Data lake: how Red Hat maintains data quality across multiple Drupal sites DrupalCon Pittsburgh 2023 1 Melissa Bent April Sides Senior Software Engineer Senior Software Engineer

A presentation at DrupalCon Pittsburgh 2023 in June 2023 in Pittsburgh, PA, USA by April Sides

Data lake: how Red Hat maintains data quality across multiple Drupal sites DrupalCon Pittsburgh 2023 1 Melissa Bent April Sides Senior Software Engineer Senior Software Engineer
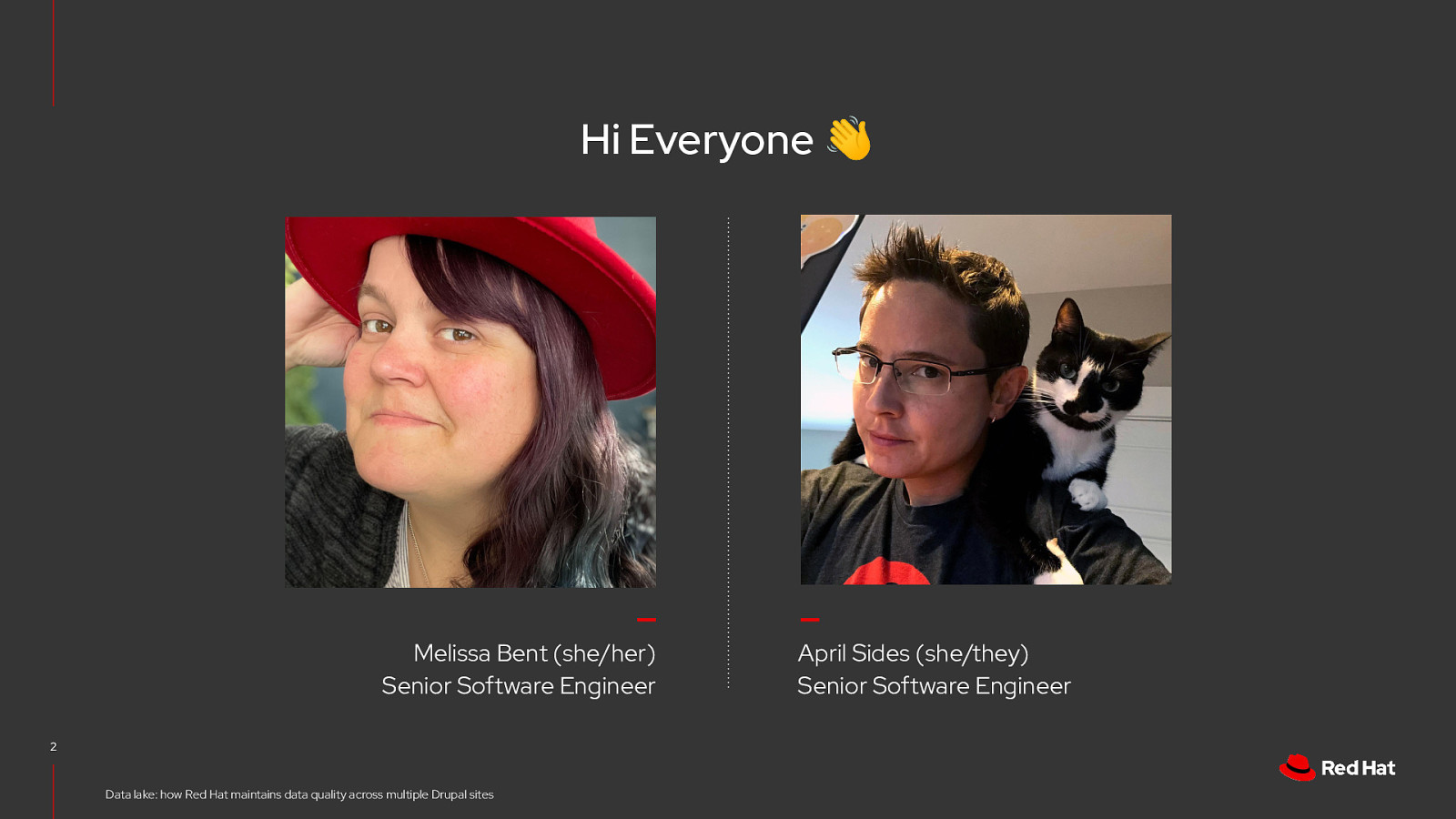
Hi Everyone 👋 Melissa Bent (she/her) Senior Software Engineer 2 Data lake: how Red Hat maintains data quality across multiple Drupal sites April Sides (she/they) Senior Software Engineer

July 7-9, 2023 DrupalAsheville.com
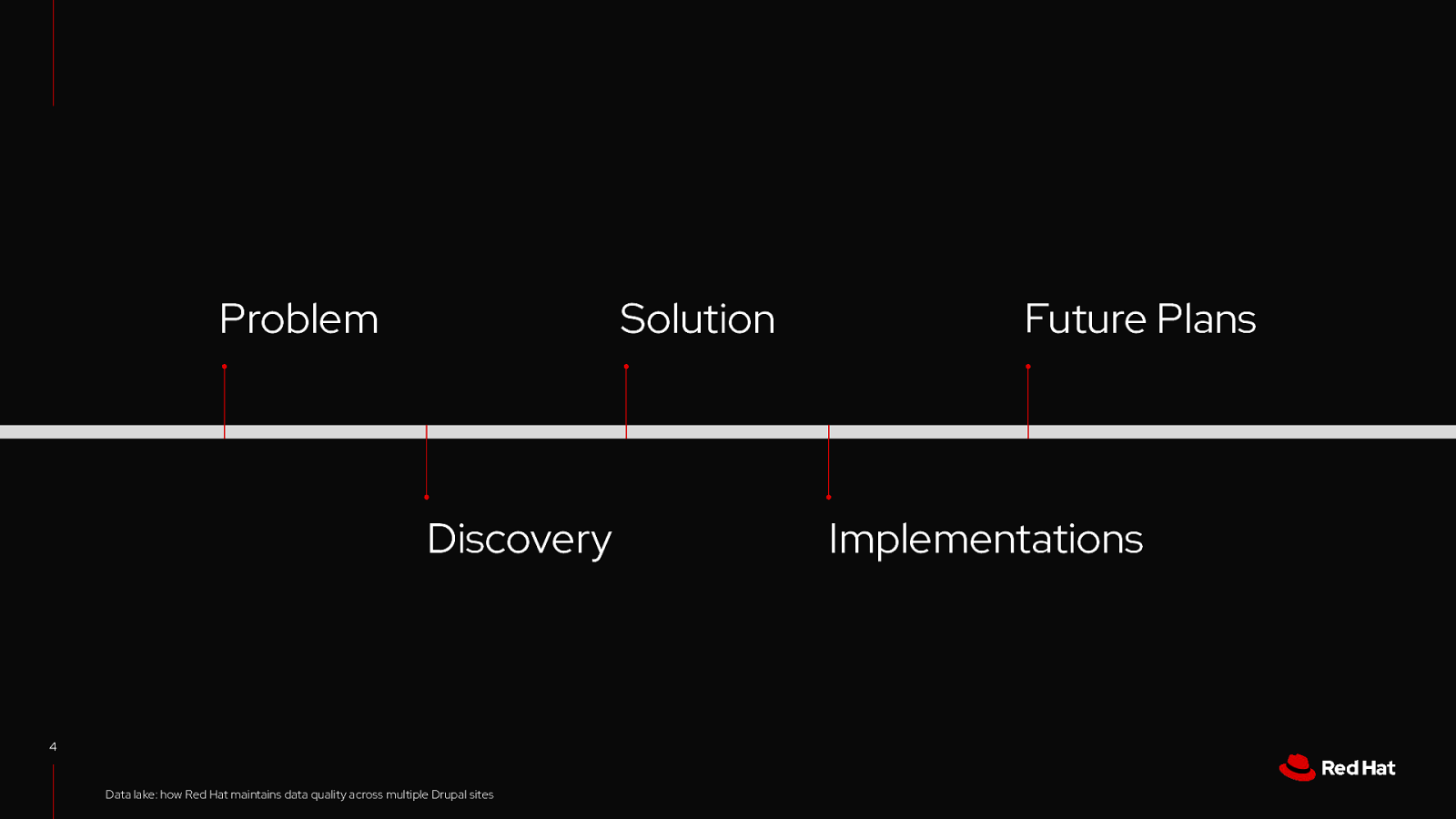
Problem Solution Discovery 4 Data lake: how Red Hat maintains data quality across multiple Drupal sites Future Plans Implementations

Problem 5

Problem Red Hat is big. Really big. 19,000+ Employees 6 35+ Countries

Problem We use a lot of different technologies across our company to serve our customers. 7

Problem Redhat.com is built on Drupal and single-page applications. 8

Problem Organizational data Manual Maintenance 9 Duplication Different Teams

Problem There has to be a better way to share data across the redhat.com ecosystem. 10

