on t t e P Eléa TRANSCENDEZ LES FRONTIÈRES LINGUISTIQUES avec des APIs de Machine Learning sur mesure


on t t e P Eléa TRANSCENDEZ LES FRONTIÈRES LINGUISTIQUES avec des APIs de Machine Learning sur mesure

PRÉSENTATION ÉL PE TT Machine Learning Engineer ON OVHcloud AI Solutions Team @EleaPetton 02 eleapttn ÉA Eléa PETTON

ÇA VOUS DIT ? “ Embarquez dans le développement d’une solution de transcription temps réel de vos contenus multimédia… ” 03

INTRODUCTION 04
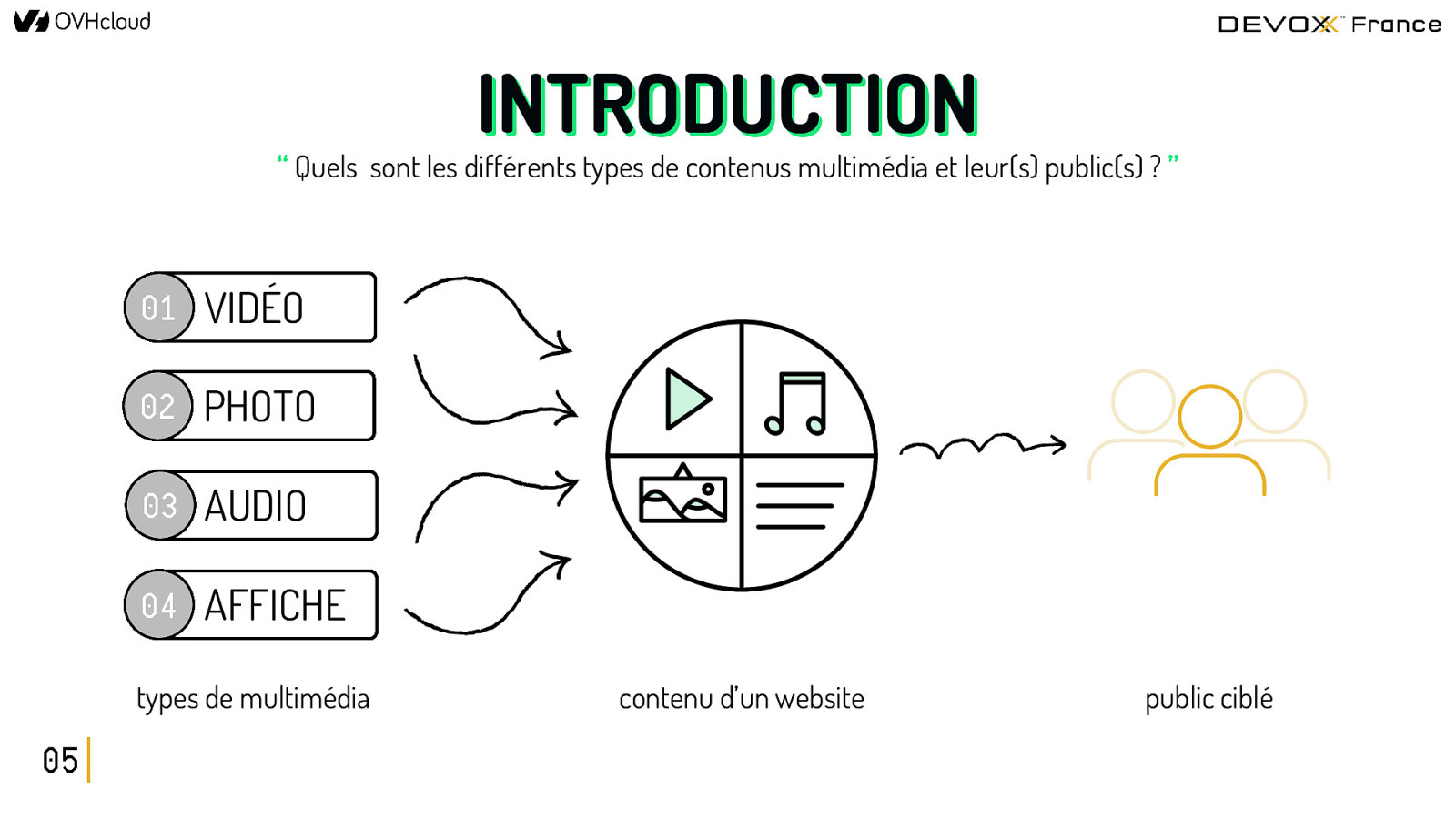
INTRODUCTION “ Quels sont les différents types de contenus multimédia et leur(s) public(s) ? ” 01 VIDÉO 02 PHOTO 03 AUDIO 04 AFFICHE types de multimédia 05 contenu d’un website public ciblé
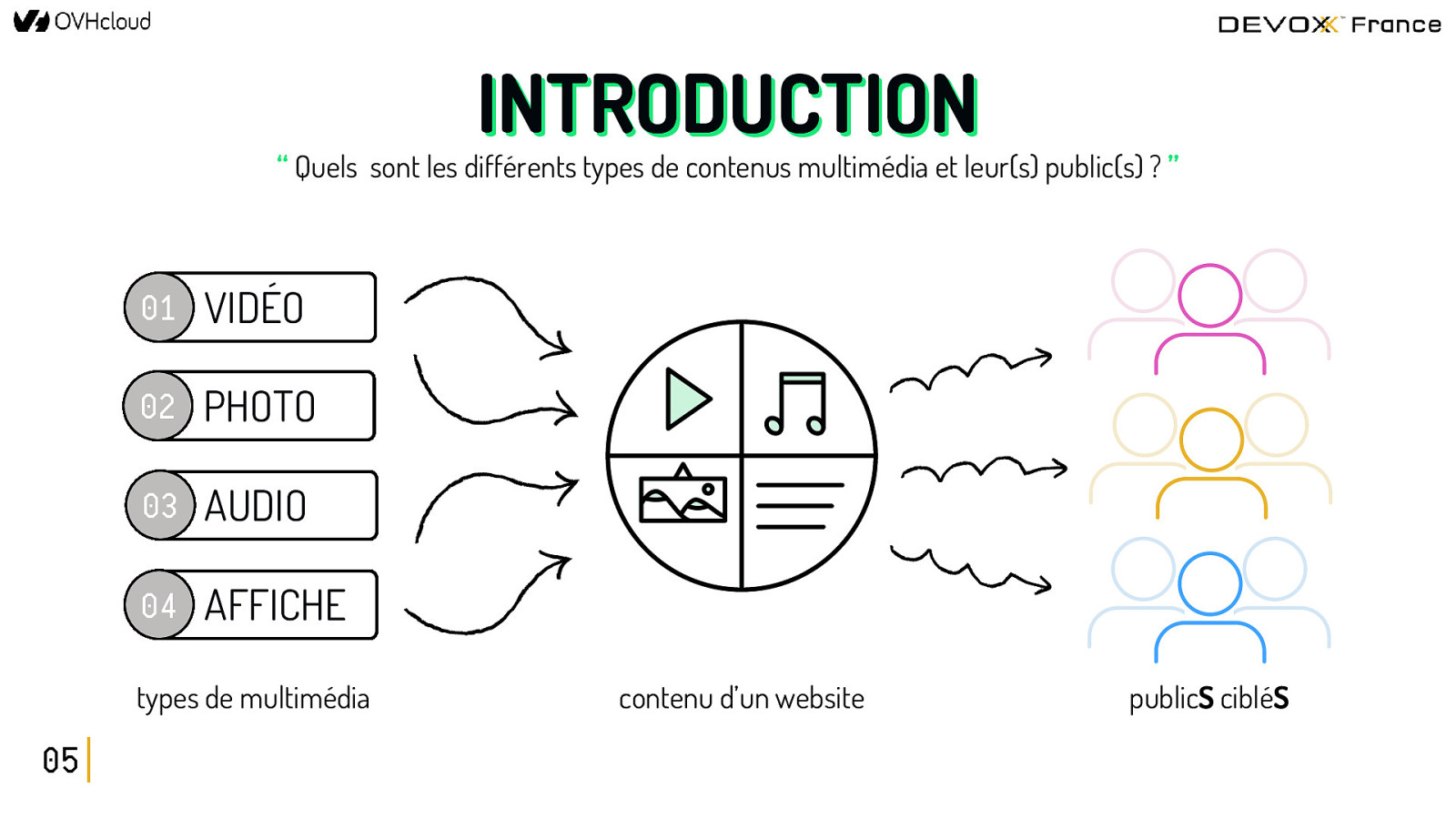
INTRODUCTION “ Quels sont les différents types de contenus multimédia et leur(s) public(s) ? ” 01 VIDÉO 02 PHOTO 03 AUDIO 04 AFFICHE types de multimédia 05 contenu d’un website publicS cibléS

TRANSFORMER SES CONTENUS MULTIMEDIA, QU’EST-CE QUE ÇA VEUT DIRE ? TRADUCTION TRANSCRIPTION Tran scen dez le APIs s fron de M tières achin dans e Le lingu le istiq temp développ arning su avec r e s rée l de vo ment d’u mesure : des ne so em b a s con lu rq tenu s mu tion de tr a ltimé dias ! nscr 06 Changer la langue de… Passer de l’oral à l’écrit pour… sa page web son post Twitter, LinkedIn, … ses slides sous-titrer des vidéos, podcasts garder le contenu d’une réunion SYNTHÈSE VOCALE DESCRIPTION Et si l’IA vous permettait d’élargir l’impact de vos différents contenus multimédias et de favoriser l’inclusivité ? Aujourd’hui, les médias et les réseaux sociaux sont omniprésents dans nos vies professionnelles et personnelles : vidéos, Tweets, posts, forums ou encore lives Twitch. Ces différents types de médias permettent aux entreprises et créateurs de contenus de promouvoir leurs activités et de fidéliser leurs communautés. Mais vous êtes-vous déjà interrogés sur le rôle de la langue choisie lors de la création de vos contenus ? L’utilisation d’une seule langue peut constituer un obstacle à la promotion de vos activités. La transcription et la traduction de vos contenus multimédias pourraient être la solution ! Adaptez vos vidéos dans différentes langues et rendez le contenu accessible à un public plus large, augmentant ainsi sa portée et son impact. Passer de l’écrit à l’oral pour… favoriser l’accessibilité doubler les voix Décrire ou résumer… une vidéo, un podcast le contenu d’une réunion une documentation

ET EN PRATIQUE, ÇA DONNE QUOI ? Multimedia translator Transcribe your video: https://www.youtube.com/… French Voice Male 07 English Subtitles .mp4 Download
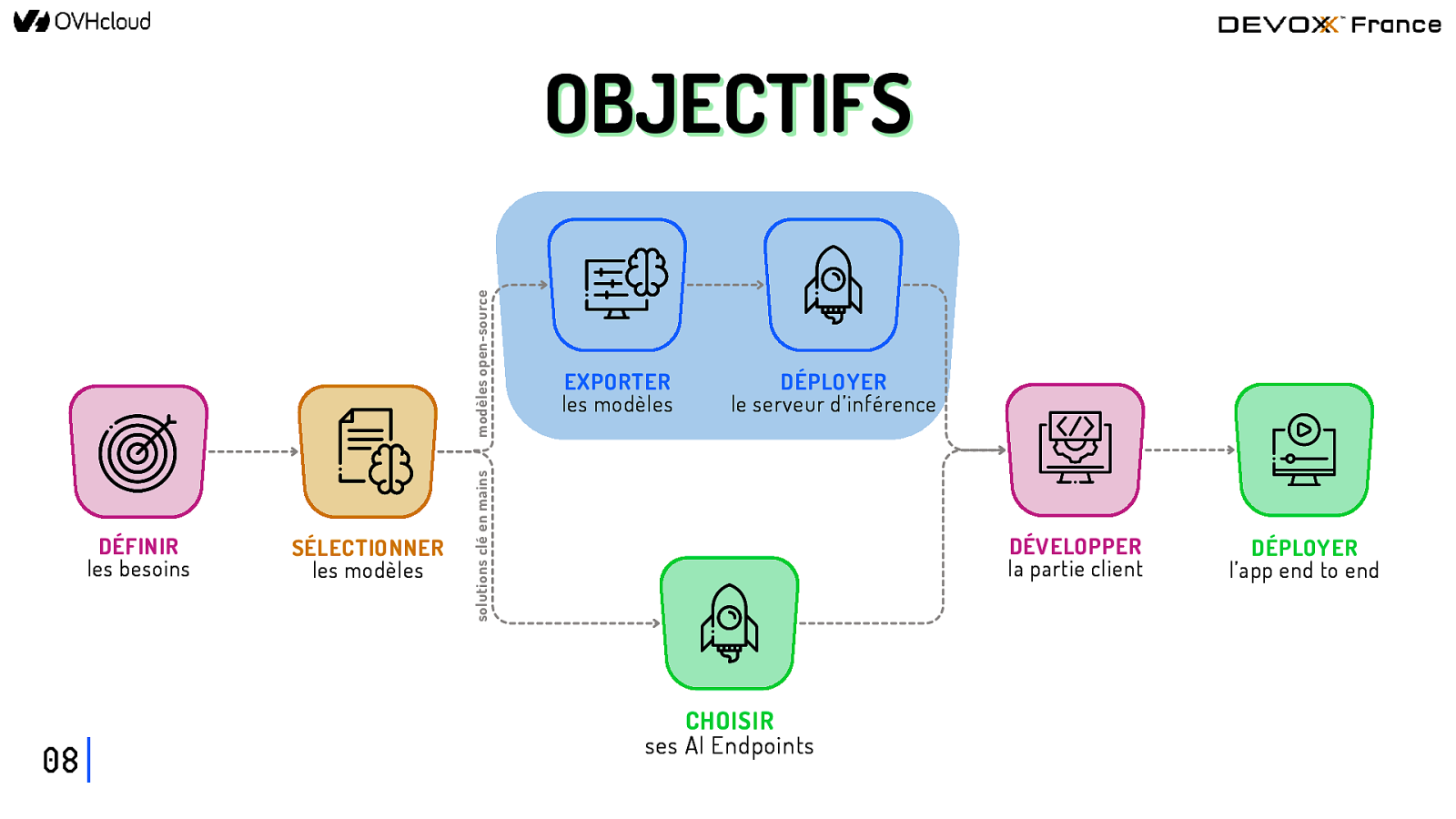
DÉFINIR les besoins 08 SÉLECTIONNER les modèles EXPORTER les modèles DÉPLOYER le serveur d’inférence solutions clé en mains modèles open-source OBJECTIFS DÉVELOPPER la partie client CHOISIR ses AI Endpoints DÉPLOYER l’app end to end

