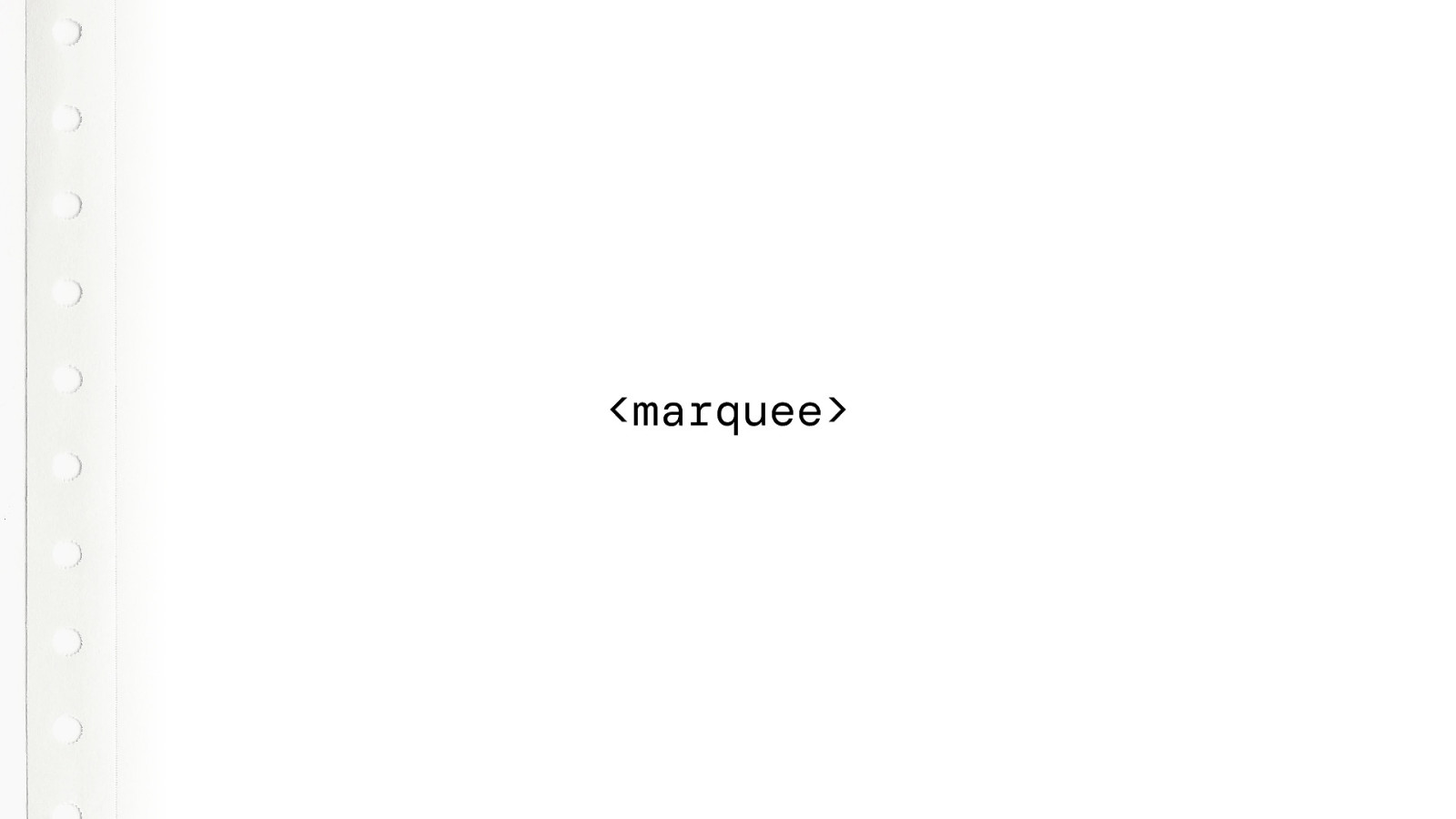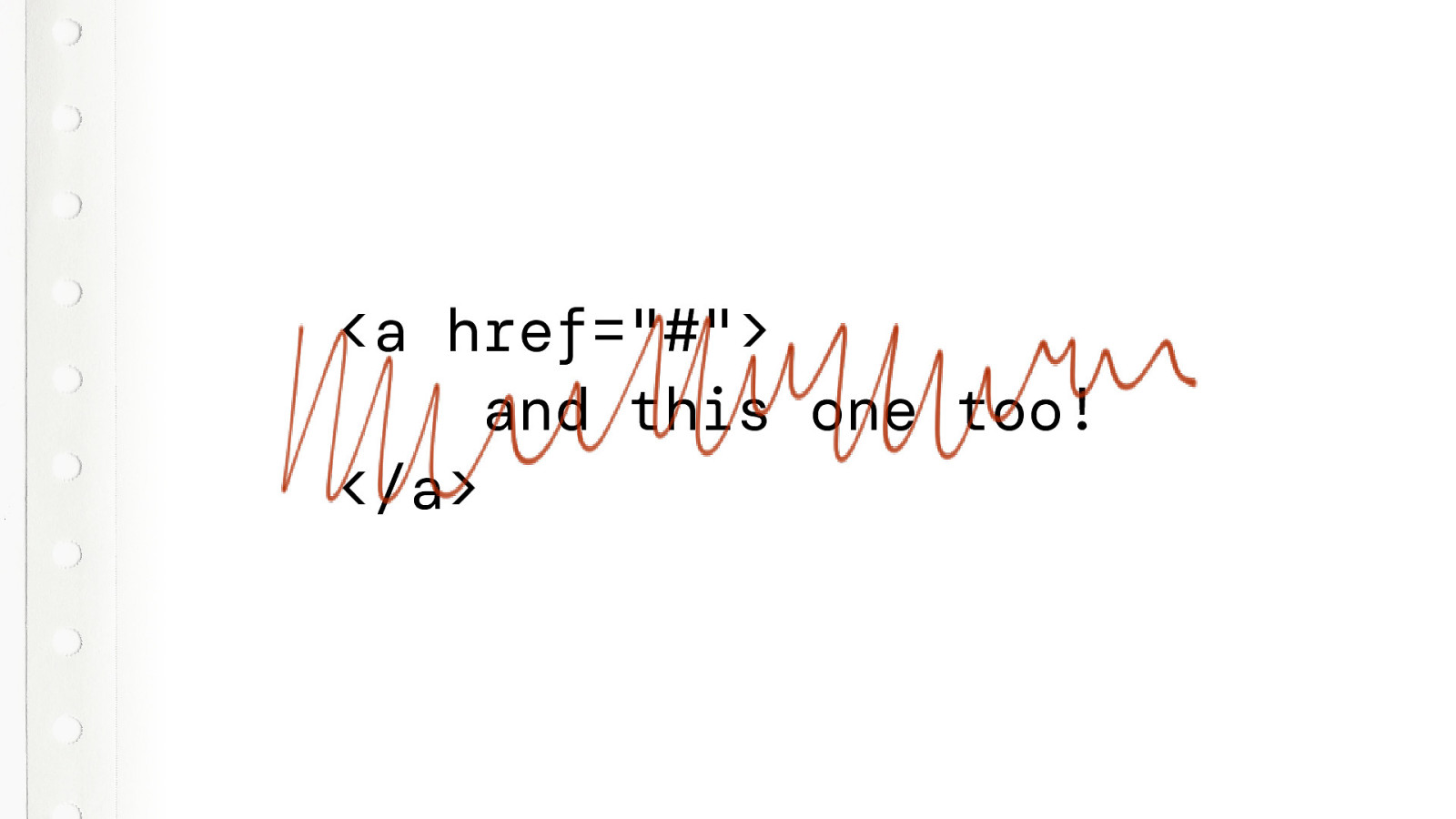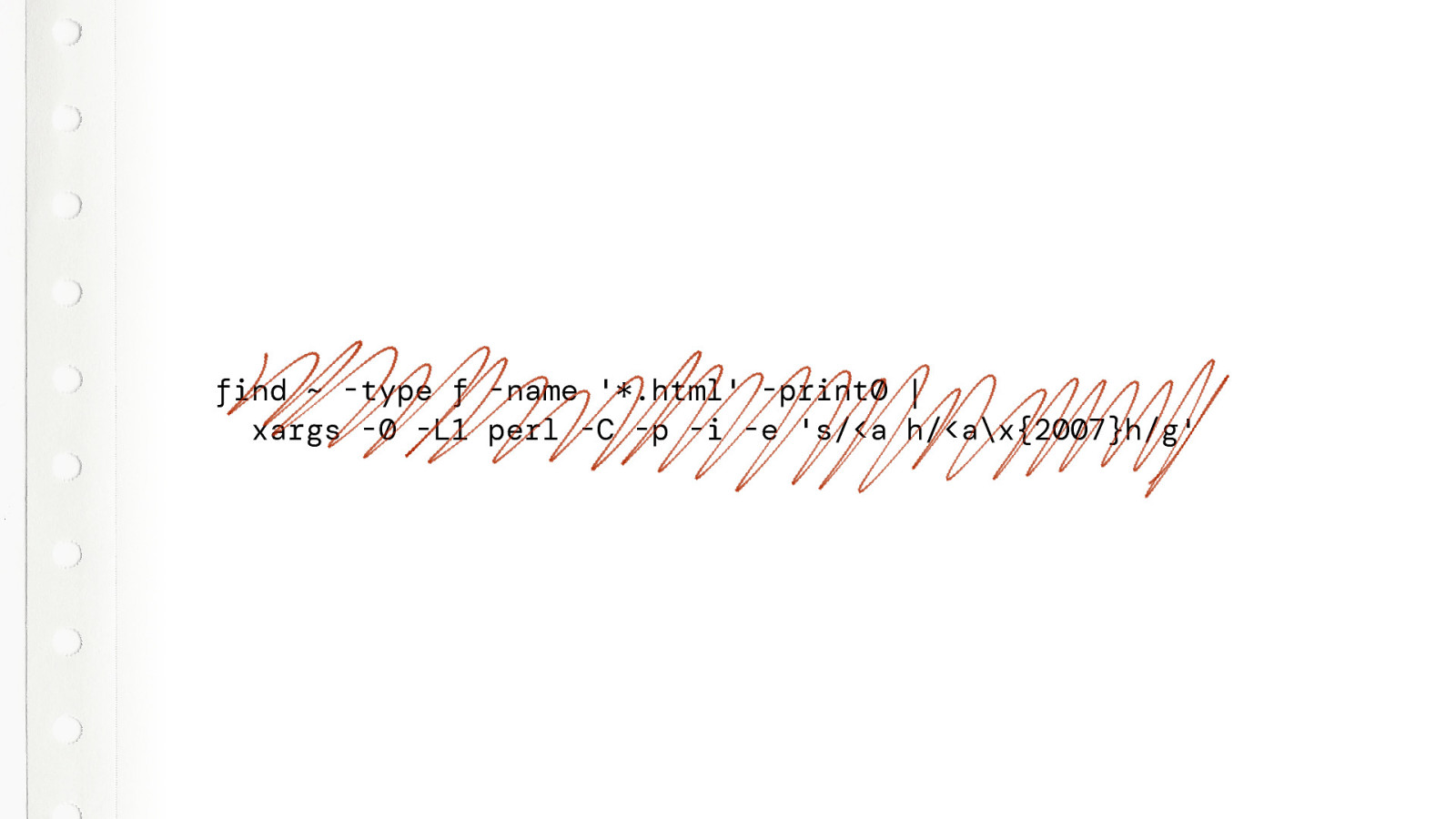A presentation at HalfStack London in in London, UK by Niels Leenheer

Resilience
Hi, I’m Niels. I’m a Front-end developer. 30 years and counting. My first official job title was…
Webmaster. This is me back in 1994, working on my first website. As you can see I am holding the power sword which gives you the ability to write flawless HTML and defeat Skeletor, the lord of the JavaScripts.
If I counted correctly, this is the 12th time I am giving a talk at HalfStack. I just love the mix of web development topics and to see people use browser APIs and Javascript in creative and unexpected ways.
So… now the awkward thing… I know this is technically a JavaScript conference…
Except my talk will have no Javascript. No React. No Node. Not even Deno and Typescript. No script at all. Except for noscript.
The noscript tag.
For this talk we’re going back to basics and back in time. We’re going to ask the important questions, like…
Can you nest noscript tags?
Can you style a noscript tag?
And what happens when you put a script tag in a noscript tag?
And we’re going to talk about the one thing that HTML is…. that JavaScript simply is not. Whenever you make a mistake in Javascript something bad will happen. One typo and your build will fail. Or worse your browser will… Explode!. Really. True story.
But not HTML. Resilience against errors and mistakes is build into the fabric of HTML. You are allowed to make mistakes. In fact you are expected to make mistakes, because HTML was intended to be used by non-professionals. Everybody can make a website.
Just read the source code of another website, try it for yourself and call yourself a webmaster. That is what I did. That is what I still do… Except now I ask ChatGPT and Copilot to solve my problems and I call myself a front-end developer. Or when I feel expensive, I am a front-end engineer. But in my heart I am still a webmaster.
