
A presentation at Confluent VUG by Robin Moffatt

@rmoff #ConfluentVUG From Zero to Hero with Kafka Connect a.k.a. A practical guide to becoming l33t with Kafka Connect
Housekeeping • Slides: yes! (https://cnfl.io/meetup-hub) • Recording: yes! (in due course) • Questions: yes! • Video: if you’d like! @rmoff | #ConfluentVUG | @confluentinc
$ whoami • Robin Moffatt (@rmoff) • Senior Developer Advocate at Confluent (Apache Kafka, not Wikis 😉) • Working in data & analytics since 2001 • Oracle ACE Director (Alumnus) http://rmoff.dev/talks · http://rmoff.dev/blog · http://rmoff.dev/youtube @rmoff | @confluentinc
What is Kafka Connect? @rmoff | #ConfluentVUG | @confluentinc
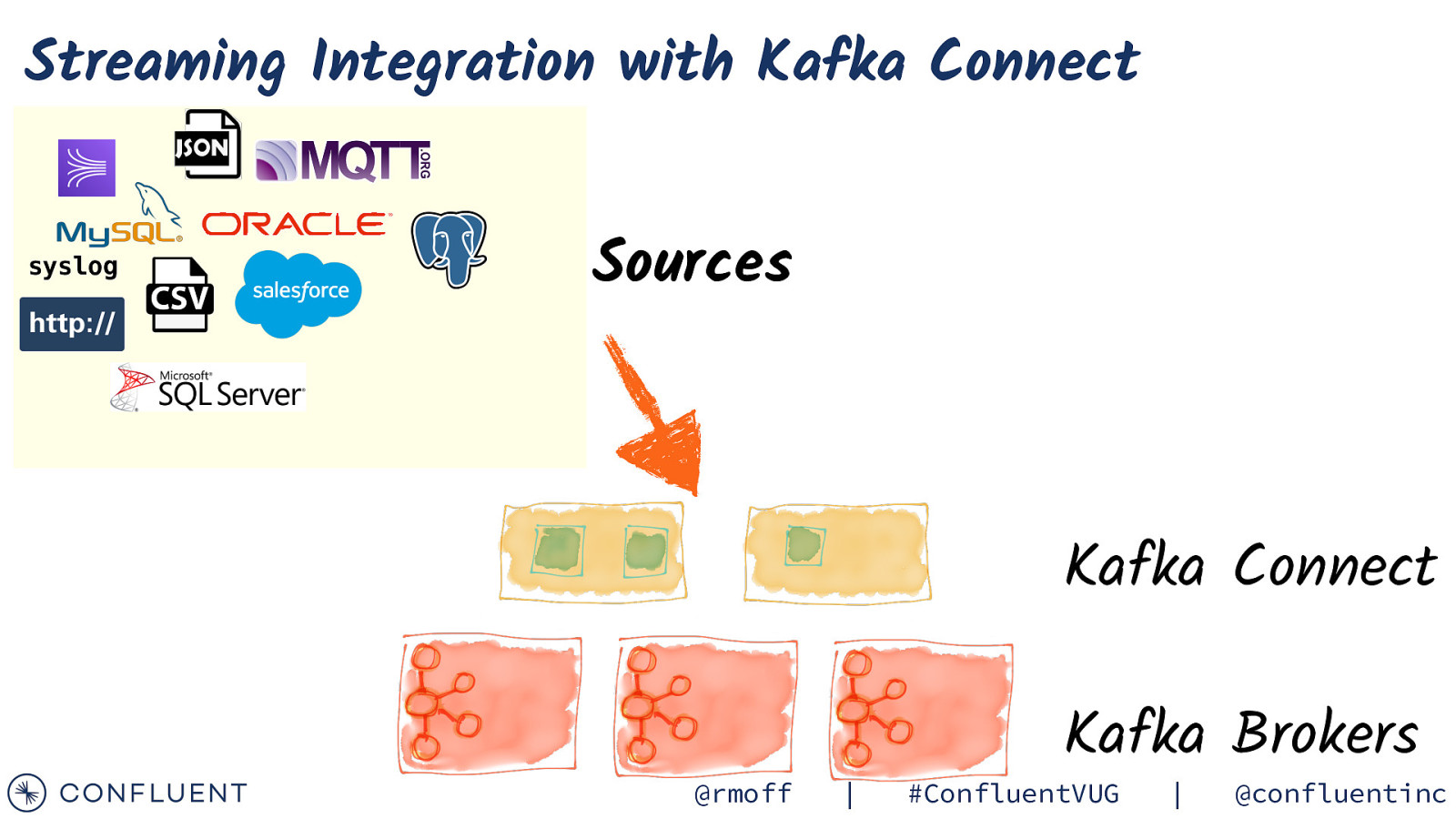
Streaming Integration with Kafka Connect syslog Sources Kafka Connect @rmoff | Kafka Brokers #ConfluentVUG | @confluentinc
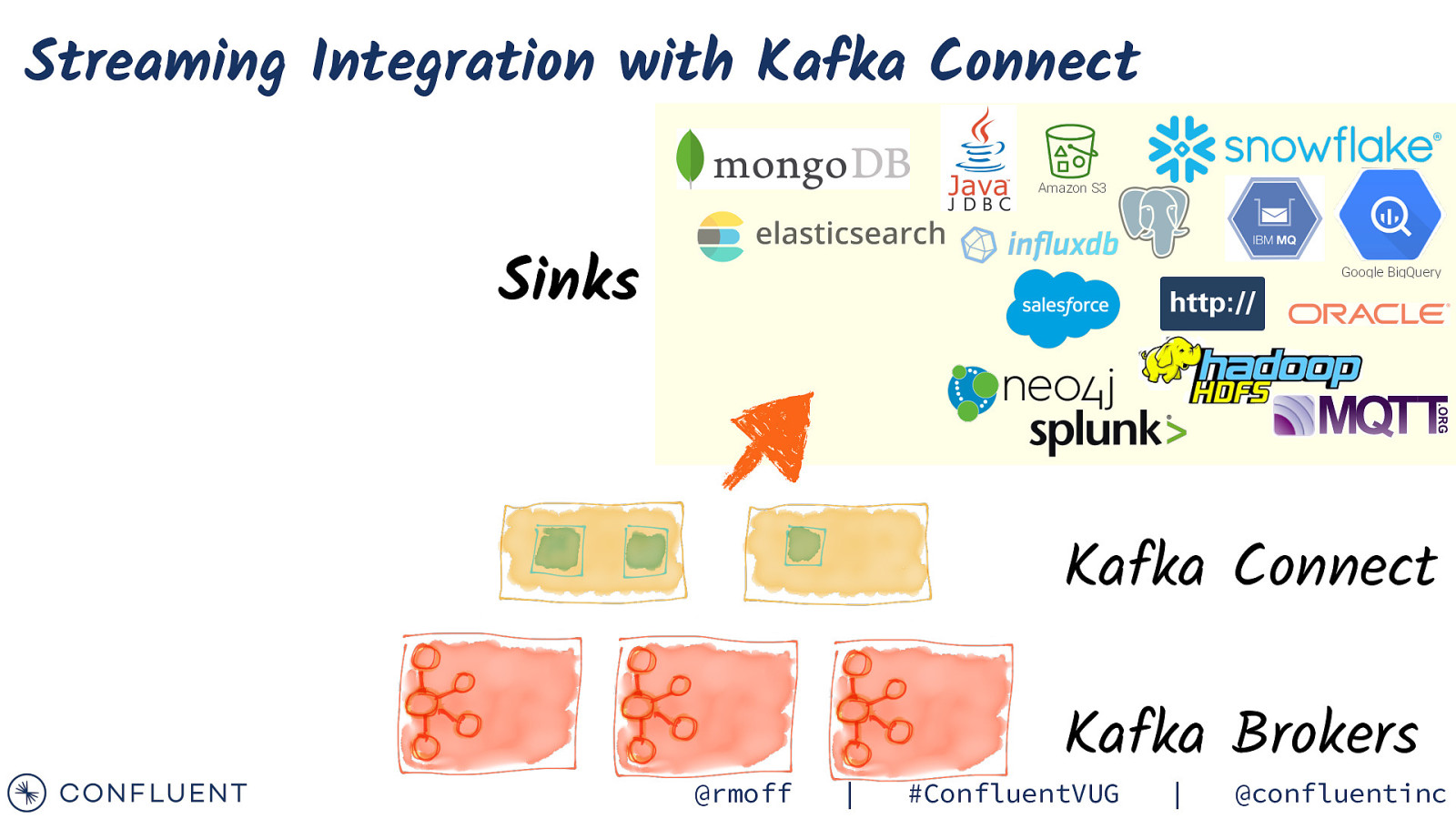
Streaming Integration with Kafka Connect Amazon S3 Sinks Google BigQuery Kafka Connect @rmoff | Kafka Brokers #ConfluentVUG | @confluentinc
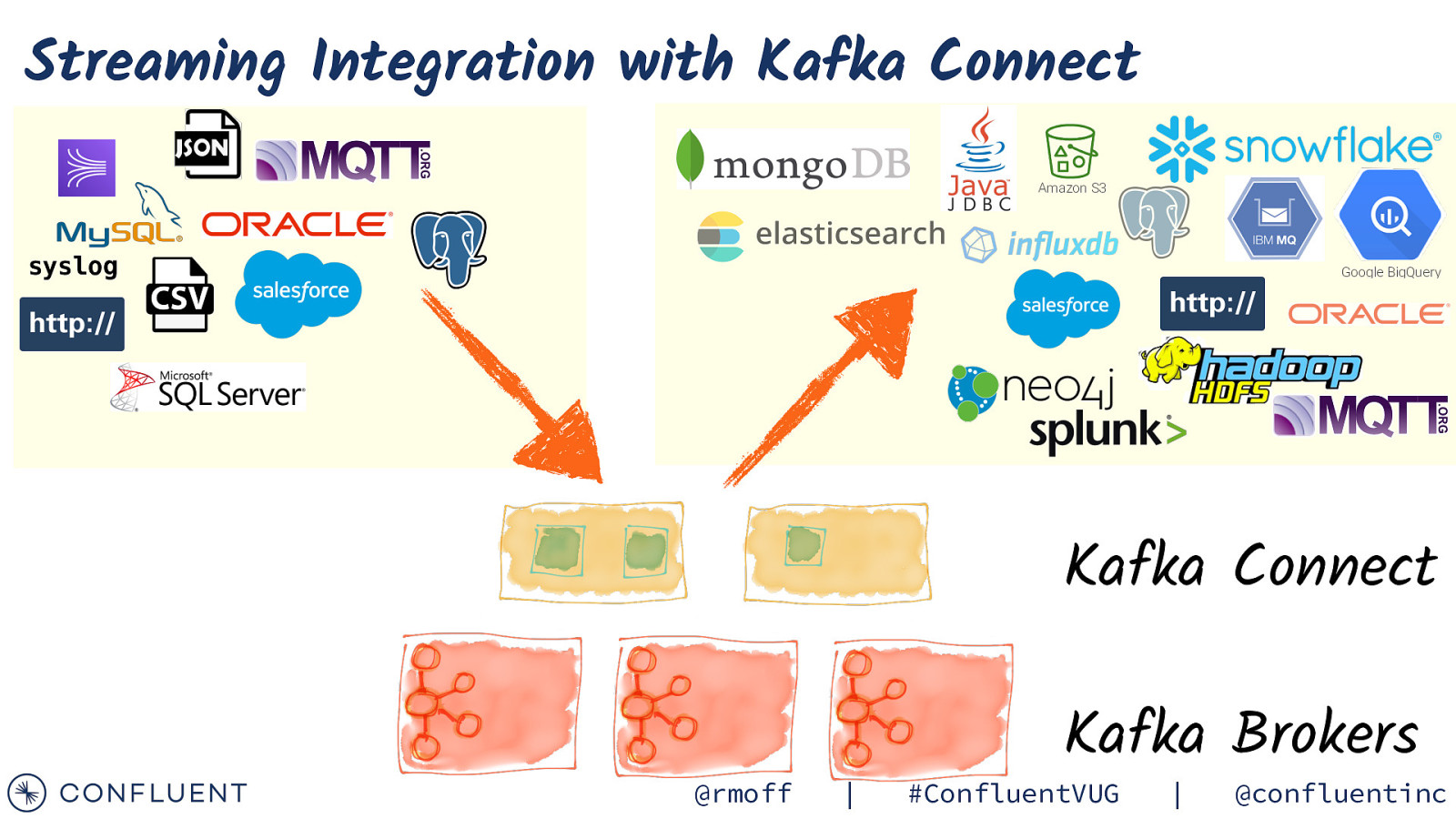
Streaming Integration with Kafka Connect Amazon S3 syslog Google BigQuery Kafka Connect @rmoff | Kafka Brokers #ConfluentVUG | @confluentinc
Look Ma, No Code! { “connector.class”: “io.confluent.connect.jdbc.JdbcSourceConnector”, “connection.url”: https://docs.confluent.io/current/connect/ “jdbc:mysql://asgard:3306/demo”, “table.whitelist”: “sales,orders,customers” } @rmoff | #ConfluentVUG | @confluentinc
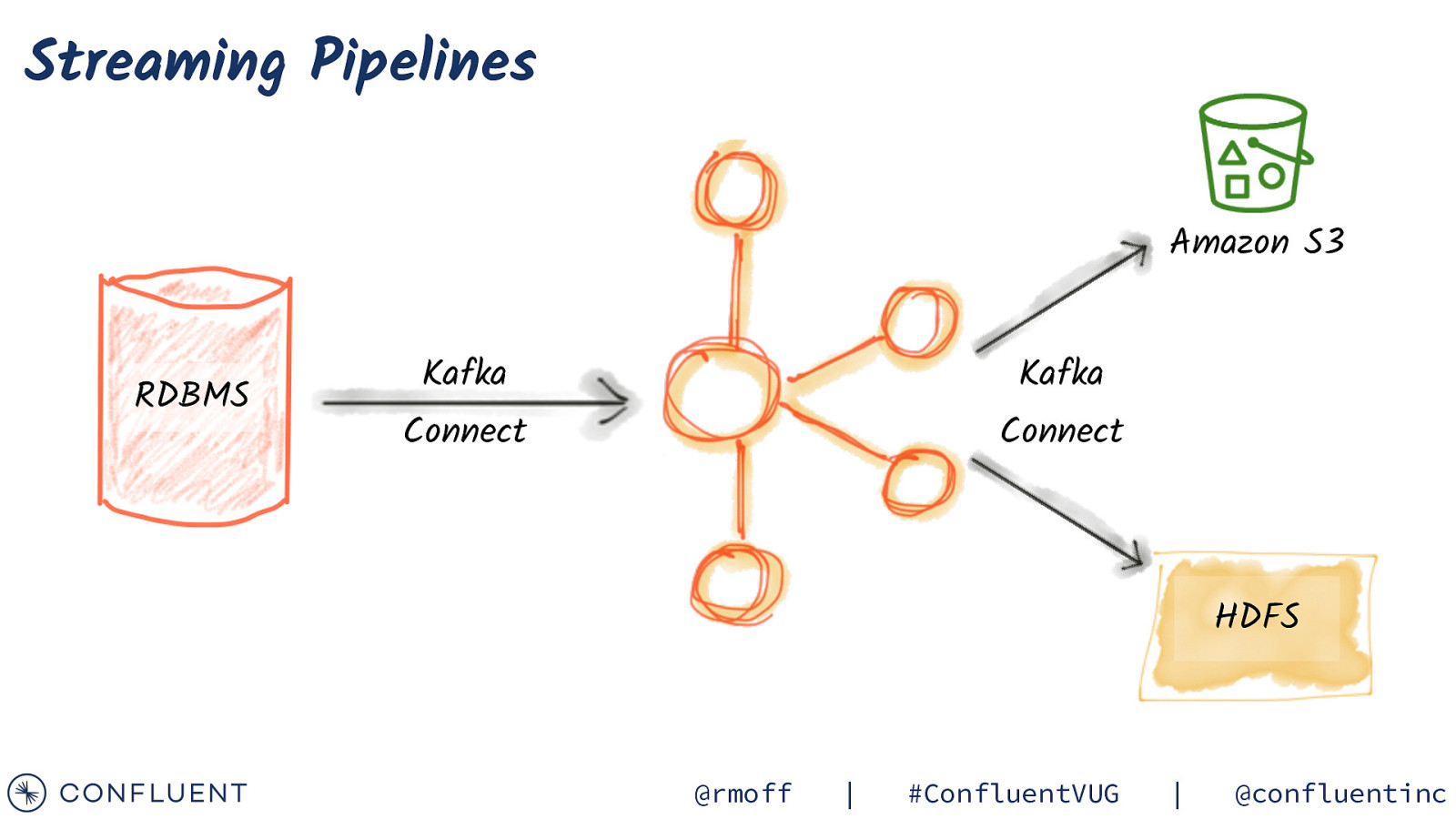
Streaming Pipelines Amazon S3 RDBMS Kafka Kafka Connect Connect HDFS @rmoff | #ConfluentVUG | @confluentinc
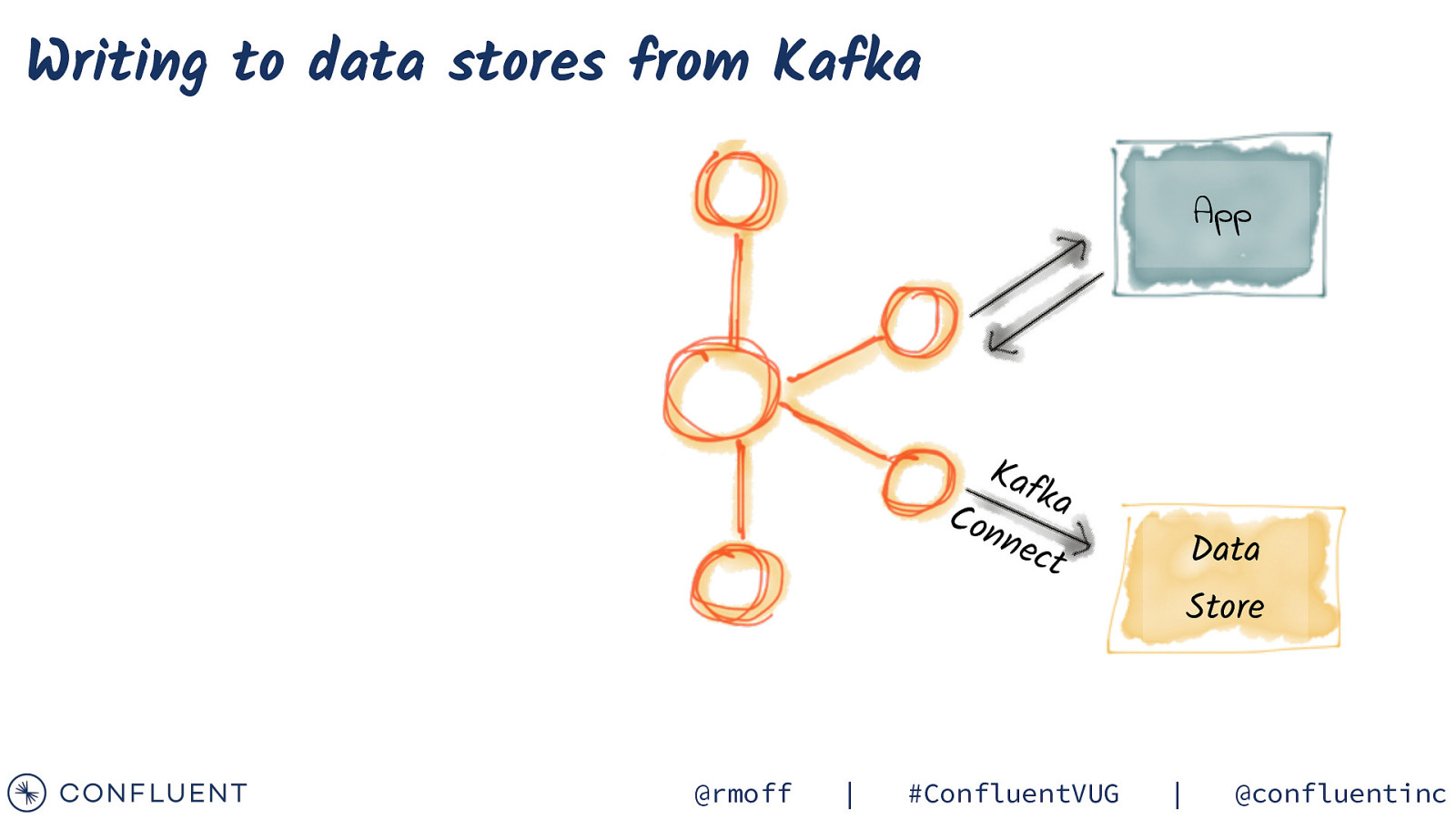
Writing to data stores from Kafka App Kaf ka Con nec Data t @rmoff | #ConfluentVUG Store | @confluentinc
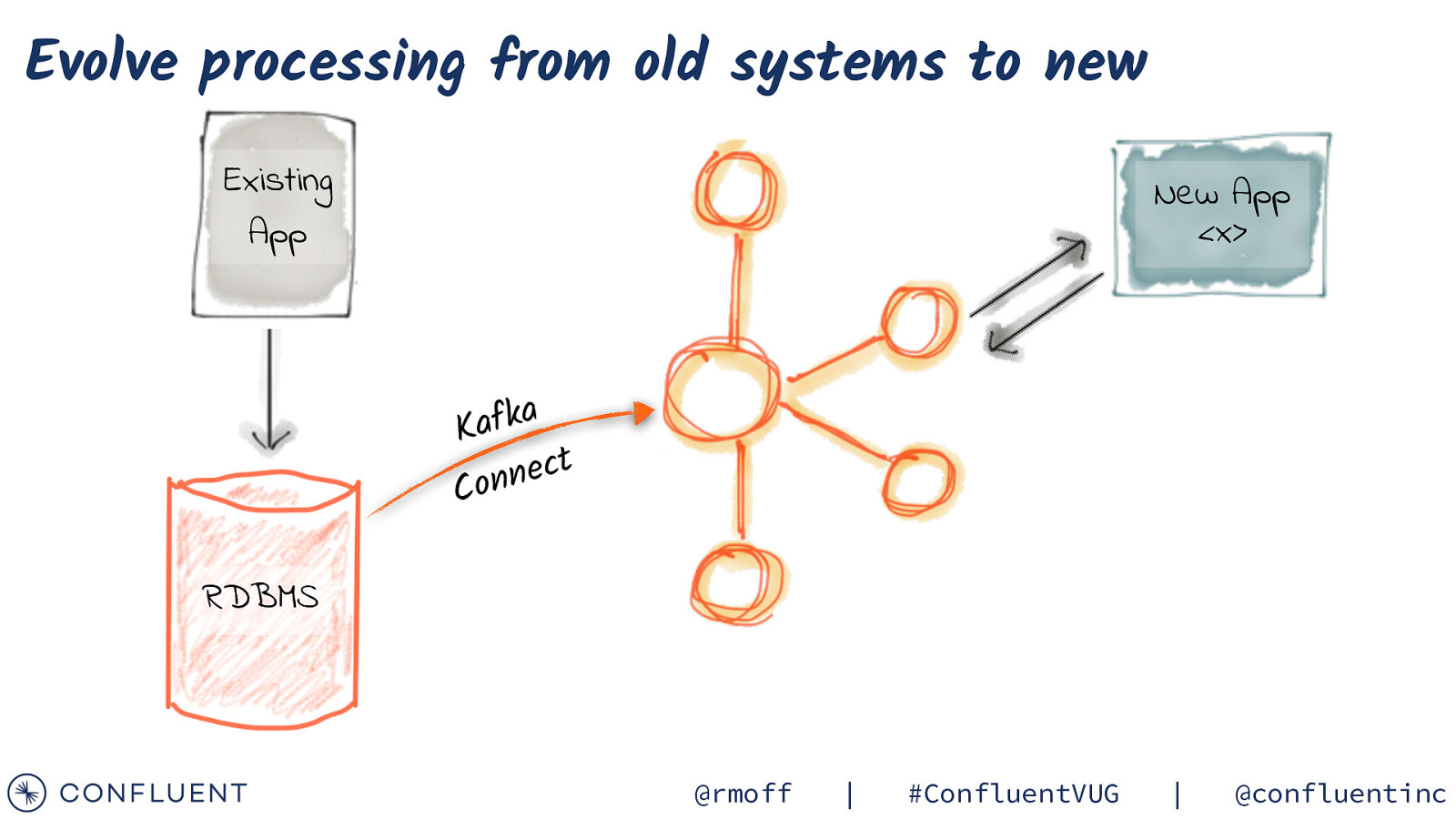
Evolve processing from old systems to new Existing App New App <x> a k f Ka t c e n n o C RDBMS @rmoff | #ConfluentVUG | @confluentinc
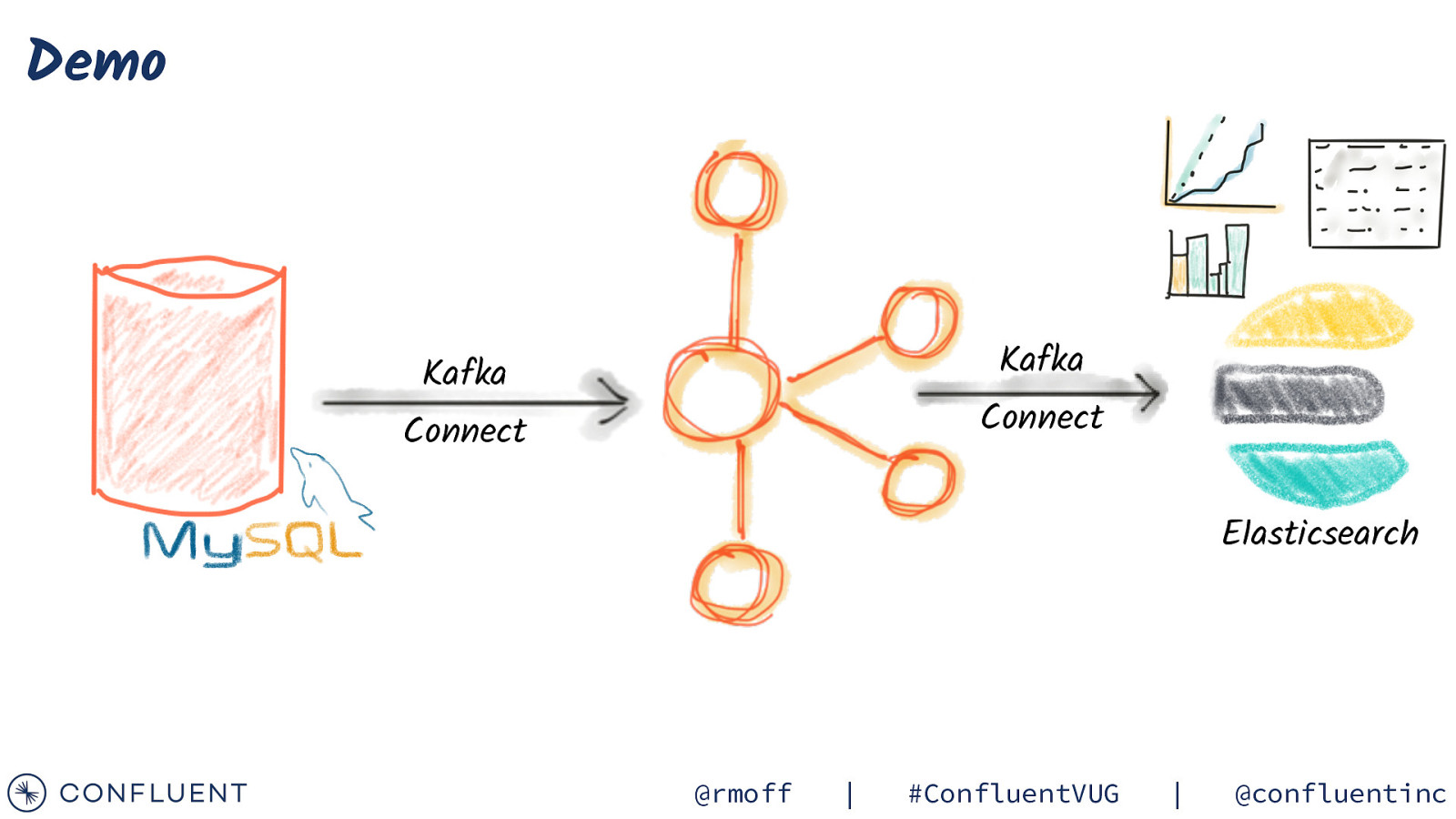
Demo http:!//rmoff.dev/kafka-connect-code @rmoff | #ConfluentVUG | @confluentinc
Demo Kafka Kafka Connect Connect Elasticsearch @rmoff | #ConfluentVUG | @confluentinc
Configuring Kafka Connect Inside the API - connectors, transforms, converters @rmoff | #ConfluentVUG | @confluentinc
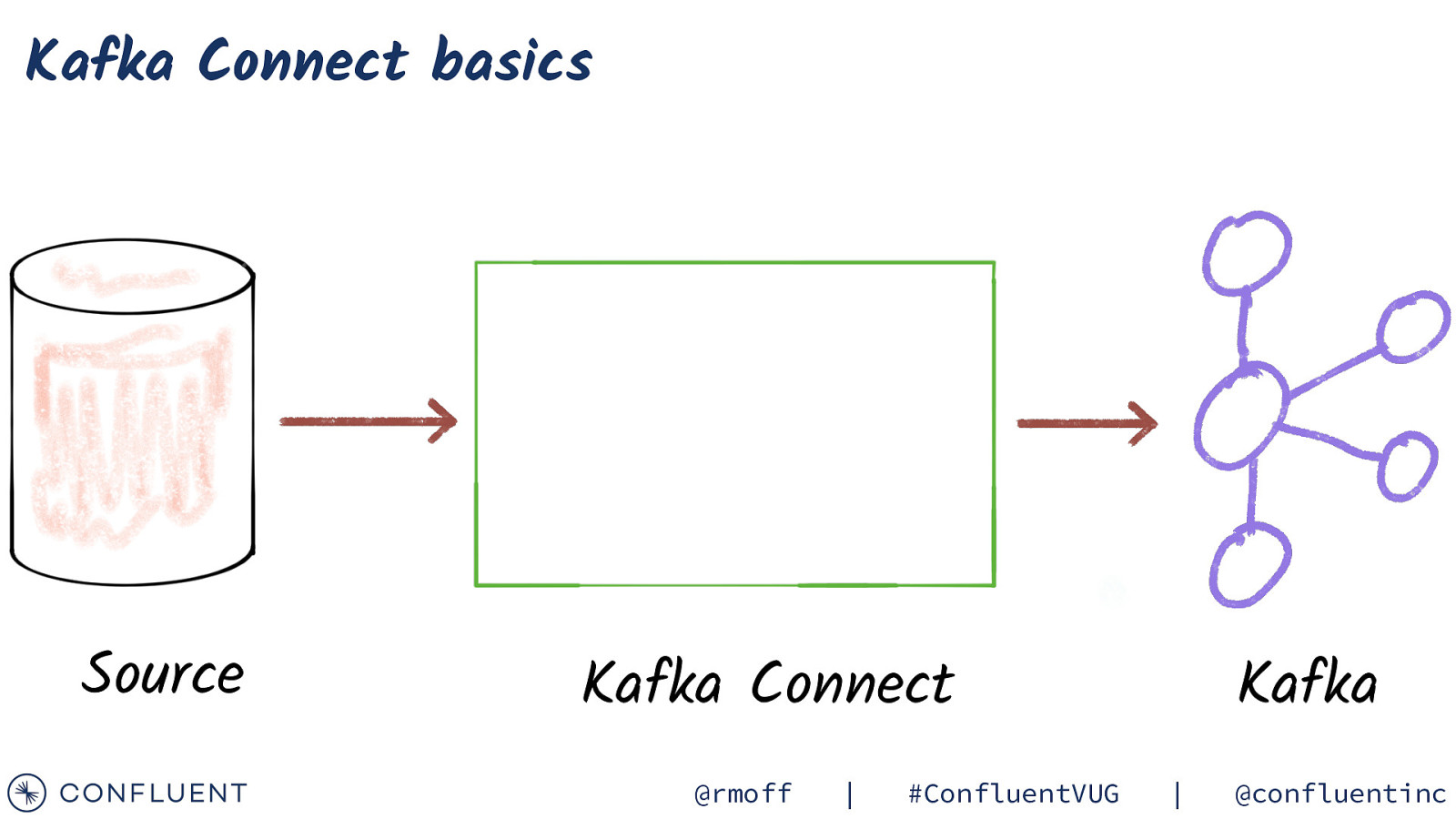
Kafka Connect basics Source Kafka Connect @rmoff | #ConfluentVUG Kafka | @confluentinc
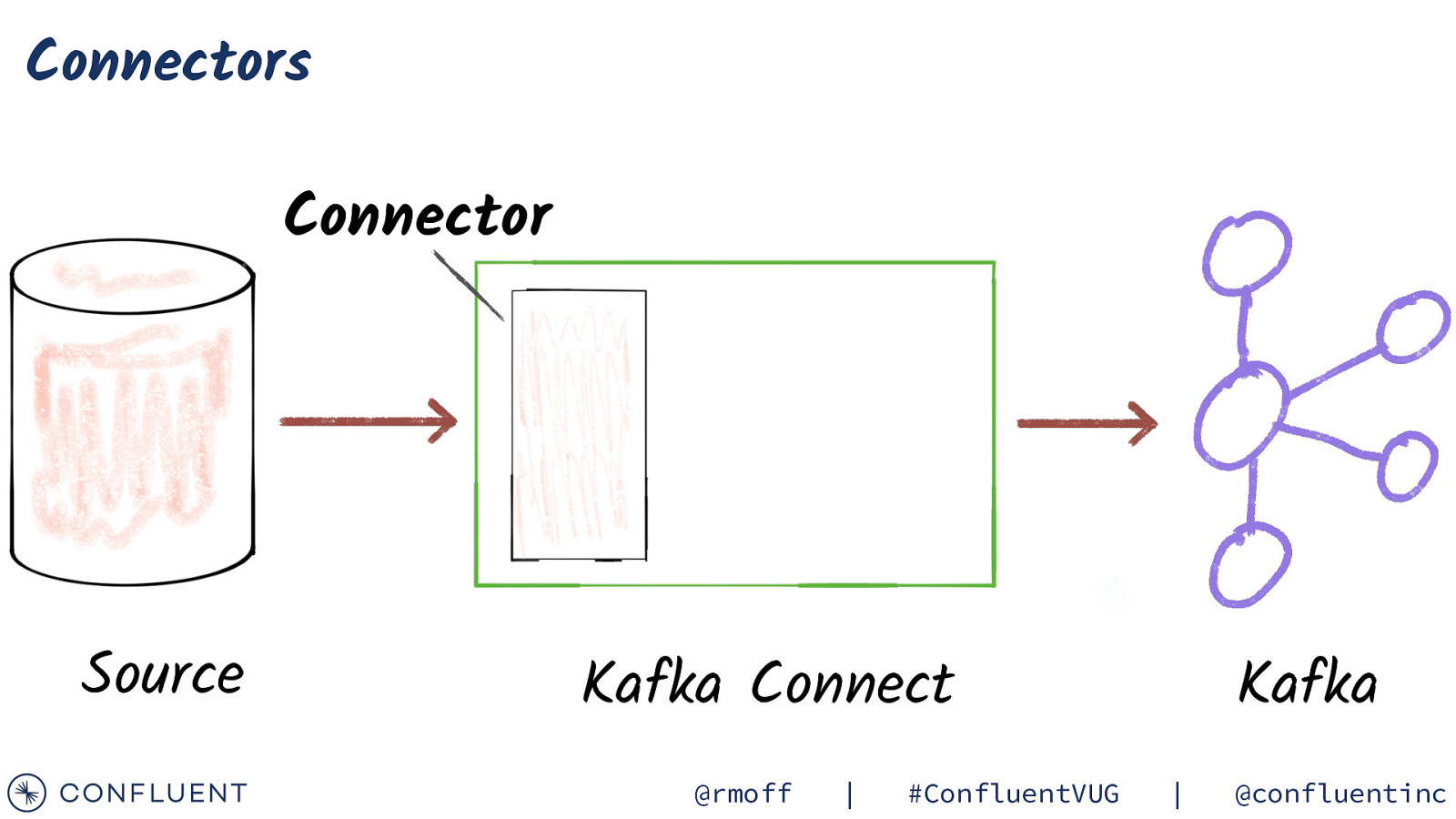
Connectors Connector Source Kafka Connect @rmoff | #ConfluentVUG Kafka | @confluentinc
Connectors “config”: { […] “connector.class”: “io.confluent.connect.jdbc.JdbcSinkConnector”, “connection.url”: “jdbc:postgresql://postgres:5432/”, “topics”: “asgard.demo.orders”, } @rmoff | #ConfluentVUG | @confluentinc
