
A presentation at Strata Data Conference, London in in London, UK by Robin Moffatt

https://cnfl.io/ksql-workshop-prereq Real-time SQL stream processing at ® scale with Apache Kafka and KSQL @rmoff #stratadata
@rmoff #stratadata https://cnfl.io/ksql-workshop-prereq • Make sure you allocate Docker >=8GB memory docker system info | grep Memory • Clone the repo • Pull the git images as instructed in the doc https://cnfl.io/start-ksql-workshop 3. Start Confluent Platform Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
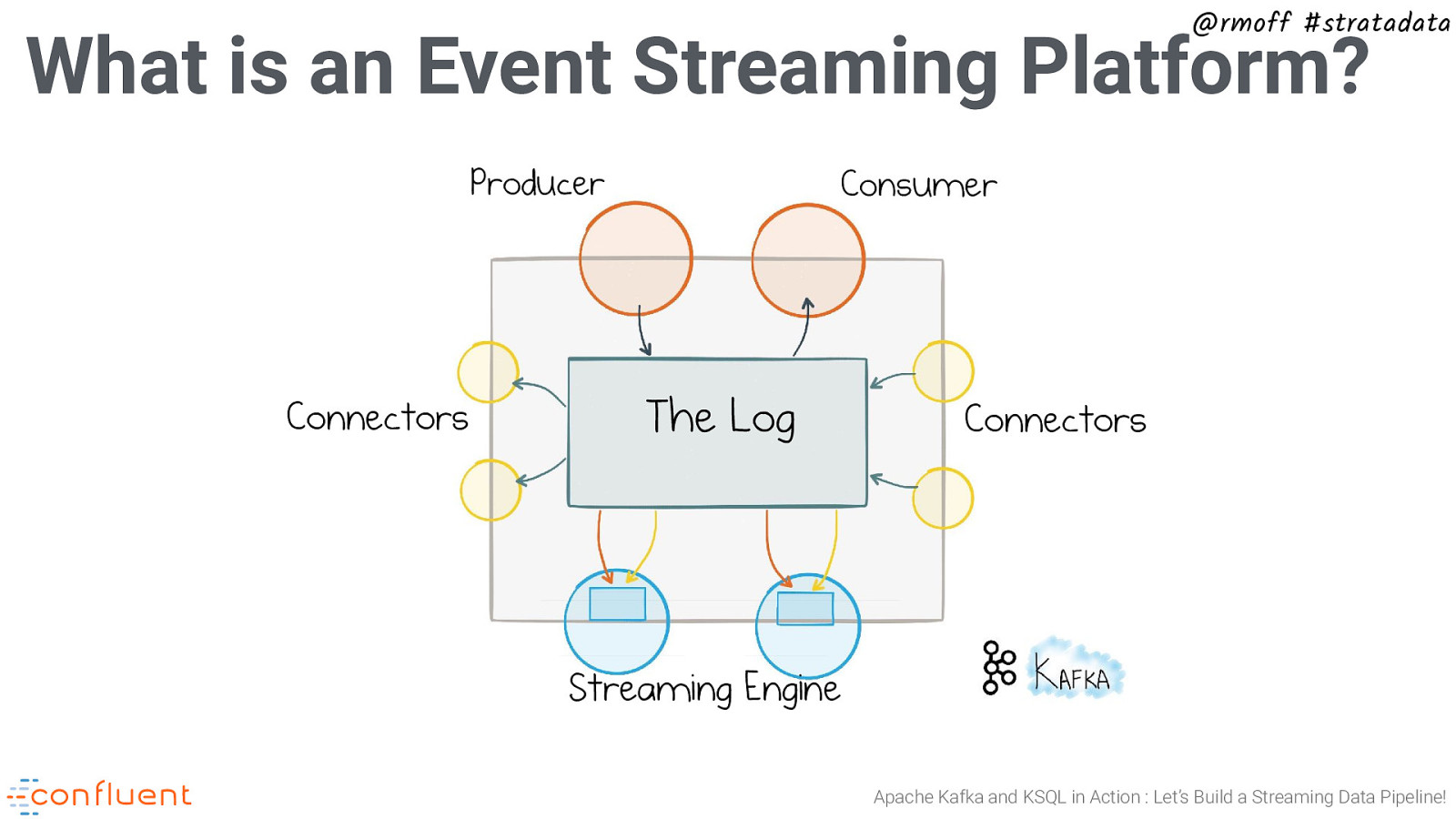
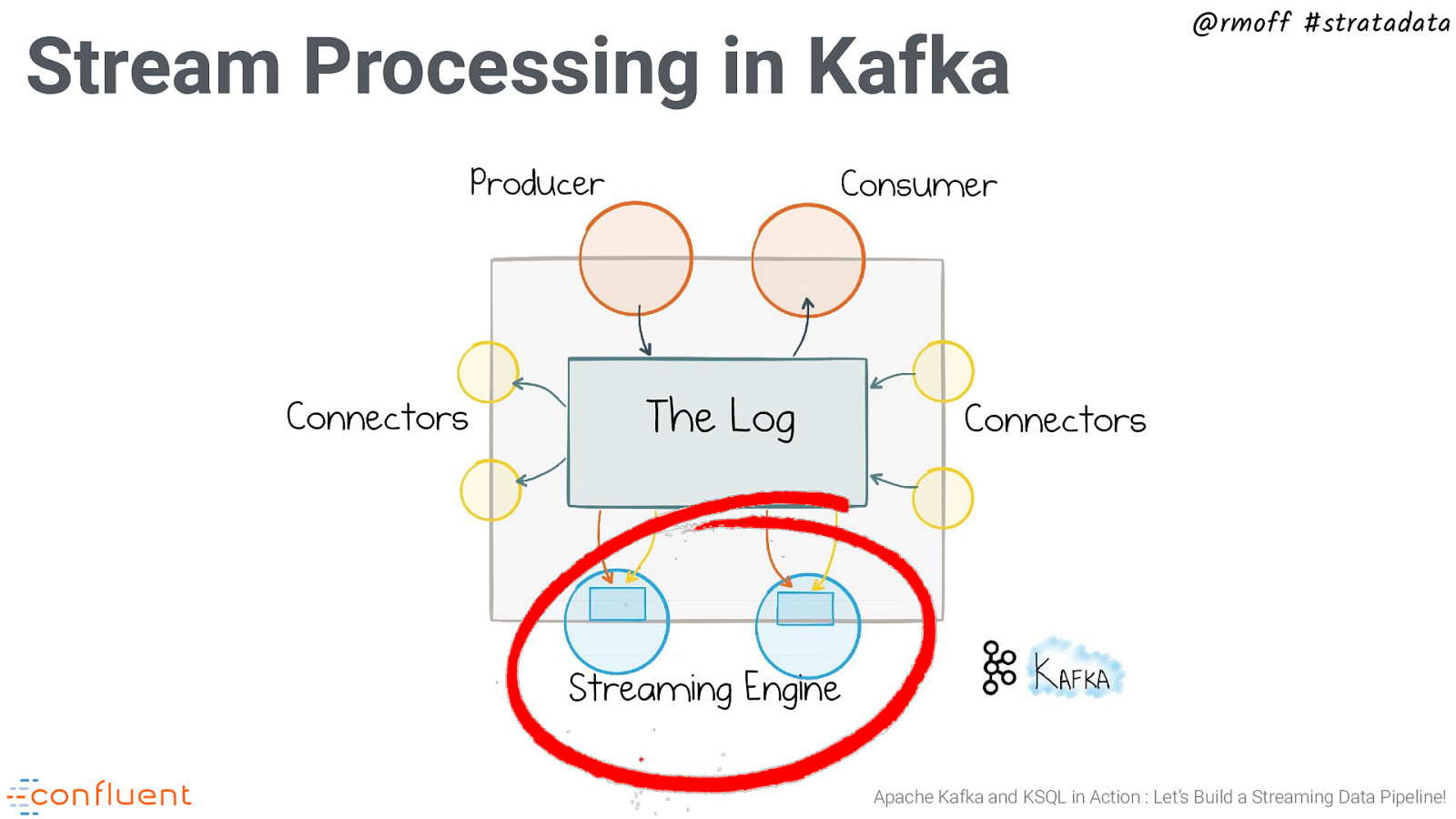
@rmoff #stratadata What is an Event Streaming Platform? Producer Connectors Consumer The Log Connectors Streaming Engine Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
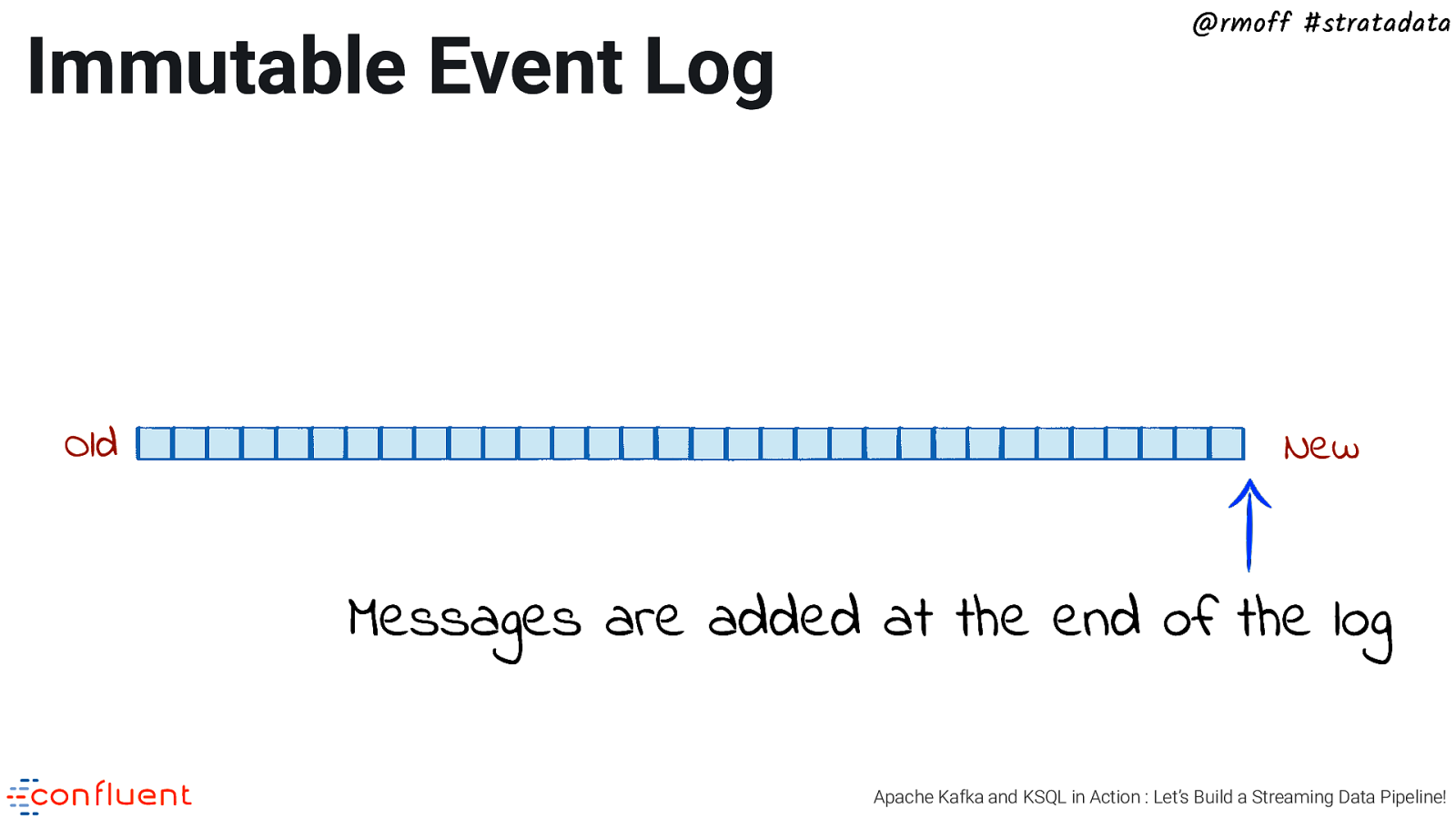
Immutable Event Log Old @rmoff #stratadata New Messages are added at the end of the log Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata Topics Clicks Orders Customers Topics are similar in concept to tables in a database Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata Partitions Clicks p0 P1 P2 Messages are guaranteed to be strictly ordered within a partition Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
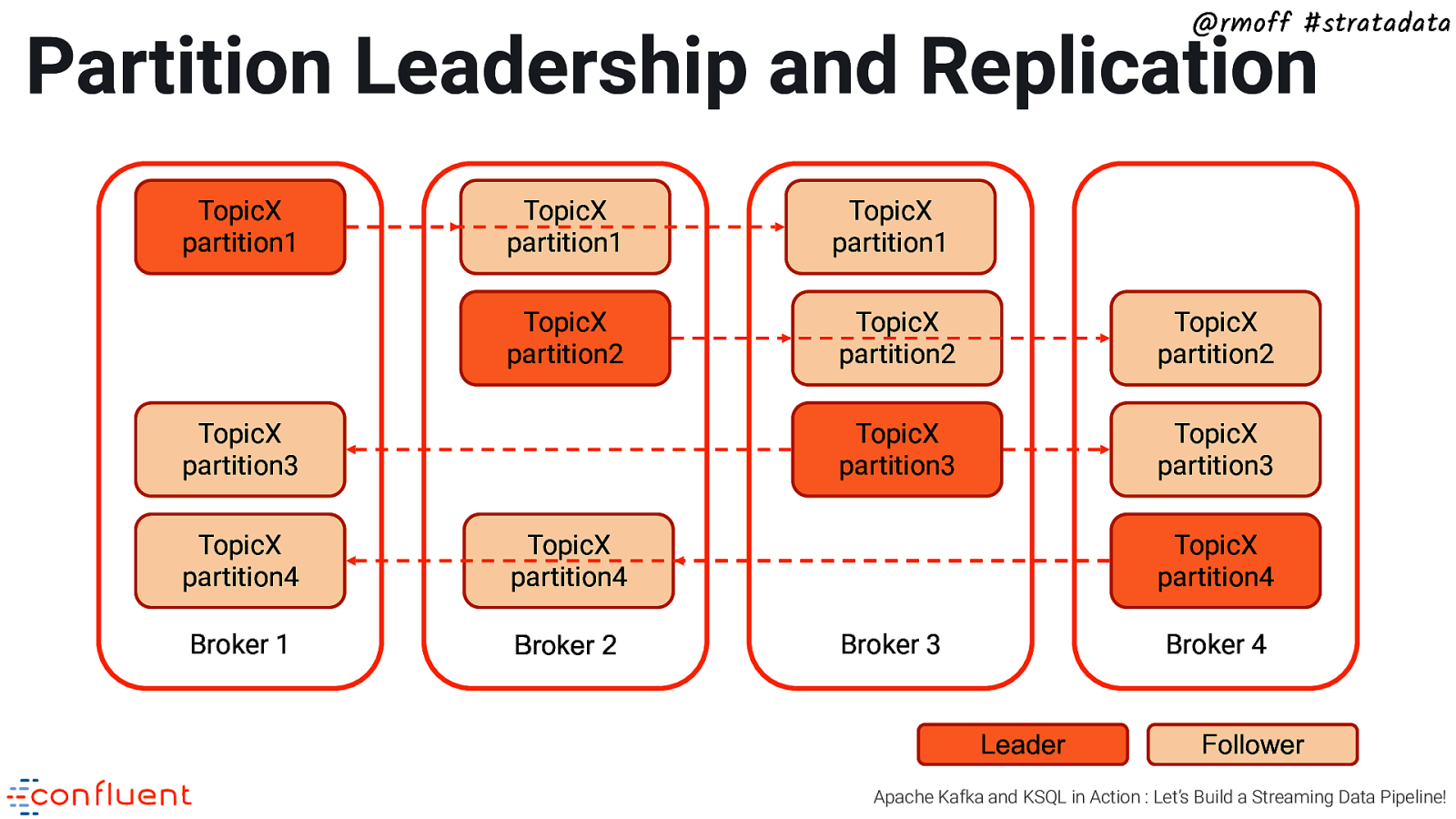
@rmoff #stratadata Partition Leadership and Replication TopicX partition1 TopicX partition1 TopicX partition1 TopicX partition2 TopicX partition2 TopicX partition2 TopicX partition3 TopicX partition3 TopicX partition3 TopicX partition4 TopicX partition4 Broker 1 Broker 2 TopicX partition4 Broker 3 Broker 4 Leader Follower Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
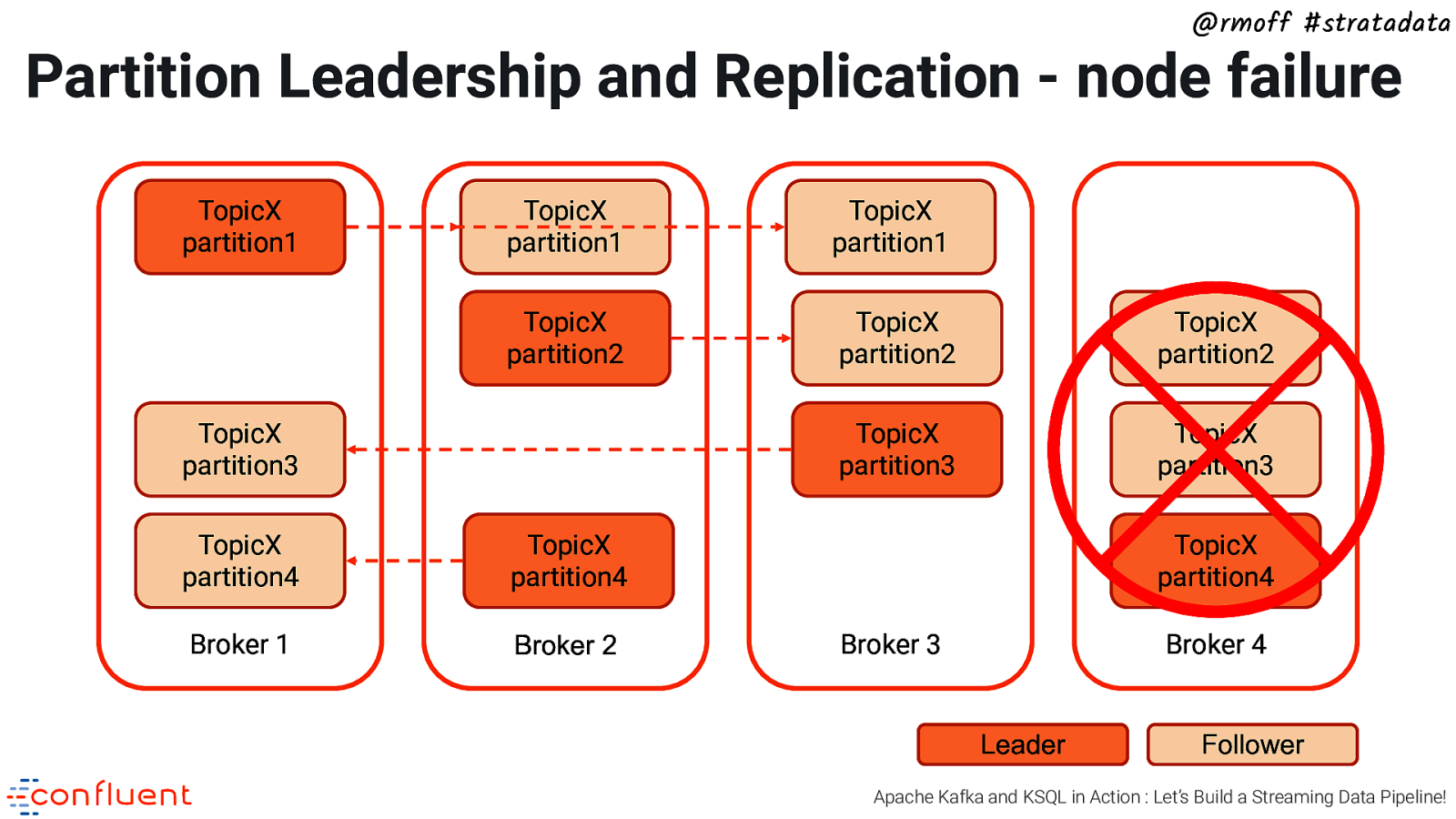
@rmoff #stratadata Partition Leadership and Replication - node failure TopicX partition1 TopicX partition1 TopicX partition1 TopicX partition2 TopicX partition2 TopicX partition2 TopicX partition3 TopicX partition3 TopicX partition3 TopicX partition4 TopicX partition4 Broker 1 Broker 2 TopicX partition4 Broker 3 Broker 4 Leader Follower Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
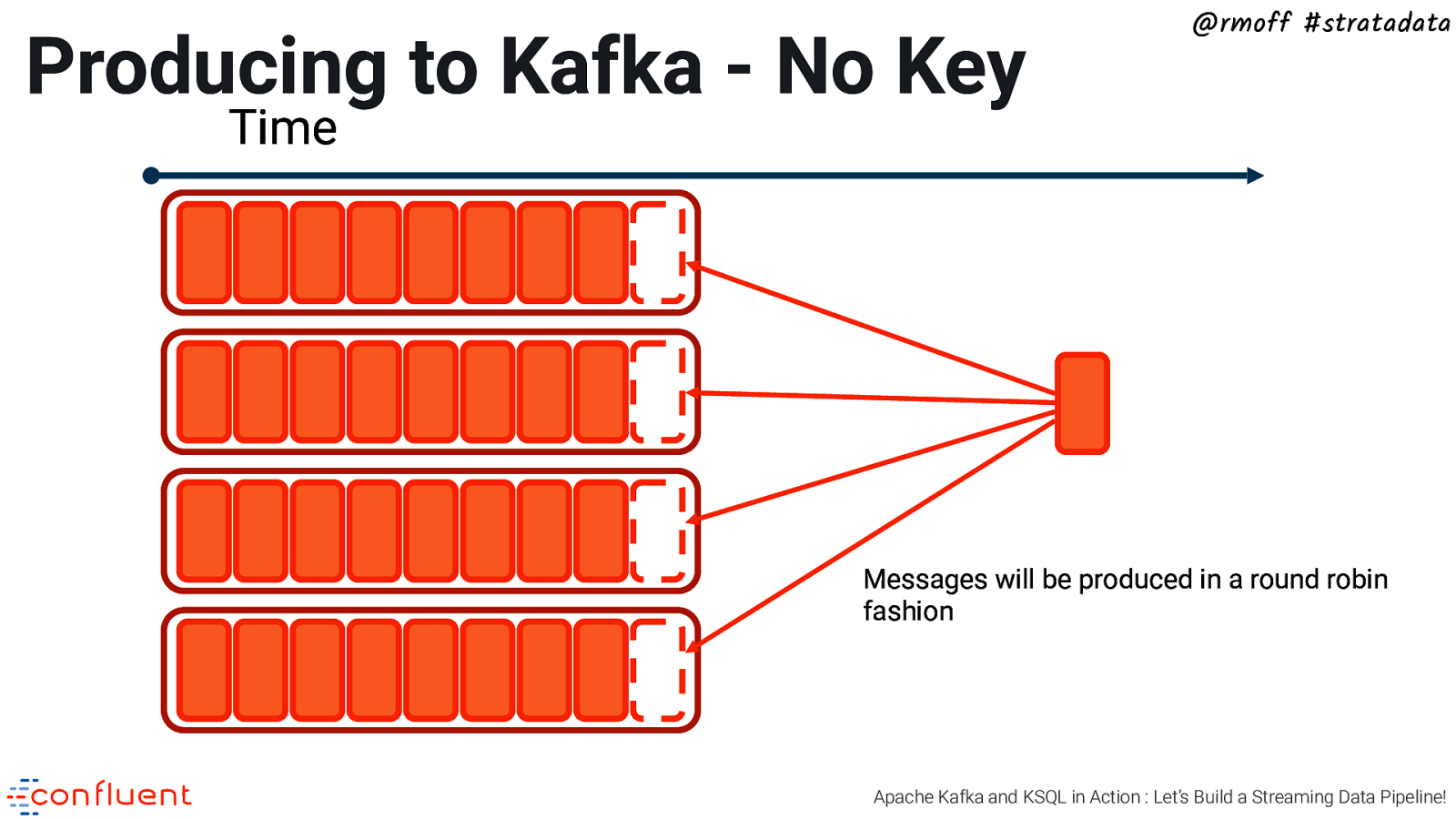
Producing to Kafka - No Key @rmoff #stratadata Time Messages will be produced in a round robin fashion Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
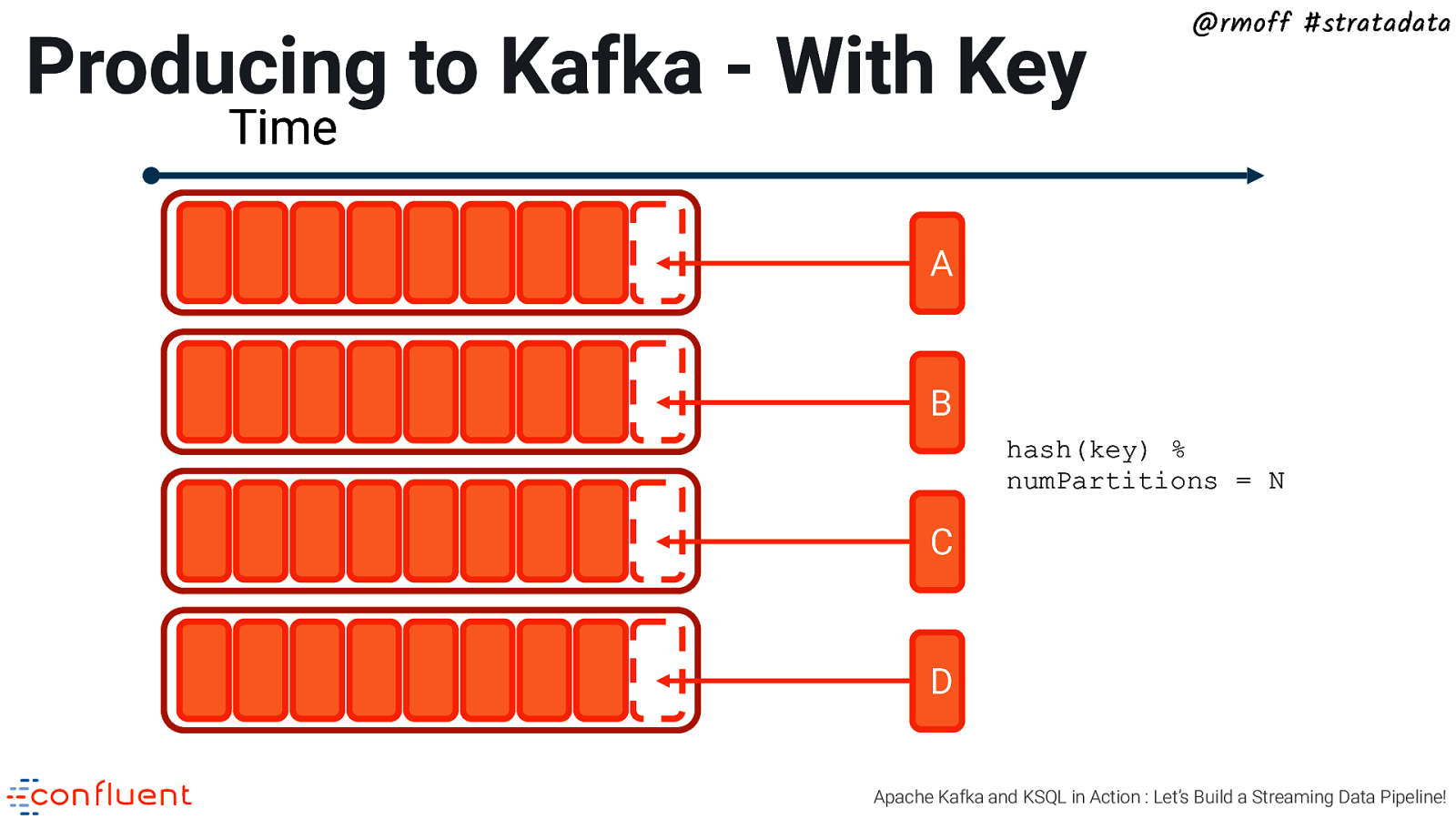
Producing to Kafka - With Key @rmoff #stratadata Time A B hash(key) % numPartitions = N C D Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
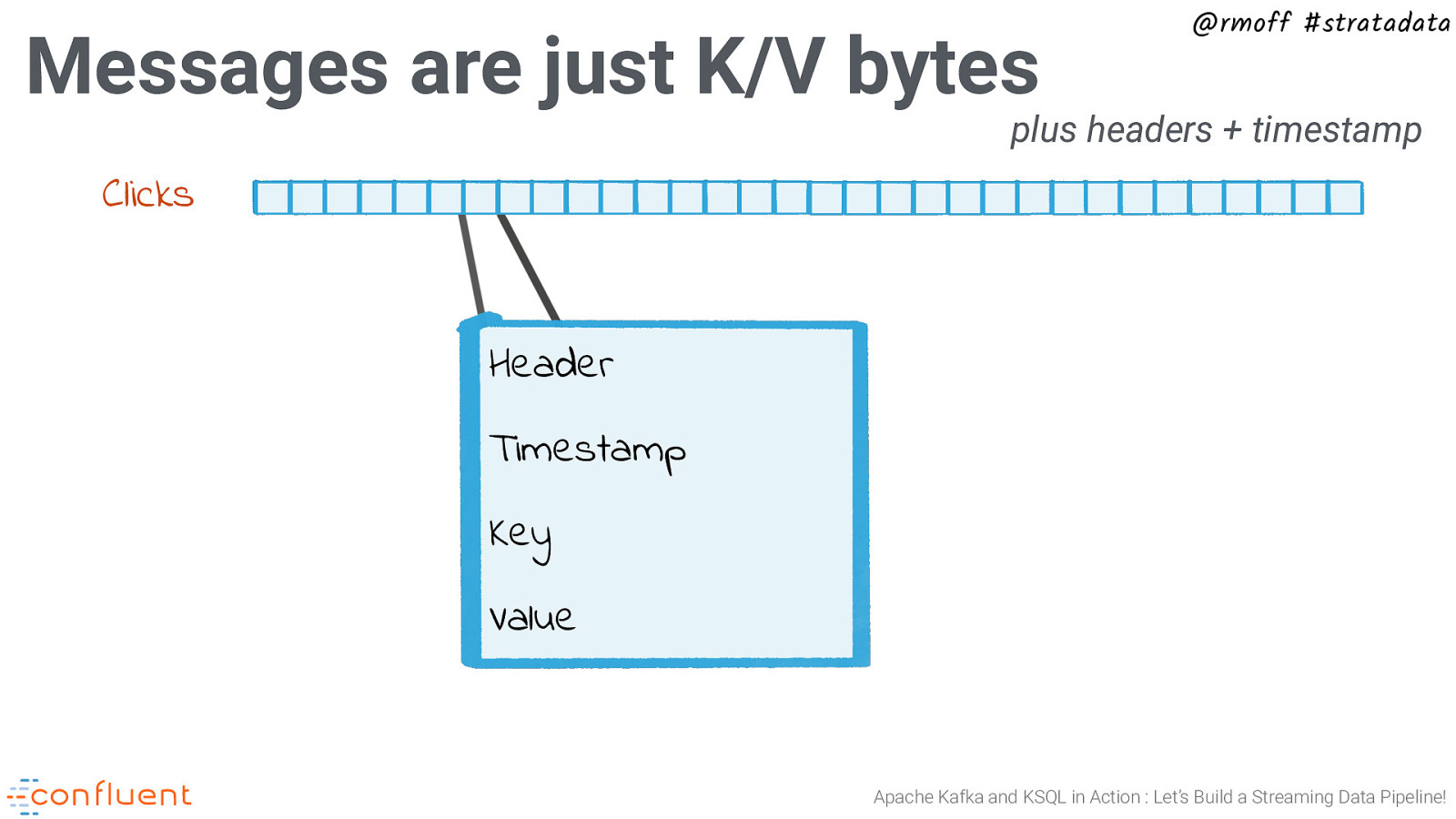
Messages are just K/V bytes @rmoff #stratadata plus headers + timestamp Clicks Header Timestamp Key Value Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
