
A presentation at The Knowledge Graph Conference 2025 in in New York, NY, USA by Nandana Mihindukulasooriya

The State of the Art Large Language Models for Knowledge Graph Construction from Text: Techniques, Tools, and Challenges Nandana Mihindukulasooriya Senior Research Scientist | IBM Research
Agenda Relation Extraction Task Relation extraction and related tasks in the literature. RE Benchmarks Summary of relation extraction benchmarks. RE Approches Methods and approaches for relation extraction focused on LLMs.
Relation Extraction and Related Tasks
Relation Extraction Irene Morgan, who was born and raised in Baltimore, lived on Long Island. Named Entity Recognition Irene Morgan, who was born and raised in Baltimore, lived on Long Island. [PLACE] [PERSON] [PLACE] Relation Extraction Irene Morgan, who was born and raised in Baltimore, lived on Long Island. per:city_of_birth 4
(Binary) Relation Extraction Irene Morgan, who was born and raised in Baltimore, lived on Long Island. per:city_of_birth
<Head Entity, Relationship, Tail Entity> <Subject, Relationship, Object> Relationship is selected from a set of predefined canonical relations. 5Relations are not predefined, automatically discovered in text. A large number of sparse and diverse relations Need to further steps of clustering, canonicalization, alignment to map to a set of KG relations. Open Information Extraction from the Web. Banko et al. IJACAI 2007.
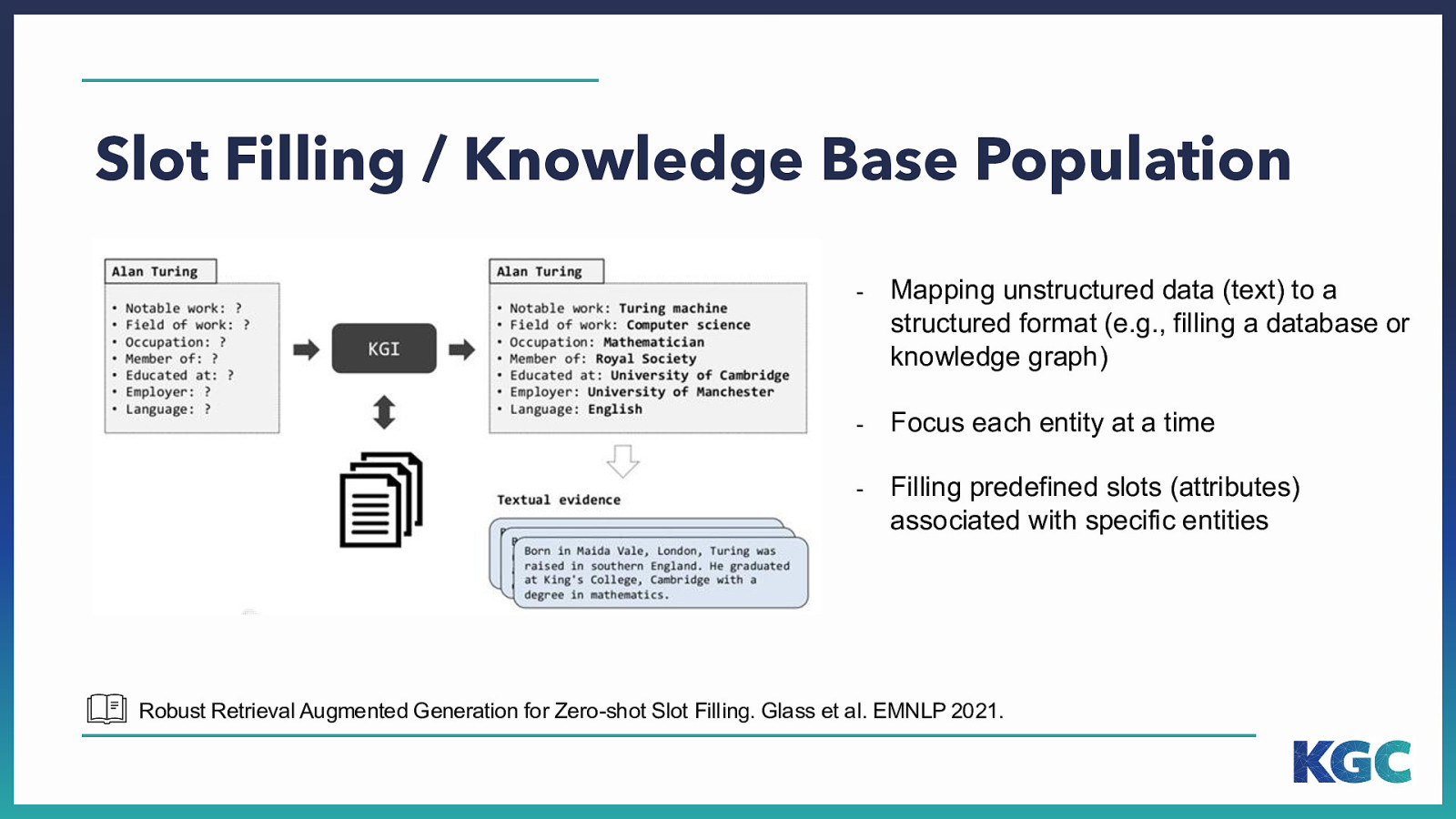
Filling predefined slots (attributes) associated with specific entities Robust Retrieval Augmented Generation for Zero-shot Slot Filling. Glass et al. EMNLP 2021.
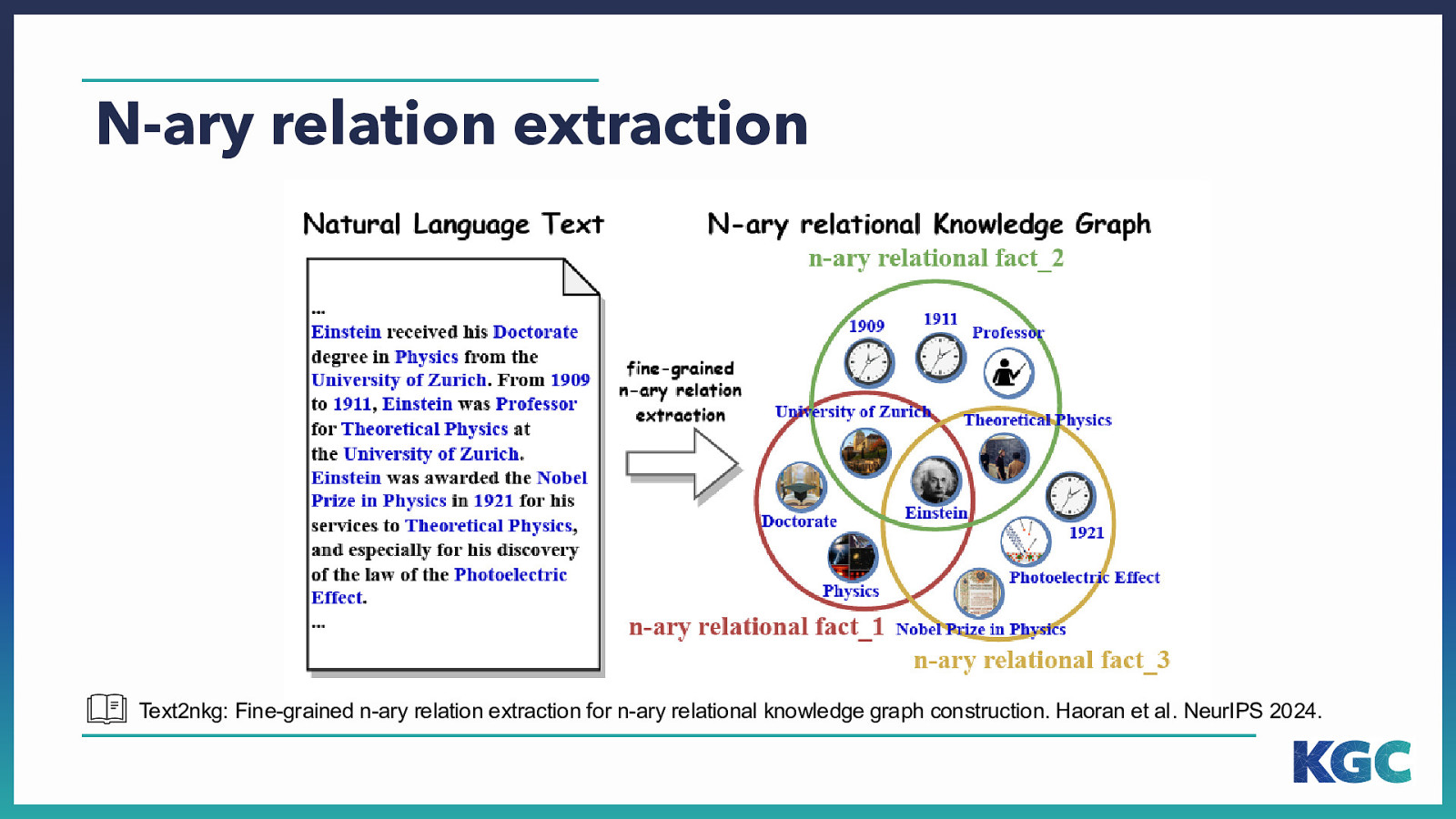
N-ary relation extraction Text2nkg: Fine-grained n-ary relation extraction for n-ary relational knowledge graph construction. Haoran et al. NeurIPS 2024.
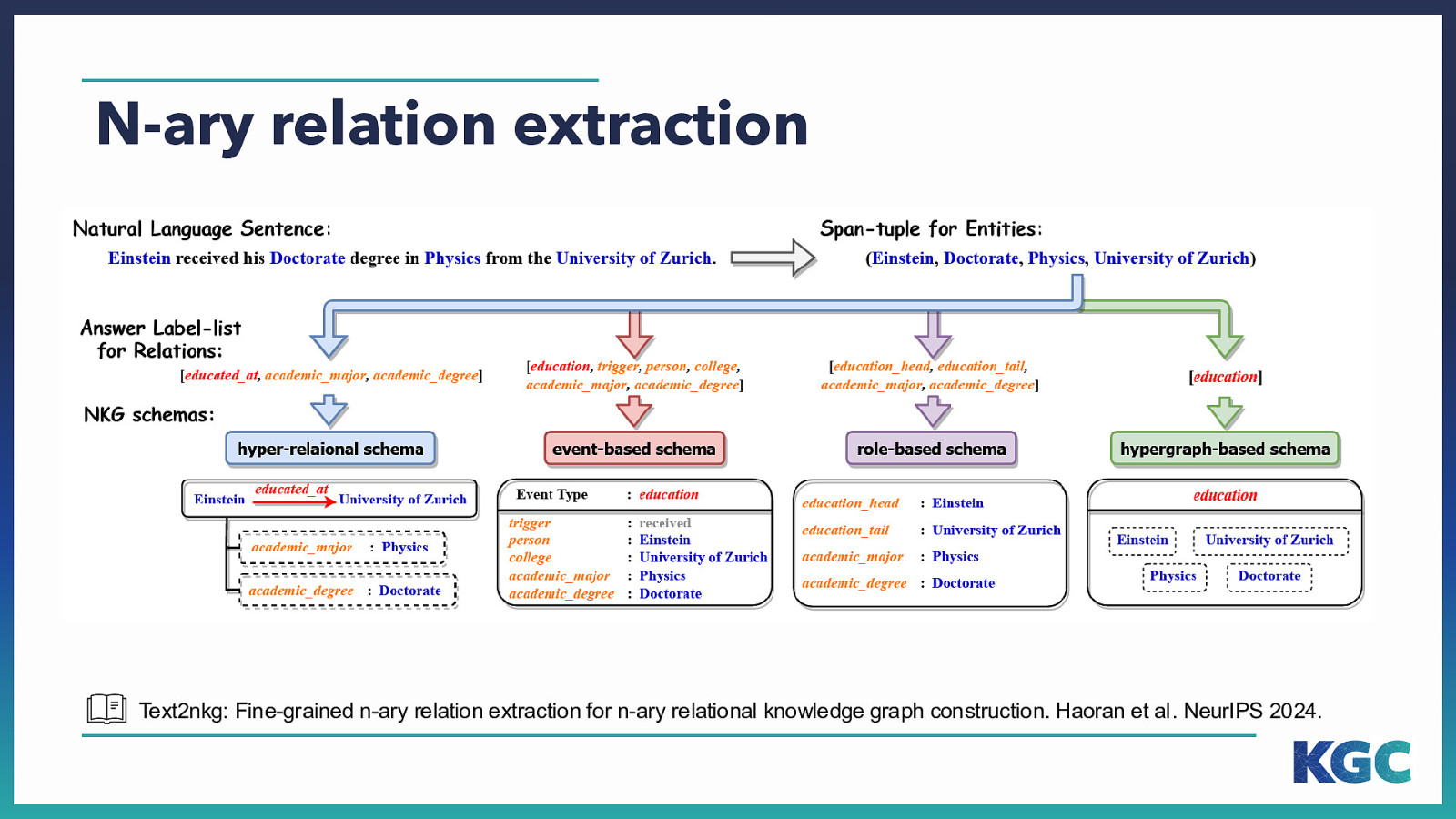
N-ary relation extraction Text2nkg: Fine-grained n-ary relation extraction for n-ary relational knowledge graph construction. Haoran et al. NeurIPS 2024.
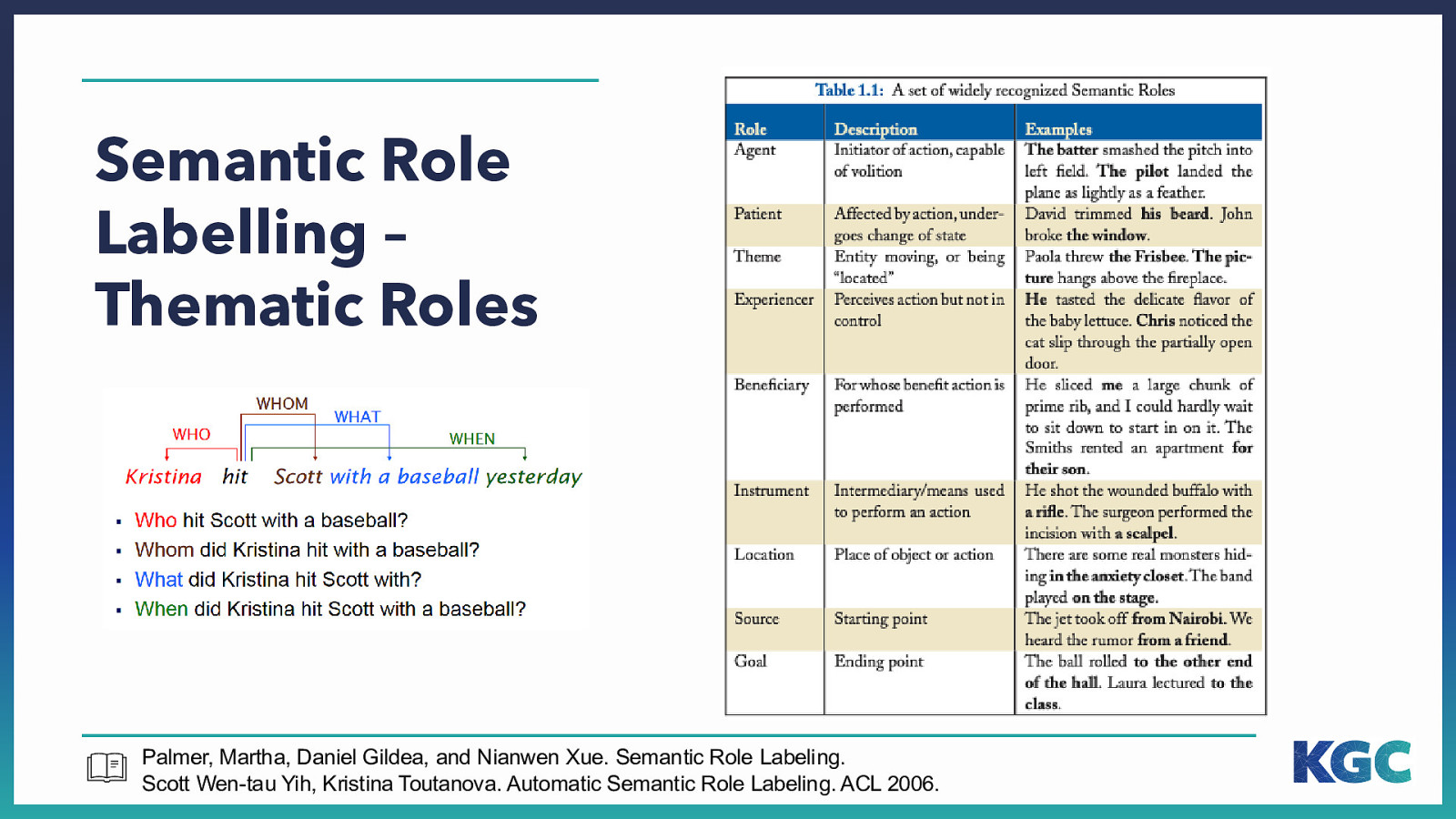
Semantic Role Labelling – Thematic Roles Palmer, Martha, Daniel Gildea, and Nianwen Xue. Semantic Role Labeling. Scott Wen-tau Yih, Kristina Toutanova. Automatic Semantic Role Labeling. ACL 2006.