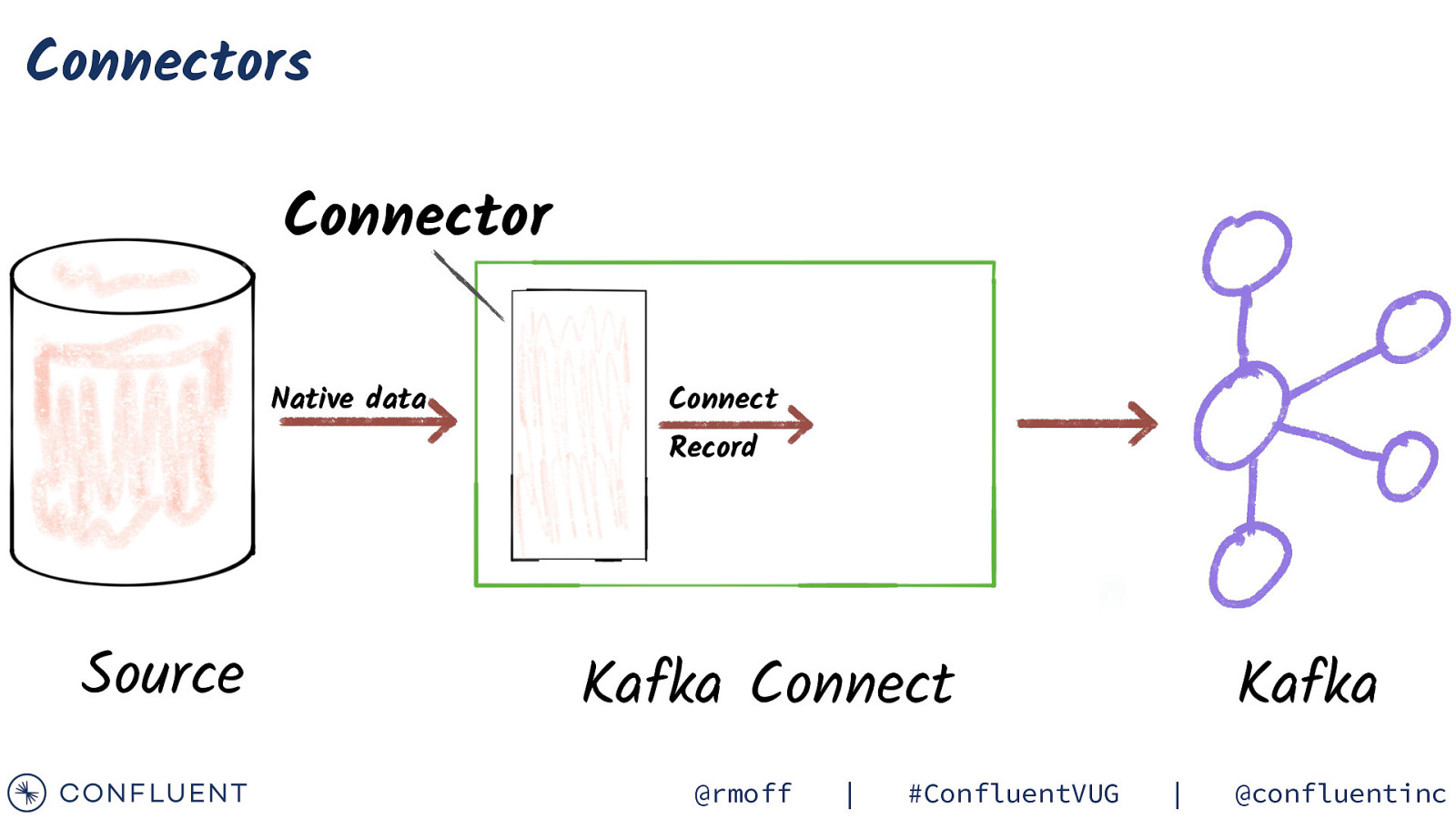
Connectors Connector Native data Connect Record Source Kafka Connect @rmoff | #ConfluentVUG Kafka | @confluentinc
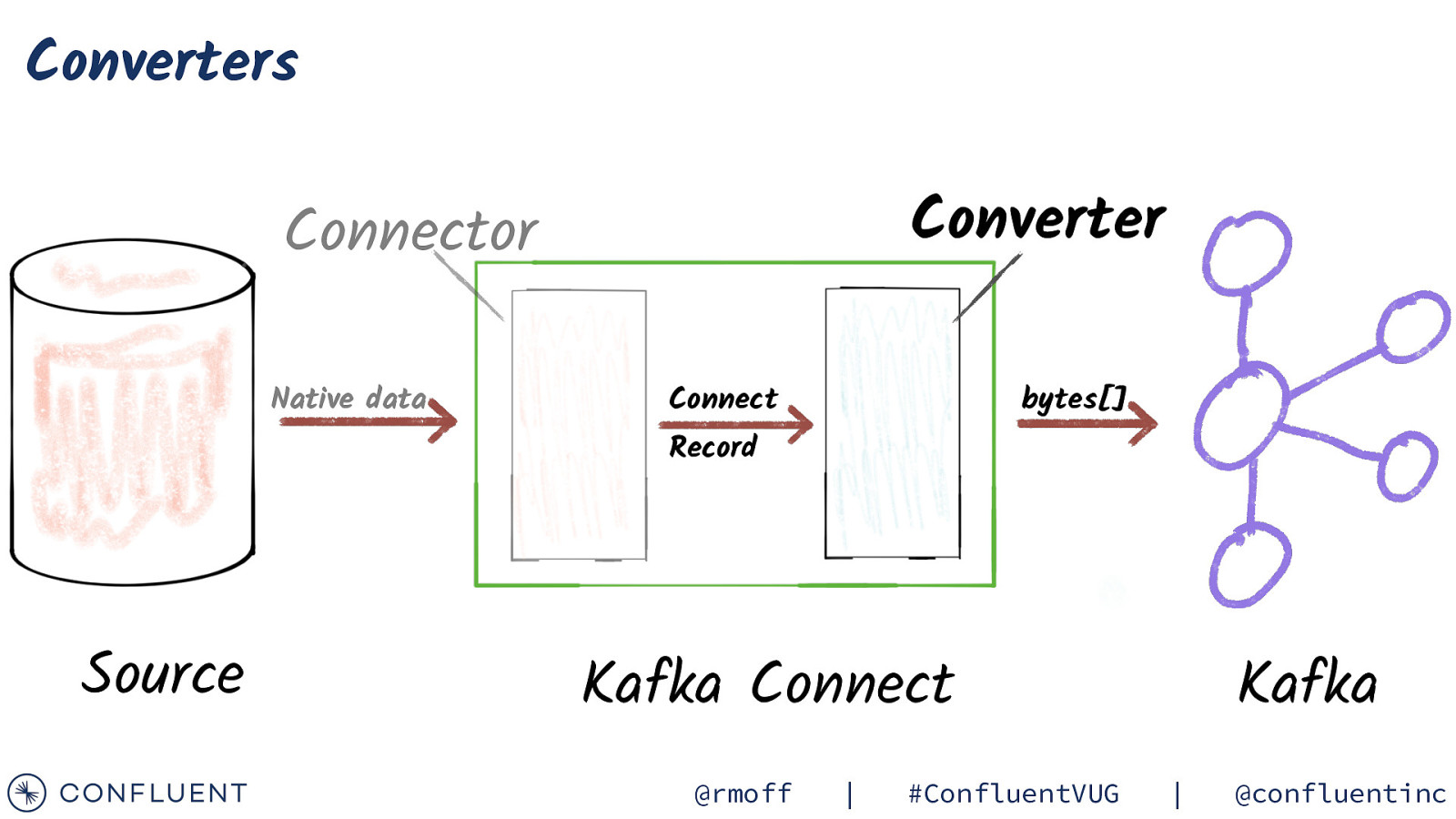
Converters Converter Connector Native data Connect bytes[] Record Source Kafka Connect @rmoff | #ConfluentVUG Kafka | @confluentinc
Serialisation & Schemas JSON Avro Protobuf Schema JSON CSV 👍 👍 👍 😬 https://rmoff.dev/qcon-schemas @rmoff | #ConfluentVUG | @confluentinc
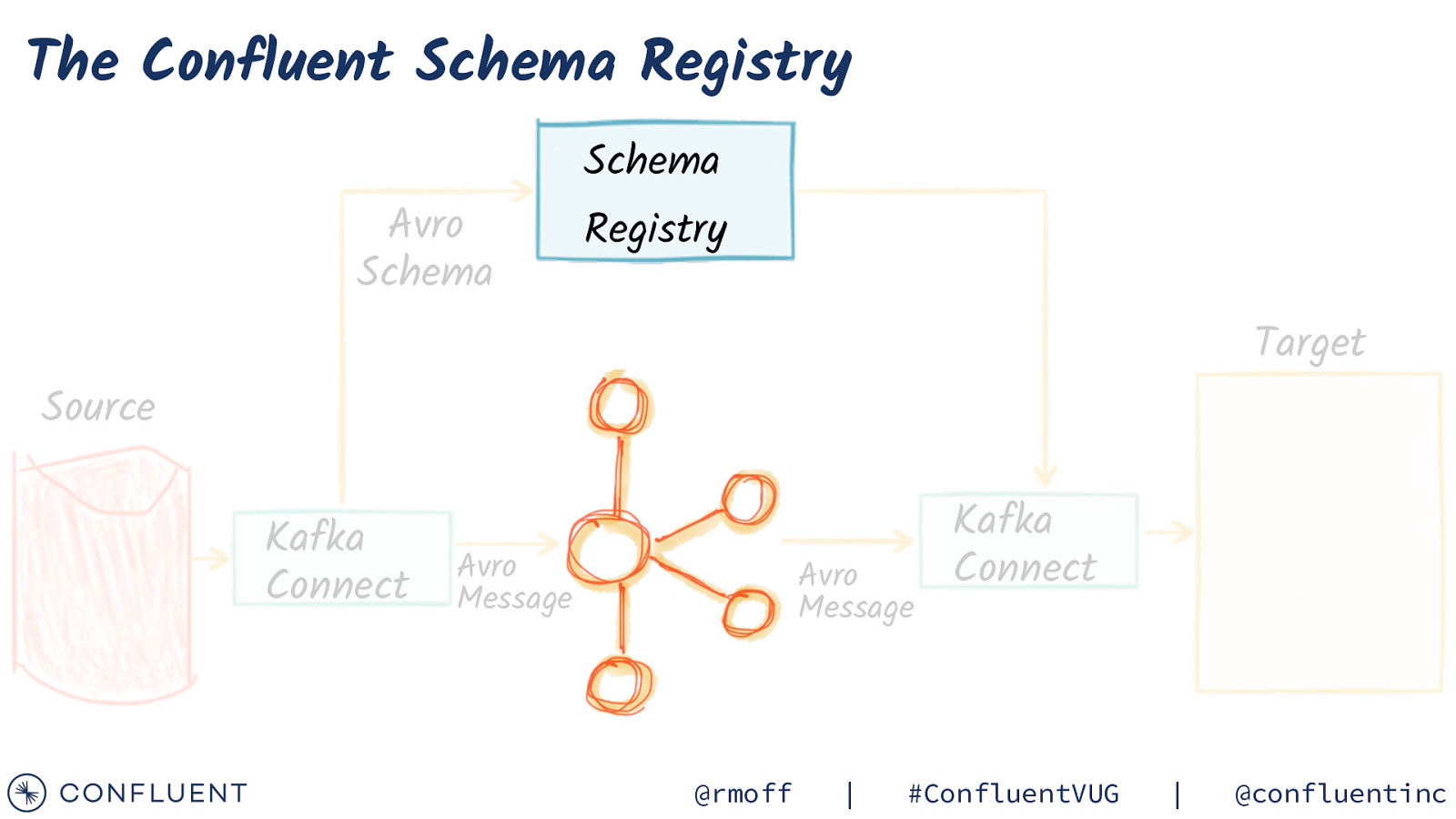
The Confluent Schema Registry Avro Schema Schema Registry Target Source Kafka Connect Avro Message Avro Message @rmoff | Kafka Connect #ConfluentVUG | @confluentinc
Converters key.converter=org.apache.kafka.connect.storage.StringConverter value.converter=io.confluent.connect.avro.AvroConverter value.converter.schema.registry.url=http://localhost:8081 Set as a global default per-worker; optionally can be overriden per-connector @rmoff | #ConfluentVUG | @confluentinc
What about internal converters? value.converter=org.apache.kafka.connect.json.JsonConverter internal.value.converter=org.apache.kafka.connect.json.JsonConverter key.internal.value.converter=org.apache.kafka.connect.json.JsonConverter value.internal.value.converter=org.apache.kafka.connect.json.JsonConverter key.internal.value.converter.bork.bork.bork=org.apache.kafka.connect.json.JsonConverter key.internal.value.please.just.work.converter=org.apache.kafka.connect.json.JsonConverter @rmoff | #ConfluentVUG | @confluentinc
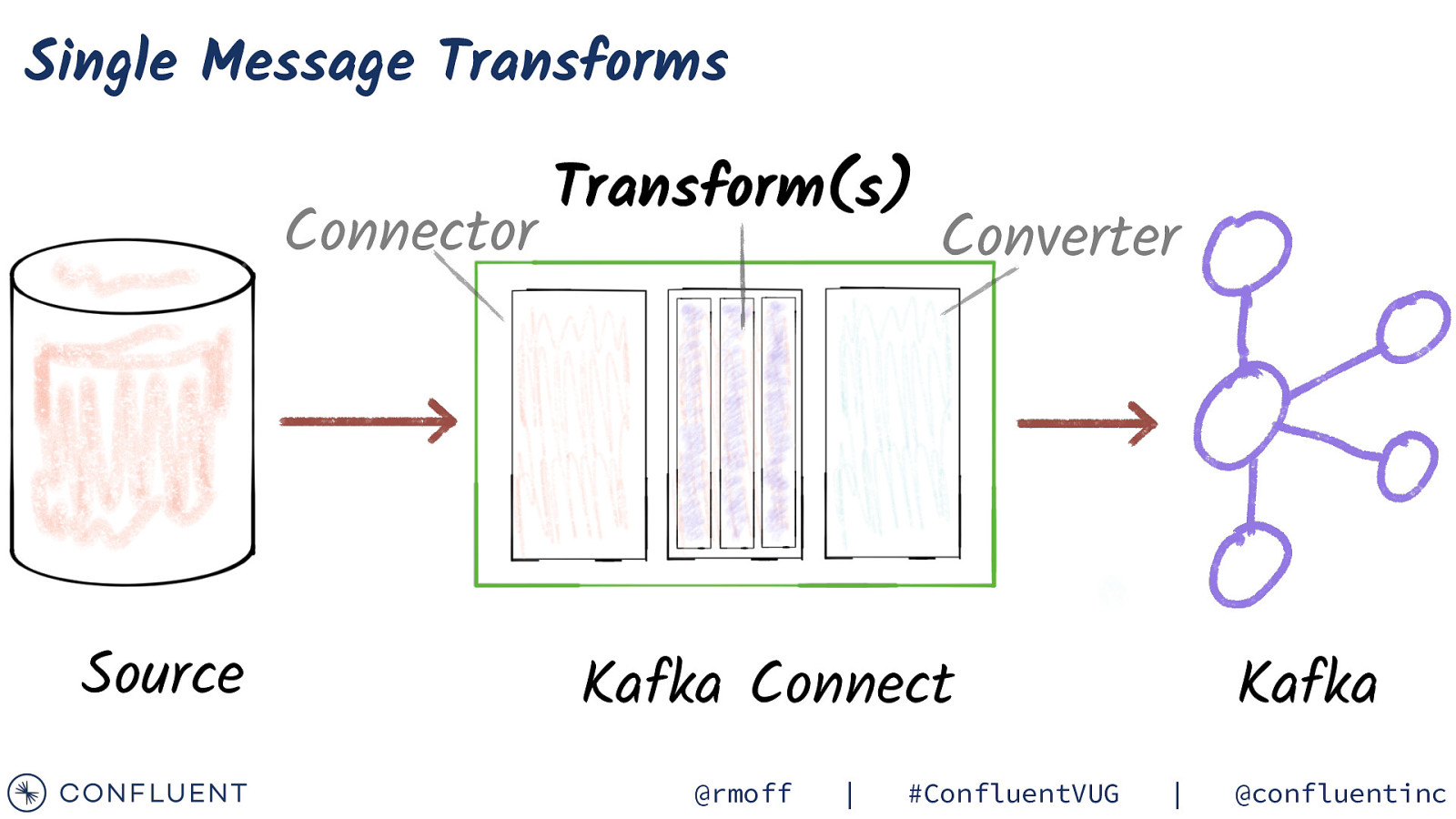
Single Message Transforms Connector Source Transform(s) Converter Kafka Connect @rmoff | #ConfluentVUG Kafka | @confluentinc
Single Message Transforms “config”: { Do these transforms […] “transforms”: “addDateToTopic,labelFooBar”, “transforms.addDateToTopic.type”: “org.apache.kafka.connect.transforms.TimestampRouter”, “transforms.addDateToTopic.topic.format”: “${topic}-${timestamp}”, “transforms.addDateToTopic.timestamp.format”: “YYYYMM”, “transforms.labelFooBar.type”: “org.apache.kafka.connect.transforms.ReplaceField$Value”, “transforms.labelFooBar.renames”: “delivery_address:shipping_address”, } Transforms config Config per transform @rmoff | #ConfluentVUG | @confluentinc
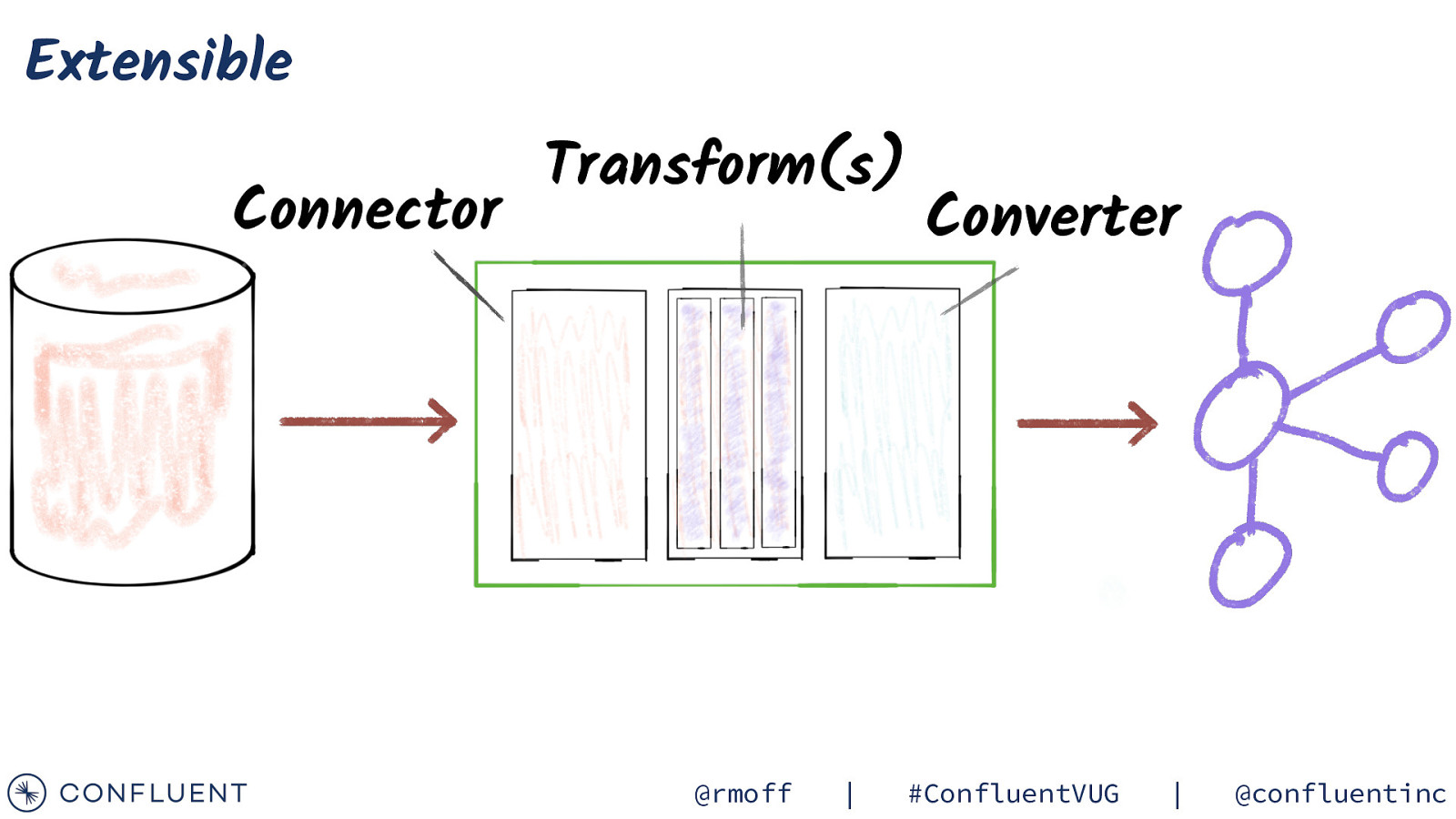
Extensible Connector Transform(s) @rmoff | Converter #ConfluentVUG | @confluentinc
Confluent Hub hub.confluent.io @rmoff | #ConfluentVUG | @confluentinc
Deploying Kafka Connect Connectors, Tasks, and Workers @rmoff | #ConfluentVUG | @confluentinc
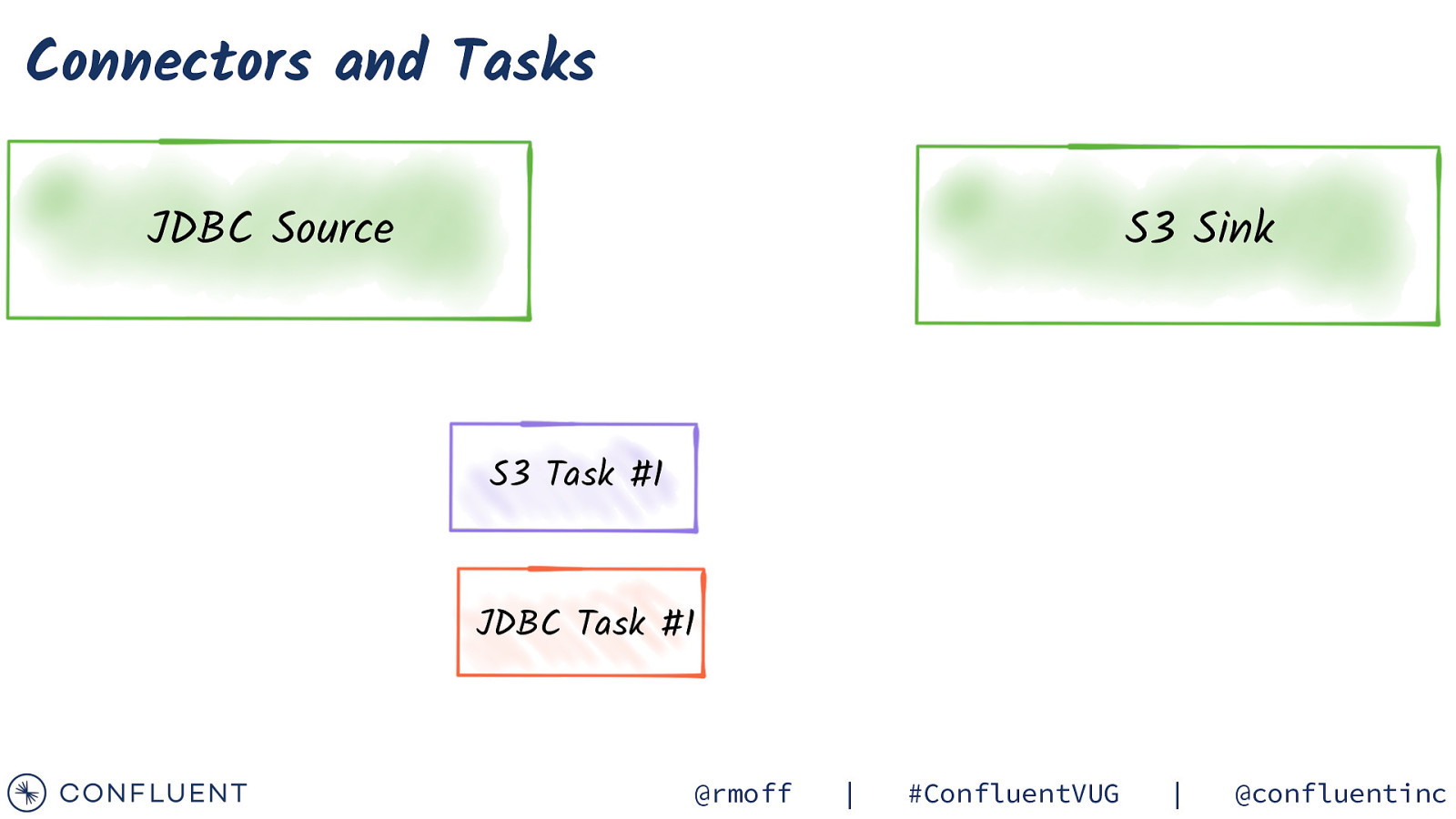
