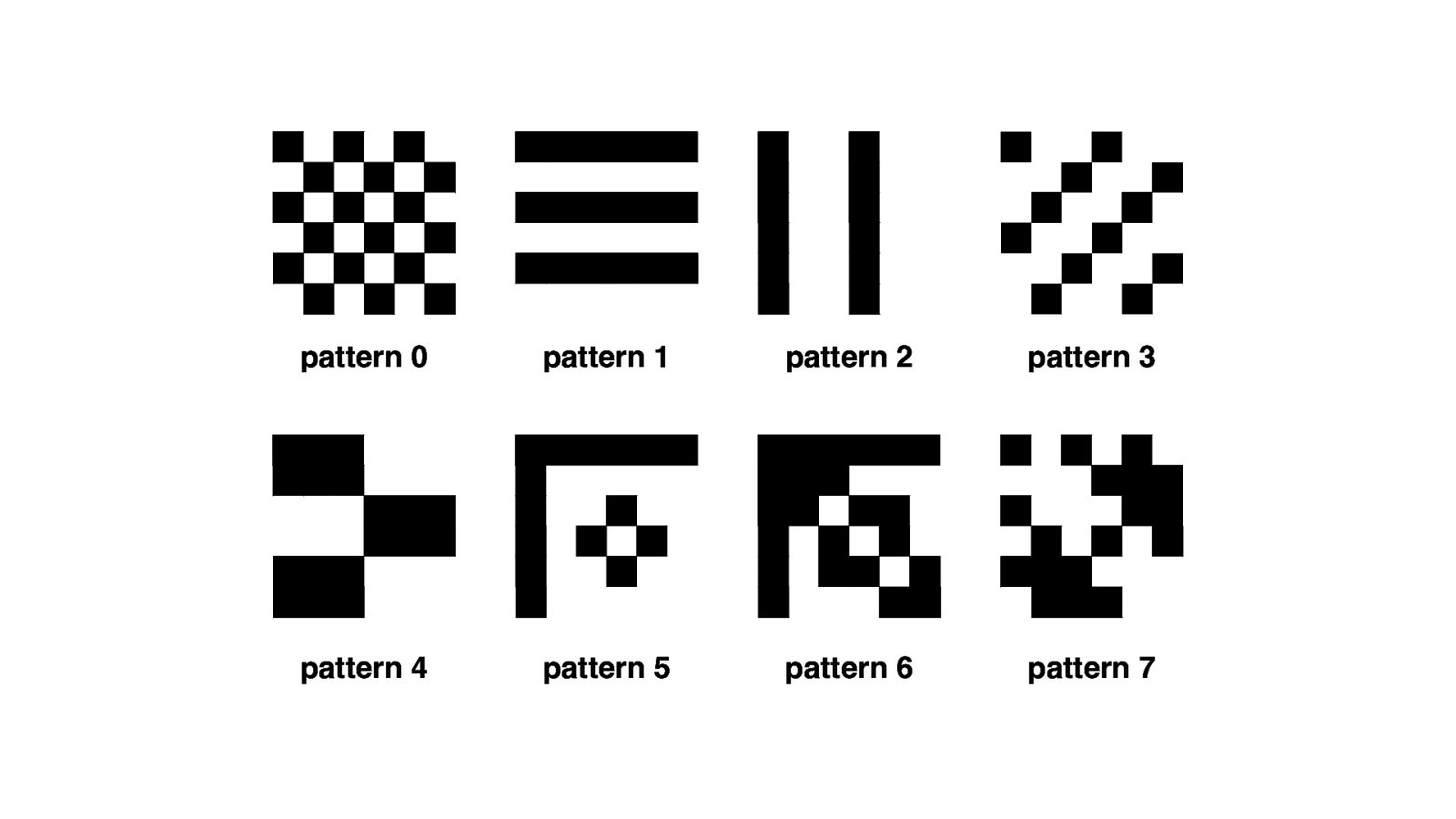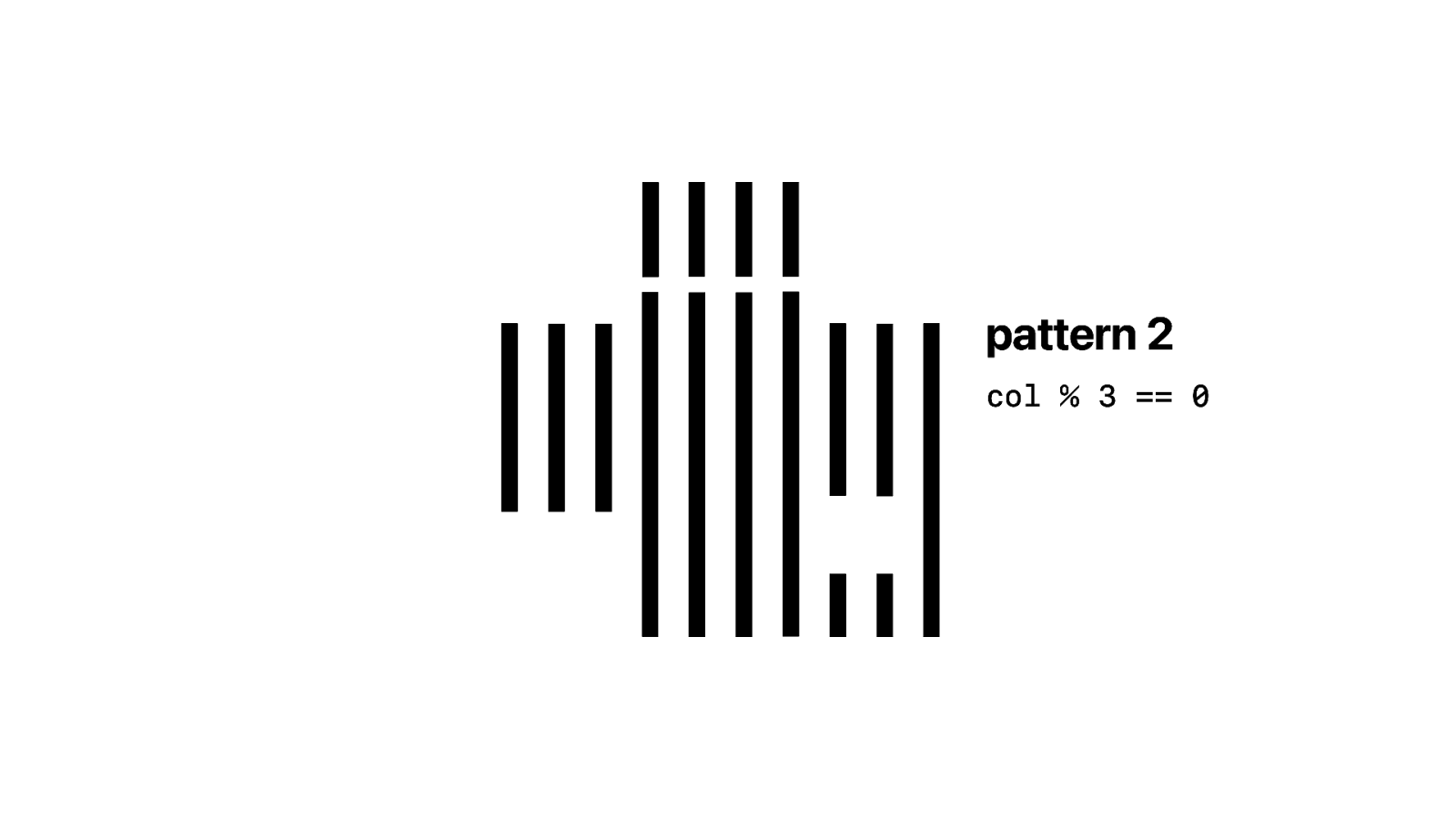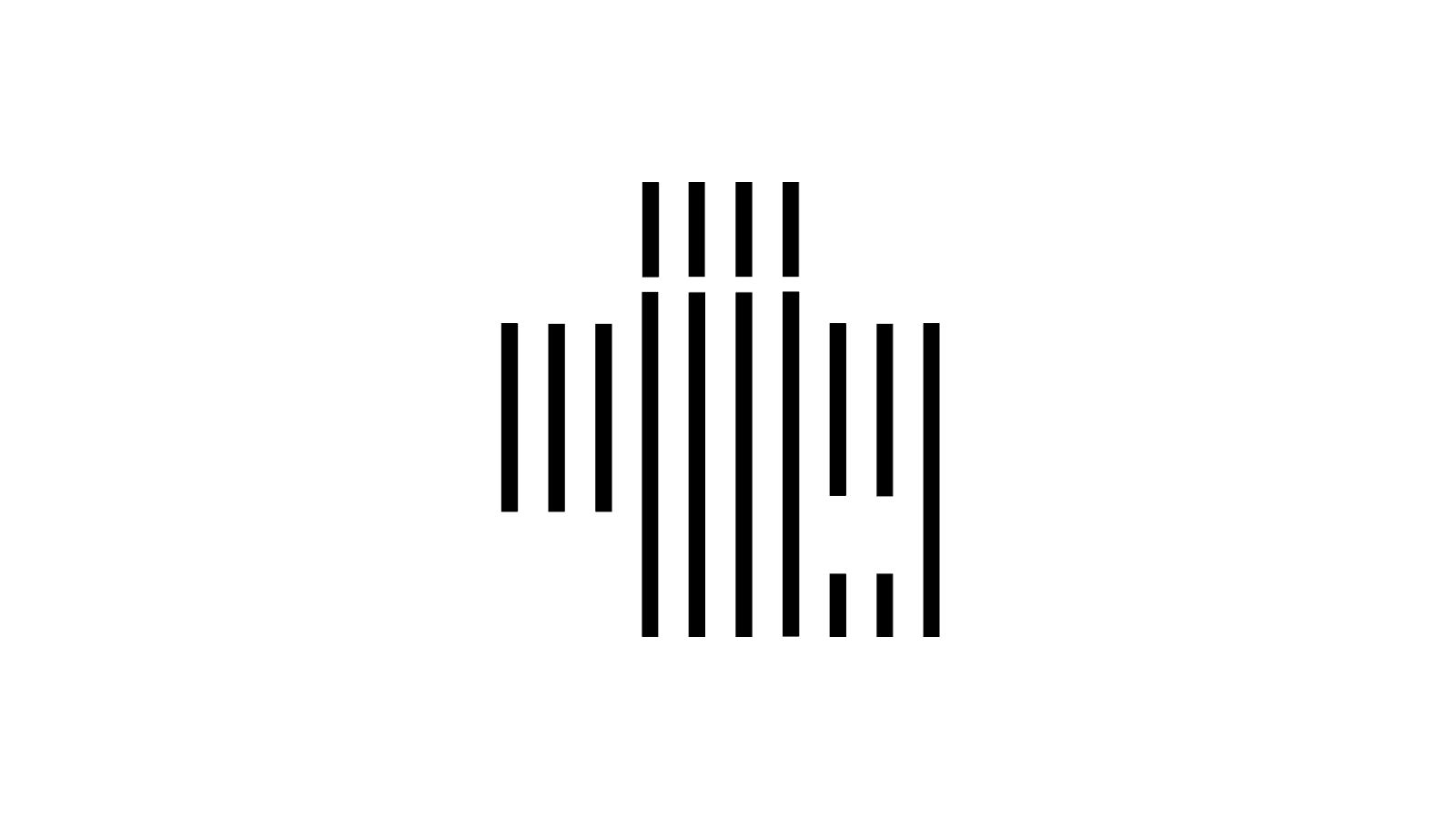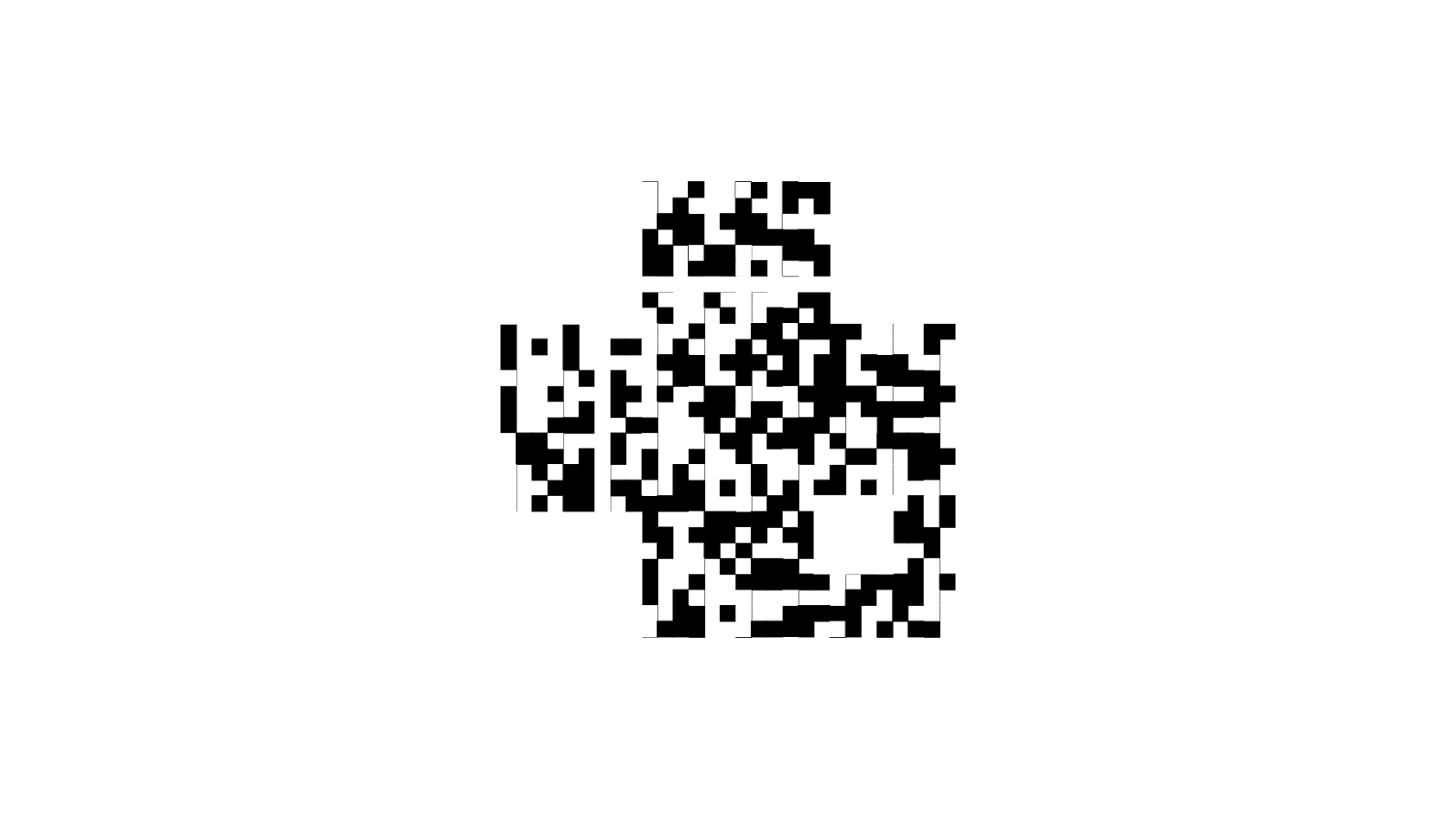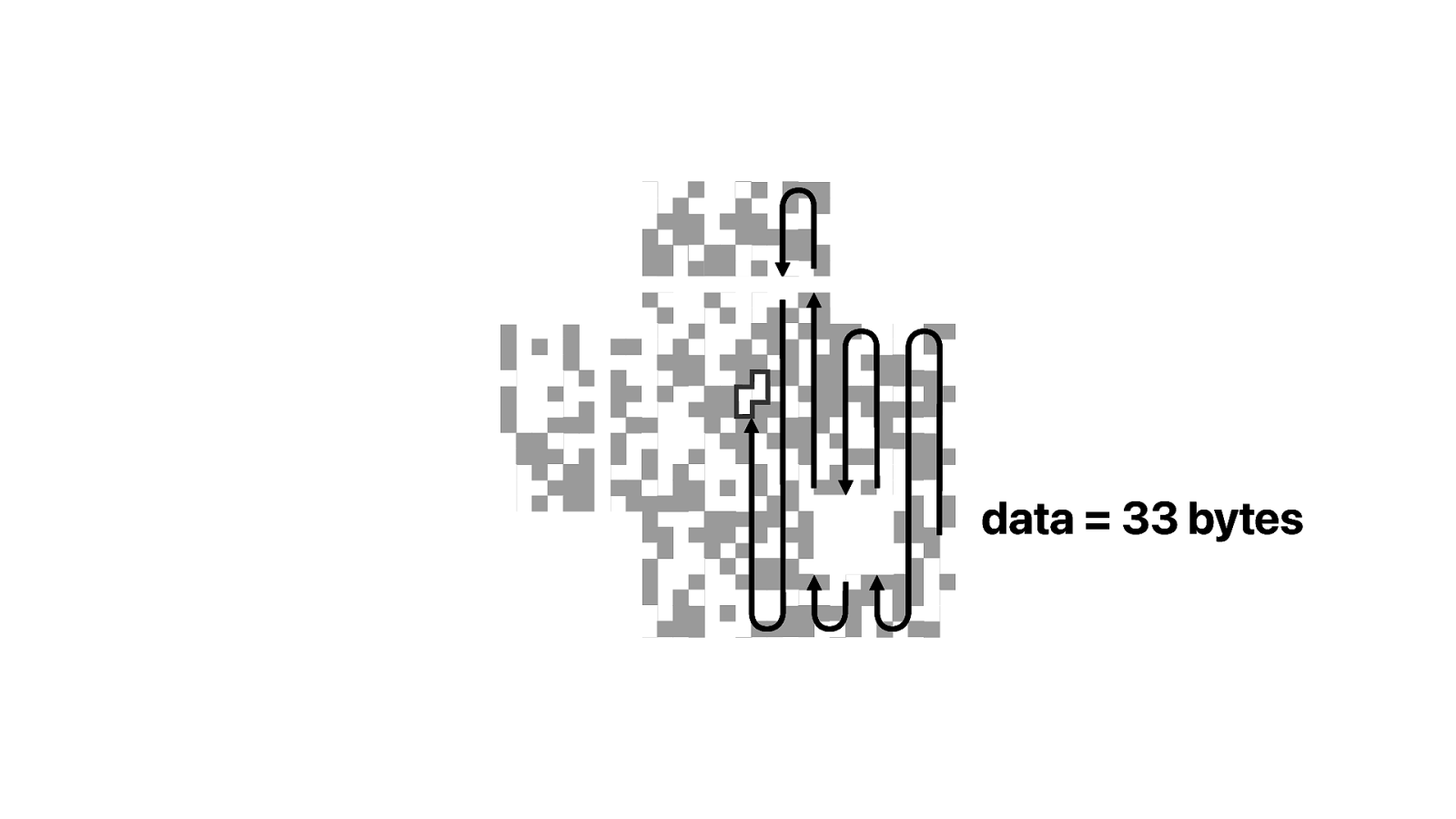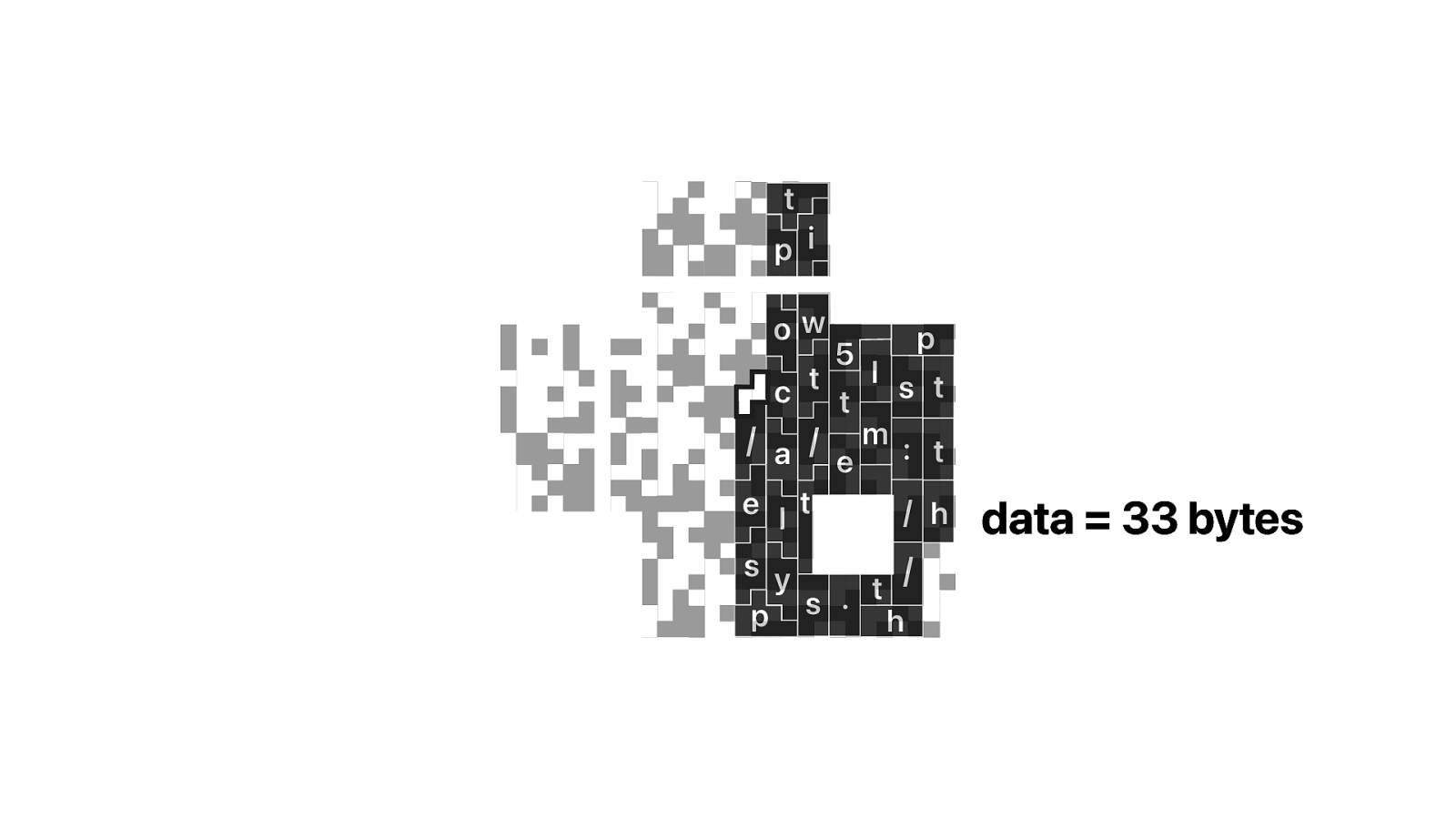A presentation at HalfStack London in in London, UK by Niels Leenheer

Sharing cat gifs after the twitpocalypse