DÉFINIR les besoins 09

QUELS SONT NOS PERSONAE ? Transcrire les meetings Se développer à l’international Retranscrire les meetings à l’écrit Transcrire les meetings dans une autre langues Résumer les meetings Traduire du contenu multimedia pour un usage multilingue Adapter les vidéos pour un public mondial Être plus inclusif ! Élargir son public… En tant que créateur de contenu, j’aimerais élargir ma communauté Créer et publier un contenu plus attrayant 10 Sous-titrer les vidéos pour les personnes malentendantes Inclure les personnes qui ne parlent pas la même langue
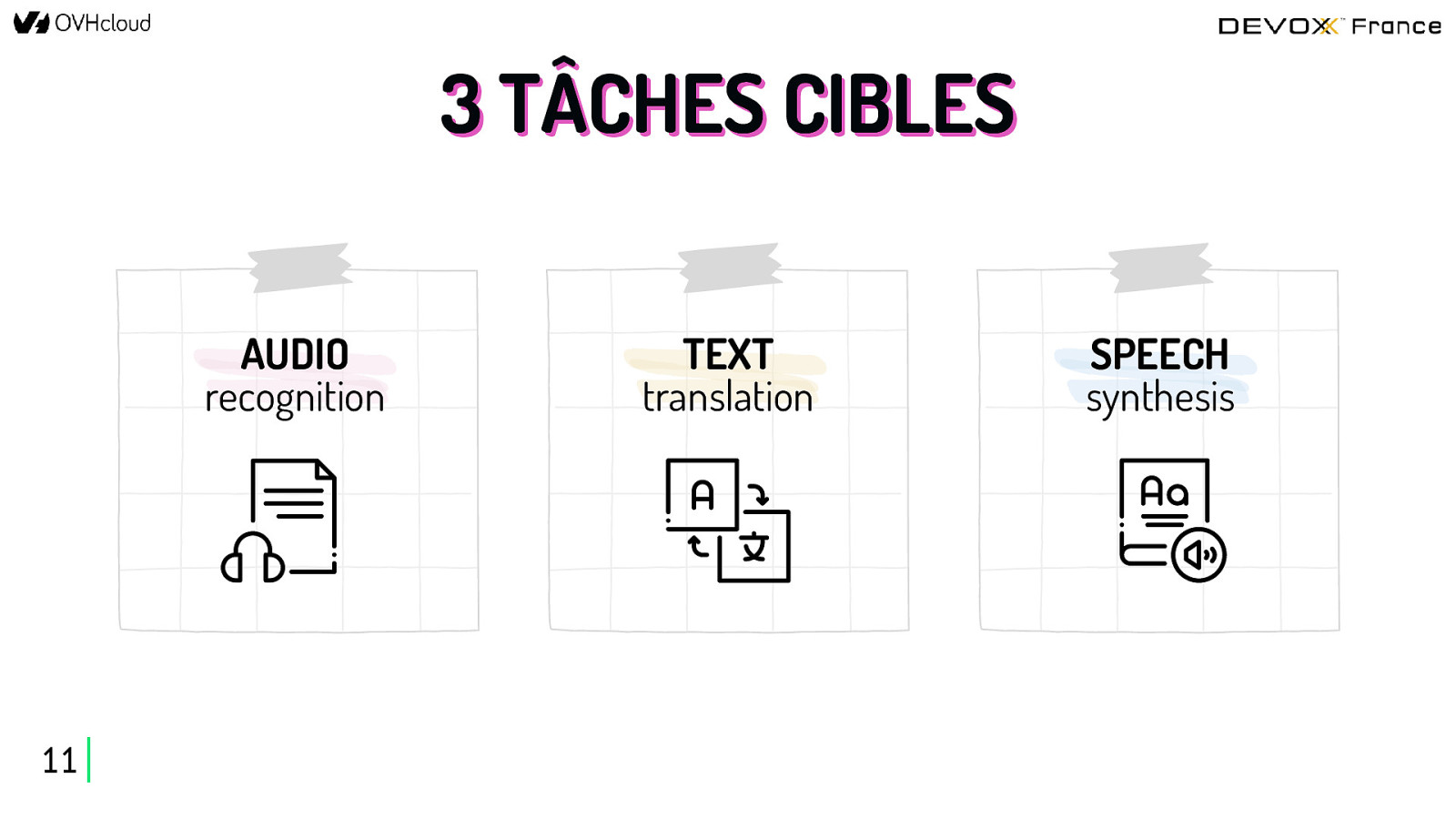
3 TÂCHES CIBLES AUDIO recognition 11 TEXT translation SPEECH synthesis

SÉLECTIONNER les modèles 12
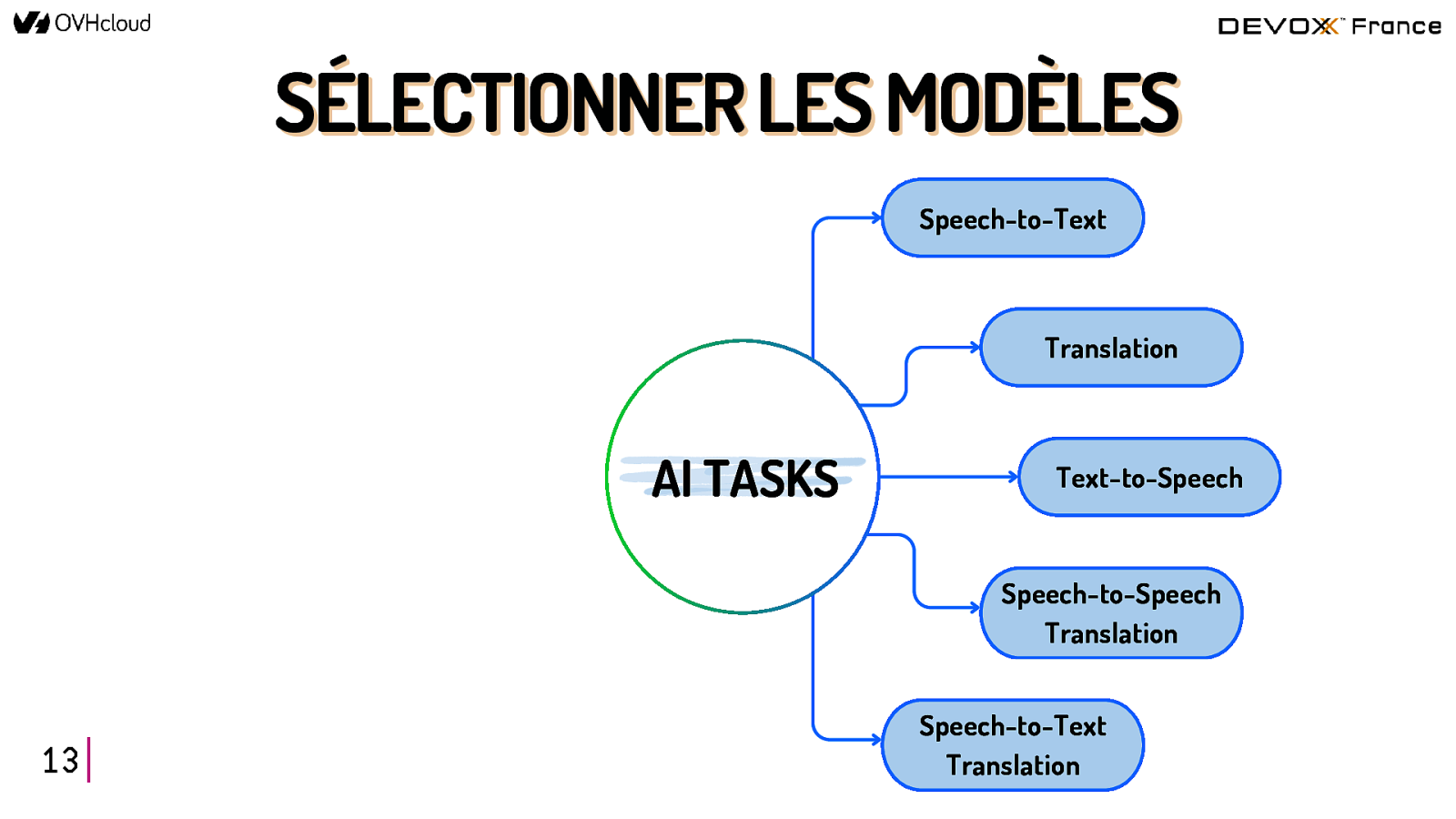
SÉLECTIONNER LES MODÈLES Speech-to-Text Translation AI TASKS Text-to-Speech Speech-to-Speech Translation 13 Speech-to-Text Translation
SÉLECTIONNER LES MODÈLES Anglais LANGUES Espagnol Allemand 13 Français
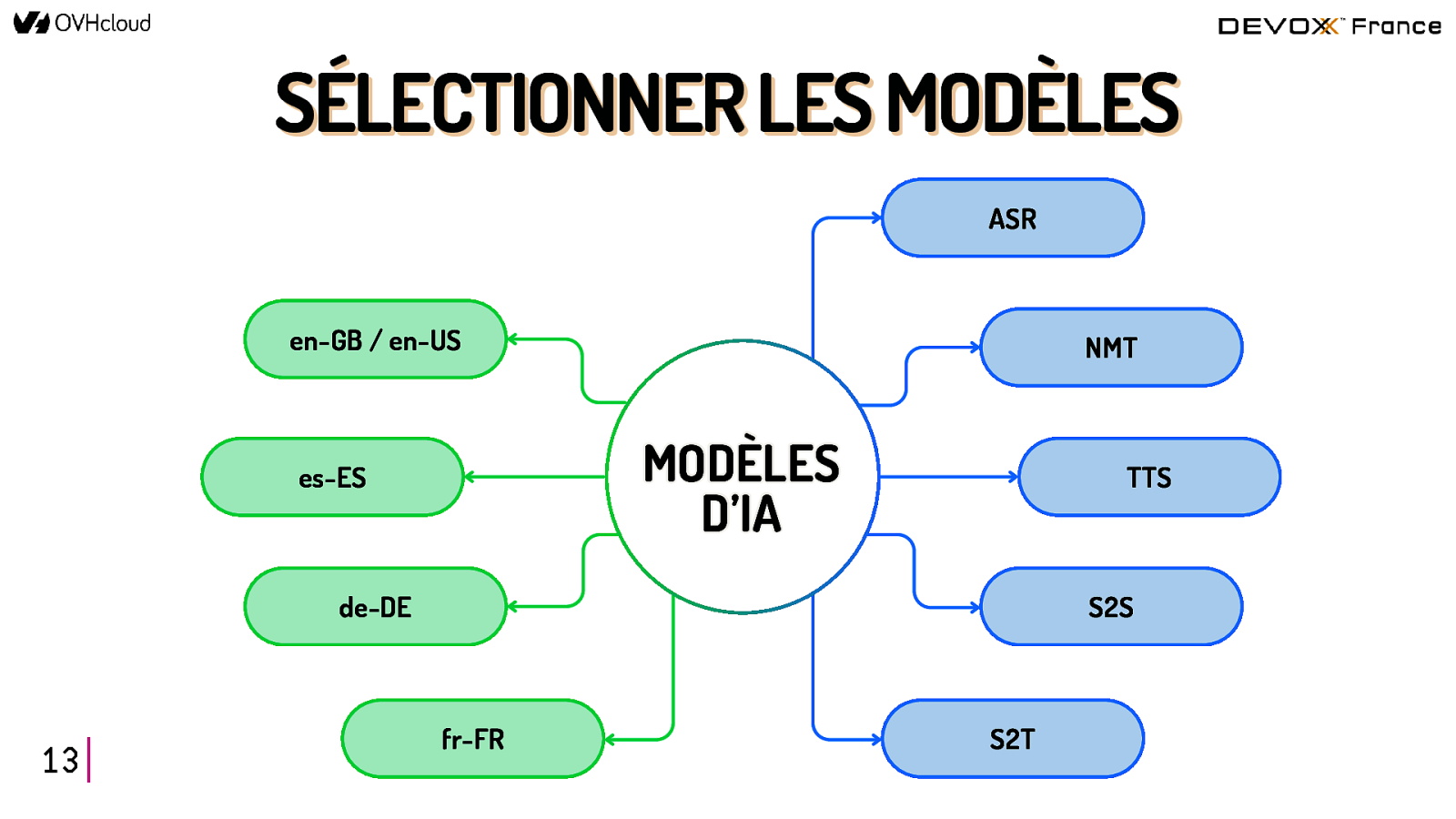
SÉLECTIONNER LES MODÈLES ASR en-GB / en-US NMT MODÈLES D’IA es-ES TTS de-DE 13 S2S fr-FR S2T
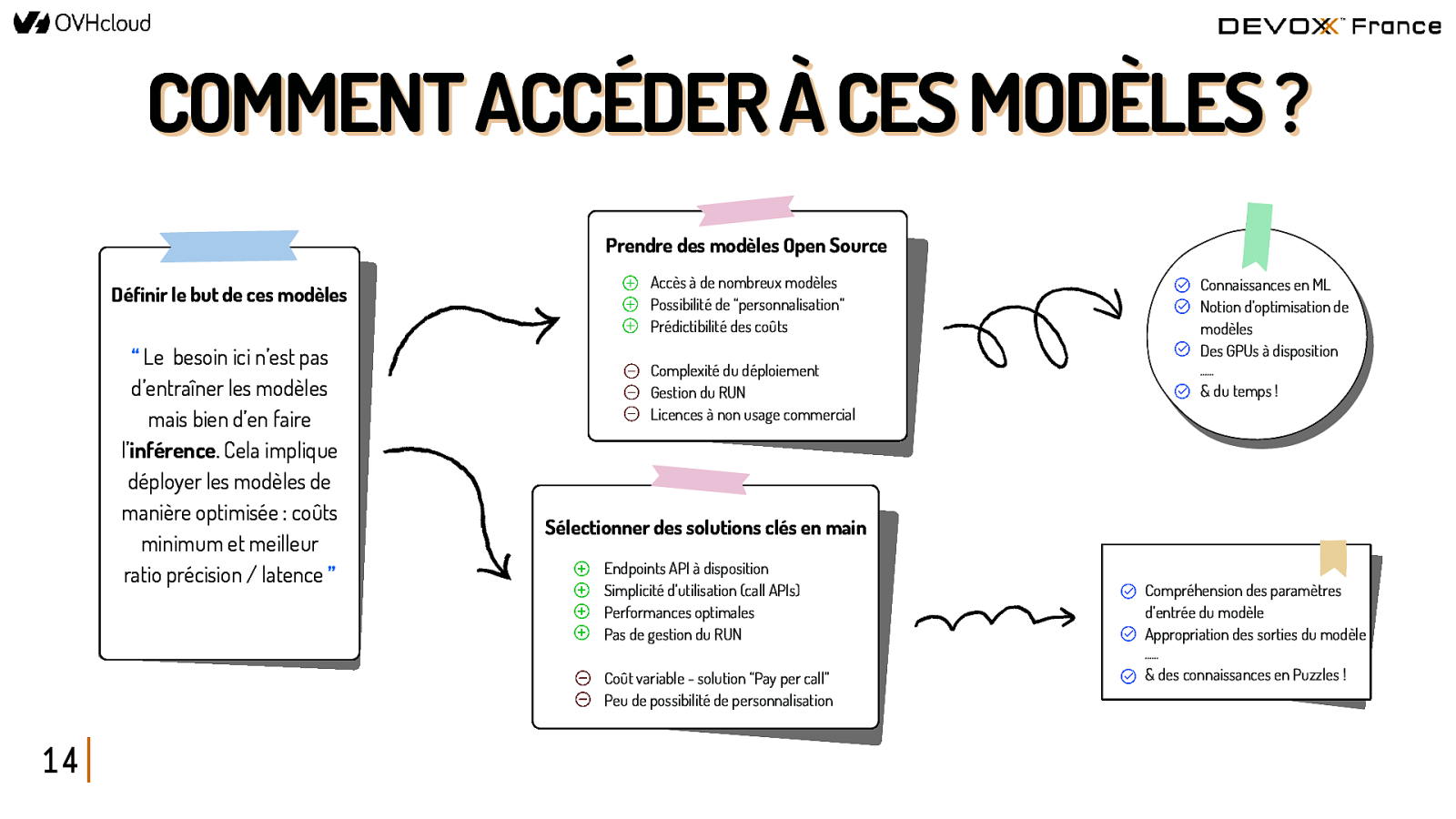
COMMENT ACCÉDER À CES MODÈLES ? Prendre des modèles Open Source Définir le but de ces modèles “ Le besoin ici n’est pas d’entraîner les modèles mais bien d’en faire l’inférence. Cela implique déployer les modèles de manière optimisée : coûts minimum et meilleur ratio précision / latence ” Accès à de nombreux modèles Possibilité de “personnalisation” Prédictibilité des coûts Connaissances en ML Notion d’optimisation de modèles Des GPUs à disposition Complexité du déploiement Gestion du RUN Licences à non usage commercial …… & du temps ! Sélectionner des solutions clés en main Endpoints API à disposition Simplicité d’utilisation (call APIs) Performances optimales Pas de gestion du RUN Compréhension des paramètres d’entrée du modèle Appropriation des sorties du modèle …… Coût variable - solution “Pay per call” Peu de possibilité de personnalisation 14 & des connaissances en Puzzles !