This is Tim. Tim is a Web Developer. Back in the 80s, he was a engineer at CERN - you know the particle accelerator thing - and he wanted to make publishing research and managing information easier allowing scientists to at CERN to collaborate with colleagues around the world.
So he did what comes naturally to every engineer, come up with overly complicated ways to solve ‘simple’ problems. Let’s build a world wide network of connected information. A world wide web of knowledge if you will. Can’t be too difficult, right? So he wrote a paper “Information Management: A Proposal”.
His supervisor - Mike Sendall - though it was interesting and wrote this on top of his paper…
“vague but exciting”. And that started the whole World Wide Web revolution.
He created WorldWideWeb - which was the name of the first browser - which was not just a browser, but also an editor, and created the first website. Not with the vaguest idea that it would lead to the web of today, but to let everybody - anybody - publish information. And it already had the concept of resilience. Sir Tim. THE web developer. And yes, that is his real job title.
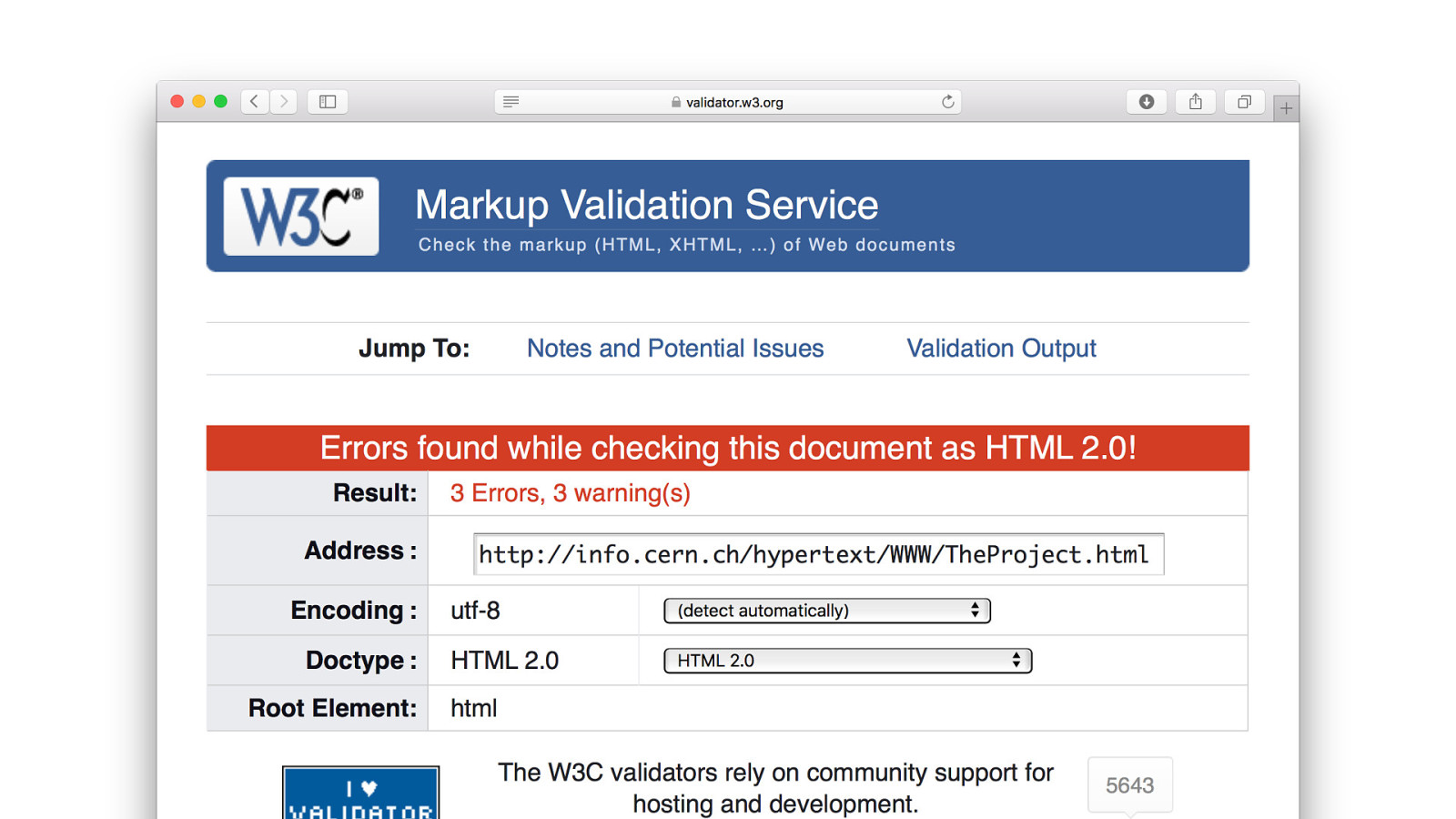
That first website is still here. Still works. After more than 30 years. Any browser will work. This is in my opinion amazing. This truly is resilience.
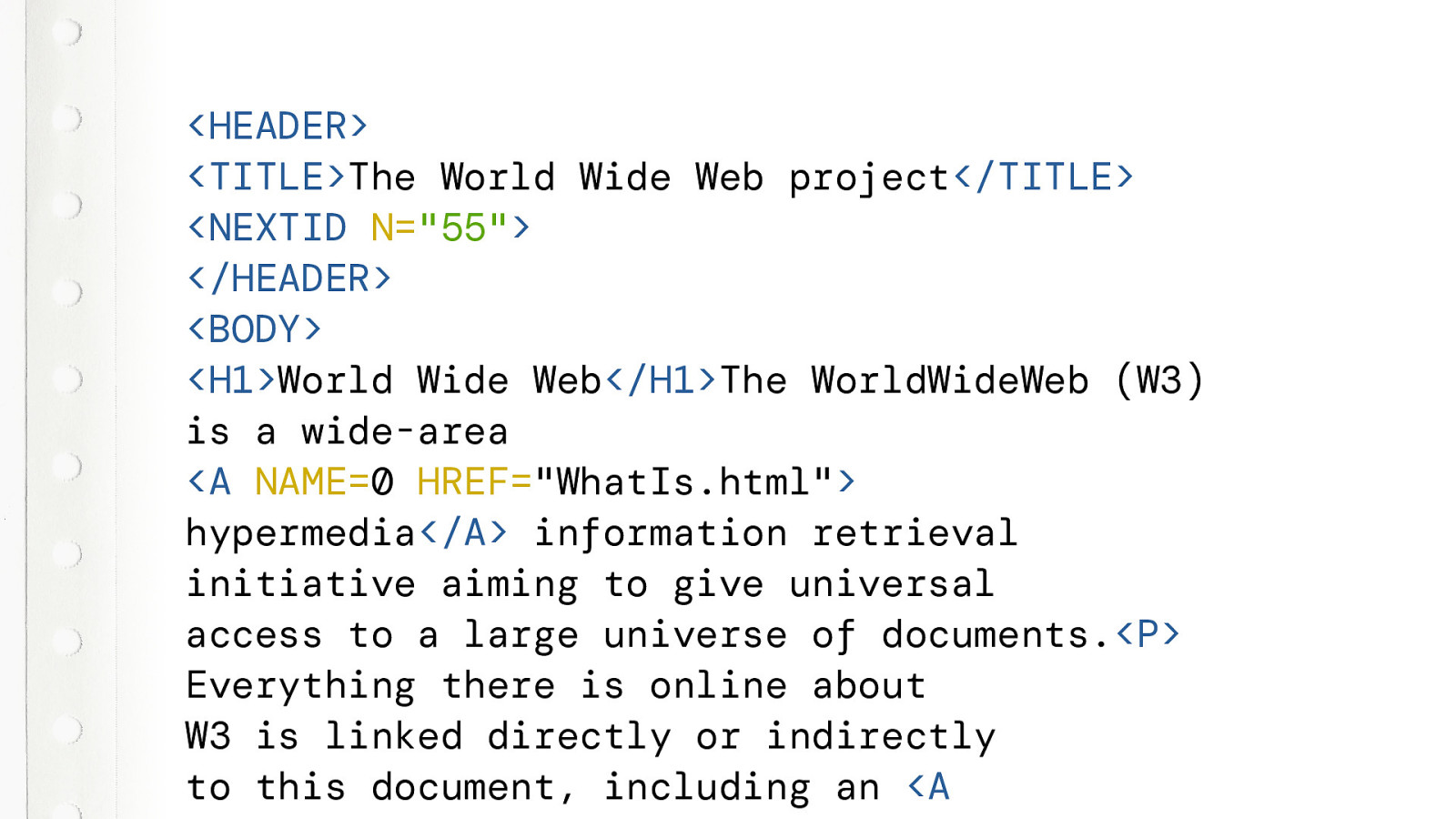
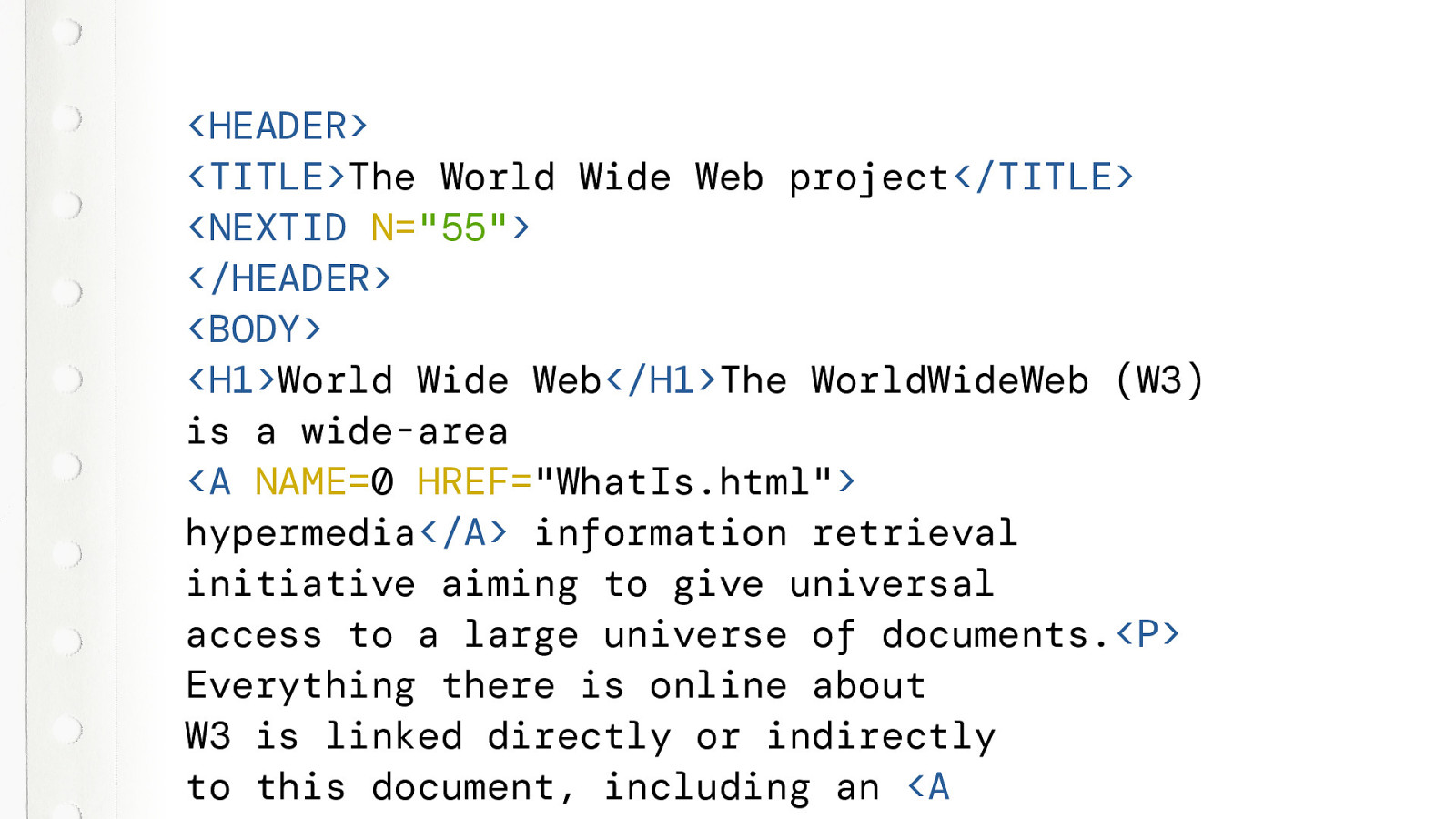
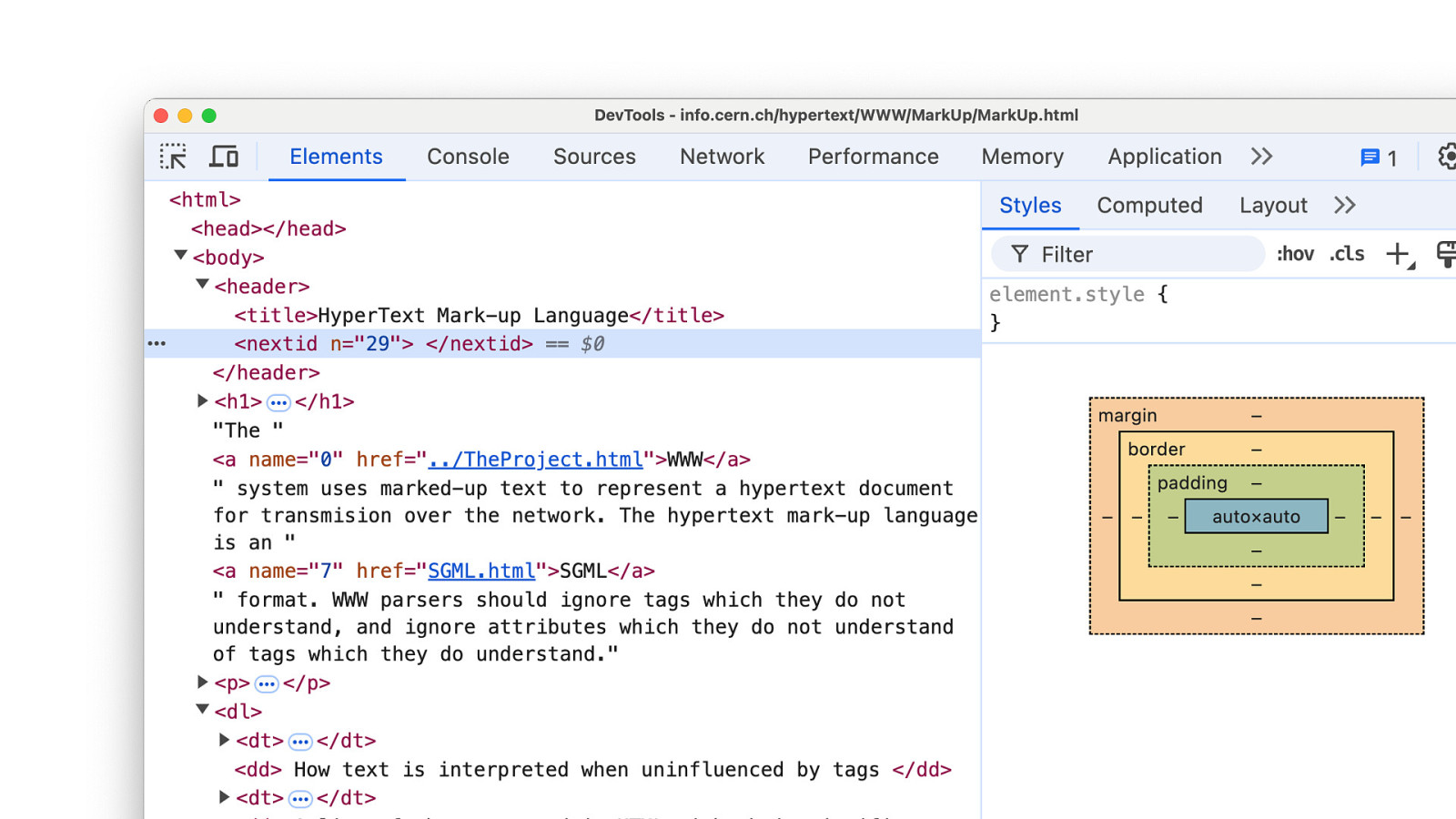
So lets look at the source code. It even looks like HTML, but a bit weird. We can see familiar tags, like BODY, H1, P and A. But also NEXTID tag and a TITLE in a HEADER tag. And where is the HTML tag?
