X/Bluesky: @gamussa

A presentation at Geecon in May 2025 in Kraków, Poland by Viktor Gamov

X/Bluesky: @gamussa

Viktor GAMOV Principal Developer Advocate | Con luent co-author of Manning’s Ka ka in Action f f f THE CLOUD CONNECTIVITY COMPANY X/Bluesky: @gamussa Kong Con idential

Slides and Video https://speaking.gamov.io/ X/Bluesky: @gamussa

What is Apache Flink?

What is Flink? Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. X/Bluesky: @gamussa
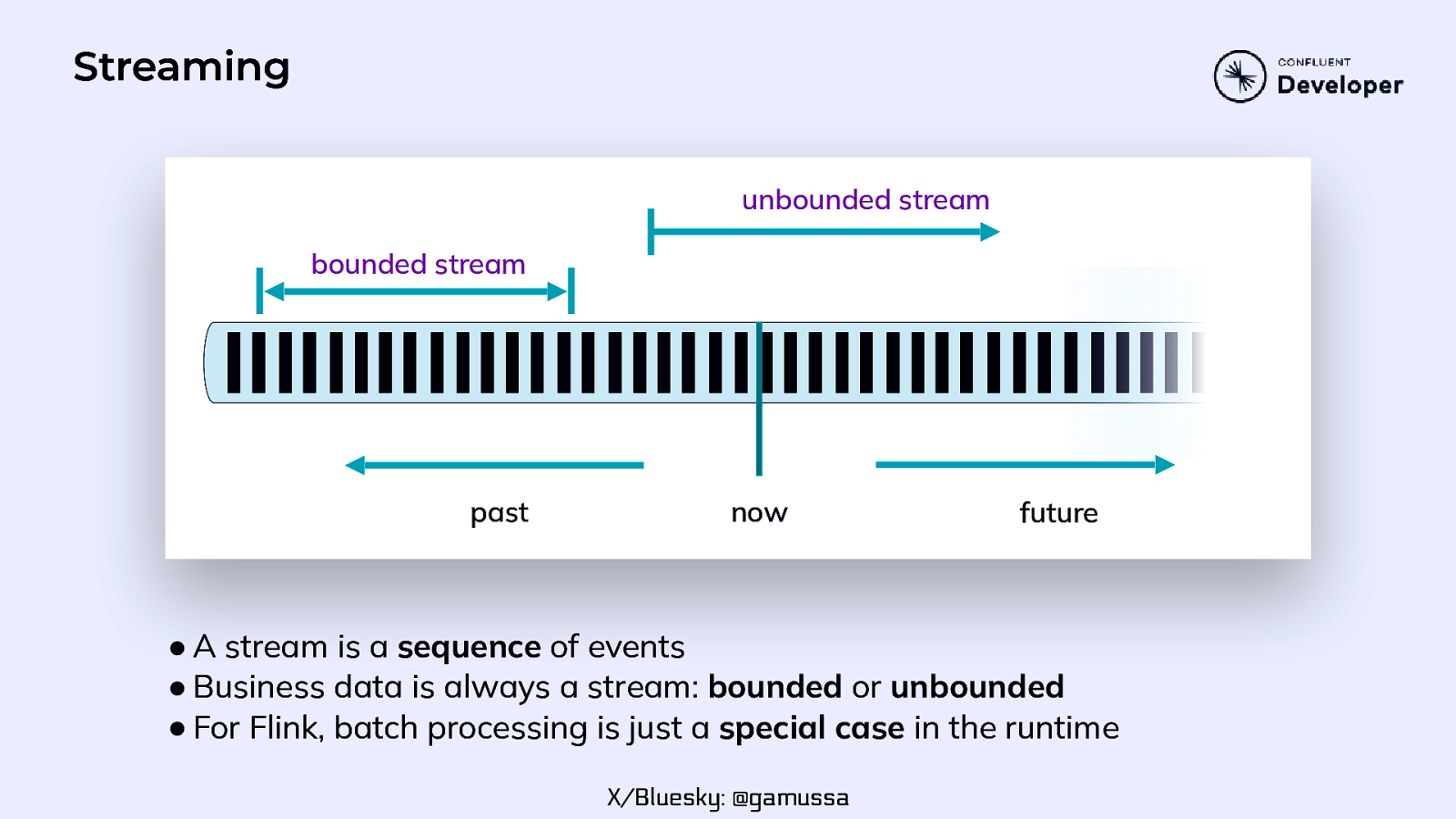
Streaming unbounded stream bounded stream past now future ● A stream is a sequence of events ● Business data is always a stream: bounded or unbounded ● For Flink, batch processing is just a special case in the runtime X/Bluesky: @gamussa

Key Features of Flink
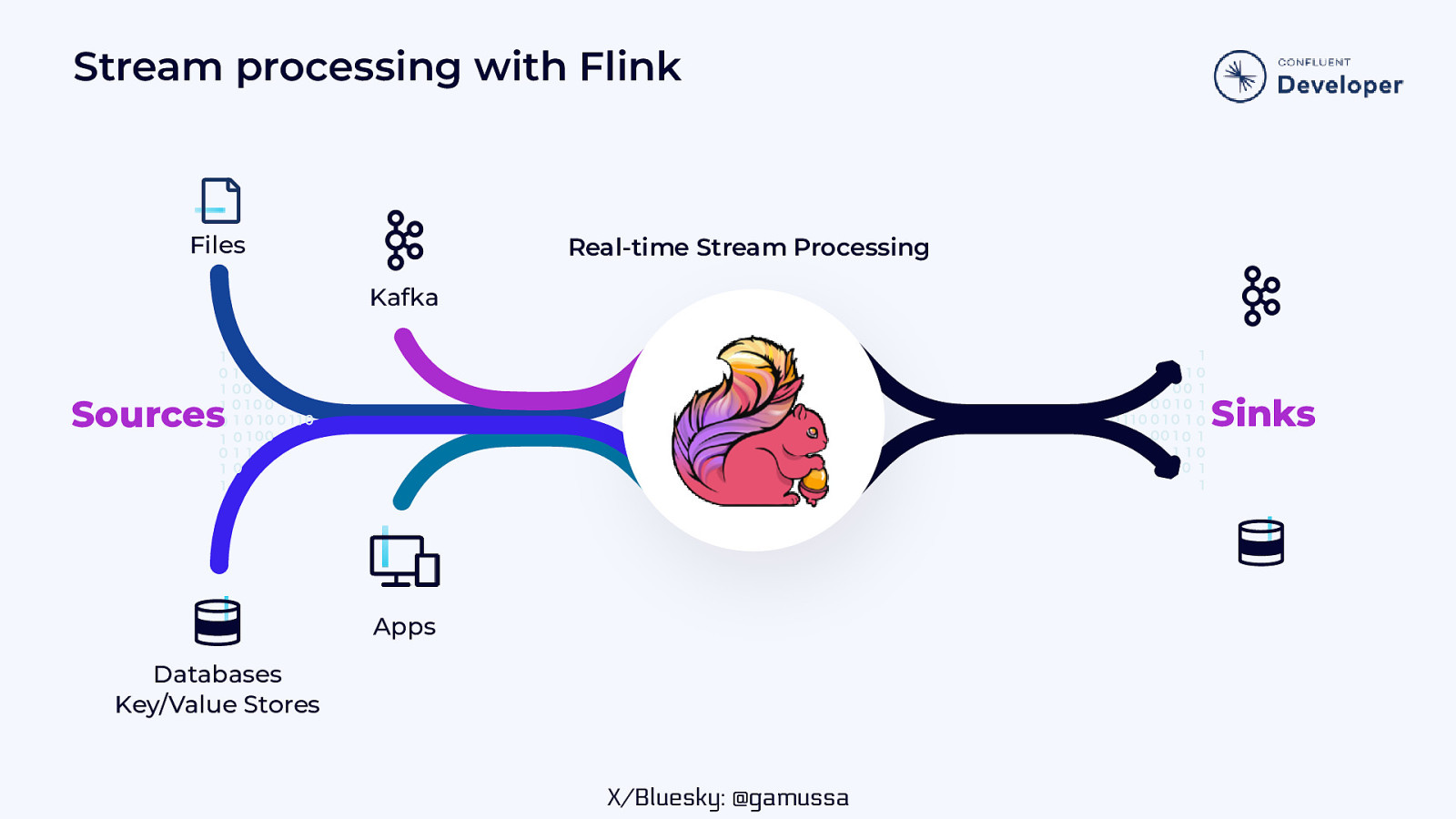
Stream processing with Flink Files Real-time Stream Processing Kafka Sinks Sources Apps Databases Key/Value Stores X/Bluesky: @gamussa
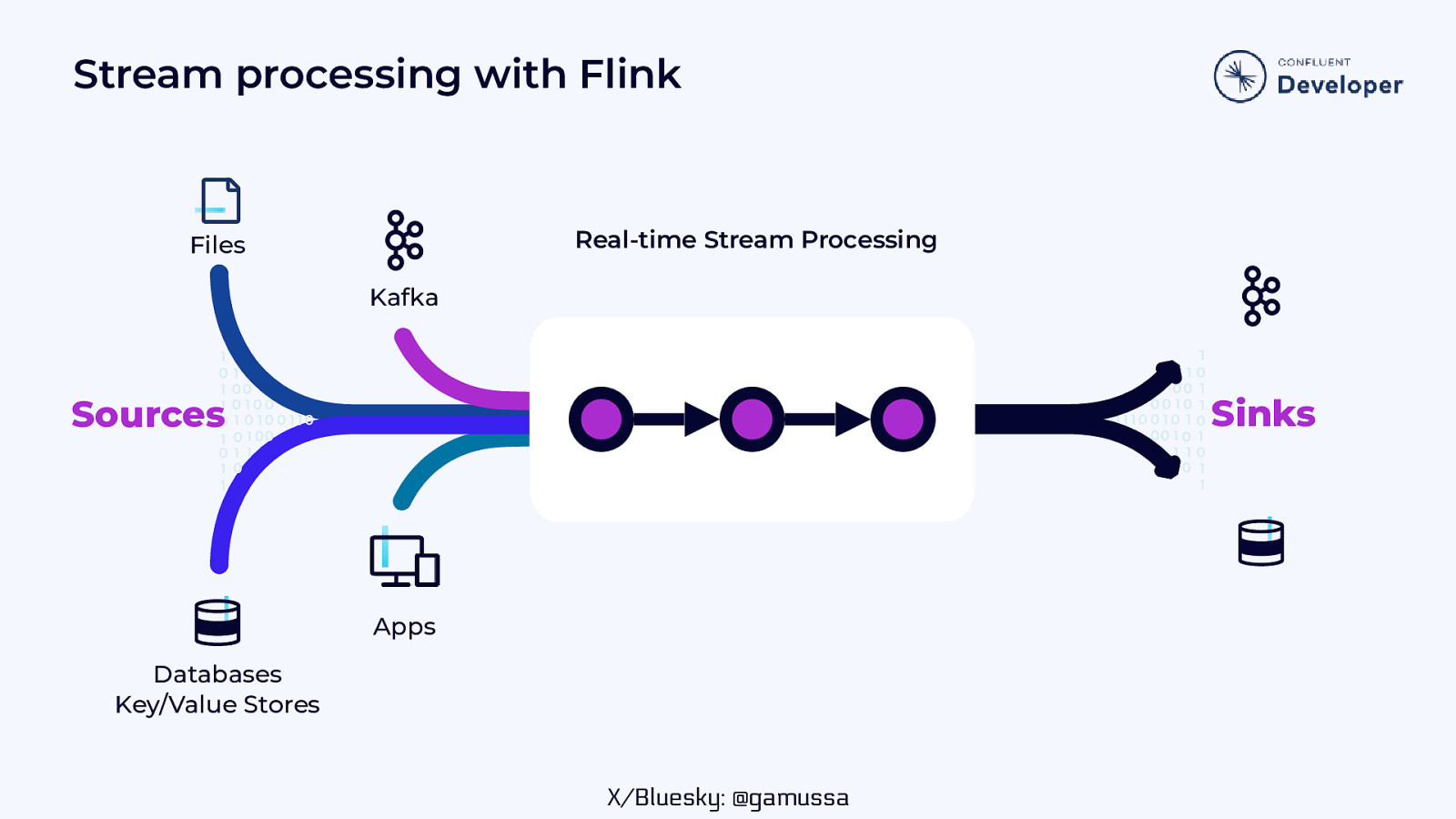
