A presentation at Moscow JUG in in Moscow, Russia by Viktor Gamov

ЗАчем нам БД? Нам База не нужна… May, 2019 / Moscow, Russia @gamussa | #jugmsk | @ConfluentINc
2 @gamussa | #jugmsk | @ConfluentINc
Friendly reminder Follow @gamussa 📸🖼🏋 Tag @gamussa With #jugmsk @confluentinc
4 Special thanks! @bbejeck @MatthiasJSax @gamussa | #jugmsk | @ConfluentINc
https://cnfl.io/streams-movie-demo @gamussa | #jugmsk | @ConfluentINc
6 Agenda Kafka Streams 101 What is state and why stateful stream processing? Technical Deep Dive on Interactive Queries What does IQ provide? State handling with Kafka Streams How to use IQ? @gamussa | #jugmsk | @ConfluentINc
Kafka Streams 101 @gamussa | #jugmsk | @ConfluentINc
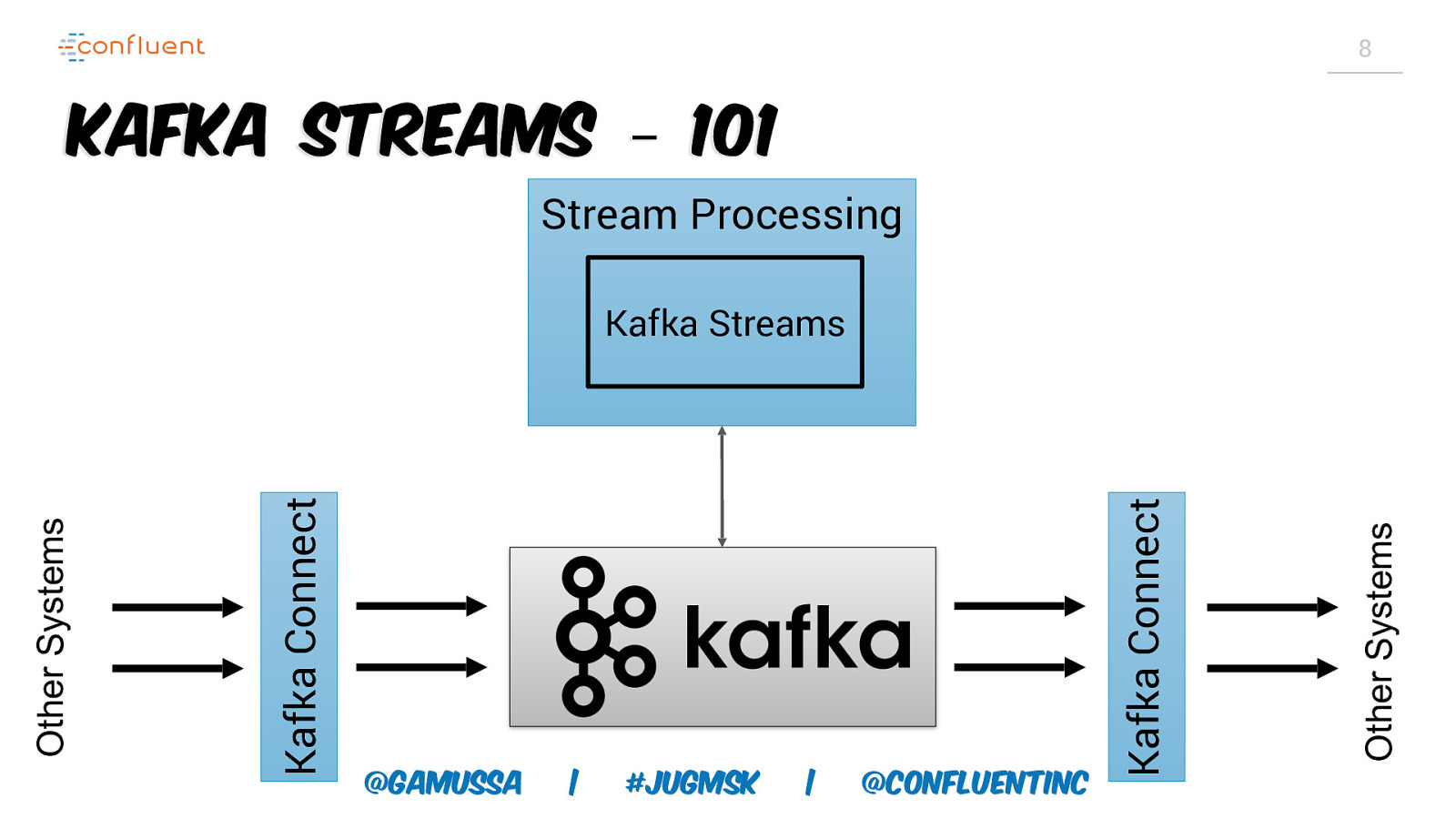
8 Kafka Streams – 101 Stream Processing @gamussa | #jugmsk | @ConfluentINc Other Systems Kafka Connect Kafka Connect Other Systems Kafka Streams
https://twitter.com/monitoring_king/status/1048264580743479296
10 LET’S TALK ABOUT THIS FRAMEWORK OF YOURS. I THINK ITS GOOD, EXCEPT IT SUCKS @gamussa | #jugmsk | @ConfluentINc
11 SO LET ME SHOW KAFKA STREAMS THAT WAY IT MIGHT BE REALLY GOOD @gamussa | #jugmsk | @ConfluentINc
