A presentation at Kafka Summit San Francisco 2019 in in San Francisco, CA, USA by Viktor Gamov

Streaming on Kubernetes: Does it have to be the hard way? Fall, 2019 / San Francisco, Ca 2019 @gamussa @gamussa || #KafkaSummit #kafkasummit || @ConfluentINc @ConfluentINc
2 @gamussa | #KafkaSummit | @ConfluentINc
3 I build highly scalable Hello World apps @gamussa | #KafkaSummit | @ConfluentINc
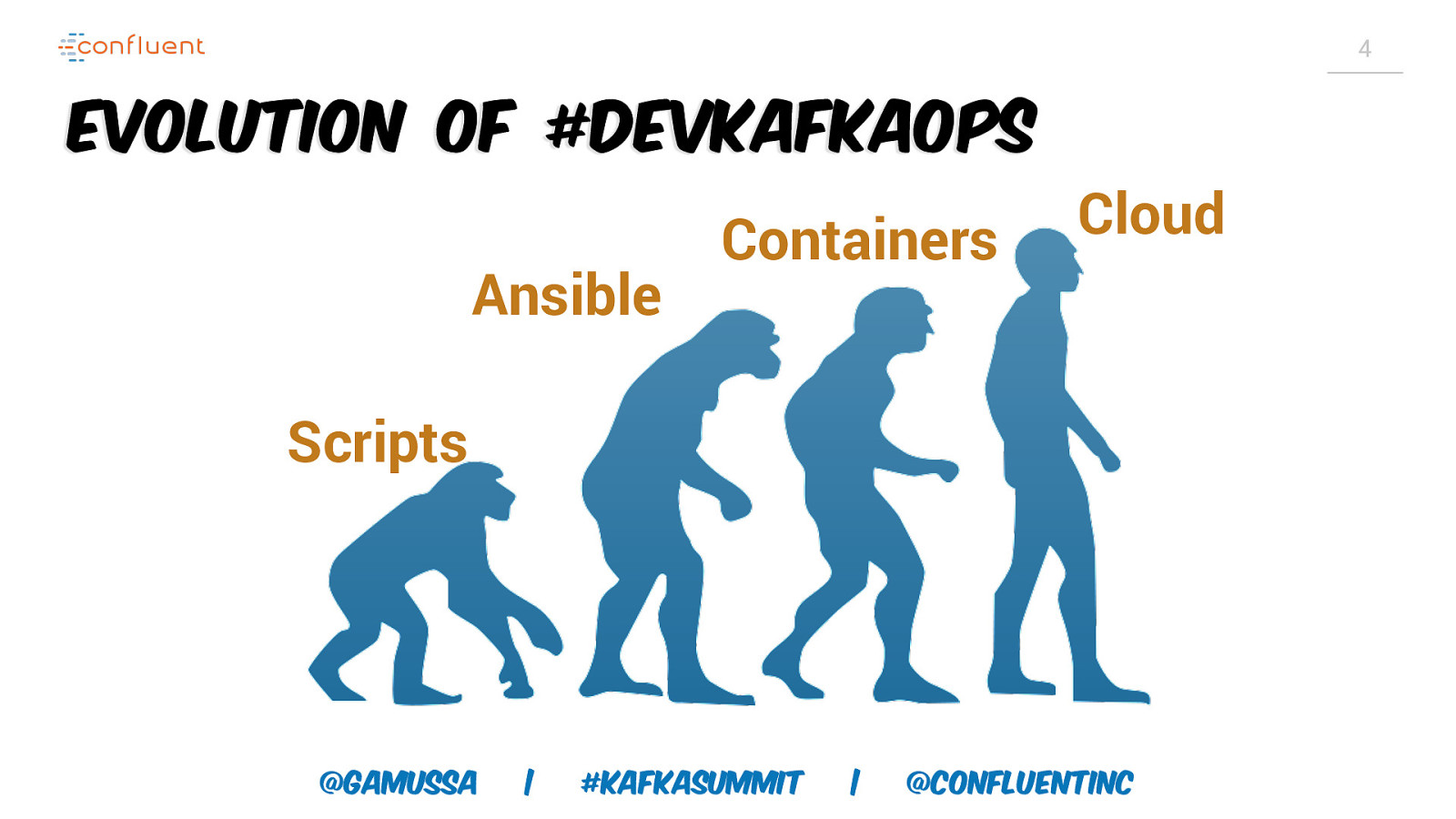
4 Evolution of #devkafkaops Ansible Containers Cloud Scripts @gamussa | #KafkaSummit | @ConfluentINc
6 @gamussa | #KafkaSummit | @ConfluentINc
7 https://twitter.com/claesmogren/status/1108456688175079424 @gamussa | #KafkaSummit | @ConfluentINc
8 https://twitter.com/claesmogren/status/1108456688175079424 https://twitter.com/QuinnyPig/status/1150927901782499330 @gamussa | #KafkaSummit | @ConfluentINc
9 🙋 @gamussa | #KafkaSummit | @ConfluentINc
10 Who run stateless apps in Kubernetes? 🙋 Who thinks it’s a good idea? Who run stateful apps in Kubernetes? Who thinks it’s a good idea? @gamussa | #KafkaSummit | @ConfluentINc