Semantic Role Labelling – PropBank & AMR Banarescu, Laura, et al. “Abstract Meaning Representation for Sembanking.” 2013.
Sentence-level Relation Extraction • The task of extracting relationships between entities within a single sentence Irene Morgan, who was born and raised in Baltimore, lived on Long Island. per:city_of_birth
Document-level Relation Extraction • The task of extracting relationships between entities across an entire document considering the broader context, coreferences, longdistance dependencies, etc. DocRED: A Large-Scale Document-Level Relation Extraction Dataset. Yao et al. ACL 2019.
Sentences from the Document Corpus Some additional steps are required • Entity clustering / canonicalization • Entity resolution • Entity linking • (adding new entities if necessary) • Schema matching • Relation linking DWIE: An entity-centric dataset for multi-task document-level information extraction. Klim Zaporojets, Johannes Deleu, Chris Develder, Thomas Demeester. Information Processing and Management 2021.
Relation Extraction Benchmarks
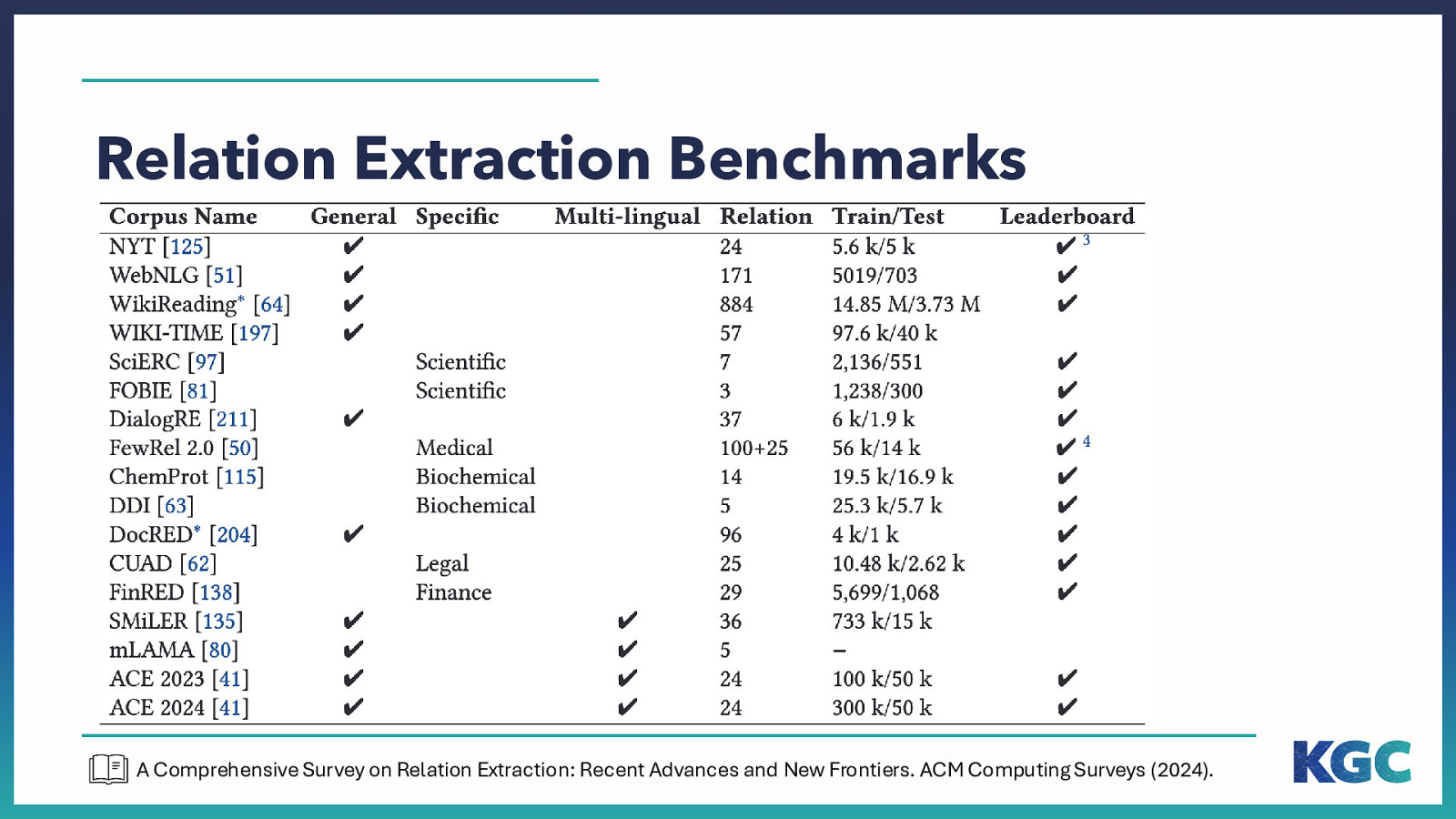
Relation Extraction Benchmarks A Comprehensive Survey on Relation Extraction: Recent Advances and New Frontiers. ACM Computing Surveys (2024).
Relation Extraction Benchmarks SemEval-07 Task 4 (2007) SemEval2010 ACE ACE Task 8 (2004) (2005) (2010) Google WebNLG (2017) WD-UKPLAB (2017) WIKI (2019) TACRED T-REx DocRED (2017) (2018) (2019) WebNLG FewRel FewRel2 NYT ADE RE (2018) (2019) (2010) (2012) (2013) (2017) MUC-TR CoNLL (1998) (2004) REBEL TEKGEN (2021) (2021) WdRef KELM DWIE (2025) (2021) (2021) Re-TACRED (2021) KERED SynthIE NYT21 (2022) (2023) (2021) Text2KGBench (2023) 1998 2004 2005 2007 2010 2012 2013 2017 2018 2019 2021 2022 2023
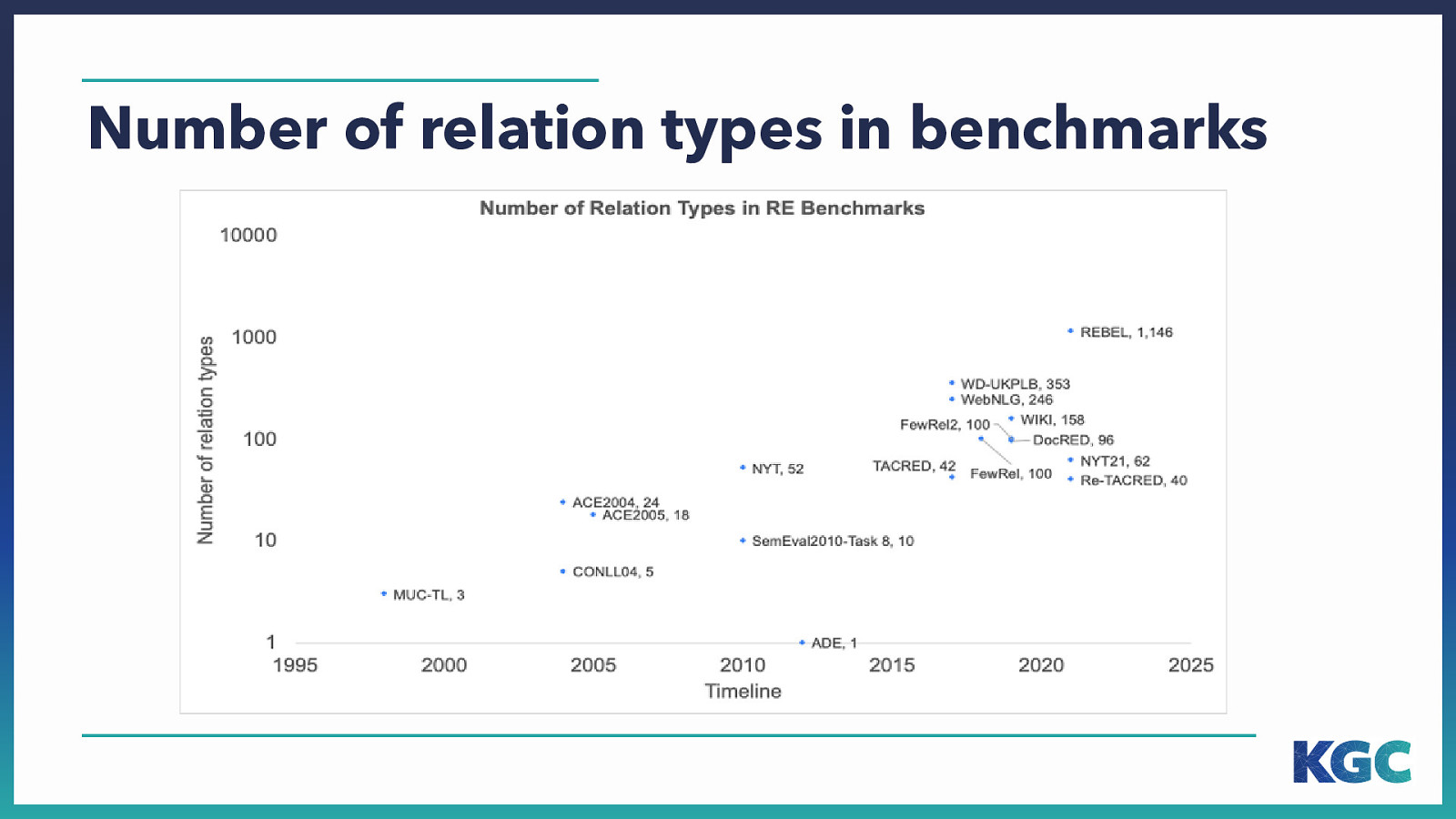
Number of relation types in benchmarks
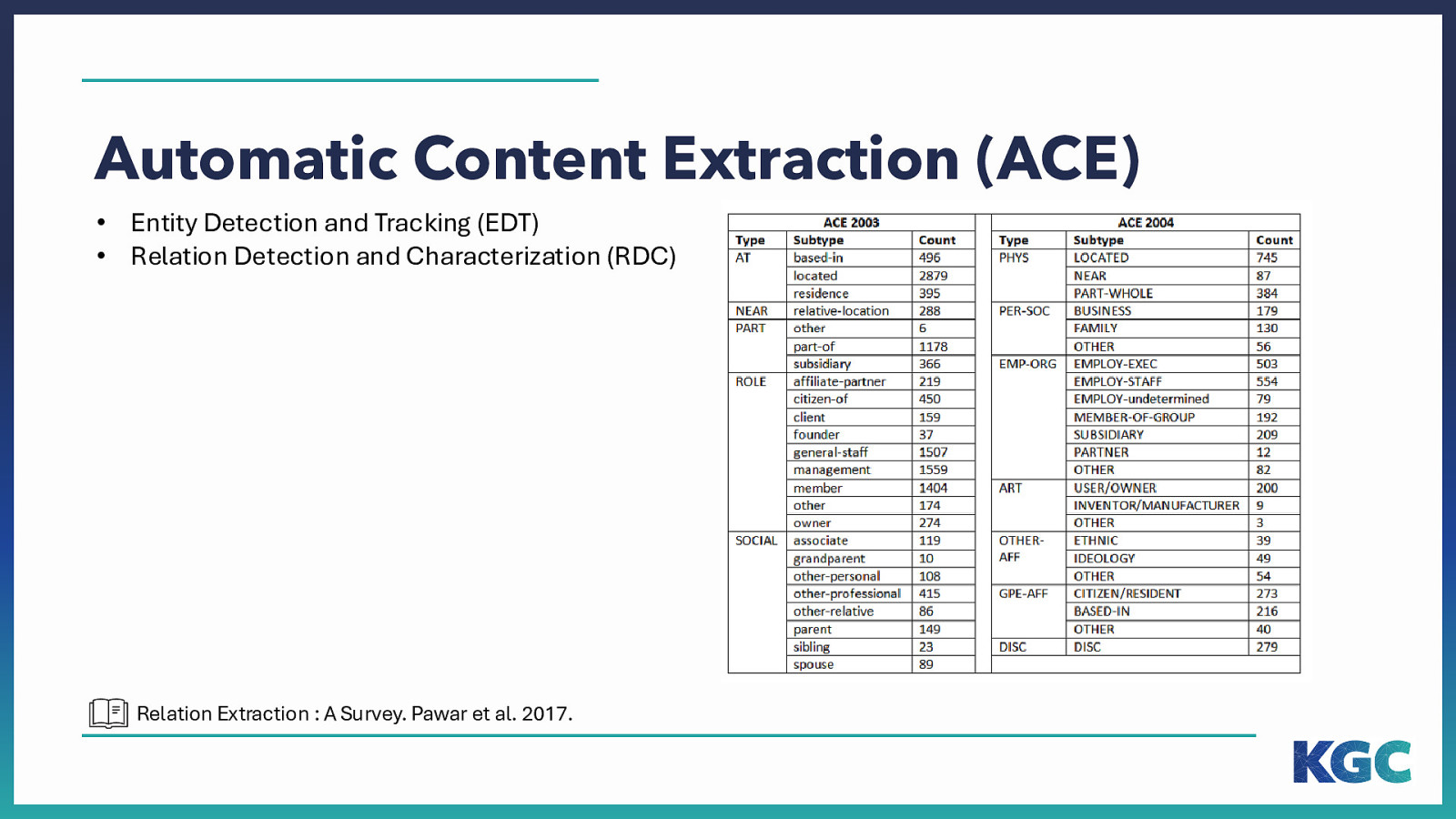
Automatic Content Extraction (ACE) • Entity Detection and Tracking (EDT) • Relation Detection and Characterization (RDC) Relation Extraction : A Survey. Pawar et al. 2017.