But it still works. No errors. The page just renders fine.
Why does it still work? Browsers will simply “ignore” tags that it does not recognise. This quote is directly from that first website.
So a modern browser will see this NEXTID tag - which it really does not understand… the browser will ignore the tag.
Well, ignore is a bit of a strong word. That tag is turned in to an element in the DOM, it’s still there. It’s still a NEXTID element, but it has no special meaning. It’s just a element, kinda like a regular SPAN element.
In fact this is why NOSCRIPT works.
If your browser does not support scripting, it also does not support the NOSCRIPT tag. It will “ignore” it an turn it into a generic HTML element. Like a span. So the fallback content will be visible.
If your browser does support scripting, it also supports the NOSCRIPT tag. And by “support”, I mean that it actively makes sure that the NOSCRIPT element and all of its descendant do not show up on screen.
This is one of the basic principles of HTML. It ensures forward and backwards compatibility. You could use a browser from 1995, such as Mosaic and load the HalfStack website. It will work. Without any styling of course, because CSS did not exist yet. But still, you can read the text and click links. This is what resilience means.
With this mechanism you can do cool stuff , like bring back your favourite tags from the past.
Like the BLINK tag. Yeah, let’s bring back the BLINK tag.
In currently browsers the BLINK tag is just like any other unknown tag. It’s basically a SPAN. So the text will show up on screen, but it is not blinking. This we need to fix.
So, just add a little CSS and we can style our BLINK tag. An infinite animation between two keyframes. Turning on and off the visibility. This will work. We’ve brought back the BLINK tag. And NO I’m not going to demo this.
And why stop with the BLINK tag. We can do the same for the MARQUEE tag. It’s a little bit more difficult, but we can get this working. All we need to do is………. wait. We don’t need to do anything.
MARQUEE actually still works in all browsers. I didn’t realise this. It’s deprecated by the HTML5 spec, it isn’t actually “baseline”… but you can actually still use it….. If you wanted to…. Seriously, don’t.
What is it that makes HTML so resilient? What makes it so flexible and error friendly? What is it that makes it special?
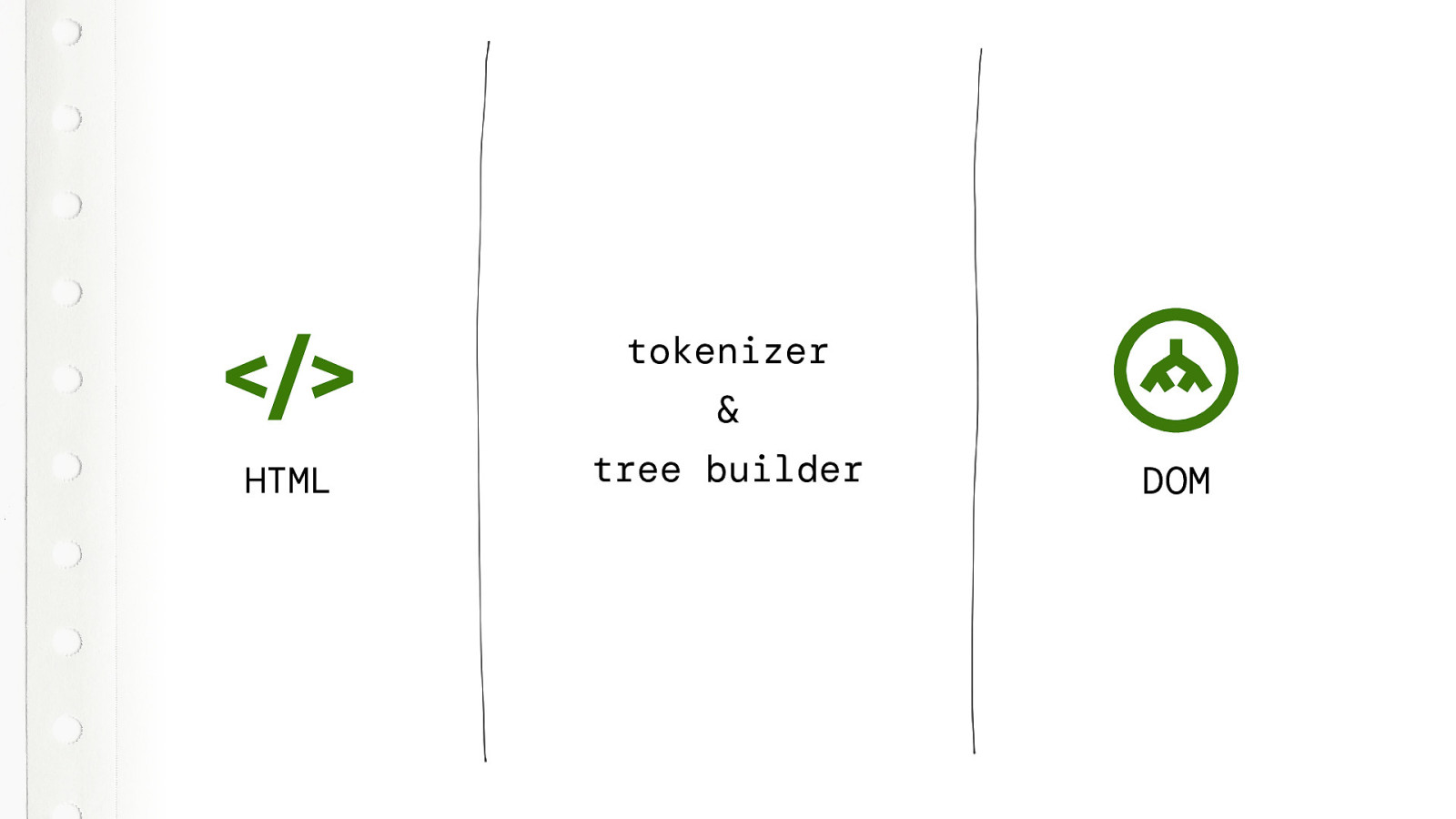
All the magic happens between your HTML source files and the Document Object Model, The DOM.
When the browser parses your HTML file, it uses a tokenizer and a tree builder. And those two build the DOM tree that the browser uses to render the page. The browser doesn’t render the HTML, it renders the DOM.
The tokenizer
Basically does nothing more than just analyse that HTML file character by character. And it tries to extract all the information it needs to build that DOM tree.
So when we have a piece of HTML like this, it will start with in an initial state.
The data state. It sees the SMALLER THAN SIGN and thinks this might be a tag. So it goes to the…
TAG OPEN STATE. It sees the letter A and continues with the
TAG NAME STATE and adds that letter A to the tag name. It then sees a SPACE.
and switches state again…
And so on… character by character…
So now it has all the data about this tag. It knows the TAG NAME, the ATTRIBUTE NAME and the ATTRIBUTE VALUE.
It now has the token and emits it to the tree builder
There are 68 different states
Some are simple.
Most are a bit more complicated.
But most importantly. When it encounters a PARSE ERROR, it will not stop processing the file. It will not show an error message. It will switch to a different state and just continue on.
Together, all of these rules determine what HTML looks like. And in this case in particular it determines what TAG names are allowed to look like. It determines which characters are allowed an which are not. And just like the rest of HTML, the tokenizer is very forgiving.
This is a tag.
As long as the first character of the tag name is an ascii letter, we’re good. And this is not an upside down “n”, but a “u”.
To be fair, the equals sign is a parse error, but the rules specify exactly what needs to happen in this case. The first equals sign becomes the attribute name.
Now I know what you are thinking. This is an accident waiting to happen. But this is why custom elements work.
This is why Angular works. Yes, attributes can start with an asterisk. And yes parenthesis in an attribute name is also fine.
It’s why Vue works. An attribute that starts with an at sign… no problem.
But, yeah… you can go too far. According to the HTML parser spec, this is a valid tag. Not a HTML tag, but a tag nonetheless.
This too… Oh…. Eh wait… No this is a mistake. This is obviously…
No not a proper tag.
Yeah, let’s check the spec. If the tag name contains a space it switches to the before attribute name state.
But yeah…..
This is not a space. For typographic reasons there are many different spaces of different sizes. All of them white space. But this is not unicode code point 20. This is not a space. This is a FIGURE SPACE.
Now, if you really want to mess with your coworker, just run this script on his or her computer. It will replace all spaces between the a and the href to a figure space. In all HTML documents. This will really mess every up.
Every document will suddenly be completely screwed up… And the funny part is, when you look at the documents in code editor with a monospaced font, you can’t see the difference…. Pretty evil, right. So actually… don’t do this.
Seriously, don’t do this. I’m not responsible for anything that happens.
