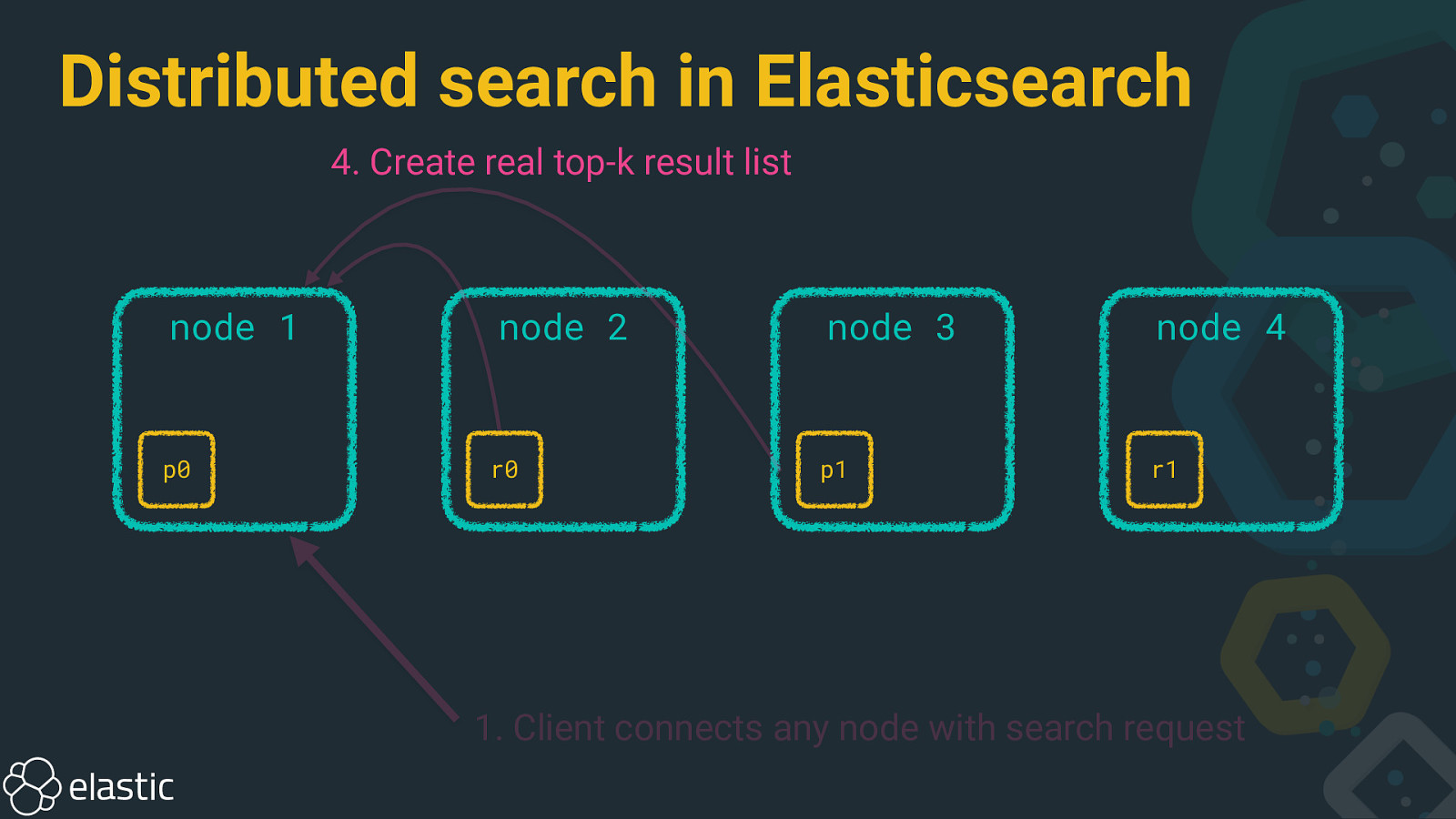
Distributed search in Elasticsearch 4. Create real top-k result list node 1 p0 node 2 r0 node 3 node 4 p1 r1
