
A presentation at ApacheCon by Robin Moffatt

ApacheCon @ Home 2020 Integrating Databases and Apache Kafka ® @rmoff #acah2020
Photo by Emily Morter on Unsplash @rmoff | #acah2020
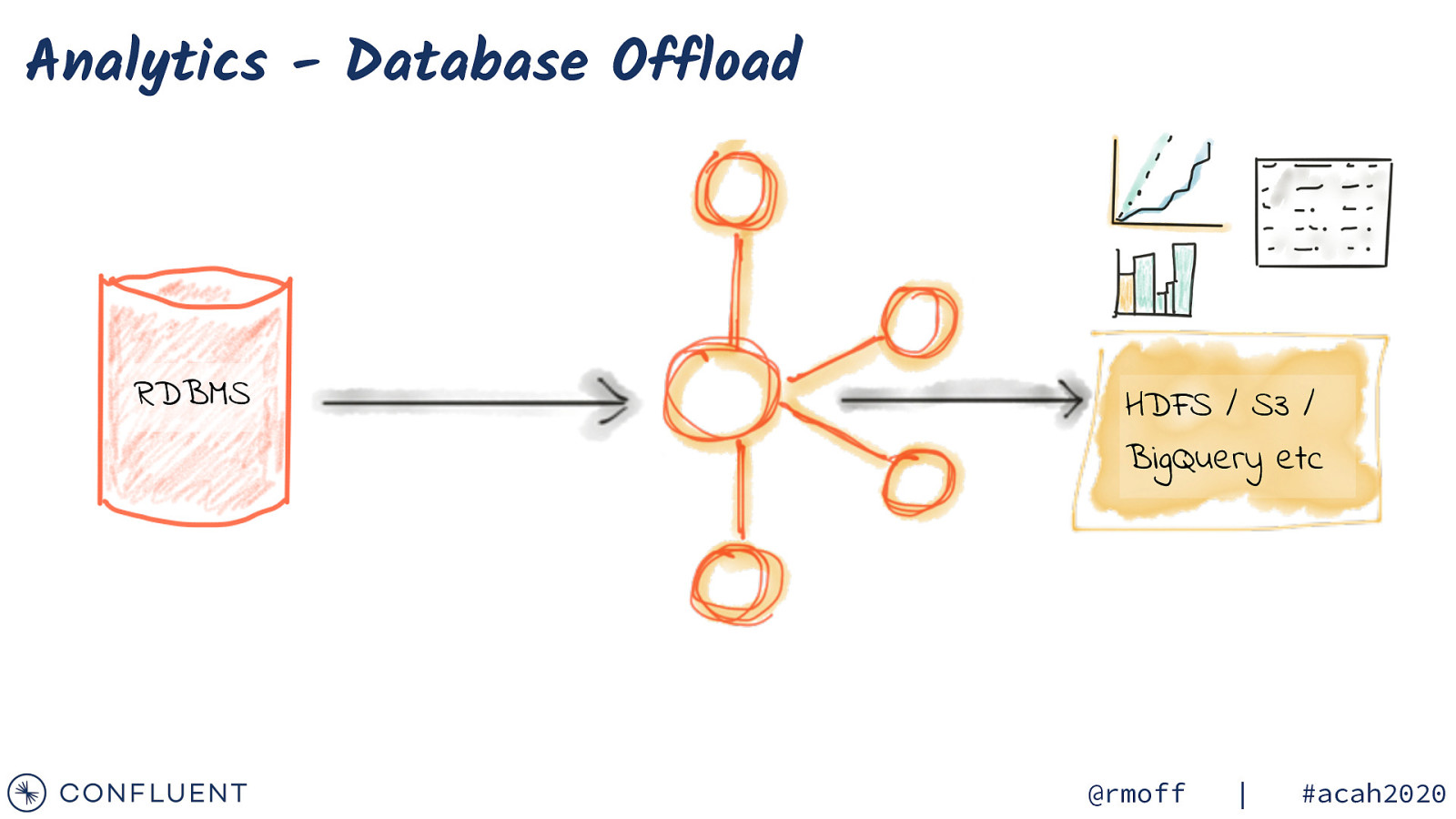
Analytics - Database Offload RDBMS HDFS / S3 / BigQuery etc @rmoff | #acah2020
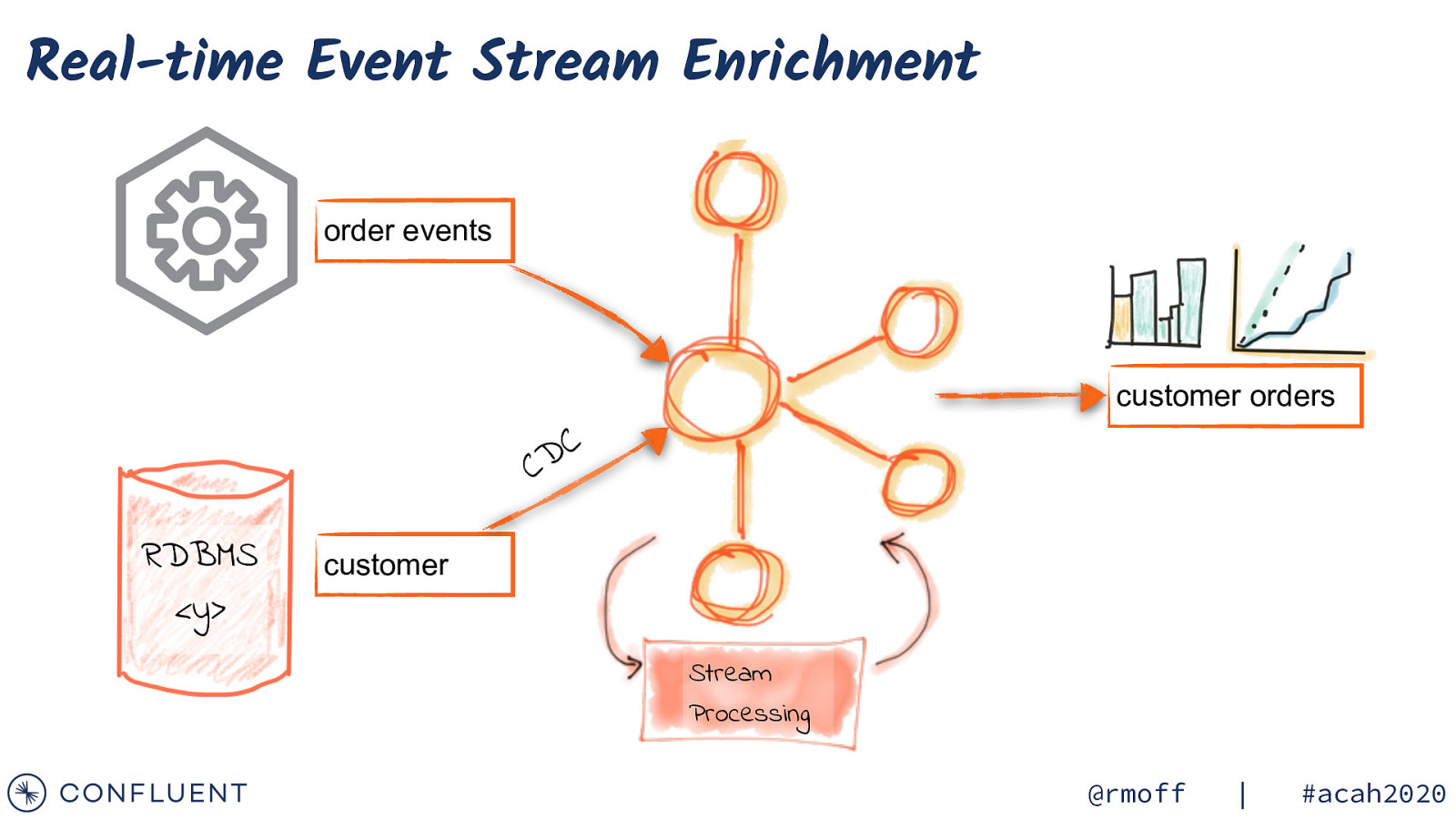
Real-time Event Stream Enrichment order events customer orders C D C RDBMS <y> customer Stream Processing @rmoff | #acah2020
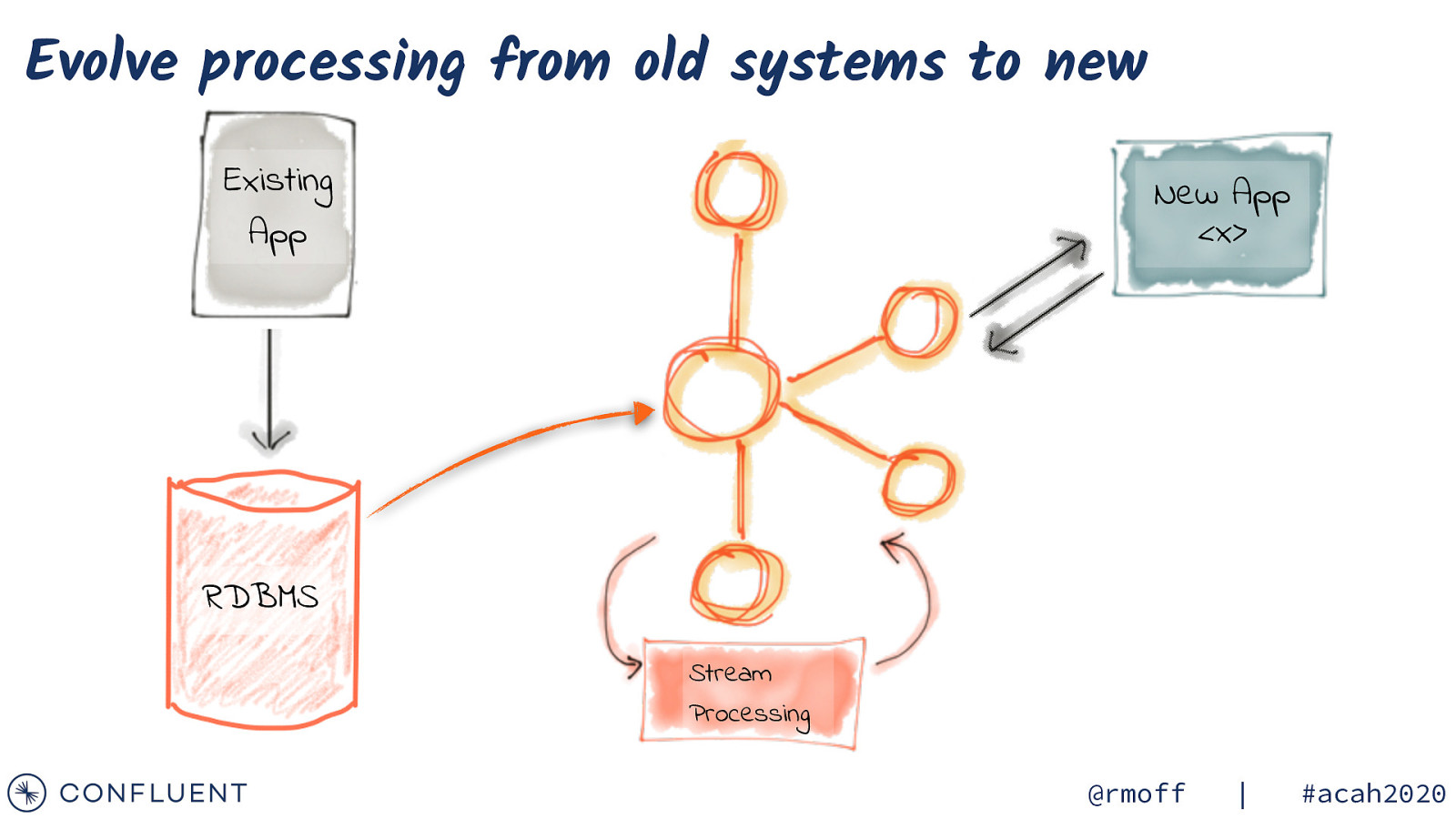
Evolve processing from old systems to new Existing App New App <x> RDBMS Stream Processing @rmoff | #acah2020
“ But streaming…I’ve just got data in a database…right? @rmoff | #acah2020
“ Bold claim: all your data is event streams @rmoff | #acah2020
Human generated events A Sale A Stock movement @rmoff | #acah2020
Machine generated events Networking IoT Applications @rmoff | #acah2020
Databases @rmoff | #acah2020
Do you think that’s a table you are querying? @rmoff | #acah2020
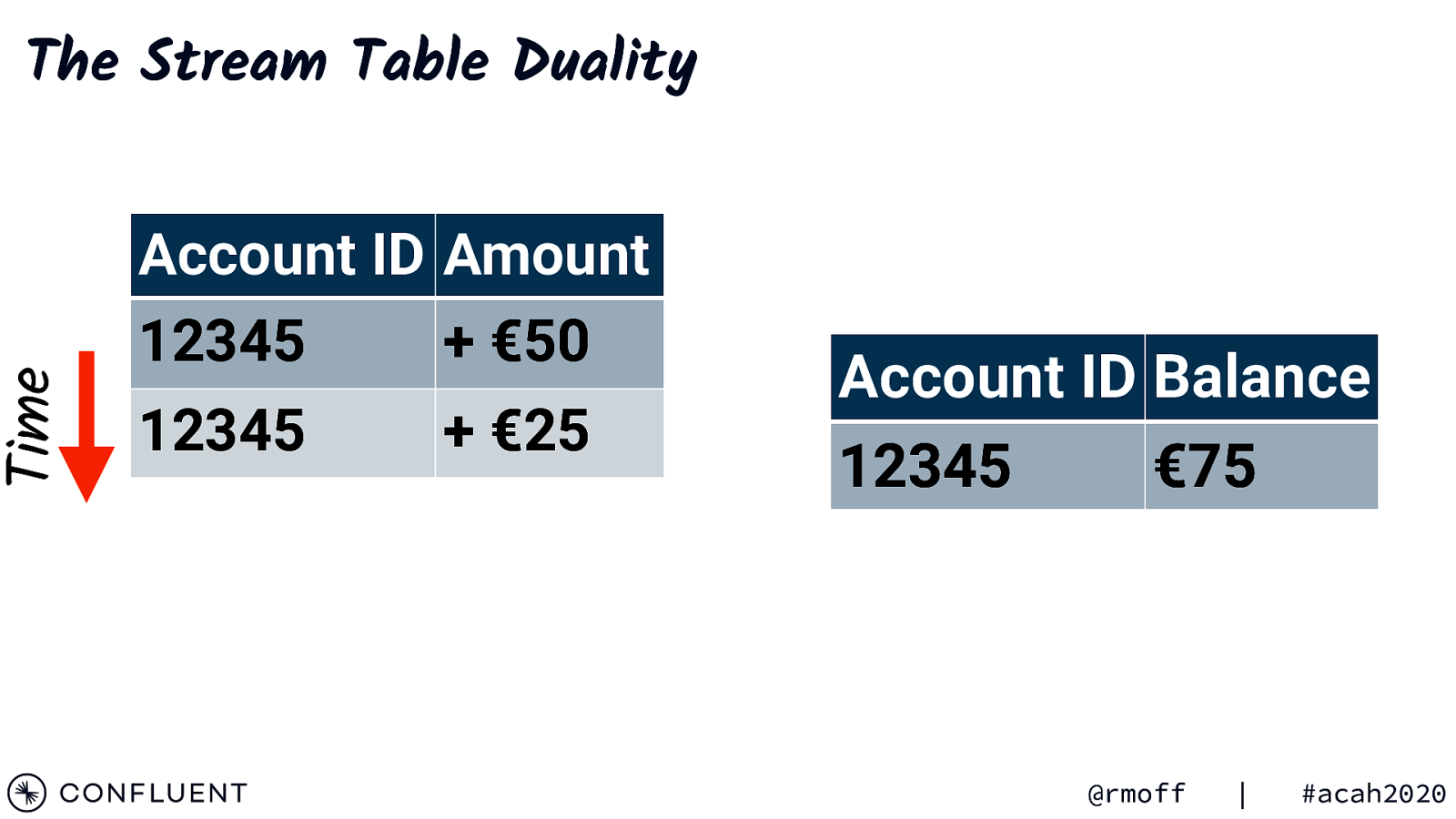
The Stream Table Duality Account ID Balance 12345 €50 @rmoff | #acah2020
Time The Stream Table Duality Account ID Amount 12345 + €50 Account ID Balance 12345 €50 @rmoff | #acah2020
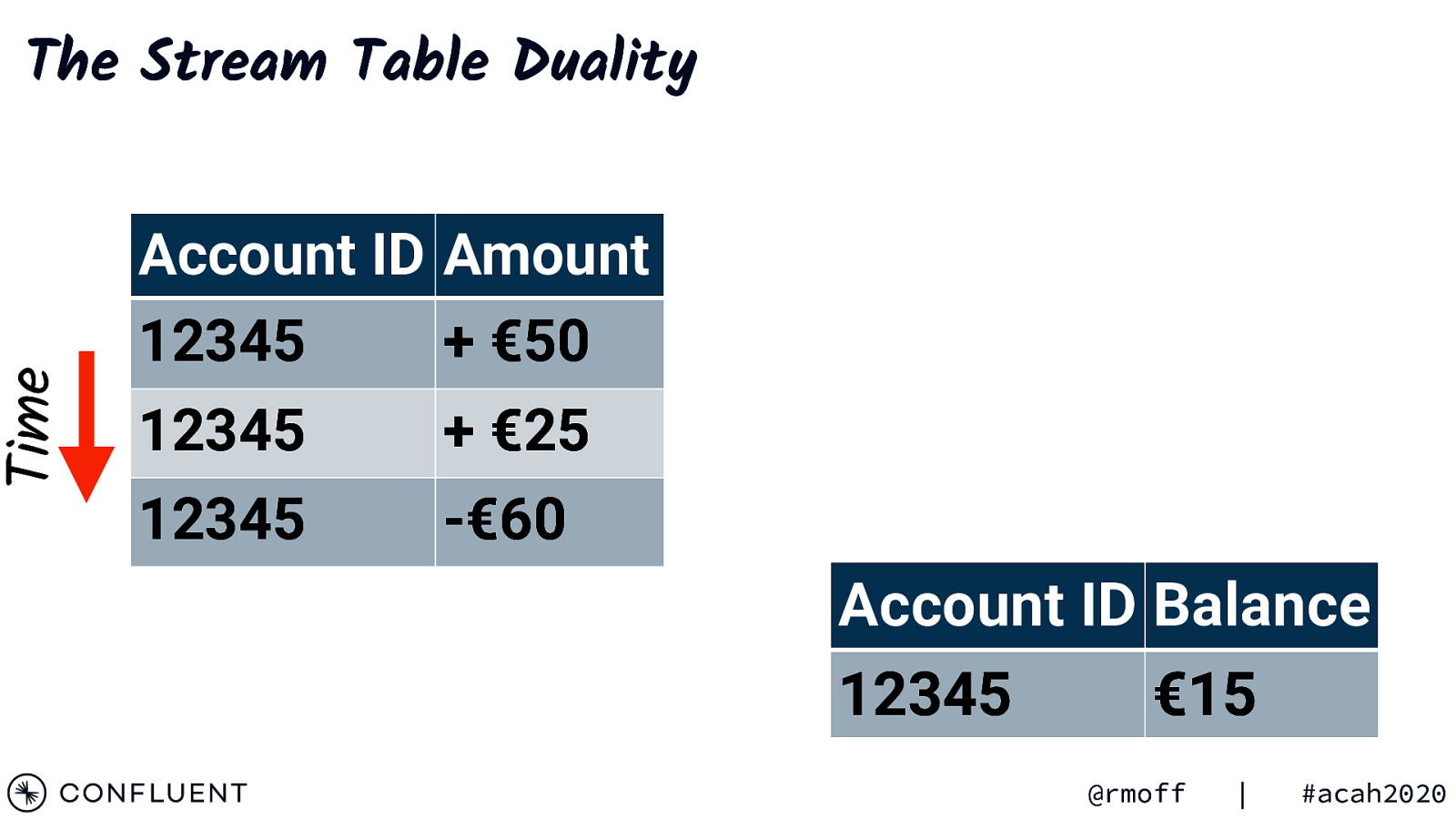
Time The Stream Table Duality Account ID Amount 12345 + €50 12345
Time The Stream Table Duality Account ID Amount 12345 + €50 12345
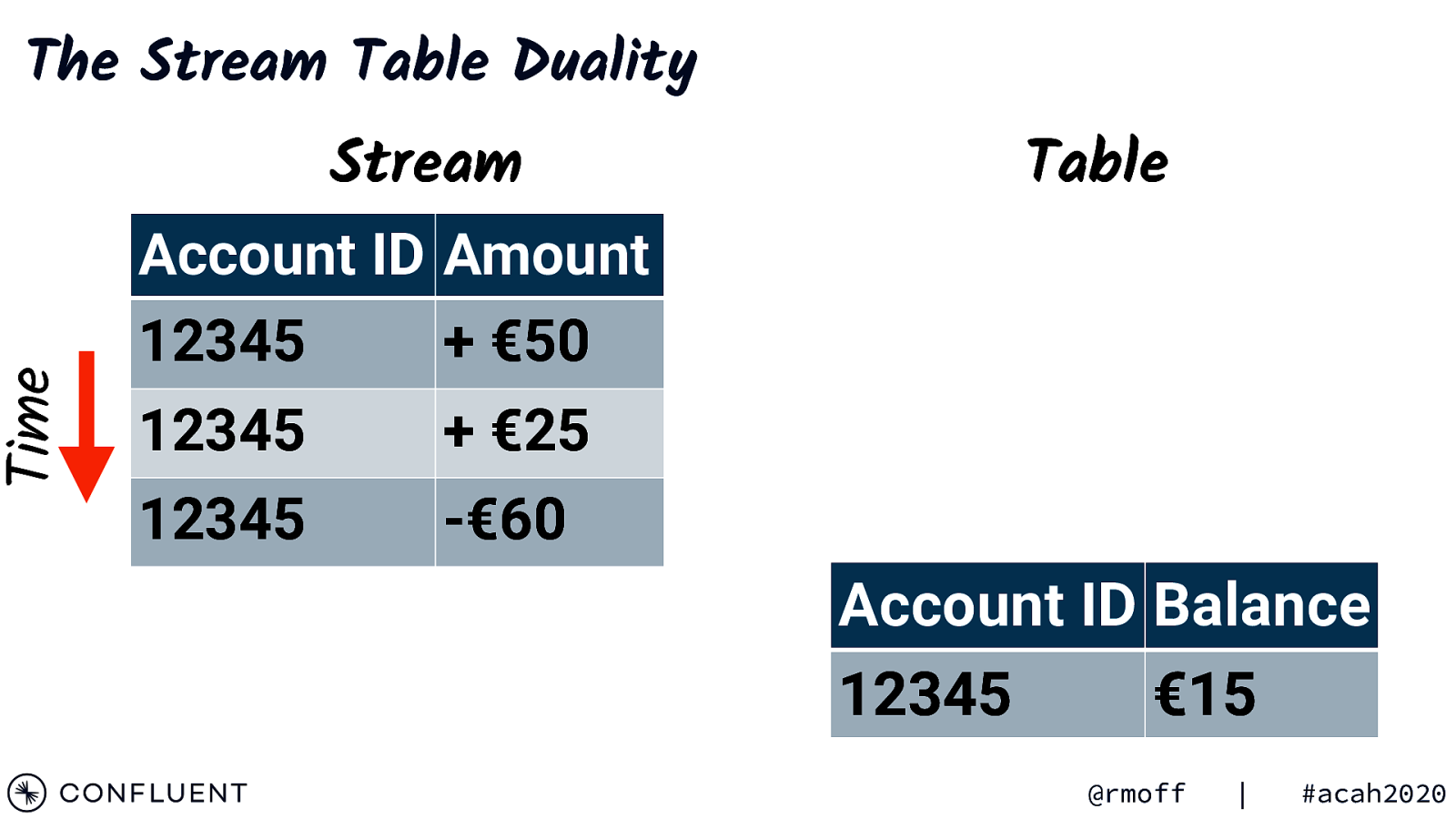
Time The Stream Table Duality Stream Table Account ID Amount 12345 + €50 12345