Stream processing with Flink Real-time Stream Processing Files Kafka Sinks Sources Apps Databases Key/Value Stores X/Bluesky: @gamussa

Introduction to DataStream API

// Set up the execution environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // Create a DataStream from some elements DataStream<String> inputStream = env.fromData(“apple”, “banana”, “cherry”, “date”, “elderberry”); // Perform a transformation DataStream<Tuple2<String, Integer>> resultStream = inputStream .map(value -> new Tuple2<>(value, value.length())) .returns(Types.TUPLE(Types.STRING, Types.INT)); // Print the results to the console resultStream.print(); // Execute the Flink job env.execute(“Simple Flink Job”); @gamussa | @confluentinc | @apacheflink
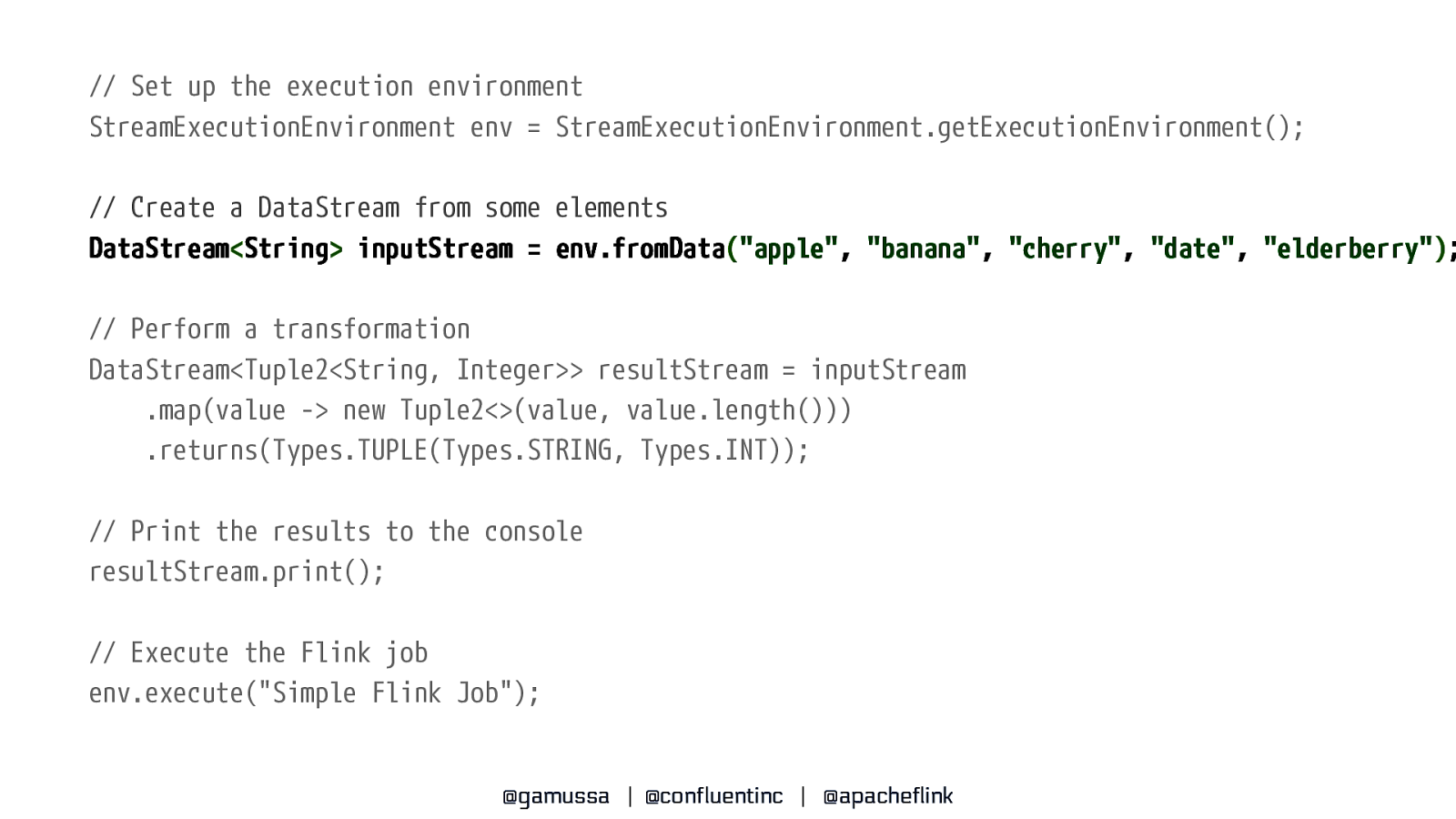
// Set up the execution environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // Create a DataStream from some elements DataStream<String> inputStream = env.fromData(“apple”, “banana”, “cherry”, “date”, “elderberry”); // Perform a transformation DataStream<Tuple2<String, Integer>> resultStream = inputStream .map(value -> new Tuple2<>(value, value.length())) .returns(Types.TUPLE(Types.STRING, Types.INT)); // Print the results to the console resultStream.print(); // Execute the Flink job env.execute(“Simple Flink Job”); @gamussa | @confluentinc | @apacheflink
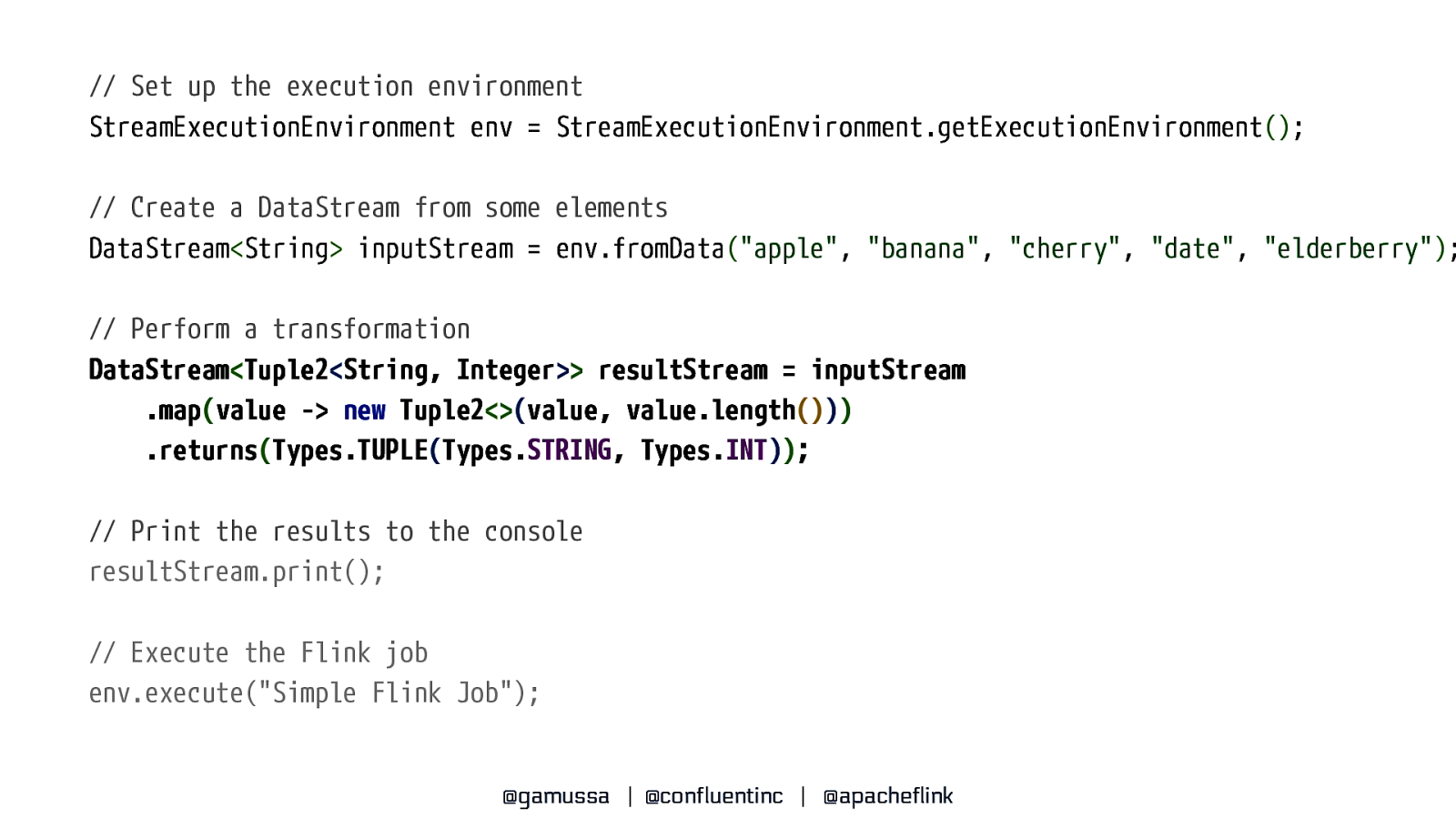
// Set up the execution environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // Create a DataStream from some elements DataStream<String> inputStream = env.fromData(“apple”, “banana”, “cherry”, “date”, “elderberry”); // Perform a transformation DataStream<Tuple2<String, Integer>> resultStream = inputStream .map(value -> new Tuple2<>(value, value.length())) .returns(Types.TUPLE(Types.STRING, Types.INT)); // Print the results to the console resultStream.print(); // Execute the Flink job env.execute(“Simple Flink Job”); @gamussa | @confluentinc | @apacheflink

