Viens dompter ta première IA en Python 🧠 🐍

A presentation at Codeurs en Seine in October 2023 in Rouen, France by Thierry Chantier

Viens dompter ta première IA en Python 🧠 🐍

📝 Pense bête et liens 🔗 https://ovh.to/Zz5AnhE

Combien de personnes participent au lab ? Fotis Fotopoulos

MERCI !!!

Thierry Chantier DevRel @OVHcloud TitiMoby@mamot.fr TitiMoby 🔗 https://noti.st/titimoby

Stéphane Philippart 🏷 🥑 DeveloperRelations@OVHCloud 🦄 🏷 Co-creator of TADx (Agile, Dev, DevOps meetups in Tours) 🧠 Padawan Intelligence Artificielle 🏕 🐦 @wildagsx 🔗 https://philippart-s.github.io/blog 🐙 https://github.com/philippart-s/ 💬 https://www.linkedin.com/in/philippartstephane/

📝 Que va-t-on voir aujourd’hui ? 🧠 Les principes dans l’intelligence artificielle 🐍 Le kit de survie Python pour suivre ce workshop Un CDE c’est quoi et ça sert à quoi ? ☁ Les ressources utilisées chez OVHcloud En avant pour le développement : un notebook, un job d’entraînement et une application utilisant le modèle

Qui êtes vous ? ● ● ● ● ● Dev Dev Python Data Scientist Machine Learning Engineer Autre

Intelligence Artificielle

Les différentes catégories de l’IA 👉 Actuellement IA ~ Machine Learning 👉 Artificial Narrow Intelligence (ANI) / Weak AI 👉 Artificial General Intelligence (AGI) / Strong AI 👉 Artificial Super Intelligence (ASI)
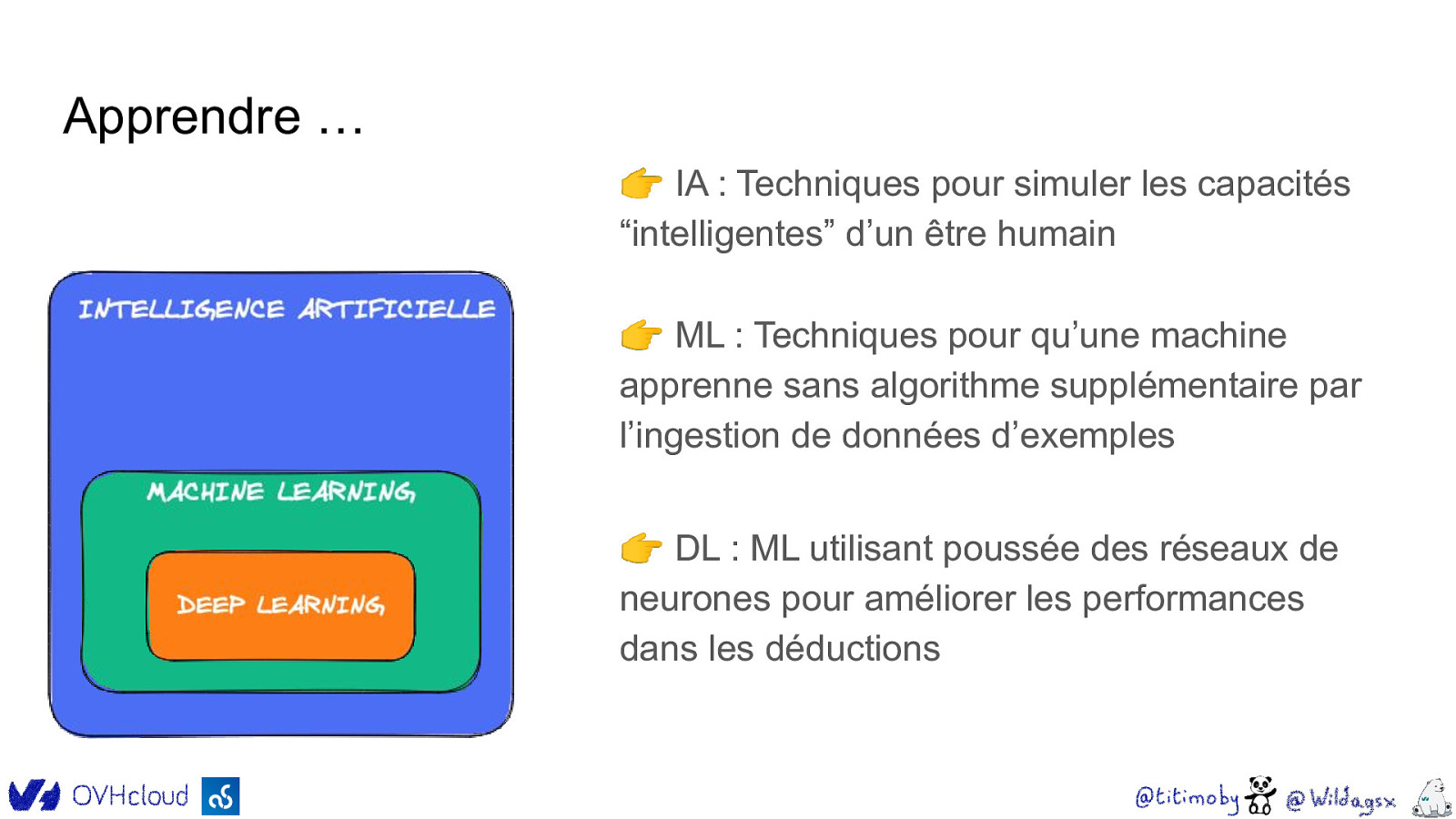
Apprendre … 👉 IA : Techniques pour simuler les capacités “intelligentes” d’un être humain 👉 ML : Techniques pour qu’une machine apprenne sans algorithme supplémentaire par l’ingestion de données d’exemples 👉 DL : ML utilisant poussée des réseaux de neurones pour améliorer les performances dans les déductions
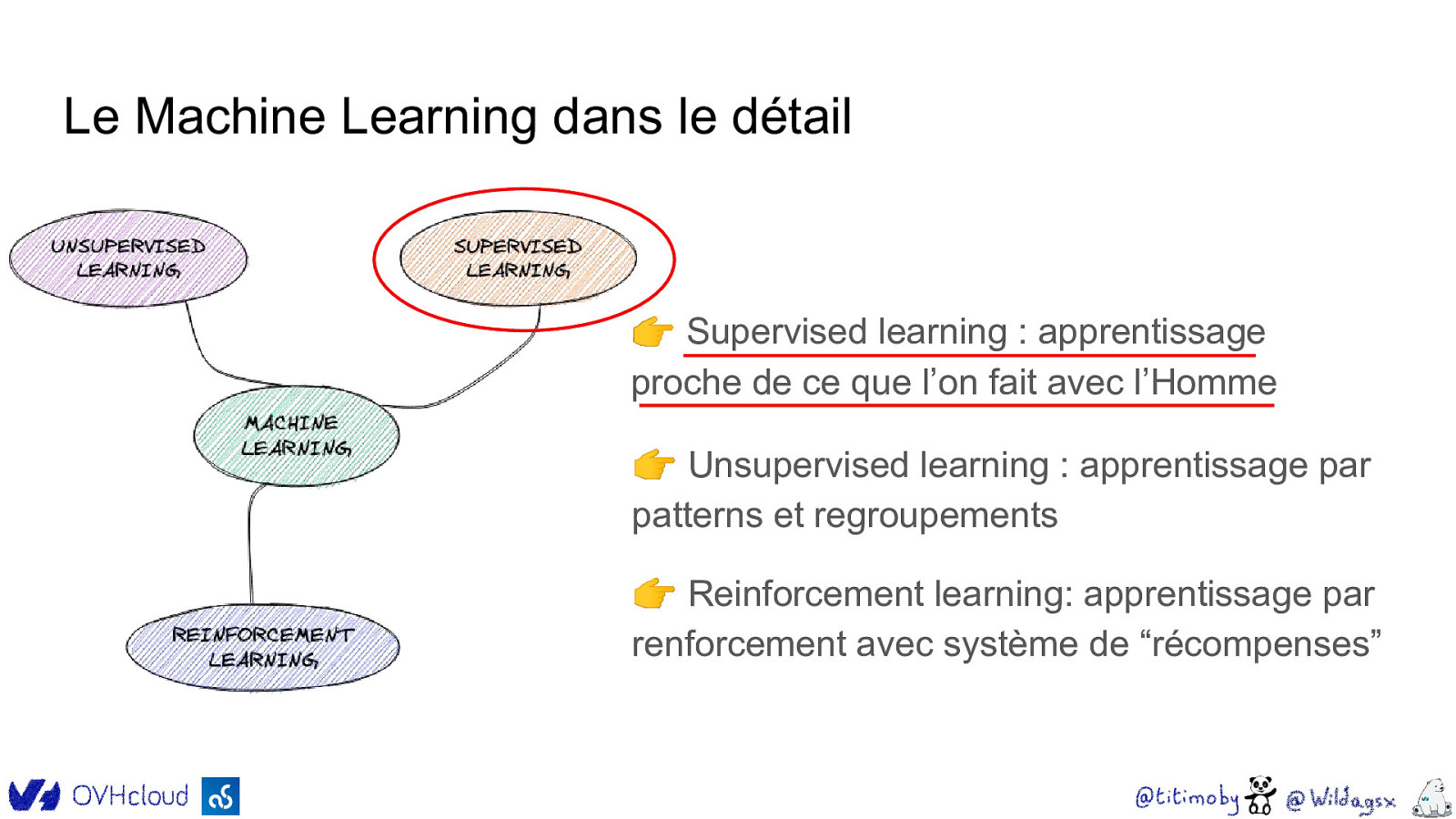
Le Machine Learning dans le détail 👉 Supervised learning : apprentissage proche de ce que l’on fait avec l’Homme 👉 Unsupervised learning : apprentissage par patterns et regroupements 👉 Reinforcement learning: apprentissage par renforcement avec système de “récompenses”

