
A presentation at Code.Talks in in Hamburg, Germany by Robin Moffatt

The Changing Face of ETL Event-Driven Architectures for Data Engineers Photo by rmoff #codetalks @rmoff
The Changing Face of ETL Event-Driven Architectures for Data Engineers Photo by rmoff #codetalks @rmoff
Photo by Samuel Sianipar on Unsplash
Photo by Khai Sze Ong on Unsplash
Photo by Rainier Ridao on Unsplash
Photo by Rohit Tandon on Unsplash
Photo by Theodore Moore on Unsplash
Photo by Cristian Grecu on Unsplash
Photo by Patrick Fore on Unsplash It used to be so simple @rmoff #codetalks The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Photo by Eugenio Mazzone on Unsplash More Sources The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Photo by Tom Barrett on Unsplash More Targets The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Photo by Kirill on Unsplash More Data The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Batches and Buckets The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Applications Respond Photo by Deva Darshan from Pexels → an order was placed! Analytics Tell Us What Happened → how many orders were placed The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks The Changing Face of ETL: Event-Driven Architectures for Data Engineers
Photo by NASA on Unsplash @rmoff #codetalks The Changing Face of ETL: Event-Driven Architectures for Data Engineers
Photo by Mark Kamalov on Unsplash Events
@rmoff #codetalks “ An event is both: * Notification * State transfer The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks A Customer Experience The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks A Sensor Reading The Changing Face of ETL: Event-Driven Architectures for Data Engineers
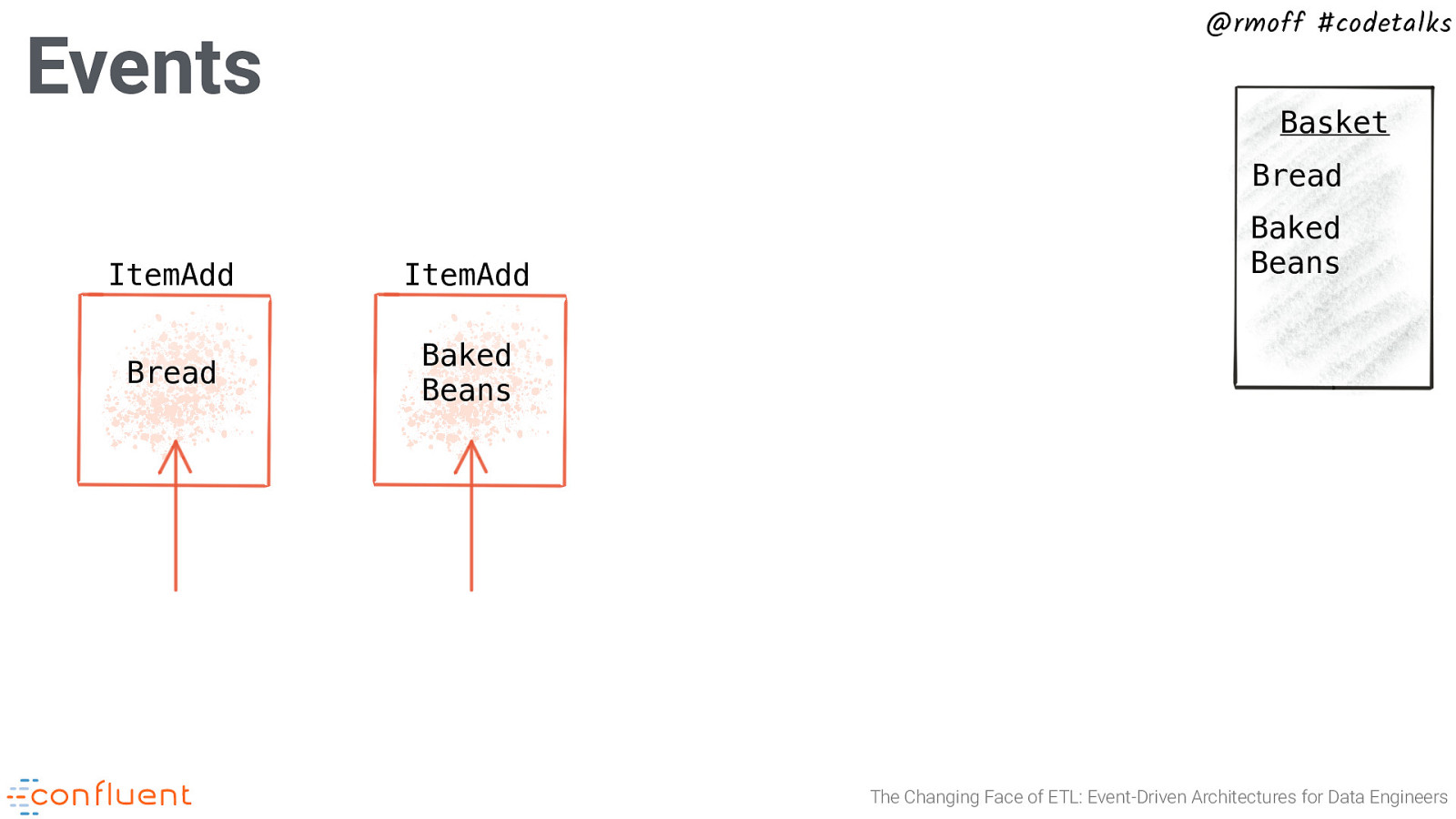
Events @rmoff #codetalks Basket Bread Tinned Spaghetti The Changing Face of ETL: Event-Driven Architectures for Data Engineers
Events @rmoff #codetalks Basket Bread ItemAdd Bread The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Events Basket Bread ItemAdd ItemAdd Bread Baked Beans Baked Beans The Changing Face of ETL: Event-Driven Architectures for Data Engineers
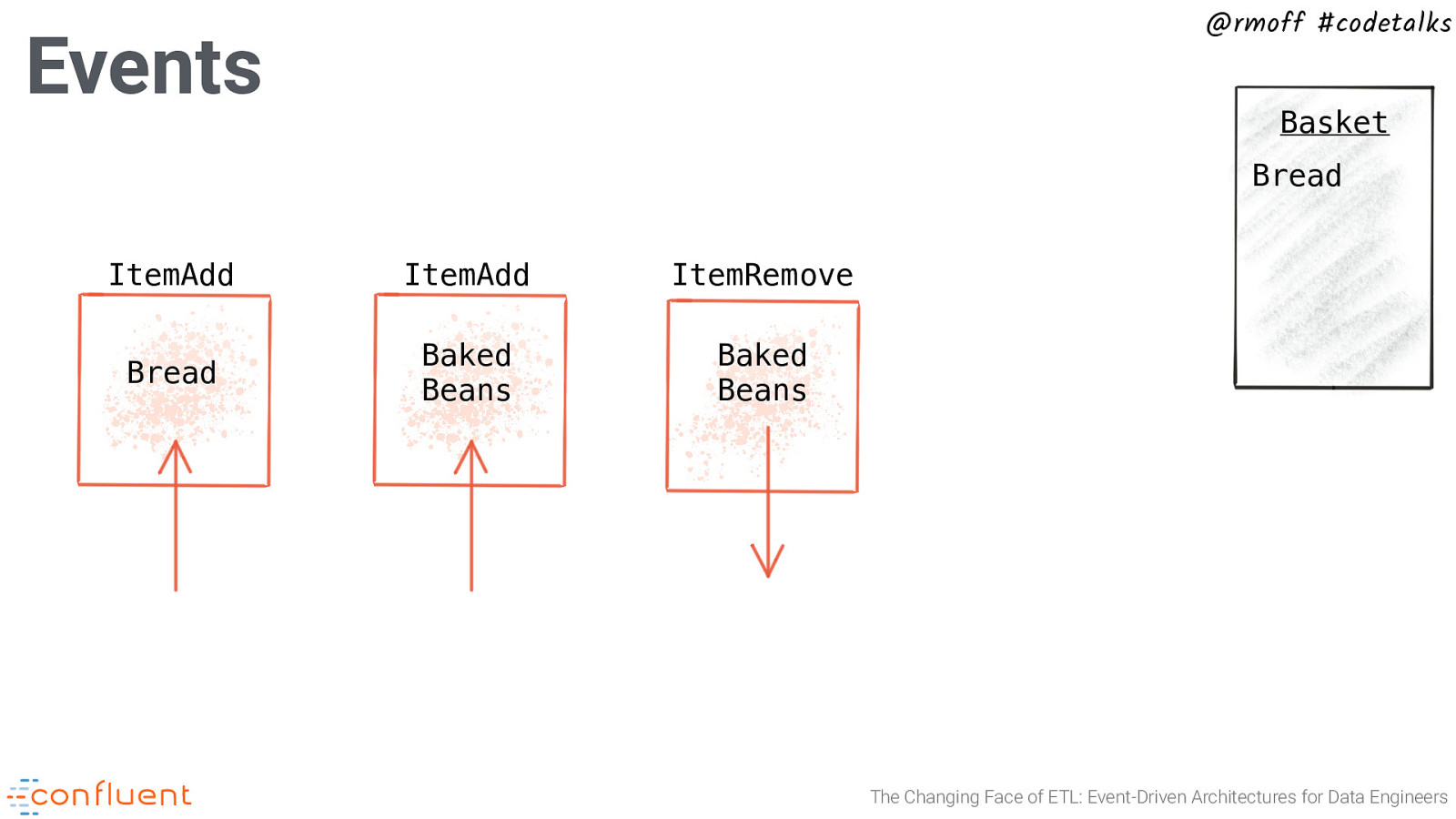