11 #devkafkaops Well, it’s tricky © Translating an existing architecture to Kubernetes External access to brokers and other components Persistent Storage options on prem and clouds Security Configuration and Upgrades @gamussa | #KafkaSummit | @ConfluentINc
12 kafkaesque world of Kafka on Kubernetes @gamussa | #KafkaSummit | @ConfluentINc
13 Dude, you said «it doesn’t have to be hard way» @gamussa | #KafkaSummit | @ConfluentINc
14 @Micha8LNg @gamussa | #KafkaSummit | @ConfluentINc
DO KAFKA ON KUBERNETES DEMO AND EVERYONE LOOSES THEIR MINDS @gamussa | #KafkaSummit | @ConfluentINc 15
Tweet, yeah 🚀 Follow @gamussa @confluentinc 📸🖼%😂 Tag @gamussa With #KafkaSummit
17 Kubernetes Fundamentals @gamussa | #KafkaSummit | @ConfluentINc
18 @gamussa | #KafkaSummit | @ConfluentINc
19 Kubernetes ●Schedules and allocates resources ●Networking between Pods ●Storage ●Service Discovery @gamussa | #KafkaSummit | @ConfluentINc
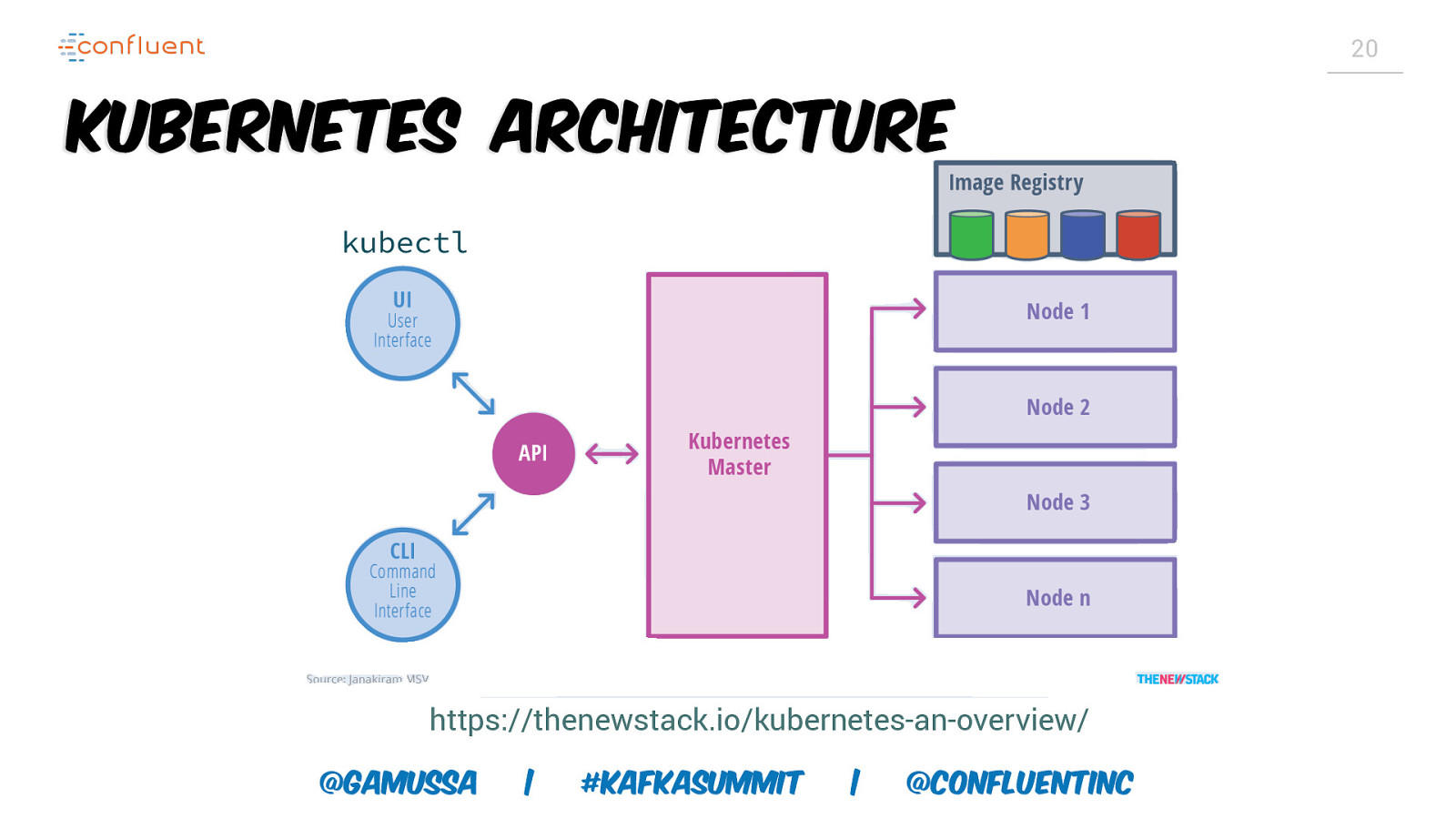
20 Kubernetes Architecture kubectl https://thenewstack.io/kubernetes-an-overview/ @gamussa | #KafkaSummit | @ConfluentINc
21 @gamussa | #KafkaSummit | @ConfluentINc
22 Pod • Basic Unit of Deployment in Kubernetes • A collection of containers sharing: • Namespace • Network • Volumes @gamussa | #KafkaSummit | @ConfluentINc
23 Storage • Persistent Volume (PV) & Persistent Volume Claim (PVC) • PV is a piece of storage that is provisioned dynamic or static of any individual pod that uses the PV @gamussa | #KafkaSummit | @ConfluentINc
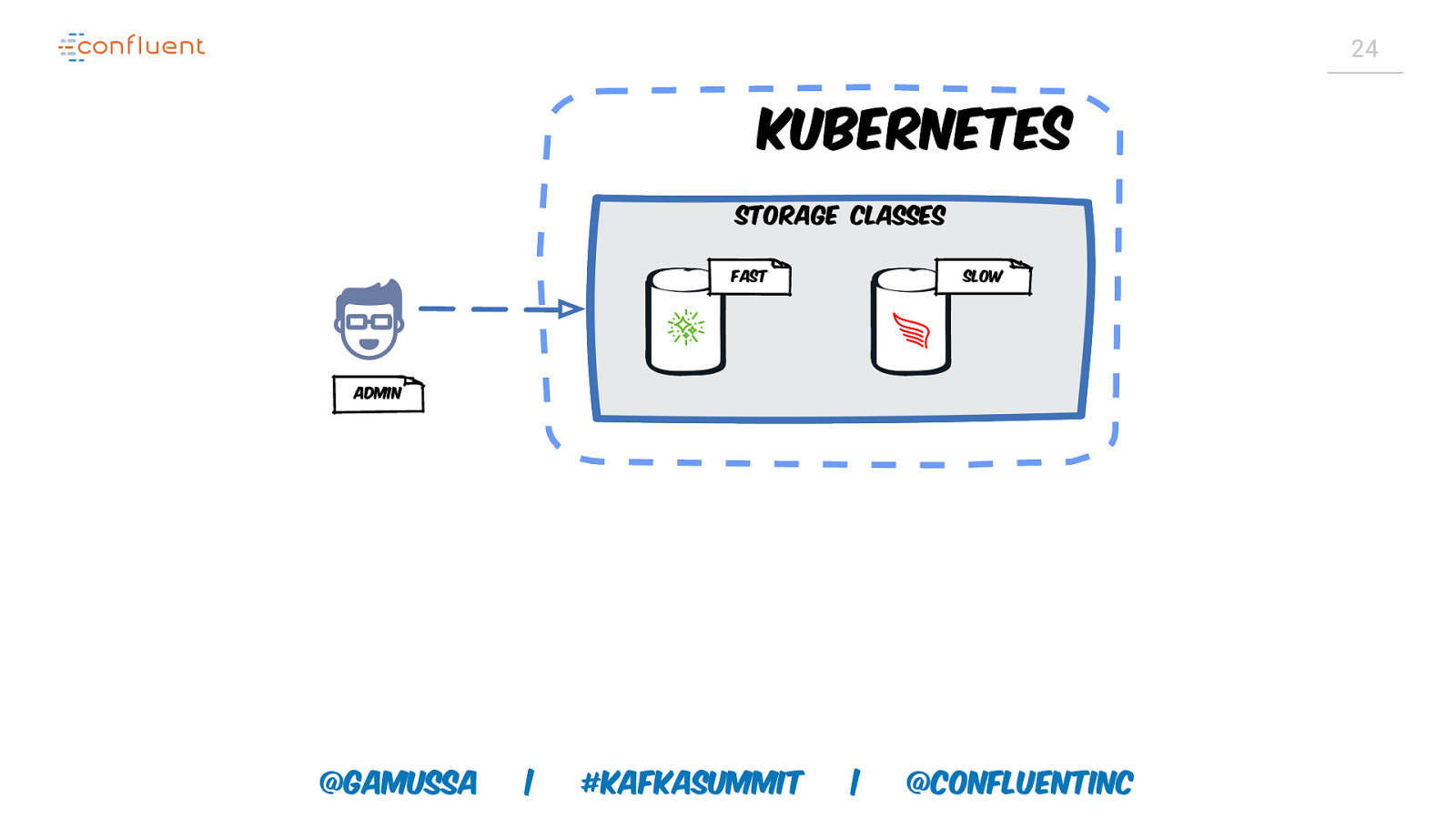
24 Kubernetes Storage classes Fast Slow Admin @gamussa | #KafkaSummit | @ConfluentINc
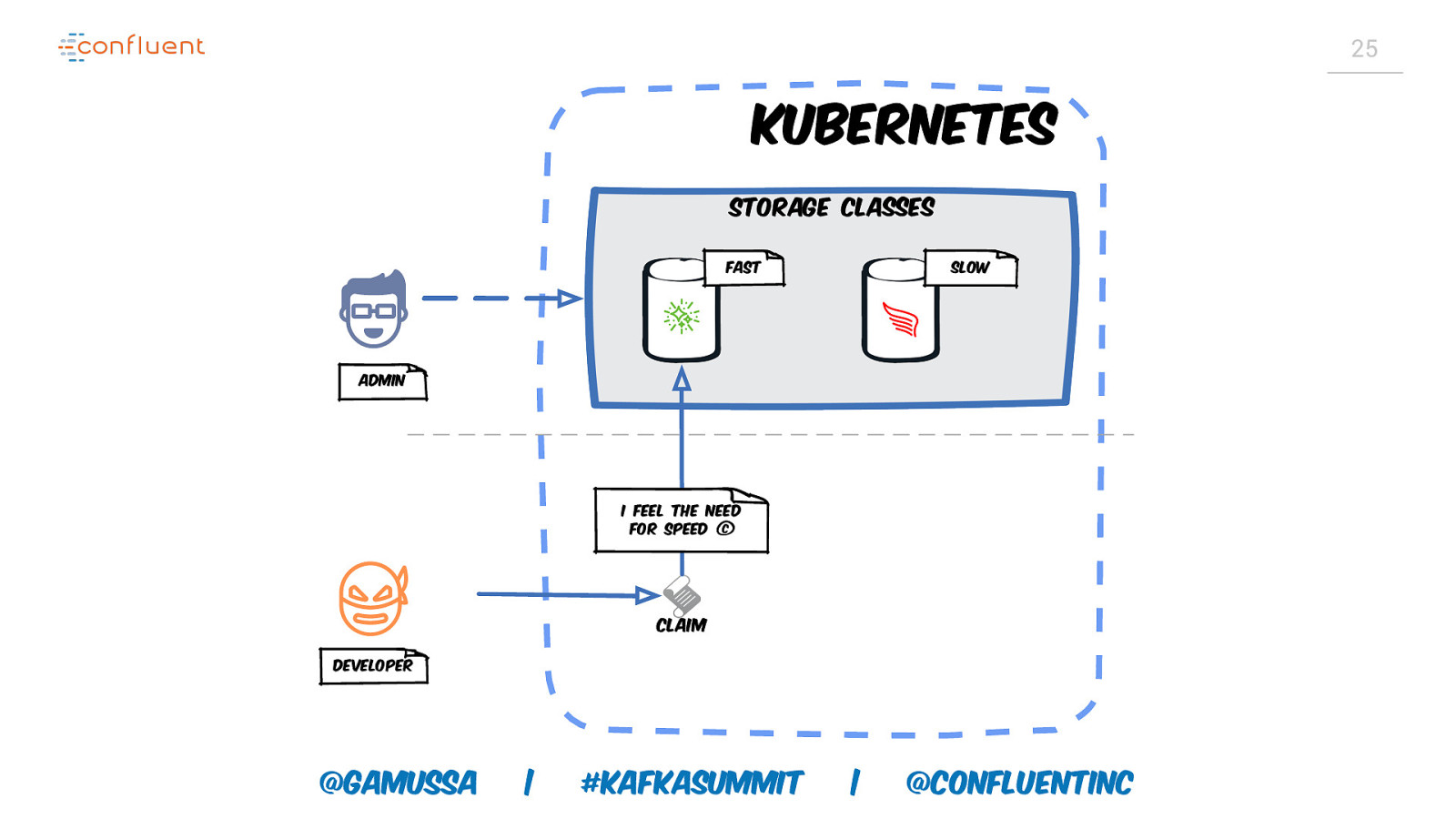
25 Kubernetes Storage classes Fast Slow Admin I feel the need for speed © Claim Developer @gamussa | #KafkaSummit | @ConfluentINc
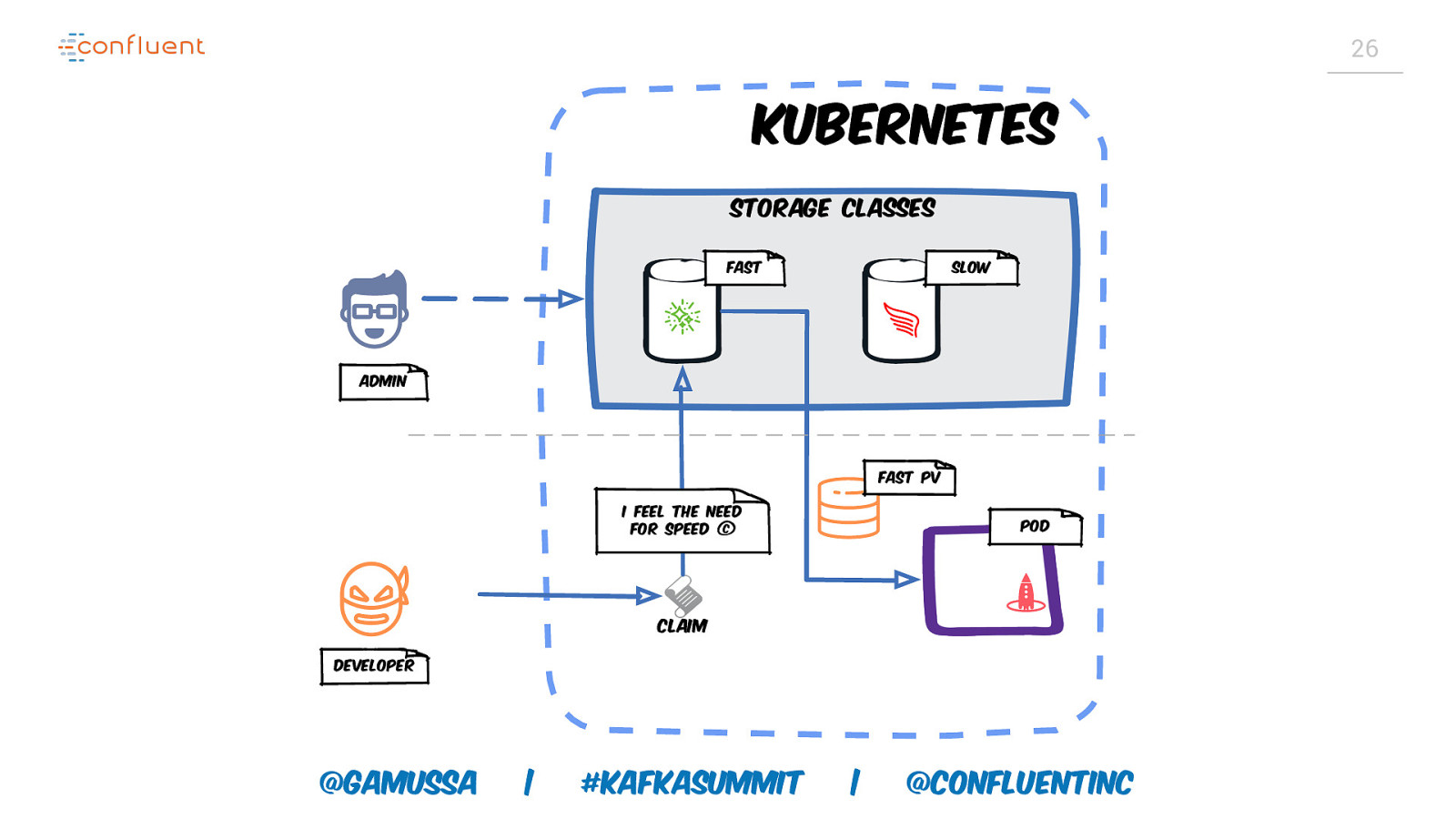
26 Kubernetes Storage classes Fast Slow Admin Fast PV I feel the need for speed © Pod Claim Developer @gamussa | #KafkaSummit | @ConfluentINc
