SQL, NoSQL and Beyond Lorna Jane Mitchell, IBM Slides: https://lornajane.net/resources

A presentation at PHP Yorkshire in April 2018 in York, UK by Lorna Jane Mitchell

SQL, NoSQL and Beyond Lorna Jane Mitchell, IBM Slides: https://lornajane.net/resources

Beyond MySQL MySQL is great! If you're ready for something different, how about: • PostgreSQL • Redis • CouchDB @lornajane

PostgreSQL @lornajane

About PostgreSQL Homepage: https://www.postgresql.org/ • Open source project • Powerful, relational database @lornajane

PostgreSQL Myths and Surprises Myth 1: PostgreSQL is more complicated than MySQL @lornajane

PostgreSQL Myths and Surprises Myth 1: PostgreSQL is more complicated than MySQL Not true. They are both approachable from both CLI and other web/GUI tools, PostgreSQL has the best CLI help I've ever seen. @lornajane

PostgreSQL Myths and Surprises Myth 1: PostgreSQL is more complicated than MySQL Not true. They are both approachable from both CLI and other web/GUI tools, PostgreSQL has the best CLI help I've ever seen. Myth 2: PostgreSQL is more strict than MySQL @lornajane

PostgreSQL Myths and Surprises Myth 1: PostgreSQL is more complicated than MySQL Not true. They are both approachable from both CLI and other web/GUI tools, PostgreSQL has the best CLI help I've ever seen. Myth 2: PostgreSQL is more strict than MySQL True! But standards-compliant is a feature IMO @lornajane

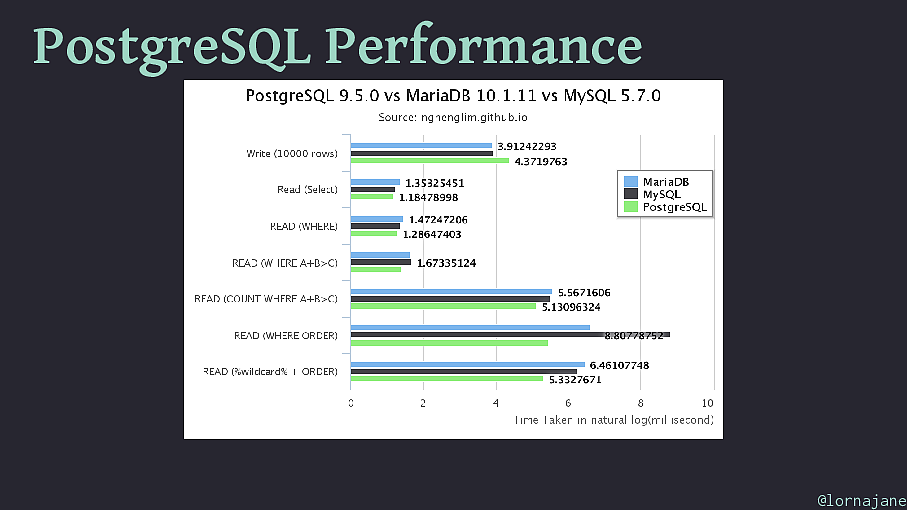
PostgreSQL Myths and Surprises Myth 1: PostgreSQL is more complicated than MySQL Not true. They are both approachable from both CLI and other web/GUI tools, PostgreSQL has the best CLI help I've ever seen. Myth 2: PostgreSQL is more strict than MySQL True! But standards-compliant is a feature IMO Myth 3: PostgreSQL is slower than MySQL for simple things @lornajane

PostgreSQL Myths and Surprises Myth 1: PostgreSQL is more complicated than MySQL Not true. They are both approachable from both CLI and other web/GUI tools, PostgreSQL has the best CLI help I've ever seen. Myth 2: PostgreSQL is more strict than MySQL True! But standards-compliant is a feature IMO Myth 3: PostgreSQL is slower than MySQL for simple things Not true. PostgreSQL has better query planning so is likely to be faster at everything, and also has more features. @lornajane
PostgreSQL Performance @lornajane

Data Types PostgreSQL has data types to suit more data needs: • UUID data type to create unique identifiers • JSON and JSONB for working with JSON data @lornajane