@rmoff #codetalks Events Basket Bread ItemAdd ItemAdd ItemRemove Bread Baked Beans Baked Beans The Changing Face of ETL: Event-Driven Architectures for Data Engineers
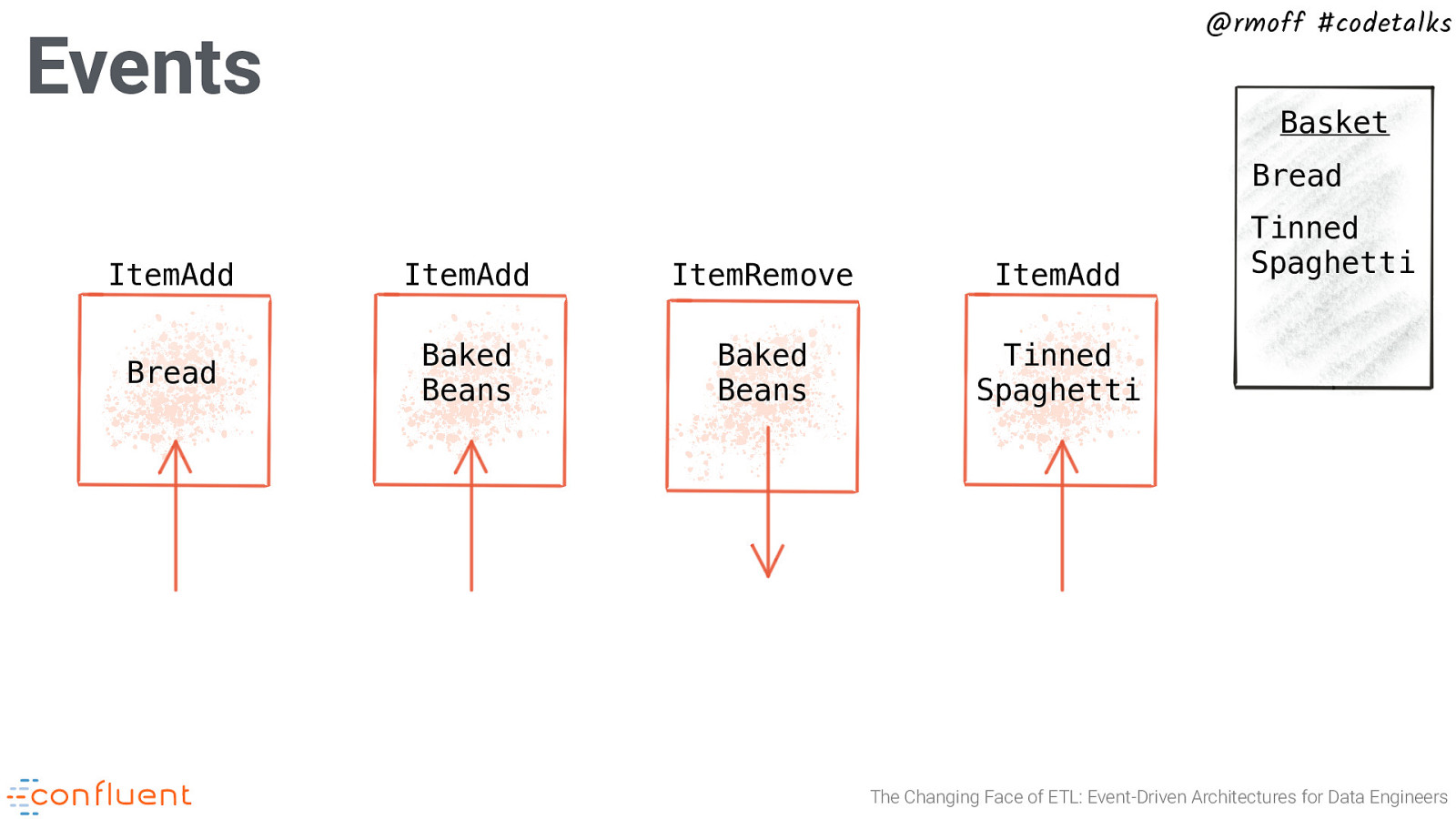
@rmoff #codetalks Events Basket Bread ItemAdd ItemAdd ItemRemove ItemAdd Bread Baked Beans Baked Beans Tinned Spaghetti Tinned Spaghetti The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Events Basket Bread ItemAdd ItemAdd ItemRemove ItemAdd Bread Baked Beans Baked Beans Tinned Spaghetti Tinned Spaghetti The Changing Face of ETL: Event-Driven Architectures for Data Engineers
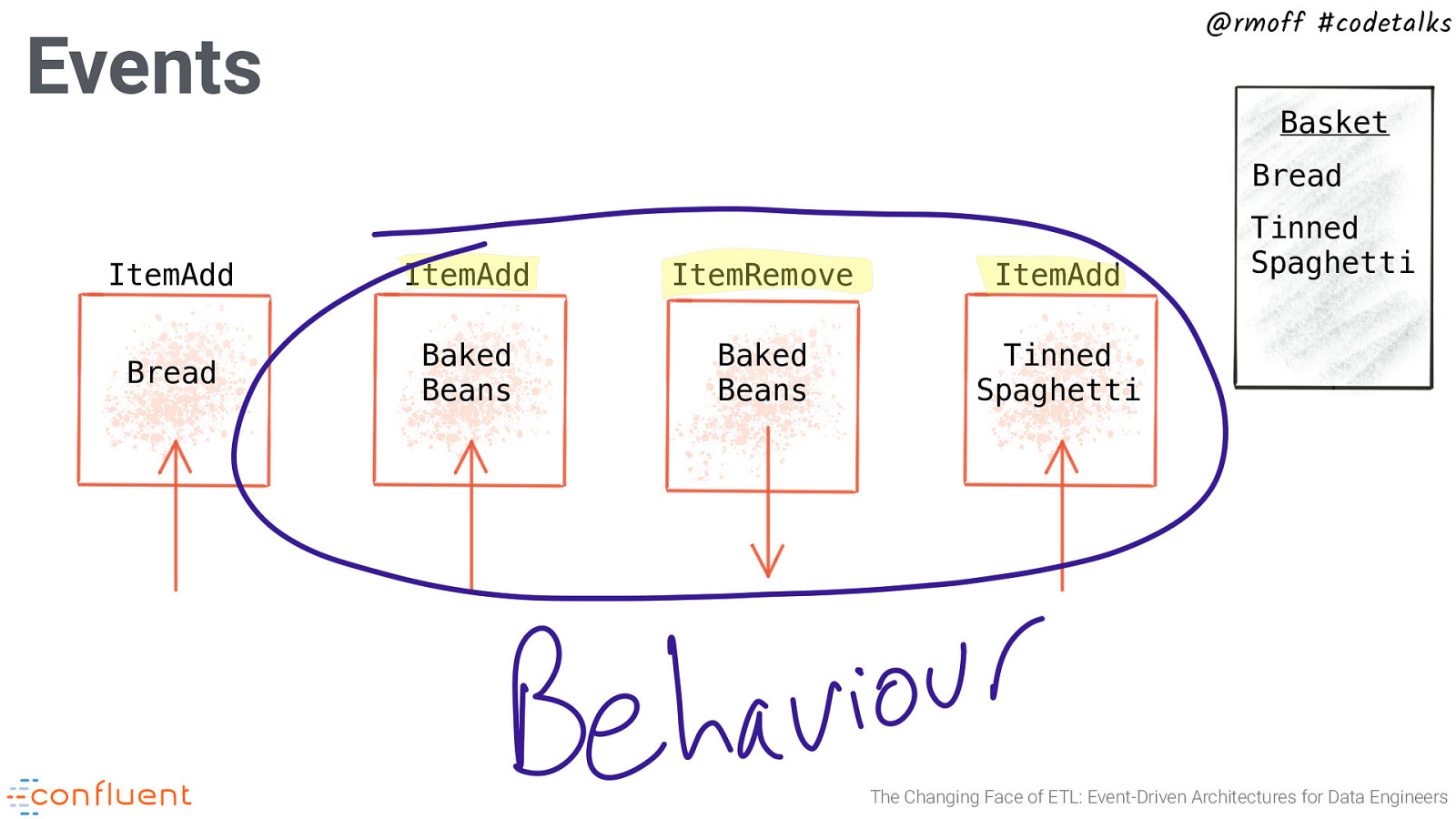
@rmoff #codetalks Events Basket Bread ItemAdd ItemAdd ItemRemove ItemAdd Bread Baked Beans Baked Beans Tinned Spaghetti Tinned Spaghetti The Changing Face of ETL: Event-Driven Architectures for Data Engineers
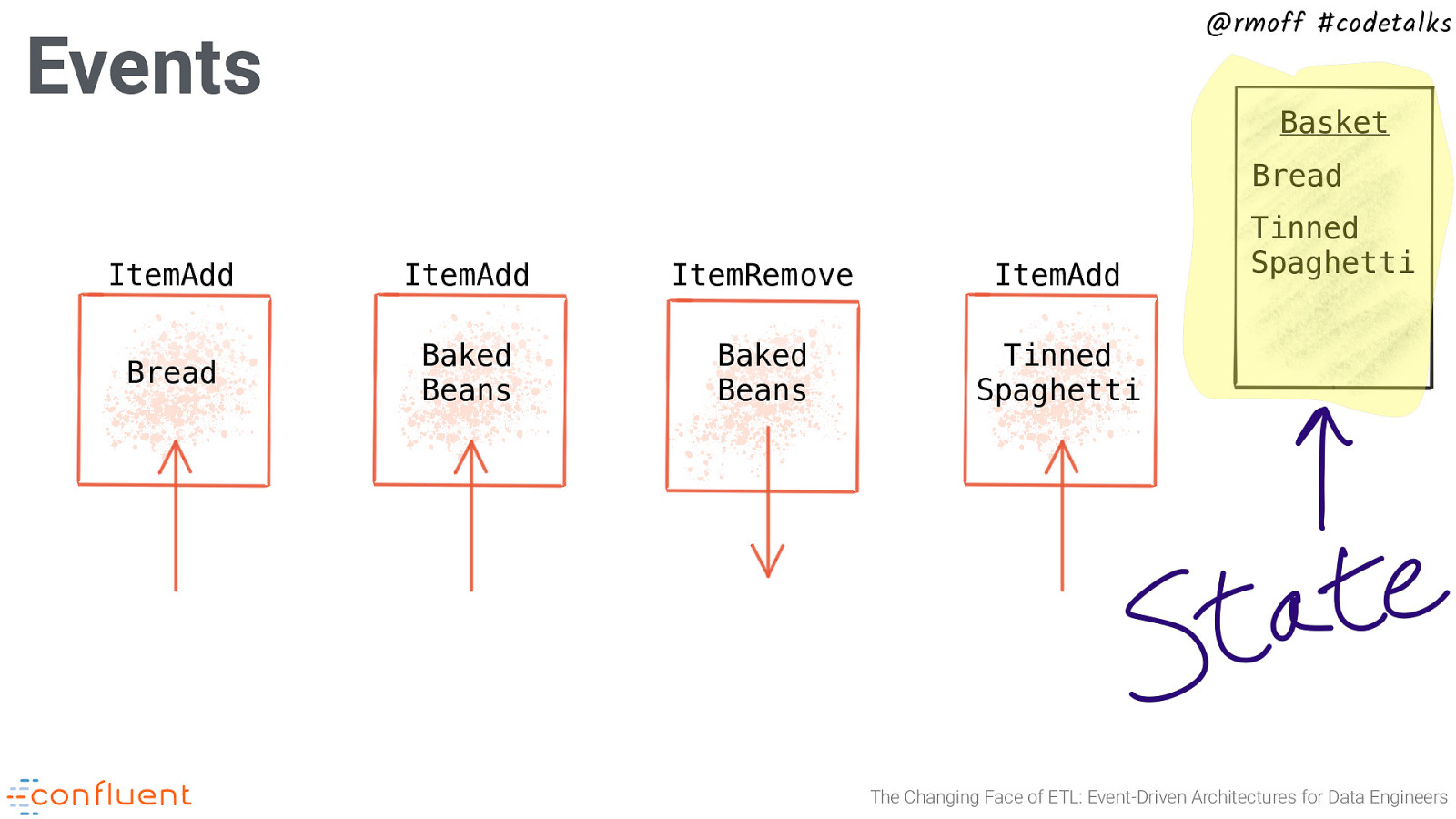
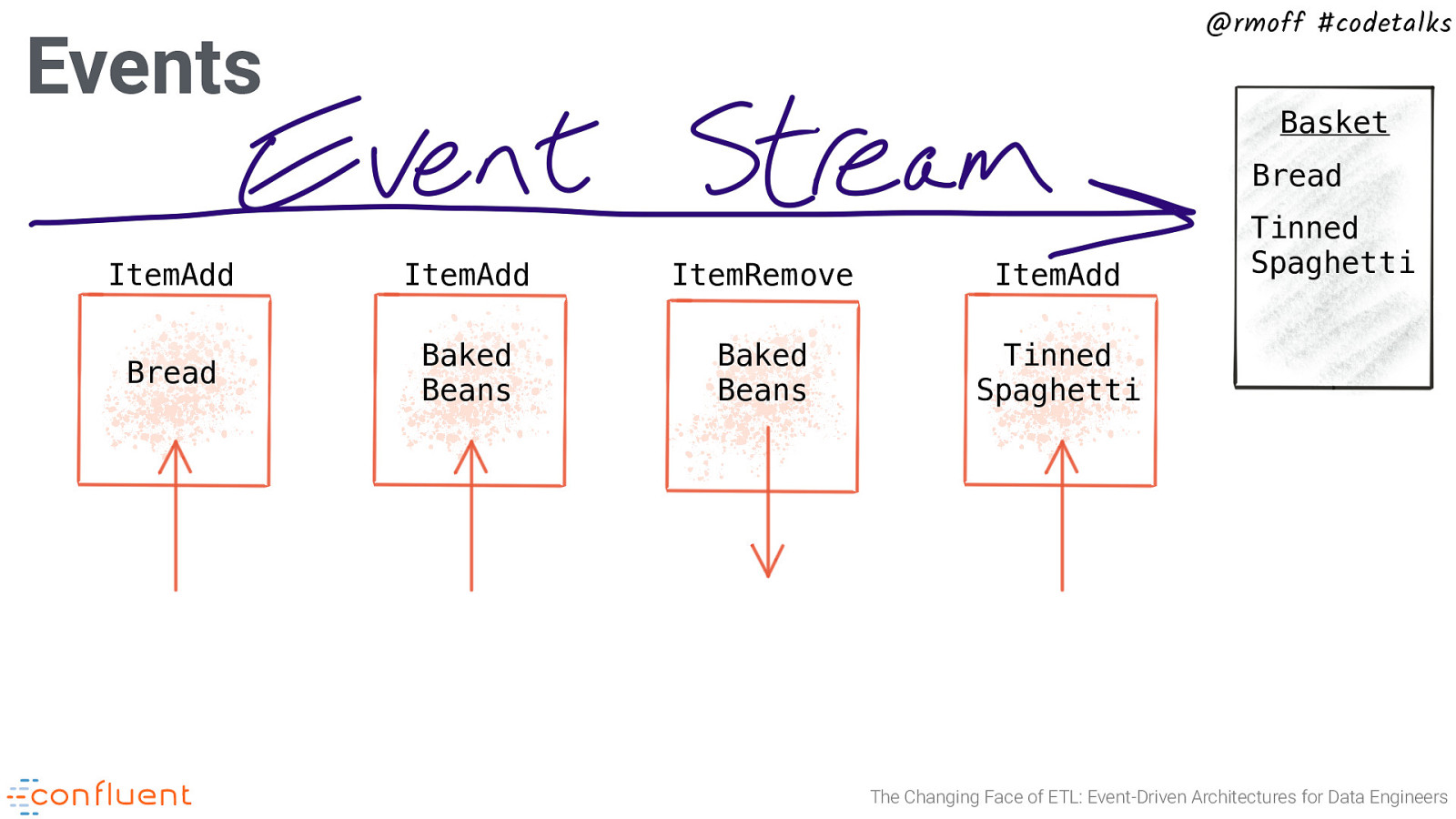
@rmoff #codetalks Events Basket Bread ItemAdd ItemAdd ItemRemove ItemAdd Bread Baked Beans Baked Beans Tinned Spaghetti Tinned Spaghetti The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Databases The Changing Face of ETL: Event-Driven Architectures for Data Engineers
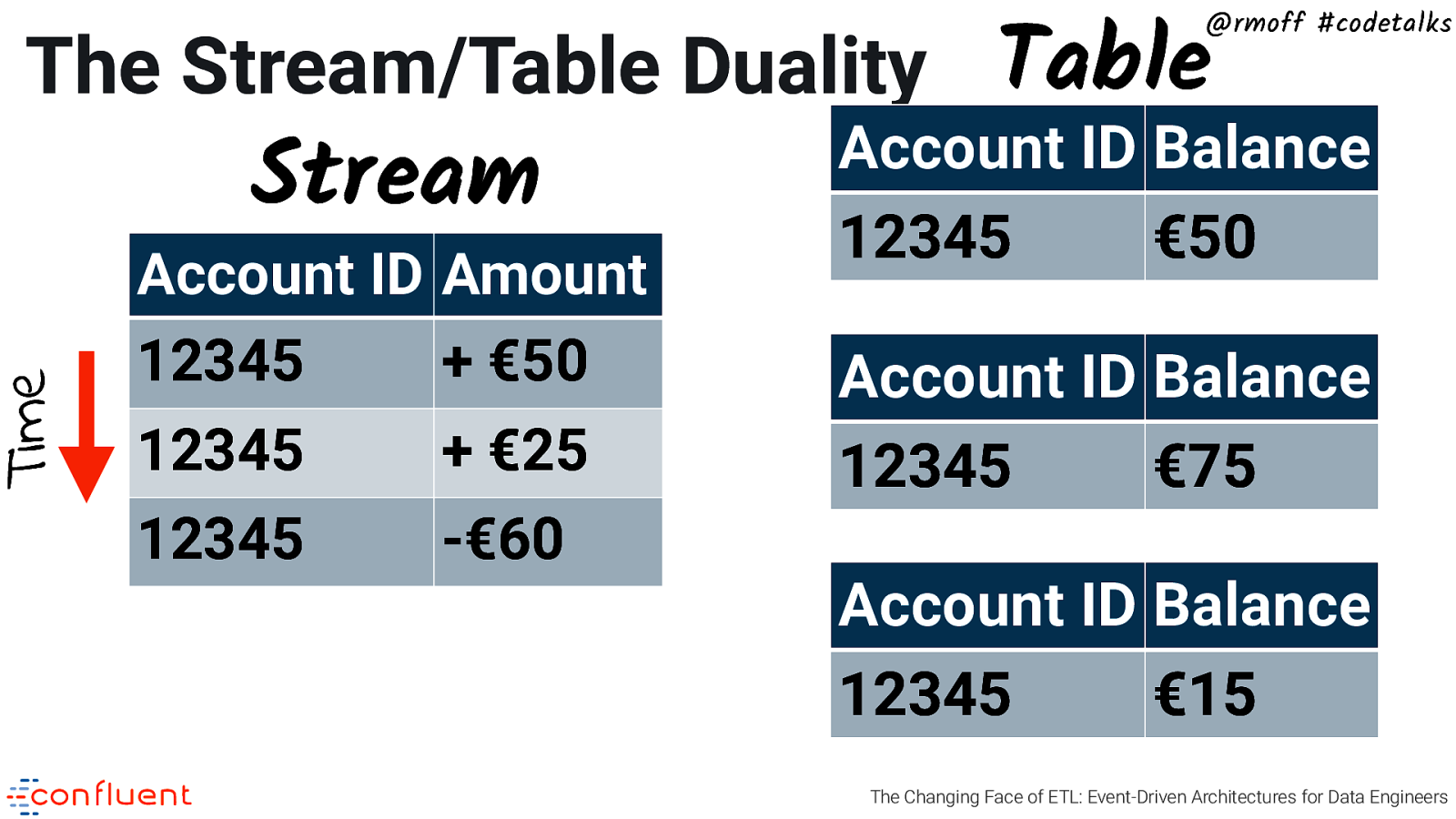
Time The Stream/Table Duality Table @rmoff #codetalks Stream Account ID Amount 12345 + €50 12345
@rmoff #codetalks The truth is the log. The database is a cache of a subset of the log. —Pat Helland Immutability Changes Everything http://cidrdb.org/cidr2015/Papers/CIDR15_Paper16.pdf The Changing Face of ETL: Event-Driven Architectures for Data Engineers Photo by Bobby Burch on Unsplash
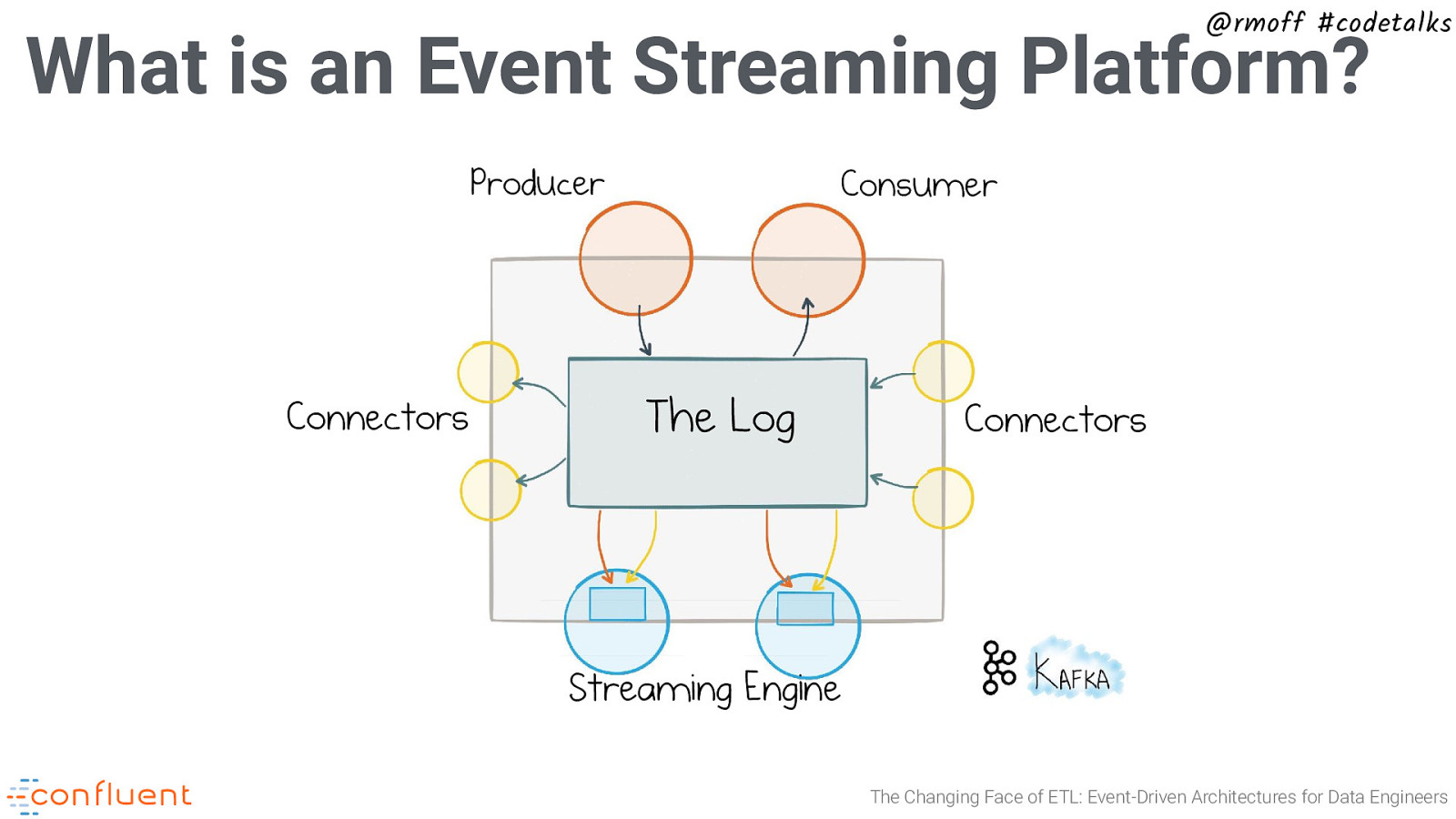
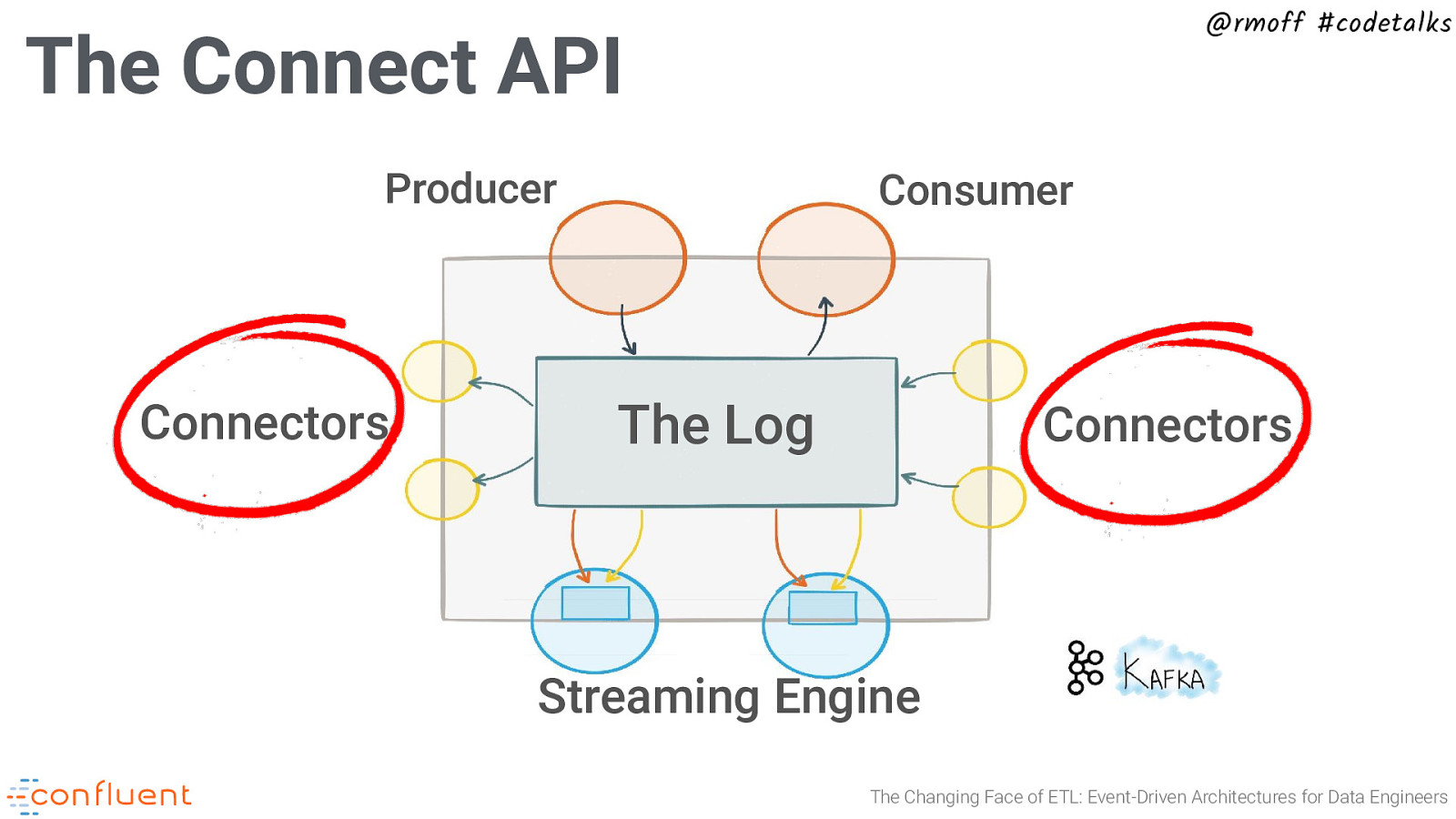
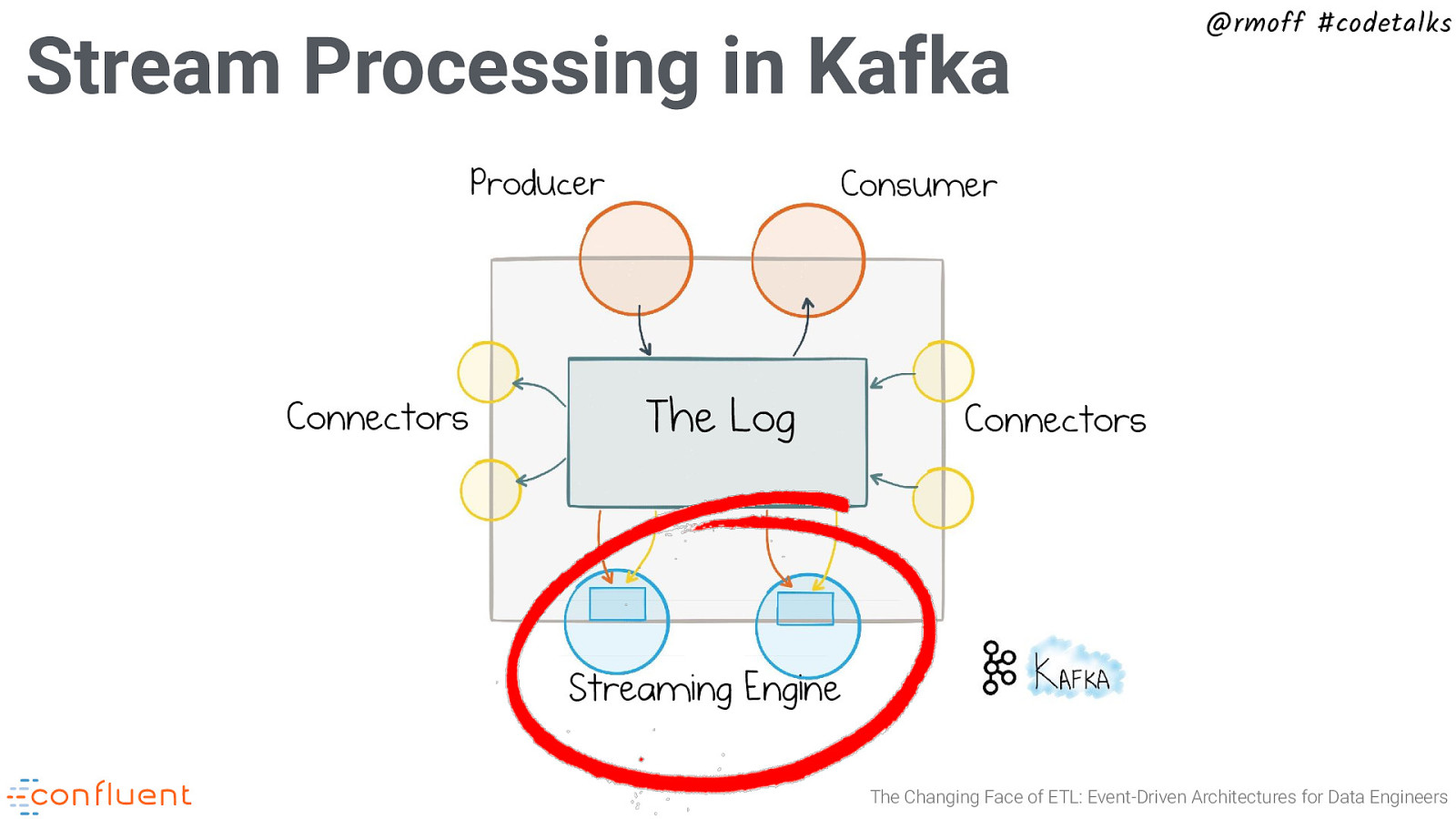
@rmoff #codetalks What is an Event Streaming Platform? Producer Connectors Consumer The Log Connectors Streaming Engine The Changing Face of ETL: Event-Driven Architectures for Data Engineers
Immutable Event Log Old @rmoff #codetalks New Messages are added at the end of the log The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Topics Clicks Orders Customers Topics are similar in concept to tables in a database The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Partitions Clicks p0 P1 P2 Messages are guaranteed to be strictly ordered within a partition The Changing Face of ETL: Event-Driven Architectures for Data Engineers