Sans donnée … pas d’intelligence ! 🧹 La plupart du temps les données sont brutes : il faudra les nettoyer, les pré-traiter, les transformer, … 📀 Il va falloir les transformer en Dataset (en gros une base de données pour IA) et les labelliser 🧪 Un dataset contient les données d’apprentissage, de validations et de tests 🧮 Enfin, ce sont des vecteurs et autres matrices qui seront manipulés par le modèle
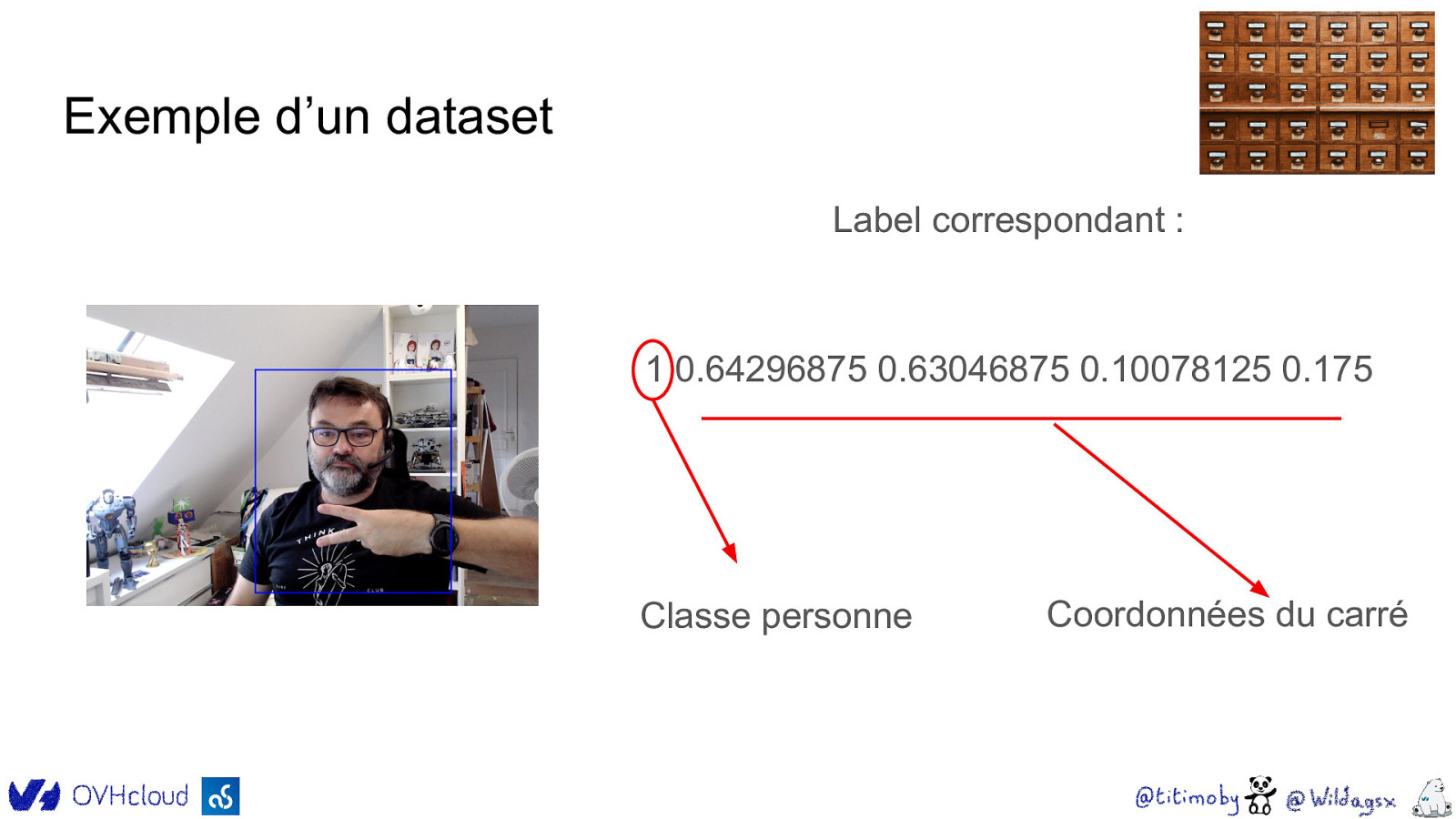
Exemple d’un dataset Label correspondant : 1 0.64296875 0.63046875 0.10078125 0.175 Classe personne Coordonnées du carré

Les modèles dans l’IA 🧠 C’est le cerveau de votre application 🔢 C’est ici que l’on retrouve les formules mathématiques 👉 Différents en fonction des tâches de machine learning
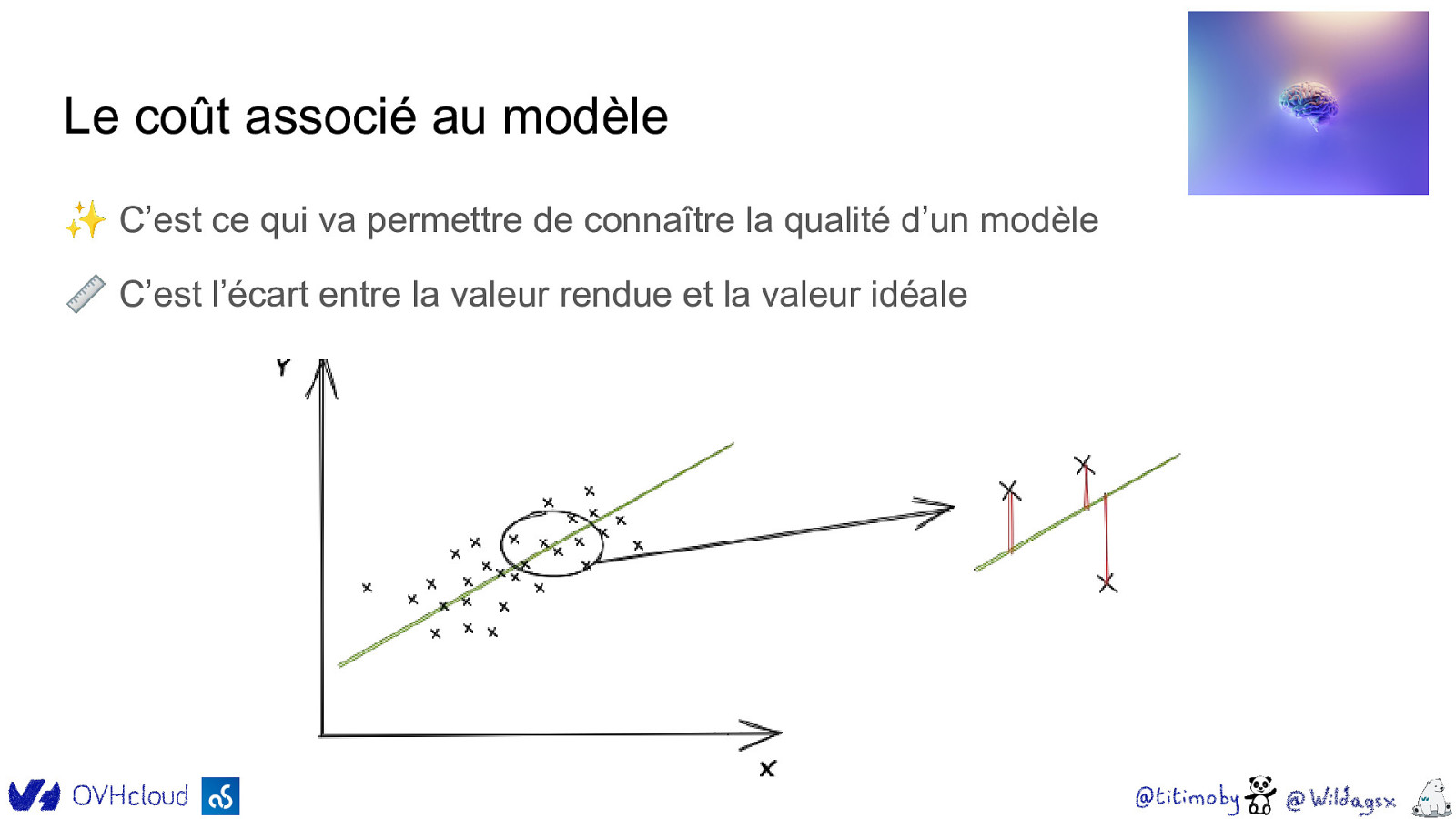
Le coût associé au modèle ✨ C’est ce qui va permettre de connaître la qualité d’un modèle 📏 C’est l’écart entre la valeur rendue et la valeur idéale
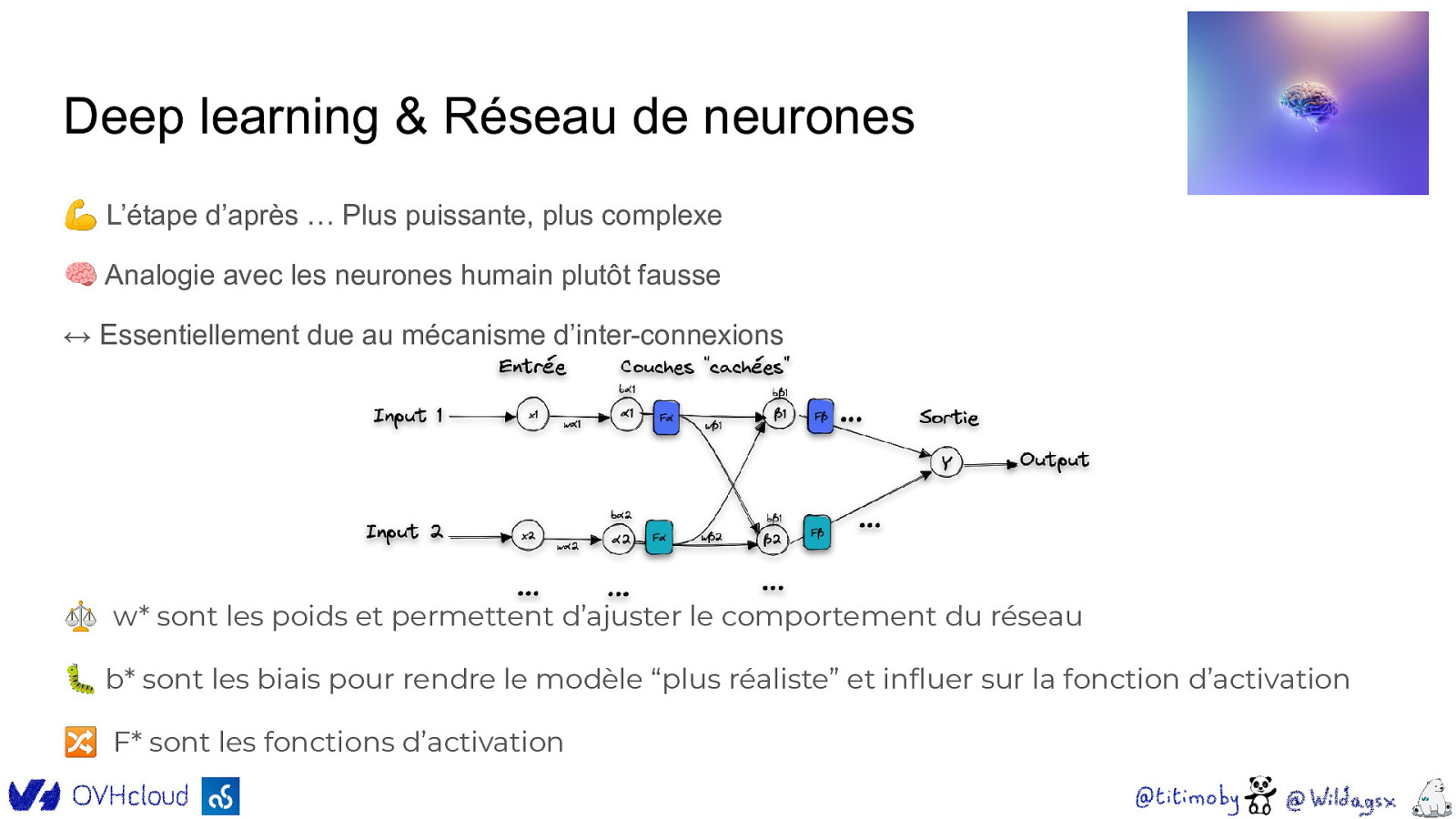
Deep learning & Réseau de neurones 💪 L’étape d’après … Plus puissante, plus complexe 🧠 Analogie avec les neurones humain plutôt fausse ↔ Essentiellement due au mécanisme d’inter-connexions ⚖ w* sont les poids et permettent d’ajuster le comportement du réseau 🐛 b* sont les biais pour rendre le modèle “plus réaliste” et influer sur la fonction d’activation 🔀 F* sont les fonctions d’activation
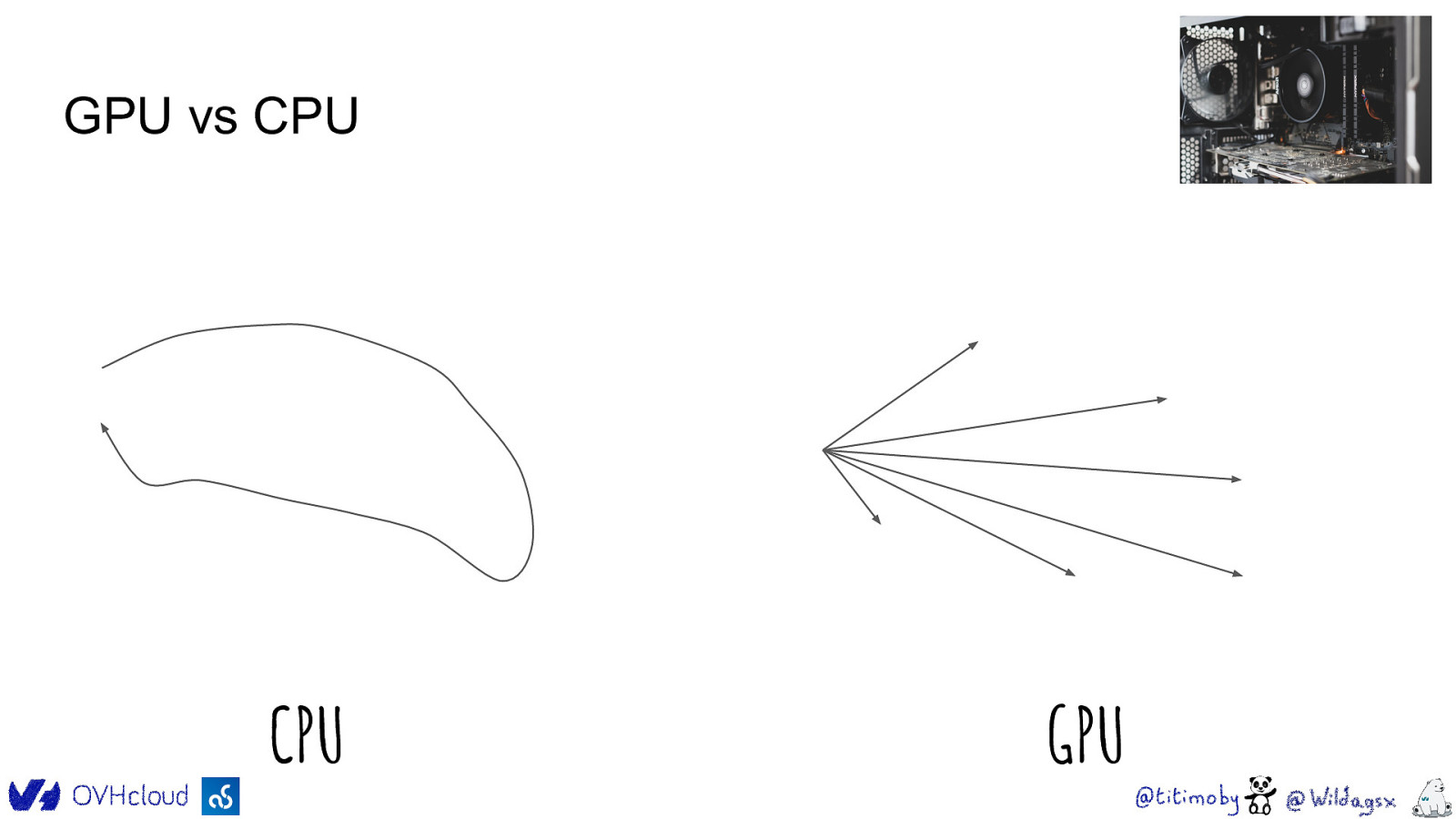
GPU vs CPU �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� CPU �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� �� GPU �� �� ��

