
A presentation at GOTOpia by Robin Moffatt

Kafka as a Platform: the Ecosystem from the Ground Up Robin Moffatt | #GOTOpia | @rmoff
EVENTS @rmoff | #GOTOpia | @confluentinc
EVENTS @rmoff | #GOTOpia | @confluentinc
• • EVENTS d e n e p p a h g n i h t e Som d e n e p p a h t a Wh
Human generated events A Sale A Stock movement @rmoff | #GOTOpia | @confluentinc
Machine generated events IoT Networking Applications @rmoff | #GOTOpia | @confluentinc
EVENTS are EVERYWHERE @rmoff | #GOTOpia | @confluentinc
EVENTS y r e v ^ are POWERFUL @rmoff | #GOTOpia | @confluentinc
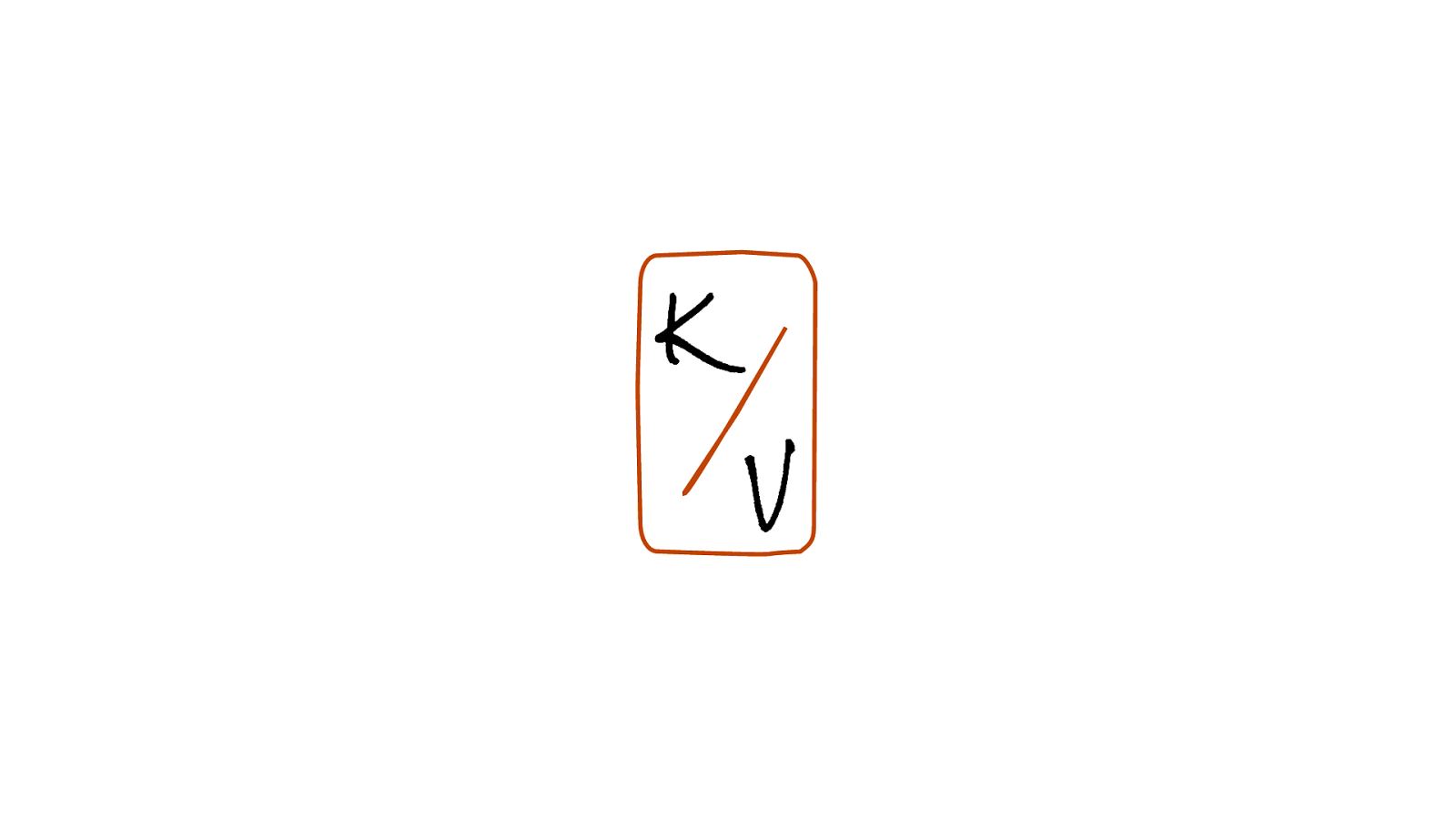
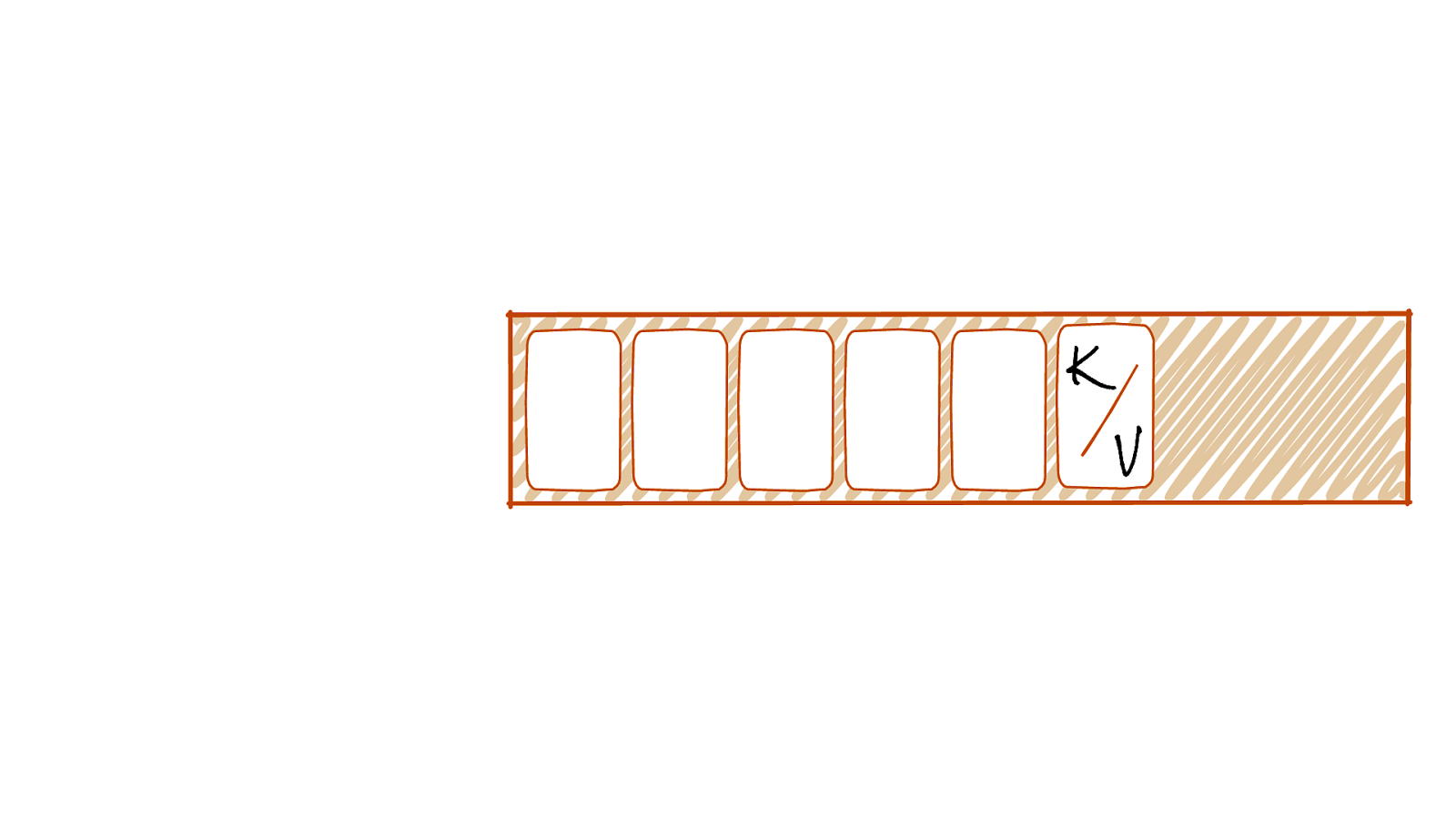
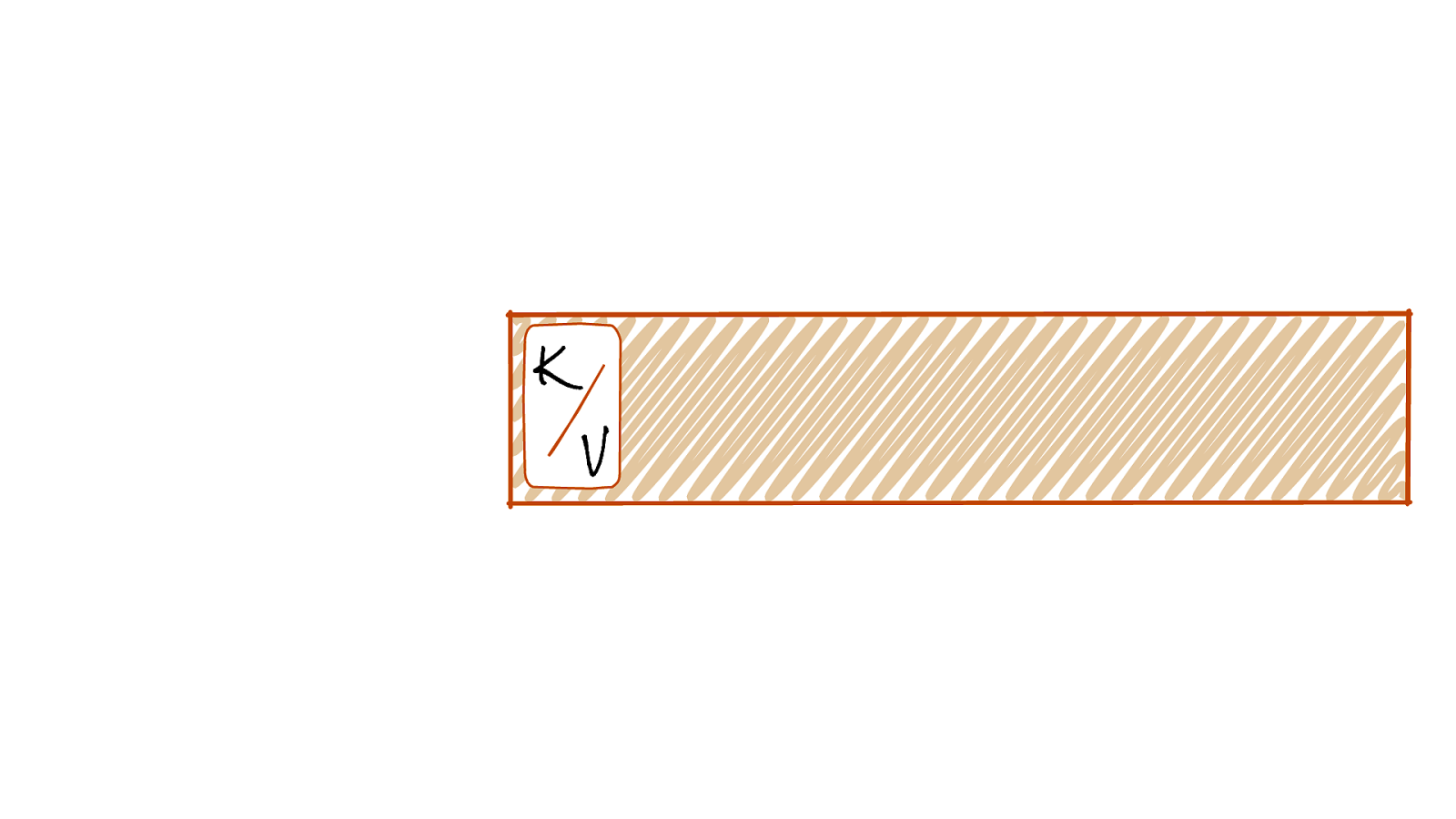
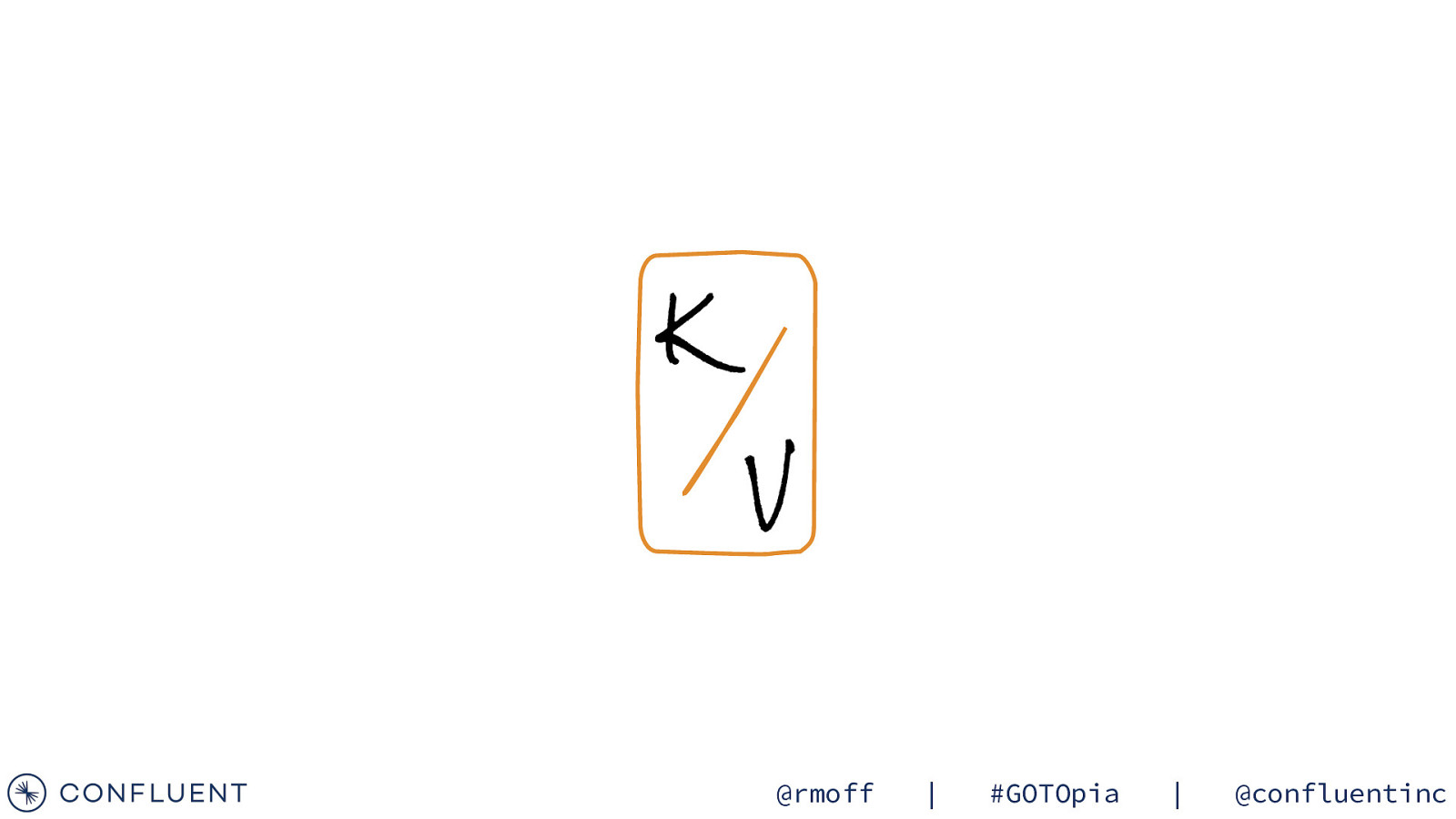
K V
LOG @rmoff | #GOTOpia | @confluentinc
K V
K V
K V
K V
K V
K V
K V
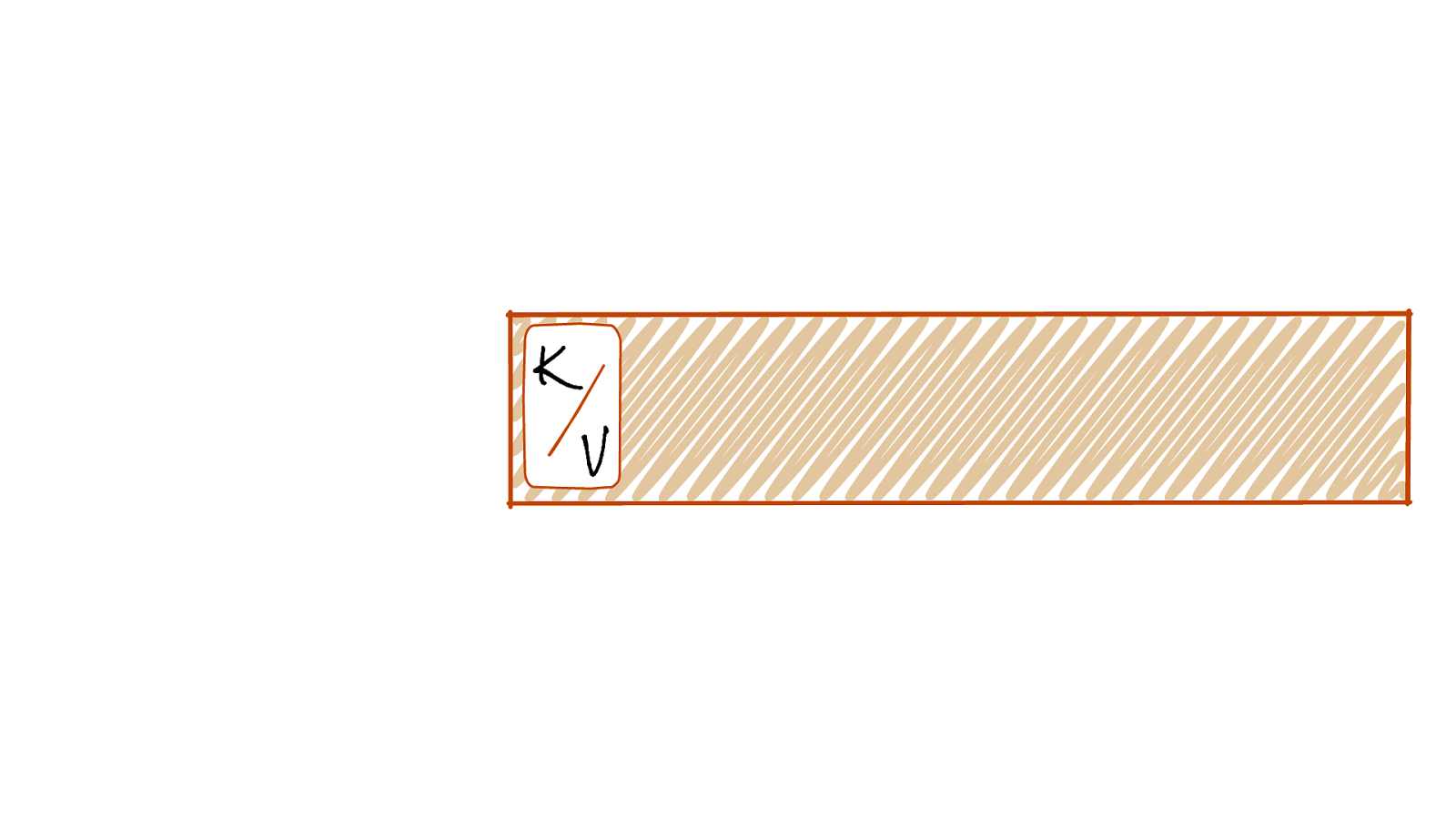
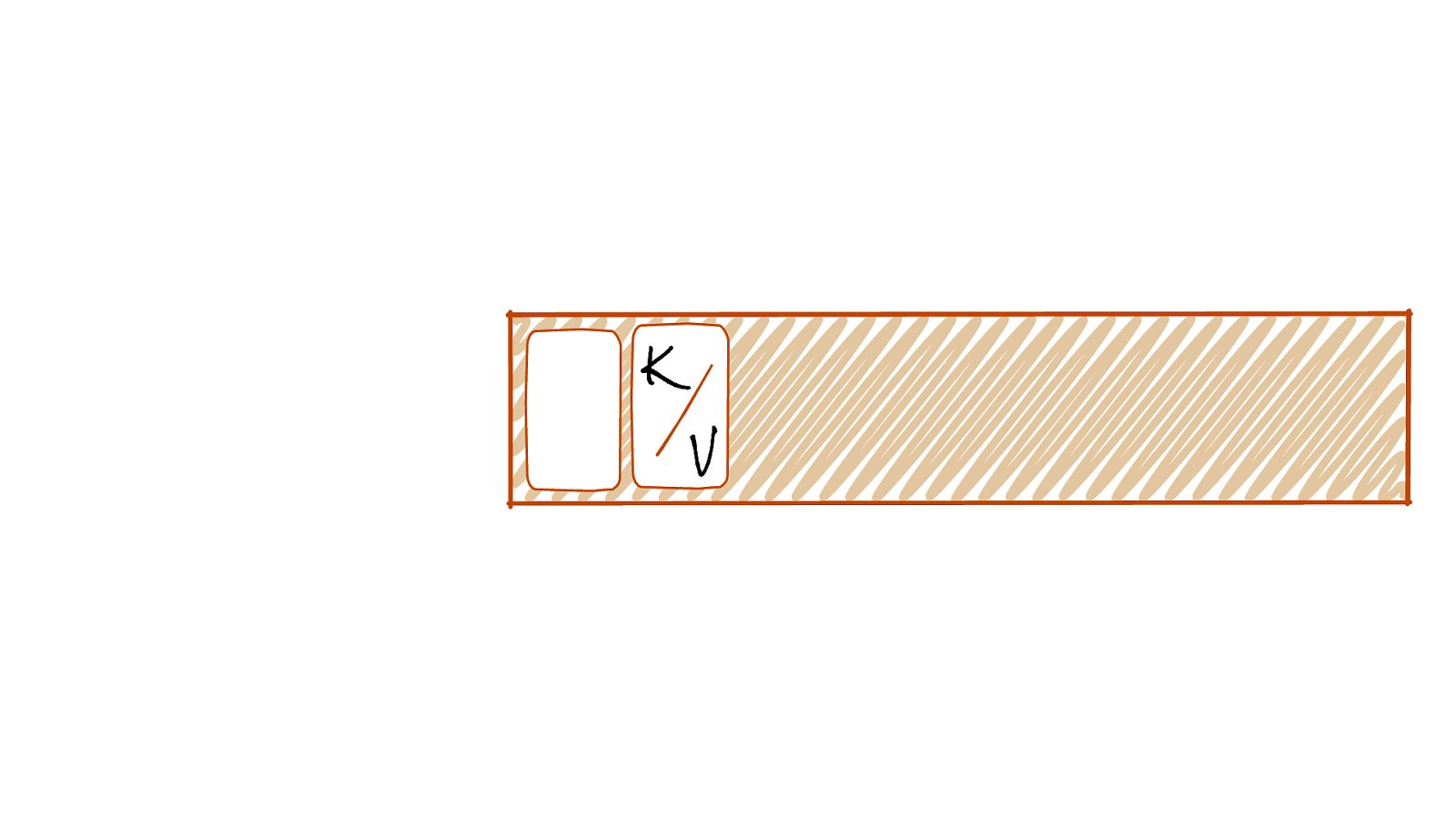
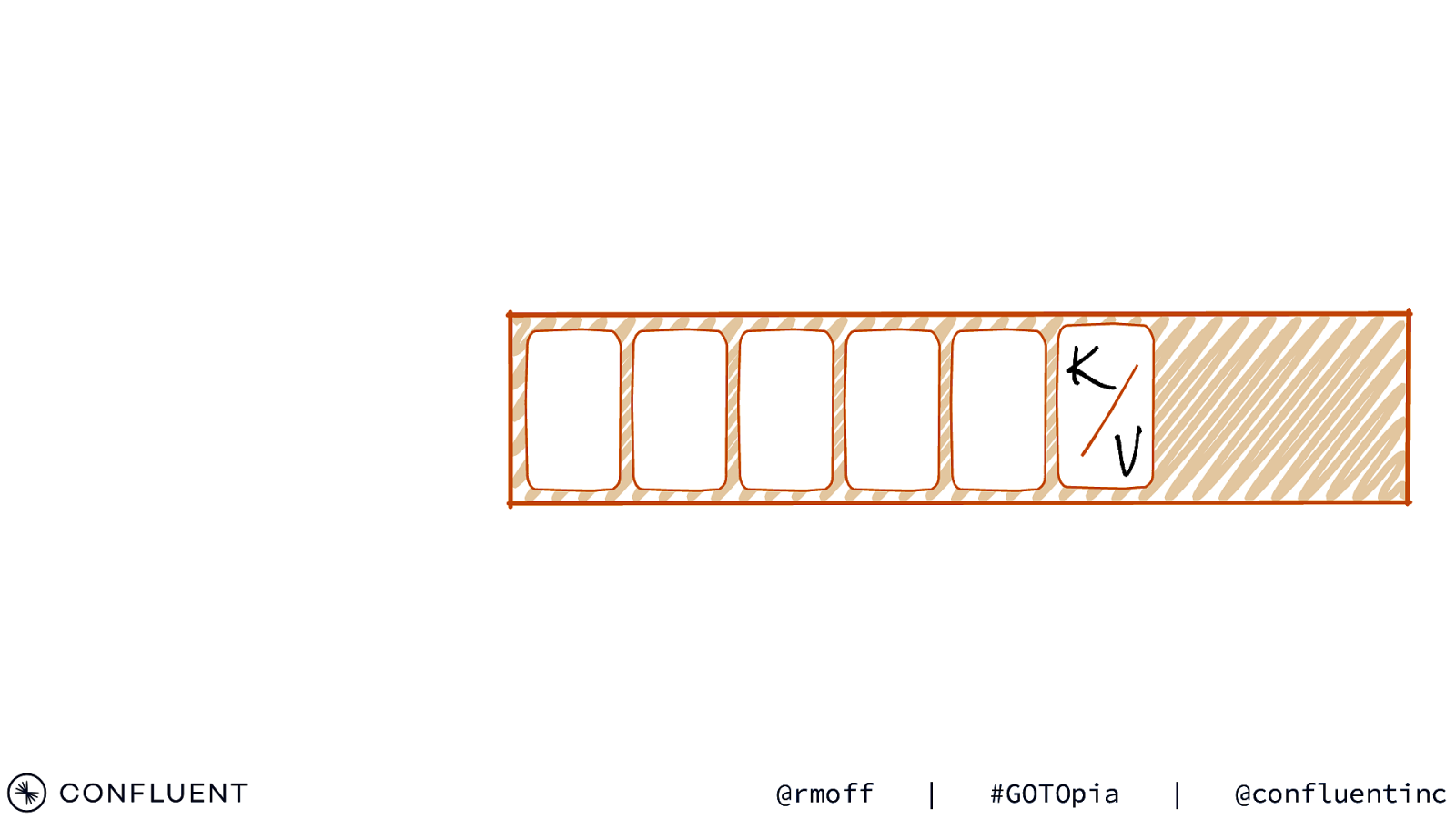
Immutable Event Log Old New Events are added at the end of the log @rmoff | #GOTOpia | @confluentinc
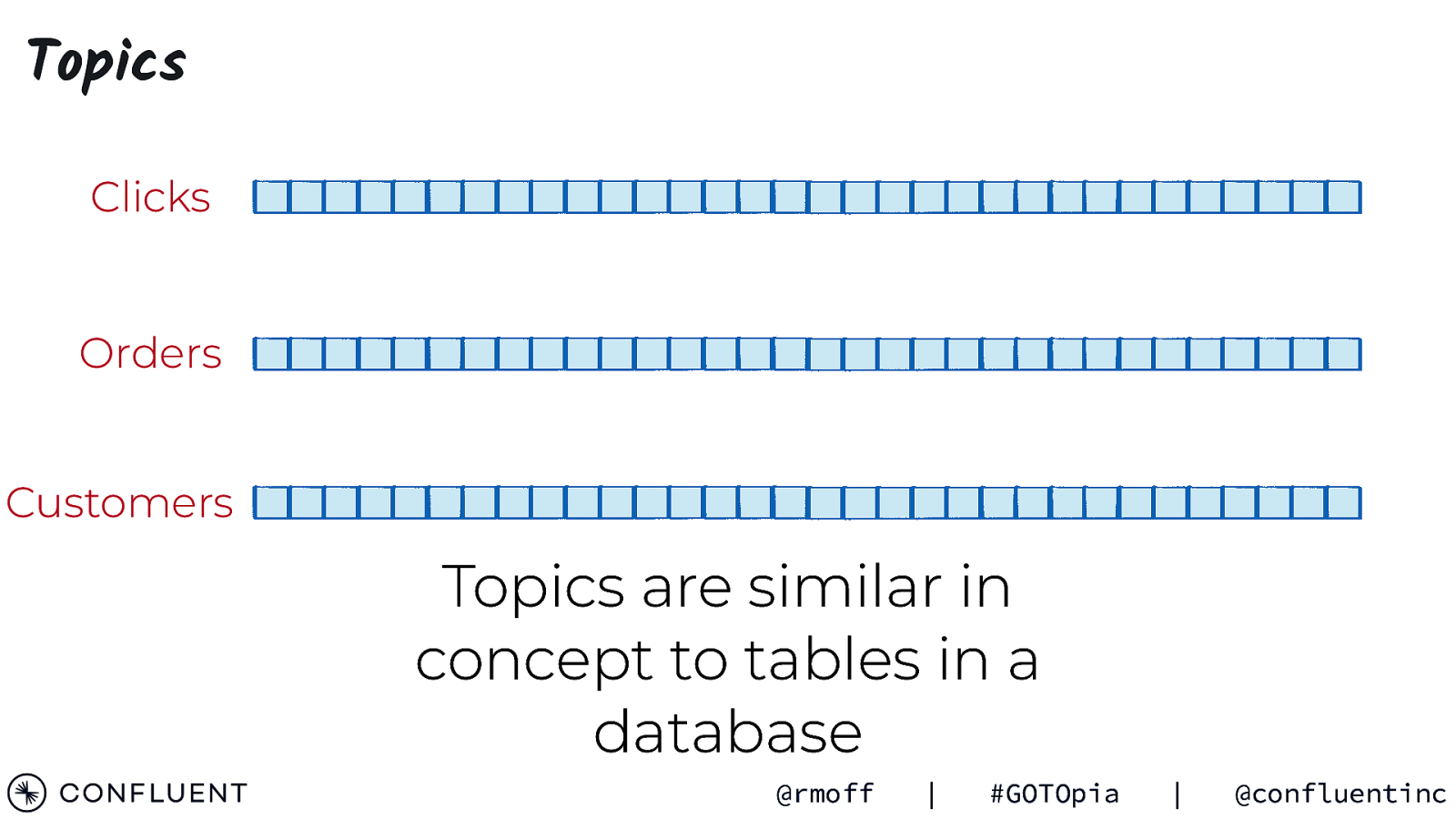
TOPICS @rmoff | #GOTOpia | @confluentinc
Topics Clicks Orders Customers Topics are similar in concept to tables in a database @rmoff | #GOTOpia | @confluentinc
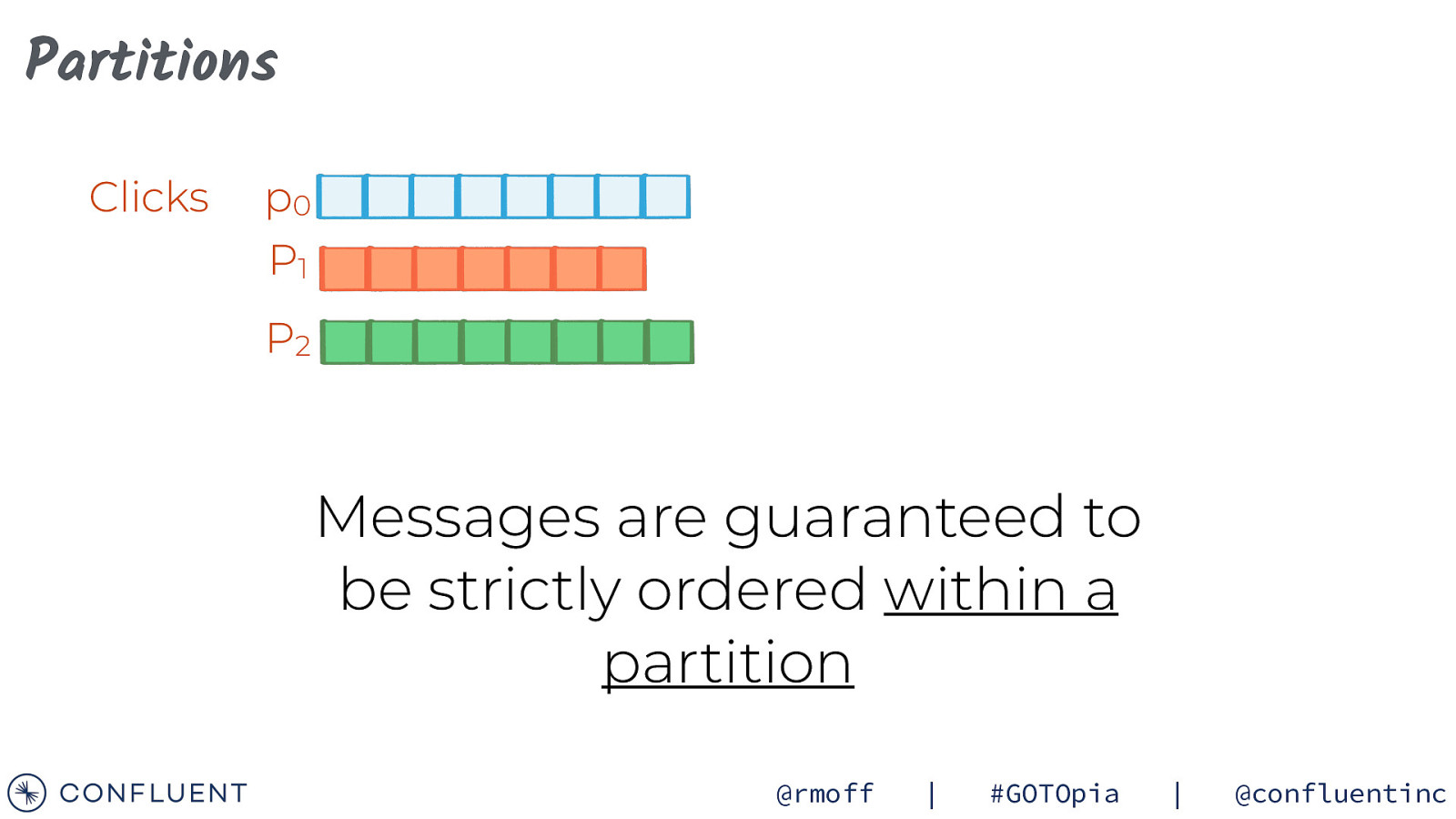
PARTITIONS @rmoff | #GOTOpia | @confluentinc
Partitions Clicks p0 P1 P2 Messages are guaranteed to be strictly ordered within a partition @rmoff | #GOTOpia | @confluentinc
PUB / SUB @rmoff | #GOTOpia | @confluentinc
PUB / SUB @rmoff | #GOTOpia | @confluentinc
Producing data Old New Messages are added at the end of the log @rmoff | #GOTOpia | @confluentinc
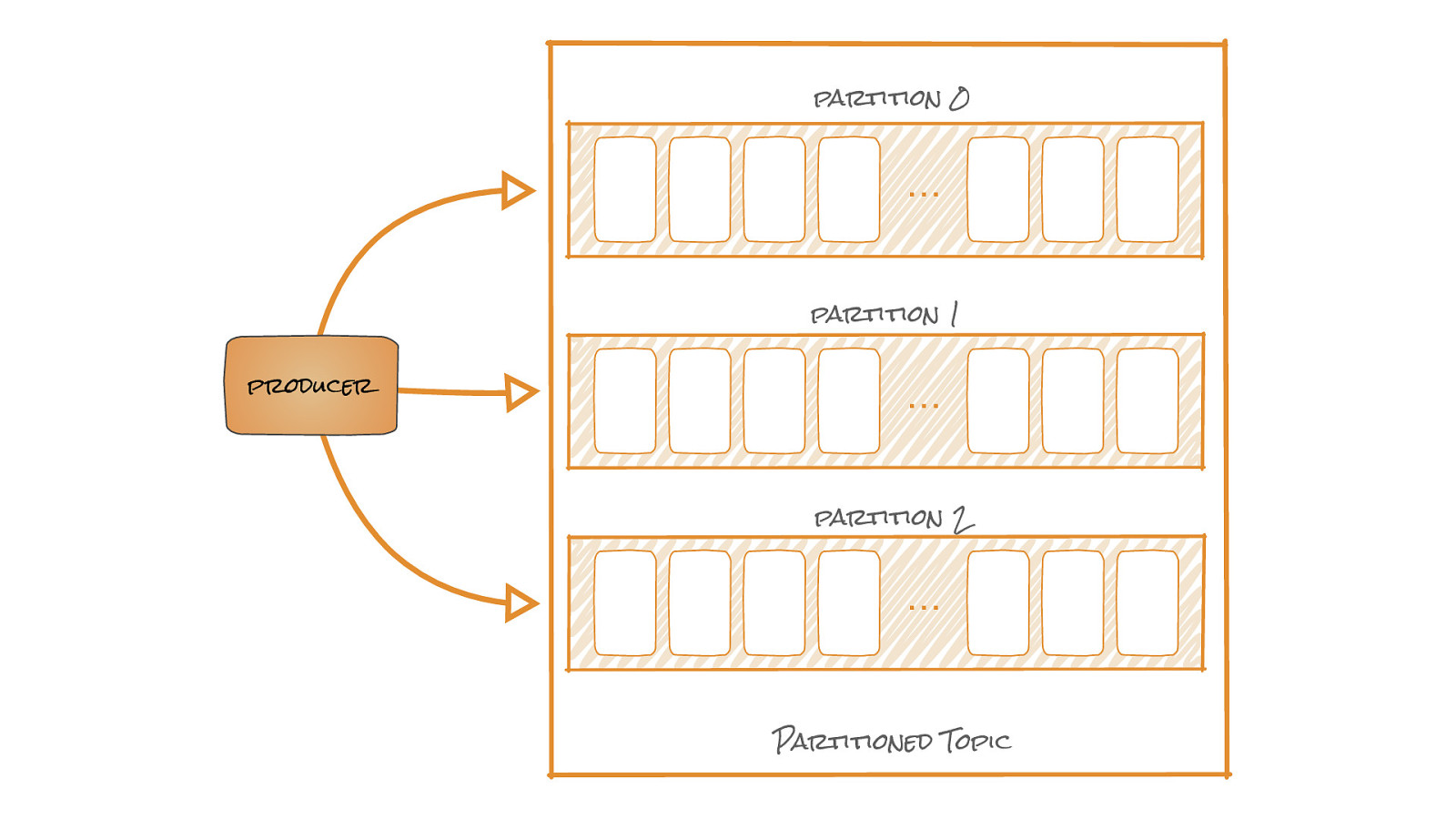
partition 0 … partition 1 producer … partition 2 … Partitioned Topic