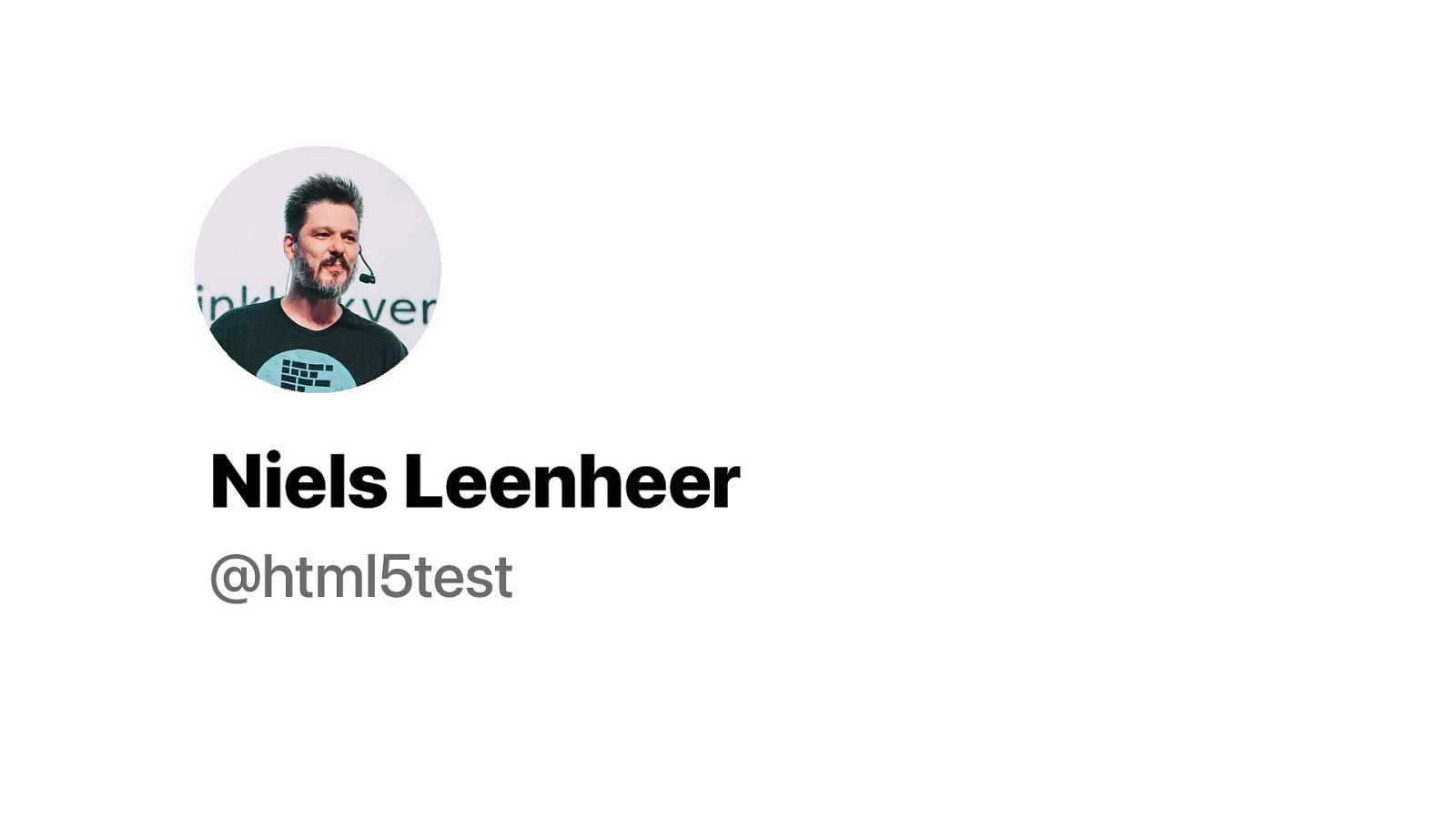
Hi. I’m Niels and I am @html5test on Twitter. At least I still was this morning. [checking telephone] Yes! I still am. But of course it is impossible to predict exactly will Twitter will implode. Could be this afternoon. Could be tomorrow. Oh wait… This isn’t entirely accurate.
