LULLABOT Custom Drupal Data Migration: A Georgia GovHUB Story DC ATLANTA 2019 + + SIDES GEORGIA GOVHUB MIGRATION APRIL 1

A presentation at DrupalCamp Atlanta 2019 in September 2019 in Atlanta, GA, USA by April Sides

LULLABOT Custom Drupal Data Migration: A Georgia GovHUB Story DC ATLANTA 2019 + + SIDES GEORGIA GOVHUB MIGRATION APRIL 1

I’ve worked at Lullabot for a little over year now The migration of Georgia.gov was my first project, And my first migration So I’m really excited to tell you all about it

I am also lead organizer of Drupal Camp Asheville Which is July 10-12 next year Be sure to grab a sticker at registration And I hope you will join us next summer!

At Lullabot we provide strategy, design, and Drupal development for large-scale publishers If you are interested in working with us, let’s chat

Karen Stevenson, Director of Technology Has a lot of migration experience And provided a lot of guidance and direction Marcos Cano, Senior Developer Did all of the file migrations And was instrumental in keeping our code clean and organized Darren Petersen, Senior Technical Project Manager Our fearless leader And was key for keeping us moving James Sansbury, Development Manager Responsible for the devops and magic That made our work possible

Also want to give a shout out to the Digital Services Georgia team They are definitely one of my favorite clients