The truth is the log. The database is a cache of a subset of the log. —Pat Helland Immutability Changes Everything http://cidrdb.org/cidr2015/Papers/CIDR15_Paper16.pdf Photo by Bobby Burch on Unsplash @rmoff | #acah2020
Photo by Vadim Sherbakov on Unsplash @rmoff | #acah2020
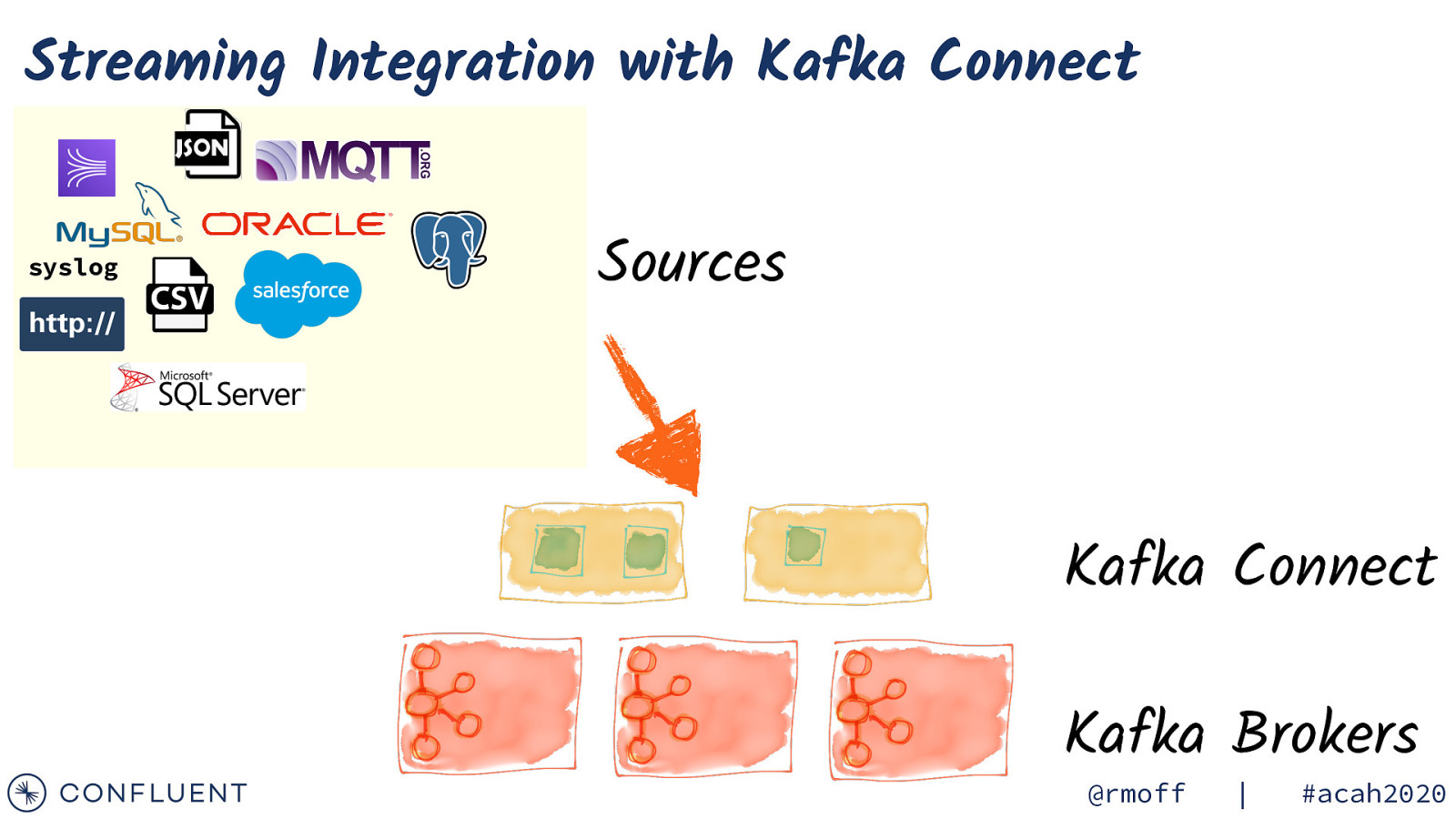
Streaming Integration with Kafka Connect syslog Sources Kafka Connect Kafka Brokers @rmoff | #acah2020
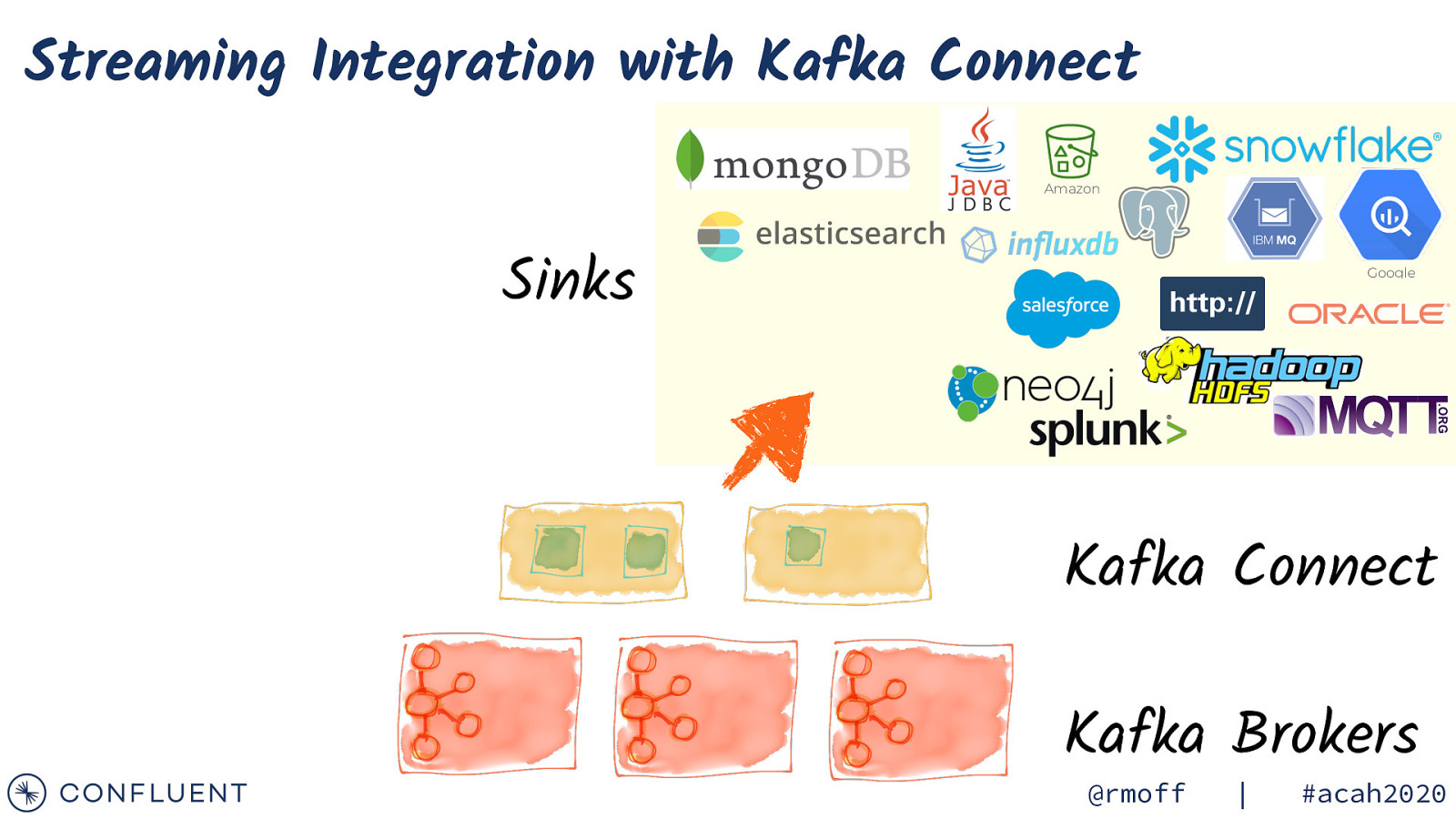
Streaming Integration with Kafka Connect Amazon Sinks Google Kafka Connect Kafka Brokers @rmoff | #acah2020
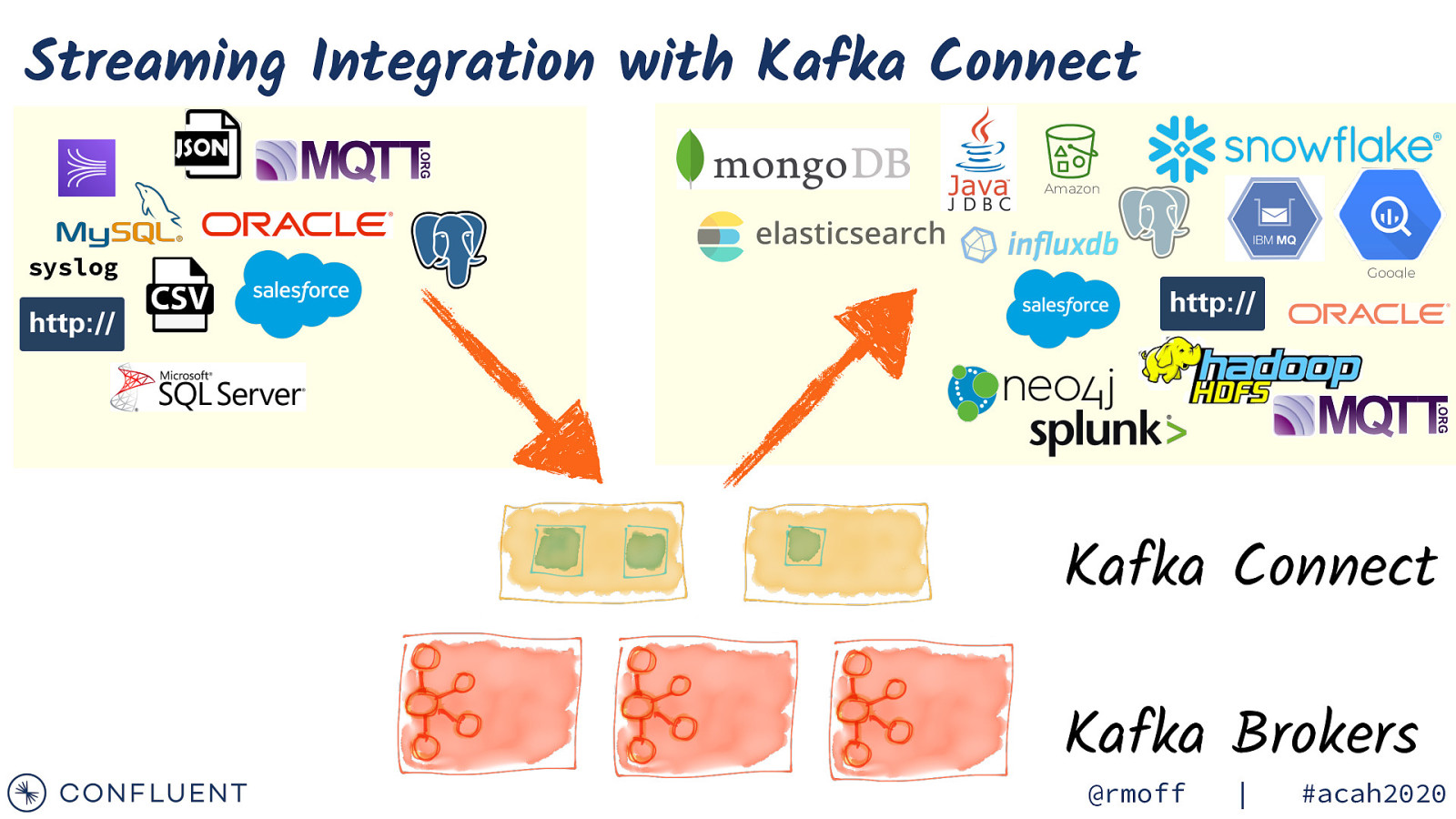
Streaming Integration with Kafka Connect Amazon syslog Google Kafka Connect Kafka Brokers @rmoff | #acah2020
Look Ma, No Code! { “connector.class”: “io.confluent.connect.jdbc.JdbcSourceConnector”, “connection.url”: “jdbc:mysql://asgard:3306/demo”, “table.whitelist”: “sales,orders,customers” } @rmoff | #acah2020
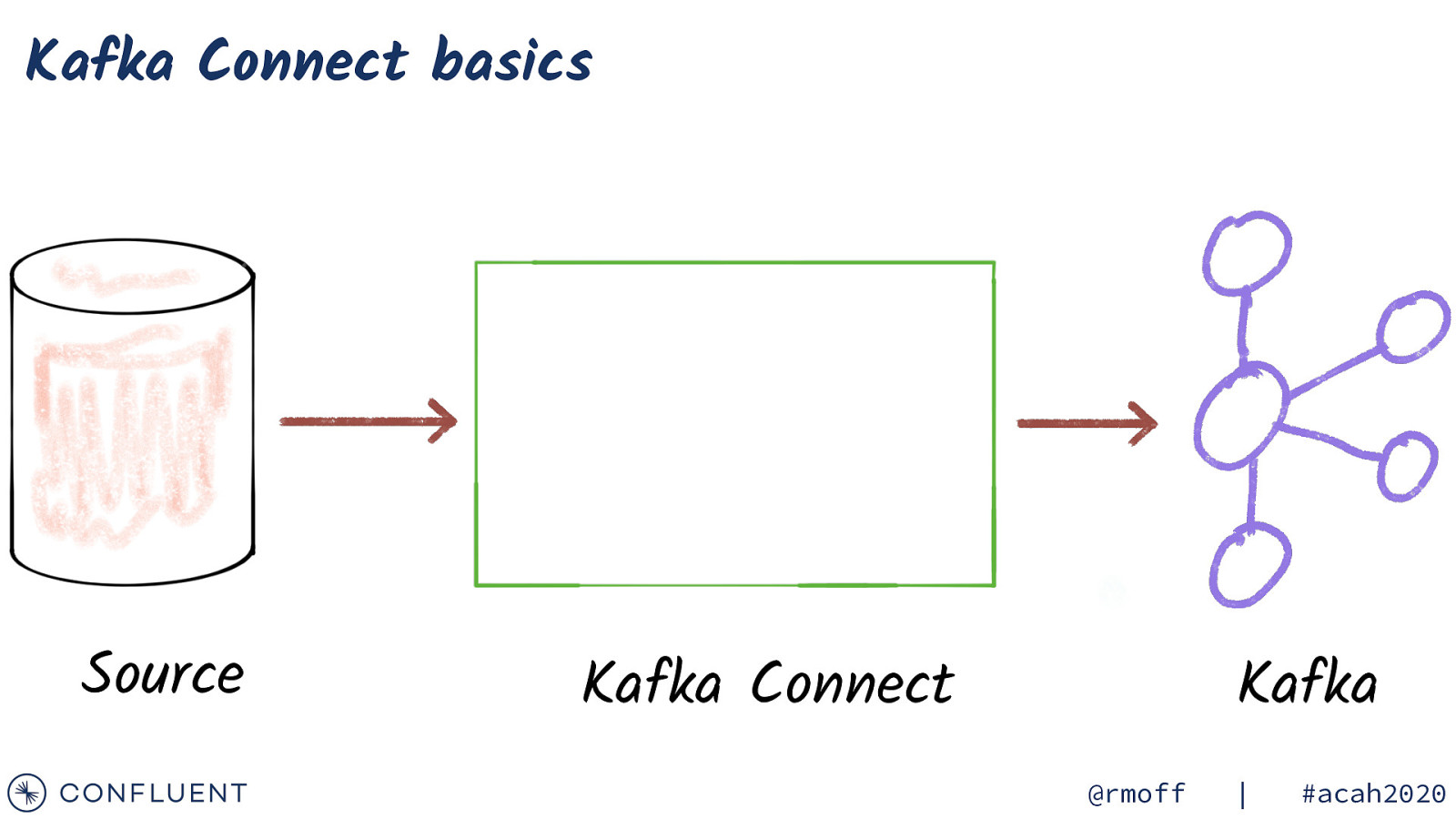
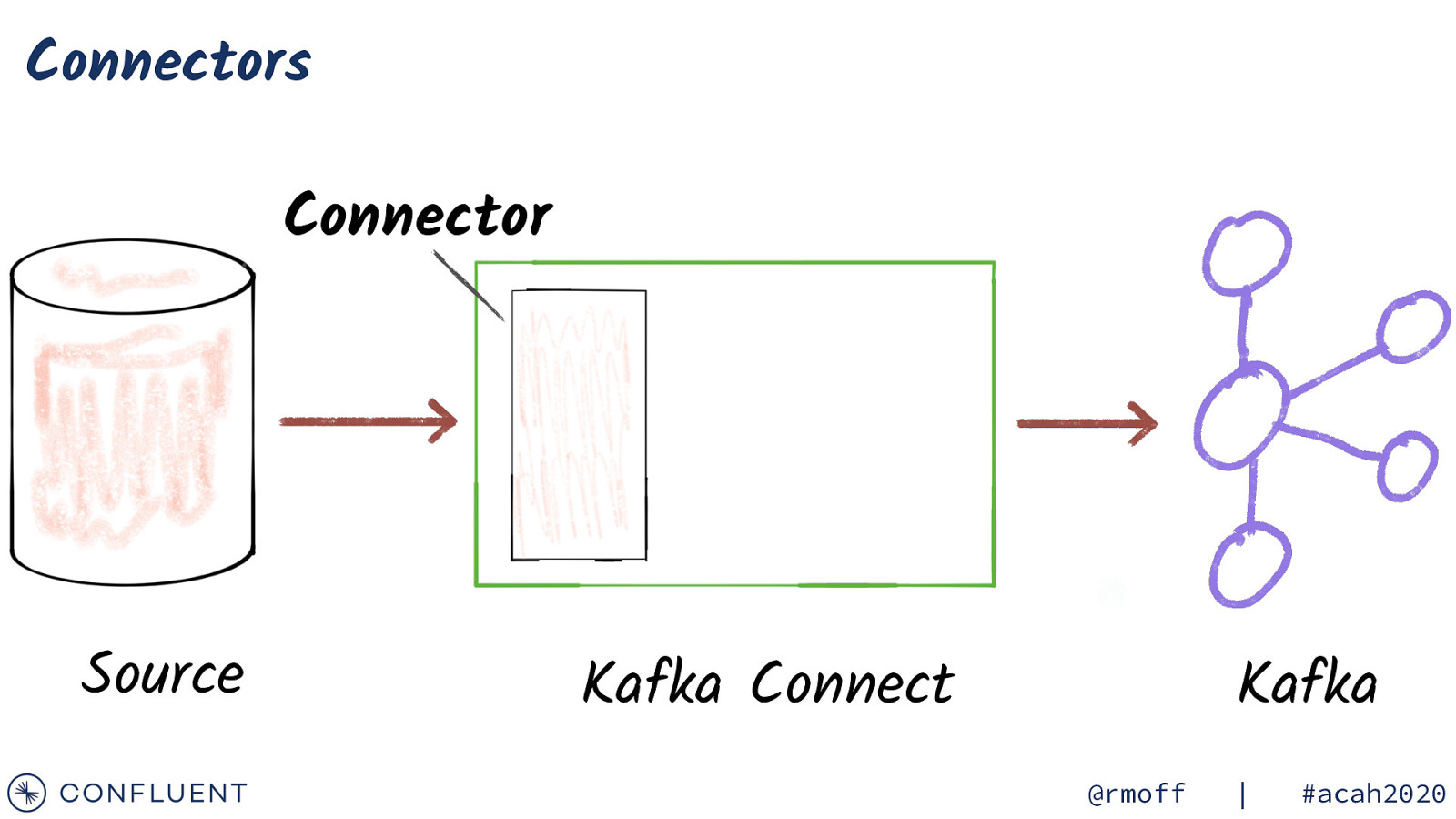
Kafka Connect basics Source Kafka Connect Kafka @rmoff | #acah2020
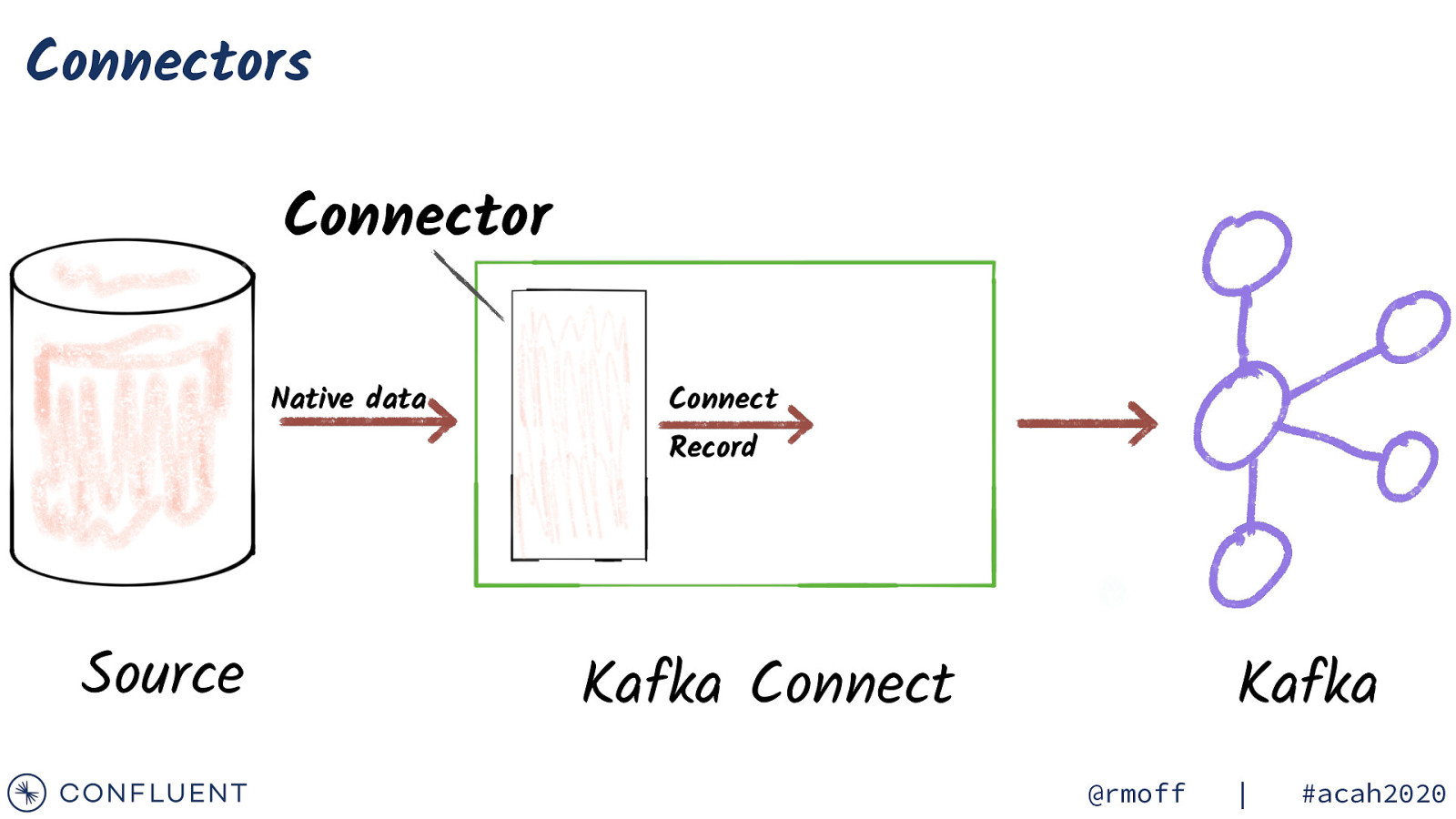
Connectors Connector Source Kafka Connect Kafka @rmoff | #acah2020
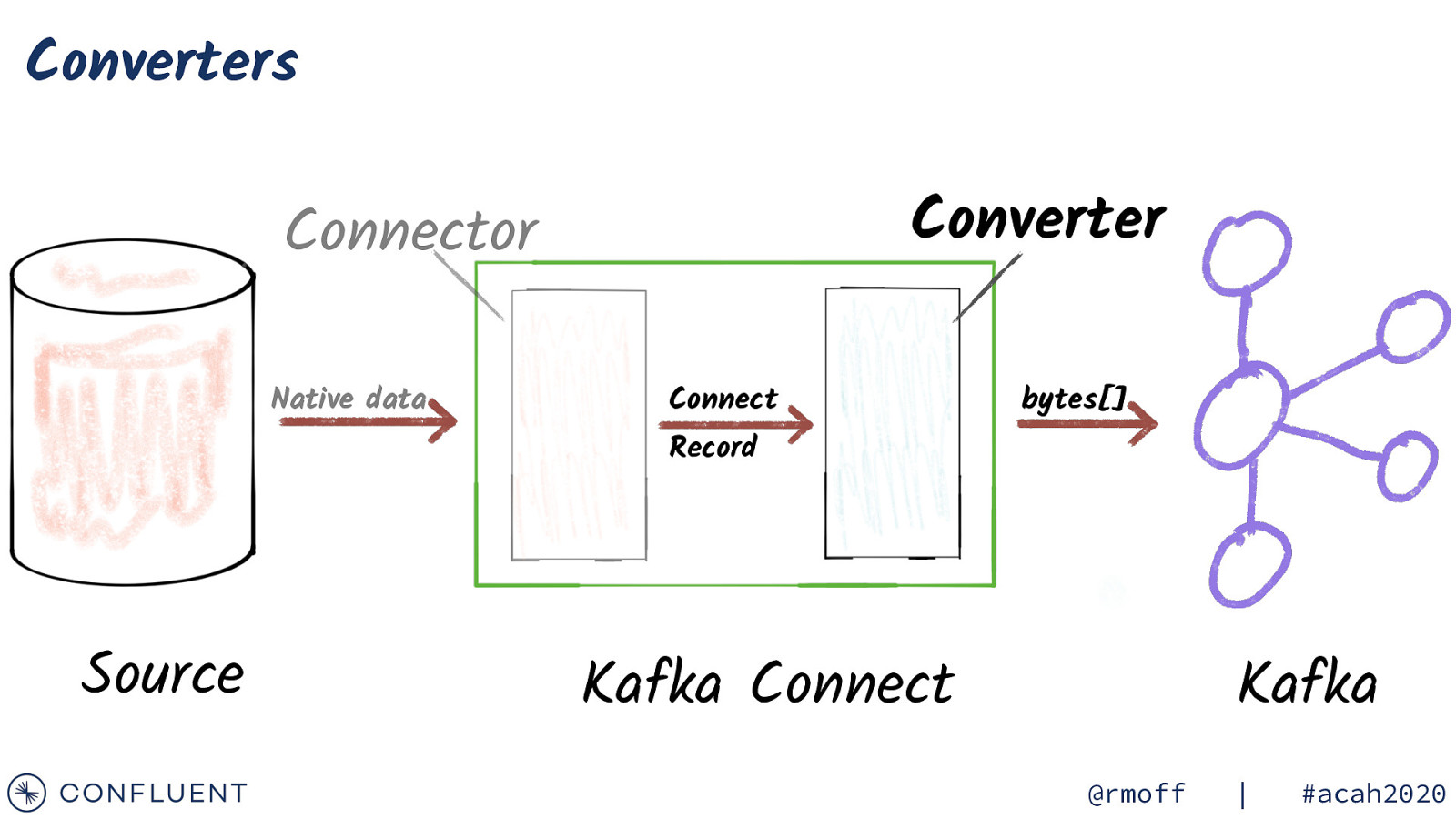
Connectors Connector Native data Connect Record Source Kafka Connect Kafka @rmoff | #acah2020
Converters Converter Connector Native data Connect bytes[] Record Source Kafka Connect Kafka @rmoff | #acah2020
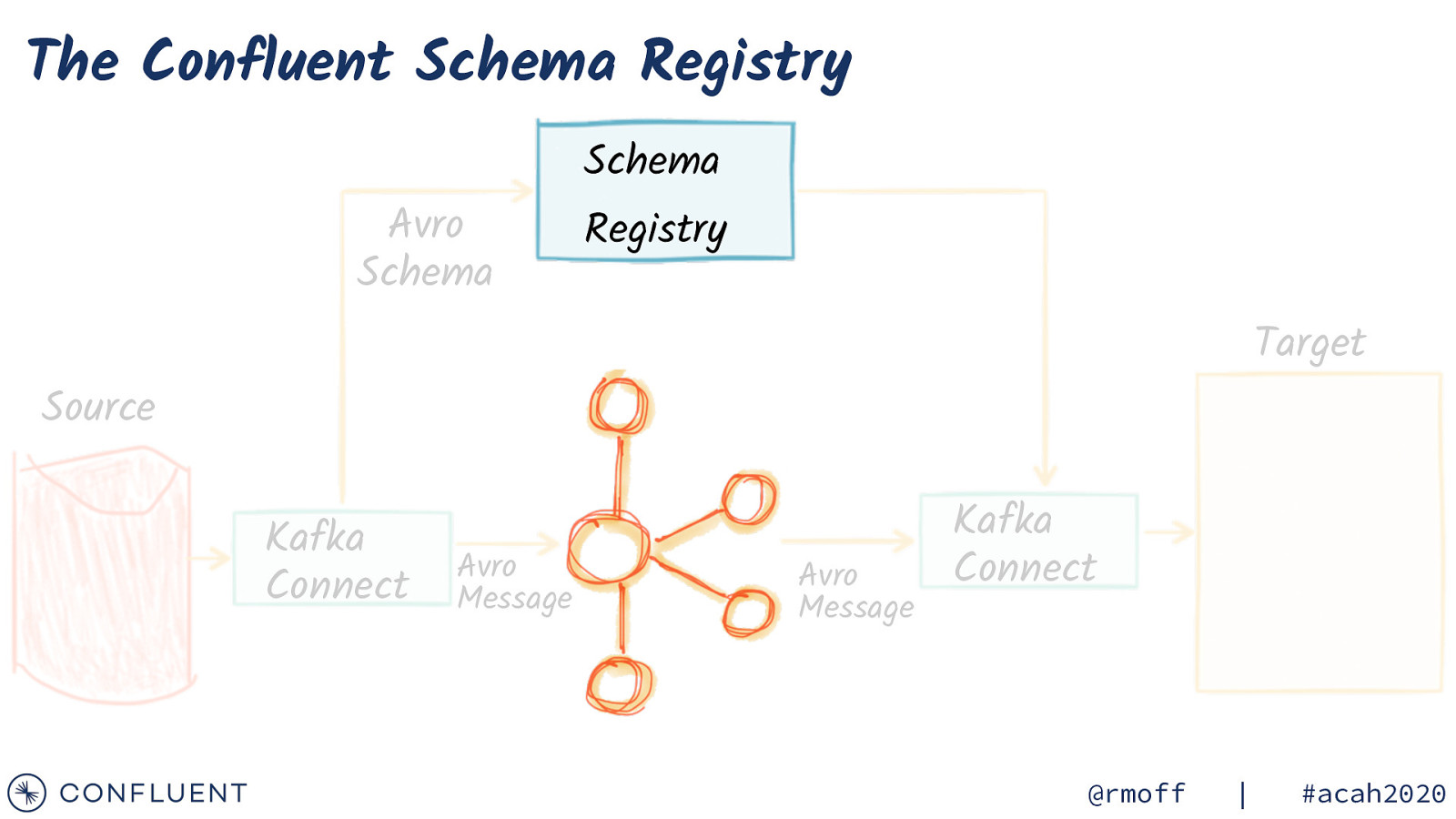
Serialisation & Schemas JSON Avro Protobuf Schema JSON CSV 👍 👍 👍 😬 https://rmoff.dev/qcon-schemas @rmoff | #acah2020
