Continuous Accessibility: Strategies for Success at Scale
By Melanie Sumner, Accessibility Lead for HashiCorp

A presentation at Emerging Tech East in April 2024 in Philadelphia, PA, USA by Melanie Sumner Temple

By Melanie Sumner, Accessibility Lead for HashiCorp

In addition to being the accessibility lead at HashiCorp, Melanie Sumner is an invited expert for the WAI-ARIA Working Group, and a member of the Ember.js Core Team

https://helios.hashicorp.design is what I’ve been working on in my dayjob during the last couple of years

I also give a lot of talks about accessibility, and they’re available on Notist: https://noti.st/melsumner

I am the author of Continuous Accessibility and hold the copyright for it. Link: https://continuousaccessibility.com


The first section will be…well, naming things is hard so I’m calling it “The Vision” which I’ll be real, feels a little bit pretentious but idk. Anyway, we’ll first set the stage for what continuous accessibility is, so we have a shared definition at least for this talk.

Next, we’ll talk about starting where you are, because I don’t want you to get stuck in any part of this talk and think “that’s great but I’ll never be able to do that at work.” So we’ll identify place where you might actually be at work, because accessibility is a journey and we all gotta start somewhere.

Plan. Implement. Scale. Measure. Then we’ll get into the strategic implementation of the idea. What do you need to plan for? How will you measure it?

What action steps support our desired outcomes?

What is Continuous Accessibility?

The last one is the most important. We want our users to love our apps and keep using them for years and years.

In software engineering today, we have continuous integration
And we have continuous deployment. And these two things have made our lives as engineers so much better. I mean, do you remember in the before times when we didn’t have these things?
And these concepts really are what inspired the idea of continuous accessibility. But How will we get there? How can we deliberately achieve this vision? We have to be on purpose.

For the purpose of this talk, we’ll use my definition of Continuous Accessibility. It is the approach to ensuring that code intended to be displayed in browsers can be continuously checked and monitored for digital accessibility requirements through a novel application of existing software engineering concepts and Web Content Accessibility Guidelines (WCAG).

So first, I want everyone to think about where they are and some pre-work or parallel work that might need to be done Because accessibility is a journey that requires passion, patience and persistence.
And because after every time I’ve given this talk before, I’ve inevitably had a developer tell me “this is a great idea but I have BLOCKERS, Mel.”
So this is a new section to this talk to…talk about the potential blockers, and help you think about problem solving for those. Or even better, finding other people at your company who are good at solving the business blockers so you can focus on the code blockers.

Do decision makers understand? you get to have some expectations from your executives. So let’s talk about those.

If you don’t currently have these things, it might be difficult to get other management on board. At HashiCorp, having an executive sponsor for the work was important to getting everyone else on board. We were then unblocked to ship things like a plan of record, a proposed company-wide accessibility statement, and just generally do the work.
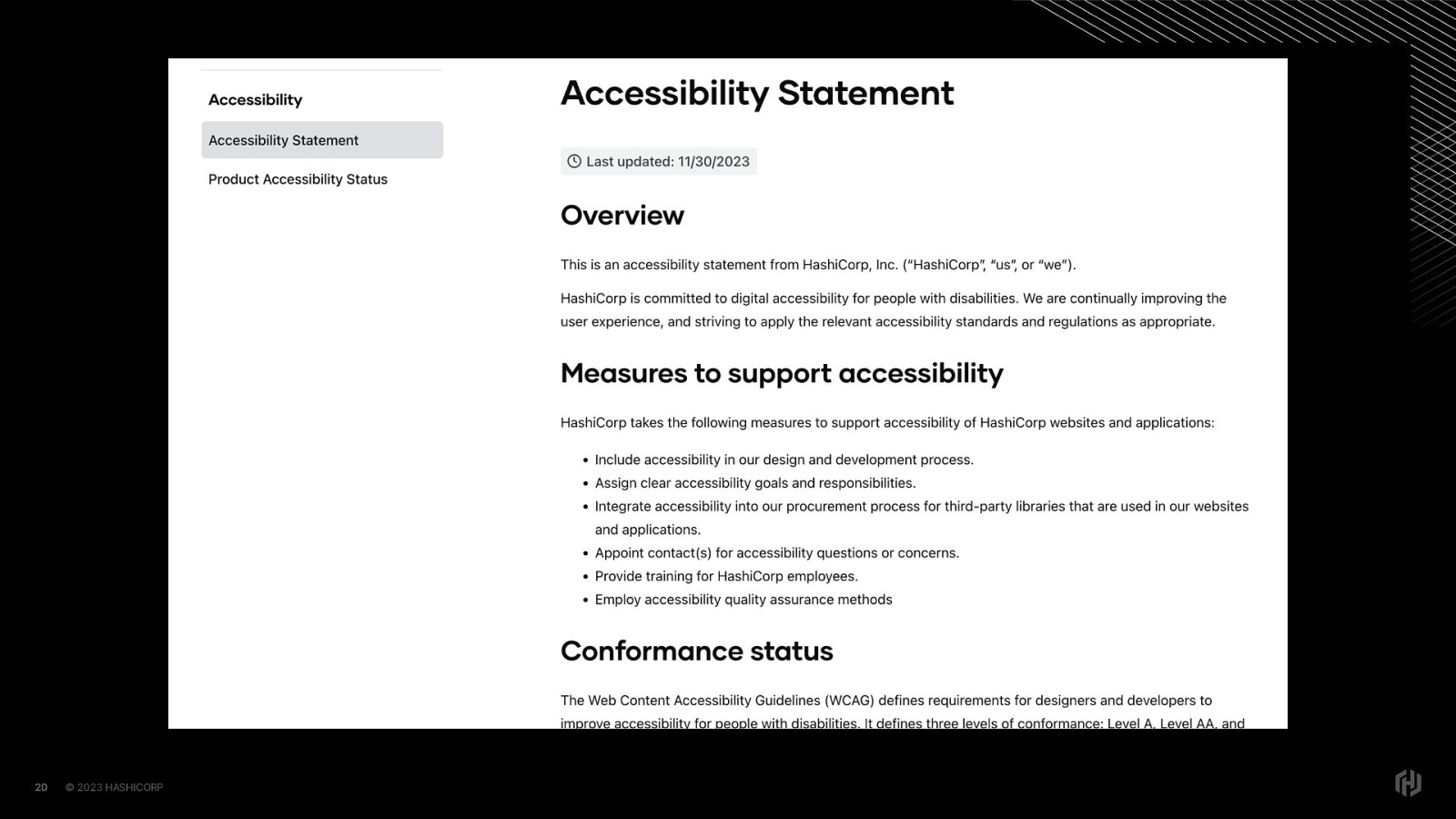
Because our leadership explicitly said “Accessibility is important to us”
If you were to visit hashicorp dot com slash accessibility,you’d see that we’ve integrated an accessibility statement into our trust center, demonstrating that we’re just as committed to accessibility as we are to privacy and security.

Are you getting the time you need?

Are you getting accessible designs?

Heuristics for interaction design already include accessibility concepts. Designers learn design heuristics. But what they don’t often learn is that these design heuristics directly correlate with accessibility concepts.

