@redpilla @stewartbryson

A presentation at UKOUG Techfest 2019 in December 2019 in Brighton, UK by Stewart Bryson

@redpilla @stewartbryson

Founder & CEO Red Pill Analytics twitter: @stewartbryson medium: @stewartbryson linkedin: stewartbryson




Partnerships Data Warehouse Analytics ANALYTICS @redpilla Data-engineering & ETL

https://medium.com/free-code-camp/the-rise-of-the-data-engineer-91be18f1e603 @redpilla We’re hiring. @stewartbryson

@redpilla @stewartbryson “There’s a multitude of reasons why complex pieces of software are not developed using drag and drop tools: it’s that ultimately code is the best abstraction there is for software.” Maxime Beauchemin, The Rise of the Data Engineer, Jan 20, 2017

@redpilla @stewartbryson

What’s so different about ETL? @redpilla @stewartbryson

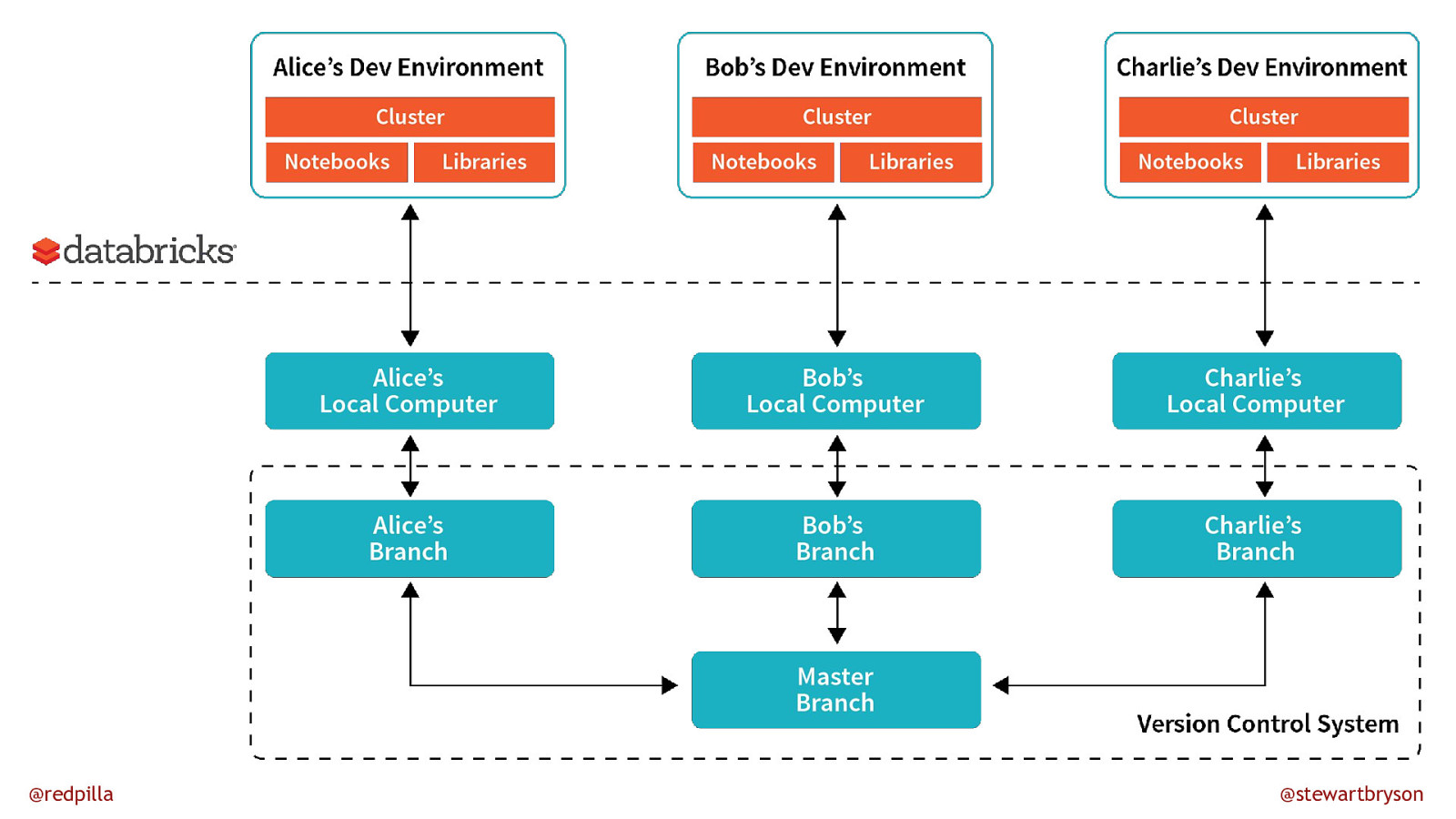
Code versus Clicks Source control CI/CD Collaboration Code anywhere @redpilla Faster Easier to start Any discipline Business friendly @stewartbryson