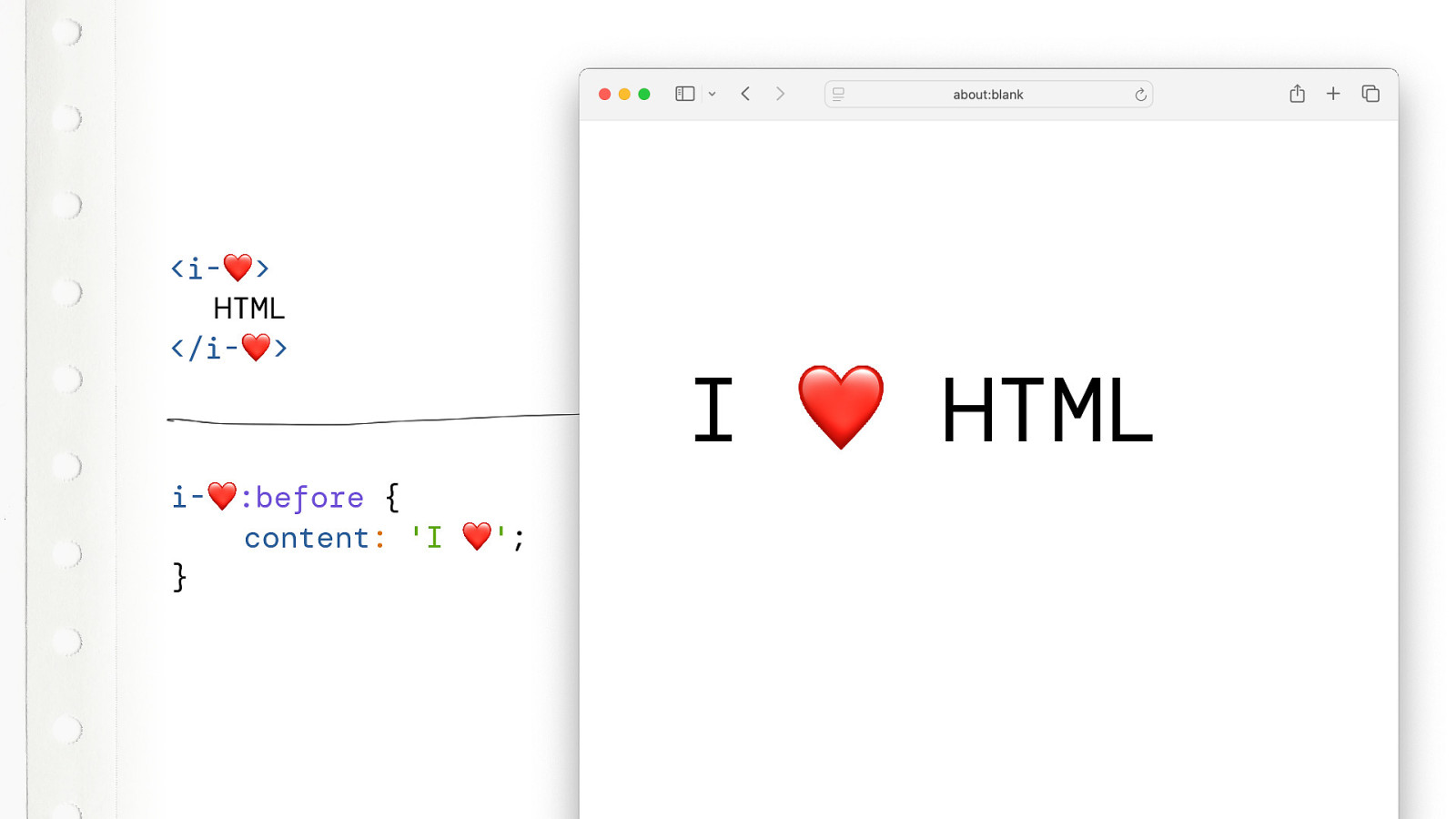
So, can you break HTML? Can you put an emoji in an tag name or attribute name and break HTML? Well, no. Not really. This….
is allowed…. eh… wait….
this is allowed…. yes. Emoji are just unicode and you can put any unicode character in a tag name as long as it starts with a regular letter.
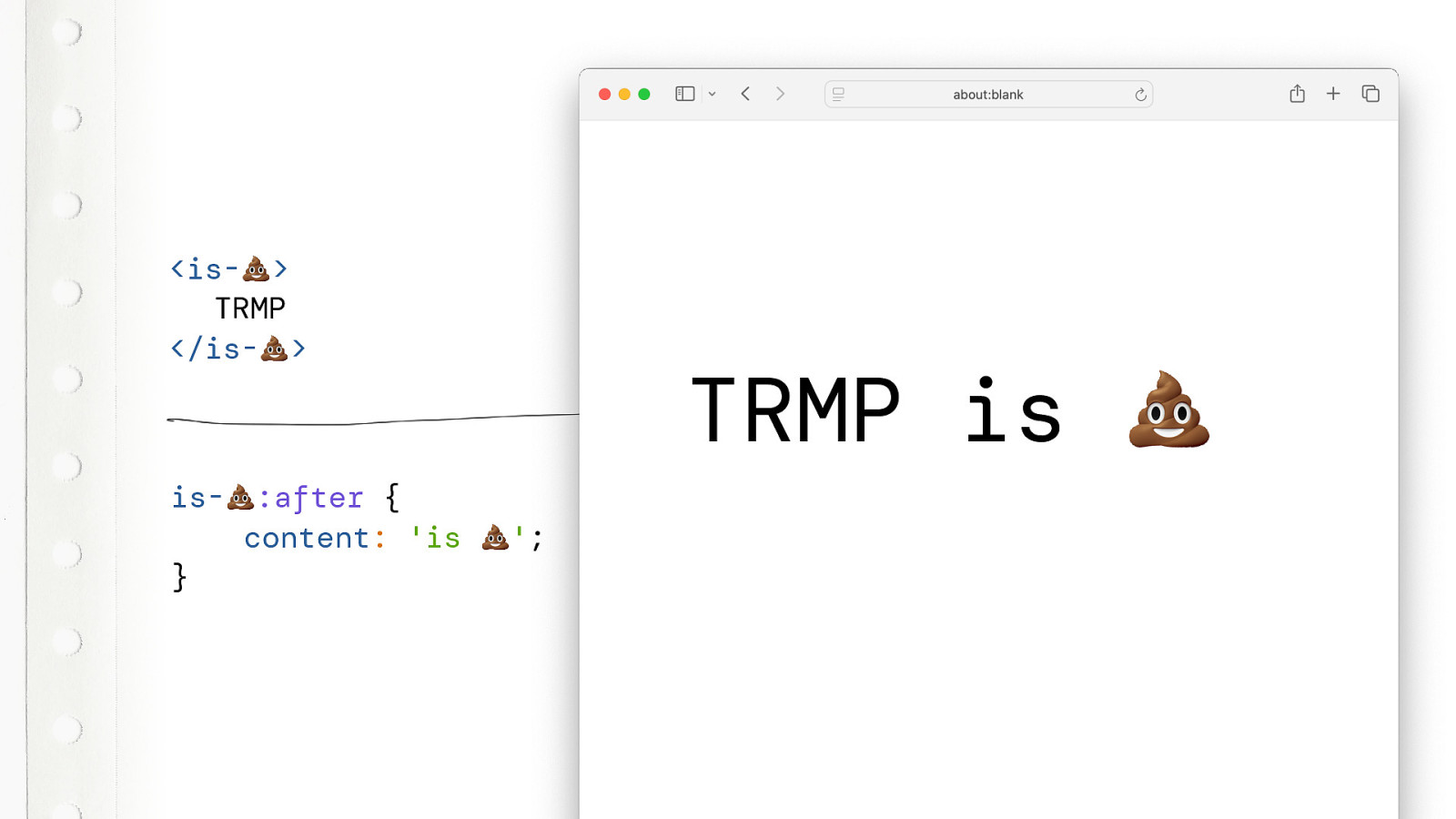
And you can style it like this. This works. Just sprinkle a little bit of CSS and voila. And it doesn’t have to be I Love. It can be Is shit. And it doesn’t have to be HTML. It can be any random 4 letter combination.
Of course nobody serious would want to use emoji’s in production, right…?
Anyone remember this?
Now I am not saying nothing matters. All tags are equal and semantics are not important…
Semantically this is just as bad as…
This… These are not a buttons.
This is a button. It works as a button. You can tab to it. You can click it. And it’s free.
All the tags we created are not HTML tags. They have no function. You can style them, but that is it. Functionality wise they are nothing more than a <span>.
The other reason why HTML is so resilient is the tree builder. The tree builder receives the tokens from the tokenizer and actually builds the DOM tree with it. Sounds easy, but it really is more complicated than it seems.
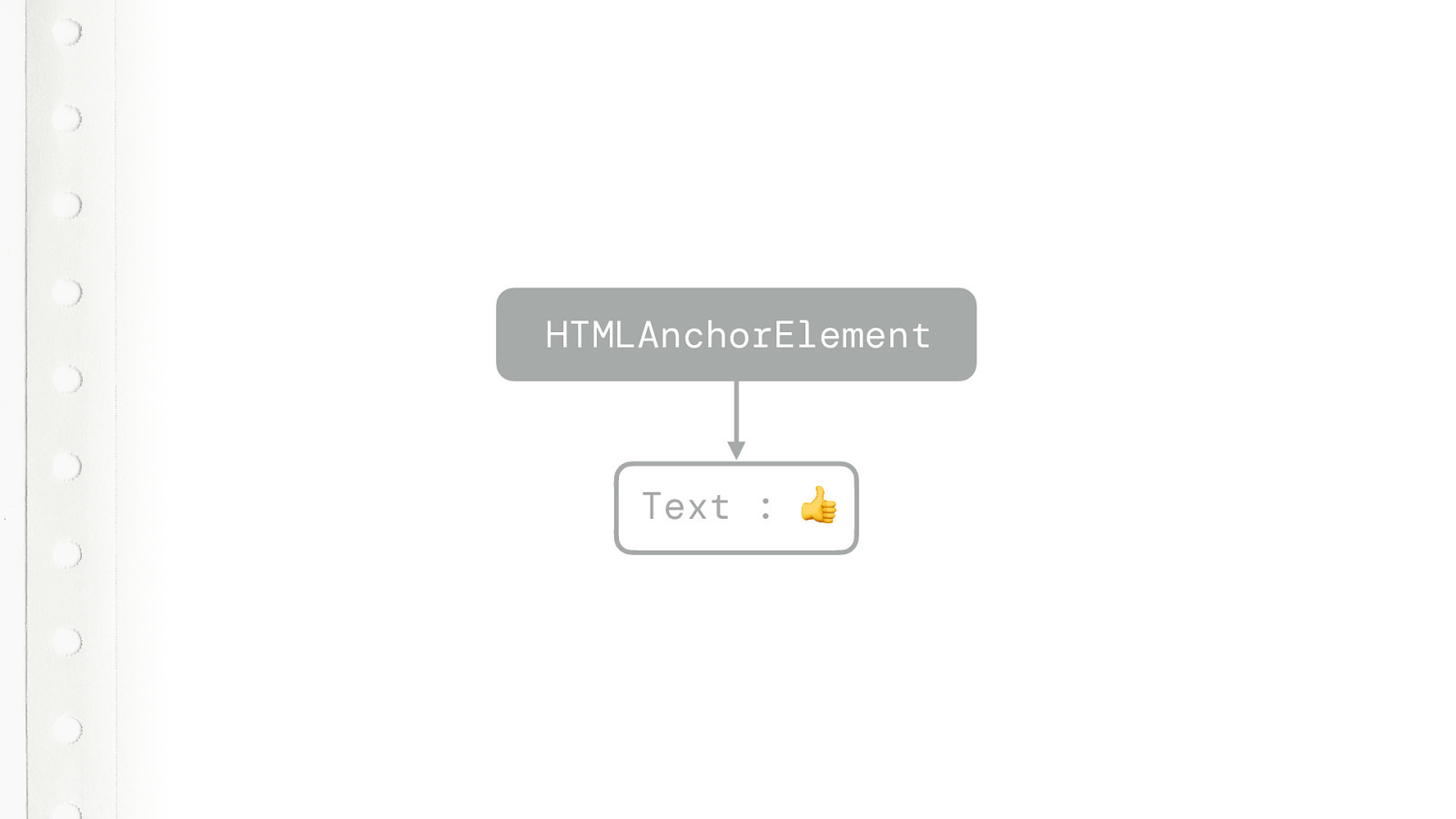
So, if we have a piece of HTML like this. A simple a tag with some text in it. The tokenizer will produce three different tokens.
The open tag, the character token and the closing tag.