Discovery 11

Discovery Product Experience access.redhat.com/products 12 Data lake: how Red Hat maintains data quality across multiple Drupal sites
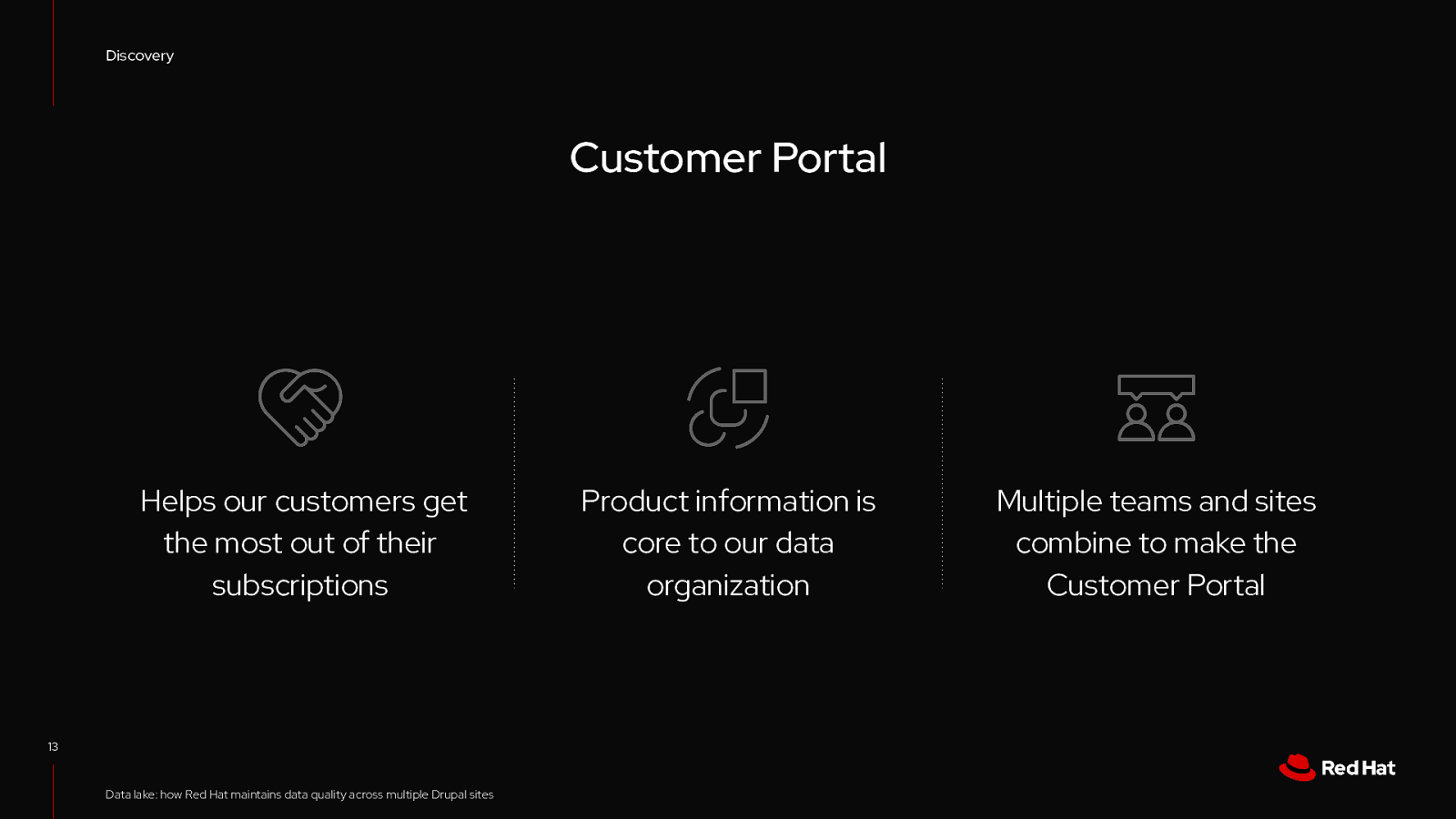
Discovery Customer Portal Helps our customers get the most out of their subscriptions 13 Data lake: how Red Hat maintains data quality across multiple Drupal sites Product information is core to our data organization Multiple teams and sites combine to make the Customer Portal
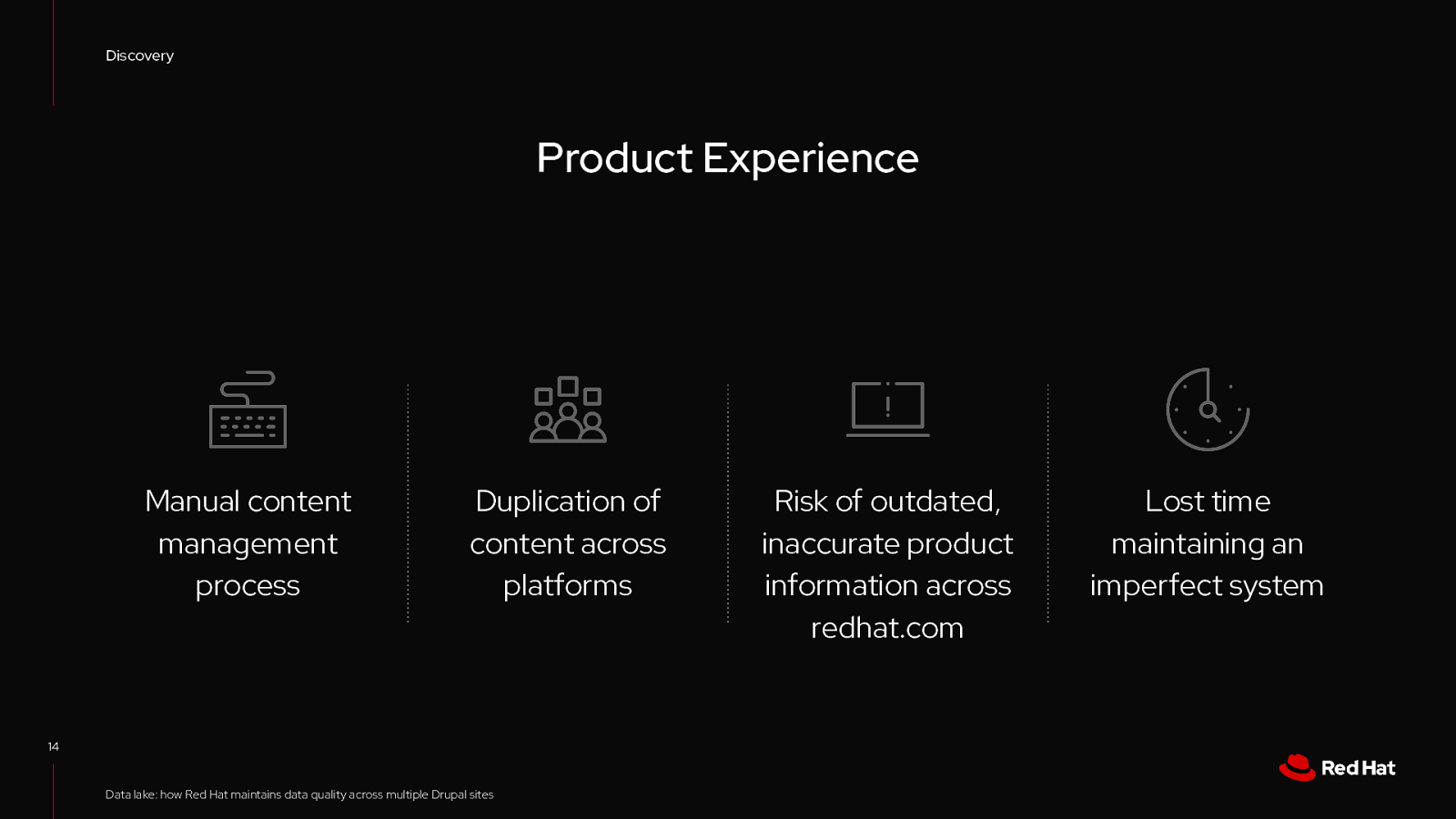
Discovery Product Experience Manual content management process Duplication of content across platforms 14 Data lake: how Red Hat maintains data quality across multiple Drupal sites Risk of outdated, inaccurate product information across redhat.com Lost time maintaining an imperfect system
Discovery Requirements Share data in a scalable/maintainable way Provide flexible data model/schema Connect with current tech stacks Serve as a single source of truth 15 Data lake: how Red Hat maintains data quality across multiple Drupal sites

Solution 16

Solution Data Lake 17 Data lake: how Red Hat maintains data quality across multiple Drupal sites

Solution Data Lake Share data in a scalable/maintainable way Provide flexible data model/schema Scalable, low-maintenance Flexible structure, schema-on-read option Connect with current tech stacks Drupal module, GraphQL, PHP Driver Serve as a single source of truth Bring your own governance 18 Data lake: how Red Hat maintains data quality across multiple Drupal sites

Solution Challenges Protect against “data rot” 19 Data lake: how Red Hat maintains data quality across multiple Drupal sites Establish governance plan Security and privacy compliance

Solution Advantages Scalability 20 Data lake: how Red Hat maintains data quality across multiple Drupal sites Simple architecture Additional “caching” layer

Solution 21 Data lake: how Red Hat maintains data quality across multiple Drupal sites
Solution Indexing Custom Search API Backend Search API’s index management 22 Data lake: how Red Hat maintains data quality across multiple Drupal sites Flexible schema for each data source Drupal’s access control, data model, and editorial experience
Solution Retrieval Single-page applications GraphQL 23 Data lake: how Red Hat maintains data quality across multiple Drupal sites Drupal PHP MongoDB Driver

