
A presentation at SLOconf Monthly Meetup by Julie Gunderson

The Road To Resilience: Chaos Engineering, GameDays, & Disaster Recovery Julie Gunderson, Sr. Reliability Advocate @Gremlin @julie_gund
Reliability is no Accident @julie_gund
Recent News Headlines @julie_gund
4
Recent News Headlines @julie_gund
Julie Gunderson Sr. Reliability Advocate Julie@gremlin.com @julie_gund
Gene Kim Jez Humble Nicole Forsgren @julie_gund
Accelerate was published in 2018 by Nicole Forsgren, Jez Humble and Gene Kim. The evidence collected prior to the release of the book refuted the bimodal notion in tech that you have to choose between speed and stability. They discovered that speed actually depends on stability, so good tech practices give you both. @julie_gund
Today we will explore three key practices that improve tempo and stability @julie_gund
What is tempo and stability? Tempo is measured by deployment frequency and change lead time Stability is measured by mean time to recover (MTTR) and change failure rate @julie_gund
What is tempo and stability? Tempo Deployment Frequency The rate that software is deployed to production or an app store (e.g. within a range of multiple times a day to once a year) Tempo Change Lead Time The time it takes to go from a customer making a request to the request being satisfied Stability Mean Time To Recover (MTTR) The mean time it takes a company to recover from downtime of their software Stability Change Failure Rate The likelihood of defect changes (e.g. ⅕ ) @julie_gund
What are the three key practices? @julie_gund
Three Key Practices: 1. Chaos Engineering 2. GameDays 3. Disaster Recovery @julie_gund
“Build systems that are designed to be deployed easily, can detect and tolerate failures, and can have various components of the system updated independently.” - Accelerate @julie_gund
What is the best way to know if your system can detect and tolerate failure? @julie_gund
Chaos Engineering
Chaos Engineering (Let’s see a dependency demo!) @julie_gund