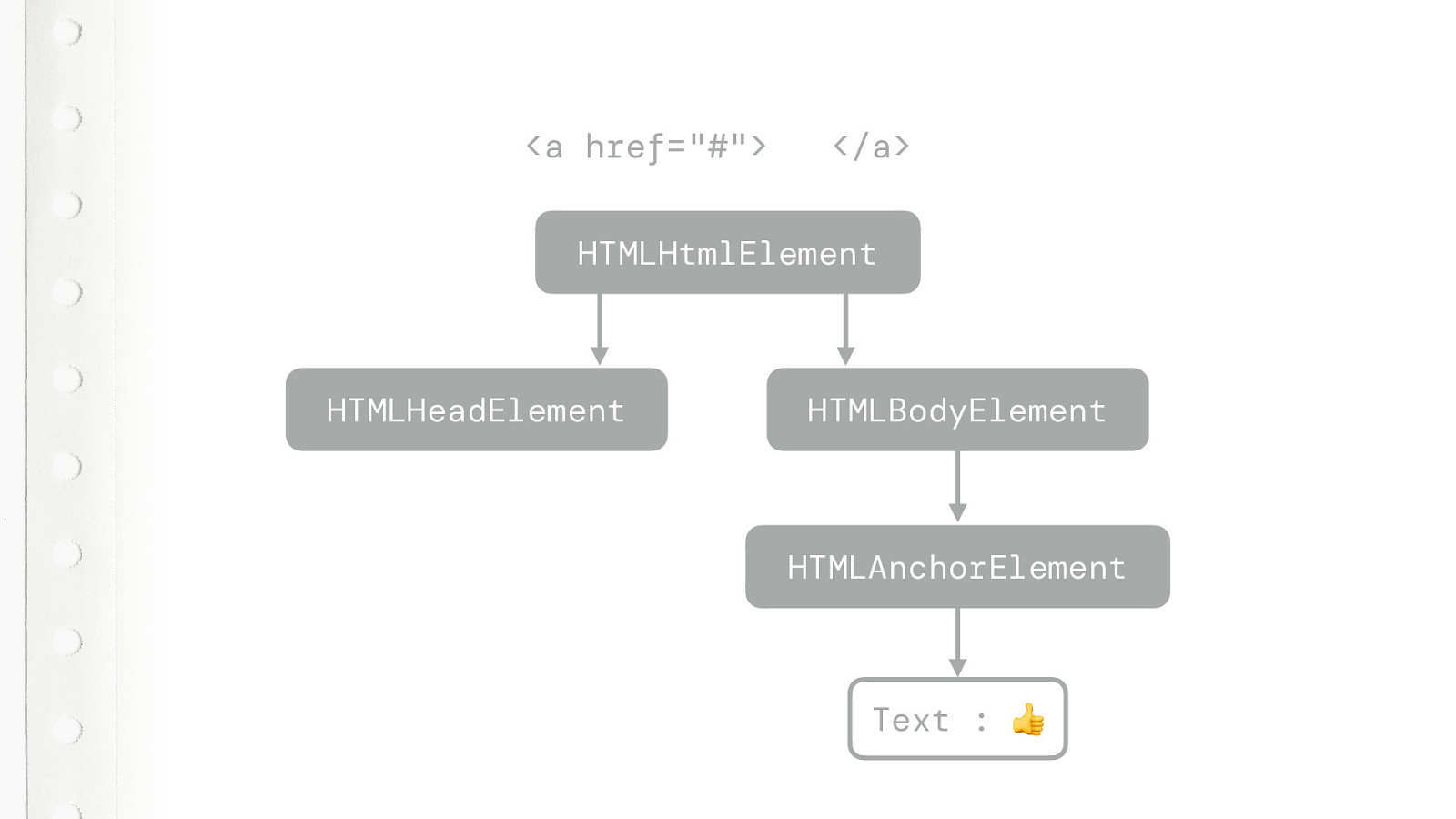
And the tree builder turns that into a HTMLAnchorElement DOM node and a text node. Still simple so far. But that is actually not what happens when the tree builder receives these tokens. It does so much more.
It actually creates missing elements that are required for your HTML document. Let’s see what happens.
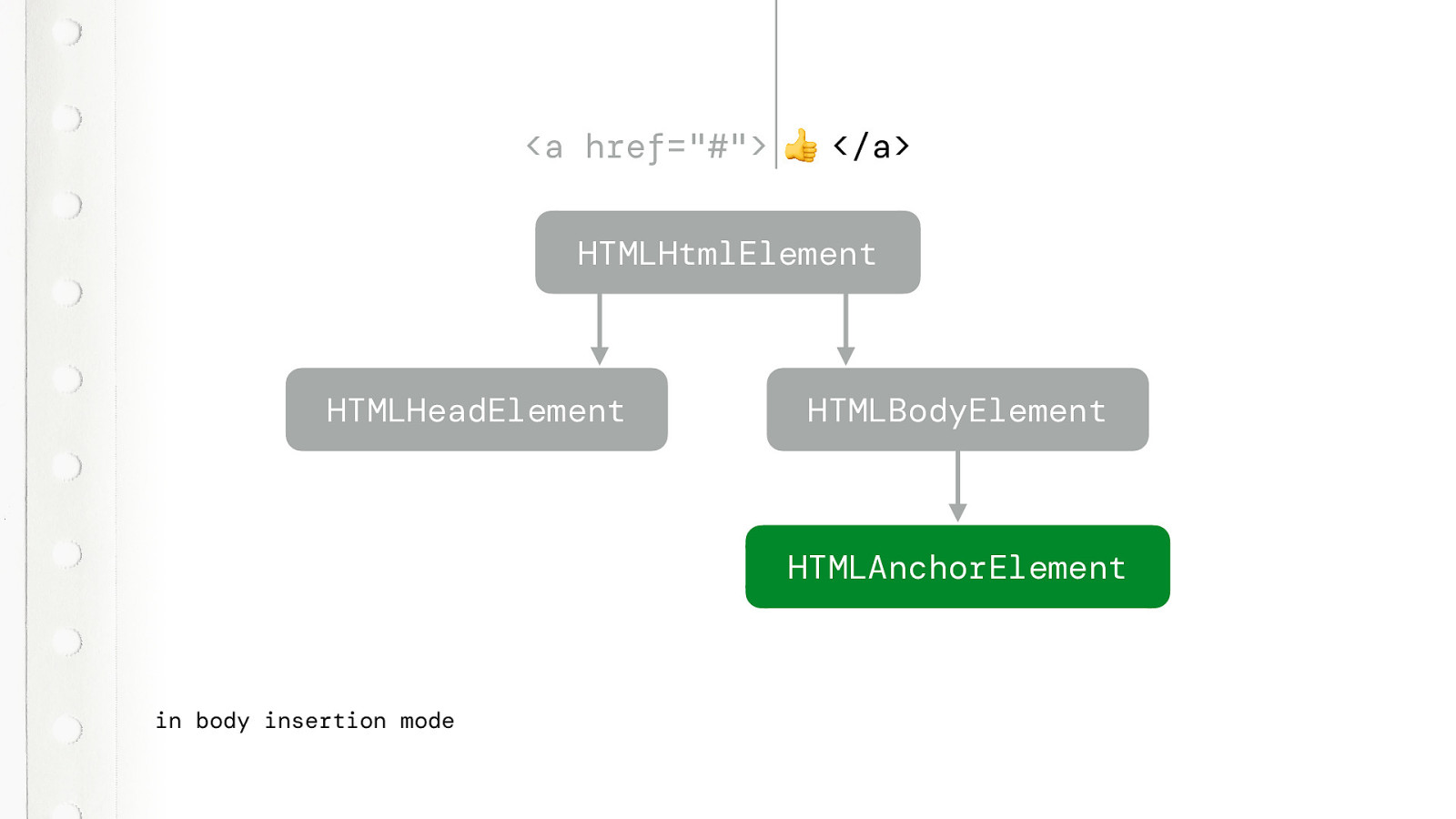
So, the first token is a A TAG OPEN token, but that does not make sense in this context
So it creates the HTMLHtmlElement
Then the HTMLHeadElement
And a HTMLBodyElement… and now the A tag open finally makes sense.
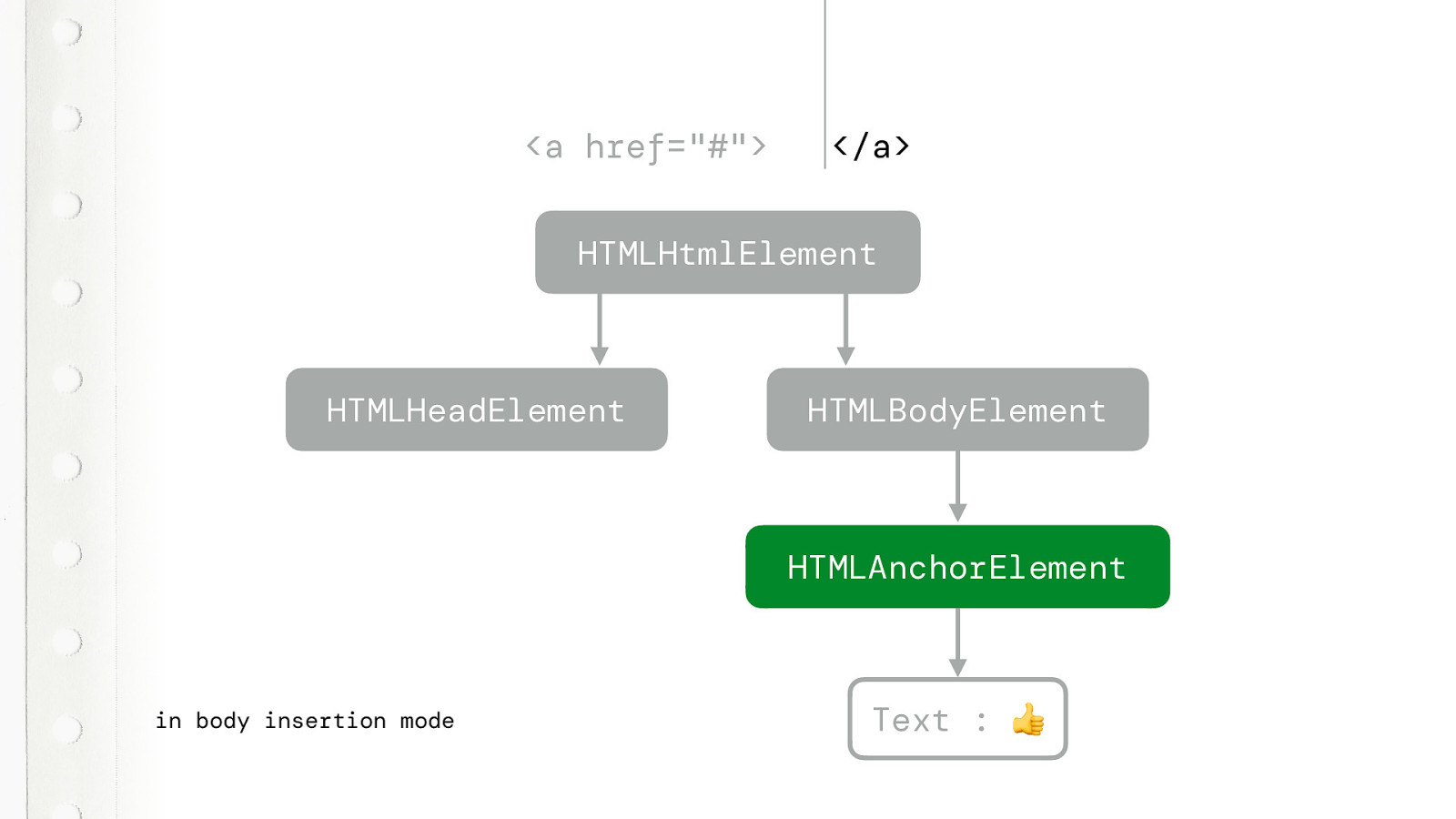
So it creates it….
And the text node.
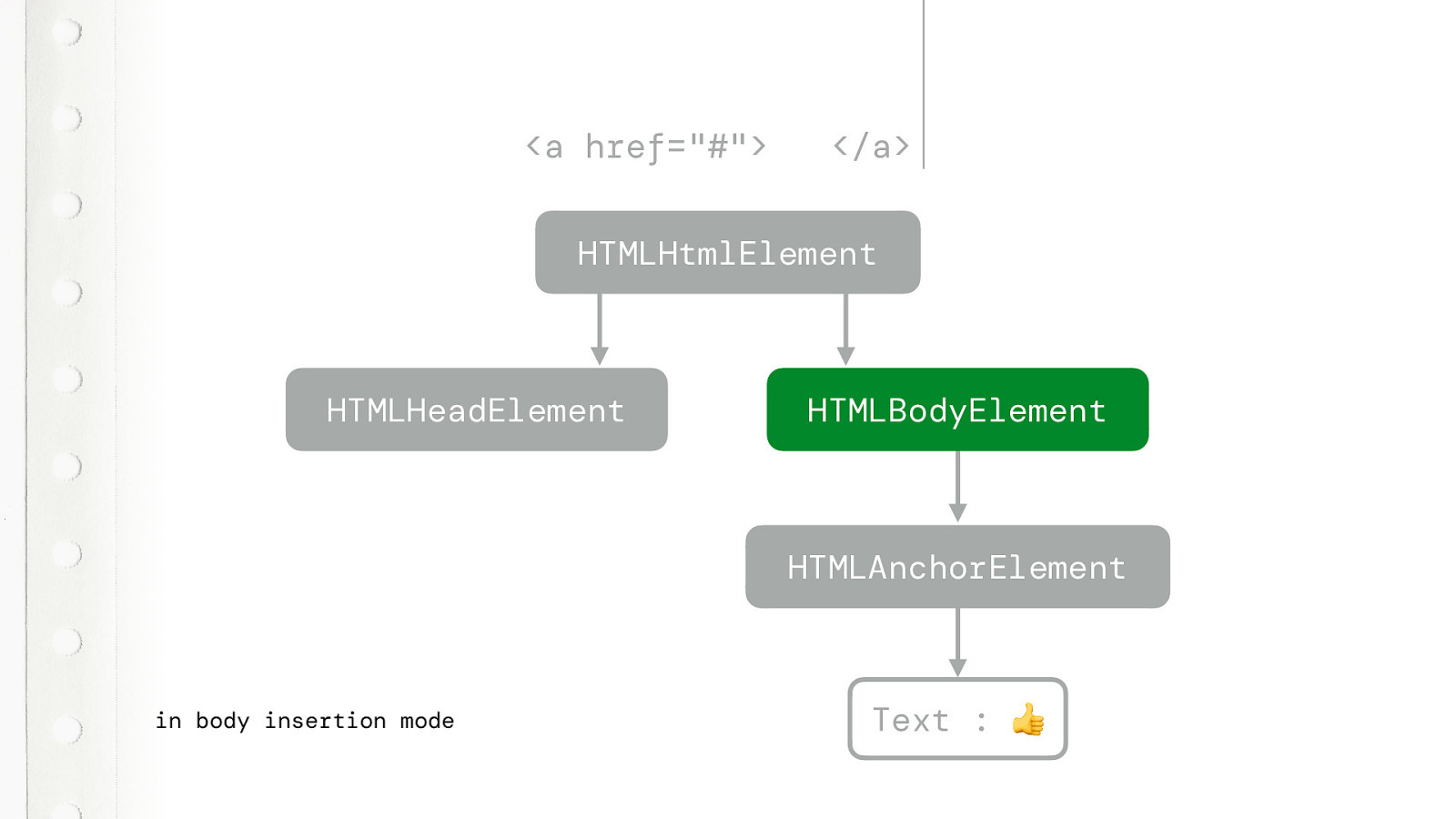
And closes the Anchor element.