// Set up the execution environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // Create a DataStream from some elements DataStream<String> inputStream = env.fromData(“apple”, “banana”, “cherry”, “date”, “elderberry”); // Perform a transformation DataStream<Tuple2<String, Integer>> resultStream = inputStream .map(value -> new Tuple2<>(value, value.length())) .returns(Types.TUPLE(Types.STRING, Types.INT)); // Print the results to the console resultStream.print(); // Execute the Flink job env.execute(“Simple Flink Job”); @gamussa | @confluentinc | @apacheflink
The JobGraph (or topology) X/Bluesky: @gamussa
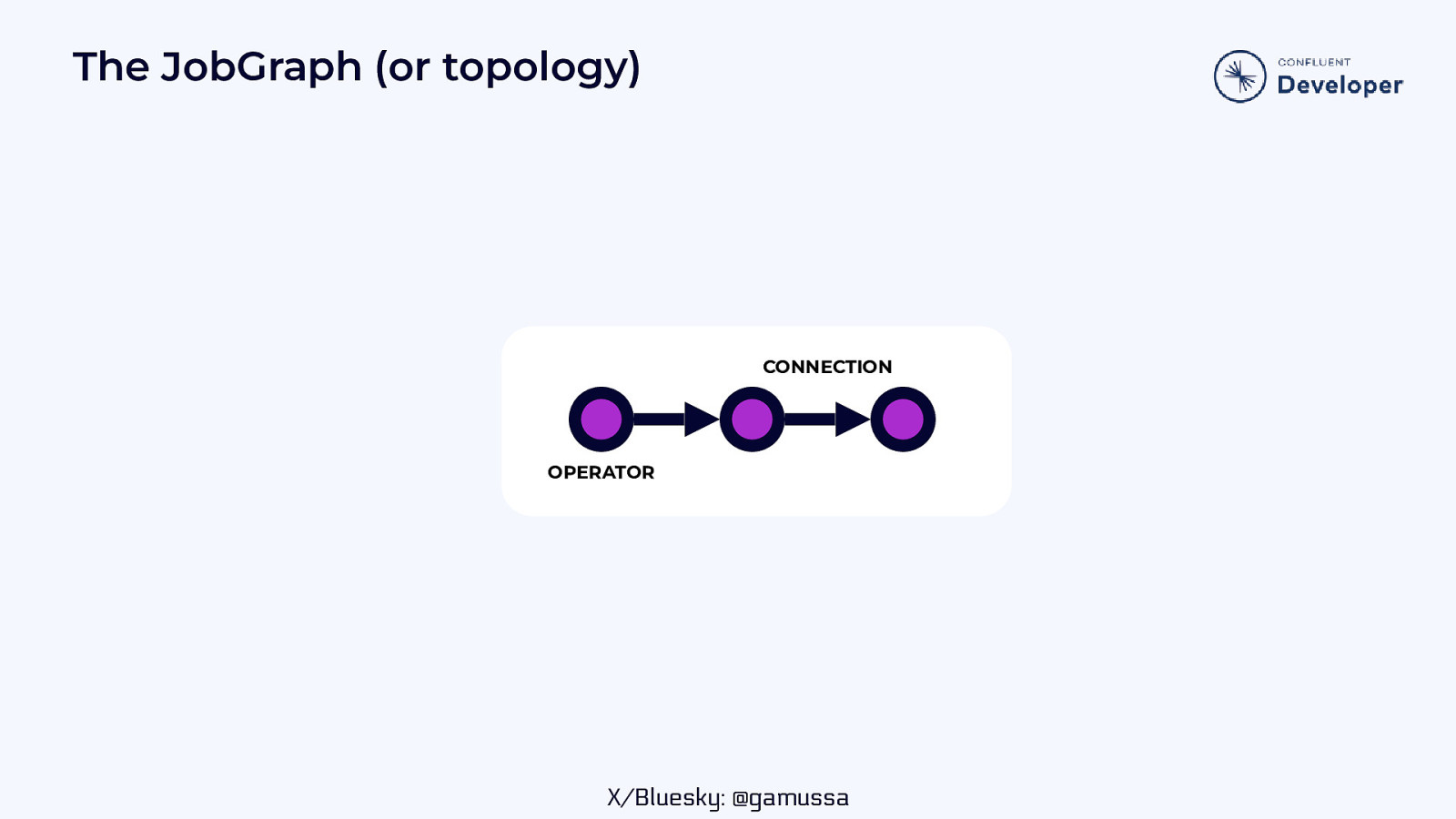
The JobGraph (or topology) CONNECTION OPERATOR X/Bluesky: @gamussa
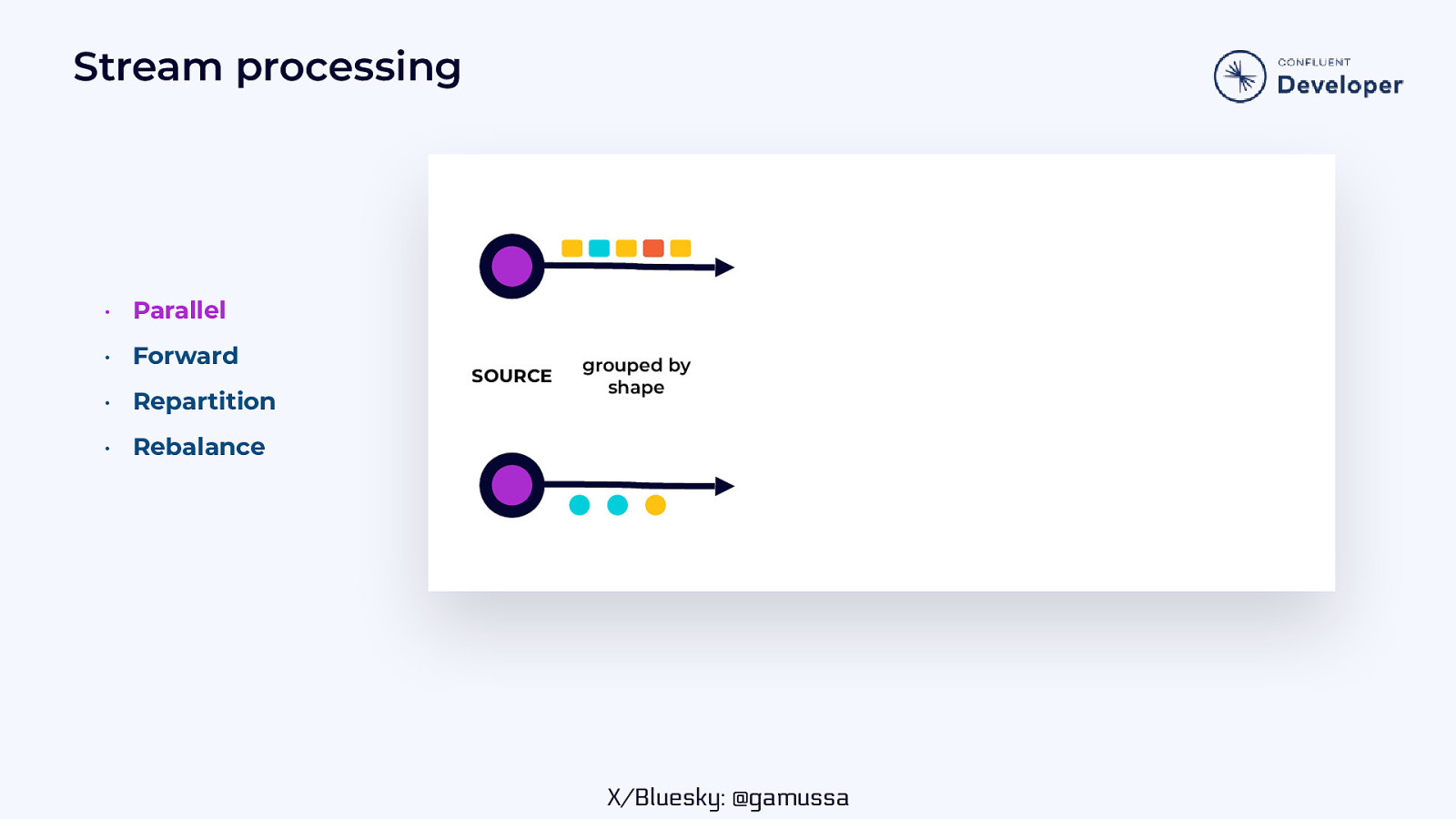
Stream processing • Parallel • Forward • Repartition SOURCE grouped by shape • Rebalance X/Bluesky: @gamussa
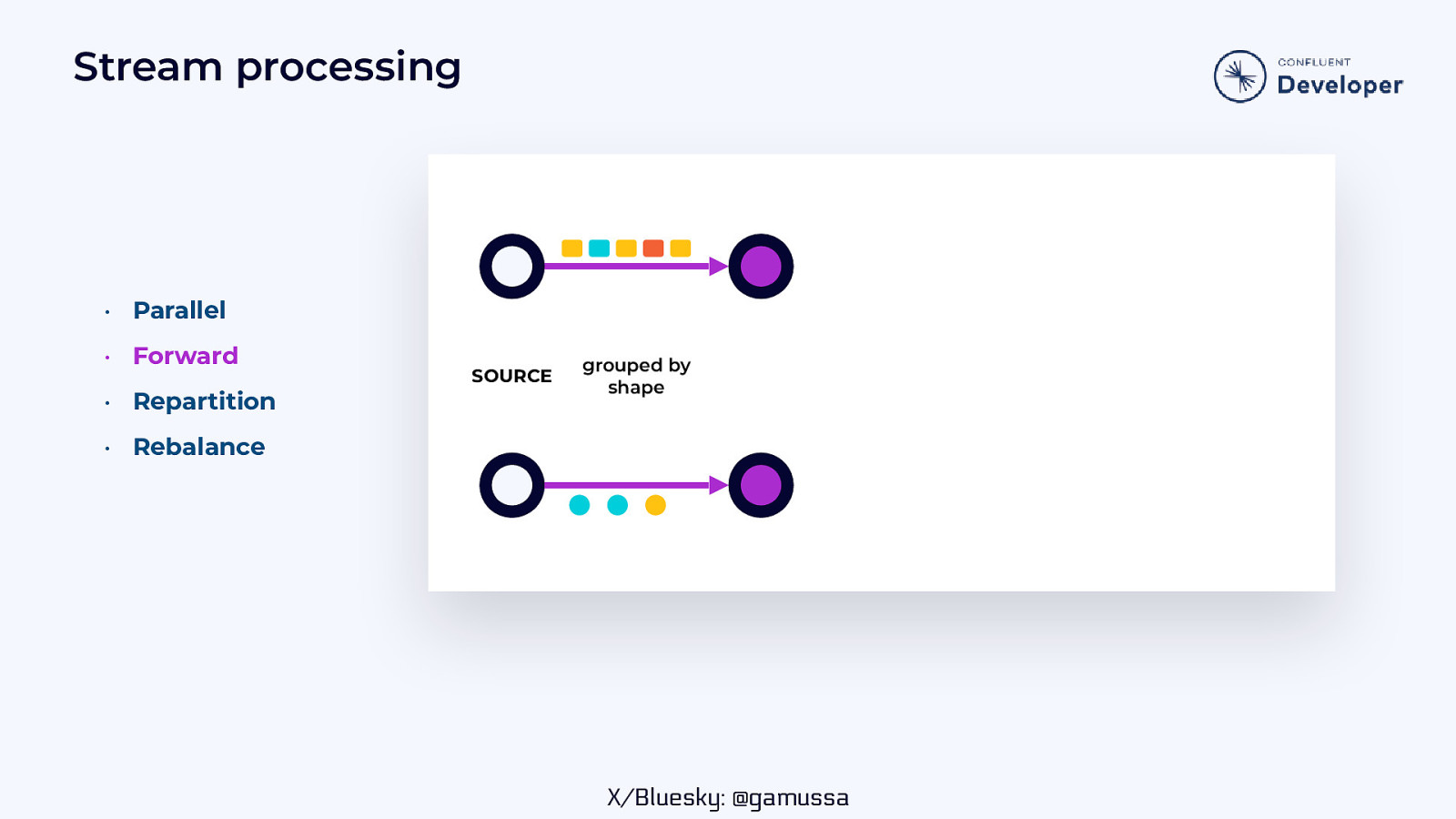
