Designing with Linked Data
26 years ago a young and fresh-faced computer scientist was sitting in his office at the CERN nuclear research facility in Geneva. Some called him Tim.

A presentation at Information Architecture Summit 2014 in March 2014 in San Diego, CA, USA by Mike Atherton

26 years ago a young and fresh-faced computer scientist was sitting in his office at the CERN nuclear research facility in Geneva. Some called him Tim.

CERN computer scientist Tim Berners-Lee was frustrated with the fact that the various academic research papers he wanted to access and reference were all out of reach; in libraries and closed research systems, despite the fact that these papers frequently cross-referenced one another.
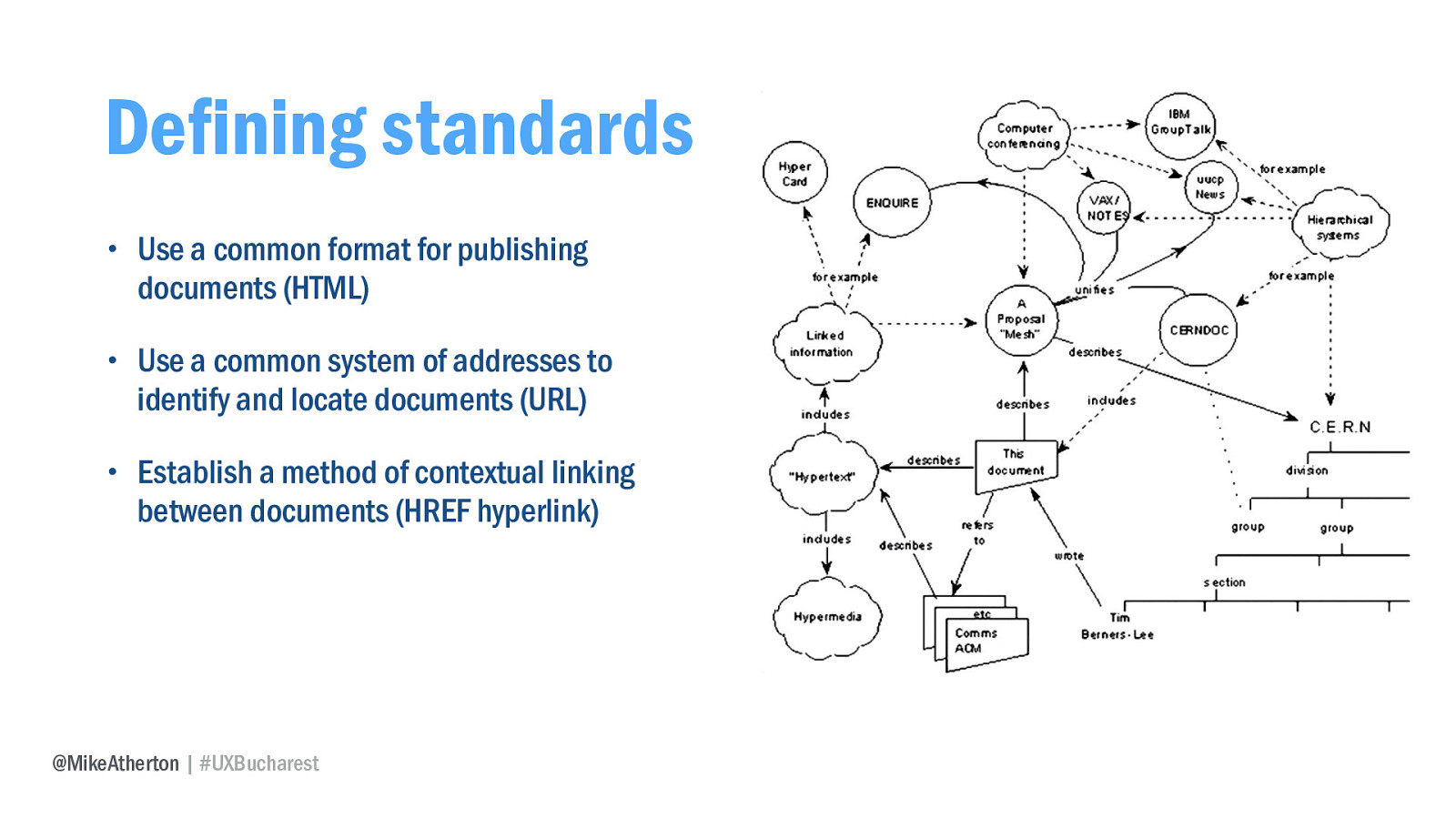
He devised a networked system of documents with some basic principles. Everyone would use the same markup format to publish documents, and we’d have a common system of addresses to identify and locate those documents. And most importantly, there was a common method for linking documents together.

Feedback from his boss was ‘vague, but exciting…’ The web was a gift to the world. Universal access to information, with a decentralised, democratic way to connect content in useful and unexpected ways for the betterment of understanding. The betterment of mankind.

And what did we do with it? We had fun! Publishing anything and everything. A web of great content that gave rise to an practice of human information architects to help make sense of it all.

And a well-written document is a joy forever, but we realised that when these documents talked about interesting real-world things, they did so in a way that only fellow humans could really understand.

As humans, we’re great at extracting meaning and context from the things we read. We know the difference between a review of Casablanca the movie and Casablanca the city.

We know that if we simply tag our document with a keyword, that our understanding of ‘apple’ might mean something completely different in another context.
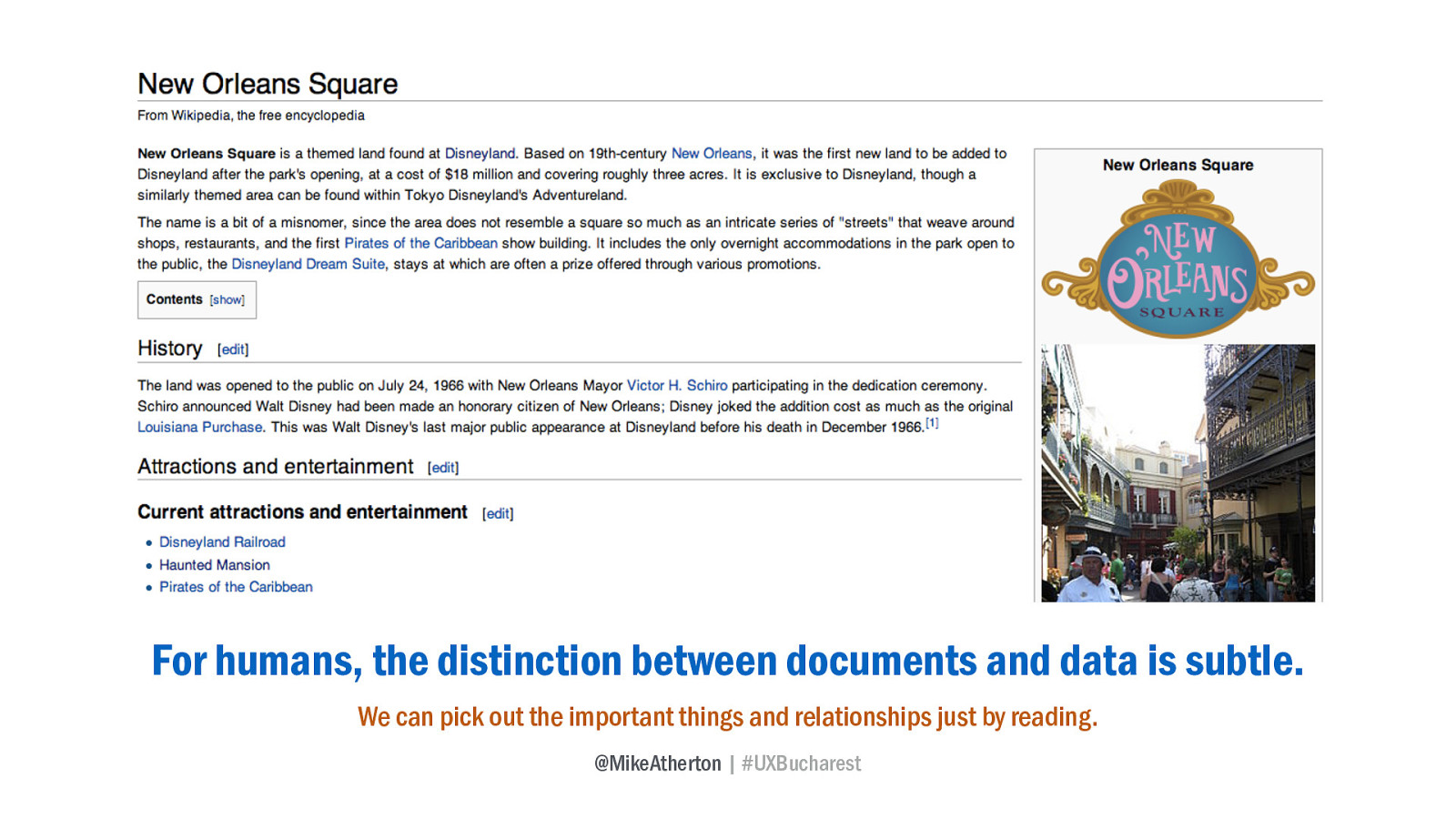
We all know (don’t we?) that New Orleans Square is a land within Disneyland, which is a park in Anaheim, California created by Walt Disney, and that the square is home to the Haunted Mansion attraction.
If we didn’t, we could read this article and pick out not only those things, but understand the relationships between them.

But to a computer, it’s all just stuff. The documents live in flatland, and computers can’t just figure out all the interesting things and relationships like we can. If they could, we could just ask questions directly, and the computer could answer:
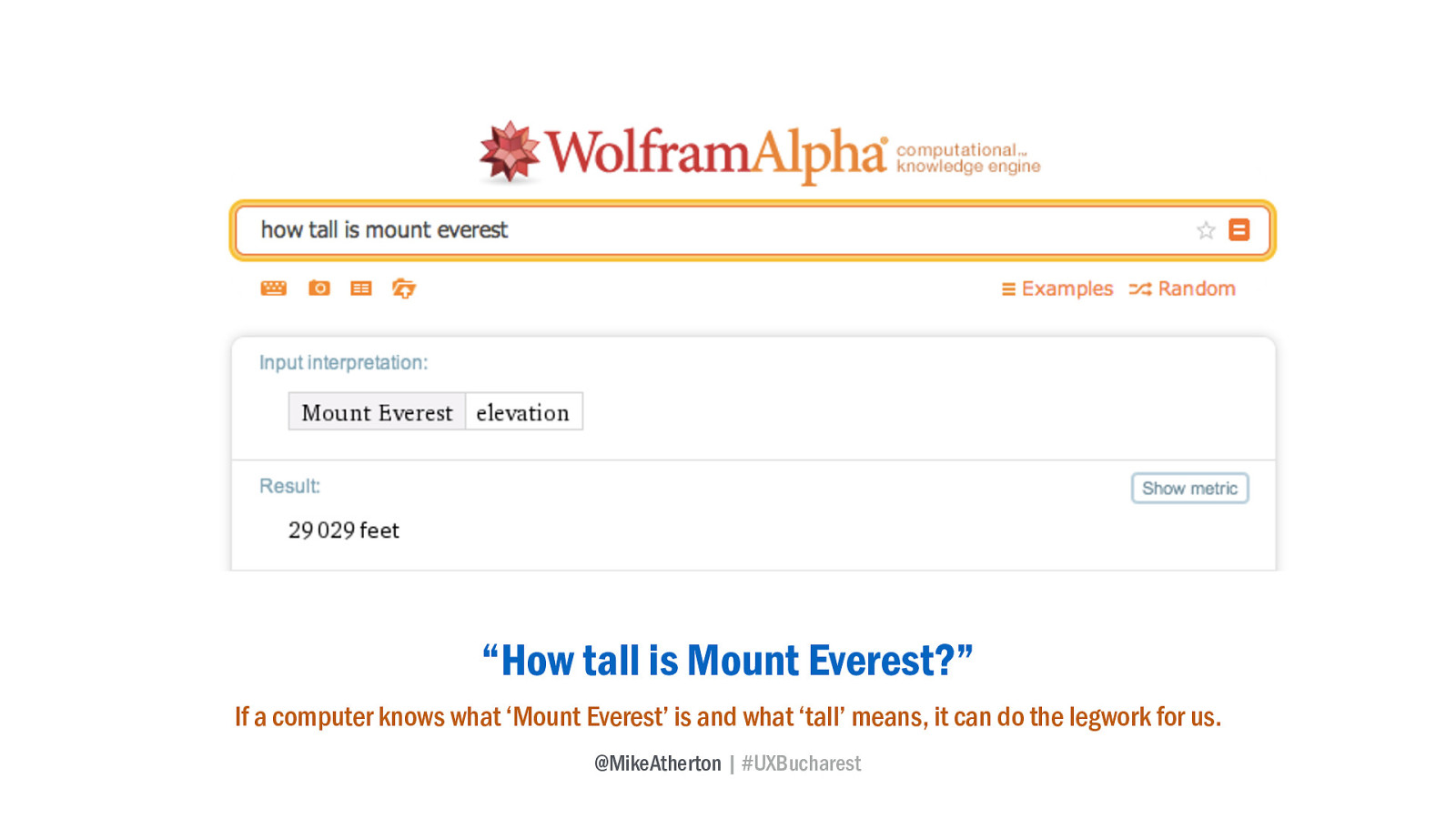
“How tall is Mount Everest?” If a computer knows what ‘Mount Everest’ is and what ‘tall’ means, it can do the legwork for us.
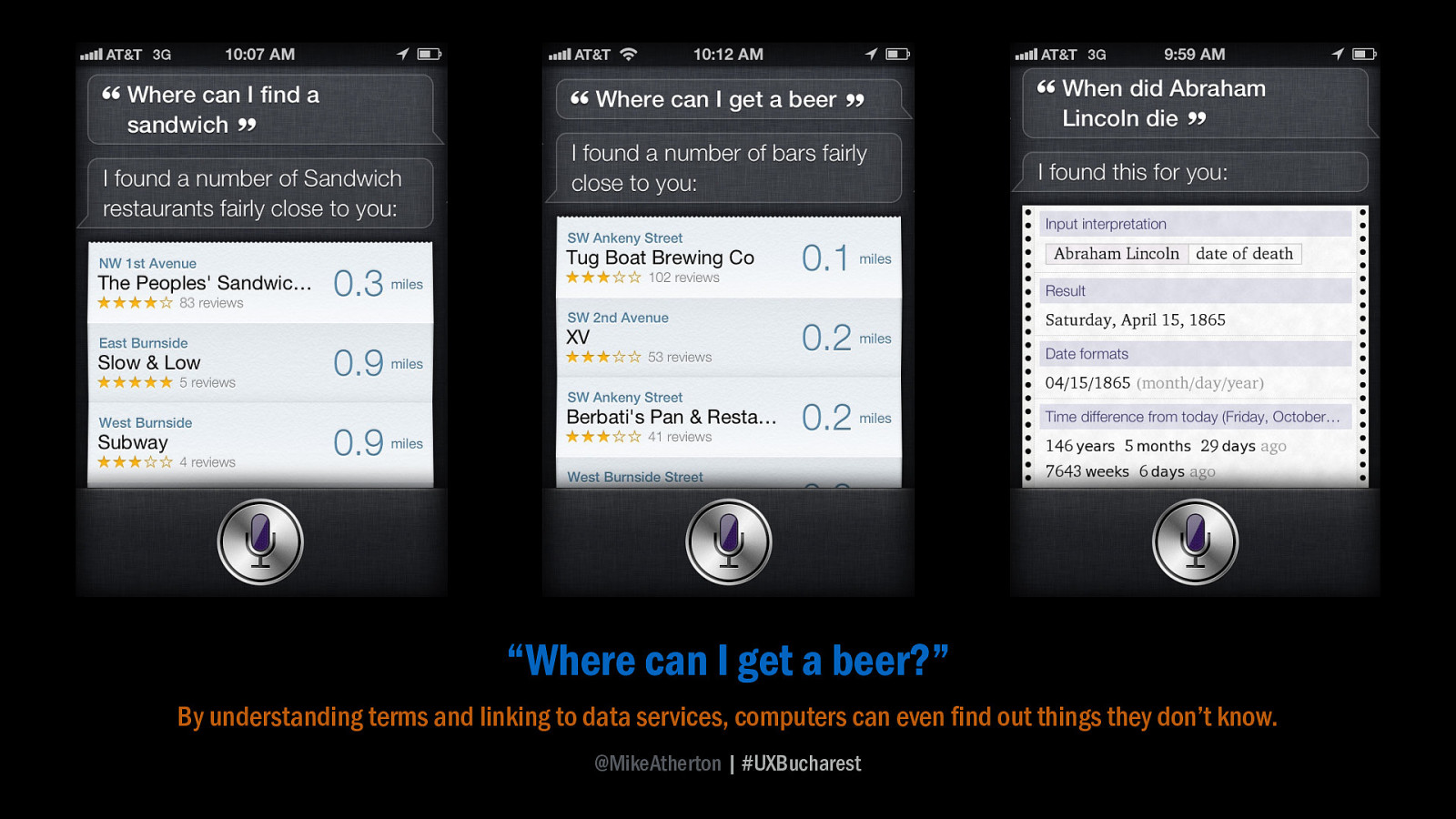
“Where can I get a beer?” The computer not only needs to know what beer is, what ‘where’ means, but also where I am, and possible answers to the question.