What we will cover

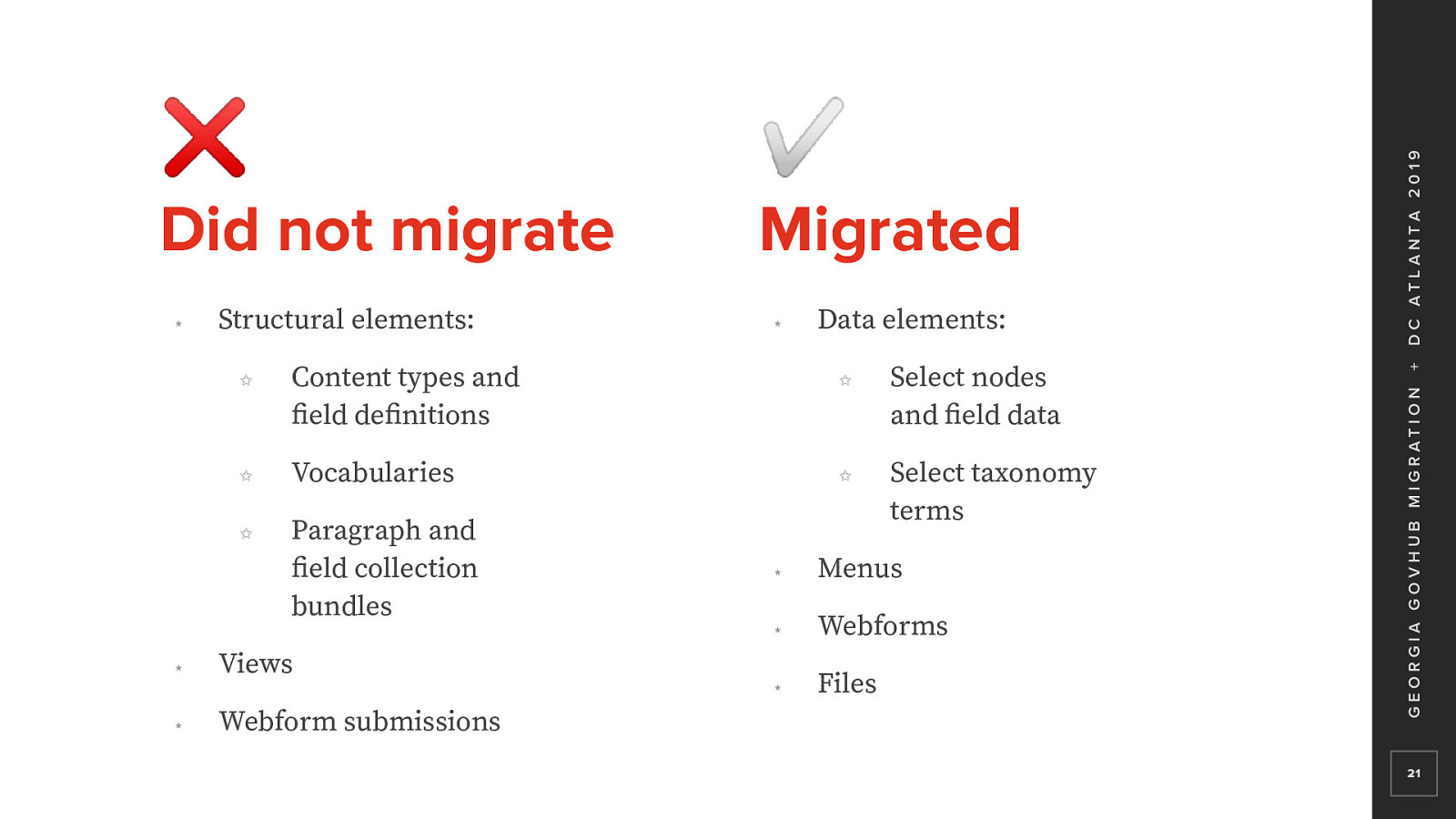
Discovery and Planning

In migration, we move content from a source to a destination Each site in the multisite setup has its own database Micro-content types were Drupal content types But they are not accessible as standalone nodes Only viewable as an entity embed or an entity reference The use of multisite, number of sites, and the new architecture of D8 are really the points that made this migration very complex and custom
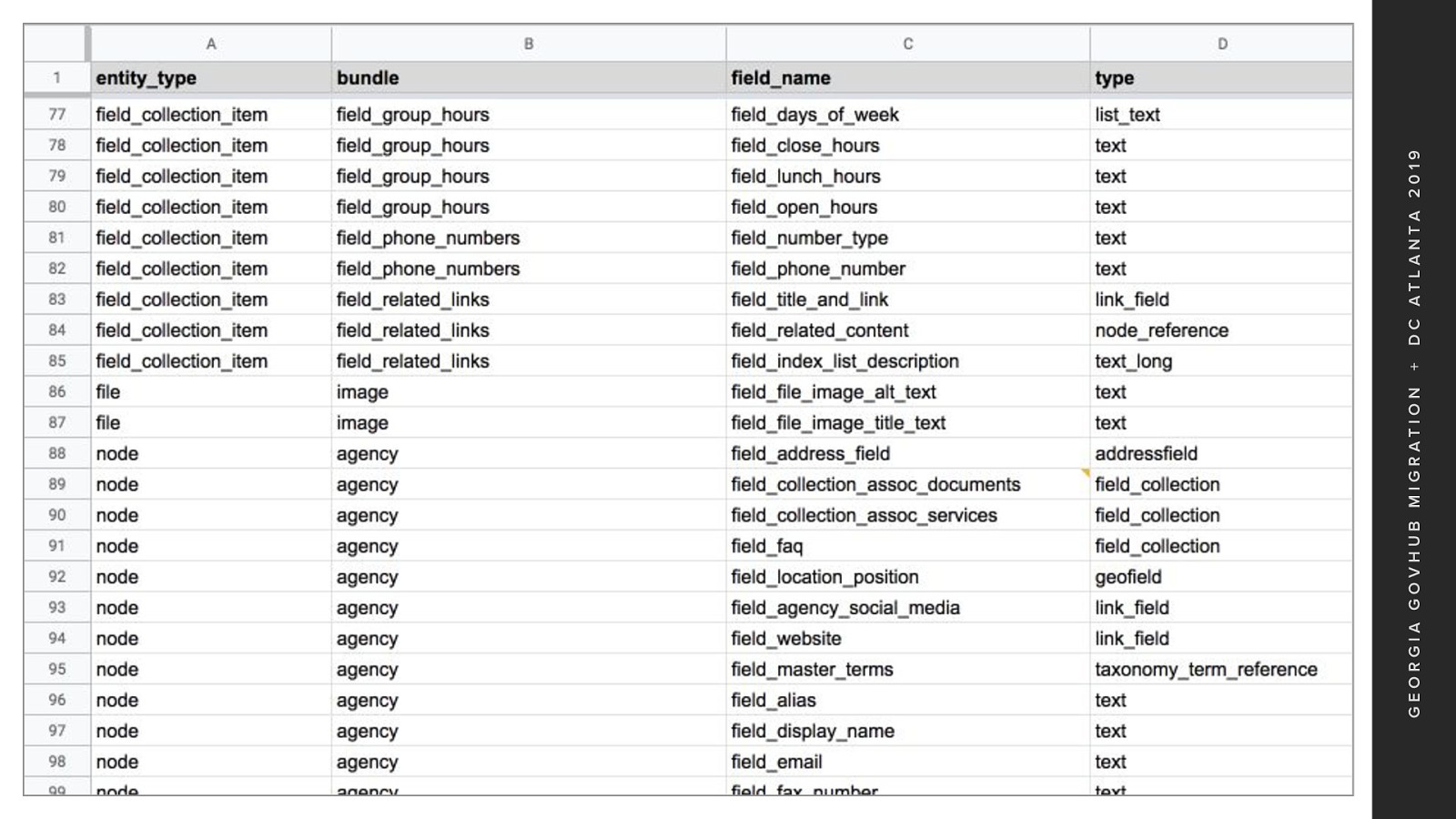
Kicking off the discovery, Karen Stevenson collected all field instances for all entity types using a script And converted it to a Google Sheet This was very useful in determining our source fields for field mapping
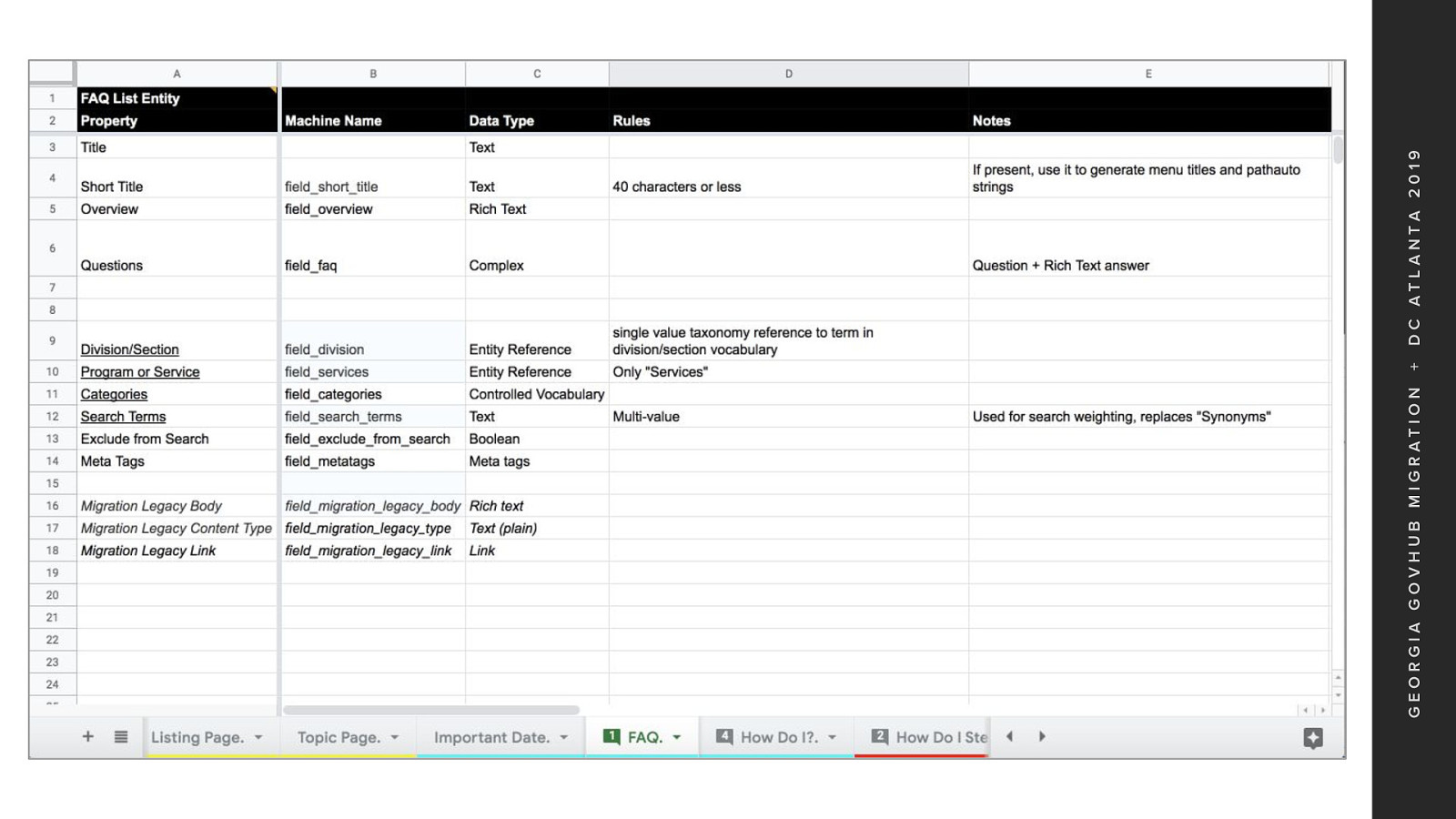
At the same time, the content strategy team delivered content model documentation for the new D8 architecture This documentation was used to manually build the new content types in D8 We also used this document to determine destination fields for field mapping
