A presentation at Tech Talk @ Tagesspiegel by Gunnar Bittersmann

TIL warum nicht GROẞ

Unicode und das große ẞ
The following resources were mentioned during the presentation or are useful additional information.
This file is a supplement to the UnicodeData.txt file. It does not define any properties, but rather provides additional information about the casing of Unicode characters, for situations when casing incurs a change in string length or is dependent on context or locale.
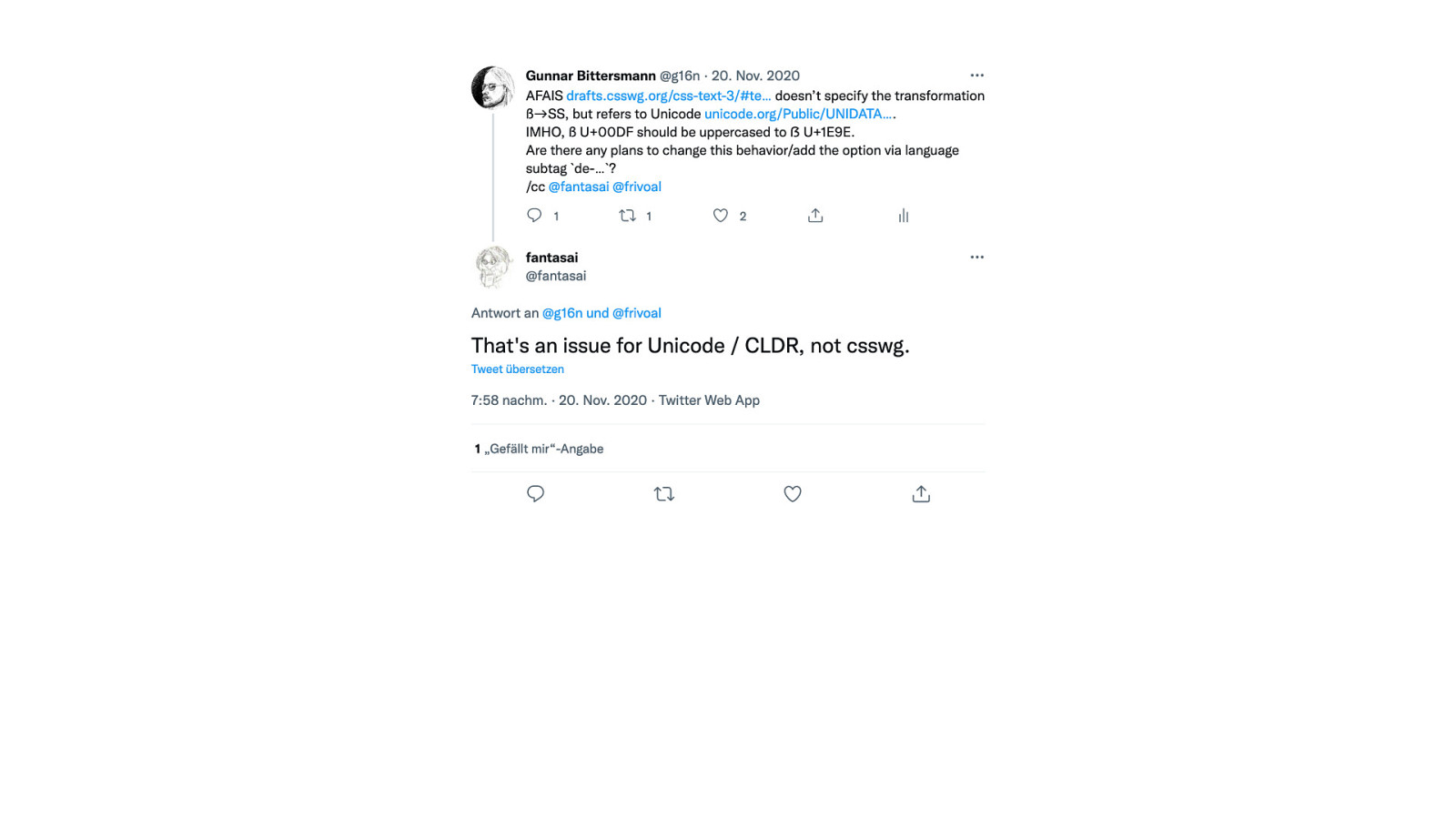
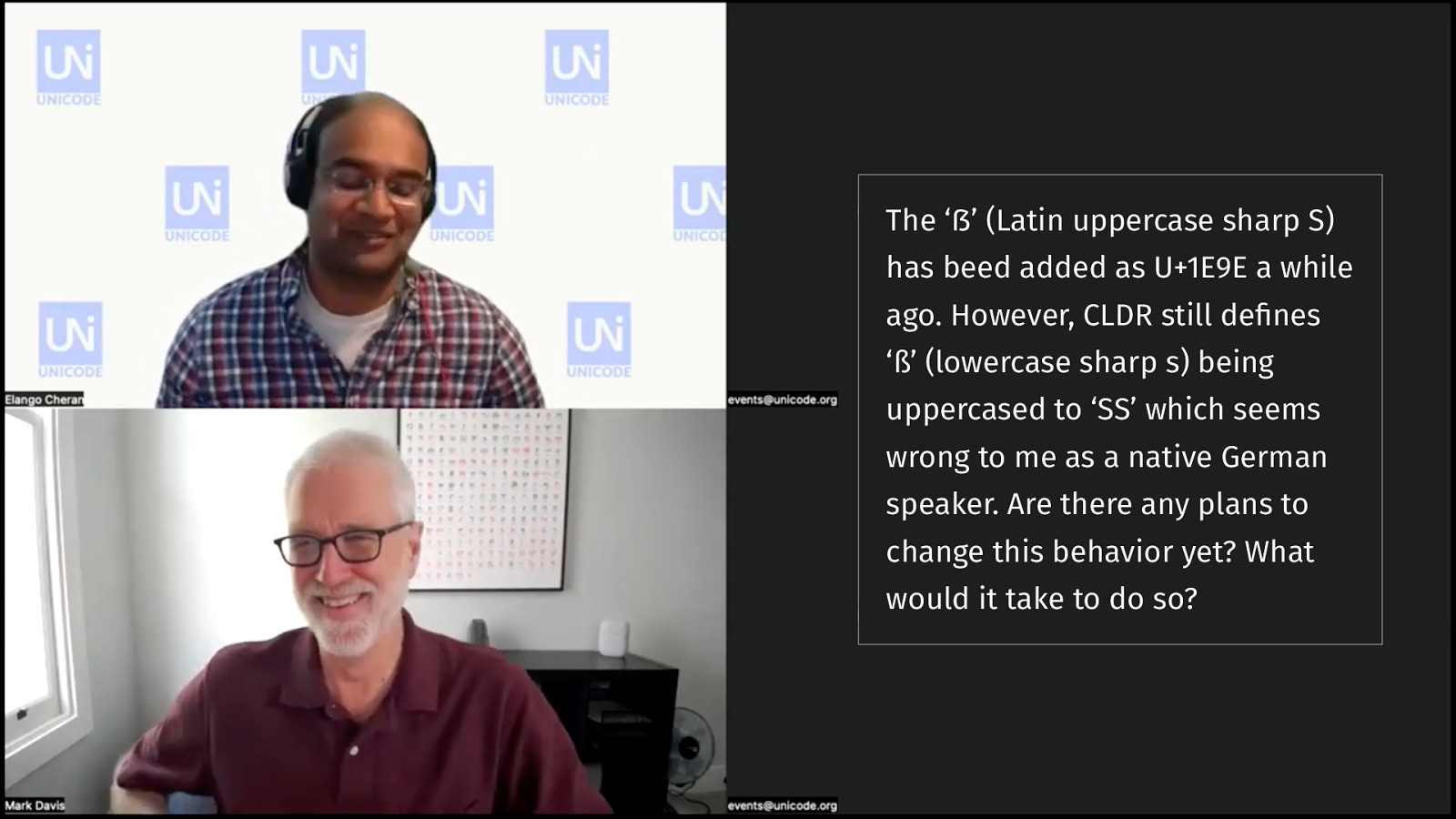
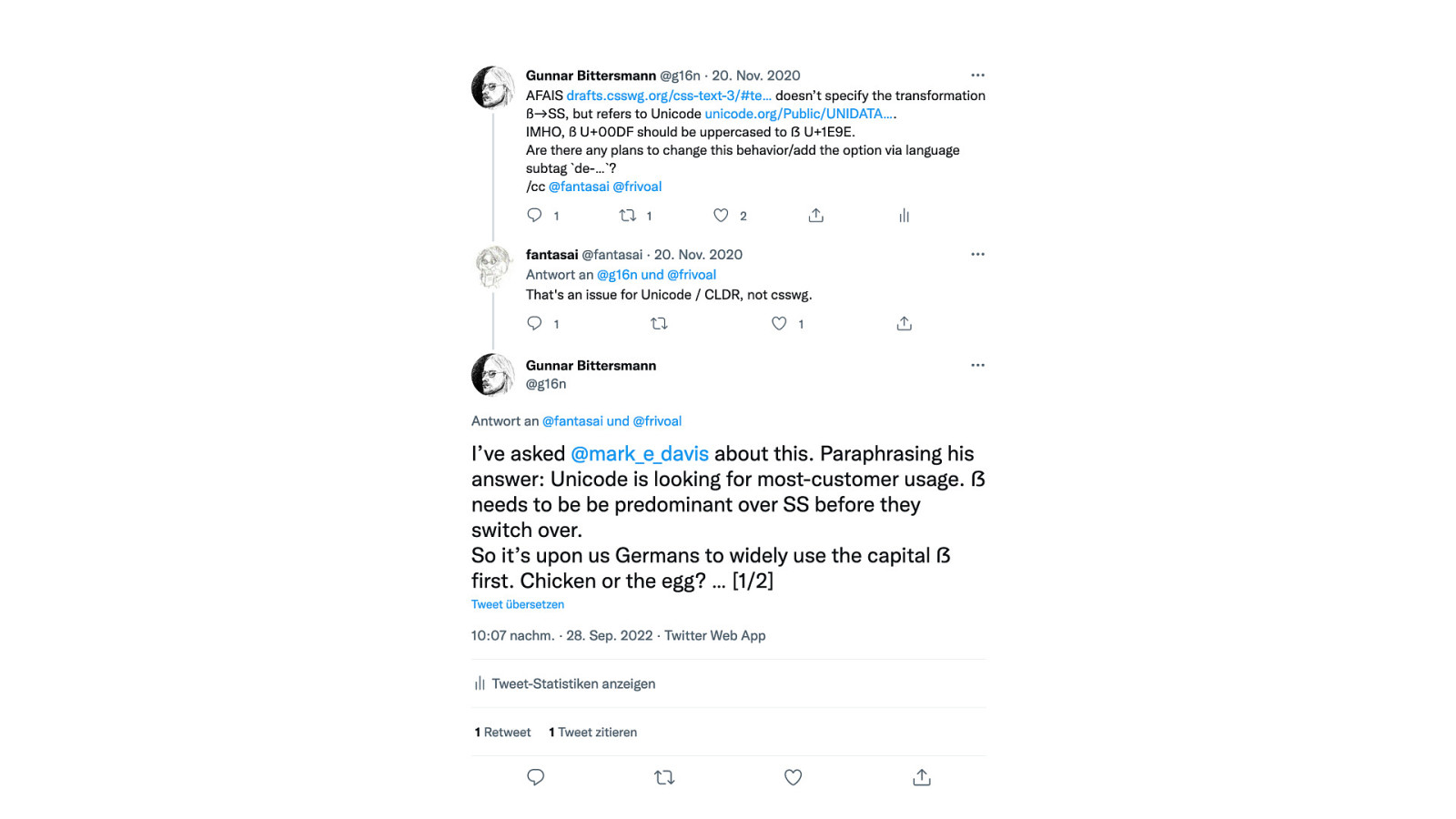
