Eléa Petton 6 OCTOBRE 2023

A presentation at DevFest Perros-Guirec in October 2023 in Perros-Guirec, France by Eléa PETTON

Eléa Petton 6 OCTOBRE 2023

ÉLÉA PETTON Machine Learning Engineer AI Solutions Team @EleaPetton eleapttn Eléa PETTON 2
L’optimisation, c’est la clé ! OBJECTIFS 3

L’optimisation en IA, c’est quoi ? DÉFINITIONS 4

OPTIMISATION Performance A quel point le modèle est précis, efficace et pertinent ? Explicabilité Le fonctionnement et les résultats du modèle sont-ils intelligibles et transparents ? Durabilité Est-ce que les coûts et la quantité d’énergie utilisée permettent de rendre cette IA durable ? 5
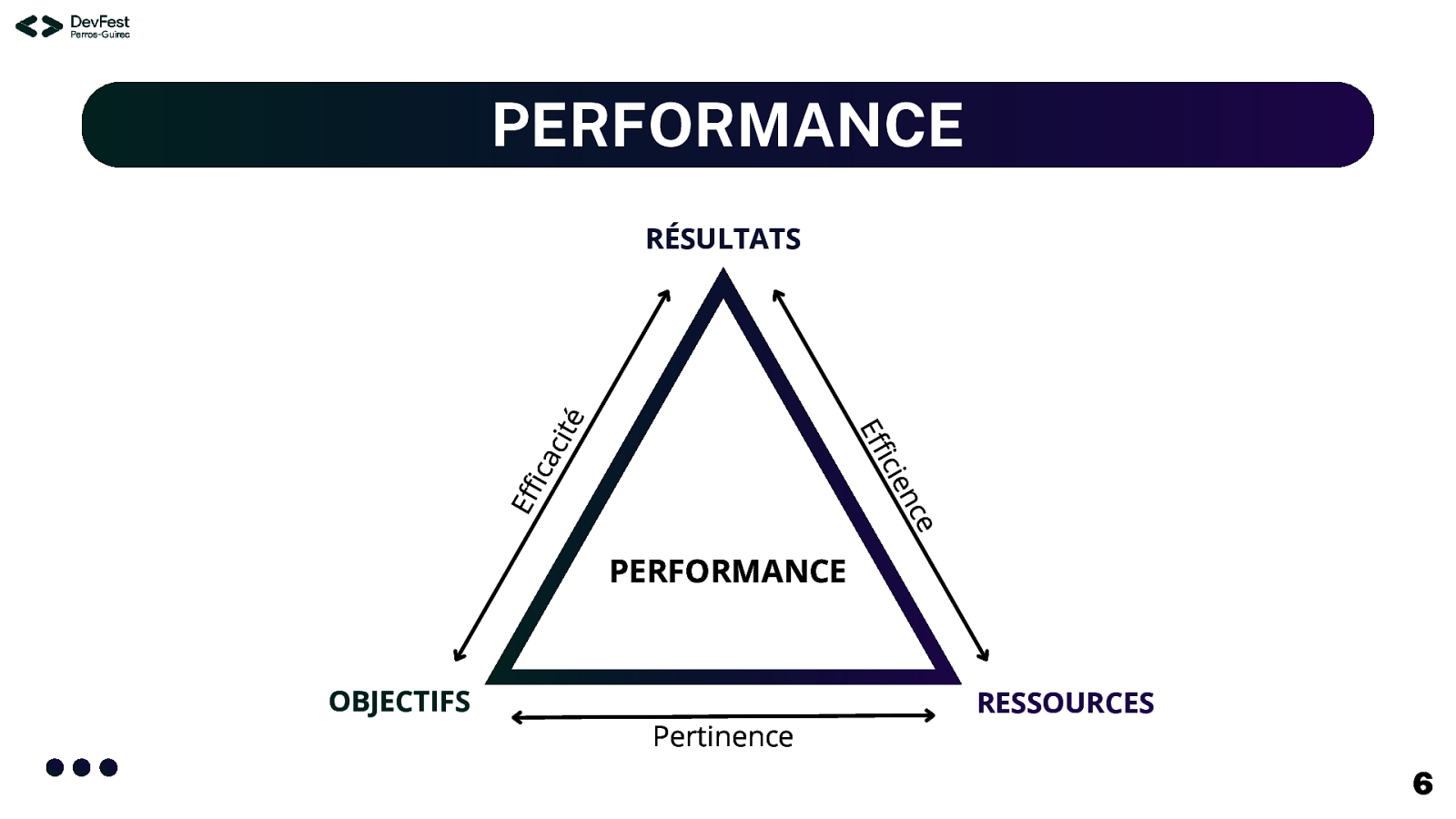
PERFORMANCE e nc icie Eff Eff ica cit é RÉSULTATS PERFORMANCE OBJECTIFS Pertinence RESSOURCES 6
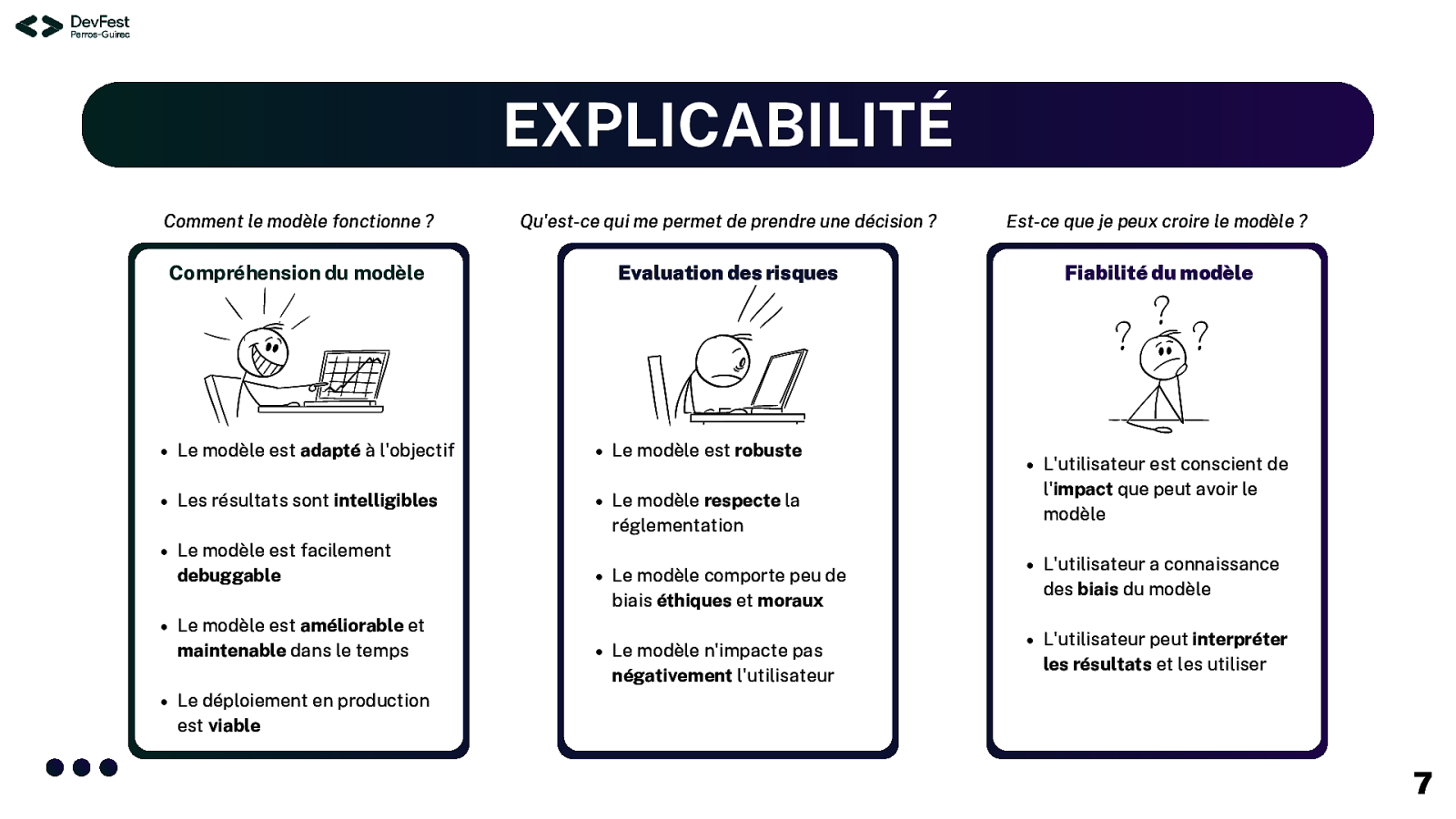
EXPLICABILITÉ Comment le modèle fonctionne ? Qu’est-ce qui me permet de prendre une décision ? Est-ce que je peux croire le modèle ? Compréhension du modèle Evaluation des risques Fiabilité du modèle Le modèle est adapté à l’objectif Le modèle est robuste Les résultats sont intelligibles Le modèle respecte la réglementation Le modèle est facilement debuggable Le modèle est améliorable et maintenable dans le temps Le modèle comporte peu de biais éthiques et moraux Le modèle n’impacte pas négativement l’utilisateur L’utilisateur est conscient de l’impact que peut avoir le modèle L’utilisateur a connaissance des biais du modèle L’utilisateur peut interpréter les résultats et les utiliser Le déploiement en production est viable 7
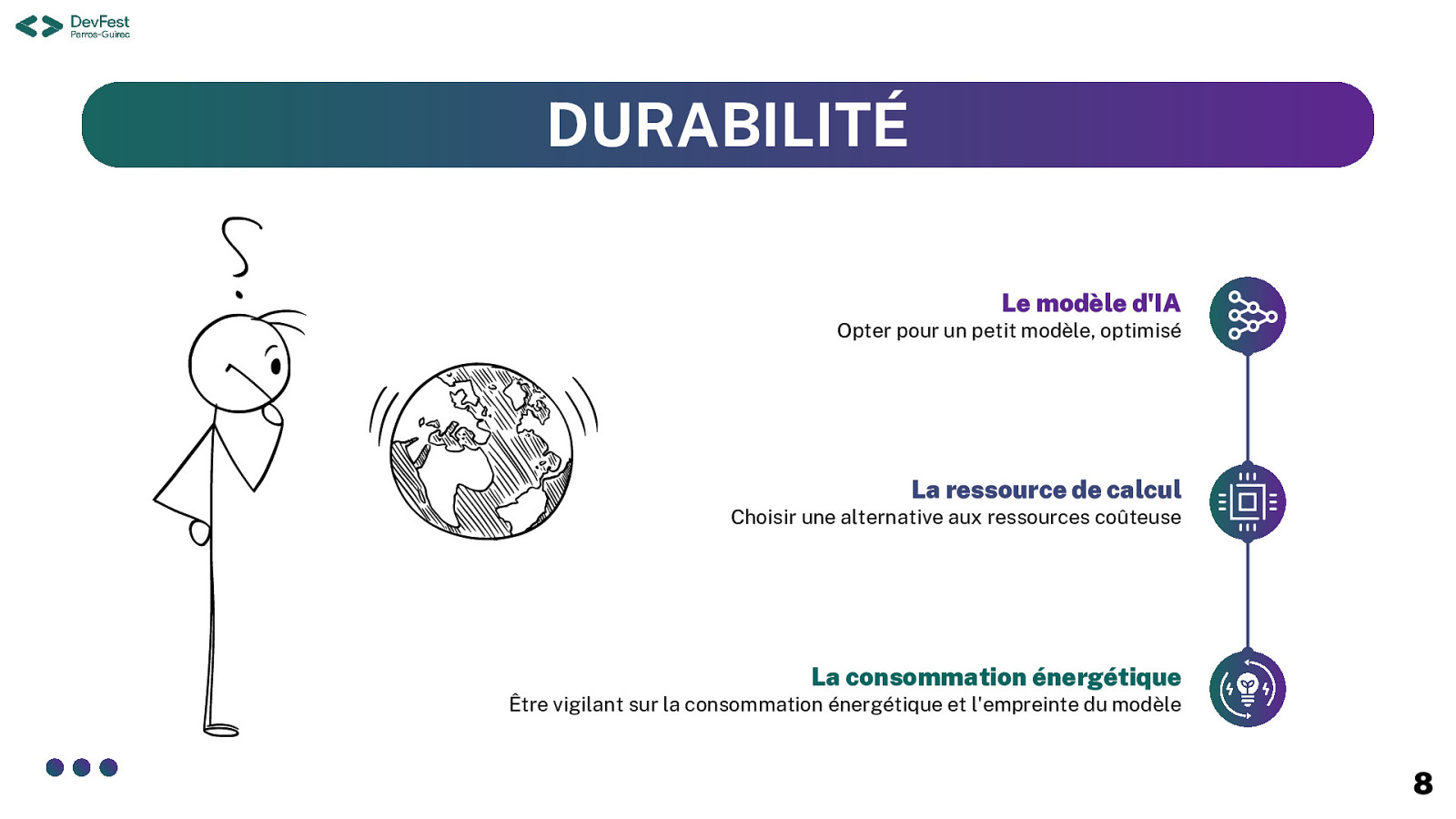
DURABILITÉ Le modèle d’IA Opter pour un petit modèle, optimisé La ressource de calcul Choisir une alternative aux ressources coûteuse La consommation énergétique Être vigilant sur la consommation énergétique et l’empreinte du modèle 8