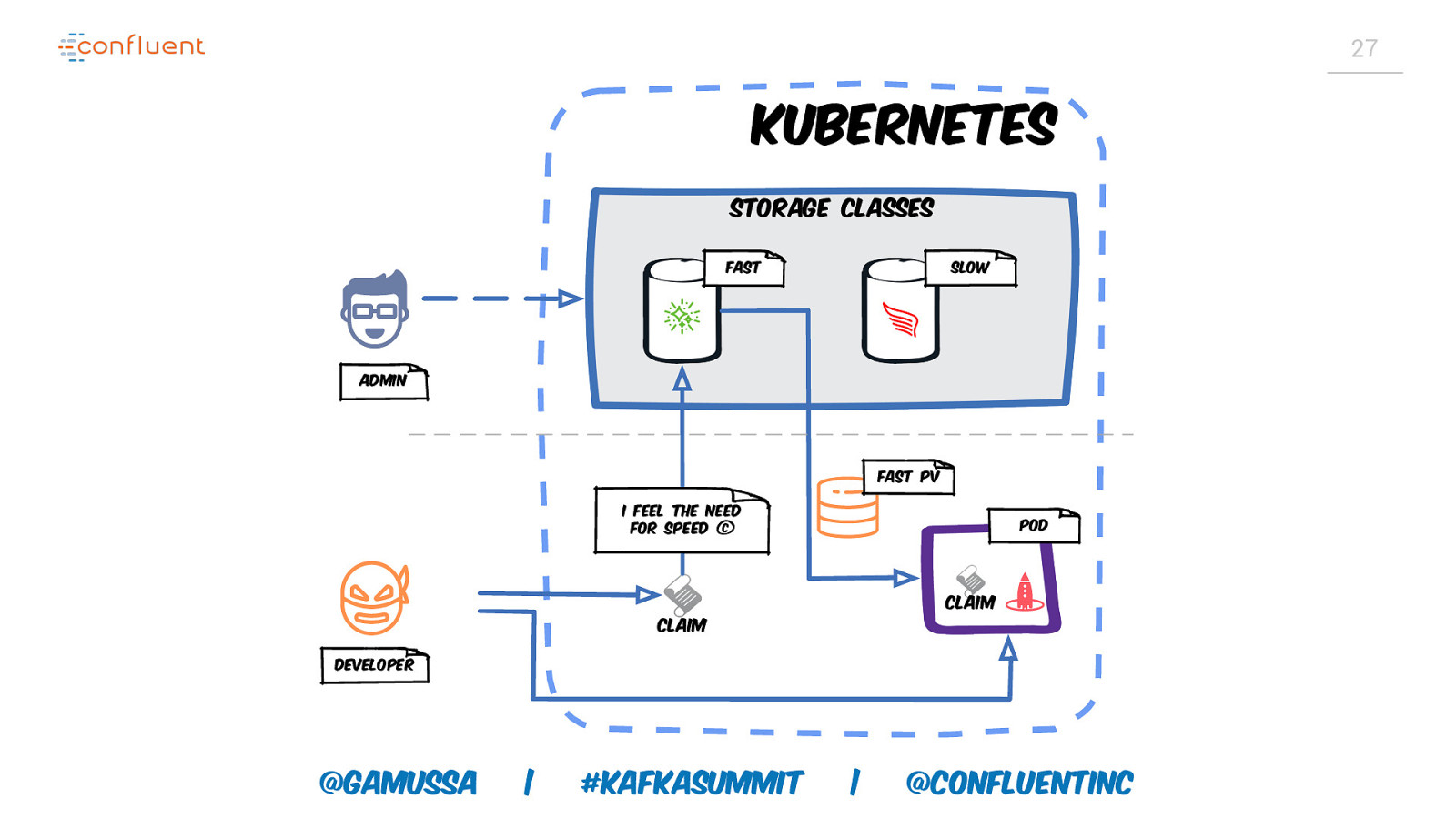
27 Kubernetes Storage classes Fast Slow Admin Fast PV I feel the need for speed © Pod Claim Claim Developer @gamussa | #KafkaSummit | @ConfluentINc
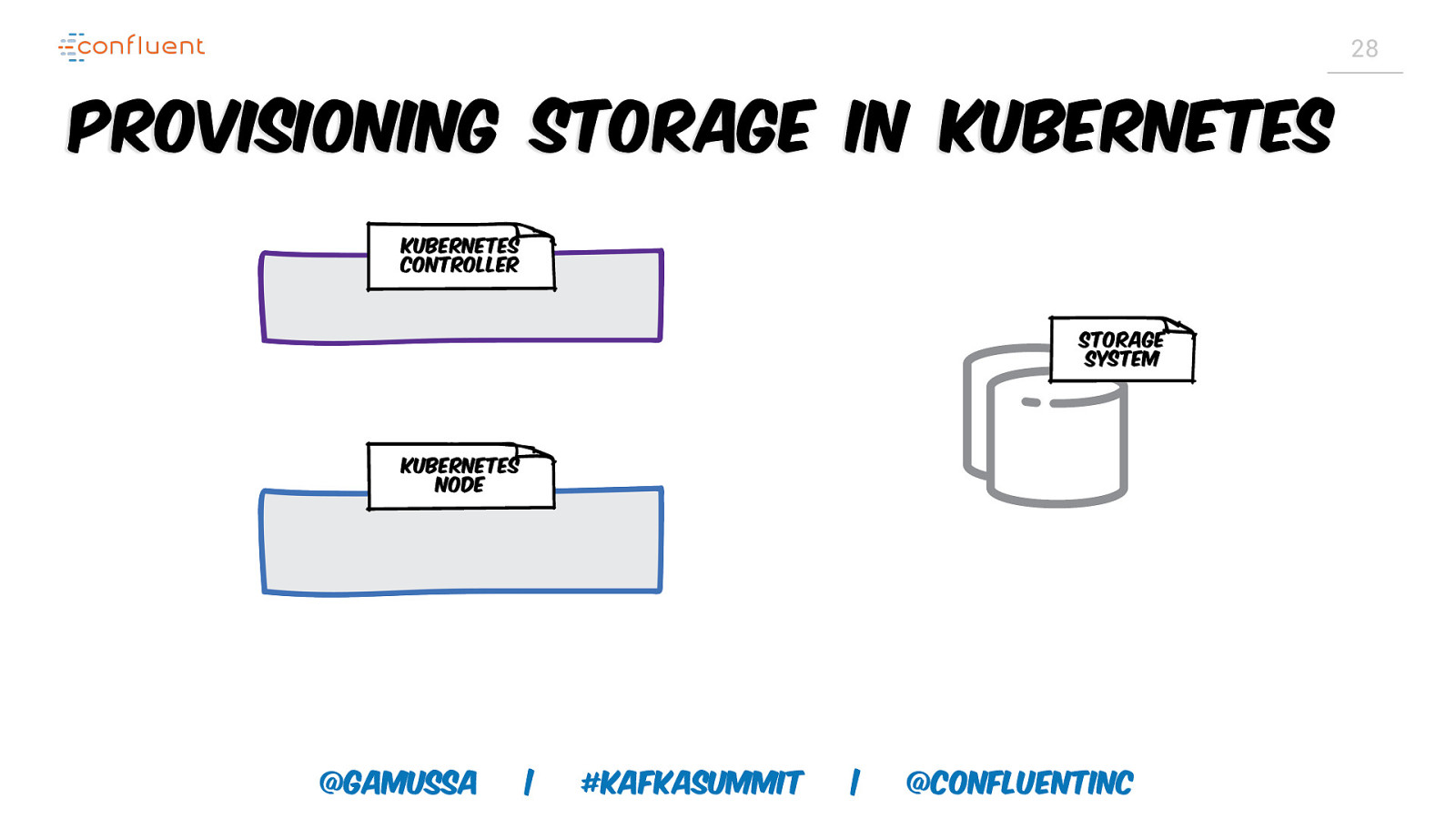
28 Provisioning storage in Kubernetes Kubernetes controller Storage System Kubernetes node @gamussa | #KafkaSummit | @ConfluentINc
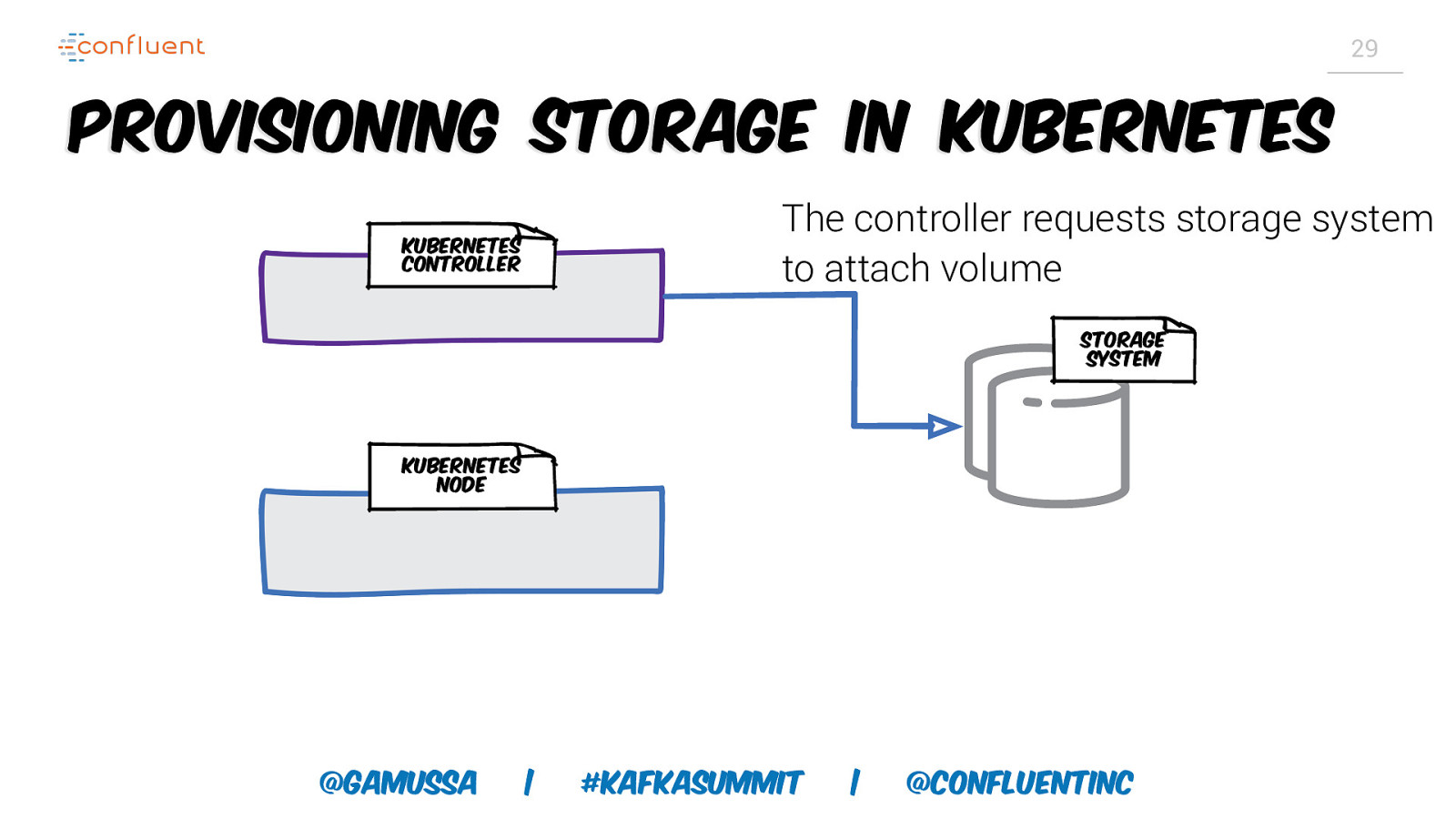
29 Provisioning storage in Kubernetes The controller requests storage system to attach volume Kubernetes controller Storage System Kubernetes node @gamussa | #KafkaSummit | @ConfluentINc
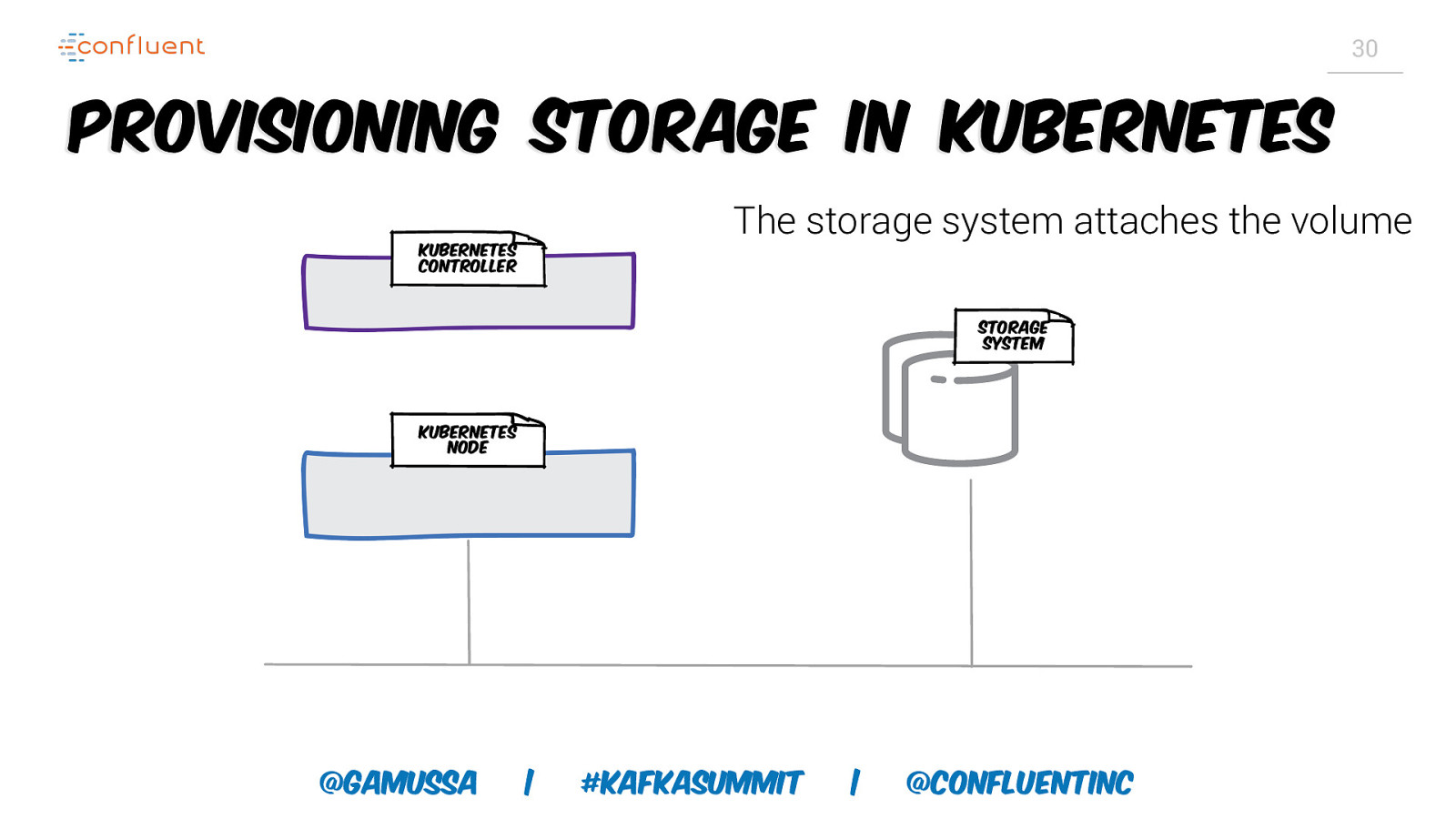
30 Provisioning storage in Kubernetes The storage system attaches the volume Kubernetes controller Storage System Kubernetes node @gamussa | #KafkaSummit | @ConfluentINc
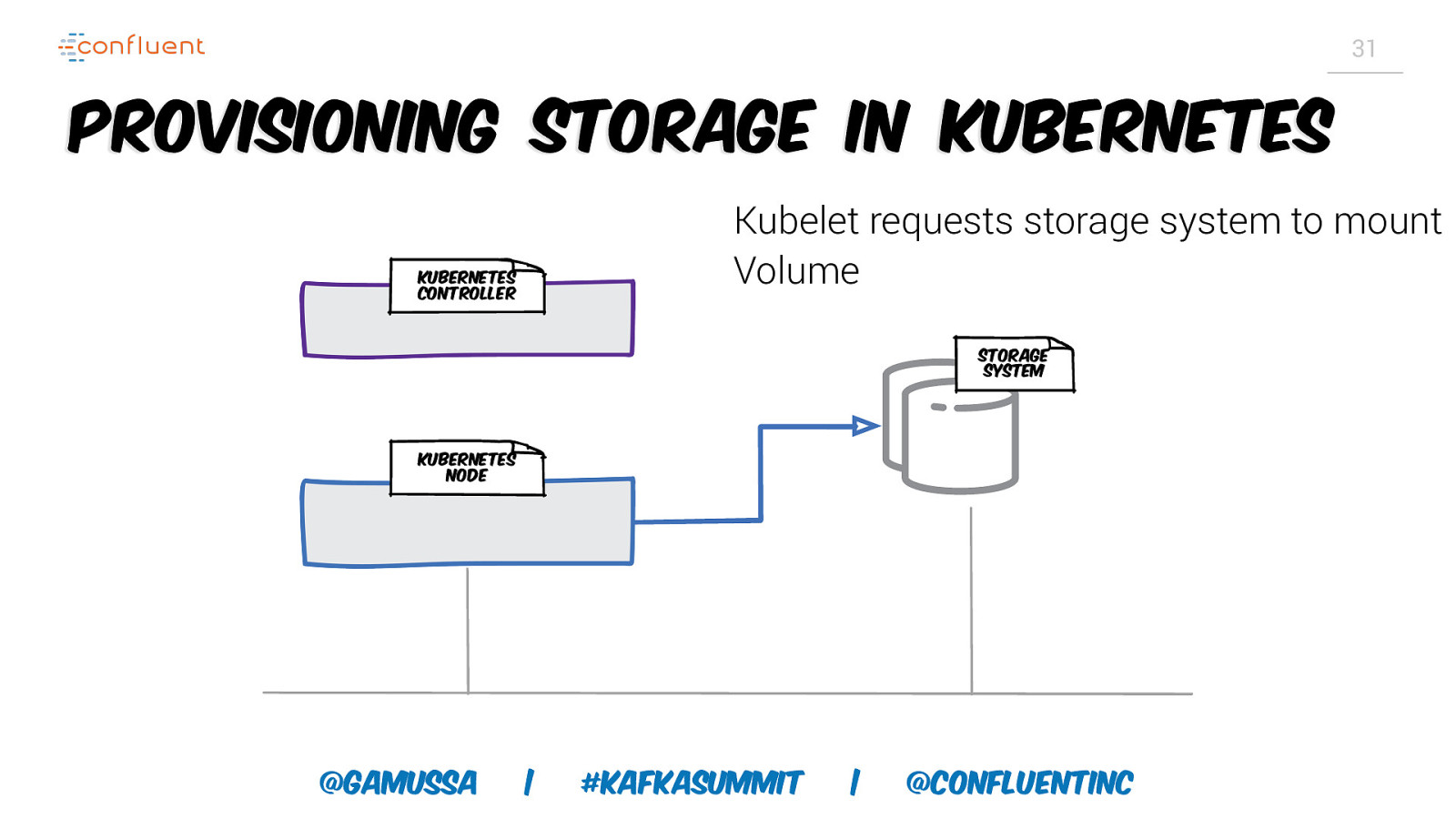