Now just really quickly- Jakob Nielsen recently said a bunch of incorrect things about accessibility, and publicly, and I don’t endorse or agree with what he said.
So while I did custom make these graphics, I haven’t had time since he said those things to re-design these graphics. So please pardon me there.
Anyway. There are well know design concepts such as “recognition rather than recall” that relates to accessibility heuristics such as “users can make sense of the consent and understand how to operate the system”
This sometimes translates in applications to consistency and predictability, too. I like to tell teams, “I don’t want us to do it the wrong way, but if we’re wrong about this, let’s at least be consistently wrong.”
That way the user isn’t getting a different experience inside each of our apps, but can remember “oh when I’m in this application, the menu or tables work a certain way”
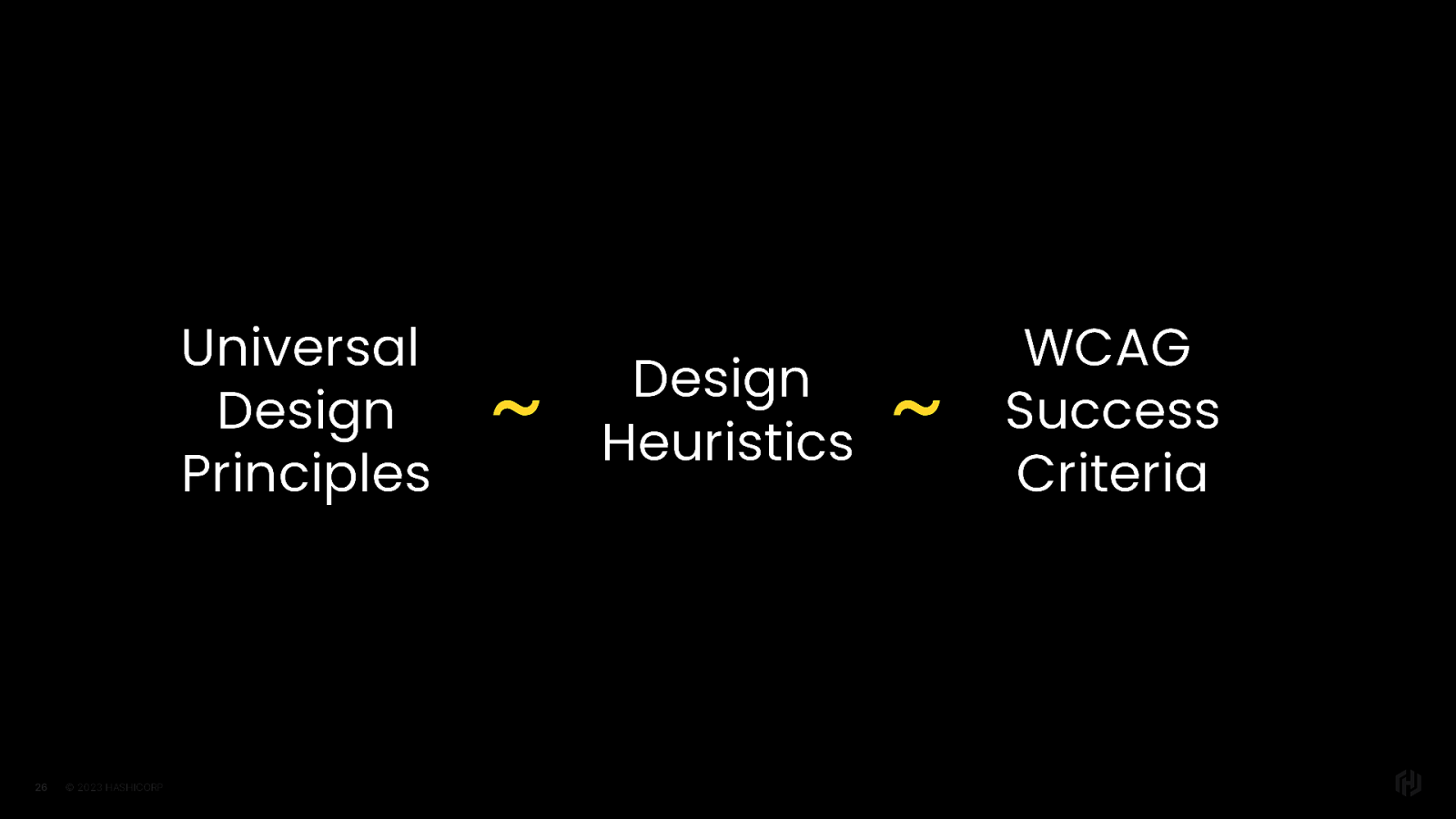
And even beyond that, you’ll find that universal design principles map to design heuristics, which also map to accessibility criteria in WCAG.
ITS ALL CONNECTED
But big brain aside, by understanding ourselves that all of these things are related to each other, we can make designers our partners in success.





Additionally, there are tools that provide design support for accessibility. Especially for the popular design tool Figma, Level Access and Stark are just two of the community plugins that help support accessible design.
https://www.figma.com/community/tag/a11y/plugins
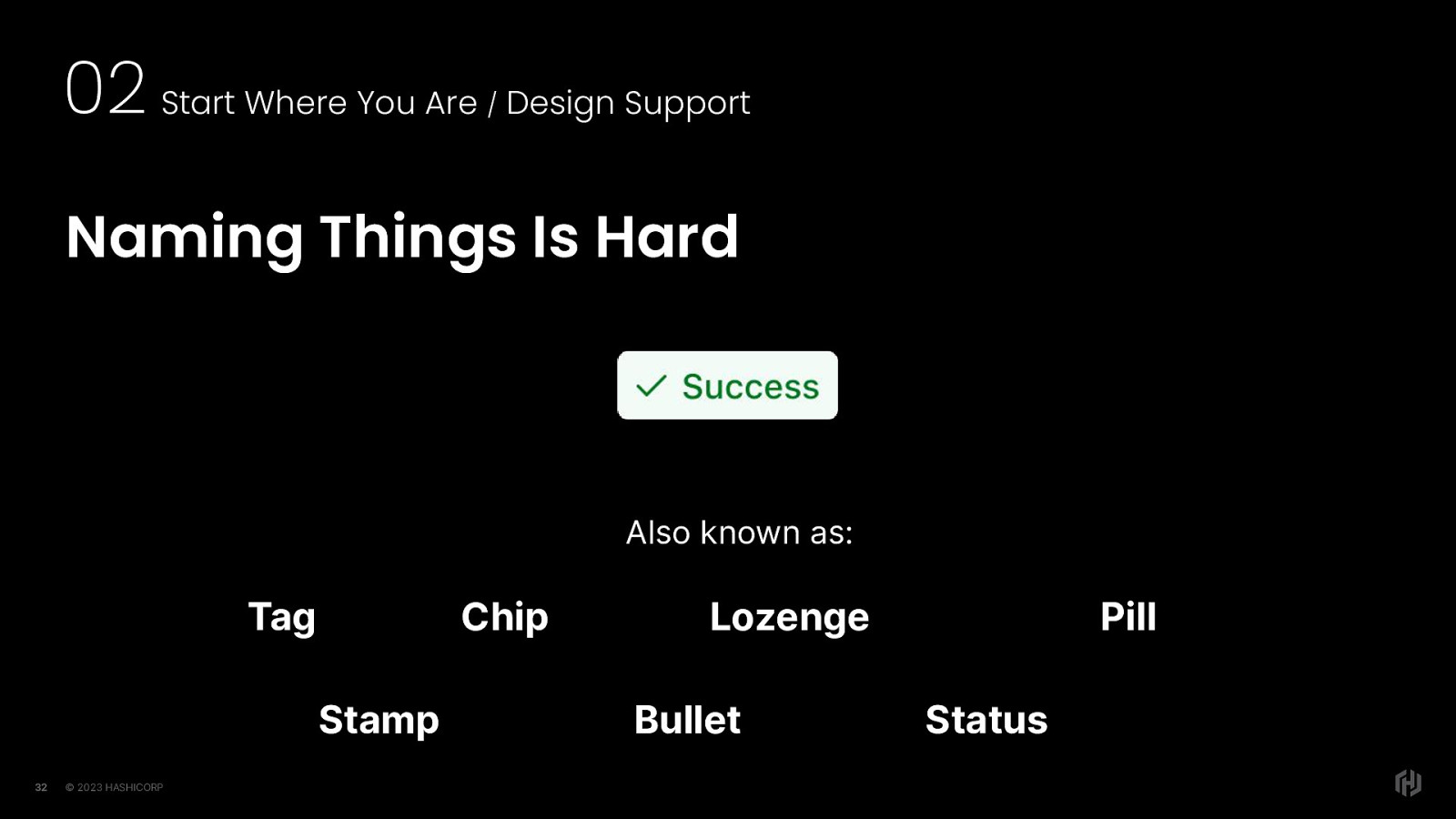
Our design system. has a badge component. But when we looked around we saw that other design systems had any given number of names for the same thing, like tag, chip, lozenge, pill, etc. So we decided to do something to reduce the gap between design and development: name things the same way. This means that the components have the same names and even the APIs have the same names. We’re reducing that gap so we can move faster by having a shared language.