Stream processing • Parallel • Forward • Repartition SOURCE grouped by shape • Rebalance X/Bluesky: @gamussa
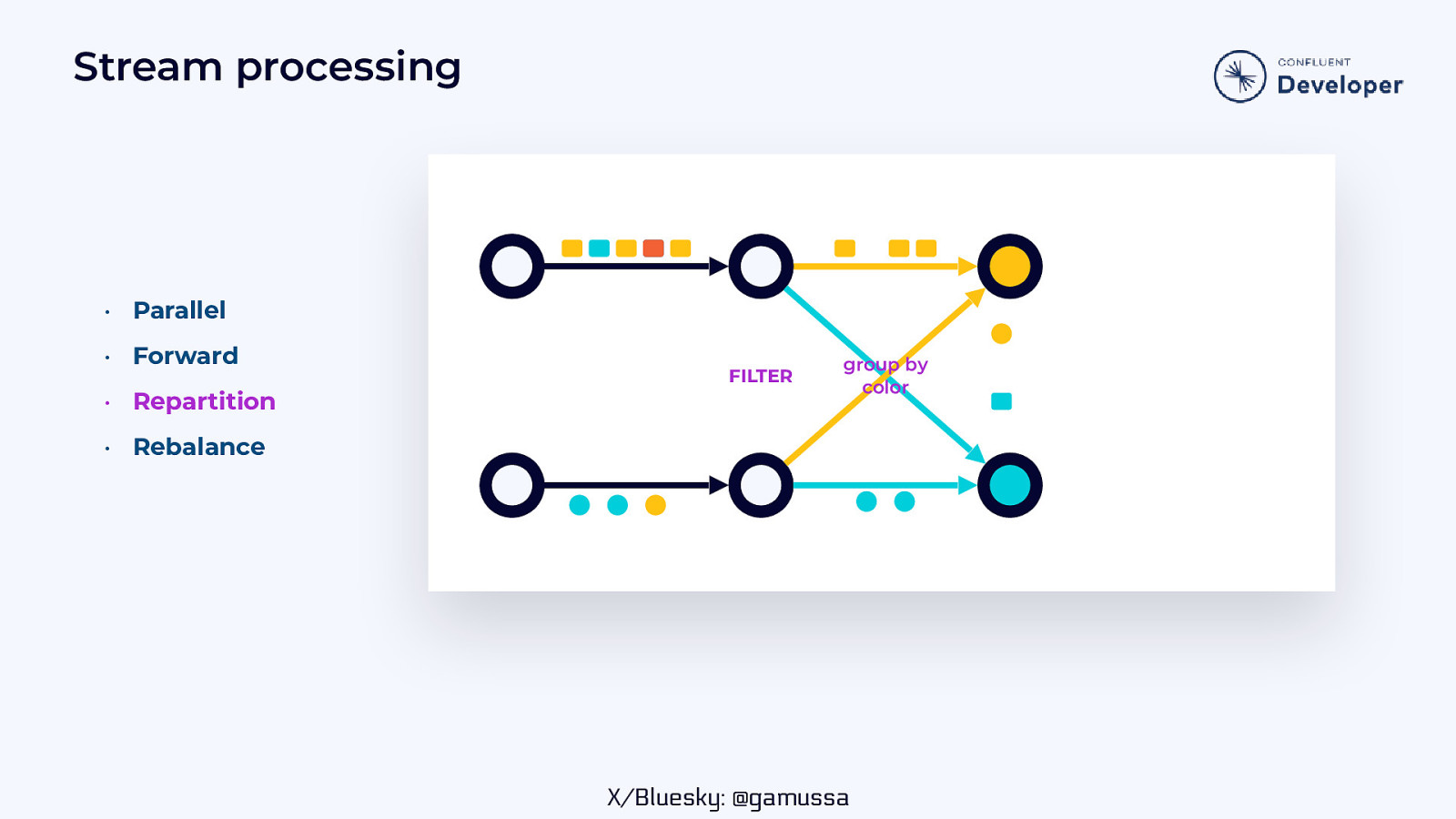
Stream processing • Parallel • Forward • Repartition FILTER group by color • Rebalance X/Bluesky: @gamussa
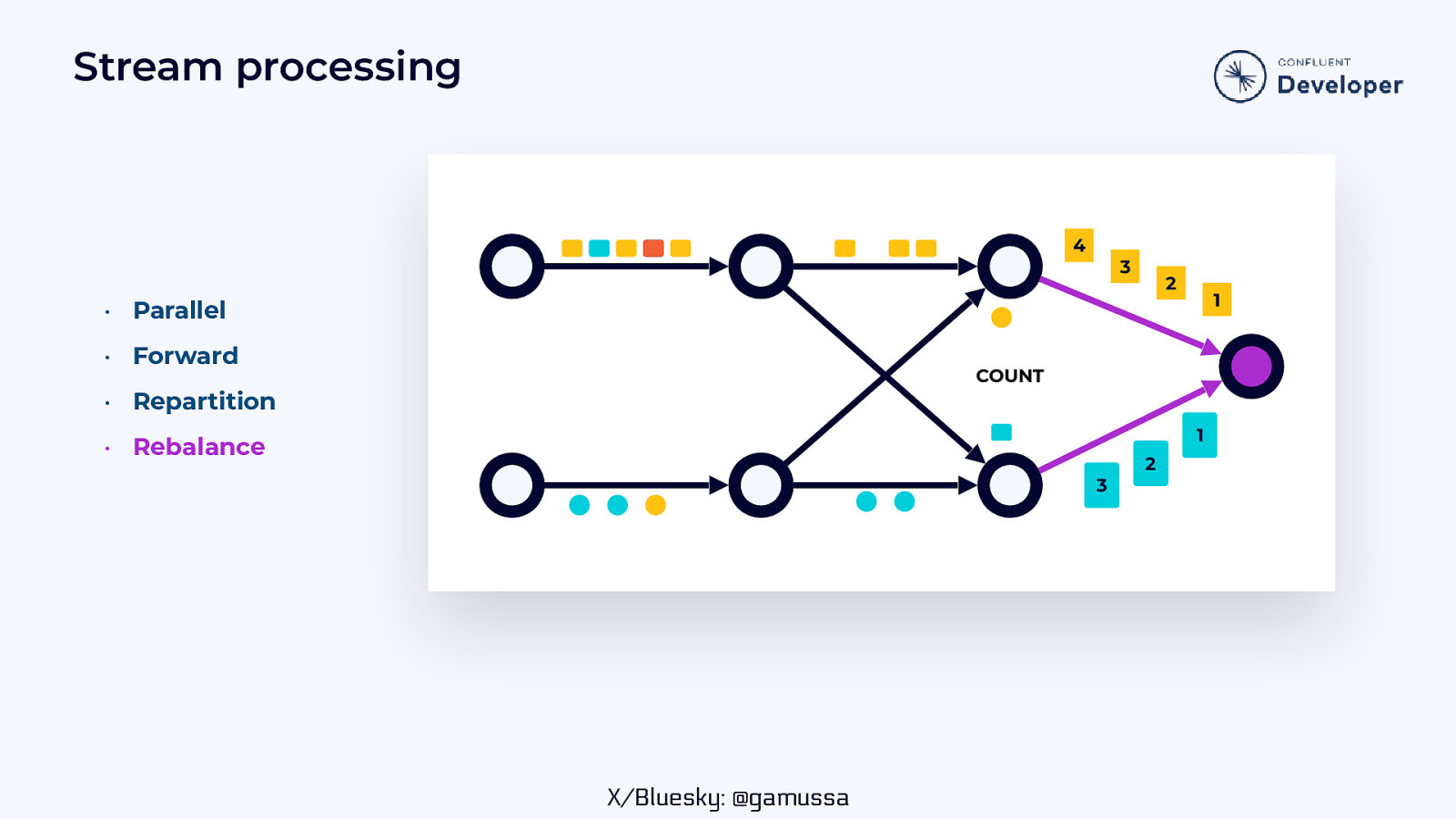
Stream processing 4 3 2 1 • Parallel • Forward COUNT • Repartition 1 • Rebalance 3 X/Bluesky: @gamussa 2
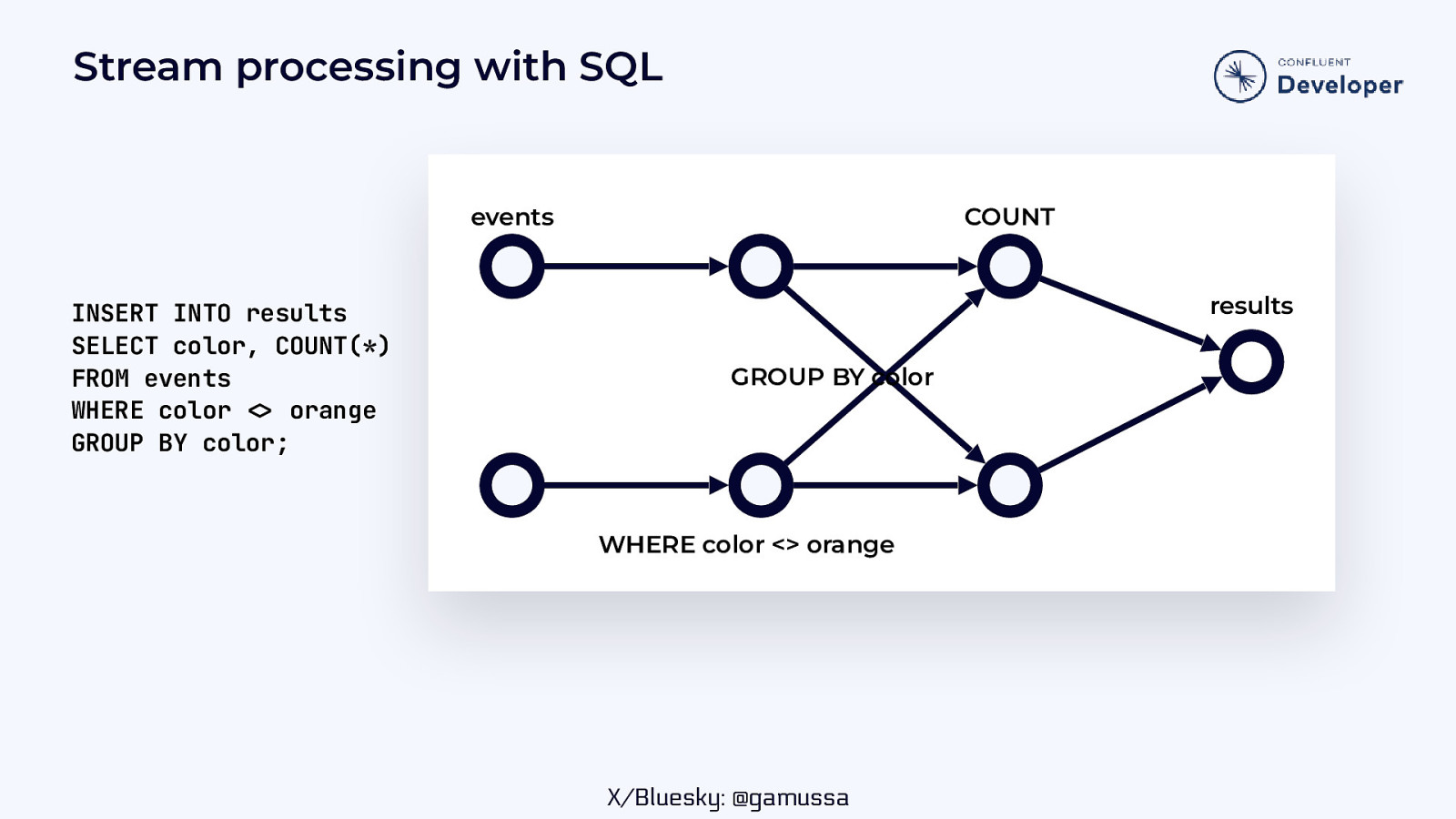
Stream processing with SQL events INSERT INTO results SELECT color, COUNT(*) FROM events WHERE color orange GROUP BY color; COUNT results GROUP BY color WHERE color <> orange
< X/Bluesky: @gamussa
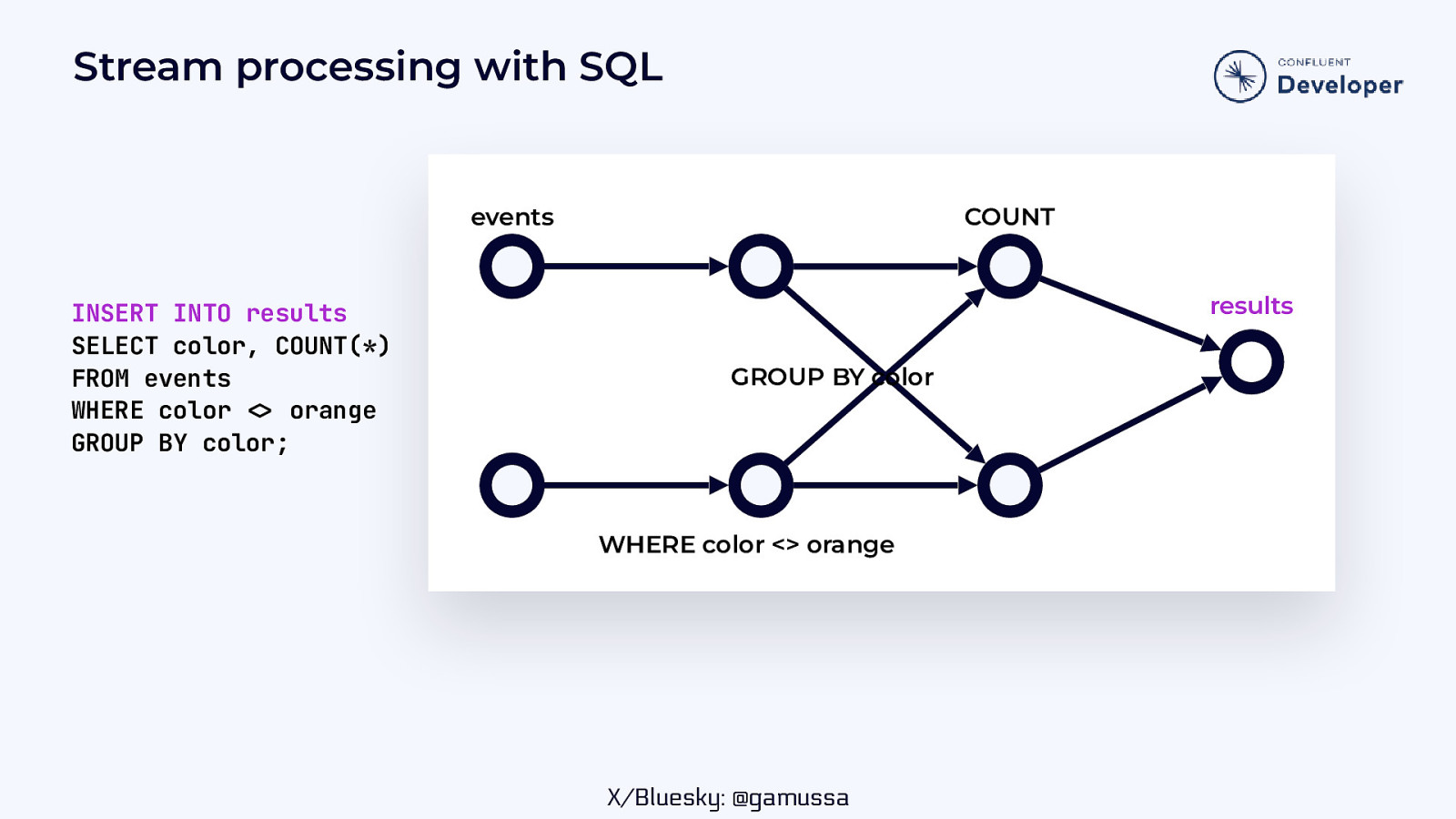
Stream processing with SQL events INSERT INTO results SELECT color, COUNT(*) FROM events WHERE color orange GROUP BY color; COUNT results GROUP BY color WHERE color <> orange
< X/Bluesky: @gamussa
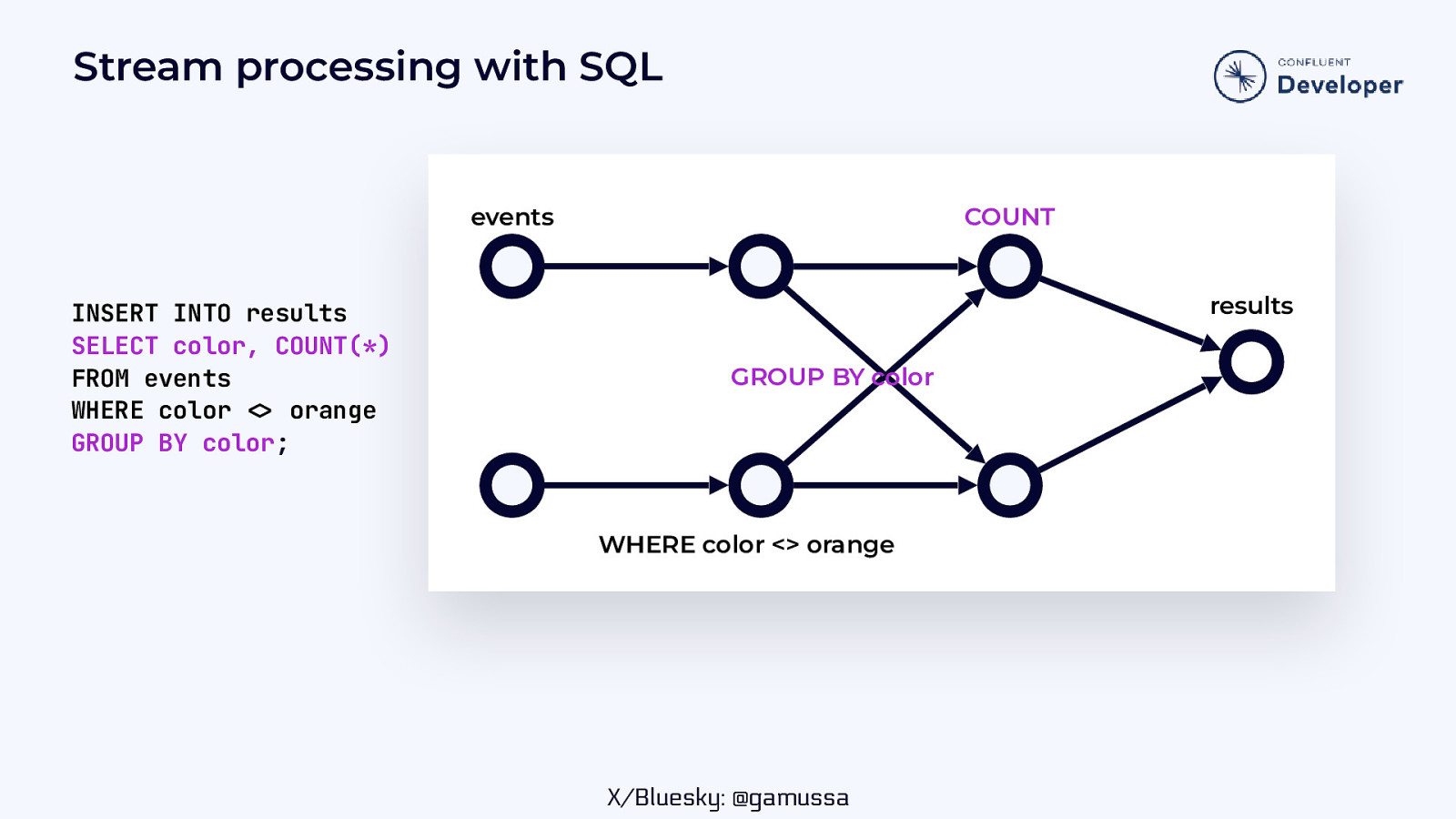