And we’re done. We actually now have a DOM that makes sense and is complete. It creates all the nodes that were missing. And this is why that very first HTML page works, even though it didn’t have an HTML element. Even without that HEAD element it will work just fine. It just re-creates the missing elements.
There is now a HTML and HEAD tag. And it move the HEADER tag to the body, because that is where it makes sense.
But it also fixes your mistakes. So if the tree builder encounters some tags that are not nested in the right way, it will try to make sense of it. For example.
Everyone makes mistakes. And we don’t want this to happen.
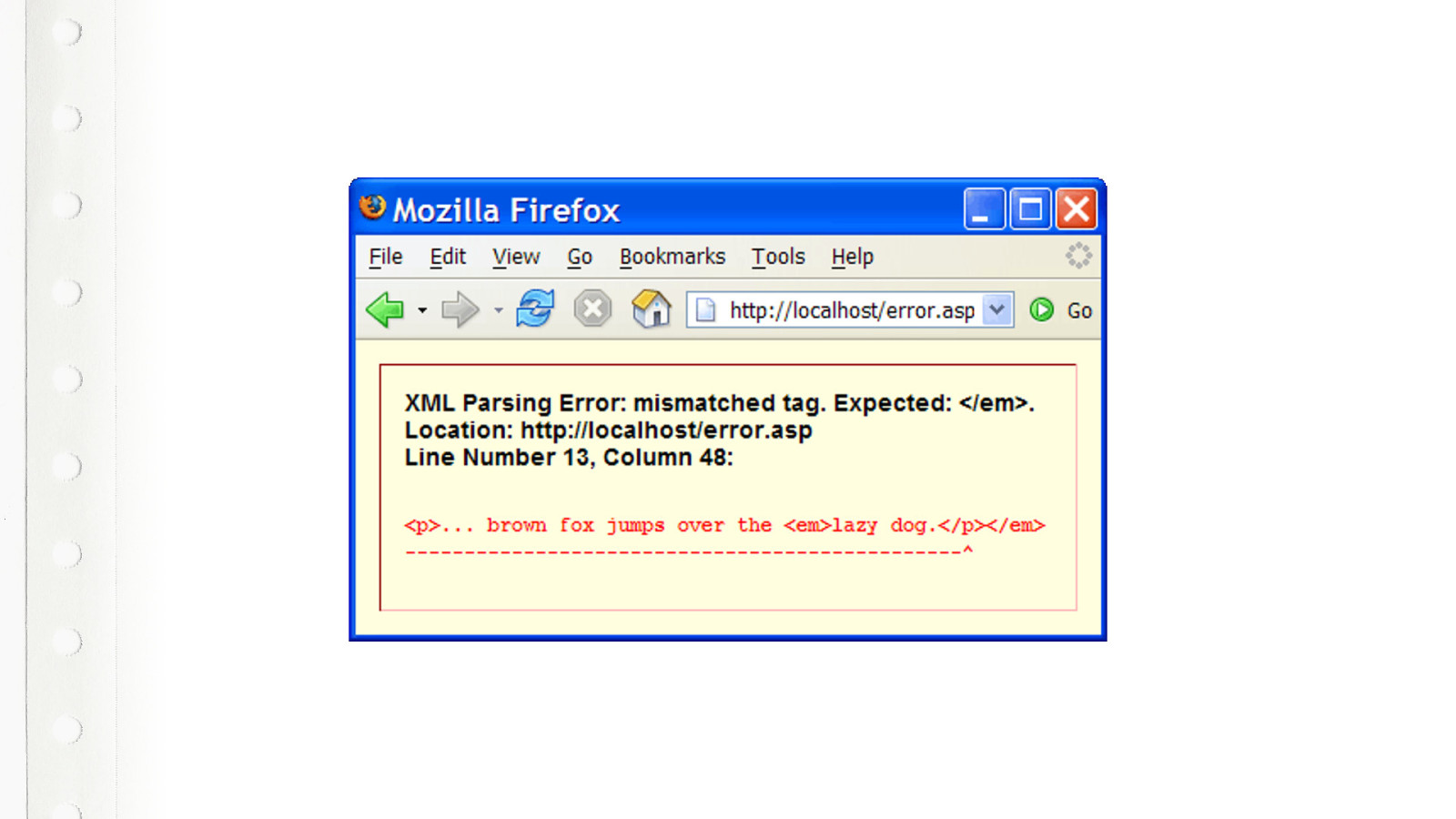
We don’t want to go back to the days of XHTML. Where every document had to be very strictly conforming to the spec, otherwise the browser would just give up and show the ugly error message.
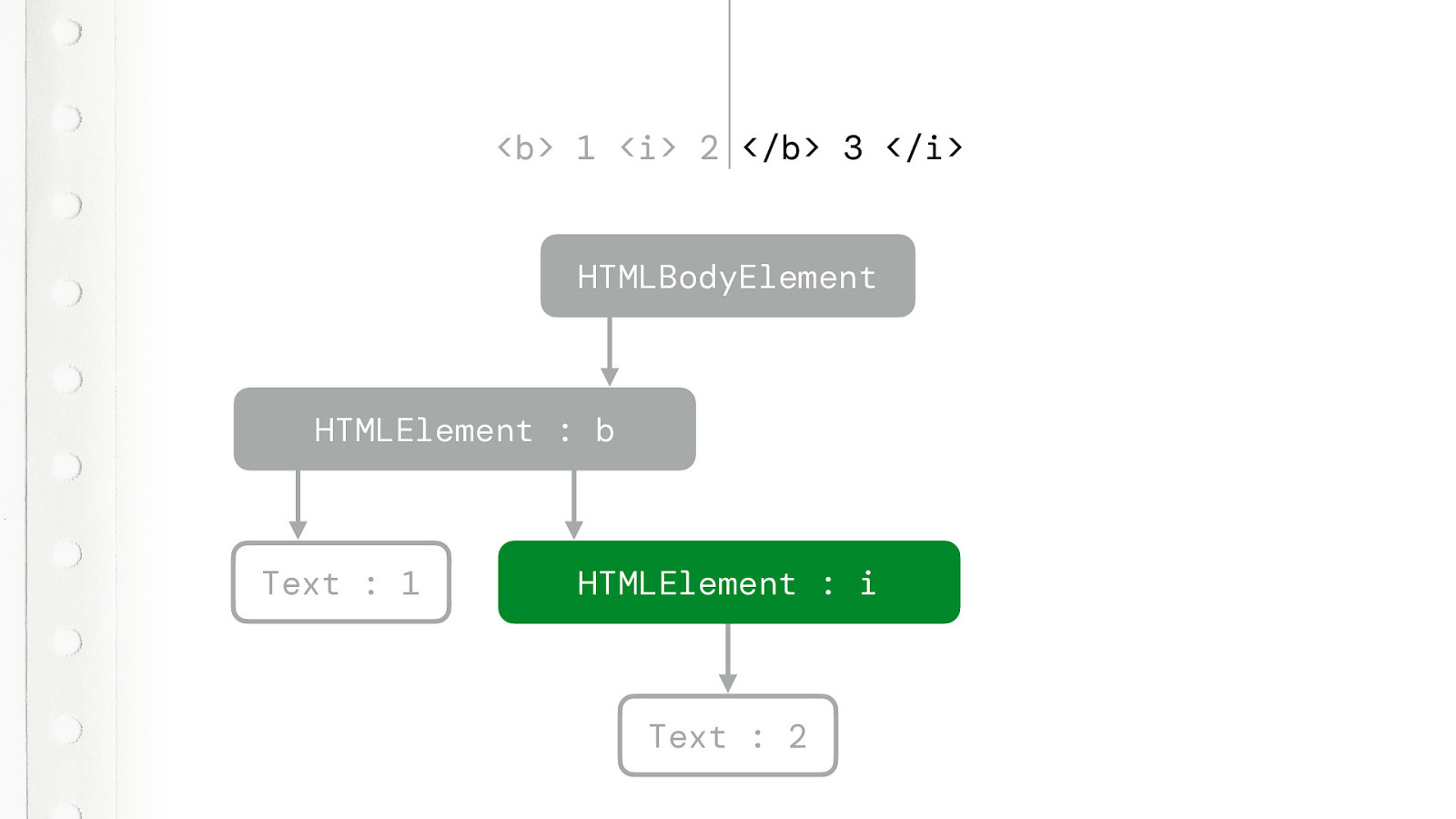
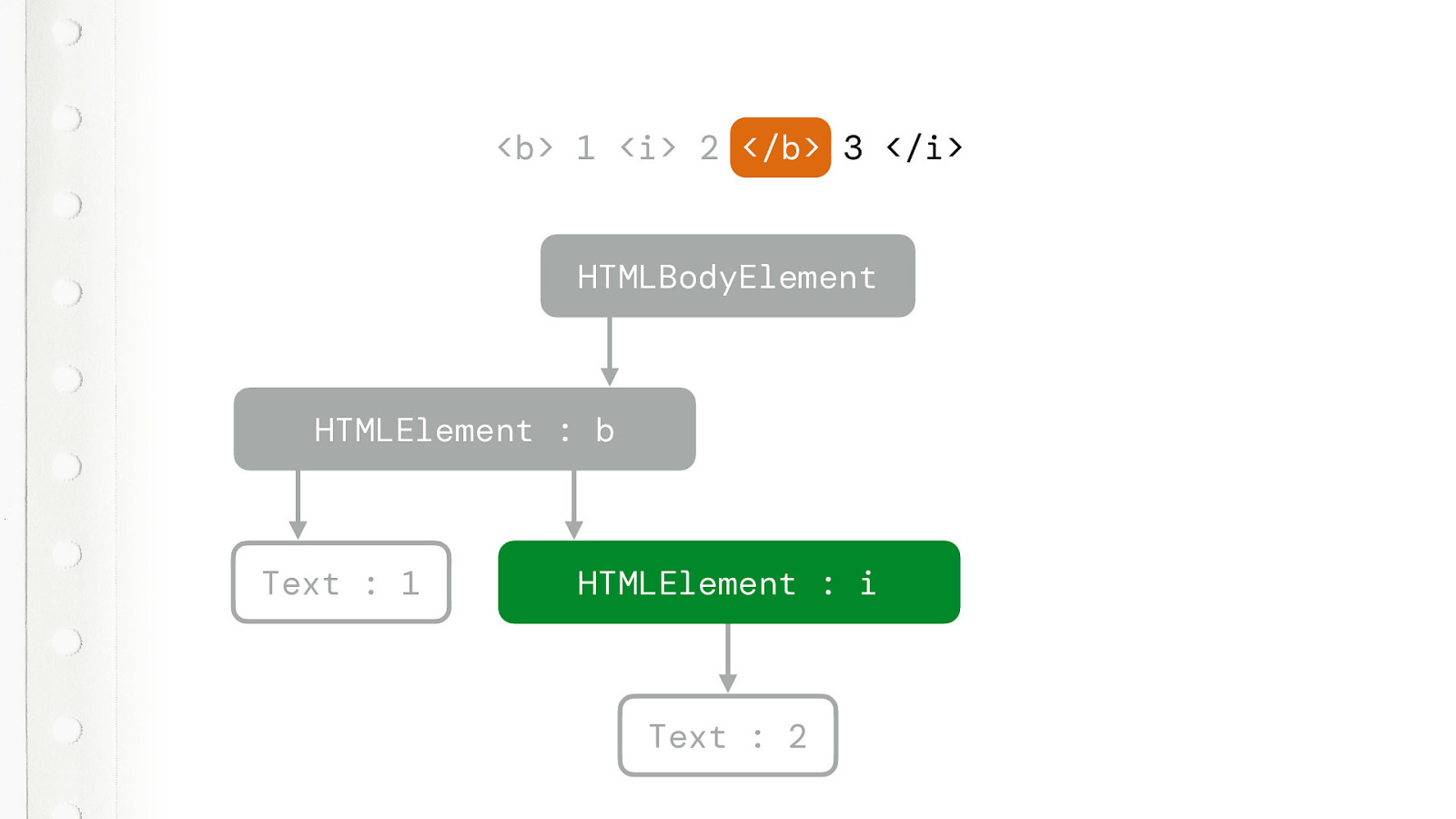
Fortunately with HTML5 browsers won’t throw an error anymore. This will just render. In a very specific way, defined by the spec. No interpretation differences between browsers. This will work in a very specific way. Quiz time. What style will the 3 be? Will the browser ignore the closing B tag, or close the I tag? Or what? Who here knows…?
