Industrialiser des projets IA avec OVHcloud Elea Petton & Horacio González 2022-05-12

A presentation at DataOps.Rocks in May 2022 in Paris, France by Horacio Gonzalez

Industrialiser des projets IA avec OVHcloud Elea Petton & Horacio González 2022-05-12

Qui sommes nous ? Et qui est OVHcloud ?

Eléa Petton

Horacio Gonzalez @LostInBrittany Espagnol perdu en Bretagne… Flutter

OVHcloud Web Cloud & Telcom 30 Data Centers in 12 locations 1 Million+ Servers produced since 1999 Private Cloud 34 Points of Presence on a 20 TBPS Bandwidth Network 1.5 Million Customers across 132 countries Public Cloud 2200 Employees worldwide 3.8 Million Websites hosting Storage 115K Private Cloud VMS running 1.5 Billion Euros Invested since 2016 300K Public Cloud instances running P.U.E. 1.09 Energy efficiency indicator 380K Physical Servers running in our data centers 20+ Years in Business Disrupting since 1999 Network & Security

Les différents visages de l’IA Et des gens qui travaillent avec
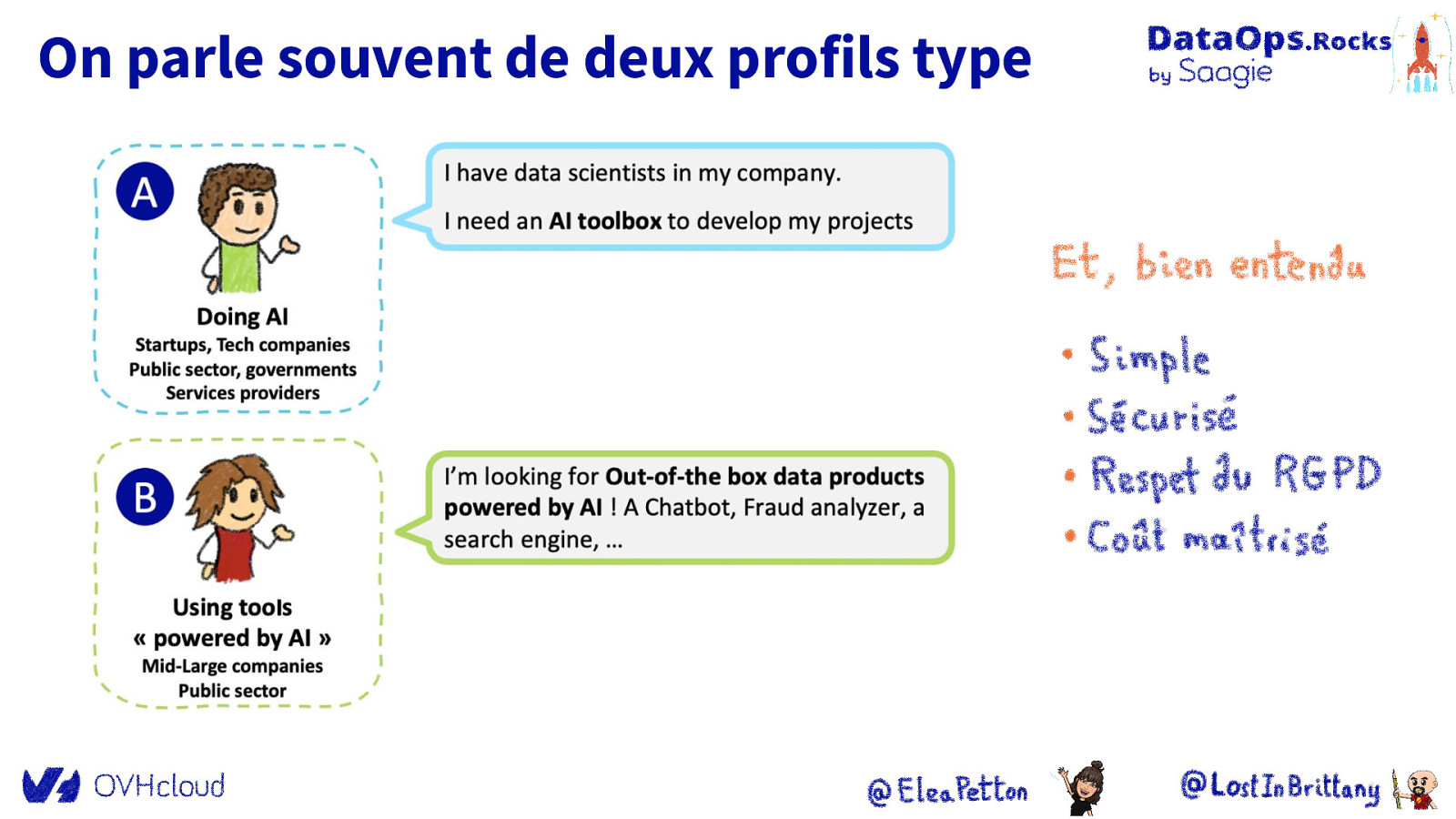
On parle souvent de deux profils type

Mais il y a un troisième : DevOps/SRE/DataOps

Ils parlent des langages différents
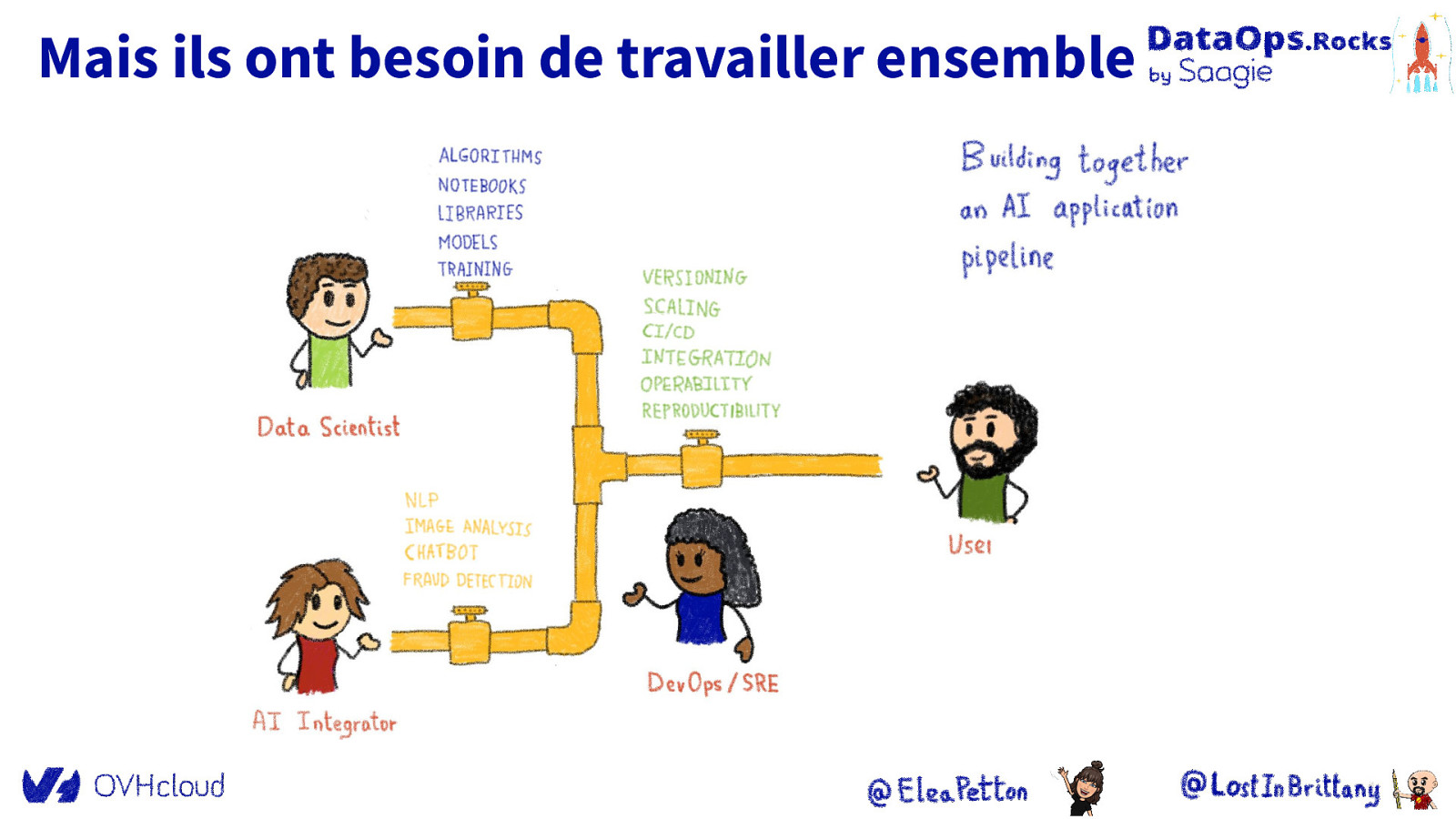
Mais ils ont besoin de travailler ensemble