REBEL • Wikipedia abstracts as text • Entity spans are extracted using hyperlinks • All relations and values from Wikidata for those entities • A Natural Language Inference (NLI) model used to check for entailment REBEL: Relation extraction by end-to-end language generation. Cabot and Navigli. EMNLP 2021.
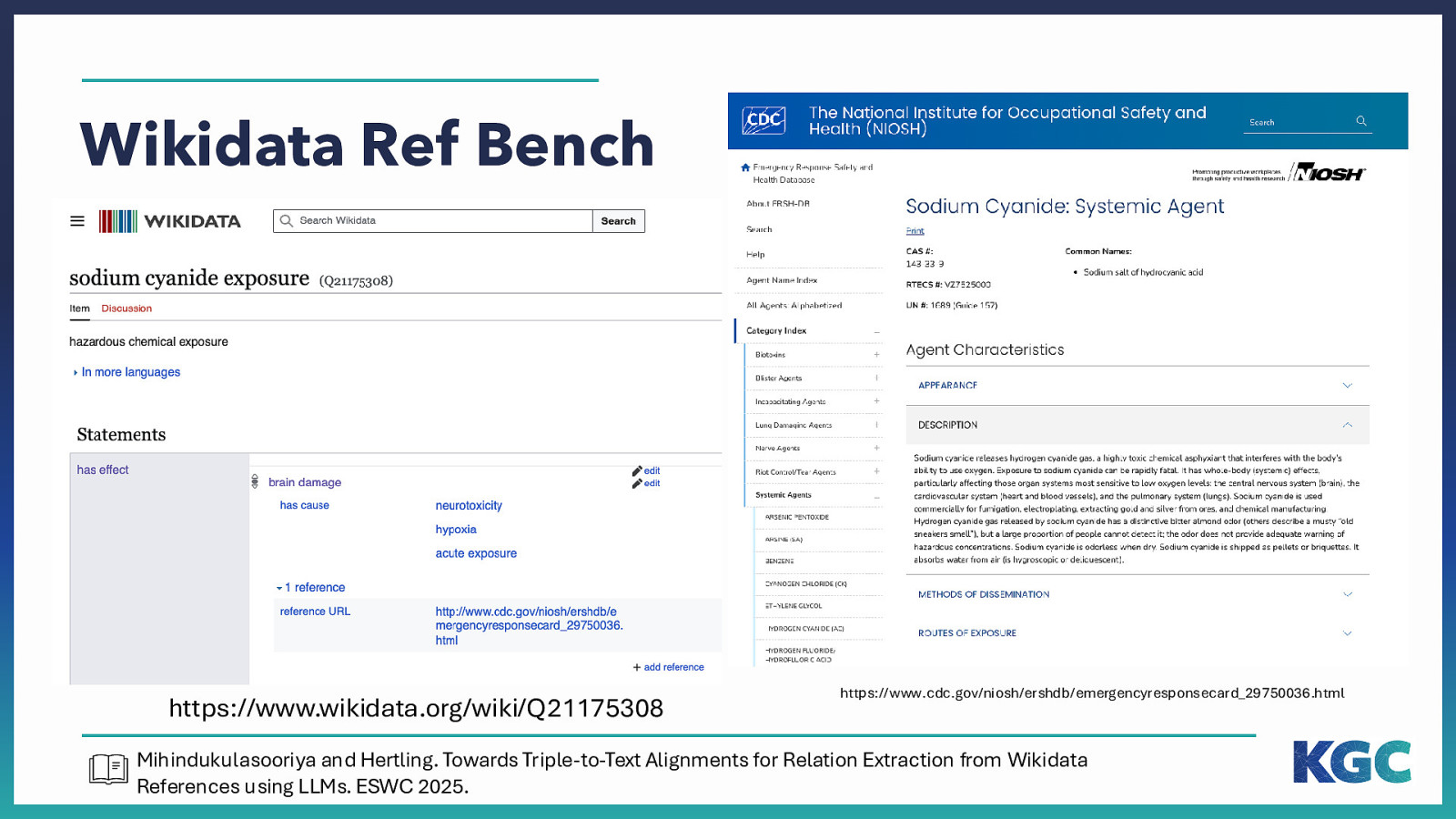
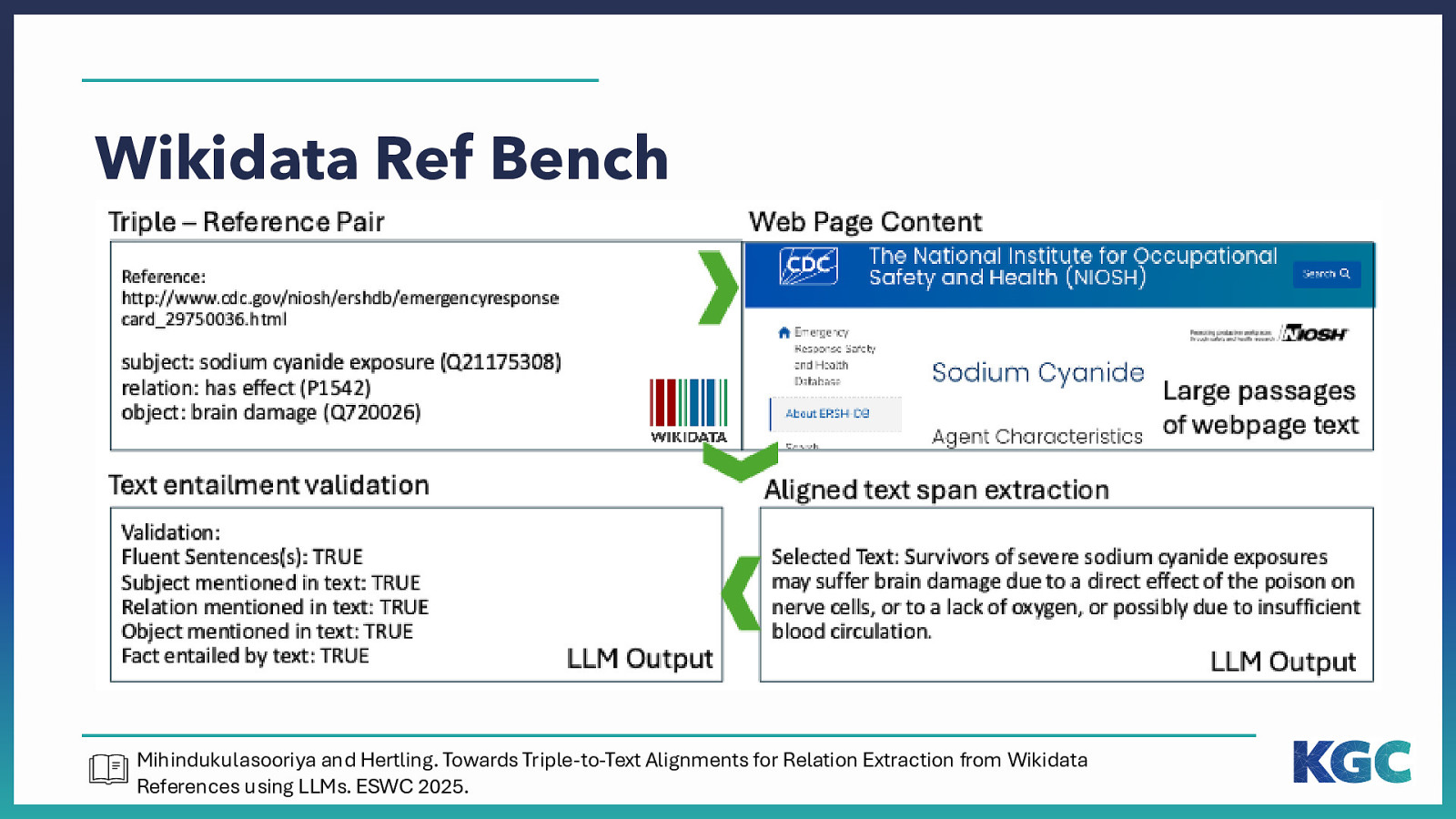
Wikidata Ref Bench https://www.wikidata.org/wiki/Q21175308 https://www.cdc.gov/niosh/ershdb/emergencyresponsecard_29750036.html Mihindukulasooriya and Hertling. Towards Triple-to-Text Alignments for Relation Extraction from Wikidata References using LLMs. ESWC 2025.
Wikidata Ref Bench Mihindukulasooriya and Hertling. Towards Triple-to-Text Alignments for Relation Extraction from Wikidata References using LLMs. ESWC 2025.
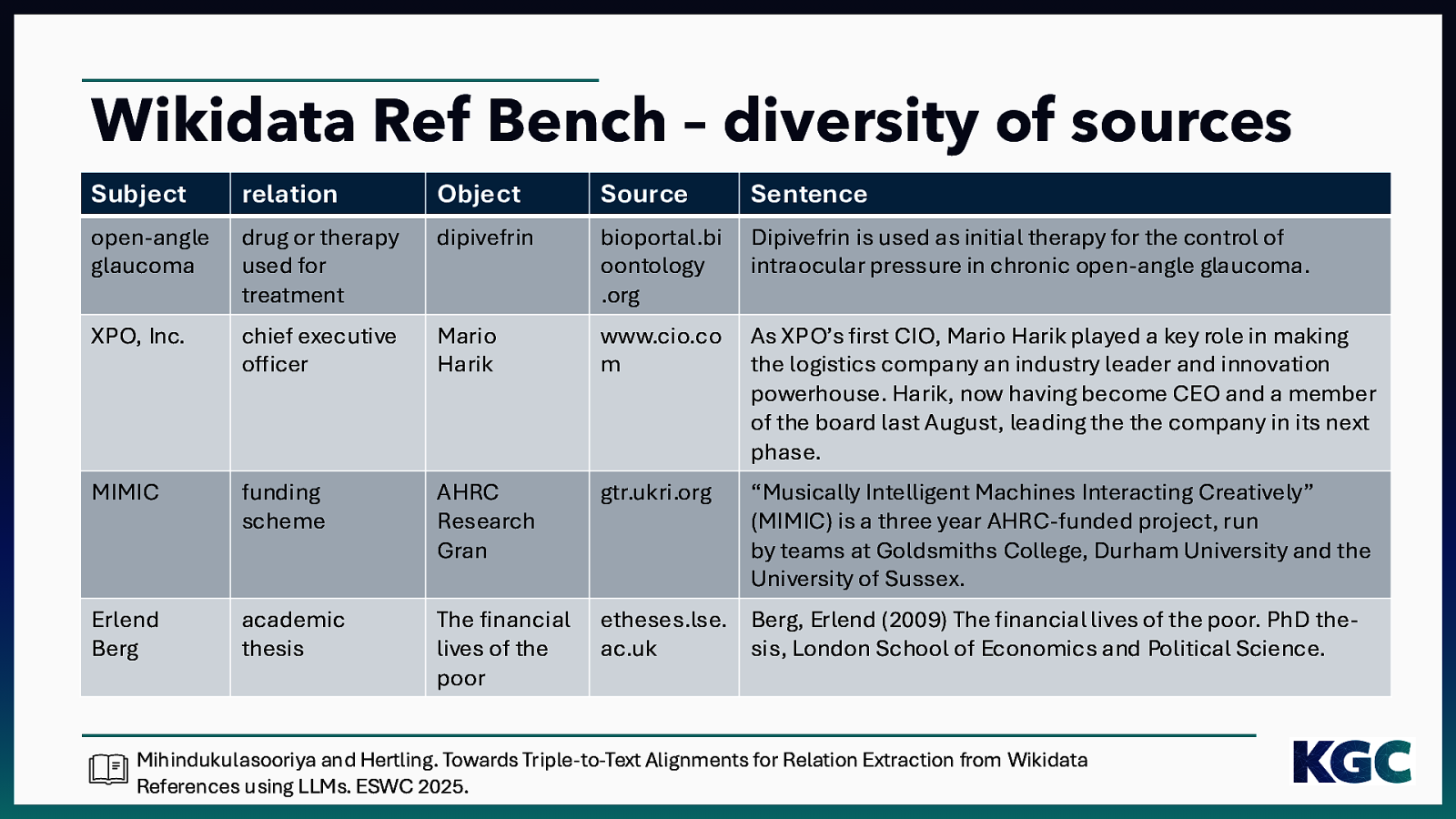
Wikidata Ref Bench – diversity of sources Subject relation Object Source Sentence open-angle glaucoma drug or therapy used for treatment dipivefrin bioportal.bi oontology .org Dipivefrin is used as initial therapy for the control of intraocular pressure in chronic open-angle glaucoma. XPO, Inc. chief executive officer Mario Harik www.cio.co m As XPO’s first CIO, Mario Harik played a key role in making the logistics company an industry leader and innovation powerhouse. Harik, now having become CEO and a member of the board last August, leading the the company in its next phase. MIMIC funding scheme AHRC Research Gran gtr.ukri.org “Musically Intelligent Machines Interacting Creatively” (MIMIC) is a three year AHRC-funded project, run by teams at Goldsmiths College, Durham University and the University of Sussex. Erlend Berg academic thesis The financial lives of the poor etheses.lse. Berg, Erlend (2009) The financial lives of the poor. PhD theac.uk sis, London School of Economics and Political Science. Mihindukulasooriya and Hertling. Towards Triple-to-Text Alignments for Relation Extraction from Wikidata References using LLMs. ESWC 2025.