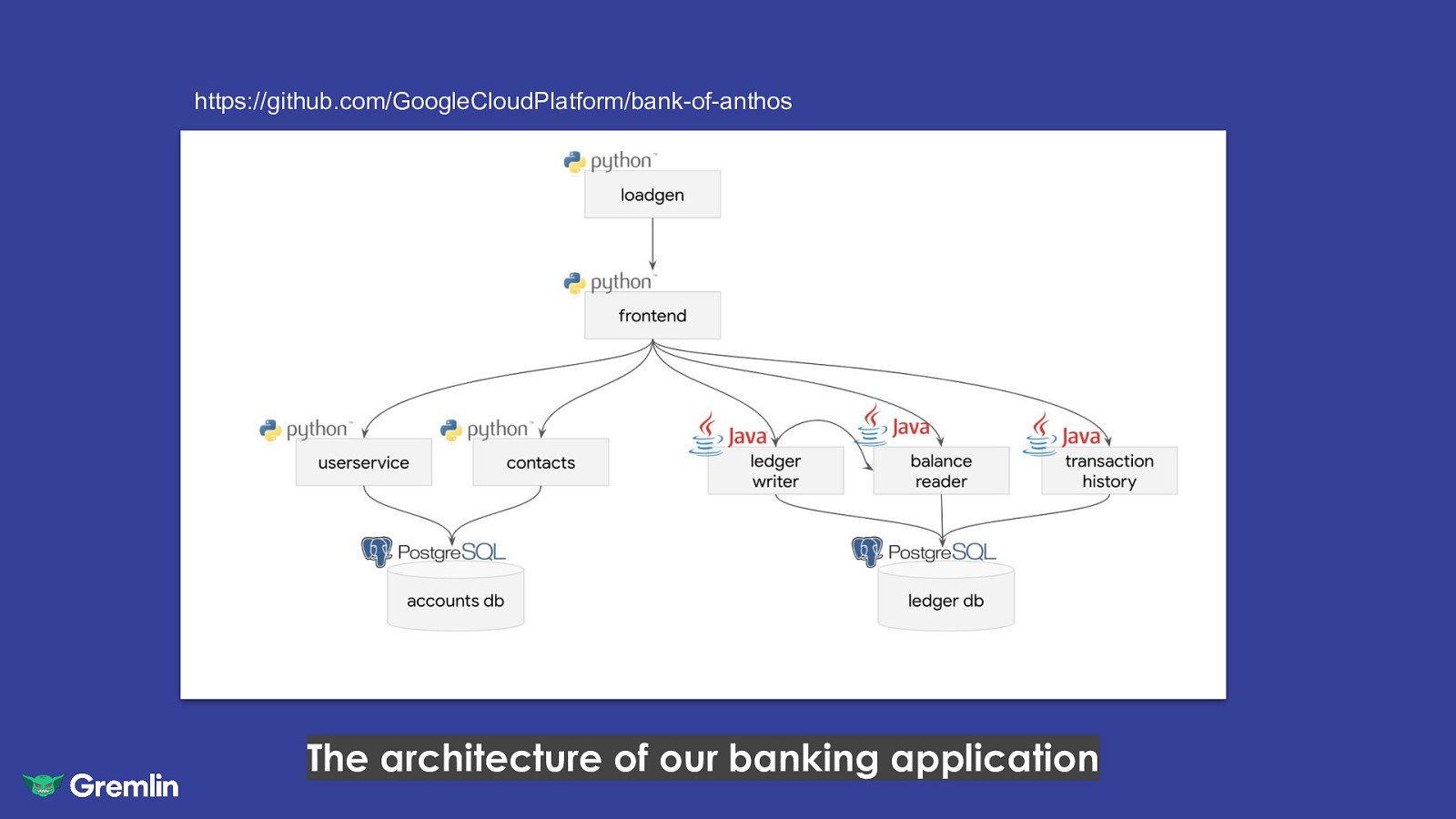
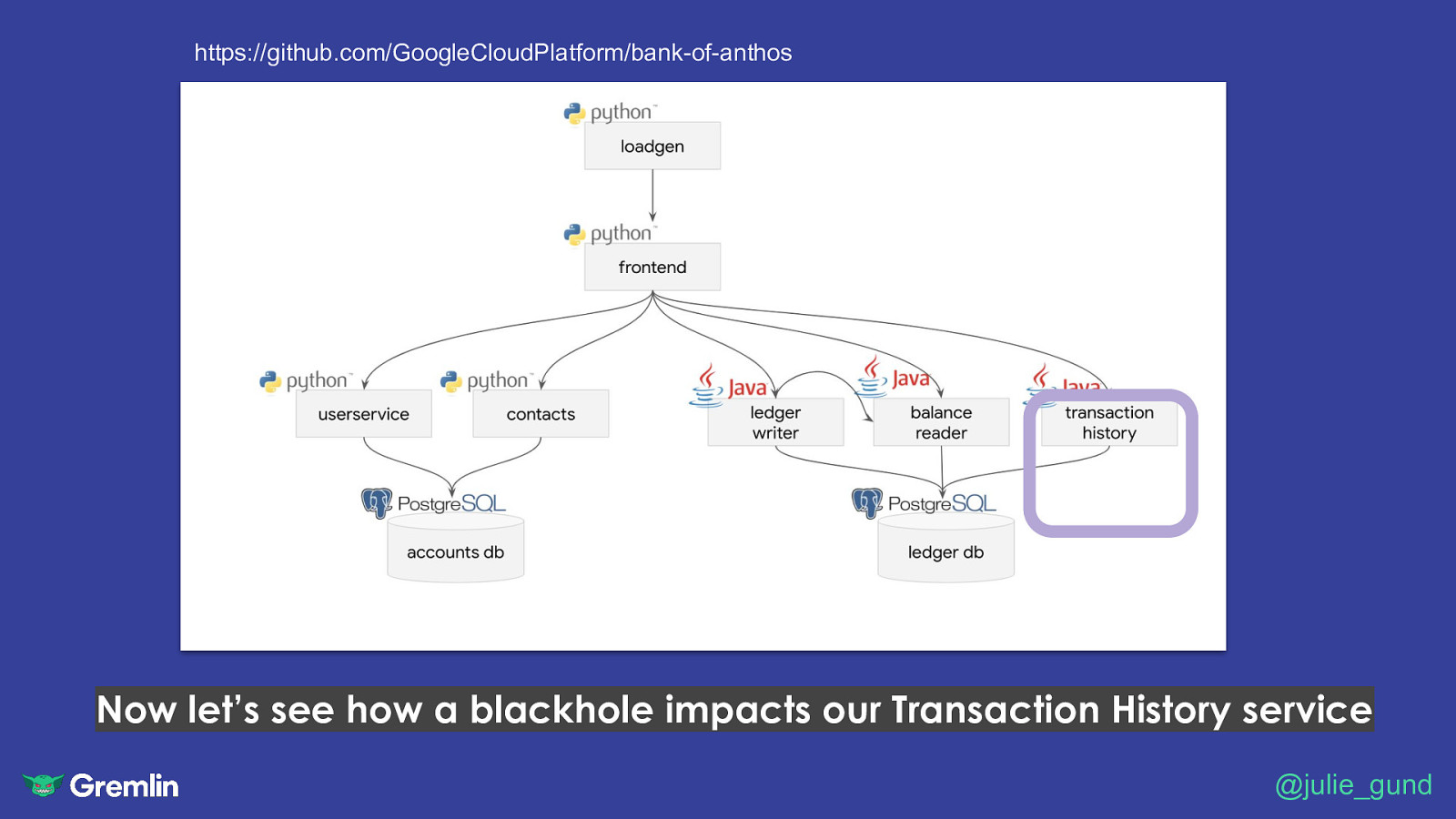
https://github.com/GoogleCloudPlatform/bank-of-anthos The architecture of our banking application
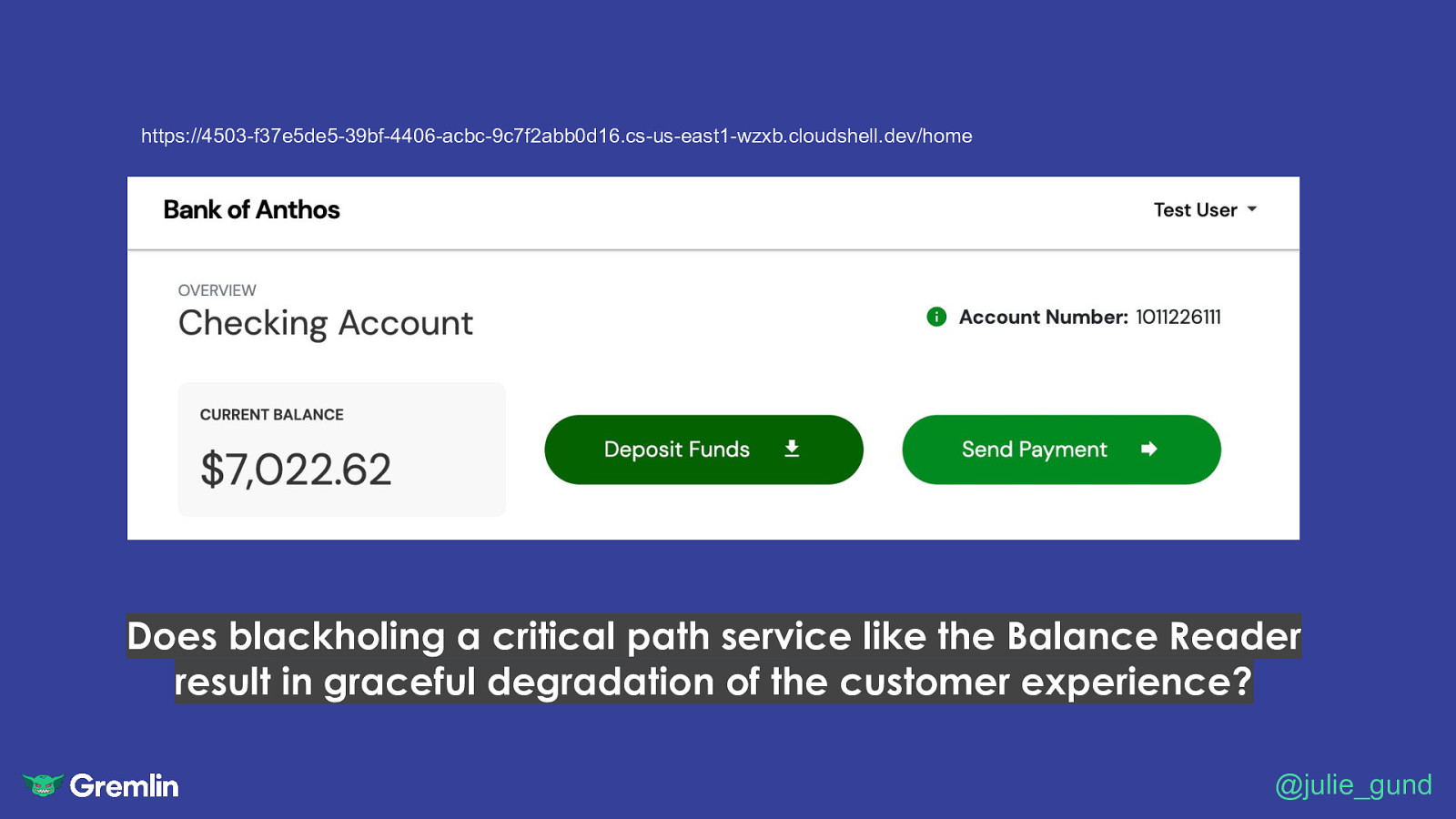
https://4503-f37e5de5-39bf-4406-acbc-9c7f2abb0d16.cs-us-east1-wzxb.cloudshell.dev/home Does blackholing a critical path service like the Balance Reader result in graceful degradation of the customer experience? @julie_gund
https://app.gremlin.com/attacks/new/kubernetes Does blackholing a critical path service like the Balance Reader result in graceful degradation of the customer experience? @julie_gund
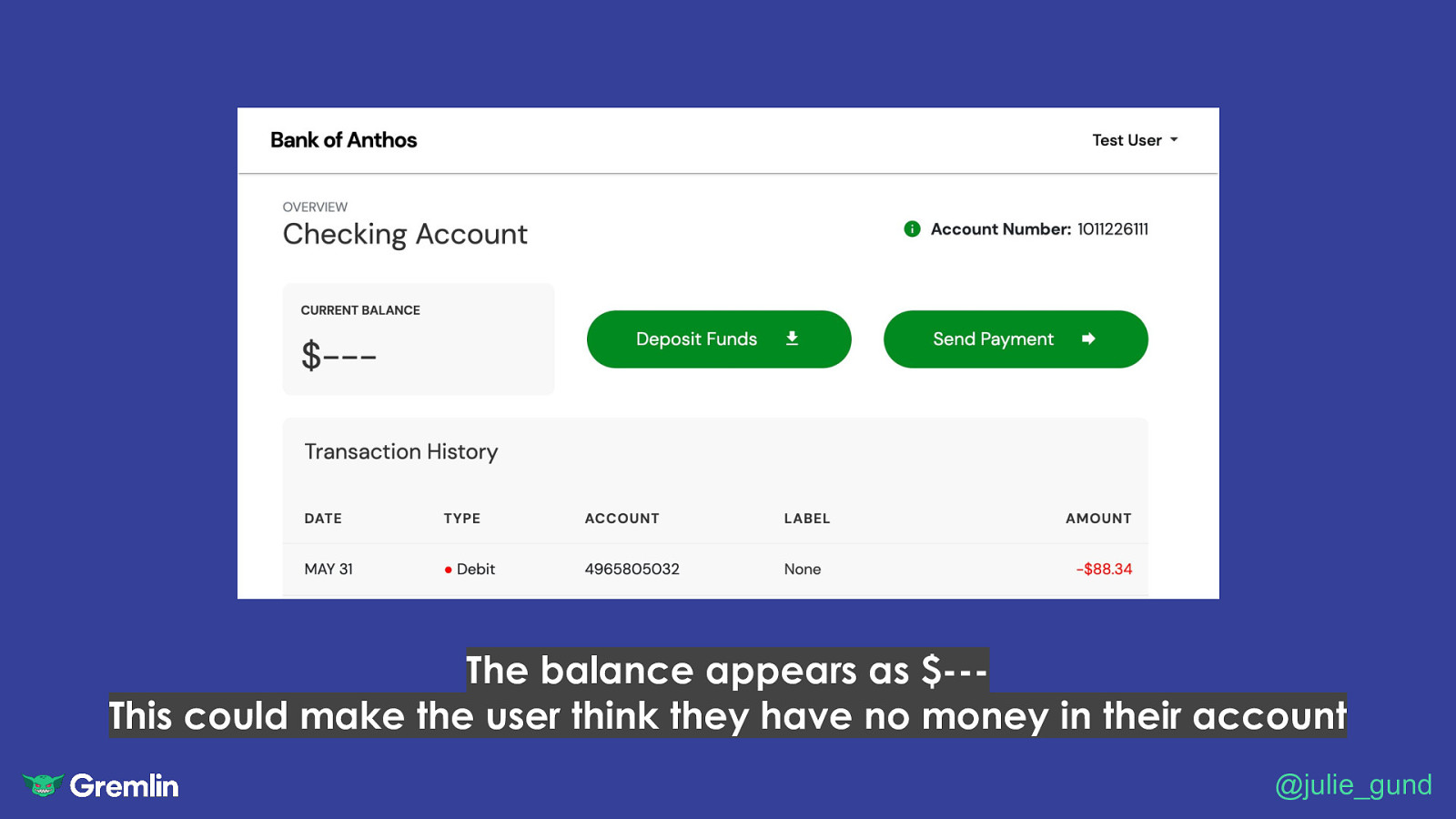
The balance appears as $—This could make the user think they have no money in their account @julie_gund
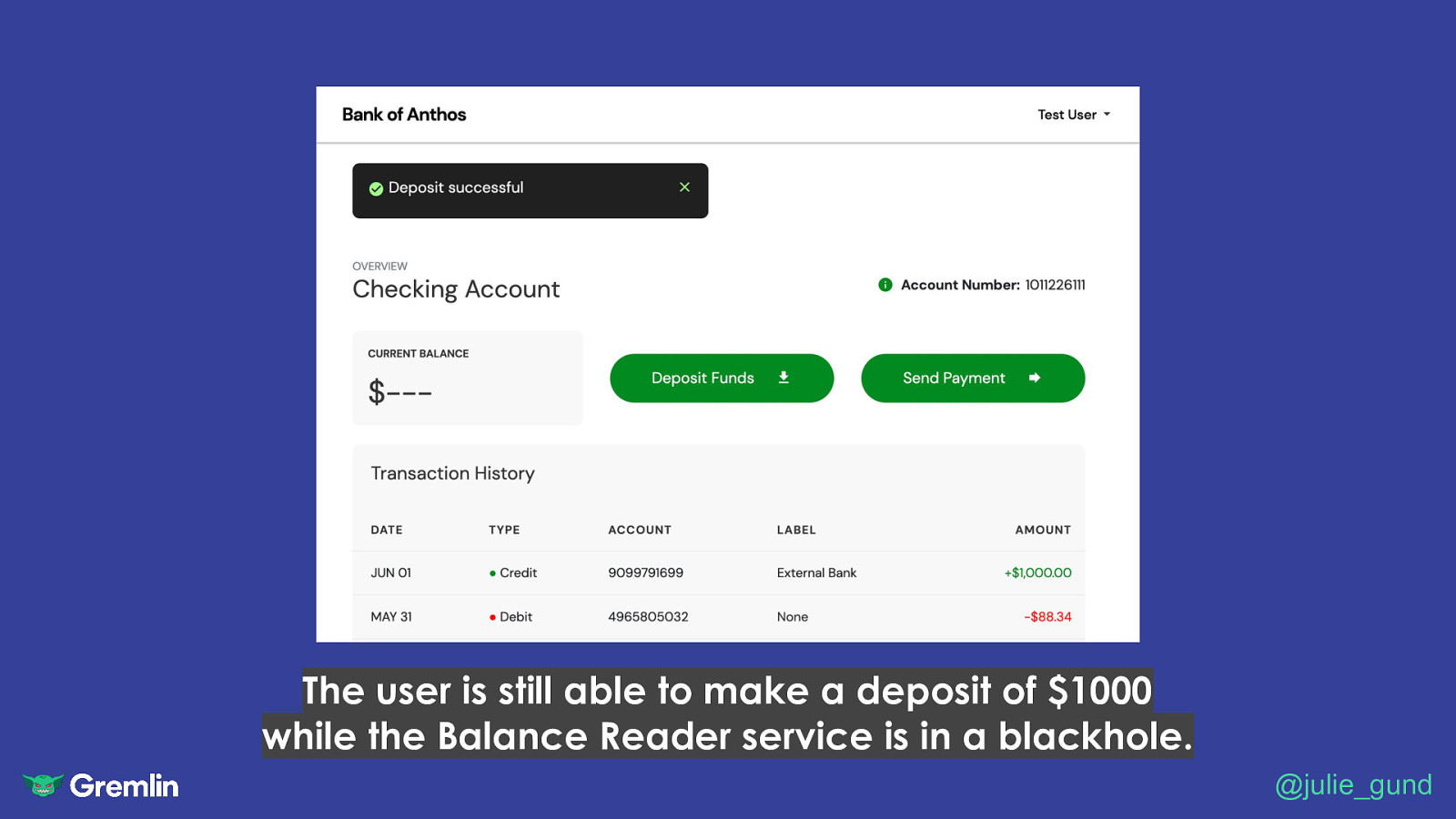
The user is still able to make a deposit of $1000 while the Balance Reader service is in a blackhole. @julie_gund
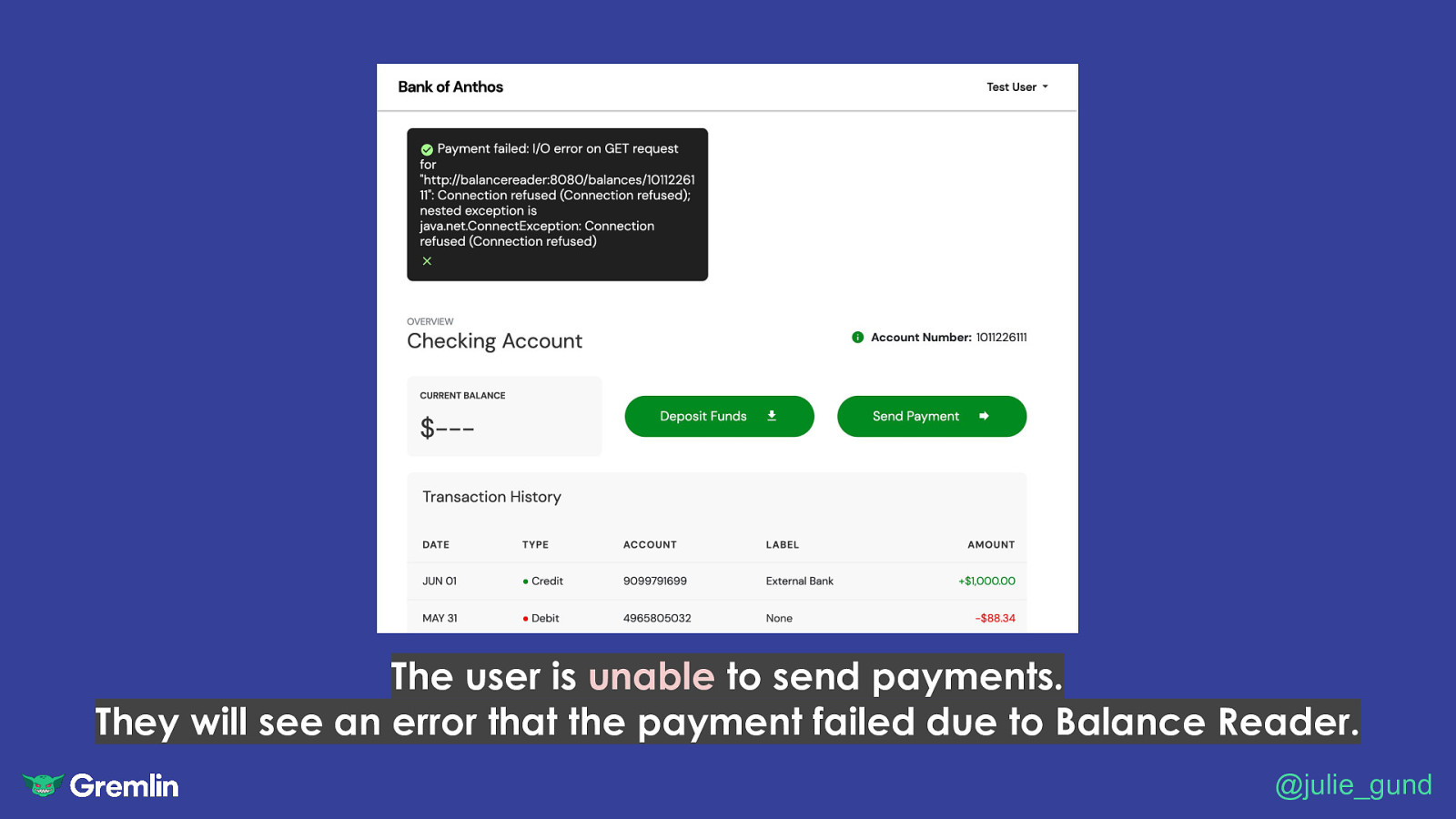