OPTIMISATION D’UN MODÈLE D’IA Regardons ça de plus près ! 9

LES ÉLÉMENTS-CLÉS Liste de courses Le besoin Définir la cible, le cas d’usage métier. La donnée Récolter, nettoyer, traiter et extraire la donnée. Le modèle Construire, entraîner, tester le modèle d’IA. Les métriques Evaluer, améliorer, optimiser le modèle. La décision Comparer, interpréter, décider de la meilleure solution. 10

12 ÉTAPES DE L’OPTIMISATION 1- Définir le cas d’usage 7- Construire le modèle 2- Récolter la donnée 8- Entraîner le modèle 3- Explorer la donnée 9- Evaluer le modèle 4- Nettoyer la donnée 10- Optimiser le modèle 5- Feature Engineering 11- Comparer les résultats 6- Sélectionner les caractéristiques 12- Décider du modèle à déployer 11
Ça, c’est notre objectif ! DÉFINIR LE CAS D’USAGE 12

DÉFINIR LE CAS D’USAGE Produit : site de e-commerce de vêtements Objectif : avoir le sentiment moyen des consommateurs pour pouvoir améliorer les produits et l’expérience client Une IA nous permettrait d’améliorer l’expérience client en se basant sur leurs avis… Solution : déployer un modèle d’IA permettant de classifier les avis clients laissés sur les différents produits Contraintes : budget restreint, utilisation quotidienne 13

Ça fait beaucoup de données… RÉCOLTER LA DONNÉE 14

RÉCOLTER LA DONNÉE Dataset : Women Clothing e-commerce reviews Je crois que j’ai trouvé les données qu’il nous faut ! Description : le jeu de données contient plusieurs informations de natures différentes review_text : contenu du commentaire age : âge du client rating : notation de 1 à 5 étoiles positive_feedback_count : nombre de retours positifs division_name : catégorie de taille du produit department_name : catégorie du produit concerné class_name : produit concerné recommended_ind : label pour de la classification binaire 15