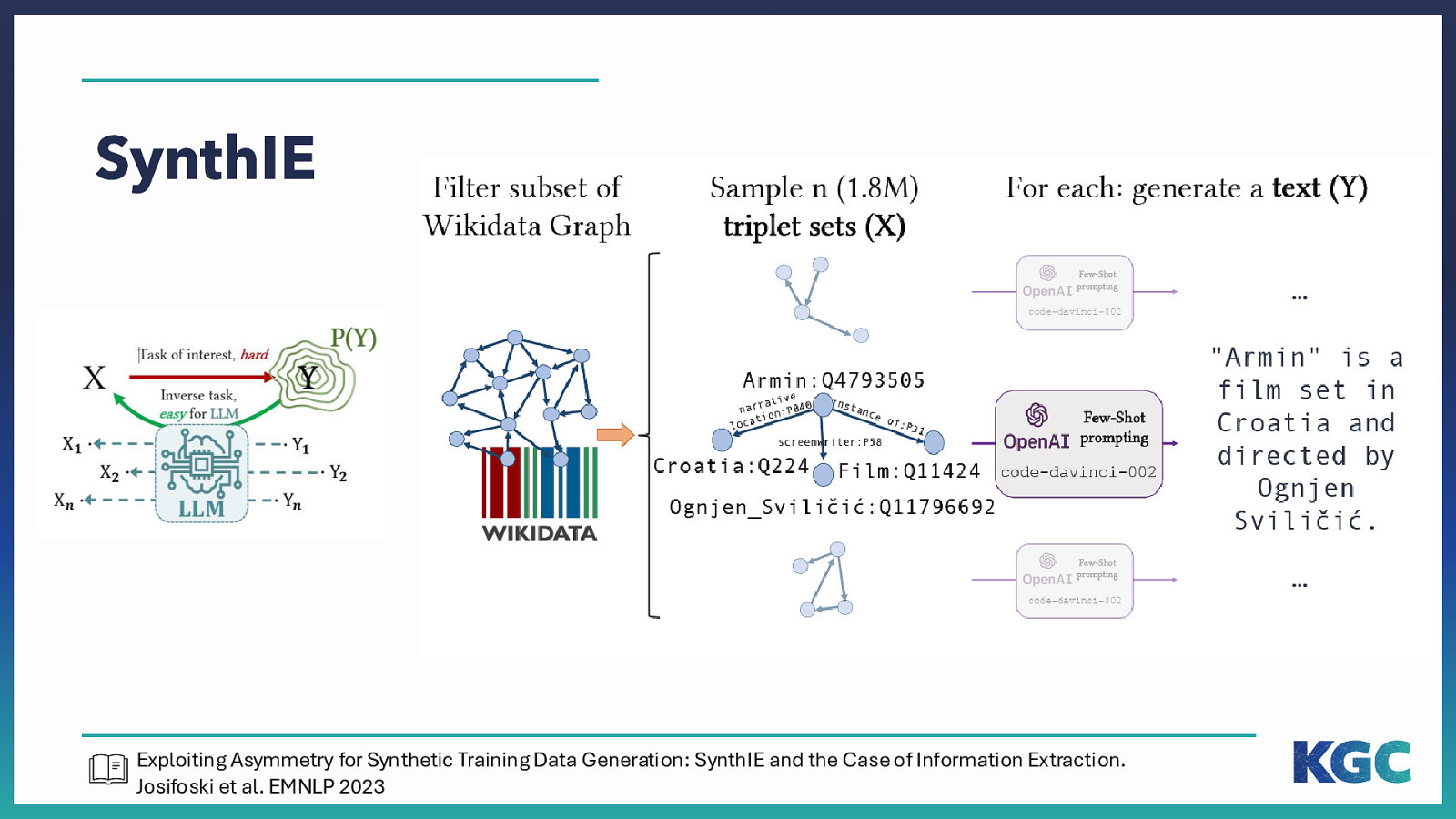
SynthIE Exploiting Asymmetry for Synthetic Training Data Generation: SynthIE and the Case of Information Extraction. Josifoski et al. EMNLP 2023
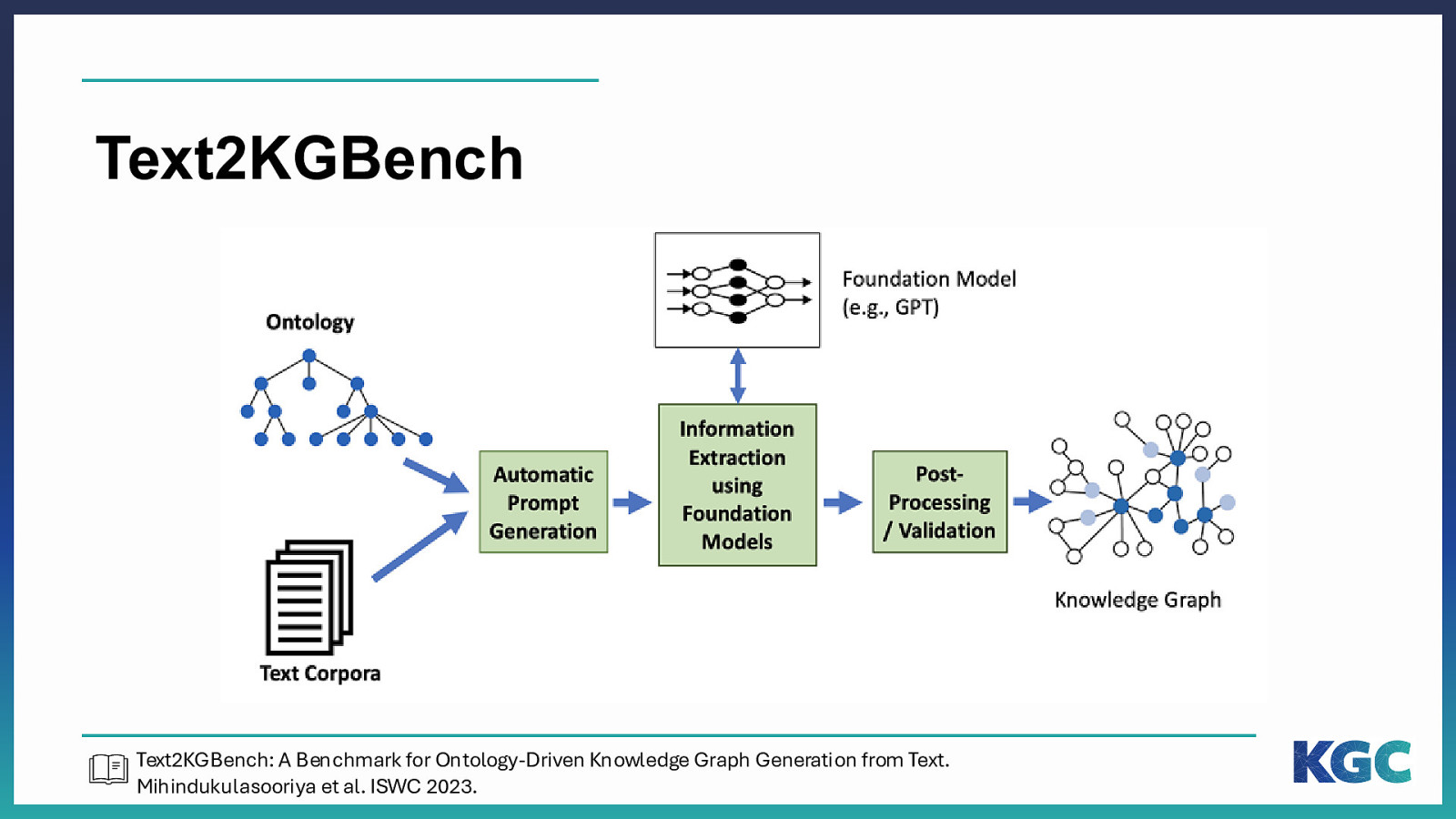
Text2KGBench • Inputs • An ontology • A set of sentences • Outputs • Triples aligned with each sentence(s) of text conforming to the ontology Text2KGBench: A Benchmark for Ontology-Driven Knowledge Graph Generation from Text. Mihindukulasooriya et al. ISWC 2023.
Text2KGBench Text2KGBench: A Benchmark for Ontology-Driven Knowledge Graph Generation from Text. Mihindukulasooriya et al. ISWC 2023.
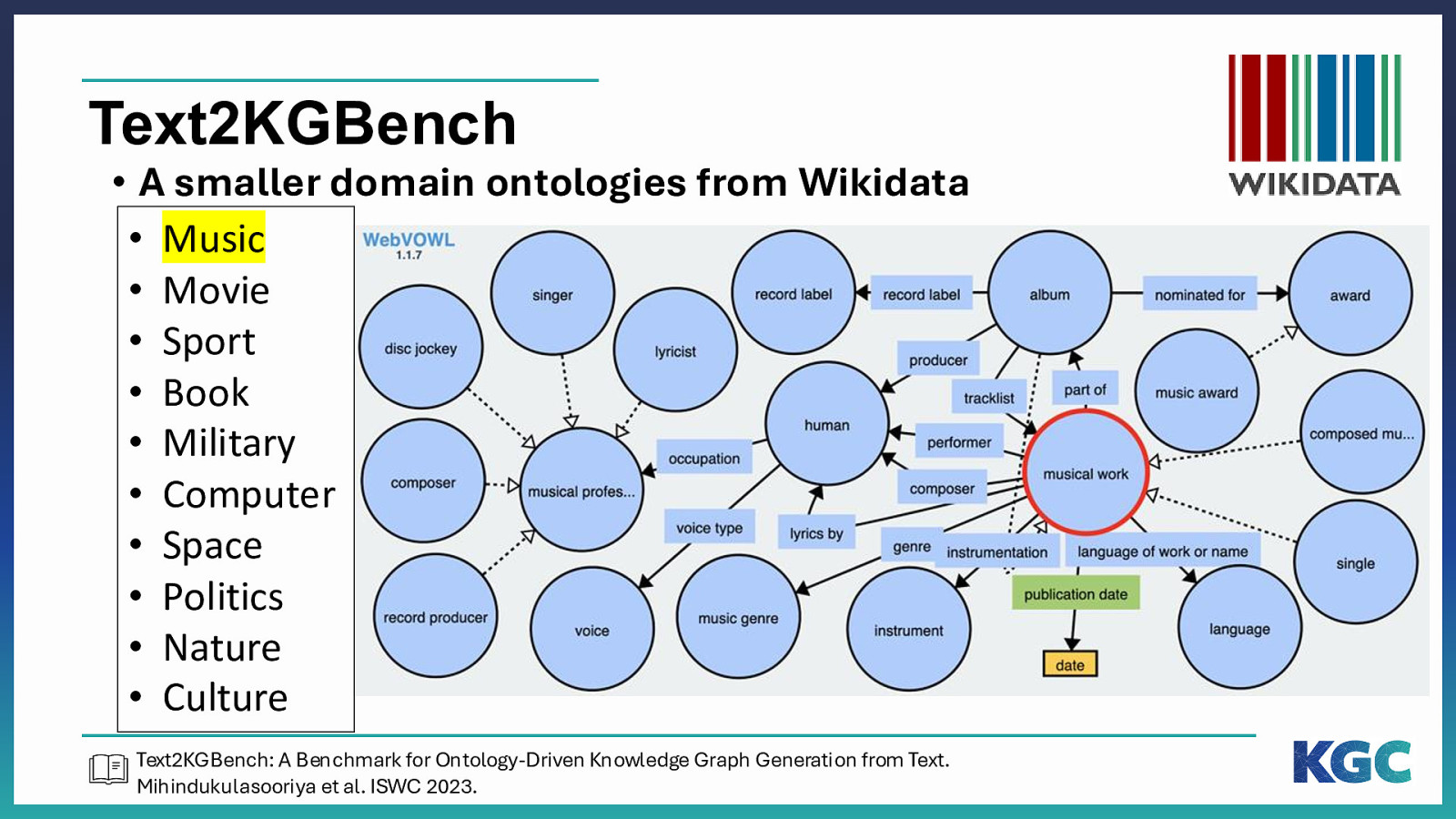
Text2KGBench • A smaller domain ontologies from Wikidata • Music • Movie • Sport • Book • Military • Computer • Space • Politics • Nature • Culture Text2KGBench: A Benchmark for Ontology-Driven Knowledge Graph Generation from Text. Mihindukulasooriya et al. ISWC 2023.
Text2KGBench • Aligned sentence selection • • For each ontology, a subset of triple-sentence pairs chosen based on the relations / classes of the ontology TekGen corpus provides Wikipedia sentences aligned to Wikidata triples (16M aligned triple-sentence pairs with 663 Wikidata relations) The Lion King is an animated musical drama film directed by Roger Allers and Rob Minkoff, produced by Don Hahn. director (“Lion King”, “Roger Allers”) director (“Lion King”, “Rob Minkoff”) producer (“Lion King”, “Don Hah”) Text2KGBench: A Benchmark for Ontology-Driven Knowledge Graph Generation from Text. Mihindukulasooriya et al. ISWC 2023.
Text2KGBench • Unseen sentence generation • Language models have seen these sentence during pre-training • There is a possibility of data leakage in training data • Will the results differ significantly on totally unseen sentences? John Doe starred in the film The Fake Movie that was released in 2025. cast member (“The Fake Movie”, “John Doe”) publication date (“The Fake Movie”, 2025) Text2KGBench: A Benchmark for Ontology-Driven Knowledge Graph Generation from Text. Mihindukulasooriya et al. ISWC 2023.
Text2KGBench • The baseline uses in-context learning • Best examples are selected using sentence similarity (SBERT) from training data • Other approaches to use training data to improve • For fine-tuning/instructiontuning the models • For prompt-tuning the models • Other improvements • • • • Ontology verbalization Self-reflection / critique Chain-of-thought Constrained beam search
Text2KGBench – Evaluation Metrics • Fact extraction accuracy – Precision (P), Recall (R), and F1 • System generated triples compared to ground truth triples • Ground truth may not be exhaustive • to avoid false negative and out-of-context triples, a locally closed approach considering only relations in ground truth • Ontology conformance • Does the LLM adhere to the ontology provided in the prompt • Currently only checks if the relations are canonical ones from the ontology • Can be further extended to ensure domain/range and other constraints • Hallucinations • We expect the triples to be faithful to the input sentence provided • Subject entity / object should be present in the sentence • Stemming is used to address morphological variations (further work is needed to make this robust) Text2KGBench: A Benchmark for Ontology-Driven Knowledge Graph Generation from Text. Mihindukulasooriya et al. ISWC 2023.
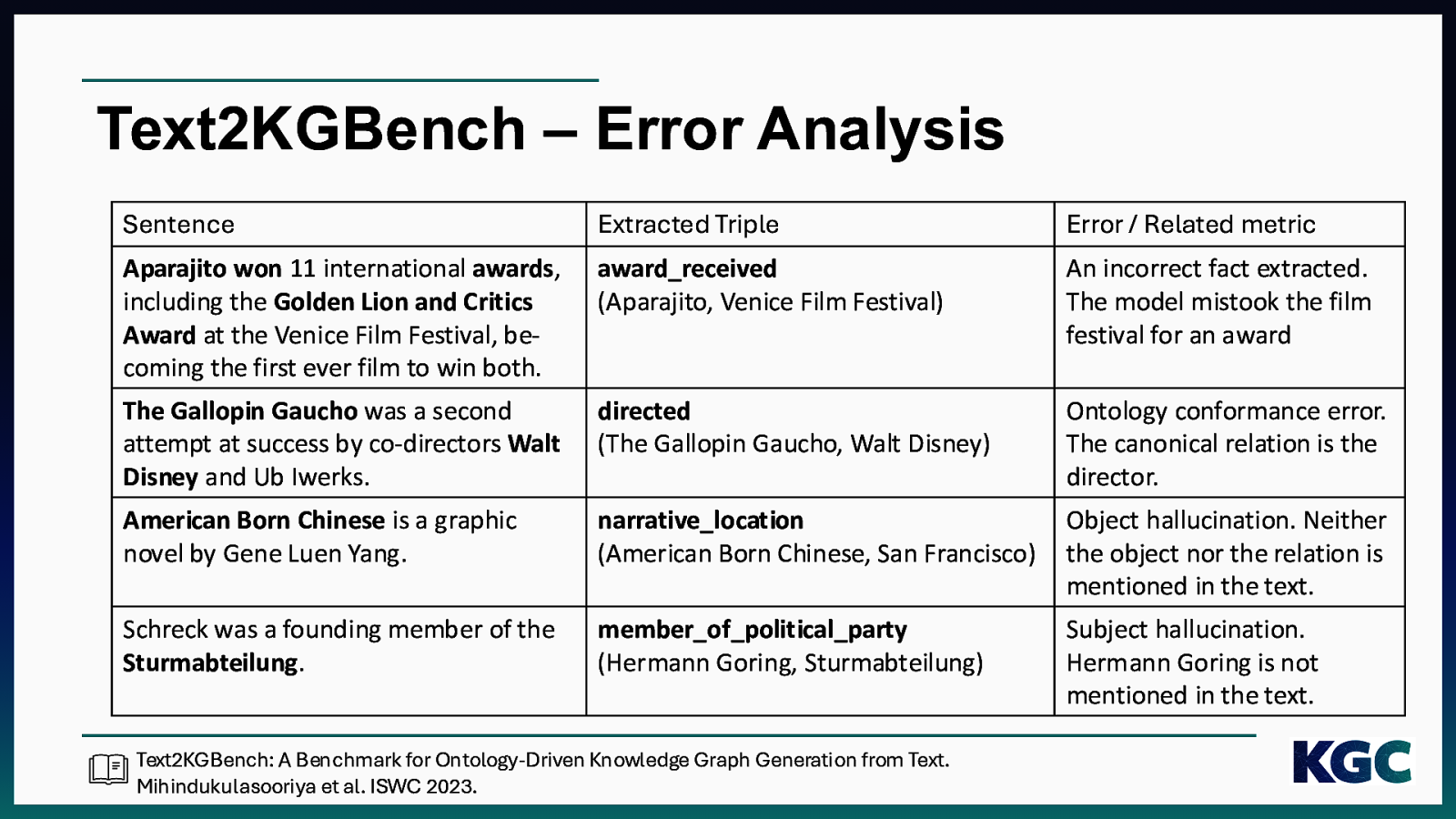
Text2KGBench – Error Analysis Sentence Extracted Triple Error / Related metric Aparajito won 11 international awards, including the Golden Lion and Critics Award at the Venice Film Festival, becoming the first ever film to win both. award_received (Aparajito, Venice Film Festival) An incorrect fact extracted. The model mistook the film festival for an award The Gallopin Gaucho was a second attempt at success by co-directors Walt Disney and Ub Iwerks. directed (The Gallopin Gaucho, Walt Disney) Ontology conformance error. The canonical relation is the director. American Born Chinese is a graphic novel by Gene Luen Yang. narrative_location (American Born Chinese, San Francisco) Object hallucination. Neither the object nor the relation is mentioned in the text. Schreck was a founding member of the Sturmabteilung. member_of_political_party (Hermann Goring, Sturmabteilung) Subject hallucination. Hermann Goring is not mentioned in the text. Text2KGBench: A Benchmark for Ontology-Driven Knowledge Graph Generation from Text. Mihindukulasooriya et al. ISWC 2023.