The Confluent Schema Registry Avro Schema Schema Registry Target Source Kafka Connect Avro Message Avro Message Kafka Connect @rmoff | #acah2020
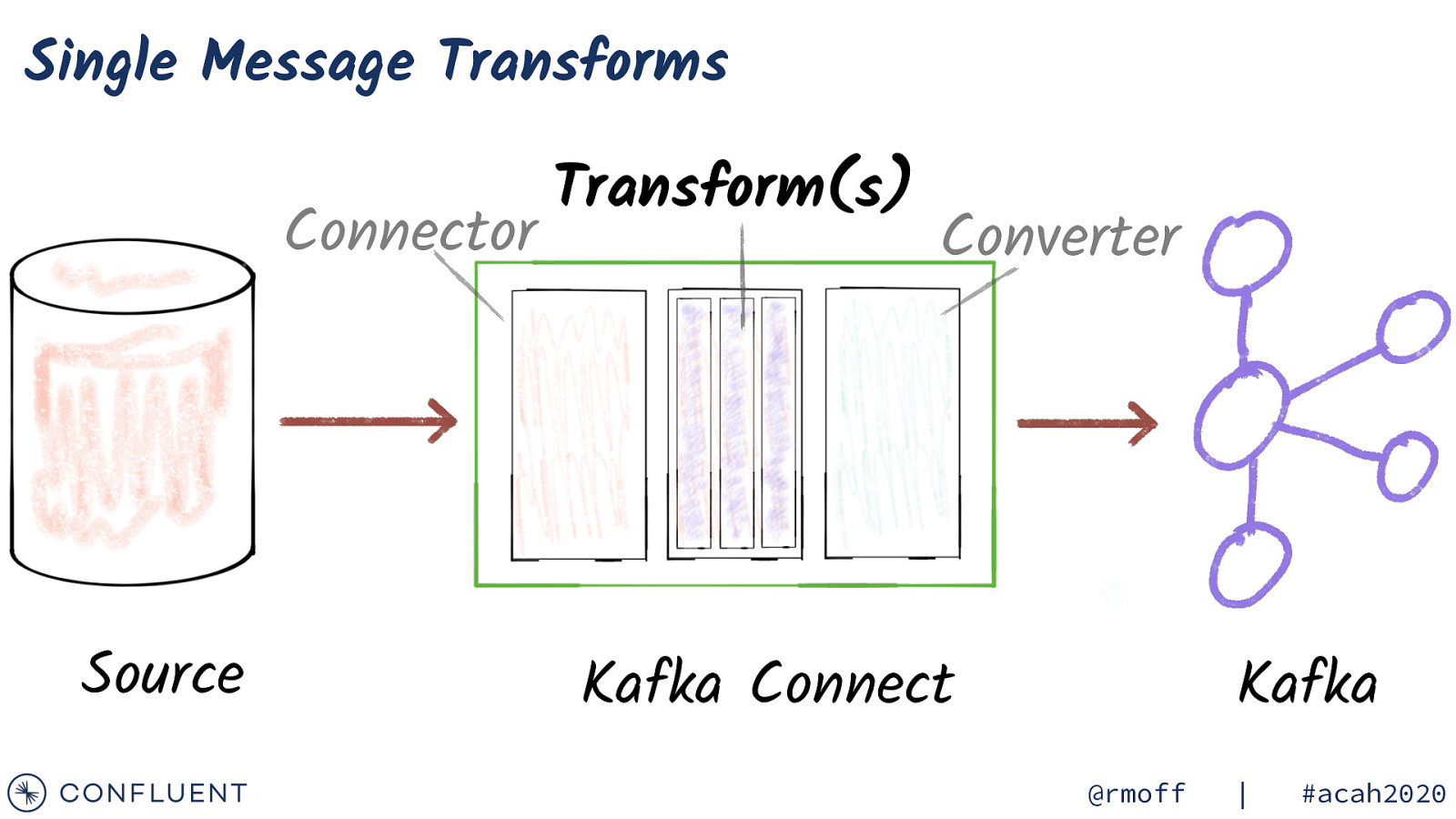
Single Message Transforms Connector Source Transform(s) Converter Kafka Connect Kafka @rmoff | #acah2020
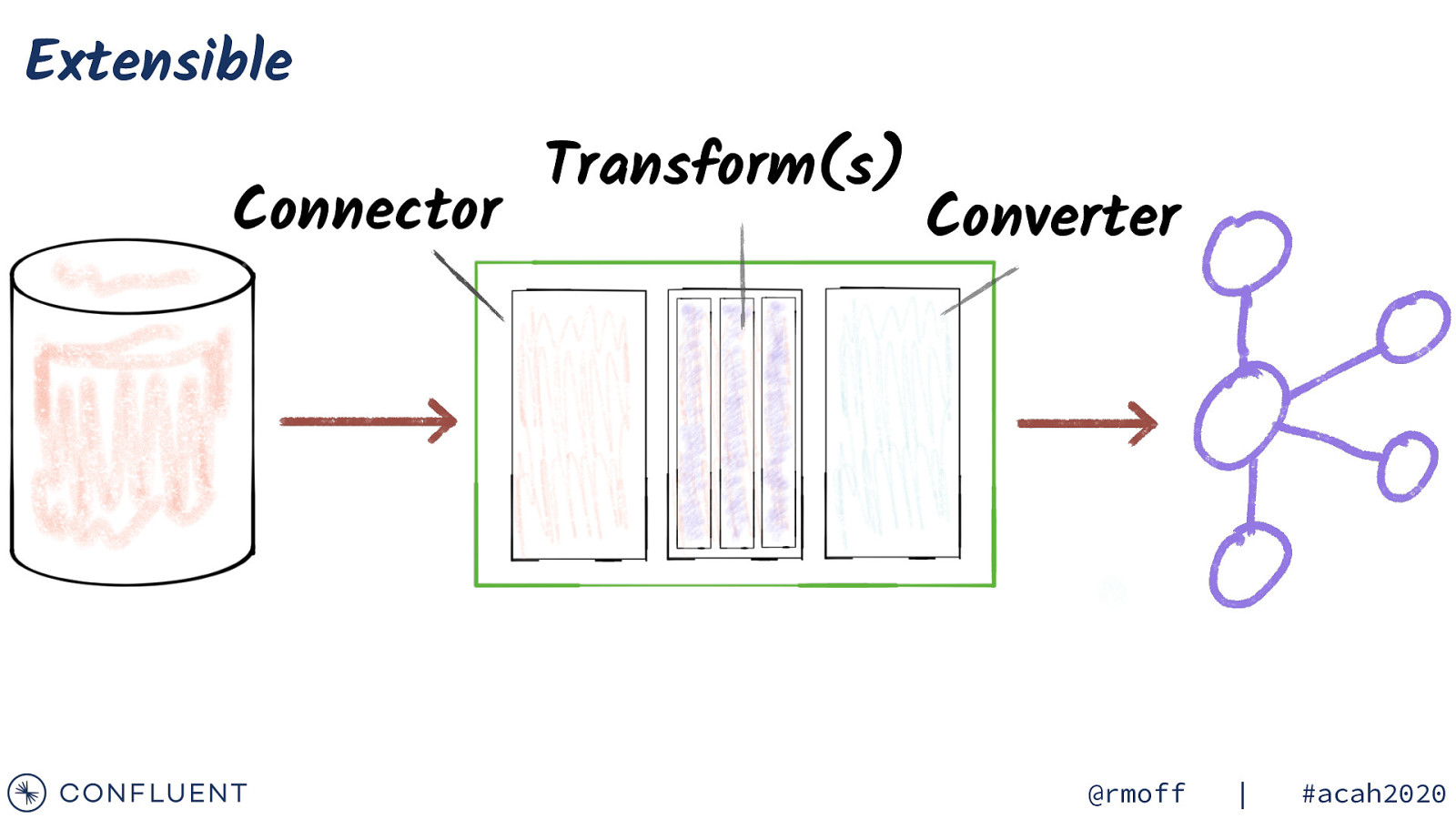
Extensible Connector Transform(s) Converter @rmoff | #acah2020
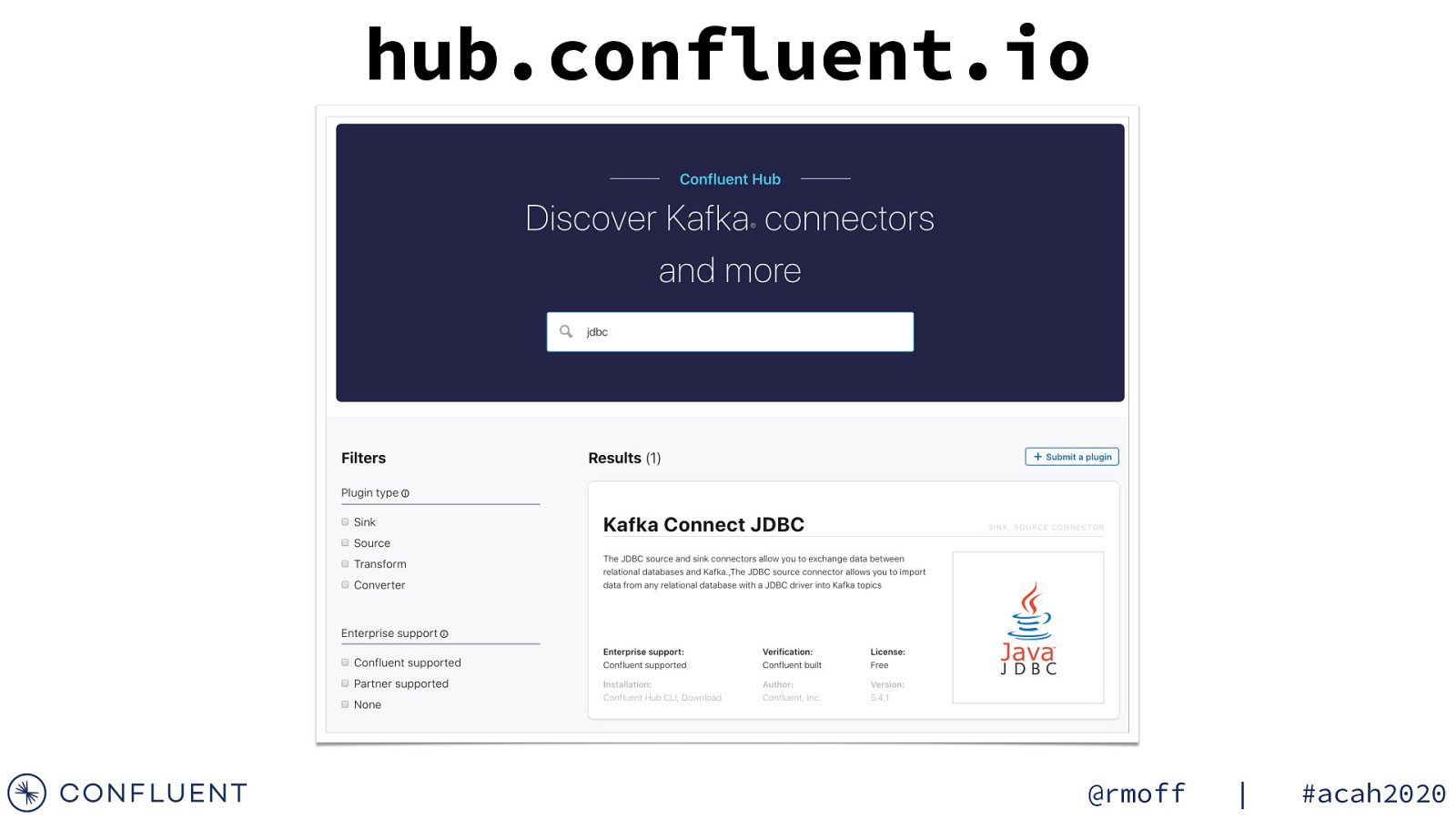
hub.confluent.io @rmoff | #acah2020
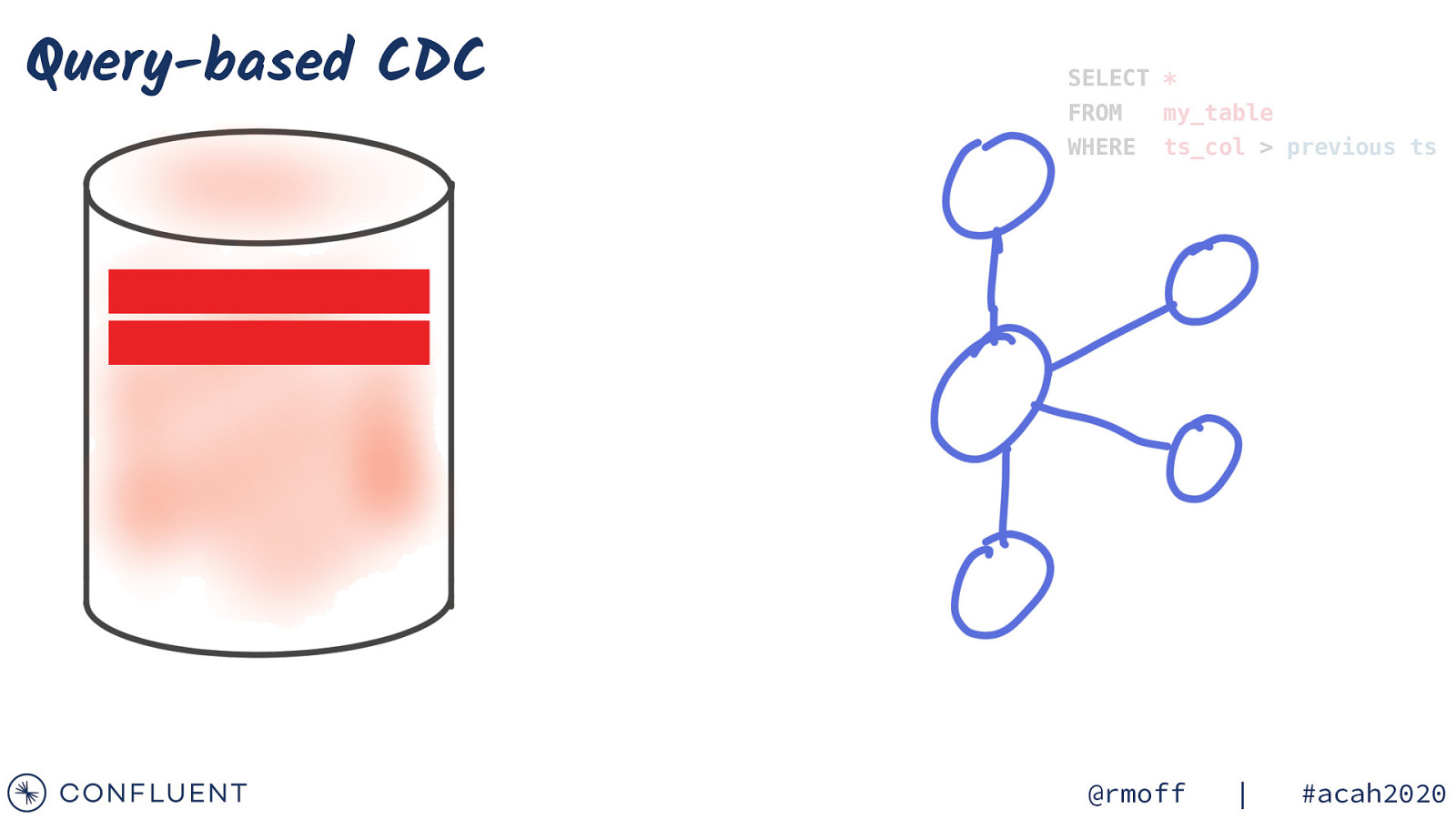
Change-Data-Capture (CDC) Query-based Log-based @rmoff | #acah2020
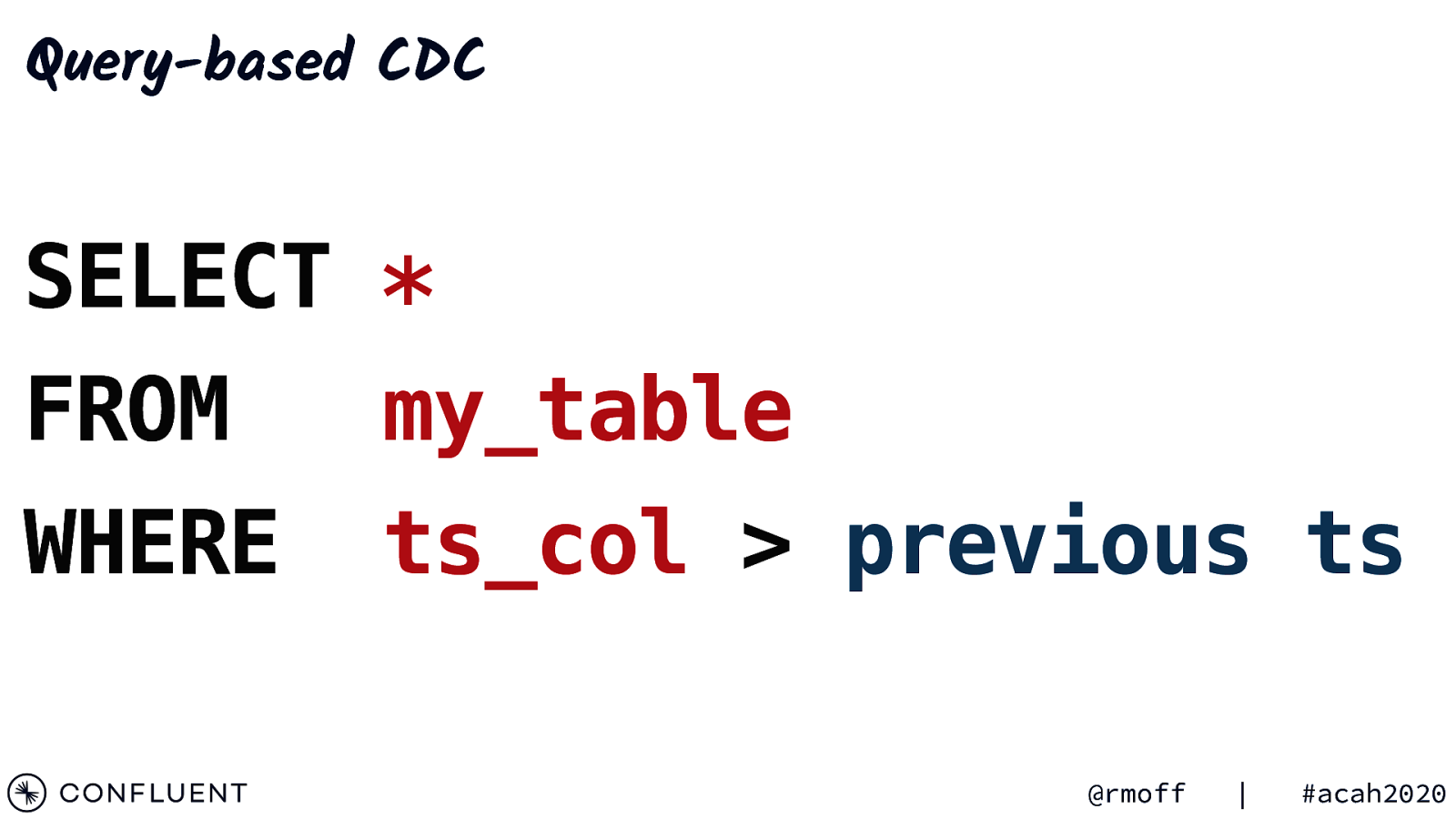
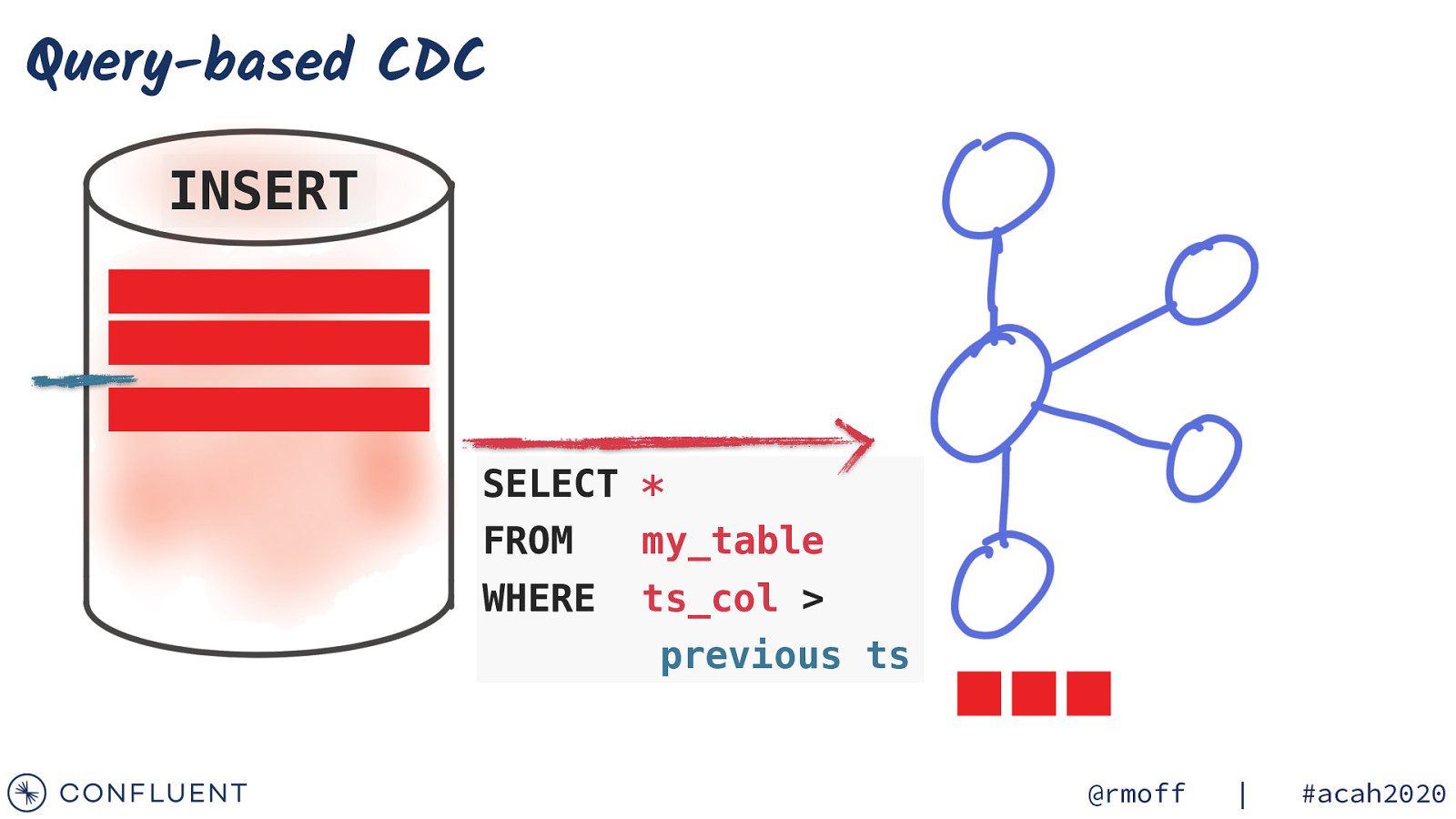
Query-based CDC SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #acah2020
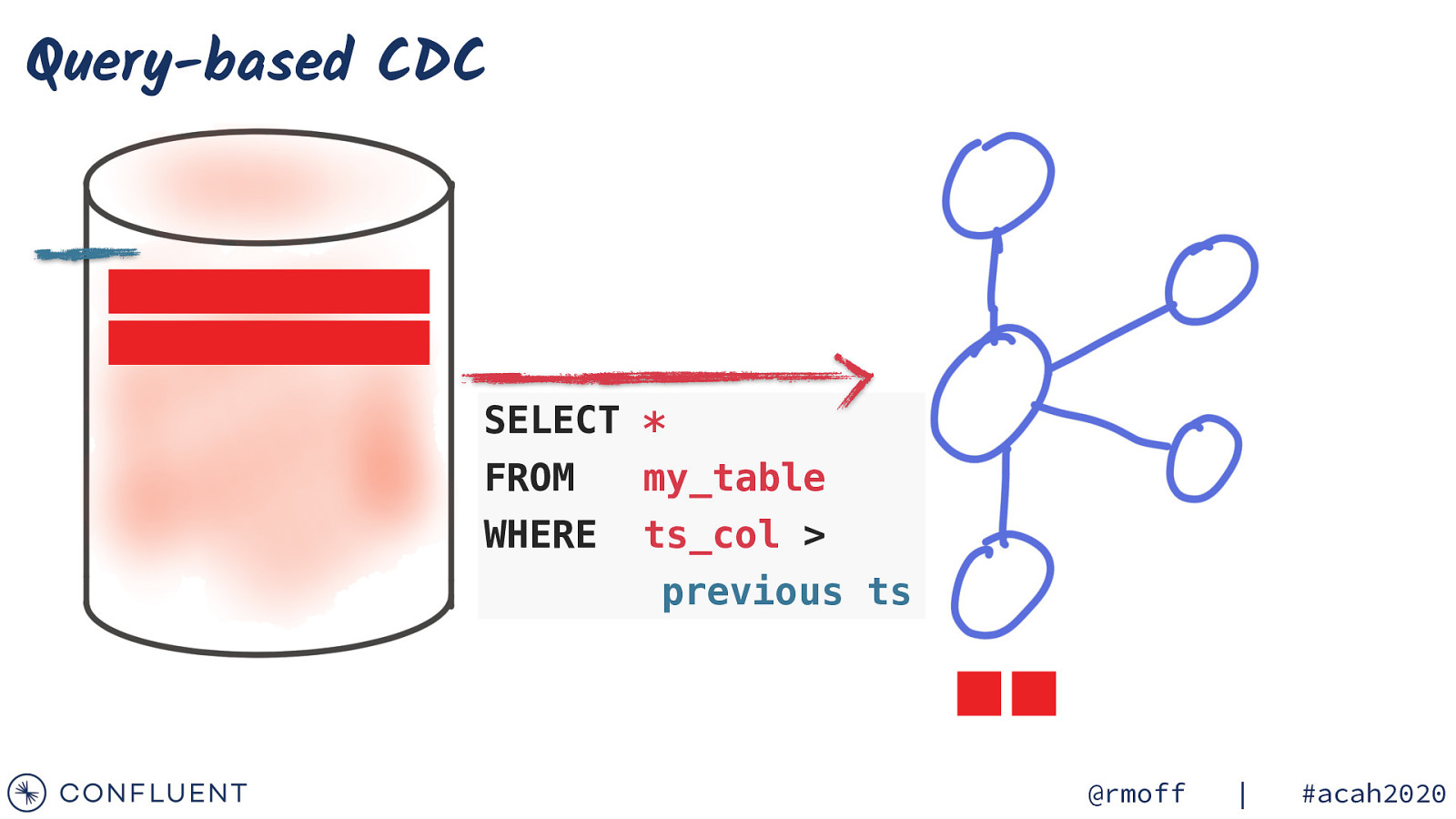
Query-based CDC SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #acah2020
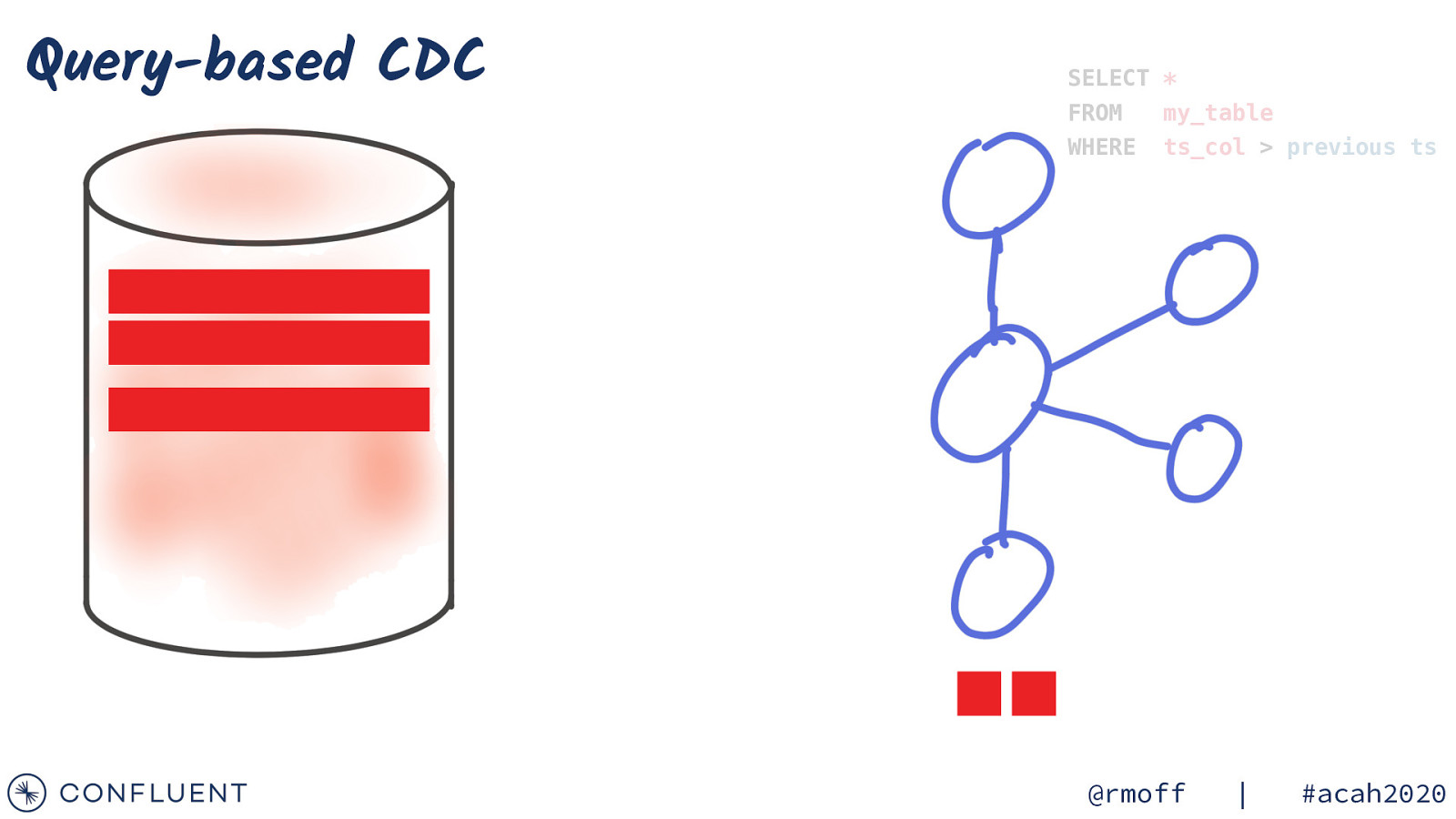
Query-based CDC SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #acah2020
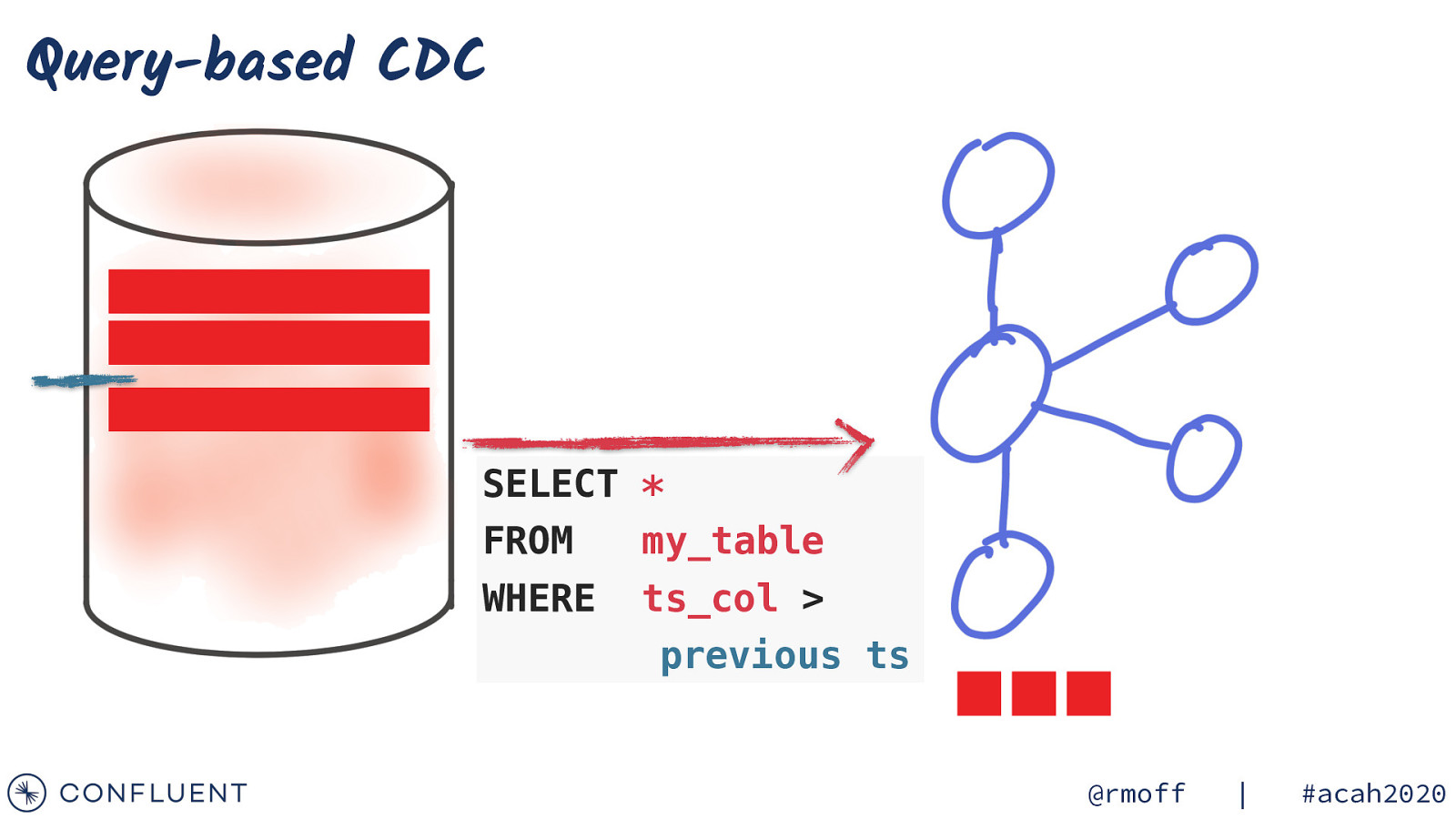
Query-based CDC SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #acah2020
Query-based CDC SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #acah2020
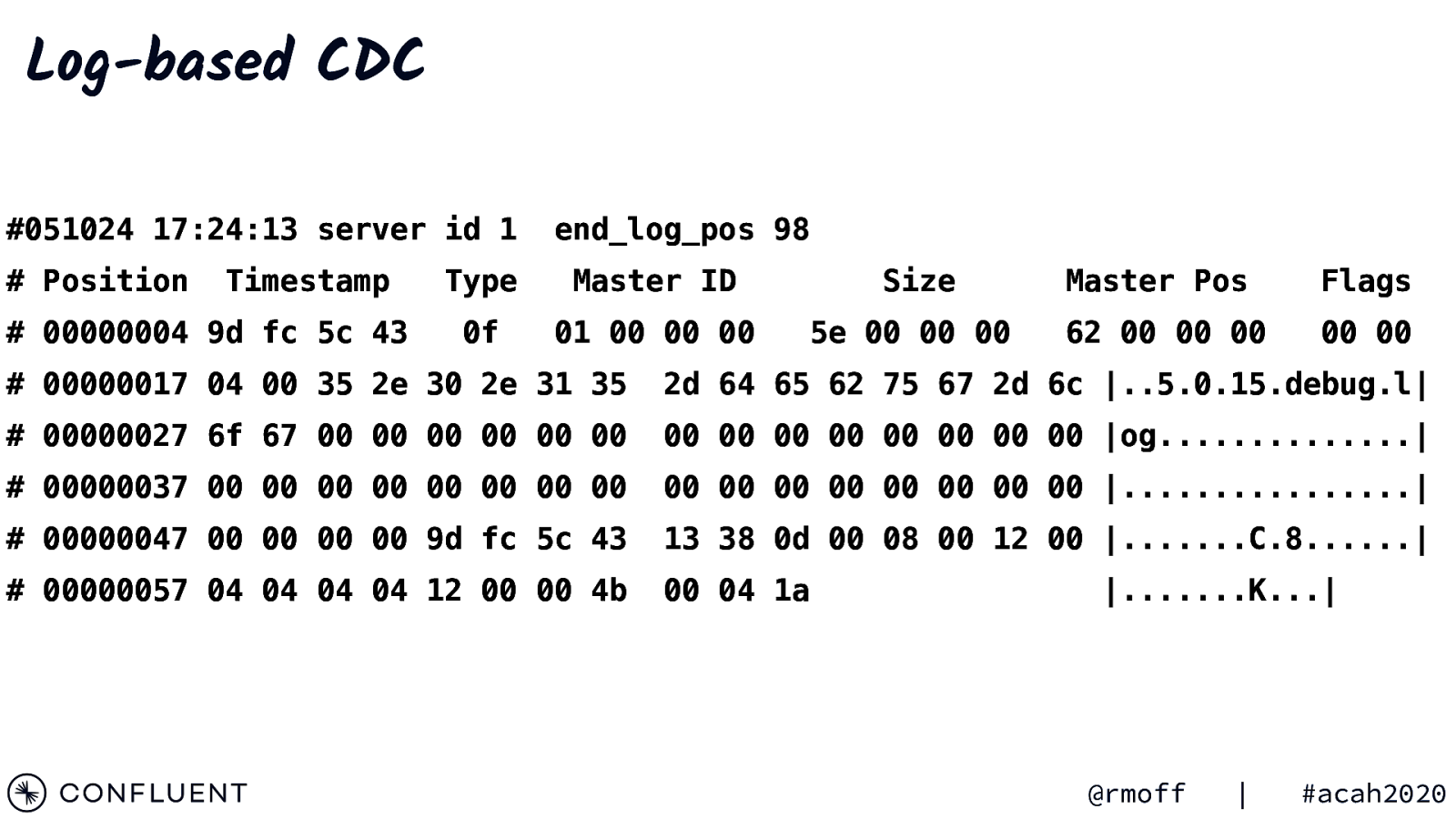
Log-based CDC #051024 17:24:13 server id 1 # Position Timestamp
end_log_pos 98 Type Master ID 0f 01 00 00 00 Size 5e 00 00 00 Master Pos Flags 62 00 00 00 00 00
2d 64 65 62 75 67 2d 6c |..5.0.15.debug.l|
00 00 00 00 00 00 00 00 |og…………..|
00 00 00 00 00 00 00 00 |…………….|
13 38 0d 00 08 00 12 00 |…….C.8……|