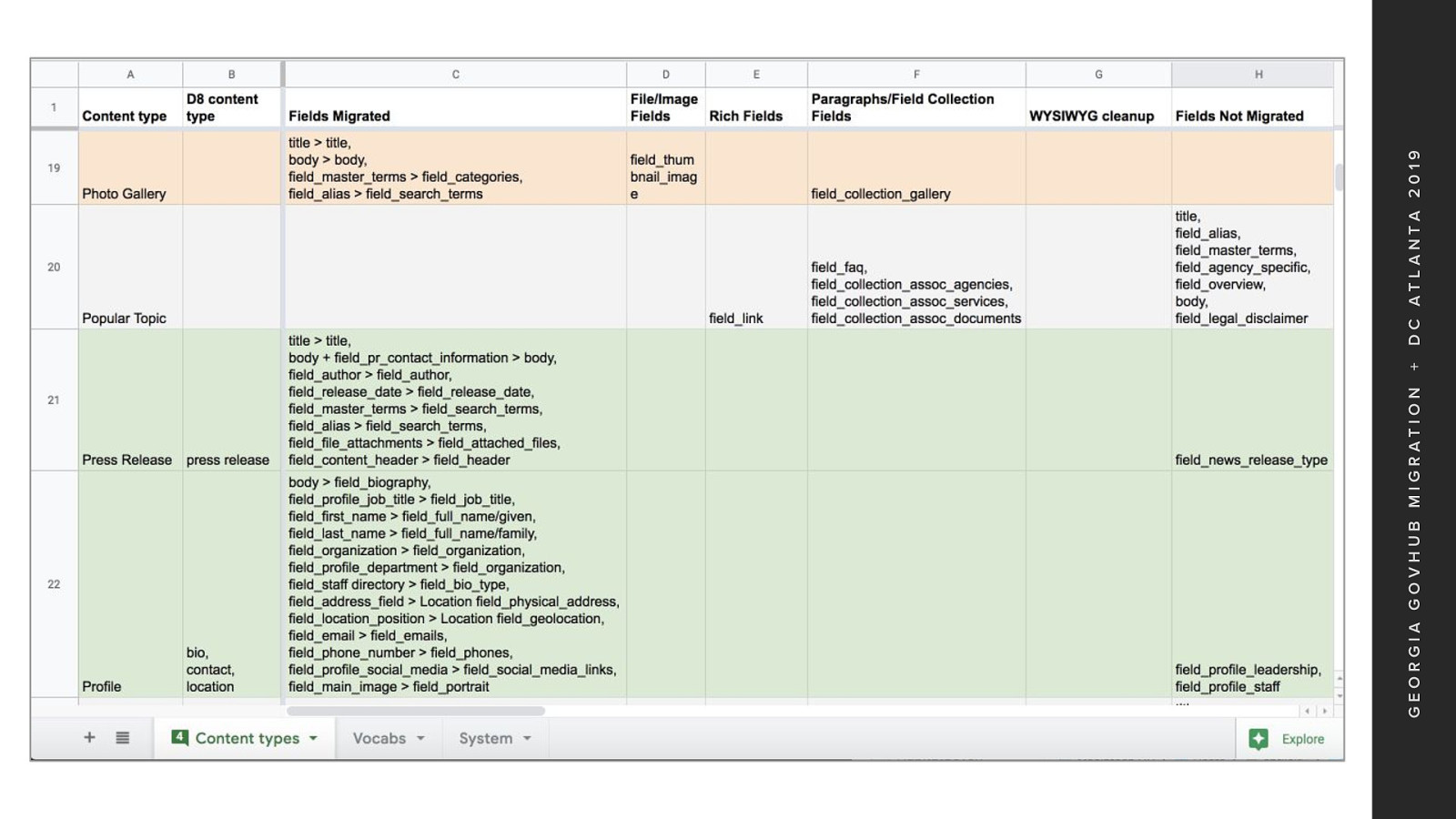
This document was created to track the field mappings The various phases of solution complexity And the status of each D7 content type’s migration
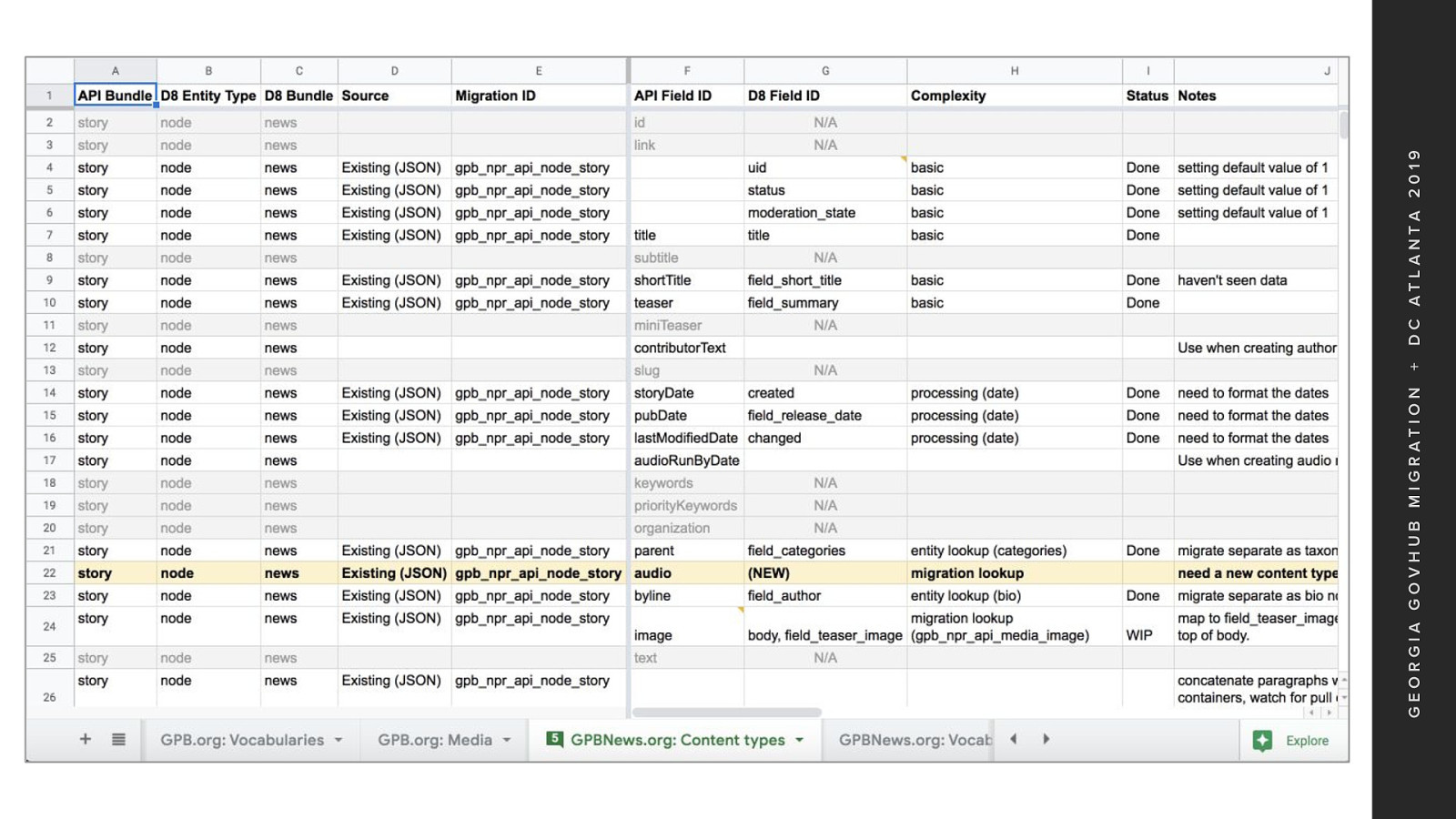
I also want to show a new iteration of field mapping documentation that I’m using in a current project. This one is based on the source fields from Karen’s field instance document There is some conditional formatting applied to highlight new fields or content types And to grey-out fields that will not be migrated There is more duplication in the frozen columns on the left and the document is long But the status of migration is shifted from content type or entity to field status
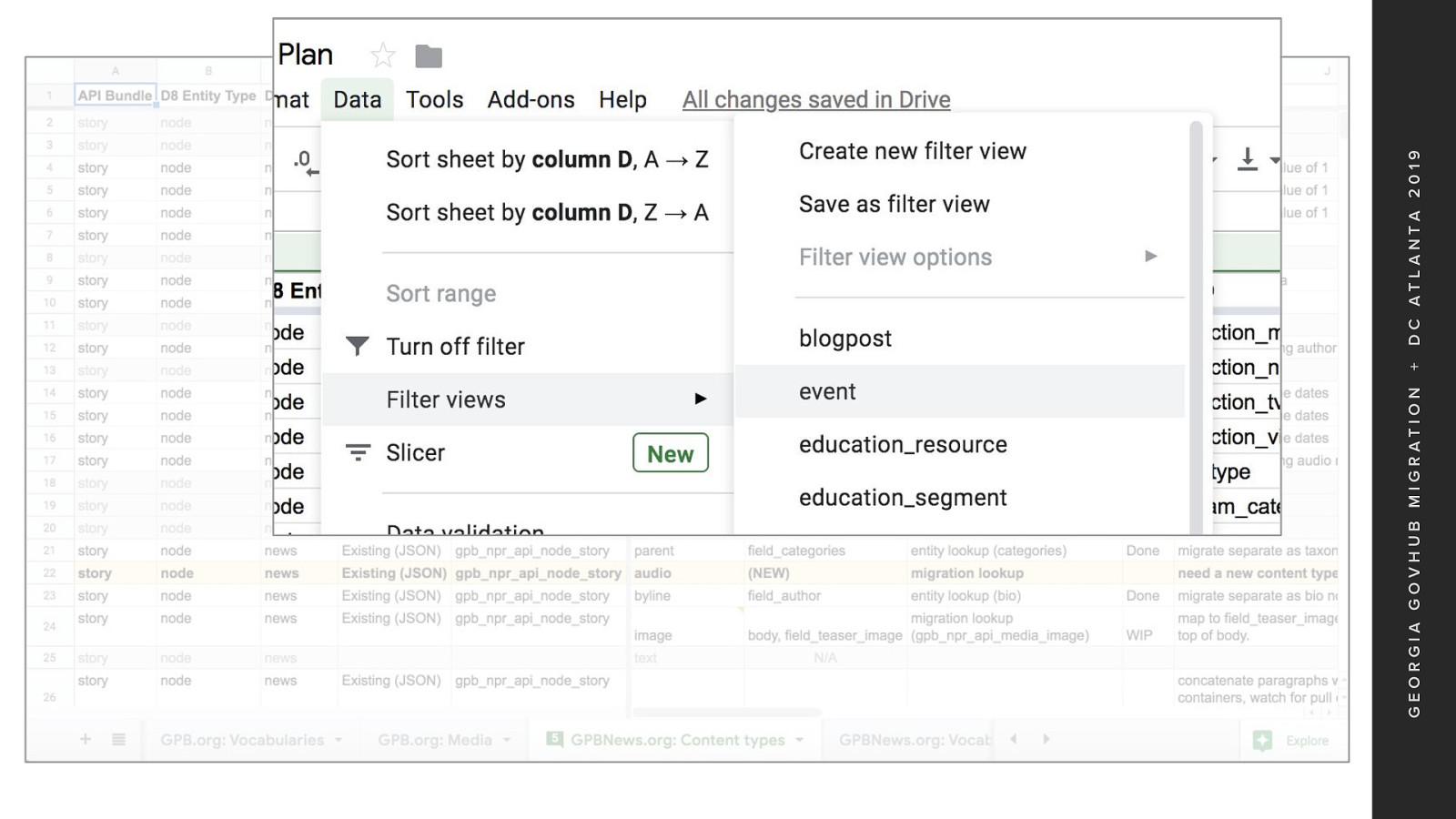
To view a single content type during development A data filter view can be created for each content type That will allow for content type focussed viewing I think this format is going to be an improved way to manage the migration development