Purposefully integrate accessibility. Ok now let’s dig in to the strategic implementation of continuous accessibility.

The well-established principles of continuous software engineering remind us to





We have to be on purpose.
At its core, there are three parts to our planning process

First, we must have a plan for the code we already have. How will we improve its accessibility while still moving forward with new features?

Second, we must plan for the code we will have in the future, the code we will create.

And finally, we must have a plan for how to measure our work and show our progress.

So let’s talk about planning step one: planning for the code we already have.

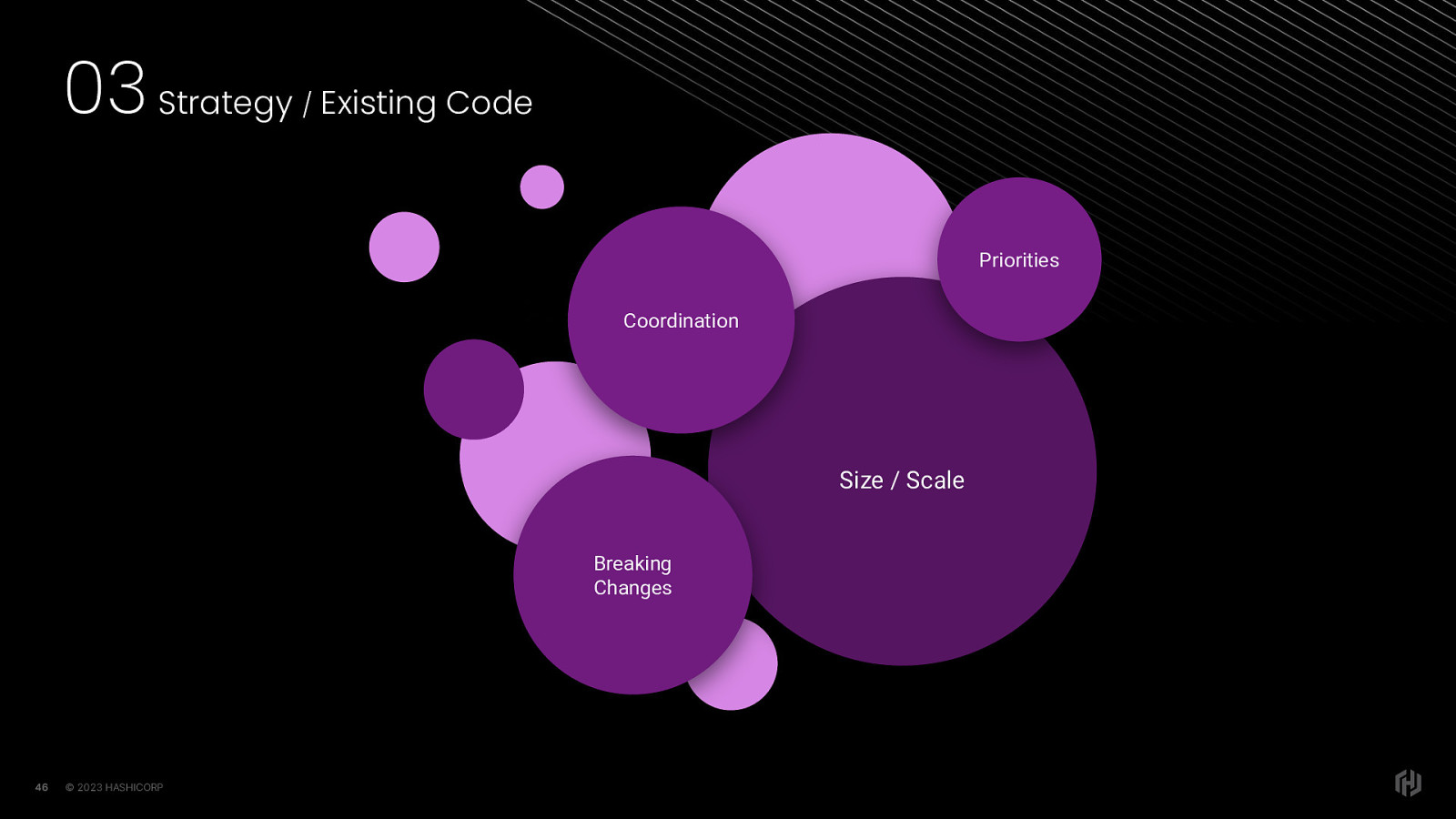
We have to think about these things for apps at scale. Or even, apps that WANT to scale. It can be tricky to update a dependency especially when it includes breaking changes. Depending on the size of your codebase, taking in a new version of a dependency can mean extra developer coordination about which new features to use, or when to do the implementation work. There are also product and business priorities to consider.
Features we create for accessibility automation should make it simpler to deliver improved products and tooling to support accessibility as a facet of our craft. We can’t just deliver accessibility improvements in a vacuum and expect things to go well.
Again, we have to be on purpose. We have to deliver in a way that our teams are, if not excited, at least willing to adopt.

For the code we have now, we could wait for our users to report issues to us- but we run the the risk of losing customers, or reduced engagement from our current customers.

We could also rely on audits to tell us where the issues are…but again, this is a little late in the app creation process.

Ideally, we are automating checks with linting and testing, periodically checking the code we already have and making sure that the new code we are crafting is conformant. This gives us higher level of confidence that as technology progresses, our applications still work as expected. Of course, there is still a lot of opportunity for innovation in this area.

The automation-first approach allows automation to be our first line of defense backed up by the accessibility audits that we might need for certain customers who require accessibility as condition of purchase and finally backed up by user reports (because users still will tell us when they run into blockers)

Next, let’s think about the code we will write tomorrow

Of course, We will keep following the principles of continuous software engineering. I want to zero in on number three: letting computers perform repetitive tasks, so people can solve hard problems. In the area of accessibility automation especially, this is where we are seeing more innovation…and I think where, if I can successfully convince you, we will continue to see even more innovation in the future.
To do that, Let’s take a look at the way automation in accessibility can help.

Developers have access to automated testing for dynamic code analysis
Through through the axe-core library (pause)
that has been…and can be… integrated into the continuous integration and delivery mechanisms that are already used to test and deliver our code.
These days, developers have a lot of options too! Axe-core has been implemented in many tools, like Lighthouse or Microsoft’s Accessibility Insights. Even EmberJS, the open-source javascript framework that I work on, has a library called ember-a11y-testing that can be integrated into an Ember app for automated accessibility testing.

