LMAO Helps During Outages

A presentation at Conf42: Site Reliability Engineering 2022 in June 2022 in by Richard

LMAO Helps During Outages

Richard Lewis www.gogorichie.com • Sr. DevOps Consultant • 20+ years of working with Operations and Software Development Team • Organizer of Chicago Monitoring Enthusiast meetup community • Diehard Chicago White Sox fan!
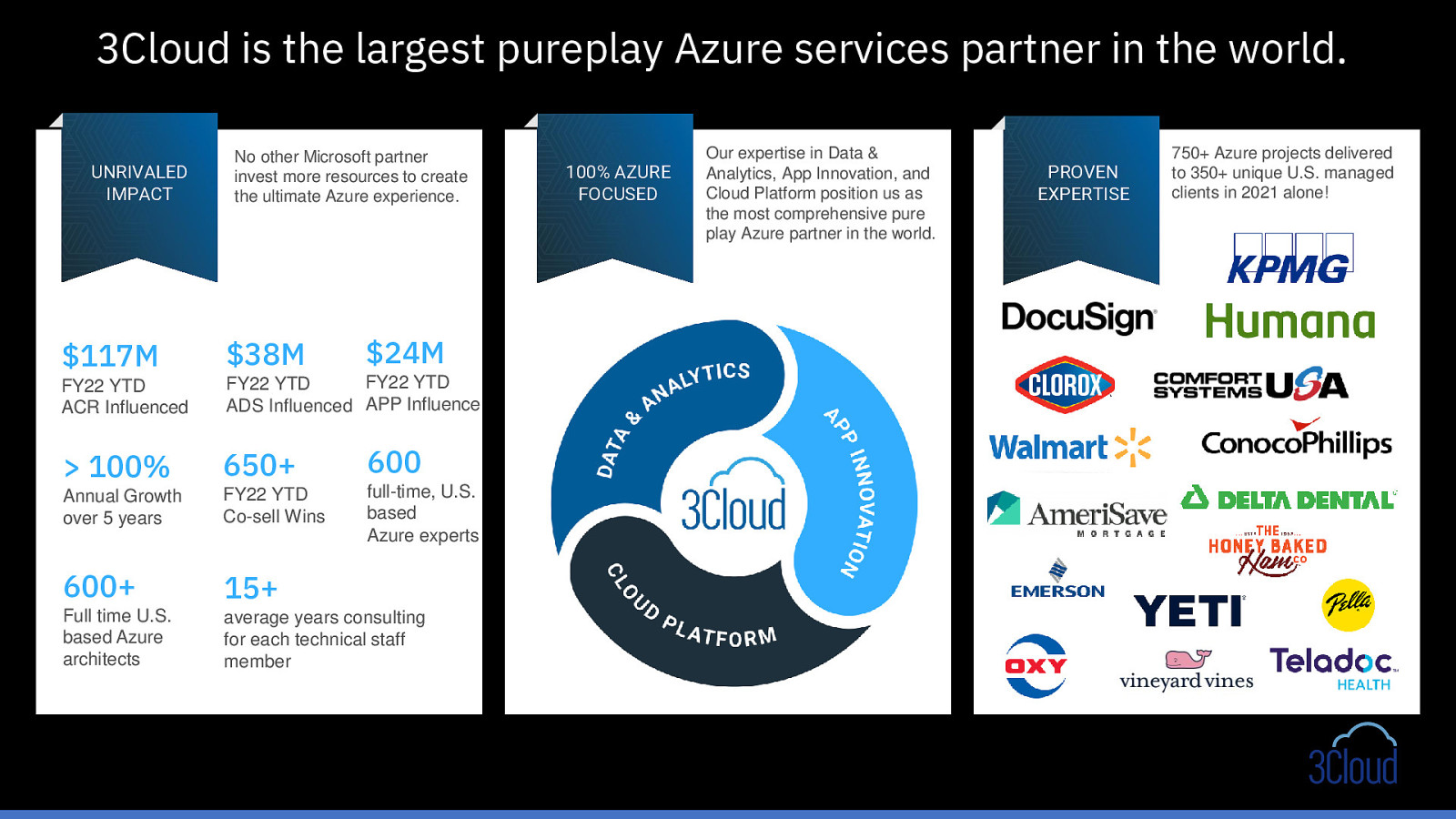
3Cloud is the largest pureplay Azure services partner in the world. UNRIVALED IMPACT No other Microsoft partner invest more resources to create the ultimate Azure experience. $24M $117M $38M FY22 YTD ACR Influenced FY22 YTD FY22 YTD ADS Influenced APP Influence
100% 650+ 600 Annual Growth over 5 years FY22 YTD Co-sell Wins full-time, U.S. based Azure experts 600+ 15+ Full time U.S. based Azure architects average years consulting for each technical staff member 100% AZURE FOCUSED Our expertise in Data & Analytics, App Innovation, and Cloud Platform position us as the most comprehensive pure play Azure partner in the world. PROVEN EXPERTISE 750+ Azure projects delivered to 350+ unique U.S. managed clients in 2021 alone!