package main import ( “gopkg.in/confluentinc/confluent-kafka-go.v1/kafka” ) func main() { topic := “test_topic” p, _ := kafka.NewProducer(&kafka.ConfigMap{ “bootstrap.servers”: “localhost:9092”}) defer p.Close() p.Produce(&kafka.Message{ TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: 0}, Value: []byte(“Hello world”)}, nil) }
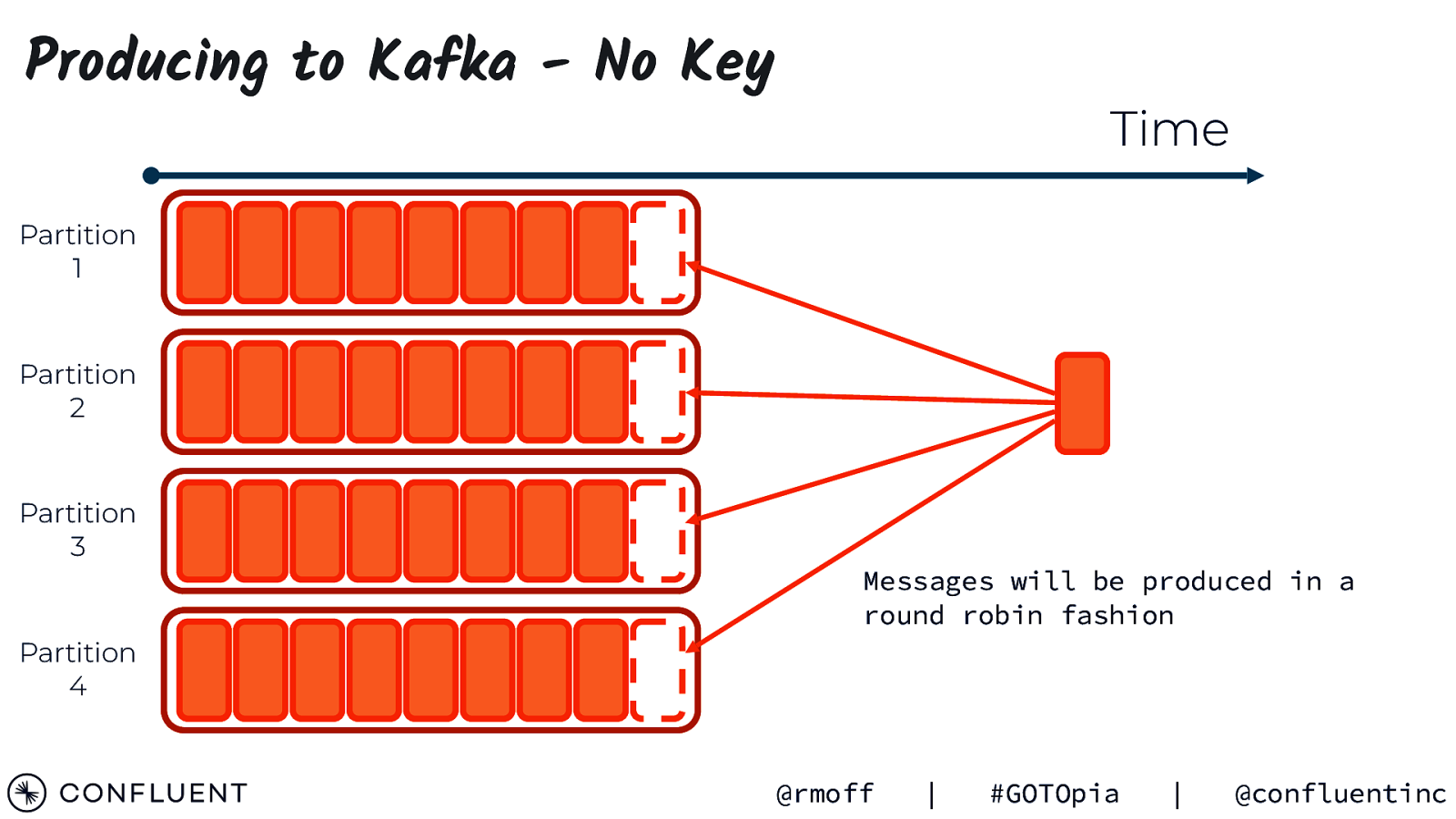
Producing to Kafka - No Key Time Partition 1 Partition 2 Partition 3 Messages will be produced in a round robin fashion Partition 4 @rmoff | #GOTOpia | @confluentinc
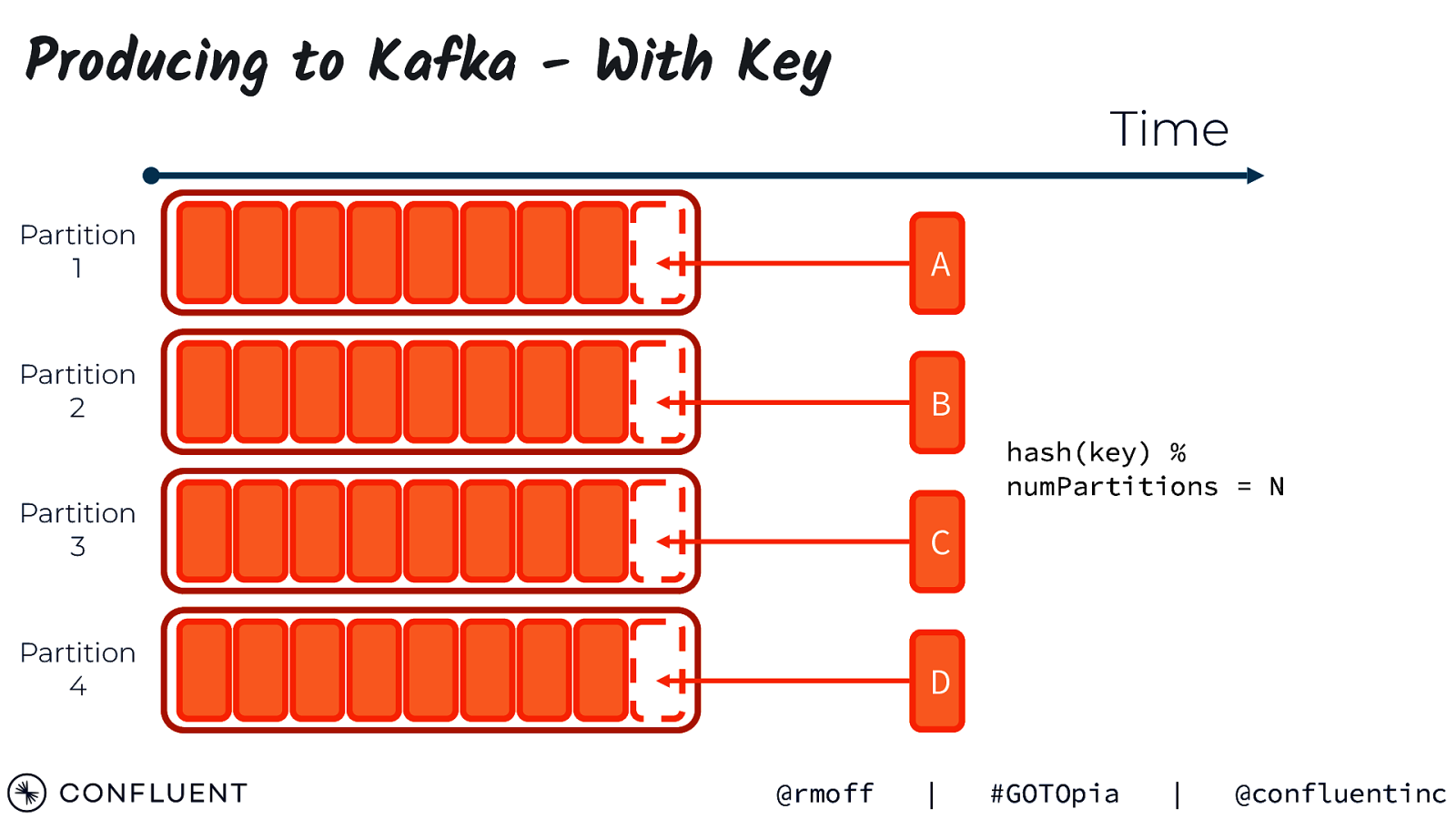
Producing to Kafka - With Key Time Partition 1 A Partition 2 B hash(key) % numPartitions = N Partition 3 C Partition 4 D @rmoff | #GOTOpia | @confluentinc
Producers partition 0 … partition 1 producer … partition 2 … Partitioned Topic • A client application • Puts messages into topics • Handles partitioning, network protocol • Java, Go, .NET, C/C++, Python • Also every other language Plus REST proxy if not
PUB / SUB @rmoff | #GOTOpia | @confluentinc
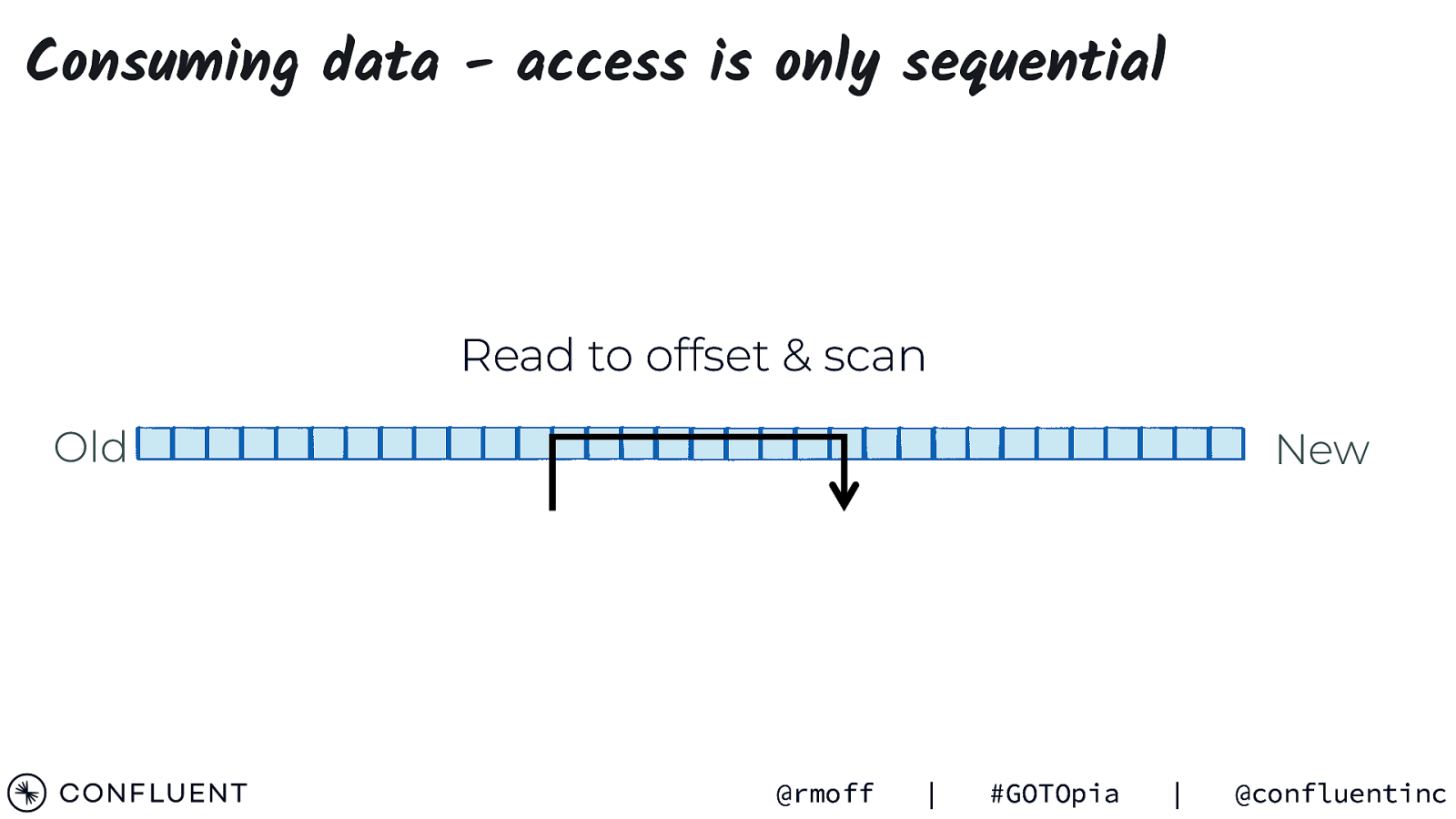
Consuming data - access is only sequential Read to offset & scan Old New @rmoff | #GOTOpia | @confluentinc
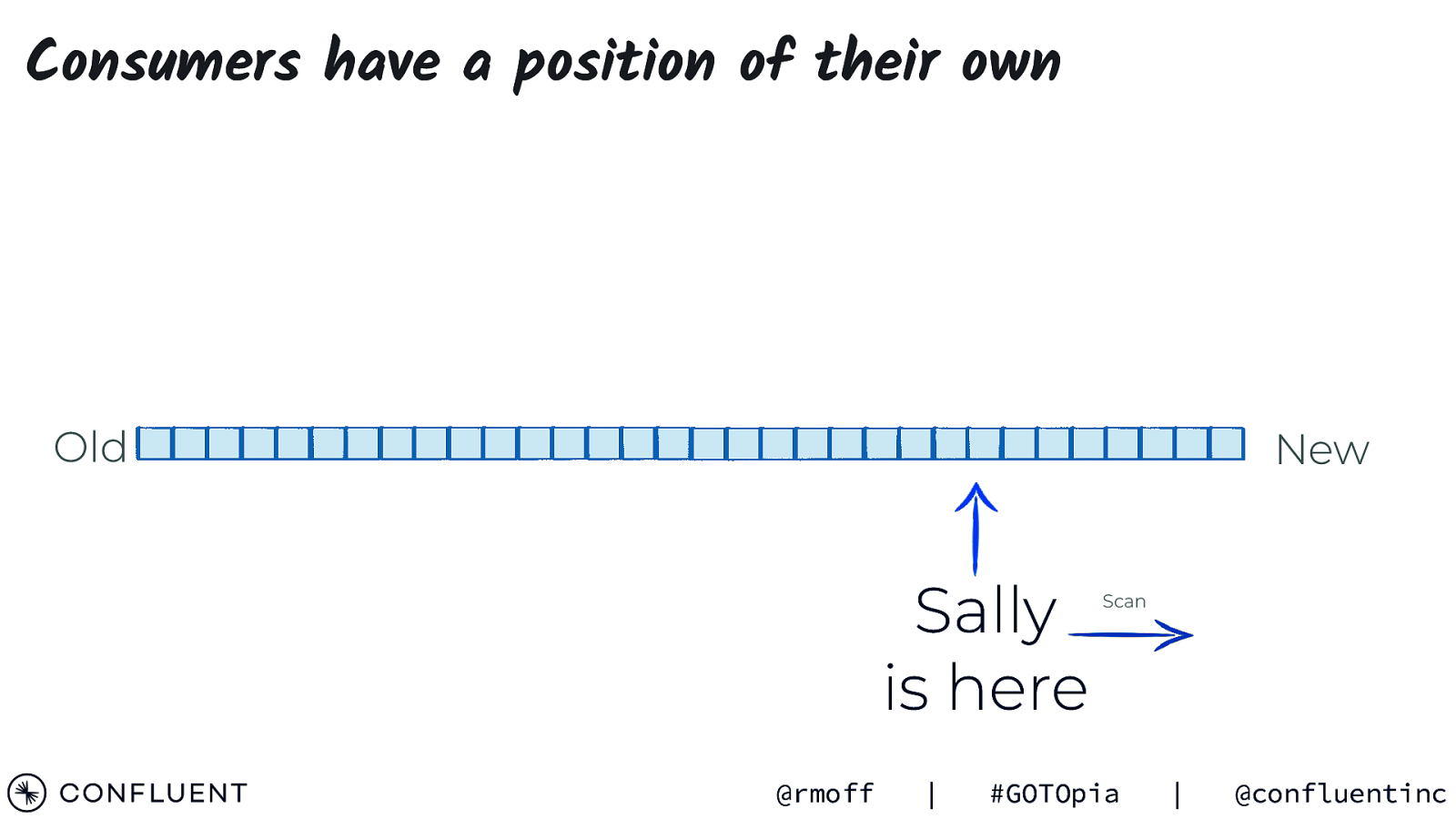
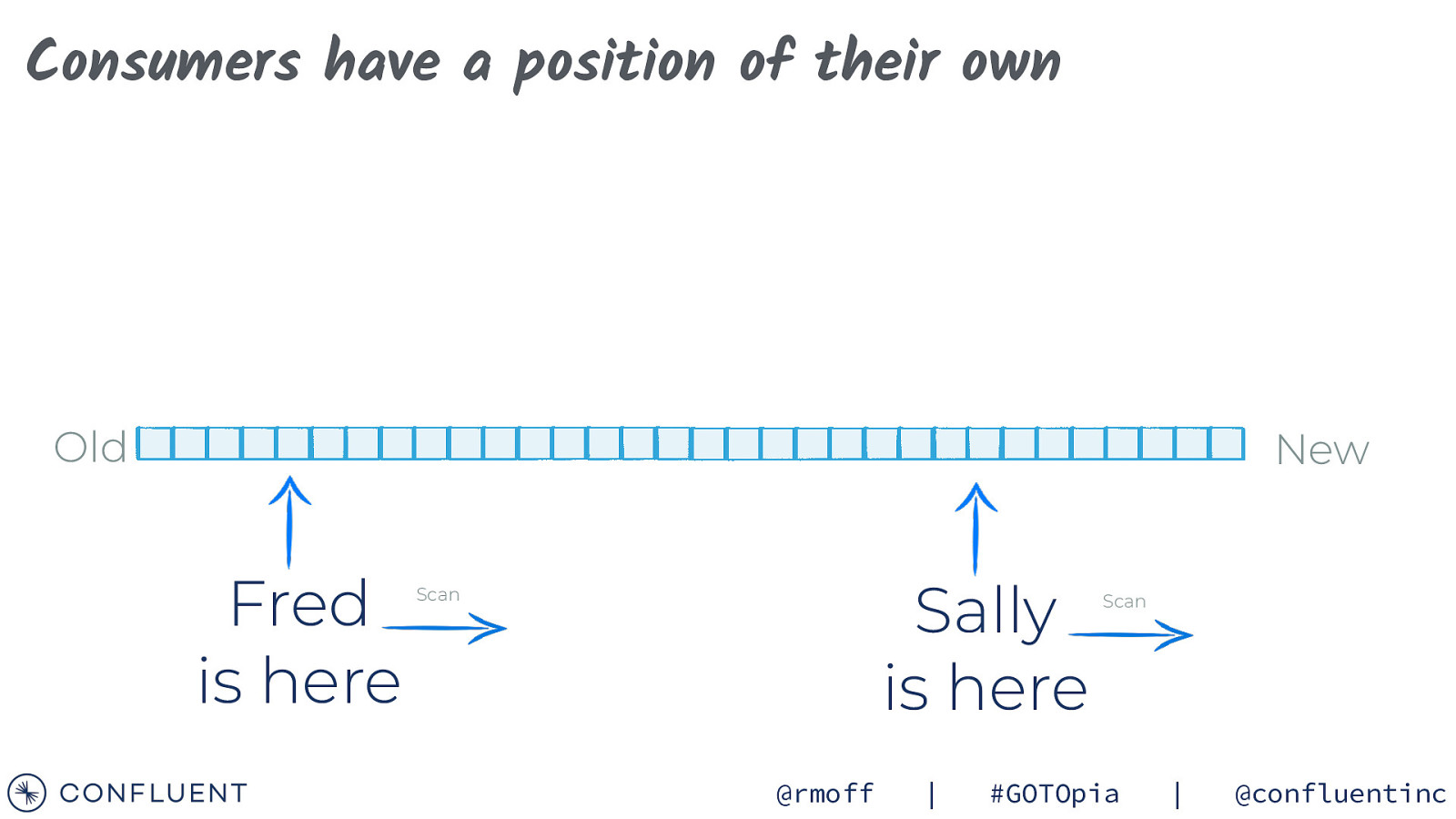
Consumers have a position of their own Old New Sally is here @rmoff | Scan #GOTOpia | @confluentinc
Consumers have a position of their own Old New Fred is here Sally is here Scan @rmoff | Scan #GOTOpia | @confluentinc
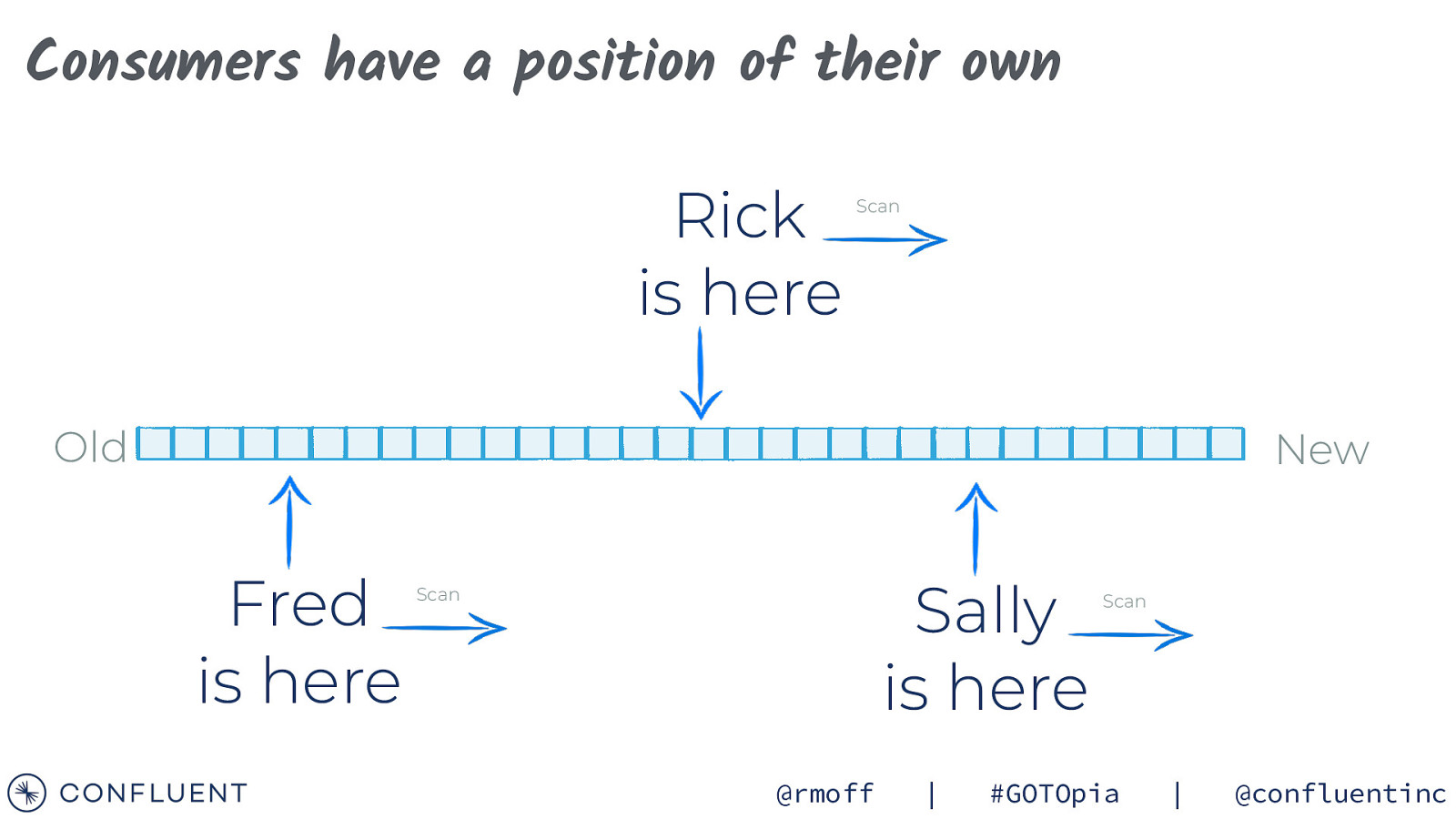
Consumers have a position of their own Rick is here Scan Old New Fred is here Sally is here Scan @rmoff | Scan #GOTOpia | @confluentinc