Stream processing with SQL events INSERT INTO results SELECT color, COUNT(*) FROM events WHERE color orange GROUP BY color; COUNT results GROUP BY color WHERE color <> orange
< X/Bluesky: @gamussa
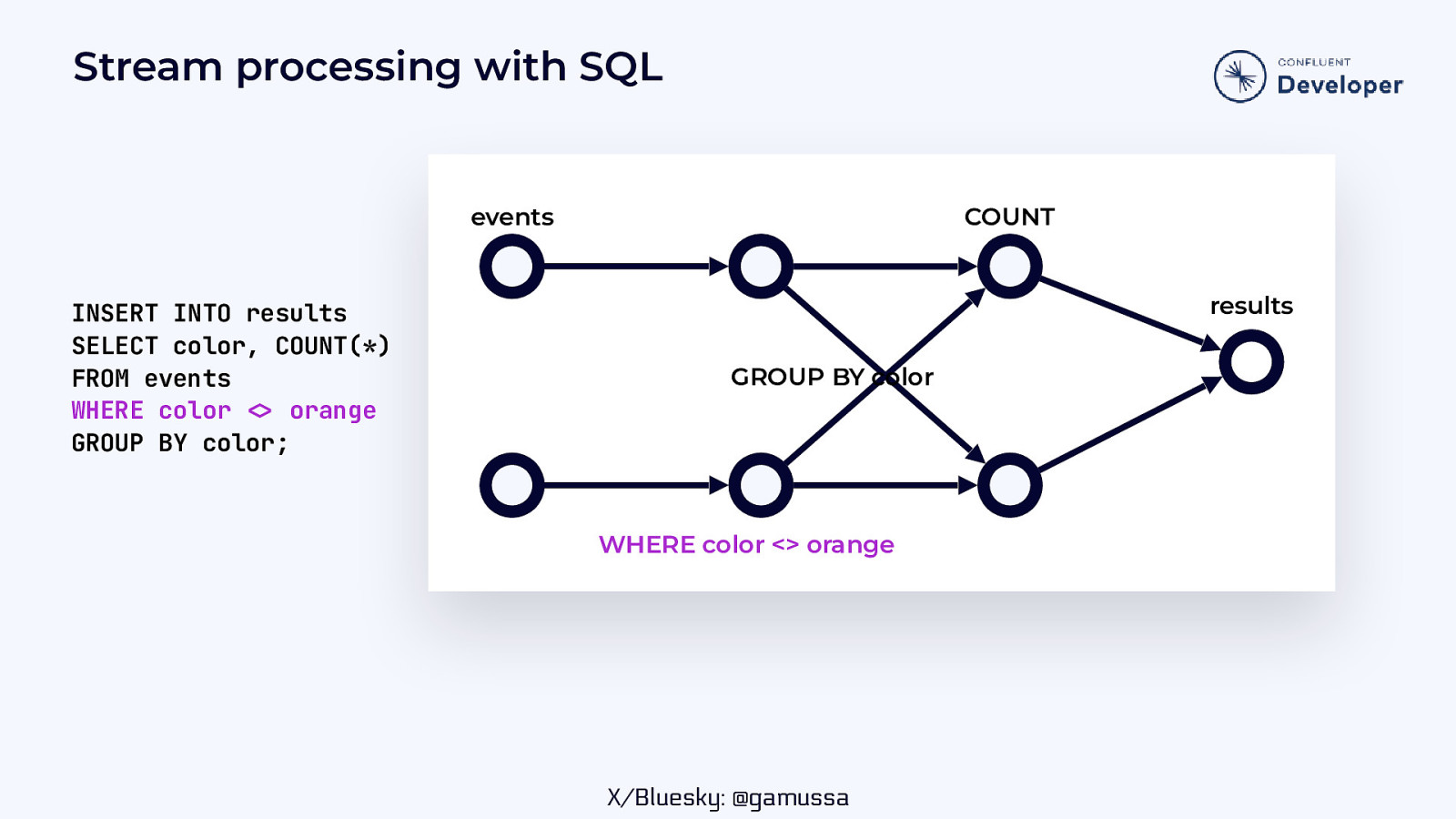
Stream processing with SQL events INSERT INTO results SELECT color, COUNT(*) FROM events WHERE color orange GROUP BY color; COUNT results GROUP BY color WHERE color <> orange
< X/Bluesky: @gamussa
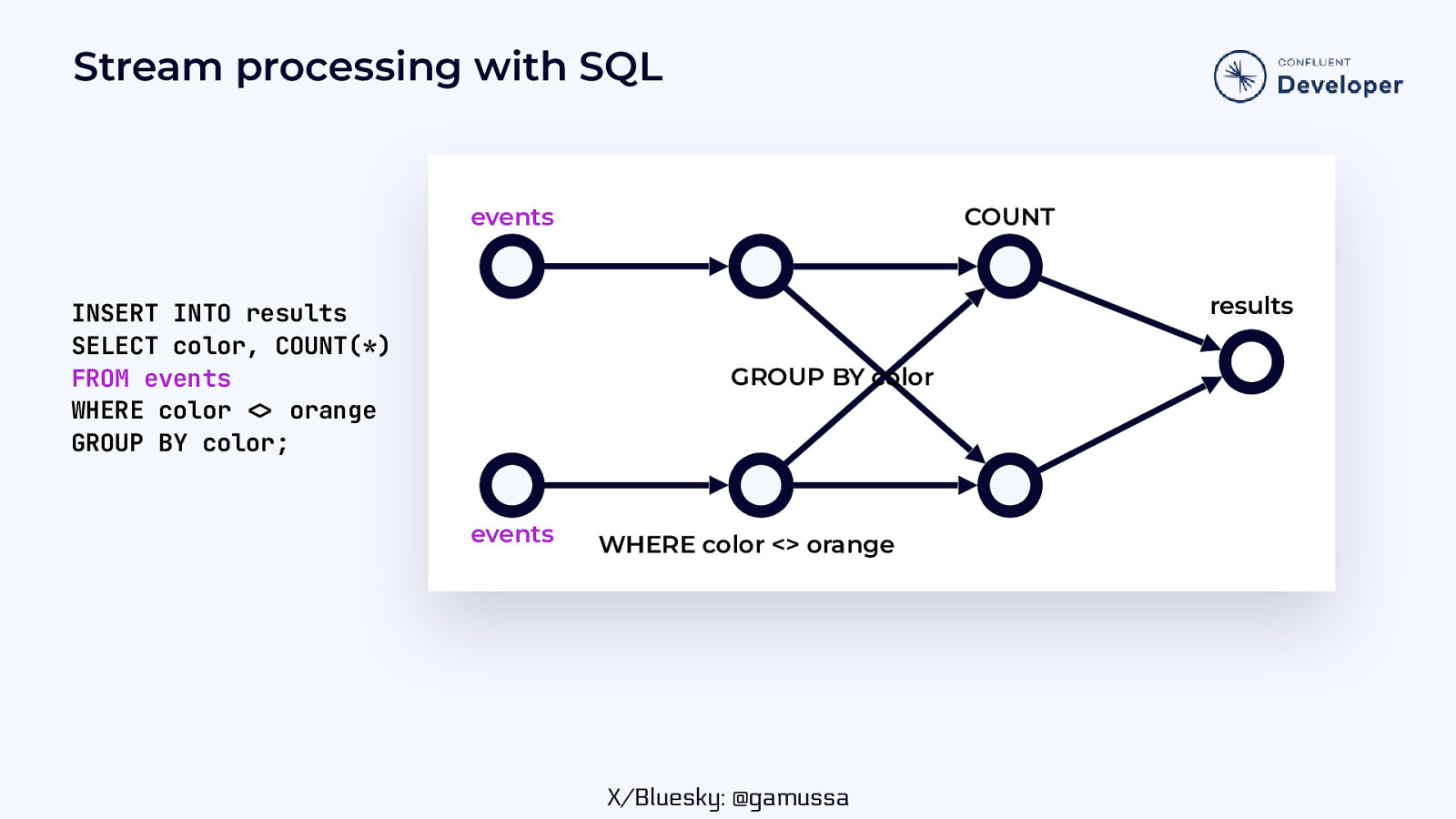
Stream processing with SQL events COUNT results INSERT INTO results SELECT color, COUNT(*) FROM events WHERE color orange GROUP BY color; GROUP BY color events WHERE color <> orange
< X/Bluesky: @gamussa
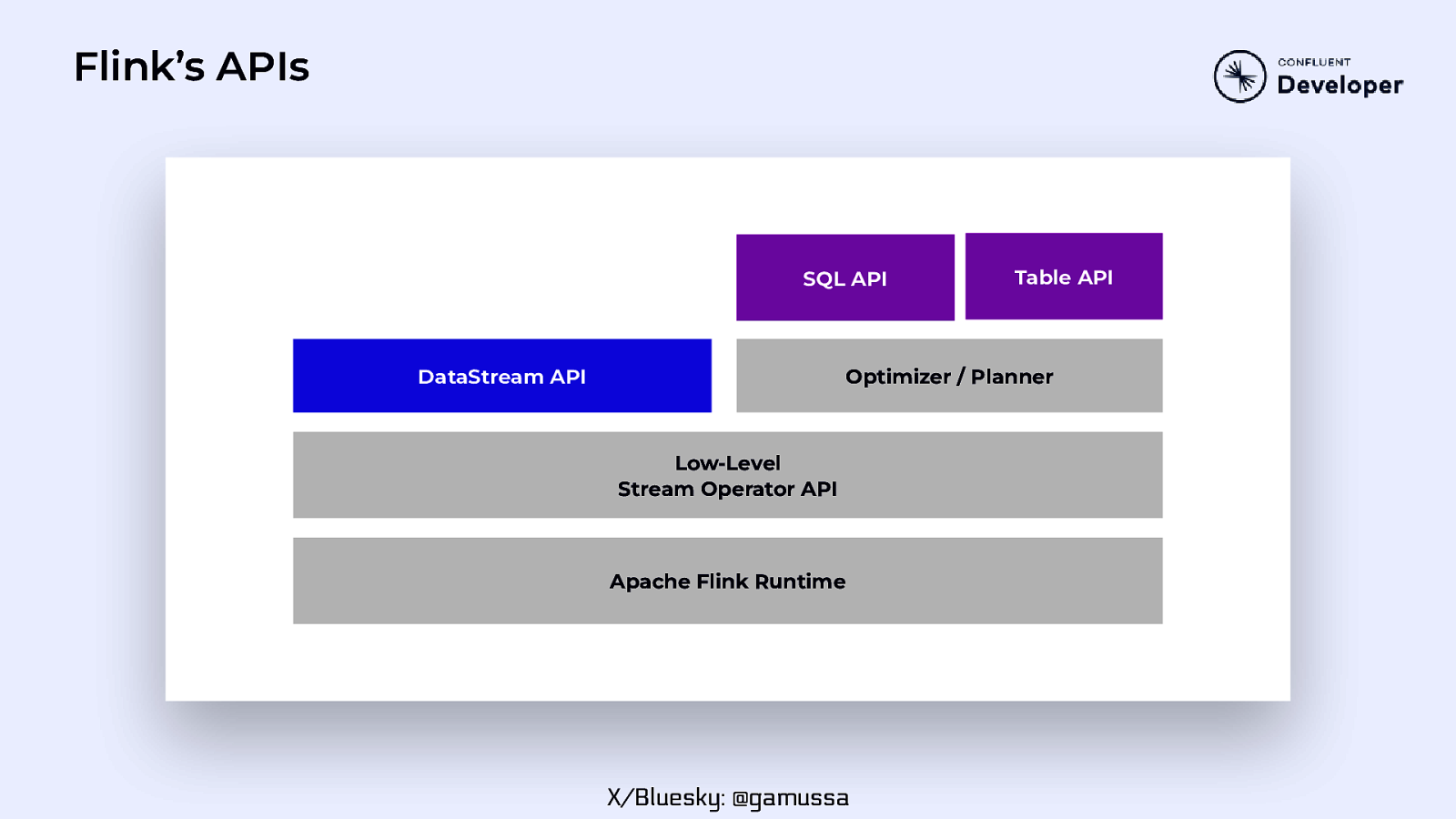
Flink’s APIs SQL API Table API Optimizer / Planner DataStream API Low-Level Stream Operator API Apache Flink Runtime X/Bluesky: @gamussa
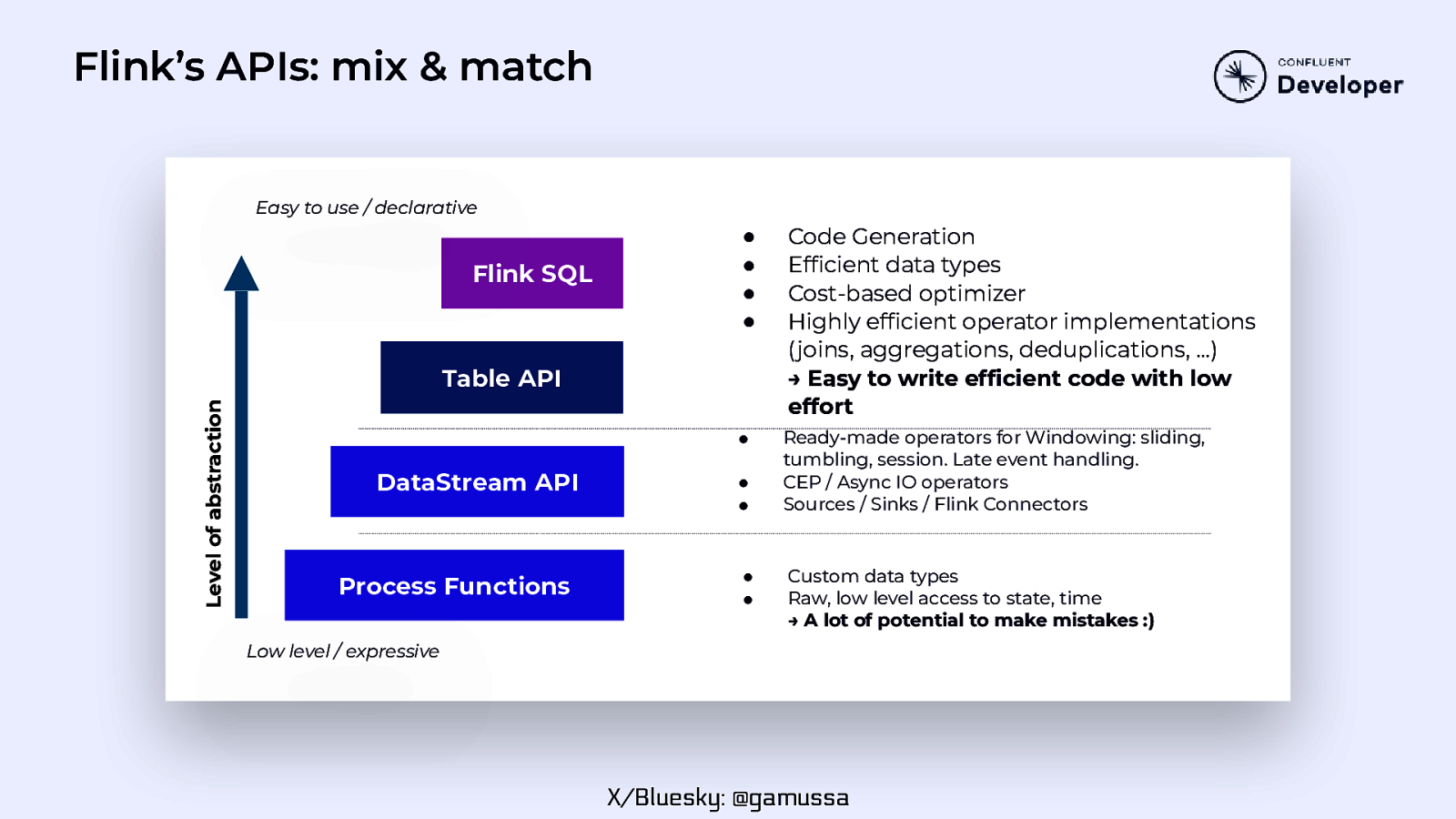
Flink’s APIs: mix & match Easy to use / declarative Flink SQL ● ● ● ● Code Generation Efficient data types Cost-based optimizer Highly efficient operator