Cloud Development Environment

Cloud Development Environment Le code du projet Un éditeur de code Un environnement d’exécution

A la demande ● ● ● ● Pour tester une idée Expérimenter différentes solutions Partager une session de travail entre collègues … sky is the limit (et le coût de votre offre de CDE 😇 )

Reproductible ● Environnement décrit précisément ● Configuration versionnée avec le code ● Cohérence entre l’environnement et le code lui même

Le CDE pour cet atelier : Gitpod ● ● ● ● Simplement ajouter https://gitpod.io/# devant l’URL de votre repository Deux fichiers 📝 de configuration : .gitpod.dockerfile .gitpod.yml Possibilité d’avoir par projets ou globales : ○ Clés SSH ○ variables d’environnement Tunneling possible avec le poste local

Python : 101 pour cet atelier

Python : pourquoi ce choix ? ● 🛠 Langage simple d’approche mais qui reste complet ● 🔋 “All batteries included” ● 🔬 Choix des communautés data science et data analysis

Python : concepts pour aujourd’hui ● 📁 Les fichiers requirements.txt ● 📝 L’instruction import ● 📚 Notebooks

Faire de l’Intelligence Artificielle à OVHcloud Public Cloud AI Notebooks : JupyterLab et VSCode, images pré-construites AI Training : GPU as a Service AI Deploy : CaaS pour l’IA

Workshop time !

🔀 Fork du repository GitHub Projet à forker : https://github.com/devrel-workshop/101-AI-and-py https://ovh.to/ofPmni6

Démarrage de GitPod
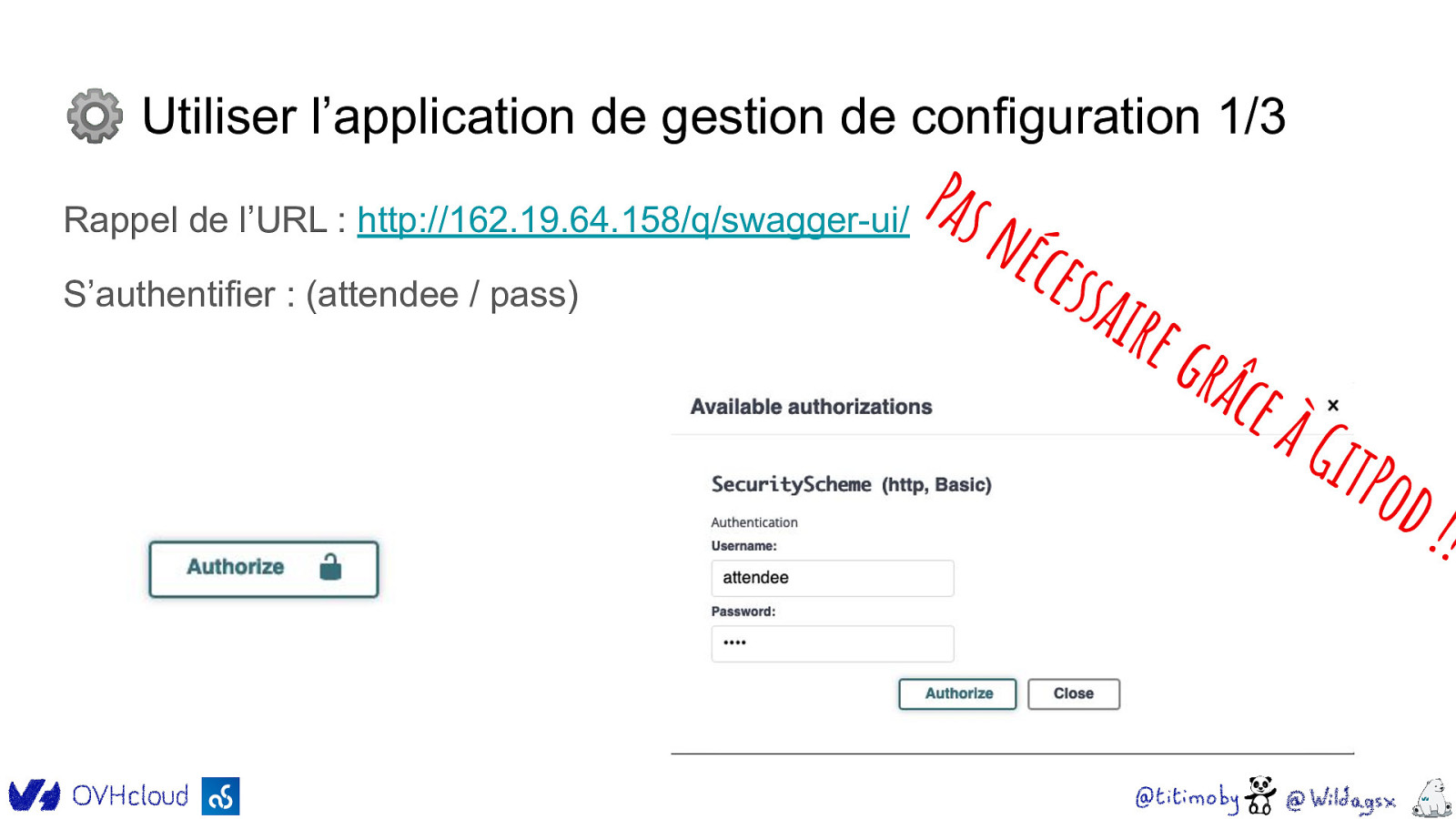
⚙ Utiliser l’application de gestion de configuration 1/3 Rappel de l’URL : http://162.19.64.158/q/swagger-ui/ S’authentifier : (attendee / pass) Pas n éces sair e gr âce à Gi tPod !!
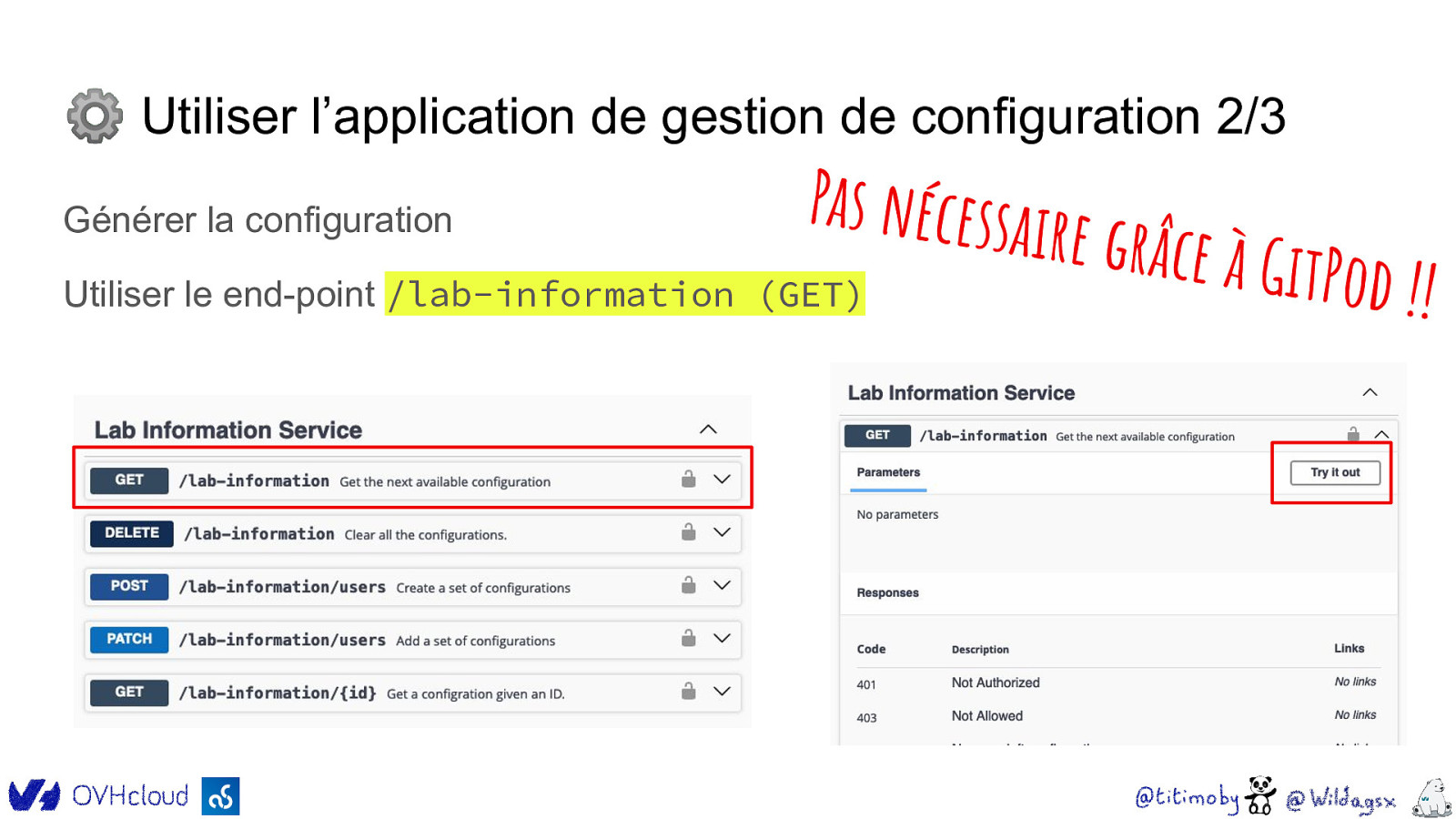
⚙ Utiliser l’application de gestion de configuration 2/3 Générer la configuration Pas nécessai r Utiliser le end-point /lab-information (GET) e grâce à Git Pod !!
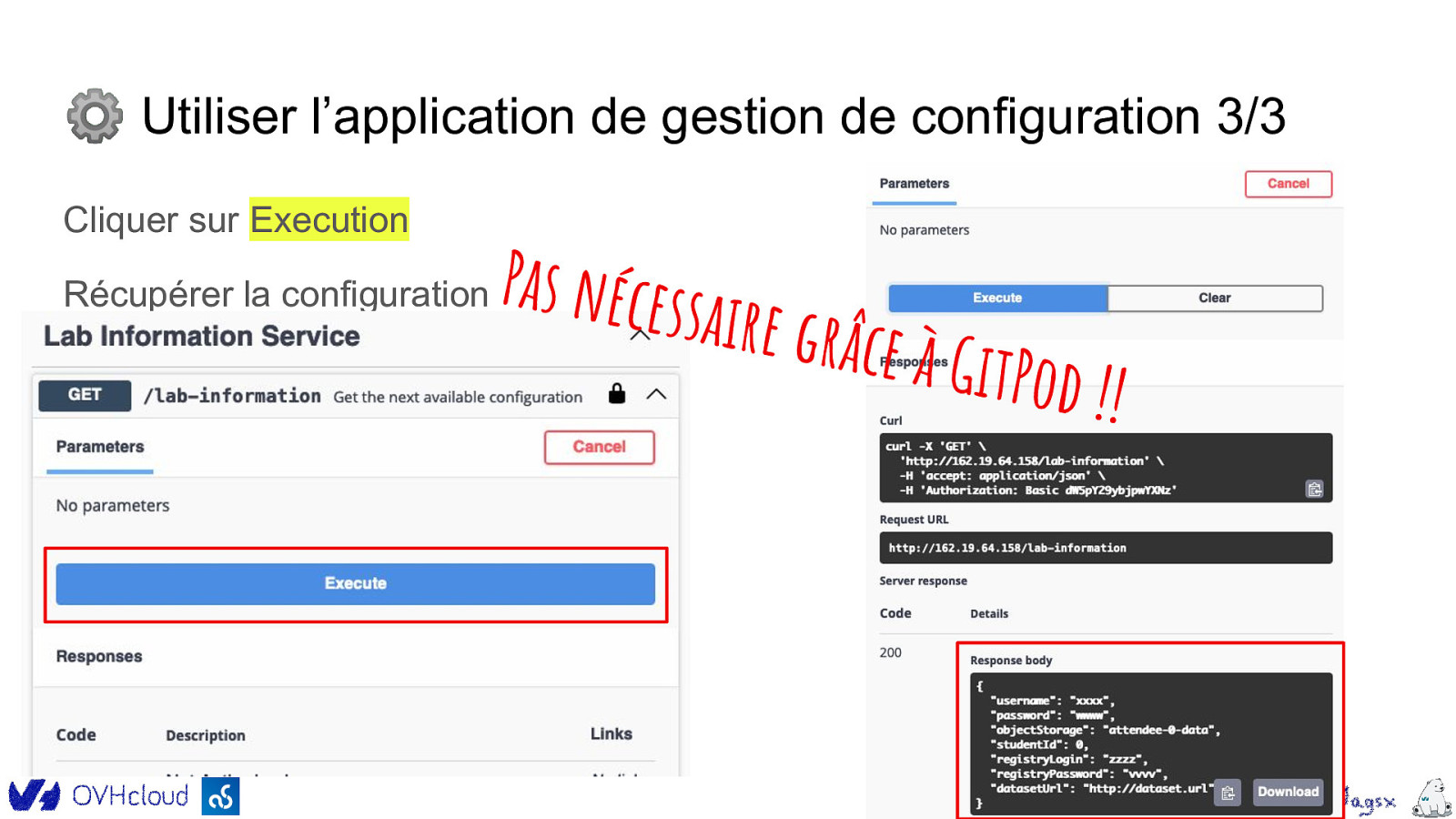
⚙ Utiliser l’application de gestion de configuration 3/3 Cliquer sur Execution Récupérer la configuration Pas nécess a ire grâce à GitPod ! !