Partons en exploration ! EXPLORER LA DONNÉE 16

EXPLORER LA DONNÉE Les éléments à vérifier : vérification de la qualité et de la pertinence du jeu de données On y voit déjà un petit peu plus clair ! Equilibre des classes : proportions respectées entre les classes Corrélation entre les données : similarités entre les types de données Longueur des commentaires : nombre de caractères dans chaque commentaire Pertinence des données : utilité de l’information Fréquence des mots : nombre de fois où les mots sont utilisés dans les commentaires 17
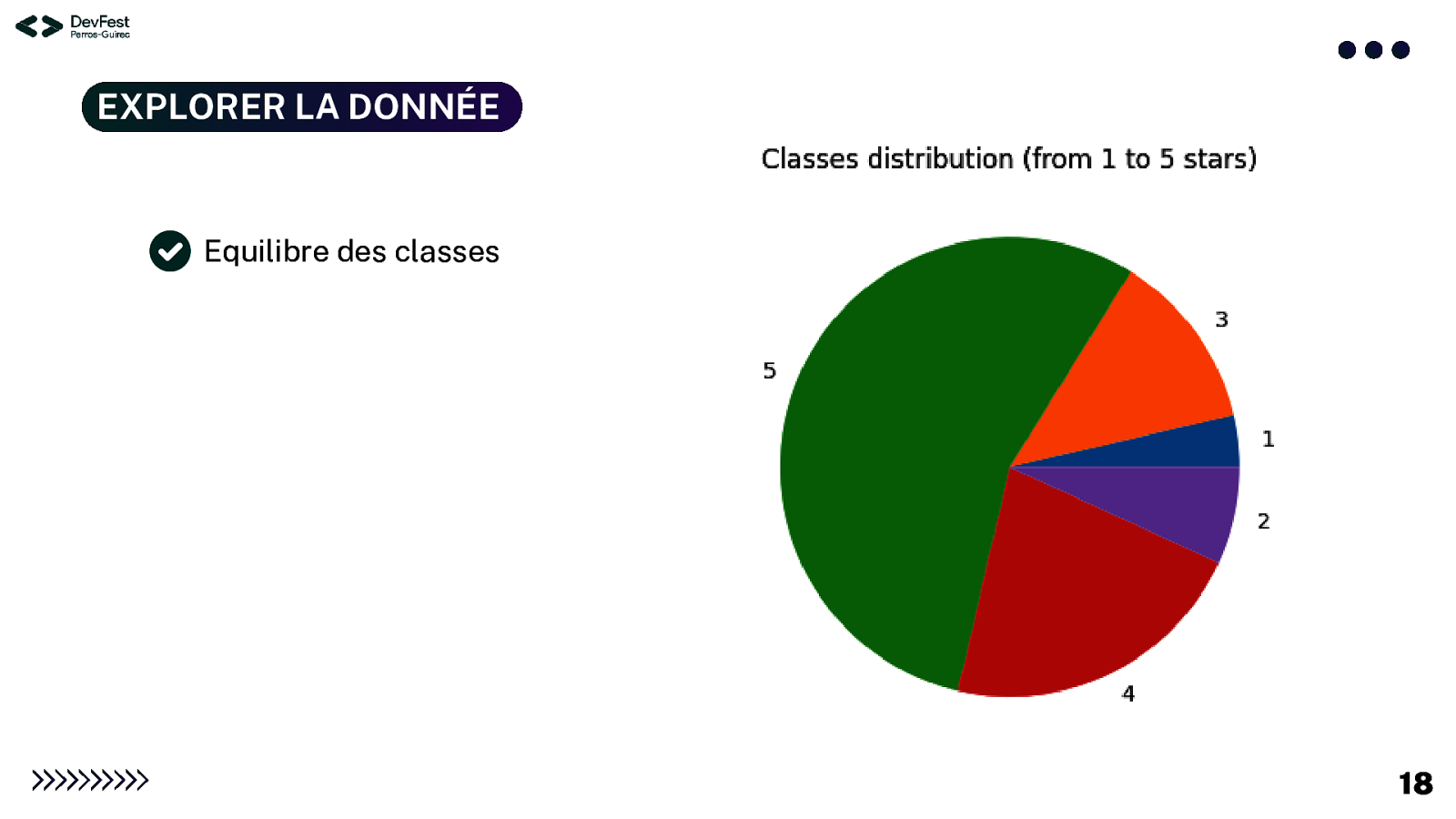
EXPLORER LA DONNÉE Equilibre des classes 18
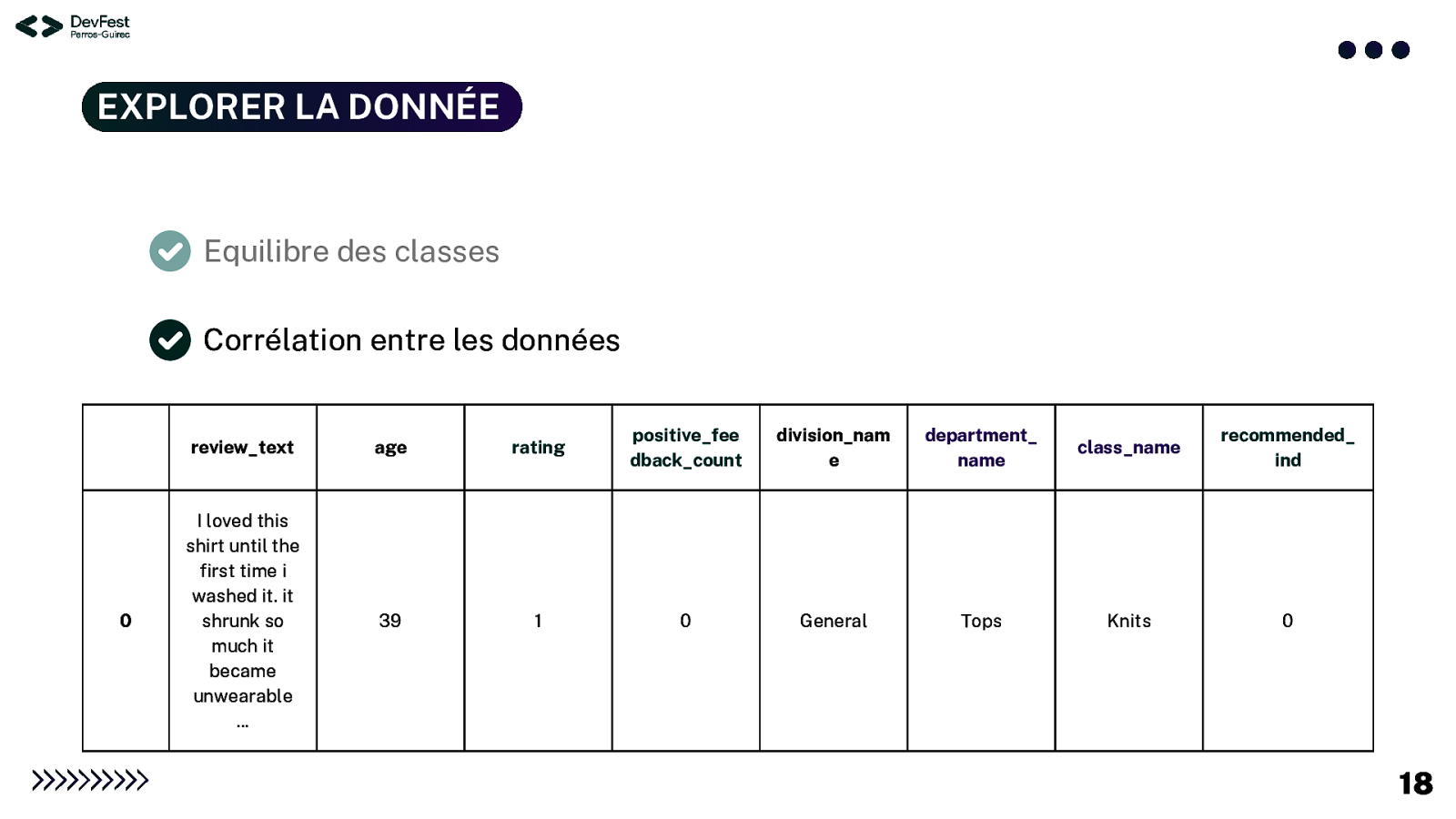
EXPLORER LA DONNÉE Equilibre des classes Corrélation entre lesdonnées 0 review_text age rating positive_fee dback_count division_nam e department_ name class_name recommended_ ind I loved this shirt until the first time i washed it. it shrunk so much it became unwearable … 39 1 0 General Tops Knits 0 18
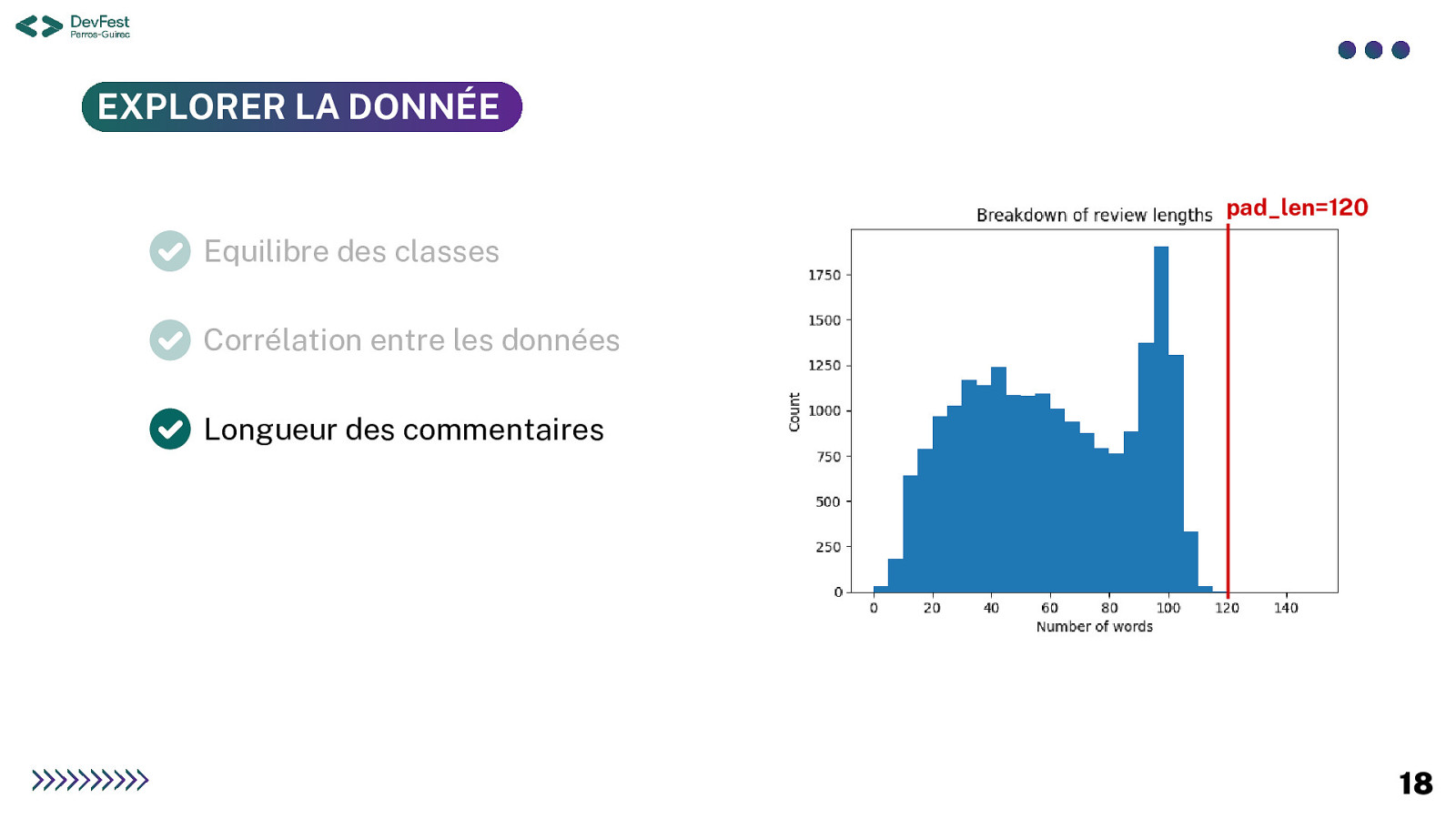
EXPLORER LA DONNÉE pad_len=120 Equilibre des classes Corrélation entre lesdonnées Longueur des commentaires 18
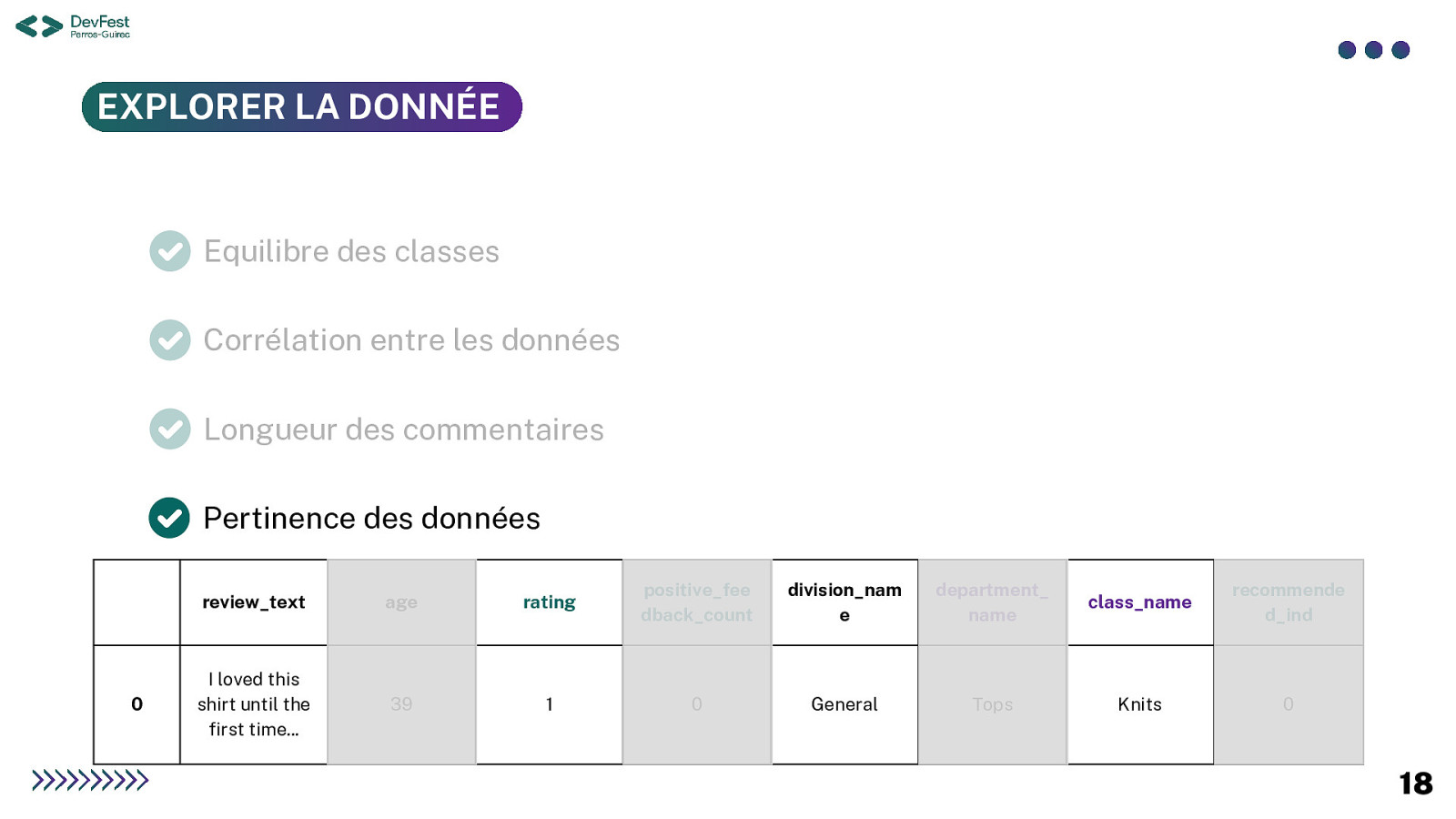
EXPLORER LA DONNÉE Equilibre des classes Corrélation entre lesdonnées Longueur des commentaires Pertinence des données 0 review_text age rating positive_fee dback_count division_nam e department_ name class_name recommende d_ind I loved this shirt until the first time… 39 1 0 General Tops Knits 0 18