12 We need a processing cluster like Spark or Flink @gamussa | #jugmsk | @ConfluentINc
13 I want write apps not an infrastructure @gamussa | #jugmsk | @ConfluentINc
14 You can’t do distributed stream processing without cluster @gamussa | #jugmsk | @ConfluentINc
15 @gamussa | #jugmsk | @ConfluentINc
16 Stay and write your Java apps, I’m going to write ETL jobs @gamussa | #jugmsk | @ConfluentINc
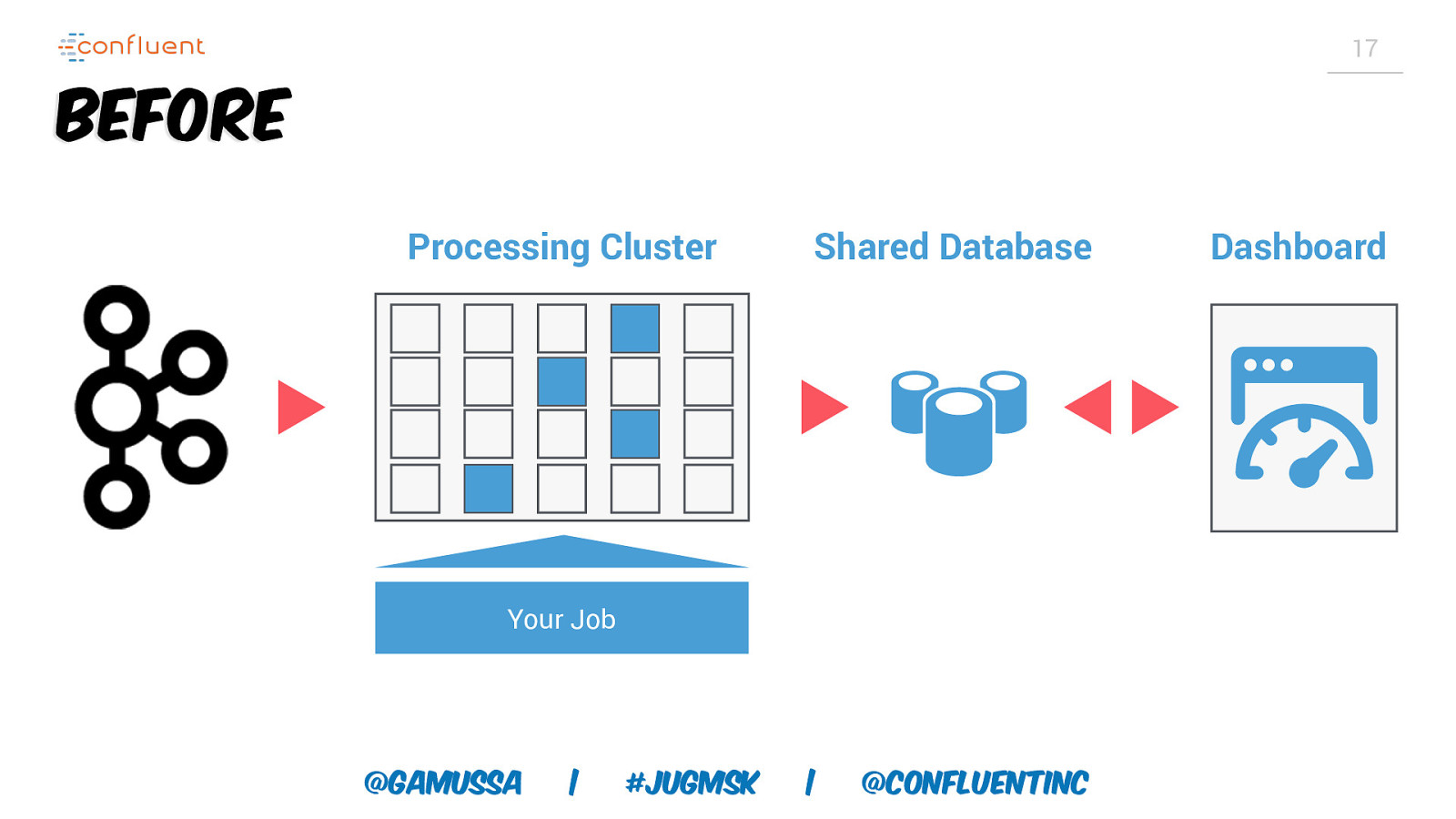
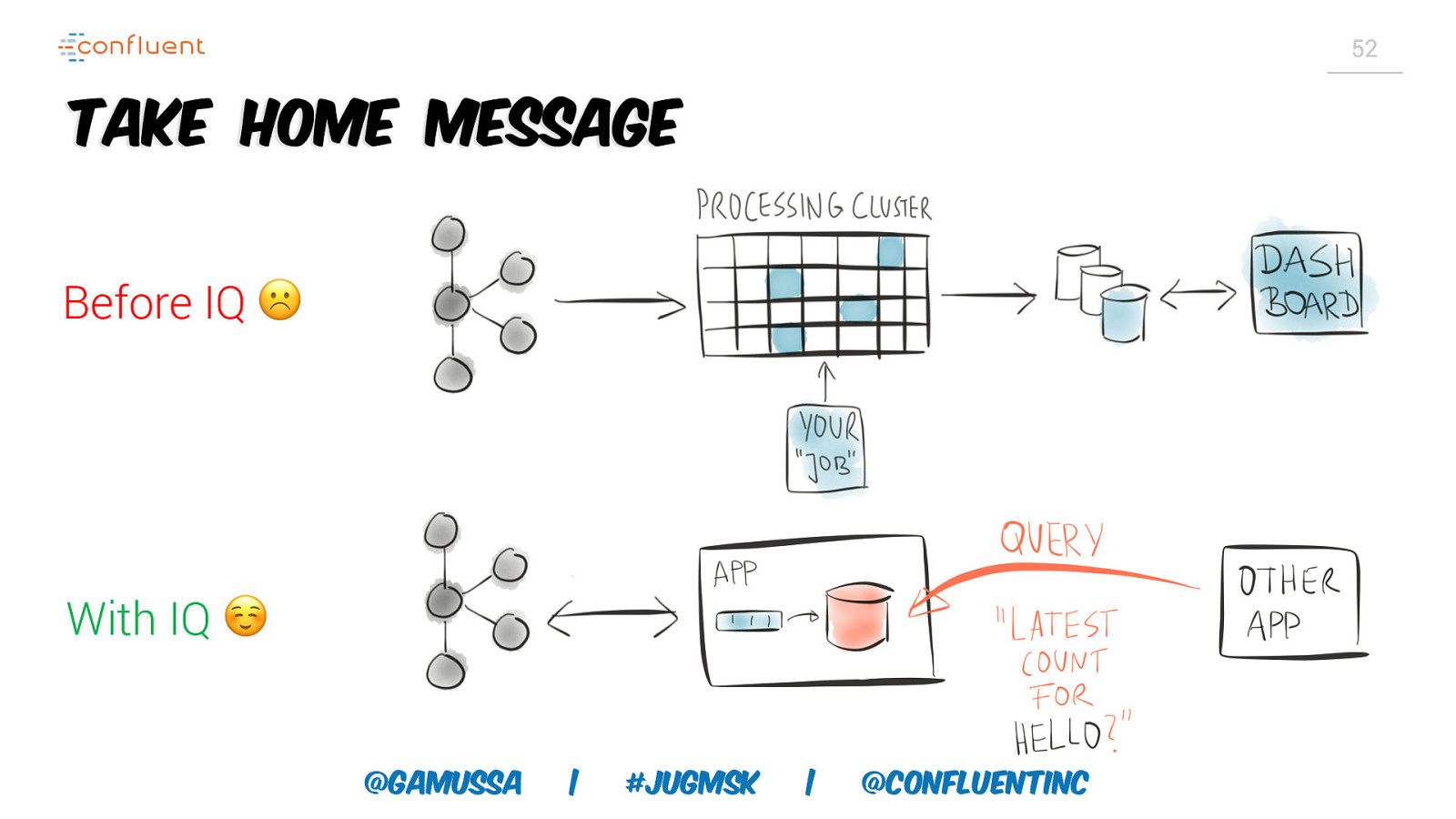
17 Before Processing Cluster Shared Database Your Job @gamussa | #jugmsk | @ConfluentINc Dashboard
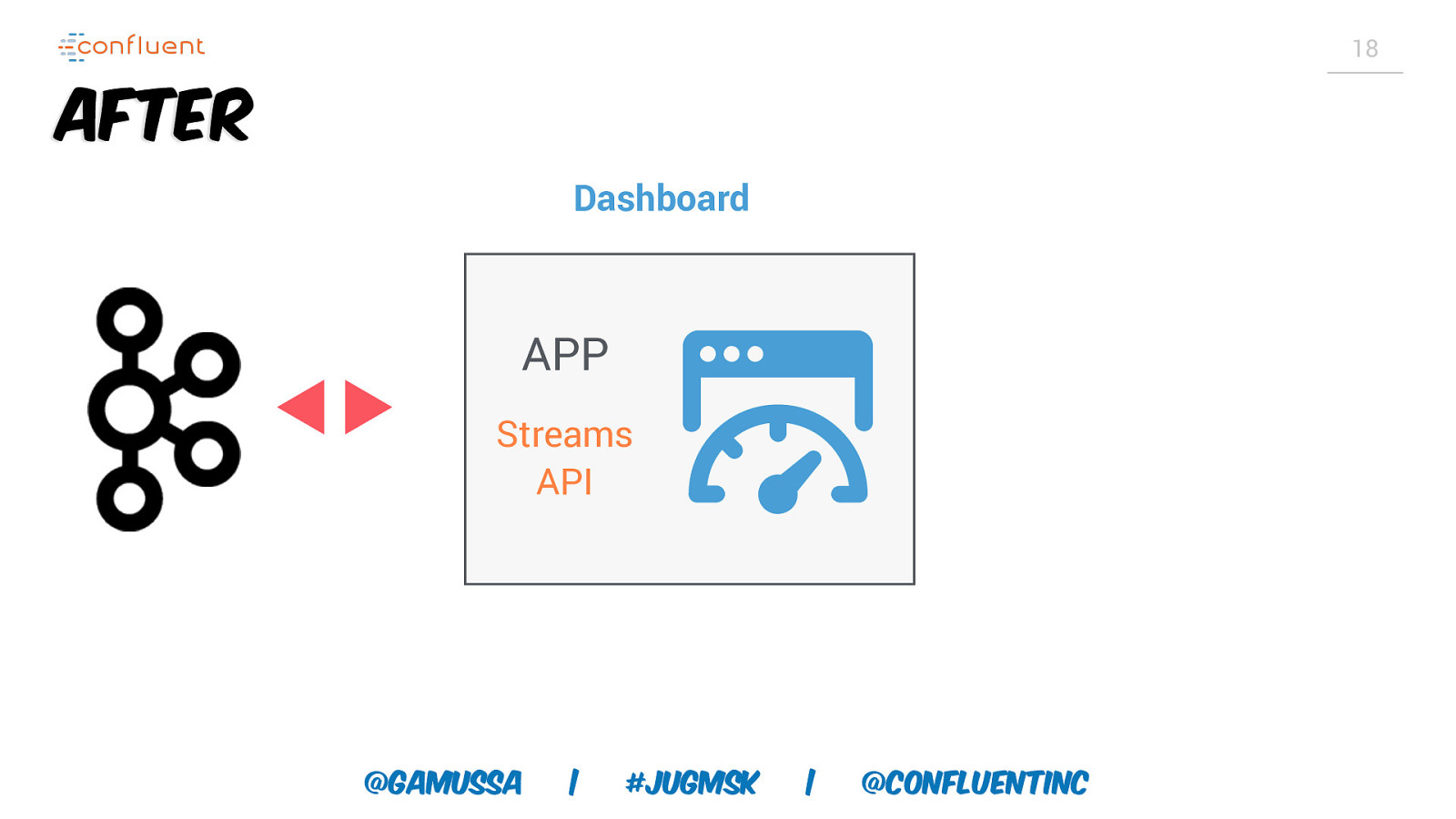
18 After Dashboard APP Streams API @gamussa | #jugmsk | @ConfluentINc
the KAFKA STREAMS API is a JAVA API to BUILD REAL-TIME APPLICATIONS @gamussa | #jugmsk | @confluentinc
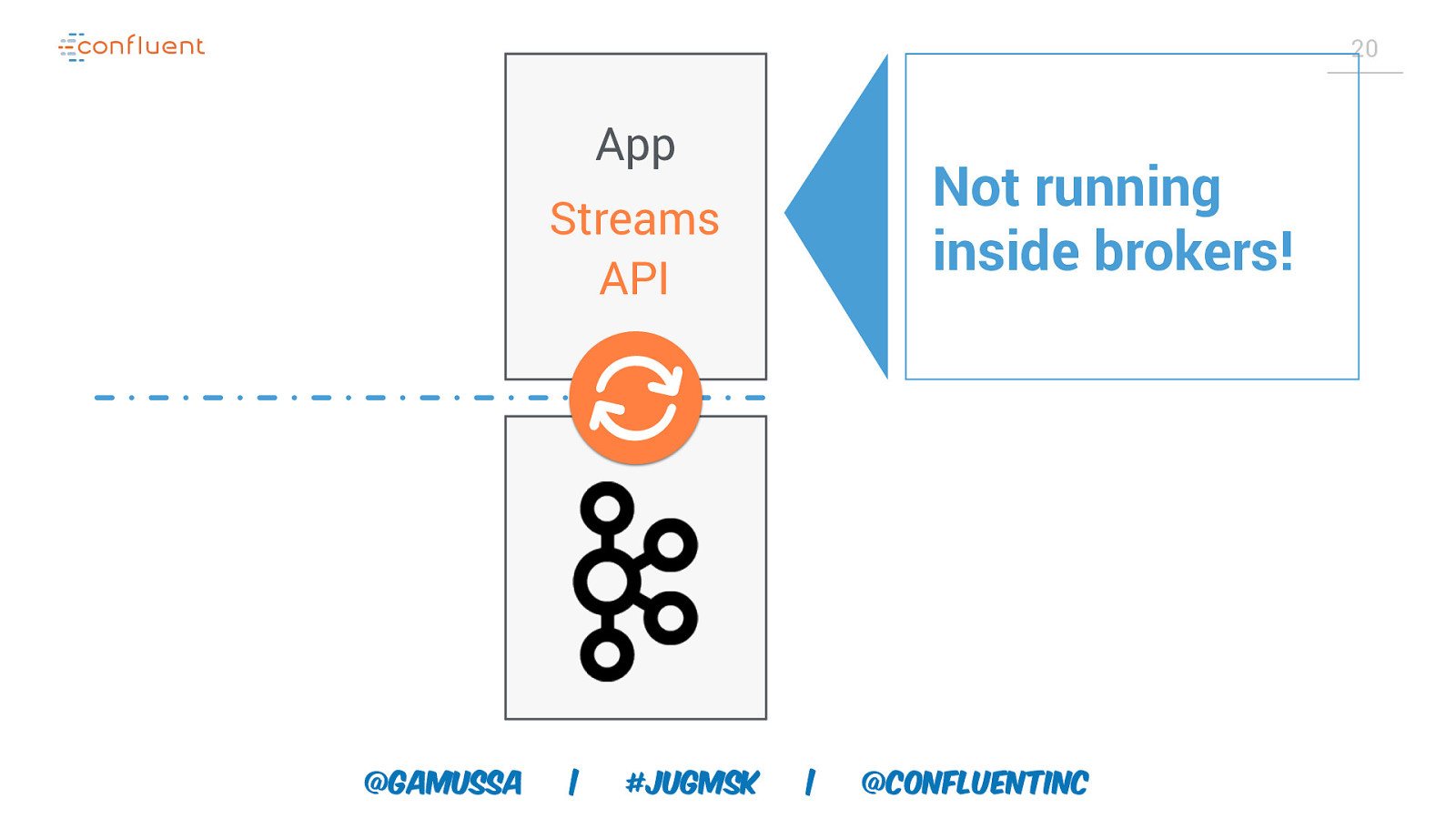
20 App Not running inside brokers! Streams API @gamussa | #jugmsk | @ConfluentINc
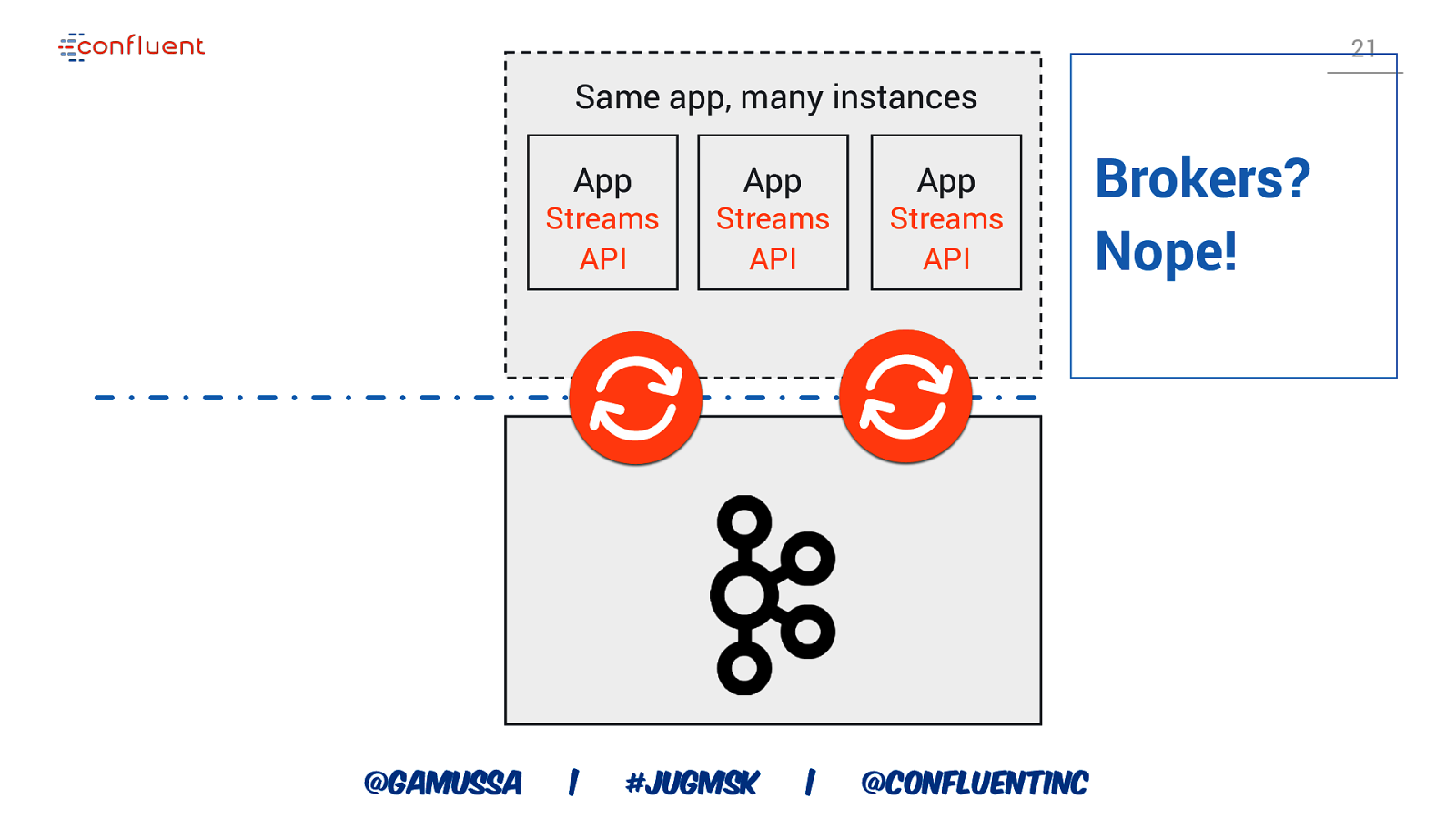
21 Same app, many instances App Streams API @gamussa | App Streams API #jugmsk | App Streams API @ConfluentINc Brokers? Nope!