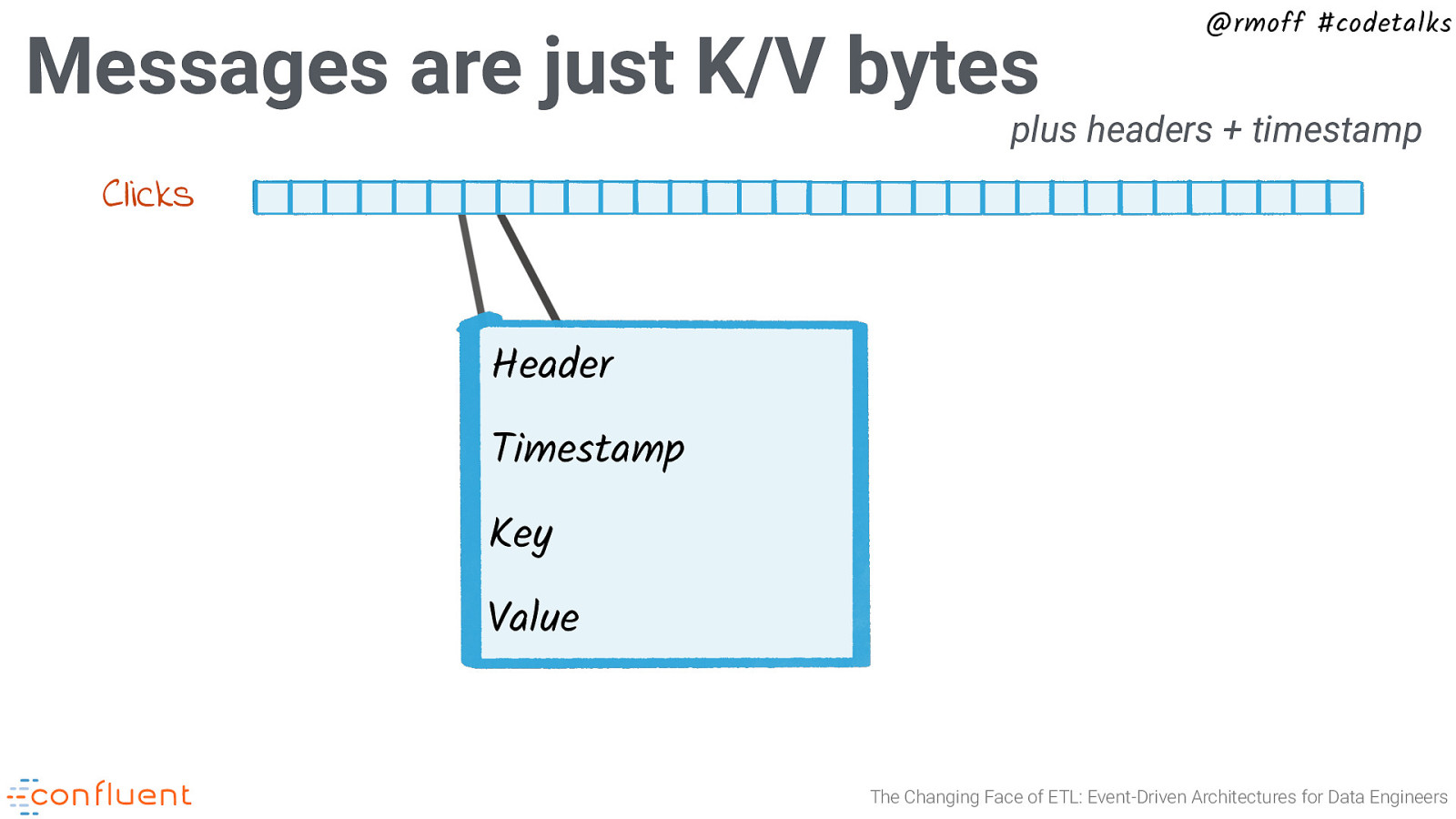
Messages are just K/V bytes @rmoff #codetalks plus headers + timestamp Clicks Header Timestamp Key Value The Changing Face of ETL: Event-Driven Architectures for Data Engineers
Messages are just K/V bytes @rmoff #codetalks With great power comes great responsibility Avro -> Confluent Schema Registry Protobuf JSON CSV https://qconnewyork.com/system/files/presentation-slides/qcon_17_-_schemas_and_apis.pdf The Changing Face of ETL: Event-Driven Architectures for Data Engineers
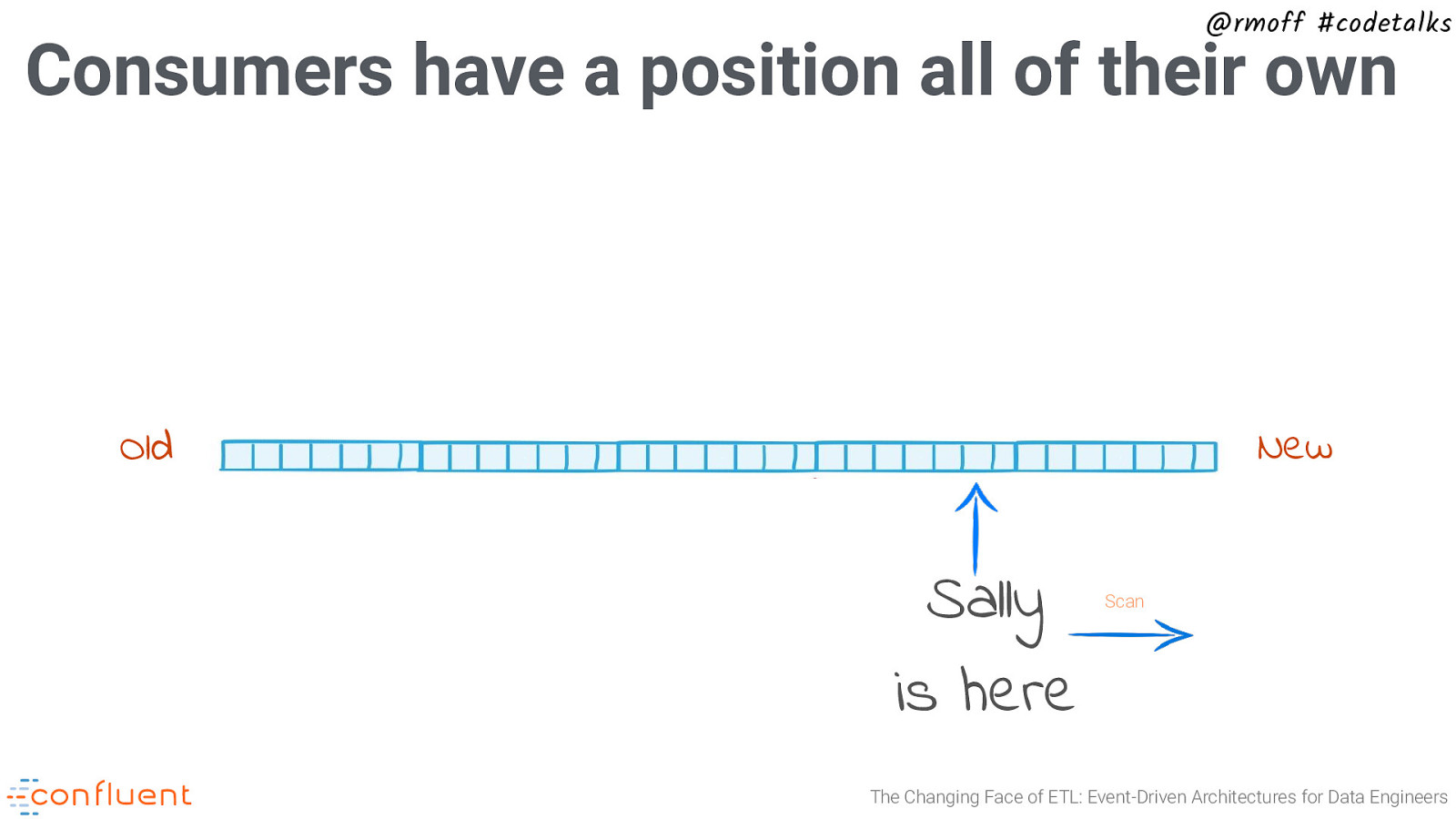
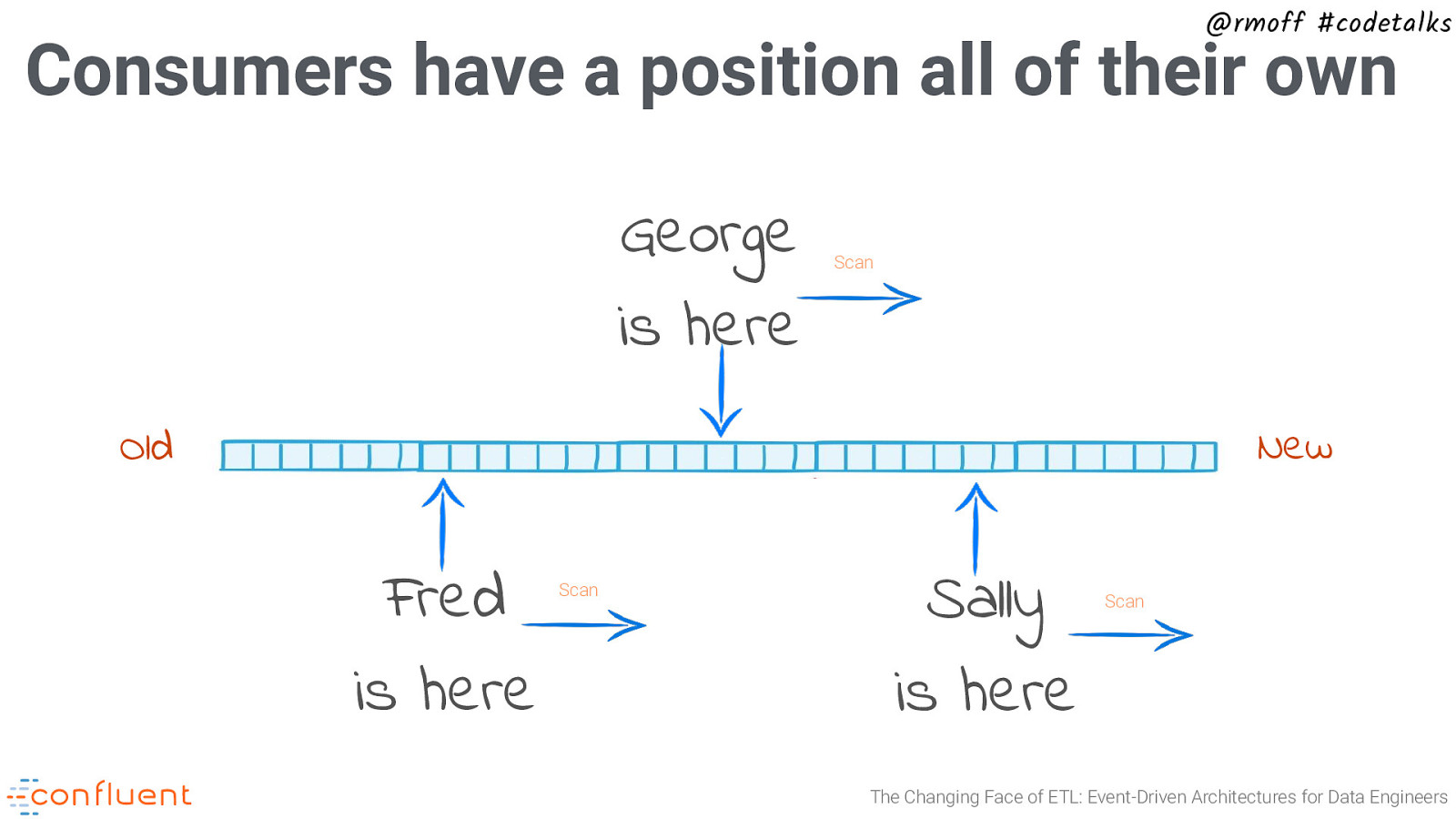
@rmoff #codetalks Consumers have a position all of their own New Old Sally is here Scan The Changing Face of ETL: Event-Driven Architectures for Data Engineers
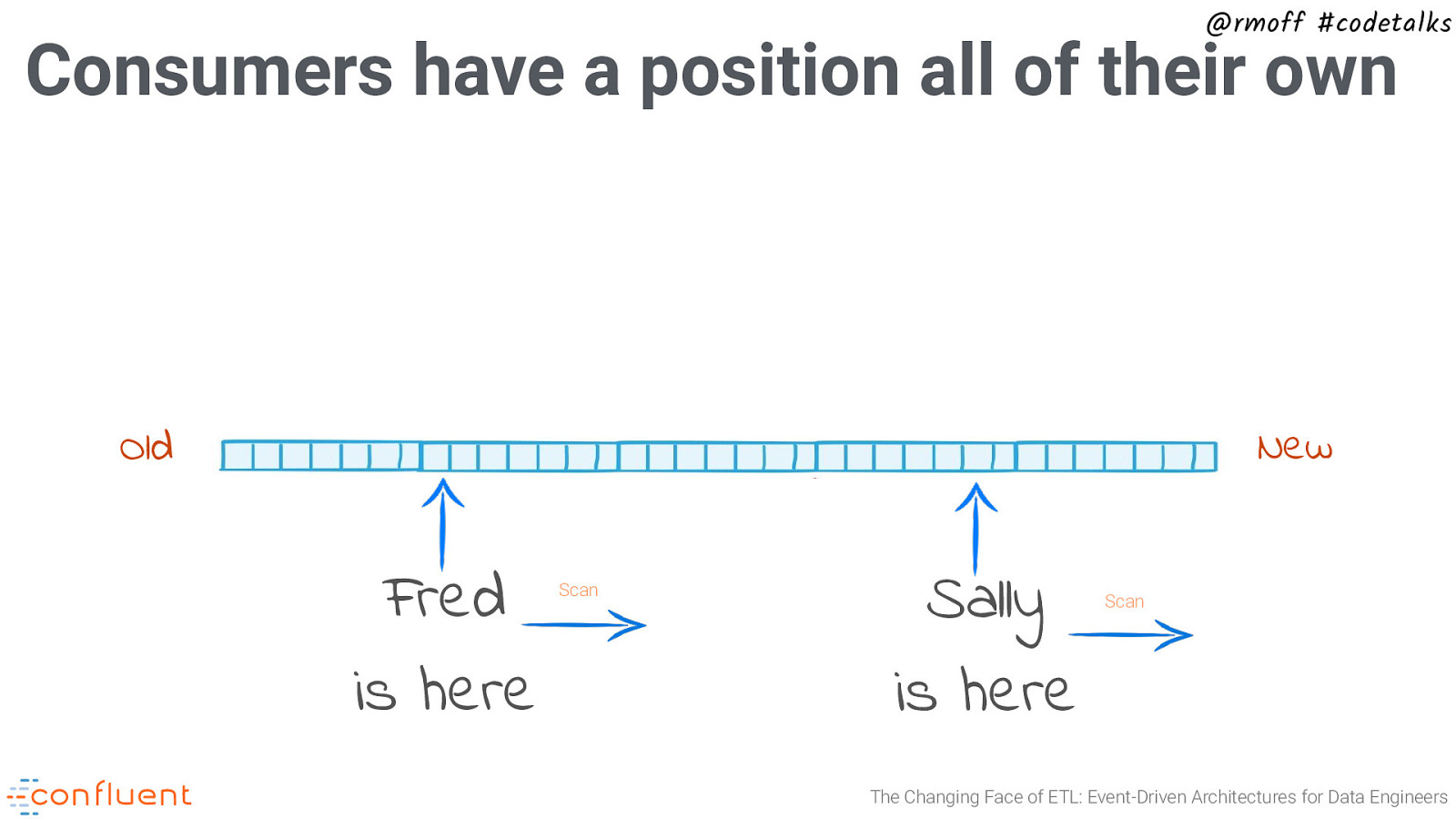
@rmoff #codetalks Consumers have a position all of their own New Old Fred is here Scan Sally is here Scan The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Consumers have a position all of their own George is here Scan New Old Fred is here Scan Sally is here Scan The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks The Connect API Producer Connectors Consumer The Log Connectors Streaming Engine The Changing Face of ETL: Event-Driven Architectures for Data Engineers
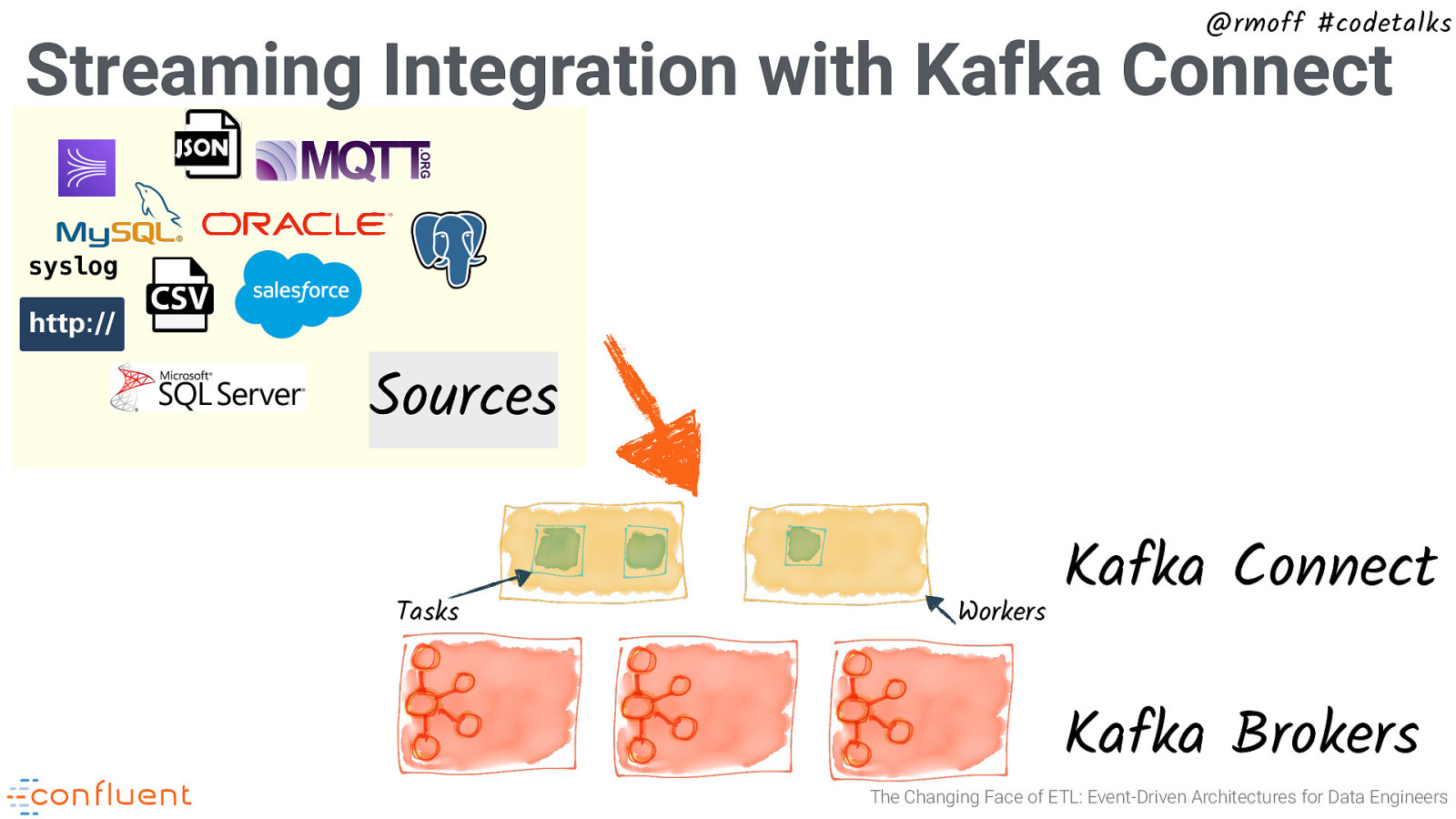
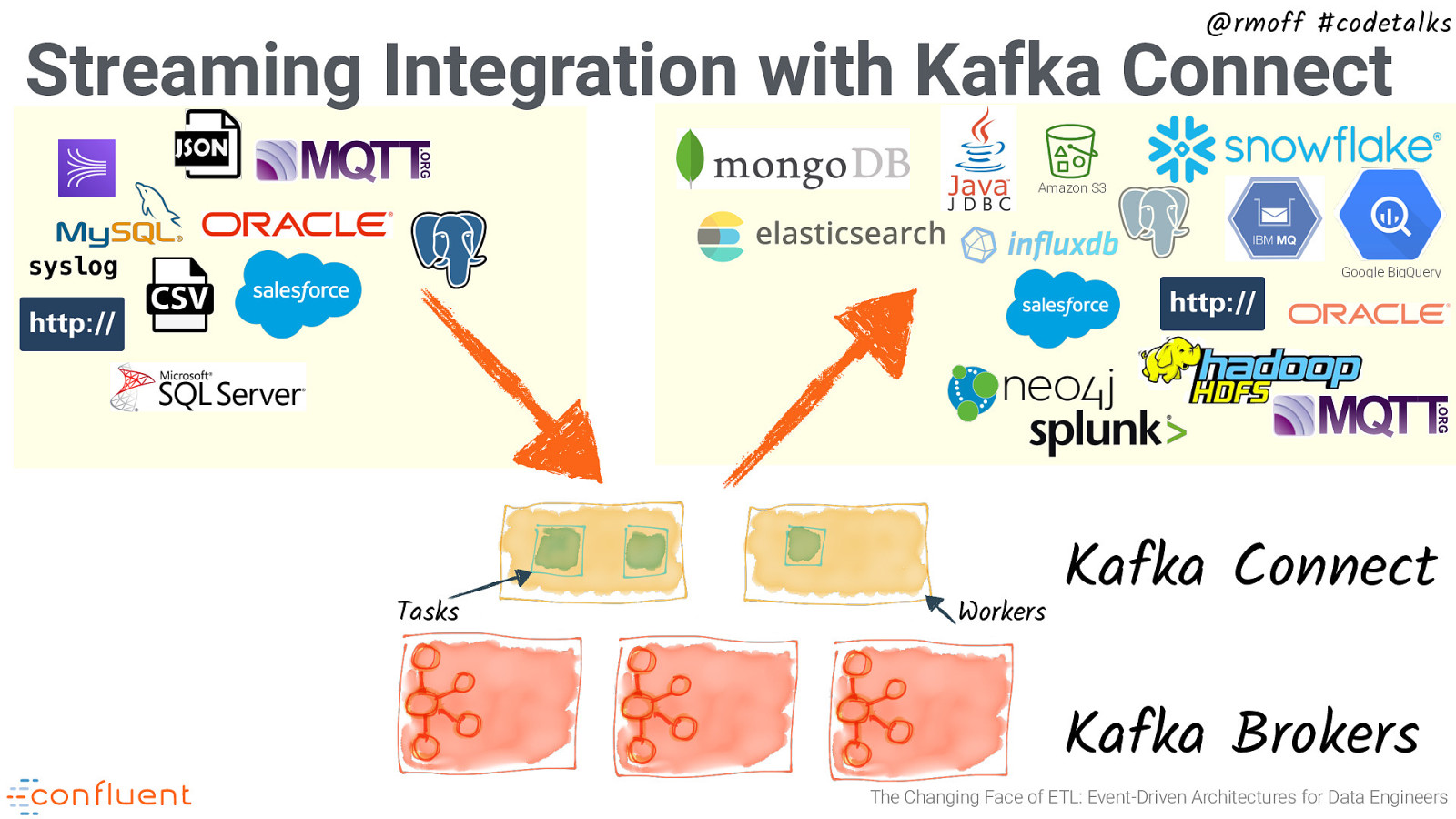
@rmoff #codetalks Streaming Integration with Kafka Connect syslog Sources Tasks Workers Kafka Connect Kafka Brokers The Changing Face of ETL: Event-Driven Architectures for Data Engineers
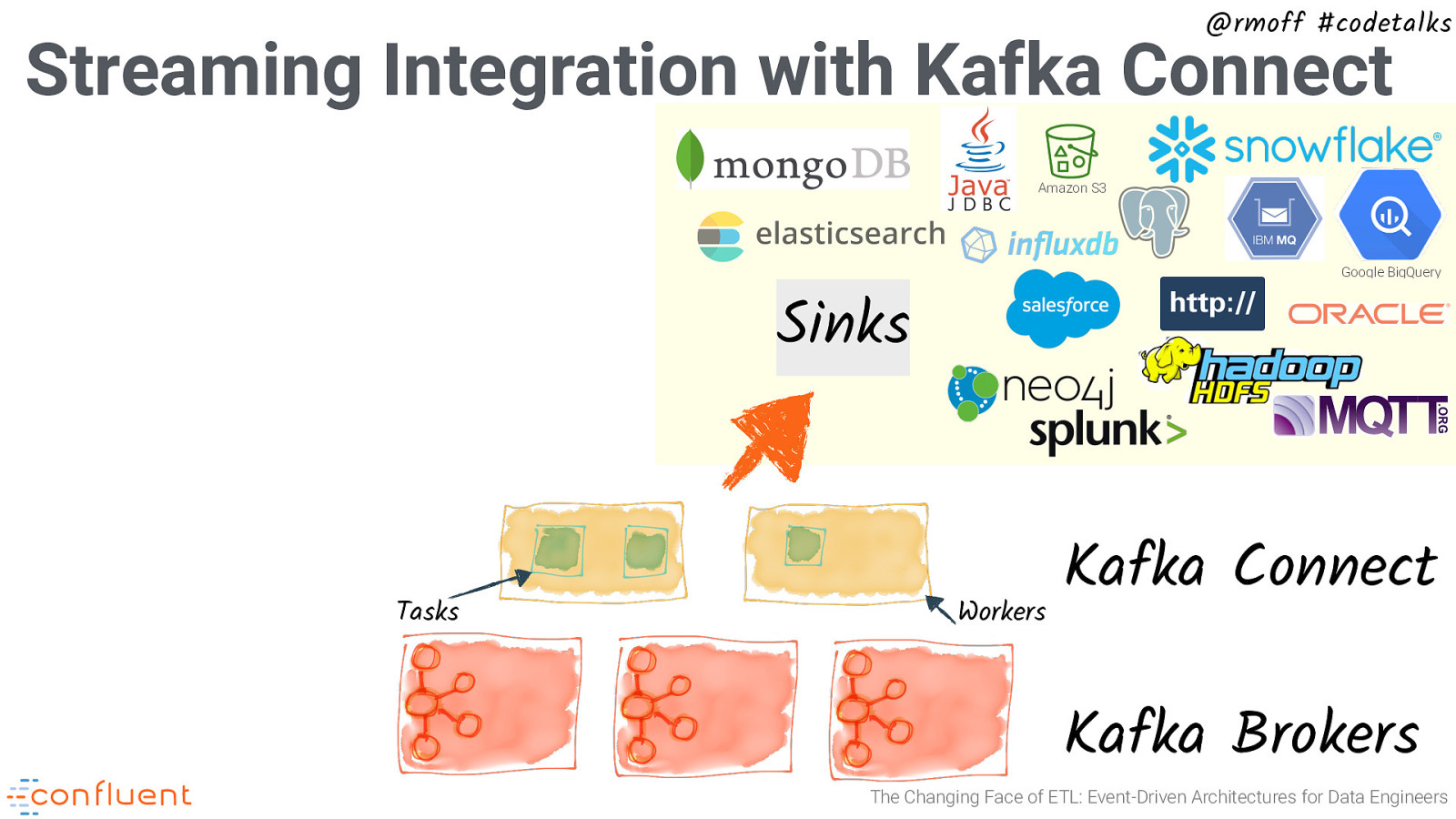
@rmoff #codetalks Streaming Integration with Kafka Connect Amazon S3 Google BigQuery Sinks Tasks Workers Kafka Connect Kafka Brokers The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Streaming Integration with Kafka Connect Amazon S3 syslog Google BigQuery Tasks Workers Kafka Connect Kafka Brokers The Changing Face of ETL: Event-Driven Architectures for Data Engineers
Stream Processing in Kafka Producer Connectors @rmoff #codetalks Consumer The Log Connectors Streaming Engine The Changing Face of ETL: Event-Driven Architectures for Data Engineers