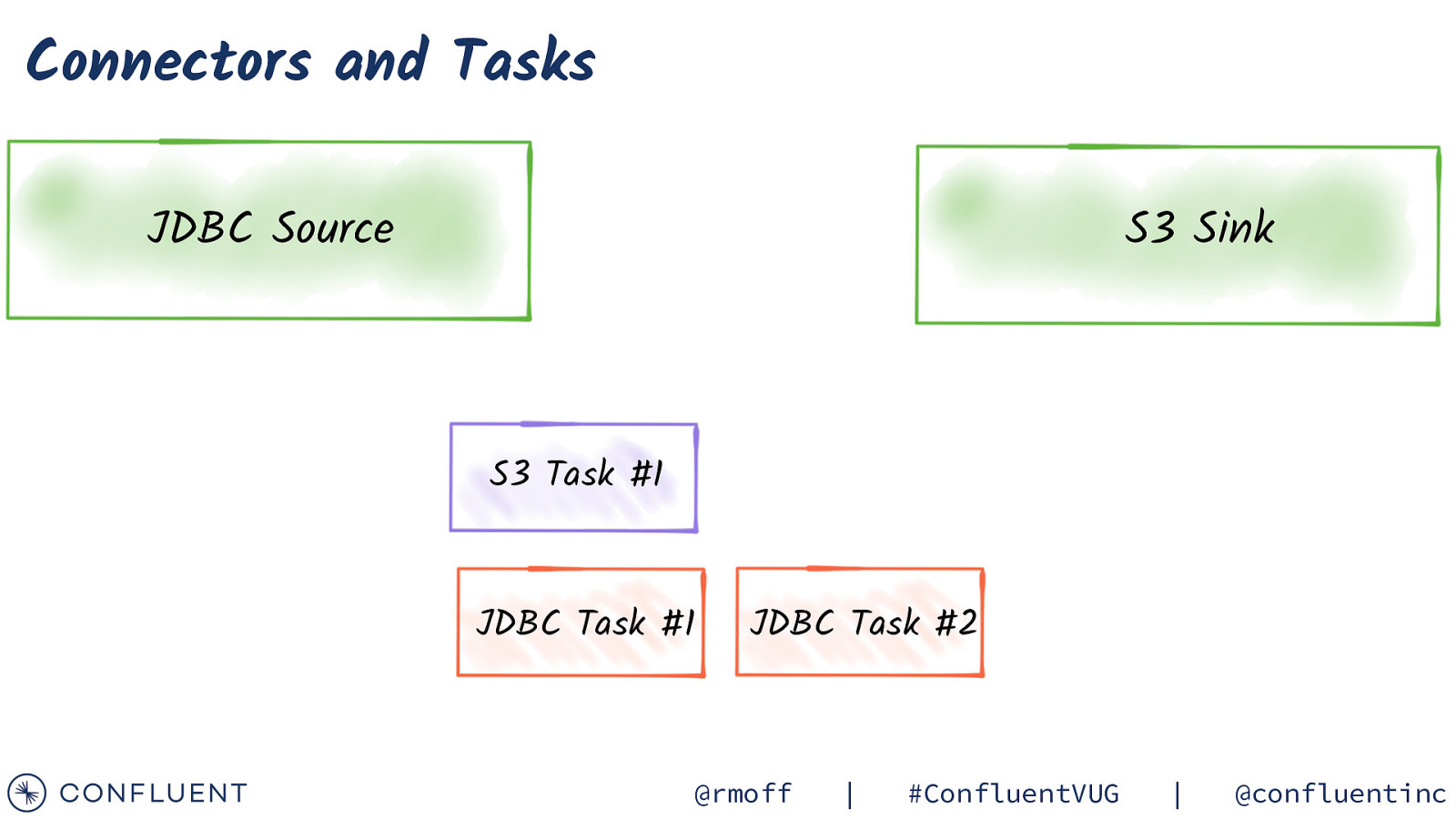
Connectors and Tasks JDBC Source S3 Sink S3 Task #1 JDBC Task #1 JDBC Task #2 @rmoff | #ConfluentVUG | @confluentinc
Connectors and Tasks JDBC Source S3 Sink S3 Task #1 JDBC Task #1 JDBC Task #2 @rmoff | #ConfluentVUG | @confluentinc
Connectors and Tasks JDBC Source S3 Sink S3 Task #1 JDBC Task #1 JDBC Task #2 @rmoff | #ConfluentVUG | @confluentinc
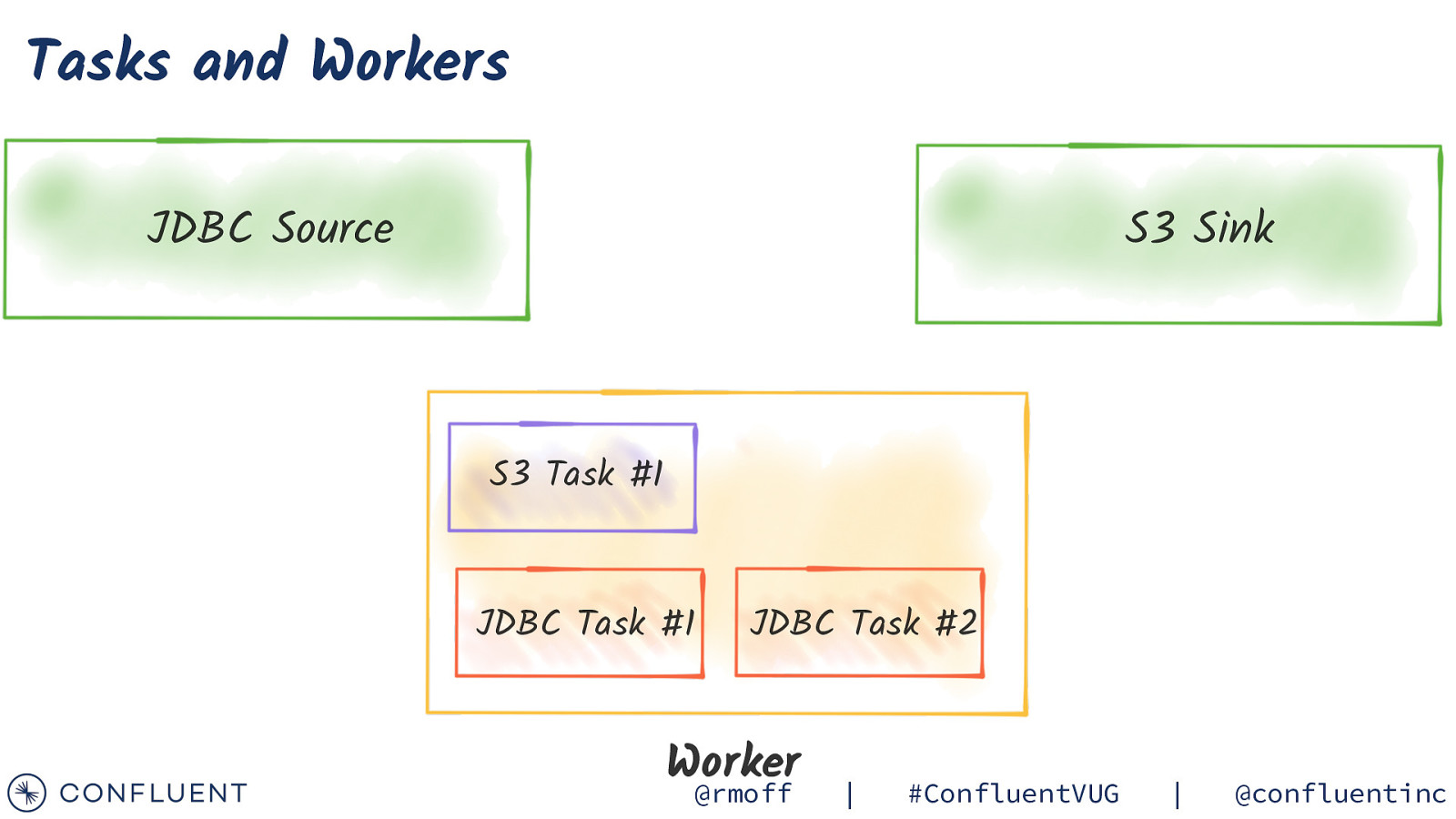
Tasks and Workers JDBC Source S3 Sink S3 Task #1 JDBC Task #1 JDBC Task #2 Worker @rmoff | #ConfluentVUG | @confluentinc
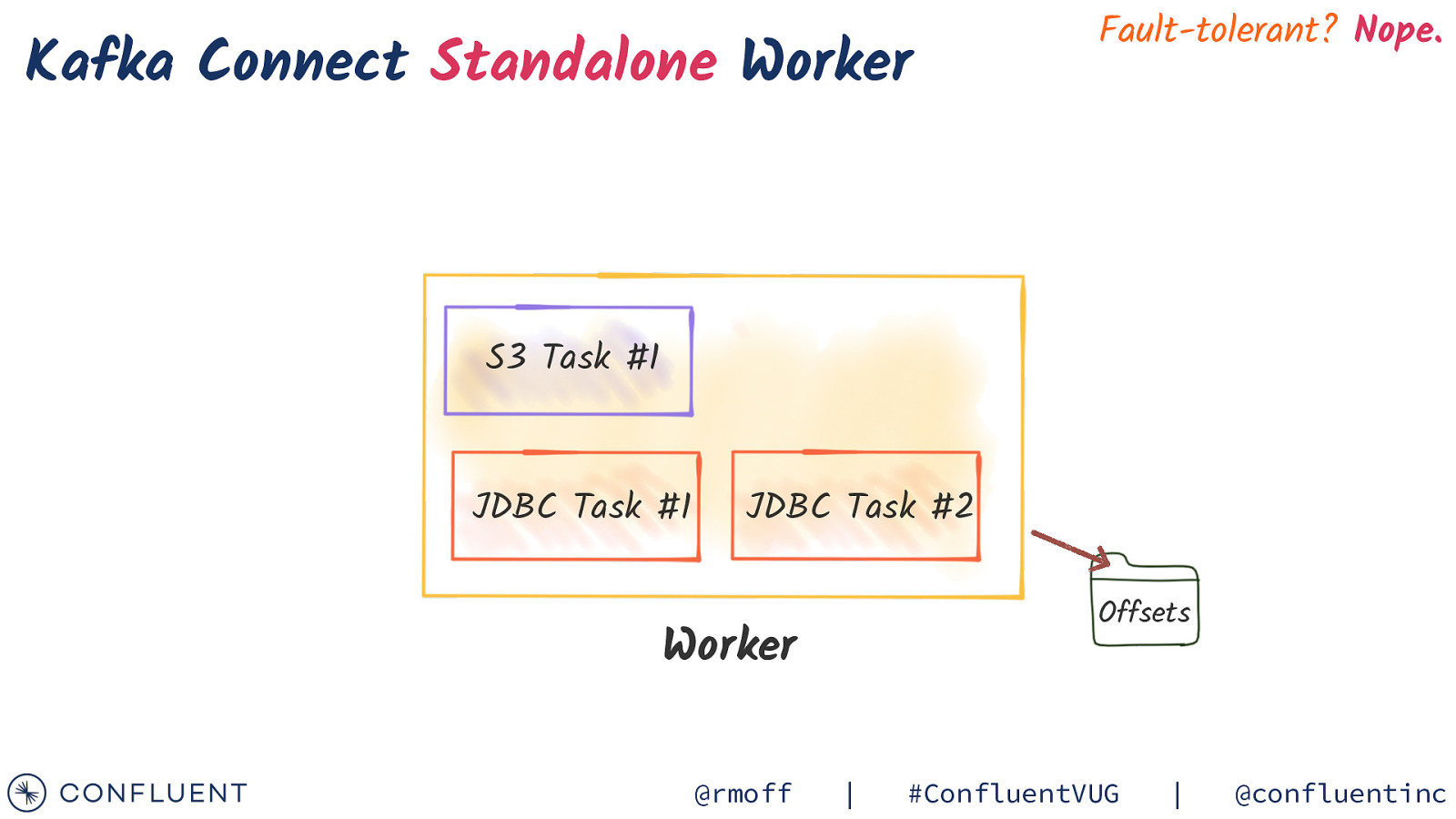
Kafka Connect Standalone Worker Fault-tolerant? Nope. S3 Task #1 JDBC Task #1 JDBC Task #2 Offsets Worker @rmoff | #ConfluentVUG | @confluentinc
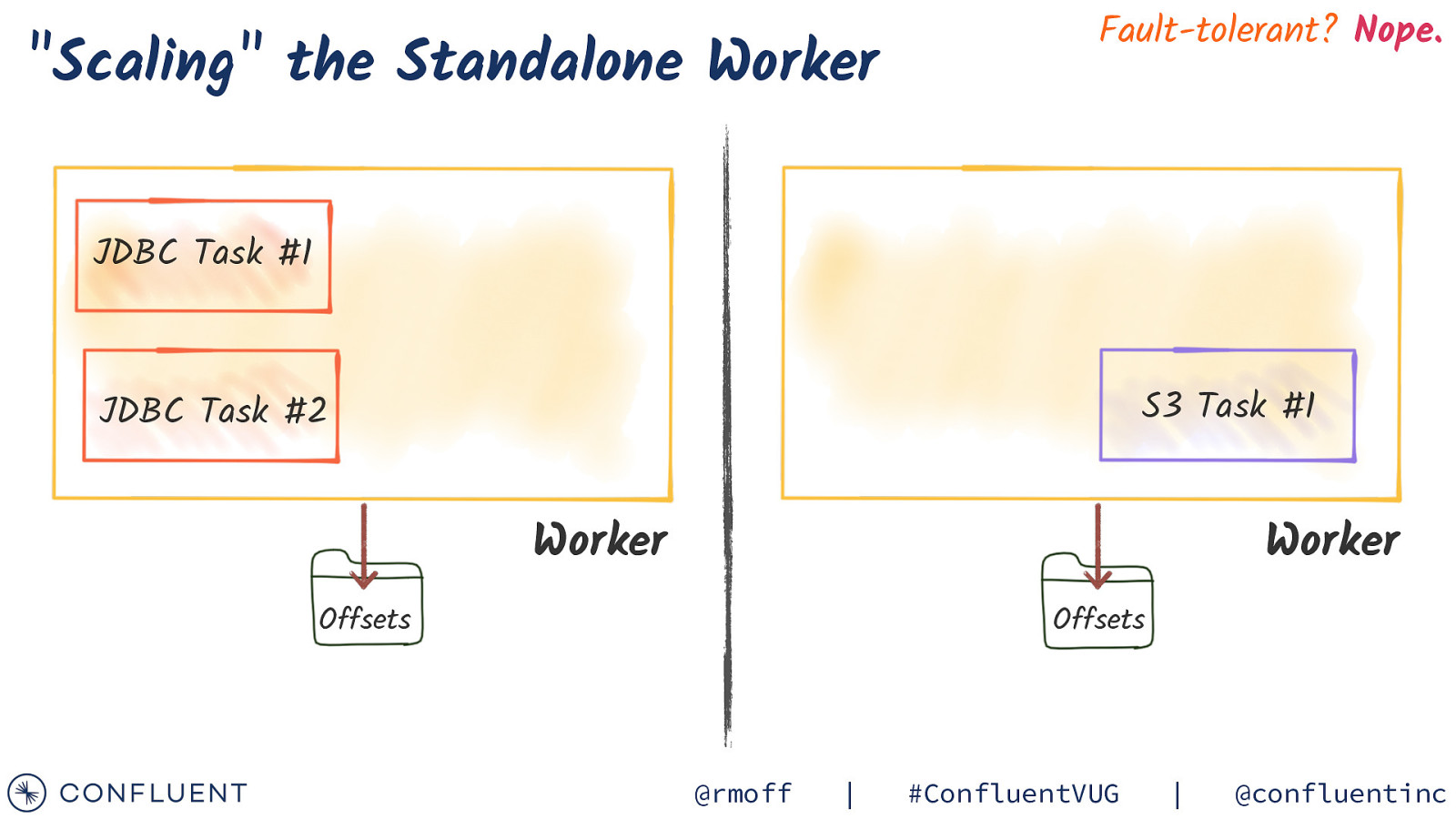
“Scaling” the Standalone Worker Fault-tolerant? Nope. JDBC Task #1 S3 Task #1 JDBC Task #2 Worker Worker Offsets Offsets @rmoff | #ConfluentVUG | @confluentinc
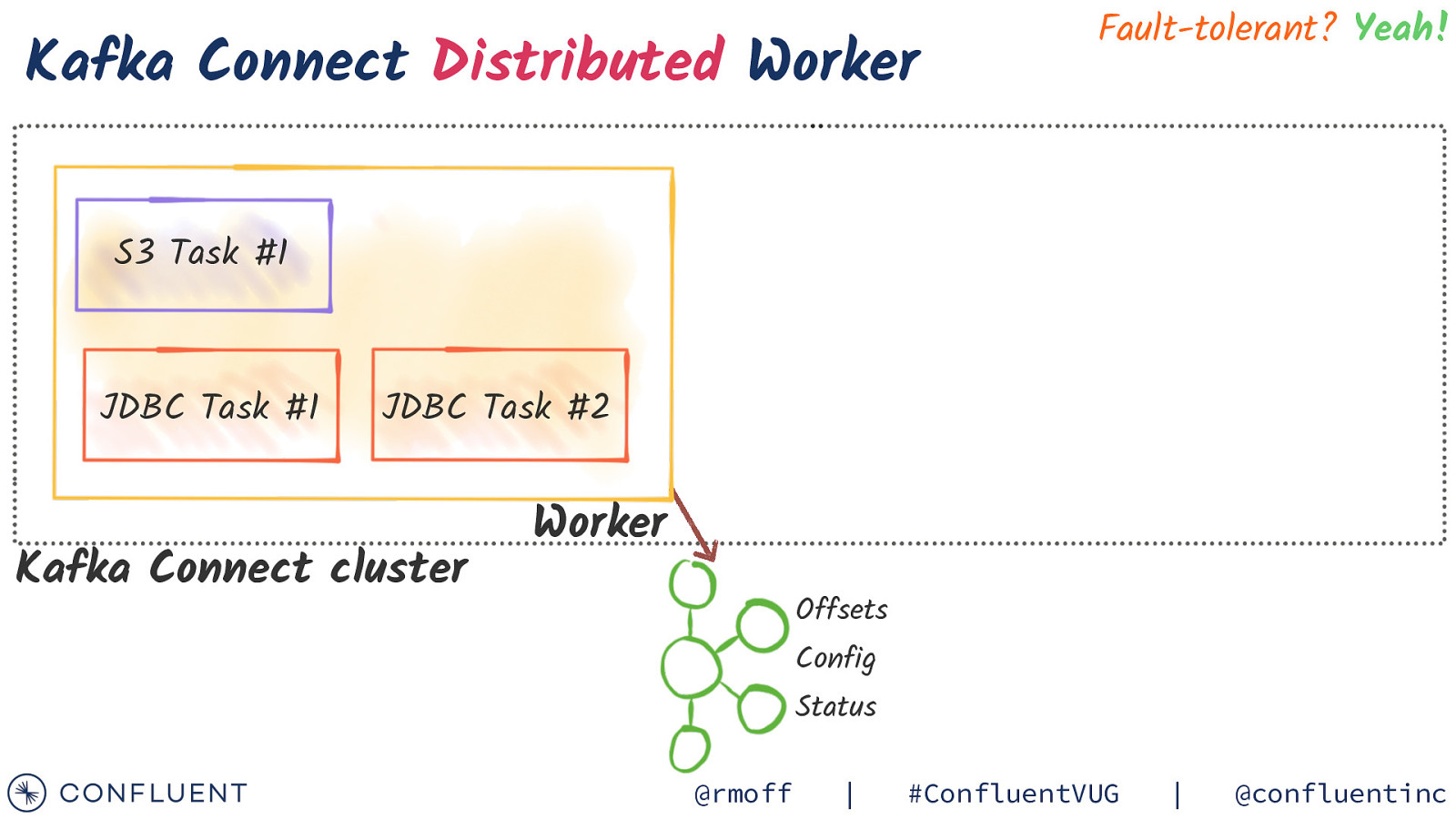
Kafka Connect Distributed Worker Fault-tolerant? Yeah! S3 Task #1 JDBC Task #1 JDBC Task #2 Kafka Connect cluster Worker Offsets Config Status @rmoff | #ConfluentVUG | @confluentinc
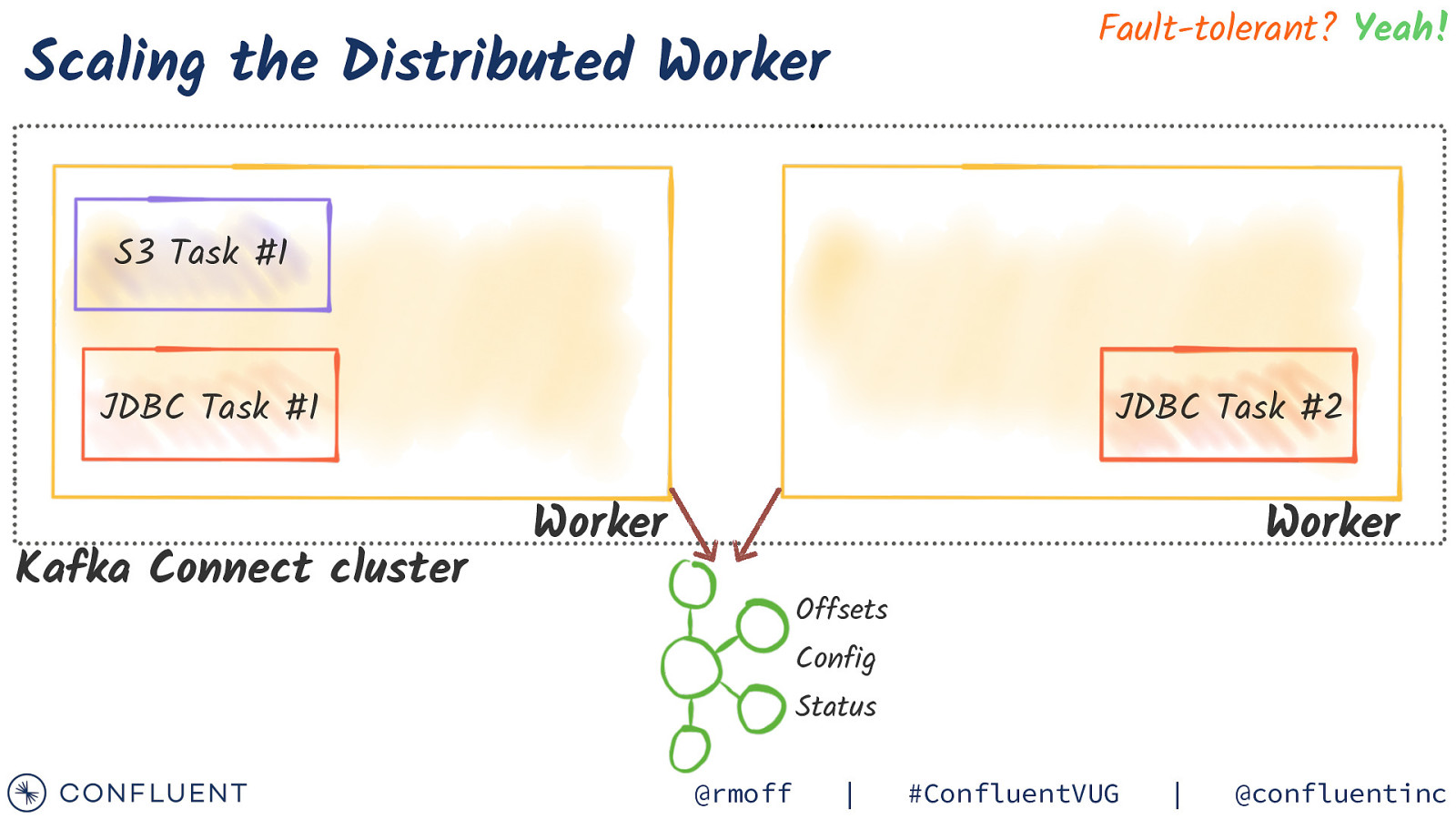
Fault-tolerant? Yeah! Scaling the Distributed Worker S3 Task #1 JDBC Task #1 Kafka Connect cluster JDBC Task #2 Worker Worker Offsets Config Status @rmoff | #ConfluentVUG | @confluentinc
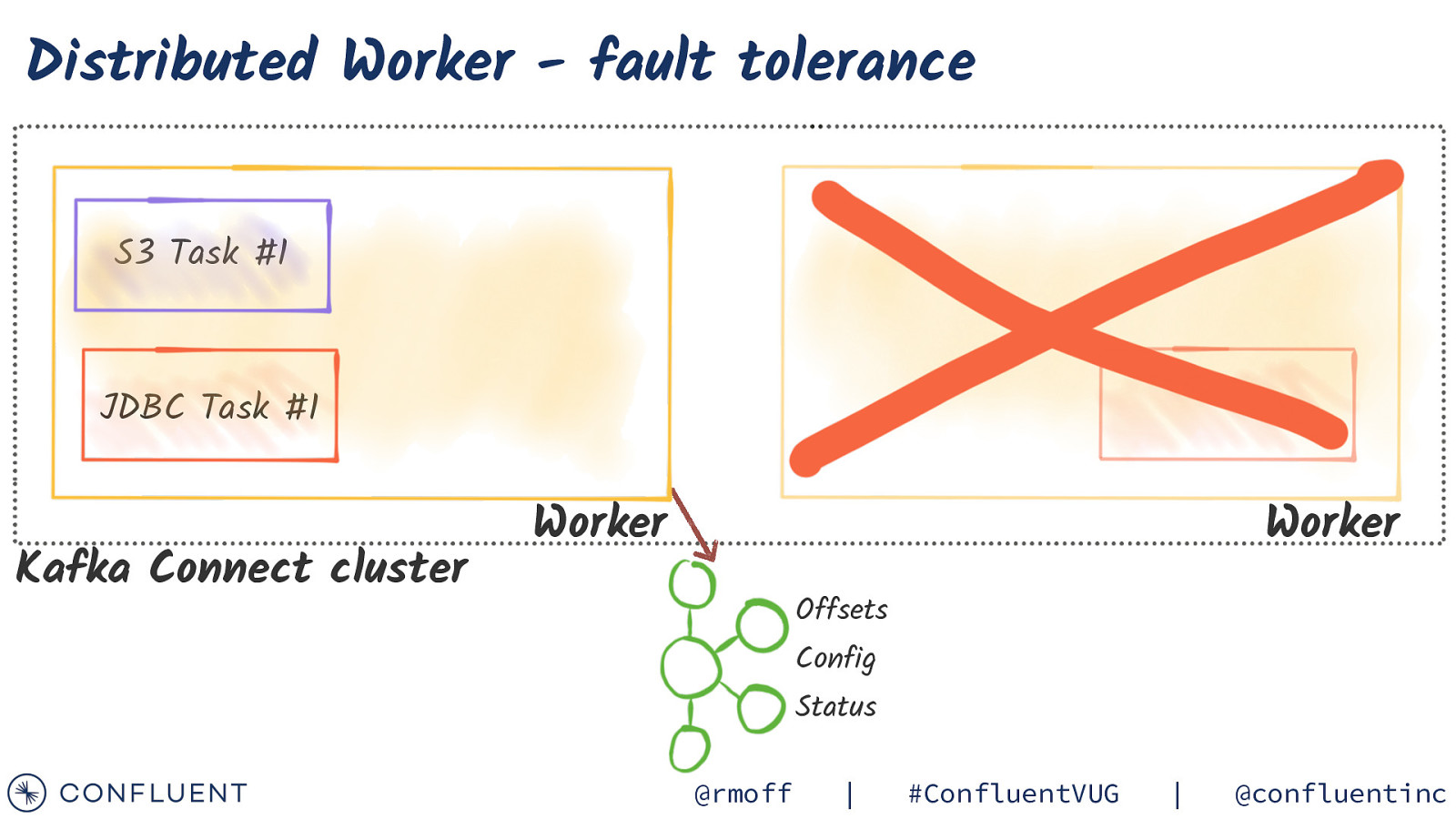
Distributed Worker - fault tolerance S3 Task #1 JDBC Task #1 Kafka Connect cluster Worker Worker Offsets Config Status @rmoff | #ConfluentVUG | @confluentinc
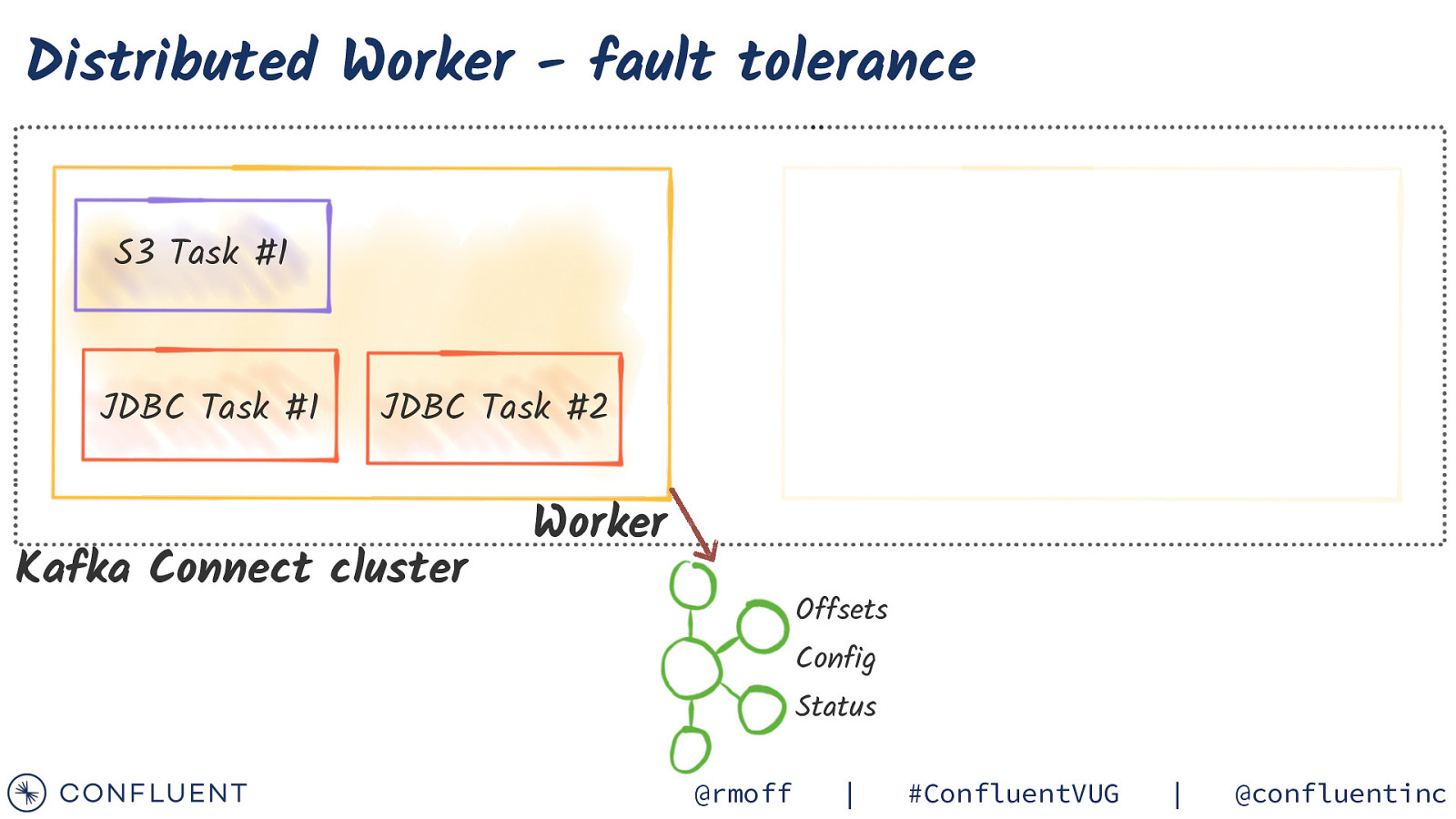
Distributed Worker - fault tolerance S3 Task #1 JDBC Task #1 JDBC Task #2 Kafka Connect cluster Worker Offsets Config Status @rmoff | #ConfluentVUG | @confluentinc
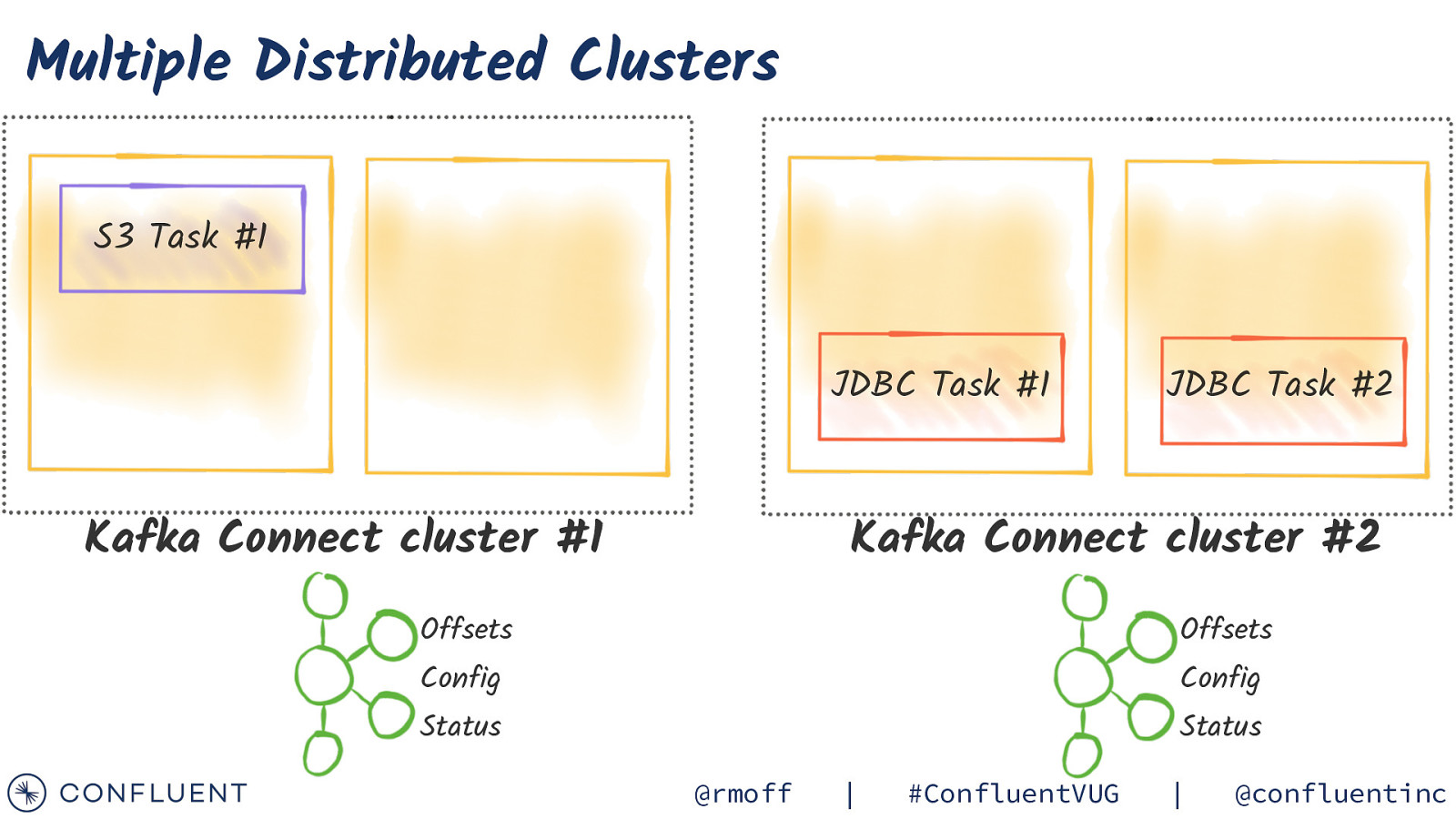
Multiple Distributed Clusters S3 Task #1 JDBC Task #1 Kafka Connect cluster #1 JDBC Task #2 Kafka Connect cluster #2 Offsets Offsets Config Config Status Status @rmoff | #ConfluentVUG | @confluentinc
Containers @rmoff | #ConfluentVUG | @confluentinc
Kafka Connect images on Docker Hub kafka-connect-elasticsearch kafka-connect-jdbc kafka-connect-hdfs […] confluentinc/cp-kafka-connect-base @rmoff confluentinc/cp-kafka-connect | #ConfluentVUG | @confluentinc
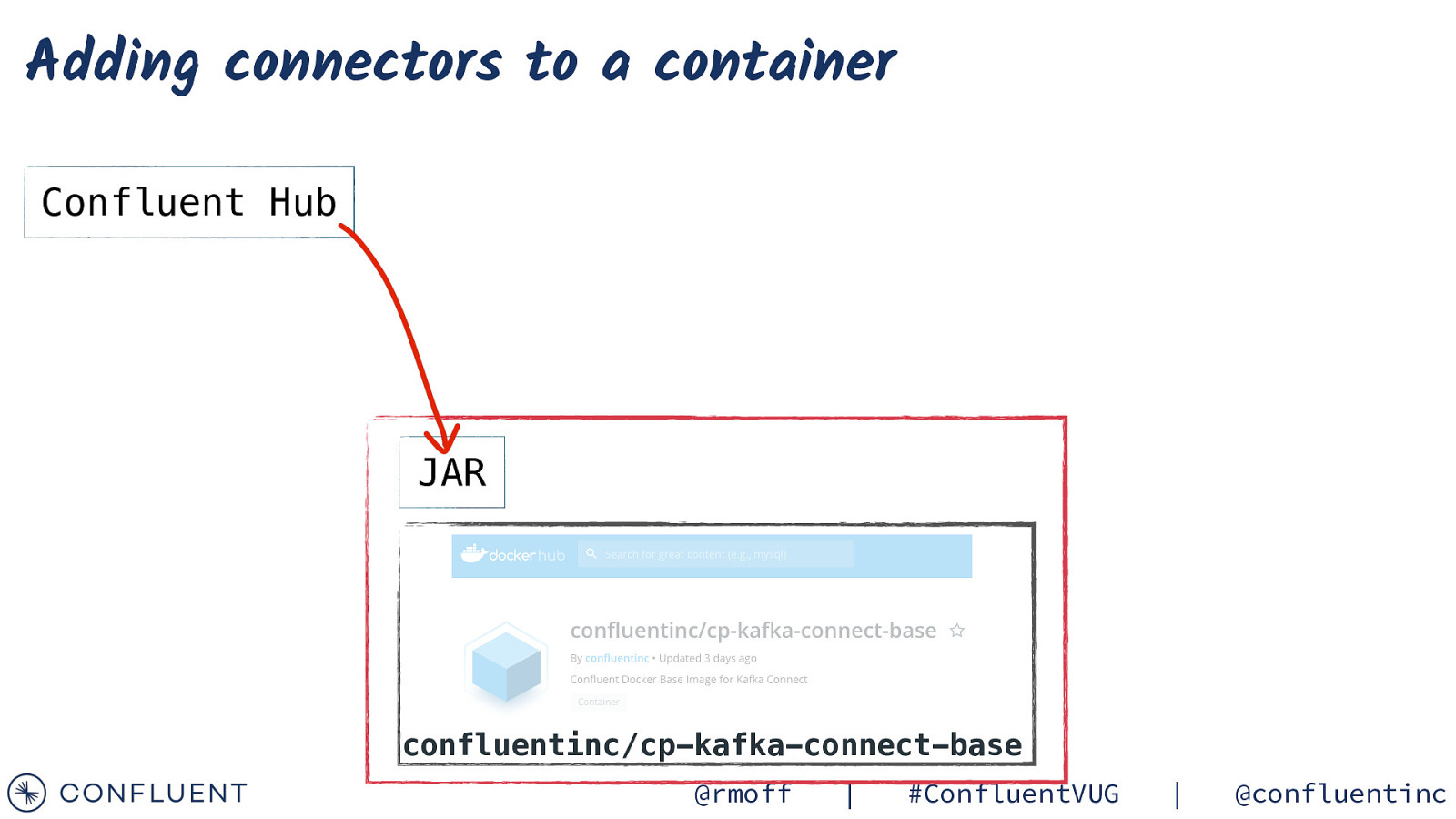
Adding connectors to a container Confluent Hub JAR confluentinc/cp-kafka-connect-base @rmoff | #ConfluentVUG | @confluentinc
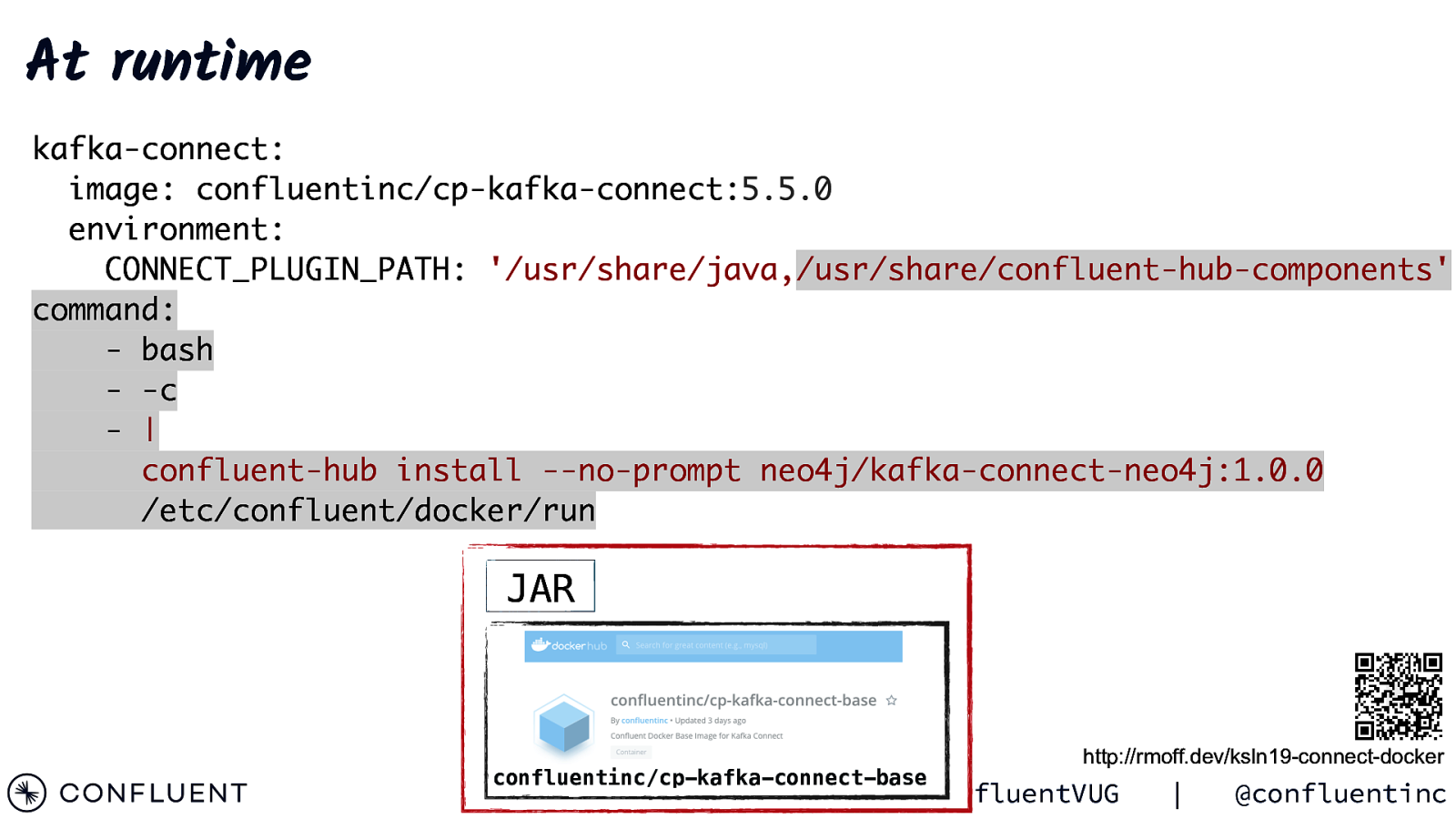