So lets take a look.The first part is pretty straightforward.
We get a B and I element with the correct text… But what happens now?
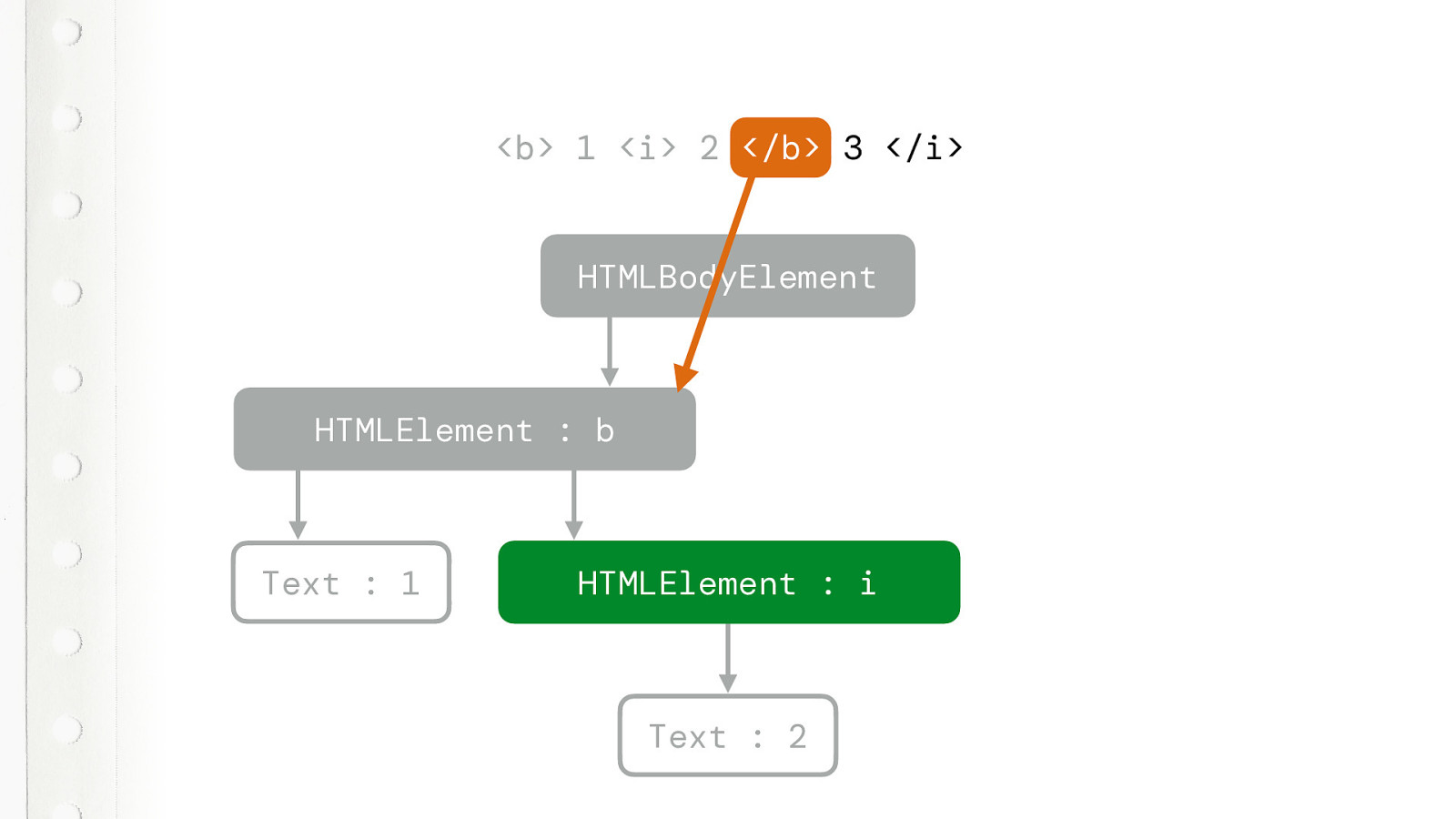
But now we get the CLOSING B TAG token. This is not what the tree builder expected. So it tries to figure out which tag it needs to close.
And that is this one. So it closes this one and goes back to the BODY element.
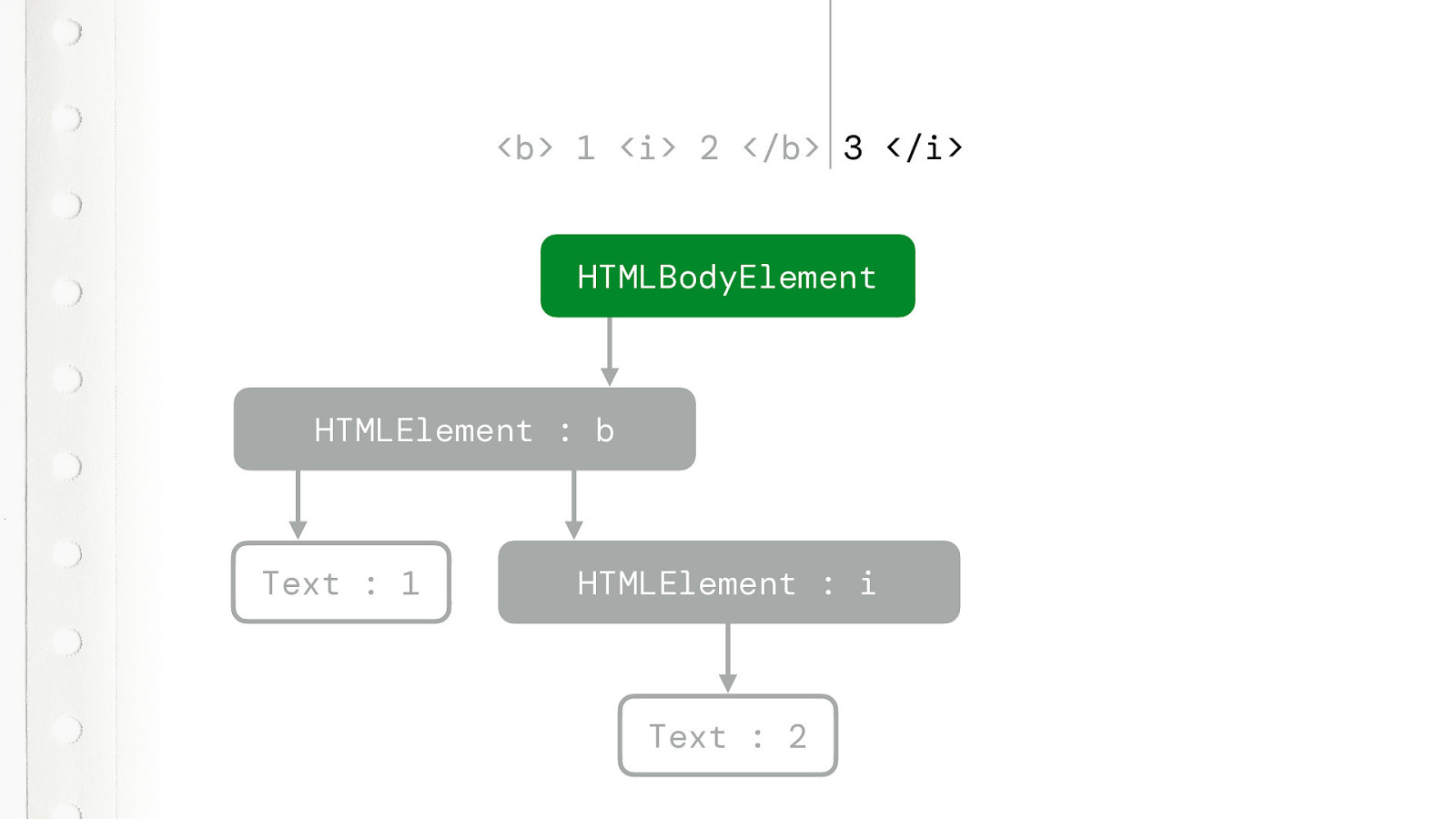
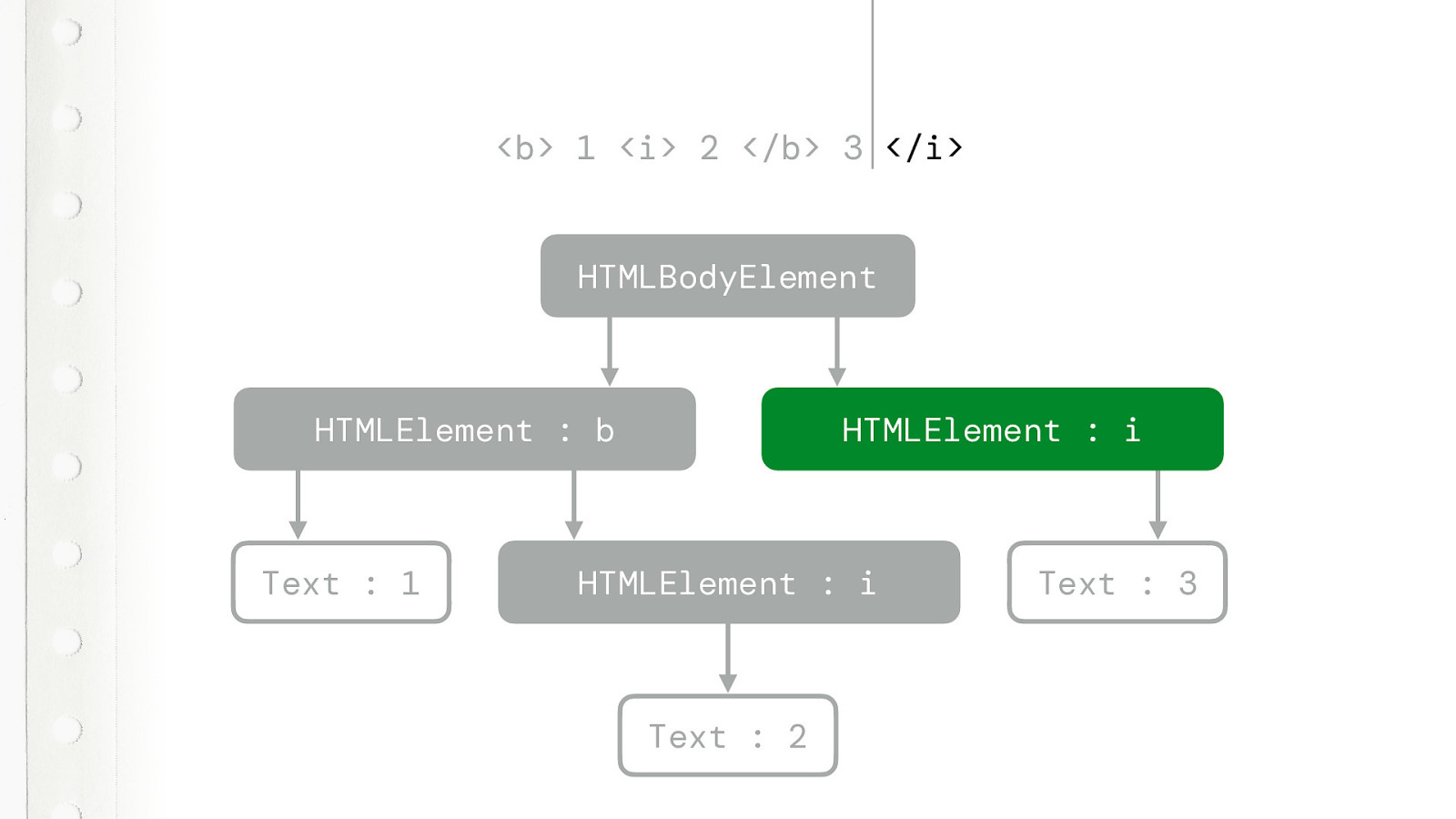
Then it sees another text token. But it does something special. It maintains a list of active formatting elements. The B is an formatting element, but we just closed it. So that list contains just one. The I element. That one is still active. We never closed it.
So that text token, not only creates a text node. It also creates a new element for that still active formatting element. So the 3 is italic.
And that brings us back to the first website created by Tim Web developer.