UTILISER l’Open Source 15

COMMENT TROUVER CES MODÈLES ? https://huggingface.co/tasks 16
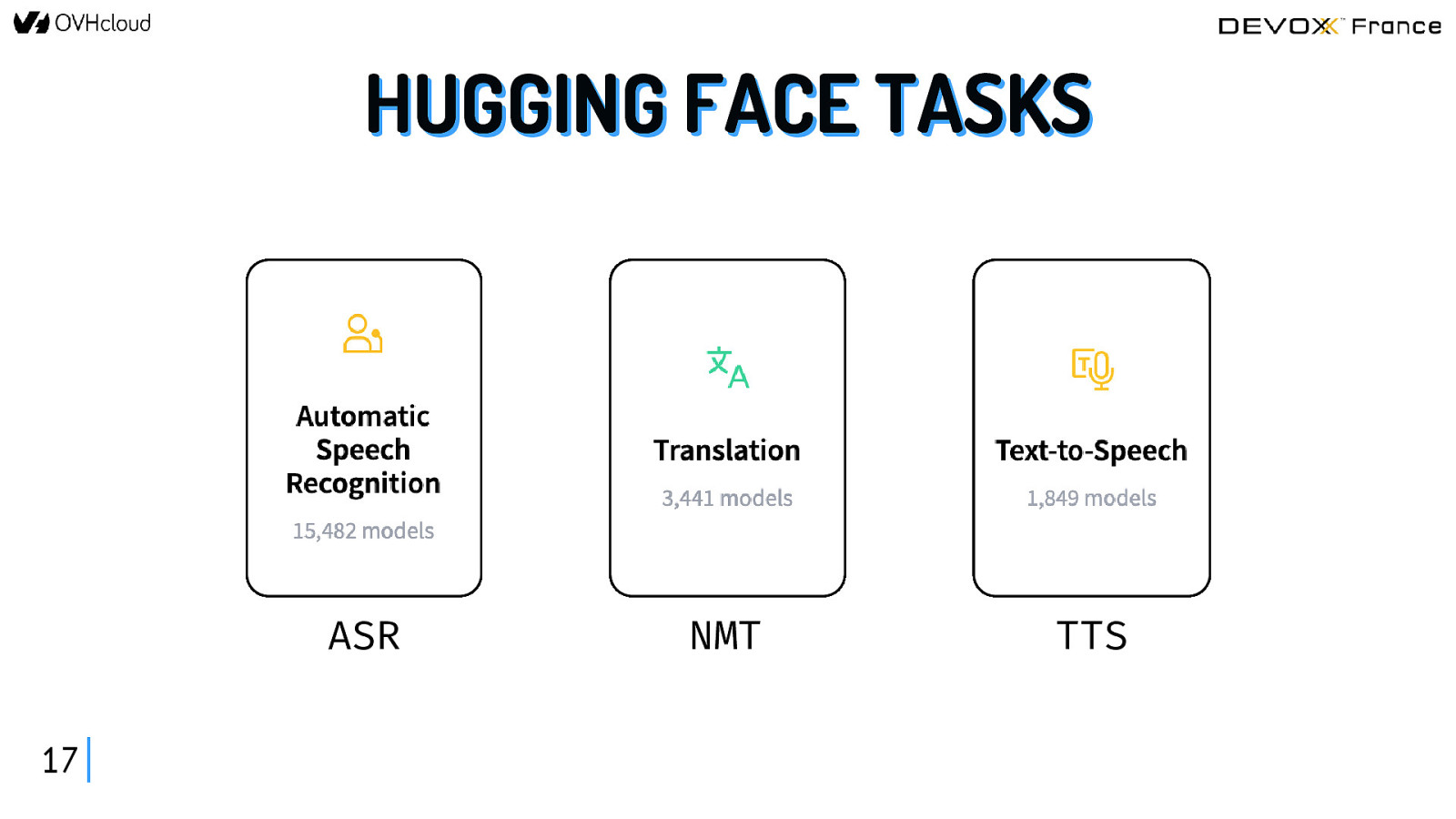
HUGGING FACE TASKS ASR 17 NMT TTS
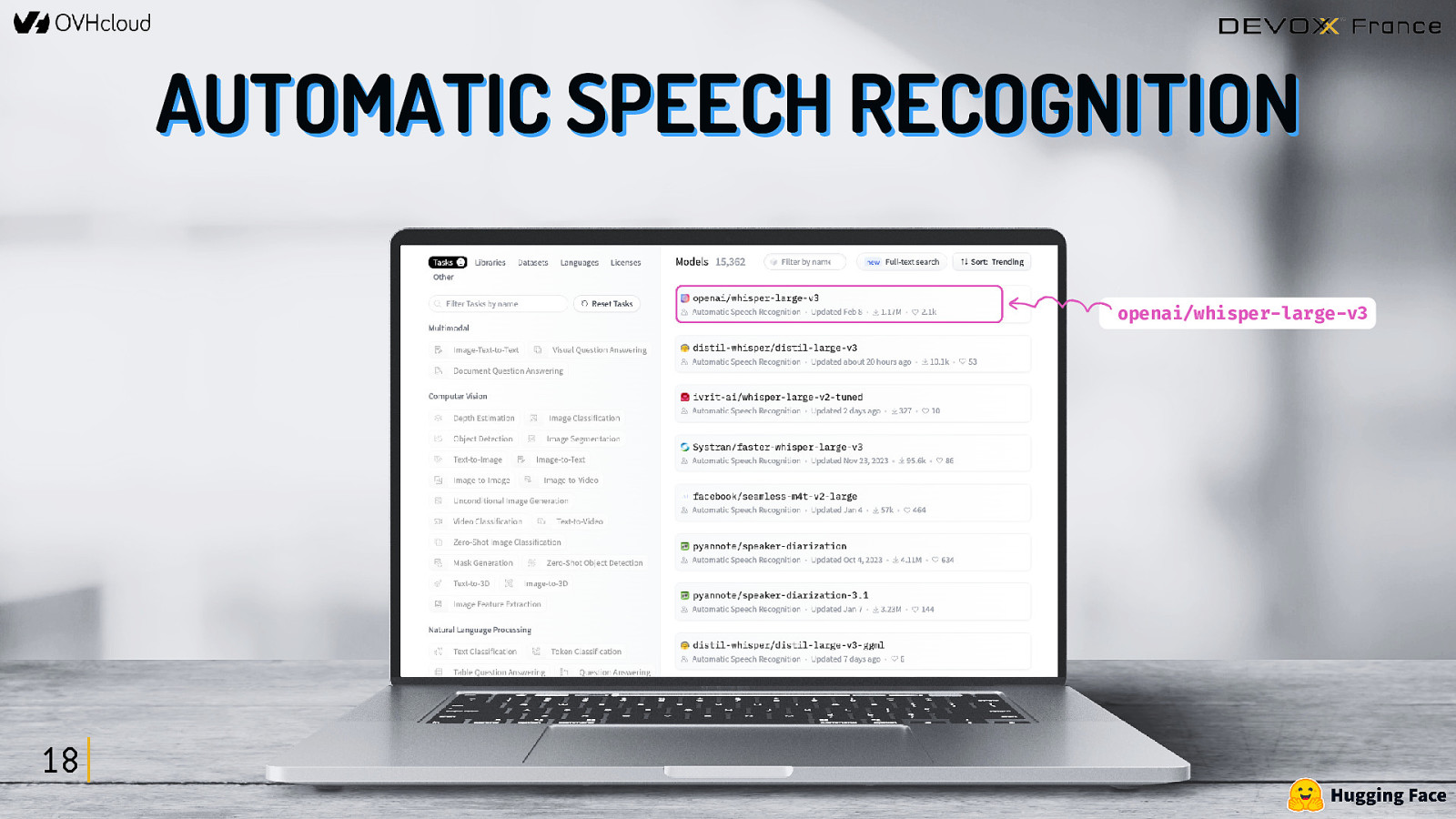
AUTOMATIC SPEECH RECOGNITION openai/whisper-large-v3 18
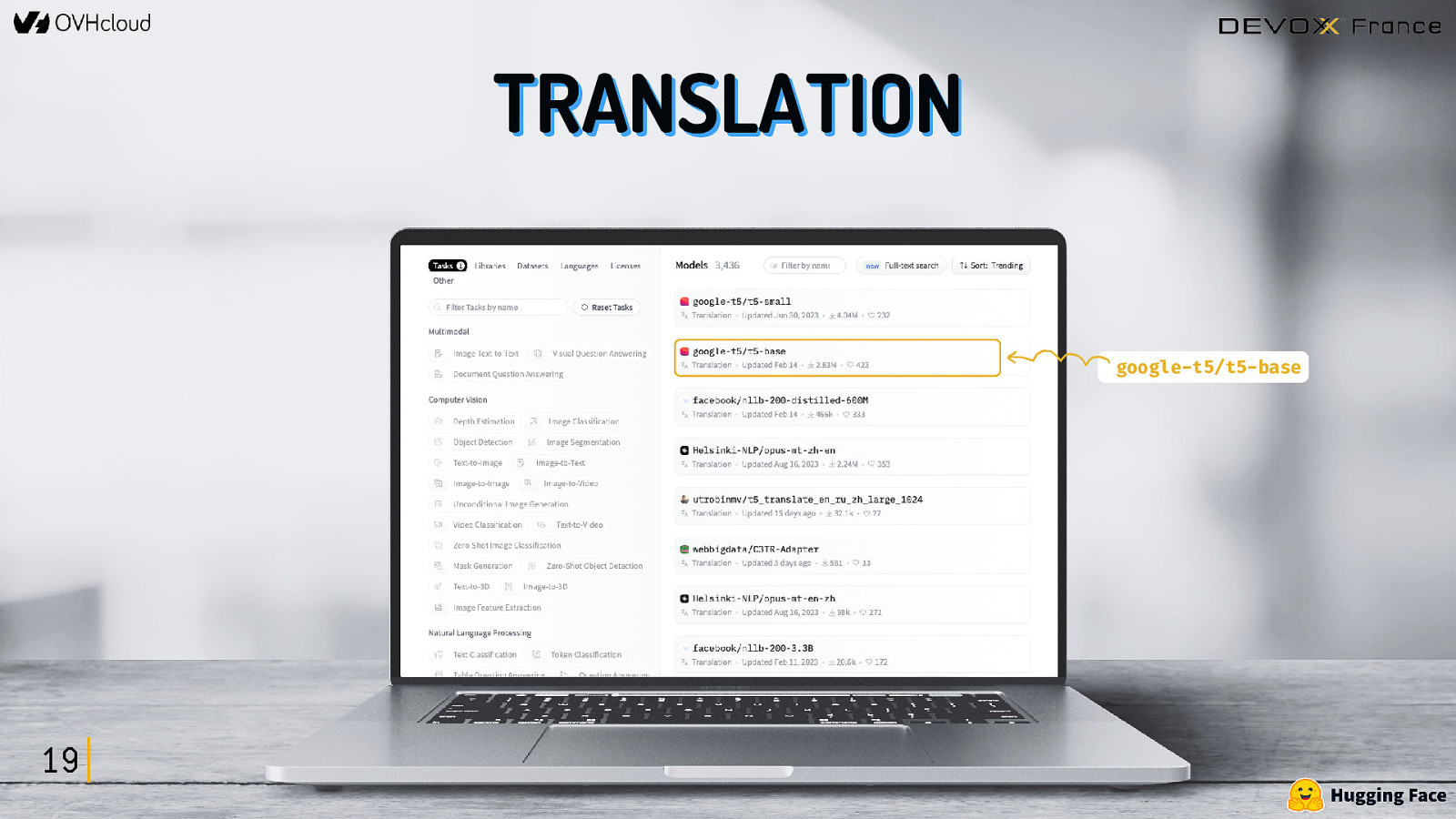
TRANSLATION google-t5/t5-base 19
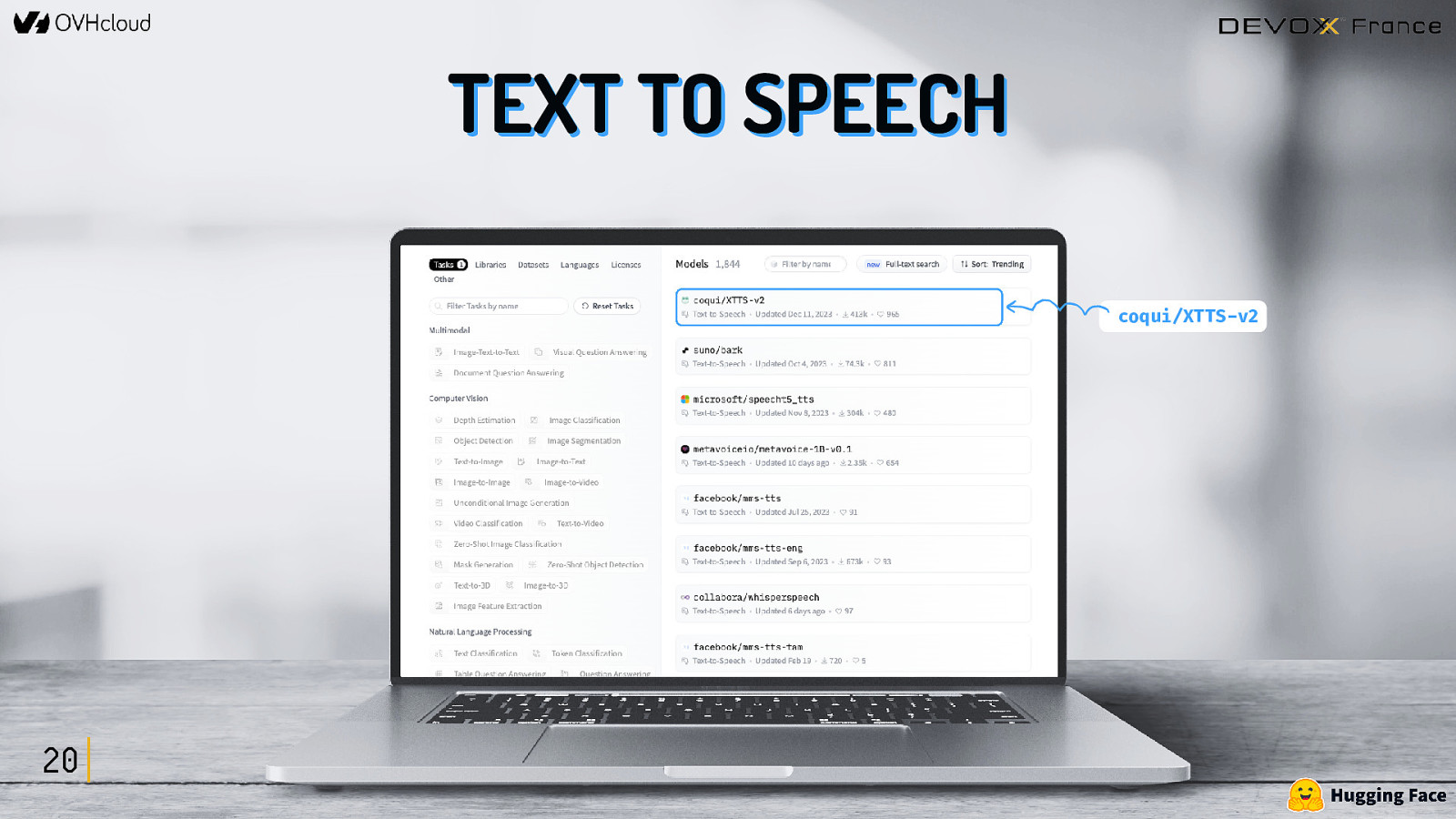
TEXT TO SPEECH coqui/XTTS-v2 20
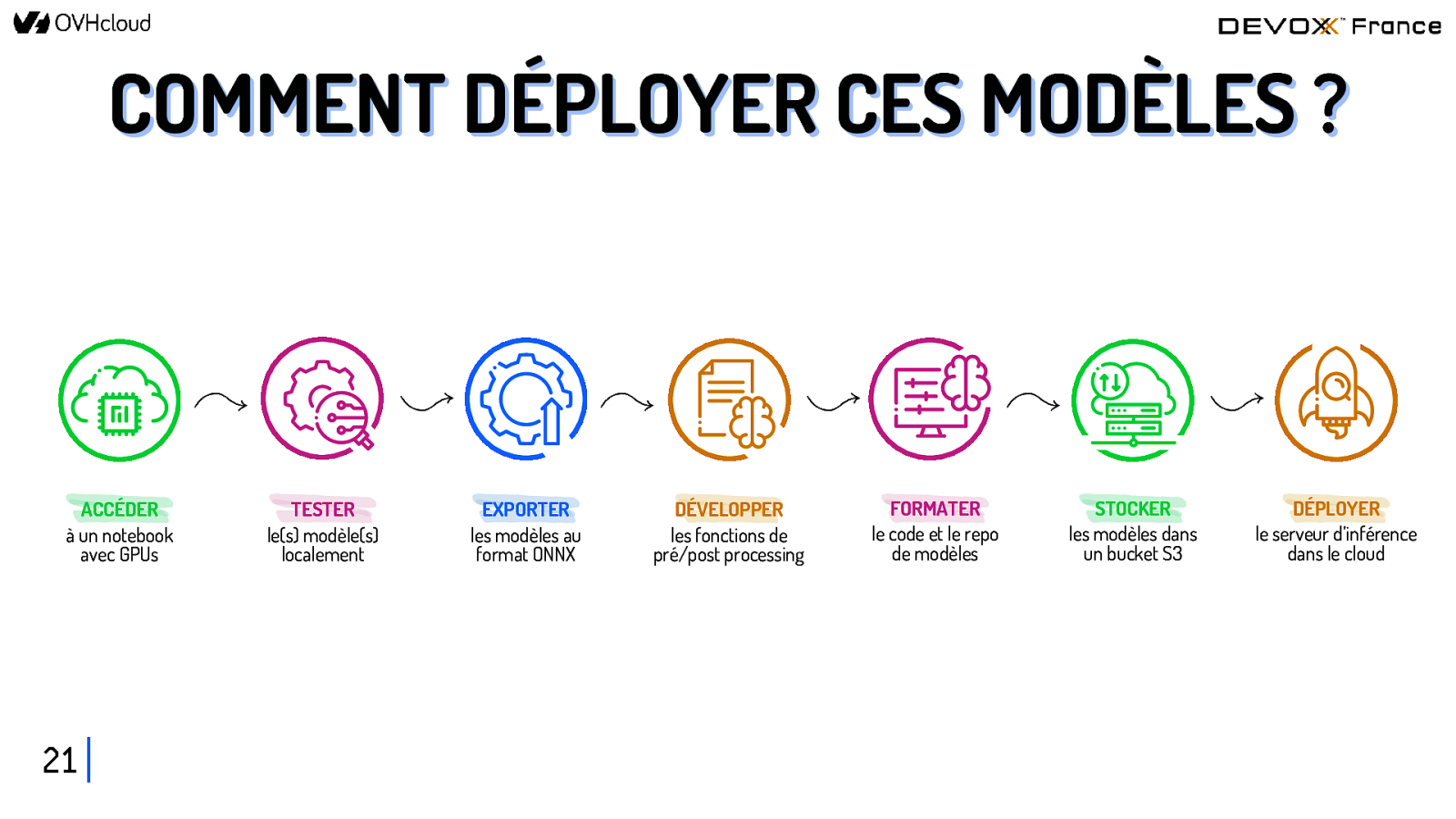
COMMENT DÉPLOYER CES MODÈLES ? ACCÉDER à un notebook avec GPUs 21 TESTER le(s) modèle(s) localement EXPORTER les modèles au format ONNX DÉVELOPPER les fonctions de pré/post processing FORMATER le code et le repo de modèles STOCKER les modèles dans un bucket S3 DÉPLOYER le serveur d’inférence dans le cloud
COMMENT DÉPLOYER CES MODÈLES ? ACCÉDER à un notebook avec GPUs 21 TESTER le(s) modèle(s) localement EXPORTER les modèles au format ONNX DÉVELOPPER les fonctions de pré/post processing FORMATER le code et le repo de modèles STOCKER les modèles dans un bucket S3 DÉPLOYER le serveur d’inférence dans le cloud

