A presentation at St. Petersburg Kafka Meetup in in St Petersburg, Russia by Viktor Gamov

Kafka Streams и KSQL: как перестать строить кластера и начать обрабатывать стримы ST. PETERSBURG KAFKA MEETUP, OCTOBER 2018
@gamussa #KafkaSPB @confluentinc
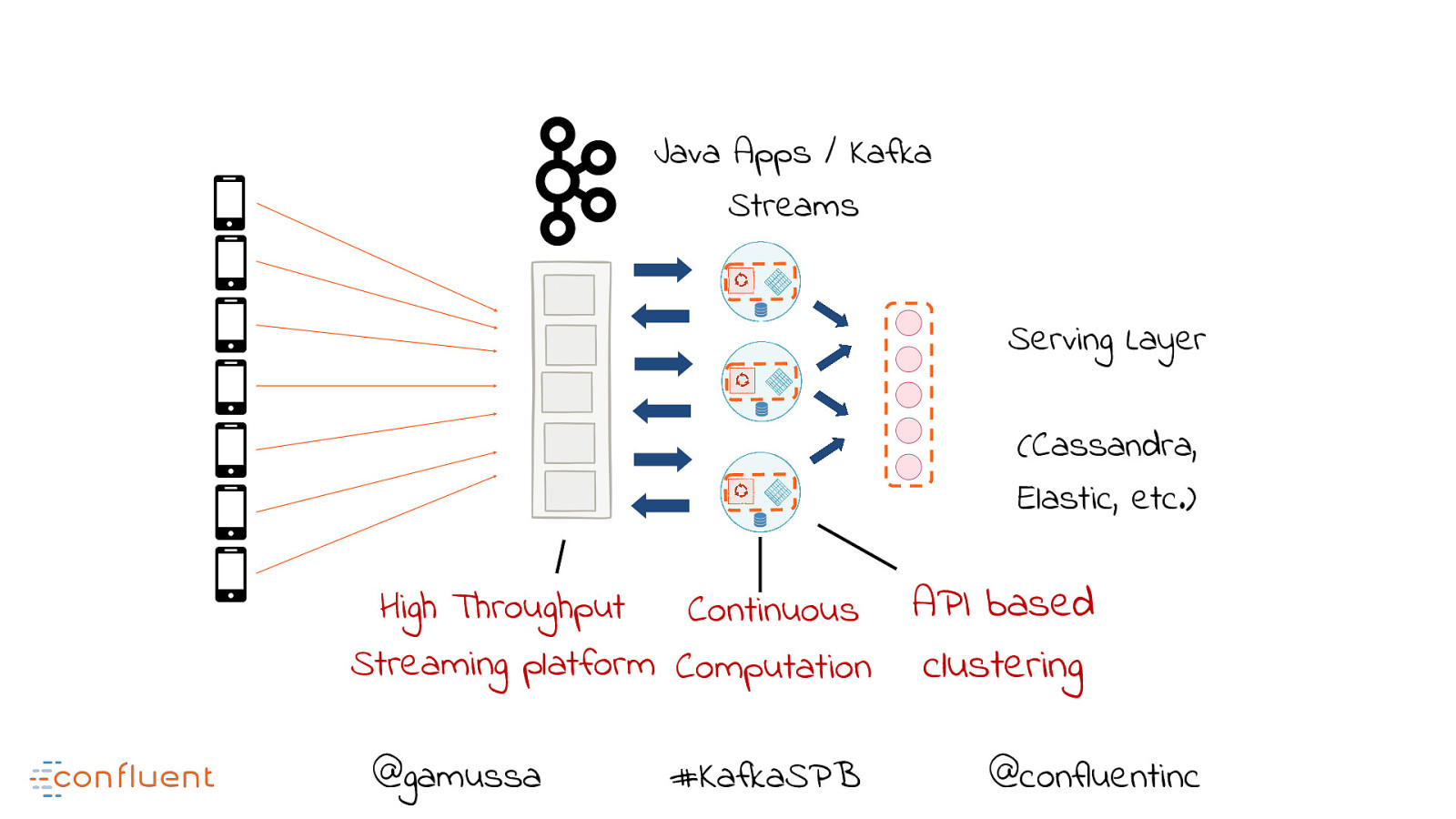
Java Apps / Kafka Streams Serving Layer (Cassandra, Elastic, etc.) High Throughput Continuous Streaming platform Computation @gamussa #KafkaSPB @ API based clustering @confluentinc
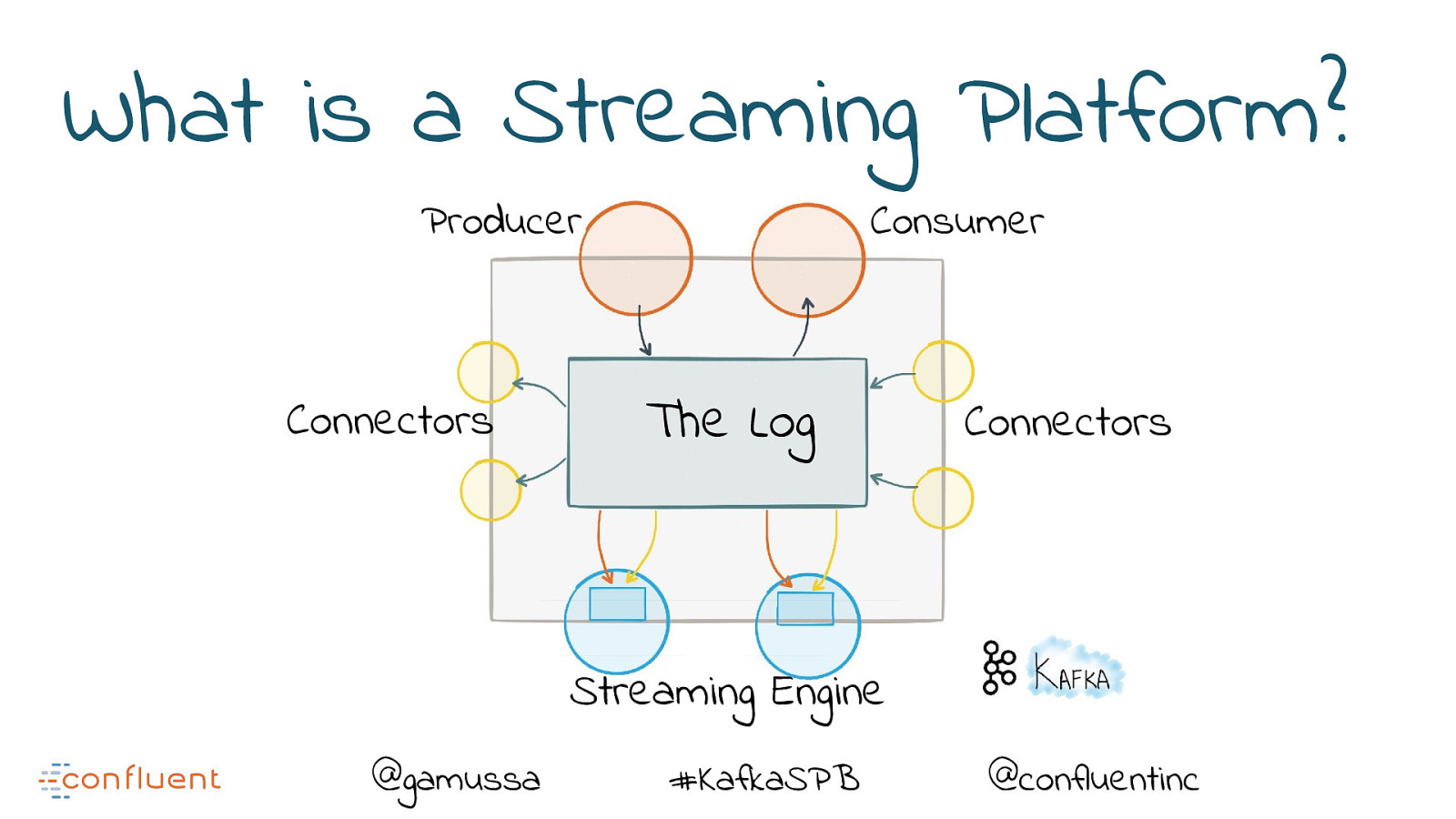
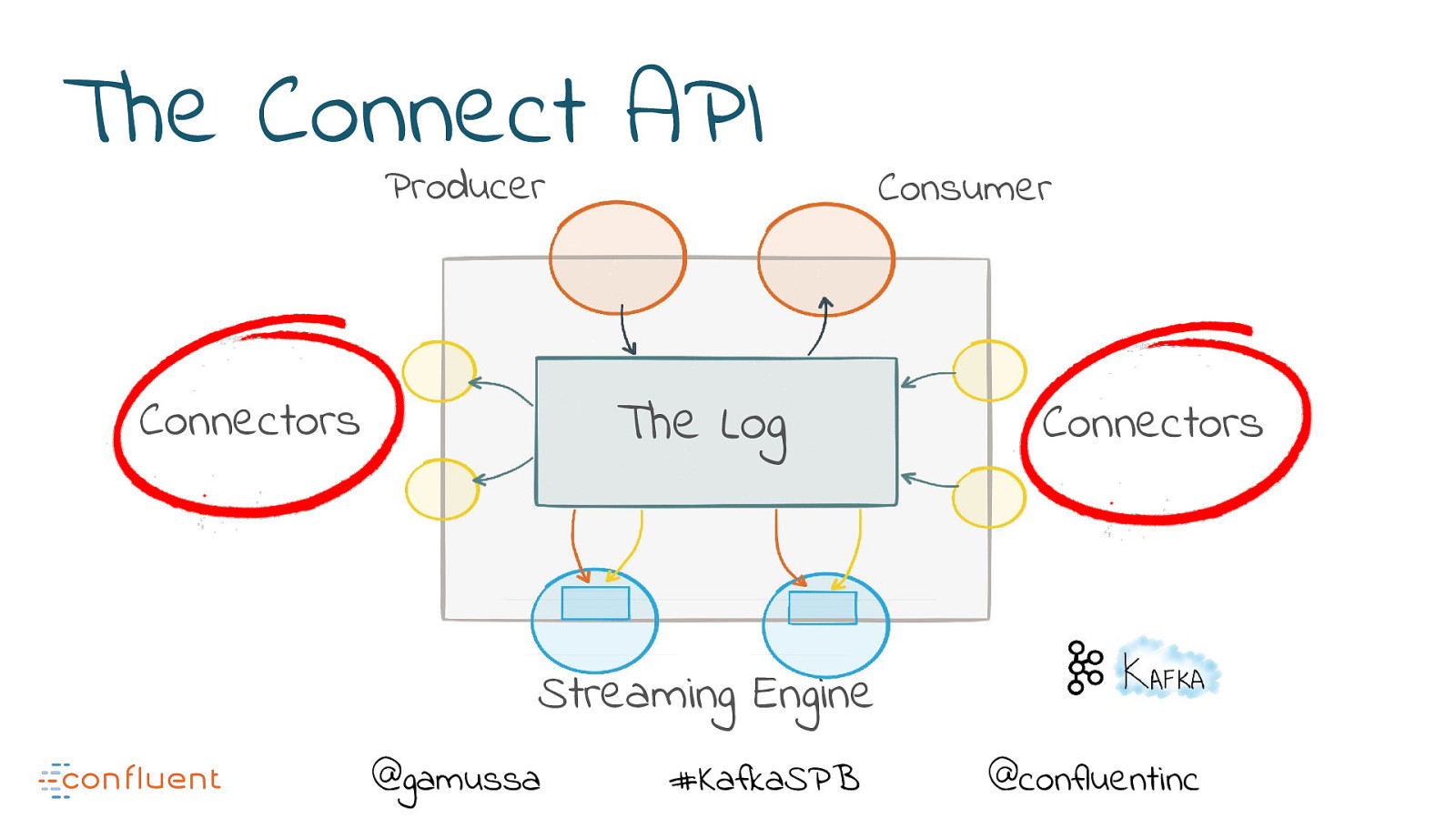
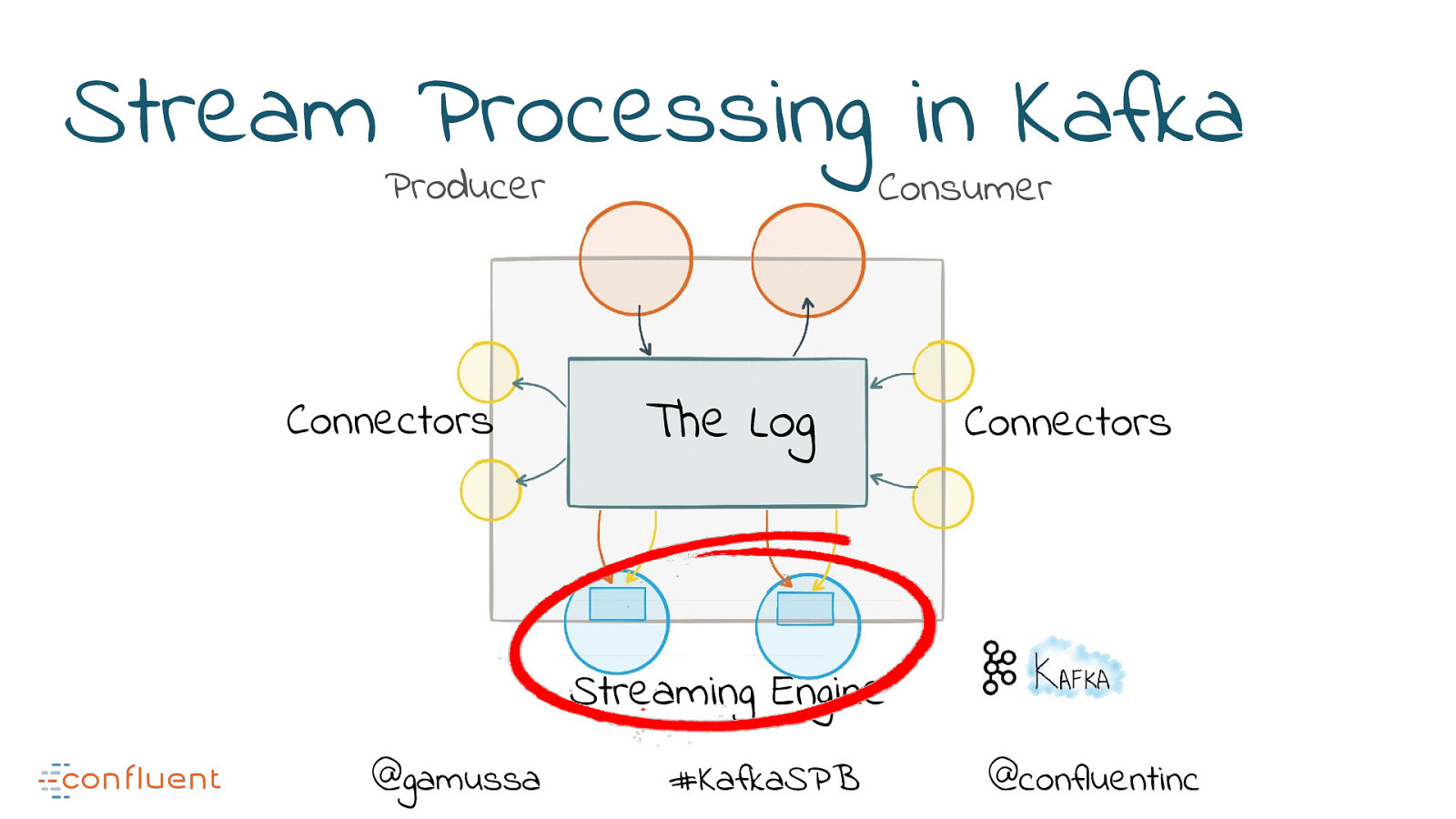
What is a Streaming Platform? Producer Connectors Consumer The Log Connectors Streaming Engine @gamussa #KafkaSPB @confluentinc
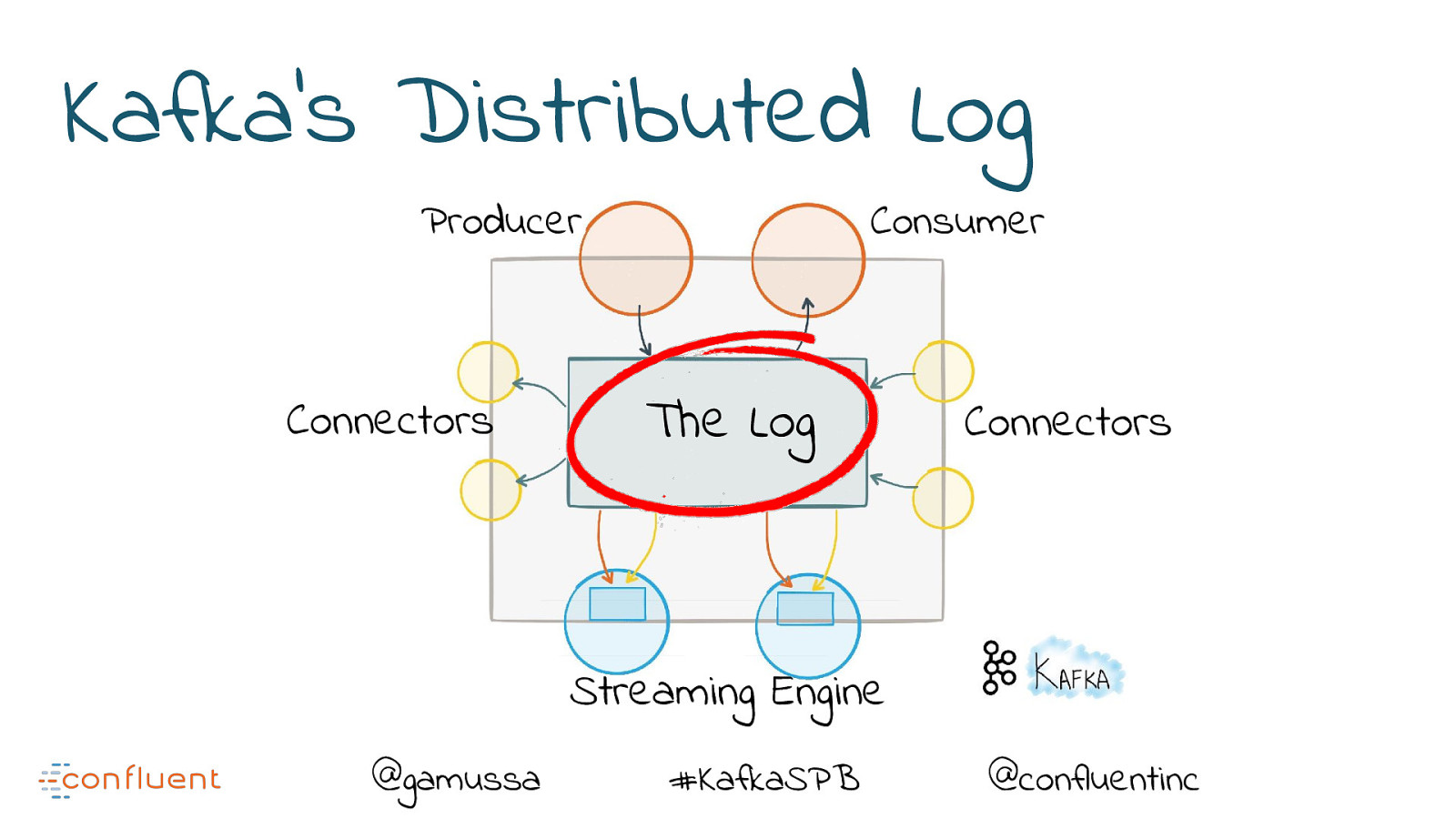
Kafka’s Distributed Log Producer Connectors Consumer The Log Connectors Streaming Engine @gamussa #KafkaSPB @confluentinc
The log is a simple idea New Old Messages are added at the end of the log @gamussa #KafkaSPB @confluentinc
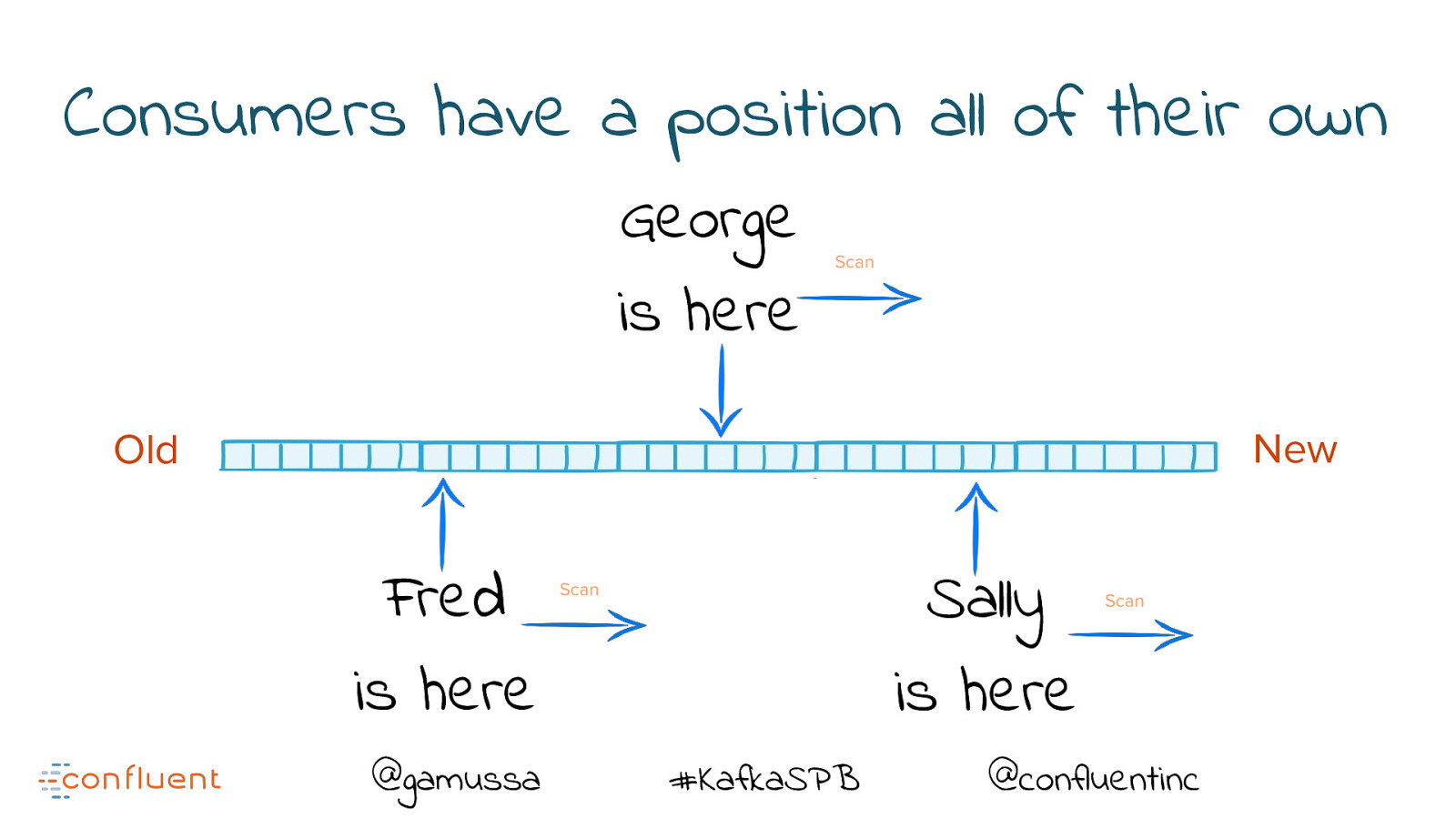