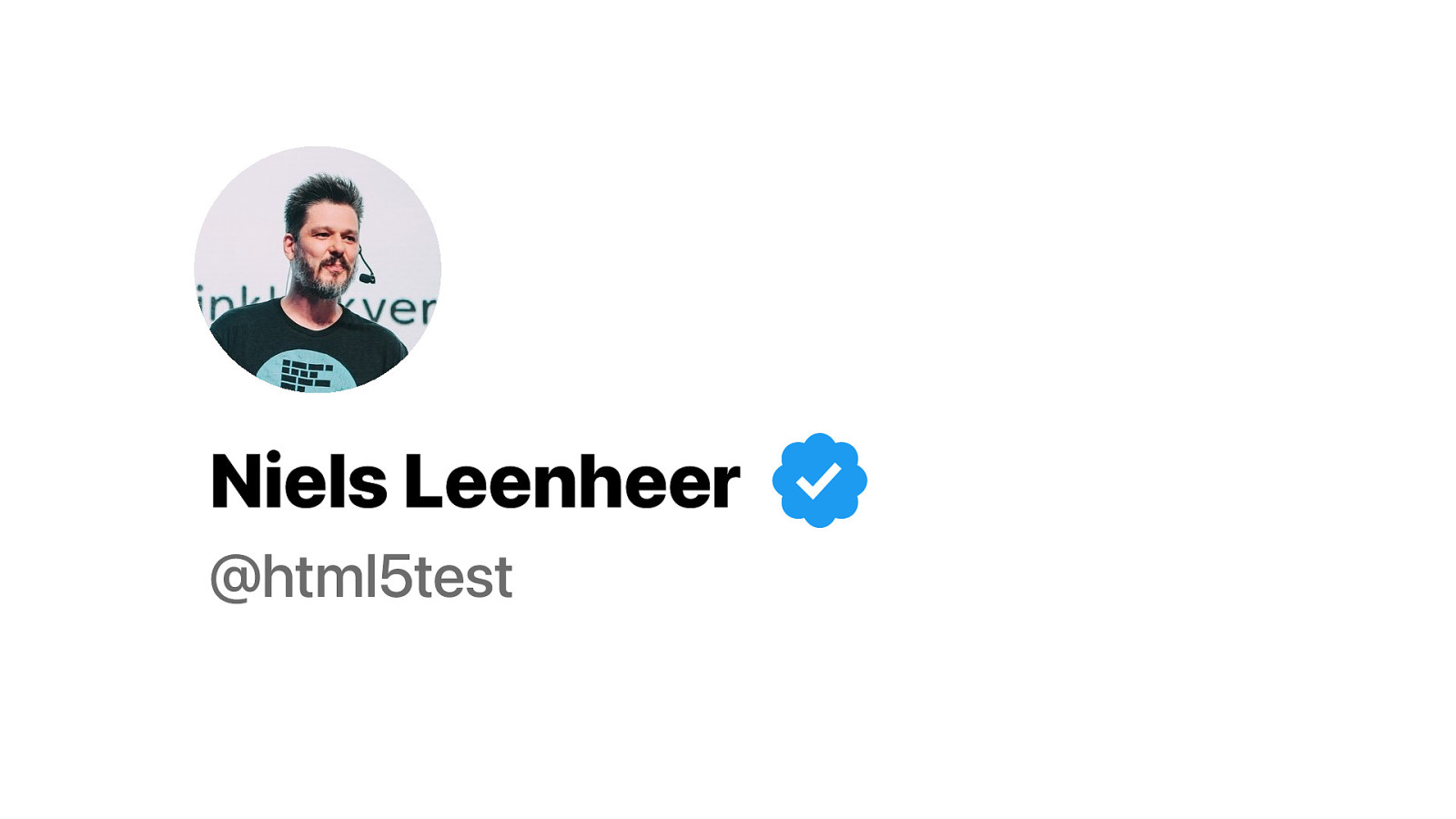
Yeah…. That is better. My blue verification badge. Of course that badge does not mean anything. You can just change your name to anything.
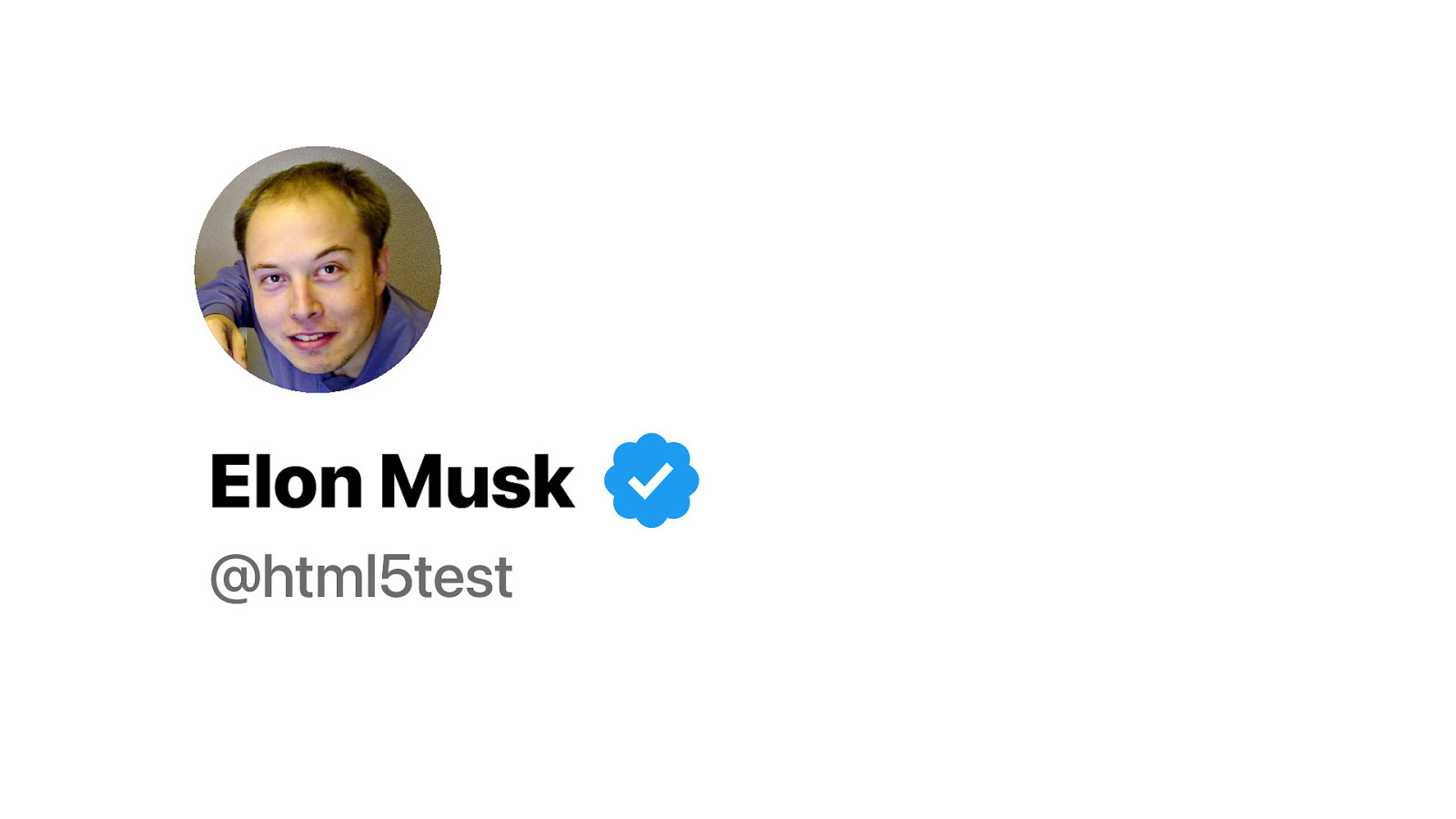
So if you want you can call me Elon too. But let’s not tell Elon, right? Because he will personally suspend my account.