ACCÉDER à un notebook 22
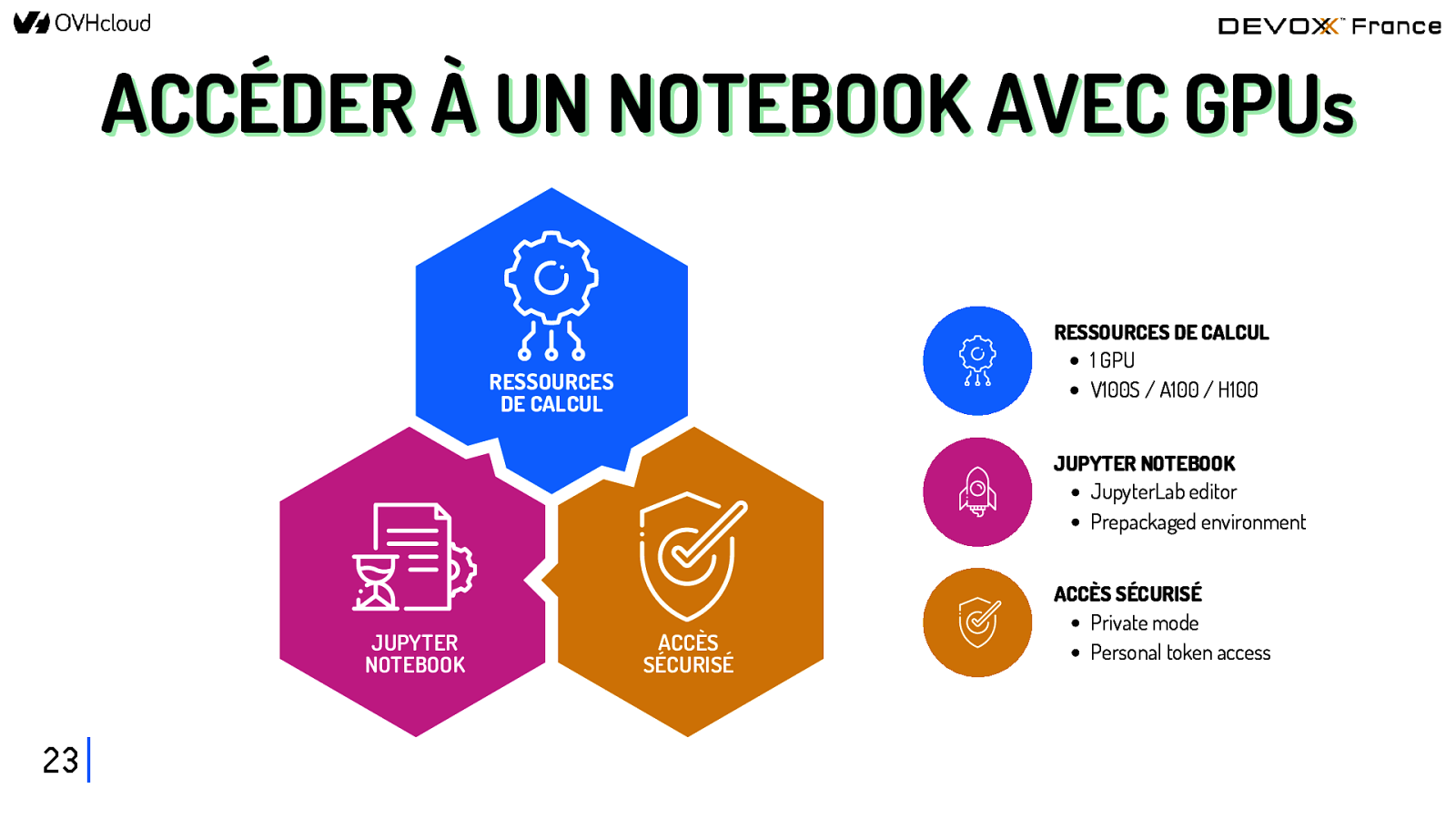
ACCÉDER À UN NOTEBOOK AVEC GPUs RESSOURCES DE CALCUL 1 GPU V100S / A100 / H100 RESSOURCES DE CALCUL JUPYTER NOTEBOOK JupyterLab editor Prepackaged environment JUPYTER NOTEBOOK 23 ACCÈS SÉCURISÉ ACCÈS SÉCURISÉ Private mode Personal token access

OVHcloud - AI NOTEBOOKS 24 01 NOTEBOOK AS A SERVICE Nptebooks JupyterLab ou VS Code préconfigurés 02 RESSOURCES DE CALCUL Le notebook est lancé dans le cloud avec GPU (ou CPU) 03 MODE DE FACTURATION Le client est facturé à la minute utilisée 04 ENVIRONNEMENT PRÉ-PACKAGÉ Frameworks ML disponibles : PyTorch, TensorFlow, Transformers, … 05 PERSISTANCE DU WORKSPACE Conservation du workspace de l’utilisateur entre les exécutions pour conserver les packages installés
COMMENT DÉPLOYER CES MODÈLES ? ACCÉDER à un notebook avec GPUs 25 TESTER le(s) modèle(s) localement EXPORTER les modèles au format ONNX DÉVELOPPER les fonctions de pré/post processing FORMATER le code et le repo de modèles STOCKER les modèles dans un bucket S3 DÉPLOYER le serveur d’inférence dans le cloud

TESTER les modèles 26
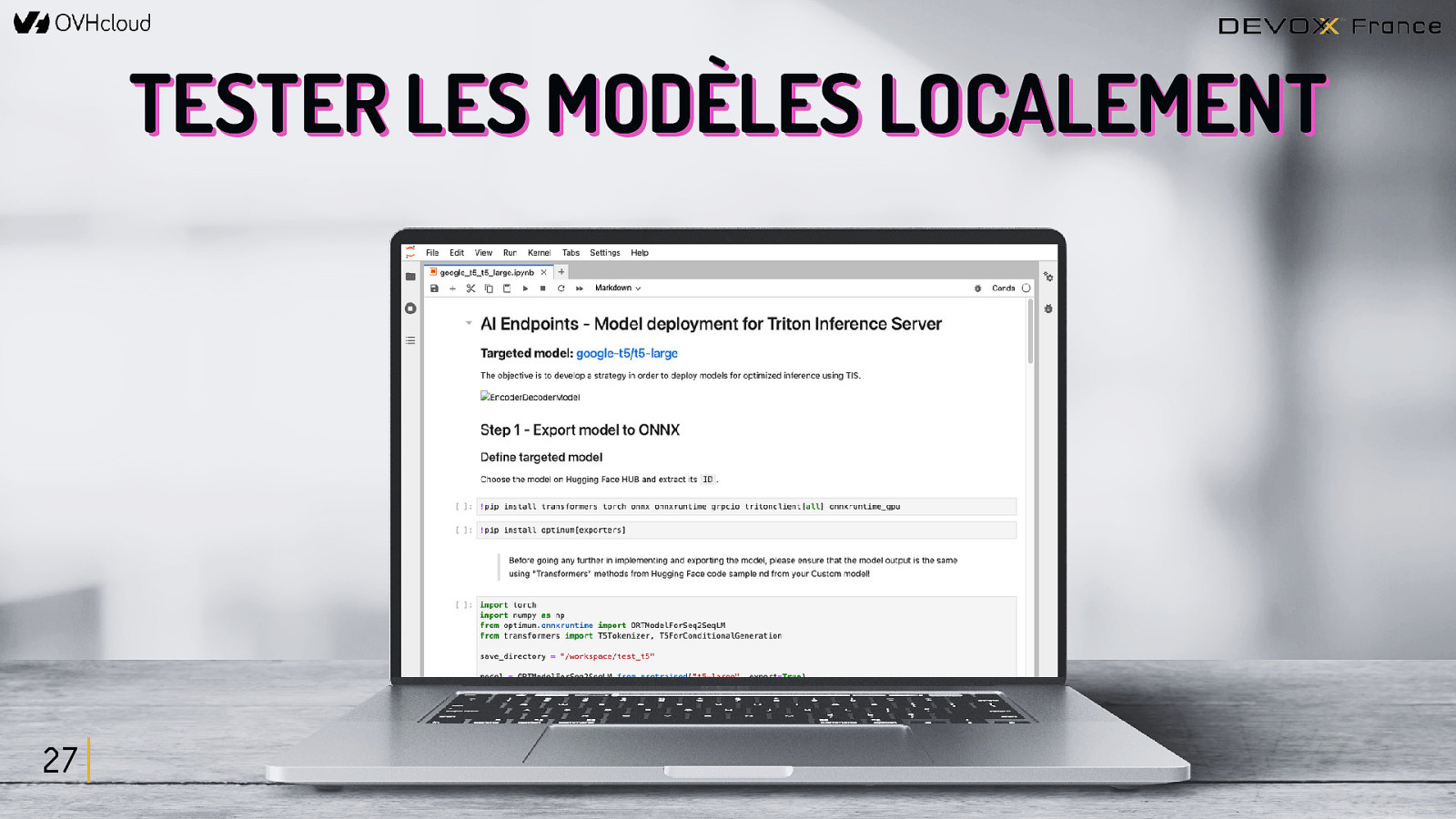
TESTER LES MODÈLES LOCALEMENT 27
COMMENT DÉPLOYER CES MODÈLES ? ACCÉDER à un notebook avec GPUs 28 TESTER le(s) modèle(s) localement EXPORTER les modèles au format ONNX DÉVELOPPER les fonctions de pré/post processing FORMATER le code et le repo de modèles STOCKER les modèles dans un bucket S3 DÉPLOYER le serveur d’inférence dans le cloud

OONNNNX X EXPORTER les modèles 29
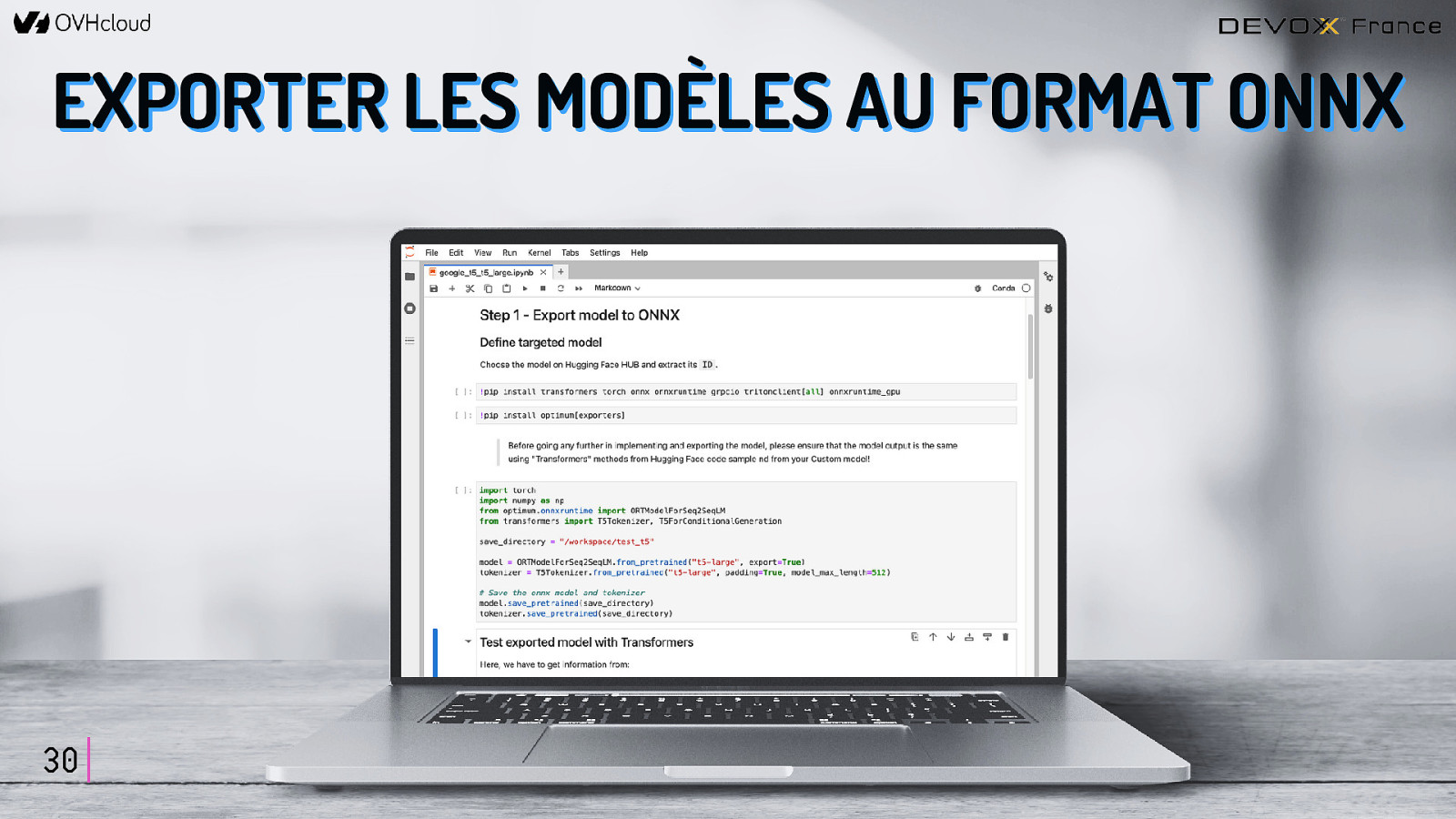
EXPORTER LES MODÈLES AU FORMAT ONNX 30
COMMENT DÉPLOYER CES MODÈLES ? ACCÉDER à un notebook avec GPUs 31 TESTER le(s) modèle(s) localement EXPORTER les modèles au format ONNX DÉVELOPPER les fonctions de pré/post processing FORMATER le code et le repo de modèles STOCKER les modèles dans un bucket S3 DÉPLOYER le serveur d’inférence dans le cloud