⚡ Initialisation de l’environnement GitPod ● ● Créer un compte GitPod (se connecter avec son compte GitHub) Prendre le modèle large
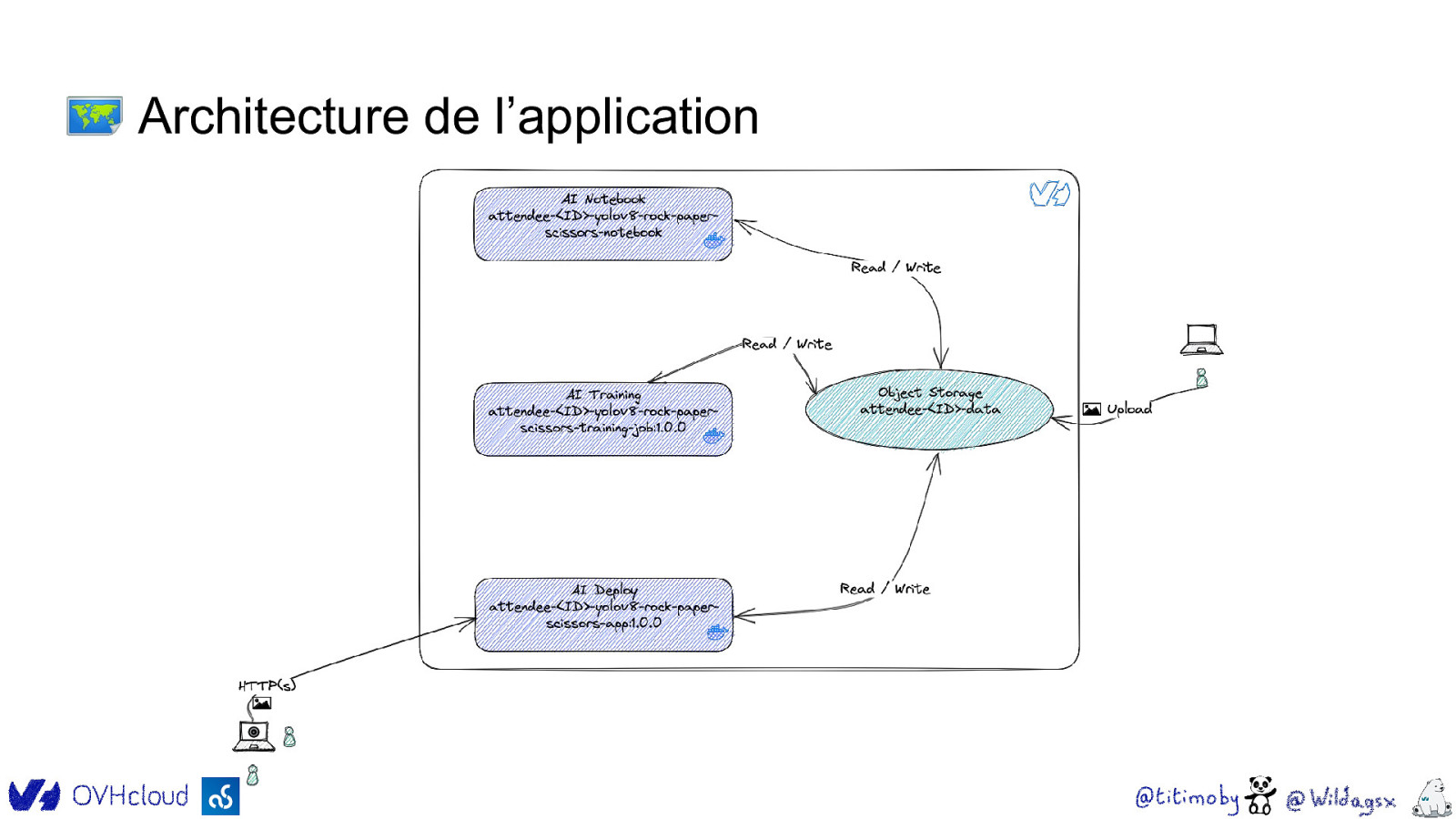
🗺 Architecture de l’application

Modèle avec AI Notebook

📄 Instructions https://github.com/devrel-workshop/101-AI-and-py/bl ob/main/docs/notebook.md https://ovh.to/MDaTnP3

🔐 Authentication via la CLI ovhai ovhai login Pas n éces sair How do you want to login: e gr âce
Terminal (login directly inside this terminal) Browser (open a login page on your browser) ℹ Utiliser le compte récupéré à l’étape précédente ℹ à Gi tPod !!

⚡ Création du Notebook ovhai notebook run conda jupyterlab \ —name attendee-$STUDENT_ID-yolov8-rock-paper-scissors-notebook \ —gpu 1 \ —volume attendee-$STUDENT_ID-data@GRA:/workspace/attendee:RW:cache \ —volume https://github.com/devrel-workshop/101-AI-and-py.git:/workspace/101-ai-la b-sources:RO