Consumers have a position all of their own George is here Scan New Old Fred is here @gamussa Sally is here Scan #KafkaSPB Scan @confluentinc
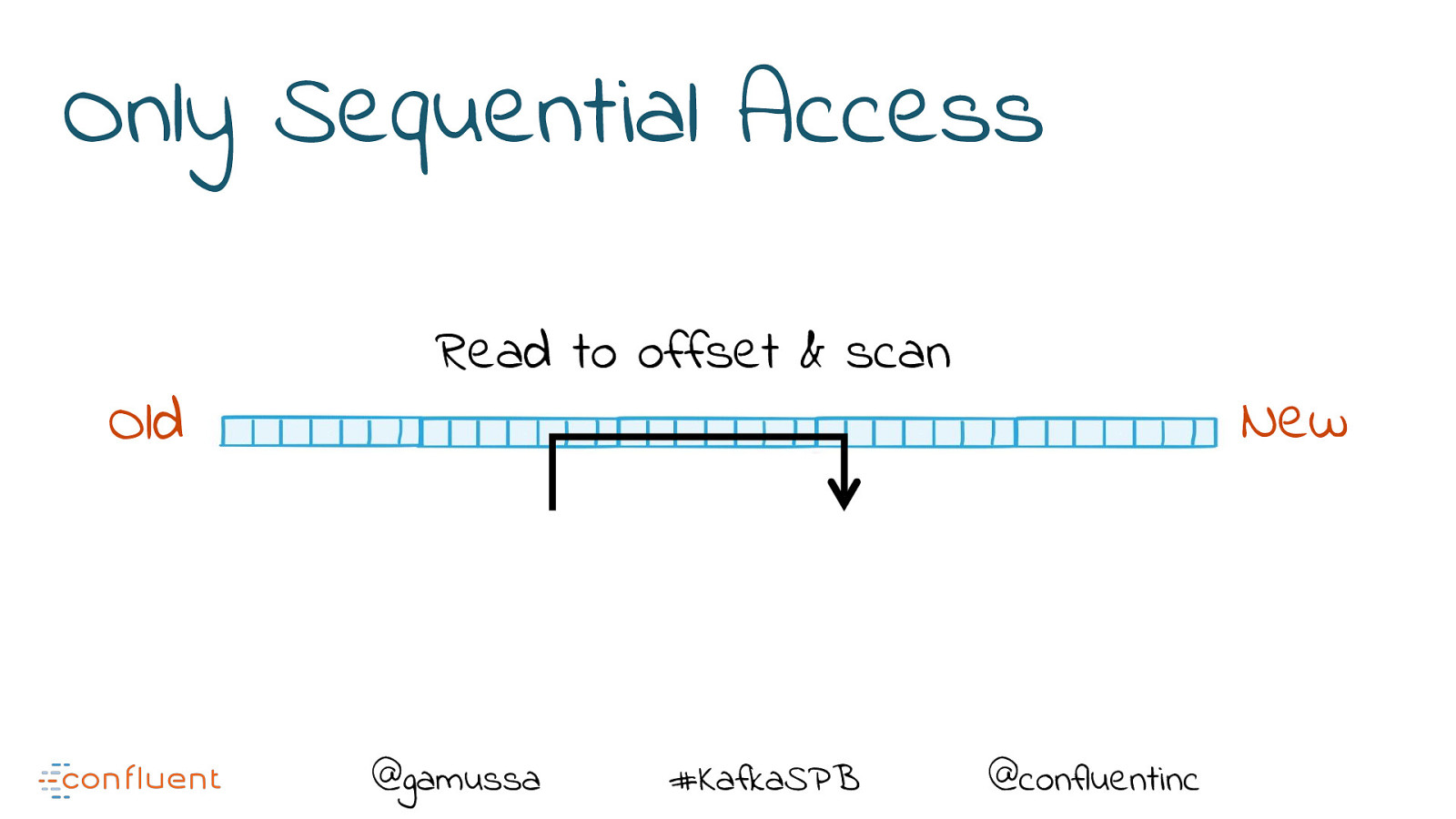
Only Sequential Access Old Read to offset & scan @gamussa #KafkaSPB New @confluentinc
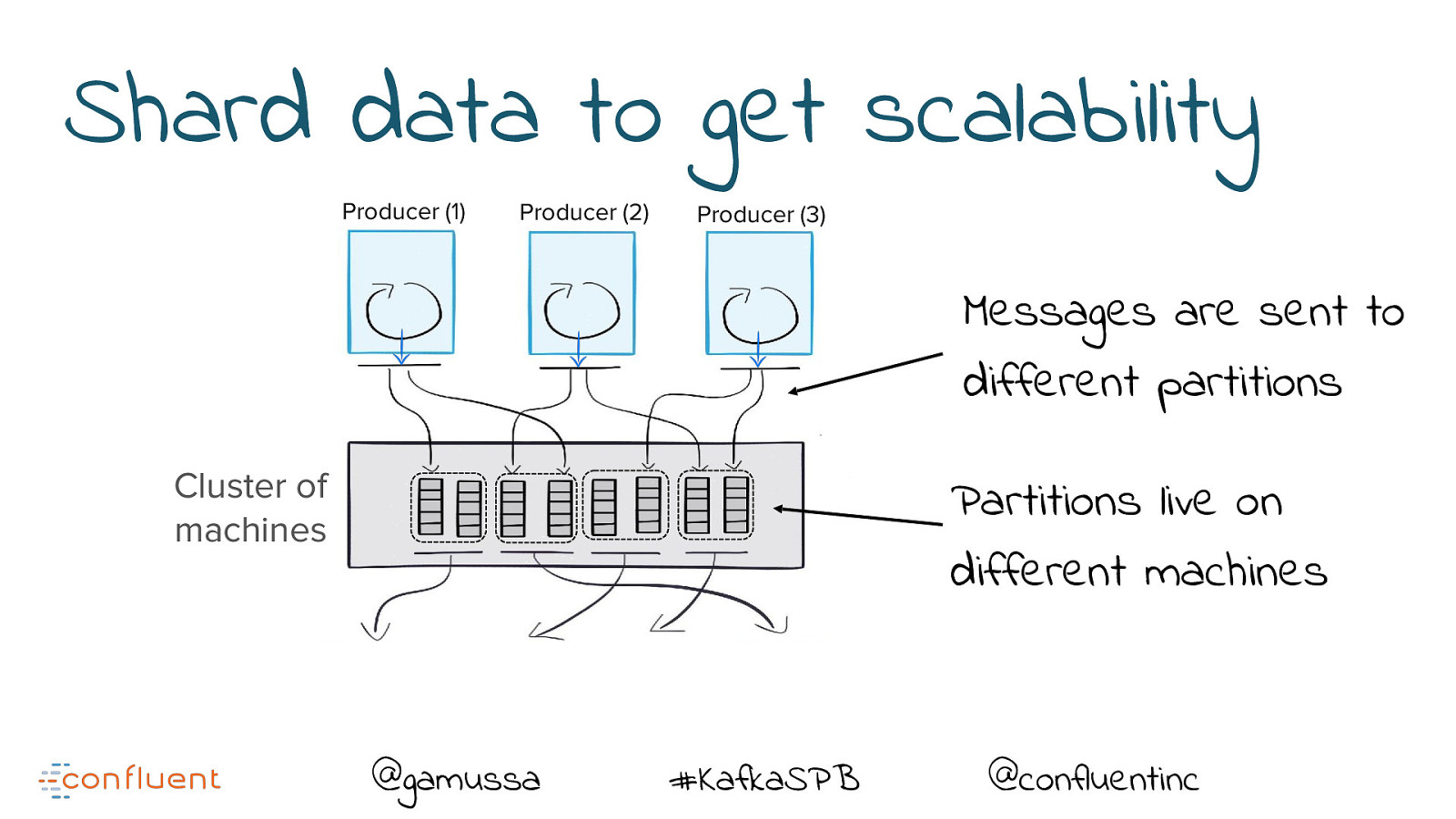
Shard data to get scalability Producer (1) Producer (2) Producer (3) Messages are sent to different partitions Cluster of machines Partitions live on different machines @gamussa #KafkaSPB @confluentinc
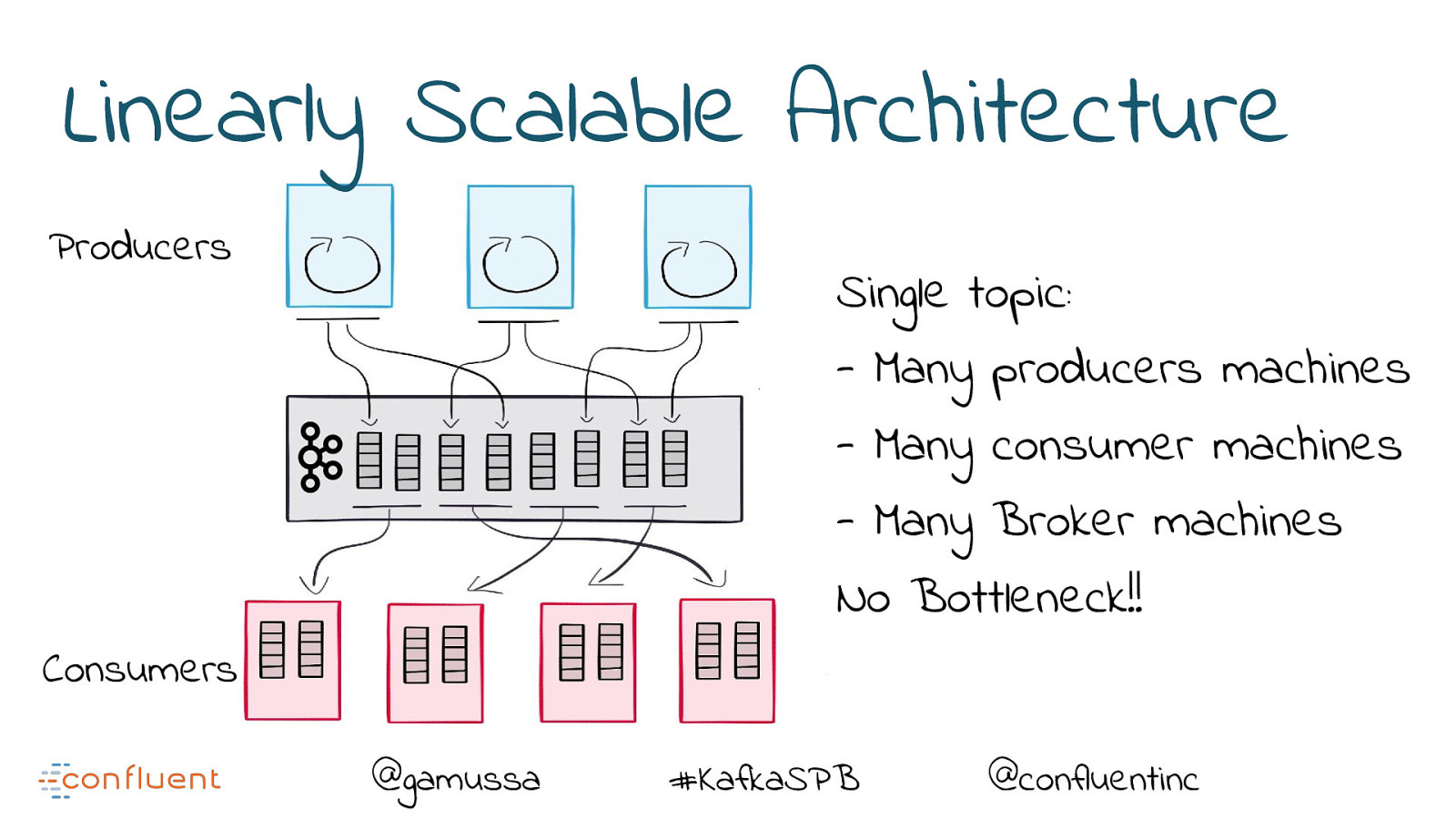
Linearly Scalable Architecture Producers Single topic: - Many producers machines - Many consumer machines - Many Broker machines No Bottleneck!! Consumers @gamussa #KafkaSPB @confluentinc
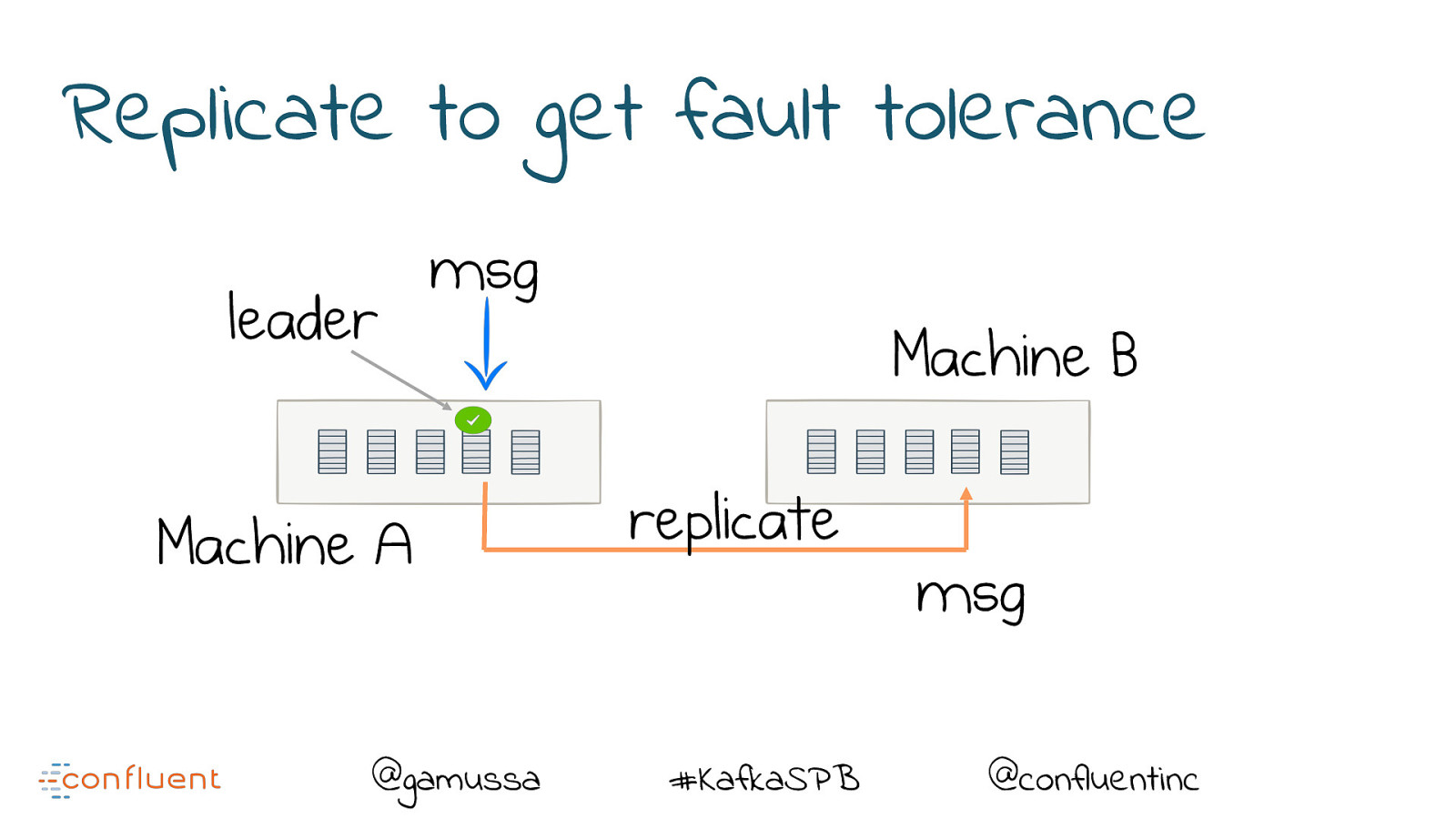
Replicate to get fault tolerance leader msg Machine A @gamussa Machine B replicate #KafkaSPB msg @confluentinc
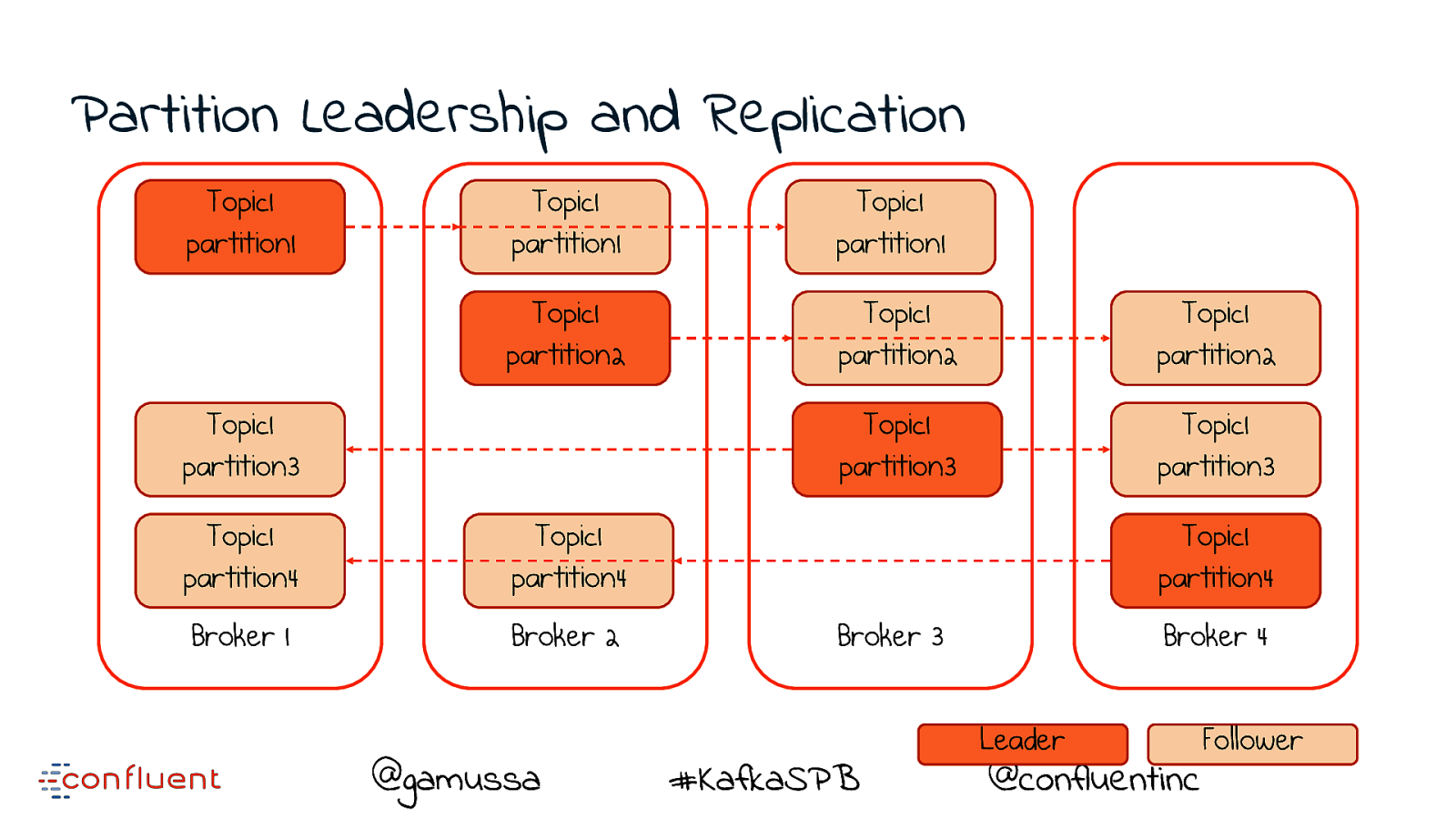