At runtime kafka-connect: image: confluentinc/cp-kafka-connect:5.5.0 environment: CONNECT_PLUGIN_PATH: ‘/usr/share/java,/usr/share/confluent-hub-components’ command: - bash - -c - | confluent-hub install —no-prompt neo4j/kafka-connect-neo4j:1.0.0 /etc/confluent/docker/run JAR confluentinc/cp-kafka-connect-base @rmoff | http://rmoff.dev/ksln19-connect-docker #ConfluentVUG | @confluentinc
Build a new image FROM confluentinc/cp-kafka-connect-base:5.5.0 ENV CONNECT_PLUGIN_PATH=”/usr/share/java,/usr/share/confluent-hub-components” RUN confluent-hub install —no-prompt neo4j/kafka-connect-neo4j:1.0.0 JAR confluentinc/cp-kafka-connect-base @rmoff | #ConfluentVUG | @confluentinc
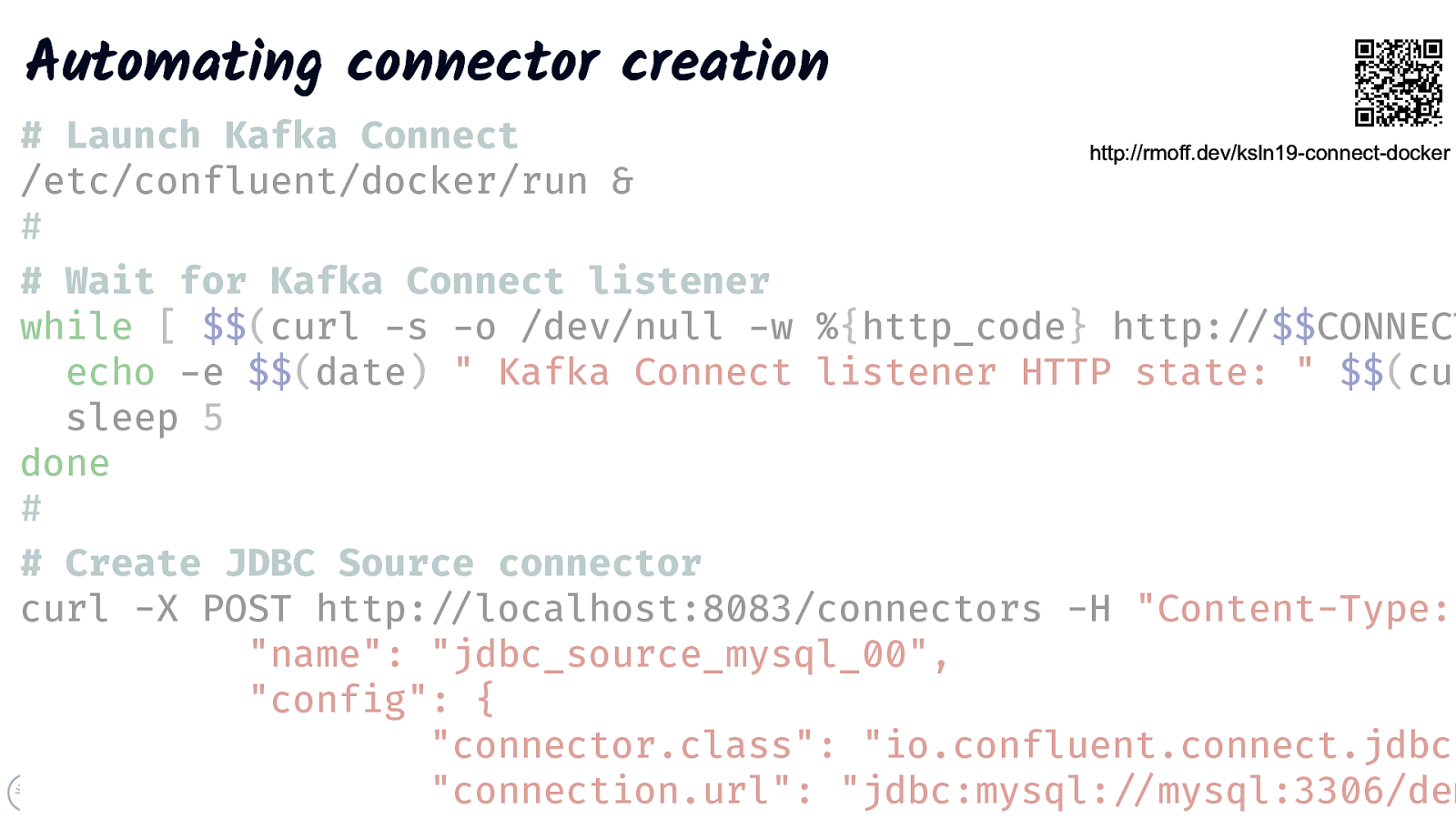
Automating connector creation
Automating connector creation
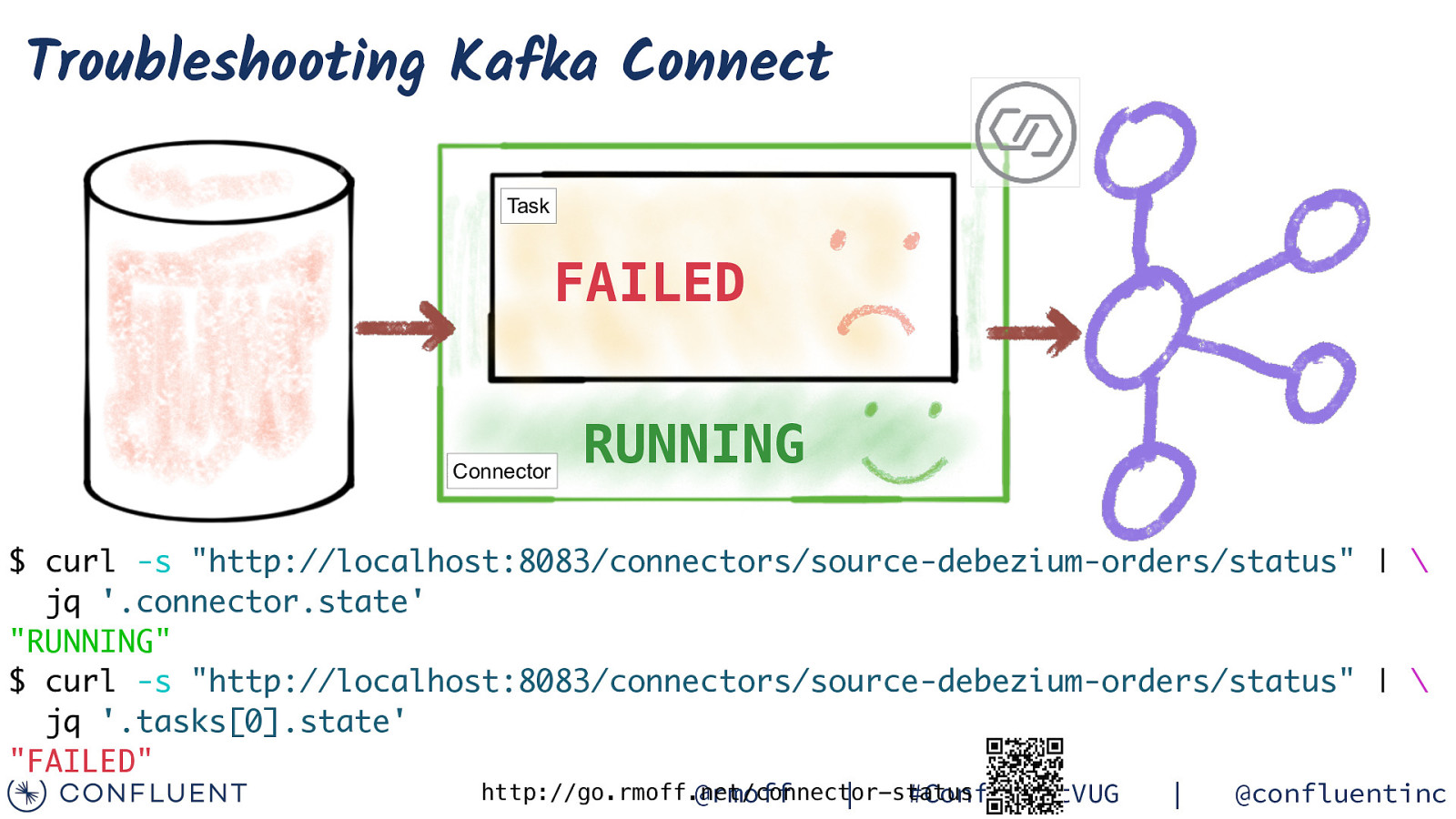
Troubleshooting Kafka Connect @rmoff | #ConfluentVUG | @confluentinc
Troubleshooting Kafka Connect Task FAILED Connector RUNNING $ curl -s “http://localhost:8083/connectors/source-debezium-orders/status” | \ jq ‘.connector.state’ “RUNNING” $ curl -s “http://localhost:8083/connectors/source-debezium-orders/status” | \ jq ‘.tasks[0].state’ “FAILED” http://go.rmoff.net/connector-status @rmoff | #ConfluentVUG | @confluentinc
Troubleshooting Kafka Connect curl -s “http:!//localhost:8083/connectors/source-debezium-orders-00/status” | jq ‘.tasks[0].trace’ “org.apache.kafka.connect.errors.ConnectException\n\tat io.debezium.connector.mysql.AbstractReader.wrap(AbstractReader.java:230)\n\tat io.debezium.connector.mysql.AbstractReader.failed(AbstractReader.java:197)\n\tat io.debezium.connector.mysql.BinlogReader$ReaderThreadLifecycleListener.onCommunicationFailure(BinlogReader.java:1018)\n\t at com.github.shyiko.mysql.binlog.BinaryLogClient.listenForEventPackets(BinaryLogClient.java:950)\n\tat com.github.shyiko.mysql.binlog.BinaryLogClient.connect(BinaryLogClient.java:580)\n\tat com.github.shyiko.mysql.binlog.BinaryLogClient$7.run(BinaryLogClient.java:825)\n\tat java.lang.Thread.run(Thread.java:748)\nCaused by: java.io.EOFException\n\tat com.github.shyiko.mysql.binlog.io.ByteArrayInputStream.read(ByteArrayInputStream.java:190)\n\tat com.github.shyiko.mysql.binlog.io.ByteArrayInputStream.readInteger(ByteArrayInputStream.java:46)\n\tat com.github.shyiko.mysql.binlog.event.deserialization.EventHeaderV4Deserializer.deserialize(EventHeaderV4Deserializer.java :35)\n\tat com.github.shyiko.mysql.binlog.event.deserialization.EventHeaderV4Deserializer.deserialize(EventHeaderV4Deserializer.java :27)\n\tat com.github.shyiko.mysql.binlog.event.deserialization.EventDeserializer.nextEvent(EventDeserializer.java:212)\n\tat io.debezium.connector.mysql.BinlogReader$1.nextEvent(BinlogReader.java:224)\n\tat com.github.shyiko.mysql.binlog.BinaryLogClient.listenForEventPackets(BinaryLogClient.java:922)\n\t!!… 3 more\n” @rmoff | #ConfluentVUG | @confluentinc