EXPLORER LA DONNÉE Equilibre des classes Corrélation entre lesdonnées Longueur des commentaires Pertinence des données term frequence 00 302 000 55 0000 1 00020b 2 000mah 3 … … zymox 1 zyrtec 1 zz 1 zzzzzzz 1 ítem 3 [13 594 rows x 2 columns] Fréquence des mots suppression des mots qui ne sont présents qu’une seule fois term frequence>1 00 302 000 55 00020b 2 000mah 3 01 8 … … zte 7 zucchini 20 zumba 5 zwave 4 ítem 3 [7 972 rows x 2 columns] 18
Il est temps de faire du ménage ! NETTOYER LA DONNÉE 19
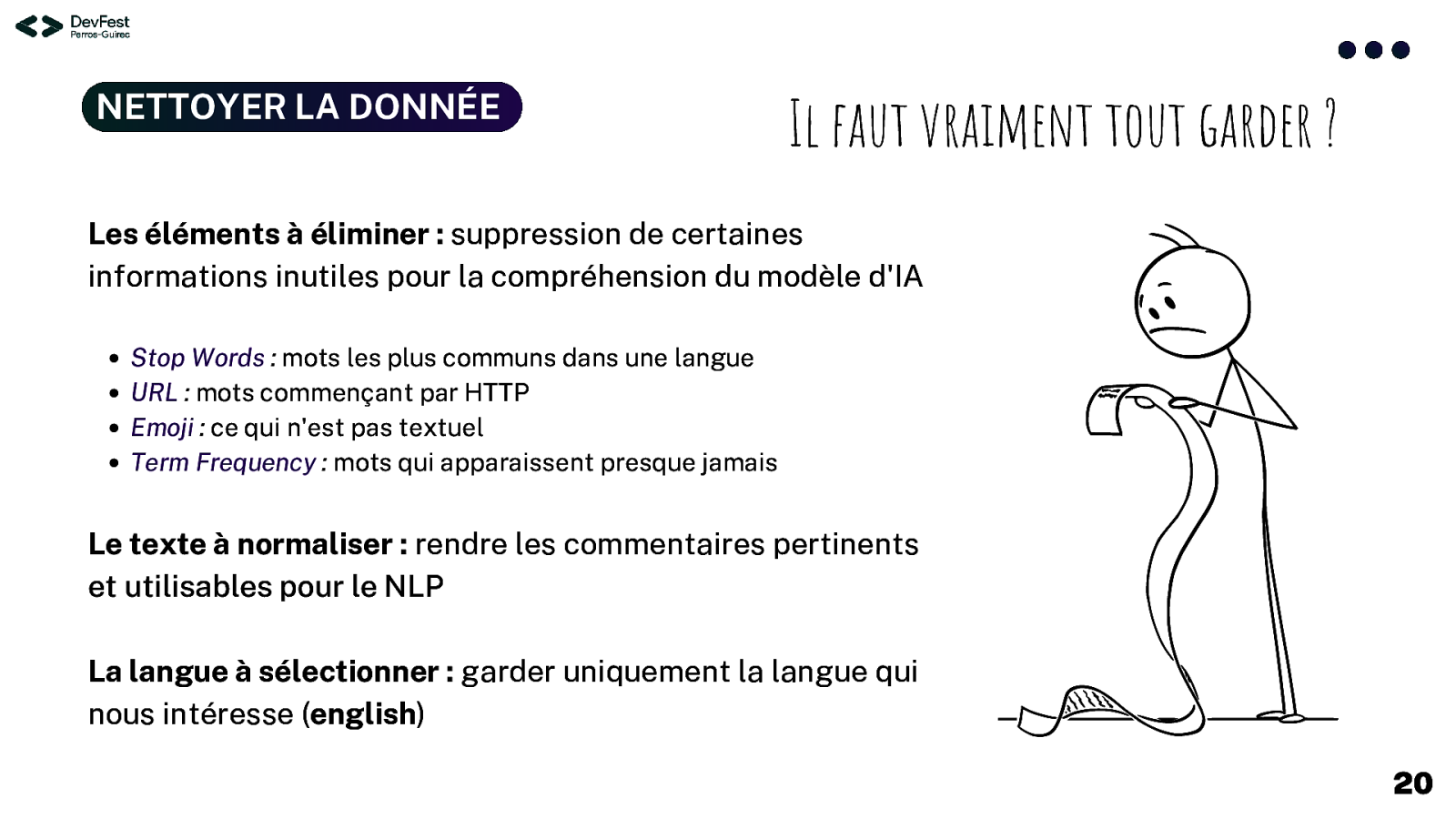
NETTOYER LA DONNÉE Il faut vraiment tout garder ? Les éléments à éliminer : suppression de certaines informations inutiles pour la compréhension du modèle d’IA Stop Words : mots les plus communs dans une langue URL : mots commençant par HTTP Emoji : ce qui n’est pas textuel Term Frequency : mots qui apparaissent presque jamais Le texte à normaliser : rendre les commentaires pertinents et utilisables pour le NLP La langue à sélectionner : garder uniquement la langue qui nous intéresse (english) 20

NETTOYER LA DONNÉE Application du “Data cleaning” sur les reviews special characters most used words url scores extra whitespace 21

NETTOYER LA DONNÉE Application du “Data cleaning” sur les reviews Suppression des “Stop Words” Stop words 21

NETTOYER LA DONNÉE Application du “Data cleaning” sur les reviews Suppression des “Stop Words” Standardisation du text 21
C’est le moment de faire un choix… SÉLECTIONNER LES CARACTÉRISTIQUES 22

SÉLECTIONNER LES CARACTÉRISTIQUES Et si on n’en gardait que 2 ? Garder uniquement l’information utile : sélectionner parmi les types de données lesquelles sont les plus pertinentes rating : notation de 1 à 5 étoiles review_text : contenu du commentaire 0 rating review_text 1 I loved this shirt until the first time… 23
Comment utiliser ces informations ? FEATURE ENGINEERING 24
FEATURE ENGINEERING Traiter l’information : harmoniser et rendre intelligible le jeu de données Comment faire pour que mon IA comprenne ces informations ? Valeurs manquantes : gestion des cases vides dans le jeu de données Encodage : gestion des variables catégorielles Standardisation : égalisation du poids de chaque dimension rating 1 2 … 5 encodage label_id 0 1 … 4 25
Quand faut y aller, faut y aller ! CHOISIR / CONSTRUIRE LE MODÈLE 26
CHOISIR / CONSTRUIRE LE MODÈLE Regardons le deuxième modèle Fine-Tune un modèle de type “BERT” Fine-Tune un modèle de type “LSTM” Utiliser un modèle existant disponible “on-shelf” 27
Un jour je serai la meilleure IA… ENTRAÎNER LES MODÈLES 28

ENTRAÎNER LES MODÈLES Entraînement des 2 modèles BERT et LSTM : Précision des modèles Durée du training des modèles Consommation des ressources (1 GPU - Tesla V100S) Coût de l’entraînement (prix) 29
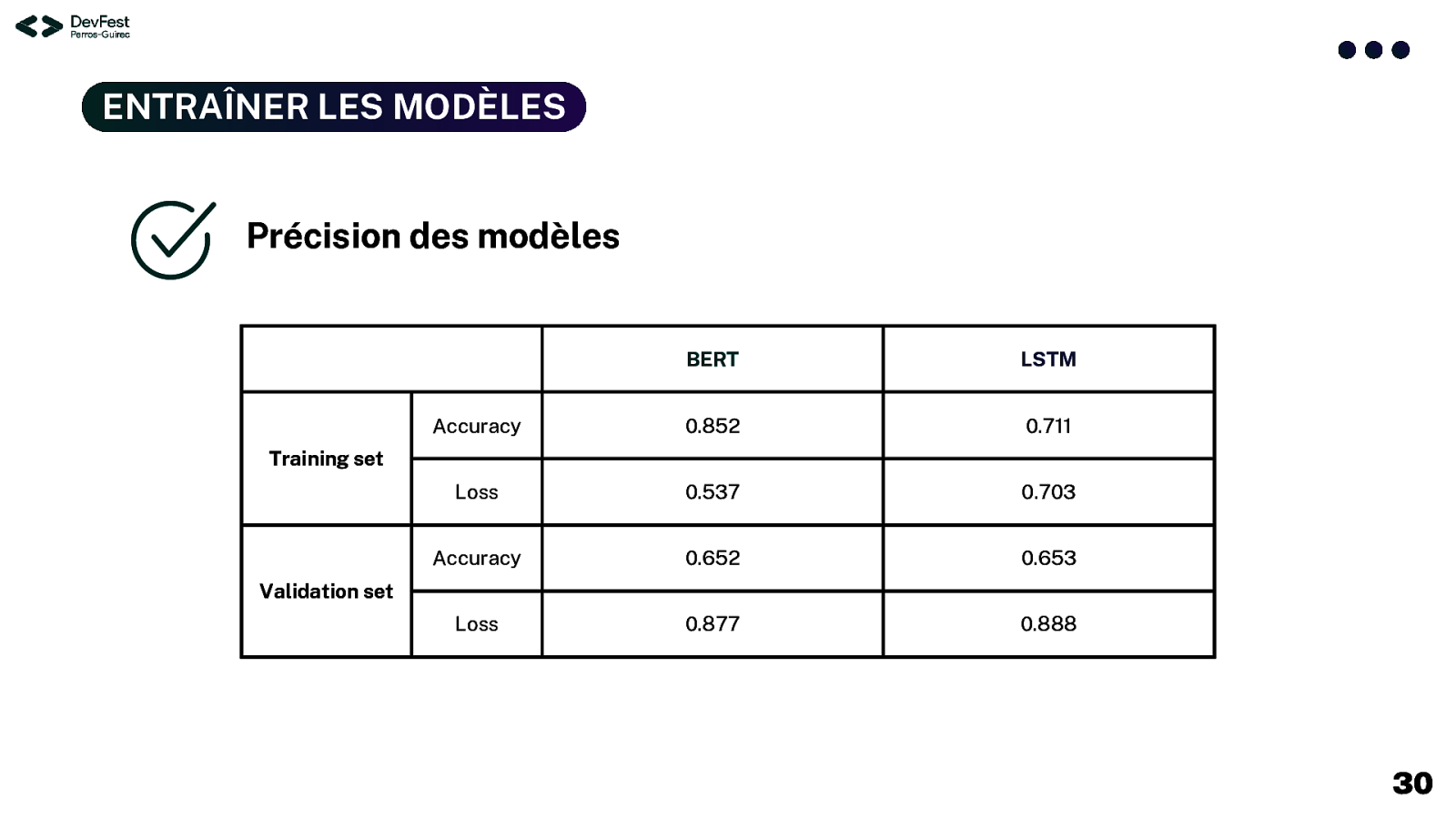
ENTRAÎNER LES MODÈLES Précision des modèles BERT LSTM Accuracy 0.852 0.711 Loss 0.537 0.703 Accuracy 0.652 0.653 Loss 0.877 0.888 Training set Validation set 30