Le challenge de l’intégration Intégrer les processus et outils des équipes IA/ML, Dev & DataOps
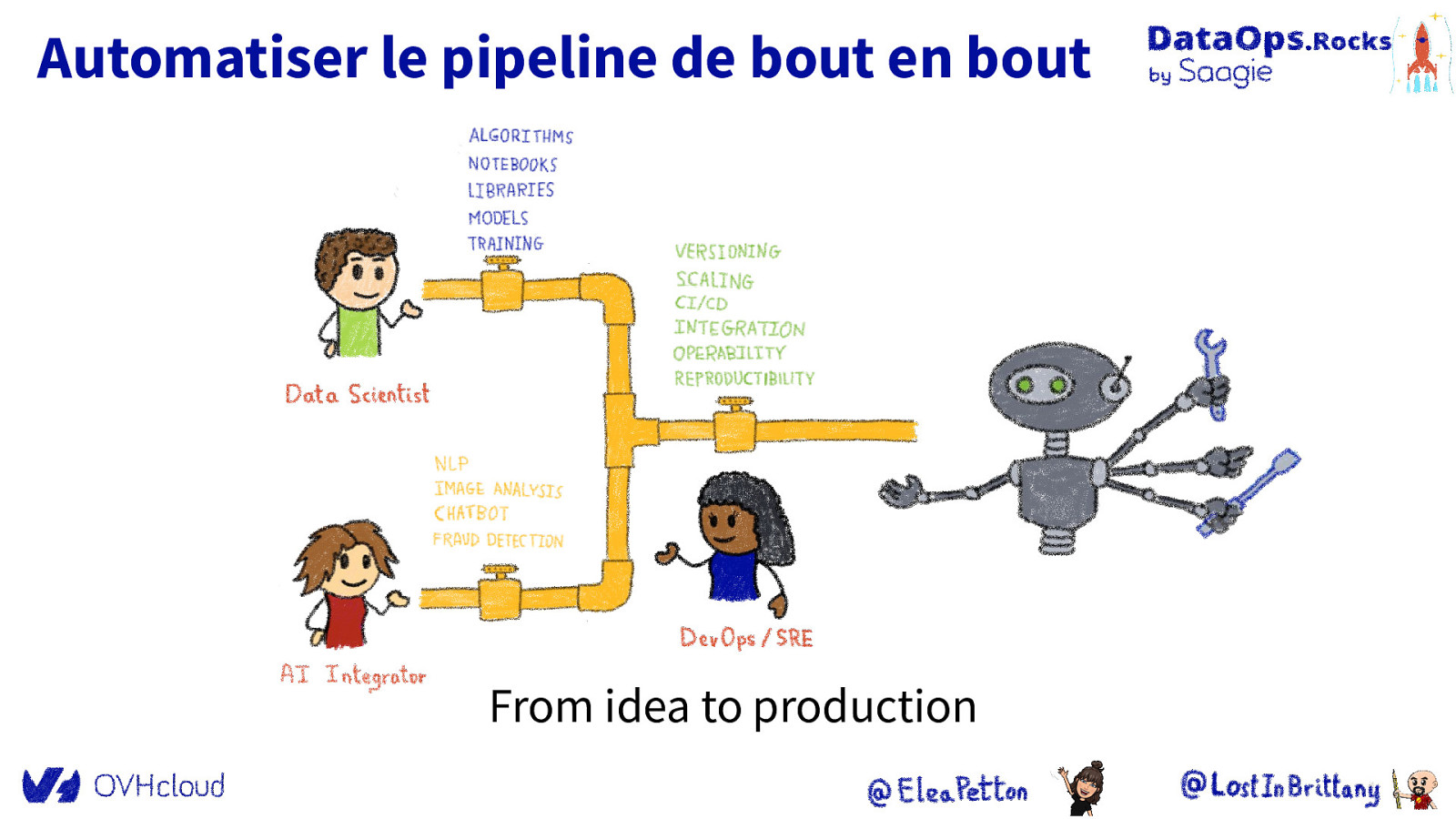
Automatiser le pipeline de bout en bout From idea to production