Why LMAO?

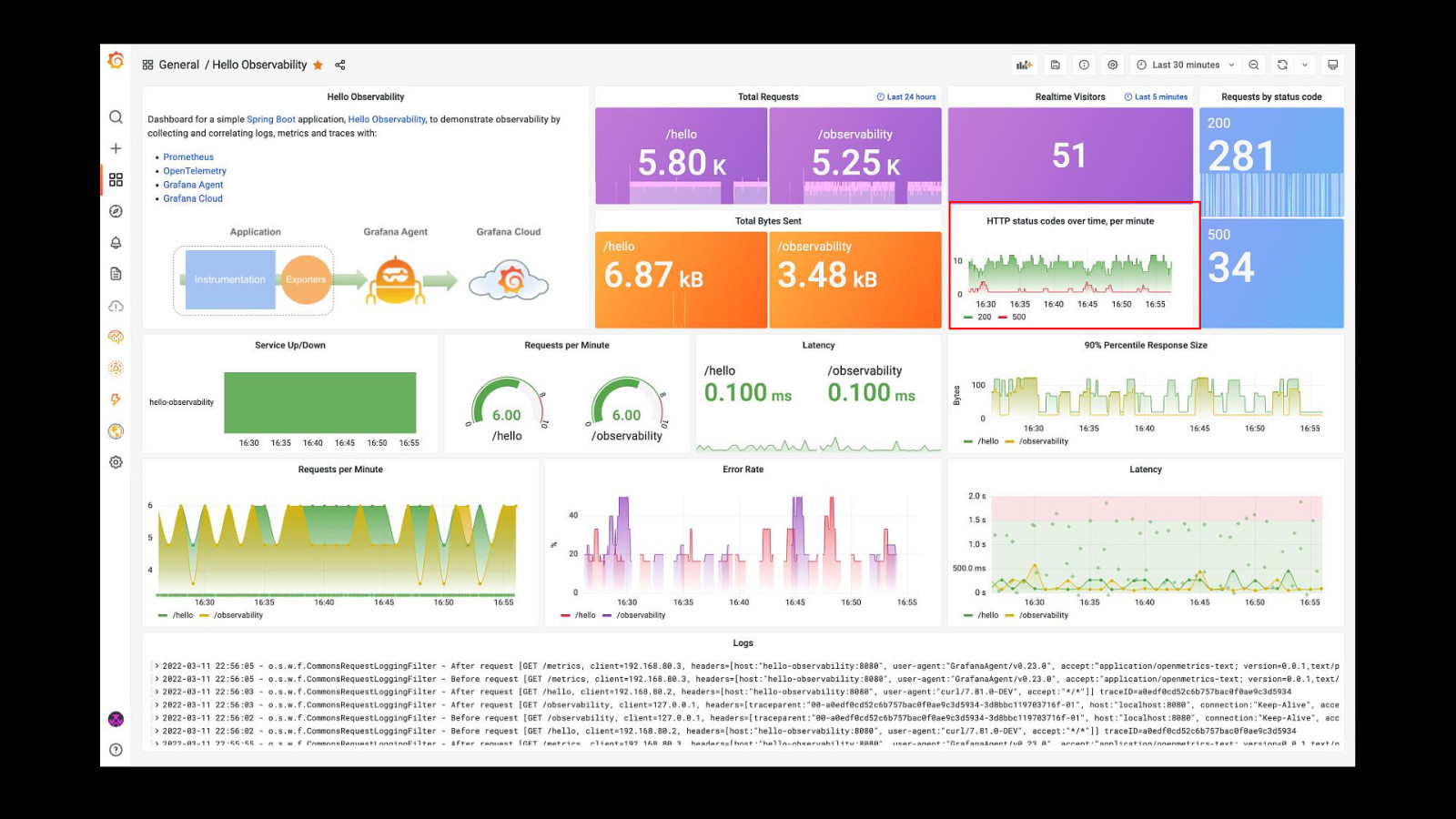
Things Needed For A Strategy Logs Metrics Alerts Observability Tool