Messages are just K/V bytes @rmoff #stratadata With great power comes great responsibility Avro -> Confluent Schema Registry Protobuf JSON CSV https://qconnewyork.com/system/files/presentation-slides/qcon_17_-_schemas_and_apis.pdf Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
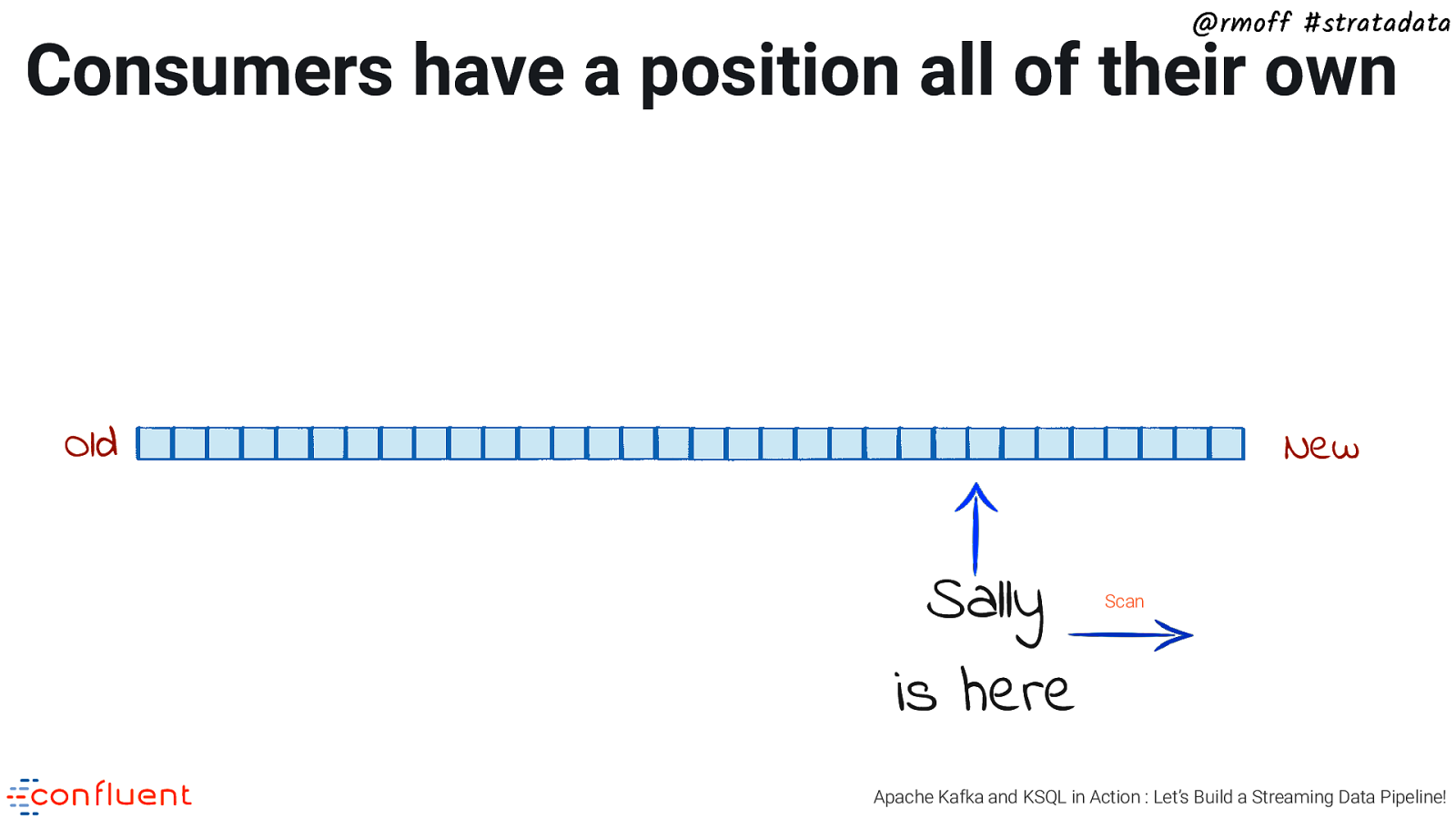
@rmoff #stratadata Consumers have a position all of their own Old New Sally is here Scan Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
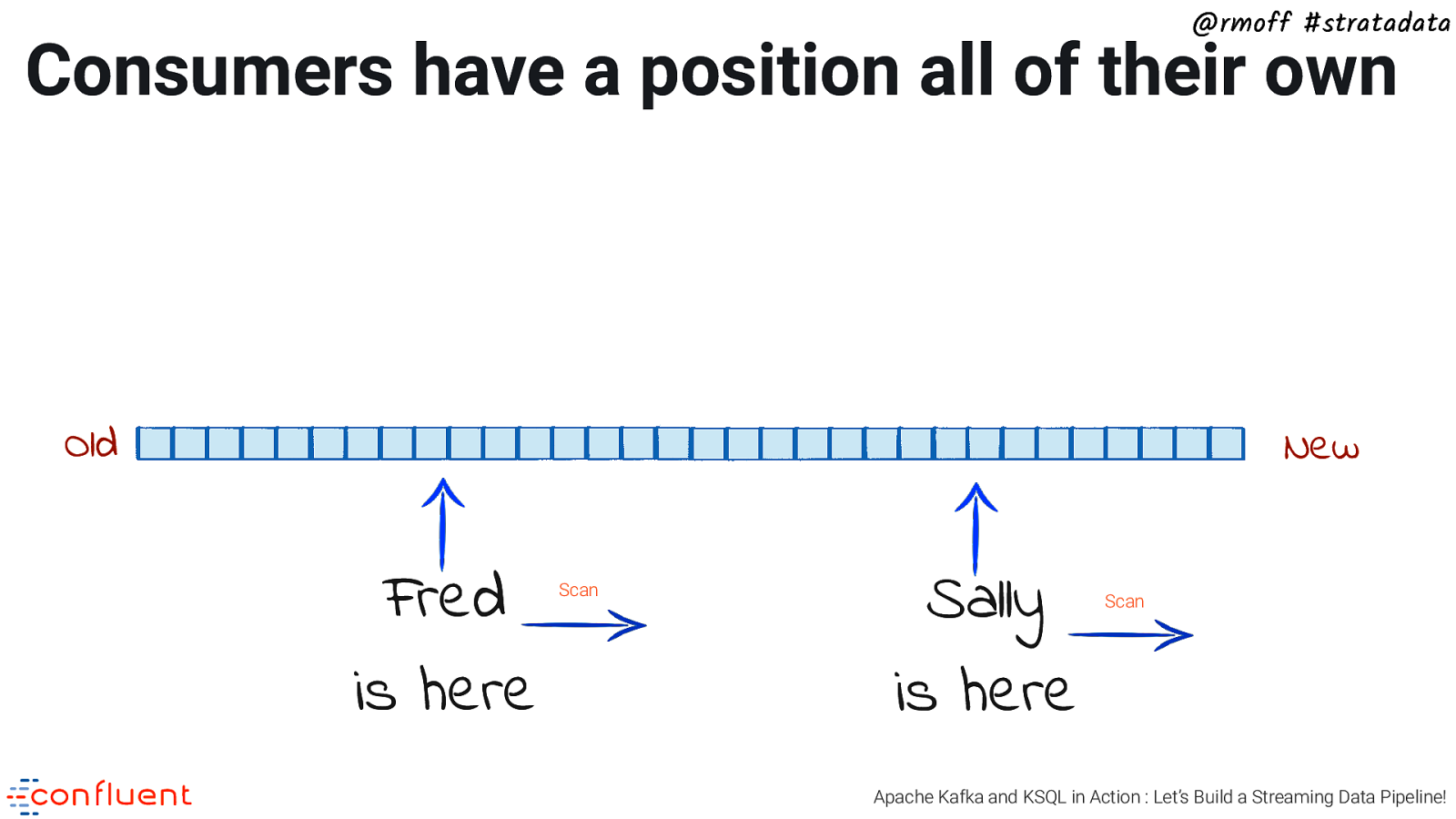
@rmoff #stratadata Consumers have a position all of their own Old New Fred is here Scan Sally is here Scan Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
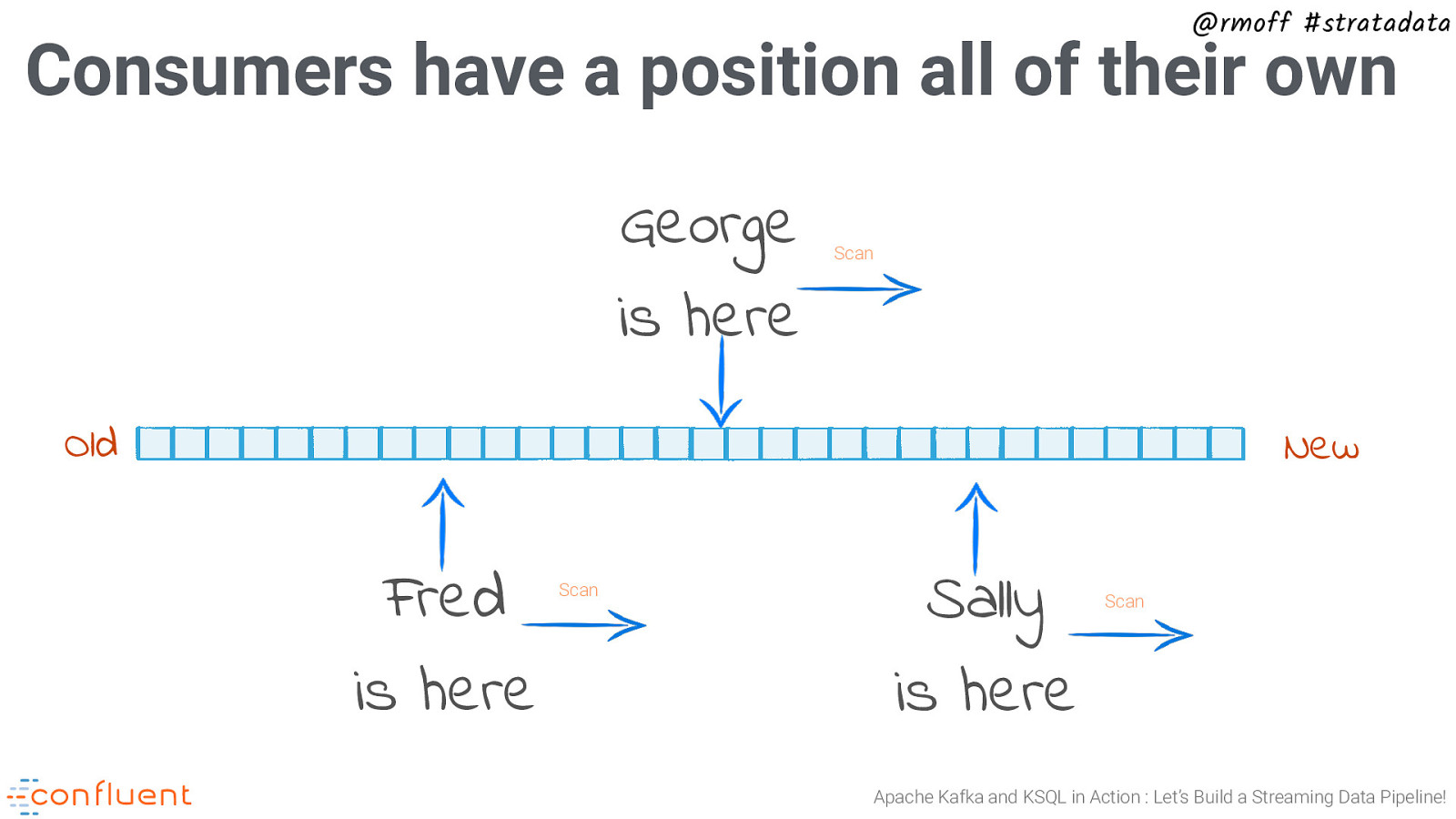
@rmoff #stratadata Consumers have a position all of their own George is here Scan Old New Fred is here Scan Sally is here Scan Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
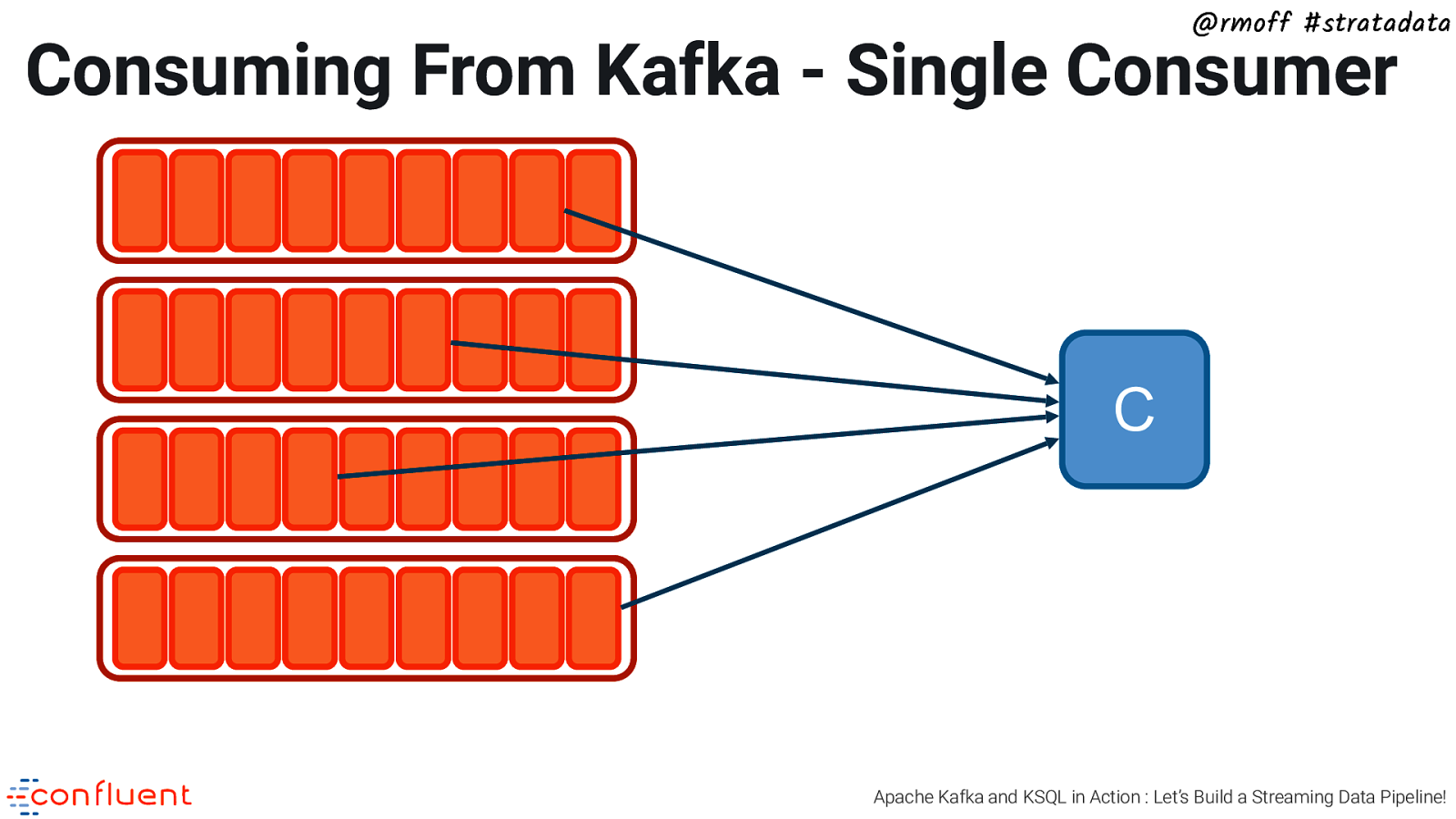
@rmoff #stratadata Consuming From Kafka - Single Consumer C Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
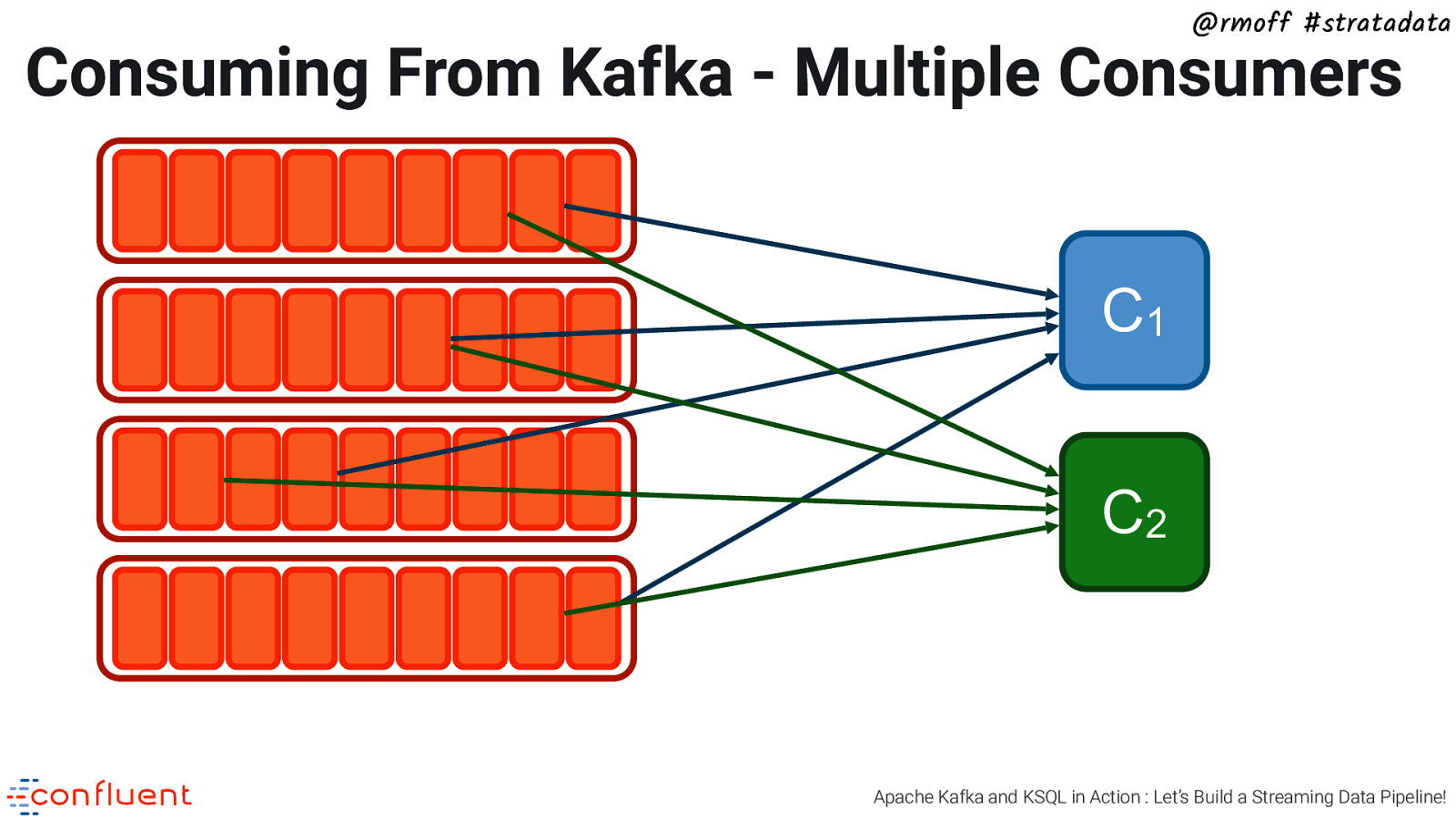
@rmoff #stratadata Consuming From Kafka - Multiple Consumers C1 C2 Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
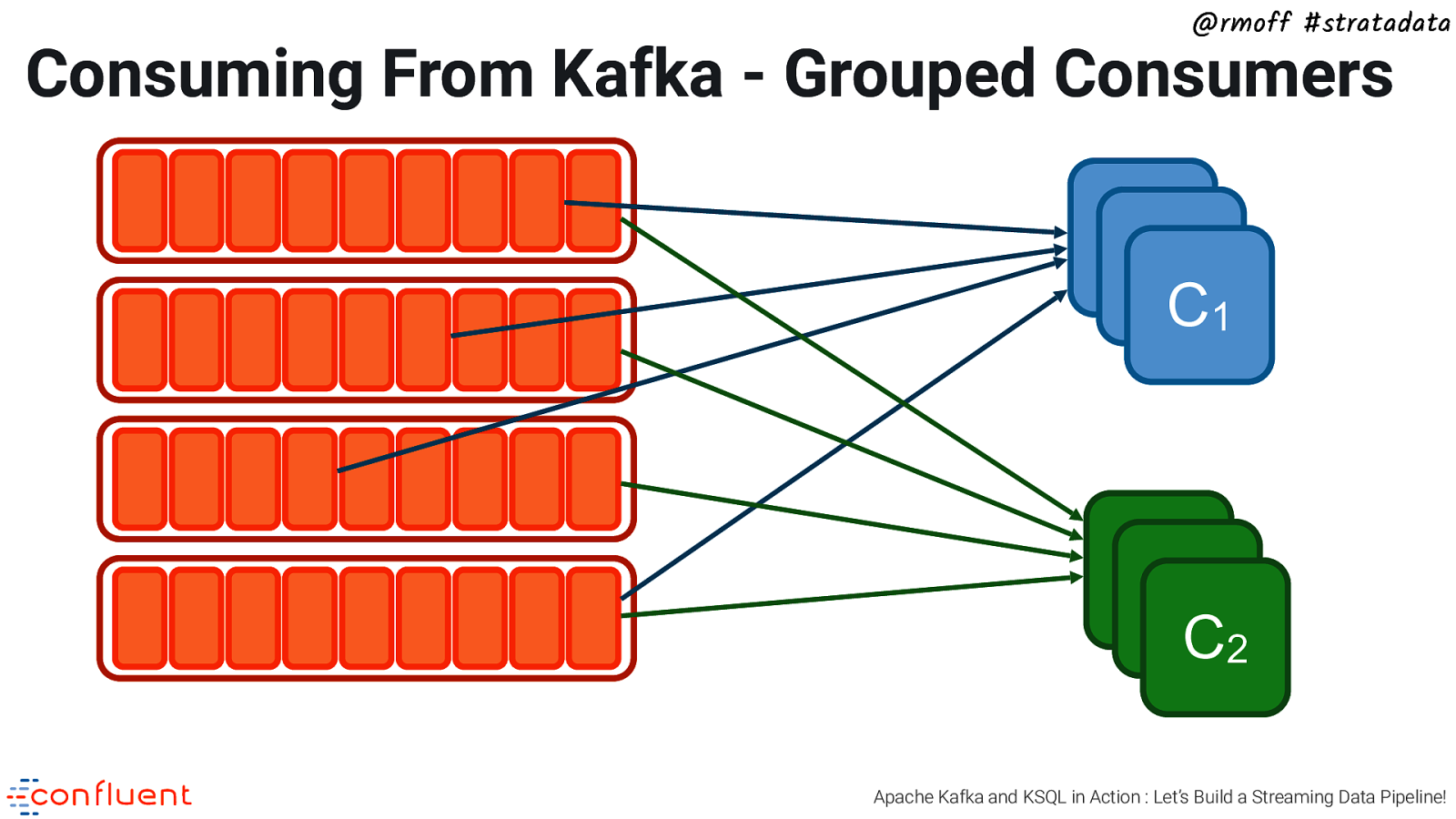
@rmoff #stratadata Consuming From Kafka - Grouped Consumers CC C1 CC C2 Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
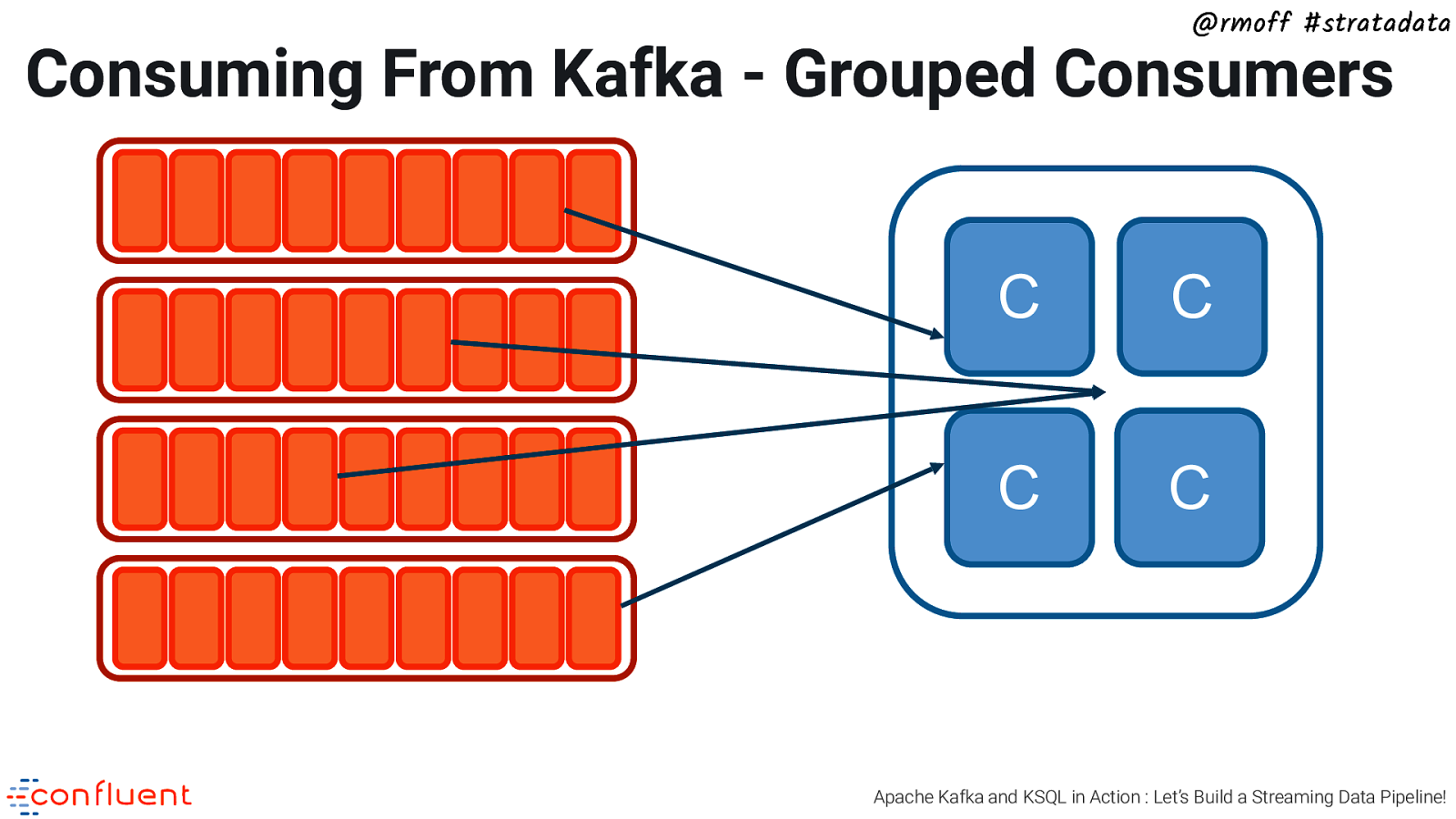
@rmoff #stratadata Consuming From Kafka - Grouped Consumers C C C C Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
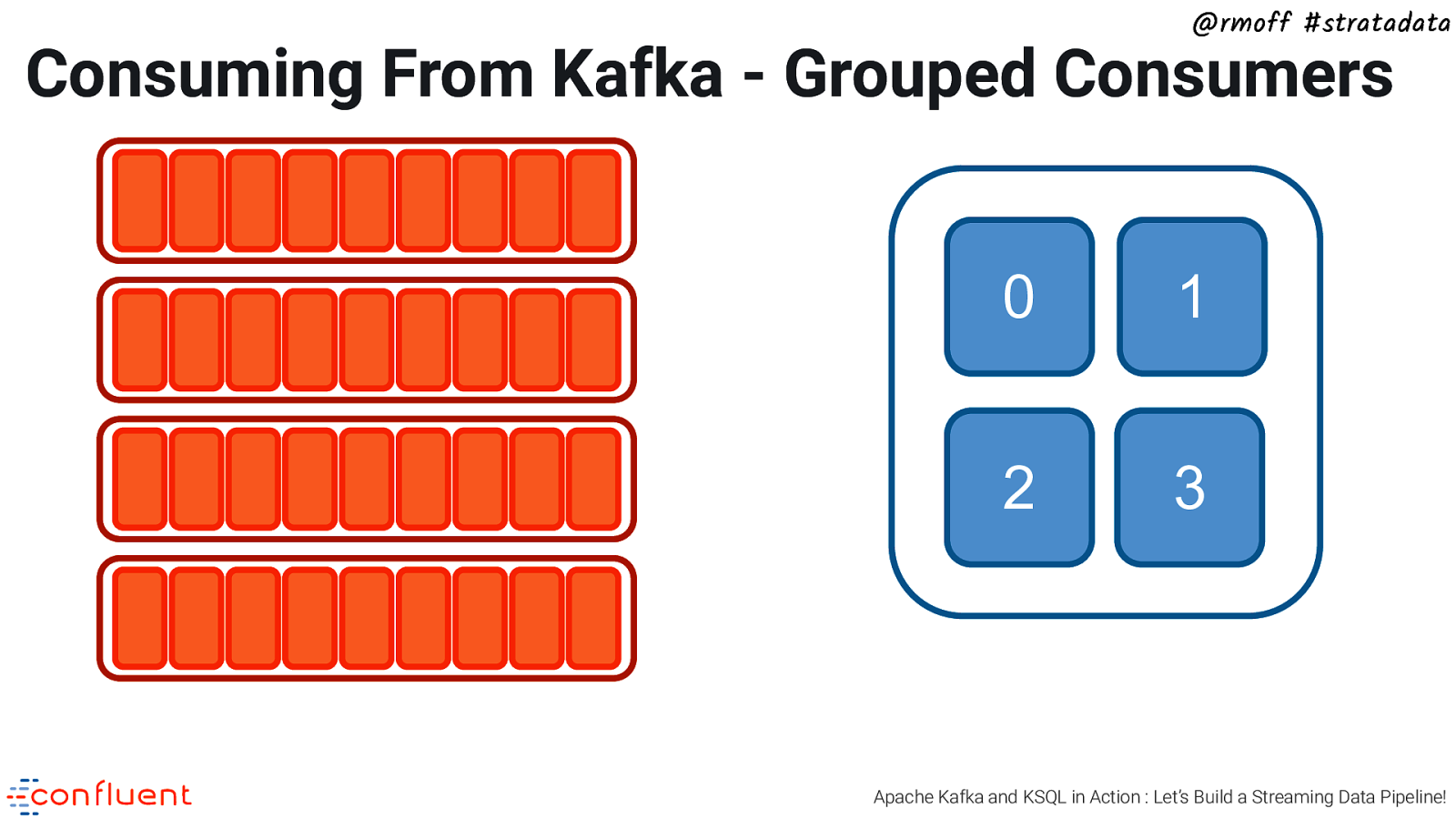
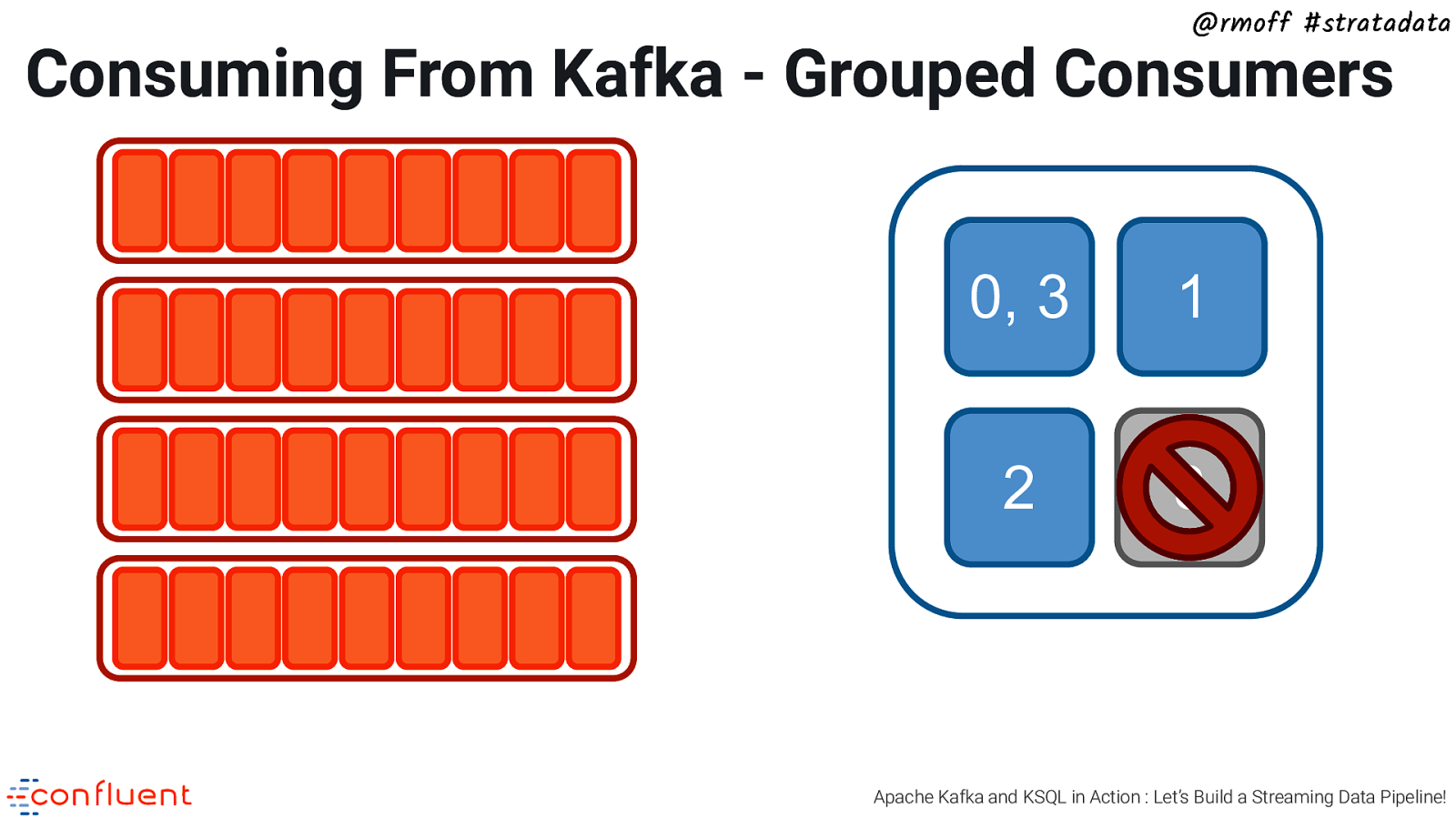
@rmoff #stratadata Consuming From Kafka - Grouped Consumers 0 1 2 3 Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata Consuming From Kafka - Grouped Consumers 0 1 2 3 Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
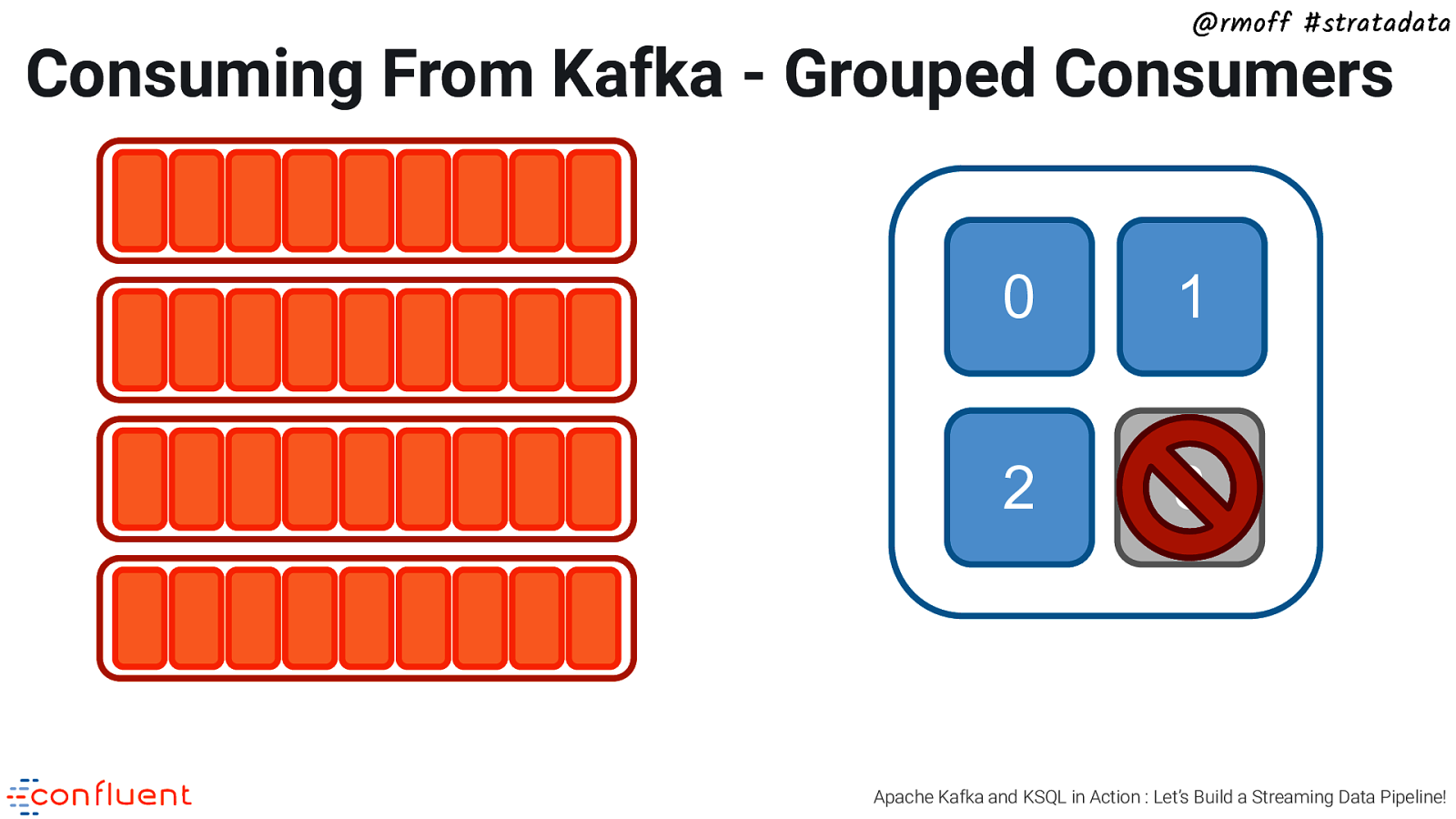
@rmoff #stratadata Consuming From Kafka - Grouped Consumers 0, 3 1 2 3 Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
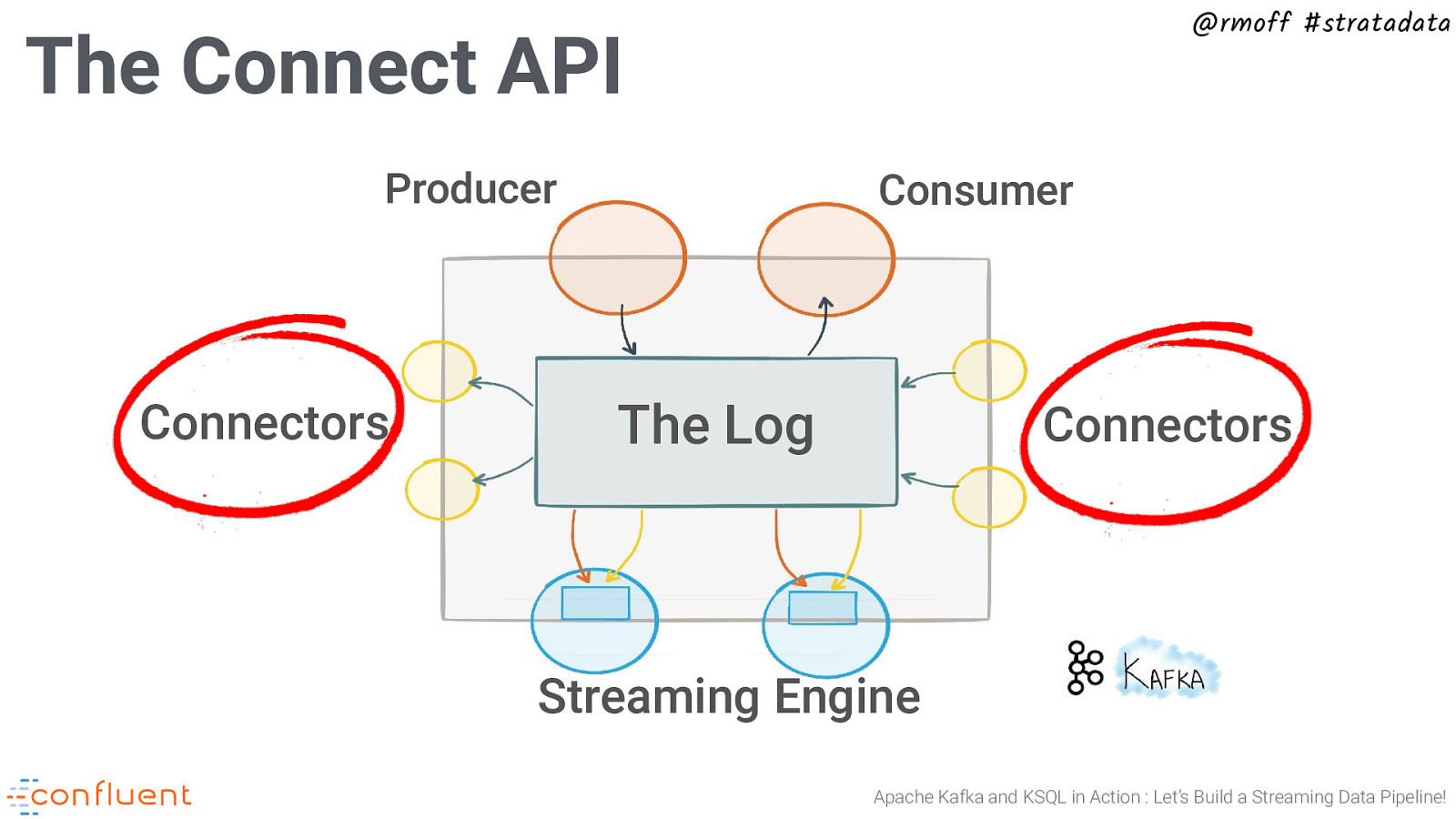
@rmoff #stratadata The Connect API Producer Connectors Consumer The Log Connectors Streaming Engine Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
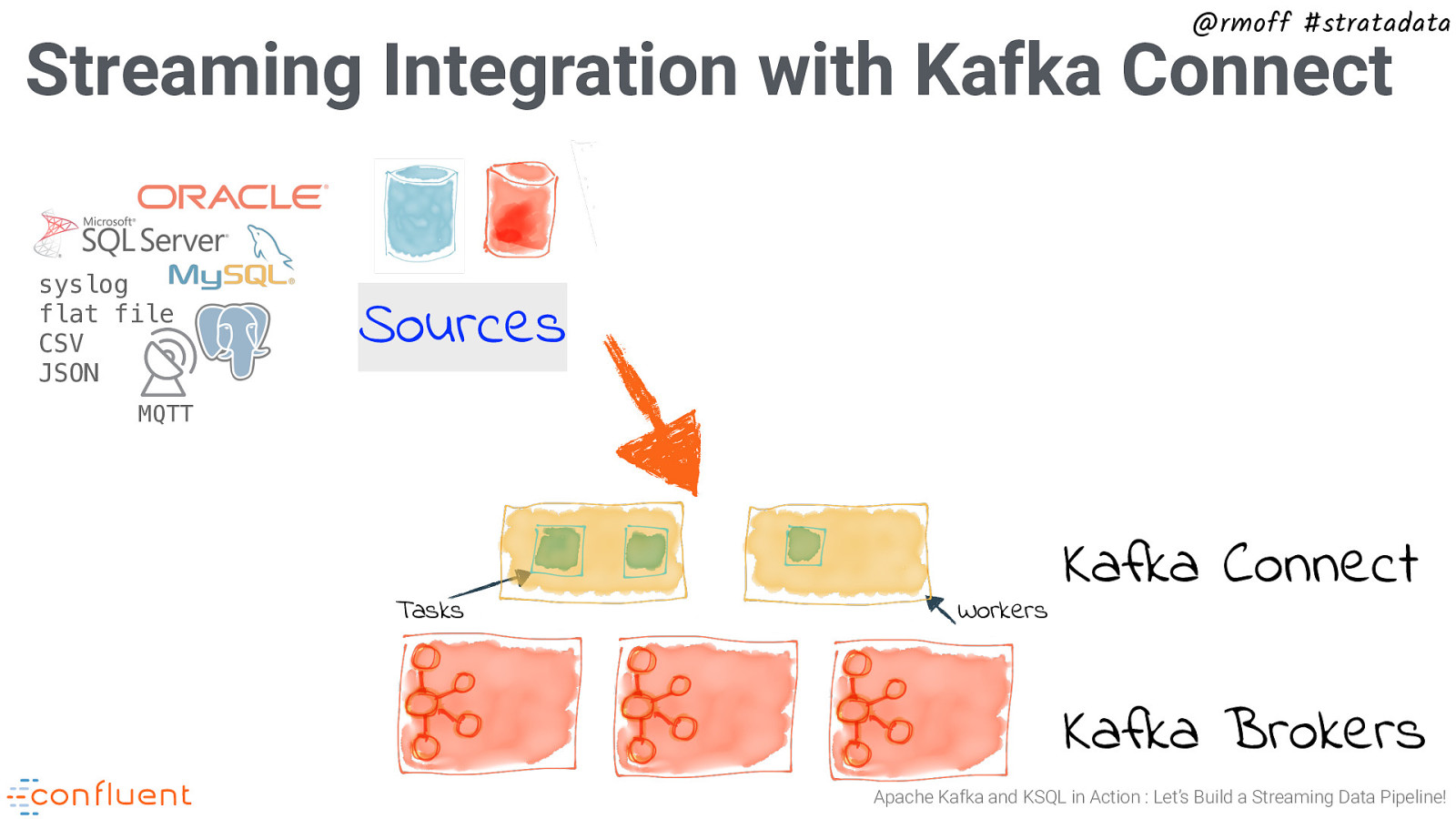
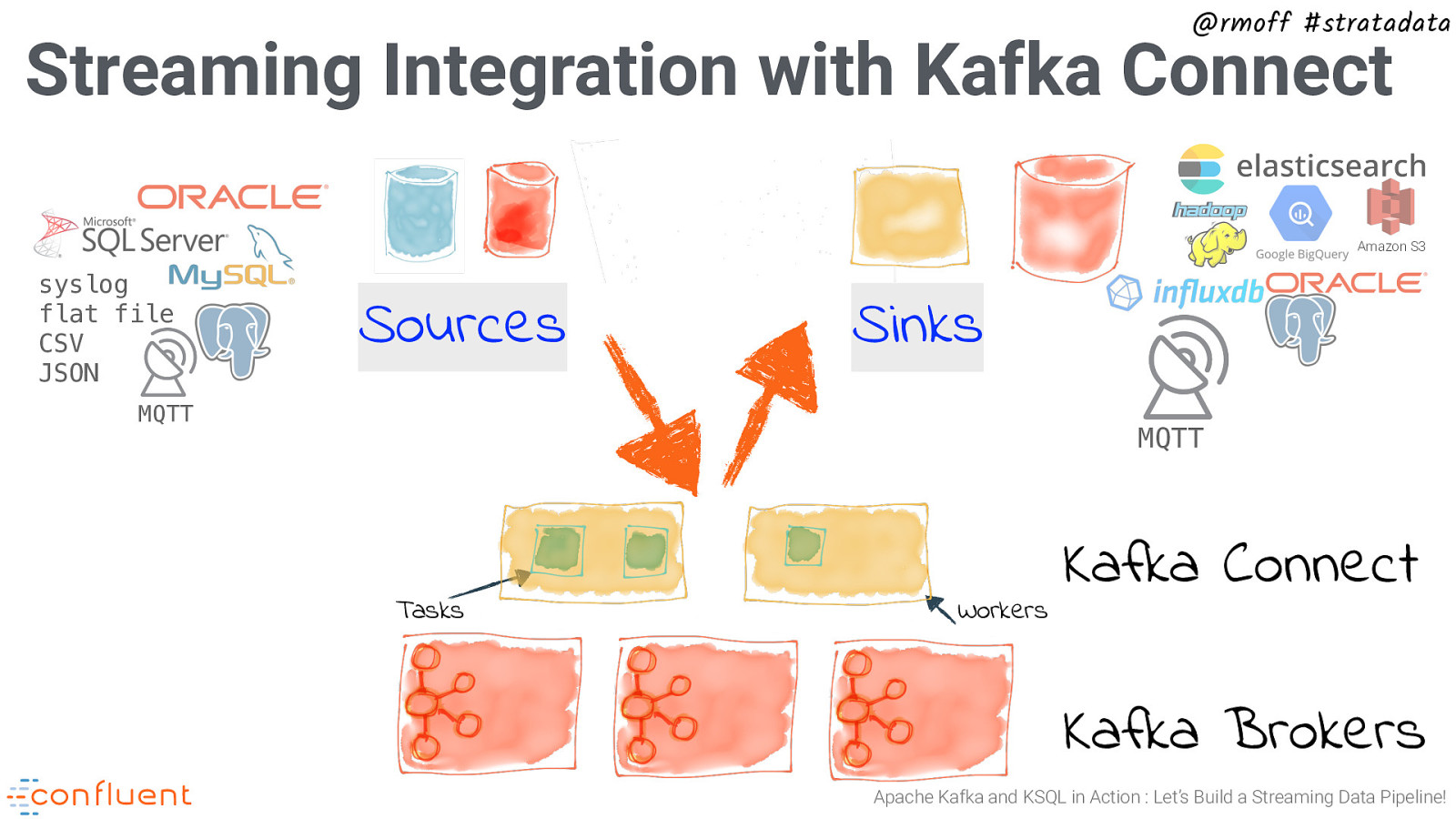
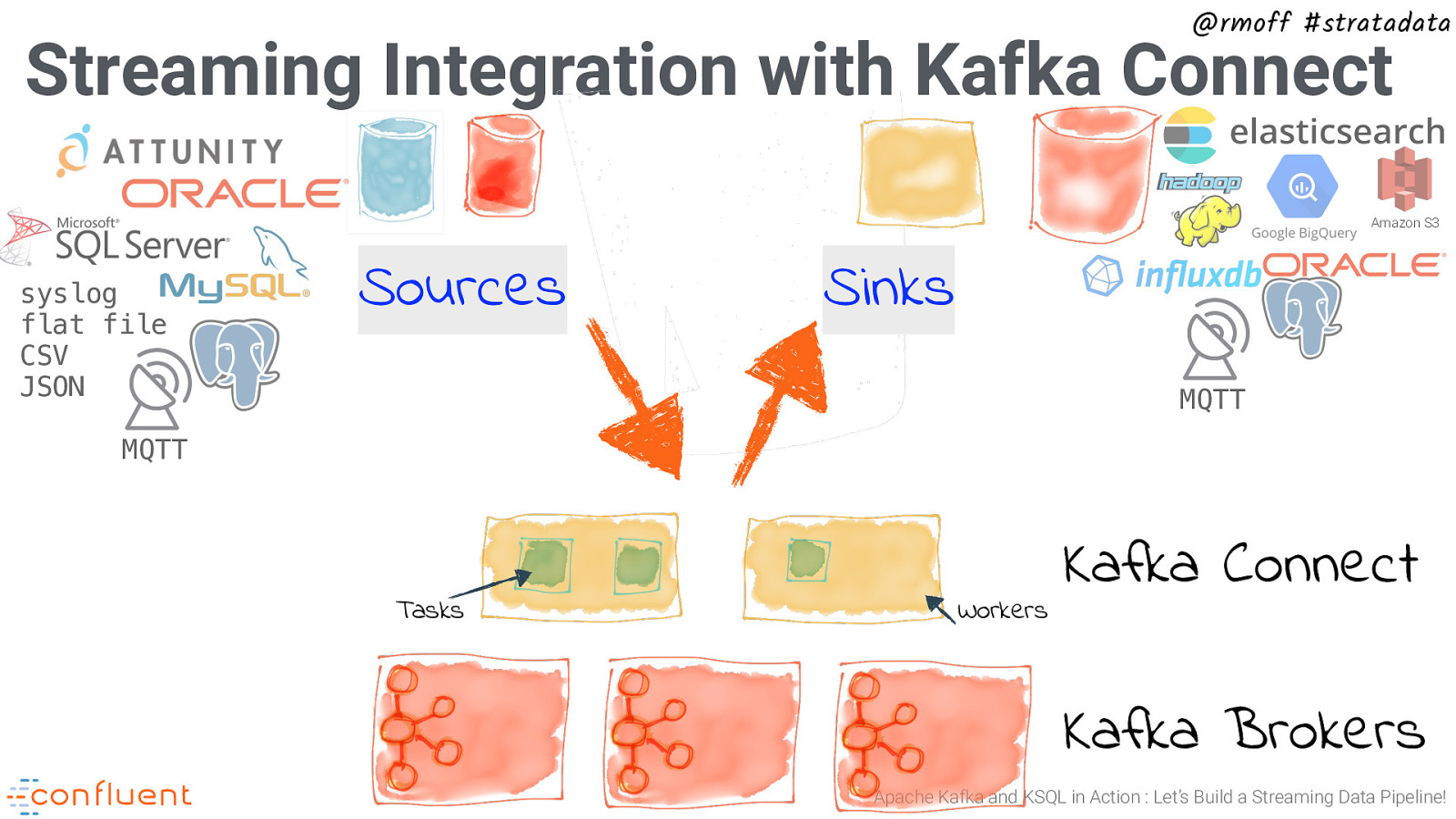
@rmoff #stratadata Streaming Integration with Kafka Connect syslog flat file CSV JSON Sources MQTT Tasks Workers Kafka Connect Kafka Brokers Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