implementations (joins, aggregations, deduplications, …) → Easy to write efficient code with low effort ● Ready-made operators for Windowing: sliding, tumbling, session. Late event handling. CEP / Async IO operators Sources / Sinks / Flink Connectors Level of abstraction Table API DataStream API Process Functions ● ● ● ● Custom data types Raw, low level access to state, time → A lot of potential to make mistakes :) Low level / expressive X/Bluesky: @gamussa

State Management
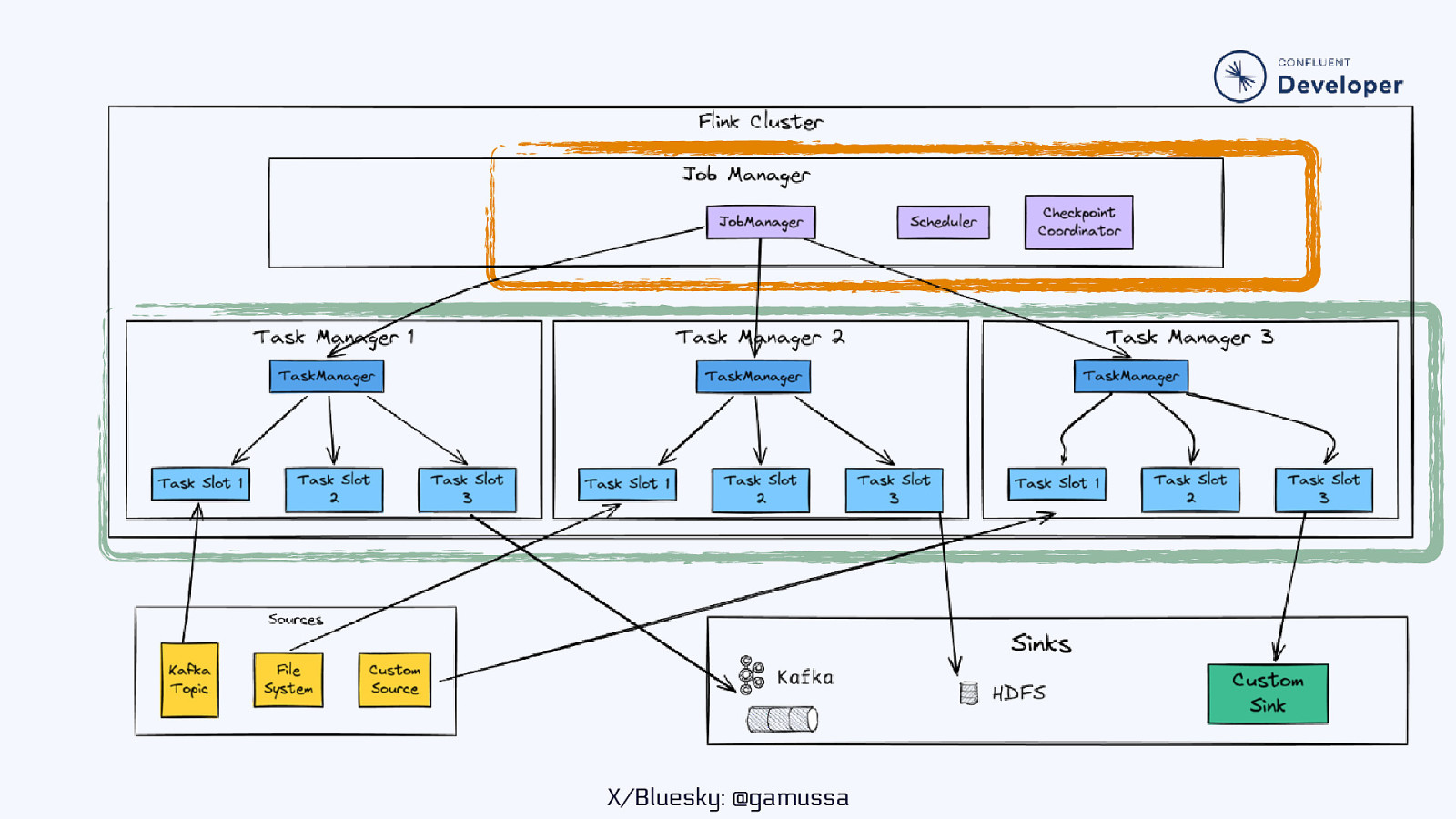
X/Bluesky: @gamussa
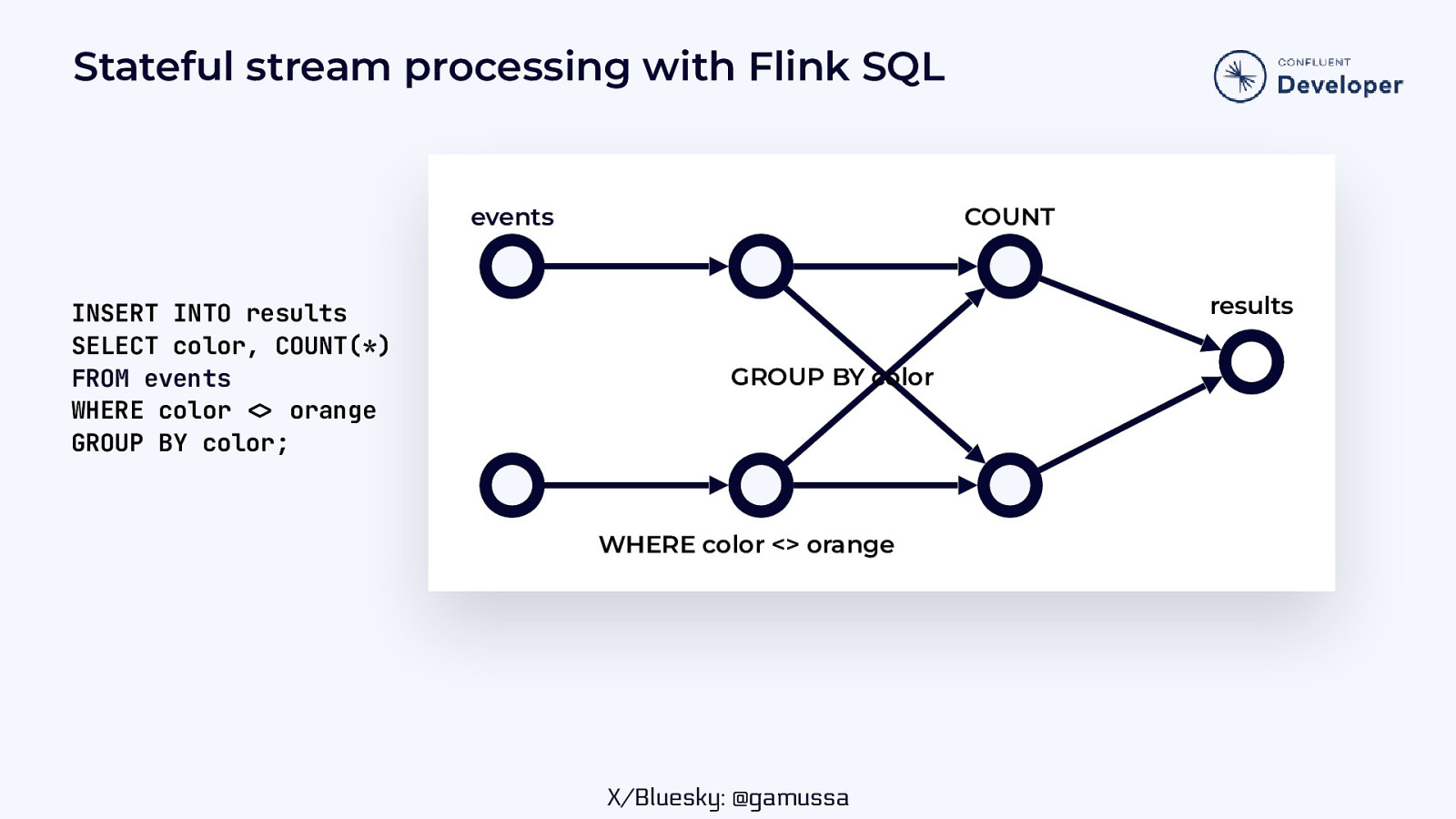
Stateful stream processing with Flink SQL events INSERT INTO results SELECT color, COUNT(*) FROM events WHERE color orange GROUP BY color; COUNT results GROUP BY color WHERE color <> orange
< X/Bluesky: @gamussa
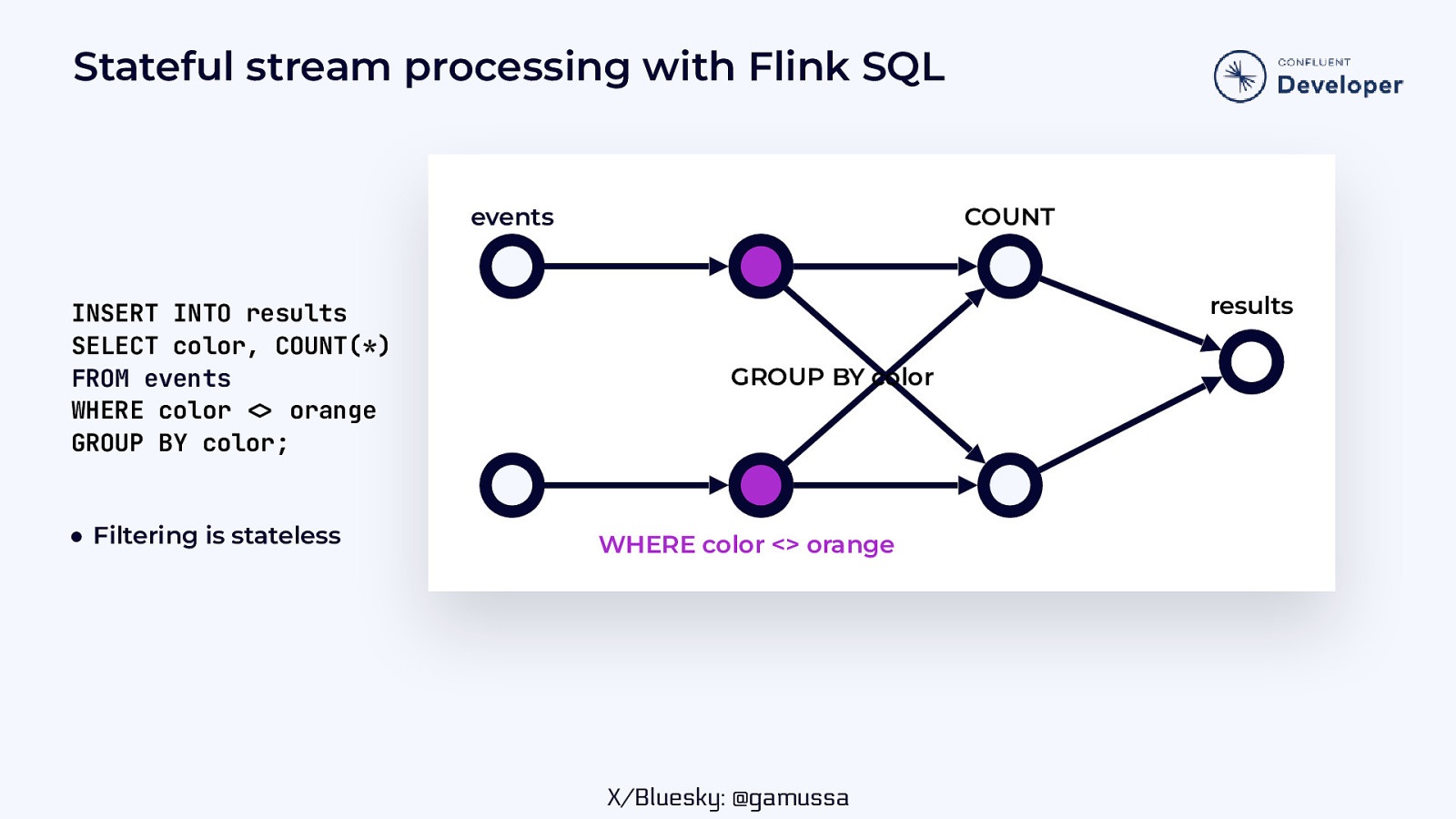
Stateful stream processing with Flink SQL events INSERT INTO results SELECT color, COUNT(*) FROM events WHERE color orange GROUP BY color; ● Filtering is stateless COUNT results GROUP BY color WHERE color <> orange