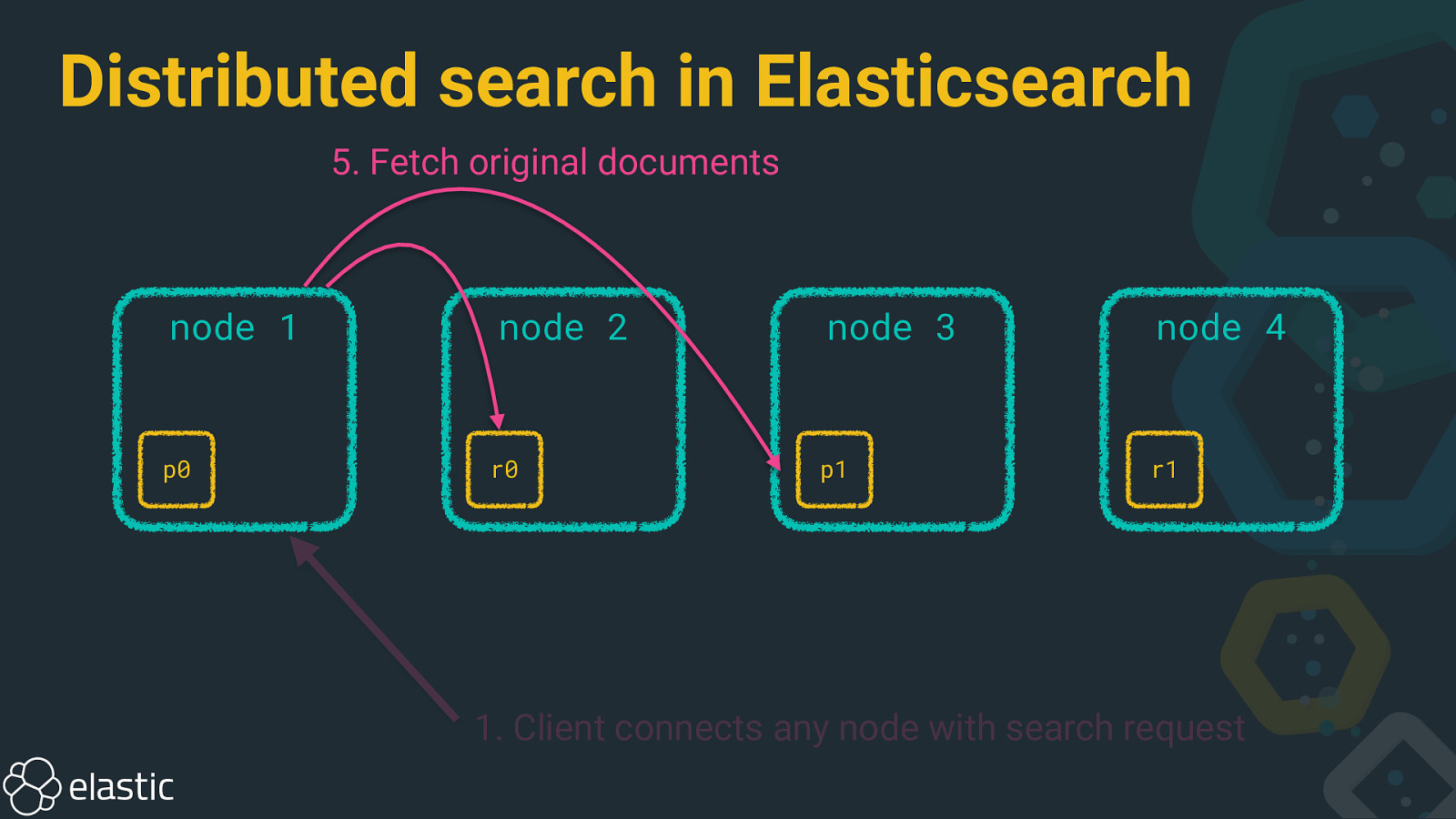
Distributed search in Elasticsearch 5. Fetch original documents node 1 p0 node 2 r0 node 3 node 4 p1 r1