Relation Extraction Approaches
Traditional relation extraction approaches • Rule-based approaches • Lexical analysis and phrase patterns • Syntax analysis, dependency trees, and semantic parsing • Weak supervision / distant supervision approaches • Noise reduction approaches • Embedding based approaches • Auxiliary information • Supervised learning approaches • Feature-based methods • Kernel-based methods • LSTMs, CNNs, GNNs A Review of Relation Extraction. Bach, Nguyen, and Sameer Badaskar. Literature Review for Language and Statistics (2007) Relation Extraction using Distant Supervision: A Survey. Smirnova, A. and Cudré-Mauroux. ACM Computing Surveys (2018).
Large Language Models-based Approaches Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond. Yang et al. ACM Transactions on Knowledge Discovery from Data (2024)
Relation Extraction Models A Comprehensive Survey on Relation Extraction: Recent Advances and New Frontiers. ACM Computing Surveys (2024).
Pipeline based RE A Comprehensive Survey on Relation Extraction: Recent Advances and New Frontiers. ACM Computing Surveys (2024).
Entity Overlaps NEO: No Entity Overlap SEO: Single Entity Overlap EPO: Entity Pair Overlap A Comprehensive Survey on Relation Extraction: Recent Advances and New Frontiers. ACM Computing Surveys (2024).
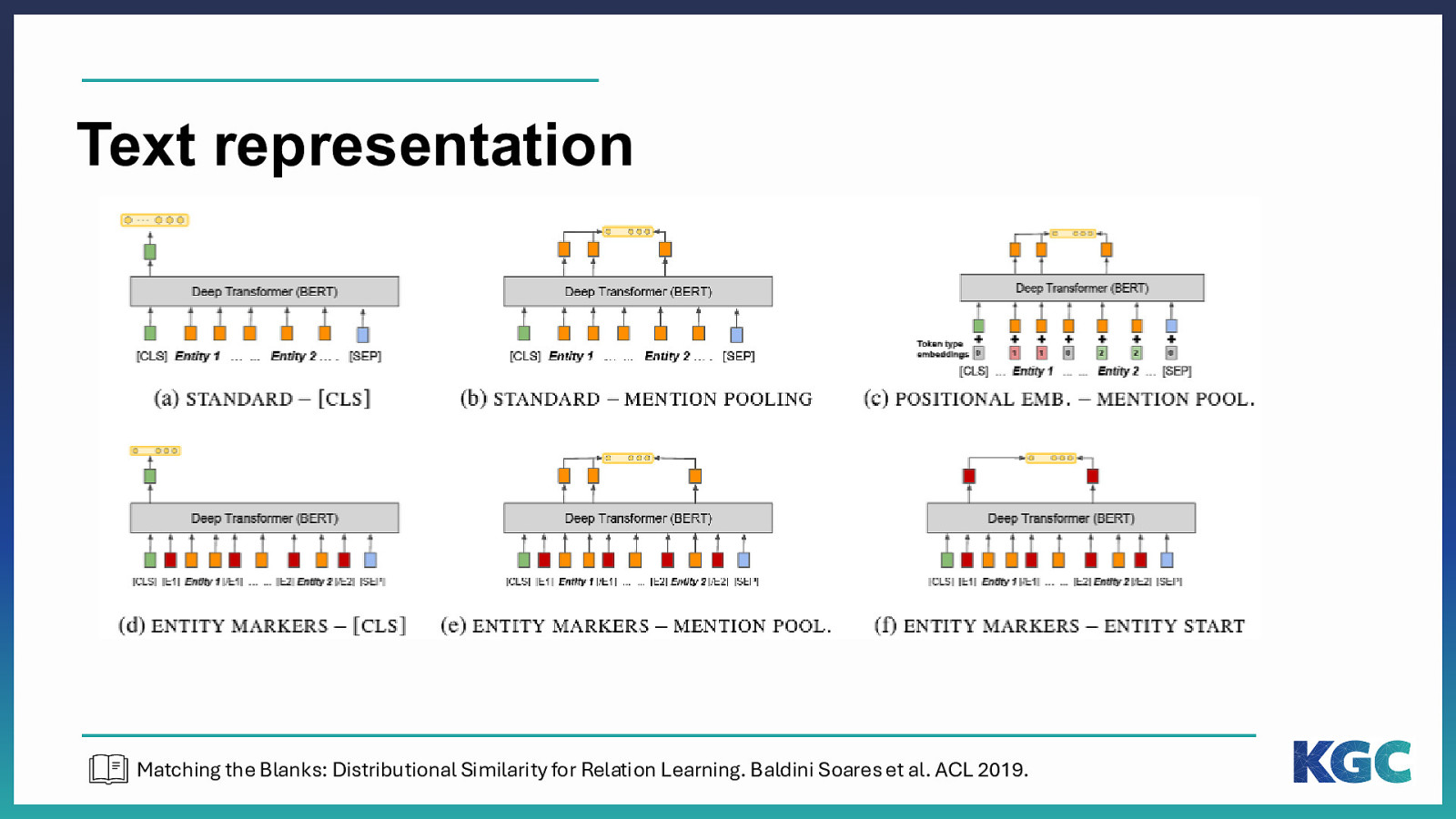
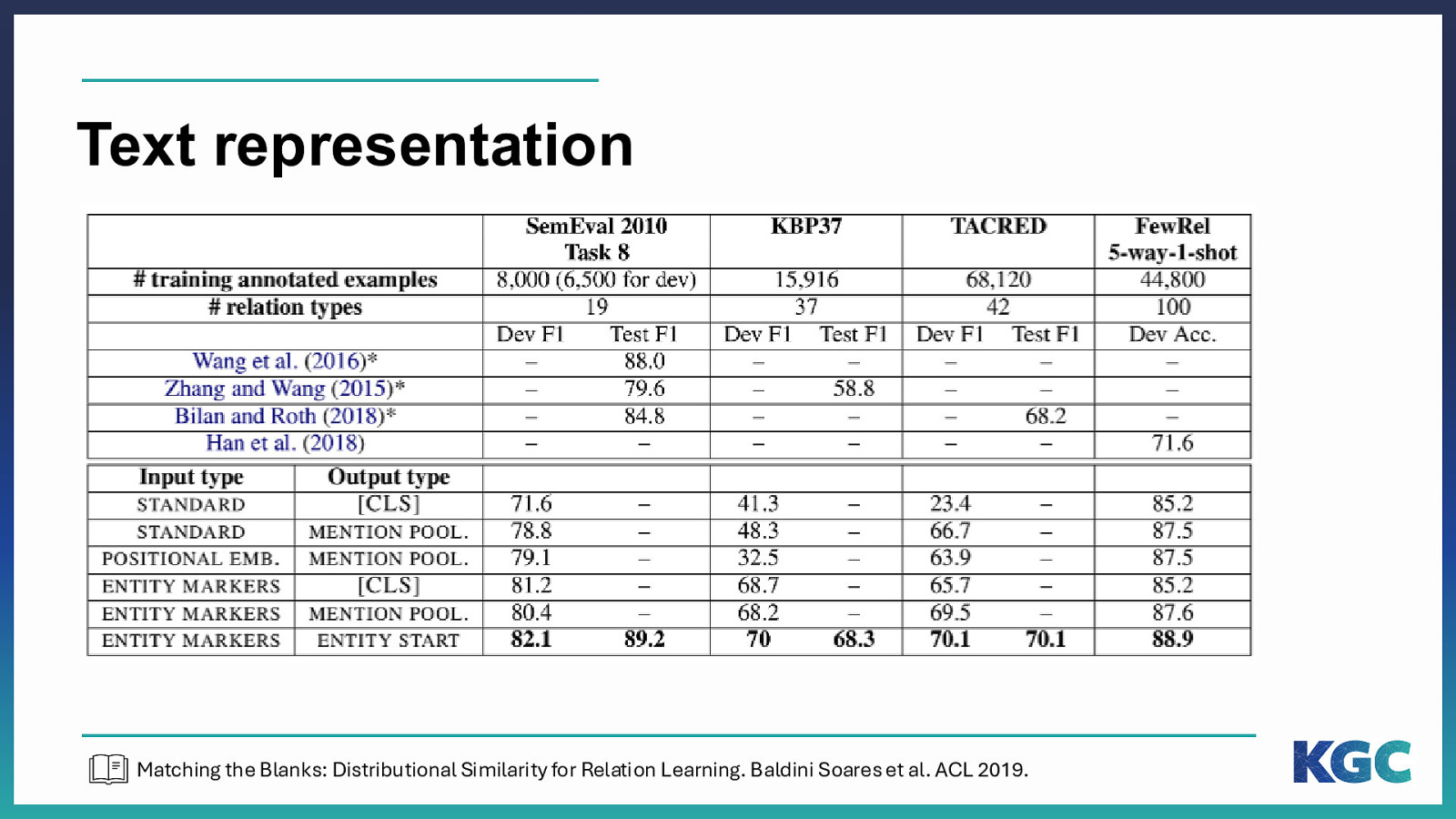
Text representation Matching the Blanks: Distributional Similarity for Relation Learning. Baldini Soares et al. ACL 2019.
Text representation Matching the Blanks: Distributional Similarity for Relation Learning. Baldini Soares et al. ACL 2019.
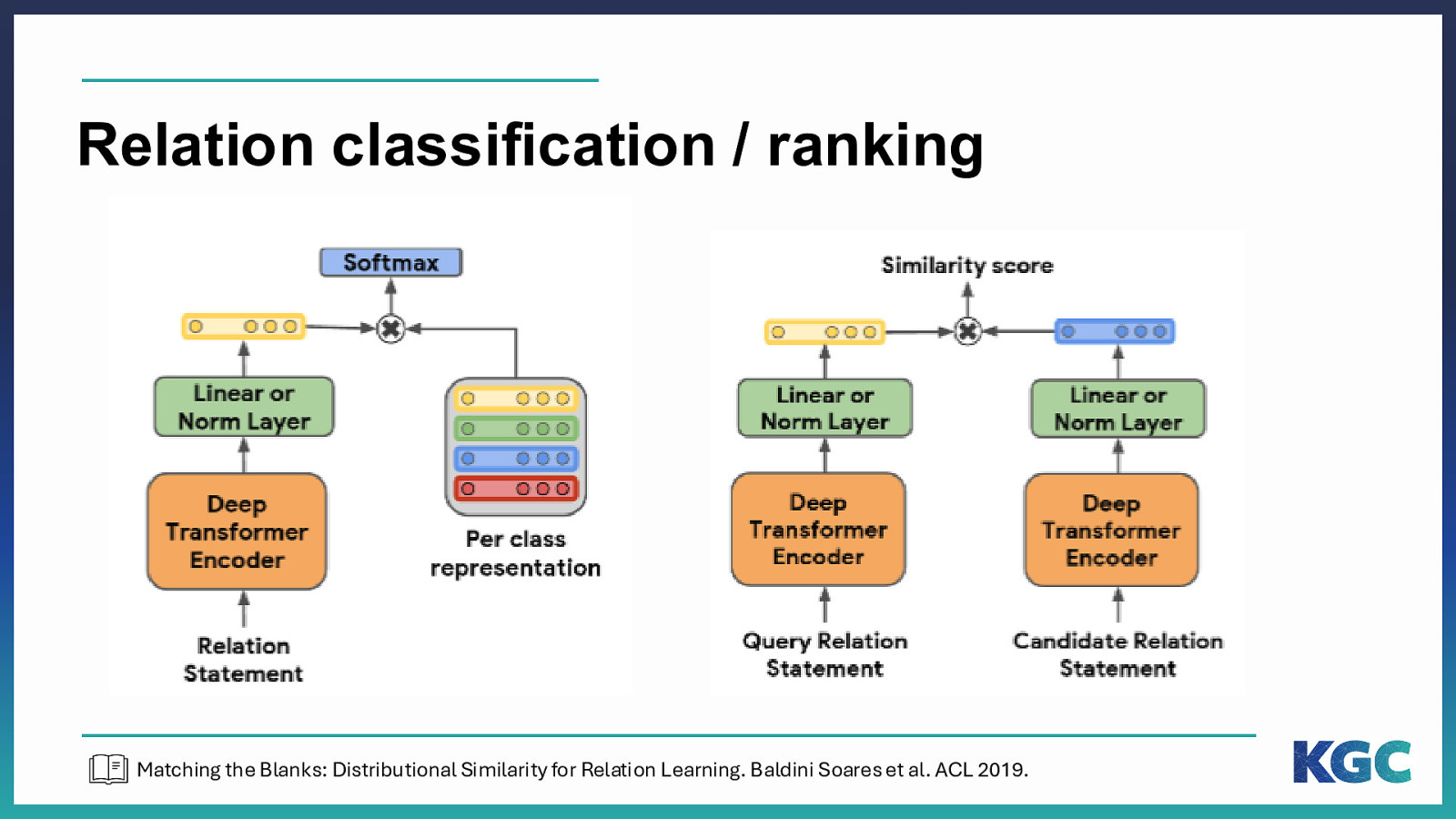
Relation classification / ranking Matching the Blanks: Distributional Similarity for Relation Learning. Baldini Soares et al. ACL 2019.