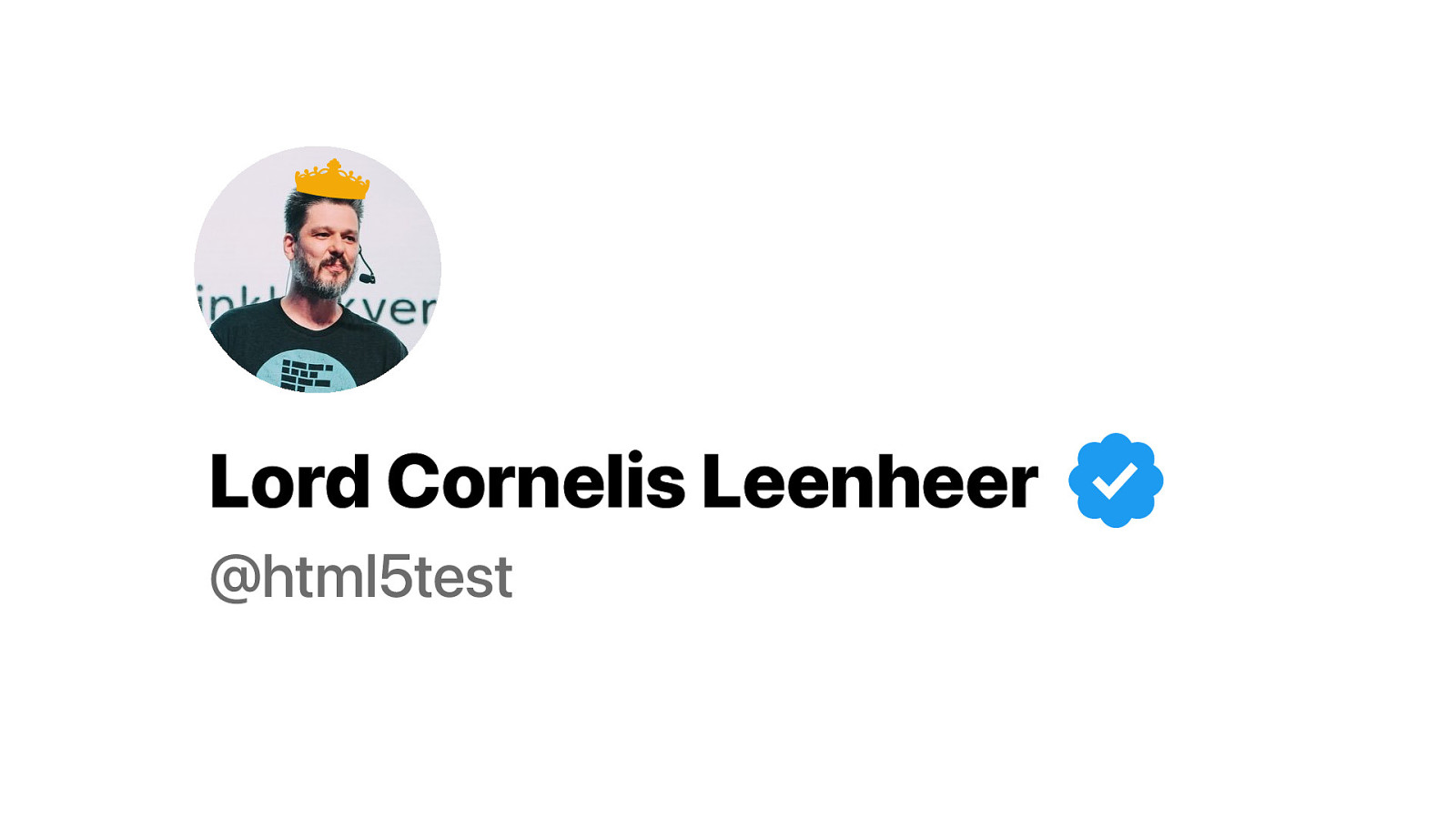
Call me Lord Cornelis. Yes. I like this. And Twitter verified it. You have to call me Lord from now on. Twitter says so.
I don’t want risk getting my account suspended… So…. Did I buy a 5 square feet plot of land in Scotland so that I am a land owner and according to Scottish tradition I now have the right to call myself Lord?
Yes. Yes I did. My name is Lord Cornelis Leenheer.
Now on one hand I love to see Elon fail miserably. Last week has been fun.
But on the other hand. I’ve been active on this platform for almost 15 years. I owe a lot the community on Twitter. I have good friends that I first met on Twitter. And how would I make terrible dad jokes after the twitpocalypse?
But tweets do have consequences.
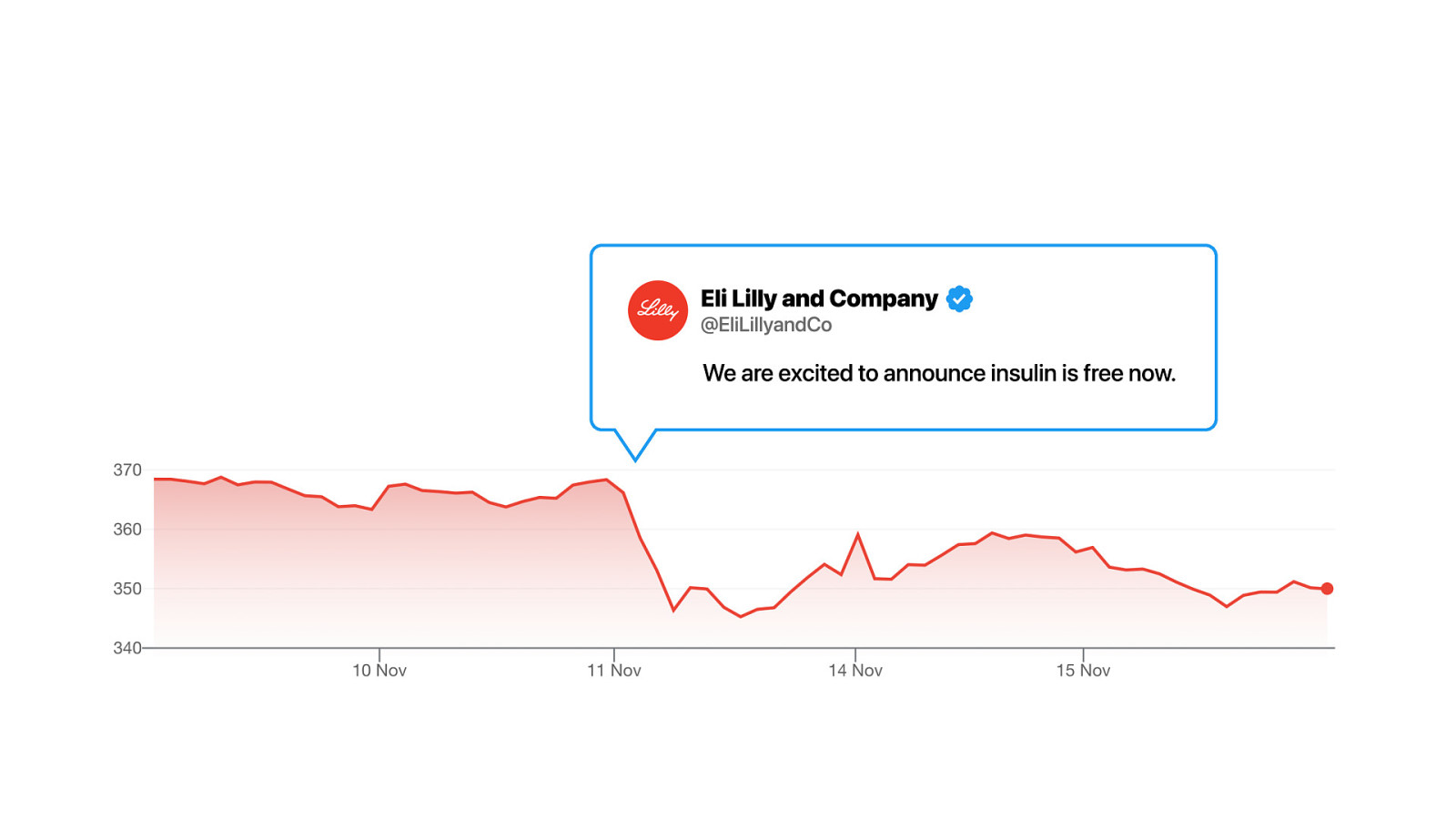
This happened to the Eli Lilly stock after this tweet. Now they actually deserve this for artificially inflating prices of Insulin.
So it is not completely innocent.
Just one troll needs to get on Putins nerve and he’ll go thermo nuclear on our asses. Bombs will rain down on the Twitter datacenter’s.
A nuclear twitpocalypse is basically inevitable. 44 billion down the drain… and everybody will be dead, but let’s not focus on that.
Okay, some of us will survive and live underground for a while. We will be conquered by talking apes and monkeys. But luckily some astronauts will rescue us from slavery. I saw that in a documentary once.
So now what? We need to rebuild society. Bring civilisation back. And that means sharing meaningless photos about your food. And of course cat gifs. And I say GIF, because after the twitpocalypse everyone agrees it is GIF. – All the JIF people were eaten by monkeys.
And the most important question, will there actually be cats left, or will they mutate into horrible monsters like flerkins that will come out night and try to eat our children. Those are the important questions that I think about when I lay awake in my bed at night.
But good news. Everything we need to rebuild society is already in your browser.
If you were sensible - Like me - you would have bought a massive supply of mutant cat repellant and installed a gif sharing PWA beforehand. And that PWA will keep working after Twitter is gone.
And because networks will be down, we need a new way of transmitting data. So why not do it visually. Our PWA is going to use the getUserMedia API to capture video…
And we’re going to need WebAssembly to analyse that video, because JavaScript is just too slow for this. And the whole analysation happens in a WebWorker.
But what are we going to analyze? What is the perfect way to visualise data in a machine readable way.
QR codes…. Obviously!
Have you ever wondered how an QR code is encoded? Why it looks like it looks?
First there are the finder patterns. This is used to recognise this is a QR code and determine the basic geometry.
Have you ever noticed this box? It is used to determine the alignment. If you have some larger codes, you can even have multiple of them.
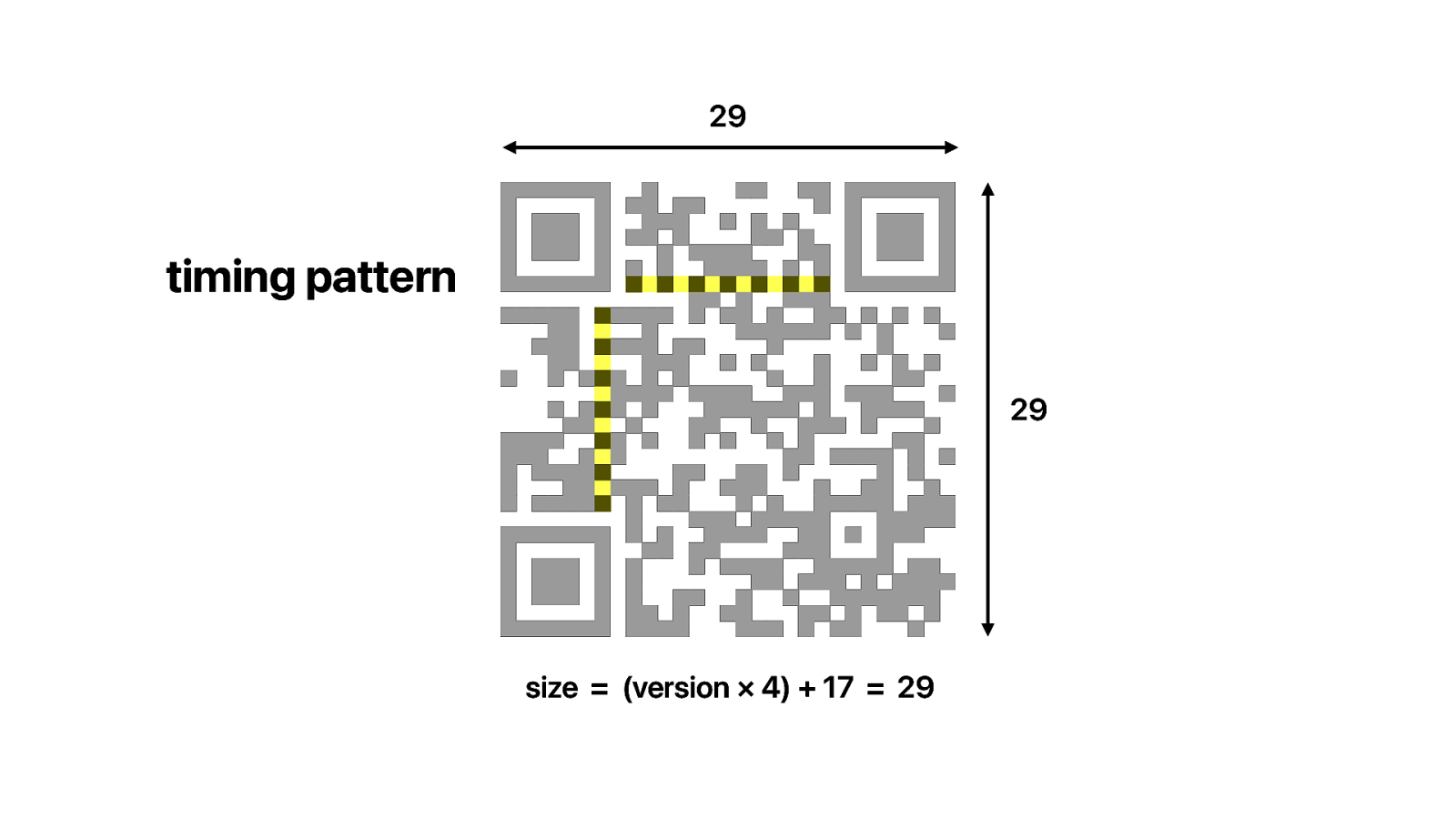
Then there is the timing pattern. This can be used to determine the version of the QR code. And by version I actually mean the size.