OVHcloud & IA Notre réponse à l’automatisation du pipeline de l’IA
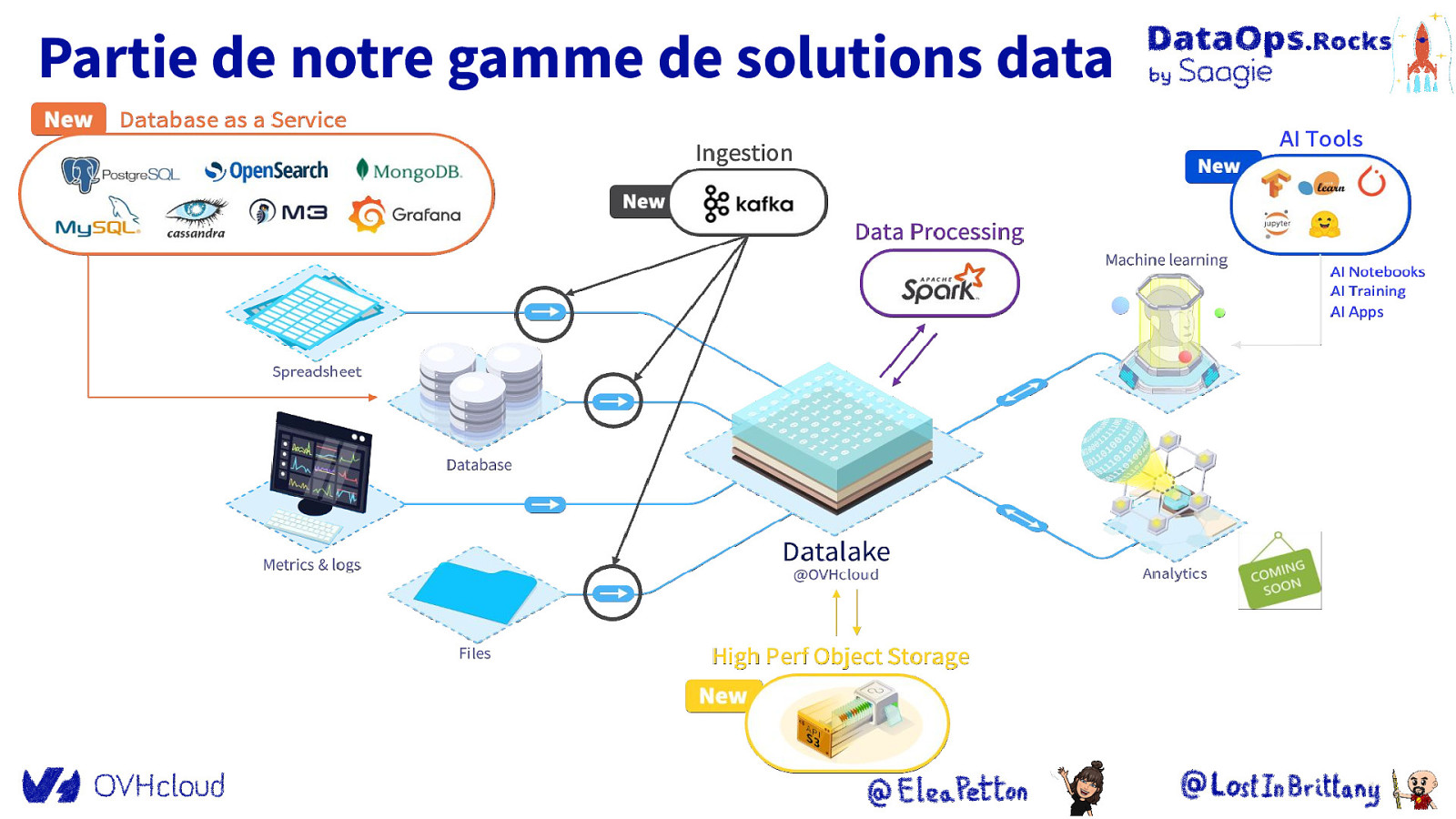
Partie de notre gamme de solutions data
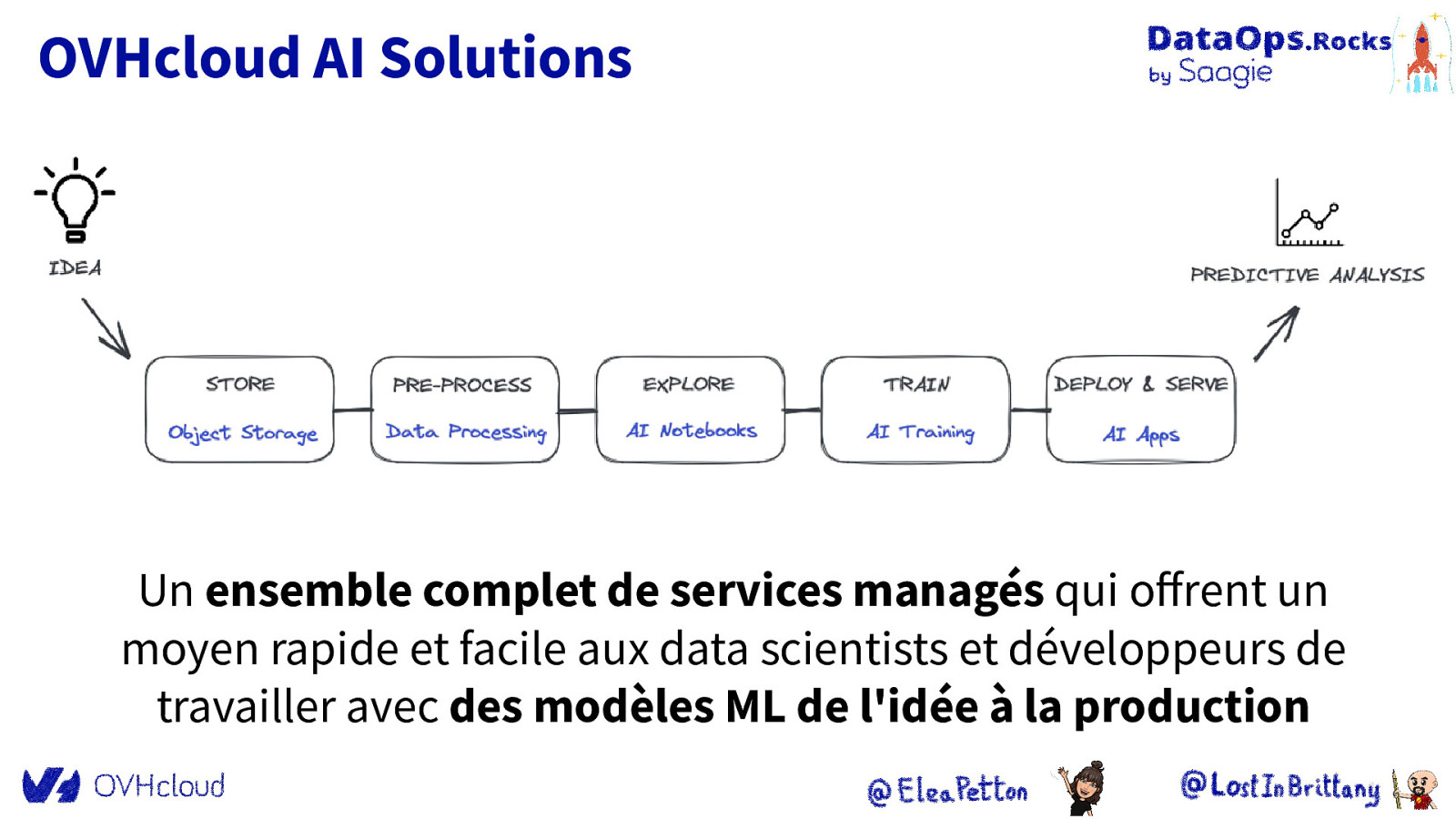
OVHcloud AI Solutions Un ensemble complet de services managés qui offrent un moyen rapide et facile aux data scientists et développeurs de travailler avec des modèles ML de l’idée à la production
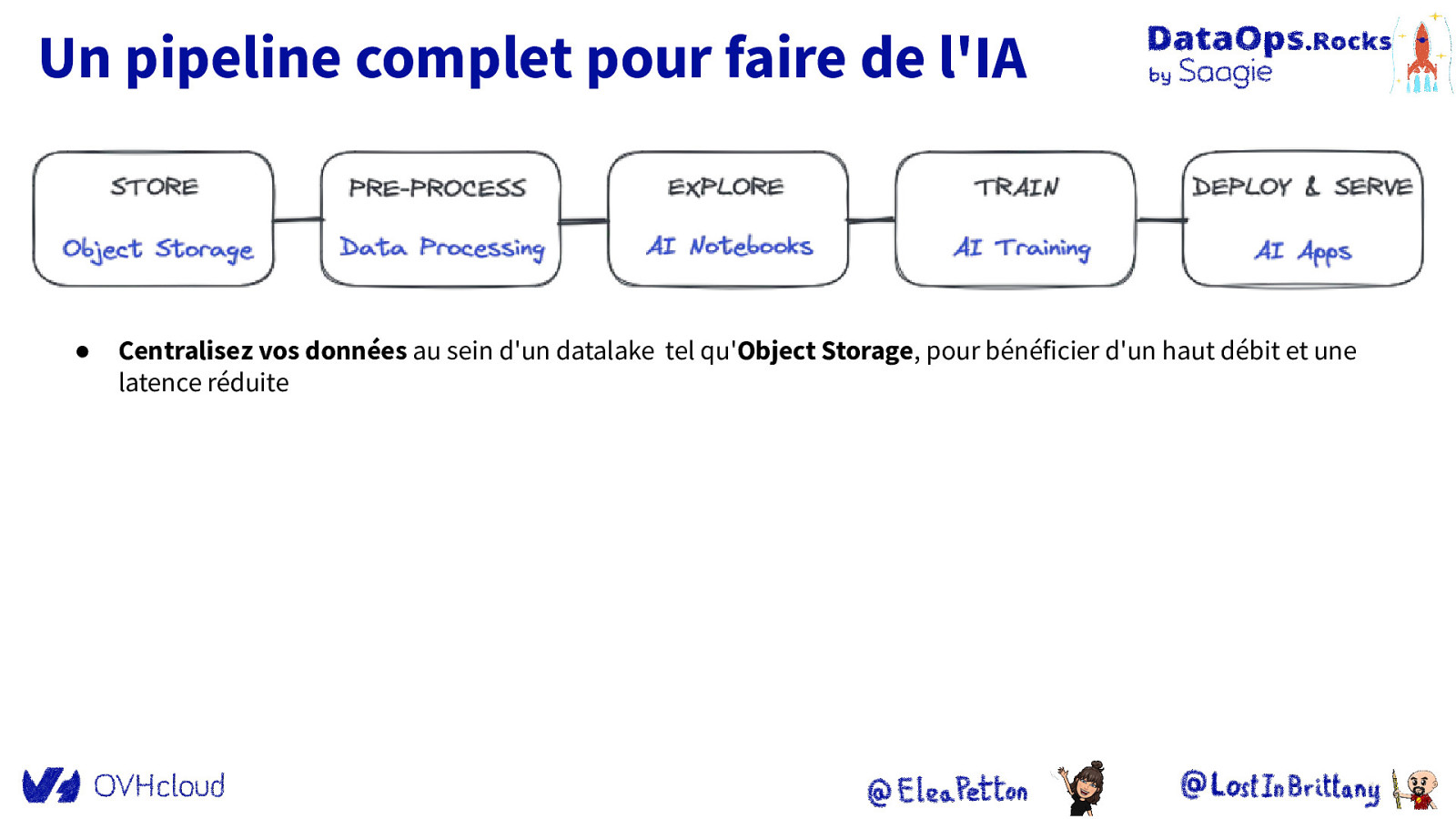
Un pipeline complet pour faire de l’IA ● Centralisez vos données au sein d’un datalake tel qu’Object Storage, pour bénéficier d’un haut débit et une latence réduite
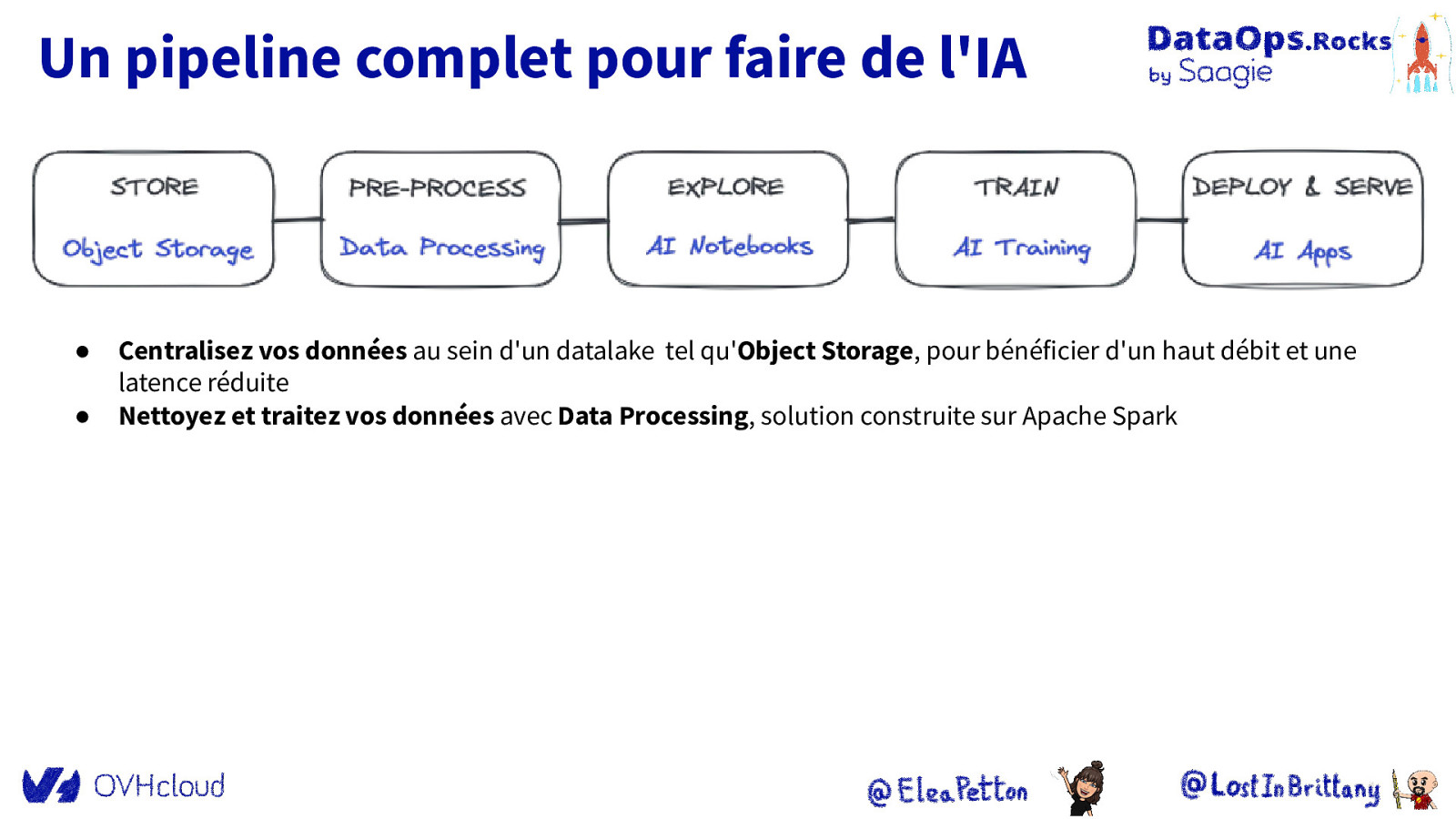
Un pipeline complet pour faire de l’IA ● ● Centralisez vos données au sein d’un datalake tel qu’Object Storage, pour bénéficier d’un haut débit et une latence réduite Nettoyez et traitez vos données avec Data Processing, solution construite sur Apache Spark
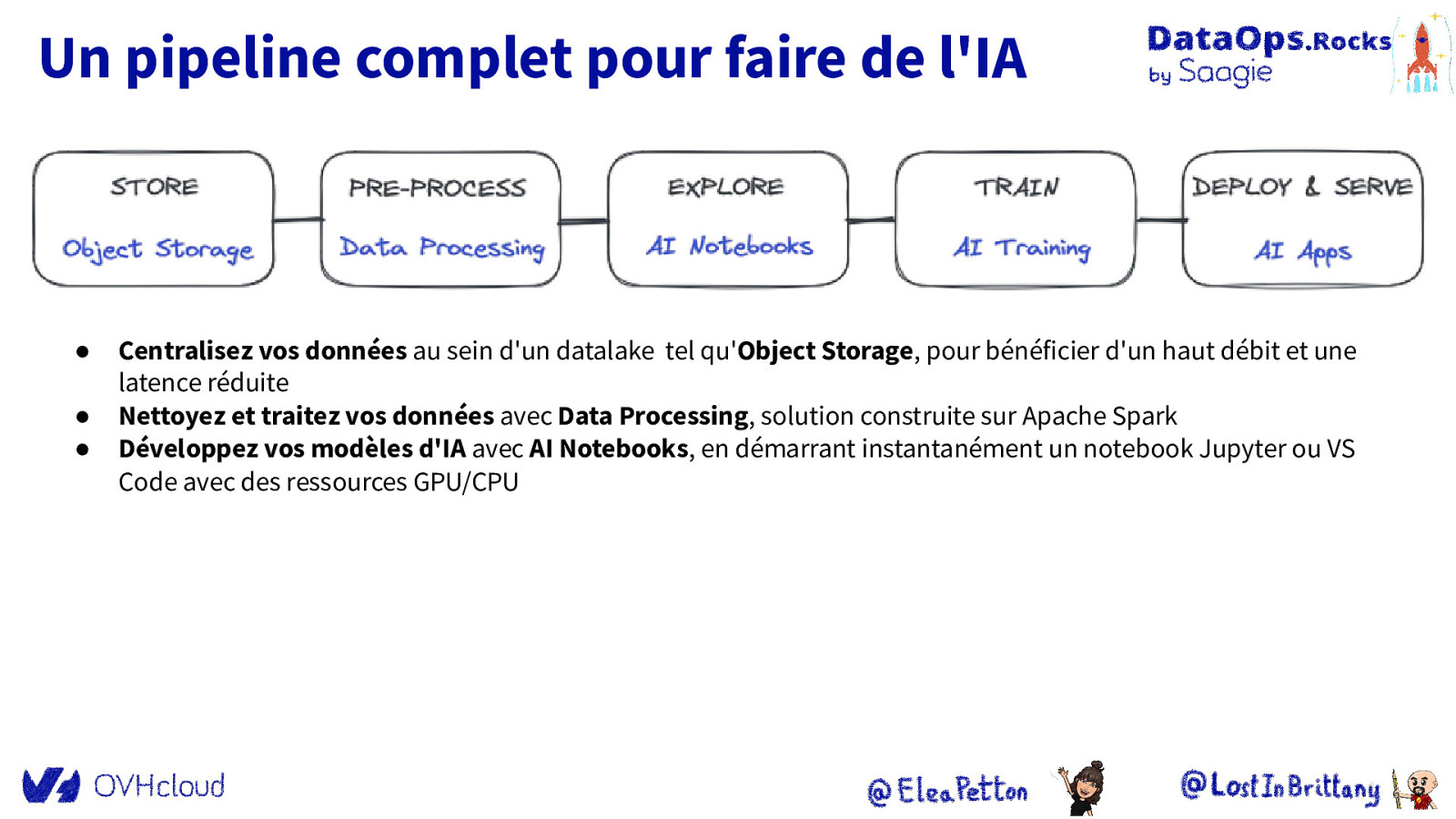
Un pipeline complet pour faire de l’IA ● ● ● Centralisez vos données au sein d’un datalake tel qu’Object Storage, pour bénéficier d’un haut débit et une latence réduite Nettoyez et traitez vos données avec Data