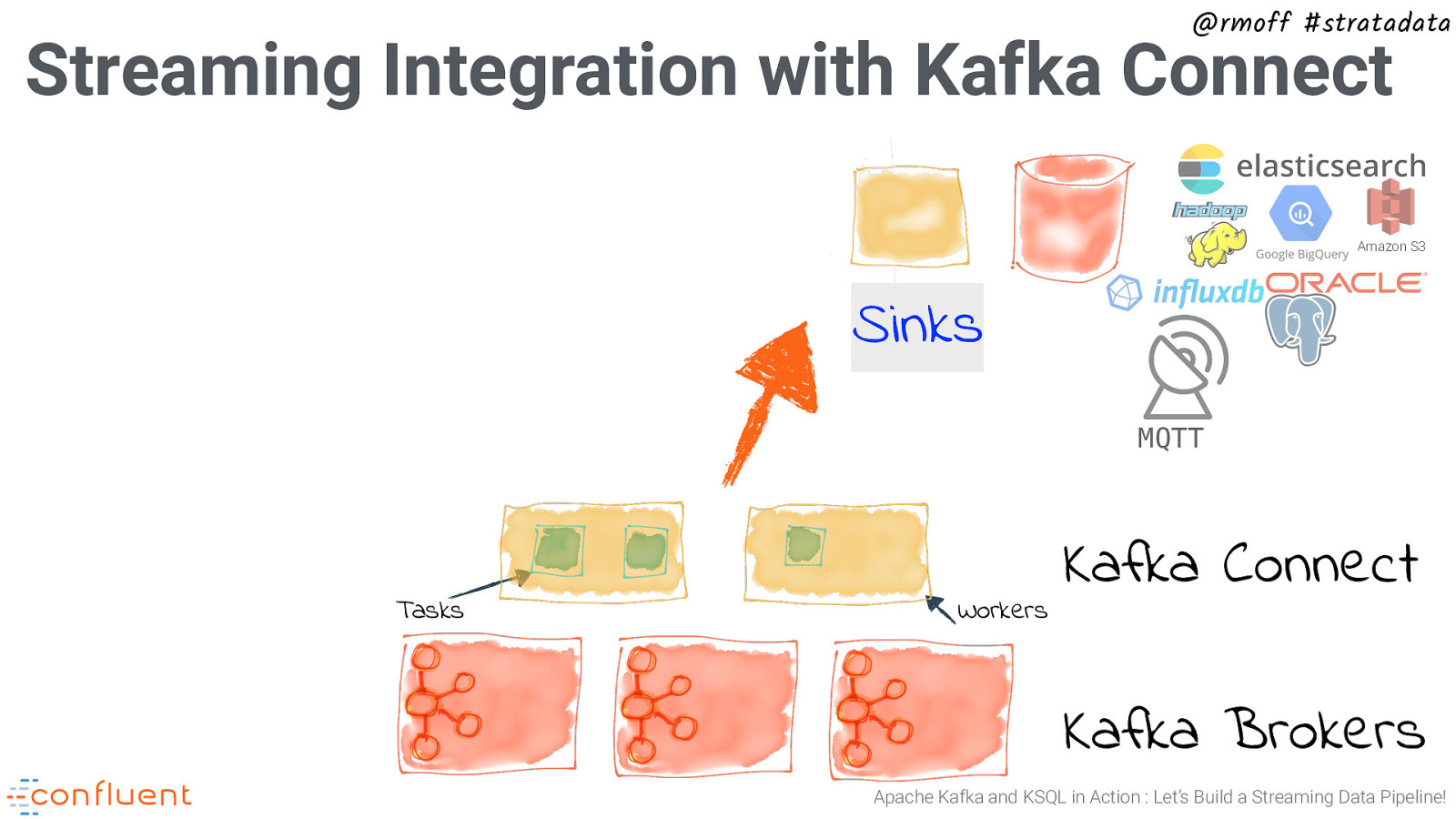
@rmoff #stratadata Streaming Integration with Kafka Connect Amazon S3 Sinks MQTT Tasks Workers Kafka Connect Kafka Brokers Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata Streaming Integration with Kafka Connect Amazon S3 syslog flat file CSV JSON Sources Sinks MQTT MQTT Tasks Workers Kafka Connect Kafka Brokers Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
Stream Processing in Kafka Producer Connectors @rmoff #stratadata Consumer The Log Connectors Streaming Engine Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
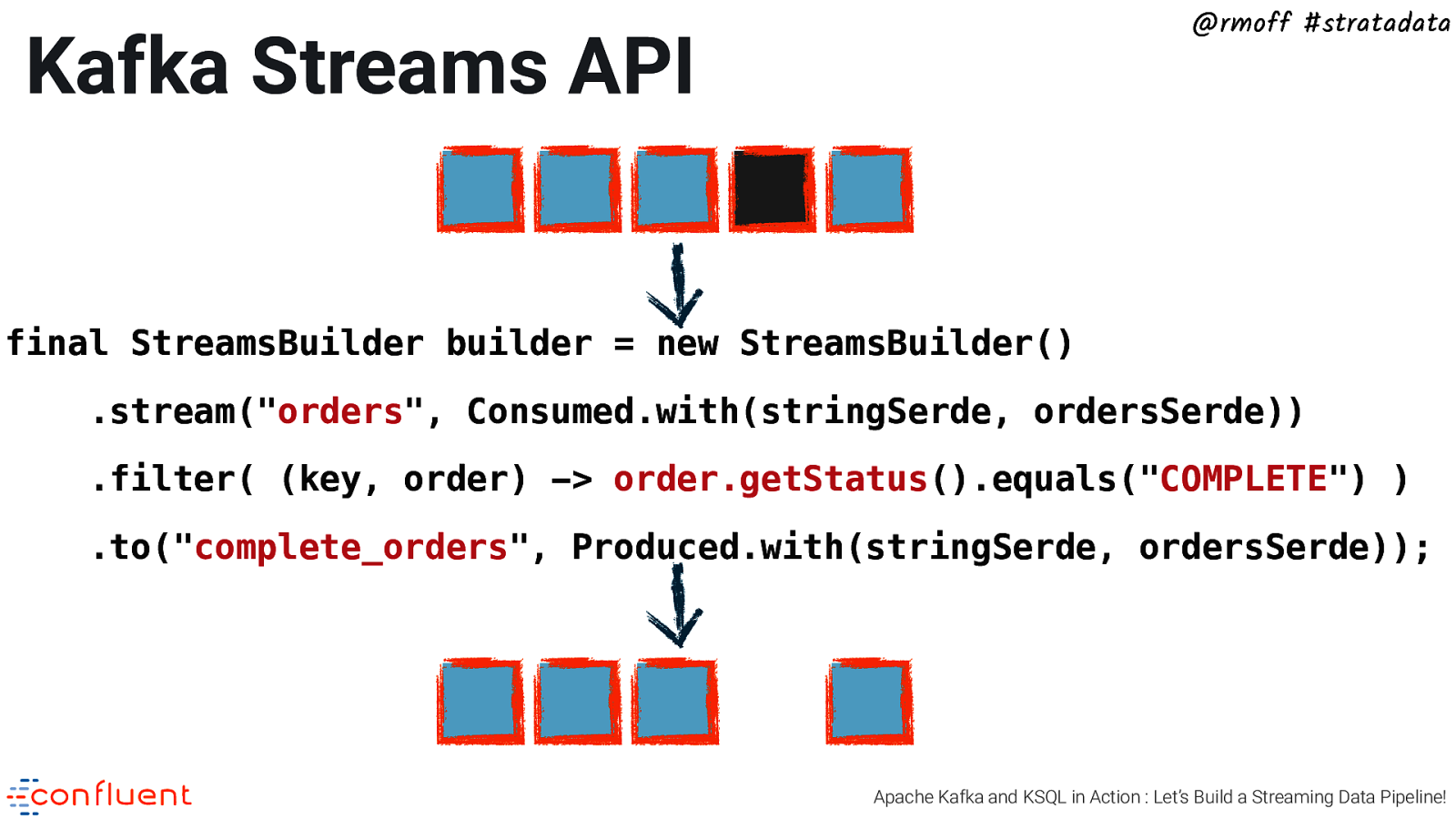
@rmoff #stratadata Kafka Streams API final StreamsBuilder builder = new StreamsBuilder() .stream(“orders”, Consumed.with(stringSerde, ordersSerde)) .filter( (key, order) -> order.getStatus().equals(“COMPLETE”) ) .to(“complete_orders”, Produced.with(stringSerde, ordersSerde)); Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
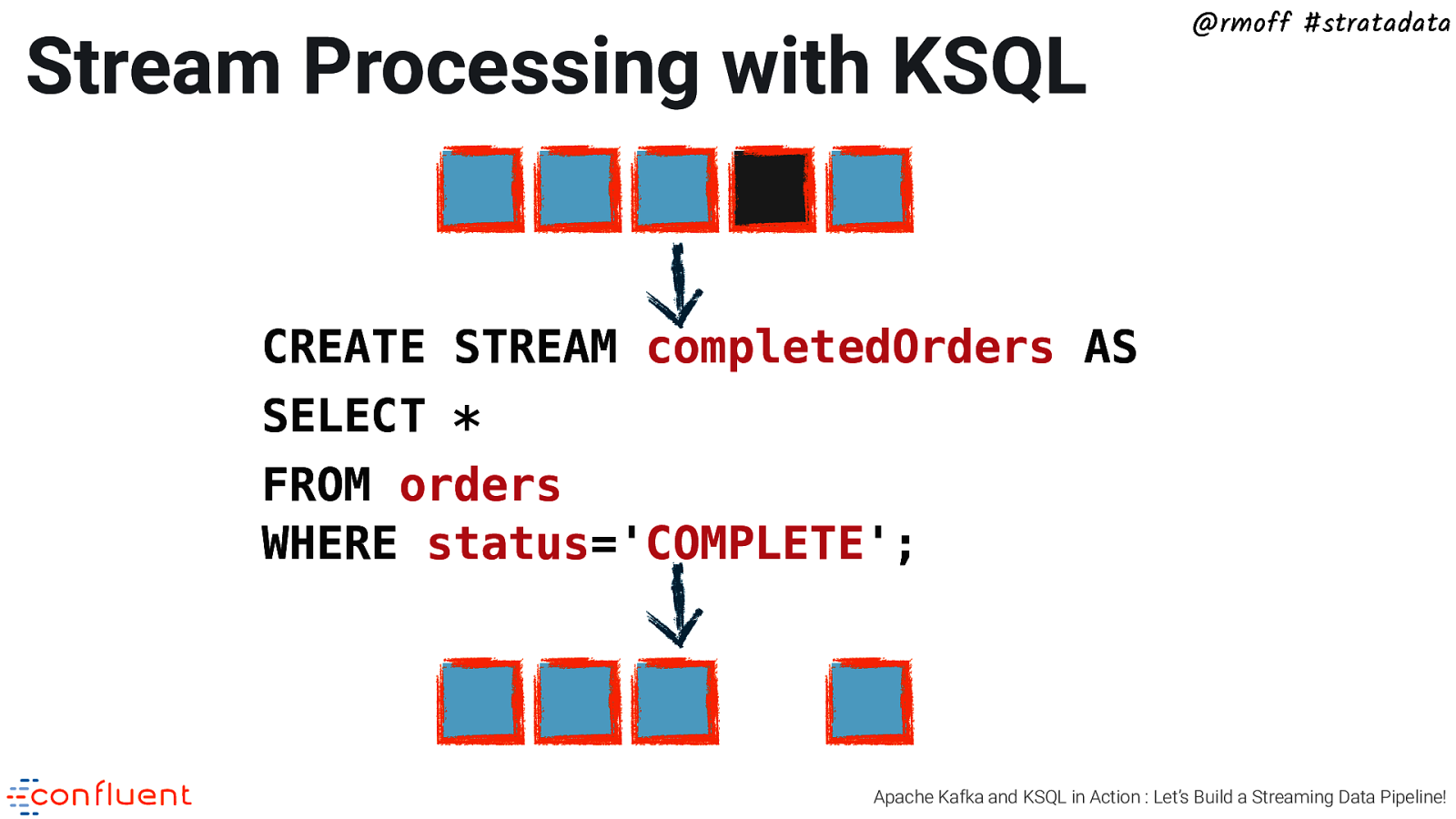
Stream Processing with KSQL @rmoff #stratadata CREATE STREAM completedOrders AS SELECT * FROM orders WHERE status=’COMPLETE’; Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata http://cnfl.io/book-bundle Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
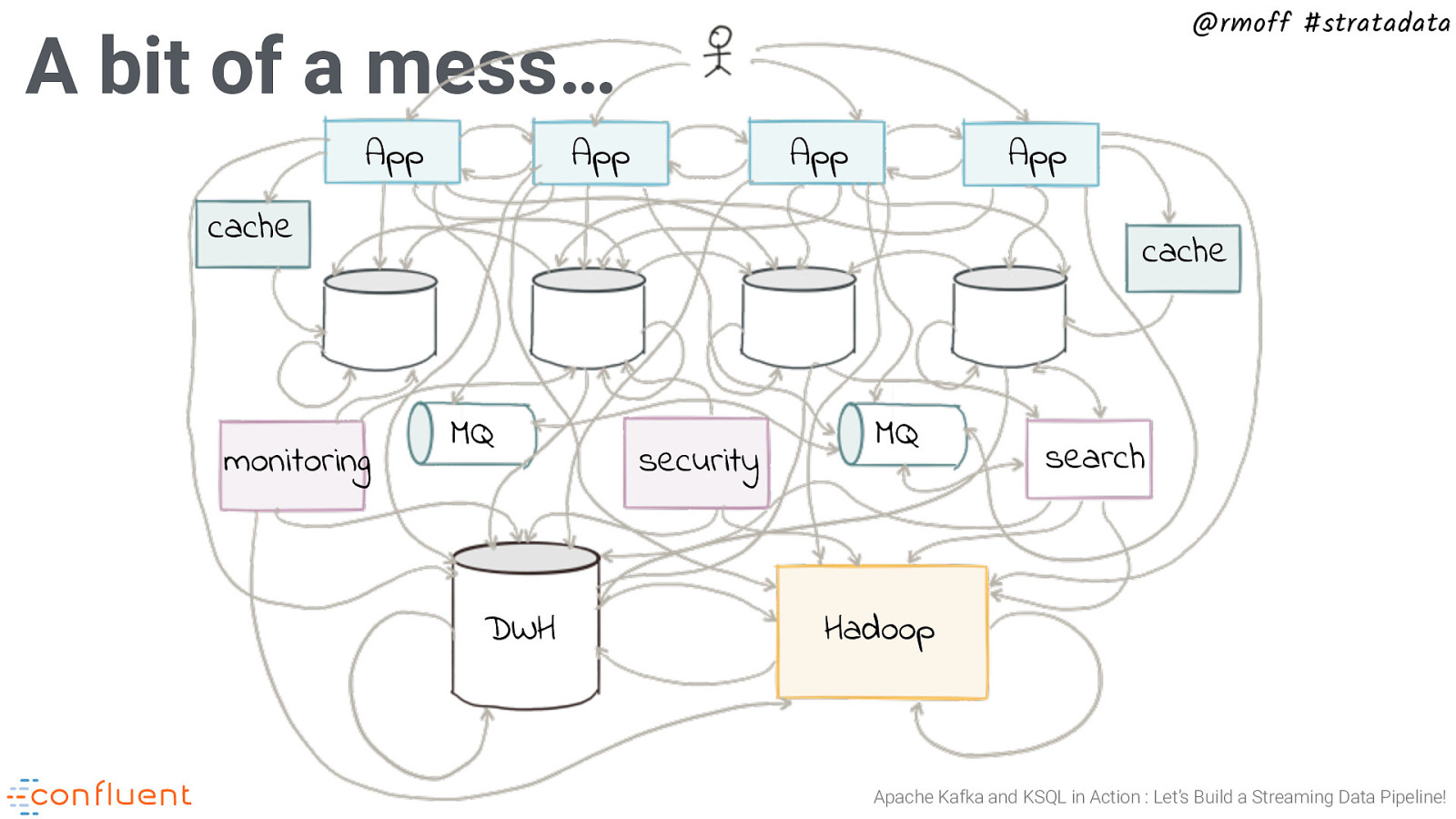
@rmoff #stratadata A bit of a mess… App App App App cache monitoring cache MQ DWH security MQ search Hadoop Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
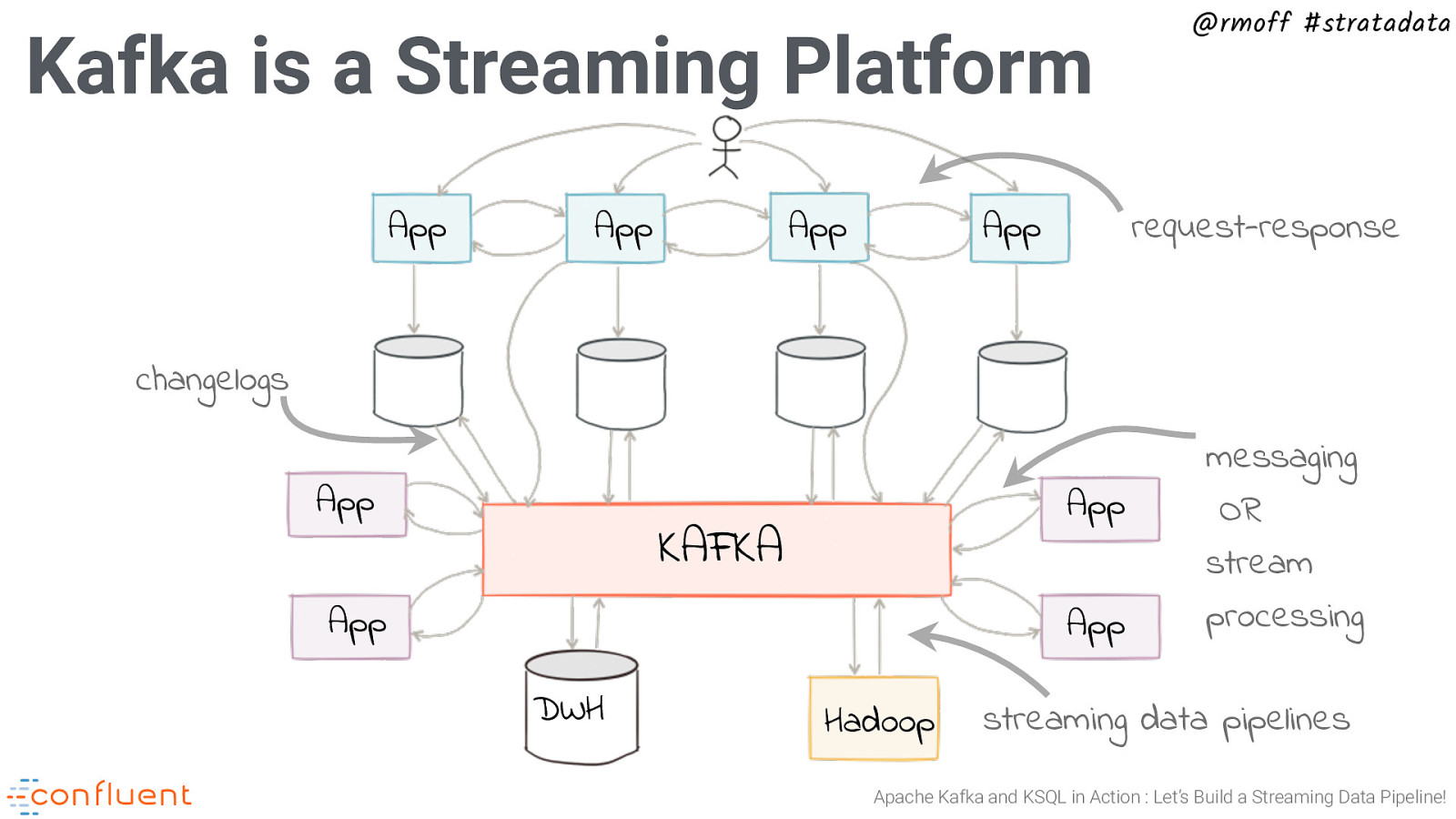
Kafka is a Streaming Platform App App App App @rmoff #stratadata request-response changelogs App App KAFKA App App DWH Hadoop messaging OR stream processing streaming data pipelines Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
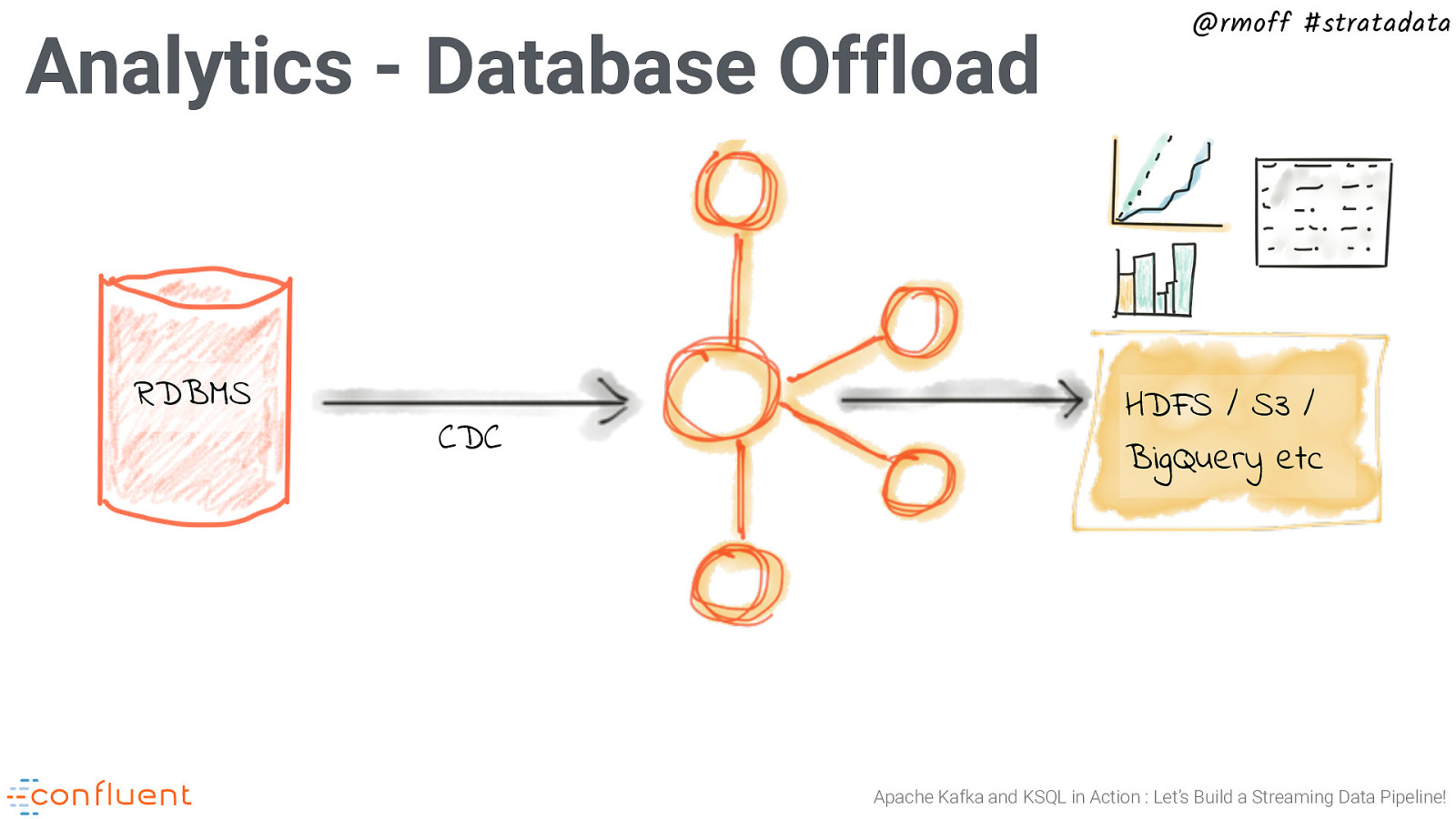
Analytics - Database Offload RDBMS CDC @rmoff #stratadata HDFS / S3 / BigQuery etc Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
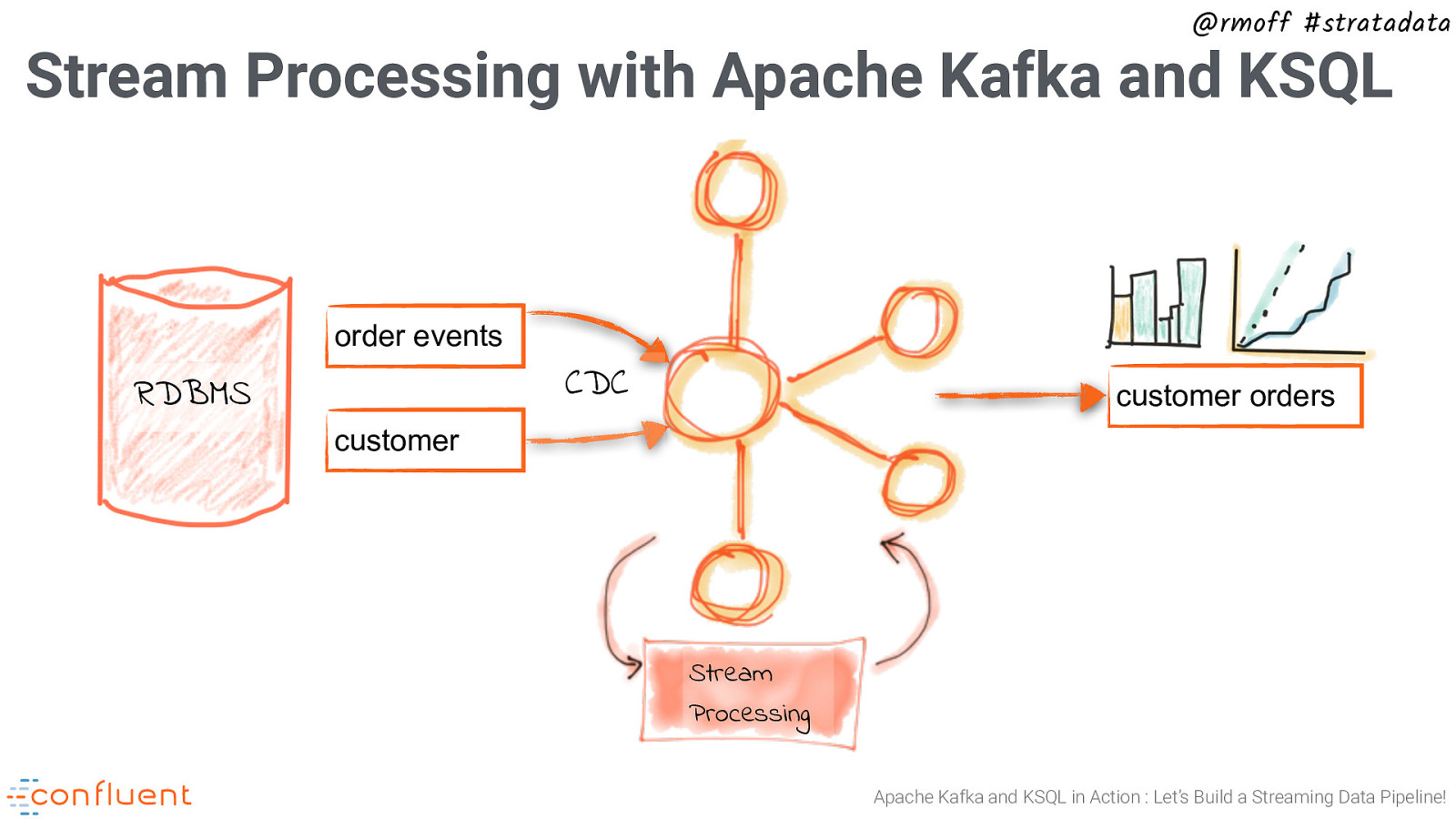
@rmoff #stratadata Stream Processing with Apache Kafka and KSQL order events CDC RDBMS customer orders customer Stream Processing Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
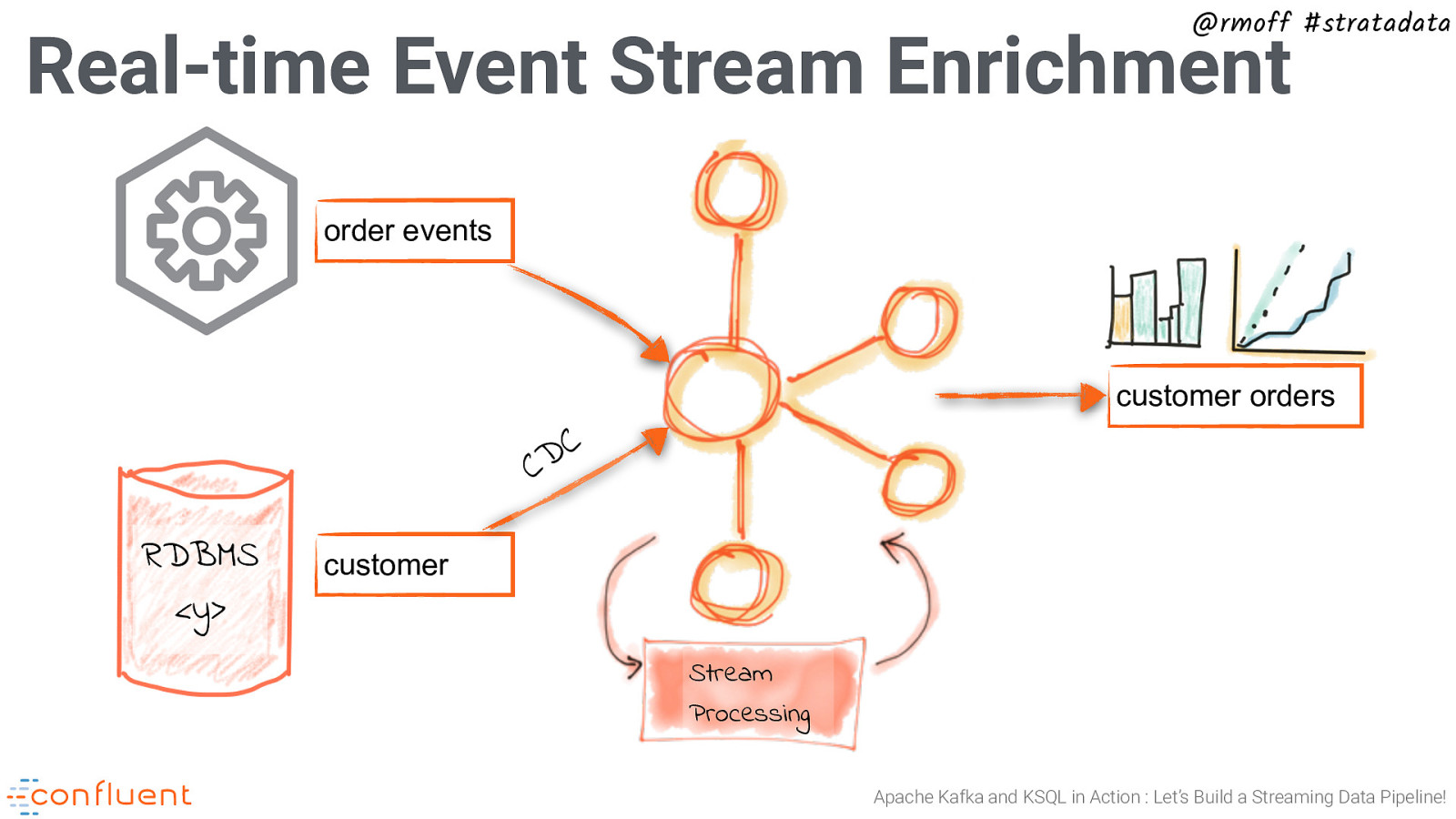
@rmoff #stratadata Real-time Event Stream Enrichment order events customer orders C D C RDBMS <y> customer Stream Processing Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
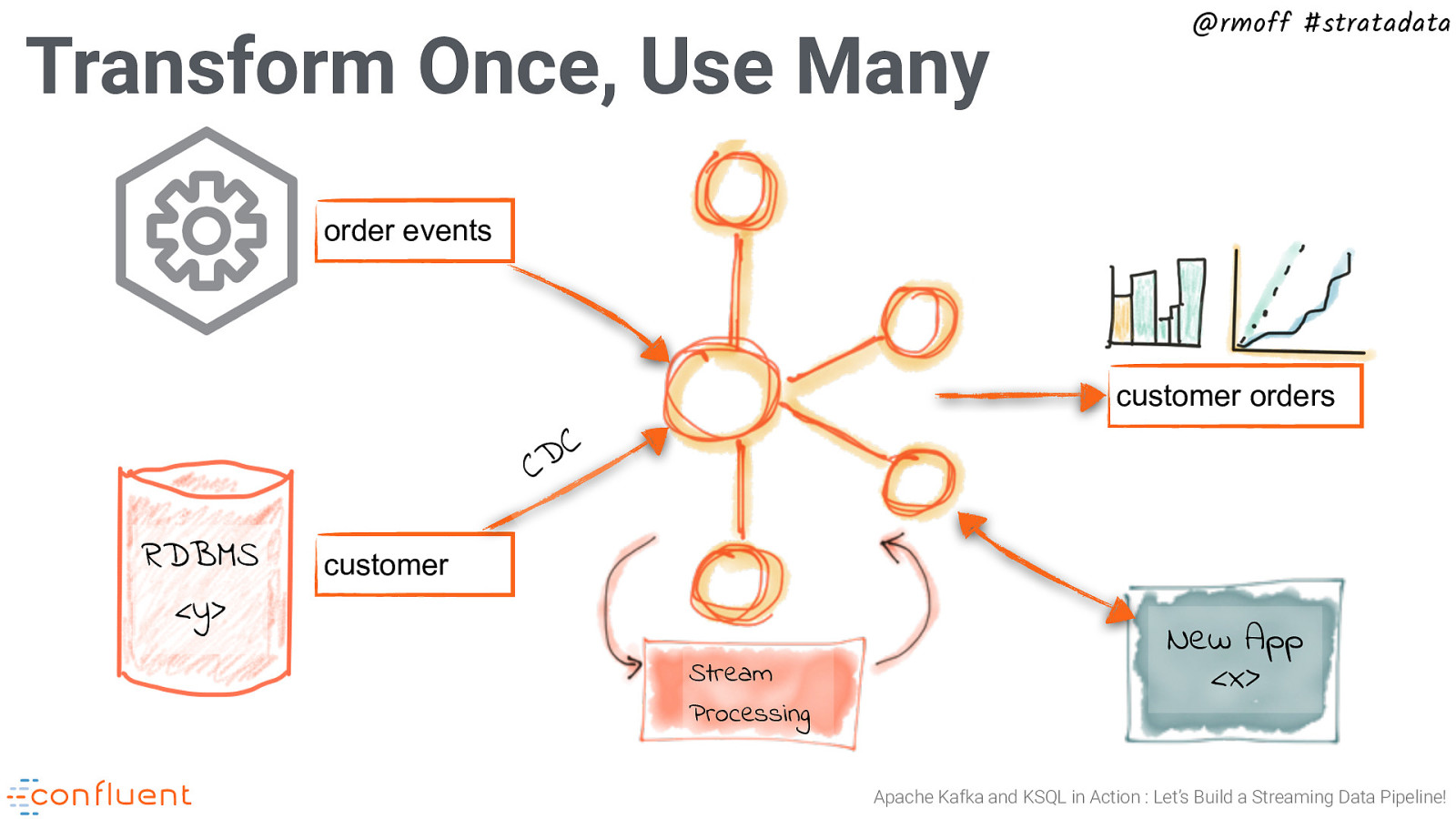
Transform Once, Use Many @rmoff #stratadata order events customer orders C D C RDBMS <y> customer Stream Processing New App <x> Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
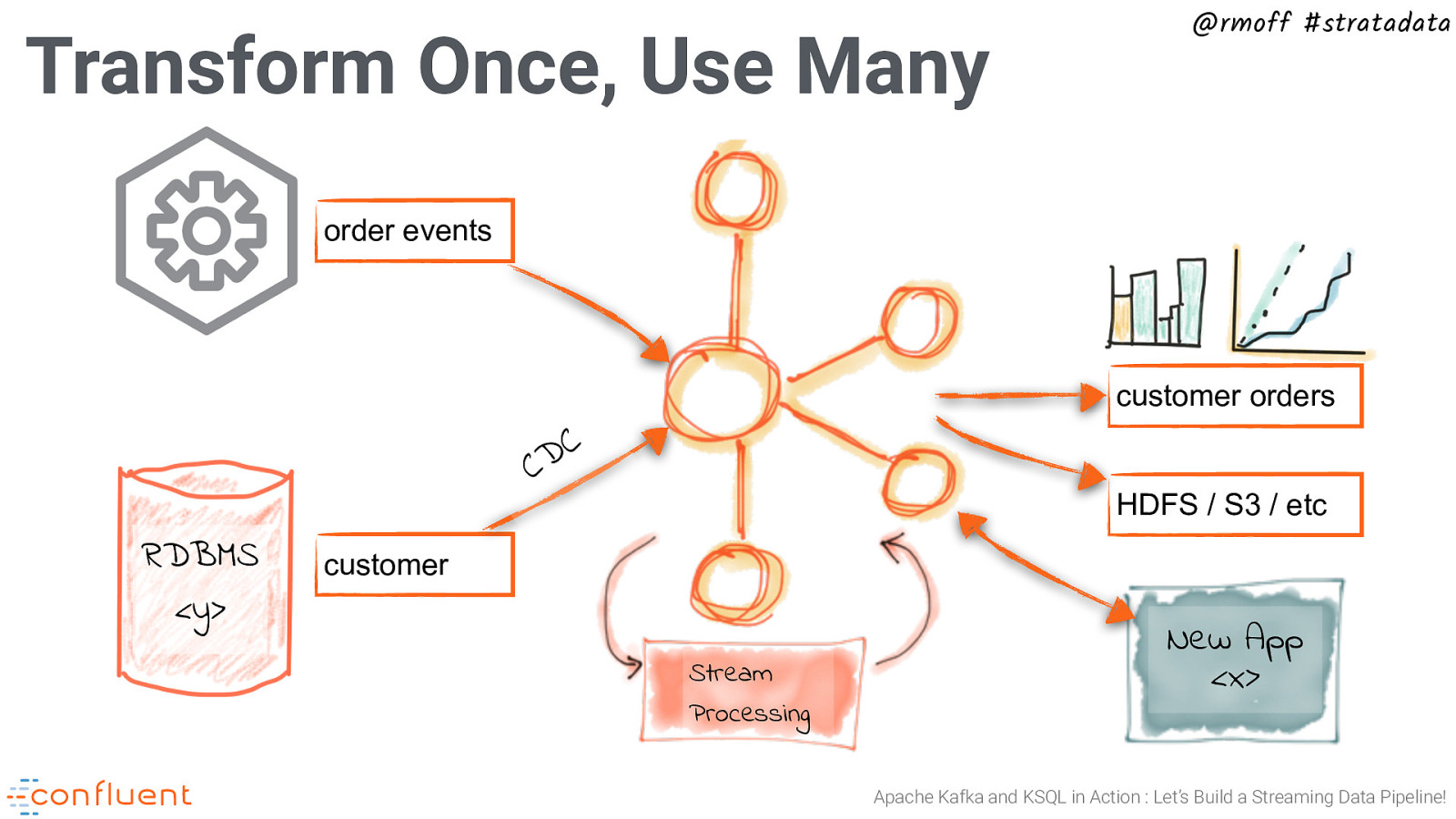