The log is the source of truth $ confluent log connect $ docker-compose logs kafka-connect $ cat /var/log/kafka/connect.log @rmoff | #ConfluentVUG | @confluentinc
Dynamic log levels (Added in Apache Kafka 2.4 / Confluent Platform 5.4) curl -s http://localhost:8083/admin/loggers/ | jq { “org.apache.kafka.connect.runtime.rest”: { “level”: “WARN” }, “org.reflections”: { “level”: “ERROR” }, “root”: { “level”: “INFO” } } curl -s -X PUT http://localhost:8083/admin/loggers/io.debezium -H “Content-Type:application/json” -d ‘{“level”: “TRACE”}’ https://rmoff.dev/kc-dynamic-log-level @rmoff | #ConfluentVUG | @confluentinc
Kafka Connect @rmoff | #ConfluentVUG | @confluentinc
Kafka Connect “Task is being killed and will not recover until manually restarted” Symptom not Cause @rmoff | #ConfluentVUG | @confluentinc
Kafka Connect @rmoff | #ConfluentVUG | @confluentinc
Error Handling and Dead Letter Queues @rmoff | #ConfluentVUG | @confluentinc
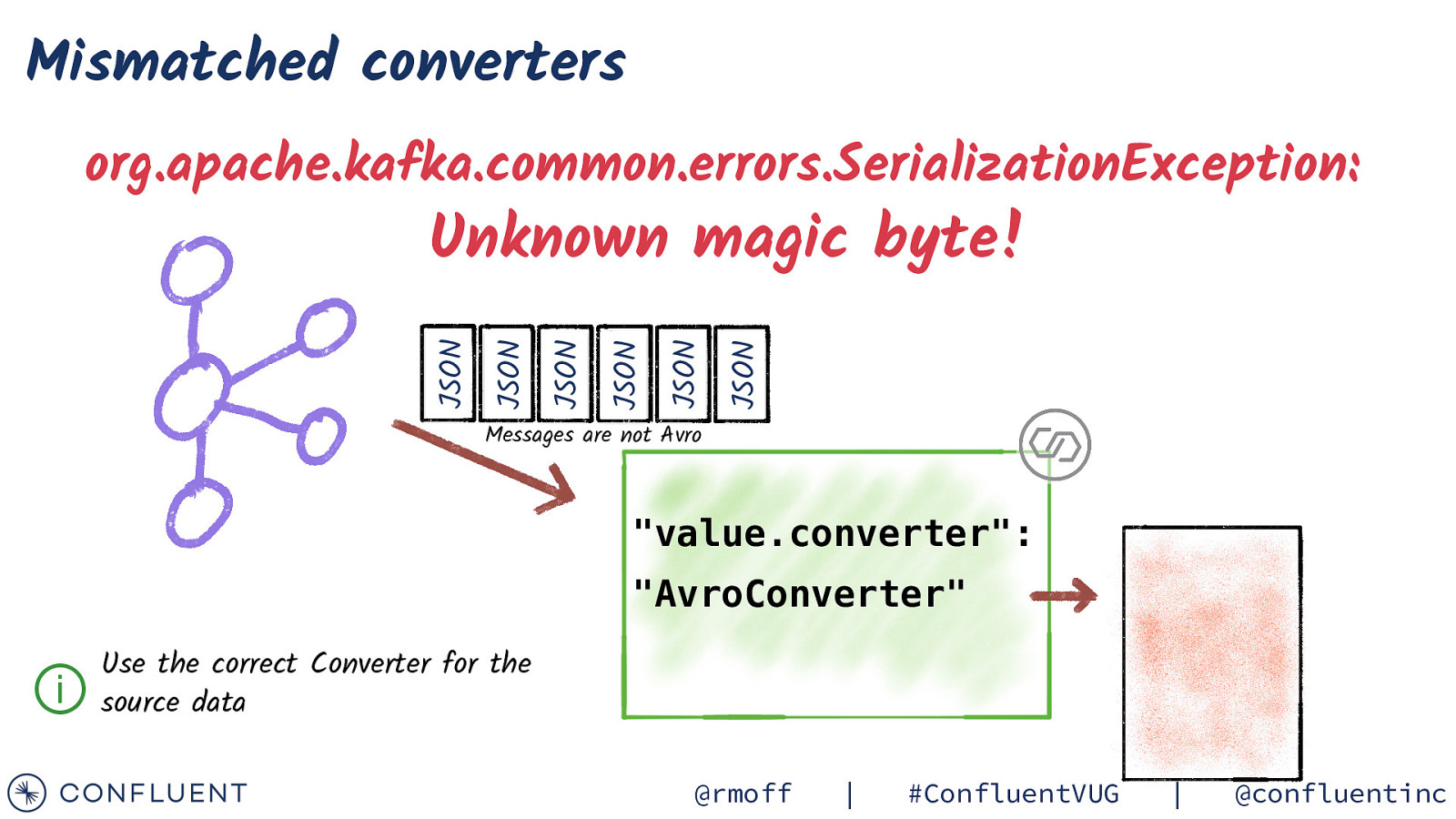
Mismatched converters org.apache.kafka.common.errors.SerializationException: Unknown magic byte! @rmoff | #ConfluentVUG | @confluentinc
Mismatched converters org.apache.kafka.common.errors.SerializationException: JSON JSON JSON JSON JSON JSON Unknown magic byte! Messages are not Avro “value.converter”: “AvroConverter” ⓘ Use the correct Converter for the source data @rmoff | #ConfluentVUG | @confluentinc
Mixed serialisation methods org.apache.kafka.common.errors.SerializationException: Avro Avro JSON Avro JSON JSON Unknown magic byte! Some messages are not Avro “value.converter”: “AvroConverter” ⓘ Use error handling to deal with bad messages @rmoff | #ConfluentVUG | @confluentinc
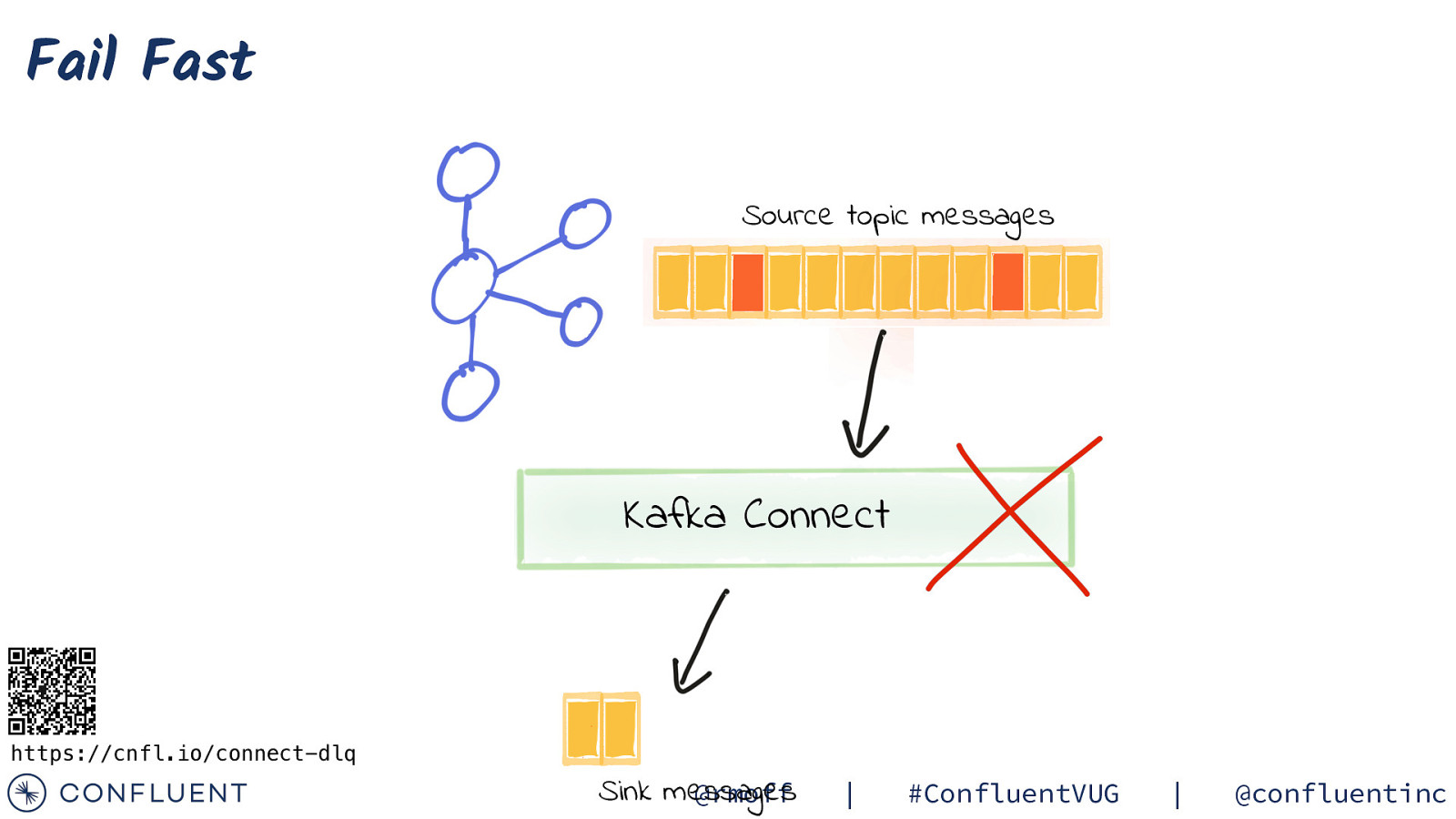
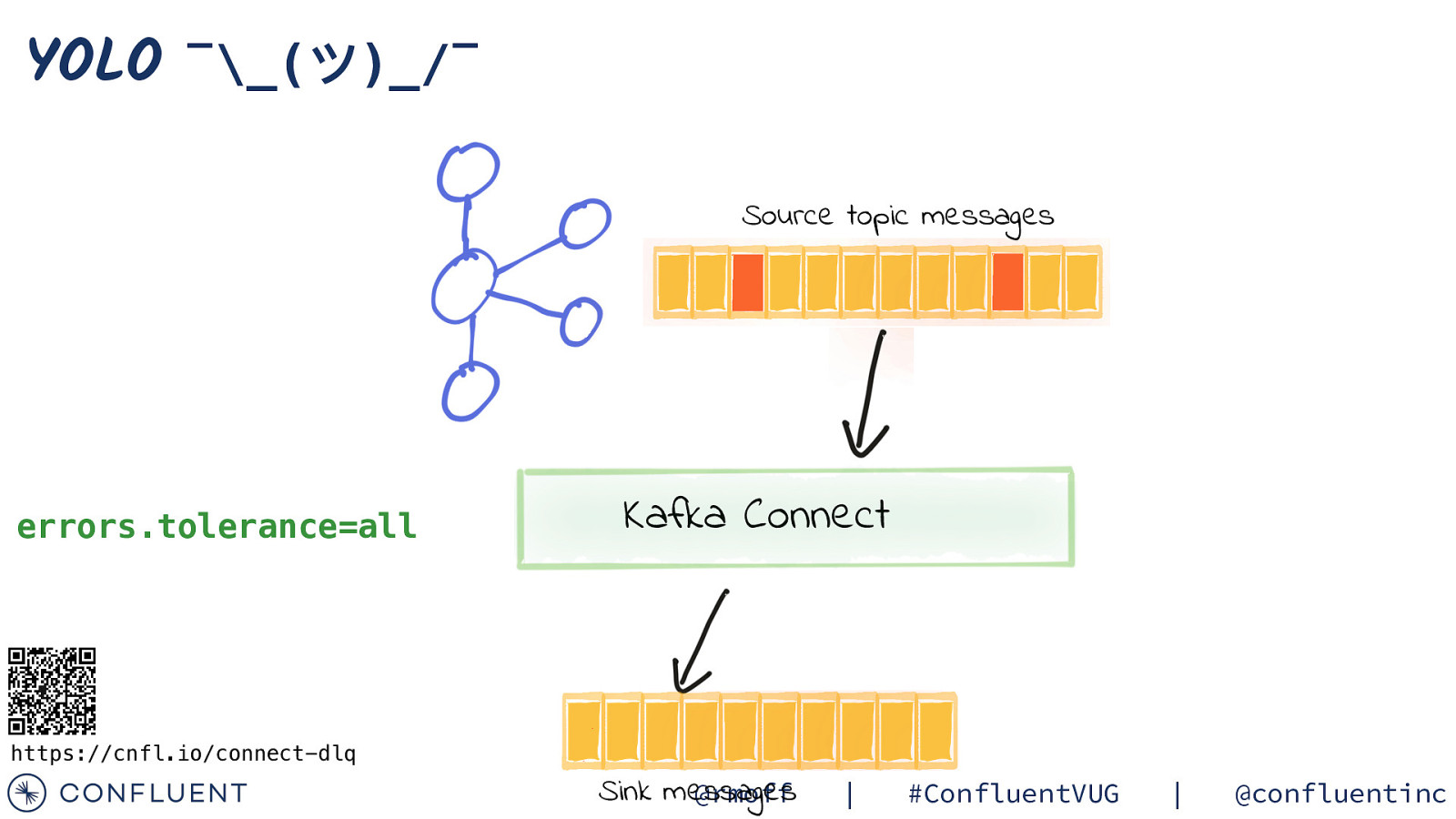
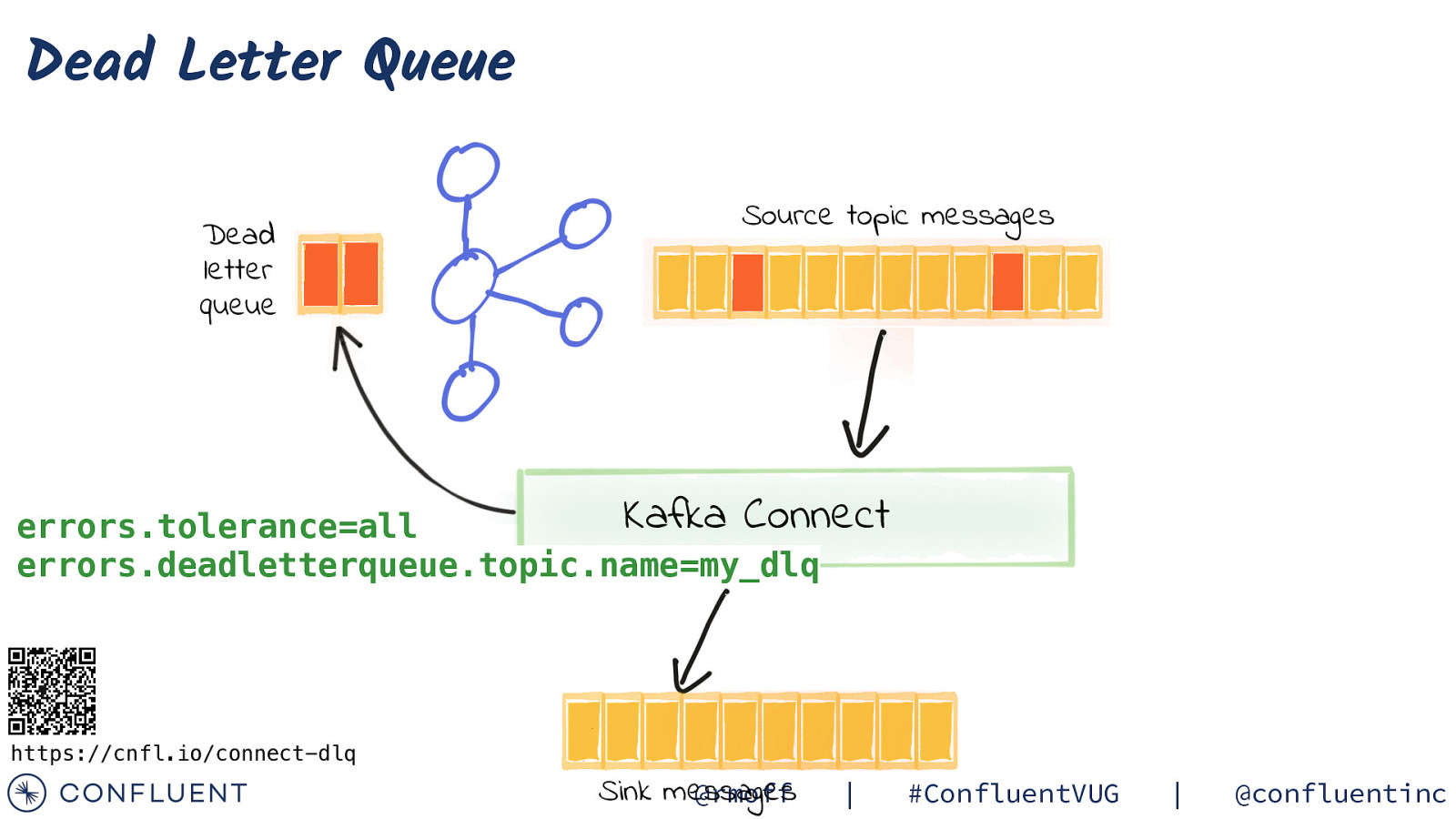
Error Handling and DLQ https://cnfl.io/connect-dlq @rmoff | #ConfluentVUG | @confluentinc
Fail Fast Source topic messages Kafka Connect https://cnfl.io/connect-dlq Sink messages @rmoff | #ConfluentVUG | @confluentinc
YOLO ¯_(ツ)_/¯ Source topic messages errors.tolerance=all Kafka Connect https://cnfl.io/connect-dlq Sink messages @rmoff | #ConfluentVUG | @confluentinc
Dead Letter Queue Dead letter queue Source topic messages Kafka Connect errors.tolerance=all errors.deadletterqueue.topic.name=my_dlq https://cnfl.io/connect-dlq Sink messages @rmoff | #ConfluentVUG | @confluentinc
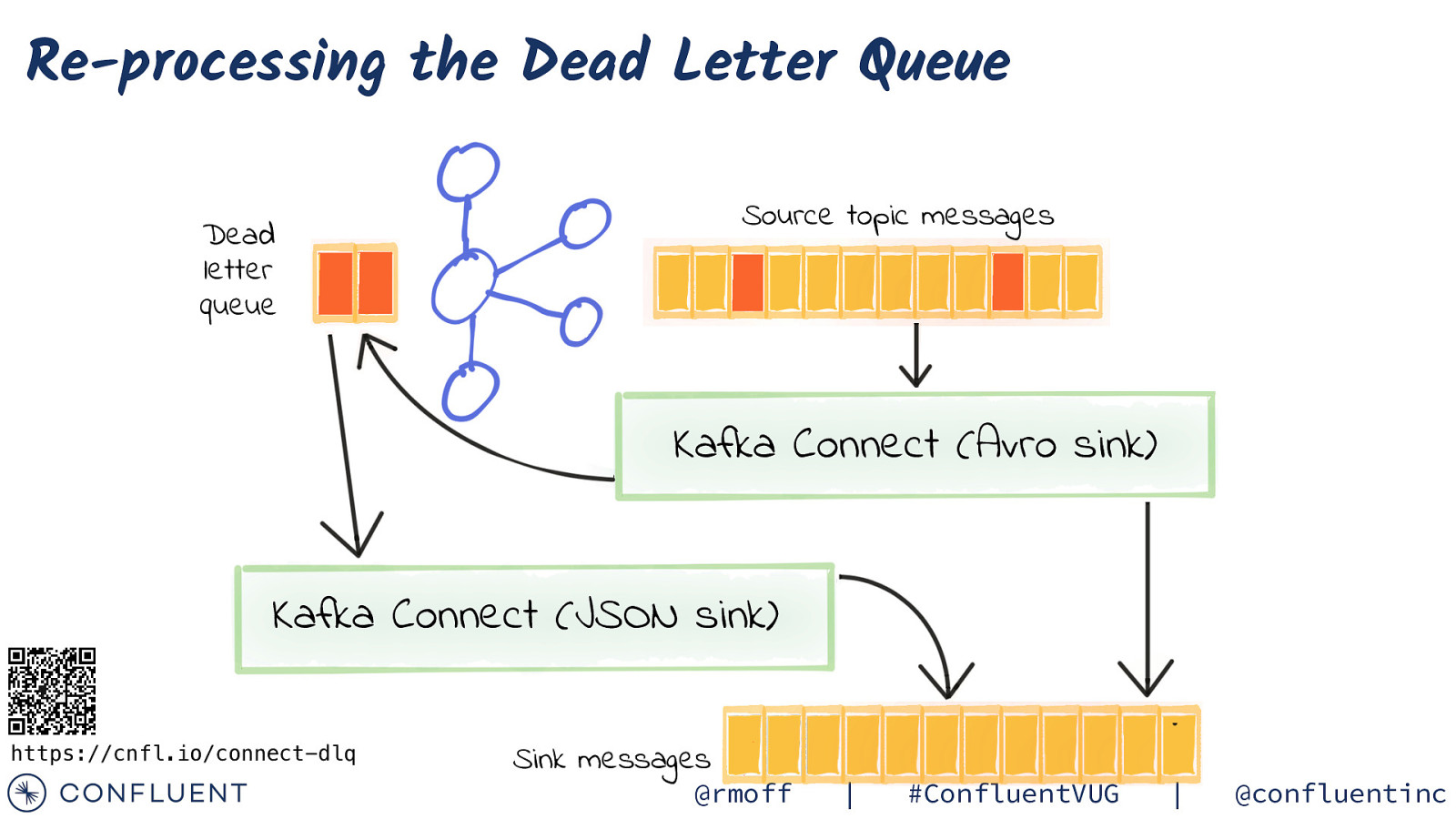
Re-processing the Dead Letter Queue Source topic messages Dead letter queue Kafka Connect (Avro sink) Kafka Connect (JSON sink) https://cnfl.io/connect-dlq Sink messages @rmoff | #ConfluentVUG | @confluentinc