DÉVELOPPER les fonctions pre/post 32
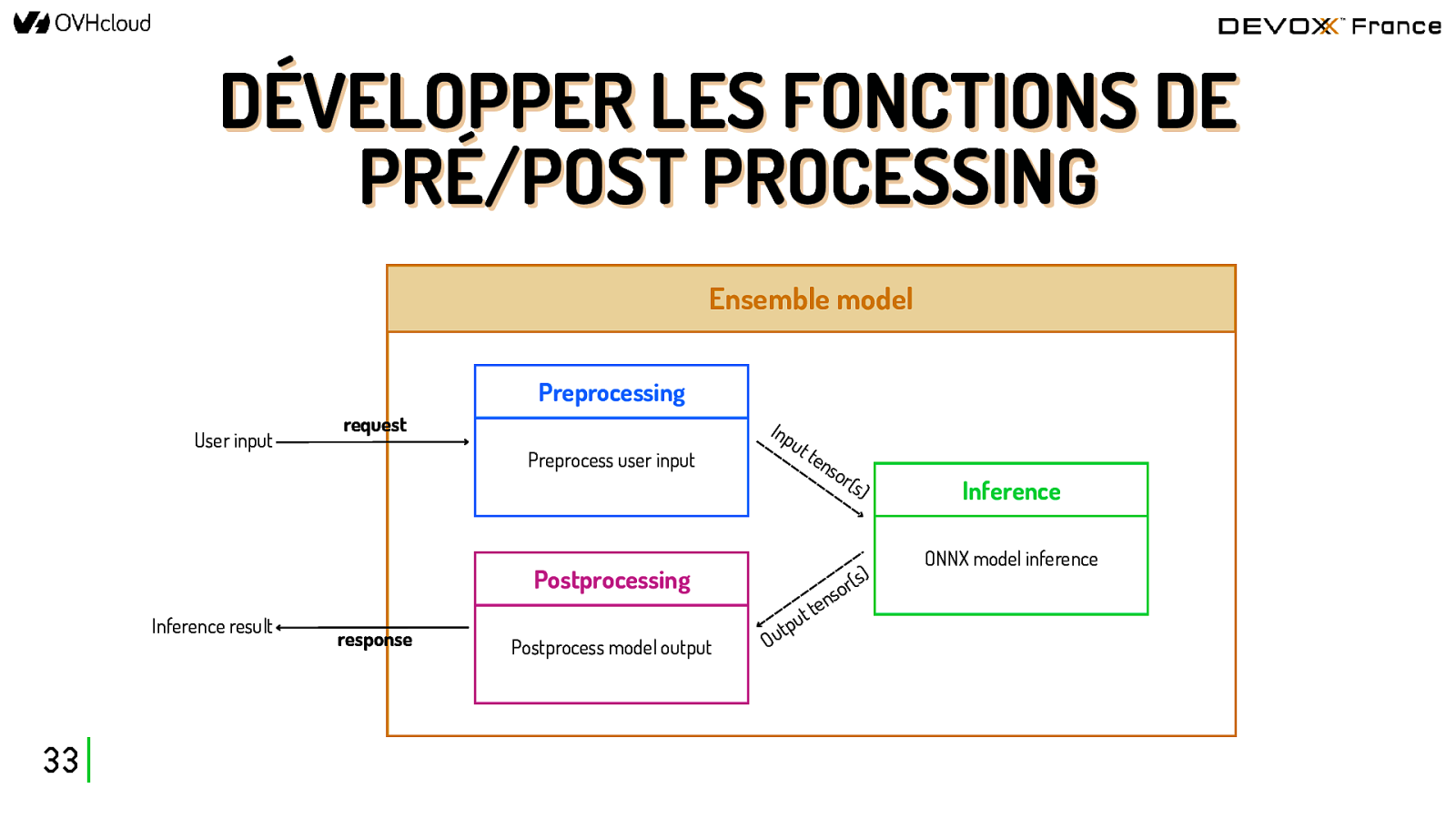
DÉVELOPPER LES FONCTIONS DE PRÉ/POST PROCESSING Ensemble model Preprocessing User input request Preprocess user input Postprocessing Inference result 33 response Postprocess model output Inp ut ten sor (s) s) ( r so n te t tpu u O Inference ONNX model inference
COMMENT DÉPLOYER CES MODÈLES ? ACCÉDER à un notebook avec GPUs 34 TESTER le(s) modèle(s) localement EXPORTER les modèles au format ONNX DÉVELOPPER les fonctions de pré/post processing FORMATER le code et le repo de modèles STOCKER les modèles dans un bucket S3 DÉPLOYER le serveur d’inférence dans le cloud

FORMATER le code et le repo 35
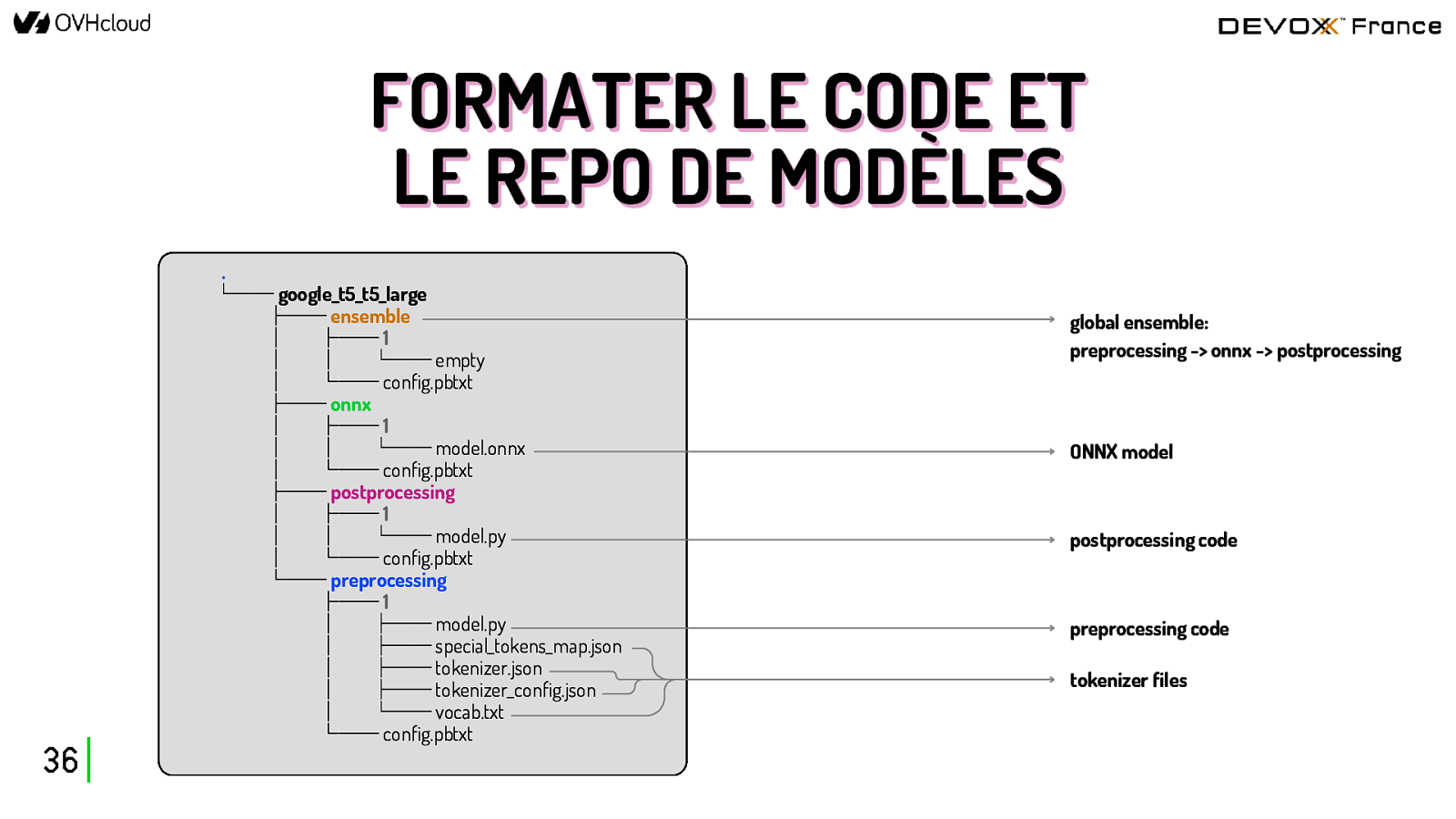
FORMATER LE CODE ET LE REPO DE MODÈLES . 36 └── google_t5_t5_large ├── ensemble │ ├── 1 │ │ └── empty │ └── config.pbtxt ├── onnx │ ├── 1 │ │ └── model.onnx │ └── config.pbtxt ├── postprocessing │ ├── 1 │ │ └── model.py │ └── config.pbtxt └── preprocessing ├── 1 │ ├── model.py │ ├── special_tokens_map.json │ ├── tokenizer.json │ ├── tokenizer_config.json │ └── vocab.txt └── config.pbtxt global ensemble: preprocessing -> onnx -> postprocessing ONNX model postprocessing code preprocessing code tokenizer files
COMMENT DÉPLOYER CES MODÈLES ? ACCÉDER à un notebook avec GPUs 37 TESTER le(s) modèle(s) localement EXPORTER les modèles au format ONNX DÉVELOPPER les fonctions de pré/post processing FORMATER le code et le repo de modèles STOCKER les modèles dans un bucket S3 DÉPLOYER le serveur d’inférence dans le cloud

STOCKER les modèles 38
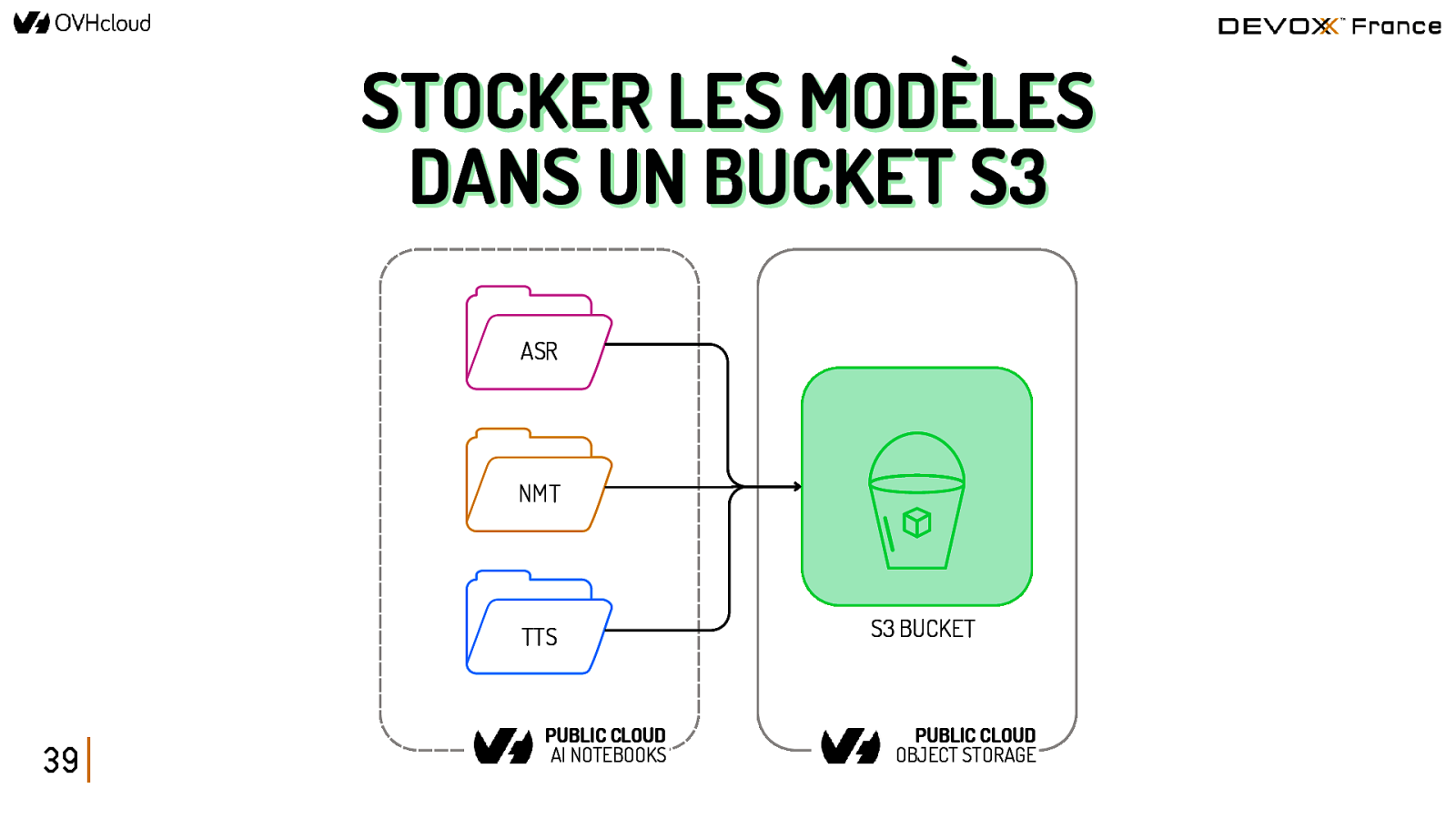
STOCKER LES MODÈLES DANS UN BUCKET S3 ASR NMT TTS 39 PUBLIC CLOUD AI NOTEBOOKS S3 BUCKET PUBLIC CLOUD OBJECT STORAGE
COMMENT DÉPLOYER CES MODÈLES ? ACCÉDER à un notebook avec GPUs 40 TESTER le(s) modèle(s) localement EXPORTER les modèles au format ONNX DÉVELOPPER les fonctions de pré/post processing FORMATER le code et le repo de modèles STOCKER les modèles dans un bucket S3 DÉPLOYER le serveur d’inférence dans le cloud