Data Types: UUID We can use a UUID as a primary key: CREATE
TABLE
products
(
product_id
uuid
primary
key
default
uuid_generate_v4 (),
display_name
varchar ( 255 ) ); INSERT
INTO
products
( display_name )
VALUES
( 'Jumper' )
RETURNING
product_id ; product_id | display_name -------------------------------------+-------------- 73089ae3-c0a9-4c0a-8287-e0f6ec41a200 | Jumper @lornajane

RETURNING Keyword Look at that insert statement again INSERT
INTO
products
( display_name )
VALUES
( 'Jumper' )
RETURNING
product_id ; The RETURNING keyword allows us to retrieve a field in one step

Data Types: JSONB Add a column to the table to hold attributes ALTER
TABLE
products
ADD
COLUMN
attrs
jsonb ; Add some data INSERT
INTO
products
( display_name ,
attrs )
VALUES ( 'Dress' ,
'{"length": {"value": 61, "units":"inch"}, "pockets":true, "colour":"teal"}' ); @lornajane

Data Types: JSONB We can use the JSON in our WHERE clause SELECT
display_name
AS
product ,
'colour'
AS
colour
FROM
products
WHERE
'pockets'
=
'true' ; product | colour ---------+-------- Cardi | red Dress | teal Jeans | indigo (3 rows) @lornajane

Indexes Examples might be: • Primary key ensuring uniqueness • Some other unique key • Indexes facilitating fast lookup on one or more columns • Indexes that use expressions @lornajane

Indexes: Primary key Primary keys are always unique CREATE
TABLE
employees
(
id
serial
primary
key ,
name
text
); The serial data type is numeric and incrementing @lornajane

Indexes: Expressions Use an expression if you'll use one when fetching data CREATE
TABLE
employees
(
id
serial
primary
key ,
name
text
); CREATE
INDEX
name_idx
ON
employees
( lower ( name )); @lornajane

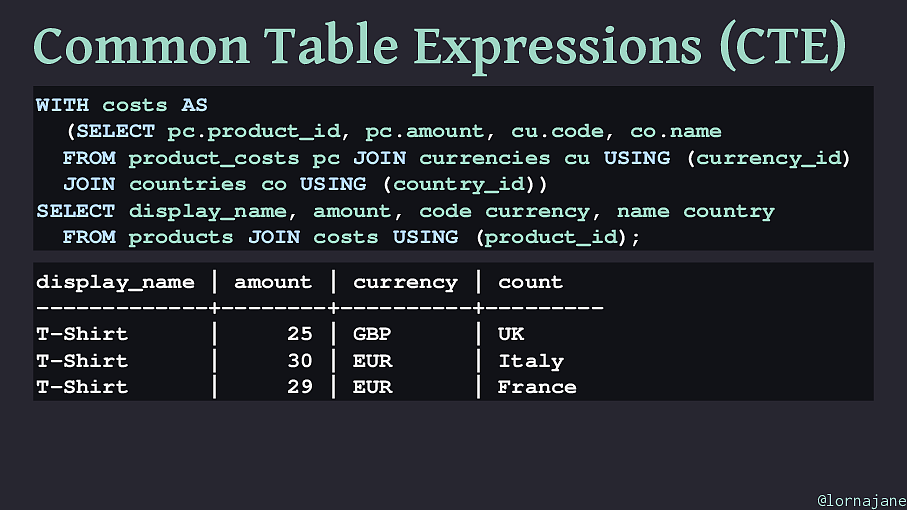
Common Table Expressions (CTE) Feature enables declaring extra statements to use later Moves complexity out of subqueries, making more readable and reusable elements to the query Syntax: WITH
meaningfulname
AS
( subquery
goes
here
joining
whatever ) SELECT
....
FROM
meaningfulname
... @lornajane
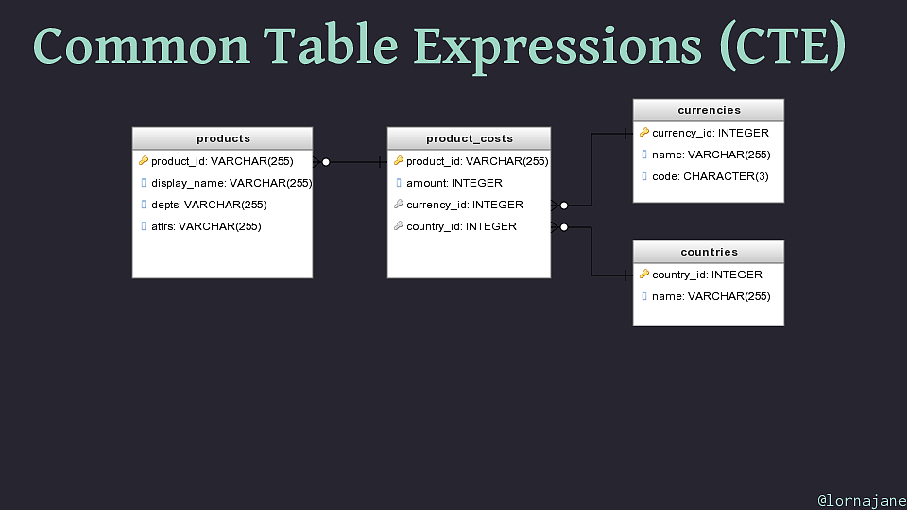
Common Table Expressions (CTE) @lornajane
Common Table Expressions (CTE) WITH
costs
AS
( SELECT
pc . product_id ,
pc . amount ,
cu . code ,
co . name
FROM
product_costs
pc
JOIN
currencies
cu
USING
( currency_id )
JOIN
countries
co
USING
( country_id )) SELECT
display_name ,
amount ,
code
currency ,
name
country
FROM
products
JOIN
costs
USING
( product_id ); display_name | amount | currency | count -------------+--------+----------+--------- T-Shirt | 25 | GBP | UK T-Shirt | 30 | EUR | Italy T-Shirt | 29 | EUR | France @lornajane