📝 Connexion au JupyterLab $ ovhai notebook list | grep attendee-$STUDENT_ID ID NAME STATE Xxx attendee-<ID>-yolov8-rock-paper-scissors-notebook RUNNING AGE FRAMEWORK VERSION 6d conda conda-py39-cuda11.8-v22-4 EDITOR URL jupyterlab https://efb3fda1-7b0e-42ed-b6e6-341881071d84.notebook.gra.ai.cloud.ovh.net ℹ Utiliser le compte créé précédemment ℹ
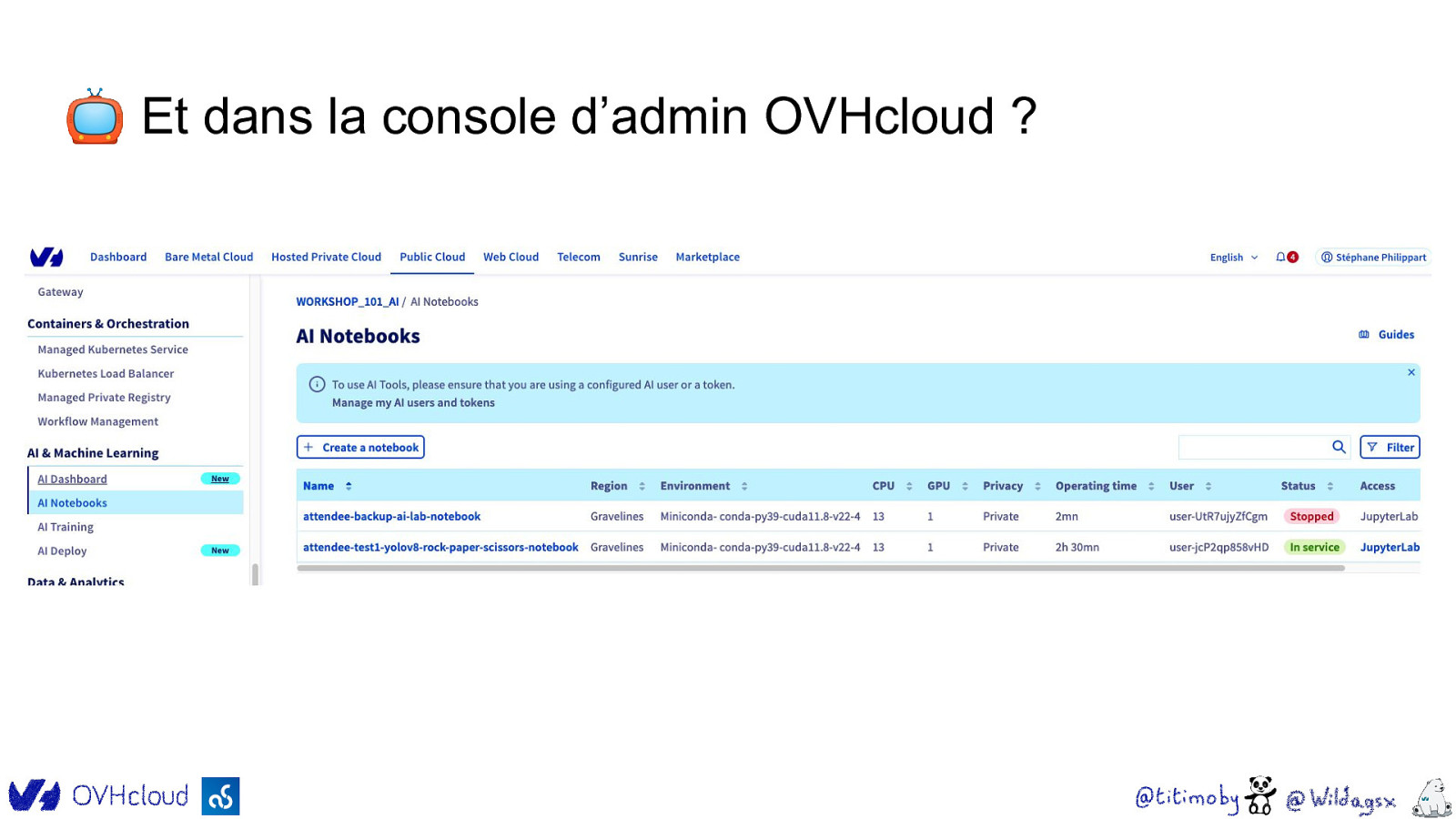
📺 Et dans la console d’admin OVHcloud ?

🗃 Organisation du Notebook Répertoire de sources du workshop - RO Répertoire de sources d’exemples - RO Répertoire des données du workshop - RW File > New Terminal ● ● /workspace/101-ai-lab-sources/ init_ai_env.sh

📀 Data 🗃 Source des données : Roboflow - Rock Paper Scissors SXSW Image Dataset 🗃 Object storage utilisé : ● attendee-$STUDENT_ID-data : ○ ○ ○ ○ ○ Zone de travail pour le / la participant·e Dataset Images de tests Répertoires de travail pour l’entraînement Modèle exporté

🏞 YoloV8 🔡 You Only Look Once 🔗 https://docs.ultralytics.com/ - https://github.com/ultralytics/ultralytics 🏞 Classification / Détection / Segmentation / Détection / Pose 🏞 Entraîné sur le dataset COCO 🐍 Lib python prête à l’emploi 🧠 Utilisation du plus petit modèle avec “seulement” 3.2 millions de paramètres

Un mot sur le transfert learning 🔄 Réutiliser un modèle déjà entraîné 🔎 Le spécialiser dans un domaine bien précis Exemple : détection d’objets divers qui devient une détection de signes
🚀 Exécution du Notebook 1/2 ▶ “Jouer” les cellules du Notebook (bouton ▶) ⤵ Récupération du dataset ⤵ Récupération des dépendances ✅ Vérification de la configuration matérielle (1 GPU) et logicielle (Ultralytics) ⤵ Récupération du modèle yolov8n pré-entraîné sur COCO 🧪 Tester le modèle non entraîné avec une image de joueur

🚀 Exécution du Notebook 2/2 🧠 Entraîner le modèle avec les données du dataset “pierre / feuille / ciseaux” 🔬 Etude de la qualité du modèle 🧪 Tester le nouveau modèle, l’importance des “epochs” 💾 Sauvegarder le modèle

🎉 Bravo vous avez créé votre premier modèle d’intelligence artificielle !! 🎉

Entraînement avec AI Training Clique Images

📄 Instructions https://github.com/devrel-workshop/101-AI-and-py/bl ob/main/docs/training.md https://ovh.to/z84huKC

ℹ Rappels ● ● C’est le même compte que celui du Notebook C’est le même object storage que celui du Notebook

🐳 Création de l’image 📂 Répertoire de travail : src/training - Dockerfile: le dockerfile pour construire l’image Requirements.txt : fichier de gestion des dépendances Python Train.py : script Python pour l’entraînement du modèle 🐳 Fabrication de l’image 🐛 (Optionnel) Run / debug locallement ⬆ Push de l’image dans la registry : <user>/ <pass>
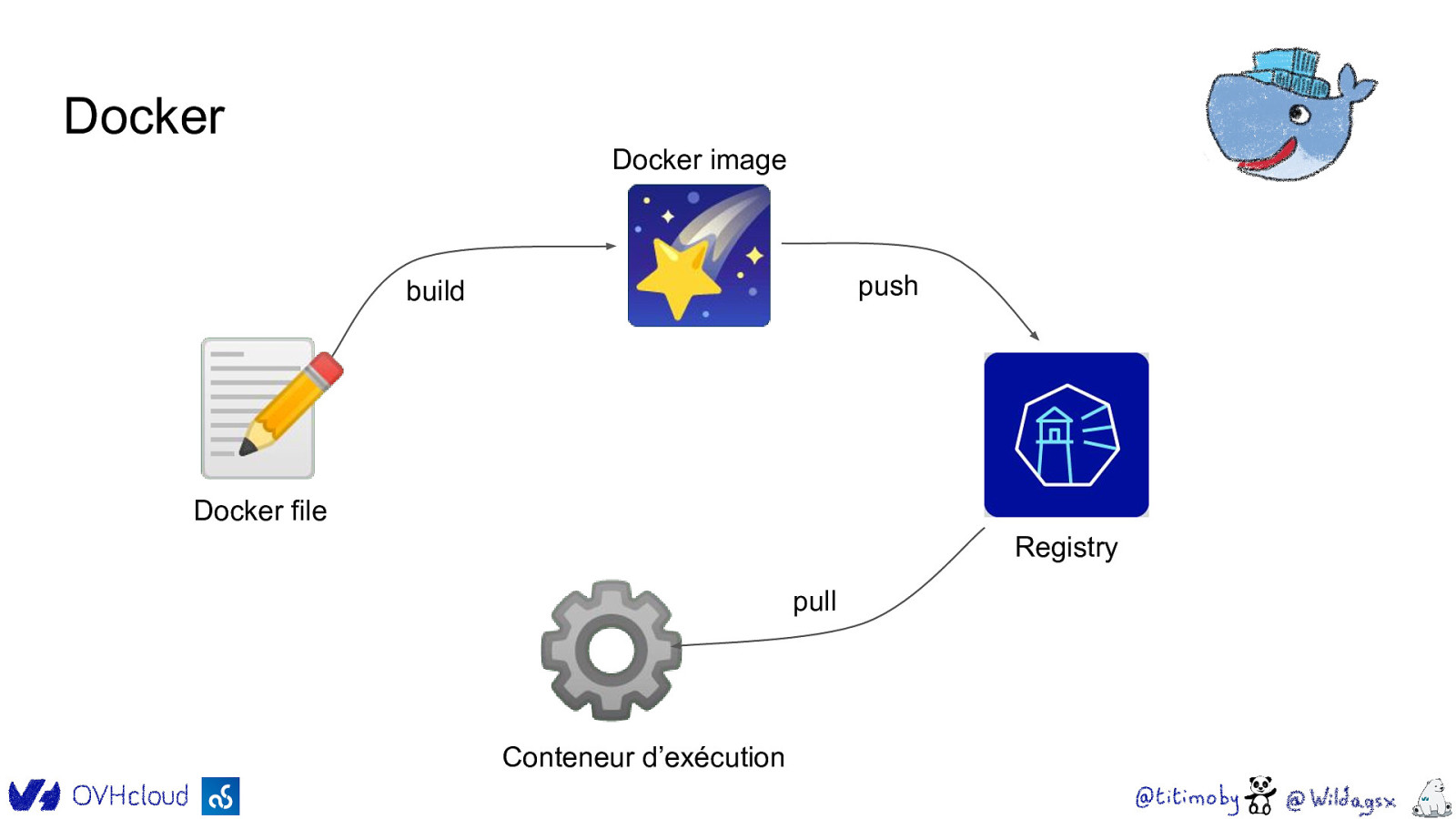
Docker Docker image build 🌠 push 📝 Docker file Registry ⚙ Conteneur d’exécution pull

⚡ Création du Job ovhai job run \ —name attendee-$STUDENT_ID-yolov8-rock-paper-scissors-training-job \ —gpu 1 \ —env NB_OF_EPOCHS=50 \ —volume attendee-$STUDENT_ID-data@GRA:/workspace/attendee:RW:cache \ —unsecure-http \ $REGISTRY_NAME/$STUDENT_ID/yolov8-rock-paper-scissors-training-job:1.0.0

