Stream, Materialize, Serve Knitting Flawless Pipelines with Kafka, Flink, and Pinot Tim Berglund VP DevRel, Confluent Viktor Gamov Principal Developer Advocate @gamussa | developer.confluent.io | @tlberglund

A presentation at RTA Summit in May 2025 in by Viktor Gamov

Stream, Materialize, Serve Knitting Flawless Pipelines with Kafka, Flink, and Pinot Tim Berglund VP DevRel, Confluent Viktor Gamov Principal Developer Advocate @gamussa | developer.confluent.io | @tlberglund

What is Apache Pinot ? ™ @gamussa | developer.confluent.io | @tlberglund

“Apache Pinot is a real-time distributed OLAP database, designed to serve OLAP workloads on streaming data with extreme low latency and high concurrency.” @gamussa | developer.confluent.io | @tlberglund
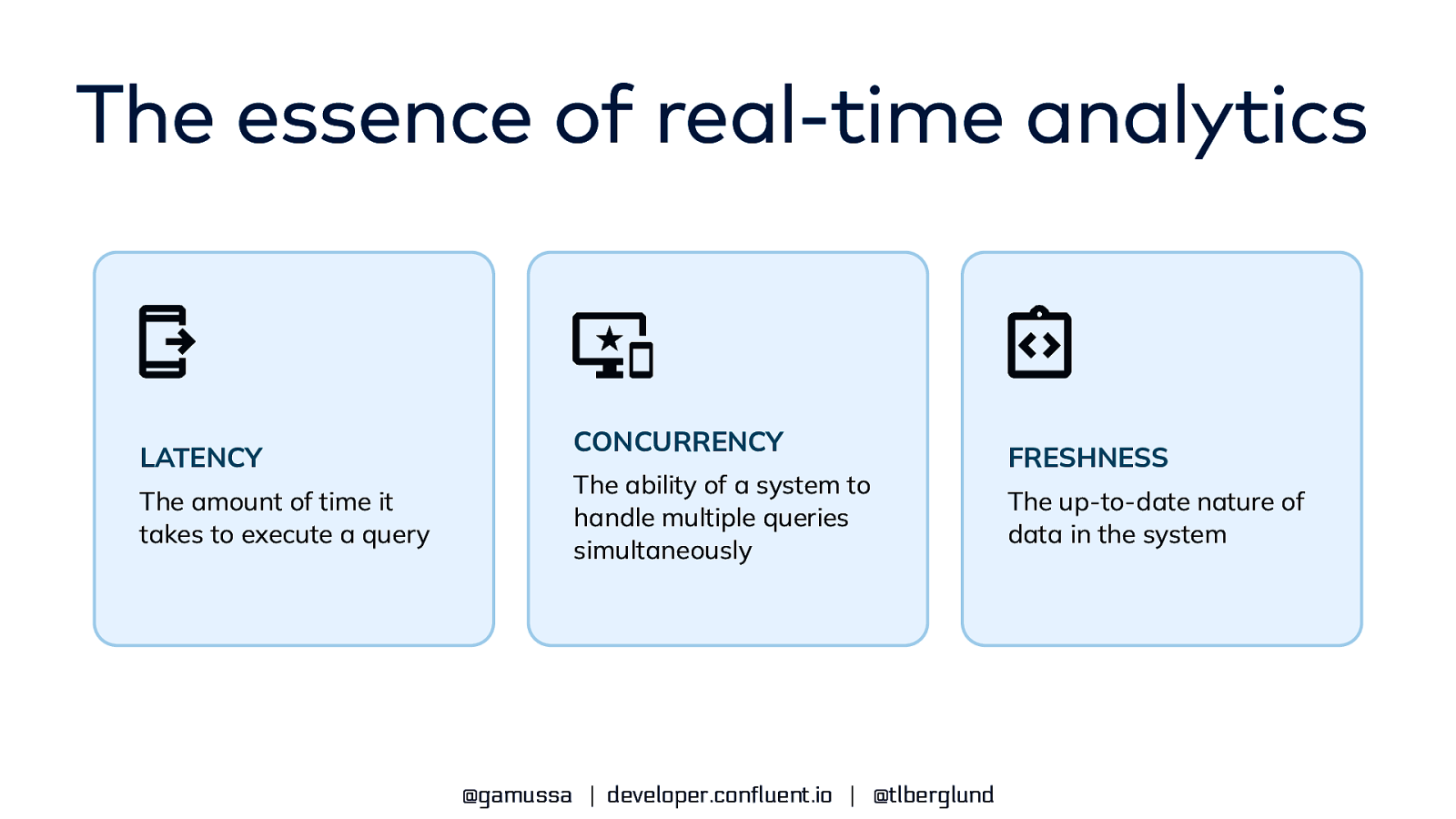
The essence of real-time analytics LATENCY The amount of time it takes to execute a query CONCURRENCY The ability of a system to handle multiple queries simultaneously @gamussa | developer.confluent.io | @tlberglund FRESHNESS The up-to-date nature of data in the system