Or by asking the computer to return only results which match specific criteria, we can get all kinds of interesting insights into human behaviour.

We create new value when we publish information that computers can make sense of. So much so, that six years ago at the Web’s 20th anniversary, Tim Berners-Lee asked us to put our raw data on the web. Don’t massage it, don’t hold onto it until you’ve built your own beautiful website around it.
Just publish it now.

He said there are three rules for publishing data. We need to use those http web addresses (URIs) to stand in for things - people, places, concepts. I would have a URI to denote me. So would this city. If something has a URI, we can point to it whenever we want to make reference to it. It becomes a fixed, common reference point which disambiguates and defines that damn thing. We can express how the things relate to those other things, located anywhere.

Second rule is that useful data is returned to me in a standard format. The kind of information I’d want to know about that person, place, or thing in a way that I can reuse and ideally that a computer can make sense of too.

Third and most important rule: it’s got relationships. Not just information about my height or weight or shoe size, but that I am ‘speaking’ at ‘UX Lisbon’, that I ‘know’ other people, that I’m ‘from’ Bolton in England. And whenever a relationship is expressed between two things, each thing is given one of those http addresses to identify it.

By insisting on relationships, this connective tissue between people, places, and things creates a web of machine-readable data on top of the existing web of documents. This he called Linked Data, and by connecting the raw data you’re creating a much richer - arguably more useful - network of knowledge than connecting documents alone.

Research can be much more precise when cross-referencing datasets instead of searching the text of documents, as these researchers looking into Alzheimer’s treatments discovered.

By linking different sets of data we can better make sense of information, creating new value in all kind of markets. We can even bootstrap content-rich products, even when we have no content of our own.

esterday a group of us did some content modelling. Let’s remind ourselves of what we mean by a content model.
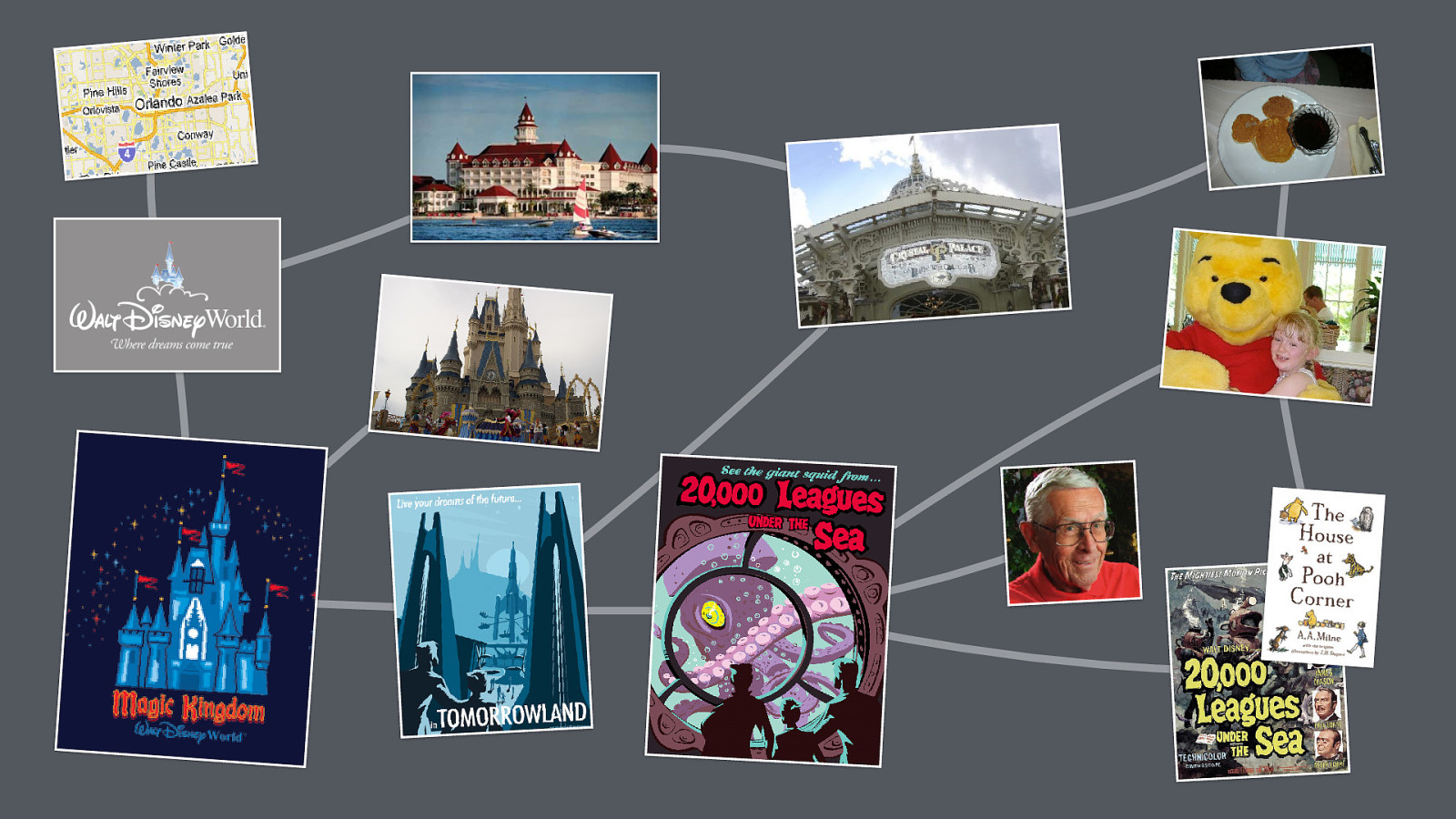
By modelling the things and relationships that exist in your subject domain, I like to think that you’re taking a more holistic mental modelling view of your subject, showing the things that people think about, regardless of whether your business covers that bit. In that sense content models model truth, not websites.
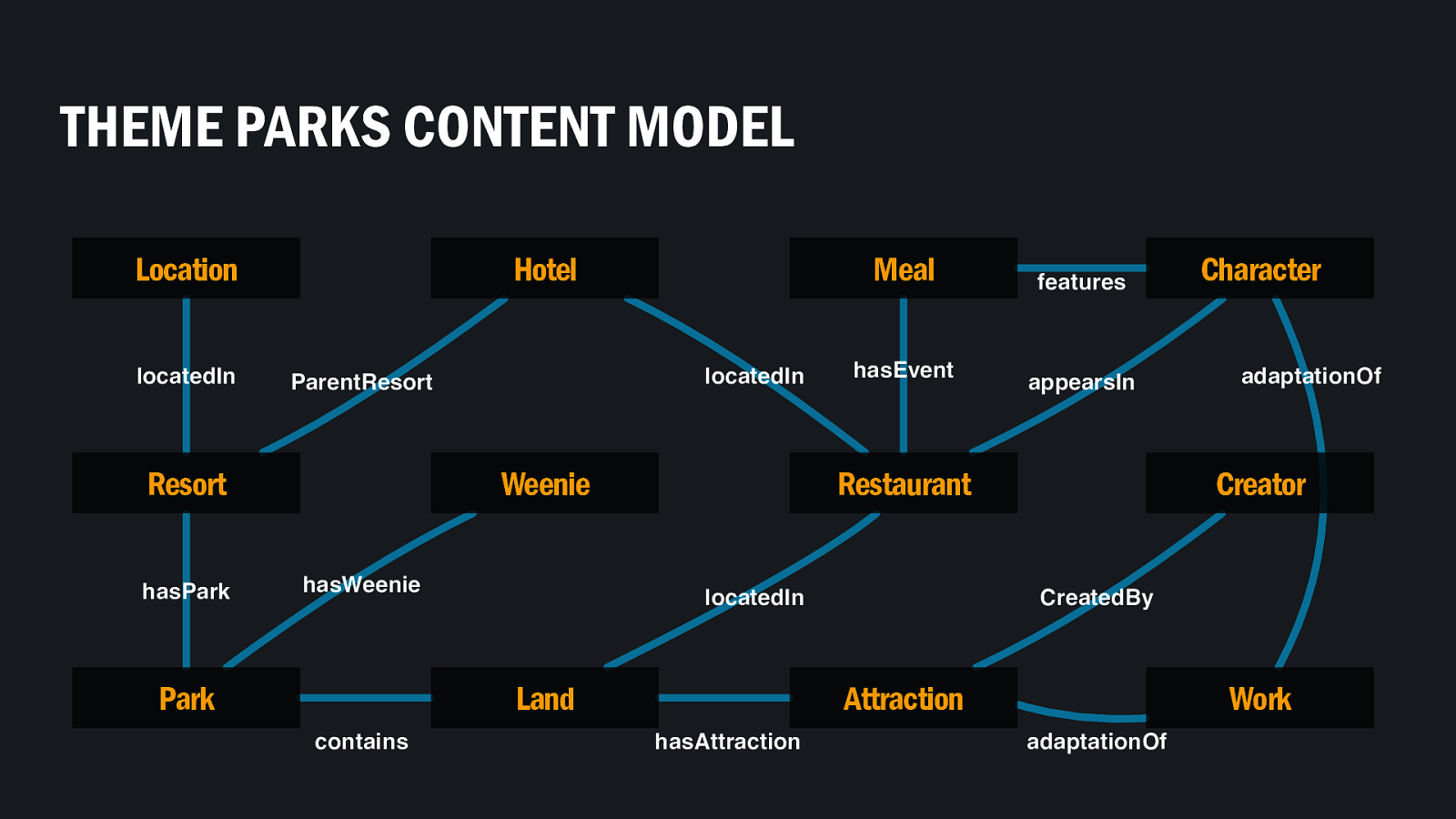
And to be thorough in your content modelling, you haven’t just labelled the boxes, but you’ve labelled the arrows too - describing the nature of the relationship between two things - such as saying an Imagineer created an attraction. But our content model is a general form. It describes in general how different types of things relate to one another.
Let’s try a specific example, and as Tim Berners-Lee asks, use http addresses to describe each thing, and one to describe the relationship itself.