Another tool we developed for discover is A custom Drush 9 command in a custom Drupal 8 module Called Squealer It runs in the Drupal 8 site Using the Drupal 7 database configured in settings.php for each site

There are a number of scans that this command will run on the D7 site Some issues were fixed in D7 prior to running a migration So this was helpful in identifying those issues As well as informing the migration logic
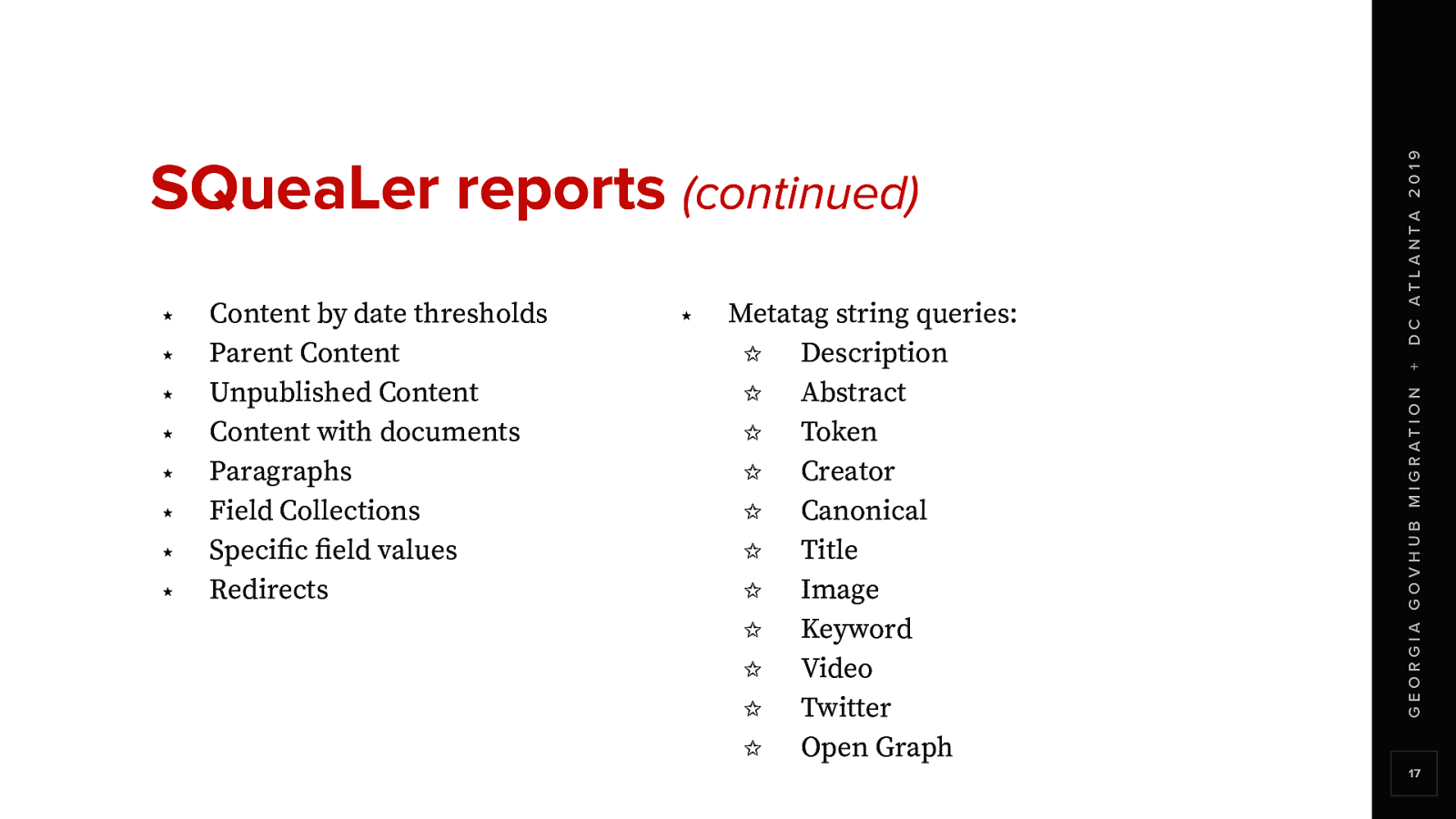
The list grew as we had other questions throughout the development process Adding new reports meant we could automatically Scan each site As a part of the migration workflow
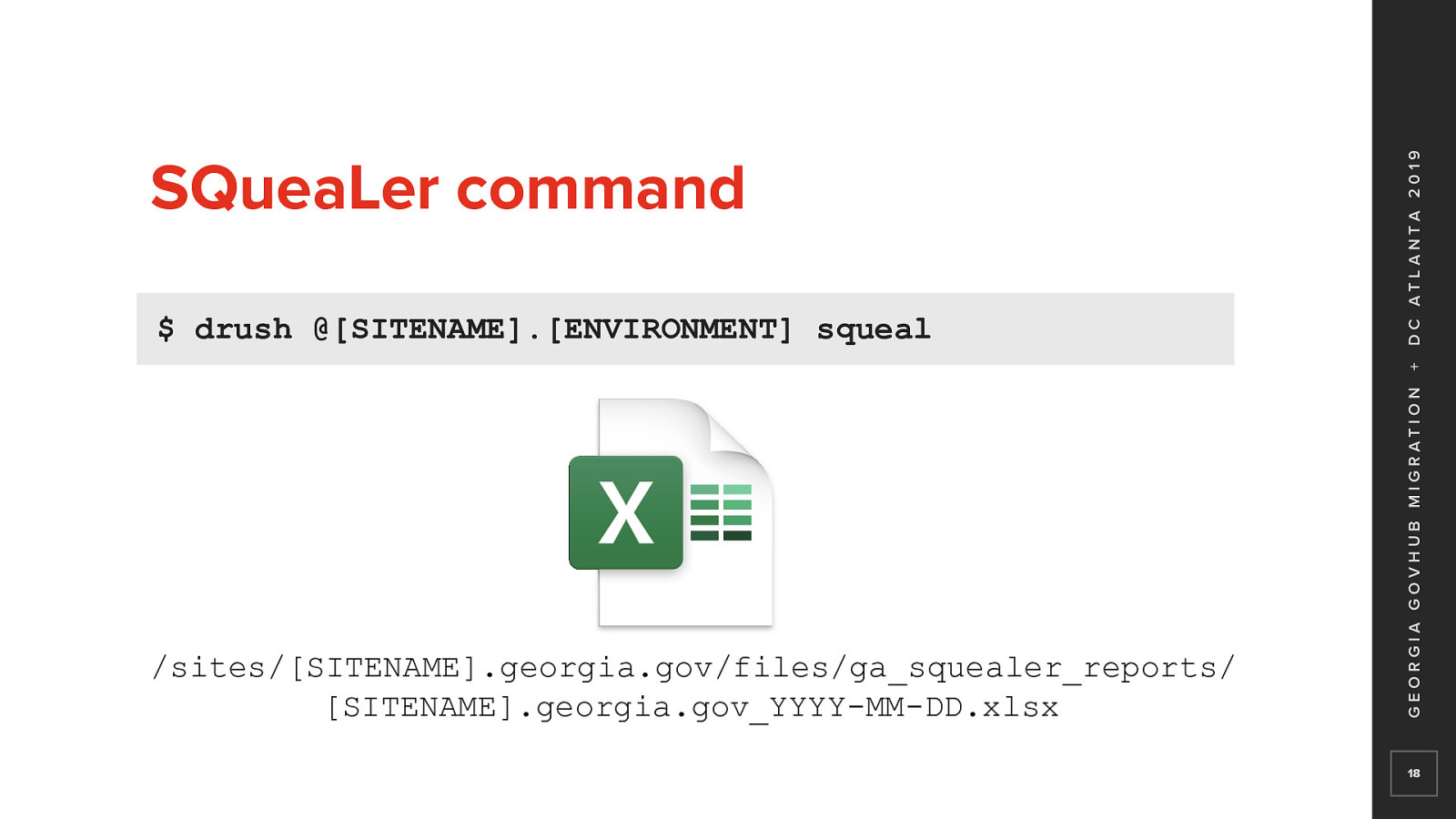
That generates an Excel file in the site’s files directory In a new ga_squealer_reports directory And dated with the current date
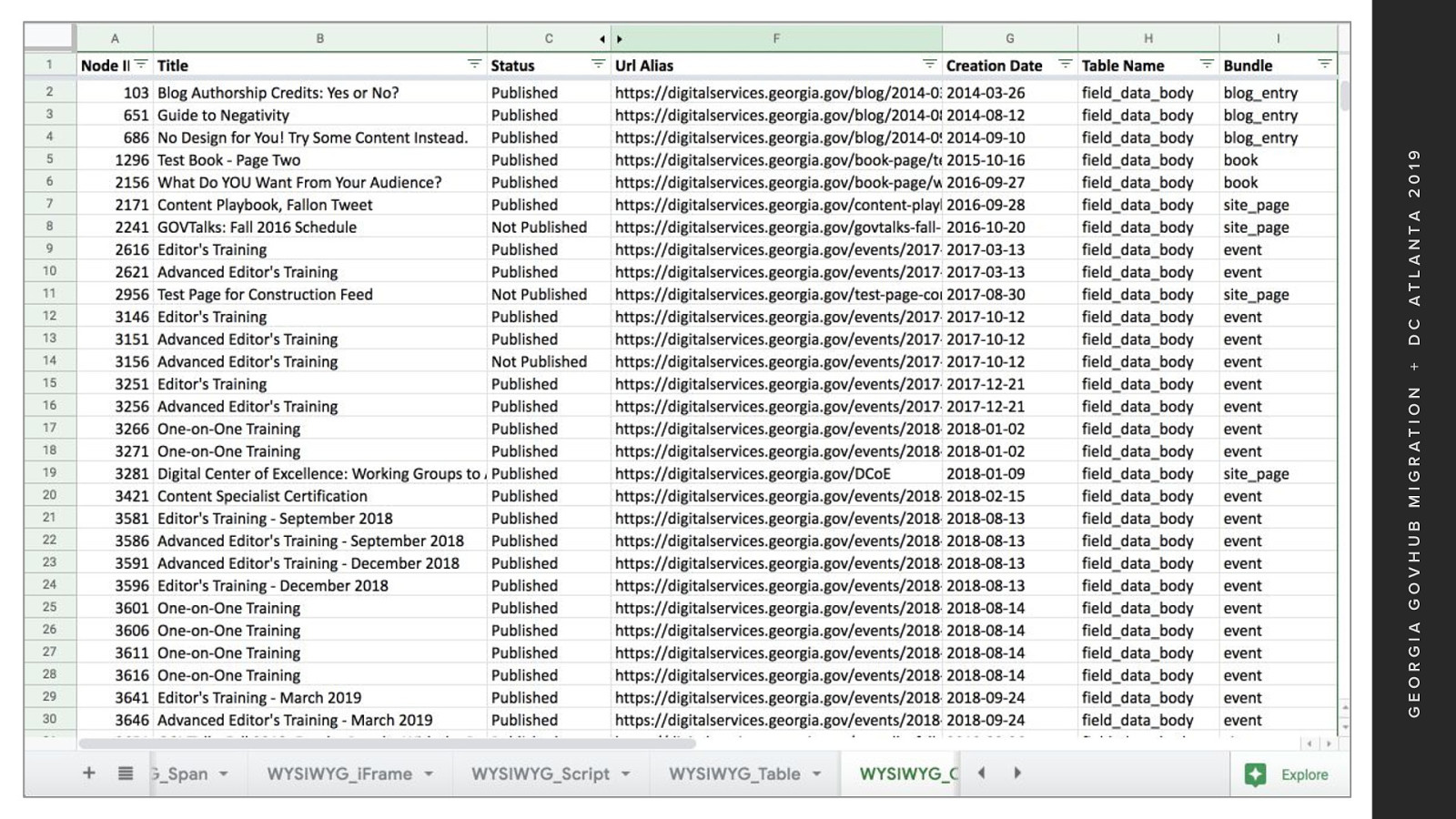
The reports generated looked like this With tabs for each scan The goal was to trace an issue back to the Node level, With a link to the D7 site to investigate further

Strategies and Workflow

I included Migrate Source UI Even though it wasn’t necessary for the automated site migration The client wanted a way to import content during and after the migration So we used this module to import CSV files Using the migration system The ga_migrate_source_ui module contains additional logic And migration configuration specific to these sites Our main migration module is ga_migrate And ga_migrate_site was used for site specific overrides Which I’ll talk more about later


Tugboat is a Lullabot product This was my first time using it and it’s amazing how much time it saved Each PR generates a preview site that can be Used to test code prior to merge Or shown to the client for review It was very much integrated into our workflow for this project

As far as our development workflow We decided to focus on basic fields for each content type first Then move into more complexity from there For example, a PR would be submitted for blog_posts With only the field mappings of fields we determined were basic A future PR would then add field mappings for rich fields Then file/image fields etc. This allowed the client to review our progress incrementally And kept our PRs small and reviewable


Something that was very helpful for this migration was a custom logging solution. Marcos developed a way for us to track various skips or exceptions throughout the migration logic.

We used this function If our logic skipped a row and we felt we needed a record of that If something unexpected occurred All sorts of cases with varying severity And ways to track down the issue
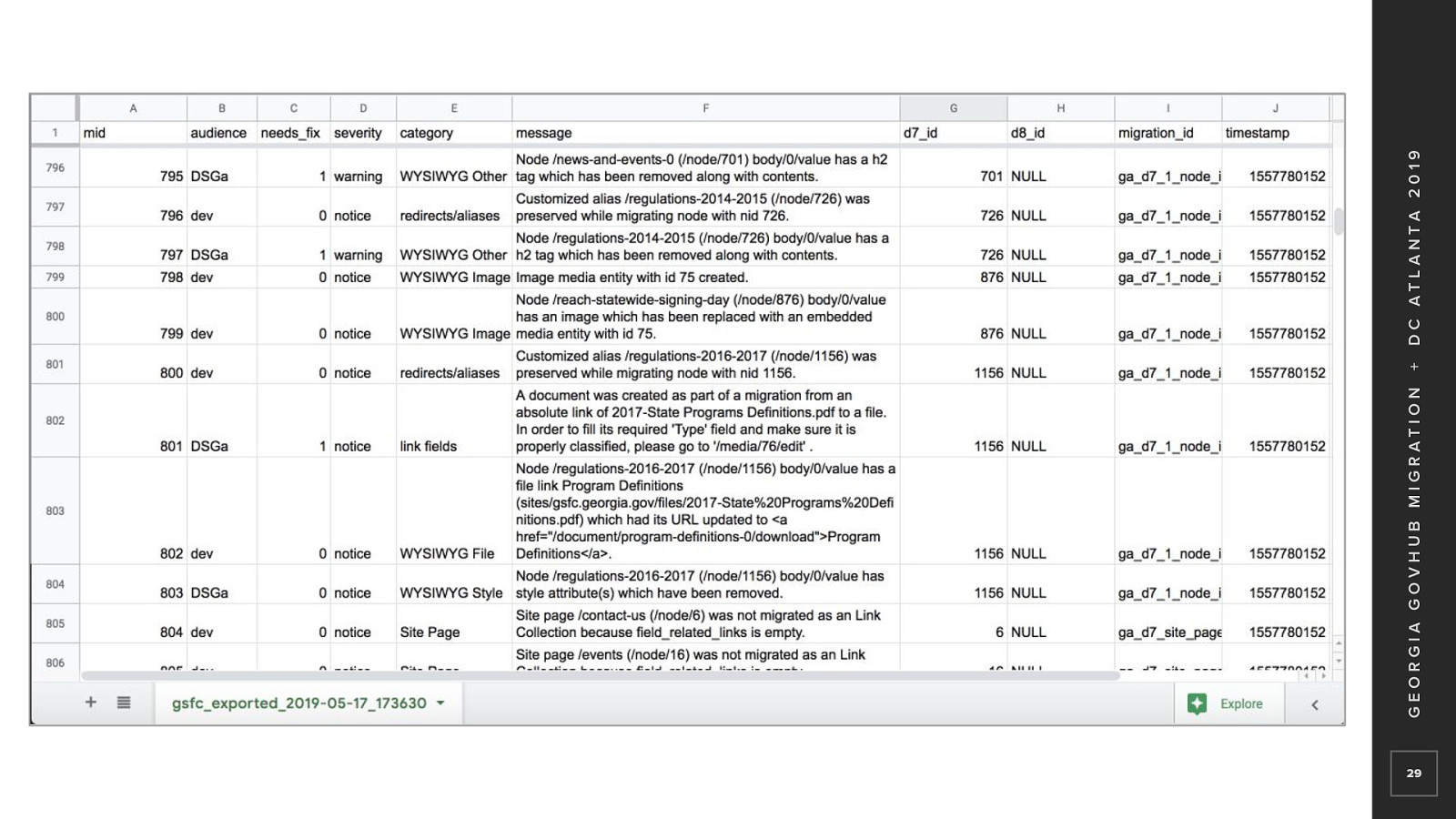
A custom drush command would generate a TSV file from the table of messages And that was imported into Google Sheets for sharing This was very useful when tracking down edge case issues As we fine tuned the migrations