Implementations 24

Implementations Product Experience access.redhat.com/products 25 Data lake: how Red Hat maintains data quality across multiple Drupal sites
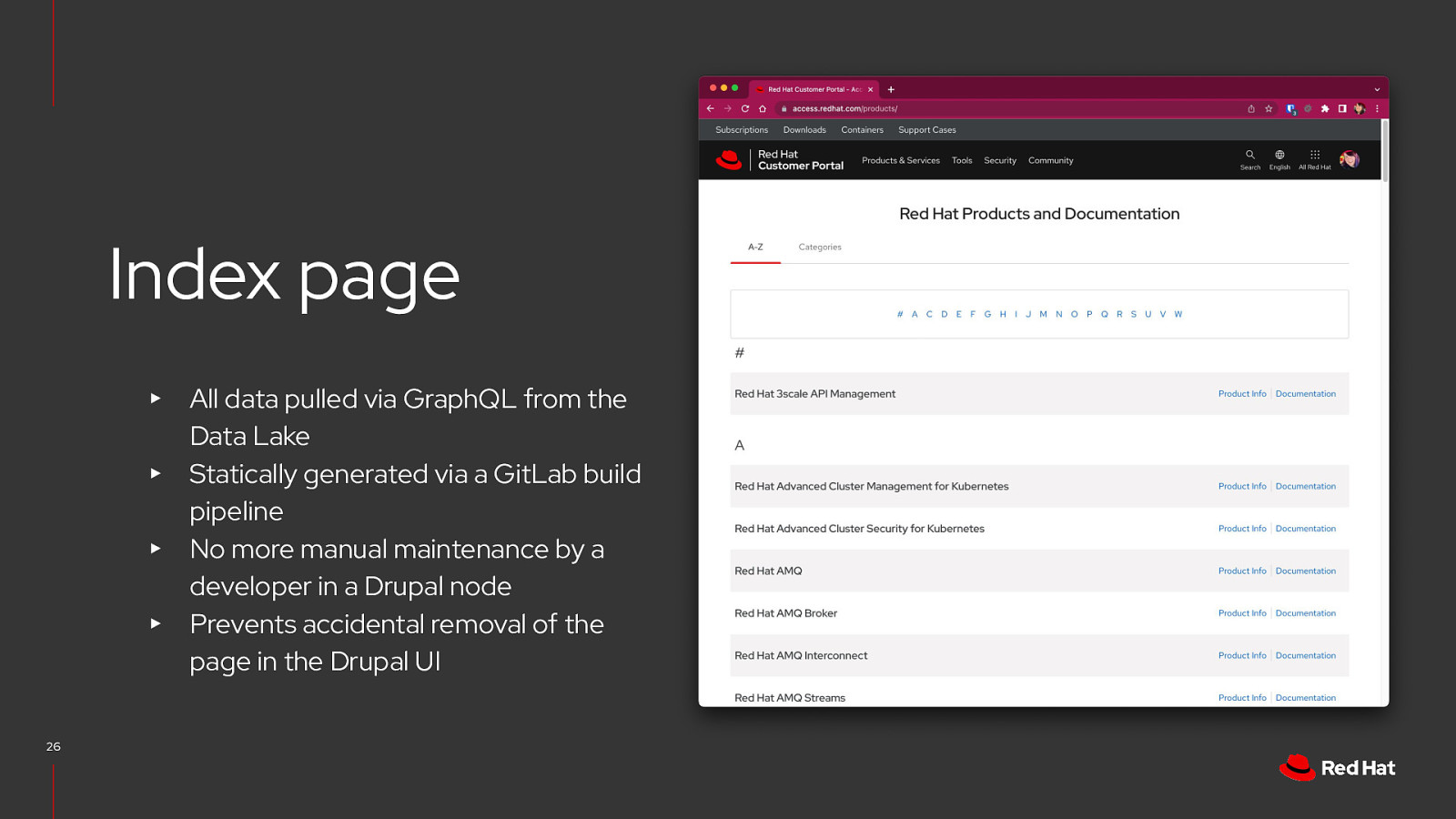
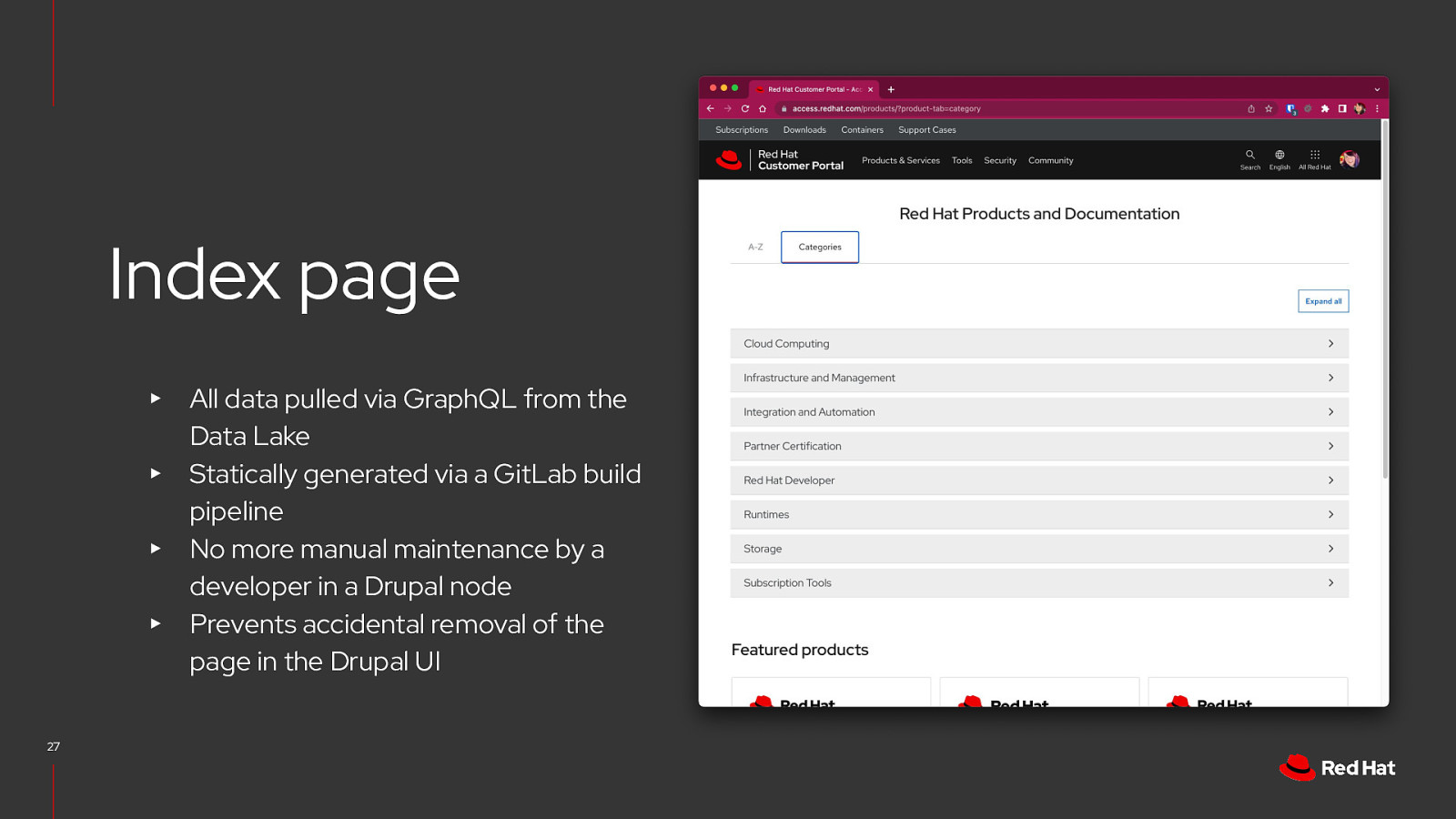
Index page All data pulled via GraphQL from the Data Lake ▸ Statically generated via a GitLab build pipeline ▸ No more manual maintenance by a developer in a Drupal node ▸ Prevents accidental removal of the page in the Drupal UI ▸ 26
Index page All data pulled via GraphQL from the Data Lake ▸ Statically generated via a GitLab build pipeline ▸ No more manual