Common errors @rmoff | #ConfluentVUG | @confluentinc
Mixed serialisation methods No fields found using key and value schemas for table: foo-bar @rmoff | #ConfluentVUG | @confluentinc
Mixed serialisation methods No fields found using key and value schemas for table: foo-bar JsonDeserializer with schemas.enable requires “schema” and “payload” fields and may not contain additional fields @rmoff | #ConfluentVUG | @confluentinc
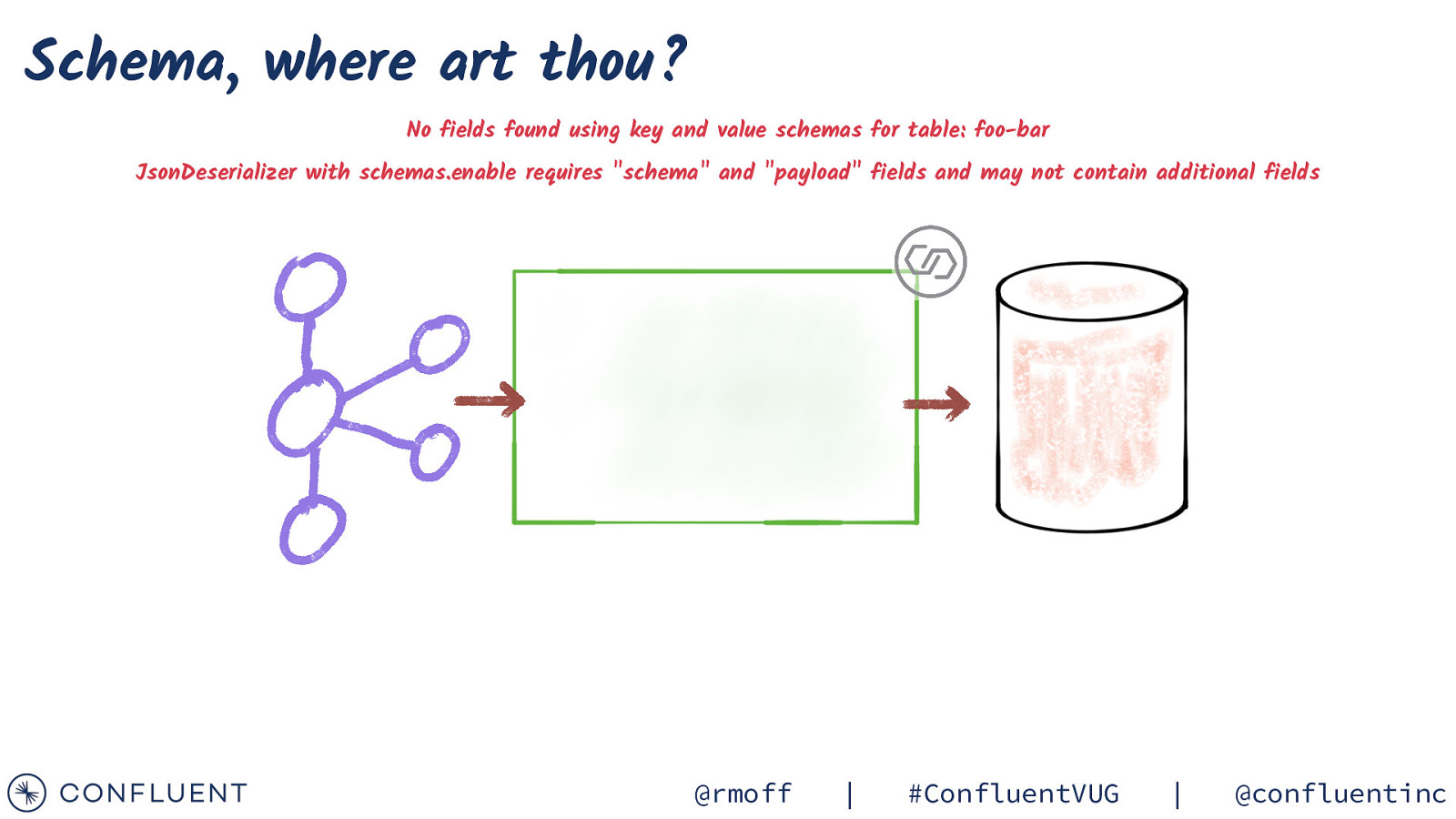
Schema, where art thou? No fields found using key and value schemas for table: foo-bar JsonDeserializer with schemas.enable requires “schema” and “payload” fields and may not contain additional fields @rmoff | #ConfluentVUG | @confluentinc
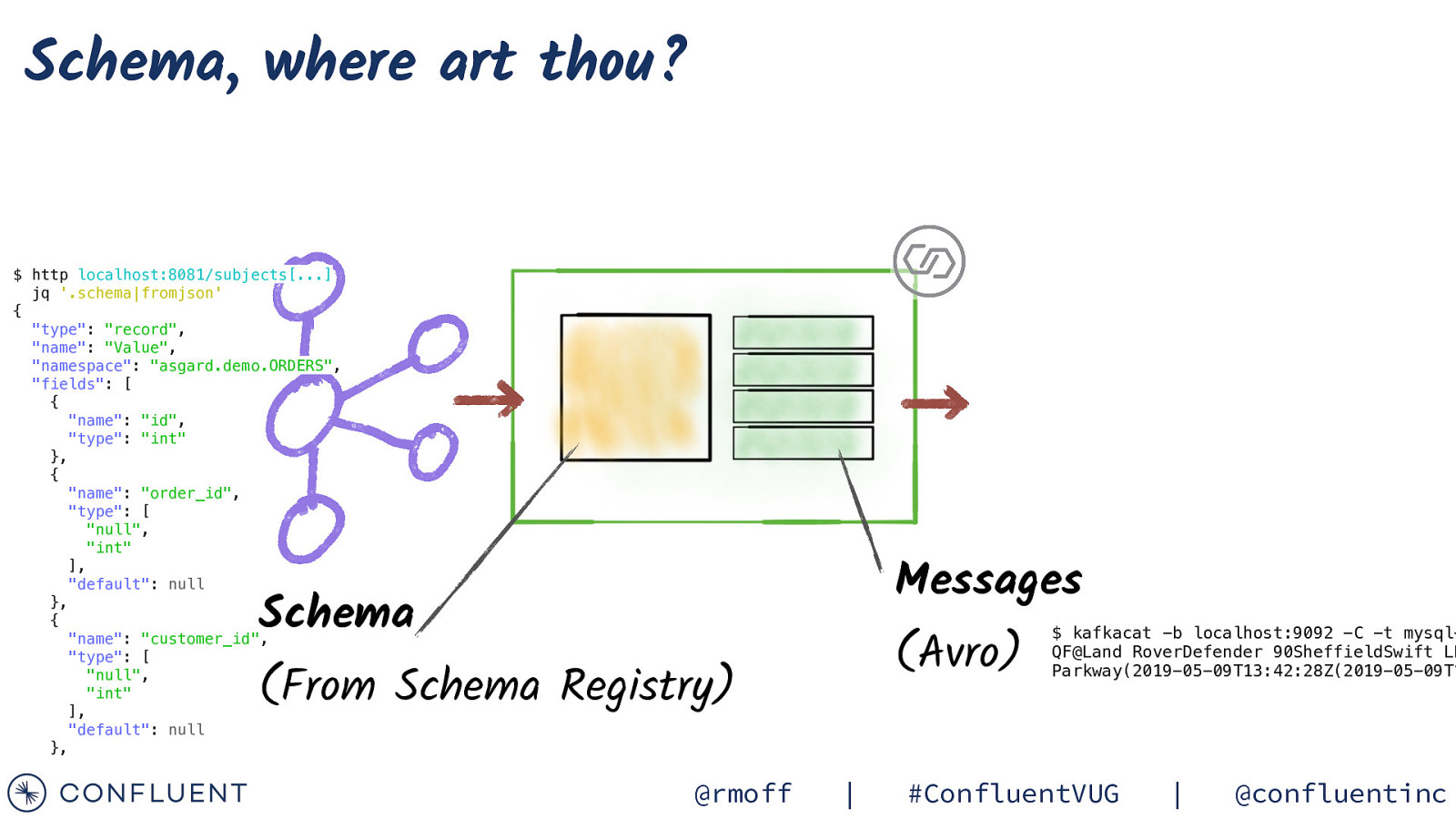
Schema, where art thou? $ http localhost:8081/subjects[…] jq ‘.schema|fromjson’ { “type”: “record”, “name”: “Value”, “namespace”: “asgard.demo.ORDERS”, “fields”: [ { “name”: “id”, “type”: “int” }, { “name”: “order_id”, “type”: [ “null”, “int” ], “default”: null }, { “name”: “customer_id”, “type”: [ “null”, “int” ], “default”: null }, Messages Schema (Avro) (From Schema Registry) @rmoff | $ kafkacat -b localhost:9092 -C -t mysqlQF@Land RoverDefender 90SheffieldSwift LL Parkway(2019-05-09T13:42:28Z(2019-05-09T1 #ConfluentVUG | @confluentinc
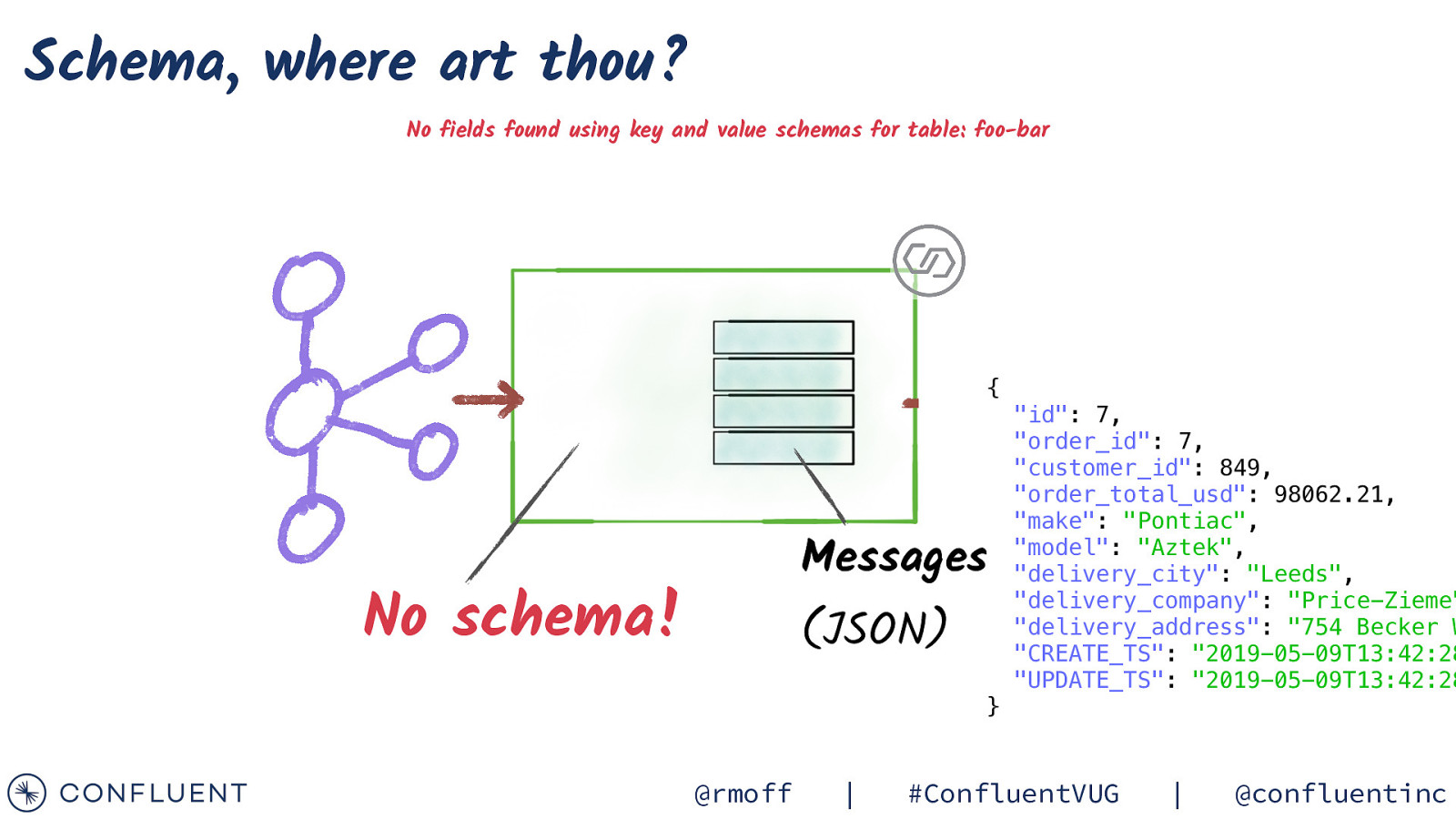
Schema, where art thou? No fields found using key and value schemas for table: foo-bar { Messages No schema! (JSON) “id”: 7, “order_id”: 7, “customer_id”: 849, “order_total_usd”: 98062.21, “make”: “Pontiac”, “model”: “Aztek”, “delivery_city”: “Leeds”, “delivery_company”: “Price-Zieme” “delivery_address”: “754 Becker W “CREATE_TS”: “2019-05-09T13:42:28 “UPDATE_TS”: “2019-05-09T13:42:28 } @rmoff | #ConfluentVUG | @confluentinc
Schema, where art thou? No fields found using key and value schemas for table: foo-bar -> You need a schema! -> Use Avro, or use JSON with schemas.enable=true Either way, you need to re-configure the producer of the data Or, use ksqlDB to impose a schema on the JSON/CSV data and reserialise it to Avro 👍 🎥 https://rmoff.dev/jdbc-sink-schemas 📝 https://www.confluent.io/blog/data-wrangling-apache-kafka-ksql @rmoff | #ConfluentVUG | @confluentinc
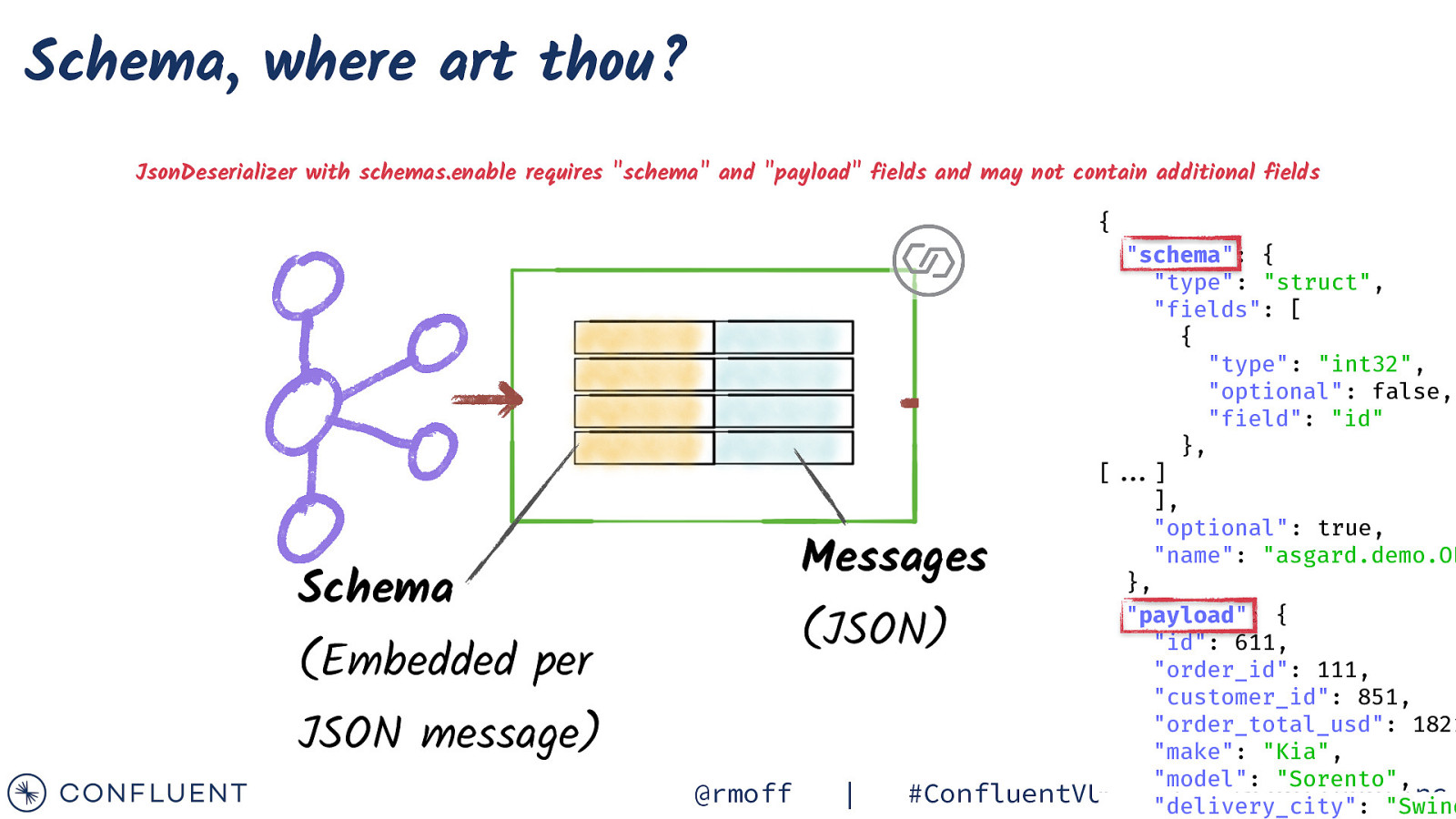
Schema, where art thou? JsonDeserializer with schemas.enable requires “schema” and “payload” fields and may not contain additional fields { “schema”: { “type”: “struct”, “fields”: [ { “type”: “int32”, “optional”: false, “field”: “id” }, [“”…] ], “optional”: true, “name”: “asgard.demo.OR }, “payload”: { “id”: 611, “order_id”: 111, “customer_id”: 851, “order_total_usd”: 1821 “make”: “Kia”, “model”: “Sorento”, #ConfluentVUG “delivery_city”: | @confluentinc “Swind Messages Schema (JSON) (Embedded per JSON message) @rmoff |