So how did we migrate 85+ sites? The answer is in phases And sites are still being migrated

Migration phases are staggered in groups of about 6 sites over 2 week periods In each phase, this is an overview of the procedures

Karen recently told me this was the most complex migration she’s ever done Most migrations are not this complicated But I picked out some of our more complex problems with solutions to share This will get a little more technical so hold onto your hats

I give credit to Karen for this solution
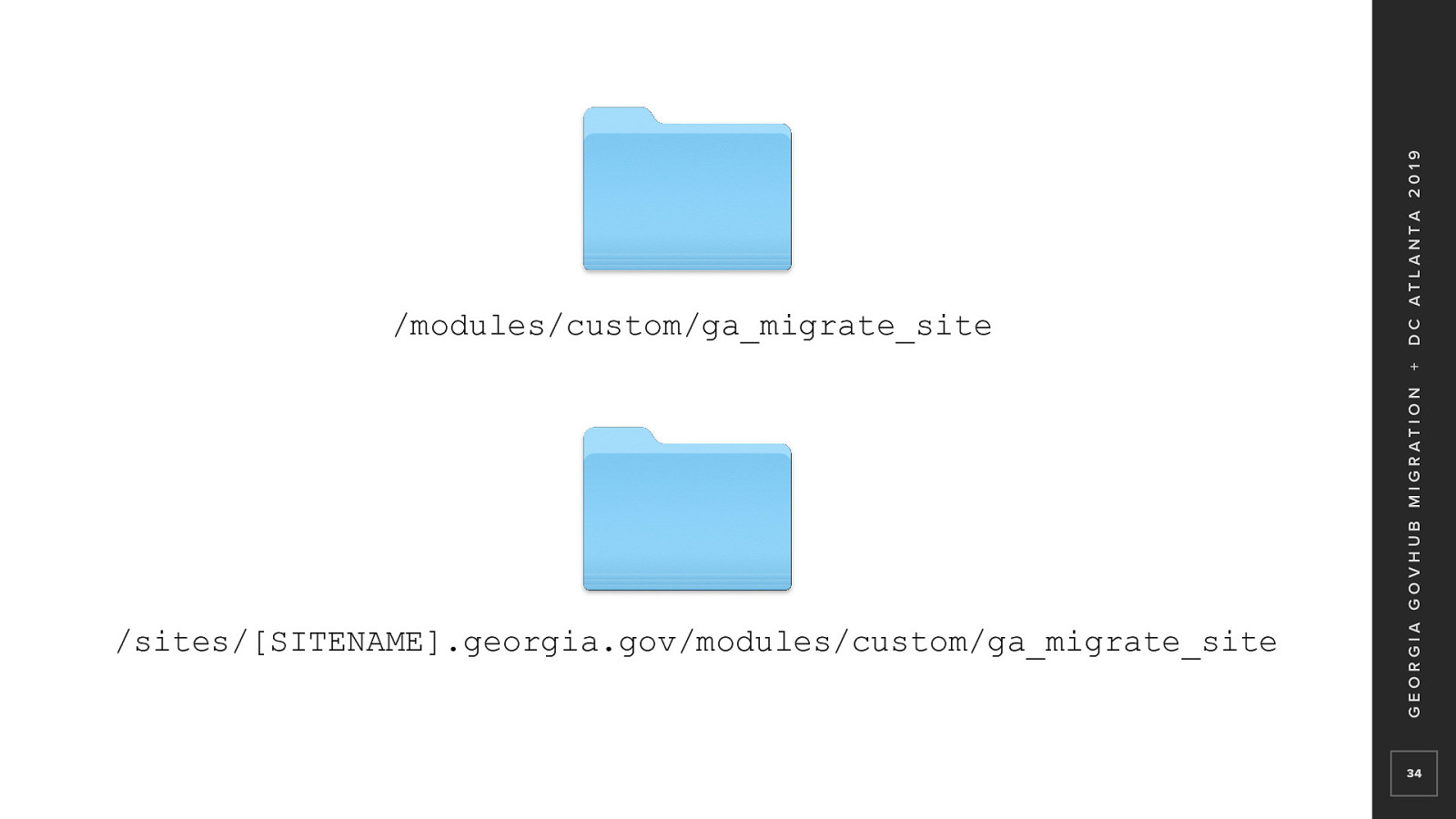
As I said earlier, Ga_migrate was our main migration module So a module was created in the top level modules directory called ga_migrate_site At this level, the module is mostly empty with a few defaults For any site that needed to override migration logic, We would copy the module into the sites module directory And add our override logic If the module exists in the site’s module directory, That is the version that is recognized by Drupal

The ga_migrate_site module is enabled for all sites And is set to run after ga_migrate based on module order
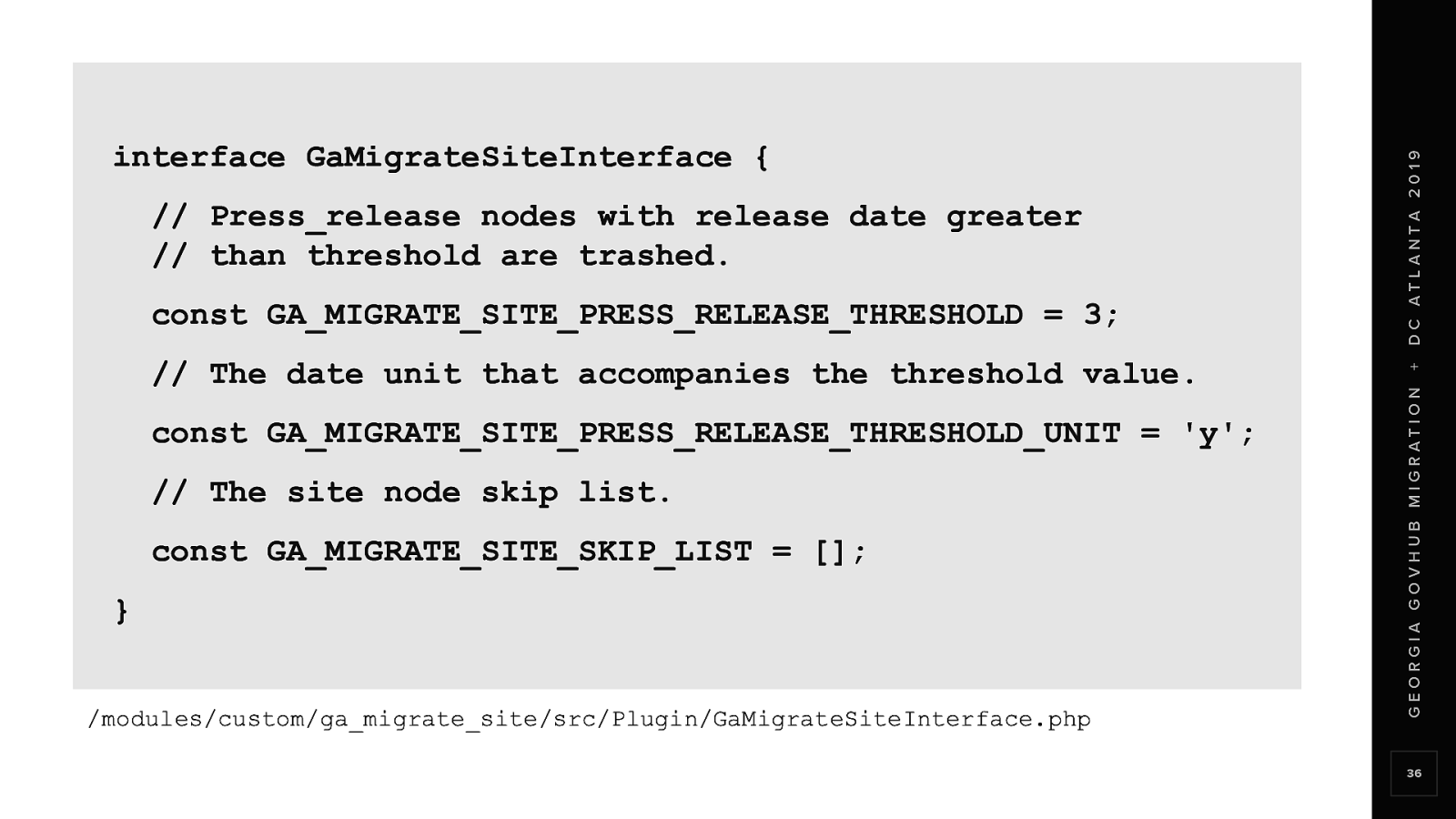
The only real code in ga_migrate_site is an interface That sets values for a few constants Used in migration logic If a site doesn’t want to override these values, We just leave this code alone These constants include values used in ga_migrate logic To change the state of press releases After the press release migration If they are older than 3 years A site can also list specific nodes to skip in the skip list This was mostly used to skip a node that was replaced with a view page