31 Provisioning storage in Kubernetes Kubelet requests storage system to mount Volume Kubernetes controller Storage System Kubernetes node @gamussa | #KafkaSummit | @ConfluentINc
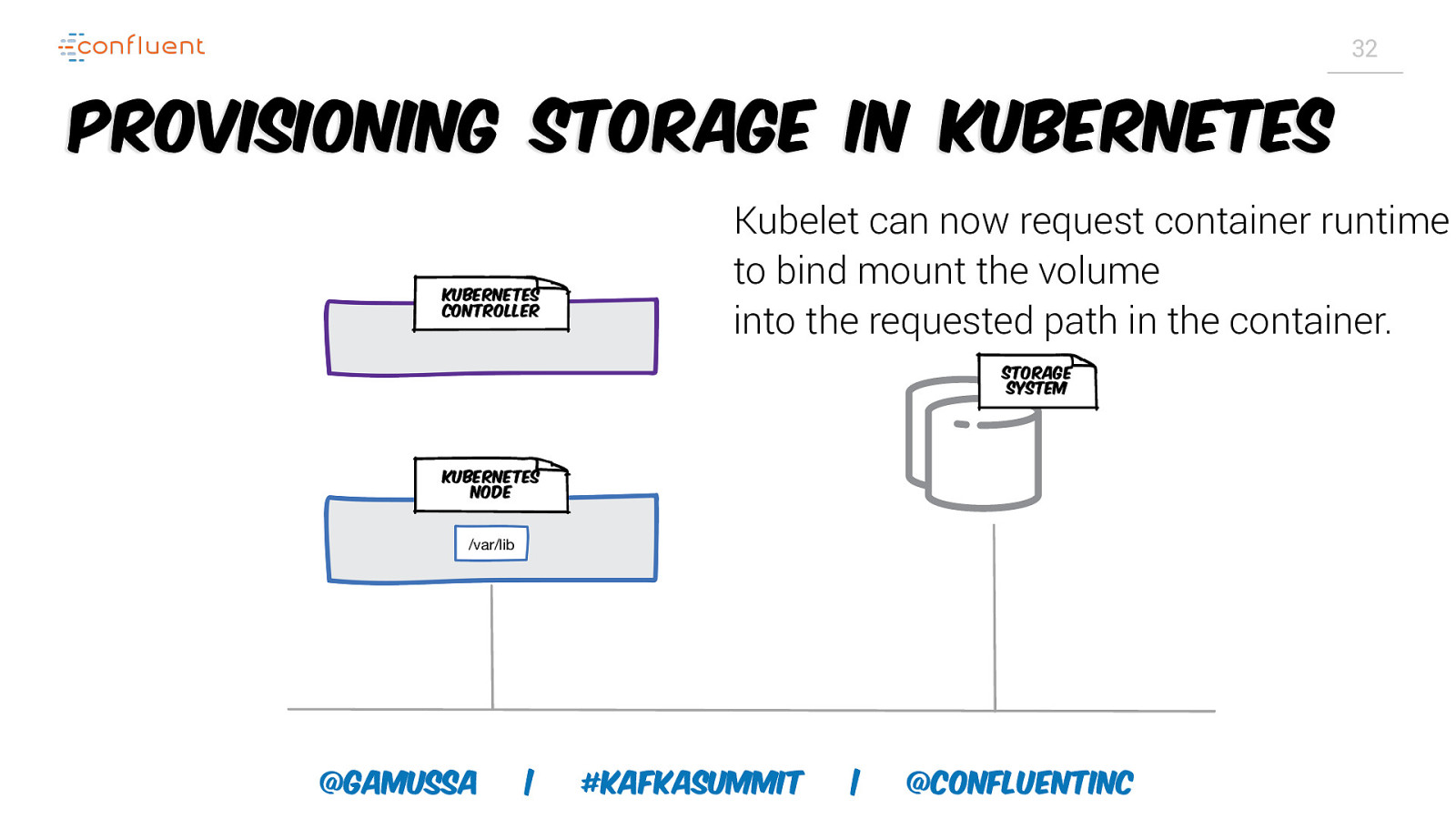
32 Provisioning storage in Kubernetes Kubernetes controller Kubelet can now request container runtime to bind mount the volume into the requested path in the container. Storage System Kubernetes node /var/lib @gamussa | #KafkaSummit | @ConfluentINc
33 But I just want to deploy kafka @gamussa | #KafkaSummit | @ConfluentINc
35 Confluent Operator: Apache Kafka on Kubernetes made simple Confluent Platform Docker Images Run Apache Kafka and Confluent Confluent Operator Platform as a cloud-native application on Kubernetes to minimize operating complexity and Kubernetes AWS Azure GCP RH OpenShift Mesosphere Pivotal increase developer agility On-Premises @gamussa | #KafkaSummit | @ConfluentINc Cloud
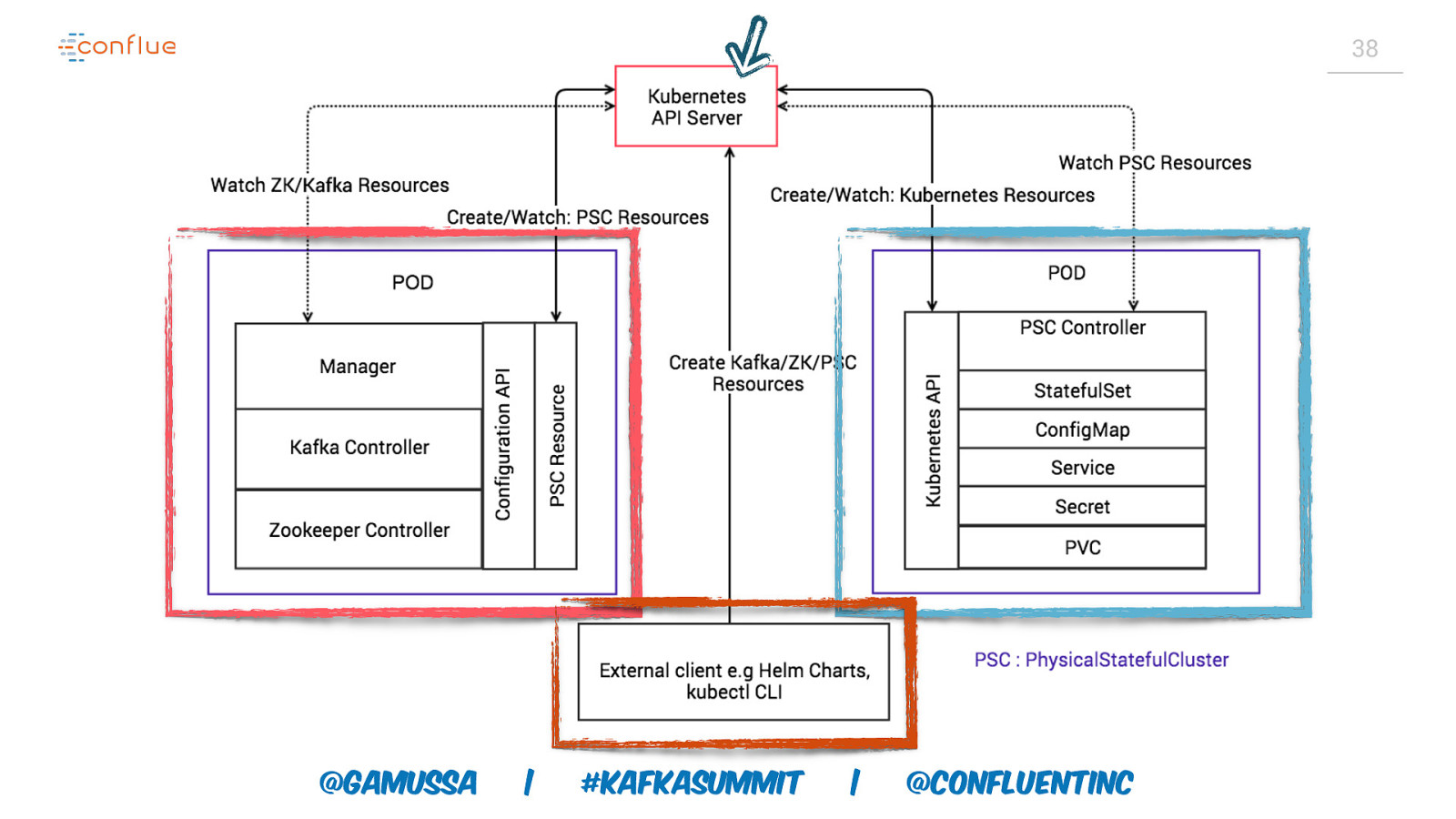
Custom resource controller
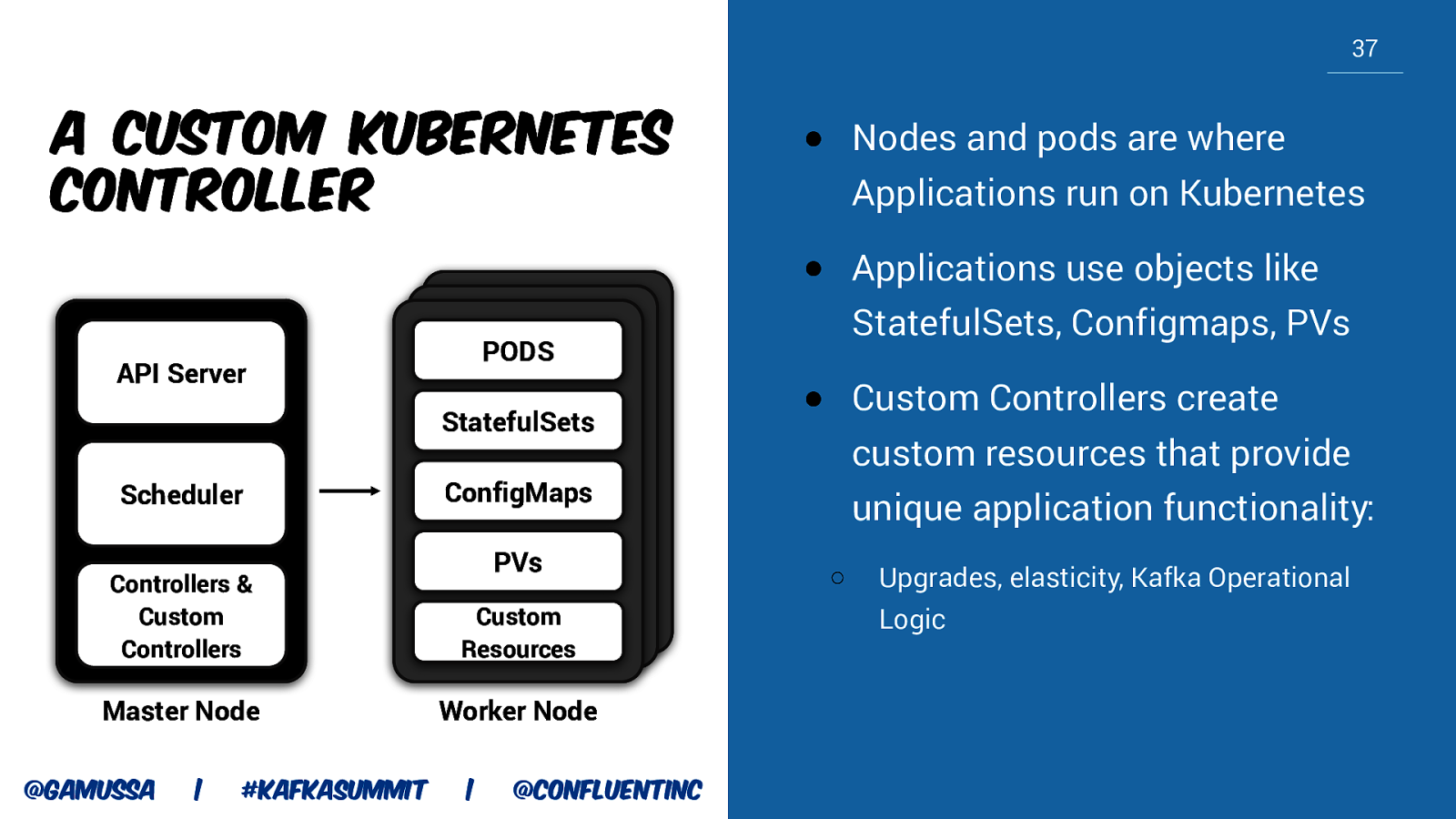