Transform Once, Use Many @rmoff #stratadata order events customer orders C D C RDBMS <y> HDFS / S3 / etc customer Stream Processing New App <x> Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
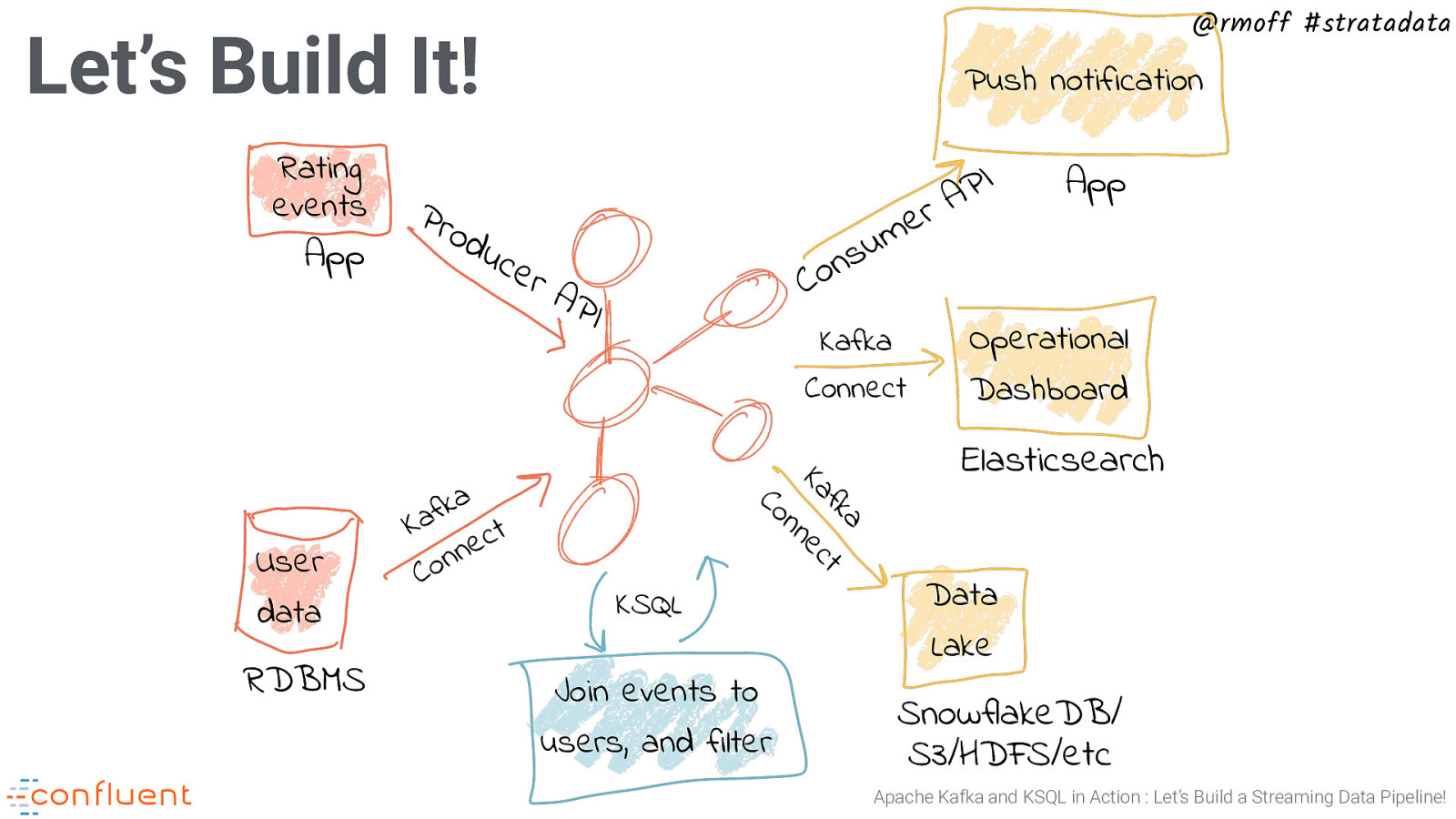
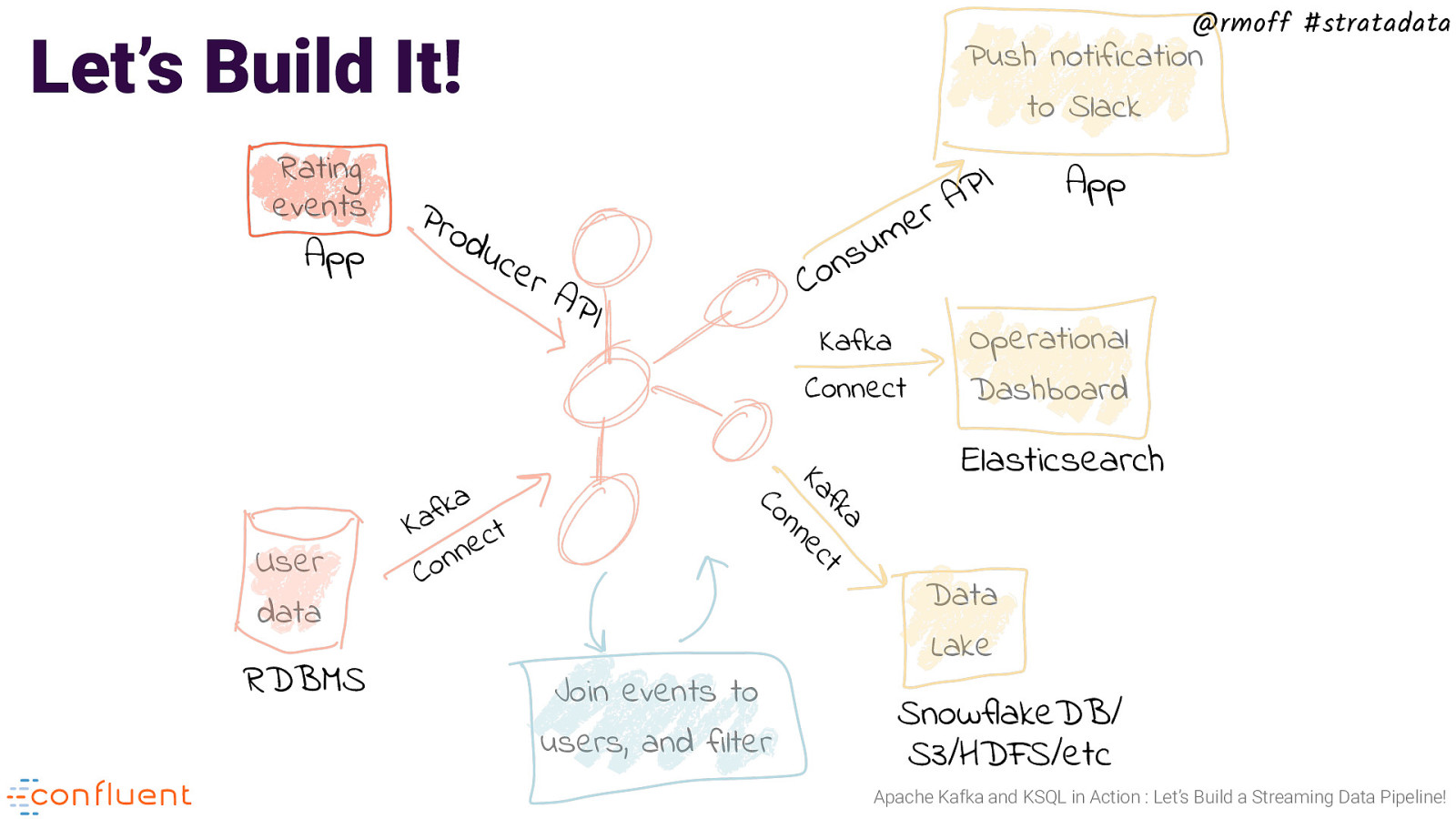
@rmoff #stratadata Let’s Build It! Rating events App a k f a K t c e n n o C App u s n o C uc e rA PI Kafka Connect a fk t Ka ec n RDBMS I P A r e m Operational Dashboard Elasticsearch n Co User data Pro d Push notification KSQL Join events to users, and filter Data Lake SnowflakeDB/ S3/HDFS/etc Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
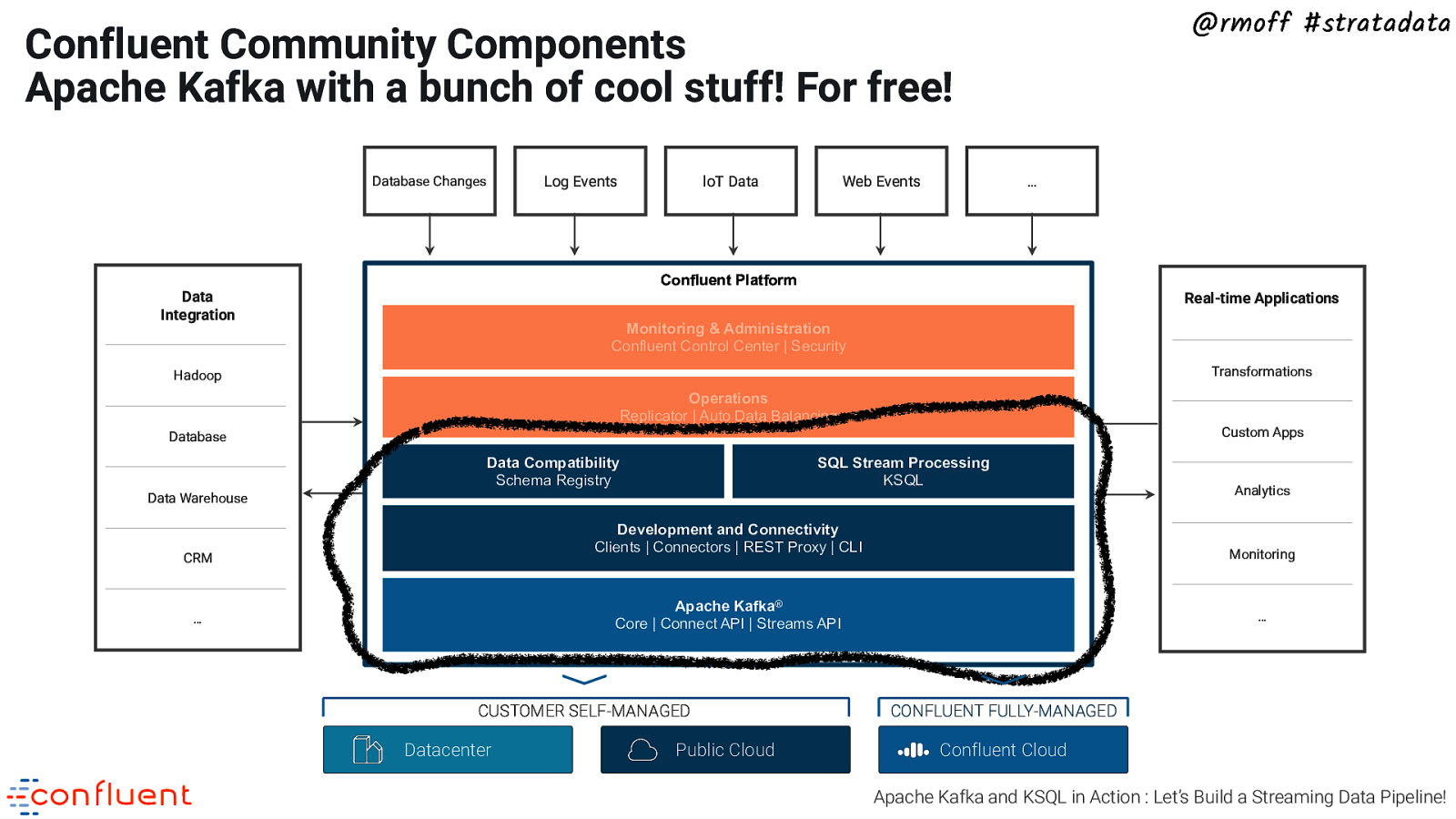
@rmoff #stratadata Confluent Community Components Apache Kafka with a bunch of cool stuff! For free! Log Events Database Changes loT Data Web Events … Confluent Platform Data Integration Real-time Applications Monitoring & Administration Confluent Control Center | Security Confluent Platform Transformations Hadoop Operations Replicator | Auto Data Balancing Custom Apps Database Data Compatibility Schema Registry SQL Stream Processing KSQL Data Warehouse Development and Connectivity Clients | Connectors | REST Proxy | CLI CRM Monitoring Apache Kafka® Core | Connect API | Streams API … CUSTOMER SELF-MANAGED Datacenter Public Cloud Analytics … CONFLUENT FULLY-MANAGED Confluent Cloud Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
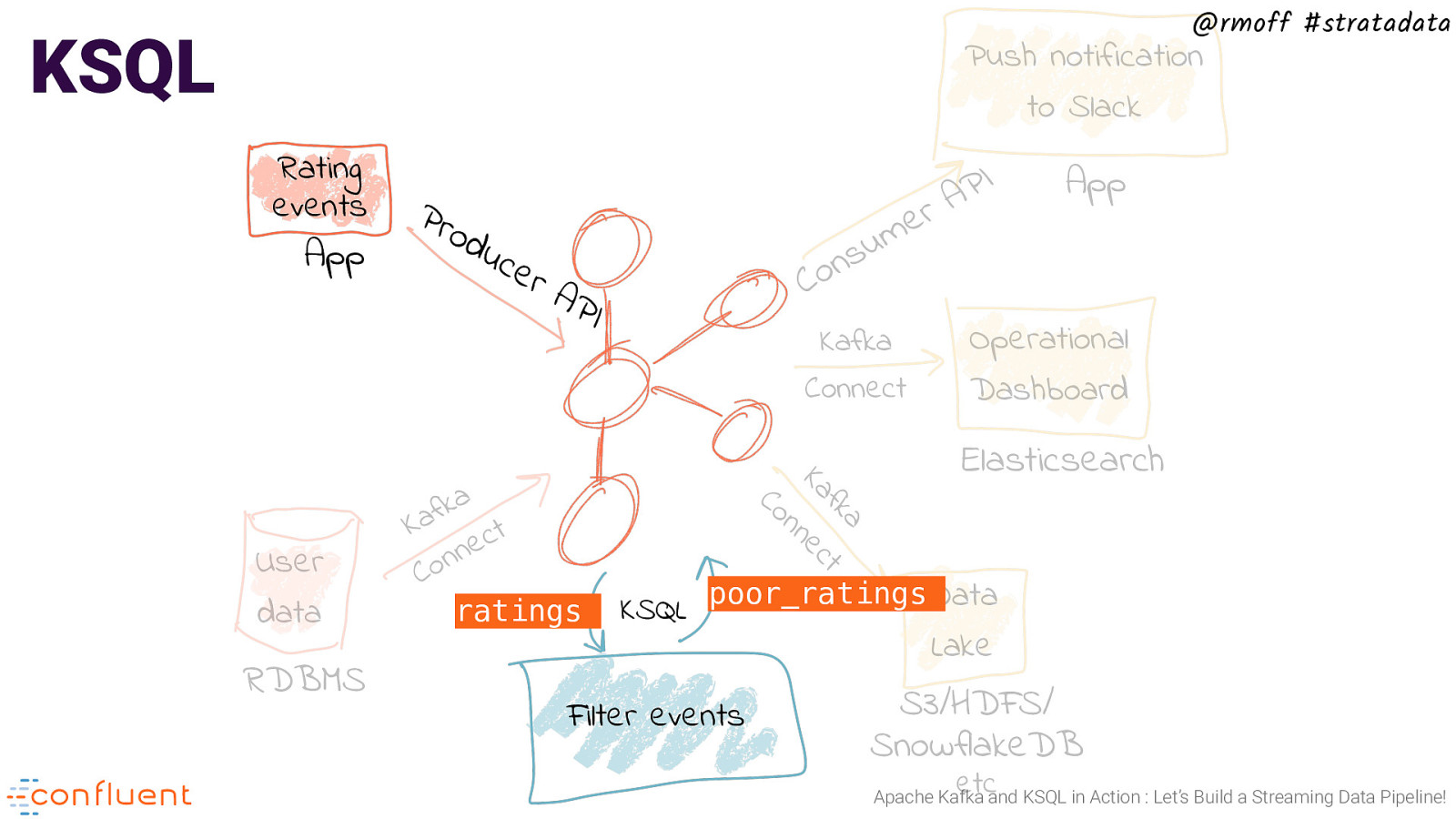
@rmoff #stratadata KSQL Push notification to Slack Rating events App Kafka Connect a fk t Ka ec n RDBMS u s n o C uc e rA PI a k f a K t c e n n o C ratings App Operational Dashboard Elasticsearch n Co User data Pro d I P A r e m poor_ratings Data KSQL Filter events Lake S3/HDFS/ SnowflakeDB etc Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata KSQL is the Streaming SQL Engine for Apache Kafka Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
Filter messages with KSQL @rmoff #stratadata completedOrders orders → → → → → → → → → → → 01, £10.00, 05, £10.00, 06, £24.00, 02, £12.33, 04, £5.50, → COMPLETE COMPLETE COMPLETE PENDING COMPLETE CREATE STREAM completedOrders AS SELECT * FROM orders WHERE status=’COMPLETE’; → → → → → → → → → → → 01, £10.00, 06, £24.00, 02, £12.33, 04, £5.50, → COMPLETE COMPLETE COMPLETE COMPLETE Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
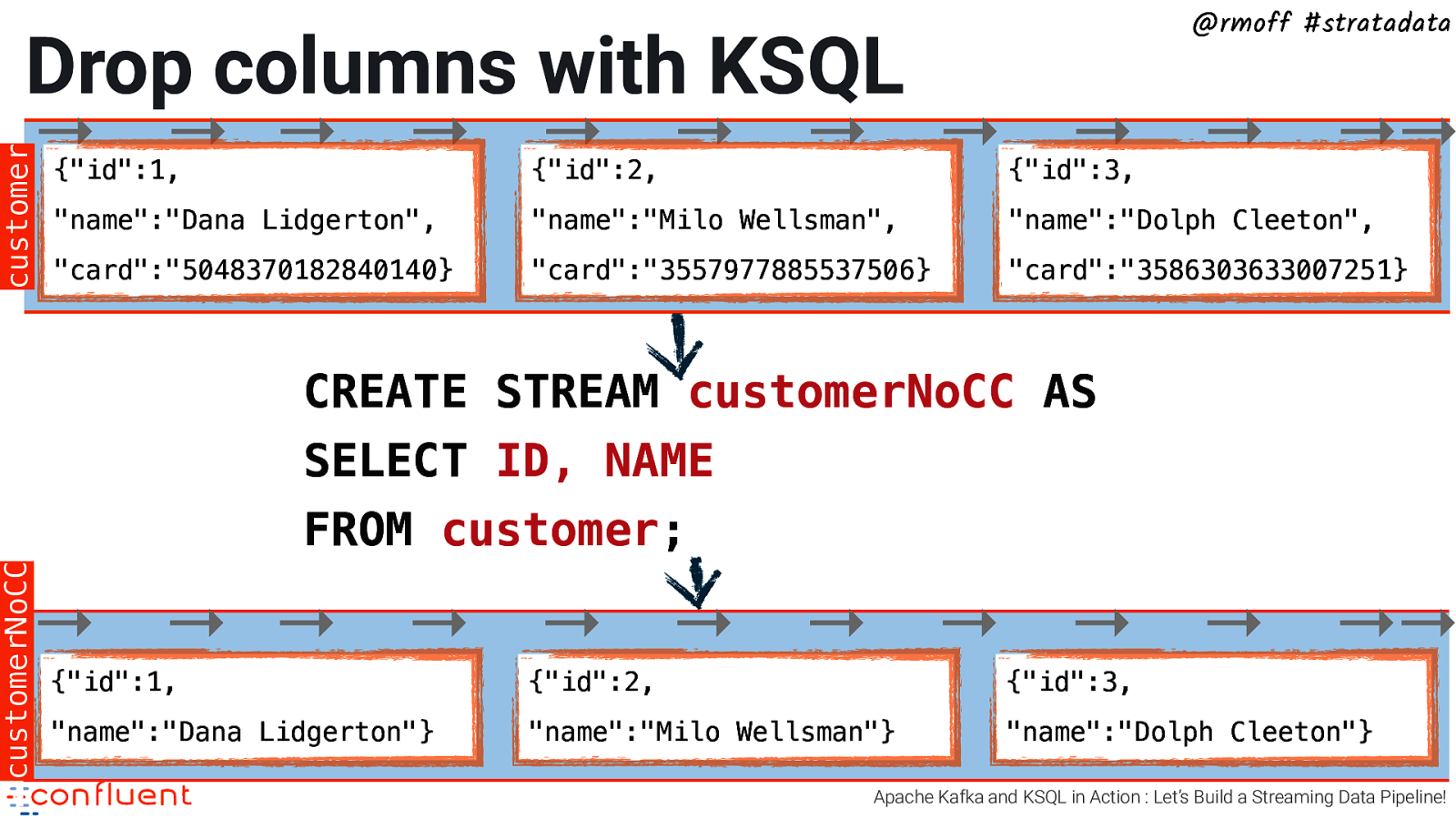