EVALUER LES MODÈLES Durée du training / consommation des ressources BERT LSTM Temps de l’entraînement (min) 11 24 Consommation GPU (%) 99 25 31
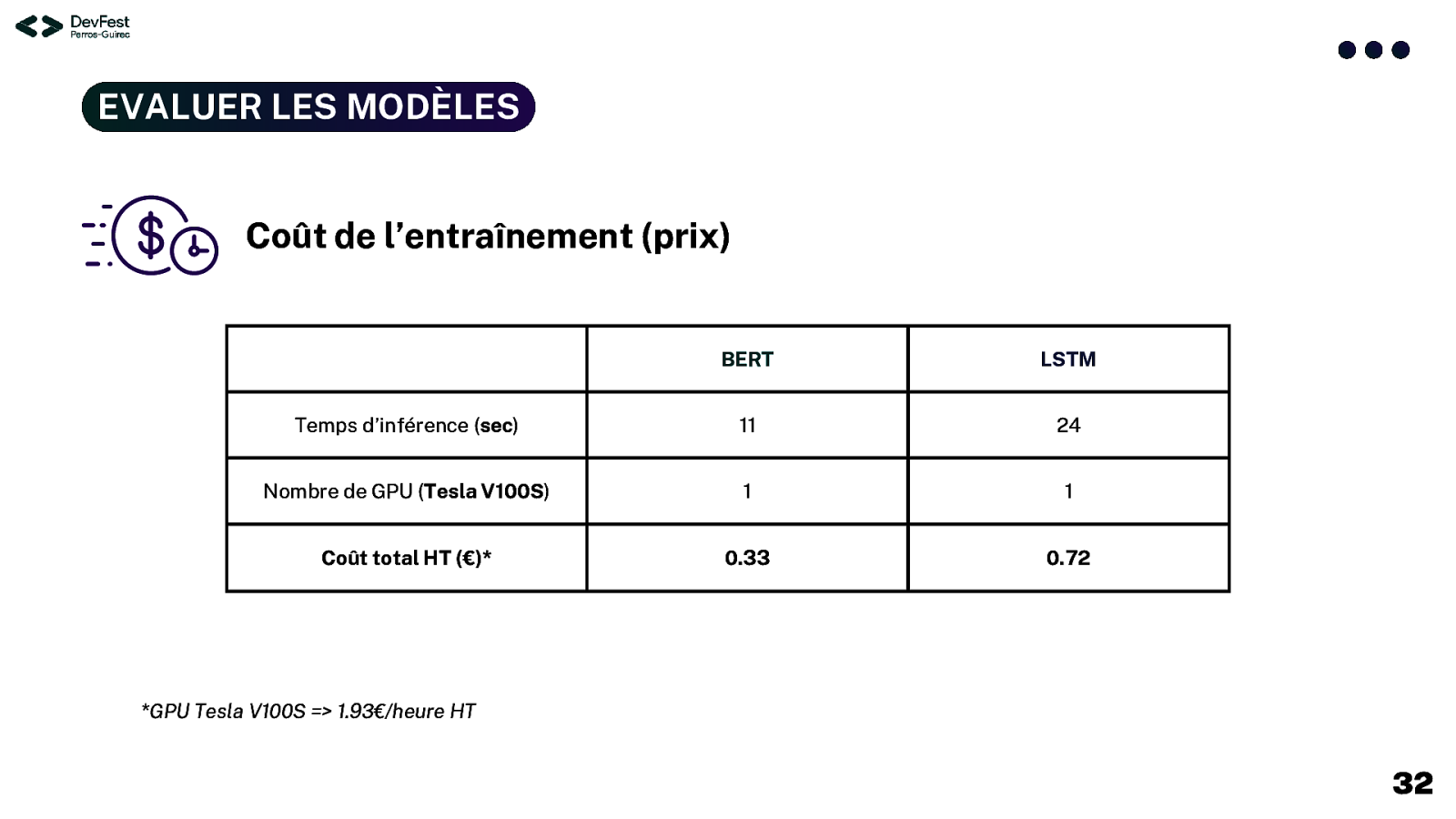
EVALUER LES MODÈLES Coût de l’entraînement (prix) BERT LSTM Temps d’inférence (sec) 11 24 Nombre de GPU (Tesla V100S) 1 1 Coût total HT (€)* 0.33 0.72 *GPU Tesla V100S => 1.93€/heure HT 32

ça fait beaucoup d’informations… EVALUER LES MODÈLES 33

EVALUER LES MODÈLES Evaluation des 3 modèles sur le dataset de test : Précision des modèles Latence des modèles Consommation des ressources (GPU) Coût de l’inférence (prix) 34