maintenance by a developer in a Drupal node ▸ Prevents accidental removal of the page in the Drupal UI ▸ 27
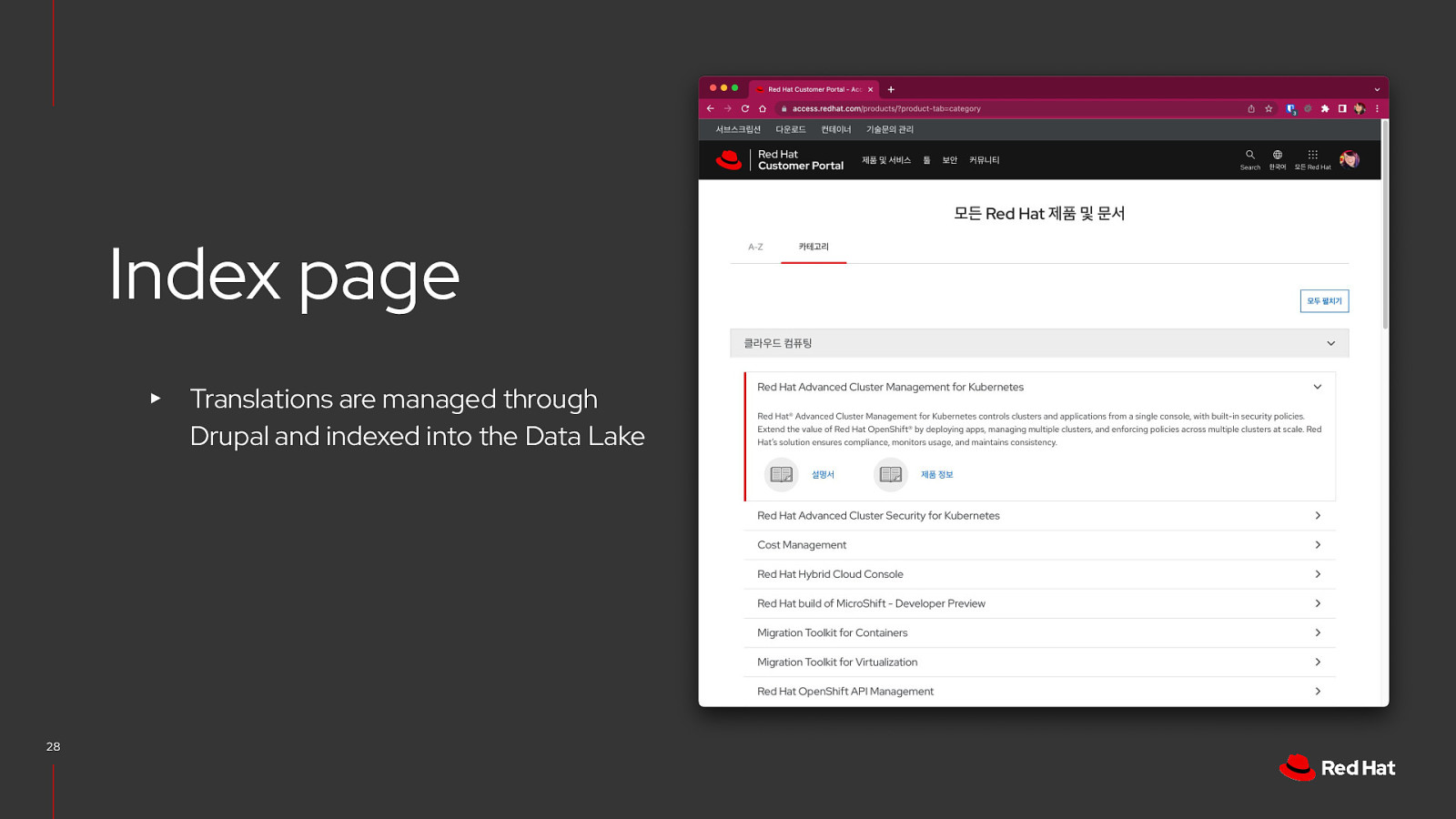
Index page ▸ 28 Translations are managed through Drupal and indexed into the Data Lake
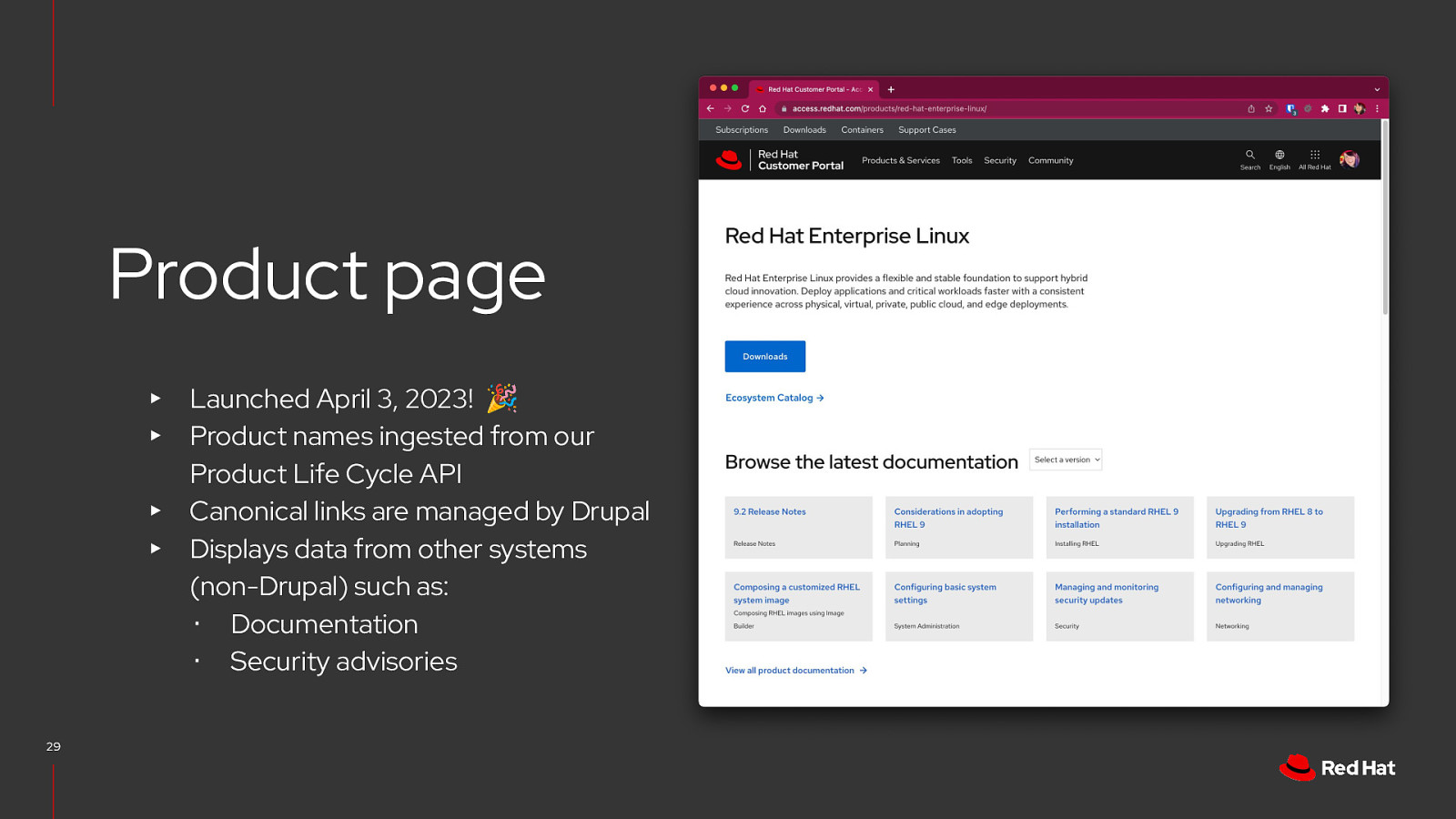
Product page Launched April 3, 2023! 🎉 Product names ingested from our Product Life Cycle API ▸ Canonical links are managed by Drupal ▸ Displays data from other systems (non-Drupal) such as: ・ Documentation ・ Security advisories ▸ ▸ 29
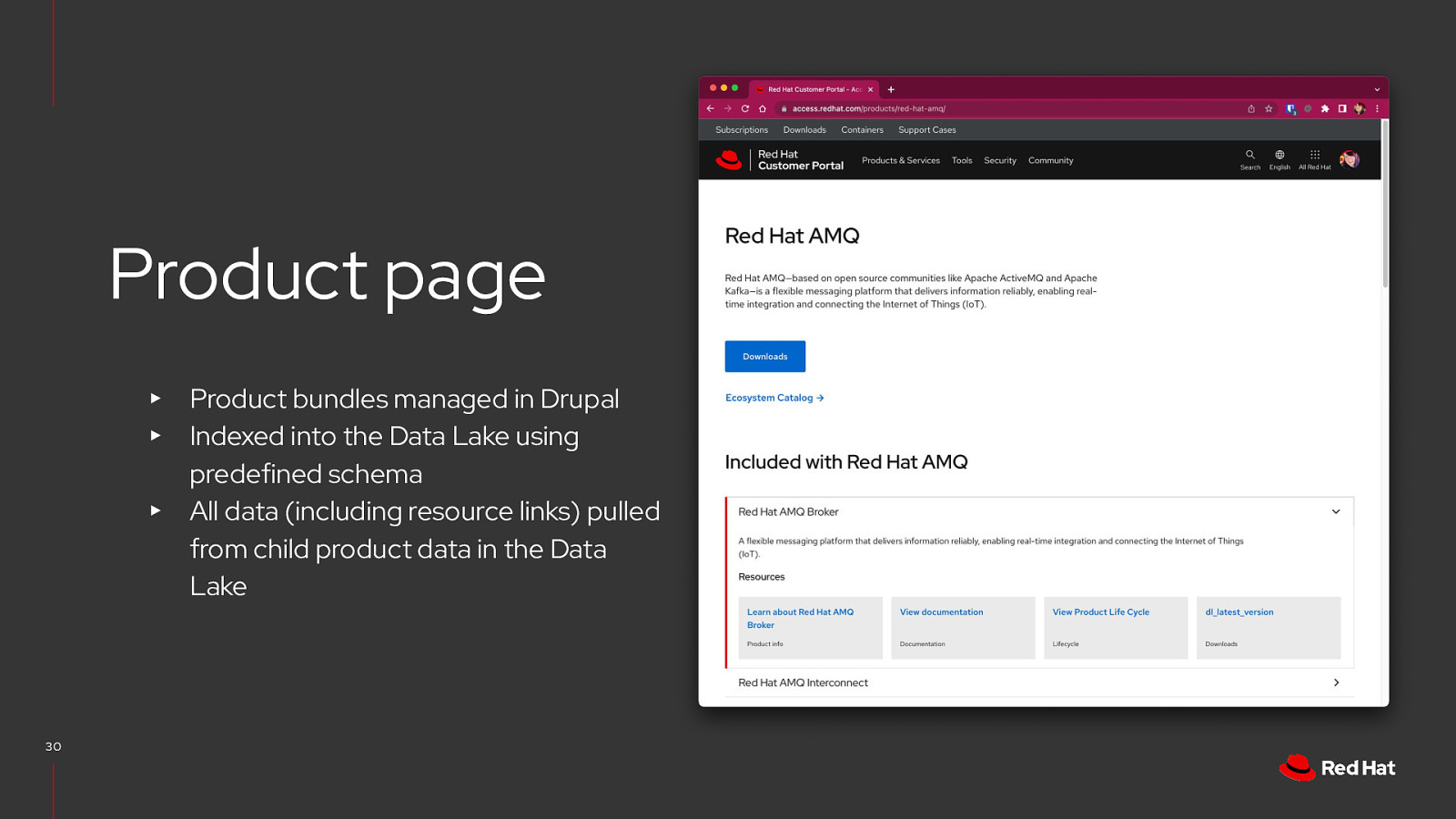