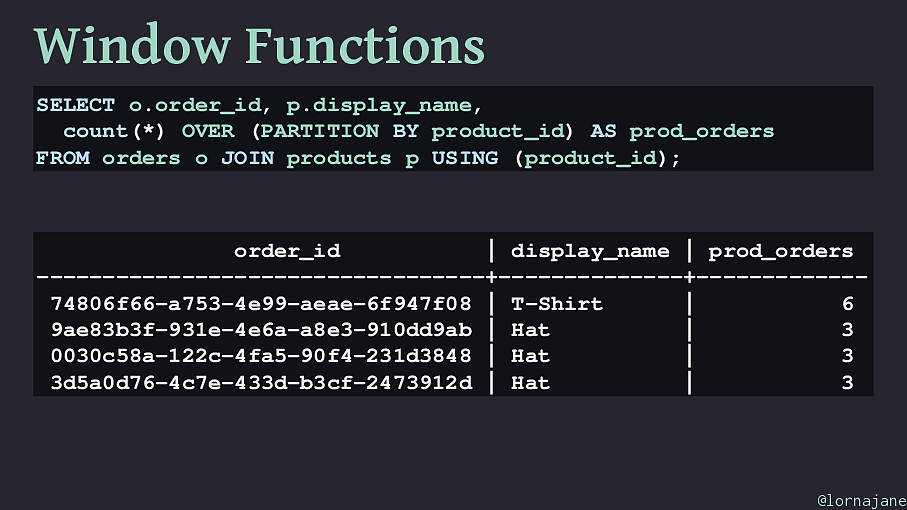
Window Functions Window functions allow us to calculate aggregate values while still returning the individual rows. e.g. a list of orders, including how many of this product were ordered in total @lornajane
Window Functions SELECT
o . order_id ,
p . display_name ,
count ( * )
OVER
( PARTITION
BY
product_id )
AS
prod_orders FROM
orders
o
JOIN
products
p
USING
( product_id ); order_id | display_name | prod_orders ----------------------------------+--------------+------------- 74806f66-a753-4e99-aeae-6f947f08 | T-Shirt | 6 9ae83b3f-931e-4e6a-a8e3-910dd9ab | Hat | 3 0030c58a-122c-4fa5-90f4-231d3848 | Hat | 3 3d5a0d76-4c7e-433d-b3cf-2473912d | Hat | 3 @lornajane

PostgreSQL Tips and Resources • PhpMyAdmin equivalent: https://www.pgadmin.org/ • Best in-shell help I've ever seen (type \h [something] ) • JSON features • Indexes on expression • Choose where nulls go by adding NULLS FIRST|LAST to your ORDER BY • Fabulous support for geographic data http://postgis.net/ • Get a hosted version from https://www.ibm.com/cloud/ @lornajane

Redis @lornajane

About Redis Homepage: http://redis.io/ Stands for: REmote DIctionary Service An open source, in-memory datastore for key/value storage, and much more @lornajane