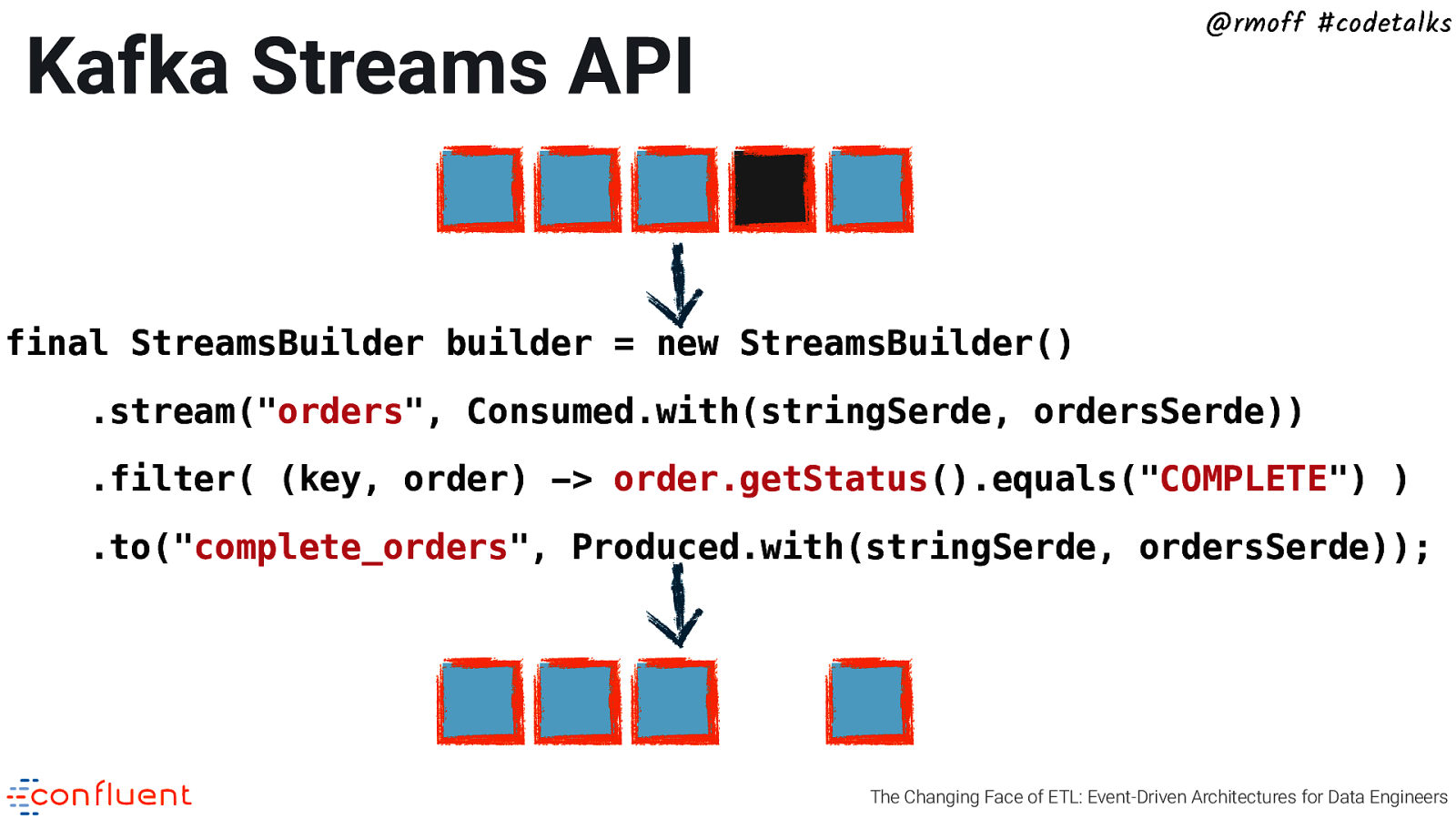
@rmoff #codetalks Kafka Streams API final StreamsBuilder builder = new StreamsBuilder() .stream(“orders”, Consumed.with(stringSerde, ordersSerde)) .filter( (key, order) -> order.getStatus().equals(“COMPLETE”) ) .to(“complete_orders”, Produced.with(stringSerde, ordersSerde)); The Changing Face of ETL: Event-Driven Architectures for Data Engineers
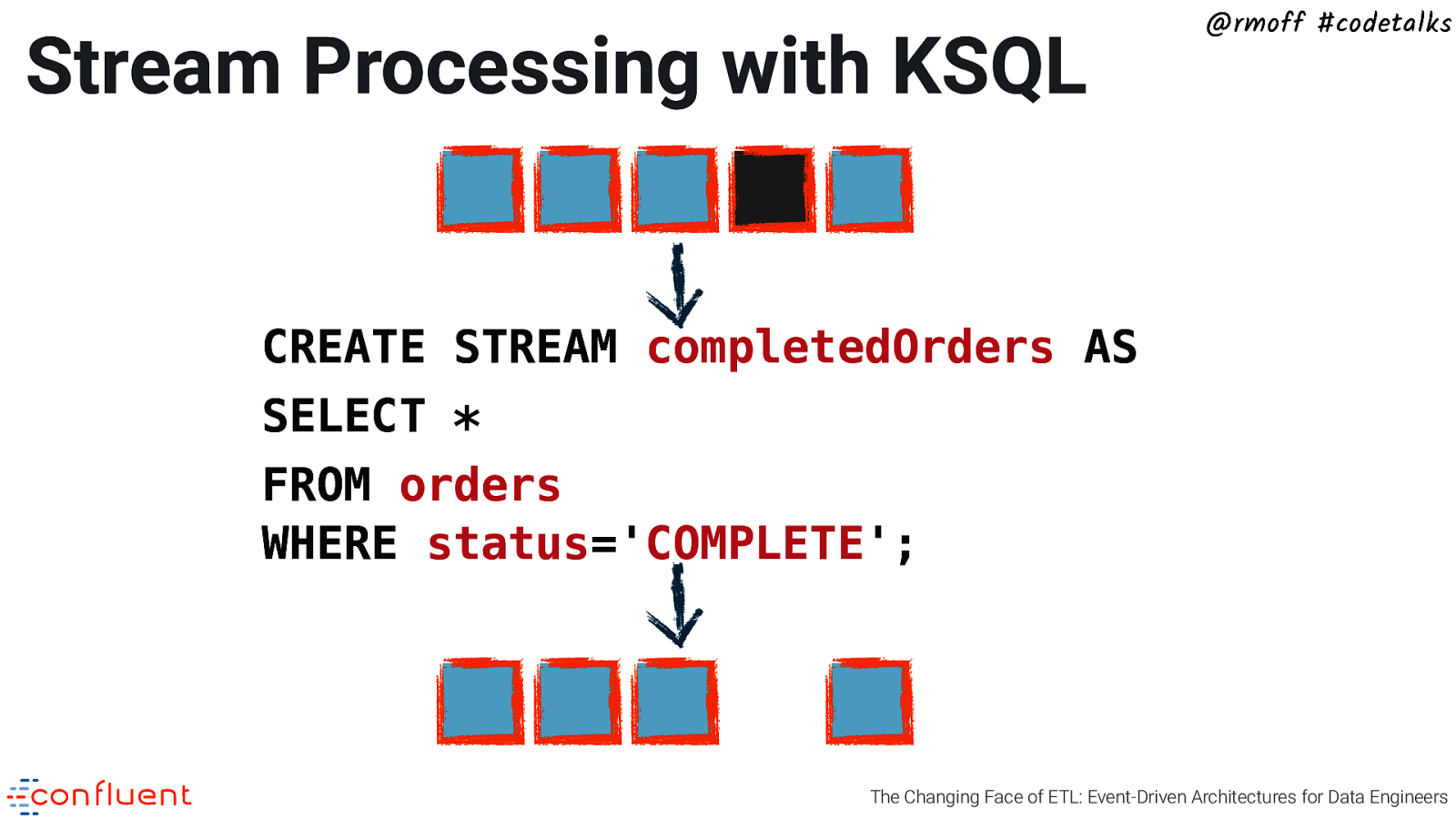
Stream Processing with KSQL @rmoff #codetalks CREATE STREAM completedOrders AS SELECT * FROM orders WHERE status=’COMPLETE’; The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Photo by Ash from Modern Afflatus on Unsplash This is Something New The Changing Face of ETL: Event-Driven Architectures for Data Engineers
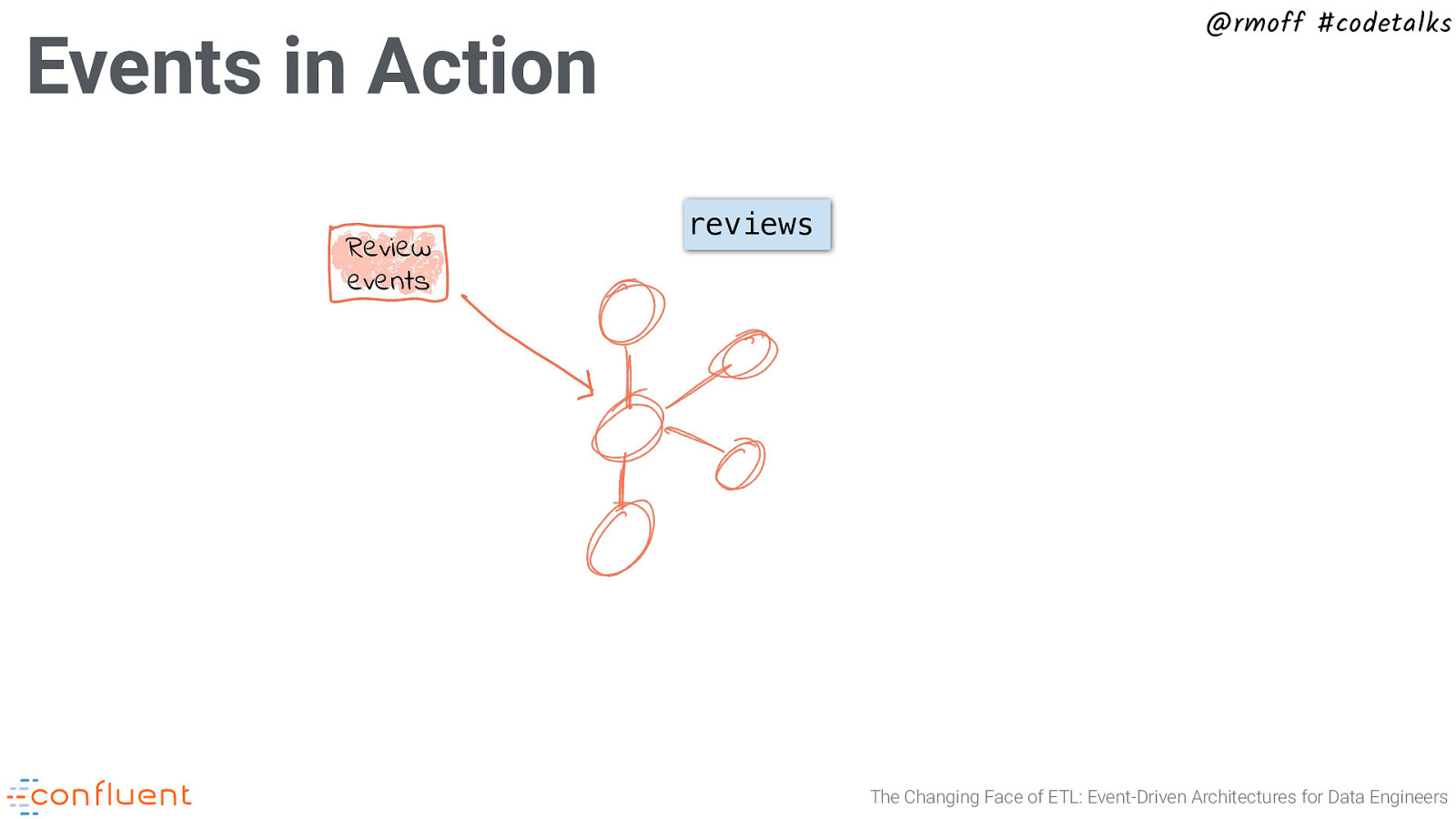
@rmoff #codetalks Events in Action Review events reviews The Changing Face of ETL: Event-Driven Architectures for Data Engineers
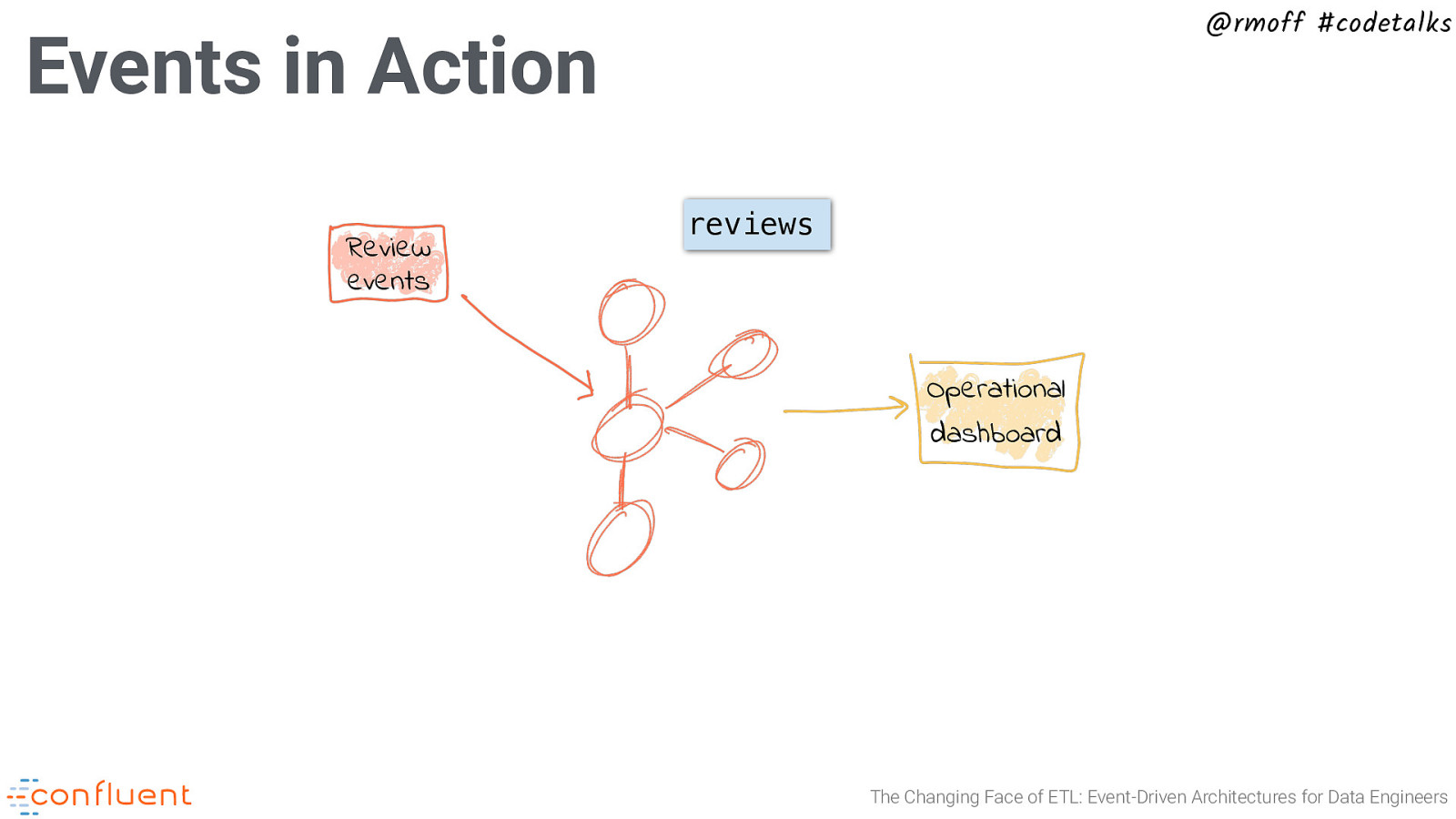
@rmoff #codetalks Events in Action Review events reviews Operational dashboard The Changing Face of ETL: Event-Driven Architectures for Data Engineers
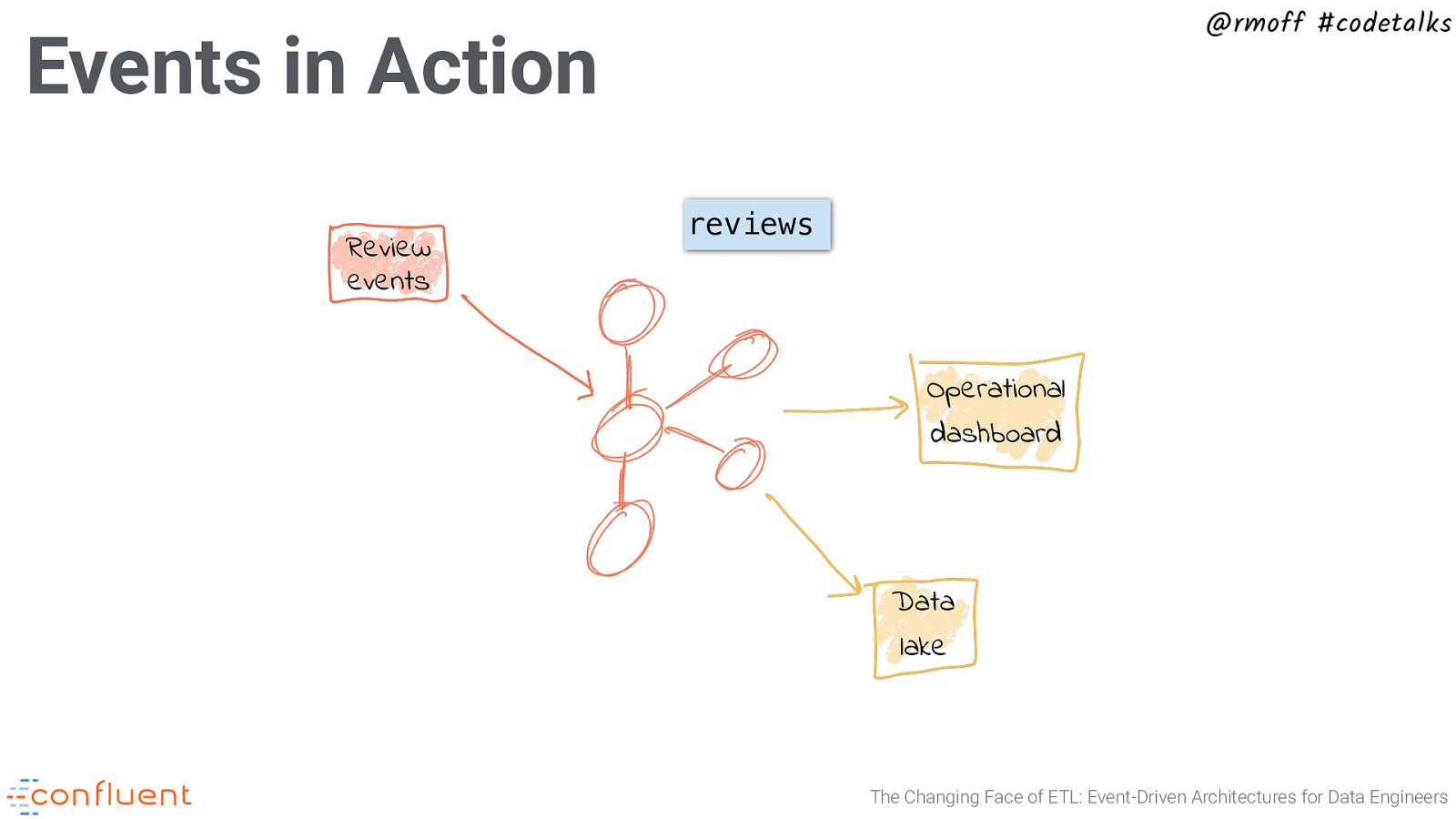
@rmoff #codetalks Events in Action Review events reviews Operational dashboard Data lake The Changing Face of ETL: Event-Driven Architectures for Data Engineers
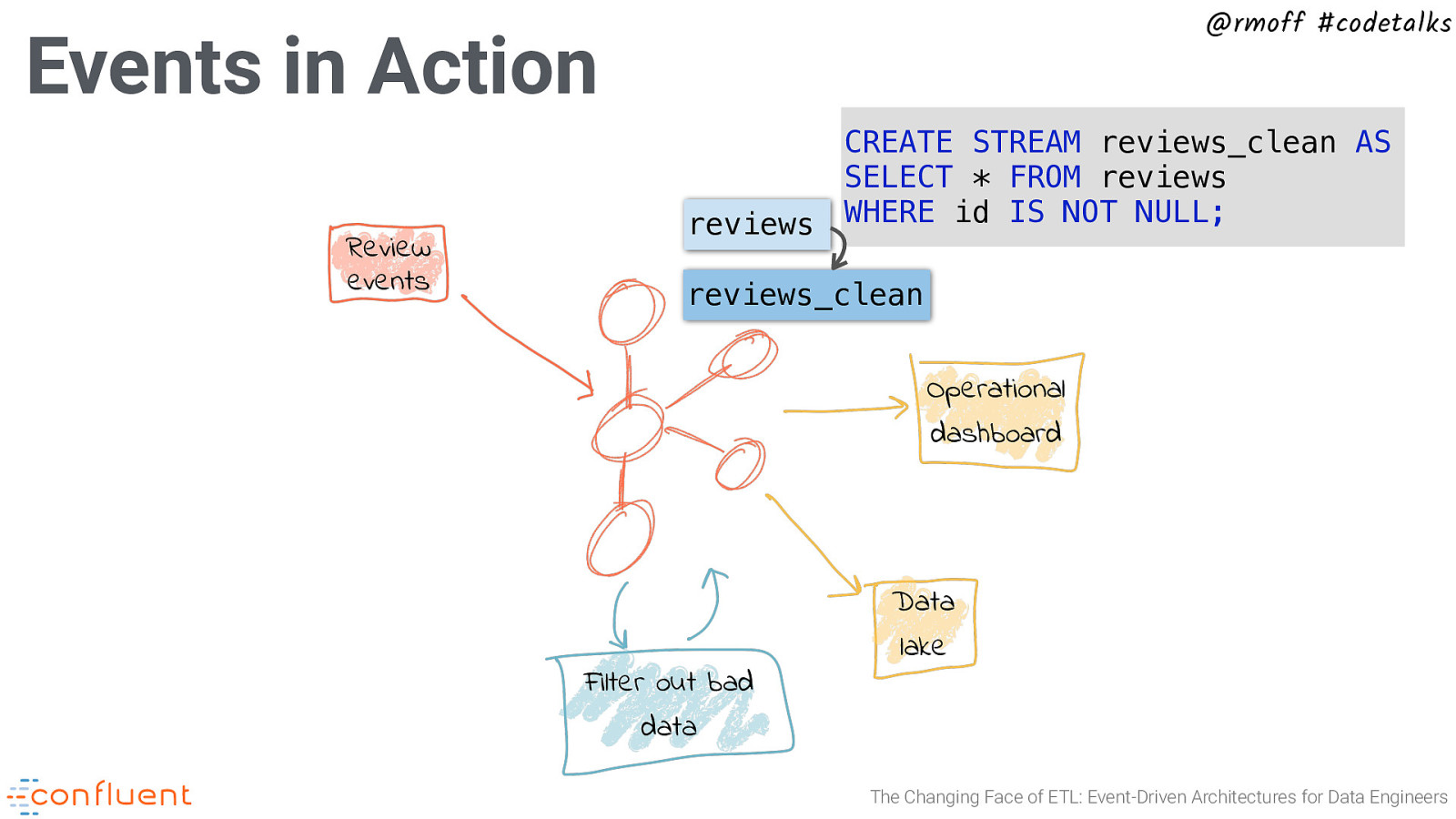
@rmoff #codetalks Events in Action Review events CREATE STREAM reviews_clean AS SELECT * FROM reviews WHERE id IS NOT NULL; reviews reviews_clean Operational dashboard Filter out bad data Data lake The Changing Face of ETL: Event-Driven Architectures for Data Engineers
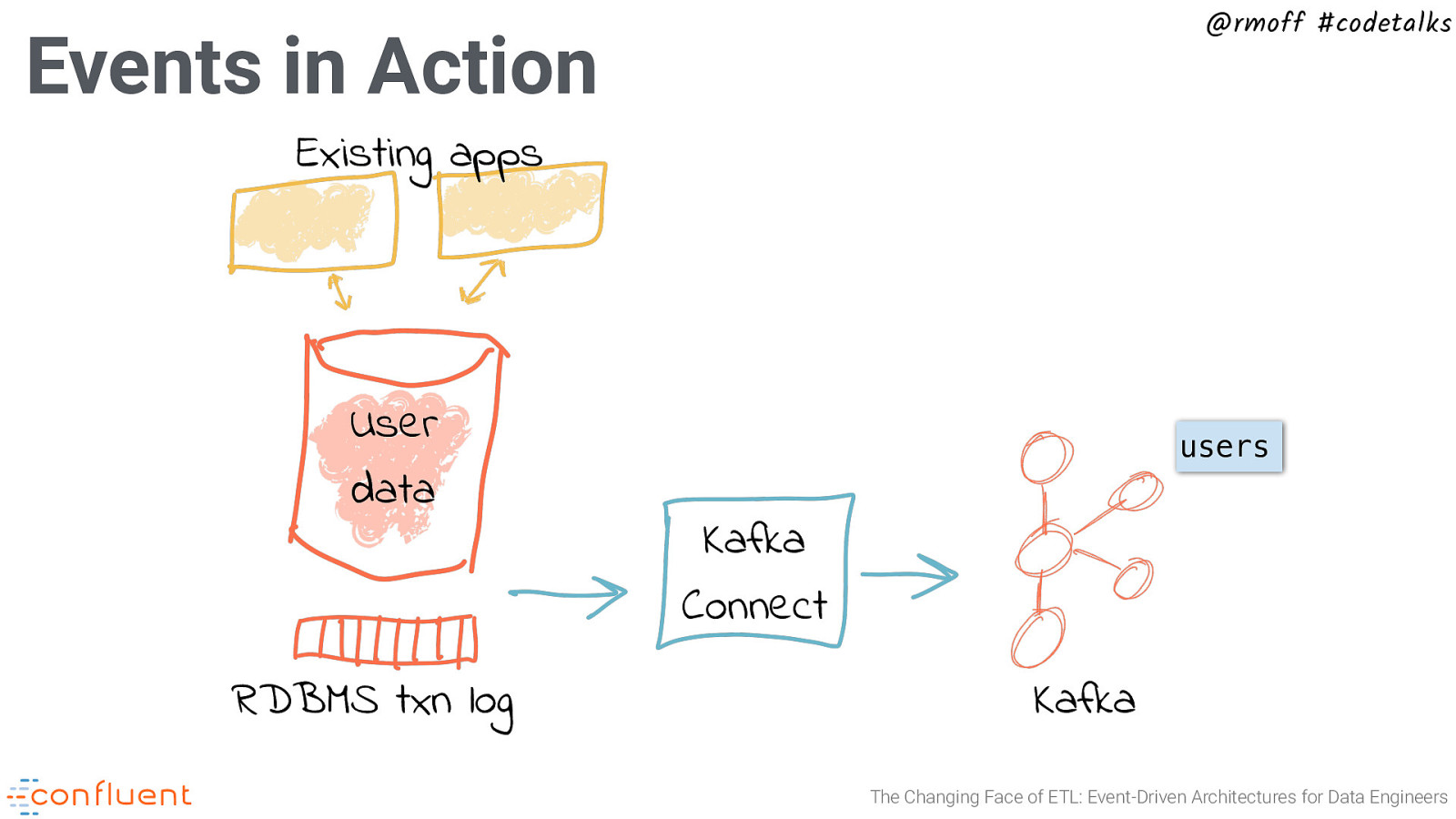
@rmoff #codetalks Events in Action Existing apps User data RDBMS txn log users Kafka Connect Kafka The Changing Face of ETL: Event-Driven Architectures for Data Engineers
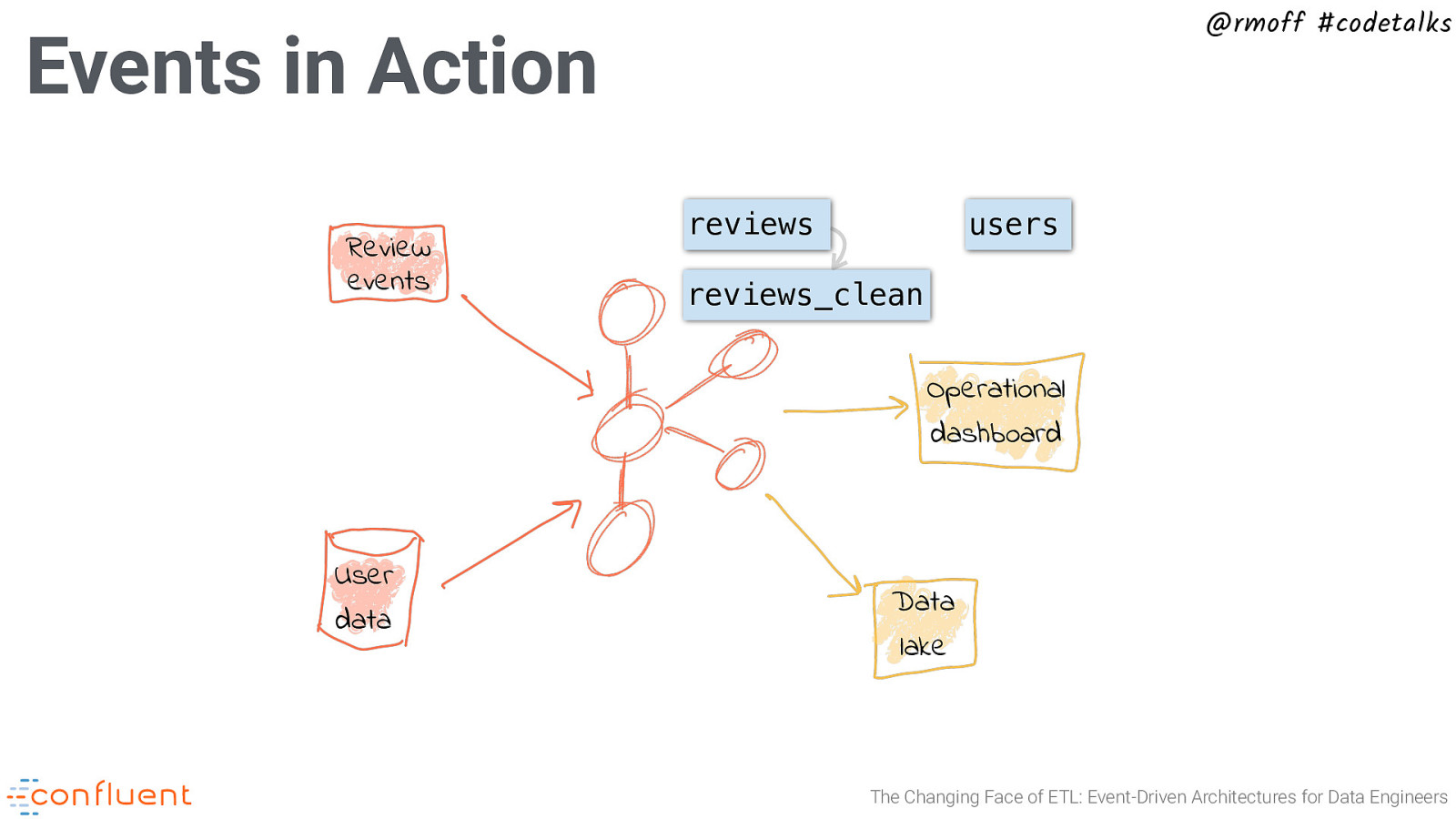
@rmoff #codetalks Events in Action Review events reviews users reviews_clean Operational dashboard User data Data lake The Changing Face of ETL: Event-Driven Architectures for Data Engineers
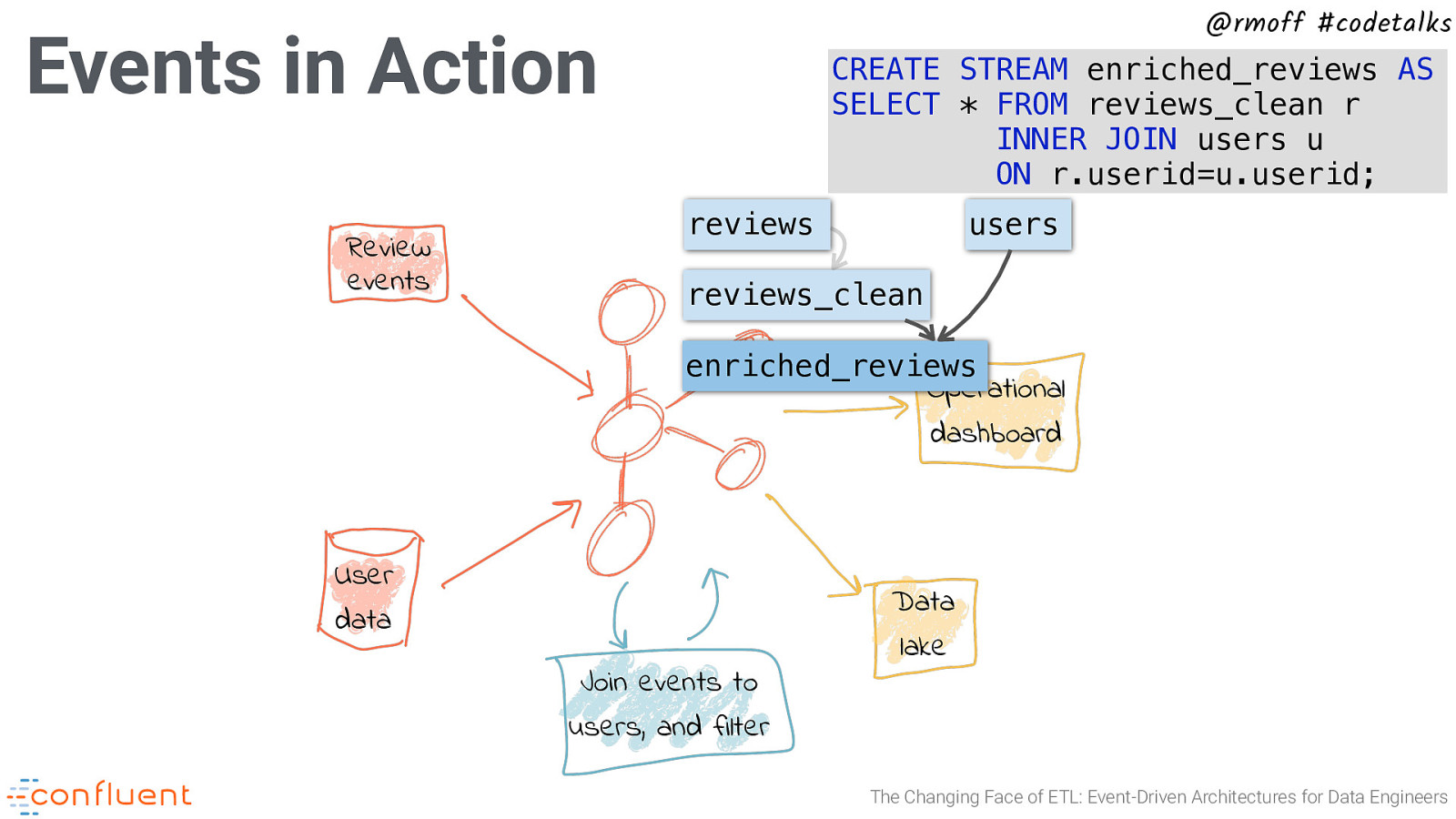