00 04 1a |…….K…| @rmoff | #acah2020
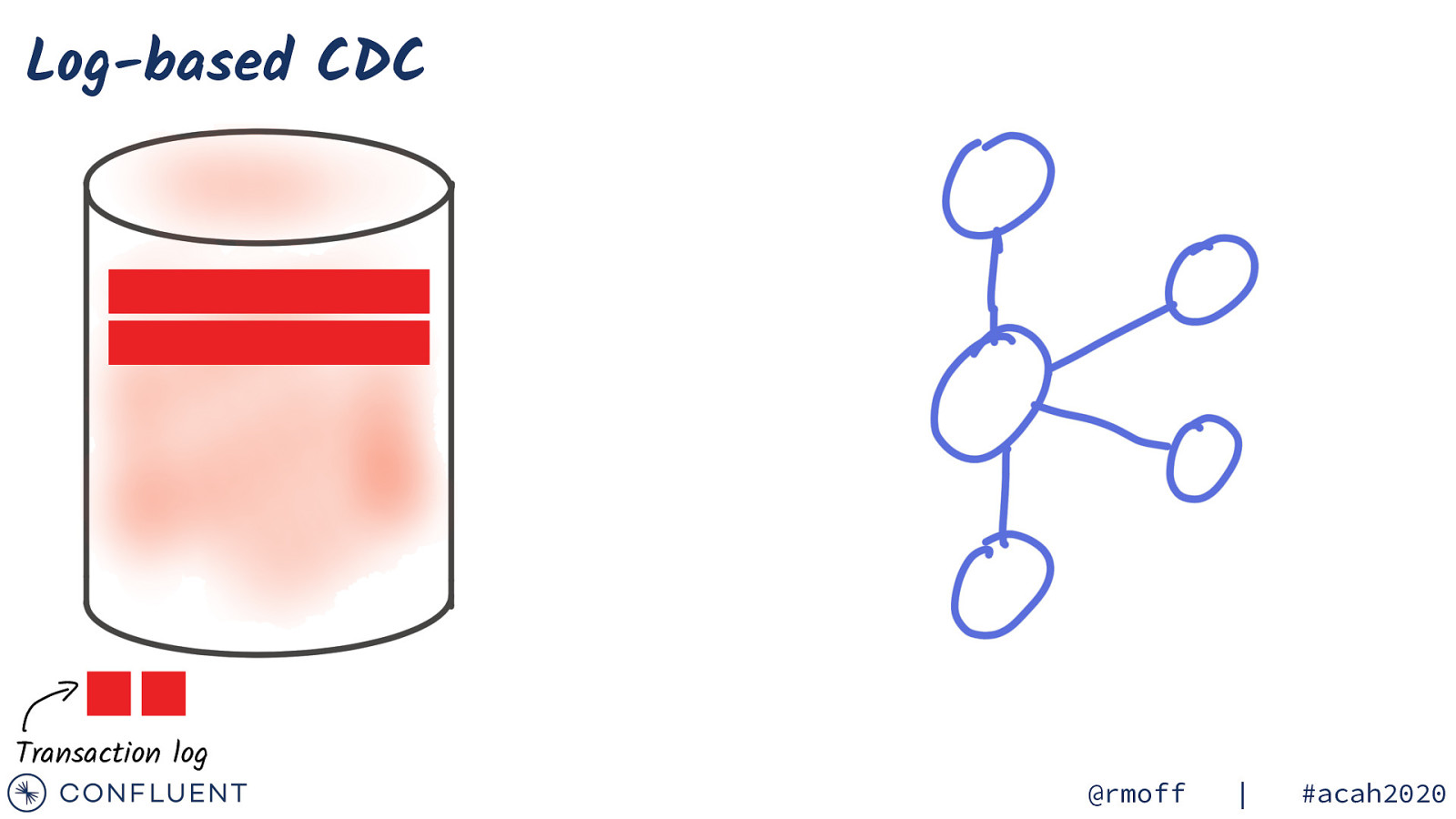
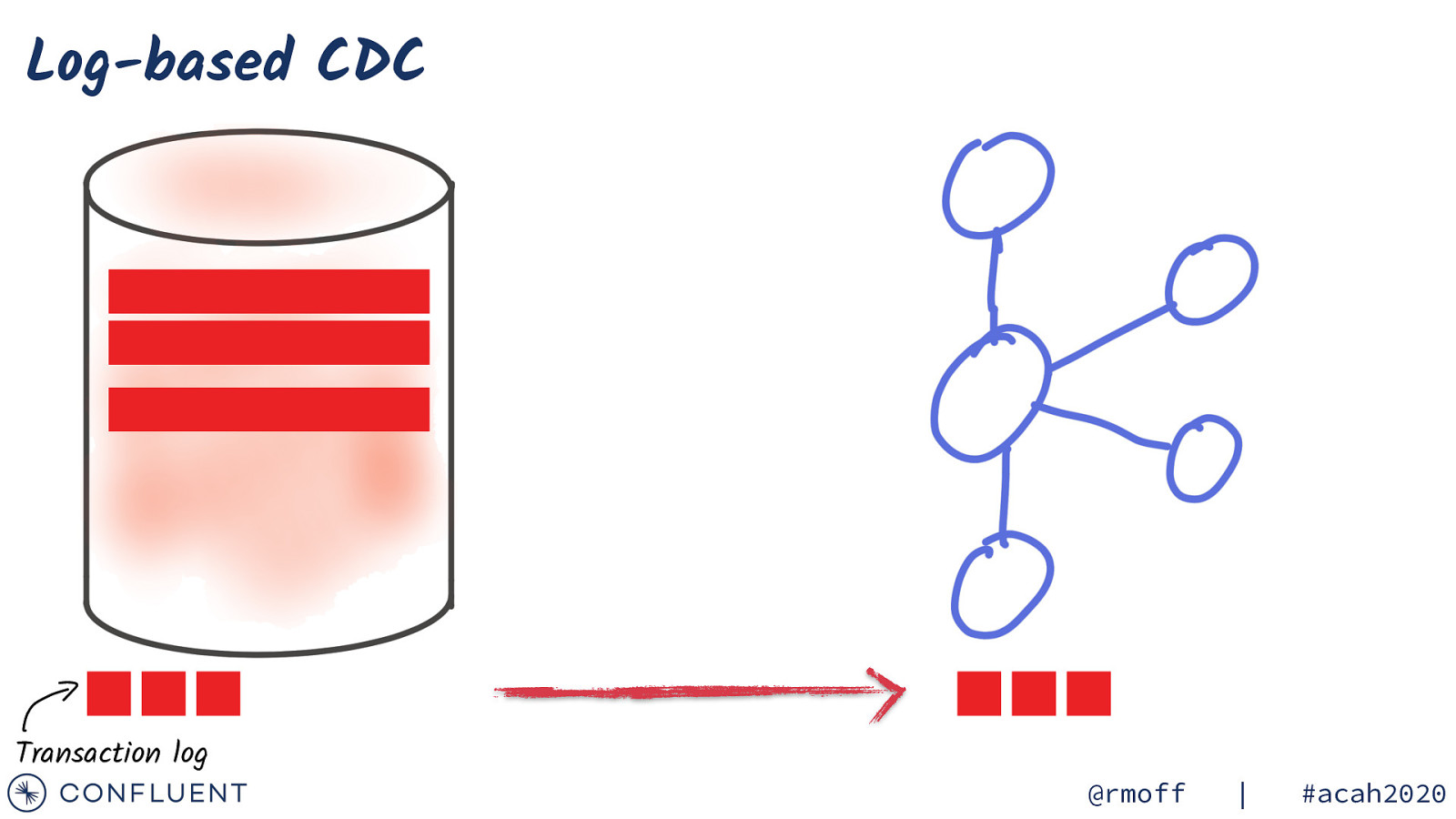
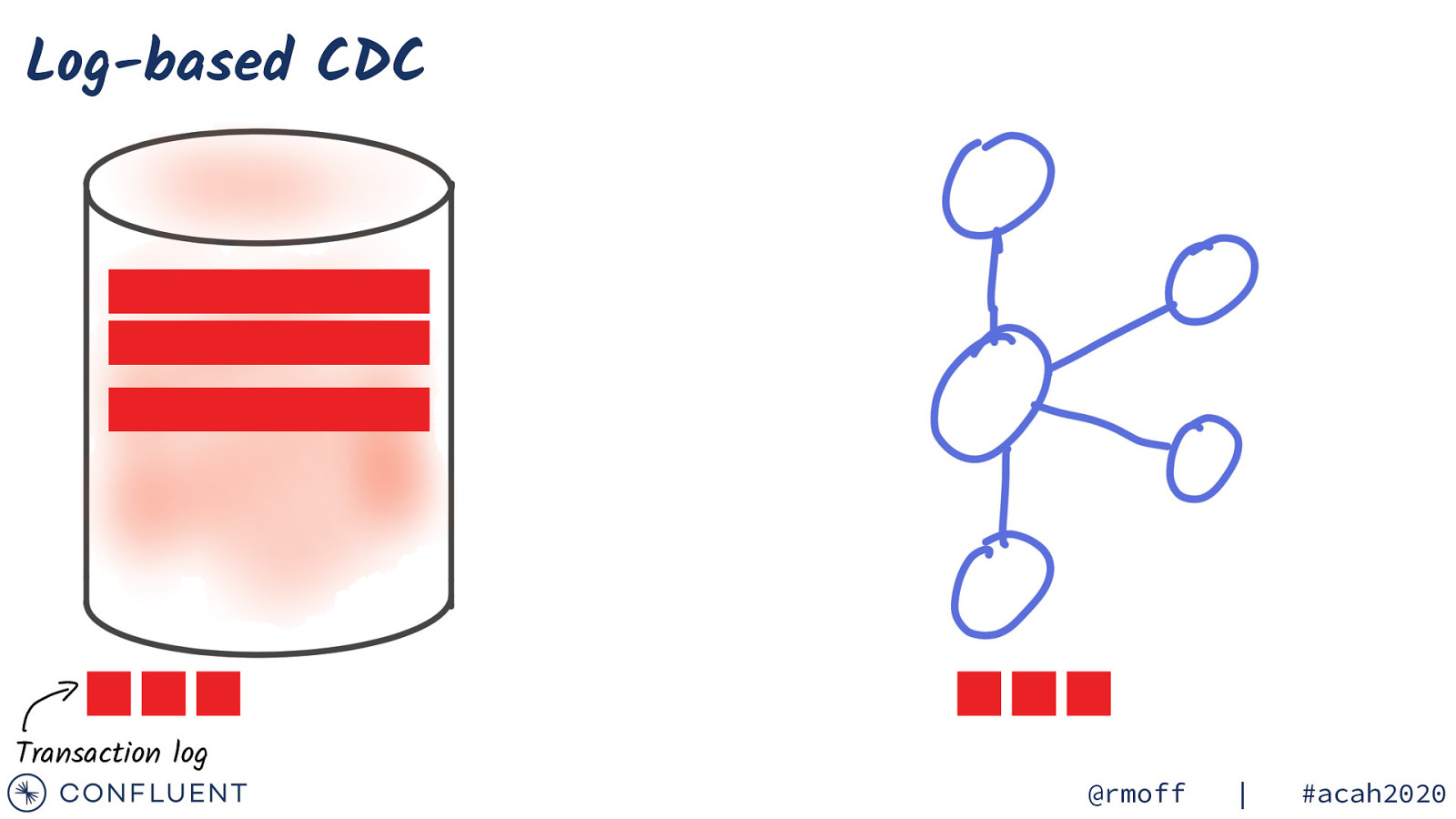
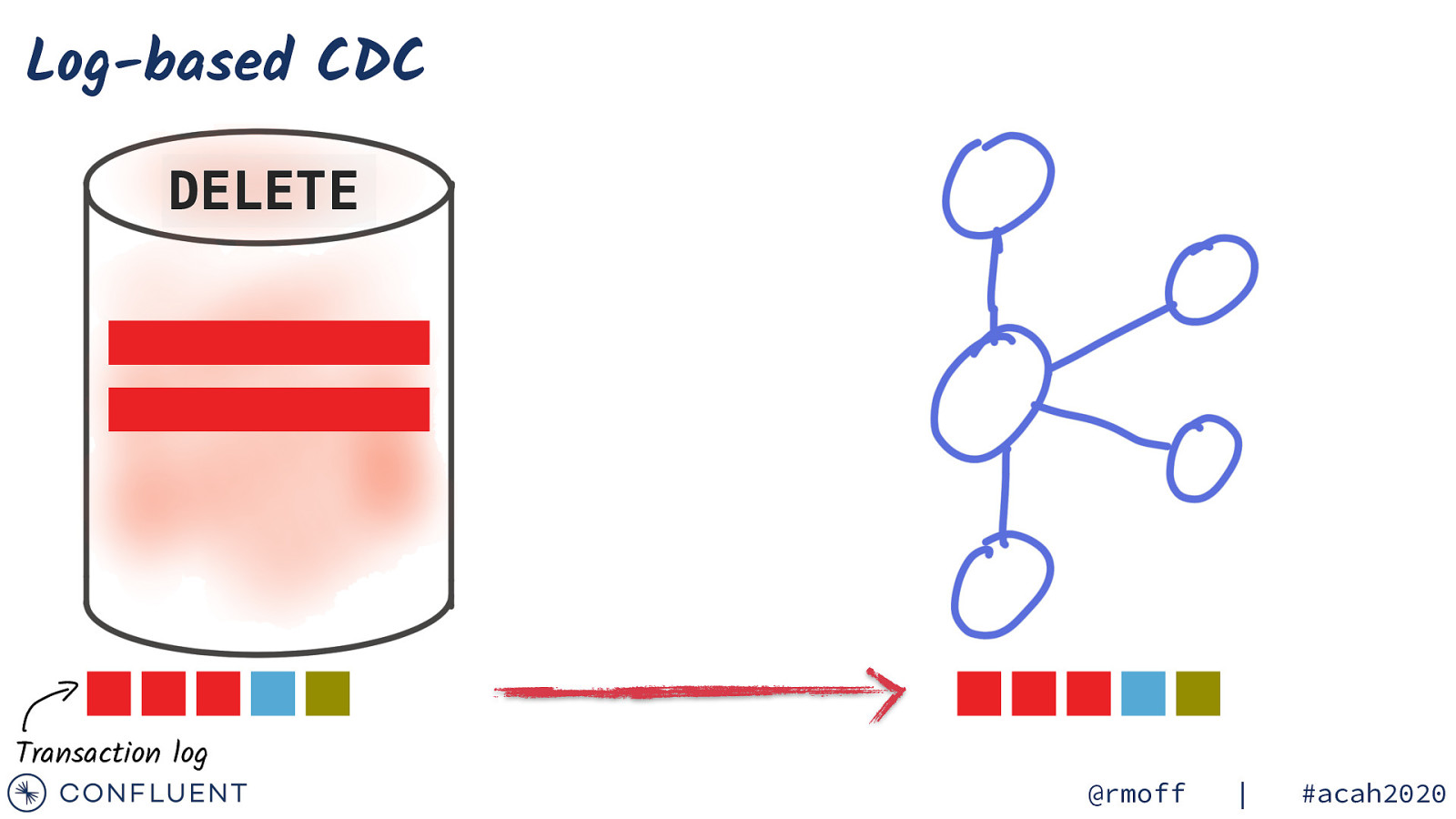
Log-based CDC Transaction log @rmoff | #acah2020
Log-based CDC Transaction log @rmoff | #acah2020
Log-based CDC Transaction log @rmoff | #acah2020
Log-based CDC Transaction log @rmoff | #acah2020
Demo Time! https://rmoff.dev/cdc-demo @rmoff | #acah2020
@rmoff | #acah2020
Query-based CDC SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #acah2020
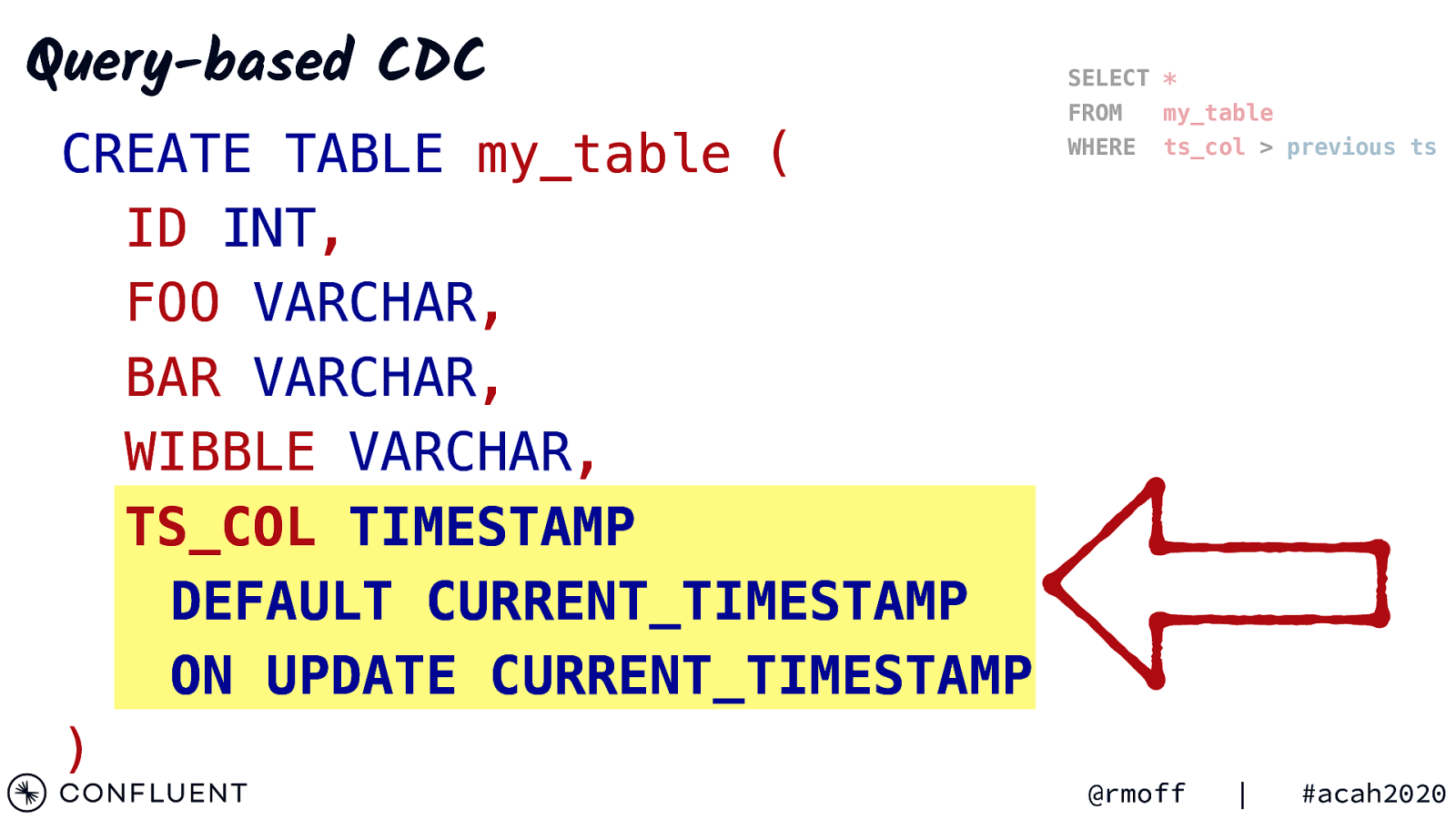
Query-based CDC CREATE TABLE my_table ( ID INT, FOO VARCHAR, BAR VARCHAR, WIBBLE VARCHAR, TS_COL TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP ) SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #acah2020
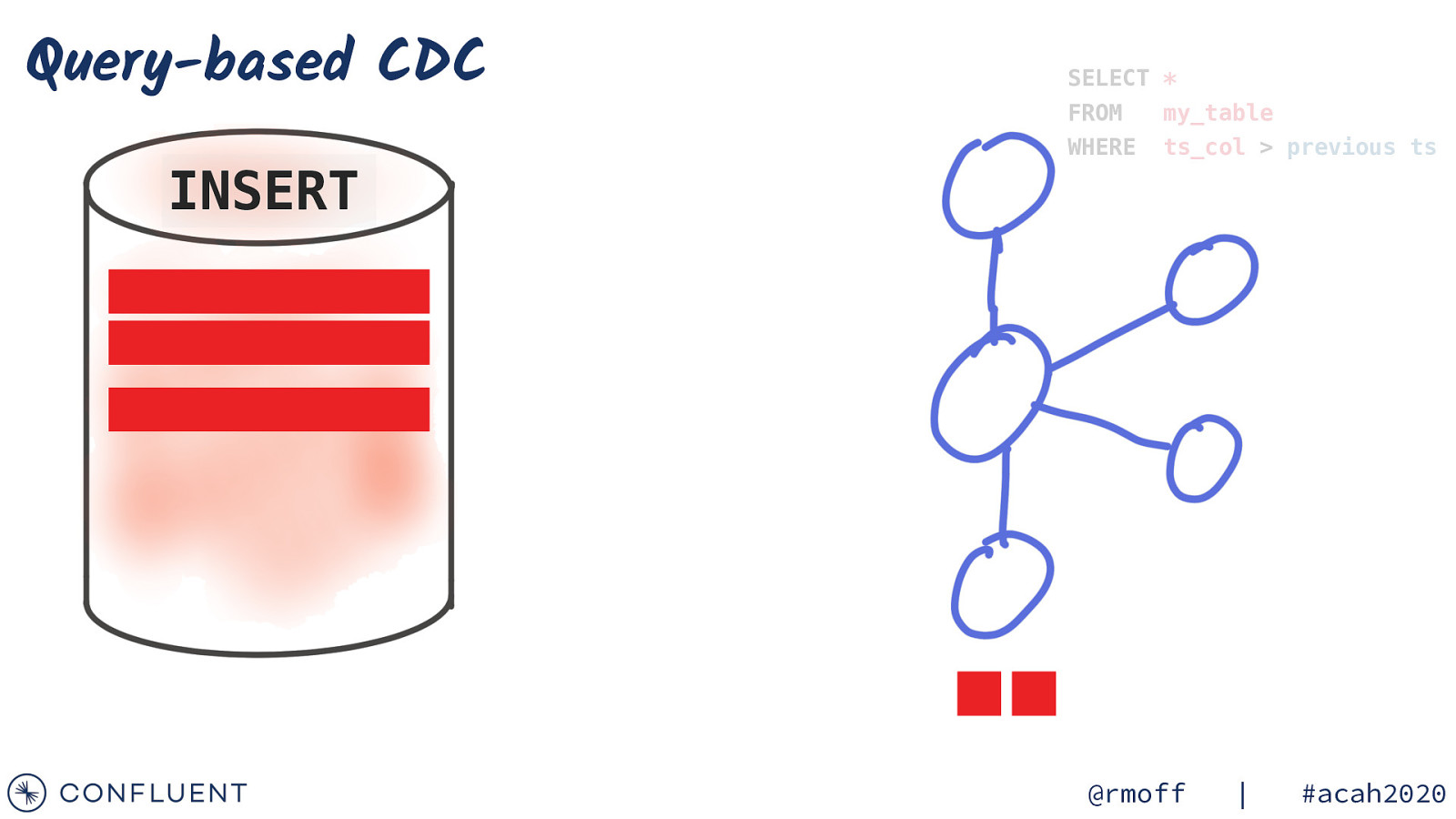
Query-based CDC INSERT SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #acah2020
Query-based CDC INSERT SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #acah2020
Query-based CDC UPDATE @rmoff | #acah2020
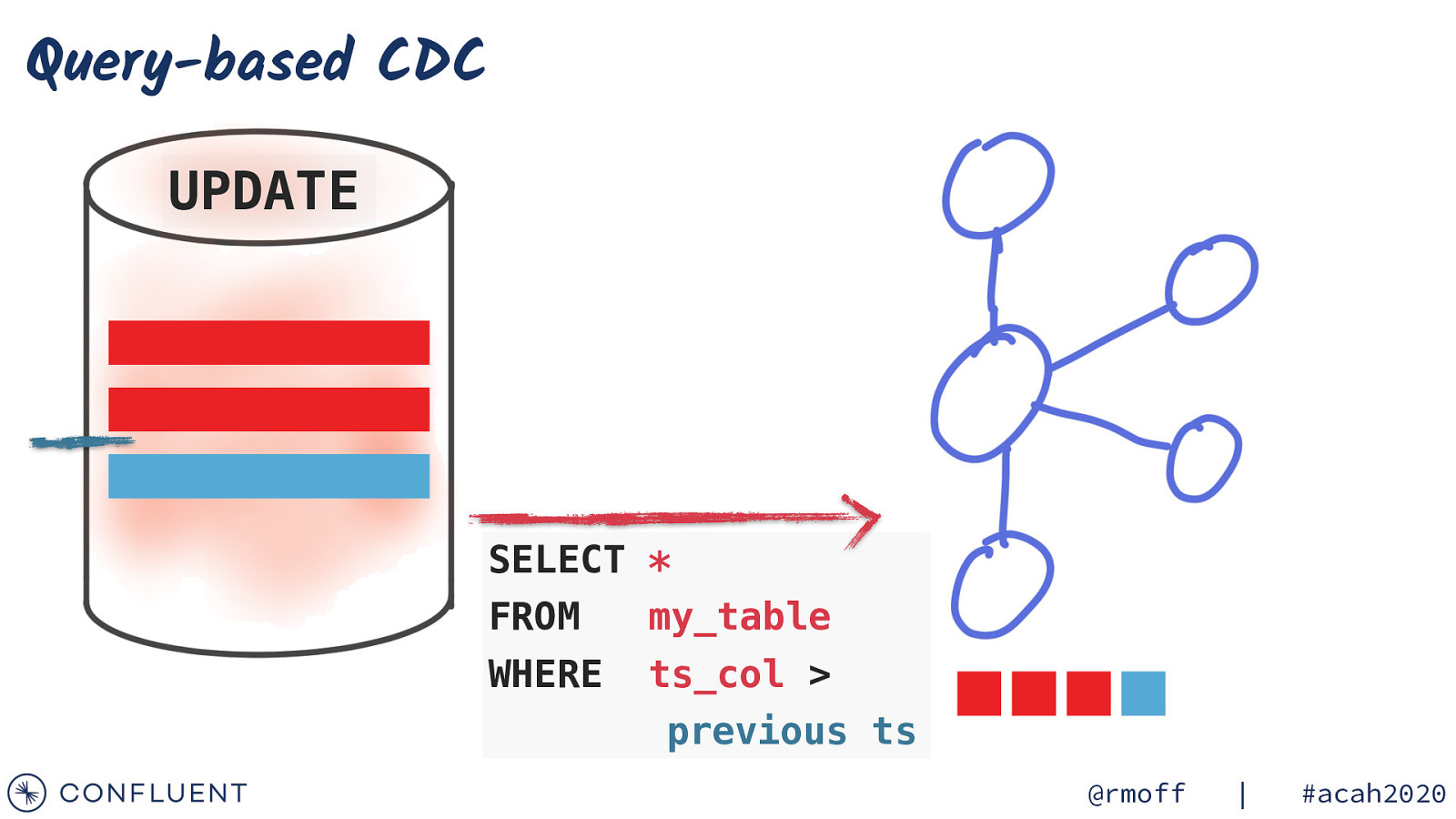
Query-based CDC UPDATE SELECT * FROM my_table WHERE ts_col > previous ts @rmoff | #acah2020
Query-based CDC DELETE @rmoff | #acah2020
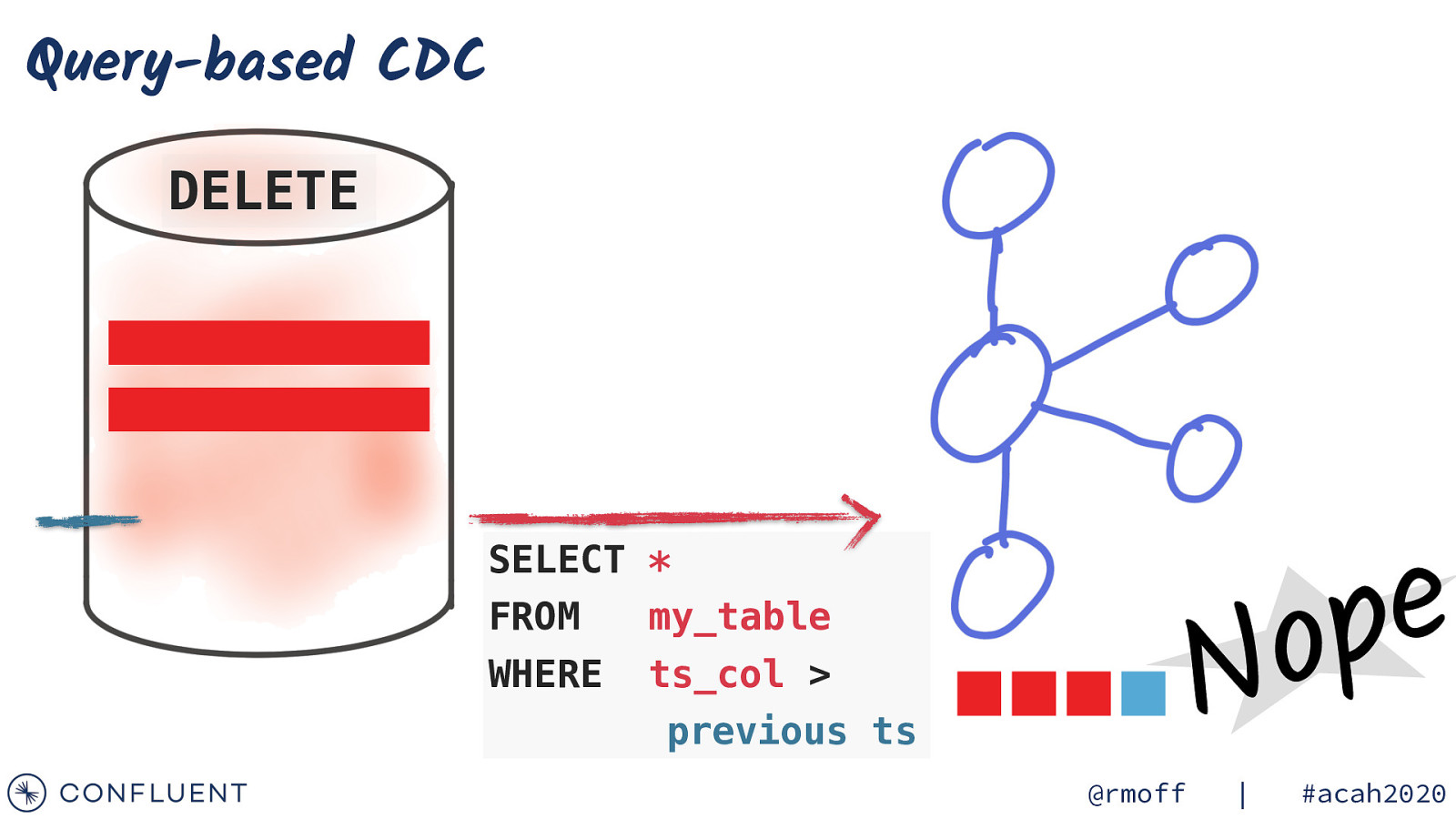
Query-based CDC DELETE e p o SELECT * FROM my_table WHERE ts_col > previous ts @rmoff N | #acah2020
Query-based CDC orderID status address updateTS SELECT * FROM orders WHERE updateTS > previous ts @rmoff | #acah2020