c, _ := kafka.NewConsumer(&cm) defer c.Close() c.Subscribe(topic, nil) for { select { case ev := <-c.Events(): switch ev.(type) { case *kafka.Message: km := ev.(*kafka.Message) fmt.Printf(“✅ Message ‘%v’ received from topic ‘%v’\n”, string(km.Value), string(*km.TopicPartition.Topic)) } } }
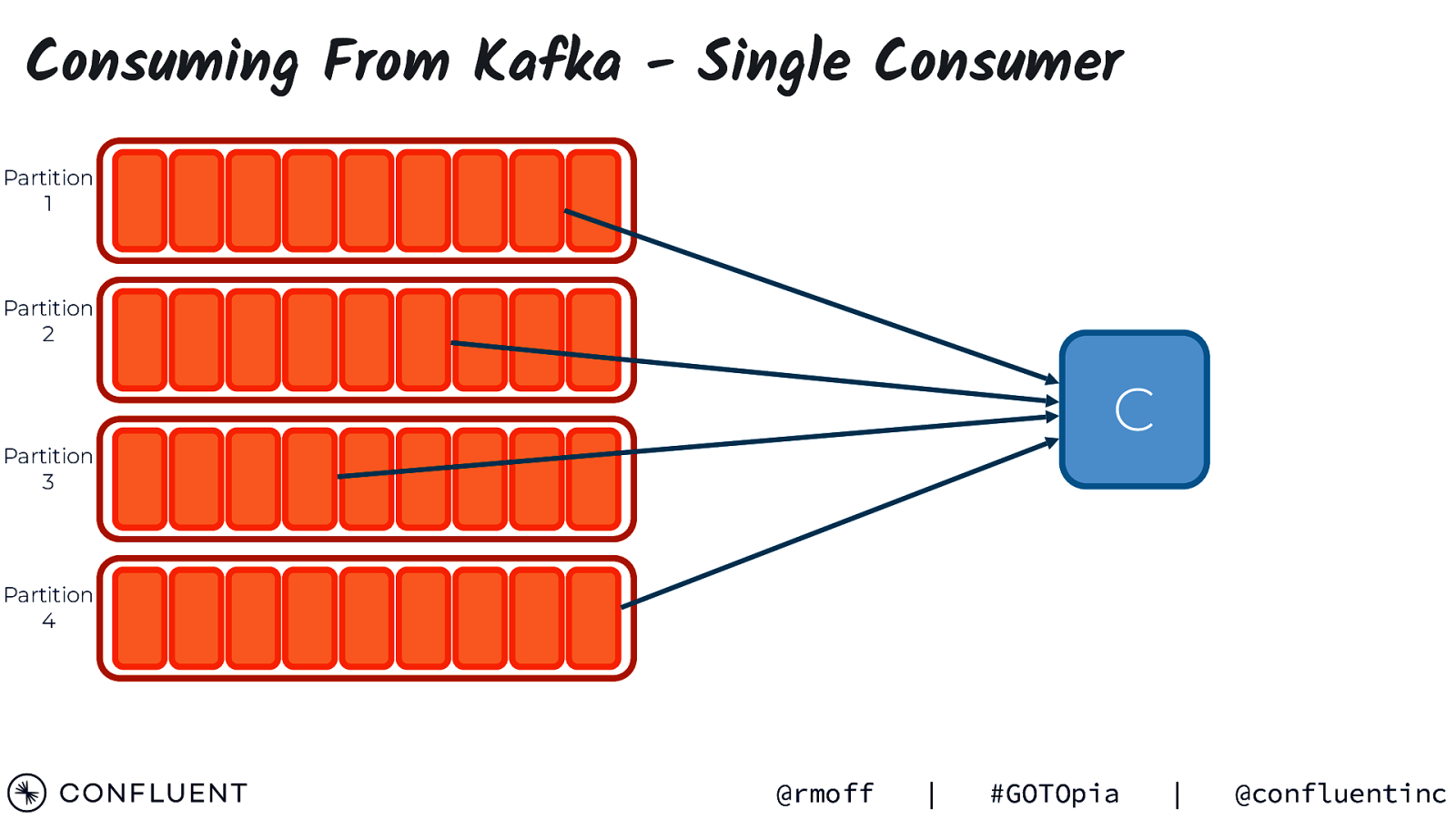
Consuming From Kafka - Single Consumer Partition 1 Partition 2 C Partition 3 Partition 4 @rmoff | #GOTOpia | @confluentinc
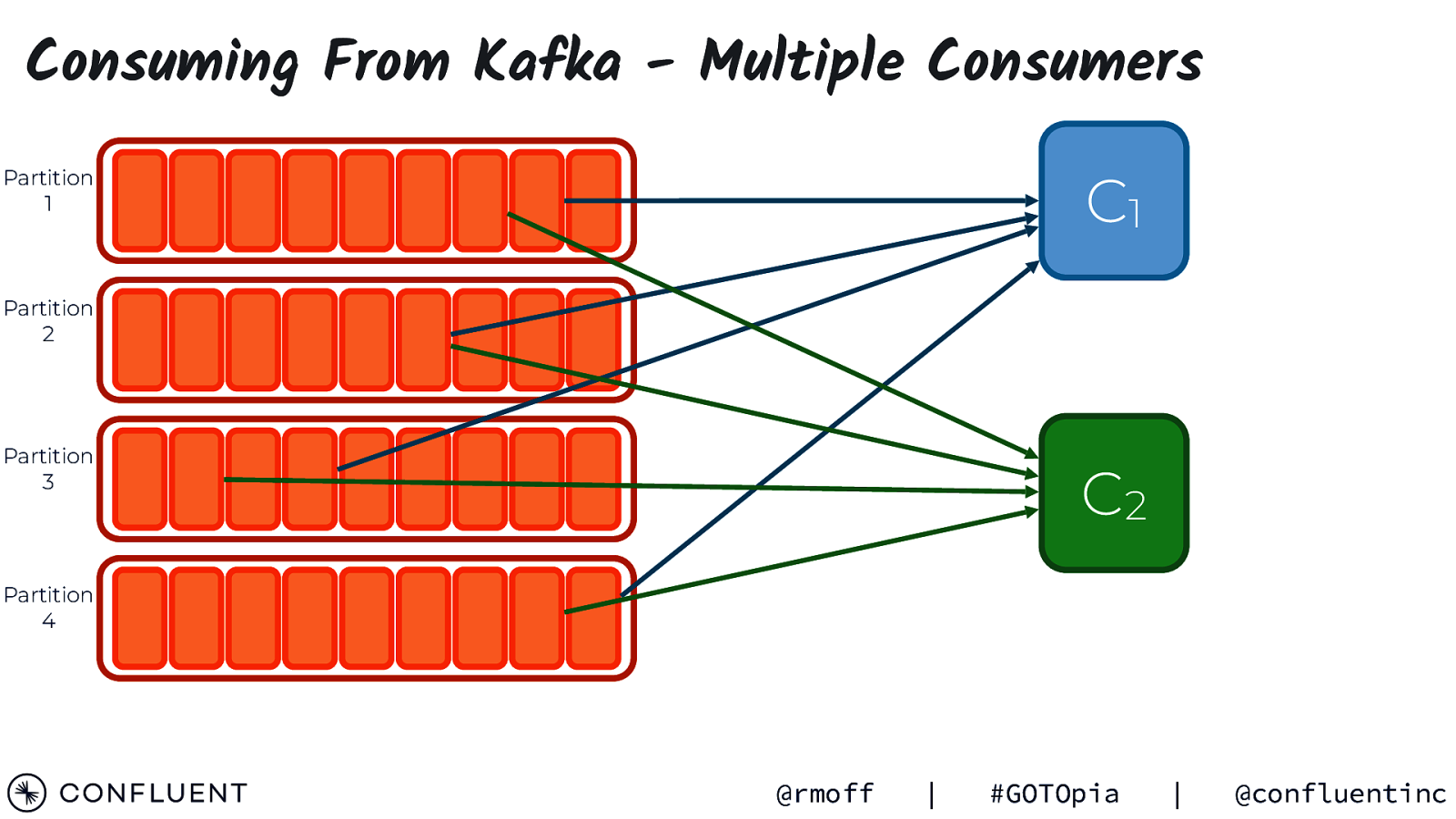
Consuming From Kafka - Multiple Consumers C1 Partition 1 Partition 2 Partition 3 C2 Partition 4 @rmoff | #GOTOpia | @confluentinc
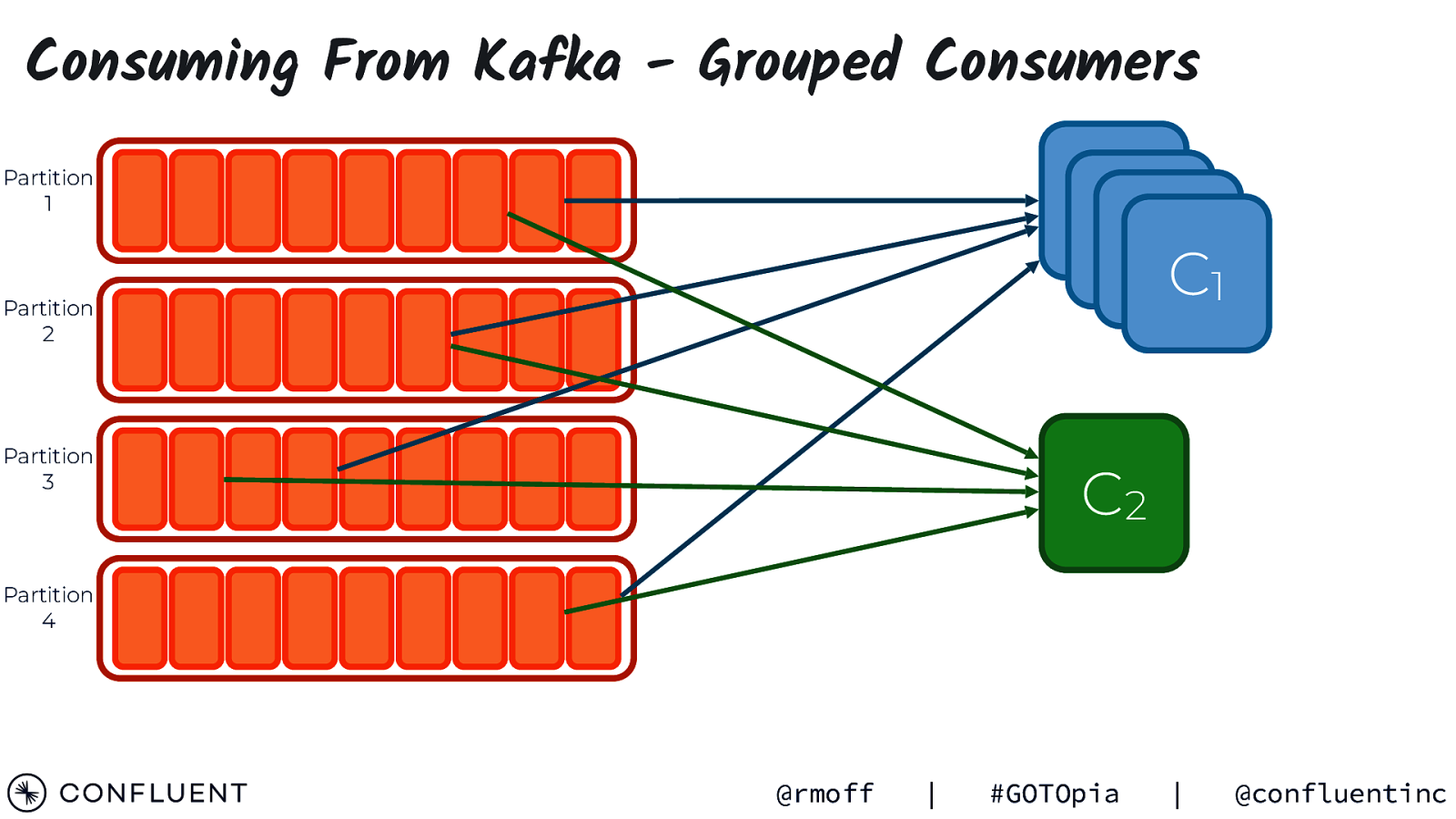
Consuming From Kafka - Grouped Consumers CC1 1 CC1 1 Partition 1 Partition 2 Partition 3 C2 Partition 4 @rmoff | #GOTOpia | @confluentinc
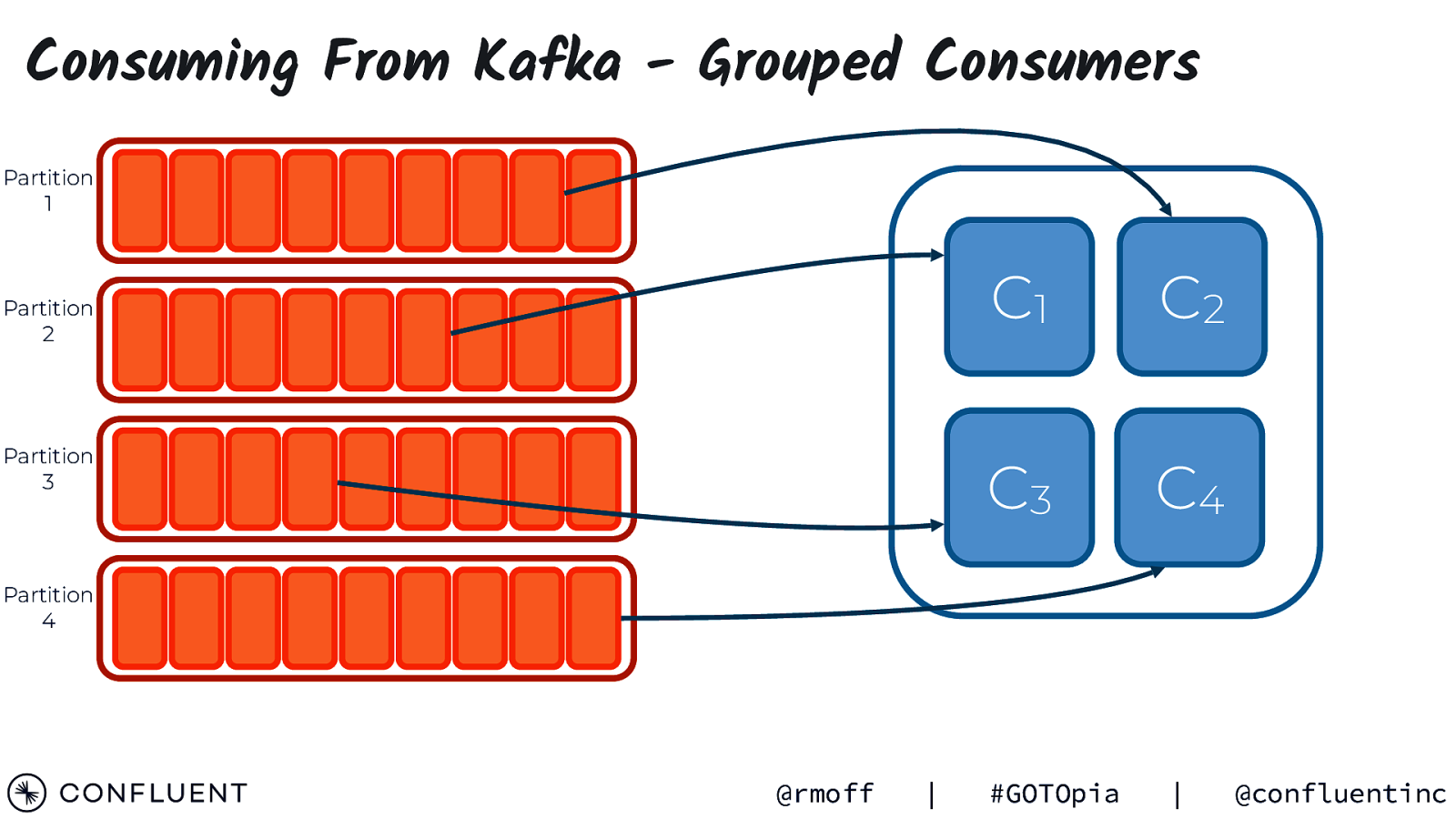
Consuming From Kafka - Grouped Consumers Partition 1 Partition 2 Partition 3 C1 C2 C3 C4 Partition 4 @rmoff | #GOTOpia | @confluentinc
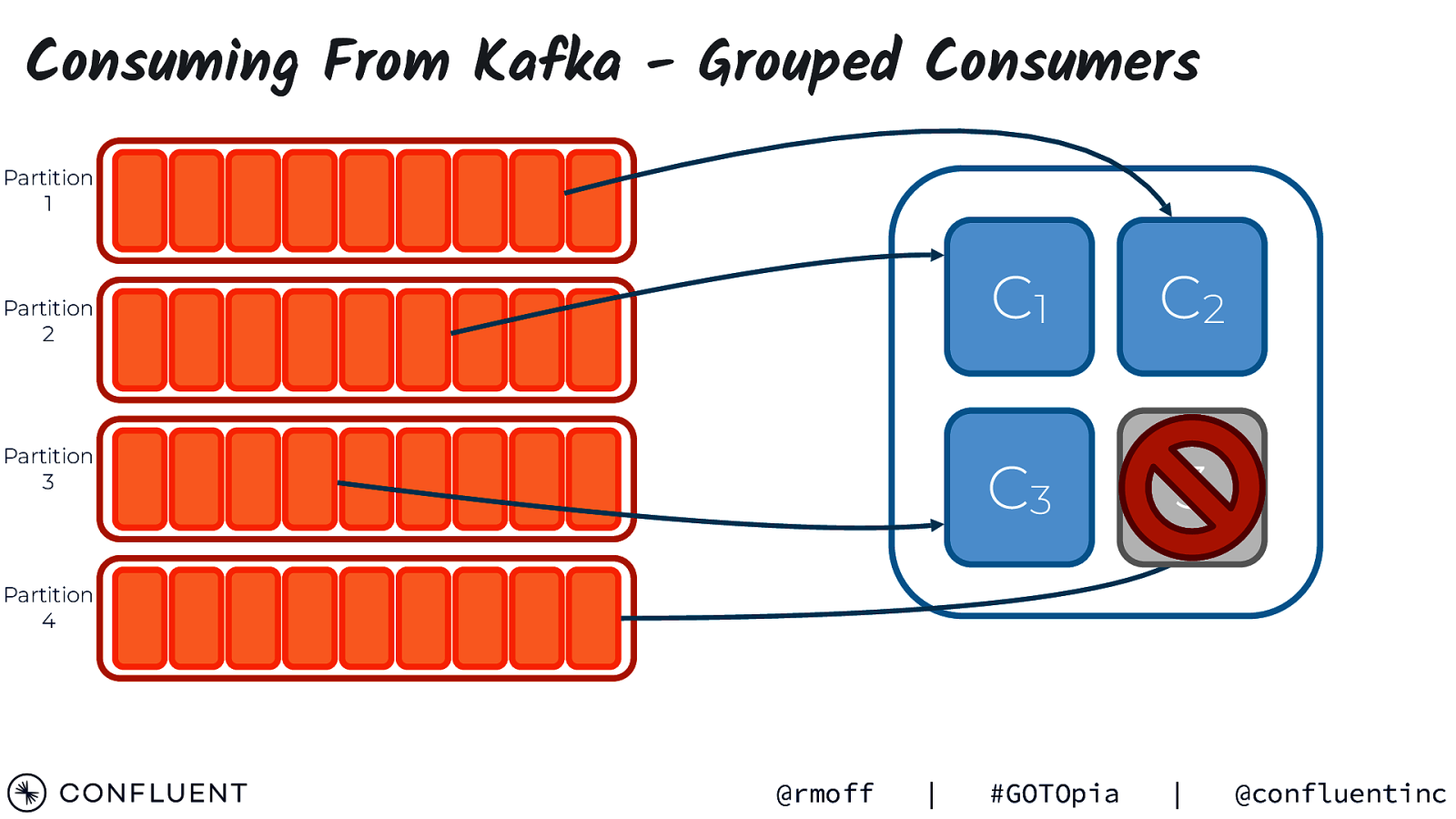
Consuming From Kafka - Grouped Consumers Partition 1 Partition 2 Partition 3 C1 C2 C3 3 #GOTOpia | Partition 4 @rmoff | @confluentinc
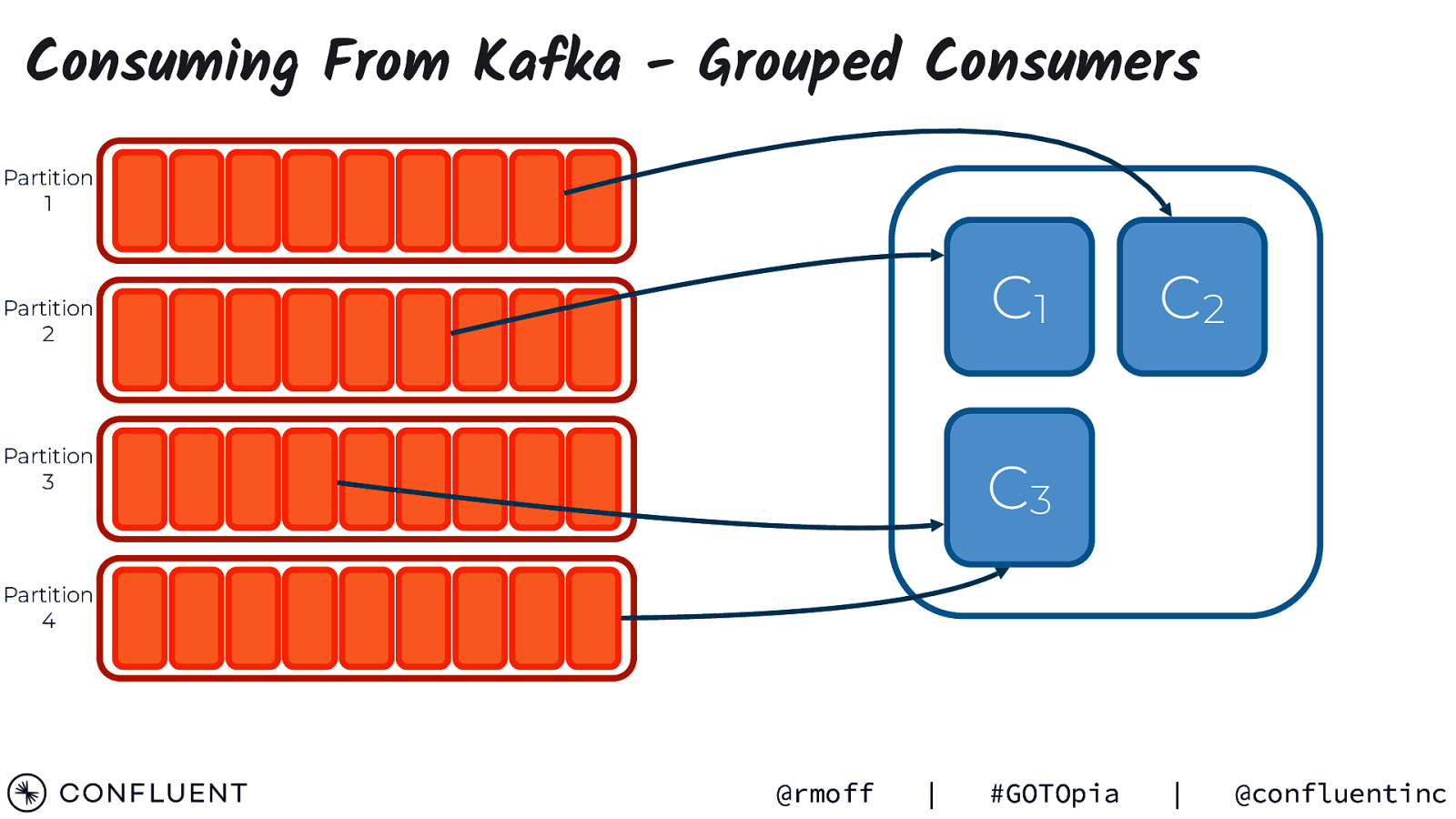
Consuming From Kafka - Grouped Consumers Partition 1 C1 Partition 2 Partition 3 C2 C3 Partition 4 @rmoff | #GOTOpia | @confluentinc
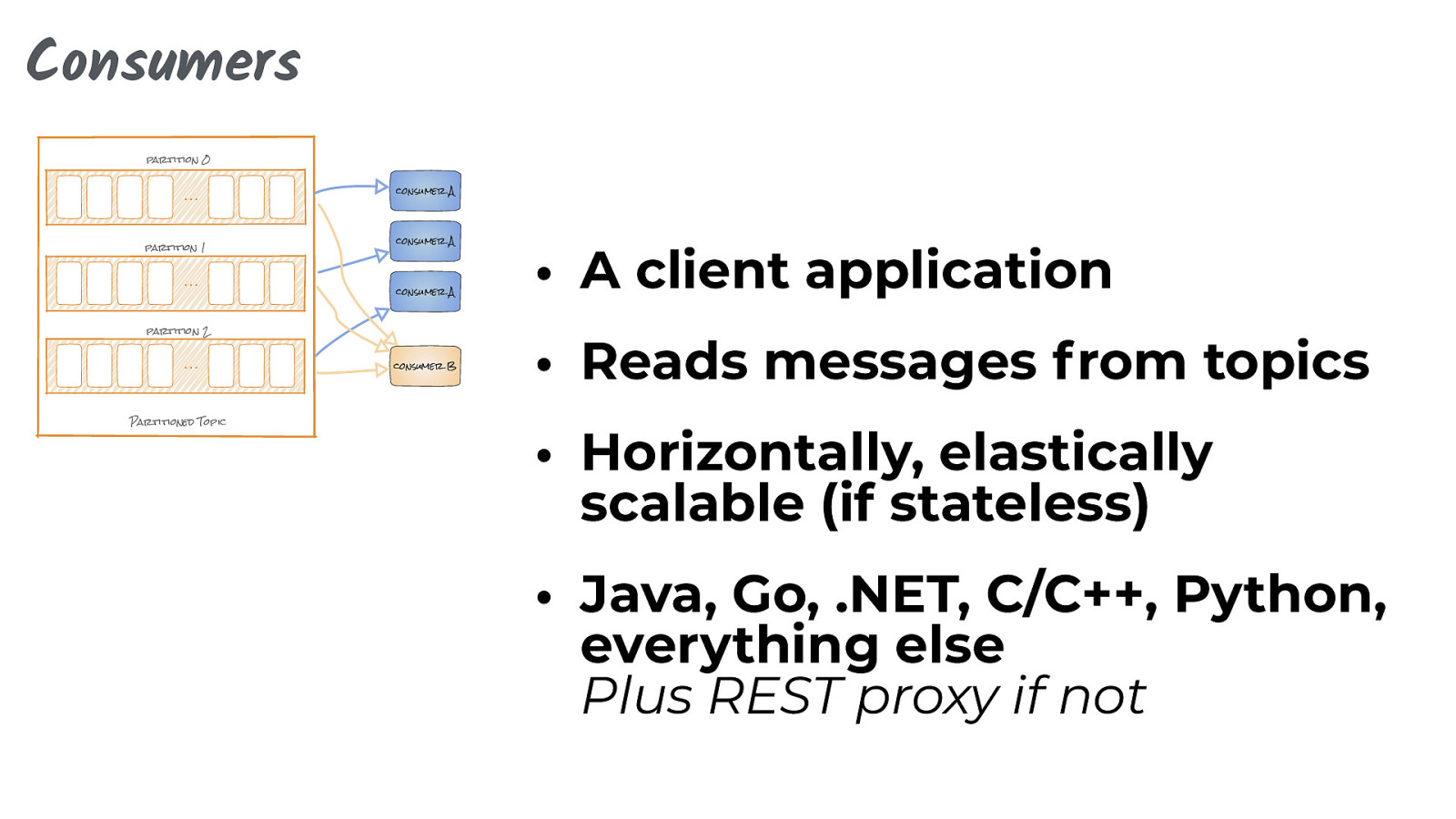
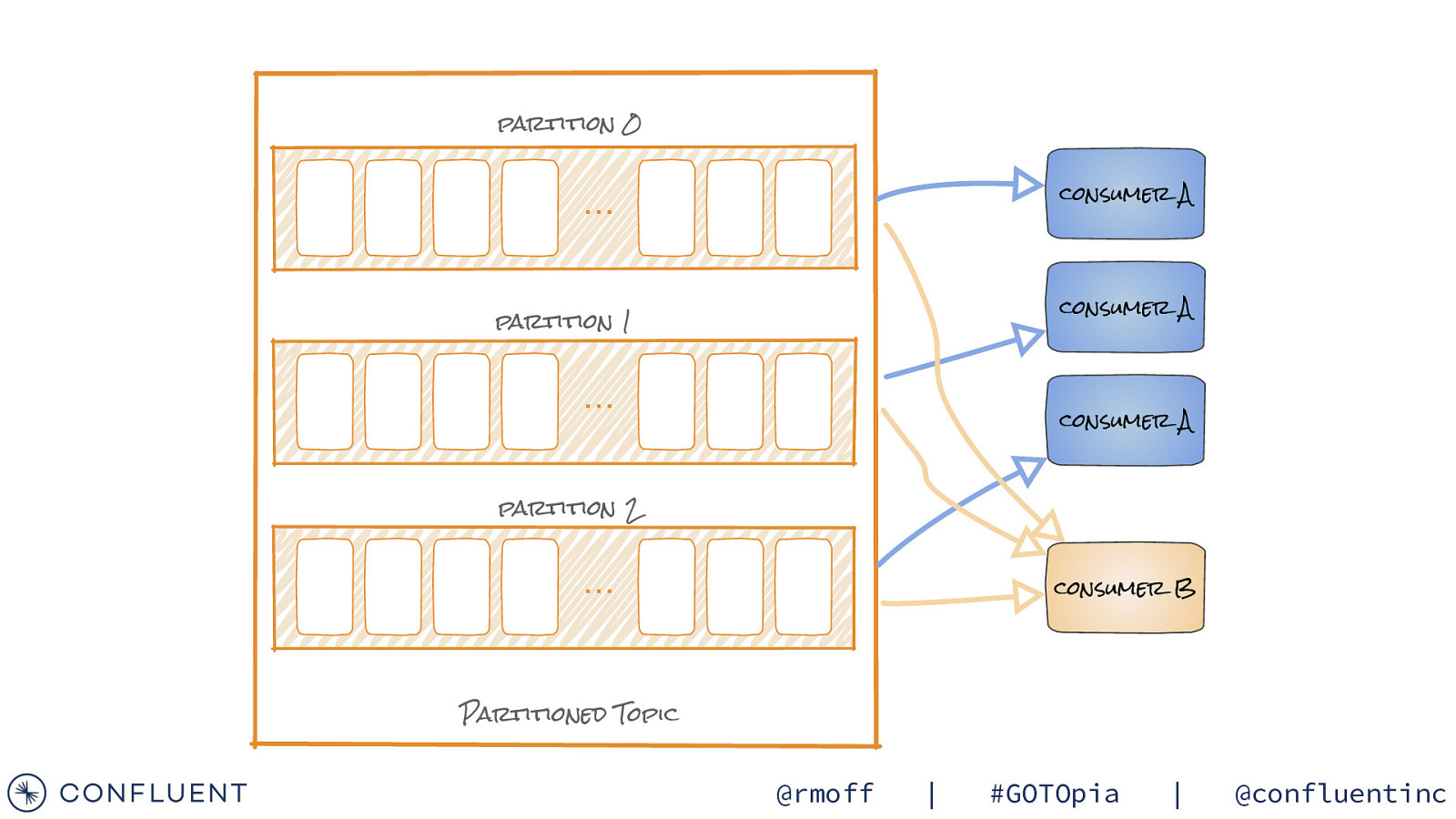
Consumers partition 0 … partition 1 … consumer A consumer A consumer A partition 2 … Partitioned Topic consumer B • A client application • Reads messages from topics • Horizontally, elastically scalable (if stateless) • Java, Go, .NET, C/C++, Python, everything else Plus REST proxy if not
BROKERS and REPLICATION @rmoff | #GOTOpia | @confluentinc