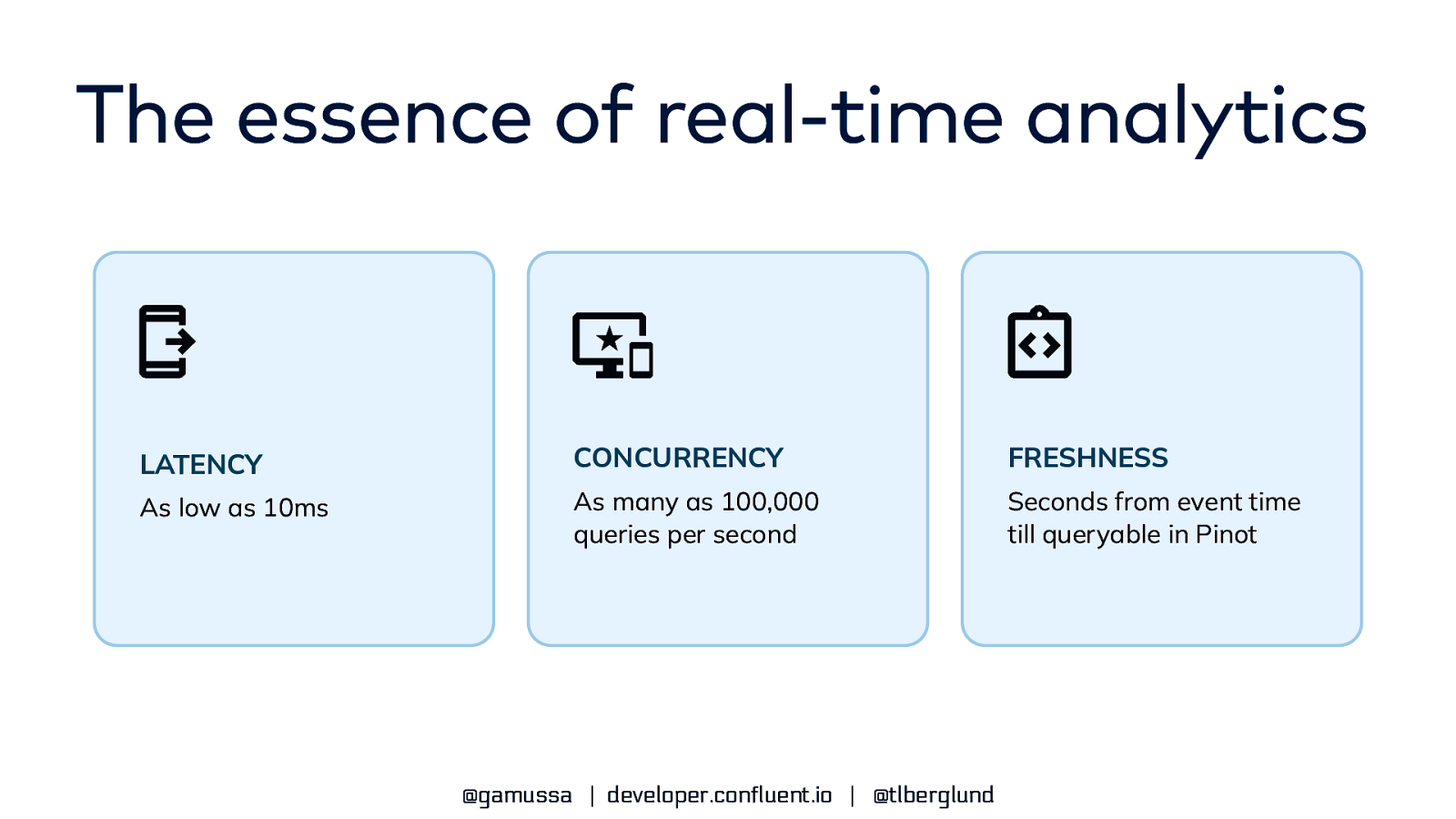
The essence of real-time analytics LATENCY CONCURRENCY FRESHNESS As low as 10ms As many as 100,000 queries per second Seconds from event time till queryable in Pinot @gamussa | developer.confluent.io | @tlberglund
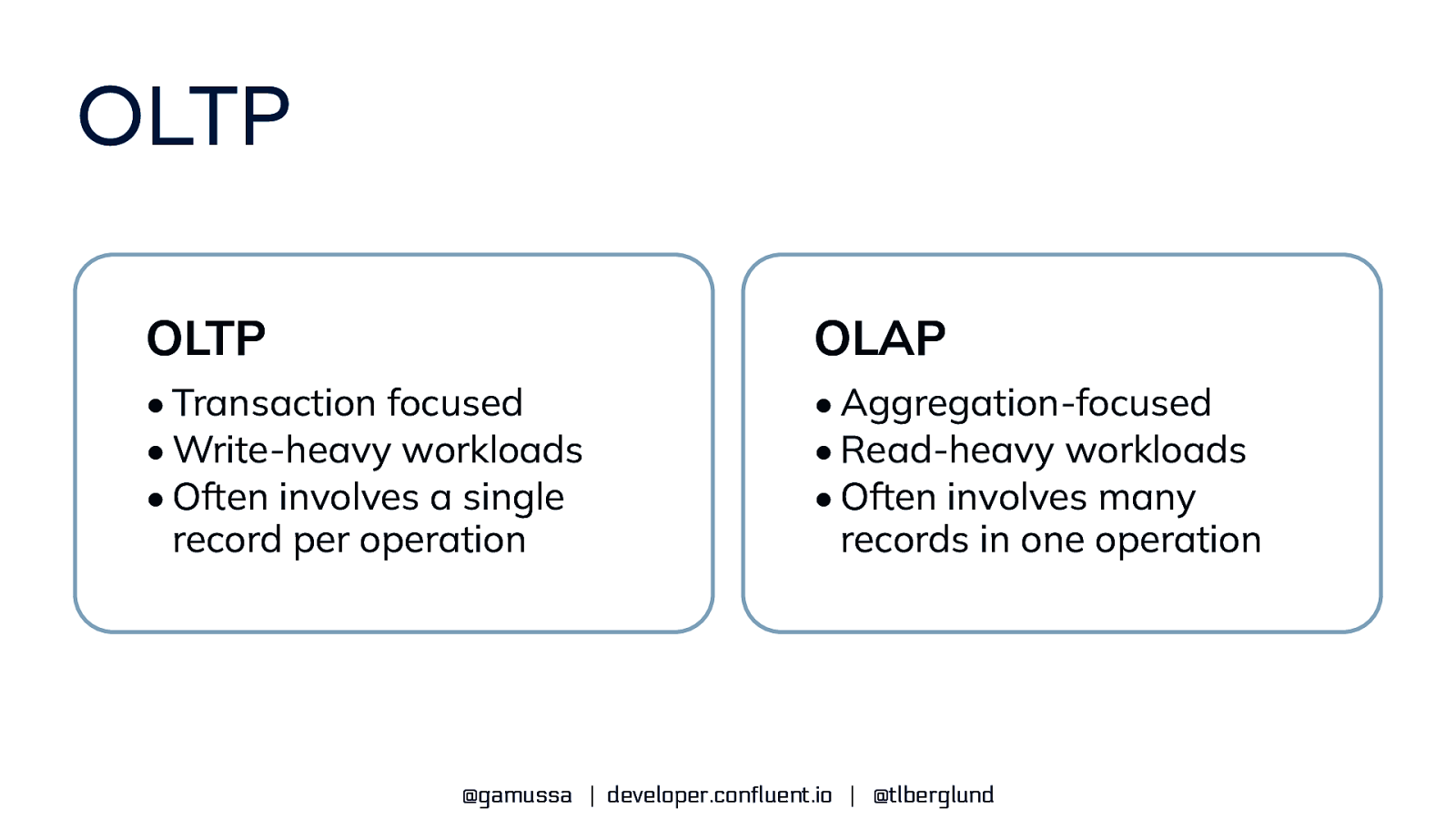
OLTP OLTP OLAP • Transaction focused • Write-heavy workloads • Often involves a single record per operation • Aggregation-focused • Read-heavy workloads • Often involves many records in one operation @gamussa | developer.confluent.io | @tlberglund