Query-based CDC orderID status address updateTS 42 29 Acacia Road 10:54:29 SHIPPED SELECT * FROM orders WHERE updateTS > previous ts { } “orderID”: 42, “status”: “SHIPPED”, “address”: “29 Acacia Road”, “updateTS”: “10:54:29” @rmoff | #acah2020
10:54:01 PENDING INSERT INTO orders (orderID, status) VALUES (42, ‘PENDING’); @rmoff | #acah2020
Query-based CDC orderID status address 42 1640 Riverside Drive 10:54:20 PENDING updateTS UPDATE orders SET address = ‘1640 Riverside Drive’ WHERE orderID = 42; @rmoff | #acah2020
Query-based CDC orderID status address updateTS 42 29 Acacia Road 10:54:25 PENDING UPDATE orders SET address = ‘29 Acacia Road’ WHERE orderID = 42; @rmoff | #acah2020
Query-based CDC orderID status address updateTS 42 29 Acacia Road 10:54:29 SHIPPED UPDATE orders SET status = ‘SHIPPED’ WHERE orderID = 42; @rmoff | #acah2020
Query-based CDC orderID status orderID address status 42 SHIPPED 42 address 29 PENDING Acacia Road — updateTS updateTS 10:54:29 10:54:01 42 PENDING 1640 Riverside Drive 10:54:20 42 PENDING 29 Acacia Road 10:54:25 42 SHIPPED 29 Acacia Road 10:54:29 @rmoff | #acah2020
Query-based CDC orderID status address updateTS 42 29 Acacia Road 10:54:29 SHIPPED SELECT * FROM orders WHERE updateTS > previous ts { } “orderID”: 42, “status”: “SHIPPED”, “address”: “29 Acacia Road”, “updateTS”: “10:54:29” @rmoff | #acah2020
Query-based CDC ✅ Usually easier to setup ✅ Requires fewer permissions 🛑 Needs specific columns in source schema to track changes 🛑 Impact of polling the DB (or higher latencies tradeoff) Photo by Matese Fields on Unsplash 🛑 Can’t track deletes 🛑 Can’t track multiple events between polling interval Read more: http://cnfl.io/kafka-cdc @rmoff | #acah2020