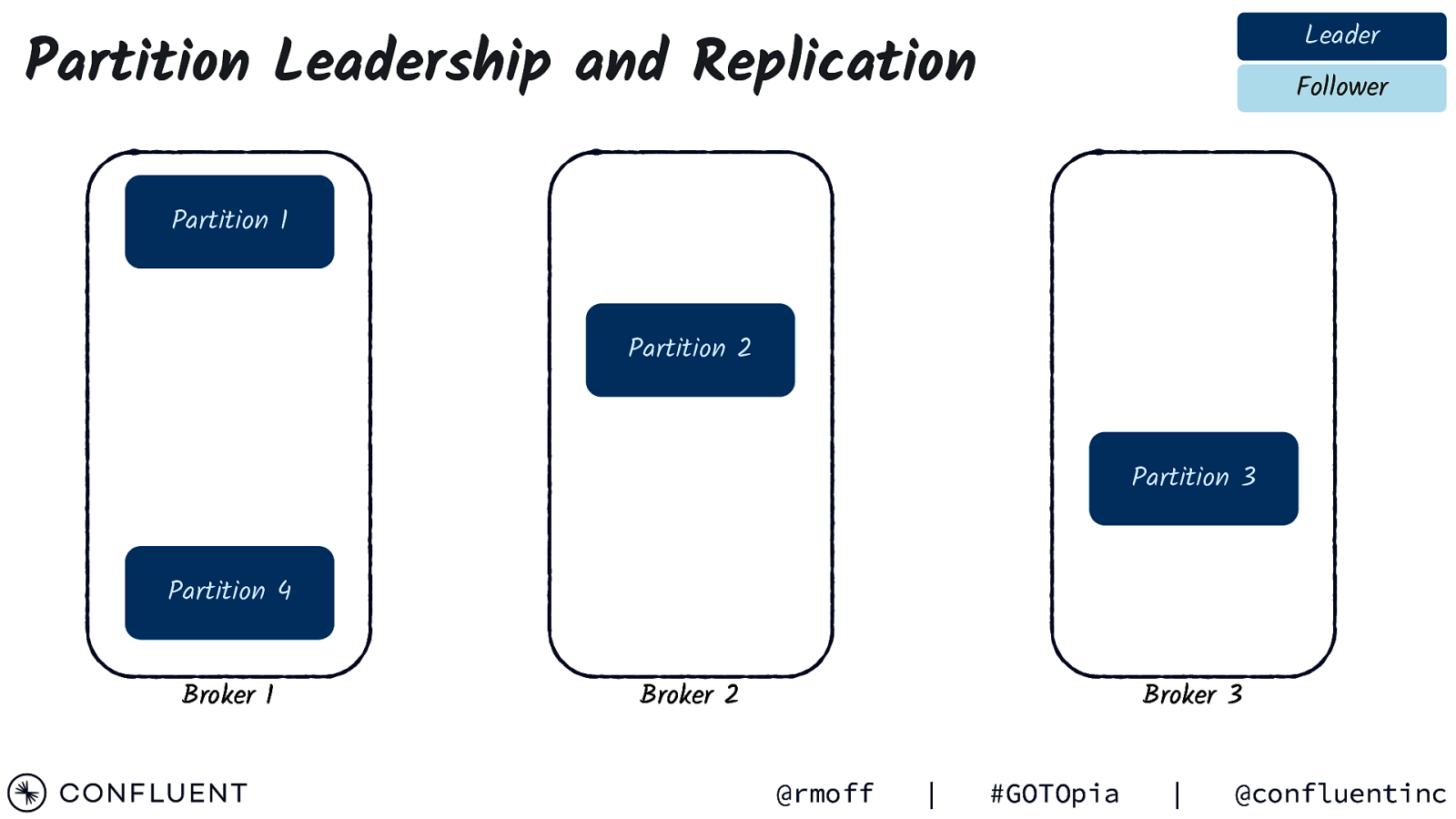
Leader Partition Leadership and Replication Follower Partition 1 Partition 2 Partition 3 Partition 4 Broker 1 Broker 2 Broker 3 @rmoff | #GOTOpia | @confluentinc
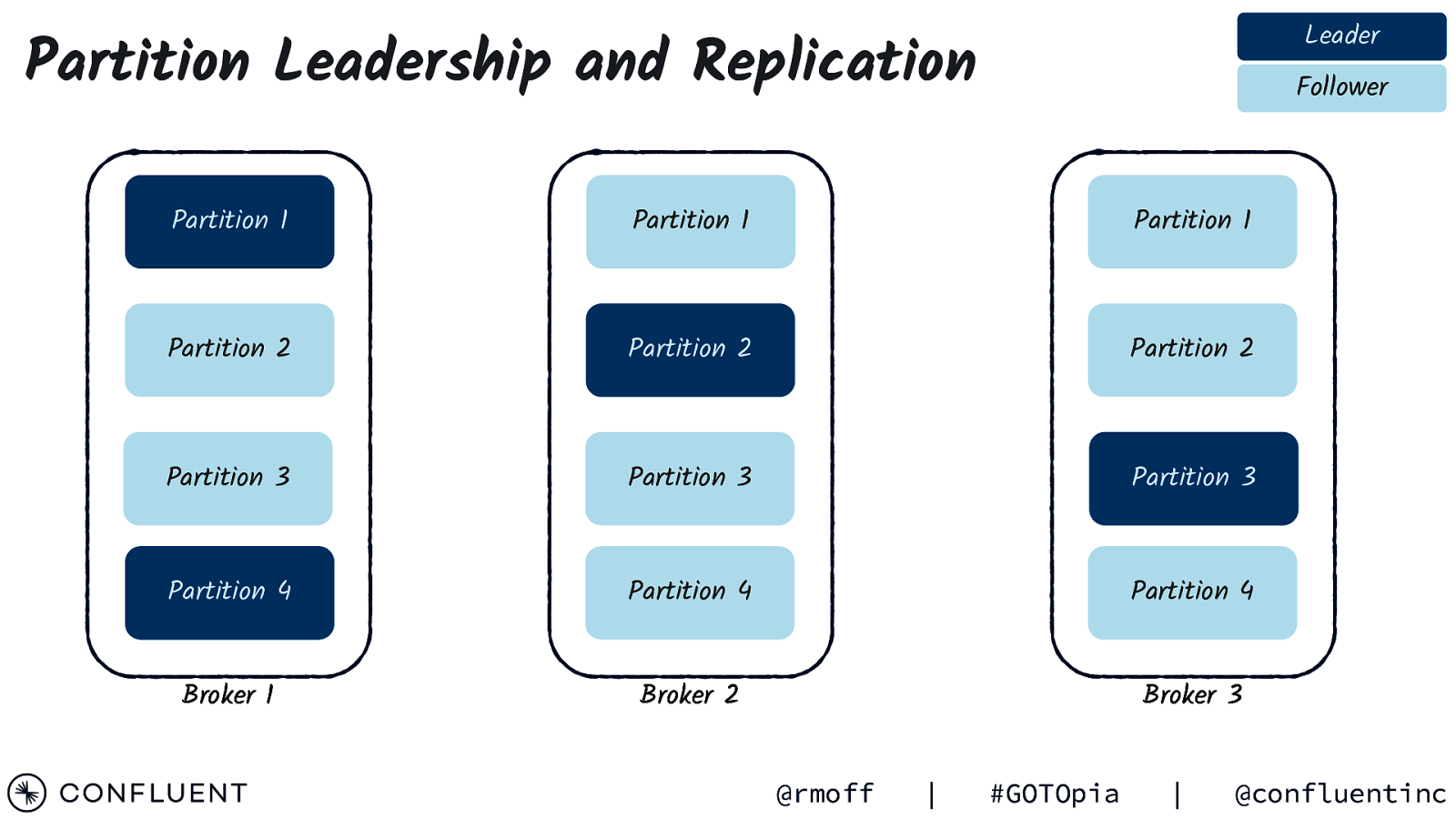
Leader Partition Leadership and Replication Follower Partition 1 Partition 1 Partition 1 Partition 2 Partition 2 Partition 2 Partition 3 Partition 3 Partition 3 Partition 4 Partition 4 Partition 4 Broker 1 Broker 2 Broker 3 @rmoff | #GOTOpia | @confluentinc
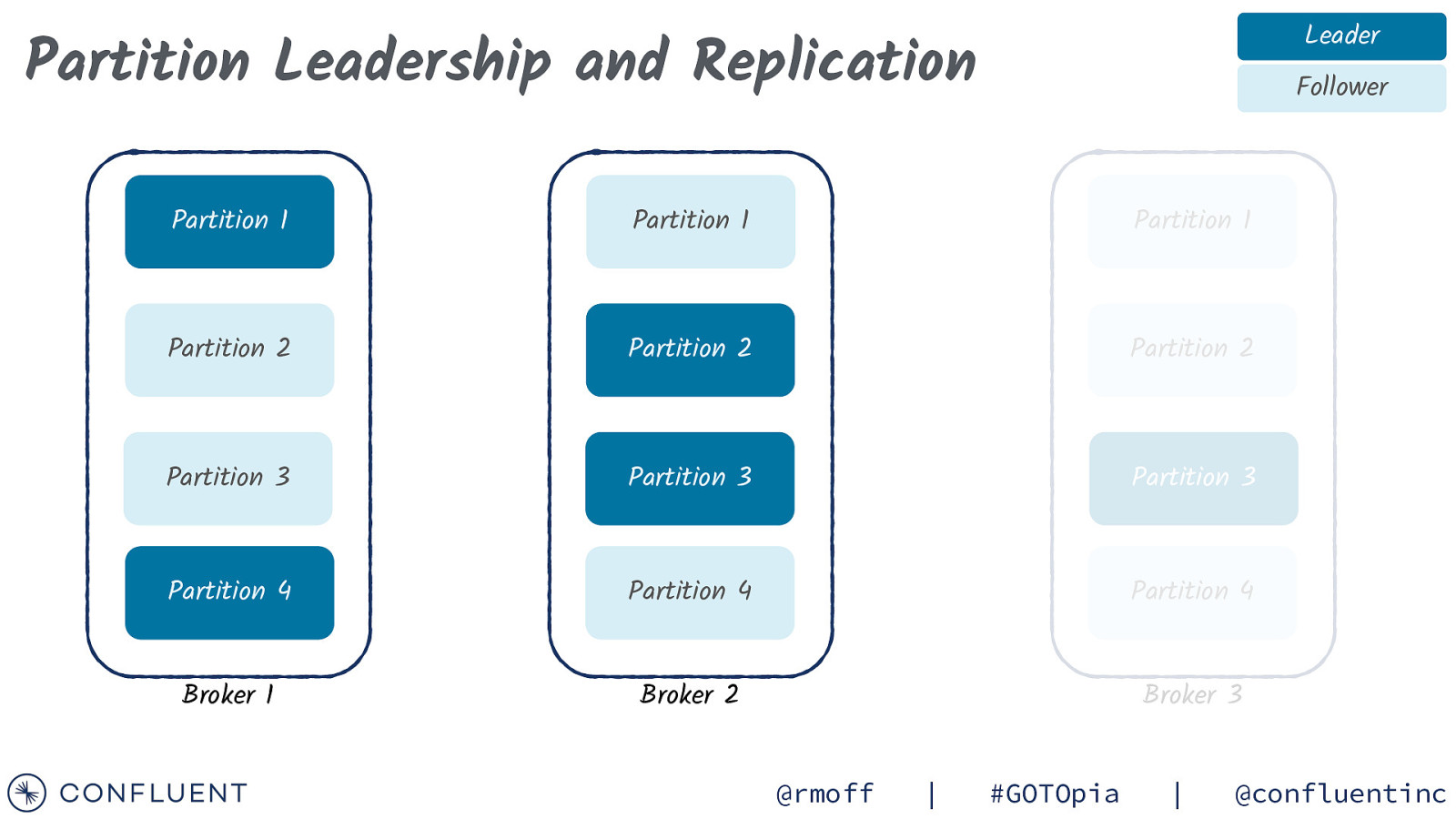
Leader Partition Leadership and Replication Follower Partition 1 Partition 1 Partition 1 Partition 2 Partition 2 Partition 2 Partition 3 Partition 3 Partition 3 Partition 4 Partition 4 Partition 4 Broker 1 Broker 2 Broker 3 @rmoff | #GOTOpia | @confluentinc
So far, this is Pretty good @rmoff | #GOTOpia | @confluentinc
So far, this is Pretty good but I’ve not finished yet… @rmoff | #GOTOpia | @confluentinc
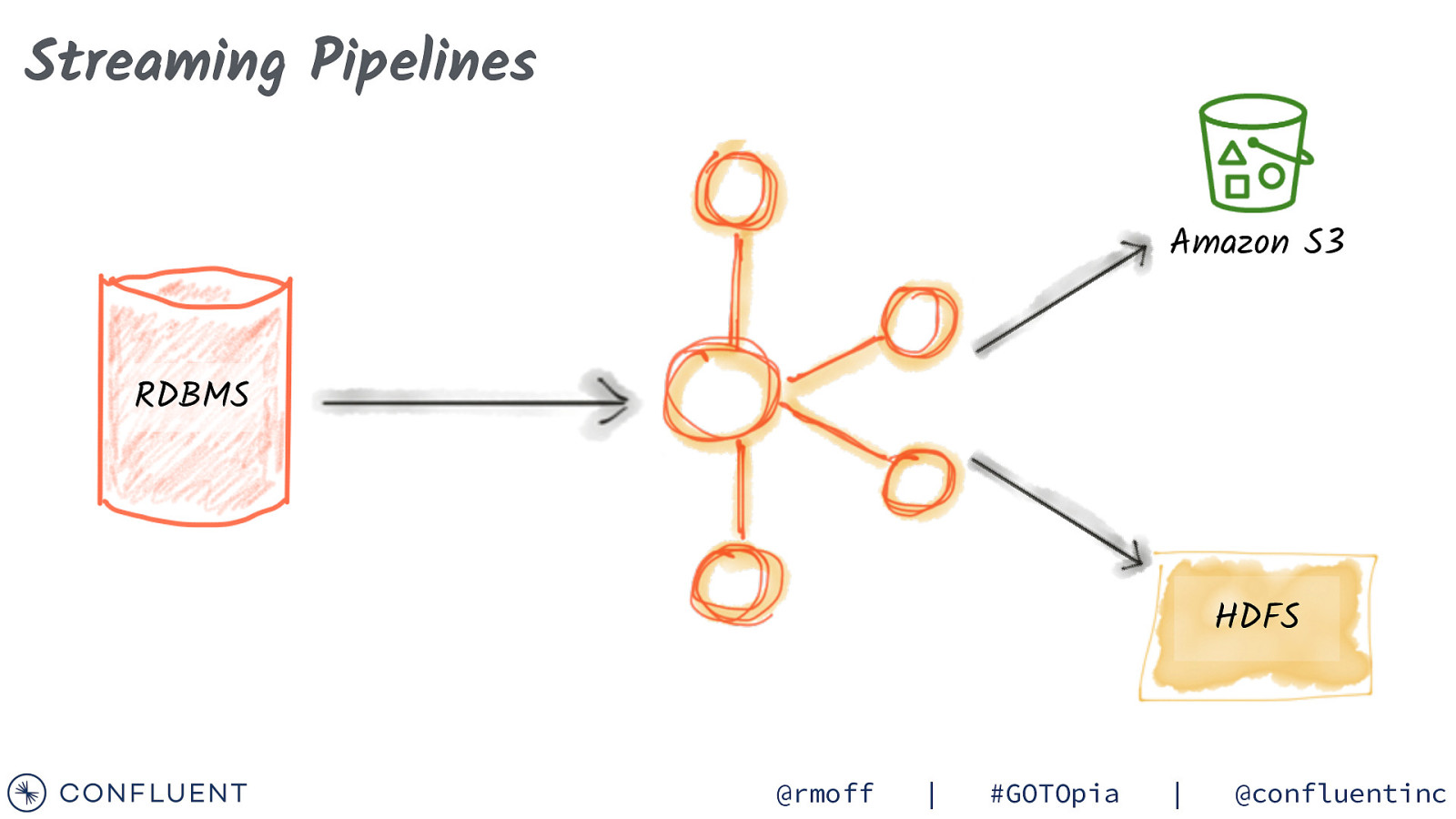
Streaming Pipelines Amazon S3 RDBMS HDFS @rmoff | #GOTOpia | @confluentinc
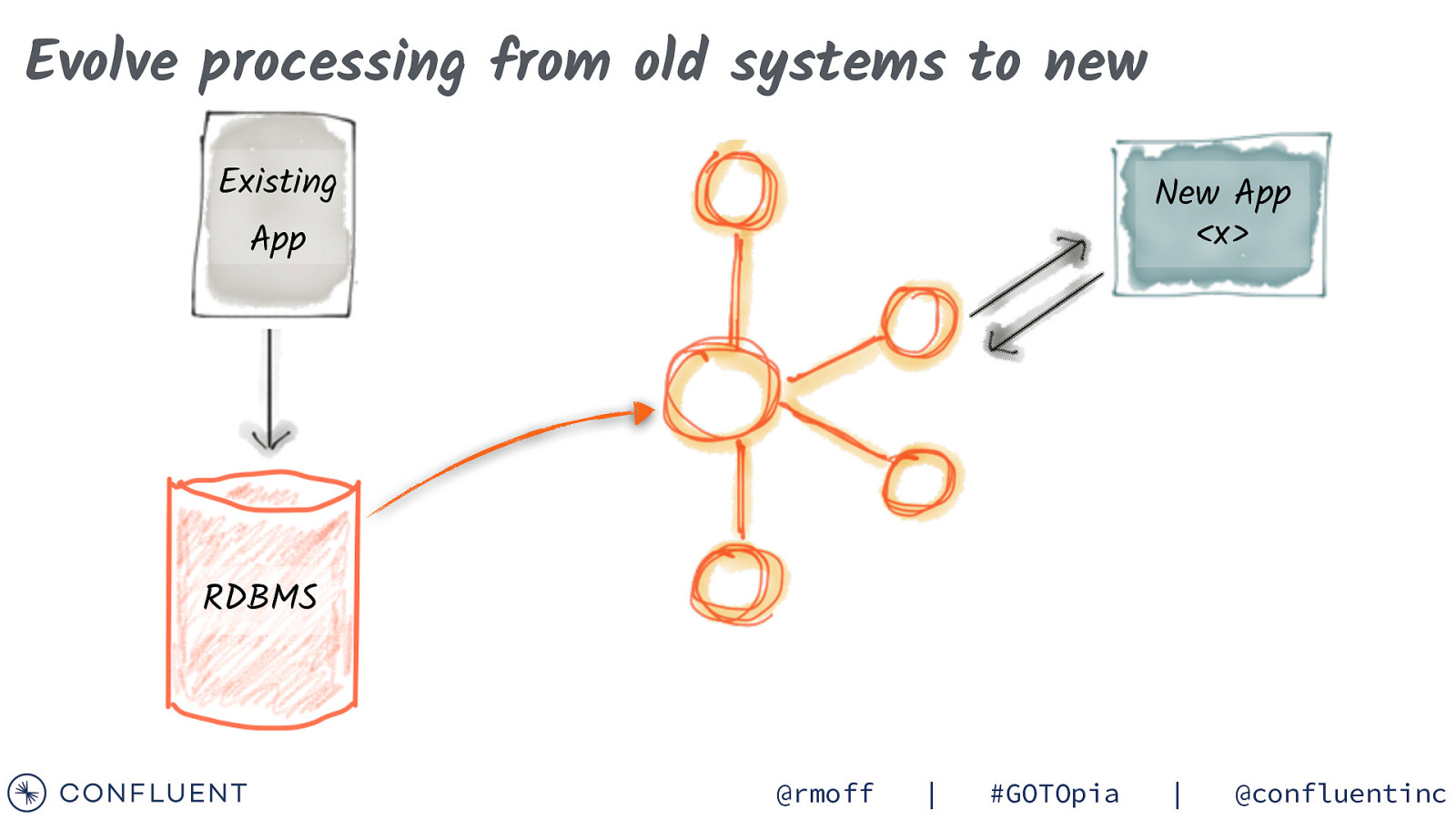
Evolve processing from old systems to new Existing New App <x> App RDBMS @rmoff | #GOTOpia | @confluentinc
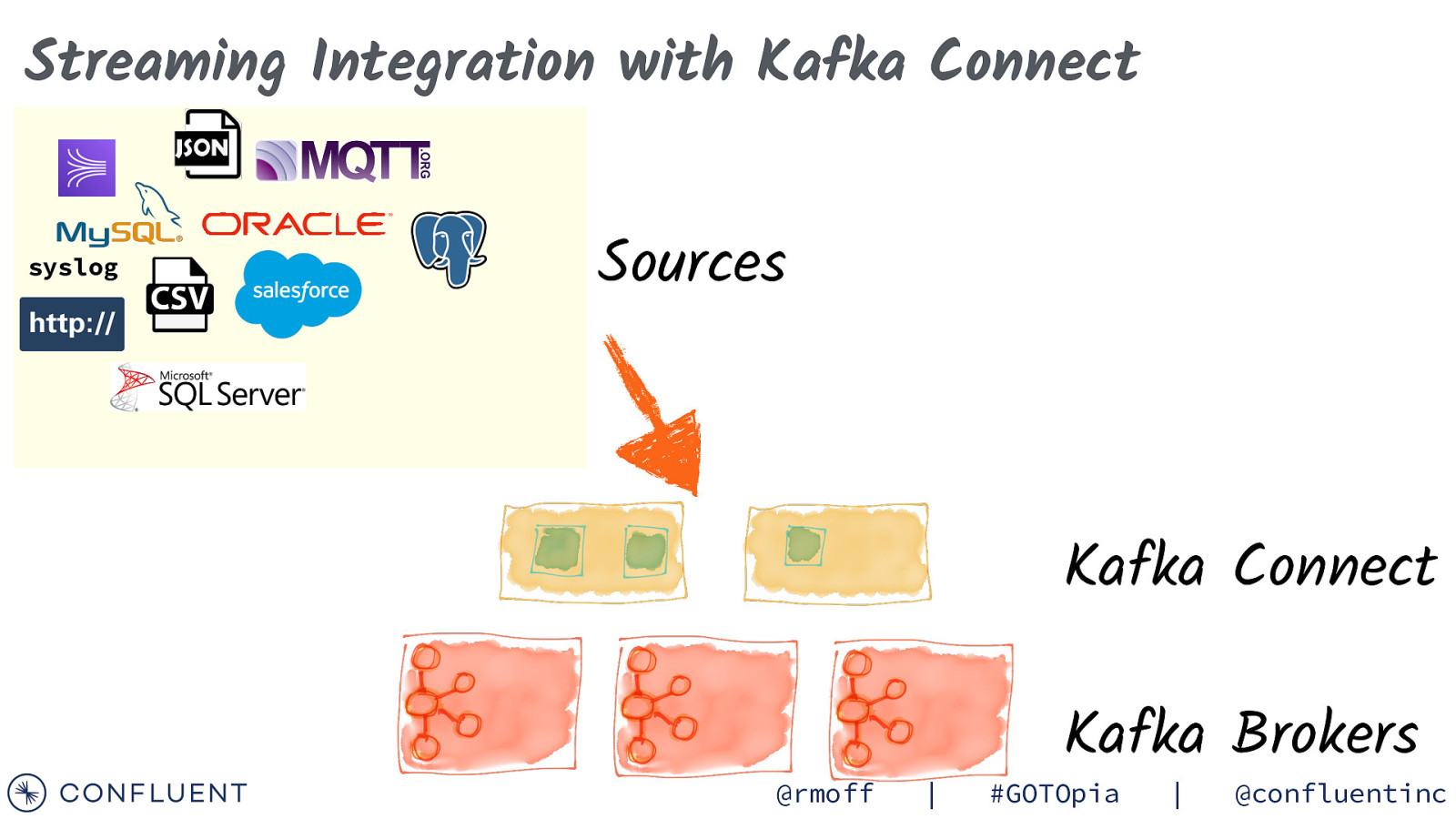
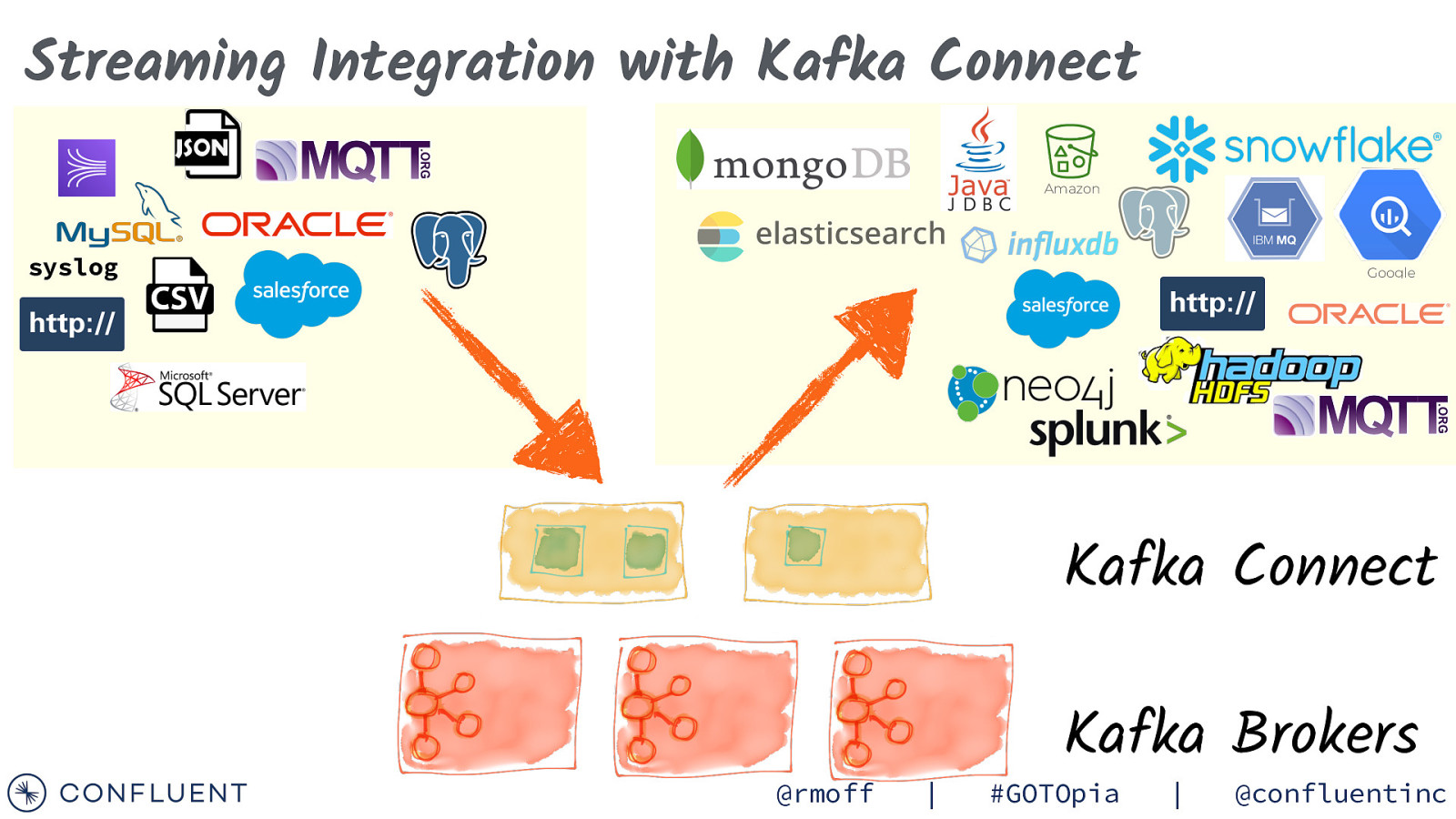
Streaming Integration with Kafka Connect syslog Sources Kafka Connect @rmoff | Kafka Brokers #GOTOpia | @confluentinc
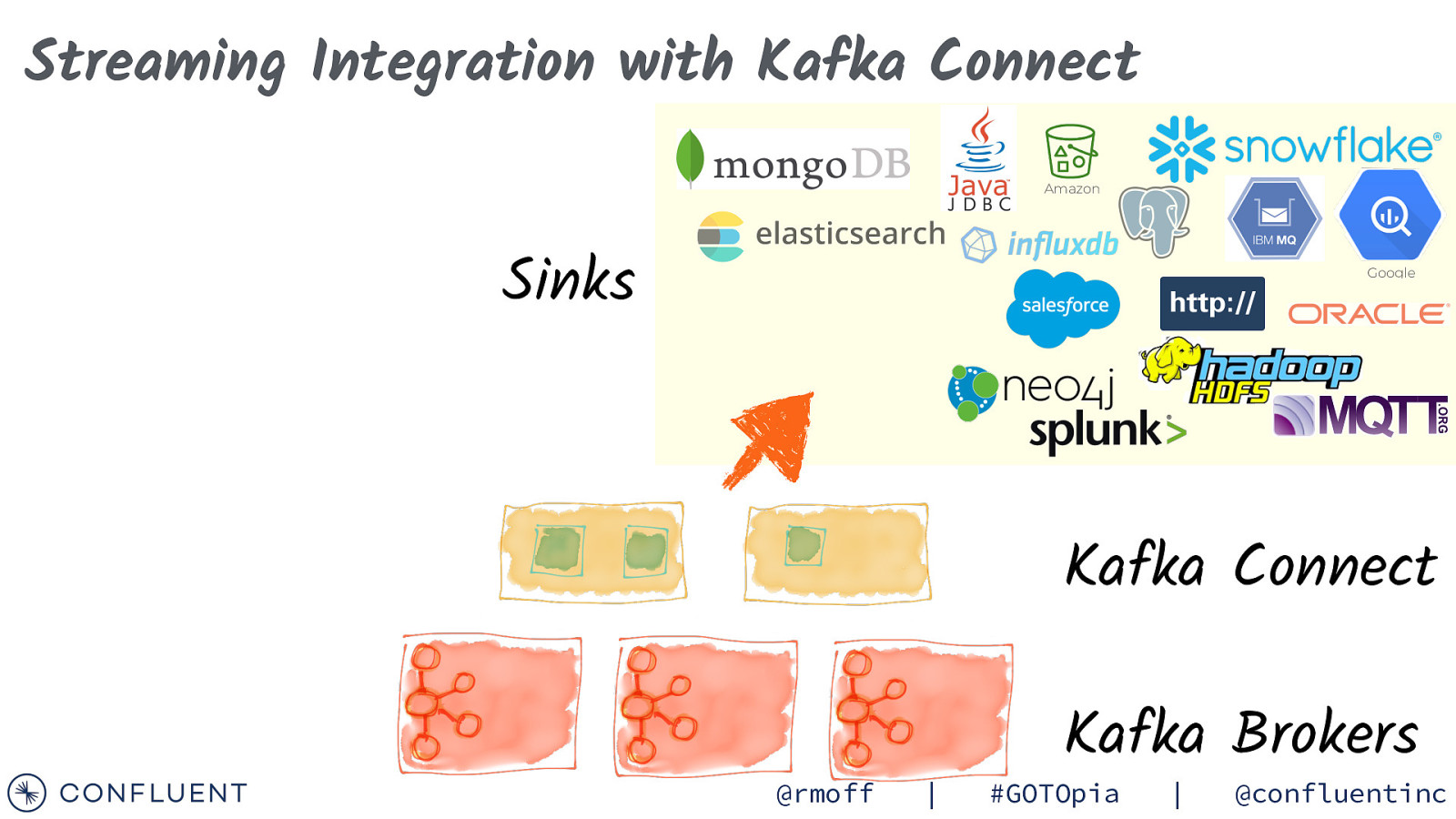
Streaming Integration with Kafka Connect Amazon Sinks Google Kafka Connect @rmoff | Kafka Brokers #GOTOpia | @confluentinc
Streaming Integration with Kafka Connect Amazon syslog Google Kafka Connect @rmoff | Kafka Brokers #GOTOpia | @confluentinc