@rmoff #codetalks Events in Action Review events CREATE CREATE SELECT SELECT STREAM enriched_reviews AS STREAM reviews_clean AS ** FROM reviews_clean r FROM reviews INNER JOIN users u WHERE id IS NOT NULL ON r.userid=u.userid; reviews users reviews_clean enriched_reviews Operational dashboard User data Join events to users, and filter Data lake The Changing Face of ETL: Event-Driven Architectures for Data Engineers
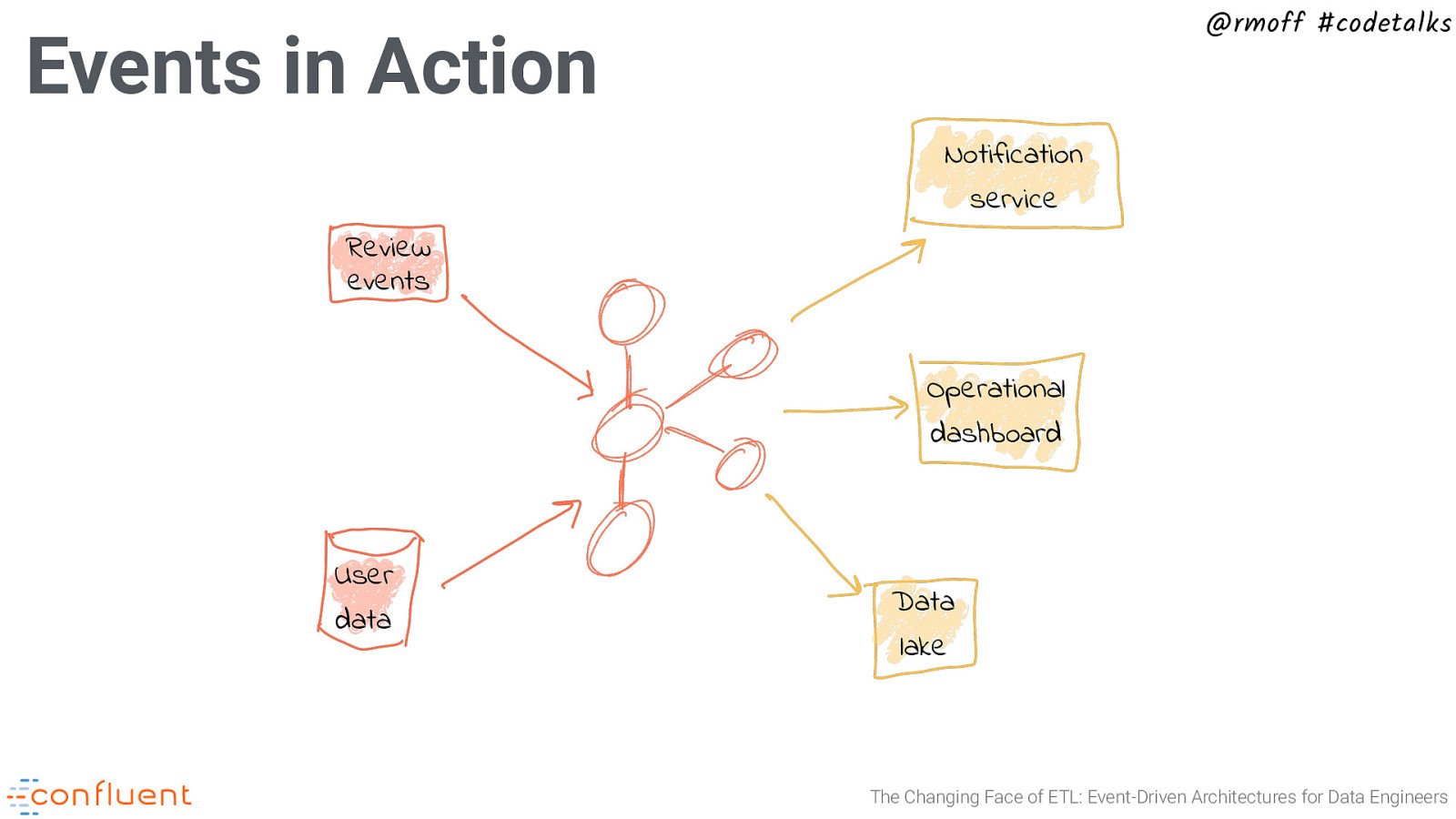
@rmoff #codetalks Events in Action Notification service Review events Operational dashboard User data Data lake The Changing Face of ETL: Event-Driven Architectures for Data Engineers
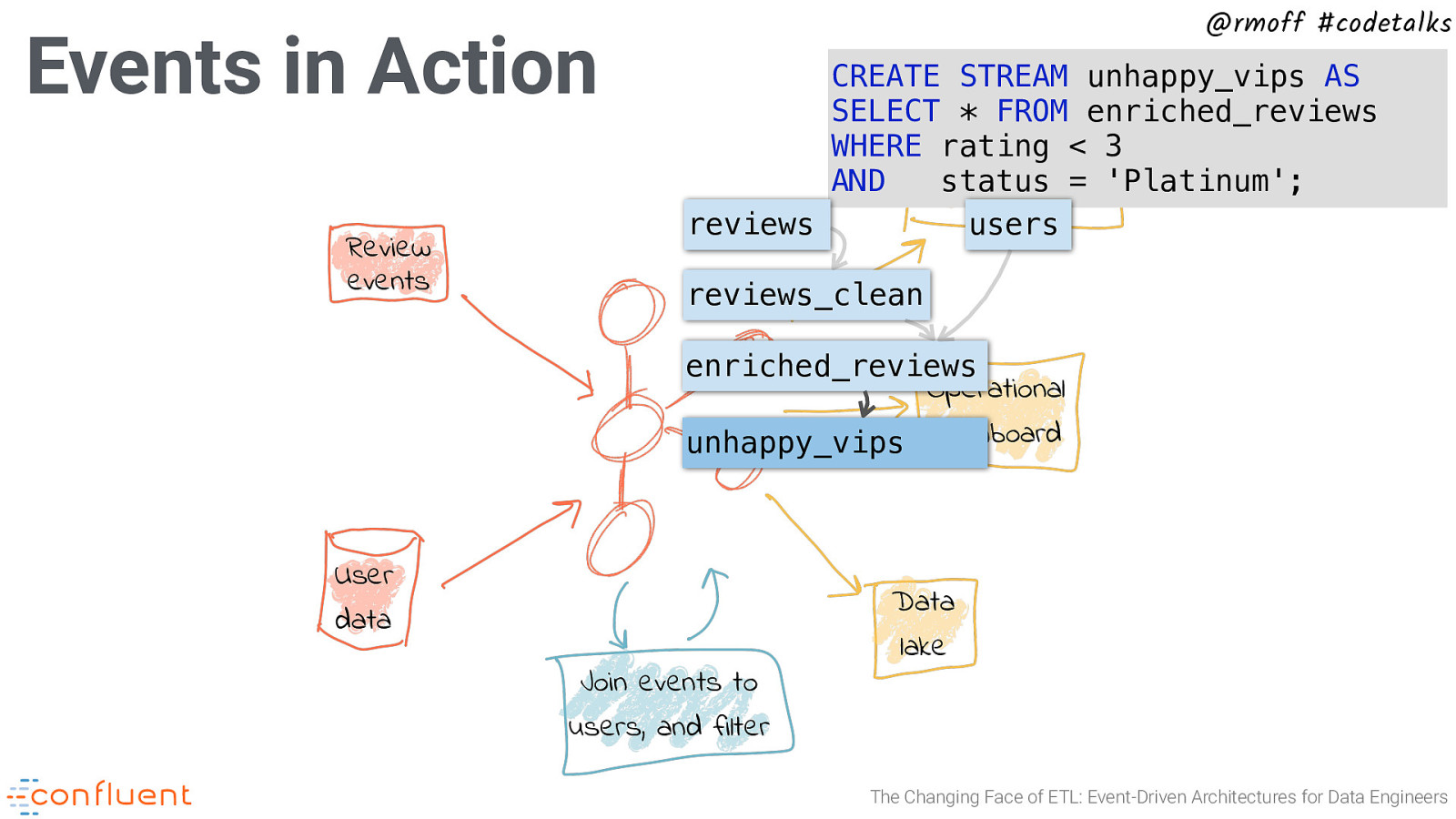
Events in Action Review events @rmoff #codetalks CREATE STREAM unhappy_vips AS SELECT * FROM enriched_reviews WHERE rating Notification< 3 AND status = ‘Platinum’; service reviews users reviews_clean enriched_reviews Operational dashboard unhappy_vips User data Join events to users, and filter Data lake The Changing Face of ETL: Event-Driven Architectures for Data Engineers
Photo by rmoff The Power of an Event-Driven Architecture
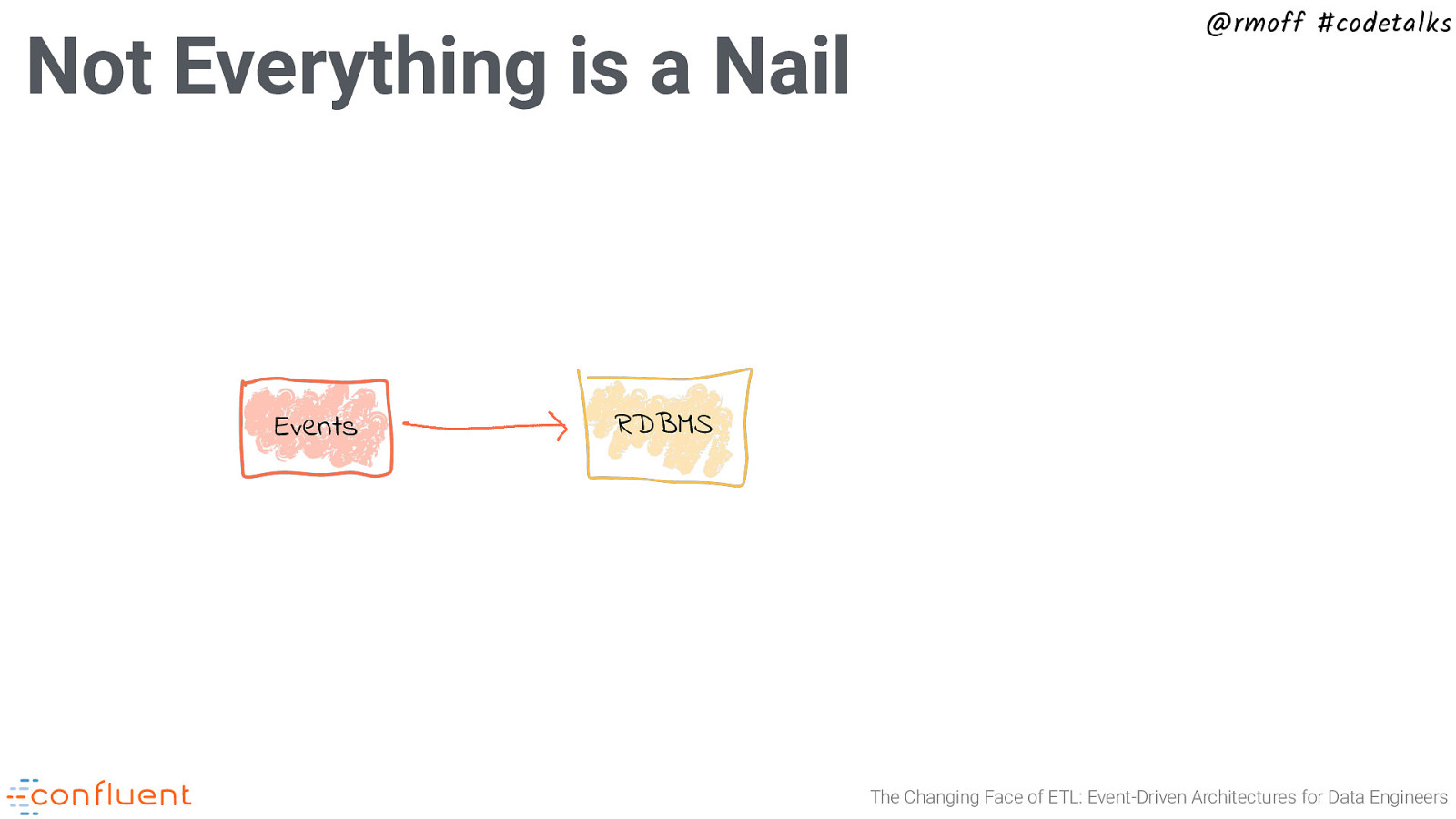
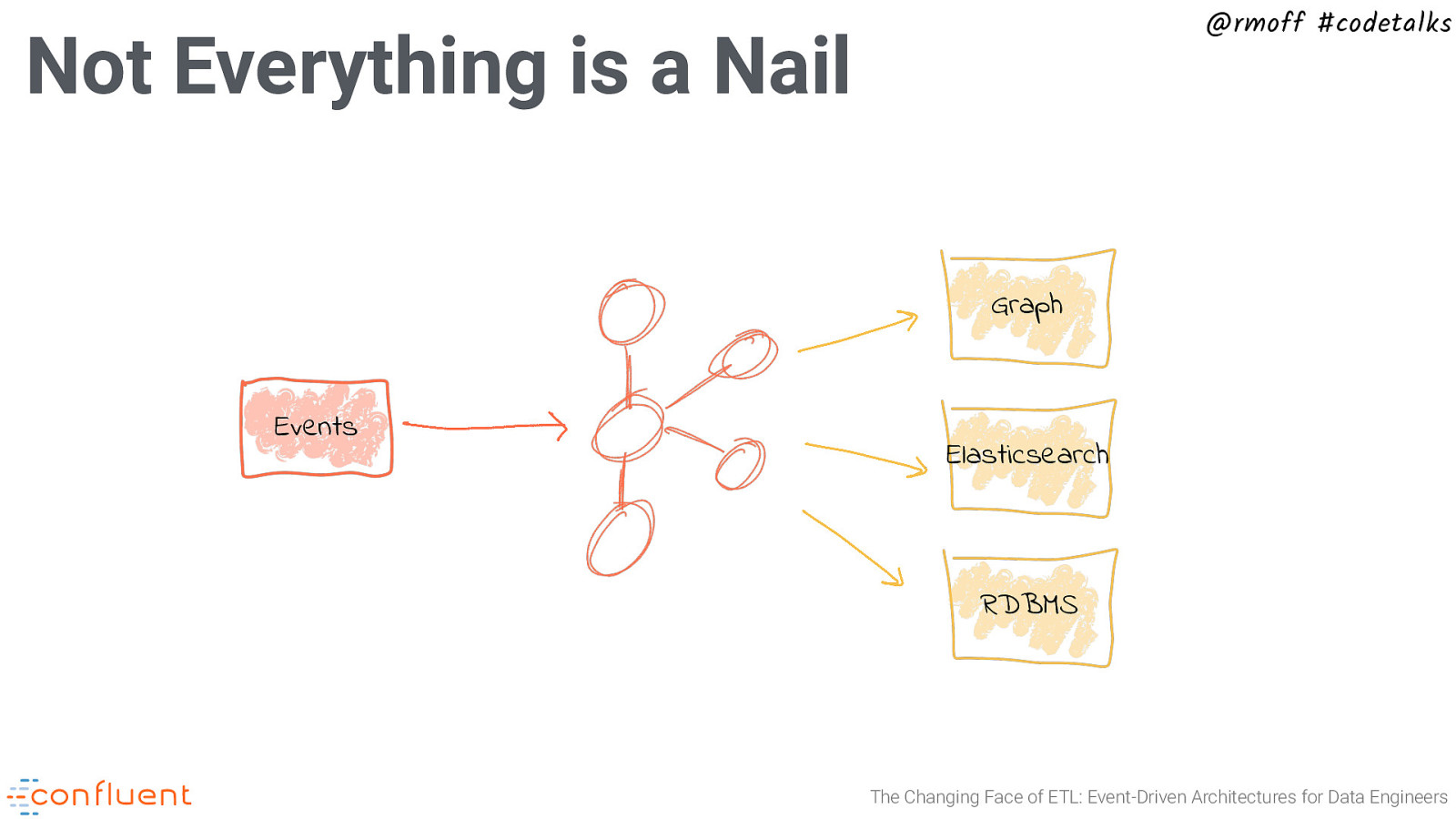
Not Everything is a Nail Events @rmoff #codetalks RDBMS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
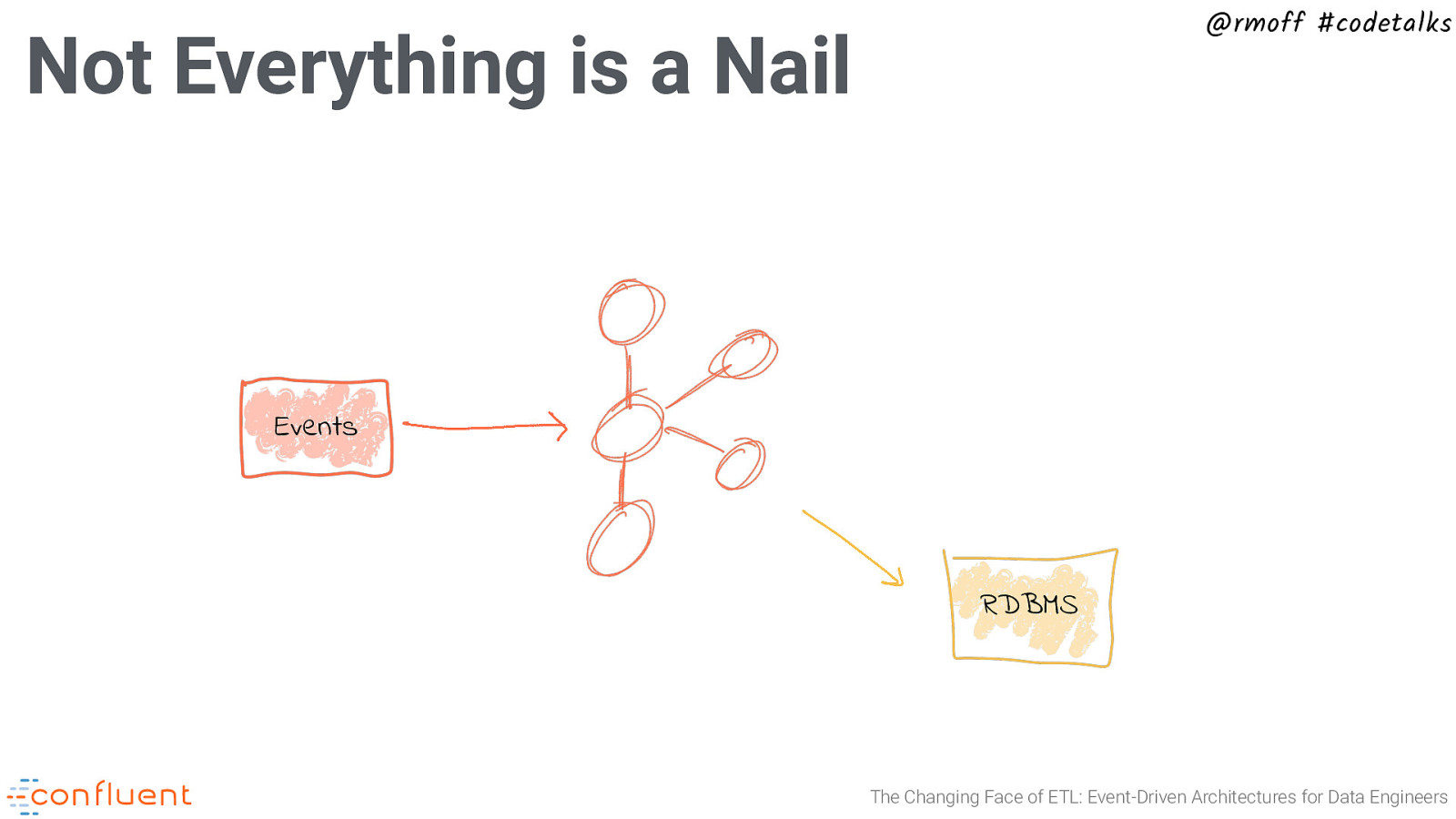
@rmoff #codetalks Not Everything is a Nail Events RDBMS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
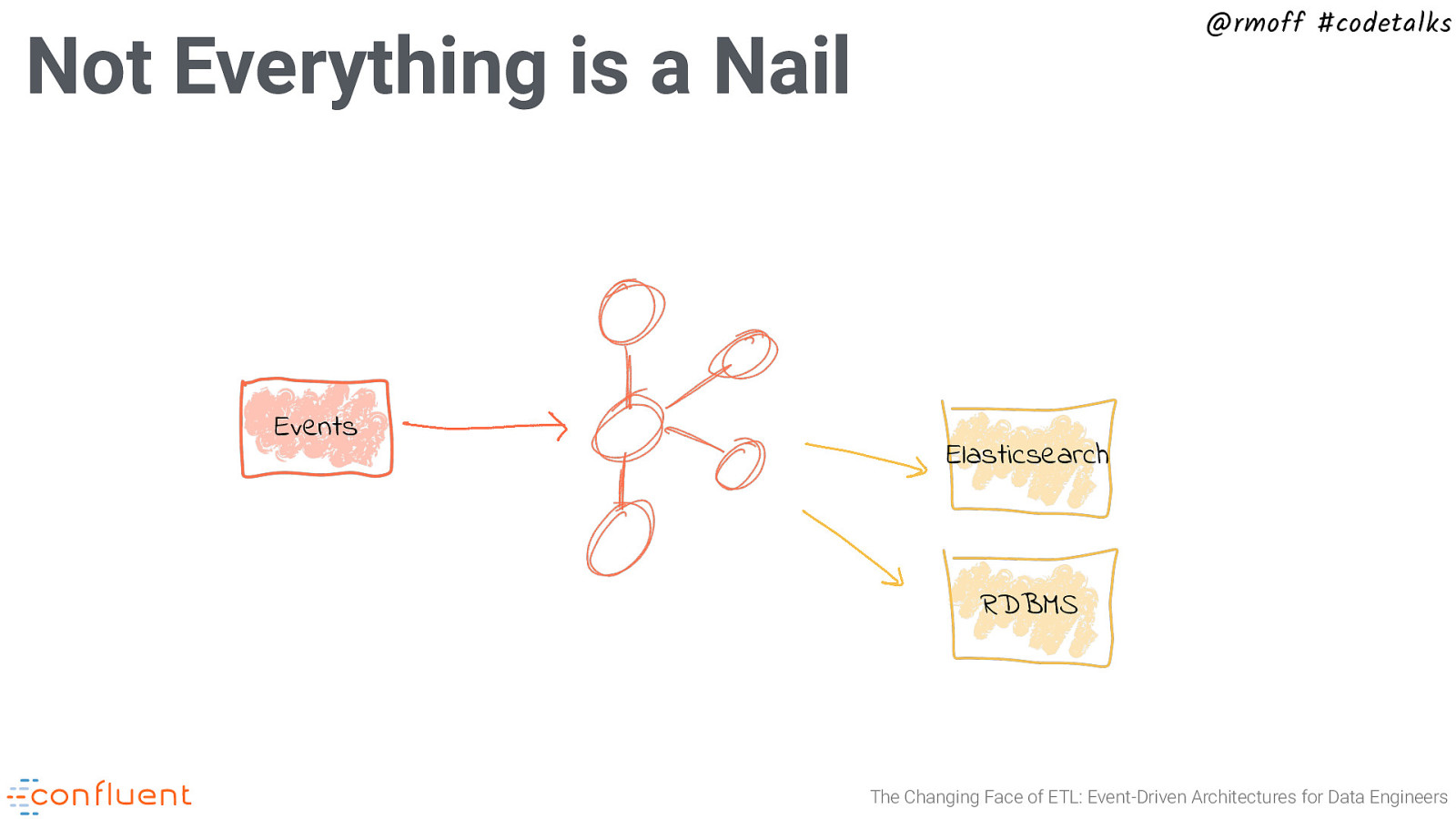
@rmoff #codetalks Not Everything is a Nail Events Elasticsearch RDBMS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Not Everything is a Nail Graph Events Elasticsearch RDBMS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
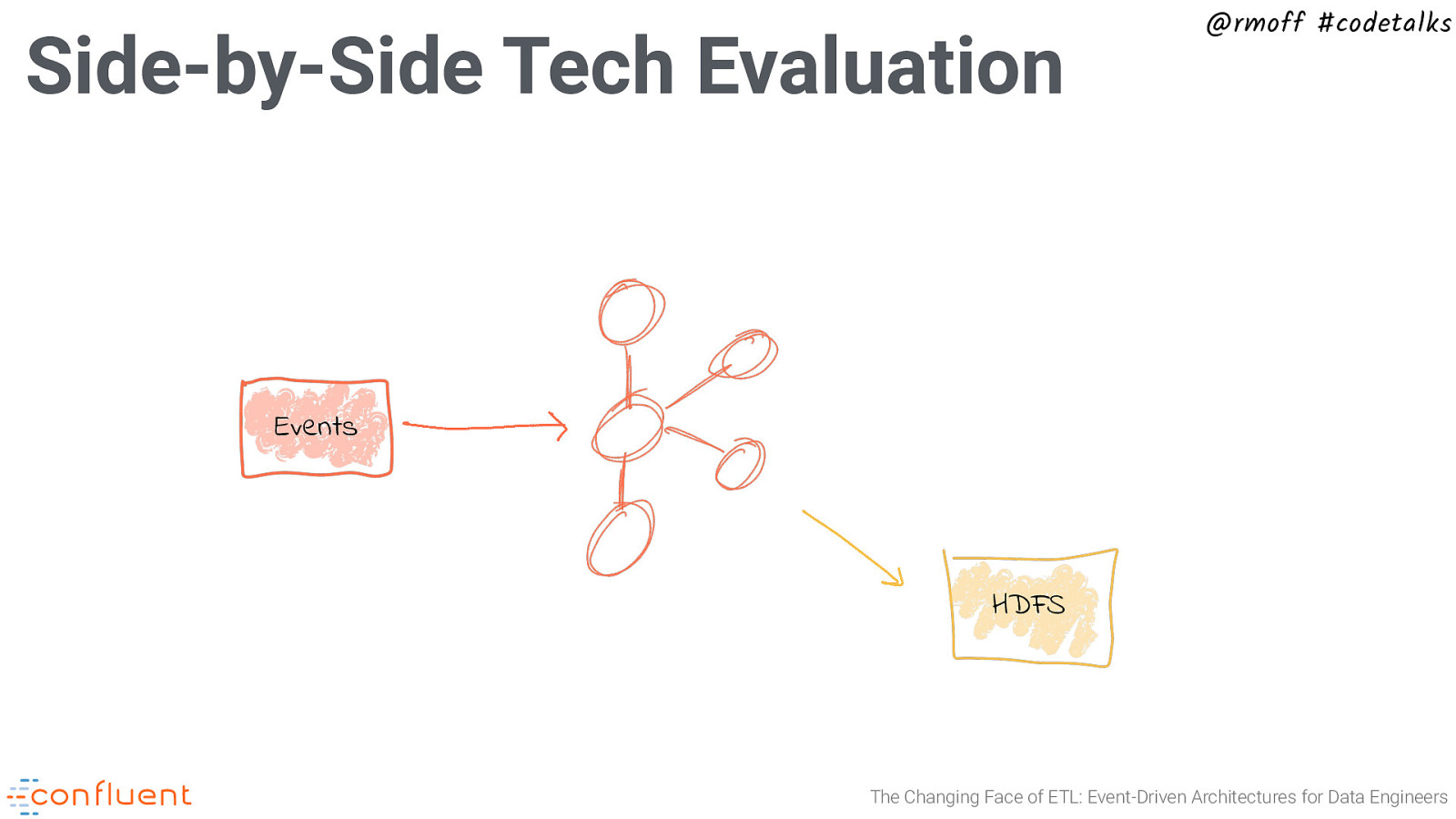
Side-by-Side Tech Evaluation @rmoff #codetalks Events HDFS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
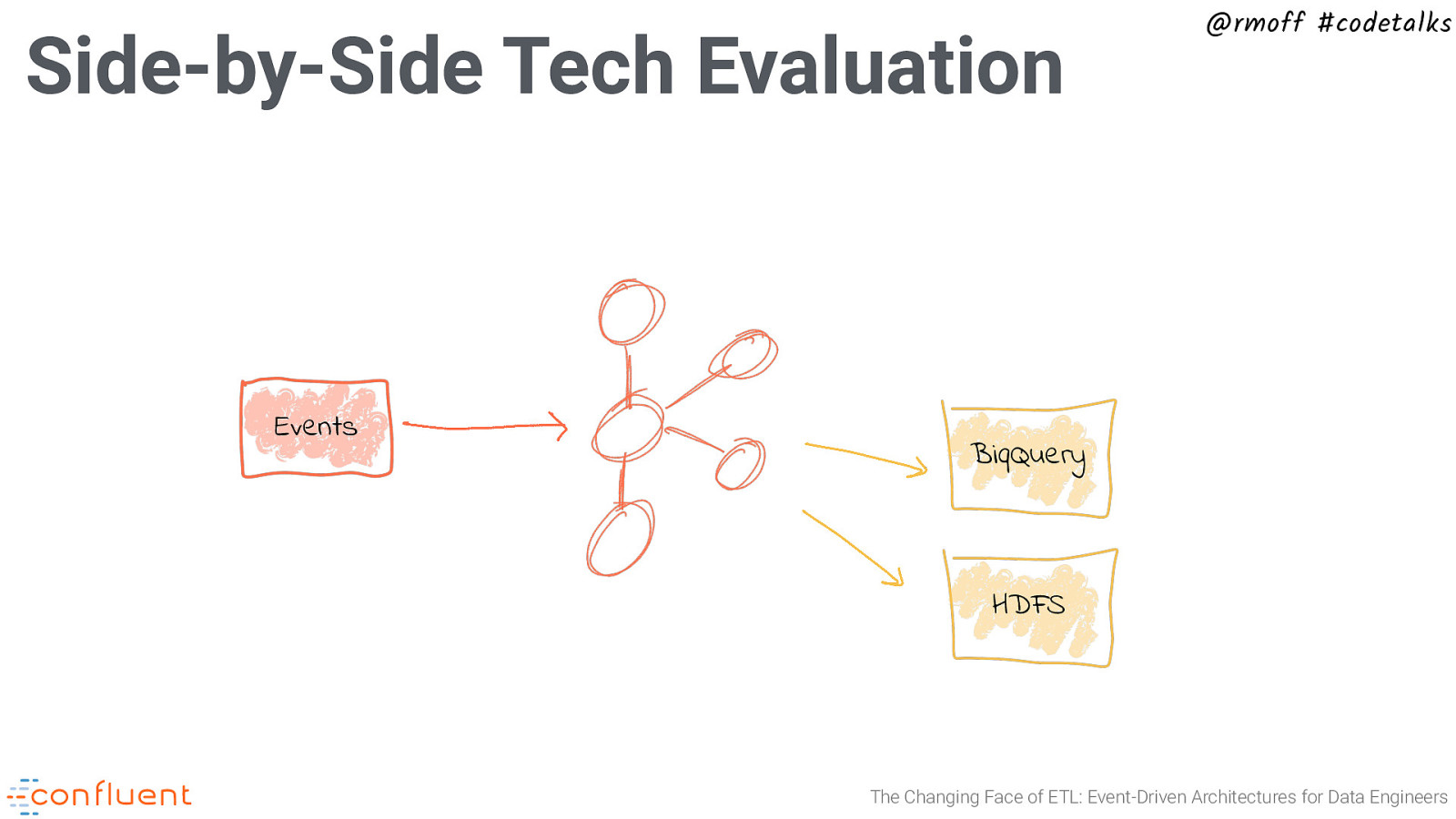
Side-by-Side Tech Evaluation Events @rmoff #codetalks BiqQuery HDFS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
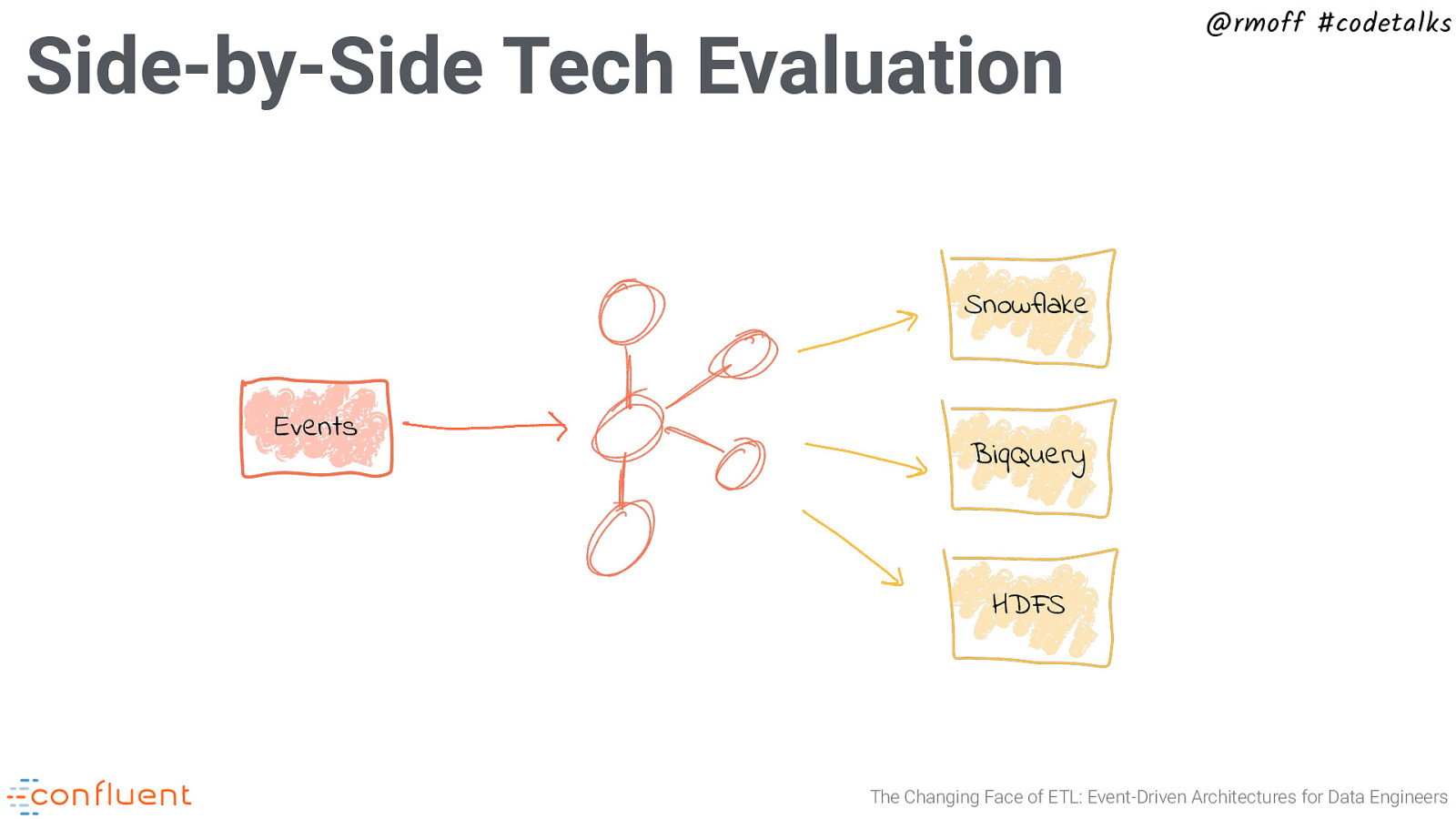
Side-by-Side Tech Evaluation @rmoff #codetalks Snowflake Events BiqQuery HDFS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
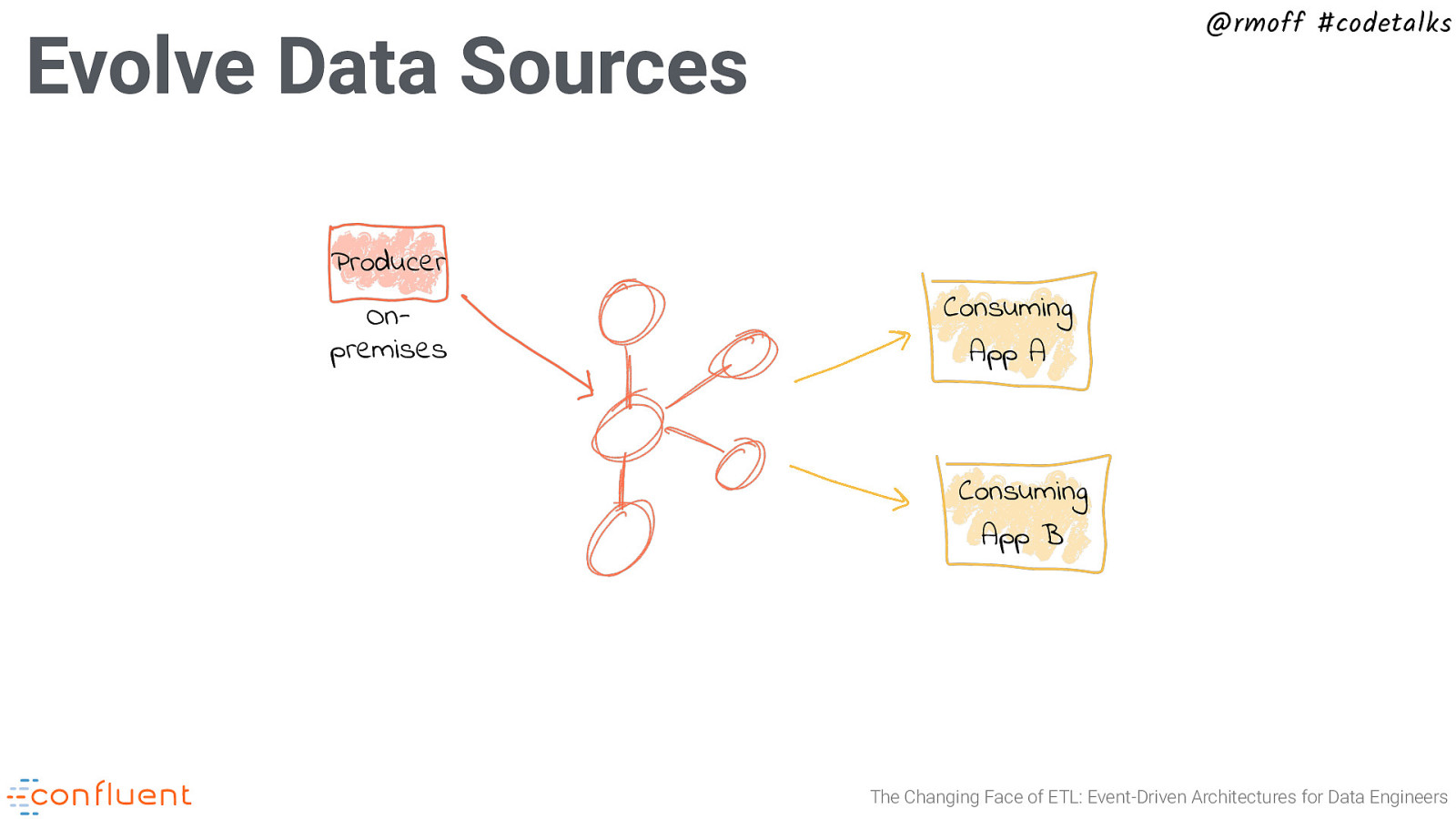