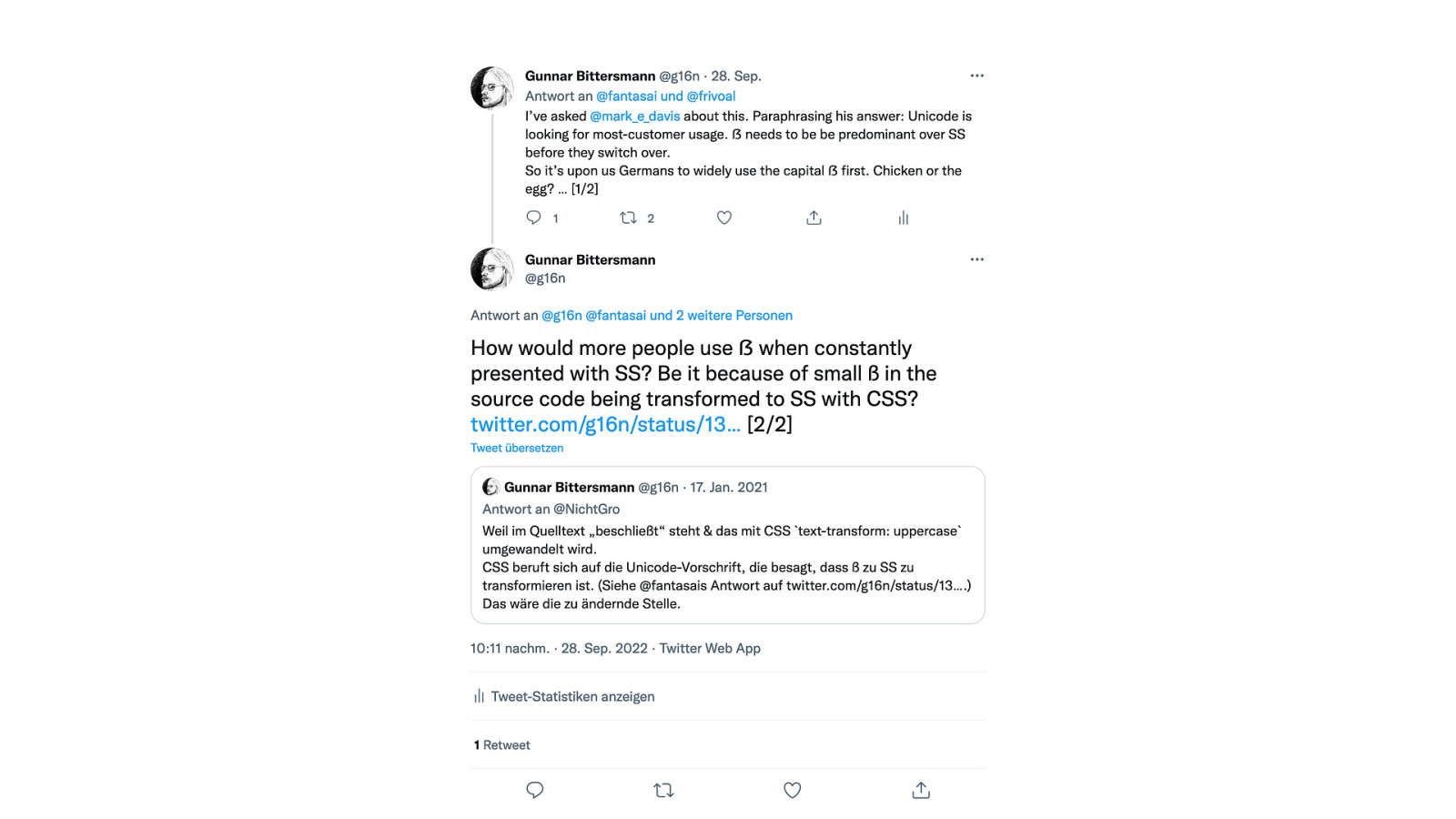
Mark Davis answers my question:
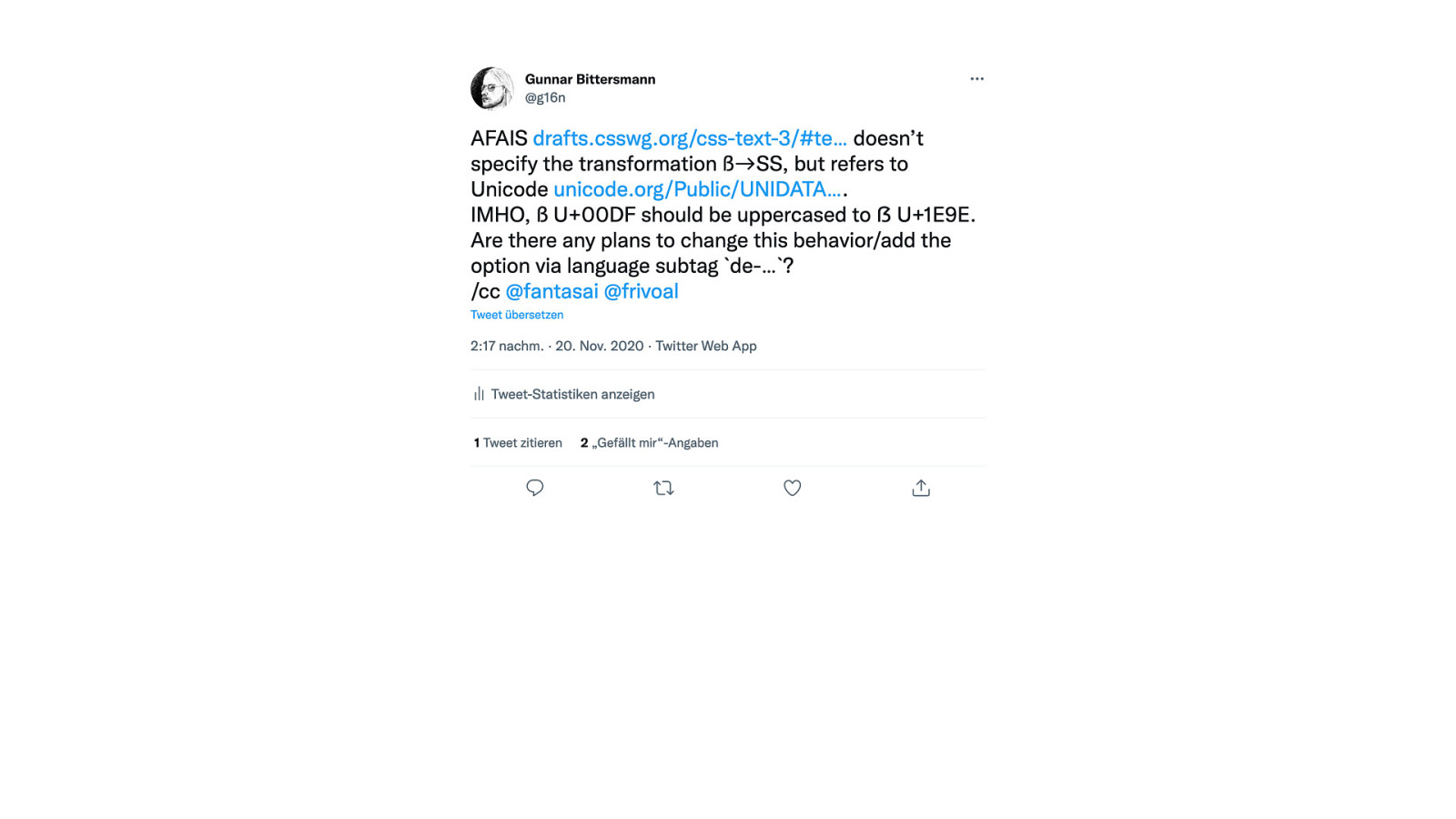
The ẞ (Latin uppercase sharp S) has beed added as U+1E9E a while ago. However, CLDR still defines ß (lowercase sharp s) being uppercased to SS which seems wrong to me as a native German speaker. Are there any plans to change this behavior yet? What would it take to do so?