Partition Leadership and Replication Topic1 partition1 Topic1 partition1 Topic1 partition1 Topic1 partition2 Topic1 partition2 Topic1 partition2 Topic1 partition3 Topic1 partition3 Topic1 partition3 Topic1 partition4 Topic1 partition4 Broker 1 Broker 2 @gamussa Topic1 partition4 Broker 3 #KafkaSPB Broker 4 Leader Follower @confluentinc
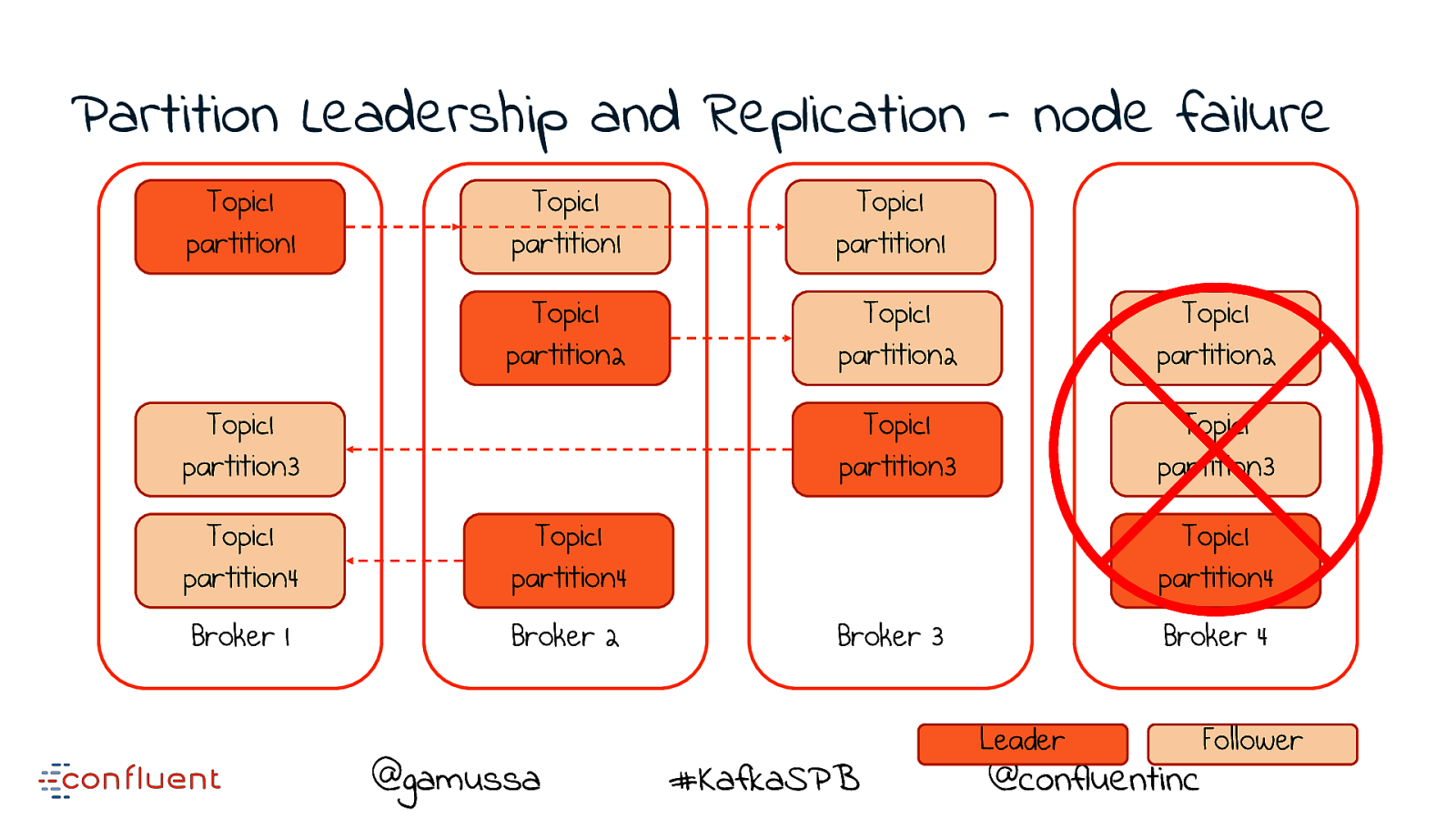
Replication provides resiliency A ‘replica’ takes over on machine failure @gamussa #KafkaSPB @confluentinc
Partition Leadership and Replication - node failure Topic1 partition1 Topic1 partition1 Topic1 partition1 Topic1 partition2 Topic1 partition2 Topic1 partition2 Topic1 partition3 Topic1 partition3 Topic1 partition3 Topic1 partition4 Topic1 partition4 Broker 1 Broker 2 @gamussa Topic1 partition4 Broker 3 #KafkaSPB Broker 4 Leader Follower @confluentinc
CONSUMERS CONSUMER GROUP CONSUMER GROUP COORDINATOR
Talk is cheap! Show me code! https://cnfl.io/streams-movie
The Connect API Producer The Log Connectors Consumer Connectors Streaming Engine @gamussa #KafkaSPB @confluentinc
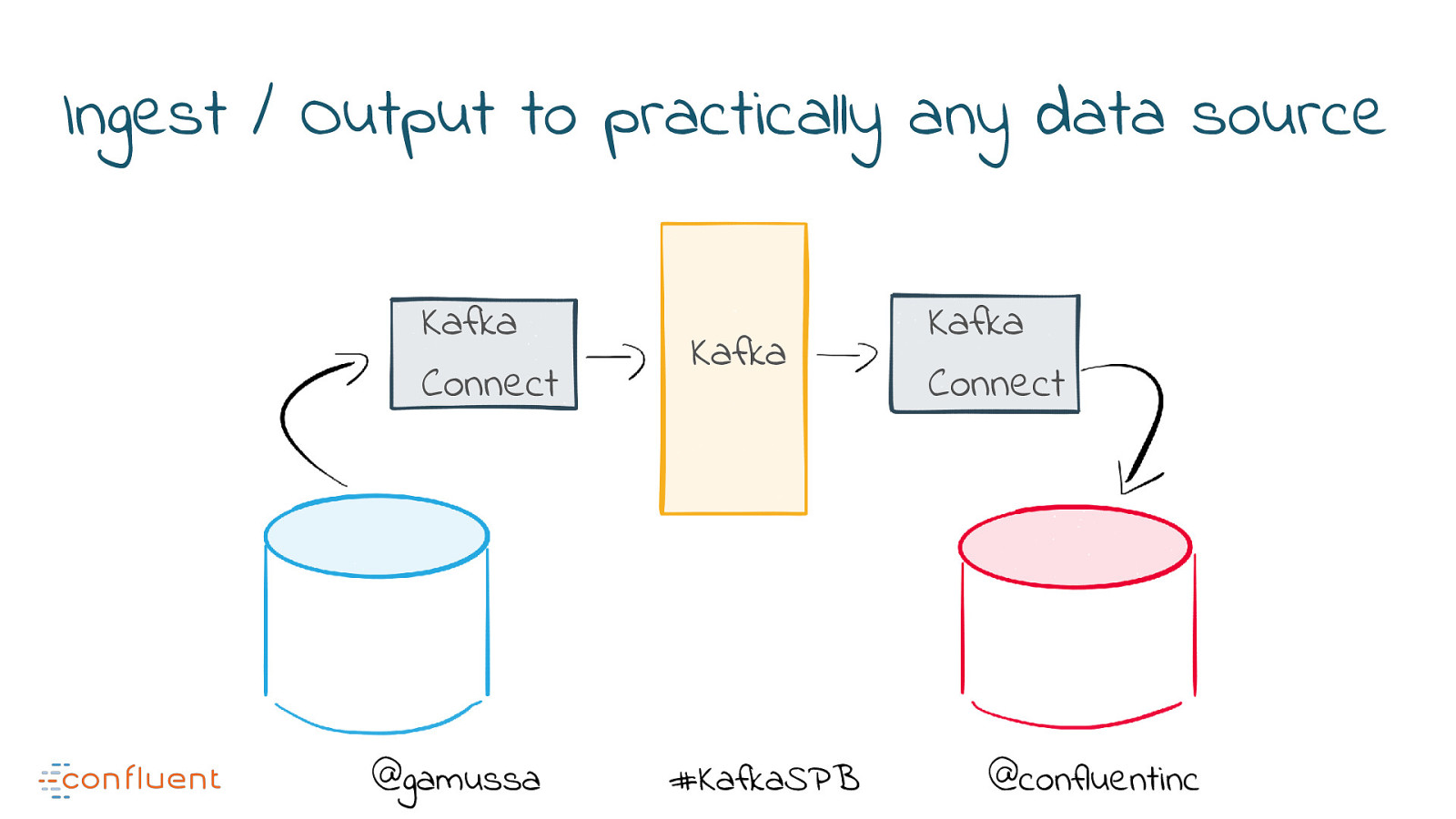