@rmoff #codetalks Evolve Data Sources Producer Onpremises Consuming App A Consuming App B The Changing Face of ETL: Event-Driven Architectures for Data Engineers
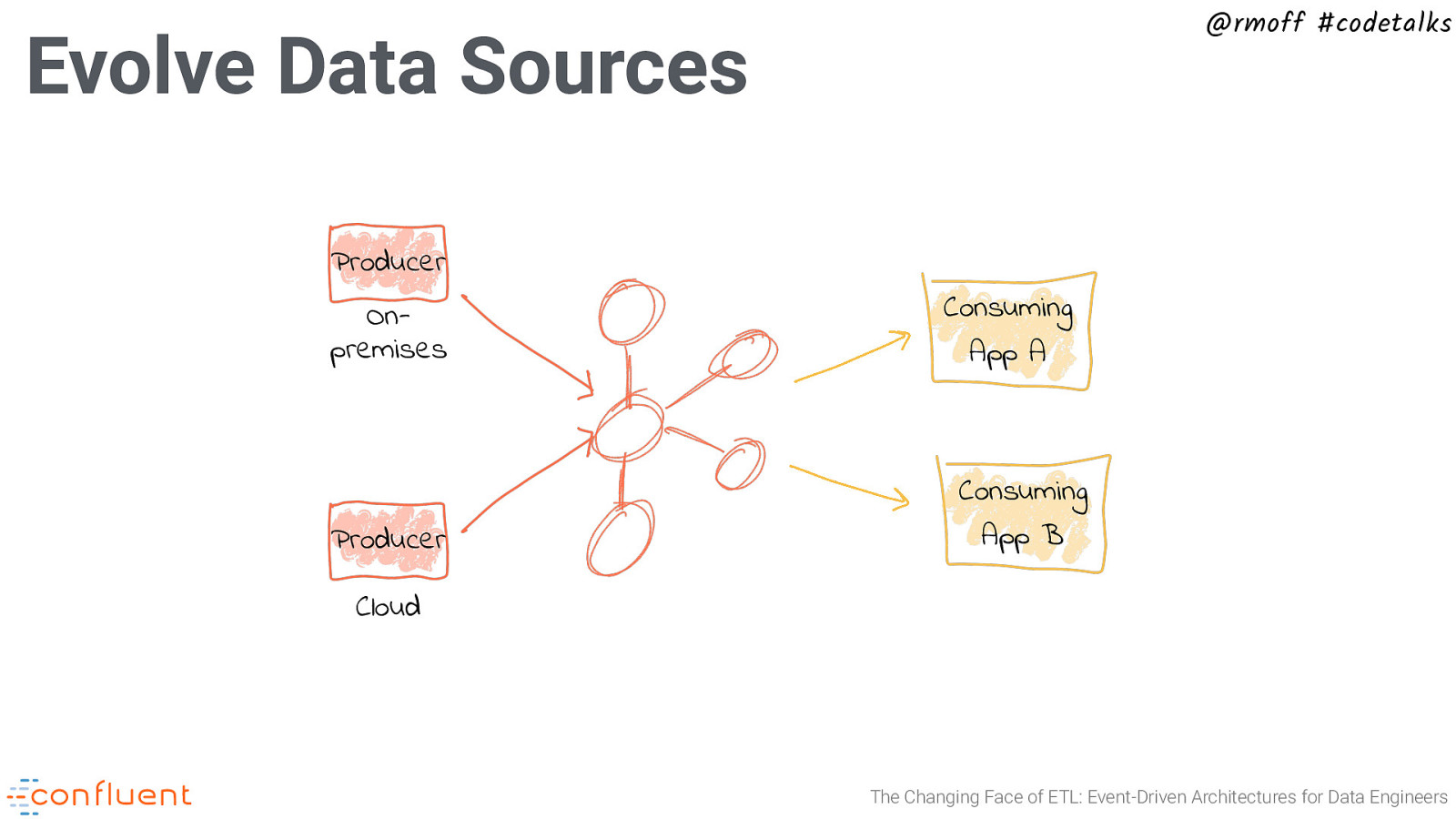
@rmoff #codetalks Evolve Data Sources Producer Onpremises Producer Consuming App A Consuming App B Cloud The Changing Face of ETL: Event-Driven Architectures for Data Engineers
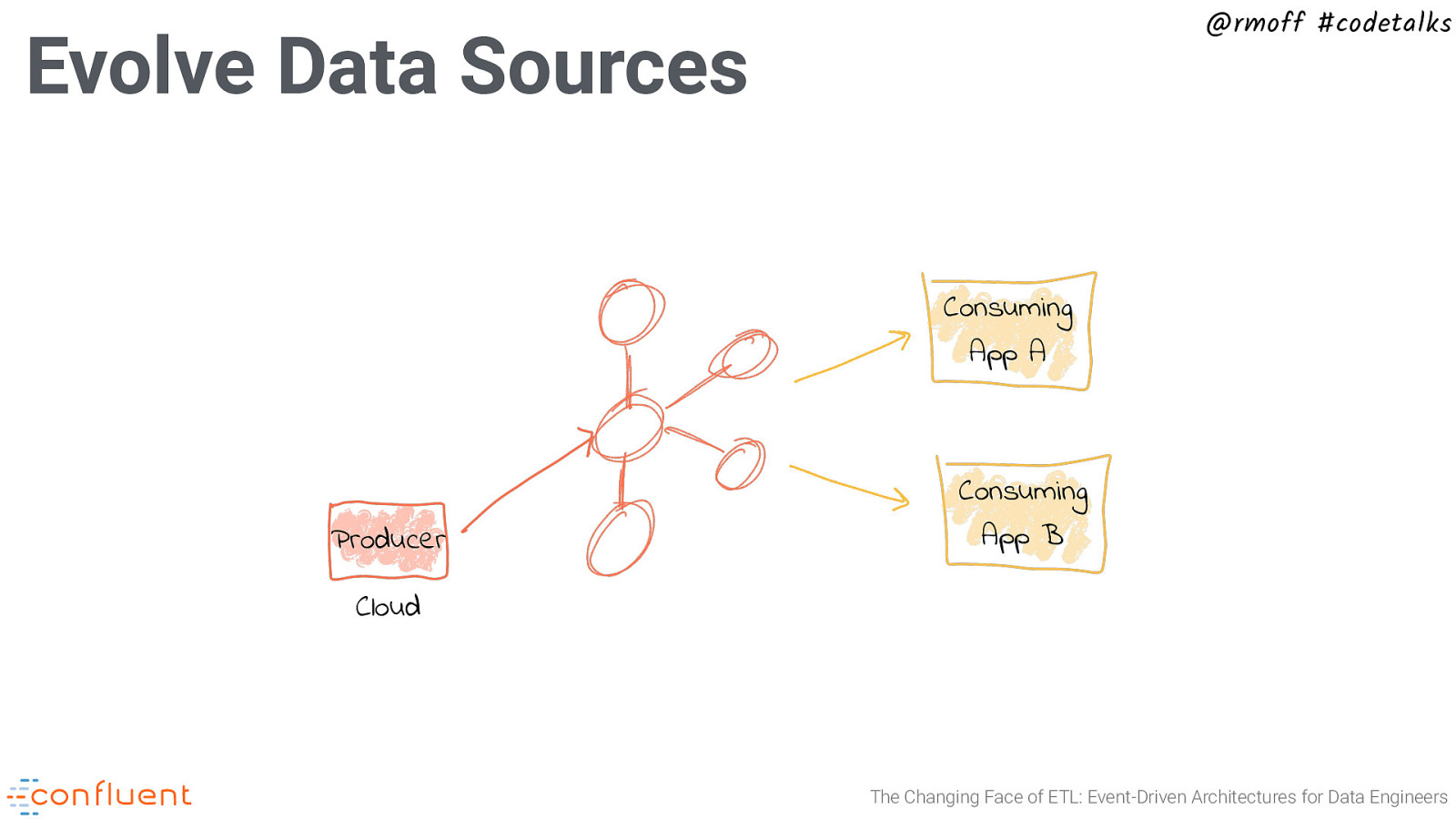
@rmoff #codetalks Evolve Data Sources Consuming App A Producer Consuming App B Cloud The Changing Face of ETL: Event-Driven Architectures for Data Engineers
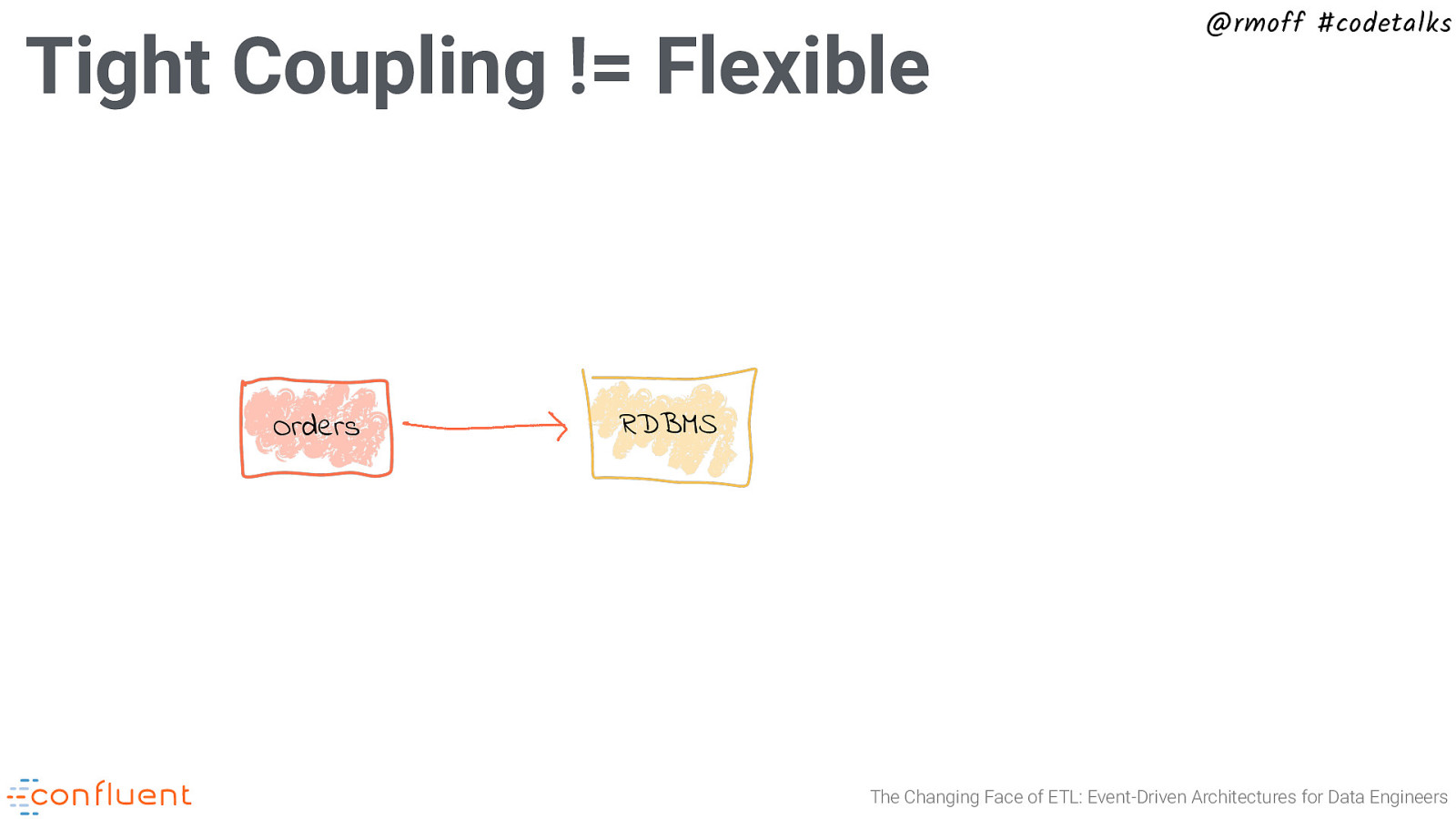
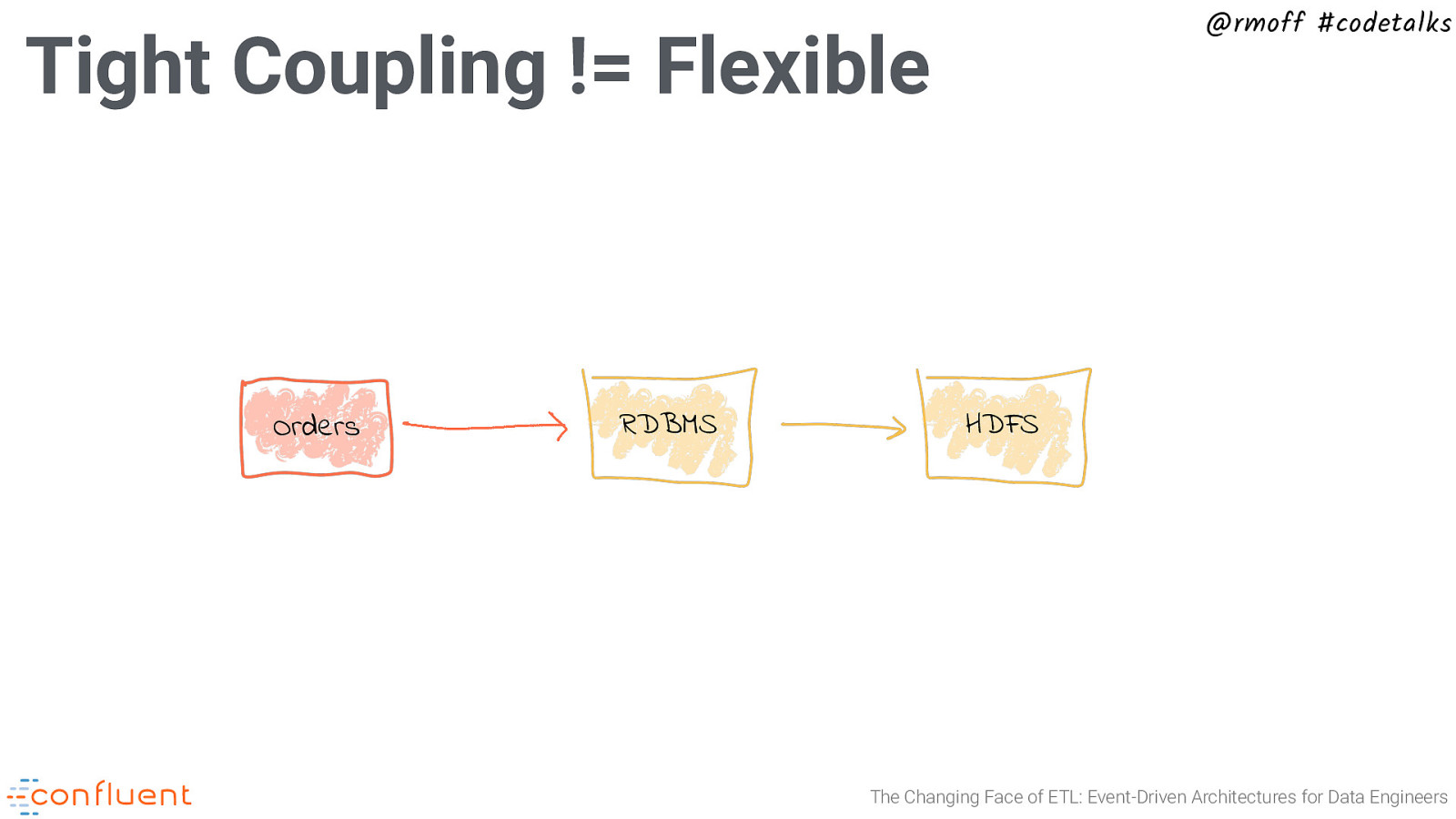
Tight Coupling != Flexible Orders @rmoff #codetalks RDBMS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Tight Coupling != Flexible Orders RDBMS HDFS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
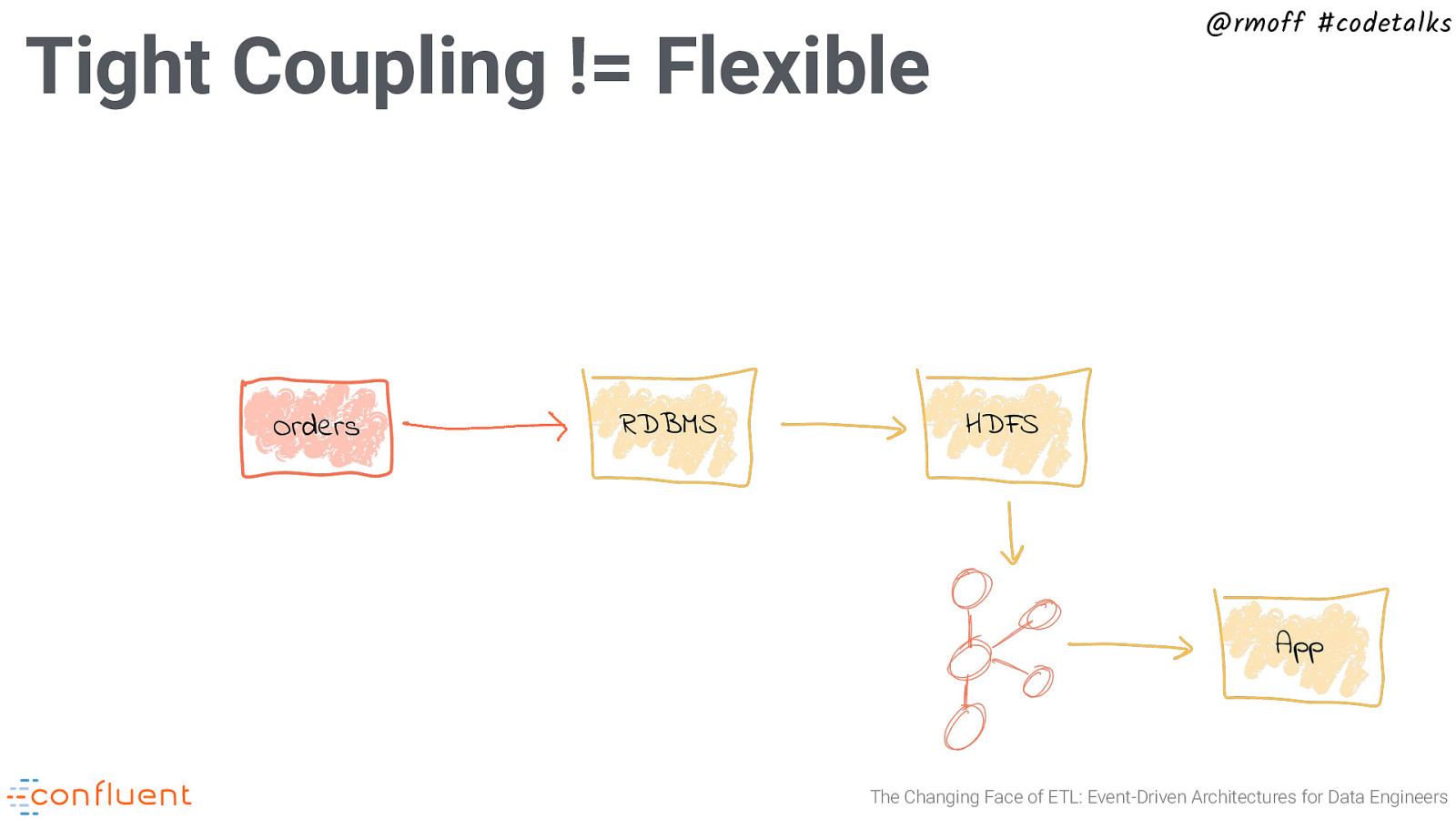
@rmoff #codetalks Tight Coupling != Flexible Orders RDBMS HDFS App The Changing Face of ETL: Event-Driven Architectures for Data Engineers
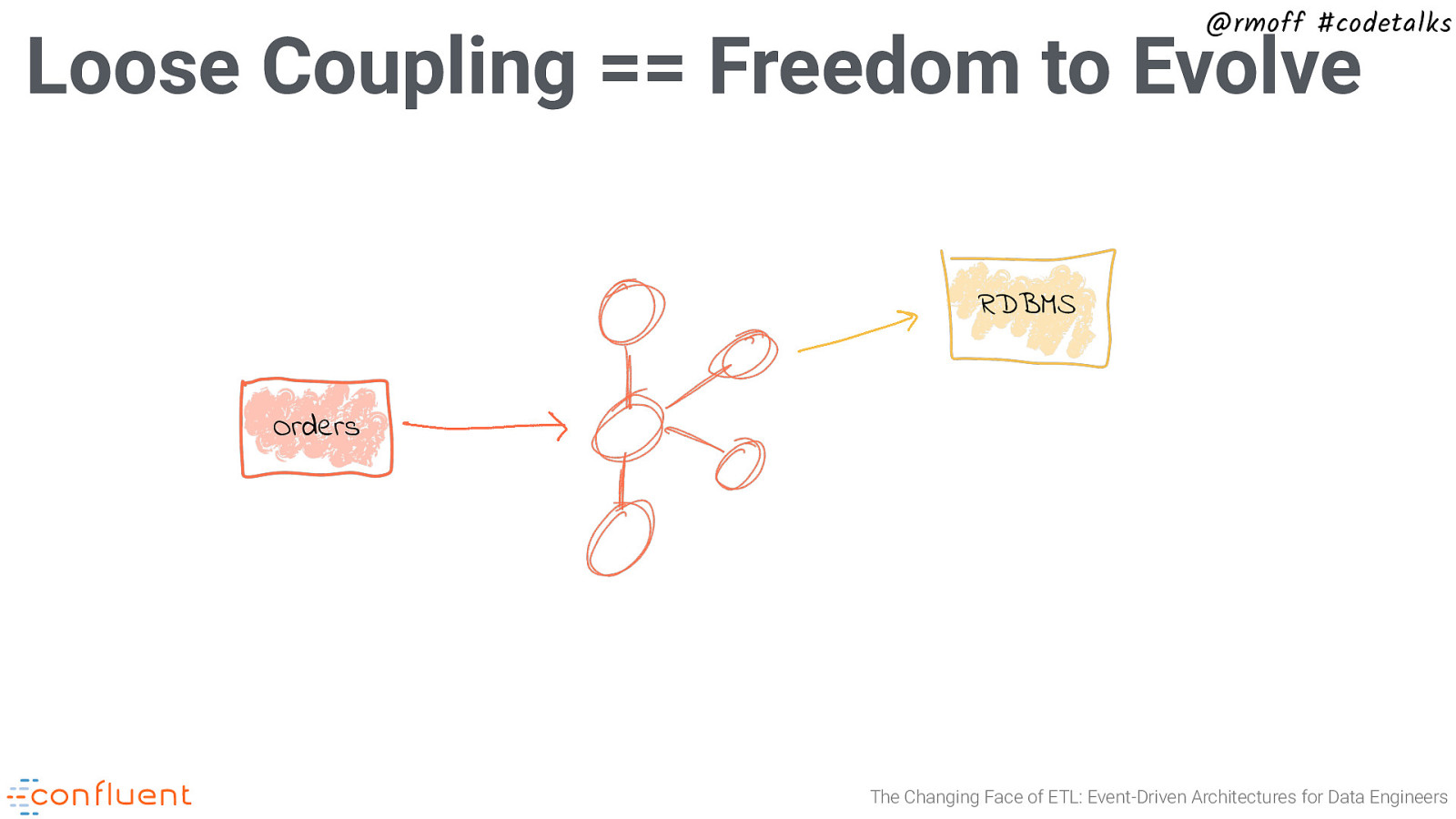
@rmoff #codetalks Loose Coupling == Freedom to Evolve RDBMS Orders The Changing Face of ETL: Event-Driven Architectures for Data Engineers
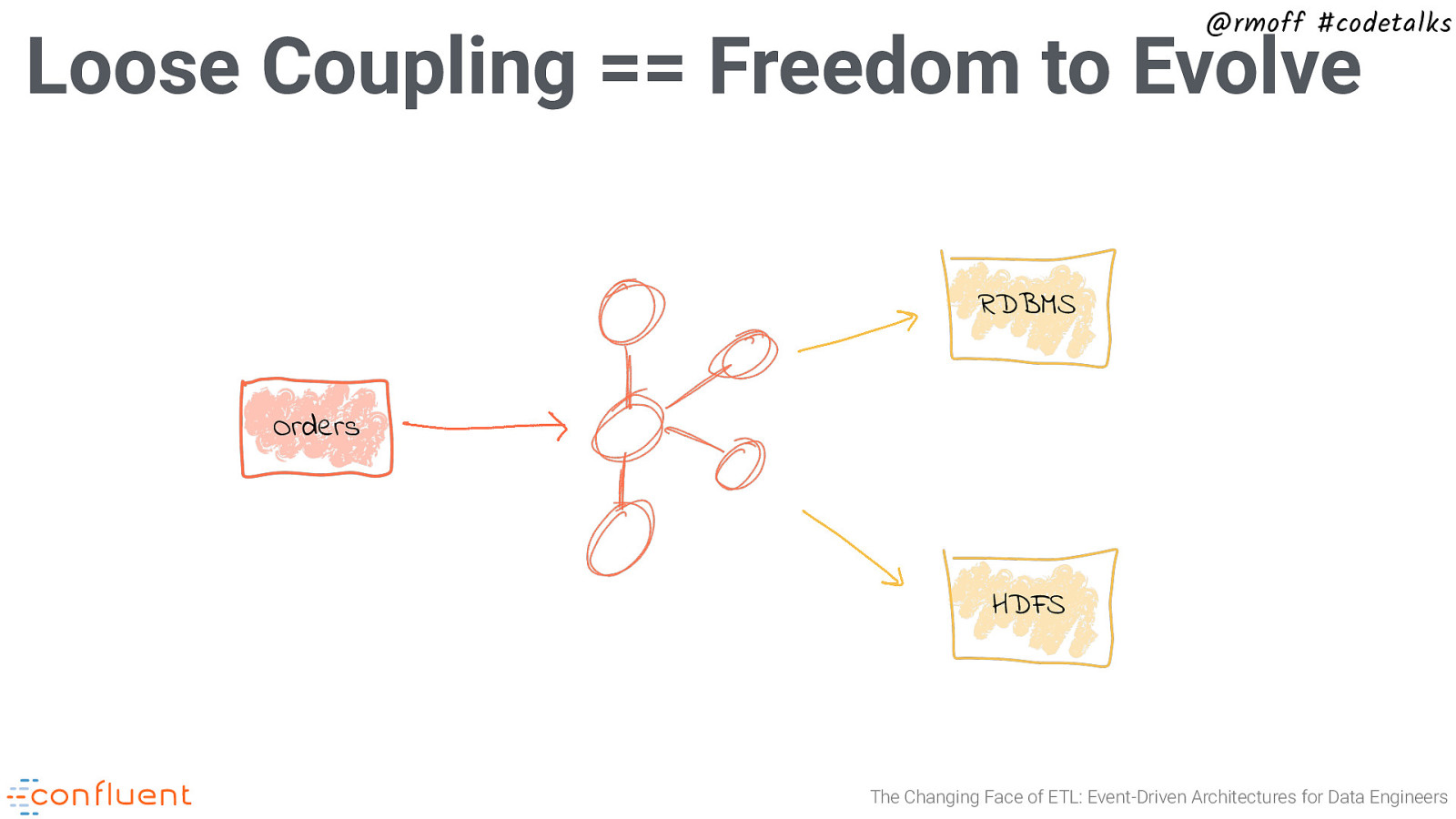
@rmoff #codetalks Loose Coupling == Freedom to Evolve RDBMS Orders HDFS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
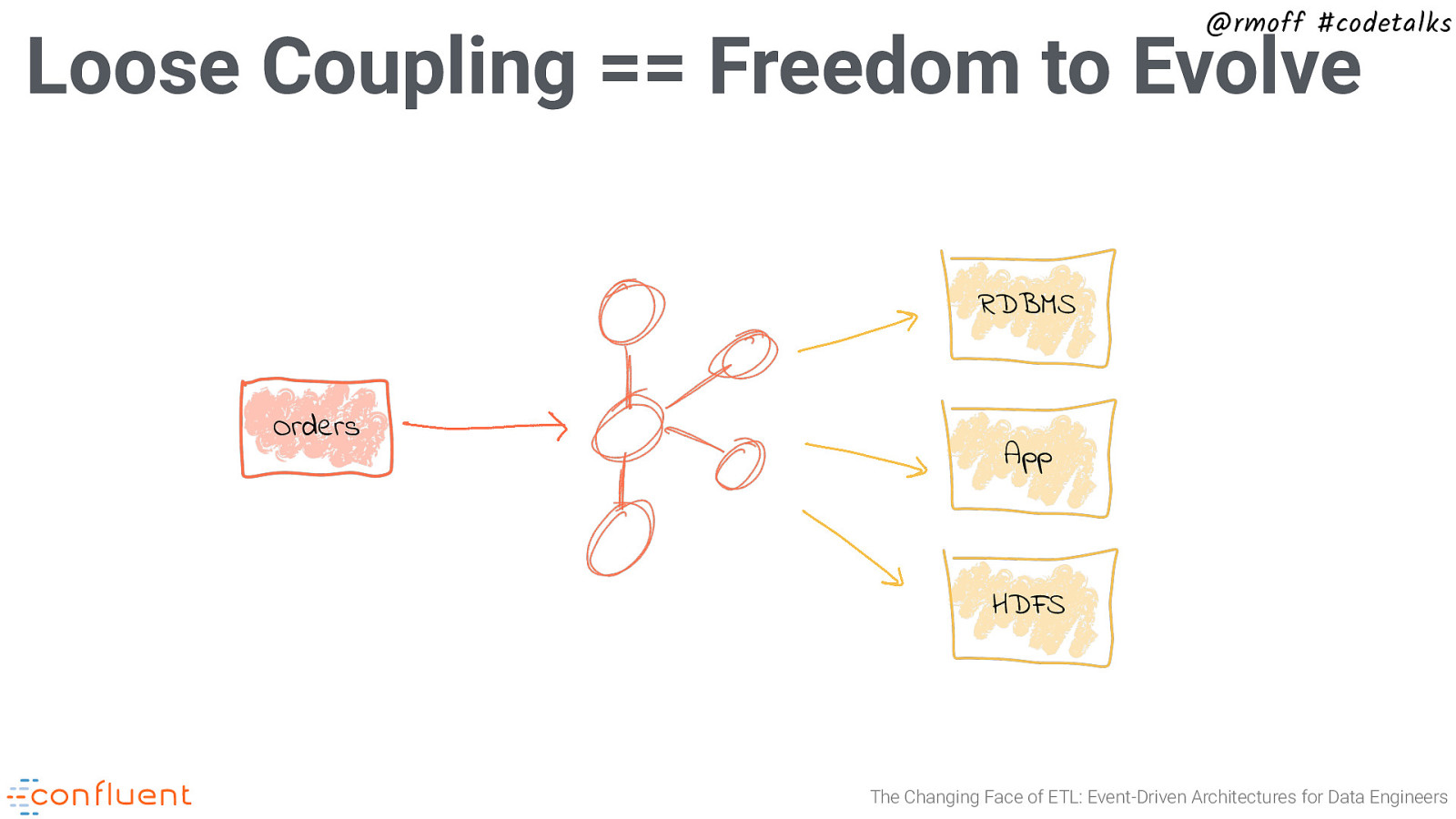
@rmoff #codetalks Loose Coupling == Freedom to Evolve RDBMS Orders App HDFS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
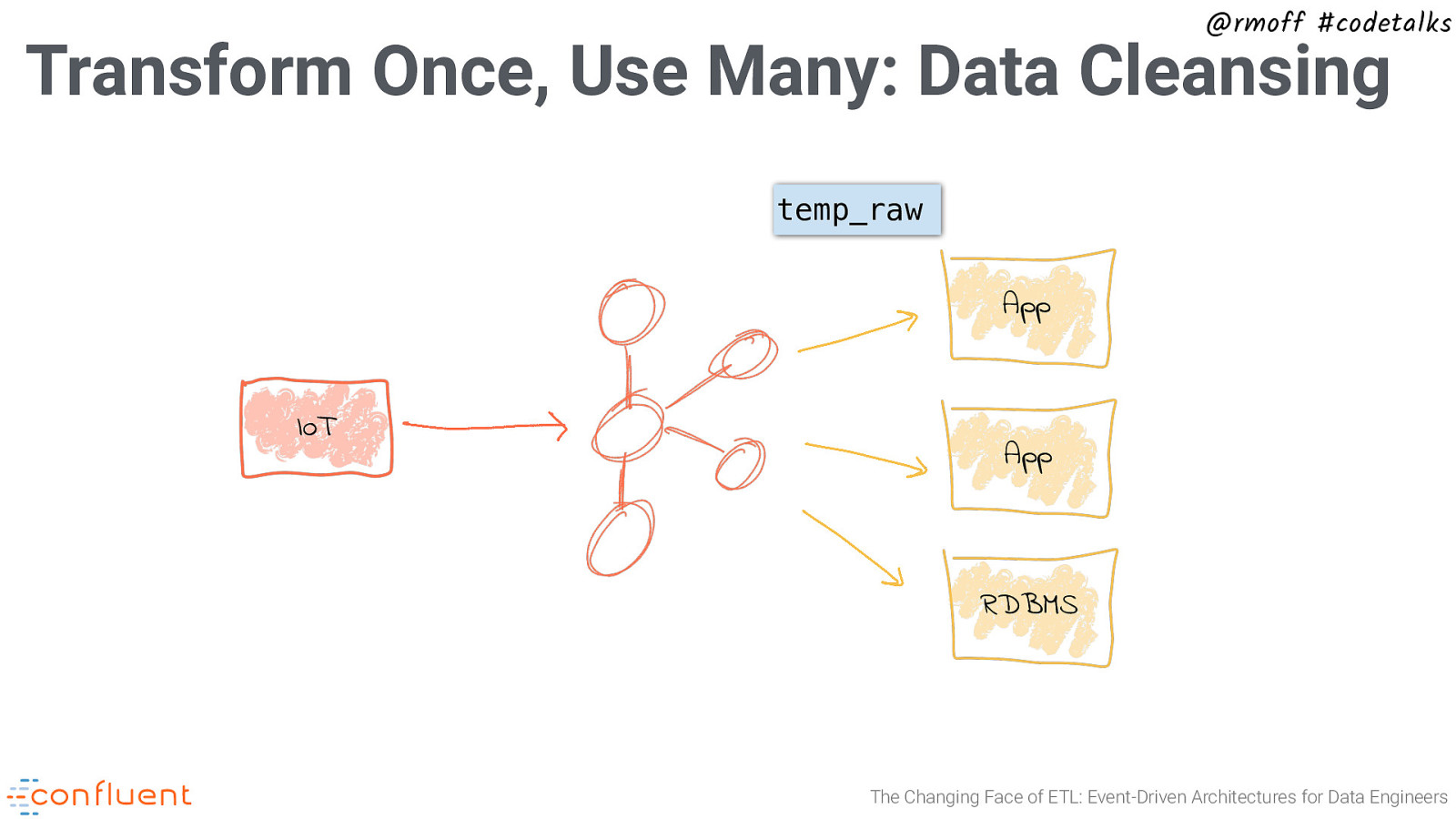
@rmoff #codetalks Transform Once, Use Many: Data Cleansing temp_raw App IoT App RDBMS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Transform Once, Use Many: Data Cleansing sensor_id time_epoch 42 1551136074 42 1551136125 1551136125 42 1551138129 IoT reading 13.05 13.11 13.11 13.04 temp_raw App App RDBMS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Transform Once, Use Many: Data Cleansing sensor_id time_epoch 42 1551136074 42 1551136125 1551136125 42 1551138129 IoT reading 13.05 13.11 13.11 13.04 temp_raw Cleanse App App Cleanse RDBMS Cleanse The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Transform Once, Use