Active Disks A Case for Remote Execution in Network-Attached Storage Erik Riedel Carnegie Mellon University http://www.cs.cmu.edu/~riedel Carnegie Mellon Parallel Data Laboratory

A presentation at Parallel Data Lab Annual Retreat in November 1997 in Pittsburgh, PA, USA by erik riedel

Active Disks A Case for Remote Execution in Network-Attached Storage Erik Riedel Carnegie Mellon University http://www.cs.cmu.edu/~riedel Carnegie Mellon Parallel Data Laboratory

Introduction l Trends » processing power at storage is increasing » bottlenecks are in other parts of the system l Opportunity » allow application-specific code to execute inside storage devices » use shipped functions at storage to offload network and client/server work Carnegie Mellon Parallel Data Laboratory

Outline l Trends l Opportunity l Potential applications l Experiment l Mechanisms l Conclusions & future work Carnegie Mellon Parallel Data Laboratory

Trends l Increased processing power on drives » 100 MHz RISC core coming soon » not involved in fastpath processing – lots of idle cycles – needs “value added” work to do l System bottlenecks shifting » drive throughput is not the major problem – network utilization – client/server processing Carnegie Mellon Parallel Data Laboratory

Trends (2) l l Majority of aggregate CPU (and soon memory?) in a system is at the disks Microsoft TerraServer » 4-CPU AlphaServer 4100 – (4 x 400 = 1,600 MIPS) – 2,048 MB RAM » 320 disks (1.3 TB) – (320 x 25 = 8,000 MIPS) – (320 x 1 = 320 MB) l Compaq ProLiant TPC-C » Four 200 MHz Pentium Pros – (4 x 200 = 800 MIPS) – 4,096 MB RAM » 113 disks (708 GB) – (113 x 25 = 2,825 MIPS) – (113 x 1 = 113 MB) » largest part of system cost is the storage Carnegie Mellon Parallel Data Laboratory

Opportunity l Candidate applications » can leverage the available parallelism – highly concurrent workloads – lots of drives compensate for lower relative MIPS » are localized to small amounts of data – process as data “streams past” » have small code/cycle footprint per byte » can use scheduling, management primitives – enable a new range of storage functions Carnegie Mellon Parallel Data Laboratory

Opportunity (2) l Classes of applications » filtering - search, association matching, sort » batching - collective I/O scheduling » real-time - video server » storage management - backup, layout » specialized support - locks, transactions Carnegie Mellon Parallel Data Laboratory