Ingest / Output to practically any data source Kafka Connect @gamussa Kafka #KafkaSPB Kafka Connect @confluentinc
Ingest/Output from/to many data sources Amazon S3 Elasticsearch HDFS JDBC Couchbase Cassandra Oracle SAP Vertica Blockchain @gamussa DynamoDB FTP Github BigQuery Google Pub Sub RethinkDB Salesforce Solr Splunk #KafkaSPB JMX Kenesis MongoDB MQTT NATS Postgres Rabbit Redis Twitter @confluentinc
Stream Processing in Kafka Producer Connectors Consumer The Log Connectors Streaming Engine @gamussa #KafkaSPB @confluentinc
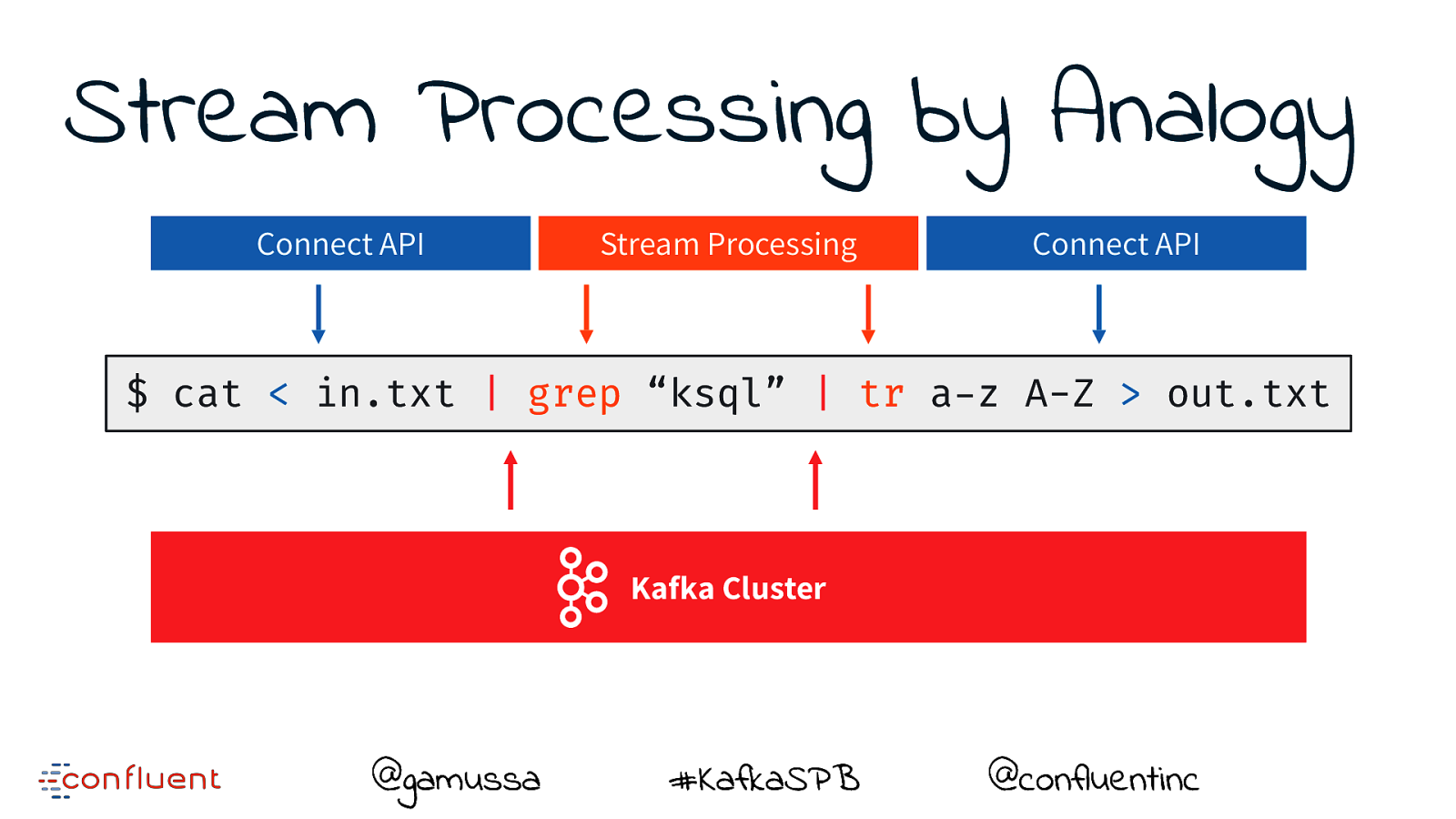
Stream Processing by Analogy Connect API Stream Processing Connect API $ cat < in.txt | grep “ksql” | tr a-z A-Z > out.txt Kafka Cluster @gamussa #KafkaSPB @confluentinc
Streaming is the toolset for dealing with events as they move! @gamussa #KafkaSPB @confluentinc
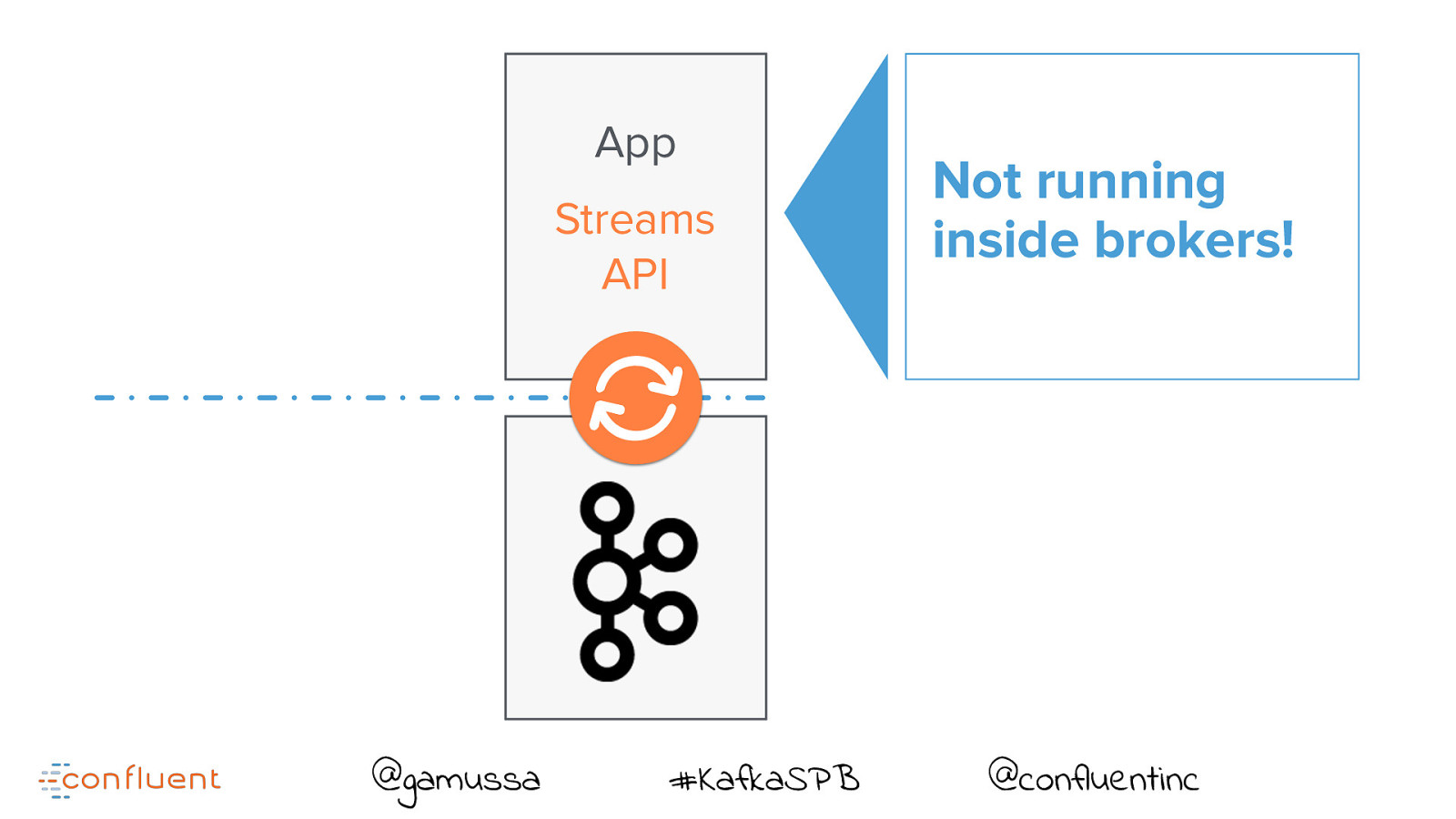
App Streams API @gamussa #KafkaSPB Not running inside brokers! @confluentinc
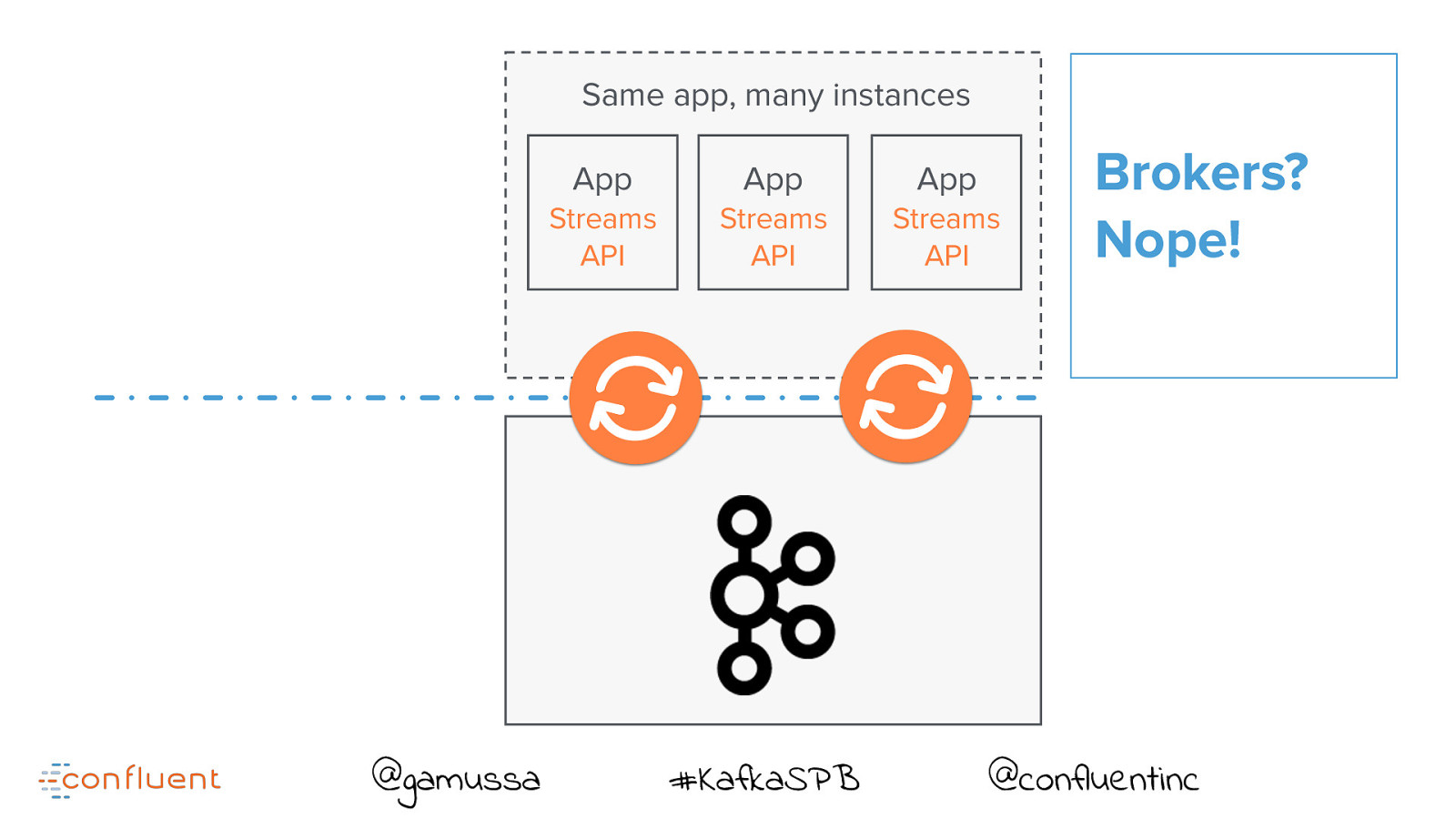