Product page Product bundles managed in Drupal Indexed into the Data Lake using predefined schema ▸ All data (including resource links) pulled from child product data in the Data Lake ▸ ▸ 30
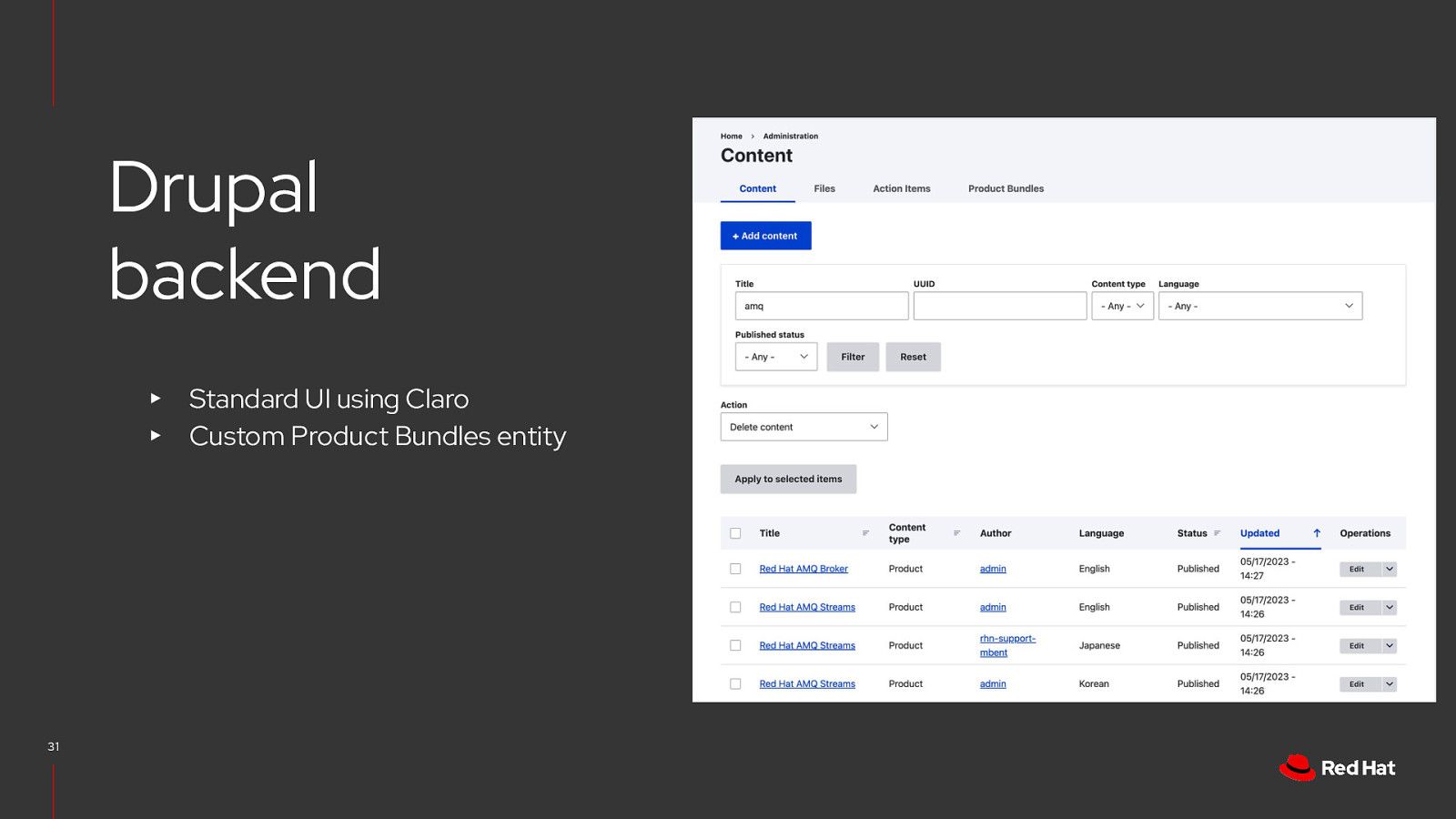
Drupal backend ▸ ▸ 31 Standard UI using Claro Custom Product Bundles entity
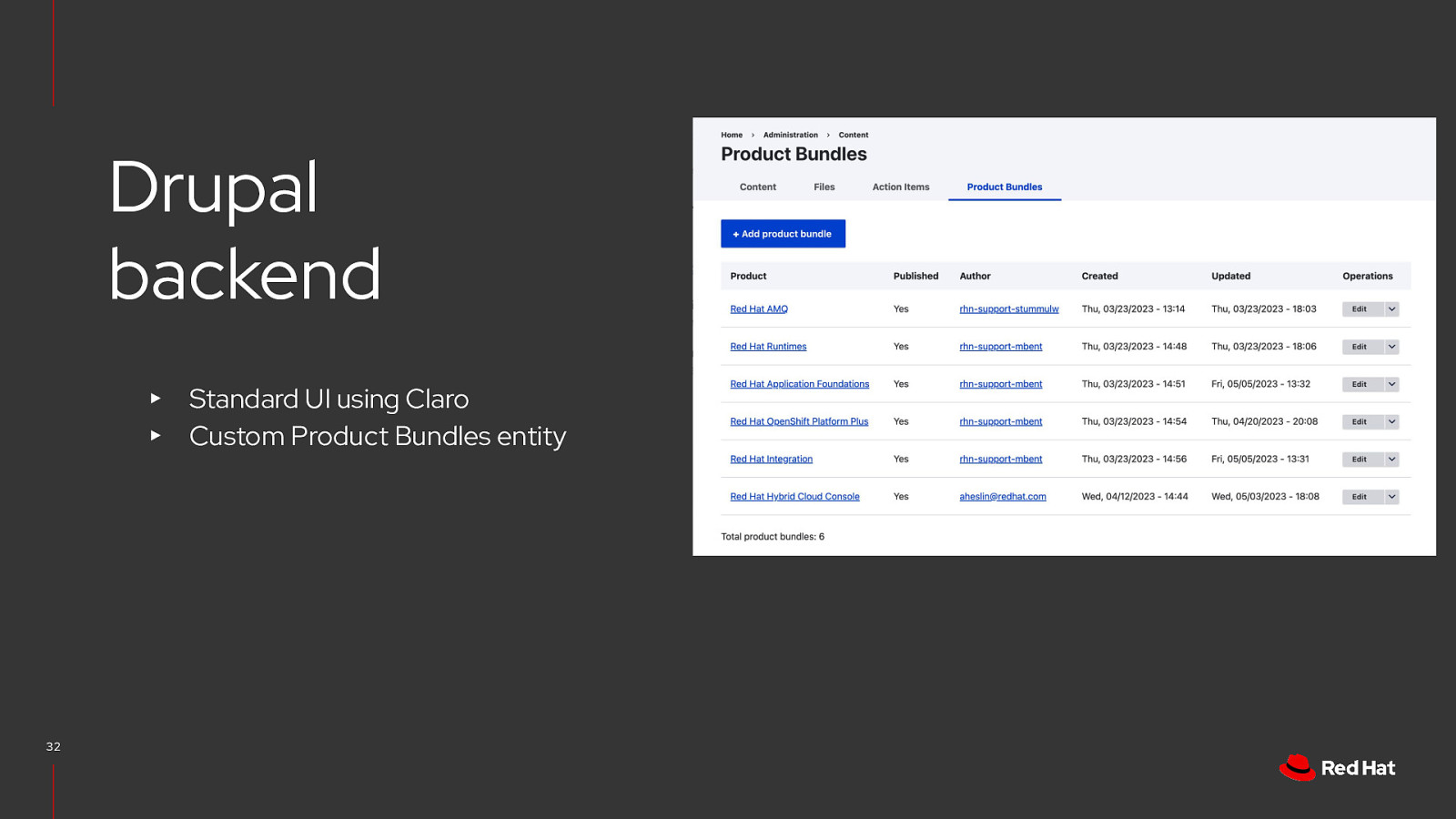
Drupal backend ▸ ▸ 32 Standard UI using Claro Custom Product Bundles entity
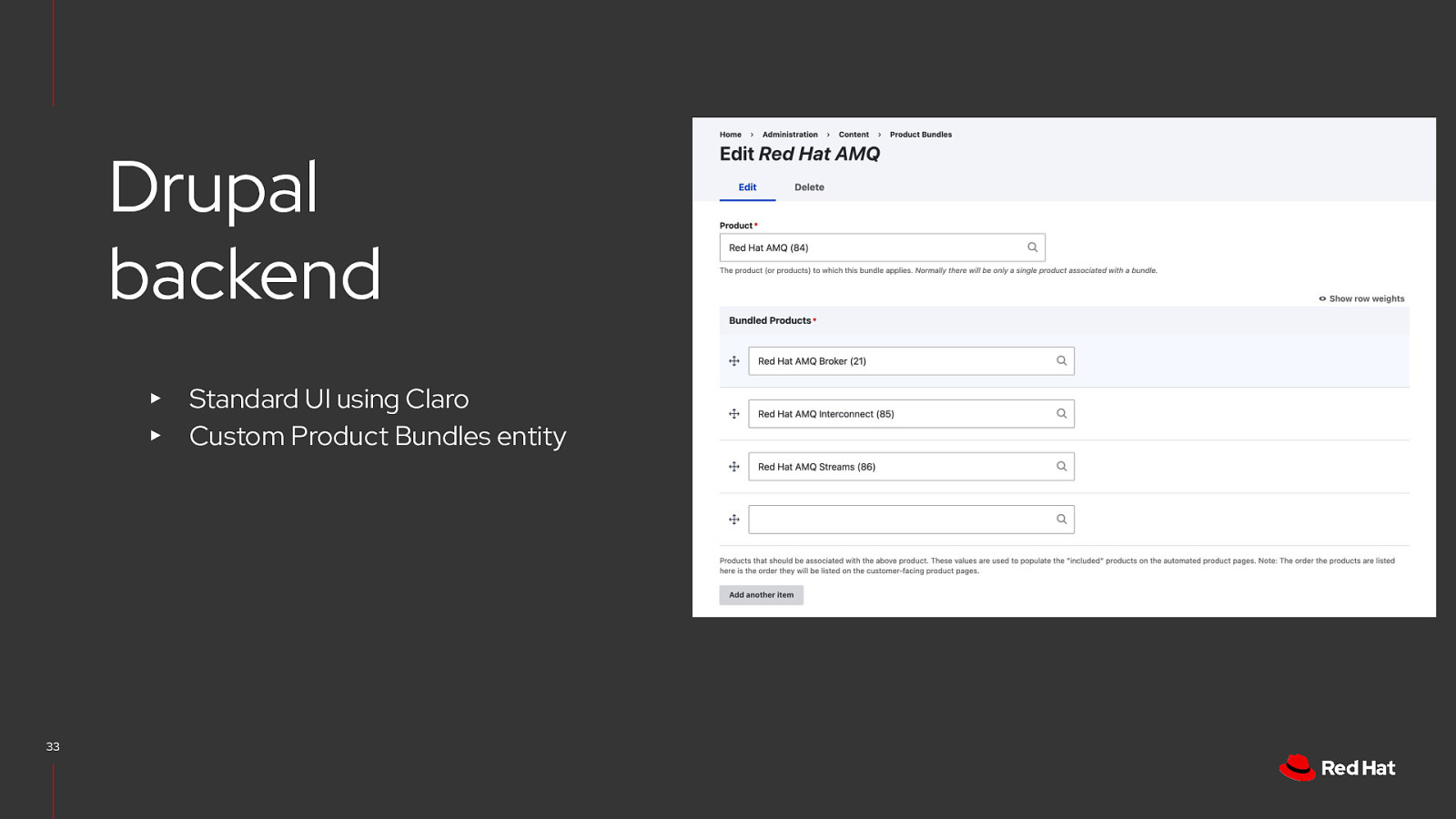
Drupal backend ▸ ▸ 33 Standard UI using Claro Custom Product Bundles entity
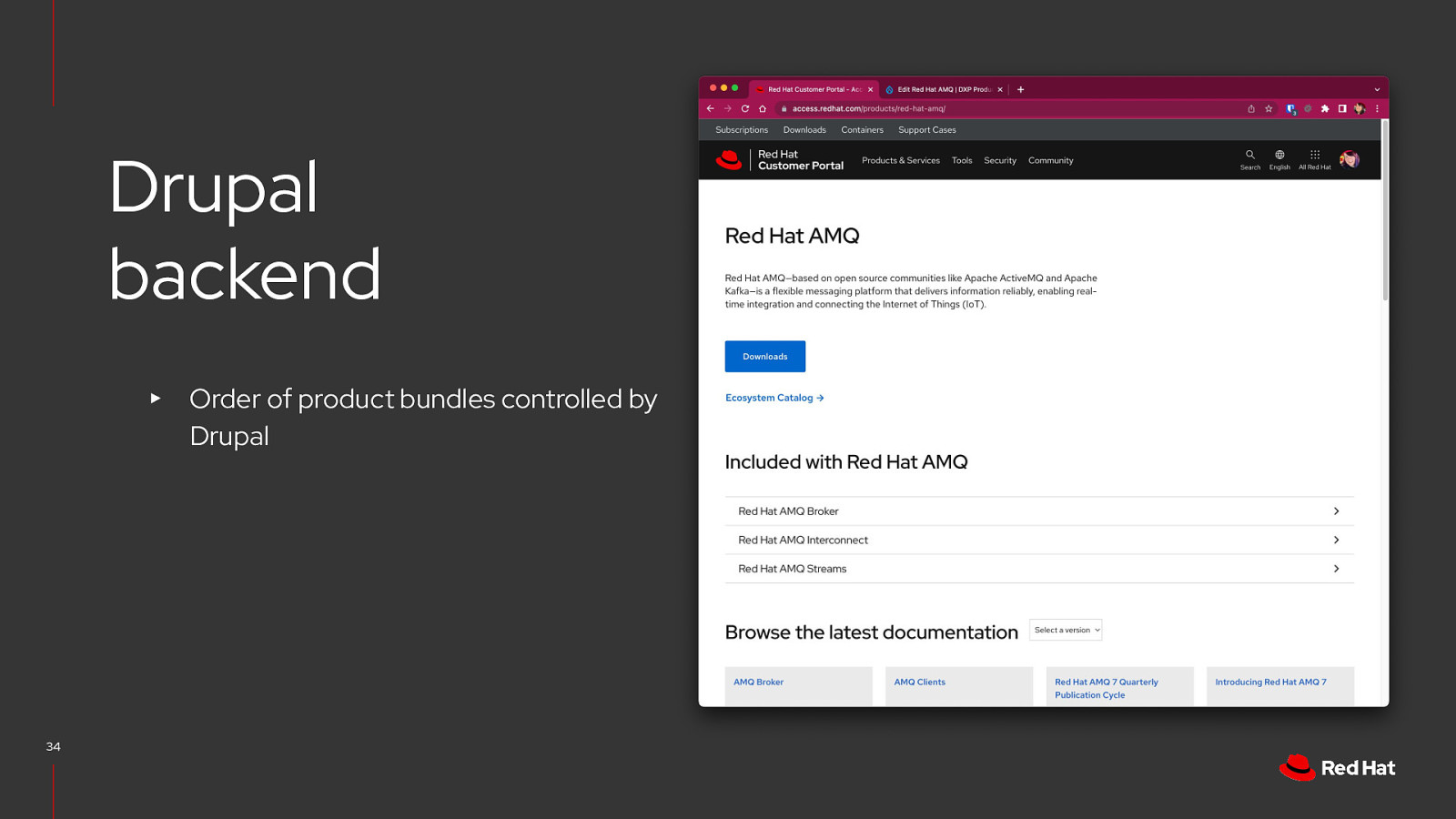
Drupal backend ▸ 34 Order of product bundles controlled by Drupal