There are 13 modules in this timing pattern. In the terminology of qr codes each bit, each square, white or black, is called a module.
13 - 1 / 4 = 3.
This is version 3.
And version 3 is aways 29 modules wide and high.
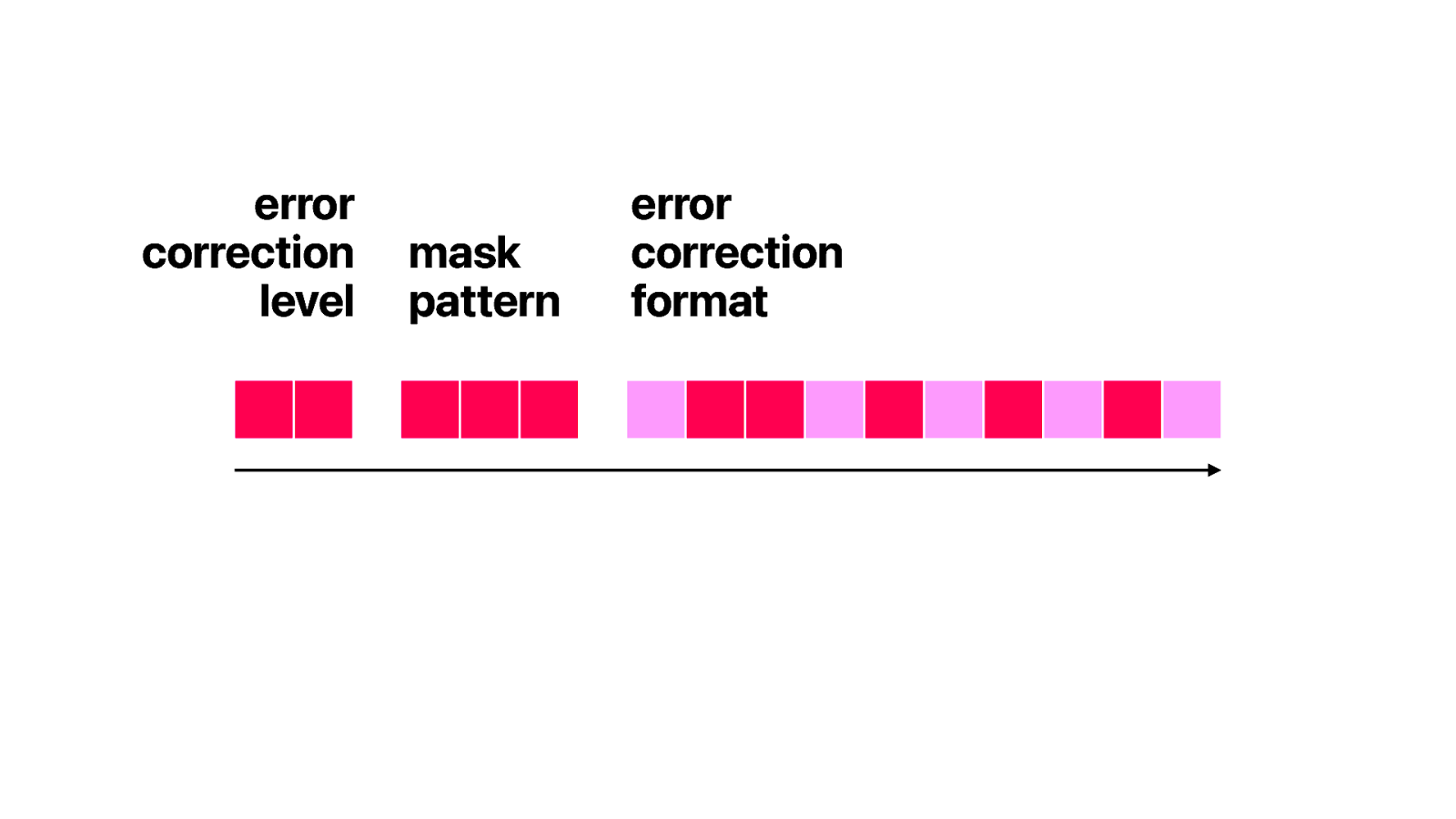
Right next to the finder patterns is the format information.
The information is actually included twice. Once in the top left…
… and once in the right and the bottom.
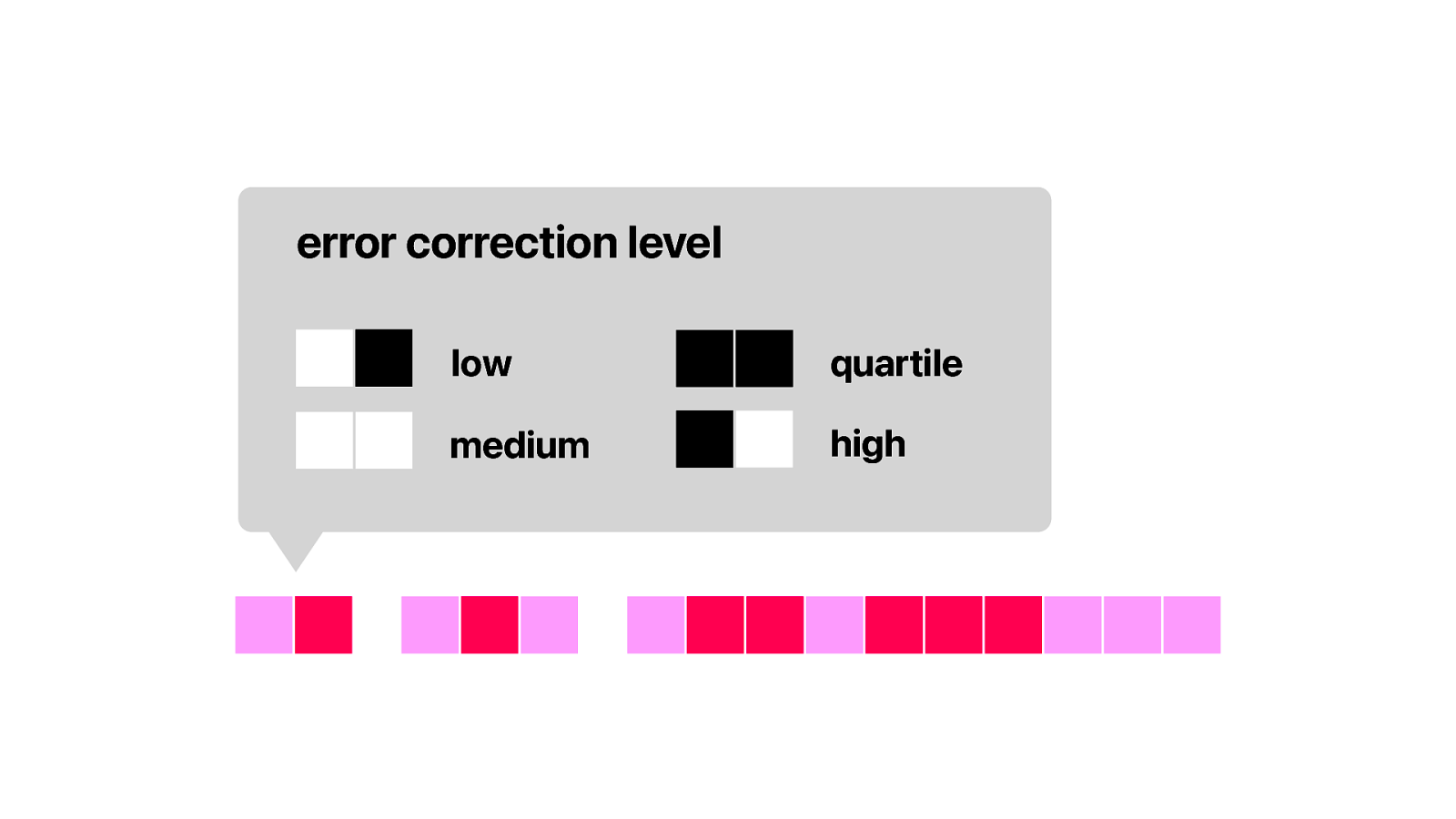
The format information consists of info about error correction and the mask pattern.
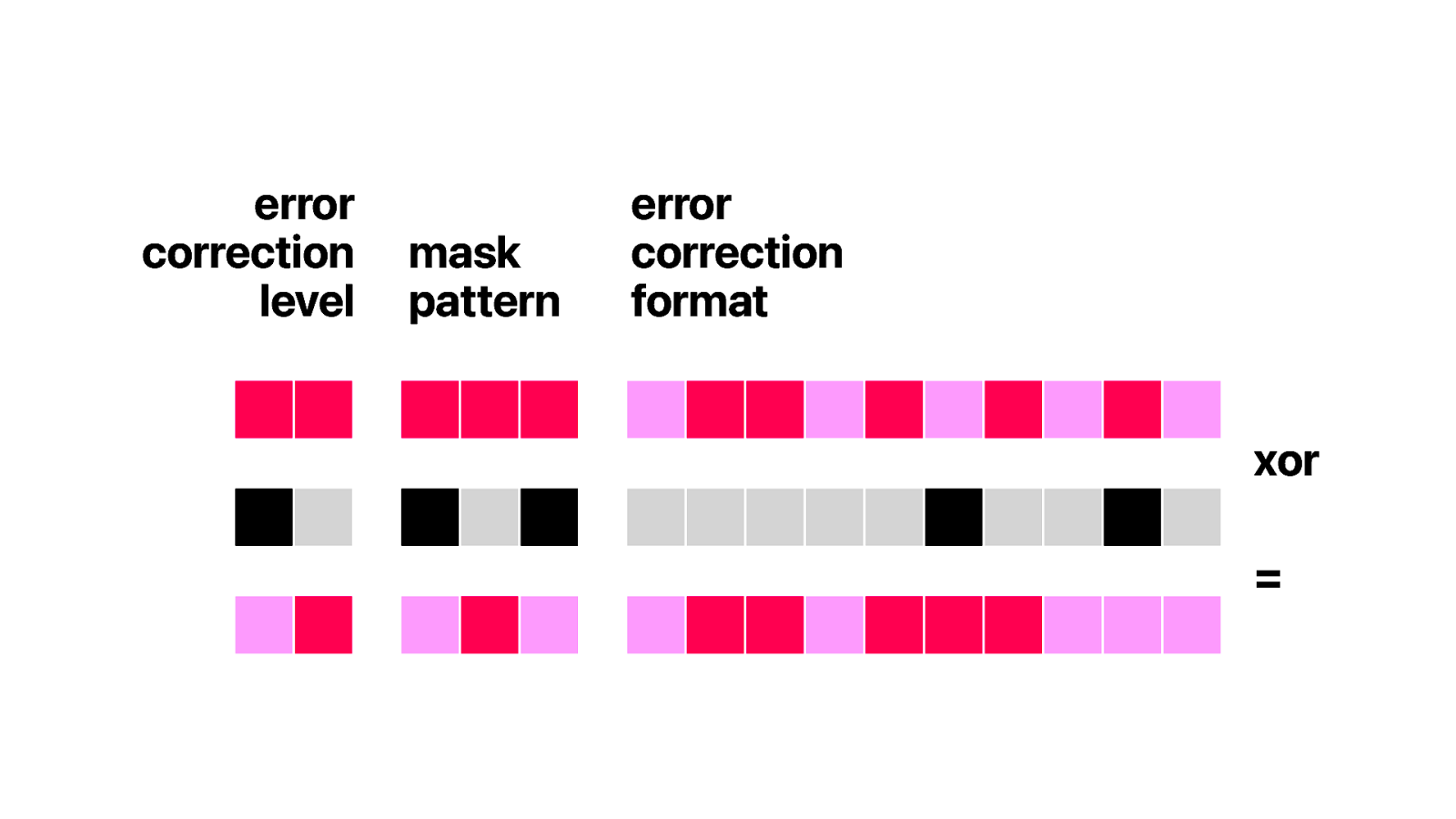
But first we need to “uncook” the raw data we found using a special 15 bit format mask. This is to make sure there aren’t any long dark or white areas in the format information causing reading errors.