Same app, many instances @gamussa App App App Streams API Streams API Streams API #KafkaSPB Brokers? Nope! @confluentinc
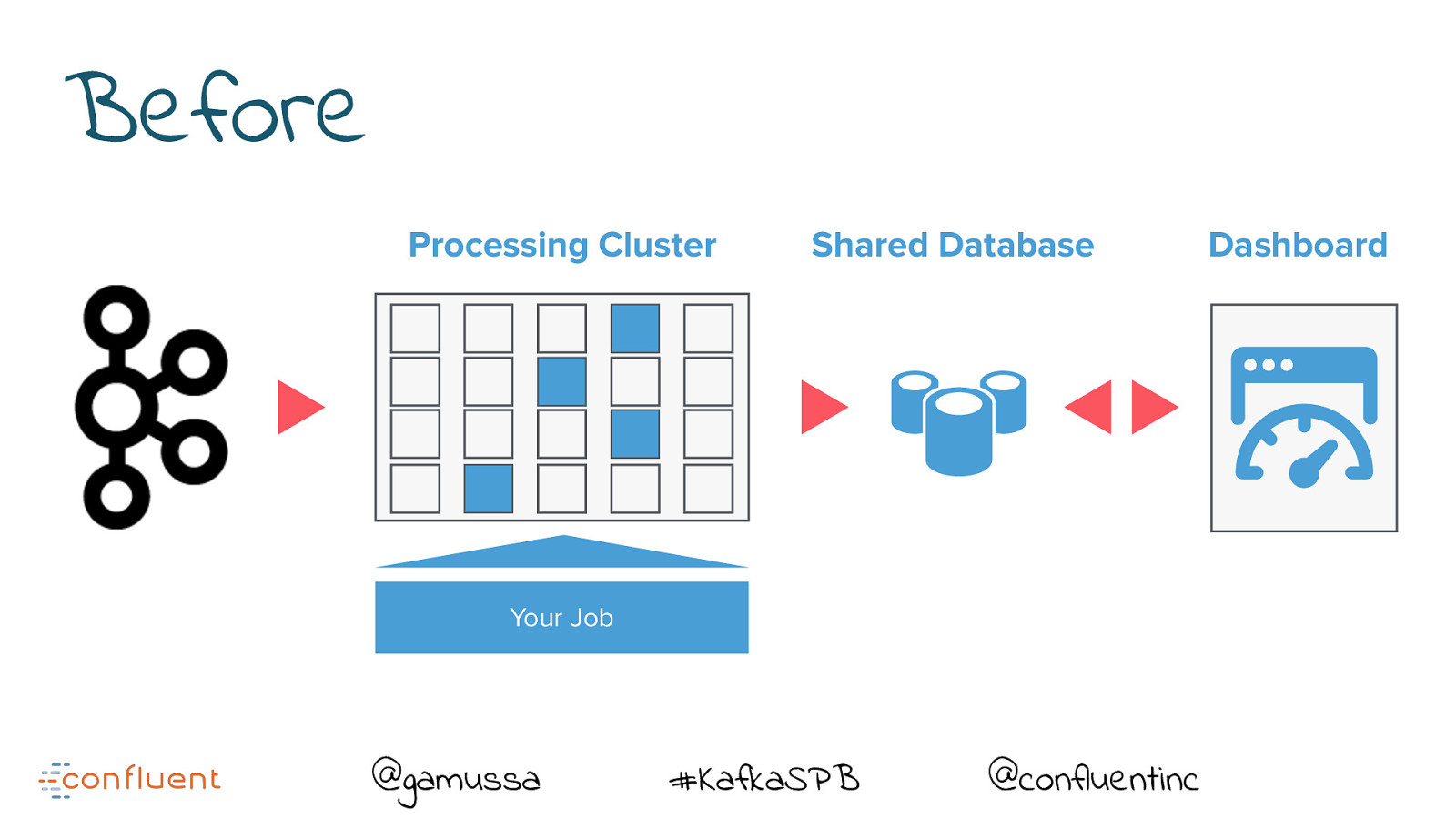
Before Processing Cluster Shared Database Your Job @gamussa #KafkaSPB @confluentinc Dashboard
As developers, we want to build APPS not INFRASTRUCTURE @gamussa #KafkaSPB @confluentinc
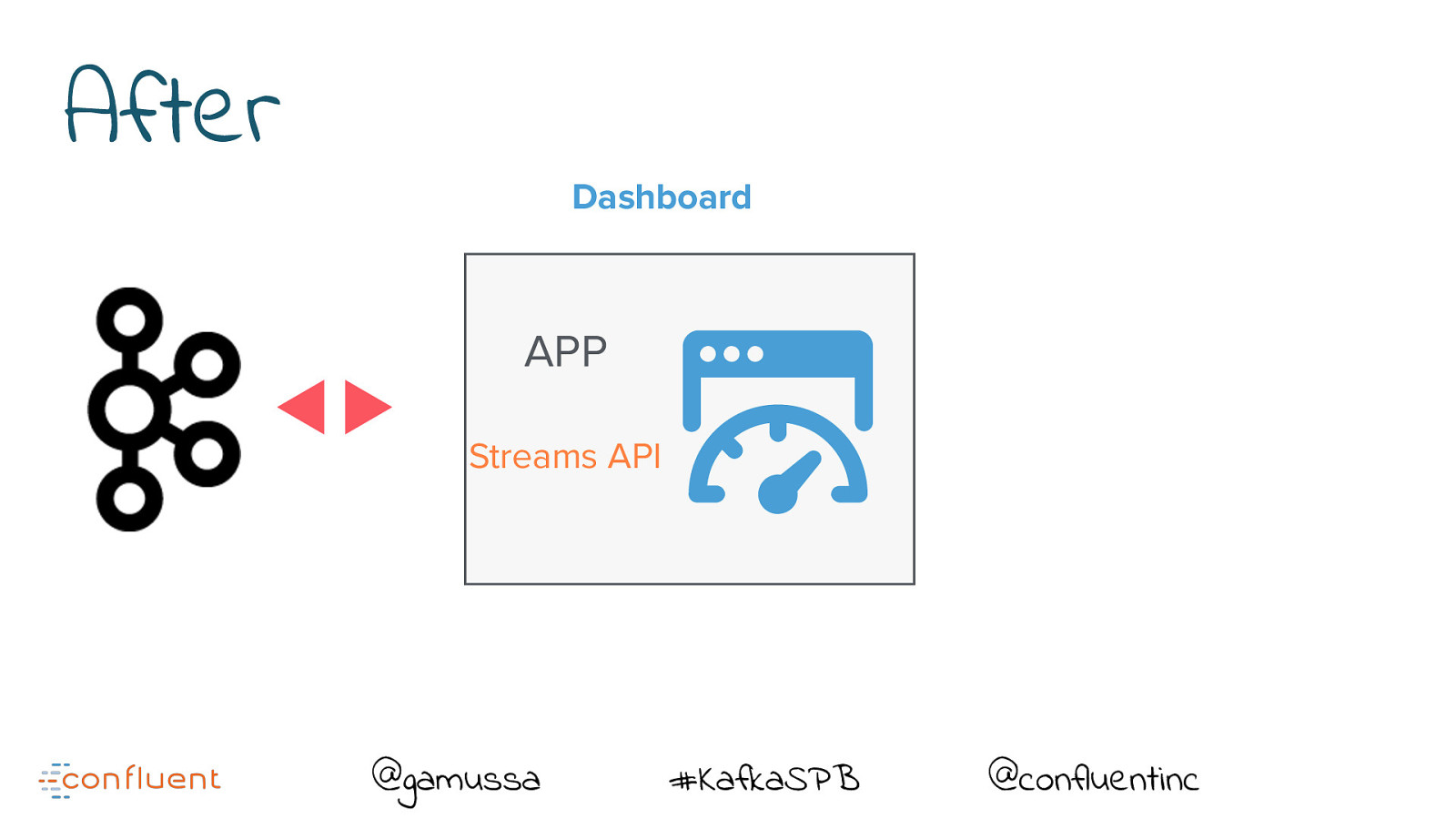
After Dashboard APP Streams API @gamussa #KafkaSPB @confluentinc
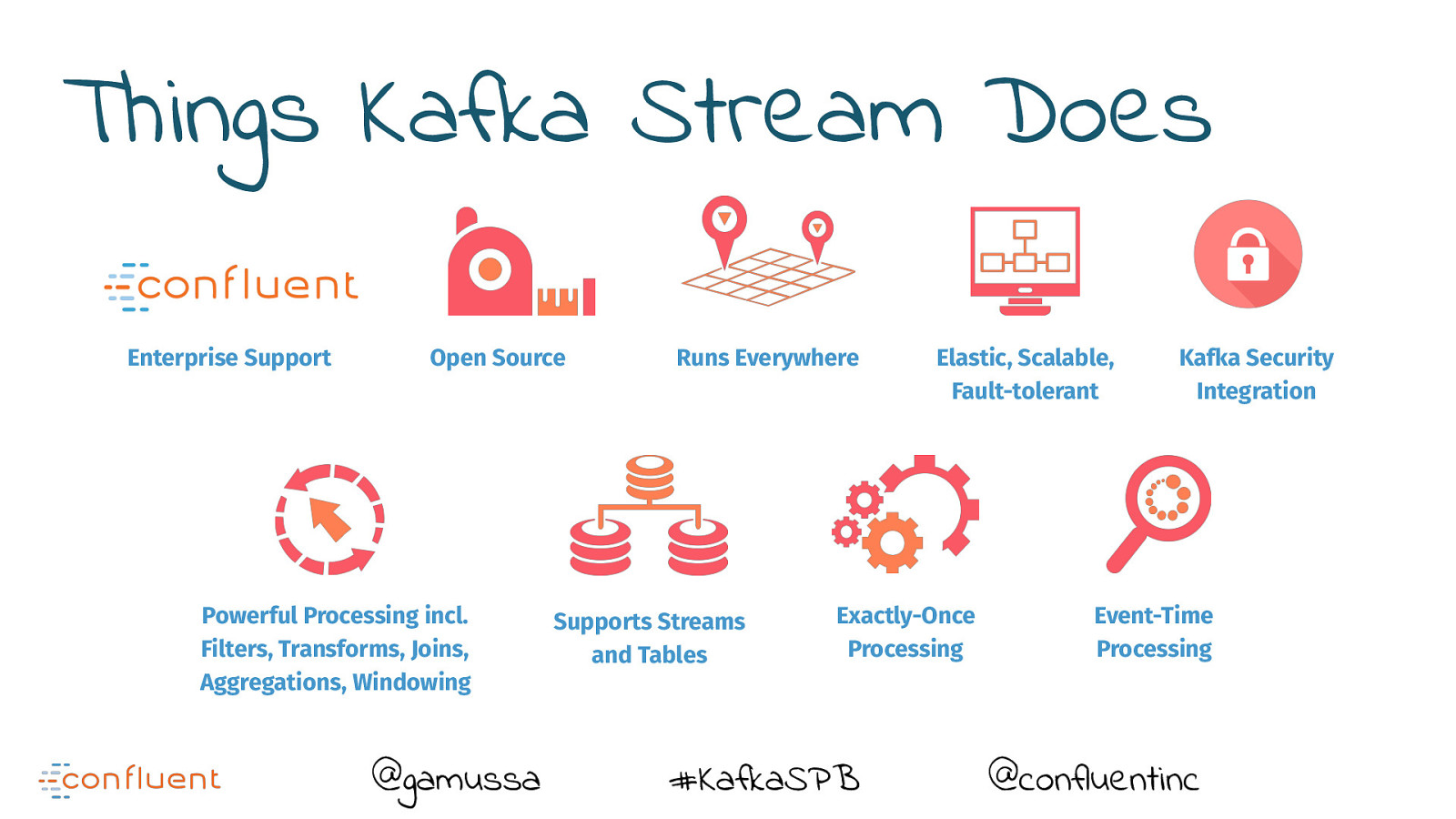
Things Kafka Stream Does Enterprise Support Open Source Powerful Processing incl. Filters, Transforms, Joins, Aggregations, Windowing @gamussa Runs Everywhere Supports Streams and Tables Elastic, Scalable, Fault-tolerant Exactly-Once Processing #KafkaSPB Kafka Security Integration Event-Time Processing @confluentinc
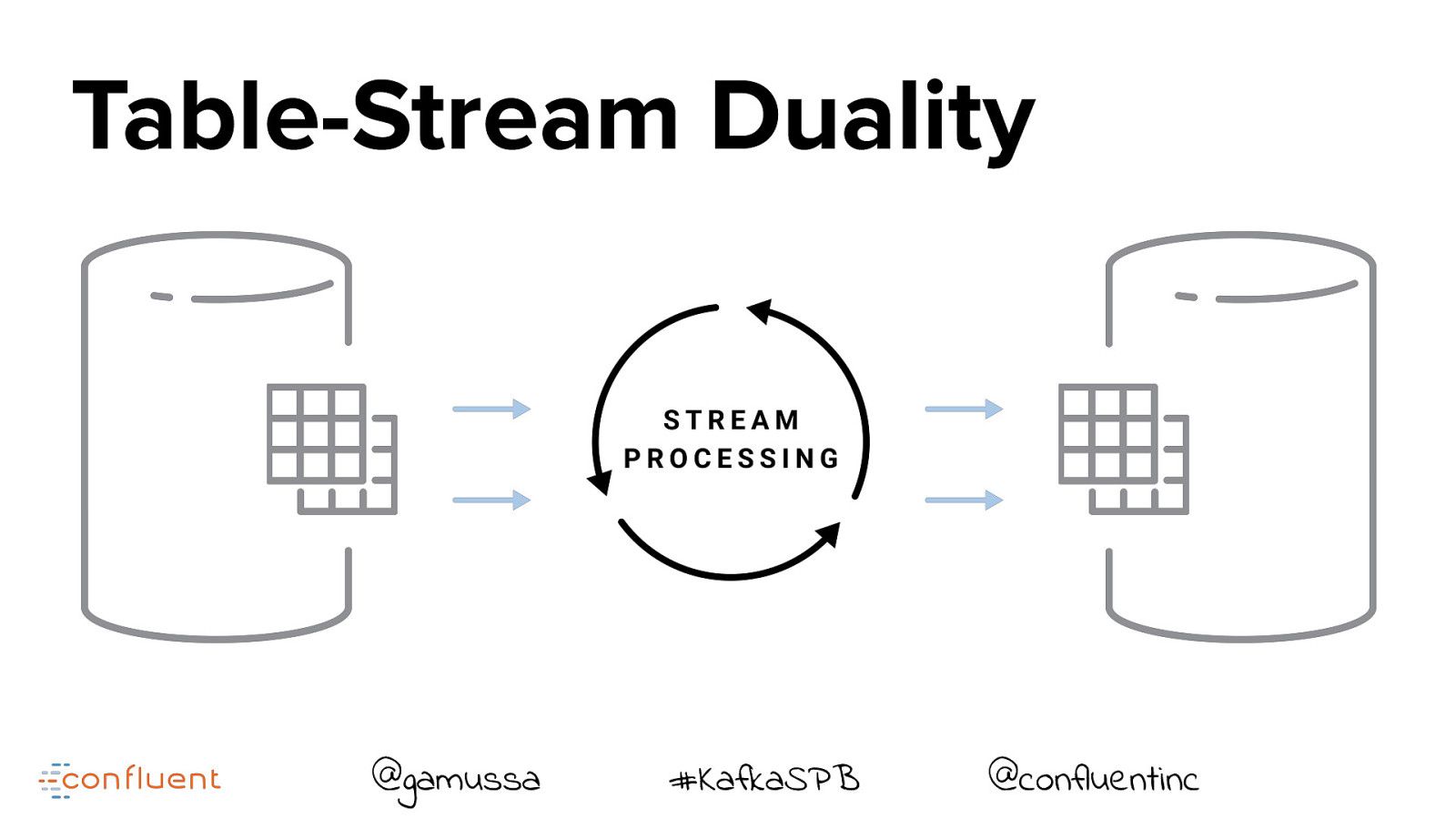
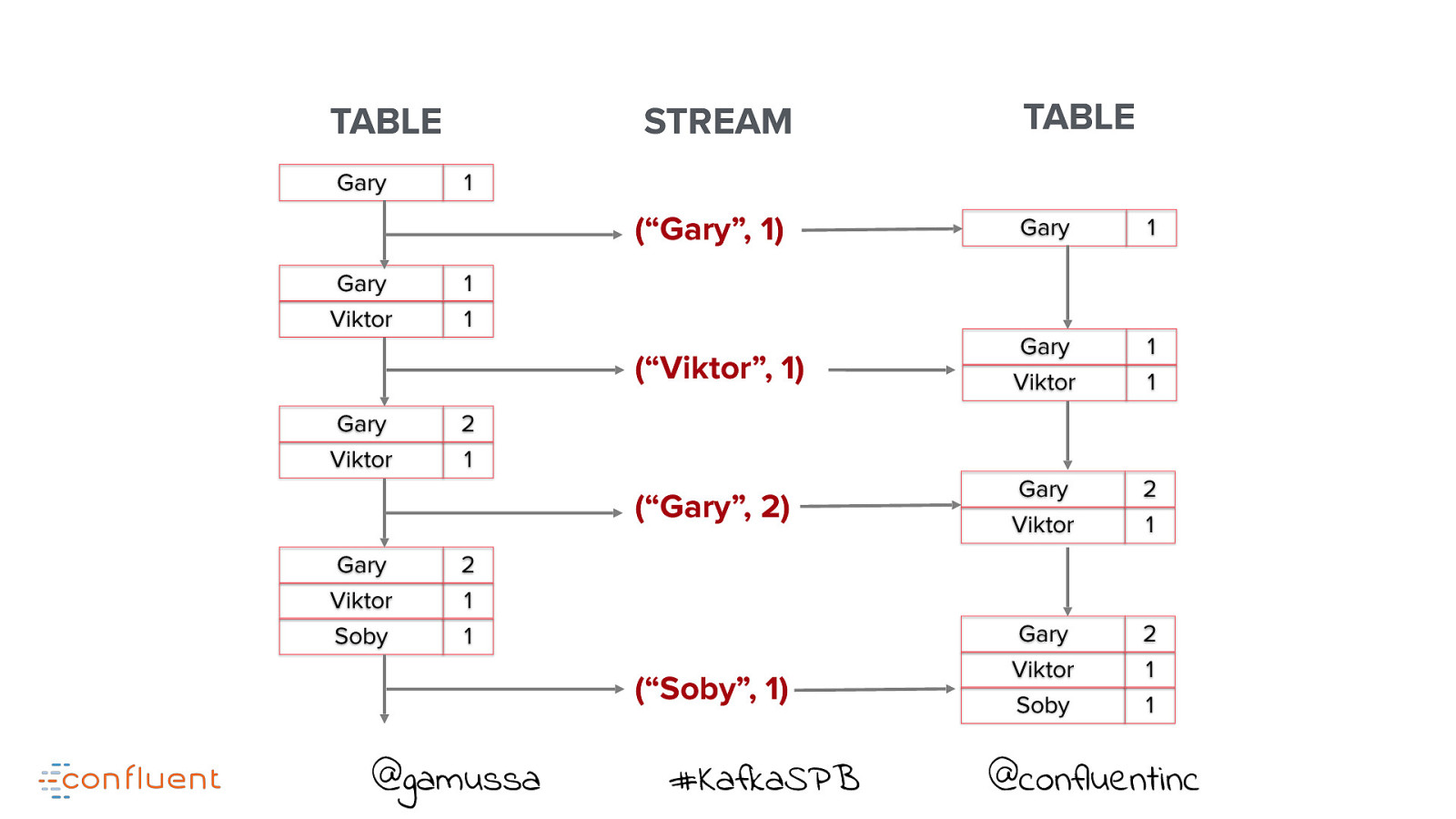
Table-Stream Duality @gamussa #KafkaSPB @confluentinc
Do you think that’s a table you are querying ?