Look Ma, No Code! { “connector.class”: “io.confluent.connect.jdbc.JdbcSourceConnector”, “connection.url”: “jdbc:mysql://asgard:3306/demo”, “table.whitelist”: “sales,orders,customers” } @rmoff | #GOTOpia | @confluentinc
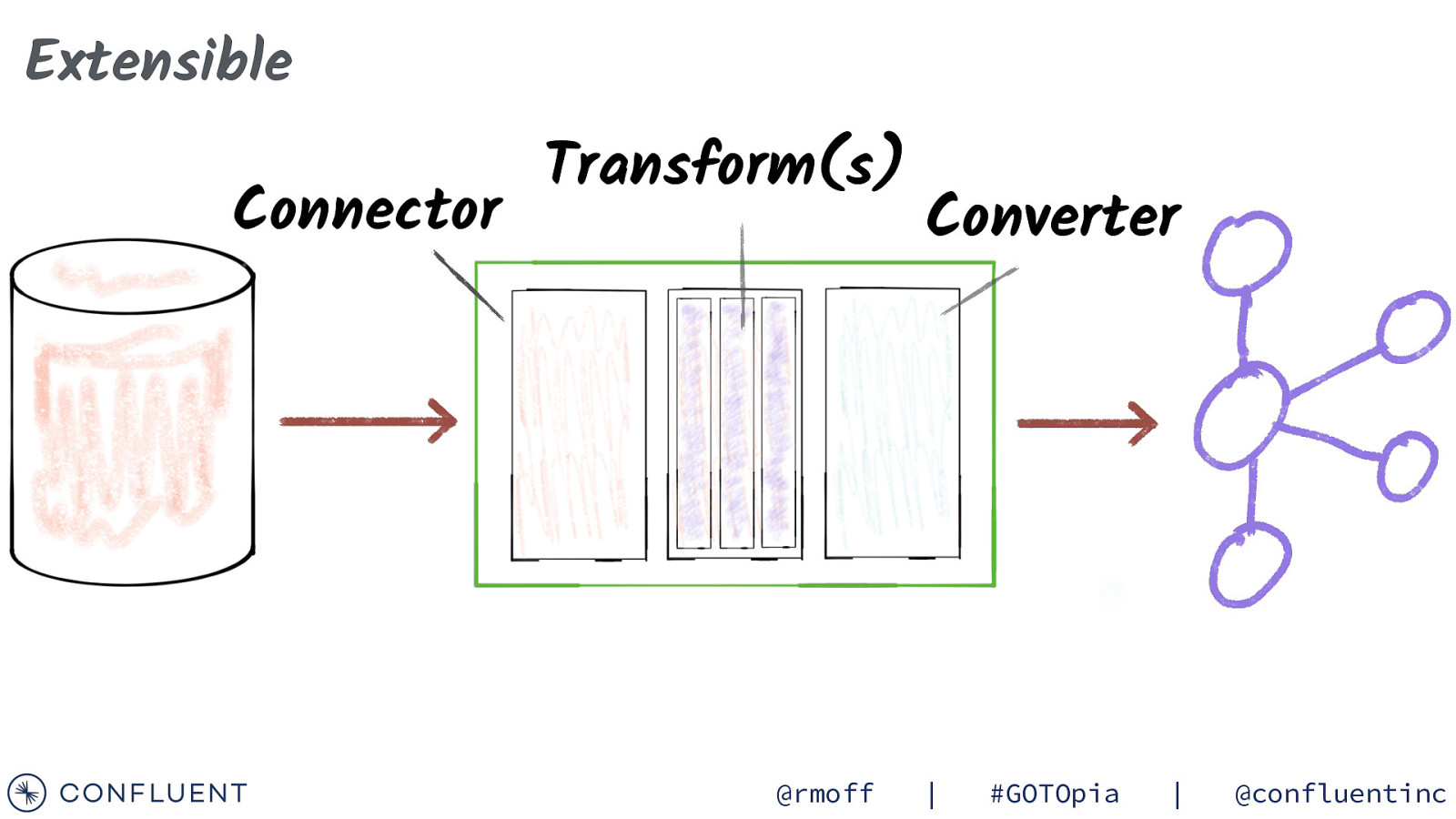
Extensible Connector Transform(s) @rmoff Converter | #GOTOpia | @confluentinc
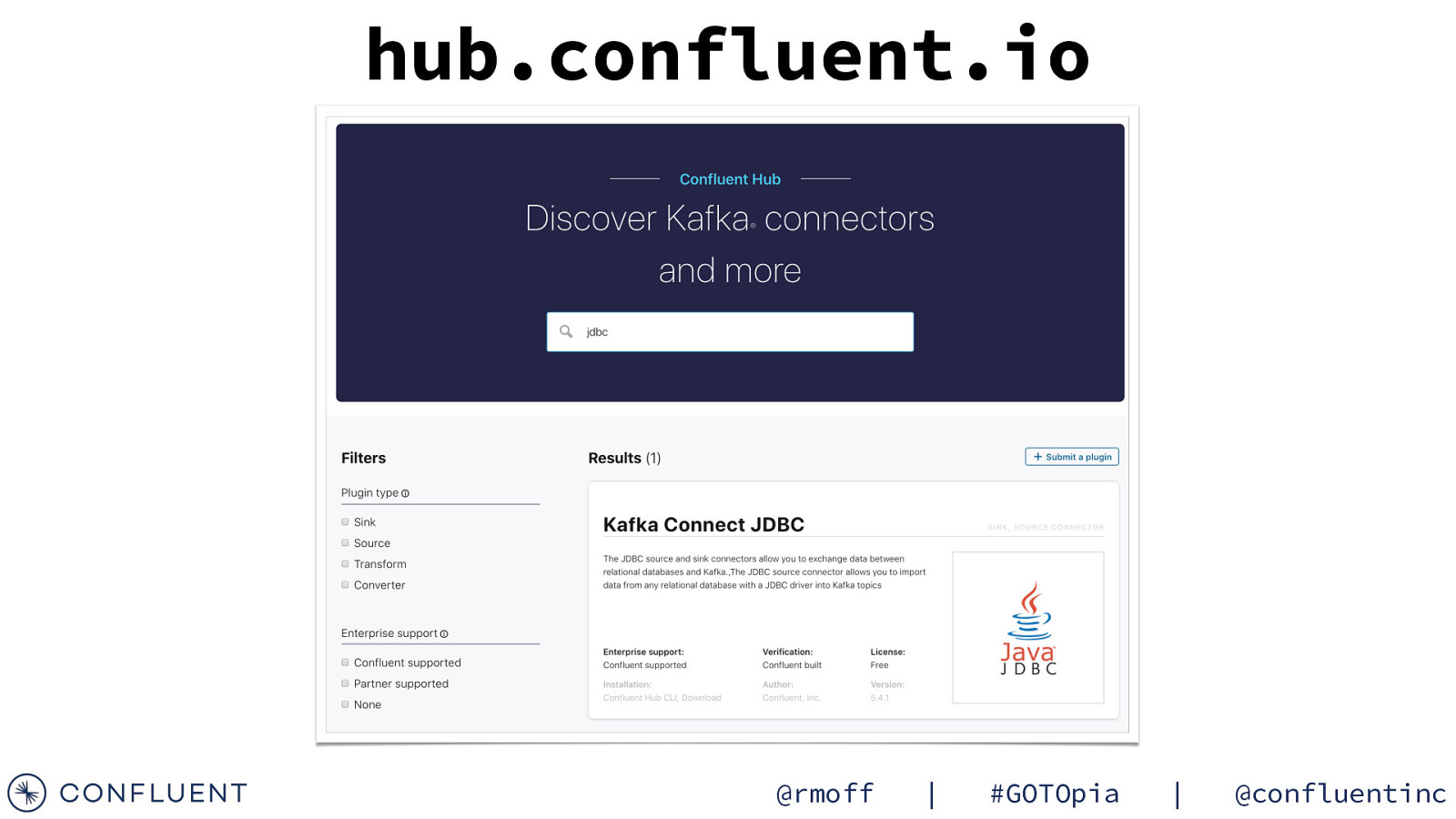
hub.confluent.io @rmoff | #GOTOpia | @confluentinc
K V
K V
K V
K V
K V ? s i h t s ’ t a h w … t i a W
Lack of schemas – Coupling teams and services 2001 2001 Citrus Heights-Sunrise Blvd Citrus_Hghts 60670001 3400293 34 SAC Sacramento SV Sacramento Valley SAC Sacramento County APCD SMA8 Sacramento Metropolitan Area CA 6920 Sacramento 28 6920 13588 7400 Sunrise Blvd 95610 38 41 56 38.6988889 121 16 15.98999977 -121.271111 10 4284781 650345 52 @rmoff | #GOTOpia | @confluentinc
Serialisation & Schemas JSON Avro Protobuf Schema JSON CSV @rmoff | #GOTOpia | @confluentinc
Serialisation & Schemas JSON Avro Protobuf Schema JSON CSV 👍 👍 👍 😬 https://rmoff.dev/qcon-schemas @rmoff | #GOTOpia | @confluentinc
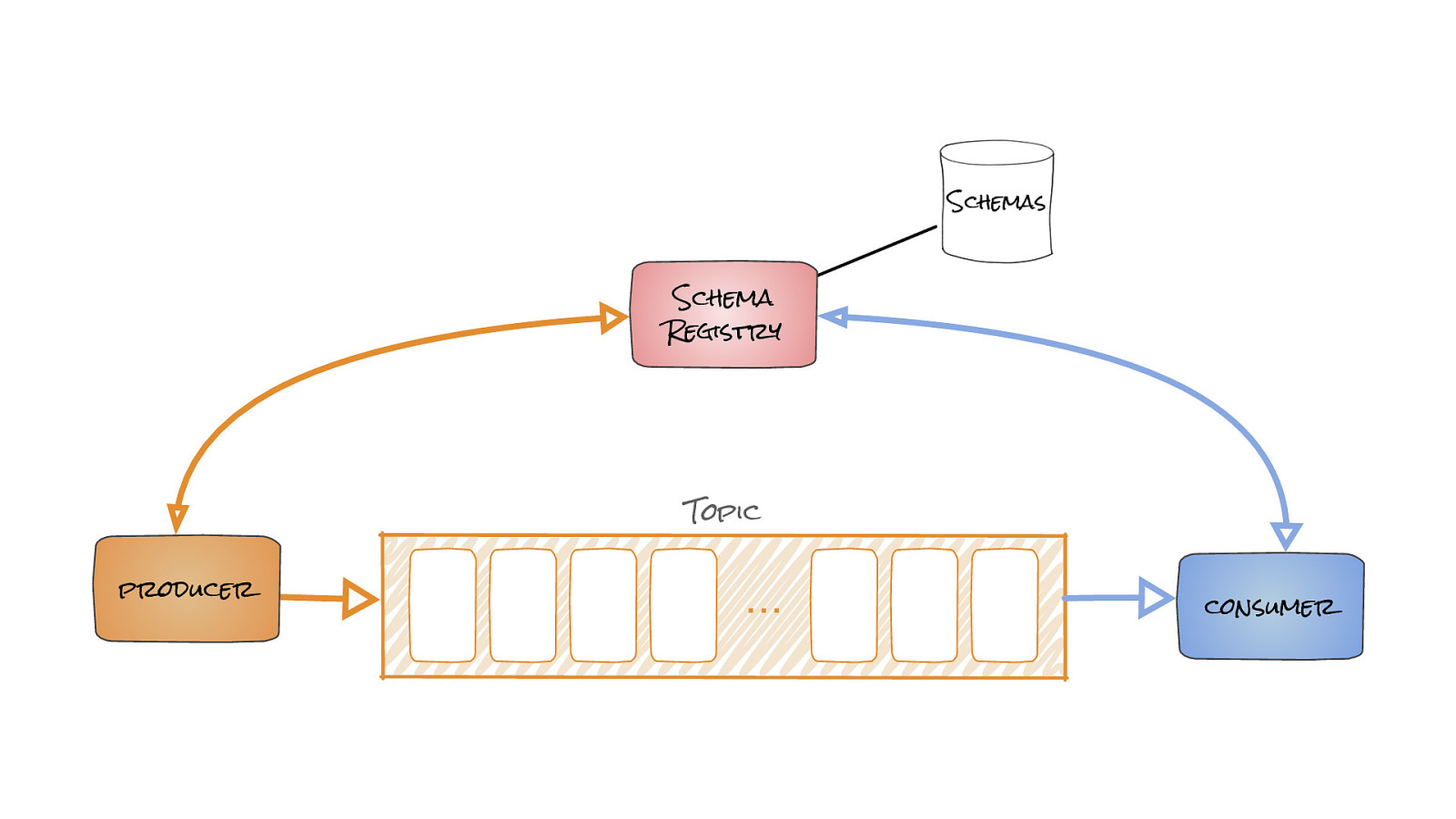
Schemas Schema Registry Topic producer … consumer
partition 0 consumer A … consumer A partition 1 … consumer A partition 2 … consumer B Partitioned Topic @rmoff | #GOTOpia | @confluentinc
consumer A consumer A consumer A @rmoff | #GOTOpia | @confluentinc
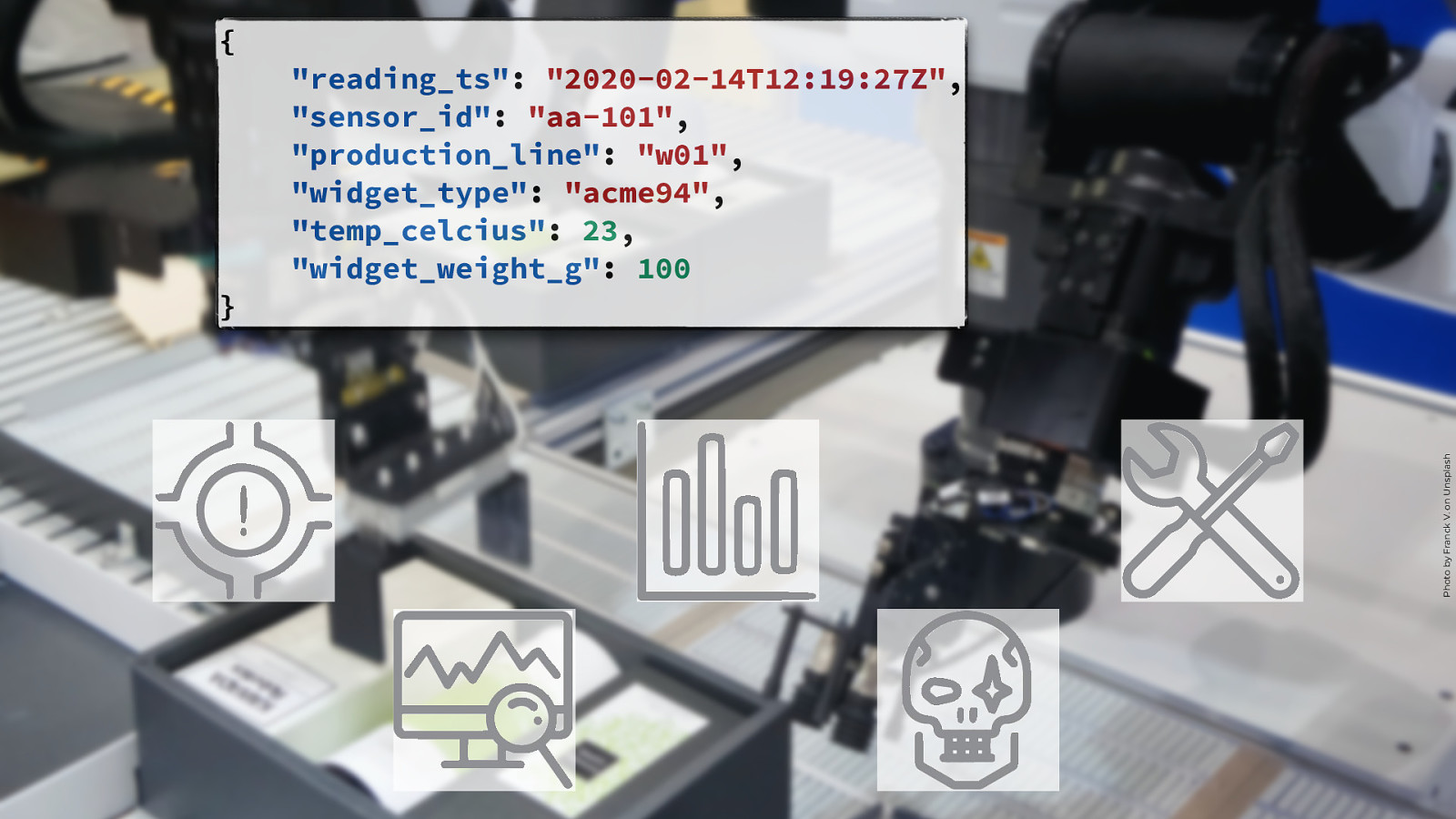
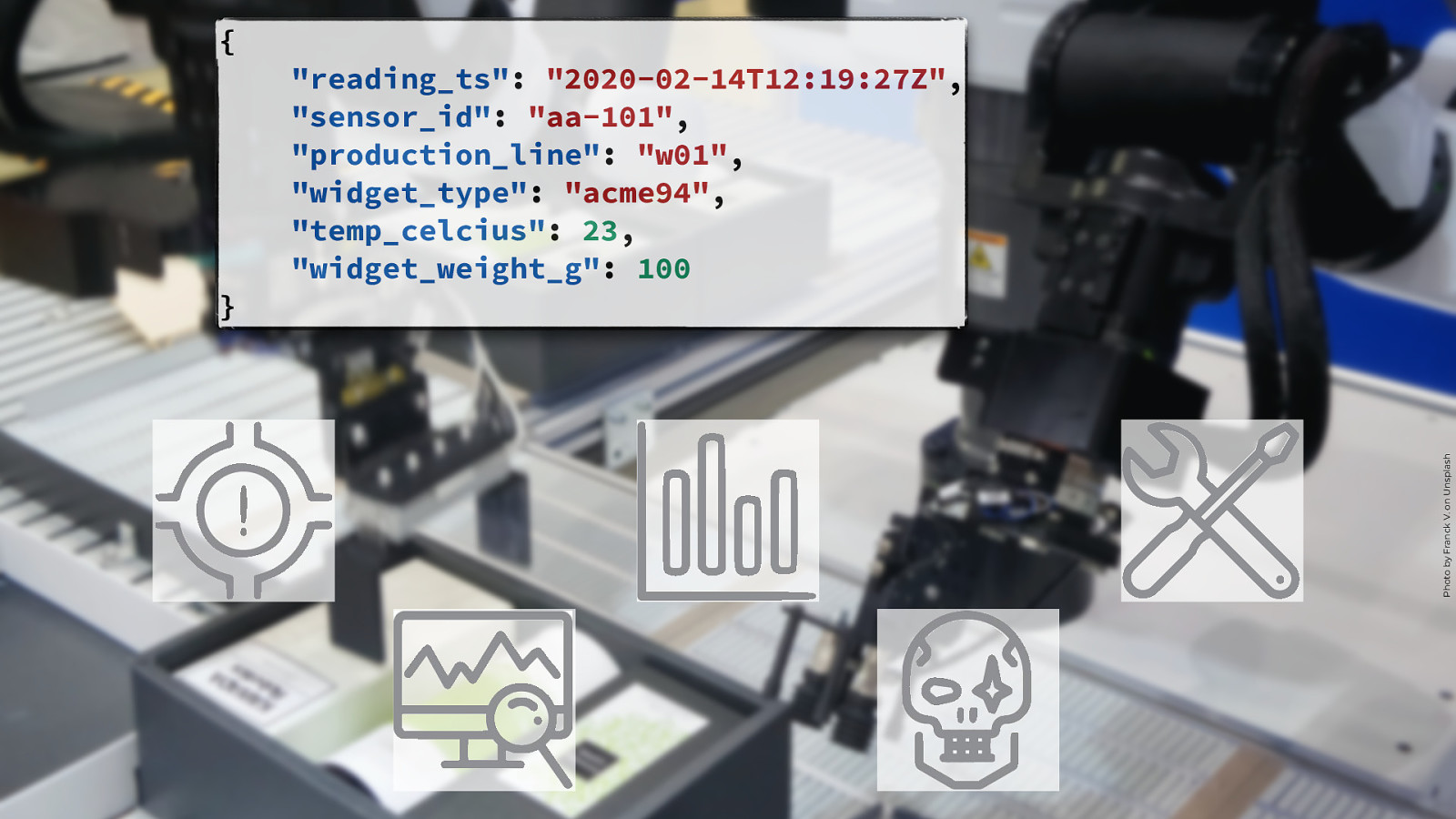
} “reading_ts”: “2020-02-14T12:19:27Z”, “sensor_id”: “aa-101”, “production_line”: “w01”, “widget_type”: “acme94”, “temp_celcius”: 23, “widget_weight_g”: 100 Photo by Franck V. on Unsplash { @rmoff | #GOTOpia | @confluentinc
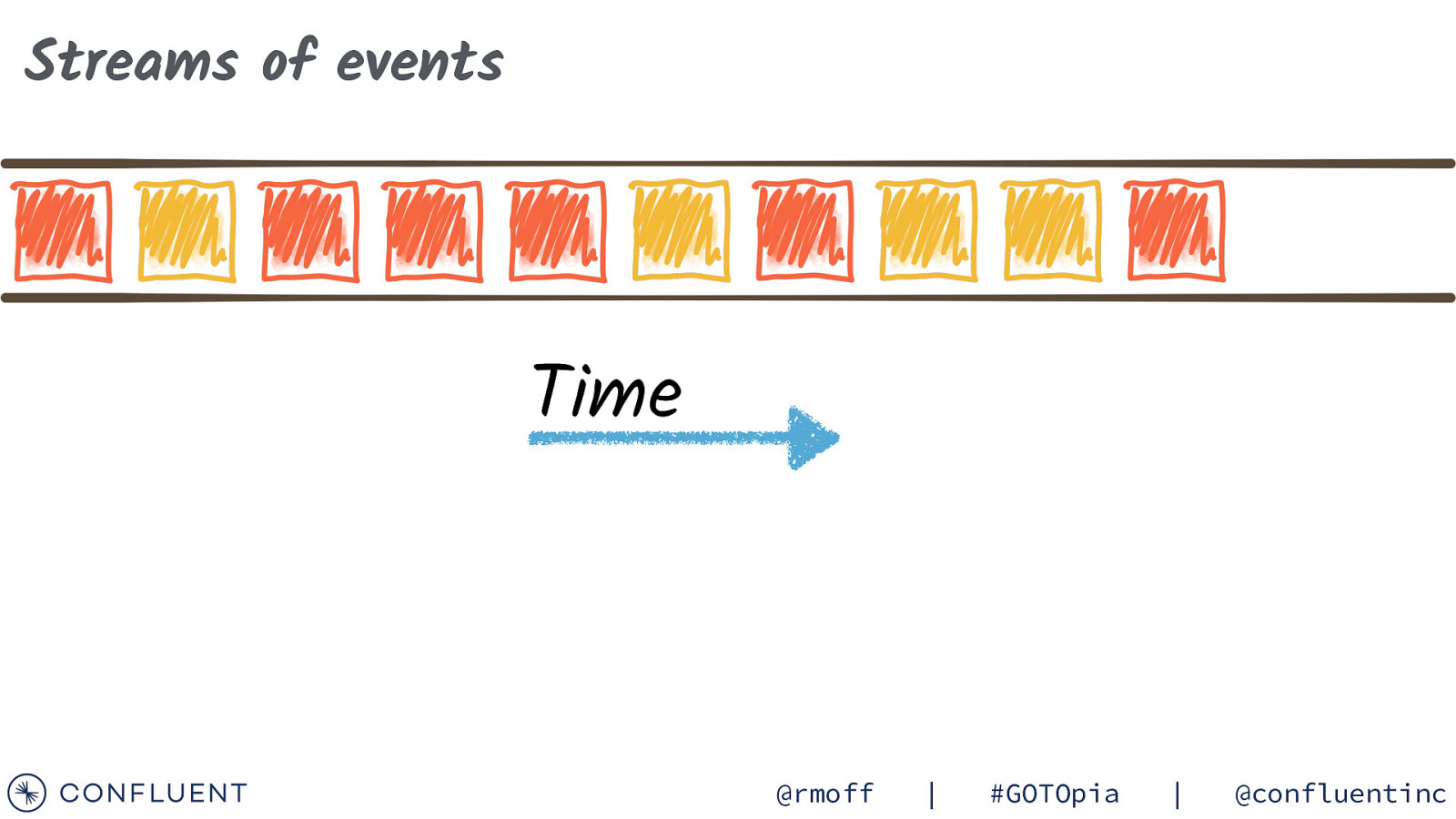