Processing, solution construite sur Apache Spark Développez vos modèles d’IA avec AI Notebooks, en démarrant instantanément un notebook Jupyter ou VS Code avec des ressources GPU/CPU
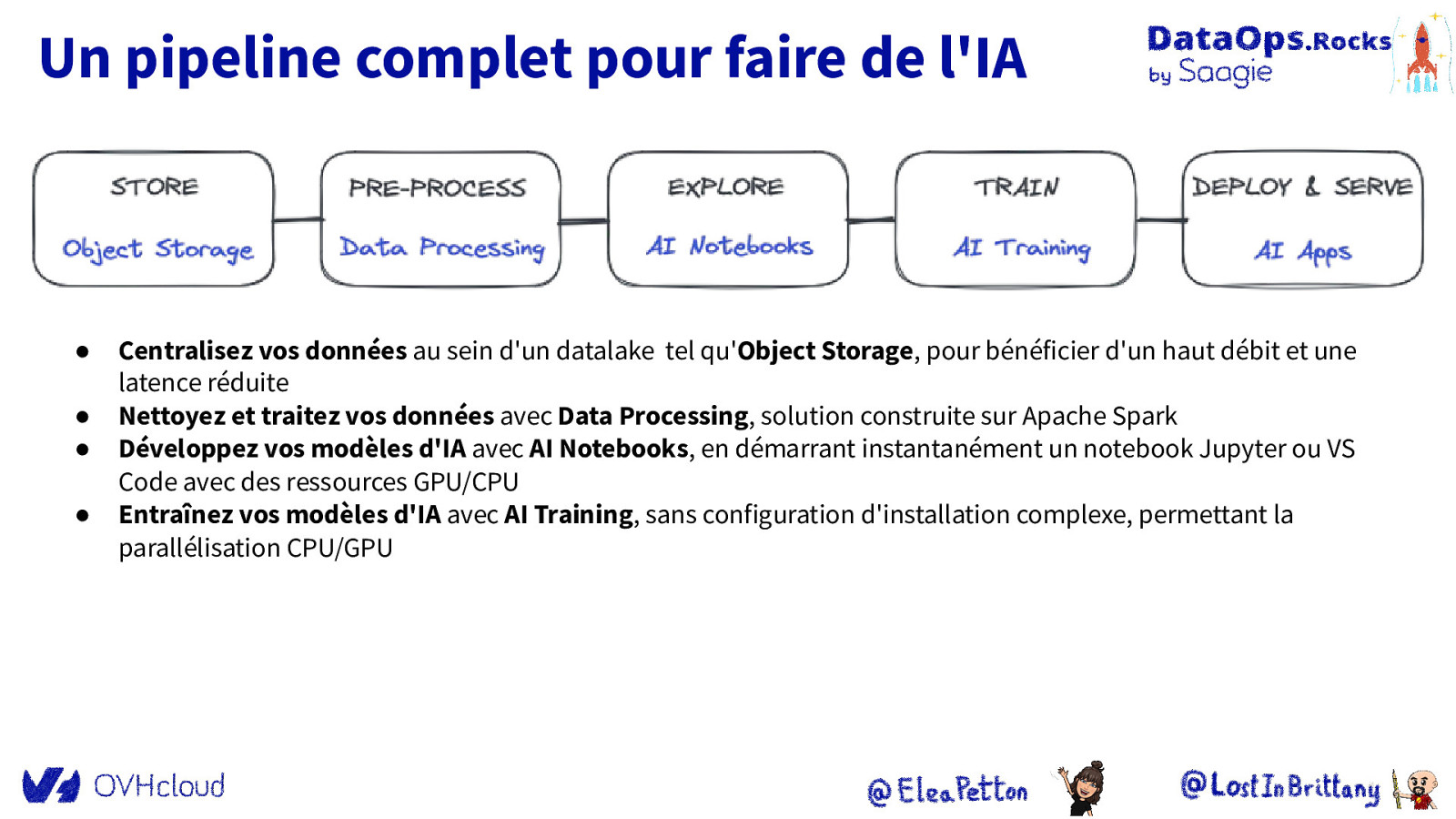
Un pipeline complet pour faire de l’IA ● ● ● ● Centralisez vos données au sein d’un datalake tel qu’Object Storage, pour bénéficier d’un haut débit et une latence réduite Nettoyez et traitez vos données avec Data Processing, solution construite sur Apache Spark Développez vos modèles d’IA avec AI Notebooks, en démarrant instantanément un notebook Jupyter ou VS Code avec des ressources GPU/CPU Entraînez vos modèles d’IA avec AI Training, sans configuration d’installation complexe, permettant la parallélisation CPU/GPU
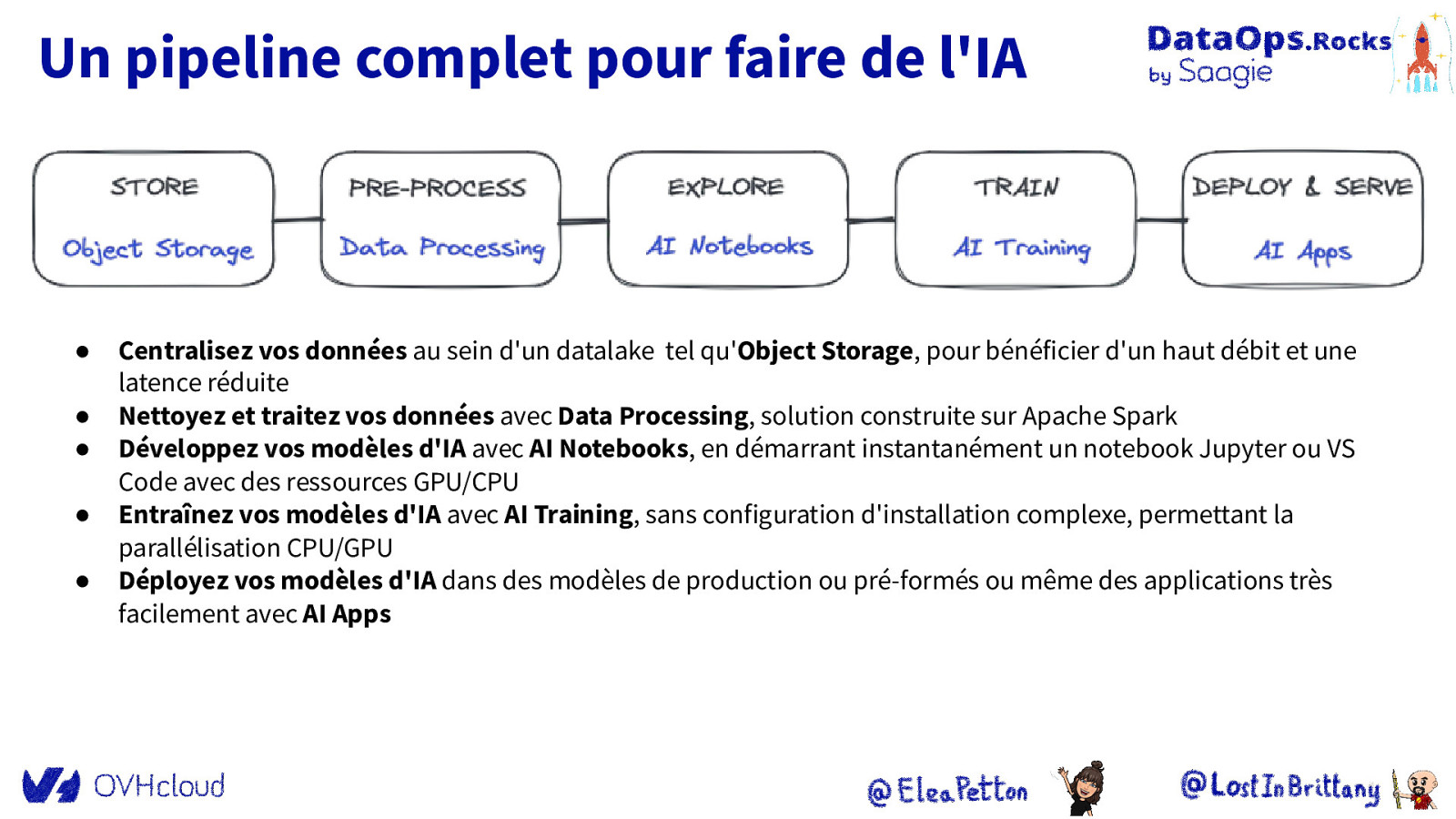
Un pipeline complet pour faire de l’IA ● ● ● ● ● Centralisez vos données au sein d’un datalake tel qu’Object Storage, pour bénéficier d’un haut débit et une latence réduite Nettoyez et traitez vos données avec Data Processing, solution construite sur Apache Spark Développez vos modèles d’IA avec AI Notebooks, en démarrant instantanément un notebook Jupyter