22 Stateful Stream Processing What is State? ○ Anything your application needs to “remember” beyond the scope of a single record @gamussa | #jugmsk | @ConfluentINc
23 Stateful Stream Processing Stateless operators: ○ filter, map, flatMap, foreach Stateful operator: ○ Aggregations ○ Any window operation ○ Joins ○ CEP @gamussa | #jugmsk | @ConfluentINc
24 Stock Trade Stats Example KStream<String, Trade> source = builder.stream(STOCK_TOPIC); KStream<Windowed<String>, TradeStats> stats = source .groupByKey() .windowedBy(TimeWindows.of(5000).advanceBy(1000)) .aggregate(TradeStats::new, (k, v, tradestats) -> tradestats.add(v), Materialized.<~>as(“trade-aggregates”) .withValueSerde(new TradeStatsSerde())) .toStream() .mapValues(TradeStats::computeAvgPrice); stats.to(STATS_OUT_TOPIC, Produced.keySerde(WindowedSerdes.timeWindowedSerdeFrom(String.class))); @gamussa | #jugmsk | @ConfluentINc
25 Stock Trade Stats Example KStream<String, Trade> source = builder.stream(STOCK_TOPIC); KStream<Windowed<String>, TradeStats> stats = source .groupByKey() .windowedBy(TimeWindows.of(5000).advanceBy(1000)) .aggregate(TradeStats::new, (k, v, tradestats) -> tradestats.add(v), Materialized.<~>as(“trade-aggregates”) .withValueSerde(new TradeStatsSerde())) .toStream() .mapValues(TradeStats::computeAvgPrice); stats.to(STATS_OUT_TOPIC, Produced.keySerde(WindowedSerdes.timeWindowedSerdeFrom(String.class))); @gamussa | #jugmsk | @ConfluentINc