@rmoff | #acah2020
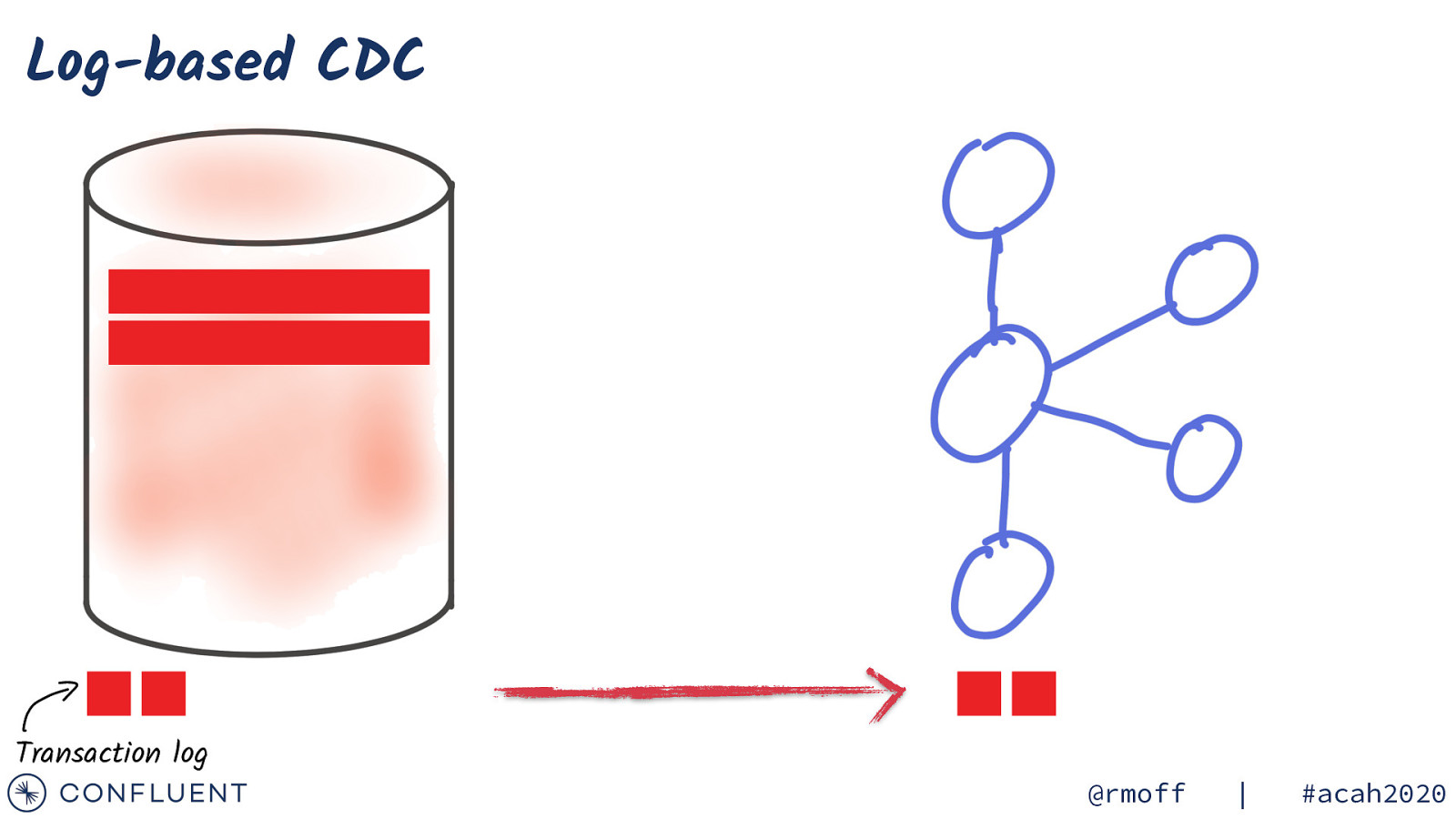
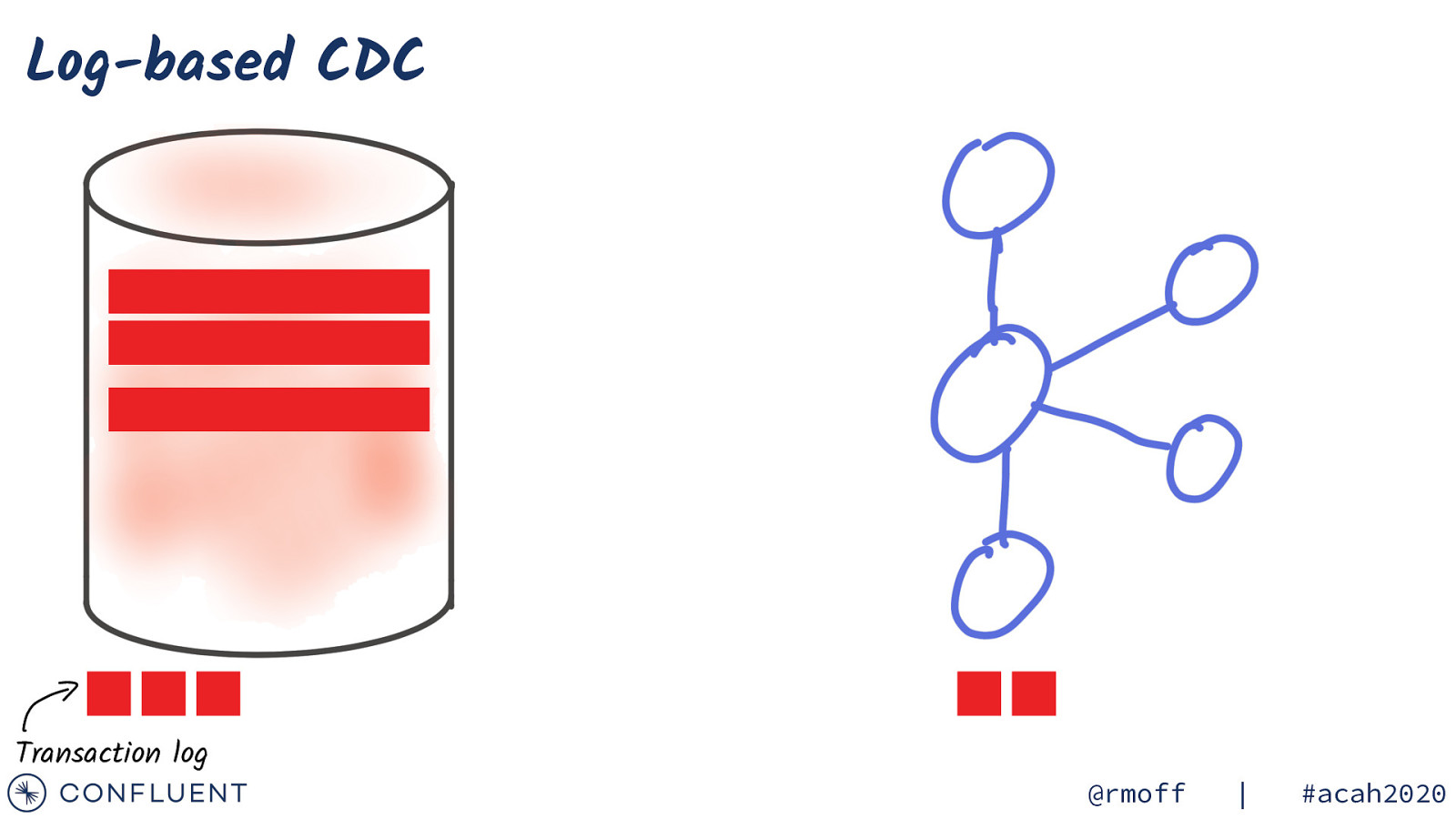
Log-based CDC Transaction log @rmoff | #acah2020
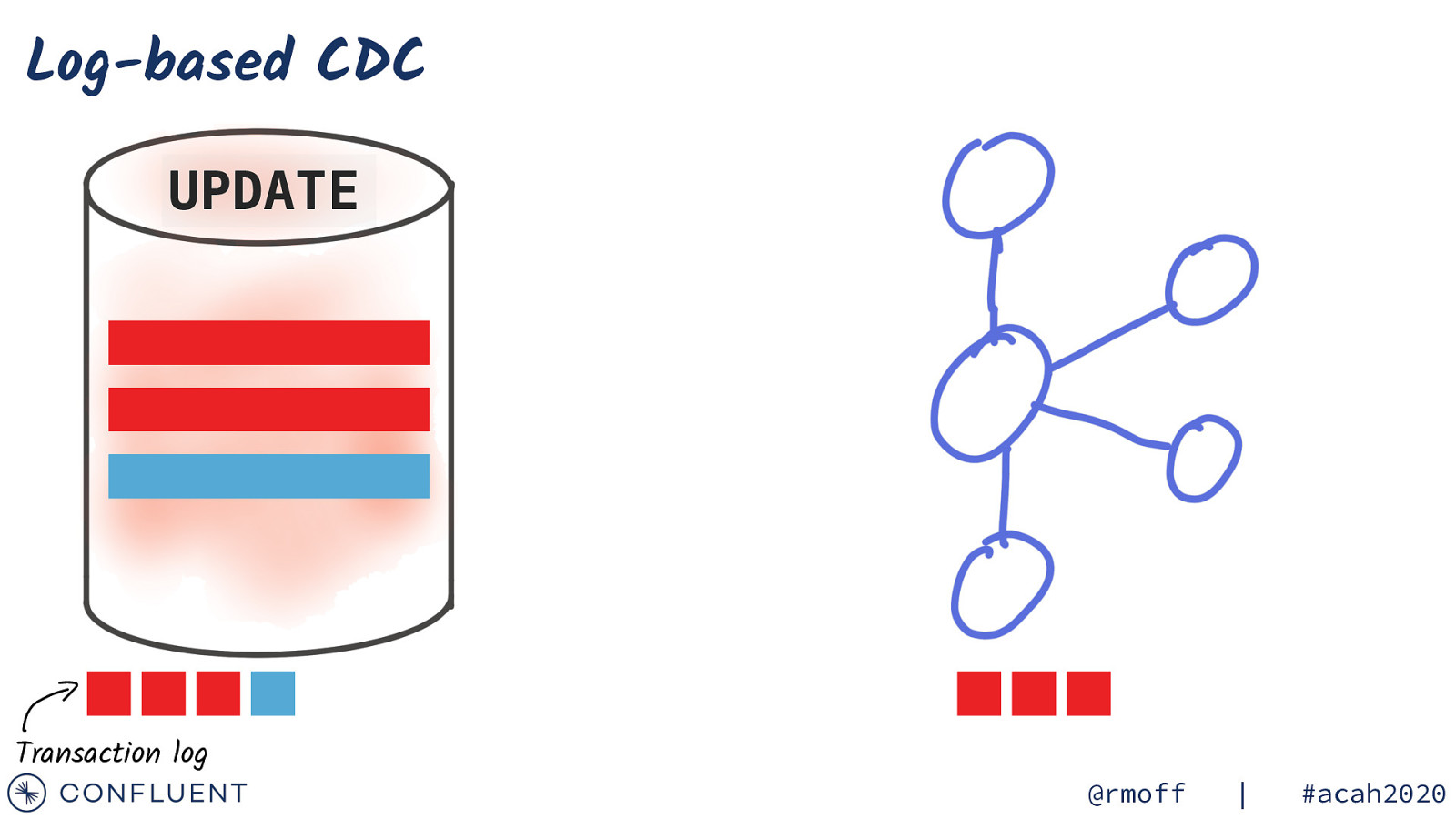
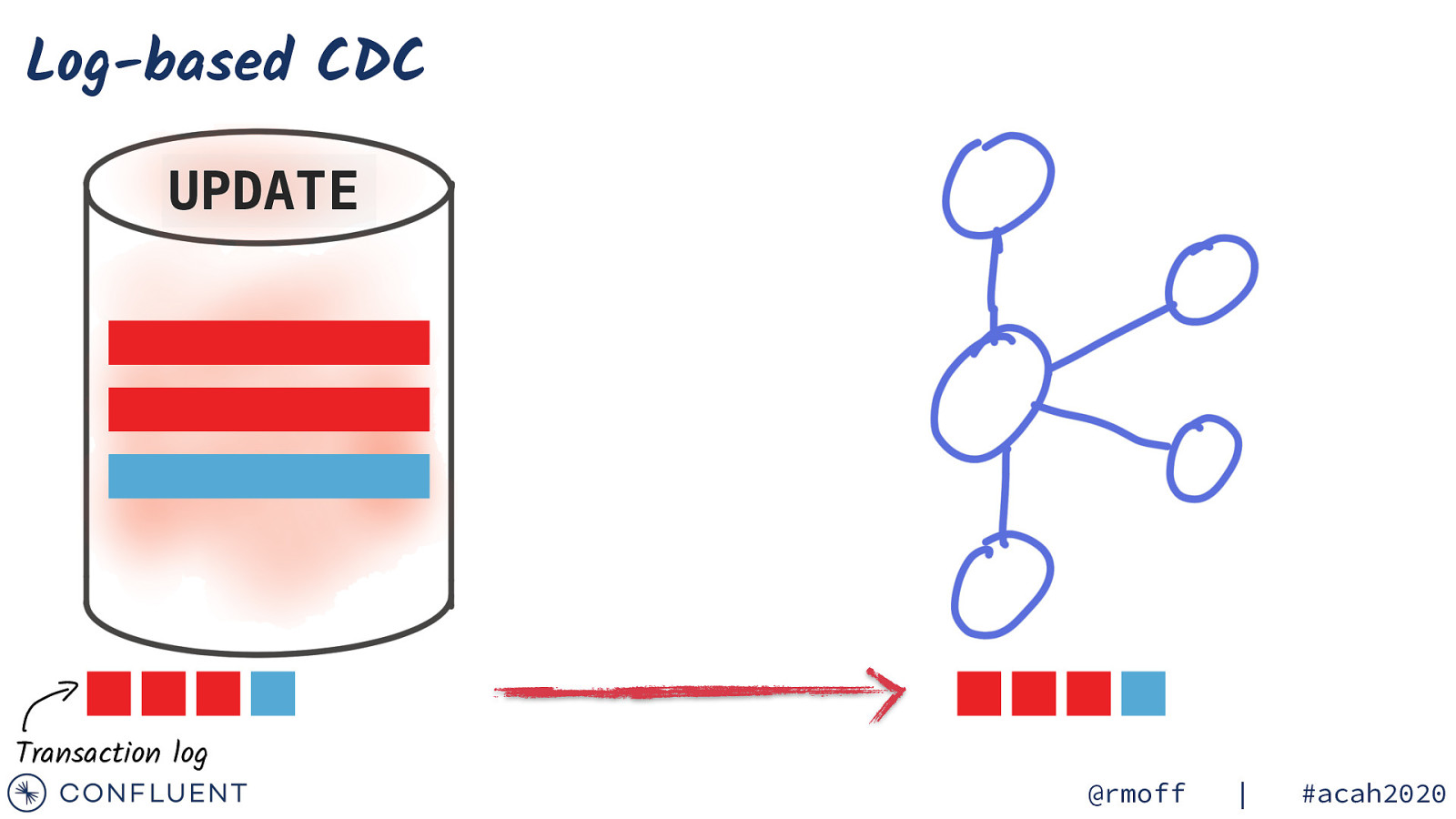
Log-based CDC UPDATE Transaction log @rmoff | #acah2020
Log-based CDC UPDATE Transaction log @rmoff | #acah2020
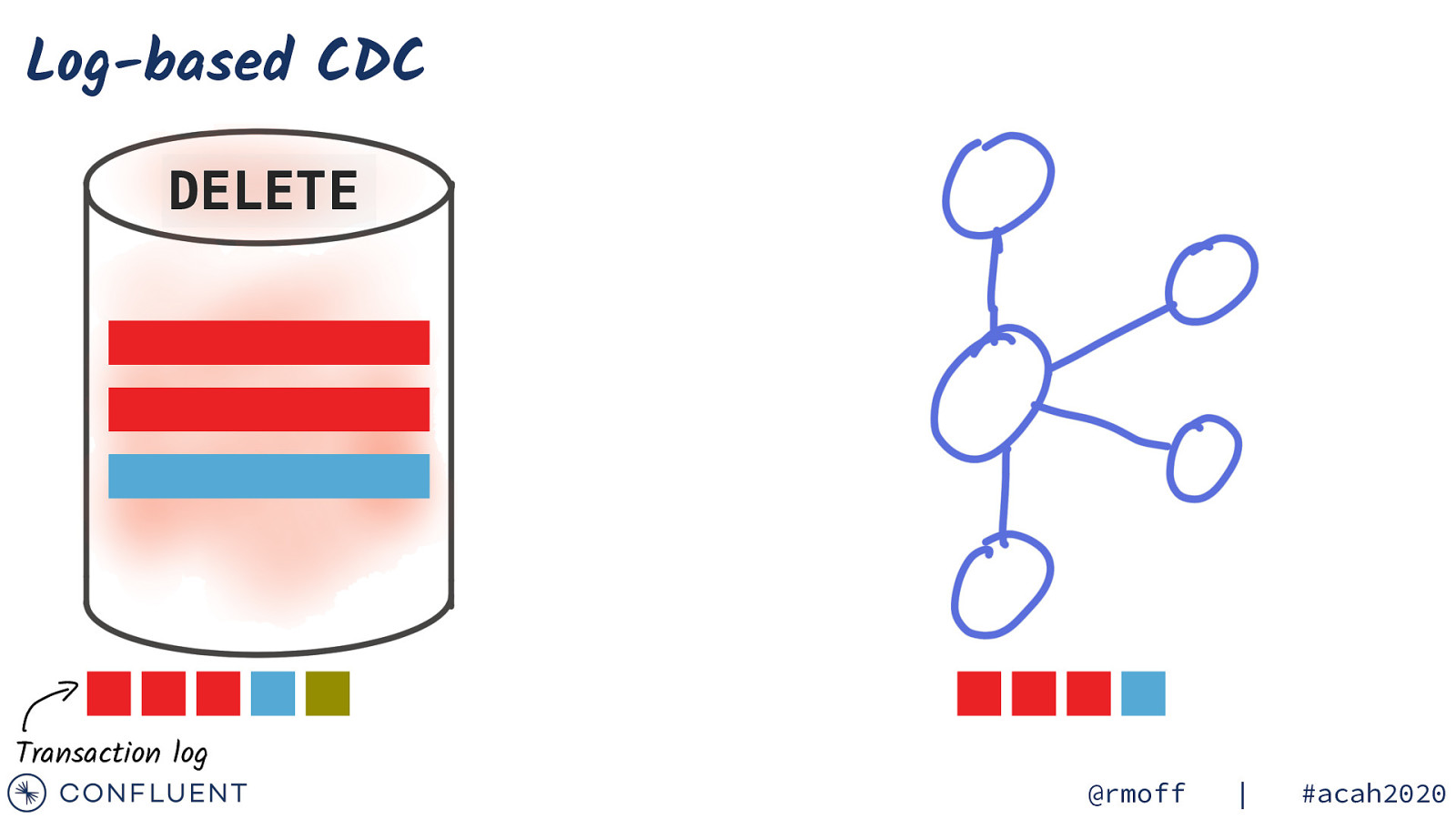
Log-based CDC DELETE Transaction log @rmoff | #acah2020
Log-based CDC DELETE Transaction log @rmoff | #acah2020
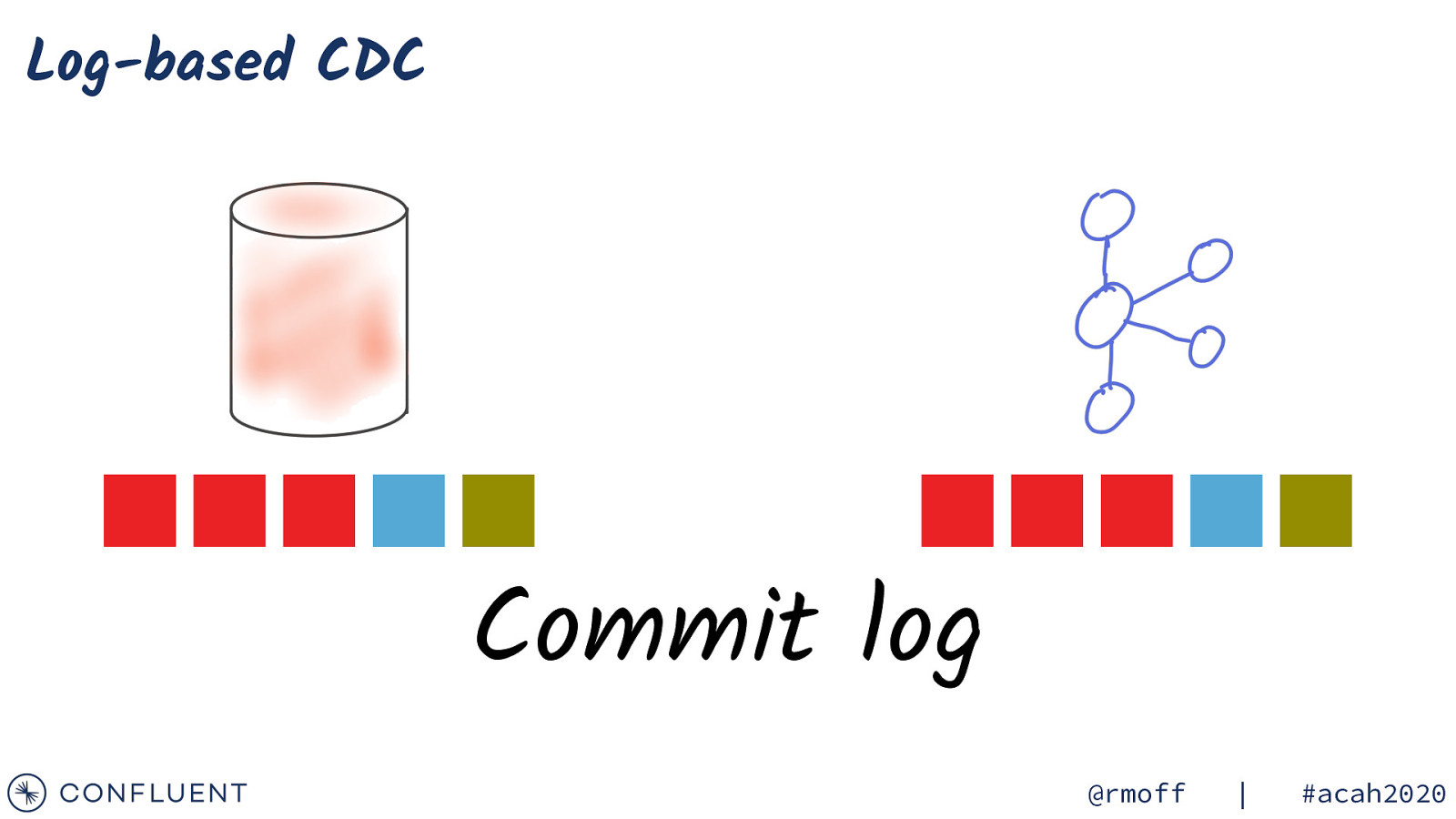
Log-based CDC Commit log @rmoff | #acah2020
Photo by Sebastian Pociecha on Unsplash Log-based CDC ✅ Greater data fidelity ✅ Lower latency ✅ Lower impact on source 🛑 More setup steps 🛑 Higher system privileges required 🛑 For propriatory databases, usually $$$ Read more: http://cnfl.io/kafka-cdc @rmoff | #acah2020
tl;dr : which tool do I use? • If you’re wanting to do query-based CDC, the choice is simple: confluent.io/hub @rmoff | #acah2020
Which Log-Based CDC Tool? • Open Source RDBMS, e.g. MySQL, PostgreSQL • Debezium • (+ paid options) • Proprietory RDBMS, e.g. Oracle, MS SQL, DB2 • Oracle GoldenGate • Debezium + XStream • Qlik (Attunity) • Mainframe e.g. VSAM, IMS • IBM InfoSphere Data Replication • SQData • Attunity • HVR • SQData • tcVISION • tcVISION • Etc See also: https://rmoff.dev/oracle @rmoff | #acah2020
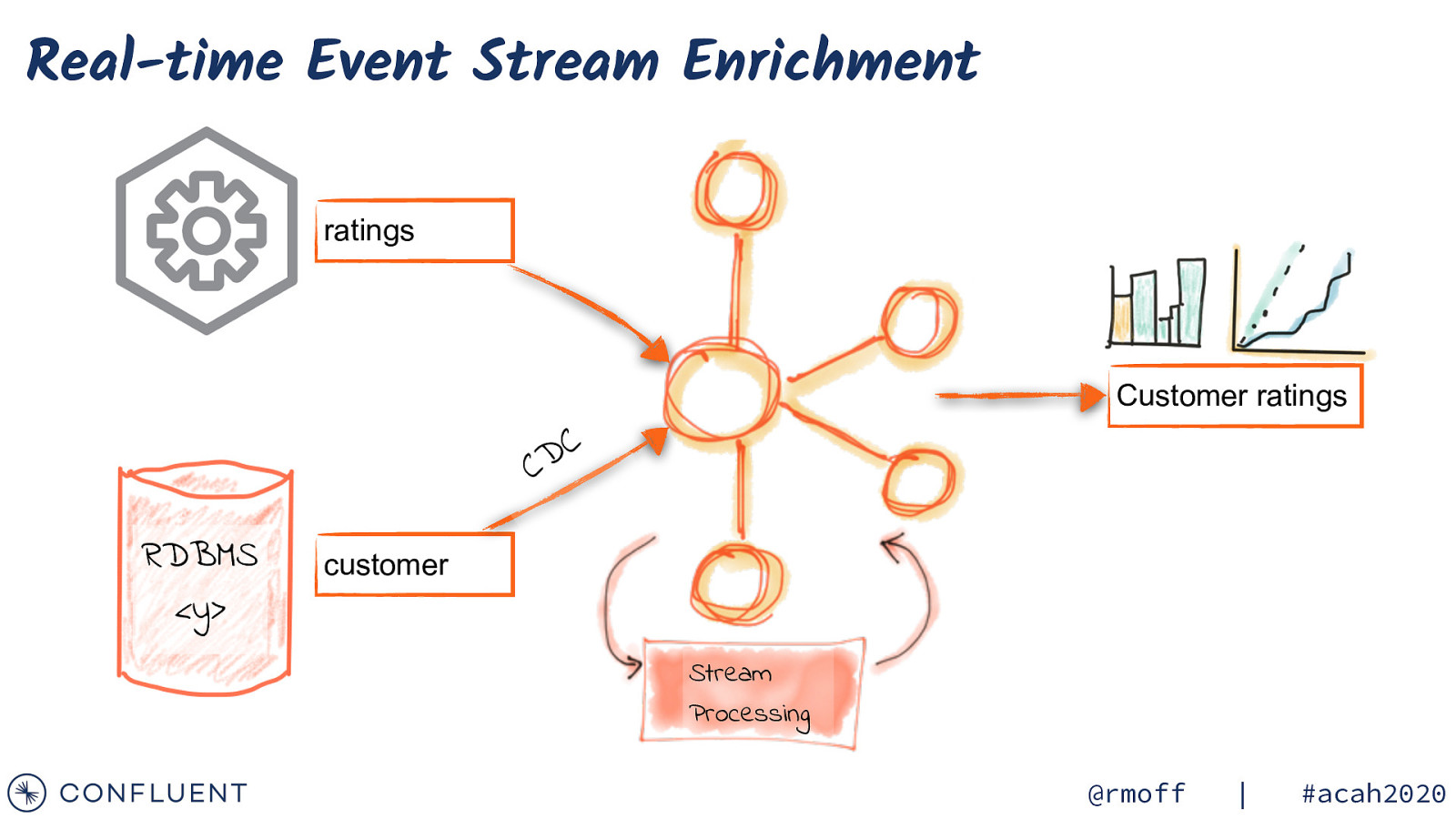