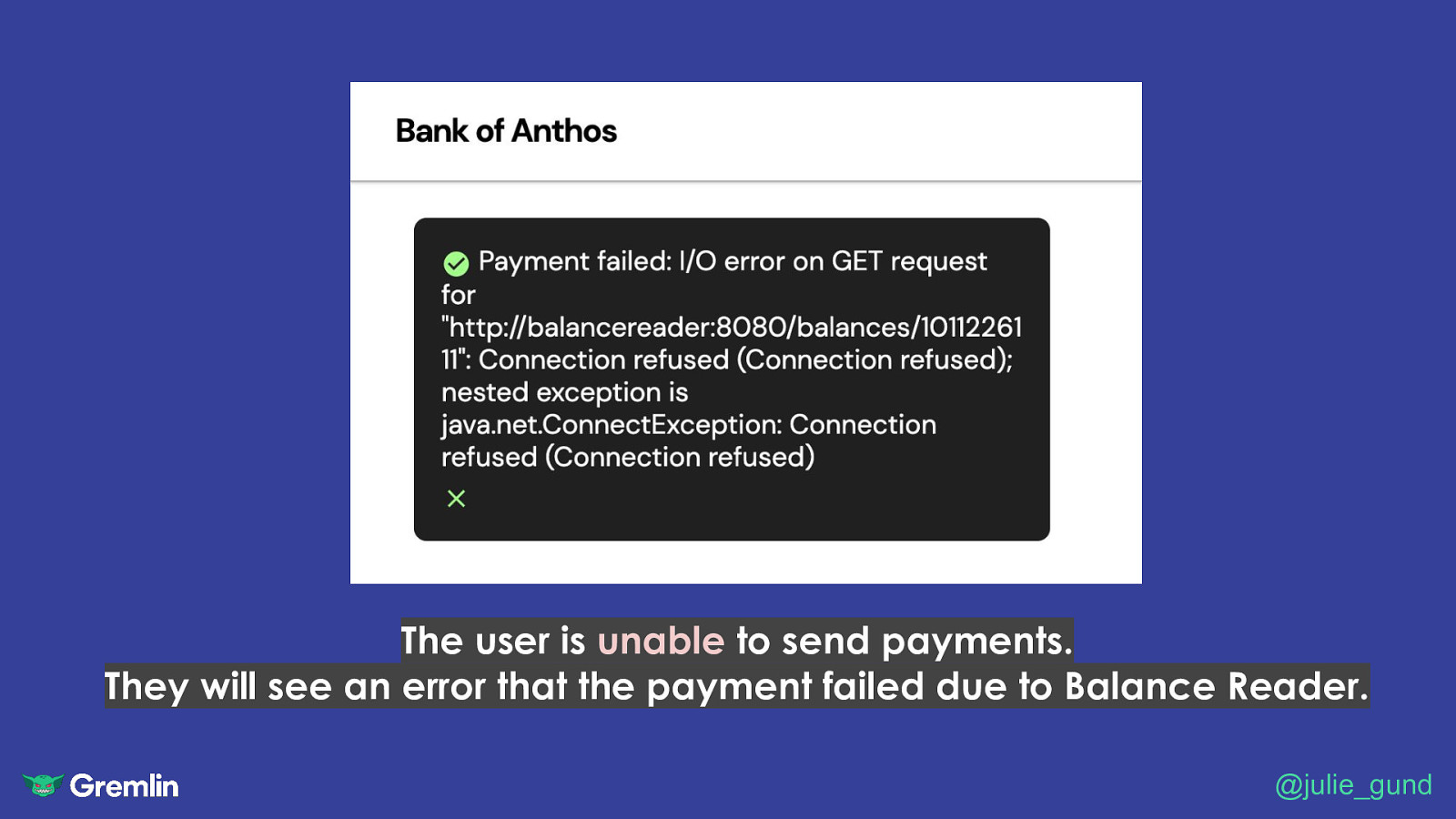
The user is unable to send payments. They will see an error that the payment failed due to Balance Reader. @julie_gund
The user is unable to send payments. They will see an error that the payment failed due to Balance Reader. @julie_gund
Free demo environment to learn about black holes 1. Use this link to install with minikube on google cloud shell: https://ssh.cloud.google.com/cloudshell/editor?show=ide&cloudshell_git_ repo=https://github.com/GoogleCloudPlatform/bank-of-anthos&cloudshe ll_workspace=.&cloudshell_tutorial=extras/cloudshell/tutorial.md 2. Click minikube → start 3. In Cloud Shell terminal, run kubectl apply -f bank-of-anthos/extras/jwt/jwt-secret.yaml 4. Click <> Cloud Code → Run on Kubernetes, change to port 4503 5. To create black holes, create a namespace for gremlin and install gremlin as helm chart https://github.com/gremlin/helm @julie_gund
https://github.com/GoogleCloudPlatform/bank-of-anthos Now let’s see how a blackhole impacts our Transaction History service @julie_gund