🚑 Plan B ovhai job run \ —name attendee-$STUDENT_ID-yolov8-rock-paper-scissors-training-job \ —gpu 1 \ —env NB_OF_EPOCHS=50 \ —volume attendee-$STUDENT_ID-data@GRA:/workspace/attendee:RW:cache \ —unsecure-http \ $REGISTRY_NAME/backup/yolov8-rock-paper-scissors-training-job:1.0.0
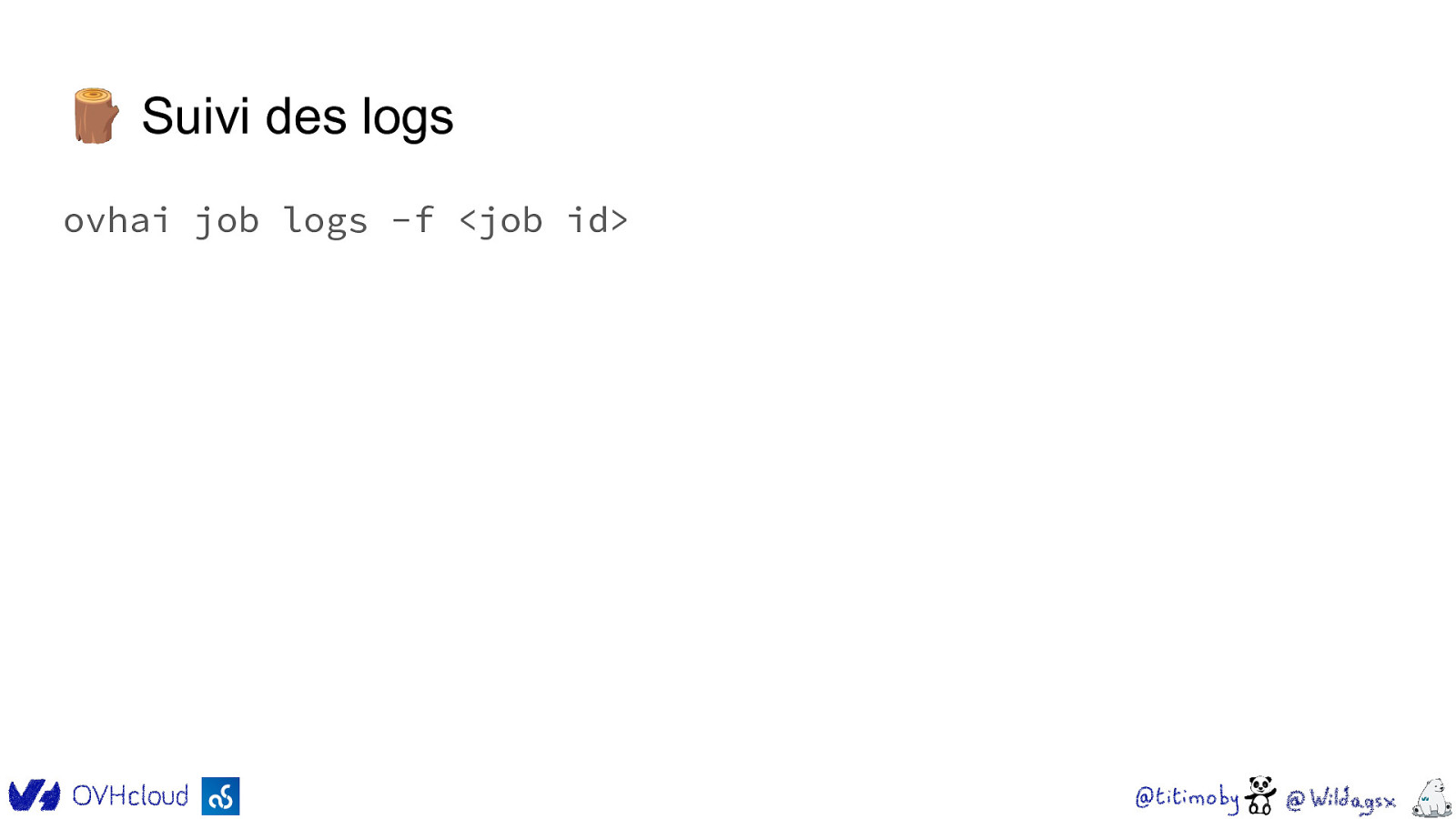
🪵 Suivi des logs ovhai job logs -f <job id>
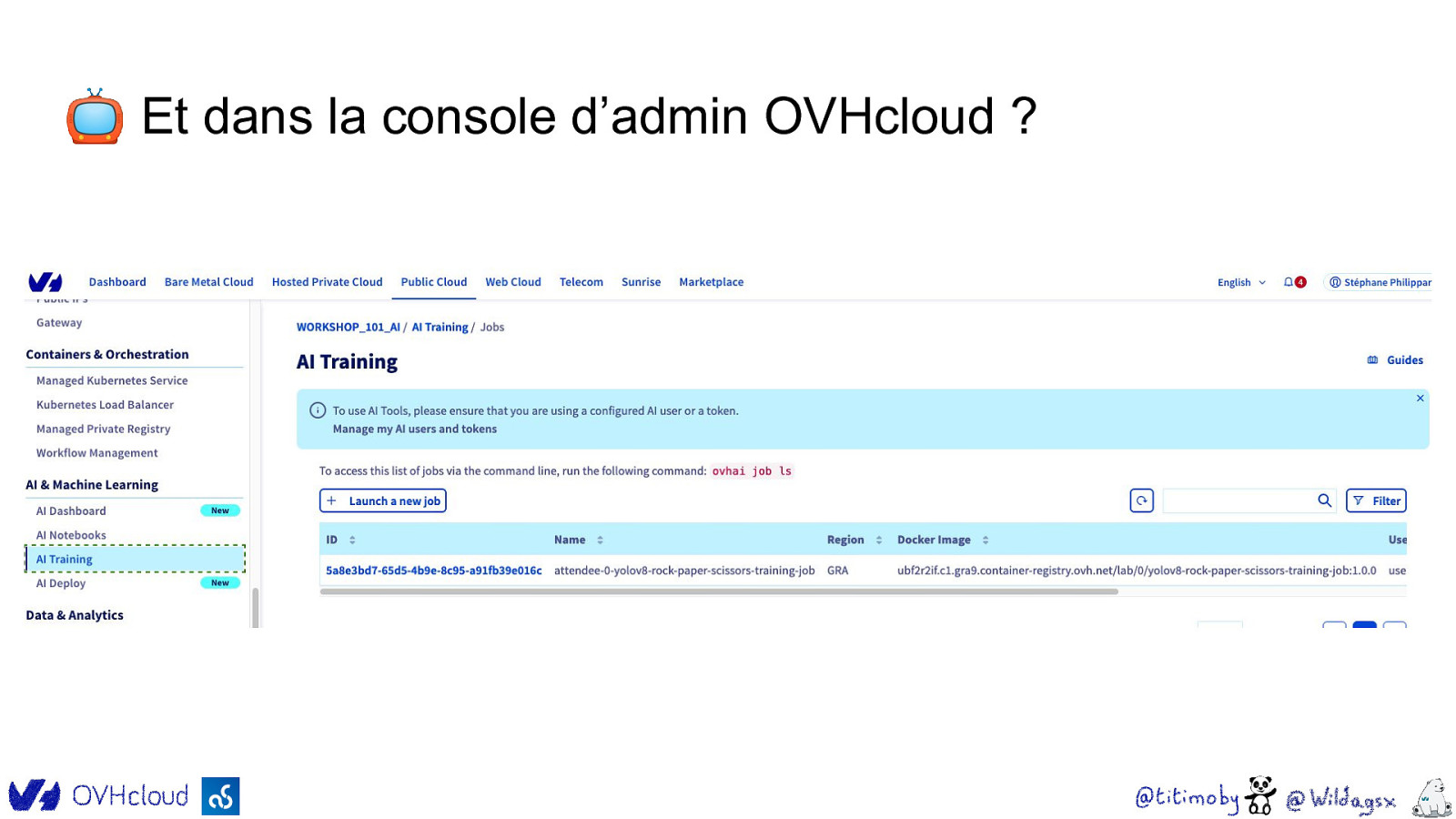
📺 Et dans la console d’admin OVHcloud ?

🎉 Bravo vous avez entrainé votre premier modèle d’intelligence artificielle !! 🎉

Application avec AI Deploy

📄 Instructions https://github.com/devrel-workshop/101-AI-and-py/bl ob/main/docs/application.md https://ovh.to/4tu9bxc

🐳 Création de l’image 📂 Répertoire de travail : src/app - Dockerfile: le dockerfile pour construire l’image Requirements.txt : fichier de gestion des dépendances Python App.py : script Python pour la création de l’application 🗑 Si nécessaire supprimer les images d’entraînement 🐳 Fabrication de l’image 🐛 (Optionnel) Run / debug locallement ⬆ Push de l’image dans la registry : lab-user / Passw0rd
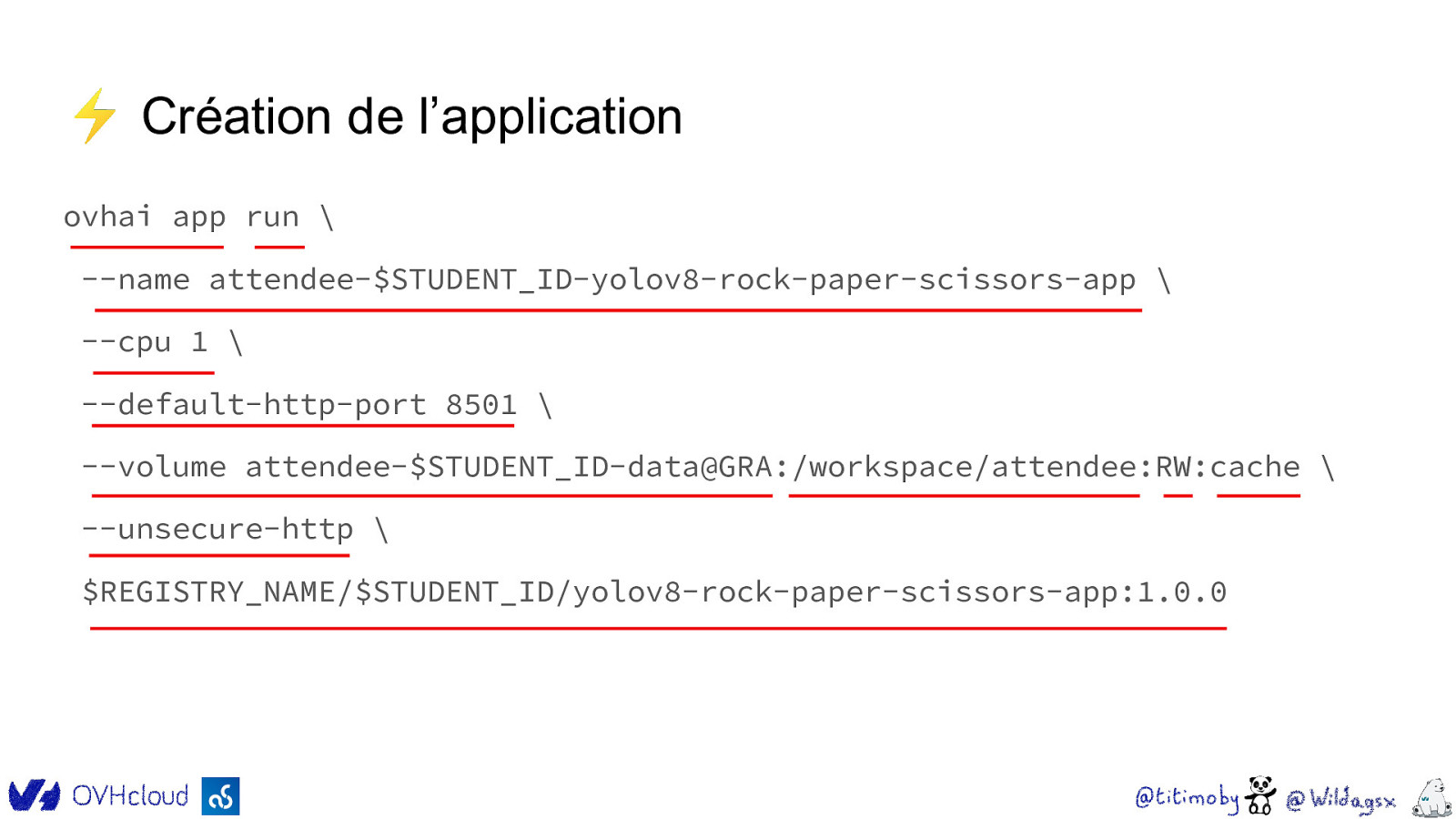
⚡ Création de l’application ovhai app run \ —name attendee-$STUDENT_ID-yolov8-rock-paper-scissors-app \ —cpu 1 \ —default-http-port 8501 \ —volume attendee-$STUDENT_ID-data@GRA:/workspace/attendee:RW:cache \ —unsecure-http \ $REGISTRY_NAME/$STUDENT_ID/yolov8-rock-paper-scissors-app:1.0.0