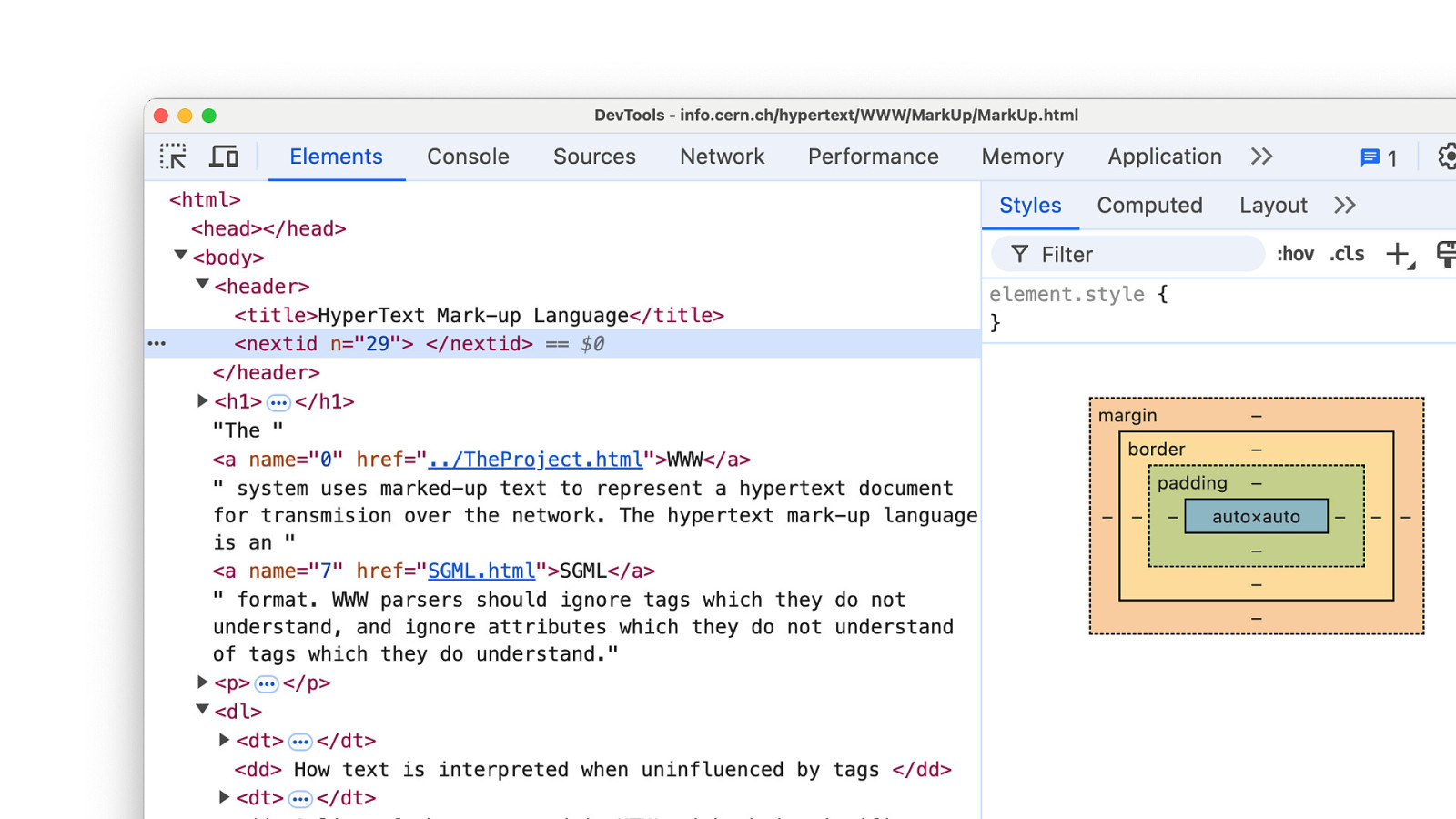
If you validate that very first website. You’ll get some errors. One reason is because the validator only goes back to version 2 and that very first website is not even HTML 1. But there is also something else. There is an actual error in that very first document.
And that just confirms to me that allowing errors is something that is build into the DNA of HTML. Did you see it? Here! There is an CLOSING A TAG without a OPENING A TAG. Just a simple mistake, but the browser won’t care.
And again, this is what makes HTML special. This is what makes HTML for everyone. You don’t need a computer science degree to make a website. You are allowed to make mistakes.
Everybody can make a website. Some will be bad. Some will be good. It can be about Star Trek fanfic, or React. Or your cats. It can be about any other random unimportant subject. But it will be a website. And the browser will render it.
I think that is beautiful. That is what the web is about. Not just about consuming content, but also making content. It is about sharing knowledge. It’s about making connections.
I get a little bit sad that nowadays almost nobody has a personal website anymore. We all use commercial platforms like WordPress, Facebook or …X. And that is understandable - web development has become too difficult. You need a computer science degree just to install your development environment.
For you and me this isn’t a problem. We are webmasters. We rule the web. We copy and paste, experiment and have fun with tags and elements. But it makes me a little bit sad most people are dependent on platforms owned by madmen with super inflated ego’s and wannabe dictators.
This isn’t what the web is supposed to be. I know photo feels a long time ago. A lot has changed in the world. But the web should be for everybody. So, if you don’t have a website. Make one. Experiment. It doesn’t have to be good. Make content and share knowledge. That is the web.
Oh, I have a website. Compared to some of other personal website I see it is pretty rubbish. But it is MY website. And it works in all browsers. And I share knowledge on it.
So finally let’s get back to the NOSCRIPT tag. With what we’ve learned we can now answer the questions from the beginning.
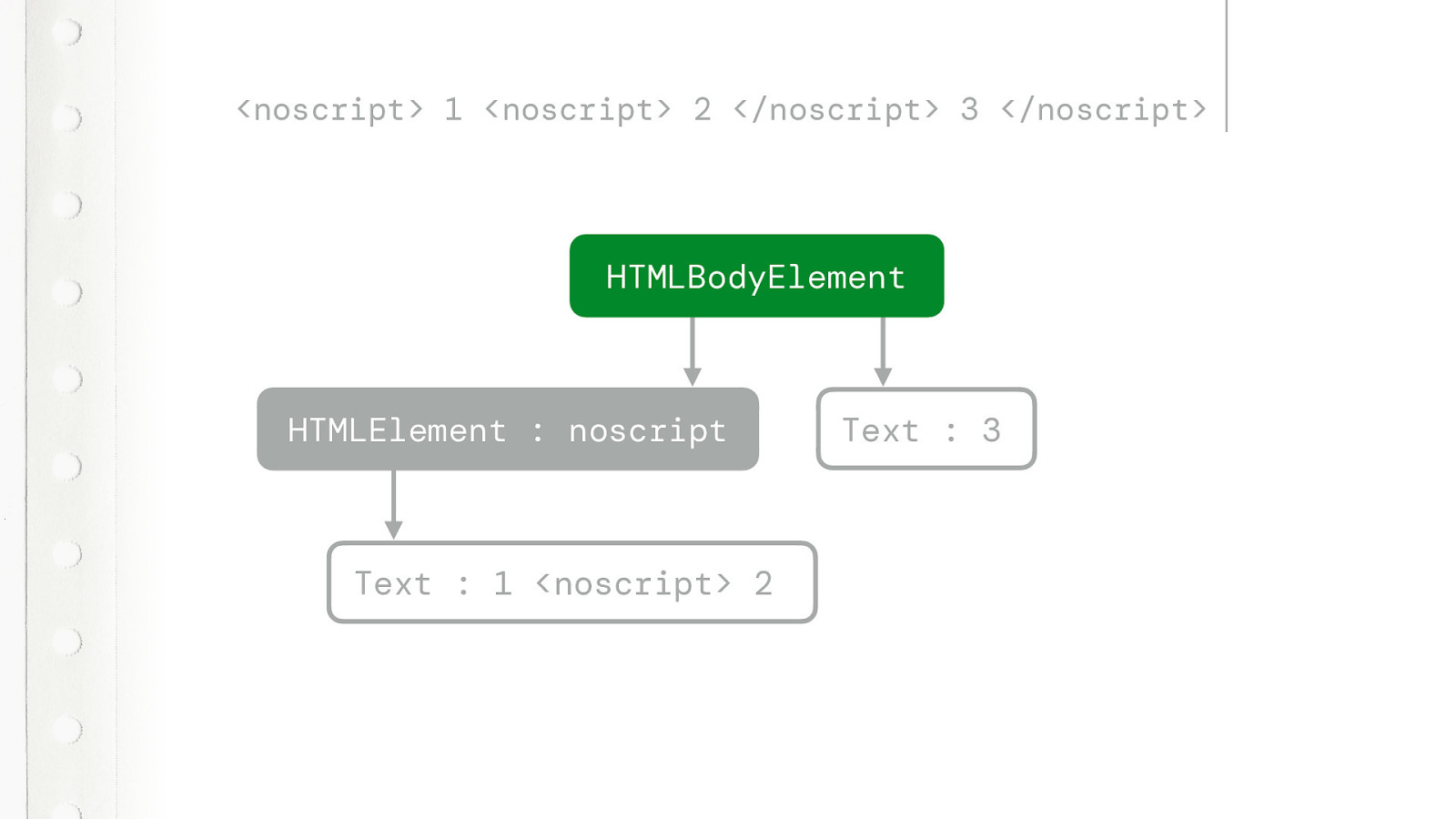
What happens when you nest two NOSCRIPT TAGS? Well lets just see.
The second noscript tag isn’t a tag at all. Everything will be text until the browser encounters a closing noscript tag. Everything, including the second opening noscript tag. And it will simply ignore the second now lonely closing noscript tag.
What happens when you try to style a NOSCRIPT tag? For example set visibility to visible. Set the display to block. Opacity? Bang important?
Well, that simply does not work. The contents of the NOSCRIPT tag is not hidden by CSS which you can override. It is ignored in the renderer. The NOSCRIPT tag will never be rendered. It is the only element that is de fined do absolutely nothing.
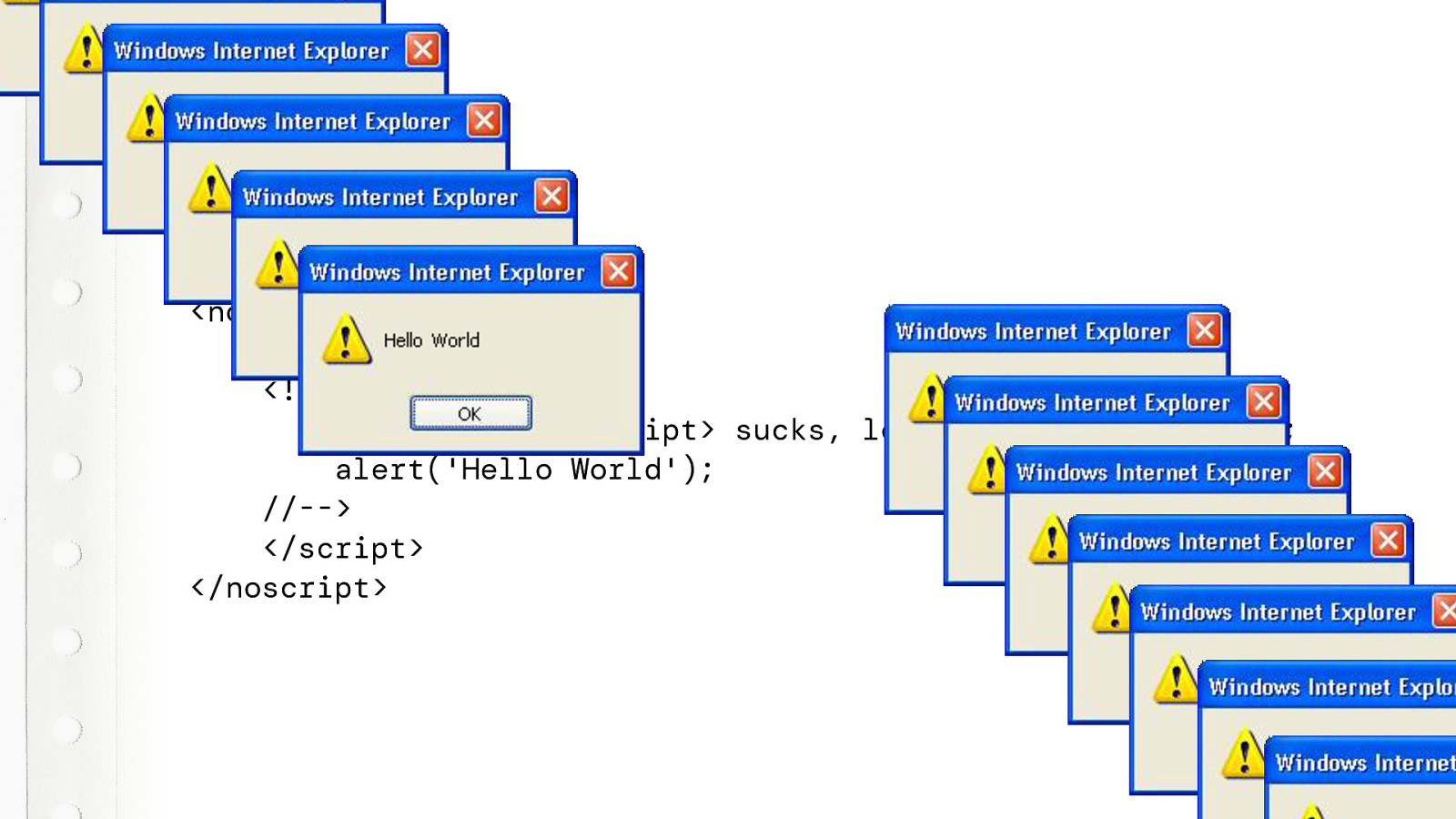
And a SCRIPT TAG inside of a NOSCRIPT tag. Well I’m sorry.
That is obviously not going to work. Why would you want to do that?
Except…. Yeah….
And with that, I’ve officially used JavaScript in my talk.
Thank you!

Niels has shown some of the most amazing web API with hardware demos over the years at HalfStack. He’s back again this year to time travel back to 1994 and rediscover one of the most important principles of the web.
Here’s what was said about this presentation on social media.