37 a custom Kubernetes controller PODS API Server StatefulSets Scheduler PVs Custom Resources Master Node Worker Node | #KafkaSummit Applications run on Kubernetes ● Applications use objects like StatefulSets, Configmaps, PVs ● Custom Controllers create custom resources that provide unique application functionality: ConfigMaps Controllers & Custom Controllers @gamussa ● Nodes and pods are where | @ConfluentINc ○ Upgrades, elasticity, Kafka Operational Logic
38 @gamussa | #KafkaSummit | @ConfluentINc
39 Workloads Deployment @gamussa | #KafkaSummit | @ConfluentINc
40 Usual suspects Certified container images @gamussa Operator Helm Charts | #KafkaSummit | @ConfluentINc
Rolling Upgrade Kafka Broker Upgrades: 1. Stop the broker, upgrade Kafka 2. Wait for Partition Leader reassignment 3. Start the upgraded broker 4. Wait for zero under-replicated partitions 5. Upgrade the next broker
43 Will it Scale Spin up new brokers, connect workers easily Manual Rebalance required in v1.0 Determine balancing plan Execute balancing plan Monitor Resources @gamussa | #KafkaSummit | @ConfluentINc
44 One More Thing…
45 Usual suspects Certified container images @gamussa | #KafkaSummit | @ConfluentINc
46 Kotlin DSL for Kubernetes fun main() { val client = DefaultKafkaClient().inNamespace(“operator”) println(client.kafkaClusters().list()) client.kafkaClusters().create( newKafkaCluster { metadata { name = “kafka” } spec { replicas = 3 } } ) println(client.kafkaClusters().list()) } @gamussa | #KafkaSummit | @ConfluentINc
47 Kotlin DSL for Kubernetes fun main() { val client = DefaultKafkaClient().inNamespace(“operator”) println(client.kafkaClusters().list()) client.kafkaClusters().create( newKafkaCluster { metadata { name = “kafka” } spec { replicas = 3 } } ) println(client.kafkaClusters().list()) @gamussa | #KafkaSummit | @ConfluentINc }
48 @gamussa | #KafkaSummit | @ConfluentINc
Thanks! @gamussa viktor@confluent.io @Micha8LNg michael.ng@confluent.io https://slackpass.io/confluentcommunity #kubernetes @gamussa | @ #KafkaSummit | @ConfluentINc
50

When it comes to choosing a distributed streaming platform for real-time data pipelines, everyone knows the answer – Apache Kafka! And when it comes to deploying applications at scale without needing to integrate different pieces of infrastructure yourself, the answer nowadays is increasingly Kubernetes. However, with all great things, the devil is truly in the details. While Kubernetes does provide all the building blocks that are needed, a lot of thought is required to truly create an enterprise-grade Kafka platform that can be used in production. In this technical deep dive, Michael and Viktor will go through challenges and pitfalls of managing Kafka on Kubernetes as well as the goals and lessons learned from the development of the Confluent Operator for Kubernetes.
The following resources were mentioned during the presentation or are useful additional information.
Presentation materials
Here’s what was said about this presentation on social media.