26 Stock Trade Stats Example KStream<String, Trade> source = builder.stream(STOCK_TOPIC); KStream<Windowed<String>, TradeStats> stats = source .groupByKey() .windowedBy(TimeWindows.of(5000).advanceBy(1000)) .aggregate(TradeStats::new, (k, v, tradestats) -> tradestats.add(v), Materialized.<~>as(“trade-aggregates”) .withValueSerde(new TradeStatsSerde())) .toStream() .mapValues(TradeStats::computeAvgPrice); stats.to(STATS_OUT_TOPIC, Produced.keySerde(WindowedSerdes.timeWindowedSerdeFrom(String.class))); @gamussa | #jugmsk | @ConfluentINc
27 Stock Trade Stats Example KStream<String, Trade> source = builder.stream(STOCK_TOPIC); KStream<Windowed<String>, TradeStats> stats = source .groupByKey() .windowedBy(TimeWindows.of(5000).advanceBy(1000)) .aggregate(TradeStats::new, (k, v, tradestats) -> tradestats.add(v), Materialized.<~>as(“trade-aggregates”) .withValueSerde(new TradeStatsSerde())) .toStream() .mapValues(TradeStats::computeAvgPrice); stats.to(STATS_OUT_TOPIC, Produced.keySerde(WindowedSerdes.timeWindowedSerdeFrom(String.class))); @gamussa | #jugmsk | @ConfluentINc
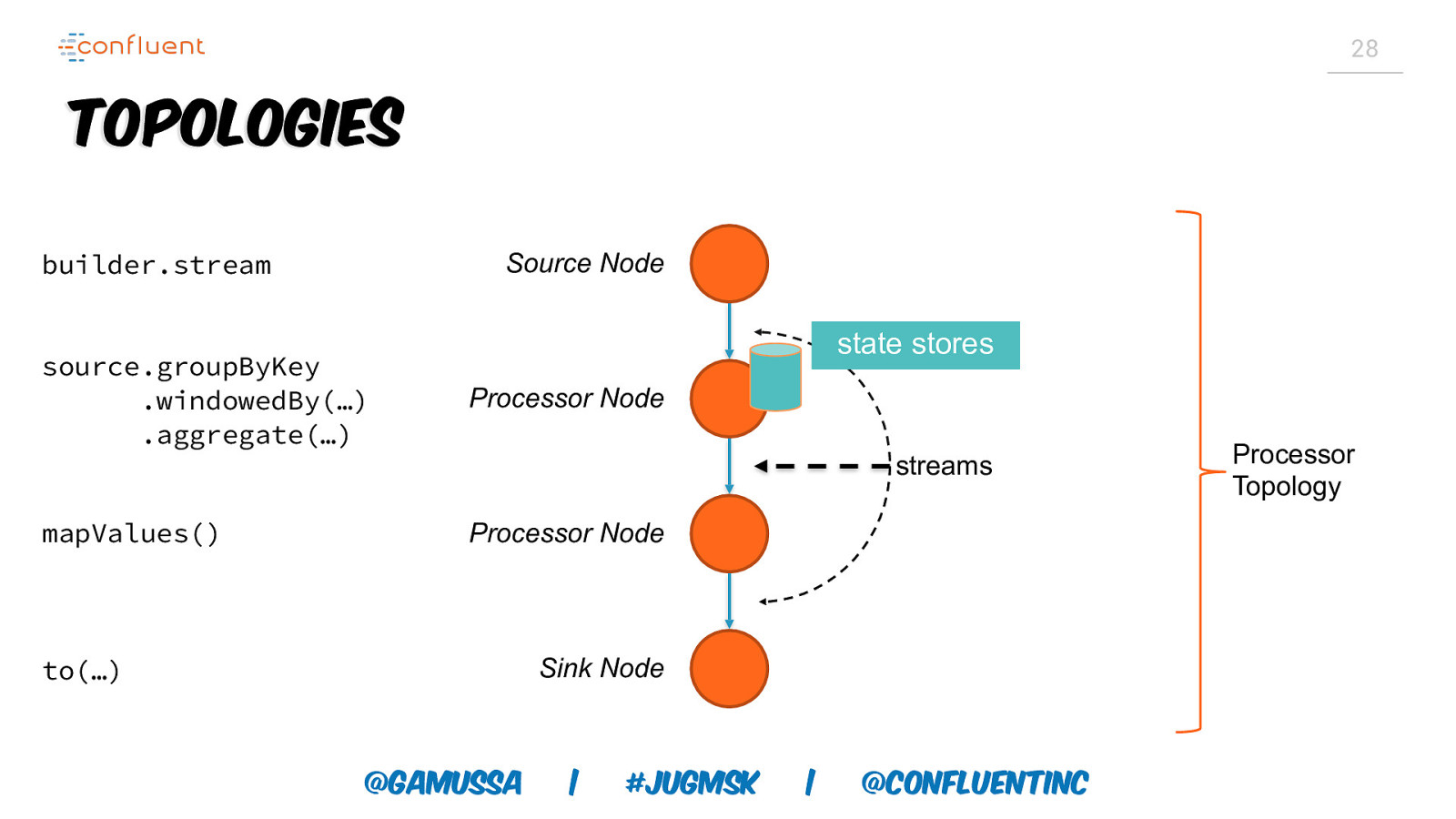
28 Topologies builder.stream Source Node state stores source.groupByKey .windowedBy(…) .aggregate(…) Processor Node mapValues() Processor Node streams Sink Node to(…) @gamussa | #jugmsk | @ConfluentINc Processor Topology
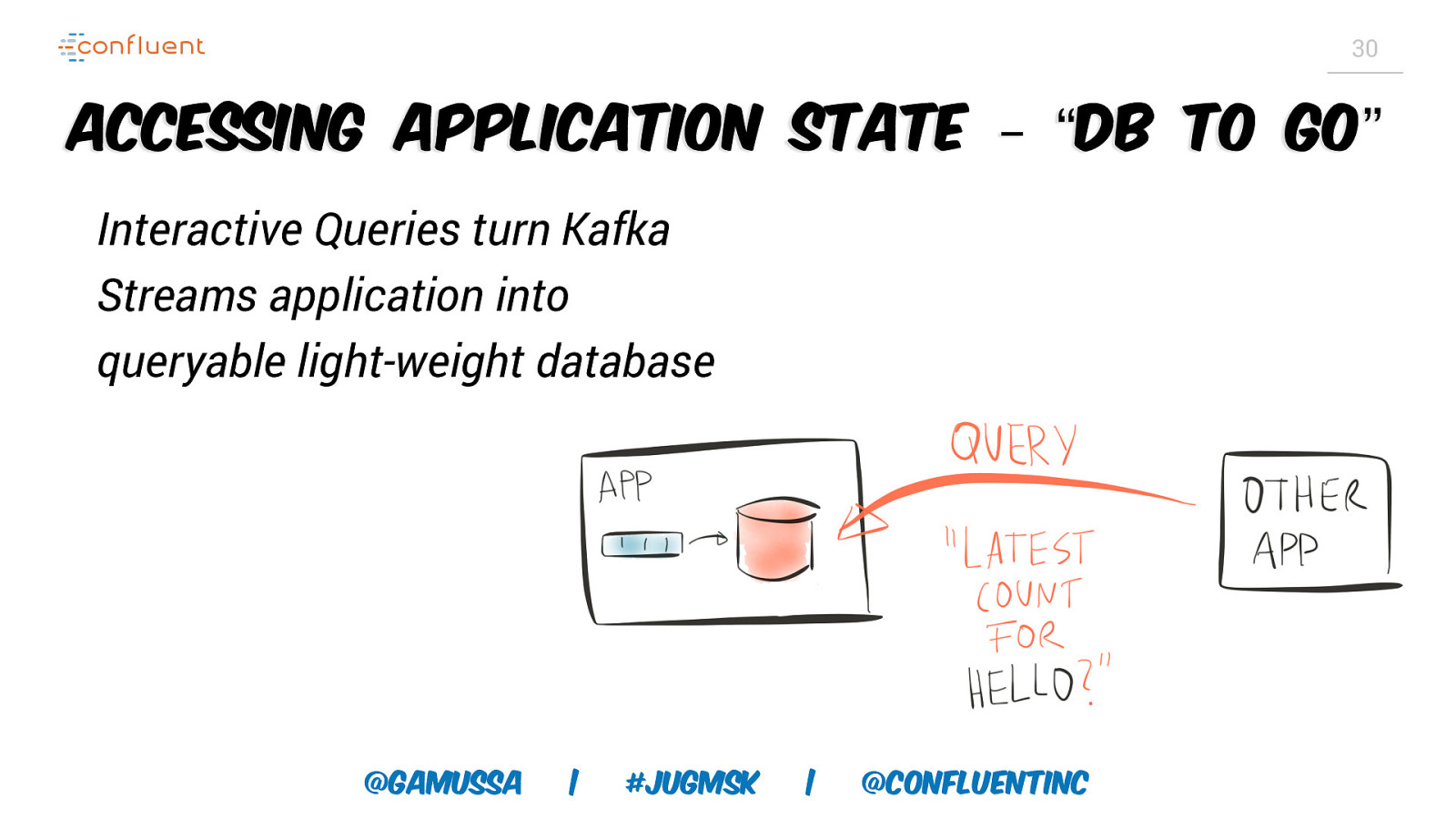
29 Accessing Application State External DB: query database Local State: Interactive Queries ○ Allows to query the local DB instances ○ Kafka Streams application is the database ○ Read-Only access (no “external” state updates) ○ Works for DSL or Processor API @gamussa | #jugmsk | @ConfluentINc
30 Accessing Application State – “DB to go” Interactive Queries turn Kafka Streams application into queryable light-weight database @gamussa | #jugmsk | @ConfluentINc