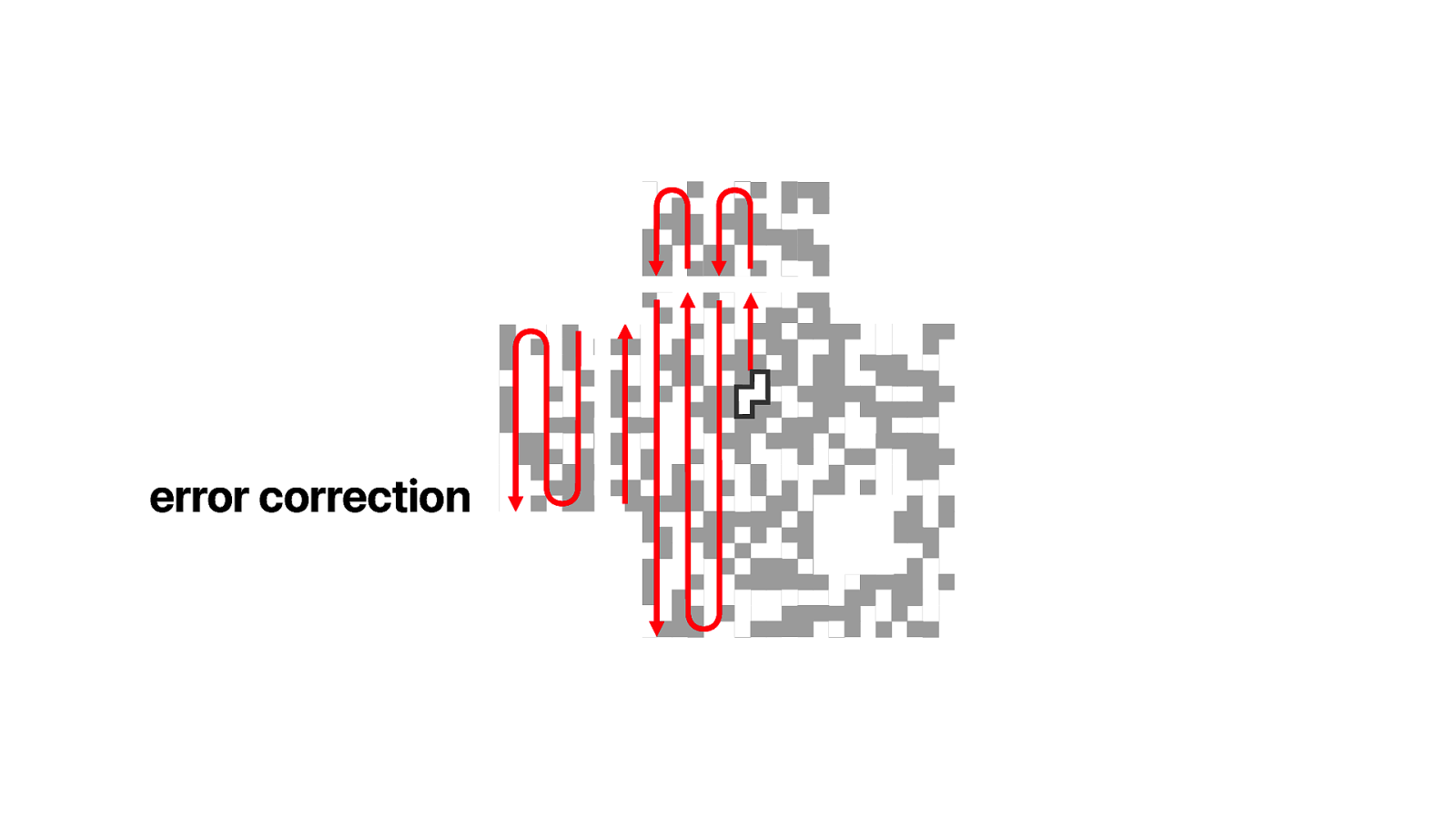
Now look at the resulting data. We are using low error correction. That means we can expect to recover about 7% of the data when the qr code is partially covered by something else. This is also how you can put logo’s on top of the QR code. The data under the logo is recovered using error correction.
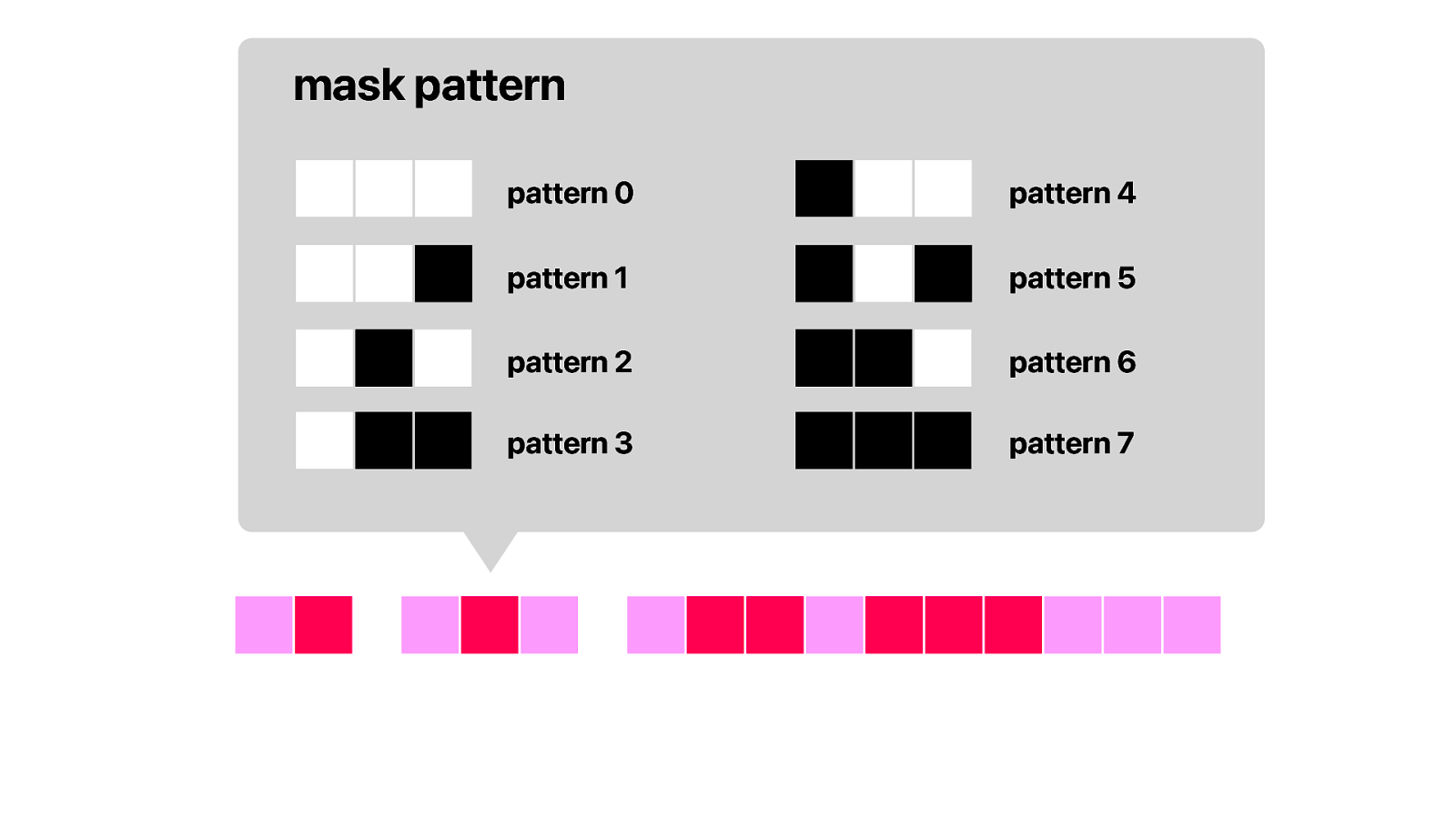
Then the mask pattern.There are 8 different types of patterns, which are all baked into the algorithm to encode and decode QR codes.
These patterns are defined by a simple mathematical formulas and when encoding it is applied to the raw data using xor.
In our case we are using pattern 2, which are vertical lines every 3 modules. And if we are decoding and need to do the reverse of a xor.
And we only need to do this on the data area of the QR code. Not any of the finder, timing and alignment patterns.
So we end up with the raw data of the QR code
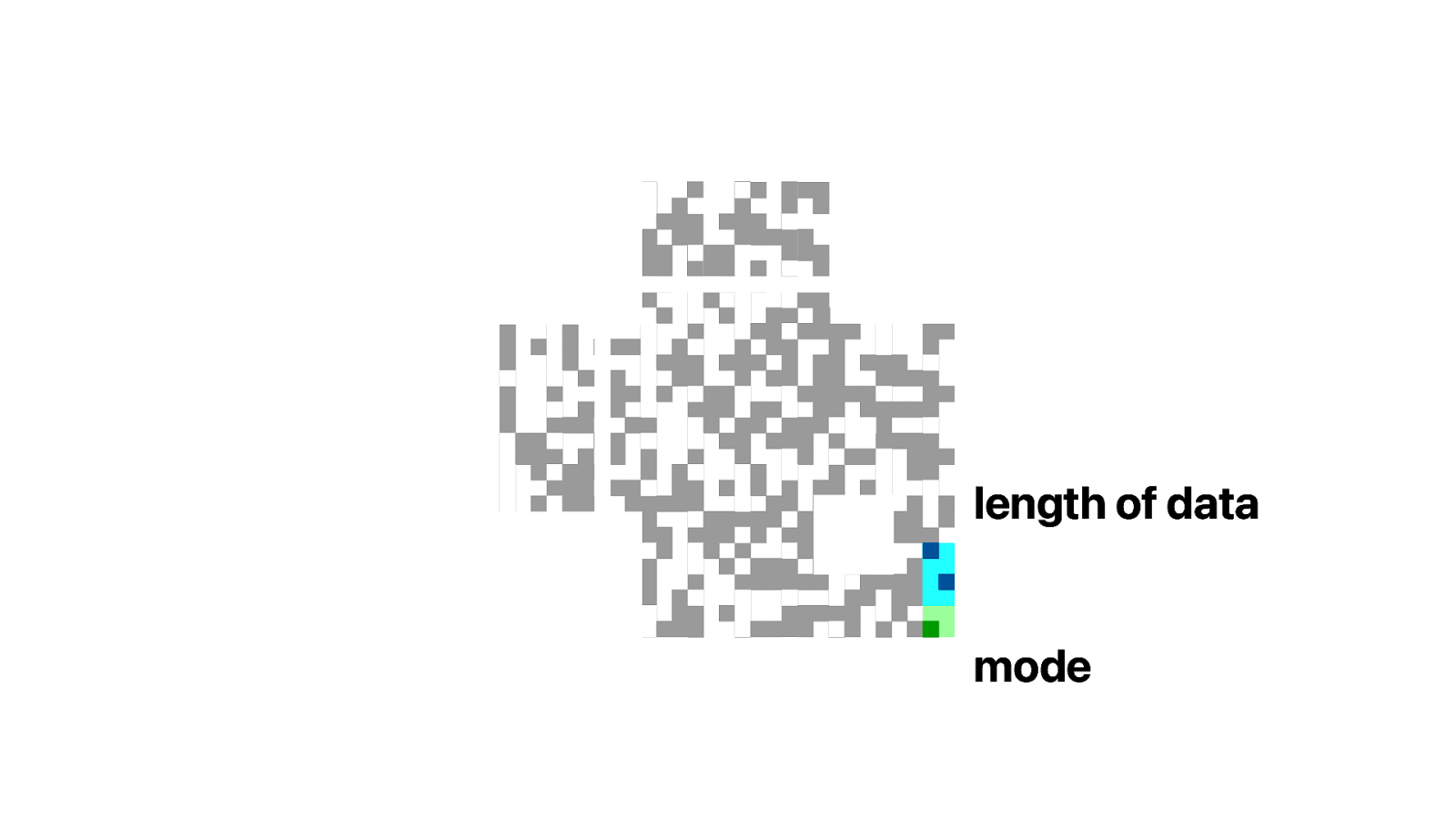
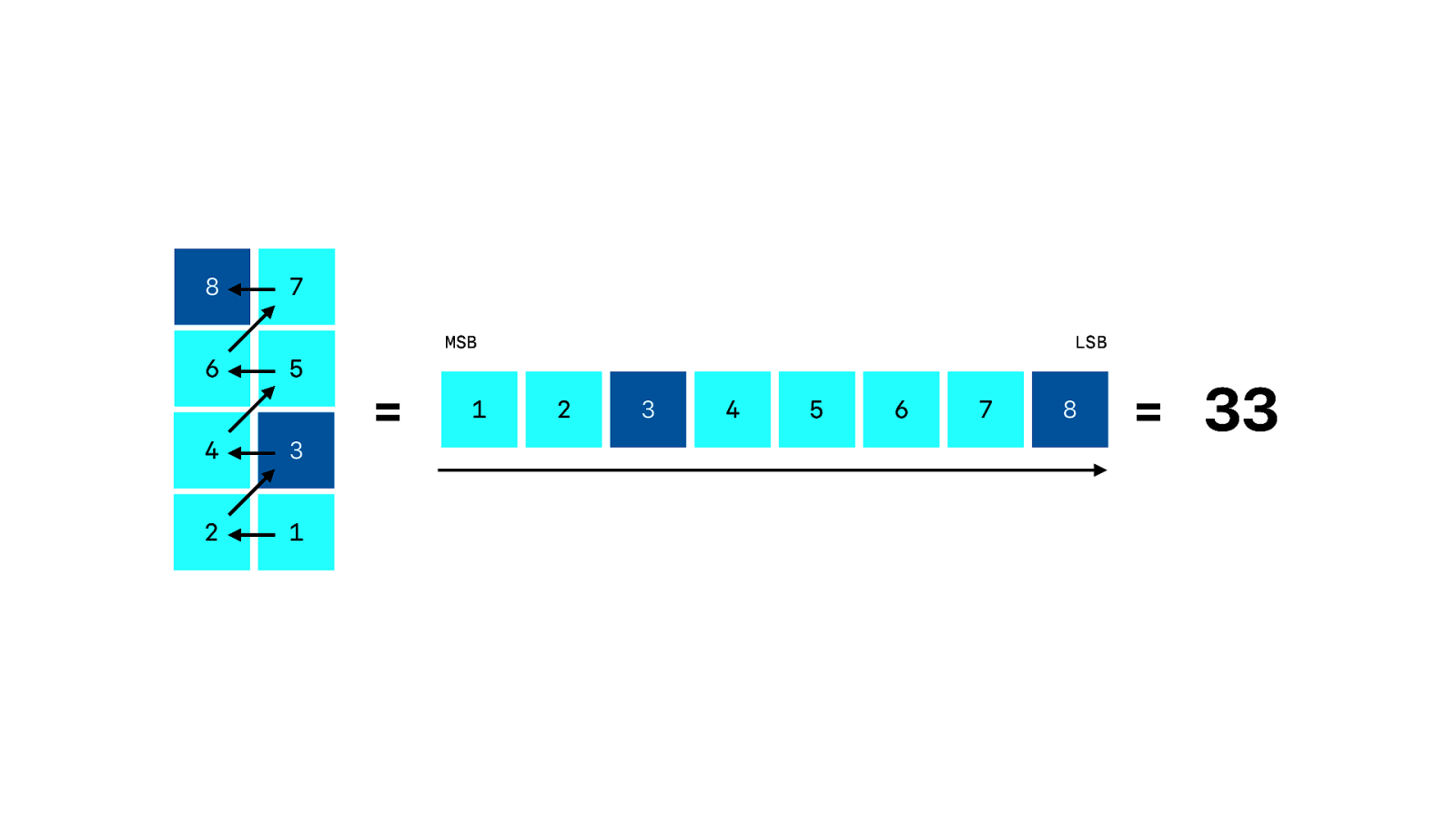
The data starts in the bottom right. First we have a block for the encoding mode. Then a block with the length of the data.