Data Model ● Pinot uses the completely familiar tabular data model ● Table creation and schema definition expressed in JSON ● Queries expressed in SQL

Kafka + Pinot Streaming Ingestion @gamussa | developer.confluent.io | @tlberglund
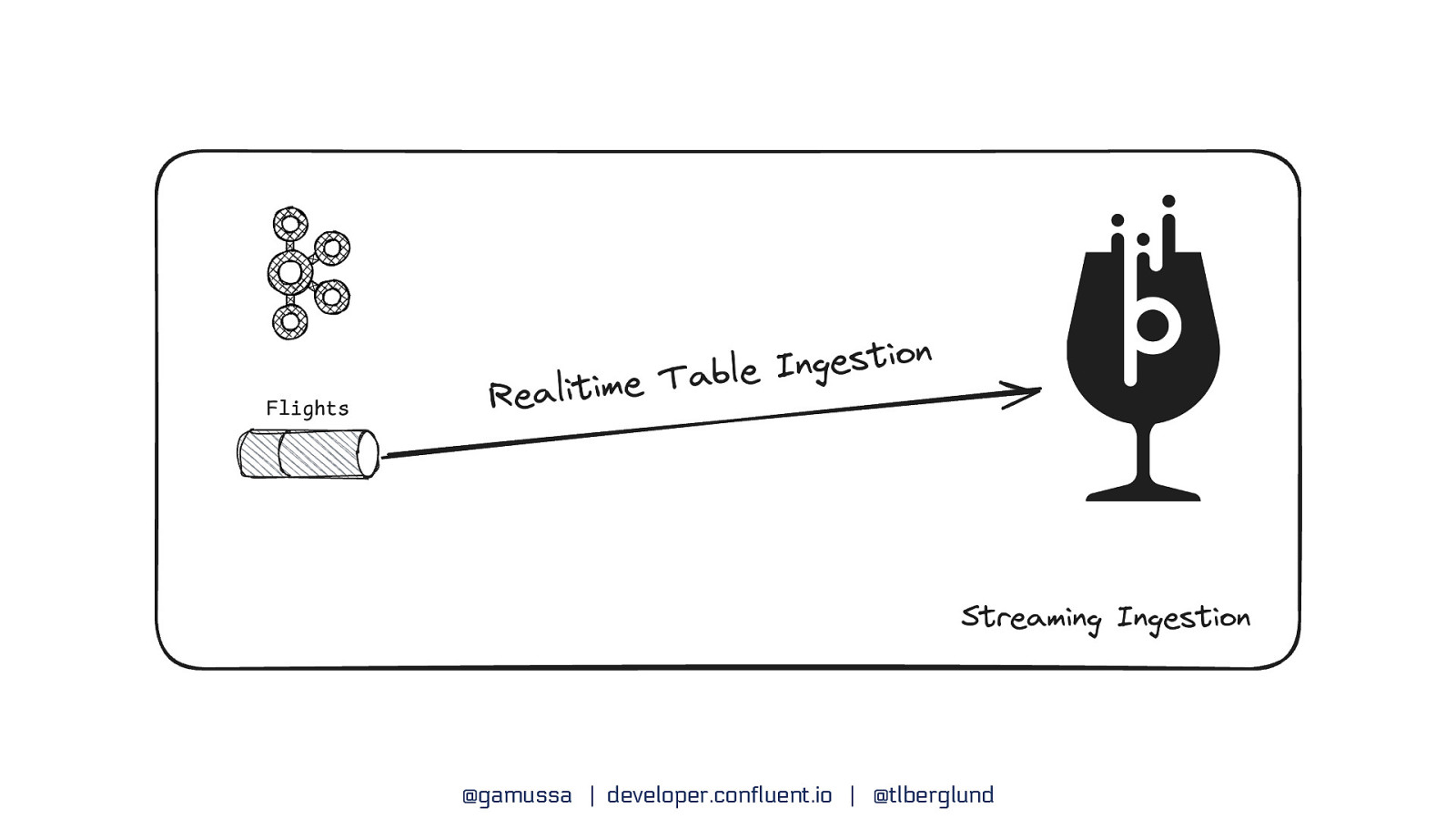
@gamussa | developer.confluent.io | @tlberglund