ou VS Code avec des ressources GPU/CPU Entraînez vos modèles d’IA avec AI Training, sans configuration d’installation complexe, permettant la parallélisation CPU/GPU Déployez vos modèles d’IA dans des modèles de production ou pré-formés ou même des applications très facilement avec AI Apps
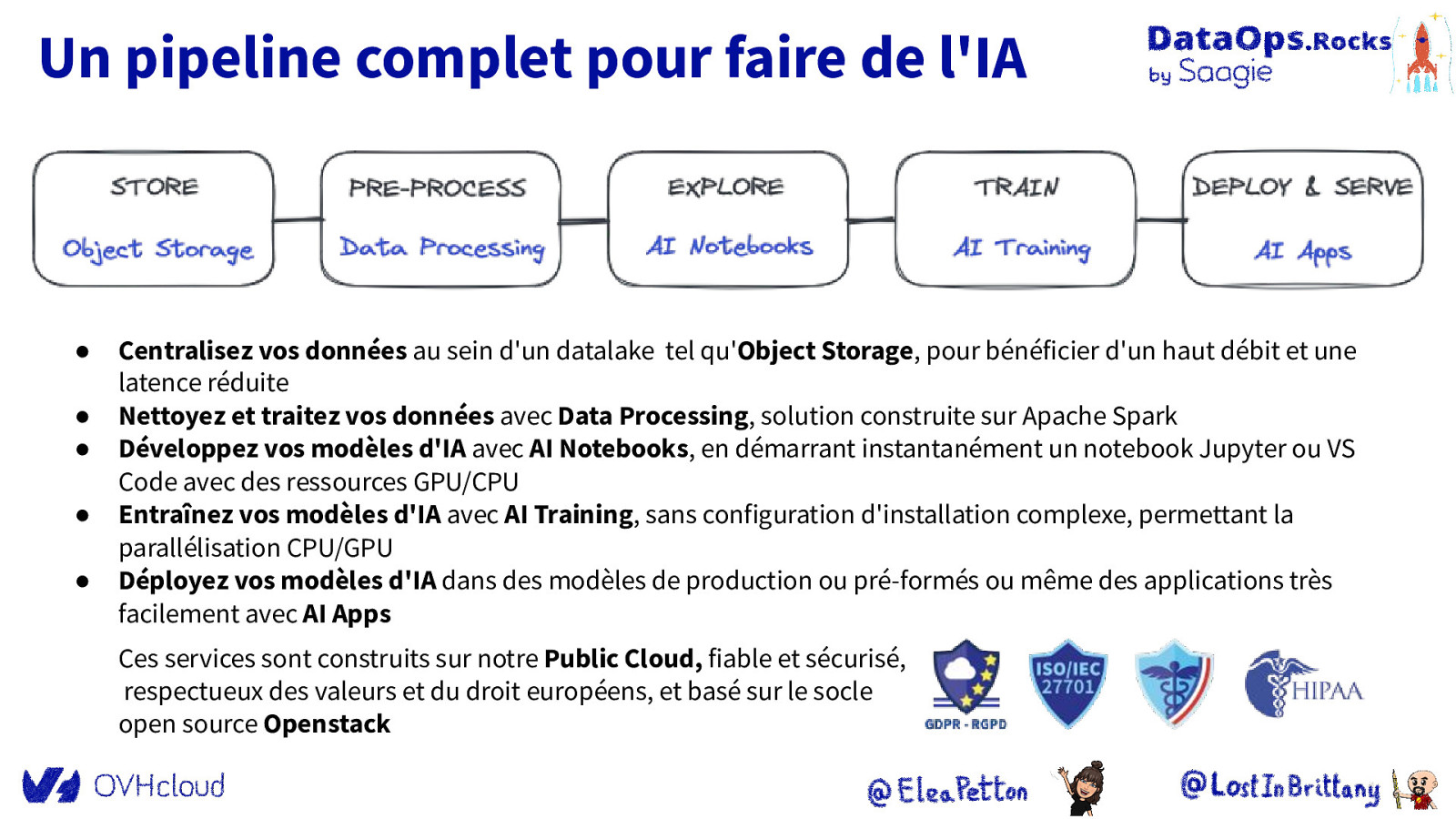
Un pipeline complet pour faire de l’IA ● ● ● ● ● Centralisez vos données au sein d’un datalake tel qu’Object Storage, pour bénéficier d’un haut débit et une latence réduite Nettoyez et traitez vos données avec Data Processing, solution construite sur Apache Spark Développez vos modèles d’IA avec AI Notebooks, en démarrant instantanément un notebook Jupyter ou VS Code avec des ressources GPU/CPU Entraînez vos modèles d’IA avec AI Training, sans configuration d’installation complexe, permettant la parallélisation CPU/GPU Déployez vos modèles d’IA dans des modèles de production ou pré-formés ou même des applications très facilement avec AI Apps Ces services sont construits sur notre Public Cloud, fiable et sécurisé, respectueux des valeurs et du droit européens, et basé sur le socle open source Openstack