@rmoff #stratadata Drop columns with KSQL customer → → → → → → → → → → →→ {“id”:1, {“id”:2, {“id”:3, “name”:”Dana Lidgerton”, “name”:”Milo Wellsman”, “name”:”Dolph Cleeton”, “card”:”5048370182840140} “card”:”3557977885537506} “card”:”3586303633007251} CREATE STREAM customerNoCC AS SELECT ID, NAME customerNoCC FROM customer; → → → → → → → → → → →→ {“id”:1, {“id”:2, {“id”:3, “name”:”Dana Lidgerton”} “name”:”Milo Wellsman”} “name”:”Dolph Cleeton”} Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
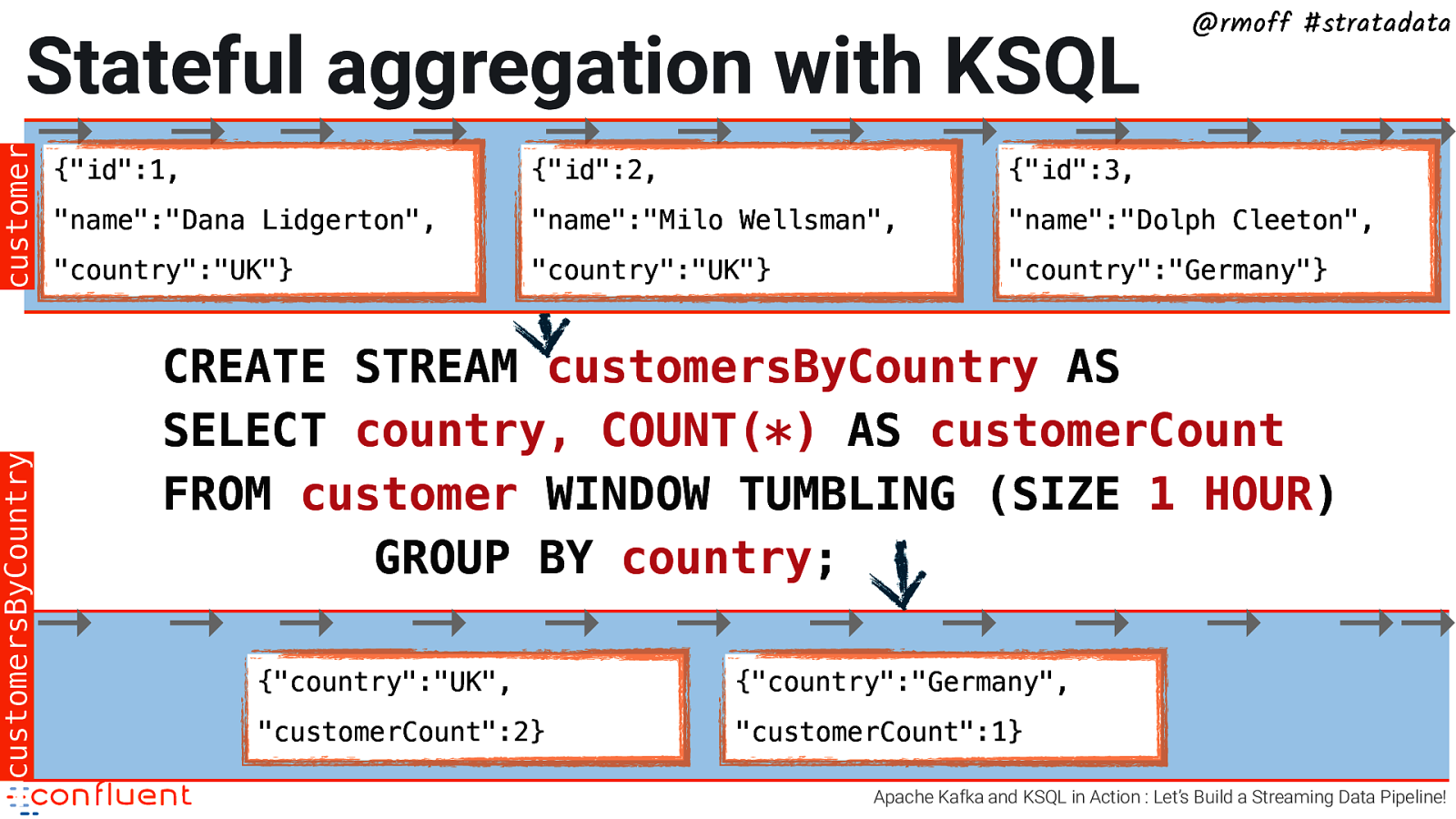
Stateful aggregation with KSQL @rmoff #stratadata customersByCountry customer → → → → → → → → → → →→ {“id”:1, {“id”:2, {“id”:3, “name”:”Dana Lidgerton”, “name”:”Milo Wellsman”, “name”:”Dolph Cleeton”, “country”:”UK”} “country”:”UK”} “country”:”Germany”} CREATE STREAM customersByCountry AS SELECT country, COUNT(*) AS customerCount FROM customer WINDOW TUMBLING (SIZE 1 HOUR) GROUP BY country; → → → → → → → → → → →→ {“country”:”UK”, {“country”:”Germany”, “customerCount”:2} “customerCount”:1} Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata KSQL for Anomaly Detection Identifying patterns or anomalies in real-time data, surfaced in milliseconds CREATE TABLE possible_fraud AS SELECT card_number, count() FROM authorization_attempts WINDOW TUMBLING (SIZE 5 SECONDS) GROUP BY card_number HAVING count() > 3; Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata KSQL for Data Transformation Make simple derivations of existing topics from the command line CREATE STREAM pageviews WITH (PARTITIONS=4, VALUE_FORMAT=’AVRO’) AS SELECT * FROM pageviews_json; Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
KSQL for Streaming ETL @rmoff #stratadata Joining, filtering, and aggregating streams of event data CREATE STREAM vip_actions AS SELECT userid, page, action FROM clickstream c LEFT JOIN users u ON c.userid = u.user_id WHERE u.level = ‘Platinum’; Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
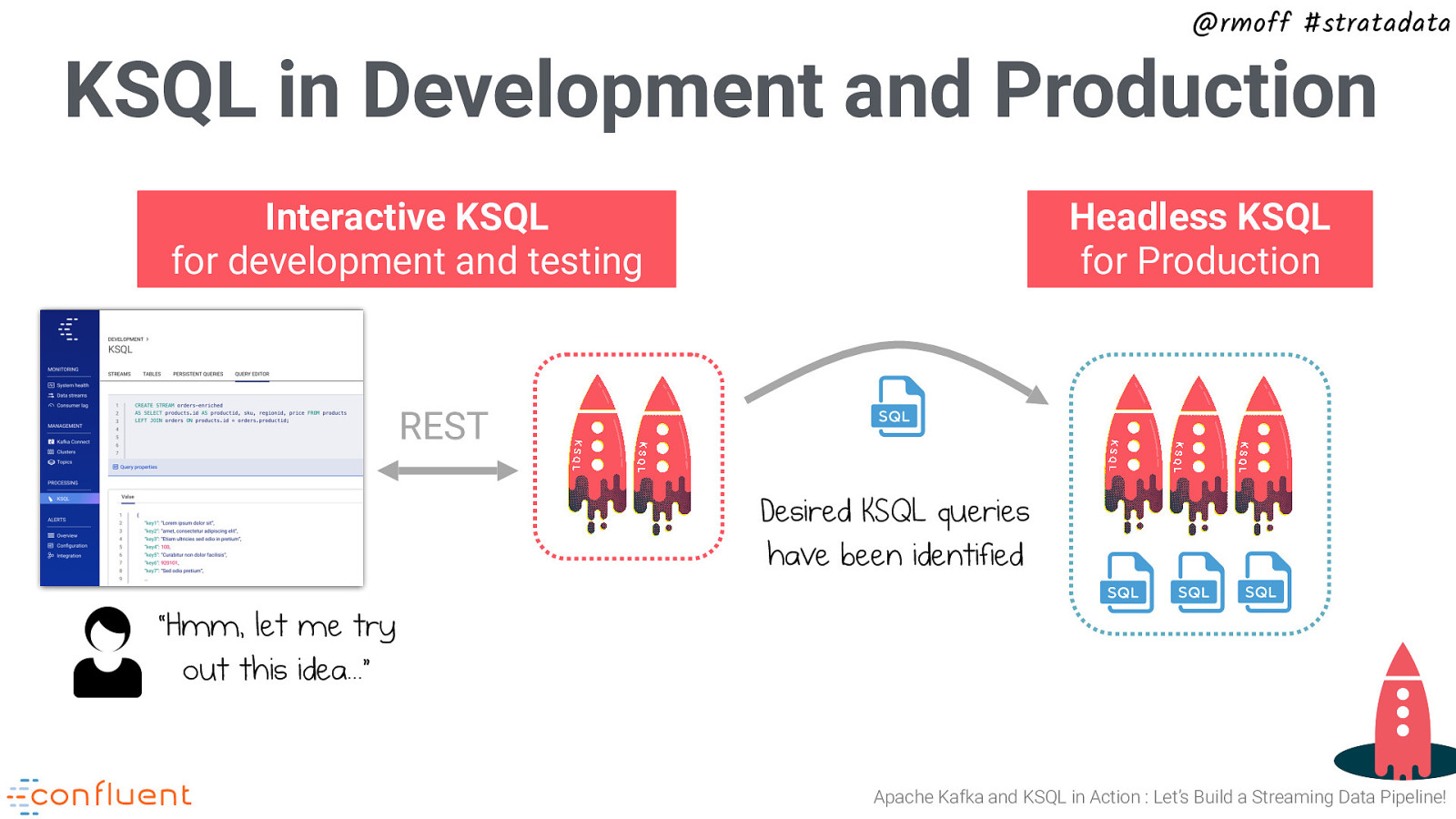
@rmoff #stratadata KSQL in Development and Production Interactive KSQL for development and testing Headless KSQL for Production REST Desired KSQL queries have been identified “Hmm, let me try out this idea…” Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
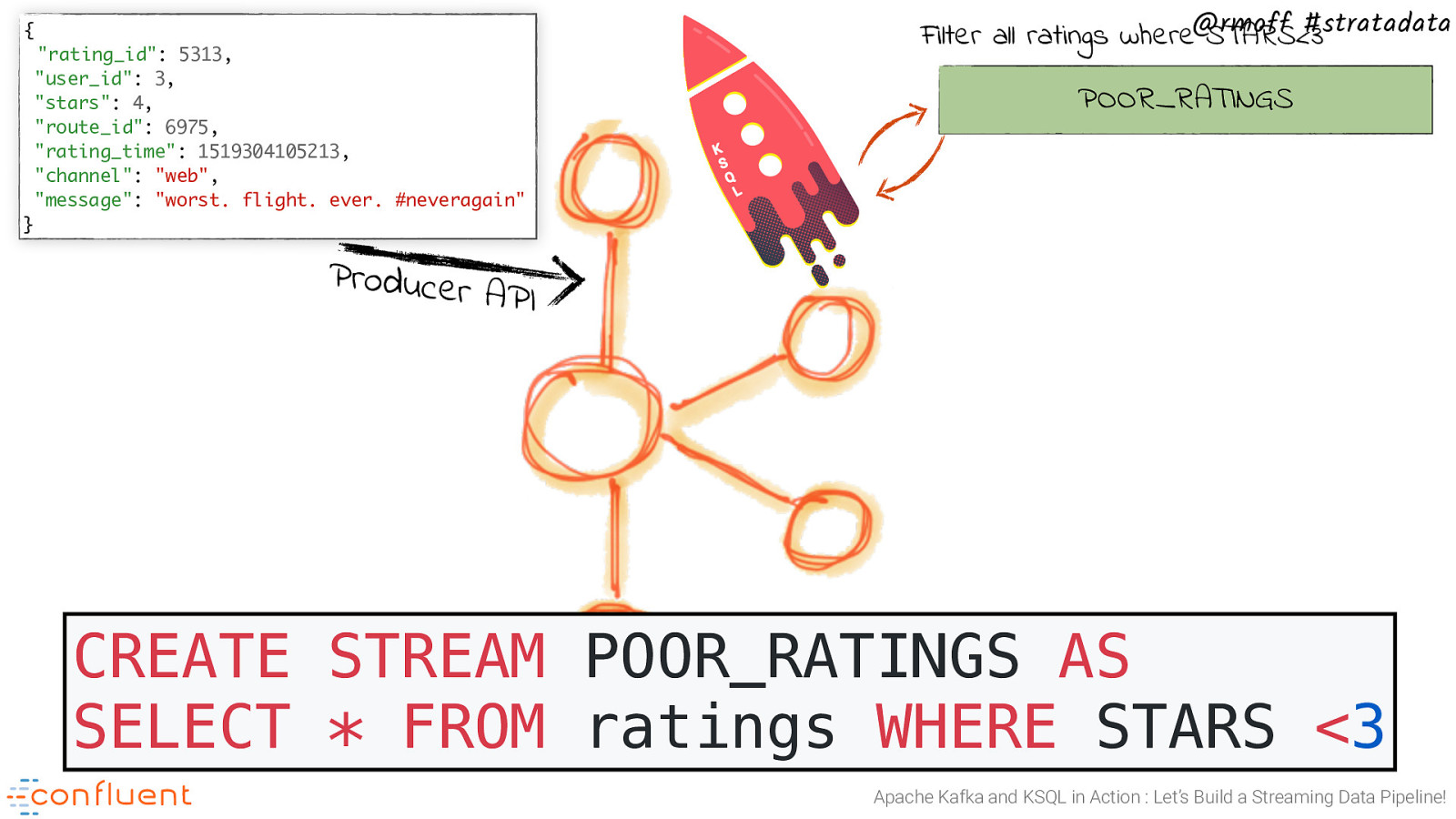
{ “rating_id”: 5313, “user_id”: 3, “stars”: 4, “route_id”: 6975, “rating_time”: 1519304105213, “channel”: “web”, “message”: “worst. flight. ever. #neveragain” @rmoff #stratadata Filter all ratings where STARS<3 POOR_RATINGS } Producer API CREATE STREAM POOR_RATINGS AS SELECT * FROM ratings WHERE STARS <3 Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata https://cnfl.io/start-ksql-workshop 4. KSQL 5. Querying and filtering streams of data 6. Creating a Kafka topic populated by a filtered stream Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata Let’s Build It! Rating events App a k f a K t c e n n o C App u s n o C uc e rA PI Kafka Connect a fk t Ka ec n RDBMS I P A r e m Operational Dashboard Elasticsearch n Co User data Pro d Push notification to Slack Join events to users, and filter Data Lake SnowflakeDB/ S3/HDFS/etc Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