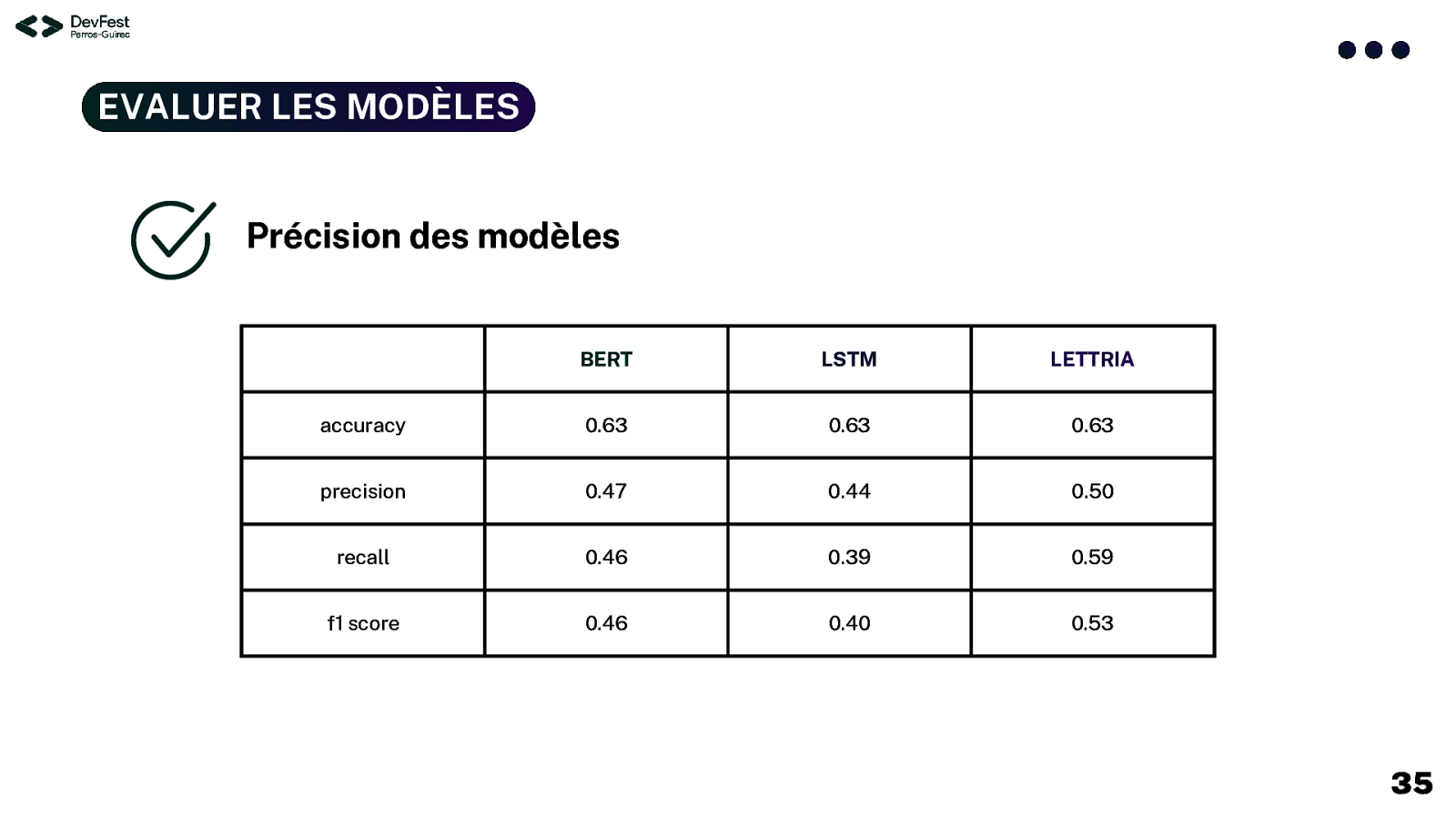
EVALUER LES MODÈLES Précision des modèles BERT LSTM LETTRIA accuracy 0.63 0.63 0.63 precision 0.47 0.44 0.50 recall 0.46 0.39 0.59 f1 score 0.46 0.40 0.53 35
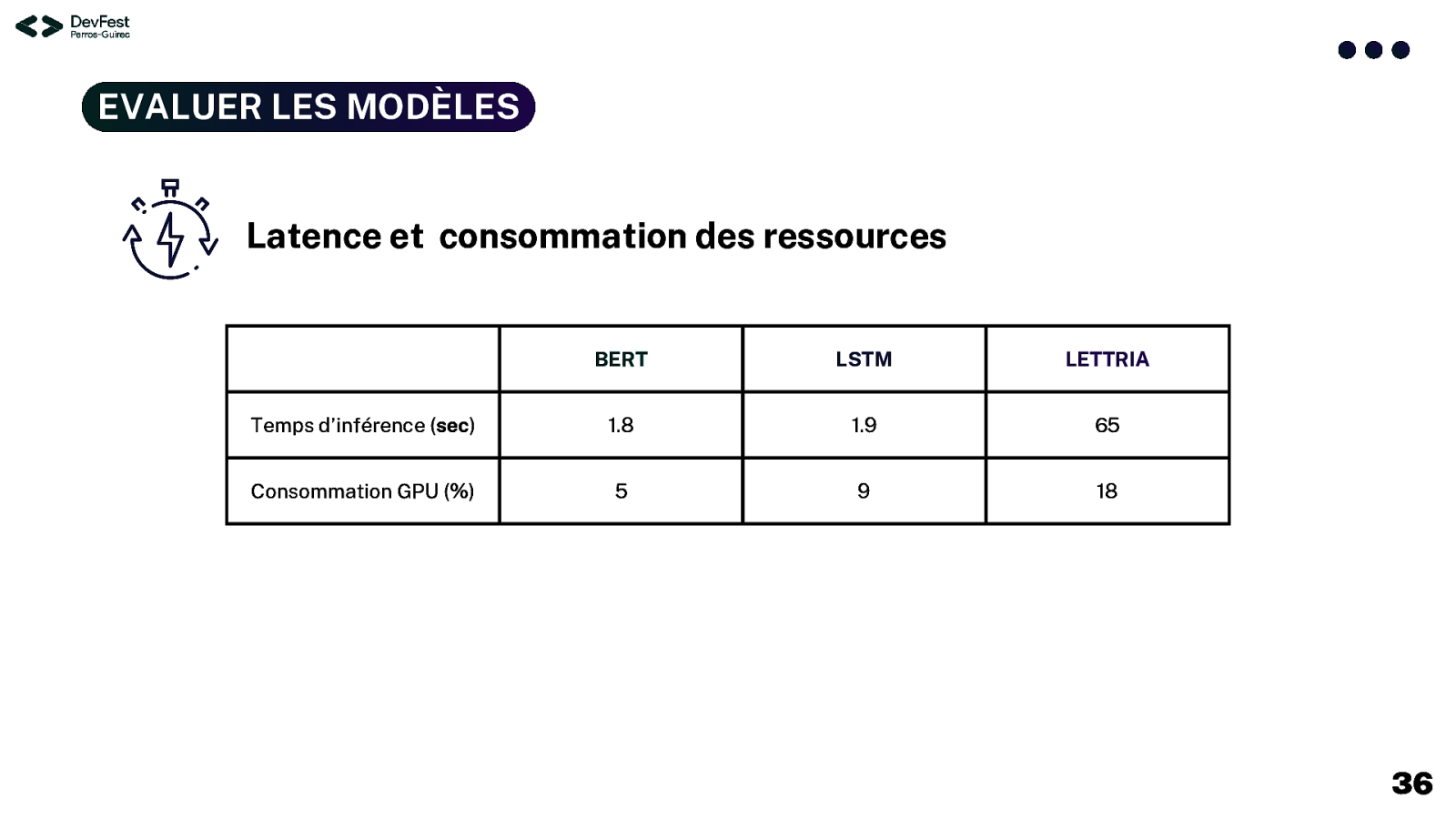
EVALUER LES MODÈLES Latence et consommation des ressources BERT LSTM LETTRIA Temps d’inférence (sec) 1.8 1.9 65 Consommation GPU (%) 5 9 18 36
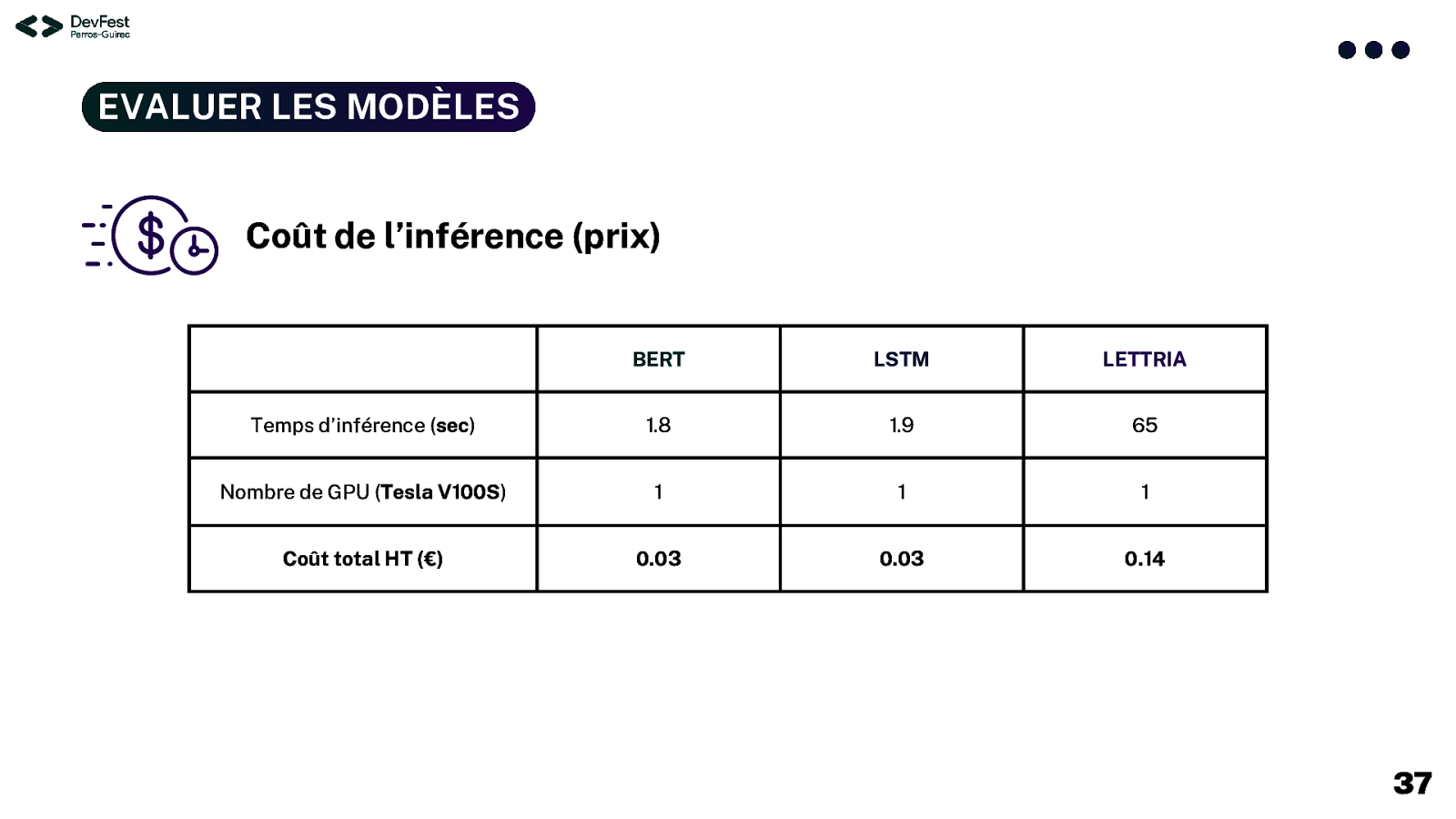
EVALUER LES MODÈLES Coût de l’inférence (prix) BERT LSTM LETTRIA Temps d’inférence (sec) 1.8 1.9 65 Nombre de GPU (Tesla V100S) 1 1 1 Coût total HT (€) 0.03 0.03 0.14 37