Assumption: Code is better, but harder. @redpilla @stewartbryson
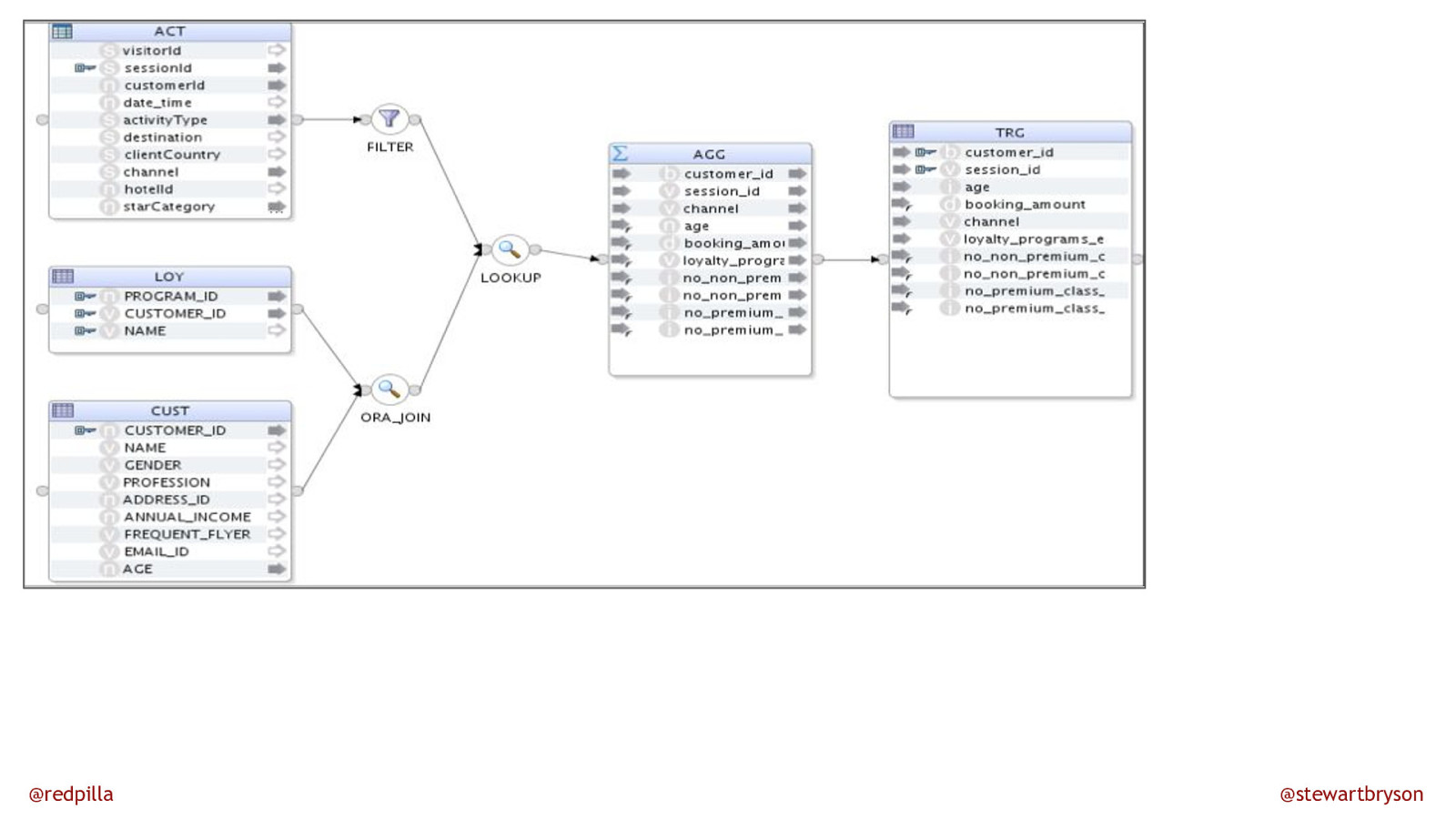
@redpilla @stewartbryson
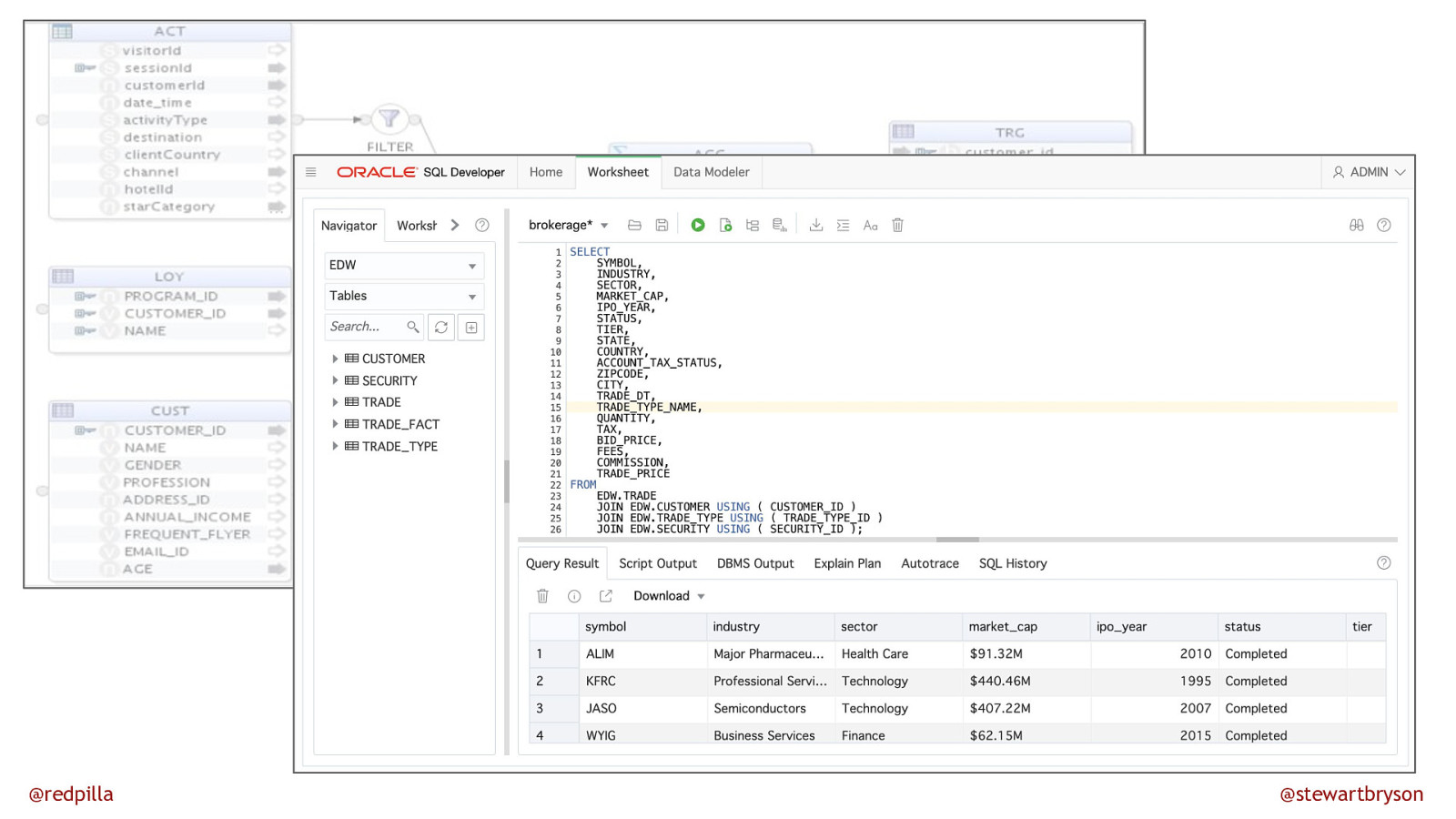
@redpilla @stewartbryson
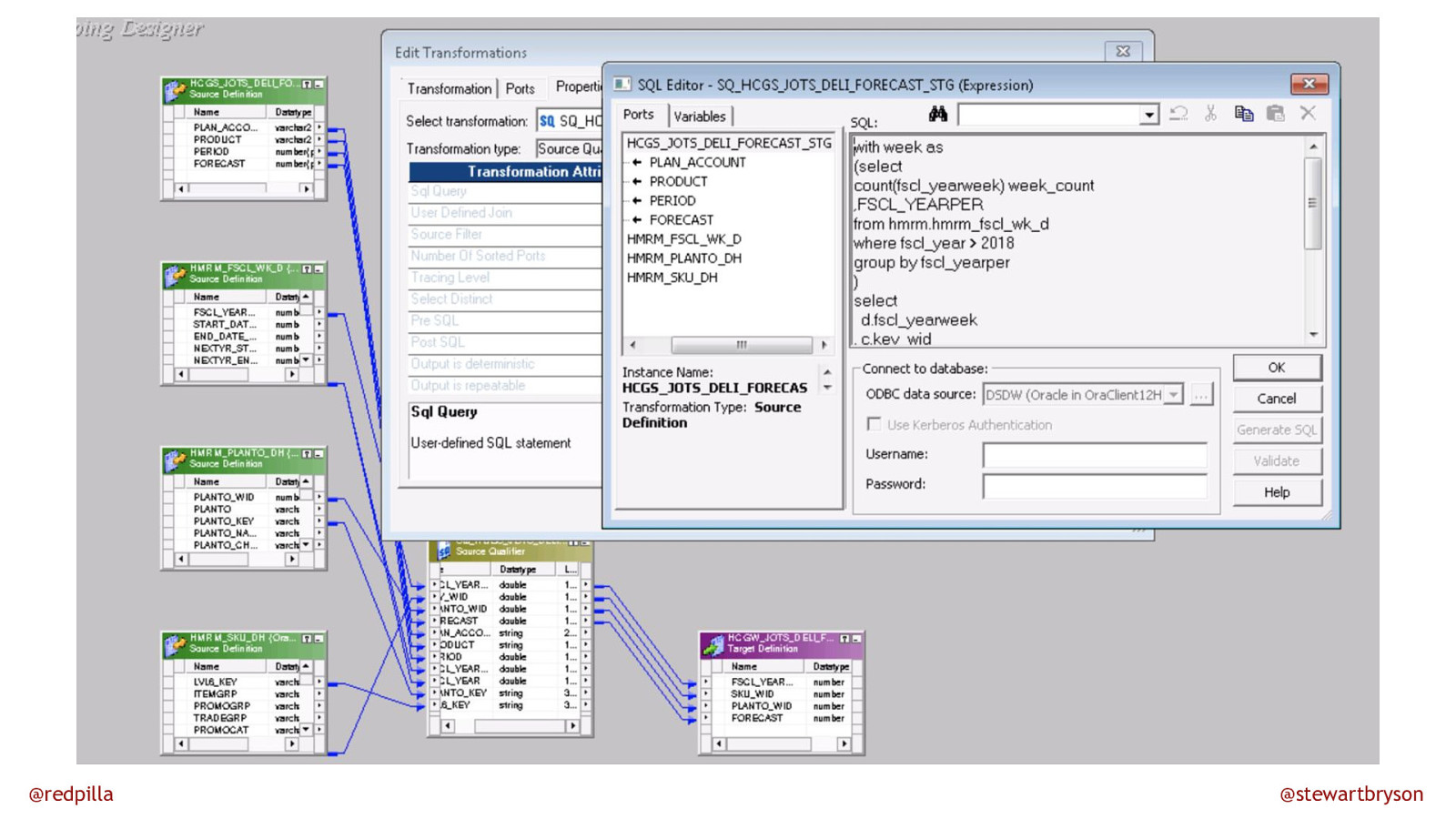
@redpilla @stewartbryson
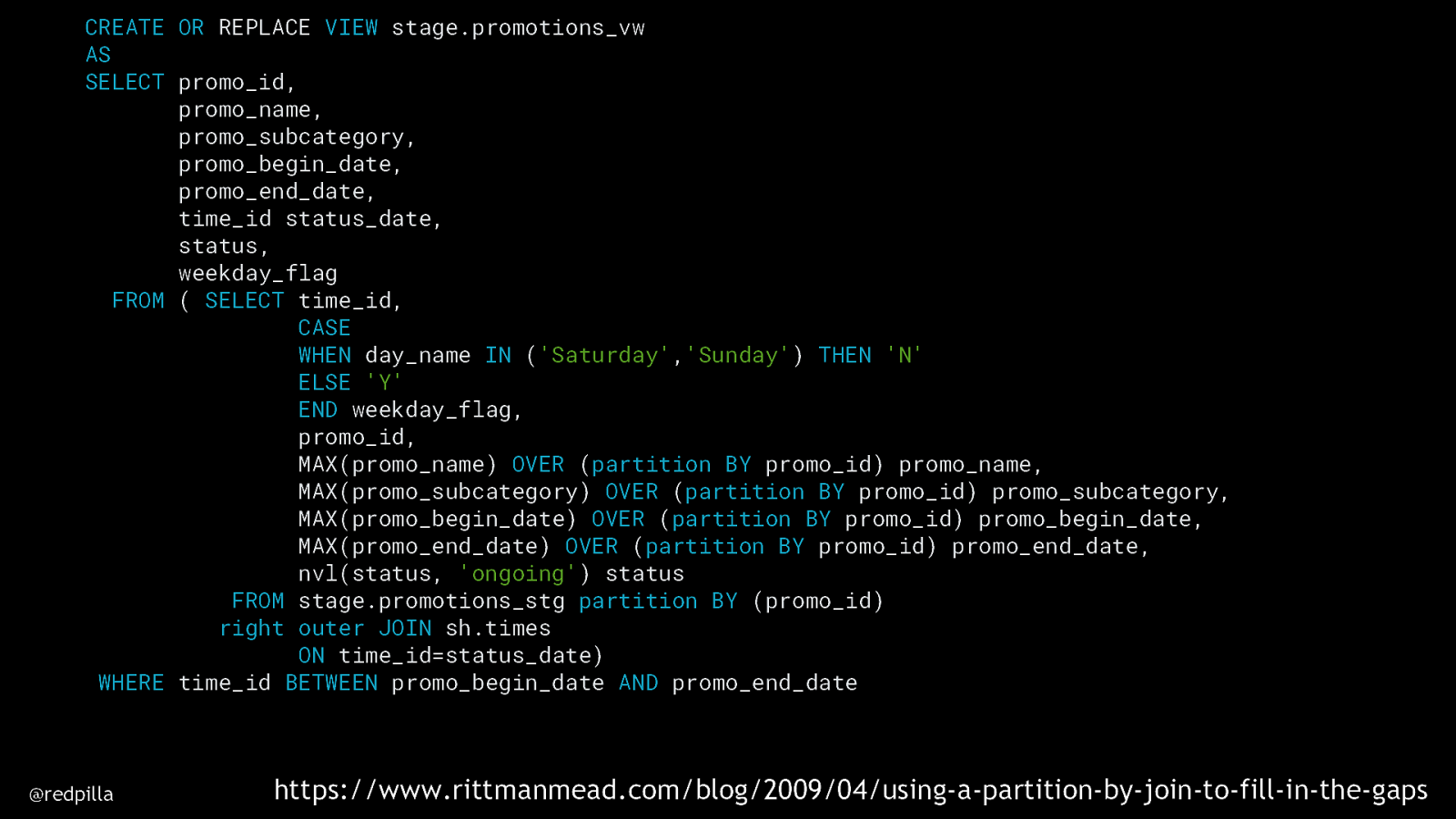
CREATE OR REPLACE VIEW stage.promotions_vw AS SELECT promo_id, promo_name, promo_subcategory, promo_begin_date, promo_end_date, time_id status_date, status, weekday_flag FROM ( SELECT time_id, CASE WHEN day_name IN (‘Saturday’,’Sunday’) THEN ‘N’ ELSE ‘Y’ END weekday_flag, promo_id, MAX(promo_name) OVER (partition BY promo_id) promo_name, MAX(promo_subcategory) OVER (partition BY promo_id) promo_subcategory, MAX(promo_begin_date) OVER (partition BY promo_id) promo_begin_date, MAX(promo_end_date) OVER (partition BY promo_id) promo_end_date, nvl(status, ‘ongoing’) status FROM stage.promotions_stg partition BY (promo_id) right outer JOIN sh.times ON time_id=status_date) WHERE time_id BETWEEN promo_begin_date AND promo_end_date @redpilla https://www.rittmanmead.com/blog/2009/04/using-a-partition-by-join-to-fill-in-the-gaps
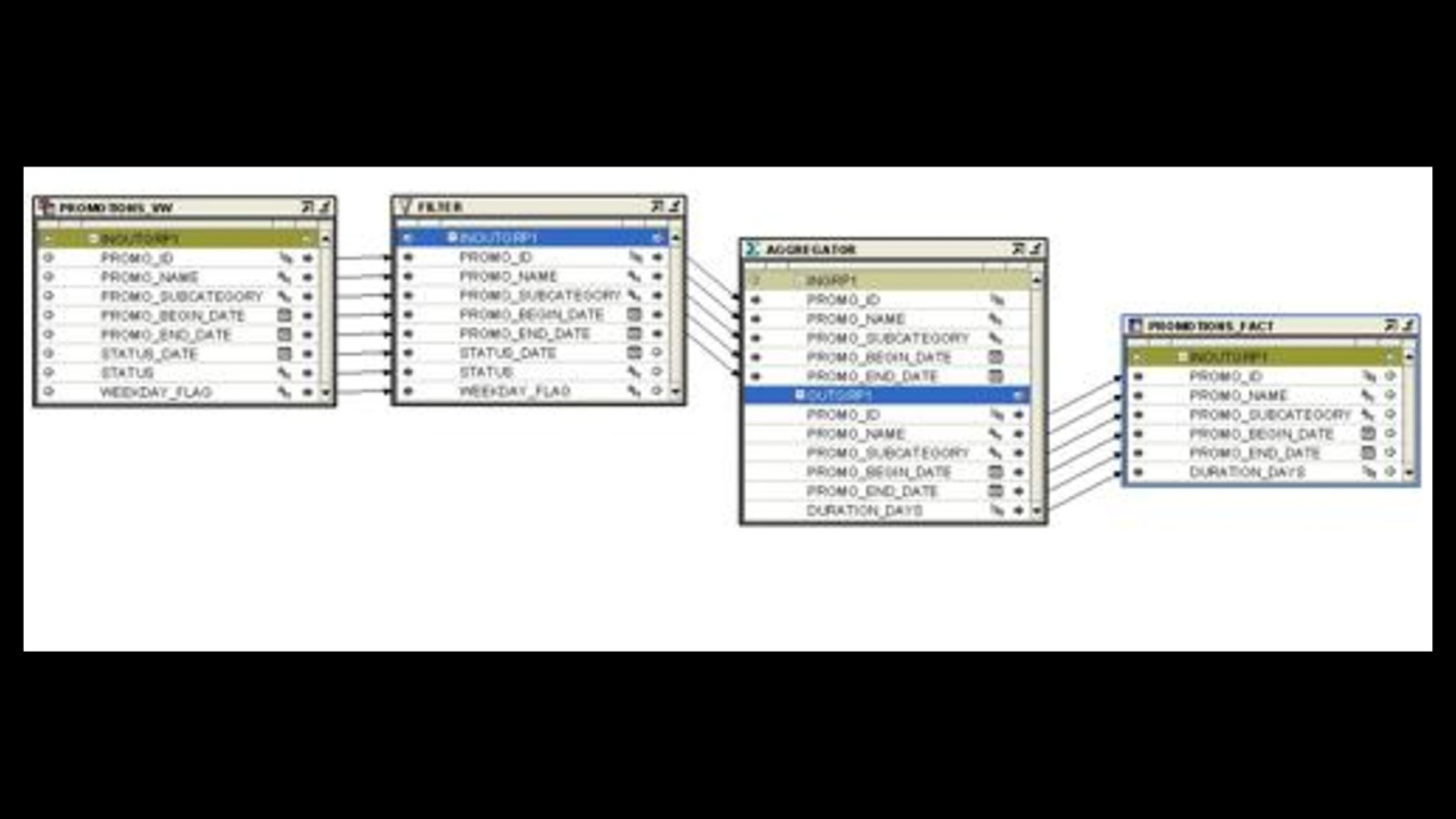
@redpilla @stewartbryson https://www.rittmanmead.com/blog/2009/04/using-a-partition-by-join-to-fill-in-the-gaps
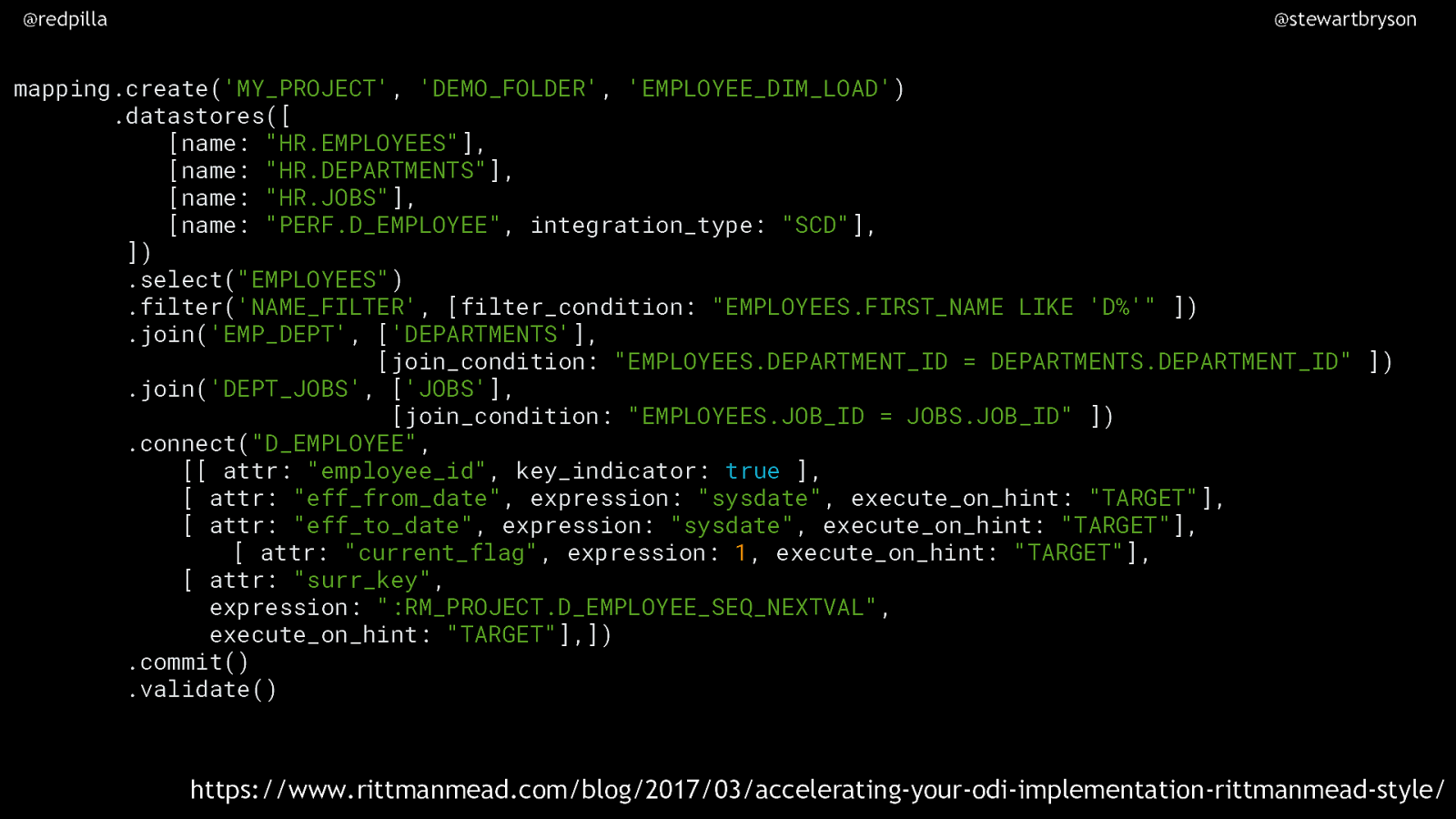
@redpilla @stewartbryson mapping.create(‘MY_PROJECT’, ‘DEMO_FOLDER’, ‘EMPLOYEE_DIM_LOAD’) .datastores([ [name: “HR.EMPLOYEES”], [name: “HR.DEPARTMENTS”], [name: “HR.JOBS”], [name: “PERF.D_EMPLOYEE”, integration_type: “SCD”], ]) .select(“EMPLOYEES”) .filter(‘NAME_FILTER’, [filter_condition: “EMPLOYEES.FIRST_NAME LIKE ‘D%’” ]) .join(‘EMP_DEPT’, [‘DEPARTMENTS’], [join_condition: “EMPLOYEES.DEPARTMENT_ID = DEPARTMENTS.DEPARTMENT_ID” ]) .join(‘DEPT_JOBS’, [‘JOBS’], [join_condition: “EMPLOYEES.JOB_ID = JOBS.JOB_ID” ]) .connect(“D_EMPLOYEE”, [[ attr: “employee_id”, key_indicator: true ], [ attr: “eff_from_date”, expression: “sysdate”, execute_on_hint: “TARGET”], [ attr: “eff_to_date”, expression: “sysdate”, execute_on_hint: “TARGET”], [ attr: “current_flag”, expression: 1, execute_on_hint: “TARGET”], [ attr: “surr_key”, expression: “:RM_PROJECT.D_EMPLOYEE_SEQ_NEXTVAL”, execute_on_hint: “TARGET”],]) .commit() .validate() https://www.rittmanmead.com/blog/2017/03/accelerating-your-odi-implementation-rittmanmead-style/ https://www.rittmanmead.com/blog/2009/04/using-a-partition-by-join-to-fill-in-the-gaps
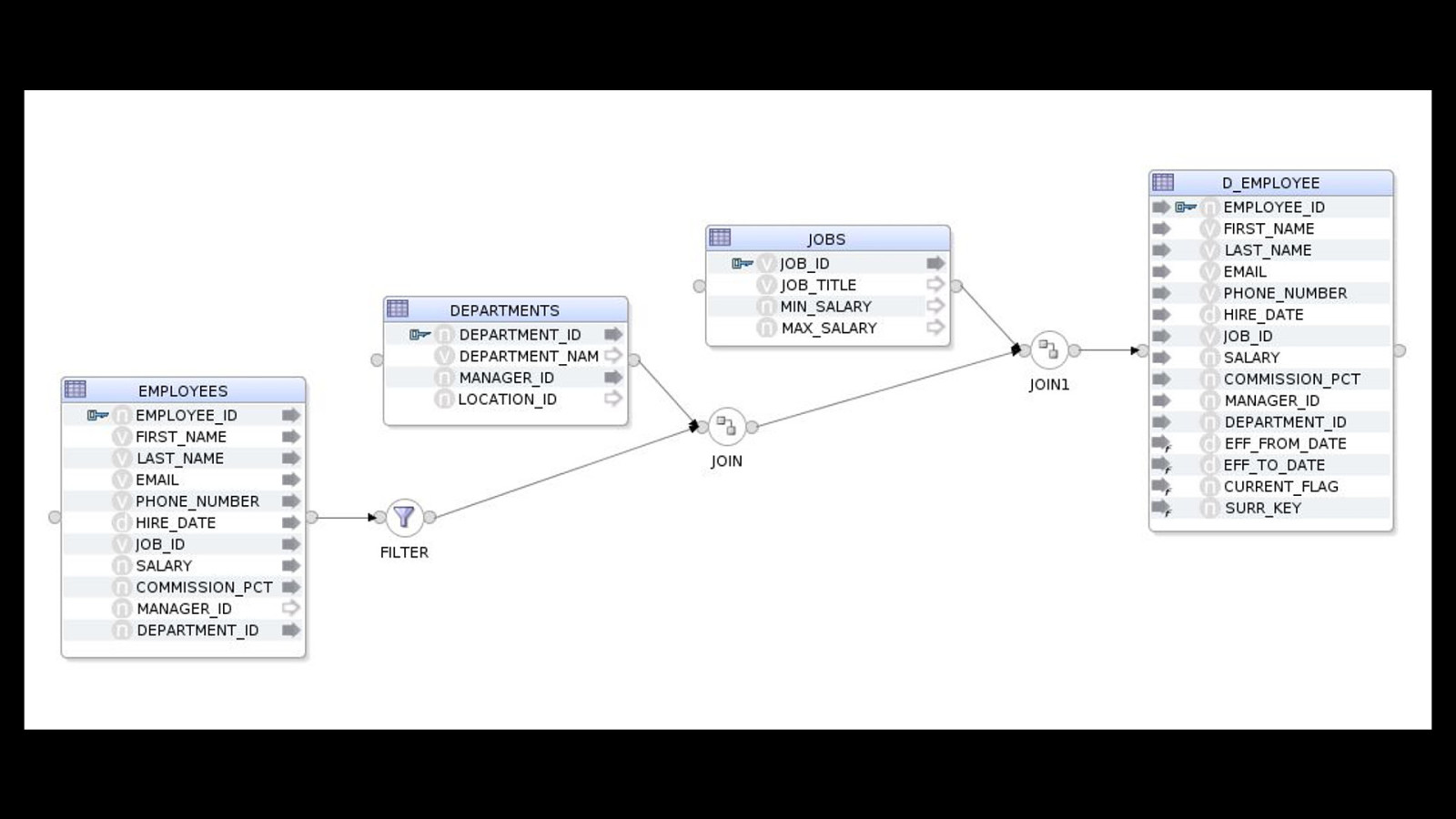
@redpilla @stewartbryson https://www.rittmanmead.com/blog/2017/03/accelerating-your-odi-implementation-rittmanmead-style/
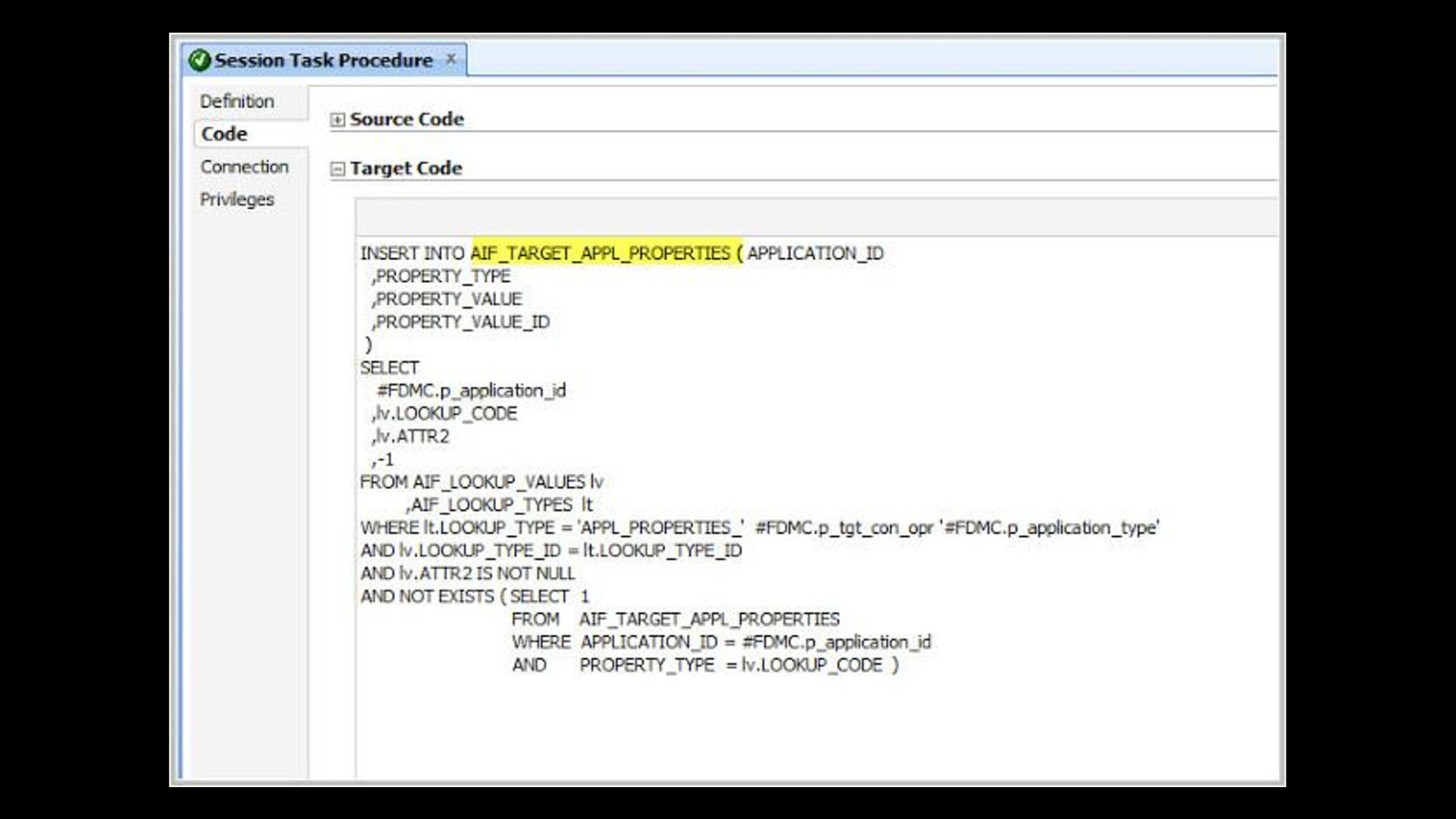
@redpilla @stewartbryson