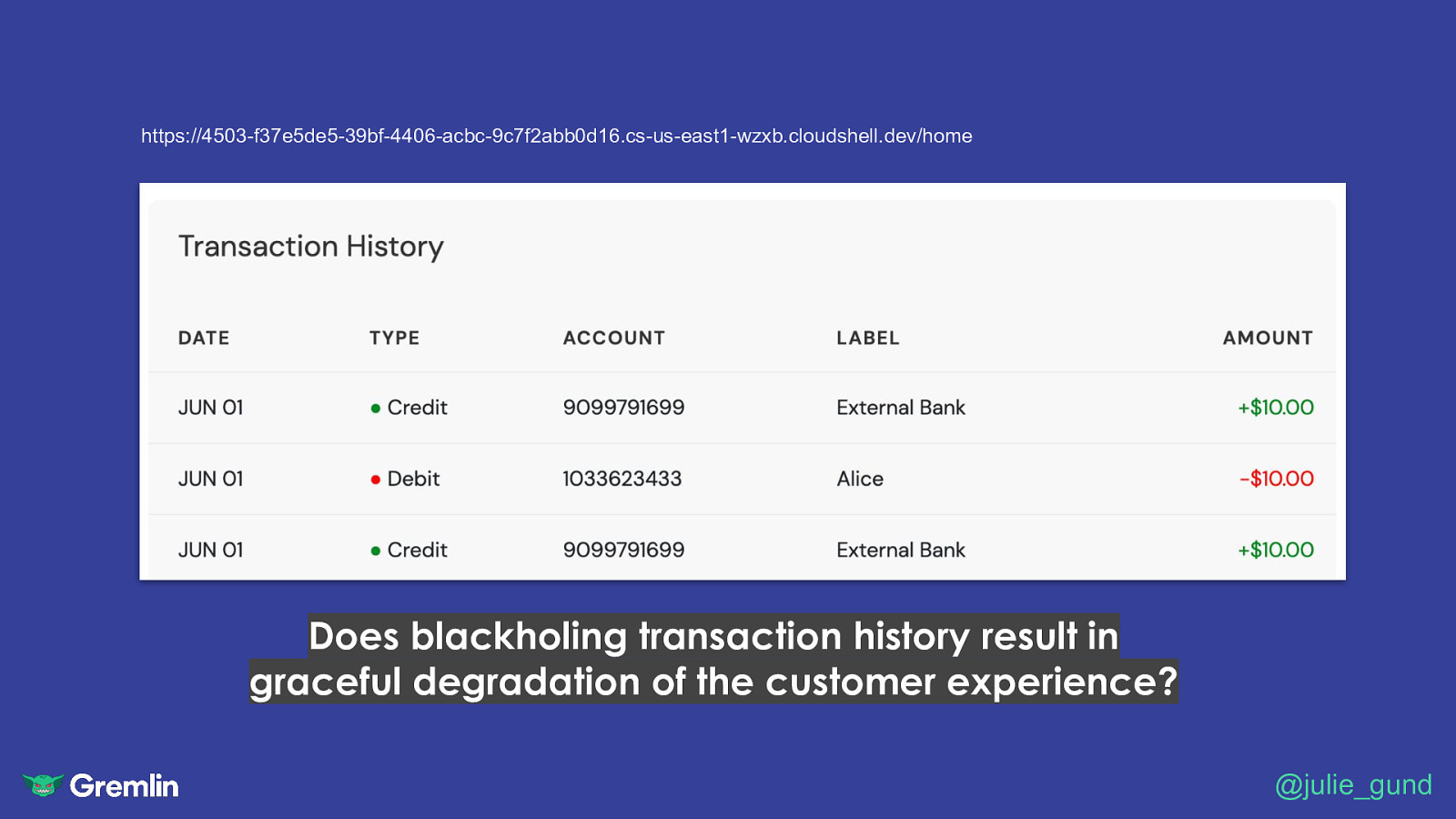
https://4503-f37e5de5-39bf-4406-acbc-9c7f2abb0d16.cs-us-east1-wzxb.cloudshell.dev/home Does blackholing transaction history result in graceful degradation of the customer experience? @julie_gund
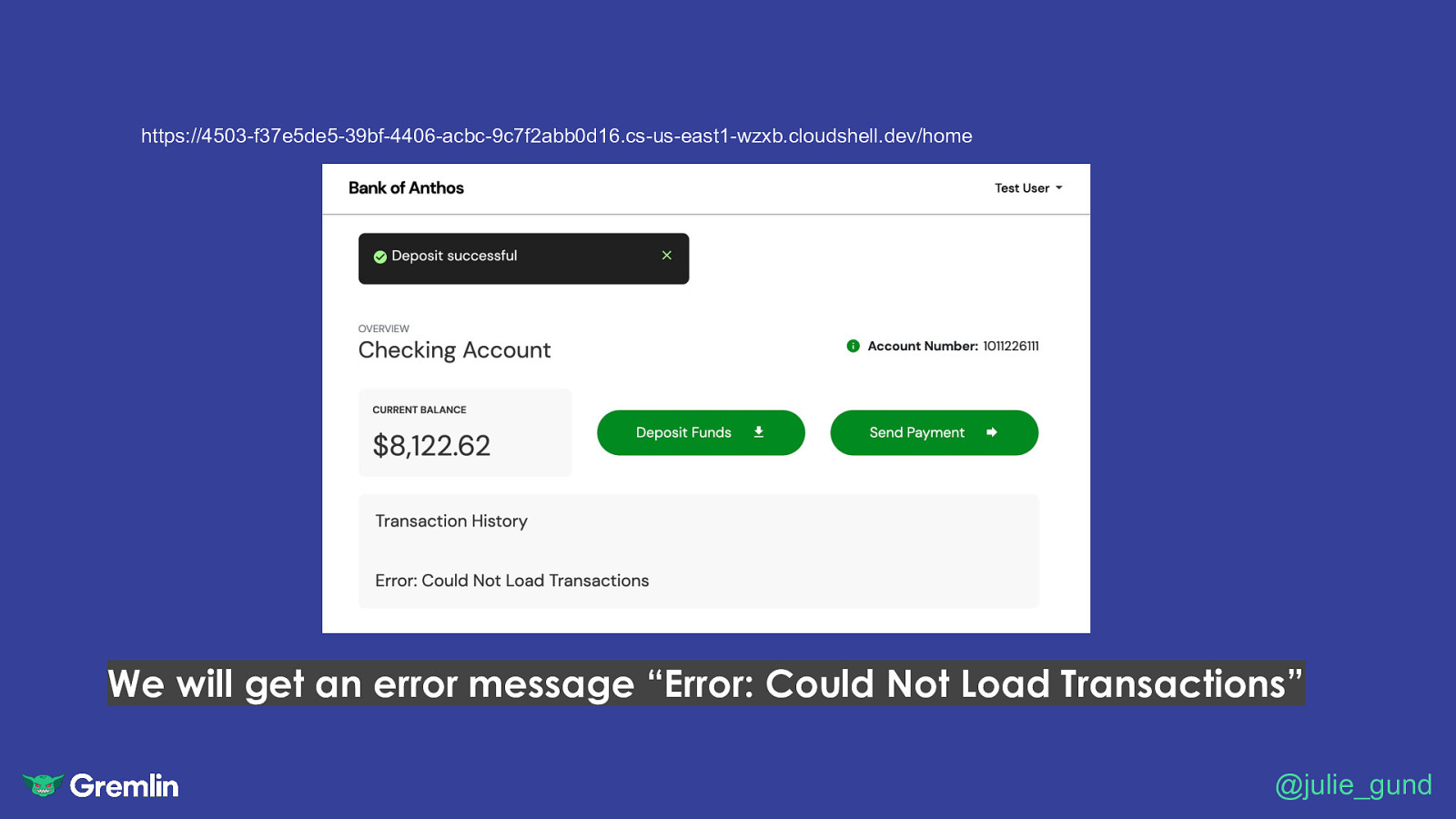
https://4503-f37e5de5-39bf-4406-acbc-9c7f2abb0d16.cs-us-east1-wzxb.cloudshell.dev/home We will get an error message “Error: Could Not Load Transactions” @julie_gund
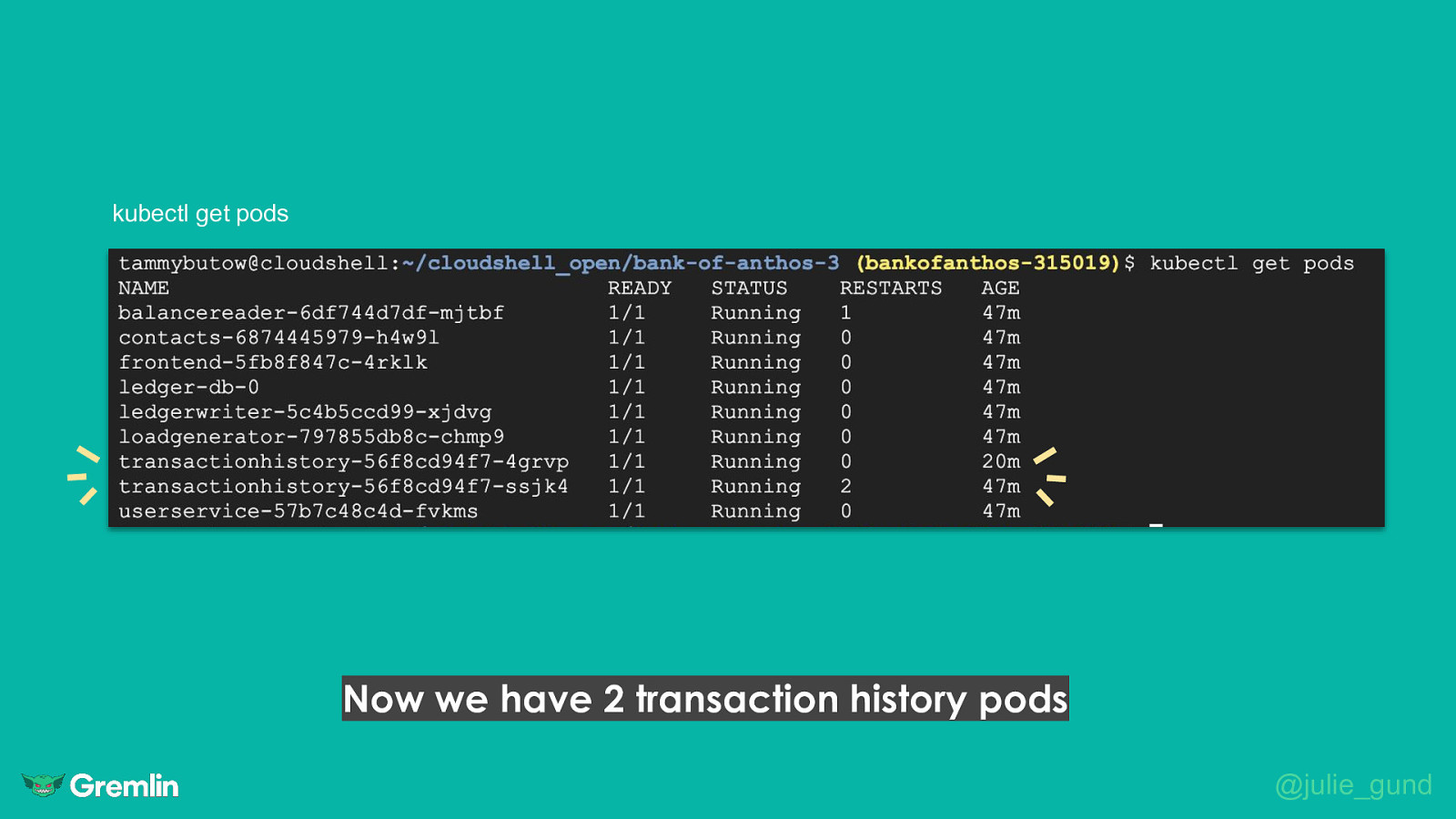
kubectl scale deployment transactionhistory —replicas=2 What can we do to mitigate against a blackhole? Depending on the service, scaling replicas may work well @julie_gund
kubectl get pods Now we have 2 transaction history pods @julie_gund
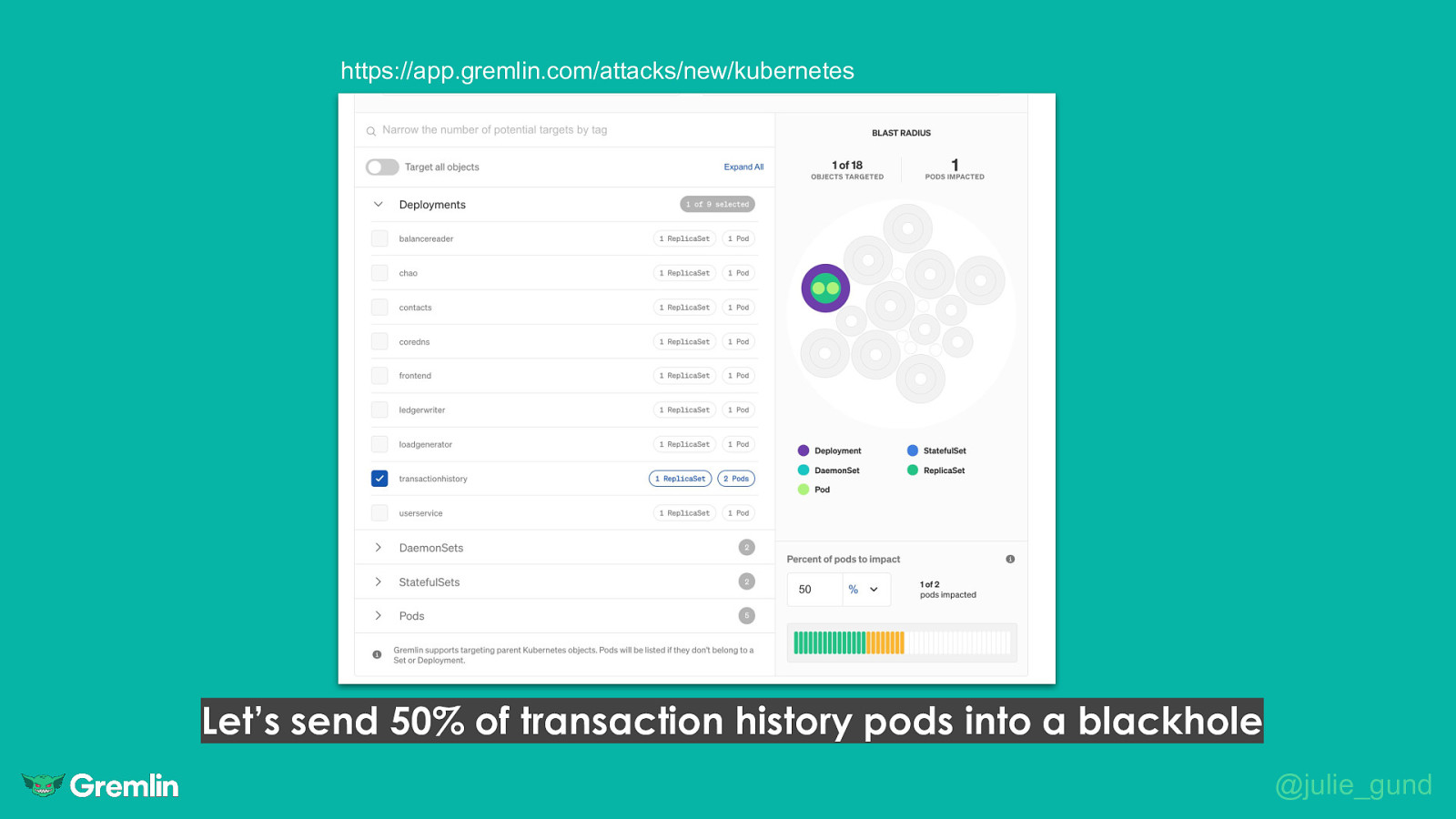
https://app.gremlin.com/attacks/new/kubernetes Let’s send 50% of transaction history pods into a blackhole @julie_gund
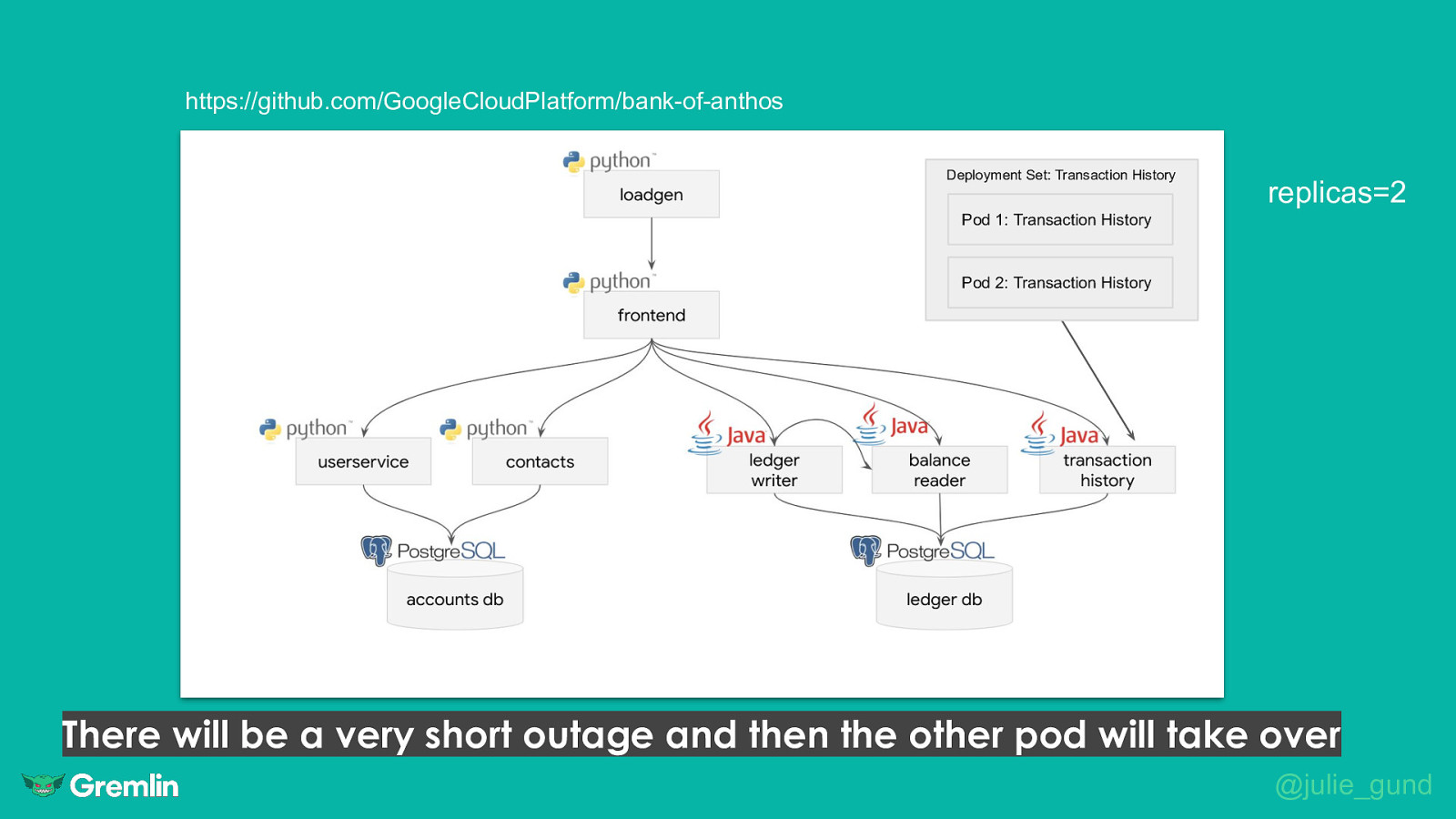