After all that. Now you… Manage data in Drupal Index the data to the Data Lake Query the Data Lake with GraphQL Build the page via GitLab pipeline Set your refresh every 30 minutes Enjoy your newly automated life 35

36

Implementations developers.redhat.com 37 Data lake: how Red Hat maintains data quality across multiple Drupal sites

Implementations A Learning Path is a curated collection of content, directing users to learn more about a particular topic or product. 38
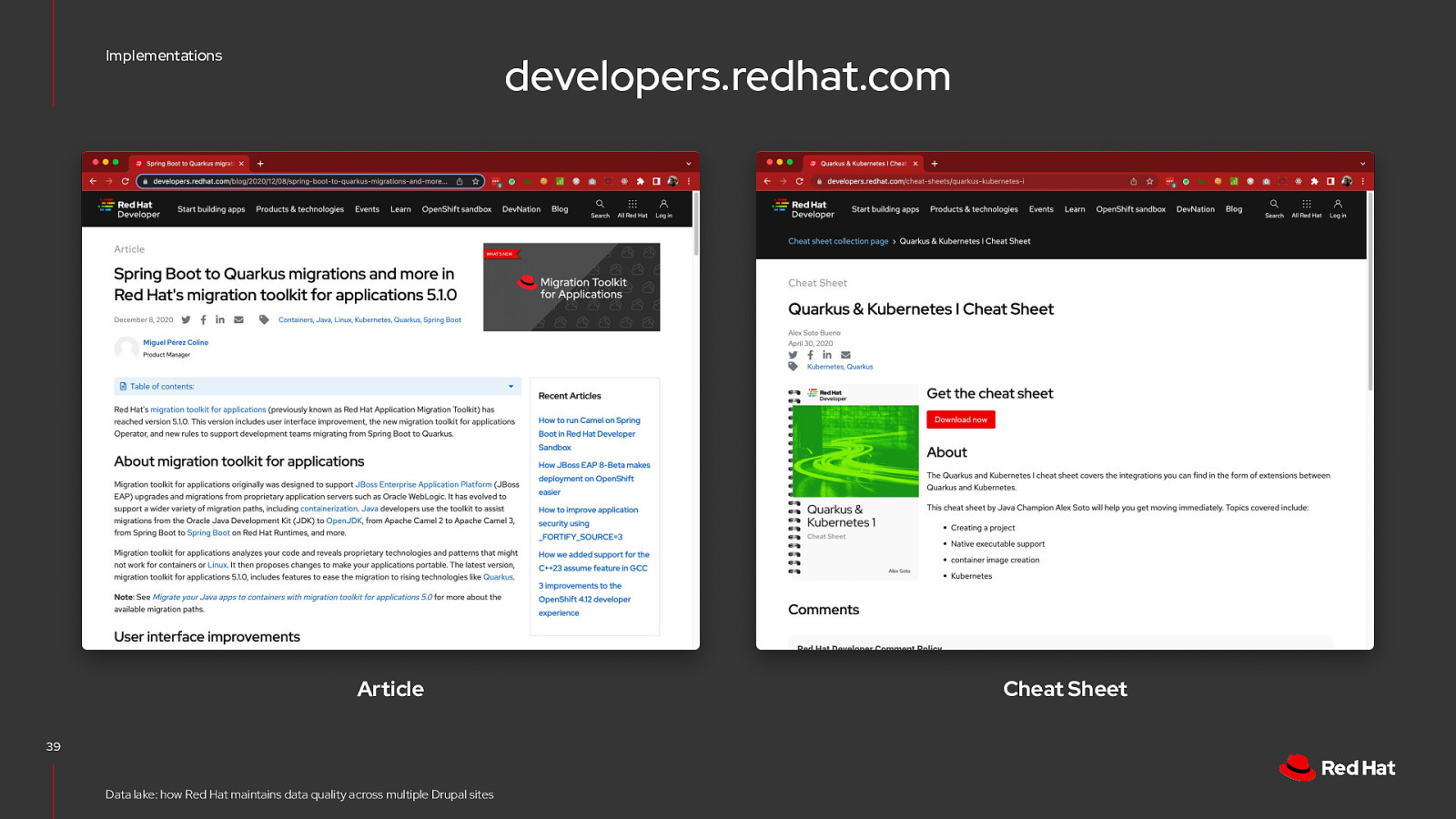
Implementations developers.redhat.com Article 39 Data lake: how Red Hat maintains data quality across multiple Drupal sites Cheat Sheet
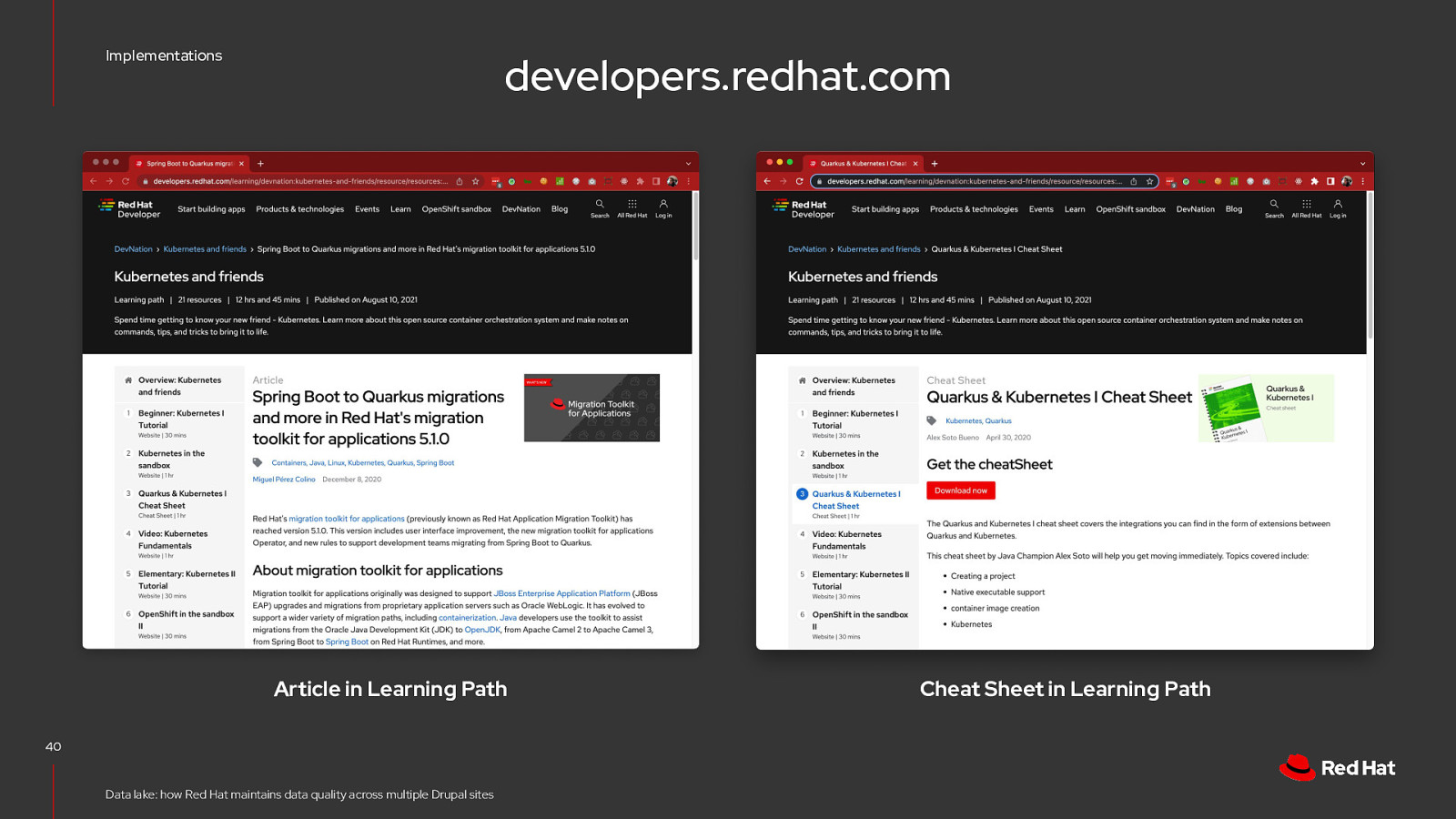
Implementations developers.redhat.com Article in Learning Path 40 Data lake: how Red Hat maintains data quality across multiple Drupal sites Cheat Sheet in Learning Path
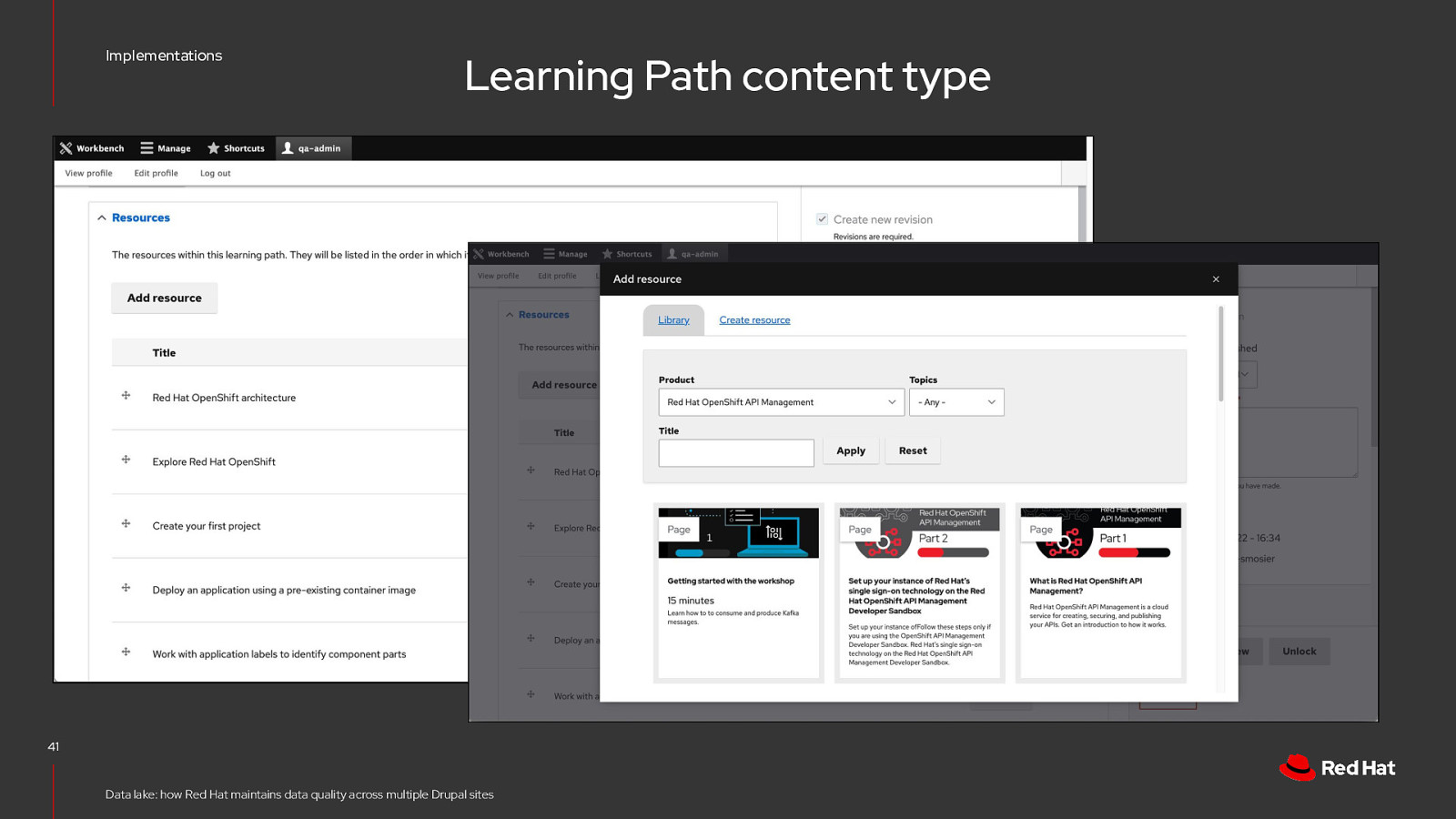