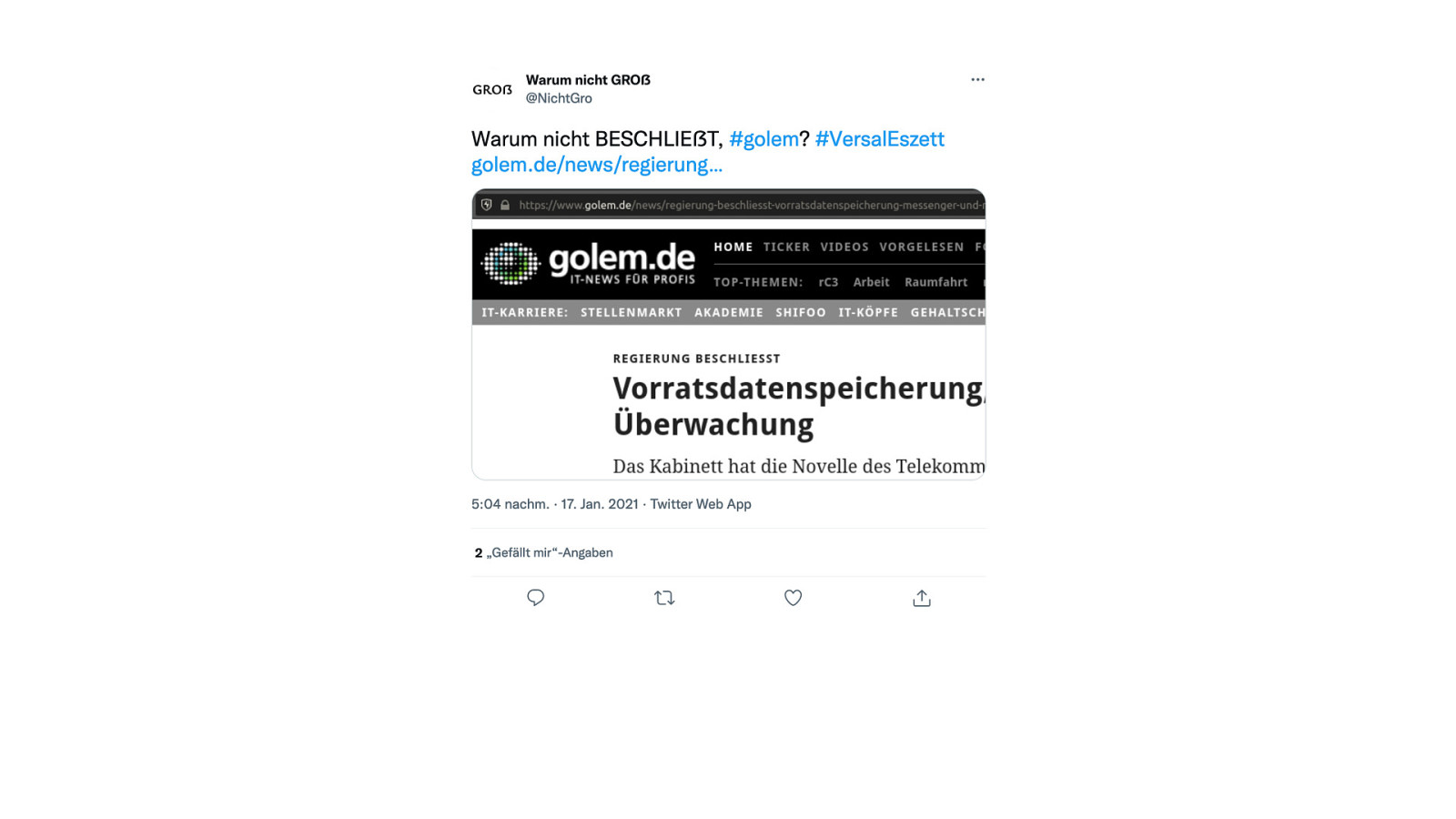
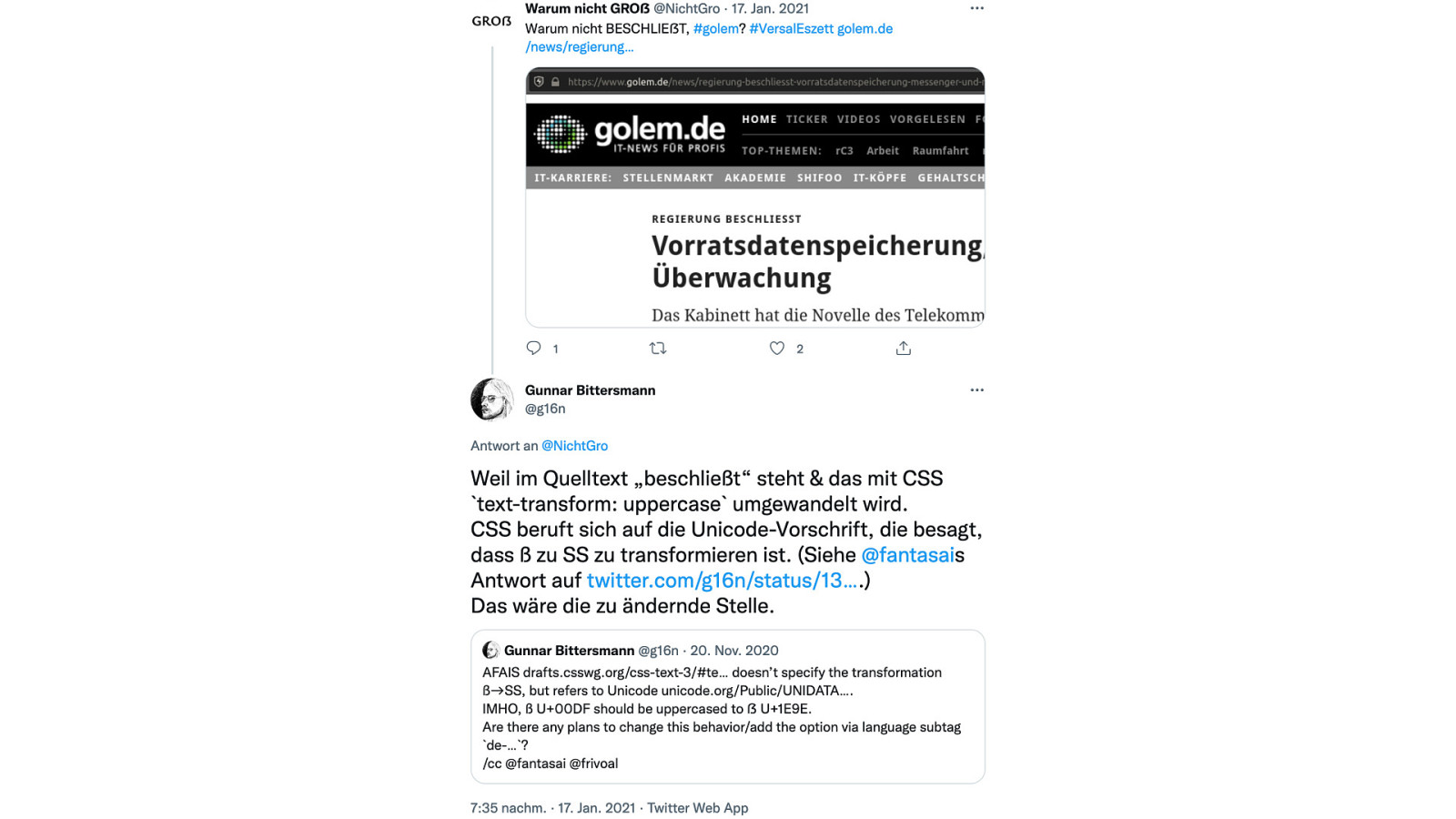
Here’s what was said about this presentation on social media.