Streams of events Time @rmoff | #GOTOpia | @confluentinc
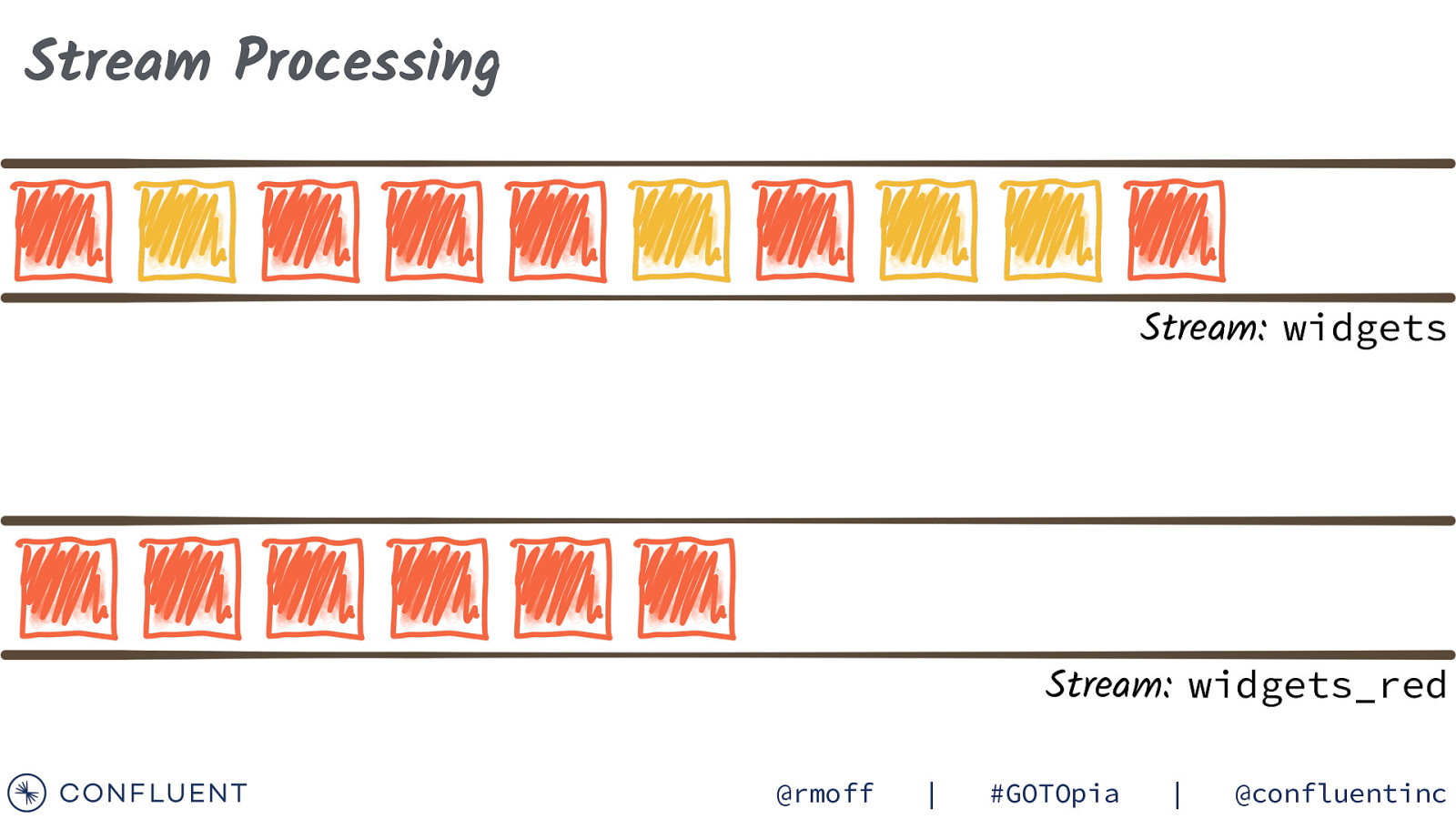
Stream Processing Stream: widgets Stream: widgets_red @rmoff | #GOTOpia | @confluentinc
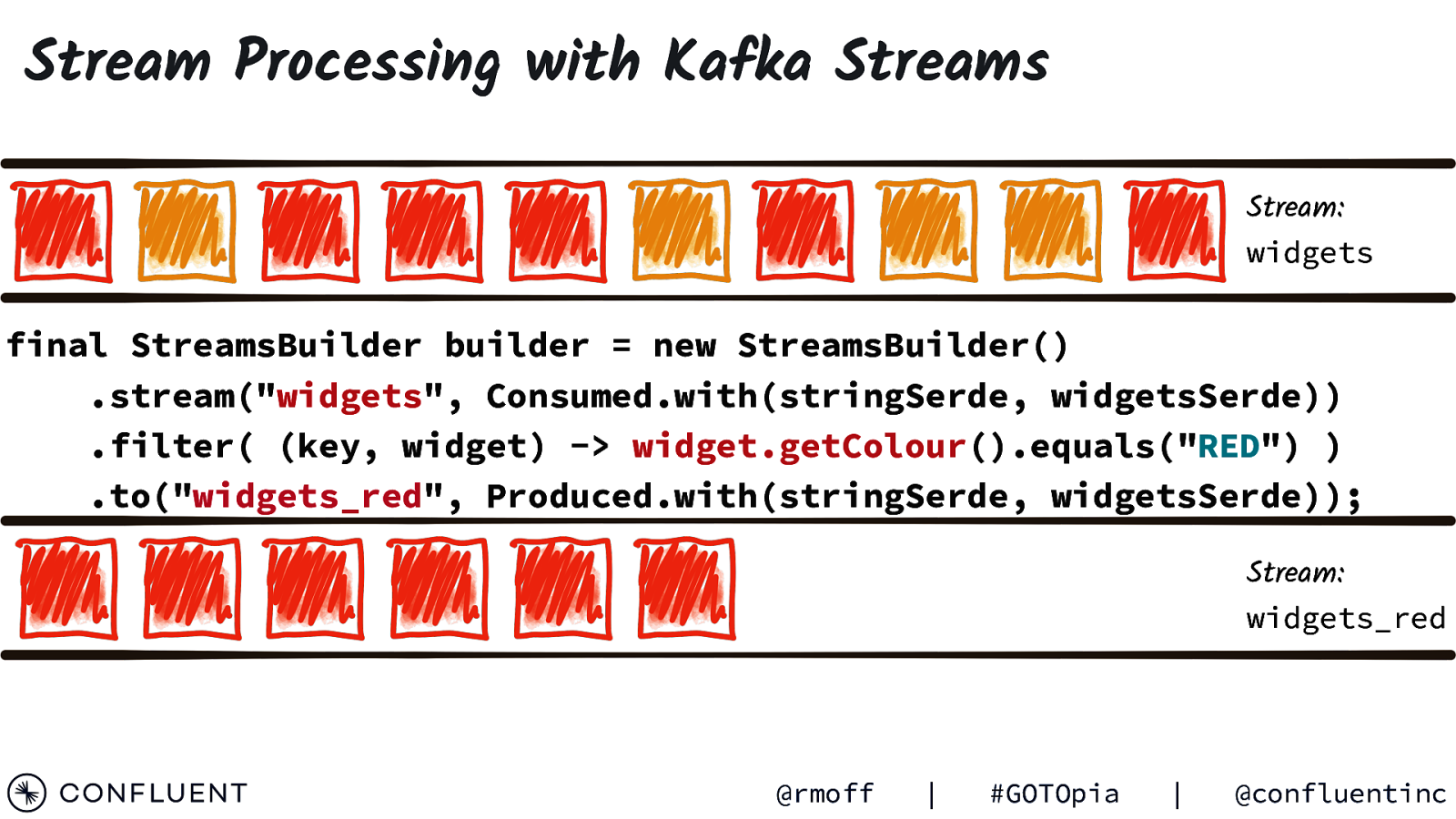
Stream Processing with Kafka Streams Stream: widgets final StreamsBuilder builder = new StreamsBuilder() .stream(“widgets”, Consumed.with(stringSerde, widgetsSerde)) .filter( (key, widget) -> widget.getColour().equals(“RED”) ) .to(“widgets_red”, Produced.with(stringSerde, widgetsSerde)); Stream: widgets_red @rmoff | #GOTOpia | @confluentinc
Streams Application Streams Application Streams Application @rmoff | #GOTOpia | @confluentinc
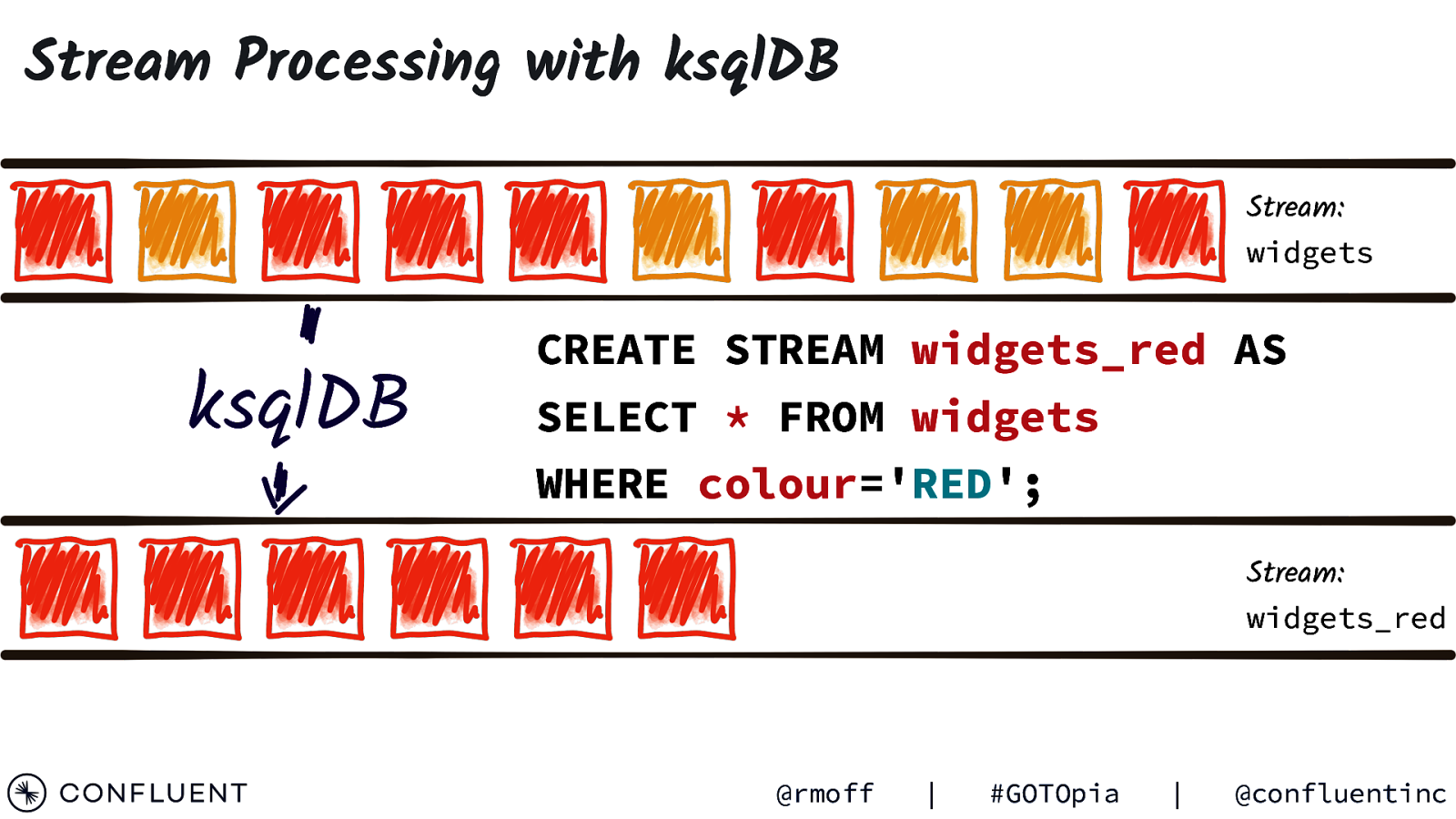
Stream Processing with ksqlDB Stream: widgets ksqlDB CREATE STREAM widgets_red AS SELECT * FROM widgets WHERE colour=’RED’; Stream: widgets_red @rmoff | #GOTOpia | @confluentinc
} “reading_ts”: “2020-02-14T12:19:27Z”, “sensor_id”: “aa-101”, “production_line”: “w01”, “widget_type”: “acme94”, “temp_celcius”: 23, “widget_weight_g”: 100 Photo by Franck V. on Unsplash { @rmoff | #GOTOpia | @confluentinc
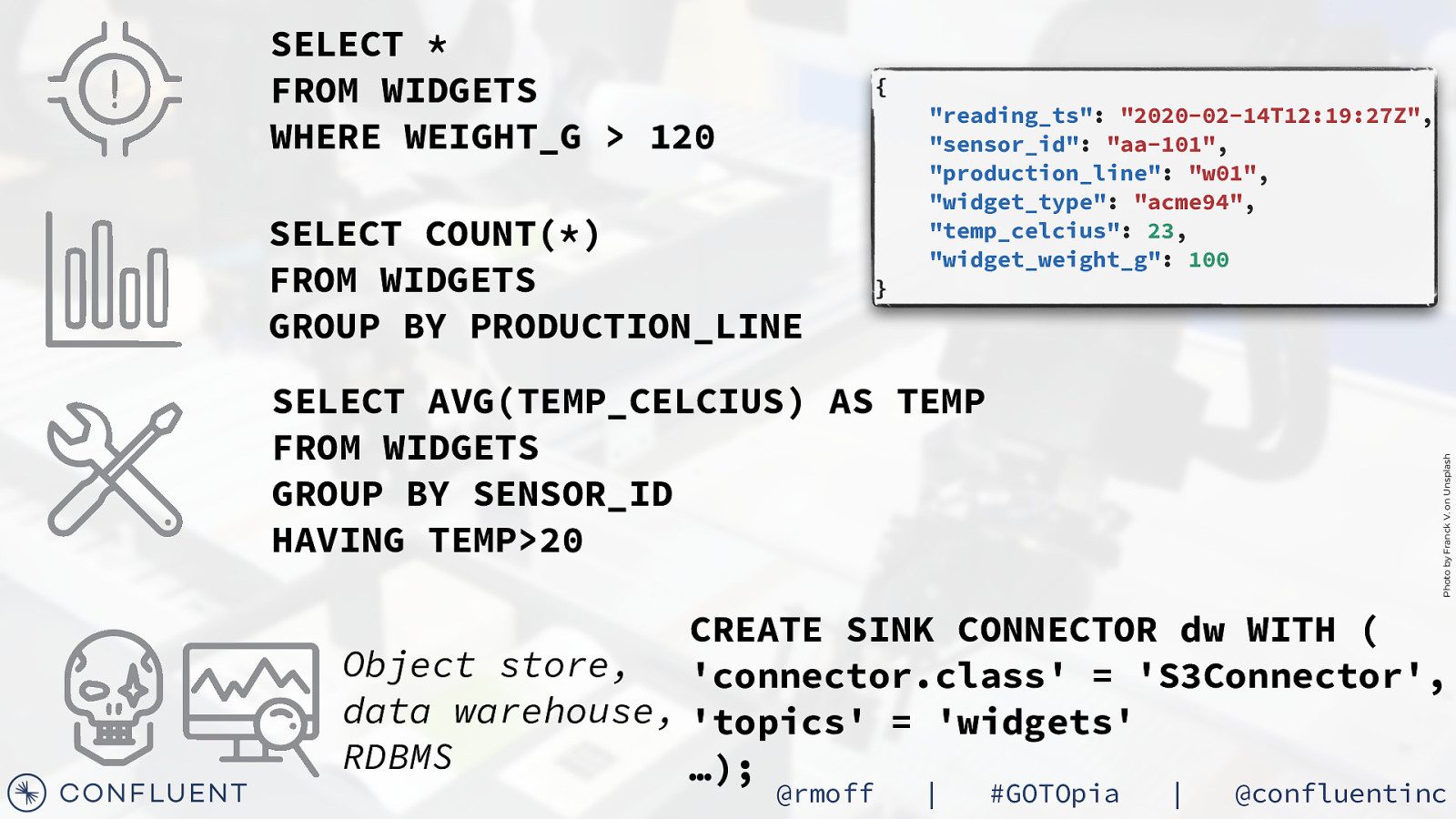
SELECT * FROM WIDGETS WHERE WEIGHT_G > 120 { SELECT COUNT(*) FROM WIDGETS GROUP BY PRODUCTION_LINE } “reading_ts”: “2020-02-14T12:19:27Z”, “sensor_id”: “aa-101”, “production_line”: “w01”, “widget_type”: “acme94”, “temp_celcius”: 23, “widget_weight_g”: 100 Photo by Franck V. on Unsplash SELECT AVG(TEMP_CELCIUS) AS TEMP FROM WIDGETS GROUP BY SENSOR_ID HAVING TEMP>20 CREATE SINK CONNECTOR dw WITH ( Object store, ‘connector.class’ = ‘S3Connector’, data warehouse, ‘topics’ = ‘widgets’ RDBMS …); @rmoff | #GOTOpia | @confluentinc
Photo by Raoul Droog on Unsplas DEMO @rmoff | #GOTOpia | @confluentinc