Here we’ve referenced two real-world things using web addresses, and we’ve borrowed a term to describe the relationship from a third-party vocabulary.
This fact we’ve just asserted is data. But there’s a small problem. The pages we’ve referenced are designed for humans. Remember that rule of returning information that a computer can make sense of? We have a standard method of publishing documents (HTML) so shouldn’t there be standards for publishing linked data?

In fact there are. A few in fact, but I’m going to look at RDF, the Resource Description Framework, is the lingua franca for data integration.
It works exactly as we’ve just described, with a structure of noun, verb, noun, or more properly; subject, predicate, object. And this little 3-part story about what did what to what is called a ‘triple’.

There are various ways to write down RDF, either using long-form notation, or using a more compact syntax like Turtle. Triples get stored in a kind of database called a Triplestore, and if we make our data openly-available then that triplestore is available for anyone to query or connect their data to.
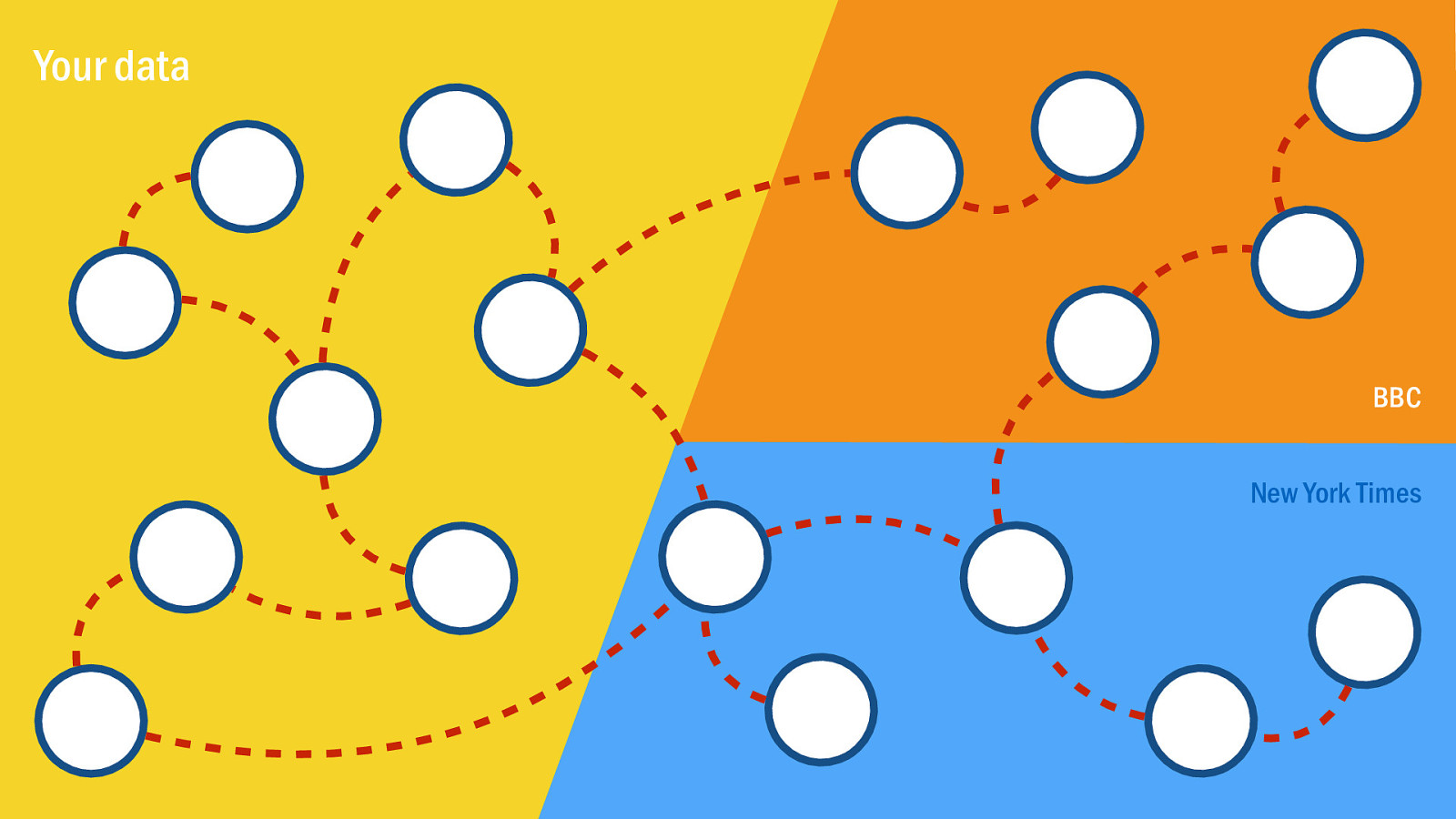
If everyone publishes data in RDF, and if we want to express a relationship from any one thing to any other thing, then we simply join the dots to connect one triple to another, not just within our own triplestore, but any triplestore anywhere.
The idea is as simple and democratic as creating links between webpages, but this time we’re doing it for data. Thinking about architecture at web-scale; considering not only the content and data we create, but how that meshes into the bigger picture.

It helps to have common vocabulary; a set of publicly-available and agreed shared keys to reference when defining a specific thing, similar to how we might sometimes reference a Wikipedia article when we want to explain a concept to someone.
Great for humans, but what about computers?
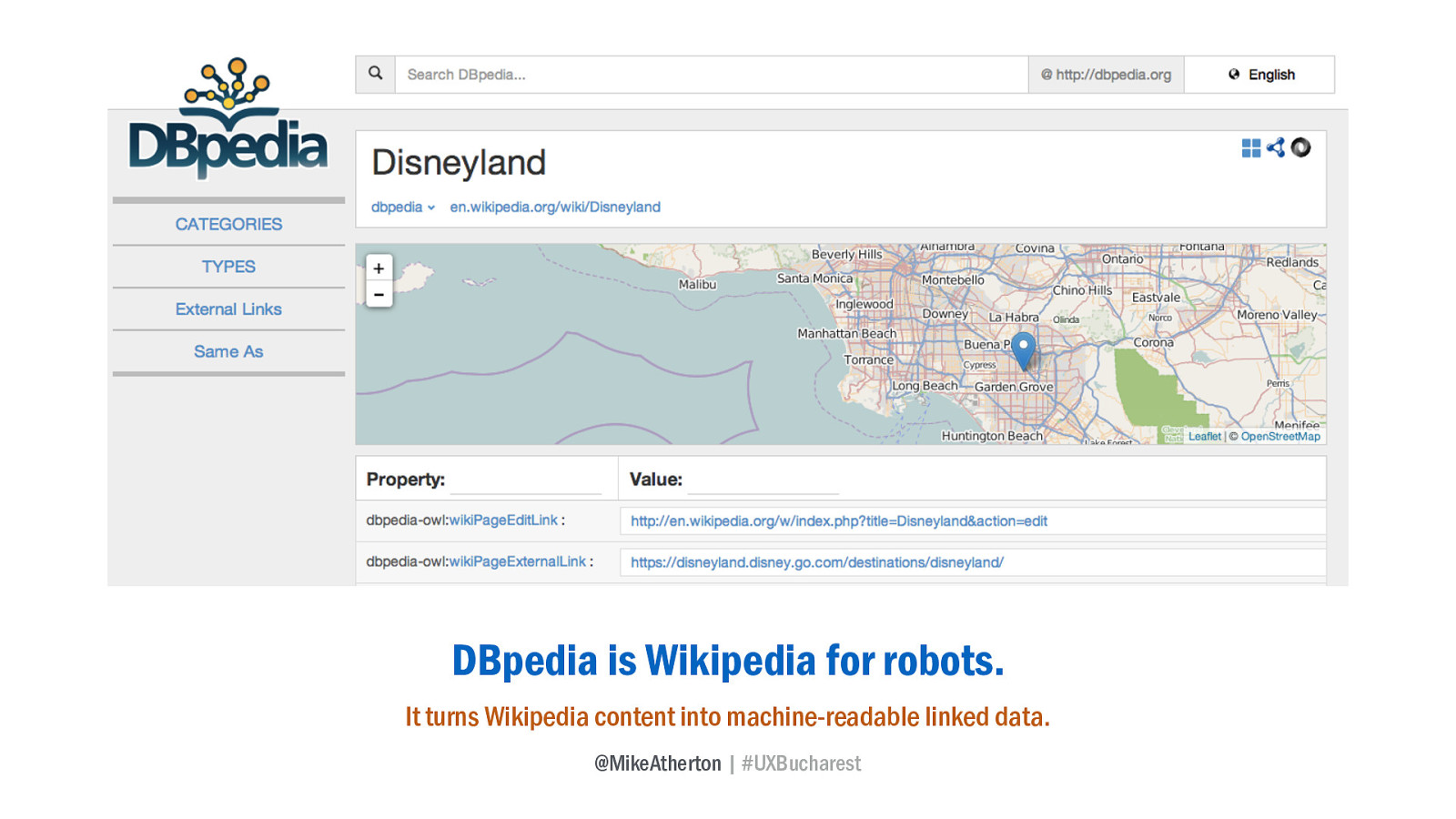
The DBpedia project is an effort to create structured data from Wikipedia content. For any concept, it holds a whole bunch of related data that a computer can read. Here’s Disneyland.
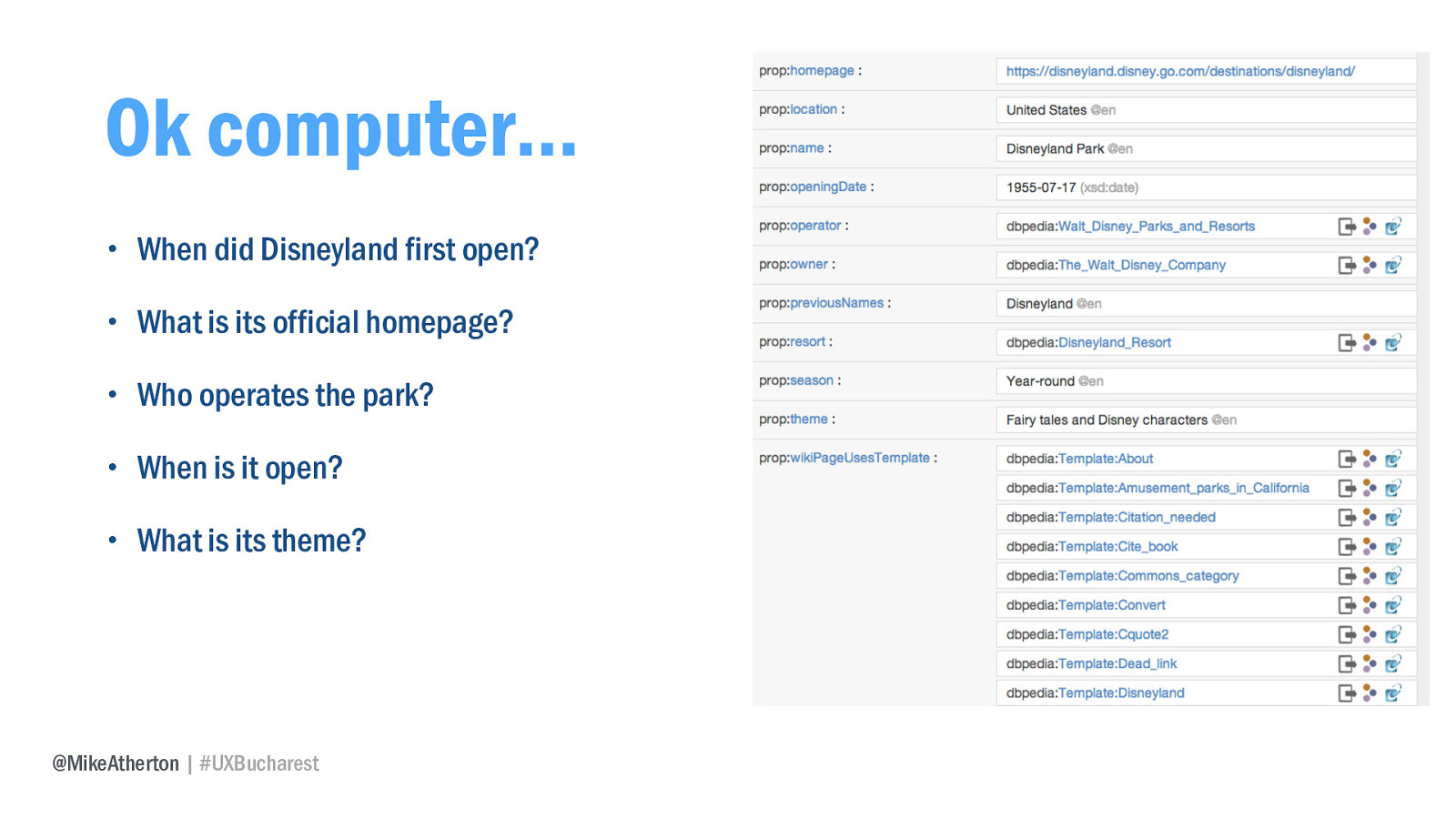
I can ask DBpedia when Disneyland first opened, where exactly on earth it’s located, which attractions I can find there - all as easily as if it were in my own database, and thus I can surface this information directly on my own website. Valuable content and information, created by the crowd and available to me for free.
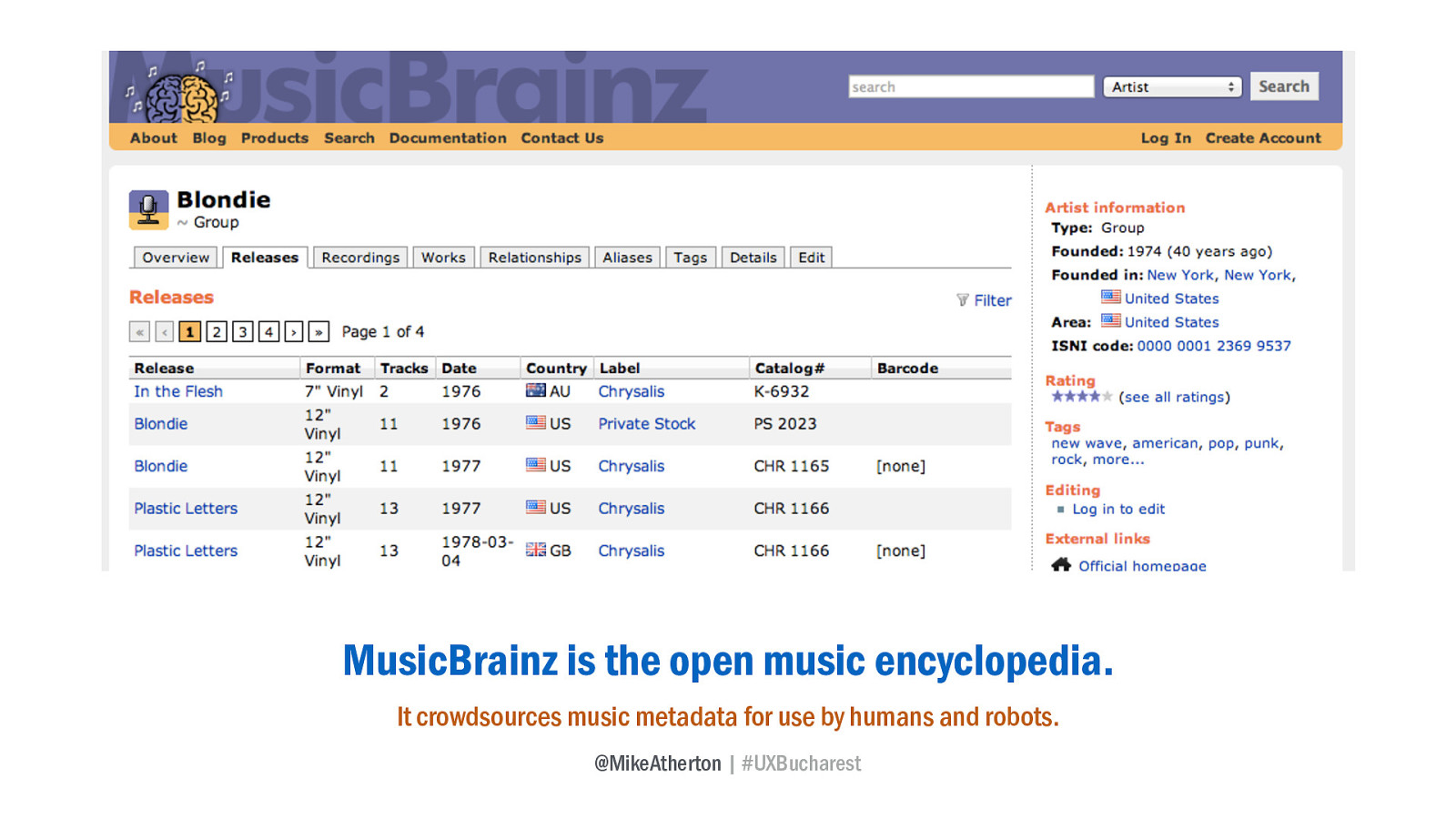
MusicBrainz is a similar project, this time focused on music identification; a database for humans and robots to identify and connect artists, albums, songs, labels, and genres of music. All published out as linked open data and free for me to plunder and add value to my own product.