< X/Bluesky: @gamussa
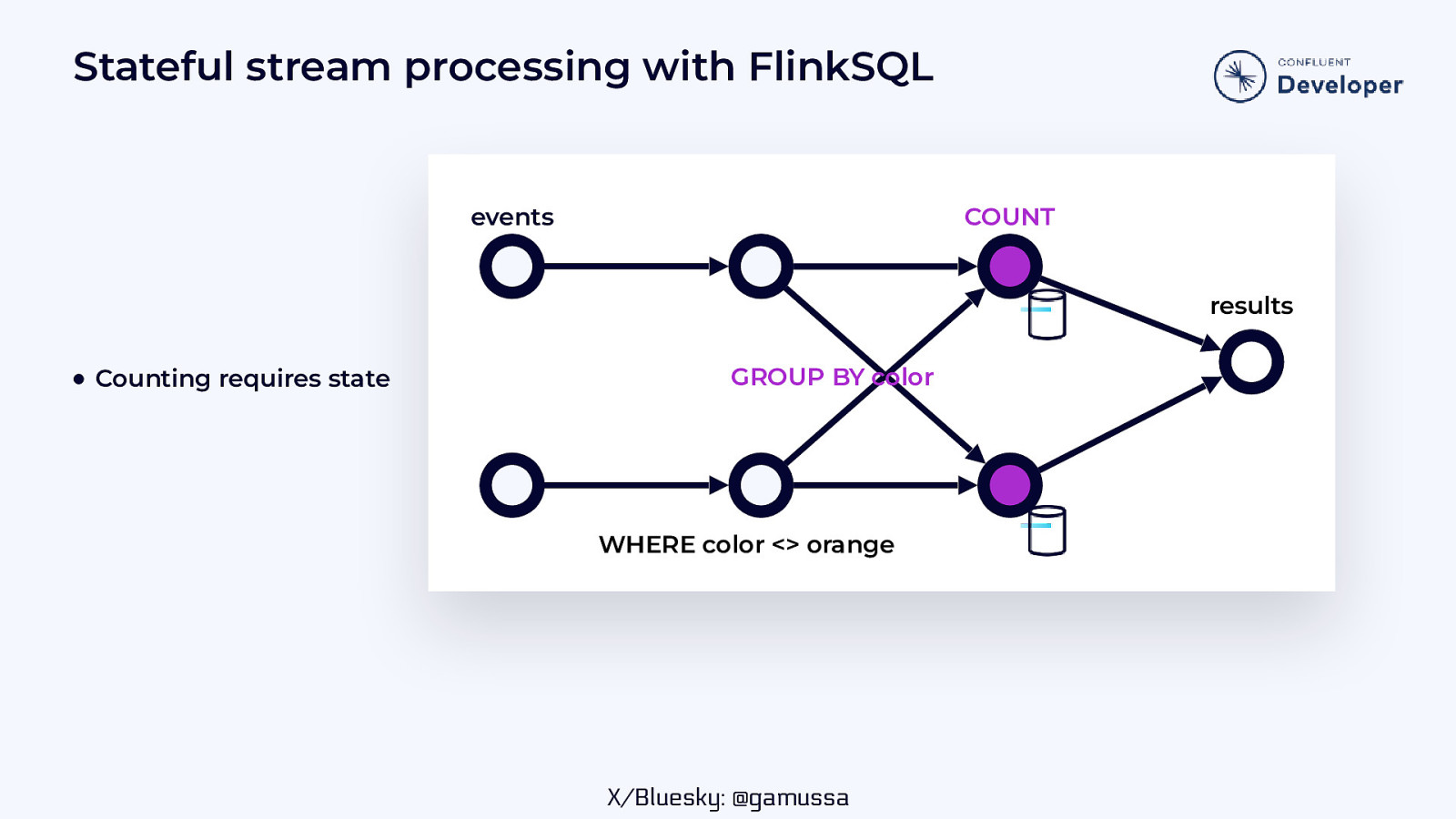
Stateful stream processing with FlinkSQL events COUNT results ● Counting requires state GROUP BY color WHERE color <> orange X/Bluesky: @gamussa
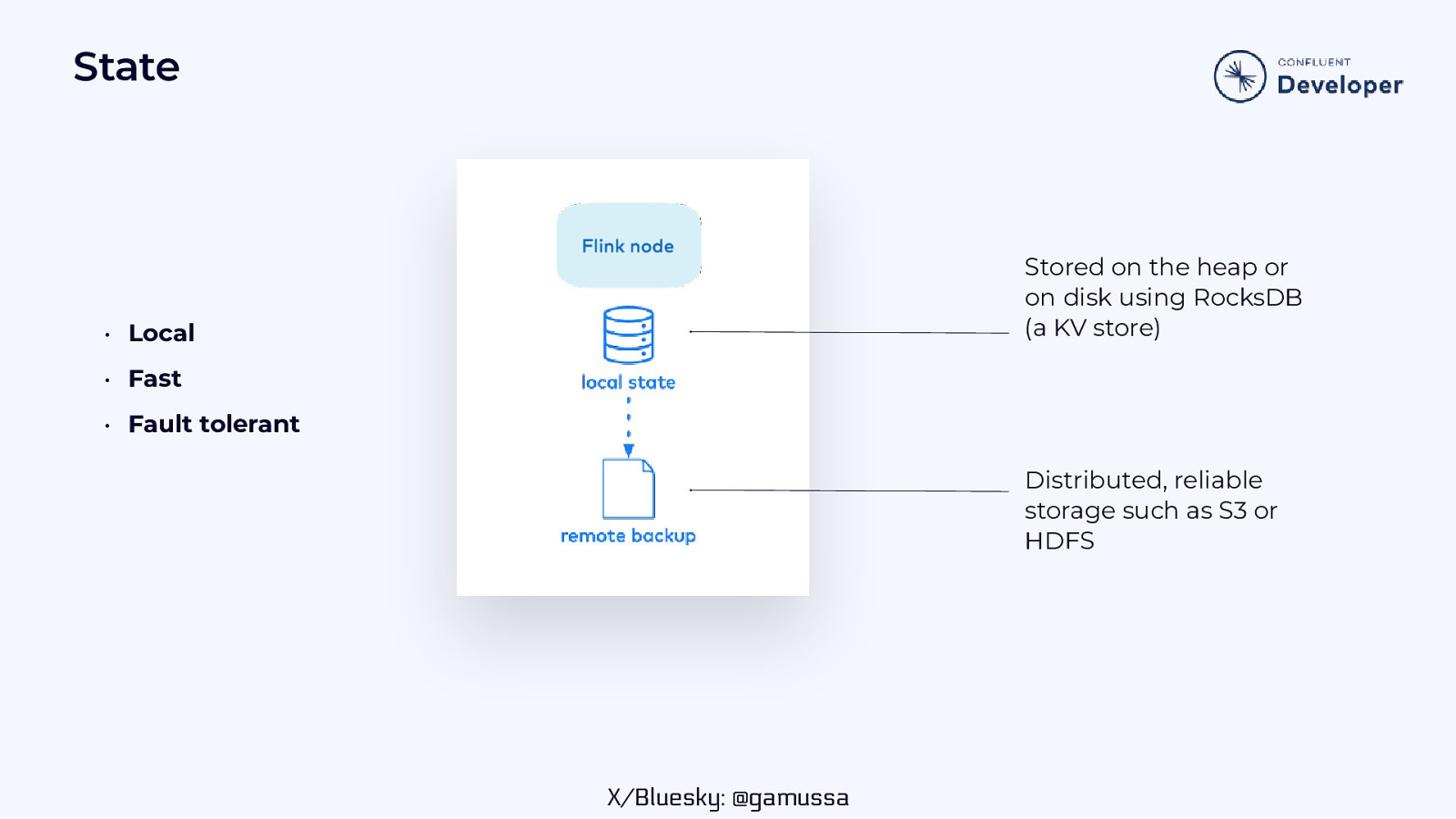
State Stored on the heap or on disk using RocksDB (a KV store) • Local • Fast • Fault tolerant Distributed, reliable storage such as S3 or HDFS X/Bluesky: @gamussa
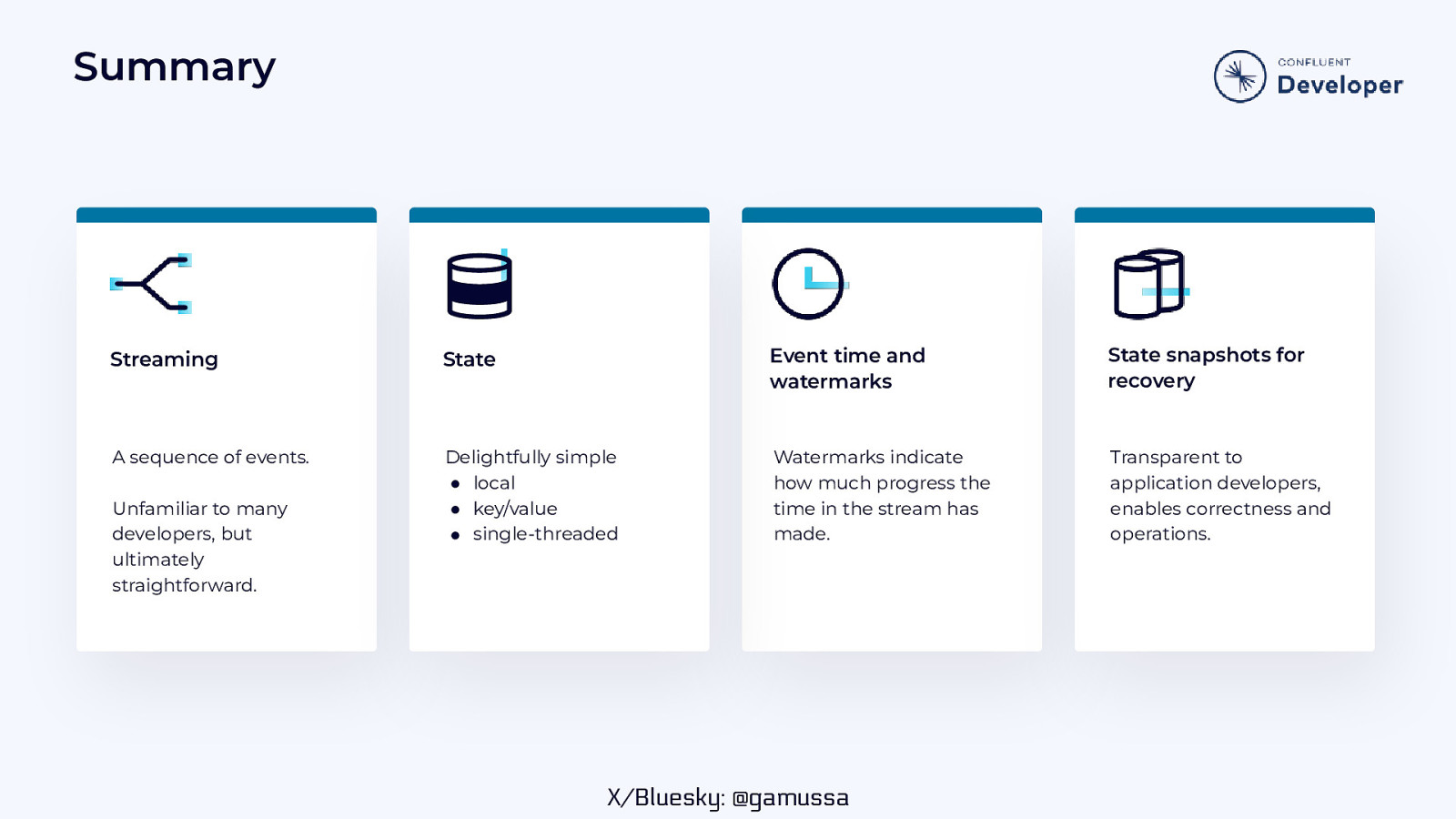
Summary Streaming State Event time and watermarks State snapshots for recovery A sequence of events. Delightfully simple ● local ● key/value ● single-threaded Watermarks indicate how much progress the time in the stream has made. Transparent to application developers, enables correctness and operations. Unfamiliar to many developers, but ultimately straightforward. X/Bluesky: @gamussa


As Always Have a Nice Day… X/Bluesky: @gamussa