Summary @rmoff | #GOTOpia | @confluentinc
@rmoff | #GOTOpia | @confluentinc
K V @rmoff | #GOTOpia | @confluentinc
K V @rmoff | #GOTOpia | @confluentinc
The Log @rmoff | #GOTOpia | @confluentinc
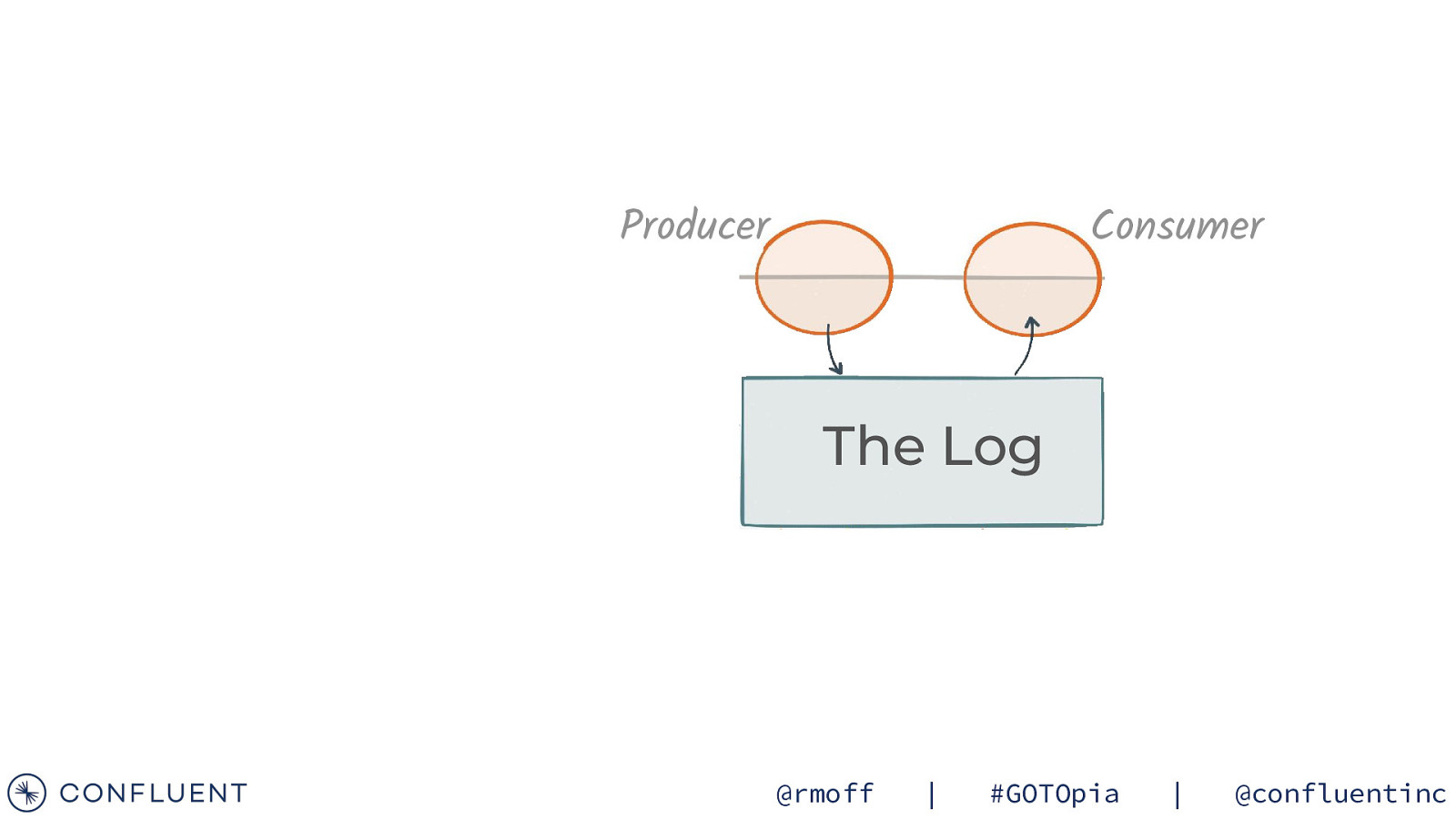
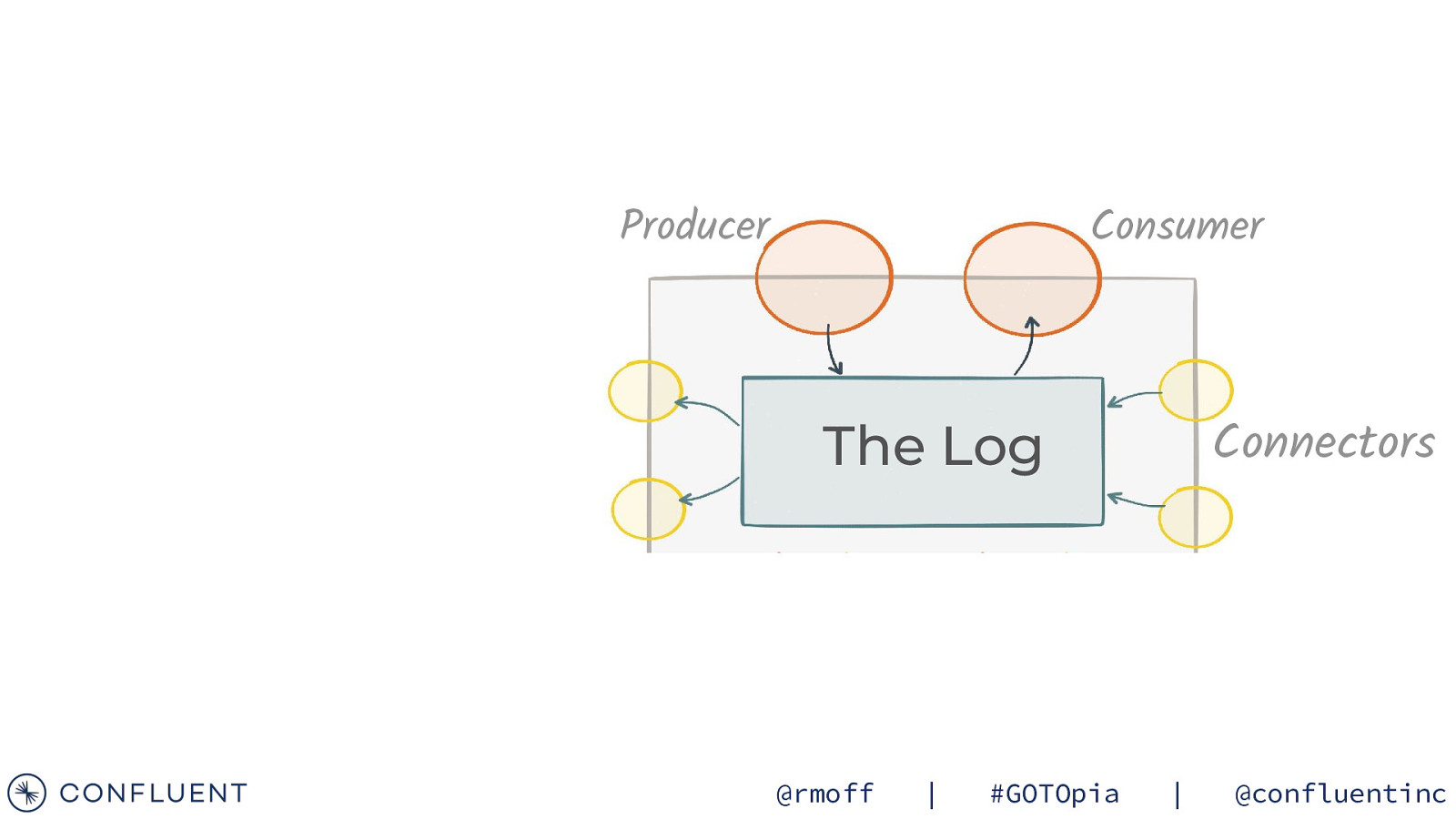
Producer Consumer The Log @rmoff | #GOTOpia | @confluentinc
Producer Consumer Connectors The Log @rmoff | #GOTOpia | @confluentinc
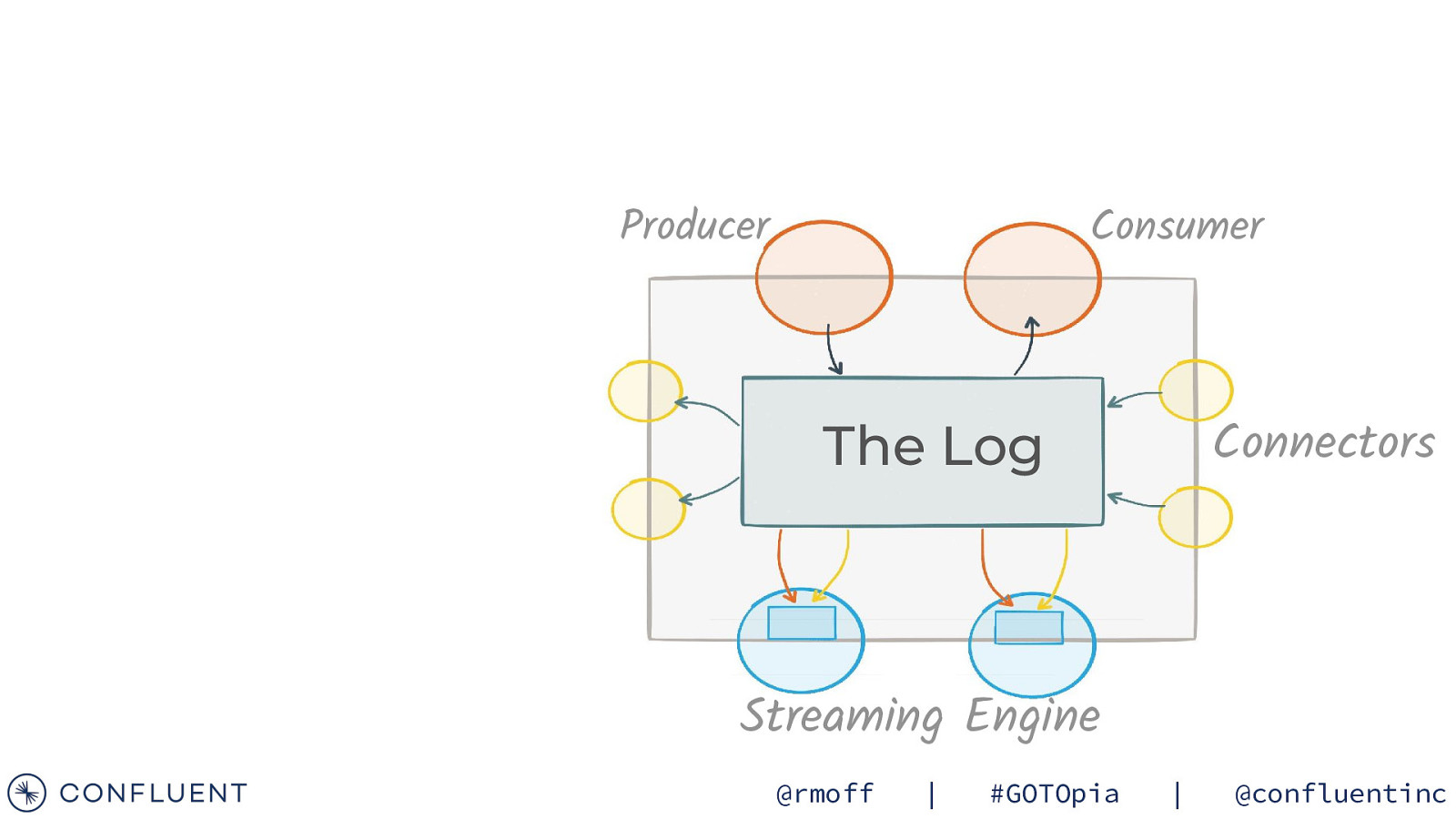
Producer Consumer Connectors The Log Streaming Engine @rmoff | #GOTOpia | @confluentinc
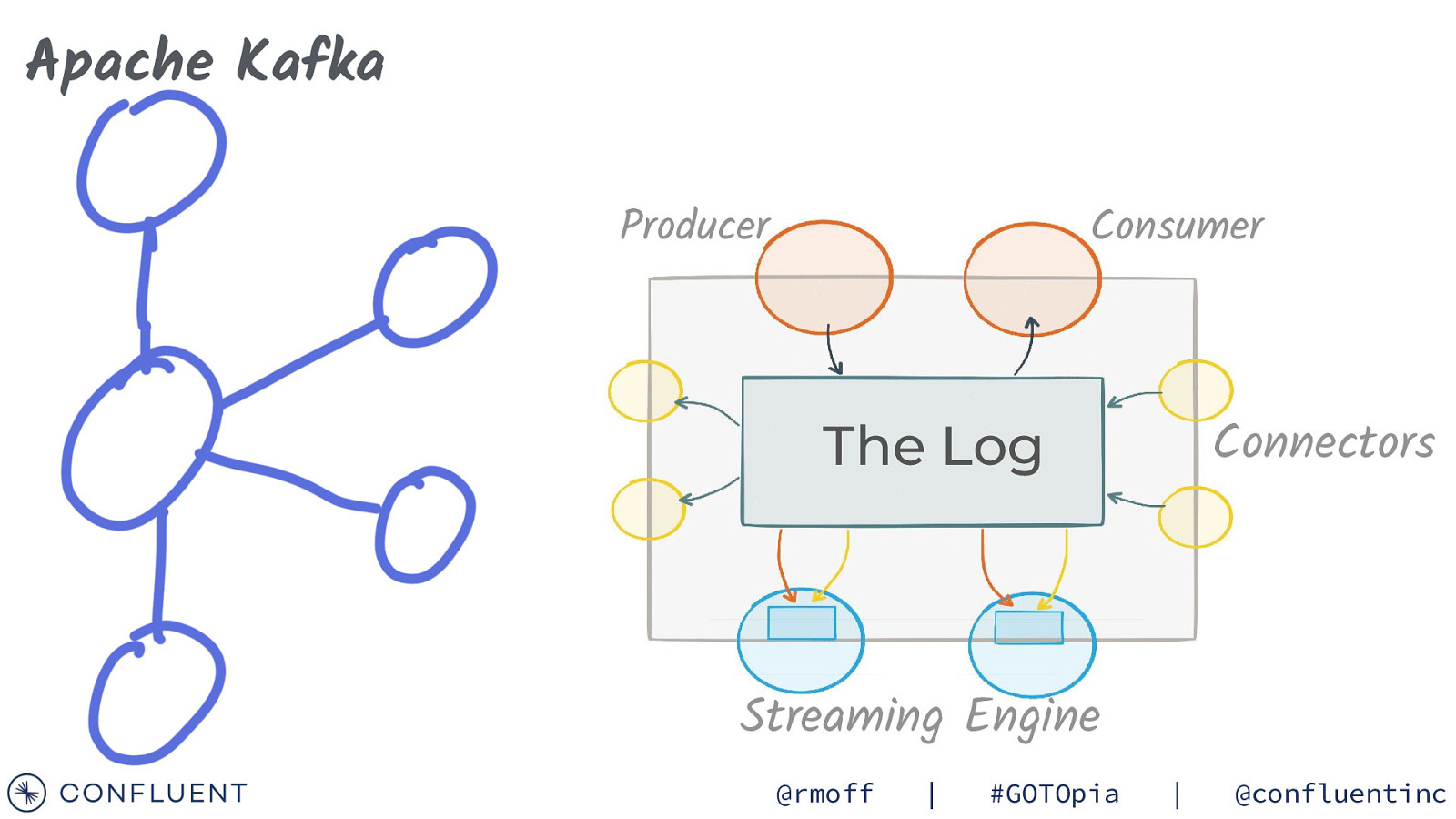
Apache Kafka Producer Consumer Connectors The Log Streaming Engine @rmoff | #GOTOpia | @confluentinc
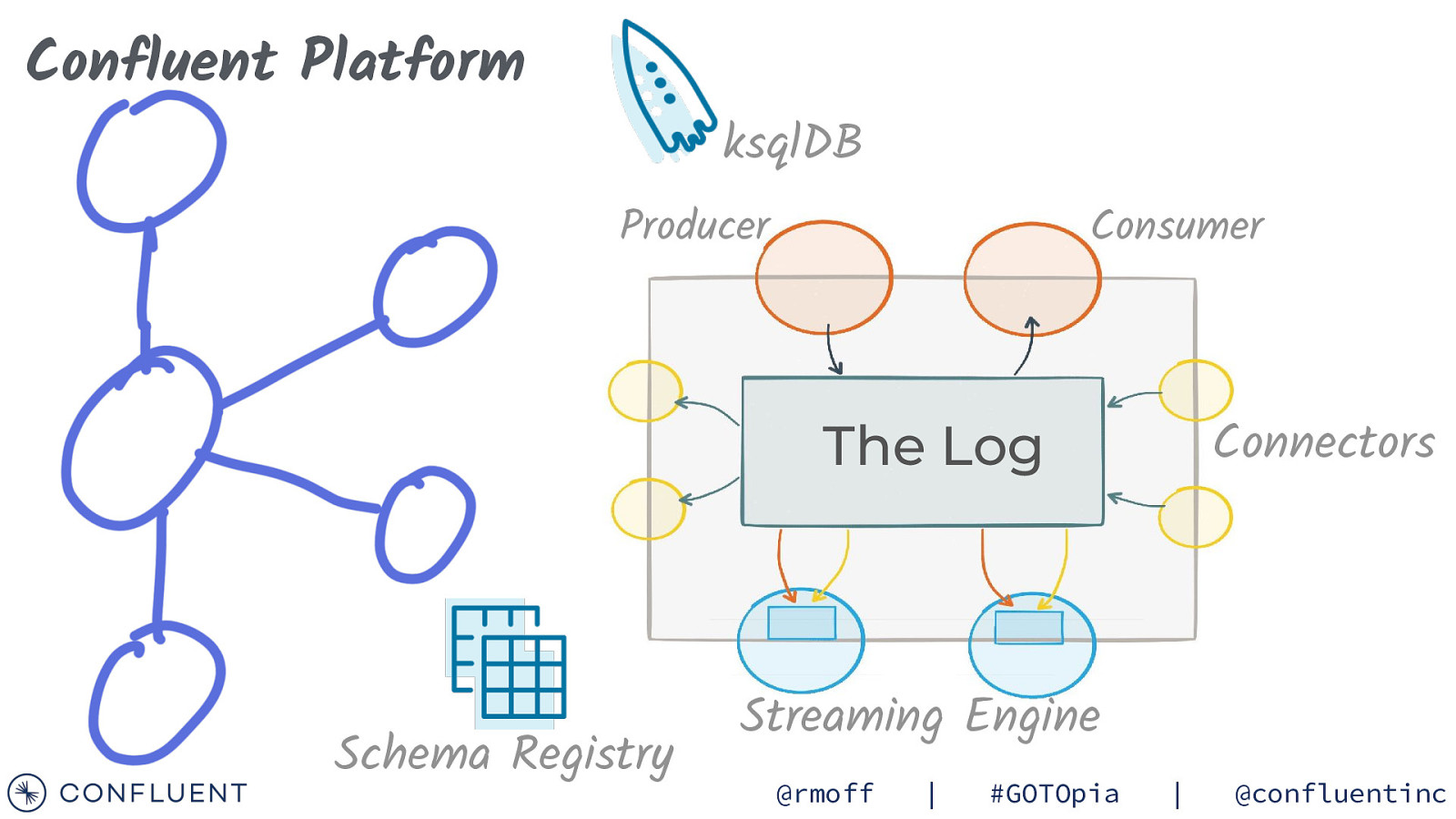
Confluent Platform ksqlDB Producer Consumer Connectors The Log Schema Registry Streaming Engine @rmoff | #GOTOpia | @confluentinc
Free Books! https://rmoff.dev/gotopia @rmoff | #GOTOpia | @confluentinc
60 DE VA DV $200 USD off your bill each calendar month for the first three months when you sign up https://rmoff.dev/ccloud Free money! (additional $60 towards your bill 😄 ) Fully Managed Kafka as a Service * T&C: https://www.confluent.io/confluent-cloud-promo-disclaimer
Learn Kafka. Start building with Apache Kafka at Confluent Developer. developer.confluent.io
#EOF @rmoff rmoff.dev/talks youtube.com/rmoff

Kafka has become a key data infrastructure technology, and we all have at least a vague sense that it is a messaging system, but what else is it? How can an overgrown message bus be getting this much buzz? Well, because Kafka is merely the center of a rich streaming data platform that invites detailed exploration.