Using these shared identifiers, I can say that the web page I’m creating refers to a specific concept identified by the URI at another service.
I connect my page to this web of data by stating that the concept I’m referring to is equivalent to the concept defined by someone else; opening the gateways to let data flow across the web.

So how are people using this? Let’s go back to the BBC.

The BBC wanted to get more people listening to their radio stations. They have 10 national radio stations, each catering to different audiences and playing different kinds of music. How can I figure out which stations, indeed which shows, I should listen to?
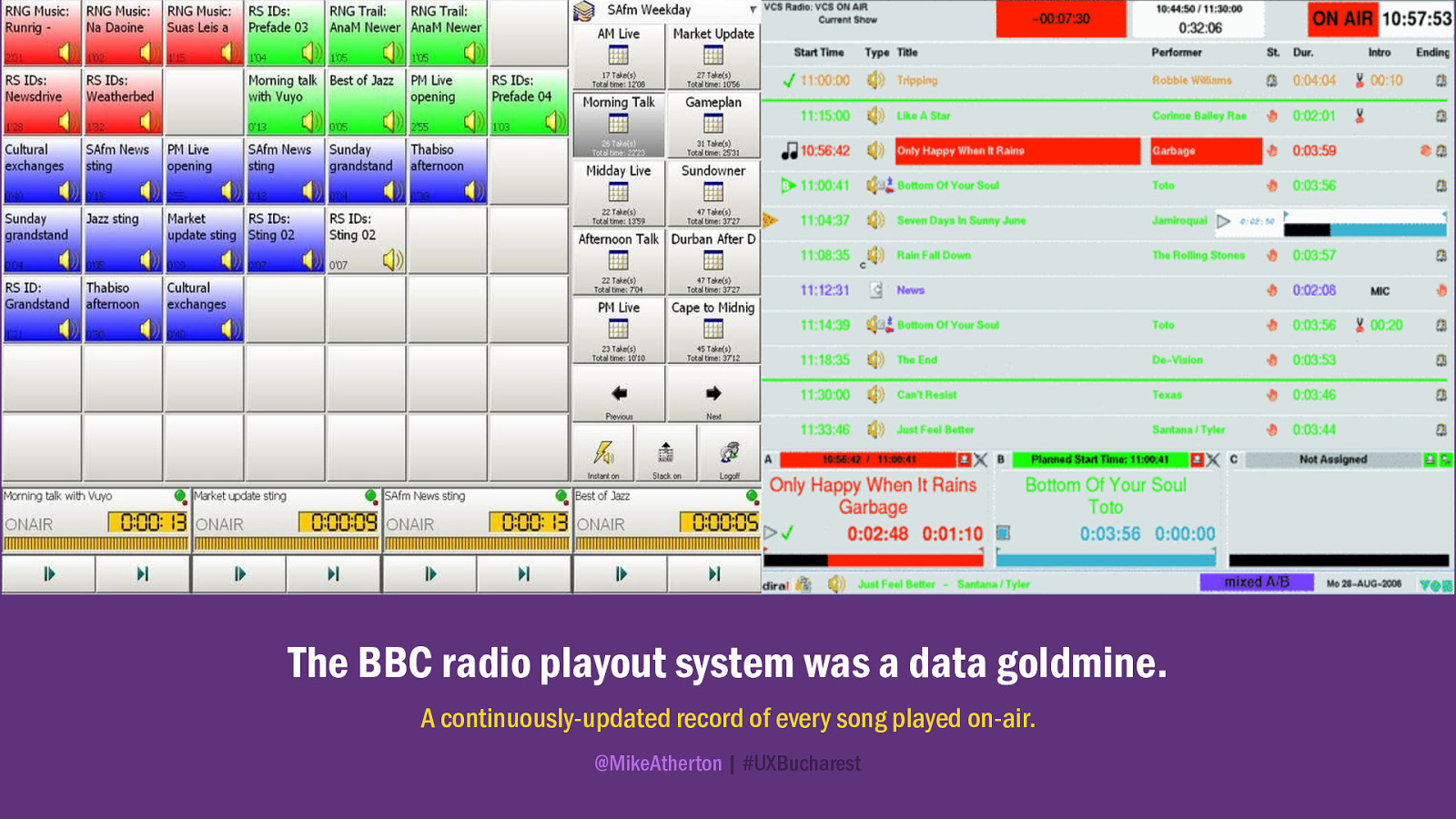
The web team first went to the radio people and discovered a gold mine of data. A log of every song played out on air, so that the licensing people are happy and the artists get paid. Here was a list of every song played, when it was played, and on which show. Business as usual for radio, but no-one had considered the value of publishing this data.
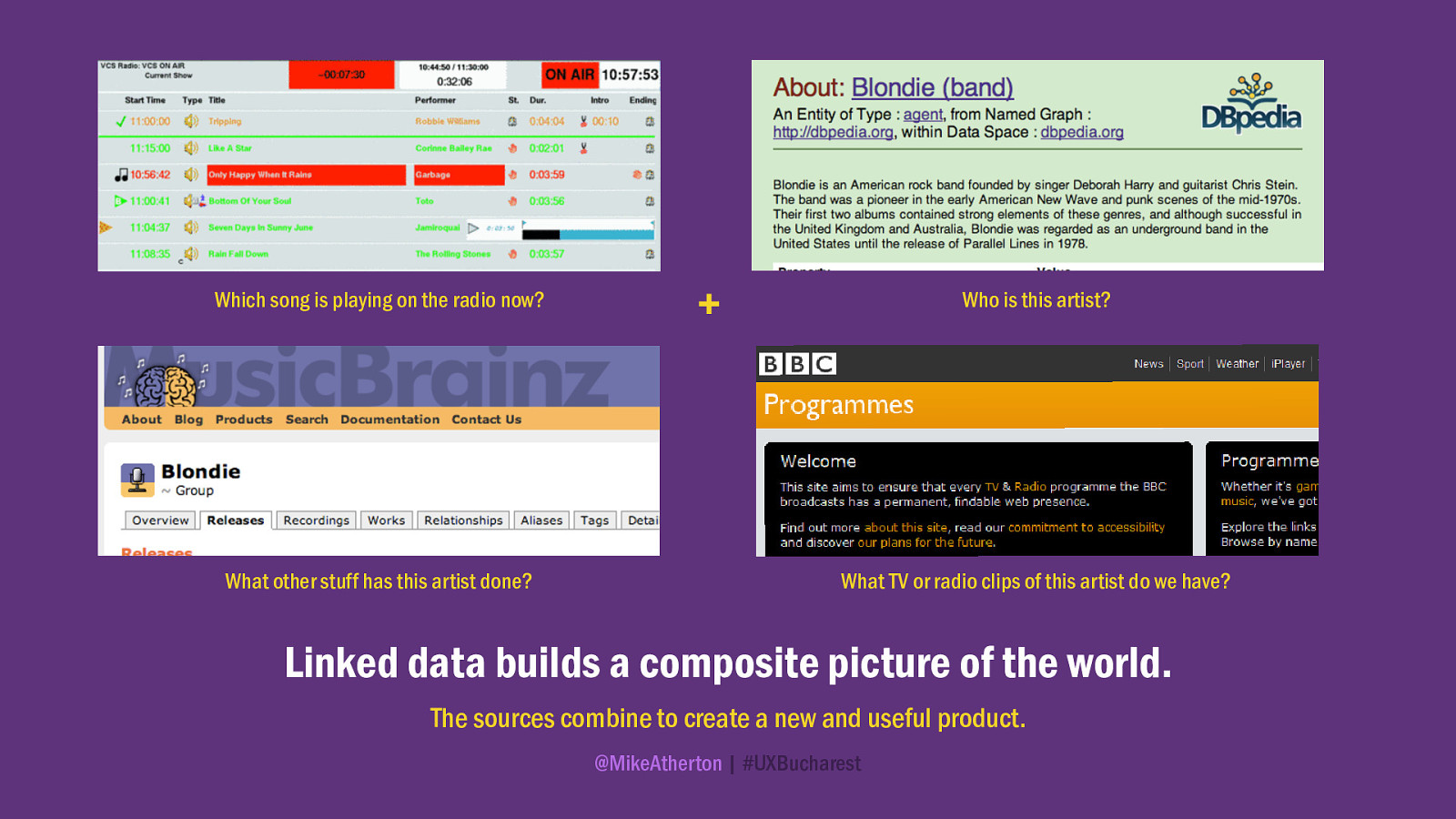
The team were able to take this information and by using the shared keys from DBpedia and Musicbrainz which identified the artists, were quickly and cheaply able to build a whole new product for exploring music.
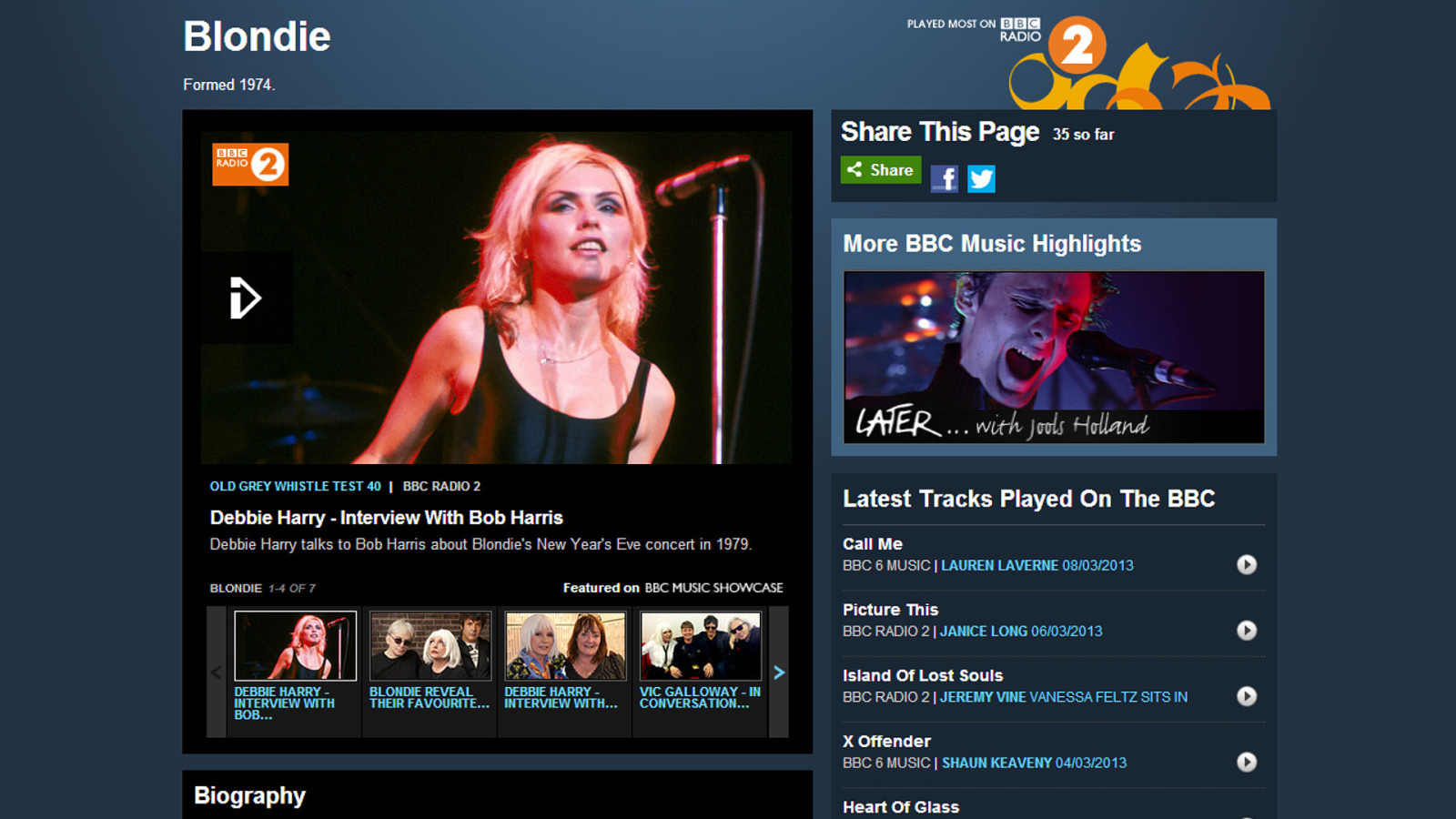
For almost any artist now played on the BBC, there’s a music artist page. But only the radio playlist data is coming from the BBC. All the other rich content is syndicated in automatically from third-party sources, including the contextual links to related artists, which provide this site with its lateral navigation.
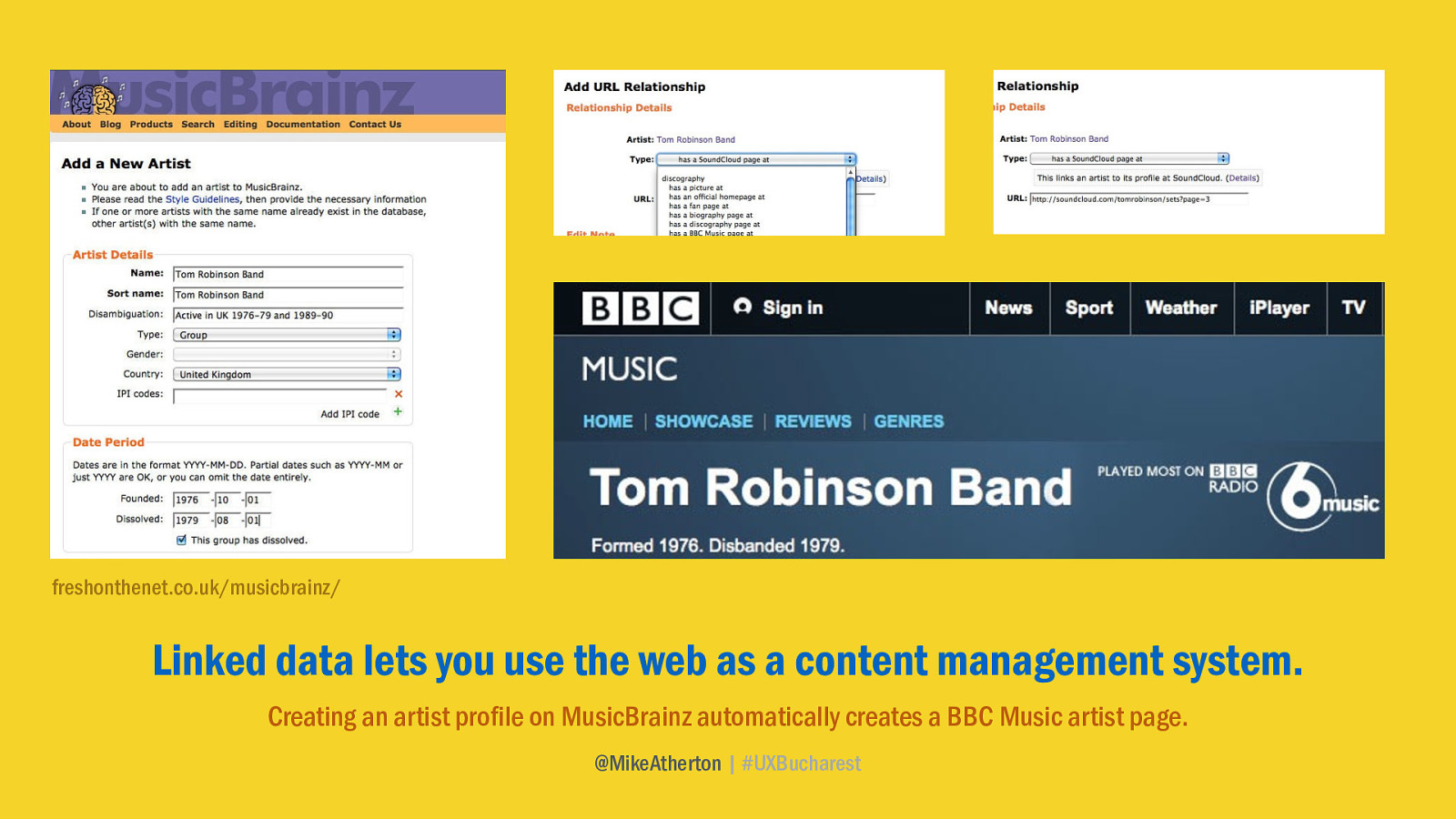
Rather thrillingly, MusicBrainz allows artists to create their own profile, listing their songs, blogs, Soundcloud page, Youtube videos and more. And because the BBC Music site is powered by MusicBrainz linked data, that information will be used to generate a brand new artist page on the BBC Music site.
If you’ve ever wanted to get your ukulele trio band on the BBC, this is how to do it. Thinking at web-scale. Using the web as a CMS.