For static analysis, developers can use ember-template-lint, jsx-a11y, and lit-a11y…even vue-a11y is coming along. Each have varied levels of support.
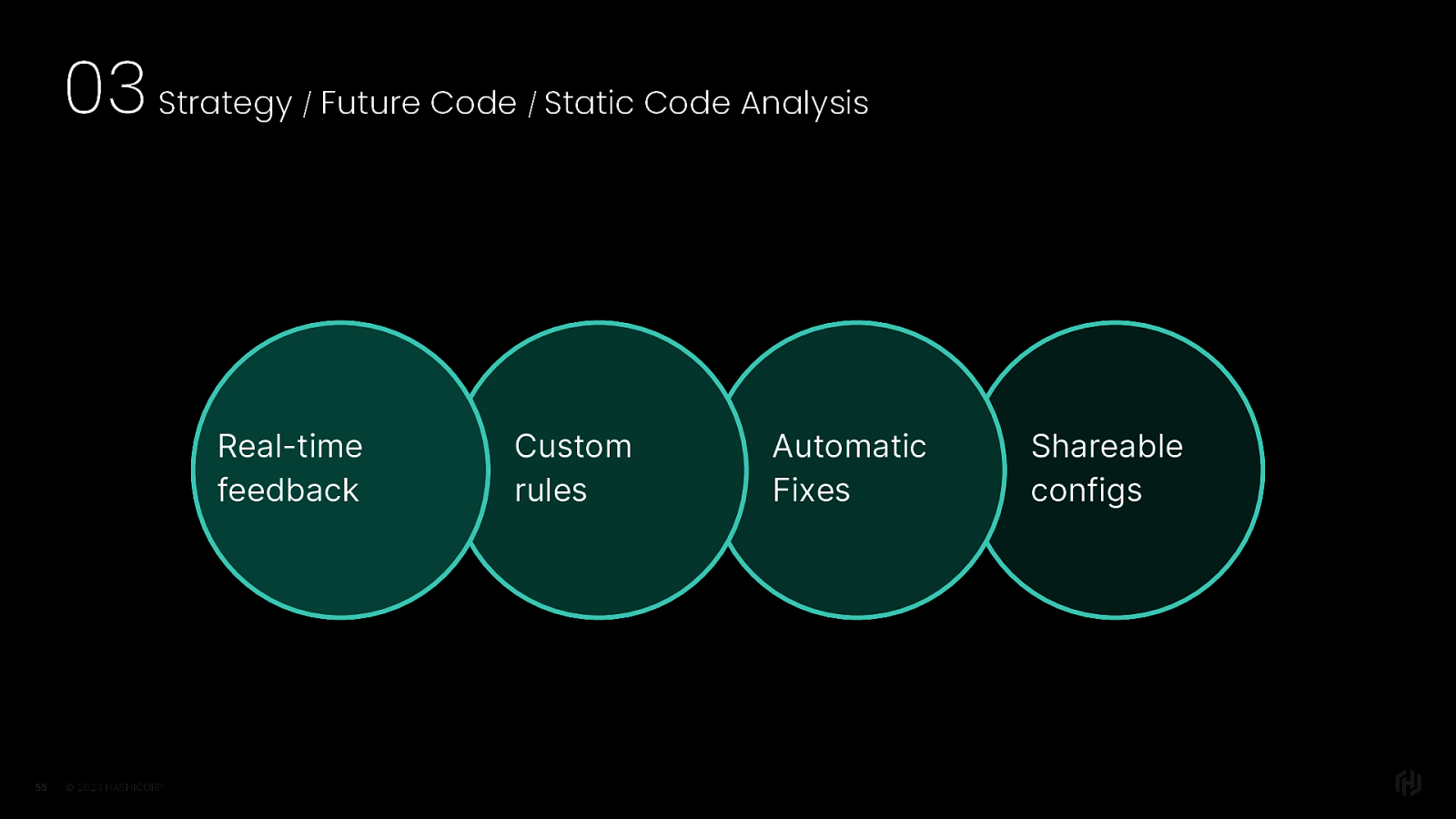
I want to talk a little bit about static code analysis. They all mostly work the same, but I’ll talk through it by talking about ember-template-lint because that the one I’m most familiar with and have been working on for a few years now. Here’s some of the benefits: Developers can get linting feedback while they are writing their code It also supports a plugin system that allows teams to define and use custom rules Some rules have automatic fixes built right in, and running the ”fix” flag will cleanup all of the auto-fixable issues Finally, it supports sharing configs across projects, so you can ensure that all of your teams are on the same page, which I think is especially really valuable in today’s globally-distributed workforce

It’s also possible that you find these two options a little narrow, so I’m adding a new type of code analysis here. Let’s call it “anytime” code analysis There are some E2E testing frameworks and some enterprise companies tend to like having separate E2E tests. Accessibility testing can be added here too! I have also set up accessibility tests to run…at my convenience, via GitHub Actions.

So quick story: Before version 3.0 of ember-template-lint, the print-pending flag gave us a way to roll out new rules. you could take a list of current errors and basically make an “ignore these errors” list in the linter- but it relied entirely on teams to be proactive and treat that list as a burndown list, not an “ignore permanently forever” list. Of course, quality engineering teams understood that we didn’t really want them to ignore these errors forever, but it’s easy to forget about something that doesn’t have a deadline.
Now, at this time I was working for a giant tech company with a 10+ year codebase.
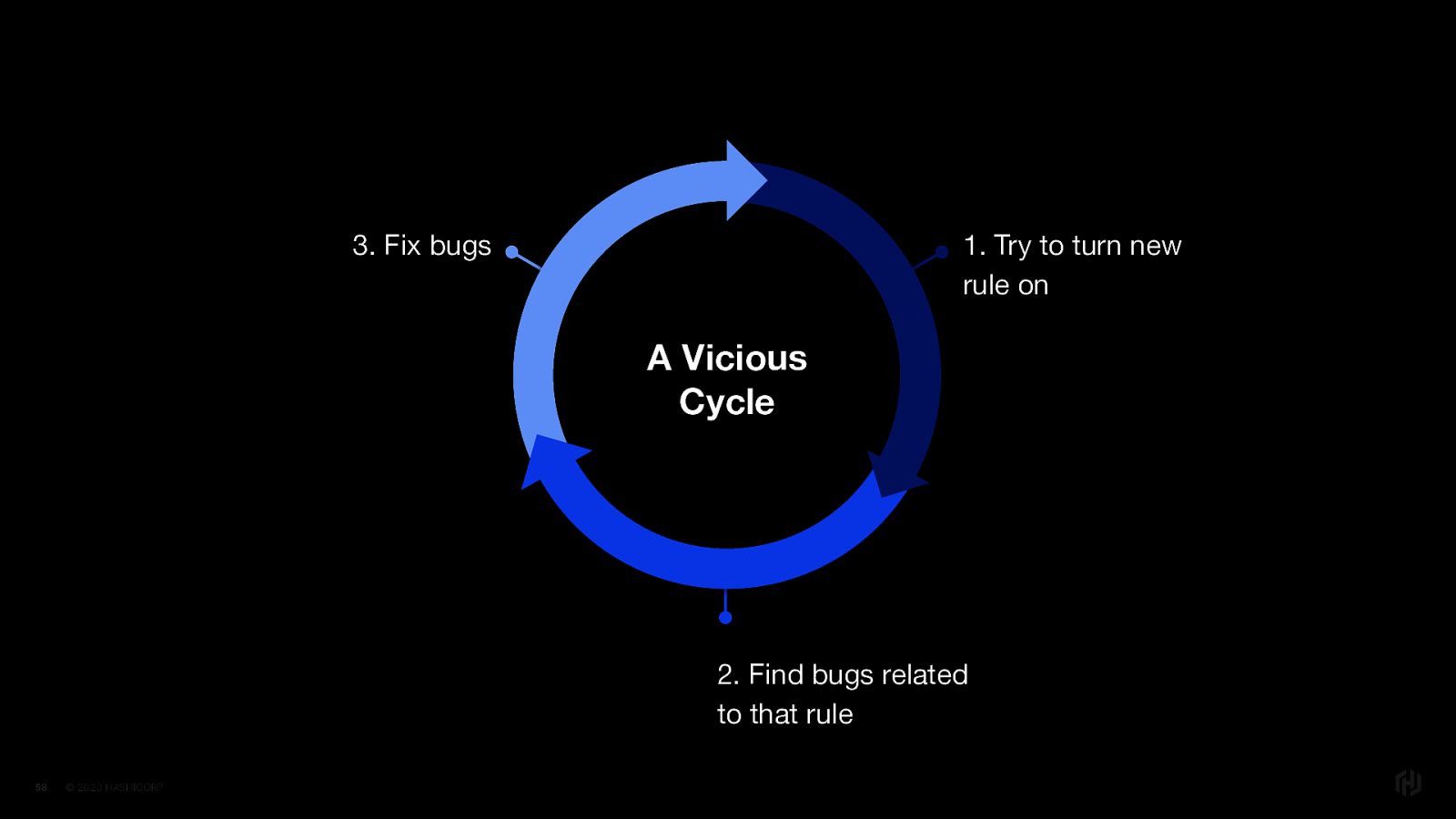
One approach was to turn a rule off completely until all existing instances of that error were fixed. Of course, this led to a never ending cycle of trying to turn a rule on, finding new bugs, fixing those bugs…and starting all over again
This is because by the time you fixed all the errors, new code would appear with those same errors.
Not only is this approach time-consuming and costly… it can really disincentivize teams to keep up with best practices.