Many: Data Cleansing sensor_id time_epoch 42 1551136074 42 1551136125 1551136125 42 1551138129 reading 13.05 13.11 13.11 13.04 IoT temp_clean sensor_id 42 42 42 App time_epoch 1551136074 1551136125 1551138129 reading 13.05 13.11 13.04 App temp_raw SENSOR_ID IS NOT NULL RDBMS The Changing Face of ETL: Event-Driven Architectures for Data Engineers
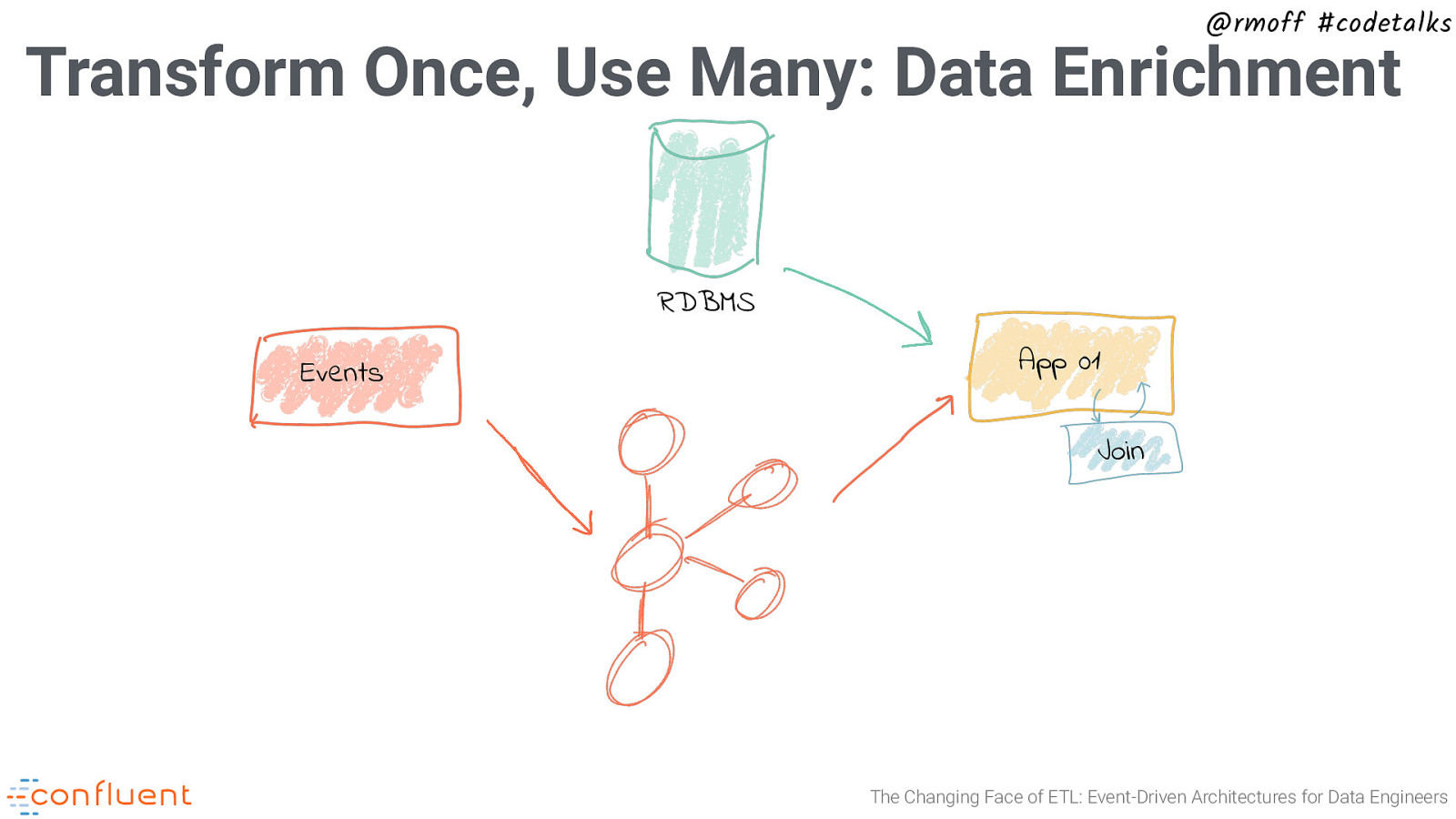
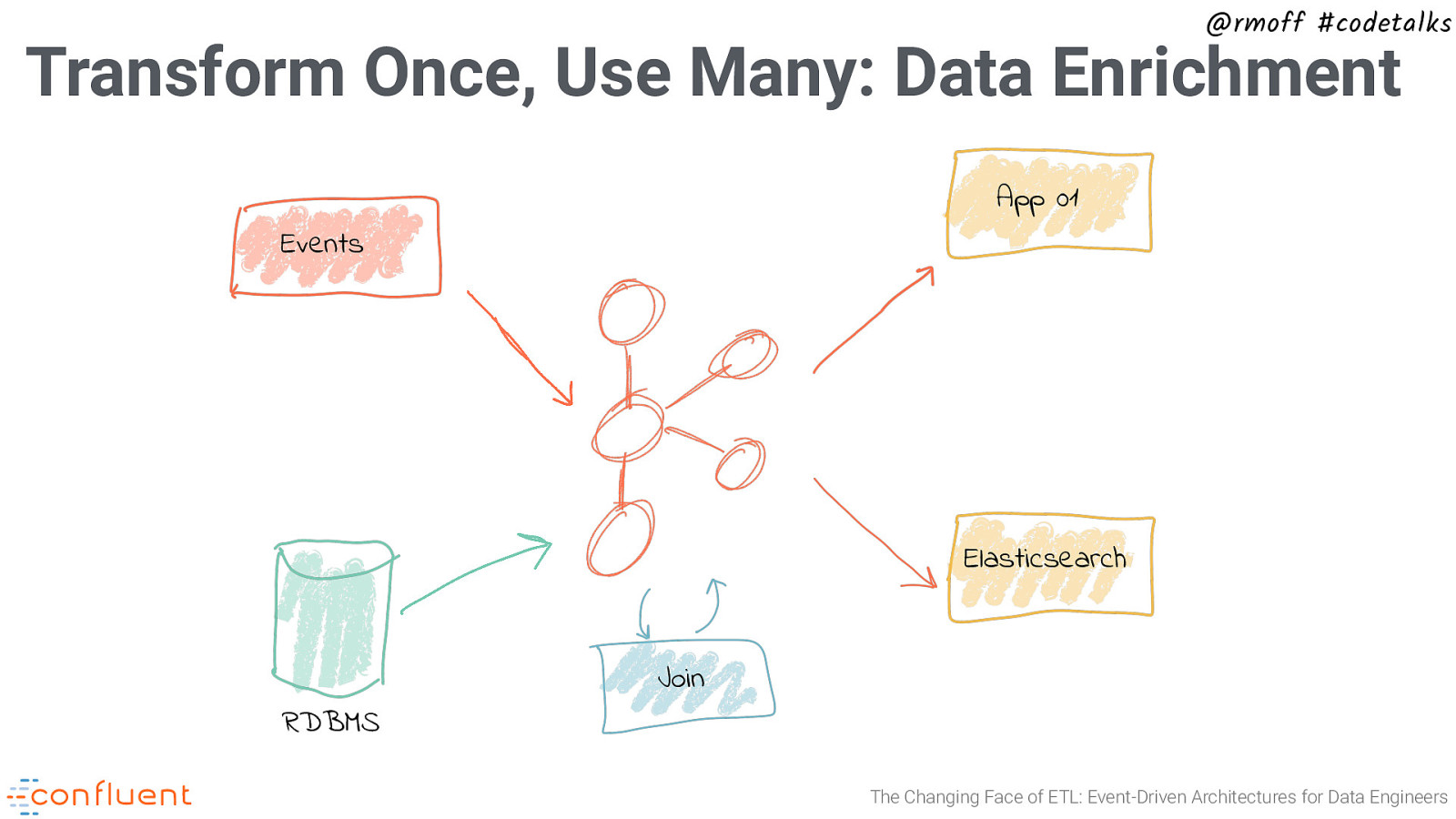
@rmoff #codetalks Transform Once, Use Many: Data Enrichment RDBMS Events App 01 Join The Changing Face of ETL: Event-Driven Architectures for Data Engineers
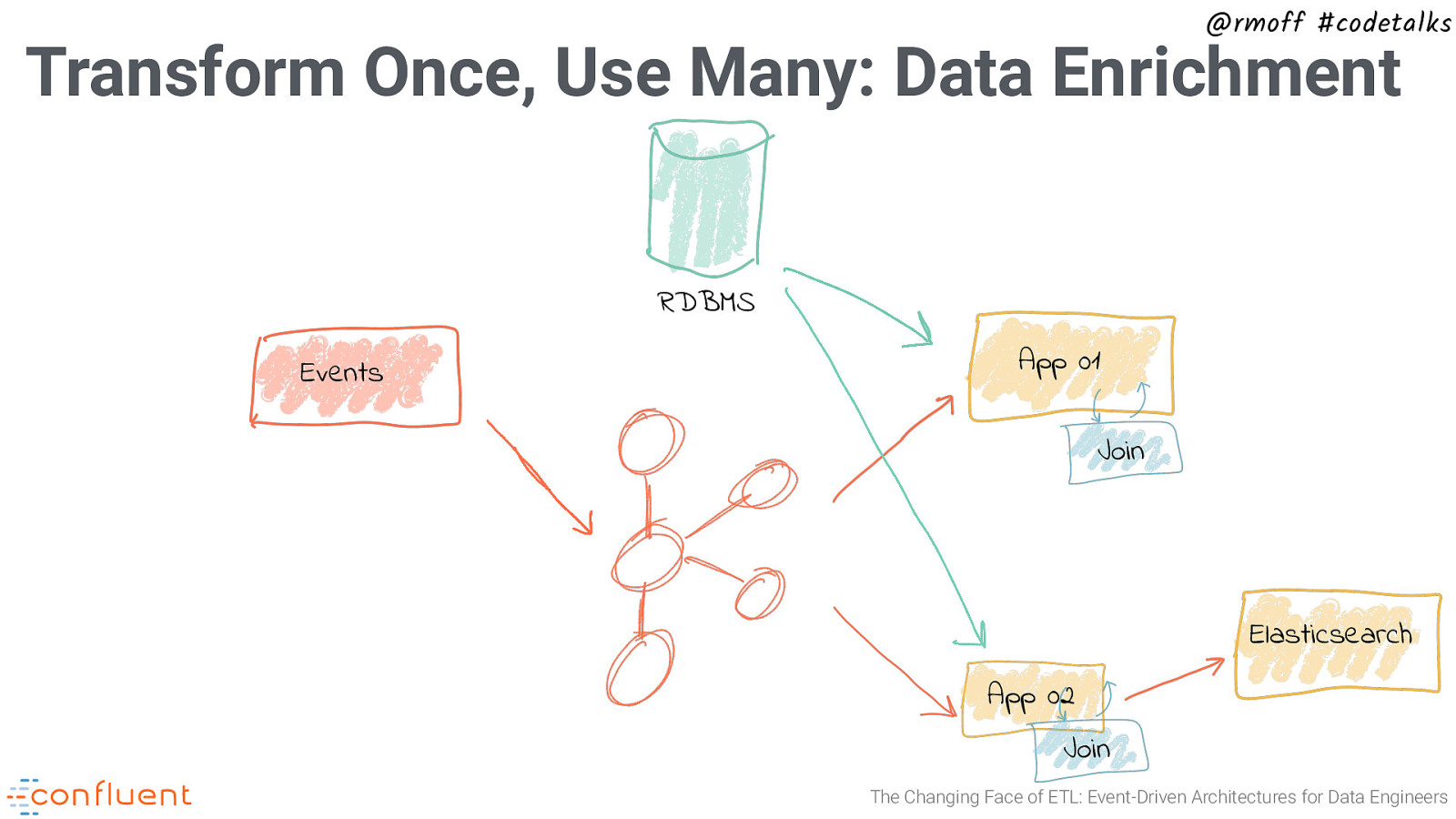
@rmoff #codetalks Transform Once, Use Many: Data Enrichment RDBMS Events App 01 Join Elasticsearch App 02 Join The Changing Face of ETL: Event-Driven Architectures for Data Engineers
@rmoff #codetalks Transform Once, Use Many: Data Enrichment App 01 Events Elasticsearch RDBMS Join The Changing Face of ETL: Event-Driven Architectures for Data Engineers
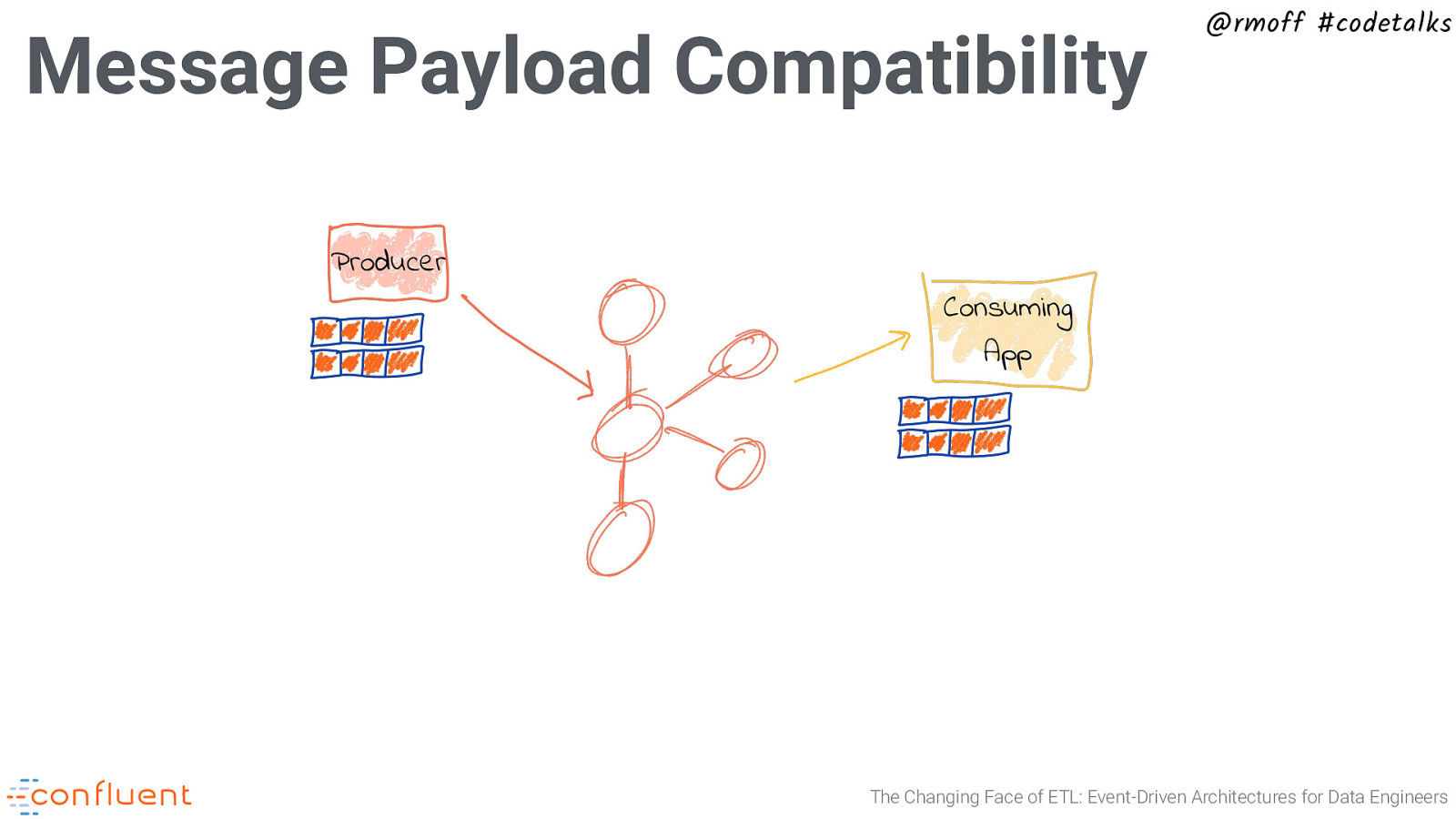
Message Payload Compatibility @rmoff #codetalks Producer Consuming App The Changing Face of ETL: Event-Driven Architectures for Data Engineers
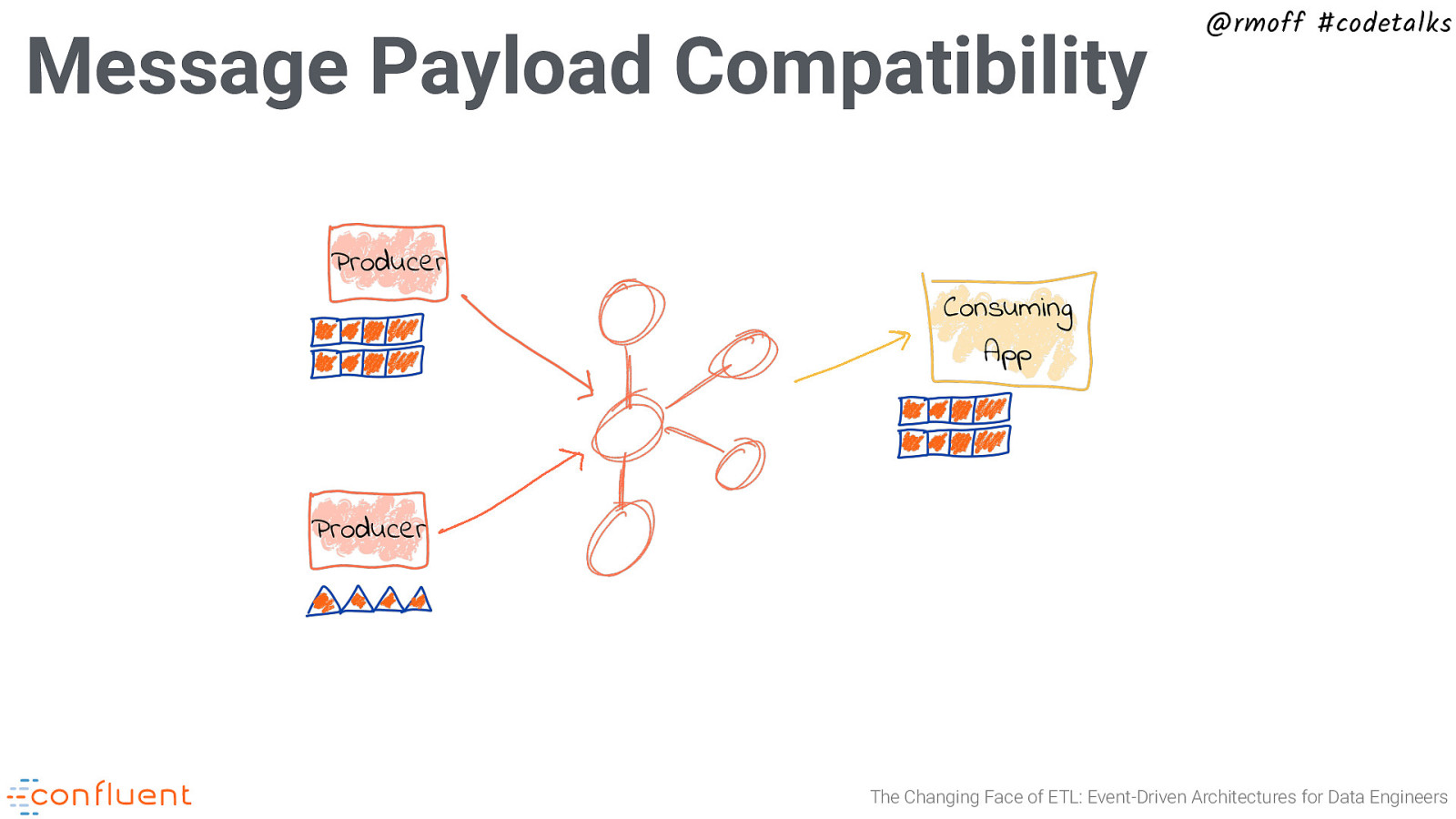
Message Payload Compatibility @rmoff #codetalks Producer Consuming App Producer The Changing Face of ETL: Event-Driven Architectures for Data Engineers
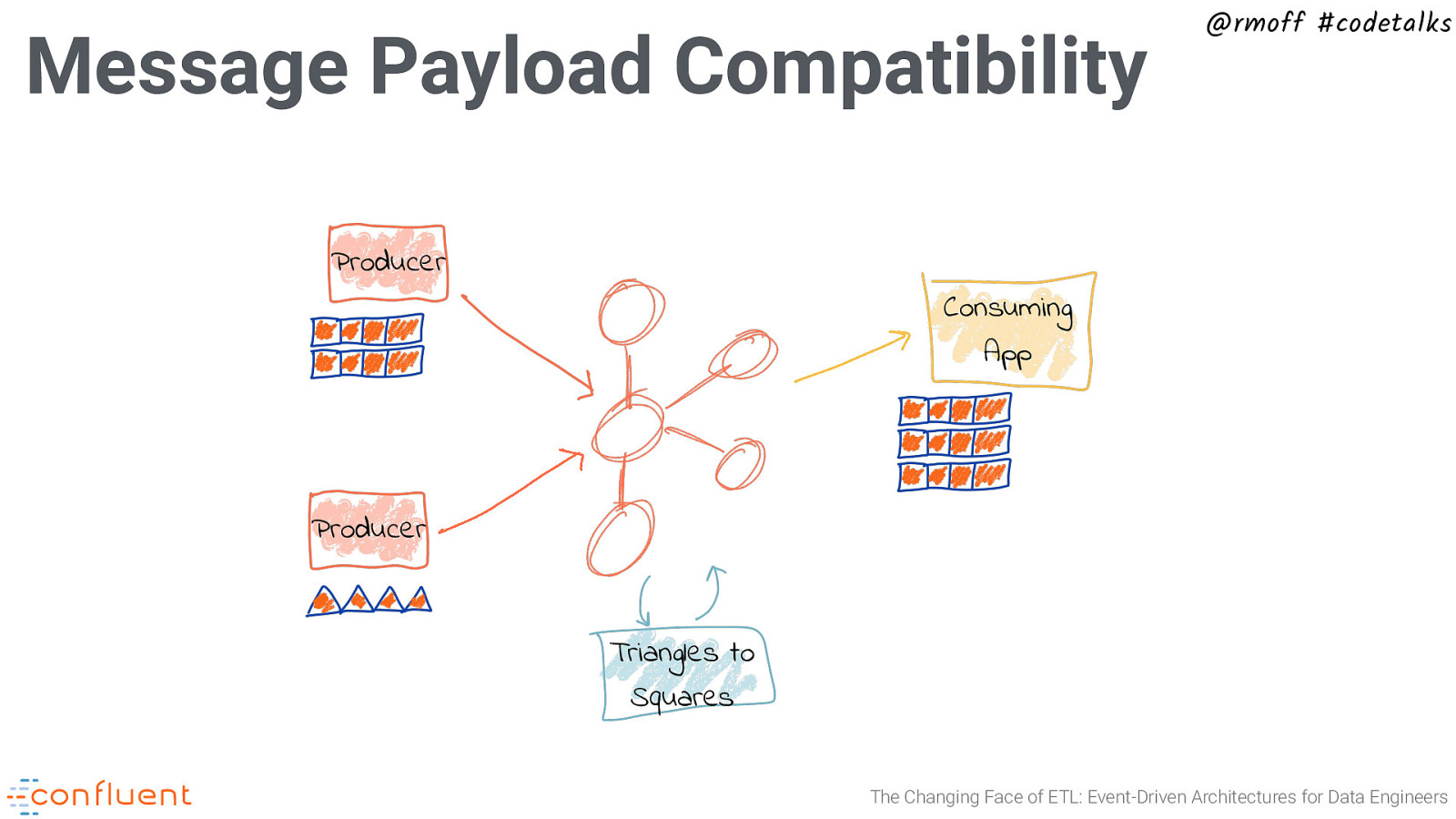
Message Payload Compatibility @rmoff #codetalks Producer Consuming App Producer Triangles to Squares The Changing Face of ETL: Event-Driven Architectures for Data Engineers
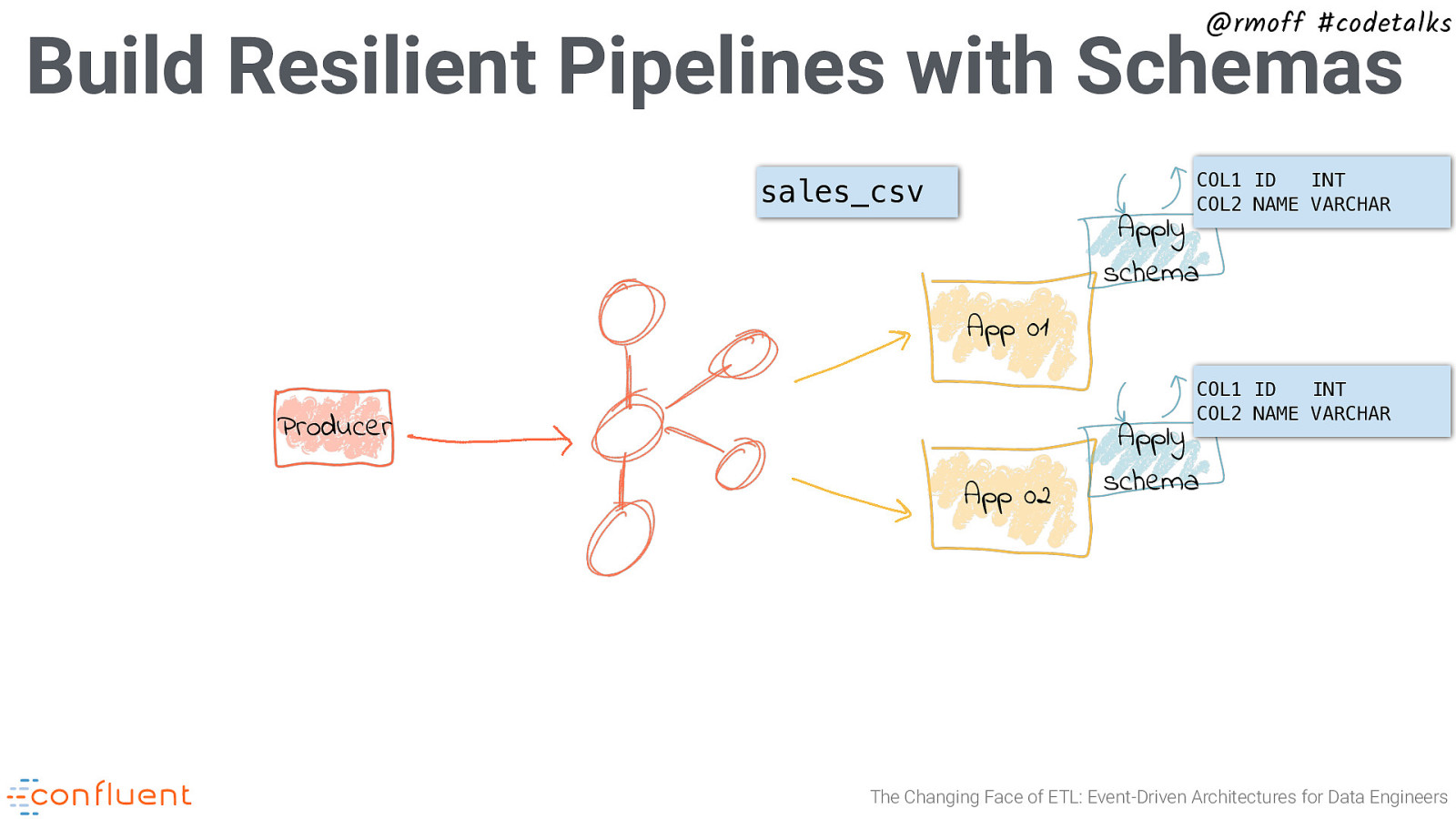
@rmoff #codetalks Build Resilient Pipelines with Schemas COL1 ID INT COL2 NAME VARCHAR sales_csv Apply schema App 01 COL1 ID INT COL2 NAME VARCHAR Producer App 02 Apply schema The Changing Face of ETL: Event-Driven Architectures for Data Engineers
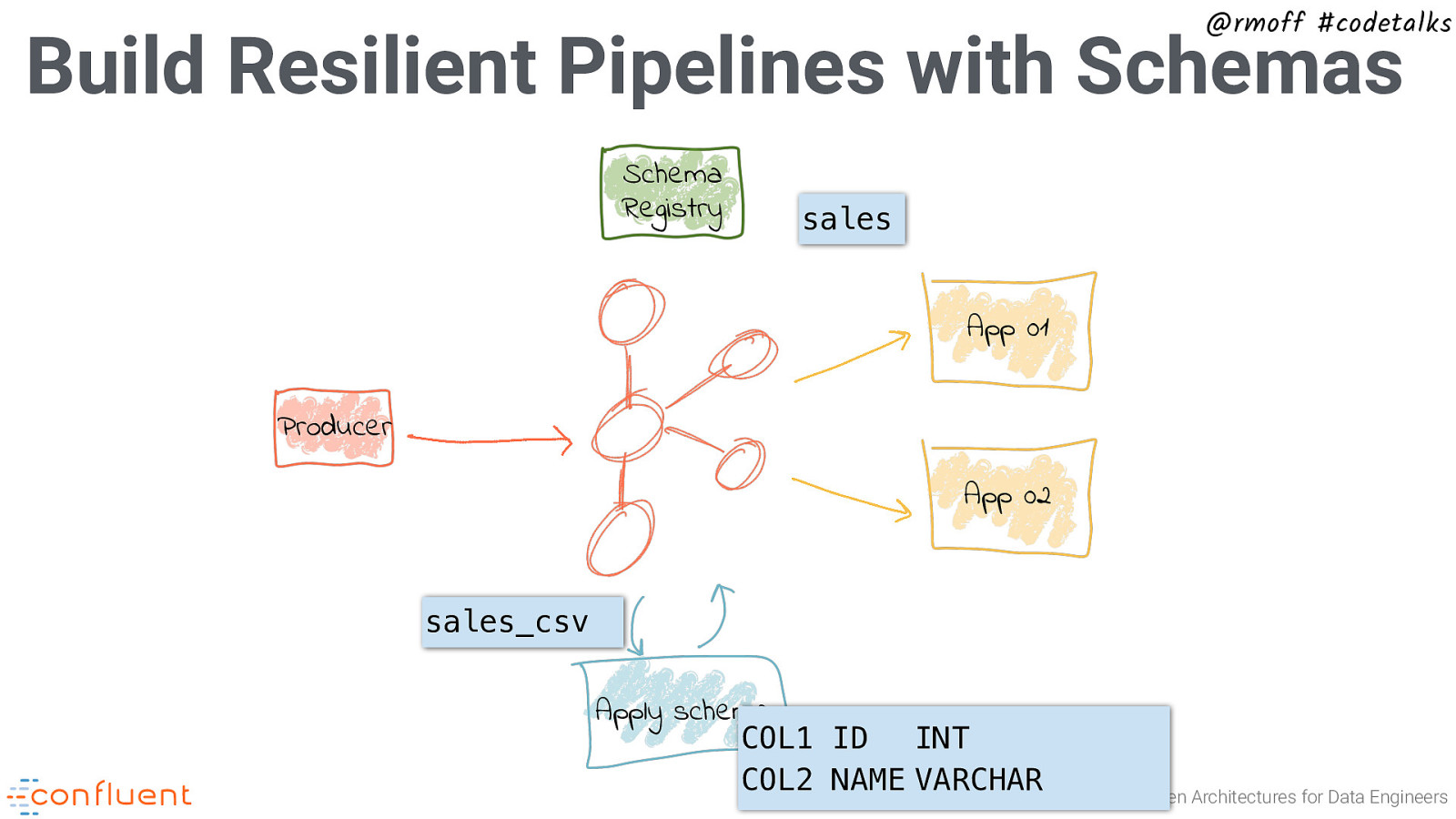
@rmoff #codetalks Build Resilient Pipelines with Schemas Schema Registry sales App 01 Producer App 02 sales_csv Apply schema COL1 ID INT COL2 NAME VARCHAR The Changing Face of ETL: Event-Driven Architectures for Data Engineers
Photo by rmoff Say NO to brittle pipelines
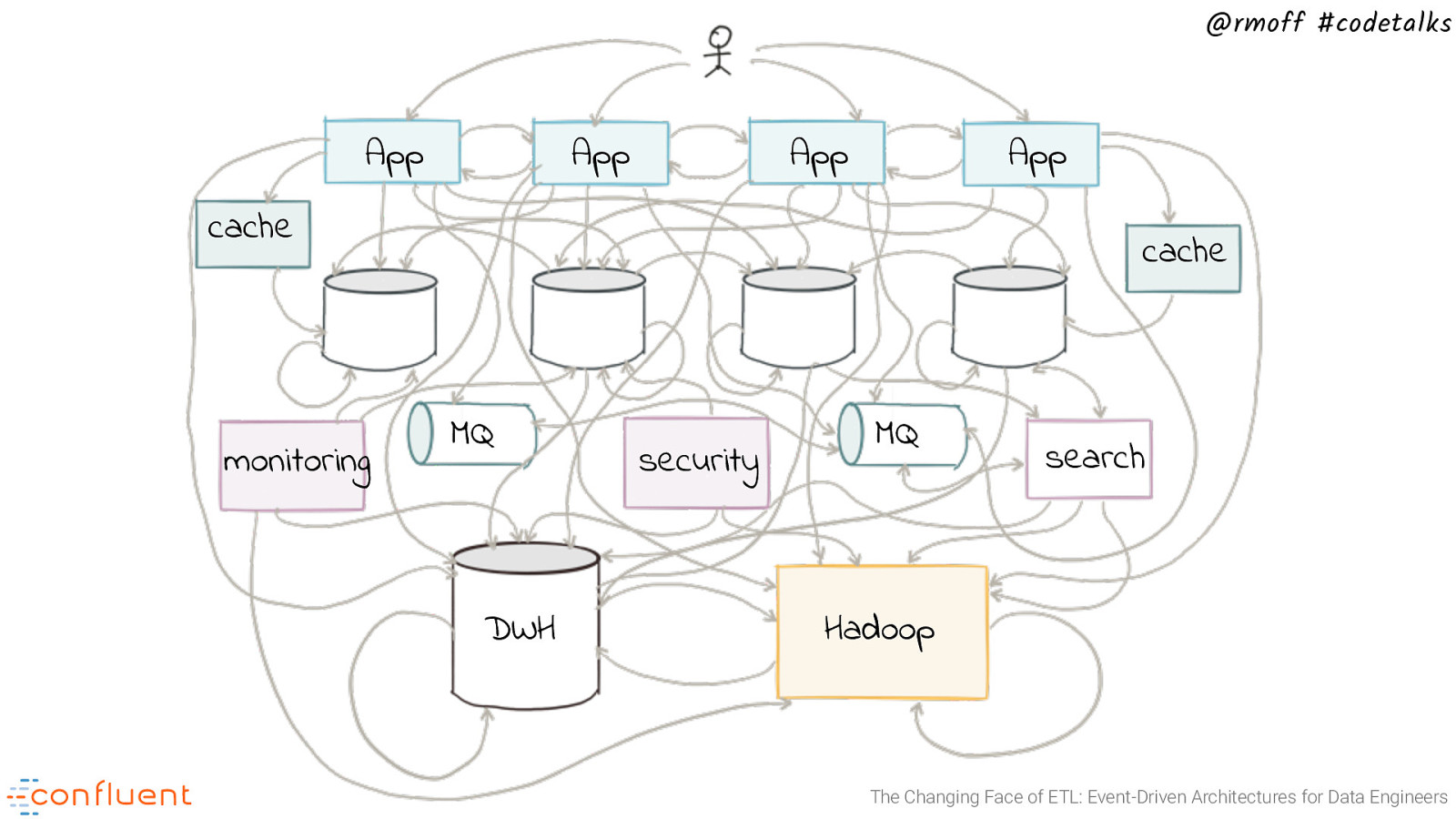