Kafka + Flink + Pinot Knitting Flawless Pipelines @gamussa | developer.confluent.io | @tlberglund

Flink 101 @gamussa | developer.confluent.io | @tlberglund

«Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.» @gamussa | developer.confluent.io | @tlberglund
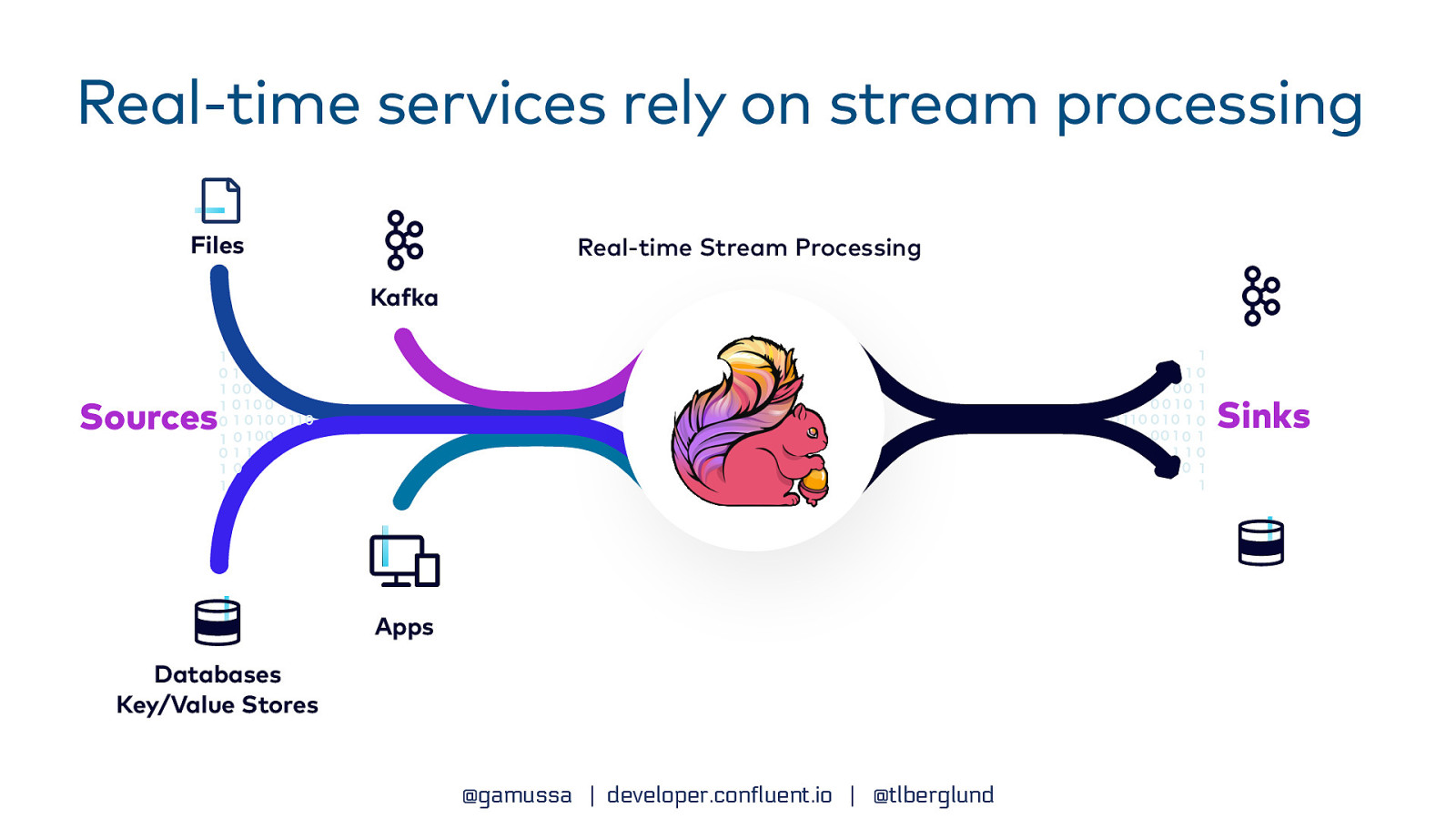
Real-time services rely on stream processing Files Real-time Stream Processing Ka ka Sinks Sources Apps Databases Key/Value Stores f @gamussa | developer.confluent.io | @tlberglund