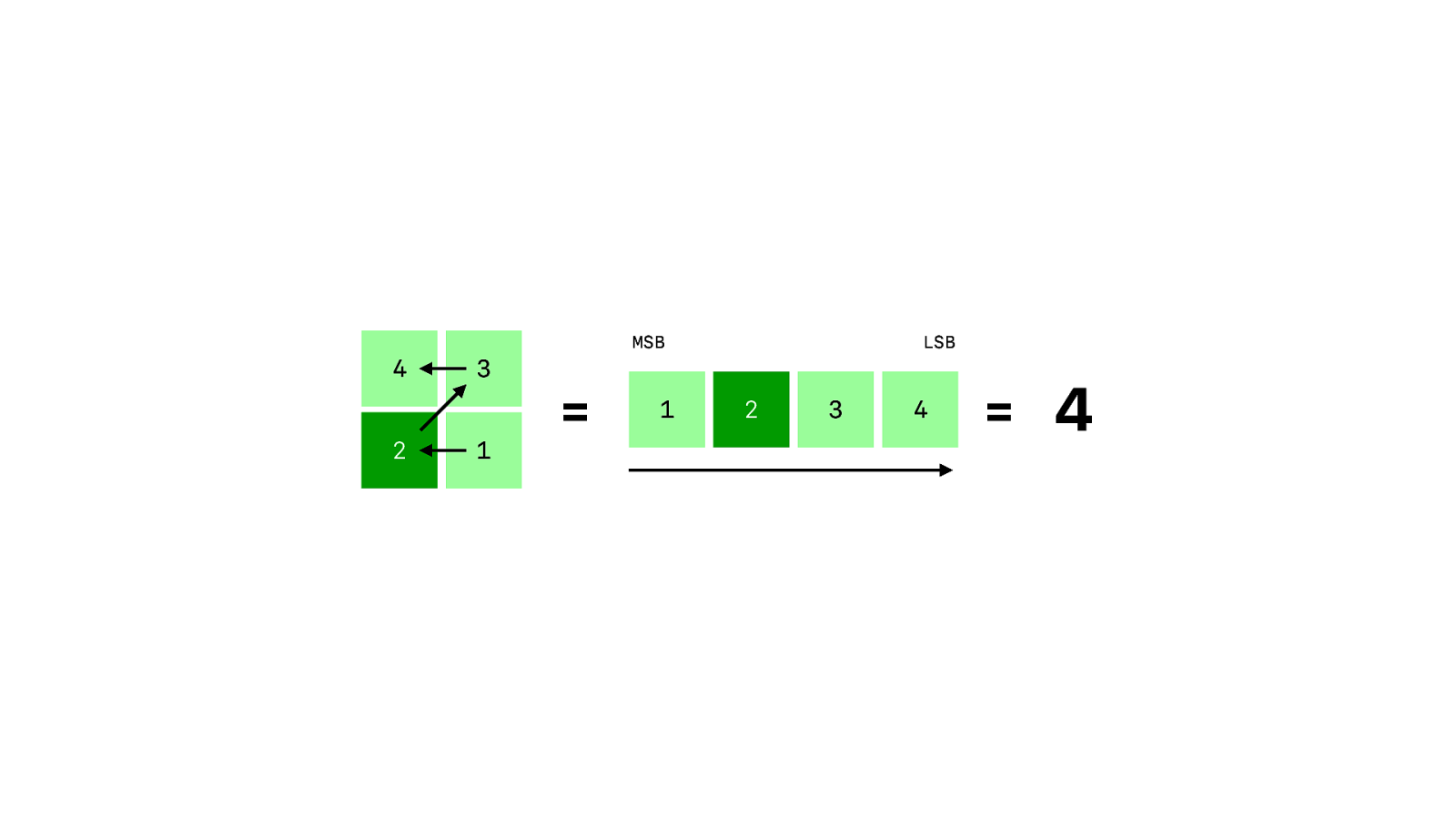
The encoding mode is just 4 modules. In this case the data is encoded using format 4, which is an Latin-1 encoded string. There are encodings for numeric data, alphanumeric strings and Japanese Kanji.
The block that contains the length is 8 modules in our case, but that depends on the mode and version of the QR code. In our case we have 33 characters of data that we need to decode. And since we are using Latin-1, each character is one byte.
The data then just snake across the QR code. Followed by an end of message terminator.
And when we decode each of the 33 bytes we get…
https://html5te.st/twitpocalypse/, our PWA
And the remaining data? Those are blocks of Reed-Solomon error correction data.
Now you probably know more about QR codes that you wanted to know. And we have a code that we can use to represent a fairly limited number of bytes. It is error resilient and can easily be machine read. So how can we use this to transmit a gif…
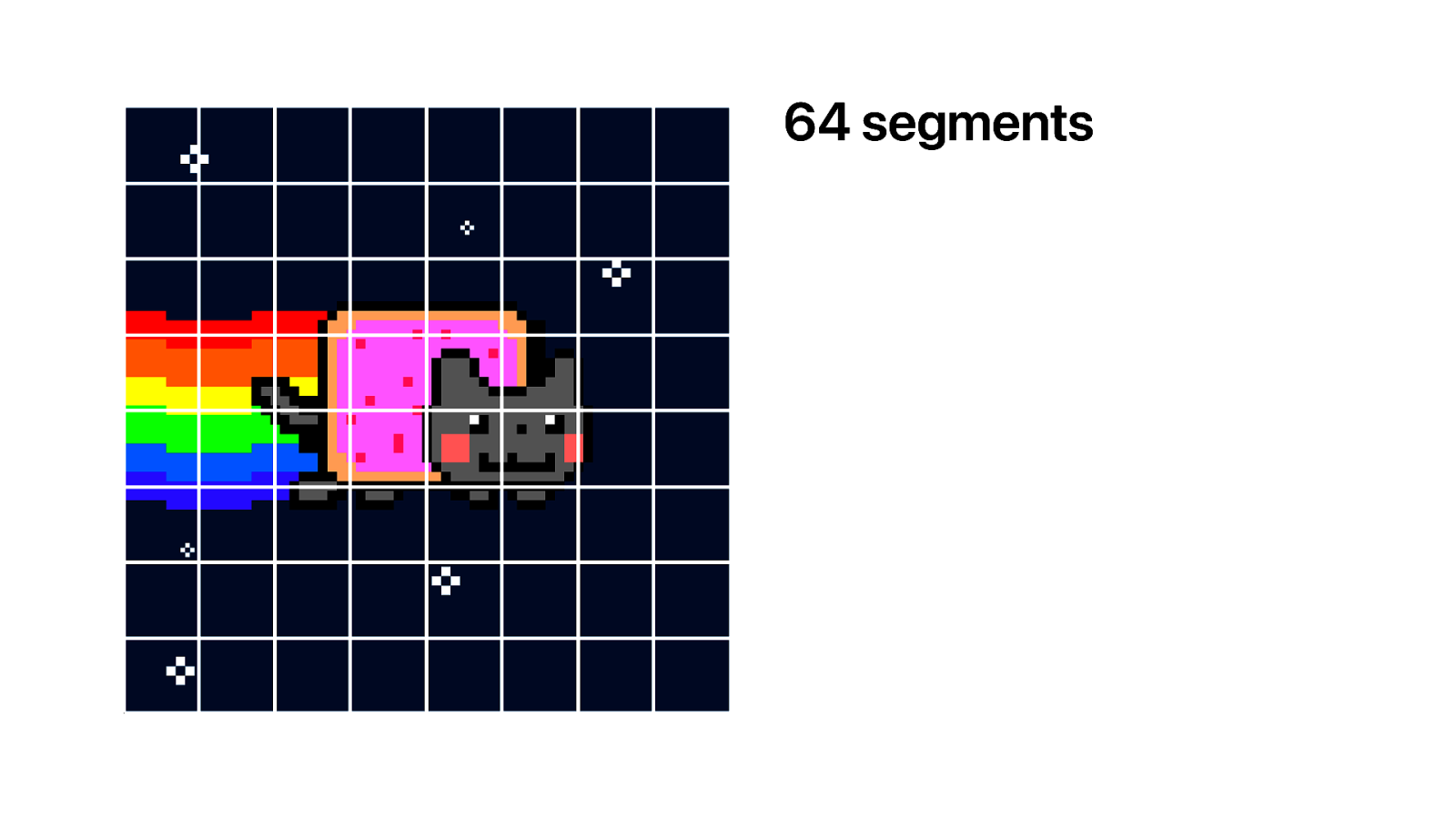
So let’s go over this. We take our cat gif of 128 x 128 pixels and split it into…
…64 segment. Because we are not going to transmit this image in one go. We’re going to split it up and load progressively.