DÉPLOYER le serveur d’inférence 41

DÉPLOYER LE SERVEUR D’INFÉRENCE DANS LE CLOUD RESSOURCES DE CALCUL 1 GPU V100s RESSOURCES DE CALCUL HAUTE DISPONIBILITÉ API scalable à la volée Nombre de réplicas personnalisable HAUTE DISPONIBILITÉ 42 ACCÈS SÉCURISÉ ACCÈS SÉCURISÉ Model privé Token d’accès unique
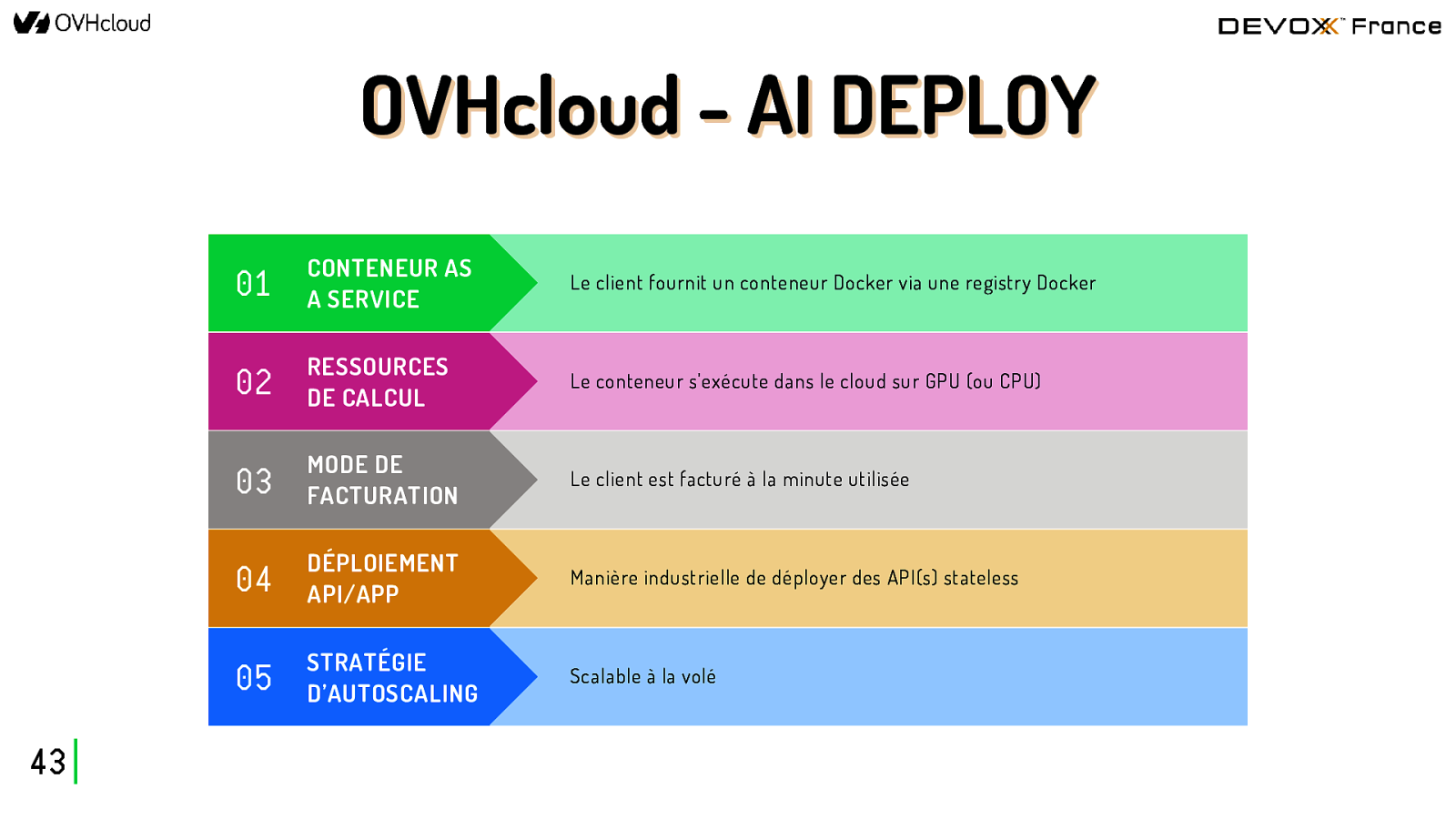
OVHcloud - AI DEPLOY 43 01 CONTENEUR AS A SERVICE Le client fournit un conteneur Docker via une registry Docker 02 RESSOURCES DE CALCUL Le conteneur s’exécute dans le cloud sur GPU (ou CPU) 03 MODE DE FACTURATION Le client est facturé à la minute utilisée 04 DÉPLOIEMENT API/APP Manière industrielle de déployer des API(s) stateless 05 STRATÉGIE D’AUTOSCALING Scalable à la volé
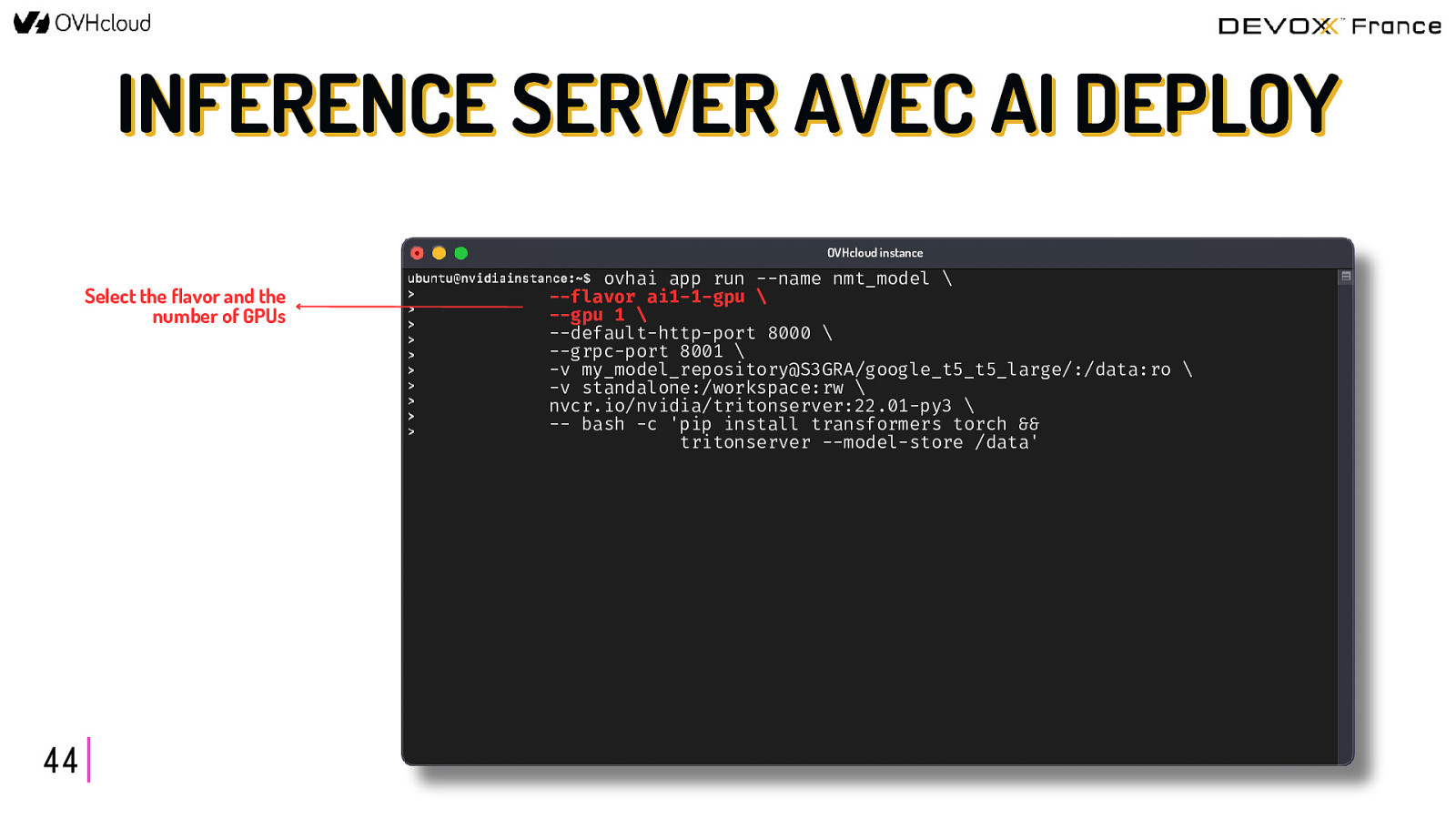
INFERENCE SERVER AVEC AI DEPLOY OVHcloud instance Select the flavor and the number of GPUs 44 ovhai app run —name nmt_model \ —flavor ai1-1-gpu \ —gpu 1 \ —default-http-port 8000 \ —grpc-port 8001 \ -v my_model_repository@S3GRA/google_t5_t5_large/:/data:ro \ -v standalone:/workspace:rw \ nvcr.io/nvidia/tritonserver:22.01-py3 \ — bash -c ‘pip install transformers torch && tritonserver —model-store /data’
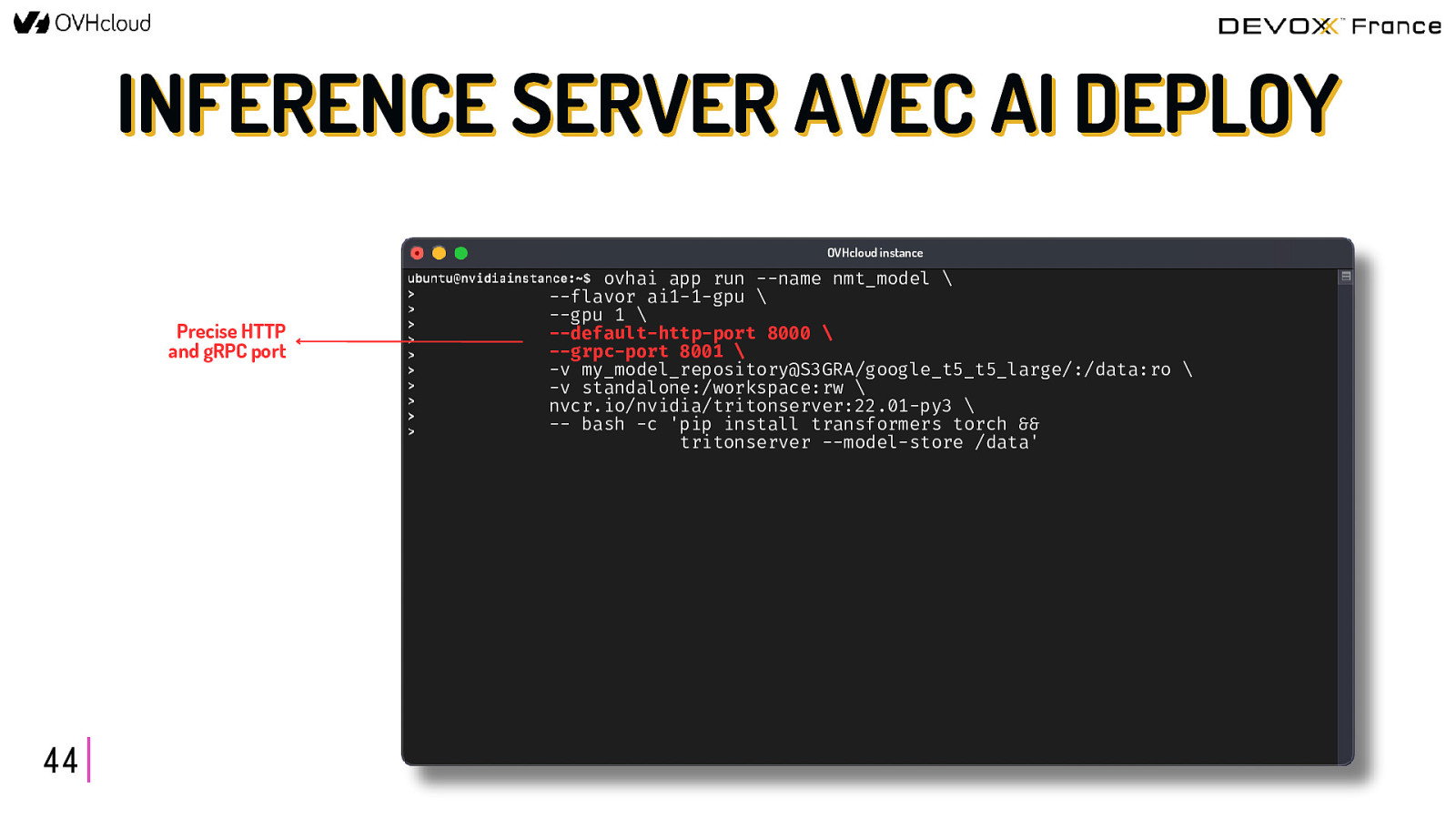
INFERENCE SERVER AVEC AI DEPLOY OVHcloud instance Precise HTTP and gRPC port 44 ovhai app run —name nmt_model \ —flavor ai1-1-gpu \ —gpu 1 \ —default-http-port 8000 \ —grpc-port 8001 \ -v my_model_repository@S3GRA/google_t5_t5_large/:/data:ro \ -v standalone:/workspace:rw \ nvcr.io/nvidia/tritonserver:22.01-py3 \ — bash -c ‘pip install transformers torch && tritonserver —model-store /data’
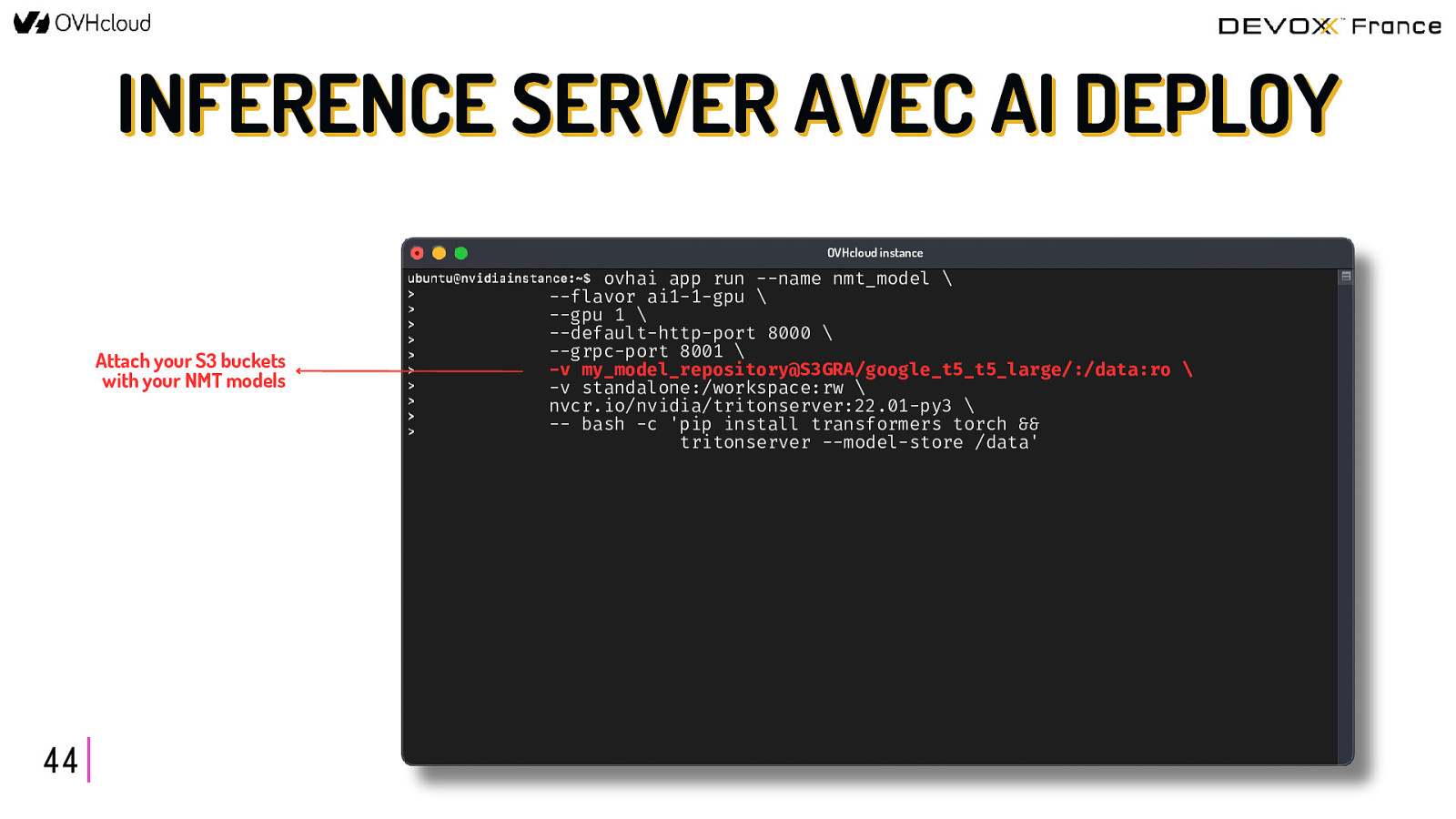
INFERENCE SERVER AVEC AI DEPLOY OVHcloud instance Attach your S3 buckets with your NMT models 44 ovhai app run —name nmt_model \ —flavor ai1-1-gpu \ —gpu 1 \ —default-http-port 8000 \ —grpc-port 8001 \ -v my_model_repository@S3GRA/google_t5_t5_large/:/data:ro \ -v standalone:/workspace:rw \ nvcr.io/nvidia/tritonserver:22.01-py3 \ — bash -c ‘pip install transformers torch && tritonserver —model-store /data’
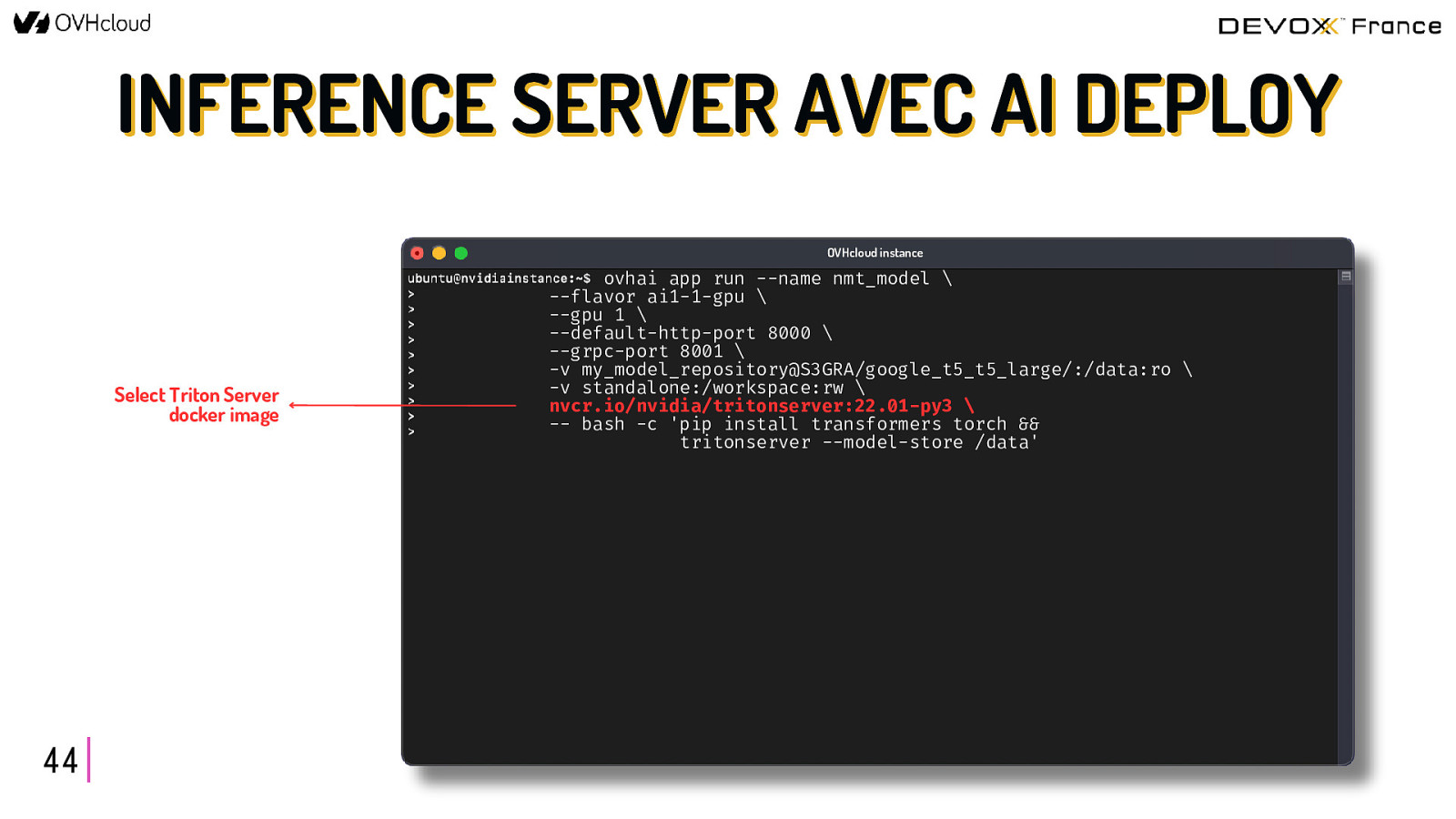
INFERENCE SERVER AVEC AI DEPLOY OVHcloud instance Select Triton Server docker image 44 ovhai app run —name nmt_model \ —flavor ai1-1-gpu \ —gpu 1 \ —default-http-port 8000 \ —grpc-port 8001 \ -v my_model_repository@S3GRA/google_t5_t5_large/:/data:ro \ -v standalone:/workspace:rw \ nvcr.io/nvidia/tritonserver:22.01-py3 \ — bash -c ‘pip install transformers torch && tritonserver —model-store /data’
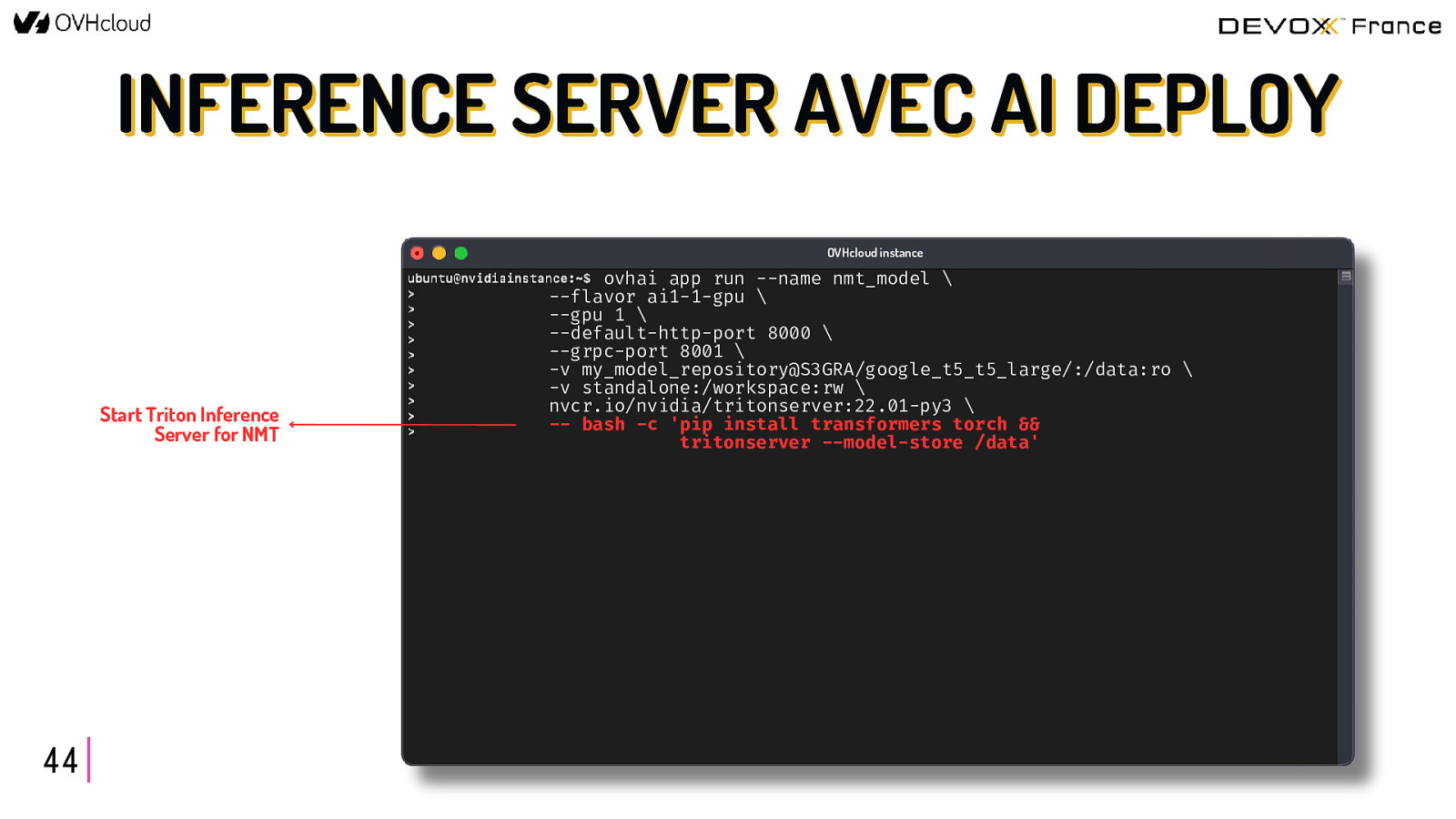
INFERENCE SERVER AVEC AI DEPLOY OVHcloud instance Start Triton Inference Server for NMT 44 ovhai app run —name nmt_model \ —flavor ai1-1-gpu \ —gpu 1 \ —default-http-port 8000 \ —grpc-port 8001 \ -v my_model_repository@S3GRA/google_t5_t5_large/:/data:ro \ -v standalone:/workspace:rw \ nvcr.io/nvidia/tritonserver:22.01-py3 \ — bash -c ‘pip install transformers torch && tritonserver —model-store /data’