What is Flink SQL @gamussa | developer.confluent.io | @tlberglund

A standards-compliant SQL engine for processing both batch and streaming data with the scalability, performance, and consistency of Apache Flink @gamussa | developer.confluent.io | @tlberglund

How does Flink work with Kafka? @gamussa | developer.confluent.io | @tlberglund

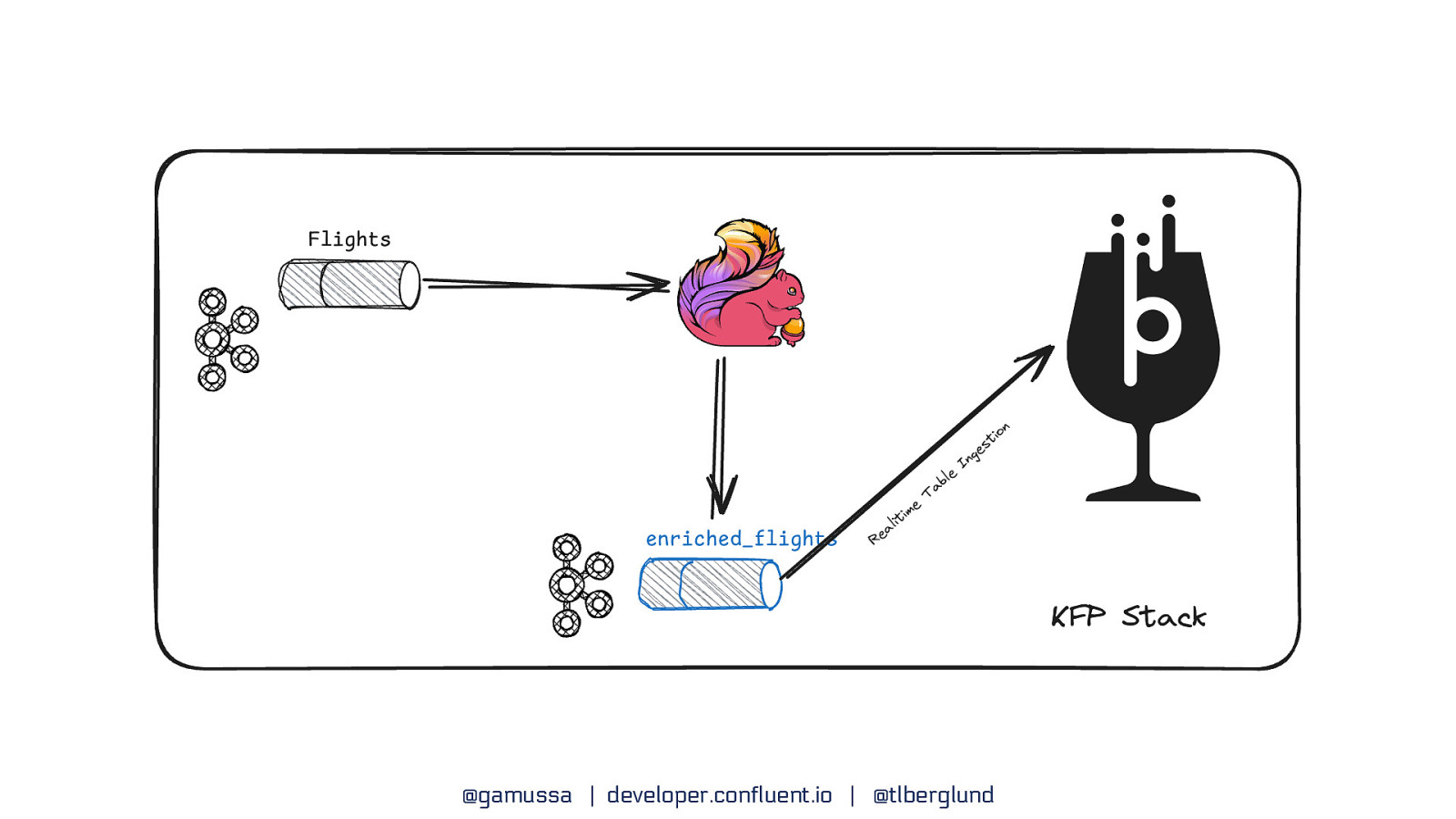
@gamussa | developer.confluent.io | @tlberglund
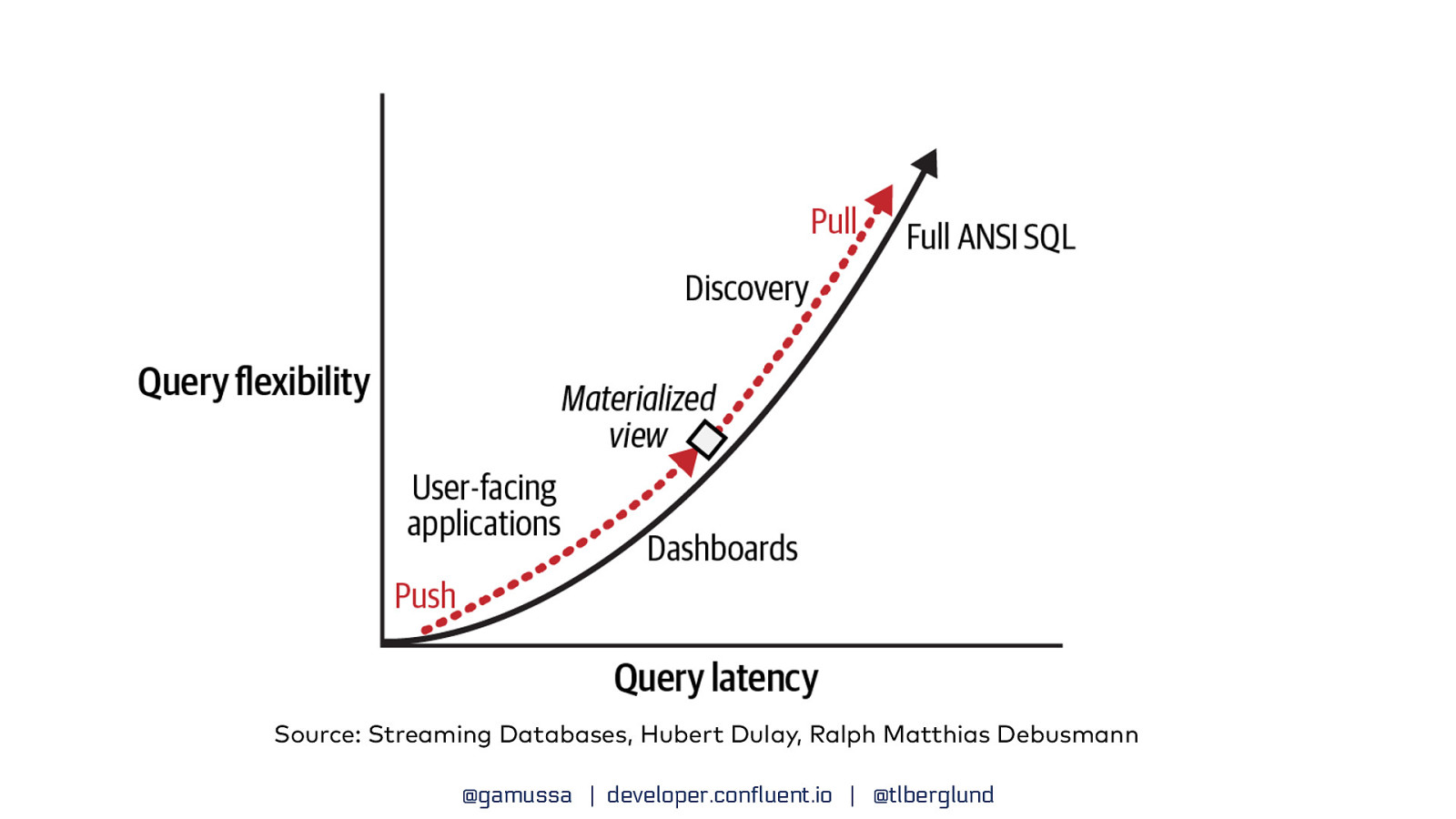
Source: Streaming Databases, Hubert Dulay, Ralph Matthias Debusmann @gamussa | developer.confluent.io | @tlberglund

Check out developer.confluent.io @tlberglund | @gamussa