Là ça devient compliqué… OPTIMISER LE MODÈLE 38
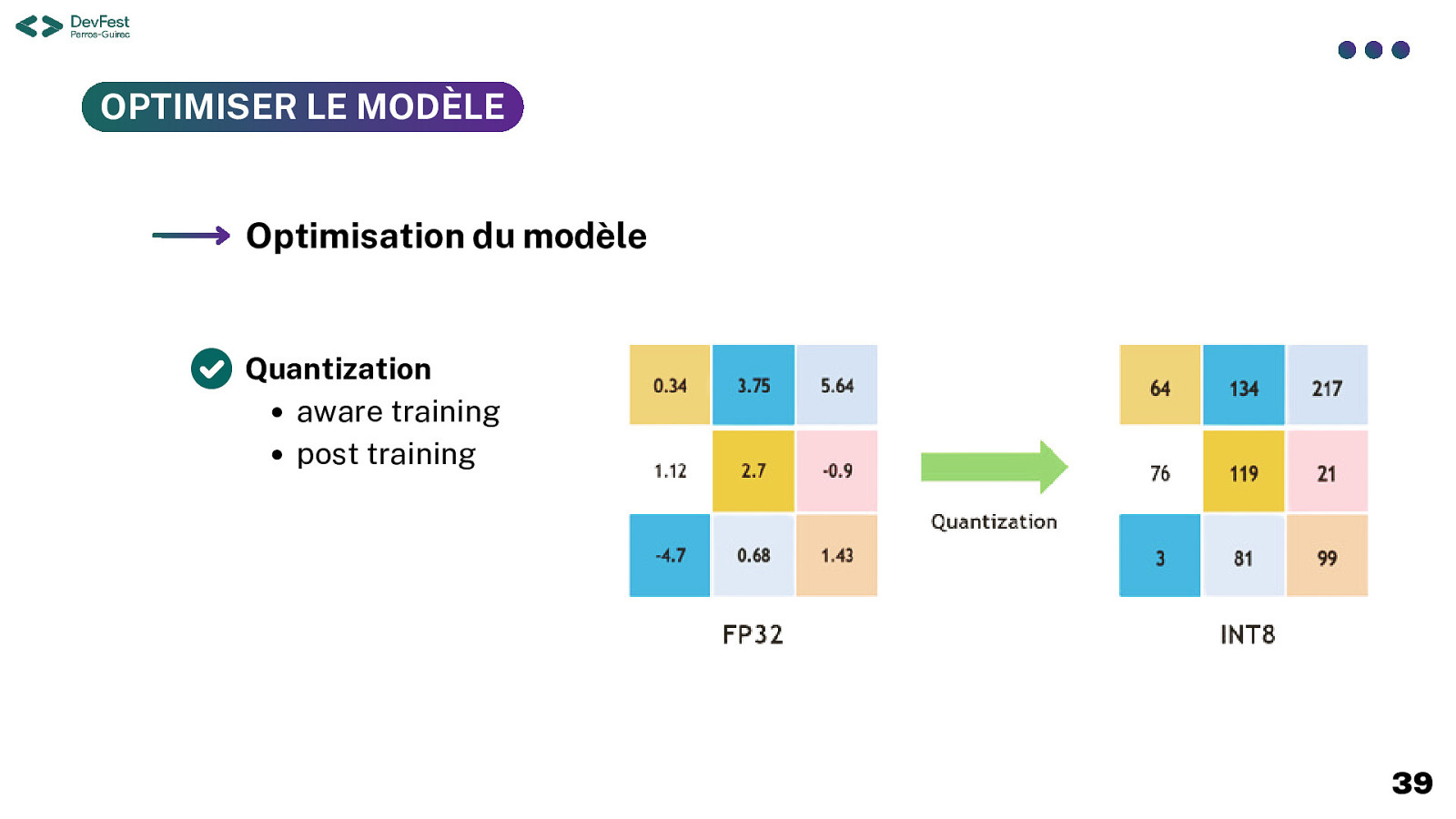
OPTIMISER LE MODÈLE Optimisation du modèle Quantization aware training post training 39
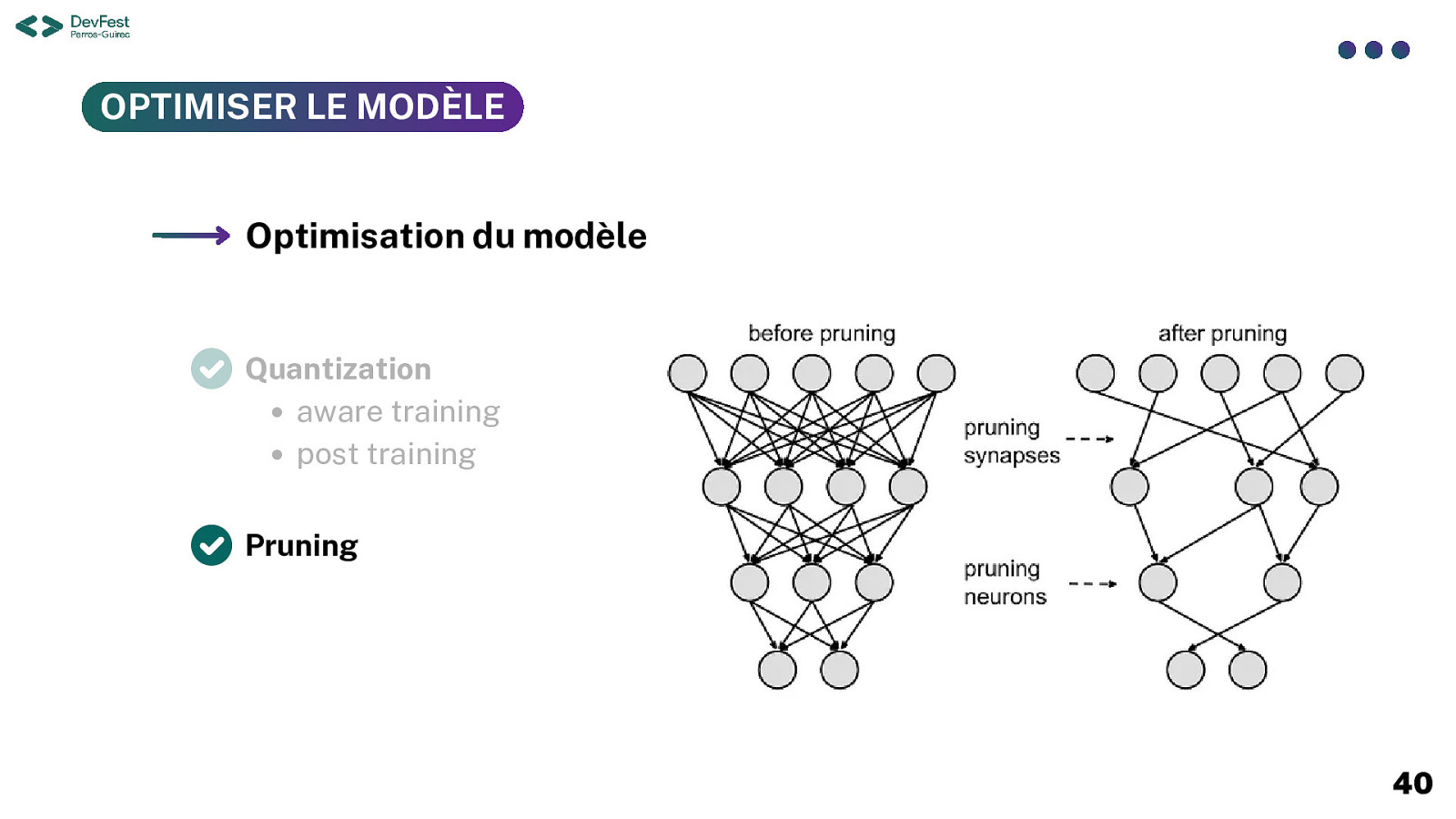
OPTIMISER LE MODÈLE Optimisation du modèle Quantization aware training post training Pruning 40
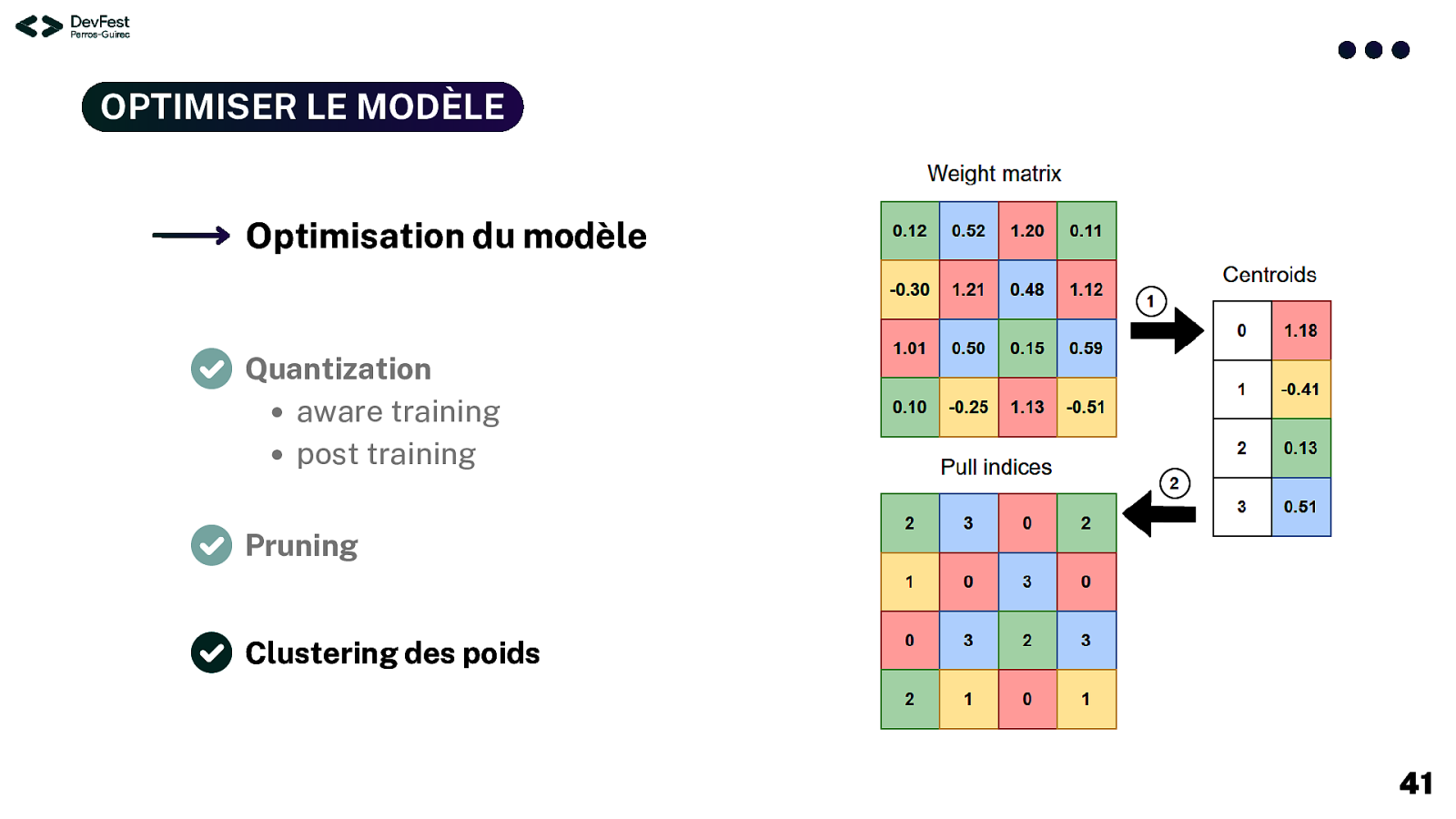
OPTIMISER LE MODÈLE Optimisation du modèle Quantization aware training post training Pruning Clustering des poids 41
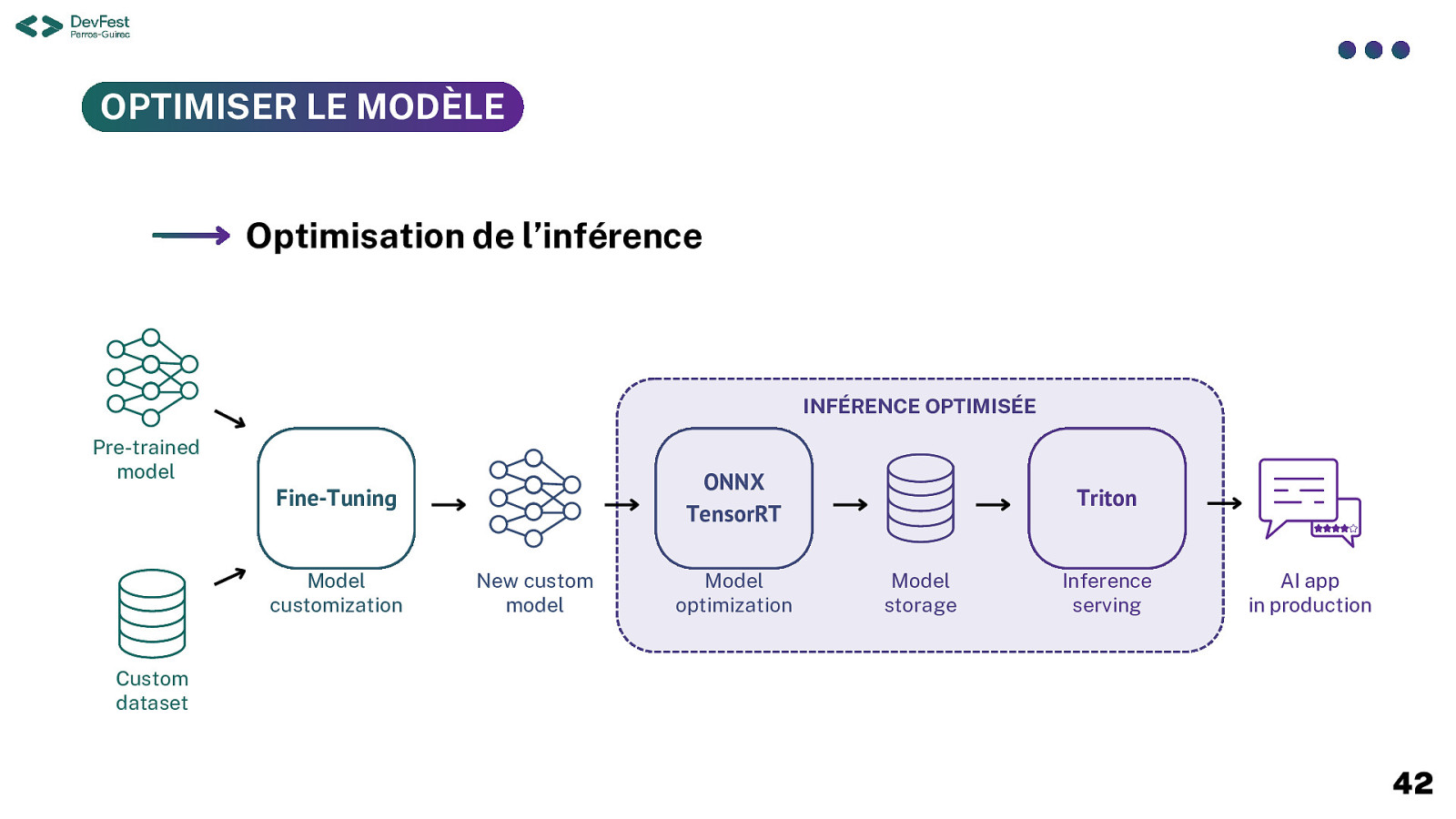
OPTIMISER LE MODÈLE Optimisation de l’inférence INFÉRENCE OPTIMISÉE Pre-trained model ONNX TensorRT Fine-Tuning Model customization New custom model Model optimization Triton Model storage Inference serving AI app in production Custom dataset 42