Applications - TIP Suite l Reduce data transfer w/ “low” cost » agrep - significant filtering » xDataSlice - some filtering » gnuld - expensive computation » Sphinx - cpu intensive » Postgres – indexed join - poor locality w/o hints – unindexed select - good filtering Carnegie Mellon Parallel Data Laboratory
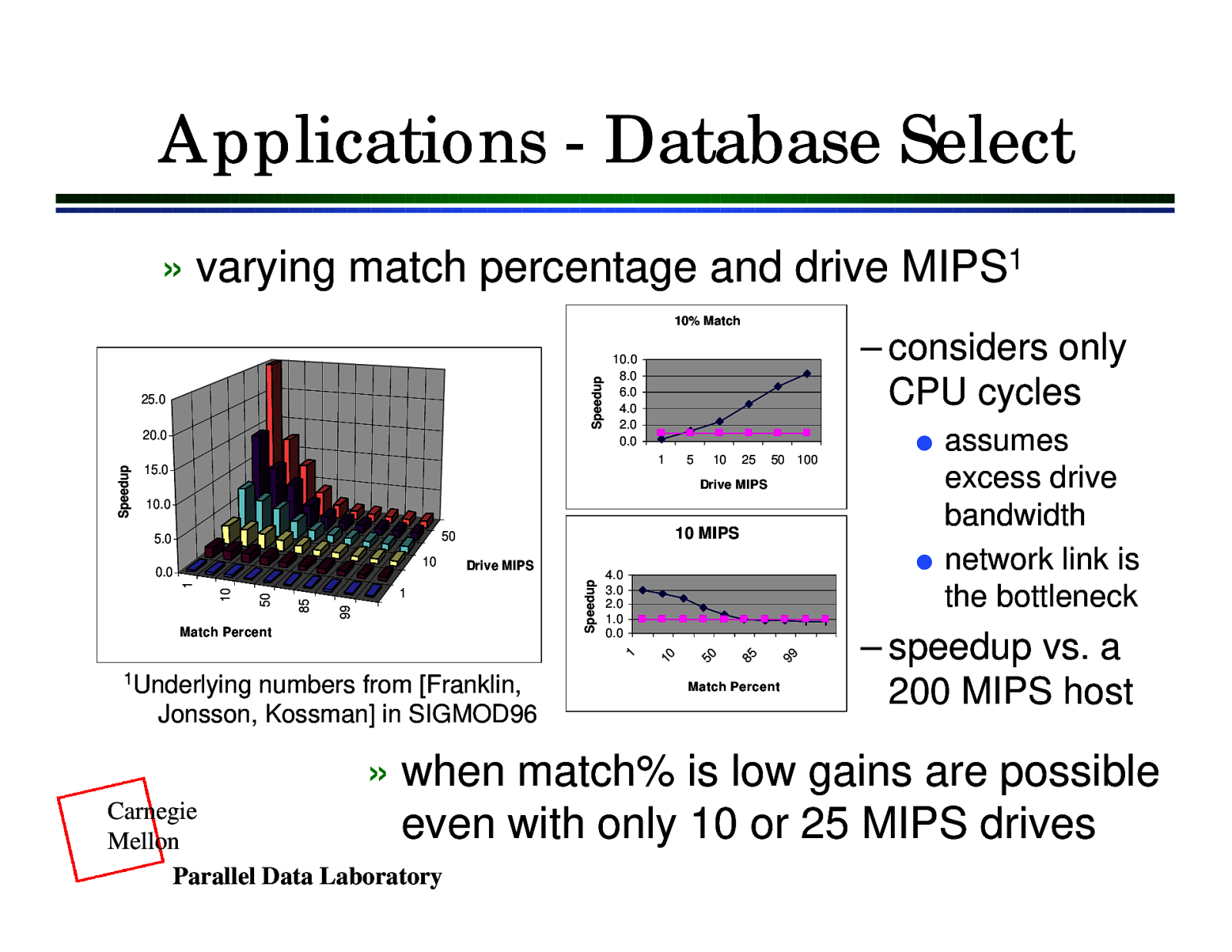
Applications - Database Select » varying match percentage and drive MIPS1 Speedup 10% Match 25.0 l 1 15.0 5 10 25 50 100 Drive MIPS 10.0 10 MIPS 50 1Underlying numbers from [Franklin, Jonsson, Kossman] in SIGMOD96 99 1 Match Percent l 4.0 3.0 2.0 1.0 0.0 85 1 99 85 50 10 1 Drive MIPS 