Implementations Learning Path content type 41 Data lake: how Red Hat maintains data quality across multiple Drupal sites
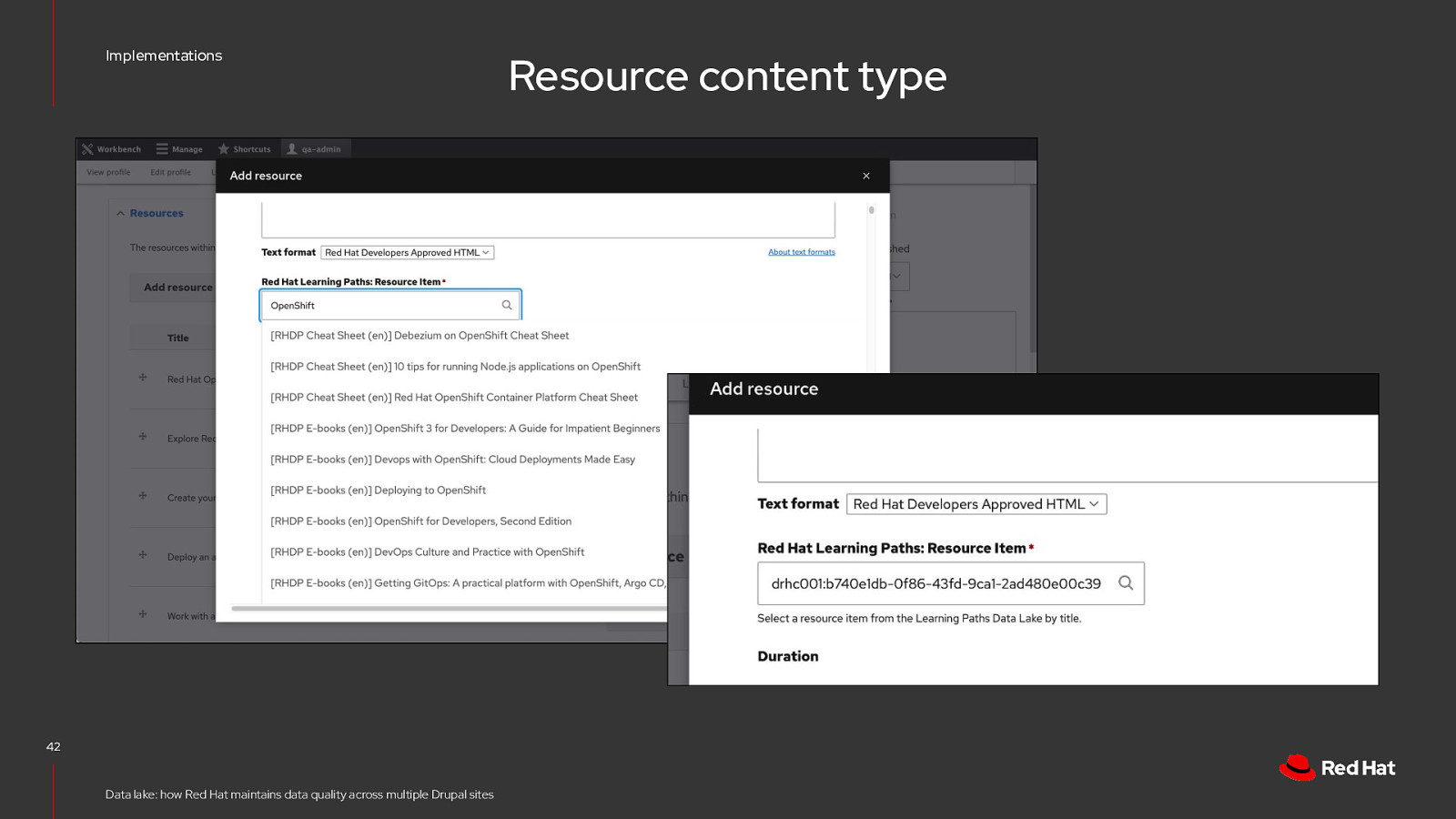
Implementations 42 Data lake: how Red Hat maintains data quality across multiple Drupal sites Resource content type
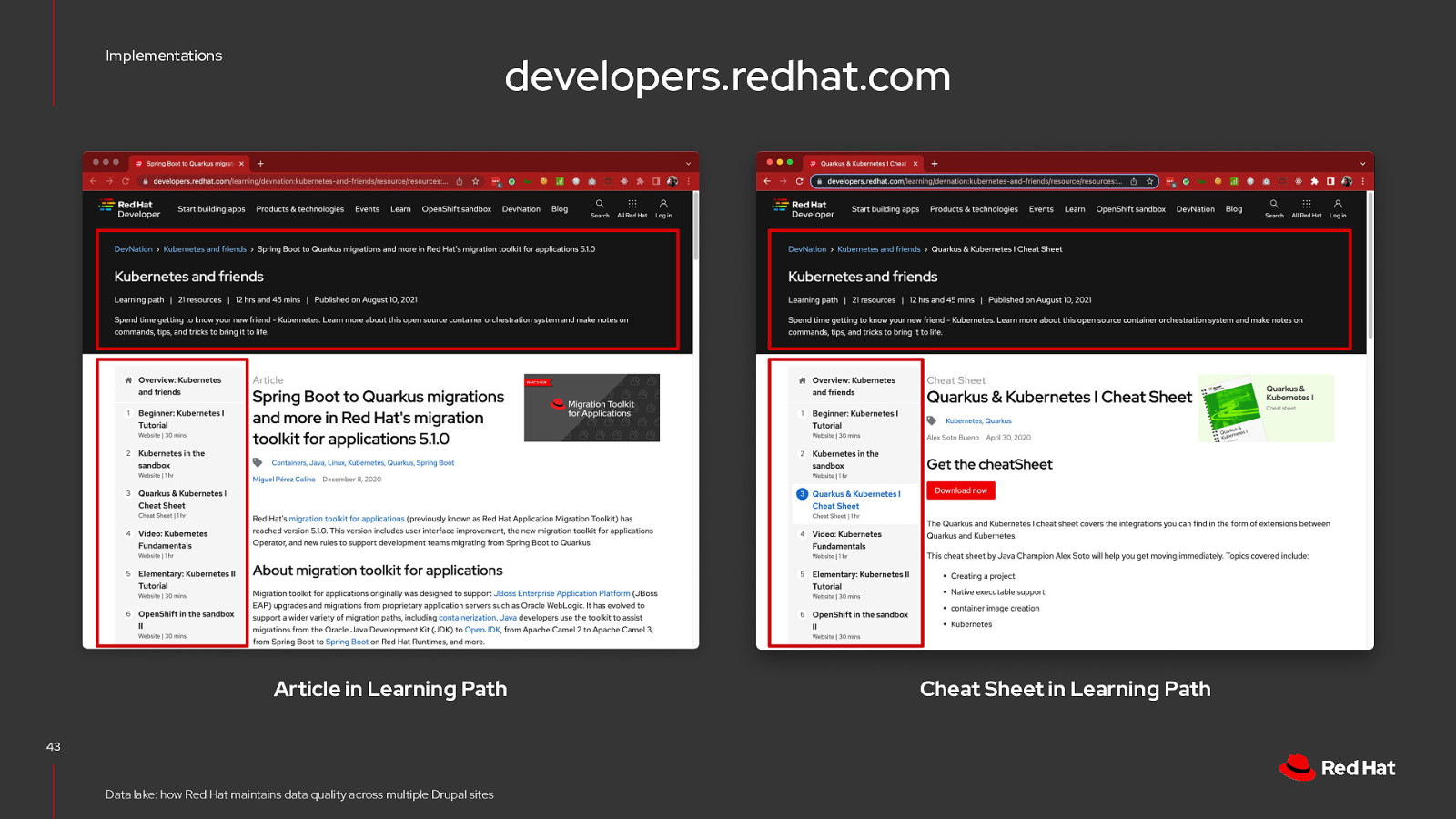
Implementations developers.redhat.com Article in Learning Path 43 Data lake: how Red Hat maintains data quality across multiple Drupal sites Cheat Sheet in Learning Path
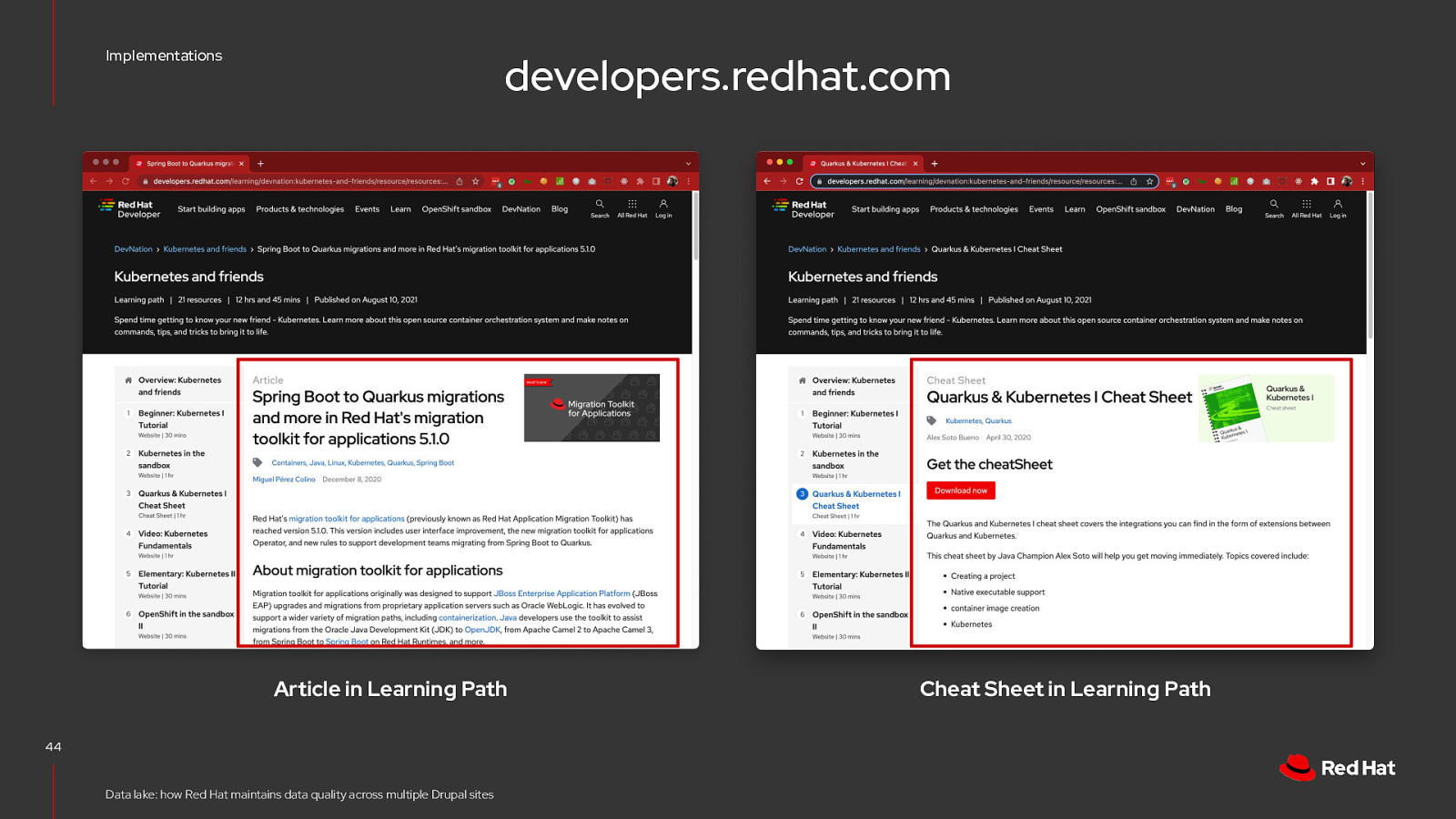
Implementations developers.redhat.com Article in Learning Path 44 Data lake: how Red Hat maintains data quality across multiple Drupal sites Cheat Sheet in Learning Path
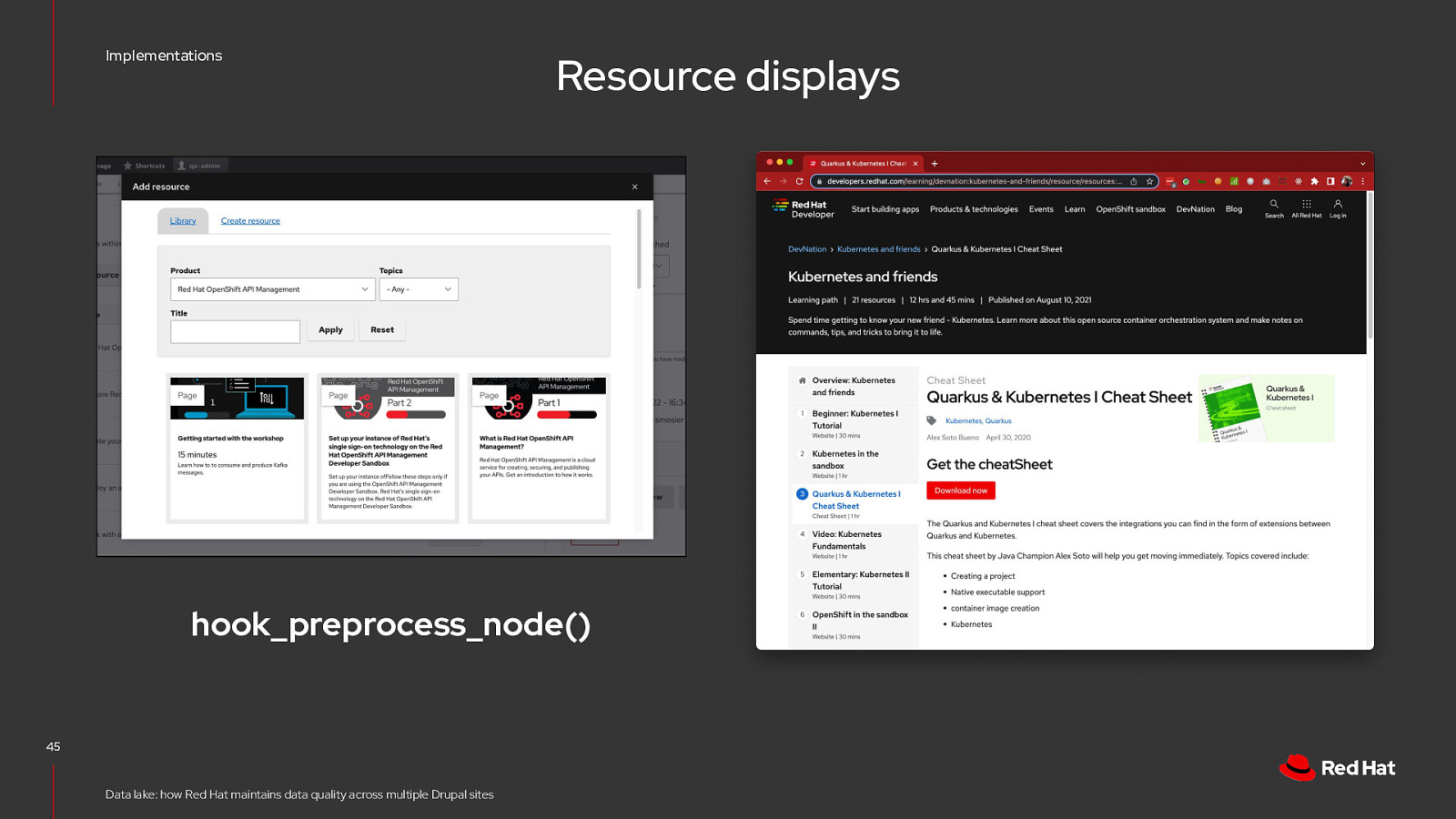
Implementations Resource displays hook_preprocess_node() 45 Data lake: how Red Hat maintains data quality across multiple Drupal sites
Implementations Shared module Learning Paths shared module 46 Data lake: how Red Hat maintains data quality across multiple Drupal sites