I was so excited that I had the opportunity to implement accessibility linting into our giant codebase and omg all the things were going to be accessible.
It was going to be great! I was going to be a hero!
But I simply couldn’t fix the issues fast enough to get the rule turned on. We would have had to get everyone to stop writing new features, and that just wasn’t going to happen.
I was sad. Okay, I was devastated. Then I was determined.

So we had issues that could go into the lost void of forever Or stuck in a cycle of always almost ready to turn a rule on We needed to do something different.

Enter support for the TODO. Instead of only having the option to set a rule to warning or error, We can now instruct the linter to find all existing instances of a rule being broken, and create a “todo” for each. This improves on the previous approach in a couple of ways. After a period of time, this “todo” turns into a warning And then an error (which acts as a forcing function), because then the build breaks.
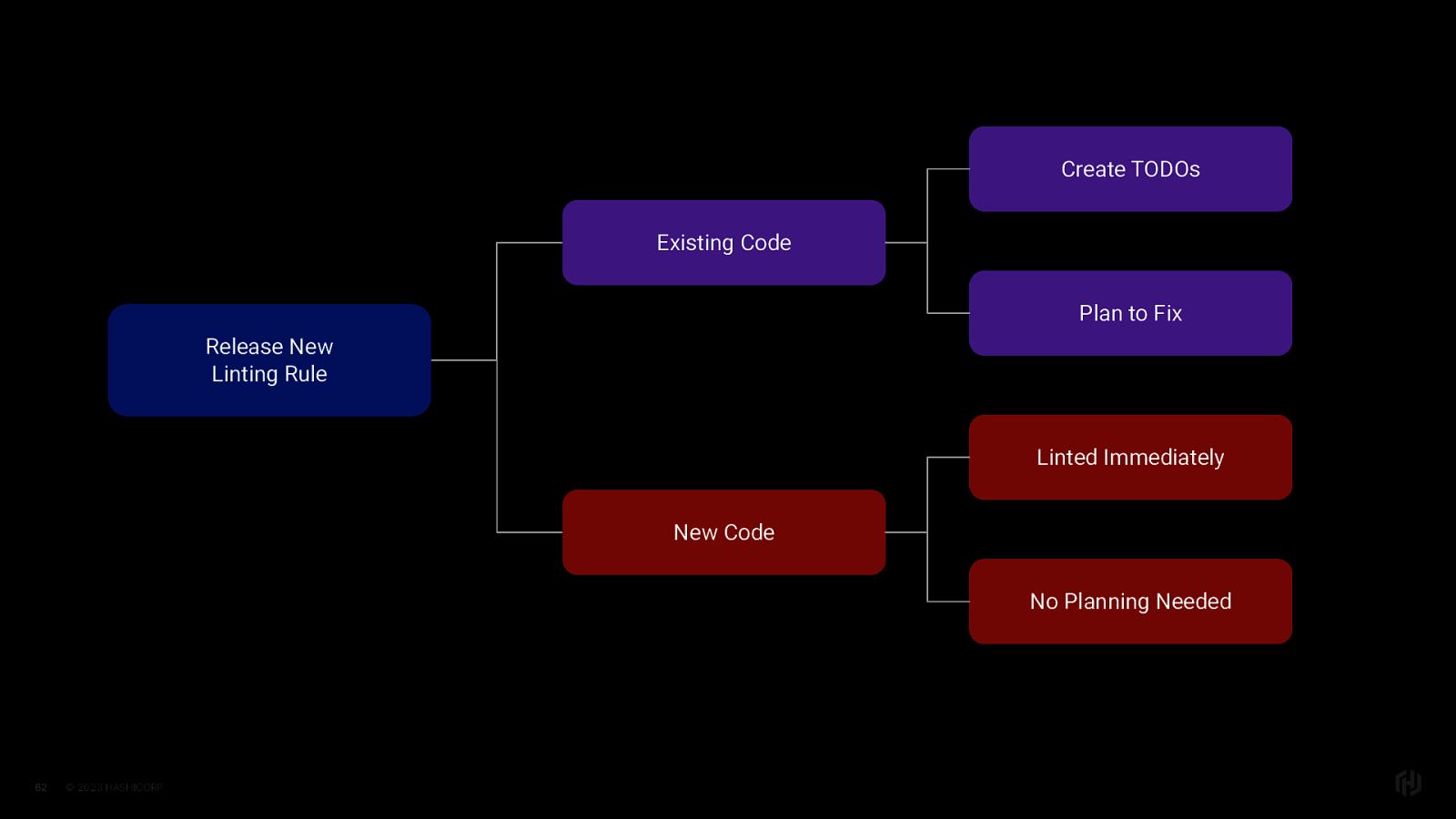
If we look at this from the perspective of the code we already have and the code we will create, we see that we can break the problem into different parts, so we can immediately benefit.
When a new lint rule is released,
Which is kind of useful especially if you’re new to accessibility engineering in general, figuring out how to fix the issue on the new code can teach you how to fix the issues on the code marked with TODOs.

Which code analysis strategy will you want to use?
It depends, TBH. You’ll want to figure out what works best for you and your team.
I think you could have a combination of all of them. I like static code analysis in my IDE (those red squigglies are really useful to me! I like dynamic code analysis because I want to KNOW that the code that is committed to my repository works I like being able to occasionally run a GitHub action and just check on things sometimes.

Now you might be wondering, okay but can’t teams just create a new todo? And the answer is, yes, of course they can.
This approach is about empowering developer teams to move faster. This is about giving PMs the right information so they can make the best planning decisions to support their teams. This is about guidance, not control.


Just in case you haven’t had to work with metrics yet, or haven’t in a while, let’s review four of the commonly accepted key criteria of quality metrics: Meaningful. They must be connected to the goals and/or strategy of our organization. Controllable. If a metric is not under your control or influence, it is not meaningful to report (even if it is useful to know about). Easy to Access. Metrics should be easy to find, easy to identify and visible to management Actionable. Any metrics that we define MUST have actionable outcomes.

but what do we mean when we say actionable outcomes? well, we can use metrics to diagnose a problem improve a process set a goal or observe trends that can inform future work

But before I get into the specific metrics that I think we should be measuring, I want to remind us of Goodhart’s Law- our metrics should never themselves become the entire point. We won’t achieve the outcomes we are after (improved accessibility and user experience) if we merely game the system.
There’s a balance to be had; we need to measure things in a business environment, but we need to deliver quality for our users, not only meet a metric or fulfill a WCAG Success Criterion.

First metric: Potential Violation Count. This metric sets the baseline for us. Now, we all know that there are an infinite number of ways that things can go wrong in any given application. But that isn’t what we mean here. With potential violation count, we want make the unknown problem a known problem, then solve for each. The baseline is the total number of individual ways an application could fail the legal accessibility requirements. but how do we get that itemized number? In WCAG we have success criteria, known techniques, and common failures. There are also location-specific Legal Standards like Section 508 in the US. Of course all of these potential violations represent massive effort that has already been completed by user researchers but how do you get that information in a practical way?


We do this by making an itemized list. There will, of course, be some overlap, but this work is worth doing because it gives us the peace of mind that we really know the edges of this problem. We’re turning an area of ambiguity into an area of clarity We’re making the unknown edges of the problem known and that can help give us confidence.