50 10 0.0 10 5.0 Speedup Speedup 20.0 – considers only CPU cycles 10.0 8.0 6.0 4.0 2.0 0.0 Match Percent assumes excess drive bandwidth network link is the bottleneck – speedup vs. a 200 MIPS host » when match% is low gains are possible even with only 10 or 25 MIPS drives Carnegie Mellon Parallel Data Laboratory
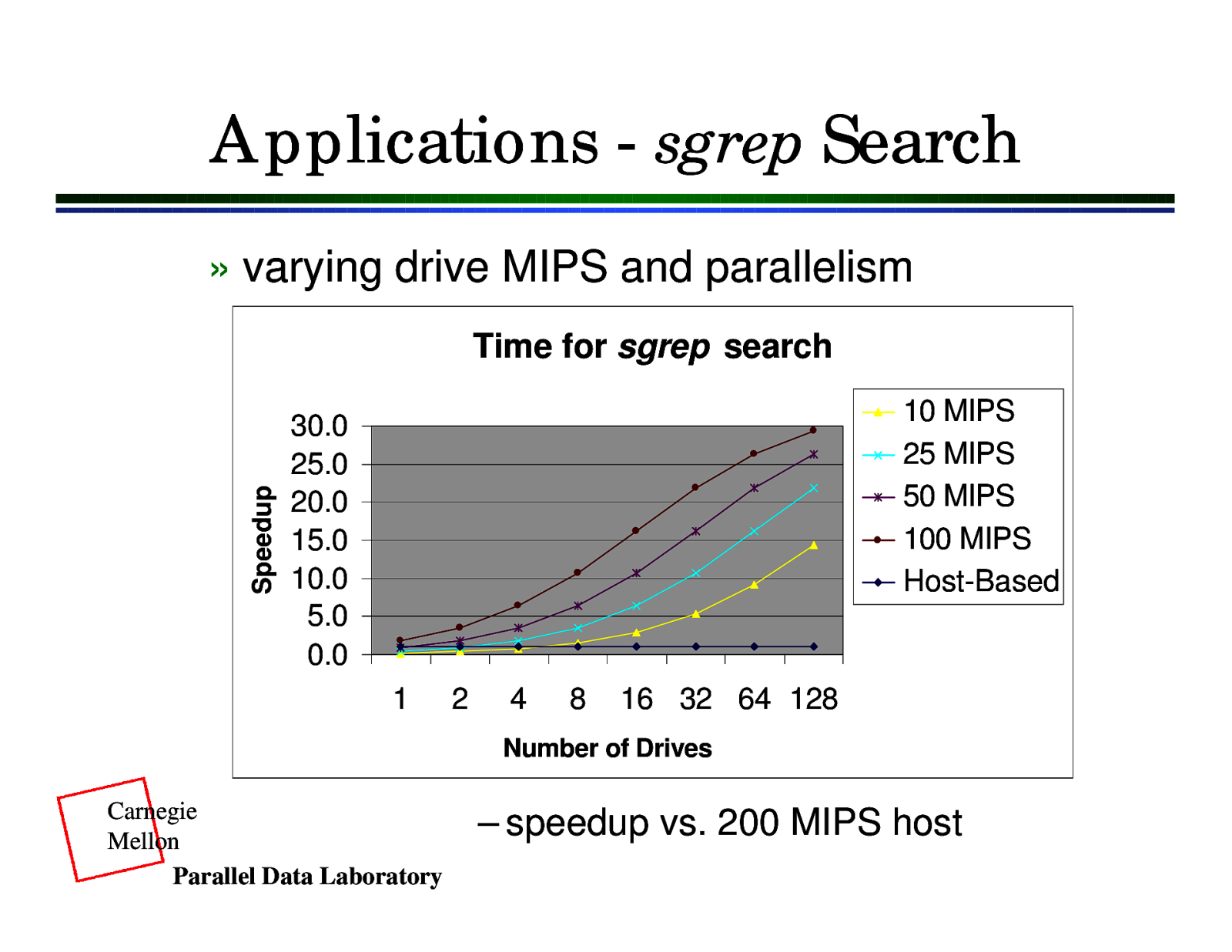
Applications - sgrep Search » varying drive MIPS and parallelism Speedup Time for sgrep search 10 MIPS 25 MIPS 50 MIPS 100 MIPS Host-Based 30.0 25.0 20.0 15.0 10.0 5.0 0.0 1 2 4 8 16 32 64 128 Number of Drives Carnegie Mellon Parallel Data Laboratory – speedup vs. 200 MIPS host