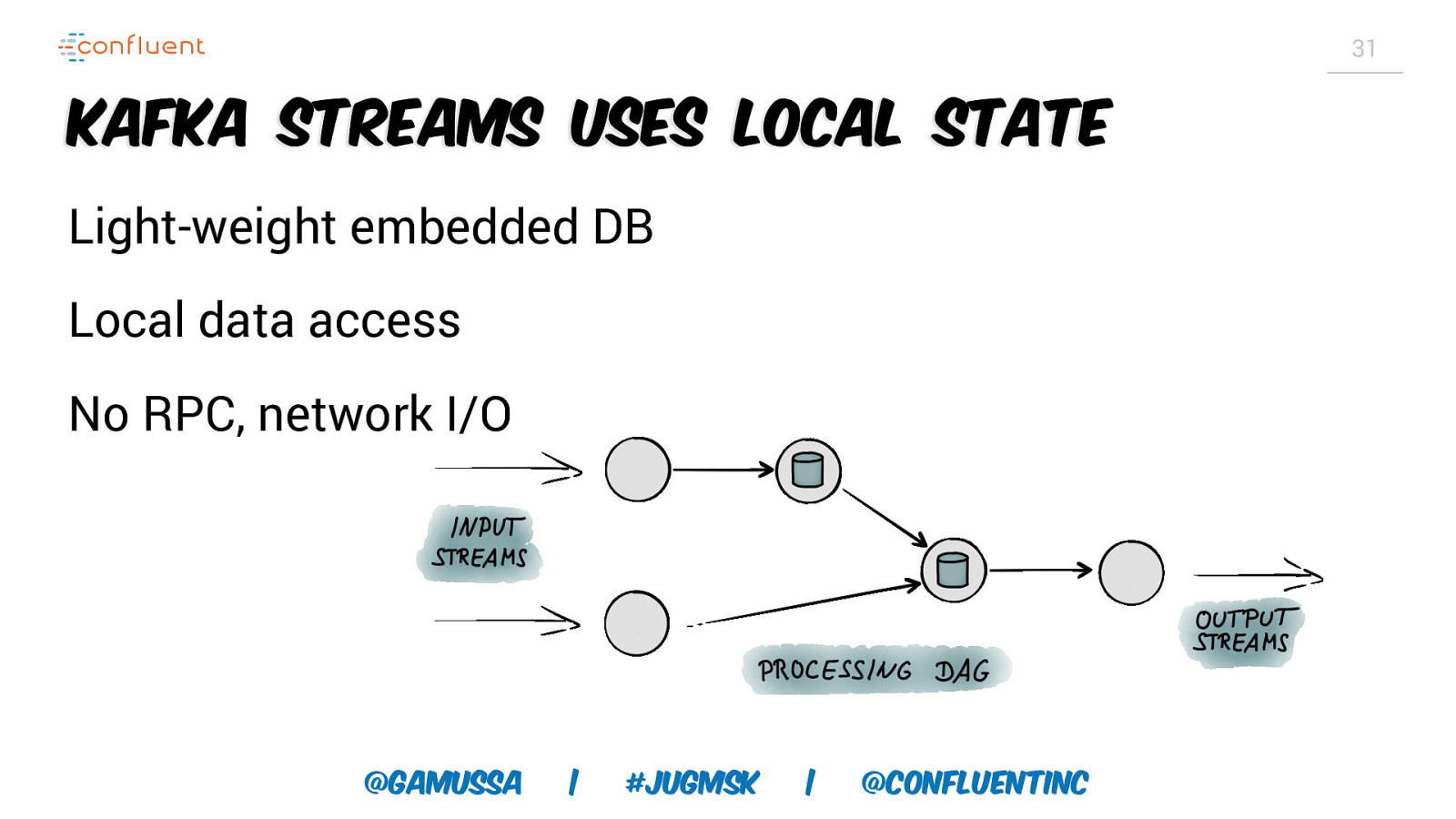
31 Kafka Streams uses Local State Light-weight embedded DB Local data access No RPC, network I/O @gamussa | #jugmsk | @ConfluentINc
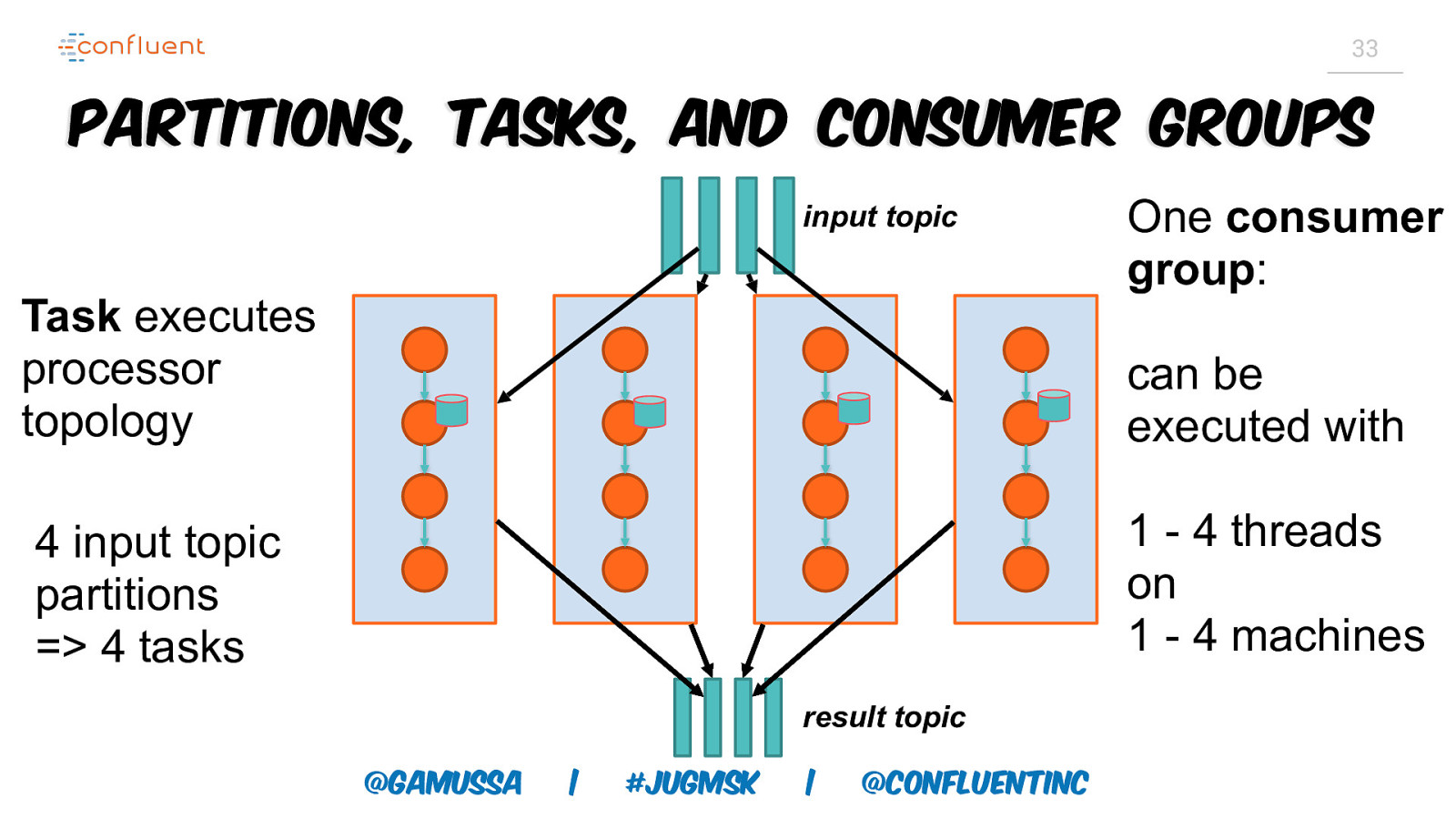
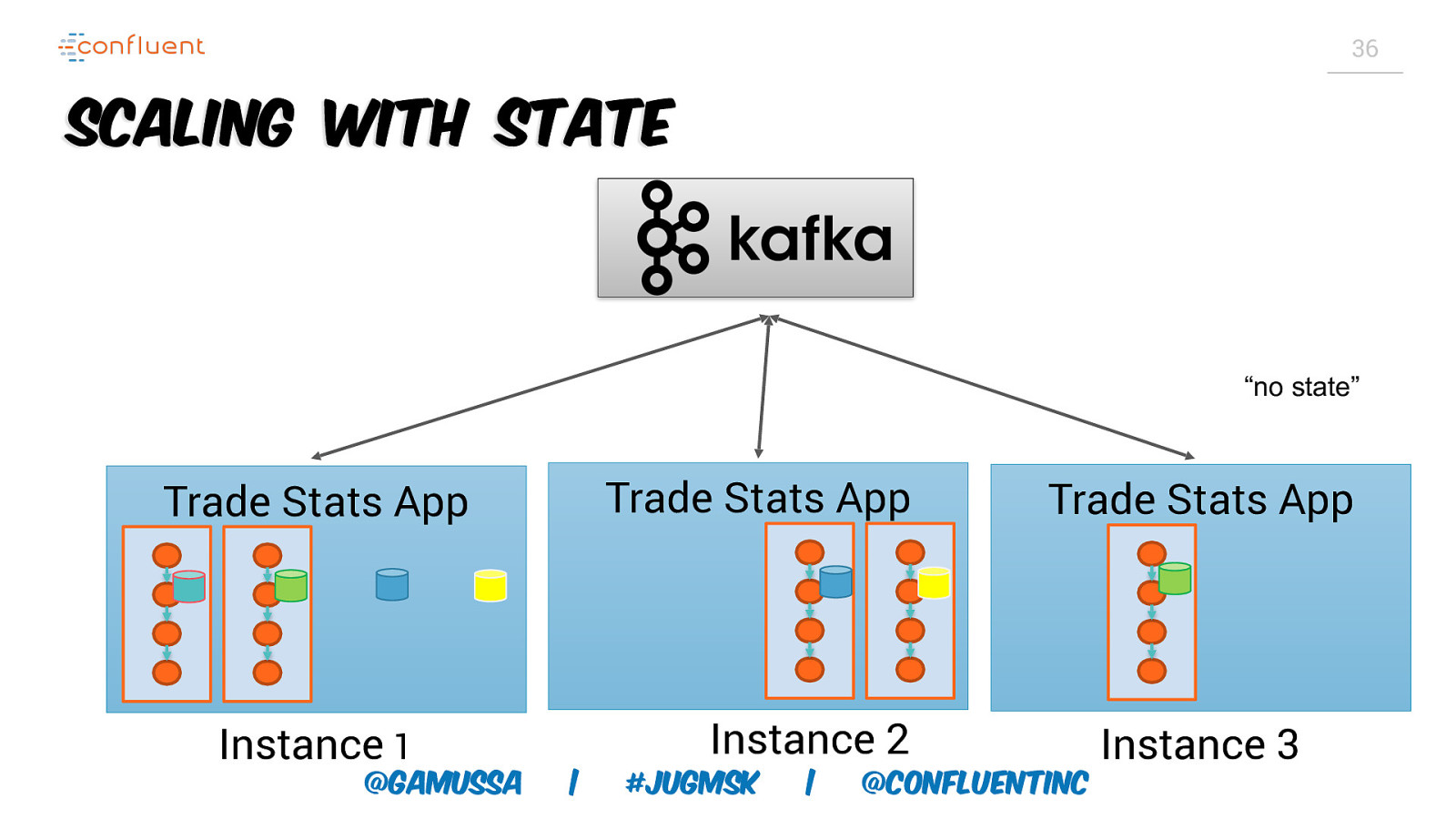
32 Scaling Local State Topics are scaled via partitions Kafka Streams scales via tasks • 1:1 mapping from input topic partitions to tasks State can be sharded based on partitions • Local DB for each shard • 1:1 mapping from state shard to task @gamussa | #jugmsk | @ConfluentINc
33 Partitions, Tasks, and Consumer Groups input topic Task executes processor topology One consumer group: can be executed with 1 - 4 threads on 1 - 4 machines 4 input topic partitions => 4 tasks result topic @gamussa | #jugmsk | @ConfluentINc
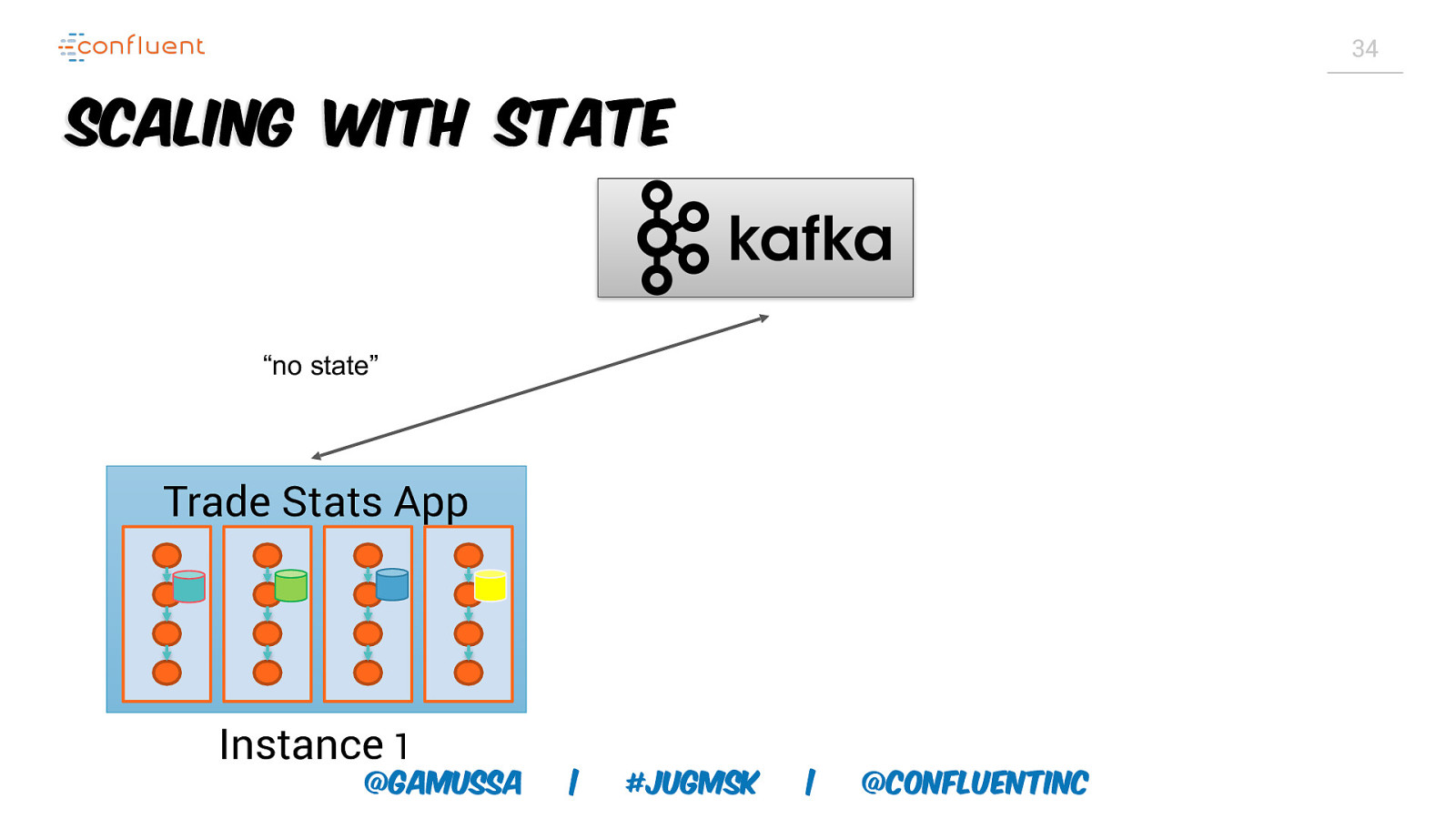
34 Scaling with State “no state” Trade Stats App Instance 1 @gamussa | #jugmsk | @ConfluentINc
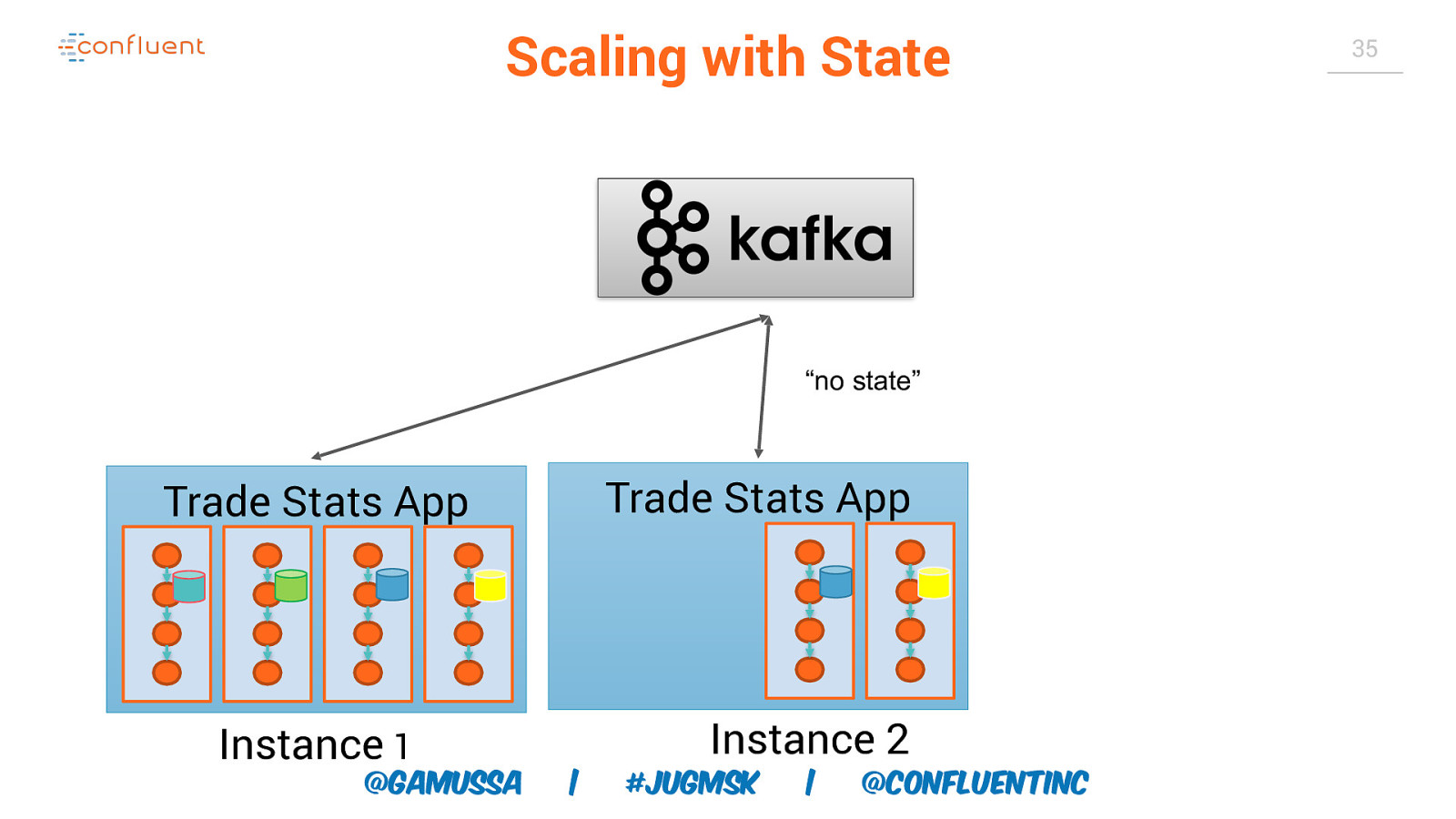
Scaling with State “no state” Trade Stats App Trade Stats App Instance 1 @gamussa Instance 2 | #jugmsk | @ConfluentINc 35
36 Scaling with State “no state” Trade Stats App Trade Stats App Instance 1 @gamussa Trade Stats App Instance 2 | #jugmsk | @ConfluentINc Instance 3
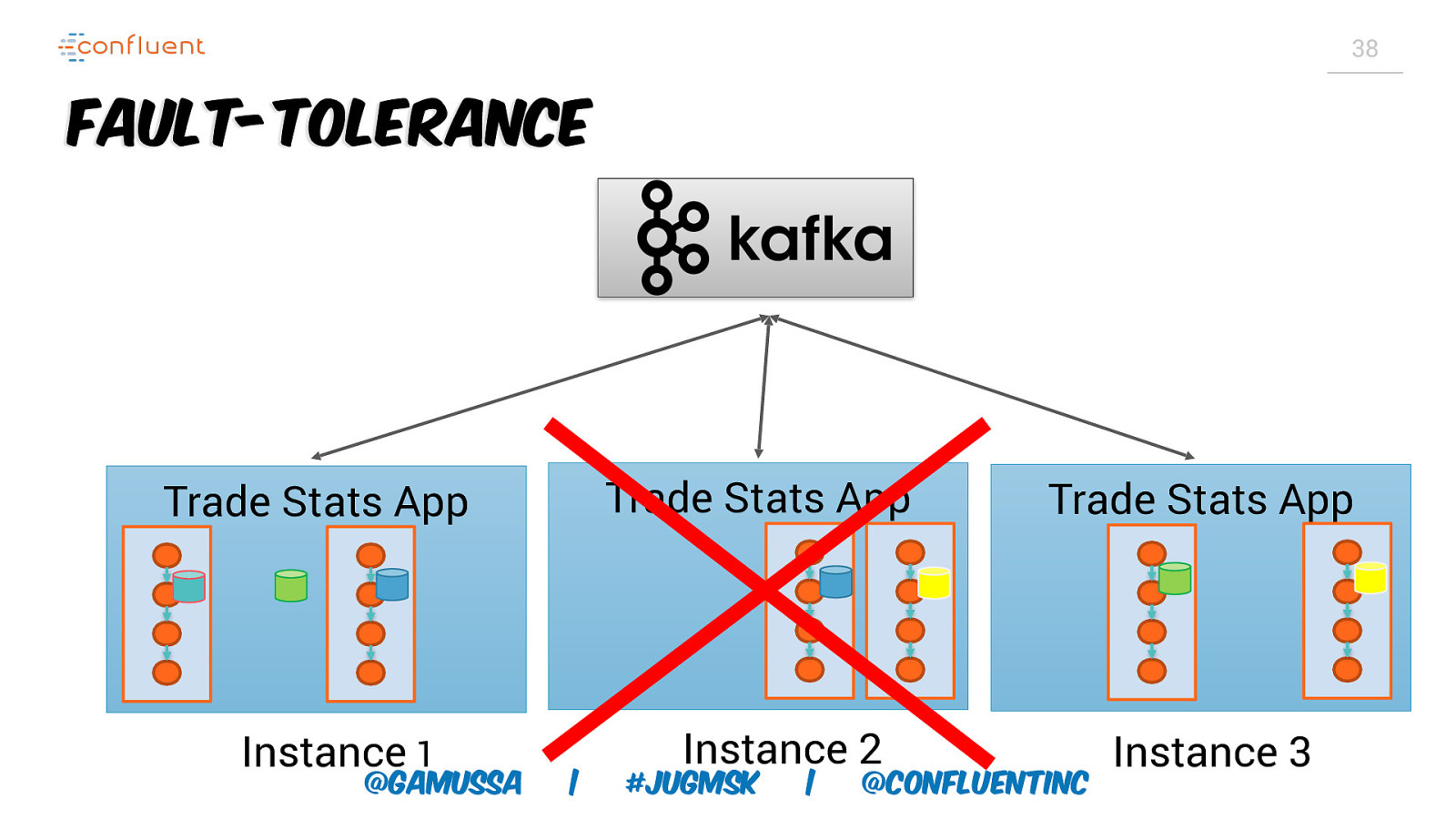
37 Scaling and FaultTolerance Two Sides of Same Coin @gamussa | #jugmsk | @ConfluentINc
38 Fault-Tolerance Trade Stats App Trade Stats App Instance 1 @gamussa | Instance 2 #jugmsk | Trade Stats App @ConfluentINc Instance 3
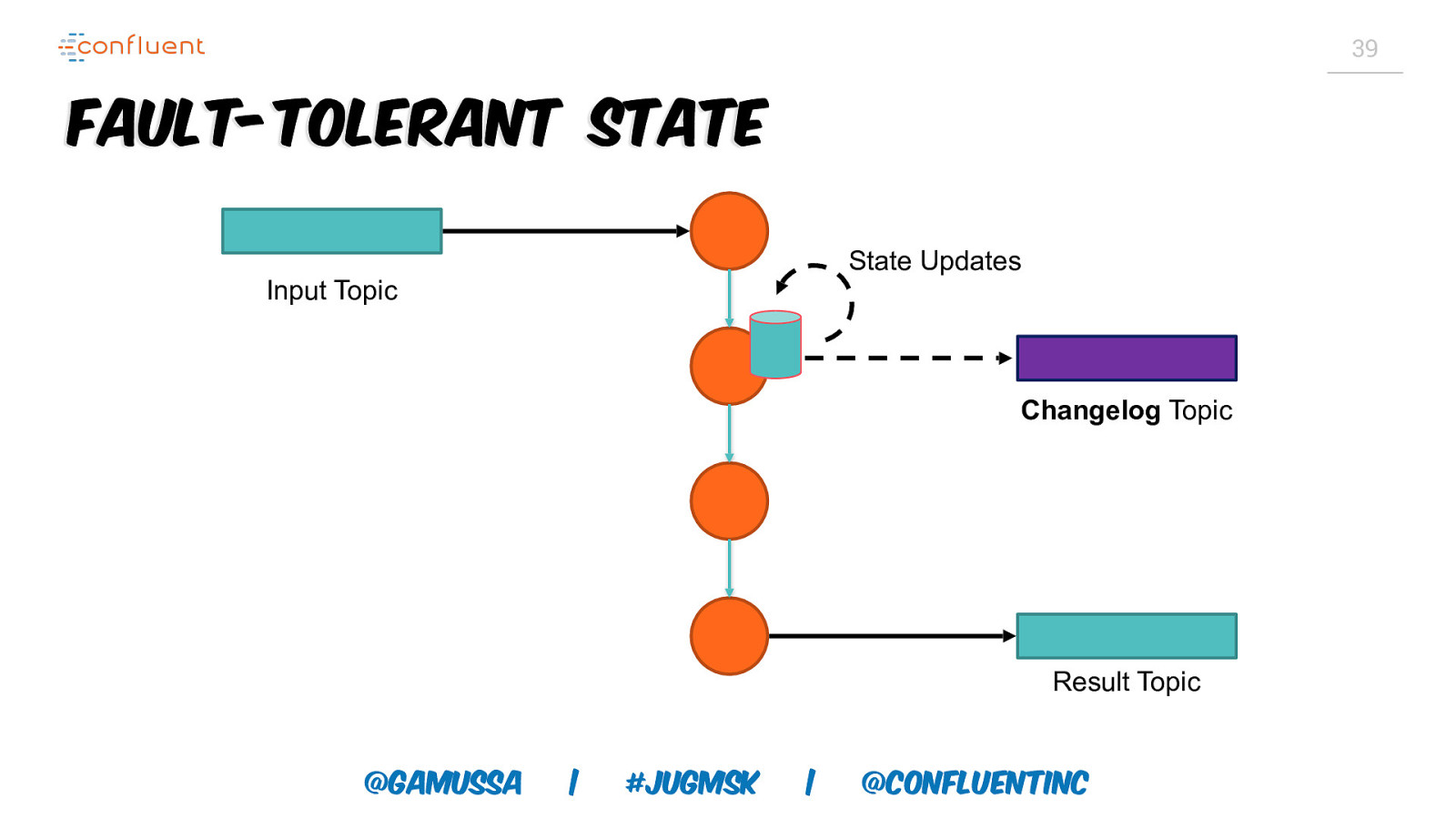
39 Fault-Tolerant State State Updates Input Topic Changelog Topic Result Topic @gamussa | #jugmsk | @ConfluentINc