We can use Linked Data to build up a composite picture of a topic. Even if the different facts are held by different providers, it doesn’t matter. With Linked Data we’re thinking about information architecture and content strategy at web-scale.
The web becomes one big database.

Databases we often query using something called SQL. Linked data has its own version, called SPARQL. It works in a similar way and allows us to pull results from one or more linked data sources.

Using SPARQL I could ask questions like:
Who wrote Great Expectations? Which attractions are housed in Tomorrowland in the Magic Kingdom? Which Schwarzenegger movies from IMDB also appear in Wikipedia?
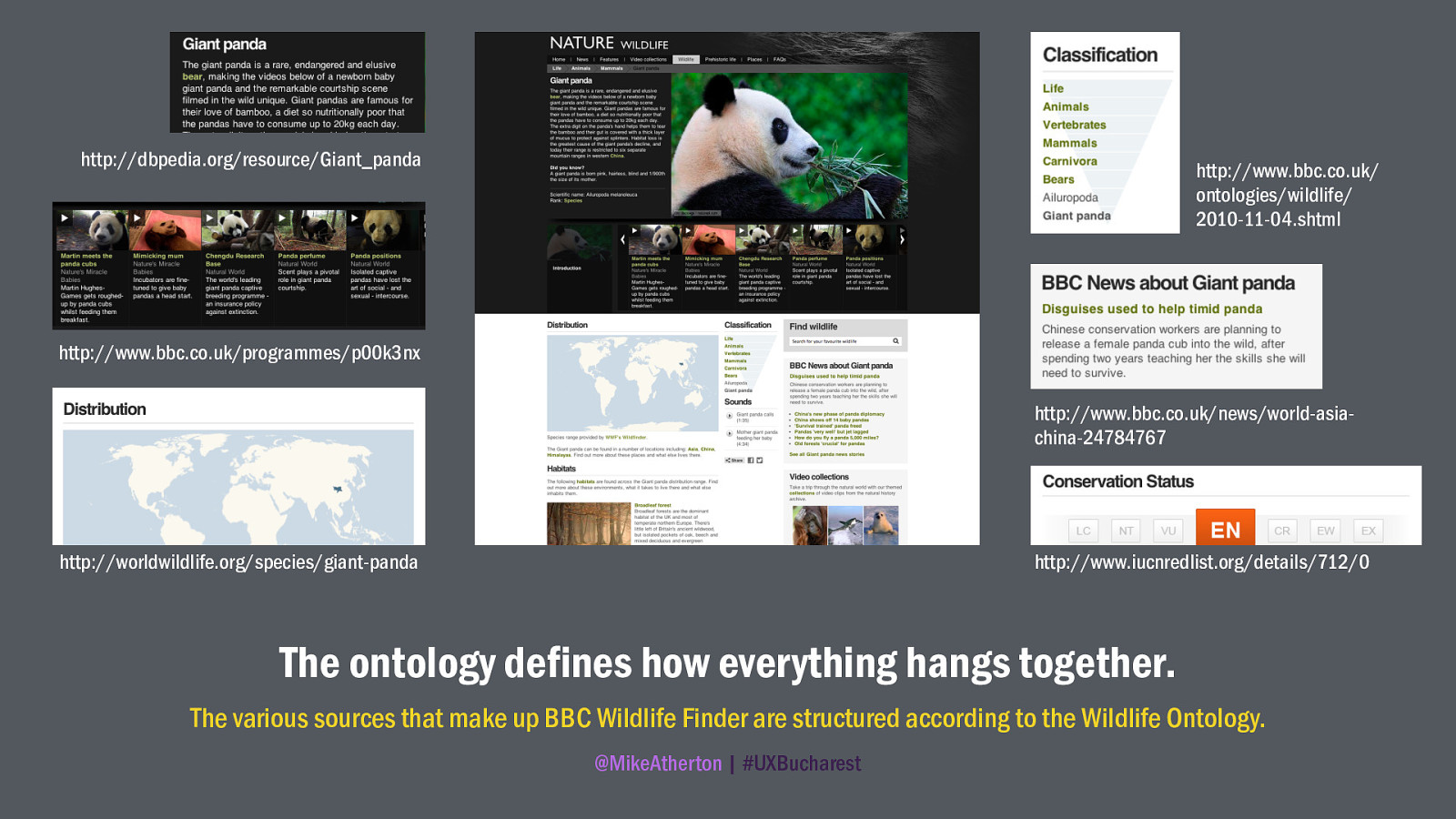
Products like the BBC Wildlife Finder could only have existed by pulling in third-party data which was too expensive for the BBC to produce themselves. The BBC’s own principal contributions were the video content and the Wildlife Ontology.