Experiment - SampleSort l Two stage parallel sort » sample data » create distribution histogram » distribute data to clients based on histogram » sort locally at clients » write back in sorted order l Observation » filter operation on key ranges Carnegie Mellon Parallel Data Laboratory

Experiment - NasdSort l Implementation on NASD prototype » two simple functions “shipped” to drive – sample() l read() request that returns only a subset of the data – scan() l l read() request that returns data for a specific key range buffers data from other ranges for later requests » single master collects samples » synchronization handled at the drives Carnegie Mellon Parallel Data Laboratory

Experiment - NasdSort (2) l Future extensions » larger data sets – add a merge phase at the end » perform entire sort at drives – more complex than scan() and sample() – requires more cycles – requires additional memory » examine other sorting algorithms – different scheduling characteristics Carnegie Mellon Parallel Data Laboratory

Mechanisms l Execution environment » protect the drive and data – against corruption/“leaks” l Programming environment » how to specify remote code – how to “split” applications in the brave new world l Resource management » competition within the drive – sector bandwidth, cache space, processor cycles Carnegie Mellon Parallel Data Laboratory
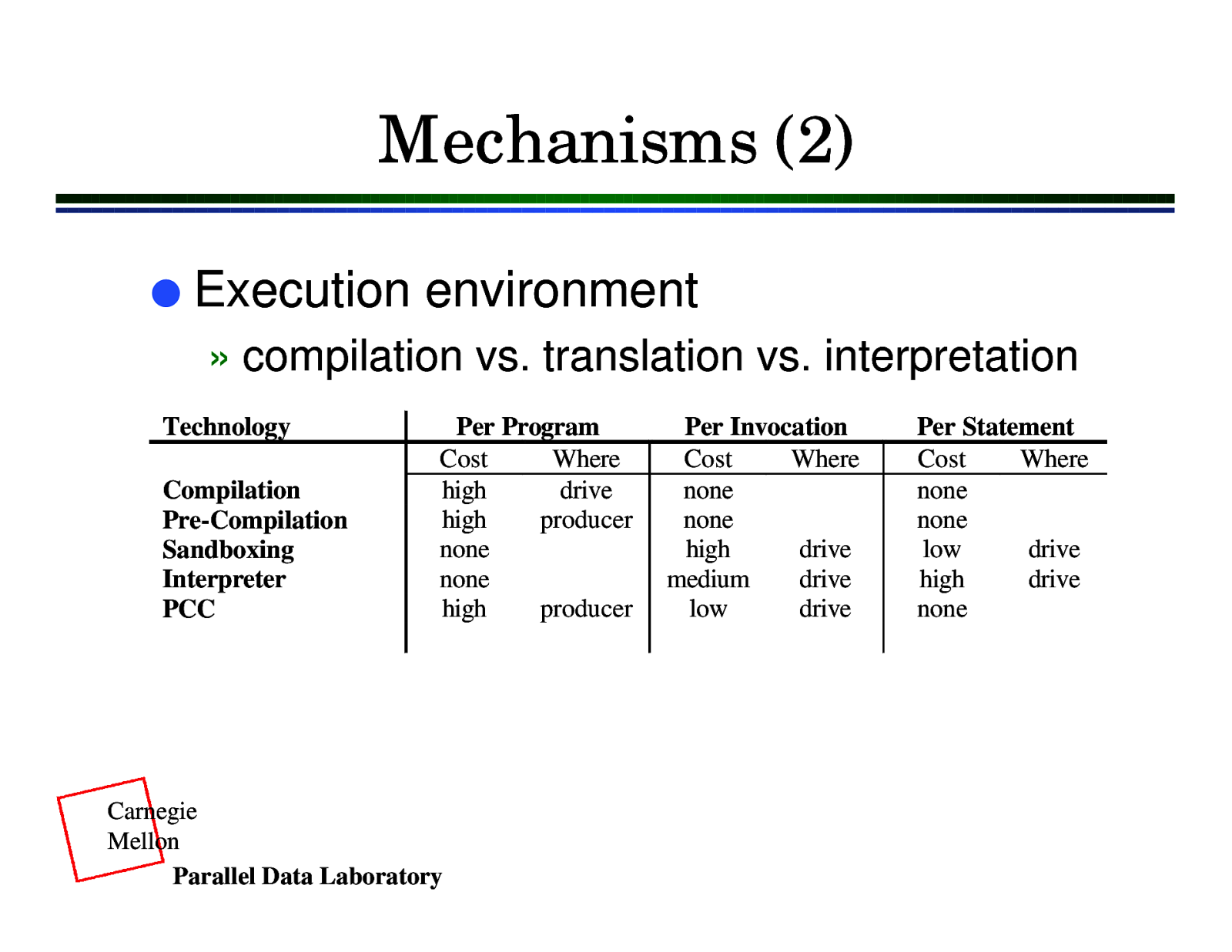
Mechanisms (2) l Execution environment » compilation vs. translation vs. interpretation Technology Compilation Pre-Compilation Sandboxing Interpreter PCC Per Program Cost Where high drive high producer none none high producer Carnegie Mellon Parallel Data Laboratory Per Invocation Cost Where none none high drive medium drive low drive Per Statement Cost Where none none low drive high drive none

Mechanisms (3) l Internal drive interface Functionality Filter basic filesystem API stdin/stdout to requestor asynchronous “callbacks” long(ish)-term state time/deadlines real-time scheduler admission control drive internals - query cache internals - query layout internals - control cache internals - control layout internals - control ordering internals – “eavesdrop” requests initiate commands to 3rd parties object locks/atomicity X X Carnegie Mellon Parallel Data Laboratory ? Video Stream X X X X X ? Batching Manage ment X X X X X X X ? X ? Transact ions X X ? X X X X X X ? ? ? X