Real-time Event Stream Enrichment ratings Customer ratings C D C RDBMS <y> customer Stream Processing @rmoff | #acah2020
Demo Time! https://rmoff.dev/cdc-demo @rmoff | #acah2020
on Photo by Want to learn more? CTAs, not CATs (sorry, not sorry) @rmoff | #acah2020
Free Books! https://rmoff.dev/acah20 @rmoff | #acah2020
60 DE VA DV $200 USD off your bill each calendar month for the first three months when you sign up https://rmoff.dev/ccloud Free money! (additional $60 towards your bill 😄 ) Fully Managed Apache Kafka as a Service T&C: https://www.confluent.io/confluent-cloud-promo-disclaimer
Learn Kafka. Start building with Apache Kafka at Confluent Developer. developer.confluent.io
Confluent Community Slack group cnfl.io/slack @rmoff | #acah2020
Further reading / watching https://rmoff.dev/kafka-talks @rmoff | #acah2020
#EOF @rmoff rmoff.dev/talks youtube.com/rmoff

Companies new and old are all recognising the importance of a low-latency, scalable, fault-tolerant data backbone, in the form of the Apache Kafka streaming platform. With Kafka, developers can integrate multiple sources and systems, which enables low latency analytics, event-driven architectures and the population of multiple downstream systems.
In this talk, we’ll look at one of the most common integration requirements - connecting databases to Kafka. We’ll consider the concept that all data is a stream of events, including that residing within a database. We’ll look at why we’d want to stream data from a database, including driving