Uses of Redis Usually used in addition to a primary data store for: • caching • session data • simple queues Anywhere you would use Memcache, use Redis @lornajane

Redis Feature Overview • stores strings, numbers, hashes, sets ... • supports key expiry/lifetime • very simple protocols, use redis-cli • great monitoring tools @lornajane

Storing Key/Value Pairs Store, expire and fetch values.
set risky_feature on OK
expire risky_feature 3 (integer) 1
get risky_feature "on"
get risky_feature (nil) Shorthand for set and expire: setex risky_feature 3 on @lornajane

Storing Hashes Use a hash for related data ( h is for hash, m is for multi)
hmset featured:hat name Sunhat colour white OK
hkeys featured:hat
hvals featured:hat

Finding Keys in Redis The SCAN keyword can help us find things 127.0.0.1:6379
hset person:lorna twitter lornajane (integer) 1 127.0.0.1:6379
scan 0 match person:*
hscan person:lorna 0

Queues using Redis Lists
LPUSH todo breakfast (integer) 1
LPUSH todo newspaper (integer) 2
BRPOP todo 1
BRPOP todo 1

Configurable Durability This is a tradeoff between risk of data loss, and speed. • by default, redis snapshots (writes to disk) periodically • the snapshot frequency is configurable by time and by number of writes • use the appendonly log to make redis eventually durable @lornajane

Redis: Tips and Resources • Replication and clustering are simple! • Sorted sets • Supports pub/sub: • SUBSCRIBE comments then PUBLISH comments message • Excellent documentation http://redis.io/documentation • Reference card https://dzone.com/refcardz • For PHP, predis/predis from composer or phpiredis • Get a hosted version from https://www.ibm.com/cloud/ @lornajane

CouchDB @lornajane

About CouchDB Homepage: http://couchdb.apache.org/ A database built from familiar components • HTTP interface • Web interface Fauxton • JS map/reduce views CouchDB is a NoSQL Document Database @lornajane

Schemaless Database Design We can store data of any shape and size @lornajane

Documents and Versions When I create a record, I supply an id and it gets a rev : $ curl -X PUT http://localhost:5984/products/1234 -d '{"type": "t-shirt", "dept": "womens", "size": "L"}' {"ok":true,"id":"1234","rev":"1-bce9d948a37e72729e689145286fd3ee"} (alternatively, POST and CouchDB will generate the id) @lornajane
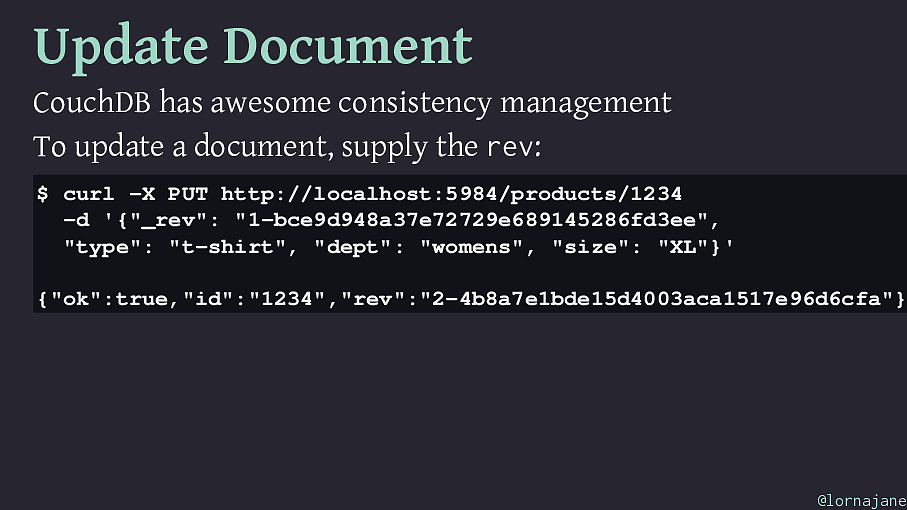
Update Document CouchDB has awesome consistency management To update a document, supply the rev : $ curl -X PUT http://localhost:5984/products/1234 -d '{"_rev": "1-bce9d948a37e72729e689145286fd3ee", "type": "t-shirt", "dept": "womens", "size": "XL"}' {"ok":true,"id":"1234","rev":"2-4b8a7e1bde15d4003aca1517e96d6cfa"} @lornajane