🚑 Plan B ● ● Copie du modèle entraîné: ovhai bucket object copy attendee-backup-data@GRA —container attendee-$STUDENT_ID-data best.torchscript best.torchscript Exécution de l’image backup: ovhai app run \ —name attendee-$STUDENT_ID-yolov8-rock-paper-scissors-app \ —cpu 1 \ —default-http-port 8501 \ —volume attendee-$STUDENT_ID-data@GRA:/workspace/attendee:RW:cache \ —unsecure-http \ $REGISTRY_NAME/backup/yolov8-rock-paper-scissors-app:1.0.0
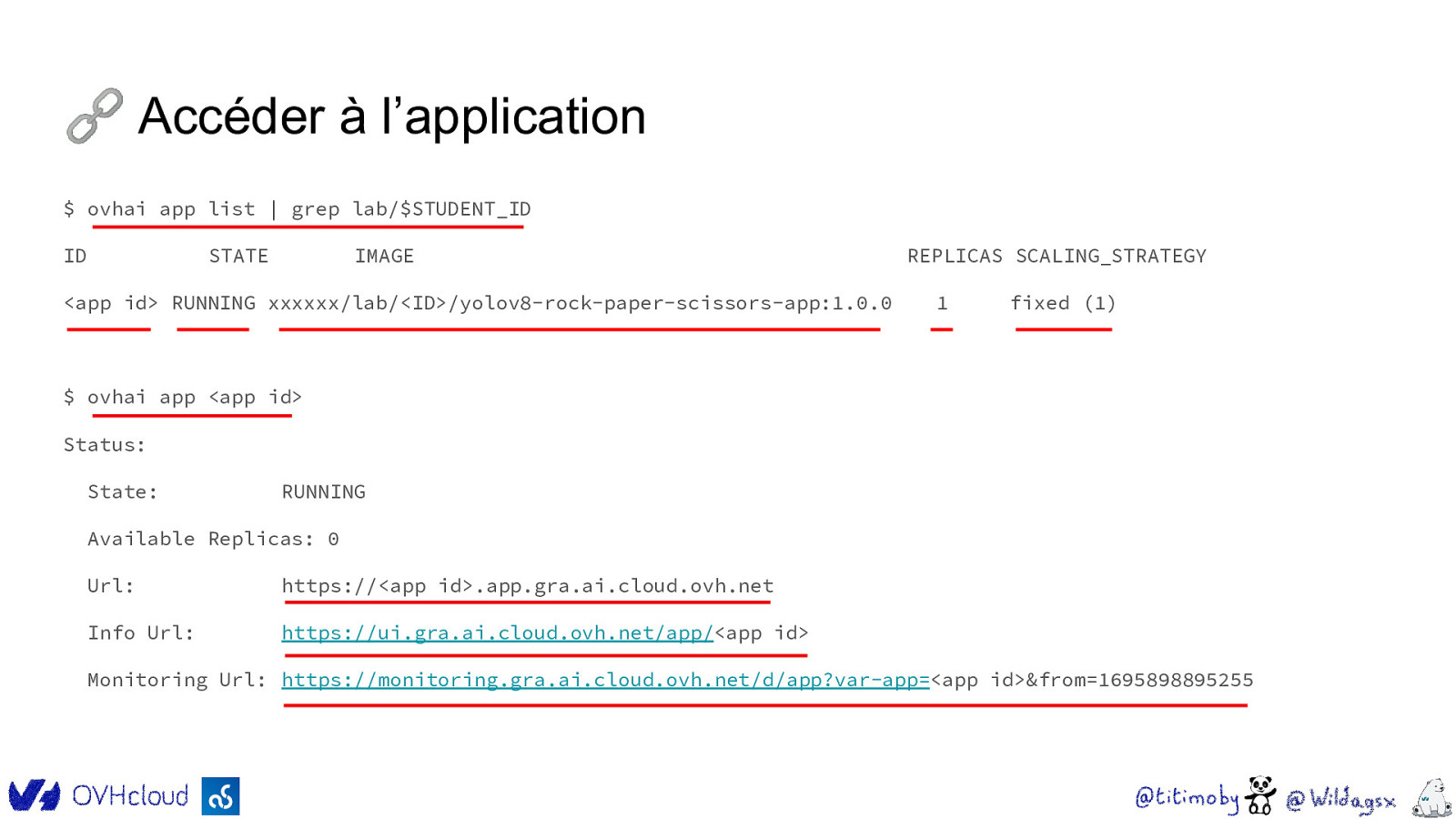
🔗 Accéder à l’application $ ovhai app list | grep lab/$STUDENT_ID ID STATE IMAGE <app id> RUNNING xxxxxx/lab/<ID>/yolov8-rock-paper-scissors-app:1.0.0 REPLICAS SCALING_STRATEGY 1 fixed (1) $ ovhai app <app id> Status: State: RUNNING Available Replicas: 0 Url: https://<app id>.app.gra.ai.cloud.ovh.net Info Url: https://ui.gra.ai.cloud.ovh.net/app/<app id> Monitoring Url: https://monitoring.gra.ai.cloud.ovh.net/d/app?var-app=<app id>&from=1695898895255
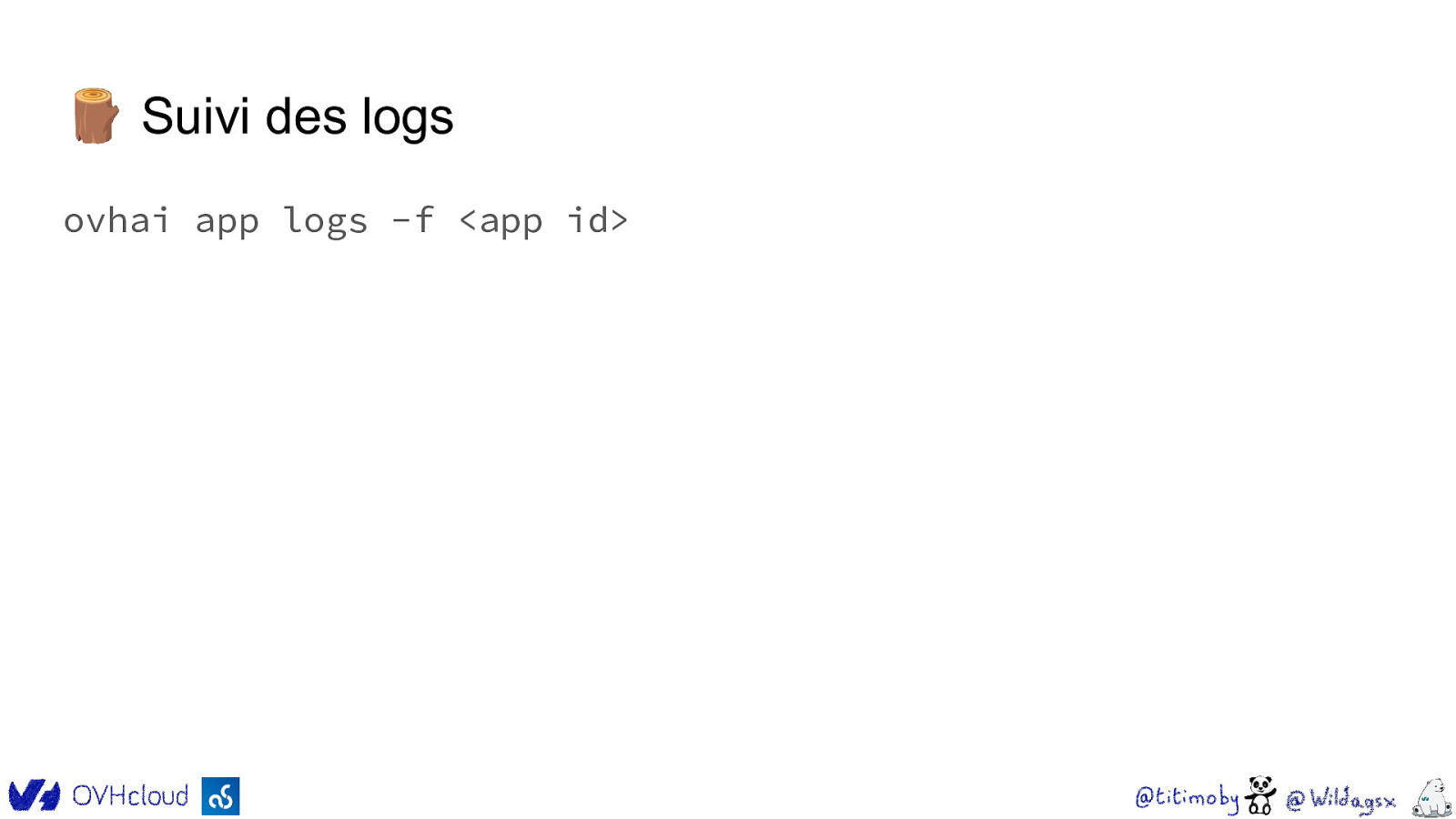
🪵 Suivi des logs ovhai app logs -f <app id>
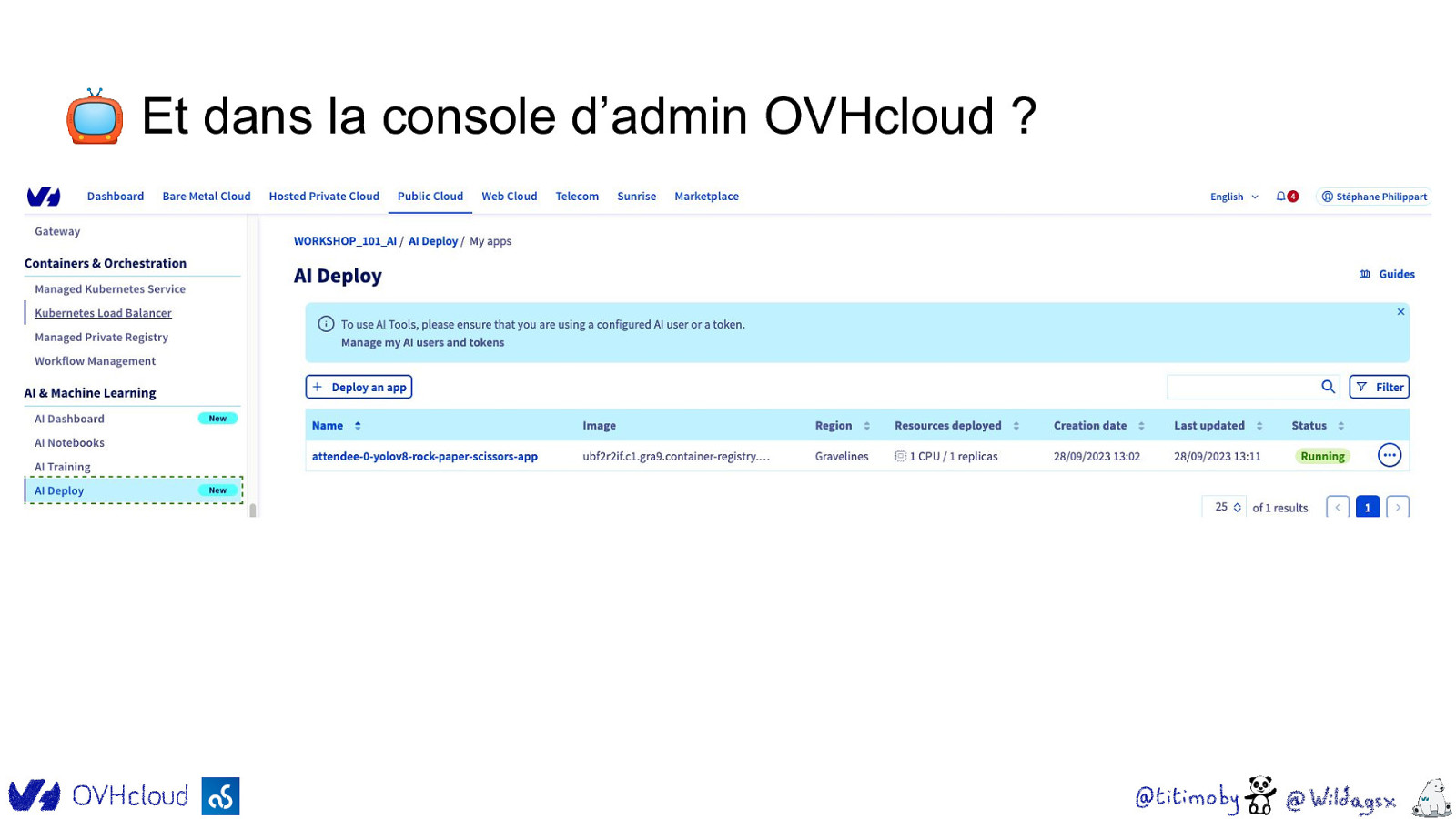
📺 Et dans la console d’admin OVHcloud ?