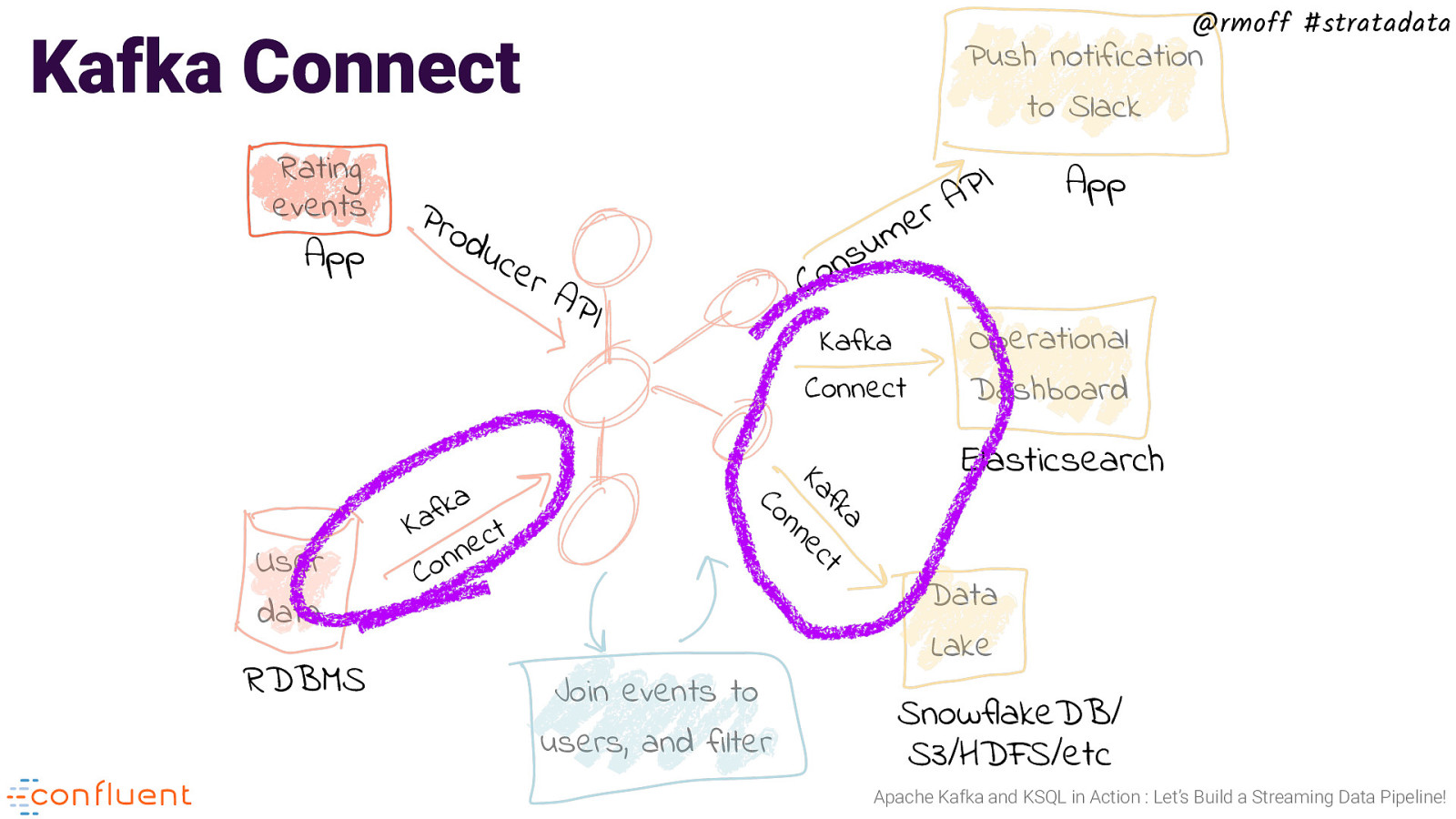
@rmoff #stratadata Kafka Connect Rating events App a k f a K t c e n n o C App u s n o C uc e rA PI Kafka Connect a fk t Ka ec n RDBMS I P A r e m Operational Dashboard Elasticsearch n Co User data Pro d Push notification to Slack Join events to users, and filter Data Lake SnowflakeDB/ S3/HDFS/etc Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata Streaming Integration with Kafka Connect Amazon S3 syslog flat file CSV JSON Sources Sinks MQTT MQTT Tasks Workers Kafka Connect Kafka Brokers Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
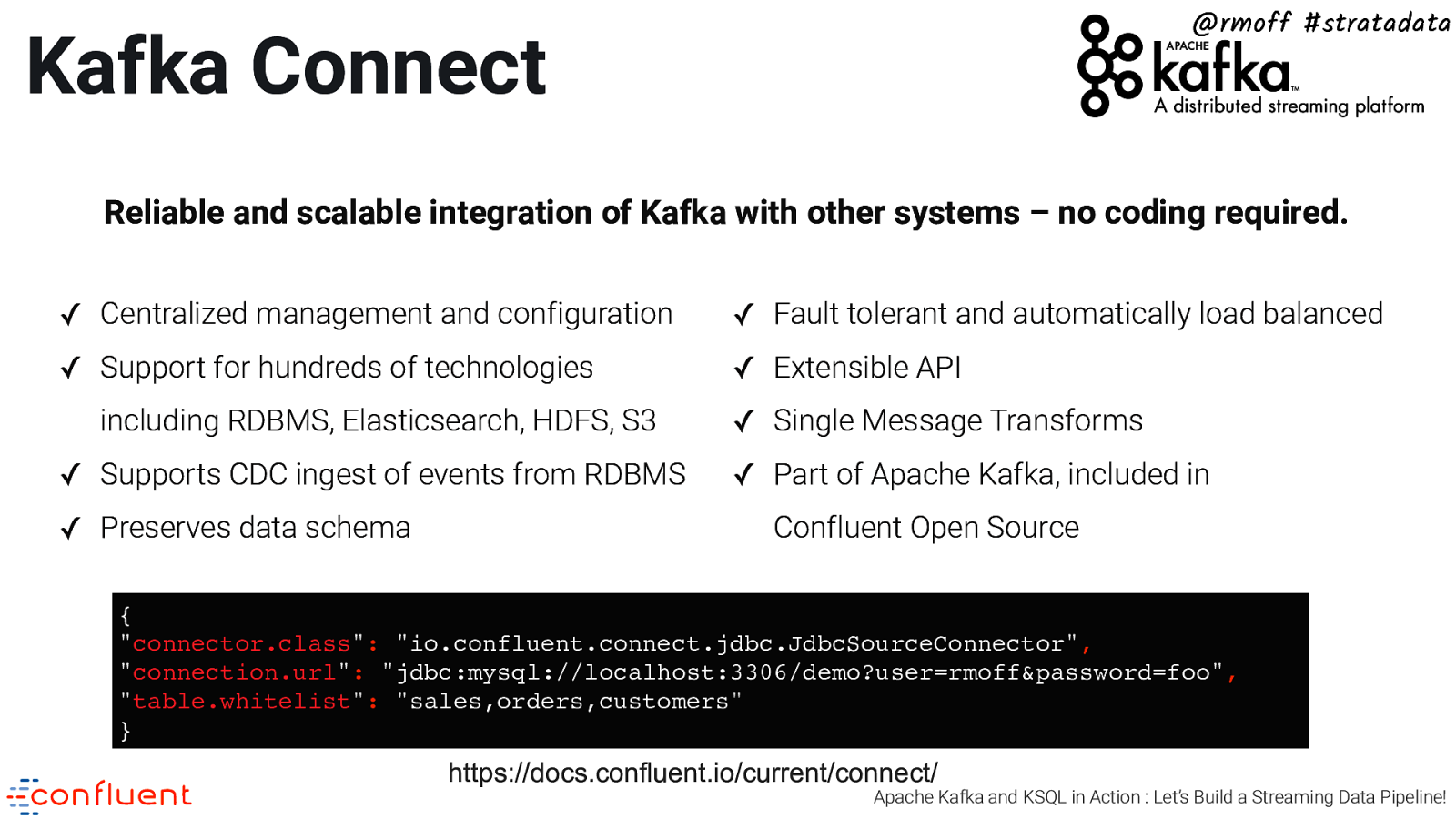
@rmoff #stratadata Kafka Connect Reliable and scalable integration of Kafka with other systems – no coding required. ✓ Centralized management and configuration ✓ Fault tolerant and automatically load balanced ✓ Support for hundreds of technologies ✓ Extensible API including RDBMS, Elasticsearch, HDFS, S3 ✓ Supports CDC ingest of events from RDBMS ✓ Preserves data schema ✓ Single Message Transforms ✓ Part of Apache Kafka, included in Confluent Open Source { “connector.class”: “io.confluent.connect.jdbc.JdbcSourceConnector”, “connection.url”: “jdbc:mysql://localhost:3306/demo?user=rmoff&password=foo”, “table.whitelist”: “sales,orders,customers” } https://docs.confluent.io/current/connect/ Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
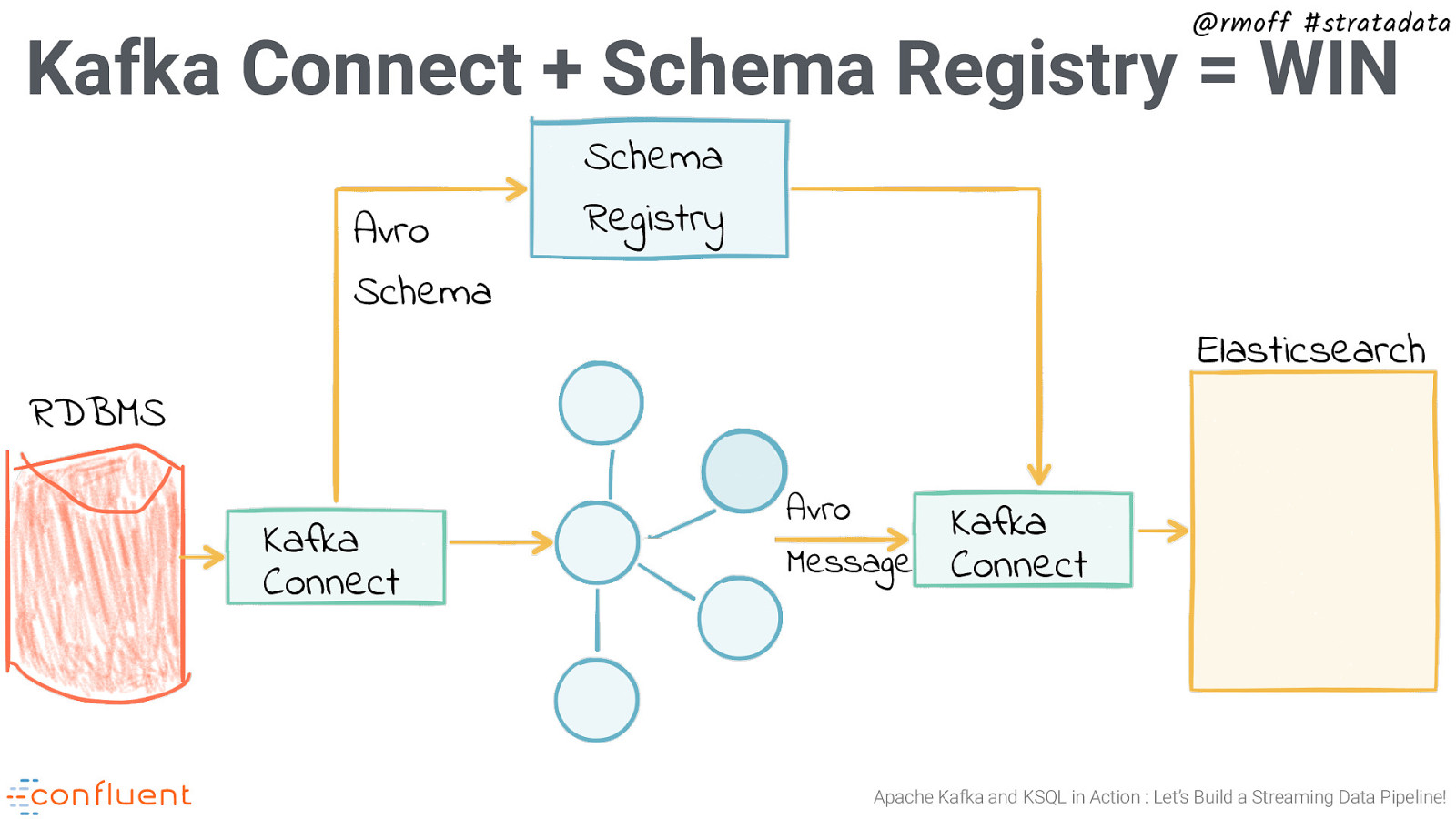
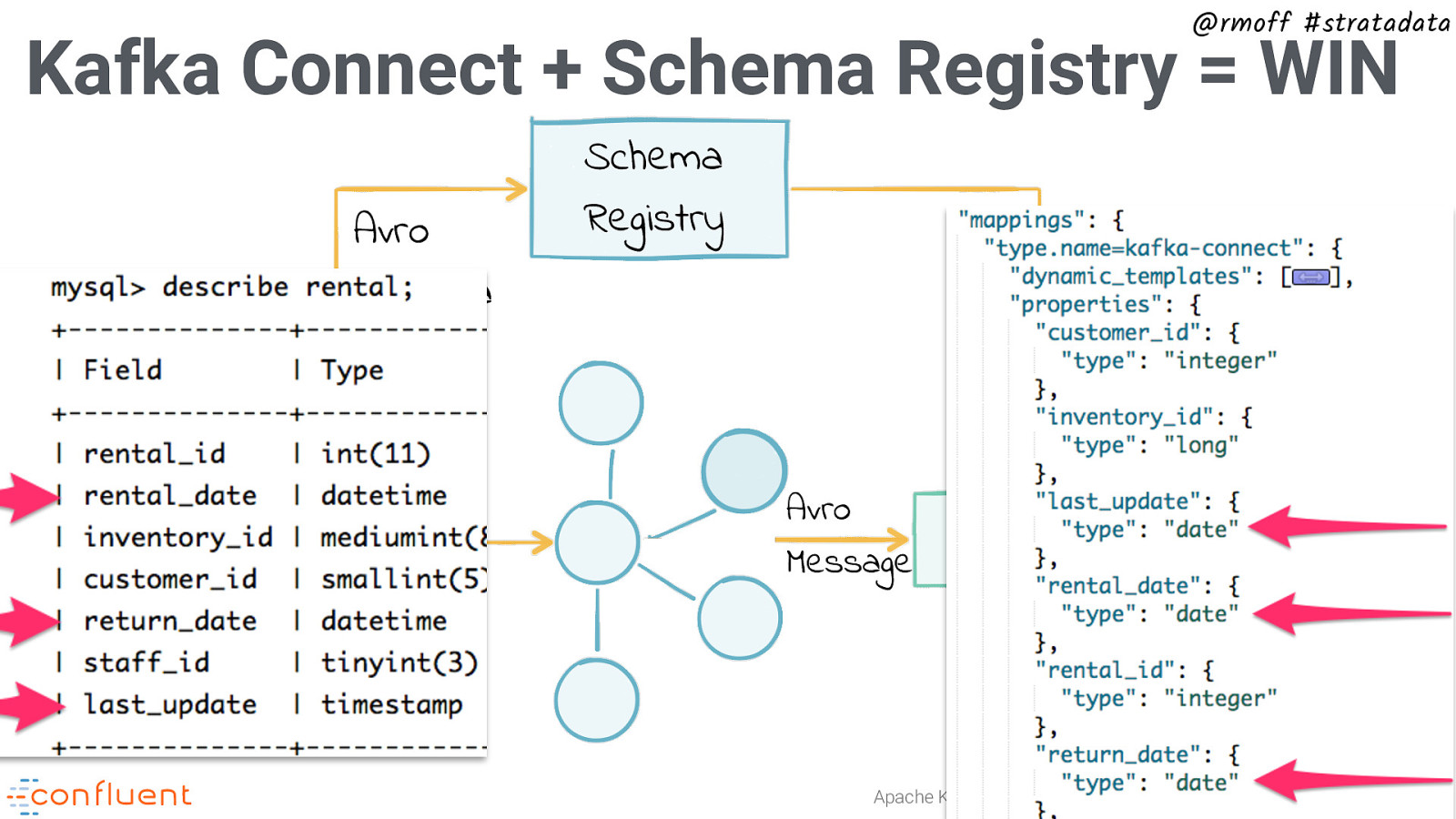
@rmoff #stratadata Kafka Connect + Schema Registry = WIN Avro Schema Schema Registry Elasticsearch RDBMS Kafka Connect Avro Message Kafka Connect Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata Kafka Connect + Schema Registry = WIN Avro Schema Schema Registry Elasticsearch RDBMS Kafka Connect Avro Message Kafka Connect Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
Confluent Hub @rmoff #stratadata • One-stop place to discover and download : • Connectors • Transformations • Converters hub.confluent.io Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
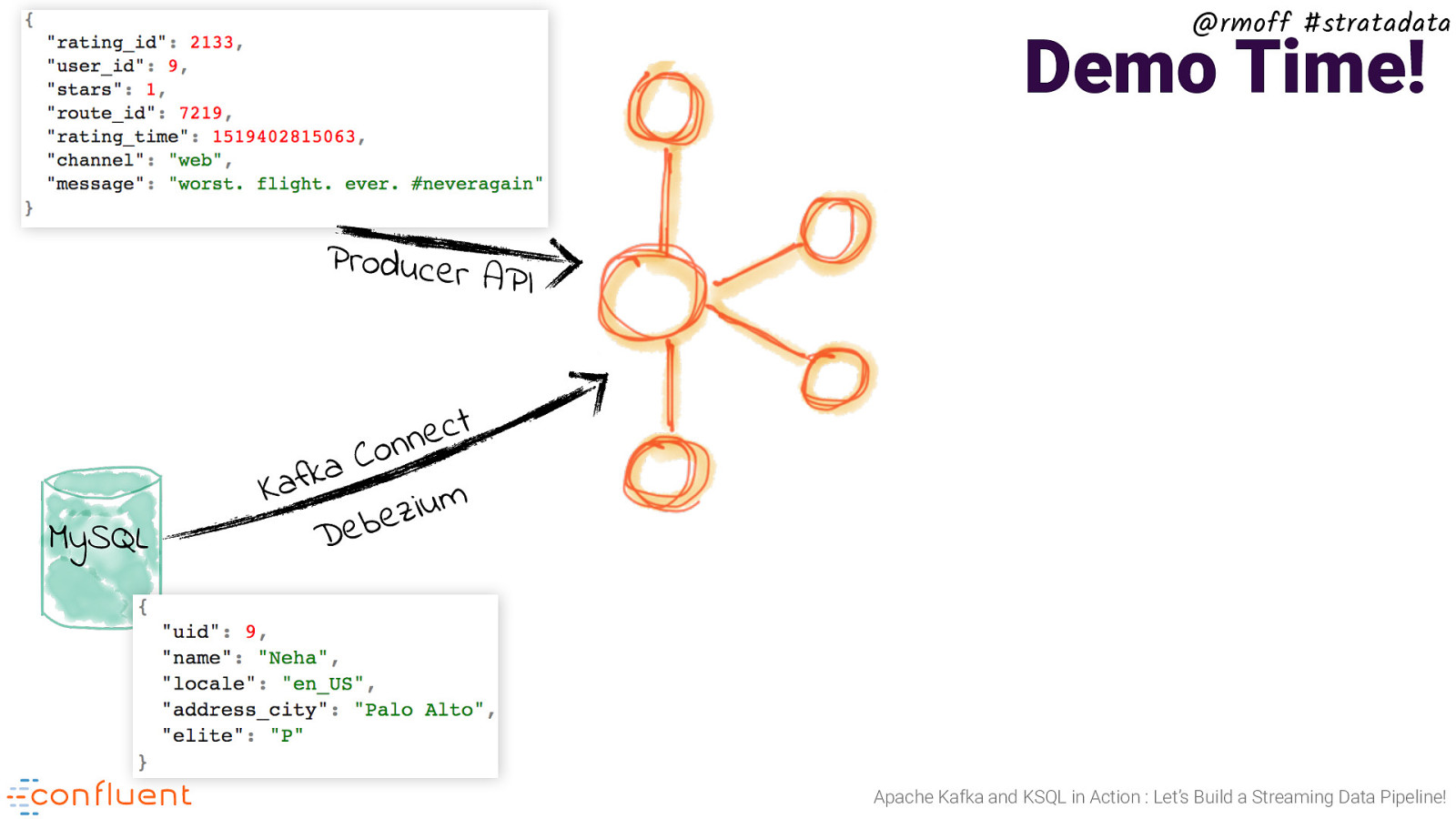
@rmoff #stratadata Demo Time! Producer API MySQL t c e n n o C a k f Ka m u i z e b e D Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata Do you think that’s a table you are querying? Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