@rmoff #codetalks App App App App cache monitoring cache MQ DWH security MQ search Hadoop The Changing Face of ETL: Event-Driven Architectures for Data Engineers
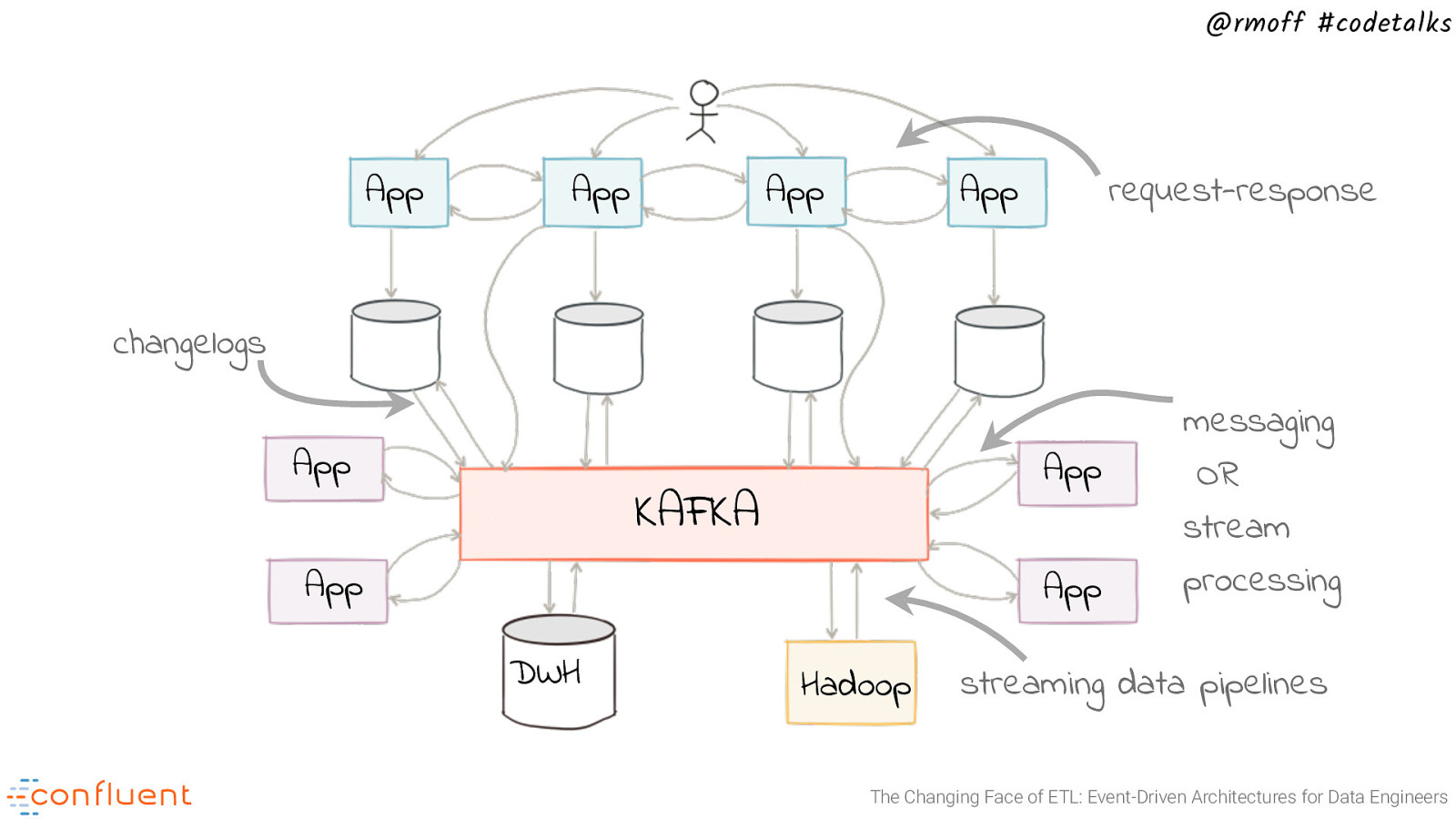
@rmoff #codetalks App App App App request-response changelogs App App KAFKA App App DWH Hadoop messaging OR stream processing streaming data pipelines The Changing Face of ETL: Event-Driven Architectures for Data Engineers
Photo by rmoff Events model the real world
Event streaming platform Photo by rmoff Native stream processing Data when you need it Data persistence Flexibility & scalability
Fully Managed Kafka as a Service
@rmoff #codetalks http://cnfl.io/book-bundle The Changing Face of ETL: Event-Driven Architectures for Data Engineers
Photo by rmoff @rmoff #codetalks https://talks.rmoff.net http://cnfl.io/slack

Data integration in architectures built on static, update-in-place datastores inevitably end up with pathologically high degrees of coupling and poor scalability. This has been the standard practice for decades, as we attempt to build data pipelines on top of databases that do a poor job modeling the fundamental objects that drive our businesses and systems: events.
Events carry both notification and state, and form a powerful primitive on which to build systems for developers and data engineers alike. Developers benefit from the asynchronous communication that events enable between services, and data engineers benefit from the integration capabilities. Everyone gains from using the standards-based, scalable and resilient streaming platform.
In this talk, we’ll discuss the concepts of events, their relevance to both software engineers and data engineers and their ability to unify architectures in a powerful way. We’ll see how stream processing makes sense in both a microservices and ETL environment, and why analytics, data integration and ETL fit naturally into a streaming world.
The following resources were mentioned during the presentation or are useful additional information.
Provides managed Apache Kafka, Schema Registry, KSQL, etc
Here’s what was said about this presentation on social media.





































 for free. You
can too.
for free. You
can too.