Pay as you go, simple, et avec un prix ultra-compétitif Object storage Prix par GB, a partir de: 0,01 € HT /mois /GB stockage + 0,01€ HT /GB trafic sortant Combien ça coûte 50 hours de AI Notebook avec 1 x NVIDIA V100 GPU ? 87 € 121 € 161 € GCP Azure 195 € (exemple: 10TB = 100€ HT/mois) GRA + BHS AI Notebooks / AI Training Prix par GPU par minute, à partir de : 1,75€ /heure /gpu (NVIDIA V100s 32GB) Pris par CPU par minute, à partir de : 0,03€ /heure /cpu (Intel Xeon 1vCPU + 4GB) OVHcloud AI-standard 1 x V100S 32GB Standard_V100 Standard_NC6s_v3 1 x V100 16GB 1 x V100 16GB AWS P3.2xlarge 1 x V100 16GB Prices in EU datacenters, without storage attached, no period commitment.
Différentes familles en IA

Pourquoi le son en IA ?

Sons de mammifères marins
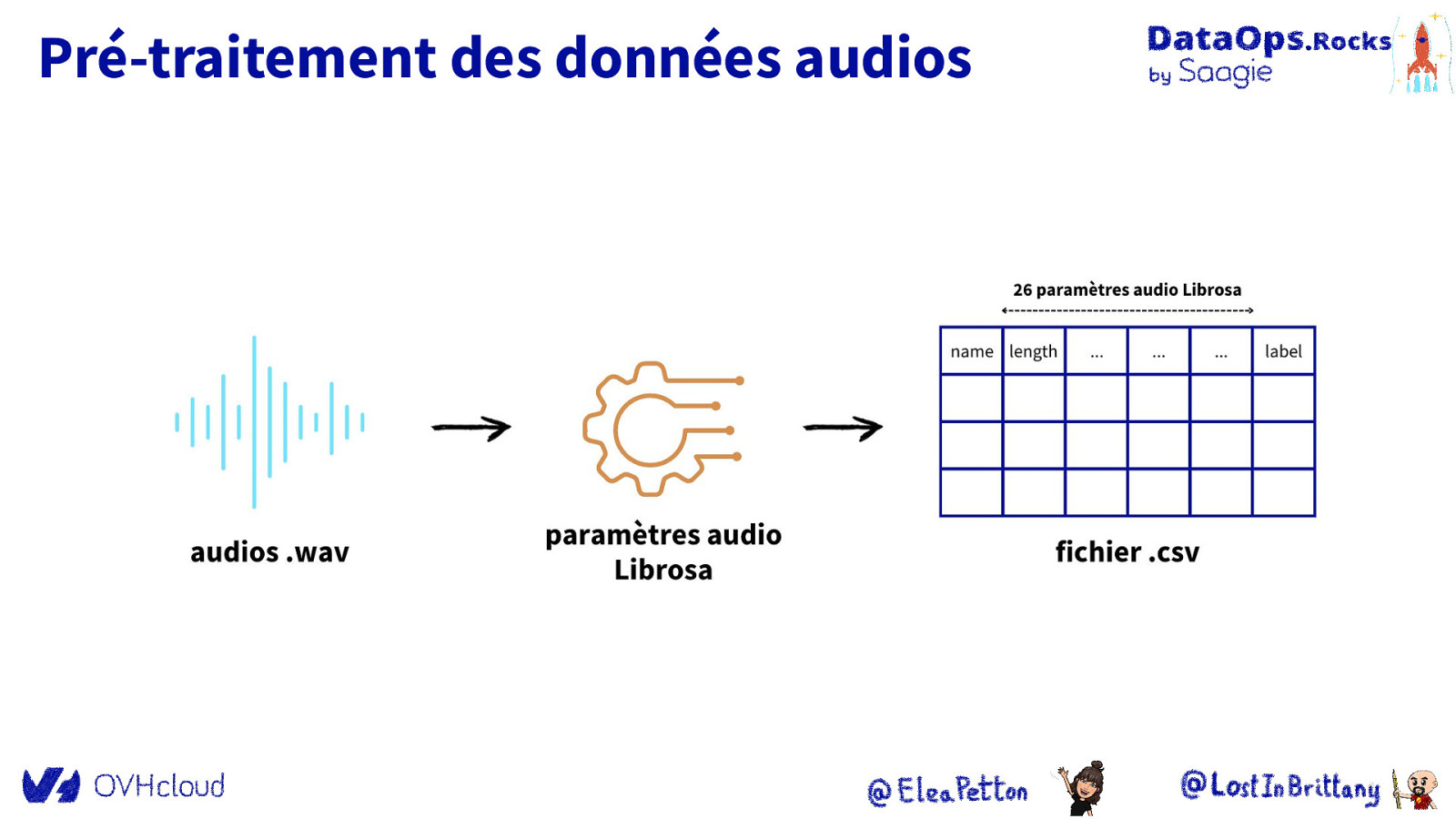
Pré-traitement des données audios