Schema, where art thou? JsonDeserializer with schemas.enable requires “schema” and “payload” fields and may not contain additional fields -> Your JSON must be structured as expected. @rmoff | { “schema”: { “type”: “struct”, “fields”: [ { “type”: “int32”, “optional”: false, “field”: “id” }, [“”…] ], “optional”: true, “name”: “asgard.demo.ORDERS }, “payload”: { “id”: 611, “order_id”: 111, “customer_id”: 851, #ConfluentVUG | @confluentinc “order_total_usd”: 182190.9
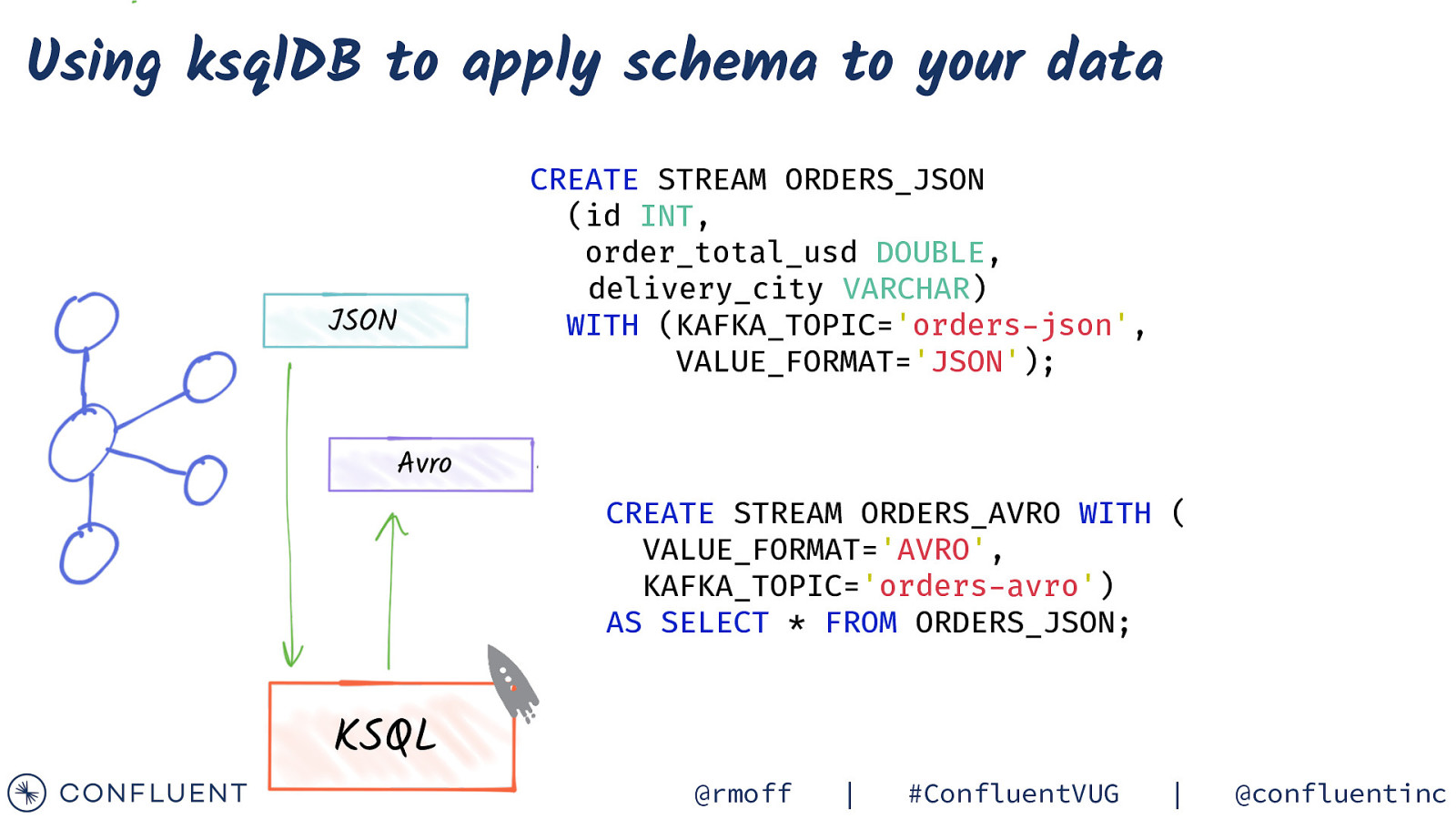
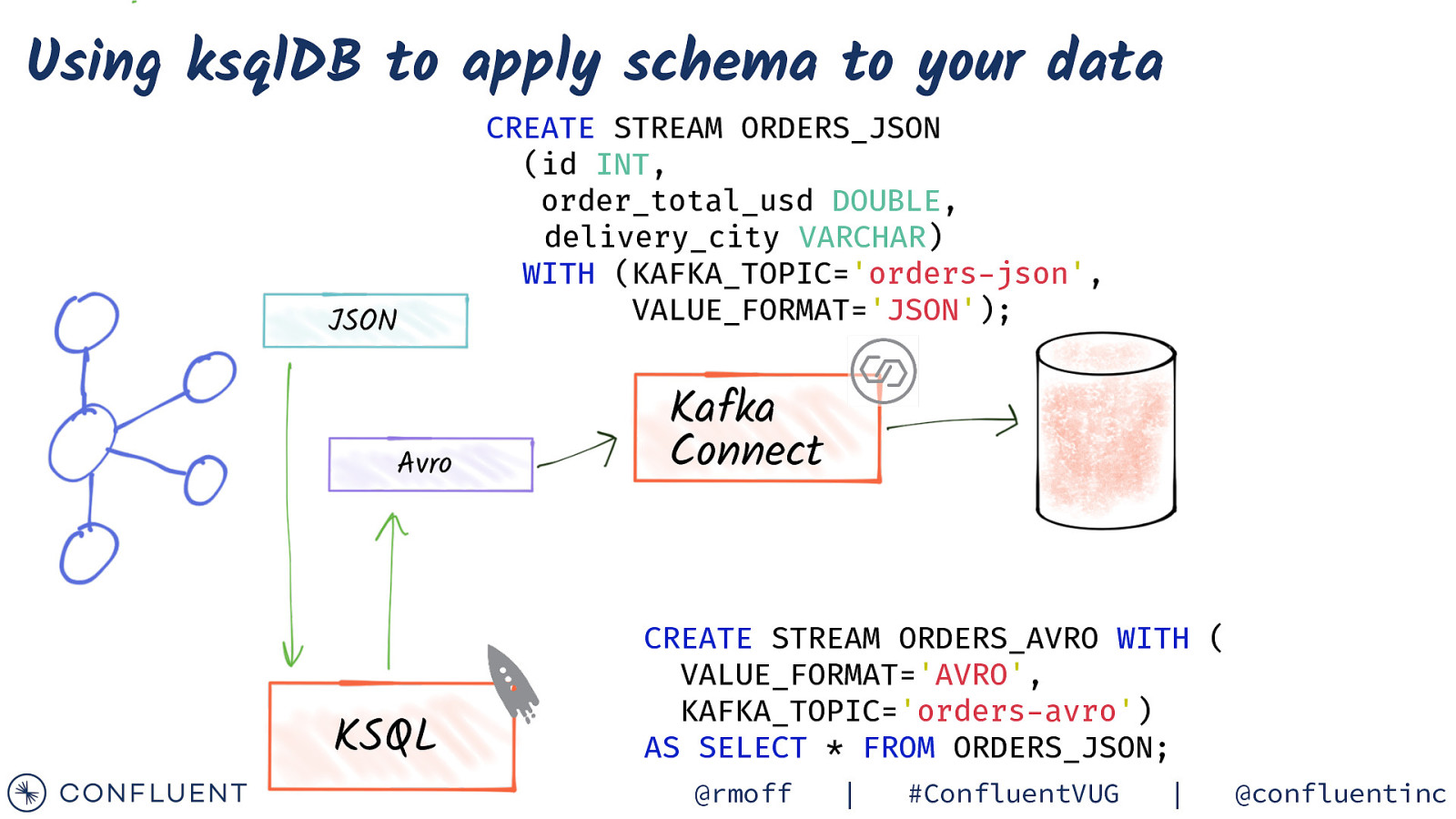
Using ksqlDB to apply schema to your data JSON Avro CREATE STREAM ORDERS_JSON (id INT, order_total_usd DOUBLE, delivery_city VARCHAR) WITH (KAFKA_TOPIC=’orders-json’, VALUE_FORMAT=’JSON’); Kafka Connect CREATE STREAM ORDERS_AVRO WITH ( VALUE_FORMAT=’AVRO’, KAFKA_TOPIC=’orders-avro’) AS SELECT * FROM ORDERS_JSON; KSQL @rmoff | #ConfluentVUG | @confluentinc
Using ksqlDB to apply schema to your data JSON Avro KSQL CREATE STREAM ORDERS_JSON (id INT, order_total_usd DOUBLE, delivery_city VARCHAR) WITH (KAFKA_TOPIC=’orders-json’, VALUE_FORMAT=’JSON’); Kafka Connect CREATE STREAM ORDERS_AVRO WITH ( VALUE_FORMAT=’AVRO’, KAFKA_TOPIC=’orders-avro’) AS SELECT * FROM ORDERS_JSON; @rmoff | #ConfluentVUG | @confluentinc
Metrics and Monitoring @rmoff | #ConfluentVUG | @confluentinc
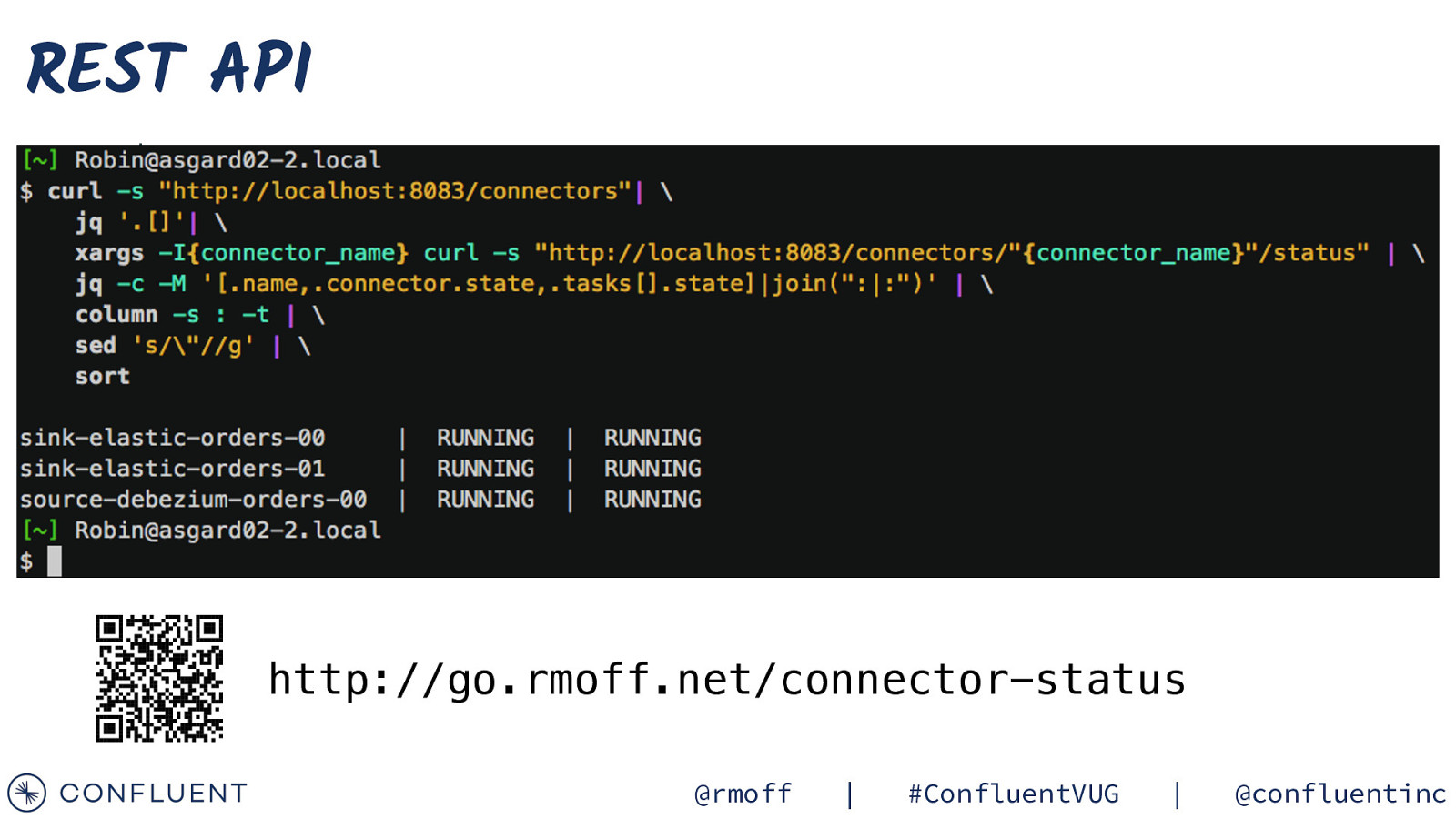
REST API • sort • peco http://go.rmoff.net/connector-status @rmoff | #ConfluentVUG | @confluentinc
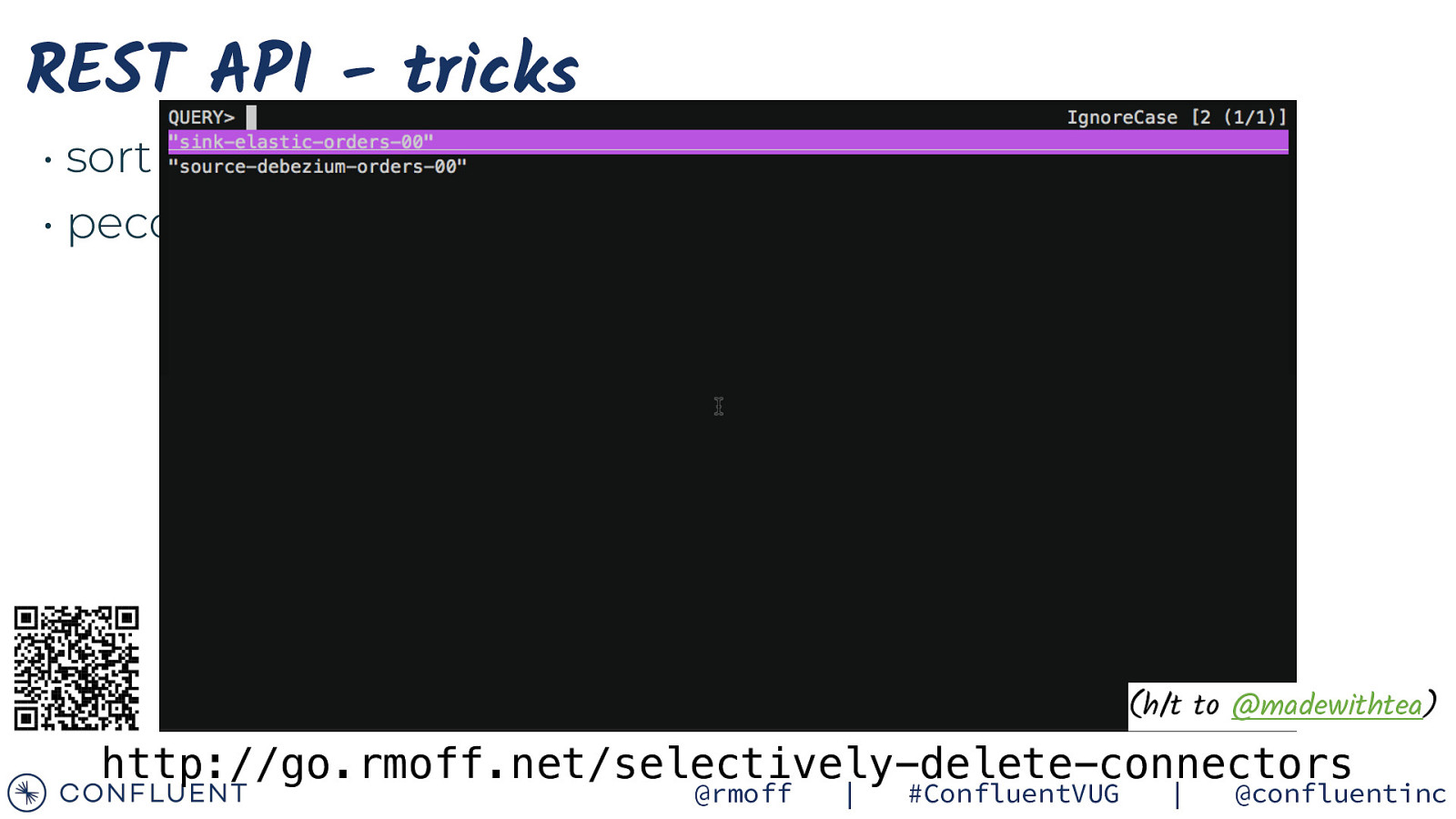
REST API - tricks • sort • peco (h/t to @madewithtea) http://go.rmoff.net/selectively-delete-connectors @rmoff | #ConfluentVUG | @confluentinc
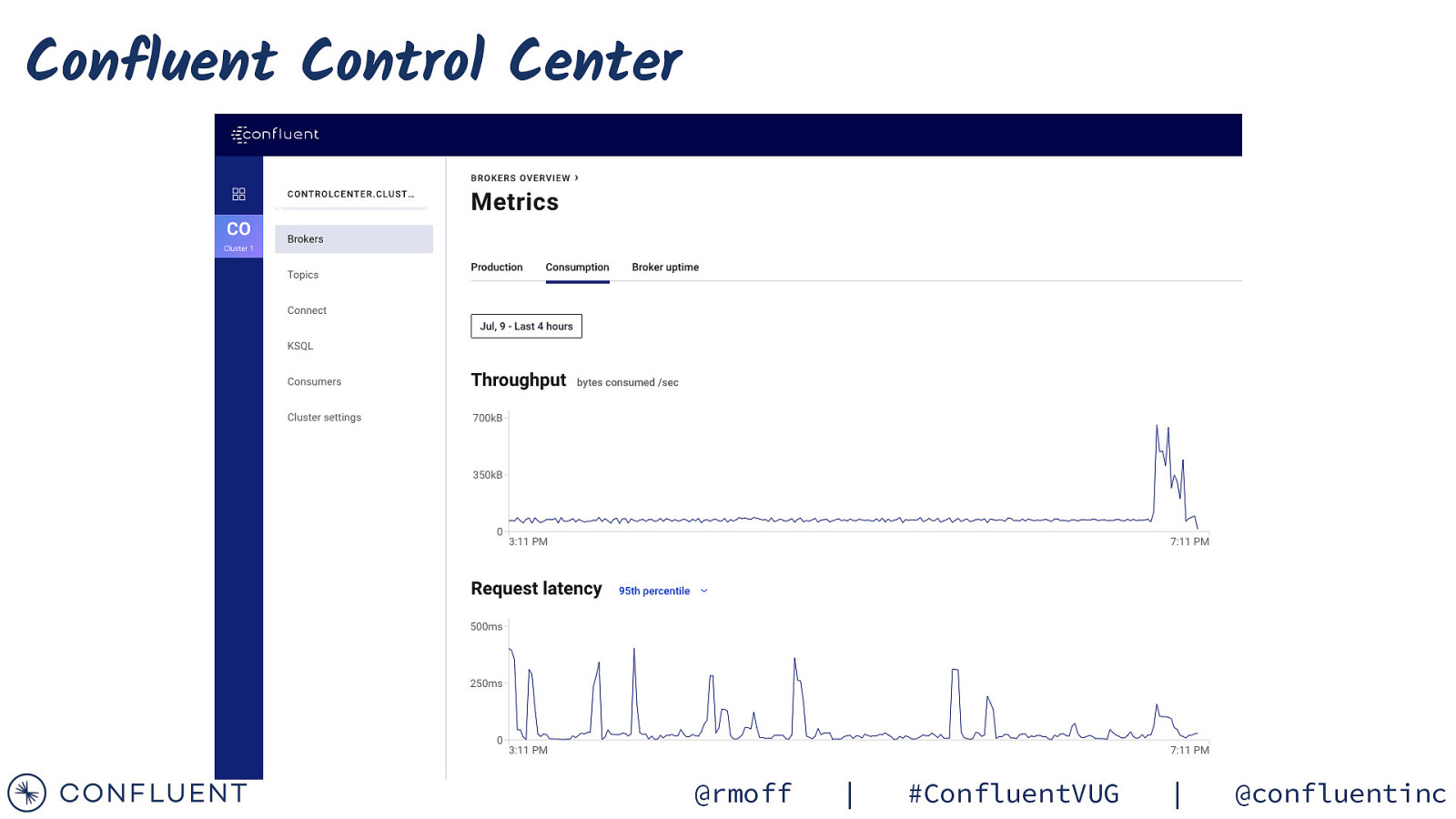
Confluent Control Center @rmoff | #ConfluentVUG | @confluentinc
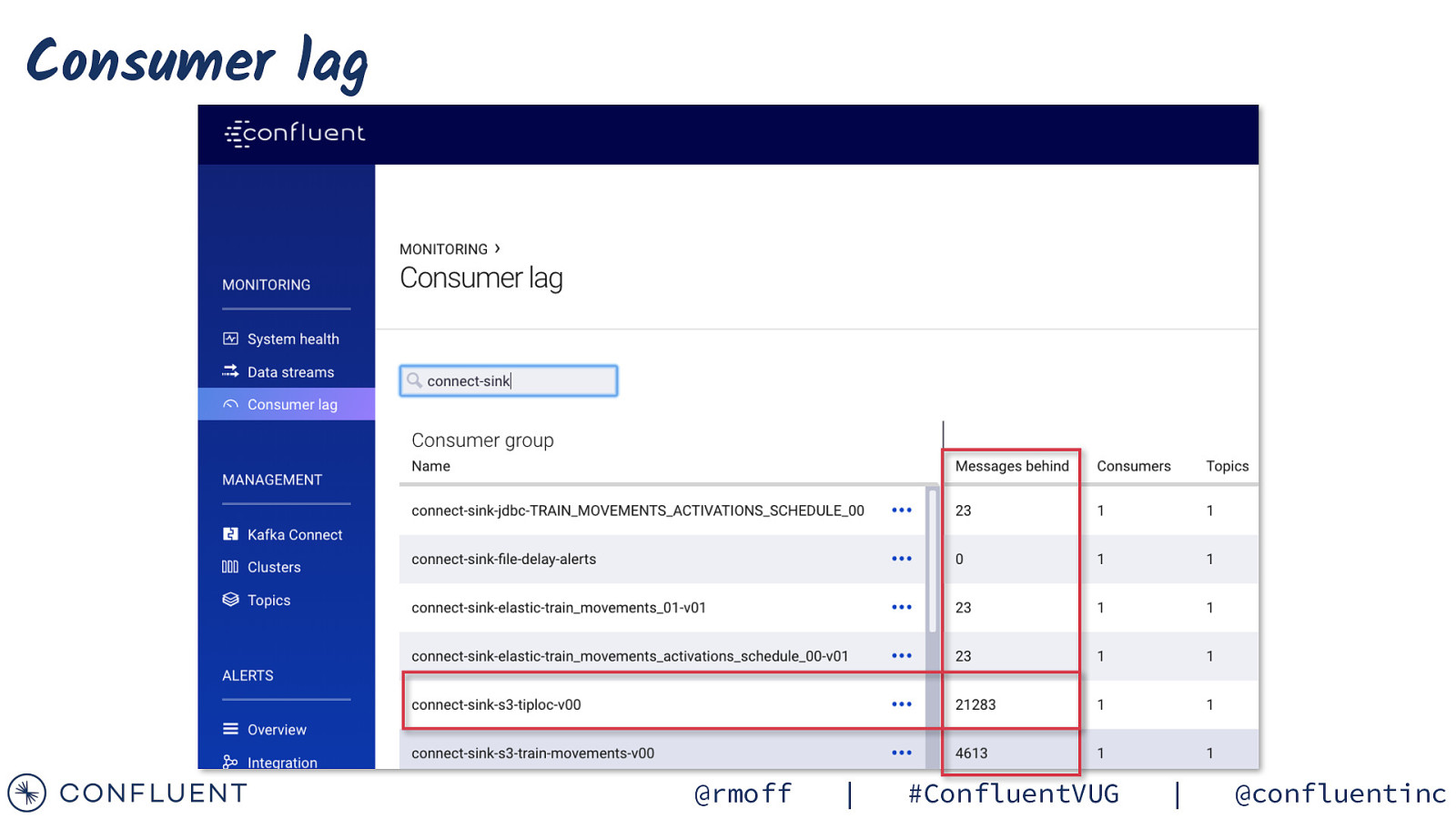
Consumer lag @rmoff | #ConfluentVUG | @confluentinc
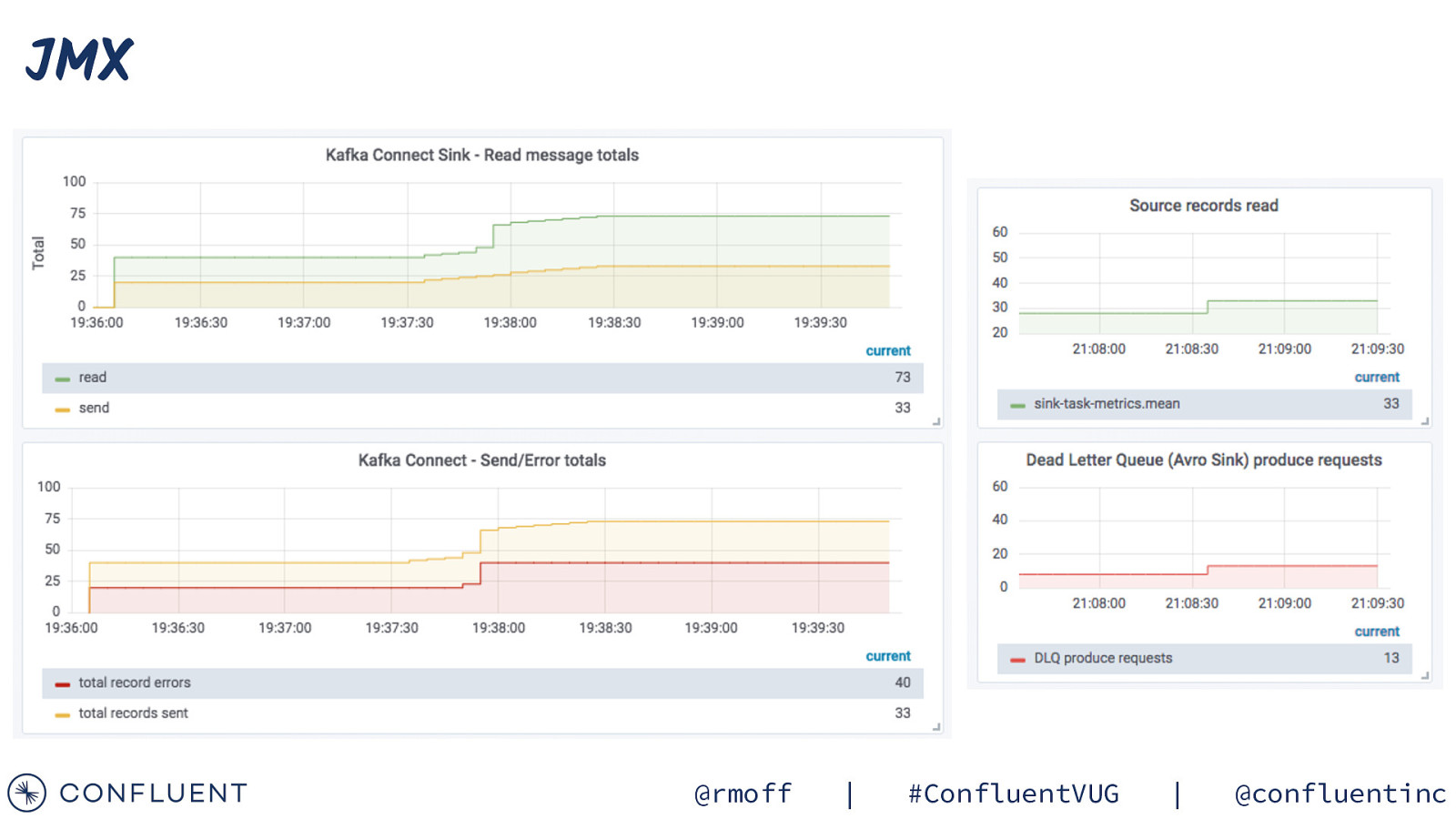
JMX @rmoff | #ConfluentVUG | @confluentinc
on Photo by Want to learn more? CTAs, not CATs (sorry, not sorry) @rmoff | #ConfluentVUG | @confluentinc
THE CONFLUENT MEETUP HUB ALL UPCOMING MEETUPS NEW EVENT EMAIL ALERTS VIDEOS OF PAST MEETUPS SLIDES FROM THE TALKS cnfl.io/meetup-hub
Free Books! https://rmoff.dev/2my @rmoff | #ConfluentVUG | @confluentinc
60 DE VA DV $50 USD off your bill each calendar month for the first three months when you sign up https://rmoff.dev/ccloud Free money! (additional $60 towards your bill 😄 ) Fully Managed Kafka as a Service * Limited availability. Activate by 11th September 2020. Expires after 90 days of activation. Any unused promo value on the expiration date will be forfeited.