Let’s give some love to the Ontology. Scary word, not such a scary thing. Really just a list of definitions so that everyone knows what you mean when you say what you say. And if you got an ology, you’re a scientist!
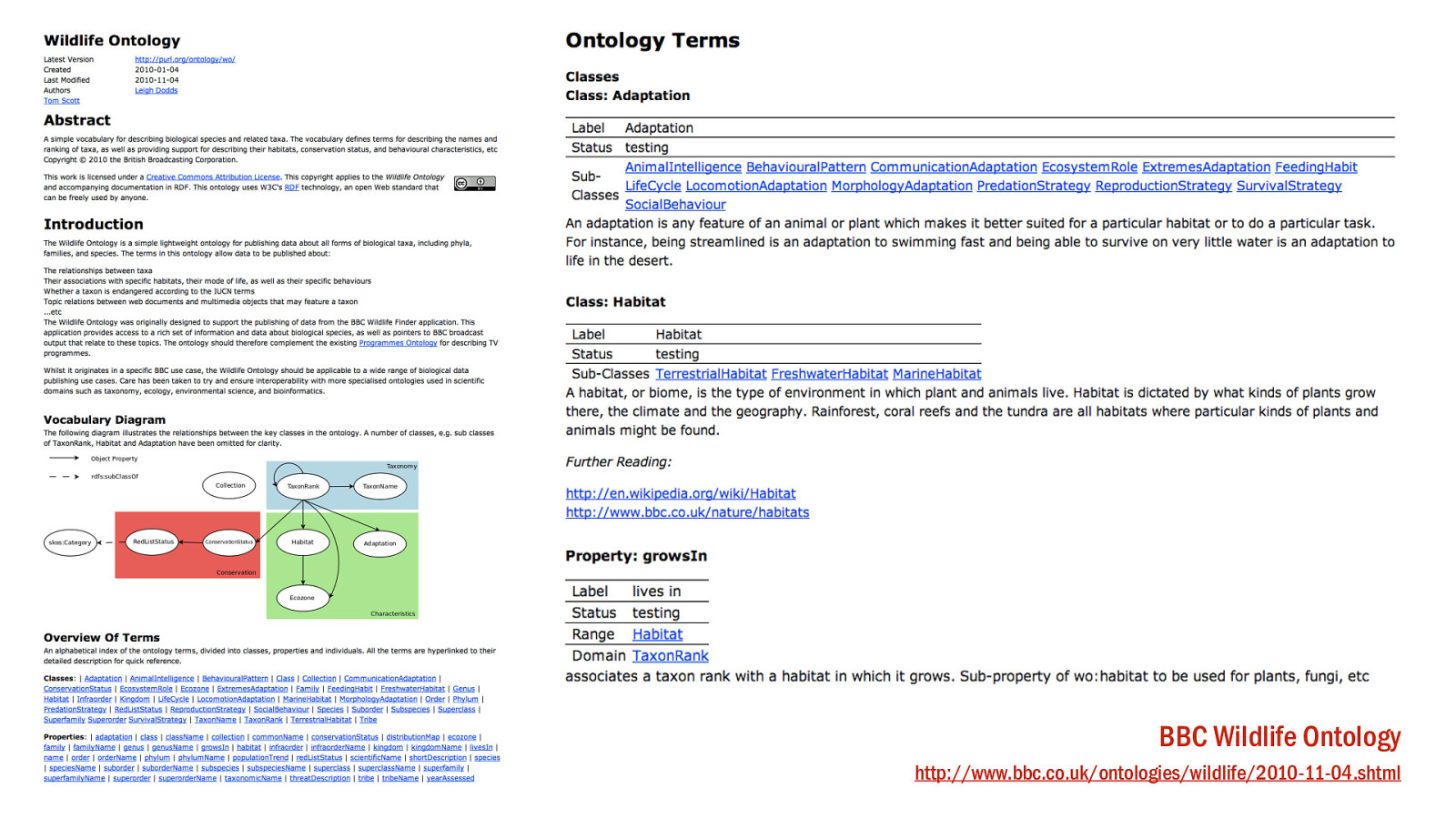
An ontology here is our vocabulary of terms. Classes describe the types of thing in the model - so a class might be ‘Habitat’ of which ‘Broadleaf Forest’ would be an example, or ‘instance’.
Properties tend to define the relationships between things. Some of the Wildlife property names are self-explanatory; ‘growsIn’ or ‘livesIn’. That vocabulary helps us describe what our things are actually examples of, and provide us with the verbs - the ‘predicates’ we need for our RDF triple.

But ontologies begin by having an understanding of how we want our subject to hang together. BBC News wanted to create a more structured relationship between news articles. In reality news reports aren’t completely discrete; usually they are part of of an overarching and ongoing news story.
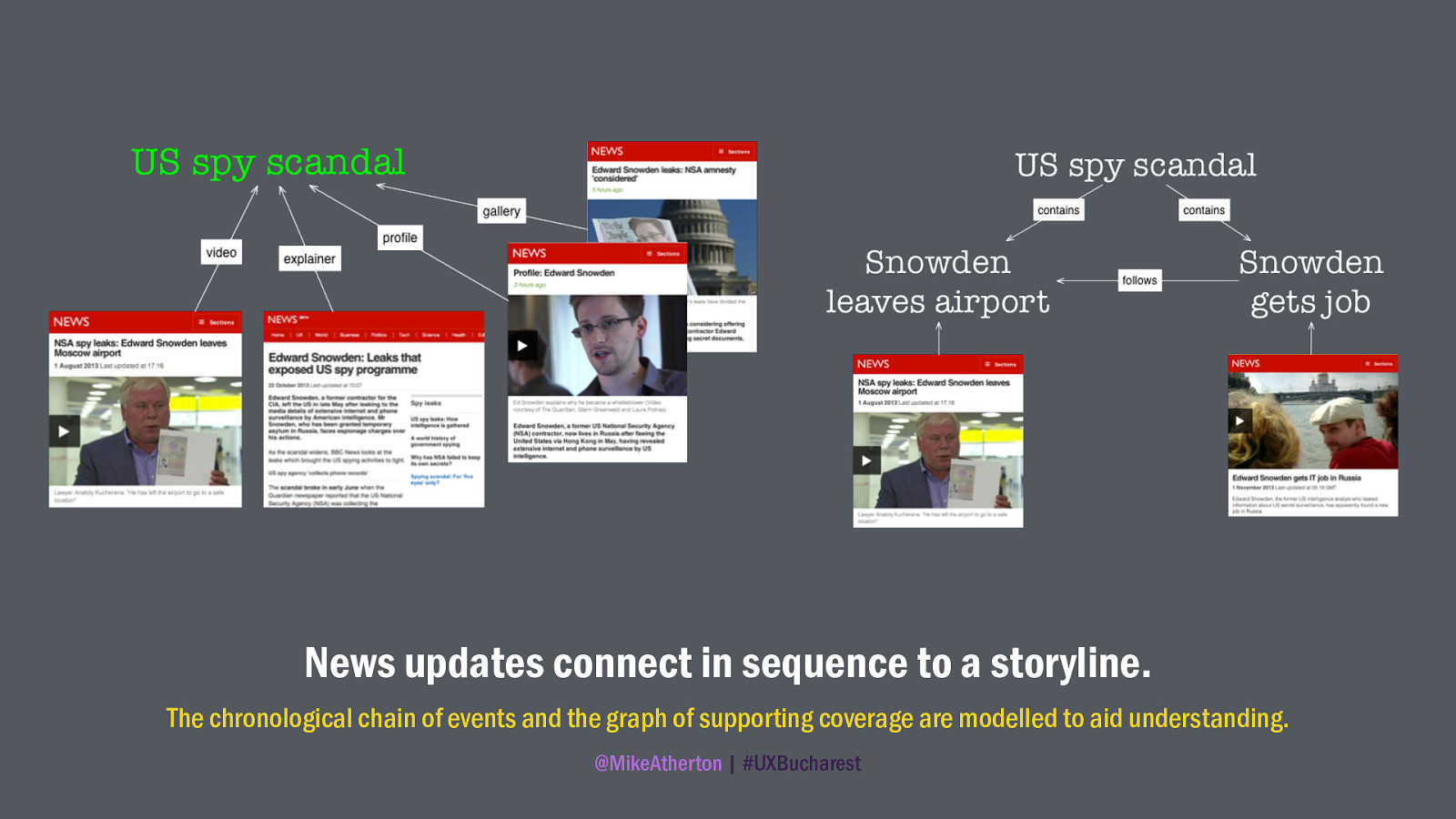
Thus they started to model how the subject of news really hangs together; creating the semantic concept of the storyline, and the ways in which different kinds of article (long-form, breaking updates, videos, profiles, explainers, and galleries) might connect.