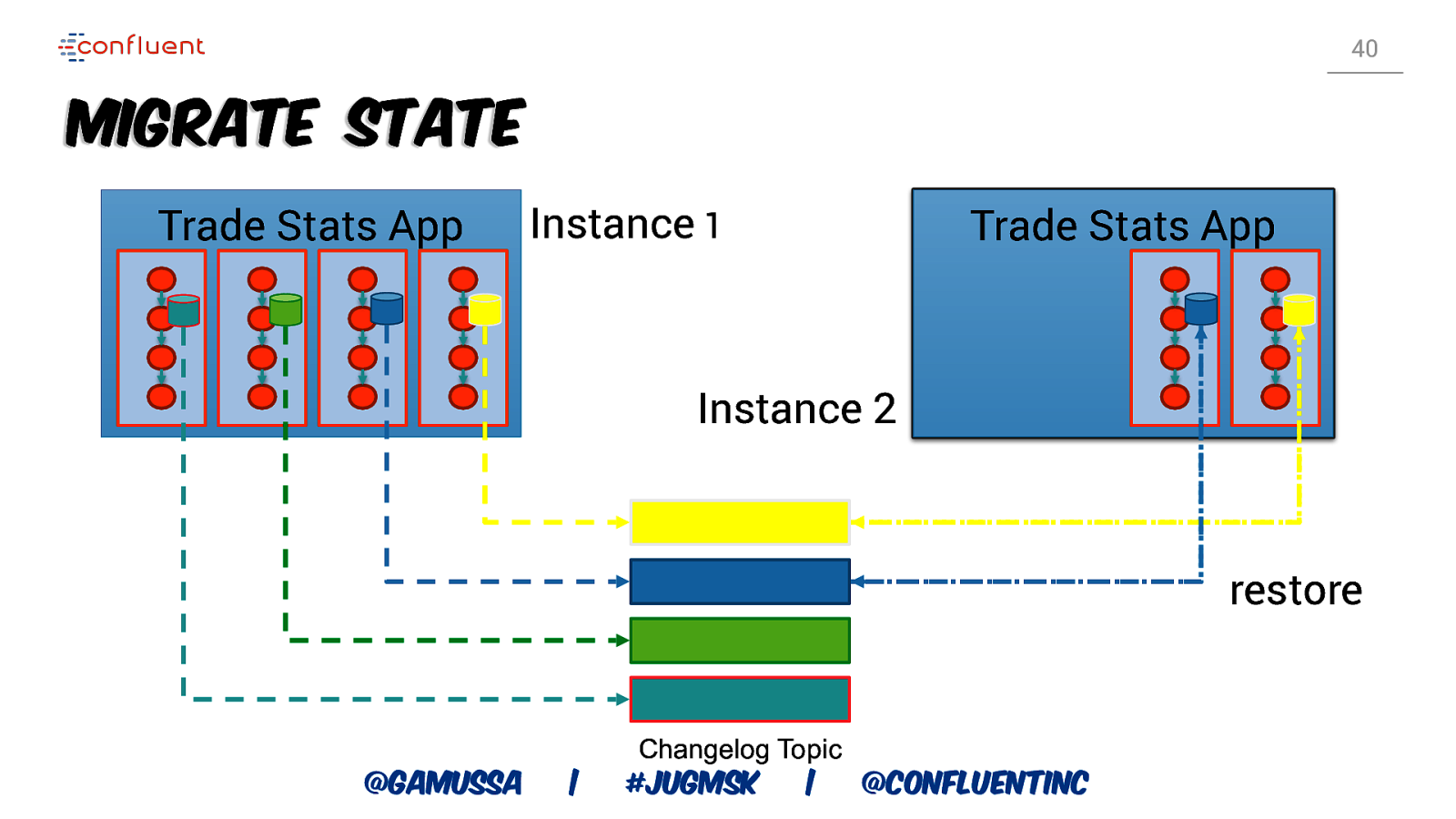
40 Migrate State Trade Stats App Instance 1 Trade Stats App Instance 2 restore @gamussa | Changelog Topic #jugmsk | @ConfluentINc
41 Recovery Time Changelog topics are log compacted Size of changelog topic linear in size of state Large state implies high recovery times @gamussa | #jugmsk | @ConfluentINc
42 Recovery Overhead Recovery overhead is proportional to ○ segment-size / state-size Segment-size is smaller than state-size => reduced overhead Update changelog topic segment size accordingly ○ topic config: log.segments.bytes ○ log cleaner interval important, too @gamussa | #jugmsk | @ConfluentINc
Query your app… not database @gamussa | #jugmsk | @ConfluentINc
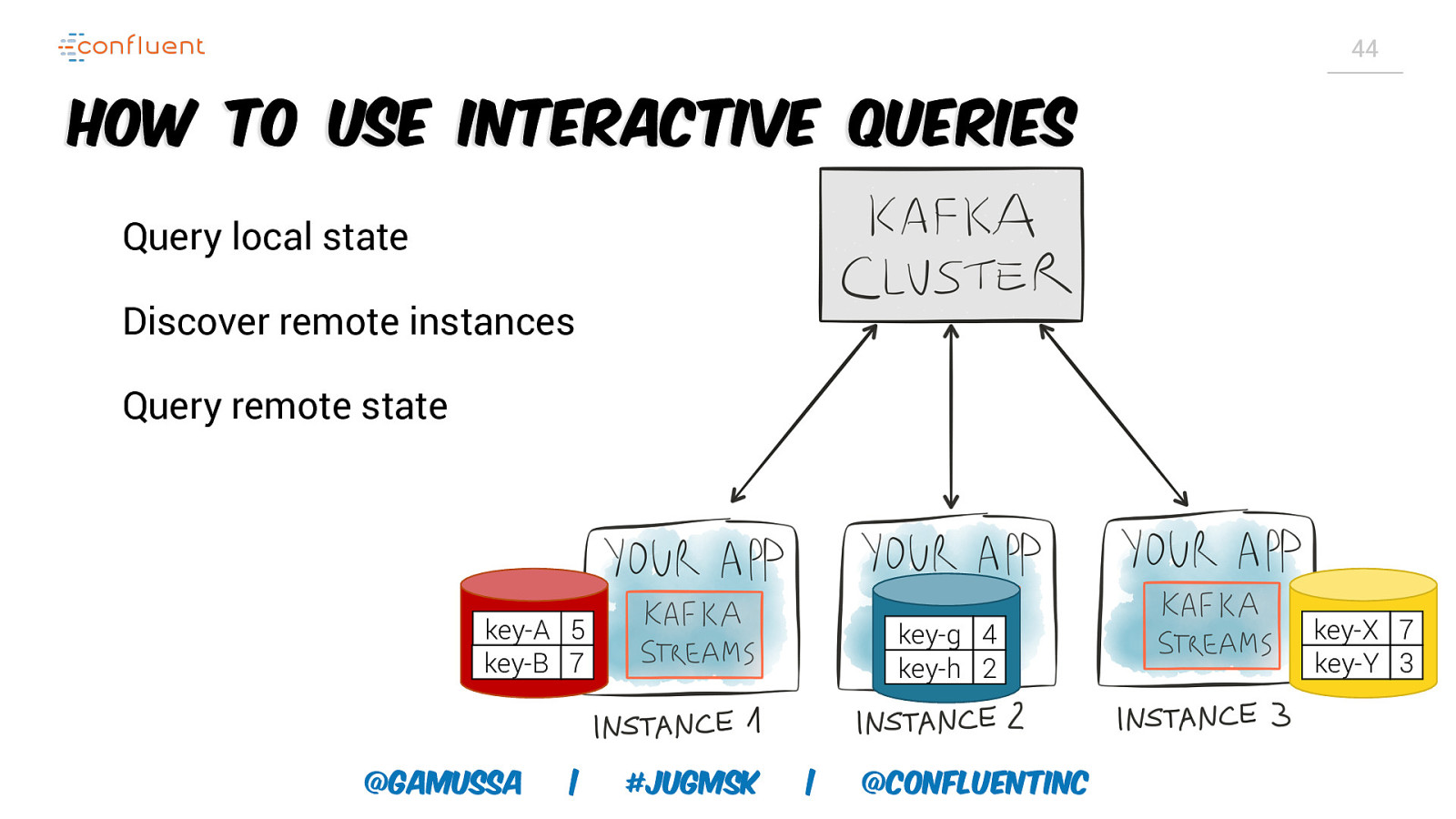
44 How to use Interactive Queries Query local state Discover remote instances Query remote state key-A 5 key-B 7 @gamussa | key-g 4 key-h 2 #jugmsk | @ConfluentINc key-X 7 key-Y 3
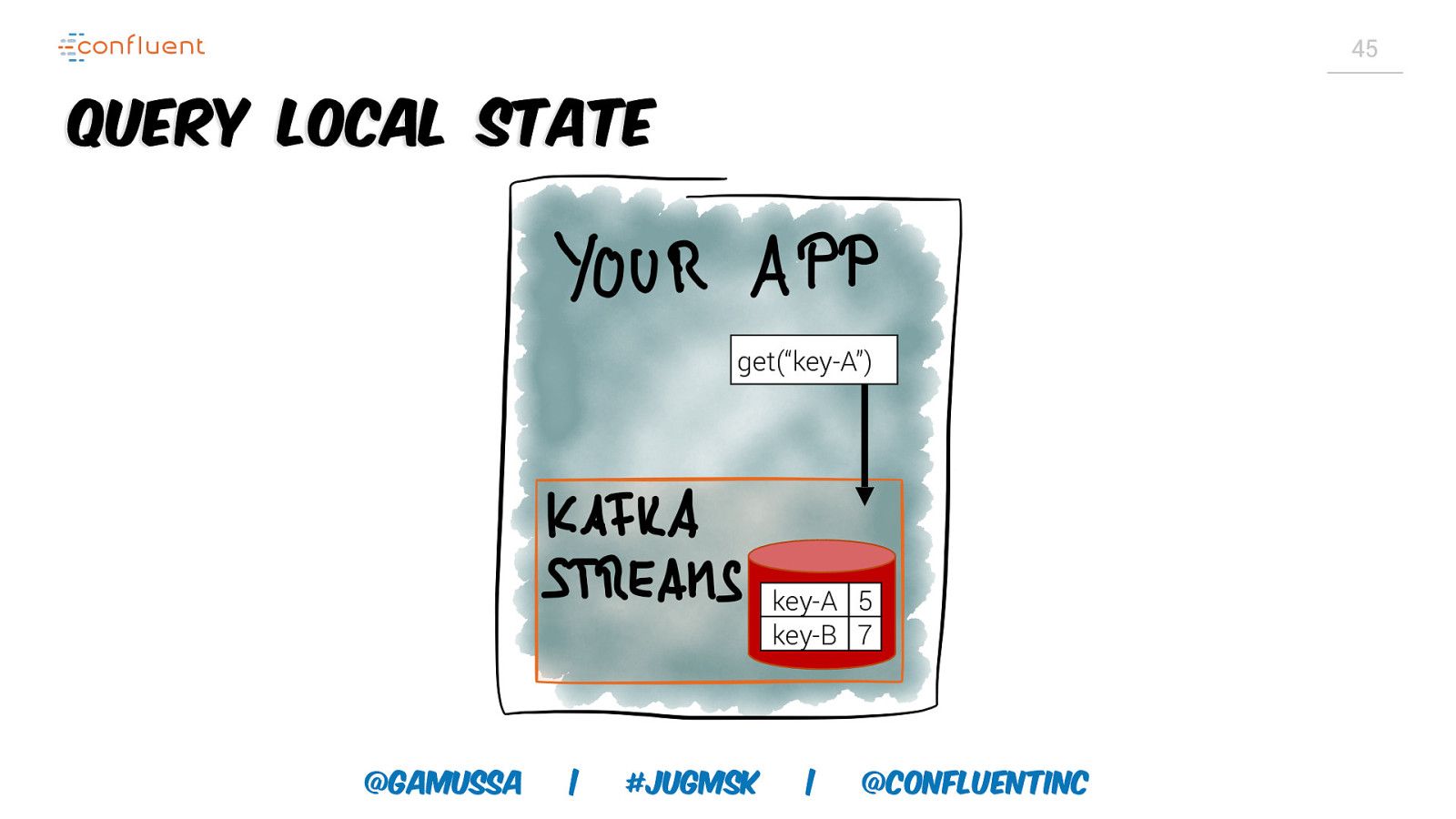
45 Query Local State get(“key-A”) key-A 5 key-B 7 @gamussa | #jugmsk | @ConfluentINc
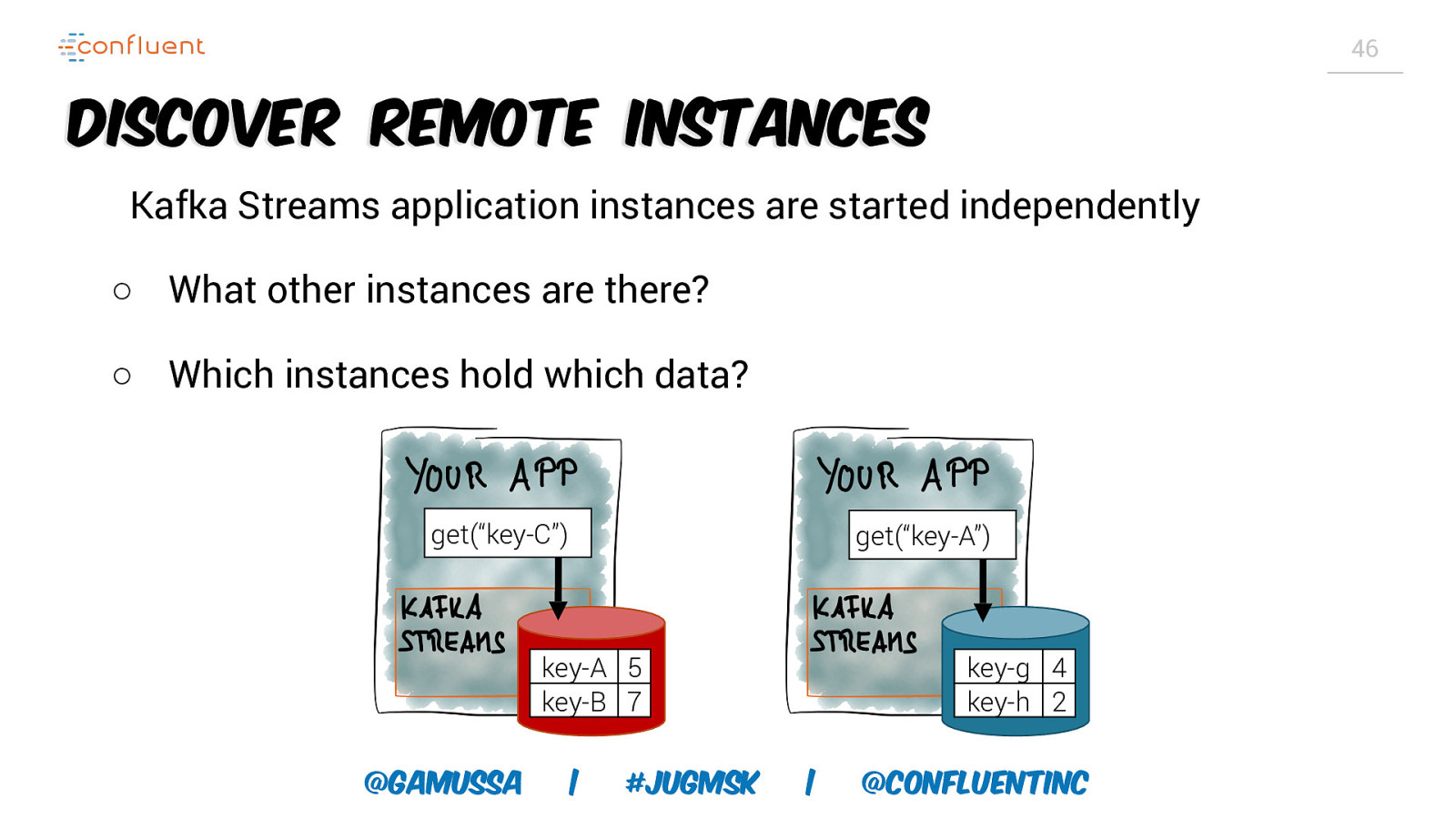
46 Discover Remote Instances Kafka Streams application instances are started independently ○ What other instances are there? ○ Which instances hold which data? get(“key-C”) get(“key-A”) key-A 5 key-B 7 @gamussa | #jugmsk key-g 4 key-h 2 | @ConfluentINc
47 Discover Remote Instances Kafka Streams metadata API to the rescue: ○ KafkaStreams#allMetadata() ○ KafkaStreams#allMetadataForStore(String storeName) ○ KafkaStreams#allMetadataForKey( String storeName, K key, Serializer<K> keySerializer) Returns StreamsMetadata object @gamussa | #jugmsk | @ConfluentINc