The default module file is empty But the site specific version can implement these hooks


In D7, the site had two types of paragraphs Container Paragraphs used for layout purposes
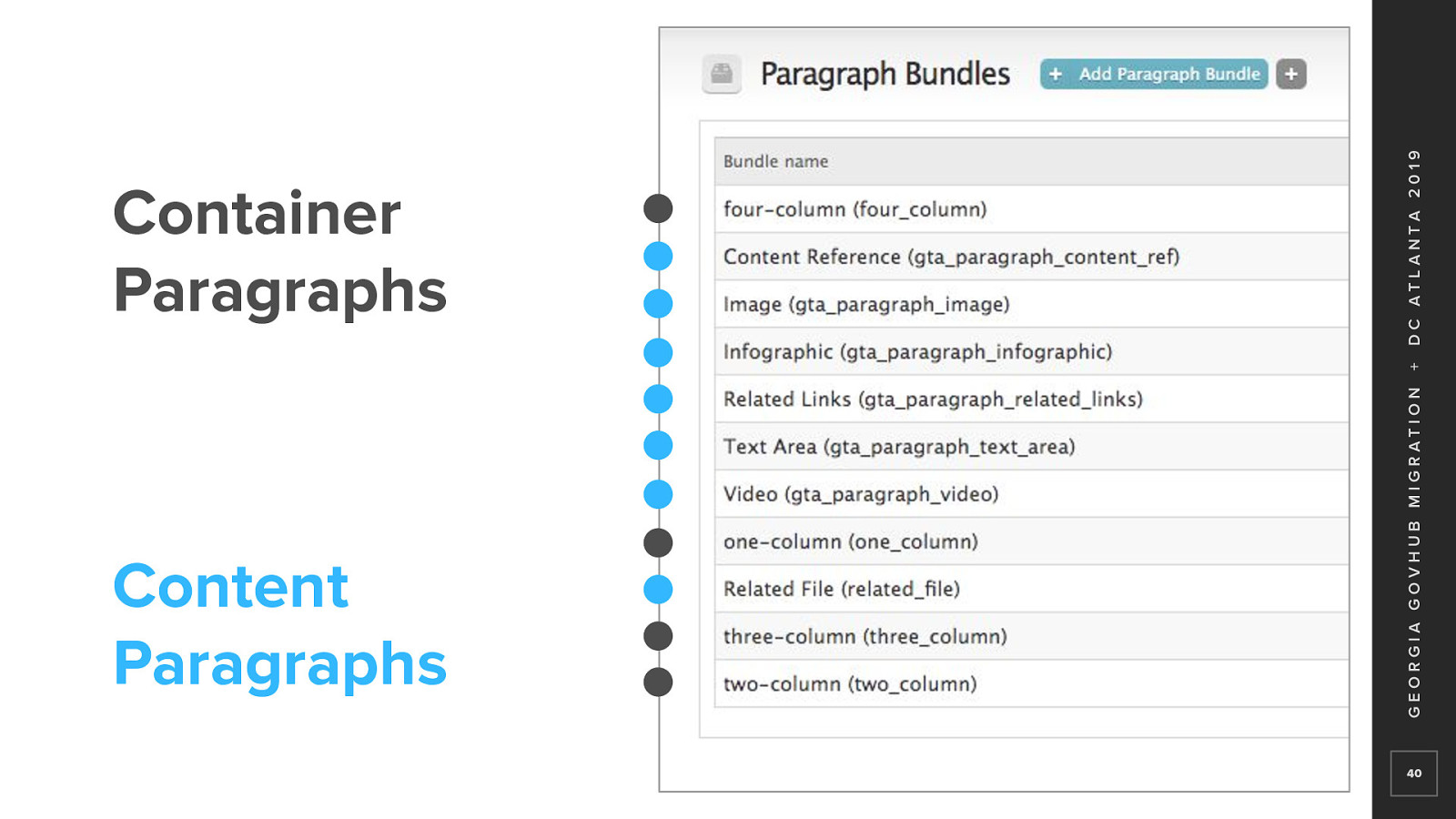
And content paragraphs Where the content actually lived
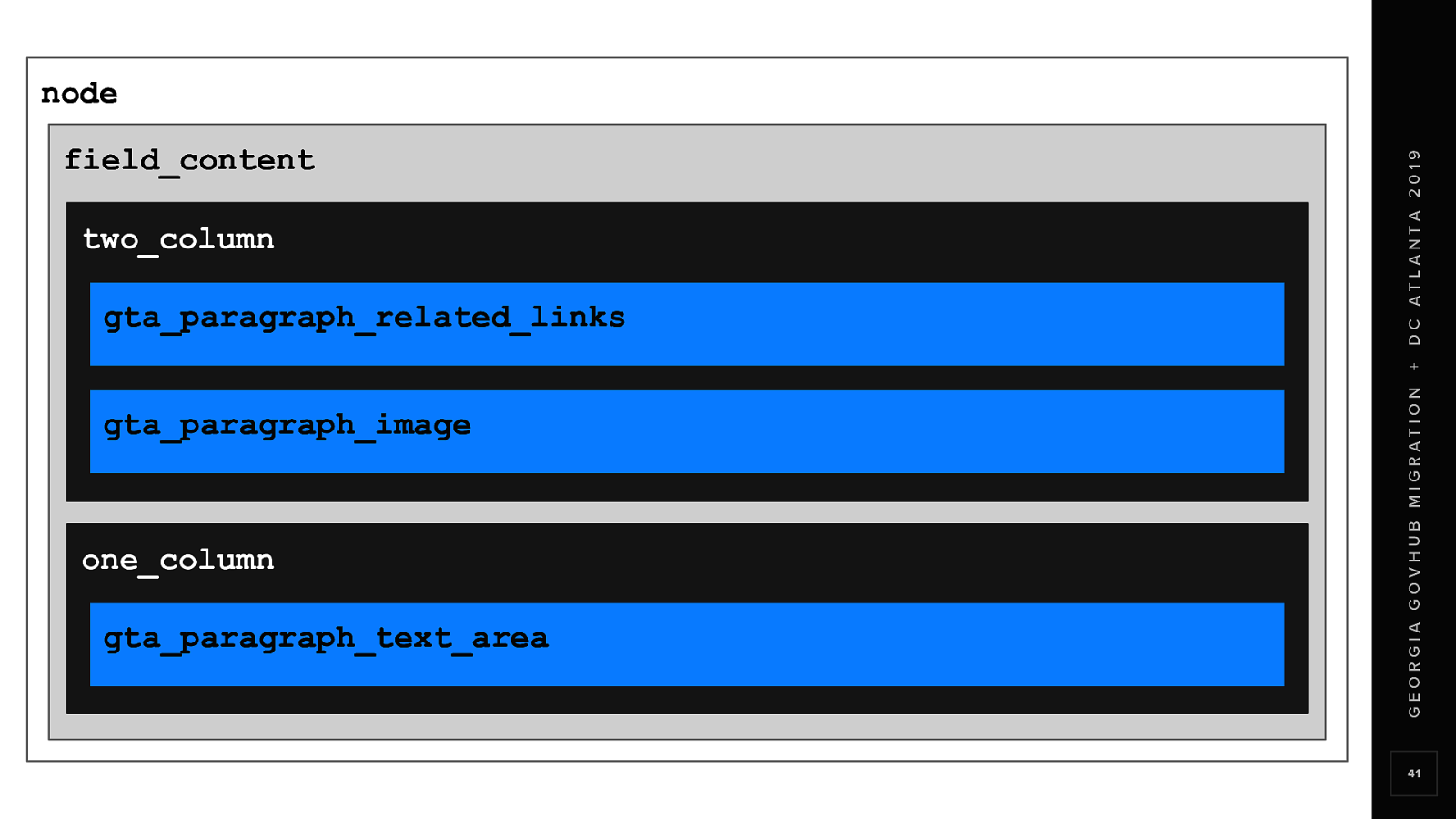
So, to look at an example node Field_content would hold container paragraphs And the container paragraphs would hold one or more content paragraphs


In the migration configuration We processed field_content Using a custom process plugin in the ga_migrate module And stored the final rendered markup in a pseudo-field or temporary field It’s kind of like a custom variable specifically for this migration