Implementations 47 Data lake: how Red Hat maintains data quality across multiple Drupal sites

Future Plans 48

Future Plans Customer Portal Standardizing Product taxonomy across Customer Portal microsites and beyond Integrating with other systems at Red Hat 49 Data lake: how Red Hat maintains data quality across multiple Drupal sites

Future Plans Content Syndicated Patterns “Shared patterns” with embedded content for banners, footers, marketing content, etc. 50 Data lake: how Red Hat maintains data quality across multiple Drupal sites

Future Plans Learning Paths Learning Path discovery 51 Data lake: how Red Hat maintains data quality across multiple Drupal sites

Wrap up 52

Wrap up Code Repository MongoDB Data Lake https://red.ht/dc2023 URL is shortened to make it easier to find the sandbox project. Full URL: https://www.drupal.org/sandbox/merauluka/3363610 53 Data lake: how Red Hat maintains data quality across multiple Drupal sites

Drupal Contrib Modules Resources Allow Only One https://www.drupal.org/project/allow_only_one Automatic Entity Label https://www.drupal.org/project/auto_entitylabel Entity Browser https://www.drupal.org/project/entity_browser 54

Drupal Contrib Modules Resources External Data Source https://www.drupal.org/project/external_data_source MongoDB https://www.drupal.org/project/mongodb Search API https://www.drupal.org/project/search_api 55
Thank you Questions? Melissa Bent April Sides Red Hat linkedin.com/in/melissabent linkedin.com/in/aprilsides linkedin.com/company/red-hat twitter.com/merauluka twitter.com/weekbeforenext youtube.com/user/RedHatVideos facebook.com/redhatinc twitter.com/RedHat 56