TABLE Gary Gary Viktor Gary Viktor Gary Viktor Soby STREAM TABLE 1 (“Gary”, 1) Gary 1 (“Viktor”, 1) Gary Viktor 1 1 (“Gary”, 2) Gary Viktor 2 1 Gary Viktor Soby 2 1 1 1 1 2 1 2 1 1 (“Soby”, 1) @gamussa #KafkaSPB @confluentinc
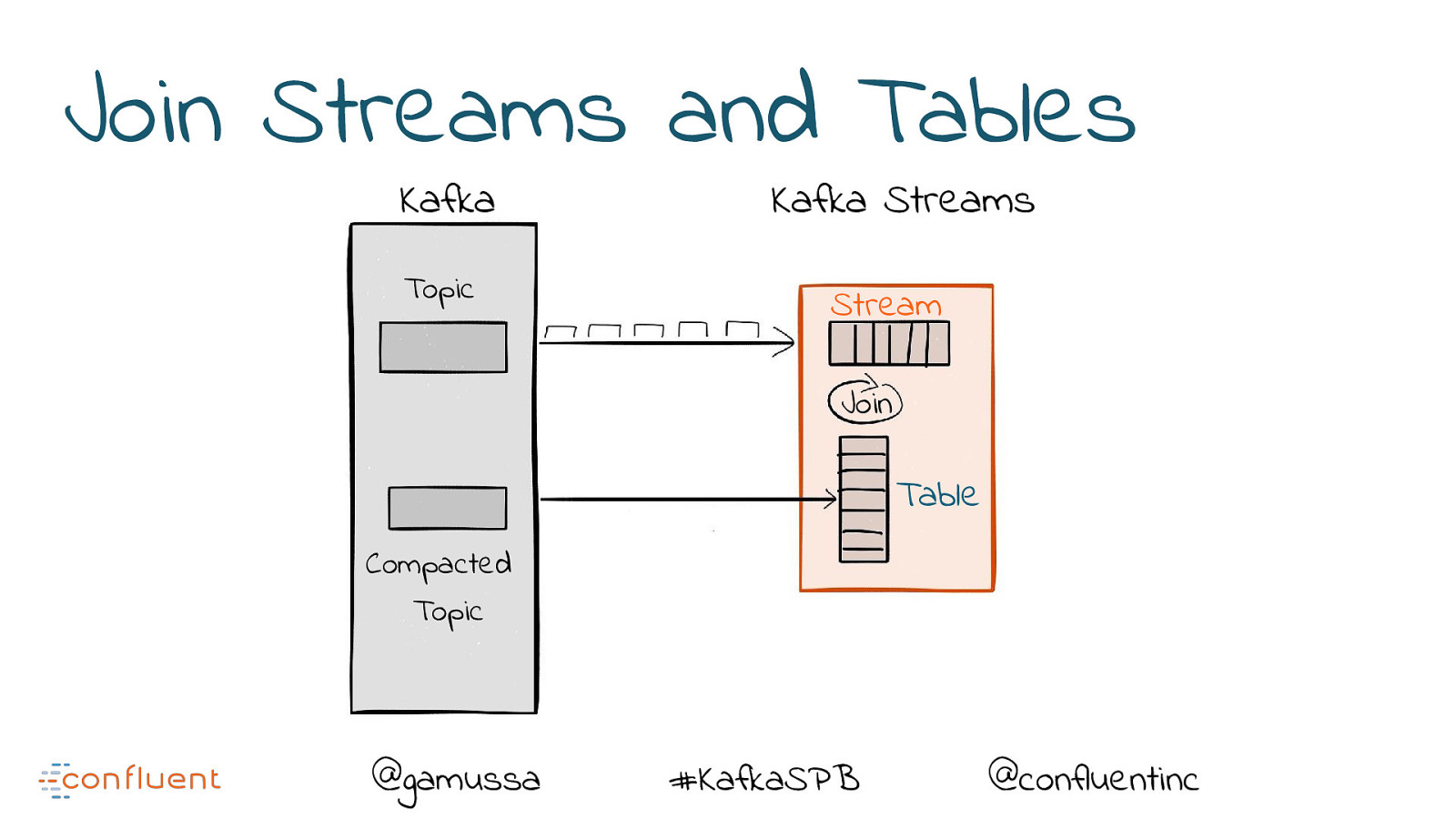
Join Streams and Tables Kafka Topic Kafka Streams Stream Join Table Compacted Topic @gamussa #KafkaSPB @confluentinc
Talk is cheap! Show me code!
What’s next?
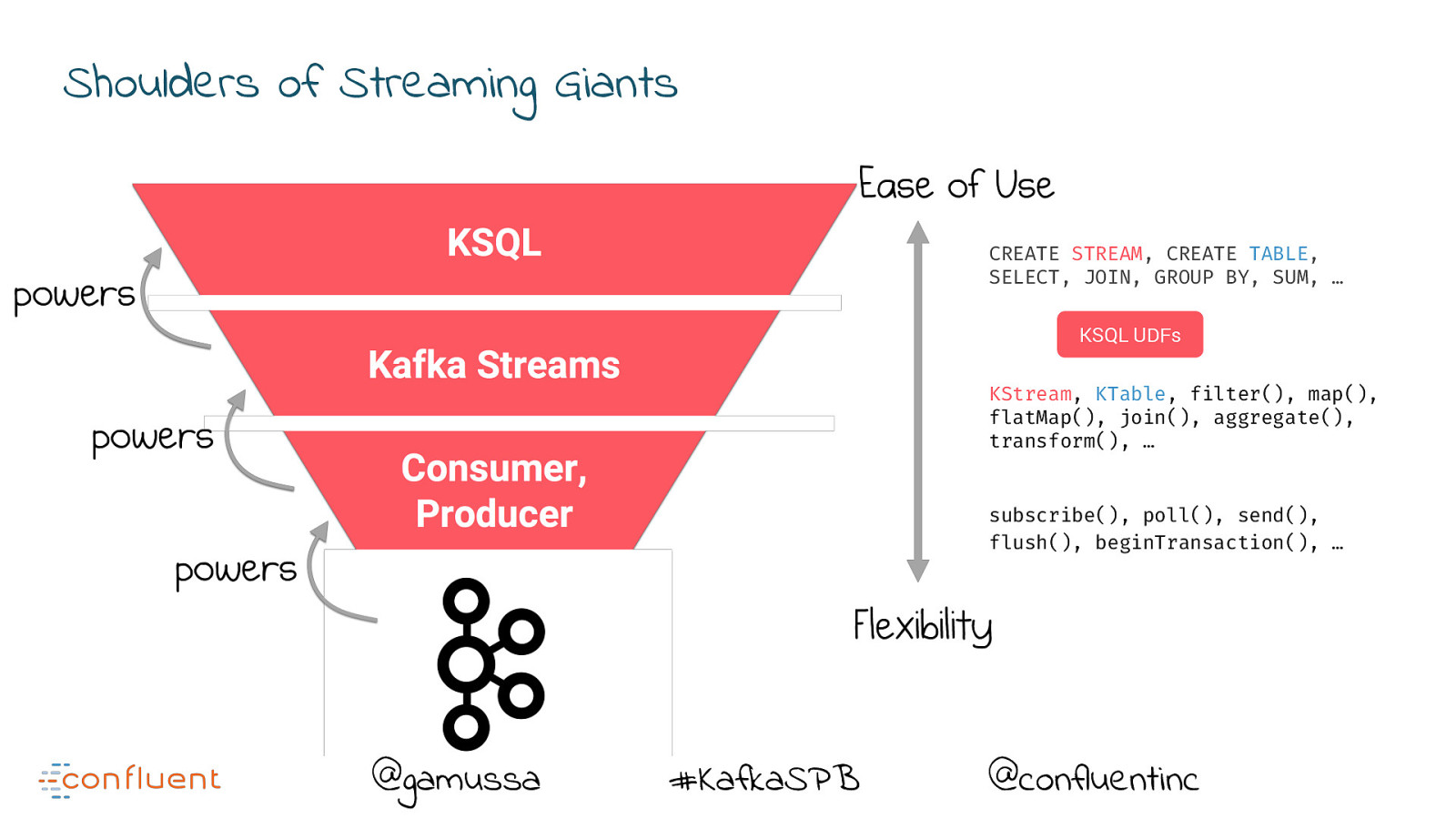
Shoulders of Streaming Giants CREATE STREAM, CREATE TABLE, SELECT, JOIN, GROUP BY, SUM, … KSQL UDFs KStream, KTable, filter(), map(), flatMap(), join(), aggregate(), transform(), … subscribe(), poll(), send(), flush(), beginTransaction(), … @gamussa #KafkaSPB @confluentinc
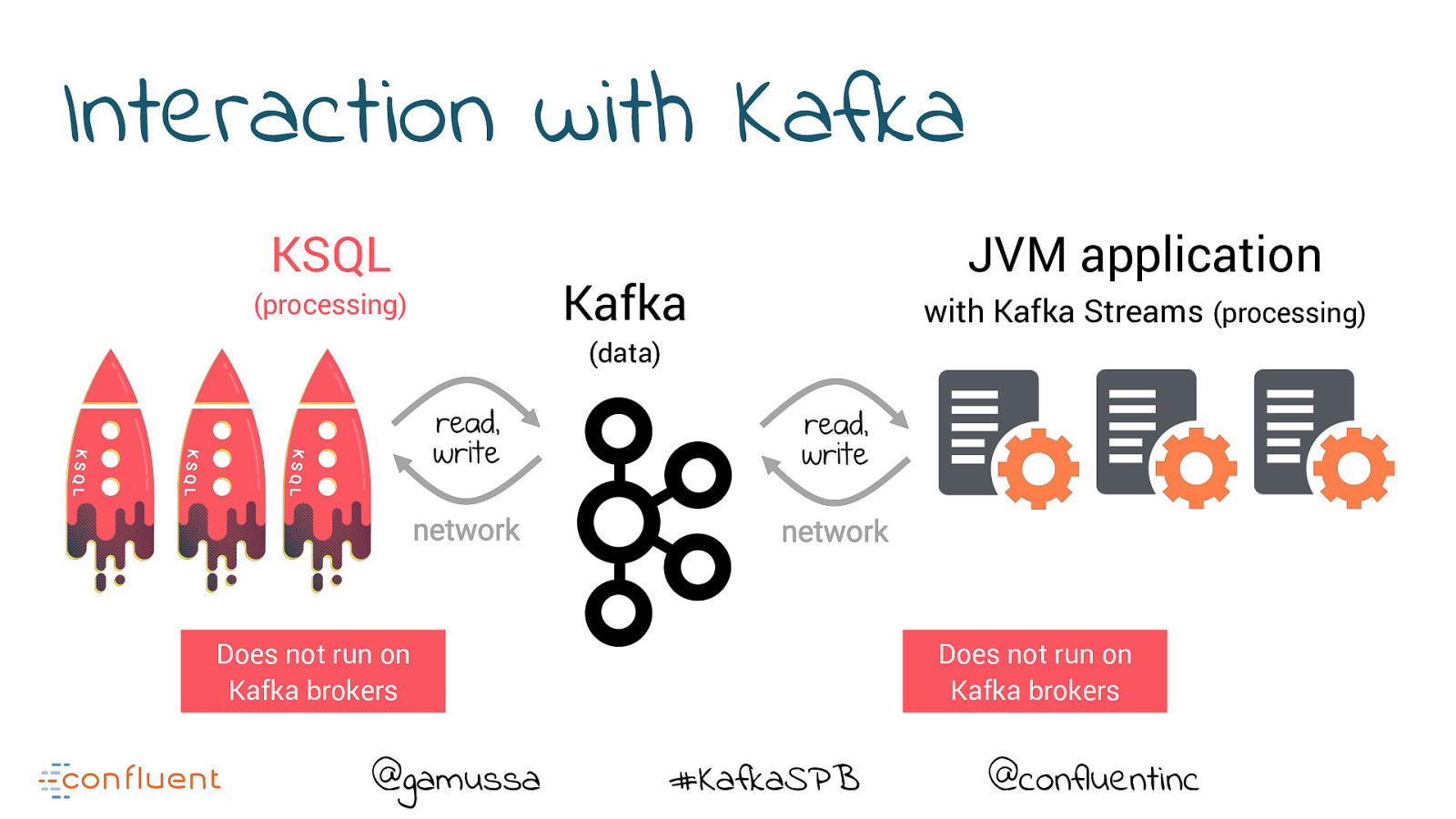
Interaction with Kafka KSQL (processing) Kafka JVM application with Kafka Streams (processing) (data) Does not run on Kafka brokers @gamussa Does not run on Kafka brokers #KafkaSPB @confluentinc
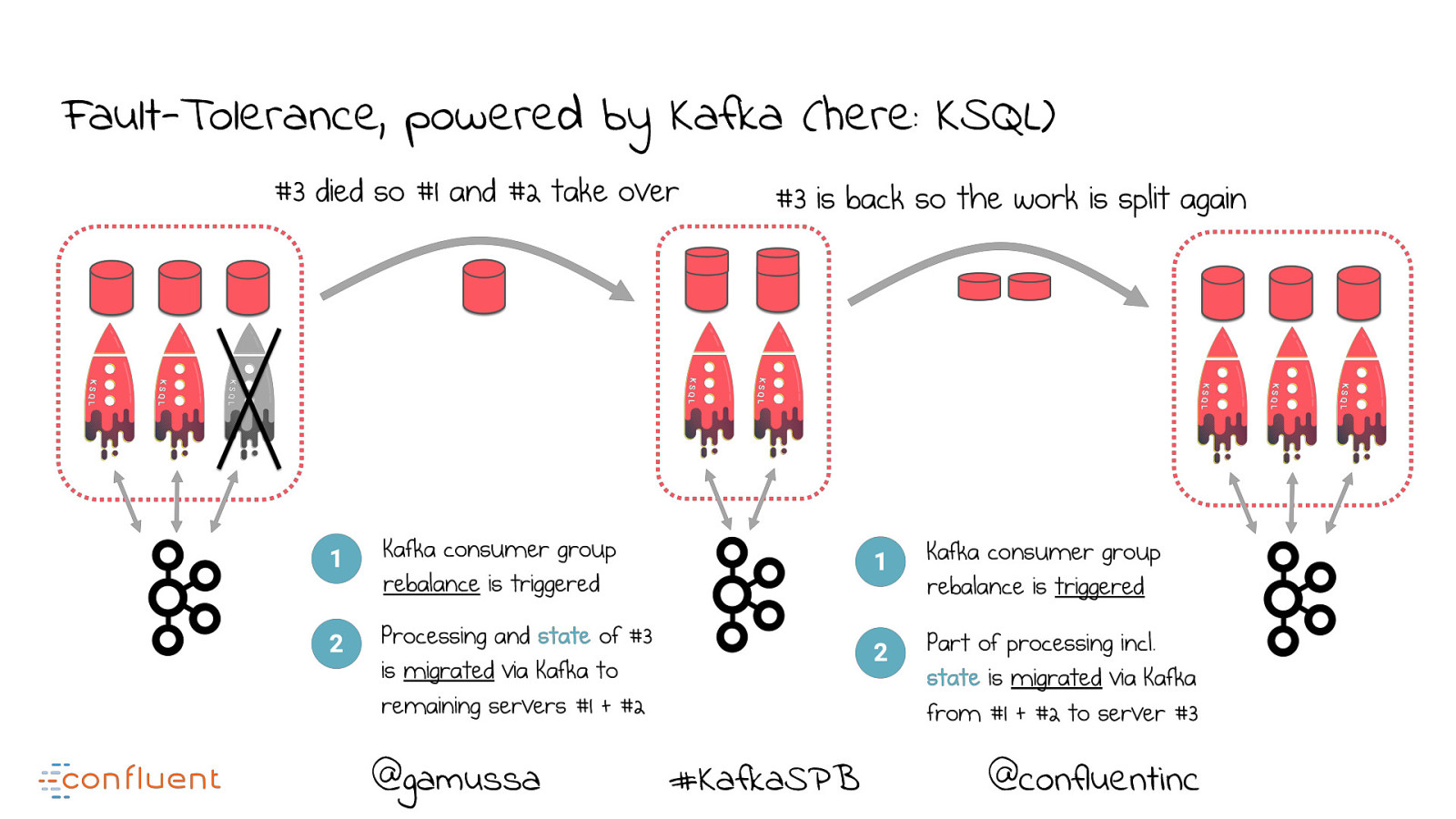
Fault-Tolerance, powered by Kafka (here: KSQL) @gamussa #KafkaSPB @confluentinc