Code >> GUI >> Code @redpilla @stewartbryson
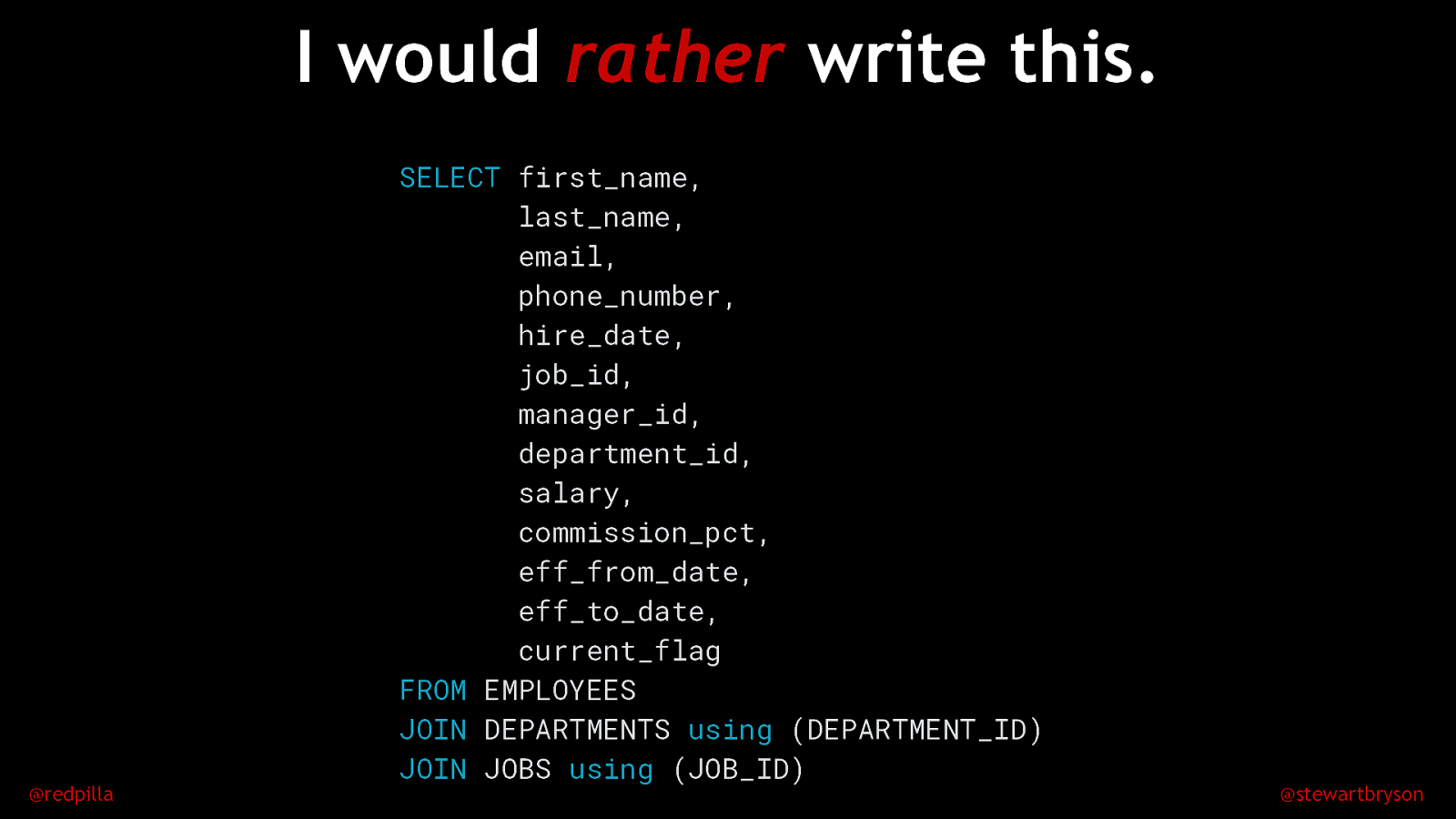
I would rather write this. @redpilla SELECT first_name, last_name, email, phone_number, hire_date, job_id, manager_id, department_id, salary, commission_pct, eff_from_date, eff_to_date, current_flag FROM EMPLOYEES JOIN DEPARTMENTS using (DEPARTMENT_ID) JOIN JOBS using (JOB_ID) @stewartbryson