What Are We Talking About? Platform Support Strategies Creating a standard for knowledge sharing Reduction in mean time to resolution (MTTR) Building Psychological confidence within your team

Logs & Metrics • Provide insight into the what and when • What happened? • How many errors • How many request • When did it happen? • How long was the duration

Alerts Pages Tickets Or

Alert Trauma Little Richard On-Call 365 16hrs a day No way to remote connect to office No logging framework Burned out within 6 months

Managing Alerts Effectively Scheduling team members appropriately. Avoid alert fatigue where possible. Collect data on the alerts and look for ways to reduce them regularly. Be cautious when introducing new alerts
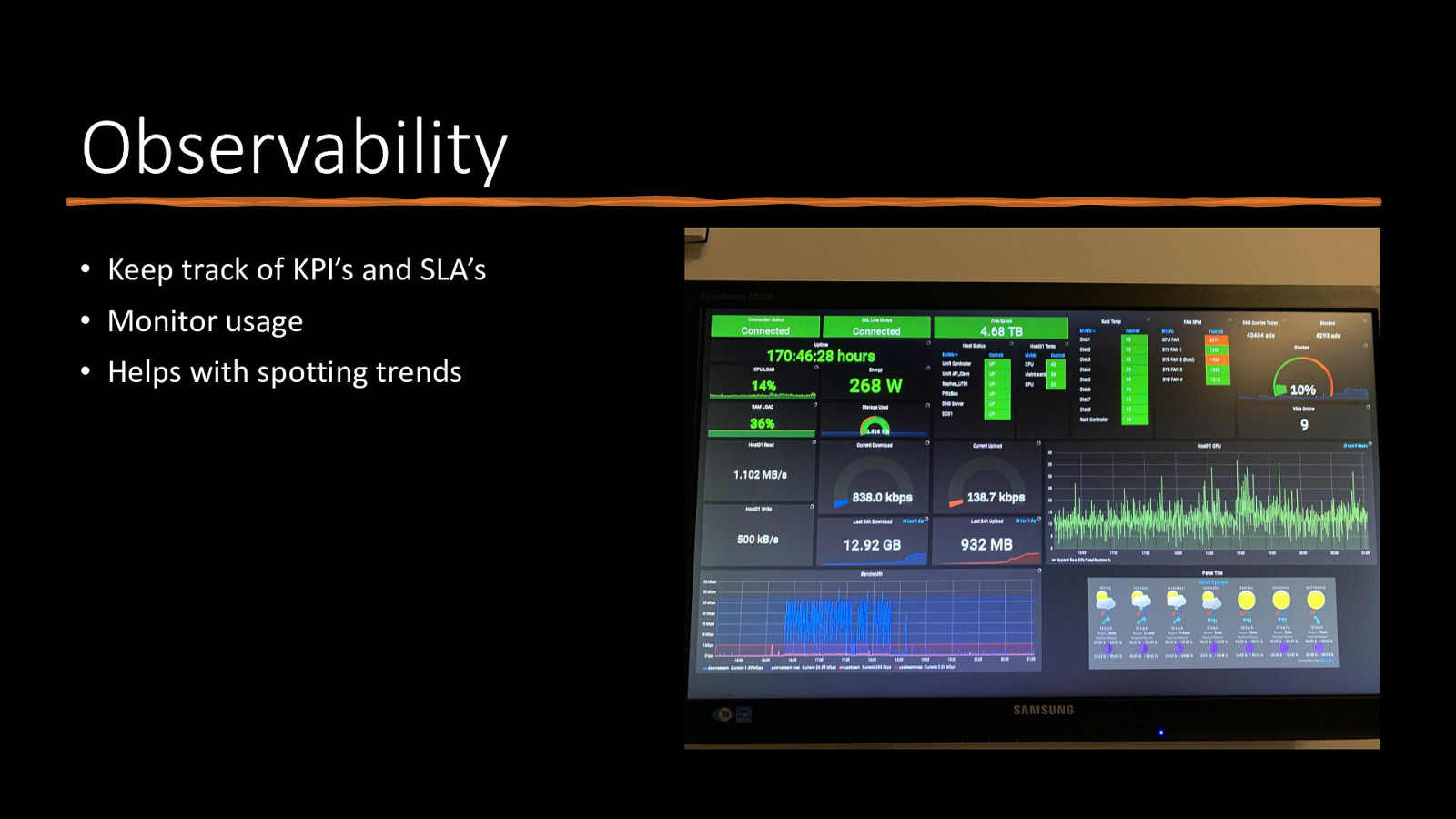
Observability • Keep track of KPI’s and SLA’s • Monitor usage • Helps with spotting trends
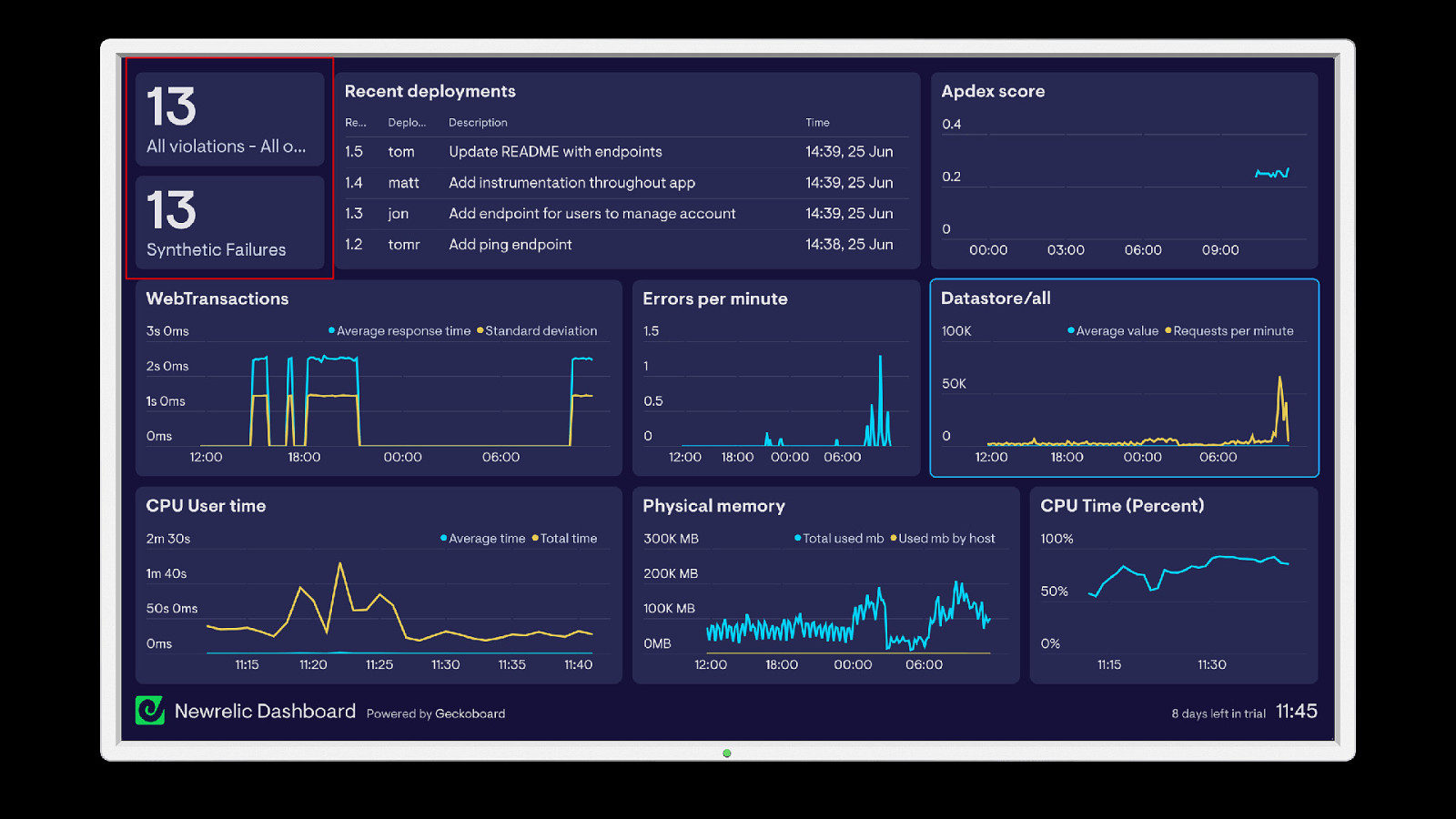
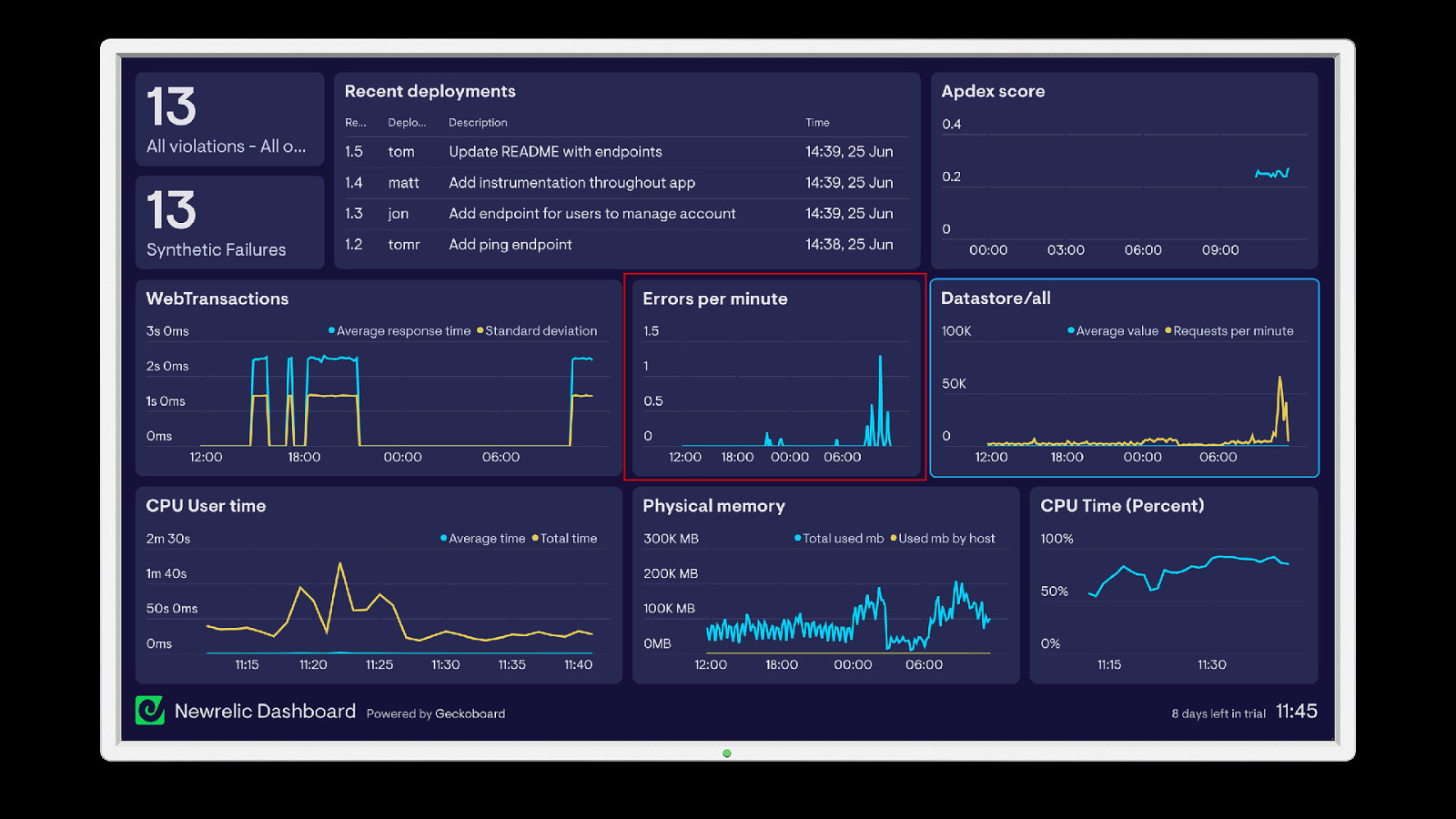
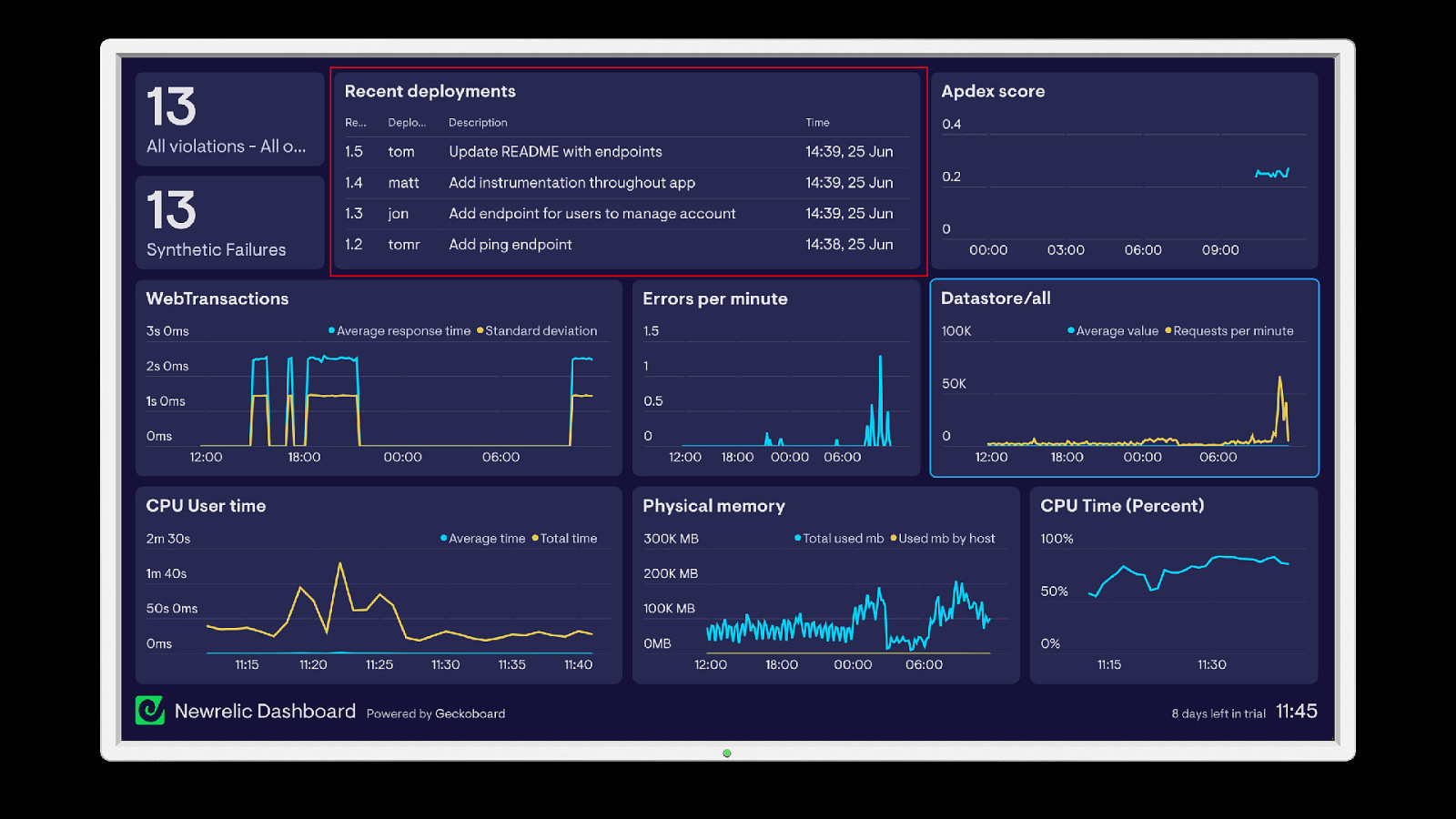
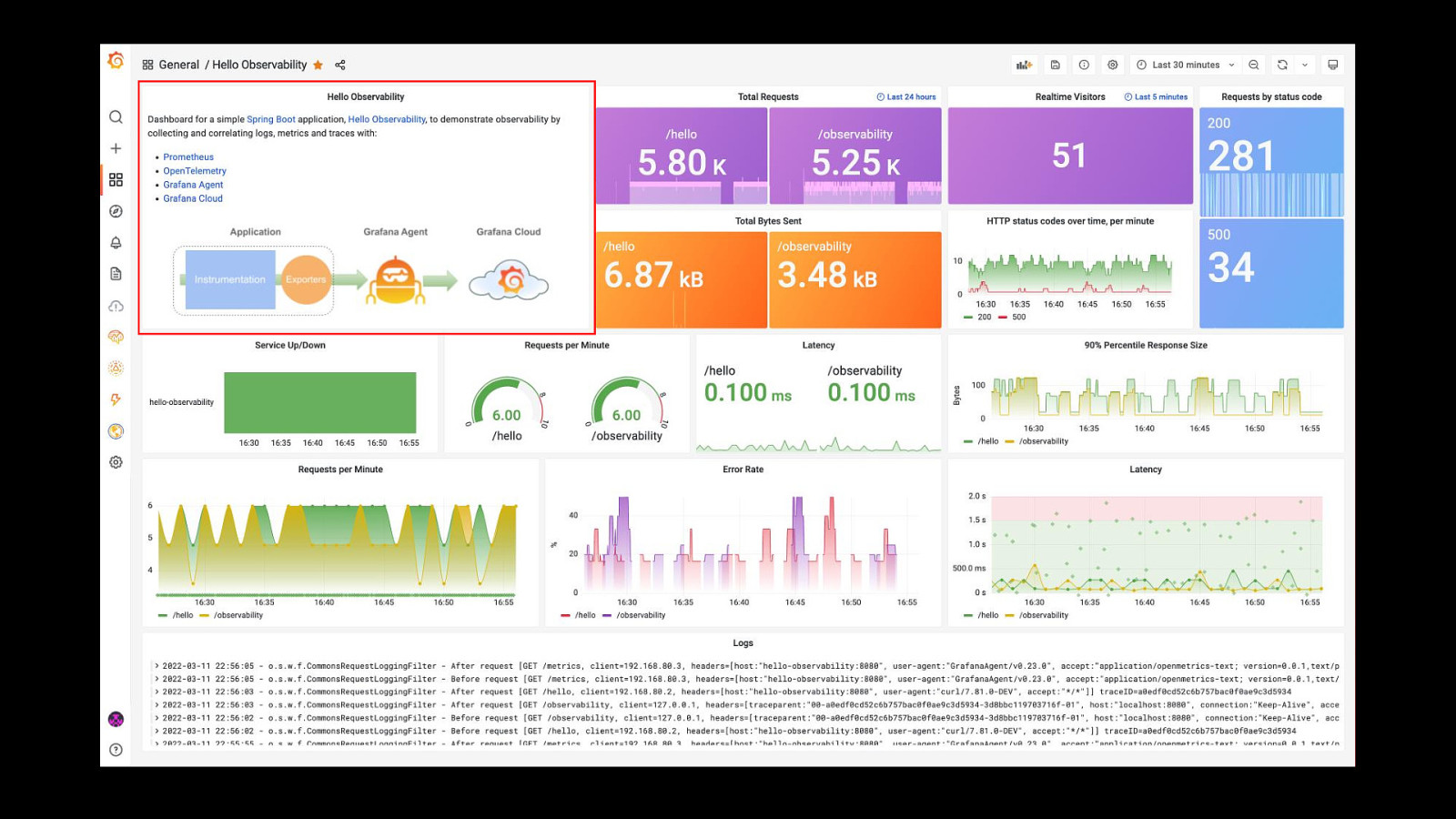
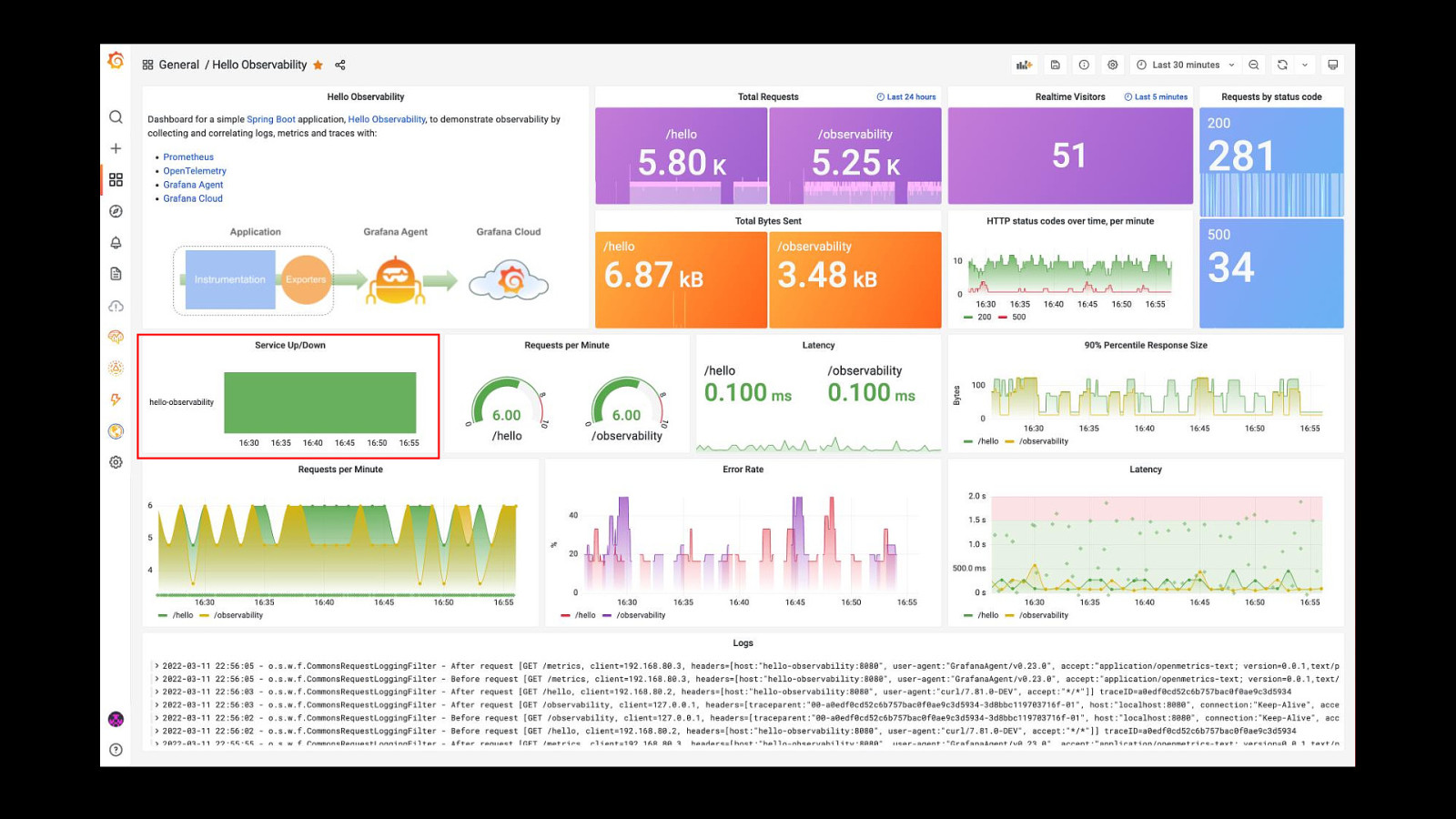

Preparing The Team Have a playbook Practice for outages

What Should Be In It? • Playbook should located where the on-call team will be able to access it quickly. • Links to application relate observability tools • Details about the golden signals for application. • Relevant information from previously outage. • Application owner contact details • Anything else you might find important.

Preparation and Training

Practice Chaos Engineering Concept created by Netflix. The goal Increase resiliency Identify and address single points of failure early. Gives you the ability to test your documentation and processes. https://techhq.com/2019/03/how-netflix-pioneered-chaos-engineering/

Postmortems

Recap of the Outage • Should be done within a day or so post incident • What went right? • What went wrong? • Where do we get lucky? https://sre.google/sre-book/postmortem-culture/

Take Aways • Have a LMAO strategy in place. • Have the appropriate documentation ready to go. • Update documentation regularly. • Avoid alert fatigue. • Run readiness preparation drills.

Thank You Richard Lewis Twitter: @gogorichie Email: Richard@gogorichie.com