48 Discover Remote Instances StreamsMetadata object ○ Host information (server/port) according to application.server config ○ State store names of hosted stores ○ TopicPartition mapped to the store (ie, shard) @gamussa | #jugmsk | @ConfluentINc
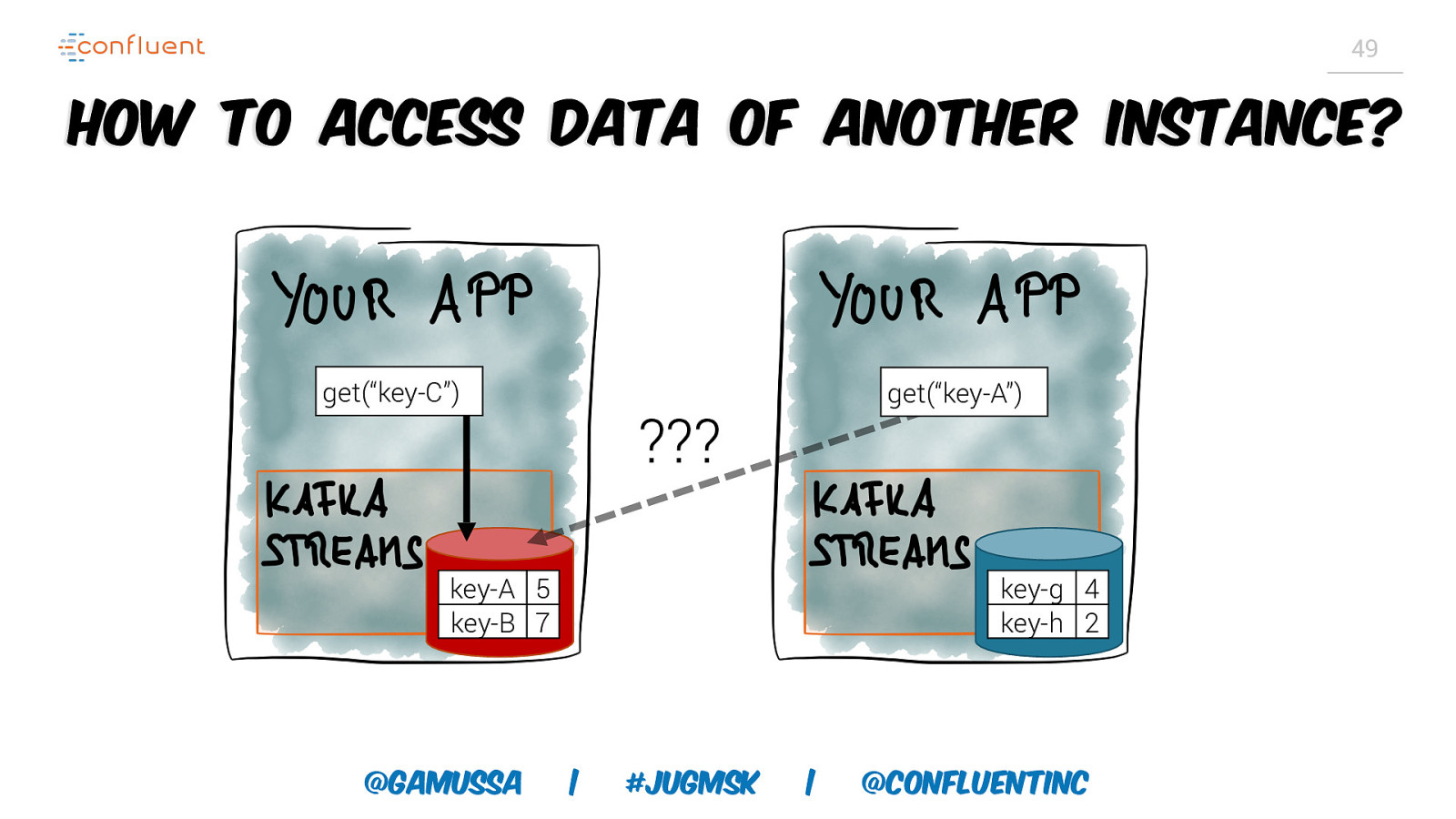
49 How to access data of another instance? get(“key-C”) get(“key-A”) ??? key-A 5 key-B 7 @gamussa key-g 4 key-h 2 | #jugmsk | @ConfluentINc
50 Query remote state via RPC Choose whatever you like: ○ REST ○ gRPC ○ Apache Thrift ○ XML-RPC ○ Java RMI ○ SOAP @gamussa | #jugmsk | @ConfluentINc
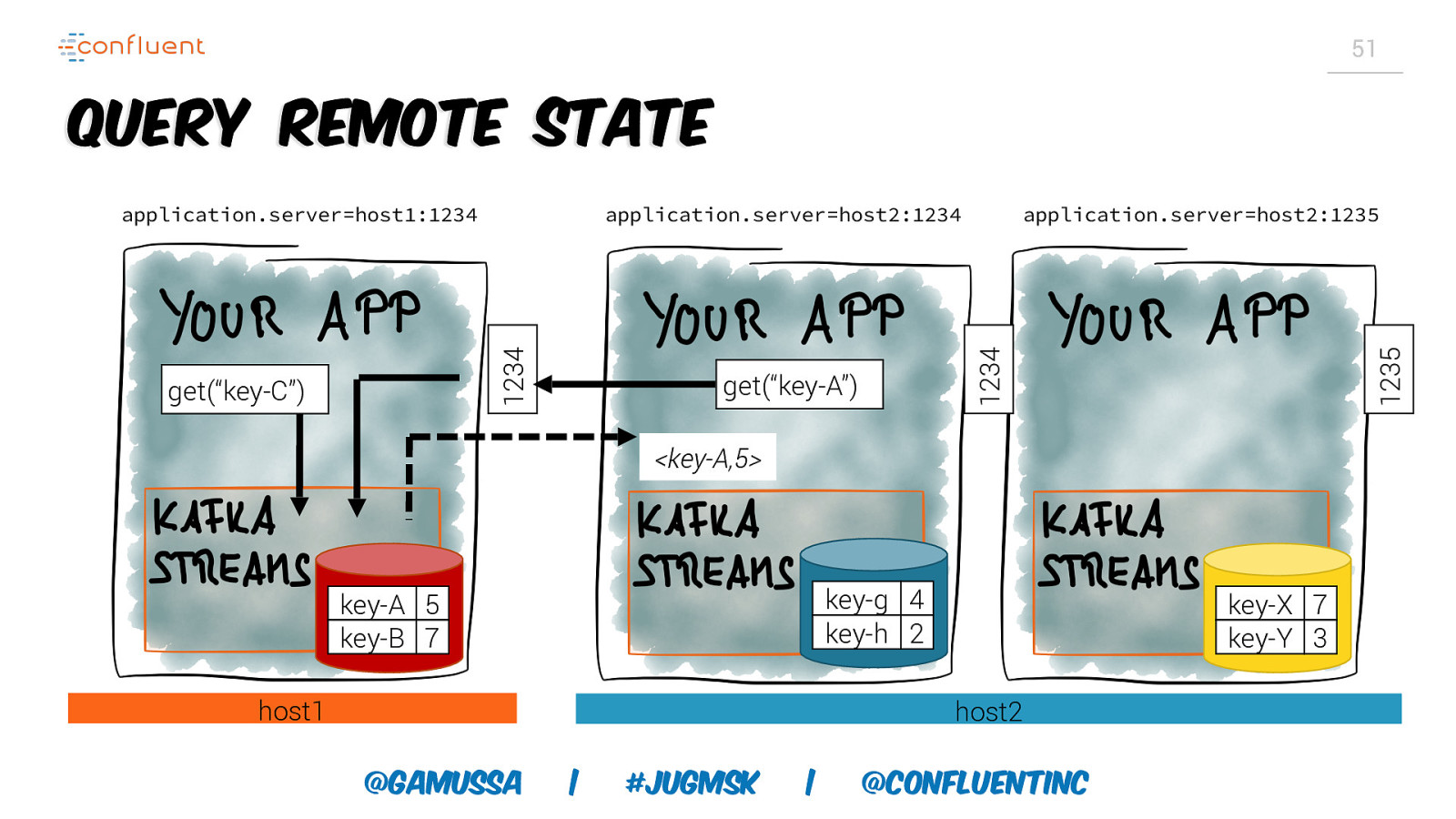
51 Query remote state get(“key-A”) 1235 get(“key-C”) application.server=host2:1235 1234 application.server=host2:1234 1234 application.server=host1:1234 <key-A,5> key-g 4 key-h 2 key-A 5 key-B 7 host1 key-X 7 key-Y 3 host2 @gamussa | #jugmsk | @ConfluentINc
52 Take Home Message Before IQ ☹ With IQ ☺ @gamussa | #jugmsk | @ConfluentINc
53 PROS There are fewer moving pieces; no external database It enables faster and more efficient use of the application state It provides better isolation It allows for flexibility Mix-and-match local an remote DB @gamussa | #jugmsk | @ConfluentINc
54 Cons It may involve moving away from a datastore you know and trust You might want to scale storage independently of processing You might need customized queries, specific to some datastores @gamussa | #jugmsk | @ConfluentINc
55 🛑 Stop! Demo time! @gamussa | #jugmsk | @ConfluentINc
56 Summary Interactive Queries is a powerful abstractions that simplifies stateful stream processing There are still cases for which external database/storage might be a better fit – with IQ you can choose! @gamussa | #jugmsk | @ConfluentINc