Un notebook pour entraîner mon IA

Une app pour utiliser mon IA
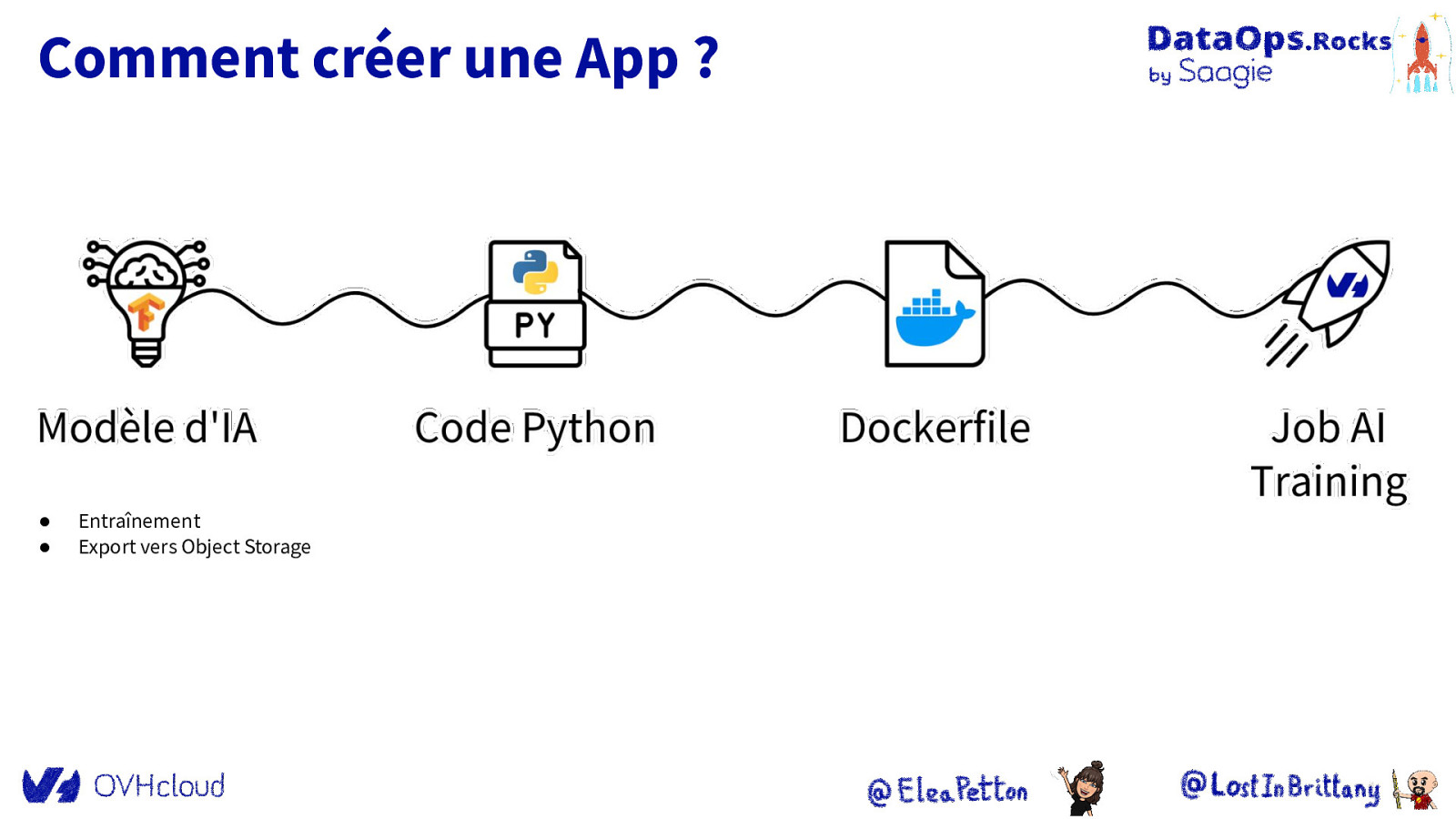
Comment créer une App ? ● ● Entraînement Export vers Object Storage
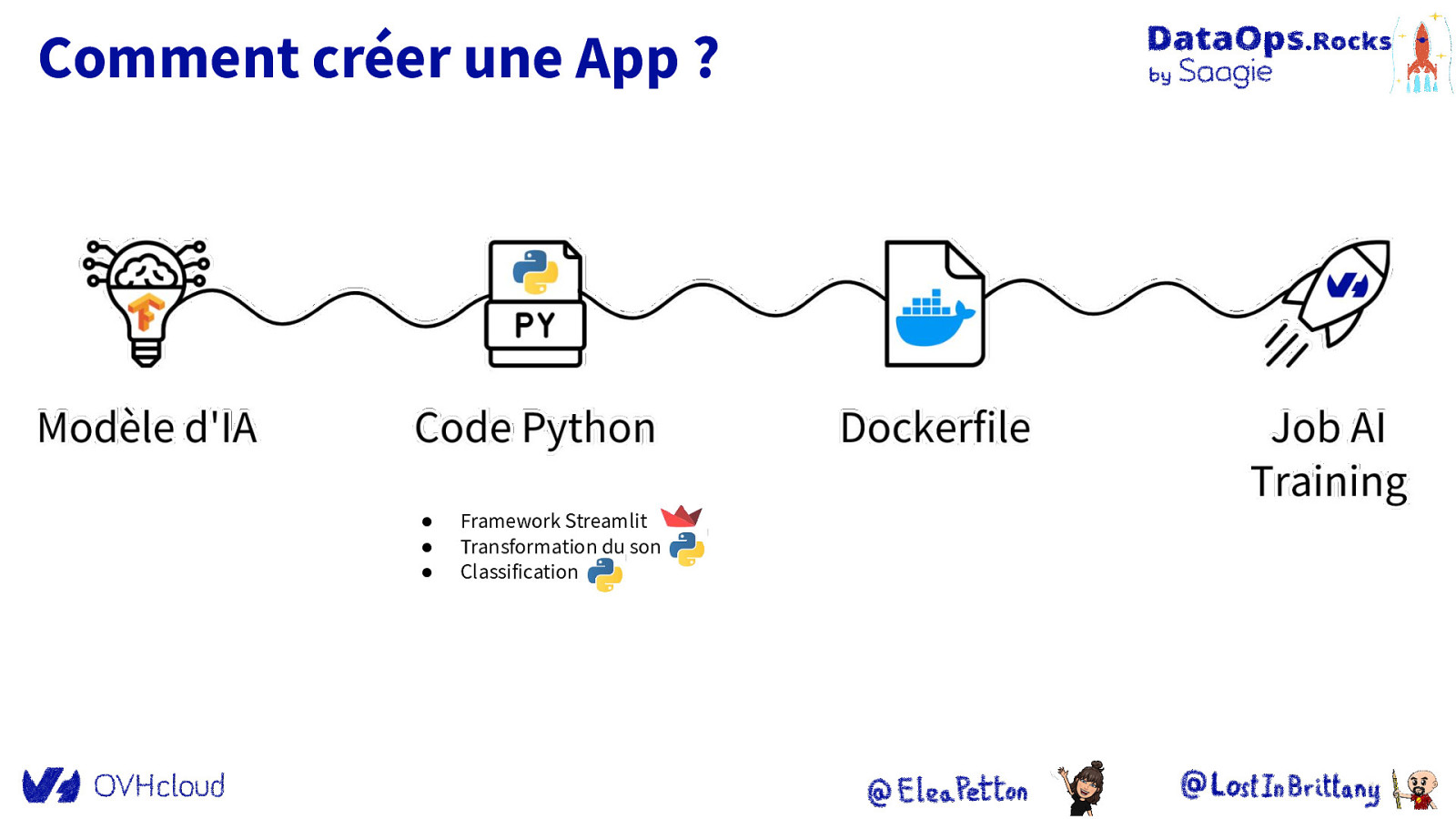
Comment créer une App ? ● ● ● Framework Streamlit Transformation du son Classification
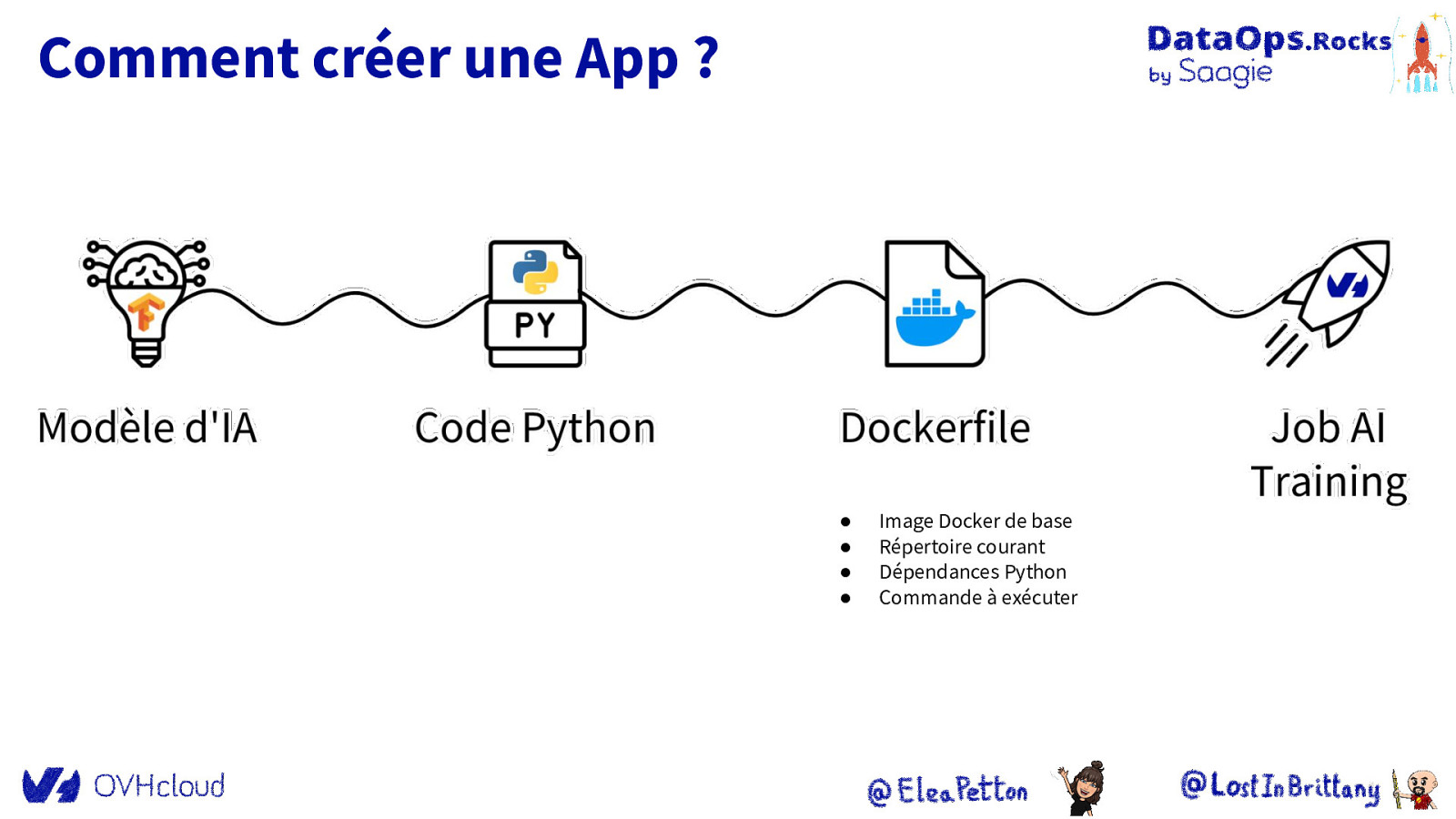
Comment créer une App ? ● ● ● ● Image Docker de base Répertoire courant Dépendances Python Commande à exécuter
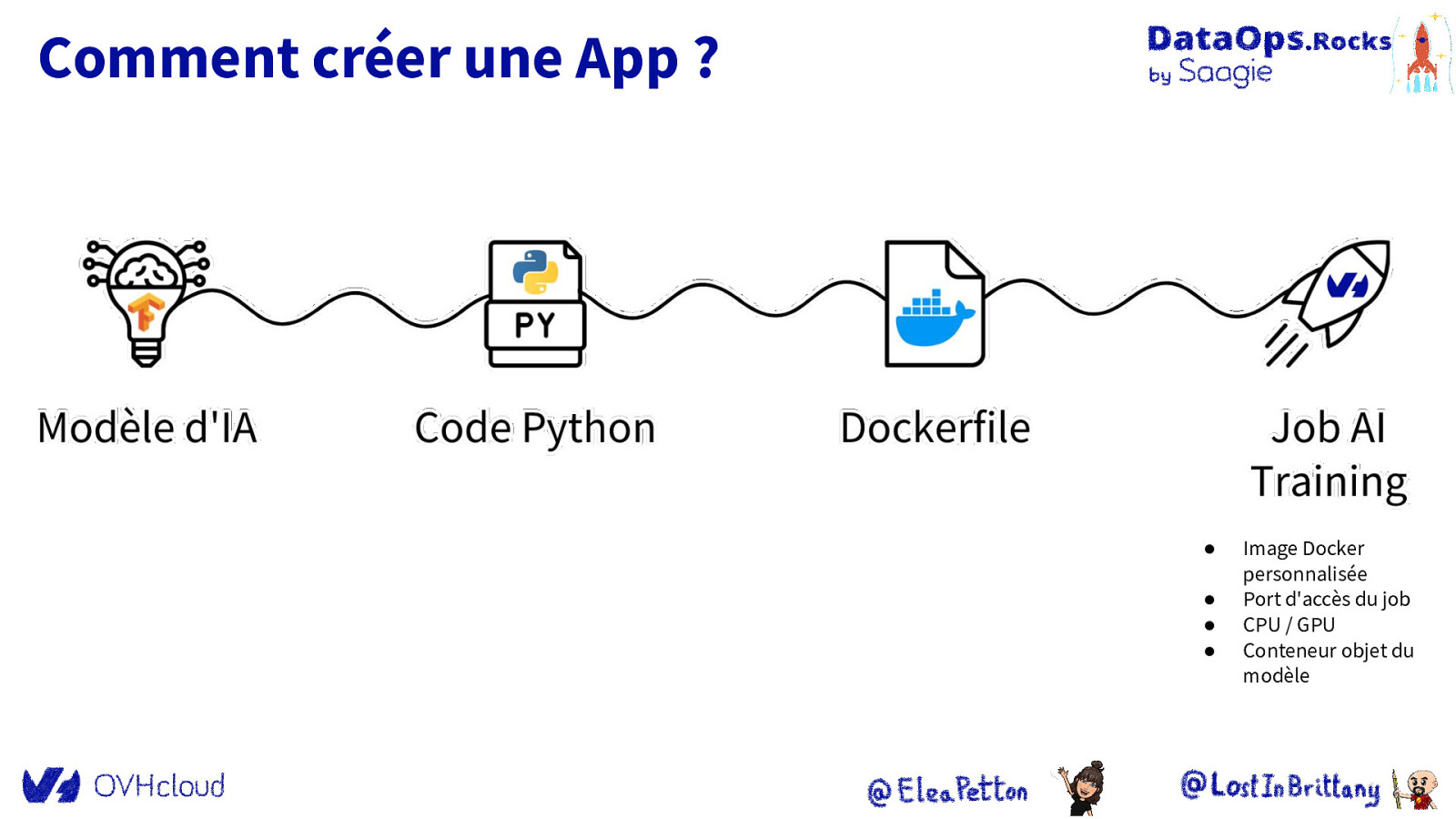
Comment créer une App ? ● ● ● ● Image Docker personnalisée Port d’accès du job CPU / GPU Conteneur objet du modèle
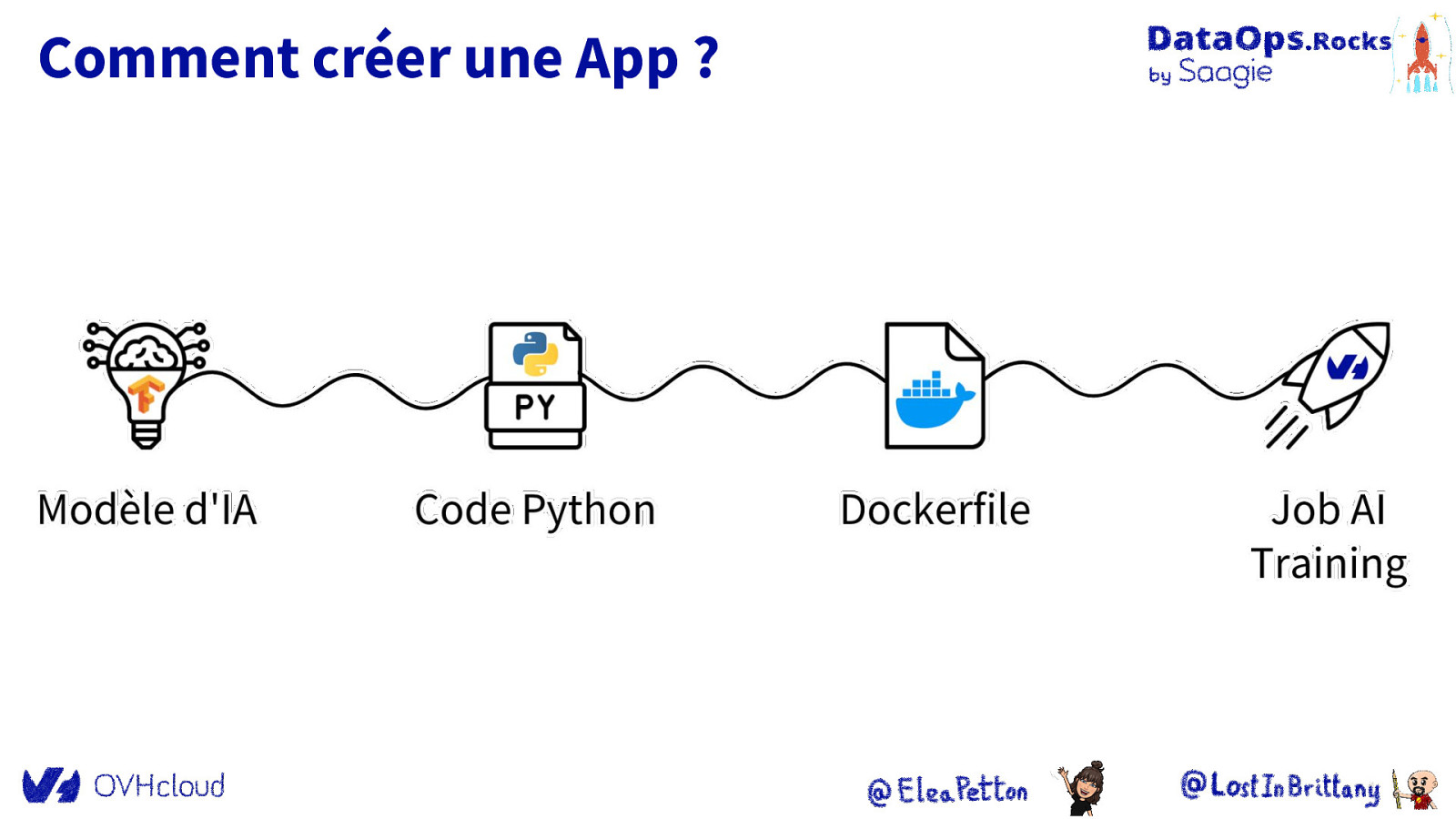
Comment créer une App ?