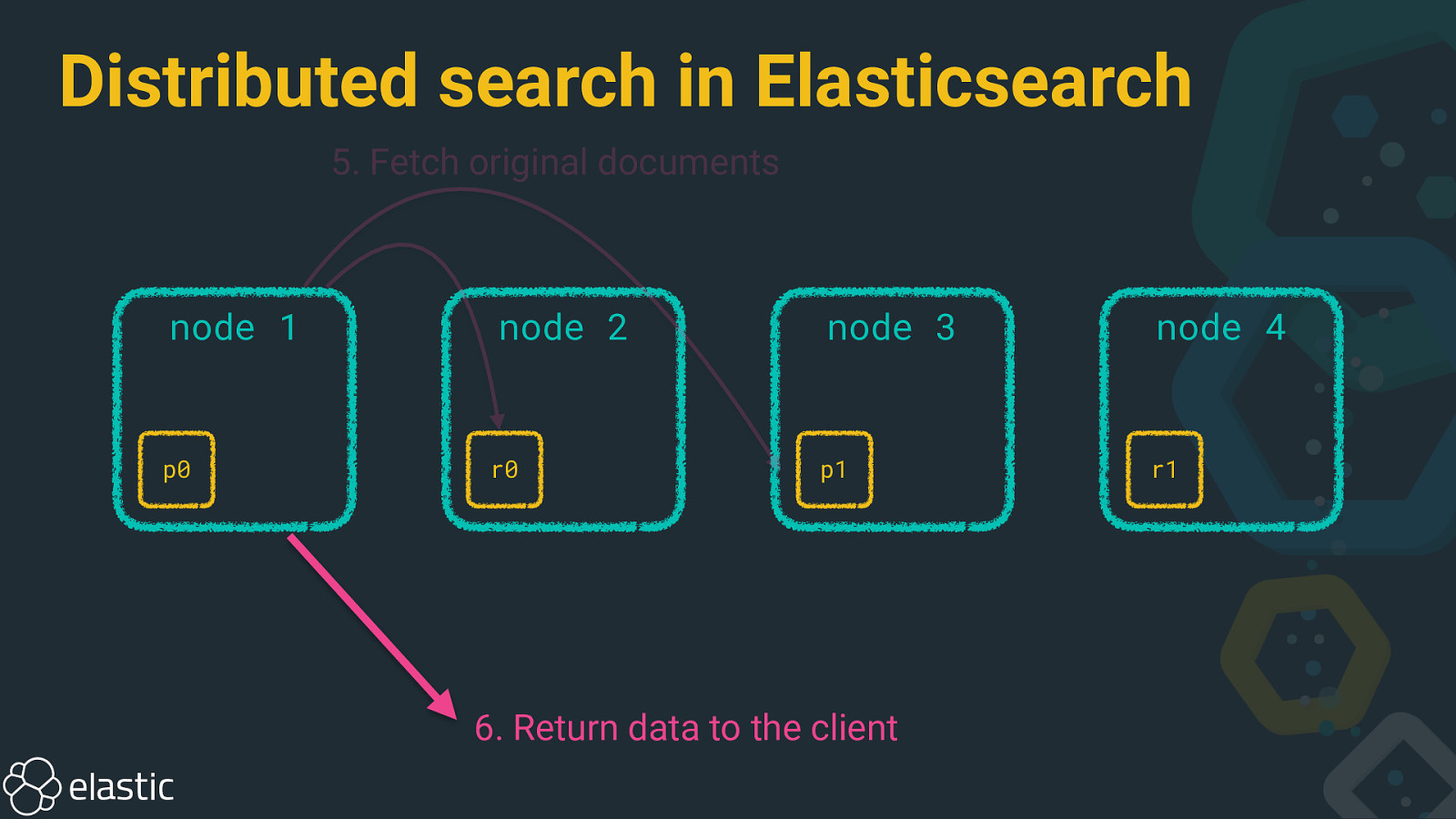
Distributed search in Elasticsearch 5. Fetch original documents node 1 p0 node 2 r0 node 3 node 4 p1 r1 6. Return data to the client