@redpilla @stewartbryson

@redpilla @stewartbryson

@redpilla @stewartbryson We aren’t starting with a blank slate. @stewartbryson
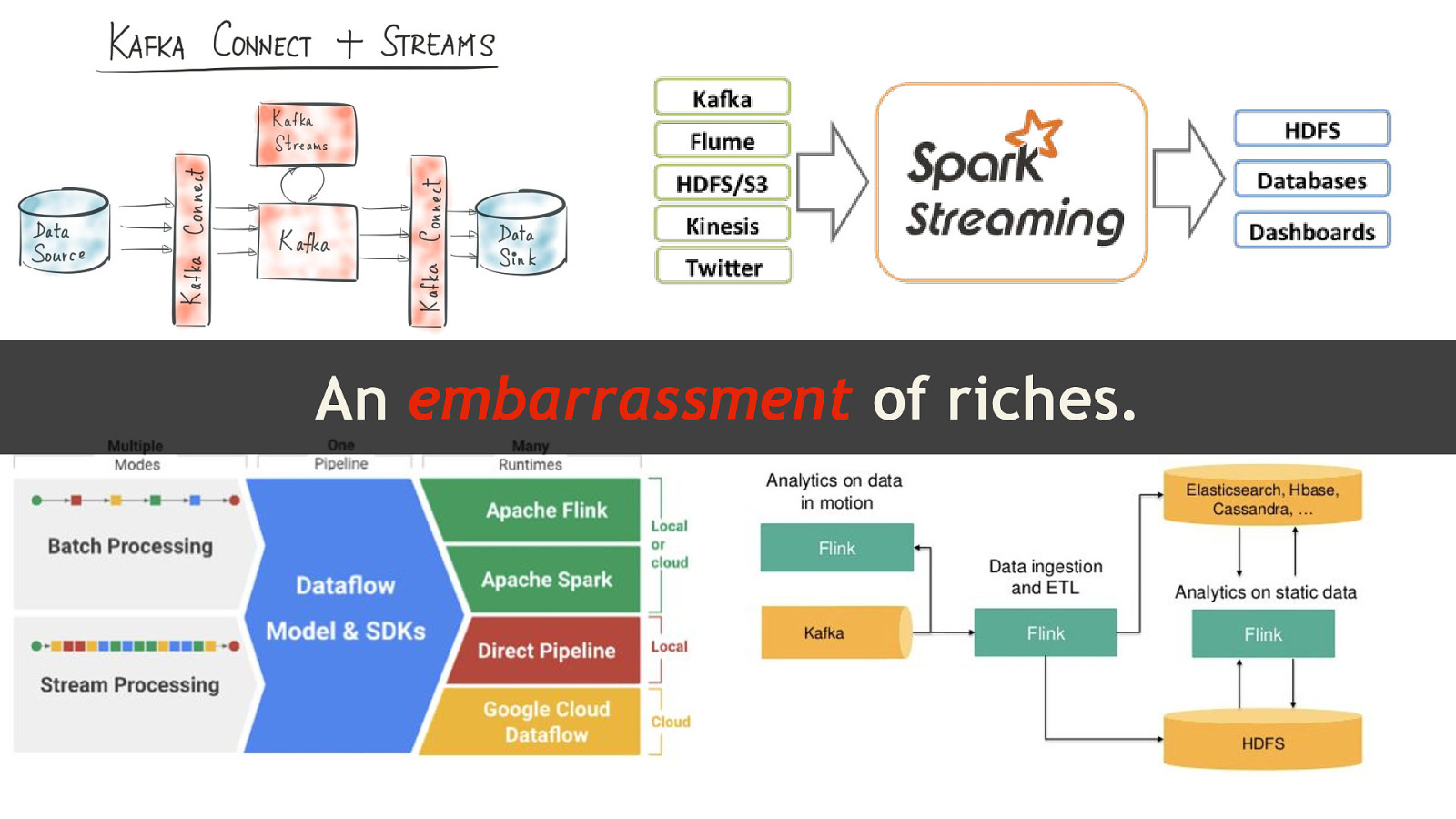
An embarrassment of riches. @redpilla @stewartbryson

Why Spark? @redpilla @stewartbryson

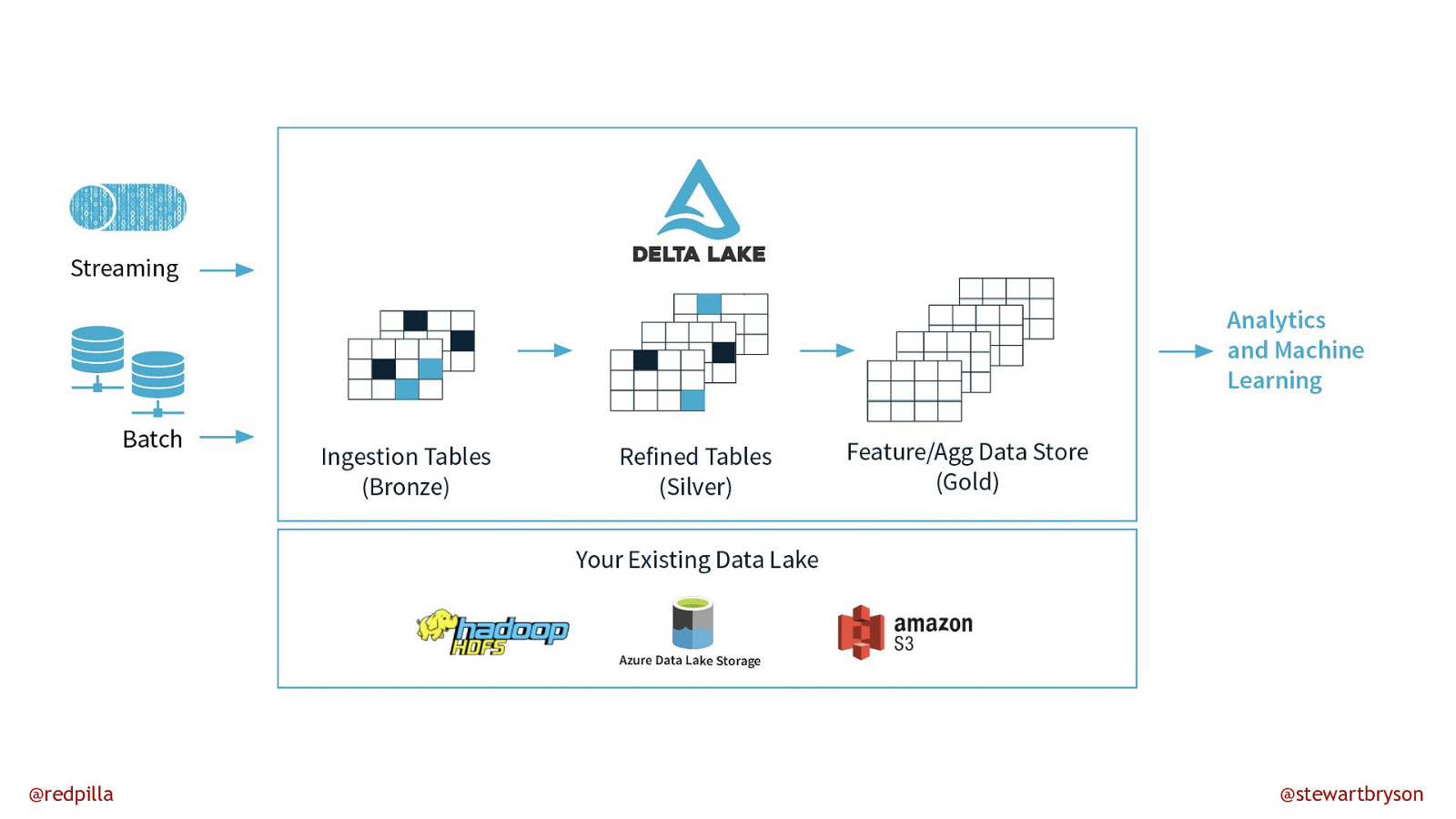
Why Databricks? @redpilla @stewartbryson
@redpilla @stewartbryson
@redpilla @stewartbryson

Demonstration @redpilla @stewartbryson