Some of you who are already familiar with the WCAG Success Criteria might be wondering, why not just use those? Well, it’s because they cover generalities rather than specifics.
For example, WCAG 1.3.1 (Info and Relationships) is a single success criterion but relates to at least 25+ different failure scenarios.
Linting rules have to cover one specific failure, catching as many potential implementation syntax errors as possible

https://a11y-automation.dev Before you think “oh my gosh that kind of list seems like a lot of work” – let me share an effort that has already begun to itemize potential violations. It’s an open source project called the a11y automation tracker, and intends to compile each one of these itemized potential violations with details.
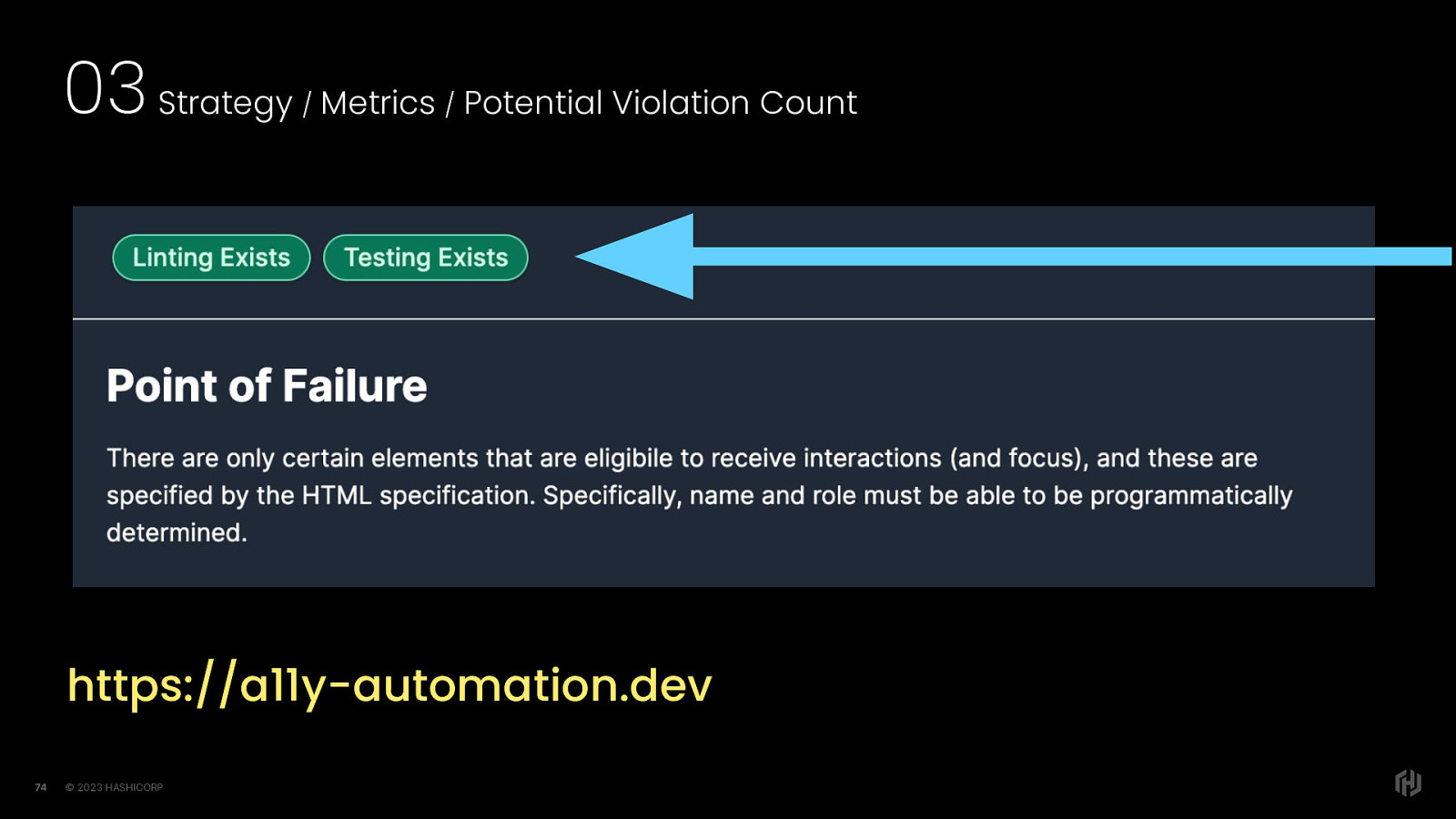
There is an overall list, but there is also the ability to dive into each potential violation and see the details about how it can currently be tested,
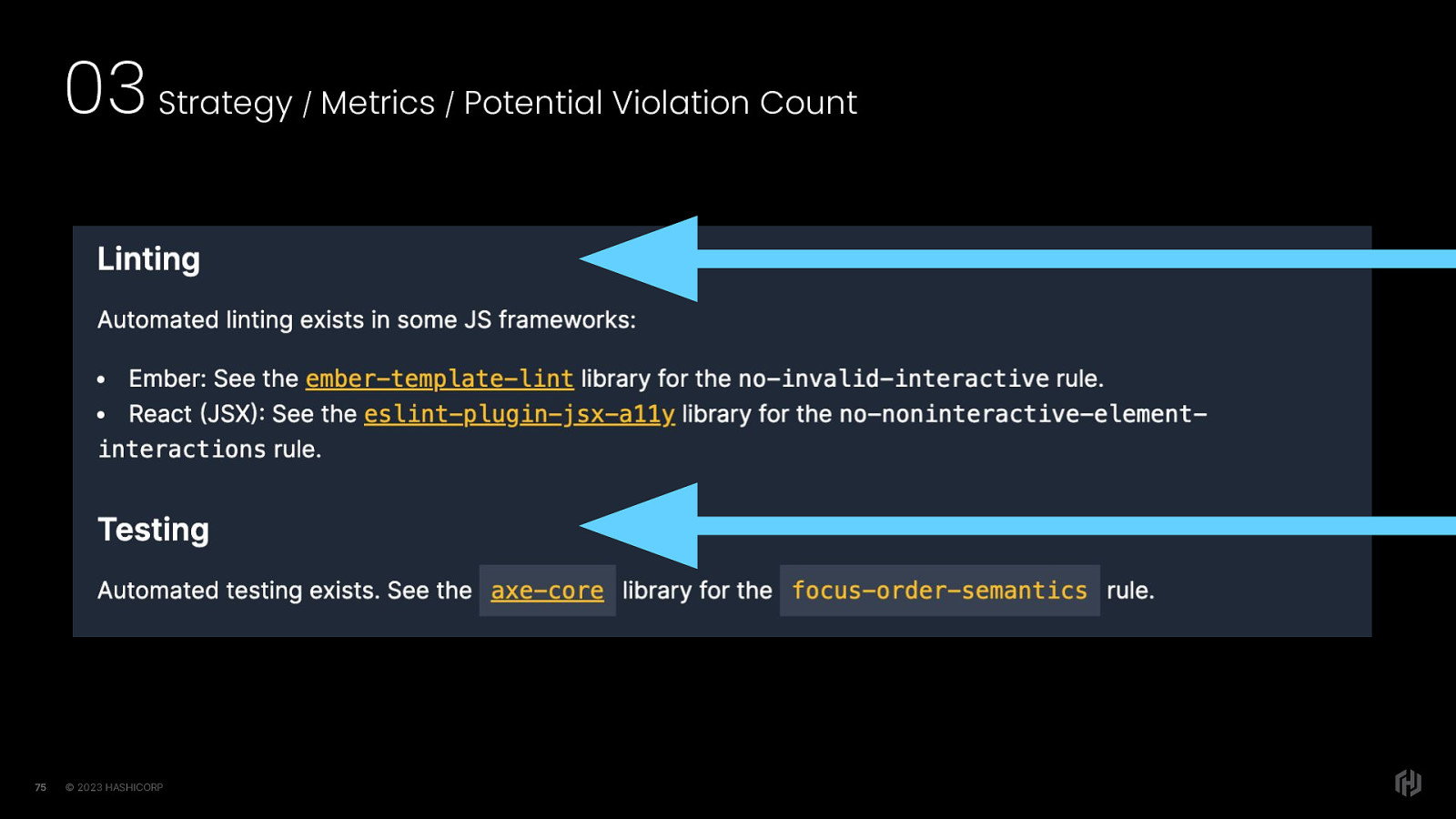
The existing linting rules and the libraries they are in The testing rules and the libraries they are in, and the relevant WCAG Success Criteria, with links do documentation. Of these potential failures, my initial analysis has indicated that about half of potential violations that we have compiled are either already automated or are potentially automatable.

By identifying the edges of the potential violation count, we can then determine related metrics:
Violations for which we can provide automated linting for static analysis Violations for which we can provide automated testing for dynamic analysis Violations that require developer-authored tests Violations that require manual testing These metrics are useful if we build tooling! Once we set a baseline we can target improvements.