Each article and storyline has the people, places, and subjects that they’re about. Journalists are given the tools tag their stories with web-scale identifying concepts.
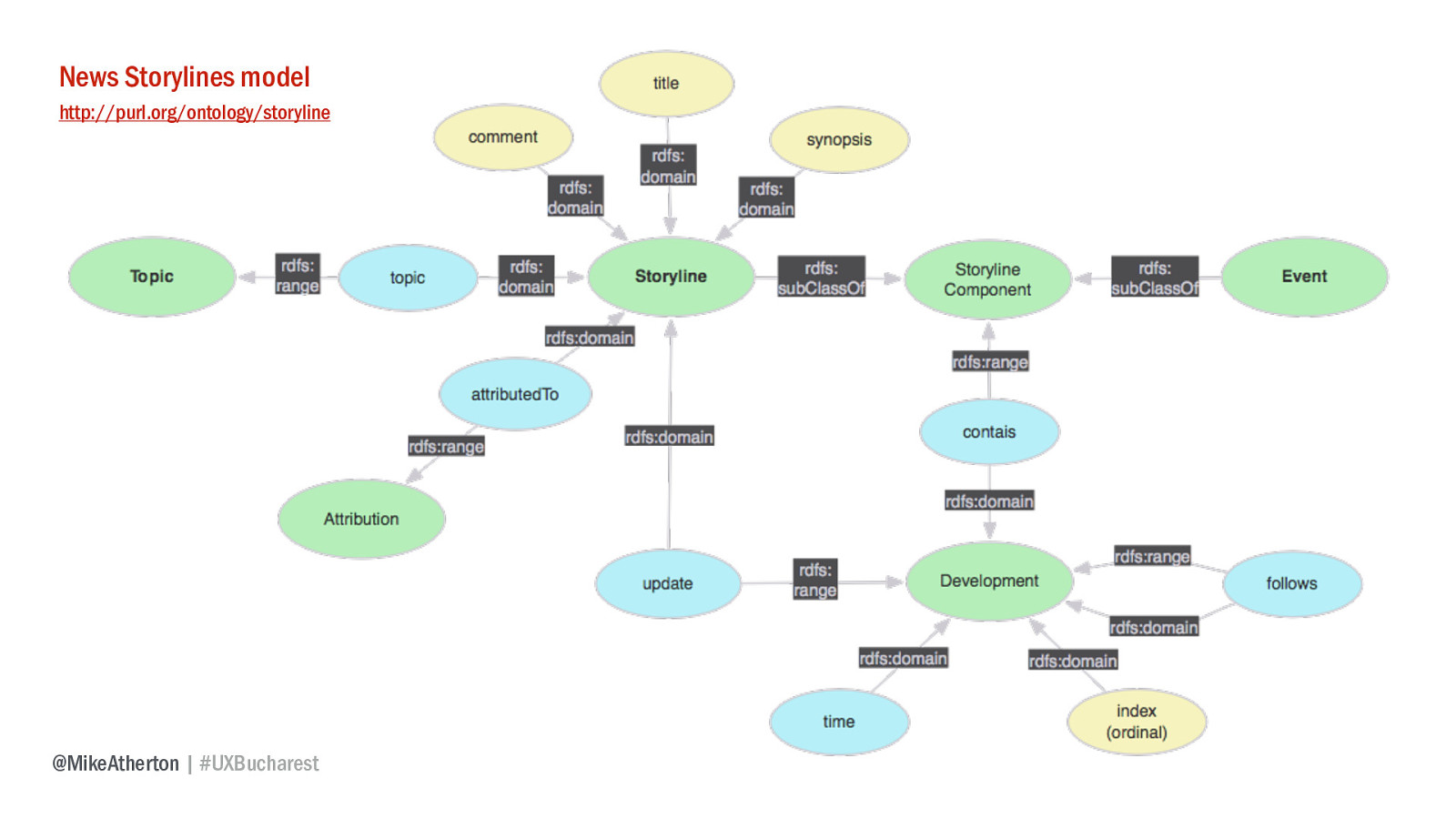
From these concepts we get the news storyline model, which defines the vocabulary for each class and property of thing.
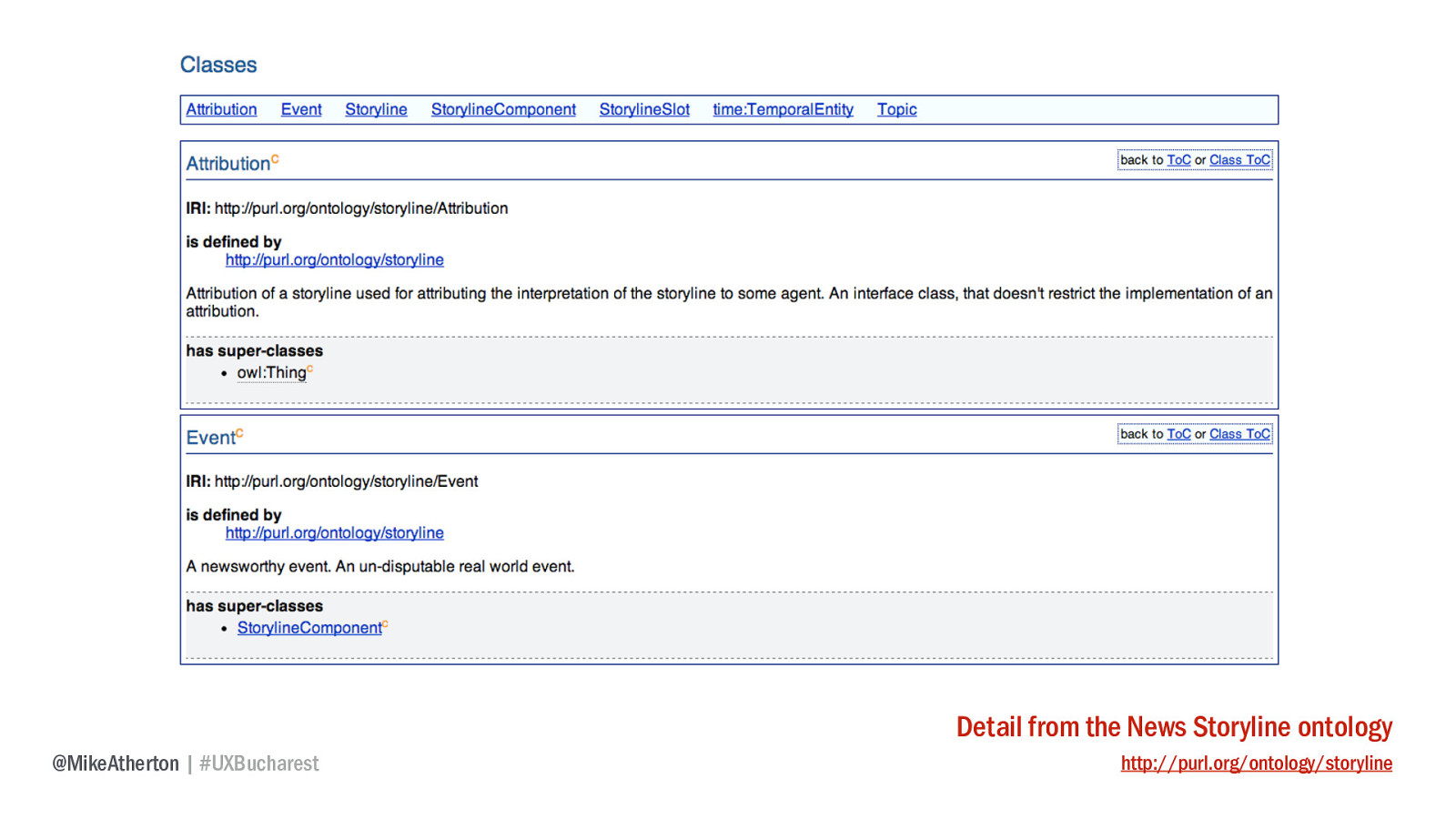
And from this we get the published ontology document itself, half a dozen classes and some properties, but immensely powerful to create a cohesive information architecture of news events - allowing users to explore news, eliminating laborious curation by hand, and allowing events of the past to connect with those of the present.
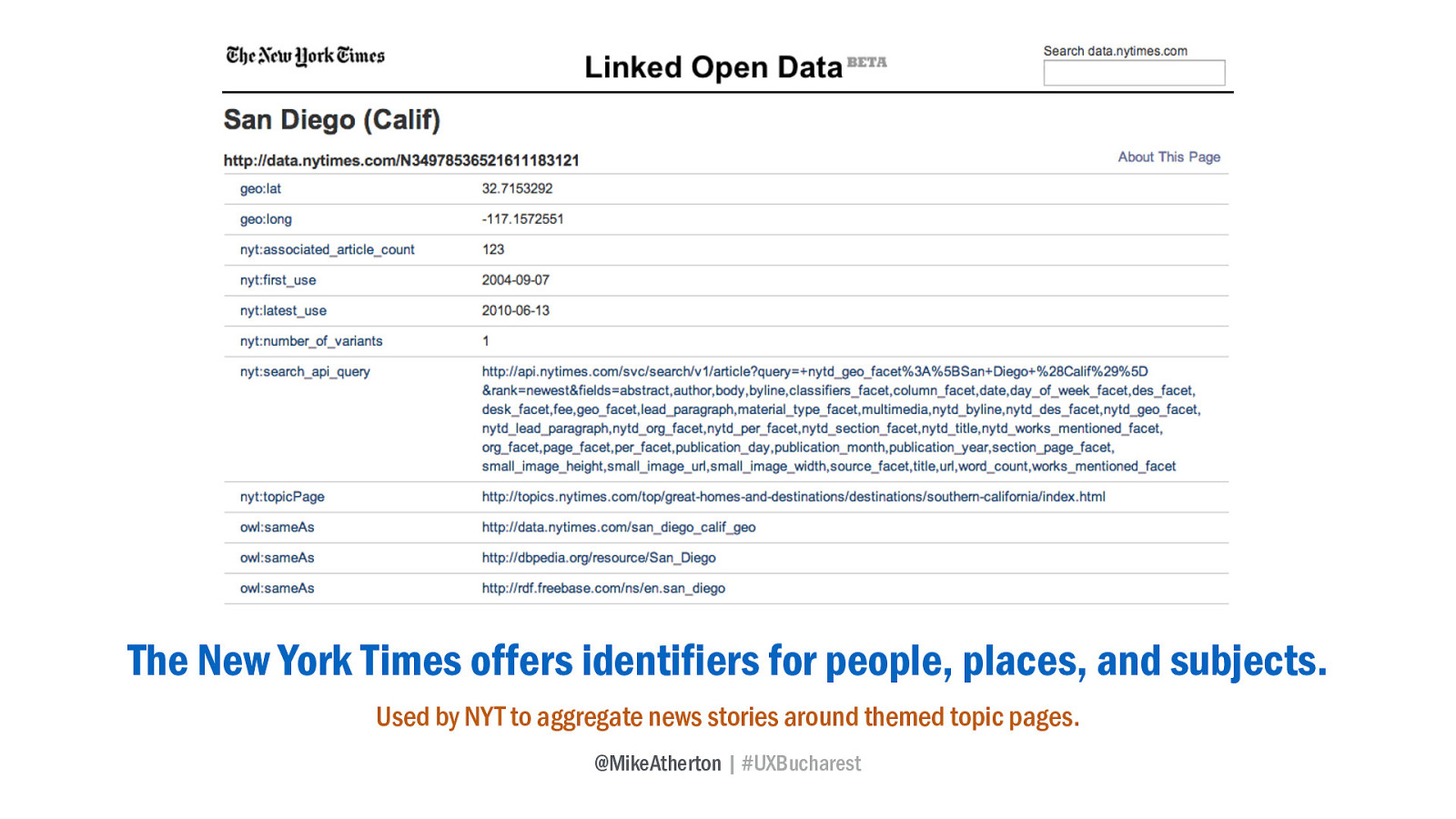
Other media organisations have also sought a linked data approach to structuring news, notably the New York Times who offer linked open data on thousands of people, places, and subjects.
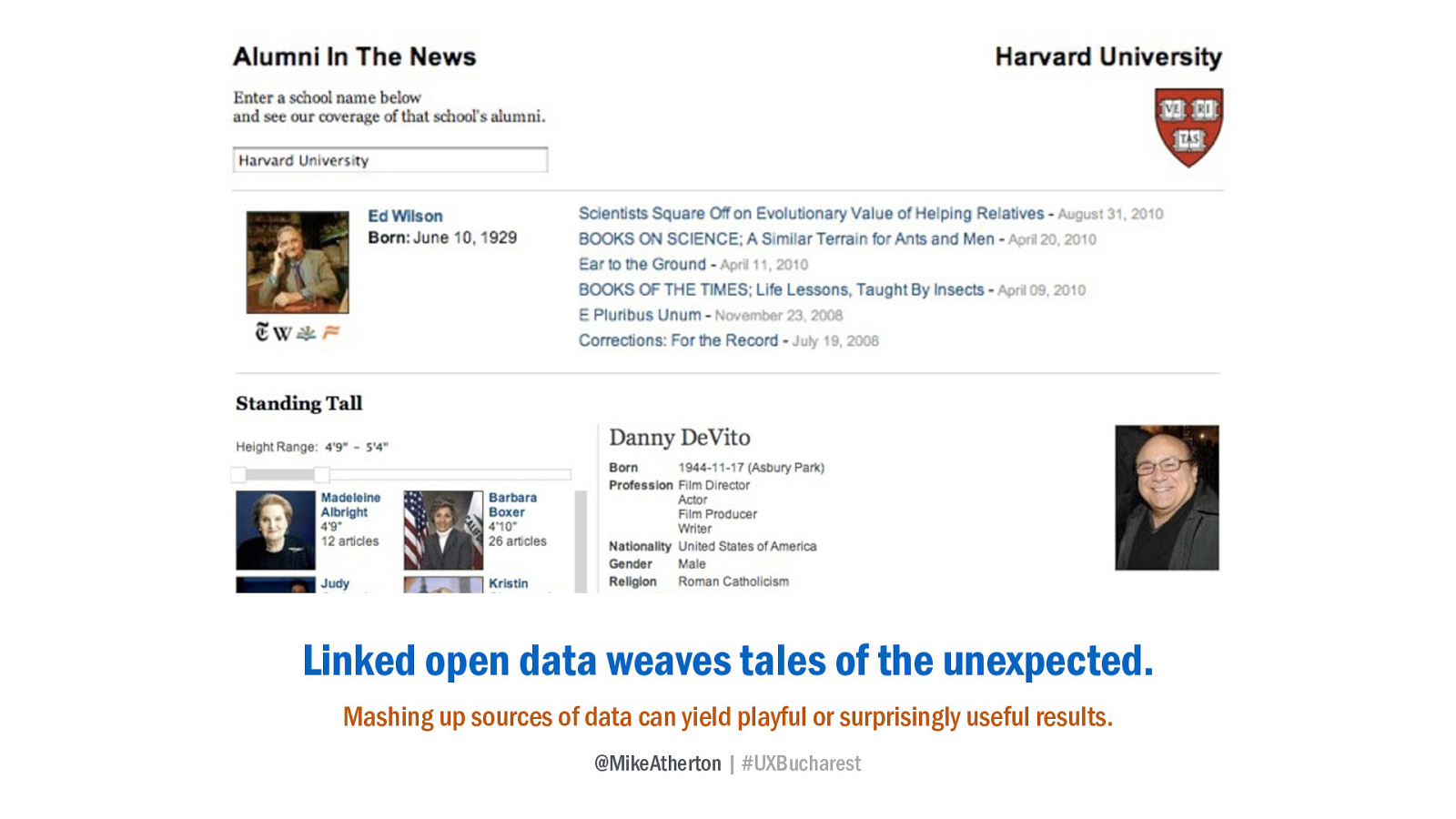
They’ve been having fun making prototype products, like Alumni in the News, gathering news stories about people who graduated from any US college, or Standing Tall that allows you to browse news stories by the height of the person involved - all by mashing up different sources of linked open data.

You may have noticed I’ve been talking about linked data and linked open data. Strictly speaking, linked data doesn’t have to be openly licensed for reuse, but when it is you increase the likelihood of people consuming your data and all these wonderful network effects become possible.
In fact there’s a star rating system for ranking the openness of your data. At the most basic level, just publish your raw data now under an open licence creative commons will do. Doesn’t matter which format–it can even be a scanned image. To earn your second star, publish it in some kind of structured format. Even an Excel spreadsheet is fine, as long as you’re okay with people taking it and using it. If you use a non-proprietary format (so CSV instead of Excel) that gets you three stars. Four stars is for thinking at web-scale. Using those URI addresses to refer to your things, so that people can point to them from across the web. But the grand prize is the five star rating, which is about relationships.
Link your data to other data so that both consumer and publisher benefit from the network effect.
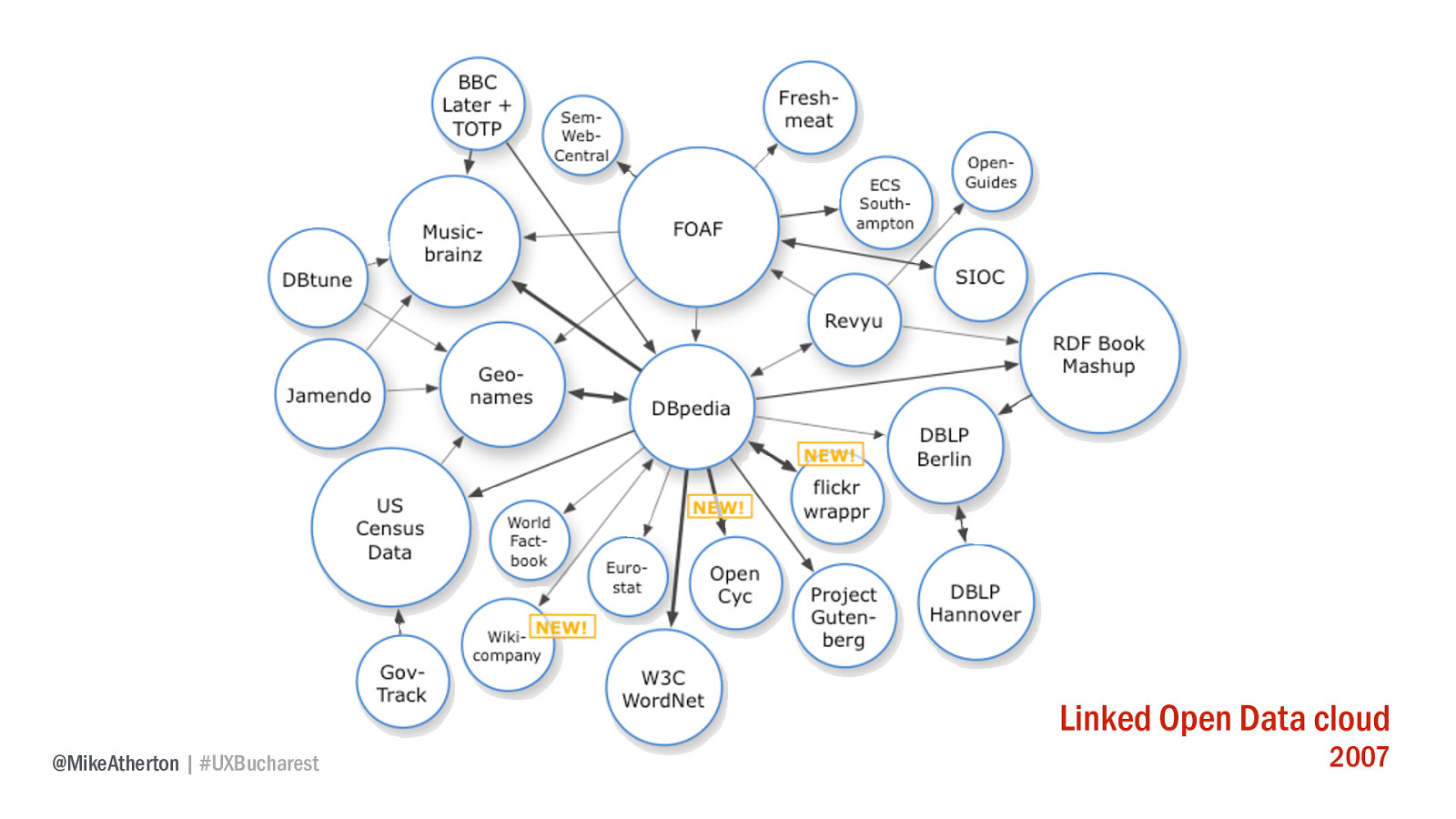
The network cloud of linked data is growing rapidly. A few years ago just a handful of services were linking to each other.