57 Summary Music example: https://github.com/confluentinc/ examples/blob/master/kafka-streams/src/main/java/io/ confluent/examples/streams/interactivequeries/kafkamusic/ KafkaMusicExample.java Streaming Movie Ratings: https://github.com/ confluentinc/demo-scene/tree/master/streams-movie-demo @gamussa | #jugmsk | @ConfluentINc
Thanks! @gamussa viktor@confluent.io We are hiring! https://www.confluent.io/careers/ @gamussa | @ #jugmsk | @ConfluentINc
59

Рост популярности Apache Kafka, как потоковой платформы, потребовал пересмотра традиционного подхода к распределенной обработке данных. Kafka Streams позволяет разрабатывать приложения без каких-либо кластеров. Подход «кластер на коленке» позволяет начать разработку и не задумываться о том, сможем ли мы потом масштабироваться (spoiler alert: Сможем!).
А слабо выкинуть традиционную базу данных для хранения результатов и промежуточного состояния?
В этом докладе Виктор расскажет про Interactive Queries — часть API Kafka Streams, которая позволяет получить доступ к состоянию приложения без использования традиционных хранилищ — БД, кэшей и тп. Посмотрим, как такой подход позволяет упростить архитектуру для использования Kafka Stream в микросервисах.
Как обычно, кроме доклада по слайдам, будет демонстрация, а кроме того, примеры кода на Java и Kotlin, и живое обсуждение!
Готовьте свои вопросы и жизненные ситуации.
The following resources were mentioned during the presentation or are useful additional information.
Here’s what was said about this presentation on social media.