applications in Kafka from events upstream. We’ll discuss the different methods for connecting databases to Kafka, and the pros and cons of each. Techniques including Change-Data-Capture (CDC) and Kafka Connect will be covered, as well as an exploration of the power of ksqlDB for performing transformations such as joins on the inbound data.
Attendees of this talk will learn:
The following resources were mentioned during the presentation or are useful additional information.
Fully Managed Apache Kafka, Schema Registry, ksqlDB, and Connectors.
Blog about the options for getting data from Oracle into Kafka
A conference talk covering the options for getting data from Oracle into Kafka
Kafka 101 - introducing the concepts, the APIs, and the ecosystem
Try out the demo for yourself - all you need is Docker and Docker Compose.
Free eBooks to download, including Kafka: The Definitive Guide.
Tutorials, videos, blogs, podcasts, and more - all for developers working with Apache Kafka and Confluent Platform
Huge list of connectors for Kafka Connect
A fun blog showing what you can do with ksqlDB and Kafka
Learn all about ksqlDB in this 45 minute talk & live demo
Learn all about Kafka Connect (including the connectors available with ksqlDB)
Apache Kafka and Confluent Platform in Action! Using live streams of rail movement data in all sorts of useful ways for analysis and applications.
Here’s what was said about this presentation on social media.





































 for free. You
can too.
for free. You
can too.