Now this diagram is bursting at the seams. It reminds me of the early days of the web when there were phone books published listing all the world’s websites. Imagine a world where there were as many data sources to play with as there are websites.
It’s happening already, and you can help.

An easy way to get started is to make your web pages robot-readable.

There’s a form of RDF called RDFa, which can be put directly inside the HTML of your webpage and can be used to describe what your page is about, but at web-scale.

Let’s say we had a page for a city council. Using RDFa we can tell the computer that our page is talking about the same thing identified by an existing linked data resource, first by stating what we mean by ‘about’ (by using a common vocabulary) and then by referencing the URI of that resource.
We can also tell the computer that this council governs a specific geographic region, again by defining what ‘governs’ means (according to a standard ontology) and referencing a URI which identifies that region. All these elements can live in the header of our page, or be used to markup a part of the page.

We can publish our own ontology. If you have a content model which defines the things in your subject and the relationships between them, a lot of your work is done.

Ontologies are documents that describe how your subject domain hangs together. Many existing ontologies are already published to work from or build upon. These vocabularies are intended to be reusable.
When everyone uses the same terms for things, or at least maps their terms to our terms, the web of data all joins up.

Content management systems like Drupal and Umbraco have growing support for exporting document structure to RDF.
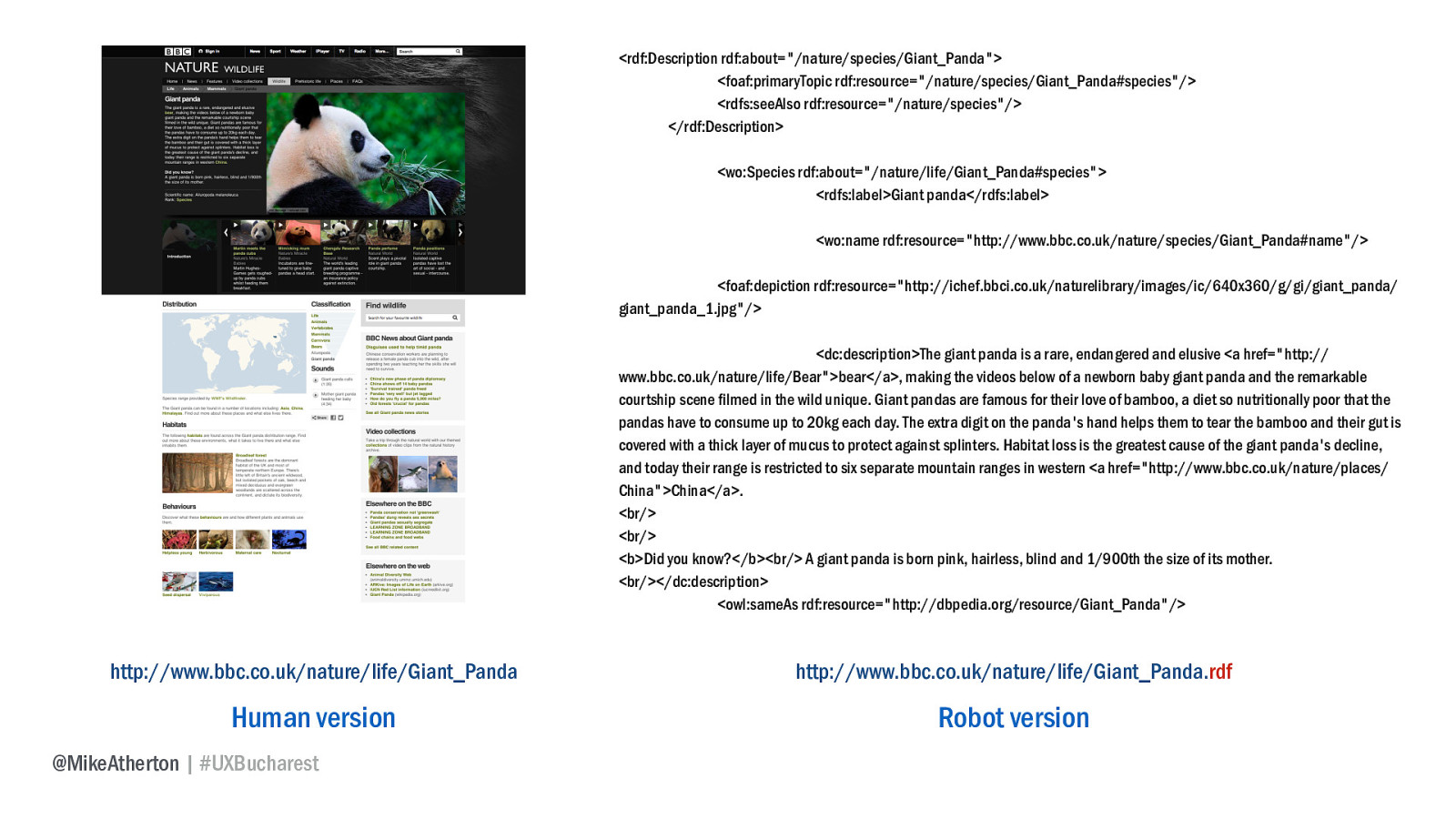
What you’re really trying to get to is publishing out a robot-readable version of any page that has a human version. If you want to see how Wildlife Finder does that, just add .RDF to the end of any of their addresses.

We can go on a treasure hunt, because we may discover through our content model that we have some missing pieces. A content model is a mental model of our subject domain, so we can start to check off the things we have within our business.

Markup your own content with RDF. Maybe define and publish your own ontology which defines your subject domain. And go on a quest - using the Linked Data cloud as your treasure map. Make use of the valuable data and content it would be otherwise too expensive to source and maintain.

If we want to get really brave, we can build powerful prototypes with a little code. Rails is a popular choice for taking linked data queries and using them to generate prototype websites. Python too, which is a language we’re teaching kids in schools these days.
I’m not suggesting we’re suddenly capable of developing production-ready applications, but with a grasp of the basics we can start to play with this data first hand.
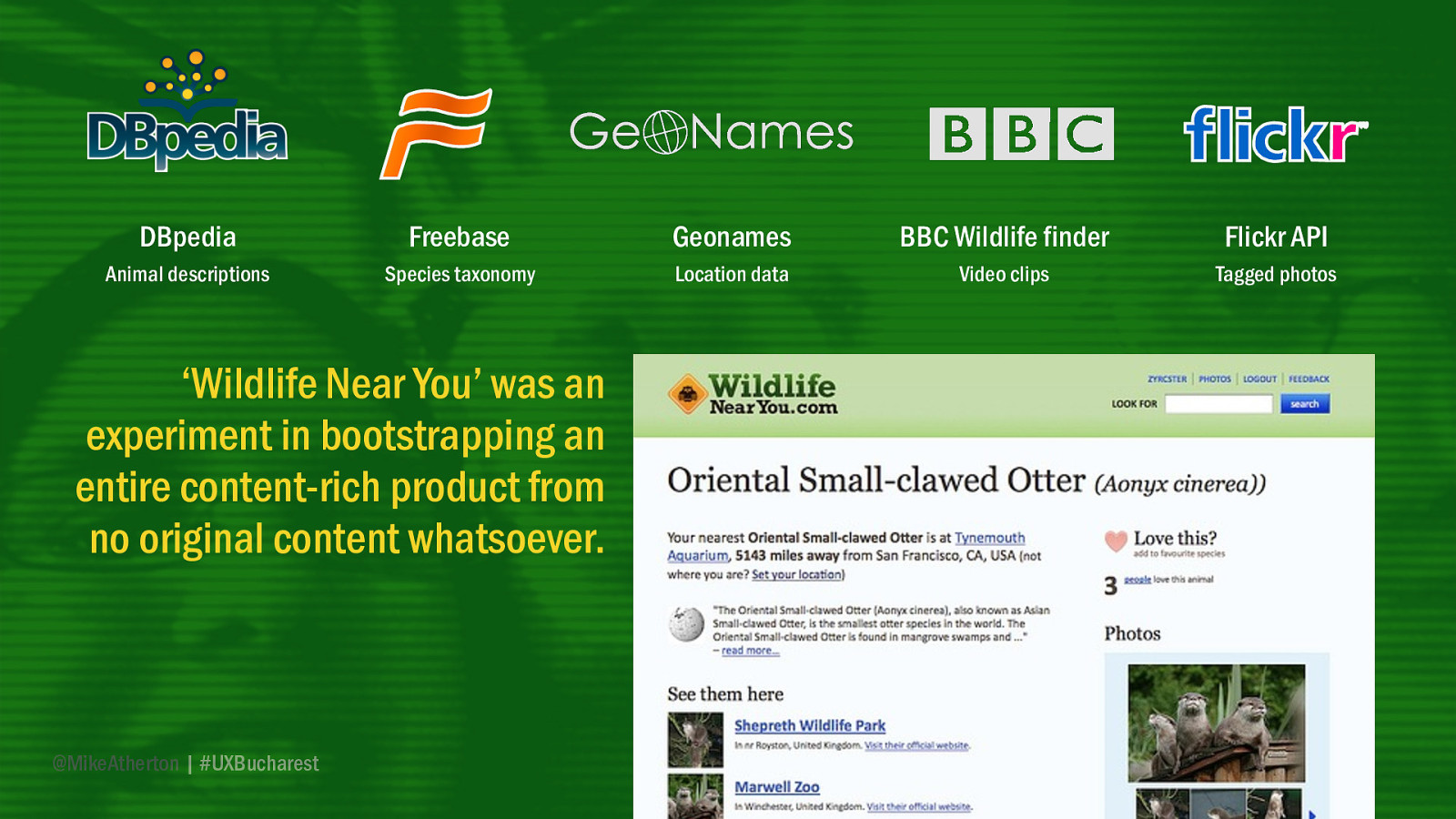
That’s what Simon Willison and Natalie Downe did when they wanted to answer the burning question ‘Where can I see my nearest llama?’. By combining the Linked Data sources of DBpedia, Freebase, Geonames, and BBC Wildlife Finder, along with the Flickr API, they were able to pull together a product called ‘Wildlife Near You’ (don’t look for it - it’s not there anymore).
By letting users upload their animal sightings, it allowed you to input any species of animal and find out the nearest zoo or sanctuary where you could see it. It’s a content-rich product, built from no original content whatsoever, just open sources of free data.

This is IA, content strategy, product design at web-scale, and playing is the key. This morning, Lisa spoke about the supply chain for architecting the information age. Here are the raw materials.
We have a world full of data sources to play with. What could you make of them? Perhaps it’s no longer just about making sense of the stuff within our business, but in recombining the data on the web in new and useful ways.

The web is bigger than all of us. Tim-Berners Lee once said that its most important facet is universality. We should embrace that, and consider when we create, structure, and publish our content not just what is this doing for my customers, but how does this benefit the web as a whole?
Maybe that’s corporate social responsibility for the digital age.

Last year the web turned 25. So now we’re in the second 25 years. Web 2.0 you might say. Some of us were there back at the start, struggling with clunky command-line tools and dial-up modems, yet overwhelmed by the dizzying possibilities of publishing in real-time from our bedroom to the world.

We hear a lot these days about the need to bust out of UX silos. To talk to the business, bridge divisions and share knowledge. Right from the start, the web was invented to do exactly this through its most important element; the hyperlink.

As designers we connect with people to connect them to information. The web was designed for exactly this; building understanding by connecting knowledge.

Right now I think we have a fear of commitment. We don’t seem to want to build for the long-term. In this world you’re either a truck or you’re a highway a product, or a service-level infrastructure. An API if you will.
We have Product Managers, so why don’t we have Service Managers? Products, like trucks, come and go. But service infrastructures–the data-driven highways of the internet–can last much longer.

The future of knowledge sharing on the web needs us to open these pathways. We are capable of taming the roots and branches of knowledge and making limitless connections across boundaries.
Information architecture isn’t just site mapping and card sorting. We all need to become adept at working with the native fabric of the web.

The linked data community is still a cottage industry; albeit one with inherently global intent. Like us, they believe in building connections, sharing knowledge, and architecting understanding. Perhaps we should get together?

It’s all one web. Let’s play in this decentralised, desiloed, democratic and data-driven information space, never doubting that a small group of thoughtful, committed citizens can change the world.
Indeed, it is the only thing that ever has.