Resource Management l How to “control” the impact at drive » limit functions to the cost of a “normal” op – allow 2-3x the resources of a read() operation » allow functions only during “idle” periods – problematic in the presence of prefetching e.g. » allocate a specific amount of resources to RE – allocate that among all active functions » TIP-like model cost/benefit – minimize total application wait Carnegie Mellon Parallel Data Laboratory
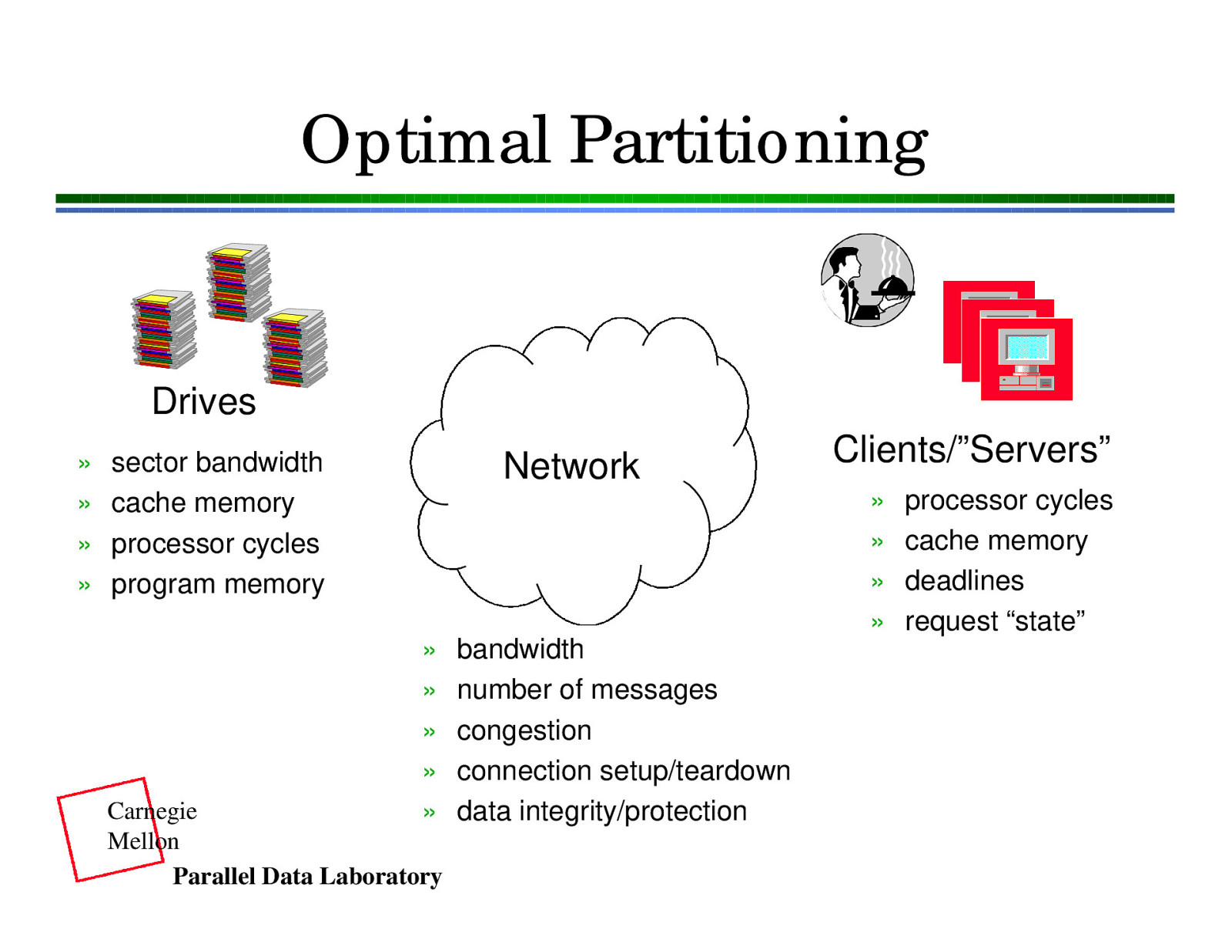
Optimal Partitioning Drives » » » » sector bandwidth cache memory processor cycles program memory Network Clients/”Servers” » » » » » » » » » Carnegie Mellon Parallel Data Laboratory bandwidth number of messages congestion connection setup/teardown data integrity/protection processor cycles cache memory deadlines request “state”

Conclusions Significant “free” processing capability available on storage devices l Potential for improving performance across a range of application classes l Opportunity for value-add directly at storage devices l Carnegie Mellon Parallel Data Laboratory

Future Work l Resource management » admission control for shipped functions l Trusted environment » pre-compilation for safety Storage management applications l Additional domains l » data warehousing » web servers Carnegie Mellon Parallel Data Laboratory

Related Work l Active technologies » Active Networks (MIT), Liquid software (Arizona), Postscript (Adobe) l Database technologies » Hybrid-shipping (Maryland), nowSort (Berkeley), Parallel database systems, Database machines, Channel programs Carnegie Mellon Parallel Data Laboratory

Related Work (2) l Extensible operating systems » SPIN (Washington), exokernel (MIT), VINO (Harvard), Scout (Arizona), Synthetix (OGI) l Language technologies » OmniWare (Berkeley/CMU), Toba (Arizona), Javelin (Santa Barbara), Inferno (Bell Labs), Proof-Carrying Code (CMU) l Object Technologies » CORBA, DataBlades (Sybase), DCOM Carnegie Mellon Parallel Data Laboratory