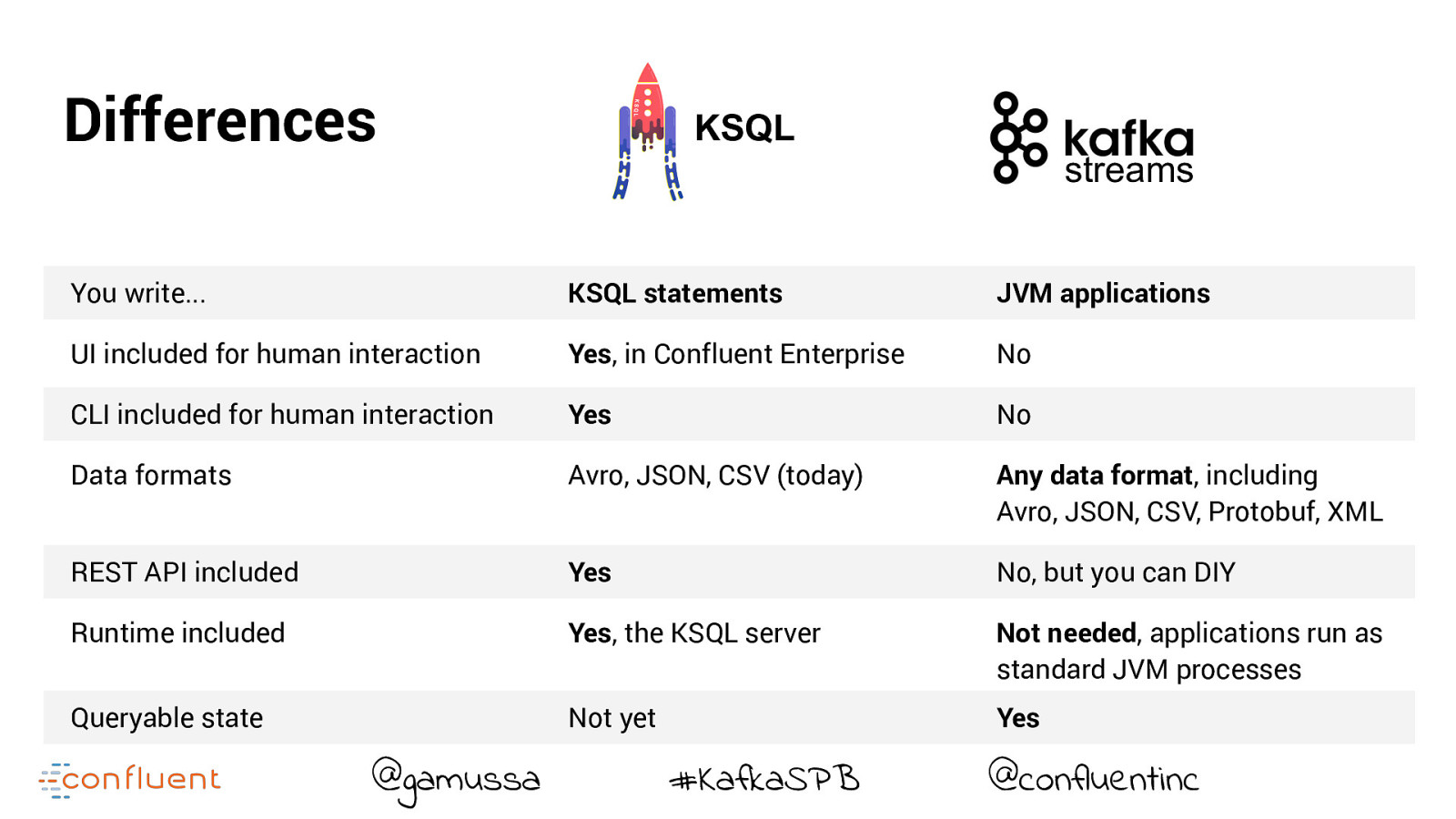
Differences KSQL streams You write... KSQL statements JVM applications UI included for human interaction Yes, in Confluent Enterprise No CLI included for human interaction Yes No Data formats Avro, JSON, CSV (today) Any data format, including Avro, JSON, CSV, Protobuf, XML REST API included Yes No, but you can DIY Runtime included Yes, the KSQL server Not needed, applications run as standard JVM processes Queryable state Not yet Yes @gamussa #KafkaSPB @confluentinc
One more thing… @gamussa @ @ATLspring @confluentinc
@gamussa @ @ATLspring @confluentinc
@gamussa @ @ATLspring @confluentinc
A Major New Paradigm @gamussa @ @ATLspring @confluentinc
Thanks! @gamussa viktor@confluent.io We are hiring! https://www.confluent.io/careers/ @gamussa #KafkaSPB @ @confluentinc
https://t.me/AwesomeKafka_ru https://t.me/proKafka

Работа с постоянно меняющимися данными, особенно при требованиях низкой задержки, довольно непростая задача. Но должно ли все быть так сложно? Apache Kafka давно стала стандартным средством для решения задач распределенной обработки потоковой информации. И многим знакомы особенности архитектуры Kafka и ее pub/sub APIs. А знаете ли вы, что Kafka также включает средства обработки потоковых данных в реальном времени?
Виктор Гамов представит Kafka Streams (Java фреймворк для обработки потоковых данных) и KSQL – пожалуй, лучшее, что случалось в мире Kafka со времен изобретения самой Кафки! К слову, KSQL позволяет создавать сложные системы обработки потоков практически без кода (ну, конечно, если вы не считаете написание (K)SQL-запросов программированием). Он расскажет о том, как развернуть приложения, покажет рабочий код, который заставит вас думать о батч-обработке, как о мифах Древней Греции! Также обсудим потоковую передачу систем данных из древней истории пакетной обработки в текущую эпоху потоковых данных! Никаких предварительных знаний о потоках Кафки, KSQL не требуется.
Here’s what was said about this presentation on social media.