Aggregations

Aggregations - cardinality node 1 p0 node 2 p1 POST /sales/_search?size=0 { “aggs” : { “type_count” : { “cardinality” : { “field” : “type” } } } }
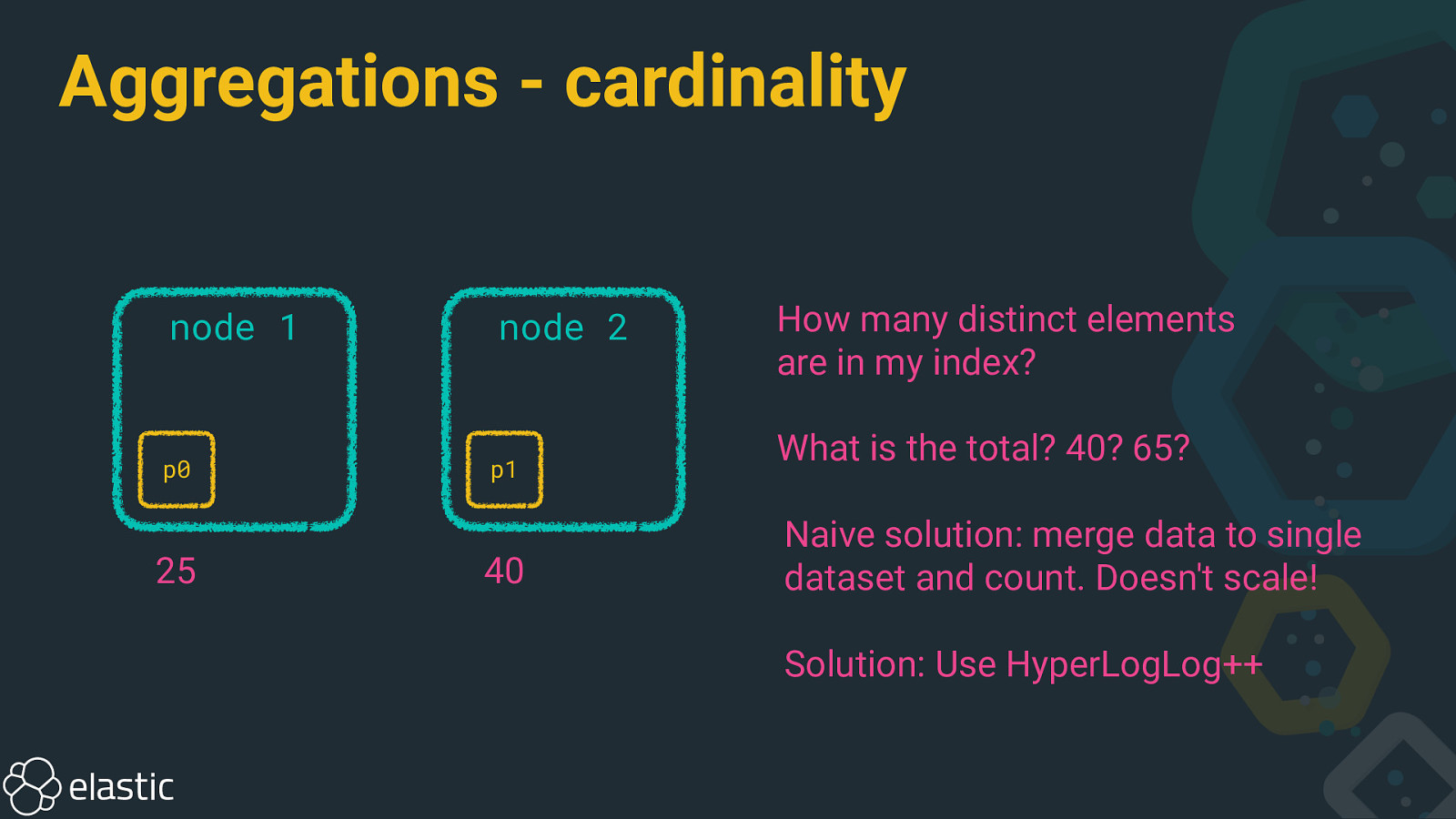
Aggregations - cardinality node 1 p0 25 node 2 p1 40 How many distinct elements are in my index? What is the total? 40? 65? Naive solution: merge data to single dataset and count. Doesn’t scale! Solution: Use HyperLogLog++