https://github.com/GoogleCloudPlatform/bank-of-anthos Deployment Set: Transaction History replicas=2 Pod 1: Transaction History Pod 2: Transaction History There will be a very short outage and then the other pod will take over @julie_gund
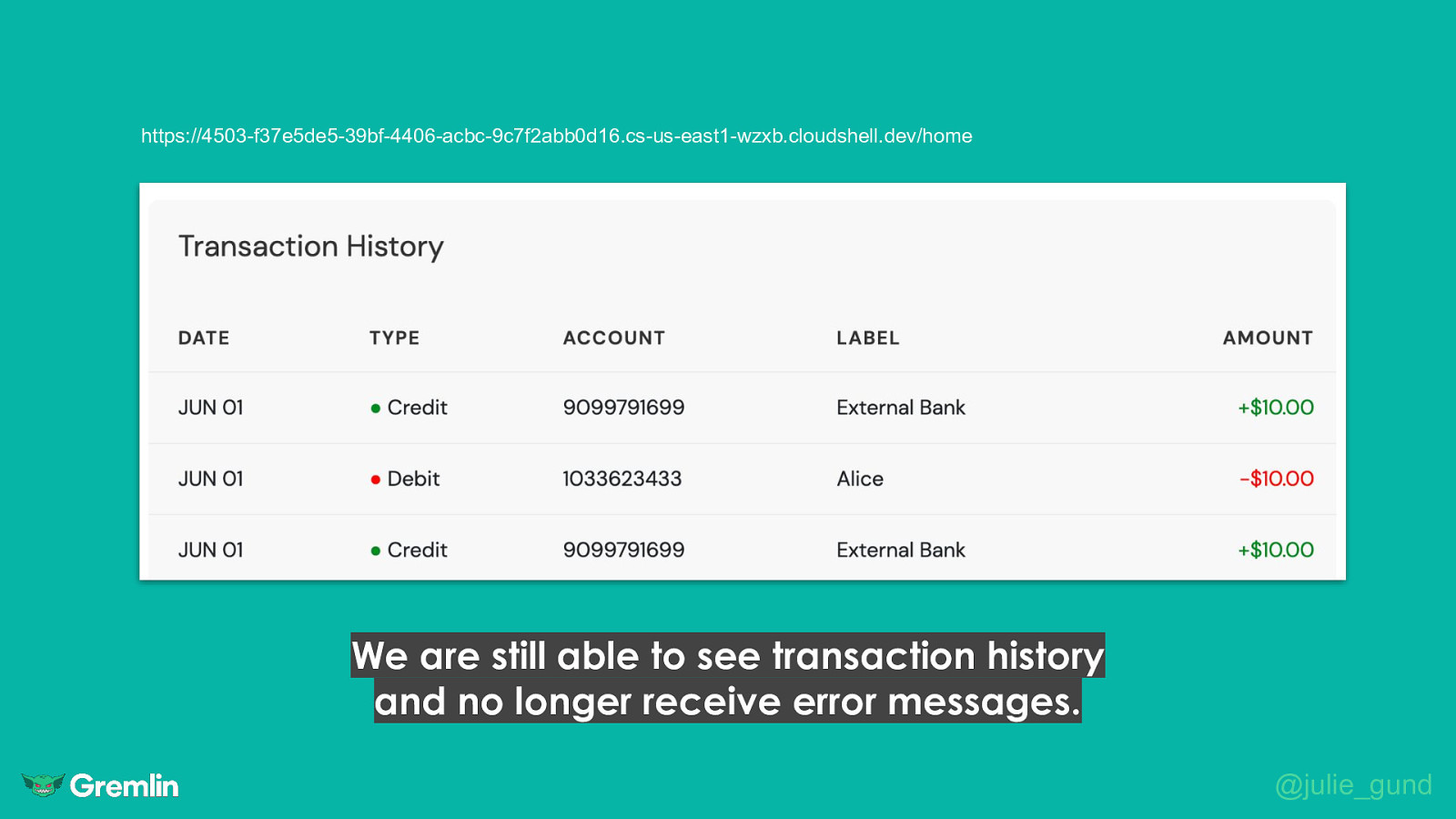
https://4503-f37e5de5-39bf-4406-acbc-9c7f2abb0d16.cs-us-east1-wzxb.cloudshell.dev/home We are still able to see transaction history and no longer receive error messages. @julie_gund
GoogleCloudPlatform/bank-of-anthos @julie_gund
Key Practice #2: GameDays @julie_gund
How can GameDays Improve Tempo and Stability? Accelerate shares that Game Days are a great way to build relationships within an organization. This is a cultural must-do to become a high-performing organization. @julie_gund
What is an Example GameDay? Invite 4+ people to attend (2+ teams). Spike load (Gatling) and introduce failure (Gremlin). Minimum time required = 10min @julie_gund
What are More Example GameDays? ● Dependency Testing (Flex) ● Capacity Plan Testing ● Autoscaling Testing @julie_gund