BESOIN D’UNE SOLUTION CLÉ EN MAIN ? 45

CHOISIR ses AI Endpoints 47

OVHcloud - AI ENDPOINTS 48
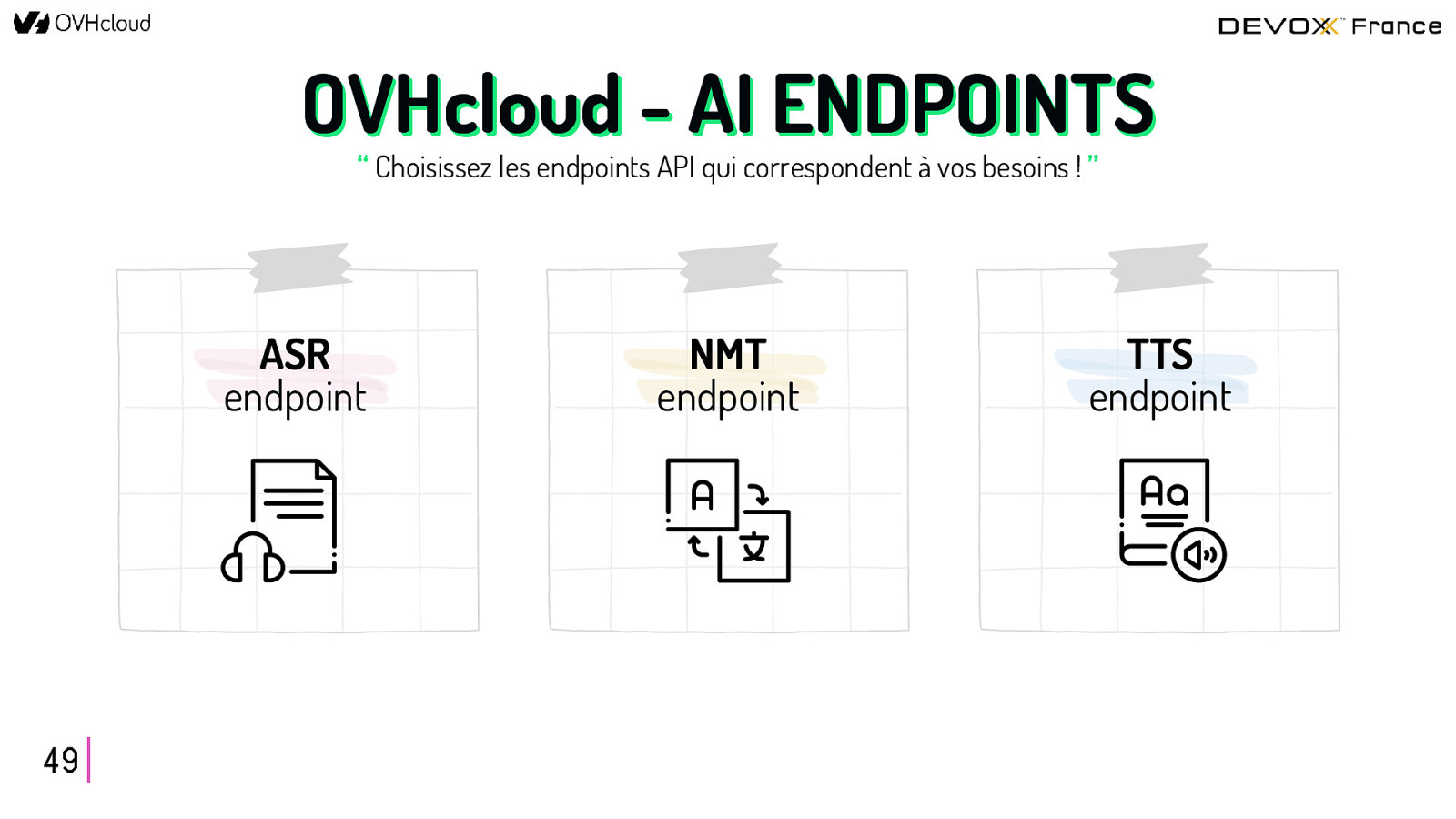
OVHcloud - AI ENDPOINTS “ Choisissez les endpoints API qui correspondent à vos besoins ! ” ASR endpoint 49 NMT endpoint TTS endpoint

COMMENT CONNECTER CES AI ENDPOINTS ENTRE EUX ? 50
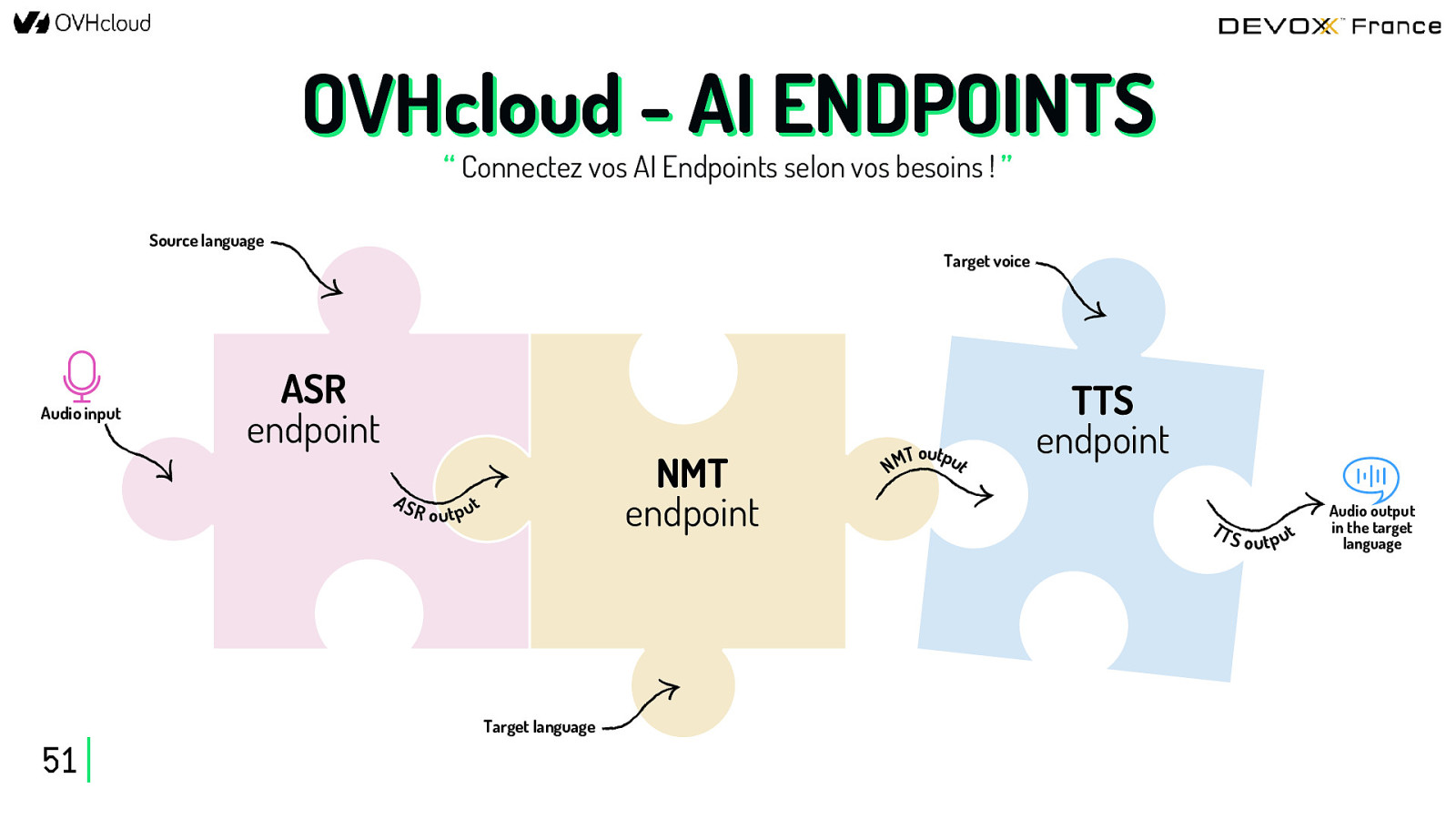
OVHcloud - AI ENDPOINTS “ Connectez vos AI Endpoints selon vos besoins ! ” Source language Audio input Target voice ASR endpoint AS NMT endpoint R o u t p ut Target language 51 T output M N TTS endpoint TT S o ut p ut Audio output in the target language

DÉVELOPPER la partie client 52

DÉVELOPPER LA PARTIE CLIENT Entrer un lien de vidéo YouTube Transcrire la partie audio de la vidéo en texte Sous-titrer la vidéo dans n’importe quelle langue Doubler la voix de le vidéo dans une autre langue Choisir le genre de la voix de doublage Télécharger la vidéo résultante 53

DÉVELOPPER LA PARTIE CLIENT SRT GÉNÉRER un fichier SRT de sous-titres 54 CONSERVER les silences pendant la traduction DOUBLER l’audio d’une vidéo dans une autre langue

DÉVELOPPER LA PARTIE CLIENT SRT GÉNÉRER un fichier SRT de sous-titres 54 CONSERVER les silences pendant la traduction DOUBLER l’audio d’une vidéo dans une autre langue
GÉNÉRER UN FICHIER SRT 55

DÉVELOPPER LA PARTIE CLIENT SRT GÉNÉRER un fichier SRT de sous-titres 56 CONSERVER les silences pendant la traduction DOUBLER l’audio d’une vidéo dans une autre langue
CONSERVER LES SILENCES 57