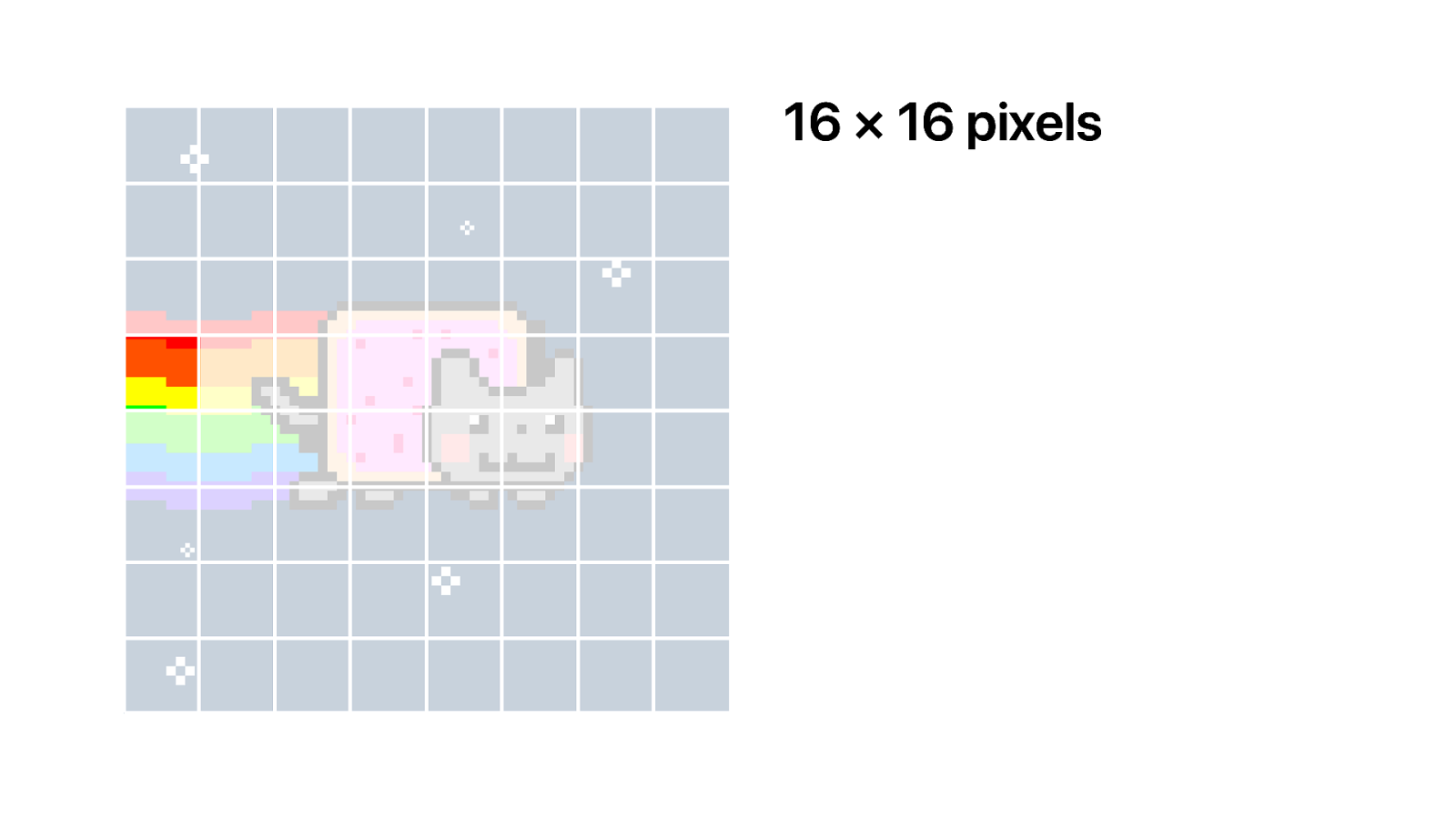
Each one of these segments is a PNG image of 16x16 pixels.
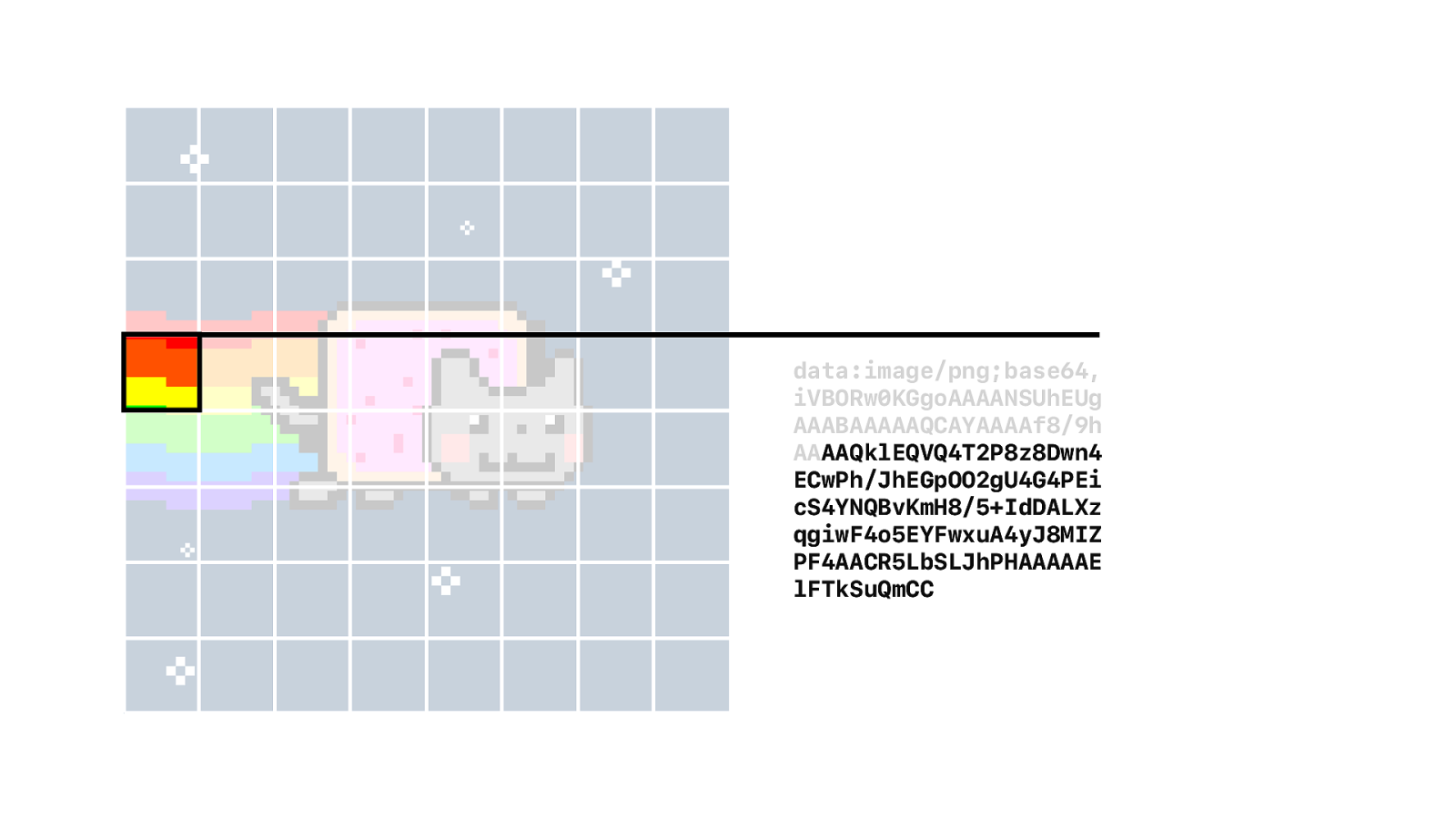
And we encode it using Base64. That is just a text string.
But the header of the PNG is identical for every segment… so we can skip the header and only encode the data that actually matters.
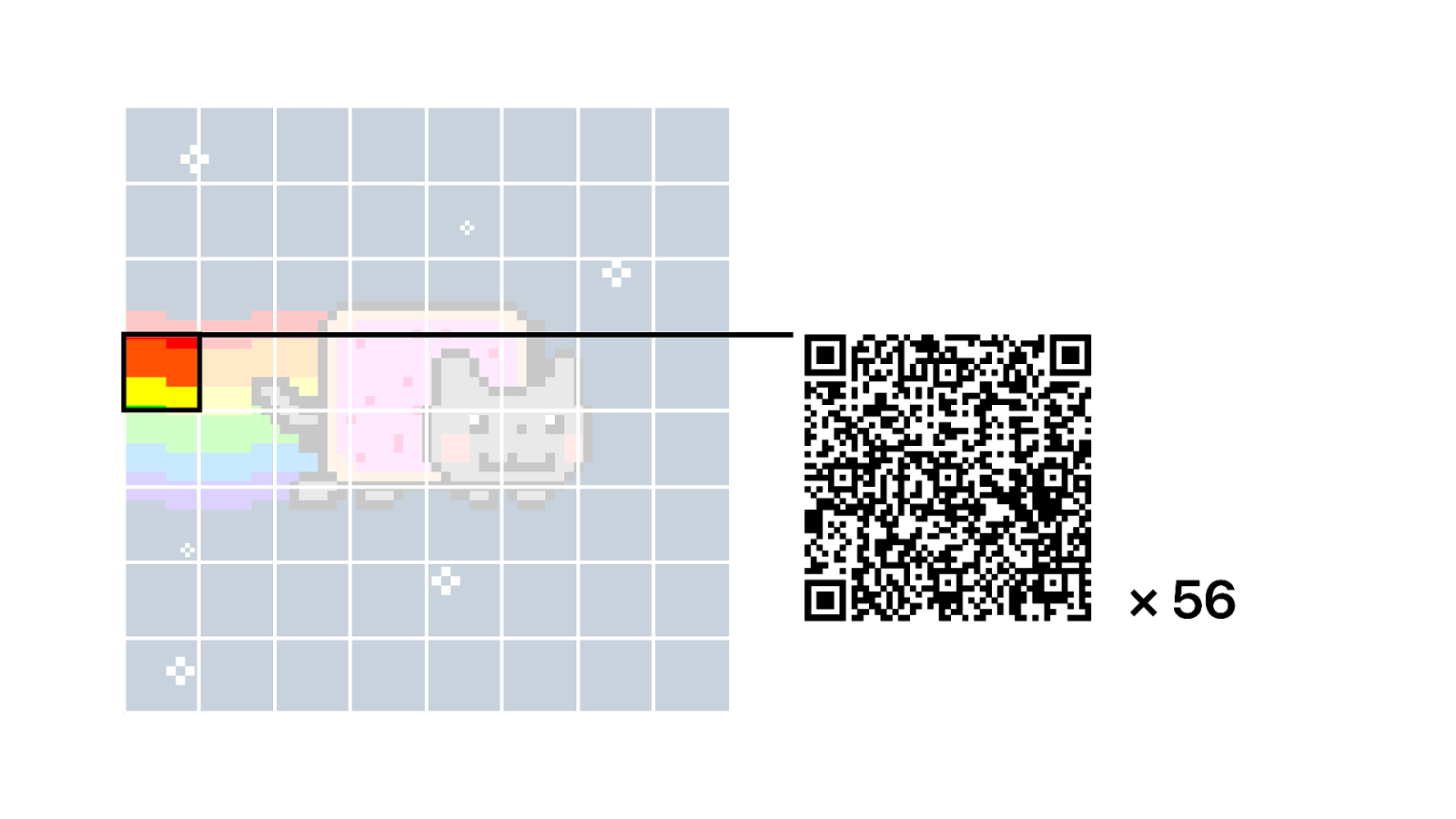
And we encode that data as a QR code. You’ll notice there are 56 QR codes, that is because some of the segments are identical. But some segments are larger than a QR code can contain. So in the end we are left with 56.
And we show these codes after each other. 4 per second. That takes just shy of 13 seconds and will transfer almost 5000 bytes. So in practice we’ve created a 300 baud modem. That is faster than the modem of my first computer. Yeah I’m old.
And on the other end we use the camera to scan, web workers and web assembly to analyse the qr code. We’re using a library Zbar which is a QR code decoding library written in C. It’s old. It’s from 2007. I’ll put it in other terms. It’s on Sourceforge.
But did you know you can use the BarcodeDetector API which is supported in Chromium based browser like Chrome and Edge.
So let’s see how this actually works in practice.