How can Disaster Recovery Improve Tempo and Stability? “For DiRT-style events to be successful, an organization first needs to accept system and process failures as a means of learning… we design tests that require engineers from several groups who might not normally work together to interact with each other. That way, should a real large-scale disaster ever strike, these people will already have strong working relationships” - Kripa Krishnan, Director of Cloud Operations @ Google @julie_gund
What is an example DiRT? Invite 4+ people to attend. Failover 5 core services using the Gremlin blackhole. (safer than a shutdown and faster to recover) Minimum time required = 5 minutes @julie_gund
Can you automate this? Yes!!! @julie_gund
Are you ready to become a Gremlin-certified Chaos Engineering Practitioner? gremlin.com/certification
State of Chaos Engineering Report “Top-performing Chaos Engineering teams boast four nines of availability (52 min of downtime a year) with an MTTR of less than one hour.” - Kolton Andrus gremlin.com/state-of-chaos-engineering/2021 @julie_gund
Thank you! Thank you! @julie_gund

Over the years a lot of research has been conducted and many books have been written on how to improve the resilience of our software. This talk will dive deep into the three keep practices identified by the authors of Accelerate to improve reliability: Chaos Engineering, GameDays, and Disaster Recovery. We will discuss the key measures of tempo and stability, and how practicing Chaos Engineering will increase both.
We will be walking through the Google Cloud open source Bank of Anthos application to illustrate why teams should focus on the customer experience and how to test for failures.
Attendees will learn practical tips that you can put into action focused on resource consumption, capacity planning, region failover, decoupling services and deployment pain





























 for free. You
can too.
for free. You
can too.