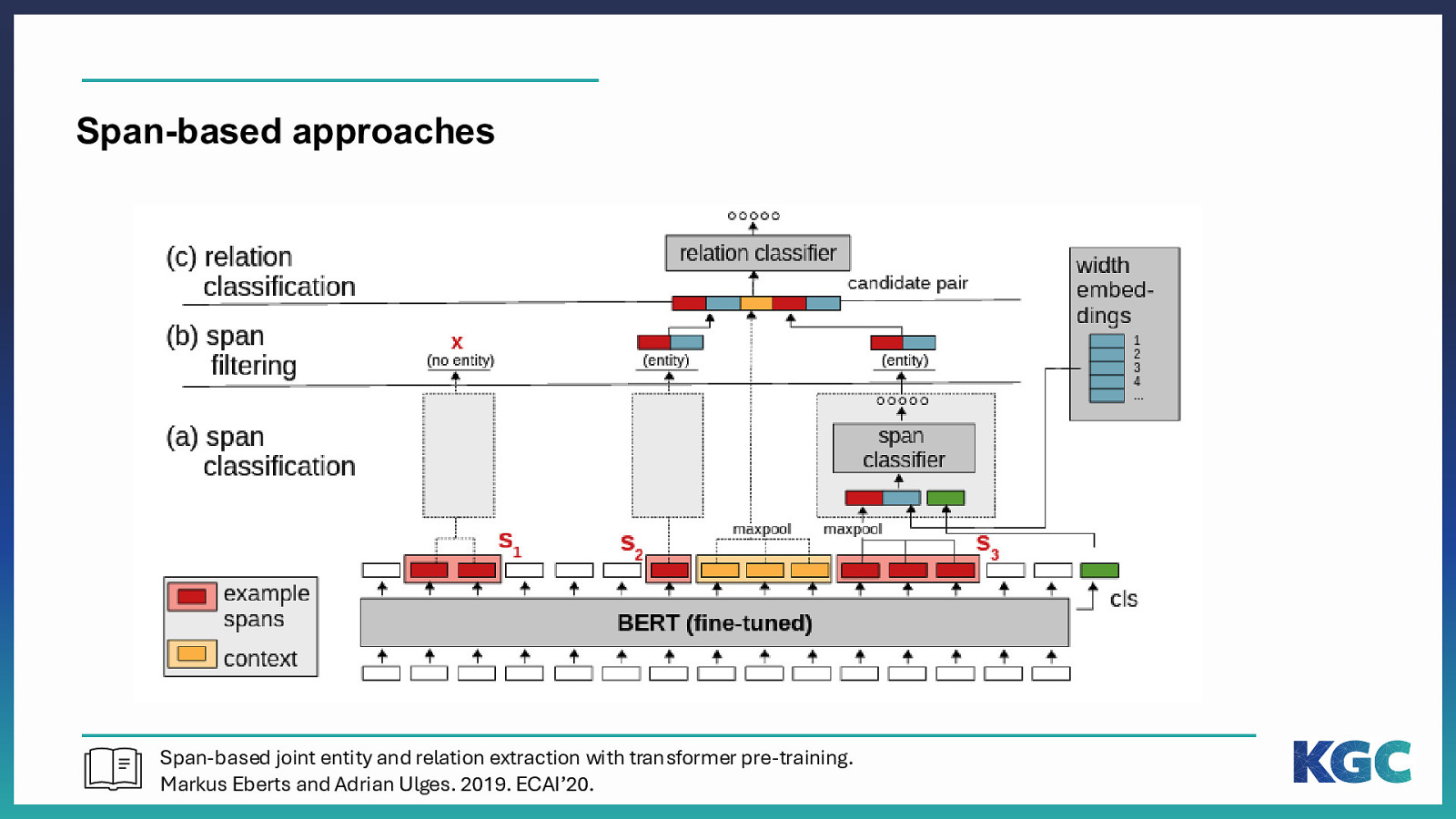
Span-based approaches Span-based joint entity and relation extraction with transformer pre-training. Markus Eberts and Adrian Ulges. 2019. ECAI’20.
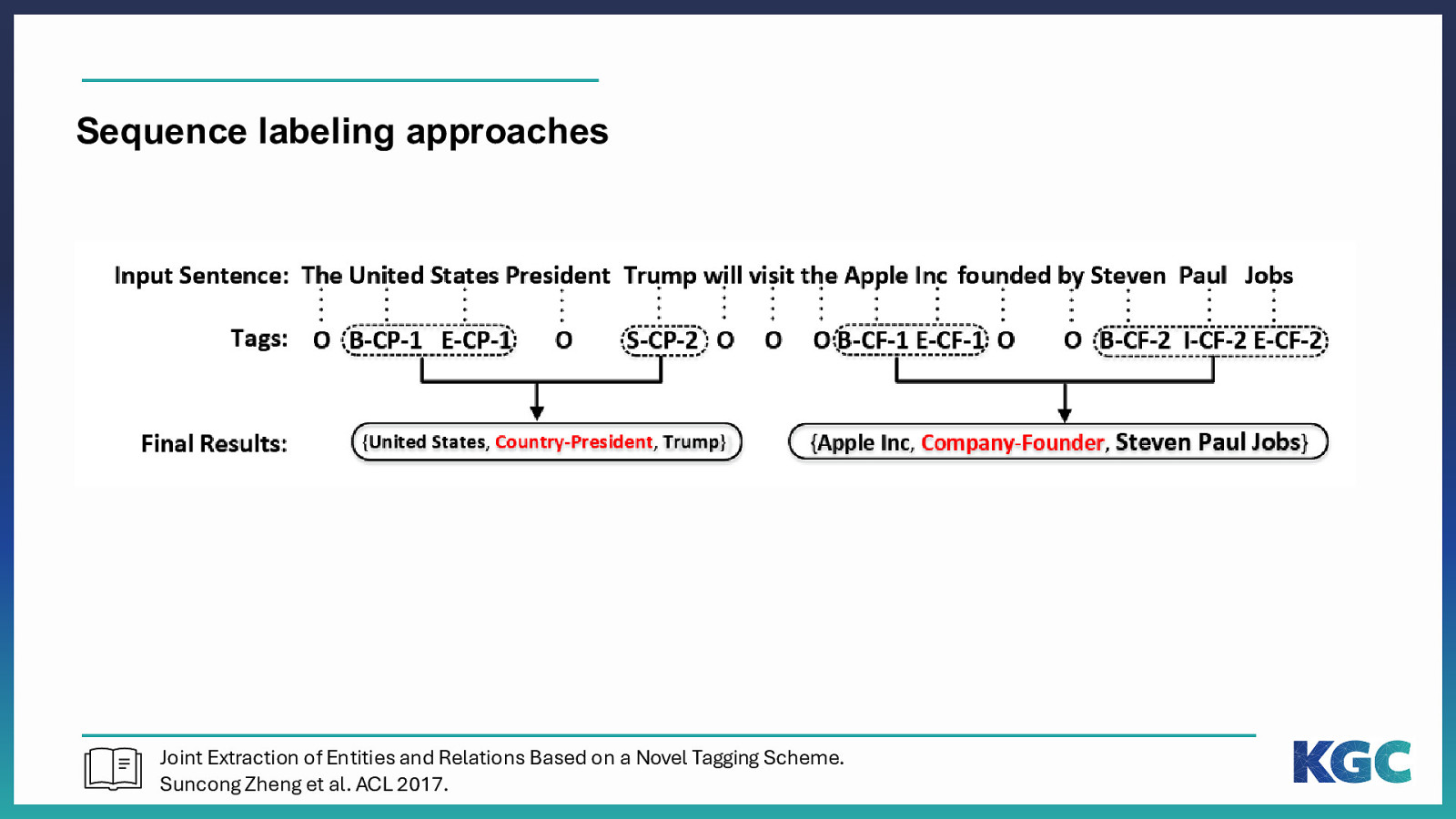
Sequence labeling approaches Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. Suncong Zheng et al. ACL 2017.
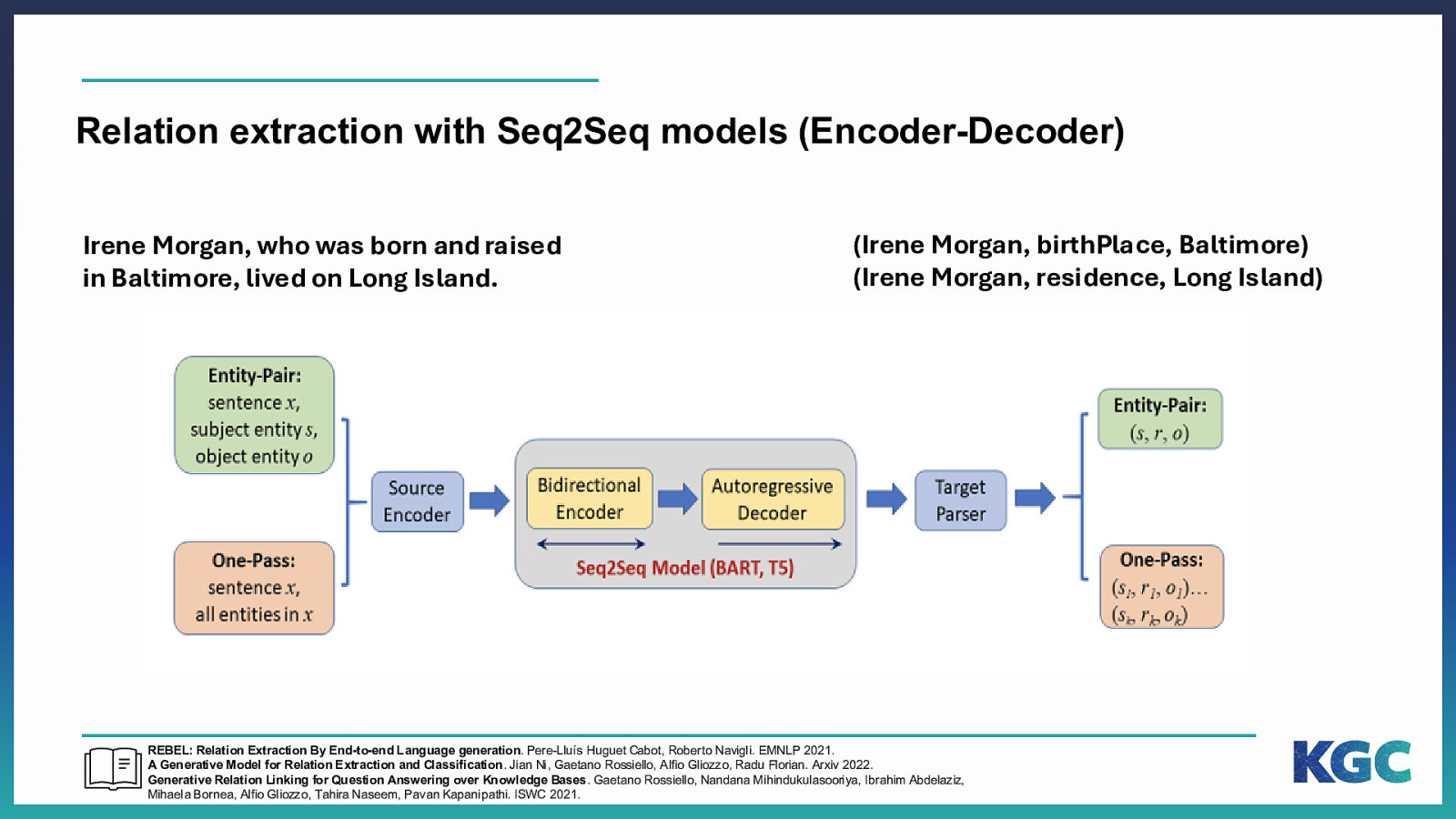
Relation extraction with Seq2Seq models (Encoder-Decoder) Irene Morgan, who was born and raised in Baltimore, lived on Long Island. (Irene Morgan, birthPlace, Baltimore) (Irene Morgan, residence, Long Island) REBEL: Relation Extraction By End-to-end Language generation. Pere-Lluís Huguet Cabot, Roberto Navigli. EMNLP 2021. A Generative Model for Relation Extraction and Classification. Jian Ni, Gaetano Rossiello, Alfio Gliozzo, Radu Florian. Arxiv 2022. Generative Relation Linking for Question Answering over Knowledge Bases. Gaetano Rossiello, Nandana Mihindukulasooriya, Ibrahim Abdelaziz, Mihaela Bornea, Alfio Gliozzo, Tahira Naseem, Pavan Kapanipathi. ISWC 2021.
Relation extraction with Seq2Seq models (Encoder-Decoder) KnowGL: Knowledge Generation and Linking from Text. Gaetano Rossiello, Faisal Chowdhury, Nandana Mihindukulasooriya, Owen Cornec and Alfio Gliozzo. AAAI 2023.
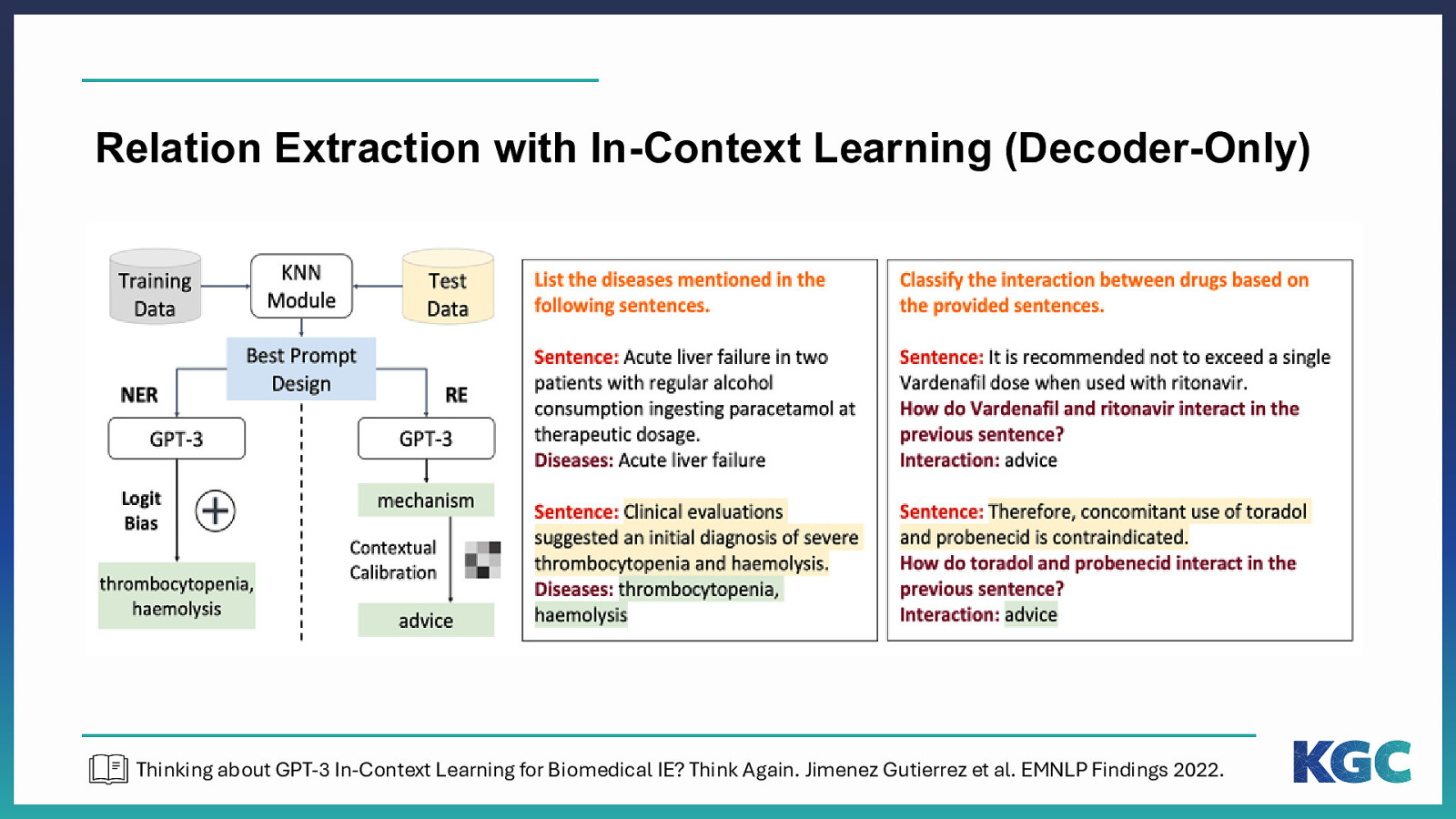
Relation Extraction with In-Context Learning (Decoder-Only) Thinking about GPT-3 In-Context Learning for Biomedical IE? Think Again. Jimenez Gutierrez et al. EMNLP Findings 2022.