De quoi avons nous finalement besoin ? most pow erful AI COMPARER LES RÉSULTATS SUSTAINAB LE AI 43
RAPPEL - LE CAS D’USAGE Produit : site de e-commerce de vêtements Objectif : avoir le sentiment moyen des consommateurs pour pouvoir améliorer les produits et l’expérience client Une IA nous permettrait d’améliorer l’expérience client en se basant sur leurs avis… Solution : déployer un modèle d’IA permettant de classifier les avis clients laissés sur les différents produits Contraintes : budget restreint, utilisation quotidienne 44

COMPARER LES RÉSULTATS Qu’est-ce qui correspond le plus à mon besoin ? BERT LSTM LETTRIA ✅ Précision Latence ✅ Consommation ✅ Prix ✅ ✅ ✅ 45
En route vers la mise en production ! DÉCIDER DU MODÈLE À DÉPLOYER 46
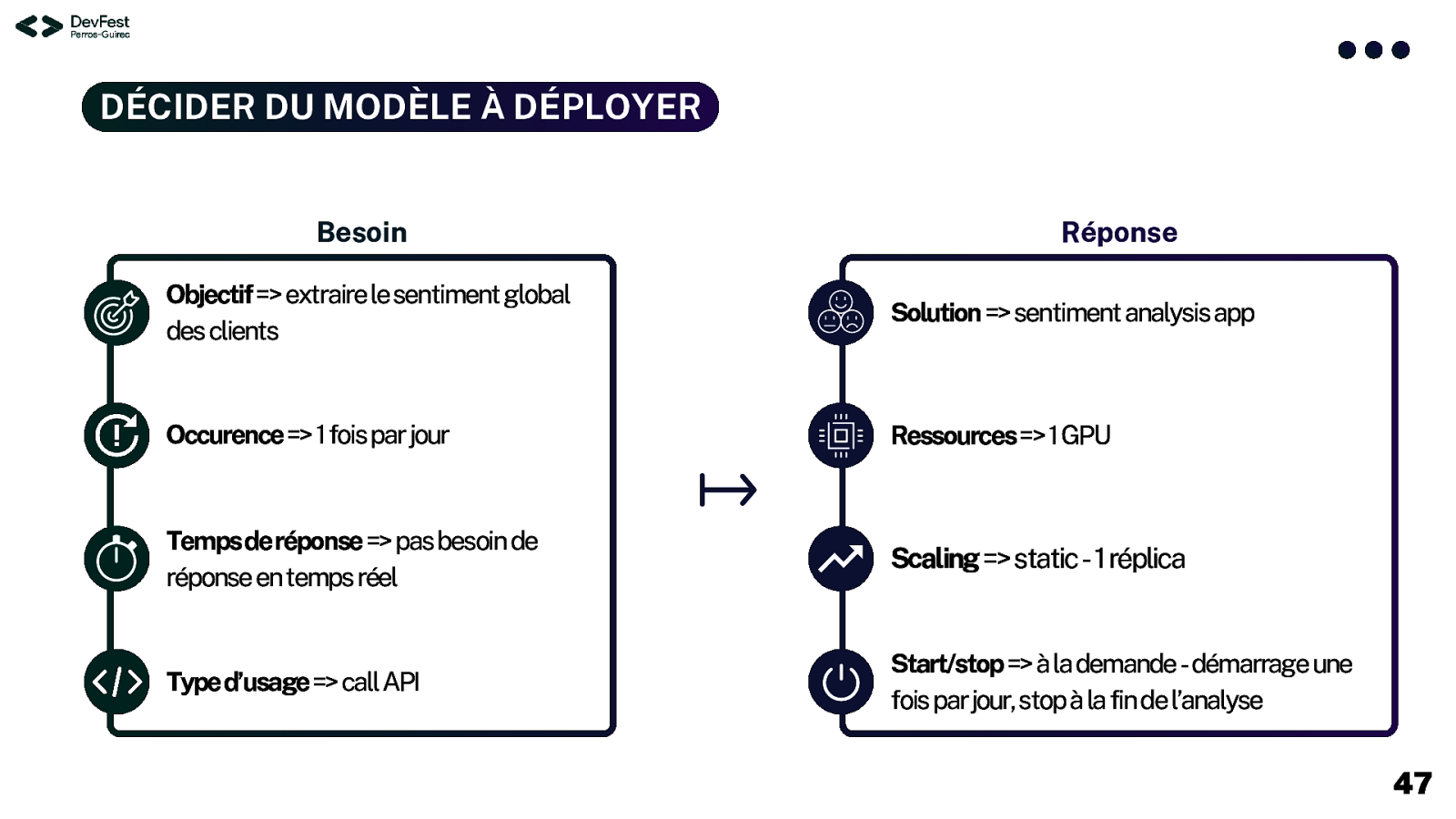
DÉCIDER DU MODÈLE À DÉPLOYER Besoin Réponse Objectif => extraire le sentiment global des clients Solution => sentiment analysis app Occurence => 1 fois par jour Ressources => 1 GPU Temps de réponse => pas besoin de réponse en temps réel Scaling => static - 1 réplica Type d’usage => call API Start/stop => à la demande - démarrage une fois par jour, stop à la fin de l’analyse 47
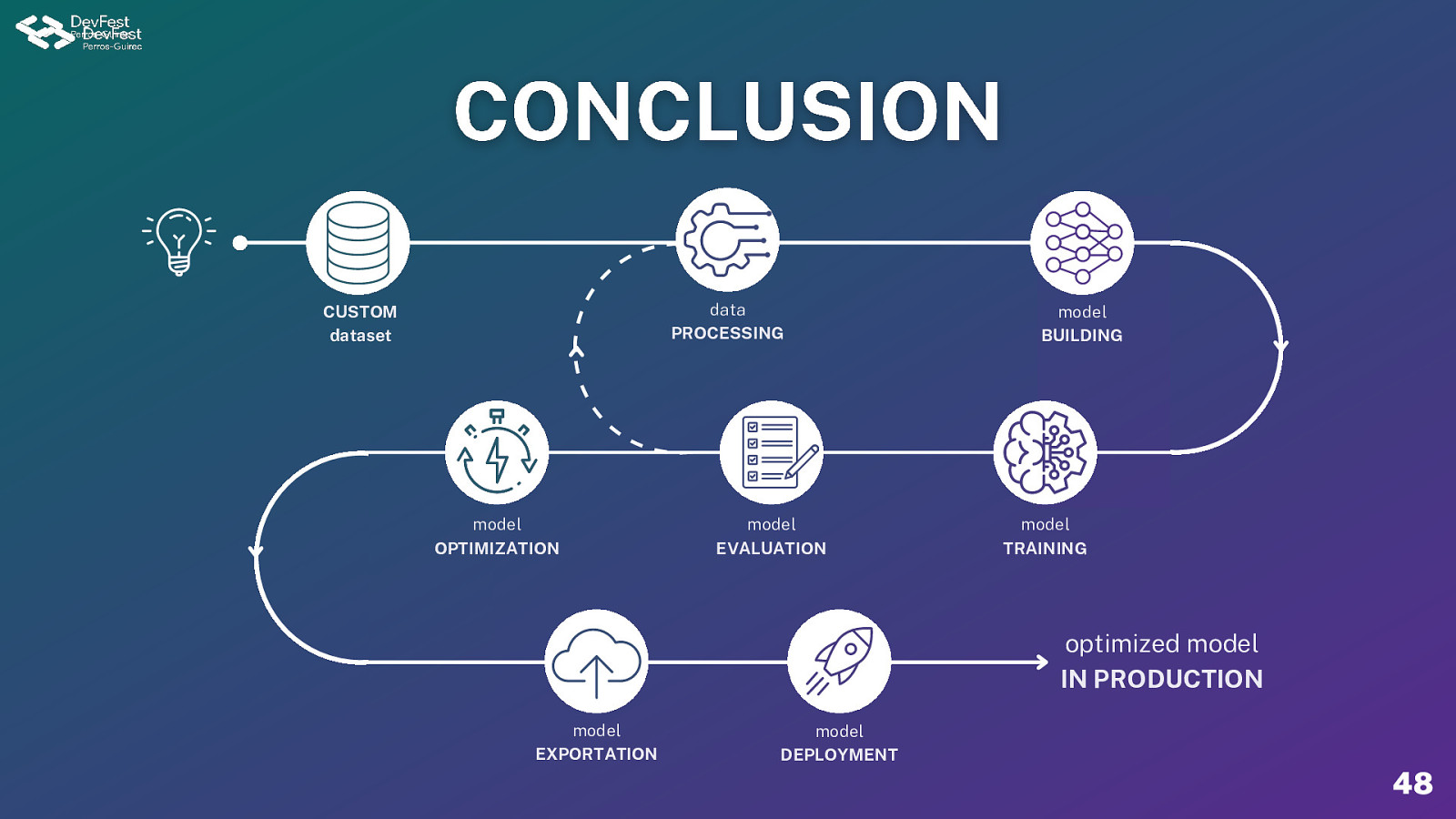
data PROCESSING CUSTOM dataset model OPTIMIZATION model EVALUATION model BUILDING model TRAINING optimized model IN PRODUCTION model EXPORTATION model DEPLOYMENT 48


AQ UE US NO I ER S IM S D’ IA ? OPT RÉFÉRENCES T DEVON OIN SP L Repo GitHub : https://github.com/eleapttn/project-model-optimization-sentiment-analysis.git OVHcloud AI documentations : https://help.ovhcloud.com/csm/worldeuro-documentation-public-cloud-ai-and-machine-learning? id=kb_browse_cat&kb_id=574a8325551974502d4c6e78b7421938&kb_category=1f34d555f49801102d4ca4d466a7fd7d Women e-commerce clothing reviews dataset : https://github.com/ya-stack/Women-s-Ecommerce-Clothing-Reviews BERT VS. LSTM: Performances in Sentiment Classification - https://medium.com/@cd_24/bert-vs-lstm-performances-in-sentimentclassification-b82075184d60 10 steps to build and optimize a ML model - https://dev.to/mage_ai/10-steps-to-build-and-optimize-a-ml-model-4a3h Fine-tuning BERT model for Sentiment Analysis - https://www.geeksforgeeks.org/fine-tuning-bert-model-for-sentiment-analysis/ Sentiment Analysis using LSTM - https://jagathprasad0.medium.com/sentiment-analysis-using-lstmb3efee46c956#:~:text=Long%20short%2Dterm%20memory%20is,short%2Dterm%20memory%20of%20data. Sentiment Analysis with LSTM - https://www.analyticsvidhya.com/blog/2022/01/sentiment-analysis-with-lstm/ Model optmization techniques - https://medium.com/analytics-vidhya/model-optimization-techniques-79a3a96b6427 NOS È MOD LE

AQ UE US NO D E T VON N I O SP L I ER S IM D’ IA ? OPT S NOS M È OD E L