In this talk, we’ll look at the entire streaming platform provided by Apache Kafka and the Confluent community components. Starting with a lonely key-value pair, we’ll build up topics, partitioning, replication, and low-level Producer and Consumer APIs. We’ll group consumers into elastically scalable, fault-tolerant application clusters, then layer on more sophisticated stream processing APIs like Kafka Streams and ksqlDB. We’ll help teams collaborate around data formats with schema management. We’ll integrate with legacy systems without writing custom code. By the time we’re done, the open-source project we thought was Big Data’s answer to message queues will have become an enterprise-grade streaming platform, all in 45 minutes.
The following resources were mentioned during the presentation or are useful additional information.
Fully Managed Apache Kafka, Schema Registry, ksqlDB, and Connectors.
Blog about the options for getting data from Oracle into Kafka
A conference talk covering the options for getting data from Oracle into Kafka
Free eBooks to download, including Kafka: The Definitive Guide.
Tutorials, videos, blogs, podcasts, and more - all for developers working with Apache Kafka and Confluent Platform
Huge list of connectors for Kafka Connect
A fun blog showing what you can do with ksqlDB and Kafka
Learn all about ksqlDB in this 45 minute talk & live demo
Learn all about Kafka Connect (including the connectors available with ksqlDB)
Apache Kafka and Confluent Platform in Action! Using live streams of rail movement data in all sorts of useful ways for analysis and applications.
Here’s what was said about this presentation on social media.

































 for free. You
can too.
for free. You
can too.