Time The Stream/Table Duality Stream Account ID Amount 12345 + €50 12345
The truth is the log. The database is a cache of a subset of the log. —Pat Helland Immutability Changes Everything http://cidrdb.org/cidr2015/Papers/CIDR15_Paper16.pdf Photo by Bobby Burch on Unsplash
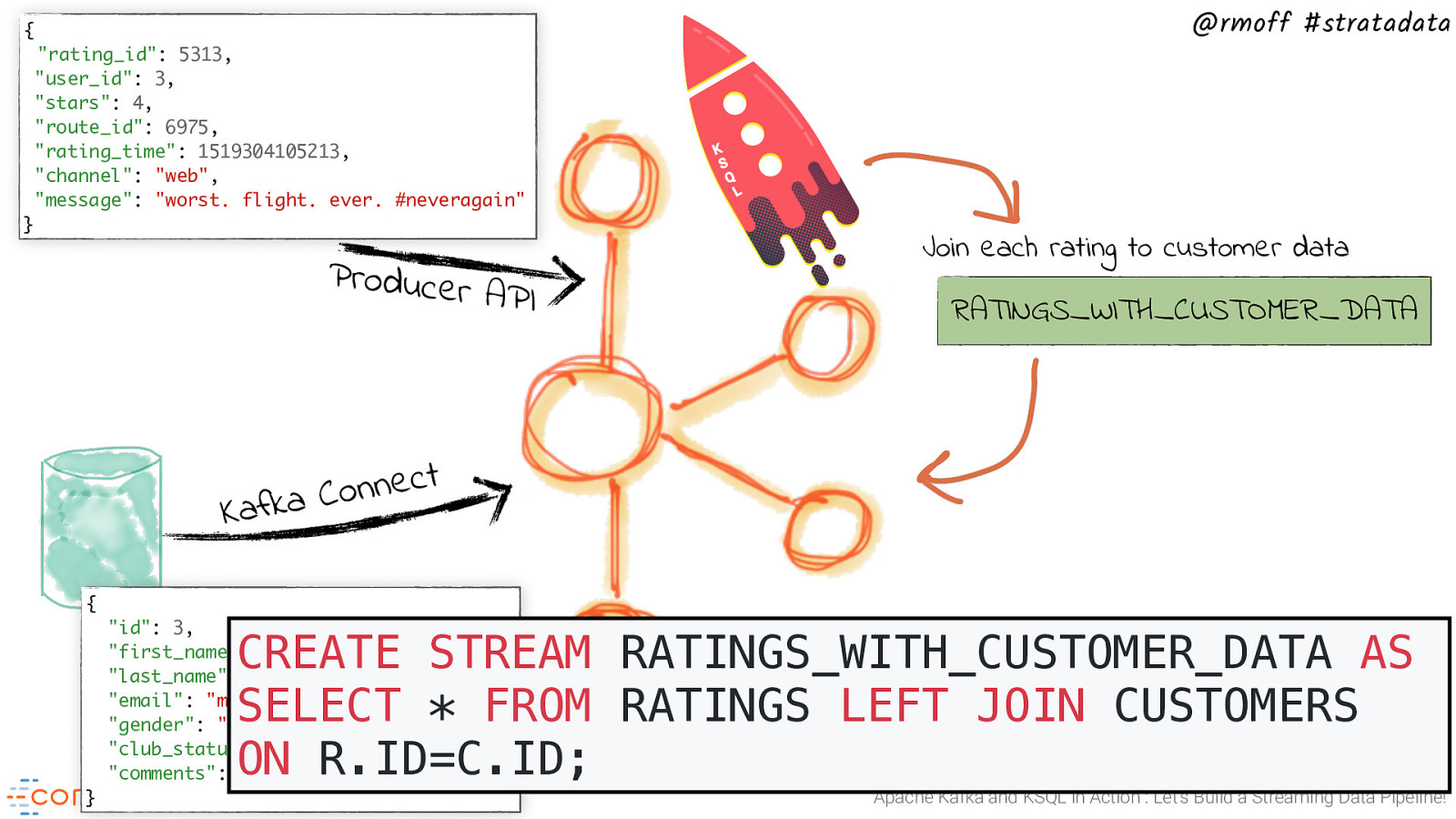
{ “rating_id”: 5313, “user_id”: 3, “stars”: 4, “route_id”: 6975, “rating_time”: 1519304105213, “channel”: “web”, “message”: “worst. flight. ever. #neveragain” } Producer API @rmoff #stratadata Join each rating to customer data RATINGS_WITH_CUSTOMER_DATA t c e n n o C a k f a K { “id”: 3, “first_name”: “Merilyn”, “last_name”: “Doughartie”, “email”: “mdoughartie1@dedecms.com”, “gender”: “Female”, “club_status”: “platinum”, “comments”: “none” CREATE STREAM RATINGS_WITH_CUSTOMER_DATA AS SELECT * FROM RATINGS LEFT JOIN CUSTOMERS ON R.ID=C.ID; } Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
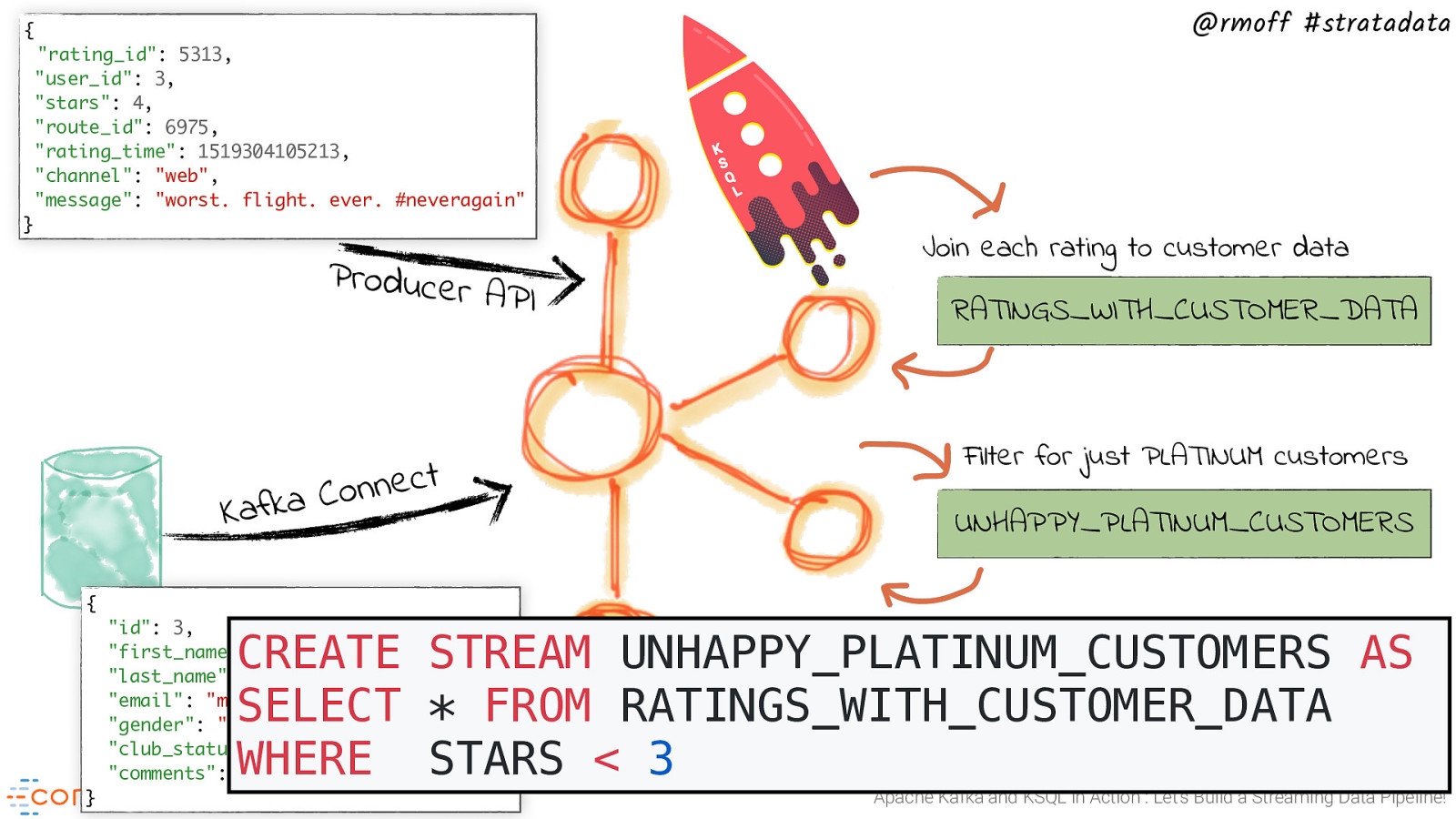
{ “rating_id”: 5313, “user_id”: 3, “stars”: 4, “route_id”: 6975, “rating_time”: 1519304105213, “channel”: “web”, “message”: “worst. flight. ever. #neveragain” } Producer API t c e n n o C a k f a K @rmoff #stratadata Join each rating to customer data RATINGS_WITH_CUSTOMER_DATA Filter for just PLATINUM customers UNHAPPY_PLATINUM_CUSTOMERS { “id”: 3, “first_name”: “Merilyn”, “last_name”: “Doughartie”, “email”: “mdoughartie1@dedecms.com”, “gender”: “Female”, “club_status”: “platinum”, “comments”: “none” CREATE STREAM UNHAPPY_PLATINUM_CUSTOMERS AS SELECT * FROM RATINGS_WITH_CUSTOMER_DATA WHERE STARS < 3 } Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
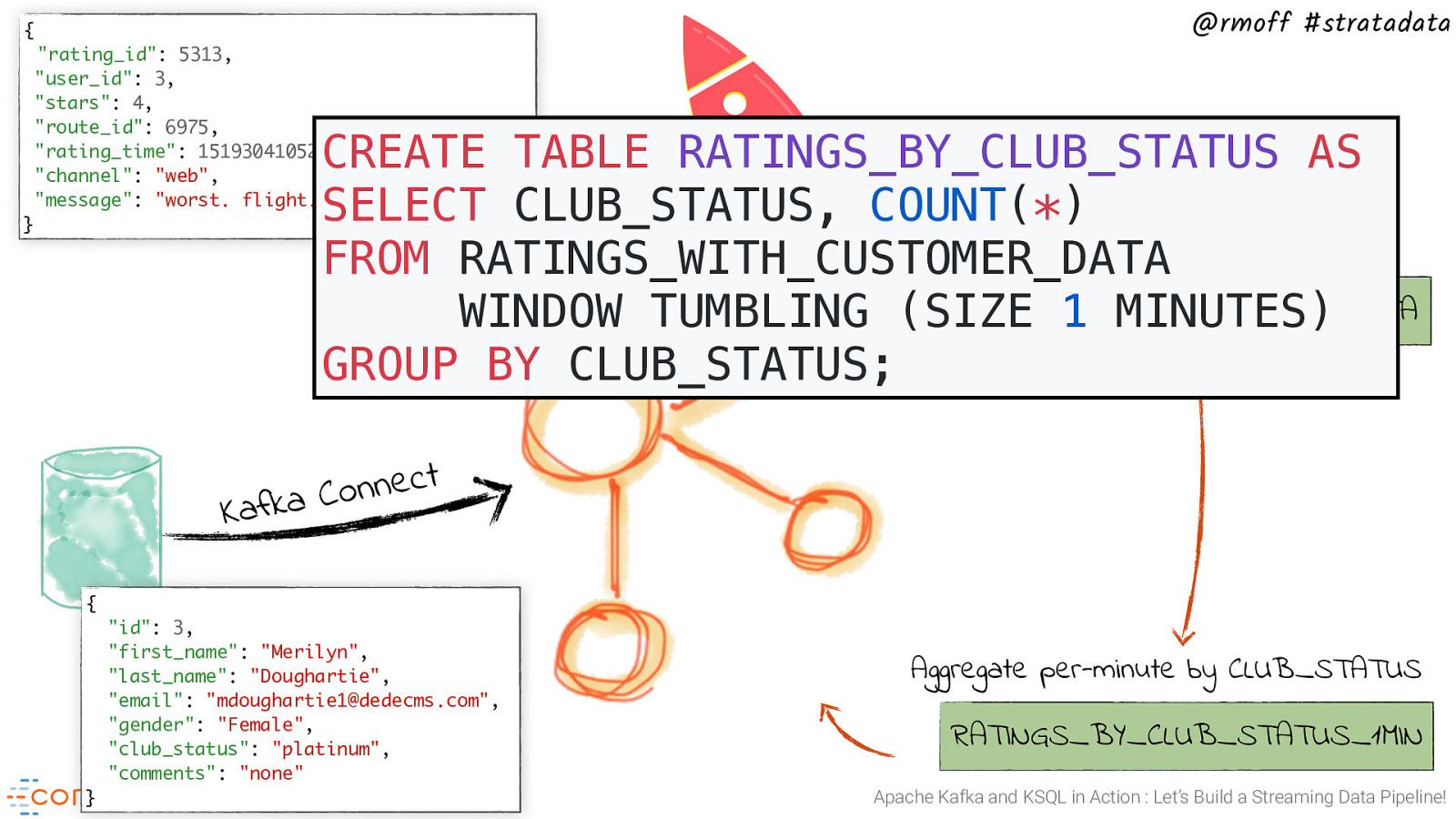
{ “rating_id”: 5313, “user_id”: 3, “stars”: 4, “route_id”: 6975, “rating_time”: 1519304105213, “channel”: “web”, “message”: “worst. flight. ever. #neveragain” @rmoff #stratadata CREATE TABLE RATINGS_BY_CLUB_STATUS AS SELECT CLUB_STATUS, COUNT(*) Join each rating to customer data FROM RATINGS_WITH_CUSTOMER_DATA Producer API RATINGS_WITH_CUSTOMER_DATA WINDOW TUMBLING (SIZE 1 MINUTES) GROUP BY CLUB_STATUS; } t c e n n o C a k f a K { “id”: 3, “first_name”: “Merilyn”, “last_name”: “Doughartie”, “email”: “mdoughartie1@dedecms.com”, “gender”: “Female”, “club_status”: “platinum”, “comments”: “none” } Aggregate per-minute by CLUB_STATUS RATINGS_BY_CLUB_STATUS_1MIN Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
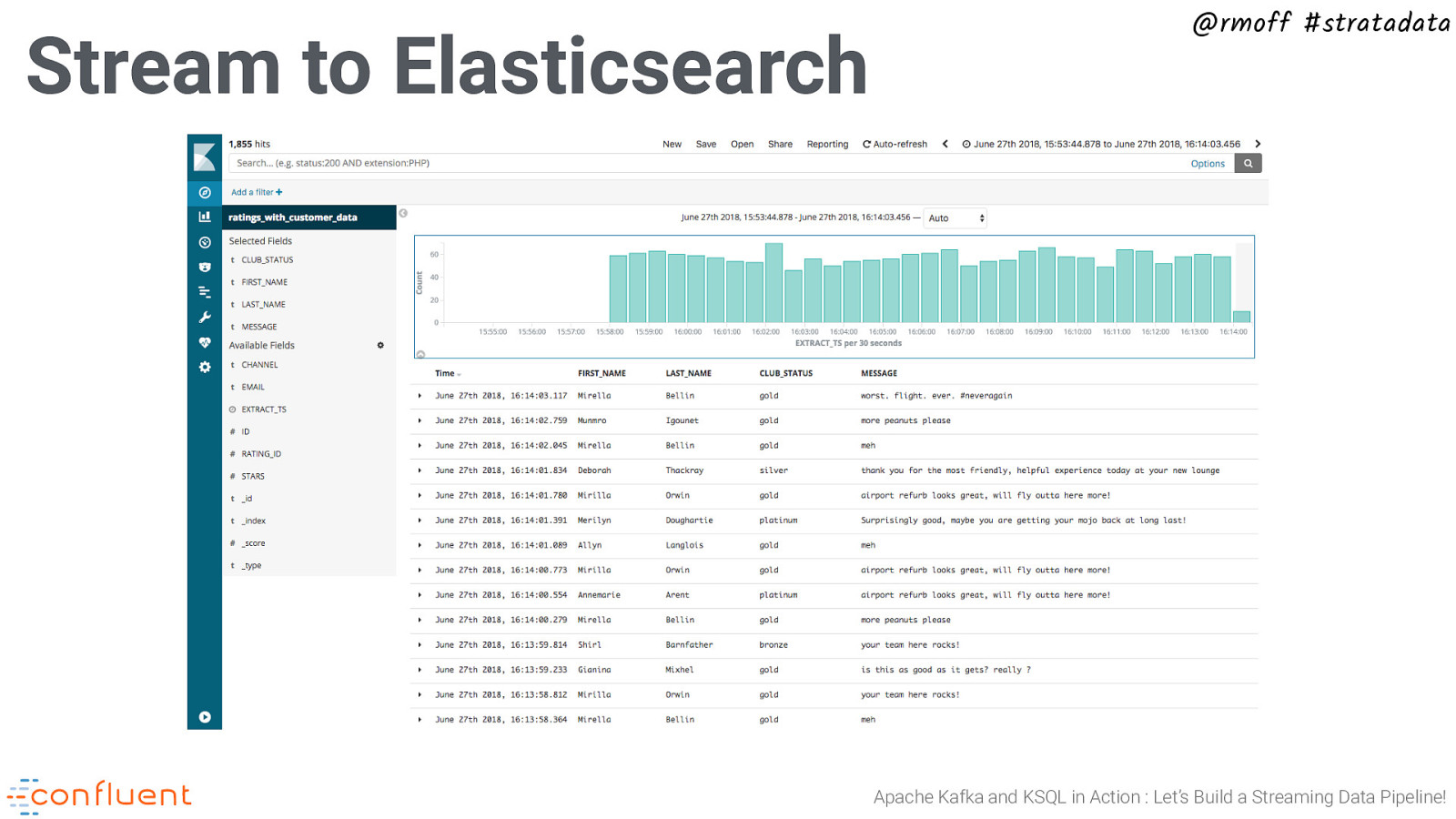