HyperLogLog++ • Hash based counting • Trades in memory for accuracy • Fixed memory usage, based on configurable precision • Result: Small mergeable data structure, can easily be sent over the network

Aggregations - percentile node 1 p0 node 2 p1 GET latency/_search { “size”: 0, “aggs” : { “load_time_outlier” : { “percentiles” : { “field” : “load_time” } } } }

T-Digest • Extreme percentiles are more accurate than the Median • Percentiles are divided into buckets • When buckets grow over a boundary, approximation kicks in, saving memory in the process • The exact level of inaccuracy is difficult to generalize • Alternative: HDR histograms

Probabilistic data structures • bloom/cuckoo/quotient filters (membership check) • HyperLogLog++ (cardinality) • T-Digest, DDSketch, HDR histogram (percentile) • Count-Min sketch (frequency, top-k) • Hashing (similarity)
Demo Try it out yourself! https://ela.st/jade-hochschule-samples

Elastic Cloud Free 30 day trial https://ela.st/university-wilhelmshaven
Upcoming trends & summary … or why you should take a closer look at search

Search is not just google… • “Just google it” does not cut it • Enterprise search: Intranet/G-Drive/Dropbox • Ecommerce search • SIEM • Observability: Logging, APM & Metrics

Search is not ‘done’ • Constant improvement • Data structures & algorithms (BKD tree for geo shapes) • Academic research moves to industry thanks to Apache Lucene

Search is still tough • Language specific analysis • Smart query parsing (nike red hoodie xl) • Geo based search • Anomaly detection • Incoporating feedback loops

Upcoming trends • Learning-to-Rank • Deep Learning • Feedback loop

Summary • Everything is a search problem! • Search is hard… and interesting • Distributed systems are hard… and interesting • Domain knowledge required • Data keeps exploding, good job chances!

Literature Books, books, books


Resources Links, links, links

Links https://lucene.apache.org/core/8_2_0/core/org/apache/lucene/search/similarities/ TFIDFSimilarity.html https://www.elastic.co/blog/whats-new-in-lucene-8 https://www.elastic.co/blog/faster-retrieval-of-top-hits-in-elasticsearch-with-block-max-wand https://speakerdeck.com/elastic/amusing-algorithms-and-data-structures https://www.elastic.co/blog/index-sorting-elasticsearch-6-0 https://raft.github.io/ https://github.com/elastic/elasticsearch-formal-models https://gist.github.com/spinscale/b62c8b357fae7db3f14b7d3127758951

Links - probabilistic data structures https://github.com/addthis/stream-lib https://github.com/DataDog/sketches-java https://github.com/HdrHistogram/HdrHistogram https://github.com/JohnStarich/java-skip-list https://github.com/addthis/stream-lib https://static.googleusercontent.com/media/research.google.com/fr/ pubs/archive/40671.pdf
Q&A Alexander Reelsen alex@elastic.co @spinscale