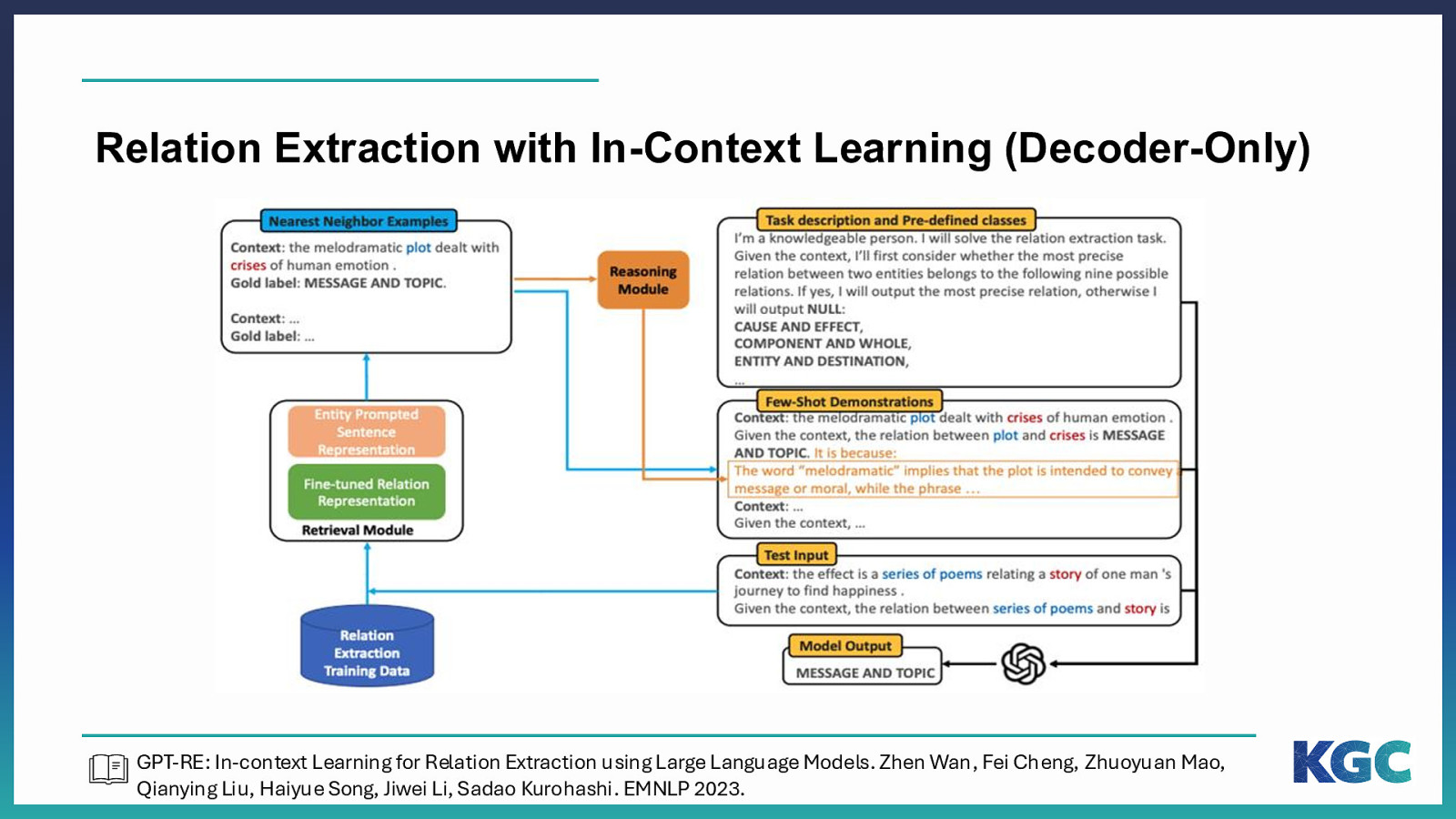
Relation Extraction with In-Context Learning (Decoder-Only) GPT-RE: In-context Learning for Relation Extraction using Large Language Models. Zhen Wan, Fei Cheng, Zhuoyuan Mao, Qianying Liu, Haiyue Song, Jiwei Li, Sadao Kurohashi. EMNLP 2023.
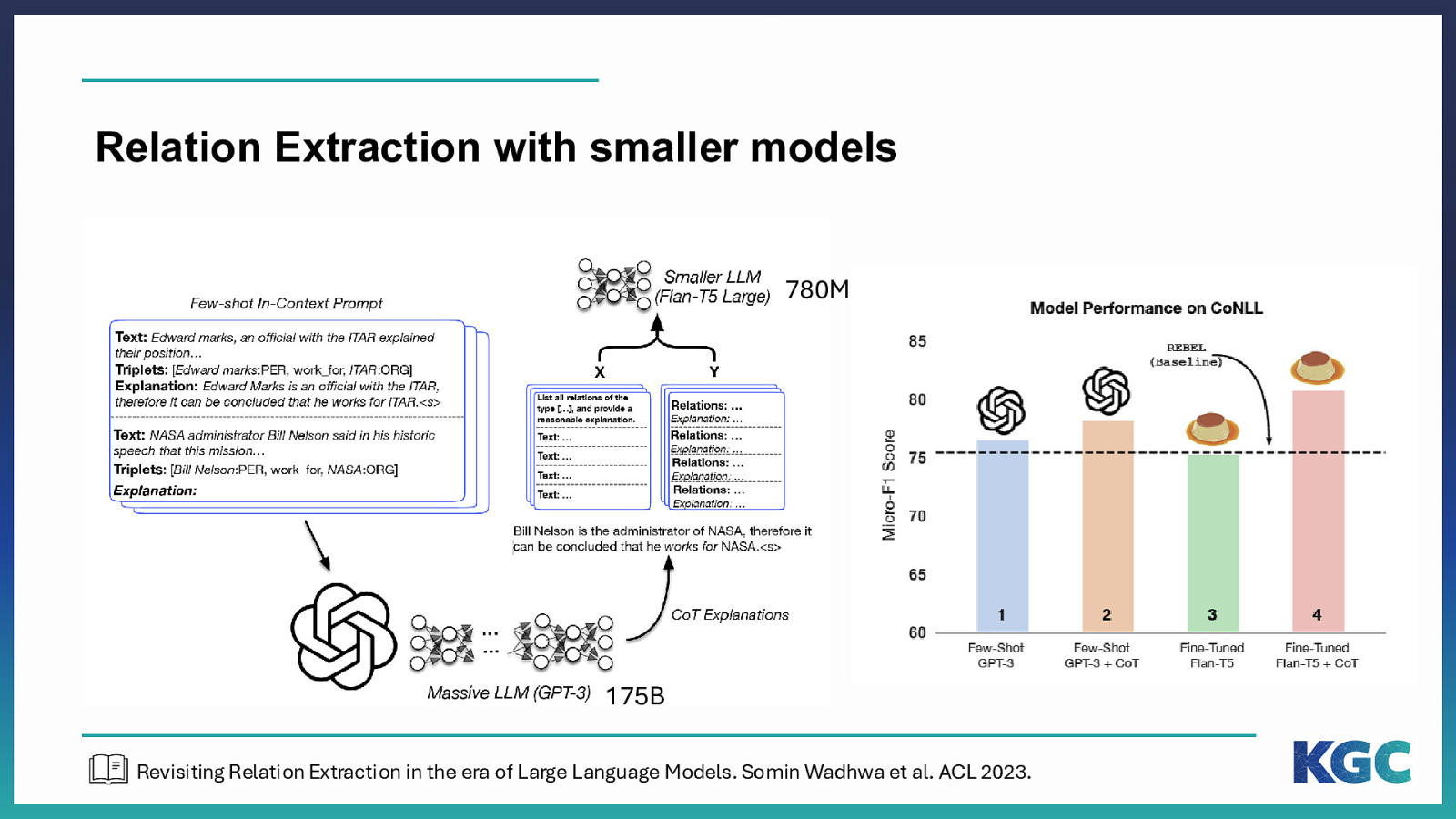
Relation Extraction with smaller models 780M 175B Revisiting Relation Extraction in the era of Large Language Models. Somin Wadhwa et al. ACL 2023.
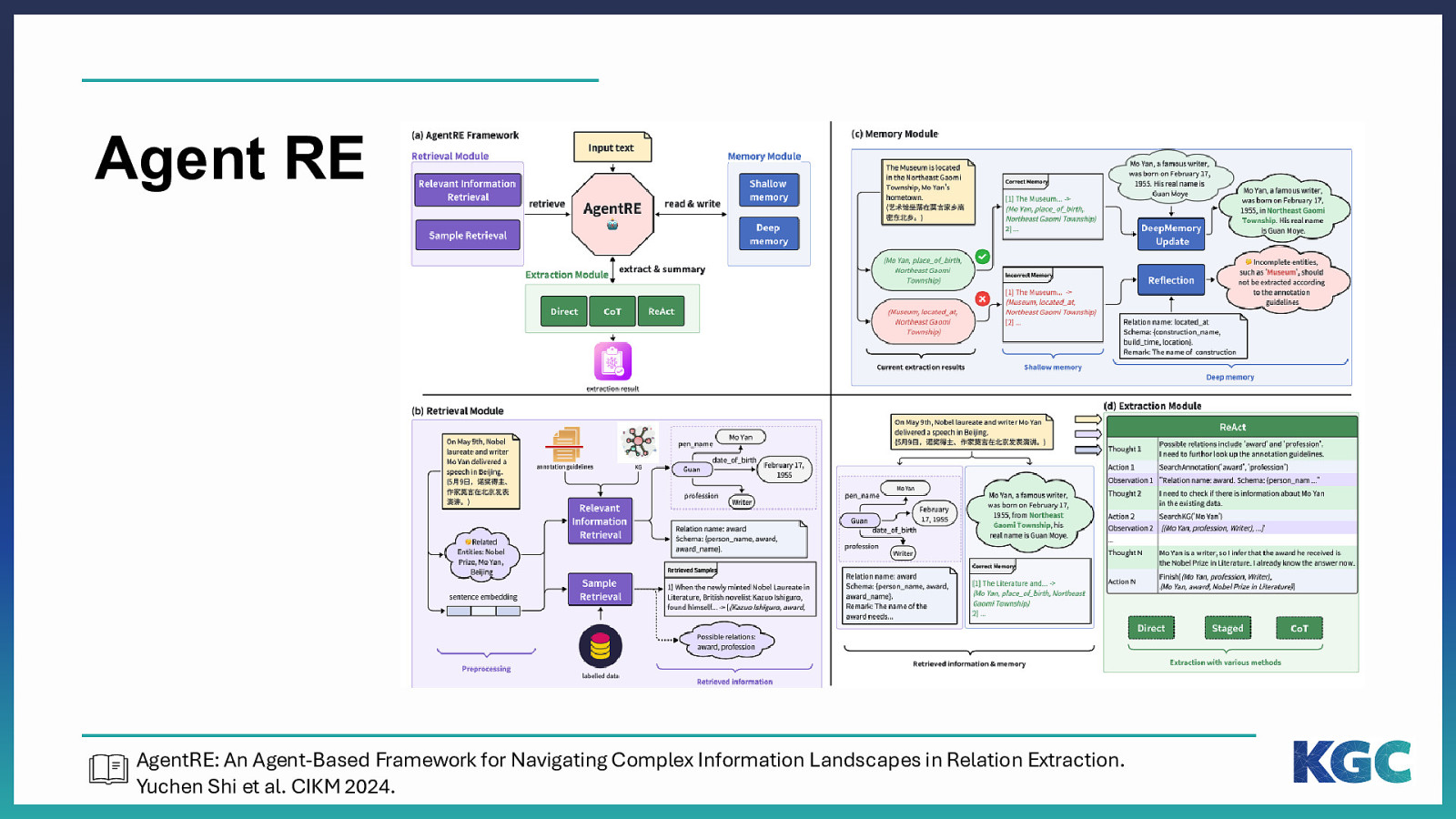
Agent RE AgentRE: An Agent-Based Framework for Navigating Complex Information Landscapes in Relation Extraction. Yuchen Shi et al. CIKM 2024.