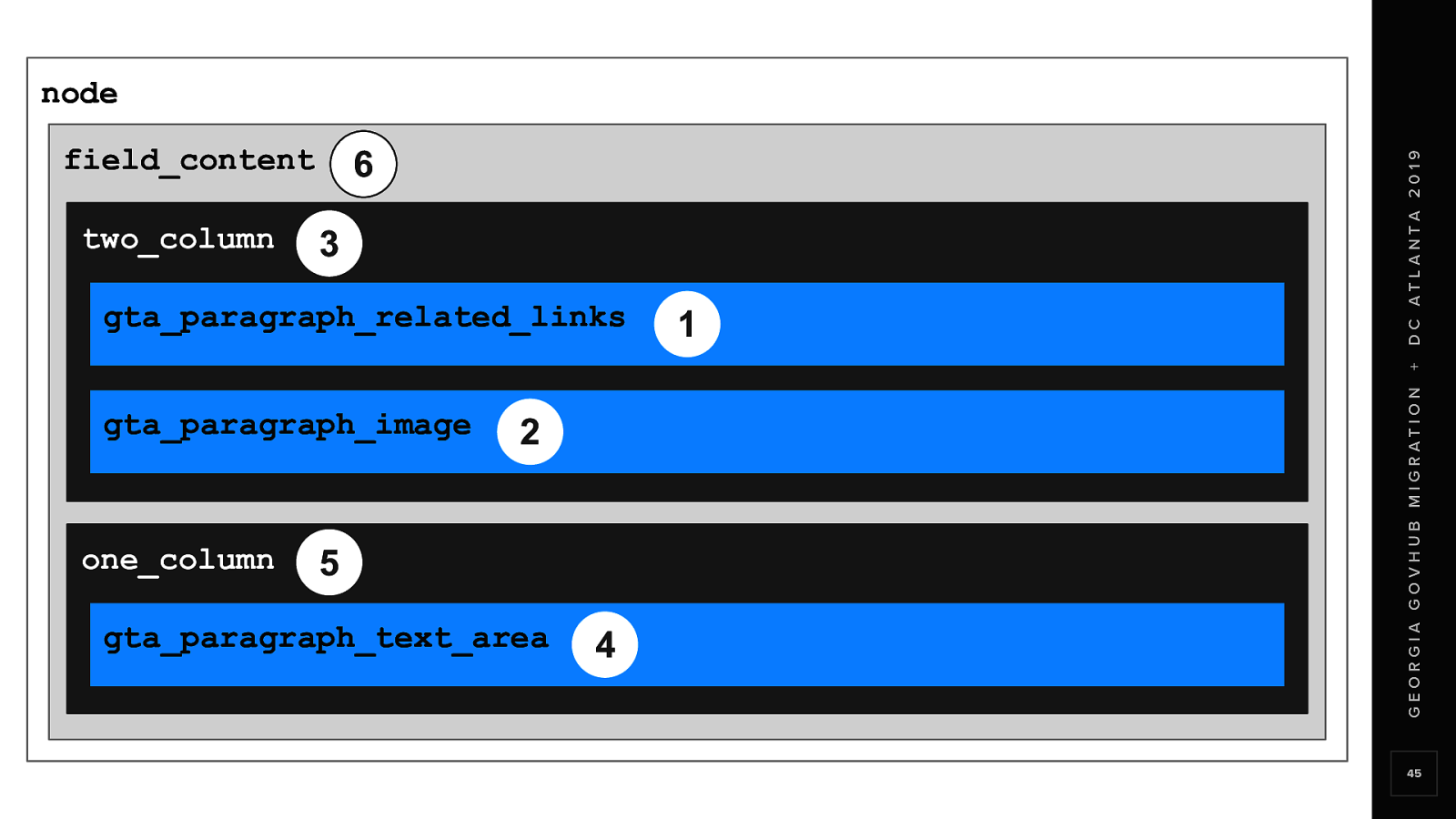
Using a recursive function, the process plugin iterates deep until it hits a content paragraph, renders at that level and then renders it’s way back out until it reaches the field level. The last step is to concatenate all of the rendered markup into one string.

Once we have that markup string, It can be added to the Body field using the concat process plugin This concatenates the value we created from field_content And the D7 Body field value

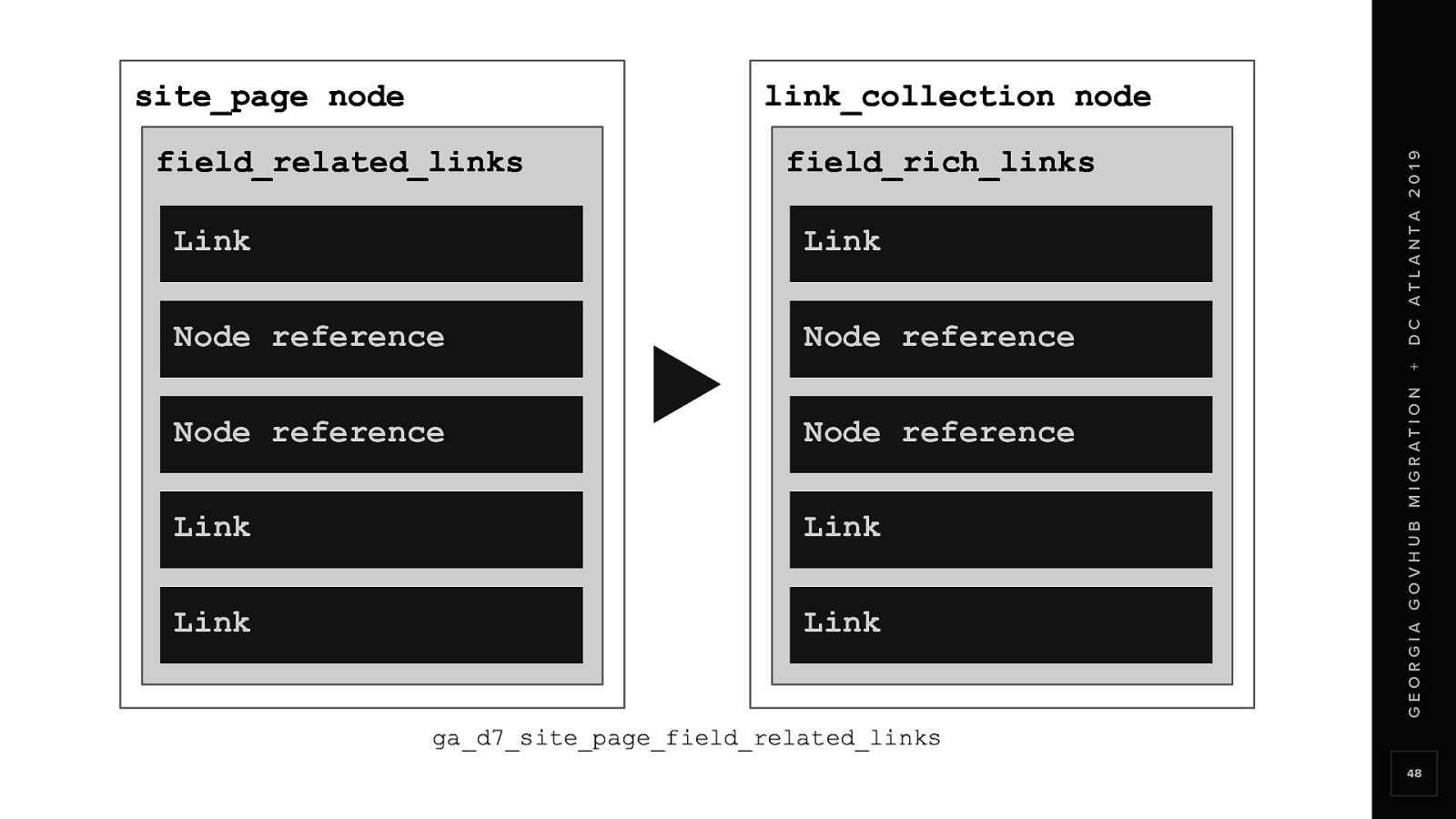
This is an example for a Site Page We migrated the related links field to a Link Collection node in D8 Prior to the actual Site Page migration So that we could embed the new Link Collection node In the Body field during the Site Page migration So this is a separate migration, only for field_related_links

During the Site Page migration We identify the Link Collection node created previously based on the nid of the Site Page Generate the entity embed code for that node And add the markup to the Body field

So the migration configuration looks like this Look up the Link Collection node using the current nid And a custom process plugin to generate the embed code

Then that value is added to the Body field

Sounds simple enough The Site Page migration Depends on the field_related_links migration So that the Link Collection node is created first Then the Site Page embeds in the Body field during its migration
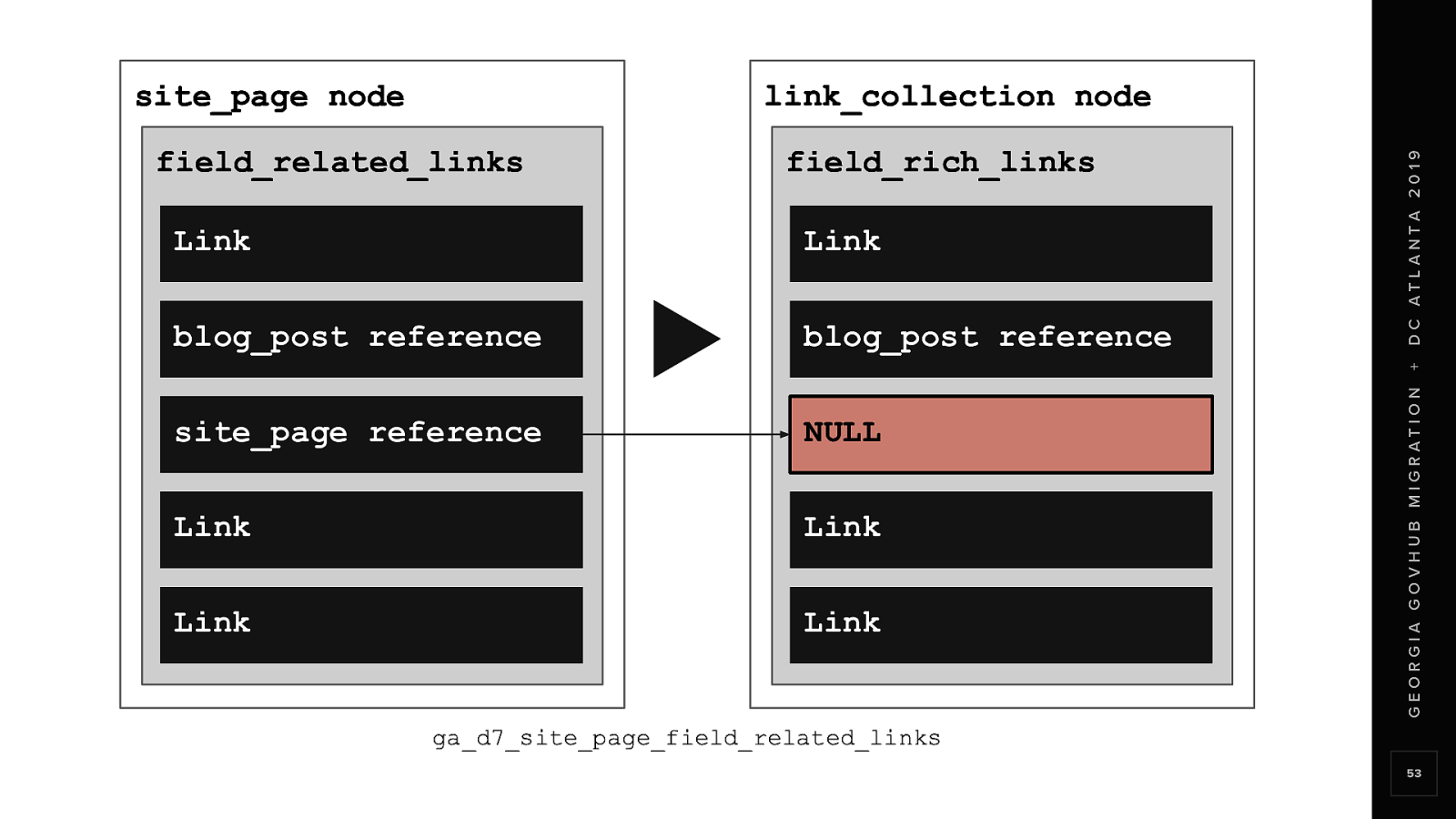
But here is the catch What if field_related_links is referencing a Site Page that hasn’t migrated yet Because the Site Page migration happens after the field_related_links migration The value migrated is empty because the node does not yet exist in D8