Stream to Elasticsearch @rmoff #stratadata Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata https://cnfl.io/start-ksql-workshop 7. Kafka Connect / Integrating Kafka with a database 8. The Stream/Table duality 9. Joining Data in KSQL 10. Streaming Aggregates 11. Optional: Stream data to Elasticsearch Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
https://www.confluent.io/ksql http://cnfl.io/demo-scene http://cnfl.io/book-bundle http://cnfl.io/slack @rmoff #stratadata @rmoff Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata Related Talks •The Changing Face of ETL: Event-Driven Architectures for Data Engineers • 📖 Slides •Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline! • 📖 Slides • 👾 Code •ATM Fraud detection with Kafka and KSQL • 📽 Recording • 📖 Slides • 👾 Code • 📽 Recording •No More Silos: Integrating Databases and Apache Kafka • 📖 Slides • 👾 Code (MySQL) •Embrace the Anarchy: Apache Kafka’s Role in Modern Data Architectures • 📖 Slides • 👾 Code (Oracle) • 📽 Recording • 📽 Recording Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!
@rmoff #stratadata Resources • CDC Spreadsheet #EOF • Blog: No More Silos: How to Integrate your Databases with Apache Kafka and CDC • #partner-engineering on Slack for questions • BD team (#partners / partners@confluent.io) can help with introductions on a given sales op Apache Kafka and KSQL in Action : Let’s Build a Streaming Data Pipeline!

Have you ever thought that you needed to be a programmer to do stream processing and build streaming data pipelines? Think again. Apache Kafka is a distributed, scalable, and fault-tolerant streaming platform that provides low-latency pub-sub messaging coupled with a native storage and stream processing capabilities. Integrating Kafka with RDBMS, NoSQL, and object stores is simple with Kafka Connect, part of Apache Kafka. KSQL—the open source SQL streaming engine for Apache Kafka—makes it possible to build stream processing applications at scale, written using a familiar SQL interface.
Robin Moffatt walks you through the architectural reasoning for Apache Kafka and the benefits of real-time integration. You’ll then build a streaming data pipeline using nothing but your bare hands, Kafka Connect, and KSQL.
Gasp as you filter events in real time! Be amazed at how we can enrich streams of data with data from RDBMS! Be astonished at the power of streaming aggregates for anomaly detection!
Topics include:
The following resources were mentioned during the presentation or are useful additional information.
The following code examples from the presentation can be tried out live.
Here’s what was said about this presentation on social media.



















 for free. You
can too.
for free. You
can too.