So let’s talk about metrics related to bugs
We can do total bug count, but I think valid bug count is more useful.
We can then break this down further by specific facets; was it found with automated testing or manual testing? Did an audit uncover the issue?

And further, we want to break valid bugs down into bug severity. To make things easier for ourselves, we can use the same four categories that aXe uses: Critical, Serious, Major and minor.
This way we can determine an SLA for time to fix; and that’s something you can define within your own program.
I’ve seen companies require that critical a11y bugs be fixed within 72 hours; these are things that would completely block a user from completing an essential task AT ALL but minor bugs like, a main element with the role of main on it? That’s just poorly written code. Those can get up to 90 days to fix.
So the minor issues can be fixed during a hackathon or even given to junior developers to investigate and fix (and avoid in the future). But critical bugs need to be addressed immediately because they prevent users from completing the tasks that the website was designed to allow users to complete.


We can also measure Time to Fix
Time to Fix % of Time to Fix within the defined SLA Incentives! Who produces a higher number of bugs and should receive additional training? What IC or team prioritizes bug fixes and should be recognized/rewarded?

We can also start to think about how to measure potential accessibility health– meaning, the variables that contribute to the ability of our application to be accessible.
We could measure the ability of an application to be accessible! Think back to Automation Count: How many automated checks exist? How many automated checks could exist but don’t yet? How many manual checks need to be completed no matter what? (useful for planning)

Are teams receiving training? Is it working? Are product owners and/or engineering managers informed? Are teams given enough time to do the work properly? Are teams using a design system? Can we measure its accessibility? Does the documentation include accessibility information?
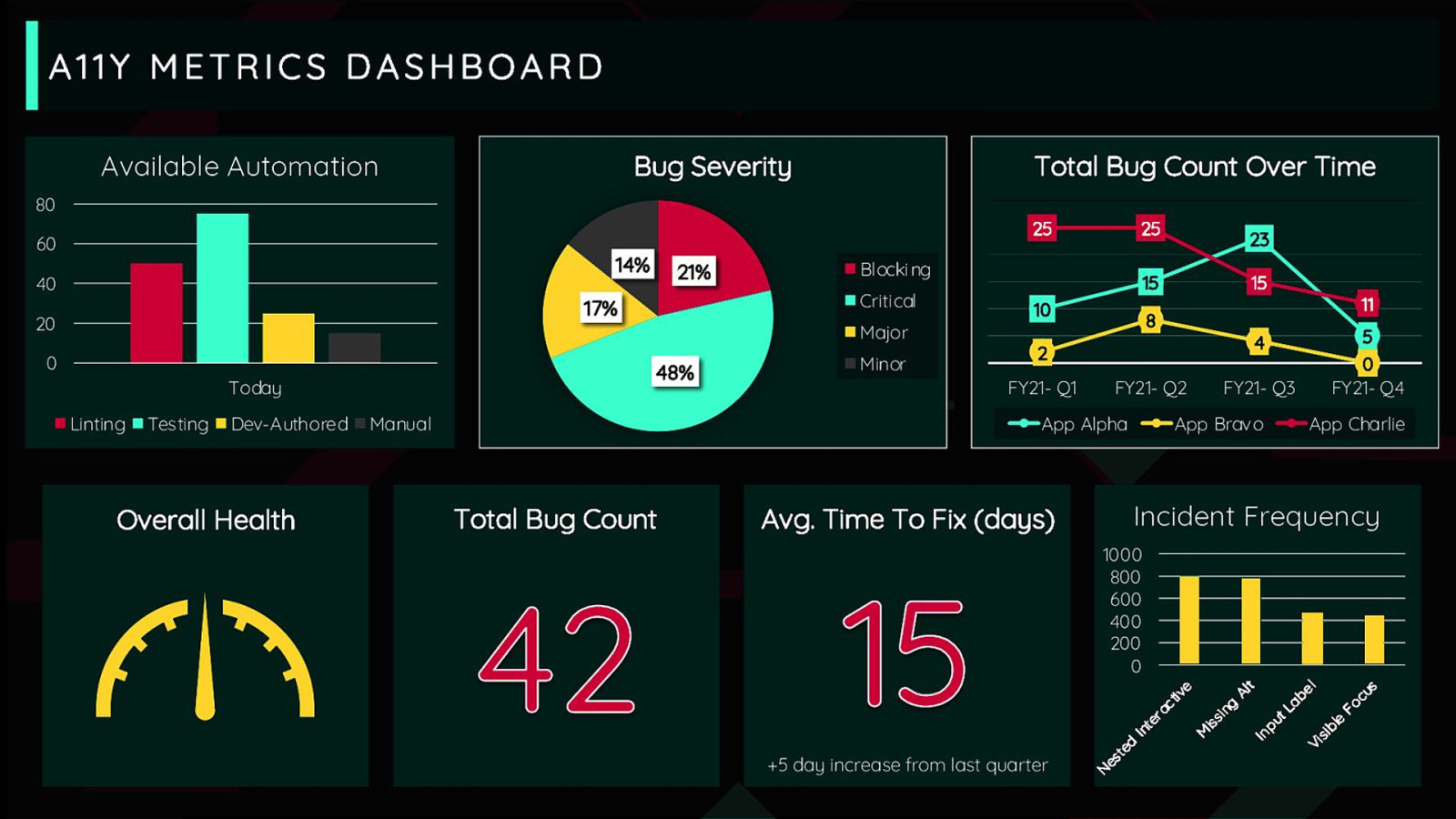
Imagine being able to check in on a product to see how it’s doing and get all of that information easily and quickly.
It could be used to inform decisions: rationalize time, budget, etc. It could be used to demonstrate that an investment in accessibility tooling for designers and engineers could make a big difference. It could be used by sales teams when a potential client wants to know about our app’s accessibility conformance Frankly, there are a lot of use cases but they all come down to this: everyone will be more informed about the decisions they make.

And it’s not enough to decide on metrics
Periodically, our metrics need to be reviewed.
We should expect to see some results from our efforts.
If the process is working, we should see a reduction in valid bug count over time. We might need to look at our process more critically if that number keeps going up. As teams receive training, they should be producing fewer issues. Are we able to track that?

In addition to trend analysis, we can use the metrics we gather to inform future work. Like, Which potential violations currently require manual testing but could reasonably be automated? Just hasn’t been done yet? What violations happen the most? Is there something we could create to make that problem go away or make it easier? How could we make it faster for developers to fix the issues that seem to take a long time to resolve? Is it a code problem? Is it a tooling challenge? Is it a problematic process?
I think there could reasonably be additional metrics to be considered here, but the ones we’ve discussed give us a solid start to quantifying accessibility in our engineering practice, bringing us closer to continuous accessibility.

Okay, last bit. We’re almost there, I promise.
Let’s talk about expected outcomes and a few action steps.

I think the single biggest thing that we can give not only ourselves but also our senior management is information. The information they need to support us from a business perspective. The thing is, accessibility IS a civil right, and it is also an emotional issue. And that seems like it’s at odds with business IN GENERAL. But I envision an environment where it doesn’t have to be. We can accept, as a company value, that accessibility is a facet of quality. We can also rationalize the work that needs doing…with numbers. Just like every other part of the business. Maybe in a perfect world, we wouldn’t have to do these things, but also…we CAN do this, so why not give business what it needs? After all, the outcomes are what matters.

Greater confidence in the quality of your code

More easily deliver accessible experiences at scale

You will responsibly reduce the company’s risk.
The risk of losing potential customers, The risk of decreased usage from existing customers, Or even the risk of facing accessibility lawsuits.