Changes API Get a full list of newest changes since you last asked http://localhost:5984/products/_changes?since=7 ~ $ curl http://localhost:5984/products/_changes?since=7 {"results":[ {"seq":9,"id":"123", "changes":[{"rev":"2-7d1f78e72d38d6698a917f8834bfb5f8"}]} ], Polling/Long polling or continuous change updates are available, and they can be filtered. @lornajane

Replication CouchDB has the best database replication options imaginable: • ad-hoc or continuous • one directional or bi directional • conflicts handled safely (best fault tolerance ever) @lornajane

CouchDB Views • Written in Javascript • Use MapReduce • The map results are stored • Can be used either for filtering, or for aggregation @lornajane

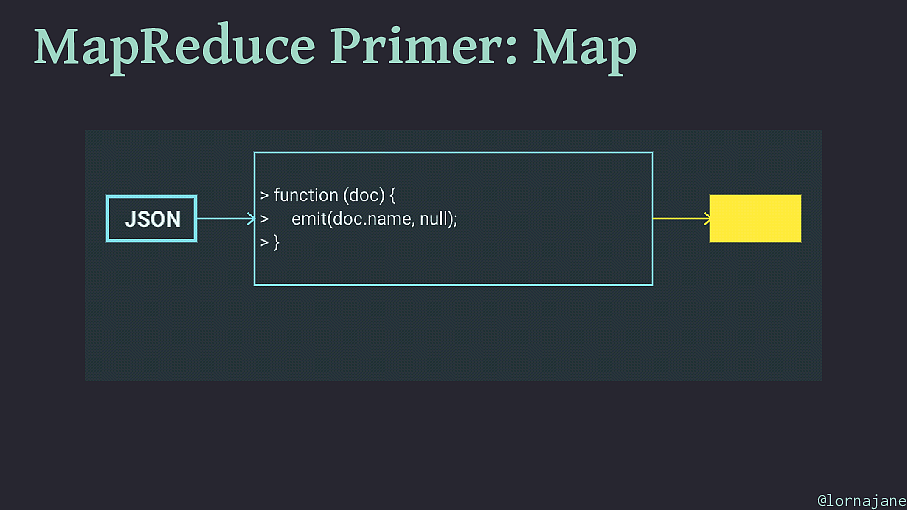
MapReduce Primer: Map • Examine each document, "emit" 0+ keys/value pairs • Scales well because each document is independent • To filter a collection of documents, use map step only @lornajane