So we added a stubbing process to the field_related_links migration That would create stubbed or empty reference nodes in D8 The stubbed nodes will later be completed by the Site Page migration In this particular case, We aren’t using any value from this process We just want the stubbed nodes to be created
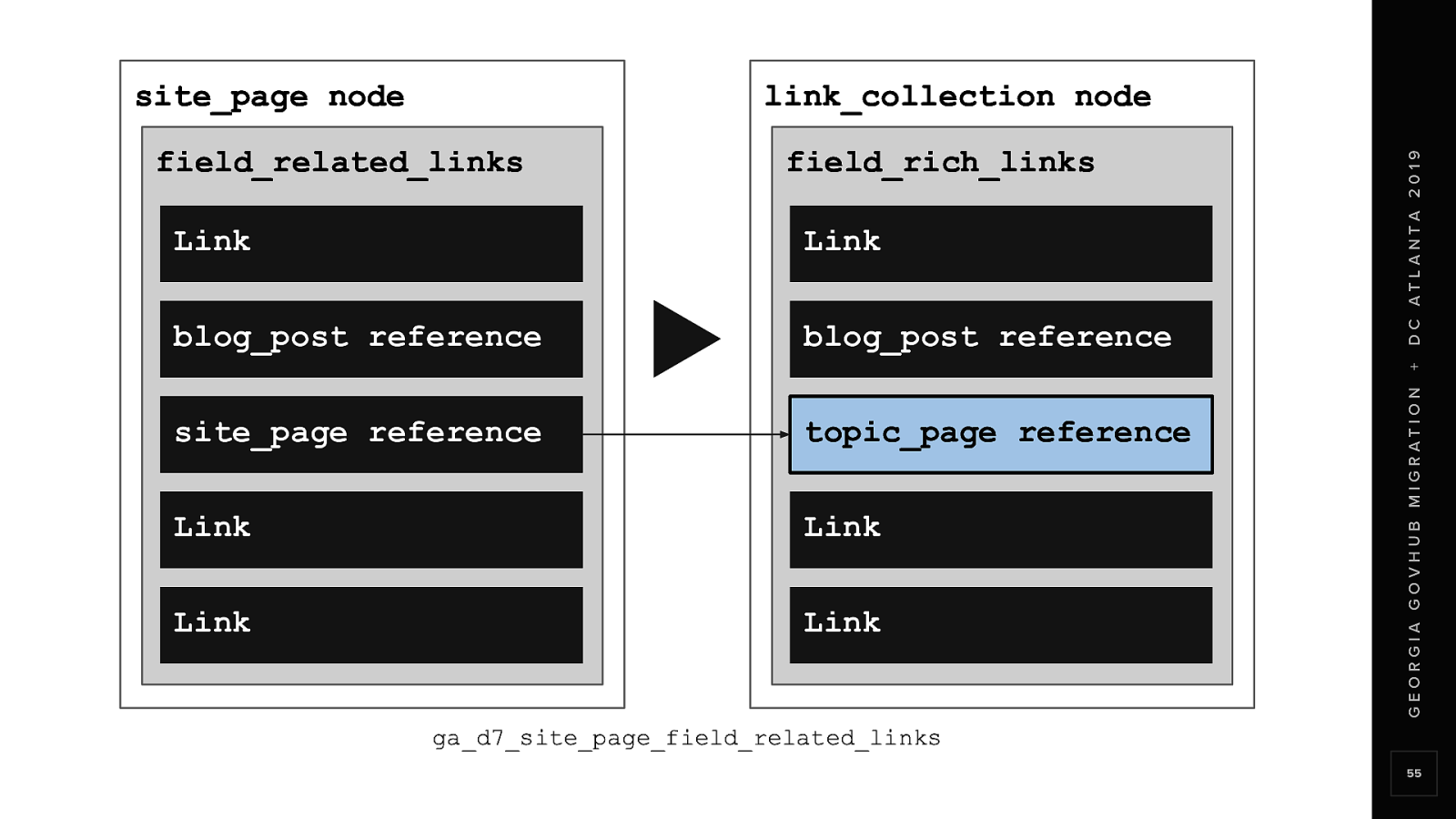
So now, when the field_related_links migration runs The missing Site Page will have a reference in D8
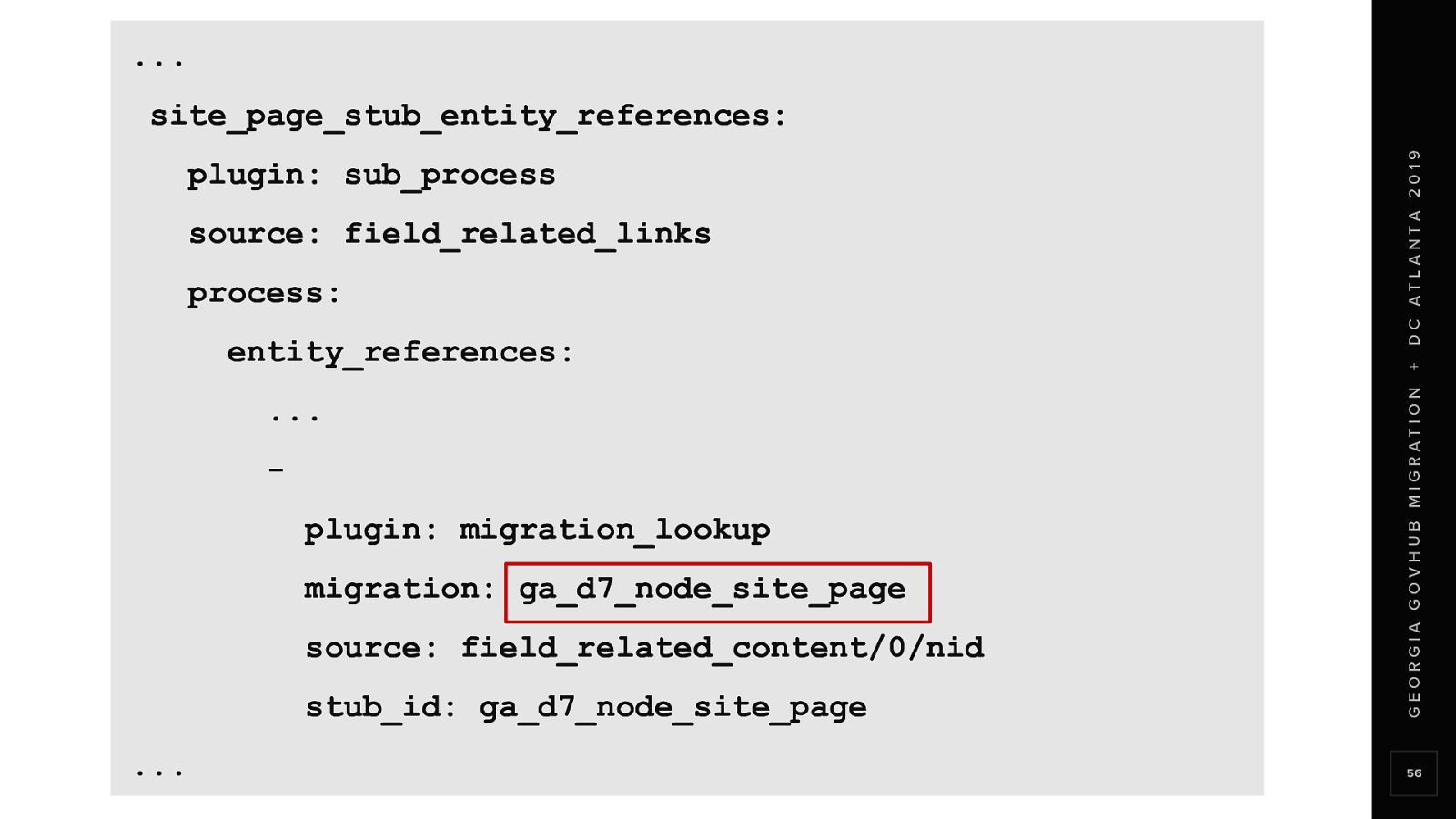
The tricky part is here By referencing the Site Page migration in the migration_lookup process plugin That migration becomes a dependency of the field_related_links migration

So now our dependencies look something like this Our migrations are technically dependent on each other

The Site Page migration id is alphabetically before the field_related_links migration, so it works

I created an issue on Drupal.org to explore a way to make this work without a hack And to explain the issue if someone else gets stuck It’s likely an edge case so this work around may be the preferred solution


In the latest Migrate Plus module There is a process plugin that converts HTML to a Document Object Model Object We implemented this solution later in the project to replace our use of regular expressions For a more robust solution In the migration configuration, We stacked our process plugins in an array Converting the markup to a DOM object Running a custom process plugin to filter and alter it Then converting it back to markup

If you’ve never used the DOM Object in PHP, It’s a bit of a black box And Xdebug is not very useful

This is the process I found most helpful for each change

This is a basic example in code format The removeElementAndContent() call is for a custom method With logic specific to that process

Some of the alterations we handled in our custom process plugin


If you are interested in learning about other aspects of the Georgia.gov project I encourage you to check out these two presentations

If you are interested in learning more about migration from Lullabot We have a couple of recent articles and a Podcast And we are in the process of writing more Stay tuned!