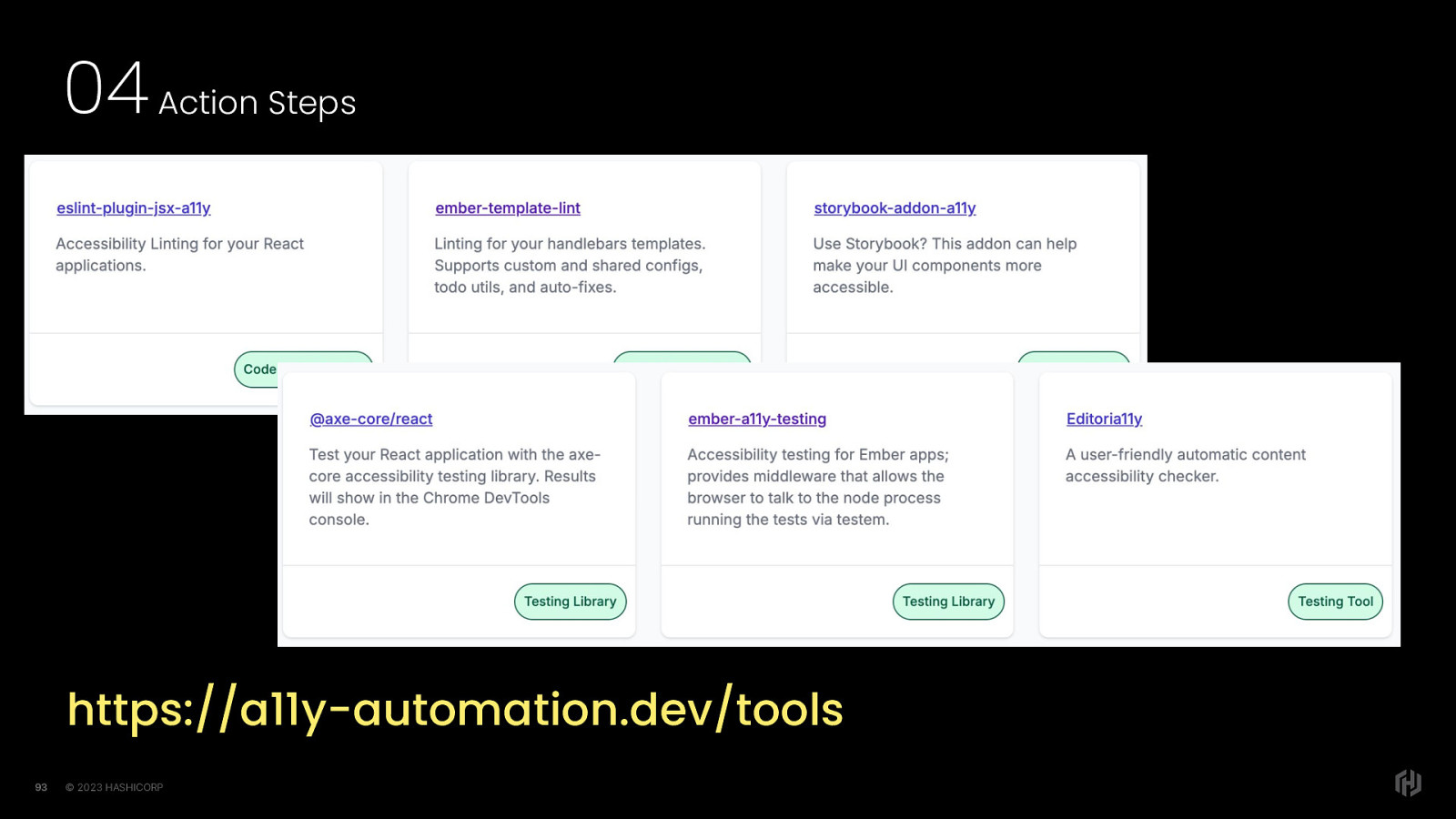
https://a11y-automation.dev/tools - There are a lot of potential tools out there that you can use, and most of them are highly configurable so you can get the best results for your team
And we can talk specifically more about that if you’re interested, feel free to find me after the talk.


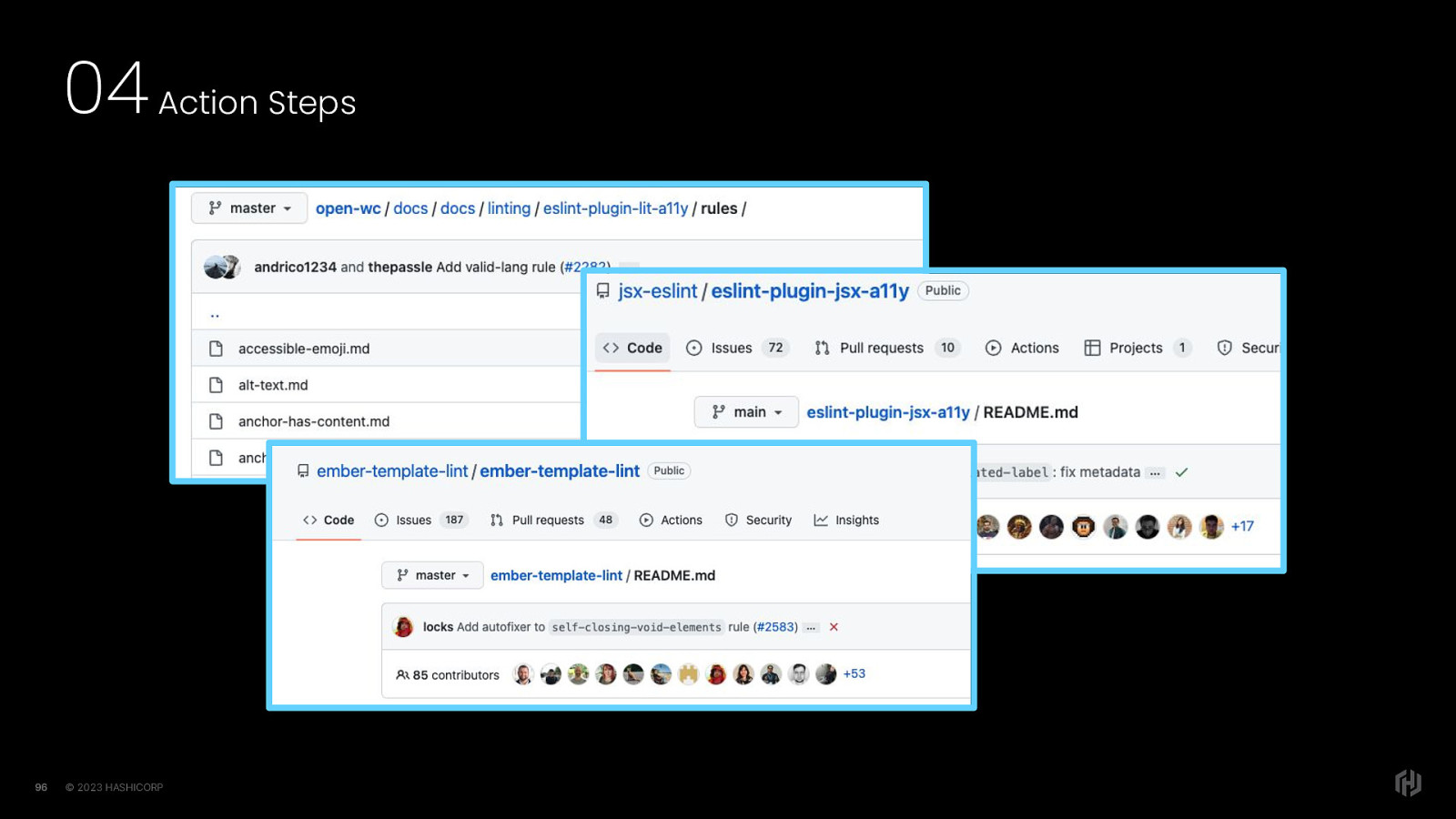
Or, perhaps you can contribute to some of the open-source projects that exist to provide linting rules for the framework your company uses.

You can use sites like Please fund a-eleven-y dot com a website that provides a list of the known areas where funding or support would improve the state of accessibility across the web. Maybe your company has engineer time that can be used to help solve some of these issues. Maybe your company has funding that can be allocated to hire technical writers to improve the state of accessibility documentation.

And remember this: you do not require permission to create accessible code. I hope that this talk has helped you see that continuous accessibility is something we can achieve but even if you still feel powerless to change the way your team works, you have the power to improve the way you think and you write code. Empower yourself to learn more, dig deeper, and improve the quality of your own code.
Thank you.