Learn Kafka. Start building with Apache Kafka at Confluent Developer. developer.confluent.io
Confluent Community Slack group cnfl.io/slack @rmoff | #ConfluentVUG | @confluentinc
Further reading / watching • Kafka as a Platform: the Ecosystem from the Ground Up http://rmoff.dev/youtube • https://rmoff.dev/kafka101 • Apache Kafka and ksqlDB in Action: Let’s Build a Streaming Data Pipeline! • https://rmoff.dev/ljc-kafka-01 • From Zero to Hero with Kafka Connect • https://rmoff.dev/ljc-kafka-02 • Introduction to ksqlDB • https://rmoff.dev/ljc-kafka-03 • Integrating Oracle and Kafka • https://rmoff.dev/oracle-and-kafka • The Changing Face of ETL: Event-Driven Architectures for Data Engineers • https://rmoff.dev/oredev19-changing-face-of-etl • 🚂On Track with Apache Kafka: Building a Streaming Platform solution with Rail Data • https://rmoff.dev/oredev19-on-track-with-kafka @rmoff | #ConfluentVUG | @confluentinc
@rmoff #ConfluentVUG #EOF https://talks.rmoff.net

Integrating Apache Kafka with other systems in a reliable and scalable way is often a key part of a streaming platform. Fortunately, Apache Kafka includes the Connect API that enables streaming integration both in and out of Kafka. Like any technology, understanding its architecture and deployment patterns is key to successful use, as is knowing where to go looking when things aren’t working.
This talk will discuss the key design concepts within Kafka Connect and the pros and cons of standalone vs distributed deployment modes. We’ll do a live demo of building pipelines with Kafka Connect for streaming data in from databases, and out to targets including Elasticsearch. With some gremlins along the way, we’ll go hands-on in methodically diagnosing and resolving common issues encountered with Kafka Connect. The talk will finish off by discussing more advanced topics including Single Message Transforms, and deployment of Kafka Connect in containers.
The following resources were mentioned during the presentation or are useful additional information.
Fully Managed Apache Kafka, Schema Registry, ksqlDB, and Connectors
Huge list of connectors for Kafka Connect
Free eBooks to download, including Kafka: The Definitive Guide.
All you need is Docker & Docker Compose!
Same talk, different occassion.
The ins and outs of streaming data from RDBMS into Kafka, including how to choose between query-based CDC (JDBC Source connector) and log-based CDC (e.g. Debezium, GoldenGate, etc)











































 for free. You
can too.
for free. You
can too.