DÉVELOPPER LA PARTIE CLIENT SRT GÉNÉRER un fichier SRT de sous-titres 58 CONSERVER les silences pendant la traduction DOUBLER l’audio d’une vidéo dans une autre langue
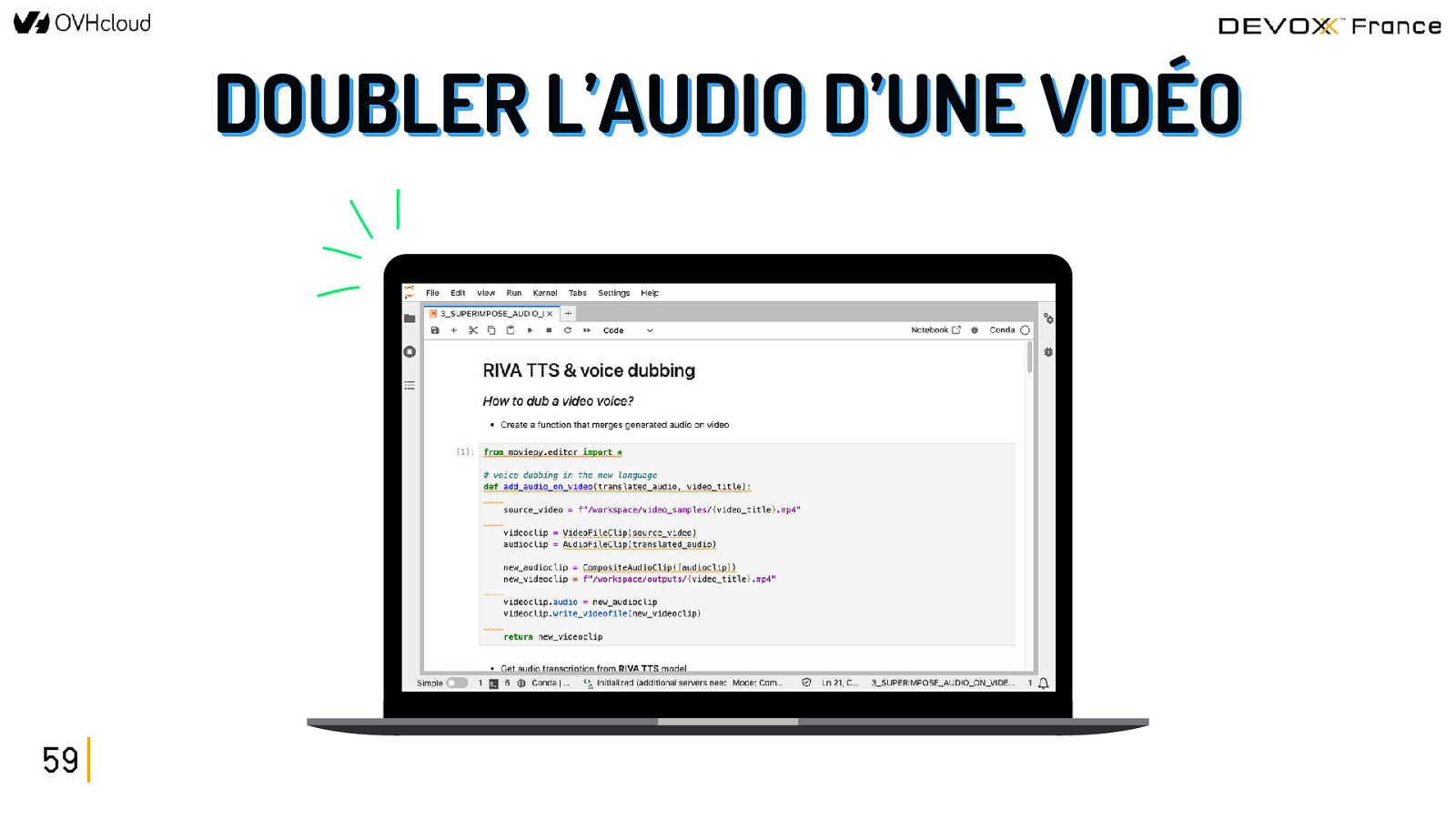
DOUBLER L’AUDIO D’UNE VIDÉO 59

DÉPLOYER l’app end-to-end 60
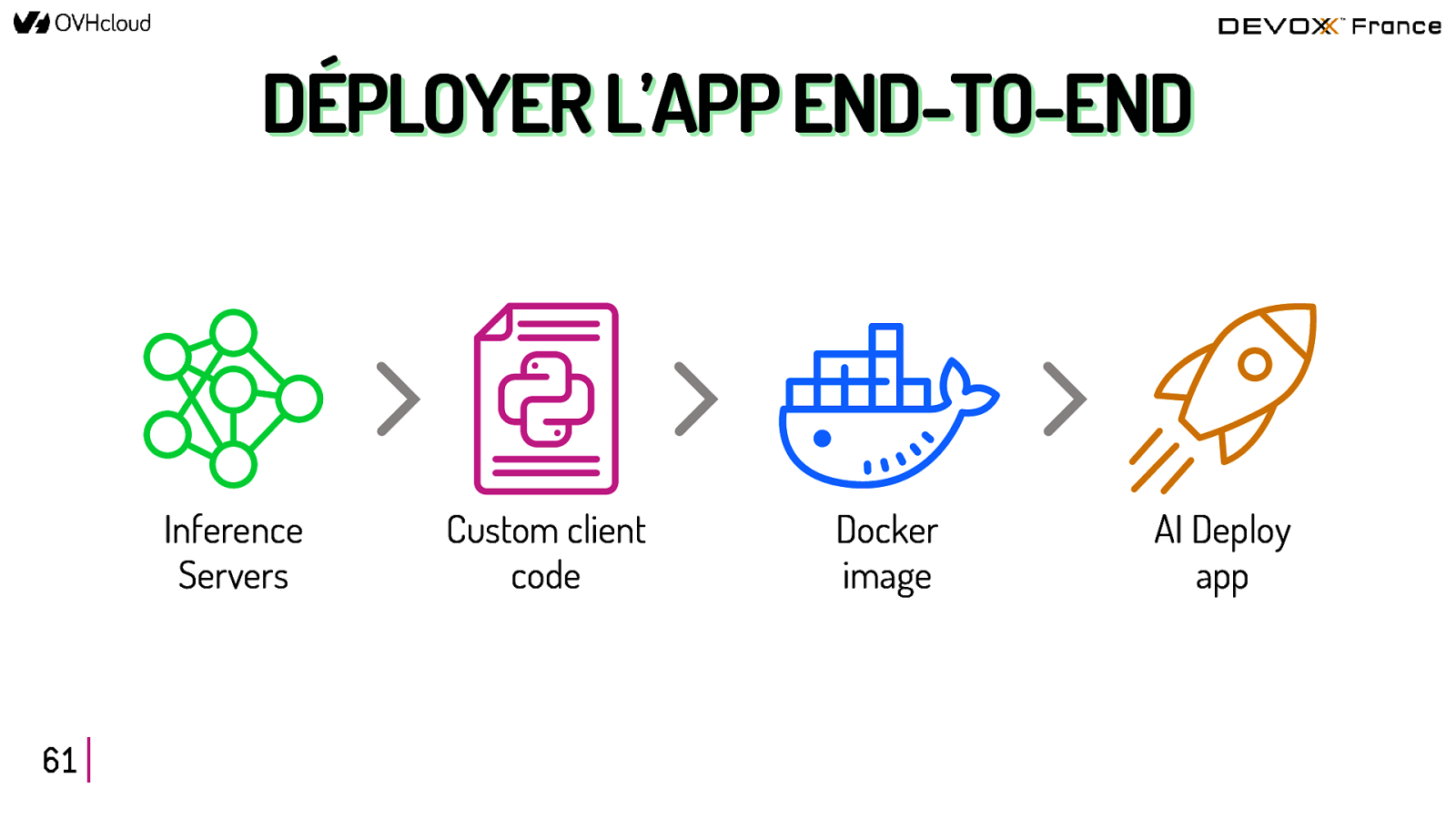
DÉPLOYER L’APP END-TO-END Inference Servers 61 Custom client code Docker image AI Deploy app
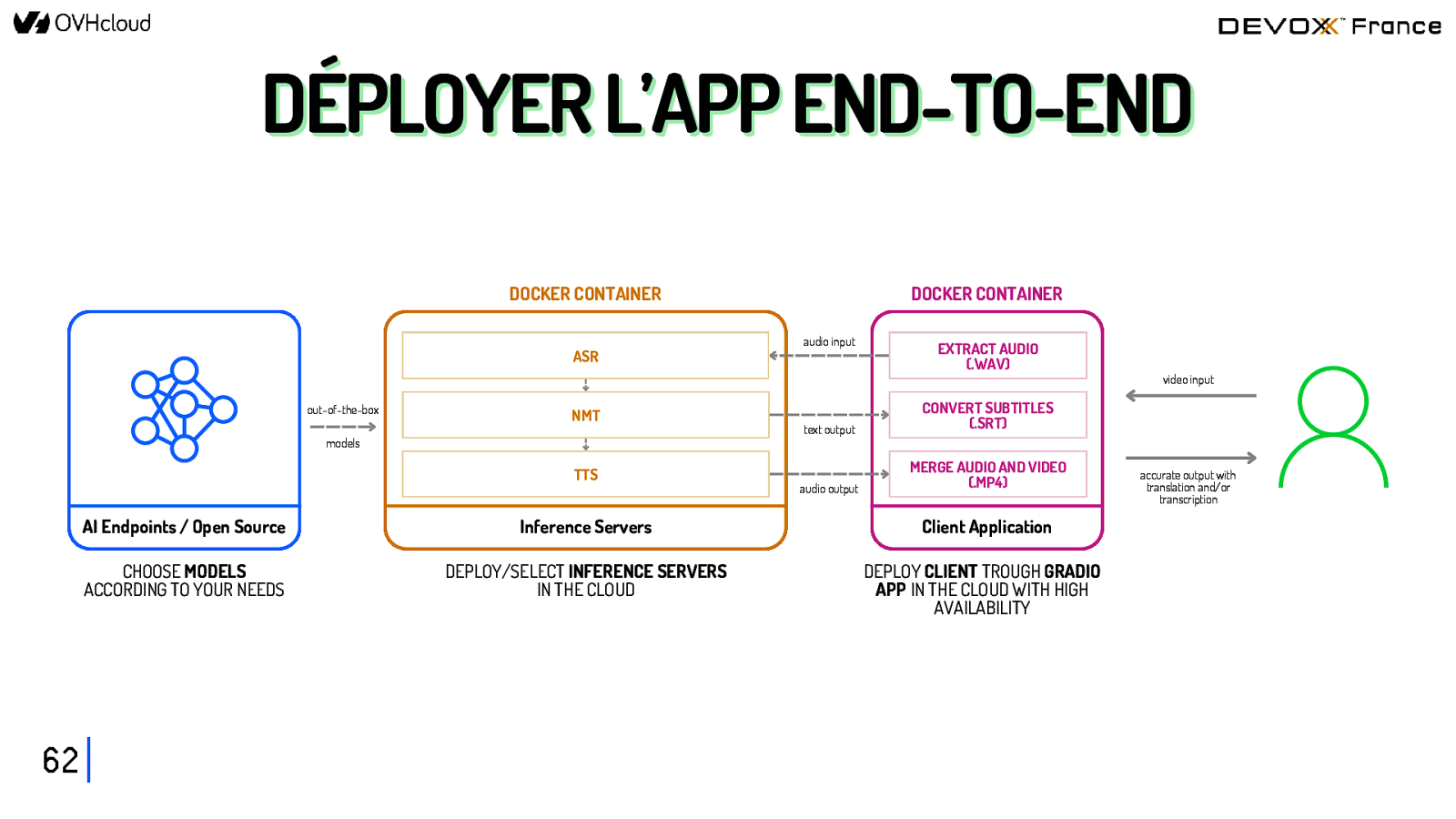
DÉPLOYER L’APP END-TO-END DOCKER CONTAINER ASR out-of-the-box NMT models TTS 62 DOCKER CONTAINER audio input EXTRACT AUDIO (.WAV) text output CONVERT SUBTITLES (.SRT) audio output MERGE AUDIO AND VIDEO (.MP4) AI Endpoints / Open Source Inference Servers Client Application CHOOSE MODELS ACCORDING TO YOUR NEEDS DEPLOY/SELECT INFERENCE SERVERS IN THE CLOUD DEPLOY CLIENT TROUGH GRADIO APP IN THE CLOUD WITH HIGH AVAILABILITY video input accurate output with translation and/or transcription

DÉMO de l’app 63

DÉMO DE L’APP 64

DÉMO DE L’APP 65 https://bit.ly/multimedia-translator-devoxx

CONCLUSION 66
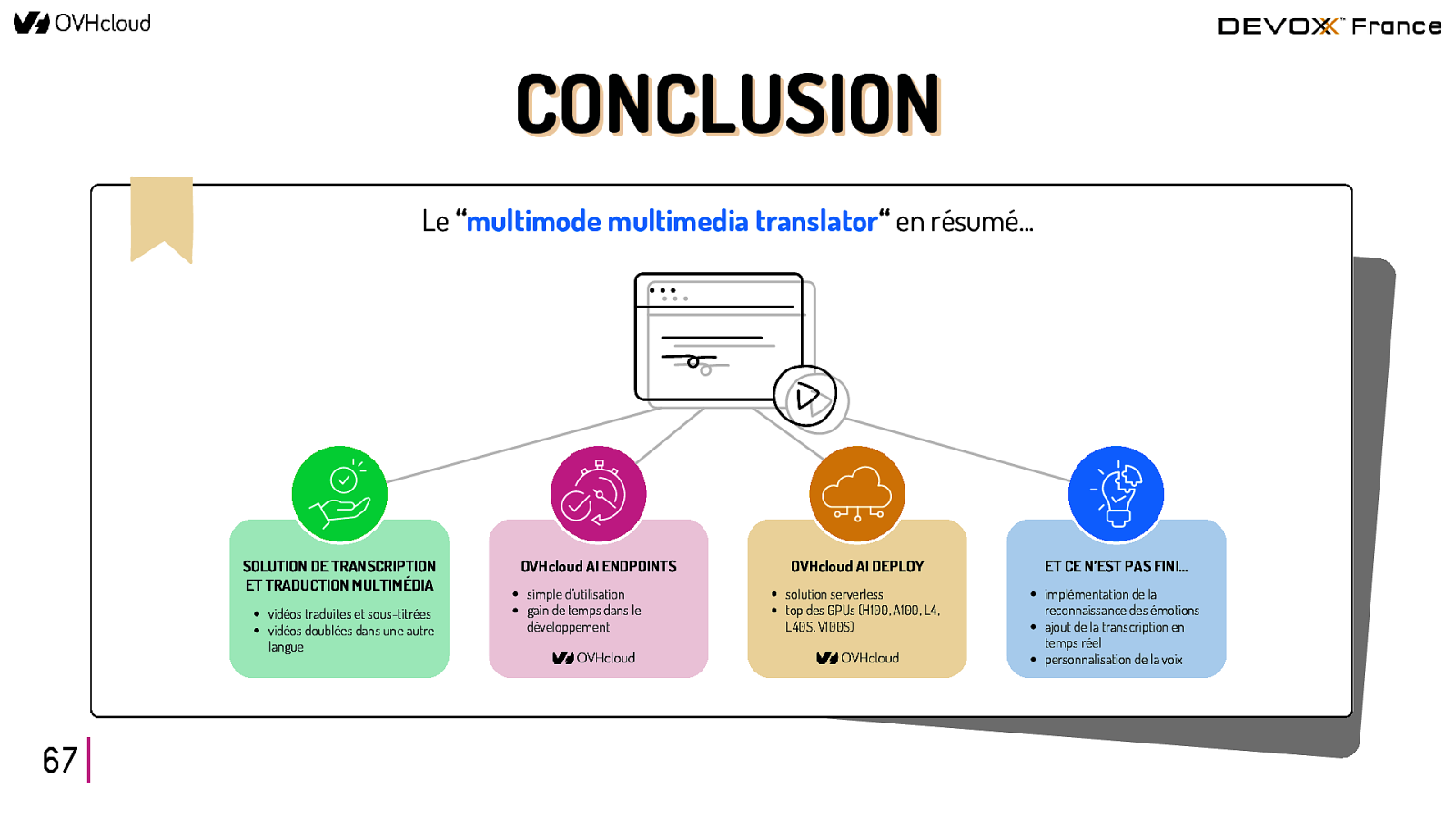
CONCLUSION Le “multimode multimedia translator“ en résumé… SOLUTION DE TRANSCRIPTION ET TRADUCTION MULTIMÉDIA vidéos traduites et sous-titrées vidéos doublées dans une autre langue 67 OVHcloud AI ENDPOINTS simple d’utilisation gain de temps dans le développement OVHcloud AI DEPLOY solution serverless top des GPUs (H100, A100, L4, L40S, V100S) ET CE N’EST PAS FINI… implémentation de la reconnaissance des émotions ajout de la transcription en temps réel personnalisation de la voix

OVHcloud AI ENDPOINTS 68 https://endpoints.ai.cloud.ovh.net/

MERCI !

À VOUS DE TESTER ! https://bit.ly/multimedia-translator-devoxx