MapReduce Primer: Map @lornajane
MapReduce Primer: Map @lornajane
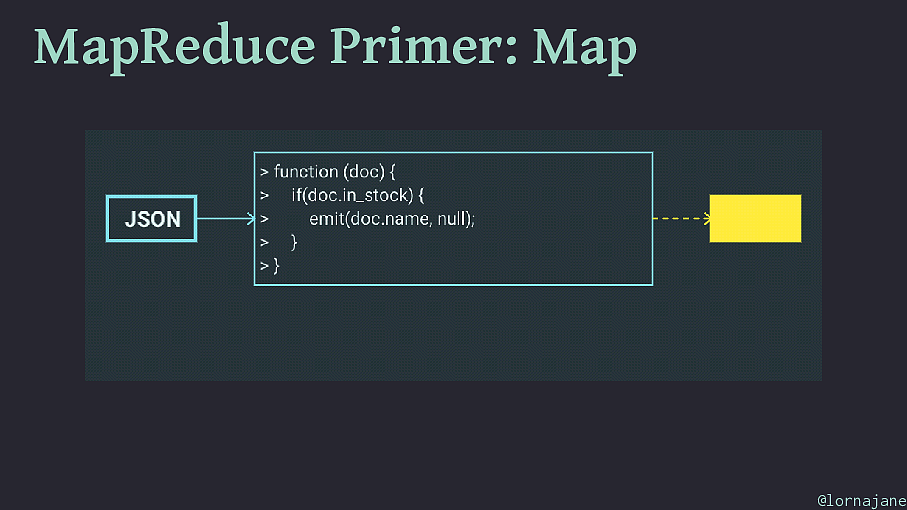
MapReduce Primer: Map @lornajane
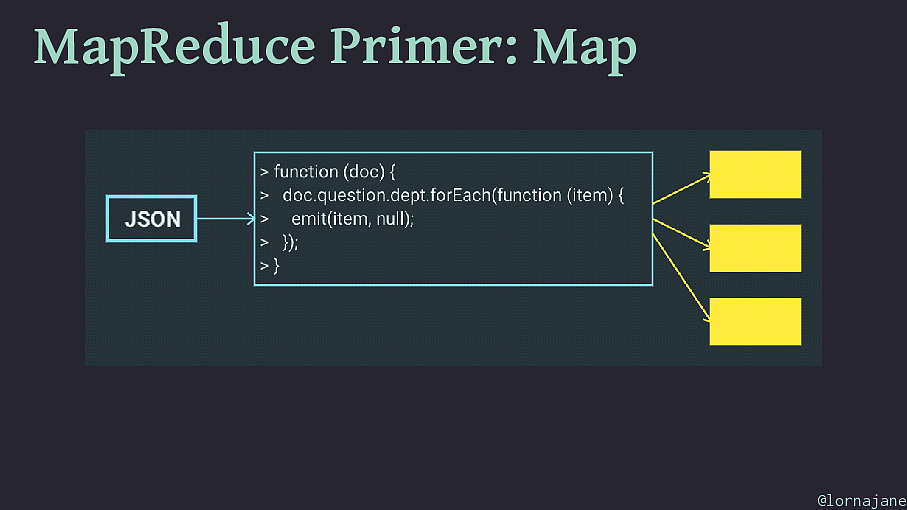
MapReduce Primer: Map @lornajane
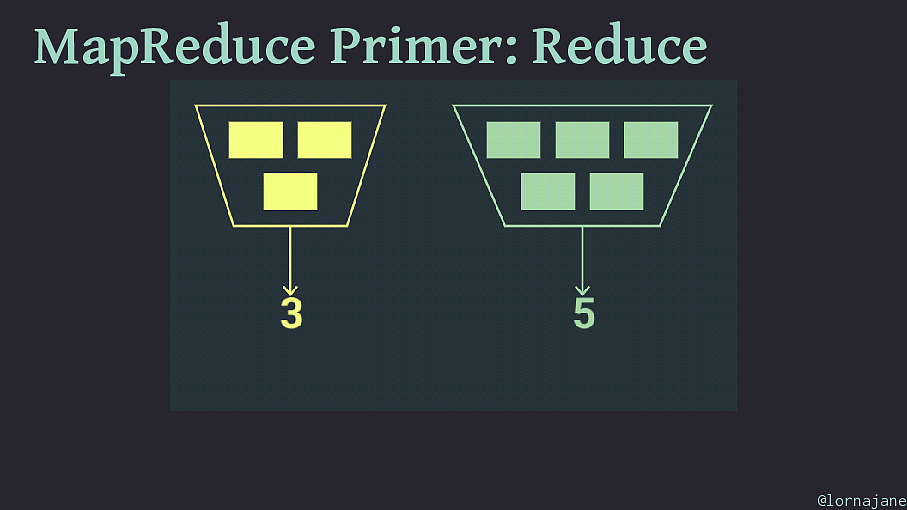
MapReduce Primer: Reduce @lornajane

MapReduce Primer: Reduce • "Reduce" values in batches with the same key • CouchDB has useful built in functions for most things • Use reduce step when you want aggregate data • (SQL equivalent: a query with GROUP BY ) @lornajane

CouchDB Views: Example http://localhost:5984/products/_design/products/_view/coun t?group=true { "rows" :[
{ "key" :[ "mens" , "t-shirt" ], "value" : 1 },
{ "key" :[ "womens" , "bag" ], "value" : 3 },
{ "key" :[ "womens" , "shoes" ], "value" : 1 },
{ "key" :[ "womens" , "t-shirt" ], "value" : 2 } ]} @lornajane

CouchDB Views: Example http://localhost:5984/products/_design/products/_view/coun t?group_level=1 { "rows" :[
{ "key" :[ "mens" ], "value" : 1 },
{ "key" :[ "womens" ], "value" : 6 } ]} @lornajane

CouchDB Tips and Resources • CouchDB Definitive Guide http://guide.couchdb.org • Javascript implementation https://pouchdb.com/ • PHP CouchDB library: https://github.com/ibm-watson-data-lab/php-couchdb • Get a hosted version from https://www.ibm.com/cloud/ @lornajane

SQL, NoSQL and Beyond @lornajane

Thanks Feedback: https://joind.in/talk/f4061 Slides: http://lornajane.net/resources Further reading: Seven Databases in Seven Weeks Contact: • lorna.mitchell@uk.ibm.com • @lornajane @lornajane