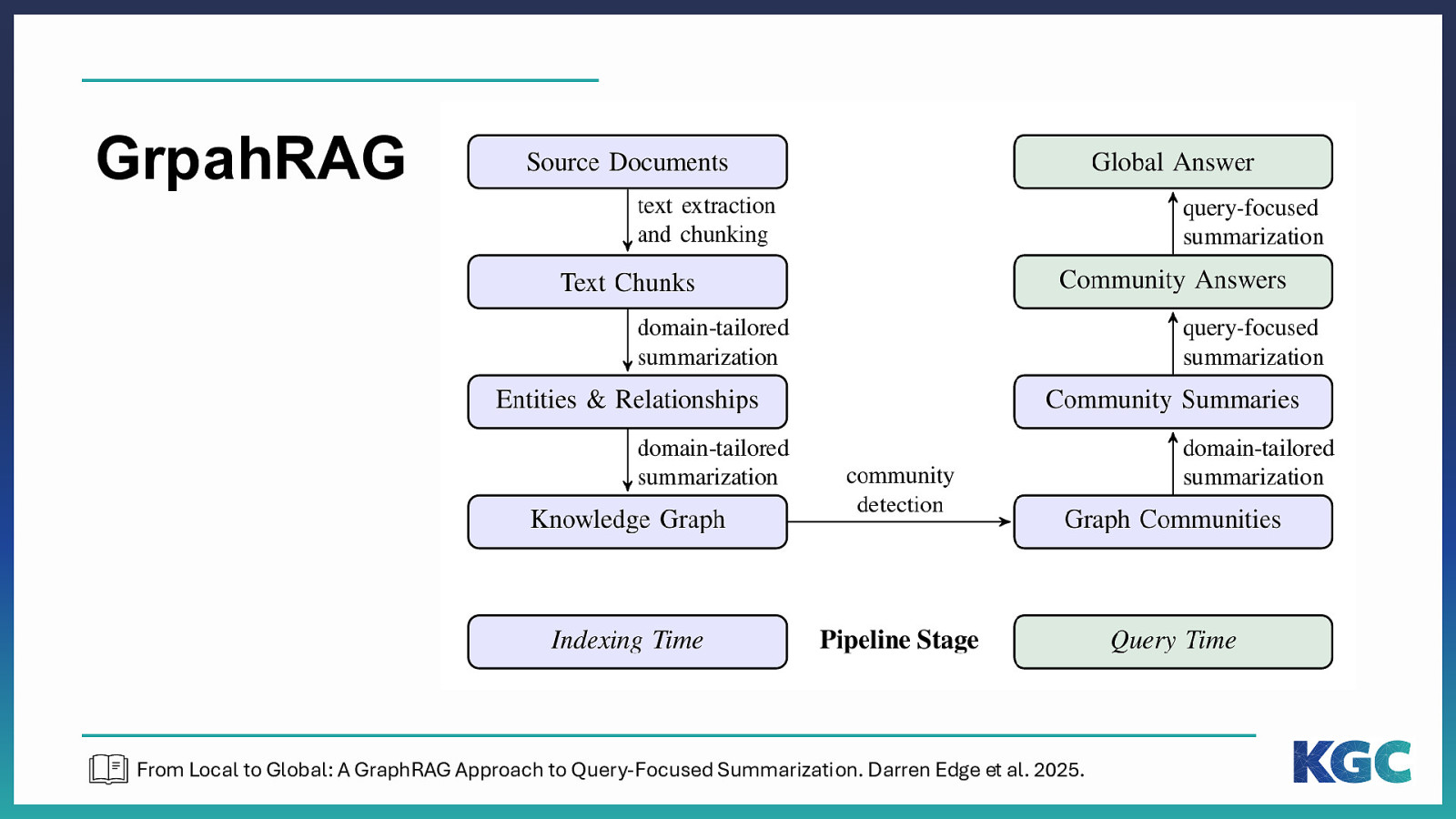
GrpahRAG From Local to Global: A GraphRAG Approach to Query-Focused Summarization. Darren Edge et al. 2025.
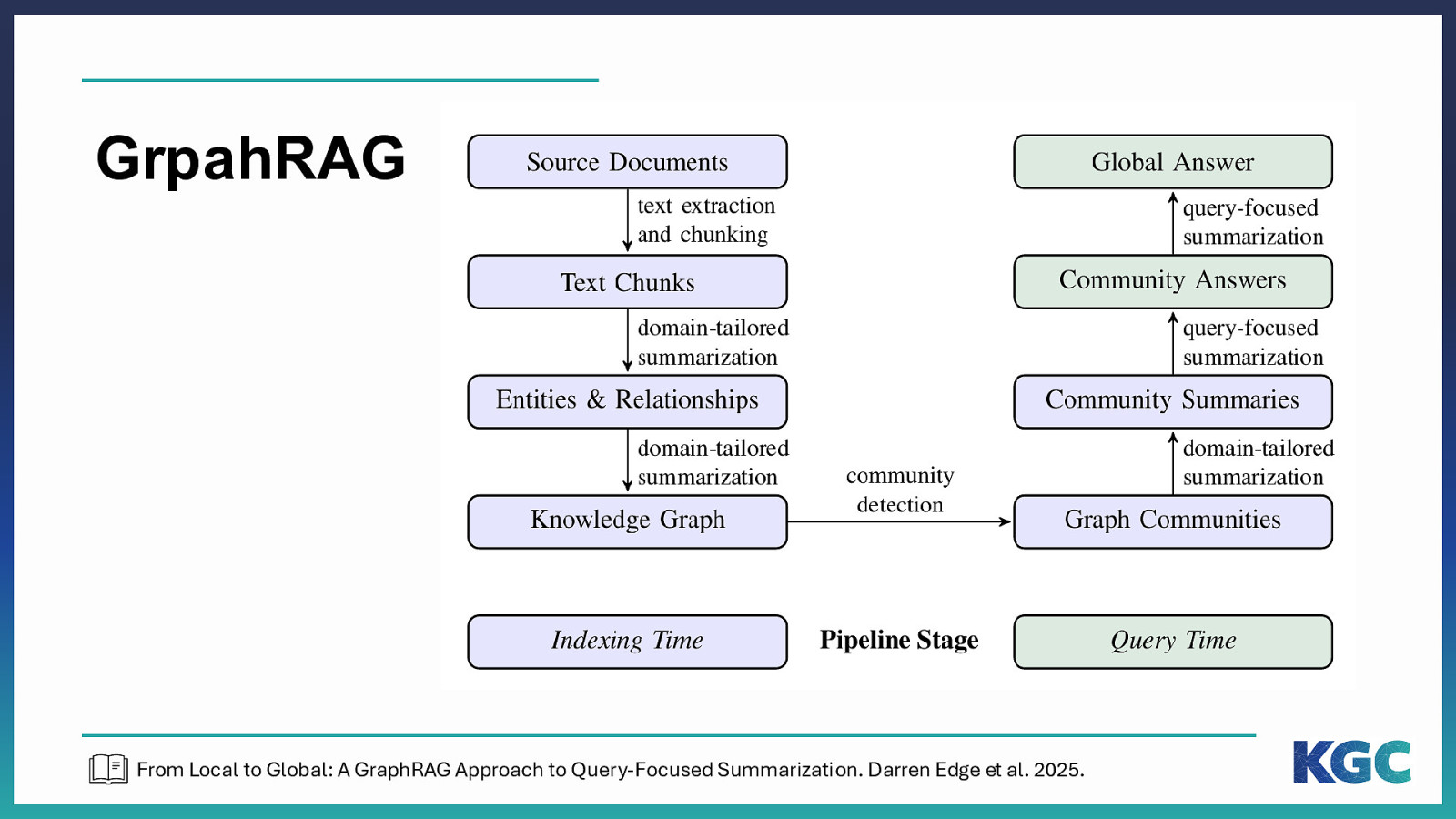
GrpahRAG From Local to Global: A GraphRAG Approach to Query-Focused Summarization. Darren Edge et al. 2025.
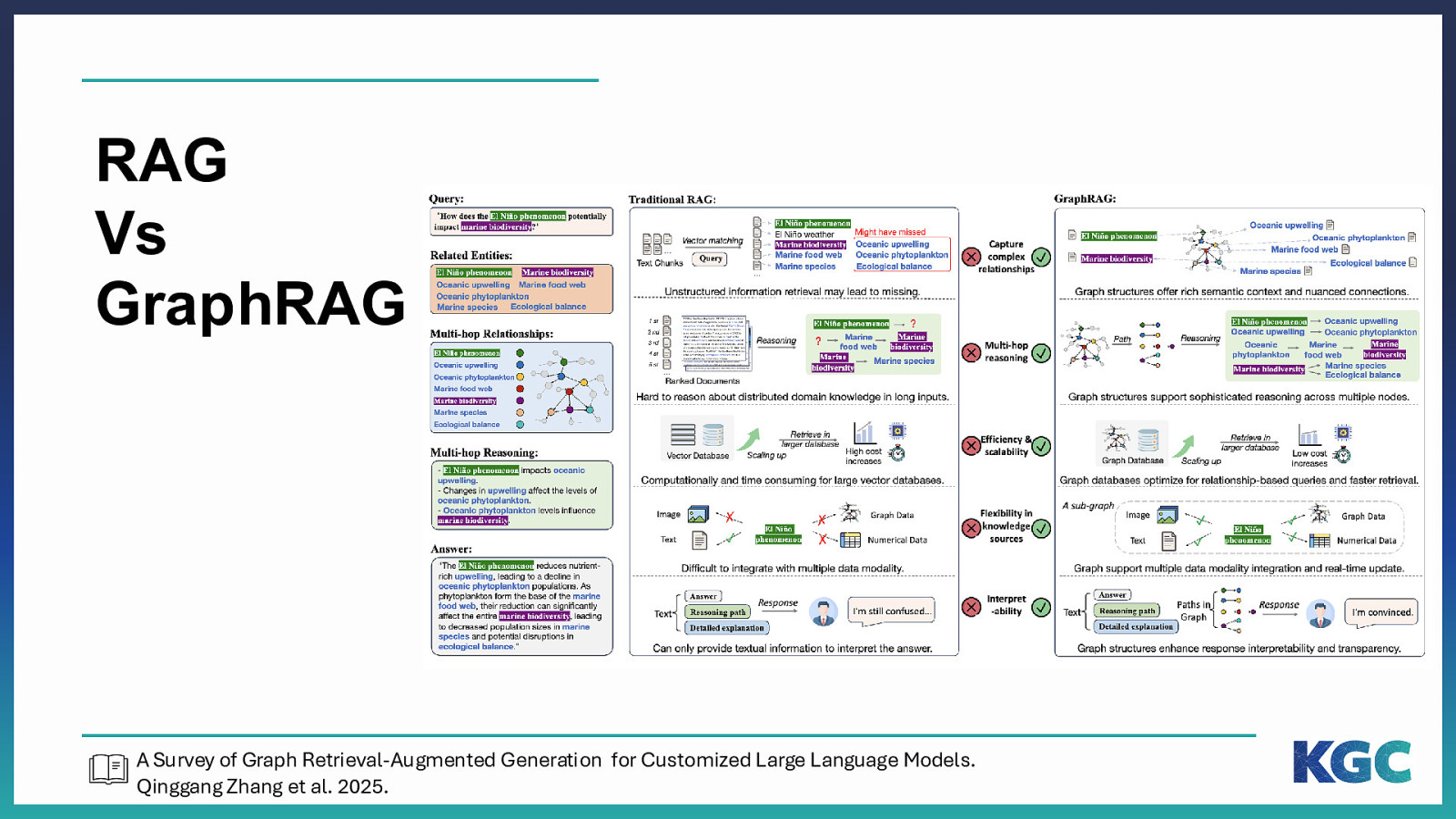
RAG Vs GraphRAG A Survey of Graph Retrieval-Augmented Generation for Customized Large Language Models. Qinggang Zhang et al. 2025.
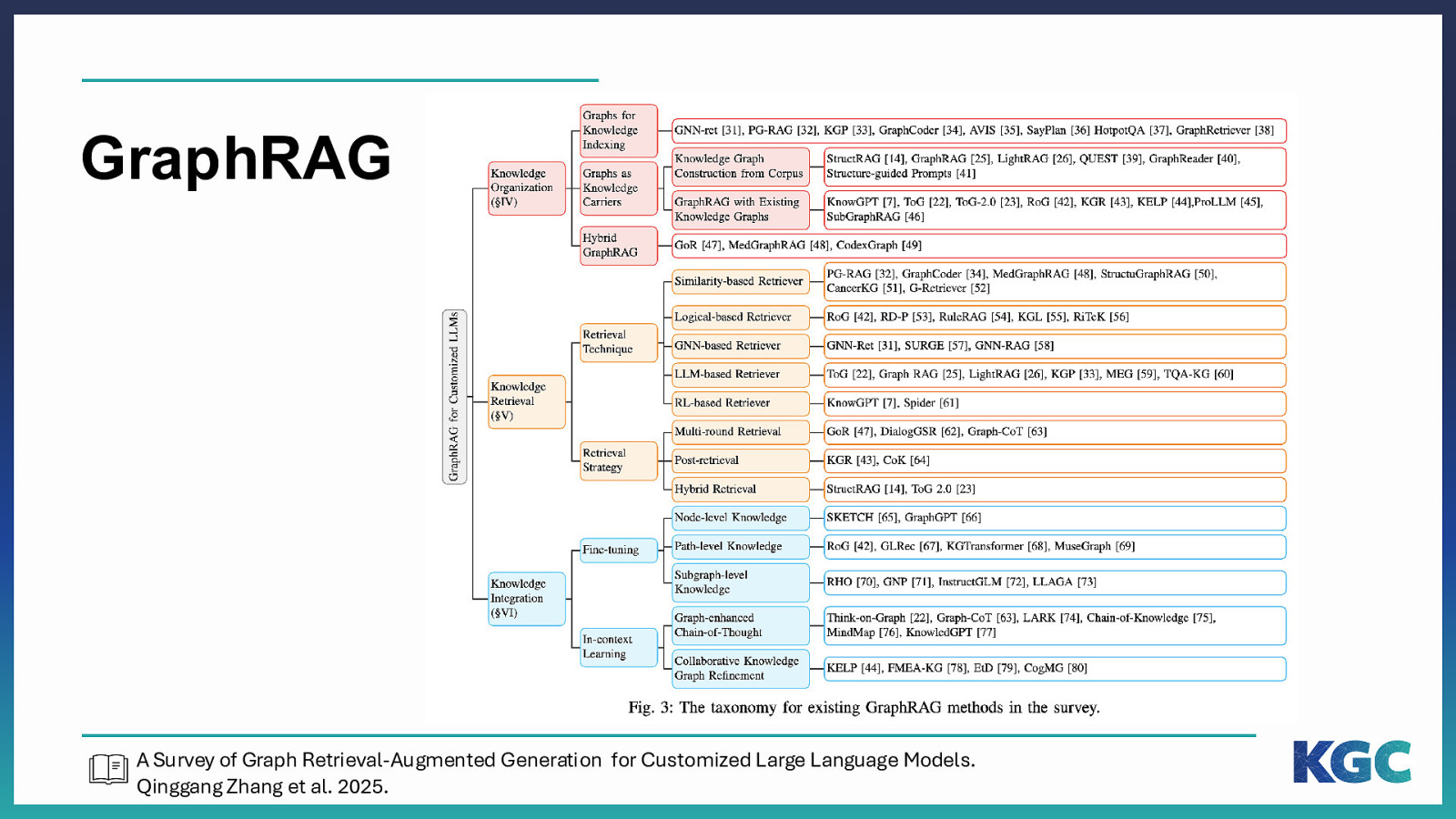
GraphRAG A Survey of Graph Retrieval-Augmented Generation for Customized Large Language Models. Qinggang Zhang et al. 2025.
RE Challenges A Comprehensive Survey on Relation Extraction: Recent Advances and New Frontiers. Zhao et al. ACM Computing Surveys. 2024.
The State of the Art Large Language Models for Knowledge Graph Construction from Text: Techniques, Tools, and Challenges Nandana Mihindukulasooriya Senior Research Scientist | IBM Research
Insert Handle Here

Knowledge graphs (KGs) play a crucial role in modern applications. However, automatically constructing a KG from natural language text is challenging due to the complexities of natural languages. This tutorial will focus on the state-of-the-art LLM-based methods, techniques, and tools for constructing knowledge graphs from text, discussing their capabilities, limitations, and current challenges. During the last year, emerging topics such as Retrieval Augmented Generation (RAG), GraphRAG, Chain-of-Thought, LLM Agents, and reasoning models have driven the development of numerous new entity and relation extraction methods that are helpful for KG generation from text.
This talk aims to summarize the research progress in KG construction from text, with a specific focus on the information acquisition branch that includes relation extraction, covering state-of-the-art transformer methods and tools. Our session will explore the theoretical foundations of innovative approaches while also providing practical, hands-on exercises for deeper understanding. This overview will be valuable for both practitioners engaged in building organizational knowledge graphs and academics interested in the cutting edge of research.
Here’s what was said about this presentation on social media.


























 for free. You
can too.
for free. You
can too.