🎉 Bravo vous avez créé votre première application basée sur l’intelligence artificielle !! 🎉

🧳 Take away / Next ? 🧳

Un workflow typique dans l’IA 📀 Il faut une très grande quantité de données 📀 La plupart du temps la donnée est brute ⚠ Attention aux coûts (stockage, lecture / écriture)

Un workflow typique dans l’IA 🎛 Créer des datasets nettoyés (Valeurs manquantes, Normalisation, …) 🎛 Il existe des datasets pré-créés (gratuits ou payants) 🎯 Le but est de traduire les données brutes dans un langage compréhensible par le modèle
Un workflow typique dans l’IA 🧠 Le “cerveau” de l’application Fait par les Data Scientist 🧮 Basé sur des opérations mathématiques 📝 Utilise des éditeurs (JupyterLab, complexes Matlab, VSCode, …) 🧠 Réseaux de neurones artificiels
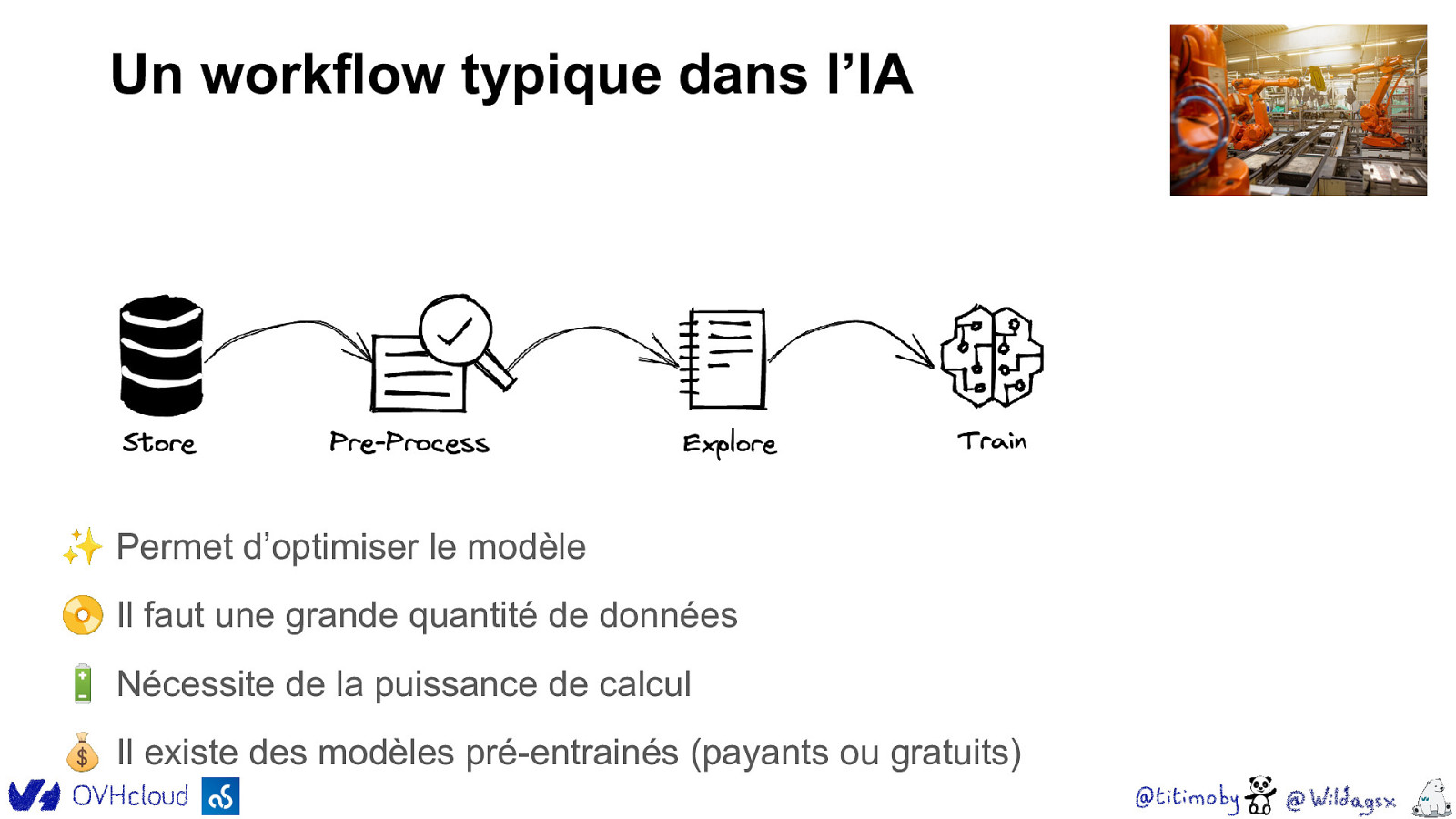
Un workflow typique dans l’IA ✨ Permet d’optimiser le modèle 📀 Il faut une grande quantité de données 🔋 Nécessite de la puissance de calcul 💰 Il existe des modèles pré-entrainés (payants ou gratuits)
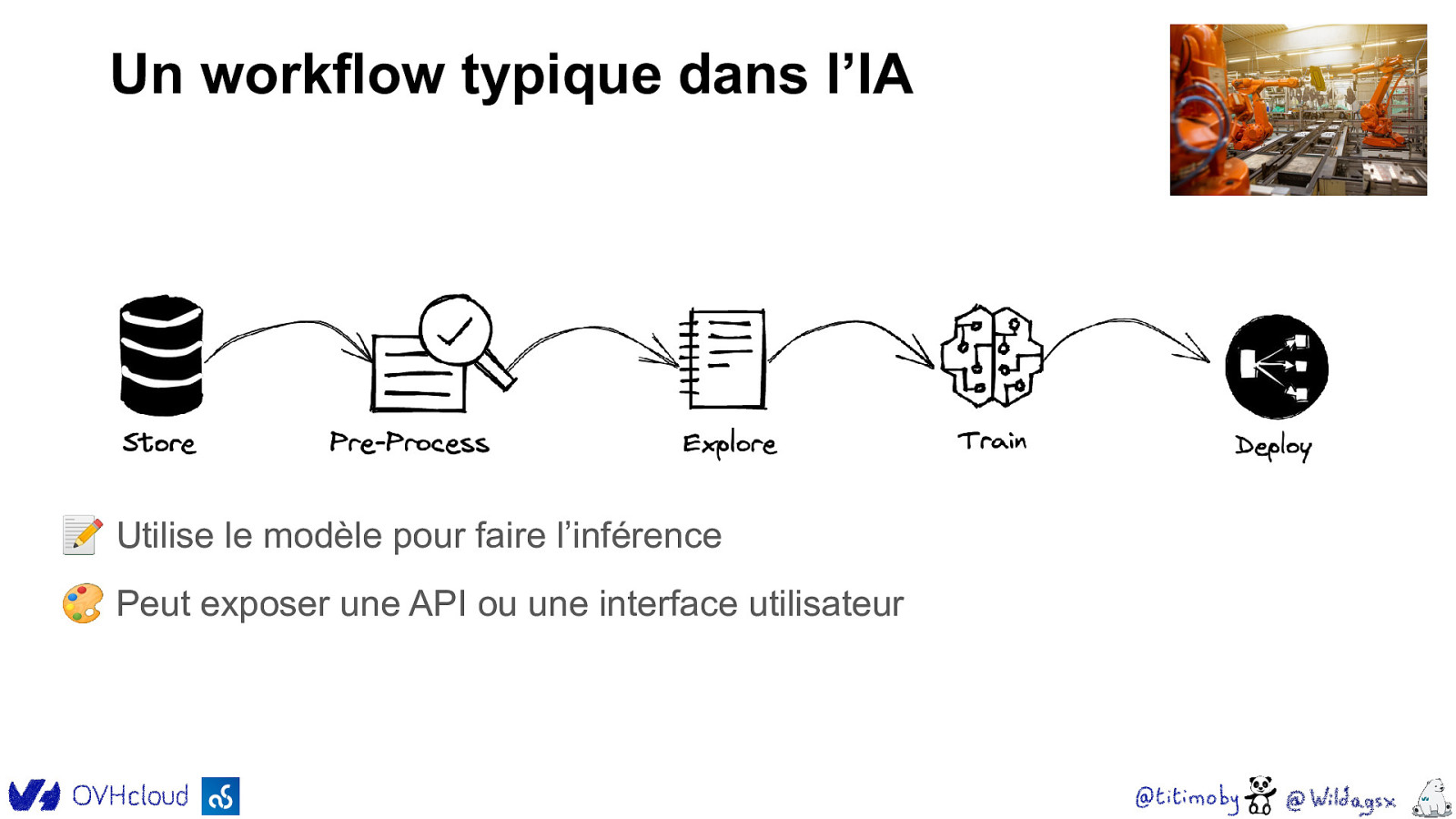
Un workflow typique dans l’IA 📝 Utilise le modèle pour faire l’inférence 🎨 Peut exposer une API ou une interface utilisateur

Les métiers Jason Leung

La ou le Data Scientist 🔎 Analyse et manipulation des données Développement 🧠 Machine Learning 🧮 Mathématiques % Statistiques

La ou le Machine Learning engineer Data Science 🧮 Mathématiques % Statistiques Développement 🧰 Frameworks & outillages IA ☁ Cloud et conteneurisation Ops

La développeuse ou le développeur 🐍 Python Concepts IA Développement 🧰 Frameworks et outillages IA ☁ Cloud et conteneurisation

Goh Rhy Yan

Les biais 🤷 Les IA sont créées par des humains 📀 Les données sont de plus ou moins bonne qualité 🏷 La labellisation des données est souvent faite par des humains

L’IA n’est pas source de vérité % Cela ne reste que des statistiques 🤔 C’est une estimation 🤖 Cela n’est qu’une aide à la décision et ne remplace pas un·e humain·e

La course à la puissance 📀 Toujours plus de données 🧮 De modèles toujours plus gros avec plus de couches 🔋 Plus de puissance de calcul 📈 Des consommations qui augmentent 🧠 Utiliser l’IA de manière “intelligente” 📉 Avoir de la performance avec moins de consommation
La diversité des CDE ● ● ● Un éditeur Le code du projet Un conteneur d’execution Gitpod GitHub Codespaces Jetbrains Space Amazon Dev environments

Python ● ● ● Facile à apprendre Complet pour votre futur Langage de prédilection du monde de l’IA aujourd’hui … ● ● ● … d’autres langages sont prêts pour demain Chaque contexte mérite son langage Pas de langage miracle universel Golearn Langchain pour Java Tensorflow js

Merci !!!! Slides https://ovh.to/ofPmXWY Feedbacks https://ovh.to/FEM3HSz Code source https://ovh.to/ofPmni6

OVHcloud recrute : https://ovh.to/4tu91L6 Eric Prouzet


🔗 Ressources (liens, …) 🔗

Liens 🔗 Documentations OVHcloud univers IA 🔗 Repository GitHub du workshop 🔗 https://unsplash.com/ 🔗 https://deepai.org/machine-learning-glossary-and-terms/weight-artificial-neural-network 🔗 https://medium.com/mlearning-ai/introduction-to-neural-networks-weights-biases-and-activation-270ebf2545aa 📽 https://www.youtube.com/@MachineLearnia 🔗 https://gitpod.io