Test de mon App
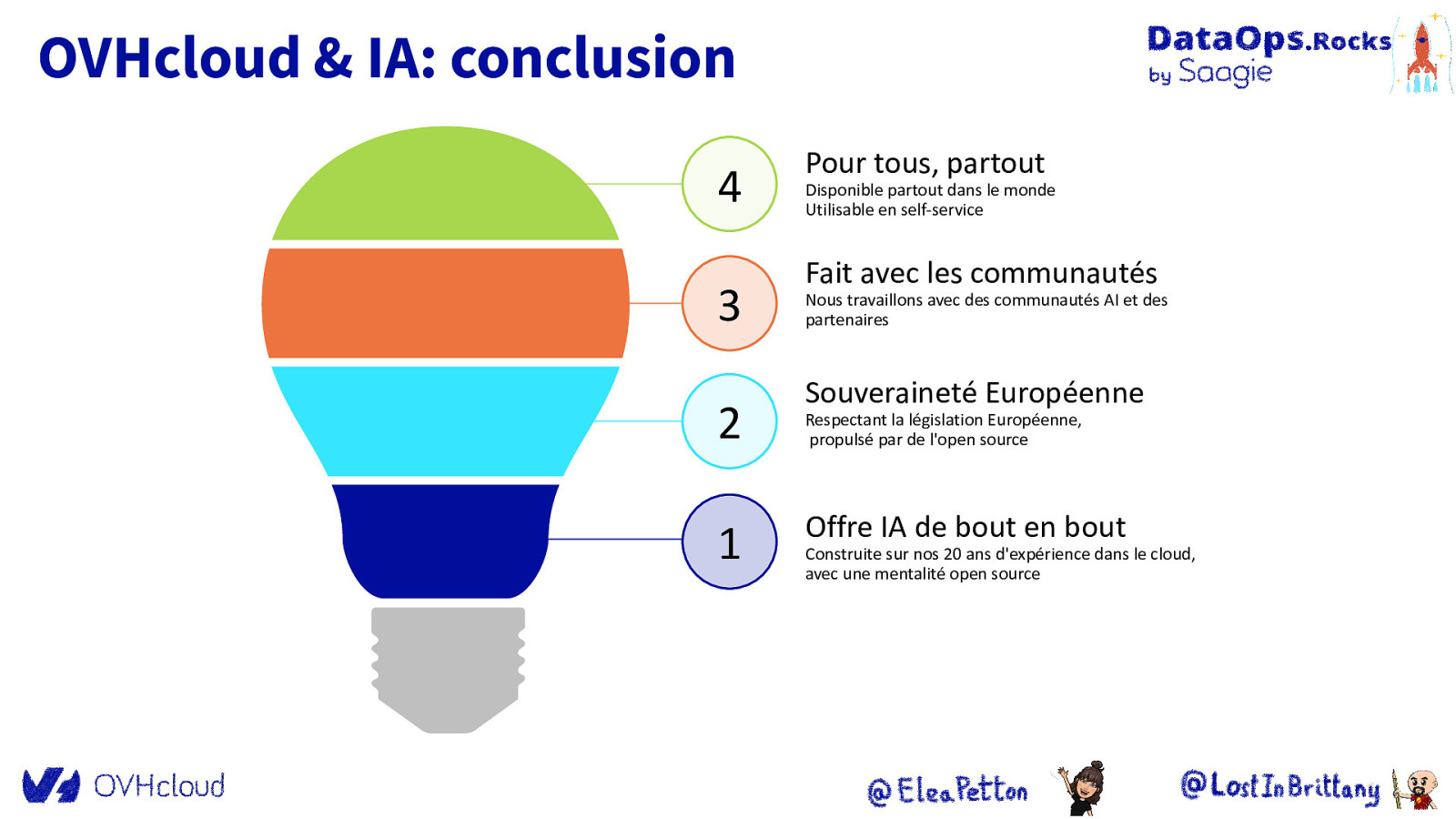
OVHcloud & IA: conclusion 4 3 2 1 Pour tous, partout Disponible partout dans le monde Utilisable en self-service Fait avec les communautés Nous travaillons avec des communautés AI et des partenaires Souveraineté Européenne Respectant la législation Européenne, propulsé par de l’open source Offre IA de bout en bout Construite sur nos 20 ans d’expérience dans le cloud, avec une mentalité open source

That’s all, folks! Thank you all!

Pour tester ● Le notebook : https://github.com/ovh/ai-training-examples/blob/main/notebooks/tensorflow/tuto/notebook-marine-sound-classification.ipynb ● La doc du notebook : https://docs.ovh.com/gb/en/publiccloud/ai/notebooks/tuto-marine-mammal-sounds-classification/ ● L’app : https://github.com/ovh/ai-training-examples/tree/main/jobs/streamlit/marine_sounds_classification_app ● La doc de l’app : https://docs.ovh.com/gb/en/publiccloud/ai/training/tuto-streamlit-sounds-classification/ ● L’article de blog : https://blog.ovhcloud.com/ai-notebooks-analyze-and-classify-sounds-with-ai/

Références ● ● ● ● ● ● ● ● ● ● ● TensorFlow : https://www.tensorflow.org/guide?hl=fr JupyterLab : https://jupyter.org/ Pandas : https://pandas.pydata.org/ Sklearn : https://scikit-learn.org/stable/ Numpy : https://numpy.org/ Matplotlib : https://matplotlib.org/ Dataset des sons de mammifères marins : https://www.kaggle.com/datasets/shreyj1729/best-of-watkins-marine-mammal-sound-database Informations sur la dataset : https://cis.whoi.edu/science/B/whalesounds/index.cfm Classification de musique avec un CNN : https://blog.clairvoyantsoft.com/music-genre-classification-using-cnn-ef9461553726 Classification des genre musicaux : https://towardsdatascience.com/music-genre-classification-with-python-c714d032f0d8 Pré-traitement des données en Machine Learning : https://towardsdatascience.com/introduction-to-data-preprocessing-in-machine-learning-a9fa83a5dc9d